

Upload pathology_nuclei_segmentation_classification version 0.2.7
Browse files- LICENSE +201 -0
- configs/evaluate.json +172 -0
- configs/inference.json +154 -0
- configs/inference_trt.json +10 -0
- configs/logging.conf +21 -0
- configs/metadata.json +135 -0
- configs/multi_gpu_train.json +40 -0
- configs/train.json +532 -0
- docs/README.md +185 -0
- docs/data_license.txt +6 -0
- models/model.pt +3 -0
- models/stage0/model.pt +3 -0
- scripts/prepare_patches.py +235 -0
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
configs/evaluate.json
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"val_images": "$list(sorted(glob.glob(@dataset_dir + '/Test/image*.npy')))",
|
| 3 |
+
"val_labels": "$list(sorted(glob.glob(@dataset_dir + '/Test/label*.npy')))",
|
| 4 |
+
"data_list": "$[{'image': i, 'label': j} for i, j in zip(@val_images, @val_labels)]",
|
| 5 |
+
"network_def": {
|
| 6 |
+
"_target_": "HoVerNet",
|
| 7 |
+
"mode": "@hovernet_mode",
|
| 8 |
+
"adapt_standard_resnet": true,
|
| 9 |
+
"in_channels": 3,
|
| 10 |
+
"out_classes": 5
|
| 11 |
+
},
|
| 12 |
+
"sw_batch_size": 16,
|
| 13 |
+
"validate#dataset": {
|
| 14 |
+
"_target_": "CacheDataset",
|
| 15 |
+
"data": "@data_list",
|
| 16 |
+
"transform": "@validate#preprocessing",
|
| 17 |
+
"cache_rate": 1.0,
|
| 18 |
+
"num_workers": 4
|
| 19 |
+
},
|
| 20 |
+
"validate#preprocessing_transforms": [
|
| 21 |
+
{
|
| 22 |
+
"_target_": "LoadImaged",
|
| 23 |
+
"keys": [
|
| 24 |
+
"image",
|
| 25 |
+
"label"
|
| 26 |
+
]
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"_target_": "SplitDimd",
|
| 30 |
+
"keys": "label",
|
| 31 |
+
"output_postfixes": [
|
| 32 |
+
"inst",
|
| 33 |
+
"type"
|
| 34 |
+
],
|
| 35 |
+
"dim": -1
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"_target_": "EnsureChannelFirstd",
|
| 39 |
+
"keys": [
|
| 40 |
+
"image",
|
| 41 |
+
"label_inst",
|
| 42 |
+
"label_type"
|
| 43 |
+
],
|
| 44 |
+
"channel_dim": -1
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"_target_": "CastToTyped",
|
| 48 |
+
"keys": [
|
| 49 |
+
"image",
|
| 50 |
+
"label_inst"
|
| 51 |
+
],
|
| 52 |
+
"dtype": "$torch.int"
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"_target_": "ScaleIntensityRanged",
|
| 56 |
+
"keys": "image",
|
| 57 |
+
"a_min": 0.0,
|
| 58 |
+
"a_max": 255.0,
|
| 59 |
+
"b_min": 0.0,
|
| 60 |
+
"b_max": 1.0,
|
| 61 |
+
"clip": true
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
"_target_": "ComputeHoVerMapsd",
|
| 65 |
+
"keys": "label_inst"
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"_target_": "Lambdad",
|
| 69 |
+
"keys": "label_inst",
|
| 70 |
+
"func": "$lambda x: x > 0",
|
| 71 |
+
"overwrite": "label"
|
| 72 |
+
},
|
| 73 |
+
{
|
| 74 |
+
"_target_": "CastToTyped",
|
| 75 |
+
"keys": [
|
| 76 |
+
"image",
|
| 77 |
+
"label_inst",
|
| 78 |
+
"label_type"
|
| 79 |
+
],
|
| 80 |
+
"dtype": "$torch.float32"
|
| 81 |
+
}
|
| 82 |
+
],
|
| 83 |
+
"validate#handlers": [
|
| 84 |
+
{
|
| 85 |
+
"_target_": "CheckpointLoader",
|
| 86 |
+
"load_path": "$os.path.join(@bundle_root, 'models', 'model.pt')",
|
| 87 |
+
"load_dict": {
|
| 88 |
+
"model": "@network"
|
| 89 |
+
}
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"_target_": "StatsHandler",
|
| 93 |
+
"output_transform": "$lambda x: None",
|
| 94 |
+
"iteration_log": false
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"_target_": "MetricsSaver",
|
| 98 |
+
"save_dir": "@output_dir",
|
| 99 |
+
"metrics": [
|
| 100 |
+
"val_mean_dice"
|
| 101 |
+
],
|
| 102 |
+
"metric_details": [
|
| 103 |
+
"val_mean_dice"
|
| 104 |
+
],
|
| 105 |
+
"batch_transform": "$lambda x: [xx['image'].meta for xx in x]",
|
| 106 |
+
"summary_ops": "*"
|
| 107 |
+
}
|
| 108 |
+
],
|
| 109 |
+
"validate#inferer": {
|
| 110 |
+
"_target_": "SlidingWindowHoVerNetInferer",
|
| 111 |
+
"roi_size": "@patch_size",
|
| 112 |
+
"sw_batch_size": "@sw_batch_size",
|
| 113 |
+
"overlap": "$1.0 - float(@out_size) / float(@patch_size)",
|
| 114 |
+
"padding_mode": "constant",
|
| 115 |
+
"cval": 0,
|
| 116 |
+
"progress": true,
|
| 117 |
+
"extra_input_padding": "$((@patch_size - @out_size) // 2,) * 4"
|
| 118 |
+
},
|
| 119 |
+
"postprocessing_pred": {
|
| 120 |
+
"_target_": "Compose",
|
| 121 |
+
"transforms": [
|
| 122 |
+
{
|
| 123 |
+
"_target_": "HoVerNetInstanceMapPostProcessingd",
|
| 124 |
+
"sobel_kernel_size": 21,
|
| 125 |
+
"marker_threshold": 0.5,
|
| 126 |
+
"marker_radius": 2,
|
| 127 |
+
"device": "@device"
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"_target_": "HoVerNetNuclearTypePostProcessingd",
|
| 131 |
+
"device": "@device"
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"_target_": "SaveImaged",
|
| 135 |
+
"keys": "instance_map",
|
| 136 |
+
"meta_keys": "image_meta_dict",
|
| 137 |
+
"output_ext": ".nii.gz",
|
| 138 |
+
"output_dir": "@output_dir",
|
| 139 |
+
"output_postfix": "instance_map",
|
| 140 |
+
"output_dtype": "uint32",
|
| 141 |
+
"separate_folder": false
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"_target_": "SaveImaged",
|
| 145 |
+
"keys": "type_map",
|
| 146 |
+
"meta_keys": "image_meta_dict",
|
| 147 |
+
"output_ext": ".nii.gz",
|
| 148 |
+
"output_dir": "@output_dir",
|
| 149 |
+
"output_postfix": "type_map",
|
| 150 |
+
"output_dtype": "uint8",
|
| 151 |
+
"separate_folder": false
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"_target_": "Lambdad",
|
| 155 |
+
"keys": "instance_map",
|
| 156 |
+
"func": "$lambda x: x > 0",
|
| 157 |
+
"overwrite": "nucleus_prediction"
|
| 158 |
+
}
|
| 159 |
+
]
|
| 160 |
+
},
|
| 161 |
+
"validate#postprocessing": {
|
| 162 |
+
"_target_": "Lambdad",
|
| 163 |
+
"keys": "pred",
|
| 164 |
+
"func": "@postprocessing_pred"
|
| 165 |
+
},
|
| 166 |
+
"initialize": [
|
| 167 |
+
"$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 168 |
+
],
|
| 169 |
+
"run": [
|
| 170 |
+
"$@validate#evaluator.run()"
|
| 171 |
+
]
|
| 172 |
+
}
|
configs/inference.json
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import glob",
|
| 4 |
+
"$import os"
|
| 5 |
+
],
|
| 6 |
+
"bundle_root": ".",
|
| 7 |
+
"output_dir": "$os.path.join(@bundle_root, 'eval')",
|
| 8 |
+
"dataset_dir": "/workspace/Data/Pathology/CoNSeP/Test/Images",
|
| 9 |
+
"num_cpus": 2,
|
| 10 |
+
"batch_size": 1,
|
| 11 |
+
"sw_batch_size": 16,
|
| 12 |
+
"hovernet_mode": "fast",
|
| 13 |
+
"patch_size": 256,
|
| 14 |
+
"out_size": 164,
|
| 15 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 16 |
+
"network_def": {
|
| 17 |
+
"_target_": "HoVerNet",
|
| 18 |
+
"mode": "@hovernet_mode",
|
| 19 |
+
"adapt_standard_resnet": true,
|
| 20 |
+
"in_channels": 3,
|
| 21 |
+
"out_classes": 5
|
| 22 |
+
},
|
| 23 |
+
"network": "$@network_def.to(@device)",
|
| 24 |
+
"preprocessing": {
|
| 25 |
+
"_target_": "Compose",
|
| 26 |
+
"transforms": [
|
| 27 |
+
{
|
| 28 |
+
"_target_": "LoadImaged",
|
| 29 |
+
"keys": "image",
|
| 30 |
+
"reader": "$monai.data.PILReader",
|
| 31 |
+
"converter": "$lambda x: x.convert('RGB')"
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"_target_": "EnsureChannelFirstd",
|
| 35 |
+
"keys": "image"
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"_target_": "CastToTyped",
|
| 39 |
+
"keys": "image",
|
| 40 |
+
"dtype": "float32"
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
"_target_": "ScaleIntensityRanged",
|
| 44 |
+
"keys": "image",
|
| 45 |
+
"a_min": 0.0,
|
| 46 |
+
"a_max": 255.0,
|
| 47 |
+
"b_min": 0.0,
|
| 48 |
+
"b_max": 1.0,
|
| 49 |
