

Upload 4 files
Browse files
docs/source/en/tutorials/inspect_runs.md
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Inspecting runs with OpenTelemetry
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
> [!TIP]
|
| 6 |
+
> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
|
| 7 |
+
|
| 8 |
+
## Why log your agent runs?
|
| 9 |
+
|
| 10 |
+
Agent runs are complicated to debug.
|
| 11 |
+
|
| 12 |
+
Validating that a run went properly is hard, since agent workflows are [unpredictable by design](../conceptual_guides/intro_agents) (if they were predictable, you'd just be using good old code).
|
| 13 |
+
|
| 14 |
+
And inspecting a run is hard as well: multi-step agents tend to quickly fill a console with logs, and most of the errors are just "LLM dumb" kind of errors, from which the LLM auto-corrects in the next step by writing better code or tool calls.
|
| 15 |
+
|
| 16 |
+
So using instrumentation to record agent runs is necessary in production for later inspection and monitoring!
|
| 17 |
+
|
| 18 |
+
We've adopted the [OpenTelemetry](https://opentelemetry.io/) standard for instrumenting agent runs.
|
| 19 |
+
|
| 20 |
+
This means that you can just run some instrumentation code, then run your agents normally, and everything gets logged into your platform. Below are some examples of how to do this with different OpenTelemetry backends.
|
| 21 |
+
|
| 22 |
+
Here's how it then looks like on the platform:
|
| 23 |
+
|
| 24 |
+
<div class="flex justify-center">
|
| 25 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/smolagents/inspect_run_phoenix.gif"/>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## Setting up telemetry with Arize AI Phoenix
|
| 30 |
+
First install the required packages. Here we install [Phoenix by Arize AI](https://github.com/Arize-ai/phoenix) because that's a good solution to collect and inspect the logs, but there are other OpenTelemetry-compatible platforms that you could use for this collection & inspection part.
|
| 31 |
+
|
| 32 |
+
```shell
|
| 33 |
+
pip install 'smolagents[telemetry,toolkit]'
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Then run the collector in the background.
|
| 37 |
+
|
| 38 |
+
```shell
|
| 39 |
+
python -m phoenix.server.main serve
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
Finally, set up `SmolagentsInstrumentor` to trace your agents and send the traces to Phoenix default endpoint.
|
| 43 |
+
|
| 44 |
+
```python
|
| 45 |
+
from phoenix.otel import register
|
| 46 |
+
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
|
| 47 |
+
|
| 48 |
+
register()
|
| 49 |
+
SmolagentsInstrumentor().instrument()
|
| 50 |
+
```
|
| 51 |
+
Then you can run your agents!
|
| 52 |
+
|
| 53 |
+
```py
|
| 54 |
+
from smolagents import (
|
| 55 |
+
CodeAgent,
|
| 56 |
+
ToolCallingAgent,
|
| 57 |
+
WebSearchTool,
|
| 58 |
+
VisitWebpageTool,
|
| 59 |
+
InferenceClientModel,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
model = InferenceClientModel()
|
| 63 |
+
|
| 64 |
+
search_agent = ToolCallingAgent(
|
| 65 |
+
tools=[WebSearchTool(), VisitWebpageTool()],
|
| 66 |
+
model=model,
|
| 67 |
+
name="search_agent",
|
| 68 |
+
description="This is an agent that can do web search.",
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
manager_agent = CodeAgent(
|
| 72 |
+
tools=[],
|
| 73 |
+
model=model,
|
| 74 |
+
managed_agents=[search_agent],
|
| 75 |
+
)
|
| 76 |
+
manager_agent.run(
|
| 77 |
+
"If the US keeps its 2024 growth rate, how many years will it take for the GDP to double?"
|
| 78 |
+
)
|
| 79 |
+
```
|
| 80 |
+
Voilà!
|
| 81 |
+
You can then navigate to `http://0.0.0.0:6006/projects/` to inspect your run!
|
| 82 |
+
|
| 83 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/smolagents/inspect_run_phoenix.png">
|
| 84 |
+
|
| 85 |
+
You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
|
| 86 |
+
|
| 87 |
+
## Setting up telemetry with Langfuse
|
| 88 |
+
|
| 89 |
+
This part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.
|
| 90 |
+
|
| 91 |
+
> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.
|
| 92 |
+
|
| 93 |
+
### Step 1: Install Dependencies
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
%pip install smolagents
|
| 97 |
+
%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
### Step 2: Set Up Environment Variables
|
| 101 |
+
|
| 102 |
+
Set your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).
|
| 103 |
+
|
| 104 |
+
Also, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.
|
| 105 |
+
|
| 106 |
+
```python
|
| 107 |
+
import os
|
| 108 |
+
import base64
|
| 109 |
+
|
| 110 |
+
LANGFUSE_PUBLIC_KEY="pk-lf-..."
|
| 111 |
+
LANGFUSE_SECRET_KEY="sk-lf-..."
|
| 112 |
+
LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
|
| 113 |
+
|
| 114 |
+
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
|
| 115 |
+
# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
|
| 116 |
+
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
|
| 117 |
+
|
| 118 |
+
# your Hugging Face token
|
| 119 |
+
os.environ["HF_TOKEN"] = "hf_..."
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
### Step 3: Initialize the `SmolagentsInstrumentor`
|
| 123 |
+
|
| 124 |
+
Initialize the `SmolagentsInstrumentor` before your application code. Configure `tracer_provider` and add a span processor to export traces to Langfuse. `OTLPSpanExporter()` uses the endpoint and headers from the environment variables.
