Spaces:
Runtime error

Runtime error
File size: 13,613 Bytes
443f920 495e63f 443f920 495e63f 443f920 495e63f |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 |
---
title: vggt
app_file: demo_gradio.py
sdk: gradio
sdk_version: 5.34.2
---
<div align="center">
<h1>VGGT: Visual Geometry Grounded Transformer</h1>
<a href="https://jytime.github.io/data/VGGT_CVPR25.pdf" target="_blank" rel="noopener noreferrer">
<img src="https://img.shields.io/badge/Paper-VGGT" alt="Paper PDF">
</a>
<a href="https://arxiv.org/abs/2503.11651"><img src="https://img.shields.io/badge/arXiv-2503.11651-b31b1b" alt="arXiv"></a>
<a href="https://vgg-t.github.io/"><img src="https://img.shields.io/badge/Project_Page-green" alt="Project Page"></a>
<a href='https://huggingface.co/spaces/facebook/vggt'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a>
**[Visual Geometry Group, University of Oxford](https://www.robots.ox.ac.uk/~vgg/)**; **[Meta AI](https://ai.facebook.com/research/)**
[Jianyuan Wang](https://jytime.github.io/), [Minghao Chen](https://silent-chen.github.io/), [Nikita Karaev](https://nikitakaraevv.github.io/), [Andrea Vedaldi](https://www.robots.ox.ac.uk/~vedaldi/), [Christian Rupprecht](https://chrirupp.github.io/), [David Novotny](https://d-novotny.github.io/)
</div>
```bibtex
@inproceedings{wang2025vggt,
title={VGGT: Visual Geometry Grounded Transformer},
author={Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}
```
## Updates
- [June 13, 2025] Honored to receive the Best Paper Award at CVPR 2025! Apologies if I’m slow to respond to queries or GitHub issues these days. If you’re interested, our oral presentation is available [here](https://docs.google.com/presentation/d/1JVuPnuZx6RgAy-U5Ezobg73XpBi7FrOh/edit?usp=sharing&ouid=107115712143490405606&rtpof=true&sd=true). (Note: it’s shared in .pptx format with animations — quite large, but feel free to use it as a template if helpful.)
- [June 2, 2025] Added a script to run VGGT and save predictions in COLMAP format, with bundle adjustment support optional. The saved COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) or other NeRF/Gaussian splatting libraries.
- [May 3, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available in the [evaluation](https://github.com/facebookresearch/vggt/tree/evaluation) branch.
- [Apr 13, 2025] Training code is being gradually cleaned and uploaded to the [training](https://github.com/facebookresearch/vggt/tree/training) branch. It will be merged into the main branch once finalized.
## Overview
Visual Geometry Grounded Transformer (VGGT, CVPR 2025) is a feed-forward neural network that directly infers all key 3D attributes of a scene, including extrinsic and intrinsic camera parameters, point maps, depth maps, and 3D point tracks, **from one, a few, or hundreds of its views, within seconds**.
## Quick Start
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
```bash
git clone [email protected]:facebookresearch/vggt.git
cd vggt
pip install -r requirements.txt
```
Alternatively, you can install VGGT as a package (<a href="docs/package.md">click here</a> for details).
Now, try the model with just a few lines of code:
```python
import torch
from vggt.models.vggt import VGGT
from vggt.utils.load_fn import load_and_preprocess_images
device = "cuda" if torch.cuda.is_available() else "cpu"
# bfloat16 is supported on Ampere GPUs (Compute Capability 8.0+)
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
# Initialize the model and load the pretrained weights.
# This will automatically download the model weights the first time it's run, which may take a while.
model = VGGT.from_pretrained("facebook/VGGT-1B").to(device)
# Load and preprocess example images (replace with your own image paths)
image_names = ["path/to/imageA.png", "path/to/imageB.png", "path/to/imageC.png"]
images = load_and_preprocess_images(image_names).to(device)
with torch.no_grad():
with torch.cuda.amp.autocast(dtype=dtype):
# Predict attributes including cameras, depth maps, and point maps.
predictions = model(images)
```
The model weights will be automatically downloaded from Hugging Face. If you encounter issues such as slow loading, you can manually download them [here](https://huggingface.co/facebook/VGGT-1B/blob/main/model.pt) and load, or:
```python
model = VGGT()
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
```
## Detailed Usage
<details>
<summary>Click to expand</summary>
You can also optionally choose which attributes (branches) to predict, as shown below. This achieves the same result as the example above. This example uses a batch size of 1 (processing a single scene), but it naturally works for multiple scenes.