+
"clip": true
|
| 50 |
+
}
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
"data_list": "$[{'image': image} for image in glob.glob(os.path.join(@dataset_dir, '*.png'))]",
|
| 54 |
+
"dataset": {
|
| 55 |
+
"_target_": "Dataset",
|
| 56 |
+
"data": "@data_list",
|
| 57 |
+
"transform": "@preprocessing"
|
| 58 |
+
},
|
| 59 |
+
"dataloader": {
|
| 60 |
+
"_target_": "DataLoader",
|
| 61 |
+
"dataset": "@dataset",
|
| 62 |
+
"batch_size": "@batch_size",
|
| 63 |
+
"shuffle": false,
|
| 64 |
+
"num_workers": "@num_cpus",
|
| 65 |
+
"pin_memory": true
|
| 66 |
+
},
|
| 67 |
+
"inferer": {
|
| 68 |
+
"_target_": "SlidingWindowHoVerNetInferer",
|
| 69 |
+
"roi_size": "@patch_size",
|
| 70 |
+
"sw_batch_size": "@sw_batch_size",
|
| 71 |
+
"overlap": "$1.0 - float(@out_size) / float(@patch_size)",
|
| 72 |
+
"padding_mode": "constant",
|
| 73 |
+
"cval": 0,
|
| 74 |
+
"progress": true,
|
| 75 |
+
"extra_input_padding": "$((@patch_size - @out_size) // 2,) * 4"
|
| 76 |
+
},
|
| 77 |
+
"sub_keys": [
|
| 78 |
+
"horizontal_vertical",
|
| 79 |
+
"nucleus_prediction",
|
| 80 |
+
"type_prediction"
|
| 81 |
+
],
|
| 82 |
+
"postprocessing": {
|
| 83 |
+
"_target_": "Compose",
|
| 84 |
+
"transforms": [
|
| 85 |
+
{
|
| 86 |
+
"_target_": "FlattenSubKeysd",
|
| 87 |
+
"keys": "pred",
|
| 88 |
+
"sub_keys": "$@sub_keys",
|
| 89 |
+
"delete_keys": true
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"_target_": "HoVerNetInstanceMapPostProcessingd",
|
| 93 |
+
"sobel_kernel_size": 21,
|
| 94 |
+
"marker_threshold": 0.4,
|
| 95 |
+
"marker_radius": 2
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"_target_": "HoVerNetNuclearTypePostProcessingd"
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"_target_": "FromMetaTensord",
|
| 102 |
+
"keys": [
|
| 103 |
+
"image"
|
| 104 |
+
]
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"_target_": "SaveImaged",
|
| 108 |
+
"keys": "instance_map",
|
| 109 |
+
"meta_keys": "image_meta_dict",
|
| 110 |
+
"output_ext": ".nii.gz",
|
| 111 |
+
"output_dir": "@output_dir",
|
| 112 |
+
"output_postfix": "instance_map",
|
| 113 |
+
"output_dtype": "uint32",
|
| 114 |
+
"separate_folder": false
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"_target_": "SaveImaged",
|
| 118 |
+
"keys": "type_map",
|
| 119 |
+
"meta_keys": "image_meta_dict",
|
| 120 |
+
"output_ext": ".nii.gz",
|
| 121 |
+
"output_dir": "@output_dir",
|
| 122 |
+
"output_postfix": "type_map",
|
| 123 |
+
"output_dtype": "uint8",
|
| 124 |
+
"separate_folder": false
|
| 125 |
+
}
|
| 126 |
+
]
|
| 127 |
+
},
|
| 128 |
+
"handlers": [
|
| 129 |
+
{
|
| 130 |
+
"_target_": "CheckpointLoader",
|
| 131 |
+
"load_path": "$os.path.join(@bundle_root, 'models', 'model.pt')",
|
| 132 |
+
"map_location": "@device",
|
| 133 |
+
"load_dict": {
|
| 134 |
+
"model": "@network"
|
| 135 |
+
}
|
| 136 |
+
}
|
| 137 |
+
],
|
| 138 |
+
"evaluator": {
|
| 139 |
+
"_target_": "SupervisedEvaluator",
|
| 140 |
+
"device": "@device",
|
| 141 |
+
"val_data_loader": "@dataloader",
|
| 142 |
+
"val_handlers": "@handlers",
|
| 143 |
+
"network": "@network",
|
| 144 |
+
"postprocessing": "@postprocessing",
|
| 145 |
+
"inferer": "@inferer",
|
| 146 |
+
"amp": true
|
| 147 |
+
},
|
| 148 |
+
"initialize": [
|
| 149 |
+
"$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 150 |
+
],
|
| 151 |
+
"run": [
|
| 152 |
+
"[email protected]()"
|
| 153 |
+
]
|
| 154 |
+
}
|
configs/inference_trt.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"+imports": [
|
| 3 |
+
"$from monai.networks import trt_compile"
|
| 4 |
+
],
|
| 5 |
+
"trt_args": {
|
| 6 |
+
"output_names": "$@sub_keys",
|
| 7 |
+
"dynamic_batchsize": "$[1, @sw_batch_size, @sw_batch_size]"
|
| 8 |
+
},
|
| 9 |
+
"network": "$trt_compile(@network_def.to(@device), @bundle_root + '/models/model.pt', args=@trt_args)"
|
| 10 |
+
}
|
configs/logging.conf
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[loggers]
|
| 2 |
+
keys=root
|
| 3 |
+
|
| 4 |
+
[handlers]
|
| 5 |
+
keys=consoleHandler
|
| 6 |
+
|
| 7 |
+
[formatters]
|
| 8 |
+
keys=fullFormatter
|
| 9 |
+
|
| 10 |
+
[logger_root]
|
| 11 |
+
level=INFO
|
| 12 |
+
handlers=consoleHandler
|
| 13 |
+
|
| 14 |
+
[handler_consoleHandler]
|
| 15 |
+
class=StreamHandler
|
| 16 |
+
level=INFO
|
| 17 |
+
formatter=fullFormatter
|
| 18 |
+
args=(sys.stdout,)
|
| 19 |
+
|
| 20 |
+
[formatter_fullFormatter]
|
| 21 |
+
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
configs/metadata.json
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_hovernet_20221124.json",
|
| 3 |
+
"version": "0.2.7",
|
| 4 |
+
"changelog": {
|
| 5 |
+
"0.2.7": "update to huggingface hosting",
|
| 6 |
+
"0.2.6": "update tensorrt benchmark results",
|
| 7 |
+
"0.2.5": "enable tensorrt",
|
| 8 |
+
"0.2.4": "update to use monai 1.3.1",
|
| 9 |
+
"0.2.3": "remove meta_dict usage",
|
| 10 |
+
"0.2.2": "add requiremnts for torchvision",
|
| 11 |
+
"0.2.1": "fix the wrong GPU index issue of multi-node",
|
| 12 |
+
"0.2.0": "Update README for how to download dataset",
|
| 13 |
+
"0.1.9": "add RAM warning",
|
| 14 |
+
"0.1.8": "Update README for pretrained weights and save metrics in evaluate",
|
| 15 |
+
"0.1.7": "Update README Formatting",
|
| 16 |
+
"0.1.6": "add non-deterministic note",
|
| 17 |
+
"0.1.5": "update benchmark on A100",
|
| 18 |
+
"0.1.4": "adapt to BundleWorkflow interface",
|
| 19 |
+
"0.1.3": "add name tag",
|
| 20 |
+
"0.1.2": "update the workflow figure",
|
| 21 |
+
"0.1.1": "update to use monai 1.1.0",
|
| 22 |
+
"0.1.0": "complete the model package"
|
| 23 |
+
},
|
| 24 |
+
"monai_version": "1.4.0",
|
| 25 |
+
"pytorch_version": "2.4.0",
|
| 26 |
+
"numpy_version": "1.24.4",
|
| 27 |
+
"optional_packages_version": {
|
| 28 |
+
"scikit-image": "0.23.2",
|
| 29 |
+
"torchvision": "0.19.0",
|
| 30 |
+
"scipy": "1.13.1",
|
| 31 |
+
"tqdm": "4.66.4",
|
| 32 |
+
"pillow": "10.4.0",
|
| 33 |
+
"pytorch-ignite": "0.4.11",
|
| 34 |
+
"tensorboard": "2.17.0",
|
| 35 |
+
"nibabel": "5.2.1"
|
| 36 |
+
},
|
| 37 |
+
"name": "Nuclear segmentation and classification",
|
| 38 |
+
"task": "Nuclear segmentation and classification",
|
| 39 |
+
"description": "A simultaneous segmentation and classification of nuclei within multitissue histology images based on CoNSeP data",
|
| 40 |
+
"authors": "MONAI team",
|
| 41 |
+
"copyright": "Copyright (c) MONAI Consortium",
|
| 42 |
+
"data_source": "https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/",
|
| 43 |
+
"data_type": "numpy",
|
| 44 |
+
"image_classes": "RGB image with intensity between 0 and 255",
|
| 45 |
+
"label_classes": "a dictionary contains binary nuclear segmentation, hover map and pixel-level classification",
|
| 46 |
+
"pred_classes": "a dictionary contains scalar probability for binary nuclear segmentation, hover map and pixel-level classification",
|
| 47 |
+
"eval_metrics": {
|
| 48 |
+
"Binary Dice": 0.8291
|
| 49 |
+
},
|
| 50 |
+
"intended_use": "This is an example, not to be used for diagnostic purposes",
|
| 51 |
+
"references": [
|
| 52 |
+
"Simon Graham. 'HoVer-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology Images.' Medical Image Analysis, 2019. https://arxiv.org/abs/1812.06499"
|
| 53 |
+
],
|
| 54 |
+
"network_data_format": {
|
| 55 |
+
"inputs": {
|
| 56 |
+
"image": {
|
| 57 |
+
"type": "image",
|
| 58 |
+
"format": "magnitude",
|
| 59 |
+
"num_channels": 3,
|
| 60 |
+
"spatial_shape": [
|
| 61 |
+
"256",
|
| 62 |
+
"256"
|
| 63 |
+
],
