diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..9015195dda3ea336e4b7de9e56e03a6154787b12
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,9 @@
+# ignore large files and runtime outputs
+*.pth
+*.pt
+*.engine
+*.onnx
+engines/
+D-FINE/weight/
+examples/
+output/
diff --git a/D-FINE/.github/ISSUE_TEMPLATE/bug_report.md b/D-FINE/.github/ISSUE_TEMPLATE/bug_report.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd84ea7824f11be1eeda22377549cbc1aec7f980
--- /dev/null
+++ b/D-FINE/.github/ISSUE_TEMPLATE/bug_report.md
@@ -0,0 +1,38 @@
+---
+name: Bug report
+about: Create a report to help us improve
+title: ''
+labels: ''
+assignees: ''
+
+---
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**To Reproduce**
+Steps to reproduce the behavior:
+1. Go to '...'
+2. Click on '....'
+3. Scroll down to '....'
+4. See error
+
+**Expected behavior**
+A clear and concise description of what you expected to happen.
+
+**Screenshots**
+If applicable, add screenshots to help explain your problem.
+
+**Desktop (please complete the following information):**
+ - OS: [e.g. iOS]
+ - Browser [e.g. chrome, safari]
+ - Version [e.g. 22]
+
+**Smartphone (please complete the following information):**
+ - Device: [e.g. iPhone6]
+ - OS: [e.g. iOS8.1]
+ - Browser [e.g. stock browser, safari]
+ - Version [e.g. 22]
+
+**Additional context**
+Add any other context about the problem here.
diff --git a/D-FINE/.github/ISSUE_TEMPLATE/feature_request.md b/D-FINE/.github/ISSUE_TEMPLATE/feature_request.md
new file mode 100644
index 0000000000000000000000000000000000000000..bbcbbe7d61558adde3cbfd0c7a63a67c27ed6d30
--- /dev/null
+++ b/D-FINE/.github/ISSUE_TEMPLATE/feature_request.md
@@ -0,0 +1,20 @@
+---
+name: Feature request
+about: Suggest an idea for this project
+title: ''
+labels: ''
+assignees: ''
+
+---
+
+**Is your feature request related to a problem? Please describe.**
+A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
+
+**Describe the solution you'd like**
+A clear and concise description of what you want to happen.
+
+**Describe alternatives you've considered**
+A clear and concise description of any alternative solutions or features you've considered.
+
+**Additional context**
+Add any other context or screenshots about the feature request here.
diff --git a/D-FINE/.github/workflows/is.yml b/D-FINE/.github/workflows/is.yml
new file mode 100644
index 0000000000000000000000000000000000000000..4d986ee418c2754f2a55ea59b453f6ea7fe10030
--- /dev/null
+++ b/D-FINE/.github/workflows/is.yml
@@ -0,0 +1,63 @@
+name: Issue Screening
+
+on:
+ issues:
+ types: [opened, edited]
+
+jobs:
+ screen-issues:
+ runs-on: ubuntu-latest
+
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v2
+
+ - name: Get details and check for keywords
+ id: issue_check
+ uses: actions/github-script@v5
+ with:
+ script: |
+ const issue = context.payload.issue;
+ const issueNumber = issue.number;
+ const title = (issue.title || "").toLowerCase();
+ const body = (issue.body || "").toLowerCase();
+ core.setOutput('number', issueNumber);
+
+ const keywords = ["spam", "badword", "inappropriate", "suspicious", "unusual", "star", "stars", "buy", "buying"];
+ let containsKeyword = false;
+
+ console.log(`Checking issue #${issueNumber} for whole word keywords...`);
+ for (const keyword of keywords) {
+ const regex = new RegExp(`\\b${keyword}\\b`);
+ if (regex.test(title) || regex.test(body)) {
+ containsKeyword = true;
+ console.log(`Whole word keyword '${keyword}' found in issue #${issueNumber}.`);
+ break;
+ }
+ }
+
+ console.log(`Keyword check for issue #${issueNumber} completed. contains_keyword=${containsKeyword}`);
+ core.setOutput('contains_keyword', containsKeyword);
+
+ - name: Close and Modify Issue if it contains keywords
+ if: steps.issue_check.outputs.contains_keyword == 'true'
+ uses: actions/github-script@v5
+ with:
+ github-token: ${{ secrets.ISSUE }}
+ script: |
+ const issueNumber = ${{ steps.issue_check.outputs.number }};
+ try {
+ console.log(`Attempting to close, clear body, and rename title of issue #${issueNumber} due to keyword.`);
+ await github.rest.issues.update({
+ owner: context.repo.owner,
+ repo: context.repo.repo,
+ issue_number: issueNumber,
+ state: 'closed',
+ title: "Cleared suspicious issues",
+ body: ""
+ });
+ console.log(`Successfully closed, cleared body, and renamed title of issue #${issueNumber}.`);
+ } catch (error) {
+ console.error(`Failed to update issue #${issueNumber}:`, error);
+ throw error;
+ }
diff --git a/D-FINE/.github/workflows/pre-commit.yml b/D-FINE/.github/workflows/pre-commit.yml
new file mode 100644
index 0000000000000000000000000000000000000000..81eb8e77ad55e71ad54ab6d8fa8ba3f11b1fcfe1
--- /dev/null
+++ b/D-FINE/.github/workflows/pre-commit.yml
@@ -0,0 +1,15 @@
+name: pre-commit
+
+on:
+ pull_request:
+ branches: [master]
+ push:
+ branches: [master]
+
+jobs:
+ pre-commit:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - uses: actions/setup-python@v3
+ - uses: pre-commit/action@v3.0.1
diff --git a/D-FINE/.gitignore b/D-FINE/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..8d9c92cabb5cb5f00d245e465d7d3f425201cd10
--- /dev/null
+++ b/D-FINE/.gitignore
@@ -0,0 +1,10 @@
+# existing entries
+output/
+*.pyc
+wandb/
+*.onnx
+weight/dfine-s.pth
+
+# ignore tensorRT engine files
+*.engine
+engines/
\ No newline at end of file
diff --git a/D-FINE/.pre-commit-config.yaml b/D-FINE/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c7d884a01131a5725d0cdf9666b97fc75d134df1
--- /dev/null
+++ b/D-FINE/.pre-commit-config.yaml
@@ -0,0 +1,68 @@
+# Copyright The Lightning team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+default_language_version:
+ python: python3
+
+ci:
+ autofix_prs: true
+ autoupdate_commit_msg: "[pre-commit.ci] pre-commit suggestions"
+ autoupdate_schedule: quarterly
+ # submodules: true
+
+repos:
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v5.0.0
+ hooks:
+ - id: end-of-file-fixer
+ - id: trailing-whitespace
+ # - id: check-json # skip for incompatibility with .devcontainer/devcontainer.json
+ - id: check-yaml
+ - id: check-toml
+ - id: check-docstring-first
+ - id: check-executables-have-shebangs
+ - id: check-case-conflict
+ # - id: check-added-large-files
+ # args: ["--maxkb=100", "--enforce-all"]
+ - id: detect-private-key
+
+ # - repo: https://github.com/PyCQA/docformatter
+ # rev: v1.7.5
+ # hooks:
+ # - id: docformatter
+ # additional_dependencies: [tomli]
+ # args: ["--in-place"]
+
+ - repo: https://github.com/executablebooks/mdformat
+ rev: 0.7.17
+ hooks:
+ - id: mdformat
+ exclude: '^.*\.md$'
+ args: ["--number"]
+ additional_dependencies:
+ - mdformat-gfm
+ - mdformat-black
+ - mdformat_frontmatter
+
+ - repo: https://github.com/astral-sh/ruff-pre-commit
+ rev: v0.6.9
+ hooks:
+ # try to fix what is possible
+ - id: ruff
+ args: ["--fix", "--ignore", "E501,F401,F403,F841,E741"]
+ # # perform formatting updates
+ # - id: ruff-format
+ # validate if all is fine with preview mode
+ - id: ruff
+ args: ["--ignore", "E501,F401,F403,F841,E741"]
diff --git a/D-FINE/Dockerfile b/D-FINE/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..9d8af8b8968b72d4be7983aa1d24411d8c7a321d
--- /dev/null
+++ b/D-FINE/Dockerfile
@@ -0,0 +1,48 @@
+FROM registry.cn-hangzhou.aliyuncs.com/peterande/dfine:v1
+
+# FULL BUILDING INFO:
+
+# docker login --username=xxx registry.cn-hangzhou.aliyuncs.com
+# cd [PATH_2_Dockerfile]
+# docker build -t xxx:v1 .
+# docker tag xxx:v1 registry.cn-hangzhou.aliyuncs.com/xxx/xxx:v1
+# docker push registry.cn-hangzhou.aliyuncs.com/xxx/xxx:v1
+
+# FROM dockerpull.com/nvidia/cuda:12.0.1-cudnn8-devel-ubuntu18.04
+# ARG DEBIAN_FRONTEND=noninteractive
+# ENV PATH="/root/miniconda3/bin:${PATH}"
+# ARG PATH="/root/miniconda3/bin:${PATH}"
+
+# RUN sed -i "s/archive.ubuntu./mirrors.aliyun./g" /etc/apt/sources.list
+# RUN sed -i "s/deb.debian.org/mirrors.aliyun.com/g" /etc/apt/sources.list
+# RUN sed -i "s/security.debian.org/mirrors.aliyun.com\/debian-security/g" /etc/apt/sources.list
+# RUN sed -i 's/archive.ubuntu.com/mirrors.ustc.edu.cn/g' /etc/apt/sources.list
+
+# RUN apt-get update && apt-get install -y --no-install-recommends apt-utils && \
+# apt-get upgrade -y && \
+# apt-get install -y vim git libgl1-mesa-glx libglib2.0-0 libsm6 && \
+# apt-get install -y libxrender1 libxext6 tmux wget htop && \
+# apt-get install -y build-essential gcc g++ gdb binutils pciutils net-tools iputils-ping iproute2 git vim wget curl make openssh-server openssh-client tmux tree man unzip unrar
+
+# ENV PYTHONIOENCODING=UTF-8
+
+# RUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && \
+# mkdir /root/.conda && \
+# bash Miniconda3-latest-Linux-x86_64.sh -b && \
+# rm -f Miniconda3-latest-Linux-x86_64.sh && \
+# conda init bash
+
+# RUN conda config --set show_channel_urls yes \
+# && echo "channels:" > ~/.condarc \
+# && echo " - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/" >> ~/.condarc \
+# && echo " - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/" >> ~/.condarc \
+# && echo "show_channel_urls: true" \
+# && cat ~/.condarc \
+# && pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple \
+# && cat ~/.config/pip/pip.conf
+
+# RUN python3 -m pip install --upgrade pip && \
+# python3 -m pip install --upgrade setuptools
+
+# RUN python3 -m pip install jupyterlab pycocotools PyYAML tensorboard scipy
+# RUN python3 -m pip --default-timeout=10000 install torch torchvision
diff --git a/D-FINE/LICENSE b/D-FINE/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/D-FINE/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/D-FINE/README.md b/D-FINE/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b0cc4242bb9f7c0b23ed48118264f47f5ec4cfc
--- /dev/null
+++ b/D-FINE/README.md
@@ -0,0 +1,700 @@
+
+
+English | [简体中文](README_cn.md) | [日本語](README_ja.md) | [English Blog](src/zoo/dfine/blog.md) | [中文博客](src/zoo/dfine/blog_cn.md)
+
+
+ D-FINE: Redefine Regression Task of DETRs as Fine‑grained Distribution Refinement
+
+If you like D-FINE, please give us a ⭐! Your support motivates us to keep improving!
+
+
+
+
+
+
+D-FINE is a powerful real-time object detector that redefines the bounding box regression task in DETRs as Fine-grained Distribution Refinement (FDR) and introduces Global Optimal Localization Self-Distillation (GO-LSD), achieving outstanding performance without introducing additional inference and training costs.
+
+
+ Video
+
+We conduct object detection using D-FINE and YOLO11 on a complex street scene video from [YouTube](https://www.youtube.com/watch?v=CfhEWj9sd9A). Despite challenging conditions such as backlighting, motion blur, and dense crowds, D-FINE-X successfully detects nearly all targets, including subtle small objects like backpacks, bicycles, and traffic lights. Its confidence scores and the localization precision for blurred edges are significantly higher than those of YOLO11.
+
+
+
+https://github.com/user-attachments/assets/e5933d8e-3c8a-400e-870b-4e452f5321d9
+
+
+
+## 🚀 Updates
+- [x] **\[2024.10.18\]** Release D-FINE series.
+- [x] **\[2024.10.25\]** Add custom dataset finetuning configs ([#7](https://github.com/Peterande/D-FINE/issues/7)).
+- [x] **\[2024.10.30\]** Update D-FINE-L (E25) pretrained model, with performance improved by 2.0%.
+- [x] **\[2024.11.07\]** Release **D-FINE-N**, achiving 42.8% APval on COCO @ 472 FPST4!
+
+## Model Zoo
+
+### COCO
+| Model | Dataset | APval | #Params | Latency | GFLOPs | config | checkpoint | logs |
+| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+**D‑FINE‑N** | COCO | **42.8** | 4M | 2.12ms | 7 | [yml](./configs/dfine/dfine_hgnetv2_n_coco.yml) | [42.8](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_n_coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/coco/dfine_n_coco_log.txt)
+**D‑FINE‑S** | COCO | **48.5** | 10M | 3.49ms | 25 | [yml](./configs/dfine/dfine_hgnetv2_s_coco.yml) | [48.5](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_s_coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/coco/dfine_s_coco_log.txt)
+**D‑FINE‑M** | COCO | **52.3** | 19M | 5.62ms | 57 | [yml](./configs/dfine/dfine_hgnetv2_m_coco.yml) | [52.3](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_m_coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/coco/dfine_m_coco_log.txt)
+**D‑FINE‑L** | COCO | **54.0** | 31M | 8.07ms | 91 | [yml](./configs/dfine/dfine_hgnetv2_l_coco.yml) | [54.0](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_l_coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/coco/dfine_l_coco_log.txt)
+**D‑FINE‑X** | COCO | **55.8** | 62M | 12.89ms | 202 | [yml](./configs/dfine/dfine_hgnetv2_x_coco.yml) | [55.8](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_x_coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/coco/dfine_x_coco_log.txt)
+
+
+### Objects365+COCO
+| Model | Dataset | APval | #Params | Latency | GFLOPs | config | checkpoint | logs |
+| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+**D‑FINE‑S** | Objects365+COCO | **50.7** | 10M | 3.49ms | 25 | [yml](./configs/dfine/objects365/dfine_hgnetv2_s_obj2coco.yml) | [50.7](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_s_obj2coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj2coco/dfine_s_obj2coco_log.txt)
+**D‑FINE‑M** | Objects365+COCO | **55.1** | 19M | 5.62ms | 57 | [yml](./configs/dfine/objects365/dfine_hgnetv2_m_obj2coco.yml) | [55.1](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_m_obj2coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj2coco/dfine_m_obj2coco_log.txt)
+**D‑FINE‑L** | Objects365+COCO | **57.3** | 31M | 8.07ms | 91 | [yml](./configs/dfine/objects365/dfine_hgnetv2_l_obj2coco.yml) | [57.3](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_l_obj2coco_e25.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj2coco/dfine_l_obj2coco_log_e25.txt)
+**D‑FINE‑X** | Objects365+COCO | **59.3** | 62M | 12.89ms | 202 | [yml](./configs/dfine/objects365/dfine_hgnetv2_x_obj2coco.yml) | [59.3](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_x_obj2coco.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj2coco/dfine_x_obj2coco_log.txt)
+
+**We highly recommend that you use the Objects365 pre-trained model for fine-tuning:**
+
+⚠️ **Important**: Please note that this is generally beneficial for complex scene understanding. If your categories are very simple, it might lead to overfitting and suboptimal performance.
+
+ 🔥 Pretrained Models on Objects365 (Best generalization)
+
+| Model | Dataset | APval | AP5000 | #Params | Latency | GFLOPs | config | checkpoint | logs |
+| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+**D‑FINE‑S** | Objects365 | **31.0** | **30.5** | 10M | 3.49ms | 25 | [yml](./configs/dfine/objects365/dfine_hgnetv2_s_obj365.yml) | [30.5](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_s_obj365.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj365/dfine_s_obj365_log.txt)
+**D‑FINE‑M** | Objects365 | **38.6** | **37.4** | 19M | 5.62ms | 57 | [yml](./configs/dfine/objects365/dfine_hgnetv2_m_obj365.yml) | [37.4](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_m_obj365.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj365/dfine_m_obj365_log.txt)
+**D‑FINE‑L** | Objects365 | - | **40.6** | 31M | 8.07ms | 91 | [yml](./configs/dfine/objects365/dfine_hgnetv2_l_obj365.yml) | [40.6](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_l_obj365.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj365/dfine_l_obj365_log.txt)
+**D‑FINE‑L (E25)** | Objects365 | **44.7** | **42.6** | 31M | 8.07ms | 91 | [yml](./configs/dfine/objects365/dfine_hgnetv2_l_obj365.yml) | [42.6](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_l_obj365_e25.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj365/dfine_l_obj365_log_e25.txt)
+**D‑FINE‑X** | Objects365 | **49.5** | **46.5** | 62M | 12.89ms | 202 | [yml](./configs/dfine/objects365/dfine_hgnetv2_x_obj365.yml) | [46.5](https://github.com/Peterande/storage/releases/download/dfinev1.0/dfine_x_obj365.pth) | [url](https://raw.githubusercontent.com/Peterande/storage/refs/heads/master/logs/obj365/dfine_x_obj365_log.txt)
+- **E25**: Re-trained and extended the pretraining to 25 epochs.
+- **APval** is evaluated on *Objects365* full validation set.
+- **AP5000** is evaluated on the first 5000 samples of the *Objects365* validation set.
+
+
+**Notes:**
+- **APval** is evaluated on *MSCOCO val2017* dataset.
+- **Latency** is evaluated on a single T4 GPU with $batch\\_size = 1$, $fp16$, and $TensorRT==10.4.0$.
+- **Objects365+COCO** means finetuned model on *COCO* using pretrained weights trained on *Objects365*.
+
+
+
+## Quick start
+
+### Setup
+
+```shell
+conda create -n dfine python=3.11.9
+conda activate dfine
+pip install -r requirements.txt
+```
+
+
+### Data Preparation
+
+
+ COCO2017 Dataset
+
+1. Download COCO2017 from [OpenDataLab](https://opendatalab.com/OpenDataLab/COCO_2017) or [COCO](https://cocodataset.org/#download).
+1. Modify paths in [coco_detection.yml](./configs/dataset/coco_detection.yml)
+
+ ```yaml
+ train_dataloader:
+ img_folder: /data/COCO2017/train2017/
+ ann_file: /data/COCO2017/annotations/instances_train2017.json
+ val_dataloader:
+ img_folder: /data/COCO2017/val2017/
+ ann_file: /data/COCO2017/annotations/instances_val2017.json
+ ```
+
+
+
+
+ Objects365 Dataset
+
+1. Download Objects365 from [OpenDataLab](https://opendatalab.com/OpenDataLab/Objects365).
+
+2. Set the Base Directory:
+```shell
+export BASE_DIR=/data/Objects365/data
+```
+
+3. Extract and organize the downloaded files, resulting directory structure:
+
+```shell
+${BASE_DIR}/train
+├── images
+│ ├── v1
+│ │ ├── patch0
+│ │ │ ├── 000000000.jpg
+│ │ │ ├── 000000001.jpg
+│ │ │ └── ... (more images)
+│ ├── v2
+│ │ ├── patchx
+│ │ │ ├── 000000000.jpg
+│ │ │ ├── 000000001.jpg
+│ │ │ └── ... (more images)
+├── zhiyuan_objv2_train.json
+```
+
+```shell
+${BASE_DIR}/val
+├── images
+│ ├── v1
+│ │ ├── patch0
+│ │ │ ├── 000000000.jpg
+│ │ │ └── ... (more images)
+│ ├── v2
+│ │ ├── patchx
+│ │ │ ├── 000000000.jpg
+│ │ │ └── ... (more images)
+├── zhiyuan_objv2_val.json
+```
+
+4. Create a New Directory to Store Images from the Validation Set:
+```shell
+mkdir -p ${BASE_DIR}/train/images_from_val
+```
+
+5. Copy the v1 and v2 folders from the val directory into the train/images_from_val directory
+```shell
+cp -r ${BASE_DIR}/val/images/v1 ${BASE_DIR}/train/images_from_val/
+cp -r ${BASE_DIR}/val/images/v2 ${BASE_DIR}/train/images_from_val/
+```
+
+6. Run remap_obj365.py to merge a subset of the validation set into the training set. Specifically, this script moves samples with indices between 5000 and 800000 from the validation set to the training set.
+```shell
+python tools/remap_obj365.py --base_dir ${BASE_DIR}
+```
+
+
+7. Run the resize_obj365.py script to resize any images in the dataset where the maximum edge length exceeds 640 pixels. Use the updated JSON file generated in Step 5 to process the sample data. Ensure that you resize images in both the train and val datasets to maintain consistency.
+```shell
+python tools/resize_obj365.py --base_dir ${BASE_DIR}
+```
+
+8. Modify paths in [obj365_detection.yml](./configs/dataset/obj365_detection.yml)
+
+ ```yaml
+ train_dataloader:
+ img_folder: /data/Objects365/data/train
+ ann_file: /data/Objects365/data/train/new_zhiyuan_objv2_train_resized.json
+ val_dataloader:
+ img_folder: /data/Objects365/data/val/
+ ann_file: /data/Objects365/data/val/new_zhiyuan_objv2_val_resized.json
+ ```
+
+
+
+
+
+CrowdHuman
+
+Download COCO format dataset here: [url](https://aistudio.baidu.com/datasetdetail/231455)
+
+
+
+
+Custom Dataset
+
+To train on your custom dataset, you need to organize it in the COCO format. Follow the steps below to prepare your dataset:
+
+1. **Set `remap_mscoco_category` to `False`:**
+
+ This prevents the automatic remapping of category IDs to match the MSCOCO categories.
+
+ ```yaml
+ remap_mscoco_category: False
+ ```
+
+2. **Organize Images:**
+
+ Structure your dataset directories as follows:
+
+ ```shell
+ dataset/
+ ├── images/
+ │ ├── train/
+ │ │ ├── image1.jpg
+ │ │ ├── image2.jpg
+ │ │ └── ...
+ │ ├── val/
+ │ │ ├── image1.jpg
+ │ │ ├── image2.jpg
+ │ │ └── ...
+ └── annotations/
+ ├── instances_train.json
+ ├── instances_val.json
+ └── ...
+ ```
+
+ - **`images/train/`**: Contains all training images.
+ - **`images/val/`**: Contains all validation images.
+ - **`annotations/`**: Contains COCO-formatted annotation files.
+
+3. **Convert Annotations to COCO Format:**
+
+ If your annotations are not already in COCO format, you'll need to convert them. You can use the following Python script as a reference or utilize existing tools:
+
+ ```python
+ import json
+
+ def convert_to_coco(input_annotations, output_annotations):
+ # Implement conversion logic here
+ pass
+
+ if __name__ == "__main__":
+ convert_to_coco('path/to/your_annotations.json', 'dataset/annotations/instances_train.json')
+ ```
+
+4. **Update Configuration Files:**
+
+ Modify your [custom_detection.yml](./configs/dataset/custom_detection.yml).
+
+ ```yaml
+ task: detection
+
+ evaluator:
+ type: CocoEvaluator
+ iou_types: ['bbox', ]
+
+ num_classes: 777 # your dataset classes
+ remap_mscoco_category: False
+
+ train_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/yourdataset/train
+ ann_file: /data/yourdataset/train/train.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: True
+ num_workers: 4
+ drop_last: True
+ collate_fn:
+ type: BatchImageCollateFunction
+
+ val_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/yourdataset/val
+ ann_file: /data/yourdataset/val/ann.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: False
+ num_workers: 4
+ drop_last: False
+ collate_fn:
+ type: BatchImageCollateFunction
+ ```
+
+
+
+
+## Usage
+
+ COCO2017
+
+
+1. Set Model
+```shell
+export model=l # n s m l x
+```
+
+2. Training
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/dfine_hgnetv2_${model}_coco.yml --use-amp --seed=0
+```
+
+
+3. Testing
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/dfine_hgnetv2_${model}_coco.yml --test-only -r model.pth
+```
+
+
+4. Tuning
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/dfine_hgnetv2_${model}_coco.yml --use-amp --seed=0 -t model.pth
+```
+
+
+
+
+ Objects365 to COCO2017
+
+1. Set Model
+```shell
+export model=l # n s m l x
+```
+
+2. Training on Objects365
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/objects365/dfine_hgnetv2_${model}_obj365.yml --use-amp --seed=0
+```
+
+3. Tuning on COCO2017
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/objects365/dfine_hgnetv2_${model}_obj2coco.yml --use-amp --seed=0 -t model.pth
+```
+
+
+4. Testing
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/dfine_hgnetv2_${model}_coco.yml --test-only -r model.pth
+```
+
+
+
+
+ Custom Dataset
+
+1. Set Model
+```shell
+export model=l # n s m l x
+```
+
+2. Training on Custom Dataset
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/custom/dfine_hgnetv2_${model}_custom.yml --use-amp --seed=0
+```
+
+3. Testing
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/custom/dfine_hgnetv2_${model}_custom.yml --test-only -r model.pth
+```
+
+4. Tuning on Custom Dataset
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/custom/objects365/dfine_hgnetv2_${model}_obj2custom.yml --use-amp --seed=0 -t model.pth
+```
+
+5. **[Optional]** Modify Class Mappings:
+
+When using the Objects365 pre-trained weights to train on your custom dataset, the example assumes that your dataset only contains the classes `'Person'` and `'Car'`. For faster convergence, you can modify `self.obj365_ids` in `src/solver/_solver.py` as follows:
+
+
+```python
+self.obj365_ids = [0, 5] # Person, Cars
+```
+You can replace these with any corresponding classes from your dataset. The list of Objects365 classes with their corresponding IDs:
+https://github.com/Peterande/D-FINE/blob/352a94ece291e26e1957df81277bef00fe88a8e3/src/solver/_solver.py#L330
+
+New training command:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/dfine/custom/dfine_hgnetv2_${model}_custom.yml --use-amp --seed=0 -t model.pth
+```
+
+However, if you don't wish to modify the class mappings, the pre-trained Objects365 weights will still work without any changes. Modifying the class mappings is optional and can potentially accelerate convergence for specific tasks.
+
+
+
+
+
+
+ Customizing Batch Size
+
+For example, if you want to double the total batch size when training D-FINE-L on COCO2017, here are the steps you should follow:
+
+1. **Modify your [dataloader.yml](./configs/dfine/include/dataloader.yml)** to increase the `total_batch_size`:
+
+ ```yaml
+ train_dataloader:
+ total_batch_size: 64 # Previously it was 32, now doubled
+ ```
+
+2. **Modify your [dfine_hgnetv2_l_coco.yml](./configs/dfine/dfine_hgnetv2_l_coco.yml)**. Here’s how the key parameters should be adjusted:
+
+ ```yaml
+ optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000025 # doubled, linear scaling law
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.0005 # doubled, linear scaling law
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001 # need a grid search
+
+ ema: # added EMA settings
+ decay: 0.9998 # adjusted by 1 - (1 - decay) * 2
+ warmups: 500 # halved
+
+ lr_warmup_scheduler:
+ warmup_duration: 250 # halved
+ ```
+
+
+
+
+
+ Customizing Input Size
+
+If you'd like to train **D-FINE-L** on COCO2017 with an input size of 320x320, follow these steps:
+
+1. **Modify your [dataloader.yml](./configs/dfine/include/dataloader.yml)**:
+
+ ```yaml
+
+ train_dataloader:
+ dataset:
+ transforms:
+ ops:
+ - {type: Resize, size: [320, 320], }
+ collate_fn:
+ base_size: 320
+ dataset:
+ transforms:
+ ops:
+ - {type: Resize, size: [320, 320], }
+ ```
+
+2. **Modify your [dfine_hgnetv2.yml](./configs/dfine/include/dfine_hgnetv2.yml)**:
+
+ ```yaml
+ eval_spatial_size: [320, 320]
+ ```
+
+
+
+## Tools
+
+ Deployment
+
+
+1. Setup
+```shell
+pip install onnx onnxsim
+export model=l # n s m l x
+```
+
+2. Export onnx
+```shell
+python tools/deployment/export_onnx.py --check -c configs/dfine/dfine_hgnetv2_${model}_coco.yml -r model.pth
+```
+
+3. Export [tensorrt](https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html)
+```shell
+trtexec --onnx="model.onnx" --saveEngine="model.engine" --fp16
+```
+
+
+
+
+ Inference (Visualization)
+
+
+1. Setup
+```shell
+pip install -r tools/inference/requirements.txt
+export model=l # n s m l x
+```
+
+
+
+2. Inference (onnxruntime / tensorrt / torch)
+
+Inference on images and videos is now supported.
+```shell
+python tools/inference/onnx_inf.py --onnx model.onnx --input image.jpg # video.mp4
+python tools/inference/trt_inf.py --trt model.engine --input image.jpg
+python tools/inference/torch_inf.py -c configs/dfine/dfine_hgnetv2_${model}_coco.yml -r model.pth --input image.jpg --device cuda:0
+```
+
+
+
+ Benchmark
+
+1. Setup
+```shell
+pip install -r tools/benchmark/requirements.txt
+export model=l # n s m l x
+```
+
+
+2. Model FLOPs, MACs, and Params
+```shell
+python tools/benchmark/get_info.py -c configs/dfine/dfine_hgnetv2_${model}_coco.yml
+```
+
+2. TensorRT Latency
+```shell
+python tools/benchmark/trt_benchmark.py --COCO_dir path/to/COCO2017 --engine_dir model.engine
+```
+
+
+
+ Fiftyone Visualization
+
+1. Setup
+```shell
+pip install fiftyone
+export model=l # n s m l x
+```
+4. Voxel51 Fiftyone Visualization ([fiftyone](https://github.com/voxel51/fiftyone))
+```shell
+python tools/visualization/fiftyone_vis.py -c configs/dfine/dfine_hgnetv2_${model}_coco.yml -r model.pth
+```
+
+
+
+ Others
+
+1. Auto Resume Training
+```shell
+bash reference/safe_training.sh
+```
+
+2. Converting Model Weights
+```shell
+python reference/convert_weight.py model.pth
+```
+
+
+## Figures and Visualizations
+
+
+ FDR and GO-LSD
+
+1. Overview of D-FINE with FDR. The probability distributions that act as a more fine-
+grained intermediate representation are iteratively refined by the decoder layers in a residual manner.
+Non-uniform weighting functions are applied to allow for finer localization.
+
+
+
+
+
+2. Overview of GO-LSD process. Localization knowledge from the final layer’s refined
+distributions is distilled into earlier layers through DDF loss with decoupled weighting strategies.
+
+
+
+
+
+
+
+
+ Distributions
+
+Visualizations of FDR across detection scenarios with initial and refined bounding boxes, along with unweighted and weighted distributions.
+
+
+
+
+
+
+
+
+ Hard Cases
+
+The following visualization demonstrates D-FINE's predictions in various complex detection scenarios. These include cases with occlusion, low-light conditions, motion blur, depth of field effects, and densely populated scenes. Despite these challenges, D-FINE consistently produces accurate localization results.
+
+
+
+
+
+
+
+
+
+
+
+
+
+## Citation
+If you use `D-FINE` or its methods in your work, please cite the following BibTeX entries:
+
+ bibtex
+
+```latex
+@misc{peng2024dfine,
+ title={D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement},
+ author={Yansong Peng and Hebei Li and Peixi Wu and Yueyi Zhang and Xiaoyan Sun and Feng Wu},
+ year={2024},
+ eprint={2410.13842},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+## Acknowledgement
+Our work is built upon [RT-DETR](https://github.com/lyuwenyu/RT-DETR).
+Thanks to the inspirations from [RT-DETR](https://github.com/lyuwenyu/RT-DETR), [GFocal](https://github.com/implus/GFocal), [LD](https://github.com/HikariTJU/LD), and [YOLOv9](https://github.com/WongKinYiu/yolov9).
+
+✨ Feel free to contribute and reach out if you have any questions! ✨
diff --git a/D-FINE/README_cn.md b/D-FINE/README_cn.md
new file mode 100644
index 0000000000000000000000000000000000000000..c9beb8e0b90ec358790cf1d823663cf06ecab317
--- /dev/null
+++ b/D-FINE/README_cn.md
@@ -0,0 +1,673 @@
+
+
+[English](README.md) | 简体中文 | [日本語](README_ja.md) | [English Blog](src/zoo/dfine/blog.md) | [中文博客](src/zoo/dfine/blog_cn.md)
+
+
+ D-FINE: Redefine Regression Task of DETRs as Fine‑grained Distribution Refinement
+
+
+
+
+
+
+
+
+
+
+## 引用
+もし`D-FINE`やその方法をあなたの仕事で使用する場合、以下のBibTeXエントリを引用してください:
+
+ bibtex
+
+```latex
+@misc{peng2024dfine,
+ title={D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement},
+ author={Yansong Peng and Hebei Li and Peixi Wu and Yueyi Zhang and Xiaoyan Sun and Feng Wu},
+ year={2024},
+ eprint={2410.13842},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+## 謝辞
+私たちの仕事は [RT-DETR](https://github.com/lyuwenyu/RT-DETR) に基づいています。
+[RT-DETR](https://github.com/lyuwenyu/RT-DETR), [GFocal](https://github.com/implus/GFocal), [LD](https://github.com/HikariTJU/LD), および [YOLOv9](https://github.com/WongKinYiu/yolov9) からのインスピレーションに感謝します。
+
+✨ 貢献を歓迎し、質問があればお気軽にお問い合わせください! ✨
diff --git a/D-FINE/configs/dataset/coco_detection.yml b/D-FINE/configs/dataset/coco_detection.yml
new file mode 100644
index 0000000000000000000000000000000000000000..670c3e3371e778f1751ea69bc7b9d00f4f08f76a
--- /dev/null
+++ b/D-FINE/configs/dataset/coco_detection.yml
@@ -0,0 +1,41 @@
+task: detection
+
+evaluator:
+ type: CocoEvaluator
+ iou_types: ['bbox', ]
+
+num_classes: 80
+remap_mscoco_category: True
+
+train_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/COCO2017/train2017/
+ ann_file: /data/COCO2017/annotations/instances_train2017.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: True
+ num_workers: 4
+ drop_last: True
+ collate_fn:
+ type: BatchImageCollateFunction
+
+
+val_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/COCO2017/val2017/
+ ann_file: /data/COCO2017/annotations/instances_val2017.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: False
+ num_workers: 4
+ drop_last: False
+ collate_fn:
+ type: BatchImageCollateFunction
diff --git a/D-FINE/configs/dataset/crowdhuman_detection.yml b/D-FINE/configs/dataset/crowdhuman_detection.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0a4bbad39f3d30795573eb885ac37b12f7576f3a
--- /dev/null
+++ b/D-FINE/configs/dataset/crowdhuman_detection.yml
@@ -0,0 +1,41 @@
+task: detection
+
+evaluator:
+ type: CocoEvaluator
+ iou_types: ['bbox', ]
+
+num_classes: 1 # your dataset classes
+remap_mscoco_category: False
+
+train_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/CrowdHuman/coco/CrowdHuman_train
+ ann_file: /data/CrowdHuman/coco/Chuman-train.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: True
+ num_workers: 4
+ drop_last: True
+ collate_fn:
+ type: BatchImageCollateFunction
+
+
+val_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/CrowdHuman/coco/CrowdHuman_val
+ ann_file: /data/CrowdHuman/coco/Chuman-val.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: False
+ num_workers: 4
+ drop_last: False
+ collate_fn:
+ type: BatchImageCollateFunction
diff --git a/D-FINE/configs/dataset/custom_detection.yml b/D-FINE/configs/dataset/custom_detection.yml
new file mode 100644
index 0000000000000000000000000000000000000000..35435ad68e29d99d8f9f69100cd56a2c403fe710
--- /dev/null
+++ b/D-FINE/configs/dataset/custom_detection.yml
@@ -0,0 +1,41 @@
+task: detection
+
+evaluator:
+ type: CocoEvaluator
+ iou_types: ['bbox', ]
+
+num_classes: 777 # your dataset classes
+remap_mscoco_category: False
+
+train_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/yourdataset/train
+ ann_file: /data/yourdataset/train/train.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: True
+ num_workers: 4
+ drop_last: True
+ collate_fn:
+ type: BatchImageCollateFunction
+
+
+val_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/yourdataset/val
+ ann_file: /data/yourdataset/val/val.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: False
+ num_workers: 4
+ drop_last: False
+ collate_fn:
+ type: BatchImageCollateFunction
diff --git a/D-FINE/configs/dataset/obj365_detection.yml b/D-FINE/configs/dataset/obj365_detection.yml
new file mode 100644
index 0000000000000000000000000000000000000000..e58fdbc18206810e2c2b8bcbacb2abe5e6138798
--- /dev/null
+++ b/D-FINE/configs/dataset/obj365_detection.yml
@@ -0,0 +1,41 @@
+task: detection
+
+evaluator:
+ type: CocoEvaluator
+ iou_types: ['bbox', ]
+
+num_classes: 366
+remap_mscoco_category: False
+
+train_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/Objects365/data/train
+ ann_file: /data/Objects365/data/train/new_zhiyuan_objv2_train_resized.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: True
+ num_workers: 4
+ drop_last: True
+ collate_fn:
+ type: BatchImageCollateFunction
+
+
+val_dataloader:
+ type: DataLoader
+ dataset:
+ type: CocoDetection
+ img_folder: /data/Objects365/data/val/
+ ann_file: /data/Objects365/data/val/new_zhiyuan_objv2_val_resized.json
+ return_masks: False
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: False
+ num_workers: 4
+ drop_last: False
+ collate_fn:
+ type: BatchImageCollateFunction
diff --git a/D-FINE/configs/dataset/voc_detection.yml b/D-FINE/configs/dataset/voc_detection.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1f9ceeb8881653d496ac5fd02c465aea5306d72f
--- /dev/null
+++ b/D-FINE/configs/dataset/voc_detection.yml
@@ -0,0 +1,40 @@
+task: detection
+
+evaluator:
+ type: CocoEvaluator
+ iou_types: ['bbox', ]
+
+num_classes: 20
+
+train_dataloader:
+ type: DataLoader
+ dataset:
+ type: VOCDetection
+ root: ./dataset/voc/
+ ann_file: trainval.txt
+ label_file: label_list.txt
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: True
+ num_workers: 4
+ drop_last: True
+ collate_fn:
+ type: BatchImageCollateFunction
+
+
+val_dataloader:
+ type: DataLoader
+ dataset:
+ type: VOCDetection
+ root: ./dataset/voc/
+ ann_file: test.txt
+ label_file: label_list.txt
+ transforms:
+ type: Compose
+ ops: ~
+ shuffle: False
+ num_workers: 4
+ drop_last: False
+ collate_fn:
+ type: BatchImageCollateFunction
diff --git a/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_l_ch.yml b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_l_ch.yml
new file mode 100644
index 0000000000000000000000000000000000000000..761bcf8caeb9ec85f4d759011a1a1bb7f18ceceb
--- /dev/null
+++ b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_l_ch.yml
@@ -0,0 +1,44 @@
+__include__: [
+ '../../dataset/crowdhuman_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_l_crowdhuman
+
+
+HGNetv2:
+ name: 'B4'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000125
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 140
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 120
+ collate_fn:
+ stop_epoch: 120
+ ema_restart_decay: 0.9999
+ base_size_repeat: 4
diff --git a/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_m_ch.yml b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_m_ch.yml
new file mode 100644
index 0000000000000000000000000000000000000000..48d37f118a2bf5c019c56f0268117f20382cdc36
--- /dev/null
+++ b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_m_ch.yml
@@ -0,0 +1,60 @@
+__include__: [
+ '../../dataset/crowdhuman_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_m_crowdhuman
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B2'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 4 # 5 6
+ eval_idx: -1 # -2 -3
+
+HybridEncoder:
+ in_channels: [384, 768, 1536]
+ hidden_dim: 256
+ depth_mult: 0.67
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000025
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000025
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 220
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 200
+ collate_fn:
+ stop_epoch: 200
+ ema_restart_decay: 0.9999
+ base_size_repeat: 6
diff --git a/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_n_ch.yml b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_n_ch.yml
new file mode 100644
index 0000000000000000000000000000000000000000..51528bcf2454202d21b0ea4f53fc3c66e1a627f4
--- /dev/null
+++ b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_n_ch.yml
@@ -0,0 +1,82 @@
+__include__: [
+ '../../dataset/crowdhuman_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_n_crowdhuman
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+
+HybridEncoder:
+ in_channels: [512, 1024]
+ feat_strides: [16, 32]
+
+ # intra
+ hidden_dim: 128
+ use_encoder_idx: [1]
+ dim_feedforward: 512
+
+ # cross
+ expansion: 0.34
+ depth_mult: 0.5
+
+
+DFINETransformer:
+ feat_channels: [128, 128]
+ feat_strides: [16, 32]
+ hidden_dim: 128
+ dim_feedforward: 512
+ num_levels: 2
+
+ num_layers: 3
+ eval_idx: -1
+
+ num_points: [6, 6]
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0004
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.0004
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0008
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+# Increase to search for the optimal ema
+epochs: 220
+train_dataloader:
+ total_batch_size: 128
+ dataset:
+ transforms:
+ policy:
+ epoch: 200
+ collate_fn:
+ stop_epoch: 200
+ ema_restart_decay: 0.9999
+ base_size_repeat: ~
+
+val_dataloader:
+ total_batch_size: 256
diff --git a/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_s_ch.yml b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_s_ch.yml
new file mode 100644
index 0000000000000000000000000000000000000000..55ab8b87350750901cca494d4643370bb127196e
--- /dev/null
+++ b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_s_ch.yml
@@ -0,0 +1,65 @@
+__include__: [
+ '../../dataset/crowdhuman_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_s_crowdhuman
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 3 # 4 5 6
+ eval_idx: -1 # -2 -3 -4
+
+HybridEncoder:
+ in_channels: [256, 512, 1024]
+ hidden_dim: 256
+ depth_mult: 0.34
+ expansion: 0.5
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0002
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.0002
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0004
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+# Increase to search for the optimal ema
+epochs: 220
+train_dataloader:
+ total_batch_size: 64
+ dataset:
+ transforms:
+ policy:
+ epoch: 200
+ collate_fn:
+ stop_epoch: 200
+ ema_restart_decay: 0.9999
+ base_size_repeat: 20
+
+val_dataloader:
+ total_batch_size: 128
diff --git a/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_x_ch.yml b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_x_ch.yml
new file mode 100644
index 0000000000000000000000000000000000000000..2ab49a021e298fc53d80658d2d5102cce1687a4c
--- /dev/null
+++ b/D-FINE/configs/dfine/crowdhuman/dfine_hgnetv2_x_ch.yml
@@ -0,0 +1,55 @@
+__include__: [
+ '../../dataset/crowdhuman_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_x_crowdhuman
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B5'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+HybridEncoder:
+ hidden_dim: 384
+ dim_feedforward: 2048
+
+DFINETransformer:
+ feat_channels: [384, 384, 384]
+ reg_scale: 8
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000025
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 140
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 120
+ collate_fn:
+ stop_epoch: 120
+ ema_restart_decay: 0.9998
+ base_size_repeat: 3
diff --git a/D-FINE/configs/dfine/custom/dfine_hgnetv2_l_custom.yml b/D-FINE/configs/dfine/custom/dfine_hgnetv2_l_custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7526401f57b831d5dc3b0d7e1a3adc7b92411e63
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/dfine_hgnetv2_l_custom.yml
@@ -0,0 +1,44 @@
+__include__: [
+ '../../dataset/custom_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_l_custom
+
+
+HGNetv2:
+ name: 'B4'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000125
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 80 # 72 + 2n
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 72
+ collate_fn:
+ stop_epoch: 72
+ ema_restart_decay: 0.9999
+ base_size_repeat: 4
diff --git a/D-FINE/configs/dfine/custom/dfine_hgnetv2_m_custom.yml b/D-FINE/configs/dfine/custom/dfine_hgnetv2_m_custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..bf31c1c431fa8a173992c7ac62b78ff64f831476
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/dfine_hgnetv2_m_custom.yml
@@ -0,0 +1,60 @@
+__include__: [
+ '../../dataset/custom_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_m_custom
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B2'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 4 # 5 6
+ eval_idx: -1 # -2 -3
+
+HybridEncoder:
+ in_channels: [384, 768, 1536]
+ hidden_dim: 256
+ depth_mult: 0.67
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000025
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000025
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 132 # 120 + 4n
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 120
+ collate_fn:
+ stop_epoch: 120
+ ema_restart_decay: 0.9999
+ base_size_repeat: 6
diff --git a/D-FINE/configs/dfine/custom/dfine_hgnetv2_n_custom.yml b/D-FINE/configs/dfine/custom/dfine_hgnetv2_n_custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6cd63aaa5b34ab50f08a8ace04f27122319111ed
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/dfine_hgnetv2_n_custom.yml
@@ -0,0 +1,76 @@
+__include__:
+ [
+ "../../dataset/custom_detection.yml",
+ "../../runtime.yml",
+ "../include/dataloader.yml",
+ "../include/optimizer.yml",
+ "../include/dfine_hgnetv2.yml",
+ ]
+
+output_dir: ../../../inference_output
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: "B0"
+ return_idx: [2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+HybridEncoder:
+ in_channels: [512, 1024]
+ feat_strides: [16, 32]
+
+ # intra
+ hidden_dim: 128
+ use_encoder_idx: [1]
+ dim_feedforward: 512
+
+ # cross
+ expansion: 0.34
+ depth_mult: 0.5
+
+DFINETransformer:
+ feat_channels: [128, 128]
+ feat_strides: [16, 32]
+ hidden_dim: 128
+ dim_feedforward: 512
+ num_levels: 2
+
+ num_layers: 3
+ eval_idx: -1
+
+ num_points: [6, 6]
+
+optimizer:
+ type: AdamW
+ params:
+ - params: "^(?=.*backbone)(?!.*norm|bn).*$"
+ lr: 0.0004
+ - params: "^(?=.*backbone)(?=.*norm|bn).*$"
+ lr: 0.0004
+ weight_decay: 0.
