diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a997a5970f7125d68e65ee441e7dca8a5c3c857
--- /dev/null
+++ b/app.py
@@ -0,0 +1,82 @@
+import os
+import streamlit as st
+from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
+from llama_index.embeddings.huggingface import HuggingFaceEmbedding
+from llama_index.legacy.callbacks import CallbackManager
+from llama_index.llms.openai_like import OpenAILike
+
+# Create an instance of CallbackManager
+callback_manager = CallbackManager()
+
+api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/" #使用浦语api
+model = "internlm2.5-latest"
+api_key = "eyJ0eXBlIjoiSldUIiwiYWxnIjoiSFM1MTIifQ.eyJqdGkiOiI1MDIyOTcwMyIsInJvbCI6IlJPTEVfUkVHSVNURVIiLCJpc3MiOiJPcGVuWExhYiIsImlhdCI6MTczNTU3MTAzNywiY2xpZW50SWQiOiJlYm1ydm9kNnlvMG5semFlazF5cCIsInBob25lIjoiMTU3MjY5NDEyOTYiLCJ1dWlkIjoiYTliN2RkNTctMzhjMy00OWMyLTkzZjktNGZhOGQzMDU3ZjliIiwiZW1haWwiOiJrYWlhYWJiQDE2My5jb20iLCJleHAiOjE3NTExMjMwMzd9.8sHrwlGX3oApzFVIs-imqyLH86GXeOVpF88a_GhtgaN9nLi8KTvbBOARy_AP0mXyhGtGAUknQUWD4g3WD3-Fww"
+
+llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
+
+os.system('git lfs install')
+os.system('git clone https://www.modelscope.cn/Ceceliachenen/paraphrase-multilingual-MiniLM-L12-v2.git')
+
+
+st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
+st.title("llama_index_demo")
+
+# 初始化模型
+@st.cache_resource
+def init_models():
+ embed_model = HuggingFaceEmbedding(
+ model_name="./paraphrase-multilingual-MiniLM-L12-v2"
+ )
+ Settings.embed_model = embed_model
+
+ #用初始化llm
+ Settings.llm = llm
+
+ documents = SimpleDirectoryReader("./data").load_data()
+ index = VectorStoreIndex.from_documents(documents)
+ query_engine = index.as_query_engine()
+
+ return query_engine
+
+# 检查是否需要初始化模型
+if 'query_engine' not in st.session_state:
+ st.session_state['query_engine'] = init_models()
+
+def greet2(question):
+ response = st.session_state['query_engine'].query(question)
+ return response
+
+# Store LLM generated responses
+if "messages" not in st.session_state.keys():
+ st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
+
+ # Display or clear chat messages
+for message in st.session_state.messages:
+ with st.chat_message(message["role"]):
+ st.write(message["content"])
+
+def clear_chat_history():
+ st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
+
+st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
+
+# Function for generating LLaMA2 response
+def generate_llama_index_response(prompt_input):
+ return greet2(prompt_input)
+
+# User-provided prompt
+if prompt := st.chat_input():
+ st.session_state.messages.append({"role": "user", "content": prompt})
+ with st.chat_message("user"):
+ st.write(prompt)
+
+# Gegenerate_llama_index_response last message is not from assistant
+if st.session_state.messages[-1]["role"] != "assistant":
+ with st.chat_message("assistant"):
+ with st.spinner("Thinking..."):
+ response = generate_llama_index_response(prompt)
+ placeholder = st.empty()
+ placeholder.markdown(response)
+ message = {"role": "assistant", "content": response}
+ st.session_state.messages.append(message)
+
diff --git a/data/xtuner/.github/CONTRIBUTING.md b/data/xtuner/.github/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..09eab9a11f2729b5bdebf211cc77fa44c62c104f
--- /dev/null
+++ b/data/xtuner/.github/CONTRIBUTING.md
@@ -0,0 +1,258 @@
+## Contributing to InternLM
+
+Welcome to the XTuner community! All kinds of contributions are welcomed, including but not limited to
+
+**Fix bug**
+
+You can directly post a Pull Request to fix typo in code or documents
+
+The steps to fix the bug of code implementation are as follows.
+
+1. If the modification involve significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss with you and propose an proper solution.
+
+2. Posting a pull request after fixing the bug and adding corresponding unit test.
+
+**New Feature or Enhancement**
+
+1. If the modification involve significant changes, you should create an issue to discuss with our developers to propose an proper design.
+2. Post a Pull Request after implementing the new feature or enhancement and add corresponding unit test.
+
+**Document**
+
+You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
+
+### Pull Request Workflow
+
+If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the develop mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. Fork and clone
+
+If you are posting a pull request for the first time, you should fork the XTuner repository by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repository will appear under your GitHub profile.
+
+ +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/xtuner.git
+```
+
+After that, you should add official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:InternLM/xtuner.git
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/xtuner.git (fetch)
+origin git@github.com:{username}/xtuner.git (push)
+upstream git@github.com:InternLM/xtuner.git (fetch)
+upstream git@github.com:InternLM/xtuner.git (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of InternLM. **Note**: The following code should be executed under the XTuner directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/xtuner.git
+```
+
+After that, you should add official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:InternLM/xtuner.git
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/xtuner.git (fetch)
+origin git@github.com:{username}/xtuner.git (push)
+upstream git@github.com:InternLM/xtuner.git (fetch)
+upstream git@github.com:InternLM/xtuner.git (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of InternLM. **Note**: The following code should be executed under the XTuner directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+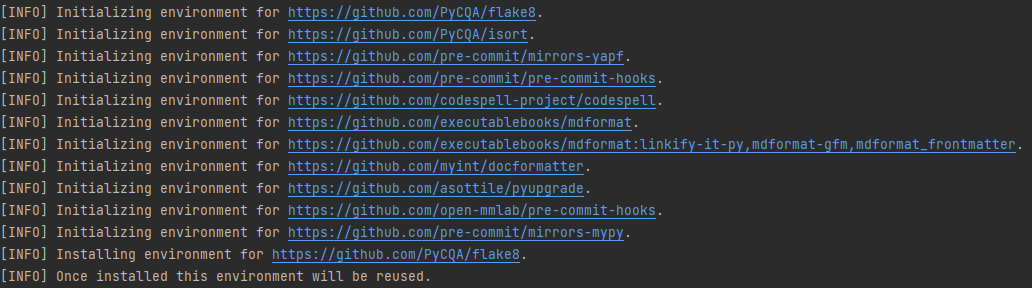 +
+
+
+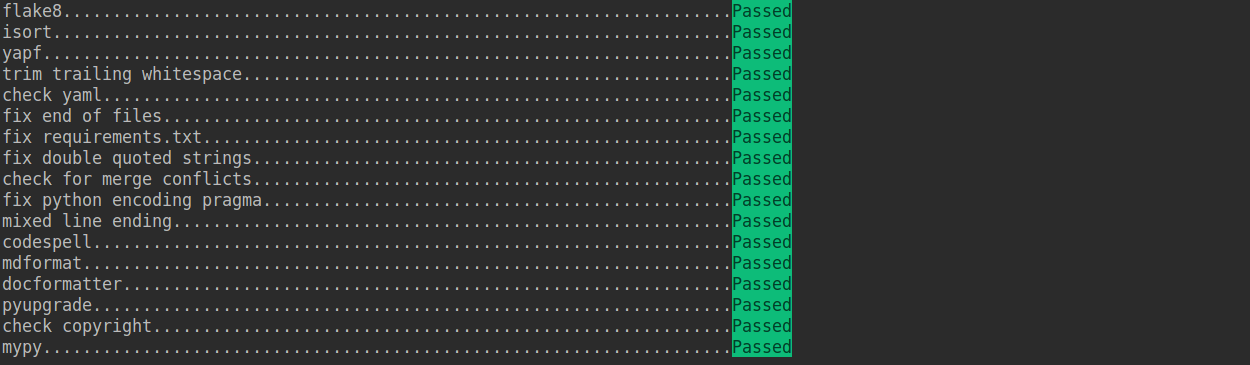 +
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+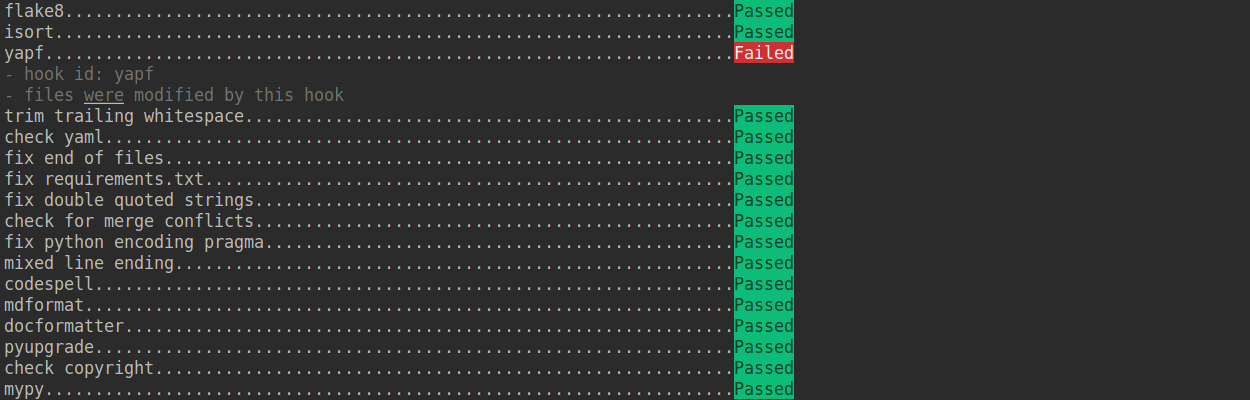 +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- XTuner introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- XTuner introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+ +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) If it is your first contribution, please sign the CLA
+
+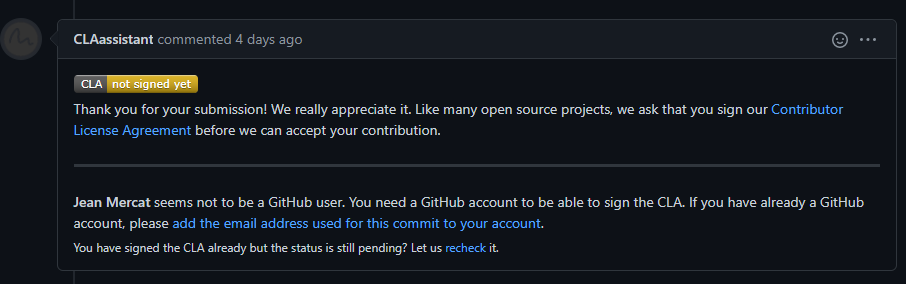 +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+ +
+XTuner will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+XTuner will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](../setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/data/xtuner/.github/workflows/deploy.yml b/data/xtuner/.github/workflows/deploy.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b2c6f0bc208ca0f3d2aba1d4dc04d97fb51cacbd
--- /dev/null
+++ b/data/xtuner/.github/workflows/deploy.yml
@@ -0,0 +1,26 @@
+name: deploy
+
+on: push
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ build-n-publish:
+ runs-on: ubuntu-latest
+ if: startsWith(github.event.ref, 'refs/tags')
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.8
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.8
+ - name: Build XTuner
+ run: |
+ pip install wheel
+ python setup.py sdist bdist_wheel
+ - name: Publish distribution to PyPI
+ run: |
+ pip install twine
+ twine upload dist/* -u __token__ -p ${{ secrets.pypi_password }}
diff --git a/data/xtuner/.github/workflows/lint.yml b/data/xtuner/.github/workflows/lint.yml
new file mode 100644
index 0000000000000000000000000000000000000000..74a733eb81e8e3e3b7c6ca1c08de8856d6cfb81e
--- /dev/null
+++ b/data/xtuner/.github/workflows/lint.yml
@@ -0,0 +1,23 @@
+name: lint
+
+on: [push, pull_request]
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ lint:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.8
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.8
+ - name: Install pre-commit hook
+ run: |
+ pip install pre-commit
+ pre-commit install
+ - name: Linting
+ run: pre-commit run --all-files
diff --git a/data/xtuner/.gitignore b/data/xtuner/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..ffe3444b8cdb2ec3e6791d047d0593fcf9d20d41
--- /dev/null
+++ b/data/xtuner/.gitignore
@@ -0,0 +1,124 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/*/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+# custom
+data/
+data
+.vscode
+.idea
+.DS_Store
+*.pkl
+*.pkl.json
+*.log.json
+work_dirs/
+
+# Pytorch
+*.pth
+*.py~
+*.sh~
+
+# srun
+*.out
+batchscript-*
diff --git a/data/xtuner/.owners.yml b/data/xtuner/.owners.yml
new file mode 100644
index 0000000000000000000000000000000000000000..996ae4c69c03821b2b79a1b7a4233988cf0623ee
--- /dev/null
+++ b/data/xtuner/.owners.yml
@@ -0,0 +1,8 @@
+assign:
+ issues: disabled
+ pull_requests: disabled
+ strategy:
+ random
+ # daily-shift-based
+ schedule:
+ '*/1 * * * *'
diff --git a/data/xtuner/.pre-commit-config-zh-cn.yaml b/data/xtuner/.pre-commit-config-zh-cn.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4b9f51976e4b46db4db69952f437e43d72581070
--- /dev/null
+++ b/data/xtuner/.pre-commit-config-zh-cn.yaml
@@ -0,0 +1,51 @@
+exclude: ^tests/data/|^xtuner/tools/model_converters/modeling_internlm2_reward/
+repos:
+ - repo: https://gitee.com/openmmlab/mirrors-flake8
+ rev: 5.0.4
+ hooks:
+ - id: flake8
+ args: ["--exclude=xtuner/model/transformers_models/*"]
+ - repo: https://gitee.com/openmmlab/mirrors-isort
+ rev: 5.11.5
+ hooks:
+ - id: isort
+ - repo: https://gitee.com/openmmlab/mirrors-yapf
+ rev: v0.32.0
+ hooks:
+ - id: yapf
+ - repo: https://gitee.com/openmmlab/mirrors-pre-commit-hooks
+ rev: v4.3.0
+ hooks:
+ - id: trailing-whitespace
+ - id: check-yaml
+ - id: end-of-file-fixer
+ - id: requirements-txt-fixer
+ - id: double-quote-string-fixer
+ - id: check-merge-conflict
+ - id: fix-encoding-pragma
+ args: ["--remove"]
+ - id: mixed-line-ending
+ args: ["--fix=lf"]
+ - repo: https://gitee.com/openmmlab/mirrors-codespell
+ rev: v2.2.1
+ hooks:
+ - id: codespell
+ - repo: https://gitee.com/openmmlab/mirrors-mdformat
+ rev: 0.7.9
+ hooks:
+ - id: mdformat
+ args: ["--number"]
+ additional_dependencies:
+ - mdformat-openmmlab
+ - mdformat_frontmatter
+ - linkify-it-py
+ - repo: https://gitee.com/openmmlab/mirrors-docformatter
+ rev: v1.3.1
+ hooks:
+ - id: docformatter
+ args: ["--in-place", "--wrap-descriptions", "79"]
+ - repo: https://github.com/asottile/pyupgrade
+ rev: v3.0.0
+ hooks:
+ - id: pyupgrade
+ args: ["--py36-plus"]
diff --git a/data/xtuner/.pre-commit-config.yaml b/data/xtuner/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f6bbfd6339aeba49dbae8a0edc425a6e3f0c8eb2
--- /dev/null
+++ b/data/xtuner/.pre-commit-config.yaml
@@ -0,0 +1,53 @@
+exclude: ^tests/data/|^xtuner/tools/model_converters/modeling_internlm2_reward/
+repos:
+ - repo: https://github.com/PyCQA/flake8
+ rev: 5.0.4
+ hooks:
+ - id: flake8
+ args: ["--exclude=xtuner/model/transformers_models/*"]
+ - repo: https://github.com/PyCQA/isort
+ rev: 5.11.5
+ hooks:
+ - id: isort
+ - repo: https://github.com/pre-commit/mirrors-yapf
+ rev: v0.32.0
+ hooks:
+ - id: yapf
+ exclude: 'xtuner/parallel/sequence/__init__.py'
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.3.0
+ hooks:
+ - id: trailing-whitespace
+ - id: check-yaml
+ - id: end-of-file-fixer
+ - id: requirements-txt-fixer
+ - id: double-quote-string-fixer
+ - id: check-merge-conflict
+ - id: fix-encoding-pragma
+ args: ["--remove"]
+ - id: mixed-line-ending
+ args: ["--fix=lf"]
+ - repo: https://github.com/codespell-project/codespell
+ rev: v2.2.1
+ hooks:
+ - id: codespell
+ - repo: https://github.com/executablebooks/mdformat
+ rev: 0.7.9
+ hooks:
+ - id: mdformat
+ args: ["--number"]
+ additional_dependencies:
+ - mdformat-openmmlab
+ - mdformat_frontmatter
+ - linkify-it-py
+ exclude: 'docs/zh_cn/user_guides/sequence_parallel.md'
+ - repo: https://github.com/myint/docformatter
+ rev: v1.3.1
+ hooks:
+ - id: docformatter
+ args: ["--in-place", "--wrap-descriptions", "79"]
+ - repo: https://github.com/asottile/pyupgrade
+ rev: v3.0.0
+ hooks:
+ - id: pyupgrade
+ args: ["--py36-plus"]
diff --git a/data/xtuner/LICENSE b/data/xtuner/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/data/xtuner/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/data/xtuner/MANIFEST.in b/data/xtuner/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..36e1610bf8093a8355a58d7d9779697a64931313
--- /dev/null
+++ b/data/xtuner/MANIFEST.in
@@ -0,0 +1,2 @@
+recursive-include xtuner/configs *.py *.yml *.json
+recursive-include xtuner/tools *.sh *.py
diff --git a/data/xtuner/README.md b/data/xtuner/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..263d300c7a17778e3be4ff6f64cd262995f98527
--- /dev/null
+++ b/data/xtuner/README.md
@@ -0,0 +1,302 @@
+
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](../setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/data/xtuner/.github/workflows/deploy.yml b/data/xtuner/.github/workflows/deploy.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b2c6f0bc208ca0f3d2aba1d4dc04d97fb51cacbd
--- /dev/null
+++ b/data/xtuner/.github/workflows/deploy.yml
@@ -0,0 +1,26 @@
+name: deploy
+
+on: push
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ build-n-publish:
+ runs-on: ubuntu-latest
+ if: startsWith(github.event.ref, 'refs/tags')
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.8
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.8
+ - name: Build XTuner
+ run: |
+ pip install wheel
+ python setup.py sdist bdist_wheel
+ - name: Publish distribution to PyPI
+ run: |
+ pip install twine
+ twine upload dist/* -u __token__ -p ${{ secrets.pypi_password }}
diff --git a/data/xtuner/.github/workflows/lint.yml b/data/xtuner/.github/workflows/lint.yml
new file mode 100644
index 0000000000000000000000000000000000000000..74a733eb81e8e3e3b7c6ca1c08de8856d6cfb81e
--- /dev/null
+++ b/data/xtuner/.github/workflows/lint.yml
@@ -0,0 +1,23 @@
+name: lint
+
+on: [push, pull_request]
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ lint:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.8
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.8
+ - name: Install pre-commit hook
+ run: |
+ pip install pre-commit
+ pre-commit install
+ - name: Linting
+ run: pre-commit run --all-files
diff --git a/data/xtuner/.gitignore b/data/xtuner/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..ffe3444b8cdb2ec3e6791d047d0593fcf9d20d41
--- /dev/null
+++ b/data/xtuner/.gitignore
@@ -0,0 +1,124 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/*/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+# custom
+data/
+data
+.vscode
+.idea
+.DS_Store
+*.pkl
+*.pkl.json
+*.log.json
+work_dirs/
+
+# Pytorch
+*.pth
+*.py~
+*.sh~
+
+# srun
+*.out
+batchscript-*
diff --git a/data/xtuner/.owners.yml b/data/xtuner/.owners.yml
new file mode 100644
index 0000000000000000000000000000000000000000..996ae4c69c03821b2b79a1b7a4233988cf0623ee
--- /dev/null
+++ b/data/xtuner/.owners.yml
@@ -0,0 +1,8 @@
+assign:
+ issues: disabled
+ pull_requests: disabled
+ strategy:
+ random
+ # daily-shift-based
+ schedule:
+ '*/1 * * * *'
diff --git a/data/xtuner/.pre-commit-config-zh-cn.yaml b/data/xtuner/.pre-commit-config-zh-cn.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4b9f51976e4b46db4db69952f437e43d72581070
--- /dev/null
+++ b/data/xtuner/.pre-commit-config-zh-cn.yaml
@@ -0,0 +1,51 @@
+exclude: ^tests/data/|^xtuner/tools/model_converters/modeling_internlm2_reward/
+repos:
+ - repo: https://gitee.com/openmmlab/mirrors-flake8
+ rev: 5.0.4
+ hooks:
+ - id: flake8
+ args: ["--exclude=xtuner/model/transformers_models/*"]
+ - repo: https://gitee.com/openmmlab/mirrors-isort
+ rev: 5.11.5
+ hooks:
+ - id: isort
+ - repo: https://gitee.com/openmmlab/mirrors-yapf
+ rev: v0.32.0
+ hooks:
+ - id: yapf
+ - repo: https://gitee.com/openmmlab/mirrors-pre-commit-hooks
+ rev: v4.3.0
+ hooks:
+ - id: trailing-whitespace
+ - id: check-yaml
+ - id: end-of-file-fixer
+ - id: requirements-txt-fixer
+ - id: double-quote-string-fixer
+ - id: check-merge-conflict
+ - id: fix-encoding-pragma
+ args: ["--remove"]
+ - id: mixed-line-ending
+ args: ["--fix=lf"]
+ - repo: https://gitee.com/openmmlab/mirrors-codespell
+ rev: v2.2.1
+ hooks:
+ - id: codespell
+ - repo: https://gitee.com/openmmlab/mirrors-mdformat
+ rev: 0.7.9
+ hooks:
+ - id: mdformat
+ args: ["--number"]
+ additional_dependencies:
+ - mdformat-openmmlab
+ - mdformat_frontmatter
+ - linkify-it-py
+ - repo: https://gitee.com/openmmlab/mirrors-docformatter
+ rev: v1.3.1
+ hooks:
+ - id: docformatter
+ args: ["--in-place", "--wrap-descriptions", "79"]
+ - repo: https://github.com/asottile/pyupgrade
+ rev: v3.0.0
+ hooks:
+ - id: pyupgrade
+ args: ["--py36-plus"]
diff --git a/data/xtuner/.pre-commit-config.yaml b/data/xtuner/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f6bbfd6339aeba49dbae8a0edc425a6e3f0c8eb2
--- /dev/null
+++ b/data/xtuner/.pre-commit-config.yaml
@@ -0,0 +1,53 @@
+exclude: ^tests/data/|^xtuner/tools/model_converters/modeling_internlm2_reward/
+repos:
+ - repo: https://github.com/PyCQA/flake8
+ rev: 5.0.4
+ hooks:
+ - id: flake8
+ args: ["--exclude=xtuner/model/transformers_models/*"]
+ - repo: https://github.com/PyCQA/isort
+ rev: 5.11.5
+ hooks:
+ - id: isort
+ - repo: https://github.com/pre-commit/mirrors-yapf
+ rev: v0.32.0
+ hooks:
+ - id: yapf
+ exclude: 'xtuner/parallel/sequence/__init__.py'
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.3.0
+ hooks:
+ - id: trailing-whitespace
+ - id: check-yaml
+ - id: end-of-file-fixer
+ - id: requirements-txt-fixer
+ - id: double-quote-string-fixer
+ - id: check-merge-conflict
+ - id: fix-encoding-pragma
+ args: ["--remove"]
+ - id: mixed-line-ending
+ args: ["--fix=lf"]
+ - repo: https://github.com/codespell-project/codespell
+ rev: v2.2.1
+ hooks:
+ - id: codespell
+ - repo: https://github.com/executablebooks/mdformat
+ rev: 0.7.9
+ hooks:
+ - id: mdformat
+ args: ["--number"]
+ additional_dependencies:
+ - mdformat-openmmlab
+ - mdformat_frontmatter
+ - linkify-it-py
+ exclude: 'docs/zh_cn/user_guides/sequence_parallel.md'
+ - repo: https://github.com/myint/docformatter
+ rev: v1.3.1
+ hooks:
+ - id: docformatter
+ args: ["--in-place", "--wrap-descriptions", "79"]
+ - repo: https://github.com/asottile/pyupgrade
+ rev: v3.0.0
+ hooks:
+ - id: pyupgrade
+ args: ["--py36-plus"]
diff --git a/data/xtuner/LICENSE b/data/xtuner/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/data/xtuner/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/data/xtuner/MANIFEST.in b/data/xtuner/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..36e1610bf8093a8355a58d7d9779697a64931313
--- /dev/null
+++ b/data/xtuner/MANIFEST.in
@@ -0,0 +1,2 @@
+recursive-include xtuner/configs *.py *.yml *.json
+recursive-include xtuner/tools *.sh *.py
diff --git a/data/xtuner/README.md b/data/xtuner/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..263d300c7a17778e3be4ff6f64cd262995f98527
--- /dev/null
+++ b/data/xtuner/README.md
@@ -0,0 +1,302 @@
+
+

+
+
+[](https://github.com/InternLM/xtuner/stargazers)
+[](https://github.com/InternLM/xtuner/blob/main/LICENSE)
+[](https://pypi.org/project/xtuner/)
+[](https://pypi.org/project/xtuner/)
+[](https://github.com/InternLM/xtuner/issues)
+[](https://github.com/InternLM/xtuner/issues)
+
+👋 join us on [](https://cdn.vansin.top/internlm/xtuner.jpg)
+[](https://twitter.com/intern_lm)
+[](https://discord.gg/xa29JuW87d)
+
+🔍 Explore our models on
+[](https://huggingface.co/xtuner)
+[](https://www.modelscope.cn/organization/xtuner)
+[](https://openxlab.org.cn/usercenter/xtuner)
+[](https://www.wisemodel.cn/organization/xtuner)
+
+English | [简体中文](README_zh-CN.md)
+
+
+

+
+
+
+
+
+|
+ Models
+ |
+
+ SFT Datasets
+ |
+
+ Data Pipelines
+ |
+
+ Algorithms
+ |
+
+
+|
+
+ |
+
+
+ |
+
+
+ |
+
+
+ |
+
+
+
+
+## 🛠️ Quick Start
+
+### Installation
+
+- It is recommended to build a Python-3.10 virtual environment using conda
+
+ ```bash
+ conda create --name xtuner-env python=3.10 -y
+ conda activate xtuner-env
+ ```
+
+- Install XTuner via pip
+
+ ```shell
+ pip install -U xtuner
+ ```
+
+ or with DeepSpeed integration
+
+ ```shell
+ pip install -U 'xtuner[deepspeed]'
+ ```
+
+- Install XTuner from source
+
+ ```shell
+ git clone https://github.com/InternLM/xtuner.git
+ cd xtuner
+ pip install -e '.[all]'
+ ```
+
+### Fine-tune
+
+XTuner supports the efficient fine-tune (*e.g.*, QLoRA) for LLMs. Dataset prepare guides can be found on [dataset_prepare.md](./docs/en/user_guides/dataset_prepare.md).
+
+- **Step 0**, prepare the config. XTuner provides many ready-to-use configs and we can view all configs by
+
+ ```shell
+ xtuner list-cfg
+ ```
+
+ Or, if the provided configs cannot meet the requirements, please copy the provided config to the specified directory and make specific modifications by
+
+ ```shell
+ xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
+ vi ${SAVE_PATH}/${CONFIG_NAME}_copy.py
+ ```
+
+- **Step 1**, start fine-tuning.
+
+ ```shell
+ xtuner train ${CONFIG_NAME_OR_PATH}
+ ```
+
+ For example, we can start the QLoRA fine-tuning of InternLM2.5-Chat-7B with oasst1 dataset by
+
+ ```shell
+ # On a single GPU
+ xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2
+ # On multiple GPUs
+ (DIST) NPROC_PER_NODE=${GPU_NUM} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2
+ (SLURM) srun ${SRUN_ARGS} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --launcher slurm --deepspeed deepspeed_zero2
+ ```
+
+ - `--deepspeed` means using [DeepSpeed](https://github.com/microsoft/DeepSpeed) 🚀 to optimize the training. XTuner comes with several integrated strategies including ZeRO-1, ZeRO-2, and ZeRO-3. If you wish to disable this feature, simply remove this argument.
+
+ - For more examples, please see [finetune.md](./docs/en/user_guides/finetune.md).
+
+- **Step 2**, convert the saved PTH model (if using DeepSpeed, it will be a directory) to Hugging Face model, by
+
+ ```shell
+ xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH} ${SAVE_PATH}
+ ```
+
+### Chat
+
+XTuner provides tools to chat with pretrained / fine-tuned LLMs.
+
+```shell
+xtuner chat ${NAME_OR_PATH_TO_LLM} --adapter {NAME_OR_PATH_TO_ADAPTER} [optional arguments]
+```
+
+For example, we can start the chat with InternLM2.5-Chat-7B :
+
+```shell
+xtuner chat internlm/internlm2_5-chat-7b --prompt-template internlm2_chat
+```
+
+For more examples, please see [chat.md](./docs/en/user_guides/chat.md).
+
+### Deployment
+
+- **Step 0**, merge the Hugging Face adapter to pretrained LLM, by
+
+ ```shell
+ xtuner convert merge \
+ ${NAME_OR_PATH_TO_LLM} \
+ ${NAME_OR_PATH_TO_ADAPTER} \
+ ${SAVE_PATH} \
+ --max-shard-size 2GB
+ ```
+
+- **Step 1**, deploy fine-tuned LLM with any other framework, such as [LMDeploy](https://github.com/InternLM/lmdeploy) 🚀.
+
+ ```shell
+ pip install lmdeploy
+ python -m lmdeploy.pytorch.chat ${NAME_OR_PATH_TO_LLM} \
+ --max_new_tokens 256 \
+ --temperture 0.8 \
+ --top_p 0.95 \
+ --seed 0
+ ```
+
+ 🔥 Seeking efficient inference with less GPU memory? Try 4-bit quantization from [LMDeploy](https://github.com/InternLM/lmdeploy)! For more details, see [here](https://github.com/InternLM/lmdeploy/tree/main#quantization).
+
+### Evaluation
+
+- We recommend using [OpenCompass](https://github.com/InternLM/opencompass), a comprehensive and systematic LLM evaluation library, which currently supports 50+ datasets with about 300,000 questions.
+
+## 🤝 Contributing
+
+We appreciate all contributions to XTuner. Please refer to [CONTRIBUTING.md](.github/CONTRIBUTING.md) for the contributing guideline.
+
+## 🎖️ Acknowledgement
+
+- [Llama 2](https://github.com/facebookresearch/llama)
+- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
+- [QLoRA](https://github.com/artidoro/qlora)
+- [LMDeploy](https://github.com/InternLM/lmdeploy)
+- [LLaVA](https://github.com/haotian-liu/LLaVA)
+
+## 🖊️ Citation
+
+```bibtex
+@misc{2023xtuner,
+ title={XTuner: A Toolkit for Efficiently Fine-tuning LLM},
+ author={XTuner Contributors},
+ howpublished = {\url{https://github.com/InternLM/xtuner}},
+ year={2023}
+}
+```
+
+## License
+
+This project is released under the [Apache License 2.0](LICENSE). Please also adhere to the Licenses of models and datasets being used.
diff --git a/data/xtuner/docs/en/.readthedocs.yaml b/data/xtuner/docs/en/.readthedocs.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..67b9c44e72a1945134a22796a17df026ce24c27c
--- /dev/null
+++ b/data/xtuner/docs/en/.readthedocs.yaml
@@ -0,0 +1,16 @@
+version: 2
+
+build:
+ os: ubuntu-22.04
+ tools:
+ python: "3.8"
+
+formats:
+ - epub
+
+python:
+ install:
+ - requirements: requirements/docs.txt
+
+sphinx:
+ configuration: docs/en/conf.py
diff --git a/data/xtuner/docs/en/Makefile b/data/xtuner/docs/en/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/data/xtuner/docs/en/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/data/xtuner/docs/en/_static/css/readthedocs.css b/data/xtuner/docs/en/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..34ed824ba96141ae07eb484df49f93bdbc7832ec
--- /dev/null
+++ b/data/xtuner/docs/en/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../image/logo.png");
+ background-size: 177px 40px;
+ height: 40px;
+ width: 177px;
+}
diff --git a/data/xtuner/docs/en/_static/image/logo.png b/data/xtuner/docs/en/_static/image/logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..0d6b754c98ae1d2c39de384d51b84d4c2f94c373
Binary files /dev/null and b/data/xtuner/docs/en/_static/image/logo.png differ
diff --git a/data/xtuner/docs/en/acceleration/benchmark.rst b/data/xtuner/docs/en/acceleration/benchmark.rst
new file mode 100644
index 0000000000000000000000000000000000000000..813fc7d5a900ae34213559b4f971b637dc067e91
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/benchmark.rst
@@ -0,0 +1,2 @@
+Benchmark
+=========
diff --git a/data/xtuner/docs/en/acceleration/deepspeed.rst b/data/xtuner/docs/en/acceleration/deepspeed.rst
new file mode 100644
index 0000000000000000000000000000000000000000..e3dcaccc05429e664d5987d97c959be4ecff9c85
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/deepspeed.rst
@@ -0,0 +1,2 @@
+DeepSpeed
+=========
diff --git a/data/xtuner/docs/en/acceleration/flash_attn.rst b/data/xtuner/docs/en/acceleration/flash_attn.rst
new file mode 100644
index 0000000000000000000000000000000000000000..a080373ef49a2a311ca375207437fd56fc40b297
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/flash_attn.rst
@@ -0,0 +1,2 @@
+Flash Attention
+===============
diff --git a/data/xtuner/docs/en/acceleration/hyper_parameters.rst b/data/xtuner/docs/en/acceleration/hyper_parameters.rst
new file mode 100644
index 0000000000000000000000000000000000000000..04b82b7e6189ce1a7bb24b2848b214f8462a7aff
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/hyper_parameters.rst
@@ -0,0 +1,2 @@
+HyperParameters
+===============
diff --git a/data/xtuner/docs/en/acceleration/length_grouped_sampler.rst b/data/xtuner/docs/en/acceleration/length_grouped_sampler.rst
new file mode 100644
index 0000000000000000000000000000000000000000..2fc723212a40c3d3e76539b50ccea49940da4640
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/length_grouped_sampler.rst
@@ -0,0 +1,2 @@
+Length Grouped Sampler
+======================
diff --git a/data/xtuner/docs/en/acceleration/pack_to_max_length.rst b/data/xtuner/docs/en/acceleration/pack_to_max_length.rst
new file mode 100644
index 0000000000000000000000000000000000000000..aaddd36aa6ade763959917621fa161015058bd94
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/pack_to_max_length.rst
@@ -0,0 +1,2 @@
+Pack to Max Length
+==================
diff --git a/data/xtuner/docs/en/acceleration/train_extreme_long_sequence.rst b/data/xtuner/docs/en/acceleration/train_extreme_long_sequence.rst
new file mode 100644
index 0000000000000000000000000000000000000000..d326bd690119ce91e5ac7b0dd664f0c5ceb11ab8
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/train_extreme_long_sequence.rst
@@ -0,0 +1,2 @@
+Train Extreme Long Sequence
+===========================
diff --git a/data/xtuner/docs/en/acceleration/train_large_scale_dataset.rst b/data/xtuner/docs/en/acceleration/train_large_scale_dataset.rst
new file mode 100644
index 0000000000000000000000000000000000000000..026ce9dae2ce292d2e34f2c2eafa2b51b4cc9ad1
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/train_large_scale_dataset.rst
@@ -0,0 +1,2 @@
+Train Large-scale Dataset
+=========================
diff --git a/data/xtuner/docs/en/acceleration/varlen_flash_attn.rst b/data/xtuner/docs/en/acceleration/varlen_flash_attn.rst
new file mode 100644
index 0000000000000000000000000000000000000000..2fad725f35bbdd0bc492d5c0d569080d5f362522
--- /dev/null
+++ b/data/xtuner/docs/en/acceleration/varlen_flash_attn.rst
@@ -0,0 +1,2 @@
+Varlen Flash Attention
+======================
diff --git a/data/xtuner/docs/en/chat/agent.md b/data/xtuner/docs/en/chat/agent.md
new file mode 100644
index 0000000000000000000000000000000000000000..1da3ebc104432a8be76908998d6d4b1178232854
--- /dev/null
+++ b/data/xtuner/docs/en/chat/agent.md
@@ -0,0 +1 @@
+# Chat with Agent
diff --git a/data/xtuner/docs/en/chat/llm.md b/data/xtuner/docs/en/chat/llm.md
new file mode 100644
index 0000000000000000000000000000000000000000..5c556180c87e83f6511bbe58beeb49126567e740
--- /dev/null
+++ b/data/xtuner/docs/en/chat/llm.md
@@ -0,0 +1 @@
+# Chat with LLM
diff --git a/data/xtuner/docs/en/chat/lmdeploy.md b/data/xtuner/docs/en/chat/lmdeploy.md
new file mode 100644
index 0000000000000000000000000000000000000000..f4114a3a50fa76f4d57c49b59f418c9882599b1b
--- /dev/null
+++ b/data/xtuner/docs/en/chat/lmdeploy.md
@@ -0,0 +1 @@
+# Accelerate chat by LMDeploy
diff --git a/data/xtuner/docs/en/chat/vlm.md b/data/xtuner/docs/en/chat/vlm.md
new file mode 100644
index 0000000000000000000000000000000000000000..54101dcbc0b8888247f49f2d4be325e5d35722ae
--- /dev/null
+++ b/data/xtuner/docs/en/chat/vlm.md
@@ -0,0 +1 @@
+# Chat with VLM
diff --git a/data/xtuner/docs/en/conf.py b/data/xtuner/docs/en/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..457ca52327054b8b6306772ff28c5ec65fa3c6f3
--- /dev/null
+++ b/data/xtuner/docs/en/conf.py
@@ -0,0 +1,109 @@
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import os
+import sys
+
+from sphinx.ext import autodoc
+
+sys.path.insert(0, os.path.abspath('../..'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'XTuner'
+copyright = '2024, XTuner Contributors'
+author = 'XTuner Contributors'
+
+# The full version, including alpha/beta/rc tags
+version_file = '../../xtuner/version.py'
+with open(version_file) as f:
+ exec(compile(f.read(), version_file, 'exec'))
+__version__ = locals()['__version__']
+# The short X.Y version
+version = __version__
+# The full version, including alpha/beta/rc tags
+release = __version__
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.napoleon',
+ 'sphinx.ext.viewcode',
+ 'sphinx.ext.intersphinx',
+ 'sphinx_copybutton',
+ 'sphinx.ext.autodoc',
+ 'sphinx.ext.autosummary',
+ 'myst_parser',
+ 'sphinxarg.ext',
+]
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# Exclude the prompt "$" when copying code
+copybutton_prompt_text = r'\$ '
+copybutton_prompt_is_regexp = True
+
+language = 'en'
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_theme = 'sphinx_book_theme'
+html_logo = '_static/image/logo.png'
+html_theme_options = {
+ 'path_to_docs': 'docs/en',
+ 'repository_url': 'https://github.com/InternLM/xtuner',
+ 'use_repository_button': True,
+}
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+# html_static_path = ['_static']
+
+# Mock out external dependencies here.
+autodoc_mock_imports = [
+ 'cpuinfo',
+ 'torch',
+ 'transformers',
+ 'psutil',
+ 'prometheus_client',
+ 'sentencepiece',
+ 'vllm.cuda_utils',
+ 'vllm._C',
+ 'numpy',
+ 'tqdm',
+]
+
+
+class MockedClassDocumenter(autodoc.ClassDocumenter):
+ """Remove note about base class when a class is derived from object."""
+
+ def add_line(self, line: str, source: str, *lineno: int) -> None:
+ if line == ' Bases: :py:class:`object`':
+ return
+ super().add_line(line, source, *lineno)
+
+
+autodoc.ClassDocumenter = MockedClassDocumenter
+
+navigation_with_keys = False
diff --git a/data/xtuner/docs/en/dpo/modify_settings.md b/data/xtuner/docs/en/dpo/modify_settings.md
new file mode 100644
index 0000000000000000000000000000000000000000..d78cc40e6e67e2cd99da4172923ebf1fd5b799b4
--- /dev/null
+++ b/data/xtuner/docs/en/dpo/modify_settings.md
@@ -0,0 +1,83 @@
+## Modify DPO Training Configuration
+
+This section introduces config parameters related to DPO (Direct Preference Optimization) training. For more details on XTuner config files, please refer to [Modifying Training Configuration](https://xtuner.readthedocs.io/zh-cn/latest/training/modify_settings.html).
+
+### Loss Function
+
+In DPO training, you can choose different types of loss functions according to your needs. XTuner provides various loss function options, such as `sigmoid`, `hinge`, `ipo`, etc. You can select the desired loss function type by setting the `dpo_loss_type` parameter.
+
+Additionally, you can control the temperature coefficient in the loss function by adjusting the `loss_beta` parameter. The `label_smoothing` parameter can be used for smoothing labels.
+
+```python
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+dpo_loss_type = 'sigmoid' # One of ['sigmoid', 'hinge', 'ipo', 'kto_pair', 'sppo_hard', 'nca_pair', 'robust']
+loss_beta = 0.1
+label_smoothing = 0.0
+```
+
+### Modifying the Model
+
+Users can modify `pretrained_model_name_or_path` to change the pretrained model.
+
+```python
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b-sft'
+```
+
+### Training Data
+
+In DPO training, you can specify the maximum number of tokens for a single sample sequence using the `max_length` parameter. XTuner will automatically truncate or pad the data.
+
+```python
+# Data
+max_length = 2048
+```
+
+In the configuration file, we use the `train_dataset` field to specify the training dataset. You can specify the dataset loading method using the `dataset` field and the dataset mapping function using the `dataset_map_fn` field.
+
+```python
+#######################################################################
+# PART 3 Dataset & Dataloader #
+#######################################################################
+sampler = SequenceParallelSampler \
+ if sequence_parallel_size > 1 else DefaultSampler
+
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(type=load_dataset, path='mlabonne/orpo-dpo-mix-40k'),
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=orpo_dpo_mix_40k_map_fn,
+ is_dpo=True,
+ is_reward=False,
+ reward_token_id=-1,
+ num_proc=32,
+ use_varlen_attn=use_varlen_attn,
+ max_packed_length=max_packed_length,
+ shuffle_before_pack=True,
+)
+
+train_dataloader = dict(
+ batch_size=batch_size,
+ num_workers=dataloader_num_workers,
+ dataset=train_dataset,
+ sampler=dict(type=sampler, shuffle=True),
+ collate_fn=dict(
+ type=preference_collate_fn, use_varlen_attn=use_varlen_attn))
+```
+
+In the above configuration, we use `load_dataset` to load the `mlabonne/orpo-dpo-mix-40k` dataset from Hugging Face and use `orpo_dpo_mix_40k_map_fn` as the dataset mapping function.
+
+For more information on handling datasets and writing dataset mapping functions, please refer to the [Preference Dataset Section](../reward_model/preference_data.md).
+
+### Accelerating Training
+
+When training with preference data, we recommend enabling the [Variable-Length Attention Mechanism](https://xtuner.readthedocs.io/zh-cn/latest/acceleration/varlen_flash_attn.html) to avoid memory waste caused by length differences between chosen and rejected samples within a single preference. You can enable the variable-length attention mechanism by setting `use_varlen_attn=True`.
+
+XTuner also supports many training acceleration methods. For details on how to use them, please refer to the [Acceleration Strategies Section](https://xtuner.readthedocs.io/zh-cn/latest/acceleration/hyper_parameters.html).
diff --git a/data/xtuner/docs/en/dpo/overview.md b/data/xtuner/docs/en/dpo/overview.md
new file mode 100644
index 0000000000000000000000000000000000000000..0c20946e3470eafe96f292b48cb2efc1eb036c1d
--- /dev/null
+++ b/data/xtuner/docs/en/dpo/overview.md
@@ -0,0 +1,27 @@
+## Introduction to DPO
+
+### Overview
+
+DPO (Direct Preference Optimization) is a method used in large language model training for directly optimizing human preferences. Unlike traditional reinforcement learning methods, DPO directly uses human preference data to optimize the model, thereby improving the quality of generated content to better align with human preferences. DPO also eliminates the need to train a Reward Model and a Critic Model, avoiding the complexity of reinforcement learning algorithms, reducing training overhead, and enhancing training efficiency.
+
+Many algorithms have made certain improvements to DPO's loss function. In XTuner, besides DPO, we have also implemented loss functions from papers such as [Identity Preference Optimization (IPO)](https://huggingface.co/papers/2310.12036). To use these algorithms, please refer to the [Modify DPO Settings](./modify_settings.md) section. We also provide some [example configurations](https://github.com/InternLM/xtuner/tree/main/xtuner/configs/dpo) for reference.
+
+In addition to DPO, there are alignment algorithms like [ORPO](https://arxiv.org/abs/2403.07691) that do not require a reference model. ORPO uses the concept of odds ratio to optimize the model by penalizing rejected samples during the training process, thereby adapting more effectively to the chosen samples. ORPO eliminates the dependence on a reference model, making the training process more simplified and efficient. The training method for ORPO in XTuner is very similar to DPO, and we provide some [example configurations](https://github.com/InternLM/xtuner/tree/main/xtuner/configs/orpo). Users can refer to the DPO tutorial to modify the configuration.
+
+### Features of DPO Training in XTuner
+
+DPO training in XTuner offers the following significant advantages:
+
+1. **Latest Algorithms**: In addition to supporting standard DPO, XTuner also supports improved DPO algorithms or memory efficient algorithms like ORPO that do not rely on reference models.
+
+2. **Reducing Memory Waste**: Due to the length differences in chosen and rejected data in preference datasets, padding tokens during data concatenation can cause memory waste. In XTuner, by utilizing the variable-length attention feature from Flash Attention2, preference pairs are packed into the same sequence during training, significantly reducing memory waste caused by padding tokens. This not only improves memory efficiency but also allows for training larger models or handling more data under the same hardware conditions.
+
+ 
+
+3. **Efficient Training**: Leveraging XTuner's QLoRA training capabilities, the reference model can be converted into a policy model with the LoRA adapter removed, eliminating the memory overhead of the reference model weights and significantly reducing DPO training costs.
+
+4. **Long Text Training**: With XTuner's sequence parallel functionality, long text data can be trained efficiently.
+
+### Getting Started
+
+Refer to the [Quick Start Guide](./quick_start.md) to understand the basic concepts. For more information on configuring training parameters, please see the [Modify DPO Settings](./modify_settings.md) section.
diff --git a/data/xtuner/docs/en/dpo/quick_start.md b/data/xtuner/docs/en/dpo/quick_start.md
new file mode 100644
index 0000000000000000000000000000000000000000..19fffbf8b4eeb45ea8b457608a78630fa4d9bade
--- /dev/null
+++ b/data/xtuner/docs/en/dpo/quick_start.md
@@ -0,0 +1,71 @@
+## Quick Start with DPO
+
+In this section, we will introduce how to use XTuner to train a 1.8B DPO (Direct Preference Optimization) model to help you get started quickly.
+
+### Preparing Pretrained Model Weights
+
+We use the model [InternLM2-chat-1.8b-sft](https://huggingface.co/internlm/internlm2-chat-1_8b-sft), as the initial model for DPO training to align human preferences.
+
+Set `pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b-sft'` in the training configuration file, and the model files will be automatically downloaded when training starts. If you need to download the model weights manually, please refer to the section [Preparing Pretrained Model Weights](https://xtuner.readthedocs.io/zh-cn/latest/preparation/pretrained_model.html), which provides detailed instructions on how to download model weights from Huggingface or Modelscope. Here are the links to the models on HuggingFace and ModelScope:
+
+- HuggingFace link: https://huggingface.co/internlm/internlm2-chat-1_8b-sft
+- ModelScope link: https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-chat-1_8b-sft/summary
+
+### Preparing Training Data
+
+In this tutorial, we use the [mlabonne/orpo-dpo-mix-40k](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) dataset from Huggingface as an example.
+
+```python
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(
+ type=load_dataset,
+ path='mlabonne/orpo-dpo-mix-40k'),
+ dataset_map_fn=orpo_dpo_mix_40k_map_fn,
+ is_dpo=True,
+ is_reward=False,
+)
+```
+
+Using the above configuration in the configuration file will automatically download and process this dataset. If you want to use other open-source datasets from Huggingface or custom datasets, please refer to the [Preference Dataset](../reward_model/preference_data.md) section.
+
+### Preparing Configuration File
+
+XTuner provides several ready-to-use configuration files, which can be viewed using `xtuner list-cfg`. Execute the following command to copy a configuration file to the current directory.
+
+```bash
+xtuner copy-cfg internlm2_chat_1_8b_dpo_full .
+```
+
+Open the copied configuration file. If you choose to download the model and dataset automatically, no modifications are needed. If you want to specify paths to your pre-downloaded model and dataset, modify the `pretrained_model_name_or_path` and the `path` parameter in `dataset` under `train_dataset`.
+
+For more training parameter configurations, please refer to the section [Modifying DPO Training Configuration](./modify_settings.md) section.
+
+### Starting the Training
+
+After completing the above steps, you can start the training task using the following commands.
+
+```bash
+# Single machine, single GPU
+xtuner train ./internlm2_chat_1_8b_dpo_full_copy.py
+# Single machine, multiple GPUs
+NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm2_chat_1_8b_dpo_full_copy.py
+# Slurm cluster
+srun ${SRUN_ARGS} xtuner train ./internlm2_chat_1_8b_dpo_full_copy.py --launcher slurm
+```
+
+### Model Conversion
+
+XTuner provides integrated tools to convert models to HuggingFace format. Simply execute the following commands:
+
+```bash
+# Create a directory for HuggingFace format parameters
+mkdir work_dirs/internlm2_chat_1_8b_dpo_full_copy/iter_15230_hf
+
+# Convert format
+xtuner convert pth_to_hf internlm2_chat_1_8b_dpo_full_copy.py \
+ work_dirs/internlm2_chat_1_8b_dpo_full_copy/iter_15230.pth \
+ work_dirs/internlm2_chat_1_8b_dpo_full_copy/iter_15230_hf
+```
+
+This will convert the XTuner's ckpt to the HuggingFace format.
diff --git a/data/xtuner/docs/en/evaluation/hook.md b/data/xtuner/docs/en/evaluation/hook.md
new file mode 100644
index 0000000000000000000000000000000000000000..de9e98c88665b4cb2741edb3c6e5adaef39e7116
--- /dev/null
+++ b/data/xtuner/docs/en/evaluation/hook.md
@@ -0,0 +1 @@
+# Evaluation during training
diff --git a/data/xtuner/docs/en/evaluation/mmbench.md b/data/xtuner/docs/en/evaluation/mmbench.md
new file mode 100644
index 0000000000000000000000000000000000000000..5421b1c96ac973f7a47839cb2478d63997473d94
--- /dev/null
+++ b/data/xtuner/docs/en/evaluation/mmbench.md
@@ -0,0 +1 @@
+# MMBench (VLM)
diff --git a/data/xtuner/docs/en/evaluation/mmlu.md b/data/xtuner/docs/en/evaluation/mmlu.md
new file mode 100644
index 0000000000000000000000000000000000000000..4bfabff8fa0c0492fe376413ab68dd4382f14cd4
--- /dev/null
+++ b/data/xtuner/docs/en/evaluation/mmlu.md
@@ -0,0 +1 @@
+# MMLU (LLM)
diff --git a/data/xtuner/docs/en/evaluation/opencompass.md b/data/xtuner/docs/en/evaluation/opencompass.md
new file mode 100644
index 0000000000000000000000000000000000000000..eb24da882f1ab04691e1bc87cf74a62809184d69
--- /dev/null
+++ b/data/xtuner/docs/en/evaluation/opencompass.md
@@ -0,0 +1 @@
+# Evaluate with OpenCompass
diff --git a/data/xtuner/docs/en/get_started/installation.md b/data/xtuner/docs/en/get_started/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..007e61553cc9c487db4639fe832d28b7835d22b8
--- /dev/null
+++ b/data/xtuner/docs/en/get_started/installation.md
@@ -0,0 +1,52 @@
+### Installation
+
+In this section, we will show you how to install XTuner.
+
+## Installation Process
+
+We recommend users to follow our best practices for installing XTuner.
+It is recommended to use a conda virtual environment with Python-3.10 to install XTuner.
+
+### Best Practices
+
+**Step 0.** Create a Python-3.10 virtual environment using conda.
+
+```shell
+conda create --name xtuner-env python=3.10 -y
+conda activate xtuner-env
+```
+
+**Step 1.** Install XTuner.
+
+Case a: Install XTuner via pip:
+
+```shell
+pip install -U xtuner
+```
+
+Case b: Install XTuner with DeepSpeed integration:
+
+```shell
+pip install -U 'xtuner[deepspeed]'
+```
+
+Case c: Install XTuner from the source code:
+
+```shell
+git clone https://github.com/InternLM/xtuner.git
+cd xtuner
+pip install -e '.[all]'
+# "-e" indicates installing the project in editable mode, so any local modifications to the code will take effect without reinstalling.
+```
+
+## Verify the installation
+
+To verify if XTuner is installed correctly, we will use a command to print the configuration files.
+
+**Print Configuration Files:** Use the command `xtuner list-cfg` in the command line to verify if the configuration files can be printed.
+
+```shell
+xtuner list-cfg
+```
+
+You should see a list of XTuner configuration files, corresponding to the ones in [xtuner/configs](https://github.com/InternLM/xtuner/tree/main/xtuner/configs) in the source code.
diff --git a/data/xtuner/docs/en/get_started/overview.md b/data/xtuner/docs/en/get_started/overview.md
new file mode 100644
index 0000000000000000000000000000000000000000..c257c83c6a3aabd31401cd49343d86a2ee89c899
--- /dev/null
+++ b/data/xtuner/docs/en/get_started/overview.md
@@ -0,0 +1,5 @@
+# Overview
+
+This chapter introduces you to the framework and workflow of XTuner, and provides detailed tutorial links.
+
+## What is XTuner
diff --git a/data/xtuner/docs/en/get_started/quickstart.md b/data/xtuner/docs/en/get_started/quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..23198bf3b7cae45461148c04560ca5e80c0b0e80
--- /dev/null
+++ b/data/xtuner/docs/en/get_started/quickstart.md
@@ -0,0 +1,308 @@
+# Quickstart
+
+In this section, we will show you how to use XTuner to fine-tune a model to help you get started quickly.
+
+After installing XTuner successfully, we can start fine-tuning the model. In this section, we will demonstrate how to use XTuner to apply the QLoRA algorithm to fine-tune InternLM2-Chat-7B on the Colorist dataset.
+
+The Colorist dataset ([HuggingFace link](https://huggingface.co/datasets/burkelibbey/colors); [ModelScope link](https://www.modelscope.cn/datasets/fanqiNO1/colors/summary)) is a dataset that provides color choices and suggestions based on color descriptions. A model fine-tuned on this dataset can be used to give a hexadecimal color code based on the user's description of the color. For example, when the user enters "a calming but fairly bright light sky blue, between sky blue and baby blue, with a hint of fluorescence due to its brightness", the model will output , which matches the user's description. There are a few sample data from this dataset:
+
+| Enligsh Description | Chinese Description | Color |
+| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------ |
+| Light Sky Blue: A calming, fairly bright color that falls between sky blue and baby blue, with a hint of slight fluorescence due to its brightness. | 浅天蓝色:一种介于天蓝和婴儿蓝之间的平和、相当明亮的颜色,由于明亮而带有一丝轻微的荧光。 | #66ccff:  |
+| Bright red: This is a very vibrant, saturated and vivid shade of red, resembling the color of ripe apples or fresh blood. It is as red as you can get on a standard RGB color palette, with no elements of either blue or green. | 鲜红色: 这是一种非常鲜艳、饱和、生动的红色,类似成熟苹果或新鲜血液的颜色。它是标准 RGB 调色板上的红色,不含任何蓝色或绿色元素。 | #ee0000:  |
+| Bright Turquoise: This color mixes the freshness of bright green with the tranquility of light blue, leading to a vibrant shade of turquoise. It is reminiscent of tropical waters. | 明亮的绿松石色:这种颜色融合了鲜绿色的清新和淡蓝色的宁静,呈现出一种充满活力的绿松石色调。它让人联想到热带水域。 | #00ffcc:  |
+
+## Prepare the model weights
+
+Before fine-tuning the model, we first need to prepare the weights of the model.
+
+### Download from HuggingFace
+
+```bash
+pip install -U huggingface_hub
+
+# Download the model weights to Shanghai_AI_Laboratory/internlm2-chat-7b
+huggingface-cli download internlm/internlm2-chat-7b \
+ --local-dir Shanghai_AI_Laboratory/internlm2-chat-7b \
+ --local-dir-use-symlinks False \
+ --resume-download
+```
+
+### Download from ModelScope
+
+Since pulling model weights from HuggingFace may lead to an unstable download process, slow download speed and other problems, we can choose to download the weights of InternLM2-Chat-7B from ModelScope when experiencing network issues.
+
+```bash
+pip install -U modelscope
+
+# Download the model weights to the current directory
+python -c "from modelscope import snapshot_download; snapshot_download('Shanghai_AI_Laboratory/internlm2-chat-7b', cache_dir='.')"
+```
+
+After completing the download, we can start to prepare the dataset for fine-tuning.
+
+The HuggingFace link and ModelScope link are attached here:
+
+- The HuggingFace link is located at: https://huggingface.co/internlm/internlm2-chat-7b
+- The ModelScope link is located at: https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-chat-7b/summary
+
+## Prepare the fine-tuning dataset
+
+### Download from HuggingFace
+
+```bash
+git clone https://huggingface.co/datasets/burkelibbey/colors
+```
+
+### Download from ModelScope
+
+Due to the same reason, we can choose to download the dataset from ModelScope.
+
+```bash
+git clone https://www.modelscope.cn/datasets/fanqiNO1/colors.git
+```
+
+The HuggingFace link and ModelScope link are attached here:
+
+- The HuggingFace link is located at: https://huggingface.co/datasets/burkelibbey/colors
+- The ModelScope link is located at: https://modelscope.cn/datasets/fanqiNO1/colors
+
+## Prepare the config
+
+XTuner provides several configs out-of-the-box, which can be viewed via `xtuner list-cfg`. We can use the following command to copy a config to the current directory.
+
+```bash
+xtuner copy-cfg internlm2_7b_qlora_colorist_e5 .
+```
+
+Explanation of the config name:
+
+| Config Name | internlm2_7b_qlora_colorist_e5 |
+| ----------- | ------------------------------ |
+| Model Name | internlm2_7b |
+| Algorithm | qlora |
+| Dataset | colorist |
+| Epochs | 5 |
+
+The directory structure at this point should look like this:
+
+```bash
+.
+├── colors
+│ ├── colors.json
+│ ├── dataset_infos.json
+│ ├── README.md
+│ └── train.jsonl
+├── internlm2_7b_qlora_colorist_e5_copy.py
+└── Shanghai_AI_Laboratory
+ └── internlm2-chat-7b
+ ├── config.json
+ ├── configuration_internlm2.py
+ ├── configuration.json
+ ├── generation_config.json
+ ├── modeling_internlm2.py
+ ├── pytorch_model-00001-of-00008.bin
+ ├── pytorch_model-00002-of-00008.bin
+ ├── pytorch_model-00003-of-00008.bin
+ ├── pytorch_model-00004-of-00008.bin
+ ├── pytorch_model-00005-of-00008.bin
+ ├── pytorch_model-00006-of-00008.bin
+ ├── pytorch_model-00007-of-00008.bin
+ ├── pytorch_model-00008-of-00008.bin
+ ├── pytorch_model.bin.index.json
+ ├── README.md
+ ├── special_tokens_map.json
+ ├── tokenization_internlm2_fast.py
+ ├── tokenization_internlm2.py
+ ├── tokenizer_config.json
+ └── tokenizer.model
+```
+
+## Modify the config
+
+In this step, we need to modify the model path and dataset path to local paths and modify the dataset loading method.
+In addition, since the copied config is based on the Base model, we also need to modify the `prompt_template` to adapt to the Chat model.
+
+```diff
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+- pretrained_model_name_or_path = 'internlm/internlm2-7b'
++ pretrained_model_name_or_path = './Shanghai_AI_Laboratory/internlm2-chat-7b'
+
+# Data
+- data_path = 'burkelibbey/colors'
++ data_path = './colors/train.jsonl'
+- prompt_template = PROMPT_TEMPLATE.default
++ prompt_template = PROMPT_TEMPLATE.internlm2_chat
+
+...
+#######################################################################
+# PART 3 Dataset & Dataloader #
+#######################################################################
+train_dataset = dict(
+ type=process_hf_dataset,
+- dataset=dict(type=load_dataset, path=data_path),
++ dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=colors_map_fn,
+ template_map_fn=dict(
+ type=template_map_fn_factory, template=prompt_template),
+ remove_unused_columns=True,
+ shuffle_before_pack=True,
+ pack_to_max_length=pack_to_max_length)
+```
+
+Therefore, `pretrained_model_name_or_path`, `data_path`, `prompt_template`, and the `dataset` fields in `train_dataset` are modified.
+
+## Start fine-tuning
+
+Once having done the above steps, we can start fine-tuning using the following command.
+
+```bash
+# Single GPU
+xtuner train ./internlm2_7b_qlora_colorist_e5_copy.py
+# Multiple GPUs
+NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm2_7b_qlora_colorist_e5_copy.py
+# Slurm
+srun ${SRUN_ARGS} xtuner train ./internlm2_7b_qlora_colorist_e5_copy.py --launcher slurm
+```
+
+The correct training log may look similar to the one shown below:
+
+```text
+01/29 21:35:34 - mmengine - INFO - Iter(train) [ 10/720] lr: 9.0001e-05 eta: 0:31:46 time: 2.6851 data_time: 0.0077 memory: 12762 loss: 2.6900
+01/29 21:36:02 - mmengine - INFO - Iter(train) [ 20/720] lr: 1.9000e-04 eta: 0:32:01 time: 2.8037 data_time: 0.0071 memory: 13969 loss: 2.6049 grad_norm: 0.9361
+01/29 21:36:29 - mmengine - INFO - Iter(train) [ 30/720] lr: 1.9994e-04 eta: 0:31:24 time: 2.7031 data_time: 0.0070 memory: 13969 loss: 2.5795 grad_norm: 0.9361
+01/29 21:36:57 - mmengine - INFO - Iter(train) [ 40/720] lr: 1.9969e-04 eta: 0:30:55 time: 2.7247 data_time: 0.0069 memory: 13969 loss: 2.3352 grad_norm: 0.8482
+01/29 21:37:24 - mmengine - INFO - Iter(train) [ 50/720] lr: 1.9925e-04 eta: 0:30:28 time: 2.7286 data_time: 0.0068 memory: 13969 loss: 2.2816 grad_norm: 0.8184
+01/29 21:37:51 - mmengine - INFO - Iter(train) [ 60/720] lr: 1.9863e-04 eta: 0:29:58 time: 2.7048 data_time: 0.0069 memory: 13969 loss: 2.2040 grad_norm: 0.8184
+01/29 21:38:18 - mmengine - INFO - Iter(train) [ 70/720] lr: 1.9781e-04 eta: 0:29:31 time: 2.7302 data_time: 0.0068 memory: 13969 loss: 2.1912 grad_norm: 0.8460
+01/29 21:38:46 - mmengine - INFO - Iter(train) [ 80/720] lr: 1.9681e-04 eta: 0:29:05 time: 2.7338 data_time: 0.0069 memory: 13969 loss: 2.1512 grad_norm: 0.8686
+01/29 21:39:13 - mmengine - INFO - Iter(train) [ 90/720] lr: 1.9563e-04 eta: 0:28:36 time: 2.7047 data_time: 0.0068 memory: 13969 loss: 2.0653 grad_norm: 0.8686
+01/29 21:39:40 - mmengine - INFO - Iter(train) [100/720] lr: 1.9426e-04 eta: 0:28:09 time: 2.7383 data_time: 0.0070 memory: 13969 loss: 1.9819 grad_norm: 0.9127
+```
+
+Before training begins, the output of the model is as shown below:
+
+```text
+2024/01/29 21:34:58 - mmengine - INFO - before_train in EvaluateChatHook.
