Spaces:
Sleeping

Sleeping
File size: 18,109 Bytes
33d4721 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 |
# LLM Finetuning with AutoTrain Advanced
AutoTrain Advanced makes it easy to fine-tune large language models (LLMs) for your specific use cases. This guide covers everything you need to know about LLM fine-tuning.
## Key Features
- Simple data preparation with CSV and JSONL formats
- Support for multiple training approaches (SFT, DPO, ORPO)
- Built-in chat templates
- Local and cloud training options
- Optimized training parameters
## Supported Training Methods
AutoTrain supports multiple specialized trainers:
- `llm`: Generic LLM trainer
- `llm-sft`: Supervised Fine-Tuning trainer
- `llm-reward`: Reward modeling trainer
- `llm-dpo`: Direct Preference Optimization trainer
- `llm-orpo`: ORPO (Optimal Reward Policy Optimization) trainer
## Data Preparation
LLM finetuning accepts data in CSV and JSONL formats. JSONL is the preferred format.
How data is formatted depends on the task you are training the LLM for.
### Classic Text Generation
For text generation, the data should be in the following format:
| text |
|---------------------------------------------------------------|
| wikipedia is a free online encyclopedia |
| it is a collaborative project |
| that anyone can edit |
| wikipedia is the largest and most popular general reference work on the internet |
An example dataset for this format can be found here: [stas/openwebtext-10k](https://huggingface.co/datasets/stas/openwebtext-10k)
Example tasks:
- Text generation
- Code completion
Compatible trainers:
- SFT Trainer
- Generic Trainer
### Chatbot / question-answering / code generation / function calling
For this task, you can use CSV or JSONL data. If you are formatting the data yourself (adding start, end tokens, etc.), you can use CSV or JSONL format.
If you do not want to format the data yourself and want `--chat-template` parameter to format the data for you, you must use JSONL format.
In both cases, CSV and JSONL can be used interchangeably but JSONL is the most preferred format.
To train a chatbot, your data will have `content` and `role`. Some models support `system` role as well.
Here is an example of a chatbot dataset (single sample):
```
[{'content': 'Help write a letter of 100 -200 words to my future self for '
'Kyra, reflecting on her goals and aspirations.',
'role': 'user'},
{'content': 'Dear Future Self,\n'
'\n'
"I hope you're happy and proud of what you've achieved. As I "
"write this, I'm excited to think about our goals and how far "
"you've come. One goal was to be a machine learning engineer. I "
"hope you've worked hard and become skilled in this field. Keep "
'learning and innovating. Traveling was important to us. I hope '
"you've seen different places and enjoyed the beauty of our "
'world. Remember the memories and lessons. Starting a family '
'mattered to us. If you have kids, treasure every moment. Be '
'patient, loving, and grateful for your family.\n'
'\n'
'Take care of yourself. Rest, reflect, and cherish the time you '
'spend with loved ones. Remember your dreams and celebrate what '
"you've achieved. Your determination brought you here. I'm "
"excited to see the person you've become, the impact you've made, "
'and the love and joy in your life. Embrace opportunities and '
'keep dreaming big.\n'
'\n'
'With love,\n'
'Kyra',
'role': 'assistant'}]
```
As you can see, the data has `content` and `role` columns. The `role` column can be `user` or `assistant` or `system`.
This data is, however, not formatted for training. You can use the `--chat-template` parameter to format the data during training.
`--chat-template` supports the following kinds of templates:
- `none` (default)
- `zephyr`
- `chatml`
- `tokenizer`: use chat template mentioned in tokenizer config
A multi-line sample is also shown below:
```json
[{"content": "hello", "role": "user"}, {"content": "hi nice to meet you", "role": "assistant"}]
[{"content": "how are you", "role": "user"}, {"content": "I am fine", "role": "assistant"}]
[{"content": "What is your name?", "role": "user"}, {"content": "My name is Mary", "role": "assistant"}]
[{"content": "Which is the best programming language?", "role": "user"}, {"content": "Python", "role": "assistant"}]
.
.
.
```
An example dataset for this format can be found here: [HuggingFaceH4/no_robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots)
If you dont want to format the data using `--chat-template`, you can format the data yourself and use the following format:
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHelp write a letter of 100 -200 words to my future self for Kyra, reflecting on her goals and aspirations.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nDear Future Self,\n\nI hope you're happy and proud of what you've achieved. As I write this, I'm excited to think about our goals and how far you've come. One goal was to be a machine learning engineer. I hope you've worked hard and become skilled in this field. Keep learning and innovating. Traveling was important to us. I hope you've seen different places and enjoyed the beauty of our world. Remember the memories and lessons. Starting a family mattered to us. If you have kids, treasure every moment. Be patient, loving, and grateful for your family.\n\nTake care of yourself. Rest, reflect, and cherish the time you spend with loved ones. Remember your dreams and celebrate what you've achieved. Your determination brought you here. I'm excited to see the person you've become, the impact you've made, and the love and joy in your life. Embrace opportunities and keep dreaming big.\n\nWith love,\nKyra<|eot_id|>
```
A sample multi-line dataset is shown below:
```json
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhello<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nhi nice to meet you<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhow are you<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nI am fine<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat is your name?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nMy name is Mary<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhich is the best programming language?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nPython<|eot_id|>"}]
.
