
File size: 9,833 Bytes
02aa18d |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
# Model Overview
This bundle is for Nvidia MAISI (Medical AI for Synthetic Imaging), a 3D Latent Diffusion Model that can generate large CT images with paired segmentation masks, variable volume size and voxel size, as well as controllable organ/tumor size.
The inference workflow of MAISI is depicted in the figure below. It first generates latent features from random noise by applying multiple denoising steps using the trained diffusion model. Then it decodes the denoised latent features into images using the trained autoencoder.
<p align="center">
<img src="https://developer.download.nvidia.com/assets/Clara/Images/maisi_workflow_1.0.1.png" alt="MAISI inference scheme">
</p>
MAISI is based on the following papers:
[**Latent Diffusion:** Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." CVPR 2022.](https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf)
[**ControlNet:** Lvmin Zhang, Anyi Rao, Maneesh Agrawala; “Adding Conditional Control to Text-to-Image Diffusion Models.” ICCV 2023.](https://openaccess.thecvf.com/content/ICCV2023/papers/Zhang_Adding_Conditional_Control_to_Text-to-Image_Diffusion_Models_ICCV_2023_paper.pdf)
[**Rectified Flow:** Liu, Xingchao, and Chengyue Gong. "Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow." ICLR 2023.](https://arxiv.org/pdf/2209.03003)
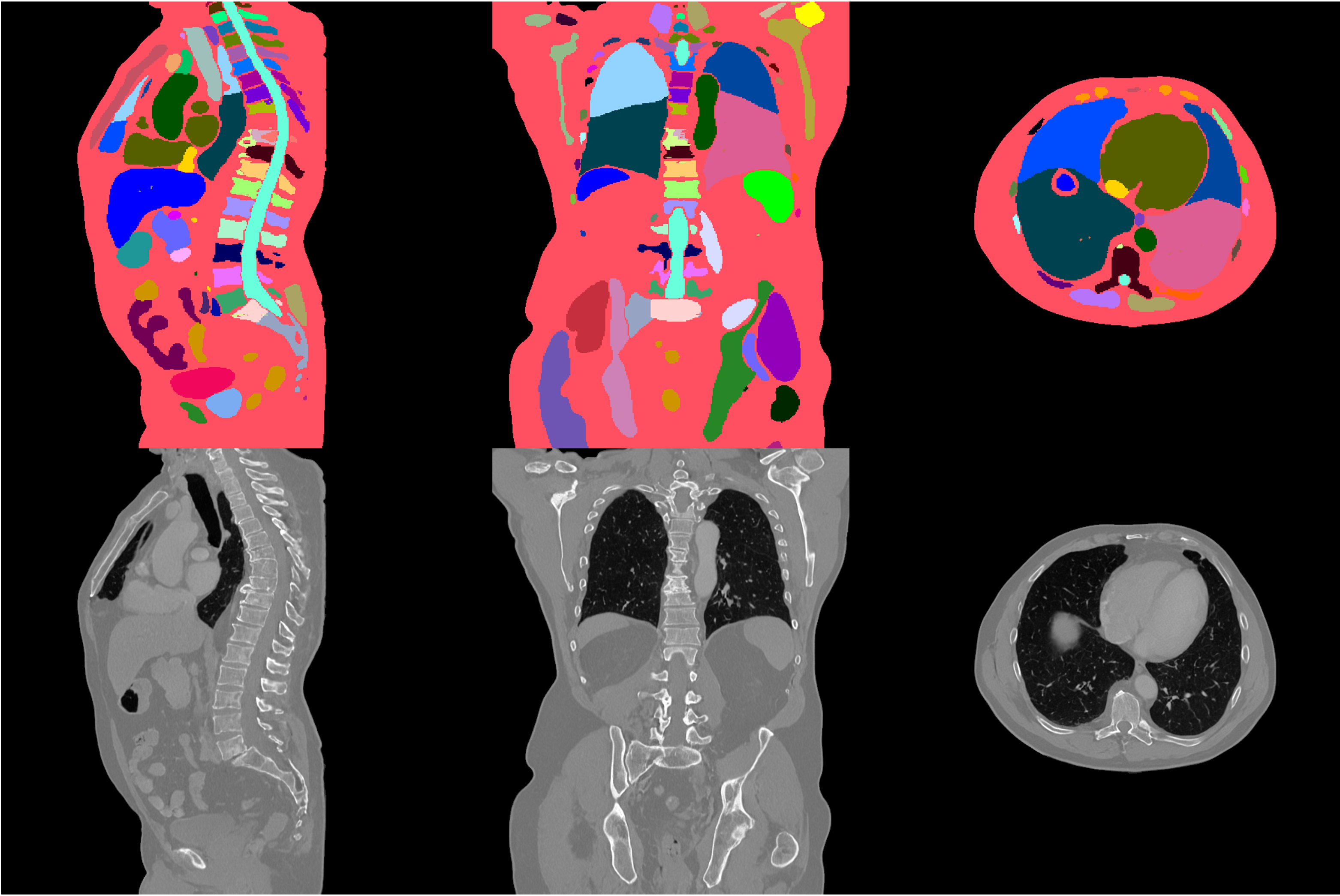
#### Example synthetic image
An example result from inference is shown below:
### Inference configuration
The inference requires:
- GPU: at least 58GB GPU memory for 512 x 512 x 512
- Disk Memory: at least 21GB disk memory
#### Inference parameters:
The information for the inference input, like body region and anatomy to generate, is stored in [./configs/inference.json](../configs/inference.json). Please feel free to play with it. Here are the details of the parameters.
