

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,201 +1,104 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
library_name: transformers
|
| 3 |
-
|
| 4 |
---
|
| 5 |
|
| 6 |
-
#
|
| 7 |
-
|
| 8 |
-
<!-- Provide a quick summary of what the model is/does. -->
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
## Model Details
|
| 13 |
-
|
| 14 |
-
### Model Description
|
| 15 |
-
|
| 16 |
-
<!-- Provide a longer summary of what this model is. -->
|
| 17 |
-
|
| 18 |
-
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
|
| 19 |
-
|
| 20 |
-
- **Developed by:** [More Information Needed]
|
| 21 |
-
- **Funded by [optional]:** [More Information Needed]
|
| 22 |
-
- **Shared by [optional]:** [More Information Needed]
|
| 23 |
-
- **Model type:** [More Information Needed]
|
| 24 |
-
- **Language(s) (NLP):** [More Information Needed]
|
| 25 |
-
- **License:** [More Information Needed]
|
| 26 |
-
- **Finetuned from model [optional]:** [More Information Needed]
|
| 27 |
-
|
| 28 |
-
### Model Sources [optional]
|
| 29 |
-
|
| 30 |
-
<!-- Provide the basic links for the model. -->
|
| 31 |
-
|
| 32 |
-
- **Repository:** [More Information Needed]
|
| 33 |
-
- **Paper [optional]:** [More Information Needed]
|
| 34 |
-
- **Demo [optional]:** [More Information Needed]
|
| 35 |
-
|
| 36 |
-
## Uses
|
| 37 |
-
|
| 38 |
-
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 39 |
-
|
| 40 |
-
### Direct Use
|
| 41 |
-
|
| 42 |
-
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 43 |
-
|
| 44 |
-
[More Information Needed]
|
| 45 |
-
|
| 46 |
-
### Downstream Use [optional]
|
| 47 |
-
|
| 48 |
-
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 49 |
-
|
| 50 |
-
[More Information Needed]
|
| 51 |
-
|
| 52 |
-
### Out-of-Scope Use
|
| 53 |
-
|
| 54 |
-
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 55 |
-
|
| 56 |
-
[More Information Needed]
|
| 57 |
-
|
| 58 |
-
## Bias, Risks, and Limitations
|
| 59 |
-
|
| 60 |
-
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 61 |
-
|
| 62 |
-
[More Information Needed]
|
| 63 |
-
|
| 64 |
-
### Recommendations
|
| 65 |
-
|
| 66 |
-
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 67 |
-
|
| 68 |
-
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 69 |
-
|
| 70 |
-
## How to Get Started with the Model
|
| 71 |
-
|
| 72 |
-
Use the code below to get started with the model.
|
| 73 |
-
|
| 74 |
-
[More Information Needed]
|
| 75 |
-
|
| 76 |
-
## Training Details
|
| 77 |
-
|
| 78 |
-
### Training Data
|
| 79 |
-
|
| 80 |
-
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 81 |
-
|
| 82 |
-
[More Information Needed]
|
| 83 |
-
|
| 84 |
-
### Training Procedure
|
| 85 |
-
|
| 86 |
-
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 87 |
-
|
| 88 |
-
#### Preprocessing [optional]
|
| 89 |
-
|
| 90 |
-
[More Information Needed]
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
#### Training Hyperparameters
|
| 94 |
-
|
| 95 |
-
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 96 |
-
|
| 97 |
-
#### Speeds, Sizes, Times [optional]
|
| 98 |
-
|
| 99 |
-
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 100 |
-
|
| 101 |
-
[More Information Needed]
|
| 102 |
-
|
| 103 |
-
## Evaluation
|
| 104 |
-
|
| 105 |
-
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 106 |
-
|
| 107 |
-
### Testing Data, Factors & Metrics
|
| 108 |
-
|
| 109 |
-
#### Testing Data
|
| 110 |
-
|
| 111 |
-
<!-- This should link to a Dataset Card if possible. -->
|
| 112 |
-
|
| 113 |
-
[More Information Needed]
|
| 114 |
-
|
| 115 |
-
#### Factors
|
| 116 |
-
|
| 117 |
-
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 118 |
-
|
| 119 |
-
[More Information Needed]
|
| 120 |
-
|