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
```python
|
| 128 |
+
from opentelemetry.sdk.trace import TracerProvider
|
| 129 |
+
|
| 130 |
+
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
|
| 131 |
+
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
|
| 132 |
+
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
|
| 133 |
+
|
| 134 |
+
trace_provider = TracerProvider()
|
| 135 |
+
trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
|
| 136 |
+
|
| 137 |
+
SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
### Step 4: Run your smolagent
|
| 141 |
+
|
| 142 |
+
```python
|
| 143 |
+
from smolagents import (
|
| 144 |
+
CodeAgent,
|
| 145 |
+
ToolCallingAgent,
|
| 146 |
+
WebSearchTool,
|
| 147 |
+
VisitWebpageTool,
|
| 148 |
+
InferenceClientModel,
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
model = InferenceClientModel(
|
| 152 |
+
model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
search_agent = ToolCallingAgent(
|
| 156 |
+
tools=[WebSearchTool(), VisitWebpageTool()],
|
| 157 |
+
model=model,
|
| 158 |
+
name="search_agent",
|
| 159 |
+
description="This is an agent that can do web search.",
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
manager_agent = CodeAgent(
|
| 163 |
+
tools=[],
|
| 164 |
+
model=model,
|
| 165 |
+
managed_agents=[search_agent],
|
| 166 |
+
)
|
| 167 |
+
manager_agent.run(
|
| 168 |
+
"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
|
| 169 |
+
)
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
### Step 5: View Traces in Langfuse
|
| 173 |
+
|
| 174 |
+
After running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
|
| 175 |
+
|
| 176 |
+
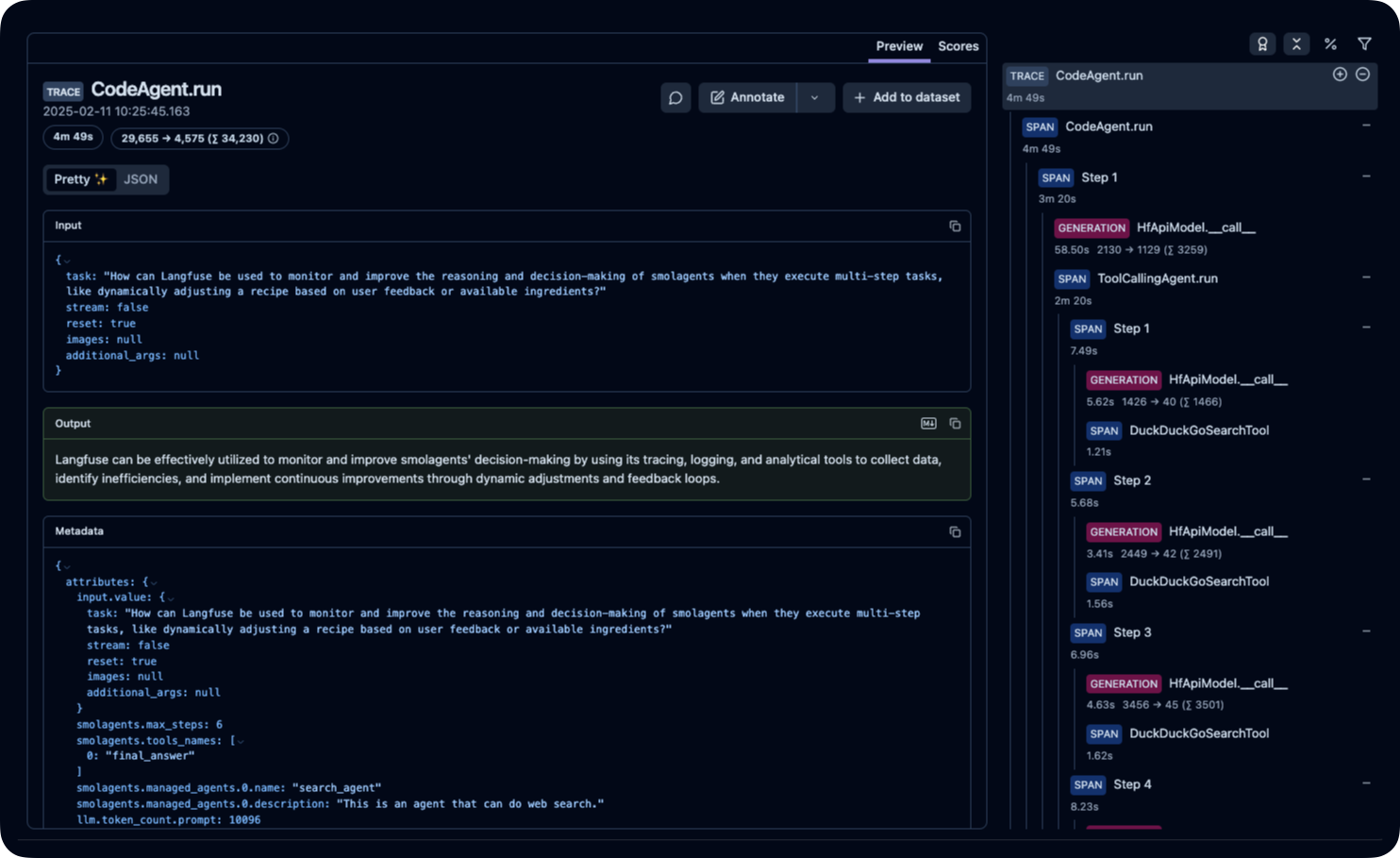
|
| 177 |
+
|
| 178 |
+
_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
|
docs/source/en/tutorials/memory.md
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 📚 Manage your agent's memory
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
In the end, an agent can be defined by simple components: it has tools, prompts.
|
| 6 |
+
And most importantly, it has a memory of past steps, drawing a history of planning, execution, and errors.
|
| 7 |
+
|
| 8 |
+
### Replay your agent's memory
|
| 9 |
+
|
| 10 |
+
We propose several features to inspect a past agent run.
|
| 11 |
+
|
| 12 |
+
You can instrument the agent's run to display it in a great UI that lets you zoom in/out on specific steps, as highlighted in the [instrumentation guide](./inspect_runs).
|
| 13 |
+
|
| 14 |
+
You can also use `agent.replay()`, as follows:
|
| 15 |
+
|
| 16 |
+
After the agent has run:
|
| 17 |
+
```py
|
| 18 |
+
from smolagents import InferenceClientModel, CodeAgent
|
| 19 |
+
|
| 20 |
+
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
|
| 21 |
+
|
| 22 |
+
result = agent.run("What's the 20th Fibonacci number?")
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
If you want to replay this last run, just use:
|
| 26 |
+
```py
|
| 27 |
+
agent.replay()
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
### Dynamically change the agent's memory
|
| 31 |
+
|
| 32 |
+
Many advanced use cases require dynamic modification of the agent's memory.
|
| 33 |
+
|
| 34 |
+
You can access the agent's memory using:
|
| 35 |
+
|
| 36 |
+
```py
|
| 37 |
+
from smolagents import ActionStep
|
| 38 |
+
|
| 39 |
+
system_prompt_step = agent.memory.system_prompt
|
| 40 |
+
print("The system prompt given to the agent was:")
|
| 41 |
+
print(system_prompt_step.system_prompt)
|
| 42 |
+
|
| 43 |
+
task_step = agent.memory.steps[0]
|
| 44 |
+
print("\n\nThe first task step was:")
|
| 45 |
+
print(task_step.task)
|
| 46 |
+
|
| 47 |
+
for step in agent.memory.steps:
|
| 48 |
+
if isinstance(step, ActionStep):
|
| 49 |
+
if step.error is not None:
|
| 50 |
+
print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
|
| 51 |
+
else:
|
| 52 |
+
print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
Use `agent.memory.get_full_steps()` to get full steps as dictionaries.
|
| 56 |
+
|
| 57 |
+
You can also use step callbacks to dynamically change the agent's memory.
|
| 58 |
+
|
| 59 |
+
Step callbacks can access the `agent` itself in their arguments, so they can access any memory step as highlighted above, and change it if needed. For instance, let's say you are observing screenshots of each step performed by a web browser agent. You want to log the newest screenshot, and remove the images from ancient steps to save on token costs.
|
| 60 |
+
|
| 61 |
+
You could run something like the following.
|
| 62 |
+
_Note: this code is incomplete, some imports and object definitions have been removed for the sake of concision, visit [the original script](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to get the full working code._
|
| 63 |
+
|
| 64 |
+
```py
|
| 65 |
+
import helium
|
| 66 |
+
from PIL import Image
|
| 67 |
+
from io import BytesIO
|
| 68 |
+
from time import sleep
|
| 69 |
+
|
| 70 |
+
def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
|
| 71 |
+
sleep(1.0) # Let JavaScript animations happen before taking the screenshot
|
| 72 |
+
driver = helium.get_driver()
|
| 73 |
+
latest_step = memory_step.step_number
|
| 74 |
+
for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
|
| 75 |
+
if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
|
| 76 |
+
previous_memory_step.observations_images = None
|
| 77 |
+
png_bytes = driver.get_screenshot_as_png()
|
| 78 |
+
image = Image.open(BytesIO(png_bytes))
|
| 79 |
+
memory_step.observations_images = [image.copy()]
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
Then you should pass this function in the `step_callbacks` argument upon initialization of your agent:
|
| 83 |
+
|
| 84 |
+
```py
|
| 85 |
+
CodeAgent(
|
| 86 |
+
tools=[WebSearchTool(), go_back, close_popups, search_item_ctrl_f],
|
| 87 |
+
model=model,
|
| 88 |
+
additional_authorized_imports=["helium"],
|
| 89 |
+
step_callbacks=[update_screenshot],
|
| 90 |
+
max_steps=20,
|
| 91 |
+
verbosity_level=2,
|
| 92 |
+
)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
Head to our [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to see the full working example.