+ - params: "^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$"
+ weight_decay: 0.
+
+ lr: 0.0008
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+# Increase to search for the optimal ema
+epochs: 135
+train_dataloader:
+ total_batch_size: 32
+ dataset:
+ transforms:
+ policy:
+ epoch: 123
+ collate_fn:
+ stop_epoch: 123
+ ema_restart_decay: 0.9999
+ base_size_repeat: ~
+
+val_dataloader:
+ total_batch_size: 32
diff --git a/D-FINE/configs/dfine/custom/dfine_hgnetv2_s_custom.yml b/D-FINE/configs/dfine/custom/dfine_hgnetv2_s_custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..285cb77bf7e6519522ab0622c03eae59a258677c
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/dfine_hgnetv2_s_custom.yml
@@ -0,0 +1,65 @@
+__include__: [
+ '../../dataset/custom_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_s_custom
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 3 # 4 5 6
+ eval_idx: -1 # -2 -3 -4
+
+HybridEncoder:
+ in_channels: [256, 512, 1024]
+ hidden_dim: 256
+ depth_mult: 0.34
+ expansion: 0.5
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0002
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.0002
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0004
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+# Increase to search for the optimal ema
+epochs: 220
+train_dataloader:
+ total_batch_size: 64
+ dataset:
+ transforms:
+ policy:
+ epoch: 200
+ collate_fn:
+ stop_epoch: 200
+ ema_restart_decay: 0.9999
+ base_size_repeat: 20
+
+val_dataloader:
+ total_batch_size: 128
diff --git a/D-FINE/configs/dfine/custom/dfine_hgnetv2_x_custom.yml b/D-FINE/configs/dfine/custom/dfine_hgnetv2_x_custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..2ba564607d4cb7f2ceb313ff14be6114d6b248af
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/dfine_hgnetv2_x_custom.yml
@@ -0,0 +1,55 @@
+__include__: [
+ '../../dataset/custom_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_x_custom
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B5'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+HybridEncoder:
+ hidden_dim: 384
+ dim_feedforward: 2048
+
+DFINETransformer:
+ feat_channels: [384, 384, 384]
+ reg_scale: 8
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000025
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 80 # 72 + 2n
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 72
+ collate_fn:
+ stop_epoch: 72
+ ema_restart_decay: 0.9998
+ base_size_repeat: 3
diff --git a/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_l_obj2custom.yml b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_l_obj2custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ef6a95dfc8bae3fef4ce6d60cb980cf349bfaaa6
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_l_obj2custom.yml
@@ -0,0 +1,53 @@
+__include__: [
+ '../../../dataset/custom_detection.yml',
+ '../../../runtime.yml',
+ '../../include/dataloader.yml',
+ '../../include/optimizer.yml',
+ '../../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_l_obj2custom
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B4'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+ pretrained: False
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000125
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 36 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 30
+ collate_fn:
+ stop_epoch: 30
+ ema_restart_decay: 0.9999
+ base_size_repeat: 4
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_m_obj2custom.yml b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_m_obj2custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f21fbbc7cc7c76671bc2e589c7ce087ba1e4f6ea
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_m_obj2custom.yml
@@ -0,0 +1,66 @@
+__include__: [
+ '../../../dataset/custom_detection.yml',
+ '../../../runtime.yml',
+ '../../include/dataloader.yml',
+ '../../include/optimizer.yml',
+ '../../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_m_obj2custom
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B2'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+ pretrained: False
+
+DFINETransformer:
+ num_layers: 4 # 5 6
+ eval_idx: -1 # -2 -3
+
+HybridEncoder:
+ in_channels: [384, 768, 1536]
+ hidden_dim: 256
+ depth_mult: 0.67
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000025
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000025
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 56 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 48
+ collate_fn:
+ stop_epoch: 48
+ ema_restart_decay: 0.9999
+ base_size_repeat: 6
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_s_obj2custom.yml b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_s_obj2custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9a74e34d67edc86f896049ea15c5af56d57a269d
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_s_obj2custom.yml
@@ -0,0 +1,67 @@
+__include__: [
+ '../../../dataset/custom_detection.yml',
+ '../../../runtime.yml',
+ '../../include/dataloader.yml',
+ '../../include/optimizer.yml',
+ '../../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_s_obj2custom
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+ pretrained: False
+
+DFINETransformer:
+ num_layers: 3 # 4 5 6
+ eval_idx: -1 # -2 -3 -4
+
+HybridEncoder:
+ in_channels: [256, 512, 1024]
+ hidden_dim: 256
+ depth_mult: 0.34
+ expansion: 0.5
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000125
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000125
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 64 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 56
+ collate_fn:
+ stop_epoch: 56
+ ema_restart_decay: 0.9999
+ base_size_repeat: 10
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_x_obj2custom.yml b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_x_obj2custom.yml
new file mode 100644
index 0000000000000000000000000000000000000000..717812f2814356dfad169de9ba1a2185787debc9
--- /dev/null
+++ b/D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_x_obj2custom.yml
@@ -0,0 +1,62 @@
+__include__: [
+ '../../../dataset/custom_detection.yml',
+ '../../../runtime.yml',
+ '../../include/dataloader.yml',
+ '../../include/optimizer.yml',
+ '../../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_x_obj2custom
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B5'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+ pretrained: False
+
+HybridEncoder:
+ # intra
+ hidden_dim: 384
+ dim_feedforward: 2048
+
+DFINETransformer:
+ feat_channels: [384, 384, 384]
+ reg_scale: 8
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000025
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 36 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 30
+ collate_fn:
+ stop_epoch: 30
+ ema_restart_decay: 0.9999
+ base_size_repeat: 3
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/dfine_hgnetv2_l_coco.yml b/D-FINE/configs/dfine/dfine_hgnetv2_l_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..718074c376b7fe5809cb48db800f457e6372a9b3
--- /dev/null
+++ b/D-FINE/configs/dfine/dfine_hgnetv2_l_coco.yml
@@ -0,0 +1,44 @@
+__include__: [
+ '../dataset/coco_detection.yml',
+ '../runtime.yml',
+ './include/dataloader.yml',
+ './include/optimizer.yml',
+ './include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_l_coco
+
+
+HGNetv2:
+ name: 'B4'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000125
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 80 # 72 + 2n
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 72
+ collate_fn:
+ stop_epoch: 72
+ ema_restart_decay: 0.9999
+ base_size_repeat: 4
diff --git a/D-FINE/configs/dfine/dfine_hgnetv2_m_coco.yml b/D-FINE/configs/dfine/dfine_hgnetv2_m_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9837eacc64e8db31b8bf4dddd2728a56ed4a0f82
--- /dev/null
+++ b/D-FINE/configs/dfine/dfine_hgnetv2_m_coco.yml
@@ -0,0 +1,60 @@
+__include__: [
+ '../dataset/coco_detection.yml',
+ '../runtime.yml',
+ './include/dataloader.yml',
+ './include/optimizer.yml',
+ './include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_m_coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B2'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 4 # 5 6
+ eval_idx: -1 # -2 -3
+
+HybridEncoder:
+ in_channels: [384, 768, 1536]
+ hidden_dim: 256
+ depth_mult: 0.67
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.00002
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.00002
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0002
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+# Increase to search for the optimal ema
+epochs: 132 # 120 + 4n
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 120
+ collate_fn:
+ stop_epoch: 120
+ ema_restart_decay: 0.9999
+ base_size_repeat: 6
diff --git a/D-FINE/configs/dfine/dfine_hgnetv2_n_coco.yml b/D-FINE/configs/dfine/dfine_hgnetv2_n_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f0c3a1a4f3dd777fc9bd6a6fb010e9a8e4d7771f
--- /dev/null
+++ b/D-FINE/configs/dfine/dfine_hgnetv2_n_coco.yml
@@ -0,0 +1,82 @@
+__include__: [
+ '../dataset/coco_detection.yml',
+ '../runtime.yml',
+ './include/dataloader.yml',
+ './include/optimizer.yml',
+ './include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_n_coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+
+HybridEncoder:
+ in_channels: [512, 1024]
+ feat_strides: [16, 32]
+
+ # intra
+ hidden_dim: 128
+ use_encoder_idx: [1]
+ dim_feedforward: 512
+
+ # cross
+ expansion: 0.34
+ depth_mult: 0.5
+
+
+DFINETransformer:
+ feat_channels: [128, 128]
+ feat_strides: [16, 32]
+ hidden_dim: 128
+ dim_feedforward: 512
+ num_levels: 2
+
+ num_layers: 3
+ eval_idx: -1
+
+ num_points: [6, 6]
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0004
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.0004
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0008
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+# Increase to search for the optimal ema
+epochs: 160 # 148 + 4n
+train_dataloader:
+ total_batch_size: 128
+ dataset:
+ transforms:
+ policy:
+ epoch: 148
+ collate_fn:
+ stop_epoch: 148
+ ema_restart_decay: 0.9999
+ base_size_repeat: ~
+
+val_dataloader:
+ total_batch_size: 256
diff --git a/D-FINE/configs/dfine/dfine_hgnetv2_s_coco.yml b/D-FINE/configs/dfine/dfine_hgnetv2_s_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..e7aaa22e4c7752fe165d9b3739f87a31752d1e61
--- /dev/null
+++ b/D-FINE/configs/dfine/dfine_hgnetv2_s_coco.yml
@@ -0,0 +1,61 @@
+__include__: [
+ '../dataset/coco_detection.yml',
+ '../runtime.yml',
+ './include/dataloader.yml',
+ './include/optimizer.yml',
+ './include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_s_coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 3 # 4 5 6
+ eval_idx: -1 # -2 -3 -4
+
+HybridEncoder:
+ in_channels: [256, 512, 1024]
+ hidden_dim: 256
+ depth_mult: 0.34
+ expansion: 0.5
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0001
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.0001
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0002
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+# Increase to search for the optimal ema
+epochs: 132 # 120 + 4n
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 120
+ collate_fn:
+ stop_epoch: 120
+ ema_restart_decay: 0.9999
+ base_size_repeat: 20
diff --git a/D-FINE/configs/dfine/dfine_hgnetv2_x_coco.yml b/D-FINE/configs/dfine/dfine_hgnetv2_x_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..38d976b39bac97934e7c0deb3e91c77be9efeb79
--- /dev/null
+++ b/D-FINE/configs/dfine/dfine_hgnetv2_x_coco.yml
@@ -0,0 +1,56 @@
+__include__: [
+ '../dataset/coco_detection.yml',
+ '../runtime.yml',
+ './include/dataloader.yml',
+ './include/optimizer.yml',
+ './include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_x_coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B5'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+HybridEncoder:
+ # intra
+ hidden_dim: 384
+ dim_feedforward: 2048
+
+DFINETransformer:
+ feat_channels: [384, 384, 384]
+ reg_scale: 8
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000025
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+# Increase to search for the optimal ema
+epochs: 80 # 72 + 2n
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 72
+ collate_fn:
+ stop_epoch: 72
+ ema_restart_decay: 0.9998
+ base_size_repeat: 3
diff --git a/D-FINE/configs/dfine/include/dataloader.yml b/D-FINE/configs/dfine/include/dataloader.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3f7c67c81407f5279cb7b620a3241a3c1b6db1be
--- /dev/null
+++ b/D-FINE/configs/dfine/include/dataloader.yml
@@ -0,0 +1,39 @@
+
+train_dataloader:
+ dataset:
+ transforms:
+ ops:
+ - {type: RandomPhotometricDistort, p: 0.5}
+ - {type: RandomZoomOut, fill: 0}
+ - {type: RandomIoUCrop, p: 0.8}
+ - {type: SanitizeBoundingBoxes, min_size: 1}
+ - {type: RandomHorizontalFlip}
+ - {type: Resize, size: [640, 640], }
+ - {type: SanitizeBoundingBoxes, min_size: 1}
+ - {type: ConvertPILImage, dtype: 'float32', scale: True}
+ - {type: ConvertBoxes, fmt: 'cxcywh', normalize: True}
+ policy:
+ name: stop_epoch
+ epoch: 72 # epoch in [71, ~) stop `ops`
+ ops: ['RandomPhotometricDistort', 'RandomZoomOut', 'RandomIoUCrop']
+
+ collate_fn:
+ type: BatchImageCollateFunction
+ base_size: 640
+ base_size_repeat: 3
+ stop_epoch: 72 # epoch in [72, ~) stop `multiscales`
+
+ shuffle: True
+ total_batch_size: 32 # total batch size equals to 32 (4 * 8)
+ num_workers: 4
+
+
+val_dataloader:
+ dataset:
+ transforms:
+ ops:
+ - {type: Resize, size: [640, 640], }
+ - {type: ConvertPILImage, dtype: 'float32', scale: True}
+ shuffle: False
+ total_batch_size: 64
+ num_workers: 4
diff --git a/D-FINE/configs/dfine/include/dfine_hgnetv2.yml b/D-FINE/configs/dfine/include/dfine_hgnetv2.yml
new file mode 100644
index 0000000000000000000000000000000000000000..91ad4a0859d85faf4748e1f822174e11e9ab3bd4
--- /dev/null
+++ b/D-FINE/configs/dfine/include/dfine_hgnetv2.yml
@@ -0,0 +1,82 @@
+task: detection
+
+model: DFINE
+criterion: DFINECriterion
+postprocessor: DFINEPostProcessor
+
+use_focal_loss: True
+eval_spatial_size: [640, 640] # h w
+
+DFINE:
+ backbone: HGNetv2
+ encoder: HybridEncoder
+ decoder: DFINETransformer
+
+HGNetv2:
+ pretrained: True
+ local_model_dir: weight/hgnetv2/
+
+HybridEncoder:
+ in_channels: [512, 1024, 2048]
+ feat_strides: [8, 16, 32]
+
+ # intra
+ hidden_dim: 256
+ use_encoder_idx: [2]
+ num_encoder_layers: 1
+ nhead: 8
+ dim_feedforward: 1024
+ dropout: 0.
+ enc_act: 'gelu'
+
+ # cross
+ expansion: 1.0
+ depth_mult: 1
+ act: 'silu'
+
+
+DFINETransformer:
+ feat_channels: [256, 256, 256]
+ feat_strides: [8, 16, 32]
+ hidden_dim: 256
+ num_levels: 3
+
+ num_layers: 6
+ eval_idx: -1
+ num_queries: 300
+
+ num_denoising: 100
+ label_noise_ratio: 0.5
+ box_noise_scale: 1.0
+
+ # NEW
+ reg_max: 32
+ reg_scale: 4
+
+ # Auxiliary decoder layers dimension scaling
+ # "eg. If num_layers: 6 eval_idx: -4,
+ # then layer 3, 4, 5 are auxiliary decoder layers."
+ layer_scale: 1 # 2
+
+
+ num_points: [3, 6, 3] # [4, 4, 4] [3, 6, 3]
+ cross_attn_method: default # default, discrete
+ query_select_method: default # default, agnostic
+
+
+DFINEPostProcessor:
+ num_top_queries: 300
+
+
+DFINECriterion:
+ weight_dict: {loss_vfl: 1, loss_bbox: 5, loss_giou: 2, loss_fgl: 0.15, loss_ddf: 1.5}
+ losses: ['vfl', 'boxes', 'local']
+ alpha: 0.75
+ gamma: 2.0
+ reg_max: 32
+
+ matcher:
+ type: HungarianMatcher
+ weight_dict: {cost_class: 2, cost_bbox: 5, cost_giou: 2}
+ alpha: 0.25
+ gamma: 2.0
diff --git a/D-FINE/configs/dfine/include/optimizer.yml b/D-FINE/configs/dfine/include/optimizer.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8ec87c771f0df3749d67a58191618c8ece839291
--- /dev/null
+++ b/D-FINE/configs/dfine/include/optimizer.yml
@@ -0,0 +1,36 @@
+use_amp: True
+use_ema: True
+ema:
+ type: ModelEMA
+ decay: 0.9999
+ warmups: 1000
+ start: 0
+
+
+epochs: 72
+clip_max_norm: 0.1
+
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm).*$'
+ lr: 0.0000125
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+lr_scheduler:
+ type: MultiStepLR
+ milestones: [500]
+ gamma: 0.1
+
+lr_warmup_scheduler:
+ type: LinearWarmup
+ warmup_duration: 500
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_l_obj2coco.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_l_obj2coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f4fda6302bdbbc86c61efb90b649bb63513ba9d4
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_l_obj2coco.yml
@@ -0,0 +1,52 @@
+__include__: [
+ '../../dataset/coco_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_l_obj2coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B4'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000125
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 36 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 30
+ collate_fn:
+ stop_epoch: 30
+ ema_restart_decay: 0.9999
+ base_size_repeat: 4
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_l_obj365.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_l_obj365.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c7a2876bc99a7da49823e161d25baa0777c39ee4
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_l_obj365.yml
@@ -0,0 +1,49 @@
+__include__: [
+ '../../dataset/obj365_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_l_obj365
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B4'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000125
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+# weight_decay: 0.00005 # Faster convergence (optional)
+
+
+epochs: 24 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 500
+ collate_fn:
+ stop_epoch: 500
+ base_size_repeat: 4
+
+checkpoint_freq: 1
+print_freq: 1000
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_m_obj2coco.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_m_obj2coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..fd77cca65d667f36f196e5c60781db97fb217304
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_m_obj2coco.yml
@@ -0,0 +1,65 @@
+__include__: [
+ '../../dataset/coco_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_m_obj2coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B2'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 4 # 5 6
+ eval_idx: -1 # -2 -3
+
+HybridEncoder:
+ in_channels: [384, 768, 1536]
+ hidden_dim: 256
+ depth_mult: 0.67
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000025
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000025
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 56 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 48
+ collate_fn:
+ stop_epoch: 48
+ ema_restart_decay: 0.9999
+ base_size_repeat: 6
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_m_obj365.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_m_obj365.yml
new file mode 100644
index 0000000000000000000000000000000000000000..108d4e6b67b3174f55e5628a6087714aca3a4047
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_m_obj365.yml
@@ -0,0 +1,62 @@
+__include__: [
+ '../../dataset/obj365_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: .output/dfine_hgnetv2_s_obj365
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B2'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 4 # 5 6
+ eval_idx: -1 # -2 -3
+
+HybridEncoder:
+ in_channels: [384, 768, 1536]
+ hidden_dim: 256
+ depth_mult: 0.67
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000025
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000025
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+# weight_decay: 0.00005 # Faster convergence (optional)
+
+
+epochs: 36 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 500
+ collate_fn:
+ stop_epoch: 500
+ base_size_repeat: 6
+
+checkpoint_freq: 1
+print_freq: 1000
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_n_obj2coco.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_n_obj2coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6febf65826810b9566e42f3b2d8276baa9436987
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_n_obj2coco.yml
@@ -0,0 +1,88 @@
+__include__: [
+ '../../dataset/coco_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_n_obj2coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+
+HybridEncoder:
+ in_channels: [512, 1024]
+ feat_strides: [16, 32]
+
+ # intra
+ hidden_dim: 128
+ use_encoder_idx: [1]
+ dim_feedforward: 512
+
+ # cross
+ expansion: 0.34
+ depth_mult: 0.5
+
+
+DFINETransformer:
+ feat_channels: [128, 128]
+ feat_strides: [16, 32]
+ hidden_dim: 128
+ dim_feedforward: 512
+ num_levels: 2
+
+ num_layers: 3
+ eval_idx: -1
+
+ num_points: [6, 6]
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0004
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.0004
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0008
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+
+epochs: 64 # Early stop
+train_dataloader:
+ total_batch_size: 128
+ dataset:
+ transforms:
+ policy:
+ epoch: 56
+ collate_fn:
+ stop_epoch: 56
+ ema_restart_decay: 0.9999
+ base_size_repeat: ~
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
+
+val_dataloader:
+ total_batch_size: 256
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_n_obj365.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_n_obj365.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b5f148aba541fdc413c0c6f665595afdf08238d8
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_n_obj365.yml
@@ -0,0 +1,84 @@
+__include__: [
+ '../../dataset/obj365_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_n_obj365
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+
+HybridEncoder:
+ in_channels: [512, 1024]
+ feat_strides: [16, 32]
+
+ # intra
+ hidden_dim: 128
+ use_encoder_idx: [1]
+ dim_feedforward: 512
+
+ # cross
+ expansion: 0.34
+ depth_mult: 0.5
+
+
+DFINETransformer:
+ feat_channels: [128, 128]
+ feat_strides: [16, 32]
+ hidden_dim: 128
+ dim_feedforward: 512
+ num_levels: 2
+
+ num_layers: 3
+ eval_idx: -1
+
+ num_points: [6, 6]
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0004
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.0004
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.0008
+ betas: [0.9, 0.999]
+ weight_decay: 0.0001
+
+
+
+epochs: 48 # Early stop
+train_dataloader:
+ total_batch_size: 128
+ dataset:
+ transforms:
+ policy:
+ epoch: 500
+ collate_fn:
+ stop_epoch: 500
+ base_size_repeat: ~
+
+checkpoint_freq: 1
+print_freq: 500
+
+val_dataloader:
+ total_batch_size: 256
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_s_obj2coco.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_s_obj2coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9fa01e2e6fd250189a956b0c5be3ca0f5a8d0527
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_s_obj2coco.yml
@@ -0,0 +1,66 @@
+__include__: [
+ '../../dataset/coco_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_s_obj2coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 3 # 4 5 6
+ eval_idx: -1 # -2 -3 -4
+
+HybridEncoder:
+ in_channels: [256, 512, 1024]
+ hidden_dim: 256
+ depth_mult: 0.34
+ expansion: 0.5
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000125
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000125
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 64 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 56
+ collate_fn:
+ stop_epoch: 56
+ ema_restart_decay: 0.9999
+ base_size_repeat: 10
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_s_obj365.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_s_obj365.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1e98a0db0a9b575d8c743755f4f0fcae66cdc956
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_s_obj365.yml
@@ -0,0 +1,63 @@
+__include__: [
+ '../../dataset/obj365_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_s_obj365
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B0'
+ return_idx: [1, 2, 3]
+ freeze_at: -1
+ freeze_norm: False
+ use_lab: True
+
+DFINETransformer:
+ num_layers: 3 # 4 5 6
+ eval_idx: -1 # -2 -3 -4
+
+HybridEncoder:
+ in_channels: [256, 512, 1024]
+ hidden_dim: 256
+ depth_mult: 0.34
+ expansion: 0.5
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.000125
+ -
+ params: '^(?=.*backbone)(?=.*norm|bn).*$'
+ lr: 0.000125
+ weight_decay: 0.
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn|bias)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+# weight_decay: 0.00005 # Faster convergence (optional)
+
+
+epochs: 36 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 500
+ collate_fn:
+ stop_epoch: 500
+ base_size_repeat: 20
+
+checkpoint_freq: 1
+print_freq: 1000
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_x_obj2coco.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_x_obj2coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..738c75d3699dd6e4c61c252fe3b837dbb9ef8104
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_x_obj2coco.yml
@@ -0,0 +1,61 @@
+__include__: [
+ '../../dataset/coco_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_x_obj2coco
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B5'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+HybridEncoder:
+ # intra
+ hidden_dim: 384
+ dim_feedforward: 2048
+
+DFINETransformer:
+ feat_channels: [384, 384, 384]
+ reg_scale: 8
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000025
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+
+
+epochs: 36 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 30
+ collate_fn:
+ stop_epoch: 30
+ ema_restart_decay: 0.9999
+ base_size_repeat: 3
+
+ema:
+ warmups: 0
+
+lr_warmup_scheduler:
+ warmup_duration: 0
diff --git a/D-FINE/configs/dfine/objects365/dfine_hgnetv2_x_obj365.yml b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_x_obj365.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0449d724c551cdde2626d615517cd2d4a30a040e
--- /dev/null
+++ b/D-FINE/configs/dfine/objects365/dfine_hgnetv2_x_obj365.yml
@@ -0,0 +1,58 @@
+__include__: [
+ '../../dataset/obj365_detection.yml',
+ '../../runtime.yml',
+ '../include/dataloader.yml',
+ '../include/optimizer.yml',
+ '../include/dfine_hgnetv2.yml',
+]
+
+output_dir: ./output/dfine_hgnetv2_x_obj365
+
+
+DFINE:
+ backbone: HGNetv2
+
+HGNetv2:
+ name: 'B5'
+ return_idx: [1, 2, 3]
+ freeze_stem_only: True
+ freeze_at: 0
+ freeze_norm: True
+
+HybridEncoder:
+ # intra
+ hidden_dim: 384
+ dim_feedforward: 2048
+
+DFINETransformer:
+ feat_channels: [384, 384, 384]
+ reg_scale: 8
+
+optimizer:
+ type: AdamW
+ params:
+ -
+ params: '^(?=.*backbone)(?!.*norm|bn).*$'
+ lr: 0.0000025
+ -
+ params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bn)).*$'
+ weight_decay: 0.
+
+ lr: 0.00025
+ betas: [0.9, 0.999]
+ weight_decay: 0.000125
+# weight_decay: 0.00005 # Faster convergence (optional)
+
+
+epochs: 24 # Early stop
+train_dataloader:
+ dataset:
+ transforms:
+ policy:
+ epoch: 500
+ collate_fn:
+ stop_epoch: 500
+ base_size_repeat: 3
+
+checkpoint_freq: 1
+print_freq: 1000
diff --git a/D-FINE/configs/runtime.yml b/D-FINE/configs/runtime.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b99af4af03fa5241315d4a5f46c7a742e36aca15
--- /dev/null
+++ b/D-FINE/configs/runtime.yml
@@ -0,0 +1,24 @@
+print_freq: 100
+output_dir: './logs'
+checkpoint_freq: 12
+
+
+sync_bn: True
+find_unused_parameters: False
+
+
+use_amp: False
+scaler:
+ type: GradScaler
+ enabled: True
+
+
+use_ema: False
+ema:
+ type: ModelEMA
+ decay: 0.9999
+ warmups: 1000
+
+use_wandb: False
+project_name: D-FINE # for wandb
+exp_name: baseline # wandb experiment name
diff --git a/D-FINE/reference/convert_weight.py b/D-FINE/reference/convert_weight.py
new file mode 100644
index 0000000000000000000000000000000000000000..6dd3207064fcda2b14c2a9ef58f375d1984965ac
--- /dev/null
+++ b/D-FINE/reference/convert_weight.py
@@ -0,0 +1,30 @@
+import argparse
+import os
+
+import torch
+
+
+def save_only_ema_weights(checkpoint_file):
+ """Extract and save only the EMA weights."""
+ checkpoint = torch.load(checkpoint_file, map_location="cpu")
+
+ weights = {}
+ if "ema" in checkpoint:
+ weights["model"] = checkpoint["ema"]["module"]
+ else:
+ raise ValueError("The checkpoint does not contain 'ema'.")
+
+ dir_name, base_name = os.path.split(checkpoint_file)
+ name, ext = os.path.splitext(base_name)
+ output_file = os.path.join(dir_name, f"{name}_converted{ext}")
+
+ torch.save(weights, output_file)
+ print(f"EMA weights saved to {output_file}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Extract and save only EMA weights.")
+ parser.add_argument("checkpoint_file", type=str, help="Path to the input checkpoint file.")
+
+ args = parser.parse_args()
+ save_only_ema_weights(args.checkpoint_file)
diff --git a/D-FINE/reference/safe_training.sh b/D-FINE/reference/safe_training.sh
new file mode 100644
index 0000000000000000000000000000000000000000..d3c752a48f27511a353d65dbb9e8f97146ad4817
--- /dev/null
+++ b/D-FINE/reference/safe_training.sh
@@ -0,0 +1,97 @@
+#!/bin/bash
+
+# Function to display the menu for selecting model size
+select_model_size() {
+ echo "Select model size:"
+ select size in s m l x; do
+ case $size in
+ s|m|l|x)
+ echo "You selected model size: $size"
+ MODEL_SIZE=$size
+ break
+ ;;
+ *)
+ echo "Invalid selection. Please try again."
+ ;;
+ esac
+ done
+}
+
+# Function to display the menu for selecting task
+select_task() {
+ echo "Select task:"
+ select task in obj365 obj2coco coco; do
+ case $task in
+ obj365|obj2coco|coco)
+ echo "You selected task: $task"
+ TASK=$task
+ break
+ ;;
+ *)
+ echo "Invalid selection. Please try again."
+ ;;
+ esac
+ done
+}
+
+# Function to ask if the user wants to save logs to a txt file
+ask_save_logs() {
+ while true; do
+ read -p "Do you want to save logs to a txt file? (y/n): " yn
+ case $yn in
+ [Yy]* )
+ SAVE_LOGS=true
+ break
+ ;;
+ [Nn]* )
+ SAVE_LOGS=false
+ break
+ ;;
+ * ) echo "Please answer yes or no.";;
+ esac
+ done
+}
+
+# Call the functions to let the user select
+select_model_size
+select_task
+ask_save_logs
+
+# Set config file and output directory based on selection
+if [ "$TASK" = "coco" ]; then
+ CONFIG_FILE="configs/dfine/dfine_hgnetv2_${MODEL_SIZE}_${TASK}.yml"
+else
+ CONFIG_FILE="configs/dfine/objects365/dfine_hgnetv2_${MODEL_SIZE}_${TASK}.yml"
+fi
+
+OUTPUT_DIR="output/${MODEL_SIZE}_${TASK}"
+
+# Construct the training command
+TRAIN_CMD="CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c $CONFIG_FILE --use-amp --seed=0 --output-dir $OUTPUT_DIR"
+
+# Append log redirection if SAVE_LOGS is true
+if [ "$SAVE_LOGS" = true ]; then
+ LOG_FILE="${MODEL_SIZE}_${TASK}.txt"
+ TRAIN_CMD="$TRAIN_CMD &> \"$LOG_FILE\" 2>&1 &"
+else
+ TRAIN_CMD="$TRAIN_CMD &"
+fi
+
+# Run the training command
+eval $TRAIN_CMD
+if [ $? -ne 0 ]; then
+ echo "First training failed, restarting with resume option..."
+ while true; do
+ RESUME_CMD="CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c $CONFIG_FILE --use-amp --seed=0 --output-dir $OUTPUT_DIR -r ${OUTPUT_DIR}/last.pth"
+ if [ "$SAVE_LOGS" = true ]; then
+ LOG_FILE="${MODEL_SIZE}_${TASK}_2.txt"
+ RESUME_CMD="$RESUME_CMD &> \"$LOG_FILE\" 2>&1 &"
+ else
+ RESUME_CMD="$RESUME_CMD &"
+ fi
+ eval $RESUME_CMD
+ if [ $? -eq 0 ]; then
+ break
+ fi
+ done
+fi
diff --git a/D-FINE/requirements.txt b/D-FINE/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..aadfb81c81431f1f45303ae39b8dfe2152f8b91b
--- /dev/null
+++ b/D-FINE/requirements.txt
@@ -0,0 +1,9 @@
+torch>=2.0.1
+torchvision>=0.15.2
+faster-coco-eval>=1.6.6
+PyYAML
+tensorboard
+scipy
+calflops
+transformers
+loguru
diff --git a/D-FINE/src/__init__.py b/D-FINE/src/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..15e3d5ad68a5c62fae207a677da0684c1fe0ae57
--- /dev/null
+++ b/D-FINE/src/__init__.py
@@ -0,0 +1,6 @@
+"""
+Copyright (c) 2024 The D-FINE Authors. All Rights Reserved.
+"""
+
+# for register purpose
+from . import data, nn, optim, zoo
diff --git a/D-FINE/src/core/__init__.py b/D-FINE/src/core/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a938d563fcd095634776f6549085f8df61e4a145
--- /dev/null
+++ b/D-FINE/src/core/__init__.py
@@ -0,0 +1,9 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from ._config import BaseConfig
+from .workspace import GLOBAL_CONFIG, create, register
+from .yaml_config import YAMLConfig
+from .yaml_utils import *
diff --git a/D-FINE/src/core/_config.py b/D-FINE/src/core/_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..3bef075630a101f055619594824e3f549f2b99d2
--- /dev/null
+++ b/D-FINE/src/core/_config.py
@@ -0,0 +1,299 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from pathlib import Path
+from typing import Callable, Dict, List
+
+import torch
+import torch.nn as nn
+from torch.cuda.amp.grad_scaler import GradScaler
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import LRScheduler
+from torch.utils.data import DataLoader, Dataset
+from torch.utils.tensorboard import SummaryWriter
+
+__all__ = [
+ "BaseConfig",
+]
+
+
+class BaseConfig(object):
+ # TODO property
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ self.task: str = None
+
+ # instance / function
+ self._model: nn.Module = None
+ self._postprocessor: nn.Module = None
+ self._criterion: nn.Module = None
+ self._optimizer: Optimizer = None
+ self._lr_scheduler: LRScheduler = None
+ self._lr_warmup_scheduler: LRScheduler = None
+ self._train_dataloader: DataLoader = None
+ self._val_dataloader: DataLoader = None
+ self._ema: nn.Module = None
+ self._scaler: GradScaler = None
+ self._train_dataset: Dataset = None
+ self._val_dataset: Dataset = None
+ self._collate_fn: Callable = None
+ self._evaluator: Callable[[nn.Module, DataLoader, str],] = None
+ self._writer: SummaryWriter = None
+
+ # dataset
+ self.num_workers: int = 0
+ self.batch_size: int = None
+ self._train_batch_size: int = None
+ self._val_batch_size: int = None
+ self._train_shuffle: bool = None
+ self._val_shuffle: bool = None
+
+ # runtime
+ self.resume: str = None
+ self.tuning: str = None
+
+ self.epochs: int = None
+ self.last_epoch: int = -1
+
+ self.use_amp: bool = False
+ self.use_ema: bool = False
+ self.ema_decay: float = 0.9999
+ self.ema_warmups: int = 2000
+ self.sync_bn: bool = False
+ self.clip_max_norm: float = 0.0
+ self.find_unused_parameters: bool = None
+
+ self.seed: int = None
+ self.print_freq: int = None
+ self.checkpoint_freq: int = 1
+ self.output_dir: str = None
+ self.summary_dir: str = None
+ self.device: str = ""
+
+ @property
+ def model(self) -> nn.Module:
+ return self._model
+
+ @model.setter
+ def model(self, m):
+ assert isinstance(m, nn.Module), f"{type(m)} != nn.Module, please check your model class"
+ self._model = m
+
+ @property
+ def postprocessor(self) -> nn.Module:
+ return self._postprocessor
+
+ @postprocessor.setter
+ def postprocessor(self, m):
+ assert isinstance(m, nn.Module), f"{type(m)} != nn.Module, please check your model class"
+ self._postprocessor = m
+
+ @property
+ def criterion(self) -> nn.Module:
+ return self._criterion
+
+ @criterion.setter
+ def criterion(self, m):
+ assert isinstance(m, nn.Module), f"{type(m)} != nn.Module, please check your model class"
+ self._criterion = m
+
+ @property
+ def optimizer(self) -> Optimizer:
+ return self._optimizer
+
+ @optimizer.setter
+ def optimizer(self, m):
+ assert isinstance(
+ m, Optimizer
+ ), f"{type(m)} != optim.Optimizer, please check your model class"
+ self._optimizer = m
+
+ @property
+ def lr_scheduler(self) -> LRScheduler:
+ return self._lr_scheduler
+
+ @lr_scheduler.setter
+ def lr_scheduler(self, m):
+ assert isinstance(
+ m, LRScheduler
+ ), f"{type(m)} != LRScheduler, please check your model class"
+ self._lr_scheduler = m
+
+ @property
+ def lr_warmup_scheduler(self) -> LRScheduler:
+ return self._lr_warmup_scheduler
+
+ @lr_warmup_scheduler.setter
+ def lr_warmup_scheduler(self, m):
+ self._lr_warmup_scheduler = m
+
+ @property
+ def train_dataloader(self) -> DataLoader:
+ if self._train_dataloader is None and self.train_dataset is not None:
+ loader = DataLoader(
+ self.train_dataset,
+ batch_size=self.train_batch_size,
+ num_workers=self.num_workers,
+ collate_fn=self.collate_fn,
+ shuffle=self.train_shuffle,
+ )
+ loader.shuffle = self.train_shuffle
+ self._train_dataloader = loader
+
+ return self._train_dataloader
+
+ @train_dataloader.setter
+ def train_dataloader(self, loader):
+ self._train_dataloader = loader
+
+ @property
+ def val_dataloader(self) -> DataLoader:
+ if self._val_dataloader is None and self.val_dataset is not None:
+ loader = DataLoader(
+ self.val_dataset,
+ batch_size=self.val_batch_size,
+ num_workers=self.num_workers,
+ drop_last=False,
+ collate_fn=self.collate_fn,
+ shuffle=self.val_shuffle,
+ persistent_workers=True,
+ )
+ loader.shuffle = self.val_shuffle
+ self._val_dataloader = loader
+
+ return self._val_dataloader
+
+ @val_dataloader.setter
+ def val_dataloader(self, loader):
+ self._val_dataloader = loader
+
+ @property
+ def ema(self) -> nn.Module:
+ if self._ema is None and self.use_ema and self.model is not None:
+ from ..optim import ModelEMA
+
+ self._ema = ModelEMA(self.model, self.ema_decay, self.ema_warmups)
+ return self._ema
+
+ @ema.setter
+ def ema(self, obj):
+ self._ema = obj
+
+ @property
+ def scaler(self) -> GradScaler:
+ if self._scaler is None and self.use_amp and torch.cuda.is_available():
+ self._scaler = GradScaler()
+ return self._scaler
+
+ @scaler.setter
+ def scaler(self, obj: GradScaler):
+ self._scaler = obj
+
+ @property
+ def val_shuffle(self) -> bool:
+ if self._val_shuffle is None:
+ print("warning: set default val_shuffle=False")
+ return False
+ return self._val_shuffle
+
+ @val_shuffle.setter
+ def val_shuffle(self, shuffle):
+ assert isinstance(shuffle, bool), "shuffle must be bool"
+ self._val_shuffle = shuffle
+
+ @property
+ def train_shuffle(self) -> bool:
+ if self._train_shuffle is None:
+ print("warning: set default train_shuffle=True")
+ return True
+ return self._train_shuffle
+
+ @train_shuffle.setter
+ def train_shuffle(self, shuffle):
+ assert isinstance(shuffle, bool), "shuffle must be bool"
+ self._train_shuffle = shuffle
+
+ @property
+ def train_batch_size(self) -> int:
+ if self._train_batch_size is None and isinstance(self.batch_size, int):
+ print(f"warning: set train_batch_size=batch_size={self.batch_size}")
+ return self.batch_size
+ return self._train_batch_size
+
+ @train_batch_size.setter
+ def train_batch_size(self, batch_size):
+ assert isinstance(batch_size, int), "batch_size must be int"
+ self._train_batch_size = batch_size
+
+ @property
+ def val_batch_size(self) -> int:
+ if self._val_batch_size is None:
+ print(f"warning: set val_batch_size=batch_size={self.batch_size}")
+ return self.batch_size
+ return self._val_batch_size
+
+ @val_batch_size.setter
+ def val_batch_size(self, batch_size):
+ assert isinstance(batch_size, int), "batch_size must be int"
+ self._val_batch_size = batch_size
+
+ @property
+ def train_dataset(self) -> Dataset:
+ return self._train_dataset
+
+ @train_dataset.setter
+ def train_dataset(self, dataset):
+ assert isinstance(dataset, Dataset), f"{type(dataset)} must be Dataset"
+ self._train_dataset = dataset
+
+ @property
+ def val_dataset(self) -> Dataset:
+ return self._val_dataset
+
+ @val_dataset.setter
+ def val_dataset(self, dataset):
+ assert isinstance(dataset, Dataset), f"{type(dataset)} must be Dataset"
+ self._val_dataset = dataset
+
+ @property
+ def collate_fn(self) -> Callable:
+ return self._collate_fn
+
+ @collate_fn.setter
+ def collate_fn(self, fn):
+ assert isinstance(fn, Callable), f"{type(fn)} must be Callable"
+ self._collate_fn = fn
+
+ @property
+ def evaluator(self) -> Callable:
+ return self._evaluator
+
+ @evaluator.setter
+ def evaluator(self, fn):
+ assert isinstance(fn, Callable), f"{type(fn)} must be Callable"
+ self._evaluator = fn
+
+ @property
+ def writer(self) -> SummaryWriter:
+ if self._writer is None:
+ if self.summary_dir:
+ self._writer = SummaryWriter(self.summary_dir)
+ elif self.output_dir:
+ self._writer = SummaryWriter(Path(self.output_dir) / "summary")
+ return self._writer
+
+ @writer.setter
+ def writer(self, m):
+ assert isinstance(m, SummaryWriter), f"{type(m)} must be SummaryWriter"
+ self._writer = m
+
+ def __repr__(self):
+ s = ""
+ for k, v in self.__dict__.items():
+ if not k.startswith("_"):
+ s += f"{k}: {v}\n"
+ return s
diff --git a/D-FINE/src/core/workspace.py b/D-FINE/src/core/workspace.py
new file mode 100644
index 0000000000000000000000000000000000000000..b99e317f7699651dd3c19df70013051738bc0aa1
--- /dev/null
+++ b/D-FINE/src/core/workspace.py
@@ -0,0 +1,178 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import functools
+import importlib
+import inspect
+from collections import defaultdict
+from typing import Any, Dict, List, Optional
+
+GLOBAL_CONFIG = defaultdict(dict)
+
+
+def register(dct: Any = GLOBAL_CONFIG, name=None, force=False):
+ """
+ dct:
+ if dct is Dict, register foo into dct as key-value pair
+ if dct is Clas, register as modules attibute
+ force
+ whether force register.