.
.
```
An example dataset for this format can be found here: [timdettmers/openassistant-guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco)
In the examples above, we have seen only two turns: one from the user and one from the assistant. However, you can have multiple turns from the user and assistant in a single sample.
Chat models can be trained using the following trainers:
- SFT Trainer:
- requires only `text` column
- example dataset: [HuggingFaceH4/no_robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots)
- Generic Trainer:
- requires only `text` column
- example dataset: [HuggingFaceH4/no_robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots)
- Reward Trainer:
- requires `text` and `rejected_text` columns
- example dataset: [trl-lib/ultrafeedback_binarized](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized)
- DPO Trainer:
- requires `prompt`, `text`, and `rejected_text` columns
- example dataset: [trl-lib/ultrafeedback_binarized](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized)
- ORPO Trainer:
- requires `prompt`, `text`, and `rejected_text` columns
- example dataset: [trl-lib/ultrafeedback_binarized](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized)
The only difference between the data format for reward trainer and DPO/ORPO trainer is that the reward trainer requires only `text` and `rejected_text` columns, while the DPO/ORPO trainer requires an additional `prompt` column.
## Best Practices for LLM Fine-tuning
### Memory Optimization
- Use appropriate `block_size` and `model_max_length` for your hardware
- Enable mixed precision training when possible
- Utilize PEFT techniques for large models
### Data Quality
- Clean and validate your training data
- Ensure balanced conversation samples
- Use appropriate chat templates
### Training Tips
- Start with small learning rates
- Monitor training metrics using tensorboard
- Validate model outputs during training
### Related Resources
- [AutoTrain Documentation](https://huggingface.co/docs/autotrain)
- [Example Fine-tuned Models](https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads)
- [Training Datasets](https://huggingface.co/datasets?task_categories=task_categories:text-generation)
## Training
### Local Training
Locally the training can be performed by using `autotrain --config config.yaml` command. The `config.yaml` file should contain the following parameters:
```yaml
task: llm-orpo
base_model: meta-llama/Meta-Llama-3-8B-Instruct
project_name: autotrain-llama3-8b-orpo
log: tensorboard
backend: local
data:
path: argilla/distilabel-capybara-dpo-7k-binarized
train_split: train
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt
params:
block_size: 1024
model_max_length: 8192
max_prompt_length: 512
epochs: 3
batch_size: 2
lr: 3e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 4
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
```
In the above config file, we are training a model using the ORPO trainer.
The model is trained on the `meta-llama/Meta-Llama-3-8B-Instruct` model.
The data is `argilla/distilabel-capybara-dpo-7k-binarized` dataset. The `chat_template` parameter is set to `chatml`.
The `column_mapping` parameter is used to map the columns in the dataset to the required columns for the ORPO trainer.
The `params` section contains the training parameters such as `block_size`, `model_max_length`, `epochs`, `batch_size`, `lr`, `peft`, `quantization`, `target_modules`, `padding`, `optimizer`, `scheduler`, `gradient_accumulation`, and `mixed_precision`.
The `hub` section contains the username and token for the Hugging Face account and the `push_to_hub` parameter is set to `true` to push the trained model to the Hugging Face Hub.
If you have training file locally, you can change data part to:
```yaml
data:
path: path/to/training/file
train_split: train # name of the training file
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt
```
The above assumes you have `train.csv` or `train.jsonl` in the `path/to/training/file` directory and you will be applying `chatml` template to the data.
You can run the training using the following command:
```bash
$ autotrain --config config.yaml
```
More example config files for finetuning different types of lllm and different tasks can be found in the [here](https://github.com/huggingface/autotrain-advanced/tree/main/configs/llm_finetuning).