|
| 64 |
+
"dtype": "float32",
|
| 65 |
+
"value_range": [
|
| 66 |
+
0,
|
| 67 |
+
255
|
| 68 |
+
],
|
| 69 |
+
"is_patch_data": true,
|
| 70 |
+
"channel_def": {
|
| 71 |
+
"0": "image"
|
| 72 |
+
}
|
| 73 |
+
}
|
| 74 |
+
},
|
| 75 |
+
"outputs": {
|
| 76 |
+
"nucleus_prediction": {
|
| 77 |
+
"type": "probability",
|
| 78 |
+
"format": "segmentation",
|
| 79 |
+
"num_channels": 3,
|
| 80 |
+
"spatial_shape": [
|
| 81 |
+
"164",
|
| 82 |
+
"164"
|
| 83 |
+
],
|
| 84 |
+
"dtype": "float32",
|
| 85 |
+
"value_range": [
|
| 86 |
+
0,
|
| 87 |
+
1
|
| 88 |
+
],
|
| 89 |
+
"is_patch_data": true,
|
| 90 |
+
"channel_def": {
|
| 91 |
+
"0": "background",
|
| 92 |
+
"1": "nuclei"
|
| 93 |
+
}
|
| 94 |
+
},
|
| 95 |
+
"horizontal_vertical": {
|
| 96 |
+
"type": "probability",
|
| 97 |
+
"format": "regression",
|
| 98 |
+
"num_channels": 2,
|
| 99 |
+
"spatial_shape": [
|
| 100 |
+
"164",
|
| 101 |
+
"164"
|
| 102 |
+
],
|
| 103 |
+
"dtype": "float32",
|
| 104 |
+
"value_range": [
|
| 105 |
+
0,
|
| 106 |
+
1
|
| 107 |
+
],
|
| 108 |
+
"is_patch_data": true,
|
| 109 |
+
"channel_def": {
|
| 110 |
+
"0": "horizontal distances map",
|
| 111 |
+
"1": "vertical distances map"
|
| 112 |
+
}
|
| 113 |
+
},
|
| 114 |
+
"type_prediction": {
|
| 115 |
+
"type": "probability",
|
| 116 |
+
"format": "classification",
|
| 117 |
+
"num_channels": 2,
|
| 118 |
+
"spatial_shape": [
|
| 119 |
+
"164",
|
| 120 |
+
"164"
|
| 121 |
+
],
|
| 122 |
+
"dtype": "float32",
|
| 123 |
+
"value_range": [
|
| 124 |
+
0,
|
| 125 |
+
1
|
| 126 |
+
],
|
| 127 |
+
"is_patch_data": true,
|
| 128 |
+
"channel_def": {
|
| 129 |
+
"0": "background",
|
| 130 |
+
"1": "type of nucleus for each pixel"
|
| 131 |
+
}
|
| 132 |
+
}
|
| 133 |
+
}
|
| 134 |
+
}
|
| 135 |
+
}
|
configs/multi_gpu_train.json
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"device": "$torch.device('cuda:' + os.environ['LOCAL_RANK'])",
|
| 3 |
+
"network": {
|
| 4 |
+
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
| 5 |
+
"module": "$@network_def.to(@device)",
|
| 6 |
+
"device_ids": [
|
| 7 |
+
"@device"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
"train#sampler": {
|
| 11 |
+
"_target_": "DistributedSampler",
|
| 12 |
+
"dataset": "@train#dataset",
|
| 13 |
+
"even_divisible": true,
|
| 14 |
+
"shuffle": true
|
| 15 |
+
},
|
| 16 |
+
"train#dataloader#sampler": "@train#sampler",
|
| 17 |
+
"train#dataloader#shuffle": false,
|
| 18 |
+
"train#trainer#train_handlers": "$@train#train_handlers[: -3 if dist.get_rank() > 0 else None]",
|
| 19 |
+
"validate#sampler": {
|
| 20 |
+
"_target_": "DistributedSampler",
|
| 21 |
+
"dataset": "@validate#dataset",
|
| 22 |
+
"even_divisible": false,
|
| 23 |
+
"shuffle": false
|
| 24 |
+
},
|
| 25 |
+
"validate#dataloader#sampler": "@validate#sampler",
|
| 26 |
+
"validate#evaluator#val_handlers": "$None if dist.get_rank() > 0 else @validate#handlers",
|
| 27 |
+
"initialize": [
|
| 28 |
+
"$import torch.distributed as dist",
|
| 29 |
+
"$dist.is_initialized() or dist.init_process_group(backend='nccl')",
|
| 30 |
+
"$torch.cuda.set_device(@device)",
|
| 31 |
+
"$monai.utils.set_determinism(seed=321)",
|
| 32 |
+
"$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 33 |
+
],
|
| 34 |
+
"run": [
|
| 35 |
+
"$@train#trainer.run()"
|
| 36 |
+
],
|
| 37 |
+
"finalize": [
|
| 38 |
+
"$dist.is_initialized() and dist.destroy_process_group()"
|
| 39 |
+
]
|
| 40 |
+
}
|
configs/train.json
ADDED
|
@@ -0,0 +1,532 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import glob",
|
| 4 |
+
"$import os",
|
| 5 |
+
"$import skimage"
|
| 6 |
+
],
|
| 7 |
+
"bundle_root": ".",
|
| 8 |
+
"ckpt_dir_stage0": "$os.path.join(@bundle_root, 'models', 'stage0')",
|
| 9 |
+
"ckpt_dir_stage1": "$os.path.join(@bundle_root, 'models')",
|
| 10 |
+
"ckpt_path_stage0": "$os.path.join(@ckpt_dir_stage0, 'model.pt')",
|
| 11 |
+
"output_dir": "$os.path.join(@bundle_root, 'eval')",
|
| 12 |
+
"dataset_dir": "/workspace/Data/Pathology/CoNSeP/Prepared/",
|
| 13 |
+
"train_images": "$list(sorted(glob.glob(@dataset_dir + '/Train/*image.npy')))",
|
| 14 |
+
"val_images": "$list(sorted(glob.glob(@dataset_dir + '/Test/*image.npy')))",
|
| 15 |
+
"train_inst_map": "$list(sorted(glob.glob(@dataset_dir + '/Train/*inst_map.npy')))",
|
| 16 |
+
"val_inst_map": "$list(sorted(glob.glob(@dataset_dir + '/Test/*inst_map.npy')))",
|
| 17 |
+
"train_type_map": "$list(sorted(glob.glob(@dataset_dir + '/Train/*type_map.npy')))",
|
| 18 |
+
"val_type_map": "$list(sorted(glob.glob(@dataset_dir + '/Test/*type_map.npy')))",
|
| 19 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 20 |
+
"stage": 0,
|
| 21 |
+
"epochs": 50,
|
| 22 |
+
"batch_size": 16,
|
| 23 |
+
"val_interval": 1,
|
| 24 |
+
"learning_rate": 0.0001,
|
| 25 |
+
"amp": true,
|
| 26 |
+
"hovernet_mode": "fast",
|
| 27 |
+
"patch_size": 256,
|
| 28 |
+
"out_size": 164,
|
| 29 |
+
"ckpt_dir": "$@ckpt_dir_stage0 if @stage == 0 else @ckpt_dir_stage1",
|
| 30 |
+
"network_def": {
|
| 31 |
+
"_target_": "HoVerNet",
|
| 32 |
+
"mode": "@hovernet_mode",
|
| 33 |
+
"in_channels": 3,
|
| 34 |
+
"out_classes": 5,
|
| 35 |
+
"adapt_standard_resnet": true,
|
| 36 |
+
"pretrained_url": null,
|
| 37 |
+
"freeze_encoder": true
|
| 38 |
+
},
|
| 39 |
+
"network": "$@network_def.to(@device)",
|
| 40 |
+
"loss": {
|
| 41 |
+
"_target_": "HoVerNetLoss",
|
| 42 |
+
"lambda_hv_mse": 1.0
|
| 43 |
+
},
|
| 44 |
+
"optimizer": {
|
| 45 |
+
"_target_": "torch.optim.Adam",
|
| 46 |
+
"params": "$filter(lambda p: p.requires_grad, @network.parameters())",
|
| 47 |
+
"lr": "@learning_rate",
|
| 48 |
+
"weight_decay": 1e-05
|
| 49 |
+
},
|
| 50 |
+
"lr_scheduler": {
|
| 51 |
+
"_target_": "torch.optim.lr_scheduler.StepLR",
|
| 52 |
+
"optimizer": "@optimizer",
|
| 53 |
+
"step_size": 25
|
| 54 |
+
},
|
| 55 |
+
"train": {
|
| 56 |
+
"preprocessing_transforms": [
|
| 57 |
+
{
|
| 58 |
+
"_target_": "LoadImaged",
|
| 59 |
+
"keys": [
|
| 60 |
+
"image",
|
| 61 |
+
"label_inst",
|
| 62 |
+
"label_type"
|
| 63 |
+
]
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"_target_": "EnsureChannelFirstd",
|
| 67 |
+
"keys": [
|
| 68 |
+
"image",
|
| 69 |
+
"label_inst",
|
| 70 |
+
"label_type"
|
| 71 |
+
],
|
| 72 |
+
"channel_dim": -1
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"_target_": "Lambdad",
|
| 76 |
+
"keys": "label_inst",
|
| 77 |
+
"func": "$lambda x: skimage.measure.label(x)"
|
| 78 |
+
},
|
| 79 |
+
{
|
| 80 |
+
"_target_": "RandAffined",
|
| 81 |
+
"keys": [
|
| 82 |
+
"image",
|
| 83 |
+
"label_inst",
|
| 84 |
+
"label_type"
|
| 85 |
+
],
|
| 86 |
+
"prob": 1.0,
|
| 87 |
+
"rotate_range": [
|
| 88 |
+
"$np.pi"
|
| 89 |
+
],
|
| 90 |
+
"scale_range": [
|
| 91 |
+
[
|
| 92 |
+
-0.2,
|
| 93 |
+
0.2
|
| 94 |
+
],
|
| 95 |
+
[
|
| 96 |
+
-0.2,
|
| 97 |
+
0.2
|
| 98 |
+
]
|
| 99 |
+
],
|
| 100 |
+
"shear_range": [
|
| 101 |
+
[
|
| 102 |
+
-0.05,
|
| 103 |
+
0.05
|
| 104 |
+
],
|
| 105 |
+
[
|
| 106 |
+
-0.05,
|
| 107 |
+
0.05
|
| 108 |
+
]
|
| 109 |
+
],
|
| 110 |
+
"translate_range": [
|
| 111 |
+
[
|
| 112 |
+
-6,
|
| 113 |
+
6
|
| 114 |
+
],
|
| 115 |
+
[
|
| 116 |
+
-6,
|
| 117 |
+
6
|
| 118 |
+
]
|
| 119 |
+
],
|
| 120 |
+
"padding_mode": "zeros",
|
| 121 |
+
"mode": "nearest"
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"_target_": "CenterSpatialCropd",
|
| 125 |
+
"keys": [
|
| 126 |
+
"image"
|
| 127 |
+
],
|
| 128 |
+
"roi_size": [
|
| 129 |
+
"@patch_size",
|
| 130 |
+
"@patch_size"