+ """
+
+ def decorator(foo):
+ register_name = foo.__name__ if name is None else name
+ if not force:
+ if inspect.isclass(dct):
+ assert not hasattr(dct, foo.__name__), f"module {dct.__name__} has {foo.__name__}"
+ else:
+ assert foo.__name__ not in dct, f"{foo.__name__} has been already registered"
+
+ if inspect.isfunction(foo):
+
+ @functools.wraps(foo)
+ def wrap_func(*args, **kwargs):
+ return foo(*args, **kwargs)
+
+ if isinstance(dct, dict):
+ dct[foo.__name__] = wrap_func
+ elif inspect.isclass(dct):
+ setattr(dct, foo.__name__, wrap_func)
+ else:
+ raise AttributeError("")
+ return wrap_func
+
+ elif inspect.isclass(foo):
+ dct[register_name] = extract_schema(foo)
+
+ else:
+ raise ValueError(f"Do not support {type(foo)} register")
+
+ return foo
+
+ return decorator
+
+
+def extract_schema(module: type):
+ """
+ Args:
+ module (type),
+ Return:
+ Dict,
+ """
+ argspec = inspect.getfullargspec(module.__init__)
+ arg_names = [arg for arg in argspec.args if arg != "self"]
+ num_defualts = len(argspec.defaults) if argspec.defaults is not None else 0
+ num_requires = len(arg_names) - num_defualts
+
+ schame = dict()
+ schame["_name"] = module.__name__
+ schame["_pymodule"] = importlib.import_module(module.__module__)
+ schame["_inject"] = getattr(module, "__inject__", [])
+ schame["_share"] = getattr(module, "__share__", [])
+ schame["_kwargs"] = {}
+ for i, name in enumerate(arg_names):
+ if name in schame["_share"]:
+ assert i >= num_requires, "share config must have default value."
+ value = argspec.defaults[i - num_requires]
+
+ elif i >= num_requires:
+ value = argspec.defaults[i - num_requires]
+
+ else:
+ value = None
+
+ schame[name] = value
+ schame["_kwargs"][name] = value
+
+ return schame
+
+
+def create(type_or_name, global_cfg=GLOBAL_CONFIG, **kwargs):
+ """ """
+ assert type(type_or_name) in (type, str), "create should be modules or name."
+
+ name = type_or_name if isinstance(type_or_name, str) else type_or_name.__name__
+
+ if name in global_cfg:
+ if hasattr(global_cfg[name], "__dict__"):
+ return global_cfg[name]
+ else:
+ raise ValueError("The module {} is not registered".format(name))
+
+ cfg = global_cfg[name]
+
+ if isinstance(cfg, dict) and "type" in cfg:
+ _cfg: dict = global_cfg[cfg["type"]]
+ # clean args
+ _keys = [k for k in _cfg.keys() if not k.startswith("_")]
+ for _arg in _keys:
+ del _cfg[_arg]
+ _cfg.update(_cfg["_kwargs"]) # restore default args
+ _cfg.update(cfg) # load config args
+ _cfg.update(kwargs) # TODO recive extra kwargs
+ name = _cfg.pop("type") # pop extra key `type` (from cfg)
+
+ return create(name, global_cfg)
+
+ module = getattr(cfg["_pymodule"], name)
+ module_kwargs = {}
+ module_kwargs.update(cfg)
+
+ # shared var
+ for k in cfg["_share"]:
+ if k in global_cfg:
+ module_kwargs[k] = global_cfg[k]
+ else:
+ module_kwargs[k] = cfg[k]
+
+ # inject
+ for k in cfg["_inject"]:
+ _k = cfg[k]
+
+ if _k is None:
+ continue
+
+ if isinstance(_k, str):
+ if _k not in global_cfg:
+ raise ValueError(f"Missing inject config of {_k}.")
+
+ _cfg = global_cfg[_k]
+
+ if isinstance(_cfg, dict):
+ module_kwargs[k] = create(_cfg["_name"], global_cfg)
+ else:
+ module_kwargs[k] = _cfg
+
+ elif isinstance(_k, dict):
+ if "type" not in _k.keys():
+ raise ValueError("Missing inject for `type` style.")
+
+ _type = str(_k["type"])
+ if _type not in global_cfg:
+ raise ValueError(f"Missing {_type} in inspect stage.")
+
+ # TODO
+ _cfg: dict = global_cfg[_type]
+ # clean args
+ _keys = [k for k in _cfg.keys() if not k.startswith("_")]
+ for _arg in _keys:
+ del _cfg[_arg]
+ _cfg.update(_cfg["_kwargs"]) # restore default values
+ _cfg.update(_k) # load config args
+ name = _cfg.pop("type") # pop extra key (`type` from _k)
+ module_kwargs[k] = create(name, global_cfg)
+
+ else:
+ raise ValueError(f"Inject does not support {_k}")
+
+ # TODO hard code
+ module_kwargs = {k: v for k, v in module_kwargs.items() if not k.startswith("_")}
+
+ # TODO for **kwargs
+ # extra_args = set(module_kwargs.keys()) - set(arg_names)
+ # if len(extra_args) > 0:
+ # raise RuntimeError(f'Error: unknown args {extra_args} for {module}')
+
+ return module(**module_kwargs)
diff --git a/D-FINE/src/core/yaml_config.py b/D-FINE/src/core/yaml_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f7faf41e4f3ecc4bf6826b1923e2499c1abdc73
--- /dev/null
+++ b/D-FINE/src/core/yaml_config.py
@@ -0,0 +1,187 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import copy
+import re
+
+import torch
+import torch.nn as nn
+import torch.optim as optim
+from torch.utils.data import DataLoader
+
+from ._config import BaseConfig
+from .workspace import create
+from .yaml_utils import load_config, merge_config, merge_dict
+
+
+class YAMLConfig(BaseConfig):
+ def __init__(self, cfg_path: str, **kwargs) -> None:
+ super().__init__()
+
+ cfg = load_config(cfg_path)
+ cfg = merge_dict(cfg, kwargs)
+
+ self.yaml_cfg = copy.deepcopy(cfg)
+
+ for k in super().__dict__:
+ if not k.startswith("_") and k in cfg:
+ self.__dict__[k] = cfg[k]
+
+ @property
+ def global_cfg(self):
+ return merge_config(self.yaml_cfg, inplace=False, overwrite=False)
+
+ @property
+ def model(self) -> torch.nn.Module:
+ if self._model is None and "model" in self.yaml_cfg:
+ self._model = create(self.yaml_cfg["model"], self.global_cfg)
+ return super().model
+
+ @property
+ def postprocessor(self) -> torch.nn.Module:
+ if self._postprocessor is None and "postprocessor" in self.yaml_cfg:
+ self._postprocessor = create(self.yaml_cfg["postprocessor"], self.global_cfg)
+ return super().postprocessor
+
+ @property
+ def criterion(self) -> torch.nn.Module:
+ if self._criterion is None and "criterion" in self.yaml_cfg:
+ self._criterion = create(self.yaml_cfg["criterion"], self.global_cfg)
+ return super().criterion
+
+ @property
+ def optimizer(self) -> optim.Optimizer:
+ if self._optimizer is None and "optimizer" in self.yaml_cfg:
+ params = self.get_optim_params(self.yaml_cfg["optimizer"], self.model)
+ self._optimizer = create("optimizer", self.global_cfg, params=params)
+ return super().optimizer
+
+ @property
+ def lr_scheduler(self) -> optim.lr_scheduler.LRScheduler:
+ if self._lr_scheduler is None and "lr_scheduler" in self.yaml_cfg:
+ self._lr_scheduler = create("lr_scheduler", self.global_cfg, optimizer=self.optimizer)
+ print(f"Initial lr: {self._lr_scheduler.get_last_lr()}")
+ return super().lr_scheduler
+
+ @property
+ def lr_warmup_scheduler(self) -> optim.lr_scheduler.LRScheduler:
+ if self._lr_warmup_scheduler is None and "lr_warmup_scheduler" in self.yaml_cfg:
+ self._lr_warmup_scheduler = create(
+ "lr_warmup_scheduler", self.global_cfg, lr_scheduler=self.lr_scheduler
+ )
+ return super().lr_warmup_scheduler
+
+ @property
+ def train_dataloader(self) -> DataLoader:
+ if self._train_dataloader is None and "train_dataloader" in self.yaml_cfg:
+ self._train_dataloader = self.build_dataloader("train_dataloader")
+ return super().train_dataloader
+
+ @property
+ def val_dataloader(self) -> DataLoader:
+ if self._val_dataloader is None and "val_dataloader" in self.yaml_cfg:
+ self._val_dataloader = self.build_dataloader("val_dataloader")
+ return super().val_dataloader
+
+ @property
+ def ema(self) -> torch.nn.Module:
+ if self._ema is None and self.yaml_cfg.get("use_ema", False):
+ self._ema = create("ema", self.global_cfg, model=self.model)
+ return super().ema
+
+ @property
+ def scaler(self):
+ if self._scaler is None and self.yaml_cfg.get("use_amp", False):
+ self._scaler = create("scaler", self.global_cfg)
+ return super().scaler
+
+ @property
+ def evaluator(self):
+ if self._evaluator is None and "evaluator" in self.yaml_cfg:
+ if self.yaml_cfg["evaluator"]["type"] == "CocoEvaluator":
+ from ..data import get_coco_api_from_dataset
+
+ base_ds = get_coco_api_from_dataset(self.val_dataloader.dataset)
+ self._evaluator = create("evaluator", self.global_cfg, coco_gt=base_ds)
+ else:
+ raise NotImplementedError(f"{self.yaml_cfg['evaluator']['type']}")
+ return super().evaluator
+
+ @property
+ def use_wandb(self) -> bool:
+ return self.yaml_cfg.get("use_wandb", False)
+
+ @staticmethod
+ def get_optim_params(cfg: dict, model: nn.Module):
+ """
+ E.g.:
+ ^(?=.*a)(?=.*b).*$ means including a and b
+ ^(?=.*(?:a|b)).*$ means including a or b
+ ^(?=.*a)(?!.*b).*$ means including a, but not b
+ """
+ assert "type" in cfg, ""
+ cfg = copy.deepcopy(cfg)
+
+ if "params" not in cfg:
+ return model.parameters()
+
+ assert isinstance(cfg["params"], list), ""
+
+ param_groups = []
+ visited = []
+ for pg in cfg["params"]:
+ pattern = pg["params"]
+ params = {
+ k: v
+ for k, v in model.named_parameters()
+ if v.requires_grad and len(re.findall(pattern, k)) > 0
+ }
+ pg["params"] = params.values()
+ param_groups.append(pg)
+ visited.extend(list(params.keys()))
+ # print(params.keys())
+
+ names = [k for k, v in model.named_parameters() if v.requires_grad]
+
+ if len(visited) < len(names):
+ unseen = set(names) - set(visited)
+ params = {k: v for k, v in model.named_parameters() if v.requires_grad and k in unseen}
+ param_groups.append({"params": params.values()})
+ visited.extend(list(params.keys()))
+ # print(params.keys())
+
+ assert len(visited) == len(names), ""
+
+ return param_groups
+
+ @staticmethod
+ def get_rank_batch_size(cfg):
+ """compute batch size for per rank if total_batch_size is provided."""
+ assert ("total_batch_size" in cfg or "batch_size" in cfg) and not (
+ "total_batch_size" in cfg and "batch_size" in cfg
+ ), "`batch_size` or `total_batch_size` should be choosed one"
+
+ total_batch_size = cfg.get("total_batch_size", None)
+ if total_batch_size is None:
+ bs = cfg.get("batch_size")
+ else:
+ from ..misc import dist_utils
+
+ assert (
+ total_batch_size % dist_utils.get_world_size() == 0
+ ), "total_batch_size should be divisible by world size"
+ bs = total_batch_size // dist_utils.get_world_size()
+ return bs
+
+ def build_dataloader(self, name: str):
+ bs = self.get_rank_batch_size(self.yaml_cfg[name])
+ global_cfg = self.global_cfg
+ if "total_batch_size" in global_cfg[name]:
+ # pop unexpected key for dataloader init
+ _ = global_cfg[name].pop("total_batch_size")
+ print(f"building {name} with batch_size={bs}...")
+ loader = create(name, global_cfg, batch_size=bs)
+ loader.shuffle = self.yaml_cfg[name].get("shuffle", False)
+ return loader
diff --git a/D-FINE/src/core/yaml_utils.py b/D-FINE/src/core/yaml_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b77e0719129e2639cf96d1f5d9606879df3c046b
--- /dev/null
+++ b/D-FINE/src/core/yaml_utils.py
@@ -0,0 +1,126 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import copy
+import os
+from typing import Any, Dict, List, Optional
+
+import yaml
+
+from .workspace import GLOBAL_CONFIG
+
+__all__ = [
+ "load_config",
+ "merge_config",
+ "merge_dict",
+ "parse_cli",
+]
+
+
+INCLUDE_KEY = "__include__"
+
+
+def load_config(file_path, cfg=dict()):
+ """load config"""
+ _, ext = os.path.splitext(file_path)
+ assert ext in [".yml", ".yaml"], "only support yaml files"
+
+ with open(file_path) as f:
+ file_cfg = yaml.load(f, Loader=yaml.Loader)
+ if file_cfg is None:
+ return {}
+
+ if INCLUDE_KEY in file_cfg:
+ base_yamls = list(file_cfg[INCLUDE_KEY])
+ for base_yaml in base_yamls:
+ if base_yaml.startswith("~"):
+ base_yaml = os.path.expanduser(base_yaml)
+
+ if not base_yaml.startswith("/"):
+ base_yaml = os.path.join(os.path.dirname(file_path), base_yaml)
+
+ with open(base_yaml) as f:
+ base_cfg = load_config(base_yaml, cfg)
+ merge_dict(cfg, base_cfg)
+
+ return merge_dict(cfg, file_cfg)
+
+
+def merge_dict(dct, another_dct, inplace=True) -> Dict:
+ """merge another_dct into dct"""
+
+ def _merge(dct, another) -> Dict:
+ for k in another:
+ if k in dct and isinstance(dct[k], dict) and isinstance(another[k], dict):
+ _merge(dct[k], another[k])
+ else:
+ dct[k] = another[k]
+
+ return dct
+
+ if not inplace:
+ dct = copy.deepcopy(dct)
+
+ return _merge(dct, another_dct)
+
+
+def dictify(s: str, v: Any) -> Dict:
+ if "." not in s:
+ return {s: v}
+ key, rest = s.split(".", 1)
+ return {key: dictify(rest, v)}
+
+
+def parse_cli(nargs: List[str]) -> Dict:
+ """
+ parse command-line arguments
+ convert `a.c=3 b=10` to `{'a': {'c': 3}, 'b': 10}`
+ """
+ cfg = {}
+ if nargs is None or len(nargs) == 0:
+ return cfg
+
+ for s in nargs:
+ s = s.strip()
+ k, v = s.split("=", 1)
+ d = dictify(k, yaml.load(v, Loader=yaml.Loader))
+ cfg = merge_dict(cfg, d)
+
+ return cfg
+
+
+def merge_config(cfg, another_cfg=GLOBAL_CONFIG, inplace: bool = False, overwrite: bool = False):
+ """
+ Merge another_cfg into cfg, return the merged config
+
+ Example:
+
+ cfg1 = load_config('./dfine_r18vd_6x_coco.yml')
+ cfg1 = merge_config(cfg, inplace=True)
+
+ cfg2 = load_config('./dfine_r50vd_6x_coco.yml')
+ cfg2 = merge_config(cfg2, inplace=True)
+
+ model1 = create(cfg1['model'], cfg1)
+ model2 = create(cfg2['model'], cfg2)
+ """
+
+ def _merge(dct, another):
+ for k in another:
+ if k not in dct:
+ dct[k] = another[k]
+
+ elif isinstance(dct[k], dict) and isinstance(another[k], dict):
+ _merge(dct[k], another[k])
+
+ elif overwrite:
+ dct[k] = another[k]
+
+ return cfg
+
+ if not inplace:
+ cfg = copy.deepcopy(cfg)
+
+ return _merge(cfg, another_cfg)
diff --git a/D-FINE/src/data/__init__.py b/D-FINE/src/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb6b8d4b3548d1dc65244000b810b7f78548296c
--- /dev/null
+++ b/D-FINE/src/data/__init__.py
@@ -0,0 +1,20 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from ._misc import convert_to_tv_tensor
+from .dataloader import *
+from .dataset import *
+from .transforms import *
+
+
+# def set_epoch(self, epoch) -> None:
+# self.epoch = epoch
+# def _set_epoch_func(datasets):
+# """Add `set_epoch` for datasets
+# """
+# from ..core import register
+# for ds in datasets:
+# register(ds)(set_epoch)
+# _set_epoch_func([CIFAR10, VOCDetection, CocoDetection])
diff --git a/D-FINE/src/data/_misc.py b/D-FINE/src/data/_misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..74c1e3fb444e8096486f500efe670ab35720b13e
--- /dev/null
+++ b/D-FINE/src/data/_misc.py
@@ -0,0 +1,62 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import importlib.metadata
+
+from torch import Tensor
+
+if "0.15.2" in importlib.metadata.version("torchvision"):
+ import torchvision
+
+ torchvision.disable_beta_transforms_warning()
+
+ from torchvision.datapoints import BoundingBox as BoundingBoxes
+ from torchvision.datapoints import BoundingBoxFormat, Image, Mask, Video
+ from torchvision.transforms.v2 import SanitizeBoundingBox as SanitizeBoundingBoxes
+
+ _boxes_keys = ["format", "spatial_size"]
+
+elif "0.17" > importlib.metadata.version("torchvision") >= "0.16":
+ import torchvision
+
+ torchvision.disable_beta_transforms_warning()
+
+ from torchvision.transforms.v2 import SanitizeBoundingBoxes
+ from torchvision.tv_tensors import BoundingBoxes, BoundingBoxFormat, Image, Mask, Video
+
+ _boxes_keys = ["format", "canvas_size"]
+
+elif importlib.metadata.version("torchvision") >= "0.17":
+ import torchvision
+ from torchvision.transforms.v2 import SanitizeBoundingBoxes
+ from torchvision.tv_tensors import BoundingBoxes, BoundingBoxFormat, Image, Mask, Video
+
+ _boxes_keys = ["format", "canvas_size"]
+
+else:
+ raise RuntimeError("Please make sure torchvision version >= 0.15.2")
+
+
+def convert_to_tv_tensor(tensor: Tensor, key: str, box_format="xyxy", spatial_size=None) -> Tensor:
+ """
+ Args:
+ tensor (Tensor): input tensor
+ key (str): transform to key
+
+ Return:
+ Dict[str, TV_Tensor]
+ """
+ assert key in (
+ "boxes",
+ "masks",
+ ), "Only support 'boxes' and 'masks'"
+
+ if key == "boxes":
+ box_format = getattr(BoundingBoxFormat, box_format.upper())
+ _kwargs = dict(zip(_boxes_keys, [box_format, spatial_size]))
+ return BoundingBoxes(tensor, **_kwargs)
+
+ if key == "masks":
+ return Mask(tensor)
diff --git a/D-FINE/src/data/dataloader.py b/D-FINE/src/data/dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce2c0a161aa7dd6513c49eb5a9cf90603e7126d7
--- /dev/null
+++ b/D-FINE/src/data/dataloader.py
@@ -0,0 +1,122 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import random
+from functools import partial
+
+import torch
+import torch.nn.functional as F
+import torch.utils.data as data
+import torchvision
+import torchvision.transforms.v2 as VT
+from torch.utils.data import default_collate
+from torchvision.transforms.v2 import InterpolationMode
+from torchvision.transforms.v2 import functional as VF
+
+from ..core import register
+
+torchvision.disable_beta_transforms_warning()
+
+
+__all__ = [
+ "DataLoader",
+ "BaseCollateFunction",
+ "BatchImageCollateFunction",
+ "batch_image_collate_fn",
+]
+
+
+@register()
+class DataLoader(data.DataLoader):
+ __inject__ = ["dataset", "collate_fn"]
+
+ def __repr__(self) -> str:
+ format_string = self.__class__.__name__ + "("
+ for n in ["dataset", "batch_size", "num_workers", "drop_last", "collate_fn"]:
+ format_string += "\n"
+ format_string += " {0}: {1}".format(n, getattr(self, n))
+ format_string += "\n)"
+ return format_string
+
+ def set_epoch(self, epoch):
+ self._epoch = epoch
+ self.dataset.set_epoch(epoch)
+ self.collate_fn.set_epoch(epoch)
+
+ @property
+ def epoch(self):
+ return self._epoch if hasattr(self, "_epoch") else -1
+
+ @property
+ def shuffle(self):
+ return self._shuffle
+
+ @shuffle.setter
+ def shuffle(self, shuffle):
+ assert isinstance(shuffle, bool), "shuffle must be a boolean"
+ self._shuffle = shuffle
+
+
+@register()
+def batch_image_collate_fn(items):
+ """only batch image"""
+ return torch.cat([x[0][None] for x in items], dim=0), [x[1] for x in items]
+
+
+class BaseCollateFunction(object):
+ def set_epoch(self, epoch):
+ self._epoch = epoch
+
+ @property
+ def epoch(self):
+ return self._epoch if hasattr(self, "_epoch") else -1
+
+ def __call__(self, items):
+ raise NotImplementedError("")
+
+
+def generate_scales(base_size, base_size_repeat):
+ scale_repeat = (base_size - int(base_size * 0.75 / 32) * 32) // 32
+ scales = [int(base_size * 0.75 / 32) * 32 + i * 32 for i in range(scale_repeat)]
+ scales += [base_size] * base_size_repeat
+ scales += [int(base_size * 1.25 / 32) * 32 - i * 32 for i in range(scale_repeat)]
+ return scales
+
+
+@register()
+class BatchImageCollateFunction(BaseCollateFunction):
+ def __init__(
+ self,
+ stop_epoch=None,
+ ema_restart_decay=0.9999,
+ base_size=640,
+ base_size_repeat=None,
+ ) -> None:
+ super().__init__()
+ self.base_size = base_size
+ self.scales = (
+ generate_scales(base_size, base_size_repeat) if base_size_repeat is not None else None
+ )
+ self.stop_epoch = stop_epoch if stop_epoch is not None else 100000000
+ self.ema_restart_decay = ema_restart_decay
+ # self.interpolation = interpolation
+
+ def __call__(self, items):
+ images = torch.cat([x[0][None] for x in items], dim=0)
+ targets = [x[1] for x in items]
+
+ if self.scales is not None and self.epoch < self.stop_epoch:
+ # sz = random.choice(self.scales)
+ # sz = [sz] if isinstance(sz, int) else list(sz)
+ # VF.resize(inpt, sz, interpolation=self.interpolation)
+
+ sz = random.choice(self.scales)
+ images = F.interpolate(images, size=sz)
+ if "masks" in targets[0]:
+ for tg in targets:
+ tg["masks"] = F.interpolate(tg["masks"], size=sz, mode="nearest")
+ raise NotImplementedError("")
+
+ return images, targets
diff --git a/D-FINE/src/data/dataset/__init__.py b/D-FINE/src/data/dataset/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb758883da55c7928c60deb1b41dfb5ac1e42b7b
--- /dev/null
+++ b/D-FINE/src/data/dataset/__init__.py
@@ -0,0 +1,17 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+# from ._dataset import DetDataset
+from .cifar_dataset import CIFAR10
+from .coco_dataset import (
+ CocoDetection,
+ mscoco_category2label,
+ mscoco_category2name,
+ mscoco_label2category,
+)
+from .coco_eval import CocoEvaluator
+from .coco_utils import get_coco_api_from_dataset
+from .voc_detection import VOCDetection
+from .voc_eval import VOCEvaluator
diff --git a/D-FINE/src/data/dataset/_dataset.py b/D-FINE/src/data/dataset/_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..62b131efd186db9cafd86c736bc93a0b572a46eb
--- /dev/null
+++ b/D-FINE/src/data/dataset/_dataset.py
@@ -0,0 +1,27 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torch.utils.data as data
+
+
+class DetDataset(data.Dataset):
+ def __getitem__(self, index):
+ img, target = self.load_item(index)
+ if self.transforms is not None:
+ img, target, _ = self.transforms(img, target, self)
+ return img, target
+
+ def load_item(self, index):
+ raise NotImplementedError(
+ "Please implement this function to return item before `transforms`."
+ )
+
+ def set_epoch(self, epoch) -> None:
+ self._epoch = epoch
+
+ @property
+ def epoch(self):
+ return self._epoch if hasattr(self, "_epoch") else -1
diff --git a/D-FINE/src/data/dataset/cifar_dataset.py b/D-FINE/src/data/dataset/cifar_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e825da7d201bb5ba20f5ea0d0ad89e23a453c2f5
--- /dev/null
+++ b/D-FINE/src/data/dataset/cifar_dataset.py
@@ -0,0 +1,25 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from typing import Callable, Optional
+
+import torchvision
+
+from ...core import register
+
+
+@register()
+class CIFAR10(torchvision.datasets.CIFAR10):
+ __inject__ = ["transform", "target_transform"]
+
+ def __init__(
+ self,
+ root: str,
+ train: bool = True,
+ transform: Optional[Callable] = None,
+ target_transform: Optional[Callable] = None,
+ download: bool = False,
+ ) -> None:
+ super().__init__(root, train, transform, target_transform, download)
diff --git a/D-FINE/src/data/dataset/coco_dataset.py b/D-FINE/src/data/dataset/coco_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..22b3c3719a36ca5721761ec8d4c6cc96c9244276
--- /dev/null
+++ b/D-FINE/src/data/dataset/coco_dataset.py
@@ -0,0 +1,280 @@
+"""
+Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+Mostly copy-paste from https://github.com/pytorch/vision/blob/13b35ff/references/detection/coco_utils.py
+
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import faster_coco_eval.core.mask as coco_mask
+from faster_coco_eval.utils.pytorch import FasterCocoDetection
+import torch
+import torchvision
+import os
+from PIL import Image
+
+from ...core import register
+from .._misc import convert_to_tv_tensor
+from ._dataset import DetDataset
+
+torchvision.disable_beta_transforms_warning()
+Image.MAX_IMAGE_PIXELS = None
+
+__all__ = ["CocoDetection"]
+
+
+@register()
+class CocoDetection(FasterCocoDetection, DetDataset):
+ __inject__ = [
+ "transforms",
+ ]
+ __share__ = ["remap_mscoco_category"]
+
+ def __init__(
+ self, img_folder, ann_file, transforms, return_masks=False, remap_mscoco_category=False
+ ):
+ super(FasterCocoDetection, self).__init__(img_folder, ann_file)
+ self._transforms = transforms
+ self.prepare = ConvertCocoPolysToMask(return_masks)
+ self.img_folder = img_folder
+ self.ann_file = ann_file
+ self.return_masks = return_masks
+ self.remap_mscoco_category = remap_mscoco_category
+
+ def __getitem__(self, idx):
+ img, target = self.load_item(idx)
+ if self._transforms is not None:
+ img, target, _ = self._transforms(img, target, self)
+ return img, target
+
+ def load_item(self, idx):
+ image, target = super(FasterCocoDetection, self).__getitem__(idx)
+ image_id = self.ids[idx]
+ image_path = os.path.join(self.img_folder, self.coco.loadImgs(image_id)[0]["file_name"])
+ target = {"image_id": image_id, "image_path": image_path, "annotations": target}
+
+ if self.remap_mscoco_category:
+ image, target = self.prepare(image, target, category2label=mscoco_category2label)
+ else:
+ image, target = self.prepare(image, target)
+
+ target["idx"] = torch.tensor([idx])
+
+ if "boxes" in target:
+ target["boxes"] = convert_to_tv_tensor(
+ target["boxes"], key="boxes", spatial_size=image.size[::-1]
+ )
+
+ if "masks" in target:
+ target["masks"] = convert_to_tv_tensor(target["masks"], key="masks")
+
+ return image, target
+
+ def extra_repr(self) -> str:
+ s = f" img_folder: {self.img_folder}\n ann_file: {self.ann_file}\n"
+ s += f" return_masks: {self.return_masks}\n"
+ if hasattr(self, "_transforms") and self._transforms is not None:
+ s += f" transforms:\n {repr(self._transforms)}"
+ if hasattr(self, "_preset") and self._preset is not None:
+ s += f" preset:\n {repr(self._preset)}"
+ return s
+
+ @property
+ def categories(
+ self,
+ ):
+ return self.coco.dataset["categories"]
+
+ @property
+ def category2name(
+ self,
+ ):
+ return {cat["id"]: cat["name"] for cat in self.categories}
+
+ @property
+ def category2label(
+ self,
+ ):
+ return {cat["id"]: i for i, cat in enumerate(self.categories)}
+
+ @property
+ def label2category(
+ self,
+ ):
+ return {i: cat["id"] for i, cat in enumerate(self.categories)}
+
+
+def convert_coco_poly_to_mask(segmentations, height, width):
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = torch.as_tensor(mask, dtype=torch.uint8)
+ mask = mask.any(dim=2)
+ masks.append(mask)
+ if masks:
+ masks = torch.stack(masks, dim=0)
+ else:
+ masks = torch.zeros((0, height, width), dtype=torch.uint8)
+ return masks
+
+
+class ConvertCocoPolysToMask(object):
+ def __init__(self, return_masks=False):
+ self.return_masks = return_masks
+
+ def __call__(self, image: Image.Image, target, **kwargs):
+ w, h = image.size
+
+ image_id = target["image_id"]
+ image_id = torch.tensor([image_id])
+
+ image_path = target["image_path"]
+
+ anno = target["annotations"]
+
+ anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ boxes = [obj["bbox"] for obj in anno]
+ # guard against no boxes via resizing
+ boxes = torch.as_tensor(boxes, dtype=torch.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2].clamp_(min=0, max=w)
+ boxes[:, 1::2].clamp_(min=0, max=h)
+
+ category2label = kwargs.get("category2label", None)
+ if category2label is not None:
+ labels = [category2label[obj["category_id"]] for obj in anno]
+ else:
+ labels = [obj["category_id"] for obj in anno]
+
+ labels = torch.tensor(labels, dtype=torch.int64)
+
+ if self.return_masks:
+ segmentations = [obj["segmentation"] for obj in anno]
+ masks = convert_coco_poly_to_mask(segmentations, h, w)
+
+ keypoints = None
+ if anno and "keypoints" in anno[0]:
+ keypoints = [obj["keypoints"] for obj in anno]
+ keypoints = torch.as_tensor(keypoints, dtype=torch.float32)
+ num_keypoints = keypoints.shape[0]
+ if num_keypoints:
+ keypoints = keypoints.view(num_keypoints, -1, 3)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+ boxes = boxes[keep]
+ labels = labels[keep]
+ if self.return_masks:
+ masks = masks[keep]
+ if keypoints is not None:
+ keypoints = keypoints[keep]
+
+ target = {}
+ target["boxes"] = boxes
+ target["labels"] = labels
+ if self.return_masks:
+ target["masks"] = masks
+ target["image_id"] = image_id
+ target["image_path"] = image_path
+ if keypoints is not None:
+ target["keypoints"] = keypoints
+
+ # for conversion to coco api
+ area = torch.tensor([obj["area"] for obj in anno])
+ iscrowd = torch.tensor([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno])
+ target["area"] = area[keep]
+ target["iscrowd"] = iscrowd[keep]
+
+ target["orig_size"] = torch.as_tensor([int(w), int(h)])
+ # target["size"] = torch.as_tensor([int(w), int(h)])
+
+ return image, target
+
+
+mscoco_category2name = {
+ 1: "person",
+ 2: "bicycle",
+ 3: "car",
+ 4: "motorcycle",
+ 5: "airplane",
+ 6: "bus",
+ 7: "train",
+ 8: "truck",
+ 9: "boat",
+ 10: "traffic light",
+ 11: "fire hydrant",
+ 13: "stop sign",
+ 14: "parking meter",
+ 15: "bench",
+ 16: "bird",
+ 17: "cat",
+ 18: "dog",
+ 19: "horse",
+ 20: "sheep",
+ 21: "cow",
+ 22: "elephant",
+ 23: "bear",
+ 24: "zebra",
+ 25: "giraffe",
+ 27: "backpack",
+ 28: "umbrella",
+ 31: "handbag",
+ 32: "tie",
+ 33: "suitcase",
+ 34: "frisbee",
+ 35: "skis",
+ 36: "snowboard",
+ 37: "sports ball",
+ 38: "kite",
+ 39: "baseball bat",
+ 40: "baseball glove",
+ 41: "skateboard",
+ 42: "surfboard",
+ 43: "tennis racket",
+ 44: "bottle",
+ 46: "wine glass",
+ 47: "cup",
+ 48: "fork",
+ 49: "knife",
+ 50: "spoon",
+ 51: "bowl",
+ 52: "banana",
+ 53: "apple",
+ 54: "sandwich",
+ 55: "orange",
+ 56: "broccoli",
+ 57: "carrot",
+ 58: "hot dog",
+ 59: "pizza",
+ 60: "donut",
+ 61: "cake",
+ 62: "chair",
+ 63: "couch",
+ 64: "potted plant",
+ 65: "bed",
+ 67: "dining table",
+ 70: "toilet",
+ 72: "tv",
+ 73: "laptop",
+ 74: "mouse",
+ 75: "remote",
+ 76: "keyboard",
+ 77: "cell phone",
+ 78: "microwave",
+ 79: "oven",
+ 80: "toaster",
+ 81: "sink",
+ 82: "refrigerator",
+ 84: "book",
+ 85: "clock",
+ 86: "vase",
+ 87: "scissors",
+ 88: "teddy bear",
+ 89: "hair drier",
+ 90: "toothbrush",
+}
+
+mscoco_category2label = {k: i for i, k in enumerate(mscoco_category2name.keys())}
+mscoco_label2category = {v: k for k, v in mscoco_category2label.items()}
diff --git a/D-FINE/src/data/dataset/coco_eval.py b/D-FINE/src/data/dataset/coco_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..ac0cb631e25e46443179cd54fb7d8012b11ab458
--- /dev/null
+++ b/D-FINE/src/data/dataset/coco_eval.py
@@ -0,0 +1,22 @@
+"""
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+COCO evaluator that works in distributed mode.
+Mostly copy-paste from https://github.com/pytorch/vision/blob/edfd5a7/references/detection/coco_eval.py
+The difference is that there is less copy-pasting from pycocotools
+in the end of the file, as python3 can suppress prints with contextlib
+
+# MiXaiLL76 replacing pycocotools with faster-coco-eval for better performance and support.
+"""
+
+from faster_coco_eval.utils.pytorch import FasterCocoEvaluator
+
+from ...core import register
+
+__all__ = [
+ "CocoEvaluator",
+]
+
+
+@register()
+class CocoEvaluator(FasterCocoEvaluator):
+ pass
diff --git a/D-FINE/src/data/dataset/coco_utils.py b/D-FINE/src/data/dataset/coco_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..216816c77a61a0b971dfdd55910cc5138ef2ff29
--- /dev/null
+++ b/D-FINE/src/data/dataset/coco_utils.py
@@ -0,0 +1,191 @@
+"""
+copy and modified https://github.com/pytorch/vision/blob/main/references/detection/coco_utils.py
+
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import faster_coco_eval.core.mask as coco_mask
+import torch
+import torch.utils.data
+import torchvision
+import torchvision.transforms.functional as TVF
+from faster_coco_eval import COCO
+
+
+def convert_coco_poly_to_mask(segmentations, height, width):
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = torch.as_tensor(mask, dtype=torch.uint8)
+ mask = mask.any(dim=2)
+ masks.append(mask)
+ if masks:
+ masks = torch.stack(masks, dim=0)
+ else:
+ masks = torch.zeros((0, height, width), dtype=torch.uint8)
+ return masks
+
+
+class ConvertCocoPolysToMask:
+ def __call__(self, image, target):
+ w, h = image.size
+
+ image_id = target["image_id"]
+
+ anno = target["annotations"]
+
+ anno = [obj for obj in anno if obj["iscrowd"] == 0]
+
+ boxes = [obj["bbox"] for obj in anno]
+ # guard against no boxes via resizing
+ boxes = torch.as_tensor(boxes, dtype=torch.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2].clamp_(min=0, max=w)
+ boxes[:, 1::2].clamp_(min=0, max=h)
+
+ classes = [obj["category_id"] for obj in anno]
+ classes = torch.tensor(classes, dtype=torch.int64)
+
+ segmentations = [obj["segmentation"] for obj in anno]
+ masks = convert_coco_poly_to_mask(segmentations, h, w)
+
+ keypoints = None
+ if anno and "keypoints" in anno[0]:
+ keypoints = [obj["keypoints"] for obj in anno]
+ keypoints = torch.as_tensor(keypoints, dtype=torch.float32)
+ num_keypoints = keypoints.shape[0]
+ if num_keypoints:
+ keypoints = keypoints.view(num_keypoints, -1, 3)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+ boxes = boxes[keep]
+ classes = classes[keep]
+ masks = masks[keep]
+ if keypoints is not None:
+ keypoints = keypoints[keep]
+
+ target = {}
+ target["boxes"] = boxes
+ target["labels"] = classes
+ target["masks"] = masks
+ target["image_id"] = image_id
+ if keypoints is not None:
+ target["keypoints"] = keypoints
+
+ # for conversion to coco api
+ area = torch.tensor([obj["area"] for obj in anno])
+ iscrowd = torch.tensor([obj["iscrowd"] for obj in anno])
+ target["area"] = area
+ target["iscrowd"] = iscrowd
+
+ return image, target
+
+
+def _coco_remove_images_without_annotations(dataset, cat_list=None):
+ def _has_only_empty_bbox(anno):
+ return all(any(o <= 1 for o in obj["bbox"][2:]) for obj in anno)
+
+ def _count_visible_keypoints(anno):
+ return sum(sum(1 for v in ann["keypoints"][2::3] if v > 0) for ann in anno)
+
+ min_keypoints_per_image = 10
+
+ def _has_valid_annotation(anno):
+ # if it's empty, there is no annotation
+ if len(anno) == 0:
+ return False
+ # if all boxes have close to zero area, there is no annotation
+ if _has_only_empty_bbox(anno):
+ return False
+ # keypoints task have a slight different criteria for considering
+ # if an annotation is valid
+ if "keypoints" not in anno[0]:
+ return True
+ # for keypoint detection tasks, only consider valid images those
+ # containing at least min_keypoints_per_image
+ if _count_visible_keypoints(anno) >= min_keypoints_per_image:
+ return True
+ return False
+
+ ids = []
+ for ds_idx, img_id in enumerate(dataset.ids):
+ ann_ids = dataset.coco.getAnnIds(imgIds=img_id, iscrowd=None)
+ anno = dataset.coco.loadAnns(ann_ids)
+ if cat_list:
+ anno = [obj for obj in anno if obj["category_id"] in cat_list]
+ if _has_valid_annotation(anno):
+ ids.append(ds_idx)
+
+ dataset = torch.utils.data.Subset(dataset, ids)
+ return dataset
+
+
+def convert_to_coco_api(ds):
+ coco_ds = COCO()
+ # annotation IDs need to start at 1, not 0, see torchvision issue #1530
+ ann_id = 1
+ dataset = {"images": [], "categories": [], "annotations": []}
+ categories = set()
+ for img_idx in range(len(ds)):
+ # find better way to get target
+ # targets = ds.get_annotations(img_idx)
+ # img, targets = ds[img_idx]
+
+ img, targets = ds.load_item(img_idx)
+ width, height = img.size
+
+ image_id = targets["image_id"].item()
+ img_dict = {}
+ img_dict["id"] = image_id
+ img_dict["width"] = width
+ img_dict["height"] = height
+ dataset["images"].append(img_dict)
+ bboxes = targets["boxes"].clone()
+ bboxes[:, 2:] -= bboxes[:, :2] # xyxy -> xywh
+ bboxes = bboxes.tolist()
+ labels = targets["labels"].tolist()
+ areas = targets["area"].tolist()
+ iscrowd = targets["iscrowd"].tolist()
+ if "masks" in targets:
+ masks = targets["masks"]
+ # make masks Fortran contiguous for coco_mask
+ masks = masks.permute(0, 2, 1).contiguous().permute(0, 2, 1)
+ if "keypoints" in targets:
+ keypoints = targets["keypoints"]
+ keypoints = keypoints.reshape(keypoints.shape[0], -1).tolist()
+ num_objs = len(bboxes)
+ for i in range(num_objs):
+ ann = {}
+ ann["image_id"] = image_id
+ ann["bbox"] = bboxes[i]
+ ann["category_id"] = labels[i]
+ categories.add(labels[i])
+ ann["area"] = areas[i]
+ ann["iscrowd"] = iscrowd[i]
+ ann["id"] = ann_id
+ if "masks" in targets:
+ ann["segmentation"] = coco_mask.encode(masks[i].numpy())
+ if "keypoints" in targets:
+ ann["keypoints"] = keypoints[i]
+ ann["num_keypoints"] = sum(k != 0 for k in keypoints[i][2::3])
+ dataset["annotations"].append(ann)
+ ann_id += 1
+ dataset["categories"] = [{"id": i} for i in sorted(categories)]
+ coco_ds.dataset = dataset
+ coco_ds.createIndex()
+ return coco_ds
+
+
+def get_coco_api_from_dataset(dataset):
+ # FIXME: This is... awful?