+2024/01/29 21:35:03 - mmengine - INFO - Sample output:
+<|im_start|>system
+You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+<|im_end|>
+<|im_start|>user
+请给我一个像天空一样清澈透明的蓝色。<|im_end|>
+<|im_start|>assistant
+为了匹配您所描述的“像天空一样清澈透明的蓝色”,我建议您选择一种名为“天蓝”(Cerulean)的颜色。这种颜色通常被用来代表天空、海洋和清澈的水域,它具有明亮
+
+2024/01/29 21:35:07 - mmengine - INFO - Sample output:
+<|im_start|>system
+You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+<|im_end|>
+<|im_start|>user
+Please give me a clear blue like the sky.<|im_end|>
+<|im_start|>assistant
+The color you're describing is a clear, bright blue that resembles the color of the sky on a sunny day. This color is often referred to as "sky blue" or "cerulean blue." Here are some specific color codes and names that
+```
+
+After training, the output of the model is as shown below:
+
+```text
+2024/01/29 22:08:07 - mmengine - INFO - Sample output:
+<|im_start|>system
+You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+<|im_end|>
+<|im_start|>user
+请给我一个像天空一样清澈透明的蓝色。<|im_end|>
+<|im_start|>assistant
+#1099ee<|im_end|>
+
+2024/01/29 22:08:08 - mmengine - INFO - Sample output:
+<|im_start|>system
+You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+<|im_end|>
+<|im_start|>user
+Please give me a clear blue like the sky.<|im_end|>
+<|im_start|>assistant
+#0066dd<|im_end|>
+```
+
+The color of the model output is shown below:
+
+- 天空一样清澈透明的蓝色:
+- A clear blue like the sky: 
+
+It is clear that the output of the model after training has been fully aligned with the content of the dataset.
+
+# Model Convert + LoRA Merge
+
+After training, we will get several `.pth` files that do **NOT** contain all the parameters of the model, but store the parameters updated by the training process of the QLoRA algorithm. Therefore, we need to convert these `.pth` files to HuggingFace format and merge them into the original LLM weights.
+
+### Model Convert
+
+XTuner has already integrated the tool of converting the model to HuggingFace format. We can use the following command to convert the model.
+
+```bash
+# Create the directory to store parameters in hf format
+mkdir work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf
+
+# Convert the model to hf format
+xtuner convert pth_to_hf internlm2_7b_qlora_colorist_e5_copy.py \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720.pth \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf
+```
+
+This command will convert `work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720.pth` to hf format based on the contents of the config `internlm2_7b_qlora_colorist_e5_copy.py` and will save it in `work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf`.
+
+### LoRA Merge
+
+XTuner has also integrated the tool of merging LoRA weights, we just need to execute the following command:
+
+```bash
+# Create the directory to store the merged weights
+mkdir work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged
+
+# Merge the weights
+xtuner convert merge Shanghai_AI_Laboratory/internlm2-chat-7b \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged \
+ --max-shard-size 2GB
+```
+
+Similar to the command above, this command will read the original parameter path `Shanghai_AI_Laboratory/internlm2-chat-7b` and the path of parameter which has been converted to hf format `work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf` and merge the two parts of the parameters and save them in `work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged`, where the maximum file size for each parameter slice is 2GB.
+
+## Chat with the model
+
+To better appreciate the model's capabilities after merging the weights, we can chat with the model. XTuner also integrates the tool of chatting with models. We can start a simple demo to chat with the model with the following command:
+
+```bash
+xtuner chat work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged \
+ --prompt-template internlm2_chat \
+ --system-template colorist
+```
+
+Of course, we can also choose not to merge the weights and instead chat directly with the LLM + LoRA Adapter, we just need to execute the following command:
+
+```bash
+xtuner chat Shanghai_AI_Laboratory/internlm2-chat-7b
+ --adapter work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf \
+ --prompt-template internlm2_chat \
+ --system-template colorist
+```
+
+where `work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged` is the path to the merged weights, `--prompt-template internlm2_chat` specifies that the chat template is InternLM2-Chat, and `-- system-template colorist` specifies that the System Prompt for conversations with models is the template required by the Colorist dataset.
+
+There is an example below:
+
+```text
+double enter to end input (EXIT: exit chat, RESET: reset history) >>> A calming but fairly bright light sky blue, between sky blue and baby blue, with a hint of fluorescence due to its brightness.
+
+#66ccff<|im_end|>
+```
+
+The color of the model output is shown below:
+
+A calming but fairly bright light sky blue, between sky blue and baby blue, with a hint of fluorescence due to its brightness: .
diff --git a/data/xtuner/docs/en/index.rst b/data/xtuner/docs/en/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..c4c18d31ab03f6f9bf91f3d40f5cfeb626735f66
--- /dev/null
+++ b/data/xtuner/docs/en/index.rst
@@ -0,0 +1,123 @@
+.. xtuner documentation master file, created by
+ sphinx-quickstart on Tue Jan 9 16:33:06 2024.
+ You can adapt this file completely to your liking, but it should at least
+ contain the root `toctree` directive.
+
+Welcome to XTuner's documentation!
+==================================
+
+.. figure:: ./_static/image/logo.png
+ :align: center
+ :alt: xtuner
+ :class: no-scaled-link
+
+.. raw:: html
+
+
+ All-IN-ONE toolbox for LLM
+
+
+
+
+
+ Star
+ Watch
+ Fork
+
+
+
+
+Documentation
+-------------
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started/overview.md
+ get_started/installation.md
+ get_started/quickstart.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Preparation
+
+ preparation/pretrained_model.rst
+ preparation/prompt_template.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Training
+
+ training/modify_settings.rst
+ training/custom_sft_dataset.rst
+ training/custom_pretrain_dataset.rst
+ training/custom_agent_dataset.rst
+ training/multi_modal_dataset.rst
+ training/open_source_dataset.rst
+ training/visualization.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: DPO
+
+ dpo/overview.md
+ dpo/quick_start.md
+ dpo/modify_settings.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Reward Model
+
+ reward_model/overview.md
+ reward_model/quick_start.md
+ reward_model/modify_settings.md
+ reward_model/preference_data.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Acceleration
+
+ acceleration/deepspeed.rst
+ acceleration/pack_to_max_length.rst
+ acceleration/flash_attn.rst
+ acceleration/varlen_flash_attn.rst
+ acceleration/hyper_parameters.rst
+ acceleration/length_grouped_sampler.rst
+ acceleration/train_large_scale_dataset.rst
+ acceleration/train_extreme_long_sequence.rst
+ acceleration/benchmark.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Chat
+
+ chat/llm.md
+ chat/agent.md
+ chat/vlm.md
+ chat/lmdeploy.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Evaluation
+
+ evaluation/hook.md
+ evaluation/mmlu.md
+ evaluation/mmbench.md
+ evaluation/opencompass.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Models
+
+ models/supported.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: InternEvo Migration
+
+ internevo_migration/internevo_migration.rst
+ internevo_migration/ftdp_dataset/ftdp.rst
+ internevo_migration/ftdp_dataset/Case1.rst
+ internevo_migration/ftdp_dataset/Case2.rst
+ internevo_migration/ftdp_dataset/Case3.rst
+ internevo_migration/ftdp_dataset/Case4.rst
diff --git a/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case1.rst b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case1.rst
new file mode 100644
index 0000000000000000000000000000000000000000..c8eb0c76afa4c5630d910c3fce05eea62e2a9a08
--- /dev/null
+++ b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case1.rst
@@ -0,0 +1,2 @@
+Case 1
+======
diff --git a/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case2.rst b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case2.rst
new file mode 100644
index 0000000000000000000000000000000000000000..74069f68f830fe2de5ee641266b4a9aad585ea7a
--- /dev/null
+++ b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case2.rst
@@ -0,0 +1,2 @@
+Case 2
+======
diff --git a/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case3.rst b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case3.rst
new file mode 100644
index 0000000000000000000000000000000000000000..d963b538b55c70a12978e738e1f3d6db399f445f
--- /dev/null
+++ b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case3.rst
@@ -0,0 +1,2 @@
+Case 3
+======
diff --git a/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case4.rst b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case4.rst
new file mode 100644
index 0000000000000000000000000000000000000000..1f7626933c512221449355c3eae138d9ea681955
--- /dev/null
+++ b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/Case4.rst
@@ -0,0 +1,2 @@
+Case 4
+======
diff --git a/data/xtuner/docs/en/internevo_migration/ftdp_dataset/ftdp.rst b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/ftdp.rst
new file mode 100644
index 0000000000000000000000000000000000000000..613568f151b54848f747c0740161d01e905359a2
--- /dev/null
+++ b/data/xtuner/docs/en/internevo_migration/ftdp_dataset/ftdp.rst
@@ -0,0 +1,2 @@
+ftdp
+====
diff --git a/data/xtuner/docs/en/internevo_migration/internevo_migration.rst b/data/xtuner/docs/en/internevo_migration/internevo_migration.rst
new file mode 100644
index 0000000000000000000000000000000000000000..869206508d772d8503003f7669a134a1d44fce7e
--- /dev/null
+++ b/data/xtuner/docs/en/internevo_migration/internevo_migration.rst
@@ -0,0 +1,2 @@
+InternEVO Migration
+===================
diff --git a/data/xtuner/docs/en/make.bat b/data/xtuner/docs/en/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..954237b9b9f2b248bb1397a15c055c0af1cad03e
--- /dev/null
+++ b/data/xtuner/docs/en/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.https://www.sphinx-doc.org/
+ exit /b 1
+)
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/data/xtuner/docs/en/models/supported.md b/data/xtuner/docs/en/models/supported.md
new file mode 100644
index 0000000000000000000000000000000000000000..c61546e5209d69ef0824b54bada46c18de3d8f72
--- /dev/null
+++ b/data/xtuner/docs/en/models/supported.md
@@ -0,0 +1 @@
+# Supported Models
diff --git a/data/xtuner/docs/en/notes/changelog.md b/data/xtuner/docs/en/notes/changelog.md
new file mode 100644
index 0000000000000000000000000000000000000000..2c9678539d213e5bbca90bbf4449cfbe4dfd7936
--- /dev/null
+++ b/data/xtuner/docs/en/notes/changelog.md
@@ -0,0 +1,25 @@
+
+
+# Changelog
+
+## v0.1.0 (2023.08.30)
+
+XTuner is released! 🔥🔥🔥
+
+### Highlights
+
+- XTuner supports LLM fine-tuning on consumer-grade GPUs. The minimum GPU memory required for 7B LLM fine-tuning is only **8GB**.
+- XTuner supports various LLMs, datasets, algorithms and training pipelines.
+- Several fine-tuned adapters are released simultaneously, including various gameplays such as the colorist LLM, plugins-based LLM, and many more. For further details, please visit [XTuner on HuggingFace](https://huggingface.co/xtuner)!
diff --git a/data/xtuner/docs/en/preparation/pretrained_model.rst b/data/xtuner/docs/en/preparation/pretrained_model.rst
new file mode 100644
index 0000000000000000000000000000000000000000..a3ac291ac1e74801c032a581b9e0b2afaf180a91
--- /dev/null
+++ b/data/xtuner/docs/en/preparation/pretrained_model.rst
@@ -0,0 +1,2 @@
+Pretrained Model
+================
diff --git a/data/xtuner/docs/en/preparation/prompt_template.rst b/data/xtuner/docs/en/preparation/prompt_template.rst
new file mode 100644
index 0000000000000000000000000000000000000000..43ccb98e31eaca7c05368628475613f515371810
--- /dev/null
+++ b/data/xtuner/docs/en/preparation/prompt_template.rst
@@ -0,0 +1,2 @@
+Prompt Template
+===============
diff --git a/data/xtuner/docs/en/reward_model/modify_settings.md b/data/xtuner/docs/en/reward_model/modify_settings.md
new file mode 100644
index 0000000000000000000000000000000000000000..4f41ca300865bc83bd02b727cc6b61696f8617fb
--- /dev/null
+++ b/data/xtuner/docs/en/reward_model/modify_settings.md
@@ -0,0 +1,100 @@
+## Modify Reward Model Training Configuration
+
+This section introduces the config related to Reward Model training. For more details on XTuner config files, please refer to [Modify Settings](https://xtuner.readthedocs.io/zh-cn/latest/training/modify_settings.html).
+
+### Loss Function
+
+XTuner uses the [Bradley–Terry Model](https://en.wikipedia.org/wiki/Bradley%E2%80%93Terry_model) for preference modeling in the Reward Model. You can specify `loss_type="ranking"` to use ranking loss. XTuner also implements the focal loss function proposed in InternLM2, which adjusts the weights of difficult and easy samples to avoid overfitting. You can set `loss_type="focal"` to use this loss function. For a detailed explanation of this loss function, please refer to the [InternLM2 Technical Report](https://arxiv.org/abs/2403.17297).
+
+Additionally, to maintain stable reward model output scores, we have added a constraint term in the loss. You can specify `penalty_type='log_barrier'` or `penalty_type='L2'` to enable log barrier or L2 constraints, respectively.
+
+```python
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+loss_type = 'focal' # 'ranking' or 'focal'
+penalty_type = 'log_barrier' # 'log_barrier' or 'L2'
+```
+
+### Modifying the Model
+
+Users can modify `pretrained_model_name_or_path` to change the pretrained model.
+
+Note that XTuner calculates reward scores by appending a special token at the end of the data. Therefore, when switching models with different vocabularies, the ID of this special token also needs to be modified accordingly. We usually use an unused token at the end of the vocabulary as the reward token.
+
+For example, in InternLM2, we use `[UNUSED_TOKEN_130]` as the reward token:
+
+```python
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b-sft'
+reward_token_id = 92527 # use [UNUSED_TOKEN_130] as reward token
+```
+
+If the user switches to the llama3 model, we can use `<|reserved_special_token_0|>` as the reward token:
+
+```python
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+pretrained_model_name_or_path = 'meta-llama/Meta-Llama-3-8B-Instruct'
+reward_token_id = 128002 # use <|reserved_special_token_0|> as reward token
+```
+
+### Training Data
+
+In Reward Model training, you can specify the maximum number of tokens for a single sample sequence using `max_length`. XTuner will automatically truncate or pad the data.
+
+```python
+# Data
+max_length = 2048
+```
+
+In the configuration file, we use the `train_dataset` field to specify the training dataset. You can specify the dataset loading method using the `dataset` field and the dataset mapping function using the `dataset_map_fn` field.
+
+```python
+#######################################################################
+# PART 3 Dataset & Dataloader #
+#######################################################################
+sampler = SequenceParallelSampler \
+ if sequence_parallel_size > 1 else DefaultSampler
+
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(
+ type=load_dataset,
+ path='argilla/ultrafeedback-binarized-preferences-cleaned'),
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=orpo_dpo_mix_40k_map_fn,
+ is_dpo=False,
+ is_reward=True,
+ reward_token_id=reward_token_id,
+ num_proc=32,
+ use_varlen_attn=use_varlen_attn,
+ max_packed_length=max_packed_length,
+ shuffle_before_pack=True,
+)
+
+train_dataloader = dict(
+ batch_size=batch_size,
+ num_workers=dataloader_num_workers,
+ dataset=train_dataset,
+ sampler=dict(type=sampler, shuffle=True),
+ collate_fn=dict(
+ type=preference_collate_fn, use_varlen_attn=use_varlen_attn))
+```
+
+In the above configuration, we use `load_dataset` to load the `argilla/ultrafeedback-binarized-preferences-cleaned` dataset from Hugging Face, using `orpo_dpo_mix_40k_map_fn` as the dataset mapping function (this is because `orpo_dpo_mix_40k` and `ultrafeedback-binarized-preferences-cleaned` have the same format, so the same mapping function is used).
+
+For more information on handling datasets and writing dataset mapping functions, please refer to the [Preference Data Section](./preference_data.md).
+
+### Accelerating Training
+
+When training with preference data, we recommend enabling the [Variable-Length Attention Mechanism](https://xtuner.readthedocs.io/zh-cn/latest/acceleration/varlen_flash_attn.html) to avoid memory waste caused by length differences between chosen and rejected samples within a single preference. You can enable the variable-length attention mechanism by setting `use_varlen_attn=True`.
+
+XTuner also supports many training acceleration methods. For details on how to use them, please refer to the [Acceleration Strategies Section](https://xtuner.readthedocs.io/zh-cn/latest/acceleration/hyper_parameters.html).
diff --git a/data/xtuner/docs/en/reward_model/overview.md b/data/xtuner/docs/en/reward_model/overview.md
new file mode 100644
index 0000000000000000000000000000000000000000..eb210140c7e88df9912429d900709f54cfa3be5b
--- /dev/null
+++ b/data/xtuner/docs/en/reward_model/overview.md
@@ -0,0 +1,43 @@
+## Introduction to Reward Model
+
+### Overview
+
+The Reward Model is a crucial component in the reinforcement learning process. Its primary task is to predict reward values based on given inputs, guiding the direction of the learning algorithm. In RLHF (Reinforcement Learning from Human Feedback), the Reward Model acts as a proxy for human preferences, helping the reinforcement learning algorithm optimize strategies more effectively.
+
+In large language model training, the Reward Model typically refers to the Preference Model. By providing good and bad (chosen & rejected) responses to the same prompts during training, it fits human preferences and predicts a reward value during inference to guide the optimization of the Actor model in the RLHF process.
+
+Applications of the Reward Model include but are not limited to:
+
+- **RLHF Training**: During RLHF training such as the Proximal Policy Optimization (PPO) algorithm, the Reward Model provides reward signals, improve the quality of generated content, and align it more closely with human preferences.
+- **BoN Sampling**: In the Best-of-N (BoN) sampling process, users can use the Reward Model to score multiple responses to the same prompt and select the highest-scoring generated result, thereby enhancing the model's output.
+- **Data Construction**: The Reward Model can be used to evaluate and filter training data or replace manual annotation to construct DPO training data.
+
+### Features of Reward Model Training in XTuner
+
+The Reward Model training in XTuner offers the following significant advantages:
+
+1. **Latest Training Techniques**: XTuner integrates the Reward Model training loss function from InternLM2, which stabilizes the numerical range of reward scores and reduces overfitting on simple samples (see [InternLM2 Technical Report](https://arxiv.org/abs/2403.17297) for details).
+
+2. **Reducing Memory Waste**: Due to the length differences in chosen and rejected data in preference datasets, padding tokens during data concatenation can cause memory waste. In XTuner, by utilizing the variable-length attention feature from Flash Attention2, preference pairs are packed into the same sequence during training, significantly reducing memory waste caused by padding tokens. This not only improves memory efficiency but also allows for training larger models or handling more data under the same hardware conditions.
+
+
+
+3. **Efficient Training**: Leveraging XTuner's QLoRA training capabilities, we can perform full parameter training only on the Reward Model's Value Head, while using QLoRA fine-tuning on the language model itself, substantially reducing the memory overhead of model training.
+
+4. **Long Text Training**: With XTuner's sequence parallel functionality, long text data can be trained efficiently.
+
+
+
+### Getting Started
+
+Refer to the [Quick Start Guide](./quick_start.md) to understand the basic concepts. For more information on configuring training parameters, please see the [Modifying Reward Model Settings](./modify_settings.md) section.
+
+### Open-source Models
+
+We use XTuner to train the InternLM2 Reward Models from the InternLM2 Technical Report, welcome to download and use:
+
+| Model | Transformers(HF) | ModelScope(HF) | OpenXLab(HF) | RewardBench Score |
+| ------------------------- | -------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------- |
+| **InternLM2-1.8B-Reward** | [🤗internlm2-1_8b-reward](https://huggingface.co/internlm/internlm2-1_8b-reward) | [internlm2-1_8b-reward](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-1_8b-reward/summary) | [](https://openxlab.org.cn/models/detail/OpenLMLab/internlm2-1_8b-reward) | 80.6 |
+| **InternLM2-7B-Reward** | [🤗internlm2-7b-reward](https://huggingface.co/internlm/internlm2-7b-reward) | [internlm2-7b-reward](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-7b-reward/summary) | [](https://openxlab.org.cn/models/detail/OpenLMLab/internlm2-7b-reward) | 86.6 |
+| **InternLM2-20B-Reward** | [🤗internlm2-20b-reward](https://huggingface.co/internlm/internlm2-20b-reward) | [internlm2-20b-reward](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-20b-reward/summary) | [](https://openxlab.org.cn/models/detail/OpenLMLab/internlm2-20b-reward) | 89.5 |
diff --git a/data/xtuner/docs/en/reward_model/preference_data.md b/data/xtuner/docs/en/reward_model/preference_data.md
new file mode 100644
index 0000000000000000000000000000000000000000..2f304e627a29bc8e6acb73705a15f676551c5d24
--- /dev/null
+++ b/data/xtuner/docs/en/reward_model/preference_data.md
@@ -0,0 +1,110 @@
+## Preference Dataset
+
+### Overview
+
+XTuner's Reward Model, along with DPO, ORPO, and other algorithms that training on preference data, adopts the same data format. Each training sample in the preference dataset needs to contain the following three fields: `prompt`, `chosen`, and `rejected`. The values for each field follow the [OpenAI chat message](https://platform.openai.com/docs/api-reference/chat/create) format. A specific example is as follows:
+
+```json
+{
+ "prompt": [
+ {
+ "role": "system",
+ "content": "You are a helpful assistant."
+ },
+ {
+ "role": "user",
+ "content": "Who won the world series in 2020?"
+ },
+ {
+ "role": "assistant",
+ "content": "The Los Angeles Dodgers won the World Series in 2020."
+ },
+ {
+ "role": "user",
+ "content": "Where was it played?"
+ }
+ ],
+ "chosen": [
+ {
+ "role": "assistant",
+ "content": "The 2020 World Series was played at Globe Life Field in Arlington, Texas."
+ }
+ ],
+ "rejected": [
+ {
+ "role": "assistant",
+ "content": "I don't know."
+ }
+ ]
+}
+```
+
+When conducting Reward Model training or DPO training, XTuner processes the preference dataset into different training labels based on the type of training task.
+
+
+
+As shown in the above image, for Reward Model training, we follow the ChatGPT training method by adding a special `<|reward|>` token at the end of the conversation data and calculating the loss only on the logits output by this token. For DPO series algorithm training, we mask the tokens in the prompt part and calculate the loss only on the chosen and rejected responses. In the configuration file, we control the dataset type through the `is_reward` and `is_dpo` fields in the dataset.
+
+### Training with Custom Data
+
+After understanding the data format of a single sample, you only need to save the converted data in [JSON Lines](https://jsonlines.org/) format. Each line in the file is a sample.
+
+```json
+{"prompt": [{"content": "How can I learn to better regulate my emotions as a grown adult?", "role": "user"}], "chosen": [{"content": "You could do emotional regulation exercises with me, and try to notice and practice ways that you could better control your emotions in real life.", "role": "assistant"}], "rejected": [{"content": "Do you mean how can you learn to be more emotionally mature?", "role": "assistant"}]}
+{"prompt": [{"content": "What are some interesting things I can add to a grilled cheese sandwich?", "role": "user"}, {"content": "A tomato, a slice of pickle, some chopped pickles, some chopped green onions. Also, some mayonnaise if you like.", "role": "assistant"}, {"content": "Sounds great. Anything else?", "role": "user"}], "chosen": [{"content": "If you’d like something a little different, I recommend grating some horseradish on top of the sandwich.", "role": "assistant"}], "rejected": [{"content": "Maybe some nice fresh basil?", "role": "assistant"}]}
+{"prompt": [{"content": "How do I bob for apples?", "role": "user"}], "chosen": [{"content": "Ah! Do you mean the game of “applesauce,” or do you mean the idea of “to bob for apples”?", "role": "assistant"}], "rejected": [{"content": "Sorry, I don’t know that term.", "role": "assistant"}]}
+......
+```
+
+After preparing the custom dataset, you need to fill in the path to your saved data in the `data_files` field in the configuration file. You can load multiple JSONL files simultaneously for training.
+
+```python
+#######################################################################
+# PART 3 Dataset & Dataloader #
+#######################################################################
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(
+ type=load_jsonl_dataset,
+ data_files=[
+ '/your/jsonl/path/here.jsonl',
+ '/your/another/jsonl/path/here.jsonl'
+ ]),
+)
+```
+
+### Training with Open Source Datasets
+
+Similar to configuring SFT data in XTuner, when using open-source datasets from Hugging Face, you only need to define a mapping function `map_fn` to process the dataset format into XTuner's data format.
+
+Taking `Intel/orca_dpo_pairs` as an example, this dataset has `system`, `question`, `chosen`, and `rejected` fields, with each field's value in text format instead of the [OpenAI chat message](https://platform.openai.com/docs/api-reference/chat/create) format. Therefore, we need to define a mapping function for this dataset:
+
+```python
+def intel_orca_dpo_map_fn(example):
+ prompt = [{
+ 'role': 'system',
+ 'content': example['system']
+ }, {
+ 'role': 'user',
+ 'content': example['question']
+ }]
+ chosen = [{'role': 'assistant', 'content': example['chosen']}]
+ rejected = [{'role': 'assistant', 'content': example['rejected']}]
+ return {'prompt': prompt, 'chosen': chosen, 'rejected': rejected}
+```
+
+As shown in the code, `intel_orca_dpo_map_fn` processes the four fields in the original data, converting them into `prompt`, `chosen`, and `rejected` fields, and ensures each field follows the [OpenAI chat message](https://platform.openai.com/docs/api-reference/chat/create) format, maintaining uniformity in subsequent data processing flows.
+
+After defining the mapping function, you need to import it in the configuration file and configure it in the `dataset_map_fn` field.
+
+```python
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(
+ type=load_dataset,
+ path='Intel/orca_dpo_pairs'),
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=intel_orca_dpo_map_fn,
+)
+```
diff --git a/data/xtuner/docs/en/reward_model/quick_start.md b/data/xtuner/docs/en/reward_model/quick_start.md
new file mode 100644
index 0000000000000000000000000000000000000000..5c802be2f33f9c25d1bb018de07c38ea09d86c69
--- /dev/null
+++ b/data/xtuner/docs/en/reward_model/quick_start.md
@@ -0,0 +1,85 @@
+## Quick Start Guide for Reward Model
+
+In this section, we will introduce how to use XTuner to train a 1.8B Reward Model, helping you get started quickly.
+
+### Preparing Pretrained Model Weights
+
+According to the paper [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155), we use a language model fine-tuned with SFT as the initialization model for the Reward Model. Here, we use [InternLM2-chat-1.8b-sft](https://huggingface.co/internlm/internlm2-chat-1_8b-sft) as the initialization model.
+
+Set `pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b-sft'` in the training configuration file, and the model files will be automatically downloaded when training starts. If you need to download the model weights manually, please refer to the section [Preparing Pretrained Model Weights](https://xtuner.readthedocs.io/zh-cn/latest/preparation/pretrained_model.html), which provides detailed instructions on how to download model weights from Huggingface or Modelscope. Here are the links to the models on HuggingFace and ModelScope:
+
+- HuggingFace link: https://huggingface.co/internlm/internlm2-chat-1_8b-sft
+- ModelScope link: https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-chat-1_8b-sft/summary
+
+### Preparing Training Data
+
+In this tutorial, we use the [UltraFeedback](https://arxiv.org/abs/2310.01377) dataset as an example. For convenience, we use the preprocessed [argilla/ultrafeedback-binarized-preferences-cleaned](https://huggingface.co/datasets/argilla/ultrafeedback-binarized-preferences-cleaned) dataset from Huggingface.
+
+```python
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(
+ type=load_dataset,
+ path='argilla/ultrafeedback-binarized-preferences-cleaned'),
+ dataset_map_fn=orpo_dpo_mix_40k_map_fn,
+ is_dpo=False,
+ is_reward=True,
+)
+```
+
+Using the above configuration in the configuration file will automatically download and process this dataset. If you want to use other open-source datasets from Huggingface or custom datasets, please refer to the [Preference Dataset](./preference_data.md) section.
+
+### Preparing Configuration Files
+
+XTuner provides several ready-to-use configuration files, which can be viewed using `xtuner list-cfg`. Execute the following command to copy a configuration file to the current directory.
+
+```bash
+xtuner copy-cfg internlm2_chat_1_8b_reward_full_ultrafeedback .
+```
+
+Open the copied configuration file. If you choose to download the model and dataset automatically, no modifications are needed. If you want to specify paths to your pre-downloaded model and dataset, modify the `pretrained_model_name_or_path` and the `path` parameter in `dataset` under `train_dataset`.
+
+For more training parameter configurations, please refer to the section [Modifying Reward Training Configuration](./modify_settings.md).
+
+### Starting the Training
+
+After completing the above steps, you can start the training task using the following commands.
+
+```bash
+# Single node single GPU
+xtuner train ./internlm2_chat_1_8b_reward_full_ultrafeedback_copy.py
+# Single node multiple GPUs
+NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm2_chat_1_8b_reward_full_ultrafeedback_copy.py
+# Slurm cluster
+srun ${SRUN_ARGS} xtuner train ./internlm2_chat_1_8b_reward_full_ultrafeedback_copy.py --launcher slurm
+```
+
+The correct training log should look like the following (running on a single A800 GPU):
+
+```
+06/06 16:12:11 - mmengine - INFO - Iter(train) [ 10/15230] lr: 3.9580e-07 eta: 2:59:41 time: 0.7084 data_time: 0.0044 memory: 18021 loss: 0.6270 acc: 0.0000 chosen_score_mean: 0.0000 rejected_score_mean: 0.0000 num_samples: 4.0000 num_tokens: 969.0000
+06/06 16:12:17 - mmengine - INFO - Iter(train) [ 20/15230] lr: 8.3536e-07 eta: 2:45:25 time: 0.5968 data_time: 0.0034 memory: 42180 loss: 0.6270 acc: 0.5000 chosen_score_mean: 0.0013 rejected_score_mean: 0.0010 num_samples: 4.0000 num_tokens: 1405.0000
+06/06 16:12:22 - mmengine - INFO - Iter(train) [ 30/15230] lr: 1.2749e-06 eta: 2:37:18 time: 0.5578 data_time: 0.0024 memory: 32121 loss: 0.6270 acc: 0.7500 chosen_score_mean: 0.0016 rejected_score_mean: 0.0011 num_samples: 4.0000 num_tokens: 932.0000
+06/06 16:12:28 - mmengine - INFO - Iter(train) [ 40/15230] lr: 1.7145e-06 eta: 2:36:05 time: 0.6033 data_time: 0.0025 memory: 42186 loss: 0.6270 acc: 0.7500 chosen_score_mean: 0.0027 rejected_score_mean: 0.0016 num_samples: 4.0000 num_tokens: 994.0000
+06/06 16:12:35 - mmengine - INFO - Iter(train) [ 50/15230] lr: 2.1540e-06 eta: 2:41:03 time: 0.7166 data_time: 0.0027 memory: 42186 loss: 0.6278 acc: 0.5000 chosen_score_mean: 0.0031 rejected_score_mean: 0.0032 num_samples: 4.0000 num_tokens: 2049.0000
+06/06 16:12:40 - mmengine - INFO - Iter(train) [ 60/15230] lr: 2.5936e-06 eta: 2:33:37 time: 0.4627 data_time: 0.0023 memory: 30238 loss: 0.6262 acc: 1.0000 chosen_score_mean: 0.0057 rejected_score_mean: 0.0030 num_samples: 4.0000 num_tokens: 992.0000
+06/06 16:12:46 - mmengine - INFO - Iter(train) [ 70/15230] lr: 3.0331e-06 eta: 2:33:18 time: 0.6018 data_time: 0.0025 memory: 42186 loss: 0.6247 acc: 0.7500 chosen_score_mean: 0.0117 rejected_score_mean: 0.0055 num_samples: 4.0000 num_tokens: 815.0000
+```
+
+### Model Conversion
+
+XTuner provides integrated tools to convert models to HuggingFace format. Simply execute the following commands:
+
+```bash
+# Create a directory to store HF format parameters
+mkdir work_dirs/internlm2_chat_1_8b_reward_full_ultrafeedback_copy/iter_15230_hf
+
+# Convert the format
+xtuner convert pth_to_hf internlm2_chat_1_8b_reward_full_ultrafeedback_copy.py \
+ work_dirs/internlm2_chat_1_8b_reward_full_ultrafeedback_copy.py/iter_15230.pth \
+ work_dirs/internlm2_chat_1_8b_reward_full_ultrafeedback_copy.py/iter_15230_hf
+```
+
+This will convert the XTuner's ckpt to the HuggingFace format.
+
+Note: Since the Reward Model type is not integrated into the official transformers library, only the Reward Models trained with InternLM2 will be converted to the `InternLM2ForRewardModel` type. Other models will default to the `SequenceClassification` type (for example, LLaMa3 will be converted to the `LlamaForSequenceClassification` type).
diff --git a/data/xtuner/docs/en/switch_language.md b/data/xtuner/docs/en/switch_language.md
new file mode 100644
index 0000000000000000000000000000000000000000..ff7c4c42502846c4fe3fc52f0bc2c2aec09c4f02
--- /dev/null
+++ b/data/xtuner/docs/en/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/data/xtuner/docs/en/training/custom_agent_dataset.rst b/data/xtuner/docs/en/training/custom_agent_dataset.rst
new file mode 100644
index 0000000000000000000000000000000000000000..b4ad82f0196b547767922df9e72bbc2224cbac72
--- /dev/null
+++ b/data/xtuner/docs/en/training/custom_agent_dataset.rst
@@ -0,0 +1,2 @@
+Custom Agent Dataset
+====================
diff --git a/data/xtuner/docs/en/training/custom_pretrain_dataset.rst b/data/xtuner/docs/en/training/custom_pretrain_dataset.rst
new file mode 100644
index 0000000000000000000000000000000000000000..00ef0e0cb5c65524ed895691a09e0daa6c03a9e1
--- /dev/null
+++ b/data/xtuner/docs/en/training/custom_pretrain_dataset.rst
@@ -0,0 +1,2 @@
+Custom Pretrain Dataset
+=======================
diff --git a/data/xtuner/docs/en/training/custom_sft_dataset.rst b/data/xtuner/docs/en/training/custom_sft_dataset.rst
new file mode 100644
index 0000000000000000000000000000000000000000..39a0f7c33713aafe429a5d069aa4fc6794dc8d36
--- /dev/null
+++ b/data/xtuner/docs/en/training/custom_sft_dataset.rst
@@ -0,0 +1,2 @@
+Custom SFT Dataset
+==================
diff --git a/data/xtuner/docs/en/training/modify_settings.rst b/data/xtuner/docs/en/training/modify_settings.rst
new file mode 100644
index 0000000000000000000000000000000000000000..382aca87221142ee1aae4a08657b31f419084093
--- /dev/null
+++ b/data/xtuner/docs/en/training/modify_settings.rst
@@ -0,0 +1,2 @@
+Modify Settings
+===============
diff --git a/data/xtuner/docs/en/training/multi_modal_dataset.rst b/data/xtuner/docs/en/training/multi_modal_dataset.rst
new file mode 100644
index 0000000000000000000000000000000000000000..e3d174a1bc5319b6b68aa753c984bd2d6b70a023
--- /dev/null
+++ b/data/xtuner/docs/en/training/multi_modal_dataset.rst
@@ -0,0 +1,2 @@
+Multi-modal Dataset
+===================
diff --git a/data/xtuner/docs/en/training/open_source_dataset.rst b/data/xtuner/docs/en/training/open_source_dataset.rst
new file mode 100644
index 0000000000000000000000000000000000000000..8627b439d5a031c42db99503491547706cbc6b2b
--- /dev/null
+++ b/data/xtuner/docs/en/training/open_source_dataset.rst
@@ -0,0 +1,2 @@
+Open Source Datasets
+====================
diff --git a/data/xtuner/docs/en/training/visualization.rst b/data/xtuner/docs/en/training/visualization.rst
new file mode 100644
index 0000000000000000000000000000000000000000..255c7e88f1d30566d26434cf144b482a79202184
--- /dev/null
+++ b/data/xtuner/docs/en/training/visualization.rst
@@ -0,0 +1,2 @@
+Visualization
+=============
diff --git a/data/xtuner/docs/en/user_guides/chat.md b/data/xtuner/docs/en/user_guides/chat.md
new file mode 100644
index 0000000000000000000000000000000000000000..82c8ee7230cd76bf547bfdac084c8af0ff26ed76
--- /dev/null
+++ b/data/xtuner/docs/en/user_guides/chat.md
@@ -0,0 +1,128 @@
+# Chat with fine-tuned LLMs
+
+## Chat with [InternLM](https://github.com/InternLM/InternLM)
+
+### InternLM-7B
+
+- InternLM-7B, oasst1
+
+ ```shell
+ xtuner chat internlm/internlm-7b --adapter xtuner/internlm-7b-qlora-oasst1 --prompt-template internlm_chat
+ ```
+
+- InternLM-7B, Arxiv Gentitle
+
+ ```shell
+ xtuner chat internlm/internlm-7b --adapter xtuner/internlm-7b-qlora-arxiv-gentitle --prompt-template internlm_chat --system-template arxiv_gentile
+ ```
+
+- InternLM-7B, Colorist
+
+ ```shell
+ xtuner chat internlm/internlm-7b --adapter xtuner/internlm-7b-qlora-colorist --prompt-template internlm_chat --system-template colorist
+ ```
+
+- InternLM-7B, Alpaca-enzh
+
+ ```shell
+ xtuner chat internlm/internlm-7b --adapter xtuner/internlm-7b-qlora-alpaca-enzh --prompt-template internlm_chat --system-template alpaca
+ ```
+
+- InternLM-7B, MSAgent **(Lagent ReAct!)**
+
+ ```shell
+ export SERPER_API_KEY="xxx" # Please get the key from https://serper.dev to support google search!
+ xtuner chat internlm/internlm-7b --adapter xtuner/internlm-7b-qlora-msagent-react --lagent
+ ```
+
+### InternLM-Chat-7B
+
+- InternLM-Chat-7B, oasst1
+
+ ```shell
+ xtuner chat internlm/internlm-chat-7b --adapter xtuner/internlm-chat-7b-qlora-oasst1 --prompt-template internlm_chat
+ ```
+
+- InternLM-Chat-7B, Alpaca-enzh
+
+ ```shell
+ xtuner chat internlm/internlm-chat-7b --adapter xtuner/internlm-chat-7b-qlora-alpaca-enzh --prompt-template internlm_chat --system-template alpaca
+ ```
+
+### InternLM-20B
+
+- InternLM-20B, oasst1
+
+ ```shell
+ xtuner chat internlm/internlm-20b --adapter xtuner/internlm-20b-qlora-oasst1 --prompt-template internlm_chat
+ ```
+
+- InternLM-20B, Arxiv Gentitle
+
+ ```shell
+ xtuner chat internlm/internlm-20b --adapter xtuner/internlm-20b-qlora-arxiv-gentitle --prompt-template internlm_chat --system-template arxiv_gentile
+ ```
+
+- InternLM-20B, Colorist
+
+ ```shell
+ xtuner chat internlm/internlm-20b --adapter xtuner/internlm-20b-qlora-colorist --prompt-template internlm_chat --system-template colorist
+ ```
+
+- InternLM-20B, Alpaca-enzh
+
+ ```shell
+ xtuner chat internlm/internlm-20b --adapter xtuner/internlm-20b-qlora-alpaca-enzh --prompt-template internlm_chat --system-template alpaca
+ ```
+
+- InternLM-20B, MSAgent **(Lagent ReAct!)**
+
+ ```shell
+ export SERPER_API_KEY="xxx" # Please get the key from https://serper.dev to support google search!
+ xtuner chat internlm/internlm-20b --adapter xtuner/internlm-20b-qlora-msagent-react --lagent
+ ```
+
+### InternLM-Chat-20B
+
+- InternLM-Chat-20B, oasst1
+
+ ```shell
+ xtuner chat internlm/internlm-chat-20b --adapter xtuner/internlm-chat-20b-qlora-oasst1 --prompt-template internlm_chat
+ ```
+
+- InternLM-Chat-20B, Alpaca-enzh
+
+ ```shell
+ xtuner chat internlm/internlm-chat-20b --adapter xtuner/internlm-chat-20b-qlora-alpaca-enzh --prompt-template internlm_chat --system-template alpaca
+ ```
+
+## Chat with [Llama2](https://github.com/facebookresearch/llama)
+
+> Don't forget to use `huggingface-cli login` and input your access token first to access Llama2! See [here](https://huggingface.co/docs/hub/security-tokens#user-access-tokens) to learn how to obtain your access token.
+
+### Llama-2-7B
+
+- Llama-2-7B, MOSS-003-SFT **(plugins!)**
+
+ ```shell
+ export SERPER_API_KEY="xxx" # Please get the key from https://serper.dev to support google search!
+ xtuner chat meta-llama/Llama-2-7b-hf --adapter xtuner/Llama-2-7b-qlora-moss-003-sft --bot-name Llama2 --prompt-template moss_sft --system-template moss_sft --with-plugins calculate solve search --no-streamer
+ ```
+
+- Llama-2-7B, MSAgent **(Lagent ReAct!)**
+
+ ```shell
+ export SERPER_API_KEY="xxx" # Please get the key from https://serper.dev to support google search!
+ xtuner chat meta-llama/Llama-2-7b-hf --adapter xtuner/Llama-2-7b-qlora-msagent-react --lagent
+ ```
+
+## Chat with [Qwen](https://github.com/QwenLM)
+
+### Qwen-7B
+
+- Qwen-7B, MOSS-003-SFT **(plugins!)**
+
+ ```shell
+ export SERPER_API_KEY="xxx" # Please get the key from https://serper.dev to support google search!
+ xtuner chat Qwen/Qwen-7B --adapter xtuner/Qwen-7B-qlora-moss-003-sft --bot-name Qwen --prompt-template moss_sft --system-template moss_sft --with-plugins calculate solve search
+ ```
diff --git a/data/xtuner/docs/en/user_guides/dataset_format.md b/data/xtuner/docs/en/user_guides/dataset_format.md
new file mode 100644
index 0000000000000000000000000000000000000000..46e3d6f80ae58930554f178779f0fc0f1d7b433e
--- /dev/null
+++ b/data/xtuner/docs/en/user_guides/dataset_format.md
@@ -0,0 +1,193 @@
+# Dataset Format
+
+- [Incremental Pre-training Dataset Format](#incremental-pre-training-dataset-format)
+- [Single-turn Dialogue Dataset Format](#single-turn-dialogue-dataset-format)
+- [Multi-turn Dialogue Dataset Format](#multi-turn-dialogue-dataset-format)
+ - [Method 1](#method-1)
+ - [Method 2](#method-2)
+ - [Method in XTuner](#method-in-xtuner)
+
+The Supervised Finetune (SFT) of large language models aims to improve the performance of pre-trained models on specific tasks through supervised fine-tuning. To support as many downstream tasks as possible, XTuner supports three dataset formats: incremental pre-training, single-turn dialogue, and multi-turn dialogue.
+
+- The incremental pre-training dataset is used to enhance the model's capabilities in a specific domain or task.
+- Single-turn and multi-turn dialogue datasets are often used in the instruction tuning stage to enhance the model's ability to respond to specific instructions.
+
+In the instruction tuning phase, our goal is to train the language model to answer based on human instructions. **Therefore, generally only the loss of the response part (Output) is used for gradient backpropagation, while the loss of the instruction part (System, Input) is not used for weight updates.** Based on this, we introduce "system", "input" and "output" fields when preprocessing the dataset. The "system", "input" fields are used to save fields that do not need to compute loss, such as system and user instructions, whereas the "output" field is used to save fields that do need to compute loss, such as the GroundTruth answers corresponding to input instructions.
+
+To unify the incremental pre-training, single-turn dialogue, and multi-turn dialogue dataset formats, we set the dataset format to the following form:
+
+```json
+[{
+ "conversation":[
+ {
+ "system": "xxx",
+ "input": "xxx",
+ "output": "xxx"
+ }
+ ]
+},
+{
+ "conversation":[
+ {
+ "system": "xxx",
+ "input": "xxx",
+ "output": "xxx"
+ },
+ {
+ "input": "xxx",
+ "output": "xxx"
+ }
+ ]
+}]
+```
+
+Throughout the training phase, we amalgamate several "system", "input" and "output" pairs from a single data instance, which we then feed into the model. Loss is computed concurrently at each position, yet only the loss associated with the "output" component participates in the gradient backpropagation process. This process is elucidated in the figure below.
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+ 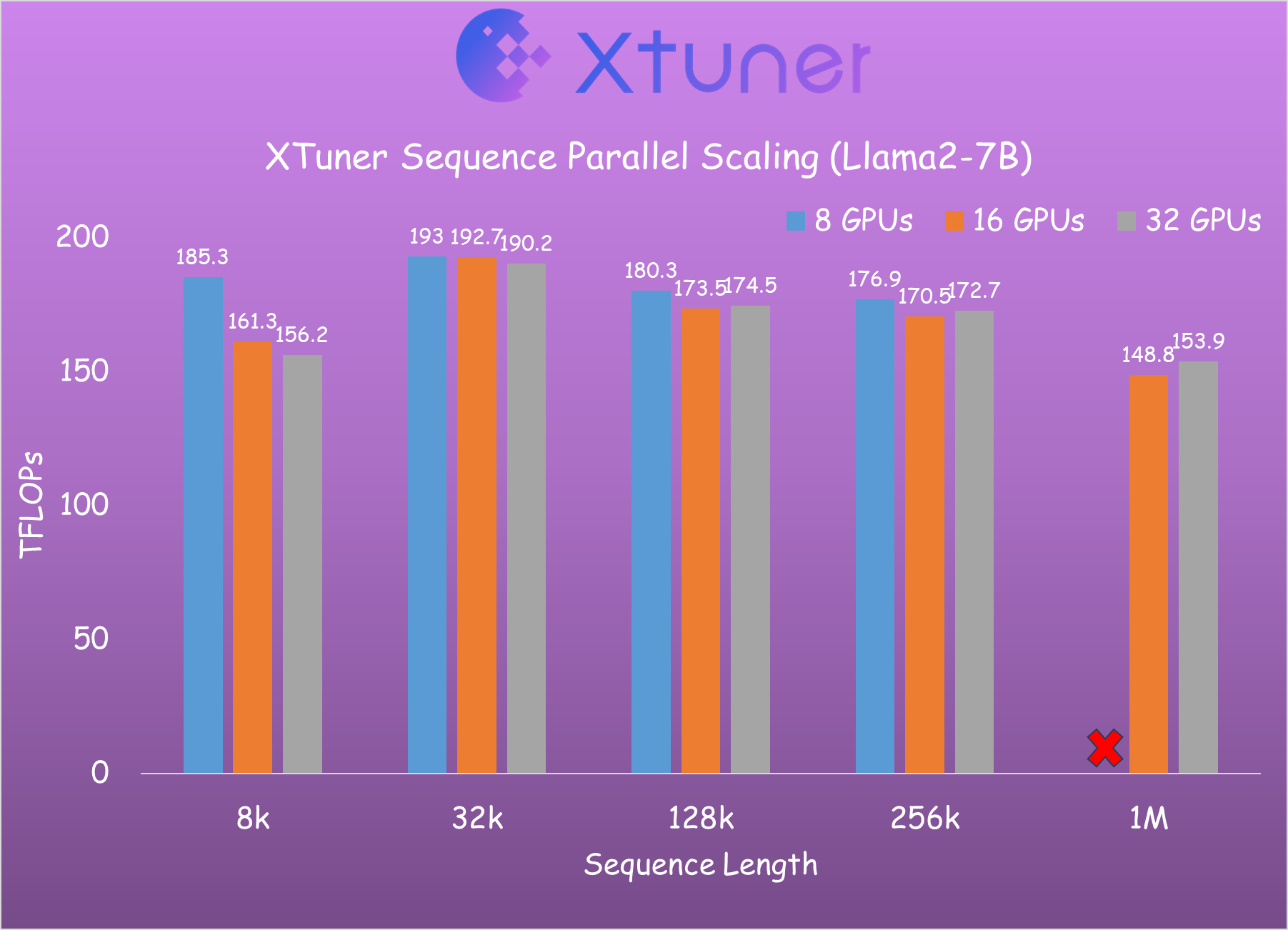 +
+
+
+
+优化目标
+========
+
+尽管开源模型支持的序列长度不断被刷新,但主流的显存优化策略(如 ZeRO 系列)却不足以解决大模型、长序列训练问题。
+如表 1 所示,使用 ZeRO-3 显存优化策略训练超长序列时,单纯增加 GPU 数量无法解决超长序列带来的 OOM 问题;
+这是因为,ZeRO-3 只能优化模型参数和优化器状态占用的显存, **超长训列训练过程中的显存开销主要来自激活值,而非模型参数和优化器状态**。
+
+
+.. list-table:: **表 1 不同序列长度时,使用 ZeRO-3 训练 128k 上下文 yi-34B 模型的训练情况**
+ :widths: 25 15 10 15 25
+ :header-rows: 1
+
+ * - SP
+ - Model
+ - ZeRO
+ - GPUs
+ - TGS
+ * - 1
+ - yi-34B
+ - ZeRO-3
+ - 16
+ - OOM
+ * - 1
+ - yi-34B
+ - ZeRO-3
+ - 32
+ - OOM
+ * - 1
+ - yi-34B
+ - ZeRO-3
+ - 64
+ - OOM
+ * - 8
+ - yi-34B
+ - ZeRO-3
+ - 16
+ - 227
+
+
+为解决长序列训练过程中的显存问题,Megatron-LM 团队和 DeepSpeed 团队分别提出了两种序列并行算法,通过对长序列进行切分的方法来降低单 GPU 上计算的序列长度。XTuner 中的序列并行设计思路参考了 DeepSpeed 的工作 `DeepSpeed Ulysses `_,并加以优化, **以实现一键开启序列并行策略** 。三者的对比如下:
+
+.. list-table:: **表 2 Megatron-LM、DeepSpeed Ulysses 与 XTuner 的序列并行实现对比**
+ :widths: 50 50 50
+ :header-rows: 1
+
+ * -
+ - Attention 通信量
+ - 代码侵入
+ * - Megatron-LM
+ - O(N)
+ - 较高
+ * - DeepSpeed Ulysses
+ - O(N / P)
+ - 较高
+ * - XTuner
+ - O(N / P)
+ - 无
+
+
+
+支持情况
+========
+
+.. list-table::
+ :widths: 25 25
+ :header-rows: 1
+
+ * - 模型
+ - 序列并行支持情况
+ * - baichuan 1/2
+ - ❌
+ * - chatglm 2/3
+ - ❌
+ * - deepseek
+ - ✅
+ * - gemma
+ - ❌
+ * - internlm 2
+ - ✅
+ * - llama 2
+ - ✅
+ * - mistral
+ - ✅
+ * - qwen 1/1.5
+ - ✅
+ * - starcoder
+ - ❌
+ * - yi
+ - ✅
+ * - zephyr
+ - ✅
+
+其他模型的序列并行功能尚在开发中。
+
+训练
+====
+
+.. note::
+ 使用序列并行策略需要首先安装 `flash attn `_ (参考 `flash attn 安装 `_ ,安装过程需要 cuda)
+
+步骤1:修改 config
+------------------
+
+可以通过运行以下命令查看 XTuner 提供的训练不同模型的配置文件:
+
+.. code-block:: console
+
+ $ xtuner list-cfg
+
+针对任一 config 修改 `sequence_parallel_size` 即可使用序列并行策略:
+
+.. code-block:: diff
+
+ # parallel
+ - sequence_parallel_size = 1
+ + sequence_parallel_size = 4 # take `sequence_parallel_size = 4`` as an example
+
+另外,若需要进一步拓展模型的长文本处理能力,需要进一步修改 config 中的 `max_position_embeddings` 字段。例如需要将模型的上下文长度拓展为 64K 时,可进行如下修改:
+
+.. code-block:: diff
+
+ + max_position_embeddings = 65536
+
+ #######################################################################
+ # PART 2 Model & Tokenizer #
+ #######################################################################
+ model = dict(
+ type=SupervisedFinetune,
+ + max_position_embeddings = max_position_embeddings,
+ ...)
+
+步骤2:开始训练
+----------------
+
+需要使用 DeepSpeed 进行训练:
+
+.. code-block:: console
+
+ $ # torchrun
+ $ NPROC_PER_NODE=${GPU_NUM} xtuner train ${CONFIG_PATH} --deepspeed deepspeed_zero2
+ $ # slurm
+ $ srun ${SRUN_ARGS} xtuner train ${CONFIG_PATH} --launcher slurm --deepspeed deepspeed_zero2
+
+
+.. tip::
+ ``${CONFIG_PATH}`` 为步骤 1 中修改得到的 config 文件路径
+
+.. tip::
+ 可根据实际情况选择使用不同的 zero 策略
+
+
+实现方案
+=========
+
+XTuner 中的序列并行设计思路参考了 DeepSpeed 的工作 `DeepSpeed Ulysses `_,并加以优化,以达到直接基于 transformers 算法库或 Huggingface Hub 上的开源模型训练 1M 以上超长序列的目标。
+
+.. raw:: html
+
+
+  +
+
+
+.. raw:: html
+
+
+ 图 1 序列并行实现方案
+
+
+图 1 展示了序列并行策略的实现方案。由于 Transformer 结构较为规整,除 attention 计算外,其他计算过程中 token 之间不会互相影响(即每个 token 的计算是独立的),这一条件为序列并行提供了有利条件。上图展示了序列并行的核心设计。设由 P 个 GPUs 共同计算一个长度为 N 的长序列,在 Attention 计算的第一阶段,长度为 N / P 的子序列会通过线性层投影为 Query、Key、Value。接下来, QKV Tensor 会在参与序列并行计算的多个 GPUs 之间通过高度优化的 all-to-all 通信算子汇聚,得到序列长度为 N ,但更少注意力头的子序列。注意力计算后,通过另一个 all-to-all 通信算子将其转换为长度为 N / P 的子序列,进行后续计算。伪代码如下所示。
+
+.. code-block:: python
+
+ # Pseudo code for an Attention Layer
+ # Input: hidden_states with shape (bs, seq_len, dim)
+ # Output: attn_out with shape (bs, seq_len, dim)
+ def attn_forward(hidden_states):
+ q, k, v = qkv_proj(hidden_states)
+ q, k, v = reshape(q, k, v) # (bs, q_len, dim) -> (bs, q_len, nhead, hdim)
+ q, k = apply_rotary_pos_emb(q, k, cos, sin)
+ sp_size = get_sequence_parallel_world_size()
+ # (bs, q_len, nhead, hdim) -> (bs, q_len * sp_size, nhead / sp_size, hdim)
+ q, k, v = all_to_all(q, k, v, sp_size)
+ attn_out = local_attn(q, k, v)
+ # (bs, q_len * sp_size, nhead / sp_size, hdim) -> (bs, q_len, nhead, hdim)
+ attn_out = all_to_all(attn_out)
+ attn_out = reshape(attn_out) # (bs, q_len, nhead, hdim) -> (bs, q_len, dim)
+ attn_out = o_proj(attn_out)
+ return attn_out
+
+
+序列并行 API
+=============
+
+为了方便在其他 repo 中使用序列并行策略,XTuner 中抽象出了序列并行所必须的五个 API 接口:
+
+- 序列并行分布式环境初始化 (init_sequence_parallel)
+- 适配序列并行的 Data Sampler (SequenceParallelSampler)
+- 数据 Pad 与切分 (pad_for_sequence_parallel, split_for_sequence_parallel)
+- 适配序列并行的 Attention (dispatch_modules)
+- reduce loss 以正确打印训练损失 (reduce_sequence_parallel_loss)
+
+分布式环境初始化
+-------------------
+
+由于序列并行算法会将长序列切分为 `sequence_parallel_world_size` 块,并将每个子序列分发给对应的 GPU 独立进行计算。因此需要在训练开始前初始化序列并行分布式环境,以指定哪几块 GPU 共同负责一个长序列输入的计算。
+
+一个 `sequence_parallel_world_size = 4` 的示例如下:
+
+.. code-block:: python
+
+ # We have to initialize the distributed training environment first.
+ # Here is an example when training on slurm scheduler
+ # from xtuner.parallel.sequence import init_dist
+ # init_dist('slurm', 'nccl', init_backend='deepspeed')
+ from xtuner.parallel.sequence import init_sequence_parallel
+ sequence_parallel_world_size = 4
+ init_sequence_parallel(sequence_parallel_world_size)
+
+.. tip::
+ 上述过程在 ``xtuner/engine/_strategy/deepspeed.py`` 中实现。
+
+Data Sampler
+--------------
+
+在使用序列并行后,Dataloader 的采样策略需要进一步调整。例如当 `sequence_parallel_world_size = 4` 时,4 块 GPU 从 Dataloader 拿到的数据需要是完全一样的。
+
+在构建 Dataloader 时搭配 XTuner 中提供的 `SequenceParallelSampler` 使用即可:
+
+.. code-block:: python
+
+ from xtuner.parallel.sequence import SequenceParallelSampler
+ dataloader = DataLoader(
+ train_dataset, sampler=SequenceParallelSampler(train_dataset),
+ **other_dataloader_params)
+
+数据 Pad 与切分
+---------------
+
+由于每条训练数据的长度可能不尽相同,我们需要将数据进行 Pad 以使得序列长度可以被 `sequence_parallel_world_size` 整除,这样一条长数据才能被均等地分发给不同的 GPU 上。
+
+训练过程中需要被 Pad 的 Tensor 往往有 input_ids, labels, position_ids, attention_mask 四个,pad 的过程可以通过以下方式实现:
+
+.. code-block:: python
+
+ from xtuner.parallel.sequence import pad_for_sequence_parallel
+ input_ids, labels, position_ids, attention_mask = pad_for_sequence_parallel(
+ input_ids, labels, position_ids, attention_mask)
+
+如果训练过程用不到 attention_mask,那么可以:
+
+.. code-block:: python
+
+ input_ids, labels, position_ids, _ = pad_for_sequence_parallel(
+ input_ids, labels, position_ids)
+
+Pad 后,我们需要对长序列均等切分:
+
+.. code-block:: python
+
+ from xtuner.parallel.sequence import split_for_sequence_parallel
+ # attention mask should not be split
+ input_ids, labels, position_ids = split_for_sequence_parallel(
+ input_ids, labels, position_ids)
+
+.. tip::
+ 以上两步在 ``xtuner/dataset/collate_fns/default_collate_fn.py`` 中实现。
+
+Attention
+-----------
+
+在 Attention 的计算过程中,序列中的不同 token 是不能独立运算的,但不同的 attention head 之间的计算却是独立的。因此,如第一节所述,需要在计算 Attention 前后(即 qkv_proj 后和 o_proj 前)分别插入一个 all-to-all 操作。
+
+XTuner 提供了 dispatch_modules 接口以支持修改模型 Attention 的计算方式:
+
+.. code-block:: python
+
+ from xtuner.model.modules import dispatch_modules
+ model: AutoModelForCausalLM
+ dispatch_modules(model)
+
+.. tip::
+ 上述过程在 ``xtuner/model/sft.py`` 中实现。
+
+Reduce Loss
+-------------
+
+这个 API 对于保证训练的正确性不是必须的,但对于观测模型训练状态,打印训练 loss 是非常有用的。
+
+.. code-block:: python
+
+ from xtuner.parallel.sequence import reduce_sequence_parallel_loss
+ outputs = llm(input_ids=input_ids, labels=labels, **kwargs)
+ num_tokens_per_rank = (labels != -100).sum()
+ # Suppose sequence parallel world size equals to 4,
+ # losses on rank0, rank1, rank2, rank3 are different.
+ loss = reduce_sequence_parallel_loss(outputs.loss, num_tokens_per_rank)
+ # After loss reduction, losses on rank0, rank1, rank2, rank3 are the same.
+
+.. tip::
+ 上述过程在 ``xtuner/model/sft.py`` 中实现。
diff --git a/data/xtuner/docs/zh_cn/acceleration/train_large_scale_dataset.rst b/data/xtuner/docs/zh_cn/acceleration/train_large_scale_dataset.rst
new file mode 100644
index 0000000000000000000000000000000000000000..f0925f050833f65442262ac7933fecbcd2775436
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/acceleration/train_large_scale_dataset.rst
@@ -0,0 +1,205 @@
+================
+超大规模数据集
+================
+
+在线数据处理
+===============
+
+XTuner
+默认采用在线数据预处理的策略,这样可以降低用户使用门槛,以达到“开箱即用”的要求。然而,在线数据处理的弊端在于,当数据集过大时,数据处理过程耗时相对较多,可能会触发
+``nccl timeout`` 报错。
+
+为什么会出现 ``nccl timeout``?
+------------------------------------
+
+使用 XTuner 训练模型时,在训练开始前会首先通过
+`process_hf_dataset `__
+函数对整个训练集进行数据预处理,得到模型训练所需要的 ``input_ids``,
+``labels`` 等数据。
+
+由于数据预处理操作是一个 CPU 任务,因此在分布式训练过程中,如果多个 rank
+各自执行预处理任务,会造成 CPU 资源抢占,拖慢数据处理速度。因此 XTuner
+中采用的策略是统一由 rank0 处理,完成后通过
+``torch.distributed.broadcast_object_list`` 接口广播至其他
+rank。这样,不同 rank 就会得到一份完全一样的数据集。
+
+然而,当使用 ``nccl``
+通信策略时,\ ``torch.distributed.broadcast_object_list``
+广播操作的超时时间与 ``nccl`` 通信超时时间相同(默认为 30
+分钟)。当训练数据集较大时,rank0 可能无法在 30
+分钟内处理完全部数据,这样就会导致 ``nccl timeout`` 报错。若修改
+``nccl`` 通信超时时间,则除数据预处理外的其他涉及 ``nccl``
+通信的超时时间设置都会被修改。
+
+解决方案
+-----------
+
+为解决上述问题,可以在训练开始前设置环境变量 ``XTUNER_DATASET_TIMEOUT``
+为一个更大的数(默认为 30 分钟超时,可以酌情将其调大,如:120):
+
+.. code:: console
+
+ $ # On multiple GPUs(torchrun)
+ $ XTUNER_DATASET_TIMEOUT=120 NPROC_PER_NODE=${GPU_NUM} xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero1
+ $ # On multiple GPUs(slurm)
+ $ XTUNER_DATASET_TIMEOUT=120 srun ${SRUN_ARGS} xtuner train ${CONFIG_NAME_OR_PATH} --launcher slurm --deepspeed deepspeed_zero1
+
+.. note::
+ 该超时设置只针对数据预处理阶段的广播操作生效。
+
+离线数据处理
+===============
+
+当训练数据量非常大时,每次训练的时候都先在线处理数据可能会极为耗时。我们可以先对原始数据进行离线处理并保存至本地,随后的多次训练可以读入本地离线处理好的数据后直接开始训练。
+
+第一小节介绍如何针对纯语言模型训练所使用的文本数据进行离线处理,第二小节将会介绍如何离线处理
+Llava 训练数据。
+
+.. warning::
+
+ 当切换了 tokenizer 或修改了数据处理中的超参数(如:单条数据的最大长度 ``max_length`` 等)时,需要重新离线处理数据,否则会导致训练报错。
+
+语言模型训练数据离线处理
+-------------------------
+
+为便于介绍,本节以
+`internlm2_7b_qlora_alpaca_e3.py `__
+配置文件为基础,介绍如何离线处理数据集,并使用离线处理的数据集进行训练。
+
+步骤 1:导出目标 config 文件
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+
+``internlm2_7b_qlora_alpaca_e3.py`` 是 XTuner 提供的使用 QLora 算法在
+Alpaca 数据集上微调 Internlm2-7B 模型的配置文件。通过以下命令可以将该
+config 拷贝至当前目录下:
+
+.. code::
+
+ xtuner copy-cfg internlm2_7b_qlora_alpaca_e3 .
+
+.. tip::
+ 执行以上命令后,当前目录下会新增一个名为
+ ``internlm2_7b_qlora_alpaca_e3_copy.py`` 的配置文件(与
+ `internlm2_7b_qlora_alpaca_e3.py `__
+ 完全一样)。
+
+步骤 2:离线处理数据集
+^^^^^^^^^^^^^^^^^^^^^^
+
+使用以下命令可离线预处理原始数据:
+
+.. code::
+
+ python xtuner/tools/process_untokenized_datasets.py \
+ internlm2_7b_qlora_alpaca_e3_copy.py \
+ --save-folder /folder/to/save/processed/dataset
+
+.. note::
+ 这里的第一个参数为 Step 1 中修改过的 config
+ 文件,第二个参数为预处理过的数据集的保存路径。
+
+.. note::
+
+ 上述命令会在 internlm2_7b_qlora_alpaca_e3_copy.py
+ 同级目录下新建一个 internlm2_7b_qlora_alpaca_e3_copy_modified.py
+ 文件,后续训练中需要使用该配置文件,而非
+ ``internlm2_7b_qlora_alpaca_e3_copy.py`` 。
+
+步骤 3:启动训练
+^^^^^^^^^^^^^^^^
+
+可以通过以下命令启动训练:
+
+.. code:: console
+
+ $ # On multiple GPUs(torchrun)
+ $ NPROC_PER_NODE=${GPU_NUM} xtuner train internlm2_7b_qlora_alpaca_e3_copy_modified.py --deepspeed deepspeed_zero1
+ $ # On multiple GPUs(slurm)
+ $ srun ${SRUN_ARGS} xtuner train internlm2_7b_qlora_alpaca_e3_copy_modified.py --launcher slurm --deepspeed deepspeed_zero1
+
+
+.. note::
+ 训练中需要使用步骤 2 新生成的
+ internlm2_7b_qlora_alpaca_e3_copy_modified.py 文件,而非
+ internlm2_7b_qlora_alpaca_e3_copy.py 文件。
+
+Llava 训练数据离线处理
+---------------------------
+
+为便于介绍,本节以
+`llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain.py `__
+配置文件为基础,介绍如何离线处理数据集,并使用离线处理的数据集进行训练。
+
+
+步骤 1:导出目标 config 文件
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+
+``llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain.py``
+是 XTuner 提供的基于 internlm2-chat-7b 训练 Llava
+模型配置文件。可以通过以下命令将该 config 拷贝至当前目录下:
+
+.. code:: console
+
+ $ xtuner copy-cfg llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain .
+
+.. note::
+ 执行以上命令后,当前目录下会新增一个名为
+ ``llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain_copy.py``
+ 的配置文件(与
+ `llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain.py `__
+ 完全一样)。
+
+
+
+步骤 2:离线处理数据集
+^^^^^^^^^^^^^^^^^^^^^^
+
+使用以下命令可离线预处理原始数据:
+
+.. code:: console
+
+ $ python xtuner/tools/process_untokenized_llava_data.py llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain_copy.py \
+ $ --save-folder /folder/to/save/processed/llava/data
+
+处理后可以读取离线处理后的数据集查看是否符合预期:
+
+.. code:: python
+
+ from datasets import load_from_disk
+ ds = load_from_disk('/folder/to/save/processed/llava/data')
+ print(ds)
+
+步骤 3:修改 config 文件
+^^^^^^^^^^^^^^^^^^^^^^^^
+
+修改 config 文件以便程序运行时直接读取预处理的 Llava 数据:
+
+.. code:: diff
+
+ #######################################################################
+ # PART 3 Dataset & Dataloader #
+ #######################################################################
+ llava_dataset = dict(
+ - data_path=data_path,
+ - tokenizer=tokenizer,
+ + offline_processed_text_folder=/folder/to/save/processed/llava/data
+ ...)
+
+.. note::
+ 其中,\ ``/folder/to/save/processed/llava/data`` 为步骤 2
+ 保存的离线处理数据路径。
+
+步骤 4:开始训练
+^^^^^^^^^^^^^^^^
+
+使用步骤 3 修改得到的 config 训练即可:
+
+.. code:: console
+
+ $ # On a single GPU
+ $ xtuner train llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain_copy.py --deepspeed deepspeed_zero2
+
+ $ # On multiple GPUs (torchrun)
+ $ NPROC_PER_NODE=${GPU_NUM} xtuner train llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain_copy.py --deepspeed deepspeed_zero2
+ $ # On multiple GPUs (slurm)
+ $ srun ${SRUN_ARGS} xtuner train llava_internlm2_chat_7b_clip_vit_large_p14_336_e1_gpu8_pretrain_copy.py --launcher slurm --deepspeed deepspeed_zero2
diff --git a/data/xtuner/docs/zh_cn/acceleration/varlen_flash_attn.rst b/data/xtuner/docs/zh_cn/acceleration/varlen_flash_attn.rst
new file mode 100644
index 0000000000000000000000000000000000000000..2667394234cf539d5faa497edaa3620473ecb69b
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/acceleration/varlen_flash_attn.rst
@@ -0,0 +1,162 @@
+===============================================
+Varlen Attention
+===============================================
+
+\ :ref:`数据集拼接 ` \ 一节中,我们讨论了“数据集拼接”策略对模型训练效率的显著提升。
+理论上,数据集拼接可能会对注意力(Attention)机制的计算过程产生影响。这是因为,在未采用数据拼接策略的情况下,
+每条数据在计算注意力时仅与自身相关联。然而,当采用数据拼接策略后,由多条短数据拼接成的长数据在计算注意力时会相互关联。
+以一个由若干短数据拼接成长度为 4096 的数据为例,如果不采用变长注意力机制,在注意力计算阶段,每个 token 将会关注全部 4096 个 tokens ,如图左侧所示。
+
+相反,在使用变长注意力机制的情况下,每个 token 在注意力计算阶段仅会关注其所在短数据中的所有 tokens ,如图右侧所示。因此, **变长注意力机制确保了无论是否采用“数据集拼接”策略,模型训练的行为保持一致性。**
+
+.. raw:: html
+
+
+  +
+
变长注意力计算原理(拷贝自 https://github.com/InternLM/InternEvo/blob/develop/doc/usage.md)
+
+
+支持列表
+=====================
+
+.. note::
+
+ 使用变长注意力需要首先安装 `flash attn `_ (
+ 参考 `flash attn 安装 `_ )
+
+.. list-table::
+ :widths: 25 50
+ :header-rows: 1
+
+ * - 模型
+ - Flash Attention 支持情况
+ * - baichuan 1/2
+ - ❌
+ * - chatglm 2/3
+ - ❌
+ * - deepseek
+ - ✅
+ * - gemma
+ - ❌
+ * - internlm 1/2
+ - ✅
+ * - llama 2
+ - ✅
+ * - mistral
+ - ✅
+ * - qwen 1/1.5
+ - ❌
+ * - starcoder
+ - ❌
+ * - yi
+ - ✅
+ * - zephyr
+ - ✅
+
+使用变长注意力机制训练
+=========================
+
+步骤 1:安装 flash_attn
+--------------------------
+
+XTuner 中实现的变长注意力需要依赖 Flash Attention 2,可通过以下命令安装(需要 cuda):
+
+.. code:: console
+
+ $ MAX_JOBS=4 pip install flash-attn --no-build-isolation
+
+.. tip::
+ 更多安装方式请参考 `flash attn 安装 `_
+
+步骤 2:查找模板 config
+---------------------------
+
+XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
+
+.. code-block:: console
+
+ $ xtuner list-cfg -p internlm
+
+.. tip::
+ ``-p`` 为模糊查找,若想训练其他模型,可以修改 ``internlm`` 为 XTuner 支持的其他模型名称。
+
+步骤 3:复制 config 文件
+-----------------------------
+
+导出需要使用的 config :
+
+.. code-block:: bash
+
+ xtuner copy-cfg ${CONFIG_NAME} ${SAVE_DIR}
+
+例如通过下列命令将名为 ``internlm_7b_full_oasst1_e3`` 的 config 导出至当前目录下:
+
+.. code-block:: console
+
+ $ xtuner copy-cfg internlm_7b_full_oasst1_e3 .
+
+.. note::
+
+ 当前目录下会存在一个新 config
+ ``internlm_7b_full_oasst1_e3_copy.py`` 。
+
+步骤 4:修改 config 文件
+-------------------------------
+
+将步骤 3 复制得到的 config 文件中的 ``use_varlen_attn`` 属性由 False 改为 True 即可激活变长注意力训练机制:
+
+.. code-block:: diff
+
+ ...
+ #######################################################################
+ # PART 1 Settings #
+ #######################################################################
+ # Model
+ pretrained_model_name_or_path = 'internlm/internlm-7b'
+ - use_varlen_attn = False
+ + use_varlen_attn = True
+ ...
+
+.. warning::
+
+ 当设置 ``use_varlen_attn = True`` 后, ``batch_size = 2, max_length = 2k`` 的配置与 ``batch_size = 1, max_length = 4k`` 的配置训练行为是近似的,
+ 因此 XTuner 目前只支持了 ``batch_size = 1`` 的情况。另外, ``use_varlen_attn = True`` 时 ``pack_to_max_length`` 也需设置为 True。
+
+步骤 5:开始训练
+-----------------------
+
+.. code-block:: bash
+
+ xtuner train ${CONFIG_NAME_OR_PATH}
+
+例如,我们可以基于步骤 4 中修改得到的 `internlm_7b_full_oasst1_e3_copy.py` 进行训练:
+
+.. code-block:: console
+
+ $ # On a single GPU
+ $ xtuner train internlm_7b_full_oasst1_e3_copy.py --deepspeed deepspeed_zero1
+ $ # On multiple GPUs(torchrun)
+ $ NPROC_PER_NODE=${GPU_NUM} xtuner train internlm_7b_full_oasst1_e3_copy.py --deepspeed deepspeed_zero1
+ $ # On multiple GPUs(slurm)
+ $ srun ${SRUN_ARGS} xtuner train internlm_7b_full_oasst1_e3_copy.py --launcher slurm --deepspeed deepspeed_zero1
+
+.. tip::
+ ``--deepspeed`` 表示使用 `DeepSpeed `_ 🚀 来优化训练过程。若未安装 DeepSpeed ,可通过 ``pip install deepspeed>=0.12.3`` 进行安装。XTuner 内置了多种策略,包括 ZeRO-1、ZeRO-2、ZeRO-3 等。如果用户期望关闭此功能,请直接移除此参数。
+
+步骤 6:模型转换
+^^^^^^^^^^^^^^^^^^^^^^^^^^^
+
+将保存的 PTH 模型(如果使用的DeepSpeed,则将会是一个文件夹)转换为 HuggingFace 模型:
+
+.. code-block:: bash
+
+ xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH} ${SAVE_PATH}
+
+对应上面的例子,模型转换脚本为:
+
+.. code-block:: bash
+
+ xtuner convert pth_to_hf internlm_7b_full_oasst1_e3_copy.py ${PTH} ${SAVE_PATH}
+
+.. note::
+ 其中 ``${PTH}`` 为训练权重保存的路径,若训练时未指定,默认保存在 ``./work_dirs/internlm_7b_full_oasst1_e3_copy`` 路径下。
diff --git a/data/xtuner/docs/zh_cn/chat/agent.md b/data/xtuner/docs/zh_cn/chat/agent.md
new file mode 100644
index 0000000000000000000000000000000000000000..c3b0d7a6fad8dbd585fd56bf3062d751d1e46866
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/chat/agent.md
@@ -0,0 +1 @@
+# 智能体模型对话
diff --git a/data/xtuner/docs/zh_cn/chat/llm.md b/data/xtuner/docs/zh_cn/chat/llm.md
new file mode 100644
index 0000000000000000000000000000000000000000..336e1b014eadd438e48b0c7cfa8ed06213c55896
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/chat/llm.md
@@ -0,0 +1 @@
+# 语言模型对话
diff --git a/data/xtuner/docs/zh_cn/chat/lmdeploy.md b/data/xtuner/docs/zh_cn/chat/lmdeploy.md
new file mode 100644
index 0000000000000000000000000000000000000000..36d9bf3f9a08dbbeb757e8c5769abe941d9345ec
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/chat/lmdeploy.md
@@ -0,0 +1 @@
+# 使用 LMDeploy 优化推理速度
diff --git a/data/xtuner/docs/zh_cn/chat/vlm.md b/data/xtuner/docs/zh_cn/chat/vlm.md
new file mode 100644
index 0000000000000000000000000000000000000000..3a84a3c7eef684d0d53a425cf5dbe48e5c57b2cc
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/chat/vlm.md
@@ -0,0 +1 @@
+# 视觉-语言模型对话
diff --git a/data/xtuner/docs/zh_cn/conf.py b/data/xtuner/docs/zh_cn/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..f64d7ea52eb78d8a933a2cf08dd9534f5726725b
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/conf.py
@@ -0,0 +1,109 @@
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import os
+import sys
+
+from sphinx.ext import autodoc
+
+sys.path.insert(0, os.path.abspath('../..'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'XTuner'
+copyright = '2024, XTuner Contributors'
+author = 'XTuner Contributors'
+
+# The full version, including alpha/beta/rc tags
+version_file = '../../xtuner/version.py'
+with open(version_file) as f:
+ exec(compile(f.read(), version_file, 'exec'))
+__version__ = locals()['__version__']
+# The short X.Y version
+version = __version__
+# The full version, including alpha/beta/rc tags
+release = __version__
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.napoleon',
+ 'sphinx.ext.viewcode',
+ 'sphinx.ext.intersphinx',
+ 'sphinx_copybutton',
+ 'sphinx.ext.autodoc',
+ 'sphinx.ext.autosummary',
+ 'myst_parser',
+ 'sphinxarg.ext',
+]
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# Exclude the prompt "$" when copying code
+copybutton_prompt_text = r'\$ '
+copybutton_prompt_is_regexp = True
+
+language = 'zh_CN'
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_theme = 'sphinx_book_theme'
+html_logo = '_static/image/logo.png'
+html_theme_options = {
+ 'path_to_docs': 'docs/zh_cn',
+ 'repository_url': 'https://github.com/InternLM/xtuner',
+ 'use_repository_button': True,
+}
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+# html_static_path = ['_static']
+
+# Mock out external dependencies here.
+autodoc_mock_imports = [
+ 'cpuinfo',
+ 'torch',
+ 'transformers',
+ 'psutil',
+ 'prometheus_client',
+ 'sentencepiece',
+ 'vllm.cuda_utils',
+ 'vllm._C',
+ 'numpy',
+ 'tqdm',
+]
+
+
+class MockedClassDocumenter(autodoc.ClassDocumenter):
+ """Remove note about base class when a class is derived from object."""
+
+ def add_line(self, line: str, source: str, *lineno: int) -> None:
+ if line == ' Bases: :py:class:`object`':
+ return
+ super().add_line(line, source, *lineno)
+
+
+autodoc.ClassDocumenter = MockedClassDocumenter
+
+navigation_with_keys = False
diff --git a/data/xtuner/docs/zh_cn/dpo/modify_settings.md b/data/xtuner/docs/zh_cn/dpo/modify_settings.md
new file mode 100644
index 0000000000000000000000000000000000000000..2365be25cb78e47376bbb5298be1834c25cfbd94
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/dpo/modify_settings.md
@@ -0,0 +1,83 @@
+## 修改 DPO 训练配置
+
+本章节仅介绍与 DPO(Direct Preference Optimization)训练相关的配置参数,更多 XTuner 配置文件的细节,请参考[修改训练配置](https://xtuner.readthedocs.io/zh-cn/latest/training/modify_settings.html)
+
+### 损失函数
+
+在 DPO 训练中,你可以根据需求选择不同的损失函数类型。XTuner 提供了多种损失函数选项,如 `sigmoid`、`hinge`、`ipo` 等。可以通过设置 `dpo_loss_type` 参数来选择使用的损失函数类型。
+
+此外,你还可以通过调整 `loss_beta` 参数来控制损失函数中的温度系数。同时,`label_smoothing` 参数可以用于平滑标签。
+
+```python
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+dpo_loss_type = 'sigmoid' # One of ['sigmoid', 'hinge', 'ipo', 'kto_pair', 'sppo_hard', 'nca_pair', 'robust']
+loss_beta = 0.1
+label_smoothing = 0.0
+```
+
+### 修改模型
+
+用户可以修改 `pretrained_model_name_or_path` 对预训练模型进行修改。
+
+```python
+#######################################################################
+# PART 1 Settings #
+#######################################################################
+# Model
+pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b-sft'
+```
+
+### 训练数据
+
+在 DPO 训练中,你可以通过 `max_length` 来指定单个样本序列的最大 token 数,XTuner 会自动对数据进行截断或是填充。
+
+```python
+# Data
+max_length = 2048
+```
+
+在配置文件中,我们通过 `train_dataset` 字段来指定训练数据集,你可以通过 `dataset` 字段指定数据集的加载方式,通过 `dataset_map_fn` 字段指定数据集的映射函数。
+
+```python
+#######################################################################
+# PART 3 Dataset & Dataloader #
+#######################################################################
+sampler = SequenceParallelSampler \
+ if sequence_parallel_size > 1 else DefaultSampler
+
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(type=load_dataset, path='mlabonne/orpo-dpo-mix-40k'),
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=orpo_dpo_mix_40k_map_fn,
+ is_dpo=True,
+ is_reward=False,
+ reward_token_id=-1,
+ num_proc=32,
+ use_varlen_attn=use_varlen_attn,
+ max_packed_length=max_packed_length,
+ shuffle_before_pack=True,
+)
+
+train_dataloader = dict(
+ batch_size=batch_size,
+ num_workers=dataloader_num_workers,
+ dataset=train_dataset,
+ sampler=dict(type=sampler, shuffle=True),
+ collate_fn=dict(
+ type=preference_collate_fn, use_varlen_attn=use_varlen_attn))
+```
+
+上述配置中,我们使用了 `load_dataset` 来加载 huggingface 上的 `mlabonne/orpo-dpo-mix-40k` 数据集,使用 `orpo_dpo_mix_40k_map_fn` 作为数据集映射函数。
+
+关于如何处理数据集以及如何编写数据集映射函数,请参考[偏好数据集章节](../reward_model/preference_data.md)。
+
+### 加速训练
+
+在使用偏好数据训练时,我们推荐您开启[变长注意力机制](https://xtuner.readthedocs.io/zh-cn/latest/acceleration/varlen_flash_attn.html), 以避免单个偏好内的 chosen 和 rejected 的样本长度差异造成的显存浪费。你可以通过 `use_varlen_attn=True` 来开启变长注意力机制。
+
+XTuner 中还支持了大量的训练加速方法,关于它们的使用方法,请参考[加速策略章节](https://xtuner.readthedocs.io/zh-cn/latest/acceleration/hyper_parameters.html)。
diff --git a/data/xtuner/docs/zh_cn/dpo/overview.md b/data/xtuner/docs/zh_cn/dpo/overview.md
new file mode 100644
index 0000000000000000000000000000000000000000..d3c3a7aadbe91cdcac94e339cee2ffa27544bcf4
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/dpo/overview.md
@@ -0,0 +1,27 @@
+## DPO 介绍
+
+### 简介
+
+DPO(Direct Preference Optimization,直接偏好优化)是一种在大语言模型训练中用于直接优化模型偏好的方法。与传统的强化学习方法不同,DPO 直接使用人类偏好数据进行模型优化,从而提高生成内容的质量,使其更符合人类偏好。DPO 利用人类偏好数据,直接对模型进行优化,省略了训练 Reward Model 的训练过程,与 PPO 相比进一步省去了 Critic Model,不但避免了复杂的强化学习算法,减少了训练开销,同时还提高了训练效率。
+
+DPO 拥有大量的衍生算法,它们对 DPO 的损失函数进行了一定程度上的改进,我们在 XTuner 中除了 DPO 还实现了[Identity Preference Optimisation (IPO)](https://huggingface.co/papers/2310.12036),[Kahneman-Tversky Optimisation (KTO)](https://github.com/ContextualAI/HALOs)等论文中的损失函数,如需使用这些算法,请参考[修改 DPO 配置](./modify_settings.md)章节。我们也提供了一些[示例配置](https://github.com/InternLM/xtuner/tree/main/xtuner/configs/dpo)用于参考。
+
+除了 DPO 之外,还出现了如 [ORPO](https://arxiv.org/abs/2403.07691) 等无需参考模型的对齐算法。ORPO 采用了对数比值(odds ratio)的概念来优化模型,通过在模型训练过程中惩罚那些被拒绝的样本,从而更有效地适应被选择的样本。ORPO 消除了对参考模型的依赖,使得训练过程更加简化且高效。XTuner 中 ORPO 的训练方式与 DPO 非常类似,我们提供了一些 ORPO 的[示例配置](https://github.com/InternLM/xtuner/tree/main/xtuner/configs/orpo),用户可以参考 DPO 的教程对配置进行修改。
+
+### XTuner 中 DPO 训练的优势
+
+XTuner 中的 DPO 训练具备以下显著优势:
+
+1. **支持最新的算法**:XTuner除了支持标准的 DPO 之外,还支持了大量的衍生算法,同时也支持ORPO等不依赖参考模型的高效算法。
+
+2. **减少显存浪费**:由于偏好数据中的 chosen 和 rejected 数据通常存在长度上的差异,因此在训练数据的拼接时会存在填充(padding token),造成显存浪费。在 XTuner 中,基于 Flash Attention2 中的[变长注意力](https://xtuner.readthedocs.io/zh-cn/latest/acceleration/varlen_flash_attn.html)功能,我们在训练过程中通过将偏好数据打包到同一个序列中,显著减少了由于 padding token 带来的显存浪费。这不仅提高了显存的利用效率,还使得在相同硬件条件下可以训练更大的模型或处理更多的数据。
+
+
+
+3. **高效训练**:借助 XTuner 的 QLoRA 训练功能,参考模型能够被转化为移除LoRA适配器的语言模型,从而省去了参考模型权重的显存占用,大幅降低了 DPO 的训练开销。
+
+4. **长文本训练**: 借助 XTuner 的序列并行功能,能够对长文本数据进行训练。
+
+### 开始训练
+
+请参阅[快速上手](./quick_start.md)来了解最基本的概念,若希望了解更多训练参数配置相关的内容,请参考[修改DPO配置](./modify_settings.md)章节。
diff --git a/data/xtuner/docs/zh_cn/dpo/quick_start.md b/data/xtuner/docs/zh_cn/dpo/quick_start.md
new file mode 100644
index 0000000000000000000000000000000000000000..a92152b0f7e5f764631a06f03056eedaab4daa00
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/dpo/quick_start.md
@@ -0,0 +1,71 @@
+## DPO 快速上手
+
+在本章节中,我们将介绍如何使用 XTuner 训练 1.8B 的 DPO(Direct Preference Optimization)模型,以帮助您快速上手。
+
+### 准备预训练模型权重
+
+我们使用经过 SFT 的语言模型[InternLM2-chat-1.8b-sft](https://huggingface.co/internlm/internlm2-chat-1_8b-sft)作为 DPO 模型的初始化模型来进行偏好对齐。
+
+在训练配置文件中设置`pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b-sft'`,则会在启动训练时自动下载模型文件。若您需要手动下载模型权重,那么请参考[准备预训练模型权重](https://xtuner.readthedocs.io/zh-cn/latest/preparation/pretrained_model.html)章节,其中详细说明了如何从 Huggingface 或者是 Modelscope 下载模型权重的方法。这里我们附上模型的 HuggingFace 链接与 ModelScope 链接:
+
+- HuggingFace 链接位于:https://huggingface.co/internlm/internlm2-chat-1_8b-sft
+- ModelScope 链接位于:https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-chat-1_8b-sft/summary
+
+### 准备训练数据
+
+在本教程中使用 Huggingface 上的[mlabonne/orpo-dpo-mix-40k](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k)数据集作为演示,
+
+```python
+train_dataset = dict(
+ type=build_preference_dataset,
+ dataset=dict(
+ type=load_dataset,
+ path='mlabonne/orpo-dpo-mix-40k'),
+ dataset_map_fn=orpo_dpo_mix_40k_map_fn,
+ is_dpo=True,
+ is_reward=False,
+)
+```
+
+在配置文件中使用以上配置,即可自动下载并处理该数据集。如果您希望使用其他 Huggingface 上的开源数据集或是使用自定义的数据集,请参阅[偏好数据集](../reward_model/preference_data.md)章节。
+
+### 准备配置文件
+
+XTuner 提供了多个开箱即用的配置文件,可以通过 `xtuner list-cfg` 查看。我们执行如下指令,以复制一个配置文件到当前目录。
+
+```bash
+xtuner copy-cfg internlm2_chat_1_8b_dpo_full .
+```
+
+打开复制后的配置文件,如果您选择自动下载模型和数据集,则无需修改配置。若您希望填入您预先下载的模型路径和数据集路径,请修改配置中的`pretrained_model_name_or_path`以及`train_dataset`中`dataset`的`path`参数。
+
+更多的训练参数配置,请参阅[修改DPO训练配置](./modify_settings.md)章节。
+
+### 启动训练
+
+在完成上述操作后,便可以使用下面的指令启动训练任务了。
+
+```bash
+# 单机单卡
+xtuner train ./internlm2_chat_1_8b_dpo_full_copy.py
+# 单机多卡
+NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm2_chat_1_8b_dpo_full_copy.py
+# slurm 集群
+srun ${SRUN_ARGS} xtuner train ./internlm2_chat_1_8b_dpo_full_copy.py --launcher slurm
+```
+
+### 模型转换
+
+XTuner 已经集成好了将模型转换为 HuggingFace 格式的工具,我们只需要执行
+
+```bash
+# 创建存放 hf 格式参数的目录
+mkdir work_dirs/internlm2_chat_1_8b_dpo_full_copy/iter_15230_hf
+
+# 转换格式
+xtuner convert pth_to_hf internlm2_chat_1_8b_dpo_full_copy.py \
+ work_dirs/internlm2_chat_1_8b_dpo_full_copy.py/iter_15230.pth \
+ work_dirs/internlm2_chat_1_8b_dpo_full_copy.py/iter_15230_hf
+```
+
+便能够将 XTuner 的 ckpt 转换为 Huggingface 格式的模型。
diff --git a/data/xtuner/docs/zh_cn/evaluation/hook.md b/data/xtuner/docs/zh_cn/evaluation/hook.md
new file mode 100644
index 0000000000000000000000000000000000000000..80d36f10ad10e9b4d14a6ce48ecc3979150e2b4f
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/evaluation/hook.md
@@ -0,0 +1 @@
+# 训练过程中评测
diff --git a/data/xtuner/docs/zh_cn/evaluation/mmbench.md b/data/xtuner/docs/zh_cn/evaluation/mmbench.md
new file mode 100644
index 0000000000000000000000000000000000000000..5421b1c96ac973f7a47839cb2478d63997473d94
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/evaluation/mmbench.md
@@ -0,0 +1 @@
+# MMBench (VLM)
diff --git a/data/xtuner/docs/zh_cn/evaluation/mmlu.md b/data/xtuner/docs/zh_cn/evaluation/mmlu.md
new file mode 100644
index 0000000000000000000000000000000000000000..4bfabff8fa0c0492fe376413ab68dd4382f14cd4
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/evaluation/mmlu.md
@@ -0,0 +1 @@
+# MMLU (LLM)
diff --git a/data/xtuner/docs/zh_cn/evaluation/opencompass.md b/data/xtuner/docs/zh_cn/evaluation/opencompass.md
new file mode 100644
index 0000000000000000000000000000000000000000..dbd7a49502c1ebc7d341c550f40563904b9522c2
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/evaluation/opencompass.md
@@ -0,0 +1 @@
+# 使用 OpenCompass 评测
diff --git a/data/xtuner/docs/zh_cn/get_started/installation.rst b/data/xtuner/docs/zh_cn/get_started/installation.rst
new file mode 100644
index 0000000000000000000000000000000000000000..b5eedbf1018d93c35fa35f2850142fc92017fe71
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/get_started/installation.rst
@@ -0,0 +1,49 @@
+==================================
+安装
+==================================
+
+本节中,我们将演示如何安装 XTuner。
+
+最佳实践
+========
+
+我们推荐用户参照我们的最佳实践安装 XTuner。
+推荐使用 Python-3.10 的 conda 虚拟环境安装 XTuner。
+
+**步骤 0.** 使用 conda 先构建一个 Python-3.10 的虚拟环境
+
+.. code-block:: console
+
+ $ conda create --name xtuner-env python=3.10 -y
+ $ conda activate xtuner-env
+
+**步骤 1.** 安装 XTuner
+
+方案a: 通过 pip 直接安装
+
+.. code-block:: console
+
+ $ pip install -U 'xtuner[deepspeed]'
+
+方案b: 从源码安装
+
+.. code-block:: console
+
+ $ git clone https://github.com/InternLM/xtuner.git
+ $ cd xtuner
+ $ pip install -e '.[deepspeed]'
+
+.. note::
+
+ "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效
+
+验证
+========
+
+为了验证 XTuner 是否安装正确,我们将使用命令打印配置文件。
+
+**打印配置文件:** 在命令行中使用 ``xtuner list-cfg`` 验证是否能打印配置文件列表。
+
+.. code-block:: console
+
+ $ xtuner list-cfg
diff --git a/data/xtuner/docs/zh_cn/get_started/quickstart.rst b/data/xtuner/docs/zh_cn/get_started/quickstart.rst
new file mode 100644
index 0000000000000000000000000000000000000000..4bec2a5ace2796662303cd5a09001492366c95be
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/get_started/quickstart.rst
@@ -0,0 +1,415 @@
+快速上手
+========
+
+本节中,我们将演示如何使用 XTuner 微调模型,帮助您快速上手 XTuner。
+
+在成功安装 XTuner
+后,便可以开始进行模型的微调。在本节中,我们将演示如何使用 XTuner,应用
+QLoRA 算法在 Colorist 数据集上微调 InternLM2-Chat-7B。
+
+Colorist 数据集(\ `HuggingFace
+链接 `__\ ;\ `ModelScope
+链接 `__\ )是一个根据颜色描述提供颜色选择与建议的数据集,经过该数据集微调的模型可以做到根据用户对于颜色的描述,从而给出16进制下的颜色编码,如用户输入“宁静而又相当明亮的浅天蓝色,介于天蓝色和婴儿蓝之间,因其亮度而带有一丝轻微的荧光感。”,模型输出
+|image1|\ ,该颜色很符合用户的描述。以下是该数据集的几条样例数据:
+
++-----------------------+-----------------------+-------------------+
+| 英文描述 | 中文描述 | 颜色 |
++=======================+=======================+===================+
+| Light Sky Blue: A | 浅天蓝色 | #66ccff: |image8| |
+| calming, fairly | :一种介于天蓝和婴儿 | |
+| bright color that | 蓝之间的平和、相当明 | |
+| falls between sky | 亮的颜色,由于明亮而 | |
+| blue and baby blue, | 带有一丝轻微的荧光。 | |
+| with a hint of slight | | |
+| fluorescence due to | | |
+| its brightness. | | |
++-----------------------+-----------------------+-------------------+
+| Bright red: This is a | 鲜红色: | #ee0000: |image9| |
+| very vibrant, | 这是一种非常鲜 | |
+| saturated and vivid | 艳、饱和、生动的红色 | |
+| shade of red, | ,类似成熟苹果或新鲜 | |
+| resembling the color | 血液的颜色。它是标准 | |
+| of ripe apples or | RGB | |
+| fresh blood. It is as | 调色板上的红色,不含 | |
+| red as you can get on | 任何蓝色或绿色元素。 | |
+| a standard RGB color | | |
+| palette, with no | | |
+| elements of either | | |
+| blue or green. | | |
++-----------------------+-----------------------+-------------------+
+| Bright Turquoise: | 明亮的绿松石 | #00ffcc: |
+| This color mixes the | 色:这种颜色融合了鲜 | |image10| |
+| freshness of bright | 绿色的清新和淡蓝色的 | |
+| green with the | 宁静,呈现出一种充满 | |
+| tranquility of light | 活力的绿松石色调。它 | |
+| blue, leading to a | 让人联想到热带水域。 | |
+| vibrant shade of | | |
+| turquoise. It is | | |
+| reminiscent of | | |
+| tropical waters. | | |
++-----------------------+-----------------------+-------------------+
+
+准备模型权重
+------------
+
+在微调模型前,首先要准备待微调模型的权重。
+
+.. _从-huggingface-下载-1:
+
+从 HuggingFace 下载
+~~~~~~~~~~~~~~~~~~~
+
+.. code:: bash
+
+ pip install -U huggingface_hub
+
+ # 拉取模型至 Shanghai_AI_Laboratory/internlm2-chat-7b
+ huggingface-cli download internlm/internlm2-chat-7b \
+ --local-dir Shanghai_AI_Laboratory/internlm2-chat-7b \
+ --local-dir-use-symlinks False \
+ --resume-download
+
+.. _从-modelscope-下载-1:
+
+从 ModelScope 下载
+~~~~~~~~~~~~~~~~~~
+
+由于从 HuggingFace
+拉取模型权重,可能存在下载过程不稳定、下载速度过慢等问题。因此在下载过程遇到网络问题时,我们则可以选择从
+ModelScope 下载 InternLM2-Chat-7B 的权重。
+
+.. code:: bash
+
+ pip install -U modelscope
+
+ # 拉取模型至当前目录
+ python -c "from modelscope import snapshot_download; snapshot_download('Shanghai_AI_Laboratory/internlm2-chat-7b', cache_dir='.')"
+
+在完成下载后,便可以开始准备微调数据集了。
+
+此处附上 HuggingFace 链接与 ModelScope 链接:
+
+- HuggingFace
+ 链接位于:\ https://huggingface.co/internlm/internlm2-chat-7b
+
+- ModelScope
+ 链接位于:\ https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-chat-7b/summary
+
+准备微调数据集
+--------------
+
+接下来,我们需要准备微调数据集。
+
+.. _从-huggingface-下载-2:
+
+从 HuggingFace 下载
+~~~~~~~~~~~~~~~~~~~
+
+.. code:: bash
+
+ git clone https://huggingface.co/datasets/burkelibbey/colors
+
+.. _从-modelscope-下载-2:
+
+从 ModelScope 下载
+~~~~~~~~~~~~~~~~~~
+
+由于相同的问题,因此我们可以选择从 ModelScope 下载所需要的微调数据集。
+
+.. code:: bash
+
+ git clone https://www.modelscope.cn/datasets/fanqiNO1/colors.git
+
+此处附上 HuggingFace 链接与 ModelScope 链接:
+
+- HuggingFace
+ 链接位于:\ https://huggingface.co/datasets/burkelibbey/colors
+
+- ModelScope 链接位于:\ https://modelscope.cn/datasets/fanqiNO1/colors
+
+准备配置文件
+------------
+
+XTuner 提供了多个开箱即用的配置文件,可以通过 ``xtuner list-cfg``
+查看。我们执行如下指令,以复制一个配置文件到当前目录。
+
+.. code:: bash
+
+ xtuner copy-cfg internlm2_7b_qlora_colorist_e5 .
+
+配置文件名的解释:
+
+======== ==============================
+配置文件 internlm2_7b_qlora_colorist_e5
+======== ==============================
+模型名 internlm2_7b
+使用算法 qlora
+数据集 colorist
+训练时长 5 epochs
+======== ==============================
+
+此时该目录文件结构应如下所示:
+
+.. code:: bash
+
+ .
+ ├── colors
+ │ ├── colors.json
+ │ ├── dataset_infos.json
+ │ ├── README.md
+ │ └── train.jsonl
+ ├── internlm2_7b_qlora_colorist_e5_copy.py
+ └── Shanghai_AI_Laboratory
+ └── internlm2-chat-7b
+ ├── config.json
+ ├── configuration_internlm2.py
+ ├── configuration.json
+ ├── generation_config.json
+ ├── modeling_internlm2.py
+ ├── pytorch_model-00001-of-00008.bin
+ ├── pytorch_model-00002-of-00008.bin
+ ├── pytorch_model-00003-of-00008.bin
+ ├── pytorch_model-00004-of-00008.bin
+ ├── pytorch_model-00005-of-00008.bin
+ ├── pytorch_model-00006-of-00008.bin
+ ├── pytorch_model-00007-of-00008.bin
+ ├── pytorch_model-00008-of-00008.bin
+ ├── pytorch_model.bin.index.json
+ ├── README.md
+ ├── special_tokens_map.json
+ ├── tokenization_internlm2_fast.py
+ ├── tokenization_internlm2.py
+ ├── tokenizer_config.json
+ └── tokenizer.model
+
+修改配置文件
+------------
+
+| 在这一步中,我们需要修改待微调模型路径和数据路径为本地路径,并且修改数据集加载方式。
+| 此外,由于复制得到的配置文件是基于基座(Base)模型的,所以还需要修改
+ ``prompt_template`` 以适配对话(Chat)模型。
+
+.. code:: diff
+
+ #######################################################################
+ # PART 1 Settings #
+ #######################################################################
+ # Model
+ - pretrained_model_name_or_path = 'internlm/internlm2-7b'
+ + pretrained_model_name_or_path = './Shanghai_AI_Laboratory/internlm2-chat-7b'
+
+ # Data
+ - data_path = 'burkelibbey/colors'
+ + data_path = './colors/train.jsonl'
+ - prompt_template = PROMPT_TEMPLATE.default
+ + prompt_template = PROMPT_TEMPLATE.internlm2_chat
+
+ ...
+ #######################################################################
+ # PART 3 Dataset & Dataloader #
+ #######################################################################
+ train_dataset = dict(
+ type=process_hf_dataset,
+ - dataset=dict(type=load_dataset, path=data_path),
+ + dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=colors_map_fn,
+ template_map_fn=dict(
+ type=template_map_fn_factory, template=prompt_template),
+ remove_unused_columns=True,
+ shuffle_before_pack=True,
+ pack_to_max_length=pack_to_max_length)
+
+因此在这一步中,修改了
+``pretrained_model_name_or_path``\ 、\ ``data_path``\ 、\ ``prompt_template``
+以及 ``train_dataset`` 中的 ``dataset`` 字段。
+
+启动微调
+--------
+
+在完成上述操作后,便可以使用下面的指令启动微调任务了。
+
+.. code:: bash
+
+ # 单机单卡
+ xtuner train ./internlm2_7b_qlora_colorist_e5_copy.py
+ # 单机多卡
+ NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm2_7b_qlora_colorist_e5_copy.py
+ # slurm 情况
+ srun ${SRUN_ARGS} xtuner train ./internlm2_7b_qlora_colorist_e5_copy.py --launcher slurm
+
+正确输出的训练日志应类似如下所示:
+
+.. code:: text
+
+ 01/29 21:35:34 - mmengine - INFO - Iter(train) [ 10/720] lr: 9.0001e-05 eta: 0:31:46 time: 2.6851 data_time: 0.0077 memory: 12762 loss: 2.6900
+ 01/29 21:36:02 - mmengine - INFO - Iter(train) [ 20/720] lr: 1.9000e-04 eta: 0:32:01 time: 2.8037 data_time: 0.0071 memory: 13969 loss: 2.6049 grad_norm: 0.9361
+ 01/29 21:36:29 - mmengine - INFO - Iter(train) [ 30/720] lr: 1.9994e-04 eta: 0:31:24 time: 2.7031 data_time: 0.0070 memory: 13969 loss: 2.5795 grad_norm: 0.9361
+ 01/29 21:36:57 - mmengine - INFO - Iter(train) [ 40/720] lr: 1.9969e-04 eta: 0:30:55 time: 2.7247 data_time: 0.0069 memory: 13969 loss: 2.3352 grad_norm: 0.8482
+ 01/29 21:37:24 - mmengine - INFO - Iter(train) [ 50/720] lr: 1.9925e-04 eta: 0:30:28 time: 2.7286 data_time: 0.0068 memory: 13969 loss: 2.2816 grad_norm: 0.8184
+ 01/29 21:37:51 - mmengine - INFO - Iter(train) [ 60/720] lr: 1.9863e-04 eta: 0:29:58 time: 2.7048 data_time: 0.0069 memory: 13969 loss: 2.2040 grad_norm: 0.8184
+ 01/29 21:38:18 - mmengine - INFO - Iter(train) [ 70/720] lr: 1.9781e-04 eta: 0:29:31 time: 2.7302 data_time: 0.0068 memory: 13969 loss: 2.1912 grad_norm: 0.8460
+ 01/29 21:38:46 - mmengine - INFO - Iter(train) [ 80/720] lr: 1.9681e-04 eta: 0:29:05 time: 2.7338 data_time: 0.0069 memory: 13969 loss: 2.1512 grad_norm: 0.8686
+ 01/29 21:39:13 - mmengine - INFO - Iter(train) [ 90/720] lr: 1.9563e-04 eta: 0:28:36 time: 2.7047 data_time: 0.0068 memory: 13969 loss: 2.0653 grad_norm: 0.8686
+ 01/29 21:39:40 - mmengine - INFO - Iter(train) [100/720] lr: 1.9426e-04 eta: 0:28:09 time: 2.7383 data_time: 0.0070 memory: 13969 loss: 1.9819 grad_norm: 0.9127
+
+在训练开始前,可以看到模型的输出如下所示:
+
+.. code:: text
+
+ 2024/01/29 21:34:58 - mmengine - INFO - before_train in EvaluateChatHook.
+ 2024/01/29 21:35:03 - mmengine - INFO - Sample output:
+ <|im_start|>system
+ You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+ <|im_end|>
+ <|im_start|>user
+ 请给我一个像天空一样清澈透明的蓝色。<|im_end|>
+ <|im_start|>assistant
+ 为了匹配您所描述的“像天空一样清澈透明的蓝色”,我建议您选择一种名为“天蓝”(Cerulean)的颜色。这种颜色通常被用来代表天空、海洋和清澈的水域,它具有明亮
+
+ 2024/01/29 21:35:07 - mmengine - INFO - Sample output:
+ <|im_start|>system
+ You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+ <|im_end|>
+ <|im_start|>user
+ Please give me a clear blue like the sky.<|im_end|>
+ <|im_start|>assistant
+ The color you're describing is a clear, bright blue that resembles the color of the sky on a sunny day. This color is often referred to as "sky blue" or "cerulean blue." Here are some specific color codes and names that
+
+而在训练完全完成后,可以观察到模型的输出如下所示:
+
+.. code:: text
+
+ 2024/01/29 22:08:07 - mmengine - INFO - Sample output:
+ <|im_start|>system
+ You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+ <|im_end|>
+ <|im_start|>user
+ 请给我一个像天空一样清澈透明的蓝色。<|im_end|>
+ <|im_start|>assistant
+ #1099ee<|im_end|>
+
+ 2024/01/29 22:08:08 - mmengine - INFO - Sample output:
+ <|im_start|>system
+ You are a professional color designer. Please provide the corresponding colors based on the description of Human.
+ <|im_end|>
+ <|im_start|>user
+ Please give me a clear blue like the sky.<|im_end|>
+ <|im_start|>assistant
+ #0066dd<|im_end|>
+
+模型输出的颜色如下所示:
+
+- 天空一样清澈透明的蓝色:\ |image11|
+
+- A clear blue like the sky: |image12|
+
+不难发现,模型在经过训练后,其输出已经完全与数据集内容所对齐了。
+
+.. _模型转换--lora-合并:
+
+模型转换 + LoRA 合并
+--------------------
+
+在训练完成后,我们会得到几个 ``.pth`` 文件,这些文件存储了 QLoRA
+算法训练过程所更新的参数,而\ **不是**\ 模型的全部参数。因此我们需要将这些
+``.pth`` 文件转换为 HuggingFace 格式,并合并入原始的语言模型权重中。
+
+模型转换
+~~~~~~~~
+
+XTuner 已经集成好了将模型转换为 HuggingFace 格式的工具,我们只需要执行
+
+.. code:: bash
+
+ # 创建存放 hf 格式参数的目录
+ mkdir work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf
+
+ # 转换格式
+ xtuner convert pth_to_hf internlm2_7b_qlora_colorist_e5_copy.py \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720.pth \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf
+
+该条转换命令将会根据配置文件 ``internlm2_7b_qlora_colorist_e5_copy.py``
+的内容,将
+``work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720.pth`` 转换为 hf
+格式,并保存在
+``work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf`` 位置。
+
+LoRA 合并
+~~~~~~~~~
+
+XTuner 也已经集成好了合并 LoRA 权重的工具,我们只需执行如下指令:
+
+.. code:: bash
+
+ # 创建存放合并后的参数的目录
+ mkdir work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged
+
+ # 合并参数
+ xtuner convert merge Shanghai_AI_Laboratory/internlm2-chat-7b \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf \
+ work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged \
+ --max-shard-size 2GB
+
+与转换命令类似,该条合并参数命令会读取原始参数路径
+``Shanghai_AI_Laboratory/internlm2-chat-7b`` 以及转换为 hf
+格式的部分参数路径
+``work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf``\ ,将两部分参数合并后保存于
+``work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged``\ ,其中每个参数切片的最大文件大小为
+2GB。
+
+与模型对话
+----------
+
+在合并权重后,为了更好地体会到模型的能力,XTuner
+也集成了与模型对话的工具。通过如下命令,便可以启动一个与模型对话的简易
+Demo。
+
+.. code:: bash
+
+ xtuner chat work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged \
+ --prompt-template internlm2_chat \
+ --system-template colorist
+
+当然,我们也可以选择不合并权重,而是直接与 LLM + LoRA Adapter
+进行对话,我们只需要执行如下指令:
+
+.. code:: bash
+
+ xtuner chat Shanghai_AI_Laboratory/internlm2-chat-7b
+ --adapter work_dirs/internlm2_7b_qlora_colorist_e5_copy/iter_720_hf \
+ --prompt-template internlm2_chat \
+ --system-template colorist
+
+其中 ``work_dirs/internlm2_7b_qlora_colorist_e5_copy/merged``
+是合并后的权重路径,\ ``--prompt-template internlm2_chat``
+指定了对话模板为 InternLM2-Chat,\ ``--system-template colorist``
+则是指定了与模型对话时的 System Prompt 为 Colorist 数据集所要求的模板。
+
+以下是一个例子:
+
+.. code:: text
+
+ double enter to end input (EXIT: exit chat, RESET: reset history) >>> 宁静而又相当明亮的浅天蓝色,介于天蓝色和婴儿蓝之间,因其亮度而带有一丝轻微的荧光感。
+
+ #66ccff<|im_end|>
+
+其颜色如下所示:
+
+宁静而又相当明亮的浅天蓝色,介于天蓝色和婴儿蓝之间,因其亮度而带有一丝轻微的荧光感。:\ |image13|
+
+.. |image1| image:: https://img.shields.io/badge/%2366ccff-66CCFF
+.. |image2| image:: https://img.shields.io/badge/%2366ccff-66CCFF
+.. |image3| image:: https://img.shields.io/badge/%23ee0000-EE0000
+.. |image4| image:: https://img.shields.io/badge/%2300ffcc-00FFCC
+.. |image5| image:: https://img.shields.io/badge/%2366ccff-66CCFF
+.. |image6| image:: https://img.shields.io/badge/%23ee0000-EE0000
+.. |image7| image:: https://img.shields.io/badge/%2300ffcc-00FFCC
+.. |image8| image:: https://img.shields.io/badge/%2366ccff-66CCFF
+.. |image9| image:: https://img.shields.io/badge/%23ee0000-EE0000
+.. |image10| image:: https://img.shields.io/badge/%2300ffcc-00FFCC
+.. |image11| image:: https://img.shields.io/badge/天空一样清澈透明的蓝色-1099EE
+.. |image12| image:: https://img.shields.io/badge/A_clear_blue_like_the_sky-0066DD
+.. |image13| image:: https://img.shields.io/badge/宁静而又相当明亮的浅天蓝色,介于天蓝色和婴儿蓝之间,因其亮度而带有一丝轻微的荧光感。-66CCFF
diff --git a/data/xtuner/docs/zh_cn/index.rst b/data/xtuner/docs/zh_cn/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..4acf0e8829c8d86a643038d0f30b1772bfdbca00
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/index.rst
@@ -0,0 +1,97 @@
+.. xtuner documentation master file, created by
+ sphinx-quickstart on Tue Jan 9 16:33:06 2024.
+ You can adapt this file completely to your liking, but it should at least
+ contain the root `toctree` directive.
+
+欢迎来到 XTuner 的中文文档
+==================================
+
+.. figure:: ./_static/image/logo.png
+ :align: center
+ :alt: xtuner
+ :class: no-scaled-link
+
+.. raw:: html
+
+
+ LLM 一站式工具箱
+
+
+
+
+
+ Star
+ Watch
+ Fork
+
+
+
+
+文档
+-------------
+.. toctree::
+ :maxdepth: 2
+ :caption: 开始使用
+
+ get_started/installation.rst
+ get_started/quickstart.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 准备
+
+ preparation/pretrained_model.rst
+ preparation/prompt_template.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 训练
+
+ training/open_source_dataset.rst
+ training/custom_sft_dataset.rst
+ training/custom_pretrain_dataset.rst
+ training/multi_modal_dataset.rst
+ acceleration/train_large_scale_dataset.rst
+ training/modify_settings.rst
+ training/visualization.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: DPO
+
+ dpo/overview.md
+ dpo/quick_start.md
+ dpo/modify_settings.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Reward Model
+
+ reward_model/overview.md
+ reward_model/quick_start.md
+ reward_model/modify_settings.md
+ reward_model/preference_data.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 加速训练
+
+ acceleration/deepspeed.rst
+ acceleration/flash_attn.rst
+ acceleration/varlen_flash_attn.rst
+ acceleration/pack_to_max_length.rst
+ acceleration/length_grouped_sampler.rst
+ acceleration/train_extreme_long_sequence.rst
+ acceleration/hyper_parameters.rst
+ acceleration/benchmark.rst
+
+
+.. toctree::
+ :maxdepth: 1
+ :caption: InternEvo 迁移
+
+ internevo_migration/differences.rst
+ internevo_migration/ftdp_dataset/tokenized_and_internlm2.rst
+ internevo_migration/ftdp_dataset/processed_and_internlm2.rst
+ internevo_migration/ftdp_dataset/processed_and_others.rst
+ internevo_migration/ftdp_dataset/processed_normal_chat.rst
diff --git a/data/xtuner/docs/zh_cn/internevo_migration/differences.rst b/data/xtuner/docs/zh_cn/internevo_migration/differences.rst
new file mode 100644
index 0000000000000000000000000000000000000000..68c7f318fa2865d82c418988d1beb6d06ea5d4e9
--- /dev/null
+++ b/data/xtuner/docs/zh_cn/internevo_migration/differences.rst
@@ -0,0 +1,320 @@
+==============
+主要差异
+==============
+
+总览
+=============
+
+XTuner 可以复现 InternEvo (train_internlm) 仓库训练得到的开源模型
+internlm/internlm2-chat-7b 的训练精度。
+
+下面是 XTuner 和 InternEvo (train_internlm)
+在相同数据集上训练相同基座模型的训练结果对比:
+
+.. list-table::
+ :widths: 50 25 25
+ :header-rows: 1
+
+ * - 能力类别
+ - xtuner
+ - internevo
+ * - 全数据集平均(无智能体)
+ - 56.44
+ - 55.26
+ * - 全维度平均(无智能体)
+ - 49.58
+ - 48.96
+ * - 语言 Language
+ - 64.77
+ - 62.41
+ * - 知识 Knowledge
+ - 52.24
+ - 52.52
+ * - 推理 Reasoning
+ - 65.5
+ - 63.91
+ * - 数学 Mathematics
+ - 30.95
+ - 30.26
+ * - 代码 Coding
+ - 38.91
+ - 41.06
+ * - 长文本 LongEval
+ - 45.09
+ - 43.62
+ * - 智能体 Agent
+ - 44.85
+ - 43.97
+ * - 数学题智能体
+ - 37
+ - 37.19
+ * - CIBench
+ - 79.07
+ - 69.78
+ * - PluginEval
+ - 65.57
+ - 65.62
+
+64 \* A100 的训练时间对比如下:
+
+=========== ==========
+xtuner internevo
+=========== ==========
+15 h 55 min 16h 09 min
+=========== ==========
+
+.. tip::
+ 使用 XTuner 提供的序列并行算法可以进一步提升训练速度,使用方式请参考
+ \ :ref:`序列并行文档 ` \ 。
+
+
+适配
+==========
+
+在从 InternEvo (train_internlm) 向 XTuner
+迁移的过程中,我们需要关注模型、数据以及训练策略这三个方面的适配问题。后续内容将详细阐述如何进行适配。
+
+
+模型
+-------
+
+InternEvo 在训练时读取和保存的模型权重满足以下目录结构(以 tp2pp2
+为例):
+
+.. code::
+
+ |-- root
+ |-- model_config.pt
+ |-- model_tp0_pp0.pt
+ |-- model_tp0_pp1.pt
+ |-- model_tp1_pp0.pt
+ |-- model_tp1_pp1.pt
+
+其中,\ ``model_config.pt`` 保存模型权重的一些 meta 信息,其余 4 个
+checkpoint 则分别保存 4 组 GPUs 上的模型权重。因此,InternEvo
+训练过程中要求读取预训练权重的 tp、pp 策略与训练使用的 tp、pp
+策略一致才能正常读取预训练权重进行训练。
+
+XTuner 支持基于 Huggingface Hub 上的模型进行训练,如下修改 config
+内容即可将基座模型从 internlm2-7b 切换为 internlm2-20b:
+
+.. code:: diff
+
+ #######################################################################
+ # PART 1 Settings #
+ #######################################################################
+ # Model
+ - pretrained_model_name_or_path = 'internlm/internlm2-7b'
+ + pretrained_model_name_or_path = 'internlm/internlm2-20b'
+
+数据
+---------
+
+InternEvo
+在训练过程中通常会把多条数据拼接为一个特定的最大长度,随后输入模型训练。其配置往往满足以下形式:
+
+.. code:: python
+
+ data = dict(
+ seq_len=SEQ_LEN,
+ pack_sample_into_one=False,
+ min_length=MIN_LENGTH,
+ train_folder=TRAIN_FOLDER,
+ dataset_weights=DATASET_WEIGHTS,
+ ...)
+
+其中,数据配比 (``dataset_weights=DATASET_WEIGHTS``) 功能 XTuner
+尚未支持。\ ``TRAIN_FOLDER`` 中的训练数据需要满足 ftdp tokenized
+数据集格式:
+
+.. code::
+
+ |-- TRAIN_FOLDER
+ |-- cn
+ | |-- dataset1
+ | | |-- data1.bin
+ | | |-- data1.bin.meta
+ | |-- dataset2
+ | | |-- data2.bin
+ | | |-- data2.bin.meta
+
+在 XTuner 中实现在线数据集拼接策略需要参考
+``xtuner/configs/internlm/internlm2_7b/internlm2_7b_w_internevo_dataset.py``
+文件中的配置:
+
+.. code:: diff
+
+ #######################################################################
+ # PART 1 Settings #
+ #######################################################################
+ # Data
+ - dataset_folder = '/path/to/sft/data/folder'
+ + dataset_folder = TRAIN_FOLDER
+ - max_length = 32768
+ + max_length = SEQ_LEN
+
+ #######################################################################
+ # PART 3 Dataset & Dataloader #
+ #######################################################################
+ train_dataset = dict(
+ type=build_packed_dataset,
+ dataset_cfg=dict(
+ type=load_intern_repo_tokenized_dataset,
+ data_order_path=None,
+ folder=dataset_folder,
+ - min_length=0,
+ + min_length=MIN_LENGTH,
+ file_type='.bin'),
+ packed_length=max_length,
+ seed=1024)
+
+.. note::
+
+ 需要注意,由于训练数据喂给模型的先后顺序可能对训练结果造成影响,因此建议不要轻易修改上述配置中的 ``seed`` 选项。同时,可参考 \ :ref:`获取数据顺序 ` \ 进一步固定数据顺序。
+
+训练策略
+------------
+
+Varlen Attention
+~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+InternEvo 通过设置
+`数据配置 `__
+中的 ``pack_sample_into_one`` 参数为 False
+来使用“变长注意力机制”(见下图右侧)。
+
+.. code:: python
+
+ data = dict(
+ pack_sample_into_one=False,
+ ...)
+
+.. raw:: html
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+# 序列并行:训练极长序列大模型的系统优化
+
+
+
+XTuner 中的序列并行设计思路参考了 DeepSpeed 的工作 [DeepSpeed Ulysses](https://arxiv.org/abs/2309.14509),并加以优化,以达到直接基于 transformers 算法库或 Huggingface Hub 上的开源模型训练 1M 以上超长序列的目标。
+
+## 简介
+
+从生成性AI到科研模型,长序列训练正在变得非常重要。
+
+在生成性AI领域,会话式AI、长文档摘要、代码库理解和例如 Sora 这种视频生成任务都需要在空间和时间层面对长上下文进行推理。
+
+对于科学AI来说,长序列同样至关重要,它为更好地理解结构生物学、医疗保健、气候和天气预测以及大分子模拟打开了大门。
+
+然而,尽管序列长度的重要性不断增长,XTuner 现有的显存优化策略(如 zero 系列),却不足以解决大模型、长序列训练问题。
+
+同时,受限于通信效率,现有的许多序列并行方法也不够高效。
+
+另外,现有的序列并行方法普遍存在较多的代码侵入式修改,易用性和维护性都要大打折扣。同时也不满足 XTuner 基于 transformers 算法库或 Huggingface Hub 上的开源模型直接进行训练的要求。
+
+
+

+
+
+
+
+
+

+
+

+
+
+
+
+
+

+
+

+
+

+
![]() '
+ IMG_END_TOKEN = ''
+
+ IMAGENET_MEAN = (0.485, 0.456, 0.406)
+ IMAGENET_STD = (0.229, 0.224, 0.225)
+
+ def __init__(self,
+ model_path,
+ template,
+ data_paths,
+ image_folders=None,
+ repeat_times=1,
+ max_length=8192):
+ self.template = template
+ self.max_length = max_length
+
+ self.cfg = AutoConfig.from_pretrained(
+ model_path, trust_remote_code=True)
+
+ # The following modifications are only to ensure full
+ # consistency with the official template,
+ # without investigating the impact on performance.
+ if self.cfg.llm_config.architectures[0] == 'Phi3ForCausalLM':
+ self._system = 'You are an AI assistant whose name is Phi-3.'
+ self.template[
+ 'INSTRUCTION'] = '<|user|>\n{input}<|end|><|assistant|>\n'
+ elif self.cfg.llm_config.architectures[0] == 'InternLM2ForCausalLM':
+ self._system = 'You are an AI assistant whose name ' \
+ 'is InternLM (书生·浦语).'
+ self.template['SYSTEM'] = '<|im_start|>system\n{system}<|im_end|>'
+ self.template[
+ 'INSTRUCTION'] = '<|im_start|>user\n{input}' \
+ '<|im_end|><|im_start|>assistant\n'
+ else:
+ raise NotImplementedError
+
+ self.min_dynamic_patch = self.cfg.min_dynamic_patch
+ self.max_dynamic_patch = self.cfg.max_dynamic_patch
+ self.downsample_ratio = self.cfg.downsample_ratio
+ self.image_size = self.cfg.force_image_size
+ self.use_thumbnail = self.cfg.use_thumbnail
+ patch_size = self.cfg.vision_config.patch_size
+ self.patch_token = int(
+ (self.image_size // patch_size)**2 * (self.downsample_ratio**2))
+ self.tokenizer = AutoTokenizer.from_pretrained(
+ model_path, trust_remote_code=True)
+ self.transformer = T.Compose([
+ T.Lambda(lambda img: img.convert('RGB')
+ if img.mode != 'RGB' else img),
+ T.Resize((self.image_size, self.image_size),
+ interpolation=InterpolationMode.BICUBIC),
+ T.ToTensor(),
+ T.Normalize(mean=self.IMAGENET_MEAN, std=self.IMAGENET_STD)
+ ])
+
+ if not isinstance(data_paths, (list, tuple)):
+ data_paths = [data_paths]
+ if not isinstance(image_folders, (list, tuple)):
+ image_folders = [image_folders]
+ if not isinstance(repeat_times, (list, tuple)):
+ repeat_times = [repeat_times]
+ assert len(data_paths) == len(image_folders) == len(repeat_times)
+
+ print_log('Starting to loading data and calc length', logger='current')
+ self.data = []
+ self.image_folder = []
+ self.group_length = []
+ self.conv2length_text = {
+ } # using dict to speedup the calculation of token length
+
+ for data_file, image_folder, repeat_time in zip(
+ data_paths, image_folders, repeat_times):
+ print_log(
+ f'=======Starting to process {data_file} =======',
+ logger='current')
+ assert repeat_time > 0
+ json_data = load_json_or_jsonl(data_file)
+ if repeat_time < 1:
+ json_data = random.sample(json_data,
+ int(len(json_data) * repeat_time))
+ elif repeat_time > 1:
+ int_repeat_time = int(repeat_time)
+ remaining_repeat_time = repeat_time - repeat_time
+ if remaining_repeat_time > 0:
+ remaining_json_data = random.sample(
+ json_data, int(len(json_data) * remaining_repeat_time))
+ json_data = json_data * int_repeat_time
+ json_data.extend(remaining_json_data)
+ else:
+ json_data = json_data * int_repeat_time
+
+ self.data.extend(json_data)
+ self.image_folder.extend([image_folder] * len(json_data))
+
+ # TODO: multi process
+ for data_item in json_data:
+ if 'length' in data_item:
+ token_length = data_item['length'] # include image token
+ else:
+ conversations = '\n'.join(
+ [temp['value'] for temp in data_item['conversations']])
+ str_length = len(conversations)
+
+ if str_length not in self.conv2length_text:
+ token_length = self.tokenizer(
+ conversations,
+ return_tensors='pt',
+ padding=False,
+ truncation=False,
+ ).input_ids.size(1)
+ self.conv2length_text[str_length] = token_length
+ else:
+ token_length = self.conv2length_text[str_length]
+
+ if 'image' in data_item and data_item['image'] is not None:
+ if 'image_wh' in data_item and data_item[
+ 'image_wh'] is not None:
+ # more accurate calculation of image token
+ image_wh = data_item['image_wh']
+ if isinstance(image_wh[0], list):
+ image_wh = image_wh[0]
+ image_token = total_image_token(
+ image_wh, self.min_dynamic_patch,
+ self.max_dynamic_patch, self.image_size,
+ self.use_thumbnail)
+ image_token = self.patch_token * image_token
+ else:
+ # max_dynamic_patch + use_thumbnail
+ image_token = self.patch_token * (
+ self.max_dynamic_patch + self.use_thumbnail)
+
+ token_length = token_length + image_token
+ else:
+ token_length = -token_length
+
+ self.group_length.append(token_length)
+ print_log(
+ f'=======total {len(json_data)} samples of {data_file}=======',
+ logger='current')
+
+ assert len(self.group_length) == len(self.data)
+ print_log('end loading data and calc length', logger='current')
+ print_log(
+ f'=======total {len(self.data)} samples=======', logger='current')
+ self._max_refetch = 1000
+
+ def __getitem__(self, index):
+ for _ in range(self._max_refetch + 1):
+ data = self.prepare_data(index)
+ # Broken images may cause the returned data to be None
+ if data is None:
+ index = self._rand_another()
+ continue
+ return data
+
+ def __len__(self):
+ return len(self.data)
+
+ @property
+ def modality_length(self):
+ return self.group_length
+
+ @property
+ def length(self):
+ group_length = np.array(self.group_length)
+ group_length = np.abs(group_length).tolist()
+ return group_length
+
+ def prepare_data(self, index):
+ data_dict: dict = self.data[index]
+ image_folder = self.image_folder[index]
+
+ out_data_dict = {}
+ if data_dict.get('image', None) is not None:
+ image_file = data_dict['image']
+ if isinstance(image_file, (list, tuple)):
+ assert len(image_file) == 1
+ image_file = image_file[0]
+
+ try:
+ image = self.get_image(os.path.join(image_folder, image_file))
+ except Exception as e:
+ print(f'Error: {e}', flush=True)
+ print_log(f'Error: {e}', logger='current')
+ return None
+
+ images = dynamic_preprocess(image, self.min_dynamic_patch,
+ self.max_dynamic_patch,
+ self.image_size, self.use_thumbnail)
+ pixel_values = [self.transformer(image) for image in images]
+ pixel_values = torch.stack(pixel_values)
+ out_data_dict['pixel_values'] = pixel_values
+
+ num_image_tokens = pixel_values.shape[0] * self.patch_token
+ image_token_str = f'{self.IMG_START_TOKEN}' \
+ f'{self.IMG_CONTEXT_TOKEN * num_image_tokens}' \
+ f'{self.IMG_END_TOKEN}'
+ token_dict = self.get_inputid_labels(data_dict['conversations'],
+ image_token_str)
+ out_data_dict.update(token_dict)
+ else:
+ token_dict = self.get_inputid_labels(data_dict['conversations'],
+ None)
+ out_data_dict.update(token_dict)
+ out_data_dict['pixel_values'] = torch.zeros(
+ 1, 3, self.image_size, self.image_size)
+ return out_data_dict
+
+ def _rand_another(self) -> int:
+ return np.random.randint(0, len(self.data))
+
+ def get_image(self, path):
+ if 's3://' in path:
+ img_bytes = get(path)
+ with io.BytesIO(img_bytes) as buff:
+ img = Image.open(buff).convert('RGB')
+ return img
+ else:
+ return Image.open(path).convert('RGB')
+
+ def get_inputid_labels(self, conversations, image_token_str) -> dict:
+ input = ''
+ out_conversation = []
+ while conversations and conversations[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ conversations = conversations[1:]
+ for msg in conversations:
+ if msg['from'] == 'human':
+ if image_token_str is None and '' in msg['value']:
+ warnings.warn(
+ f'The current data << {msg["value"]} >> is '
+ f'in plain text mode, but '
+ 'there are tags present in the data. '
+ 'We need to remove the tags.')