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"_target_": "RandFlipd",
|
| 135 |
+
"keys": [
|
| 136 |
+
"image",
|
| 137 |
+
"label_inst",
|
| 138 |
+
"label_type"
|
| 139 |
+
],
|
| 140 |
+
"prob": 0.5,
|
| 141 |
+
"spatial_axis": 0
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"_target_": "RandFlipd",
|
| 145 |
+
"keys": [
|
| 146 |
+
"image",
|
| 147 |
+
"label_inst",
|
| 148 |
+
"label_type"
|
| 149 |
+
],
|
| 150 |
+
"prob": 0.5,
|
| 151 |
+
"spatial_axis": 1
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"_target_": "OneOf",
|
| 155 |
+
"transforms": [
|
| 156 |
+
{
|
| 157 |
+
"_target_": "RandGaussianSmoothd",
|
| 158 |
+
"keys": [
|
| 159 |
+
"image"
|
| 160 |
+
],
|
| 161 |
+
"sigma_x": [
|
| 162 |
+
0.1,
|
| 163 |
+
1.1
|
| 164 |
+
],
|
| 165 |
+
"sigma_y": [
|
| 166 |
+
0.1,
|
| 167 |
+
1.1
|
| 168 |
+
],
|
| 169 |
+
"prob": 1.0
|
| 170 |
+
},
|
| 171 |
+
{
|
| 172 |
+
"_target_": "MedianSmoothd",
|
| 173 |
+
"keys": [
|
| 174 |
+
"image"
|
| 175 |
+
],
|
| 176 |
+
"radius": 1
|
| 177 |
+
},
|
| 178 |
+
{
|
| 179 |
+
"_target_": "RandGaussianNoised",
|
| 180 |
+
"keys": [
|
| 181 |
+
"image"
|
| 182 |
+
],
|
| 183 |
+
"std": 0.05,
|
| 184 |
+
"prob": 1.0
|
| 185 |
+
}
|
| 186 |
+
]
|
| 187 |
+
},
|
| 188 |
+
{
|
| 189 |
+
"_target_": "CastToTyped",
|
| 190 |
+
"keys": "image",
|
| 191 |
+
"dtype": "$np.uint8"
|
| 192 |
+
},
|
| 193 |
+
{
|
| 194 |
+
"_target_": "TorchVisiond",
|
| 195 |
+
"keys": "image",
|
| 196 |
+
"name": "ColorJitter",
|
| 197 |
+
"brightness": [
|
| 198 |
+
0.9,
|
| 199 |
+
1.1
|
| 200 |
+
],
|
| 201 |
+
"contrast": [
|
| 202 |
+
0.95,
|
| 203 |
+
1.1
|
| 204 |
+
],
|
| 205 |
+
"saturation": [
|
| 206 |
+
0.8,
|
| 207 |
+
1.2
|
| 208 |
+
],
|
| 209 |
+
"hue": [
|
| 210 |
+
-0.04,
|
| 211 |
+
0.04
|
| 212 |
+
]
|
| 213 |
+
},
|
| 214 |
+
{
|
| 215 |
+
"_target_": "AsDiscreted",
|
| 216 |
+
"keys": "label_type",
|
| 217 |
+
"to_onehot": 5
|
| 218 |
+
},
|
| 219 |
+
{
|
| 220 |
+
"_target_": "ScaleIntensityRanged",
|
| 221 |
+
"keys": "image",
|
| 222 |
+
"a_min": 0.0,
|
| 223 |
+
"a_max": 255.0,
|
| 224 |
+
"b_min": 0.0,
|
| 225 |
+
"b_max": 1.0,
|
| 226 |
+
"clip": true
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
"_target_": "CastToTyped",
|
| 230 |
+
"keys": "label_inst",
|
| 231 |
+
"dtype": "$torch.int"
|
| 232 |
+
},
|
| 233 |
+
{
|
| 234 |
+
"_target_": "ComputeHoVerMapsd",
|
| 235 |
+
"keys": "label_inst"
|
| 236 |
+
},
|
| 237 |
+
{
|
| 238 |
+
"_target_": "Lambdad",
|
| 239 |
+
"keys": "label_inst",
|
| 240 |
+
"func": "$lambda x: x > 0",
|
| 241 |
+
"overwrite": "label"
|
| 242 |
+
},
|
| 243 |
+
{
|
| 244 |
+
"_target_": "CenterSpatialCropd",
|
| 245 |
+
"keys": [
|
| 246 |
+
"label",
|
| 247 |
+
"hover_label_inst",
|
| 248 |
+
"label_inst",
|
| 249 |
+
"label_type"
|
| 250 |
+
],
|
| 251 |
+
"roi_size": [
|
| 252 |
+
"@out_size",
|
| 253 |
+
"@out_size"
|
| 254 |
+
]
|
| 255 |
+
},
|
| 256 |
+
{
|
| 257 |
+
"_target_": "AsDiscreted",
|
| 258 |
+
"keys": "label",
|
| 259 |
+
"to_onehot": 2
|
| 260 |
+
},
|
| 261 |
+
{
|
| 262 |
+
"_target_": "CastToTyped",
|
| 263 |
+
"keys": [
|
| 264 |
+
"image",
|
| 265 |
+
"label_inst",
|
| 266 |
+
"label_type"
|
| 267 |
+
],
|
| 268 |
+
"dtype": "$torch.float32"
|
| 269 |
+
}
|
| 270 |
+
],
|
| 271 |
+
"preprocessing": {
|
| 272 |
+
"_target_": "Compose",
|
| 273 |
+
"transforms": "$@train#preprocessing_transforms"
|
| 274 |
+
},
|
| 275 |
+
"dataset": {
|
| 276 |
+
"_target_": "CacheDataset",
|
| 277 |
+
"data": "$[{'image': i, 'label_inst': j, 'label_type': k} for i, j, k in zip(@train_images, @train_inst_map, @train_type_map)]",
|
| 278 |
+
"transform": "@train#preprocessing",
|
| 279 |
+
"cache_rate": 1.0,
|
| 280 |
+
"num_workers": 4
|
| 281 |
+
},
|
| 282 |
+
"dataloader": {
|
| 283 |
+
"_target_": "DataLoader",
|
| 284 |
+
"dataset": "@train#dataset",
|
| 285 |
+
"batch_size": "@batch_size",
|
| 286 |
+
"shuffle": true,
|
| 287 |
+
"num_workers": 4
|
| 288 |
+
},
|
| 289 |
+
"inferer": {
|
| 290 |
+
"_target_": "SimpleInferer"
|
| 291 |
+
},
|
| 292 |
+
"postprocessing_np": {
|
| 293 |
+
"_target_": "Compose",
|
| 294 |
+
"transforms": [
|
| 295 |
+
{
|
| 296 |
+
"_target_": "Activationsd",
|
| 297 |
+
"keys": "nucleus_prediction",
|
| 298 |
+
"softmax": true
|
| 299 |
+
},
|
| 300 |
+
{
|
| 301 |
+
"_target_": "AsDiscreted",
|
| 302 |
+
"keys": "nucleus_prediction",
|
| 303 |
+
"argmax": true
|
| 304 |
+
}
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
"postprocessing": {
|
| 308 |
+
"_target_": "Lambdad",
|
| 309 |
+
"keys": "pred",
|
| 310 |
+
"func": "$@train#postprocessing_np"
|
| 311 |
+
},
|
| 312 |
+
"handlers": [
|
| 313 |
+
{
|
| 314 |
+
"_target_": "LrScheduleHandler",
|
| 315 |
+
"lr_scheduler": "@lr_scheduler",
|
| 316 |
+
"print_lr": true
|
| 317 |
+
},
|
| 318 |
+
{
|
| 319 |
+
"_target_": "ValidationHandler",
|
| 320 |
+
"validator": "@validate#evaluator",
|
| 321 |
+
"epoch_level": true,
|
| 322 |
+
"interval": "@val_interval"
|
| 323 |
+
},
|
| 324 |
+
{
|
| 325 |
+
"_target_": "CheckpointSaver",
|
| 326 |
+
"save_dir": "@ckpt_dir",
|
| 327 |
+
"save_dict": {
|
| 328 |
+
"model": "@network"
|
| 329 |
+
},
|
| 330 |
+
"save_interval": 10,
|
| 331 |
+
"epoch_level": true,
|
| 332 |
+
"save_final": true,
|
| 333 |
+
"final_filename": "model.pt"
|
| 334 |
+
},
|
| 335 |
+
{
|
| 336 |
+
"_target_": "StatsHandler",
|
| 337 |
+
"tag_name": "train_loss",
|
| 338 |
+
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
| 339 |
+
},
|
| 340 |
+
{
|
| 341 |
+
"_target_": "TensorBoardStatsHandler",
|
| 342 |
+
"log_dir": "@output_dir",
|
| 343 |
+
"tag_name": "train_loss",
|
| 344 |
+
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
| 345 |
+
}
|
| 346 |
+
],
|
| 347 |
+
"extra_handlers": [
|
| 348 |
+
{
|
| 349 |
+
"_target_": "CheckpointLoader",
|
| 350 |
+
"load_path": "$os.path.join(@ckpt_dir_stage0, 'model.pt')",
|
| 351 |
+
"load_dict": {
|
| 352 |
+
"model": "@network"
|
| 353 |
+
}
|
| 354 |
+
}
|
| 355 |
+
],
|
| 356 |
+
"train_handlers": "$@train#extra_handlers + @train#handlers if @stage==1 else @train#handlers",
|
| 357 |
+
"key_metric": {
|
| 358 |
+
"train_mean_dice": {
|
| 359 |
+
"_target_": "MeanDice",
|
| 360 |
+
"include_background": false,
|
| 361 |
+
"output_transform": "$monai.apps.pathology.handlers.utils.from_engine_hovernet(keys=['pred', 'label'], nested_key='nucleus_prediction')"
|
| 362 |
+
}
|
| 363 |
+
},
|
| 364 |
+
"trainer": {
|
| 365 |
+
"_target_": "SupervisedTrainer",
|
| 366 |
+
"max_epochs": "@epochs",
|
| 367 |
+
"device": "@device",
|
| 368 |
+
"train_data_loader": "@train#dataloader",
|
| 369 |
+
"prepare_batch": "$monai.apps.pathology.engines.utils.PrepareBatchHoVerNet(extra_keys=['label_type', 'hover_label_inst'])",
|
| 370 |
+
"network": "@network",
|
| 371 |
+
"loss_function": "@loss",
|
| 372 |
+
"optimizer": "@optimizer",
|
| 373 |
+
"inferer": "@train#inferer",
|
| 374 |
+
"postprocessing": "@train#postprocessing",
|
| 375 |
+
"key_train_metric": "@train#key_metric",
|
| 376 |
+
"train_handlers": "@train#train_handlers",
|
| 377 |
+
"amp": "@amp"
|
| 378 |
+
}
|
| 379 |
+
},
|
| 380 |
+
"validate": {
|
| 381 |
+
"preprocessing_transforms": [
|
| 382 |
+
{
|
| 383 |
+
"_target_": "LoadImaged",
|
| 384 |
+
"keys": [
|
| 385 |
+
"image",
|
| 386 |
+
"label_inst",
|
| 387 |
+
"label_type"
|
| 388 |
+
]
|
| 389 |
+
},
|
| 390 |
+
{
|
| 391 |
+
"_target_": "EnsureChannelFirstd",
|
| 392 |
+
"keys": [
|
| 393 |
+
"image",
|
| 394 |