+ for _ in range(10):
+ if isinstance(dataset, torchvision.datasets.CocoDetection):
+ break
+ if isinstance(dataset, torch.utils.data.Subset):
+ dataset = dataset.dataset
+ if isinstance(dataset, torchvision.datasets.CocoDetection):
+ return dataset.coco
+ return convert_to_coco_api(dataset)
diff --git a/D-FINE/src/data/dataset/voc_detection.py b/D-FINE/src/data/dataset/voc_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..e6735608471aaaaafdb1ea2839f28509c337f402
--- /dev/null
+++ b/D-FINE/src/data/dataset/voc_detection.py
@@ -0,0 +1,86 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import os
+from typing import Callable, Optional
+
+import torch
+import torchvision
+import torchvision.transforms.functional as TVF
+from PIL import Image
+from sympy import im
+
+try:
+ from defusedxml.ElementTree import parse as ET_parse
+except ImportError:
+ from xml.etree.ElementTree import parse as ET_parse
+
+from ...core import register
+from .._misc import convert_to_tv_tensor
+from ._dataset import DetDataset
+
+
+@register()
+class VOCDetection(torchvision.datasets.VOCDetection, DetDataset):
+ __inject__ = [
+ "transforms",
+ ]
+
+ def __init__(
+ self,
+ root: str,
+ ann_file: str = "trainval.txt",
+ label_file: str = "label_list.txt",
+ transforms: Optional[Callable] = None,
+ ):
+ with open(os.path.join(root, ann_file), "r") as f:
+ lines = [x.strip() for x in f.readlines()]
+ lines = [x.split(" ") for x in lines]
+
+ self.images = [os.path.join(root, lin[0]) for lin in lines]
+ self.targets = [os.path.join(root, lin[1]) for lin in lines]
+ assert len(self.images) == len(self.targets)
+
+ with open(os.path.join(root + label_file), "r") as f:
+ labels = f.readlines()
+ labels = [lab.strip() for lab in labels]
+
+ self.transforms = transforms
+ self.labels_map = {lab: i for i, lab in enumerate(labels)}
+
+ def __getitem__(self, index: int):
+ image, target = self.load_item(index)
+ if self.transforms is not None:
+ image, target, _ = self.transforms(image, target, self)
+ # target["orig_size"] = torch.tensor(TVF.get_image_size(image))
+ return image, target
+
+ def load_item(self, index: int):
+ image = Image.open(self.images[index]).convert("RGB")
+ target = self.parse_voc_xml(ET_parse(self.annotations[index]).getroot())
+
+ output = {}
+ output["image_id"] = torch.tensor([index])
+ for k in ["area", "boxes", "labels", "iscrowd"]:
+ output[k] = []
+
+ for blob in target["annotation"]["object"]:
+ box = [float(v) for v in blob["bndbox"].values()]
+ output["boxes"].append(box)
+ output["labels"].append(blob["name"])
+ output["area"].append((box[2] - box[0]) * (box[3] - box[1]))
+ output["iscrowd"].append(0)
+
+ w, h = image.size
+ boxes = torch.tensor(output["boxes"]) if len(output["boxes"]) > 0 else torch.zeros(0, 4)
+ output["boxes"] = convert_to_tv_tensor(
+ boxes, "boxes", box_format="xyxy", spatial_size=[h, w]
+ )
+ output["labels"] = torch.tensor([self.labels_map[lab] for lab in output["labels"]])
+ output["area"] = torch.tensor(output["area"])
+ output["iscrowd"] = torch.tensor(output["iscrowd"])
+ output["orig_size"] = torch.tensor([w, h])
+
+ return image, output
diff --git a/D-FINE/src/data/dataset/voc_eval.py b/D-FINE/src/data/dataset/voc_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..0bee50ae4e12f4f688083cd2e5620b9602b55e7e
--- /dev/null
+++ b/D-FINE/src/data/dataset/voc_eval.py
@@ -0,0 +1,12 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torchvision
+
+
+class VOCEvaluator(object):
+ def __init__(self) -> None:
+ pass
diff --git a/D-FINE/src/data/transforms/__init__.py b/D-FINE/src/data/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f555c9f55a013eb2e174cbf32035c666146dd432
--- /dev/null
+++ b/D-FINE/src/data/transforms/__init__.py
@@ -0,0 +1,21 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from ._transforms import (
+ ConvertBoxes,
+ ConvertPILImage,
+ EmptyTransform,
+ Normalize,
+ PadToSize,
+ RandomCrop,
+ RandomHorizontalFlip,
+ RandomIoUCrop,
+ RandomPhotometricDistort,
+ RandomZoomOut,
+ Resize,
+ SanitizeBoundingBoxes,
+)
+from .container import Compose
+from .mosaic import Mosaic
diff --git a/D-FINE/src/data/transforms/_transforms.py b/D-FINE/src/data/transforms/_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3fe9173beb33669af05b61d245bed58ee0b0fa2
--- /dev/null
+++ b/D-FINE/src/data/transforms/_transforms.py
@@ -0,0 +1,161 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from typing import Any, Dict, List, Optional
+
+import PIL
+import PIL.Image
+import torch
+import torch.nn as nn
+import torchvision
+import torchvision.transforms.v2 as T
+import torchvision.transforms.v2.functional as F
+
+from ...core import register
+from .._misc import (
+ BoundingBoxes,
+ Image,
+ Mask,
+ SanitizeBoundingBoxes,
+ Video,
+ _boxes_keys,
+ convert_to_tv_tensor,
+)
+
+torchvision.disable_beta_transforms_warning()
+
+
+RandomPhotometricDistort = register()(T.RandomPhotometricDistort)
+RandomZoomOut = register()(T.RandomZoomOut)
+RandomHorizontalFlip = register()(T.RandomHorizontalFlip)
+Resize = register()(T.Resize)
+# ToImageTensor = register()(T.ToImageTensor)
+# ConvertDtype = register()(T.ConvertDtype)
+# PILToTensor = register()(T.PILToTensor)
+SanitizeBoundingBoxes = register(name="SanitizeBoundingBoxes")(SanitizeBoundingBoxes)
+RandomCrop = register()(T.RandomCrop)
+Normalize = register()(T.Normalize)
+
+
+@register()
+class EmptyTransform(T.Transform):
+ def __init__(
+ self,
+ ) -> None:
+ super().__init__()
+
+ def forward(self, *inputs):
+ inputs = inputs if len(inputs) > 1 else inputs[0]
+ return inputs
+
+
+@register()
+class PadToSize(T.Pad):
+ _transformed_types = (
+ PIL.Image.Image,
+ Image,
+ Video,
+ Mask,
+ BoundingBoxes,
+ )
+
+ def _get_params(self, flat_inputs: List[Any]) -> Dict[str, Any]:
+ sp = F.get_spatial_size(flat_inputs[0])
+ h, w = self.size[1] - sp[0], self.size[0] - sp[1]
+ self.padding = [0, 0, w, h]
+ return dict(padding=self.padding)
+
+ def __init__(self, size, fill=0, padding_mode="constant") -> None:
+ if isinstance(size, int):
+ size = (size, size)
+ self.size = size
+ super().__init__(0, fill, padding_mode)
+
+ def _transform(self, inpt: Any, params: Dict[str, Any]) -> Any:
+ fill = self._fill[type(inpt)]
+ padding = params["padding"]
+ return F.pad(inpt, padding=padding, fill=fill, padding_mode=self.padding_mode) # type: ignore[arg-type]
+
+ def __call__(self, *inputs: Any) -> Any:
+ outputs = super().forward(*inputs)
+ if len(outputs) > 1 and isinstance(outputs[1], dict):
+ outputs[1]["padding"] = torch.tensor(self.padding)
+ return outputs
+
+
+@register()
+class RandomIoUCrop(T.RandomIoUCrop):
+ def __init__(
+ self,
+ min_scale: float = 0.3,
+ max_scale: float = 1,
+ min_aspect_ratio: float = 0.5,
+ max_aspect_ratio: float = 2,
+ sampler_options: Optional[List[float]] = None,
+ trials: int = 40,
+ p: float = 1.0,
+ ):
+ super().__init__(
+ min_scale, max_scale, min_aspect_ratio, max_aspect_ratio, sampler_options, trials
+ )
+ self.p = p
+
+ def __call__(self, *inputs: Any) -> Any:
+ if torch.rand(1) >= self.p:
+ return inputs if len(inputs) > 1 else inputs[0]
+
+ return super().forward(*inputs)
+
+
+@register()
+class ConvertBoxes(T.Transform):
+ _transformed_types = (BoundingBoxes,)
+
+ def __init__(self, fmt="", normalize=False) -> None:
+ super().__init__()
+ self.fmt = fmt
+ self.normalize = normalize
+
+ def transform(self, inpt: Any, params: Dict[str, Any]) -> Any:
+ return self._transform(inpt, params)
+
+ def _transform(self, inpt: Any, params: Dict[str, Any]) -> Any:
+ spatial_size = getattr(inpt, _boxes_keys[1])
+ if self.fmt:
+ in_fmt = inpt.format.value.lower()
+ inpt = torchvision.ops.box_convert(inpt, in_fmt=in_fmt, out_fmt=self.fmt.lower())
+ inpt = convert_to_tv_tensor(
+ inpt, key="boxes", box_format=self.fmt.upper(), spatial_size=spatial_size
+ )
+
+ if self.normalize:
+ inpt = inpt / torch.tensor(spatial_size[::-1]).tile(2)[None]
+
+ return inpt
+
+
+@register()
+class ConvertPILImage(T.Transform):
+ _transformed_types = (PIL.Image.Image,)
+
+ def __init__(self, dtype="float32", scale=True) -> None:
+ super().__init__()
+ self.dtype = dtype
+ self.scale = scale
+
+ def transform(self, inpt: Any, params: Dict[str, Any]) -> Any:
+ return self._transform(inpt, params)
+
+ def _transform(self, inpt: Any, params: Dict[str, Any]) -> Any:
+ inpt = F.pil_to_tensor(inpt)
+ if self.dtype == "float32":
+ inpt = inpt.float()
+
+ if self.scale:
+ inpt = inpt / 255.0
+
+ inpt = Image(inpt)
+
+ return inpt
diff --git a/D-FINE/src/data/transforms/container.py b/D-FINE/src/data/transforms/container.py
new file mode 100644
index 0000000000000000000000000000000000000000..b40a0d66f0366b9f1460c4981be91be92eb24d31
--- /dev/null
+++ b/D-FINE/src/data/transforms/container.py
@@ -0,0 +1,99 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from typing import Any, Dict, List, Optional
+
+import torch
+import torch.nn as nn
+import torchvision
+import torchvision.transforms.v2 as T
+
+from ...core import GLOBAL_CONFIG, register
+from ._transforms import EmptyTransform
+
+torchvision.disable_beta_transforms_warning()
+
+
+@register()
+class Compose(T.Compose):
+ def __init__(self, ops, policy=None) -> None:
+ transforms = []
+ if ops is not None:
+ for op in ops:
+ if isinstance(op, dict):
+ name = op.pop("type")
+ transform = getattr(
+ GLOBAL_CONFIG[name]["_pymodule"], GLOBAL_CONFIG[name]["_name"]
+ )(**op)
+ transforms.append(transform)
+ op["type"] = name
+
+ elif isinstance(op, nn.Module):
+ transforms.append(op)
+
+ else:
+ raise ValueError("")
+ else:
+ transforms = [
+ EmptyTransform(),
+ ]
+
+ super().__init__(transforms=transforms)
+
+ if policy is None:
+ policy = {"name": "default"}
+
+ self.policy = policy
+ self.global_samples = 0
+
+ def forward(self, *inputs: Any) -> Any:
+ return self.get_forward(self.policy["name"])(*inputs)
+
+ def get_forward(self, name):
+ forwards = {
+ "default": self.default_forward,
+ "stop_epoch": self.stop_epoch_forward,
+ "stop_sample": self.stop_sample_forward,
+ }
+ return forwards[name]
+
+ def default_forward(self, *inputs: Any) -> Any:
+ sample = inputs if len(inputs) > 1 else inputs[0]
+ for transform in self.transforms:
+ sample = transform(sample)
+ return sample
+
+ def stop_epoch_forward(self, *inputs: Any):
+ sample = inputs if len(inputs) > 1 else inputs[0]
+ dataset = sample[-1]
+ cur_epoch = dataset.epoch
+ policy_ops = self.policy["ops"]
+ policy_epoch = self.policy["epoch"]
+
+ for transform in self.transforms:
+ if type(transform).__name__ in policy_ops and cur_epoch >= policy_epoch:
+ pass
+ else:
+ sample = transform(sample)
+
+ return sample
+
+ def stop_sample_forward(self, *inputs: Any):
+ sample = inputs if len(inputs) > 1 else inputs[0]
+ dataset = sample[-1]
+
+ cur_epoch = dataset.epoch
+ policy_ops = self.policy["ops"]
+ policy_sample = self.policy["sample"]
+
+ for transform in self.transforms:
+ if type(transform).__name__ in policy_ops and self.global_samples >= policy_sample:
+ pass
+ else:
+ sample = transform(sample)
+
+ self.global_samples += 1
+
+ return sample
diff --git a/D-FINE/src/data/transforms/functional.py b/D-FINE/src/data/transforms/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..10ef8b582740e7efb73fd7472948770d8c5169a6
--- /dev/null
+++ b/D-FINE/src/data/transforms/functional.py
@@ -0,0 +1,172 @@
+from typing import List, Optional
+
+import torch
+
+# needed due to empty tensor bug in pytorch and torchvision 0.5
+import torchvision
+import torchvision.transforms.functional as F
+from packaging import version
+from torch import Tensor
+
+if version.parse(torchvision.__version__) < version.parse("0.7"):
+ from torchvision.ops import _new_empty_tensor
+ from torchvision.ops.misc import _output_size
+
+
+def interpolate(input, size=None, scale_factor=None, mode="nearest", align_corners=None):
+ # type: (Tensor, Optional[List[int]], Optional[float], str, Optional[bool]) -> Tensor
+ """
+ Equivalent to nn.functional.interpolate, but with support for empty batch sizes.
+ This will eventually be supported natively by PyTorch, and this
+ class can go away.
+ """
+ if version.parse(torchvision.__version__) < version.parse("0.7"):
+ if input.numel() > 0:
+ return torch.nn.functional.interpolate(input, size, scale_factor, mode, align_corners)
+
+ output_shape = _output_size(2, input, size, scale_factor)
+ output_shape = list(input.shape[:-2]) + list(output_shape)
+ return _new_empty_tensor(input, output_shape)
+ else:
+ return torchvision.ops.misc.interpolate(input, size, scale_factor, mode, align_corners)
+
+
+def crop(image, target, region):
+ cropped_image = F.crop(image, *region)
+
+ target = target.copy()
+ i, j, h, w = region
+
+ # should we do something wrt the original size?
+ target["size"] = torch.tensor([h, w])
+
+ fields = ["labels", "area", "iscrowd"]
+
+ if "boxes" in target:
+ boxes = target["boxes"]
+ max_size = torch.as_tensor([w, h], dtype=torch.float32)
+ cropped_boxes = boxes - torch.as_tensor([j, i, j, i])
+ cropped_boxes = torch.min(cropped_boxes.reshape(-1, 2, 2), max_size)
+ cropped_boxes = cropped_boxes.clamp(min=0)
+ area = (cropped_boxes[:, 1, :] - cropped_boxes[:, 0, :]).prod(dim=1)
+ target["boxes"] = cropped_boxes.reshape(-1, 4)
+ target["area"] = area
+ fields.append("boxes")
+
+ if "masks" in target:
+ # FIXME should we update the area here if there are no boxes?
+ target["masks"] = target["masks"][:, i : i + h, j : j + w]
+ fields.append("masks")
+
+ # remove elements for which the boxes or masks that have zero area
+ if "boxes" in target or "masks" in target:
+ # favor boxes selection when defining which elements to keep
+ # this is compatible with previous implementation
+ if "boxes" in target:
+ cropped_boxes = target["boxes"].reshape(-1, 2, 2)
+ keep = torch.all(cropped_boxes[:, 1, :] > cropped_boxes[:, 0, :], dim=1)
+ else:
+ keep = target["masks"].flatten(1).any(1)
+
+ for field in fields:
+ target[field] = target[field][keep]
+
+ return cropped_image, target
+
+
+def hflip(image, target):
+ flipped_image = F.hflip(image)
+
+ w, h = image.size
+
+ target = target.copy()
+ if "boxes" in target:
+ boxes = target["boxes"]
+ boxes = boxes[:, [2, 1, 0, 3]] * torch.as_tensor([-1, 1, -1, 1]) + torch.as_tensor(
+ [w, 0, w, 0]
+ )
+ target["boxes"] = boxes
+
+ if "masks" in target:
+ target["masks"] = target["masks"].flip(-1)
+
+ return flipped_image, target
+
+
+def resize(image, target, size, max_size=None):
+ # size can be min_size (scalar) or (w, h) tuple
+
+ def get_size_with_aspect_ratio(image_size, size, max_size=None):
+ w, h = image_size
+ if max_size is not None:
+ min_original_size = float(min((w, h)))
+ max_original_size = float(max((w, h)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (w <= h and w == size) or (h <= w and h == size):
+ return (h, w)
+
+ if w < h:
+ ow = size
+ oh = int(size * h / w)
+ else:
+ oh = size
+ ow = int(size * w / h)
+
+ # r = min(size / min(h, w), max_size / max(h, w))
+ # ow = int(w * r)
+ # oh = int(h * r)
+
+ return (oh, ow)
+
+ def get_size(image_size, size, max_size=None):
+ if isinstance(size, (list, tuple)):
+ return size[::-1]
+ else:
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+ size = get_size(image.size, size, max_size)
+ rescaled_image = F.resize(image, size)
+
+ if target is None:
+ return rescaled_image, None
+
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
+ ratio_width, ratio_height = ratios
+
+ target = target.copy()
+ if "boxes" in target:
+ boxes = target["boxes"]
+ scaled_boxes = boxes * torch.as_tensor(
+ [ratio_width, ratio_height, ratio_width, ratio_height]
+ )
+ target["boxes"] = scaled_boxes
+
+ if "area" in target:
+ area = target["area"]
+ scaled_area = area * (ratio_width * ratio_height)
+ target["area"] = scaled_area
+
+ h, w = size
+ target["size"] = torch.tensor([h, w])
+
+ if "masks" in target:
+ target["masks"] = (
+ interpolate(target["masks"][:, None].float(), size, mode="nearest")[:, 0] > 0.5
+ )
+
+ return rescaled_image, target
+
+
+def pad(image, target, padding):
+ # assumes that we only pad on the bottom right corners
+ padded_image = F.pad(image, (0, 0, padding[0], padding[1]))
+ if target is None:
+ return padded_image, None
+ target = target.copy()
+ # should we do something wrt the original size?
+ target["size"] = torch.tensor(padded_image.size[::-1])
+ if "masks" in target:
+ target["masks"] = torch.nn.functional.pad(target["masks"], (0, padding[0], 0, padding[1]))
+ return padded_image, target
diff --git a/D-FINE/src/data/transforms/mosaic.py b/D-FINE/src/data/transforms/mosaic.py
new file mode 100644
index 0000000000000000000000000000000000000000..413900c552c11dd0e55584a71ebbc60758309965
--- /dev/null
+++ b/D-FINE/src/data/transforms/mosaic.py
@@ -0,0 +1,83 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import random
+
+import torch
+import torchvision
+import torchvision.transforms.v2 as T
+import torchvision.transforms.v2.functional as F
+from PIL import Image
+
+from ...core import register
+from .._misc import convert_to_tv_tensor
+
+torchvision.disable_beta_transforms_warning()
+
+
+@register()
+class Mosaic(T.Transform):
+ def __init__(
+ self,
+ size,
+ max_size=None,
+ ) -> None:
+ super().__init__()
+ self.resize = T.Resize(size=size, max_size=max_size)
+ self.crop = T.RandomCrop(size=max_size if max_size else size)
+
+ # TODO add arg `output_size` for affine`
+ # self.random_perspective = T.RandomPerspective(distortion_scale=0.5, p=1., )
+ self.random_affine = T.RandomAffine(
+ degrees=0, translate=(0.1, 0.1), scale=(0.5, 1.5), fill=114
+ )
+
+ def forward(self, *inputs):
+ inputs = inputs if len(inputs) > 1 else inputs[0]
+ image, target, dataset = inputs
+
+ images = []
+ targets = []
+ indices = random.choices(range(len(dataset)), k=3)
+ for i in indices:
+ image, target = dataset.load_item(i)
+ image, target = self.resize(image, target)
+ images.append(image)
+ targets.append(target)
+
+ h, w = F.get_spatial_size(images[0])
+ offset = [[0, 0], [w, 0], [0, h], [w, h]]
+ image = Image.new(mode=images[0].mode, size=(w * 2, h * 2), color=0)
+ for i, im in enumerate(images):
+ image.paste(im, offset[i])
+
+ offset = torch.tensor([[0, 0], [w, 0], [0, h], [w, h]]).repeat(1, 2)
+ target = {}
+ for k in targets[0]:
+ if k == "boxes":
+ v = [t[k] + offset[i] for i, t in enumerate(targets)]
+ else:
+ v = [t[k] for t in targets]
+
+ if isinstance(v[0], torch.Tensor):
+ v = torch.cat(v, dim=0)
+
+ target[k] = v
+
+ if "boxes" in target:
+ # target['boxes'] = target['boxes'].clamp(0, 640 * 2 - 1)
+ w, h = image.size
+ target["boxes"] = convert_to_tv_tensor(
+ target["boxes"], "boxes", box_format="xyxy", spatial_size=[h, w]
+ )
+
+ if "masks" in target:
+ target["masks"] = convert_to_tv_tensor(target["masks"], "masks")
+
+ image, target = self.random_affine(image, target)
+ # image, target = self.resize(image, target)
+ image, target = self.crop(image, target)
+
+ return image, target, dataset
diff --git a/D-FINE/src/data/transforms/presets.py b/D-FINE/src/data/transforms/presets.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f6d59c9bb90fde8cfd7c1f3e5f8178f496dfeba
--- /dev/null
+++ b/D-FINE/src/data/transforms/presets.py
@@ -0,0 +1,4 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
diff --git a/D-FINE/src/misc/__init__.py b/D-FINE/src/misc/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d1f95510d61aab6ac9816b112209fdd91c71bd8
--- /dev/null
+++ b/D-FINE/src/misc/__init__.py
@@ -0,0 +1,9 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from .dist_utils import setup_print, setup_seed
+from .logger import *
+from .profiler_utils import stats
+from .visualizer import *
diff --git a/D-FINE/src/misc/box_ops.py b/D-FINE/src/misc/box_ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..64dff0dc5fbab28871edf00fe942b2323ebcfd2f
--- /dev/null
+++ b/D-FINE/src/misc/box_ops.py
@@ -0,0 +1,106 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from typing import List, Tuple
+
+import torch
+import torchvision
+from torch import Tensor
+
+
+def generalized_box_iou(boxes1: Tensor, boxes2: Tensor) -> Tensor:
+ assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
+ assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
+ return torchvision.ops.generalized_box_iou(boxes1, boxes2)
+
+
+# elementwise
+def elementwise_box_iou(boxes1: Tensor, boxes2: Tensor) -> Tensor:
+ """
+ Args:
+ boxes1, [N, 4]
+ boxes2, [N, 4]
+ Returns:
+ iou, [N, ]
+ union, [N, ]
+ """
+ area1 = torchvision.ops.box_area(boxes1) # [N, ]
+ area2 = torchvision.ops.box_area(boxes2) # [N, ]
+ lt = torch.max(boxes1[:, :2], boxes2[:, :2]) # [N, 2]
+ rb = torch.min(boxes1[:, 2:], boxes2[:, 2:]) # [N, 2]
+ wh = (rb - lt).clamp(min=0) # [N, 2]
+ inter = wh[:, 0] * wh[:, 1] # [N, ]
+ union = area1 + area2 - inter
+ iou = inter / union
+ return iou, union
+
+
+def elementwise_generalized_box_iou(boxes1: Tensor, boxes2: Tensor) -> Tensor:
+ """
+ Args:
+ boxes1, [N, 4] with [x1, y1, x2, y2]
+ boxes2, [N, 4] with [x1, y1, x2, y2]
+ Returns:
+ giou, [N, ]
+ """
+ assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
+ assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
+ iou, union = elementwise_box_iou(boxes1, boxes2)
+ lt = torch.min(boxes1[:, :2], boxes2[:, :2]) # [N, 2]
+ rb = torch.max(boxes1[:, 2:], boxes2[:, 2:]) # [N, 2]
+ wh = (rb - lt).clamp(min=0) # [N, 2]
+ area = wh[:, 0] * wh[:, 1]
+ return iou - (area - union) / area
+
+
+def check_point_inside_box(points: Tensor, boxes: Tensor, eps=1e-9) -> Tensor:
+ """
+ Args:
+ points, [K, 2], (x, y)
+ boxes, [N, 4], (x1, y1, y2, y2)
+ Returns:
+ Tensor (bool), [K, N]
+ """
+ x, y = [p.unsqueeze(-1) for p in points.unbind(-1)]
+ x1, y1, x2, y2 = [x.unsqueeze(0) for x in boxes.unbind(-1)]
+
+ l = x - x1
+ t = y - y1
+ r = x2 - x
+ b = y2 - y
+
+ ltrb = torch.stack([l, t, r, b], dim=-1)
+ mask = ltrb.min(dim=-1).values > eps
+
+ return mask
+
+
+def point_box_distance(points: Tensor, boxes: Tensor) -> Tensor:
+ """
+ Args:
+ boxes, [N, 4], (x1, y1, x2, y2)
+ points, [N, 2], (x, y)
+ Returns:
+ Tensor (N, 4), (l, t, r, b)
+ """
+ x1y1, x2y2 = torch.split(boxes, 2, dim=-1)
+ lt = points - x1y1
+ rb = x2y2 - points
+ return torch.concat([lt, rb], dim=-1)
+
+
+def point_distance_box(points: Tensor, distances: Tensor) -> Tensor:
+ """
+ Args:
+ points (Tensor), [N, 2], (x, y)
+ distances (Tensor), [N, 4], (l, t, r, b)
+ Returns:
+ boxes (Tensor), (N, 4), (x1, y1, x2, y2)
+ """
+ lt, rb = torch.split(distances, 2, dim=-1)
+ x1y1 = -lt + points
+ x2y2 = rb + points
+ boxes = torch.concat([x1y1, x2y2], dim=-1)
+ return boxes
diff --git a/D-FINE/src/misc/dist_utils.py b/D-FINE/src/misc/dist_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..959ded69fe7fbeff386d0a601197fc518dc83194
--- /dev/null
+++ b/D-FINE/src/misc/dist_utils.py
@@ -0,0 +1,281 @@
+"""
+reference
+- https://github.com/pytorch/vision/blob/main/references/detection/utils.py
+- https://github.com/facebookresearch/detr/blob/master/util/misc.py#L406
+
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import atexit
+import os
+import random
+import time
+
+import numpy as np
+import torch
+import torch.backends.cudnn
+import torch.distributed
+import torch.nn as nn
+from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+from torch.nn.parallel import DataParallel as DP
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.utils.data import DistributedSampler
+
+# from torch.utils.data.dataloader import DataLoader
+from ..data import DataLoader
+
+
+def setup_distributed(
+ print_rank: int = 0,
+ print_method: str = "builtin",
+ seed: int = None,
+):
+ """
+ env setup
+ args:
+ print_rank,
+ print_method, (builtin, rich)
+ seed,
+ """
+ try:
+ # https://pytorch.org/docs/stable/elastic/run.html
+ RANK = int(os.getenv("RANK", -1))
+ LOCAL_RANK = int(os.getenv("LOCAL_RANK", -1))
+ WORLD_SIZE = int(os.getenv("WORLD_SIZE", 1))
+
+ # torch.distributed.init_process_group(backend=backend, init_method='env://')
+ torch.distributed.init_process_group(init_method="env://")
+ torch.distributed.barrier()
+
+ rank = torch.distributed.get_rank()
+ torch.cuda.set_device(rank)
+ torch.cuda.empty_cache()
+ enabled_dist = True
+ if get_rank() == print_rank:
+ print("Initialized distributed mode...")
+
+ except Exception:
+ enabled_dist = False
+ print("Not init distributed mode.")
+
+ setup_print(get_rank() == print_rank, method=print_method)
+ if seed is not None:
+ setup_seed(seed)
+
+ return enabled_dist
+
+
+def setup_print(is_main, method="builtin"):
+ """This function disables printing when not in master process"""
+ import builtins as __builtin__
+
+ if method == "builtin":
+ builtin_print = __builtin__.print
+
+ elif method == "rich":
+ import rich
+
+ builtin_print = rich.print
+
+ else:
+ raise AttributeError("")
+
+ def print(*args, **kwargs):
+ force = kwargs.pop("force", False)
+ if is_main or force:
+ builtin_print(*args, **kwargs)
+
+ __builtin__.print = print
+
+
+def is_dist_available_and_initialized():
+ if not torch.distributed.is_available():
+ return False
+ if not torch.distributed.is_initialized():
+ return False
+ return True
+
+
+@atexit.register
+def cleanup():
+ """cleanup distributed environment"""
+ if is_dist_available_and_initialized():
+ torch.distributed.barrier()
+ torch.distributed.destroy_process_group()
+
+
+def get_rank():
+ if not is_dist_available_and_initialized():
+ return 0
+ return torch.distributed.get_rank()
+
+
+def get_world_size():
+ if not is_dist_available_and_initialized():
+ return 1
+ return torch.distributed.get_world_size()
+
+
+def is_main_process():
+ return get_rank() == 0
+
+
+def save_on_master(*args, **kwargs):
+ if is_main_process():
+ torch.save(*args, **kwargs)
+
+
+def warp_model(
+ model: torch.nn.Module,
+ sync_bn: bool = False,
+ dist_mode: str = "ddp",
+ find_unused_parameters: bool = False,
+ compile: bool = False,
+ compile_mode: str = "reduce-overhead",
+ **kwargs,
+):
+ if is_dist_available_and_initialized():
+ rank = get_rank()
+ model = nn.SyncBatchNorm.convert_sync_batchnorm(model) if sync_bn else model
+ if dist_mode == "dp":
+ model = DP(model, device_ids=[rank], output_device=rank)
+ elif dist_mode == "ddp":
+ model = DDP(
+ model,
+ device_ids=[rank],
+ output_device=rank,
+ find_unused_parameters=find_unused_parameters,
+ )
+ else:
+ raise AttributeError("")
+
+ if compile:
+ model = torch.compile(model, mode=compile_mode)
+
+ return model
+
+
+def de_model(model):
+ return de_parallel(de_complie(model))
+
+
+def warp_loader(loader, shuffle=False):
+ if is_dist_available_and_initialized():
+ sampler = DistributedSampler(loader.dataset, shuffle=shuffle)
+ loader = DataLoader(
+ loader.dataset,
+ loader.batch_size,
+ sampler=sampler,
+ drop_last=loader.drop_last,
+ collate_fn=loader.collate_fn,
+ pin_memory=loader.pin_memory,
+ num_workers=loader.num_workers,
+ )
+ return loader
+
+
+def is_parallel(model) -> bool:
+ # Returns True if model is of type DP or DDP
+ return type(model) in (
+ torch.nn.parallel.DataParallel,
+ torch.nn.parallel.DistributedDataParallel,
+ )
+
+
+def de_parallel(model) -> nn.Module:
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def reduce_dict(data, avg=True):
+ """
+ Args
+ data dict: input, {k: v, ...}
+ avg bool: true
+ """
+ world_size = get_world_size()
+ if world_size < 2:
+ return data
+
+ with torch.no_grad():
+ keys, values = [], []
+ for k in sorted(data.keys()):
+ keys.append(k)
+ values.append(data[k])
+
+ values = torch.stack(values, dim=0)
+ torch.distributed.all_reduce(values)
+
+ if avg is True:
+ values /= world_size
+
+ return {k: v for k, v in zip(keys, values)}
+
+
+def all_gather(data):
+ """
+ Run all_gather on arbitrary picklable data (not necessarily tensors)
+ Args:
+ data: any picklable object
+ Returns:
+ list[data]: list of data gathered from each rank
+ """
+ world_size = get_world_size()
+ if world_size == 1:
+ return [data]
+ data_list = [None] * world_size
+ torch.distributed.all_gather_object(data_list, data)
+ return data_list
+
+
+def sync_time():
+ """sync_time"""
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+
+ return time.time()
+
+
+def setup_seed(seed: int, deterministic=False):
+ """setup_seed for reproducibility
+ torch.manual_seed(3407) is all you need. https://arxiv.org/abs/2109.08203
+ """
+ seed = seed + get_rank()
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(seed)
+
+ # memory will be large when setting deterministic to True
+ if torch.backends.cudnn.is_available() and deterministic:
+ torch.backends.cudnn.deterministic = True
+
+
+# for torch.compile
+def check_compile():
+ import warnings
+
+ import torch
+
+ gpu_ok = False
+ if torch.cuda.is_available():
+ device_cap = torch.cuda.get_device_capability()
+ if device_cap in ((7, 0), (8, 0), (9, 0)):
+ gpu_ok = True
+ if not gpu_ok:
+ warnings.warn(
+ "GPU is not NVIDIA V100, A100, or H100. Speedup numbers may be lower " "than expected."
+ )
+ return gpu_ok
+
+
+def is_compile(model):
+ import torch._dynamo
+
+ return type(model) in (torch._dynamo.OptimizedModule,)
+
+
+def de_complie(model):
+ return model._orig_mod if is_compile(model) else model
diff --git a/D-FINE/src/misc/lazy_loader.py b/D-FINE/src/misc/lazy_loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..208fb1230eb8a9a8d3051489d5c694b16020f169
--- /dev/null
+++ b/D-FINE/src/misc/lazy_loader.py
@@ -0,0 +1,70 @@
+"""
+https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/util/lazy_loader.py
+"""
+
+import importlib
+import types
+
+
+class LazyLoader(types.ModuleType):
+ """Lazily import a module, mainly to avoid pulling in large dependencies.
+
+ `paddle`, and `ffmpeg` are examples of modules that are large and not always
+ needed, and this allows them to only be loaded when they are used.
+ """
+
+ # The lint error here is incorrect.
+ def __init__(self, local_name, parent_module_globals, name, warning=None):
+ self._local_name = local_name
+ self._parent_module_globals = parent_module_globals
+ self._warning = warning
+
+ # These members allows doctest correctly process this module member without
+ # triggering self._load(). self._load() mutates parant_module_globals and
+ # triggers a dict mutated during iteration error from doctest.py.
+ # - for from_module()
+ self.__module__ = name.rsplit(".", 1)[0]
+ # - for is_routine()
+ self.__wrapped__ = None
+
+ super(LazyLoader, self).__init__(name)
+
+ def _load(self):
+ """Load the module and insert it into the parent's globals."""
+ # Import the target module and insert it into the parent's namespace
+ module = importlib.import_module(self.__name__)
+ self._parent_module_globals[self._local_name] = module
+
+ # Emit a warning if one was specified
+ if self._warning:
+ # logging.warning(self._warning)
+ # Make sure to only warn once.
+ self._warning = None
+
+ # Update this object's dict so that if someone keeps a reference to the
+ # LazyLoader, lookups are efficient (__getattr__ is only called on lookups
+ # that fail).
+ self.__dict__.update(module.__dict__)
+
+ return module
+
+ def __getattr__(self, item):
+ module = self._load()
+ return getattr(module, item)
+
+ def __repr__(self):
+ # Carefully to not trigger _load, since repr may be called in very
+ # sensitive places.
+ return f""
+
+ def __dir__(self):
+ module = self._load()
+ return dir(module)
+
+
+# import paddle.nn as nn
+# nn = LazyLoader("nn", globals(), "paddle.nn")
+
+# class M(nn.Layer):
+# def __init__(self) -> None:
+# super().__init__()
diff --git a/D-FINE/src/misc/logger.py b/D-FINE/src/misc/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c1ca1897e02114b3d6d3c55ffc88a72e8fdc593
--- /dev/null
+++ b/D-FINE/src/misc/logger.py
@@ -0,0 +1,255 @@
+"""
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+https://github.com/facebookresearch/detr/blob/main/util/misc.py
+Mostly copy-paste from torchvision references.
+"""
+
+import datetime
+import pickle
+import time
+from collections import defaultdict, deque
+from typing import Dict
+
+import torch
+import torch.distributed as tdist
+
+from .dist_utils import get_world_size, is_dist_available_and_initialized
+
+
+class SmoothedValue(object):
+ """Track a series of values and provide access to smoothed values over a
+ window or the global series average.
+ """
+
+ def __init__(self, window_size=20, fmt=None):
+ if fmt is None:
+ fmt = "{median:.4f} ({global_avg:.4f})"
+ self.deque = deque(maxlen=window_size)
+ self.total = 0.0
+ self.count = 0
+ self.fmt = fmt
+
+ def update(self, value, n=1):
+ self.deque.append(value)
+ self.count += n
+ self.total += value * n
+
+ def synchronize_between_processes(self):
+ """
+ Warning: does not synchronize the deque!
+ """
+ if not is_dist_available_and_initialized():
+ return
+ t = torch.tensor([self.count, self.total], dtype=torch.float64, device="cuda")
+ tdist.barrier()
+ tdist.all_reduce(t)
+ t = t.tolist()
+ self.count = int(t[0])
+ self.total = t[1]
+
+ @property
+ def median(self):
+ d = torch.tensor(list(self.deque))
+ return d.median().item()
+
+ @property
+ def avg(self):
+ d = torch.tensor(list(self.deque), dtype=torch.float32)
+ return d.mean().item()
+
+ @property
+ def global_avg(self):
+ return self.total / self.count
+
+ @property
+ def max(self):
+ return max(self.deque)
+
+ @property
+ def value(self):
+ return self.deque[-1]
+
+ def __str__(self):
+ return self.fmt.format(
+ median=self.median,
+ avg=self.avg,
+ global_avg=self.global_avg,
+ max=self.max,
+ value=self.value,
+ )
+
+
+def all_gather(data):
+ """
+ Run all_gather on arbitrary picklable data (not necessarily tensors)
+ Args:
+ data: any picklable object
+ Returns:
+ list[data]: list of data gathered from each rank
+ """
+ world_size = get_world_size()
+ if world_size == 1:
+ return [data]
+
+ # serialized to a Tensor
+ buffer = pickle.dumps(data)
+ storage = torch.ByteStorage.from_buffer(buffer)
+ tensor = torch.ByteTensor(storage).to("cuda")
+
+ # obtain Tensor size of each rank
+ local_size = torch.tensor([tensor.numel()], device="cuda")
+ size_list = [torch.tensor([0], device="cuda") for _ in range(world_size)]
+ tdist.all_gather(size_list, local_size)
+ size_list = [int(size.item()) for size in size_list]
+ max_size = max(size_list)
+
+ # receiving Tensor from all ranks
+ # we pad the tensor because torch all_gather does not support
+ # gathering tensors of different shapes
+ tensor_list = []
+ for _ in size_list:
+ tensor_list.append(torch.empty((max_size,), dtype=torch.uint8, device="cuda"))
+ if local_size != max_size:
+ padding = torch.empty(size=(max_size - local_size,), dtype=torch.uint8, device="cuda")
+ tensor = torch.cat((tensor, padding), dim=0)
+ tdist.all_gather(tensor_list, tensor)
+
+ data_list = []
+ for size, tensor in zip(size_list, tensor_list):
+ buffer = tensor.cpu().numpy().tobytes()[:size]
+ data_list.append(pickle.loads(buffer))
+
+ return data_list
+
+
+def reduce_dict(input_dict, average=True) -> Dict[str, torch.Tensor]:
+ """
+ Args:
+ input_dict (dict): all the values will be reduced
+ average (bool): whether to do average or sum
+ Reduce the values in the dictionary from all processes so that all processes
+ have the averaged results. Returns a dict with the same fields as
+ input_dict, after reduction.
+ """
+ world_size = get_world_size()
+ if world_size < 2:
+ return input_dict
+ with torch.no_grad():
+ names = []
+ values = []
+ # sort the keys so that they are consistent across processes
+ for k in sorted(input_dict.keys()):
+ names.append(k)
+ values.append(input_dict[k])
+ values = torch.stack(values, dim=0)
+ tdist.all_reduce(values)
+ if average:
+ values /= world_size
+ reduced_dict = {k: v for k, v in zip(names, values)}
+ return reduced_dict
+
+
+class MetricLogger(object):
+ def __init__(self, delimiter="\t"):
+ self.meters = defaultdict(SmoothedValue)
+ self.delimiter = delimiter
+
+ def update(self, **kwargs):
+ for k, v in kwargs.items():
+ if isinstance(v, torch.Tensor):
+ v = v.item()
+ assert isinstance(v, (float, int))
+ self.meters[k].update(v)
+
+ def __getattr__(self, attr):
+ if attr in self.meters:
+ return self.meters[attr]
+ if attr in self.__dict__:
+ return self.__dict__[attr]
+ raise AttributeError("'{}' object has no attribute '{}'".format(type(self).__name__, attr))
+
+ def __str__(self):
+ loss_str = []
+ for name, meter in self.meters.items():
+ loss_str.append("{}: {}".format(name, str(meter)))
+ return self.delimiter.join(loss_str)
+
+ def synchronize_between_processes(self):
+ for meter in self.meters.values():
+ meter.synchronize_between_processes()
+
+ def add_meter(self, name, meter):
+ self.meters[name] = meter
+
+ def log_every(self, iterable, print_freq, header=None):
+ i = 0
+ if not header:
+ header = ""
+ start_time = time.time()
+ end = time.time()
+ iter_time = SmoothedValue(fmt="{avg:.4f}")
+ data_time = SmoothedValue(fmt="{avg:.4f}")
+ space_fmt = ":" + str(len(str(len(iterable)))) + "d"
+ if torch.cuda.is_available():
+ log_msg = self.delimiter.join(
+ [
+ header,
+ "[{0" + space_fmt + "}/{1}]",
+ "eta: {eta}",
+ "{meters}",
+ "time: {time}",
+ "data: {data}",
+ "max mem: {memory:.0f}",
+ ]
+ )
+ else:
+ log_msg = self.delimiter.join(
+ [
+ header,
+ "[{0" + space_fmt + "}/{1}]",
+ "eta: {eta}",
+ "{meters}",
+ "time: {time}",
+ "data: {data}",
+ ]
+ )
+ MB = 1024.0 * 1024.0
+ for obj in iterable:
+ data_time.update(time.time() - end)
+ yield obj
+ iter_time.update(time.time() - end)
+ if i % print_freq == 0 or i == len(iterable) - 1:
+ eta_seconds = iter_time.global_avg * (len(iterable) - i)
+ eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
+ if torch.cuda.is_available():
+ print(
+ log_msg.format(
+ i,
+ len(iterable),
+ eta=eta_string,
+ meters=str(self),
+ time=str(iter_time),
+ data=str(data_time),
+ memory=torch.cuda.max_memory_allocated() / MB,
+ )
+ )
+ else:
+ print(
+ log_msg.format(
+ i,
+ len(iterable),
+ eta=eta_string,
+ meters=str(self),
+ time=str(iter_time),
+ data=str(data_time),
+ )
+ )
+ i += 1
+ end = time.time()
+ total_time = time.time() - start_time
+ total_time_str = str(datetime.timedelta(seconds=int(total_time)))
+ print(
+ "{} Total time: {} ({:.4f} s / it)".format(
+ header, total_time_str, total_time / len(iterable)
+ )
+ )
diff --git a/D-FINE/src/misc/profiler_utils.py b/D-FINE/src/misc/profiler_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..84db32a5c8f1691fef2bc2e163a4d09f4857ddd5
--- /dev/null
+++ b/D-FINE/src/misc/profiler_utils.py
@@ -0,0 +1,30 @@
+"""
+Copyright (c) 2024 The D-FINE Authors. All Rights Reserved.