|
| 96 |
+
|
| 97 |
+
### Run agents one step at a time
|
| 98 |
+
|
| 99 |
+
This can be useful in case you have tool calls that take days: you can just run your agents step by step.
|
| 100 |
+
This will also let you update the memory on each step.
|
| 101 |
+
|
| 102 |
+
```py
|
| 103 |
+
from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
|
| 104 |
+
|
| 105 |
+
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
|
| 106 |
+
agent.python_executor.send_tools({**agent.tools})
|
| 107 |
+
print(agent.memory.system_prompt)
|
| 108 |
+
|
| 109 |
+
task = "What is the 20th Fibonacci number?"
|
| 110 |
+
|
| 111 |
+
# You could modify the memory as needed here by inputting the memory of another agent.
|
| 112 |
+
# agent.memory.steps = previous_agent.memory.steps
|
| 113 |
+
|
| 114 |
+
# Let's start a new task!
|
| 115 |
+
agent.memory.steps.append(TaskStep(task=task, task_images=[]))
|
| 116 |
+
|
| 117 |
+
final_answer = None
|
| 118 |
+
step_number = 1
|
| 119 |
+
while final_answer is None and step_number <= 10:
|
| 120 |
+
memory_step = ActionStep(
|
| 121 |
+
step_number=step_number,
|
| 122 |
+
observations_images=[],
|
| 123 |
+
)
|
| 124 |
+
# Run one step.
|
| 125 |
+
final_answer = agent.step(memory_step)
|
| 126 |
+
agent.memory.steps.append(memory_step)
|
| 127 |
+
step_number += 1
|
| 128 |
+
|
| 129 |
+
# Change the memory as you please!
|
| 130 |
+
# For instance to update the latest step:
|
| 131 |
+
# agent.memory.steps[-1] = ...
|
| 132 |
+
|
| 133 |
+
print("The final answer is:", final_answer)
|
| 134 |
+
```
|
docs/source/en/tutorials/secure_code_execution.md
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Secure code execution
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
> [!TIP]
|
| 6 |
+
> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
|
| 7 |
+
|
| 8 |
+
### Code agents
|
| 9 |
+
|
| 10 |
+
[Multiple](https://huggingface.co/papers/2402.01030) [research](https://huggingface.co/papers/2411.01747) [papers](https://huggingface.co/papers/2401.00812) have shown that having the LLM write its actions (the tool calls) in code is much better than the current standard format for tool calling, which is across the industry different shades of "writing actions as a JSON of tools names and arguments to use".
|
| 11 |
+
|
| 12 |
+
Why is code better? Well, because we crafted our code languages specifically to be great at expressing actions performed by a computer. If JSON snippets were a better way, this package would have been written in JSON snippets and the devil would be laughing at us.
|
| 13 |
+
|
| 14 |
+
Code is just a better way to express actions on a computer. It has better:
|
| 15 |
+
- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
|
| 16 |
+
- **Object management:** how do you store the output of an action like `generate_image` in JSON?
|
| 17 |
+
- **Generality:** code is built to express simply anything you can have a computer do.
|
| 18 |
+
- **Representation in LLM training corpus:** why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus?
|
| 19 |
+
|
| 20 |
+
This is illustrated on the figure below, taken from [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030).
|
| 21 |
+
|
| 22 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/code_vs_json_actions.png">
|
| 23 |
+
|
| 24 |
+
This is why we put emphasis on proposing code agents, in this case python agents, which meant putting higher effort on building secure python interpreters.
|
| 25 |
+
|
| 26 |
+
### Local code execution??
|
| 27 |
+
|
| 28 |
+
By default, the `CodeAgent` runs LLM-generated code in your environment.
|
| 29 |
+
|
| 30 |
+
This is inherently risky, LLM-generated code could be harmful to your environment.
|
| 31 |
+
|
| 32 |
+
Malicious code execution can occur in several ways:
|
| 33 |
+
- **Plain LLM error:** LLMs are still far from perfect and may unintentionally generate harmful commands while attempting to be helpful. While this risk is low, instances have been observed where an LLM attempted to execute potentially dangerous code.
|
| 34 |
+
- **Supply chain attack:** Running an untrusted or compromised LLM could expose a system to harmful code generation. While this risk is extremely low when using well-known models on secure inference infrastructure, it remains a theoretical possibility.
|
| 35 |
+
- **Prompt injection:** an agent browsing the web could arrive on a malicious website that contains harmful instructions, thus injecting an attack into the agent's memory
|
| 36 |
+
- **Exploitation of publicly accessible agents:** Agents exposed to the public can be misused by malicious actors to execute harmful code. Attackers may craft adversarial inputs to exploit the agent's execution capabilities, leading to unintended consequences.
|
| 37 |
+
Once malicious code is executed, whether accidentally or intentionally, it can damage the file system, exploit local or cloud-based resources, abuse API services, and even compromise network security.
|
| 38 |
+
|
| 39 |
+
One could argue that on the [spectrum of agency](../conceptual_guides/intro_agents), code agents give much higher agency to the LLM on your system than other less agentic setups: this goes hand-in-hand with higher risk.
|
| 40 |
+
|
| 41 |
+
So you need to be very mindful of security.
|
| 42 |
+
|
| 43 |
+
To improve safety, we propose a range of measures that propose elevated levels of security, at a higher setup cost.
|
| 44 |
+
|
| 45 |
+
We advise you to keep in mind that no solution will be 100% safe.
|
| 46 |
+
|
| 47 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/smolagents/code_execution_safety_diagram.png">
|
| 48 |
+
|
| 49 |
+
### Our local Python executor
|
| 50 |
+
|
| 51 |
+
To add a first layer of security, code execution in `smolagents` is not performed by the vanilla Python interpreter.
|
| 52 |
+
We have re-built a more secure `LocalPythonExecutor` from the ground up.
|
| 53 |
+
|
| 54 |
+
To be precise, this interpreter works by loading the Abstract Syntax Tree (AST) from your Code and executes it operation by operation, making sure to always follow certain rules:
|
| 55 |
+
- By default, imports are disallowed unless they have been explicitly added to an authorization list by the user.
|
| 56 |
+
- Furthermore, access to submodules is disabled by default, and each must be explicitly authorized in the import list as well, or you can pass for instance `numpy.*` to allow both `numpy` and all its subpackags, like `numpy.random` or `numpy.a.b`.
|
| 57 |
+
- Note that some seemingly innocuous packages like `random` can give access to potentially harmful submodules, as in `random._os`.
|
| 58 |
+
- The total count of elementary operations processed is capped to prevent infinite loops and resource bloating.
|
| 59 |
+
- Any operation that has not been explicitly defined in our custom interpreter will raise an error.