+
"label_inst",
|
| 395 |
+
"label_type"
|
| 396 |
+
],
|
| 397 |
+
"channel_dim": -1
|
| 398 |
+
},
|
| 399 |
+
{
|
| 400 |
+
"_target_": "Lambdad",
|
| 401 |
+
"keys": "label_inst",
|
| 402 |
+
"func": "$lambda x: skimage.measure.label(x)"
|
| 403 |
+
},
|
| 404 |
+
{
|
| 405 |
+
"_target_": "CastToTyped",
|
| 406 |
+
"keys": [
|
| 407 |
+
"image",
|
| 408 |
+
"label_inst"
|
| 409 |
+
],
|
| 410 |
+
"dtype": "$torch.int"
|
| 411 |
+
},
|
| 412 |
+
{
|
| 413 |
+
"_target_": "CenterSpatialCropd",
|
| 414 |
+
"keys": [
|
| 415 |
+
"image"
|
| 416 |
+
],
|
| 417 |
+
"roi_size": [
|
| 418 |
+
"@patch_size",
|
| 419 |
+
"@patch_size"
|
| 420 |
+
]
|
| 421 |
+
},
|
| 422 |
+
{
|
| 423 |
+
"_target_": "ScaleIntensityRanged",
|
| 424 |
+
"keys": "image",
|
| 425 |
+
"a_min": 0.0,
|
| 426 |
+
"a_max": 255.0,
|
| 427 |
+
"b_min": 0.0,
|
| 428 |
+
"b_max": 1.0,
|
| 429 |
+
"clip": true
|
| 430 |
+
},
|
| 431 |
+
{
|
| 432 |
+
"_target_": "ComputeHoVerMapsd",
|
| 433 |
+
"keys": "label_inst"
|
| 434 |
+
},
|
| 435 |
+
{
|
| 436 |
+
"_target_": "Lambdad",
|
| 437 |
+
"keys": "label_inst",
|
| 438 |
+
"func": "$lambda x: x > 0",
|
| 439 |
+
"overwrite": "label"
|
| 440 |
+
},
|
| 441 |
+
{
|
| 442 |
+
"_target_": "CenterSpatialCropd",
|
| 443 |
+
"keys": [
|
| 444 |
+
"label",
|
| 445 |
+
"hover_label_inst",
|
| 446 |
+
"label_inst",
|
| 447 |
+
"label_type"
|
| 448 |
+
],
|
| 449 |
+
"roi_size": [
|
| 450 |
+
"@out_size",
|
| 451 |
+
"@out_size"
|
| 452 |
+
]
|
| 453 |
+
},
|
| 454 |
+
{
|
| 455 |
+
"_target_": "CastToTyped",
|
| 456 |
+
"keys": [
|
| 457 |
+
"image",
|
| 458 |
+
"label_inst",
|
| 459 |
+
"label_type"
|
| 460 |
+
],
|
| 461 |
+
"dtype": "$torch.float32"
|
| 462 |
+
}
|
| 463 |
+
],
|
| 464 |
+
"preprocessing": {
|
| 465 |
+
"_target_": "Compose",
|
| 466 |
+
"transforms": "$@validate#preprocessing_transforms"
|
| 467 |
+
},
|
| 468 |
+
"dataset": {
|
| 469 |
+
"_target_": "CacheDataset",
|
| 470 |
+
"data": "$[{'image': i, 'label_inst': j, 'label_type': k} for i, j, k in zip(@val_images, @val_inst_map, @val_type_map)]",
|
| 471 |
+
"transform": "@validate#preprocessing",
|
| 472 |
+
"cache_rate": 1.0,
|
| 473 |
+
"num_workers": 4
|
| 474 |
+
},
|
| 475 |
+
"dataloader": {
|
| 476 |
+
"_target_": "DataLoader",
|
| 477 |
+
"dataset": "@validate#dataset",
|
| 478 |
+
"batch_size": "@batch_size",
|
| 479 |
+
"shuffle": false,
|
| 480 |
+
"num_workers": 4
|
| 481 |
+
},
|
| 482 |
+
"inferer": {
|
| 483 |
+
"_target_": "SimpleInferer"
|
| 484 |
+
},
|
| 485 |
+
"postprocessing": "$@train#postprocessing",
|
| 486 |
+
"handlers": [
|
| 487 |
+
{
|
| 488 |
+
"_target_": "StatsHandler",
|
| 489 |
+
"iteration_log": false
|
| 490 |
+
},
|
| 491 |
+
{
|
| 492 |
+
"_target_": "TensorBoardStatsHandler",
|
| 493 |
+
"log_dir": "@output_dir",
|
| 494 |
+
"iteration_log": false
|
| 495 |
+
},
|
| 496 |
+
{
|
| 497 |
+
"_target_": "CheckpointSaver",
|
| 498 |
+
"save_dir": "@ckpt_dir",
|
| 499 |
+
"save_dict": {
|
| 500 |
+
"model": "@network"
|
| 501 |
+
},
|
| 502 |
+
"save_key_metric": true
|
| 503 |
+
}
|
| 504 |
+
],
|
| 505 |
+
"key_metric": {
|
| 506 |
+
"val_mean_dice": {
|
| 507 |
+
"_target_": "MeanDice",
|
| 508 |
+
"include_background": false,
|
| 509 |
+
"output_transform": "$monai.apps.pathology.handlers.utils.from_engine_hovernet(keys=['pred', 'label'], nested_key='nucleus_prediction')"
|
| 510 |
+
}
|
| 511 |
+
},
|
| 512 |
+
"evaluator": {
|
| 513 |
+
"_target_": "SupervisedEvaluator",
|
| 514 |
+
"device": "@device",
|
| 515 |
+
"val_data_loader": "@validate#dataloader",
|
| 516 |
+
"prepare_batch": "$monai.apps.pathology.engines.utils.PrepareBatchHoVerNet(extra_keys=['label_type', 'hover_label_inst'])",
|
| 517 |
+
"network": "@network",
|
| 518 |
+
"inferer": "@validate#inferer",
|
| 519 |
+
"postprocessing": "@validate#postprocessing",
|
| 520 |
+
"key_val_metric": "@validate#key_metric",
|
| 521 |
+
"val_handlers": "@validate#handlers",
|
| 522 |
+
"amp": "@amp"
|
| 523 |
+
}
|
| 524 |
+
},
|
| 525 |
+
"initialize": [
|
| 526 |
+
"$monai.utils.set_determinism(seed=321)",
|
| 527 |
+
"$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 528 |
+
],
|
| 529 |
+
"run": [
|
| 530 |
+
"$@train#trainer.run()"
|
| 531 |
+
]
|
| 532 |
+
}
|
docs/README.md
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Overview
|
| 2 |
+
A pre-trained model for simultaneous segmentation and classification of nuclei within multi-tissue histology images based on CoNSeP data. The details of the model can be found in [1].
|
| 3 |
+
|
| 4 |
+
The model is trained to simultaneously segment and classify nuclei, and a two-stage training approach is utilized:
|
| 5 |
+
|
| 6 |
+
- Initialize the model with pre-trained weights, and train the decoder only for 50 epochs.
|
| 7 |
+
- Finetune all layers for another 50 epochs.
|
| 8 |
+
|
| 9 |
+
There are two training modes in total. If "original" mode is specified, [270, 270] and [80, 80] are used for `patch_size` and `out_size` respectively. If "fast" mode is specified, [256, 256] and [164, 164] are used for `patch_size` and `out_size` respectively. The results shown below are based on the "fast" mode.
|
| 10 |
+
|
| 11 |
+
In this bundle, the first stage is trained with pre-trained weights from some internal data. The [original author's repo](https://github.com/vqdang/hover_net) and [torchvison](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet18_Weights) also provide pre-trained weights but for non-commercial use.
|
| 12 |
+
Each user is responsible for checking the content of models/datasets and the applicable licenses and determining if suitable for the intended use.
|
| 13 |
+
|
| 14 |
+
If you want to train the first stage with pre-trained weights, just specify `--network_def#pretrained_url <your pretrain weights URL>` in the training command below, such as [ImageNet](https://download.pytorch.org/models/resnet18-f37072fd.pth).
|
| 15 |
+
|
| 16 |
+
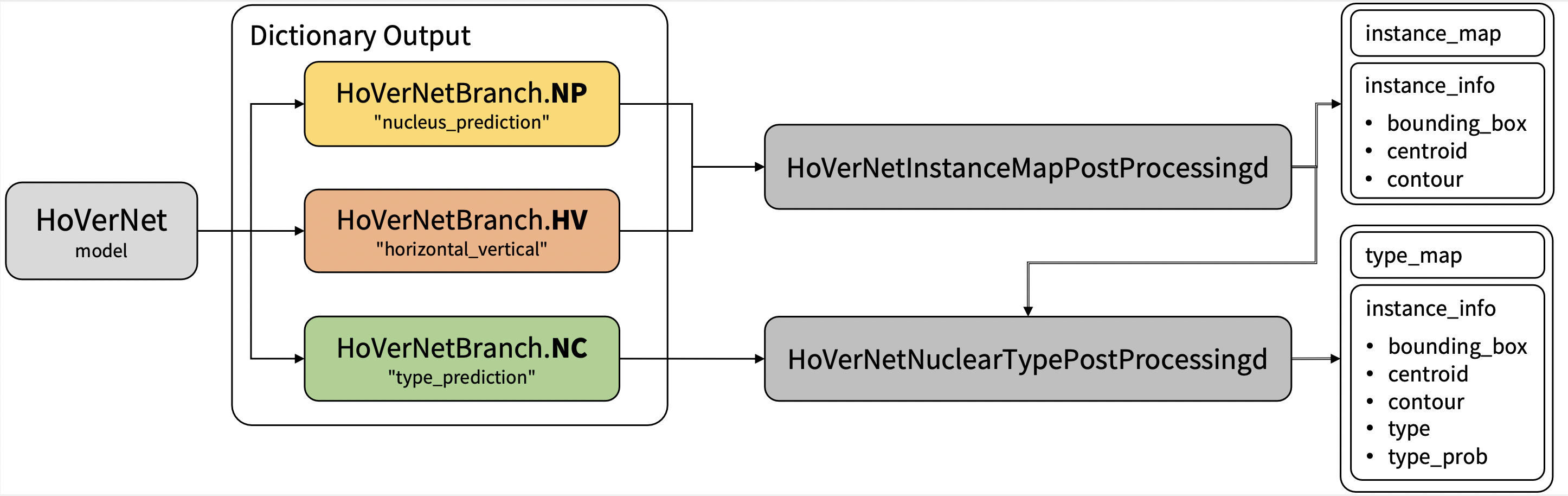
|
| 17 |
+
|
| 18 |
+
## Data
|
| 19 |
+
The training data is from <https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/>.
|
| 20 |
+
|
| 21 |
+
- Target: segment instance-level nuclei and classify the nuclei type
|
| 22 |
+
- Task: Segmentation and classification
|
| 23 |
+
- Modality: RGB images
|
| 24 |
+
- Size: 41 image tiles (2009 patches)
|
| 25 |
+
|
| 26 |
+
The provided labelled data was partitioned, based on the original split, into training (27 tiles) and testing (14 tiles) datasets.
|
| 27 |
+
|
| 28 |
+
You can download the dataset by using this command:
|
| 29 |
+
```
|
| 30 |
+
wget https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip
|
| 31 |
+
unzip consep_dataset.zip
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
### Preprocessing
|
| 35 |
+
|
| 36 |
+
After download the [datasets](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip), please run `scripts/prepare_patches.py` to prepare patches from tiles. Prepared patches are saved in `<your concep dataset path>`/Prepared. The implementation is referring to <https://github.com/vqdang/hover_net>. The command is like:
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
python scripts/prepare_patches.py --root <your concep dataset path>
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
## Training configuration
|
| 43 |
+
This model utilized a two-stage approach. The training was performed with the following:
|
| 44 |
+
|
| 45 |
+
- GPU: At least 24GB of GPU memory.