+ msg['value'] = msg['value'].replace('', '')
+ if '' in msg['value']:
+ msg['value'] = msg['value'].replace('', '').strip()
+ msg['value'] = image_token_str + '\n' + msg['value']
+ msg['value'] = msg['value'].strip()
+ input += msg['value'].strip()
+ elif msg['from'] == 'gpt':
+ out_conversation.append({
+ 'input': input,
+ 'output': msg['value'].strip()
+ })
+ input = ''
+ else:
+ raise NotImplementedError
+
+ input_ids, labels = [], []
+ for i, single_turn_conversation in enumerate(out_conversation):
+ input = single_turn_conversation.get('input', '')
+ if input is None:
+ input = ''
+ input_text = self.template.INSTRUCTION.format(
+ input=input, round=i + 1)
+
+ if i == 0:
+ system = self.template.SYSTEM.format(system=self._system)
+ input_text = system + input_text
+ input_encode = self.tokenizer.encode(
+ input_text, add_special_tokens=True)
+ else:
+ input_encode = self.tokenizer.encode(
+ input_text, add_special_tokens=False)
+ input_ids += input_encode
+ labels += [IGNORE_INDEX] * len(input_encode)
+
+ output_text = single_turn_conversation.get('output', '')
+ if self.template.get('SUFFIX', None):
+ output_text += self.template.SUFFIX
+ output_encode = self.tokenizer.encode(
+ output_text, add_special_tokens=False)
+ input_ids += output_encode
+ labels += copy.deepcopy(output_encode)
+
+ if len(input_ids) > self.max_length:
+ input_ids = input_ids[:self.max_length]
+ labels = labels[:self.max_length]
+ print_log(
+ f'Warning: input_ids length({len(input_ids)}) '
+ f'is longer than max_length, cut to {self.max_length}',
+ logger='current')
+ return {'input_ids': input_ids, 'labels': labels}
diff --git a/data/xtuner/xtuner/dataset/json_dataset.py b/data/xtuner/xtuner/dataset/json_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c7ca016300c94d19acb14bf9934d49c156a7987
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/json_dataset.py
@@ -0,0 +1,24 @@
+import json
+import os
+
+from datasets import Dataset, concatenate_datasets
+
+
+def load_json_file(data_files=None, data_dir=None, suffix=None):
+ assert (data_files is not None) != (data_dir is not None)
+ if data_dir is not None:
+ data_files = os.listdir(data_dir)
+ data_files = [os.path.join(data_dir, fn) for fn in data_files]
+ if suffix is not None:
+ data_files = [fp for fp in data_files if fp.endswith(suffix)]
+ elif isinstance(data_files, str):
+ data_files = [data_files]
+
+ dataset_list = []
+ for fp in data_files:
+ with open(fp, encoding='utf-8') as file:
+ data = json.load(file)
+ ds = Dataset.from_list(data)
+ dataset_list.append(ds)
+ dataset = concatenate_datasets(dataset_list)
+ return dataset
diff --git a/data/xtuner/xtuner/dataset/llava.py b/data/xtuner/xtuner/dataset/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fab0258af8fa507aac81a45734cee7d71ff63e3
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/llava.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import logging
+import os
+
+import torch
+from datasets import Dataset as HFDataset
+from datasets import DatasetDict, load_from_disk
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from PIL import Image
+from torch.utils.data import Dataset
+
+from xtuner.registry import BUILDER
+from .huggingface import process_hf_dataset
+from .utils import expand2square
+
+
+def load_jsonl(json_file):
+ with open(json_file) as f:
+ lines = f.readlines()
+ data = []
+ for line in lines:
+ data.append(json.loads(line))
+ return data
+
+
+class LLaVADataset(Dataset):
+
+ def __init__(self,
+ image_folder,
+ image_processor,
+ data_path=None,
+ tokenizer=None,
+ offline_processed_text_folder=None,
+ max_dataset_length=None,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ max_length=2048,
+ pad_image_to_square=False):
+ super().__init__()
+
+ assert offline_processed_text_folder or (data_path and tokenizer)
+ if offline_processed_text_folder and data_path:
+ print_log(
+ 'Both `offline_processed_text_folder` and '
+ '`data_path` are set, and we load dataset from'
+ '`offline_processed_text_folder` '
+ f'({offline_processed_text_folder})',
+ logger='current',
+ level=logging.WARNING)
+
+ if offline_processed_text_folder is not None:
+ self.text_data = load_from_disk(offline_processed_text_folder)
+ else:
+ if data_path.endswith('.json'):
+ json_data = json.load(open(data_path))
+ elif data_path.endswith('.jsonl'):
+ json_data = load_jsonl(data_path)
+ else:
+ raise NotImplementedError
+
+ for idx in range(len(json_data)):
+ if isinstance(json_data[idx]['id'], int):
+ json_data[idx]['id'] = str(json_data[idx]['id'])
+ json_data = DatasetDict({'train': HFDataset.from_list(json_data)})
+ self.text_data = process_hf_dataset(
+ dataset=json_data,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ split='train',
+ max_dataset_length=max_dataset_length,
+ remove_unused_columns=False,
+ pack_to_max_length=False,
+ with_image_token=True)
+
+ self.image_folder = image_folder
+ if isinstance(image_processor, dict) or isinstance(
+ image_processor, Config) or isinstance(image_processor,
+ ConfigDict):
+ self.image_processor = BUILDER.build(image_processor)
+ else:
+ self.image_processor = image_processor
+ self.pad_image_to_square = pad_image_to_square
+
+ @property
+ def modality_length(self):
+ length_list = []
+ for data_dict in self.text_data:
+ cur_len = len(data_dict['input_ids'])
+ if data_dict.get('image', None) is None:
+ cur_len = -cur_len
+ length_list.append(cur_len)
+ return length_list
+
+ def __len__(self):
+ return len(self.text_data)
+
+ def __getitem__(self, index):
+ data_dict = self.text_data[index]
+ if data_dict.get('image', None) is not None:
+ image_file = data_dict['image']
+ image = Image.open(os.path.join(self.image_folder,
+ image_file)).convert('RGB')
+ if self.pad_image_to_square:
+ image = expand2square(
+ image,
+ tuple(
+ int(x * 255) for x in self.image_processor.image_mean))
+ image = self.image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ data_dict['pixel_values'] = image
+ else:
+ if hasattr(self.image_processor, 'crop_size'):
+ crop_size = self.image_processor.crop_size
+ else:
+ crop_size = self.image_processor.size
+ data_dict['pixel_values'] = torch.zeros(3, crop_size['height'],
+ crop_size['width'])
+ return data_dict
diff --git a/data/xtuner/xtuner/dataset/map_fns/__init__.py b/data/xtuner/xtuner/dataset/map_fns/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a488c53eab57eedcd0437c2f239faec445292cf
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dataset_map_fns import * # noqa: F401, F403
+from .template_map_fn import template_map_fn # noqa: F401
+from .template_map_fn import template_map_fn_factory # noqa: F401
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/__init__.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..449b7b4f20efec582e419fb15f7fcc45f200a585
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/__init__.py
@@ -0,0 +1,53 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .alpaca_map_fn import alpaca_map_fn
+from .alpaca_zh_map_fn import alpaca_zh_map_fn
+from .arxiv_map_fn import arxiv_map_fn
+from .code_alpaca_map_fn import code_alpaca_map_fn
+from .colors_map_fn import colors_map_fn
+from .crime_kg_assitant_map_fn import crime_kg_assitant_map_fn
+from .default_map_fn import default_map_fn
+from .law_reference_map_fn import law_reference_map_fn
+from .llava_map_fn import llava_image_only_map_fn, llava_map_fn
+from .medical_map_fn import medical_map_fn
+from .msagent_map_fn import msagent_react_map_fn
+from .oasst1_map_fn import oasst1_map_fn
+from .openai_map_fn import openai_map_fn
+from .openorca_map_fn import openorca_map_fn
+from .pretrain_map_fn import pretrain_map_fn
+from .sql_map_fn import sql_map_fn
+from .stack_exchange_map_fn import stack_exchange_map_fn
+from .tiny_codes_map_fn import tiny_codes_map_fn
+from .wizardlm_map_fn import wizardlm_map_fn
+
+DATASET_FORMAT_MAPPING = dict(
+ alpaca=alpaca_map_fn,
+ alpaca_zh=alpaca_zh_map_fn,
+ arxiv=arxiv_map_fn,
+ code_alpaca=code_alpaca_map_fn,
+ colors=colors_map_fn,
+ crime_kg_assitan=crime_kg_assitant_map_fn,
+ default=default_map_fn,
+ law_reference=law_reference_map_fn,
+ llava_image_only=llava_image_only_map_fn,
+ llava=llava_map_fn,
+ medical=medical_map_fn,
+ msagent_react=msagent_react_map_fn,
+ oasst1=oasst1_map_fn,
+ openai=openai_map_fn,
+ openorca=openorca_map_fn,
+ pretrain=pretrain_map_fn,
+ sql=sql_map_fn,
+ stack_exchange=stack_exchange_map_fn,
+ tiny_codes=tiny_codes_map_fn,
+ wizardlm=wizardlm_map_fn,
+)
+
+__all__ = [
+ 'alpaca_map_fn', 'alpaca_zh_map_fn', 'oasst1_map_fn', 'arxiv_map_fn',
+ 'medical_map_fn', 'openorca_map_fn', 'code_alpaca_map_fn',
+ 'tiny_codes_map_fn', 'colors_map_fn', 'law_reference_map_fn',
+ 'crime_kg_assitant_map_fn', 'sql_map_fn', 'openai_map_fn',
+ 'wizardlm_map_fn', 'stack_exchange_map_fn', 'msagent_react_map_fn',
+ 'pretrain_map_fn', 'default_map_fn', 'llava_image_only_map_fn',
+ 'llava_map_fn', 'DATASET_FORMAT_MAPPING'
+]
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..d64ac3a1cb6f2d5ee5c84b2f5cb08f84d5001ac5
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_map_fn.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+def alpaca_map_fn(example):
+ if example.get('output') == '':
+ return {'conversation': []}
+ else:
+ return {
+ 'conversation': [{
+ 'input': f"{example['instruction']}\n{example['input']}",
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_zh_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_zh_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e17cfa048325af7feadc1fd0452481d65b64cd8
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_zh_map_fn.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+def alpaca_zh_map_fn(example):
+ return {
+ 'conversation': [{
+ 'input': f"{example['instruction_zh']}\n{example['input_zh']}",
+ 'output': example['output_zh']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/arxiv_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/arxiv_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..52bcc4e341708d51d474a3d9db6dcc2ad65df454
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/arxiv_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def arxiv_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.arxiv_gentile,
+ 'input': example['abstract'],
+ 'output': example['title']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/code_alpaca_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/code_alpaca_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..ece86ff209807d6e8a555eef95a3205d62aa5144
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/code_alpaca_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def code_alpaca_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.coder,
+ 'input': example['prompt'],
+ 'output': example['completion']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/colors_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/colors_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..17d08bf207cc02d74c2833f1d24da7962e4cd629
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/colors_map_fn.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def colors_map_fn(example):
+ desc = ':'.join(example['description'].split(':')[1:]).strip()
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.colorist,
+ 'input': desc,
+ 'output': example['color']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/crime_kg_assitant_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/crime_kg_assitant_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7511a98d94d53aea340a216d9f323c9ae166a41
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/crime_kg_assitant_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def crime_kg_assitant_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.lawyer,
+ 'input': example['input'],
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/default_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/default_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..0424b884839cd20168ef9c8d26e4363eb8850503
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/default_map_fn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def default_map_fn(example):
+ return {
+ 'conversation': [{
+ 'input': example['input'],
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/law_reference_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/law_reference_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..297086fa082c9c045e6f67af4d74568029b4ffd6
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/law_reference_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def law_reference_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.lawyer,
+ 'input': example['question'],
+ 'output': example['answer']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/llava_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/llava_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..a08ca395b6c4fd208a944d97e98e94fa235c15e4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/llava_map_fn.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import DEFAULT_IMAGE_TOKEN
+
+
+def llava_image_only_map_fn(example):
+ # input contains the DEFAULT_IMAGE_TOKEN only
+ messages = example['conversations']
+ input = ''
+ conversation = []
+ while messages and messages[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ messages = messages[1:]
+ for msg in messages:
+ if msg['from'] == 'human':
+ assert DEFAULT_IMAGE_TOKEN in msg['value']
+ input += DEFAULT_IMAGE_TOKEN
+ elif msg['from'] == 'gpt':
+ conversation.append({'input': input, 'output': msg['value']})
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
+
+
+def llava_map_fn(example):
+ messages = example['conversations']
+ input = ''
+ conversation = []
+ while messages and messages[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ messages = messages[1:]
+ for msg in messages:
+ if msg['from'] == 'human':
+ if DEFAULT_IMAGE_TOKEN in msg['value']:
+ msg['value'] = msg['value'].replace(DEFAULT_IMAGE_TOKEN,
+ '').strip()
+ msg['value'] = DEFAULT_IMAGE_TOKEN + '\n' + msg['value']
+ msg['value'] = msg['value'].strip()
+ input += msg['value']
+
+ elif msg['from'] == 'gpt':
+ conversation.append({'input': input, 'output': msg['value']})
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/medical_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/medical_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..60a955454bee80e283ac950ef561e642affc6eef
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/medical_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def medical_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.medical,
+ 'input': '{instruction}\n{input}'.format(**example),
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/msagent_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/msagent_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..fef8b1c5c680b58bf4a6817a6881b1adb021b3f4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/msagent_map_fn.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import re
+
+think_regex = r'(.*?)(<\|startofthink\|\>)(.*?)(<\|endofthink\|\>)'
+exec_regex = r'(<\|startofexec\|\>)(.*?)(<\|endofexec\|\>)(.*?)$'
+
+
+def replace_think(match):
+ out_text = ''
+ if match.group(1).strip() != '':
+ out_text += f'Thought:{match.group(1).strip()}\n'
+ think_text = match.group(3).replace('```JSON',
+ '').replace('```',
+ '').replace('\n', '')
+ think_json = json.loads(think_text)
+ out_text += (f"Action:{think_json['api_name']}\n"
+ f"Action Input:{think_json['parameters']}\n")
+ return out_text
+
+
+def replace_exec(match):
+ out_text = ''
+ exec_text = match.group(2).replace('```JSON',
+ '').replace('```',
+ '').replace('\n', '')
+ exec_json = json.loads(exec_text)
+ out_text += f'Response:{exec_json}\n'
+ if match.group(4).strip() != '':
+ out_text += f'Final Answer:{match.group(4).strip()}\n'
+ return out_text
+
+
+def extract_json_objects(text, decoder=json.JSONDecoder()):
+ pos = 0
+ results = []
+ while True:
+ match = text.find('{', pos)
+ if match == -1:
+ break
+ try:
+ result, index = decoder.raw_decode(text[match:])
+ if 'name' in result and 'description' in result:
+ results.append(result)
+ pos = match + index
+ else:
+ pos = match + 1
+ except ValueError:
+ pos = match + 1
+ return results
+
+
+def msagent_react_map_fn(example):
+ text = example['conversations']
+ if isinstance(text, str):
+ text = eval(text)
+ if len(text) < 2: # Filter out invalid data
+ return {'conversation': []}
+ conversation = []
+ system_text = ''
+ input_text = ''
+ for t in text:
+ if t['from'] == 'system':
+ system_text += '你是一个可以调用外部工具的助手,可以使用的工具包括:\n'
+ json_objects = extract_json_objects(t['value'])
+ api_dict = {}
+ for obj in json_objects:
+ api_dict[obj['name']] = obj['description']
+ try:
+ params = {
+ i['name']: i['description']
+ for i in obj['paths'][0]['parameters']
+ }
+ api_dict[obj['name']] += f'\n输入参数: {params}'
+ except Exception:
+ pass
+ system_text += f'{api_dict}\n'
+ system_text += (
+ '如果使用工具请遵循以下格式回复:\n```\n'
+ 'Thought:思考你当前步骤需要解决什么问题,是否需要使用工具\n'
+ f'Action:工具名称,你的工具必须从 [{str(list(api_dict.keys()))}] 选择\n'
+ 'Action Input:工具输入参数\n```\n工具返回按照以下格式回复:\n```\n'
+ 'Response:调用工具后的结果\n```\n如果你已经知道了答案,或者你不需要工具,'
+ '请遵循以下格式回复\n```\n'
+ 'Thought:给出最终答案的思考过程\n'
+ 'Final Answer:最终答案\n```\n开始!\n')
+ elif t['from'] == 'user':
+ input_text += f"{t['value']}\n"
+ elif t['from'] == 'assistant':
+ output = t['value']
+ output_response = None
+ try:
+ if '<|startofexec|>' in output:
+ output, output_response = output.split('<|startofexec|>')
+ output_response = '<|startofexec|>' + output_response
+ output, think_cnt = re.subn(
+ think_regex, replace_think, output, flags=re.DOTALL)
+ except Exception:
+ return {'conversation': []}
+
+ if think_cnt == 0:
+ output = f'Final Answer:{output}\n'
+ else:
+ output = f'{output}\n'
+ conversation.append({
+ 'system': system_text,
+ 'input': input_text,
+ 'output': output
+ })
+ system_text = ''
+ input_text = ''
+ if output_response is not None:
+ try:
+ output_response, exec_cnt = re.subn(
+ exec_regex,
+ replace_exec,
+ output_response,
+ flags=re.DOTALL)
+ if 'Final Answer:' in output_response:
+ output_response, output_answer = output_response.split(
+ 'Final Answer:')
+ output_answer = 'Final Answer:' + output_answer
+ conversation.append({
+ 'system': output_response,
+ 'output': output_answer
+ })
+ except Exception:
+ pass
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/oasst1_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/oasst1_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1e13a01525c8beacc03cc27bb36745dbe63da58
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/oasst1_map_fn.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def oasst1_map_fn(example):
+ r"""Example before preprocessing:
+ example['text'] = '### Human: Can you explain xxx'
+ '### Assistant: Sure! xxx'
+ '### Human: I didn't understand how xxx'
+ '### Assistant: It has to do with a process xxx.'
+
+ Example after preprocessing:
+ example['conversation'] = [
+ {
+ 'input': 'Can you explain xxx',
+ 'output': 'Sure! xxx'
+ },
+ {
+ 'input': 'I didn't understand how xxx',
+ 'output': 'It has to do with a process xxx.'
+ }
+ ]
+ """
+ data = []
+ for sentence in example['text'].strip().split('###'):
+ sentence = sentence.strip()
+ if sentence[:6] == 'Human:':
+ data.append(sentence[6:].strip())
+ elif sentence[:10] == 'Assistant:':
+ data.append(sentence[10:].strip())
+ if len(data) % 2:
+ # The last round of conversation solely consists of input
+ # without any output.
+ # Discard the input part of the last round, as this part is ignored in
+ # the loss calculation.
+ data.pop()
+ conversation = []
+ for i in range(0, len(data), 2):
+ single_turn_conversation = {'input': data[i], 'output': data[i + 1]}
+ conversation.append(single_turn_conversation)
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openai_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openai_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..468e738f707e0ecae75e89e6a18b91f39b466d56
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openai_map_fn.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def openai_map_fn(example):
+ """
+ Example before preprocessing:
+ example["messages"] = [
+ { "role": "system", "content": "You are an assistant that
+ occasionally misspells words." },
+ { "role": "user", "content": "Tell me a story." },
+ { "role": "assistant", "content": "One day a student
+ went to schoool." }
+ ]
+ Example after preprocessing:
+ example["conversation"] = [
+ {
+ "system": "You are an assistant that occasionally misspells
+ words.",
+ "input": "Tell me a story.",
+ "output": "One day a student went to schoool."
+ }
+ ]
+ """
+ messages = example['messages']
+ system = ''
+ input = ''
+ conversation = []
+ while messages and messages[0]['role'] == 'assistant':
+ # Skip the first one if it is from assistant
+ messages = messages[1:]
+ for msg in messages:
+ if msg['role'] == 'system':
+ system = msg['content']
+ elif msg['role'] == 'user':
+ input += msg['content']
+ elif msg['role'] == 'assistant':
+ output_with_loss = msg.get('loss', 'True')
+ output_with_loss = str(output_with_loss)
+ output_with_loss = output_with_loss.lower() == 'true'
+ conversation.append({
+ 'system': system,
+ 'input': input,
+ 'output': msg['content'],
+ 'output_with_loss': output_with_loss
+ })
+ system = ''
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openorca_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openorca_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..45e58f3b9dd8e495c27050573eac4271eb7c746c
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openorca_map_fn.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def openorca_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': example['system_prompt'],
+ 'input': example['question'],
+ 'output': example['response']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/pretrain_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/pretrain_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..861302ba8690074210ae8a751ba423075d10a240
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/pretrain_map_fn.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def pretrain_map_fn(example):
+ r"""Example before preprocessing:
+ example['text'] = 'xxx'
+
+ Example after preprocessing:
+ example['conversation'] = [
+ {
+ 'input': '',
+ 'output': 'xxx'
+ },
+ ]
+ """
+ return {
+ 'conversation': [{
+ 'input': '',
+ 'output': example['text'].strip(),
+ 'need_eos_token': False
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/sql_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/sql_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..c83434f8de496a5a15f18c3038771070b0e4b608
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/sql_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def sql_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.sql,
+ 'input': '{context}\n{question}'.format(**example),
+ 'output': example['answer']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/stack_exchange_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/stack_exchange_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fc3520e2919283133afb7ec26ff009469f38475
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/stack_exchange_map_fn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def stack_exchange_map_fn(example):
+ return {
+ 'conversation': [{
+ 'input': example['question'],
+ 'output': example['response']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/tiny_codes_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/tiny_codes_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe0cc02b48c33ab3d9a0e717c293399f74cd6cfa
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/tiny_codes_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def tiny_codes_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.coder,
+ 'input': example['prompt'],
+ 'output': example['response']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/wizardlm_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/wizardlm_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..0174760d006b3efe2240671da672e2367076d30b
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/wizardlm_map_fn.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def wizardlm_map_fn(example):
+ messages = example['conversations']
+ input = ''
+ conversation = []
+ while messages and messages[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ messages = messages[1:]
+ for msg in messages:
+ if msg['from'] == 'human':
+ input += msg['value']
+ elif msg['from'] == 'gpt':
+ conversation.append({'input': input, 'output': msg['value']})
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/template_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/template_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7673b99efcdc2e1215303755401d68f570eedf2
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/template_map_fn.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+
+from mmengine.utils.misc import get_object_from_string
+
+
+def template_map_fn(example, template):
+ conversation = example.get('conversation', [])
+ for i, single_turn_conversation in enumerate(conversation):
+ input = single_turn_conversation.get('input', '')
+ if input is None:
+ input = ''
+ input_text = template.INSTRUCTION.format(input=input, round=i + 1)
+ system = single_turn_conversation.get('system', '')
+ if system != '' and system is not None:
+ system = template.SYSTEM.format(system=system)
+ input_text = system + input_text
+ single_turn_conversation['input'] = input_text
+
+ if template.get('SUFFIX', None):
+ output_text = single_turn_conversation.get('output', '')
+ output_text += template.SUFFIX
+ single_turn_conversation['output'] = output_text
+
+ # SUFFIX_AS_EOS is False ==> need_eos_token is True
+ single_turn_conversation['need_eos_token'] = \
+ not template.get('SUFFIX_AS_EOS', False)
+ single_turn_conversation['sep'] = template.get('SEP', '')
+
+ return {'conversation': conversation}
+
+
+def template_map_fn_factory(template):
+ if isinstance(template, str): # for resume
+ template = get_object_from_string(template)
+ return partial(template_map_fn, template=template)
diff --git a/data/xtuner/xtuner/dataset/modelscope.py b/data/xtuner/xtuner/dataset/modelscope.py
new file mode 100644
index 0000000000000000000000000000000000000000..9400050c34553dc8087a0f78e62918e47835d349
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/modelscope.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import Config, ConfigDict
+
+from xtuner.registry import BUILDER
+from .huggingface import process_hf_dataset
+
+
+def process_ms_dataset(dataset, split='train', *args, **kwargs):
+ """Post-process the dataset loaded from the ModelScope Hub."""
+
+ if isinstance(dataset, (Config, ConfigDict)):
+ dataset = BUILDER.build(dataset)
+ if isinstance(dataset, dict):
+ dataset = dataset[split]
+ dataset = dataset.to_hf_dataset()
+ return process_hf_dataset(dataset, *args, **kwargs)
diff --git a/data/xtuner/xtuner/dataset/moss_sft.py b/data/xtuner/xtuner/dataset/moss_sft.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5b7122bb700847dcab584e93b3ecc44c37404d3
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/moss_sft.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import json
+import os
+
+import torch
+from mmengine.config import Config, ConfigDict
+from mmengine.logging import print_log
+from torch.utils.data import Dataset
+from tqdm import tqdm
+
+from xtuner.registry import BUILDER
+
+
+class MOSSSFTDataset(Dataset):
+
+ def __init__(self, data_file, tokenizer, max_length=2048, bot_name=None):
+ super().__init__()
+ self.bot_name = bot_name
+ self.src_data_file = data_file
+ if isinstance(tokenizer, dict) or isinstance(
+ tokenizer, Config) or isinstance(tokenizer, ConfigDict):
+ self.tokenizer = BUILDER.build(tokenizer)
+ else:
+ self.tokenizer = tokenizer
+ self.max_length = max_length
+
+ self.data = []
+ # We do not calculate losses for the meta instruction or results
+ # returned by plugins
+ # The token spans with label -100, [(span_start, span_end), ...]
+ self.no_loss_spans = []
+ self.labels = []
+
+ self.pre = len(
+ self.tokenizer.encode('<|Results|>:', add_special_tokens=False))
+ self.post = len(
+ self.tokenizer.encode('\n', add_special_tokens=False))
+
+ self.load_data()
+ self.process_data()
+
+ def load_data(self):
+ print_log('Loading MOSS SFT data...', 'current')
+ name = f'{self.tokenizer.__class__.__name__}_{self.bot_name}'
+ data_file = self.src_data_file.replace('.jsonl', f'_data_{name}')
+ no_loss_spans_file = self.src_data_file.replace(
+ '.jsonl', f'_no_loss_spans_{name}')
+ if os.path.exists(data_file) and os.path.exists(no_loss_spans_file):
+ self.data = torch.load(data_file, map_location='cpu')
+ self.no_loss_spans = torch.load(
+ no_loss_spans_file, map_location='cpu')
+ else:
+ with open(self.src_data_file) as f:
+ for line in tqdm(f):
+ sample = json.loads(line)
+
+ chat = sample['chat']
+ num_turns = int(sample['num_turns'])
+
+ meta_instruction = sample['meta_instruction']
+ if self.bot_name is not None:
+ meta_instruction = meta_instruction.replace(
+ 'MOSS', self.bot_name)
+ instruction_ids = self.tokenizer.encode(meta_instruction)
+ assert isinstance(instruction_ids,
+ list) and len(instruction_ids) > 0
+
+ input_ids = copy.deepcopy(instruction_ids)
+ no_loss_spans = [(0, len(instruction_ids))]
+ try:
+ for i in range(num_turns):
+ cur_turn_ids = []
+ cur_no_loss_spans = []
+ cur_turn = chat[f'turn_{i+1}']
+ for key, value in cur_turn.items():
+ if self.bot_name is not None:
+ value = value.replace(
+ 'MOSS', self.bot_name)
+ cur_ids = self.tokenizer.encode(
+ value, add_special_tokens=False)
+ if key == 'Tool Responses':
+ # The format tokens
+ # (<|Results|>:...\n)
+ # should have losses.
+ cur_no_loss_spans.append(
+ (len(input_ids + cur_turn_ids) +
+ self.pre,
+ len(input_ids + cur_turn_ids +
+ cur_ids) - self.post))
+
+ assert isinstance(cur_ids,
+ list) and len(cur_ids) > 0
+
+ cur_turn_ids.extend(cur_ids)
+
+ if len(input_ids + cur_turn_ids) > self.max_length:
+ break
+
+ input_ids.extend(cur_turn_ids)
+ no_loss_spans.extend(cur_no_loss_spans)
+ if len(input_ids) == len(instruction_ids):
+ continue
+
+ assert len(input_ids) > 0 and len(
+ input_ids) <= self.max_length
+
+ self.data.append(input_ids)
+ self.no_loss_spans.append(no_loss_spans)
+ except Exception:
+ pass
+ torch.save(self.data, data_file)
+ torch.save(self.no_loss_spans, no_loss_spans_file)
+ print_log(
+ f'Load data successfully, total {len(self.data)} training samples',
+ 'current')
+
+ def process_data(self):
+ for item, no_loss in zip(self.data, self.no_loss_spans):
+ label = copy.deepcopy(item)
+ for loc in no_loss:
+ label[loc[0]:loc[1]] = [-100] * (loc[1] - loc[0])
+ self.labels.append(label)
+
+ def __len__(self):
+ return len(self.data)
+
+ def __getitem__(self, index):
+ return {'input_ids': self.data[index], 'labels': self.labels[index]}
diff --git a/data/xtuner/xtuner/dataset/preference_dataset.py b/data/xtuner/xtuner/dataset/preference_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..371ef829039742762ec7c725fb3a1acd4a57b420
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/preference_dataset.py
@@ -0,0 +1,386 @@
+import copy
+import json
+import os
+from datetime import timedelta
+from functools import partial
+from multiprocessing import Process, Queue
+from typing import Callable, Dict, List
+
+import numpy as np
+import torch.distributed as dist
+import tqdm
+from datasets import Dataset as HFDataset
+from datasets import concatenate_datasets
+from mmengine.config import Config, ConfigDict
+from mmengine.logging import print_log
+from mmengine.utils.misc import get_object_from_string
+from torch.utils.data import Dataset
+from transformers import AutoTokenizer
+
+from xtuner.registry import BUILDER, MAP_FUNC
+from .huggingface import build_origin_dataset
+
+
+def _worker(
+ tokenize_fun: Callable,
+ data_queue: Queue,
+ out_queue: Queue,
+):
+ while True:
+ data_chunk = data_queue.get()
+
+ if data_chunk is None:
+ out_queue.put(None)
+ break
+ chunk_results = []
+ for idx, data in data_chunk:
+ chunk_results.append([idx, tokenize_fun(data)])
+ out_queue.put(chunk_results)
+
+
+def _chunk_data_to_queue(data_queue: Queue, data: List[Dict], chunk_size: int,
+ nproc):
+ data_iter = iter(data)
+ chunk_data = []
+ while True:
+ try:
+ item = next(data_iter)
+ except StopIteration:
+ break
+ chunk_data.append(item)
+ if len(chunk_data) == chunk_size:
+ data_queue.put(chunk_data)
+ chunk_data = []
+ if chunk_data:
+ data_queue.put(chunk_data)
+
+ for _ in range(nproc):
+ data_queue.put(None)
+
+
+def _multi_progress(tokenize_fun_p, dataset, nproc, task_num, chunksize,
+ description):
+ processes = []
+ data_queue = Queue()
+ output_queue = Queue()
+ bar = tqdm.tqdm(total=task_num, desc=description)
+ # task_id = bar.add_task(total=task_num, description=description)
+ dataset = enumerate(dataset)
+ _chunk_data_to_queue(data_queue, dataset, chunksize, nproc)
+ for _ in range(nproc):
+ process = Process(
+ target=_worker, args=(tokenize_fun_p, data_queue, output_queue))
+ process.start()
+ processes.append(process)
+
+ results = []
+ finished_process = 0
+ while finished_process < nproc:
+ chunk_results = output_queue.get()
+ if chunk_results is None:
+ finished_process += 1
+ continue
+ results.extend(chunk_results)
+ bar.update(len(chunk_results))
+ bar.refresh()
+ results = map(lambda x: x[1], sorted(results, key=lambda x: x[0]))
+ return results
+
+
+def load_jsonl_dataset(data_files=None, data_dir=None, suffix=None):
+ assert (data_files is not None) != (data_dir is not None)
+ if data_dir is not None:
+ data_files = os.listdir(data_dir)
+ data_files = [os.path.join(data_dir, fn) for fn in data_files]
+ if suffix is not None:
+ data_files = [fp for fp in data_files if fp.endswith(suffix)]
+ elif isinstance(data_files, str):
+ data_files = [data_files]
+
+ dataset_list = []
+ for fp in data_files:
+ with open(fp, encoding='utf-8') as file:
+ data = [json.loads(line) for line in file]
+ ds = HFDataset.from_list(data)
+ dataset_list.append(ds)
+ dataset = concatenate_datasets(dataset_list)
+ return dataset
+
+
+def tokenize(pair: str,
+ tokenizer: AutoTokenizer,
+ max_length: int,
+ is_reward: bool = False,
+ reward_token_id: int = -1):
+ prompt = tokenizer.apply_chat_template(
+ pair['prompt'], tokenize=False, add_generation_prompt=True)
+ chosen = tokenizer.apply_chat_template(
+ pair['prompt'] + pair['chosen'],
+ tokenize=False,
+ add_generation_prompt=False)
+ rejected = tokenizer.apply_chat_template(
+ pair['prompt'] + pair['rejected'],
+ tokenize=False,
+ add_generation_prompt=False)
+ prompt_ids = tokenizer.encode(prompt, add_special_tokens=False)
+ chosen_ids = tokenizer.encode(chosen, add_special_tokens=False)
+ rejected_ids = tokenizer.encode(rejected, add_special_tokens=False)
+
+ if len(chosen_ids) > max_length:
+ chosen_ids = chosen_ids[:max_length]
+ if len(rejected_ids) > max_length:
+ rejected_ids = rejected_ids[:max_length]
+
+ if is_reward:
+ # reward label
+ chosen_ids = chosen_ids + [reward_token_id]
+ rejected_ids = rejected_ids + [reward_token_id]
+ chosen_labels = [-100] * len(chosen_ids[:-1]) + [0]
+ rejected_labels = [-100] * len(rejected_ids[:-1]) + [1]
+ else:
+ # dpo label
+ prompt_len = min(len(prompt_ids), max_length)
+ chosen_labels = [-100] * prompt_len + copy.deepcopy(
+ chosen_ids[prompt_len:])
+ rejected_labels = [-100] * prompt_len + copy.deepcopy(
+ rejected_ids[prompt_len:])
+
+ return {
+ 'chosen_ids': chosen_ids,
+ 'rejected_ids': rejected_ids,
+ 'chosen_labels': chosen_labels,
+ 'rejected_labels': rejected_labels,
+ }
+
+
+class PreferenceDataset(Dataset):
+
+ def __init__(
+ self,
+ dataset: HFDataset,
+ tokenizer: AutoTokenizer,
+ max_length: int,
+ is_dpo: bool = True,
+ is_reward: bool = False,
+ reward_token_id: int = -1,
+ num_proc: int = 32,
+ ) -> None:
+ self.max_length = max_length
+ assert is_dpo != is_reward, \
+ 'Only one of is_dpo and is_reward can be True'
+ if is_reward:
+ assert reward_token_id != -1, \
+ 'reward_token_id should be set if is_reward is True'
+
+ self.is_dpo = is_dpo
+ self.is_reward = is_reward
+ self.reward_token_id = reward_token_id
+ self.tokenized_pairs = []
+
+ for tokenized_pair in _multi_progress(
+ partial(
+ tokenize,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ is_reward=is_reward,
+ reward_token_id=reward_token_id),
+ dataset,
+ nproc=num_proc,
+ task_num=len(dataset),
+ chunksize=num_proc,
+ description='Tokenizing dataset'):
+ self.tokenized_pairs.append(tokenized_pair)
+
+ def __len__(self):
+ return len(self.tokenized_pairs)
+
+ def __getitem__(self, idx):
+ return self.tokenized_pairs[idx]
+
+
+class PackedDatasetWrapper(Dataset):
+
+ def __init__(self,
+ dataset,
+ max_packed_length=16384,
+ shuffle_before_pack=True) -> None:
+ super().__init__()
+ self.max_packed_length = max_packed_length
+ self.lengths = []
+ self.data = []
+
+ indices = np.arange(len(dataset))
+ if shuffle_before_pack:
+ np.random.shuffle(indices)
+
+ data_bin = []
+ bin_seq_len = 0
+ removed = 0
+ for idx in indices:
+ data = dataset[int(idx)]
+ cur_len = len(data['chosen_ids']) + len(data['rejected_ids'])
+ if cur_len > max_packed_length:
+ print_log(
+ f'sequence length {cur_len} is '
+ f'larger than max_packed_length {max_packed_length}',
+ logger='current')
+ removed += 1
+ continue
+ if (bin_seq_len +
+ cur_len) > max_packed_length and len(data_bin) > 0:
+ self.data.append(data_bin)
+ self.lengths.append(bin_seq_len)
+ data_bin = []
+ bin_seq_len = 0
+ data_bin.append(data)
+ bin_seq_len += cur_len
+
+ if len(data_bin) > 0:
+ self.data.append(data_bin)
+ self.lengths.append(bin_seq_len)
+ if removed > 0:
+ print_log(
+ f'removed {removed} samples because '
+ f'of length larger than {max_packed_length}',
+ logger='current')
+ print_log(
+ f'The batch numbers of dataset is changed '
+ f'from {len(dataset)} to {len(self)} after'
+ ' using var len attention.',
+ logger='current')
+
+ def __len__(self):
+ return len(self.data)
+
+ def __getitem__(self, index):
+ pairs = self.data[index]
+ input_ids, cu_seqlens, position_ids, labels = [], [0], [], []
+
+ for pair in pairs:
+ input_ids.extend(pair['chosen_ids'])
+ input_ids.extend(pair['rejected_ids'])
+
+ position_ids.extend(list(range(len(pair['chosen_ids']))))
+ position_ids.extend(list(range(len(pair['rejected_ids']))))
+
+ labels.extend(pair['chosen_labels'])
+ labels.extend(pair['rejected_labels'])
+
+ cu_seqlens.append(cu_seqlens[-1] + len(pair['chosen_ids']))
+ cu_seqlens.append(cu_seqlens[-1] + len(pair['rejected_ids']))
+
+ return {
+ 'input_ids': input_ids,
+ 'labels': labels,
+ 'position_ids': position_ids,
+ 'cumulative_len': cu_seqlens
+ }
+
+
+def unpack_seq(seq, cu_seqlens):
+ """Unpack a packed sequence to a list of sequences with different
+ lengths."""
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+ subseqs = seq.split(seqlens)
+ return subseqs
+
+
+def broad_cast_dataset(dataset):
+ xtuner_dataset_timeout = timedelta(
+ minutes=int(os.getenv('XTUNER_DATASET_TIMEOUT', default=60)))
+ print_log(
+ f'xtuner_dataset_timeout = {xtuner_dataset_timeout}', logger='current')
+ using_dist = dist.is_available() and dist.is_initialized()
+ if using_dist:
+ # monitored barrier requires gloo process group to perform host-side sync. # noqa
+ group_gloo = dist.new_group(
+ backend='gloo', timeout=xtuner_dataset_timeout)
+ if not using_dist or dist.get_rank() == 0:
+ objects = [dataset]
+ else:
+ objects = [None]
+ if using_dist:
+ dist.monitored_barrier(
+ group=group_gloo, timeout=xtuner_dataset_timeout)
+ dist.broadcast_object_list(objects, src=0)
+ return objects[0]
+
+
+def map_dataset(dataset, dataset_map_fn, map_num_proc):
+ if isinstance(dataset_map_fn, str):
+ map_fn_obj = MAP_FUNC.get(dataset_map_fn) or get_object_from_string(
+ dataset_map_fn)
+ if map_fn_obj is not None:
+ dataset_map_fn = map_fn_obj
+ else:
+ raise TypeError('dataset_map_fn must be a function or a '
+ "registered function's string in MAP_FUNC, "
+ f"but got a string of '{dataset_map_fn}'")
+
+ dataset = dataset.map(dataset_map_fn, num_proc=map_num_proc)
+ return dataset
+
+
+def build_preference_dataset(
+ dataset: str,
+ tokenizer: AutoTokenizer,
+ max_length: int,
+ dataset_map_fn: Callable = None,
+ is_dpo: bool = True,
+ is_reward: bool = False,
+ reward_token_id: int = -1,
+ num_proc: int = 32,
+ use_varlen_attn: bool = False,
+ max_packed_length: int = 16384,
+ shuffle_before_pack: bool = True,
+) -> Dataset:
+ using_dist = dist.is_available() and dist.is_initialized()
+ tokenized_ds = None
+ if not using_dist or dist.get_rank() == 0:
+ if isinstance(tokenizer, dict) or isinstance(
+ tokenizer, Config) or isinstance(tokenizer, ConfigDict):
+ tokenizer = BUILDER.build(tokenizer)
+
+ dataset = build_origin_dataset(dataset, split='train')
+ if dataset_map_fn is not None:
+ dataset = map_dataset(
+ dataset, dataset_map_fn, map_num_proc=num_proc)
+
+ tokenized_ds = PreferenceDataset(
+ dataset=dataset,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ is_dpo=is_dpo,
+ is_reward=is_reward,
+ reward_token_id=reward_token_id,
+ num_proc=num_proc,
+ )
+ if use_varlen_attn:
+ tokenized_ds = PackedDatasetWrapper(
+ dataset=tokenized_ds,
+ max_packed_length=max_packed_length,
+ shuffle_before_pack=shuffle_before_pack,
+ )
+ tokenized_ds = broad_cast_dataset(tokenized_ds)
+ return tokenized_ds
+
+
+def intel_orca_dpo_map_fn(example):
+ prompt = [{
+ 'role': 'system',
+ 'content': example['system']
+ }, {
+ 'role': 'user',
+ 'content': example['question']
+ }]
+ chosen = [{'role': 'assistant', 'content': example['chosen']}]
+ rejected = [{'role': 'assistant', 'content': example['rejected']}]
+ return {'prompt': prompt, 'chosen': chosen, 'rejected': rejected}
+
+
+def orpo_dpo_mix_40k_map_fn(example):
+ assert len(example['chosen']) == len(example['rejected'])
+ prompt = example['chosen'][:-1]
+ chosen = example['chosen'][-1:]
+ rejected = example['rejected'][-1:]
+ return {'prompt': prompt, 'chosen': chosen, 'rejected': rejected}
diff --git a/data/xtuner/xtuner/dataset/refcoco_json.py b/data/xtuner/xtuner/dataset/refcoco_json.py
new file mode 100644
index 0000000000000000000000000000000000000000..e32f08ae459a21697e5a1736ad8a19bafaf767e5
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/refcoco_json.py
@@ -0,0 +1,496 @@
+import copy
+import itertools
+import json
+import os
+import pickle
+import time
+from collections import defaultdict
+
+import matplotlib.pyplot as plt
+import numpy as np
+import skimage.io as io
+import torch
+from datasets import Dataset as HFDataset
+from datasets import DatasetDict
+from matplotlib.patches import Polygon, Rectangle
+from mmengine.config import Config, ConfigDict
+from PIL import Image
+
+from xtuner.registry import BUILDER
+from ..registry import BUILDER
+from .huggingface import process_hf_dataset
+from .llava import LLaVADataset
+from .utils import expand2square
+
+
+class RefCOCOJsonDataset(LLaVADataset):
+ instruction_pool = [
+ '[refer] {}',
+ '[refer] give me the location of {}',
+ '[refer] where is {} ?',
+ '[refer] from this image, tell me the location of {}',
+ '[refer] the location of {} is',
+ '[refer] could you tell me the location for {} ?',
+ '[refer] where can I locate the {} ?',
+ ]
+
+ def __init__(
+ self,
+ data_path,
+ image_folder,
+ tokenizer,
+ image_processor,
+ max_dataset_length=None,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ max_length=2048,
+ pad_image_to_square=False,
+ ):
+ json_data = json.load(open(data_path))
+
+ ######################################################
+ # Only this part is different from LLaVADataset.__init__
+ json_data = self.reformat_data(json_data)
+ ######################################################
+
+ for idx in range(len(json_data)):
+ if isinstance(json_data[idx]['id'], int):
+ json_data[idx]['id'] = str(json_data[idx]['id'])
+ json_data = DatasetDict({'train': HFDataset.from_list(json_data)})
+ self.text_data = process_hf_dataset(
+ dataset=json_data,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ split='train',
+ max_dataset_length=max_dataset_length,
+ remove_unused_columns=False,
+ pack_to_max_length=False,
+ with_image_token=True)
+
+ self.image_folder = image_folder
+ if isinstance(image_processor, dict) or isinstance(
+ image_processor, Config) or isinstance(image_processor,
+ ConfigDict):
+ self.image_processor = BUILDER.build(image_processor)
+ else:
+ self.image_processor = image_processor
+ self.pad_image_to_square = pad_image_to_square
+
+ def reformat_data(self, json_data):
+ new_json_data = []
+ for sample in json_data:
+ for instruction_template in self.instruction_pool:
+ sample['conversations'] = self.gen_refcoco_conversations(
+ sample, instruction_template)
+ new_json_data.append(copy.deepcopy(sample))
+ return new_json_data
+
+ @classmethod
+ def gen_refcoco_conversations(cls, data, instruction_template='{}'):
+ """build conversition data from refcoco json data as below.
+
+ "id": "xxx",
+ "image": "xxx.jpg",
+ "conversations": [
+ {
+ "from": "human",
+ "value": "xxxx"
+ },
+ {
+ "from": "gpt",
+ "value": "xxx"
+ }
+ """
+
+ conversation = [
+ {
+ 'from': 'human',
+ 'value': ''
+ },
+ {
+ 'from': 'gpt',
+ 'value': ''
+ },
+ ]
+
+ instruction = instruction_template.format(data['sents'])
+ bbox = cls.normalize_bbox(data['bbox'], data['height'], data['width'])
+ answer = '{{<{}><{}><{}><{}>}}'.format(bbox[0], bbox[1], bbox[2],
+ bbox[3])
+ conversation[0]['value'] = instruction + '\n'
+ conversation[1]['value'] = answer
+ return conversation
+
+ @classmethod
+ def get_data_json(
+ cls,
+ ann_path,
+ image_path,
+ dataset='refcoco',
+ splitBy='unc',
+ ):
+ refer = REFER(ann_path, image_path, dataset, splitBy)
+ ref_ids = refer.getRefIds(split='train')
+
+ data = {}
+ duplicate_data = defaultdict(list)
+
+ for ref_id in ref_ids:
+ ref = refer.loadRefs(ref_id)[0]
+
+ image_id = '{:0>12}'.format(ref['image_id'])
+ sents = [sent['raw'] for sent in ref['sentences']]
+ bbox = refer.getRefBox(ref['ref_id'])
+
+ image = Image.open(image_path + '/' + image_id + '.jpg')
+
+ for sent in sents:
+ sent_id = '_'.join(sent.split(' '))
+ data_id = f'{dataset}-{splitBy}-{image_id}-{sent_id}'
+ data_item = {
+ 'id': data_id,
+ 'image': 'coco/train2017/' + image_id + '.jpg',
+ 'sents': sent,
+ 'bbox': bbox,
+ 'height': image.height,
+ 'width': image.width
+ }
+ if data_id in data:
+ duplicate_data[data_id].append(data_item)
+ else:
+ data[data_id] = data_item
+
+ return list(data.values()), list(duplicate_data.values())
+
+ @classmethod
+ def normalize_bbox(cls, bbox, height, width):
+ x, y, w, h = bbox
+
+ bbox = [x / width, y / height, (x + w) / width, (y + h) / height]
+ bbox = [int(x * 100) for x in bbox]
+ return bbox
+
+
+class RefCOCOJsonEvalDataset(RefCOCOJsonDataset):
+ instruction_pool = ['[refer] give me the location of {}']
+
+ def reformat_data(self, json_data):
+ for sample in json_data:
+ # reformat img_id
+ img_id = sample['img_id'].split('_')[-2]
+ sample['image'] = 'coco/train2017/' + img_id + '.jpg'
+ sample['id'] = f"{img_id}-{sample['sents']}"
+ return super().reformat_data(json_data)
+
+
+class InvRefCOCOJsonDataset(RefCOCOJsonDataset):
+ instruction_pool = [
+ '[identify] {}',
+ '[identify] what object is in this location {}',
+ '[identify] identify the object present at this location {}',
+ '[identify] what is it in {}',
+ '[identify] describe this object in {}',
+ '[identify] this {} is',
+ '[identify] the object in {} is',
+ ]
+
+ @classmethod
+ def gen_refcoco_conversations(cls, data, instruction_template='{}'):
+ """build conversition data from refcoco json data as below.
+
+ "id": "xxx",
+ "image": "xxx.jpg",
+ "conversations": [
+ {
+ "from": "human",
+ "value": "xxxx"
+ },
+ {
+ "from": "gpt",
+ "value": "xxx"
+ }
+ """
+
+ conversation = [
+ {
+ 'from': 'human',
+ 'value': ''
+ },
+ {
+ 'from': 'gpt',
+ 'value': ''
+ },
+ ]
+ bbox = cls.normalize_bbox(data['bbox'], data['height'], data['width'])
+ bbox_str = '{{<{}><{}><{}><{}>}}'.format(bbox[0], bbox[1], bbox[2],
+ bbox[3])
+ instruction = instruction_template.format(bbox_str)
+ answer = data['sents']
+
+ conversation[0]['value'] = instruction + '\n'
+ conversation[1]['value'] = answer
+ return conversation
+
+
+# flake8: noqa
+# Refer
+
+
+class REFER:
+
+ def __init__(self, data_root, vis_root, dataset='refcoco', splitBy='unc'):
+ # provide data_root folder which contains refclef, refcoco, refcoco+ and refcocog
+ # also provide dataset name and splitBy information
+ # e.g., dataset = 'refcoco', splitBy = 'unc'
+ # inv dataset is stored in the same path as normal dataset
+ dataset = dataset.split('inv')[-1]
+ print('loading dataset %s into memory...' % dataset)
+ self.ann_dir = os.path.join(data_root, dataset)
+ if dataset in ['refcoco', 'refcoco+', 'refcocog']:
+ self.vis_root = vis_root
+ elif dataset == 'refclef':
+ raise 'No RefClef image data'
+ else:
+ raise 'No refer dataset is called [%s]' % dataset
+
+ # load refs from data/dataset/refs(dataset).json
+ tic = time.time()
+ ref_file = os.path.join(self.ann_dir, 'refs(' + splitBy + ').p')
+ self.data = {}
+ self.data['dataset'] = dataset
+ self.data['refs'] = pickle.load(open(ref_file, 'rb'))
+
+ # load annotations from data/dataset/instances.json
+ instances_file = os.path.join(self.ann_dir, 'instances.json')
+ instances = json.load(open(instances_file))
+ self.data['images'] = instances['images']
+ self.data['annotations'] = instances['annotations']
+ self.data['categories'] = instances['categories']
+
+ # create index
+ self.createIndex()
+ print('DONE (t=%.2fs)' % (time.time() - tic))
+
+ def createIndex(self):
+ # create sets of mapping
+ # 1) Refs: {ref_id: ref}
+ # 2) Anns: {ann_id: ann}
+ # 3) Imgs: {image_id: image}
+ # 4) Cats: {category_id: category_name}
+ # 5) Sents: {sent_id: sent}
+ # 6) imgToRefs: {image_id: refs}
+ # 7) imgToAnns: {image_id: anns}
+ # 8) refToAnn: {ref_id: ann}
+ # 9) annToRef: {ann_id: ref}
+ # 10) catToRefs: {category_id: refs}
+ # 11) sentToRef: {sent_id: ref}
+ # 12) sentToTokens: {sent_id: tokens}
+ print('creating index...')
+ # fetch info from instances
+ Anns, Imgs, Cats, imgToAnns = {}, {}, {}, {}
+ for ann in self.data['annotations']:
+ Anns[ann['id']] = ann
+ imgToAnns[ann['image_id']] = imgToAnns.get(ann['image_id'],
+ []) + [ann]
+ for img in self.data['images']:
+ Imgs[img['id']] = img
+ for cat in self.data['categories']:
+ Cats[cat['id']] = cat['name']
+
+ # fetch info from refs
+ Refs, imgToRefs, refToAnn, annToRef, catToRefs = {}, {}, {}, {}, {}
+ Sents, sentToRef, sentToTokens = {}, {}, {}
+ for ref in self.data['refs']:
+ # ids
+ ref_id = ref['ref_id']
+ ann_id = ref['ann_id']
+ category_id = ref['category_id']
+ image_id = ref['image_id']
+
+ # add mapping related to ref
+ Refs[ref_id] = ref
+ imgToRefs[image_id] = imgToRefs.get(image_id, []) + [ref]
+ catToRefs[category_id] = catToRefs.get(category_id, []) + [ref]
+ refToAnn[ref_id] = Anns[ann_id]
+ annToRef[ann_id] = ref
+
+ # add mapping of sent
+ for sent in ref['sentences']:
+ Sents[sent['sent_id']] = sent
+ sentToRef[sent['sent_id']] = ref
+ sentToTokens[sent['sent_id']] = sent['tokens']
+
+ # create class members
+ self.Refs = Refs
+ self.Anns = Anns
+ self.Imgs = Imgs
+ self.Cats = Cats
+ self.Sents = Sents
+ self.imgToRefs = imgToRefs
+ self.imgToAnns = imgToAnns
+ self.refToAnn = refToAnn
+ self.annToRef = annToRef
+ self.catToRefs = catToRefs
+ self.sentToRef = sentToRef
+ self.sentToTokens = sentToTokens
+ print('index created.')
+
+ def getRefIds(self, image_ids=[], cat_ids=[], ref_ids=[], split=''):
+ image_ids = image_ids if type(image_ids) == list else [image_ids]
+ cat_ids = cat_ids if type(cat_ids) == list else [cat_ids]
+ ref_ids = ref_ids if type(ref_ids) == list else [ref_ids]
+
+ if len(image_ids) == len(cat_ids) == len(ref_ids) == len(split) == 0:
+ refs = self.data['refs']
+ else:
+ if not len(image_ids) == 0:
+ refs = [self.imgToRefs[image_id] for image_id in image_ids]
+ else:
+ refs = self.data['refs']
+ if not len(cat_ids) == 0:
+ refs = [ref for ref in refs if ref['category_id'] in cat_ids]
+ if not len(ref_ids) == 0:
+ refs = [ref for ref in refs if ref['ref_id'] in ref_ids]
+ if not len(split) == 0:
+ if split in ['testA', 'testB', 'testC']:
+ refs = [ref for ref in refs if split[-1] in ref['split']
+ ] # we also consider testAB, testBC, ...
+ elif split in ['testAB', 'testBC', 'testAC']:
+ # rarely used I guess...
+ refs = [ref for ref in refs if ref['split'] == split]
+ elif split == 'test':
+ refs = [ref for ref in refs if 'test' in ref['split']]
+ elif split == 'train' or split == 'val':
+ refs = [ref for ref in refs if ref['split'] == split]
+ else:
+ raise 'No such split [%s]' % split
+ ref_ids = [ref['ref_id'] for ref in refs]
+ return ref_ids
+
+ def getAnnIds(self, image_ids=[], cat_ids=[], ref_ids=[]):
+ image_ids = image_ids if type(image_ids) == list else [image_ids]
+ cat_ids = cat_ids if type(cat_ids) == list else [cat_ids]
+ ref_ids = ref_ids if type(ref_ids) == list else [ref_ids]
+
+ if len(image_ids) == len(cat_ids) == len(ref_ids) == 0:
+ ann_ids = [ann['id'] for ann in self.data['annotations']]
+ else:
+ if not len(image_ids) == 0:
+ lists = [
+ self.imgToAnns[image_id] for image_id in image_ids
+ if image_id in self.imgToAnns
+ ] # list of [anns]
+ anns = list(itertools.chain.from_iterable(lists))
+ else:
+ anns = self.data['annotations']
+ if not len(cat_ids) == 0:
+ anns = [ann for ann in anns if ann['category_id'] in cat_ids]
+ ann_ids = [ann['id'] for ann in anns]
+ if not len(ref_ids) == 0:
+ ids = set(ann_ids).intersection(
+ {self.Refs[ref_id]['ann_id']
+ for ref_id in ref_ids})
+ return ann_ids
+
+ def getImgIds(self, ref_ids=[]):
+ ref_ids = ref_ids if type(ref_ids) == list else [ref_ids]
+
+ if not len(ref_ids) == 0:
+ image_ids = list(
+ {self.Refs[ref_id]['image_id']
+ for ref_id in ref_ids})
+ else:
+ image_ids = self.Imgs.keys()
+ return image_ids
+
+ def getCatIds(self):
+ return self.Cats.keys()
+
+ def loadRefs(self, ref_ids=[]):
+ if type(ref_ids) == list:
+ return [self.Refs[ref_id] for ref_id in ref_ids]
+ elif type(ref_ids) == int:
+ return [self.Refs[ref_ids]]
+
+ def loadAnns(self, ann_ids=[]):
+ if type(ann_ids) == list:
+ return [self.Anns[ann_id] for ann_id in ann_ids]
+ elif type(ann_ids) == int:
+ return [self.Anns[ann_ids]]
+
+ def loadImgs(self, image_ids=[]):
+ if type(image_ids) == list:
+ return [self.Imgs[image_id] for image_id in image_ids]
+ elif type(image_ids) == int:
+ return [self.Imgs[image_ids]]
+
+ def loadCats(self, cat_ids=[]):
+ if type(cat_ids) == list:
+ return [self.Cats[cat_id] for cat_id in cat_ids]
+ elif type(cat_ids) == int:
+ return [self.Cats[cat_ids]]
+
+ def getRefBox(self, ref_id):
+ ref = self.Refs[ref_id]
+ ann = self.refToAnn[ref_id]
+ return ann['bbox'] # [x, y, w, h]
+
+ def showRef(self, ref, seg_box='box'):
+ from matplotlib.collectns import PatchCollection
+
+ ax = plt.gca()
+ # show image
+ image = self.Imgs[ref['image_id']]
+ I = io.imread(os.path.join(self.vis_root, image['file_name']))
+ ax.imshow(I)
+ # show refer expression
+ for sid, sent in enumerate(ref['sentences']):
+ print('{}. {}'.format(sid + 1, sent['sent']))
+ # show segmentations
+ if seg_box == 'seg':
+ ann_id = ref['ann_id']
+ ann = self.Anns[ann_id]
+ polygons = []
+ color = []
+ c = 'none'
+ if type(ann['segmentation'][0]) == list:
+ # polygon used for refcoco*
+ for seg in ann['segmentation']:
+ poly = np.array(seg).reshape((len(seg) / 2, 2))
+ polygons.append(Polygon(poly, True, alpha=0.4))
+ color.append(c)
+ p = PatchCollection(
+ polygons,
+ facecolors=color,
+ edgecolors=(1, 1, 0, 0),
+ linewidths=3,
+ alpha=1,
+ )
+ ax.add_collection(p) # thick yellow polygon
+ p = PatchCollection(
+ polygons,
+ facecolors=color,
+ edgecolors=(1, 0, 0, 0),
+ linewidths=1,
+ alpha=1,
+ )
+ ax.add_collection(p) # thin red polygon
+ else:
+ # mask used for refclef
+ raise NotImplementedError('RefClef is not downloaded')
+ # show bounding-box
+ elif seg_box == 'box':
+ ann_id = ref['ann_id']
+ ann = self.Anns[ann_id]
+ bbox = self.getRefBox(ref['ref_id'])
+ box_plot = Rectangle(
+ (bbox[0], bbox[1]),
+ bbox[2],
+ bbox[3],
+ fill=False,
+ edgecolor='green',
+ linewidth=3,
+ )
+ ax.add_patch(box_plot)
diff --git a/data/xtuner/xtuner/dataset/samplers/__init__.py b/data/xtuner/xtuner/dataset/samplers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8afc9bc1e2bbaae2e00a530302c24106400f2ace
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/samplers/__init__.py
@@ -0,0 +1,4 @@
+from .intern_repo import InternlmRepoSampler, InternRepoSampler
+from .length_grouped import LengthGroupedSampler
+
+__all__ = ['LengthGroupedSampler', 'InternRepoSampler', 'InternlmRepoSampler']
diff --git a/data/xtuner/xtuner/dataset/samplers/intern_repo.py b/data/xtuner/xtuner/dataset/samplers/intern_repo.py
new file mode 100644
index 0000000000000000000000000000000000000000..933719a58e5c8efa46d14bc5080bd7ed1e9b0ce4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/samplers/intern_repo.py
@@ -0,0 +1,81 @@
+import logging
+import warnings
+from typing import Iterator, Optional, Sized
+
+import numpy as np
+from mmengine import print_log
+from torch.utils.data import Sampler
+
+from xtuner.parallel.sequence import (get_data_parallel_rank,
+ get_data_parallel_world_size)
+
+
+class InternRepoSampler(Sampler):
+
+ def __init__(self,
+ dataset: Sized,
+ shuffle: bool = True,
+ seed: Optional[int] = None) -> None:
+ if seed is not None and seed != 1024:
+ warnings.warn('For alignment accuracy, seed in InternRepoSampler'
+ 'must be set to 1024.')
+ world_size = get_data_parallel_world_size()
+ rank = get_data_parallel_rank()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.shuffle = shuffle
+ self.seed = 1024
+ self.epoch = 0
+
+ self.num_samples = len(self.dataset) // world_size
+ self.total_size = self.num_samples * world_size
+
+ def __iter__(self) -> Iterator[int]:
+ """Iterate the indices."""
+ # deterministically shuffle based on epoch and seed
+ if self.shuffle:
+ rng = np.random.RandomState(self.seed + self.epoch)
+ indices = np.arange(len(self.dataset))
+ rng.shuffle(indices)
+ indices = indices.tolist()
+ else:
+ indices = np.arange(len(self.dataset)).tolist()
+
+ self.indices = indices[:self.total_size]
+
+ # subsample
+ indices = indices[self.rank:self.total_size:self.world_size]
+ self.subsample_indices = indices
+
+ return iter(indices)
+
+ def __len__(self) -> int:
+ """The number of samples in this rank."""
+ return self.num_samples
+
+ def set_epoch(self, epoch: int) -> None:
+ """Sets the epoch for this sampler.
+
+ When :attr:`shuffle=True`, this ensures all replicas use a different
+ random ordering for each epoch. Otherwise, the next iteration of this
+ sampler will yield the same ordering.
+
+ Args:
+ epoch (int): Epoch number.
+ """
+ self.epoch = epoch
+
+
+class InternlmRepoSampler(InternRepoSampler):
+
+ def __init__(self,
+ dataset: Sized,
+ shuffle: bool = True,
+ seed: Optional[int] = None) -> None:
+ super().__init__(dataset, shuffle, seed)
+ print_log(('InternlmRepoSampler will be deprecated in the future.'
+ 'Please use InternRepoSampler instead.'),
+ logger='current',
+ level=logging.WARNING)
diff --git a/data/xtuner/xtuner/dataset/samplers/length_grouped.py b/data/xtuner/xtuner/dataset/samplers/length_grouped.py
new file mode 100644
index 0000000000000000000000000000000000000000..184827837cf062972d6b024940ba6d252577efd4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/samplers/length_grouped.py
@@ -0,0 +1,164 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Iterator, Optional, Sized
+
+import torch
+from mmengine.dist import get_dist_info, sync_random_seed
+from mmengine.logging import print_log
+from torch.utils.data import ConcatDataset as TorchConcatDataset
+from torch.utils.data import Sampler
+
+
+def get_length_grouped_indices(lengths, group_batch_size, generator=None):
+
+ def process(lengths, group_batch_size, generator=None):
+ indices = torch.randperm(len(lengths), generator=generator)
+ megabatches = [
+ indices[i:i + group_batch_size].tolist()
+ for i in range(0, len(lengths), group_batch_size)
+ ]
+ megabatches = [
+ sorted(megabatch, key=lambda i: lengths[i], reverse=True)
+ for megabatch in megabatches
+ ]
+ return megabatches
+
+ assert all(leng != 0 for leng in lengths), 'Should not have zero length.'
+ if all(leng > 0 for leng in lengths) or all(leng < 0 for leng in lengths):
+ # all samples are in the same modality
+ megabatches = process(lengths, group_batch_size, generator=generator)
+ else:
+ mm_indices, mm_lengths = zip(*[(i, l) for i, l in enumerate(lengths)
+ if l > 0])
+ lang_indices, lang_lengths = zip(*[(i, -l)
+ for i, l in enumerate(lengths)
+ if l < 0])
+ mm_megabatches = []
+ for mm_megabatch in process(
+ mm_lengths, group_batch_size, generator=generator):
+ mm_megabatches.append([mm_indices[i] for i in mm_megabatch])
+ lang_megabatches = []
+ for lang_megabatch in process(
+ lang_lengths, group_batch_size, generator=generator):
+ lang_megabatches.append([lang_indices[i] for i in lang_megabatch])
+
+ last_mm = mm_megabatches[-1]
+ last_lang = lang_megabatches[-1]
+ last_batch = last_mm + last_lang
+ megabatches = mm_megabatches[:-1] + lang_megabatches[:-1]
+
+ megabatch_indices = torch.randperm(
+ len(megabatches), generator=generator)
+ megabatches = [megabatches[i] for i in megabatch_indices]
+
+ if len(last_batch) > 0:
+ megabatches.append(
+ sorted(
+ last_batch, key=lambda i: abs(lengths[i]), reverse=True))
+
+ # The rest is to get the biggest batch first.