+"""
+
+import copy
+from typing import Tuple
+
+from calflops import calculate_flops
+
+
+def stats(
+ cfg,
+ input_shape: Tuple = (1, 3, 640, 640),
+) -> Tuple[int, dict]:
+ base_size = cfg.train_dataloader.collate_fn.base_size
+ input_shape = (1, 3, base_size, base_size)
+
+ model_for_info = copy.deepcopy(cfg.model).deploy()
+
+ flops, macs, _ = calculate_flops(
+ model=model_for_info,
+ input_shape=input_shape,
+ output_as_string=True,
+ output_precision=4,
+ print_detailed=False,
+ )
+ params = sum(p.numel() for p in model_for_info.parameters())
+ del model_for_info
+
+ return params, {"Model FLOPs:%s MACs:%s Params:%s" % (flops, macs, params)}
diff --git a/D-FINE/src/misc/visualizer.py b/D-FINE/src/misc/visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa82f7c768b9254194d865f156620c9c5777bd72
--- /dev/null
+++ b/D-FINE/src/misc/visualizer.py
@@ -0,0 +1,121 @@
+""" "
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import PIL
+import numpy as np
+import torch
+import torch.utils.data
+import torchvision
+from typing import List, Dict
+
+torchvision.disable_beta_transforms_warning()
+
+__all__ = ["show_sample", "save_samples"]
+
+def save_samples(samples: torch.Tensor, targets: List[Dict], output_dir: str, split: str, normalized: bool, box_fmt: str):
+ '''
+ normalized: whether the boxes are normalized to [0, 1]
+ box_fmt: 'xyxy', 'xywh', 'cxcywh', D-FINE uses 'cxcywh' for training, 'xyxy' for validation
+ '''
+ from torchvision.transforms.functional import to_pil_image
+ from torchvision.ops import box_convert
+ from pathlib import Path
+ from PIL import ImageDraw, ImageFont
+ import os
+
+ os.makedirs(Path(output_dir) / Path(f"{split}_samples"), exist_ok=True)
+ # Predefined colors (standard color names recognized by PIL)
+ BOX_COLORS = [
+ "red", "blue", "green", "orange", "purple",
+ "cyan", "magenta", "yellow", "lime", "pink",
+ "teal", "lavender", "brown", "beige", "maroon",
+ "navy", "olive", "coral", "turquoise", "gold"
+ ]
+
+ LABEL_TEXT_COLOR = "white"
+
+ font = ImageFont.load_default()
+ font.size = 32
+
+ for i, (sample, target) in enumerate(zip(samples, targets)):
+ sample_visualization = sample.clone().cpu()
+ target_boxes = target["boxes"].clone().cpu()
+ target_labels = target["labels"].clone().cpu()
+ target_image_id = target["image_id"].item()
+ target_image_path = target["image_path"]
+ target_image_path_stem = Path(target_image_path).stem
+
+ sample_visualization = to_pil_image(sample_visualization)
+ sample_visualization_w, sample_visualization_h = sample_visualization.size
+
+ # normalized to pixel space
+ if normalized:
+ target_boxes[:, 0] = target_boxes[:, 0] * sample_visualization_w
+ target_boxes[:, 2] = target_boxes[:, 2] * sample_visualization_w
+ target_boxes[:, 1] = target_boxes[:, 1] * sample_visualization_h
+ target_boxes[:, 3] = target_boxes[:, 3] * sample_visualization_h
+
+ # any box format -> xyxy
+ target_boxes = box_convert(target_boxes, in_fmt=box_fmt, out_fmt="xyxy")
+
+ # clip to image size
+ target_boxes[:, 0] = torch.clamp(target_boxes[:, 0], 0, sample_visualization_w)
+ target_boxes[:, 1] = torch.clamp(target_boxes[:, 1], 0, sample_visualization_h)
+ target_boxes[:, 2] = torch.clamp(target_boxes[:, 2], 0, sample_visualization_w)
+ target_boxes[:, 3] = torch.clamp(target_boxes[:, 3], 0, sample_visualization_h)
+
+ target_boxes = target_boxes.numpy().astype(np.int32)
+ target_labels = target_labels.numpy().astype(np.int32)
+
+ draw = ImageDraw.Draw(sample_visualization)
+
+ # draw target boxes
+ for box, label in zip(target_boxes, target_labels):
+ x1, y1, x2, y2 = box
+
+ # Select color based on class ID
+ box_color = BOX_COLORS[int(label) % len(BOX_COLORS)]
+
+ # Draw box (thick)
+ draw.rectangle([x1, y1, x2, y2], outline=box_color, width=3)
+
+ label_text = f"{label}"
+
+ # Measure text size
+ text_width, text_height = draw.textbbox((0, 0), label_text, font=font)[2:4]
+
+ # Draw text background
+ padding = 2
+ draw.rectangle(
+ [x1, y1 - text_height - padding * 2, x1 + text_width + padding * 2, y1],
+ fill=box_color
+ )
+
+ # Draw text (LABEL_TEXT_COLOR)
+ draw.text((x1 + padding, y1 - text_height - padding), label_text,
+ fill=LABEL_TEXT_COLOR, font=font)
+
+ save_path = Path(output_dir) / f"{split}_samples" / f"{target_image_id}_{target_image_path_stem}.webp"
+ sample_visualization.save(save_path)
+
+def show_sample(sample):
+ """for coco dataset/dataloader"""
+ import matplotlib.pyplot as plt
+ from torchvision.transforms.v2 import functional as F
+ from torchvision.utils import draw_bounding_boxes
+
+ image, target = sample
+ if isinstance(image, PIL.Image.Image):
+ image = F.to_image_tensor(image)
+
+ image = F.convert_dtype(image, torch.uint8)
+ annotated_image = draw_bounding_boxes(image, target["boxes"], colors="yellow", width=3)
+
+ fig, ax = plt.subplots()
+ ax.imshow(annotated_image.permute(1, 2, 0).numpy())
+ ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
+ fig.tight_layout()
+ fig.show()
+ plt.show()
diff --git a/D-FINE/src/nn/__init__.py b/D-FINE/src/nn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4544b3c8fcdc81e0b8f8ceacdb53826a63fa3038
--- /dev/null
+++ b/D-FINE/src/nn/__init__.py
@@ -0,0 +1,16 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from .arch import *
+
+#
+from .backbone import *
+from .backbone import (
+ FrozenBatchNorm2d,
+ freeze_batch_norm2d,
+ get_activation,
+)
+from .criterion import *
+from .postprocessor import *
diff --git a/D-FINE/src/nn/arch/__init__.py b/D-FINE/src/nn/arch/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..29f908cd2dcd17f6f00a740884ee87867c454356
--- /dev/null
+++ b/D-FINE/src/nn/arch/__init__.py
@@ -0,0 +1,7 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from .classification import ClassHead, Classification
+from .yolo import YOLO
diff --git a/D-FINE/src/nn/arch/classification.py b/D-FINE/src/nn/arch/classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2875430b82837bd349fd7c658fbd2b464487b6c
--- /dev/null
+++ b/D-FINE/src/nn/arch/classification.py
@@ -0,0 +1,45 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torch.nn as nn
+
+from ...core import register
+
+__all__ = ["Classification", "ClassHead"]
+
+
+@register()
+class Classification(torch.nn.Module):
+ __inject__ = ["backbone", "head"]
+
+ def __init__(self, backbone: nn.Module, head: nn.Module = None):
+ super().__init__()
+
+ self.backbone = backbone
+ self.head = head
+
+ def forward(self, x):
+ x = self.backbone(x)
+
+ if self.head is not None:
+ x = self.head(x)
+
+ return x
+
+
+@register()
+class ClassHead(nn.Module):
+ def __init__(self, hidden_dim, num_classes):
+ super().__init__()
+ self.pool = nn.AdaptiveAvgPool2d(1)
+ self.proj = nn.Linear(hidden_dim, num_classes)
+
+ def forward(self, x):
+ x = x[0] if isinstance(x, (list, tuple)) else x
+ x = self.pool(x)
+ x = x.reshape(x.shape[0], -1)
+ x = self.proj(x)
+ return x
diff --git a/D-FINE/src/nn/arch/yolo.py b/D-FINE/src/nn/arch/yolo.py
new file mode 100644
index 0000000000000000000000000000000000000000..c40a306f67acda43793fe1474f84aee27293ea72
--- /dev/null
+++ b/D-FINE/src/nn/arch/yolo.py
@@ -0,0 +1,42 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+
+from ...core import register
+
+__all__ = [
+ "YOLO",
+]
+
+
+@register()
+class YOLO(torch.nn.Module):
+ __inject__ = [
+ "backbone",
+ "neck",
+ "head",
+ ]
+
+ def __init__(self, backbone: torch.nn.Module, neck, head):
+ super().__init__()
+ self.backbone = backbone
+ self.neck = neck
+ self.head = head
+
+ def forward(self, x, **kwargs):
+ x = self.backbone(x)
+ x = self.neck(x)
+ x = self.head(x)
+ return x
+
+ def deploy(
+ self,
+ ):
+ self.eval()
+ for m in self.modules():
+ if m is not self and hasattr(m, "deploy"):
+ m.deploy()
+ return self
diff --git a/D-FINE/src/nn/backbone/__init__.py b/D-FINE/src/nn/backbone/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..497d8dfb0a2c4108d77caa9f852d61402b4fe3dc
--- /dev/null
+++ b/D-FINE/src/nn/backbone/__init__.py
@@ -0,0 +1,17 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from .common import (
+ FrozenBatchNorm2d,
+ freeze_batch_norm2d,
+ get_activation,
+)
+from .csp_darknet import CSPPAN, CSPDarkNet
+from .csp_resnet import CSPResNet
+from .hgnetv2 import HGNetv2
+from .presnet import PResNet
+from .test_resnet import MResNet
+from .timm_model import TimmModel
+from .torchvision_model import TorchVisionModel
diff --git a/D-FINE/src/nn/backbone/common.py b/D-FINE/src/nn/backbone/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..fcdb9064a530ba018f17da8dbf622f9ab9054222
--- /dev/null
+++ b/D-FINE/src/nn/backbone/common.py
@@ -0,0 +1,117 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torch.nn as nn
+
+
+class ConvNormLayer(nn.Module):
+ def __init__(self, ch_in, ch_out, kernel_size, stride, padding=None, bias=False, act=None):
+ super().__init__()
+ self.conv = nn.Conv2d(
+ ch_in,
+ ch_out,
+ kernel_size,
+ stride,
+ padding=(kernel_size - 1) // 2 if padding is None else padding,
+ bias=bias,
+ )
+ self.norm = nn.BatchNorm2d(ch_out)
+ self.act = nn.Identity() if act is None else get_activation(act)
+
+ def forward(self, x):
+ return self.act(self.norm(self.conv(x)))
+
+
+class FrozenBatchNorm2d(nn.Module):
+ """copy and modified from https://github.com/facebookresearch/detr/blob/master/models/backbone.py
+ BatchNorm2d where the batch statistics and the affine parameters are fixed.
+ Copy-paste from torchvision.misc.ops with added eps before rqsrt,
+ without which any other models than torchvision.models.resnet[18,34,50,101]
+ produce nans.
+ """
+
+ def __init__(self, num_features, eps=1e-5):
+ super(FrozenBatchNorm2d, self).__init__()
+ n = num_features
+ self.register_buffer("weight", torch.ones(n))
+ self.register_buffer("bias", torch.zeros(n))
+ self.register_buffer("running_mean", torch.zeros(n))
+ self.register_buffer("running_var", torch.ones(n))
+ self.eps = eps
+ self.num_features = n
+
+ def _load_from_state_dict(
+ self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ ):
+ num_batches_tracked_key = prefix + "num_batches_tracked"
+ if num_batches_tracked_key in state_dict:
+ del state_dict[num_batches_tracked_key]
+
+ super(FrozenBatchNorm2d, self)._load_from_state_dict(
+ state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ )
+
+ def forward(self, x):
+ # move reshapes to the beginning
+ # to make it fuser-friendly
+ w = self.weight.reshape(1, -1, 1, 1)
+ b = self.bias.reshape(1, -1, 1, 1)
+ rv = self.running_var.reshape(1, -1, 1, 1)
+ rm = self.running_mean.reshape(1, -1, 1, 1)
+ scale = w * (rv + self.eps).rsqrt()
+ bias = b - rm * scale
+ return x * scale + bias
+
+ def extra_repr(self):
+ return "{num_features}, eps={eps}".format(**self.__dict__)
+
+
+def freeze_batch_norm2d(module: nn.Module) -> nn.Module:
+ if isinstance(module, nn.BatchNorm2d):
+ module = FrozenBatchNorm2d(module.num_features)
+ else:
+ for name, child in module.named_children():
+ _child = freeze_batch_norm2d(child)
+ if _child is not child:
+ setattr(module, name, _child)
+ return module
+
+
+def get_activation(act: str, inplace: bool = True):
+ """get activation"""
+ if act is None:
+ return nn.Identity()
+
+ elif isinstance(act, nn.Module):
+ return act
+
+ act = act.lower()
+
+ if act == "silu" or act == "swish":
+ m = nn.SiLU()
+
+ elif act == "relu":
+ m = nn.ReLU()
+
+ elif act == "leaky_relu":
+ m = nn.LeakyReLU()
+
+ elif act == "silu":
+ m = nn.SiLU()
+
+ elif act == "gelu":
+ m = nn.GELU()
+
+ elif act == "hardsigmoid":
+ m = nn.Hardsigmoid()
+
+ else:
+ raise RuntimeError("")
+
+ if hasattr(m, "inplace"):
+ m.inplace = inplace
+
+ return m
diff --git a/D-FINE/src/nn/backbone/csp_darknet.py b/D-FINE/src/nn/backbone/csp_darknet.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6efa012eaead18c4f8b7a19e259647b58593baf
--- /dev/null
+++ b/D-FINE/src/nn/backbone/csp_darknet.py
@@ -0,0 +1,203 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ...core import register
+from .common import get_activation
+
+
+def autopad(k, p=None):
+ if p is None:
+ p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
+ return p
+
+
+def make_divisible(c, d):
+ return math.ceil(c / d) * d
+
+
+class Conv(nn.Module):
+ def __init__(self, cin, cout, k=1, s=1, p=None, g=1, act="silu") -> None:
+ super().__init__()
+ self.conv = nn.Conv2d(cin, cout, k, s, autopad(k, p), groups=g, bias=False)
+ self.bn = nn.BatchNorm2d(cout)
+ self.act = get_activation(act, inplace=True)
+
+ def forward(self, x):
+ return self.act(self.bn(self.conv(x)))
+
+
+class Bottleneck(nn.Module):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, act="silu"):
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1, act=act)
+ self.cv2 = Conv(c_, c2, 3, 1, g=g, act=act)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class C3(nn.Module):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(
+ self, c1, c2, n=1, shortcut=True, g=1, e=0.5, act="silu"
+ ): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1, act=act)
+ self.cv2 = Conv(c1, c_, 1, 1, act=act)
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0, act=act) for _ in range(n)))
+ self.cv3 = Conv(2 * c_, c2, 1, act=act)
+
+ def forward(self, x):
+ return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
+
+
+class SPPF(nn.Module):
+ # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
+ def __init__(self, c1, c2, k=5, act="silu"): # equivalent to SPP(k=(5, 9, 13))
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1, act=act)
+ self.cv2 = Conv(c_ * 4, c2, 1, 1, act=act)
+ self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore") # suppress torch 1.9.0 max_pool2d() warning
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
+
+
+@register()
+class CSPDarkNet(nn.Module):
+ __share__ = ["depth_multi", "width_multi"]
+
+ def __init__(
+ self,
+ in_channels=3,
+ width_multi=1.0,
+ depth_multi=1.0,
+ return_idx=[2, 3, -1],
+ act="silu",
+ ) -> None:
+ super().__init__()
+
+ channels = [64, 128, 256, 512, 1024]
+ channels = [make_divisible(c * width_multi, 8) for c in channels]
+
+ depths = [3, 6, 9, 3]
+ depths = [max(round(d * depth_multi), 1) for d in depths]
+
+ self.layers = nn.ModuleList([Conv(in_channels, channels[0], 6, 2, 2, act=act)])
+ for i, (c, d) in enumerate(zip(channels, depths), 1):
+ layer = nn.Sequential(
+ *[Conv(c, channels[i], 3, 2, act=act), C3(channels[i], channels[i], n=d, act=act)]
+ )
+ self.layers.append(layer)
+
+ self.layers.append(SPPF(channels[-1], channels[-1], k=5, act=act))
+
+ self.return_idx = return_idx
+ self.out_channels = [channels[i] for i in self.return_idx]
+ self.strides = [[2, 4, 8, 16, 32][i] for i in self.return_idx]
+ self.depths = depths
+ self.act = act
+
+ def forward(self, x):
+ outputs = []
+ for _, m in enumerate(self.layers):
+ x = m(x)
+ outputs.append(x)
+
+ return [outputs[i] for i in self.return_idx]
+
+
+@register()
+class CSPPAN(nn.Module):
+ """
+ P5 ---> 1x1 ---------------------------------> concat --> c3 --> det
+ | up | conv /2
+ P4 ---> concat ---> c3 ---> 1x1 --> concat ---> c3 -----------> det
+ | up | conv /2
+ P3 -----------------------> concat ---> c3 ---------------------> det
+ """
+
+ __share__ = [
+ "depth_multi",
+ ]
+
+ def __init__(self, in_channels=[256, 512, 1024], depth_multi=1.0, act="silu") -> None:
+ super().__init__()
+ depth = max(round(3 * depth_multi), 1)
+
+ self.out_channels = in_channels
+ self.fpn_stems = nn.ModuleList(
+ [
+ Conv(cin, cout, 1, 1, act=act)
+ for cin, cout in zip(in_channels[::-1], in_channels[::-1][1:])
+ ]
+ )
+ self.fpn_csps = nn.ModuleList(
+ [
+ C3(cin, cout, depth, False, act=act)
+ for cin, cout in zip(in_channels[::-1], in_channels[::-1][1:])
+ ]
+ )
+
+ self.pan_stems = nn.ModuleList([Conv(c, c, 3, 2, act=act) for c in in_channels[:-1]])
+ self.pan_csps = nn.ModuleList([C3(c, c, depth, False, act=act) for c in in_channels[1:]])
+
+ def forward(self, feats):
+ fpn_feats = []
+ for i, feat in enumerate(feats[::-1]):
+ if i == 0:
+ feat = self.fpn_stems[i](feat)
+ fpn_feats.append(feat)
+ else:
+ _feat = F.interpolate(fpn_feats[-1], scale_factor=2, mode="nearest")
+ feat = torch.concat([_feat, feat], dim=1)
+ feat = self.fpn_csps[i - 1](feat)
+ if i < len(self.fpn_stems):
+ feat = self.fpn_stems[i](feat)
+ fpn_feats.append(feat)
+
+ pan_feats = []
+ for i, feat in enumerate(fpn_feats[::-1]):
+ if i == 0:
+ pan_feats.append(feat)
+ else:
+ _feat = self.pan_stems[i - 1](pan_feats[-1])
+ feat = torch.concat([_feat, feat], dim=1)
+ feat = self.pan_csps[i - 1](feat)
+ pan_feats.append(feat)
+
+ return pan_feats
+
+
+if __name__ == "__main__":
+ data = torch.rand(1, 3, 320, 640)
+
+ width_multi = 0.75
+ depth_multi = 0.33
+
+ m = CSPDarkNet(3, width_multi=width_multi, depth_multi=depth_multi, act="silu")
+ outputs = m(data)
+ print([o.shape for o in outputs])
+
+ m = CSPPAN(in_channels=m.out_channels, depth_multi=depth_multi, act="silu")
+ outputs = m(outputs)
+ print([o.shape for o in outputs])
diff --git a/D-FINE/src/nn/backbone/csp_resnet.py b/D-FINE/src/nn/backbone/csp_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..17887c78cacb27553200a683585b0329514b2617
--- /dev/null
+++ b/D-FINE/src/nn/backbone/csp_resnet.py
@@ -0,0 +1,302 @@
+"""
+https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/ppdet/modeling/backbones/cspresnet.py
+
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from collections import OrderedDict
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ...core import register
+from .common import get_activation
+
+__all__ = ["CSPResNet"]
+
+
+donwload_url = {
+ "s": "https://github.com/lyuwenyu/storage/releases/download/v0.1/CSPResNetb_s_pretrained_from_paddle.pth",
+ "m": "https://github.com/lyuwenyu/storage/releases/download/v0.1/CSPResNetb_m_pretrained_from_paddle.pth",
+ "l": "https://github.com/lyuwenyu/storage/releases/download/v0.1/CSPResNetb_l_pretrained_from_paddle.pth",
+ "x": "https://github.com/lyuwenyu/storage/releases/download/v0.1/CSPResNetb_x_pretrained_from_paddle.pth",
+}
+
+
+class ConvBNLayer(nn.Module):
+ def __init__(self, ch_in, ch_out, filter_size=3, stride=1, groups=1, padding=0, act=None):
+ super().__init__()
+ self.conv = nn.Conv2d(
+ ch_in, ch_out, filter_size, stride, padding, groups=groups, bias=False
+ )
+ self.bn = nn.BatchNorm2d(ch_out)
+ self.act = get_activation(act)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x = self.conv(x)
+ x = self.bn(x)
+ x = self.act(x)
+ return x
+
+
+class RepVggBlock(nn.Module):
+ def __init__(self, ch_in, ch_out, act="relu", alpha: bool = False):
+ super().__init__()
+ self.ch_in = ch_in
+ self.ch_out = ch_out
+ self.conv1 = ConvBNLayer(ch_in, ch_out, 3, stride=1, padding=1, act=None)
+ self.conv2 = ConvBNLayer(ch_in, ch_out, 1, stride=1, padding=0, act=None)
+ self.act = get_activation(act)
+
+ if alpha:
+ self.alpha = nn.Parameter(
+ torch.ones(
+ 1,
+ )
+ )
+ else:
+ self.alpha = None
+
+ def forward(self, x):
+ if hasattr(self, "conv"):
+ y = self.conv(x)
+ else:
+ if self.alpha:
+ y = self.conv1(x) + self.alpha * self.conv2(x)
+ else:
+ y = self.conv1(x) + self.conv2(x)
+ y = self.act(y)
+ return y
+
+ def convert_to_deploy(self):
+ if not hasattr(self, "conv"):
+ self.conv = nn.Conv2d(self.ch_in, self.ch_out, 3, 1, padding=1)
+
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.conv.weight.data = kernel
+ self.conv.bias.data = bias
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
+
+ if self.alpha:
+ return kernel3x3 + self.alpha * self._pad_1x1_to_3x3_tensor(
+ kernel1x1
+ ), bias3x3 + self.alpha * bias1x1
+ else:
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1), bias3x3 + bias1x1
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return F.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch: ConvBNLayer):
+ if branch is None:
+ return 0, 0
+ kernel = branch.conv.weight
+ running_mean = branch.norm.running_mean
+ running_var = branch.norm.running_var
+ gamma = branch.norm.weight
+ beta = branch.norm.bias
+ eps = branch.norm.eps
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape(-1, 1, 1, 1)
+ return kernel * t, beta - running_mean * gamma / std
+
+
+class BasicBlock(nn.Module):
+ def __init__(self, ch_in, ch_out, act="relu", shortcut=True, use_alpha=False):
+ super().__init__()
+ assert ch_in == ch_out
+ self.conv1 = ConvBNLayer(ch_in, ch_out, 3, stride=1, padding=1, act=act)
+ self.conv2 = RepVggBlock(ch_out, ch_out, act=act, alpha=use_alpha)
+ self.shortcut = shortcut
+
+ def forward(self, x):
+ y = self.conv1(x)
+ y = self.conv2(y)
+ if self.shortcut:
+ return x + y
+ else:
+ return y
+
+
+class EffectiveSELayer(nn.Module):
+ """Effective Squeeze-Excitation
+ From `CenterMask : Real-Time Anchor-Free Instance Segmentation` - https://arxiv.org/abs/1911.06667
+ """
+
+ def __init__(self, channels, act="hardsigmoid"):
+ super(EffectiveSELayer, self).__init__()
+ self.fc = nn.Conv2d(channels, channels, kernel_size=1, padding=0)
+ self.act = get_activation(act)
+
+ def forward(self, x: torch.Tensor):
+ x_se = x.mean((2, 3), keepdim=True)
+ x_se = self.fc(x_se)
+ x_se = self.act(x_se)
+ return x * x_se
+
+
+class CSPResStage(nn.Module):
+ def __init__(self, block_fn, ch_in, ch_out, n, stride, act="relu", attn="eca", use_alpha=False):
+ super().__init__()
+ ch_mid = (ch_in + ch_out) // 2
+ if stride == 2:
+ self.conv_down = ConvBNLayer(ch_in, ch_mid, 3, stride=2, padding=1, act=act)
+ else:
+ self.conv_down = None
+ self.conv1 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
+ self.conv2 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
+ self.blocks = nn.Sequential(
+ *[
+ block_fn(ch_mid // 2, ch_mid // 2, act=act, shortcut=True, use_alpha=use_alpha)
+ for i in range(n)
+ ]
+ )
+ if attn:
+ self.attn = EffectiveSELayer(ch_mid, act="hardsigmoid")
+ else:
+ self.attn = None
+
+ self.conv3 = ConvBNLayer(ch_mid, ch_out, 1, act=act)
+
+ def forward(self, x):
+ if self.conv_down is not None:
+ x = self.conv_down(x)
+ y1 = self.conv1(x)
+ y2 = self.blocks(self.conv2(x))
+ y = torch.concat([y1, y2], dim=1)
+ if self.attn is not None:
+ y = self.attn(y)
+ y = self.conv3(y)
+ return y
+
+
+@register()
+class CSPResNet(nn.Module):
+ layers = [3, 6, 6, 3]
+ channels = [64, 128, 256, 512, 1024]
+ model_cfg = {
+ "s": {
+ "depth_mult": 0.33,
+ "width_mult": 0.50,
+ },
+ "m": {
+ "depth_mult": 0.67,
+ "width_mult": 0.75,
+ },
+ "l": {
+ "depth_mult": 1.00,
+ "width_mult": 1.00,
+ },
+ "x": {
+ "depth_mult": 1.33,
+ "width_mult": 1.25,
+ },
+ }
+
+ def __init__(
+ self,
+ name: str,
+ act="silu",
+ return_idx=[1, 2, 3],
+ use_large_stem=True,
+ use_alpha=False,
+ pretrained=False,
+ ):
+ super().__init__()
+ depth_mult = self.model_cfg[name]["depth_mult"]
+ width_mult = self.model_cfg[name]["width_mult"]
+
+ channels = [max(round(c * width_mult), 1) for c in self.channels]
+ layers = [max(round(l * depth_mult), 1) for l in self.layers]
+ act = get_activation(act)
+
+ if use_large_stem:
+ self.stem = nn.Sequential(
+ OrderedDict(
+ [
+ (
+ "conv1",
+ ConvBNLayer(3, channels[0] // 2, 3, stride=2, padding=1, act=act),
+ ),
+ (
+ "conv2",
+ ConvBNLayer(
+ channels[0] // 2, channels[0] // 2, 3, stride=1, padding=1, act=act
+ ),
+ ),
+ (
+ "conv3",
+ ConvBNLayer(
+ channels[0] // 2, channels[0], 3, stride=1, padding=1, act=act
+ ),
+ ),
+ ]
+ )
+ )
+ else:
+ self.stem = nn.Sequential(
+ OrderedDict(
+ [
+ (
+ "conv1",
+ ConvBNLayer(3, channels[0] // 2, 3, stride=2, padding=1, act=act),
+ ),
+ (
+ "conv2",
+ ConvBNLayer(
+ channels[0] // 2, channels[0], 3, stride=1, padding=1, act=act
+ ),
+ ),
+ ]
+ )
+ )
+
+ n = len(channels) - 1
+ self.stages = nn.Sequential(
+ OrderedDict(
+ [
+ (
+ str(i),
+ CSPResStage(
+ BasicBlock,
+ channels[i],
+ channels[i + 1],
+ layers[i],
+ 2,
+ act=act,
+ use_alpha=use_alpha,
+ ),
+ )
+ for i in range(n)
+ ]
+ )
+ )
+
+ self._out_channels = channels[1:]
+ self._out_strides = [4 * 2**i for i in range(n)]
+ self.return_idx = return_idx
+
+ if pretrained:
+ if isinstance(pretrained, bool) or "http" in pretrained:
+ state = torch.hub.load_state_dict_from_url(donwload_url[name], map_location="cpu")
+ else:
+ state = torch.load(pretrained, map_location="cpu")
+ self.load_state_dict(state)
+ print(f"Load CSPResNet_{name} state_dict")
+
+ def forward(self, x):
+ x = self.stem(x)
+ outs = []
+ for idx, stage in enumerate(self.stages):
+ x = stage(x)
+ if idx in self.return_idx:
+ outs.append(x)
+
+ return outs
diff --git a/D-FINE/src/nn/backbone/hgnetv2.py b/D-FINE/src/nn/backbone/hgnetv2.py
new file mode 100644
index 0000000000000000000000000000000000000000..85d99d6c74f0971e7a48fc68e0f827053dcf40e8
--- /dev/null
+++ b/D-FINE/src/nn/backbone/hgnetv2.py
@@ -0,0 +1,579 @@
+"""
+reference
+- https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
+
+Copyright (c) 2024 The D-FINE Authors. All Rights Reserved.
+"""
+
+import logging
+import os
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ...core import register
+from .common import FrozenBatchNorm2d
+
+# Constants for initialization
+kaiming_normal_ = nn.init.kaiming_normal_
+zeros_ = nn.init.zeros_
+ones_ = nn.init.ones_
+
+__all__ = ["HGNetv2"]
+
+def safe_barrier():
+ if torch.distributed.is_available() and torch.distributed.is_initialized():
+ torch.distributed.barrier()
+ else:
+ pass
+
+def safe_get_rank():
+ if torch.distributed.is_available() and torch.distributed.is_initialized():
+ return torch.distributed.get_rank()
+ else:
+ return 0
+
+class LearnableAffineBlock(nn.Module):
+ def __init__(self, scale_value=1.0, bias_value=0.0):
+ super().__init__()
+ self.scale = nn.Parameter(torch.tensor([scale_value]), requires_grad=True)
+ self.bias = nn.Parameter(torch.tensor([bias_value]), requires_grad=True)
+
+ def forward(self, x):
+ return self.scale * x + self.bias
+
+
+class ConvBNAct(nn.Module):
+ def __init__(
+ self,
+ in_chs,
+ out_chs,
+ kernel_size,
+ stride=1,
+ groups=1,
+ padding="",
+ use_act=True,
+ use_lab=False,
+ ):
+ super().__init__()
+ self.use_act = use_act
+ self.use_lab = use_lab
+ if padding == "same":
+ self.conv = nn.Sequential(
+ nn.ZeroPad2d([0, 1, 0, 1]),
+ nn.Conv2d(in_chs, out_chs, kernel_size, stride, groups=groups, bias=False),
+ )
+ else:
+ self.conv = nn.Conv2d(
+ in_chs,
+ out_chs,
+ kernel_size,
+ stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ bias=False,
+ )
+ self.bn = nn.BatchNorm2d(out_chs)
+ if self.use_act:
+ self.act = nn.ReLU()
+ else:
+ self.act = nn.Identity()
+ if self.use_act and self.use_lab:
+ self.lab = LearnableAffineBlock()
+ else:
+ self.lab = nn.Identity()
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.bn(x)
+ x = self.act(x)
+ x = self.lab(x)
+ return x
+
+
+class LightConvBNAct(nn.Module):
+ def __init__(
+ self,
+ in_chs,
+ out_chs,
+ kernel_size,
+ groups=1,
+ use_lab=False,
+ ):
+ super().__init__()
+ self.conv1 = ConvBNAct(
+ in_chs,
+ out_chs,
+ kernel_size=1,
+ use_act=False,
+ use_lab=use_lab,
+ )
+ self.conv2 = ConvBNAct(
+ out_chs,
+ out_chs,
+ kernel_size=kernel_size,
+ groups=out_chs,
+ use_act=True,
+ use_lab=use_lab,
+ )
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.conv2(x)
+ return x
+
+
+class StemBlock(nn.Module):
+ # for HGNetv2
+ def __init__(self, in_chs, mid_chs, out_chs, use_lab=False):
+ super().__init__()
+ self.stem1 = ConvBNAct(
+ in_chs,
+ mid_chs,
+ kernel_size=3,
+ stride=2,
+ use_lab=use_lab,
+ )
+ self.stem2a = ConvBNAct(
+ mid_chs,
+ mid_chs // 2,
+ kernel_size=2,
+ stride=1,
+ use_lab=use_lab,
+ )
+ self.stem2b = ConvBNAct(
+ mid_chs // 2,
+ mid_chs,
+ kernel_size=2,
+ stride=1,
+ use_lab=use_lab,
+ )
+ self.stem3 = ConvBNAct(
+ mid_chs * 2,
+ mid_chs,
+ kernel_size=3,
+ stride=2,
+ use_lab=use_lab,
+ )
+ self.stem4 = ConvBNAct(
+ mid_chs,
+ out_chs,
+ kernel_size=1,
+ stride=1,
+ use_lab=use_lab,
+ )
+ self.pool = nn.MaxPool2d(kernel_size=2, stride=1, ceil_mode=True)
+
+ def forward(self, x):
+ x = self.stem1(x)
+ x = F.pad(x, (0, 1, 0, 1))
+ x2 = self.stem2a(x)
+ x2 = F.pad(x2, (0, 1, 0, 1))
+ x2 = self.stem2b(x2)
+ x1 = self.pool(x)
+ x = torch.cat([x1, x2], dim=1)
+ x = self.stem3(x)
+ x = self.stem4(x)
+ return x
+
+
+class EseModule(nn.Module):
+ def __init__(self, chs):
+ super().__init__()
+ self.conv = nn.Conv2d(
+ chs,
+ chs,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ )
+ self.sigmoid = nn.Sigmoid()
+
+ def forward(self, x):
+ identity = x
+ x = x.mean((2, 3), keepdim=True)
+ x = self.conv(x)
+ x = self.sigmoid(x)
+ return torch.mul(identity, x)
+
+
+class HG_Block(nn.Module):
+ def __init__(
+ self,
+ in_chs,
+ mid_chs,
+ out_chs,
+ layer_num,
+ kernel_size=3,
+ residual=False,
+ light_block=False,
+ use_lab=False,
+ agg="ese",
+ drop_path=0.0,
+ ):
+ super().__init__()
+ self.residual = residual
+
+ self.layers = nn.ModuleList()
+ for i in range(layer_num):
+ if light_block:
+ self.layers.append(
+ LightConvBNAct(
+ in_chs if i == 0 else mid_chs,
+ mid_chs,
+ kernel_size=kernel_size,
+ use_lab=use_lab,
+ )
+ )
+ else:
+ self.layers.append(
+ ConvBNAct(
+ in_chs if i == 0 else mid_chs,
+ mid_chs,
+ kernel_size=kernel_size,
+ stride=1,
+ use_lab=use_lab,
+ )
+ )
+
+ # feature aggregation
+ total_chs = in_chs + layer_num * mid_chs
+ if agg == "se":
+ aggregation_squeeze_conv = ConvBNAct(
+ total_chs,
+ out_chs // 2,
+ kernel_size=1,
+ stride=1,
+ use_lab=use_lab,
+ )
+ aggregation_excitation_conv = ConvBNAct(
+ out_chs // 2,
+ out_chs,
+ kernel_size=1,
+ stride=1,
+ use_lab=use_lab,
+ )
+ self.aggregation = nn.Sequential(
+ aggregation_squeeze_conv,
+ aggregation_excitation_conv,
+ )
+ else:
+ aggregation_conv = ConvBNAct(
+ total_chs,
+ out_chs,
+ kernel_size=1,
+ stride=1,
+ use_lab=use_lab,
+ )
+ att = EseModule(out_chs)
+ self.aggregation = nn.Sequential(
+ aggregation_conv,
+ att,
+ )
+
+ self.drop_path = nn.Dropout(drop_path) if drop_path else nn.Identity()
+
+ def forward(self, x):
+ identity = x
+ output = [x]
+ for layer in self.layers:
+ x = layer(x)
+ output.append(x)
+ x = torch.cat(output, dim=1)
+ x = self.aggregation(x)
+ if self.residual:
+ x = self.drop_path(x) + identity
+ return x
+
+
+class HG_Stage(nn.Module):
+ def __init__(
+ self,
+ in_chs,
+ mid_chs,
+ out_chs,
+ block_num,
+ layer_num,
+ downsample=True,
+ light_block=False,
+ kernel_size=3,
+ use_lab=False,
+ agg="se",
+ drop_path=0.0,
+ ):
+ super().__init__()
+ self.downsample = downsample
+ if downsample:
+ self.downsample = ConvBNAct(
+ in_chs,
+ in_chs,
+ kernel_size=3,
+ stride=2,
+ groups=in_chs,
+ use_act=False,
+ use_lab=use_lab,
+ )
+ else:
+ self.downsample = nn.Identity()
+
+ blocks_list = []
+ for i in range(block_num):
+ blocks_list.append(
+ HG_Block(
+ in_chs if i == 0 else out_chs,
+ mid_chs,
+ out_chs,
+ layer_num,
+ residual=False if i == 0 else True,
+ kernel_size=kernel_size,
+ light_block=light_block,
+ use_lab=use_lab,
+ agg=agg,
+ drop_path=drop_path[i] if isinstance(drop_path, (list, tuple)) else drop_path,
+ )
+ )
+ self.blocks = nn.Sequential(*blocks_list)
+
+ def forward(self, x):
+ x = self.downsample(x)
+ x = self.blocks(x)
+ return x
+
+
+@register()
+class HGNetv2(nn.Module):
+ """
+ HGNetV2
+ Args:
+ stem_channels: list. Number of channels for the stem block.
+ stage_type: str. The stage configuration of HGNet. such as the number of channels, stride, etc.
+ use_lab: boolean. Whether to use LearnableAffineBlock in network.
+ lr_mult_list: list. Control the learning rate of different stages.
+ Returns:
+ model: nn.Layer. Specific HGNetV2 model depends on args.
+ """
+
+ arch_configs = {
+ "B0": {
+ "stem_channels": [3, 16, 16],
+ "stage_config": {
+ # in_channels, mid_channels, out_channels, num_blocks, downsample, light_block, kernel_size, layer_num
+ "stage1": [16, 16, 64, 1, False, False, 3, 3],
+ "stage2": [64, 32, 256, 1, True, False, 3, 3],
+ "stage3": [256, 64, 512, 2, True, True, 5, 3],
+ "stage4": [512, 128, 1024, 1, True, True, 5, 3],
+ },
+ "url": "https://github.com/Peterande/storage/releases/download/dfinev1.0/PPHGNetV2_B0_stage1.pth",
+ },
+ "B1": {
+ "stem_channels": [3, 24, 32],
+ "stage_config": {
+ # in_channels, mid_channels, out_channels, num_blocks, downsample, light_block, kernel_size, layer_num
+ "stage1": [32, 32, 64, 1, False, False, 3, 3],
+ "stage2": [64, 48, 256, 1, True, False, 3, 3],
+ "stage3": [256, 96, 512, 2, True, True, 5, 3],
+ "stage4": [512, 192, 1024, 1, True, True, 5, 3],
+ },
+ "url": "https://github.com/Peterande/storage/releases/download/dfinev1.0/PPHGNetV2_B1_stage1.pth",
+ },
+ "B2": {
+ "stem_channels": [3, 24, 32],
+ "stage_config": {
+ # in_channels, mid_channels, out_channels, num_blocks, downsample, light_block, kernel_size, layer_num
+ "stage1": [32, 32, 96, 1, False, False, 3, 4],
+ "stage2": [96, 64, 384, 1, True, False, 3, 4],
+ "stage3": [384, 128, 768, 3, True, True, 5, 4],
+ "stage4": [768, 256, 1536, 1, True, True, 5, 4],
+ },
+ "url": "https://github.com/Peterande/storage/releases/download/dfinev1.0/PPHGNetV2_B2_stage1.pth",
+ },
+ "B3": {
+ "stem_channels": [3, 24, 32],
+ "stage_config": {
+ # in_channels, mid_channels, out_channels, num_blocks, downsample, light_block, kernel_size, layer_num
+ "stage1": [32, 32, 128, 1, False, False, 3, 5],
+ "stage2": [128, 64, 512, 1, True, False, 3, 5],
+ "stage3": [512, 128, 1024, 3, True, True, 5, 5],
+ "stage4": [1024, 256, 2048, 1, True, True, 5, 5],
+ },
+ "url": "https://github.com/Peterande/storage/releases/download/dfinev1.0/PPHGNetV2_B3_stage1.pth",
+ },
+ "B4": {
+ "stem_channels": [3, 32, 48],
+ "stage_config": {
+ # in_channels, mid_channels, out_channels, num_blocks, downsample, light_block, kernel_size, layer_num
+ "stage1": [48, 48, 128, 1, False, False, 3, 6],
+ "stage2": [128, 96, 512, 1, True, False, 3, 6],
+ "stage3": [512, 192, 1024, 3, True, True, 5, 6],
+ "stage4": [1024, 384, 2048, 1, True, True, 5, 6],
+ },
+ "url": "https://github.com/Peterande/storage/releases/download/dfinev1.0/PPHGNetV2_B4_stage1.pth",
+ },
+ "B5": {
+ "stem_channels": [3, 32, 64],
+ "stage_config": {
+ # in_channels, mid_channels, out_channels, num_blocks, downsample, light_block, kernel_size, layer_num
+ "stage1": [64, 64, 128, 1, False, False, 3, 6],
+ "stage2": [128, 128, 512, 2, True, False, 3, 6],
+ "stage3": [512, 256, 1024, 5, True, True, 5, 6],
+ "stage4": [1024, 512, 2048, 2, True, True, 5, 6],
+ },
+ "url": "https://github.com/Peterande/storage/releases/download/dfinev1.0/PPHGNetV2_B5_stage1.pth",
+ },
+ "B6": {
+ "stem_channels": [3, 48, 96],
+ "stage_config": {
+ # in_channels, mid_channels, out_channels, num_blocks, downsample, light_block, kernel_size, layer_num
+ "stage1": [96, 96, 192, 2, False, False, 3, 6],
+ "stage2": [192, 192, 512, 3, True, False, 3, 6],
+ "stage3": [512, 384, 1024, 6, True, True, 5, 6],
+ "stage4": [1024, 768, 2048, 3, True, True, 5, 6],
+ },
+ "url": "https://github.com/Peterande/storage/releases/download/dfinev1.0/PPHGNetV2_B6_stage1.pth",
+ },
+ }
+
+ def __init__(
+ self,
+ name,
+ use_lab=False,
+ return_idx=[1, 2, 3],
+ freeze_stem_only=True,
+ freeze_at=0,
+ freeze_norm=True,
+ pretrained=True,
+ local_model_dir="weight/hgnetv2/",
+ ):
+ super().__init__()
+ self.use_lab = use_lab
+ self.return_idx = return_idx
+
+ stem_channels = self.arch_configs[name]["stem_channels"]
+ stage_config = self.arch_configs[name]["stage_config"]
+ download_url = self.arch_configs[name]["url"]
+
+ self._out_strides = [4, 8, 16, 32]
+ self._out_channels = [stage_config[k][2] for k in stage_config]
+
+ # stem
+ self.stem = StemBlock(
+ in_chs=stem_channels[0],
+ mid_chs=stem_channels[1],
+ out_chs=stem_channels[2],
+ use_lab=use_lab,
+ )
+
+ # stages
+ self.stages = nn.ModuleList()
+ for i, k in enumerate(stage_config):
+ (
+ in_channels,
+ mid_channels,
+ out_channels,
+ block_num,
+ downsample,
+ light_block,
+ kernel_size,
+ layer_num,
+ ) = stage_config[k]
+ self.stages.append(
+ HG_Stage(
+ in_channels,
+ mid_channels,
+ out_channels,
+ block_num,
+ layer_num,
+ downsample,
+ light_block,
+ kernel_size,
+ use_lab,
+ )
+ )
+
+ if freeze_at >= 0:
+ self._freeze_parameters(self.stem)
+ if not freeze_stem_only:
+ for i in range(min(freeze_at + 1, len(self.stages))):
+ self._freeze_parameters(self.stages[i])
+
+ if freeze_norm:
+ self._freeze_norm(self)
+
+ if pretrained:
+ RED, GREEN, RESET = "\033[91m", "\033[92m", "\033[0m"
+ try:
+ # If the file doesn't exist locally, download from the URL
+ if safe_get_rank() == 0:
+ print(
+ GREEN
+ + "If the pretrained HGNetV2 can't be downloaded automatically. Please check your network connection."