### Training in Hugging Face Spaces
If you are training in Hugging Face Spaces, everything is the same as local training:
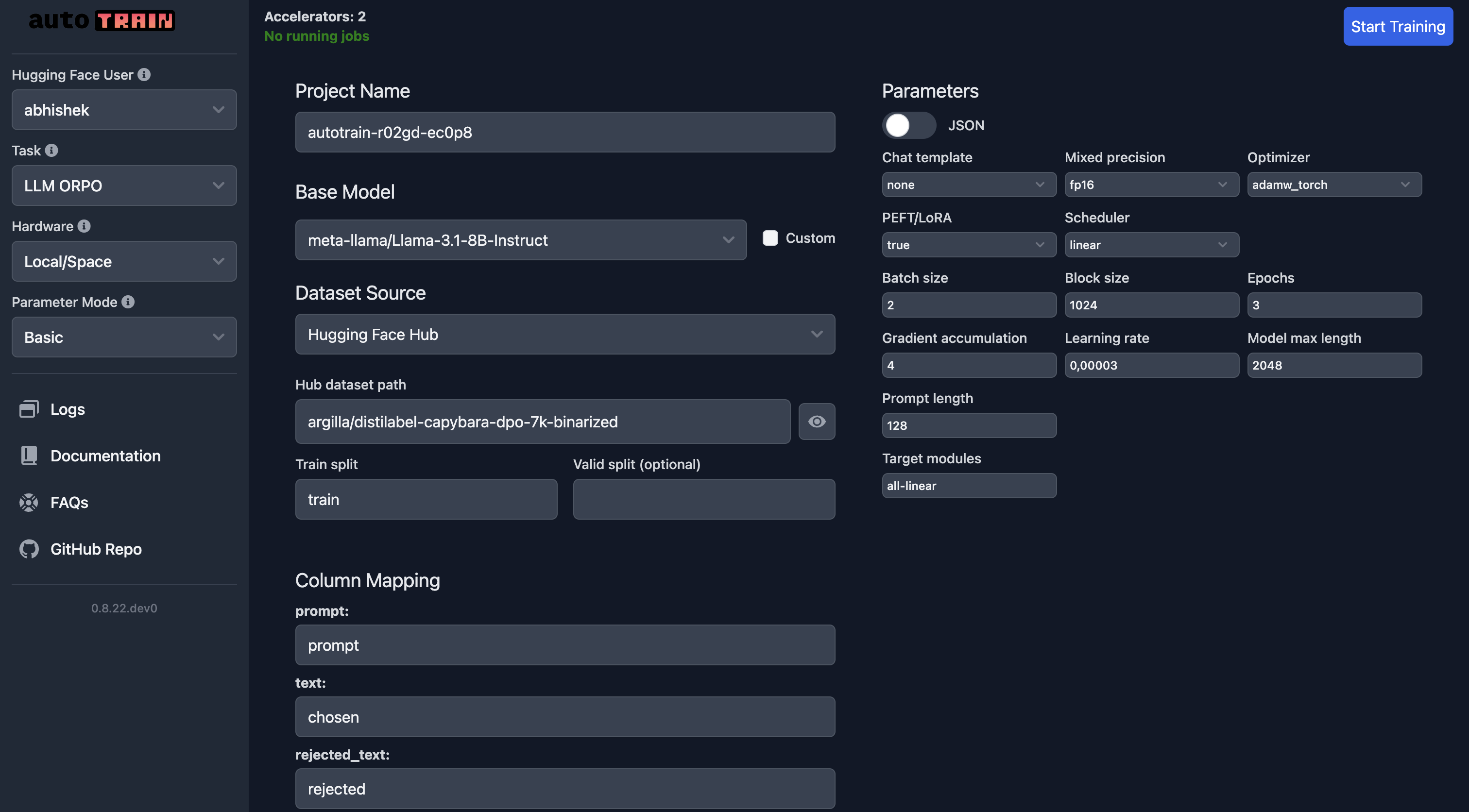
In the UI, you need to make sure you select the right model, the dataset and the splits. Special care should be taken for `column_mapping`.
Once you are happy with the parameters, you can click on the `Start Training` button to start the training process.
## Parameters
### LLM Fine Tuning Parameters
[[autodoc]] trainers.clm.params.LLMTrainingParams
### Task specific parameters
The length parameters used for different trainers can be different. Some require more context than others.
- block_size: This is the maximum sequence length or length of one block of text. Setting to -1 determines block size automatically. Default is -1.
- model_max_length: Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage. Default is 1024
- max_prompt_length: Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input. Used only for `orpo` and `dpo` trainer.
- max_completion_length: Completion length to use, for orpo: encoder-decoder models only. For dpo, it is the length of the completion text.
**NOTE**:
- block size cannot be greater than model_max_length!
- max_prompt_length cannot be greater than model_max_length!
- max_prompt_length cannot be greater than block_size!
- max_completion_length cannot be greater than model_max_length!
- max_completion_length cannot be greater than block_size!
**NOTE**: Not following these constraints will result in an error / nan losses.
#### Generic Trainer
```
--add_eos_token, --add-eos-token
Toggle whether to automatically add an End Of Sentence (EOS) token at the end of texts, which can be critical for certain
types of models like language models. Only used for `default` trainer
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
```
#### SFT Trainer
```
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
```
#### Reward Trainer
```
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
```
#### DPO Trainer
```
--dpo-beta DPO_BETA, --dpo-beta DPO_BETA
Beta for DPO trainer
--model-ref MODEL_REF
Reference model to use for DPO when not using PEFT
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models only
```
#### ORPO Trainer
```
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models only
```
|