|
| 60 |
+
|
| 61 |
+
You could try these safeguards as follows:
|
| 62 |
+
|
| 63 |
+
```py
|
| 64 |
+
from smolagents.local_python_executor import LocalPythonExecutor
|
| 65 |
+
|
| 66 |
+
# Set up custom executor, authorize package "numpy"
|
| 67 |
+
custom_executor = LocalPythonExecutor(["numpy"])
|
| 68 |
+
|
| 69 |
+
# Utilisty for pretty printing errors
|
| 70 |
+
def run_capture_exception(command: str):
|
| 71 |
+
try:
|
| 72 |
+
custom_executor(harmful_command)
|
| 73 |
+
except Exception as e:
|
| 74 |
+
print("ERROR:\n", e)
|
| 75 |
+
|
| 76 |
+
# Undefined command just do not work
|
| 77 |
+
harmful_command="!echo Bad command"
|
| 78 |
+
run_capture_exception(harmful_command)
|
| 79 |
+
# >>> ERROR: invalid syntax (<unknown>, line 1)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
# Imports like os will not be performed unless explicitly added to `additional_authorized_imports`
|
| 83 |
+
harmful_command="import os; exit_code = os.system("echo Bad command")"
|
| 84 |
+
run_capture_exception(harmful_command)
|
| 85 |
+
# >>> ERROR: Code execution failed at line 'import os' due to: InterpreterError: Import of os is not allowed. Authorized imports are: ['statistics', 'numpy', 'itertools', 'time', 'queue', 'collections', 'math', 'random', 're', 'datetime', 'stat', 'unicodedata']
|
| 86 |
+
|
| 87 |
+
# Even in authorized imports, potentially harmful packages will not be imported
|
| 88 |
+
harmful_command="import random; random._os.system('echo Bad command')"
|
| 89 |
+
run_capture_exception(harmful_command)
|
| 90 |
+
# >>> ERROR: Code execution failed at line 'random._os.system('echo Bad command')' due to: InterpreterError: Forbidden access to module: os
|
| 91 |
+
|
| 92 |
+
# Infinite loop are interrupted after N operations
|
| 93 |
+
harmful_command="""
|
| 94 |
+
while True:
|
| 95 |
+
pass
|
| 96 |
+
"""
|
| 97 |
+
run_capture_exception(harmful_command)
|
| 98 |
+
# >>> ERROR: Code execution failed at line 'while True: pass' due to: InterpreterError: Maximum number of 1000000 iterations in While loop exceeded
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
These safeguards make out interpreter is safer.
|
| 102 |
+
We have used it on a diversity of use cases, without ever observing any damage to the environment.
|
| 103 |
+
|
| 104 |
+
> [!WARNING]
|
| 105 |
+
> It's important to understand that no local python sandbox can ever be completely secure. While our interpreter provides significant safety improvements over the standard Python interpreter, it is still possible for a determined attacker or a fine-tuned malicious LLM to find vulnerabilities and potentially harm your environment.
|
| 106 |
+
>
|
| 107 |
+
> For example, if you've allowed packages like `Pillow` to process images, the LLM could generate code that creates thousands of large image files to fill your hard drive. Other advanced escape techniques might exploit deeper vulnerabilities in authorized packages.
|
| 108 |
+
>
|
| 109 |
+
> Running LLM-generated code in your local environment always carries some inherent risk. The only way to run LLM-generated code with truly robust security isolation is to use remote execution options like E2B or Docker, as detailed below.
|
| 110 |
+
|
| 111 |
+
The risk of a malicious attack is low when using well-known LLMs from trusted inference providers, but it is not zero.
|
| 112 |
+
For high-security applications or when using less trusted models, you should consider using a remote execution sandbox.
|
| 113 |
+
|
| 114 |
+
## Sandbox approaches for secure code execution
|
| 115 |
+
|
| 116 |
+
When working with AI agents that execute code, security is paramount. There are two main approaches to sandboxing code execution in smolagents, each with different security properties and capabilities:
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+

|
| 120 |
+
|
| 121 |
+
1. **Running individual code snippets in a sandbox**: This approach (left side of diagram) only executes the agent-generated Python code snippets in a sandbox while keeping the rest of the agentic system in your local environment. It's simpler to set up using `executor_type="e2b"` or `executor_type="docker"`, but it doesn't support multi-agents and still requires passing state data between your environment and the sandbox.
|
| 122 |
+
|
| 123 |
+
2. **Running the entire agentic system in a sandbox**: This approach (right side of diagram) runs the entire agentic system, including the agent, model, and tools, within a sandbox environment. This provides better isolation but requires more manual setup and may require passing sensitive credentials (like API keys) to the sandbox environment.
|
| 124 |
+
|
| 125 |
+
This guide describes how to set up and use both types of sandbox approaches for your agent applications.
|
| 126 |
+
|
| 127 |
+
### E2B setup
|
| 128 |
+
|
| 129 |
+
#### Installation
|
| 130 |
+
|
| 131 |
+
1. Create an E2B account at [e2b.dev](https://e2b.dev)
|
| 132 |
+
2. Install the required packages:
|
| 133 |
+
```bash
|
| 134 |
+
pip install 'smolagents[e2b]'
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
#### Running your agent in E2B: quick start
|
| 138 |
+
|
| 139 |
+
We provide a simple way to use an E2B Sandbox: simply add `executor_type="e2b"` to the agent initialization, as follows:
|
| 140 |
+
|
| 141 |
+
```py
|
| 142 |
+
from smolagents import InferenceClientModel, CodeAgent
|
| 143 |
+
|
| 144 |
+
agent = CodeAgent(model=InferenceClientModel(), tools=[], executor_type="e2b")
|
| 145 |
+
|
| 146 |
+
with agent:
|
| 147 |
+
agent.run("Can you give me the 100th Fibonacci number?")
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
> [!TIP]
|
| 151 |
+
> Using the agent as a context manager (with the `with` statement) ensures that the E2B sandbox is cleaned up immediately after the agent completes its task.
|
| 152 |
+
> Alternatively, you can manually call the agent's `cleanup()` method.
|
| 153 |
+
|
| 154 |
+
This solution send the agent state to the server at the start of each `agent.run()`.
|
| 155 |
+
Then the models are called from the local environment, but the generated code will be sent to the sandbox for execution, and only the output will be returned.
|
| 156 |
+
|
| 157 |
+
This is illustrated in the figure below.
|
| 158 |
+
|
| 159 |
+
<p align="center">
|
| 160 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/smolagents/sandboxed_execution.png" alt="sandboxed code execution" width=60% max-width=500px>
|
| 161 |
+
</p>
|
| 162 |
+
|
| 163 |
+
However, since any call to a [managed agent](../examples/multiagents) would require model calls, since we do not transfer secrets to the remote sandbox, the model call would lack credentials.
|
| 164 |
+
Hence this solution does not work (yet) with more complicated multi-agent setups.
|
| 165 |
+
|
| 166 |
+
#### Running your agent in E2B: multi-agents
|
| 167 |
+
|
| 168 |
+
To use multi-agents in an E2B sandbox, you need to run your agents completely from within E2B.