+ + RESET
+ )
+ print(
+ GREEN
+ + "Please check your network connection. Or download the model manually from "
+ + RESET
+ + f"{download_url}"
+ + GREEN
+ + " to "
+ + RESET
+ + f"{local_model_dir}."
+ + RESET
+ )
+ state = torch.hub.load_state_dict_from_url(
+ download_url, map_location="cpu", model_dir=local_model_dir
+ )
+ print(f"Loaded stage1 {name} HGNetV2 from URL.")
+
+ # Wait for rank 0 to download the model
+ safe_barrier()
+
+ # All processes load the downloaded model
+ model_path = local_model_dir + "PPHGNetV2_" + name + "_stage1.pth"
+ state = torch.load(model_path, map_location="cpu")
+
+ self.load_state_dict(state)
+ print(f"Loaded stage1 {name} HGNetV2 from URL.")
+
+ except (Exception, KeyboardInterrupt) as e:
+ if safe_get_rank() == 0:
+ print(f"{str(e)}")
+ logging.error(
+ RED + "CRITICAL WARNING: Failed to load pretrained HGNetV2 model" + RESET
+ )
+ logging.error(
+ GREEN
+ + "Please check your network connection. Or download the model manually from "
+ + RESET
+ + f"{download_url}"
+ + GREEN
+ + " to "
+ + RESET
+ + f"{local_model_dir}."
+ + RESET
+ )
+ exit()
+
+ def _freeze_norm(self, m: nn.Module):
+ if isinstance(m, nn.BatchNorm2d):
+ m = FrozenBatchNorm2d(m.num_features)
+ else:
+ for name, child in m.named_children():
+ _child = self._freeze_norm(child)
+ if _child is not child:
+ setattr(m, name, _child)
+ return m
+
+ def _freeze_parameters(self, m: nn.Module):
+ for p in m.parameters():
+ p.requires_grad = False
+
+ def forward(self, x):
+ x = self.stem(x)
+ outs = []
+ for idx, stage in enumerate(self.stages):
+ x = stage(x)
+ if idx in self.return_idx:
+ outs.append(x)
+ return outs
diff --git a/D-FINE/src/nn/backbone/presnet.py b/D-FINE/src/nn/backbone/presnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5543fe83568109f094441439cacf3781c711af18
--- /dev/null
+++ b/D-FINE/src/nn/backbone/presnet.py
@@ -0,0 +1,263 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from collections import OrderedDict
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ...core import register
+from .common import FrozenBatchNorm2d, get_activation
+
+__all__ = ["PResNet"]
+
+
+ResNet_cfg = {
+ 18: [2, 2, 2, 2],
+ 34: [3, 4, 6, 3],
+ 50: [3, 4, 6, 3],
+ 101: [3, 4, 23, 3],
+ # 152: [3, 8, 36, 3],
+}
+
+
+donwload_url = {
+ 18: "https://github.com/lyuwenyu/storage/releases/download/v0.1/ResNet18_vd_pretrained_from_paddle.pth",
+ 34: "https://github.com/lyuwenyu/storage/releases/download/v0.1/ResNet34_vd_pretrained_from_paddle.pth",
+ 50: "https://github.com/lyuwenyu/storage/releases/download/v0.1/ResNet50_vd_ssld_v2_pretrained_from_paddle.pth",
+ 101: "https://github.com/lyuwenyu/storage/releases/download/v0.1/ResNet101_vd_ssld_pretrained_from_paddle.pth",
+}
+
+
+class ConvNormLayer(nn.Module):
+ def __init__(self, ch_in, ch_out, kernel_size, stride, padding=None, bias=False, act=None):
+ super().__init__()
+ self.conv = nn.Conv2d(
+ ch_in,
+ ch_out,
+ kernel_size,
+ stride,
+ padding=(kernel_size - 1) // 2 if padding is None else padding,
+ bias=bias,
+ )
+ self.norm = nn.BatchNorm2d(ch_out)
+ self.act = get_activation(act)
+
+ def forward(self, x):
+ return self.act(self.norm(self.conv(x)))
+
+
+class BasicBlock(nn.Module):
+ expansion = 1
+
+ def __init__(self, ch_in, ch_out, stride, shortcut, act="relu", variant="b"):
+ super().__init__()
+
+ self.shortcut = shortcut
+
+ if not shortcut:
+ if variant == "d" and stride == 2:
+ self.short = nn.Sequential(
+ OrderedDict(
+ [
+ ("pool", nn.AvgPool2d(2, 2, 0, ceil_mode=True)),
+ ("conv", ConvNormLayer(ch_in, ch_out, 1, 1)),
+ ]
+ )
+ )
+ else:
+ self.short = ConvNormLayer(ch_in, ch_out, 1, stride)
+
+ self.branch2a = ConvNormLayer(ch_in, ch_out, 3, stride, act=act)
+ self.branch2b = ConvNormLayer(ch_out, ch_out, 3, 1, act=None)
+ self.act = nn.Identity() if act is None else get_activation(act)
+
+ def forward(self, x):
+ out = self.branch2a(x)
+ out = self.branch2b(out)
+ if self.shortcut:
+ short = x
+ else:
+ short = self.short(x)
+
+ out = out + short
+ out = self.act(out)
+
+ return out
+
+
+class BottleNeck(nn.Module):
+ expansion = 4
+
+ def __init__(self, ch_in, ch_out, stride, shortcut, act="relu", variant="b"):
+ super().__init__()
+
+ if variant == "a":
+ stride1, stride2 = stride, 1
+ else:
+ stride1, stride2 = 1, stride
+
+ width = ch_out
+
+ self.branch2a = ConvNormLayer(ch_in, width, 1, stride1, act=act)
+ self.branch2b = ConvNormLayer(width, width, 3, stride2, act=act)
+ self.branch2c = ConvNormLayer(width, ch_out * self.expansion, 1, 1)
+
+ self.shortcut = shortcut
+ if not shortcut:
+ if variant == "d" and stride == 2:
+ self.short = nn.Sequential(
+ OrderedDict(
+ [
+ ("pool", nn.AvgPool2d(2, 2, 0, ceil_mode=True)),
+ ("conv", ConvNormLayer(ch_in, ch_out * self.expansion, 1, 1)),
+ ]
+ )
+ )
+ else:
+ self.short = ConvNormLayer(ch_in, ch_out * self.expansion, 1, stride)
+
+ self.act = nn.Identity() if act is None else get_activation(act)
+
+ def forward(self, x):
+ out = self.branch2a(x)
+ out = self.branch2b(out)
+ out = self.branch2c(out)
+
+ if self.shortcut:
+ short = x
+ else:
+ short = self.short(x)
+
+ out = out + short
+ out = self.act(out)
+
+ return out
+
+
+class Blocks(nn.Module):
+ def __init__(self, block, ch_in, ch_out, count, stage_num, act="relu", variant="b"):
+ super().__init__()
+
+ self.blocks = nn.ModuleList()
+ for i in range(count):
+ self.blocks.append(
+ block(
+ ch_in,
+ ch_out,
+ stride=2 if i == 0 and stage_num != 2 else 1,
+ shortcut=False if i == 0 else True,
+ variant=variant,
+ act=act,
+ )
+ )
+
+ if i == 0:
+ ch_in = ch_out * block.expansion
+
+ def forward(self, x):
+ out = x
+ for block in self.blocks:
+ out = block(out)
+ return out
+
+
+@register()
+class PResNet(nn.Module):
+ def __init__(
+ self,
+ depth,
+ variant="d",
+ num_stages=4,
+ return_idx=[0, 1, 2, 3],
+ act="relu",
+ freeze_at=-1,
+ freeze_norm=True,
+ pretrained=False,
+ ):
+ super().__init__()
+
+ block_nums = ResNet_cfg[depth]
+ ch_in = 64
+ if variant in ["c", "d"]:
+ conv_def = [
+ [3, ch_in // 2, 3, 2, "conv1_1"],
+ [ch_in // 2, ch_in // 2, 3, 1, "conv1_2"],
+ [ch_in // 2, ch_in, 3, 1, "conv1_3"],
+ ]
+ else:
+ conv_def = [[3, ch_in, 7, 2, "conv1_1"]]
+
+ self.conv1 = nn.Sequential(
+ OrderedDict(
+ [
+ (name, ConvNormLayer(cin, cout, k, s, act=act))
+ for cin, cout, k, s, name in conv_def
+ ]
+ )
+ )
+
+ ch_out_list = [64, 128, 256, 512]
+ block = BottleNeck if depth >= 50 else BasicBlock
+
+ _out_channels = [block.expansion * v for v in ch_out_list]
+ _out_strides = [4, 8, 16, 32]
+
+ self.res_layers = nn.ModuleList()
+ for i in range(num_stages):
+ stage_num = i + 2
+ self.res_layers.append(
+ Blocks(
+ block, ch_in, ch_out_list[i], block_nums[i], stage_num, act=act, variant=variant
+ )
+ )
+ ch_in = _out_channels[i]
+
+ self.return_idx = return_idx
+ self.out_channels = [_out_channels[_i] for _i in return_idx]
+ self.out_strides = [_out_strides[_i] for _i in return_idx]
+
+ if freeze_at >= 0:
+ self._freeze_parameters(self.conv1)
+ for i in range(min(freeze_at, num_stages)):
+ self._freeze_parameters(self.res_layers[i])
+
+ if freeze_norm:
+ self._freeze_norm(self)
+
+ if pretrained:
+ if isinstance(pretrained, bool) or "http" in pretrained:
+ state = torch.hub.load_state_dict_from_url(
+ donwload_url[depth], map_location="cpu", model_dir="weight"
+ )
+ else:
+ state = torch.load(pretrained, map_location="cpu")
+ self.load_state_dict(state)
+ print(f"Load PResNet{depth} state_dict")
+
+ def _freeze_parameters(self, m: nn.Module):
+ for p in m.parameters():
+ p.requires_grad = False
+
+ def _freeze_norm(self, m: nn.Module):
+ if isinstance(m, nn.BatchNorm2d):
+ m = FrozenBatchNorm2d(m.num_features)
+ else:
+ for name, child in m.named_children():
+ _child = self._freeze_norm(child)
+ if _child is not child:
+ setattr(m, name, _child)
+ return m
+
+ def forward(self, x):
+ conv1 = self.conv1(x)
+ x = F.max_pool2d(conv1, kernel_size=3, stride=2, padding=1)
+ outs = []
+ for idx, stage in enumerate(self.res_layers):
+ x = stage(x)
+ if idx in self.return_idx:
+ outs.append(x)
+ return outs
diff --git a/D-FINE/src/nn/backbone/test_resnet.py b/D-FINE/src/nn/backbone/test_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab877ff459dbb67c9c86eddd6e764f385145a6f0
--- /dev/null
+++ b/D-FINE/src/nn/backbone/test_resnet.py
@@ -0,0 +1,83 @@
+from collections import OrderedDict
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ...core import register
+
+
+class BasicBlock(nn.Module):
+ expansion = 1
+
+ def __init__(self, in_planes, planes, stride=1):
+ super(BasicBlock, self).__init__()
+
+ self.conv1 = nn.Conv2d(
+ in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False
+ )
+ self.bn1 = nn.BatchNorm2d(planes)
+
+ self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
+ self.bn2 = nn.BatchNorm2d(planes)
+
+ self.shortcut = nn.Sequential()
+ if stride != 1 or in_planes != self.expansion * planes:
+ self.shortcut = nn.Sequential(
+ nn.Conv2d(
+ in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False
+ ),
+ nn.BatchNorm2d(self.expansion * planes),
+ )
+
+ def forward(self, x):
+ out = F.relu(self.bn1(self.conv1(x)))
+ out = self.bn2(self.conv2(out))
+ out += self.shortcut(x)
+ out = F.relu(out)
+ return out
+
+
+class _ResNet(nn.Module):
+ def __init__(self, block, num_blocks, num_classes=10):
+ super().__init__()
+ self.in_planes = 64
+
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(64)
+
+ self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
+ self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
+ self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
+ self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
+
+ self.linear = nn.Linear(512 * block.expansion, num_classes)
+
+ def _make_layer(self, block, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ layers = []
+ for stride in strides:
+ layers.append(block(self.in_planes, planes, stride))
+ self.in_planes = planes * block.expansion
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ out = F.relu(self.bn1(self.conv1(x)))
+ out = self.layer1(out)
+ out = self.layer2(out)
+ out = self.layer3(out)
+ out = self.layer4(out)
+ out = F.avg_pool2d(out, 4)
+ out = out.view(out.size(0), -1)
+ out = self.linear(out)
+ return out
+
+
+@register()
+class MResNet(nn.Module):
+ def __init__(self, num_classes=10, num_blocks=[2, 2, 2, 2]) -> None:
+ super().__init__()
+ self.model = _ResNet(BasicBlock, num_blocks, num_classes)
+
+ def forward(self, x):
+ return self.model(x)
diff --git a/D-FINE/src/nn/backbone/timm_model.py b/D-FINE/src/nn/backbone/timm_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2258a51b506d2270ae6240bfc5277f7292095bf
--- /dev/null
+++ b/D-FINE/src/nn/backbone/timm_model.py
@@ -0,0 +1,66 @@
+"""Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+
+https://towardsdatascience.com/getting-started-with-pytorch-image-models-timm-a-practitioners-guide-4e77b4bf9055#0583
+"""
+
+import torch
+from torchvision.models.feature_extraction import create_feature_extractor, get_graph_node_names
+
+from ...core import register
+from .utils import IntermediateLayerGetter
+
+
+@register()
+class TimmModel(torch.nn.Module):
+ def __init__(
+ self, name, return_layers, pretrained=False, exportable=True, features_only=True, **kwargs
+ ) -> None:
+ super().__init__()
+
+ import timm
+
+ model = timm.create_model(
+ name,
+ pretrained=pretrained,
+ exportable=exportable,
+ features_only=features_only,
+ **kwargs,
+ )
+ # nodes, _ = get_graph_node_names(model)
+ # print(nodes)
+ # features = {'': ''}
+ # model = create_feature_extractor(model, return_nodes=features)
+
+ assert set(return_layers).issubset(
+ model.feature_info.module_name()
+ ), f"return_layers should be a subset of {model.feature_info.module_name()}"
+
+ # self.model = model
+ self.model = IntermediateLayerGetter(model, return_layers)
+
+ return_idx = [model.feature_info.module_name().index(name) for name in return_layers]
+ self.strides = [model.feature_info.reduction()[i] for i in return_idx]
+ self.channels = [model.feature_info.channels()[i] for i in return_idx]
+ self.return_idx = return_idx
+ self.return_layers = return_layers
+
+ def forward(self, x: torch.Tensor):
+ outputs = self.model(x)
+ # outputs = [outputs[i] for i in self.return_idx]
+ return outputs
+
+
+if __name__ == "__main__":
+ model = TimmModel(name="resnet34", return_layers=["layer2", "layer3"])
+ data = torch.rand(1, 3, 640, 640)
+ outputs = model(data)
+
+ for output in outputs:
+ print(output.shape)
+
+ """
+ model:
+ type: TimmModel
+ name: resnet34
+ return_layers: ['layer2', 'layer4']
+ """
diff --git a/D-FINE/src/nn/backbone/torchvision_model.py b/D-FINE/src/nn/backbone/torchvision_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd207d90acdc671810b3cf17b7a3474a9c61fa2a
--- /dev/null
+++ b/D-FINE/src/nn/backbone/torchvision_model.py
@@ -0,0 +1,50 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torchvision
+
+from ...core import register
+from .utils import IntermediateLayerGetter
+
+__all__ = ["TorchVisionModel"]
+
+
+@register()
+class TorchVisionModel(torch.nn.Module):
+ def __init__(self, name, return_layers, weights=None, **kwargs) -> None:
+ super().__init__()
+
+ if weights is not None:
+ weights = getattr(torchvision.models.get_model_weights(name), weights)
+
+ model = torchvision.models.get_model(name, weights=weights, **kwargs)
+
+ # TODO hard code.
+ if hasattr(model, "features"):
+ model = IntermediateLayerGetter(model.features, return_layers)
+ else:
+ model = IntermediateLayerGetter(model, return_layers)
+
+ self.model = model
+
+ def forward(self, x):
+ return self.model(x)
+
+
+# TorchVisionModel('swin_t', return_layers=['5', '7'])
+# TorchVisionModel('resnet34', return_layers=['layer2','layer3', 'layer4'])
+
+# TorchVisionModel:
+# name: swin_t
+# return_layers: ['5', '7']
+# weights: DEFAULT
+
+
+# model:
+# type: TorchVisionModel
+# name: resnet34
+# return_layers: ['layer2','layer3', 'layer4']
+# weights: DEFAULT
diff --git a/D-FINE/src/nn/backbone/utils.py b/D-FINE/src/nn/backbone/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..58efeb386ecfb136dfe50ff697ea30adccf99e3c
--- /dev/null
+++ b/D-FINE/src/nn/backbone/utils.py
@@ -0,0 +1,56 @@
+"""
+https://github.com/pytorch/vision/blob/main/torchvision/models/_utils.py
+
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from collections import OrderedDict
+from typing import Dict, List
+
+import torch.nn as nn
+
+
+class IntermediateLayerGetter(nn.ModuleDict):
+ """
+ Module wrapper that returns intermediate layers from a model
+
+ It has a strong assumption that the modules have been registered
+ into the model in the same order as they are used.
+ This means that one should **not** reuse the same nn.Module
+ twice in the forward if you want this to work.
+
+ Additionally, it is only able to query submodules that are directly
+ assigned to the model. So if `model` is passed, `model.feature1` can
+ be returned, but not `model.feature1.layer2`.
+ """
+
+ _version = 3
+
+ def __init__(self, model: nn.Module, return_layers: List[str]) -> None:
+ if not set(return_layers).issubset([name for name, _ in model.named_children()]):
+ raise ValueError(
+ "return_layers are not present in model. {}".format(
+ [name for name, _ in model.named_children()]
+ )
+ )
+ orig_return_layers = return_layers
+ return_layers = {str(k): str(k) for k in return_layers}
+ layers = OrderedDict()
+ for name, module in model.named_children():
+ layers[name] = module
+ if name in return_layers:
+ del return_layers[name]
+ if not return_layers:
+ break
+
+ super().__init__(layers)
+ self.return_layers = orig_return_layers
+
+ def forward(self, x):
+ outputs = []
+ for name, module in self.items():
+ x = module(x)
+ if name in self.return_layers:
+ outputs.append(x)
+
+ return outputs
diff --git a/D-FINE/src/nn/criterion/__init__.py b/D-FINE/src/nn/criterion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..da74acf5f5d58baa271bfa9503c70a8b58731adb
--- /dev/null
+++ b/D-FINE/src/nn/criterion/__init__.py
@@ -0,0 +1,11 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch.nn as nn
+
+from ...core import register
+from .det_criterion import DetCriterion
+
+CrossEntropyLoss = register()(nn.CrossEntropyLoss)
diff --git a/D-FINE/src/nn/criterion/det_criterion.py b/D-FINE/src/nn/criterion/det_criterion.py
new file mode 100644
index 0000000000000000000000000000000000000000..d5dbde5bad5db0f4bfc49e1e6fe8bb8d37e18582
--- /dev/null
+++ b/D-FINE/src/nn/criterion/det_criterion.py
@@ -0,0 +1,188 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torch.distributed
+import torch.nn.functional as F
+import torchvision
+
+from ...core import register
+from ...misc import box_ops, dist_utils
+
+
+@register()
+class DetCriterion(torch.nn.Module):
+ """Default Detection Criterion"""
+
+ __share__ = ["num_classes"]
+ __inject__ = ["matcher"]
+
+ def __init__(
+ self,
+ losses,
+ weight_dict,
+ num_classes=80,
+ alpha=0.75,
+ gamma=2.0,
+ box_fmt="cxcywh",
+ matcher=None,
+ ):
+ """
+ Args:
+ losses (list[str]): requested losses, support ['boxes', 'vfl', 'focal']
+ weight_dict (dict[str, float)]: corresponding losses weight, including
+ ['loss_bbox', 'loss_giou', 'loss_vfl', 'loss_focal']
+ box_fmt (str): in box format, 'cxcywh' or 'xyxy'
+ matcher (Matcher): matcher used to match source to target
+ """
+ super().__init__()
+ self.losses = losses
+ self.weight_dict = weight_dict
+ self.alpha = alpha
+ self.gamma = gamma
+ self.num_classes = num_classes
+ self.box_fmt = box_fmt
+ assert matcher is not None, ""
+ self.matcher = matcher
+
+ def forward(self, outputs, targets, **kwargs):
+ """
+ Args:
+ outputs: Dict[Tensor], 'pred_boxes', 'pred_logits', 'meta'.
+ targets, List[Dict[str, Tensor]], len(targets) == batch_size.
+ kwargs, store other information such as current epoch id.
+ Return:
+ losses, Dict[str, Tensor]
+ """
+ matched = self.matcher(outputs, targets)
+ values = matched["values"]
+ indices = matched["indices"]
+ num_boxes = self._get_positive_nums(indices)
+
+ # Compute all the requested losses
+ losses = {}
+ for loss in self.losses:
+ l_dict = self.get_loss(loss, outputs, targets, indices, num_boxes)
+ l_dict = {k: l_dict[k] * self.weight_dict[k] for k in l_dict if k in self.weight_dict}
+ losses.update(l_dict)
+ return losses
+
+ def _get_src_permutation_idx(self, indices):
+ # permute predictions following indices
+ batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
+ src_idx = torch.cat([src for (src, _) in indices])
+ return batch_idx, src_idx
+
+ def _get_tgt_permutation_idx(self, indices):
+ # permute targets following indices
+ batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
+ tgt_idx = torch.cat([tgt for (_, tgt) in indices])
+ return batch_idx, tgt_idx
+
+ def _get_positive_nums(self, indices):
+ # number of positive samples
+ num_pos = sum(len(i) for (i, _) in indices)
+ num_pos = torch.as_tensor([num_pos], dtype=torch.float32, device=indices[0][0].device)
+ if dist_utils.is_dist_available_and_initialized():
+ torch.distributed.all_reduce(num_pos)
+ num_pos = torch.clamp(num_pos / dist_utils.get_world_size(), min=1).item()
+ return num_pos
+
+ def loss_labels_focal(self, outputs, targets, indices, num_boxes):
+ assert "pred_logits" in outputs
+ src_logits = outputs["pred_logits"]
+
+ idx = self._get_src_permutation_idx(indices)
+ target_classes_o = torch.cat([t["labels"][j] for t, (_, j) in zip(targets, indices)])
+ target_classes = torch.full(
+ src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device
+ )
+ target_classes[idx] = target_classes_o
+
+ target = F.one_hot(target_classes, num_classes=self.num_classes + 1)[..., :-1].to(
+ src_logits.dtype
+ )
+ loss = torchvision.ops.sigmoid_focal_loss(
+ src_logits, target, self.alpha, self.gamma, reduction="none"
+ )
+ loss = loss.sum() / num_boxes
+ return {"loss_focal": loss}
+
+ def loss_labels_vfl(self, outputs, targets, indices, num_boxes):
+ assert "pred_boxes" in outputs
+ idx = self._get_src_permutation_idx(indices)
+
+ src_boxes = outputs["pred_boxes"][idx]
+ target_boxes = torch.cat([t["boxes"][j] for t, (_, j) in zip(targets, indices)], dim=0)
+
+ src_boxes = torchvision.ops.box_convert(src_boxes, in_fmt=self.box_fmt, out_fmt="xyxy")
+ target_boxes = torchvision.ops.box_convert(
+ target_boxes, in_fmt=self.box_fmt, out_fmt="xyxy"
+ )
+ iou, _ = box_ops.elementwise_box_iou(src_boxes.detach(), target_boxes)
+
+ src_logits: torch.Tensor = outputs["pred_logits"]
+ target_classes_o = torch.cat([t["labels"][j] for t, (_, j) in zip(targets, indices)])
+ target_classes = torch.full(
+ src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device
+ )
+ target_classes[idx] = target_classes_o
+ target = F.one_hot(target_classes, num_classes=self.num_classes + 1)[..., :-1]
+
+ target_score_o = torch.zeros_like(target_classes, dtype=src_logits.dtype)
+ target_score_o[idx] = iou.to(src_logits.dtype)
+ target_score = target_score_o.unsqueeze(-1) * target
+
+ src_score = F.sigmoid(src_logits.detach())
+ weight = self.alpha * src_score.pow(self.gamma) * (1 - target) + target_score
+
+ loss = F.binary_cross_entropy_with_logits(
+ src_logits, target_score, weight=weight, reduction="none"
+ )
+ loss = loss.sum() / num_boxes
+ return {"loss_vfl": loss}
+
+ def loss_boxes(self, outputs, targets, indices, num_boxes):
+ assert "pred_boxes" in outputs
+ idx = self._get_src_permutation_idx(indices)
+ src_boxes = outputs["pred_boxes"][idx]
+ target_boxes = torch.cat([t["boxes"][i] for t, (_, i) in zip(targets, indices)], dim=0)
+
+ losses = {}
+ loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction="none")
+ losses["loss_bbox"] = loss_bbox.sum() / num_boxes
+
+ src_boxes = torchvision.ops.box_convert(src_boxes, in_fmt=self.box_fmt, out_fmt="xyxy")
+ target_boxes = torchvision.ops.box_convert(
+ target_boxes, in_fmt=self.box_fmt, out_fmt="xyxy"
+ )
+ loss_giou = 1 - box_ops.elementwise_generalized_box_iou(src_boxes, target_boxes)
+ losses["loss_giou"] = loss_giou.sum() / num_boxes
+ return losses
+
+ def loss_boxes_giou(self, outputs, targets, indices, num_boxes):
+ assert "pred_boxes" in outputs
+ idx = self._get_src_permutation_idx(indices)
+ src_boxes = outputs["pred_boxes"][idx]
+ target_boxes = torch.cat([t["boxes"][i] for t, (_, i) in zip(targets, indices)], dim=0)
+
+ losses = {}
+ src_boxes = torchvision.ops.box_convert(src_boxes, in_fmt=self.box_fmt, out_fmt="xyxy")
+ target_boxes = torchvision.ops.box_convert(
+ target_boxes, in_fmt=self.box_fmt, out_fmt="xyxy"
+ )
+ loss_giou = 1 - box_ops.elementwise_generalized_box_iou(src_boxes, target_boxes)
+ losses["loss_giou"] = loss_giou.sum() / num_boxes
+ return losses
+
+ def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
+ loss_map = {
+ "boxes": self.loss_boxes,
+ "giou": self.loss_boxes_giou,
+ "vfl": self.loss_labels_vfl,
+ "focal": self.loss_labels_focal,
+ }
+ assert loss in loss_map, f"do you really want to compute {loss} loss?"
+ return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
diff --git a/D-FINE/src/nn/postprocessor/__init__.py b/D-FINE/src/nn/postprocessor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0949998b69188fc1c6e5ac3a0d762170e6a435f1
--- /dev/null
+++ b/D-FINE/src/nn/postprocessor/__init__.py
@@ -0,0 +1,6 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from .nms_postprocessor import DetNMSPostProcessor
diff --git a/D-FINE/src/nn/postprocessor/box_revert.py b/D-FINE/src/nn/postprocessor/box_revert.py
new file mode 100644
index 0000000000000000000000000000000000000000..c40f0c1349ad7ca4b8f7e91b289f56c158806f83
--- /dev/null
+++ b/D-FINE/src/nn/postprocessor/box_revert.py
@@ -0,0 +1,66 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from enum import Enum
+
+import torch
+import torchvision
+from torch import Tensor
+
+
+class BoxProcessFormat(Enum):
+ """Box process format
+
+ Available formats are
+ * ``RESIZE``
+ * ``RESIZE_KEEP_RATIO``
+ * ``RESIZE_KEEP_RATIO_PADDING``
+ """
+
+ RESIZE = 1
+ RESIZE_KEEP_RATIO = 2
+ RESIZE_KEEP_RATIO_PADDING = 3
+
+
+def box_revert(
+ boxes: Tensor,
+ orig_sizes: Tensor = None,
+ eval_sizes: Tensor = None,
+ inpt_sizes: Tensor = None,
+ inpt_padding: Tensor = None,
+ normalized: bool = True,
+ in_fmt: str = "cxcywh",
+ out_fmt: str = "xyxy",
+ process_fmt=BoxProcessFormat.RESIZE,
+) -> Tensor:
+ """
+ Args:
+ boxes(Tensor), [N, :, 4], (x1, y1, x2, y2), pred boxes.
+ inpt_sizes(Tensor), [N, 2], (w, h). input sizes.
+ orig_sizes(Tensor), [N, 2], (w, h). origin sizes.
+ inpt_padding (Tensor), [N, 2], (w_pad, h_pad, ...).
+ (inpt_sizes + inpt_padding) == eval_sizes
+ """
+ assert in_fmt in ("cxcywh", "xyxy"), ""
+
+ if normalized and eval_sizes is not None:
+ boxes = boxes * eval_sizes.repeat(1, 2).unsqueeze(1)
+
+ if inpt_padding is not None:
+ if in_fmt == "xyxy":
+ boxes -= inpt_padding[:, :2].repeat(1, 2).unsqueeze(1)
+ elif in_fmt == "cxcywh":
+ boxes[..., :2] -= inpt_padding[:, :2].repeat(1, 2).unsqueeze(1)
+
+ if orig_sizes is not None:
+ orig_sizes = orig_sizes.repeat(1, 2).unsqueeze(1)
+ if inpt_sizes is not None:
+ inpt_sizes = inpt_sizes.repeat(1, 2).unsqueeze(1)
+ boxes = boxes * (orig_sizes / inpt_sizes)
+ else:
+ boxes = boxes * orig_sizes
+
+ boxes = torchvision.ops.box_convert(boxes, in_fmt=in_fmt, out_fmt=out_fmt)
+ return boxes
diff --git a/D-FINE/src/nn/postprocessor/detr_postprocessor.py b/D-FINE/src/nn/postprocessor/detr_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cccf721df4225aa90fb3e5ab60d9776536e23f6
--- /dev/null
+++ b/D-FINE/src/nn/postprocessor/detr_postprocessor.py
@@ -0,0 +1,86 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torchvision
+
+__all__ = ["DetDETRPostProcessor"]
+
+from .box_revert import BoxProcessFormat, box_revert
+
+
+def mod(a, b):
+ out = a - a // b * b
+ return out
+
+
+class DetDETRPostProcessor(nn.Module):
+ def __init__(
+ self,
+ num_classes=80,
+ use_focal_loss=True,
+ num_top_queries=300,
+ box_process_format=BoxProcessFormat.RESIZE,
+ ) -> None:
+ super().__init__()
+ self.use_focal_loss = use_focal_loss
+ self.num_top_queries = num_top_queries
+ self.num_classes = int(num_classes)
+ self.box_process_format = box_process_format
+ self.deploy_mode = False
+
+ def extra_repr(self) -> str:
+ return f"use_focal_loss={self.use_focal_loss}, num_classes={self.num_classes}, num_top_queries={self.num_top_queries}"
+
+ def forward(self, outputs, **kwargs):
+ logits, boxes = outputs["pred_logits"], outputs["pred_boxes"]
+
+ if self.use_focal_loss:
+ scores = F.sigmoid(logits)
+ scores, index = torch.topk(scores.flatten(1), self.num_top_queries, dim=-1)
+ labels = index % self.num_classes
+ # labels = mod(index, self.num_classes) # for tensorrt
+ index = index // self.num_classes
+ boxes = boxes.gather(dim=1, index=index.unsqueeze(-1).repeat(1, 1, boxes.shape[-1]))
+
+ else:
+ scores = F.softmax(logits)[:, :, :-1]
+ scores, labels = scores.max(dim=-1)
+ if scores.shape[1] > self.num_top_queries:
+ scores, index = torch.topk(scores, self.num_top_queries, dim=-1)
+ labels = torch.gather(labels, dim=1, index=index)
+ boxes = torch.gather(
+ boxes, dim=1, index=index.unsqueeze(-1).tile(1, 1, boxes.shape[-1])
+ )
+
+ if kwargs is not None:
+ boxes = box_revert(
+ boxes,
+ in_fmt="cxcywh",
+ out_fmt="xyxy",
+ process_fmt=self.box_process_format,
+ normalized=True,
+ **kwargs,
+ )
+
+ # TODO for onnx export
+ if self.deploy_mode:
+ return labels, boxes, scores
+
+ results = []
+ for lab, box, sco in zip(labels, boxes, scores):
+ result = dict(labels=lab, boxes=box, scores=sco)
+ results.append(result)
+
+ return results
+
+ def deploy(
+ self,
+ ):
+ self.eval()
+ self.deploy_mode = True
+ return self
diff --git a/D-FINE/src/nn/postprocessor/nms_postprocessor.py b/D-FINE/src/nn/postprocessor/nms_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..260e08c0b4ba0400e799590b2499b066100181c1
--- /dev/null
+++ b/D-FINE/src/nn/postprocessor/nms_postprocessor.py
@@ -0,0 +1,86 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from typing import Dict
+
+import torch
+import torch.distributed
+import torch.nn.functional as F
+import torchvision
+from torch import Tensor
+
+from ...core import register
+
+__all__ = [
+ "DetNMSPostProcessor",
+]
+
+
+@register()
+class DetNMSPostProcessor(torch.nn.Module):
+ def __init__(
+ self,
+ iou_threshold=0.7,
+ score_threshold=0.01,
+ keep_topk=300,
+ box_fmt="cxcywh",
+ logit_fmt="sigmoid",
+ ) -> None:
+ super().__init__()
+ self.iou_threshold = iou_threshold
+ self.score_threshold = score_threshold
+ self.keep_topk = keep_topk
+ self.box_fmt = box_fmt.lower()
+ self.logit_fmt = logit_fmt.lower()
+ self.logit_func = getattr(F, self.logit_fmt, None)
+ self.deploy_mode = False
+
+ def forward(self, outputs: Dict[str, Tensor], orig_target_sizes: Tensor):
+ logits, boxes = outputs["pred_logits"], outputs["pred_boxes"]
+ pred_boxes = torchvision.ops.box_convert(boxes, in_fmt=self.box_fmt, out_fmt="xyxy")
+ pred_boxes *= orig_target_sizes.repeat(1, 2).unsqueeze(1)
+
+ values, pred_labels = torch.max(logits, dim=-1)
+
+ if self.logit_func:
+ pred_scores = self.logit_func(values)
+ else:
+ pred_scores = values
+
+ # TODO for onnx export
+ if self.deploy_mode:
+ blobs = {
+ "pred_labels": pred_labels,
+ "pred_boxes": pred_boxes,
+ "pred_scores": pred_scores,
+ }
+ return blobs
+
+ results = []
+ for i in range(logits.shape[0]):
+ score_keep = pred_scores[i] > self.score_threshold
+ pred_box = pred_boxes[i][score_keep]
+ pred_label = pred_labels[i][score_keep]
+ pred_score = pred_scores[i][score_keep]
+
+ keep = torchvision.ops.batched_nms(pred_box, pred_score, pred_label, self.iou_threshold)
+ keep = keep[: self.keep_topk]
+
+ blob = {
+ "labels": pred_label[keep],
+ "boxes": pred_box[keep],
+ "scores": pred_score[keep],
+ }
+
+ results.append(blob)
+
+ return results
+
+ def deploy(
+ self,
+ ):
+ self.eval()
+ self.deploy_mode = True
+ return self
diff --git a/D-FINE/src/optim/__init__.py b/D-FINE/src/optim/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbc06c016360a3e144d7293fa9463463477c2240
--- /dev/null
+++ b/D-FINE/src/optim/__init__.py
@@ -0,0 +1,9 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from .amp import *
+from .ema import *
+from .optim import *
+from .warmup import *
diff --git a/D-FINE/src/optim/amp.py b/D-FINE/src/optim/amp.py
new file mode 100644
index 0000000000000000000000000000000000000000..5392899304ca710f506adf39d18a159923d5f0ff
--- /dev/null
+++ b/D-FINE/src/optim/amp.py
@@ -0,0 +1,12 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch.cuda.amp as amp
+
+from ..core import register
+
+__all__ = ["GradScaler"]
+
+GradScaler = register()(amp.grad_scaler.GradScaler)
diff --git a/D-FINE/src/optim/ema.py b/D-FINE/src/optim/ema.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e508b65c85e0984e8f7e4f9952dfec651c06bc8
--- /dev/null
+++ b/D-FINE/src/optim/ema.py
@@ -0,0 +1,108 @@
+"""
+D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement
+Copyright (c) 2024 The D-FINE Authors. All Rights Reserved.
+---------------------------------------------------------------------------------
+Modified from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright (c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import math
+from copy import deepcopy
+
+import torch
+import torch.nn as nn
+
+from ..core import register
+from ..misc import dist_utils
+
+__all__ = ["ModelEMA"]
+
+
+@register()
+class ModelEMA(object):
+ """
+ Model Exponential Moving Average from https://github.com/rwightman/pytorch-image-models
+ Keep a moving average of everything in the model state_dict (parameters and buffers).
+ This is intended to allow functionality like
+ https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ A smoothed version of the weights is necessary for some training schemes to perform well.
+ This class is sensitive where it is initialized in the sequence of model init,
+ GPU assignment and distributed training wrappers.
+ """
+
+ def __init__(
+ self, model: nn.Module, decay: float = 0.9999, warmups: int = 1000, start: int = 0
+ ):
+ super().__init__()
+
+ self.module = deepcopy(dist_utils.de_parallel(model)).eval()
+ # if next(model.parameters()).device.type != 'cpu':
+ # self.module.half() # FP16 EMA
+
+ self.decay = decay
+ self.warmups = warmups
+ self.before_start = 0
+ self.start = start
+ self.updates = 0 # number of EMA updates
+ if warmups == 0:
+ self.decay_fn = lambda x: decay
+ else:
+ self.decay_fn = lambda x: decay * (
+ 1 - math.exp(-x / warmups)
+ ) # decay exponential ramp (to help early epochs)
+
+ for p in self.module.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model: nn.Module):
+ if self.before_start < self.start:
+ self.before_start += 1
+ return
+ # Update EMA parameters
+ with torch.no_grad():
+ self.updates += 1
+ d = self.decay_fn(self.updates)
+ msd = dist_utils.de_parallel(model).state_dict()
+ for k, v in self.module.state_dict().items():
+ if v.dtype.is_floating_point:
+ v *= d
+ v += (1 - d) * msd[k].detach()
+
+ def to(self, *args, **kwargs):
+ self.module = self.module.to(*args, **kwargs)
+ return self
+
+ def state_dict(
+ self,
+ ):
+ return dict(module=self.module.state_dict(), updates=self.updates)
+
+ def load_state_dict(self, state, strict=True):
+ self.module.load_state_dict(state["module"], strict=strict)
+ if "updates" in state:
+ self.updates = state["updates"]
+
+ def forwad(
+ self,
+ ):
+ raise RuntimeError("ema...")
+
+ def extra_repr(self) -> str:
+ return f"decay={self.decay}, warmups={self.warmups}"
+
+
+class ExponentialMovingAverage(torch.optim.swa_utils.AveragedModel):
+ """Maintains moving averages of model parameters using an exponential decay.
+ ``ema_avg = decay * avg_model_param + (1 - decay) * model_param``
+ `torch.optim.swa_utils.AveragedModel `_
+ is used to compute the EMA.