- `"num_output_samples"`: int, the number of output image/mask pairs it will generate.
- `"spacing"`: voxel size of generated images. E.g., if set to `[1.5, 1.5, 2.0]`, it will generate images with a resolution of 1.5×1.5×2.0 mm. The spacing for x and y axes has to be between 0.5 and 3.0 mm and the spacing for the z axis has to be between 0.5 and 5.0 mm.
- `"output_size"`: volume size of generated images. E.g., if set to `[512, 512, 256]`, it will generate images with size of 512×512×256. They need to be divisible by 16. If you have a small GPU memory size, you should adjust it to small numbers. Note that `"spacing"` and `"output_size"` together decide the output field of view (FOV). For eample, if set them to `[1.5, 1.5, 2.0]`mm and `[512, 512, 256]`, the FOV is 768×768×512 mm. We recommend output_size is the FOV in x and y axis are same and to be at least 256mm for head, at least 384mm for other body regions like abdomen, and no larger than 640mm. The output size for the x and y axes can be selected from [256, 384, 512], while for the z axis, it can be chosen from [128, 256, 384, 512, 640, 768].
- `"controllable_anatomy_size"`: a list of controllable anatomy and its size scale (0--1). E.g., if set to `[["liver", 0.5],["hepatic tumor", 0.3]]`, the generated image will contain liver that have a median size, with size around 50% percentile, and hepatic tumor that is relatively small, with around 30% percentile. In addition, if the size scale is set to -1, it indicates that the organ does not exist or should be removed. The output will contain paired image and segmentation mask for the controllable anatomy.
The following organs support generation with a controllable size: ``["liver", "gallbladder", "stomach", "pancreas", "colon", "lung tumor", "bone lesion", "hepatic tumor", "colon cancer primaries", "pancreatic tumor"]``.
The raw output of the current mask generation model has a fixed size of $256^3$ voxels with a spacing of $1.5^3$ mm. If the "output_size" differs from this default, the generated masks will be resampled to the desired `"output_size"` and `"spacing"`. Note that resampling may degrade the quality of the generated masks and could trigger multiple inference attempts if the images fail to pass the [image quality check](../scripts/quality_check.py).
- `"body_region"`: Deprecated, please leave it as empty `"[]"`.
- `"anatomy_list"`: If "controllable_anatomy_size" is not specified, the output will contain paired image and segmentation mask for the anatomy in "./configs/label_dict.json".
- `"autoencoder_sliding_window_infer_size"`: in order to save GPU memory, we use sliding window inference when decoding latents to image when `"output_size"` is large. This is the patch size of the sliding window. Small value will reduce GPU memory but increase time cost. They need to be divisible by 16.
- `"autoencoder_sliding_window_infer_overlap"`: float between 0 and 1. Large value will reduce the stitching artifacts when stitching patches during sliding window inference, but increase time cost. If you do not observe seam lines in the generated image result, you can use a smaller value to save inference time.
To generate images with substantial dimensions, such as 512 × 512 × 512 or larger, using GPUs with 80GB of memory, it is advisable to configure the `"num_splits"` parameter in [the auto-encoder configuration](./configs/config_maisi.json#L11-L37) to 16. This adjustment is crucial to avoid out-of-memory issues during inference.
#### Recommended spacing for different output sizes:
|`"output_size"`| Recommended `"spacing"`|
|:-----:|:-----:|
[256, 256, 256] | [1.5, 1.5, 1.5] |
[512, 512, 128] | [0.8, 0.8, 2.5] |
[512, 512, 512] | [1.0, 1.0, 1.0] |
### Execute inference
The following code generates a synthetic image from a random sampled noise.
```
python -m monai.bundle run --config_file configs/inference.json
```
## Execute Finetuning
### Training configuration
The training was performed with the following:
- GPU: at least 60GB GPU memory for 512 x 512 x 512 volume
- Actual Model Input (the size of image embedding in latent space): 128 x 128 x 128
- AMP: True
### Run finetuning:
This config executes finetuning for pretrained ControlNet with with a new class (i.e., Kidney Tumor). When finetuning with new class names, please update `configs/train.json`'s `weighted_loss_label` and `configs/label_dict.json` accordingly. There are 8 dummy labels as placeholders in default `configs/label_dict.json` that can be used for finetuning.