|
| 46 |
+
- Actual Model Input: 256 x 256
|
| 47 |
+
- AMP: True
|
| 48 |
+
- Optimizer: Adam
|
| 49 |
+
- Learning Rate: 1e-4
|
| 50 |
+
- Loss: HoVerNetLoss
|
| 51 |
+
- Dataset Manager: CacheDataset
|
| 52 |
+
|
| 53 |
+
### Memory Consumption Warning
|
| 54 |
+
|
| 55 |
+
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
|
| 56 |
+
|
| 57 |
+
## Input
|
| 58 |
+
Input: RGB images
|
| 59 |
+
|
| 60 |
+
## Output
|
| 61 |
+
Output: a dictionary with the following keys:
|
| 62 |
+
|
| 63 |
+
1. nucleus_prediction: predict whether or not a pixel belongs to the nuclei or background
|
| 64 |
+
2. horizontal_vertical: predict the horizontal and vertical distances of nuclear pixels to their centres of mass
|
| 65 |
+
3. type_prediction: predict the type of nucleus for each pixel
|
| 66 |
+
|
| 67 |
+
## Performance
|
| 68 |
+
The achieved metrics on the validation data are:
|
| 69 |
+
|
| 70 |
+
Fast mode:
|
| 71 |
+
- Binary Dice: 0.8291
|
| 72 |
+
- PQ: 0.4973
|
| 73 |
+
- F1d: 0.7417
|
| 74 |
+
|
| 75 |
+
Note:
|
| 76 |
+
- Binary Dice is calculated based on the whole input. PQ and F1d were calculated from https://github.com/vqdang/hover_net#inference.
|
| 77 |
+
- This bundle is non-deterministic because of the bilinear interpolation used in the network. Therefore, reproducing the training process may not get exactly the same performance.
|
| 78 |
+
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
|
| 79 |
+
|
| 80 |
+
#### Training Loss and Dice
|
| 81 |
+
stage1:
|
| 82 |
+
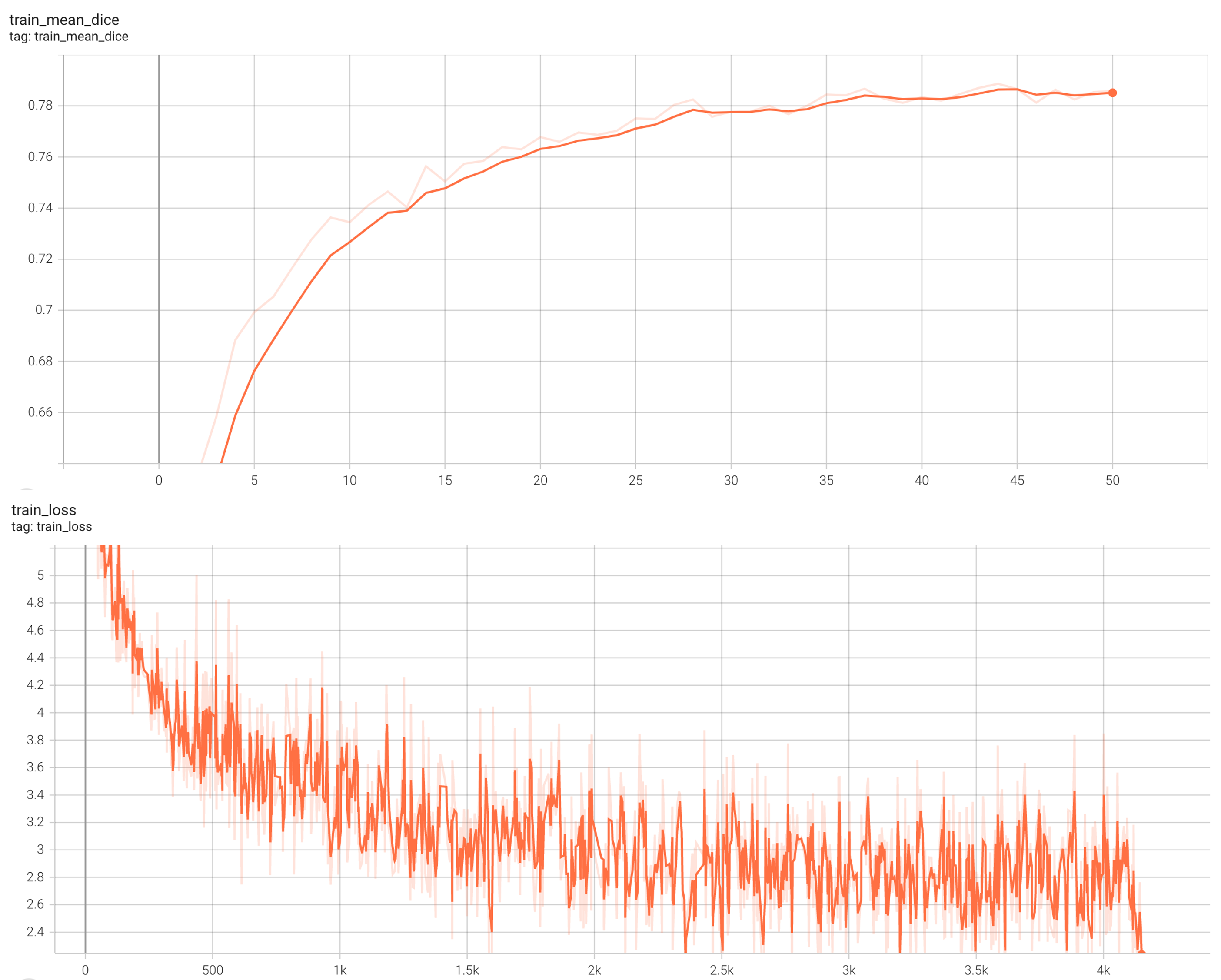
|
| 83 |
+
|
| 84 |
+
stage2:
|
| 85 |
+
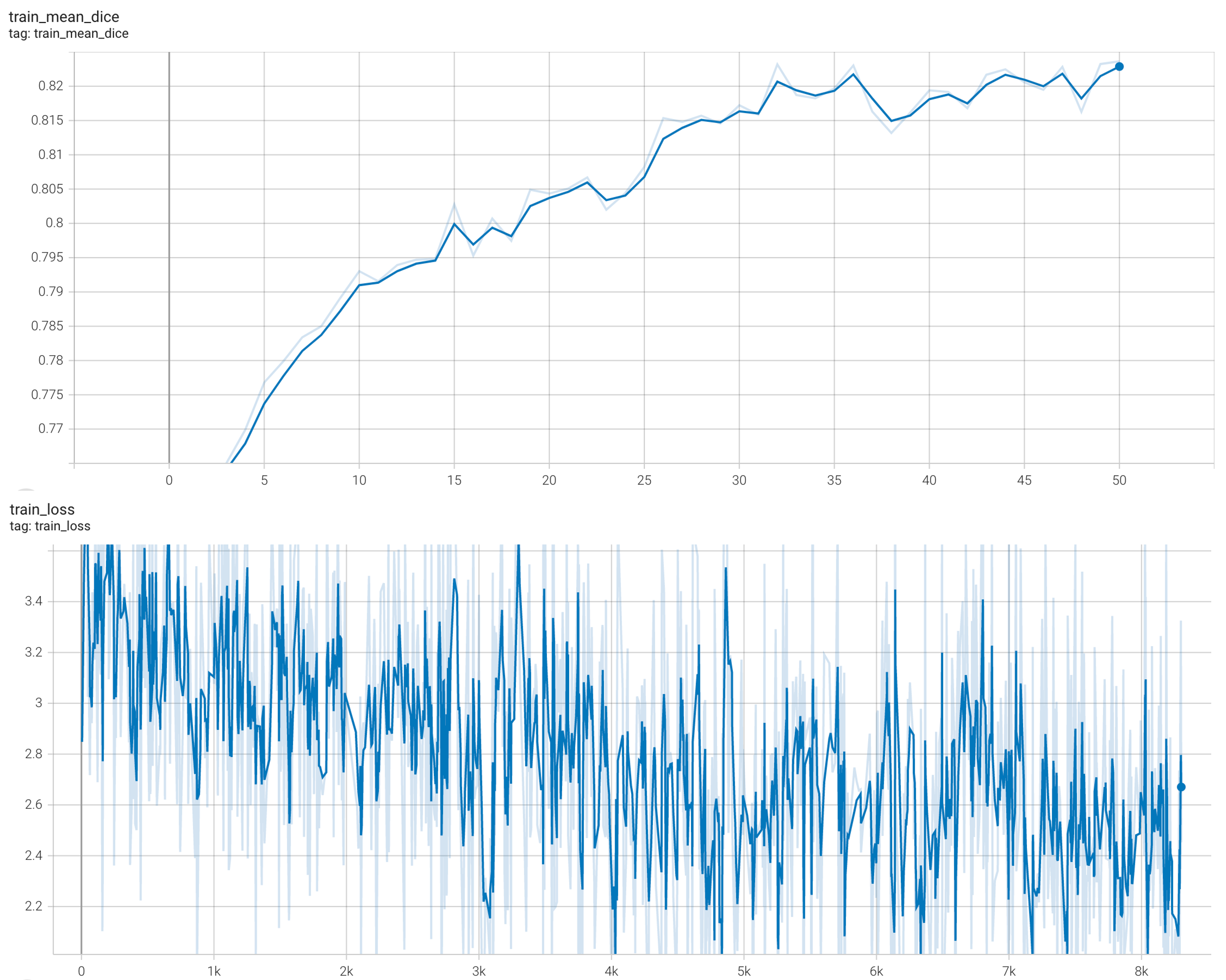
|
| 86 |
+
|
| 87 |
+
#### Validation Dice
|
| 88 |
+
stage1:
|
| 89 |
+
|
| 90 |
+
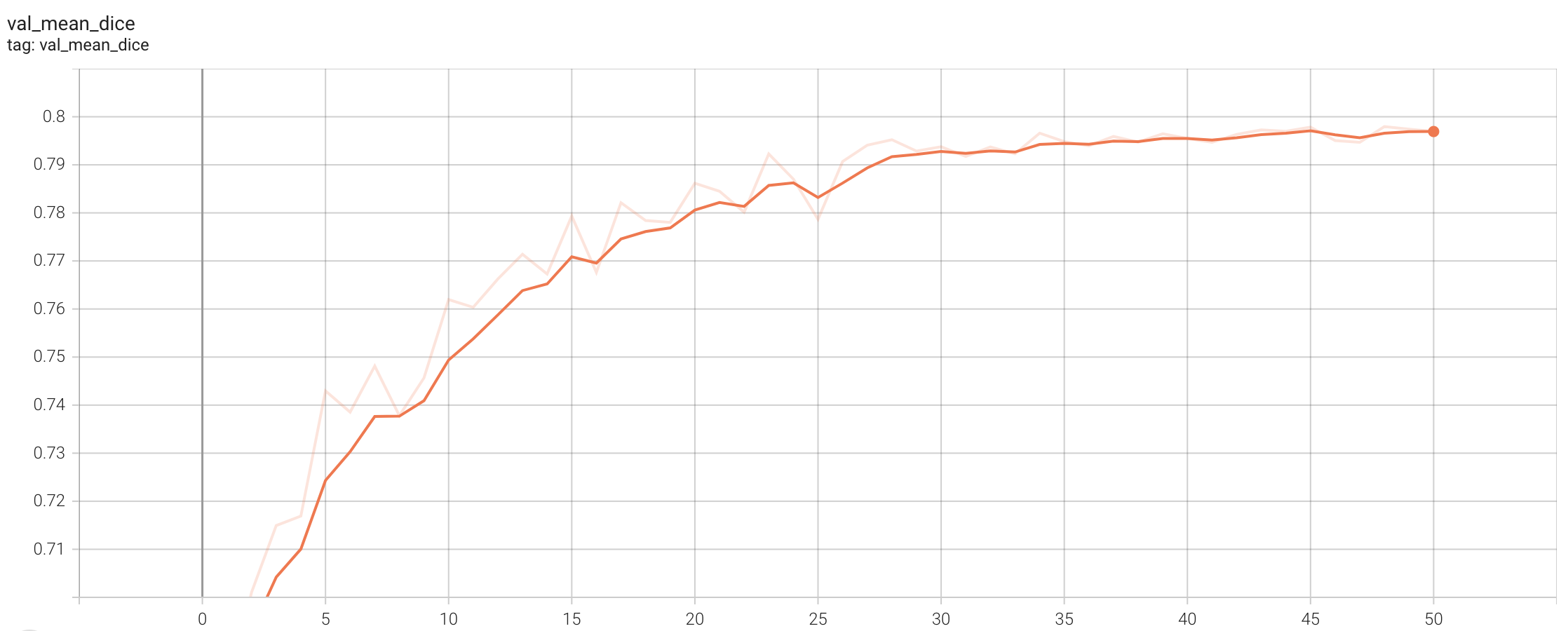
|
| 91 |
+
|
| 92 |
+
stage2:
|
| 93 |
+
|
| 94 |
+
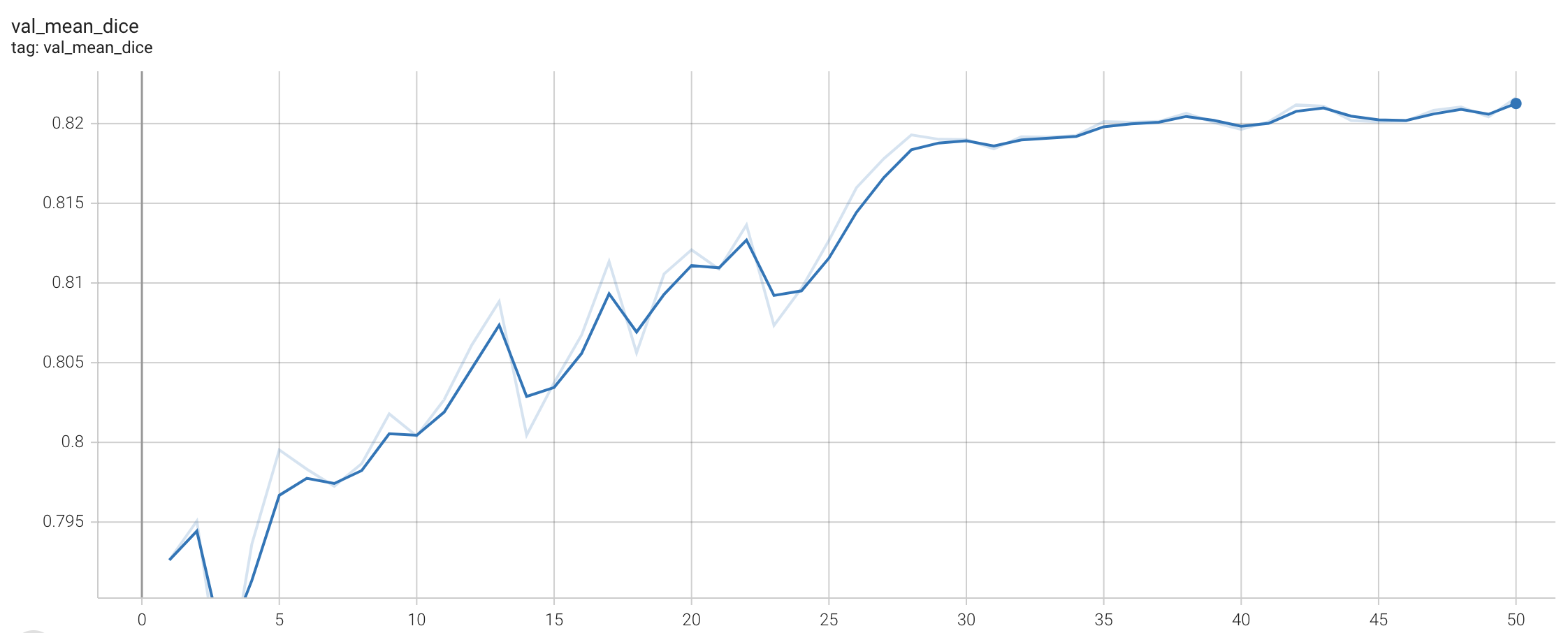
|
| 95 |
+
|
| 96 |
+
#### TensorRT speedup
|
| 97 |
+
This bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU. Please note that 32-bit precision models are benchmarked with tf32 weight format.
|
| 98 |
+
|
| 99 |
+
| method | torch_tf32(ms) | torch_amp(ms) | trt_tf32(ms) | trt_fp16(ms) | speedup amp | speedup tf32 | speedup fp16 | amp vs fp16|
|
| 100 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 101 |
+
| model computation | 24.55 | 20.14 | 10.85 | 5.63 | 1.22 | 2.26 | 4.36 | 3.58 |
|
| 102 |
+
| end2end | 3451 | 3312 | 1318 | 878 | 1.04 | 2.62 | 3.93 | 3.77 |
|
| 103 |
+
|
| 104 |
+
Where:
|
| 105 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 106 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 107 |
+
- `torch_tf32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 108 |
+
- `trt_tf32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 109 |
+
- `speedup amp`, `speedup tf32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 110 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 111 |
+
|
| 112 |
+
This result is benchmarked under:
|
| 113 |
+
- TensorRT: 10.3.0+cuda12.6
|
| 114 |
+
- Torch-TensorRT Version: 2.4.0
|
| 115 |
+
- CPU Architecture: x86-64
|
| 116 |
+
- OS: ubuntu 20.04
|
| 117 |
+
- Python version:3.10.12
|
| 118 |
+
- CUDA version: 12.6
|
| 119 |
+
- GPU models and configuration: A100 80G
|
| 120 |
+
|
| 121 |
+
## MONAI Bundle Commands
|
| 122 |
+
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 123 |
+
|
| 124 |
+
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
|
| 125 |
+
|
| 126 |
+
#### Execute training, the evaluation during the training were evaluated on patches:
|
| 127 |
+
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
|
| 128 |
+
|
| 129 |
+
- Run first stage
|
| 130 |
+
```
|
| 131 |
+
python -m monai.bundle run --config_file configs/train.json --stage 0 --dataset_dir <actual dataset path>
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
- Run second stage
|
| 135 |
+
```
|
| 136 |
+
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --stage 1 --dataset_dir <actual dataset path>