+ # Since each megabatch is sorted by descending length,
+ # the longest element is the first
+ megabatch_maximums = [
+ abs(lengths[megabatch[0]]) for megabatch in megabatches
+ ]
+ max_idx = torch.argmax(torch.tensor(megabatch_maximums)).item()
+ # Switch to put the longest element in first position
+ megabatches[0][0], megabatches[max_idx][0] = megabatches[max_idx][
+ 0], megabatches[0][0]
+
+ return [i for megabatch in megabatches for i in megabatch]
+
+
+class LengthGroupedSampler(Sampler):
+
+ def __init__(self,
+ dataset: Sized,
+ per_device_batch_size: int,
+ length_property='length',
+ mega_batch_mult: Optional[int] = None,
+ seed: Optional[int] = None,
+ round_up: bool = True) -> None:
+ print_log('LengthGroupedSampler is used.', logger='current')
+ rank, world_size = get_dist_info()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ if seed is None:
+ seed = sync_random_seed()
+ self.seed = seed
+ self.epoch = 0
+ self.round_up = round_up
+
+ if self.round_up:
+ num_iters = math.ceil(
+ len(self.dataset) / world_size / per_device_batch_size)
+ self.num_samples = num_iters * per_device_batch_size
+ self.total_size = self.num_samples * self.world_size
+ else:
+ self.num_samples = math.ceil(
+ (len(self.dataset) - rank) / world_size)
+ self.total_size = len(self.dataset)
+
+ total_batch_size = per_device_batch_size * self.world_size
+ if mega_batch_mult is None:
+ # Default for mega_batch_mult: 50 or the number to get 4
+ # megabatches, whichever is smaller.
+ mega_batch_mult = min(
+ len(self.dataset) // (total_batch_size * 4), 50)
+ # Just in case, for tiny datasets
+ if mega_batch_mult == 0:
+ mega_batch_mult = 1
+ self.group_batch_size = mega_batch_mult * total_batch_size
+
+ if isinstance(self.dataset, TorchConcatDataset):
+ length = []
+ for sub_dataset in self.dataset.datasets:
+ length.extend(getattr(sub_dataset, length_property))
+ self.length = length
+ else:
+ self.length = getattr(self.dataset, length_property)
+ assert isinstance(self.length, (list, tuple))
+
+ self.total_batch_size = total_batch_size
+ print_log(
+ f'LengthGroupedSampler construction is complete, '
+ f'and the selected attribute is {length_property}',
+ logger='current')
+
+ def __iter__(self) -> Iterator[int]:
+ """Iterate the indices."""
+ generator = torch.Generator()
+ generator.manual_seed(self.seed + self.epoch)
+ indices = get_length_grouped_indices(
+ lengths=self.length,
+ group_batch_size=self.group_batch_size,
+ generator=generator)
+ assert len(set(indices)) == len(indices)
+ # add extra samples to make it evenly divisible
+ if self.round_up:
+ indices = (
+ indices *
+ int(self.total_size / len(indices) + 1))[:self.total_size]
+ # subsample
+ assert len(indices) == self.total_size
+ indices = indices[self.rank:self.total_size:self.world_size]
+ assert len(indices) == self.num_samples
+ return iter(indices)
+
+ def __len__(self) -> int:
+ """The number of samples in this rank."""
+ return self.num_samples
+
+ def set_epoch(self, epoch: int) -> None:
+ """Sets the epoch for this sampler.
+
+ When :attr:`shuffle=True`, this ensures all replicas use a different
+ random ordering for each epoch. Otherwise, the next iteration of this
+ sampler will yield the same ordering.
+
+ Args:
+ epoch (int): Epoch number.
+ """
+ self.epoch = epoch
diff --git a/data/xtuner/xtuner/dataset/utils.py b/data/xtuner/xtuner/dataset/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..84336ddb2f61e53535ef57f5b8660279cabda055
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/utils.py
@@ -0,0 +1,271 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import base64
+import copy
+import io
+from io import BytesIO
+from itertools import chain
+
+import numpy as np
+import requests
+from PIL import Image
+
+from xtuner.utils import DEFAULT_IMAGE_TOKEN, IGNORE_INDEX, IMAGE_TOKEN_INDEX
+
+
+def get_bos_eos_token_ids(tokenizer):
+ if tokenizer.__class__.__name__ in [
+ 'QWenTokenizer', 'QWen2Tokenizer', 'Qwen2TokenizerFast'
+ ]:
+ bos_token_id = []
+ eos_token_id = tokenizer.eos_token_id
+ assert eos_token_id is not None, \
+ 'Please set eos_token for Qwen tokenizer!'
+ elif tokenizer.__class__.__name__ == 'ChatGLMTokenizer':
+ bos_token_id = [64790, 64792]
+ eos_token_id = tokenizer.eos_token_id
+ else:
+ bos_token_id = tokenizer.bos_token_id
+ eos_token_id = tokenizer.eos_token_id
+ if isinstance(bos_token_id, int):
+ bos_token_id = [bos_token_id]
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ return bos_token_id, eos_token_id
+
+
+def encode_fn(example,
+ tokenizer,
+ max_length,
+ input_ids_with_output=True,
+ with_image_token=False):
+ """We only support the following three scenarios:
+
+ 1. Incremental pretraining dataset.
+ example['conversation'] = [
+ {
+ 'input': '',
+ 'output': '### Human: Can you write xxx'
+ }
+ ]
+
+ 2. Single-turn conversation dataset.
+ example['conversation'] = [
+ {
+ 'input': 'Give three tips for staying healthy.',
+ 'output': '1.Eat a balanced diet xxx'
+ }
+ ]
+
+ 3. Multi-turn conversation dataset.
+ example['conversation'] = [
+ {
+ 'input': 'Give three tips for staying healthy.',
+ 'output': '1.Eat a balanced diet xxx'
+ },
+ {
+ 'input': 'Please expand on the second point.',
+ 'output': 'Here is an expanded explanation of the xxx'
+ }
+ ]
+ """
+ bos_token_id, eos_token_id = get_bos_eos_token_ids(tokenizer)
+ is_multi_turn_conversation = len(example['conversation']) > 1
+ if is_multi_turn_conversation:
+ assert input_ids_with_output
+
+ input_ids, labels = [], []
+ next_needs_bos_token = True
+ for single_turn_conversation in example['conversation']:
+ input = single_turn_conversation['input']
+ if DEFAULT_IMAGE_TOKEN in input and with_image_token:
+ chunk_encode = [
+ tokenizer.encode(chunk, add_special_tokens=False)
+ for chunk in input.split(DEFAULT_IMAGE_TOKEN)
+ ]
+ assert len(chunk_encode) == 2
+ input_encode = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ input_encode.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ input_encode.append(IMAGE_TOKEN_INDEX)
+ else:
+ input_encode = tokenizer.encode(input, add_special_tokens=False)
+ if next_needs_bos_token:
+ input_ids += bos_token_id
+ labels += [IGNORE_INDEX] * len(bos_token_id)
+ input_ids += input_encode
+ labels += [IGNORE_INDEX] * len(input_encode)
+ if input_ids_with_output:
+ # Add output
+ output_with_loss = single_turn_conversation.get(
+ 'output_with_loss', True)
+ output = single_turn_conversation['output']
+ output_encode = tokenizer.encode(output, add_special_tokens=False)
+ input_ids += output_encode
+ if output_with_loss:
+ labels += copy.deepcopy(output_encode)
+ else:
+ labels += [IGNORE_INDEX] * len(output_encode)
+ # Add EOS_TOKEN (with loss)
+ if single_turn_conversation.get('need_eos_token', True):
+ next_needs_bos_token = True
+ input_ids += eos_token_id
+ if output_with_loss:
+ labels += copy.deepcopy(eos_token_id)
+ else:
+ labels += [IGNORE_INDEX] * len(eos_token_id)
+ else:
+ next_needs_bos_token = False
+ # Add SEP (without loss)
+ sep = single_turn_conversation.get('sep', '')
+ if sep != '':
+ sep_encode = tokenizer.encode(sep, add_special_tokens=False)
+ input_ids += sep_encode
+ labels += [IGNORE_INDEX] * len(sep_encode)
+
+ if len(input_ids) > max_length:
+ input_ids = input_ids[:max_length]
+ labels = labels[:max_length]
+ return {'input_ids': input_ids, 'labels': labels}
+
+
+class Packer:
+ """Pack multiple pieces of data into one."""
+
+ def __init__(self,
+ chunk_size=2048,
+ use_varlen_attn=False,
+ drop_last=False):
+ self.chunk_size = chunk_size
+ self.residual = {'input_ids': [], 'labels': []}
+ self.use_varlen_attn = use_varlen_attn
+ self.drop_last = drop_last
+ if use_varlen_attn:
+ self.residual_cumulative_len = [0]
+
+ def get_cumulative_len(self, chunk_num):
+ ptr_l = 0
+ cumulative_len = []
+ for chunk_idx in range(chunk_num):
+ length_train = (chunk_idx + 1) * self.chunk_size
+ ptr_r = np.searchsorted(
+ self.residual_cumulative_len, length_train, side='left')
+ if self.residual_cumulative_len[ptr_r] == length_train:
+ cumulative_len_cur = \
+ self.residual_cumulative_len[ptr_l:ptr_r + 1]
+ ptr_l = ptr_r + 1
+ else:
+ cumulative_len_cur = self.residual_cumulative_len[
+ ptr_l:ptr_r] + [length_train]
+ ptr_l = ptr_r
+ cumulative_len_cur = [
+ num - chunk_idx * self.chunk_size for num in cumulative_len_cur
+ ]
+ if cumulative_len_cur[0] != 0:
+ cumulative_len_cur = [0] + cumulative_len_cur
+
+ cumulative_len.append(cumulative_len_cur)
+
+ self.residual_cumulative_len = [
+ num - length_train for num in self.residual_cumulative_len[ptr_l:]
+ ]
+ if len(self.residual_cumulative_len) == 0:
+ self.residual_cumulative_len = [0]
+ elif self.residual_cumulative_len[0] != 0:
+ self.residual_cumulative_len = [0] + self.residual_cumulative_len
+
+ return cumulative_len
+
+ def get_position_ids(self, cumulative_len):
+ position_ids = []
+ for cumulative_len_cur in cumulative_len:
+ index_cur = []
+ for i in range(len(cumulative_len_cur) - 1):
+ index_cur.extend(
+ list(
+ range(cumulative_len_cur[i + 1] - # noqa: W504
+ cumulative_len_cur[i])))
+ position_ids.append(index_cur)
+ return position_ids
+
+ def __call__(self, batch):
+ concatenated_samples = {
+ k: v + list(chain(*batch[k]))
+ for k, v in self.residual.items()
+ }
+
+ if self.use_varlen_attn:
+ for input_id in batch['input_ids']:
+ self.residual_cumulative_len.append(
+ self.residual_cumulative_len[-1] + len(input_id))
+
+ total_length = len(concatenated_samples[list(
+ concatenated_samples.keys())[0]])
+
+ if total_length >= self.chunk_size:
+ chunk_num = total_length // self.chunk_size
+ result = {
+ k: [
+ v[i:i + self.chunk_size] for i in range(
+ 0,
+ chunk_num * # noqa: W504
+ self.chunk_size,
+ self.chunk_size)
+ ]
+ for k, v in concatenated_samples.items()
+ }
+ self.residual = {
+ k: v[(chunk_num * self.chunk_size):]
+ for k, v in concatenated_samples.items()
+ }
+
+ if self.use_varlen_attn:
+ cumulative_len = self.get_cumulative_len(chunk_num)
+ result['cumulative_len'] = cumulative_len
+ result['position_ids'] = self.get_position_ids(cumulative_len)
+ else:
+ if self.drop_last:
+ result = {k: [] for k, v in concatenated_samples.items()}
+ else:
+ result = {k: [v] for k, v in concatenated_samples.items()}
+
+ self.residual = {k: [] for k in concatenated_samples.keys()}
+
+ if self.use_varlen_attn:
+ result['cumulative_len'] = [] if self.drop_last else [
+ self.residual_cumulative_len
+ ]
+ result['position_ids'] = [] if self.drop_last \
+ else self.get_position_ids([self.residual_cumulative_len])
+ self.residual_cumulative_len = [0]
+
+ return result
+
+
+def expand2square(pil_img, background_color):
+ width, height = pil_img.size
+ if width == height:
+ return pil_img
+ elif width > height:
+ result = Image.new(pil_img.mode, (width, width), background_color)
+ result.paste(pil_img, (0, (width - height) // 2))
+ return result
+ else:
+ result = Image.new(pil_img.mode, (height, height), background_color)
+ result.paste(pil_img, ((height - width) // 2, 0))
+ return result
+
+
+def load_image(image_file):
+ if image_file.startswith('http://') or image_file.startswith('https://'):
+ response = requests.get(image_file)
+ image = Image.open(BytesIO(response.content)).convert('RGB')
+ else:
+ image = Image.open(image_file).convert('RGB')
+ return image
+
+
+def decode_base64_to_image(base64_string):
+ image_data = base64.b64decode(base64_string)
+ image = Image.open(io.BytesIO(image_data))
+ return image
diff --git a/data/xtuner/xtuner/engine/__init__.py b/data/xtuner/xtuner/engine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f50972ea9f16cf0089683769475fe7043455319
--- /dev/null
+++ b/data/xtuner/xtuner/engine/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from ._strategy import DeepSpeedStrategy
+from .hooks import (DatasetInfoHook, EvaluateChatHook, ThroughputHook,
+ VarlenAttnArgsToMessageHubHook)
+from .runner import TrainLoop
+
+__all__ = [
+ 'EvaluateChatHook', 'DatasetInfoHook', 'ThroughputHook',
+ 'VarlenAttnArgsToMessageHubHook', 'DeepSpeedStrategy', 'TrainLoop'
+]
diff --git a/data/xtuner/xtuner/engine/_strategy/__init__.py b/data/xtuner/xtuner/engine/_strategy/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..bac6095f977fa39655deb1d95c67d2e641e274b4
--- /dev/null
+++ b/data/xtuner/xtuner/engine/_strategy/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .deepspeed import DeepSpeedStrategy
+
+__all__ = ['DeepSpeedStrategy']
diff --git a/data/xtuner/xtuner/engine/_strategy/deepspeed.py b/data/xtuner/xtuner/engine/_strategy/deepspeed.py
new file mode 100644
index 0000000000000000000000000000000000000000..42b7f5590dc67f1a252ea8331220700845e05584
--- /dev/null
+++ b/data/xtuner/xtuner/engine/_strategy/deepspeed.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+from mmengine._strategy import DeepSpeedStrategy as MMEngineDeepSpeedStrategy
+
+from xtuner import DS_CEPH_DIR
+from xtuner.parallel.sequence import init_sequence_parallel
+from xtuner.utils.fileio import patch_fileio
+
+
+class DeepSpeedStrategy(MMEngineDeepSpeedStrategy):
+
+ def __init__(self, *args, **kwargs):
+ sequence_parallel_size = kwargs.pop('sequence_parallel_size', 1)
+ self.sequence_parallel_size = sequence_parallel_size
+
+ super().__init__(*args, **kwargs)
+
+ from transformers.integrations.deepspeed import HfDeepSpeedConfig
+
+ # hf_deepspeed_config has to be saved as an attribute.
+ self.hf_deepspeed_config = HfDeepSpeedConfig(self.config)
+
+ def _wrap_model(self, model):
+ wrapper = super()._wrap_model(model)
+ # hard code for deepspeed zero3
+ # When utilizing Zero3, the model isn't allocated to CUDA within the
+ # `deepspeed.initialize` process.
+ assert hasattr(wrapper.model, 'data_preprocessor')
+ wrapper.model.data_preprocessor.cuda()
+ return wrapper
+
+ def save_checkpoint(self, *args, **kwargs) -> None:
+ if DS_CEPH_DIR:
+ from os import path as osp
+ work_dir_prefix = osp.split(self.work_dir)[0]
+
+ filename = kwargs['filename'].replace(work_dir_prefix, DS_CEPH_DIR)
+ kwargs['filename'] = filename
+ with patch_fileio():
+ super().save_checkpoint(*args, **kwargs)
+ else:
+ super().save_checkpoint(*args, **kwargs)
+
+ def load_checkpoint(self, *args, **kwargs) -> None:
+ if DS_CEPH_DIR:
+
+ with patch_fileio():
+ checkpoint = super().load_checkpoint(*args, **kwargs)
+ else:
+ checkpoint = super().load_checkpoint(*args, **kwargs)
+ return checkpoint
+
+ def resume(self, *args, **kwargs) -> None:
+ if DS_CEPH_DIR:
+
+ with patch_fileio():
+ checkpoint = super().resume(*args, **kwargs)
+ else:
+ checkpoint = super().resume(*args, **kwargs)
+ return checkpoint
+
+ def _setup_distributed( # type: ignore
+ self,
+ launcher: Optional[str] = None,
+ backend: str = 'nccl',
+ **kwargs,
+ ):
+ super()._setup_distributed(launcher, backend, **kwargs)
+ init_sequence_parallel(self.sequence_parallel_size)
diff --git a/data/xtuner/xtuner/engine/hooks/__init__.py b/data/xtuner/xtuner/engine/hooks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..90262425d16e198429ec0d36029a52c9fbdd8ef2
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dataset_info_hook import DatasetInfoHook
+from .evaluate_chat_hook import EvaluateChatHook
+from .hf_checkpoint_hook import HFCheckpointHook
+from .throughput_hook import ThroughputHook
+from .varlen_attn_args_to_messagehub_hook import VarlenAttnArgsToMessageHubHook
+
+__all__ = [
+ 'EvaluateChatHook', 'DatasetInfoHook', 'ThroughputHook',
+ 'VarlenAttnArgsToMessageHubHook', 'HFCheckpointHook'
+]
diff --git a/data/xtuner/xtuner/engine/hooks/dataset_info_hook.py b/data/xtuner/xtuner/engine/hooks/dataset_info_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..84dc9498a4ce0aa2cc8175c9e317e1a35ca13fc9
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/dataset_info_hook.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.hooks import Hook
+
+from xtuner.registry import BUILDER
+from xtuner.utils import DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX
+
+
+def split_list(lst, value):
+ res = []
+ tmp_res = []
+ for i in lst:
+ if i == value:
+ res.append(tmp_res)
+ tmp_res = []
+ else:
+ tmp_res.append(i)
+ res.append(tmp_res)
+ return res
+
+
+class DatasetInfoHook(Hook):
+
+ def __init__(self, tokenizer, is_intern_repo_dataset=False):
+ self.tokenizer = BUILDER.build(tokenizer)
+ self.is_intern_repo_dataset = is_intern_repo_dataset
+
+ def log(self, runner, dataset, mode='train'):
+
+ def _log(input_ids, log_prefix=''):
+ if self.is_intern_repo_dataset:
+ input_ids = [abs(x) for x in input_ids]
+ # Try to split list to be compatible with IMAGE token
+ input_ids = split_list(input_ids, IMAGE_TOKEN_INDEX)
+ text = log_prefix
+ for idx, ids in enumerate(input_ids):
+ text += self.tokenizer.decode(ids)
+ if idx != len(input_ids) - 1:
+ text += DEFAULT_IMAGE_TOKEN
+ runner.logger.info(text)
+
+ runner.logger.info(f'Num {mode} samples {len(dataset)}')
+ runner.logger.info(f'{mode} example:')
+ if 'chosen_ids' in dataset[0]:
+ _log(dataset[0]['chosen_ids'], log_prefix='chosen: ')
+ _log(dataset[0]['rejected_ids'], log_prefix='rejected: ')
+ else:
+ _log(dataset[0]['input_ids'])
+
+ def before_train(self, runner) -> None:
+ do_train = runner.train_loop is not None
+ do_eval = runner.val_loop is not None
+ if do_train:
+ train_dataset = runner.train_dataloader.dataset
+ self.log(runner, train_dataset, mode='train')
+ if do_eval:
+ eval_dataset = runner.val_dataloader.dataset
+ self.log(runner, eval_dataset, mode='eval')
+
+ def before_val(self, runner) -> None:
+ eval_dataset = runner.val_dataloader.dataset
+ self.log(runner, eval_dataset, mode='eval')
+
+ def before_test(self, runner) -> None:
+ test_dataset = runner.test_dataloader.dataset
+ self.log(runner, test_dataset, mode='test')
diff --git a/data/xtuner/xtuner/engine/hooks/evaluate_chat_hook.py b/data/xtuner/xtuner/engine/hooks/evaluate_chat_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..05d508e4c8f232a9299c1d1b7f69cfbc18262dbc
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/evaluate_chat_hook.py
@@ -0,0 +1,281 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+
+import torch
+from mmengine.dist import master_only
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+from mmengine.utils import mkdir_or_exist
+from mmengine.utils.misc import get_object_from_string
+from transformers import GenerationConfig, StoppingCriteriaList
+
+from xtuner.dataset.utils import expand2square, load_image
+from xtuner.model.utils import prepare_inputs_labels_for_multimodal
+from xtuner.registry import BUILDER
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ StopWordStoppingCriteria)
+
+
+class EvaluateChatHook(Hook):
+
+ priority = 'LOW'
+
+ def __init__(self,
+ tokenizer,
+ evaluation_inputs,
+ evaluation_images=None,
+ image_processor=None,
+ system='',
+ prompt_template=None,
+ every_n_iters=None,
+ max_new_tokens=600,
+ stop_word=None,
+ stop_words=[],
+ generation_kwargs={}):
+ self.evaluation_inputs = evaluation_inputs
+ if isinstance(self.evaluation_inputs, str):
+ self.evaluation_inputs = [self.evaluation_inputs]
+ self.evaluation_images = evaluation_images
+ if isinstance(self.evaluation_images, str):
+ self.evaluation_images = [self.evaluation_images]
+ if self.evaluation_images is not None:
+ assert len(
+ self.evaluation_images) in [1, len(self.evaluation_inputs)]
+ if len(self.evaluation_images) == 1:
+ self.evaluation_images = [self.evaluation_images[0]] * len(
+ self.evaluation_inputs)
+ self.evaluation_images = [
+ load_image(img) for img in self.evaluation_images
+ ]
+ if prompt_template is None:
+ instruction = '{input}'
+ else:
+ if isinstance(prompt_template, str): # for resume
+ prompt_template = get_object_from_string(prompt_template)
+ instruction = prompt_template.get('INSTRUCTION', '{input}')
+ if system != '':
+ system = prompt_template.get(
+ 'SYSTEM', '{system}\n').format(system=system)
+ stop_words += prompt_template.get('STOP_WORDS', [])
+ if stop_word is not None:
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ ('The `stop_word` argument is deprecated and will be removed '
+ 'in v0.3.0, use `stop_words` instead.'), DeprecationWarning)
+ stop_words.append(stop_word)
+ self.instruction = instruction
+ self.system = system
+ self.every_n_iters = every_n_iters
+ self.max_new_tokens = max_new_tokens
+ self.tokenizer = BUILDER.build(tokenizer)
+ if image_processor is not None:
+ self.image_processor = BUILDER.build(image_processor)
+ self.stop_criteria = StoppingCriteriaList()
+
+ # default generation config
+ default_generation_kwargs = dict(
+ max_new_tokens=max_new_tokens,
+ do_sample=True,
+ temperature=0.1,
+ top_p=0.75,
+ top_k=40,
+ eos_token_id=self.tokenizer.eos_token_id,
+ pad_token_id=self.tokenizer.pad_token_id
+ if self.tokenizer.pad_token_id is not None else
+ self.tokenizer.eos_token_id)
+ default_generation_kwargs.update(generation_kwargs)
+ self.gen_config = GenerationConfig(**default_generation_kwargs)
+
+ self.stop_criteria = StoppingCriteriaList()
+ for word in stop_words:
+ self.stop_criteria.append(
+ StopWordStoppingCriteria(self.tokenizer, word))
+
+ self.is_first_run = True
+
+ @master_only
+ def _save_eval_output(self, runner, eval_outputs):
+ save_path = os.path.join(runner.log_dir, 'vis_data',
+ f'eval_outputs_iter_{runner.iter}.txt')
+ mkdir_or_exist(os.path.dirname(save_path))
+ with open(save_path, 'w', encoding='utf-8') as f:
+ for i, output in enumerate(eval_outputs):
+ f.write(f'Eval output {i + 1}:\n{output}\n\n')
+
+ def _eval_images(self,
+ runner,
+ model,
+ device,
+ max_new_tokens=None,
+ save_eval_output=False):
+ if save_eval_output:
+ eval_outputs = []
+
+ for sample_image, sample_input in zip(self.evaluation_images,
+ self.evaluation_inputs):
+ image = expand2square(
+ sample_image,
+ tuple(int(x * 255) for x in self.image_processor.image_mean))
+ image = self.image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ image = image.to(device)
+ sample_input = DEFAULT_IMAGE_TOKEN + '\n' + sample_input
+ inputs = (self.system + self.instruction).format(
+ input=sample_input, round=1, **runner.cfg)
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0:
+ cur_encode = self.tokenizer.encode(chunk)
+ else:
+ cur_encode = self.tokenizer.encode(
+ chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+ input_ids = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ input_ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ input_ids.append(IMAGE_TOKEN_INDEX)
+ input_ids = torch.tensor(input_ids).to(device)
+ visual_outputs = model.visual_encoder(
+ image.unsqueeze(0).to(model.visual_encoder.dtype),
+ output_hidden_states=True)
+ pixel_values = model.projector(
+ visual_outputs.hidden_states[model.visual_select_layer][:, 1:])
+
+ mm_inputs = prepare_inputs_labels_for_multimodal(
+ llm=model.llm,
+ input_ids=input_ids.unsqueeze(0),
+ pixel_values=pixel_values)
+
+ generation_output = model.generate(
+ **mm_inputs,
+ max_new_tokens=max_new_tokens,
+ generation_config=self.gen_config,
+ bos_token_id=self.tokenizer.bos_token_id,
+ stopping_criteria=self.stop_criteria)
+ generation_output = self.tokenizer.decode(generation_output[0])
+ runner.logger.info(f'Sample output:\n'
+ f'{inputs + generation_output}\n')
+ if save_eval_output:
+ eval_outputs.append(f'{inputs + generation_output}\n')
+
+ if save_eval_output:
+ self._save_eval_output(runner, eval_outputs)
+
+ def _eval_language(self,
+ runner,
+ model,
+ device,
+ max_new_tokens=None,
+ save_eval_output=False):
+ if save_eval_output:
+ eval_outputs = []
+
+ for sample_input in self.evaluation_inputs:
+ inputs = (self.system + self.instruction).format(
+ input=sample_input, round=1, **runner.cfg)
+ input_ids = self.tokenizer.encode(inputs, return_tensors='pt')
+ input_ids = input_ids.to(device)
+ generation_output = model.generate(
+ input_ids=input_ids,
+ max_new_tokens=max_new_tokens,
+ generation_config=self.gen_config,
+ stopping_criteria=self.stop_criteria)
+ generation_output = self.tokenizer.decode(generation_output[0])
+ runner.logger.info(f'Sample output:\n{generation_output}\n')
+ if save_eval_output:
+ eval_outputs.append(f'{generation_output}\n')
+
+ if save_eval_output:
+ self._save_eval_output(runner, eval_outputs)
+
+ def _generate_samples(self,
+ runner,
+ max_new_tokens=None,
+ save_eval_output=False):
+ if max_new_tokens is None:
+ max_new_tokens = self.max_new_tokens
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+
+ device = next(iter(model.parameters())).device
+
+ if self.is_first_run:
+ # hardcode for qlora DeepSpeed ZeRO3, put buffers and QuantState to
+ # device
+ model.to(device)
+ self.is_first_run = False
+
+ is_checkpointing = model.llm.is_gradient_checkpointing
+ use_cache = model.llm.config.use_cache
+
+ # Cast to inference mode
+ model.activation_checkpointing_disable()
+ model.llm.config.use_cache = True
+ model.eval()
+ if self.evaluation_images is not None:
+ self._eval_images(runner, model, device, max_new_tokens,
+ save_eval_output)
+ else:
+ self._eval_language(runner, model, device, max_new_tokens,
+ save_eval_output)
+
+ # Cast to training mode
+ if is_checkpointing:
+ model.activation_checkpointing_enable()
+ model.llm.config.use_cache = use_cache
+ model.train()
+
+ def before_train(self, runner):
+ runner.logger.info('before_train in EvaluateChatHook.')
+ self._generate_samples(runner, max_new_tokens=50)
+
+ def _is_save_checkpoint(self, runner):
+ hooks = runner.hooks
+ checkpoint_hook = None
+ for hook in hooks:
+ if type(hook).__name__ == 'CheckpointHook':
+ checkpoint_hook = hook
+ break
+ if checkpoint_hook is None or checkpoint_hook.by_epoch:
+ return False
+
+ if checkpoint_hook.every_n_train_iters(
+ runner, checkpoint_hook.interval, checkpoint_hook.save_begin) or \
+ (checkpoint_hook.save_last and
+ checkpoint_hook.is_last_train_iter(runner)):
+ return True
+
+ return False
+
+ def after_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch=None,
+ outputs=None) -> None:
+ if self.every_n_iters is None:
+ return
+
+ save_eval_output = self._is_save_checkpoint(runner)
+
+ do_chat = (
+ save_eval_output
+ or self.every_n_train_iters(runner, self.every_n_iters))
+ if not do_chat:
+ return
+
+ runner.logger.info('after_train_iter in EvaluateChatHook.')
+ self._generate_samples(runner, save_eval_output=save_eval_output)
+
+ def after_train(self, runner):
+ runner.logger.info('after_train in EvaluateChatHook.')
+ self._generate_samples(runner)
+
+ def after_val(self, runner) -> None:
+ if self.every_n_iters is not None:
+ return
+ runner.logger.info('after_val in EvaluateChatHook.')
+ self._generate_samples(runner)
diff --git a/data/xtuner/xtuner/engine/hooks/hf_checkpoint_hook.py b/data/xtuner/xtuner/engine/hooks/hf_checkpoint_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..142af4cdbc27f34a0e4def644a742258542c2db0
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/hf_checkpoint_hook.py
@@ -0,0 +1,73 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from pathlib import Path
+from typing import Optional, Union
+
+import torch.distributed as dist
+from mmengine import print_log
+from mmengine._strategy import DeepSpeedStrategy
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+from mmengine.runner import FlexibleRunner
+
+from xtuner.registry import BUILDER
+from xtuner.utils import get_origin_state_dict
+
+DATA_BATCH = Optional[Union[dict, tuple, list]]
+
+
+class HFCheckpointHook(Hook):
+
+ priority = 95 # lower than CheckpointHook in MMEngine
+
+ def __init__(self, out_dir: Optional[Union[str, Path]] = None) -> None:
+ self.out_dir = out_dir
+
+ @staticmethod
+ def _use_shard_moe(llm):
+ config = llm.config
+ moe_implementation = getattr(config, 'moe_implementation', 'origin')
+ return moe_implementation == 'shard'
+
+ def after_run(self, runner) -> None:
+ assert isinstance(runner,
+ FlexibleRunner), 'Runner should be `FlexibleRunner`'
+ assert isinstance(
+ runner.strategy,
+ DeepSpeedStrategy), 'Strategy should be `DeepSpeedStrategy`'
+
+ if self.out_dir is None:
+ self.out_dir = osp.join(runner.work_dir, 'hf_model')
+
+ wrapped_model = runner.strategy.model
+ if wrapped_model.zero_optimization_partition_weights():
+ assert wrapped_model.zero_gather_16bit_weights_on_model_save(), \
+ ('Please set `gather_16bit_weights_on_model_save=True` '
+ 'in your DeepSpeed config.')
+ state_dict = wrapped_model._zero3_consolidated_16bit_state_dict()
+ else:
+ state_dict = wrapped_model.module_state_dict(
+ exclude_frozen_parameters=runner.strategy.
+ exclude_frozen_parameters)
+
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+ llm = model.llm
+ if (not dist.is_initialized()) or dist.get_rank() == 0:
+ # keys in state_dict are prefixed with 'llm.'
+ keys = list(state_dict.keys())
+ for k in keys:
+ val = state_dict.pop(k)
+ state_dict[k[4:]] = val
+
+ if self._use_shard_moe(llm):
+ print_log('recover the origin state_dict from merged one ...')
+ state_dict = get_origin_state_dict(state_dict, llm)
+
+ print_log(f'Saving LLM to {self.out_dir}')
+ llm.save_pretrained(self.out_dir, state_dict=state_dict)
+
+ print_log(f'Saving LLM tokenizer to {self.out_dir}')
+ tokenizer = BUILDER.build(runner.cfg.tokenizer)
+ tokenizer.save_pretrained(self.out_dir)
diff --git a/data/xtuner/xtuner/engine/hooks/throughput_hook.py b/data/xtuner/xtuner/engine/hooks/throughput_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..e74c0a0acf1e13498107364cc3cf3b4797159aaf
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/throughput_hook.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+from typing import Optional, Union
+
+import torch
+from mmengine import print_log
+from mmengine.hooks import Hook
+from mmengine.model.wrappers import is_model_wrapper
+from torch.utils._pytree import tree_flatten
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+
+DATA_BATCH = Optional[Union[dict, tuple, list]]
+
+
+class ThroughputHook(Hook):
+
+ # priority must be higher than LoggerHook (50) and lower than
+ # IterTimerHook (60)
+ priority = 55
+
+ def __init__(self,
+ use_activation_checkpointing=None,
+ hidden_size=None,
+ num_layers=None,
+ vocab_size=None,
+ mlp_ratio=None,
+ is_casual=None):
+ self.use_activation_checkpointing = use_activation_checkpointing
+ self.hidden_size = hidden_size
+ self.num_layers = num_layers
+ self.vocab_size = vocab_size
+ self.mlp_ratio = mlp_ratio
+ self.is_casual = is_casual
+
+ @staticmethod
+ def _guess_is_casual_attn(model):
+ for module in model.modules():
+ if hasattr(module, 'is_causal'):
+ return module.is_causal
+ print_log(
+ 'It\'s impossible to speculate whether casual attention was used, '
+ 'and FLOPs will be calculated as `casual = True`.', 'current')
+ return True
+
+ @staticmethod
+ def _get_batch_size_and_sequence_len(data_batch):
+ data_list, _ = tree_flatten(data_batch)
+ for data in data_list:
+ if isinstance(data, torch.Tensor):
+ return data.size(0), data.size(1)
+ raise RuntimeError('No tensor found in the batch')
+
+ @staticmethod
+ def _guess_use_activation_checkpointing(model):
+ for module in model.modules():
+ if hasattr(module, 'gradient_checkpointing'):
+ return module.gradient_checkpointing
+ return False
+
+ def before_run(self, runner) -> None:
+ if is_model_wrapper(runner.model):
+ model = runner.model.module
+ else:
+ model = runner.model
+ self.use_activation_checkpointing = \
+ (self.use_activation_checkpointing or
+ self._guess_use_activation_checkpointing(model))
+ self.hidden_size = self.hidden_size or model.config.hidden_size
+ self.num_layers = self.num_layers or model.config.num_hidden_layers
+ self.vocab_size = self.vocab_size or model.config.vocab_size
+ self.mlp_ratio = self.mlp_ratio or (model.config.intermediate_size /
+ model.config.hidden_size)
+ self.mlp_ratio *= 1.5 # has gate_proj
+ self.is_casual = self.is_casual if self.is_casual is not None \
+ else self._guess_is_casual_attn(model)
+
+ use_varlen_attn = getattr(model, 'use_varlen_attn', False)
+ if use_varlen_attn:
+ print_log(
+ 'Using variable-length Flash Attention causes an inflation'
+ ' in the FLOPs calculation.',
+ 'current',
+ level=logging.WARNING)
+
+ return
+
+ def after_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None,
+ outputs: Optional[dict] = None) -> None:
+ """Calc flops based on the paper of Megatron
+ https://deepakn94.github.io/assets/papers/megatron-sc21.pdf."""
+
+ batch_size, sequence_len = self._get_batch_size_and_sequence_len(
+ data_batch)
+ sequence_parallel_size = get_sequence_parallel_world_size()
+ sequence_len /= sequence_parallel_size
+
+ message_hub = runner.message_hub
+ iter_time = message_hub.get_scalar('train/time').current()
+
+ # We consider a language model with 𝑙 transformer layers,
+ # hidden size h, sequence length s, vocabulary size V, and
+ # training batch size B.
+ # A $A_{mxk}$ x $X_{kxn}$ matrix multiplication requires 2𝑚 ×𝑘 ×𝑛 FLOPs
+ # (factor of 2 needed to account for multiplies and adds).
+
+ # Attention Layer:
+ # qkv_proj + o_proj: 8B * s * h^2
+ # attn: 2B * s^2 * h (casual=False) and 2B * s^2 * h / 2 (casual=True)
+
+ # MLP Layer:
+ # up_proj + down_proj + gate_proj: 4B * s * h^2 * mlp_ratio
+ # (In Llama mlp_ratio = intermediate_size / hidden_size * 1.5
+ # (has gate_proj))
+
+ # The backward pass requires double the number of FLOPs since we
+ # need to calculate the gradients with respect to both input and
+ # weight tensors. In addition, we are using activation recomputation,
+ # which requires an additional forward pass before the backward pass.
+
+ # While sequence parallel will affect the FLOPs calculation in attn.
+ # Suppose the sequence length in one GPU is s and the sequence
+ # parallel world size is `sp_size`, which means the total
+ # sequence length in the attention calculation is
+ # `s * sp_size` and the number of attention heads decrease to
+ # `num_heads / sp_size`. Hence, the FLOPs in attn calculation is:
+ # 2B * (s * sp_size)^2 * (h / sp_size) (casual=False) and
+ # 2B * (s * sp_size)^2 * (h / sp_size) / 2 (casual=True)
+
+ flops_qkvo_proj = 8 * batch_size * sequence_len * self.hidden_size**2
+ flops_attn = 4 * batch_size * sequence_len**2 * self.hidden_size * \
+ sequence_parallel_size / (int(self.is_casual) + 1)
+ flops_mlp = 4 * self.mlp_ratio * batch_size * sequence_len * \
+ self.hidden_size**2
+ flops_wo_head = (3 + int(self.use_activation_checkpointing)) * (
+ flops_qkvo_proj + flops_attn + flops_mlp) * self.num_layers
+ flops_head = 3 * 2 * batch_size * sequence_len * self.hidden_size * \
+ self.vocab_size
+ flops_per_iteration = flops_wo_head + flops_head
+
+ avg_tflops_per_gpu = flops_per_iteration / 1e12 / (iter_time + 1e-12)
+ tokens_per_sec_per_gpu = batch_size * sequence_len / (
+ iter_time + 1e-12)
+
+ message_hub.update_scalar('train/tflops', avg_tflops_per_gpu)
+ message_hub.update_scalar('train/tokens_per_sec',
+ tokens_per_sec_per_gpu)
diff --git a/data/xtuner/xtuner/engine/hooks/varlen_attn_args_to_messagehub_hook.py b/data/xtuner/xtuner/engine/hooks/varlen_attn_args_to_messagehub_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc31f21aecb44b666122db152ec6809dbaa41106
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/varlen_attn_args_to_messagehub_hook.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+from mmengine import MessageHub
+from mmengine.dist import get_rank
+from mmengine.hooks import Hook
+
+DATA_BATCH = Optional[Union[dict, tuple, list]]
+
+
+class VarlenAttnArgsToMessageHubHook(Hook):
+
+ def before_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: dict = None) -> None:
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+
+ assert 'data' in data_batch.keys()
+ data = data_batch['data']
+
+ cumulative_len = data.pop('cumulative_len')
+ assert len(cumulative_len) == 1
+ cumulative_len = cumulative_len[0].cuda()
+ message_hub.update_info(f'cumulative_len_rank_{rank}', cumulative_len)
+
+ max_seqlen = data.pop('max_seqlen')
+ message_hub.update_info(f'max_seqlen_rank_{rank}', max_seqlen)
+
+ def after_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None,
+ outputs: Optional[dict] = None) -> None:
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ message_hub.update_info(f'cumulative_len_rank_{rank}', None)
+ message_hub.update_info(f'max_seqlen_rank_{rank}', None)
+
+ def before_val_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None) -> None:
+ """All subclasses should override this method, if they need any
+ operations before each validation iteration.
+
+ Args:
+ runner (Runner): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict, optional): Data from dataloader.
+ Defaults to None.
+ """
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+
+ assert 'data' in data_batch.keys()
+ data = data_batch['data']
+
+ cumulative_len = data.pop('cumulative_len')
+ assert len(cumulative_len) == 1
+ cumulative_len = cumulative_len[0].cuda()
+ message_hub.update_info(f'cumulative_len_rank_{rank}', cumulative_len)
+
+ max_seqlen = data.pop('max_seqlen')
+ message_hub.update_info(f'max_seqlen_rank_{rank}', max_seqlen)
+
+ def after_val_iter(self,
+ runner,
+ batch_idx,
+ data_batch=None,
+ outputs=None) -> None:
+ """All subclasses should override this method, if they need any
+ operations after each validation iteration.
+
+ Args:
+ runner (Runner): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict or tuple or list, optional): Data from dataloader.
+ outputs (Sequence, optional): Outputs from model.
+ """
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ message_hub.update_info(f'cumulative_len_rank_{rank}', None)
+ message_hub.update_info(f'max_seqlen_rank_{rank}', None)
diff --git a/data/xtuner/xtuner/engine/runner/__init__.py b/data/xtuner/xtuner/engine/runner/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d8d1c582b531e341dfbb299e56cbbd3db0b81e16
--- /dev/null
+++ b/data/xtuner/xtuner/engine/runner/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .loops import TrainLoop
+
+__all__ = ['TrainLoop']
diff --git a/data/xtuner/xtuner/engine/runner/loops.py b/data/xtuner/xtuner/engine/runner/loops.py
new file mode 100644
index 0000000000000000000000000000000000000000..aeb6be31ae6e09c32fb27f60c82690d4fc94b84a
--- /dev/null
+++ b/data/xtuner/xtuner/engine/runner/loops.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Union
+
+from mmengine.runner import IterBasedTrainLoop
+from torch.utils.data import DataLoader
+
+
+class TrainLoop(IterBasedTrainLoop):
+
+ def __init__(self,
+ runner,
+ dataloader: Union[DataLoader, Dict],
+ max_iters: Optional[int] = None,
+ max_epochs: Union[int, float] = None,
+ **kwargs) -> None:
+
+ if max_iters is None and max_epochs is None:
+ raise RuntimeError('Please specify the `max_iters` or '
+ '`max_epochs` in `train_cfg`.')
+ elif max_iters is not None and max_epochs is not None:
+ raise RuntimeError('Only one of `max_iters` or `max_epochs` can '
+ 'exist in `train_cfg`.')
+ else:
+ if max_iters is not None:
+ iters = int(max_iters)
+ assert iters == max_iters, ('`max_iters` should be a integer '
+ f'number, but get {max_iters}')
+ elif max_epochs is not None:
+ if isinstance(dataloader, dict):
+ diff_rank_seed = runner._randomness_cfg.get(
+ 'diff_rank_seed', False)
+ dataloader = runner.build_dataloader(
+ dataloader,
+ seed=runner.seed,
+ diff_rank_seed=diff_rank_seed)
+ iters = max_epochs * len(dataloader)
+ else:
+ raise NotImplementedError
+ super().__init__(
+ runner=runner, dataloader=dataloader, max_iters=iters, **kwargs)
diff --git a/data/xtuner/xtuner/entry_point.py b/data/xtuner/xtuner/entry_point.py
new file mode 100644
index 0000000000000000000000000000000000000000..2af774fd37843714f0ce78f8ac59bd0bfecb34c6
--- /dev/null
+++ b/data/xtuner/xtuner/entry_point.py
@@ -0,0 +1,302 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+import os
+import random
+import subprocess
+import sys
+
+from mmengine.logging import print_log
+
+import xtuner
+
+# Define valid modes
+MODES = ('list-cfg', 'copy-cfg', 'log-dataset', 'check-custom-dataset',
+ 'train', 'test', 'chat', 'convert', 'preprocess', 'mmbench',
+ 'eval_refcoco')
+
+CLI_HELP_MSG = \
+ f"""
+ Arguments received: {str(['xtuner'] + sys.argv[1:])}. xtuner commands use the following syntax:
+
+ xtuner MODE MODE_ARGS ARGS
+
+ Where MODE (required) is one of {MODES}
+ MODE_ARG (optional) is the argument for specific mode
+ ARGS (optional) are the arguments for specific command
+
+ Some usages for xtuner commands: (See more by using -h for specific command!)
+
+ 1. List all predefined configs:
+ xtuner list-cfg
+ 2. Copy a predefined config to a given path:
+ xtuner copy-cfg $CONFIG $SAVE_FILE
+ 3-1. Fine-tune LLMs by a single GPU:
+ xtuner train $CONFIG
+ 3-2. Fine-tune LLMs by multiple GPUs:
+ NPROC_PER_NODE=$NGPUS NNODES=$NNODES NODE_RANK=$NODE_RANK PORT=$PORT ADDR=$ADDR xtuner dist_train $CONFIG $GPUS
+ 4-1. Convert the pth model to HuggingFace's model:
+ xtuner convert pth_to_hf $CONFIG $PATH_TO_PTH_MODEL $SAVE_PATH_TO_HF_MODEL
+ 4-2. Merge the HuggingFace's adapter to the pretrained base model:
+ xtuner convert merge $LLM $ADAPTER $SAVE_PATH
+ xtuner convert merge $CLIP $ADAPTER $SAVE_PATH --is-clip
+ 4-3. Split HuggingFace's LLM to the smallest sharded one:
+ xtuner convert split $LLM $SAVE_PATH
+ 5-1. Chat with LLMs with HuggingFace's model and adapter:
+ xtuner chat $LLM --adapter $ADAPTER --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
+ 5-2. Chat with VLMs with HuggingFace's model and LLaVA:
+ xtuner chat $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --image $IMAGE --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
+ 6-1. Preprocess arxiv dataset:
+ xtuner preprocess arxiv $SRC_FILE $DST_FILE --start-date $START_DATE --categories $CATEGORIES
+ 6-2. Preprocess refcoco dataset:
+ xtuner preprocess refcoco --ann-path $RefCOCO_ANN_PATH --image-path $COCO_IMAGE_PATH --save-path $SAVE_PATH
+ 7-1. Log processed dataset:
+ xtuner log-dataset $CONFIG
+ 7-2. Verify the correctness of the config file for the custom dataset:
+ xtuner check-custom-dataset $CONFIG
+ 8. MMBench evaluation:
+ xtuner mmbench $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --prompt-template $PROMPT_TEMPLATE --data-path $MMBENCH_DATA_PATH
+ 9. Refcoco evaluation:
+ xtuner eval_refcoco $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --prompt-template $PROMPT_TEMPLATE --data-path $REFCOCO_DATA_PATH
+ 10. List all dataset formats which are supported in XTuner
+
+ Run special commands:
+
+ xtuner help
+ xtuner version
+
+ GitHub: https://github.com/InternLM/xtuner
+ """ # noqa: E501
+
+
+CONVERT_HELP_MSG = \
+ f"""
+ Arguments received: {str(['xtuner'] + sys.argv[1:])}. xtuner commands use the following syntax:
+
+ xtuner MODE MODE_ARGS ARGS
+
+ Where MODE (required) is one of {MODES}
+ MODE_ARG (optional) is the argument for specific mode
+ ARGS (optional) are the arguments for specific command
+
+ Some usages for convert: (See more by using -h for specific command!)
+
+ 1. Convert the pth model to HuggingFace's model:
+ xtuner convert pth_to_hf $CONFIG $PATH_TO_PTH_MODEL $SAVE_PATH_TO_HF_MODEL
+ 2. Merge the HuggingFace's adapter to the pretrained LLM:
+ xtuner convert merge $LLM $ADAPTER $SAVE_PATH
+ 3. Split HuggingFace's LLM to the smallest sharded one:
+ xtuner convert split $LLM $SAVE_PATH
+
+ GitHub: https://github.com/InternLM/xtuner
+ """ # noqa: E501
+
+
+PREPROCESS_HELP_MSG = \
+ f"""
+ Arguments received: {str(['xtuner'] + sys.argv[1:])}. xtuner commands use the following syntax:
+
+ xtuner MODE MODE_ARGS ARGS
+
+ Where MODE (required) is one of {MODES}
+ MODE_ARG (optional) is the argument for specific mode
+ ARGS (optional) are the arguments for specific command
+
+ Some usages for preprocess: (See more by using -h for specific command!)
+
+ 1. Preprocess arxiv dataset:
+ xtuner preprocess arxiv $SRC_FILE $DST_FILE --start-date $START_DATE --categories $CATEGORIES
+ 2. Preprocess refcoco dataset:
+ xtuner preprocess refcoco --ann-path $RefCOCO_ANN_PATH --image-path $COCO_IMAGE_PATH --save-path $SAVE_PATH
+
+ GitHub: https://github.com/InternLM/xtuner
+ """ # noqa: E501
+
+special = {
+ 'help': lambda: print_log(CLI_HELP_MSG, 'current'),
+ 'version': lambda: print_log(xtuner.__version__, 'current')
+}
+special = {
+ **special,
+ **{f'-{k[0]}': v
+ for k, v in special.items()},
+ **{f'--{k}': v
+ for k, v in special.items()}
+}
+
+
+def list_dataset_format():
+ from xtuner.tools import list_dataset_format
+ return list_dataset_format.__file__
+
+
+def list_cfg():
+ from xtuner.tools import list_cfg
+ return list_cfg.__file__
+
+
+def copy_cfg():
+ from xtuner.tools import copy_cfg
+ return copy_cfg.__file__
+
+
+def log_dataset():
+ from xtuner.tools import log_dataset
+ return log_dataset.__file__
+
+
+def check_custom_dataset():
+ from xtuner.tools import check_custom_dataset
+ return check_custom_dataset.__file__
+
+
+def train():
+ from xtuner.tools import train
+ return train.__file__
+
+
+def test():
+ from xtuner.tools import test
+ return test.__file__
+
+
+def chat():
+ from xtuner.tools import chat
+ return chat.__file__
+
+
+def mmbench():
+ from xtuner.tools import mmbench
+ return mmbench.__file__
+
+
+def pth_to_hf():
+ from xtuner.tools.model_converters import pth_to_hf
+ return pth_to_hf.__file__
+
+
+def merge():
+ from xtuner.tools.model_converters import merge
+ return merge.__file__
+
+
+def split():
+ from xtuner.tools.model_converters import split
+ return split.__file__
+
+
+def arxiv_preprocess():
+ from xtuner.tools.data_preprocess import arxiv as arxiv_preprocess
+ return arxiv_preprocess.__file__
+
+
+def convert_refcoco():
+ from xtuner.tools.data_preprocess import convert_refcoco
+ return convert_refcoco.__file__
+
+
+def convert_help_msg():
+ print_log(CONVERT_HELP_MSG, 'current')
+
+
+def preprocess_help_msg():
+ print_log(PREPROCESS_HELP_MSG, 'current')
+
+
+def eval_refcoco():
+ from xtuner.tools import eval_refcoco
+ return eval_refcoco.__file__
+
+
+modes = {
+ 'list-cfg': list_cfg,
+ 'copy-cfg': copy_cfg,
+ 'log-dataset': log_dataset,
+ 'check-custom-dataset': check_custom_dataset,
+ 'train': train,
+ 'test': test,
+ 'chat': chat,
+ 'mmbench': mmbench,
+ 'convert': {
+ 'pth_to_hf': pth_to_hf,
+ 'merge': merge,
+ 'split': split,
+ '--help': convert_help_msg,
+ '-h': convert_help_msg
+ },
+ 'preprocess': {
+ 'arxiv': arxiv_preprocess,
+ 'refcoco': convert_refcoco,
+ '--help': preprocess_help_msg,
+ '-h': preprocess_help_msg
+ },
+ 'eval_refcoco': eval_refcoco,
+ 'list-dataset-format': list_dataset_format
+}
+
+HELP_FUNCS = [preprocess_help_msg, convert_help_msg]
+MAP_FILE_FUNCS = [
+ list_cfg, copy_cfg, log_dataset, check_custom_dataset, train, test, chat,
+ mmbench, pth_to_hf, merge, split, arxiv_preprocess, eval_refcoco,
+ convert_refcoco, list_dataset_format
+]
+
+
+def cli():
+ args = sys.argv[1:]
+ if not args: # no arguments passed
+ print_log(CLI_HELP_MSG, 'current')
+ return
+ if args[0].lower() in special:
+ special[args[0].lower()]()
+ return
+ elif args[0].lower() in modes:
+ try:
+ fn_or_dict = modes[args[0].lower()]
+ n_arg = 0
+
+ if isinstance(fn_or_dict, dict):
+ n_arg += 1
+ fn = fn_or_dict[args[n_arg].lower()]
+ else:
+ fn = fn_or_dict
+
+ assert callable(fn)
+
+ if fn in HELP_FUNCS:
+ fn()
+ else:
+ slurm_launcher = False
+ for i in range(n_arg + 1, len(args)):
+ if args[i] == '--launcher':
+ if i + 1 < len(args) and args[i + 1] == 'slurm':
+ slurm_launcher = True
+ break
+ nnodes = int(os.environ.get('NNODES', 1))
+ nproc_per_node = int(os.environ.get('NPROC_PER_NODE', 1))
+ if slurm_launcher or (nnodes == 1 and nproc_per_node == 1):
+ subprocess.run(['python', fn()] + args[n_arg + 1:])
+ else:
+ port = os.environ.get('PORT', None)
+ if port is None:
+ port = random.randint(20000, 29999)
+ print_log(f'Use random port: {port}', 'current',
+ logging.WARNING)
+ torchrun_args = [
+ f'--nnodes={nnodes}',
+ f"--node_rank={os.environ.get('NODE_RANK', 0)}",
+ f'--nproc_per_node={nproc_per_node}',
+ f"--master_addr={os.environ.get('ADDR', '127.0.0.1')}",
+ f'--master_port={port}'
+ ]
+ subprocess.run(['torchrun'] + torchrun_args + [fn()] +
+ args[n_arg + 1:] +
+ ['--launcher', 'pytorch'])
+ except Exception as e:
+ print_log(f"WARNING: command error: '{e}'!", 'current',
+ logging.WARNING)
+ print_log(CLI_HELP_MSG, 'current', logging.WARNING)
+ return
+ else:
+ print_log('WARNING: command error!', 'current', logging.WARNING)
+ print_log(CLI_HELP_MSG, 'current', logging.WARNING)
+ return
diff --git a/data/xtuner/xtuner/evaluation/__init__.py b/data/xtuner/xtuner/evaluation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fba3e590598c3fe175f9d331e0da8883c1ef4ea8
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .metrics import MMLUMetric
+
+__all__ = ['MMLUMetric']
diff --git a/data/xtuner/xtuner/evaluation/metrics/__init__.py b/data/xtuner/xtuner/evaluation/metrics/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3efc80fd5d8aa3f7b65e43ec1a8acd98a1df3bb
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/metrics/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .mmlu_metric import MMLUMetric
+
+__all__ = ['MMLUMetric']
diff --git a/data/xtuner/xtuner/evaluation/metrics/mmlu_metric.py b/data/xtuner/xtuner/evaluation/metrics/mmlu_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad1282056a8e7691f05f579275ad0bf990796f12
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/metrics/mmlu_metric.py
@@ -0,0 +1,246 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Sequence
+
+import numpy as np
+import torch
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import print_log
+from rich.console import Console
+from rich.table import Table
+
+from xtuner.registry import BUILDER
+
+
+class MMLUMetric(BaseMetric):
+ METAINFO = {
+ 'subcategories': {
+ 'abstract_algebra': ['math'],
+ 'anatomy': ['health'],
+ 'astronomy': ['physics'],
+ 'business_ethics': ['business'],
+ 'clinical_knowledge': ['health'],
+ 'college_biology': ['biology'],
+ 'college_chemistry': ['chemistry'],
+ 'college_computer_science': ['computer science'],
+ 'college_mathematics': ['math'],
+ 'college_medicine': ['health'],
+ 'college_physics': ['physics'],
+ 'computer_security': ['computer science'],
+ 'conceptual_physics': ['physics'],
+ 'econometrics': ['economics'],
+ 'electrical_engineering': ['engineering'],
+ 'elementary_mathematics': ['math'],
+ 'formal_logic': ['philosophy'],
+ 'global_facts': ['other'],
+ 'high_school_biology': ['biology'],
+ 'high_school_chemistry': ['chemistry'],
+ 'high_school_computer_science': ['computer science'],
+ 'high_school_european_history': ['history'],
+ 'high_school_geography': ['geography'],
+ 'high_school_government_and_politics': ['politics'],
+ 'high_school_macroeconomics': ['economics'],
+ 'high_school_mathematics': ['math'],
+ 'high_school_microeconomics': ['economics'],
+ 'high_school_physics': ['physics'],
+ 'high_school_psychology': ['psychology'],
+ 'high_school_statistics': ['math'],
+ 'high_school_us_history': ['history'],
+ 'high_school_world_history': ['history'],
+ 'human_aging': ['health'],
+ 'human_sexuality': ['culture'],
+ 'international_law': ['law'],
+ 'jurisprudence': ['law'],
+ 'logical_fallacies': ['philosophy'],
+ 'machine_learning': ['computer science'],
+ 'management': ['business'],
+ 'marketing': ['business'],
+ 'medical_genetics': ['health'],
+ 'miscellaneous': ['other'],
+ 'moral_disputes': ['philosophy'],
+ 'moral_scenarios': ['philosophy'],
+ 'nutrition': ['health'],
+ 'philosophy': ['philosophy'],
+ 'prehistory': ['history'],
+ 'professional_accounting': ['other'],
+ 'professional_law': ['law'],
+ 'professional_medicine': ['health'],
+ 'professional_psychology': ['psychology'],
+ 'public_relations': ['politics'],
+ 'security_studies': ['politics'],
+ 'sociology': ['culture'],
+ 'us_foreign_policy': ['politics'],
+ 'virology': ['health'],
+ 'world_religions': ['philosophy'],
+ },
+ 'categories': {
+ 'STEM': [
+ 'physics', 'chemistry', 'biology', 'computer science', 'math',
+ 'engineering'
+ ],
+ 'humanities': ['history', 'philosophy', 'law'],
+ 'social sciences':
+ ['politics', 'culture', 'economics', 'geography', 'psychology'],
+ 'other (business, health, misc.)': ['other', 'business', 'health'],
+ },
+ }
+ METAINFO['subcategories_list'] = list({
+ subcat
+ for subcats in METAINFO['subcategories'].values() for subcat in subcats
+ })
+
+ def __init__(self, tokenizer, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ tokenizer = BUILDER.build(tokenizer)
+ self.abcd_idx = [
+ tokenizer.encode('A', add_special_tokens=False)[0],
+ tokenizer.encode('B', add_special_tokens=False)[0],
+ tokenizer.encode('C', add_special_tokens=False)[0],
+ tokenizer.encode('D', add_special_tokens=False)[0],
+ ]
+
+ @staticmethod
+ def ABCD_to_0123(abcd):
+ return {'A': 0, 'B': 1, 'C': 2, 'D': 3}[abcd]
+
+ @staticmethod
+ def find_first_zero_index(tensor):
+ indices = torch.nonzero(tensor == 0)
+ if indices.numel() > 0:
+ return indices[0].item()
+ else:
+ return None
+
+ @staticmethod
+ def accuracy(preds, gts):
+ """Computes the accuracy for preds and gts."""
+ correct = [1 if pred == gt else 0 for pred, gt in zip(preds, gts)]
+ acc = np.mean(correct) * 100
+ return acc
+
+ def process(self, data_batch: Any, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Any): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ subjects = data_batch['data_samples']['subjects']
+ gts = [
+ self.ABCD_to_0123(gt)
+ for gt in data_batch['data_samples']['labels']
+ ]
+ preds = []
+ for sample, attn_mask, subject, gt in zip(
+ data_samples, data_batch['data']['attention_mask'], subjects,
+ gts):
+ pred_logits = sample['logits']
+ first_zero_idx = self.find_first_zero_index(attn_mask)
+ pred_idx = -1 if first_zero_idx is None else first_zero_idx - 1
+ pred_logtis_abcd = pred_logits[pred_idx, self.abcd_idx]
+ pred = torch.argmax(pred_logtis_abcd).item()
+ preds.append(pred)
+ self.results.append((subject, pred, gt))
+
+ def compute_metrics(self, results: list) -> dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ subjects_results = {
+ subject: {
+ 'preds': [],
+ 'gts': []
+ }
+ for subject in self.METAINFO['subcategories'].keys()
+ }
+ subcats_results = {
+ subcat: {
+ 'preds': [],
+ 'gts': []
+ }
+ for subcat in self.METAINFO['subcategories_list']
+ }
+ cats_results = {
+ cat: {
+ 'preds': [],
+ 'gts': []
+ }
+ for cat in self.METAINFO['categories'].keys()
+ }
+ for subject, pred, gt in results:
+ subjects_results[subject]['preds'].append(pred)
+ subjects_results[subject]['gts'].append(gt)
+ subcats = self.METAINFO['subcategories'][subject]
+ for subcat in subcats:
+ subcats_results[subcat]['preds'].append(pred)
+ subcats_results[subcat]['gts'].append(gt)
+ for cat, subcats in self.METAINFO['categories'].items():
+ for subcat in subcats:
+ if subcat in subcats_results:
+ cats_results[cat]['preds'].extend(
+ subcats_results[subcat]['preds'])
+ cats_results[cat]['gts'].extend(
+ subcats_results[subcat]['gts'])
+
+ subjects_metrics = dict()
+ subcats_metrics = dict()
+ cats_metrics = dict()
+ for subject in self.METAINFO['subcategories'].keys():
+ assert len(subjects_results[subject]['preds']) == len(
+ subjects_results[subject]['gts'])
+ if len(subjects_results[subject]['preds']) == 0:
+ print_log(f'Skip subject {subject} for mmlu', 'current')
+ else:
+ score = self.accuracy(subjects_results[subject]['preds'],
+ subjects_results[subject]['gts'])
+ subjects_metrics[f'{subject}'] = score
+ for subcat in self.METAINFO['subcategories_list']:
+ assert len(subcats_results[subcat]['preds']) == len(
+ subcats_results[subcat]['gts'])
+ if len(subcats_results[subcat]['preds']) == 0:
+ print_log(f'Skip subcategory {subcat} for mmlu', 'current')
+ else:
+ score = self.accuracy(subcats_results[subcat]['preds'],
+ subcats_results[subcat]['gts'])
+ subcats_metrics[f'{subcat}'] = score
+ for cat in self.METAINFO['categories'].keys():
+ assert len(cats_results[cat]['preds']) == len(
+ cats_results[cat]['gts'])
+ if len(cats_results[cat]['preds']) == 0:
+ print_log(f'Skip category {cat} for mmlu', 'current')
+ else:
+ score = self.accuracy(cats_results[cat]['preds'],
+ cats_results[cat]['gts'])
+ cats_metrics[f'{cat}'] = score
+
+ metrics = dict()
+ metrics.update(subjects_metrics)
+ metrics.update(subcats_metrics)
+ metrics.update(cats_metrics)
+ metrics['average'] = np.mean(list(subjects_metrics.values()))
+
+ table_metrics = dict()
+ table_metrics.update(cats_metrics)
+ table_metrics['average'] = np.mean(list(subjects_metrics.values()))
+ self._print_results(table_metrics)
+ return metrics
+
+ def _print_results(self, table_metrics: dict) -> None:
+ table_title = ' MMLU Benchmark '
+ table = Table(title=table_title)
+ console = Console()
+ table.add_column('Categories', justify='left')
+ table.add_column('Accuracy (%)', justify='right')
+ for cat, acc in table_metrics.items():
+ table.add_row(cat, f'{acc:.1f}')
+ with console.capture() as capture:
+ console.print(table, end='')
+ print_log('\n' + capture.get(), 'current')
diff --git a/data/xtuner/xtuner/evaluation/metrics/reward_metric.py b/data/xtuner/xtuner/evaluation/metrics/reward_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5d019978c9ebbfe2debd42b113f64aba9274423
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/metrics/reward_metric.py
@@ -0,0 +1,102 @@
+import itertools
+from collections import defaultdict
+from typing import List, Optional, Sequence
+
+import torch
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import print_log
+from rich.console import Console
+from rich.table import Table
+
+
+class RewardMetric(BaseMetric):
+ r"""Reward model evaluation metric.
+ """
+ default_prefix: Optional[str] = ''
+
+ def __init__(self,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+
+ def process(self, data_batch, data_samples: Sequence[dict]):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+ logits = torch.cat(
+ [sample['logits'].unsqueeze(0) for sample in data_samples], dim=0)
+ labels = data_batch['data']['labels']
+ ds_names = data_batch['data_samples']['ds_names']
+ chosen_idx = torch.where(labels == 0)
+ rejected_idx = torch.where(labels == 1)
+ chosen_logits = logits[chosen_idx].cpu()
+ rejected_logits = logits[rejected_idx].cpu()
+
+ correct = (chosen_logits > rejected_logits).cpu()
+ self.results.append({
+ 'chosen_logits': chosen_logits,
+ 'rejected_logits': rejected_logits,
+ 'correct': correct,
+ 'ds_names': ds_names
+ })
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ # NOTICE: don't access `self.results` from the method.