|
| 169 |
+
|
| 170 |
+
Here is how to do it:
|
| 171 |
+
|
| 172 |
+
```python
|
| 173 |
+
from e2b_code_interpreter import Sandbox
|
| 174 |
+
import os
|
| 175 |
+
|
| 176 |
+
# Create the sandbox
|
| 177 |
+
sandbox = Sandbox()
|
| 178 |
+
|
| 179 |
+
# Install required packages
|
| 180 |
+
sandbox.commands.run("pip install smolagents")
|
| 181 |
+
|
| 182 |
+
def run_code_raise_errors(sandbox, code: str, verbose: bool = False) -> str:
|
| 183 |
+
execution = sandbox.run_code(
|
| 184 |
+
code,
|
| 185 |
+
envs={'HF_TOKEN': os.getenv('HF_TOKEN')}
|
| 186 |
+
)
|
| 187 |
+
if execution.error:
|
| 188 |
+
execution_logs = "\n".join([str(log) for log in execution.logs.stdout])
|
| 189 |
+
logs = execution_logs
|
| 190 |
+
logs += execution.error.traceback
|
| 191 |
+
raise ValueError(logs)
|
| 192 |
+
return "\n".join([str(log) for log in execution.logs.stdout])
|
| 193 |
+
|
| 194 |
+
# Define your agent application
|
| 195 |
+
agent_code = """
|
| 196 |
+
import os
|
| 197 |
+
from smolagents import CodeAgent, InferenceClientModel
|
| 198 |
+
|
| 199 |
+
# Initialize the agents
|
| 200 |
+
agent = CodeAgent(
|
| 201 |
+
model=InferenceClientModel(token=os.getenv("HF_TOKEN"), provider="together"),
|
| 202 |
+
tools=[],
|
| 203 |
+
name="coder_agent",
|
| 204 |
+
description="This agent takes care of your difficult algorithmic problems using code."
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
manager_agent = CodeAgent(
|
| 208 |
+
model=InferenceClientModel(token=os.getenv("HF_TOKEN"), provider="together"),
|
| 209 |
+
tools=[],
|
| 210 |
+
managed_agents=[agent],
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
# Run the agent
|
| 214 |
+
response = manager_agent.run("What's the 20th Fibonacci number?")
|
| 215 |
+
print(response)
|
| 216 |
+
"""
|
| 217 |
+
|
| 218 |
+
# Run the agent code in the sandbox
|
| 219 |
+
execution_logs = run_code_raise_errors(sandbox, agent_code)
|
| 220 |
+
print(execution_logs)
|
| 221 |
+
```
|
| 222 |
+
|
| 223 |
+
### Docker setup
|
| 224 |
+
|
| 225 |
+
#### Installation
|
| 226 |
+
|
| 227 |
+
1. [Install Docker on your system](https://docs.docker.com/get-started/get-docker/)
|
| 228 |
+
2. Install the required packages:
|
| 229 |
+
```bash
|
| 230 |
+
pip install 'smolagents[docker]'
|
| 231 |
+
```
|
| 232 |
+
|
| 233 |
+
#### Running your agent in Docker: quick start
|
| 234 |
+
|
| 235 |
+
Similar to the E2B Sandbox above, to quickly get started with Docker, simply add `executor_type="docker"` to the agent initialization, like:
|
| 236 |
+
|
| 237 |
+
```py
|
| 238 |
+
from smolagents import InferenceClientModel, CodeAgent
|
| 239 |
+
|
| 240 |
+
agent = CodeAgent(model=InferenceClientModel(), tools=[], executor_type="docker")
|
| 241 |
+
|
| 242 |
+
with agent:
|
| 243 |
+
agent.run("Can you give me the 100th Fibonacci number?")
|
| 244 |
+
```
|
| 245 |
+
|
| 246 |
+
> [!TIP]
|
| 247 |
+
> Using the agent as a context manager (with the `with` statement) ensures that the Docker container is cleaned immediately after the agent completes its task.
|
| 248 |
+
> Alternatively, you can manually call the agent's `cleanup()` method.
|
| 249 |
+
|
| 250 |
+
#### Advanced docker usage
|
| 251 |
+
|
| 252 |
+
If you want to run multi-agent systems in Docker, you'll need to setup a custom interpreter in a sandbox.
|
| 253 |
+
|
| 254 |
+
Here is how to setup the a Dockerfile:
|
| 255 |
+
|
| 256 |
+
```dockerfile
|
| 257 |
+
FROM python:3.10-bullseye
|
| 258 |
+
|
| 259 |
+
# Install build dependencies
|
| 260 |
+
RUN apt-get update && \
|
| 261 |
+
apt-get install -y --no-install-recommends \
|
| 262 |
+
build-essential \
|
| 263 |
+
python3-dev && \
|
| 264 |
+
pip install --no-cache-dir --upgrade pip && \
|
| 265 |
+
pip install --no-cache-dir smolagents && \
|
| 266 |
+
apt-get clean && \
|
| 267 |
+
rm -rf /var/lib/apt/lists/*
|
| 268 |
+
|
| 269 |
+
# Set working directory
|
| 270 |
+
WORKDIR /app
|
| 271 |
+
|
| 272 |
+
# Run with limited privileges
|
| 273 |
+
USER nobody
|
| 274 |
+
|
| 275 |
+
# Default command
|
| 276 |
+
CMD ["python", "-c", "print('Container ready')"]
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
Create a sandbox manager to run code:
|
| 280 |
+
|
| 281 |
+
```python
|
| 282 |
+
import docker
|
| 283 |
+
import os
|
| 284 |
+
from typing import Optional
|
| 285 |
+
|
| 286 |
+
class DockerSandbox:
|
| 287 |
+
def __init__(self):
|
| 288 |
+
self.client = docker.from_env()
|
| 289 |
+
self.container = None
|
| 290 |
+
|
| 291 |
+
def create_container(self):
|
| 292 |
+
try:
|
| 293 |
+
image, build_logs = self.client.images.build(
|
| 294 |
+
path=".",
|
| 295 |
+
tag="agent-sandbox",
|
| 296 |
+
rm=True,
|
| 297 |
+
forcerm=True,
|
| 298 |
+
buildargs={},
|
| 299 |
+
# decode=True
|
| 300 |
+
)
|
| 301 |
+
except docker.errors.BuildError as e:
|
| 302 |
+
print("Build error logs:")
|
| 303 |
+
for log in e.build_log:
|
| 304 |
+
if 'stream' in log:
|
| 305 |
+
print(log['stream'].strip())
|
| 306 |
+
raise
|
| 307 |
+
|
| 308 |
+
# Create container with security constraints and proper logging
|
| 309 |
+
self.container = self.client.containers.run(
|
| 310 |
+
"agent-sandbox",
|
| 311 |
+
command="tail -f /dev/null", # Keep container running
|
| 312 |
+
detach=True,
|
| 313 |
+
tty=True,
|
| 314 |
+
mem_limit="512m",
|
| 315 |
+
cpu_quota=50000,
|
| 316 |
+
pids_limit=100,
|
| 317 |
+
security_opt=["no-new-privileges"],
|
| 318 |
+
cap_drop=["ALL"],
|
| 319 |
+
environment={
|
| 320 |
+
"HF_TOKEN": os.getenv("HF_TOKEN")
|
| 321 |
+
},
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
def run_code(self, code: str) -> Optional[str]:
|
| 325 |
+
if not self.container:
|
| 326 |
+
self.create_container()
|
| 327 |
+
|
| 328 |
+
# Execute code in container
|
| 329 |
+
exec_result = self.container.exec_run(
|
| 330 |
+
cmd=["python", "-c", code],
|
| 331 |
+
user="nobody"
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
# Collect all output
|
| 335 |
+
return exec_result.output.decode() if exec_result.output else None
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
def cleanup(self):
|
| 339 |
+
if self.container:
|
| 340 |
+
try:
|
| 341 |
+
self.container.stop()
|
| 342 |
+
except docker.errors.NotFound:
|
| 343 |
+
# Container already removed, this is expected
|
| 344 |
+
pass
|
| 345 |
+
except Exception as e:
|
| 346 |
+
print(f"Error during cleanup: {e}")
|
| 347 |
+
finally:
|
| 348 |
+
self.container = None # Clear the reference
|
| 349 |
+
|
| 350 |
+
# Example usage:
|
| 351 |
+
sandbox = DockerSandbox()
|
| 352 |
+
|
| 353 |
+
try:
|
| 354 |
+
# Define your agent code
|
| 355 |
+
agent_code = """
|
| 356 |
+
import os
|
| 357 |
+
from smolagents import CodeAgent, InferenceClientModel
|
| 358 |
+
|
| 359 |
+
# Initialize the agent
|
| 360 |
+
agent = CodeAgent(
|
| 361 |
+
model=InferenceClientModel(token=os.getenv("HF_TOKEN"), provider="together"),
|
| 362 |
+
tools=[]
|
| 363 |
+
)
|
| 364 |
+
|
| 365 |
+
# Run the agent
|
| 366 |
+
response = agent.run("What's the 20th Fibonacci number?")