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
#### Override the `train` config to execute multi-GPU training:
|
| 140 |
+
|
| 141 |
+
- Run first stage
|
| 142 |
+
```
|
| 143 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --stage 0
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
- Run second stage
|
| 147 |
+
```
|
| 148 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --stage 1
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
#### Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
|
| 152 |
+
|
| 153 |
+
```
|
| 154 |
+
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
#### Execute inference:
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
python -m monai.bundle run --config_file configs/inference.json
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
#### Execute inference with the TensorRT model:
|
| 164 |
+
|
| 165 |
+
```
|
| 166 |
+
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
# References
|
| 170 |
+
[1] Simon Graham, Quoc Dang Vu, Shan E Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, Nasir Rajpoot, Hover-Net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images, Medical Image Analysis, 2019 https://doi.org/10.1016/j.media.2019.101563
|
| 171 |
+
|
| 172 |
+
# License
|
| 173 |
+
Copyright (c) MONAI Consortium
|
| 174 |
+
|
| 175 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 176 |
+
you may not use this file except in compliance with the License.
|
| 177 |
+
You may obtain a copy of the License at
|
| 178 |
+
|
| 179 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 180 |
+
|
| 181 |
+
Unless required by applicable law or agreed to in writing, software
|
| 182 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 183 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 184 |
+
See the License for the specific language governing permissions and
|
| 185 |
+
limitations under the License.
|
docs/data_license.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Third Party Licenses
|
| 2 |
+
-----------------------------------------------------------------------
|
| 3 |
+
|
| 4 |
+
/*********************************************************************/
|
| 5 |
+
i. CoNSeP dataset
|
| 6 |
+
https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/
|
models/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f3c427cd3e97f40b77ff612205b706475edc1039d1b8de39afcaf7add204e39c
|
| 3 |
+
size 151228832
|
models/stage0/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf6eb5a0467422c2c1ffbff72e2b4aca17dcdd8d2087bd1a27ce86fea98a1ab6
|
| 3 |
+
size 151228832
|
scripts/prepare_patches.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import math
|
| 3 |
+
import os
|
| 4 |
+
import pathlib
|
| 5 |
+
import shutil
|
| 6 |
+
from argparse import ArgumentParser
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import scipy.io as sio
|
| 10 |
+
import tqdm
|
| 11 |
+
from PIL import Image
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def load_img(path):
|
| 15 |
+
return np.array(Image.open(path).convert("RGB"))
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def load_ann(path):
|
| 19 |
+
"""
|
| 20 |
+
This function is specific to CoNSeP dataset.
|
| 21 |
+
If using other datasets, the code below may need to be modified.
|
| 22 |
+
"""
|
| 23 |
+
# assumes that ann is HxW
|
| 24 |
+
ann_inst = sio.loadmat(path)["inst_map"]
|
| 25 |
+
ann_type = sio.loadmat(path)["type_map"]
|
| 26 |
+
|
| 27 |
+
# merge classes for CoNSeP (utilise 3 nuclei classes and background keep the same with paper)
|
| 28 |
+
ann_type[(ann_type == 3) | (ann_type == 4)] = 3
|
| 29 |
+
ann_type[(ann_type == 5) | (ann_type == 6) | (ann_type == 7)] = 4
|
| 30 |
+
|
| 31 |
+
ann = np.dstack([ann_inst, ann_type])
|
| 32 |
+
ann = ann.astype("int32")
|
| 33 |
+
|
| 34 |
+
return ann
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class PatchExtractor:
|
| 38 |
+
"""Extractor to generate patches with or without padding.
|
| 39 |
+
Turn on debug mode to see how it is done.