+ metrics = {}
+
+ correct = torch.cat([res['correct'] for res in results])
+ chosen_logits = torch.cat([res['chosen_logits'] for res in results])
+ rejected_logits = torch.cat(
+ [res['rejected_logits'] for res in results])
+ ds_names = list(itertools.chain(*[res['ds_names'] for res in results]))
+
+ # group by ds_names
+ grouped_correct = defaultdict(list)
+ grouped_chosen_logits = defaultdict(list)
+ grouped_rejected_logits = defaultdict(list)
+ for i, ds_name in enumerate(ds_names):
+ grouped_correct[ds_name].append(correct[i])
+ grouped_chosen_logits[ds_name].append(chosen_logits[i])
+ grouped_rejected_logits[ds_name].append(rejected_logits[i])
+
+ # print metrics in a rich table
+ table = Table(title='Reward Metrics')
+ table.add_column('Dataset Name')
+ table.add_column('Accuracy')
+ table.add_column('Chosen Score')
+ table.add_column('Rejected Score')
+
+ for ds_name in grouped_correct.keys():
+ correct = torch.stack(grouped_correct[ds_name])
+ chosen_logits = torch.stack(grouped_chosen_logits[ds_name])
+ rejected_logits = torch.stack(grouped_rejected_logits[ds_name])
+
+ acc = correct.float().mean()
+ metrics[f'accuracy/{ds_name}'] = acc.item()
+ metrics[f'chosen_score/{ds_name}'] = chosen_logits.mean().item()
+ metrics[f'rejected_score{ds_name}'] = rejected_logits.mean().item()
+
+ table.add_row(ds_name, f'{acc:.4f}', f'{chosen_logits.mean():.4f}',
+ f'{rejected_logits.mean():.4f}')
+
+ console = Console()
+ with console.capture() as capture:
+ console.print(table, end='')
+ print_log('\n' + capture.get(), 'current')
+
+ return metrics
diff --git a/data/xtuner/xtuner/model/__init__.py b/data/xtuner/xtuner/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b3a501d4a96ccb4ed2e7d5d10ab093d08892f12
--- /dev/null
+++ b/data/xtuner/xtuner/model/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .internvl import InternVL_V1_5
+from .llava import LLaVAModel
+from .sft import SupervisedFinetune
+
+__all__ = ['SupervisedFinetune', 'LLaVAModel', 'InternVL_V1_5']
diff --git a/data/xtuner/xtuner/model/dpo.py b/data/xtuner/xtuner/model/dpo.py
new file mode 100644
index 0000000000000000000000000000000000000000..faaa43402cb077ca39d9418e778b5bcbede10ace
--- /dev/null
+++ b/data/xtuner/xtuner/model/dpo.py
@@ -0,0 +1,286 @@
+# DPO Authors: Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn 2023 # noqa
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+from transformers.integrations import is_deepspeed_zero3_enabled
+
+from xtuner.parallel.sequence import (gather_forward_split_backward,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ split_for_sequence_parallel)
+from .sft import SupervisedFinetune
+
+
+def disable_grad(model):
+ # freeze parameters
+ parameter_names = [n for n, _ in model.named_parameters()]
+ for param_name in parameter_names:
+ param = model.get_parameter(param_name)
+ param.requires_grad = False
+ return model.eval()
+
+
+def create_reference_model(model):
+ if is_deepspeed_zero3_enabled():
+ raise ValueError('DeepSpeed ZeRO-3 is enabled and is not compatible '
+ 'with `create_reference_model()`. Please instantiate '
+ 'your reference model directly with '
+ '`AutoCausalLM.from_pretrained()`.')
+ ref_model = deepcopy(model)
+ ref_model = disable_grad(ref_model)
+ return ref_model
+
+
+class DPO(SupervisedFinetune):
+ """A general class of DPO and its variants."""
+
+ def __init__(self,
+ llm,
+ ref_llm=None,
+ beta=0.1,
+ loss_type='sigmoid',
+ label_smoothing=0.0,
+ **kwargs):
+ super().__init__(llm, **kwargs)
+ self.loss_type = loss_type
+ self.label_smoothing = label_smoothing
+ self.beta = beta
+
+ if ref_llm is not None:
+ ref_llm = self.build_llm_from_cfg(
+ ref_llm, kwargs.get('use_varlen_attn', False),
+ kwargs.get('max_position_embeddings', None))
+ self.ref_llm = disable_grad(ref_llm)
+ else:
+ self.ref_llm = None if self.use_lora else create_reference_model(
+ self.llm)
+
+ def _gather_masked_logits(self, logits, labels, mask):
+ logits = torch.gather(
+ logits.log_softmax(-1), dim=2,
+ index=labels.unsqueeze(2)).squeeze(2)
+ return logits * mask
+
+ def get_logps(
+ self,
+ policy_logps, # bs, seqlen,vocab_size
+ ref_logps, # bs, seqlen,vocab_size
+ loss_mask, # bs, seqlen
+ ):
+ policy_logps = policy_logps[:, :-1].sum(-1)
+ ref_logps = ref_logps[:, :-1].sum(-1)
+ loss_mask = loss_mask[:, :-1]
+
+ if self.loss_type == 'ipo': # average_log_prob
+ policy_logps = policy_logps / loss_mask.sum(-1)
+ ref_logps = ref_logps / loss_mask.sum(-1)
+
+ policy_chosen_logps = policy_logps[::2]
+ policy_rejected_logps = policy_logps[1::2]
+ reference_chosen_logps = ref_logps[::2]
+ reference_rejected_logps = ref_logps[1::2]
+ return (policy_chosen_logps, policy_rejected_logps,
+ reference_chosen_logps, reference_rejected_logps)
+
+ def get_var_len_atten_logps(self, policy_logps, ref_logps, loss_mask,
+ cu_seqlens, attention_mask):
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+ # unpack sequence
+ unpacked_policy_logps = torch.split(policy_logps, seqlens, dim=1)
+ unpacked_ref_logps = torch.split(ref_logps, seqlens, dim=1)
+ unpacked_loss_mask = torch.split(loss_mask, seqlens, dim=1)
+ if attention_mask is not None:
+ # It indicate that we pad the original sequence, labels,
+ # position_ids and cumulative_len for sequence parallel if the
+ # attention_mask is not None.
+ # We then need to remove the padded segments.
+ assert False in attention_mask
+ unpacked_policy_logps = unpacked_policy_logps[:-1]
+ unpacked_ref_logps = unpacked_ref_logps[:-1]
+ unpacked_loss_mask = unpacked_loss_mask[:-1]
+ assert len(unpacked_policy_logps) % 2 == 0
+
+ def compute_logps(_logps, _mask):
+ _logps = _logps[:, :-1].sum(-1)
+ _mask = _mask[:, :-1]
+ if self.loss_type == 'ipo':
+ _logps /= _mask.sum(-1)
+ return _logps
+
+ (policy_chosen_logps, policy_rejected_logps, reference_chosen_logps,
+ reference_rejected_logps) = [], [], [], []
+ for i in range(len(unpacked_policy_logps) // 2):
+ chosen = unpacked_policy_logps[2 * i]
+ rejected = unpacked_policy_logps[2 * i + 1]
+ chosen_ref = unpacked_ref_logps[2 * i]
+ rejected_ref = unpacked_ref_logps[2 * i + 1]
+ chosen_mask = unpacked_loss_mask[2 * i]
+ rejected_mask = unpacked_loss_mask[2 * i + 1]
+ policy_chosen_logps.append(compute_logps(chosen, chosen_mask))
+ policy_rejected_logps.append(
+ compute_logps(rejected, rejected_mask))
+ reference_chosen_logps.append(
+ compute_logps(chosen_ref, chosen_mask))
+ reference_rejected_logps.append(
+ compute_logps(rejected_ref, rejected_mask))
+
+ return (torch.stack(policy_chosen_logps),
+ torch.stack(policy_rejected_logps),
+ torch.stack(reference_chosen_logps),
+ torch.stack(reference_rejected_logps))
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'position_ids', 'labels')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def compute_loss(self, data, data_samples=None):
+ # modified from https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py # noqa
+ # shift labels first and add a dummy label at the end, to support sequence parallel # noqa
+ data['labels'] = torch.cat(
+ (data['labels'][:, 1:], torch.zeros_like(data['labels'][:, :1])),
+ dim=1)
+ tmp_label = data['labels'].clone()
+ tmp_label[tmp_label == 0] = -100
+ all_loss_mask = data[
+ 'labels'] != -100 # loss mask of all tokens in all sp ranks # noqa
+
+ if get_sequence_parallel_world_size() > 1:
+ data = self._split_for_sequence_parallel(data)
+
+ all_logits = self.llm(**data).logits
+ with torch.no_grad():
+ if self.ref_llm is None:
+ with self.llm.disable_adapter():
+ all_ref_logits = self.llm(**data).logits
+ else:
+ all_ref_logits = self.ref_llm(**data).logits
+
+ labels = data['labels']
+ labels[labels == -100] = 0
+ loss_mask = labels != 0 # loss mask in a single sp rank
+ policy_logps = self._gather_masked_logits(all_logits, labels,
+ loss_mask)
+ ref_logps = self._gather_masked_logits(all_ref_logits, labels,
+ loss_mask)
+
+ if get_sequence_parallel_world_size() > 1:
+ policy_logps = gather_forward_split_backward(
+ policy_logps,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+ ref_logps = gather_forward_split_backward(
+ ref_logps,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+
+ if not self.use_varlen_attn:
+ (policy_chosen_logps, policy_rejected_logps,
+ reference_chosen_logps,
+ reference_rejected_logps) = self.get_logps(
+ policy_logps, ref_logps, all_loss_mask)
+ else:
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cu_seqlens = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ (policy_chosen_logps, policy_rejected_logps,
+ reference_chosen_logps,
+ reference_rejected_logps) = self.get_var_len_atten_logps(
+ policy_logps, ref_logps, all_loss_mask, cu_seqlens,
+ data['attention_mask'])
+
+ pi_logratios = policy_chosen_logps - policy_rejected_logps
+ ref_logratios = reference_chosen_logps - reference_rejected_logps
+
+ logits = pi_logratios - ref_logratios
+ if self.loss_type == 'sigmoid':
+ loss = (-F.logsigmoid(self.beta * logits) *
+ (1 - self.label_smoothing) -
+ F.logsigmoid(-self.beta * logits) * self.label_smoothing)
+ elif self.loss_type == 'robust':
+ loss = (-F.logsigmoid(self.beta * logits) *
+ (1 - self.label_smoothing) +
+ F.logsigmoid(-self.beta * logits) *
+ self.label_smoothing) / (1 - 2 * self.label_smoothing)
+ elif self.loss_type == 'hinge':
+ loss = torch.relu(1 - self.beta * logits)
+ elif self.loss_type == 'ipo':
+ # eqn (17) of the paper where beta is the regularization
+ # parameter for the IPO loss, denoted by tau in the paper. # noqa
+ loss = (logits - 1 / (2 * self.beta))**2
+ elif self.loss_type == 'kto_pair':
+ # eqn (7) of the HALOs paper
+ chosen_KL = (policy_chosen_logps -
+ reference_chosen_logps).mean().clamp(min=0)
+ rejected_KL = (policy_rejected_logps -
+ reference_rejected_logps).mean().clamp(min=0)
+
+ chosen_logratios = policy_chosen_logps - reference_chosen_logps
+ rejected_logratios = \
+ policy_rejected_logps - reference_rejected_logps
+ # As described in the KTO report, the KL term for chosen (rejected)
+ # is estimated using the rejected (chosen) half. # noqa
+ loss = torch.cat(
+ (
+ 1 - F.sigmoid(self.beta *
+ (chosen_logratios - rejected_KL)),
+ 1 - F.sigmoid(self.beta *
+ (chosen_KL - rejected_logratios)),
+ ),
+ 0,
+ )
+ elif self.loss_type == 'sppo_hard':
+ # In the paper (https://arxiv.org/pdf/2405.00675),
+ # SPPO employs a soft probability approach,
+ # estimated using the PairRM score. The probability calculation
+ # is conducted outside of the trainer class.
+ # The version described here is the hard probability version,
+ # where P in Equation (4.7) of Algorithm 1 is set to 1 for
+ # the winner and 0 for the loser.
+ a = policy_chosen_logps - reference_chosen_logps
+ b = policy_rejected_logps - reference_rejected_logps
+
+ loss = (a - 0.5 / self.beta)**2 + (b + 0.5 / self.beta)**2
+ elif self.loss_type == 'nca_pair':
+ chosen_rewards = (policy_chosen_logps -
+ reference_chosen_logps) * self.beta
+ rejected_rewards = (policy_rejected_logps -
+ reference_rejected_logps) * self.beta
+ loss = (-F.logsigmoid(chosen_rewards) -
+ 0.5 * F.logsigmoid(-chosen_rewards) -
+ 0.5 * F.logsigmoid(-rejected_rewards))
+ else:
+ raise ValueError(
+ f'Unknown loss type: {self.loss_type}. Should be one of '
+ "['sigmoid', 'hinge', 'ipo', 'kto_pair', "
+ "'sppo_hard', 'nca_pair', 'robust']")
+ # for logging
+ chosen_rewards = self.beta * (
+ policy_chosen_logps - reference_chosen_logps)
+ rejected_rewards = self.beta * (
+ policy_rejected_logps - reference_rejected_logps)
+ reward_acc = (chosen_rewards > rejected_rewards).float().mean()
+
+ loss_dict = {
+ 'loss': loss,
+ 'chosen_rewards': chosen_rewards.mean(),
+ 'rejected_rewards': rejected_rewards.mean(),
+ 'reward_acc': reward_acc,
+ 'reward_margin': (chosen_rewards - rejected_rewards).mean(),
+ }
+ return loss_dict
diff --git a/data/xtuner/xtuner/model/internvl.py b/data/xtuner/xtuner/model/internvl.py
new file mode 100644
index 0000000000000000000000000000000000000000..0358266a9ff40defc650ca62179a1c496653bed7
--- /dev/null
+++ b/data/xtuner/xtuner/model/internvl.py
@@ -0,0 +1,320 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+from typing import List, Optional, Tuple, Union
+
+import torch
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from peft import get_peft_model, prepare_model_for_kbit_training
+from torch.nn import CrossEntropyLoss
+from transformers import (AutoConfig, AutoModel, AutoTokenizer,
+ BitsAndBytesConfig)
+from transformers.modeling_outputs import CausalLMOutputWithPast
+
+from xtuner.registry import BUILDER
+from .utils import (find_all_linear_names, get_peft_model_state_dict,
+ guess_load_checkpoint, make_inputs_require_grad)
+
+
+class InternVL_V1_5(BaseModel):
+
+ def __init__(self,
+ model_path,
+ freeze_llm=False,
+ freeze_visual_encoder=False,
+ llm_lora=None,
+ visual_encoder_lora=None,
+ quantization_vit=False,
+ quantization_llm=False,
+ pretrained_pth=None):
+ print_log('Start to load InternVL_V1_5 model.', logger='current')
+ super().__init__()
+ self.freeze_llm = freeze_llm
+ self.freeze_visual_encoder = freeze_visual_encoder
+ self.use_llm_lora = llm_lora is not None
+ self.use_visual_encoder_lora = visual_encoder_lora is not None
+ self.quantization_vit = quantization_vit
+ self.quantization_llm = quantization_llm
+ if quantization_vit:
+ assert visual_encoder_lora is not None
+ if quantization_llm:
+ assert quantization_llm and llm_lora is not None
+
+ config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
+ if config.llm_config.model_type == 'internlm2':
+ config.llm_config.attn_implementation = 'flash_attention_2'
+ else:
+ config.llm_config._attn_implementation = 'flash_attention_2'
+
+ if quantization_vit is False and quantization_llm is False:
+ quantization = None
+ else:
+ llm_int8_skip_modules = ['mlp1']
+ if quantization_llm and not quantization_vit:
+ llm_int8_skip_modules.append('vision_model')
+
+ if quantization_vit and not quantization_llm:
+ llm_int8_skip_modules.append('language_model')
+
+ quantization_config = dict(
+ type=BitsAndBytesConfig,
+ llm_int8_skip_modules=llm_int8_skip_modules,
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4')
+ quantization_clazz = quantization_config.pop('type')
+ quantization = quantization_clazz(**quantization_config)
+
+ self.model = AutoModel.from_pretrained(
+ model_path,
+ torch_dtype=torch.bfloat16,
+ quantization_config=quantization,
+ config=config,
+ trust_remote_code=True)
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_path, trust_remote_code=True)
+ img_context_token_id = tokenizer.convert_tokens_to_ids('')
+ self.model.img_context_token_id = img_context_token_id
+
+ if self.freeze_llm:
+ self.model.language_model.requires_grad_(False)
+ if self.freeze_visual_encoder:
+ self.model.vision_model.requires_grad_(False)
+
+ if hasattr(self.model.language_model, 'enable_input_require_grads'):
+ self.model.language_model.enable_input_require_grads()
+ else:
+ self.model.language_model.get_input_embeddings(
+ ).register_forward_hook(make_inputs_require_grad)
+
+ self.gradient_checkpointing_enable()
+
+ if self.use_llm_lora:
+ self._prepare_llm_for_lora(llm_lora)
+
+ if self.use_visual_encoder_lora:
+ self._prepare_visual_encoder_for_lora(visual_encoder_lora)
+
+ if pretrained_pth is not None:
+ pretrained_state_dict = guess_load_checkpoint(pretrained_pth)
+
+ self.load_state_dict(pretrained_state_dict, strict=False)
+ print(f'Load pretrained weight from {pretrained_pth}')
+
+ self._count = 0
+ print_log(self, logger='current')
+ print_log('InternVL_V1_5 construction is complete', logger='current')
+
+ def _parse_lora_config(self, lora_config):
+ if isinstance(lora_config, dict) or isinstance(
+ lora_config, Config) or isinstance(lora_config, ConfigDict):
+ lora_config = BUILDER.build(lora_config)
+ return lora_config
+
+ def _prepare_llm_for_lora(self,
+ lora_config,
+ use_activation_checkpointing=True):
+ lora_config = self._parse_lora_config(lora_config)
+ self.model.language_model = prepare_model_for_kbit_training(
+ self.model.language_model, use_activation_checkpointing)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.model.language_model)
+ lora_config.target_modules = modules
+ self.model.language_model = get_peft_model(self.model.language_model,
+ lora_config)
+
+ def _prepare_visual_encoder_for_lora(self, lora_config):
+ lora_config = self._parse_lora_config(lora_config)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.model.vision_model)
+ lora_config.target_modules = modules
+ self.model.vision_model = get_peft_model(self.model.vision_model,
+ lora_config)
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.model.language_model.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.model.language_model.gradient_checkpointing_disable()
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ to_return = OrderedDict()
+ # Step 1. visual_encoder
+ if self.use_visual_encoder_lora:
+ to_return.update(
+ get_peft_model_state_dict(
+ self.model.vision_model, state_dict=state_dict))
+ elif not self.freeze_visual_encoder:
+ to_return.update({
+ k: v
+ for k, v in state_dict.items() if 'model.vision_model.' in k
+ })
+ # Step 2. LLM
+ if self.use_llm_lora:
+ to_return.update(
+ get_peft_model_state_dict(
+ self.model.language_model, state_dict=state_dict))
+ elif not self.freeze_llm:
+ to_return.update({
+ k: v
+ for k, v in state_dict.items() if 'model.language_model.' in k
+ })
+ # Step 3. Projector
+ to_return.update(
+ {k: v
+ for k, v in state_dict.items() if 'model.mlp1.' in k})
+ return to_return
+
+ def init_weights(self):
+ pass
+
+ def forward(self, data, data_samples=None, mode='loss'):
+ pixel_values = data['pixel_values']
+
+ if type(pixel_values) is list or pixel_values.ndim == 5:
+ if type(pixel_values) is list:
+ pixel_values = [
+ x.unsqueeze(0) if x.ndim == 3 else x for x in pixel_values
+ ]
+ # b*n, c, h, w
+ concat_images = torch.cat([
+ image.to(self.model.vision_model.dtype)
+ for image in pixel_values
+ ],
+ dim=0)
+ else:
+ raise NotImplementedError()
+
+ input_ids = data['input_ids']
+ position_ids = data['position_ids']
+ attention_mask = data['attention_mask']
+ # sum is 0 are text
+ image_flags = torch.sum(concat_images, dim=(1, 2, 3)) != 0
+ image_flags = image_flags.long()
+
+ labels = data['labels']
+ use_cache = False
+
+ # Directly calling this code in LORA fine-tuning
+ # will result in an error,so we must rewrite it.
+ # TODO: Once the official is fixed, we can remove it.
+ # outputs = self.model(input_ids=input_ids,
+ # position_ids=position_ids,
+ # attention_mask=attention_mask,
+ # image_flags=image_flags,
+ # pixel_values=concat_images,
+ # labels=labels,
+ # use_cache=use_cache)
+ outputs = self._llm_forward(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ image_flags=image_flags,
+ pixel_values=concat_images,
+ labels=labels,
+ use_cache=use_cache)
+ loss_dict = {'loss': outputs.loss}
+ return loss_dict
+
+ def _llm_forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ image_flags: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ return_dict = return_dict if return_dict is not None \
+ else self.model.config.use_return_dict
+
+ image_flags = image_flags.squeeze(-1)
+ # We only added the clone code here to avoid the error.
+ input_embeds = self.model.language_model.get_input_embeddings()(
+ input_ids).clone()
+
+ vit_embeds = self.model.extract_feature(pixel_values)
+ vit_embeds = vit_embeds[image_flags == 1]
+ vit_batch_size = pixel_values.shape[0]
+
+ B, N, C = input_embeds.shape
+ input_embeds = input_embeds.reshape(B * N, C)
+
+ if torch.distributed.get_rank() == 0 and self._count % 100 == 0:
+ print(f'dynamic ViT batch size: {vit_batch_size}, '
+ f'images per sample: {vit_batch_size / B}, '
+ f'dynamic token length: {N}')
+ self._count += 1
+
+ input_ids = input_ids.reshape(B * N)
+ selected = (input_ids == self.model.img_context_token_id)
+ try:
+ input_embeds[
+ selected] = input_embeds[selected] * 0.0 + vit_embeds.reshape(
+ -1, C)
+ except Exception as e:
+ vit_embeds = vit_embeds.reshape(-1, C)
+ print(f'warning: {e}, input_embeds[selected].shape='
+ f'{input_embeds[selected].shape}, '
+ f'vit_embeds.shape={vit_embeds.shape}')
+ n_token = selected.sum()
+ input_embeds[
+ selected] = input_embeds[selected] * 0.0 + vit_embeds[:n_token]
+
+ input_embeds = input_embeds.reshape(B, N, C)
+
+ outputs = self.model.language_model(
+ inputs_embeds=input_embeds,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ logits = outputs.logits
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(
+ -1, self.model.language_model.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ return (loss, ) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/model/llava.py b/data/xtuner/xtuner/model/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..36d1833d3040e65e97700d81bd11a906fbedbebd
--- /dev/null
+++ b/data/xtuner/xtuner/model/llava.py
@@ -0,0 +1,635 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os.path as osp
+import warnings
+from collections import OrderedDict
+
+import torch
+import torch.nn as nn
+from accelerate import init_empty_weights
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from peft import get_peft_model, prepare_model_for_kbit_training
+from transformers import (AddedToken, AutoConfig, CLIPImageProcessor,
+ CLIPVisionModel, LlamaForCausalLM,
+ LlamaTokenizerFast, LlavaConfig,
+ LlavaForConditionalGeneration, LlavaProcessor)
+from transformers.integrations import is_deepspeed_zero3_enabled
+
+from xtuner.registry import BUILDER
+from xtuner.utils import DEFAULT_IMAGE_TOKEN
+from .modules import ProjectorConfig, ProjectorModel, dispatch_modules
+from .modules.dispatch import SUPPORT_FLASH1, SUPPORT_FLASH2
+from .utils import (LoadWoInit, find_all_linear_names,
+ get_peft_model_state_dict, guess_load_checkpoint,
+ make_inputs_require_grad,
+ prepare_inputs_labels_for_multimodal, traverse_dict)
+
+
+def convert_state_dict_to_hf(state_dict, mapping):
+ new_state_dict = {}
+ for key, value in state_dict.items():
+ if key.endswith('.inv_freq'):
+ continue
+ for key_to_modify, new_key in mapping.items():
+ if key_to_modify in key:
+ key = key.replace(key_to_modify, new_key)
+ new_state_dict[key] = value
+ return new_state_dict
+
+
+class LLaVAModel(BaseModel):
+
+ def __init__(self,
+ llm,
+ visual_encoder,
+ freeze_llm=False,
+ freeze_visual_encoder=False,
+ visual_select_layer=-2,
+ pretrained_pth=None,
+ projector_depth=2,
+ llm_lora=None,
+ visual_encoder_lora=None,
+ use_activation_checkpointing=True,
+ max_position_embeddings=None):
+ super().__init__()
+ self.freeze_llm = freeze_llm
+ self.freeze_visual_encoder = freeze_visual_encoder
+ with LoadWoInit():
+ if isinstance(llm, dict):
+ llm = self._dispatch_lm_model_cfg(llm, max_position_embeddings)
+
+ self.llm = self._build_from_cfg_or_module(llm)
+ self.visual_encoder = self._build_from_cfg_or_module(
+ visual_encoder)
+ self.llm.config.use_cache = False
+ dispatch_modules(self.llm)
+
+ self.projector_depth = projector_depth
+ projector_config = ProjectorConfig(
+ visual_hidden_size=self.visual_encoder.config.hidden_size,
+ llm_hidden_size=self.llm.config.hidden_size,
+ depth=self.projector_depth)
+ self.projector = ProjectorModel(projector_config).to(
+ self.visual_encoder.dtype)
+
+ if self.freeze_llm:
+ self.llm.requires_grad_(False)
+ if self.freeze_visual_encoder:
+ self.visual_encoder.requires_grad_(False)
+
+ if use_activation_checkpointing:
+ # For backward compatibility
+ if hasattr(self.llm, 'enable_input_require_grads'):
+ self.llm.enable_input_require_grads()
+ else:
+ self.llm.get_input_embeddings().register_forward_hook(
+ make_inputs_require_grad)
+ if hasattr(self.visual_encoder, 'enable_input_require_grads'):
+ self.visual_encoder.enable_input_require_grads()
+ else:
+ self.visual_encoder.get_input_embeddings(
+ ).register_forward_hook(make_inputs_require_grad)
+ self.projector.enable_input_require_grads()
+
+ # enable gradient (activation) checkpointing for memory efficiency
+ self.gradient_checkpointing_enable()
+
+ self.use_llm_lora = llm_lora is not None
+ self.use_visual_encoder_lora = visual_encoder_lora is not None
+
+ if self.use_llm_lora:
+ self._prepare_llm_for_lora(llm_lora, use_activation_checkpointing)
+ if self.use_visual_encoder_lora:
+ self._prepare_visual_encoder_for_lora(
+ visual_encoder_lora, use_activation_checkpointing)
+
+ if pretrained_pth is not None:
+ pretrained_state_dict = guess_load_checkpoint(pretrained_pth)
+
+ self.load_state_dict(pretrained_state_dict, strict=False)
+ print_log(f'Load pretrained weight from {pretrained_pth}',
+ 'current')
+
+ self.visual_select_layer = visual_select_layer
+
+ self._is_init = True
+
+ self.is_first_iter = True
+
+ def _parse_lora_config(self, lora_config):
+ if isinstance(lora_config, dict) or isinstance(
+ lora_config, Config) or isinstance(lora_config, ConfigDict):
+ lora_config = BUILDER.build(lora_config)
+ return lora_config
+
+ def _prepare_llm_for_lora(self,
+ lora_config,
+ use_activation_checkpointing=True):
+ lora_config = self._parse_lora_config(lora_config)
+ self.llm = prepare_model_for_kbit_training(
+ self.llm, use_activation_checkpointing)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.llm)
+ lora_config.target_modules = modules
+ self.llm = get_peft_model(self.llm, lora_config)
+
+ def _prepare_visual_encoder_for_lora(self,
+ lora_config,
+ use_activation_checkpointing=True):
+ lora_config = self._parse_lora_config(lora_config)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.visual_encoder)
+ lora_config.target_modules = modules
+ self.visual_encoder = get_peft_model(self.visual_encoder, lora_config)
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.llm.gradient_checkpointing_enable()
+ self.visual_encoder.gradient_checkpointing_enable()
+ self.projector.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.llm.gradient_checkpointing_disable()
+ self.visual_encoder.gradient_checkpointing_disable()
+ self.projector.gradient_checkpointing_disable()
+
+ def init_weights(self):
+ pass
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ to_return = OrderedDict()
+ # Step 1. visual_encoder
+ if self.use_visual_encoder_lora:
+ to_return.update(
+ get_peft_model_state_dict(
+ self.visual_encoder, state_dict=state_dict))
+ elif not self.freeze_visual_encoder:
+ to_return.update({
+ k: v
+ for k, v in state_dict.items() if 'visual_encoder.' in k
+ })
+ # Step 2. LLM
+ if self.use_llm_lora:
+ to_return.update(
+ get_peft_model_state_dict(self.llm, state_dict=state_dict))
+ elif not self.freeze_llm:
+ to_return.update(
+ {k: v
+ for k, v in state_dict.items() if 'llm.' in k})
+ # Step 3. Projector
+ to_return.update(
+ {k: v
+ for k, v in state_dict.items() if 'projector.' in k})
+ return to_return
+
+ @staticmethod
+ def _prepare_for_long_context_training(cfg, llm_cfg,
+ max_position_embeddings):
+
+ orig_rope_scaling = getattr(llm_cfg, 'rope_scaling', None)
+ if orig_rope_scaling is None:
+ orig_rope_scaling = {'factor': 1}
+
+ orig_rope_scaling_factor = orig_rope_scaling[
+ 'factor'] if 'factor' in orig_rope_scaling.keys() else 1
+ orig_ctx_len = getattr(llm_cfg, 'max_position_embeddings', None)
+ if orig_ctx_len:
+ orig_ctx_len *= orig_rope_scaling_factor
+ if max_position_embeddings > orig_ctx_len:
+ scaling_factor = float(
+ math.ceil(max_position_embeddings / orig_ctx_len))
+ llm_cfg.rope_scaling = {
+ 'type': 'linear',
+ 'factor': scaling_factor
+ }
+
+ # hardcode for internlm2
+ llm_cfg.attn_implementation = 'flash_attention_2'
+ cfg.config = llm_cfg
+
+ return cfg, llm_cfg
+
+ @staticmethod
+ def _prepare_for_flash_attn(cfg, llm_cfg):
+ cls_name = type(llm_cfg).__name__
+ SUPPORT_SDPA_ATTN = ('LlamaConfig', 'GemmaConfig', 'MistralConfig',
+ 'MixtralConfig', 'Qwen2Config', 'Qwen2MoeConfig',
+ 'Starcoder2Config', 'Starcoder2Config',
+ 'Phi3Config')
+ SUPPORT_FLASH_ATTN2 = ('InternLM2Config', 'LlamaConfig', 'GemmaConfig',
+ 'MistralConfig', 'MixtralConfig', 'Qwen2Config',
+ 'Qwen2MoeConfig', 'Starcoder2Config',
+ 'Starcoder2Config', 'Phi3Config')
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ if getattr(cfg, 'attn_implementation', None) is not None:
+ # Flash Attention 2.0 only supports torch.float16 and
+ # torch.bfloat16 dtypes
+ if cfg.attn_implementation == 'flash_attention_2':
+ cfg.torch_dtype = torch_dtype
+ elif SUPPORT_FLASH2 and cls_name in SUPPORT_FLASH_ATTN2:
+ cfg.torch_dtype = torch_dtype
+ cfg.attn_implementation = 'flash_attention_2'
+ elif SUPPORT_FLASH1 and cls_name in SUPPORT_SDPA_ATTN:
+ cfg.attn_implementation = 'sdpa'
+
+ return cfg, llm_cfg
+
+ @staticmethod
+ def _prepare_for_qlora_zero3(cfg):
+ if (not is_deepspeed_zero3_enabled()) or (not hasattr(
+ cfg, 'quantization_config')):
+ return cfg
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ cfg.torch_dtype = torch_dtype
+ quantization_config = cfg.quantization_config
+ quantization_config.bnb_4bit_compute_dtype = torch_dtype
+ quantization_config.bnb_4bit_quant_storage = torch_dtype
+
+ return cfg
+
+ def _dispatch_lm_model_cfg(self, cfg, max_position_embeddings=None):
+ cfg = self._prepare_for_qlora_zero3(cfg)
+ pretrained_model_name_or_path = cfg.pretrained_model_name_or_path
+ llm_cfg = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=True)
+ cfg, llm_cfg = self._prepare_for_flash_attn(cfg, llm_cfg)
+ if max_position_embeddings is not None:
+ cfg, llm_cfg = self._prepare_for_long_context_training(
+ cfg, llm_cfg, max_position_embeddings)
+ return cfg
+
+ def _build_from_cfg_or_module(self, cfg_or_mod):
+ if isinstance(cfg_or_mod, nn.Module):
+ return cfg_or_mod
+ elif isinstance(cfg_or_mod, dict):
+ traverse_dict(cfg_or_mod)
+ return BUILDER.build(cfg_or_mod)
+ else:
+ raise NotImplementedError
+
+ def forward(self, data, data_samples=None, mode='loss'):
+ if self.is_first_iter:
+ # hardcode for qlora DeepSpeed ZeRO3, put buffers and QuantState to
+ # device
+ # Only required in `LLaVAModel` .
+ # We do not need this in `SupervisedFinetune` .
+ self.to(data['input_ids'].device)
+ self.is_first_iter = False
+
+ if 'pixel_values' in data:
+ visual_outputs = self.visual_encoder(
+ data['pixel_values'].to(self.visual_encoder.dtype),
+ output_hidden_states=True)
+ pixel_values = self.projector(
+ visual_outputs.hidden_states[self.visual_select_layer][:, 1:])
+ data['pixel_values'] = pixel_values
+ data = prepare_inputs_labels_for_multimodal(llm=self.llm, **data)
+
+ if mode == 'loss':
+ return self.compute_loss(data, data_samples)
+ elif mode == 'predict':
+ return self.predict(data, data_samples)
+ elif mode == 'tensor':
+ return self._forward(data, data_samples)
+ else:
+ raise NotImplementedError
+
+ def _forward(self, data, data_samples=None):
+
+ outputs = self.llm(**data)
+
+ return outputs
+
+ def predict(self, data, data_samples=None):
+ outputs = self.llm(**data)
+ logits_dict = [{'logits': logits} for logits in outputs.logits]
+ return logits_dict
+
+ def compute_loss(self, data, data_samples=None):
+ outputs = self.llm(**data)
+ loss_dict = {'loss': outputs.loss}
+ return loss_dict
+
+ def __getattr__(self, name: str):
+ try:
+ return super().__getattr__(name)
+ except AttributeError:
+ return getattr(self.llm, name)
+
+ def to_hf(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={},
+ save_format='xtuner',
+ **kwargs):
+ if save_format == 'xtuner':
+ self.to_xtuner_llava(cfg, save_dir, fp32, save_pretrained_kwargs)
+ elif save_format == 'huggingface':
+ self.to_huggingface_llava(cfg, save_dir, fp32,
+ save_pretrained_kwargs)
+ elif save_format == 'official':
+ self.to_official_llava(cfg, save_dir, fp32, save_pretrained_kwargs)
+ else:
+ raise NotImplementedError
+
+ def to_xtuner_llava(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={}):
+ # LLM
+ self.llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ self.llm.half()
+ if self.use_llm_lora:
+ llm_path = osp.join(save_dir, 'llm_adapter')
+ print_log(f'Saving LLM adapter to {llm_path}', 'current')
+ self.llm.save_pretrained(llm_path, **save_pretrained_kwargs)
+ elif not self.freeze_llm:
+ llm_path = save_dir
+ print_log(f'Saving LLM tokenizer to {llm_path}', 'current')
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ tokenizer.save_pretrained(llm_path, **save_pretrained_kwargs)
+ print_log(f'Saving LLM to {llm_path}', 'current')
+ self.llm.save_pretrained(llm_path, **save_pretrained_kwargs)
+ self.llm.config.use_cache = False
+
+ # Visual Encoder
+ if self.use_visual_encoder_lora:
+ visual_encoder_path = osp.join(save_dir, 'visual_encoder_adapter')
+ print_log(
+ f'Saving visual_encoder adapter to {visual_encoder_path}',
+ 'current')
+ self.visual_encoder.save_pretrained(visual_encoder_path,
+ **save_pretrained_kwargs)
+ elif not self.freeze_visual_encoder:
+ visual_encoder_path = osp.join(save_dir, 'visual_encoder')
+ print_log(
+ 'Saving visual_encoder image_processor to'
+ f'{visual_encoder_path}', 'current')
+ image_processor = BUILDER.build(cfg.image_processor)
+ image_processor.save_pretrained(visual_encoder_path,
+ **save_pretrained_kwargs)
+ print_log(f'Saving visual_encoder to {visual_encoder_path}',
+ 'current')
+ self.visual_encoder.save_pretrained(visual_encoder_path,
+ **save_pretrained_kwargs)
+
+ # Projector
+ projector_path = osp.join(save_dir, 'projector')
+ print_log(f'Saving projector to {projector_path}', 'current')
+ self.projector.save_pretrained(projector_path,
+ **save_pretrained_kwargs)
+
+ def to_huggingface_llava(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={}):
+
+ LLM_MAPPING = {
+ 'model': 'language_model.model',
+ 'lm_head': 'language_model.lm_head',
+ }
+ VIT_MAPPING = {
+ 'vision_model': 'vision_tower.vision_model',
+ }
+ PROJECTOR_MAPPING = {
+ 'model.0': 'multi_modal_projector.linear_1',
+ 'model.2': 'multi_modal_projector.linear_2',
+ }
+
+ assert getattr(self.llm, 'hf_quantizer', None) is None, \
+ 'This conversion format does not support quantized LLM.'
+
+ # get state_dict
+ llm = self.llm
+ if self.use_llm_lora:
+ llm = self.llm.merge_and_unload()
+ llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ llm.half()
+
+ assert isinstance(llm, LlamaForCausalLM), \
+ 'This conversion format only supports LlamaForCausalLM.'
+ llm_state_dict = llm.state_dict()
+ llm_state_dict = convert_state_dict_to_hf(llm_state_dict, LLM_MAPPING)
+
+ need_visual_encoder = (not self.freeze_visual_encoder
+ or self.use_visual_encoder_lora)
+ visual_encoder = self.visual_encoder
+ if self.use_visual_encoder_lora:
+ visual_encoder = self.visual_encoder.merge_and_unload()
+ assert isinstance(visual_encoder, CLIPVisionModel),\
+ 'This conversion format only supports CLIPVisionModel.'
+ if need_visual_encoder:
+ visual_encoder_state_dict = visual_encoder.state_dict()
+ visual_encoder_state_dict = convert_state_dict_to_hf(
+ visual_encoder_state_dict, VIT_MAPPING)
+ else:
+ visual_encoder_state_dict = {}
+
+ projector_state_dict = self.projector.state_dict()
+ projector_state_dict = convert_state_dict_to_hf(
+ projector_state_dict, PROJECTOR_MAPPING)
+
+ state_dict = {
+ **projector_state_dict,
+ **llm_state_dict,
+ **visual_encoder_state_dict
+ }
+
+ # init model
+ text_config = llm.config
+ vision_config = visual_encoder.config
+ config = LlavaConfig(
+ text_config=text_config,
+ vision_config=vision_config,
+ attn_implementation='eager')
+
+ with init_empty_weights():
+ with warnings.catch_warnings():
+ warnings.filterwarnings(
+ 'ignore', message='.*non-meta.*', category=UserWarning)
+ model = LlavaForConditionalGeneration(config)
+ model.load_state_dict(state_dict, strict=True, assign=True)
+
+ # processor
+ cfg.tokenizer.type = LlamaTokenizerFast.from_pretrained
+ tokenizer = BUILDER.build(cfg.tokenizer)
+
+ tokenizer.add_tokens(
+ AddedToken(DEFAULT_IMAGE_TOKEN, special=True, normalized=False),
+ special_tokens=True)
+ tokenizer.add_special_tokens({'pad_token': ''})
+
+ image_processor = BUILDER.build(cfg.image_processor)
+ assert isinstance(image_processor, CLIPImageProcessor),\
+ 'This conversion format only supports CLIPImageProcessor.'
+
+ processor = LlavaProcessor(
+ tokenizer=tokenizer, image_processor=image_processor)
+
+ # Pad to 64 for performance reasons
+ pad_shape = 64
+
+ pre_expansion_embeddings = \
+ model.language_model.model.embed_tokens.weight.data
+ mu = torch.mean(pre_expansion_embeddings, dim=0).float()
+ n = pre_expansion_embeddings.size()[0]
+ sigma = ((pre_expansion_embeddings - mu).T
+ @ (pre_expansion_embeddings - mu)) / n
+ dist = torch.distributions.multivariate_normal.MultivariateNormal(
+ mu, covariance_matrix=1e-5 * sigma)
+
+ # We add an image token so we need to resize the model
+ ori_vocab_size = config.text_config.vocab_size
+ tokenizer_vocab_size = tokenizer.encode('')[-1]
+ added_token = tokenizer_vocab_size - ori_vocab_size
+
+ if added_token > 0:
+ model.resize_token_embeddings(ori_vocab_size + added_token,
+ pad_shape)
+ model.language_model.model.embed_tokens.weight.data[
+ ori_vocab_size:] = torch.stack(
+ tuple(
+ dist.sample()
+ for _ in range(model.language_model.model.embed_tokens.
+ weight.data[ori_vocab_size:].shape[0])),
+ dim=0,
+ )
+ model.language_model.lm_head.weight.data[
+ ori_vocab_size:] = torch.stack(
+ tuple(dist.sample()
+ for _ in range(model.language_model.lm_head.weight.
+ data[ori_vocab_size:].shape[0])),
+ dim=0,
+ )
+ model.config.image_token_index = tokenizer.encode(
+ DEFAULT_IMAGE_TOKEN)[-1]
+ model.config.pad_token_id = tokenizer.encode('')[-1]
+
+ # save
+ print_log(f'Saving to {save_dir}', 'current')
+ model.save_pretrained(save_dir, **save_pretrained_kwargs)
+ processor.save_pretrained(save_dir, **save_pretrained_kwargs)
+
+ def to_official_llava(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={}):
+
+ VIT_MAPPING = {
+ 'vision_model': 'model.vision_tower.vision_tower.vision_model',
+ }
+ PROJECTOR_MAPPING = {
+ 'model.0': 'model.mm_projector.0',
+ 'model.2': 'model.mm_projector.2',
+ }
+
+ try:
+ from llava.model import LlavaConfig, LlavaLlamaForCausalLM
+ except ImportError:
+ raise ImportError(
+ 'Please install llava with '
+ '`pip install git+https://github.com/haotian-liu/LLaVA.git '
+ '--no-deps`.')
+
+ assert getattr(self.llm, 'hf_quantizer', None) is None, \
+ 'This conversion format does not support quantized LLM.'
+
+ # get state_dict
+ llm = self.llm
+ if self.use_llm_lora:
+ llm = self.llm.merge_and_unload()
+ llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ llm.half()
+
+ assert isinstance(llm, LlamaForCausalLM), \
+ 'This conversion format only supports LlamaForCausalLM.'
+ llm_state_dict = llm.state_dict()
+
+ need_visual_encoder = (not self.freeze_visual_encoder
+ or self.use_visual_encoder_lora)
+ visual_encoder = self.visual_encoder
+ if self.use_visual_encoder_lora:
+ visual_encoder = self.visual_encoder.merge_and_unload()
+ assert isinstance(visual_encoder, CLIPVisionModel),\
+ 'This conversion format only supports CLIPVisionModel.'
+ if need_visual_encoder:
+ visual_encoder_state_dict = visual_encoder.state_dict()
+ visual_encoder_state_dict = convert_state_dict_to_hf(
+ visual_encoder_state_dict, VIT_MAPPING)
+ else:
+ visual_encoder_state_dict = {}
+
+ projector_state_dict = self.projector.state_dict()
+ projector_state_dict = convert_state_dict_to_hf(
+ projector_state_dict, PROJECTOR_MAPPING)
+
+ state_dict = {
+ **projector_state_dict,
+ **llm_state_dict,
+ **visual_encoder_state_dict
+ }
+
+ # init model
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ image_processor = BUILDER.build(cfg.image_processor)
+ assert isinstance(image_processor, CLIPImageProcessor),\
+ 'This conversion format only supports CLIPImageProcessor.'
+
+ llava_config_dict = llm.config.__dict__.copy()
+ llava_config_dict.update(
+ dict(
+ image_aspect_ratio='pad',
+ mm_hidden_size=visual_encoder.config.hidden_size,
+ mm_projector_type=f'mlp{self.projector_depth}x_gelu',
+ mm_use_im_patch_token=False,
+ mm_use_im_start_end=False,
+ mm_vision_select_feature='patch',
+ mm_vision_select_layer=self.visual_select_layer,
+ mm_vision_tower=visual_encoder.config.name_or_path,
+ unfreeze_mm_vision_tower=need_visual_encoder,
+ model_type='llava',
+ use_cache=True,
+ use_mm_proj=True))
+
+ llava_config = LlavaConfig(**llava_config_dict)
+
+ with init_empty_weights():
+ with warnings.catch_warnings():
+ warnings.filterwarnings(
+ 'ignore', message='.*non-meta.*', category=UserWarning)
+ model = LlavaLlamaForCausalLM(llava_config)
+
+ model.load_state_dict(state_dict, strict=True, assign=True)
+
+ # save
+ print_log(f'Saving to {save_dir}', 'current')
+
+ model.save_pretrained(save_dir, **save_pretrained_kwargs)
+ image_processor.save_pretrained(save_dir, **save_pretrained_kwargs)
+ tokenizer.save_pretrained(save_dir, **save_pretrained_kwargs)
diff --git a/data/xtuner/xtuner/model/modules/__init__.py b/data/xtuner/xtuner/model/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1207a9249708ff22b19db94a028b8d06f86f53a8
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/__init__.py
@@ -0,0 +1,4 @@
+from .dispatch import dispatch_modules
+from .projector import ProjectorConfig, ProjectorModel
+
+__all__ = ['dispatch_modules', 'ProjectorConfig', 'ProjectorModel']
diff --git a/data/xtuner/xtuner/model/modules/dispatch/__init__.py b/data/xtuner/xtuner/model/modules/dispatch/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e81ec7a3aa69fe25ee4a95759cdcb377e4e1ddd7
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/__init__.py
@@ -0,0 +1,276 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import types
+
+import torch
+import transformers
+from mmengine.config.lazy import LazyObject
+from mmengine.utils import digit_version
+from transformers.utils.import_utils import is_flash_attn_2_available
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.38')
+# Transformers requires torch version >= 2.1.1 when using Torch SDPA.
+# Refer to https://github.com/huggingface/transformers/blob/caa5c65db1f4db617cdac2ad667ba62edf94dd98/src/transformers/modeling_utils.py#L1611 # noqa: E501
+SUPPORT_FLASH1 = digit_version(torch.__version__) >= digit_version('2.1.1')
+SUPPORT_FLASH2 = is_flash_attn_2_available()
+SUPPORT_FLASH = SUPPORT_FLASH1 or SUPPORT_FLASH2
+
+USE_TRITON_KERNEL = bool(os.getenv('USE_TRITON_KERNEL', default=0))
+SUPPORT_TRITON = False
+try:
+ import triton # pre-check # noqa: F401
+ import triton.language as tl # pre-check # noqa: F401
+ SUPPORT_TRITON = True
+except ImportError:
+ if USE_TRITON_KERNEL:
+ raise RuntimeError(
+ 'USE_TRITON_KERNEL is set to 1, but triton has not been installed.'
+ ' Run `pip install triton==2.1.0` to install triton.')
+
+NO_ATTN_WEIGHTS_MSG = (
+ 'Due to the implementation of the PyTorch version of flash attention, '
+ 'even when the `output_attentions` flag is set to True, it is not '
+ 'possible to return the `attn_weights`.')
+
+LOWEST_TRANSFORMERS_VERSION = dict(
+ InternLM2ForCausalLM=digit_version('4.36'),
+ InternLMForCausalLM=digit_version('4.36'),
+ LlamaForCausalLM=digit_version('4.36'),
+ Phi3ForCausalLM=digit_version('4.39'),
+ MistralForCausalLM=digit_version('4.36'),
+ # Training mixtral with lower version may lead to nccl timeout
+ # Refer to https://github.com/microsoft/DeepSpeed/issues/5066
+ MixtralForCausalLM=digit_version('4.40'),
+ CohereForCausalLM=digit_version('4.40'),
+ Qwen2ForCausalLM=digit_version('4.39'),
+ Qwen2MoeForCausalLM=digit_version('4.40'),
+ DeepseekV2ForCausalLM=digit_version('4.40'),
+)
+
+ATTN_DISPATCH_MAPPING = dict(
+ InternLM2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.internlm2', 'internlm2_attn_forward'),
+ InternLMAttention=LazyObject('xtuner.model.modules.dispatch.internlm',
+ 'internlm_attn_forward'),
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_attn_forward'),
+ Phi3FlashAttention2=LazyObject('xtuner.model.modules.dispatch.phi3',
+ 'phi3_attn_forward'),
+ MistralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_attn_forward'),
+ MixtralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_attn_forward'),
+ CohereFlashAttention2=LazyObject('xtuner.model.modules.dispatch.cohere',
+ 'cohere_attn_forward'),
+ Qwen2FlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_attn_forward'),
+ Qwen2MoeFlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_attn_forward'),
+ DeepseekV2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.deepseek_v2', 'deepseek_attn_forward'),
+)
+
+ATTN_LEGACY_DISPATCH_MAPPING = dict(
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_attn_forward_legacy'), )
+
+VARLEN_ATTN_DISPATCH_MAPPING = dict(
+ InternLM2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.internlm2',
+ 'internlm2_varlen_attn_forward'),
+ InternLMAttention=LazyObject('xtuner.model.modules.dispatch.internlm',
+ 'internlm_varlen_attn_forward'),
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_varlen_attn_forward'),
+ Phi3FlashAttention2=LazyObject('xtuner.model.modules.dispatch.phi3',
+ 'phi3_varlen_attn_forward'),
+ MistralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_varlen_attn_forward'),
+ MixtralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_varlen_attn_forward'),
+ CohereFlashAttention2=None,
+ Qwen2FlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_varlen_attn_forward'),
+ Qwen2MoeFlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_varlen_attn_forward'),
+ DeepseekV2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.deepseek_v2',
+ 'deepseek_varlen_attn_forward'),
+)
+
+VARLEN_ATTN_LEGACY_DISPATCH_MAPPING = dict(
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_varlen_attn_forward_legacy'), )
+
+RMS_DISPATCH_MAPPING = dict(
+ InternLM2RMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ InternLMRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ LlamaRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ Phi3RMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ MistralRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ MixtralRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ CohereLayerNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'layer_norm_forward'),
+ Qwen2RMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ Qwen2MoeRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+)
+
+ROTE_DISPATCH_MAPPING = dict(
+ InternLMRotaryEmbedding=LazyObject(
+ 'xtuner.model.modules.dispatch.internlm', 'InternLMRotaryEmbedding'),
+ MistralRotaryEmbedding=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'MistralRotaryEmbedding'),
+ MixtralRotaryEmbedding=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'MistralRotaryEmbedding'),
+)
+
+
+def log_once(func):
+ logged = False
+
+ def wrapper(*args, **kwargs):
+ nonlocal logged
+ if not logged:
+ logged = True
+ func(*args, **kwargs)
+ return
+
+ return wrapper
+
+
+def dispatch_attn_forward(model):
+
+ if not SUPPORT_FLASH2:
+ return
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ attn_forward = None
+ for module in model.modules():
+ name = type(module).__name__
+ if (IS_LOW_VERSION_TRANSFORMERS
+ and name in ATTN_LEGACY_DISPATCH_MAPPING):
+ if attn_forward is None:
+ attn_forward = ATTN_LEGACY_DISPATCH_MAPPING[name]
+ attn_forward = attn_forward.build()
+ print_log(f'Dispatch {name} legacy forward. {NO_ATTN_WEIGHTS_MSG}',
+ 'current')
+ module.forward = types.MethodType(attn_forward, module)
+ elif name in ATTN_DISPATCH_MAPPING:
+ if attn_forward is None:
+ attn_forward = ATTN_DISPATCH_MAPPING[name]
+ attn_forward = attn_forward.build()
+ print_log(f'Dispatch {name} forward. {NO_ATTN_WEIGHTS_MSG}',
+ 'current')
+ module.forward = types.MethodType(attn_forward, module)
+
+
+def dispatch_varlen_attn_forward(model):
+
+ if not SUPPORT_FLASH2:
+ return
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ varlen_attn_forward = None
+ for module in model.modules():
+ name = type(module).__name__
+ if (IS_LOW_VERSION_TRANSFORMERS
+ and name in VARLEN_ATTN_LEGACY_DISPATCH_MAPPING):
+ if varlen_attn_forward is None:
+ varlen_attn_forward = VARLEN_ATTN_LEGACY_DISPATCH_MAPPING[name]
+ varlen_attn_forward = varlen_attn_forward.build()
+ print_log(
+ f'Dispatch legacy {name} varlen forward. '
+ f'{NO_ATTN_WEIGHTS_MSG}', 'current')
+ module.forward = types.MethodType(varlen_attn_forward, module)
+ elif name in VARLEN_ATTN_DISPATCH_MAPPING:
+ if varlen_attn_forward is None:
+ varlen_attn_forward = VARLEN_ATTN_DISPATCH_MAPPING[name]
+ varlen_attn_forward = varlen_attn_forward.build()
+ print_log(f'Dispatch {name} varlen forward. {NO_ATTN_WEIGHTS_MSG}',
+ 'current')
+ module.forward = types.MethodType(varlen_attn_forward, module)
+
+
+def dispatch_rmsnorm_forward(model):
+
+ if (not SUPPORT_TRITON) or (not USE_TRITON_KERNEL):
+ return
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ rms_forward = None
+ for module in model.modules():
+ name = type(module).__name__
+ if name in RMS_DISPATCH_MAPPING:
+ if rms_forward is None:
+ rms_forward = RMS_DISPATCH_MAPPING[name]
+ rms_forward = rms_forward.build()
+ print_log(f'Dispatch {name} forward.', 'current')
+ module.forward = types.MethodType(rms_forward, module)
+
+
+def replace_rote(model):
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ def traverse(module):
+ for name, child in module.named_children():
+ cls_name = type(child).__name__
+ if cls_name in ROTE_DISPATCH_MAPPING:
+ assert hasattr(model.config, 'rope_theta'), \
+ '`rope_theta` should be in the model config.'
+ rope_theta = model.config.rope_theta
+
+ rote = ROTE_DISPATCH_MAPPING[cls_name]
+ rote = rote.build()
+ print_log(f'replace {cls_name}', 'current')
+ dim_model = child.inv_freq.shape[0] * 2
+ child_new = rote(dim_model, child.max_seq_len_cached,
+ rope_theta).to(
+ device=child.inv_freq.device,
+ dtype=child.inv_freq.dtype)
+ setattr(module, name, child_new)
+ else:
+ traverse(child)
+
+ traverse(model)
+
+
+def dispatch_modules(model, use_varlen_attn=False):
+
+ def check(model_name):
+ if 'ForCausalLM' not in model_name and model_name.endswith('Model'):
+ # a walkaround for reward model
+ model_name = model_name[:-5] + 'ForCausalLM'
+ msg = '{} requires transformers version at least {}, but got {}'
+ if model_name in LOWEST_TRANSFORMERS_VERSION:
+ assert TRANSFORMERS_VERSION >= LOWEST_TRANSFORMERS_VERSION[
+ model_name], msg.format(
+ model_name, LOWEST_TRANSFORMERS_VERSION[model_name],
+ TRANSFORMERS_VERSION)
+
+ check(type(model).__name__)
+ if use_varlen_attn:
+ dispatch_varlen_attn_forward(model)
+ else:
+ dispatch_attn_forward(model)
+ dispatch_rmsnorm_forward(model)
+ replace_rote(model)
+
+
+__all__ = ['dispatch_modules']
diff --git a/data/xtuner/xtuner/model/modules/dispatch/attention.py b/data/xtuner/xtuner/model/modules/dispatch/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..e89bb511cc946e521438c442caca97c1f594403b
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/attention.py
@@ -0,0 +1,97 @@
+from xtuner.parallel.sequence import sequence_parallel_wrapper
+from .utils import upad_qkv
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+
+@sequence_parallel_wrapper
+def flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ dropout_p=0.0,
+ softmax_scale=None,
+ causal=True,
+ window_size=(-1, -1), # -1 means infinite context window
+):
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout_p=dropout_p,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=window_size)
+ return attn_output
+
+
+@sequence_parallel_wrapper
+def flash_attn_w_mask(
+ query_states, # bs, q_len, nhead, h_dim
+ key_states,
+ value_states,
+ attention_mask,
+ softmax_scale=None,
+ causal=True,
+ dropout_p=0.0,
+ window_size=(-1, -1), # -1 means infinite context window
+):
+ batch_size, q_len = query_states.shape[:2]
+ query_states, key_states, value_states, indices_q, \
+ cu_seq_lens, max_seq_lens = upad_qkv(
+ query_states, key_states, value_states, attention_mask, q_len)
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ softmax_scale=softmax_scale,
+ dropout_p=dropout_p,
+ causal=causal,
+ window_size=window_size)
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, q_len)
+ return attn_output
+
+
+@sequence_parallel_wrapper
+def varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ softmax_scale=None,
+ dropout_p=0.,
+ causal=True,
+ window_size=(-1, -1), # -1 means infinite context window
+):
+ q_unpad, k_unpad, v_unpad = query_states.flatten(0, 1), key_states.flatten(
+ 0, 1), value_states.flatten(0, 1)
+ attn_output = flash_attn_varlen_func(
+ q_unpad,
+ k_unpad,
+ v_unpad,
+ cumulative_len,
+ cumulative_len,
+ max_seqlen,
+ max_seqlen,
+ softmax_scale=softmax_scale,
+ dropout_p=dropout_p,
+ return_attn_probs=False,
+ causal=causal,
+ window_size=window_size)
+ attn_output = attn_output.unsqueeze(0)
+ return attn_output
diff --git a/data/xtuner/xtuner/model/modules/dispatch/baichuan.py b/data/xtuner/xtuner/model/modules/dispatch/baichuan.py
new file mode 100644
index 0000000000000000000000000000000000000000..738c49869882a16bcea06f9efb18e41d8a76d1e8
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/baichuan.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def baichuan2_norm_head_forward(self, hidden_states):
+ norm_weight = nn.functional.normalize(self.weight)
+ return nn.functional.linear(hidden_states, norm_weight)
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos_, sin_, position_ids):
+ cos = cos_.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin_.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ q_embed = (q.float() * cos) + (rotate_half(q.float()) * sin)
+ k_embed = (k.float() * cos) + (rotate_half(k.float()) * sin)
+ return q_embed.to(q.dtype), k_embed.to(k.dtype)
+
+
+def baichuan_7b_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ proj = self.W_pack(hidden_states)
+ proj = proj.unflatten(-1, (3, self.hidden_size)).unsqueeze(0).transpose(
+ 0, -2).squeeze(-2)
+ query_states = proj[0].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = proj[1].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = proj[2].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+ # [bsz, nh, t, hd]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+ return attn_output, None, past_key_value
+
+
+def baichuan_13b_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ proj = self.W_pack(hidden_states)
+ proj = proj.unflatten(-1, (3, self.hidden_size)).unsqueeze(0).transpose(
+ 0, -2).squeeze(-2)
+ query_states = proj[0].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = proj[1].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = proj[2].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+ if attention_mask is not None:
+ if q_len == 1: # inference with cache
+ if len(attention_mask.size()) == 4:
+ attention_mask = attention_mask[:, :, -1:, :]
+ else:
+ attention_mask = attention_mask[:, -1:, :]
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/cohere.py b/data/xtuner/xtuner/model/modules/dispatch/cohere.py
new file mode 100644
index 0000000000000000000000000000000000000000..8acf067474409e4f5a7a108b2b86c762c2fad37c
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/cohere.py
@@ -0,0 +1,153 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import transformers
+from mmengine.utils import digit_version
+from transformers.models.cohere.modeling_cohere import apply_rotary_pos_emb
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+from xtuner.parallel.sequence.attention import (
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+
+try:
+ from transformers.cache_utils import Cache
+except ImportError:
+
+ class Cache:
+ pass
+
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+
+def cohere_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+):
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+ if self.use_qk_norm:
+ query_states = self.q_norm(query_states)
+ key_states = self.k_norm(key_states)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ past_key_value = getattr(self, 'past_key_value', past_key_value)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; position_ids needed for
+ # the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # TODO: These transpose are quite inefficient but Flash Attention requires
+ # the layout [batch_size, sequence_length, num_heads, head_dim].
+ # We would need to refactor the KV cache to be able to avoid many of
+ # these transpose/reshape/view.
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # Ignore copy
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # self.num_heads is used in self._upad_input method
+ # num_heads has been changed because of sequence parallel
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate)
+ else:
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ is_causal=self.is_causal,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/deepseek_v2.py b/data/xtuner/xtuner/model/modules/dispatch/deepseek_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfa3ebb6db8c4a7c1bb4e04a004d24e3f774755a
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/deepseek_v2.py
@@ -0,0 +1,308 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+from transformers.cache_utils import Cache
+
+from xtuner.model.transformers_models.deepseek_v2.modeling_deepseek import \
+ apply_rotary_pos_emb
+from xtuner.parallel.sequence import (get_sequence_parallel_world_size,
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+
+
+def deepseek_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ # DeepseekV2FlashAttention2 attention does not support output_attentions
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None, '`position_ids` should not be None.'
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+
+ if self.q_head_dim != self.v_head_dim:
+ value_states = F.pad(value_states,
+ [0, self.q_head_dim - self.v_head_dim])
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (DeepseekV2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_a_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # self.num_heads is used in self._upad_input method
+ # num_heads has been changed because of sequence parallel
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ softmax_scale=self.softmax_scale,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ if self.q_head_dim != self.v_head_dim:
+ attn_output = attn_output[:, :, :, :self.v_head_dim]
+
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads *
+ self.v_head_dim).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def deepseek_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (cumulative_len is not None) == (
+ past_key_value is None)
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None, '`position_ids` should not be None.'
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+
+ if self.q_head_dim != self.v_head_dim:
+ value_states = F.pad(value_states,
+ [0, self.q_head_dim - self.v_head_dim])
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (DeepseekV2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_a_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # ----------------- varlen flash attention forward ----------------------#
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ if is_training:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ softmax_scale=self.softmax_scale,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=True)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ softmax_scale=self.softmax_scale,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=False)
+
+ # ---------------- varlen flash attention forward end ------------------ #
+
+ if self.q_head_dim != self.v_head_dim:
+ attn_output = attn_output[:, :, :, :self.v_head_dim]
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.num_heads * self.v_head_dim)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/internlm.py b/data/xtuner/xtuner/model/modules/dispatch/internlm.py
new file mode 100644
index 0000000000000000000000000000000000000000..37ca9ad310e056bc357235fa935004da79a3edd7
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/internlm.py
@@ -0,0 +1,227 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+
+from .triton_kernels import apply_rotary_emb
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+
+class InternLMRotaryEmbedding(torch.nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+ self.inv_freq = 1.0 / (
+ base**(torch.arange(0, dim, 2).float().to(device) / dim))
+
+ # Build here to make `torch.jit.trace` work.