|
| 367 |
+
print(response)
|
| 368 |
+
"""
|
| 369 |
+
|
| 370 |
+
# Run the code in the sandbox
|
| 371 |
+
output = sandbox.run_code(agent_code)
|
| 372 |
+
print(output)
|
| 373 |
+
|
| 374 |
+
finally:
|
| 375 |
+
sandbox.cleanup()
|
| 376 |
+
```
|
| 377 |
+
|
| 378 |
+
### Best practices for sandboxes
|
| 379 |
+
|
| 380 |
+
These key practices apply to both E2B and Docker sandboxes:
|
| 381 |
+
|
| 382 |
+
- Resource management
|
| 383 |
+
- Set memory and CPU limits
|
| 384 |
+
- Implement execution timeouts
|
| 385 |
+
- Monitor resource usage
|
| 386 |
+
- Security
|
| 387 |
+
- Run with minimal privileges
|
| 388 |
+
- Disable unnecessary network access
|
| 389 |
+
- Use environment variables for secrets
|
| 390 |
+
- Environment
|
| 391 |
+
- Keep dependencies minimal
|
| 392 |
+
- Use fixed package versions
|
| 393 |
+
- If you use base images, update them regularly
|
| 394 |
+
|
| 395 |
+
- Cleanup
|
| 396 |
+
- Always ensure proper cleanup of resources, especially for Docker containers, to avoid having dangling containers eating up resources.
|
| 397 |
+
|
| 398 |
+
✨ By following these practices and implementing proper cleanup procedures, you can ensure your agent runs safely and efficiently in a sandboxed environment.
|
| 399 |
+
|
| 400 |
+
## Comparing security approaches
|
| 401 |
+
|
| 402 |
+
As illustrated in the diagram earlier, both sandboxing approaches have different security implications:
|
| 403 |
+
|
| 404 |
+
### Approach 1: Running just the code snippets in a sandbox
|
| 405 |
+
- **Pros**:
|
| 406 |
+
- Easier to set up with a simple parameter (`executor_type="e2b"` or `executor_type="docker"`)
|
| 407 |
+
- No need to transfer API keys to the sandbox
|
| 408 |
+
- Better protection for your local environment
|
| 409 |
+
- **Cons**:
|
| 410 |
+
- Doesn't support multi-agents (managed agents)
|
| 411 |
+
- Still requires transferring state between your environment and the sandbox
|
| 412 |
+
- Limited to specific code execution
|
| 413 |
+
|
| 414 |
+
### Approach 2: Running the entire agentic system in a sandbox
|
| 415 |
+
- **Pros**:
|
| 416 |
+
- Supports multi-agents
|
| 417 |
+
- Complete isolation of the entire agent system
|
| 418 |
+
- More flexible for complex agent architectures
|
| 419 |
+
- **Cons**:
|
| 420 |
+
- Requires more manual setup
|
| 421 |
+
- May require transferring sensitive API keys to the sandbox
|
| 422 |
+
- Potentially higher latency due to more complex operations
|
| 423 |
+
|
| 424 |
+
Choose the approach that best balances your security needs with your application's requirements. For most applications with simpler agent architectures, Approach 1 provides a good balance of security and ease of use. For more complex multi-agent systems where you need full isolation, Approach 2, while more involved to set up, offers better security guarantees.
|
docs/source/en/tutorials/tools.md
ADDED
|
@@ -0,0 +1,326 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Tools
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
Here, we're going to see advanced tool usage.
|
| 6 |
+
|
| 7 |
+
> [!TIP]
|
| 8 |
+
> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
### What is a tool, and how to build one?
|
| 12 |
+
|
| 13 |
+
A tool is mostly a function that an LLM can use in an agentic system.
|
| 14 |
+
|
| 15 |
+
But to use it, the LLM will need to be given an API: name, tool description, input types and descriptions, output type.
|
| 16 |
+
|
| 17 |
+
So it cannot be only a function. It should be a class.
|
| 18 |
+
|
| 19 |
+
So at core, the tool is a class that wraps a function with metadata that helps the LLM understand how to use it.
|
| 20 |
+
|
| 21 |
+
Here's how it looks:
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from smolagents import Tool
|
| 25 |
+
|
| 26 |
+
class HFModelDownloadsTool(Tool):
|
| 27 |
+
name = "model_download_counter"
|
| 28 |
+
description = """
|
| 29 |
+
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
|
| 30 |
+
It returns the name of the checkpoint."""
|
| 31 |
+
inputs = {
|
| 32 |
+
"task": {
|
| 33 |
+
"type": "string",
|
| 34 |
+
"description": "the task category (such as text-classification, depth-estimation, etc)",
|
| 35 |
+
}
|
| 36 |
+
}
|
| 37 |
+
output_type = "string"
|
| 38 |
+
|
| 39 |
+
def forward(self, task: str):
|
| 40 |
+
from huggingface_hub import list_models
|
| 41 |
+
|
| 42 |
+
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
|
| 43 |
+
return model.id
|
| 44 |
+
|
| 45 |
+
model_downloads_tool = HFModelDownloadsTool()
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
The custom tool subclasses [`Tool`] to inherit useful methods. The child class also defines:
|
| 49 |
+
- An attribute `name`, which corresponds to the name of the tool itself. The name usually describes what the tool does. Since the code returns the model with the most downloads for a task, let's name it `model_download_counter`.
|
| 50 |
+
- An attribute `description` is used to populate the agent's system prompt.
|
| 51 |
+
- An `inputs` attribute, which is a dictionary with keys `"type"` and `"description"`. It contains information that helps the Python interpreter make educated choices about the input.
|
| 52 |
+
- An `output_type` attribute, which specifies the output type. The types for both `inputs` and `output_type` should be [Pydantic formats](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema), they can be either of these: [`~AUTHORIZED_TYPES`].
|
| 53 |
+
- A `forward` method which contains the inference code to be executed.
|
| 54 |
+
|
| 55 |
+
And that's all it needs to be used in an agent!