+ """
+
+ def __init__(self, model, decay, device="cpu", use_buffers=True):
+ self.decay_fn = lambda x: decay * (1 - math.exp(-x / 2000))
+
+ def ema_avg(avg_model_param, model_param, num_averaged):
+ decay = self.decay_fn(num_averaged)
+ return decay * avg_model_param + (1 - decay) * model_param
+
+ super().__init__(model, device, ema_avg, use_buffers=use_buffers)
diff --git a/D-FINE/src/optim/optim.py b/D-FINE/src/optim/optim.py
new file mode 100644
index 0000000000000000000000000000000000000000..cec30305a6800f52ed54c2620dfd25dea51674c5
--- /dev/null
+++ b/D-FINE/src/optim/optim.py
@@ -0,0 +1,22 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch.optim as optim
+import torch.optim.lr_scheduler as lr_scheduler
+
+from ..core import register
+
+__all__ = ["AdamW", "SGD", "Adam", "MultiStepLR", "CosineAnnealingLR", "OneCycleLR", "LambdaLR"]
+
+
+SGD = register()(optim.SGD)
+Adam = register()(optim.Adam)
+AdamW = register()(optim.AdamW)
+
+
+MultiStepLR = register()(lr_scheduler.MultiStepLR)
+CosineAnnealingLR = register()(lr_scheduler.CosineAnnealingLR)
+OneCycleLR = register()(lr_scheduler.OneCycleLR)
+LambdaLR = register()(lr_scheduler.LambdaLR)
diff --git a/D-FINE/src/optim/warmup.py b/D-FINE/src/optim/warmup.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd475ef69b9b0eecc15b4cf924e341394a12ecb3
--- /dev/null
+++ b/D-FINE/src/optim/warmup.py
@@ -0,0 +1,56 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from torch.optim.lr_scheduler import LRScheduler
+
+from ..core import register
+
+
+class Warmup(object):
+ def __init__(
+ self, lr_scheduler: LRScheduler, warmup_duration: int, last_step: int = -1
+ ) -> None:
+ self.lr_scheduler = lr_scheduler
+ self.warmup_end_values = [pg["lr"] for pg in lr_scheduler.optimizer.param_groups]
+ self.last_step = last_step
+ self.warmup_duration = warmup_duration
+ self.step()
+
+ def state_dict(self):
+ return {k: v for k, v in self.__dict__.items() if k != "lr_scheduler"}
+
+ def load_state_dict(self, state_dict):
+ self.__dict__.update(state_dict)
+
+ def get_warmup_factor(self, step, **kwargs):
+ raise NotImplementedError
+
+ def step(
+ self,
+ ):
+ self.last_step += 1
+ if self.last_step >= self.warmup_duration:
+ return
+ factor = self.get_warmup_factor(self.last_step)
+ for i, pg in enumerate(self.lr_scheduler.optimizer.param_groups):
+ pg["lr"] = factor * self.warmup_end_values[i]
+
+ def finished(
+ self,
+ ):
+ if self.last_step >= self.warmup_duration:
+ return True
+ return False
+
+
+@register()
+class LinearWarmup(Warmup):
+ def __init__(
+ self, lr_scheduler: LRScheduler, warmup_duration: int, last_step: int = -1
+ ) -> None:
+ super().__init__(lr_scheduler, warmup_duration, last_step)
+
+ def get_warmup_factor(self, step):
+ return min(1.0, (step + 1) / self.warmup_duration)
diff --git a/D-FINE/src/solver/__init__.py b/D-FINE/src/solver/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..440182a086a4ee6091269f419b13815251ede869
--- /dev/null
+++ b/D-FINE/src/solver/__init__.py
@@ -0,0 +1,15 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from typing import Dict
+
+from ._solver import BaseSolver
+from .clas_solver import ClasSolver
+from .det_solver import DetSolver
+
+TASKS: Dict[str, BaseSolver] = {
+ "classification": ClasSolver,
+ "detection": DetSolver,
+}
diff --git a/D-FINE/src/solver/_solver.py b/D-FINE/src/solver/_solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..3120437bca9cd13a58db45d7e9d2b5a090fbc62f
--- /dev/null
+++ b/D-FINE/src/solver/_solver.py
@@ -0,0 +1,783 @@
+import atexit
+from datetime import datetime
+from pathlib import Path
+from typing import Dict
+
+import torch
+import torch.nn as nn
+
+from ..core import BaseConfig
+from ..misc import dist_utils
+
+
+def to(m: nn.Module, device: str):
+ if m is None:
+ return None
+ return m.to(device)
+
+
+def remove_module_prefix(state_dict):
+ new_state_dict = {}
+ for k, v in state_dict.items():
+ if k.startswith("module."):
+ new_state_dict[k[7:]] = v
+ else:
+ new_state_dict[k] = v
+ return new_state_dict
+
+
+class BaseSolver(object):
+ def __init__(self, cfg: BaseConfig) -> None:
+ self.cfg = cfg
+ self.obj365_ids = [
+ 0,
+ 46,
+ 5,
+ 58,
+ 114,
+ 55,
+ 116,
+ 65,
+ 21,
+ 40,
+ 176,
+ 127,
+ 249,
+ 24,
+ 56,
+ 139,
+ 92,
+ 78,
+ 99,
+ 96,
+ 144,
+ 295,
+ 178,
+ 180,
+ 38,
+ 39,
+ 13,
+ 43,
+ 120,
+ 219,
+ 148,
+ 173,
+ 165,
+ 154,
+ 137,
+ 113,
+ 145,
+ 146,
+ 204,
+ 8,
+ 35,
+ 10,
+ 88,
+ 84,
+ 93,
+ 26,
+ 112,
+ 82,
+ 265,
+ 104,
+ 141,
+ 152,
+ 234,
+ 143,
+ 150,
+ 97,
+ 2,
+ 50,
+ 25,
+ 75,
+ 98,
+ 153,
+ 37,
+ 73,
+ 115,
+ 132,
+ 106,
+ 61,
+ 163,
+ 134,
+ 277,
+ 81,
+ 133,
+ 18,
+ 94,
+ 30,
+ 169,
+ 70,
+ 328,
+ 226,
+ ]
+
+ def _setup(self):
+ """Avoid instantiating unnecessary classes"""
+ cfg = self.cfg
+ if cfg.device:
+ device = torch.device(cfg.device)
+ else:
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+ self.model = cfg.model
+
+ # NOTE: Must load_tuning_state before EMA instance building
+ if self.cfg.tuning:
+ print(f"Tuning checkpoint from {self.cfg.tuning}")
+ self.load_tuning_state(self.cfg.tuning)
+
+ self.model = dist_utils.warp_model(
+ self.model.to(device),
+ sync_bn=cfg.sync_bn,
+ find_unused_parameters=cfg.find_unused_parameters,
+ )
+
+ self.criterion = self.to(cfg.criterion, device)
+ self.postprocessor = self.to(cfg.postprocessor, device)
+
+ self.ema = self.to(cfg.ema, device)
+ self.scaler = cfg.scaler
+
+ self.device = device
+ self.last_epoch = self.cfg.last_epoch
+
+ self.output_dir = Path(cfg.output_dir)
+ self.output_dir.mkdir(parents=True, exist_ok=True)
+ self.writer = cfg.writer
+
+ if self.writer:
+ atexit.register(self.writer.close)
+ if dist_utils.is_main_process():
+ self.writer.add_text("config", "{:s}".format(cfg.__repr__()), 0)
+ self.use_wandb = self.cfg.use_wandb
+ if self.use_wandb:
+ try:
+ import wandb
+ self.use_wandb = True
+ except ImportError:
+ self.use_wandb = False
+
+ def cleanup(self):
+ if self.writer:
+ atexit.register(self.writer.close)
+
+ def train(self):
+ self._setup()
+ self.optimizer = self.cfg.optimizer
+ self.lr_scheduler = self.cfg.lr_scheduler
+ self.lr_warmup_scheduler = self.cfg.lr_warmup_scheduler
+
+ self.train_dataloader = dist_utils.warp_loader(
+ self.cfg.train_dataloader, shuffle=self.cfg.train_dataloader.shuffle
+ )
+ self.val_dataloader = dist_utils.warp_loader(
+ self.cfg.val_dataloader, shuffle=self.cfg.val_dataloader.shuffle
+ )
+
+ self.evaluator = self.cfg.evaluator
+
+ # NOTE: Instantiating order
+ if self.cfg.resume:
+ print(f"Resume checkpoint from {self.cfg.resume}")
+ self.load_resume_state(self.cfg.resume)
+
+ def eval(self):
+ self._setup()
+
+ self.val_dataloader = dist_utils.warp_loader(
+ self.cfg.val_dataloader, shuffle=self.cfg.val_dataloader.shuffle
+ )
+
+ self.evaluator = self.cfg.evaluator
+
+ if self.cfg.resume:
+ print(f"Resume checkpoint from {self.cfg.resume}")
+ self.load_resume_state(self.cfg.resume)
+
+ def to(self, module, device):
+ return module.to(device) if hasattr(module, "to") else module
+
+ def state_dict(self):
+ """State dict, train/eval"""
+ state = {}
+ state["date"] = datetime.now().isoformat()
+
+ # For resume
+ state["last_epoch"] = self.last_epoch
+
+ for k, v in self.__dict__.items():
+ if hasattr(v, "state_dict"):
+ v = dist_utils.de_parallel(v)
+ state[k] = v.state_dict()
+
+ return state
+
+ def load_state_dict(self, state):
+ """Load state dict, train/eval"""
+ if "last_epoch" in state:
+ self.last_epoch = state["last_epoch"]
+ print("Load last_epoch")
+
+ for k, v in self.__dict__.items():
+ if hasattr(v, "load_state_dict") and k in state:
+ v = dist_utils.de_parallel(v)
+ v.load_state_dict(state[k])
+ print(f"Load {k}.state_dict")
+
+ if hasattr(v, "load_state_dict") and k not in state:
+ if k == "ema":
+ model = getattr(self, "model", None)
+ if model is not None:
+ ema = dist_utils.de_parallel(v)
+ model_state_dict = remove_module_prefix(model.state_dict())
+ ema.load_state_dict({"module": model_state_dict})
+ print(f"Load {k}.state_dict from model.state_dict")
+ else:
+ print(f"Not load {k}.state_dict")
+
+ def load_resume_state(self, path: str):
+ """Load resume"""
+ if path.startswith("http"):
+ state = torch.hub.load_state_dict_from_url(path, map_location="cpu")
+ else:
+ state = torch.load(path, map_location="cpu")
+
+ # state['model'] = remove_module_prefix(state['model'])
+ self.load_state_dict(state)
+
+ def load_tuning_state(self, path: str):
+ """Load model for tuning and adjust mismatched head parameters"""
+ if path.startswith("http"):
+ state = torch.hub.load_state_dict_from_url(path, map_location="cpu")
+ else:
+ state = torch.load(path, map_location="cpu")
+
+ module = dist_utils.de_parallel(self.model)
+
+ # Load the appropriate state dict
+ if "ema" in state:
+ pretrain_state_dict = state["ema"]["module"]
+ else:
+ pretrain_state_dict = state["model"]
+
+ # Adjust head parameters between datasets
+ try:
+ adjusted_state_dict = self._adjust_head_parameters(
+ module.state_dict(), pretrain_state_dict
+ )
+ stat, infos = self._matched_state(module.state_dict(), adjusted_state_dict)
+ except Exception:
+ stat, infos = self._matched_state(module.state_dict(), pretrain_state_dict)
+
+ module.load_state_dict(stat, strict=False)
+ print(f"Load model.state_dict, {infos}")
+
+ @staticmethod
+ def _matched_state(state: Dict[str, torch.Tensor], params: Dict[str, torch.Tensor]):
+ missed_list = []
+ unmatched_list = []
+ matched_state = {}
+ for k, v in state.items():
+ if k in params:
+ if v.shape == params[k].shape:
+ matched_state[k] = params[k]
+ else:
+ unmatched_list.append(k)
+ else:
+ missed_list.append(k)
+
+ return matched_state, {"missed": missed_list, "unmatched": unmatched_list}
+
+ def _adjust_head_parameters(self, cur_state_dict, pretrain_state_dict):
+ """Adjust head parameters between datasets."""
+ # List of parameters to adjust
+ if (
+ pretrain_state_dict["decoder.denoising_class_embed.weight"].size()
+ != cur_state_dict["decoder.denoising_class_embed.weight"].size()
+ ):
+ del pretrain_state_dict["decoder.denoising_class_embed.weight"]
+
+ head_param_names = ["decoder.enc_score_head.weight", "decoder.enc_score_head.bias"]
+ for i in range(8):
+ head_param_names.append(f"decoder.dec_score_head.{i}.weight")
+ head_param_names.append(f"decoder.dec_score_head.{i}.bias")
+
+ adjusted_params = []
+
+ for param_name in head_param_names:
+ if param_name in cur_state_dict and param_name in pretrain_state_dict:
+ cur_tensor = cur_state_dict[param_name]
+ pretrain_tensor = pretrain_state_dict[param_name]
+ adjusted_tensor = self.map_class_weights(cur_tensor, pretrain_tensor)
+ if adjusted_tensor is not None:
+ pretrain_state_dict[param_name] = adjusted_tensor
+ adjusted_params.append(param_name)
+ else:
+ print(f"Cannot adjust parameter '{param_name}' due to size mismatch.")
+
+ return pretrain_state_dict
+
+ def map_class_weights(self, cur_tensor, pretrain_tensor):
+ """Map class weights from pretrain model to current model based on class IDs."""
+ if pretrain_tensor.size() == cur_tensor.size():
+ return pretrain_tensor
+
+ adjusted_tensor = cur_tensor.clone()
+ adjusted_tensor.requires_grad = False
+
+ if pretrain_tensor.size() > cur_tensor.size():
+ for coco_id, obj_id in enumerate(self.obj365_ids):
+ adjusted_tensor[coco_id] = pretrain_tensor[obj_id + 1]
+ else:
+ for coco_id, obj_id in enumerate(self.obj365_ids):
+ adjusted_tensor[obj_id + 1] = pretrain_tensor[coco_id]
+
+ return adjusted_tensor
+
+ def fit(self):
+ raise NotImplementedError("")
+
+ def val(self):
+ raise NotImplementedError("")
+
+
+# obj365_classes = [
+# 'Person', 'Sneakers', 'Chair', 'Other Shoes', 'Hat', 'Car', 'Lamp', 'Glasses',
+# 'Bottle', 'Desk', 'Cup', 'Street Lights', 'Cabinet/shelf', 'Handbag/Satchel',
+# 'Bracelet', 'Plate', 'Picture/Frame', 'Helmet', 'Book', 'Gloves', 'Storage box',
+# 'Boat', 'Leather Shoes', 'Flower', 'Bench', 'Potted Plant', 'Bowl/Basin', 'Flag',
+# 'Pillow', 'Boots', 'Vase', 'Microphone', 'Necklace', 'Ring', 'SUV', 'Wine Glass',
+# 'Belt', 'Moniter/TV', 'Backpack', 'Umbrella', 'Traffic Light', 'Speaker', 'Watch',
+# 'Tie', 'Trash bin Can', 'Slippers', 'Bicycle', 'Stool', 'Barrel/bucket', 'Van',
+# 'Couch', 'Sandals', 'Bakset', 'Drum', 'Pen/Pencil', 'Bus', 'Wild Bird', 'High Heels',
+# 'Motorcycle', 'Guitar', 'Carpet', 'Cell Phone', 'Bread', 'Camera', 'Canned', 'Truck',
+# 'Traffic cone', 'Cymbal', 'Lifesaver', 'Towel', 'Stuffed Toy', 'Candle', 'Sailboat',
+# 'Laptop', 'Awning', 'Bed', 'Faucet', 'Tent', 'Horse', 'Mirror', 'Power outlet',
+# 'Sink', 'Apple', 'Air Conditioner', 'Knife', 'Hockey Stick', 'Paddle', 'Pickup Truck',
+# 'Fork', 'Traffic Sign', 'Ballon', 'Tripod', 'Dog', 'Spoon', 'Clock', 'Pot', 'Cow',
+# 'Cake', 'Dinning Table', 'Sheep', 'Hanger', 'Blackboard/Whiteboard', 'Napkin',
+# 'Other Fish', 'Orange/Tangerine', 'Toiletry', 'Keyboard', 'Tomato', 'Lantern',
+# 'Machinery Vehicle', 'Fan', 'Green Vegetables', 'Banana', 'Baseball Glove',
+# 'Airplane', 'Mouse', 'Train', 'Pumpkin', 'Soccer', 'Skiboard', 'Luggage', 'Nightstand',
+# 'Tea pot', 'Telephone', 'Trolley', 'Head Phone', 'Sports Car', 'Stop Sign', 'Dessert',
+# 'Scooter', 'Stroller', 'Crane', 'Remote', 'Refrigerator', 'Oven', 'Lemon', 'Duck',
+# 'Baseball Bat', 'Surveillance Camera', 'Cat', 'Jug', 'Broccoli', 'Piano', 'Pizza',
+# 'Elephant', 'Skateboard', 'Surfboard', 'Gun', 'Skating and Skiing shoes', 'Gas stove',
+# 'Donut', 'Bow Tie', 'Carrot', 'Toilet', 'Kite', 'Strawberry', 'Other Balls', 'Shovel',
+# 'Pepper', 'Computer Box', 'Toilet Paper', 'Cleaning Products', 'Chopsticks', 'Microwave',
+# 'Pigeon', 'Baseball', 'Cutting/chopping Board', 'Coffee Table', 'Side Table', 'Scissors',
+# 'Marker', 'Pie', 'Ladder', 'Snowboard', 'Cookies', 'Radiator', 'Fire Hydrant', 'Basketball',
+# 'Zebra', 'Grape', 'Giraffe', 'Potato', 'Sausage', 'Tricycle', 'Violin', 'Egg',
+# 'Fire Extinguisher', 'Candy', 'Fire Truck', 'Billards', 'Converter', 'Bathtub',
+# 'Wheelchair', 'Golf Club', 'Briefcase', 'Cucumber', 'Cigar/Cigarette ', 'Paint Brush',
+# 'Pear', 'Heavy Truck', 'Hamburger', 'Extractor', 'Extention Cord', 'Tong',
+# 'Tennis Racket', 'Folder', 'American Football', 'earphone', 'Mask', 'Kettle',
+# 'Tennis', 'Ship', 'Swing', 'Coffee Machine', 'Slide', 'Carriage', 'Onion',
+# 'Green beans', 'Projector', 'Frisbee', 'Washing Machine/Drying Machine', 'Chicken',
+# 'Printer', 'Watermelon', 'Saxophone', 'Tissue', 'Toothbrush', 'Ice cream',
+# 'Hotair ballon', 'Cello', 'French Fries', 'Scale', 'Trophy', 'Cabbage', 'Hot dog',
+# 'Blender', 'Peach', 'Rice', 'Wallet/Purse', 'Volleyball', 'Deer', 'Goose', 'Tape',
+# 'Tablet', 'Cosmetics', 'Trumpet', 'Pineapple', 'Golf Ball', 'Ambulance', 'Parking meter',
+# 'Mango', 'Key', 'Hurdle', 'Fishing Rod', 'Medal', 'Flute', 'Brush', 'Penguin',
+# 'Megaphone', 'Corn', 'Lettuce', 'Garlic', 'Swan', 'Helicopter', 'Green Onion',
+# 'Sandwich', 'Nuts', 'Speed Limit Sign', 'Induction Cooker', 'Broom', 'Trombone',
+# 'Plum', 'Rickshaw', 'Goldfish', 'Kiwi fruit', 'Router/modem', 'Poker Card', 'Toaster',
+# 'Shrimp', 'Sushi', 'Cheese', 'Notepaper', 'Cherry', 'Pliers', 'CD', 'Pasta', 'Hammer',
+# 'Cue', 'Avocado', 'Hamimelon', 'Flask', 'Mushroon', 'Screwdriver', 'Soap', 'Recorder',
+# 'Bear', 'Eggplant', 'Board Eraser', 'Coconut', 'Tape Measur/ Ruler', 'Pig',
+# 'Showerhead', 'Globe', 'Chips', 'Steak', 'Crosswalk Sign', 'Stapler', 'Campel',
+# 'Formula 1 ', 'Pomegranate', 'Dishwasher', 'Crab', 'Hoverboard', 'Meat ball',
+# 'Rice Cooker', 'Tuba', 'Calculator', 'Papaya', 'Antelope', 'Parrot', 'Seal',
+# 'Buttefly', 'Dumbbell', 'Donkey', 'Lion', 'Urinal', 'Dolphin', 'Electric Drill',
+# 'Hair Dryer', 'Egg tart', 'Jellyfish', 'Treadmill', 'Lighter', 'Grapefruit',
+# 'Game board', 'Mop', 'Radish', 'Baozi', 'Target', 'French', 'Spring Rolls', 'Monkey',
+# 'Rabbit', 'Pencil Case', 'Yak', 'Red Cabbage', 'Binoculars', 'Asparagus', 'Barbell',
+# 'Scallop', 'Noddles', 'Comb', 'Dumpling', 'Oyster', 'Table Teniis paddle',
+# 'Cosmetics Brush/Eyeliner Pencil', 'Chainsaw', 'Eraser', 'Lobster', 'Durian', 'Okra',
+# 'Lipstick', 'Cosmetics Mirror', 'Curling', 'Table Tennis '
+# ]
+
+# coco_classes = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
+# 'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
+# 'stop sign', 'parking meter', 'bench', 'wild bird', 'cat', 'dog',
+# 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
+# 'backpack', 'umbrella', 'handbag/satchel', 'tie', 'luggage', 'frisbee',
+# 'skating and skiing shoes', 'snowboard', 'baseball', 'kite', 'baseball bat',
+# 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
+# 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl/basin',
+# 'banana', 'apple', 'sandwich', 'orange/tangerine', 'broccoli', 'carrot',
+# 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
+# 'potted plant', 'bed', 'dinning table', 'toilet', 'moniter/tv', 'laptop',
+# 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
+# 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
+# 'vase', 'scissors', 'stuffed toy', 'hair dryer', 'toothbrush']
+
+
+# obj365_classes = [
+# (0, 'Person'),
+# (1, 'Sneakers'),
+# (2, 'Chair'),
+# (3, 'Other Shoes'),
+# (4, 'Hat'),
+# (5, 'Car'),
+# (6, 'Lamp'),
+# (7, 'Glasses'),
+# (8, 'Bottle'),
+# (9, 'Desk'),
+# (10, 'Cup'),
+# (11, 'Street Lights'),
+# (12, 'Cabinet/shelf'),
+# (13, 'Handbag/Satchel'),
+# (14, 'Bracelet'),
+# (15, 'Plate'),
+# (16, 'Picture/Frame'),
+# (17, 'Helmet'),
+# (18, 'Book'),
+# (19, 'Gloves'),
+# (20, 'Storage box'),
+# (21, 'Boat'),
+# (22, 'Leather Shoes'),
+# (23, 'Flower'),
+# (24, 'Bench'),
+# (25, 'Potted Plant'),
+# (26, 'Bowl/Basin'),
+# (27, 'Flag'),
+# (28, 'Pillow'),
+# (29, 'Boots'),
+# (30, 'Vase'),
+# (31, 'Microphone'),
+# (32, 'Necklace'),
+# (33, 'Ring'),
+# (34, 'SUV'),
+# (35, 'Wine Glass'),
+# (36, 'Belt'),
+# (37, 'Monitor/TV'),
+# (38, 'Backpack'),
+# (39, 'Umbrella'),
+# (40, 'Traffic Light'),
+# (41, 'Speaker'),
+# (42, 'Watch'),
+# (43, 'Tie'),
+# (44, 'Trash bin Can'),
+# (45, 'Slippers'),
+# (46, 'Bicycle'),
+# (47, 'Stool'),
+# (48, 'Barrel/bucket'),
+# (49, 'Van'),
+# (50, 'Couch'),
+# (51, 'Sandals'),
+# (52, 'Basket'),
+# (53, 'Drum'),
+# (54, 'Pen/Pencil'),
+# (55, 'Bus'),
+# (56, 'Wild Bird'),
+# (57, 'High Heels'),
+# (58, 'Motorcycle'),
+# (59, 'Guitar'),
+# (60, 'Carpet'),
+# (61, 'Cell Phone'),
+# (62, 'Bread'),
+# (63, 'Camera'),
+# (64, 'Canned'),
+# (65, 'Truck'),
+# (66, 'Traffic cone'),
+# (67, 'Cymbal'),
+# (68, 'Lifesaver'),
+# (69, 'Towel'),
+# (70, 'Stuffed Toy'),
+# (71, 'Candle'),
+# (72, 'Sailboat'),
+# (73, 'Laptop'),
+# (74, 'Awning'),
+# (75, 'Bed'),
+# (76, 'Faucet'),
+# (77, 'Tent'),
+# (78, 'Horse'),
+# (79, 'Mirror'),
+# (80, 'Power outlet'),
+# (81, 'Sink'),
+# (82, 'Apple'),
+# (83, 'Air Conditioner'),
+# (84, 'Knife'),
+# (85, 'Hockey Stick'),
+# (86, 'Paddle'),
+# (87, 'Pickup Truck'),
+# (88, 'Fork'),
+# (89, 'Traffic Sign'),
+# (90, 'Balloon'),
+# (91, 'Tripod'),
+# (92, 'Dog'),
+# (93, 'Spoon'),
+# (94, 'Clock'),
+# (95, 'Pot'),
+# (96, 'Cow'),
+# (97, 'Cake'),
+# (98, 'Dining Table'),
+# (99, 'Sheep'),
+# (100, 'Hanger'),
+# (101, 'Blackboard/Whiteboard'),
+# (102, 'Napkin'),
+# (103, 'Other Fish'),
+# (104, 'Orange/Tangerine'),
+# (105, 'Toiletry'),
+# (106, 'Keyboard'),
+# (107, 'Tomato'),
+# (108, 'Lantern'),
+# (109, 'Machinery Vehicle'),
+# (110, 'Fan'),
+# (111, 'Green Vegetables'),
+# (112, 'Banana'),
+# (113, 'Baseball Glove'),
+# (114, 'Airplane'),
+# (115, 'Mouse'),
+# (116, 'Train'),
+# (117, 'Pumpkin'),
+# (118, 'Soccer'),
+# (119, 'Skiboard'),
+# (120, 'Luggage'),
+# (121, 'Nightstand'),
+# (122, 'Tea pot'),
+# (123, 'Telephone'),
+# (124, 'Trolley'),
+# (125, 'Head Phone'),
+# (126, 'Sports Car'),
+# (127, 'Stop Sign'),
+# (128, 'Dessert'),
+# (129, 'Scooter'),
+# (130, 'Stroller'),
+# (131, 'Crane'),
+# (132, 'Remote'),
+# (133, 'Refrigerator'),
+# (134, 'Oven'),
+# (135, 'Lemon'),
+# (136, 'Duck'),
+# (137, 'Baseball Bat'),
+# (138, 'Surveillance Camera'),
+# (139, 'Cat'),
+# (140, 'Jug'),
+# (141, 'Broccoli'),
+# (142, 'Piano'),
+# (143, 'Pizza'),
+# (144, 'Elephant'),
+# (145, 'Skateboard'),
+# (146, 'Surfboard'),
+# (147, 'Gun'),
+# (148, 'Skating and Skiing Shoes'),
+# (149, 'Gas Stove'),
+# (150, 'Donut'),
+# (151, 'Bow Tie'),
+# (152, 'Carrot'),
+# (153, 'Toilet'),
+# (154, 'Kite'),
+# (155, 'Strawberry'),
+# (156, 'Other Balls'),
+# (157, 'Shovel'),
+# (158, 'Pepper'),
+# (159, 'Computer Box'),
+# (160, 'Toilet Paper'),
+# (161, 'Cleaning Products'),
+# (162, 'Chopsticks'),
+# (163, 'Microwave'),
+# (164, 'Pigeon'),
+# (165, 'Baseball'),
+# (166, 'Cutting/chopping Board'),
+# (167, 'Coffee Table'),
+# (168, 'Side Table'),
+# (169, 'Scissors'),
+# (170, 'Marker'),
+# (171, 'Pie'),
+# (172, 'Ladder'),
+# (173, 'Snowboard'),
+# (174, 'Cookies'),
+# (175, 'Radiator'),
+# (176, 'Fire Hydrant'),
+# (177, 'Basketball'),
+# (178, 'Zebra'),
+# (179, 'Grape'),
+# (180, 'Giraffe'),
+# (181, 'Potato'),
+# (182, 'Sausage'),
+# (183, 'Tricycle'),
+# (184, 'Violin'),
+# (185, 'Egg'),
+# (186, 'Fire Extinguisher'),
+# (187, 'Candy'),
+# (188, 'Fire Truck'),
+# (189, 'Billiards'),
+# (190, 'Converter'),
+# (191, 'Bathtub'),
+# (192, 'Wheelchair'),
+# (193, 'Golf Club'),
+# (194, 'Briefcase'),
+# (195, 'Cucumber'),
+# (196, 'Cigar/Cigarette'),
+# (197, 'Paint Brush'),
+# (198, 'Pear'),
+# (199, 'Heavy Truck'),
+# (200, 'Hamburger'),
+# (201, 'Extractor'),
+# (202, 'Extension Cord'),
+# (203, 'Tong'),
+# (204, 'Tennis Racket'),
+# (205, 'Folder'),
+# (206, 'American Football'),
+# (207, 'Earphone'),
+# (208, 'Mask'),
+# (209, 'Kettle'),
+# (210, 'Tennis'),
+# (211, 'Ship'),
+# (212, 'Swing'),
+# (213, 'Coffee Machine'),
+# (214, 'Slide'),
+# (215, 'Carriage'),
+# (216, 'Onion'),
+# (217, 'Green Beans'),
+# (218, 'Projector'),
+# (219, 'Frisbee'),
+# (220, 'Washing Machine/Drying Machine'),
+# (221, 'Chicken'),
+# (222, 'Printer'),
+# (223, 'Watermelon'),
+# (224, 'Saxophone'),
+# (225, 'Tissue'),
+# (226, 'Toothbrush'),
+# (227, 'Ice Cream'),
+# (228, 'Hot Air Balloon'),
+# (229, 'Cello'),
+# (230, 'French Fries'),
+# (231, 'Scale'),
+# (232, 'Trophy'),
+# (233, 'Cabbage'),
+# (234, 'Hot Dog'),
+# (235, 'Blender'),
+# (236, 'Peach'),
+# (237, 'Rice'),
+# (238, 'Wallet/Purse'),
+# (239, 'Volleyball'),
+# (240, 'Deer'),
+# (241, 'Goose'),
+# (242, 'Tape'),
+# (243, 'Tablet'),
+# (244, 'Cosmetics'),
+# (245, 'Trumpet'),
+# (246, 'Pineapple'),
+# (247, 'Golf Ball'),
+# (248, 'Ambulance'),
+# (249, 'Parking Meter'),
+# (250, 'Mango'),
+# (251, 'Key'),
+# (252, 'Hurdle'),
+# (253, 'Fishing Rod'),
+# (254, 'Medal'),
+# (255, 'Flute'),
+# (256, 'Brush'),
+# (257, 'Penguin'),
+# (258, 'Megaphone'),
+# (259, 'Corn'),
+# (260, 'Lettuce'),
+# (261, 'Garlic'),
+# (262, 'Swan'),
+# (263, 'Helicopter'),
+# (264, 'Green Onion'),
+# (265, 'Sandwich'),
+# (266, 'Nuts'),
+# (267, 'Speed Limit Sign'),
+# (268, 'Induction Cooker'),
+# (269, 'Broom'),
+# (270, 'Trombone'),
+# (271, 'Plum'),
+# (272, 'Rickshaw'),
+# (273, 'Goldfish'),
+# (274, 'Kiwi Fruit'),
+# (275, 'Router/Modem'),
+# (276, 'Poker Card'),
+# (277, 'Toaster'),
+# (278, 'Shrimp'),
+# (279, 'Sushi'),
+# (280, 'Cheese'),
+# (281, 'Notepaper'),
+# (282, 'Cherry'),
+# (283, 'Pliers'),
+# (284, 'CD'),
+# (285, 'Pasta'),
+# (286, 'Hammer'),
+# (287, 'Cue'),
+# (288, 'Avocado'),
+# (289, 'Hami Melon'),
+# (290, 'Flask'),
+# (291, 'Mushroom'),
+# (292, 'Screwdriver'),
+# (293, 'Soap'),
+# (294, 'Recorder'),
+# (295, 'Bear'),
+# (296, 'Eggplant'),
+# (297, 'Board Eraser'),
+# (298, 'Coconut'),
+# (299, 'Tape Measure/Ruler'),
+# (300, 'Pig'),
+# (301, 'Showerhead'),
+# (302, 'Globe'),
+# (303, 'Chips'),
+# (304, 'Steak'),
+# (305, 'Crosswalk Sign'),
+# (306, 'Stapler'),
+# (307, 'Camel'),
+# (308, 'Formula 1'),
+# (309, 'Pomegranate'),
+# (310, 'Dishwasher'),
+# (311, 'Crab'),
+# (312, 'Hoverboard'),
+# (313, 'Meatball'),
+# (314, 'Rice Cooker'),
+# (315, 'Tuba'),
+# (316, 'Calculator'),
+# (317, 'Papaya'),
+# (318, 'Antelope'),
+# (319, 'Parrot'),
+# (320, 'Seal'),
+# (321, 'Butterfly'),
+# (322, 'Dumbbell'),
+# (323, 'Donkey'),
+# (324, 'Lion'),
+# (325, 'Urinal'),
+# (326, 'Dolphin'),
+# (327, 'Electric Drill'),
+# (328, 'Hair Dryer'),
+# (329, 'Egg Tart'),
+# (330, 'Jellyfish'),
+# (331, 'Treadmill'),
+# (332, 'Lighter'),
+# (333, 'Grapefruit'),
+# (334, 'Game Board'),
+# (335, 'Mop'),
+# (336, 'Radish'),
+# (337, 'Baozi'),
+# (338, 'Target'),
+# (339, 'French'),
+# (340, 'Spring Rolls'),
+# (341, 'Monkey'),
+# (342, 'Rabbit'),
+# (343, 'Pencil Case'),
+# (344, 'Yak'),
+# (345, 'Red Cabbage'),
+# (346, 'Binoculars'),
+# (347, 'Asparagus'),
+# (348, 'Barbell'),
+# (349, 'Scallop'),
+# (350, 'Noodles'),
+# (351, 'Comb'),
+# (352, 'Dumpling'),
+# (353, 'Oyster'),
+# (354, 'Table Tennis Paddle'),
+# (355, 'Cosmetics Brush/Eyeliner Pencil'),
+# (356, 'Chainsaw'),
+# (357, 'Eraser'),
+# (358, 'Lobster'),
+# (359, 'Durian'),
+# (360, 'Okra'),
+# (361, 'Lipstick'),
+# (362, 'Cosmetics Mirror'),
+# (363, 'Curling'),
+# (364, 'Table Tennis')
+# ]
diff --git a/D-FINE/src/solver/clas_engine.py b/D-FINE/src/solver/clas_engine.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc5a68026ad2dbd9086372e4a81d8e7e32dbb600
--- /dev/null
+++ b/D-FINE/src/solver/clas_engine.py
@@ -0,0 +1,74 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import torch
+import torch.nn as nn
+
+from ..misc import MetricLogger, SmoothedValue, reduce_dict
+
+
+def train_one_epoch(
+ model: nn.Module, criterion: nn.Module, dataloader, optimizer, ema, epoch, device
+):
+ """ """
+ model.train()
+
+ metric_logger = MetricLogger(delimiter=" ")
+ metric_logger.add_meter("lr", SmoothedValue(window_size=1, fmt="{value:.6f}"))
+ print_freq = 100
+ header = "Epoch: [{}]".format(epoch)
+
+ for imgs, labels in metric_logger.log_every(dataloader, print_freq, header):
+ imgs = imgs.to(device)
+ labels = labels.to(device)
+
+ preds = model(imgs)
+ loss: torch.Tensor = criterion(preds, labels, epoch)
+
+ optimizer.zero_grad()
+ loss.backward()
+ optimizer.step()
+
+ if ema is not None:
+ ema.update(model)
+
+ loss_reduced_values = {k: v.item() for k, v in reduce_dict({"loss": loss}).items()}
+ metric_logger.update(**loss_reduced_values)
+ metric_logger.update(lr=optimizer.param_groups[0]["lr"])
+
+ metric_logger.synchronize_between_processes()
+ print("Averaged stats:", metric_logger)
+
+ stats = {k: meter.global_avg for k, meter in metric_logger.meters.items()}
+ return stats
+
+
+@torch.no_grad()
+def evaluate(model, criterion, dataloader, device):
+ model.eval()
+
+ metric_logger = MetricLogger(delimiter=" ")
+ # metric_logger.add_meter('acc', SmoothedValue(window_size=1, fmt='{global_avg:.4f}'))
+ # metric_logger.add_meter('loss', SmoothedValue(window_size=1, fmt='{value:.2f}'))
+ metric_logger.add_meter("acc", SmoothedValue(window_size=1))
+ metric_logger.add_meter("loss", SmoothedValue(window_size=1))
+
+ header = "Test:"
+ for imgs, labels in metric_logger.log_every(dataloader, 10, header):
+ imgs, labels = imgs.to(device), labels.to(device)
+ preds = model(imgs)
+
+ acc = (preds.argmax(dim=-1) == labels).sum() / preds.shape[0]
+ loss = criterion(preds, labels)
+
+ dict_reduced = reduce_dict({"acc": acc, "loss": loss})
+ reduced_values = {k: v.item() for k, v in dict_reduced.items()}
+ metric_logger.update(**reduced_values)
+
+ metric_logger.synchronize_between_processes()
+ print("Averaged stats:", metric_logger)
+
+ stats = {k: meter.global_avg for k, meter in metric_logger.meters.items()}
+ return stats
diff --git a/D-FINE/src/solver/clas_solver.py b/D-FINE/src/solver/clas_solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..aefb3d0a17faf0b427cc4d153f103ffe63ccd6e3
--- /dev/null
+++ b/D-FINE/src/solver/clas_solver.py
@@ -0,0 +1,75 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import datetime
+import json
+import time
+from pathlib import Path
+
+import torch
+import torch.nn as nn
+
+from ..misc import dist_utils
+from ._solver import BaseSolver
+from .clas_engine import evaluate, train_one_epoch
+
+
+class ClasSolver(BaseSolver):
+ def fit(
+ self,
+ ):
+ print("Start training")
+ self.train()
+ args = self.cfg
+
+ n_parameters = sum(p.numel() for p in self.model.parameters() if p.requires_grad)
+ print("Number of params:", n_parameters)
+
+ output_dir = Path(args.output_dir)
+ output_dir.mkdir(exist_ok=True)
+
+ start_time = time.time()
+ start_epoch = self.last_epoch + 1
+ for epoch in range(start_epoch, args.epochs):
+ if dist_utils.is_dist_available_and_initialized():
+ self.train_dataloader.sampler.set_epoch(epoch)
+
+ train_stats = train_one_epoch(
+ self.model,
+ self.criterion,
+ self.train_dataloader,
+ self.optimizer,
+ self.ema,
+ epoch=epoch,
+ device=self.device,
+ )
+ self.lr_scheduler.step()
+ self.last_epoch += 1
+
+ if output_dir:
+ checkpoint_paths = [output_dir / "checkpoint.pth"]
+ # extra checkpoint before LR drop and every 100 epochs
+ if (epoch + 1) % args.checkpoint_freq == 0:
+ checkpoint_paths.append(output_dir / f"checkpoint{epoch:04}.pth")
+ for checkpoint_path in checkpoint_paths:
+ dist_utils.save_on_master(self.state_dict(epoch), checkpoint_path)
+
+ module = self.ema.module if self.ema else self.model
+ test_stats = evaluate(module, self.criterion, self.val_dataloader, self.device)
+
+ log_stats = {
+ **{f"train_{k}": v for k, v in train_stats.items()},
+ **{f"test_{k}": v for k, v in test_stats.items()},
+ "epoch": epoch,
+ "n_parameters": n_parameters,
+ }
+
+ if output_dir and dist_utils.is_main_process():
+ with (output_dir / "log.txt").open("a") as f:
+ f.write(json.dumps(log_stats) + "\n")
+
+ total_time = time.time() - start_time
+ total_time_str = str(datetime.timedelta(seconds=int(total_time)))
+ print("Training time {}".format(total_time_str))
diff --git a/D-FINE/src/solver/det_engine.py b/D-FINE/src/solver/det_engine.py
new file mode 100644
index 0000000000000000000000000000000000000000..b877b09b39726894e3cf1d5399d4e5419710943d
--- /dev/null
+++ b/D-FINE/src/solver/det_engine.py
@@ -0,0 +1,259 @@
+"""
+D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement
+Copyright (c) 2024 The D-FINE Authors. All Rights Reserved.
