ComfyUI on Vast.ai for ML Engineers: Architecture, Cost Controls, and Reproducible Ops

Most of us don’t run diffusion pipelines on our laptops because VRAM, power, and thermals aren’t on our side. The technical challenge is straightforward: provision a GPU with enough memory to run modern generative workflows, keep egress/storage costs under control, and make the environment repeatable across sessions.
This write-up details a production-minded setup for ComfyUI on Vast.ai (aff. link), with an emphasis on hardware selection, data/egress economics, model management at scale, and reproducibility using Hugging Face tooling.
Constraints and Goals
- Interactive UI (ComfyUI) with low cold-start time
- Sufficient VRAM for SDXL/Flux-class workloads
- Stable storage to hold model assets (checkpoints, LoRA, VAE, ControlNet)
- Minimal bandwidth surprises when pulling models and exporting outputs
- Reproducible model layout and versions (Hugging Face as source of truth)
- Quick teardown/resume to optimize spend
Hardware Selection Under Budget and VRAM Targets
Most workflows fall into one of two buckets:
- 12–16 GB VRAM: legacy SD1.5, lightweight LoRAs, modest ControlNet use
- 20–32+ GB VRAM: SDXL, heavier ControlNet stacks, larger T2I/T2V stacks, higher resolution or higher batch
Common picks from Vast.ai’s marketplace:
- RTX 3090 (24 GB): good value, robust for SDXL + ControlNet with moderate batch size
- RTX 4090 / 5090: excellent throughput; comfortable headroom for high-res or multi-condition pipelines
- RTX PRO 6000: workstation-grade stability; enough memory to avoid quantization in most pipelines
The GPU is only part of the bill. The silent killer is bandwidth egress pricing.
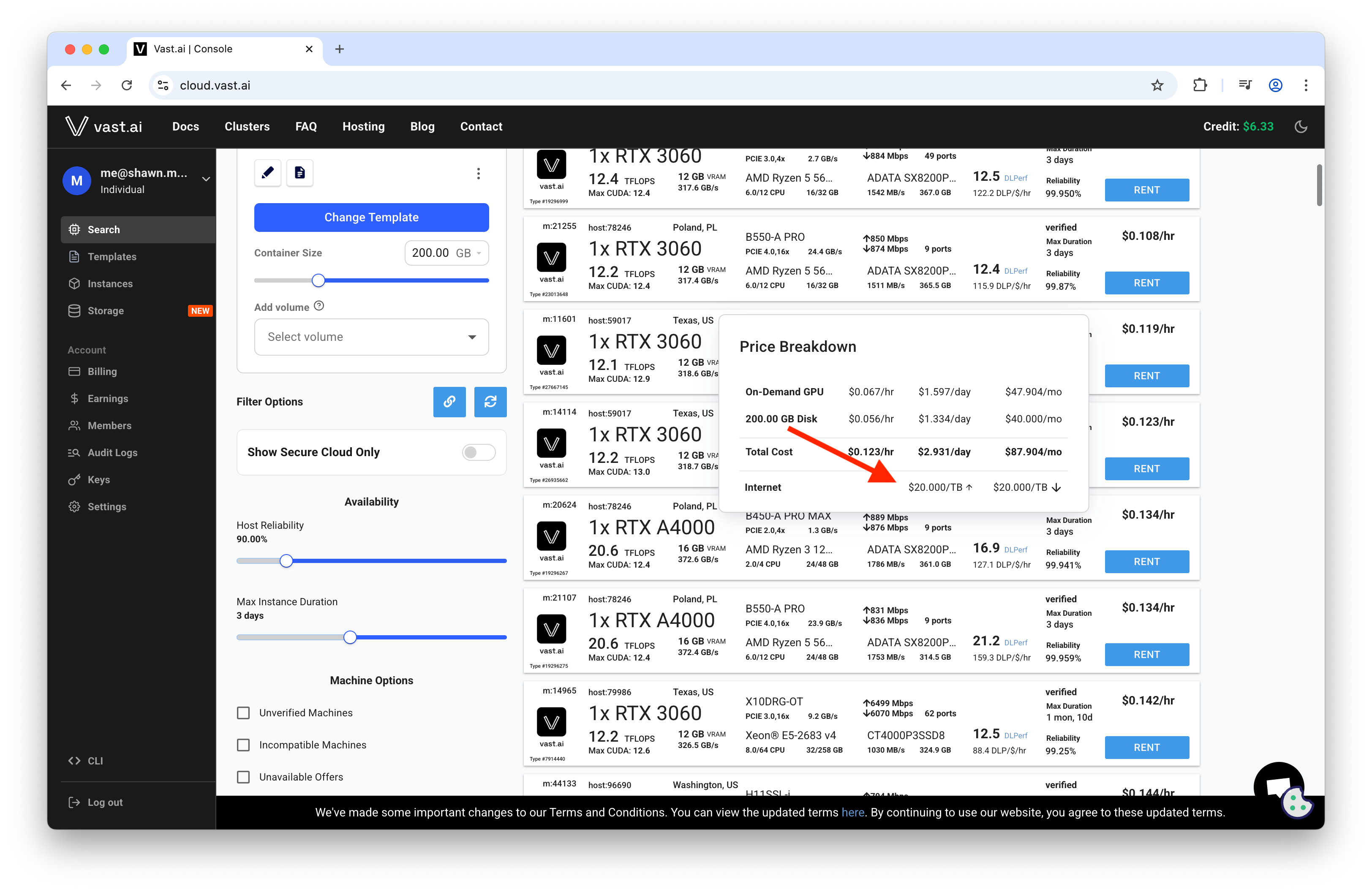
- Many hosts charge per TB of data transferred. Prices can be high ($20/TB+ in some listings).