```python
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
from vggt.utils.geometry import unproject_depth_map_to_point_map
with torch.no_grad():
with torch.cuda.amp.autocast(dtype=dtype):
images = images[None] # add batch dimension
aggregated_tokens_list, ps_idx = model.aggregator(images)
# Predict Cameras
pose_enc = model.camera_head(aggregated_tokens_list)[-1]
# Extrinsic and intrinsic matrices, following OpenCV convention (camera from world)
extrinsic, intrinsic = pose_encoding_to_extri_intri(pose_enc, images.shape[-2:])
# Predict Depth Maps
depth_map, depth_conf = model.depth_head(aggregated_tokens_list, images, ps_idx)
# Predict Point Maps
point_map, point_conf = model.point_head(aggregated_tokens_list, images, ps_idx)
# Construct 3D Points from Depth Maps and Cameras
# which usually leads to more accurate 3D points than point map branch
point_map_by_unprojection = unproject_depth_map_to_point_map(depth_map.squeeze(0),
extrinsic.squeeze(0),
intrinsic.squeeze(0))
# Predict Tracks
# choose your own points to track, with shape (N, 2) for one scene
query_points = torch.FloatTensor([[100.0, 200.0],
[60.72, 259.94]]).to(device)
track_list, vis_score, conf_score = model.track_head(aggregated_tokens_list, images, ps_idx, query_points=query_points[None])
```
Furthermore, if certain pixels in the input frames are unwanted (e.g., reflective surfaces, sky, or water), you can simply mask them by setting the corresponding pixel values to 0 or 1. Precise segmentation masks aren't necessary - simple bounding box masks work effectively (check this [issue](https://github.com/facebookresearch/vggt/issues/47) for an example).
</details>
## Interactive Demo
We provide multiple ways to visualize your 3D reconstructions. Before using these visualization tools, install the required dependencies:
```bash
pip install -r requirements_demo.txt
```
### Interactive 3D Visualization
**Please note:** VGGT typically reconstructs a scene in less than 1 second. However, visualizing 3D points may take tens of seconds due to third-party rendering, independent of VGGT's processing time. The visualization is slow especially when the number of images is large.
#### Gradio Web Interface
Our Gradio-based interface allows you to upload images/videos, run reconstruction, and interactively explore the 3D scene in your browser. You can launch this in your local machine or try it on [Hugging Face](https://huggingface.co/spaces/facebook/vggt).