|
| 40 |
+
|
| 41 |
+
Args:
|
| 42 |
+
x : input image, should be of shape HWC
|
| 43 |
+
patch_size : a tuple of (h, w)
|
| 44 |
+
step_size : a tuple of (h, w)
|
| 45 |
+
Return:
|
| 46 |
+
a list of sub patches, each patch has dtype same as x
|
| 47 |
+
|
| 48 |
+
Examples:
|
| 49 |
+
>>> xtractor = PatchExtractor((450, 450), (120, 120))
|
| 50 |
+
>>> img = np.full([1200, 1200, 3], 255, np.uint8)
|
| 51 |
+
>>> patches = xtractor.extract(img, 'mirror')
|
| 52 |
+
|
| 53 |
+
"""
|
| 54 |
+
|
| 55 |
+
def __init__(self, patch_size, step_size):
|
| 56 |
+
self.patch_type = "mirror"
|
| 57 |
+
self.patch_size = patch_size
|
| 58 |
+
self.step_size = step_size
|
| 59 |
+
|
| 60 |
+
def __get_patch(self, x, ptx):
|
| 61 |
+
pty = (ptx[0] + self.patch_size[0], ptx[1] + self.patch_size[1])
|
| 62 |
+
win = x[ptx[0] : pty[0], ptx[1] : pty[1]]
|
| 63 |
+
assert (
|
| 64 |
+
win.shape[0] == self.patch_size[0] and win.shape[1] == self.patch_size[1]
|
| 65 |
+
), "[BUG] Incorrect Patch Size {0}".format(win.shape)
|
| 66 |
+
return win
|
| 67 |
+
|
| 68 |
+
def __extract_valid(self, x):
|
| 69 |
+
"""Extracted patches without padding, only work in case patch_size > step_size.
|
| 70 |
+
|
| 71 |
+
Note: to deal with the remaining portions which are at the boundary a.k.a
|
| 72 |
+
those which do not fit when slide left->right, top->bottom), we flip
|
| 73 |
+
the sliding direction then extract 1 patch starting from right / bottom edge.
|
| 74 |
+
There will be 1 additional patch extracted at the bottom-right corner.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
x : input image, should be of shape HWC
|
| 78 |
+
patch_size : a tuple of (h, w)
|
| 79 |
+
step_size : a tuple of (h, w)
|
| 80 |
+
Return:
|
| 81 |
+
a list of sub patches, each patch is same dtype as x
|
| 82 |
+
|
| 83 |
+
"""
|
| 84 |
+
im_h = x.shape[0]
|
| 85 |
+
im_w = x.shape[1]
|
| 86 |
+
|
| 87 |
+
def extract_infos(length, patch_size, step_size):
|
| 88 |
+
flag = (length - patch_size) % step_size != 0
|
| 89 |
+
last_step = math.floor((length - patch_size) / step_size)
|
| 90 |
+
last_step = (last_step + 1) * step_size
|
| 91 |
+
return flag, last_step
|
| 92 |
+
|
| 93 |
+
h_flag, h_last = extract_infos(im_h, self.patch_size[0], self.step_size[0])
|
| 94 |
+
w_flag, w_last = extract_infos(im_w, self.patch_size[1], self.step_size[1])
|
| 95 |
+
|
| 96 |
+
sub_patches = []
|
| 97 |
+
# Deal with valid block
|
| 98 |
+
for row in range(0, h_last, self.step_size[0]):
|
| 99 |
+
for col in range(0, w_last, self.step_size[1]):
|
| 100 |
+
win = self.__get_patch(x, (row, col))
|
| 101 |
+
sub_patches.append(win)
|
| 102 |
+
# Deal with edge case
|
| 103 |
+
if h_flag:
|
| 104 |
+
row = im_h - self.patch_size[0]
|
| 105 |
+
for col in range(0, w_last, self.step_size[1]):
|
| 106 |
+
win = self.__get_patch(x, (row, col))
|
| 107 |
+
sub_patches.append(win)
|
| 108 |
+
if w_flag:
|
| 109 |
+
col = im_w - self.patch_size[1]
|
| 110 |
+
for row in range(0, h_last, self.step_size[0]):
|
| 111 |
+
win = self.__get_patch(x, (row, col))
|
| 112 |
+
sub_patches.append(win)
|
| 113 |
+
if h_flag and w_flag:
|
| 114 |
+
ptx = (im_h - self.patch_size[0], im_w - self.patch_size[1])
|
| 115 |
+
win = self.__get_patch(x, ptx)
|
| 116 |
+
sub_patches.append(win)
|
| 117 |
+
return sub_patches
|
| 118 |
+
|
| 119 |
+
def __extract_mirror(self, x):
|
| 120 |
+
"""Extracted patches with mirror padding the boundary such that the
|
| 121 |
+
central region of each patch is always within the orginal (non-padded)
|
| 122 |
+
image while all patches' central region cover the whole orginal image.
|
| 123 |
+
|
| 124 |
+
Args:
|
| 125 |
+
x : input image, should be of shape HWC
|
| 126 |
+
patch_size : a tuple of (h, w)
|
| 127 |
+
step_size : a tuple of (h, w)
|
| 128 |
+
Return:
|
| 129 |
+
a list of sub patches, each patch is same dtype as x
|
| 130 |
+
|
| 131 |
+
"""
|
| 132 |
+
diff_h = self.patch_size[0] - self.step_size[0]
|
| 133 |
+
padt = diff_h // 2
|
| 134 |
+
padb = diff_h - padt
|
| 135 |
+
|
| 136 |
+
diff_w = self.patch_size[1] - self.step_size[1]
|
| 137 |
+
padl = diff_w // 2
|
| 138 |
+
padr = diff_w - padl
|
| 139 |
+
|
| 140 |
+
pad_type = "reflect"
|
| 141 |
+
x = np.lib.pad(x, ((padt, padb), (padl, padr), (0, 0)), pad_type)
|
| 142 |
+
sub_patches = self.__extract_valid(x)
|
| 143 |
+
return sub_patches
|
| 144 |
+
|
| 145 |
+
def extract(self, x, patch_type):
|
| 146 |
+
patch_type = patch_type.lower()
|
| 147 |
+
self.patch_type = patch_type
|
| 148 |
+
if patch_type == "valid":
|
| 149 |
+
return self.__extract_valid(x)
|
| 150 |
+
elif patch_type == "mirror":
|
| 151 |
+
return self.__extract_mirror(x)
|
| 152 |
+
else:
|
| 153 |
+
raise ValueError(f"Unknown Patch Type {patch_type}")
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def main(cfg):
|
| 157 |
+
xtractor = PatchExtractor(cfg["patch_size"], cfg["step_size"])
|
| 158 |
+
for phase in cfg["phase"]:
|
| 159 |
+
img_dir = os.path.join(cfg["root"], f"{phase}/Images")
|
| 160 |
+
ann_dir = os.path.join(cfg["root"], f"{phase}/Labels")
|
| 161 |
+
|
| 162 |
+
file_list = glob.glob(os.path.join(ann_dir, f"*{cfg['label_suffix']}"))
|
| 163 |
+
file_list.sort() # ensure same ordering across platform
|
| 164 |
+
|
| 165 |
+
out_dir = f"{cfg['root']}/Prepared/{phase}"
|
| 166 |
+
if os.path.isdir(out_dir):
|
| 167 |
+
shutil.rmtree(out_dir)
|
| 168 |
+
os.makedirs(out_dir)
|
| 169 |
+
|
| 170 |
+
pbar_format = "Process File: |{bar}| {n_fmt}/{total_fmt}[{elapsed}<{remaining},{rate_fmt}]"
|
| 171 |
+
pbarx = tqdm.tqdm(total=len(file_list), bar_format=pbar_format, ascii=True, position=0)
|
| 172 |
+
|
| 173 |
+
for file_path in file_list:
|
| 174 |
+
base_name = pathlib.Path(file_path).stem
|
| 175 |
+
|
| 176 |
+
img = load_img(f"{img_dir}/{base_name}.{cfg['image_suffix']}")
|
| 177 |
+
ann = load_ann(f"{ann_dir}/{base_name}.{cfg['label_suffix']}")
|
| 178 |
+
|
| 179 |
+
np.save("{0}/label_{1}.npy".format(out_dir, base_name), ann)
|
| 180 |
+
np.save("{0}/image_{1}.npy".format(out_dir, base_name), img)
|
| 181 |
+
|
| 182 |
+
# *
|
| 183 |
+
img = np.concatenate([img, ann], axis=-1)
|
| 184 |
+
sub_patches = xtractor.extract(img, cfg["extract_type"])
|
| 185 |
+
|
| 186 |
+
pbar_format = "Extracting : |{bar}| {n_fmt}/{total_fmt}[{elapsed}<{remaining},{rate_fmt}]"
|
| 187 |
+
pbar = tqdm.tqdm(total=len(sub_patches), leave=False, bar_format=pbar_format, ascii=True, position=1)
|
| 188 |
+
|
| 189 |
+
for idx, patch in enumerate(sub_patches):
|
| 190 |
+
image_patch = patch[..., :3]
|
| 191 |
+
inst_map_patch = patch[..., 3:4]
|
| 192 |
+
type_map_patch = patch[..., 4:5]
|
| 193 |
+
np.save("{0}/{1}_{2:03d}_image.npy".format(out_dir, base_name, idx), image_patch)
|
| 194 |
+
np.save("{0}/{1}_{2:03d}_inst_map.npy".format(out_dir, base_name, idx), inst_map_patch)
|
| 195 |
+
np.save("{0}/{1}_{2:03d}_type_map.npy".format(out_dir, base_name, idx), type_map_patch)
|
| 196 |
+
pbar.update()
|
| 197 |
+
pbar.close()
|
| 198 |
+
# *
|
| 199 |
+
|
| 200 |
+
pbarx.update()
|
| 201 |
+
pbarx.close()
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def parse_arguments():
|
| 205 |
+
parser = ArgumentParser(description="Extract patches from the original images")
|
| 206 |
+
|
| 207 |
+
parser.add_argument(
|
| 208 |
+
"--root",
|
| 209 |
+
type=str,
|
| 210 |
+
default="/workspace/Data/Pathology/CoNSeP",
|
| 211 |
+
help="root path to image folder containing training/test",
|
| 212 |
+
)
|
| 213 |
+
parser.add_argument(
|
| 214 |
+
"--phase",
|
| 215 |
+
nargs="+",
|
| 216 |
+
type=str,
|
| 217 |
+
default=["Train", "Test"],
|
| 218 |
+
dest="phase",
|
| 219 |
+
help="Phases of data need to be extracted",
|
| 220 |
+
)
|
| 221 |
+
parser.add_argument("--type", type=str, default="mirror", dest="extract_type", help="Choose 'mirror' or 'valid'")
|
| 222 |
+
parser.add_argument("--is", type=str, default="png", dest="image_suffix", help="image file name suffix")
|
| 223 |
+
parser.add_argument("--ls", type=str, default="mat", dest="label_suffix", help="label file name suffix")
|
| 224 |
+
parser.add_argument("--ps", nargs="+", type=int, default=[540, 540], dest="patch_size", help="patch size")
|
| 225 |
+
parser.add_argument("--ss", nargs="+", type=int, default=[164, 164], dest="step_size", help="patch size")
|
| 226 |
+
args = parser.parse_args()
|
| 227 |
+
config_dict = vars(args)
|
| 228 |
+
|
| 229 |
+
return config_dict
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
if __name__ == "__main__":
|
| 233 |
+
cfg = parse_arguments()
|
| 234 |
+
|
| 235 |
+
main(cfg)
|