- Model pulls and large output batches will add up; check the price breakdown on every host.
Use the marketplace filters to cap egress:
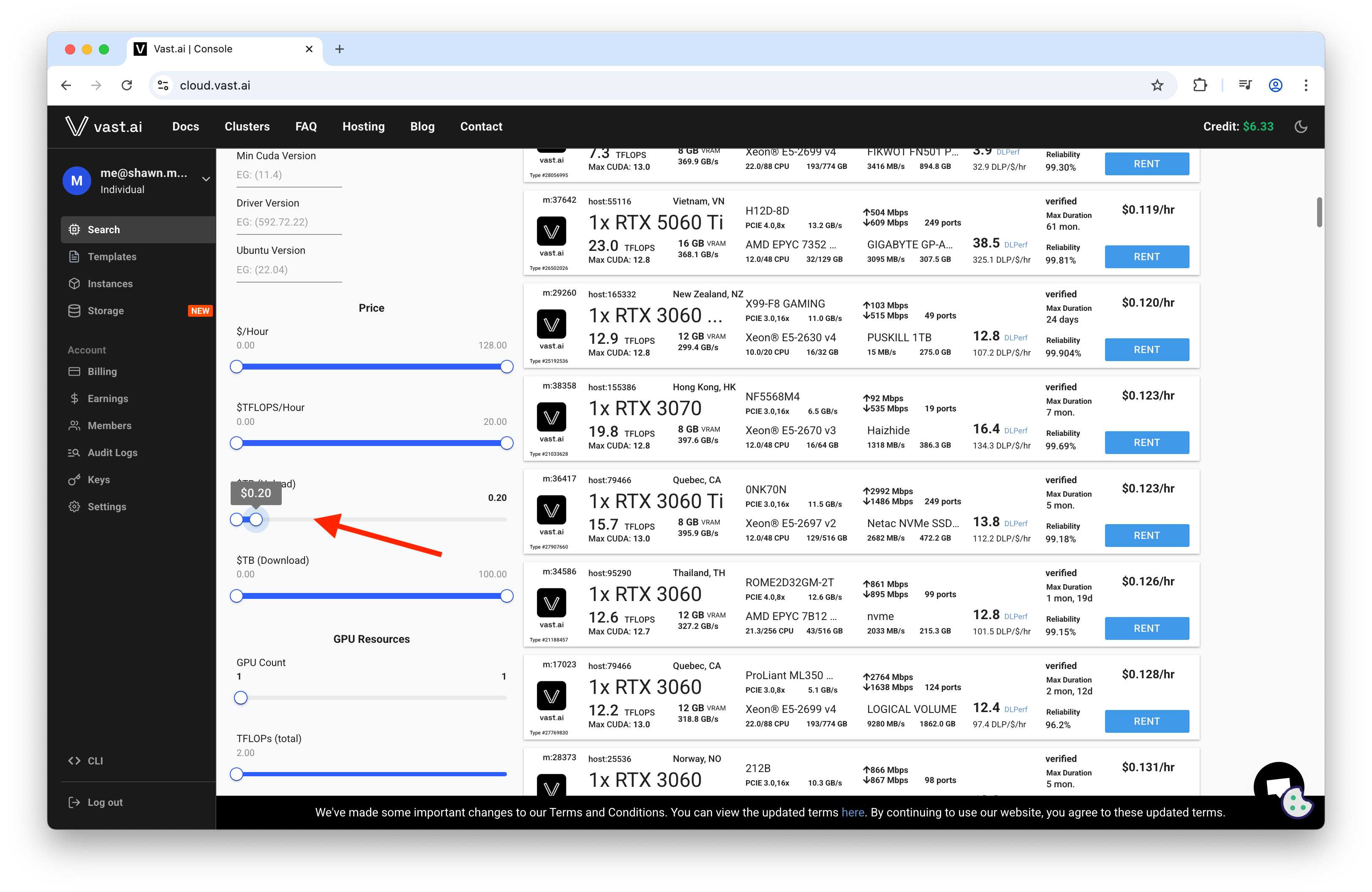
Strategy:
- Filter for low “Internet $/TB” before selecting a host.
- Pre-stage models and reuse the same instance when possible to avoid repeated downloads.
- Consider compressing outputs before download to reduce egress.
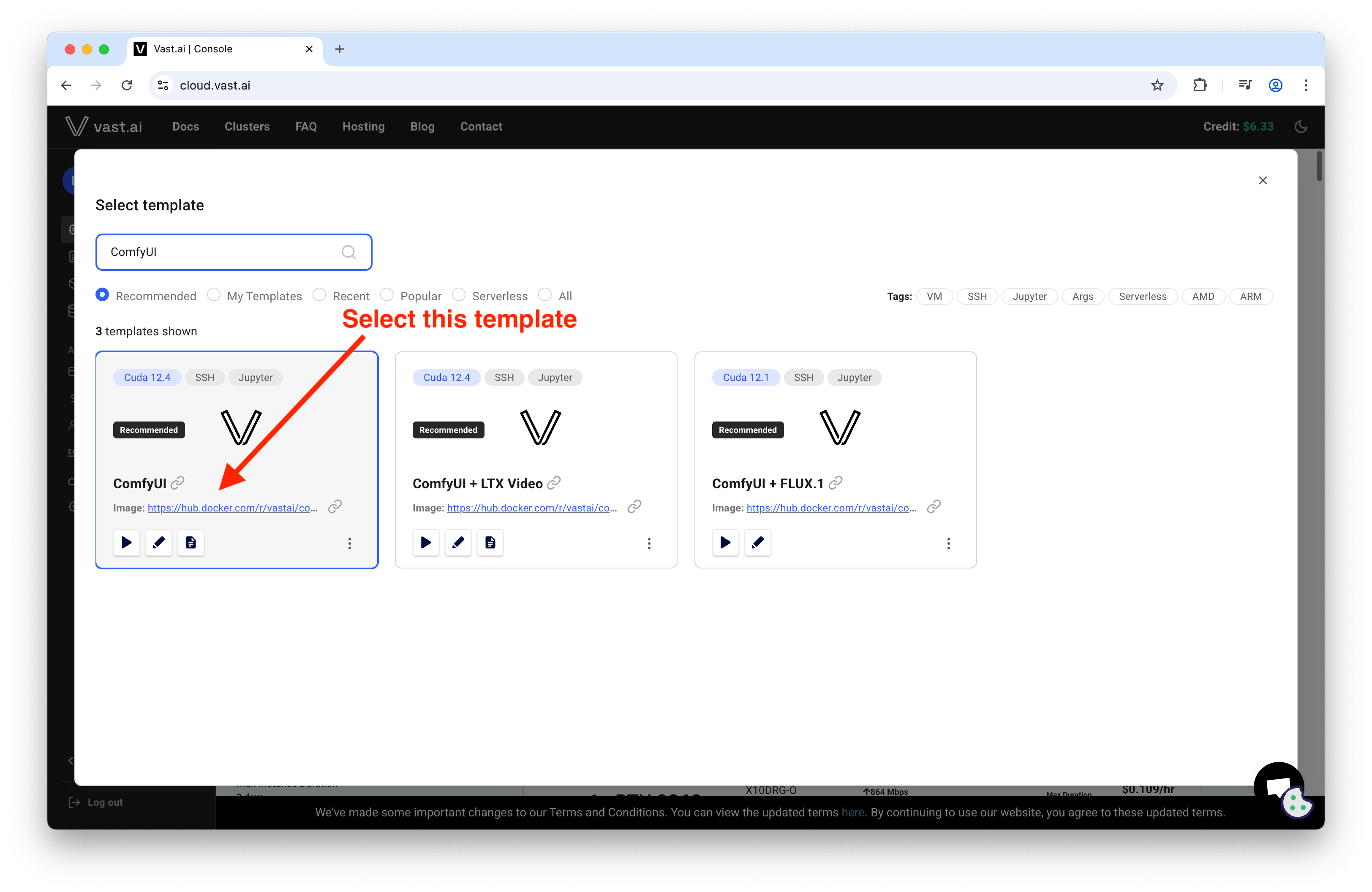
Runtime Image and Why It Matters
Use the Vast.ai ComfyUI template; it ships with CUDA, driver bindings, Jupyter, and the ComfyUI service configured. This avoids rebuilding PyTorch/CUDA stacks each time and trims cold-start time.
Storage sizing:
- 100 GB minimum if you only need a couple of models
- 200 GB is a comfortable baseline for multiple base models + LoRAs + ControlNets
- 300 GB+ if you’re curating a larger model zoo or heavy custom nodes