```
python -m monai.bundle run --config_file configs/train.json
```
### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
### Data:
The preprocessed subset of [C4KC-KiTS](https://www.cancerimagingarchive.net/collection/c4kc-kits/) dataset used in this finetuning config is provided in `./dataset/C4KC-KiTS_subset`.
```
|-*arterial*.nii.gz # original image
|-*arterial_emb*.nii.gz # encoded image embedding
KiTS-000* --|-mask*.nii.gz # original labels
|-mask_pseudo_label*.nii.gz # pseudo labels
|-mask_combined_label*.nii.gz # combined mask of original and pseudo labels
```
An example combined mask of original and pseudo labels is shown below:
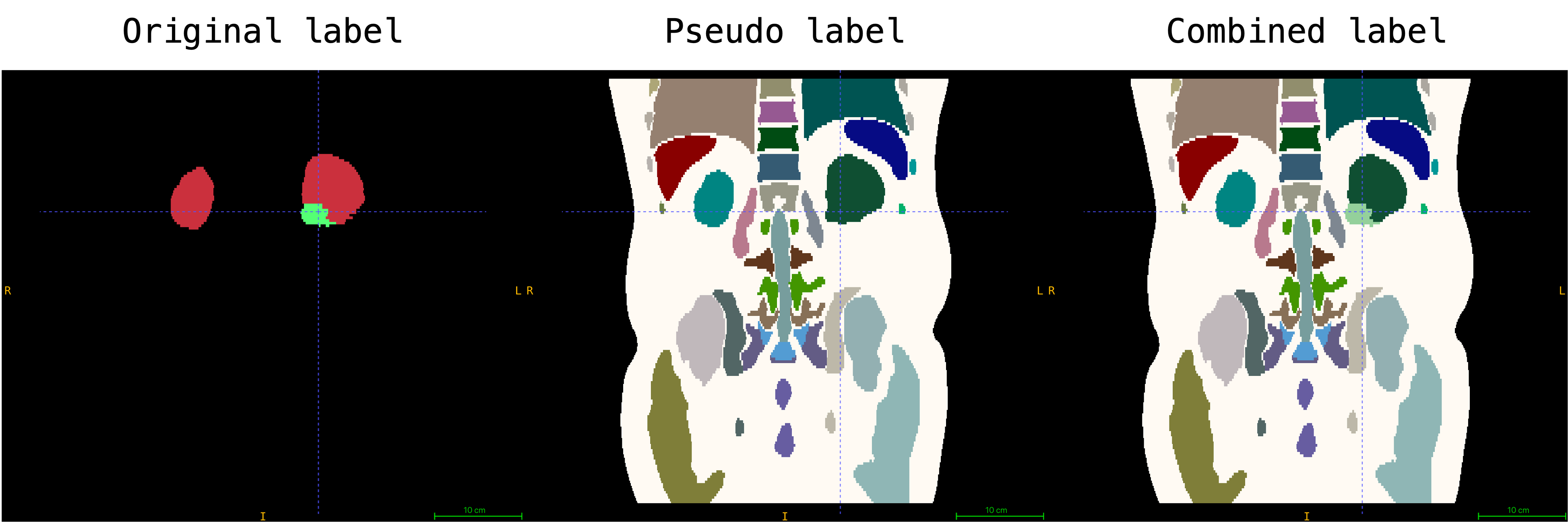
Please note that the label of Kidney Tumor is mapped to index `129` in this preprocessed dataset. The encoded image embedding is generated by provided `Autoencoder` in `./models/autoencoder_epoch273.pt` during preprocessing to save memeory usage for training. The pseudo labels are generated by [VISTA 3D](https://github.com/Project-MONAI/VISTA). In addition, the dimension of each volume and corresponding pseudo label is resampled to the closest multiple of 128 (e.g., 128, 256, 384, 512, ...).
The training workflow requires one JSON file to specify the image embedding and segmentation pairs. The example file is located in the `./dataset/C4KC-KiTS_subset.json`.
The JSON file has the following structure:
```python
{
"training": [
{
"image": "*/*arterial_emb*.nii.gz", # relative path to the image embedding file
"label": "*/mask_combined_label*.nii.gz", # relative path to the combined label file
"dim": [512, 512, 512], # the dimension of image
"spacing": [1.0, 1.0, 1.0], # the spacing of image
"top_region_index": [0, 1, 0, 0], # the top region index of the image
"bottom_region_index": [0, 0, 0, 1], # the bottom region index of the image
"fold": 0 # fold index for cross validation, fold 0 is used for training
},
...
]
}
```
# References
[1] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
# License
## Code License
This project includes code licensed under the Apache License 2.0.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
## Model Weights License
The model weights included in this project are licensed under the NCLS v1 License.
Both licenses' full texts have been combined into a single `LICENSE` file. Please refer to this `LICENSE` file for more details about the terms and conditions of both licenses.
|