File size: 4,003 Bytes
0949181 f55a4ab 8f1feba 0949181 8f1feba 0949181 f55a4ab 8f1feba 0949181 8f1feba 0949181 f55a4ab 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 8f1feba 0949181 555631d 8f1feba 555631d 0949181 8f1feba 0949181 8f1feba |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
---
library_name: transformers
tags: []
---
<!-- Provide a quick summary of what the model is/does. -->
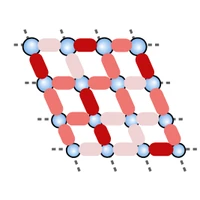
Foundation Neural-Network Quantum State trained on the two-dimension \\(J_1\\)- \\(J_2\\) Heisenberg on a \\(10\times 10\\) square lattice.
The system is described by the following Hamiltonian (with periodic boundary conditions):
$$
\hat{H} = J_1\!\!\sum_{\langle {\boldsymbol{r}},{\boldsymbol{r'}} \rangle} \hat{\boldsymbol{S}}_{\boldsymbol{r}}\cdot\hat{\boldsymbol{S}}_{\boldsymbol{r'}}
+ J_2 \!\!\!\!\sum_{\langle \langle {\boldsymbol{r}},{\boldsymbol{r'}} \rangle \rangle} \!\!\!\hat{\boldsymbol{S}}_{\boldsymbol{r}}\cdot\hat{\boldsymbol{S}}_{\boldsymbol{r'}} \ .
$$
The architecture has been trained on \\(R=100\\) different couplings \\(J_2\\) equispaced in the interval \\(J_2 \in [0.4, 0.6]\\),
using a total batch size of \\(M=16000\\) samples.
The computation has been distributed over 4 A100-64GB GPUs for few hours.
## How to Get Started with the Model
Use the code below to get started with the model. In particular, we sample the architecture for a fixed value of the coupling \\(J_2\\) using NetKet.
```python
from functools import partial
import numpy as np
import jax
import jax.numpy as jnp
import netket as nk
from huggingface_hub import hf_hub_download
import flax
from flax.training import checkpoints
flax.config.update('flax_use_orbax_checkpointing', False)
lattice = nk.graph.Hypercube(length=10, n_dim=2, pbc=True, max_neighbor_order=2)
J2 = 0.5
assert J2 >= 0.4 and J2 <= 0.6 #* the model has been trained on this interval
from transformers import FlaxAutoModel
wf = FlaxAutoModel.from_pretrained("nqs-models/j1j2_square_fnqs", trust_remote_code=True)
N_params = nk.jax.tree_size(wf.params)
print('Number of parameters = ', N_params, flush=True)
hilbert = nk.hilbert.Spin(s=1/2, N=lattice.n_nodes, total_sz=0)
hamiltonian = nk.operator.Heisenberg(hilbert=hilbert,
graph=lattice,
J=[1.0, J2],
sign_rule=[False, False]).to_jax_operator() # No Marshall sign rule
sampler = nk.sampler.MetropolisExchange(hilbert=hilbert,
graph=lattice,
d_max=2,
n_chains=16000,
sweep_size=lattice.n_nodes)
key = jax.random.PRNGKey(0)
key, subkey = jax.random.split(key, 2)
vstate = nk.vqs.MCState(sampler=sampler,
apply_fun=partial(wf.__call__, coups=J2),
sampler_seed=subkey,
n_samples=16000,
n_discard_per_chain=0,
variables=wf.params,
chunk_size=16000)
# Overwrite samples with already thermalized ones
path = hf_hub_download(repo_id="nqs-models/j1j2_square_fnqs", filename="spins")
samples = checkpoints.restore_checkpoint(ckpt_dir=path, prefix="spins", target=None)
samples = jnp.array(samples, dtype='int8')
vstate.sampler_state = vstate.sampler_state.replace(σ = samples)
import time
# Sample the model
for _ in range(10):
start = time.time()
E = vstate.expect(hamiltonian)
vstate.sample()
print("Mean: ", E.mean.real / lattice.n_nodes / 4, "\t time=", time.time()-start)
```
The time per sweep is 21s, evaluated on a single A100-40GB GPU.
### Extract hidden representation
The hidden representation associated to the input batch of configurations can be extracted as:
```python
wf = FlaxAutoModel.from_pretrained("nqs-models/j1j2_square_fnqs", trust_remote_code=True, return_z=True)
z = wf(wf.params, samples, J2)
```
#### Training Hyperparameters
Number of layers: 4
Embedding dimension: 72
Hidden dimension: 288
Number of heads: 12
Patch size: 2x2
Total number of parameters: 223,104
## Model Card Contact
Riccardo Rende ([email protected])
Luciano Loris Viteritti ([email protected]) |