```bash
python demo_gradio.py
```
<details>
<summary>Click to preview the Gradio interactive interface</summary>
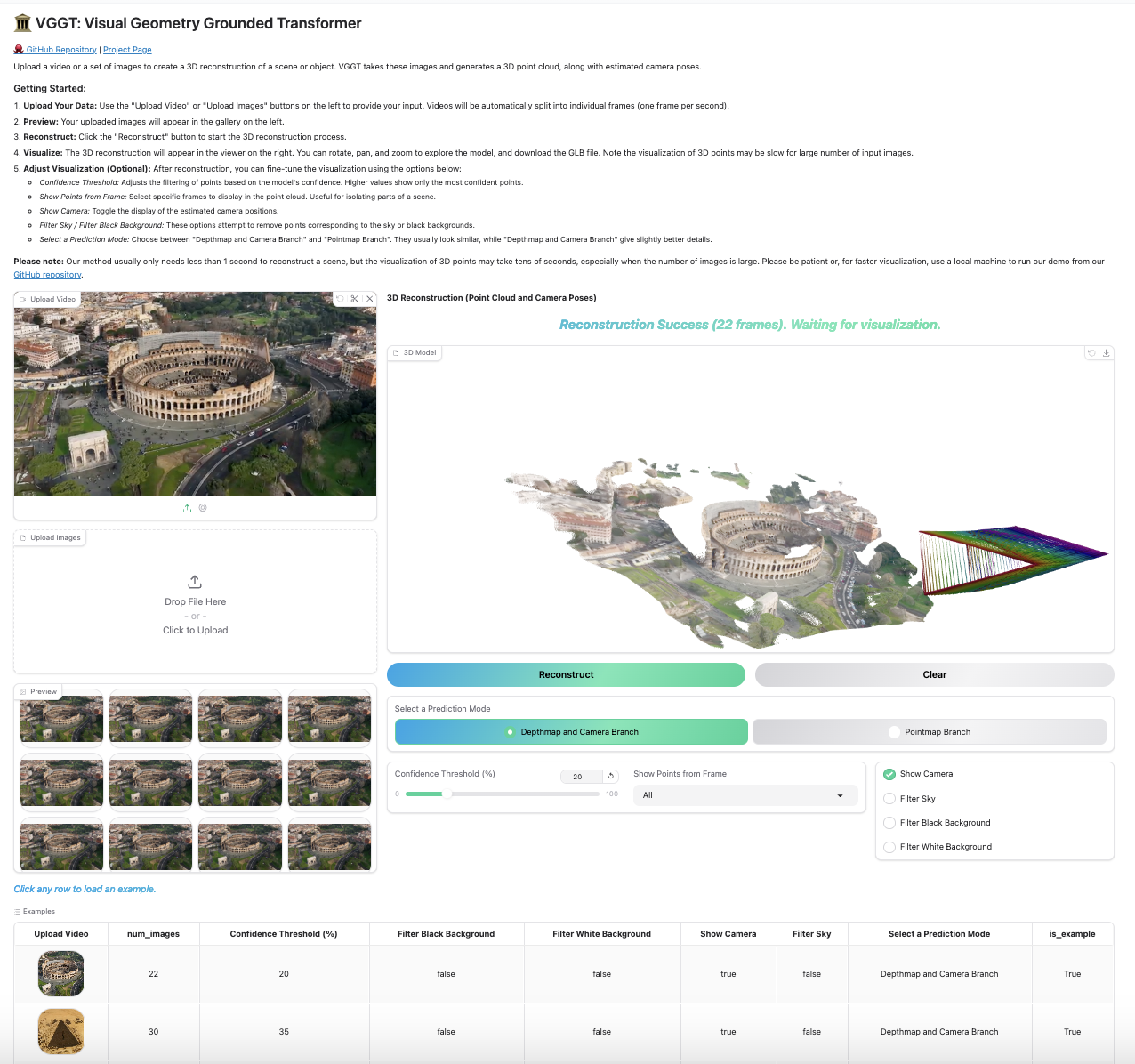
</details>
#### Viser 3D Viewer
Run the following command to run reconstruction and visualize the point clouds in viser. Note this script requires a path to a folder containing images. It assumes only image files under the folder. You can set `--use_point_map` to use the point cloud from the point map branch, instead of the depth-based point cloud.
```bash
python demo_viser.py --image_folder path/to/your/images/folder
```
## Exporting to COLMAP Format
We also support exporting VGGT's predictions directly to COLMAP format, by:
```bash
# Feedforward prediction only
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/
# With bundle adjustment
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --use_ba
# Run with bundle adjustment using reduced parameters for faster processing
# Reduces max_query_pts from 4096 (default) to 2048 and query_frame_num from 8 (default) to 5
# Trade-off: Faster execution but potentially less robust reconstruction in complex scenes (you may consider setting query_frame_num equal to your total number of images)
# See demo_colmap.py for additional bundle adjustment configuration options
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --use_ba --max_query_pts=2048 --query_frame_num=5
```
Please ensure that the images are stored in `/YOUR/SCENE_DIR/images/`. This folder should contain only the images. Check the examples folder for the desired data structure.