+ self.max_seq_len_cached = max_position_embeddings
+ t = torch.arange(
+ self.max_seq_len_cached,
+ device=self.inv_freq.device,
+ dtype=self.inv_freq.dtype)
+ freqs = torch.einsum('i,j->ij', t, self.inv_freq)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.cos_cached = emb.cos()
+ self.sin_cached = emb.sin()
+
+ def forward(self, x, seq_len):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if (seq_len > self.max_seq_len_cached
+ or self.cos_cached.device != x.device
+ or self.cos_cached.dtype != x.dtype):
+ self.max_seq_len_cached = seq_len
+ assert self.inv_freq.dtype == torch.float32
+ t = torch.arange(
+ self.max_seq_len_cached,
+ device=x.device,
+ dtype=self.inv_freq.dtype)
+ freqs = torch.einsum('i,j->ij', t, self.inv_freq.to(t.device))
+ emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
+ self.cos_cached = emb.cos().to(x.dtype)
+ self.sin_cached = emb.sin().to(x.dtype)
+ return (
+ self.cos_cached[:seq_len, ...],
+ self.sin_cached[:seq_len, ...],
+ )
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def internlm_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # Modified from https://huggingface.co/internlm/internlm-7b/blob/939a68c0dc1bd5f35b63c87d44af05ce33379061/modeling_internlm.py#L161 # noqa:E501
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(
+ 1, 2)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(
+ 1, 2)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(
+ 1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+ # [bsz, nh, t, hd]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ if SUPPORT_FLASH2:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, causal=True)
+ attn_output = attn_output.contiguous()
+ else:
+ # use flash attention implemented by pytorch
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+ attn_output = attn_output.transpose(1, 2)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
+
+
+def internlm_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # Modified from https://huggingface.co/internlm/internlm-7b/blob/939a68c0dc1bd5f35b63c87d44af05ce33379061/modeling_internlm.py#L161 # noqa:E501
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ # position_ids = message_hub.get_info(f'position_ids_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ bsz, q_len, _ = hidden_states.size()
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim)
+
+ kv_seq_len = key_states.shape[-3]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ if use_varlen_atten:
+ cos, sin = self.rotary_emb(value_states, max_seqlen)
+ query_states = apply_rotary_emb(query_states,
+ cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ key_states = apply_rotary_emb(key_states, cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ else:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ cos, sin = self.rotary_emb(value_states, kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ assert SUPPORT_FLASH2
+ if use_varlen_atten:
+ q_unpad, k_unpad, v_unpad = query_states.flatten(
+ 0, 1), key_states.flatten(0, 1), value_states.flatten(0, 1)
+ cumulative_len = torch.cat(cumulative_len, dim=0)
+ attn_output = flash_attn_varlen_func(
+ q_unpad,
+ k_unpad,
+ v_unpad,
+ cumulative_len,
+ cumulative_len,
+ max_seqlen,
+ max_seqlen,
+ 0,
+ return_attn_probs=False,
+ causal=True,
+ )
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, causal=True)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/internlm2.py b/data/xtuner/xtuner/model/modules/dispatch/internlm2.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c601f0dc66c056c979a84efbb18b9125cfb44cf
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/internlm2.py
@@ -0,0 +1,306 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+from einops import rearrange
+from mmengine import MessageHub
+from transformers.cache_utils import Cache, StaticCache
+
+from xtuner.parallel.sequence import (get_sequence_parallel_world_size,
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import SUPPORT_FLASH2, flash_attn_wo_mask, varlen_flash_attn
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+def repeat_kv_bshd(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """The hidden states go from (batch, seqlen, num_key_value_heads, head_dim)
+ to (batch, seqlen, num_attention_heads, head_dim)"""
+ batch, slen, num_key_value_heads, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, :,
+ None, :].expand(batch, slen,
+ num_key_value_heads, n_rep,
+ head_dim)
+ return hidden_states.reshape(batch, slen, num_key_value_heads * n_rep,
+ head_dim)
+
+
+def internlm2_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+):
+ if isinstance(past_key_value, StaticCache):
+ raise ValueError(
+ '`static` cache implementation is not compatible with '
+ '`attn_implementation==flash_attention_2` make sure to use `sdpa` '
+ 'in the mean time, and open an issue at '
+ 'https://github.com/huggingface/transformers')
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ 'b q (h gs d) -> b q h gs d',
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., :self.num_key_value_groups, :]
+ query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (InternLM2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.wqkv.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # self.num_heads is used in self._upad_input method
+ # num_heads has been changed because of sequence parallel
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ dropout_rate = 0.0
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate)
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.wo(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def internlm2_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+
+ if isinstance(past_key_value, StaticCache):
+ raise ValueError(
+ '`static` cache implementation is not compatible with '
+ '`attn_implementation==flash_attention_2` make sure to use `sdpa` '
+ 'in the mean time, and open an issue at '
+ 'https://github.com/huggingface/transformers')
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ bsz, q_len, _ = hidden_states.size()
+
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ 'b q (h gs d) -> b q h gs d',
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., :self.num_key_value_groups, :]
+ query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ try:
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ except RuntimeError:
+ raise RuntimeError(
+ 'You are using the old version of InternLM2 model. The '
+ '`modeling_internlm2.py` is outdated. Please update the InternLM2 '
+ 'model.')
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (InternLM2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.wqkv.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+
+ assert SUPPORT_FLASH2
+
+ dropout_rate = 0.0
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.wo(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/llama.py b/data/xtuner/xtuner/model/modules/dispatch/llama.py
new file mode 100644
index 0000000000000000000000000000000000000000..8132096fd484f43535543ed8f6de3efe36491c7b
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/llama.py
@@ -0,0 +1,524 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+from mmengine import MessageHub
+from transformers.models.llama.modeling_llama import (apply_rotary_pos_emb,
+ repeat_kv)
+from transformers.utils import is_flash_attn_greater_or_equal_2_10
+
+from .attention import (SUPPORT_FLASH2, flash_attn_w_mask, flash_attn_wo_mask,
+ varlen_flash_attn)
+from .triton_kernels import apply_rotary_emb
+
+try:
+ from transformers.cache_utils import Cache
+except ImportError:
+
+ class Cache:
+ pass
+
+
+def repeat_kv_bshd(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """The hidden states go from (batch, seqlen, num_key_value_heads, head_dim)
+ to (batch, seqlen, num_attention_heads, head_dim)"""
+ batch, slen, num_key_value_heads, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, :,
+ None, :].expand(batch, slen,
+ num_key_value_heads, n_rep,
+ head_dim)
+ return hidden_states.reshape(batch, slen, num_key_value_heads * n_rep,
+ head_dim)
+
+
+def llama_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+):
+ # Modified from https://github.com/huggingface/transformers/blob/66ce9593fdb8e340df546ddd0774eb444f17a12c/src/transformers/models/llama/modeling_llama.py#L422 # noqa:E501
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ past_key_value = getattr(self, 'past_key_value', past_key_value)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ assert SUPPORT_FLASH2
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ if is_flash_attn_greater_or_equal_2_10():
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `q_len != 1` check once Flash Attention for RoCm
+ # is bumped to 2.1. For details, please see the comment in
+ # LlamaFlashAttention2 __init__.
+ causal = self.is_causal and q_len != 1
+
+ # the shape of attention_mask used by flash_attn and
+ # F.scaled_dot_product_attention are different
+ assert attention_mask is None or attention_mask.ndim == 2, \
+ ('When using flash_attn, attention_mask.ndim should equal to 2.'
+ f'But got attention_mask.shape = {attention_mask.shape}.'
+ 'We can pass the `attn_implementation="flash_attention_2"` flag '
+ 'to `.from_pretrained` method when instantiating a Internlm2 '
+ 'model.')
+
+ if attention_mask is not None:
+ attn_output = flash_attn_w_mask(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def llama_attn_forward_legacy(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # Modified from https://github.com/huggingface/transformers/blob/ced9fd86f55ebb6b656c273f6e23f8ba50652f83/src/transformers/models/llama/modeling_llama.py#L331 # noqa:E501
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+ assert position_ids is not None
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ assert SUPPORT_FLASH2
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ if is_flash_attn_greater_or_equal_2_10():
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `q_len != 1` check once Flash Attention for RoCm
+ # is bumped to 2.1. For details, please see the comment in
+ # LlamaFlashAttention2 __init__.
+ causal = self.is_causal and q_len != 1
+
+ # the shape of attention_mask used by flash_attn and
+ # F.scaled_dot_product_attention are different
+ assert attention_mask is None or attention_mask.ndim == 2, \
+ ('When using flash_attn, attention_mask.ndim should equal to 2.'
+ f'But got attention_mask.shape = {attention_mask.shape}.'
+ 'We can pass the `attn_implementation="flash_attention_2"` flag '
+ 'to `.from_pretrained` method when instantiating a Internlm2 '
+ 'model.')
+
+ if attention_mask is not None:
+ attn_output = flash_attn_w_mask(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask=attention_mask,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
+
+
+def llama_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn('Passing `padding_mask` is deprecated and will be '
+ 'removed in v4.37. Please make sure use '
+ '`attention_mask` instead.`')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ past_key_value = getattr(self, 'past_key_value', past_key_value)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently casted
+ # in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ assert SUPPORT_FLASH2
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=True,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+def llama_varlen_attn_forward_legacy(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn('Passing `padding_mask` is deprecated and will be '
+ 'removed in v4.37. Please make sure use '
+ '`attention_mask` instead.`')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+
+ kv_seq_len = key_states.shape[-3]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ if use_varlen_atten:
+ cos, sin = self.rotary_emb(value_states, max_seqlen)
+ # position_ids (1, seq_len)
+ # cos, sin (1, seq_len, dim) -> (seq_len, dim)
+ cos = cos[position_ids].squeeze(0)
+ sin = sin[position_ids].squeeze(0)
+ query_states = apply_rotary_emb(query_states, cos, sin)
+ key_states = apply_rotary_emb(key_states, cos, sin)
+ else:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ cos, sin = self.rotary_emb(value_states, kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently casted
+ # in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ assert SUPPORT_FLASH2
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/mistral.py b/data/xtuner/xtuner/model/modules/dispatch/mistral.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc6c7fed827f229aeb286a35d2b290126f07e965
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/mistral.py
@@ -0,0 +1,447 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+import warnings
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import transformers
+from mmengine import MessageHub
+from mmengine.utils import digit_version
+from transformers.cache_utils import Cache
+from transformers.models.mistral.modeling_mistral import (apply_rotary_pos_emb,
+ repeat_kv)
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+from xtuner.parallel.sequence.attention import (
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+from .triton_kernels import apply_rotary_emb
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+
+class MistralRotaryEmbedding(nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ self.inv_freq = 1.0 / (
+ base**(torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings,
+ device=self.inv_freq.device,
+ dtype=torch.get_default_dtype())
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ freqs = torch.einsum('i,j->ij', t, self.inv_freq.to(device))
+ # Different from paper, but it uses a different permutation
+ # in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1).to(device)
+ self.cos_cached = emb.cos().to(dtype)
+ self.sin_cached = emb.sin().to(dtype)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if (seq_len > self.max_seq_len_cached
+ or self.cos_cached.device != x.device # noqa: W503
+ or self.cos_cached.dtype != x.dtype): # noqa: W503
+ self._set_cos_sin_cache(
+ seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+def repeat_kv_bshd(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """The hidden states go from (batch, seqlen, num_key_value_heads, head_dim)
+ to (batch, seqlen, num_attention_heads, head_dim)"""
+ batch, slen, num_key_value_heads, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, :,
+ None, :].expand(batch, slen,
+ num_key_value_heads, n_rep,
+ head_dim)
+ return hidden_states.reshape(batch, slen, num_key_value_heads * n_rep,
+ head_dim)
+
+
+def mistral_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads for sequence parallel
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # num_heads has been changed because of sequence parallel
+ # `self.num_heads`` is not used in self._flash_attention_forward
+ # in mistral/mixtral, we are doing this to avoid some unnecessary risk
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length=query_states.shape[1],
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+ else:
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ sliding_window=getattr(self.config, 'sliding_window', None),
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ is_causal=self.is_causal,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def mistral_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (past_key_value is None)
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37'
+ ' Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+ # attention_mask is set to None if no padding token in input_ids
+ assert attention_mask is None
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+
+ assert _flash_supports_window_size, \
+ ('The current flash attention version does not support sliding window '
+ 'attention, for a more memory efficient implementation make sure '
+ 'to upgrade flash-attn library.')
+
+ kv_seq_len = key_states.shape[-3]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ if use_varlen_atten:
+ cos, sin = self.rotary_emb(value_states, max_seqlen)
+ query_states = apply_rotary_emb(query_states,
+ cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ key_states = apply_rotary_emb(key_states, cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ else:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ # Because the input can be padded, the absolute sequence length
+ # depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window # noqa: W503
+ and cache_has_contents): # noqa: W503
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for
+ # training stability reasons, therefore the input hidden states gets
+ # silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # ----------------- flash attention forward ------------------------#
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ use_sliding_windows = (
+ _flash_supports_window_size and # noqa: W504
+ getattr(self.config, 'sliding_window', None) is not None # noqa: W503
+ and kv_seq_len > self.config.sliding_window) # noqa: W503
+ window_size = (self.config.sliding_window,
+ self.config.sliding_window) if use_sliding_windows else (-1,
+ -1)
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+
+ # ---------------- flash attention forward end ------------------- #
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/phi3.py b/data/xtuner/xtuner/model/modules/dispatch/phi3.py
new file mode 100644
index 0000000000000000000000000000000000000000..10f60f93983392643f3c1907b34af1bd48b2f03c
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/phi3.py
@@ -0,0 +1,480 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+import warnings
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+import transformers
+from mmengine import MessageHub
+from mmengine.utils import digit_version
+
+from xtuner.parallel.sequence import (get_sequence_parallel_world_size,
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+
+try:
+ from transformers.cache_utils import Cache
+except ImportError:
+
+ class Cache:
+ pass
+
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+_flash_supports_window_size = False
+try:
+ from flash_attn import flash_attn_func
+
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+
+ if not _flash_supports_window_size:
+ raise ValueError(
+ 'Please update flash-attention to support window size.')
+# else:
+except ImportError:
+ pass
+
+
+# Copied from https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/blob/3a811845d89f3c1b3f41b341d0f9f05104769f35/modeling_phi3.py#L302 # noqa:E501
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+# https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/blob/3a811845d89f3c1b3f41b341d0f9f05104769f35/modeling_phi3.py#L247 # noqa:E501
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/blob/3a811845d89f3c1b3f41b341d0f9f05104769f35/modeling_phi3.py#L255 # noqa:E501
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """ # noqa:E501
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def phi3_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+):
+ if not _flash_supports_window_size:
+ raise ValueError(
+ 'The current flash attention version does not support '
+ 'sliding window attention.')
+
+ output_attentions = False
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv = self.qkv_proj(hidden_states)
+ query_pos = self.num_heads * self.head_dim
+ query_states = qkv[..., :query_pos]
+ key_states = qkv[..., query_pos:query_pos +
+ self.num_key_value_heads * self.head_dim]
+ value_states = qkv[...,
+ query_pos + self.num_key_value_heads * self.head_dim:]
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(
+ value_states, position_ids, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_dropout = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32.
+
+ if query_states.dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.qkv_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ # (b, s // sp_world_size, nd, dim) -> (b, s, nd // sp_world_size, dim)
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states,
+ scatter_dim=2, gather_dim=1)
+ # num_heads has been changed because of sequence parallel
+ # `self.num_heads`` is not used in self._flash_attention_forward
+ # in mistral/mixtral, we are doing this to avoid some unnecessary risk
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=attn_dropout,
+ use_sliding_windows=use_sliding_windows,
+ )
+ else:
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=attn_dropout,
+ sliding_window=getattr(self.config, 'sliding_window', None),
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ is_causal=self.is_causal,
+ )
+
+ if enable_sequence_parallel:
+ # (b, s, nd // sp_world_size, dim) -> (b, s // sp_world_size, nd, dim)
+ attn_output = post_process_for_sequence_parallel_attn(
+ attn_output, scatter_dim=1, gather_dim=2)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def phi3_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ if not _flash_supports_window_size:
+ raise ValueError(
+ 'The current flash attention version does not support '
+ 'sliding window attention.')
+
+ output_attentions = False
+
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (past_key_value is None)
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37'
+ ' Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ bsz, q_len, _ = hidden_states.size()
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+ # attention_mask is set to None if no padding token in input_ids
+ # varlen attn need data packing so no padding tokens in input_ids
+ assert attention_mask is None
+
+ qkv = self.qkv_proj(hidden_states)
+ query_pos = self.num_heads * self.head_dim
+ query_states = qkv[..., :query_pos]
+ key_states = qkv[..., query_pos:query_pos +
+ self.num_key_value_heads * self.head_dim]
+ value_states = qkv[...,
+ query_pos + self.num_key_value_heads * self.head_dim:]
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(
+ value_states, position_ids, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ # In PEFT, usually we cast the layer norms in float32 for
+ # training stability reasons, therefore the input hidden states gets
+ # silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+
+ if query_states.dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.qkv_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # ----------------- flash attention forward ------------------------#
+
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ window_size = (self.config.sliding_window,
+ self.config.sliding_window) if use_sliding_windows else (-1,
+ -1)
+ attn_dropout = self.attention_dropout if self.training else 0.0
+
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=causal,
+ dropout_p=attn_dropout,
+ window_size=window_size,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=attn_dropout,
+ window_size=window_size,
+ training=self.training)
+
+ # ---------------- flash attention forward end ------------------- #
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/qwen2.py b/data/xtuner/xtuner/model/modules/dispatch/qwen2.py
new file mode 100644
index 0000000000000000000000000000000000000000..20f2f40f382e4e88daf7b40a54611d9b781460a9
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/qwen2.py
@@ -0,0 +1,380 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+import warnings
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import transformers
+from mmengine import MessageHub
+from mmengine.utils import digit_version
+from transformers.cache_utils import Cache
+from transformers.models.qwen2.modeling_qwen2 import (apply_rotary_pos_emb,
+ repeat_kv)
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+from xtuner.parallel.sequence.attention import (
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+
+def qwen2_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and self.config.use_sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads for sequence parallel
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # num_heads has been changed because of sequence parallel
+ # `self.num_heads`` is not used in self._flash_attention_forward
+ # in mistral/mixtral, we are doing this to avoid some unnecessary risk
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length=query_states.shape[1],
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+ else:
+ if (self.config.use_sliding_window
+ and getattr(self.config, 'sliding_window', None) is not None
+ and self.layer_idx >= self.config.max_window_layers):
+ # There may be bugs here, but we are aligned with Transformers
+ sliding_window = self.config.sliding_window
+ else:
+ sliding_window = None
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ sliding_window=sliding_window,
+ is_causal=self.is_causal,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def qwen2_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (past_key_value is None)
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37'
+ ' Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads for sequence parallel
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for
+ # training stability reasons, therefore the input hidden states gets
+ # silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # ----------------- flash attention forward ------------------------#
+
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and self.config.use_sliding_window)
+ # Decide whether to use SWA or not by layer index.
+ if use_sliding_windows and self.layer_idx >= self.config.max_window_layers:
+ use_sliding_windows = False
+
+ window_size = (self.config.sliding_window,
+ self.config.sliding_window) if use_sliding_windows else (-1,
+ -1)
+
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+
+ # ---------------- flash attention forward end ------------------- #
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/__init__.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed29f409f853172a0c90f0e81b0200972c379e66
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .layer_norm import layer_norm_forward
+from .rms_norm import rms_norm_forward
+from .rotary import apply_rotary_emb
+
+__all__ = ['rms_norm_forward', 'layer_norm_forward', 'apply_rotary_emb']
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/layer_norm.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/layer_norm.py
new file mode 100644
index 0000000000000000000000000000000000000000..f808d6ad157a3ddbfeb6df02960c79739fcdc088
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/layer_norm.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+
+
+def layer_norm_forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ hidden_states = F.layer_norm(
+ hidden_states, (hidden_states.shape[-1], ), eps=self.variance_epsilon)
+ hidden_states = self.weight.to(torch.float32) * hidden_states
+ return hidden_states.to(input_dtype)
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rms_norm.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rms_norm.py
new file mode 100644
index 0000000000000000000000000000000000000000..6191d55ba6e5e983d1e20c3e5282dffd439d2fd6
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rms_norm.py
@@ -0,0 +1,220 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import triton
+import triton.language as tl
+
+
+@triton.jit
+def _rms_norm_fwd_fused(
+ X, # pointer to the input
+ Y, # pointer to the output
+ W, # pointer to the weights
+ Rstd, # pointer to the 1/std
+ stride, # how much to increase the pointer when moving by 1 row
+ N, # number of columns in X
+ eps, # epsilon to avoid division by zero
+ BLOCK_SIZE: tl.constexpr,
+):
+ # Map the program id to the row of X and Y it should compute.
+ row = tl.program_id(0)
+ Y += row * stride
+ X += row * stride
+ # Compute variance
+ _var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ x = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
+ _var += x * x
+ var = tl.sum(_var, axis=0) / N
+ rstd = 1 / tl.sqrt(var + eps)
+ # Write rstd
+ tl.store(Rstd + row, rstd)
+ # Normalize and apply linear transformation
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ mask = cols < N
+ w = tl.load(W + cols, mask=mask)
+ x = tl.load(X + cols, mask=mask, other=0.).to(tl.float32)
+ x_hat = x * rstd
+ y = x_hat * w
+ # Write output
+ tl.store(Y + cols, y, mask=mask)
+
+
+@triton.jit
+def _rms_norm_bwd_dx_fused(
+ DX, # pointer to the input gradient
+ DY, # pointer to the output gradient
+ DW, # pointer to the partial sum of weights gradient
+ X, # pointer to the input
+ W, # pointer to the weights
+ Rstd, # pointer to the 1/std
+ Lock, # pointer to the lock
+ stride, # how much to increase the pointer when moving by 1 row
+ N, # number of columns in X
+ eps, # epsilon to avoid division by zero
+ GROUP_SIZE_M: tl.constexpr,
+ BLOCK_SIZE_N: tl.constexpr):
+ # Map the program id to the elements of X, DX, and DY it should compute.
+ row = tl.program_id(0)
+ cols = tl.arange(0, BLOCK_SIZE_N)
+ mask = cols < N
+ X += row * stride
+ DY += row * stride
+ DX += row * stride
+ # Offset locks and weights/biases gradient pointer for parallel reduction
+ lock_id = row % GROUP_SIZE_M
+ Lock += lock_id
+ Count = Lock + GROUP_SIZE_M
+ DW = DW + lock_id * N + cols
+ # Load data to SRAM
+ x = tl.load(X + cols, mask=mask, other=0).to(tl.float32)
+ dy = tl.load(DY + cols, mask=mask, other=0).to(tl.float32)
+ w = tl.load(W + cols, mask=mask).to(tl.float32)
+ rstd = tl.load(Rstd + row)
+ # Compute dx
+ xhat = x * rstd
+ wdy = w * dy
+ xhat = tl.where(mask, xhat, 0.)
+ wdy = tl.where(mask, wdy, 0.)
+ c1 = tl.sum(xhat * wdy, axis=0) / N
+ dx = (wdy - (xhat * c1)) * rstd
+ # Write dx
+ tl.store(DX + cols, dx, mask=mask)
+ # Accumulate partial sums for dw/db
+ partial_dw = (dy * xhat).to(w.dtype)
+ while tl.atomic_cas(Lock, 0, 1) == 1:
+ pass
+ count = tl.load(Count)
+ # First store doesn't accumulate
+ if count == 0:
+ tl.atomic_xchg(Count, 1)
+ else:
+ partial_dw += tl.load(DW, mask=mask)
+ tl.store(DW, partial_dw, mask=mask)
+ # Release the lock
+ tl.atomic_xchg(Lock, 0)
+
+
+@triton.jit
+def _rms_norm_bwd_dwdb(
+ DW, # pointer to the partial sum of weights gradient
+ FINAL_DW, # pointer to the weights gradient
+ M, # GROUP_SIZE_M
+ N, # number of columns
+ BLOCK_SIZE_M: tl.constexpr,
+ BLOCK_SIZE_N: tl.constexpr):
+ # Map the program id to the elements of DW and DB it should compute.
+ pid = tl.program_id(0)
+ cols = pid * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
+ dw = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
+ # Iterate through the rows of DW and DB to sum the partial sums.
+ for i in range(0, M, BLOCK_SIZE_M):
+ rows = i + tl.arange(0, BLOCK_SIZE_M)
+ mask = (rows[:, None] < M) & (cols[None, :] < N)
+ offs = rows[:, None] * N + cols[None, :]
+ dw += tl.load(DW + offs, mask=mask, other=0.)
+ # Write the final sum to the output.
+ sum_dw = tl.sum(dw, axis=0)
+ tl.store(FINAL_DW + cols, sum_dw, mask=cols < N)
+
+
+class RMSNorm(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x, weight, eps):
+ # allocate output
+ y = torch.empty_like(x)
+ # reshape input data into 2D tensor
+ x_arg = x.reshape(-1, x.shape[-1])
+ M, N = x_arg.shape
+ rstd = torch.empty((M, ), dtype=torch.float32, device='cuda')
+ # Less than 64KB per feature: enqueue fused kernel
+ MAX_FUSED_SIZE = 65536 // x.element_size()
+ BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
+ if N > BLOCK_SIZE:
+ raise RuntimeError(
+ "This rms norm doesn't support feature dim >= 64KB.")
+ # heuristics for number of warps
+ num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
+ # enqueue kernel
+ _rms_norm_fwd_fused[(M, )](
+ x_arg,
+ y,
+ weight,
+ rstd,
+ x_arg.stride(0),
+ N,
+ eps,
+ BLOCK_SIZE=BLOCK_SIZE,
+ num_warps=num_warps,
+ )
+ ctx.save_for_backward(x, weight, rstd)
+ ctx.BLOCK_SIZE = BLOCK_SIZE
+ ctx.num_warps = num_warps
+ ctx.eps = eps
+ return y
+
+ @staticmethod
+ def backward(ctx, dy):
+ x, w, v = ctx.saved_tensors
+ # heuristics for amount of parallel reduction stream for DW/DB
+ N = w.shape[0]
+ GROUP_SIZE_M = 64
+ if N <= 8192:
+ GROUP_SIZE_M = 96
+ if N <= 4096:
+ GROUP_SIZE_M = 128
+ if N <= 1024:
+ GROUP_SIZE_M = 256
+ # allocate output
+ locks = torch.zeros(2 * GROUP_SIZE_M, dtype=torch.int32, device='cuda')
+ _dw = torch.empty((GROUP_SIZE_M, w.shape[0]),
+ dtype=x.dtype,
+ device=w.device)
+ dw = torch.empty((w.shape[0], ), dtype=w.dtype, device=w.device)
+ dx = torch.empty_like(dy)
+ # enqueue kernel using forward pass heuristics
+ # also compute partial sums for DW and DB
+ x_arg = x.reshape(-1, x.shape[-1])
+ M, N = x_arg.shape
+ _rms_norm_bwd_dx_fused[(M, )](
+ dx,
+ dy,
+ _dw,
+ x,
+ w,
+ v,
+ locks,
+ x_arg.stride(0),
+ N,
+ ctx.eps,
+ BLOCK_SIZE_N=ctx.BLOCK_SIZE,
+ GROUP_SIZE_M=GROUP_SIZE_M,
+ num_warps=ctx.num_warps)
+
+ def grid(meta):
+ return [triton.cdiv(N, meta['BLOCK_SIZE_N'])]
+
+ # accumulate partial sums in separate kernel
+ _rms_norm_bwd_dwdb[grid](
+ _dw,
+ dw,
+ GROUP_SIZE_M,
+ N,
+ BLOCK_SIZE_M=32,
+ BLOCK_SIZE_N=128,
+ )
+ return dx, dw, None
+
+
+rms_norm = RMSNorm.apply
+
+
+def rms_norm_forward(self, hidden_states):
+ if (hidden_states.device == torch.device('cpu')
+ or self.weight.device == torch.device('cpu')):
+ raise RuntimeError(
+ 'Can not use triton kernels on cpu. Please set `USE_TRITON_KERNEL`'
+ ' environment variable to 0 before training.')
+ return rms_norm(hidden_states, self.weight, self.variance_epsilon)
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rotary.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rotary.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e09c16628751dbc769d1ca4ce7d0650de8f835b
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rotary.py
@@ -0,0 +1,327 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/rotary.py # noqa:E501
+from typing import Optional, Union
+
+import torch
+import triton
+import triton.language as tl
+
+
+@triton.jit
+def rotary_kernel(
+ OUT, # Pointers to matrices
+ X,
+ COS,
+ SIN,
+ CU_SEQLENS,
+ SEQLEN_OFFSETS, # this could be int or a pointer
+ # Matrix dimensions
+ seqlen,
+ rotary_dim,
+ seqlen_ro,
+ # strides
+ stride_out_batch,
+ stride_out_seqlen,
+ stride_out_nheads,
+ stride_out_headdim,
+ stride_x_batch,
+ stride_x_seqlen,
+ stride_x_nheads,
+ stride_x_headdim,
+ # Meta-parameters
+ BLOCK_K: tl.constexpr,
+ IS_SEQLEN_OFFSETS_TENSOR: tl.constexpr,
+ IS_VARLEN: tl.constexpr,
+ INTERLEAVED: tl.constexpr,
+ CONJUGATE: tl.constexpr,
+ BLOCK_M: tl.constexpr,
+):
+ pid_m = tl.program_id(axis=0)
+ pid_batch = tl.program_id(axis=1)
+ pid_head = tl.program_id(axis=2)
+ rotary_dim_half = rotary_dim // 2
+
+ if not IS_VARLEN:
+ X = X + pid_batch * stride_x_batch + pid_head * stride_x_nheads
+ OUT = OUT + pid_batch * stride_out_batch + pid_head * stride_out_nheads
+ else:
+ start_idx = tl.load(CU_SEQLENS + pid_batch)
+ seqlen = tl.load(CU_SEQLENS + pid_batch + 1) - start_idx
+ X = X + start_idx * stride_x_seqlen + pid_head * stride_x_nheads
+ OUT = OUT + start_idx * stride_out_seqlen + \
+ pid_head * stride_out_nheads
+
+ if pid_m * BLOCK_M >= seqlen:
+ return
+ rm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
+ if not IS_SEQLEN_OFFSETS_TENSOR:
+ rm_cs = rm + SEQLEN_OFFSETS
+ else:
+ rm_cs = rm + tl.load(SEQLEN_OFFSETS + pid_batch)
+ rk = tl.arange(0, BLOCK_K)
+ rk_half = tl.arange(0, BLOCK_K // 2)
+
+ if not INTERLEAVED:
+ # Load the 1st and 2nd halves of X, do calculation,
+ # then store to 1st and 2nd halves of OUT
+ X = X + (
+ rm[:, None] * stride_x_seqlen +
+ rk_half[None, :] * stride_x_headdim)
+ # This is different from the official implementation as the shapes of
+ # the two tensors cos and sin are (seqlen_ro, rotary_dim) instead of
+ # (seqlen_ro, rotary_dim // 2).
+ COS = COS + (rm_cs[:, None] * rotary_dim + rk_half[None, :])
+ SIN = SIN + (rm_cs[:, None] * rotary_dim + rk_half[None, :])
+ cos = tl.load(
+ COS,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_half[None, :] < rotary_dim_half),
+ other=1.0).to(tl.float32)
+ sin = tl.load(
+ SIN,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_half[None, :] < rotary_dim_half),
+ other=0.0).to(tl.float32)
+ x0 = tl.load(
+ X,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half),
+ other=0.0).to(tl.float32)
+ x1 = tl.load(
+ X + rotary_dim_half * stride_x_headdim,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half),
+ other=0.0,
+ ).to(tl.float32)
+ if CONJUGATE:
+ sin = -sin
+ o0 = x0 * cos - x1 * sin
+ o1 = x0 * sin + x1 * cos
+ # write back result
+ OUT = OUT + (
+ rm[:, None] * stride_out_seqlen +
+ rk_half[None, :] * stride_out_headdim)
+ tl.store(
+ OUT,
+ o0,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half))
+ tl.store(
+ OUT + rotary_dim_half * stride_out_headdim,
+ o1,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half),
+ )
+ else:
+ # We don't want to load X[0, 2, 4, ...] and X[1, 3, 5, ...] separately
+ # since both are slow.
+ # Instead, we load x0 = X[0, 1, 2, 3, ...] and x1 = X[1, 0, 3, 2, ...].
+ # Loading x0 will be fast but x1 will be slow.
+ # Then we load cos = COS[0, 0, 1, 1, ...] and
+ # sin = SIN[0, 0, 1, 1, ...].
+ # Then we do the calculation and use tl.where to pick put the right
+ # outputs for the even and for the odd indices.
+ rk_swap = rk + ((rk + 1) % 2) * 2 - 1 # 1, 0, 3, 2, 5, 4, ...
+ rk_repeat = tl.arange(0, BLOCK_K) // 2
+ # This is different from the official implementation as the shapes of
+ # the two tensors cos and sin are (seqlen_ro, rotary_dim) instead of
+ # (seqlen_ro, rotary_dim // 2).
+ X0 = X + (
+ rm[:, None] * stride_x_seqlen + rk[None, :] * stride_x_headdim)
+ X1 = X + (
+ rm[:, None] * stride_x_seqlen +
+ rk_swap[None, :] * stride_x_headdim)
+ COS = COS + (rm_cs[:, None] * rotary_dim + rk_repeat[None, :])
+ SIN = SIN + (rm_cs[:, None] * rotary_dim + rk_repeat[None, :])
+ cos = tl.load(
+ COS,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_repeat[None, :] < rotary_dim_half),
+ other=1.0,
+ ).to(tl.float32)
+ sin = tl.load(
+ SIN,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_repeat[None, :] < rotary_dim_half),
+ other=0.0,
+ ).to(tl.float32)
+ x0 = tl.load(
+ X0,
+ mask=(rm[:, None] < seqlen) & (rk[None, :] < rotary_dim),
+ other=0.0).to(tl.float32)
+ x1 = tl.load(
+ X1,
+ mask=(rm[:, None] < seqlen) & (rk_swap[None, :] < rotary_dim),
+ other=0.0).to(tl.float32)
+ if CONJUGATE:
+ sin = -sin
+ x0_cos = x0 * cos
+ x1_sin = x1 * sin
+ out = tl.where(rk[None, :] % 2 == 0, x0_cos - x1_sin, x0_cos + x1_sin)
+ OUT = OUT + (
+ rm[:, None] * stride_out_seqlen + rk[None, :] * stride_out_headdim)
+ tl.store(
+ OUT, out, mask=(rm[:, None] < seqlen) & (rk[None, :] < rotary_dim))
+
+
+def apply_rotary(
+ x: torch.Tensor,
+ cos: torch.Tensor,
+ sin: torch.Tensor,
+ seqlen_offsets: Union[int, torch.Tensor] = 0,
+ cu_seqlens: Optional[torch.Tensor] = None,
+ max_seqlen: Optional[int] = None,
+ interleaved=False,
+ inplace=False,
+ conjugate=False,
+) -> torch.Tensor:
+ """
+ Arguments:
+ x: (batch, seqlen, nheads, headdim) if cu_seqlens is None
+ else (total_seqlen, nheads, headdim).
+ cos: (seqlen_ro, rotary_dim)
+ sin: (seqlen_ro, rotary_dim)
+ seqlen_offsets: integer or integer tensor of size (batch,)
+ cu_seqlens: (batch + 1,) or None
+ max_seqlen: int
+ Returns:
+ y: (batch, seqlen, nheads, headdim)
+ """
+ is_varlen = cu_seqlens is not None
+ if not is_varlen:
+ batch, seqlen, nheads, headdim = x.shape
+ else:
+ assert max_seqlen is not None, ('If cu_seqlens is passed in, '
+ 'then max_seqlen must be passed')
+ total_seqlen, nheads, headdim = x.shape
+ batch_p_1 = cu_seqlens.shape[0]
+ batch = batch_p_1 - 1
+ seqlen = max_seqlen
+ seqlen_ro, rotary_dim = cos.shape
+ assert sin.shape == cos.shape
+ # rotary_dim *= 2
+ assert rotary_dim <= headdim, 'rotary_dim must be <= headdim'
+ assert headdim <= 256, 'Only support headdim <= 256'
+ assert seqlen_ro >= seqlen, 'seqlen_ro must be >= seqlen'
+
+ assert (
+ cos.dtype == sin.dtype
+ ), f'cos and sin must have the same dtype, got {cos.dtype} and {sin.dtype}'
+ assert (x.dtype == cos.dtype), (
+ f'Input and cos/sin must have the same dtype, '
+ f'got {x.dtype} and {cos.dtype}')
+
+ cos, sin = cos.contiguous(), sin.contiguous()
+ if isinstance(seqlen_offsets, torch.Tensor):
+ assert seqlen_offsets.shape == (batch, )
+ assert seqlen_offsets.dtype in [torch.int32, torch.int64]
+ seqlen_offsets = seqlen_offsets.contiguous()
+ else:
+ assert seqlen_offsets + seqlen <= seqlen_ro
+
+ output = torch.empty_like(x) if not inplace else x
+ if rotary_dim < headdim and not inplace:
+ output[..., rotary_dim:].copy_(x[..., rotary_dim:])
+
+ BLOCK_K = (32 if rotary_dim <= 32 else
+ (64 if rotary_dim <= 64 else
+ (128 if rotary_dim <= 128 else 256)))
+
+ def grid(META):
+ return (triton.cdiv(seqlen, META['BLOCK_M']), batch, nheads)
+
+ BLOCK_M = 4 if interleaved else (8 if rotary_dim <= 64 else 4)
+
+ # Need this, otherwise Triton tries to launch from cuda:0 and we get
+ # ValueError: Pointer argument (at 0) cannot be accessed from Triton
+ # (cpu tensor?)
+ with torch.cuda.device(x.device.index):
+ rotary_kernel[grid](
+ output, # data ptrs
+ x,
+ cos,
+ sin,
+ cu_seqlens,
+ seqlen_offsets,
+ seqlen, # shapes
+ rotary_dim,
+ seqlen_ro,
+ output.stride(0)
+ if not is_varlen else 0, # batch_strides if not varlen else 0
+ output.stride(-3), # seqlen_stride or total_seqlen_stride
+ output.stride(-2), # nheads_stride
+ output.stride(-1), # headdim_stride
+ x.stride(0)
+ if not is_varlen else 0, # batch_strides if not varlen else 0
+ x.stride(-3), # seqlen stride or total_seqlen_stride
+ x.stride(-2), # nheads stride
+ x.stride(-1), # headdim stride
+ BLOCK_K,
+ isinstance(seqlen_offsets, torch.Tensor),
+ is_varlen,
+ interleaved,
+ conjugate,
+ BLOCK_M,
+ )
+ return output
+
+
+class ApplyRotaryEmb(torch.autograd.Function):
+
+ @staticmethod
+ def forward(
+ ctx,
+ x,
+ cos,
+ sin,
+ interleaved=False,
+ inplace=False,
+ seqlen_offsets: Union[int, torch.Tensor] = 0,
+ cu_seqlens: Optional[torch.Tensor] = None,
+ max_seqlen: Optional[int] = None,
+ ):
+ out = apply_rotary(
+ x,
+ cos,
+ sin,
+ seqlen_offsets=seqlen_offsets,
+ cu_seqlens=cu_seqlens,
+ max_seqlen=max_seqlen,
+ interleaved=interleaved,
+ inplace=inplace,
+ )
+ if isinstance(seqlen_offsets, int):
+ ctx.save_for_backward(
+ cos, sin, cu_seqlens) # Can't save int with save_for_backward
+ ctx.seqlen_offsets = seqlen_offsets
+ else:
+ ctx.save_for_backward(cos, sin, cu_seqlens, seqlen_offsets)
+ ctx.seqlen_offsets = None
+ ctx.interleaved = interleaved
+ ctx.inplace = inplace
+ ctx.max_seqlen = max_seqlen
+ return out if not inplace else x
+
+ @staticmethod
+ def backward(ctx, do):
+ seqlen_offsets = ctx.seqlen_offsets
+ if seqlen_offsets is None:
+ cos, sin, cu_seqlens, seqlen_offsets = ctx.saved_tensors
+ else:
+ cos, sin, cu_seqlens = ctx.saved_tensors
+ # TD [2023-09-02]: For some reason Triton (2.0.0.post1) errors with
+ # "[CUDA]: invalid device context", and cloning makes it work. Idk why.
+ # Triton 2.1.0 works.
+ if not ctx.interleaved and not ctx.inplace:
+ do = do.clone()
+ dx = apply_rotary(
+ do,
+ cos,
+ sin,
+ seqlen_offsets=seqlen_offsets,
+ cu_seqlens=cu_seqlens,
+ max_seqlen=ctx.max_seqlen,
+ interleaved=ctx.interleaved,
+ inplace=ctx.inplace,
+ conjugate=True,
+ )
+ return dx, None, None, None, None, None, None, None
+
+
+apply_rotary_emb = ApplyRotaryEmb.apply
diff --git a/data/xtuner/xtuner/model/modules/dispatch/utils.py b/data/xtuner/xtuner/model/modules/dispatch/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cfa26cd1f98460a217862abe50f531389421a08
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/utils.py
@@ -0,0 +1,64 @@
+import torch
+import torch.nn.functional as F
+
+try:
+ from flash_attn.bert_padding import index_first_axis, unpad_input
+except ImportError:
+ pass
+
+
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(
+ torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+def upad_qkv(query_layer, key_layer, value_layer, attention_mask,
+ query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(
+ attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim), indices_k)
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim), indices_k)
+ if query_length == kv_seq_len:
+ # Different from the origin version as sequence parallel change
+ # the number of attention heads.
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, -1, head_dim),
+ indices_k)
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = \
+ unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
diff --git a/data/xtuner/xtuner/model/modules/dispatch/yi.py b/data/xtuner/xtuner/model/modules/dispatch/yi.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c3e0d20ce04ee04edcf70380b8fcc220d9a7321
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/yi.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ # The first two dimensions of cos and sin are always 1,
+ # so we can `squeeze` them.
+ cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+def yi_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ # use flash attention implemented by pytorch
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/projector/__init__.py b/data/xtuner/xtuner/model/modules/projector/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6196093dd5ffa4f4be0821ae2198f17a86f685f6
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/projector/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from transformers import AutoConfig, AutoModel
+
+from .configuration_projector import ProjectorConfig
+from .modeling_projector import ProjectorModel
+
+AutoConfig.register('projector', ProjectorConfig)
+AutoModel.register(ProjectorConfig, ProjectorModel)
+
+__all__ = ['ProjectorConfig', 'ProjectorModel']
diff --git a/data/xtuner/xtuner/model/modules/projector/configuration_projector.py b/data/xtuner/xtuner/model/modules/projector/configuration_projector.py
new file mode 100644
index 0000000000000000000000000000000000000000..f63ffdc4698bc867bd559370ea8766537270661c
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/projector/configuration_projector.py
@@ -0,0 +1,23 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from transformers import PretrainedConfig
+
+
+class ProjectorConfig(PretrainedConfig):
+ model_type = 'projector'
+ _auto_class = 'AutoConfig'
+
+ def __init__(
+ self,
+ visual_hidden_size=4096,
+ llm_hidden_size=4096,
+ depth=2,
+ hidden_act='gelu',
+ bias=True,
+ **kwargs,
+ ):
+ self.visual_hidden_size = visual_hidden_size
+ self.llm_hidden_size = llm_hidden_size
+ self.depth = depth
+ self.hidden_act = hidden_act
+ self.bias = bias
+ super().__init__(**kwargs)
diff --git a/data/xtuner/xtuner/model/modules/projector/modeling_projector.py b/data/xtuner/xtuner/model/modules/projector/modeling_projector.py
new file mode 100644
index 0000000000000000000000000000000000000000..d55e7588c8c3d7dc3537f1bf0a7ec4c14b1901b2
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/projector/modeling_projector.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from transformers import PreTrainedModel
+from transformers.activations import ACT2FN
+
+from .configuration_projector import ProjectorConfig
+
+
+class ProjectorModel(PreTrainedModel):
+ _auto_class = 'AutoModel'
+ config_class = ProjectorConfig
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+
+ def __init__(self, config: ProjectorConfig) -> None:
+ super().__init__(config)
+ self.gradient_checkpointing = False
+
+ modules = [
+ nn.Linear(
+ config.visual_hidden_size,
+ config.llm_hidden_size,
+ bias=config.bias)
+ ]
+ for _ in range(1, config.depth):
+ modules.append(ACT2FN[config.hidden_act])
+ modules.append(
+ nn.Linear(
+ config.llm_hidden_size,
+ config.llm_hidden_size,
+ bias=config.bias))
+ self.model = nn.Sequential(*modules)
+
+ def enable_input_require_grads(self):
+
+ def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+ self.model.register_forward_hook(make_inputs_require_grad)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, ProjectorModel):
+ module.gradient_checkpointing = value
+
+ def forward(self, x):
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = torch.utils.checkpoint.checkpoint(self.model, x)
+ else:
+ layer_outputs = self.model(x)
+ return layer_outputs
diff --git a/data/xtuner/xtuner/model/orpo.py b/data/xtuner/xtuner/model/orpo.py
new file mode 100644
index 0000000000000000000000000000000000000000..37264088acd7c852865e0dcd7795796bd8990eeb
--- /dev/null
+++ b/data/xtuner/xtuner/model/orpo.py
@@ -0,0 +1,212 @@
+# ORPO Authors: Jiwoo Hong, Noah Lee, and James Thorne
+# Official code: https://github.com/xfactlab/orpo
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+from torch import nn
+
+from xtuner.parallel.sequence import (gather_forward_split_backward,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ split_for_sequence_parallel)
+from .sft import SupervisedFinetune
+
+
+class ORPO(SupervisedFinetune):
+ """ORPO: Monolithic Preference Optimization without Reference Model
+ https://arxiv.org/abs/2403.07691
+
+ Args:
+ beta (float): Weight of the odds_ratio_loss. Defaults to 0.1.
+ """
+
+ def __init__(self, *args, beta=0.1, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.beta = beta
+
+ def _gather_masked_logits(self, logits, labels, mask):
+ logits = torch.gather(
+ logits.log_softmax(-1), dim=2,
+ index=labels.unsqueeze(2)).squeeze(2)
+ return logits * mask
+
+ def get_logps(
+ self,
+ all_logps, # bs, seqlen
+ average_log_prob,
+ loss_mask, # bs, seqlen
+ ):
+ all_logps = all_logps[:, :-1].sum(-1)
+ loss_mask = loss_mask[:, :-1]
+
+ if average_log_prob: # average_log_prob
+ all_logps = all_logps / loss_mask.sum(-1)
+
+ chosen_logps = all_logps[::2]
+ rejected_logps = all_logps[1::2]
+ return chosen_logps, rejected_logps
+
+ def get_var_len_atten_logps(self, all_logps, average_log_prob, loss_mask,
+ cu_seqlens, attention_mask):
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+ # unpack sequence
+ unpacked_logps = torch.split(all_logps, seqlens, dim=1)
+ unpacked_loss_mask = torch.split(loss_mask, seqlens, dim=1)
+ if attention_mask is not None:
+ # It indicate that we pad the original sequence, labels,
+ # position_ids and cumulative_len for sequence parallel if the
+ # attention_mask is not None.
+ # We then need to remove the padded segments.
+ assert False in attention_mask
+ unpacked_logps = unpacked_logps[:-1]
+ unpacked_loss_mask = unpacked_loss_mask[:-1]
+ assert len(unpacked_logps) % 2 == 0
+
+ def compute_logps(_logps, _mask):
+ _logps = _logps[:, :-1].sum(-1)
+ _mask = _mask[:, :-1]
+ if average_log_prob:
+ _logps /= _mask.sum(-1)
+ return _logps
+
+ chosen_logps, rejected_logps = [], []
+ for i in range(len(unpacked_logps) // 2):
+ chosen = unpacked_logps[2 * i]
+ rejected = unpacked_logps[2 * i + 1]
+ chosen_mask = unpacked_loss_mask[2 * i]
+ rejected_mask = unpacked_loss_mask[2 * i + 1]
+ chosen_logps.append(compute_logps(chosen, chosen_mask))
+ rejected_logps.append(compute_logps(rejected, rejected_mask))
+
+ return (torch.stack(chosen_logps), torch.stack(rejected_logps))
+
+ def cross_entropy_loss(self, logits, labels):
+ logits = logits[..., :-1, :].contiguous()
+ # labels are already shifted, now we need to remove the last dummy label # noqa
+ labels = labels[..., :-1].contiguous()
+ # Flatten the tokens
+ loss_fct = nn.CrossEntropyLoss()
+ logits = logits.view(-1, logits.shape[-1])
+ labels = labels.view(-1)
+ # Enable model parallelism
+ labels = labels.to(logits.device)
+ loss = loss_fct(logits, labels)
+ return loss
+
+ def odds_ratio_loss(
+ self,
+ chosen_logps: torch.FloatTensor,
+ rejected_logps: torch.FloatTensor,
+ ):
+ # modified from https://github.com/huggingface/trl/blob/b031adfdb8708f1f295eab6c3f2cb910e8fe0c23/trl/trainer/orpo_trainer.py#L597 # noqa
+ # Derived from Eqs. (4) and (7) from https://arxiv.org/abs/2403.07691 by using log identities and exp(log(P(y|x)) = P(y|x) # noqa
+ log_odds = (chosen_logps - rejected_logps) - (
+ torch.log1p(-torch.exp(chosen_logps)) -
+ torch.log1p(-torch.exp(rejected_logps)))
+ ratio = F.logsigmoid(log_odds)
+ ratio = ratio[~torch.isnan(ratio)] # select valid loss
+ losses = self.beta * ratio
+
+ chosen_rewards = self.beta * chosen_logps
+ rejected_rewards = self.beta * rejected_logps
+
+ return losses, chosen_rewards, rejected_rewards, torch.mean(
+ ratio), torch.mean(log_odds)
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'position_ids', 'labels',
+ 'chosen_rejected_tag')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def compute_loss(self, data, data_samples=None):
+ # shift labels first and add a dummy label at the end, to support sequence parallel # noqa
+ data['labels'] = torch.cat(
+ (data['labels'][:, 1:], torch.zeros_like(data['labels'][:, :1])),
+ dim=1)
+ tmp_label = data['labels'].clone()
+ tmp_label[tmp_label == 0] = -100
+ # loss mask of all tokens in all sp ranks
+ all_loss_mask = data['labels'] != -100
+
+ if self.use_varlen_attn:
+ # create a chosen rejected tag for varlen_attn ce loss
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cu_seqlens = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+
+ chosen_rejected_tag = torch.ones_like(data['labels'])
+ unpacked_tag = list(
+ torch.split(chosen_rejected_tag, seqlens, dim=1))
+ # import pdb; pdb.set_trace()
+ for i in range(len(unpacked_tag) // 2):
+ # import pdb; pdb.set_trace()
+ unpacked_tag[2 * i + 1] *= 0
+ chosen_rejected_tag = torch.cat(unpacked_tag, dim=1)
+ data['chosen_rejected_tag'] = chosen_rejected_tag
+
+ if get_sequence_parallel_world_size() > 1:
+ data = self._split_for_sequence_parallel(data)
+ chosen_rejected_tag = data.pop('chosen_rejected_tag', None)
+ all_logits = self.llm(**data).logits
+
+ labels = data['labels'].clone()
+ labels[labels == -100] = 0
+ loss_mask = labels != 0 # loss mask in a single sp rank
+ all_logps = self._gather_masked_logits(all_logits, labels, loss_mask)
+ if get_sequence_parallel_world_size() > 1:
+ all_logps = gather_forward_split_backward(
+ all_logps,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+
+ if not self.use_varlen_attn:
+ chosen_nll_loss = self.cross_entropy_loss(all_logits[::2],
+ data['labels'][::2])
+ chosen_logps, rejected_logps = self.get_logps(
+ all_logps, True, all_loss_mask)
+ else:
+ chosen_idxs = chosen_rejected_tag == 1
+ chosen_logits = all_logits[chosen_idxs]
+ chosen_labels = data['labels'][chosen_idxs]
+ chosen_nll_loss = self.cross_entropy_loss(chosen_logits,
+ chosen_labels)
+
+ chosen_logps, rejected_logps = self.get_var_len_atten_logps(
+ all_logps, True, all_loss_mask, cu_seqlens,
+ data['attention_mask'])
+ (losses, chosen_rewards, rejected_rewards, log_odds_ratio,
+ log_odds_chosen) = self.odds_ratio_loss(chosen_logps, rejected_logps)
+ losses = losses.mean()
+ # skip nan loss
+ if torch.isnan(chosen_nll_loss):
+ chosen_nll_loss = all_logits.mean() * 0
+ if torch.isnan(losses):
+ losses = all_logits.mean() * 0
+ loss = chosen_nll_loss - losses
+
+ reward_acc = (chosen_rewards > rejected_rewards).float().mean()
+
+ loss_dict = {
+ 'loss': loss,
+ 'chosen_rewards': chosen_rewards.mean(),
+ 'rejected_rewards': rejected_rewards.mean(),
+ 'reward_acc': reward_acc,
+ 'reward_margin': (chosen_rewards - rejected_rewards).mean(),
+ 'log_odds_ratio': log_odds_ratio,
+ 'log_odds_chosen': log_odds_chosen,
+ 'nll_loss': chosen_nll_loss.detach().mean()
+ }
+ return loss_dict
diff --git a/data/xtuner/xtuner/model/reward.py b/data/xtuner/xtuner/model/reward.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bc203daa8ceb5d15be11ed6a37aa9676aa6d32d
--- /dev/null
+++ b/data/xtuner/xtuner/model/reward.py
@@ -0,0 +1,490 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import math
+import os
+import warnings
+from collections import OrderedDict
+from contextlib import nullcontext
+
+import torch
+import torch.distributed as dist
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from mmengine.runner import load_checkpoint
+from peft import get_peft_model, prepare_model_for_kbit_training
+from torch import nn
+from transformers import (AutoConfig, AutoModelForSequenceClassification,
+ PreTrainedModel, PreTrainedTokenizer)
+from transformers.dynamic_module_utils import get_class_from_dynamic_module
+from transformers.integrations import is_deepspeed_zero3_enabled
+from transformers.modeling_utils import no_init_weights
+
+from xtuner.parallel.sequence import (gather_forward_split_backward,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ split_for_sequence_parallel)
+from xtuner.registry import BUILDER
+from .modules import dispatch_modules
+from .modules.dispatch import SUPPORT_FLASH1, SUPPORT_FLASH2
+from .utils import (LoadWoInit, find_all_linear_names,
+ get_peft_model_state_dict, make_inputs_require_grad,
+ traverse_dict)
+
+
+def reduce_mean(tensor):
+ """"Obtain the mean of tensor on different GPUs."""
+ if not (dist.is_available() and dist.is_initialized()):
+ return tensor
+ tensor = tensor.clone()
+ dist.all_reduce(tensor.div_(dist.get_world_size()), op=dist.ReduceOp.SUM)
+ return tensor
+
+
+def smart_tokenizer_and_embedding_resize(
+ tokenizer: PreTrainedTokenizer,
+ model: PreTrainedModel,
+):
+ """Resize embedding."""
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ params = [model.get_input_embeddings().weight]
+ if model.get_output_embeddings(
+ ) is not None and not model.config.tie_word_embeddings:
+ params.append(model.get_output_embeddings().weight)
+
+ context_maybe_zero3 = deepspeed.zero.GatheredParameters(
+ params, modifier_rank=0)
+ else:
+ context_maybe_zero3 = nullcontext()
+
+ with context_maybe_zero3:
+ current_embedding_size = model.get_input_embeddings().weight.size(0)
+
+ if len(tokenizer) > current_embedding_size:
+ assert isinstance(model.get_output_embeddings(), nn.Linear)
+
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=64)
+ with context_maybe_zero3:
+ num_new_tokens = len(tokenizer) - current_embedding_size
+ input_embeddings = model.get_input_embeddings().weight.data
+ output_embeddings = model.get_output_embeddings().weight.data
+
+ input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+ output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+
+ input_embeddings[-num_new_tokens:] = input_embeddings_avg
+ output_embeddings[-num_new_tokens:] = output_embeddings_avg
+
+ print_log(
+ f'Resized token embeddings from {current_embedding_size} to '
+ f'{len(tokenizer)}.', 'current')
+
+
+class RewardModel(BaseModel):
+
+ def __init__(
+ self,
+ llm,
+ lora=None,
+ peft_model=None,
+ use_activation_checkpointing=True,
+ use_varlen_attn=False,
+ tokenizer=None,
+ max_position_embeddings=None,
+ reward_token_id=None,
+ loss_type='ranking',
+ penalty_type='log_barrier',
+ penalty_weight=0.01,
+ ):
+ super().__init__()
+ with LoadWoInit():
+ if isinstance(llm, dict):
+ llm = self._dispatch_lm_model_cfg(llm, max_position_embeddings)
+ self.llm = self._build_from_cfg_or_module(llm).model
+ self.v_head = nn.Linear(self.llm.config.hidden_size, 1, bias=False)
+ # zero init
+ self.v_head.weight.data.zero_()
+
+ self.reward_token_id = reward_token_id
+ assert loss_type in ('ranking',
+ 'focal'), f'Unsupported loss type {loss_type}'
+ self.loss_type = loss_type
+ assert penalty_type in (
+ 'log_barrier', 'L2',
+ 'none'), f'Unsupported penalty type {penalty_type}'
+ self.penalty_type = penalty_type
+ self.penalty_weight = penalty_weight
+
+ if tokenizer is not None:
+ if isinstance(tokenizer, dict):
+ tokenizer = BUILDER.build(tokenizer)
+ smart_tokenizer_and_embedding_resize(tokenizer, self.llm)
+
+ self.llm.config.use_cache = False
+ dispatch_modules(self.llm, use_varlen_attn=use_varlen_attn)
+
+ if use_activation_checkpointing:
+ # For backward compatibility
+ if hasattr(self.llm, 'enable_input_require_grads'):
+ self.llm.enable_input_require_grads()
+ else:
+ self.llm.get_input_embeddings().register_forward_hook(
+ make_inputs_require_grad)
+
+ # enable gradient checkpointing for memory efficiency
+ self.gradient_checkpointing_enable()
+
+ if isinstance(lora, dict) or isinstance(lora, Config) or isinstance(
+ lora, ConfigDict):
+ self.lora = BUILDER.build(lora)
+ else:
+ self.lora = lora
+ self.peft_model = peft_model
+ self.use_lora = lora is not None
+ if self.use_lora:
+ self._prepare_for_lora(peft_model, use_activation_checkpointing)
+
+ self._is_init = True
+ # Determines whether to calculate attention based on the
+ # seq_len dimension (use_varlen_attn = False) or the actual length of
+ # the sequence.
+ self.use_varlen_attn = use_varlen_attn
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.llm.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.llm.gradient_checkpointing_disable()
+
+ def _prepare_for_lora(self,
+ peft_model=None,
+ use_activation_checkpointing=True):
+ self.llm = prepare_model_for_kbit_training(
+ self.llm, use_activation_checkpointing)
+ if self.lora.target_modules is None:
+ modules = find_all_linear_names(self.llm)
+ self.lora.target_modules = modules
+
+ self.llm = get_peft_model(self.llm, self.lora)
+ if peft_model is not None:
+ _ = load_checkpoint(self, peft_model)
+
+ def init_weights(self):
+ pass
+
+ @staticmethod
+ def _prepare_for_long_context_training(cfg, llm_cfg,
+ max_position_embeddings):
+ if not hasattr(llm_cfg, 'rope_scaling'):
+ print_log('Current model does not support RoPE scaling.',
+ 'current')
+ return
+
+ current_max_length = getattr(llm_cfg, 'max_position_embeddings', None)
+ if current_max_length and max_position_embeddings > current_max_length:
+ print_log(
+ f'Enlarge max model length from {current_max_length} '
+ f'to {max_position_embeddings}.', 'current')
+ scaling_factor = float(
+ math.ceil(max_position_embeddings / current_max_length))
+ else:
+ print_log(
+ 'The input `max_position_embeddings` is smaller than '
+ 'origin max length. Consider increase input length.',
+ 'current')
+ scaling_factor = 1.0
+ cfg.rope_scaling = {'type': 'linear', 'factor': scaling_factor}
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_flash_attn(cfg, llm_cfg):
+ cls_name = type(llm_cfg).__name__
+ SUPPORT_SDPA_ATTN = ('LlamaConfig', 'GemmaConfig', 'MistralConfig',
+ 'MixtralConfig', 'Qwen2Config', 'Qwen2MoeConfig',
+ 'Starcoder2Config', 'Starcoder2Config',
+ 'Phi3Config')
+ SUPPORT_FLASH_ATTN2 = ('InternLM2Config', 'LlamaConfig', 'GemmaConfig',
+ 'MistralConfig', 'MixtralConfig', 'Qwen2Config',
+ 'Qwen2MoeConfig', 'Starcoder2Config',
+ 'Starcoder2Config', 'Phi3Config')
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ if getattr(cfg, 'attn_implementation', None) is not None:
+ # Flash Attention 2.0 only supports torch.float16 and
+ # torch.bfloat16 dtypes
+ if cfg.attn_implementation == 'flash_attention_2':
+ cfg.torch_dtype = torch_dtype
+ elif SUPPORT_FLASH2 and cls_name in SUPPORT_FLASH_ATTN2:
+ cfg.torch_dtype = torch_dtype
+ cfg.attn_implementation = 'flash_attention_2'
+ elif SUPPORT_FLASH1 and cls_name in SUPPORT_SDPA_ATTN:
+ cfg.attn_implementation = 'sdpa'
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_qlora_zero3(cfg):
+ if (not is_deepspeed_zero3_enabled()) or (not hasattr(
+ cfg, 'quantization_config')):
+ return cfg
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ cfg.torch_dtype = torch_dtype
+ quantization_config = cfg.quantization_config
+ quantization_config.bnb_4bit_compute_dtype = torch_dtype
+ quantization_config.bnb_4bit_quant_storage = torch_dtype
+
+ return cfg
+
+ def _dispatch_lm_model_cfg(self, cfg, max_position_embeddings=None):
+ cfg = self._prepare_for_qlora_zero3(cfg)
+ pretrained_model_name_or_path = cfg.pretrained_model_name_or_path
+ llm_cfg = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=True)
+ cfg = self._prepare_for_flash_attn(cfg, llm_cfg)
+ if max_position_embeddings is not None:
+ cfg = self._prepare_for_long_context_training(
+ cfg, llm_cfg, max_position_embeddings)
+ return cfg
+
+ def _build_from_cfg_or_module(self, cfg_or_mod):
+ if isinstance(cfg_or_mod, nn.Module):
+ return cfg_or_mod
+ elif isinstance(cfg_or_mod, dict):
+ traverse_dict(cfg_or_mod)
+ return BUILDER.build(cfg_or_mod)
+ else:
+ raise NotImplementedError
+
+ def forward(self, data, data_samples=None, mode='loss'):
+ labels = data.pop('labels', None)
+ if mode == 'loss':
+ return self.compute_loss(data, labels)
+ elif mode == 'predict':
+ return self.predict(data, data_samples)
+ elif mode == 'tensor':
+ return self._forward(data, data_samples)
+ else:
+ raise NotImplementedError
+
+ def _forward(self, data, data_samples=None):
+ hidden_states = self.llm(**data)[0]
+ logits = self.v_head(hidden_states)
+ return logits
+
+ def predict(self, data, data_samples=None):
+ hidden_states = self.llm(**data)[0]
+ logits = self.v_head(hidden_states)
+ logits_dict = [{'logits': log} for log in logits]
+ return logits_dict
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'position_ids')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def compute_loss(self, data, labels=None):
+ if get_sequence_parallel_world_size() > 1:
+ data = self._split_for_sequence_parallel(data)
+
+ hidden_states = self.llm(**data)[0]
+ logits = self.v_head(hidden_states)
+
+ if get_sequence_parallel_world_size() > 1:
+ logits = gather_forward_split_backward(
+ logits,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+
+ chosen_idx = torch.where(labels == 0)
+ rejected_idx = torch.where(labels == 1)
+ chosen_logits = logits[chosen_idx]
+ rejected_logits = logits[rejected_idx]
+
+ num_samples = torch.tensor(len(chosen_logits)).float().to(
+ hidden_states.device)
+ avg_factor = 1.0 / num_samples
+ avg_factor = reduce_mean(avg_factor).to(hidden_states.device)
+
+ chosen_mean = reduce_mean(chosen_logits.mean().detach())
+ rejected_mean = reduce_mean(rejected_logits.mean().detach())
+ acc = reduce_mean(
+ (chosen_logits > rejected_logits).sum() / num_samples).detach()
+ num_tokens = torch.tensor(labels.shape[1]).float()
+
+ # ranking loss
+ if self.loss_type == 'ranking':
+ rank_loss = self.ranking_loss(
+ chosen_logits, rejected_logits, avg_factor=avg_factor)
+ elif self.loss_type == 'focal':
+ rank_loss = self.focal_loss(
+ chosen_logits, rejected_logits, avg_factor=avg_factor)
+ else:
+ raise NotImplementedError(
+ f'Unsupported loss type {self.loss_type}')
+
+ # penalty loss
+ if self.penalty_type == 'log_barrier':
+ penalty = self.log_barrier_penalty(
+ torch.cat([chosen_logits, rejected_logits]),
+ lower_bound=-5,
+ upper_bound=5,
+ avg_factor=avg_factor)
+ elif self.penalty_type == 'L2':
+ penalty = self.l2_penalty(
+ torch.cat([chosen_logits, rejected_logits]),
+ avg_factor=avg_factor)
+ elif self.penalty_type == 'none':
+ penalty = 0
+ else:
+ raise NotImplementedError(
+ f'Unsupported penalty type {self.penalty_type}')
+
+ loss = rank_loss + self.penalty_weight * penalty
+ loss_dict = {
+ 'loss': loss,
+ 'acc': acc,
+ 'chosen_score_mean': chosen_mean,
+ 'rejected_score_mean': rejected_mean,
+ 'num_samples': num_samples,
+ 'num_tokens': num_tokens,
+ }
+
+ return loss_dict
+
+ def ranking_loss(self, chosen_logits, rejected_logits, avg_factor):
+ rank_loss = -nn.functional.logsigmoid(chosen_logits - rejected_logits)
+ return rank_loss.sum() * avg_factor
+
+ def focal_loss(self, chosen_logits, rejected_logits, avg_factor):
+ # focal ranking loss from InternLM2 paper https://arxiv.org/abs/2403.17297 # noqa
+ rank_loss = -nn.functional.logsigmoid(chosen_logits - rejected_logits)
+ p_ij = torch.sigmoid(chosen_logits - rejected_logits)
+ p = 2 * torch.relu(p_ij - 0.5)
+ gamma = 2
+ focal_loss = ((1 - p)**gamma) * rank_loss
+ return focal_loss.sum() * avg_factor
+
+ def log_barrier_penalty(self,
+ logits,
+ lower_bound,
+ upper_bound,
+ epsilon=1e-3,
+ avg_factor=1):
+ # log barrier penalty from InternLM2 paper https://arxiv.org/abs/2403.17297 # noqa
+ logits_fp32 = logits.float()
+ logits_clamped = torch.clamp(logits_fp32, lower_bound + epsilon,
+ upper_bound - epsilon)
+ penalty = -torch.log(upper_bound - logits_clamped) - torch.log(
+ logits_clamped - lower_bound)
+ return penalty.sum() * avg_factor
+
+ def l2_penalty(self, logits, avg_factor=1):
+ return (logits**2).sum() * avg_factor
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ if not self.use_lora:
+ return state_dict
+ to_return = get_peft_model_state_dict(self.llm, state_dict=state_dict)
+ return OrderedDict(to_return)
+
+ def __getattr__(self, name: str):
+ try:
+ return super().__getattr__(name)
+ except AttributeError:
+ return getattr(self.llm, name)
+
+ def to_hf(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={},
+ **kwargs):
+ print(f'Saving LLM tokenizer to {save_dir}')
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ tokenizer.save_pretrained(save_dir)
+
+ if 'PeftModel' in self.llm.__class__.__name__:
+ # merge adapter
+ self.llm = self.llm.merge_and_unload()
+ if 'InternLM2' in self.llm.__class__.__name__:
+ from xtuner.tools.model_converters.modeling_internlm2_reward.modeling_internlm2 import \
+ InternLM2ForRewardModel # noqa
+ print(f'Saving Reward Model to {save_dir}')
+ hf_cfg = self.llm.config
+ hf_cfg.reward_token_id = self.reward_token_id if \
+ self.reward_token_id is not None else cfg.reward_token_id
+ if not fp32:
+ dtype = torch.float16
+ else:
+ dtype = torch.float32
+ with no_init_weights():
+ reward_model = InternLM2ForRewardModel._from_config(
+ hf_cfg, torch_dtype=dtype)
+ reward_model.model.load_state_dict(self.llm.state_dict())
+ reward_model.v_head.load_state_dict(self.v_head.state_dict())
+ reward_model.save_pretrained(save_dir, **save_pretrained_kwargs)
+ # fix auto_map in config
+ with open(os.path.join(save_dir, 'config.json')) as fp:
+ config_dict = json.load(fp)
+ config_dict['auto_map'][
+ 'AutoModel'] = 'modeling_internlm2.InternLM2ForRewardModel'
+ config_dict['auto_map'].pop('AutoModelForCausalLM', None)
+ with open(os.path.join(save_dir, 'config.json'), 'w') as fp:
+ json.dump(config_dict, fp, indent=2)
+ else:
+ warnings.warn(
+ f'The pretrained model type: {self.llm.__class__.__name__} '
+ 'has no reward model class defined. Use '
+ 'the SequenceClassification class instead.'