|
| 56 |
+
|
| 57 |
+
There's another way to build a tool. In the [guided_tour](../guided_tour), we implemented a tool using the `@tool` decorator. The [`tool`] decorator is the recommended way to define simple tools, but sometimes you need more than this: using several methods in a class for more clarity, or using additional class attributes.
|
| 58 |
+
|
| 59 |
+
In this case, you can build your tool by subclassing [`Tool`] as described above.
|
| 60 |
+
|
| 61 |
+
### Share your tool to the Hub
|
| 62 |
+
|
| 63 |
+
You can share your custom tool to the Hub as a Space repository by calling [`~Tool.push_to_hub`] on the tool. Make sure you've created a repository for it on the Hub and are using a token with read access.
|
| 64 |
+
|
| 65 |
+
```python
|
| 66 |
+
model_downloads_tool.push_to_hub("{your_username}/hf-model-downloads", token="<YOUR_HUGGINGFACEHUB_API_TOKEN>")
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
For the push to Hub to work, your tool will need to respect some rules:
|
| 70 |
+
- All methods are self-contained, e.g. use variables that come either from their args.
|
| 71 |
+
- As per the above point, **all imports should be defined directly within the tool's functions**, else you will get an error when trying to call [`~Tool.save`] or [`~Tool.push_to_hub`] with your custom tool.
|
| 72 |
+
- If you subclass the `__init__` method, you can give it no other argument than `self`. This is because arguments set during a specific tool instance's initialization are hard to track, which prevents from sharing them properly to the hub. And anyway, the idea of making a specific class is that you can already set class attributes for anything you need to hard-code (just set `your_variable=(...)` directly under the `class YourTool(Tool):` line). And of course you can still create a class attribute anywhere in your code by assigning stuff to `self.your_variable`.
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
Once your tool is pushed to Hub, you can visualize it. [Here](https://huggingface.co/spaces/m-ric/hf-model-downloads) is the `model_downloads_tool` that I've pushed. It has a nice gradio interface.
|
| 76 |
+
|
| 77 |
+
When diving into the tool files, you can find that all the tool's logic is under [tool.py](https://huggingface.co/spaces/m-ric/hf-model-downloads/blob/main/tool.py). That is where you can inspect a tool shared by someone else.
|
| 78 |
+
|
| 79 |
+
Then you can load the tool with [`load_tool`] or create it with [`~Tool.from_hub`] and pass it to the `tools` parameter in your agent.
|
| 80 |
+
Since running tools means running custom code, you need to make sure you trust the repository, thus we require to pass `trust_remote_code=True` to load a tool from the Hub.
|
| 81 |
+
|
| 82 |
+
```python
|
| 83 |
+
from smolagents import load_tool, CodeAgent
|
| 84 |
+
|
| 85 |
+
model_download_tool = load_tool(
|
| 86 |
+
"{your_username}/hf-model-downloads",
|
| 87 |
+
trust_remote_code=True
|
| 88 |
+
)
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### Use tools from an MCP server
|
| 92 |
+
|
| 93 |
+
Our `MCPClient` allows you to load tools from an MCP server, and gives you full control over the connection and tool management:
|
| 94 |
+
|
| 95 |
+
For stdio-based MCP servers:
|
| 96 |
+
```python
|
| 97 |
+
from smolagents import MCPClient, CodeAgent
|
| 98 |
+
from mcp import StdioServerParameters
|
| 99 |
+
import os
|
| 100 |
+
|
| 101 |
+
server_parameters = StdioServerParameters(
|
| 102 |
+
command="uvx", # Using uvx ensures dependencies are available
|
| 103 |
+
args=["--quiet", "[email protected]"],
|
| 104 |
+
env={"UV_PYTHON": "3.12", **os.environ},
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
with MCPClient(server_parameters) as tools:
|
| 108 |
+
agent = CodeAgent(tools=tools, model=model, add_base_tools=True)
|
| 109 |
+
agent.run("Please find the latest research on COVID-19 treatment.")
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
For Streamable HTTP-based MCP servers:
|
| 113 |
+
```python
|
| 114 |
+
from smolagents import MCPClient, CodeAgent
|
| 115 |
+
|
| 116 |
+
with MCPClient({"url": "http://127.0.0.1:8000/mcp", "transport": "streamable-http"}) as tools:
|
| 117 |
+
agent = CodeAgent(tools=tools, model=model, add_base_tools=True)
|
| 118 |
+
agent.run("Please find a remedy for hangover.")
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
You can also manually manage the connection lifecycle with the try...finally pattern:
|
| 122 |
+
|
| 123 |
+
```python
|
| 124 |
+
from smolagents import MCPClient, CodeAgent
|
| 125 |
+
from mcp import StdioServerParameters
|
| 126 |
+
import os
|
| 127 |
+
|
| 128 |
+
# Initialize server parameters
|
| 129 |
+
server_parameters = StdioServerParameters(
|
| 130 |
+
command="uvx",
|
| 131 |
+
args=["--quiet", "[email protected]"],
|
| 132 |
+
env={"UV_PYTHON": "3.12", **os.environ},
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
# Manually manage the connection
|
| 136 |
+
try:
|
| 137 |
+
mcp_client = MCPClient(server_parameters)
|
| 138 |
+
tools = mcp_client.get_tools()
|
| 139 |
+
|
| 140 |
+
# Use the tools with your agent
|
| 141 |
+
agent = CodeAgent(tools=tools, model=model, add_base_tools=True)
|
| 142 |
+
result = agent.run("What are the recent therapeutic approaches for Alzheimer's disease?")
|
| 143 |
+
|
| 144 |
+
# Process the result as needed
|
| 145 |
+
print(f"Agent response: {result}")
|
| 146 |
+
finally:
|
| 147 |
+
# Always ensure the connection is properly closed
|
| 148 |
+
mcp_client.disconnect()
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
You can also connect to multiple MCP servers at once by passing a list of server parameters:
|
| 152 |
+
```python
|
| 153 |
+
from smolagents import MCPClient, CodeAgent
|
| 154 |
+
from mcp import StdioServerParameters
|
| 155 |
+
import os
|
| 156 |
+
|
| 157 |
+
server_params1 = StdioServerParameters(
|
| 158 |
+
command="uvx",
|
| 159 |
+
args=["--quiet", "[email protected]"],
|
| 160 |
+
env={"UV_PYTHON": "3.12", **os.environ},
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
server_params2 = {"url": "http://127.0.0.1:8000/sse"}
|
| 164 |
+
|
| 165 |
+
with MCPClient([server_params1, server_params2]) as tools:
|
| 166 |
+
agent = CodeAgent(tools=tools, model=model, add_base_tools=True)
|
| 167 |
+
agent.run("Please analyze the latest research and suggest remedies for headaches.")