Tip: The ComfyUI models directory layout is fixed; plan your disk so you don’t have to re-provision mid-project.
Provision and Access
Rent the instance, then use the Instances view to access the portal and application endpoints.
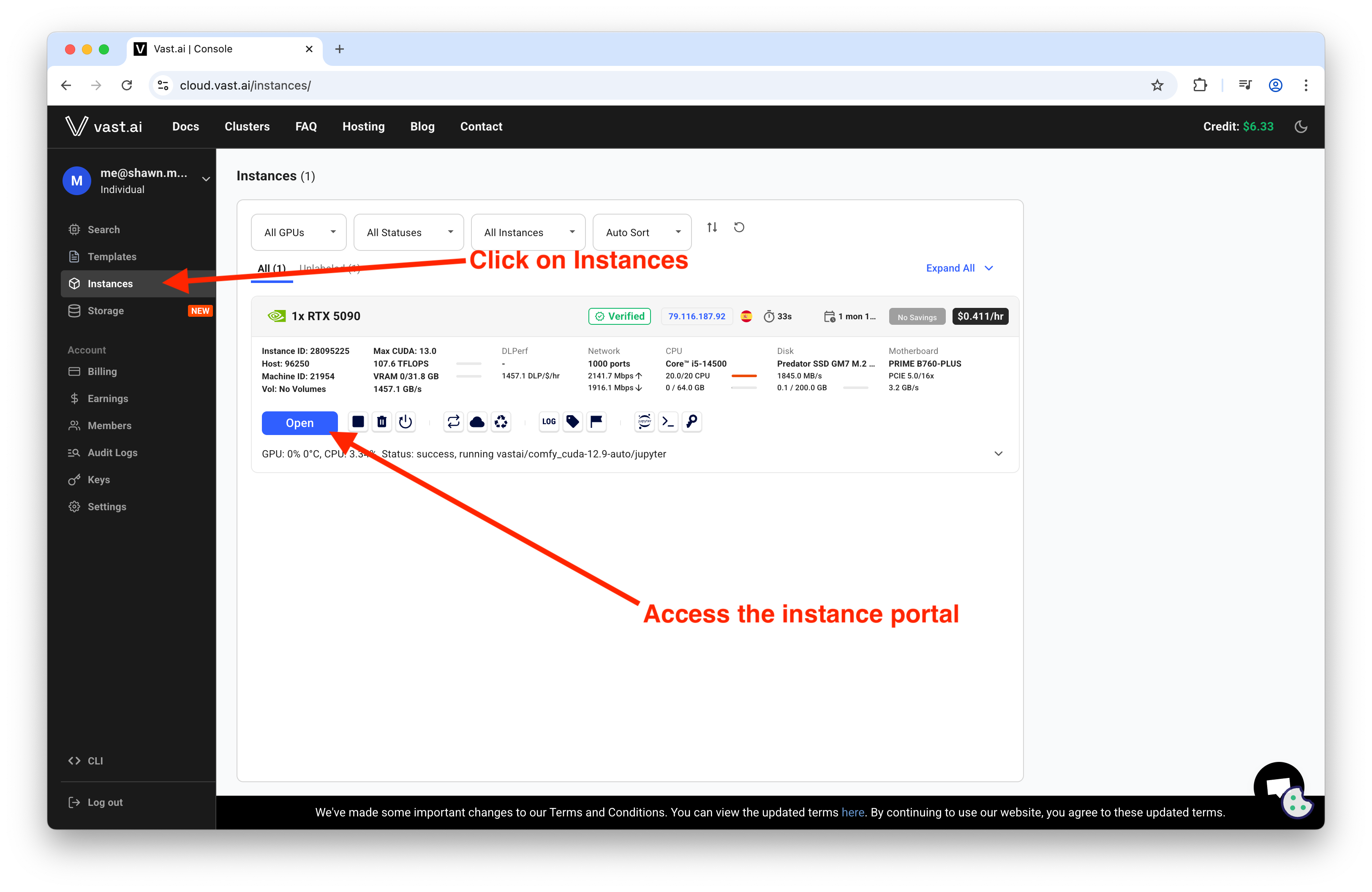
From the portal, launch ComfyUI or jump into Jupyter as needed.
The ComfyUI UI should be responsive once the container initializes:
Filesystem Layout for ComfyUI
Use these canonical paths inside the container:
- Base models (checkpoints): ComfyUI/models/checkpoints
- LoRAs: ComfyUI/models/loras
- VAE: ComfyUI/models/vae
- CLIP/Text encoders: ComfyUI/models/clip
- Upscalers: ComfyUI/models/upscale_models
- ControlNet: ComfyUI/models/controlnet
After adding assets, focus the ComfyUI canvas and press R to reload models.
Model Management at Scale
There are three viable patterns, depending on whether you prefer UI, CLI, or a generated bootstrap.
