Spaces:
Build error

Build error
| import gradio as gr | |
| import transformers | |
| from simpletransformers.classification import ClassificationModel, ClassificationArgs | |
| import torch | |
| import json | |
| # load all models | |
| deep_scc_model_args = ClassificationArgs(num_train_epochs=10,max_seq_length=300,use_multiprocessing=False) | |
| deep_scc_model = ClassificationModel("roberta", "NTUYG/DeepSCC-RoBERTa", num_labels=19, args=deep_scc_model_args, use_cuda=False) | |
| pragformer = transformers.AutoModel.from_pretrained("Pragformer/PragFormer", trust_remote_code=True) | |
| pragformer_private = transformers.AutoModel.from_pretrained("Pragformer/PragFormer_private", trust_remote_code=True) | |
| pragformer_reduction = transformers.AutoModel.from_pretrained("Pragformer/PragFormer_reduction", trust_remote_code=True) | |
| #Event Listeners | |
| with_omp_str = 'Should contain a parallel work-sharing loop construct' | |
| without_omp_str = 'Should not contain a parallel work-sharing loop construct' | |
| name_file = ['bash', 'c', 'c#', 'c++','css', 'haskell', 'java', 'javascript', 'lua', 'objective-c', 'perl', 'php', 'python','r','ruby', 'scala', 'sql', 'swift', 'vb.net'] | |
| tokenizer = transformers.AutoTokenizer.from_pretrained('NTUYG/DeepSCC-RoBERTa') | |
| with open('./HF_Pragformer/c_data.json', 'r') as f: | |
| data = json.load(f) | |
| def fill_code(code_pth): | |
| pragma = data[code_pth]['pragma'] | |
| code = data[code_pth]['code'] | |
| return 'None' if len(pragma)==0 else pragma, code | |
| def predict(code_txt): | |
| code = code_txt.lstrip().rstrip() | |
| tokenized = tokenizer.batch_encode_plus( | |
| [code], | |
| max_length = 150, | |
| pad_to_max_length = True, | |
| truncation = True | |
| ) | |
| pred = pragformer(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask'])) | |
| y_hat = torch.argmax(pred).item() | |
| return with_omp_str if y_hat==1 else without_omp_str, torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item() | |
| def is_private(code_txt): | |
| if predict(code_txt)[0] == without_omp_str: | |
| return gr.update(visible=False) | |
| code = code_txt.lstrip().rstrip() | |
| tokenized = tokenizer.batch_encode_plus( | |
| [code], | |
| max_length = 150, | |
| pad_to_max_length = True, | |
| truncation = True | |
| ) | |
| pred = pragformer_private(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask'])) | |
| y_hat = torch.argmax(pred).item() | |
| # if y_hat == 0: | |
| # return gr.update(visible=False) | |
| # else: | |
| return gr.update(value=f"Should {'not' if y_hat==0 else ''} contain private with confidence: {torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()}", visible=True) | |
| def is_reduction(code_txt): | |
| if predict(code_txt)[0] == without_omp_str: | |
| return gr.update(visible=False) | |
| code = code_txt.lstrip().rstrip() | |
| tokenized = tokenizer.batch_encode_plus( | |
| [code], | |
| max_length = 150, | |
| pad_to_max_length = True, | |
| truncation = True | |
| ) | |
| pred = pragformer_reduction(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask'])) | |
| y_hat = torch.argmax(pred).item() | |
| # if y_hat == 0: | |
| # return gr.update(visible=False) | |
| # else: | |
| return gr.update(value=f"Should {'not' if y_hat==0 else ''} contain reduction with confidence: {torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()}", visible=True) | |
| def lang_predict(code_txt): | |
| res = {} | |
| code = code_txt.replace('\n',' ').replace('\r',' ') | |
| predictions, raw_outputs = deep_scc_model.predict([code]) | |
| # preds = [name_file[predictions[i]] for i in range(5)] | |
| softmax_vals = torch.nn.Softmax(dim=1)(torch.tensor(raw_outputs)) | |
| top5 = torch.topk(softmax_vals, 5) | |
| for lang_idx, conf in zip(top5.indices.flatten(), top5.values.flatten()): | |
| res[name_file[lang_idx.item()]] = conf.item() | |
| return '\n'.join([f" {'V ' if k=='c' else 'X'}{k}: {v}" for k,v in res.items()]) | |
| # Define GUI | |
| with gr.Blocks() as pragformer_gui: | |
| gr.Markdown( | |
| """ | |
| # PragFormer Pragma Classifiction | |
| """) | |
| #with gr.Row(equal_height=True): | |
| with gr.Column(): | |
| gr.Markdown("## Input") | |