The reconstruction result (camera parameters and 3D points) will be automatically saved under `/YOUR/SCENE_DIR/sparse/` in the COLMAP format, such as:
```
SCENE_DIR/
├── images/
└── sparse/
├── cameras.bin
├── images.bin
└── points3D.bin
```
## Integration with Gaussian Splatting
The exported COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) for Gaussian Splatting training. Install `gsplat` following their official instructions (we recommend `gsplat==1.3.0`):
An example command to train the model is:
```
cd gsplat
python examples/simple_trainer.py default --data_factor 1 --data_dir /YOUR/SCENE_DIR/ --result_dir /YOUR/RESULT_DIR/
```
## Zero-shot Single-view Reconstruction
Our model shows surprisingly good performance on single-view reconstruction, although it was never trained for this task. The model does not need to duplicate the single-view image to a pair, instead, it can directly infer the 3D structure from the tokens of the single view image. Feel free to try it with our demos above, which naturally works for single-view reconstruction.
We did not quantitatively test monocular depth estimation performance ourselves, but [@kabouzeid](https://github.com/kabouzeid) generously provided a comparison of VGGT to recent methods [here](https://github.com/facebookresearch/vggt/issues/36). VGGT shows competitive or better results compared to state-of-the-art monocular approaches such as DepthAnything v2 or MoGe, despite never being explicitly trained for single-view tasks.
## Runtime and GPU Memory
We benchmark the runtime and GPU memory usage of VGGT's aggregator on a single NVIDIA H100 GPU across various input sizes.
| **Input Frames** | 1 | 2 | 4 | 8 | 10 | 20 | 50 | 100 | 200 |
|:----------------:|:-:|:-:|:-:|:-:|:--:|:--:|:--:|:---:|:---:|
| **Time (s)** | 0.04 | 0.05 | 0.07 | 0.11 | 0.14 | 0.31 | 1.04 | 3.12 | 8.75 |
| **Memory (GB)** | 1.88 | 2.07 | 2.45 | 3.23 | 3.63 | 5.58 | 11.41 | 21.15 | 40.63 |
Note that these results were obtained using Flash Attention 3, which is faster than the default Flash Attention 2 implementation while maintaining almost the same memory usage. Feel free to compile Flash Attention 3 from source to get better performance.
## Research Progression
Our work builds upon a series of previous research projects. If you're interested in understanding how our research evolved, check out our previous works:
<table border="0" cellspacing="0" cellpadding="0">
<tr>
<td align="left">
<a href="https://github.com/jytime/Deep-SfM-Revisited">Deep SfM Revisited</a>
</td>
<td style="white-space: pre;">──┐</td>
<td></td>
</tr>
<tr>
<td align="left">
<a href="https://github.com/facebookresearch/PoseDiffusion">PoseDiffusion</a>
</td>
<td style="white-space: pre;">─────►</td>
<td>
<a href="https://github.com/facebookresearch/vggsfm">VGGSfM</a> ──►
<a href="https://github.com/facebookresearch/vggt">VGGT</a>
</td>
</tr>
<tr>
<td align="left">
<a href="https://github.com/facebookresearch/co-tracker">CoTracker</a>
</td>
<td style="white-space: pre;">──┘</td>
<td></td>
</tr>
</table>
## Acknowledgements
Thanks to these great repositories: [PoseDiffusion](https://github.com/facebookresearch/PoseDiffusion), [VGGSfM](https://github.com/facebookresearch/vggsfm), [CoTracker](https://github.com/facebookresearch/co-tracker), [DINOv2](https://github.com/facebookresearch/dinov2), [Dust3r](https://github.com/naver/dust3r), [Moge](https://github.com/microsoft/moge), [PyTorch3D](https://github.com/facebookresearch/pytorch3d), [Sky Segmentation](https://github.com/xiongzhu666/Sky-Segmentation-and-Post-processing), [Depth Anything V2](https://github.com/DepthAnything/Depth-Anything-V2), [Metric3D](https://github.com/YvanYin/Metric3D) and many other inspiring works in the community.
## Checklist
- [ ] Release the training code
- [ ] Release VGGT-500M and VGGT-200M
## License
See the [LICENSE](./LICENSE.txt) file for details about the license under which this code is made available.
|