UI-first: ComfyUI Manager + Model Downloader
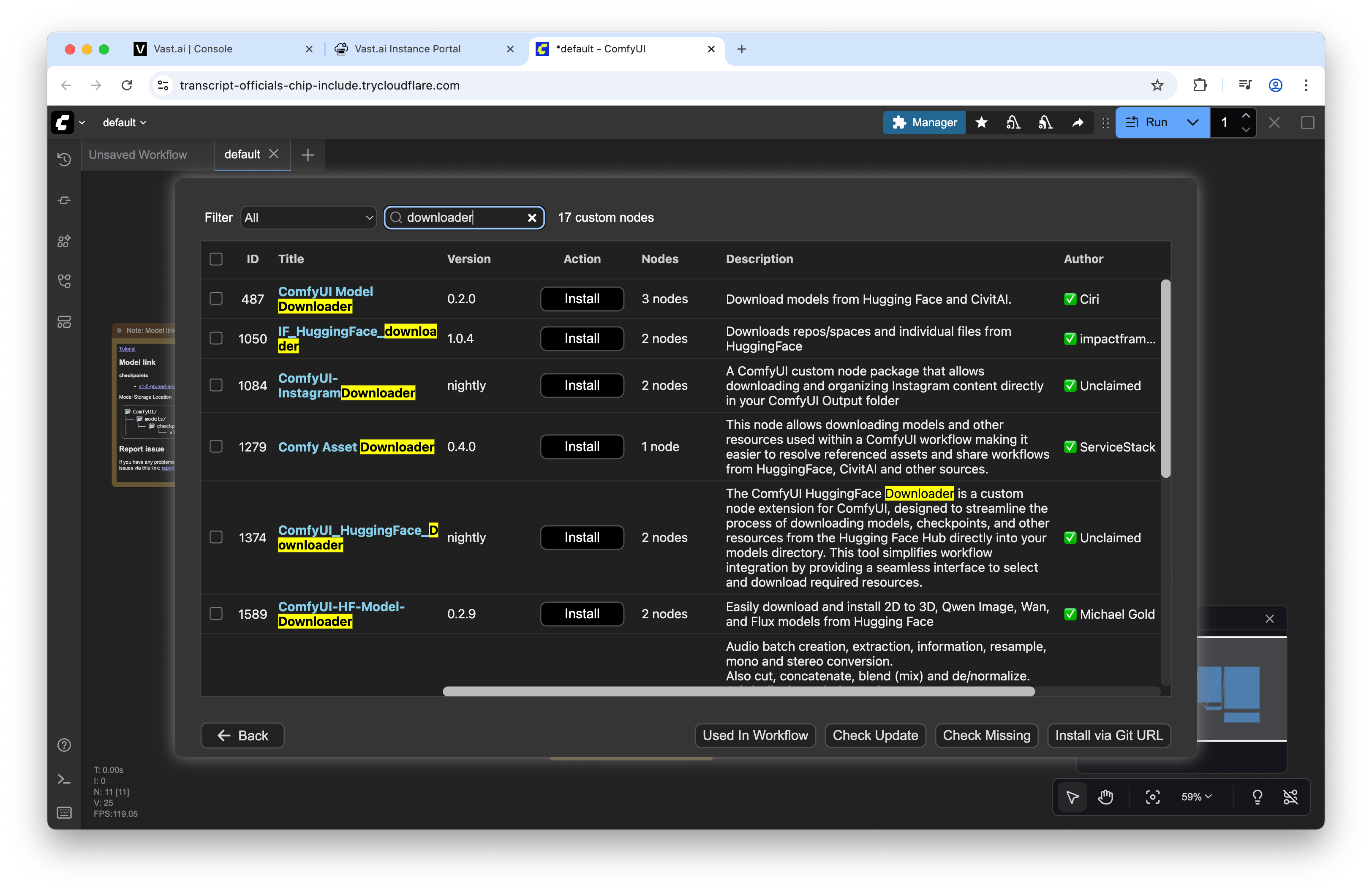
- Install “ComfyUI Model Downloader” via the Custom Nodes Manager.
- Use it to fetch models from Hugging Face or Civitai; it places files into the correct directories automatically.
- Good for ad hoc exploration. Less ideal for reproducible infrastructure.
Programmatic: Jupyter Terminal + Hugging Face Hub
Prefer explicit manifests and reproducible pulls. Inside the Jupyter Terminal:
Install dependencies:
pip install --upgrade huggingface_hub safetensors
Use a Python snippet to materialize model snapshots to the right folders:
from huggingface_hub import snapshot_download
from pathlib import Path
import shutil
# Map HF repos to ComfyUI directories
MAPPING = [
# Base SD1.5 or SDXL checkpoints
{"repo": "runwayml/stable-diffusion-v1-5", "subdir": "ComfyUI/models/checkpoints"},
# Example LoRA
{"repo": "some-user/sdxl-lora-example", "subdir": "ComfyUI/models/loras"},
# Example VAE
{"repo": "madebyollin/sdxl-vae-fp16-fix", "subdir": "ComfyUI/models/vae"},
]
for item in MAPPING:
target = Path("/workspace") / item["subdir"]
target.mkdir(parents=True, exist_ok=True)
tmp_dir = snapshot_download(
repo_id=item["repo"],
local_dir="/tmp/hf-cache",
local_dir_use_symlinks=False,
ignore_patterns=["*.md", "*.txt", "*.json"], # keep artifacts lean
)
for p in Path(tmp_dir).glob("**/*"):
if p.is_file() and p.suffix in {".safetensors", ".pt", ".ckpt"}:
shutil.copy2(p, target / p.name)
print("Model sync complete.")
Or pull a single file with wget/curl:
cd /workspace/ComfyUI/models/checkpoints
wget -O model.safetensors https://huggingface.co/ORG/REPO/resolve/main/model.safetensors
Authenticate with HF_TOKEN if needed:
export HUGGINGFACE_HUB_TOKEN=hf_xxx
Recommendation:
- Store a versioned manifest (YAML/JSON) that maps repo_id → destination directory.