| 121 |
-
#### Metrics
|
| 122 |
-
|
| 123 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 124 |
-
|
| 125 |
-
[More Information Needed]
|
| 126 |
-
|
| 127 |
-
### Results
|
| 128 |
-
|
| 129 |
-
[More Information Needed]
|
| 130 |
-
|
| 131 |
-
#### Summary
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
## Model Examination [optional]
|
| 136 |
|
| 137 |
-
|
| 138 |
|
| 139 |
-
|
| 140 |
|
| 141 |
-
|
| 142 |
|
| 143 |
-
|
| 144 |
|
| 145 |
-
|
| 146 |
|
| 147 |
-
|
| 148 |
-
- **Hours used:** [More Information Needed]
|
| 149 |
-
- **Cloud Provider:** [More Information Needed]
|
| 150 |
-
- **Compute Region:** [More Information Needed]
|
| 151 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
|
| 153 |
-
|
| 154 |
|
| 155 |
-
|
| 156 |
|
| 157 |
-
[
|
| 158 |
|
| 159 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 160 |
|
| 161 |
-
|
| 162 |
|
| 163 |
-
|
| 164 |
|
| 165 |
-
|
| 166 |
|
| 167 |
-
|
| 168 |
|
| 169 |
-
|
| 170 |
|
| 171 |
-
|
| 172 |
|
| 173 |
-
|
| 174 |
|
| 175 |
-
|
| 176 |
|
| 177 |
-
|
|
|
|
|
|
|
| 178 |
|
| 179 |
-
|
| 180 |
|
| 181 |
-
|
|
|
|
| 182 |
|
| 183 |
-
|
| 184 |
|
| 185 |
-
|
| 186 |
|
| 187 |
-
|
| 188 |
|
| 189 |
-
|
| 190 |
|
| 191 |
-
|
|
|
|
| 192 |
|
| 193 |
-
|
| 194 |
|
| 195 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 196 |
|
| 197 |
-
|
| 198 |
|
| 199 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 200 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 201 |
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
datasets:
|
| 3 |
+
- smallstepai/culturaX
|
| 4 |
+
language:
|
| 5 |
+
- mr
|
| 6 |
+
metrics:
|
| 7 |
+
- accuracy
|
| 8 |
+
tags:
|
| 9 |
+
- marathi
|
| 10 |
+
- sentiment analysis
|
| 11 |
+
- reading comprehension
|
| 12 |
+
- paraphrasing
|
| 13 |
+
- translation
|
| 14 |
+
|
| 15 |
library_name: transformers
|
| 16 |
+
pipeline_tag: text-generation
|
| 17 |
---
|
| 18 |
|
| 19 |
+
# Misal-7B
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
+
[smallstep.ai](https://www.linkedin.com/company/smallstepai/about/)
|
| 22 |
|
| 23 |
+
## What have we built?
|
| 24 |
|
| 25 |
+
Misal 7B, a pretrained and instruction tuned large language model based on Meta’s Llama 7B architecture exclusively for Marathi.
|
| 26 |
|
| 27 |
+
## How we built it?
|
| 28 |
|
| 29 |
+
Detailed blog [here](https://smallstep.ai/making-misal).
|
| 30 |
|
| 31 |
+
## Benchmarking :
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
|
| 33 |
+
We did a manual round of evaluations using internet data (we have released the evaluation data here). This is a fairly small dataset with 100 questions taken from the internet. We understand that a better evaluation method is needed to benchmark our model, this being the first iteration we decided to proceed with manual evaluation.
|
| 34 |
|
| 35 |
+
Our main aim was to see if the model understands basic instructions, if so how well is it able to understand it, hence we have limited our evaluation to Reading comprehension, Translation, Sentiment Analysis, Paraphrasing like tasks.
|
| 36 |
|
| 37 |
+
[Manual Evaluation Set ](https://huggingface.co/datasets/smallstepai/Misal-Evaluation-v0.1)
|
| 38 |
|
| 39 |
+
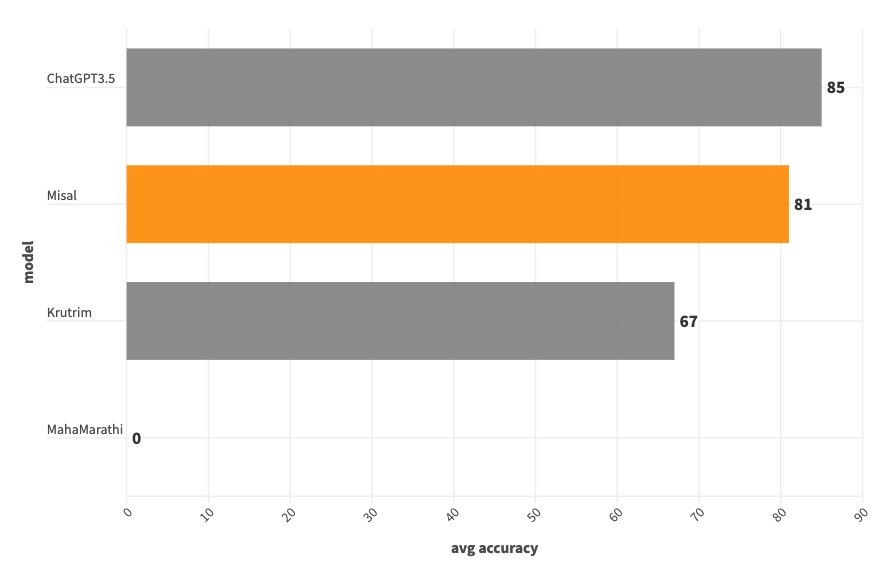
| | Misal | ChatGPT3.5 | Krutrim | MahaMarathi |
|
| 40 |
+
| --------------------- | ----- | ---------- | ------- | ----------- |
|
| 41 |
+
| reading comprehension | 88 | 68 | 40 | 0 |
|
| 42 |
+
| sentiment analysis | 68 | 76 | 60 | 0 |
|
| 43 |
+
| paraphrase | 92 | 100 | 88 | 0 |
|
| 44 |
+
| translation | 76 | 96 | 80 | 0 |
|
| 45 |
+
| average | 81 | 85 | 67 | 0 |
|
| 46 |
|
| 47 |
+
## Summary :
|
| 48 |
|
| 49 |
+
Our model beats ChatGPT 3.5 at reading comprehension.