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
> [!WARNING]
|
| 171 |
+
> **Security Warning:** Using MCP servers comes with security risks:
|
| 172 |
+
> - **Trust is essential:** Always verify the source and integrity of any MCP server before connecting to it, especially for production environments. Malicious servers can execute harmful code on your machine.
|
| 173 |
+
> - **Stdio-based MCP servers** will always execute code on your machine (that's their intended functionality).
|
| 174 |
+
> - **Streamable HTTP-based MCP servers** while the remote MCP servers will not be able to execute code on your machine, still proceed with caution.
|
| 175 |
+
|
| 176 |
+
### Import a Space as a tool
|
| 177 |
+
|
| 178 |
+
You can directly import a Gradio Space from the Hub as a tool using the [`Tool.from_space`] method!
|
| 179 |
+
|
| 180 |
+
You only need to provide the id of the Space on the Hub, its name, and a description that will help your agent understand what the tool does. Under the hood, this will use [`gradio-client`](https://pypi.org/project/gradio-client/) library to call the Space.
|
| 181 |
+
|
| 182 |
+
For instance, let's import the [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) Space from the Hub and use it to generate an image.
|
| 183 |
+
|
| 184 |
+
```python
|
| 185 |
+
image_generation_tool = Tool.from_space(
|
| 186 |
+
"black-forest-labs/FLUX.1-schnell",
|
| 187 |
+
name="image_generator",
|
| 188 |
+
description="Generate an image from a prompt"
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
image_generation_tool("A sunny beach")
|
| 192 |
+
```
|
| 193 |
+
And voilà, here's your image! 🏖️
|
| 194 |
+
|
| 195 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sunny_beach.webp">
|
| 196 |
+
|
| 197 |
+
Then you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it. This example also shows how you can pass additional arguments to the agent.
|
| 198 |
+
|
| 199 |
+
```python
|
| 200 |
+
from smolagents import CodeAgent, InferenceClientModel
|
| 201 |
+
|
| 202 |
+
model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
|
| 203 |
+
agent = CodeAgent(tools=[image_generation_tool], model=model)
|
| 204 |
+
|
| 205 |
+
agent.run(
|
| 206 |
+
"Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
|
| 207 |
+
)
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
```text
|
| 211 |
+
=== Agent thoughts:
|
| 212 |
+
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
|
| 213 |
+
|
| 214 |
+
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
|
| 215 |
+
>>> Agent is executing the code below:
|
| 216 |
+
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
|
| 217 |
+
final_answer(image)
|
| 218 |
+
```
|
| 219 |
+
|
| 220 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rabbit_spacesuit_flux.webp">
|
| 221 |
+
|
| 222 |
+
How cool is this? 🤩
|
| 223 |
+
|
| 224 |
+
### Use LangChain tools
|
| 225 |
+
|
| 226 |
+
We love Langchain and think it has a very compelling suite of tools.
|
| 227 |
+
To import a tool from LangChain, use the `from_langchain()` method.
|
| 228 |
+
|
| 229 |
+
Here is how you can use it to recreate the intro's search result using a LangChain web search tool.
|
| 230 |
+
This tool will need `pip install langchain google-search-results -q` to work properly.
|
| 231 |
+
```python
|
| 232 |
+
from langchain.agents import load_tools
|
| 233 |
+
|
| 234 |
+
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
|
| 235 |
+
|
| 236 |
+
agent = CodeAgent(tools=[search_tool], model=model)
|
| 237 |
+
|
| 238 |
+
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
### Manage your agent's toolbox
|
| 242 |
+
|
| 243 |
+
You can manage an agent's toolbox by adding or replacing a tool in attribute `agent.tools`, since it is a standard dictionary.
|
| 244 |
+
|
| 245 |
+
Let's add the `model_download_tool` to an existing agent initialized with only the default toolbox.
|
| 246 |
+
|
| 247 |
+
```python
|
| 248 |
+
from smolagents import InferenceClientModel
|
| 249 |
+
|
| 250 |
+
model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
|
| 251 |
+
|
| 252 |
+
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
|
| 253 |
+
agent.tools[model_download_tool.name] = model_download_tool
|
| 254 |
+
```
|
| 255 |
+
Now we can leverage the new tool:
|
| 256 |
+
|
| 257 |
+
```python
|
| 258 |
+
agent.run(
|
| 259 |
+
"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
|
| 260 |
+
)
|
| 261 |
+
```
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
> [!TIP]
|
| 265 |
+
> Beware of not adding too many tools to an agent: this can overwhelm weaker LLM engines.
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
### Use a collection of tools
|
| 269 |
+
|
| 270 |
+
You can leverage tool collections by using [`ToolCollection`]. It supports loading either a collection from the Hub or an MCP server tools.
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
#### Tool Collection from any MCP server
|
| 274 |
+
|
| 275 |
+
Leverage tools from the hundreds of MCP servers available on [glama.ai](https://glama.ai/mcp/servers) or [smithery.ai](https://smithery.ai/).
|
| 276 |
+
|
| 277 |
+
The MCP servers tools can be loaded with [`ToolCollection.from_mcp`].
|
| 278 |
+
|
| 279 |
+
> [!WARNING]
|
| 280 |
+
> **Security Warning:** The same security warnings mentioned for `MCPClient` apply when using `MCPClient` directly.
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
For stdio-based MCP servers, pass the server parameters as an instance of `mcp.StdioServerParameters`:
|
| 284 |
+
```py
|
| 285 |
+
from smolagents import ToolCollection, CodeAgent
|
| 286 |
+
from mcp import StdioServerParameters
|
| 287 |
+
|
| 288 |
+
server_parameters = StdioServerParameters(
|
| 289 |
+
command="uvx",
|
| 290 |
+
args=["--quiet", "[email protected]"],
|
| 291 |
+
env={"UV_PYTHON": "3.12", **os.environ},
|
| 292 |
+
)
|
| 293 |
+
|
| 294 |
+
with ToolCollection.from_mcp(server_parameters, trust_remote_code=True) as tool_collection:
|
| 295 |
+
agent = CodeAgent(tools=[*tool_collection.tools], model=model, add_base_tools=True)
|
| 296 |
+
agent.run("Please find a remedy for hangover.")
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
For Streamable HTTP-based MCP servers, simply pass a dict with parameters to `mcp.client.streamable_http.streamablehttp_client` and add the key `transport` with the value `"streamable-http"`:
|
| 300 |
+
```py
|
| 301 |
+
from smolagents import ToolCollection, CodeAgent
|
| 302 |
+
|
| 303 |
+
with ToolCollection.from_mcp({"url": "http://127.0.0.1:8000/mcp", "transport": "streamable-http"}, trust_remote_code=True) as tool_collection:
|
| 304 |
+
agent = CodeAgent(tools=[*tool_collection.tools], add_base_tools=True)
|
| 305 |
+
agent.run("Please find a remedy for hangover.")
|
| 306 |
+
```
|
| 307 |
+
|
| 308 |
+
#### Tool Collection from a collection in the Hub
|
| 309 |
+
|
| 310 |
+
You can leverage it with the slug of the collection you want to use.
|
| 311 |
+
Then pass them as a list to initialize your agent, and start using them!
|
| 312 |
+
|
| 313 |
+
```py
|
| 314 |
+
from smolagents import ToolCollection, CodeAgent
|
| 315 |
+
|
| 316 |
+
image_tool_collection = ToolCollection.from_hub(
|
| 317 |
+
collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
|
| 318 |
+
token="<YOUR_HUGGINGFACEHUB_API_TOKEN>"
|
| 319 |
+
)
|
| 320 |
+
agent = CodeAgent(tools=[*image_tool_collection.tools], model=model, add_base_tools=True)
|
| 321 |
+
|
| 322 |
+
agent.run("Please draw me a picture of rivers and lakes.")
|
| 323 |
+
```
|
| 324 |
+
|
| 325 |
+
To speed up the start, tools are loaded only if called by the agent.
|
| 326 |
+
|