- Commit this manifest to your project repo so teammates can recreate the environment.
Example manifest + importer:
# models.yaml
models:
- repo: runwayml/stable-diffusion-v1-5
dir: ComfyUI/models/checkpoints
- repo: madebyollin/sdxl-vae-fp16-fix
dir: ComfyUI/models/vae
- repo: some-user/sdxl-lora-example
dir: ComfyUI/models/loras
python - <<'PY'
import yaml, shutil
from pathlib import Path
from huggingface_hub import snapshot_download
manifest = yaml.safe_load(open("models.yaml"))
for m in manifest["models"]:
target = Path("/workspace") / m["dir"]
target.mkdir(parents=True, exist_ok=True)
tmp_dir = snapshot_download(m["repo"], local_dir="/tmp/hf-cache", local_dir_use_symlinks=False)
for p in Path(tmp_dir).glob("**/*"):
if p.is_file() and p.suffix in {".safetensors", ".ckpt", ".pt"}:
shutil.copy2(p, target / p.name)
print("Done.")
PY
Generated bootstrap: AI Launcher
If you want a one-liner that includes ComfyUI + model selection + nodes:
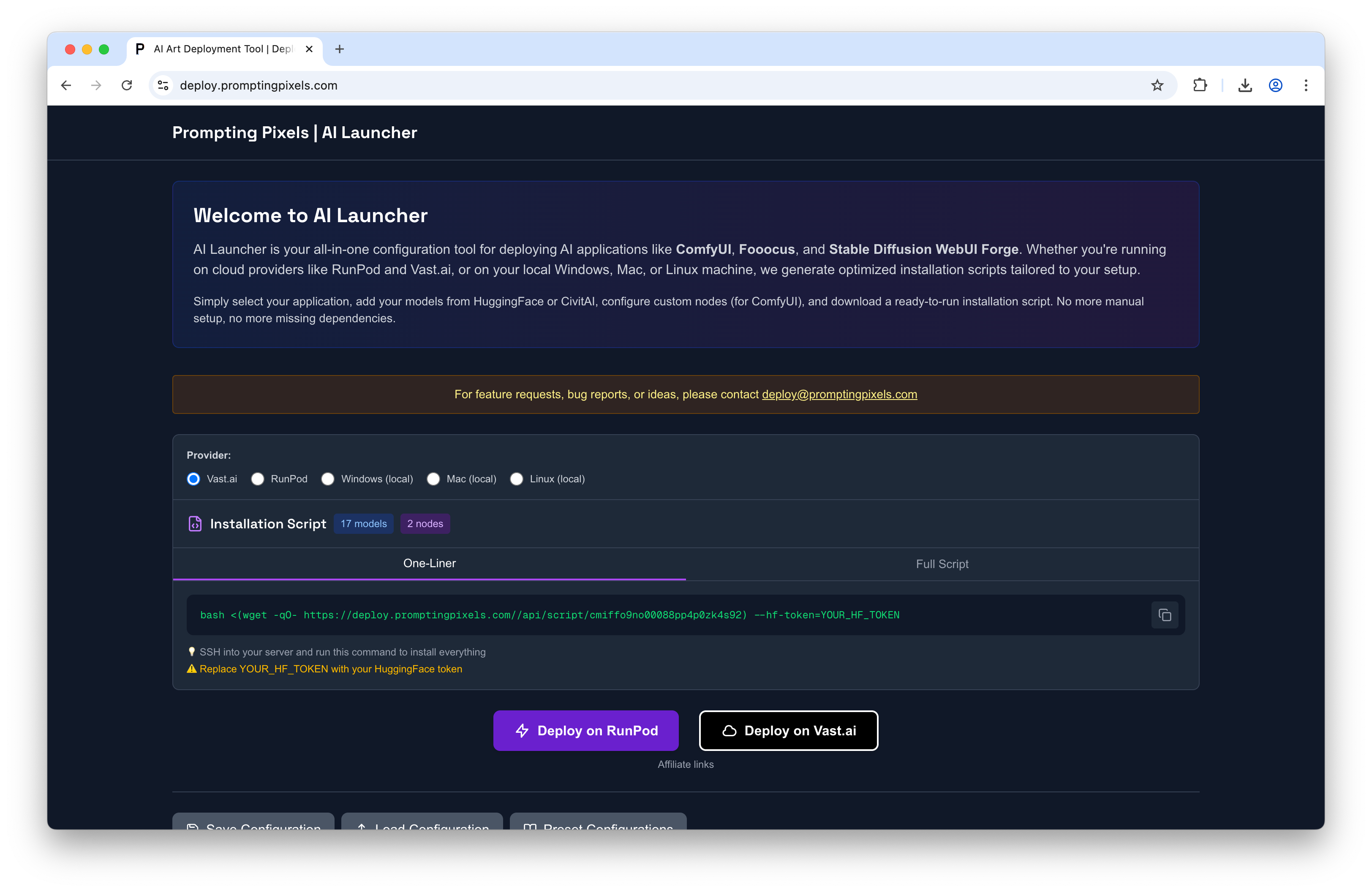
- Use the Prompting Pixels AI Launcher to compose a script - its terrific and gets the job done exceptionally well.