| with gr.Row(): | |
| with gr.Column(): | |
| drop = gr.Dropdown(list(data.keys()), label="Mix of parallel and not-parallel code snippets", value="Minyoung-Kim1110/OpenMP/Excercise/atomic/0") | |
| sample_btn = gr.Button("Sample") | |
| pragma = gr.Textbox(label="Original parallelization classification (if any)") | |
| with gr.Row(): | |
| code_in = gr.Textbox(lines=5, label="Write some C code and see if it should contain a parallel work-sharing loop construct") | |
| lang_pred = gr.Textbox(lines=5, label="DeepScc programming language prediction") | |
| submit_btn = gr.Button("Submit") | |
| with gr.Column(): | |
| gr.Markdown("## Results") | |
| with gr.Row(): | |
| label_out = gr.Textbox(label="Label") | |
| confidence_out = gr.Textbox(label="Confidence") | |
| with gr.Row(): | |
| private = gr.Textbox(label="Data-sharing attribute clause- private", visible=False) | |
| reduction = gr.Textbox(label="Data-sharing attribute clause- reduction", visible=False) | |
| code_in.change(fn=lang_predict, inputs=code_in, outputs=lang_pred) | |
| submit_btn.click(fn=predict, inputs=code_in, outputs=[label_out, confidence_out]) | |
| submit_btn.click(fn=is_private, inputs=code_in, outputs=private) | |
| submit_btn.click(fn=is_reduction, inputs=code_in, outputs=reduction) | |
| sample_btn.click(fn=fill_code, inputs=drop, outputs=[pragma, code_in]) | |
| gr.Markdown( | |
| """ | |
| ## How it Works? | |
| To use the PragFormer tool, you will need to input a C language for-loop. You can either write your own code or use the samples | |
| provided in the dropdown menu, which have been gathered from GitHub. Once you submit the code, the PragFormer model will analyze | |
| it and predict whether the for-loop should be parallelized using OpenMP. If the PragFormer model determines that parallelization | |
| is necessary, two additional models will be used to determine if adding specific data-sharing attributes, such as ***private*** or ***reduction*** clauses, is needed. | |
| ***private***- Specifies that each thread should have its own instance of a variable. | |
| ***reduction***- Specifies that one or more variables that are private to each thread are the subject of a reduction operation at | |
| the end of the parallel region. | |
| ## Description | |
| In past years, the world has switched to many-core and multi-core shared memory architectures. | |
| As a result, there is a growing need to utilize these architectures by introducing shared memory parallelization schemes to software applications. | |
| OpenMP is the most comprehensive API that implements such schemes, characterized by a readable interface. | |
| Nevertheless, introducing OpenMP into code, especially legacy code, is challenging due to pervasive pitfalls in management of parallel shared memory. | |
| To facilitate the performance of this task, many source-to-source (S2S) compilers have been created over the years, tasked with inserting OpenMP directives into | |
| code automatically. | |
| In addition to having limited robustness to their input format, these compilers still do not achieve satisfactory coverage and precision in locating parallelizable | |
| code and generating appropriate directives. | |
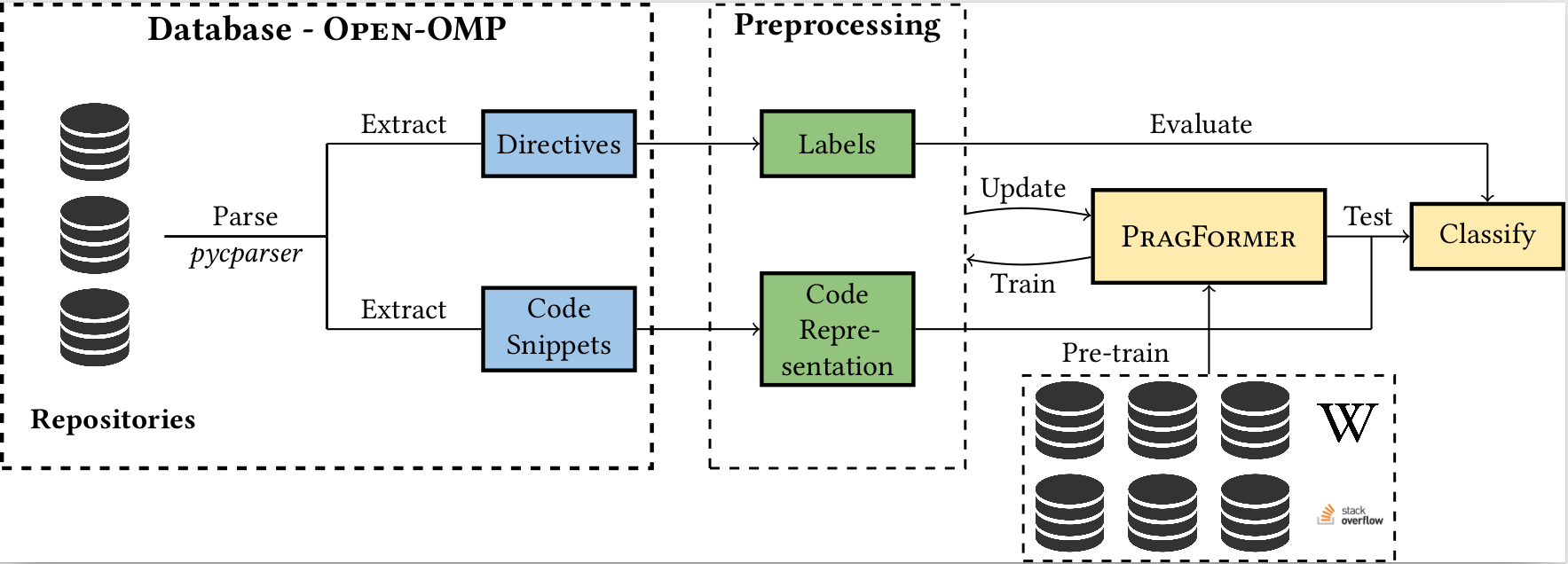
| In this work, we propose leveraging recent advances in machine learning techniques, specifically in natural language processing (NLP), to replace S2S compilers altogether. | |
| We create a database (corpus), OpenMP-OMP specifically for this goal. | |
| OpenMP-OMP contains over 28,000 code snippets, half of which contain OpenMP directives while the other half do not need parallelization at all with high probability. | |
| We use the corpus to train systems to automatically classify code segments in need of parallelization, as well as suggest individual OpenMP clauses. | |
| We train several transformer models, named PragFormer, for these tasks, and show that they outperform statistically-trained baselines and automatic S2S parallelization | |
| compilers in both classifying the overall need for an OpenMP directive and the introduction of private and reduction clauses. | |
|  | |
| """) | |
| pragformer_gui.launch() | |