+---------------------------------------------------------------------------------
+Modified from DETR (https://github.com/facebookresearch/detr/blob/main/engine.py)
+Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+"""
+
+import math
+import sys
+from typing import Dict, Iterable, List
+
+import numpy as np
+import torch
+import torch.amp
+from torch.cuda.amp.grad_scaler import GradScaler
+from torch.utils.tensorboard import SummaryWriter
+
+from ..data import CocoEvaluator
+from ..data.dataset import mscoco_category2label
+from ..misc import MetricLogger, SmoothedValue, dist_utils, save_samples
+from ..optim import ModelEMA, Warmup
+from .validator import Validator, scale_boxes
+
+
+def train_one_epoch(
+ model: torch.nn.Module,
+ criterion: torch.nn.Module,
+ data_loader: Iterable,
+ optimizer: torch.optim.Optimizer,
+ device: torch.device,
+ epoch: int,
+ use_wandb: bool,
+ max_norm: float = 0,
+ **kwargs,
+):
+ if use_wandb:
+ import wandb
+
+ model.train()
+ criterion.train()
+ metric_logger = MetricLogger(delimiter=" ")
+ metric_logger.add_meter("lr", SmoothedValue(window_size=1, fmt="{value:.6f}"))
+
+ epochs = kwargs.get("epochs", None)
+ header = "Epoch: [{}]".format(epoch) if epochs is None else "Epoch: [{}/{}]".format(epoch, epochs)
+
+ print_freq = kwargs.get("print_freq", 10)
+ writer: SummaryWriter = kwargs.get("writer", None)
+
+ ema: ModelEMA = kwargs.get("ema", None)
+ scaler: GradScaler = kwargs.get("scaler", None)
+ lr_warmup_scheduler: Warmup = kwargs.get("lr_warmup_scheduler", None)
+ losses = []
+
+ output_dir = kwargs.get("output_dir", None)
+ num_visualization_sample_batch = kwargs.get("num_visualization_sample_batch", 1)
+
+ for i, (samples, targets) in enumerate(
+ metric_logger.log_every(data_loader, print_freq, header)
+ ):
+ global_step = epoch * len(data_loader) + i
+ metas = dict(epoch=epoch, step=i, global_step=global_step, epoch_step=len(data_loader))
+
+ if global_step < num_visualization_sample_batch and output_dir is not None and dist_utils.is_main_process():
+ save_samples(samples, targets, output_dir, "train", normalized=True, box_fmt="cxcywh")
+
+ samples = samples.to(device)
+ targets = [{k: v.to(device) if isinstance(v, torch.Tensor) else v for k, v in t.items()} for t in targets]
+
+ if scaler is not None:
+ with torch.autocast(device_type=str(device), cache_enabled=True):
+ outputs = model(samples, targets=targets)
+
+ if torch.isnan(outputs["pred_boxes"]).any() or torch.isinf(outputs["pred_boxes"]).any():
+ print(outputs["pred_boxes"])
+ state = model.state_dict()
+ new_state = {}
+ for key, value in model.state_dict().items():
+ # Replace 'module' with 'model' in each key
+ new_key = key.replace("module.", "")
+ # Add the updated key-value pair to the state dictionary
+ state[new_key] = value
+ new_state["model"] = state
+ dist_utils.save_on_master(new_state, "./NaN.pth")
+
+ with torch.autocast(device_type=str(device), enabled=False):
+ loss_dict = criterion(outputs, targets, **metas)
+
+ loss = sum(loss_dict.values())
+ scaler.scale(loss).backward()
+
+ if max_norm > 0:
+ scaler.unscale_(optimizer)
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
+
+ scaler.step(optimizer)
+ scaler.update()
+ optimizer.zero_grad()
+
+ else:
+ outputs = model(samples, targets=targets)
+ loss_dict = criterion(outputs, targets, **metas)
+
+ loss: torch.Tensor = sum(loss_dict.values())
+ optimizer.zero_grad()
+ loss.backward()
+
+ if max_norm > 0:
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
+
+ optimizer.step()
+
+ # ema
+ if ema is not None:
+ ema.update(model)
+
+ if lr_warmup_scheduler is not None:
+ lr_warmup_scheduler.step()
+
+ loss_dict_reduced = dist_utils.reduce_dict(loss_dict)
+ loss_value = sum(loss_dict_reduced.values())
+ losses.append(loss_value.detach().cpu().numpy())
+
+ if not math.isfinite(loss_value):
+ print("Loss is {}, stopping training".format(loss_value))
+ print(loss_dict_reduced)
+ sys.exit(1)
+
+ metric_logger.update(loss=loss_value, **loss_dict_reduced)
+ metric_logger.update(lr=optimizer.param_groups[0]["lr"])
+
+ if writer and dist_utils.is_main_process() and global_step % 10 == 0:
+ writer.add_scalar("Loss/total", loss_value.item(), global_step)
+ for j, pg in enumerate(optimizer.param_groups):
+ writer.add_scalar(f"Lr/pg_{j}", pg["lr"], global_step)
+ for k, v in loss_dict_reduced.items():
+ writer.add_scalar(f"Loss/{k}", v.item(), global_step)
+
+ if use_wandb:
+ wandb.log(
+ {"lr": optimizer.param_groups[0]["lr"], "epoch": epoch, "train/loss": np.mean(losses)}
+ )
+ # gather the stats from all processes
+ metric_logger.synchronize_between_processes()
+ print("Averaged stats:", metric_logger)
+ return {k: meter.global_avg for k, meter in metric_logger.meters.items()}
+
+
+@torch.no_grad()
+def evaluate(
+ model: torch.nn.Module,
+ criterion: torch.nn.Module,
+ postprocessor,
+ data_loader,
+ coco_evaluator: CocoEvaluator,
+ device,
+ epoch: int,
+ use_wandb: bool,
+ **kwargs,
+):
+ if use_wandb:
+ import wandb
+
+ model.eval()
+ criterion.eval()
+ coco_evaluator.cleanup()
+
+ metric_logger = MetricLogger(delimiter=" ")
+ # metric_logger.add_meter('class_error', SmoothedValue(window_size=1, fmt='{value:.2f}'))
+ header = "Test:"
+
+ # iou_types = tuple(k for k in ('segm', 'bbox') if k in postprocessor.keys())
+ iou_types = coco_evaluator.iou_types
+ # coco_evaluator = CocoEvaluator(base_ds, iou_types)
+ # coco_evaluator.coco_eval[iou_types[0]].params.iouThrs = [0, 0.1, 0.5, 0.75]
+
+ gt: List[Dict[str, torch.Tensor]] = []
+ preds: List[Dict[str, torch.Tensor]] = []
+
+ output_dir = kwargs.get("output_dir", None)
+ num_visualization_sample_batch = kwargs.get("num_visualization_sample_batch", 1)
+
+ for i, (samples, targets) in enumerate(metric_logger.log_every(data_loader, 10, header)):
+ global_step = epoch * len(data_loader) + i
+
+ if global_step < num_visualization_sample_batch and output_dir is not None and dist_utils.is_main_process():
+ save_samples(samples, targets, output_dir, "val", normalized=False, box_fmt="xyxy")
+
+ samples = samples.to(device)
+ targets = [{k: v.to(device) if isinstance(v, torch.Tensor) else v for k, v in t.items()} for t in targets]
+
+ outputs = model(samples)
+ # with torch.autocast(device_type=str(device)):
+ # outputs = model(samples)
+
+ # TODO (lyuwenyu), fix dataset converted using `convert_to_coco_api`?
+ orig_target_sizes = torch.stack([t["orig_size"] for t in targets], dim=0)
+ # orig_target_sizes = torch.tensor([[samples.shape[-1], samples.shape[-2]]], device=samples.device)
+
+ results = postprocessor(outputs, orig_target_sizes)
+
+ # if 'segm' in postprocessor.keys():
+ # target_sizes = torch.stack([t["size"] for t in targets], dim=0)
+ # results = postprocessor['segm'](results, outputs, orig_target_sizes, target_sizes)
+
+ res = {target["image_id"].item(): output for target, output in zip(targets, results)}
+ if coco_evaluator is not None:
+ coco_evaluator.update(res)
+
+ # validator format for metrics
+ for idx, (target, result) in enumerate(zip(targets, results)):
+ gt.append(
+ {
+ "boxes": scale_boxes( # from model input size to original img size
+ target["boxes"],
+ (target["orig_size"][1], target["orig_size"][0]),
+ (samples[idx].shape[-1], samples[idx].shape[-2]),
+ ),
+ "labels": target["labels"],
+ }
+ )
+ labels = (
+ torch.tensor([mscoco_category2label[int(x.item())] for x in result["labels"].flatten()])
+ .to(result["labels"].device)
+ .reshape(result["labels"].shape)
+ ) if postprocessor.remap_mscoco_category else result["labels"]
+ preds.append(
+ {"boxes": result["boxes"], "labels": labels, "scores": result["scores"]}
+ )
+
+ # Conf matrix, F1, Precision, Recall, box IoU
+ metrics = Validator(gt, preds).compute_metrics()
+ print("Metrics:", metrics)
+ if use_wandb:
+ metrics = {f"metrics/{k}": v for k, v in metrics.items()}
+ metrics["epoch"] = epoch
+ wandb.log(metrics)
+
+ # gather the stats from all processes
+ metric_logger.synchronize_between_processes()
+ print("Averaged stats:", metric_logger)
+ if coco_evaluator is not None:
+ coco_evaluator.synchronize_between_processes()
+
+ # accumulate predictions from all images
+ if coco_evaluator is not None:
+ coco_evaluator.accumulate()
+ coco_evaluator.summarize()
+
+ stats = {}
+ # stats = {k: meter.global_avg for k, meter in metric_logger.meters.items()}
+ if coco_evaluator is not None:
+ if "bbox" in iou_types:
+ stats["coco_eval_bbox"] = coco_evaluator.coco_eval["bbox"].stats.tolist()
+ if "segm" in iou_types:
+ stats["coco_eval_masks"] = coco_evaluator.coco_eval["segm"].stats.tolist()
+
+ return stats, coco_evaluator
diff --git a/D-FINE/src/solver/det_solver.py b/D-FINE/src/solver/det_solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..96b93764a7ec7fe0ef888c550f283dd296f1a177
--- /dev/null
+++ b/D-FINE/src/solver/det_solver.py
@@ -0,0 +1,228 @@
+"""
+D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement
+Copyright (c) 2024 The D-FINE Authors. All Rights Reserved.
+---------------------------------------------------------------------------------
+Modified from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright (c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+import datetime
+import json
+import time
+
+import torch
+
+from ..misc import dist_utils, stats
+from ._solver import BaseSolver
+from .det_engine import evaluate, train_one_epoch
+
+
+class DetSolver(BaseSolver):
+ def fit(self):
+ self.train()
+ args = self.cfg
+ metric_names = ["AP50:95", "AP50", "AP75", "APsmall", "APmedium", "APlarge"]
+
+ if self.use_wandb:
+ import wandb
+
+ wandb.init(
+ project=args.yaml_cfg["project_name"],
+ name=args.yaml_cfg["exp_name"],
+ config=args.yaml_cfg,
+ )
+ wandb.watch(self.model)
+
+ n_parameters, model_stats = stats(self.cfg)
+ print(model_stats)
+ print("-" * 42 + "Start training" + "-" * 43)
+ top1 = 0
+ best_stat = {
+ "epoch": -1,
+ }
+ if self.last_epoch > 0:
+ module = self.ema.module if self.ema else self.model
+ test_stats, coco_evaluator = evaluate(
+ module,
+ self.criterion,
+ self.postprocessor,
+ self.val_dataloader,
+ self.evaluator,
+ self.device,
+ self.last_epoch,
+ self.use_wandb
+ )
+ for k in test_stats:
+ best_stat["epoch"] = self.last_epoch
+ best_stat[k] = test_stats[k][0]
+ top1 = test_stats[k][0]
+ print(f"best_stat: {best_stat}")
+
+ best_stat_print = best_stat.copy()
+ start_time = time.time()
+ start_epoch = self.last_epoch + 1
+ for epoch in range(start_epoch, args.epochs):
+ self.train_dataloader.set_epoch(epoch)
+ # self.train_dataloader.dataset.set_epoch(epoch)
+ if dist_utils.is_dist_available_and_initialized():
+ self.train_dataloader.sampler.set_epoch(epoch)
+
+ if epoch == self.train_dataloader.collate_fn.stop_epoch:
+ self.load_resume_state(str(self.output_dir / "best_stg1.pth"))
+ if self.ema:
+ self.ema.decay = self.train_dataloader.collate_fn.ema_restart_decay
+ print(f"Refresh EMA at epoch {epoch} with decay {self.ema.decay}")
+
+ train_stats = train_one_epoch(
+ self.model,
+ self.criterion,
+ self.train_dataloader,
+ self.optimizer,
+ self.device,
+ epoch,
+ epochs=args.epochs,
+ max_norm=args.clip_max_norm,
+ print_freq=args.print_freq,
+ ema=self.ema,
+ scaler=self.scaler,
+ lr_warmup_scheduler=self.lr_warmup_scheduler,
+ writer=self.writer,
+ use_wandb=self.use_wandb,
+ output_dir=self.output_dir,
+ )
+
+ if self.lr_warmup_scheduler is None or self.lr_warmup_scheduler.finished():
+ self.lr_scheduler.step()
+
+ self.last_epoch += 1
+
+ if self.output_dir and epoch < self.train_dataloader.collate_fn.stop_epoch:
+ checkpoint_paths = [self.output_dir / "last.pth"]
+ # extra checkpoint before LR drop and every 100 epochs
+ if (epoch + 1) % args.checkpoint_freq == 0:
+ checkpoint_paths.append(self.output_dir / f"checkpoint{epoch:04}.pth")
+ for checkpoint_path in checkpoint_paths:
+ dist_utils.save_on_master(self.state_dict(), checkpoint_path)
+
+ module = self.ema.module if self.ema else self.model
+ test_stats, coco_evaluator = evaluate(
+ module,
+ self.criterion,
+ self.postprocessor,
+ self.val_dataloader,
+ self.evaluator,
+ self.device,
+ epoch,
+ self.use_wandb,
+ output_dir=self.output_dir,
+ )
+
+ # TODO
+ for k in test_stats:
+ if self.writer and dist_utils.is_main_process():
+ for i, v in enumerate(test_stats[k]):
+ self.writer.add_scalar(f"Test/{k}_{i}".format(k), v, epoch)
+
+ if k in best_stat:
+ best_stat["epoch"] = (
+ epoch if test_stats[k][0] > best_stat[k] else best_stat["epoch"]
+ )
+ best_stat[k] = max(best_stat[k], test_stats[k][0])
+ else:
+ best_stat["epoch"] = epoch
+ best_stat[k] = test_stats[k][0]
+
+ if best_stat[k] > top1:
+ best_stat_print["epoch"] = epoch
+ top1 = best_stat[k]
+ if self.output_dir:
+ if epoch >= self.train_dataloader.collate_fn.stop_epoch:
+ dist_utils.save_on_master(
+ self.state_dict(), self.output_dir / "best_stg2.pth"
+ )
+ else:
+ dist_utils.save_on_master(
+ self.state_dict(), self.output_dir / "best_stg1.pth"
+ )
+
+ best_stat_print[k] = max(best_stat[k], top1)
+ print(f"best_stat: {best_stat_print}") # global best
+
+ if best_stat["epoch"] == epoch and self.output_dir:
+ if epoch >= self.train_dataloader.collate_fn.stop_epoch:
+ if test_stats[k][0] > top1:
+ top1 = test_stats[k][0]
+ dist_utils.save_on_master(
+ self.state_dict(), self.output_dir / "best_stg2.pth"
+ )
+ else:
+ top1 = max(test_stats[k][0], top1)
+ dist_utils.save_on_master(
+ self.state_dict(), self.output_dir / "best_stg1.pth"
+ )
+
+ elif epoch >= self.train_dataloader.collate_fn.stop_epoch:
+ best_stat = {
+ "epoch": -1,
+ }
+ if self.ema:
+ self.ema.decay -= 0.0001
+ self.load_resume_state(str(self.output_dir / "best_stg1.pth"))
+ print(f"Refresh EMA at epoch {epoch} with decay {self.ema.decay}")
+
+ log_stats = {
+ **{f"train_{k}": v for k, v in train_stats.items()},
+ **{f"test_{k}": v for k, v in test_stats.items()},
+ "epoch": epoch,
+ "n_parameters": n_parameters,
+ }
+
+ if self.use_wandb:
+ wandb_logs = {}
+ for idx, metric_name in enumerate(metric_names):
+ wandb_logs[f"metrics/{metric_name}"] = test_stats["coco_eval_bbox"][idx]
+ wandb_logs["epoch"] = epoch
+ wandb.log(wandb_logs)
+
+ if self.output_dir and dist_utils.is_main_process():
+ with (self.output_dir / "log.txt").open("a") as f:
+ f.write(json.dumps(log_stats) + "\n")
+
+ # for evaluation logs
+ if coco_evaluator is not None:
+ (self.output_dir / "eval").mkdir(exist_ok=True)
+ if "bbox" in coco_evaluator.coco_eval:
+ filenames = ["latest.pth"]
+ if epoch % 50 == 0:
+ filenames.append(f"{epoch:03}.pth")
+ for name in filenames:
+ torch.save(
+ coco_evaluator.coco_eval["bbox"].eval,
+ self.output_dir / "eval" / name,
+ )
+
+ total_time = time.time() - start_time
+ total_time_str = str(datetime.timedelta(seconds=int(total_time)))
+ print("Training time {}".format(total_time_str))
+
+ def val(self):
+ self.eval()
+
+ module = self.ema.module if self.ema else self.model
+ test_stats, coco_evaluator = evaluate(
+ module,
+ self.criterion,
+ self.postprocessor,
+ self.val_dataloader,
+ self.evaluator,
+ self.device,
+ epoch=-1,
+ use_wandb=False,
+ )
+
+ if self.output_dir:
+ dist_utils.save_on_master(
+ coco_evaluator.coco_eval["bbox"].eval, self.output_dir / "eval.pth"
+ )
+
+ return
diff --git a/D-FINE/src/solver/validator.py b/D-FINE/src/solver/validator.py
new file mode 100644
index 0000000000000000000000000000000000000000..e38308cebf299c7e47b27e5094455f4d82c942ed
--- /dev/null
+++ b/D-FINE/src/solver/validator.py
@@ -0,0 +1,347 @@
+import copy
+from collections import defaultdict
+from pathlib import Path
+from typing import Dict, List
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+from loguru import logger
+from torchvision.ops import box_iou
+
+
+class Validator:
+ def __init__(
+ self,
+ gt: List[Dict[str, torch.Tensor]],
+ preds: List[Dict[str, torch.Tensor]],
+ conf_thresh=0.5,
+ iou_thresh=0.5,
+ ) -> None:
+ """
+ Format example:
+ gt = [{'labels': tensor([0]), 'boxes': tensor([[561.0, 297.0, 661.0, 359.0]])}, ...]
+ len(gt) is the number of images
+ bboxes are in format [x1, y1, x2, y2], absolute values
+ """
+ self.gt = gt
+ self.preds = preds
+ self.conf_thresh = conf_thresh
+ self.iou_thresh = iou_thresh
+ self.thresholds = np.arange(0.2, 1.0, 0.05)
+ self.conf_matrix = None
+
+ def compute_metrics(self, extended=False) -> Dict[str, float]:
+ filtered_preds = filter_preds(copy.deepcopy(self.preds), self.conf_thresh)
+ metrics = self._compute_main_metrics(filtered_preds)
+ if not extended:
+ metrics.pop("extended_metrics", None)
+ return metrics
+
+ def _compute_main_metrics(self, preds):
+ (
+ self.metrics_per_class,
+ self.conf_matrix,
+ self.class_to_idx,
+ ) = self._compute_metrics_and_confusion_matrix(preds)
+ tps, fps, fns = 0, 0, 0
+ ious = []
+ extended_metrics = {}
+ for key, value in self.metrics_per_class.items():
+ tps += value["TPs"]
+ fps += value["FPs"]
+ fns += value["FNs"]
+ ious.extend(value["IoUs"])
+
+ extended_metrics[f"precision_{key}"] = (
+ value["TPs"] / (value["TPs"] + value["FPs"])
+ if value["TPs"] + value["FPs"] > 0
+ else 0
+ )
+ extended_metrics[f"recall_{key}"] = (
+ value["TPs"] / (value["TPs"] + value["FNs"])
+ if value["TPs"] + value["FNs"] > 0
+ else 0
+ )
+
+ extended_metrics[f"iou_{key}"] = np.mean(value["IoUs"])
+
+ precision = tps / (tps + fps) if (tps + fps) > 0 else 0
+ recall = tps / (tps + fns) if (tps + fns) > 0 else 0
+ f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
+ iou = np.mean(ious).item() if ious else 0
+ return {
+ "f1": f1,
+ "precision": precision,
+ "recall": recall,
+ "iou": iou,
+ "TPs": tps,
+ "FPs": fps,
+ "FNs": fns,
+ "extended_metrics": extended_metrics,
+ }
+
+ def _compute_matrix_multi_class(self, preds):
+ metrics_per_class = defaultdict(lambda: {"TPs": 0, "FPs": 0, "FNs": 0, "IoUs": []})
+ for pred, gt in zip(preds, self.gt):
+ pred_boxes = pred["boxes"]
+ pred_labels = pred["labels"]
+ gt_boxes = gt["boxes"]
+ gt_labels = gt["labels"]
+
+ # isolate each class
+ labels = torch.unique(torch.cat([pred_labels, gt_labels]))
+ for label in labels:
+ pred_cl_boxes = pred_boxes[pred_labels == label] # filter by bool mask
+ gt_cl_boxes = gt_boxes[gt_labels == label]
+
+ n_preds = len(pred_cl_boxes)
+ n_gts = len(gt_cl_boxes)
+ if not (n_preds or n_gts):
+ continue
+ if not n_preds:
+ metrics_per_class[label.item()]["FNs"] += n_gts
+ metrics_per_class[label.item()]["IoUs"].extend([0] * n_gts)
+ continue
+ if not n_gts:
+ metrics_per_class[label.item()]["FPs"] += n_preds
+ metrics_per_class[label.item()]["IoUs"].extend([0] * n_preds)
+ continue
+
+ ious = box_iou(pred_cl_boxes, gt_cl_boxes) # matrix of all IoUs
+ ious_mask = ious >= self.iou_thresh
+
+ # indeces of boxes that have IoU >= threshold
+ pred_indices, gt_indices = torch.nonzero(ious_mask, as_tuple=True)
+
+ if not pred_indices.numel(): # no predicts matched gts
+ metrics_per_class[label.item()]["FNs"] += n_gts
+ metrics_per_class[label.item()]["IoUs"].extend([0] * n_gts)
+ metrics_per_class[label.item()]["FPs"] += n_preds
+ metrics_per_class[label.item()]["IoUs"].extend([0] * n_preds)
+ continue
+
+ iou_values = ious[pred_indices, gt_indices]
+
+ # sorting by IoU to match hgihest scores first
+ sorted_indices = torch.argsort(-iou_values)
+ pred_indices = pred_indices[sorted_indices]
+ gt_indices = gt_indices[sorted_indices]
+ iou_values = iou_values[sorted_indices]
+
+ matched_preds = set()
+ matched_gts = set()
+ for pred_idx, gt_idx, iou in zip(pred_indices, gt_indices, iou_values):
+ if gt_idx.item() not in matched_gts and pred_idx.item() not in matched_preds:
+ matched_preds.add(pred_idx.item())
+ matched_gts.add(gt_idx.item())
+ metrics_per_class[label.item()]["TPs"] += 1
+ metrics_per_class[label.item()]["IoUs"].append(iou.item())
+
+ unmatched_preds = set(range(n_preds)) - matched_preds
+ unmatched_gts = set(range(n_gts)) - matched_gts
+ metrics_per_class[label.item()]["FPs"] += len(unmatched_preds)
+ metrics_per_class[label.item()]["IoUs"].extend([0] * len(unmatched_preds))
+ metrics_per_class[label.item()]["FNs"] += len(unmatched_gts)
+ metrics_per_class[label.item()]["IoUs"].extend([0] * len(unmatched_gts))
+ return metrics_per_class
+
+ def _compute_metrics_and_confusion_matrix(self, preds):
+ # Initialize per-class metrics
+ metrics_per_class = defaultdict(lambda: {"TPs": 0, "FPs": 0, "FNs": 0, "IoUs": []})
+
+ # Collect all class IDs
+ all_classes = set()
+ for pred in preds:
+ all_classes.update(pred["labels"].tolist())
+ for gt in self.gt:
+ all_classes.update(gt["labels"].tolist())
+ all_classes = sorted(list(all_classes))
+ class_to_idx = {cls_id: idx for idx, cls_id in enumerate(all_classes)}
+ n_classes = len(all_classes)
+ conf_matrix = np.zeros((n_classes + 1, n_classes + 1), dtype=int) # +1 for background class
+
+ for pred, gt in zip(preds, self.gt):
+ pred_boxes = pred["boxes"]
+ pred_labels = pred["labels"]
+ gt_boxes = gt["boxes"]
+ gt_labels = gt["labels"]
+
+ n_preds = len(pred_boxes)
+ n_gts = len(gt_boxes)
+
+ if n_preds == 0 and n_gts == 0:
+ continue
+
+ ious = box_iou(pred_boxes, gt_boxes) if n_preds > 0 and n_gts > 0 else torch.tensor([])
+ # Assign matches between preds and gts
+ matched_pred_indices = set()
+ matched_gt_indices = set()
+
+ if ious.numel() > 0:
+ # For each pred box, find the gt box with highest IoU
+ ious_mask = ious >= self.iou_thresh
+ pred_indices, gt_indices = torch.nonzero(ious_mask, as_tuple=True)
+ iou_values = ious[pred_indices, gt_indices]
+
+ # Sorting by IoU to match highest scores first
+ sorted_indices = torch.argsort(-iou_values)
+ pred_indices = pred_indices[sorted_indices]
+ gt_indices = gt_indices[sorted_indices]
+ iou_values = iou_values[sorted_indices]
+
+ for pred_idx, gt_idx, iou in zip(pred_indices, gt_indices, iou_values):
+ if (
+ pred_idx.item() in matched_pred_indices
+ or gt_idx.item() in matched_gt_indices
+ ):
+ continue
+ matched_pred_indices.add(pred_idx.item())
+ matched_gt_indices.add(gt_idx.item())
+
+ pred_label = pred_labels[pred_idx].item()
+ gt_label = gt_labels[gt_idx].item()
+
+ pred_cls_idx = class_to_idx[pred_label]
+ gt_cls_idx = class_to_idx[gt_label]
+
+ # Update confusion matrix
+ conf_matrix[gt_cls_idx, pred_cls_idx] += 1
+
+ # Update per-class metrics
+ if pred_label == gt_label:
+ metrics_per_class[gt_label]["TPs"] += 1
+ metrics_per_class[gt_label]["IoUs"].append(iou.item())
+ else:
+ # Misclassification
+ metrics_per_class[gt_label]["FNs"] += 1
+ metrics_per_class[pred_label]["FPs"] += 1
+ metrics_per_class[gt_label]["IoUs"].append(0)
+ metrics_per_class[pred_label]["IoUs"].append(0)
+
+ # Unmatched predictions (False Positives)
+ unmatched_pred_indices = set(range(n_preds)) - matched_pred_indices
+ for pred_idx in unmatched_pred_indices:
+ pred_label = pred_labels[pred_idx].item()
+ pred_cls_idx = class_to_idx[pred_label]
+ # Update confusion matrix: background row
+ conf_matrix[n_classes, pred_cls_idx] += 1
+ # Update per-class metrics
+ metrics_per_class[pred_label]["FPs"] += 1
+ metrics_per_class[pred_label]["IoUs"].append(0)
+
+ # Unmatched ground truths (False Negatives)
+ unmatched_gt_indices = set(range(n_gts)) - matched_gt_indices
+ for gt_idx in unmatched_gt_indices:
+ gt_label = gt_labels[gt_idx].item()
+ gt_cls_idx = class_to_idx[gt_label]
+ # Update confusion matrix: background column
+ conf_matrix[gt_cls_idx, n_classes] += 1
+ # Update per-class metrics
+ metrics_per_class[gt_label]["FNs"] += 1
+ metrics_per_class[gt_label]["IoUs"].append(0)
+
+ return metrics_per_class, conf_matrix, class_to_idx
+
+ def save_plots(self, path_to_save) -> None:
+ path_to_save = Path(path_to_save)
+ path_to_save.mkdir(parents=True, exist_ok=True)
+
+ if self.conf_matrix is not None:
+ class_labels = [str(cls_id) for cls_id in self.class_to_idx.keys()] + ["background"]
+
+ plt.figure(figsize=(10, 8))
+ plt.imshow(self.conf_matrix, interpolation="nearest", cmap=plt.cm.Blues)
+ plt.title("Confusion Matrix")
+ plt.colorbar()
+ tick_marks = np.arange(len(class_labels))
+ plt.xticks(tick_marks, class_labels, rotation=45)
+ plt.yticks(tick_marks, class_labels)
+
+ # Add labels to each cell
+ thresh = self.conf_matrix.max() / 2.0
+ for i in range(self.conf_matrix.shape[0]):
+ for j in range(self.conf_matrix.shape[1]):
+ plt.text(
+ j,
+ i,
+ format(self.conf_matrix[i, j], "d"),
+ horizontalalignment="center",
+ color="white" if self.conf_matrix[i, j] > thresh else "black",
+ )
+
+ plt.ylabel("True label")
+ plt.xlabel("Predicted label")
+ plt.tight_layout()
+ plt.savefig(path_to_save / "confusion_matrix.png")
+ plt.close()
+
+ thresholds = self.thresholds
+ precisions, recalls, f1_scores = [], [], []
+
+ # Store the original predictions to reset after each threshold
+ original_preds = copy.deepcopy(self.preds)
+
+ for threshold in thresholds:
+ # Filter predictions based on the current threshold
+ filtered_preds = filter_preds(copy.deepcopy(original_preds), threshold)
+ # Compute metrics with the filtered predictions
+ metrics = self._compute_main_metrics(filtered_preds)
+ precisions.append(metrics["precision"])
+ recalls.append(metrics["recall"])
+ f1_scores.append(metrics["f1"])
+
+ # Plot Precision and Recall vs Threshold
+ plt.figure()
+ plt.plot(thresholds, precisions, label="Precision", marker="o")
+ plt.plot(thresholds, recalls, label="Recall", marker="o")
+ plt.xlabel("Threshold")
+ plt.ylabel("Value")
+ plt.title("Precision and Recall vs Threshold")
+ plt.legend()
+ plt.grid(True)
+ plt.savefig(path_to_save / "precision_recall_vs_threshold.png")
+ plt.close()
+
+ # Plot F1 Score vs Threshold
+ plt.figure()
+ plt.plot(thresholds, f1_scores, label="F1 Score", marker="o")
+ plt.xlabel("Threshold")
+ plt.ylabel("F1 Score")
+ plt.title("F1 Score vs Threshold")
+ plt.grid(True)
+ plt.savefig(path_to_save / "f1_score_vs_threshold.png")
+ plt.close()
+
+ # Find the best threshold based on F1 Score (last occurence)
+ best_idx = len(f1_scores) - np.argmax(f1_scores[::-1]) - 1
+ best_threshold = thresholds[best_idx]
+ best_f1 = f1_scores[best_idx]
+
+ logger.info(
+ f"Best Threshold: {round(best_threshold, 2)} with F1 Score: {round(best_f1, 3)}"
+ )
+
+
+def filter_preds(preds, conf_thresh):
+ for pred in preds:
+ keep_idxs = pred["scores"] >= conf_thresh
+ pred["scores"] = pred["scores"][keep_idxs]
+ pred["boxes"] = pred["boxes"][keep_idxs]
+ pred["labels"] = pred["labels"][keep_idxs]
+ return preds
+
+
+def scale_boxes(boxes, orig_shape, resized_shape):
+ """
+ boxes in format: [x1, y1, x2, y2], absolute values
+ orig_shape: [height, width]
+ resized_shape: [height, width]
+ """
+ scale_x = orig_shape[1] / resized_shape[1]
+ scale_y = orig_shape[0] / resized_shape[0]
+ boxes[:, 0] *= scale_x
+ boxes[:, 2] *= scale_x
+ boxes[:, 1] *= scale_y
+ boxes[:, 3] *= scale_y
+ return boxes
diff --git a/D-FINE/src/zoo/__init__.py b/D-FINE/src/zoo/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..de38c3ace1f5fd5cebed2f8b06ba19f628db36eb
--- /dev/null
+++ b/D-FINE/src/zoo/__init__.py
@@ -0,0 +1,6 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from . import dfine
diff --git a/D-FINE/src/zoo/dfine/__init__.py b/D-FINE/src/zoo/dfine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f61af2a46ee7713025048097b6774a4e012d2751
--- /dev/null
+++ b/D-FINE/src/zoo/dfine/__init__.py
@@ -0,0 +1,11 @@
+"""
+Copied from RT-DETR (https://github.com/lyuwenyu/RT-DETR)
+Copyright(c) 2023 lyuwenyu. All Rights Reserved.
+"""
+
+from .dfine import DFINE
+from .dfine_criterion import DFINECriterion
+from .dfine_decoder import DFINETransformer
+from .hybrid_encoder import HybridEncoder
+from .matcher import HungarianMatcher
+from .postprocessor import DFINEPostProcessor
diff --git a/D-FINE/src/zoo/dfine/blog.md b/D-FINE/src/zoo/dfine/blog.md
new file mode 100644
index 0000000000000000000000000000000000000000..24abf573b3e9c73151932bfb977dd4e47c3a92f9
--- /dev/null
+++ b/D-FINE/src/zoo/dfine/blog.md
@@ -0,0 +1,90 @@
+English Blog | [中文博客](blog_cn.md)
+
+## 🔥 Revolutionizing Real-Time Object Detection: D-FINE vs. YOLO and Other DETR Models
+
+In the rapidly evolving field of real-time object detection, **D-FINE** emerges as a revolutionary approach that significantly surpasses existing models like **YOLOv10**, **YOLO11**, and **RT-DETR v1/v2/v3**, raising the performance ceiling for real-time object detection. After pretraining on the large-scale dataset Objects365, **D-FINE** far exceeds its competitor **LW-DETR**, achieving up to **59.3%** AP on the COCO dataset while maintaining excellent frame rates, parameter counts, and computational complexity. This positions **D-FINE** as a leader in the realm of real-time object detection, laying the groundwork for future research advancements.
+
+Currently, all code, weights, logs, compilation tools, and the FiftyOne visualization tool for **D-FINE** have been fully open-sourced, thanks to the codebase provided by **RT-DETR**. This includes pretraining tutorials, custom dataset tutorials, and more. We will continue to update with improvement insights and tuning strategies. We welcome everyone to raise issues and collectively promote the **D-FINE** series. We also hope you can leave a ⭐; it's the best encouragement for us.
+
+**GitHub Repo**: https://github.com/Peterande/D-FINE
+
+**ArXiv Paper**: https://arxiv.org/abs/2410.13842
+
+---
+
+### 🔍 Exploring the Key Innovations Behind D-FINE
+
+**D-FINE** redefines the regression task in DETR-based object detectors as **FDR**, and based on this, develops a performance-enhancing self-distillation mechanism **GO-LSD**. Below is a brief introduction to **FDR** and **GO-LSD**:
+
+#### **FDR (Fine-grained Distribution Refinement)** Decouples the Bounding Box Generation Process:
+
+1. **Initial Box Prediction**: Similar to traditional DETR methods, the decoder of **D-FINE** transforms object queries into several initial bounding boxes in the first layer. These boxes do not need to be highly accurate and serve only as an initialization.
+2. **Fine-Grained Distribution Optimization**: Unlike traditional methods that directly decode new bounding boxes, **D-FINE** generates four sets of probability distributions based on these initial bounding boxes in the decoder layers and iteratively optimizes these distributions layer by layer. These distributions essentially act as a "fine-grained intermediate representation" of the detection boxes. Coupled with a carefully designed weighting function **W(n)**, **D-FINE** can adjust the initial bounding boxes by fine-tuning these representations, allowing for subtle modifications or significant shifts of the edges (top, bottom, left, right). The specific process is illustrated in the figure:
+
+
+
+
+
+For readability, we will not elaborate on the mathematical formulas and the Fine-Grained Localization (FGL) Loss that aids optimization here. Interested readers can refer to the original paper for derivations.
+
+The main advantages of redefining the bounding box regression task as **FDR** are:
+
+1. **Simplified Supervision**: While optimizing detection boxes using traditional L1 loss and IoU loss, the "residual" between labels and predictions can be additionally used to constrain these intermediate probability distributions. This allows each decoder layer to more effectively focus on and address the localization errors it currently faces. As the number of layers increases, their optimization objectives become progressively simpler, thereby simplifying the overall optimization process.
+
+2. **Robustness in Complex Scenarios**: The values of these probability distributions inherently represent the confidence level of fine-tuning for each edge. This enables **D-FINE** to independently model the uncertainty of each edge at different network depths, thereby exhibiting stronger robustness in complex real-world scenarios such as occlusion, motion blur, and low-light conditions, compared to directly regressing four fixed values.
+
+3. **Flexible Optimization Mechanism**: The probability distributions are transformed into final bounding box offsets through a weighted sum. The carefully designed weighting function ensures fine-grained adjustments when the initial box is accurate and provides significant corrections when necessary.
+
+4. **Research Potential and Scalability**: By transforming the regression task into a probability distribution prediction problem consistent with classification tasks, **FDR** not only enhances compatibility with other tasks but also enables object detection models to benefit from innovations in areas such as knowledge distillation, multi-task learning, and distribution optimization, opening new avenues for future research.
+
+---
+
+#### **GO-LSD (Global Optimal Localization Self-Distillation)** Integrates Knowledge Distillation into FDR-Based Detectors Seamlessly
+
+Based on the above, object detectors equipped with the **FDR** framework satisfy the following two points:
+
+1. **Ability to Achieve Knowledge Transfer**: As Hinton mentioned in the paper *"Distilling the Knowledge in a Neural Network"*, probabilities are "knowledge." The network's output becomes probability distributions, and these distributions carry localization knowledge. By calculating the KLD loss, this "knowledge" can be transferred from deeper layers to shallower layers. This is something that traditional fixed box representations (Dirac δ functions) cannot achieve.
+
+2. **Consistent Optimization Objectives**: Since each decoder layer in the **FDR** framework shares a common goal: reducing the residual between the initial bounding box and the ground truth bounding box, the precise probability distributions generated by the final layer can serve as the ultimate target for each preceding layer and guide them through distillation.
+
+Thus, based on **FDR**, we propose **GO-LSD (Global Optimal Localization Self-Distillation)**. By implementing localization knowledge distillation between network layers, we further extend the capabilities of **D-FINE**. The specific process is illustrated in the figure:
+
+
+
+
+
+Similarly, for readability, we will not elaborate on the mathematical formulas and the Decoupled Distillation Focal (DDF) Loss that aids optimization here. Interested readers can refer to the original paper for derivations.
+
+This results in a synergistic win-win effect: as training progresses, the predictions of the final layer become increasingly accurate, and its generated soft labels can better help the preceding layers improve prediction accuracy. Conversely, the earlier layers learn to localize accurately more quickly, simplifying the optimization tasks of the deeper layers and further enhancing overall accuracy.
+
+---
+
+### Visualization of D-FINE Predictions
+
+The following visualization showcases **D-FINE**'s predictions in various complex detection scenarios. These scenarios include occlusion, low-light conditions, motion blur, depth-of-field effects, and densely populated scenes. Despite these challenges, **D-FINE** still produces accurate localization results.
+
+
+
+
+
+Additionally, the visualization below shows the prediction results of the first layer and the last layer, the corresponding distributions of the four edges, and the weighted distributions. It can be seen that the localization of the predicted boxes becomes more precise as the distributions are optimized.
+
+
+
+
+
+---
+
+### Frequently Asked Questions
+
+#### Question 1: Will FDR and GO-LSD increase the inference cost?
+
+**Answer**: No, FDR and the original prediction have almost no difference in speed, parameter count, and computational complexity, making it a seamless replacement.
+
+#### Question 2: Will FDR and GO-LSD increase the training cost?
+
+**Answer**: The increase in training cost mainly comes from how to generate the labels of the distributions. We have optimized this process, keeping the increase in training time and memory consumption to 6% and 2%, respectively, making it almost negligible.
+
+#### Question 3: Why is D-FINE faster and more lightweight than the RT-DETR series?
+
+**Answer**: Directly applying FDR and GO-LSD will significantly improve performance but will not make the network faster or lighter. Therefore, we performed a series of lightweight optimizations on RT-DETR. These adjustments led to a performance drop, but our methods compensated for these losses, achieving a perfect balance of speed, parameters, computational complexity, and performance.
diff --git a/D-FINE/src/zoo/dfine/blog_cn.md b/D-FINE/src/zoo/dfine/blog_cn.md
new file mode 100644
index 0000000000000000000000000000000000000000..04fd5df3af45605db32adfa02fab74bf4259267d
--- /dev/null
+++ b/D-FINE/src/zoo/dfine/blog_cn.md
@@ -0,0 +1,90 @@
+[English Blog](blog.md) | 中文博客
+
+## 🔥 革新实时目标检测:D-FINE 与 YOLO 和其他 DETR 模型的对比
+
+在快速发展的实时目标检测领域,**D-FINE** 作为一项革命性的方法,显著超越了现有模型(如 **YOLOv10**、**YOLO11** 及 **RT-DETR v1/v2/v3**),提升了实时目标检测的性能上限。经过大规模数据集 Objects365 的预训练,**D-FINE** 远超其竞争对手 **LW-DETR**,在 COCO 数据集上实现了高达 **59.3%** 的 AP,同时保持了卓越的帧率、参数量和计算复杂度。这使得 **D-FINE** 成为实时目标检测领域的佼佼者,为未来的研究奠定了基础。
+
+目前,D-FINE 的所有代码、权重、日志、编译工具,以及 FiftyOne 可视化工具已经全部开源,感谢 RT-DETR 提供的 codebase。其中还包括了预训练教程、自定义数据集教程等。之后还会陆续更新一些改进心得和调参攻略,欢迎大家多提 issue,共同将 D-FINE 系列发扬光大。同时希望您能随手留下一颗 ⭐,这是对我们最好的鼓励。
+
+**Github Repo**: https://github.com/Peterande/D-FINE
+
+**Arxiv Paper**: https://arxiv.org/abs/2410.13842
+
+---
+
+### 🔍 探索 D-FINE 背后的关键创新
+
+**D-FINE** 将基于 DETR 的目标检测器中的回归任务重新定义为 FDR,并在此基础上开发出了无感提升性能的自蒸馏机制 GO-LSD。下面对 FDR 和 GO-LSD 进行简要介绍:
+
+#### FDR (Fine-grained Distribution Refinement) 将检测框的生成过程拆解为:
+
+1. **初始框预测**:与传统 DETR 方法类似,**D-FINE** 的解码器 (decoder) 会在第一层将 object queries 转变为若干个初始的边界框,这些框不需要特别精准,仅作为一种初始化。
+2. **细粒度的分布优化**:**D-FINE** 解码层不会像传统方法那样直接解码出新的边界框,而是基于这些初始化的边界框,生成四组概率分布;并迭代地对这四组概率分布进行逐层优化。这些分布本质上是作为检测框的一种“细粒度中间表征”;配合精心设计的加权函数 W(n),**D-FINE** 能够通过微调这些表征来实现对初始边界框的调整,包含对其上下左右边缘进行细微的小幅度修正亦或是大幅度的搬移,具体的流程如图:
+
+
 +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+ +
+ +
+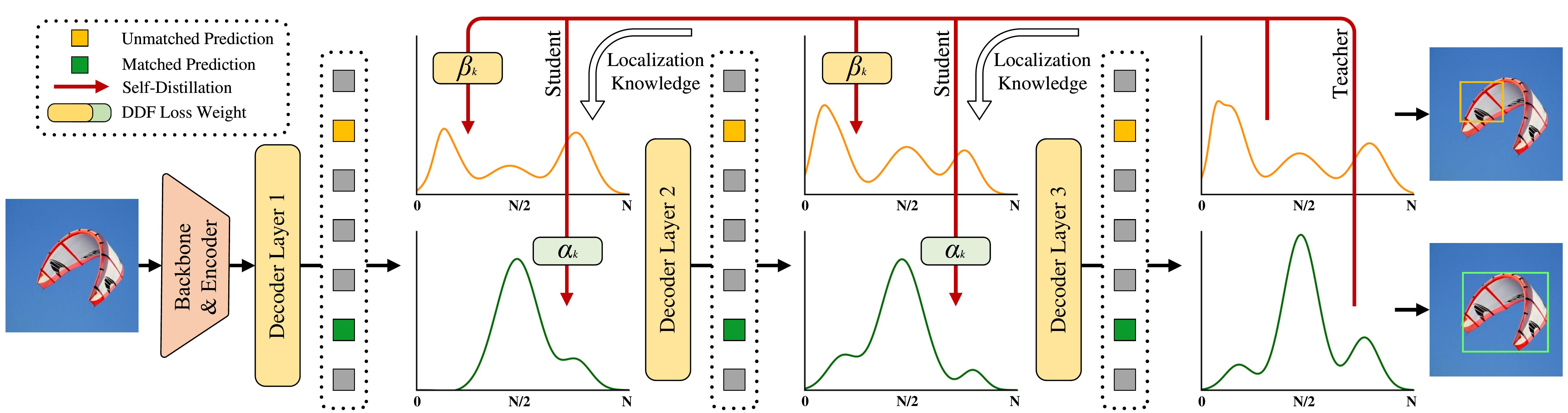 +
+ +
+ +
+