- Paste the generated command into the instance’s Jupyter Terminal.
- This is the fastest way to replicate the same curated environment across machines.
Data and Egress Strategy
Large model pulls and output downloads are the primary drivers of bandwidth costs.
Recommendations:
- Pull models from Hugging Face using snapshot_download to avoid repeated downloads and partials.
- Keep outputs inside /workspace/ComfyUI/output while iterating; batch-download at the end.
- Archive before download:
cd /workspace/ComfyUI/output
tar -czf outputs-$(date +%Y%m%d-%H%M).tar.gz *.png *.jpg
Access via Jupyter’s file browser when you need to retrieve artifacts:
Performance Tuning and VRAM Pressure
If you hit CUDA OOM or notice paging:
- Reduce batch size and/or target resolution
- Remove unnecessary nodes or intermediates in your graph
- Prefer FP16 weights where appropriate
- Switch to models with smaller memory footprints (or quantized variants when available)
- If the workload requires it, re-provision with a larger VRAM GPU
Lifecycle and Cost Control
Two cost levers matter most: compute-hourly and storage/egress.
- Running: billed hourly per GPU host
- Stopped: you keep storage; pay a daily fee for disk persistence
- Destroyed: costs drop to zero; you lose the environment and local assets
Typical pattern:
- Persist the instance when actively iterating
- Stop it overnight/weekends if disk storage fees are meaningfully lower than compute
- Destroy and rebuild only when you have automation for models and nodes
Reproducibility: Pin, Document, Automate
- Pin model repo revisions (commit SHA or tag) with snapshot_download(revision=...)
- Keep a models.yaml in your project repository
- Record node versions (git commit hashes) if you rely on custom nodes
- Use environment dumps (pip freeze) to capture the Python environment if you add extra packages
Example pinning:
snapshot_download(
"runwayml/stable-diffusion-v1-5",
revision="a1b2c3d4", # commit hash or tag
local_dir="/tmp/hf-cache",
local_dir_use_symlinks=False
)
Practical Baselines
- Disk: 200 GB
- GPU: 16 GB VRAM or higher for SDXL + extras
- Egress filter: < $1/TB when possible (lower is better)
- Model sourcing: Hugging Face via script + version-pinning
- Outputs: archive before download
Alternatives to Consider
- If you don’t need a node-graph UI, a pure Diffusers pipeline on a headless GPU host can be cheaper and easier to automate.
- If you want managed reproducibility, containerize your ComfyUI environment + models manifest and orchestrate via a provider’s API.
- If Vast.ai inventory doesn’t meet your constraints, RunPod and similar marketplaces offer comparable GPU classes; the same model manifest approach applies.
Optimization Opportunities
- Cache models on a long-lived low-cost disk volume; reattach to short-lived compute
- Use mixed precision (FP16) and check scheduler choices to balance quality/runtime
- Profile node graphs; avoid redundant encode/decode steps
- Batch prompts when possible to amortize setup cost within VRAM limits
- Encode outputs to efficient formats and compress before egress
- Track per-run metrics: VRAM peak, wall clock, egress volume; iterate systematically
With a pinned model manifest, a known-good template, and guardrails on bandwidth pricing, ComfyUI on Vast.ai becomes a repeatable, cost-aware deployment for interactive generative work—without owning the GPU.