|
| 50 |
|
| 51 |
+
While we are not able to beat ChatGPT 3.5 on remaining tasks like sentiment analysis, paraphrasing, translation, our model beats Ola Krutrim at all the tasks except translation.
|
| 52 |
|
| 53 |
+
|
| 54 |
|
| 55 |
+
## License
|
| 56 |
|
| 57 |
+
The model inherits the license from meta-llama/Llama-2-7b.
|
| 58 |
|
| 59 |
+
## Usage
|
| 60 |
|
| 61 |
+
### Installation
|
| 62 |
|
| 63 |
+
```bash
|
| 64 |
+
pip install transformers accelerate
|
| 65 |
+
```
|
| 66 |
|
| 67 |
+
### Prompt
|
| 68 |
|
| 69 |
+
```python
|
| 70 |
+
आपण एक मदतगार, आदरणीय आणि प्रामाणिक सहाय्यक आहात.नेहमी शक्य तितकी उपयुक्त उत्तर द्या. तुमची उत्तरे हानिकारक, अनैतिक, वर्णद्वेषी, लैंगिकतावादी, हानिकारक, धोकादायक किंवा बेकायदेशीर नसावीत. कृपया खात्री करा की तुमची उत्तरे सामाजिक दृष्टिकोनाने निष्पक्ष आणि सकारात्मक स्वरूपाची आहेत. जर एखाद्या प्रश्नाला काही अर्थ नसेल किंवा वस्तुस्थितीशी सुसंगती नसेल, तर उत्तर देण्याऐवजी काहीतरी बरोबर का नाही हे स्पष्ट करा. तुम्हाला एखाद्या प्रश्नाचे उत्तर माहित नसल्यास, कृपया चुकीची माहिती देऊ नये.
|
| 71 |
|
| 72 |
+
### Instruction:
|
| 73 |
|
| 74 |
+
<instruction>
|
| 75 |
|
| 76 |
+
### Input:
|
| 77 |
|
| 78 |
+
<input data>
|
| 79 |
|
| 80 |
+
### Response:
|
| 81 |
+
```
|
| 82 |
|
| 83 |
+
### PyTorch
|
| 84 |
|
| 85 |
+
```python
|
| 86 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 87 |
+
device = "cuda"
|
| 88 |
+
model = AutoModelForCausalLM.from_pretrained("smallstepai/Misal-7B-instruct-v0.1", torch_dtype=torch.bfloat16, device_map='auto')
|
| 89 |
+
tokenizer = AutoTokenizer.from_pretrained("smallstepai/Misal-7B-instruct-v0.1")
|
| 90 |
|
| 91 |
+
def ask_misal(model, tokenizer, instruction, inputs='', system_prompt='', max_new_tokens=200, device='cuda'):
|
| 92 |
|
| 93 |
+
ip = dict(system_prompt=system_prompt, instruction=instruction, inputs=inputs)
|
| 94 |
+
model_inputs = tokenizer.apply_chat_template(ip, return_tensors='pt')
|
| 95 |
+
outputs = model.generate(model_inputs.to(device), max_new_tokens=max_new_tokens)
|
| 96 |
+
response = tokenizer.decode(outputs[0]).split('### Response:')[1].strip()
|
| 97 |
+
return response
|
| 98 |
|
| 99 |
+
instruction="सादरीकरण कसे करावे?"
|
| 100 |
+
resp = ask_misal(model, tokenizer, instruction=instruction, max_new_tokens=1024)
|
| 101 |
+
print(resp)
|
| 102 |
+
```
|
| 103 |
|
| 104 |
+
### Team
|