+ 'You can refer to `xtuner/tools/model_converters/modeling_internlm2_reward` ' # noqa
+ 'to implement the reward model class.')
+
+ hf_cfg = self.llm.config
+ hf_cfg.num_labels = 1 # set the output dim to 1
+ try:
+ with no_init_weights():
+ reward_model = \
+ AutoModelForSequenceClassification.from_config(hf_cfg)
+ except Exception as e:
+ warnings.warn(f'Cannot find SequenceClassification class '
+ f'from transformers: {e}, \n'
+ 'try to find it in the dynamic module.')
+ module_file, causal_model_name = hf_cfg.auto_map[
+ 'AutoModelForCausalLM'].split('.')
+ seqcls_model_name = causal_model_name.split(
+ 'For')[0] + 'ForSequenceClassification'
+ seqcls_class = get_class_from_dynamic_module(
+ f'{module_file}.{seqcls_model_name}', hf_cfg._name_or_path)
+ with no_init_weights():
+ reward_model = seqcls_class(hf_cfg)
+ reward_model.model.load_state_dict(self.llm.state_dict())
+ reward_model.score.load_state_dict(self.v_head.state_dict())
+ reward_model.save_pretrained(save_dir, **save_pretrained_kwargs)
diff --git a/data/xtuner/xtuner/model/sft.py b/data/xtuner/xtuner/model/sft.py
new file mode 100644
index 0000000000000000000000000000000000000000..5229504891b3d921286ef0106c84ebd1349e378e
--- /dev/null
+++ b/data/xtuner/xtuner/model/sft.py
@@ -0,0 +1,336 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from collections import OrderedDict
+from contextlib import nullcontext
+
+import torch
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from mmengine.runner import load_checkpoint
+from peft import get_peft_model, prepare_model_for_kbit_training
+from torch import nn
+from transformers import AutoConfig, PreTrainedModel, PreTrainedTokenizer
+from transformers.integrations import is_deepspeed_zero3_enabled
+
+from xtuner.parallel.sequence import (get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ reduce_sequence_parallel_loss,
+ split_for_sequence_parallel)
+from xtuner.registry import BUILDER
+from .modules import dispatch_modules
+from .modules.dispatch import SUPPORT_FLASH1, SUPPORT_FLASH2
+from .utils import (LoadWoInit, find_all_linear_names,
+ get_peft_model_state_dict, make_inputs_require_grad,
+ traverse_dict)
+
+
+def smart_tokenizer_and_embedding_resize(
+ tokenizer: PreTrainedTokenizer,
+ model: PreTrainedModel,
+):
+ """Resize embedding."""
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ params = [model.get_input_embeddings().weight]
+ if model.get_output_embeddings(
+ ) is not None and not model.config.tie_word_embeddings:
+ params.append(model.get_output_embeddings().weight)
+
+ context_maybe_zero3 = deepspeed.zero.GatheredParameters(
+ params, modifier_rank=0)
+ else:
+ context_maybe_zero3 = nullcontext()
+
+ with context_maybe_zero3:
+ current_embedding_size = model.get_input_embeddings().weight.size(0)
+
+ if len(tokenizer) > current_embedding_size:
+ assert isinstance(model.get_output_embeddings(), nn.Linear)
+
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=64)
+ with context_maybe_zero3:
+ num_new_tokens = len(tokenizer) - current_embedding_size
+ input_embeddings = model.get_input_embeddings().weight.data
+ output_embeddings = model.get_output_embeddings().weight.data
+
+ input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+ output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+
+ input_embeddings[-num_new_tokens:] = input_embeddings_avg
+ output_embeddings[-num_new_tokens:] = output_embeddings_avg
+
+ print_log(
+ f'Resized token embeddings from {current_embedding_size} to '
+ f'{len(tokenizer)}.', 'current')
+
+
+class SupervisedFinetune(BaseModel):
+
+ def __init__(self,
+ llm,
+ lora=None,
+ peft_model=None,
+ use_activation_checkpointing=True,
+ use_varlen_attn=False,
+ tokenizer=None,
+ max_position_embeddings=None):
+ super().__init__()
+
+ self.llm = self.build_llm_from_cfg(llm, use_varlen_attn,
+ max_position_embeddings)
+
+ if tokenizer is not None:
+ if isinstance(tokenizer, dict):
+ tokenizer = BUILDER.build(tokenizer)
+ smart_tokenizer_and_embedding_resize(tokenizer, self.llm)
+
+ self.llm.config.use_cache = False
+ if use_activation_checkpointing:
+ # For backward compatibility
+ if hasattr(self.llm, 'enable_input_require_grads'):
+ self.llm.enable_input_require_grads()
+ else:
+ self.llm.get_input_embeddings().register_forward_hook(
+ make_inputs_require_grad)
+
+ # enable gradient checkpointing for memory efficiency
+ self.gradient_checkpointing_enable()
+
+ if isinstance(lora, dict) or isinstance(lora, Config) or isinstance(
+ lora, ConfigDict):
+ self.lora = BUILDER.build(lora)
+ else:
+ self.lora = lora
+ self.peft_model = peft_model
+ self.use_lora = lora is not None
+ if self.use_lora:
+ self._prepare_for_lora(peft_model, use_activation_checkpointing)
+
+ self._is_init = True
+ # Determines whether to calculate attention based on the
+ # seq_len dimension (use_varlen_attn = False) or the actual length of
+ # the sequence.
+ self.use_varlen_attn = use_varlen_attn
+
+ def build_llm_from_cfg(self, llm_cfg, use_varlen_attn,
+ max_position_embeddings):
+ # For forward
+ with LoadWoInit():
+ if isinstance(llm_cfg, dict):
+ llm = self._dispatch_lm_model_cfg(llm_cfg,
+ max_position_embeddings)
+ llm = self._build_from_cfg_or_module(llm)
+
+ llm.config.use_cache = False
+ dispatch_modules(llm, use_varlen_attn=use_varlen_attn)
+ return llm
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.llm.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.llm.gradient_checkpointing_disable()
+
+ def _prepare_for_lora(self,
+ peft_model=None,
+ use_activation_checkpointing=True):
+ self.llm = prepare_model_for_kbit_training(
+ self.llm, use_activation_checkpointing)
+ if self.lora.target_modules is None:
+ modules = find_all_linear_names(self.llm)
+ self.lora.target_modules = modules
+
+ self.llm = get_peft_model(self.llm, self.lora)
+ if peft_model is not None:
+ _ = load_checkpoint(self, peft_model)
+
+ def init_weights(self):
+ pass
+
+ @staticmethod
+ def _prepare_for_long_context_training(cfg, llm_cfg,
+ max_position_embeddings):
+ if not hasattr(llm_cfg, 'rope_scaling'):
+ print_log('Current model does not support RoPE scaling.',
+ 'current')
+ return
+
+ current_max_length = getattr(llm_cfg, 'max_position_embeddings', None)
+ if current_max_length and max_position_embeddings > current_max_length:
+ print_log(
+ f'Enlarge max model length from {current_max_length} '
+ f'to {max_position_embeddings}.', 'current')
+ scaling_factor = float(
+ math.ceil(max_position_embeddings / current_max_length))
+ else:
+ print_log(
+ 'The input `max_position_embeddings` is smaller than '
+ 'origin max length. Consider increase input length.',
+ 'current')
+ scaling_factor = 1.0
+ cfg.rope_scaling = {'type': 'linear', 'factor': scaling_factor}
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_flash_attn(cfg, llm_cfg):
+ cls_name = type(llm_cfg).__name__
+ SUPPORT_SDPA_ATTN = ('LlamaConfig', 'GemmaConfig', 'MistralConfig',
+ 'MixtralConfig', 'Qwen2Config', 'Qwen2MoeConfig',
+ 'Starcoder2Config', 'Starcoder2Config',
+ 'Phi3Config')
+ SUPPORT_FLASH_ATTN2 = ('InternLM2Config', 'LlamaConfig', 'GemmaConfig',
+ 'MistralConfig', 'MixtralConfig', 'Qwen2Config',
+ 'Qwen2MoeConfig', 'Starcoder2Config',
+ 'Starcoder2Config', 'Phi3Config',
+ 'DeepseekV2Config')
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ if getattr(cfg, 'attn_implementation', None) is not None:
+ # Flash Attention 2.0 only supports torch.float16 and
+ # torch.bfloat16 dtypes
+ if cfg.attn_implementation == 'flash_attention_2':
+ cfg.torch_dtype = torch_dtype
+ elif SUPPORT_FLASH2 and cls_name in SUPPORT_FLASH_ATTN2:
+ cfg.torch_dtype = torch_dtype
+ cfg.attn_implementation = 'flash_attention_2'
+ elif SUPPORT_FLASH1 and cls_name in SUPPORT_SDPA_ATTN:
+ cfg.attn_implementation = 'sdpa'
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_qlora_zero3(cfg):
+ if (not is_deepspeed_zero3_enabled()) or (not hasattr(
+ cfg, 'quantization_config')):
+ return cfg
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ cfg.torch_dtype = torch_dtype
+ quantization_config = cfg.quantization_config
+ quantization_config.bnb_4bit_compute_dtype = torch_dtype
+ quantization_config.bnb_4bit_quant_storage = torch_dtype
+
+ return cfg
+
+ def _dispatch_lm_model_cfg(self, cfg, max_position_embeddings=None):
+ cfg = self._prepare_for_qlora_zero3(cfg)
+ pretrained_model_name_or_path = cfg.pretrained_model_name_or_path
+ llm_cfg = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=True)
+ cfg = self._prepare_for_flash_attn(cfg, llm_cfg)
+ if max_position_embeddings is not None:
+ cfg = self._prepare_for_long_context_training(
+ cfg, llm_cfg, max_position_embeddings)
+ return cfg
+
+ def _build_from_cfg_or_module(self, cfg_or_mod):
+ if isinstance(cfg_or_mod, nn.Module):
+ return cfg_or_mod
+ elif isinstance(cfg_or_mod, dict):
+ traverse_dict(cfg_or_mod)
+ return BUILDER.build(cfg_or_mod)
+ else:
+ raise NotImplementedError
+
+ def forward(self, data, data_samples=None, mode='loss'):
+
+ if mode == 'loss':
+ return self.compute_loss(data, data_samples)
+ elif mode == 'predict':
+ return self.predict(data, data_samples)
+ elif mode == 'tensor':
+ return self._forward(data, data_samples)
+ else:
+ raise NotImplementedError
+
+ def _forward(self, data, data_samples=None):
+
+ outputs = self.llm(**data)
+
+ return outputs
+
+ def predict(self, data, data_samples=None):
+ outputs = self.llm(**data)
+ logits_dict = [{'logits': logits} for logits in outputs.logits]
+ return logits_dict
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'labels', 'position_ids')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def _compute_sequence_parallel_loss(self, data):
+ data = self._split_for_sequence_parallel(data)
+ outputs = self.llm(**data)
+ labels = data['labels']
+ num_tokens = (labels != -100).sum()
+ sp_group = get_sequence_parallel_group()
+ loss = reduce_sequence_parallel_loss(outputs.loss, num_tokens,
+ sp_group)
+ return {'loss': loss}
+
+ def compute_loss(self, data, data_samples=None):
+ if get_sequence_parallel_world_size() > 1:
+ return self._compute_sequence_parallel_loss(data)
+ else:
+ outputs = self.llm(**data)
+ loss_dict = {'loss': outputs.loss}
+ return loss_dict
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ if not self.use_lora:
+ return state_dict
+ to_return = get_peft_model_state_dict(self.llm, state_dict=state_dict)
+ return OrderedDict(to_return)
+
+ def __getattr__(self, name: str):
+ try:
+ return super().__getattr__(name)
+ except AttributeError:
+ return getattr(self.llm, name)
+
+ def to_hf(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={},
+ **kwargs):
+ self.llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ self.llm.half()
+ if self.use_lora:
+ print_log(f'Saving adapter to {save_dir}', 'current')
+ else:
+ print_log(f'Saving LLM tokenizer to {save_dir}', 'current')
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ tokenizer.save_pretrained(save_dir)
+ print_log(f'Saving LLM to {save_dir}', 'current')
+ self.llm.save_pretrained(save_dir, **save_pretrained_kwargs)
+ self.llm.config.use_cache = False
diff --git a/data/xtuner/xtuner/model/transformers_models/__init__.py b/data/xtuner/xtuner/model/transformers_models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..71f7ea1d42e34a3fa6b4239b86a468c2e7727b14
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/__init__.py
@@ -0,0 +1,8 @@
+from .deepseek_v2 import (DeepseekTokenizerFast, DeepseekV2Config,
+ DeepseekV2ForCausalLM, DeepseekV2Model)
+from .mixtral import MixtralConfig, MixtralForCausalLM, MixtralModel
+
+__all__ = [
+ 'DeepseekTokenizerFast', 'DeepseekV2Config', 'DeepseekV2ForCausalLM',
+ 'DeepseekV2Model', 'MixtralConfig', 'MixtralForCausalLM', 'MixtralModel'
+]
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/__init__.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a74b483ca374f0b50c9e3a5e536e54aa671cca4
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/__init__.py
@@ -0,0 +1,8 @@
+from .configuration_deepseek import DeepseekV2Config
+from .modeling_deepseek import DeepseekV2ForCausalLM, DeepseekV2Model
+from .tokenization_deepseek_fast import DeepseekTokenizerFast
+
+__all__ = [
+ 'DeepseekV2ForCausalLM', 'DeepseekV2Model', 'DeepseekV2Config',
+ 'DeepseekTokenizerFast'
+]
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/configuration_deepseek.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/configuration_deepseek.py
new file mode 100644
index 0000000000000000000000000000000000000000..daaddcf4922fcfe3617040da2717ee912a10f123
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/configuration_deepseek.py
@@ -0,0 +1,219 @@
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+logger = logging.get_logger(__name__)
+
+DEEPSEEK_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+
+# Compared to the original version, two parameters, `moe_implementation` and
+# `expert_in_one_shard`, have been added.
+class DeepseekV2Config(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`DeepseekV2Model`]. It is used to instantiate an DeepSeek
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the DeepSeek-V2.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 102400):
+ Vocabulary size of the Deep model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`DeepseekV2Model`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 11008):
+ Dimension of the MLP representations.
+ moe_intermediate_size (`int`, *optional*, defaults to 1407):
+ Dimension of the MoE representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer decoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ n_shared_experts (`int`, *optional*, defaults to None):
+ Number of shared experts, None means dense model.
+ n_routed_experts (`int`, *optional*, defaults to None):
+ Number of routed experts, None means dense model.
+ routed_scaling_factor (`float`, *optional*, defaults to 1.0):
+ Scaling factor or routed experts.
+ topk_method (`str`, *optional*, defaults to `gready`):
+ Topk method used in routed gate.
+ n_group (`int`, *optional*, defaults to None):
+ Number of groups for routed experts.
+ topk_group (`int`, *optional*, defaults to None):
+ Number of selected groups for each token(for each token, ensuring the selected experts is only within `topk_group` groups).
+ num_experts_per_tok (`int`, *optional*, defaults to None):
+ Number of selected experts, None means dense model.
+ moe_layer_freq (`int`, *optional*, defaults to 1):
+ The frequency of the MoE layer: one expert layer for every `moe_layer_freq - 1` dense layers.
+ first_k_dense_replace (`int`, *optional*, defaults to 0):
+ Number of dense layers in shallow layers(embed->dense->dense->...->dense->moe->moe...->lm_head).
+ \--k dense layers--/
+ norm_topk_prob (`bool`, *optional*, defaults to False):
+ Whether to normalize the weights of the routed experts.
+ scoring_func (`str`, *optional*, defaults to 'softmax'):
+ Method of computing expert weights.
+ aux_loss_alpha (`float`, *optional*, defaults to 0.001):
+ Auxiliary loss weight coefficient.
+ seq_aux = (`bool`, *optional*, defaults to True):
+ Whether to compute the auxiliary loss for each individual sample.
+ num_key_value_heads (`int`, *optional*):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 2048):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*):
+ Padding token id.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ Beginning of stream token id.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ End of stream token id.
+ pretraining_tp (`int`, *optional*, defaults to 1):
+ Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
+ document](https://huggingface.co/docs/transformers/parallelism) to understand more about it. This value is
+ necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
+ issue](https://github.com/pytorch/pytorch/issues/76232).
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether to tie weight embeddings
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ rope_scaling (`Dict`, *optional*):
+ Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
+ strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
+ `{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
+ `max_position_embeddings` to the expected new maximum.
+ attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ moe_implementation (`str`, *optional*, defaults to 'origin'):
+ The implementation of the moe blocks. 'origin' or 'shard'.
+ expert_in_one_shard (`int`, *optional*, defaults to None):
+ How many expert models are integrated into a shard. It is used only
+ when `moe_implementation` == 'shard'
+
+ ```python
+ >>> from transformers import DeepseekV2Model, DeepseekV2Config
+
+ >>> # Initializing a Deepseek-V2 style configuration
+ >>> configuration = DeepseekV2Config()
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = 'deepseek_v2'
+ keys_to_ignore_at_inference = ['past_key_values']
+
+ def __init__(
+ self,
+ vocab_size=102400,
+ hidden_size=4096,
+ intermediate_size=11008,
+ moe_intermediate_size=1407,
+ num_hidden_layers=30,
+ num_attention_heads=32,
+ num_key_value_heads=32,
+ n_shared_experts=None,
+ n_routed_experts=None,
+ ep_size=1,
+ routed_scaling_factor=1.0,
+ kv_lora_rank=512,
+ q_lora_rank=1536,
+ qk_rope_head_dim=64,
+ v_head_dim=128,
+ qk_nope_head_dim=128,
+ topk_method='gready',
+ n_group=None,
+ topk_group=None,
+ num_experts_per_tok=None,
+ moe_layer_freq=1,
+ first_k_dense_replace=0,
+ norm_topk_prob=False,
+ scoring_func='softmax',
+ aux_loss_alpha=0.001,
+ seq_aux=True,
+ hidden_act='silu',
+ max_position_embeddings=2048,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=None,
+ bos_token_id=100000,
+ eos_token_id=100001,
+ pretraining_tp=1,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ rope_scaling=None,
+ attention_bias=False,
+ attention_dropout=0.0,
+ moe_implementation='origin',
+ expert_in_one_shard=None,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.moe_intermediate_size = moe_intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.n_shared_experts = n_shared_experts
+ self.n_routed_experts = n_routed_experts
+ self.ep_size = ep_size
+ self.routed_scaling_factor = routed_scaling_factor
+ self.kv_lora_rank = kv_lora_rank
+ self.q_lora_rank = q_lora_rank
+ self.qk_rope_head_dim = qk_rope_head_dim
+ self.v_head_dim = v_head_dim
+ self.qk_nope_head_dim = qk_nope_head_dim
+ self.topk_method = topk_method
+ self.n_group = n_group
+ self.topk_group = topk_group
+ self.num_experts_per_tok = num_experts_per_tok
+ self.moe_layer_freq = moe_layer_freq
+ self.first_k_dense_replace = first_k_dense_replace
+ self.norm_topk_prob = norm_topk_prob
+ self.scoring_func = scoring_func
+ self.aux_loss_alpha = aux_loss_alpha
+ self.seq_aux = seq_aux
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.pretraining_tp = pretraining_tp
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+ self.moe_implementation = moe_implementation
+ self.expert_in_one_shard = expert_in_one_shard
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/modeling_deepseek.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/modeling_deepseek.py
new file mode 100644
index 0000000000000000000000000000000000000000..f58dd466fa7a4b754df2b5e7b3da8911985d182d
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/modeling_deepseek.py
@@ -0,0 +1,2037 @@
+# Copyright 2023 DeepSeek-AI and The HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch DeepSeek model."""
+import copy
+import math
+import os
+import types
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.activations import ACT2FN
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.configuration_utils import PretrainedConfig
+from transformers.modeling_attn_mask_utils import (
+ AttentionMaskConverter, _prepare_4d_attention_mask,
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa)
+from transformers.modeling_outputs import (BaseModelOutputWithPast,
+ CausalLMOutputWithPast,
+ SequenceClassifierOutputWithPast)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.pytorch_utils import (ALL_LAYERNORM_LAYERS,
+ is_torch_greater_or_equal_than_1_13)
+from transformers.utils import (add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10, logging,
+ replace_return_docstrings)
+from transformers.utils.import_utils import is_torch_fx_available
+
+from xtuner.utils import load_state_dict_into_model
+from .configuration_deepseek import DeepseekV2Config
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input # noqa
+ from flash_attn.bert_padding import index_first_axis, unpad_input
+
+# This makes `_prepare_4d_causal_attention_mask` a leaf function in the FX graph.
+# It means that the function will not be traced through and simply appear as a node in the graph.
+if is_torch_fx_available():
+ if not is_torch_greater_or_equal_than_1_13:
+ import torch.fx
+
+ _prepare_4d_causal_attention_mask = torch.fx.wrap(
+ _prepare_4d_causal_attention_mask)
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = 'DeepseekV2Config'
+
+
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(
+ torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+class DeepseekV2RMSNorm(nn.Module):
+
+ def __init__(self, hidden_size, eps=1e-6):
+ """DeepseekV2RMSNorm is equivalent to T5LayerNorm."""
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance +
+ self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+ALL_LAYERNORM_LAYERS.append(DeepseekV2RMSNorm)
+
+
+class DeepseekV2RotaryEmbedding(nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (
+ self.base
+ **(torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings,
+ device=self.inv_freq.device,
+ dtype=torch.get_default_dtype(),
+ )
+ self.max_seq_len_cached = None
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.outer(t, self.inv_freq.to(t.device))
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if self.max_seq_len_cached is None or seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(
+ seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->DeepseekV2
+class DeepseekV2LinearScalingRotaryEmbedding(DeepseekV2RotaryEmbedding):
+ """DeepseekV2RotaryEmbedding extended with linear scaling.
+
+ Credits to the Reddit user /u/kaiokendev
+ """
+
+ def __init__(
+ self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None,
+ scaling_factor=1.0,
+ ):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ t = t / self.scaling_factor
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->DeepseekV2
+class DeepseekV2DynamicNTKScalingRotaryEmbedding(DeepseekV2RotaryEmbedding):
+ """DeepseekV2RotaryEmbedding extended with Dynamic NTK scaling.
+
+ Credits to the Reddit users /u/bloc97 and /u/emozilla
+ """
+
+ def __init__(
+ self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None,
+ scaling_factor=1.0,
+ ):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+
+ if seq_len > self.max_position_embeddings:
+ base = self.base * ((self.scaling_factor * seq_len /
+ self.max_position_embeddings) -
+ (self.scaling_factor - 1))**(
+ self.dim / (self.dim - 2))
+ inv_freq = 1.0 / (
+ base
+ **(torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+
+# Inverse dim formula to find dim based on number of rotations
+def yarn_find_correction_dim(num_rotations,
+ dim,
+ base=10000,
+ max_position_embeddings=2048):
+ return (dim * math.log(max_position_embeddings /
+ (num_rotations * 2 * math.pi))) / (2 *
+ math.log(base))
+
+
+# Find dim range bounds based on rotations
+def yarn_find_correction_range(low_rot,
+ high_rot,
+ dim,
+ base=10000,
+ max_position_embeddings=2048):
+ low = math.floor(
+ yarn_find_correction_dim(low_rot, dim, base, max_position_embeddings))
+ high = math.ceil(
+ yarn_find_correction_dim(high_rot, dim, base, max_position_embeddings))
+ return max(low, 0), min(high, dim - 1) # Clamp values just in case
+
+
+def yarn_get_mscale(scale=1, mscale=1):
+ if scale <= 1:
+ return 1.0
+ return 0.1 * mscale * math.log(scale) + 1.0
+
+
+def yarn_linear_ramp_mask(min, max, dim):
+ if min == max:
+ max += 0.001 # Prevent singularity
+
+ linear_func = (torch.arange(dim, dtype=torch.float32) - min) / (max - min)
+ ramp_func = torch.clamp(linear_func, 0, 1)
+ return ramp_func
+
+
+class DeepseekV2YarnRotaryEmbedding(DeepseekV2RotaryEmbedding):
+
+ def __init__(
+ self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None,
+ scaling_factor=1.0,
+ original_max_position_embeddings=4096,
+ beta_fast=32,
+ beta_slow=1,
+ mscale=1,
+ mscale_all_dim=0,
+ ):
+ self.scaling_factor = scaling_factor
+ self.original_max_position_embeddings = original_max_position_embeddings
+ self.beta_fast = beta_fast
+ self.beta_slow = beta_slow
+ self.mscale = mscale
+ self.mscale_all_dim = mscale_all_dim
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ dim = self.dim
+
+ freq_extra = 1.0 / (
+ self.base**(torch.arange(
+ 0, dim, 2, dtype=torch.float32, device=device) / dim))
+ freq_inter = 1.0 / (
+ self.scaling_factor * self.base**(torch.arange(
+ 0, dim, 2, dtype=torch.float32, device=device) / dim))
+
+ low, high = yarn_find_correction_range(
+ self.beta_fast,
+ self.beta_slow,
+ dim,
+ self.base,
+ self.original_max_position_embeddings,
+ )
+ inv_freq_mask = 1.0 - yarn_linear_ramp_mask(low, high, dim // 2).to(
+ device=device, dtype=torch.float32)
+ inv_freq = freq_inter * (1 -
+ inv_freq_mask) + freq_extra * inv_freq_mask
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ t = torch.arange(seq_len, device=device, dtype=torch.float32)
+
+ freqs = torch.outer(t, inv_freq)
+
+ _mscale = float(
+ yarn_get_mscale(self.scaling_factor, self.mscale) /
+ yarn_get_mscale(self.scaling_factor, self.mscale_all_dim))
+
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', (emb.cos() * _mscale).to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', (emb.sin() * _mscale).to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+
+ b, h, s, d = q.shape
+ q = q.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
+
+ b, h, s, d = k.shape
+ k = k.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
+
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class DeepseekV2MLP(nn.Module):
+
+ def __init__(self, config, hidden_size=None, intermediate_size=None):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size if hidden_size is None else hidden_size
+ self.intermediate_size = (
+ config.intermediate_size
+ if intermediate_size is None else intermediate_size)
+
+ self.gate_proj = nn.Linear(
+ self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(
+ self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(
+ self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(
+ self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+class MoEGate(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.top_k = config.num_experts_per_tok
+ self.n_routed_experts = config.n_routed_experts
+ self.routed_scaling_factor = config.routed_scaling_factor
+ self.scoring_func = config.scoring_func
+ self.alpha = config.aux_loss_alpha
+ self.seq_aux = config.seq_aux
+ self.topk_method = config.topk_method
+ self.n_group = config.n_group
+ self.topk_group = config.topk_group
+
+ # topk selection algorithm
+ self.norm_topk_prob = config.norm_topk_prob
+ self.gating_dim = config.hidden_size
+ self.weight = nn.Parameter(
+ torch.empty((self.n_routed_experts, self.gating_dim)))
+ self.reset_parameters()
+
+ def reset_parameters(self) -> None:
+ import torch.nn.init as init
+
+ init.kaiming_uniform_(self.weight, a=math.sqrt(5))
+
+ def forward(self, hidden_states):
+ bsz, seq_len, h = hidden_states.shape
+ ### compute gating score
+ hidden_states = hidden_states.view(-1, h)
+ logits = F.linear(
+ hidden_states.type(torch.float32), self.weight.type(torch.float32),
+ None)
+ if self.scoring_func == 'softmax':
+ scores = logits.softmax(dim=-1, dtype=torch.float32)
+ else:
+ raise NotImplementedError(
+ f'insupportable scoring function for MoE gating: {self.scoring_func}'
+ )
+
+ ### select top-k experts
+ # fix official typos
+ if self.topk_method in ('gready', 'greedy'):
+ topk_weight, topk_idx = torch.topk(
+ scores, k=self.top_k, dim=-1, sorted=False)
+ elif self.topk_method == 'group_limited_greedy':
+ group_scores = (scores.view(bsz * seq_len, self.n_group,
+ -1).max(dim=-1).values) # [n, n_group]
+ group_idx = torch.topk(
+ group_scores, k=self.topk_group, dim=-1,
+ sorted=False)[1] # [n, top_k_group]
+ group_mask = torch.zeros_like(group_scores) # [n, n_group]
+ group_mask.scatter_(1, group_idx, 1) # [n, n_group]
+ score_mask = (group_mask.unsqueeze(-1).expand(
+ bsz * seq_len, self.n_group,
+ self.n_routed_experts // self.n_group).reshape(
+ bsz * seq_len, -1)) # [n, e]
+ tmp_scores = scores.masked_fill(~score_mask.bool(), 0.0) # [n, e]
+ topk_weight, topk_idx = torch.topk(
+ tmp_scores, k=self.top_k, dim=-1, sorted=False)
+
+ ### norm gate to sum 1
+ if self.top_k > 1 and self.norm_topk_prob:
+ denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
+ topk_weight = topk_weight / denominator
+ else:
+ topk_weight = topk_weight * self.routed_scaling_factor
+ ### expert-level computation auxiliary loss
+ if self.training and self.alpha > 0.0:
+ scores_for_aux = scores
+ aux_topk = self.top_k
+ # always compute aux loss based on the naive greedy topk method
+ topk_idx_for_aux_loss = topk_idx.view(bsz, -1)
+ if self.seq_aux:
+ scores_for_seq_aux = scores_for_aux.view(bsz, seq_len, -1)
+ ce = torch.zeros(
+ bsz, self.n_routed_experts, device=hidden_states.device)
+ ce.scatter_add_(
+ 1,
+ topk_idx_for_aux_loss,
+ torch.ones(
+ bsz, seq_len * aux_topk, device=hidden_states.device),
+ ).div_(seq_len * aux_topk / self.n_routed_experts)
+ aux_loss = (ce * scores_for_seq_aux.mean(dim=1)).sum(
+ dim=1).mean() * self.alpha
+ else:
+ mask_ce = F.one_hot(
+ topk_idx_for_aux_loss.view(-1),
+ num_classes=self.n_routed_experts)
+ ce = mask_ce.float().mean(0)
+ Pi = scores_for_aux.mean(0)
+ fi = ce * self.n_routed_experts
+ aux_loss = (Pi * fi).sum() * self.alpha
+ else:
+ aux_loss = None
+ return topk_idx, topk_weight, aux_loss
+
+
+class AddAuxiliaryLoss(torch.autograd.Function):
+ """The trick function of adding auxiliary (aux) loss, which includes the
+ gradient of the aux loss during backpropagation."""
+
+ @staticmethod
+ def forward(ctx, x, loss):
+ assert loss.numel() == 1
+ ctx.dtype = loss.dtype
+ ctx.required_aux_loss = loss.requires_grad
+ return x
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ grad_loss = None
+ if ctx.required_aux_loss:
+ grad_loss = torch.ones(
+ 1, dtype=ctx.dtype, device=grad_output.device)
+ return grad_output, grad_loss
+
+
+class ExpertShard(nn.Module):
+
+ def __init__(self, config, shard_idx, expert_in_one_shard=10):
+ super().__init__()
+ hidden_dim = config.hidden_size
+ ffn_dim = config.moe_intermediate_size
+ self.w1w3 = nn.Parameter(
+ torch.empty(expert_in_one_shard, ffn_dim * 2, hidden_dim))
+ self.w2 = nn.Parameter(
+ torch.empty(expert_in_one_shard, hidden_dim, ffn_dim))
+
+ self.act = nn.SiLU()
+ self.expert_in_one_shard = expert_in_one_shard
+ self.shard_idx = shard_idx
+
+ self.reset_parameters()
+
+ def reset_parameters(self) -> None:
+ # Different from nn.Linear module, weights of self.w1w3 and self.w2
+ # can not be initialized by DeepseekV2PreTrainedModel._init_weights method
+ self.w1w3.data.normal_(0, 0.02)
+ self.w2.data.normal_(0, 0.02)
+
+ def expert_forward(self, current_state, expert_idx):
+ w1w3 = self.w1w3[expert_idx]
+ w2 = self.w2[expert_idx]
+ gate_up_out = torch.matmul(current_state, w1w3.T)
+ gate_out, up_out = gate_up_out.chunk(2, dim=-1)
+ gate_out = self.act(gate_out)
+ out = gate_out * up_out
+ out = torch.matmul(out, w2.T)
+ return out
+
+ def forward(self, hidden_states, flat_topk_idx, y):
+ for i in range(self.expert_in_one_shard):
+ expert_idx = i + self.expert_in_one_shard * self.shard_idx
+ y[flat_topk_idx == expert_idx] = self.expert_forward(
+ hidden_states[flat_topk_idx == expert_idx], i)
+ return y
+
+
+class DeepseekV2MoEShard(nn.Module):
+ """A mixed expert module containing shared experts."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.num_experts_per_tok = config.num_experts_per_tok
+
+ if hasattr(config, 'ep_size') and config.ep_size > 1:
+ raise NotImplementedError
+ else:
+ self.ep_size = 1
+ self.experts_per_rank = config.n_routed_experts
+ self.ep_rank = 0
+ self.n_routed_experts = config.n_routed_experts
+
+ expert_in_one_shard = config.expert_in_one_shard
+ assert config.n_routed_experts % expert_in_one_shard == 0, \
+ ('n_routed_experts should be divisible by expert_in_one_shard, but got '
+ f'n_routed_experts = {config.n_routed_experts} and expert_in_one_shard = {expert_in_one_shard}')
+
+ self.shard_num = config.n_routed_experts // expert_in_one_shard
+ self.expert_in_one_shard = expert_in_one_shard
+ self.experts = nn.ModuleList([
+ ExpertShard(config, i, self.expert_in_one_shard)
+ for i in range(self.shard_num)
+ ])
+
+ self.gate = MoEGate(config)
+ if config.n_shared_experts is not None:
+ intermediate_size = config.moe_intermediate_size * config.n_shared_experts
+ self.shared_experts = DeepseekV2MLP(
+ config=config, intermediate_size=intermediate_size)
+
+ def forward(self, hidden_states):
+ if not self.training:
+ raise NotImplementedError
+
+ identity = hidden_states
+ orig_shape = hidden_states.shape
+ topk_idx, topk_weight, aux_loss = self.gate(hidden_states)
+ hidden_states = hidden_states.view(-1, hidden_states.shape[-1])
+ flat_topk_idx = topk_idx.view(-1)
+
+ hidden_states = hidden_states.repeat_interleave(
+ self.num_experts_per_tok, dim=0)
+ y = torch.empty_like(hidden_states)
+ y_dtype = y.dtype
+ for shard_index in range(self.shard_num):
+ y = self.experts[shard_index](hidden_states, flat_topk_idx, y)
+ y = ((y.view(*topk_weight.shape, -1) *
+ topk_weight.unsqueeze(-1)).sum(dim=1)).type(y_dtype)
+ y = y.view(*orig_shape)
+ y = AddAuxiliaryLoss.apply(y, aux_loss)
+
+ if self.config.n_shared_experts is not None:
+ y = y + self.shared_experts(identity)
+ return y
+
+
+class DeepseekV2MoE(nn.Module):
+ """A mixed expert module containing shared experts."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.num_experts_per_tok = config.num_experts_per_tok
+
+ if hasattr(config, 'ep_size') and config.ep_size > 1:
+ assert config.ep_size == dist.get_world_size()
+ self.ep_size = config.ep_size
+ self.experts_per_rank = config.n_routed_experts // config.ep_size
+ self.ep_rank = dist.get_rank()
+ self.experts = nn.ModuleList([
+ (DeepseekV2MLP(
+ config, intermediate_size=config.moe_intermediate_size)
+ if i >= self.ep_rank * self.experts_per_rank and i <
+ (self.ep_rank + 1) * self.experts_per_rank else None)
+ for i in range(config.n_routed_experts)
+ ])
+ else:
+ self.ep_size = 1
+ self.experts_per_rank = config.n_routed_experts
+ self.ep_rank = 0
+ self.experts = nn.ModuleList([
+ DeepseekV2MLP(
+ config, intermediate_size=config.moe_intermediate_size)
+ for i in range(config.n_routed_experts)
+ ])
+ self.gate = MoEGate(config)
+ if config.n_shared_experts is not None:
+ intermediate_size = config.moe_intermediate_size * config.n_shared_experts
+ self.shared_experts = DeepseekV2MLP(
+ config=config, intermediate_size=intermediate_size)
+
+ def forward(self, hidden_states):
+ identity = hidden_states
+ orig_shape = hidden_states.shape
+ topk_idx, topk_weight, aux_loss = self.gate(hidden_states)
+ hidden_states = hidden_states.view(-1, hidden_states.shape[-1])
+ flat_topk_idx = topk_idx.view(-1)
+ if self.training:
+ hidden_states = hidden_states.repeat_interleave(
+ self.num_experts_per_tok, dim=0)
+ y = torch.empty_like(hidden_states)
+ y_dtype = y.dtype
+ for i, expert in enumerate(self.experts):
+ y[flat_topk_idx == i] = expert(
+ hidden_states[flat_topk_idx == i])
+ y = ((y.view(*topk_weight.shape, -1) *
+ topk_weight.unsqueeze(-1)).sum(dim=1)).type(y_dtype)
+ y = y.view(*orig_shape)
+ y = AddAuxiliaryLoss.apply(y, aux_loss)
+ else:
+ y = self.moe_infer(hidden_states, topk_idx,
+ topk_weight).view(*orig_shape)
+ if self.config.n_shared_experts is not None:
+ y = y + self.shared_experts(identity)
+ return y
+
+ @torch.no_grad()
+ def moe_infer(self, x, topk_ids, topk_weight):
+ cnts = topk_ids.new_zeros((topk_ids.shape[0], len(self.experts)))
+ cnts.scatter_(1, topk_ids, 1)
+ tokens_per_expert = cnts.sum(dim=0)
+ idxs = topk_ids.view(-1).argsort()
+ sorted_tokens = x[idxs // topk_ids.shape[1]]
+ sorted_tokens_shape = sorted_tokens.shape
+ if self.ep_size > 1:
+ tokens_per_ep_rank = tokens_per_expert.view(self.ep_size,
+ -1).sum(dim=1)
+ tokens_per_expert_group = tokens_per_expert.new_empty(
+ tokens_per_expert.shape[0])
+ dist.all_to_all_single(tokens_per_expert_group, tokens_per_expert)
+ output_splits = (
+ tokens_per_expert_group.view(self.ep_size,
+ -1).sum(1).cpu().numpy().tolist())
+ gathered_tokens = sorted_tokens.new_empty(
+ tokens_per_expert_group.sum(dim=0).cpu().item(),
+ sorted_tokens.shape[1])
+ input_split_sizes = tokens_per_ep_rank.cpu().numpy().tolist()
+ dist.all_to_all(
+ list(gathered_tokens.split(output_splits)),
+ list(sorted_tokens.split(input_split_sizes)),
+ )
+ tokens_per_expert_post_gather = tokens_per_expert_group.view(
+ self.ep_size, self.experts_per_rank).sum(dim=0)
+ gatherd_idxs = np.zeros(
+ shape=(gathered_tokens.shape[0], ), dtype=np.int32)
+ s = 0
+ for i, k in enumerate(tokens_per_expert_group.cpu().numpy()):
+ gatherd_idxs[s:s + k] = i % self.experts_per_rank
+ s += k
+ gatherd_idxs = gatherd_idxs.argsort()
+ sorted_tokens = gathered_tokens[gatherd_idxs]
+ tokens_per_expert = tokens_per_expert_post_gather
+ tokens_per_expert = tokens_per_expert.cpu().numpy()
+
+ outputs = []
+ start_idx = 0
+ for i, num_tokens in enumerate(tokens_per_expert):
+ end_idx = start_idx + num_tokens
+ if num_tokens == 0:
+ continue
+ expert = self.experts[i + self.ep_rank * self.experts_per_rank]
+ tokens_for_this_expert = sorted_tokens[start_idx:end_idx]
+ expert_out = expert(tokens_for_this_expert)
+ outputs.append(expert_out)
+ start_idx = end_idx
+
+ outs = torch.cat(
+ outputs, dim=0) if len(outputs) else sorted_tokens.new_empty(0)
+ if self.ep_size > 1:
+ new_x = torch.empty_like(outs)
+ new_x[gatherd_idxs] = outs
+ gathered_tokens = new_x.new_empty(*sorted_tokens_shape)
+ dist.all_to_all(
+ list(gathered_tokens.split(input_split_sizes)),
+ list(new_x.split(output_splits)),
+ )
+ outs = gathered_tokens
+
+ new_x = torch.empty_like(outs)
+ new_x[idxs] = outs
+ final_out = (
+ new_x.view(*topk_ids.shape, -1).type(topk_weight.dtype).mul_(
+ topk_weight.unsqueeze(dim=-1)).sum(dim=1).type(new_x.dtype))
+ return final_out
+
+
+# Copied from transformers.models.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaAttention with Llama->DeepseekV2
+class DeepseekV2Attention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper."""
+
+ def __init__(self,
+ config: DeepseekV2Config,
+ layer_idx: Optional[int] = None):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ if layer_idx is None:
+ logger.warning_once(
+ f'Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will '
+ 'to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` '
+ 'when creating this class.')
+
+ self.attention_dropout = config.attention_dropout
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.q_lora_rank = config.q_lora_rank
+ self.qk_rope_head_dim = config.qk_rope_head_dim
+ self.kv_lora_rank = config.kv_lora_rank
+ self.v_head_dim = config.v_head_dim
+ self.qk_nope_head_dim = config.qk_nope_head_dim
+ self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
+
+ self.is_causal = True
+
+ if self.q_lora_rank is None:
+ self.q_proj = nn.Linear(
+ self.hidden_size, self.num_heads * self.q_head_dim, bias=False)
+ else:
+ self.q_a_proj = nn.Linear(
+ self.hidden_size,
+ config.q_lora_rank,
+ bias=config.attention_bias)
+ self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
+ self.q_b_proj = nn.Linear(
+ config.q_lora_rank,
+ self.num_heads * self.q_head_dim,
+ bias=False)
+
+ self.kv_a_proj_with_mqa = nn.Linear(
+ self.hidden_size,
+ config.kv_lora_rank + config.qk_rope_head_dim,
+ bias=config.attention_bias,
+ )
+ self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
+ self.kv_b_proj = nn.Linear(
+ config.kv_lora_rank,
+ self.num_heads *
+ (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
+ bias=False,
+ )
+
+ self.o_proj = nn.Linear(
+ self.num_heads * self.v_head_dim,
+ self.hidden_size,
+ bias=config.attention_bias,
+ )
+ self._init_rope()
+
+ self.softmax_scale = self.q_head_dim**(-0.5)
+ if self.config.rope_scaling is not None:
+ mscale_all_dim = self.config.rope_scaling.get('mscale_all_dim', 0)
+ scaling_factor = self.config.rope_scaling['factor']
+ if mscale_all_dim:
+ mscale = yarn_get_mscale(scaling_factor, mscale_all_dim)
+ self.softmax_scale = self.softmax_scale * mscale * mscale
+
+ def _init_rope(self):
+ if self.config.rope_scaling is None:
+ self.rotary_emb = DeepseekV2RotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+ else:
+ scaling_type = self.config.rope_scaling['type']
+ scaling_factor = self.config.rope_scaling['factor']
+ if scaling_type == 'linear':
+ self.rotary_emb = DeepseekV2LinearScalingRotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ elif scaling_type == 'dynamic':
+ self.rotary_emb = DeepseekV2DynamicNTKScalingRotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ elif scaling_type == 'yarn':
+ kwargs = {
+ key: self.config.rope_scaling[key]
+ for key in [
+ 'original_max_position_embeddings',
+ 'beta_fast',
+ 'beta_slow',
+ 'mscale',
+ 'mscale_all_dim',
+ ] if key in self.config.rope_scaling
+ }
+ self.rotary_emb = DeepseekV2YarnRotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ **kwargs,
+ )
+ else:
+ raise ValueError(f'Unknown RoPE scaling type {scaling_type}')
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return (tensor.view(bsz, seq_len, self.num_heads,
+ self.v_head_dim).transpose(1, 2).contiguous())
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`'
+ )
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f'The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attn_weights = (
+ torch.matmul(query_states, key_states.transpose(2, 3)) *
+ self.softmax_scale)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is'
+ f' {attn_weights.size()}')
+ assert attention_mask is not None
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
+ )
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(
+ attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(
+ attn_weights, p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.v_head_dim):
+ raise ValueError(
+ f'`attn_output` should be of size {(bsz, self.num_heads, q_len, self.v_head_dim)}, but is'
+ f' {attn_output.size()}')
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.num_heads * self.v_head_dim)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2 with Llama->DeepseekV2
+class DeepseekV2FlashAttention2(DeepseekV2Attention):
+ """DeepseekV2 flash attention module.
+
+ This module inherits from `DeepseekV2Attention` as the weights of the
+ module stays untouched. The only required change would be on the forward
+ pass where it needs to correctly call the public API of flash attention and
+ deal with padding tokens in case the input contains any of them.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignment, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10(
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # DeepseekV2FlashAttention2 attention does not support output_attentions
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`'
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+
+ if self.q_head_dim != self.v_head_dim:
+ value_states = F.pad(value_states,
+ [0, self.q_head_dim - self.v_head_dim])
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
+ # to be able to avoid many of these transpose/reshape/view.
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (DeepseekV2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_proj.weight.dtype if self.q_lora_rank is None else self.q_a_proj.weight.dtype
+
+ logger.warning_once(
+ f'The input hidden states seems to be silently casted in float32, this might be related to'
+ f' the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in'
+ f' {target_dtype}.')
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ softmax_scale=self.softmax_scale,
+ )
+ if self.q_head_dim != self.v_head_dim:
+ attn_output = attn_output[:, :, :, :self.v_head_dim]
+
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads *
+ self.v_head_dim).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length,
+ dropout=0.0,
+ softmax_scale=None,
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`int`, *optional*):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in DeepseekV2FlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ (
+ query_states,
+ key_states,
+ value_states,
+ indices_q,
+ cu_seq_lens,
+ max_seq_lens,
+ ) = self._upad_input(query_states, key_states, value_states,
+ attention_mask, query_length)
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size,
+ query_length)
+ else:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ return attn_output
+
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask,
+ query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(
+ attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim),
+ indices_k,
+ )
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim),
+ indices_k,
+ )
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, self.num_heads,
+ head_dim),
+ indices_k,
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(
+ query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+ATTENTION_CLASSES = {
+ 'eager': DeepseekV2Attention,
+ 'flash_attention_2': DeepseekV2FlashAttention2,
+}
+
+
+class DeepseekV2DecoderLayer(nn.Module):
+
+ def __init__(self, config: DeepseekV2Config, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = ATTENTION_CLASSES[config._attn_implementation](
+ config=config, layer_idx=layer_idx)
+
+ moe_implementation = config.moe_implementation
+ if moe_implementation == 'origin':
+ block = DeepseekV2MoE
+ elif moe_implementation == 'shard':
+ block = DeepseekV2MoEShard
+ else:
+ raise NotImplementedError
+
+ self.mlp = (
+ block(config) if
+ (config.n_routed_experts is not None
+ and layer_idx >= config.first_k_dense_replace and layer_idx %
+ config.moe_layer_freq == 0) else DeepseekV2MLP(config))
+ self.input_layernorm = DeepseekV2RMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = DeepseekV2RMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor,
+ torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*):
+ attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
+ query_sequence_length, key_sequence_length)` if default attention is used.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`'
+ )
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states, )
+
+ if output_attentions:
+ outputs += (self_attn_weights, )
+
+ if use_cache:
+ outputs += (present_key_value, )
+
+ return outputs
+
+
+def _load_pretrained_model(
+ cls,
+ model,
+ state_dict,
+ loaded_keys,
+ resolved_archive_file,
+ pretrained_model_name_or_path,
+ ignore_mismatched_sizes=False,
+ sharded_metadata=None,
+ _fast_init=True,
+ low_cpu_mem_usage=False,
+ device_map=None,
+ offload_folder=None,
+ offload_state_dict=None,
+ dtype=None,
+ hf_quantizer=None,
+ keep_in_fp32_modules=None,
+ gguf_path=None,
+):
+ if ((state_dict is not None) or (resolved_archive_file is None)
+ or (low_cpu_mem_usage) or (device_map is not None)
+ or (offload_folder is not None) or
+ (not (offload_state_dict is None or offload_state_dict is False))
+ or (hf_quantizer is not None) or
+ (keep_in_fp32_modules is not None and len(keep_in_fp32_modules) > 0)
+ or (gguf_path is not None)):
+ raise NotImplementedError
+
+ folder = os.path.sep.join(resolved_archive_file[0].split(os.path.sep)[:-1])
+ error_msgs = load_state_dict_into_model(model, folder)
+ return model, [], [], [], None, error_msgs
+
+
+DeepseekV2_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`DeepseekV2Config`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ 'The bare DeepseekV2 Model outputting raw hidden-states without any specific head on top.',
+ DeepseekV2_START_DOCSTRING,
+)
+class DeepseekV2PreTrainedModel(PreTrainedModel):
+ config_class = DeepseekV2Config
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+ _no_split_modules = ['DeepseekV2DecoderLayer']
+ _skip_keys_device_placement = 'past_key_values'
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs):
+ moe_implementation = kwargs.get('moe_implementation', 'origin')
+ if moe_implementation == 'origin':
+ return super().from_pretrained(pretrained_model_name_or_path,
+ *args, **kwargs)
+
+ cls._load_pretrained_model = types.MethodType(_load_pretrained_model,
+ cls)
+ return super().from_pretrained(pretrained_model_name_or_path, *args,
+ **kwargs)
+
+
+DeepseekV2_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance;
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ 'The bare DeepseekV2 Model outputting raw hidden-states without any specific head on top.',
+ DeepseekV2_START_DOCSTRING,
+)
+class DeepseekV2Model(DeepseekV2PreTrainedModel):
+ """Transformer decoder consisting of *config.num_hidden_layers* layers.
+ Each layer is a [`DeepseekV2DecoderLayer`]
+
+ Args:
+ config: DeepseekV2Config
+ """
+
+ def __init__(self, config: DeepseekV2Config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size,
+ self.padding_idx)
+ self.layers = nn.ModuleList([
+ DeepseekV2DecoderLayer(config, layer_idx)
+ for layer_idx in range(config.num_hidden_layers)
+ ])
+ self._use_sdpa = config._attn_implementation == 'sdpa'
+ self._use_flash_attention_2 = config._attn_implementation == 'flash_attention_2'
+ self.norm = DeepseekV2RMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(DeepseekV2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both input_ids and inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape[:2]
+ elif inputs_embeds is not None:
+ batch_size, seq_length = inputs_embeds.shape[:2]
+ else:
+ raise ValueError(
+ 'You have to specify either input_ids or inputs_embeds')
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`transformers.'
+ )
+ use_cache = False
+
+ past_key_values_length = 0
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(
+ past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(
+ seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length,
+ seq_length + past_key_values_length,
+ dtype=torch.long,
+ device=device,
+ )
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if self._use_flash_attention_2:
+ # 2d mask is passed through the layers
+ attention_mask = (
+ attention_mask if
+ (attention_mask is not None and 0 in attention_mask) else None)
+ elif self._use_sdpa and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+
+ # embed positions
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[
+ 2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1], )
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ next_cache = None
+ if use_cache:
+ next_cache = (
+ next_decoder_cache.to_legacy_cache()
+ if use_legacy_cache else next_decoder_cache)
+ if not return_dict:
+ return tuple(
+ v for v in
+ [hidden_states, next_cache, all_hidden_states, all_self_attns]
+ if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class DeepseekV2ForCausalLM(DeepseekV2PreTrainedModel):
+ _tied_weights_keys = ['lm_head.weight']
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = DeepseekV2Model(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(
+ config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(DeepseekV2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(
+ output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, transformers.,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, transformers., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, DeepseekV2ForCausalLM
+
+ >>> model = DeepseekV2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ return (loss, ) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ **kwargs,
+ ):
+ if past_key_values is not None:
+ if isinstance(past_key_values, Cache):
+ cache_length = past_key_values.get_seq_length()
+ past_length = past_key_values.seen_tokens
+ max_cache_length = past_key_values.get_max_length()
+ else:
+ cache_length = past_length = past_key_values[0][0].shape[2]
+ max_cache_length = None
+
+ # Keep only the unprocessed tokens:
+ # 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
+ # some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
+ # input)
+ if (attention_mask is not None
+ and attention_mask.shape[1] > input_ids.shape[1]):
+ input_ids = input_ids[:, -(attention_mask.shape[1] -
+ past_length):]
+ # 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
+ # input_ids based on the past_length.
+ elif past_length < input_ids.shape[1]:
+ input_ids = input_ids[:, past_length:]
+ # 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
+
+ # If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
+ if (max_cache_length is not None and attention_mask is not None
+ and cache_length + input_ids.shape[1] > max_cache_length):
+ attention_mask = attention_mask[:, -max_cache_length:]
+
+ position_ids = kwargs.get('position_ids', None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1]:]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {'inputs_embeds': inputs_embeds}
+ else:
+ model_inputs = {'input_ids': input_ids}
+
+ model_inputs.update({
+ 'position_ids': position_ids,
+ 'past_key_values': past_key_values,
+ 'use_cache': kwargs.get('use_cache'),
+ 'attention_mask': attention_mask,
+ })
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx.to(past_state.device))
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The DeepseekV2 Model transformer with a sequence classification head on top (linear layer).
+
+ [`DeepseekV2ForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ DeepseekV2_START_DOCSTRING,
+)
+class DeepseekV2ForSequenceClassification(DeepseekV2PreTrainedModel):
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = DeepseekV2Model(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(DeepseekV2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, transformers.,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError(
+ 'Cannot handle batch sizes > 1 if no padding token is defined.'
+ )
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.eq(
+ input_ids, self.config.pad_token_id).int().argmax(-1) -
+ 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device),
+ sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = 'regression'
+ elif self.num_labels > 1 and (labels.dtype == torch.long
+ or labels.dtype == torch.int):
+ self.config.problem_type = 'single_label_classification'
+ else:
+ self.config.problem_type = 'multi_label_classification'
+
+ if self.config.problem_type == 'regression':
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == 'single_label_classification':
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(
+ pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == 'multi_label_classification':
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits, ) + transformer_outputs[1:]
+ return ((loss, ) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/tokenization_deepseek_fast.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/tokenization_deepseek_fast.py
new file mode 100644
index 0000000000000000000000000000000000000000..89e3cbb50b61c357deeb3fd37b9eab1188018172
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/tokenization_deepseek_fast.py
@@ -0,0 +1,37 @@
+from typing import List, Optional, Union
+
+from transformers.models.llama import LlamaTokenizerFast
+
+
+class DeepseekTokenizerFast(LlamaTokenizerFast):
+
+ def convert_ids_to_tokens(
+ self,
+ ids: Union[int, List[int]],
+ skip_special_tokens: bool = False) -> Union[str, List[str]]:
+ """Converts a single index or a sequence of indices in a token or a
+ sequence of tokens, using the vocabulary and added tokens.
+
+ Args:
+ ids (`int` or `List[int]`):
+ The token id (or token ids) to convert to tokens.
+ skip_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not to remove special tokens in the decoding.
+
+ Returns:
+ `str` or `List[str]`: The decoded token(s).
+ """
+ if isinstance(ids, int):
+ return self._convert_id_to_token(ids)
+ tokens = []
+ for index in ids:
+ index = int(index)
+ if skip_special_tokens and index in self.all_special_ids:
+ continue
+ token = self._tokenizer.id_to_token(index)
+ tokens.append(token if token is not None else '')
+ return tokens
+
+ def _convert_id_to_token(self, index: int) -> Optional[str]:
+ token = self._tokenizer.id_to_token(int(index))
+ return token if token is not None else ''
diff --git a/data/xtuner/xtuner/model/transformers_models/mixtral/__init__.py b/data/xtuner/xtuner/model/transformers_models/mixtral/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..aabfd89dbbd8cb1b7f3233ecf6f2bd384aaddd03
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/mixtral/__init__.py
@@ -0,0 +1,4 @@
+from .configuration_mixtral import MixtralConfig
+from .modeling_mixtral import MixtralForCausalLM, MixtralModel
+
+__all__ = ['MixtralForCausalLM', 'MixtralModel', 'MixtralConfig']
diff --git a/data/xtuner/xtuner/model/transformers_models/mixtral/configuration_mixtral.py b/data/xtuner/xtuner/model/transformers_models/mixtral/configuration_mixtral.py
new file mode 100644
index 0000000000000000000000000000000000000000..457aefd479f4cae837e63b3af66c25de52d5ac96
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/mixtral/configuration_mixtral.py
@@ -0,0 +1,178 @@
+# Copyright 2023 Mixtral AI and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Mixtral model configuration."""
+
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+logger = logging.get_logger(__name__)
+
+
+class MixtralConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`MixtralModel`]. It is used to instantiate an
+ Mixtral model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the Mixtral-7B-v0.1 or Mixtral-7B-Instruct-v0.1.
+
+ [mixtralai/Mixtral-8x7B](https://huggingface.co/mixtralai/Mixtral-8x7B)
+ [mixtralai/Mixtral-7B-Instruct-v0.1](https://huggingface.co/mixtralai/Mixtral-7B-Instruct-v0.1)
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the Mixtral model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`MixtralModel`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 14336):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 8):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to `4096*32`):
+ The maximum sequence length that this model might ever be used with. Mixtral's sliding window attention
+ allows sequence of up to 4096*32 tokens.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*):
+ The id of the padding token.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ The id of the "beginning-of-sequence" token.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ The id of the "end-of-sequence" token.
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied.
+ rope_theta (`float`, *optional*, defaults to 1000000.0):
+ The base period of the RoPE embeddings.
+ sliding_window (`int`, *optional*):
+ Sliding window attention window size. If not specified, will default to `4096`.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ num_experts_per_tok (`int`, *optional*, defaults to 2):
+ The number of experts to root per-token, can be also interpreted as the `top-p` routing
+ parameter
+ num_local_experts (`int`, *optional*, defaults to 8):
+ Number of experts per Sparse MLP layer.
+ output_router_logits (`bool`, *optional*, defaults to `False`):
+ Whether or not the router logits should be returned by the model. Enabling this will also
+ allow the model to output the auxiliary loss. See [here]() for more details
+ router_aux_loss_coef (`float`, *optional*, defaults to 0.001):
+ The aux loss factor for the total loss.
+ router_jitter_noise (`float`, *optional*, defaults to 0.0):
+ Amount of noise to add to the router.
+ moe_implementation (`str`, *optional*, defaults to 'origin'):
+ The implementation of the moe blocks. 'origin' or 'shard'.
+ expert_in_one_shard (`int`, *optional*, defaults to None):
+ How many expert models are integrated into a shard. It is used only
+ when `moe_implementation` == 'shard'.
+
+ ```python
+ >>> from transformers import MixtralModel, MixtralConfig
+
+ >>> # Initializing a Mixtral 7B style configuration
+ >>> configuration = MixtralConfig()
+
+ >>> # Initializing a model from the Mixtral 7B style configuration
+ >>> model = MixtralModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = 'mixtral'
+ keys_to_ignore_at_inference = ['past_key_values']
+
+ def __init__(
+ self,
+ vocab_size=32000,
+ hidden_size=4096,
+ intermediate_size=14336,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=8,
+ hidden_act='silu',
+ max_position_embeddings=4096 * 32,
+ initializer_range=0.02,
+ rms_norm_eps=1e-5,
+ use_cache=True,
+ pad_token_id=None,
+ bos_token_id=1,
+ eos_token_id=2,
+ tie_word_embeddings=False,
+ rope_theta=1e6,
+ sliding_window=None,
+ attention_dropout=0.0,
+ num_experts_per_tok=2,
+ num_local_experts=8,
+ output_router_logits=False,
+ router_aux_loss_coef=0.001,
+ router_jitter_noise=0.0,
+ moe_implementation='origin',
+ expert_in_one_shard=None,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.sliding_window = sliding_window
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.attention_dropout = attention_dropout
+
+ self.num_experts_per_tok = num_experts_per_tok
+ self.num_local_experts = num_local_experts
+ self.output_router_logits = output_router_logits
+ self.router_aux_loss_coef = router_aux_loss_coef
+ self.router_jitter_noise = router_jitter_noise
+
+ self.moe_implementation = moe_implementation
+ self.expert_in_one_shard = expert_in_one_shard
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/data/xtuner/xtuner/model/transformers_models/mixtral/modeling_mixtral.py b/data/xtuner/xtuner/model/transformers_models/mixtral/modeling_mixtral.py
new file mode 100644
index 0000000000000000000000000000000000000000..94d048fe723cb2179a696fdeb4f698fb3fd870b3
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/mixtral/modeling_mixtral.py
@@ -0,0 +1,1821 @@
+# Modified from https://github.com/huggingface/transformers/blob/v4.41.0/src/transformers/models/mixtral/modeling_mixtral.py
+"""PyTorch Mixtral model."""
+import inspect
+import math
+import os
+import types
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.activations import ACT2FN
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.modeling_attn_mask_utils import (
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa)
+from transformers.modeling_outputs import (MoeCausalLMOutputWithPast,
+ MoeModelOutputWithPast,
+ SequenceClassifierOutputWithPast)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.pytorch_utils import is_torch_greater_or_equal_than_1_13
+from transformers.utils import (add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10, logging,
+ replace_return_docstrings)
+from transformers.utils.import_utils import is_torch_fx_available
+
+from xtuner.utils import load_state_dict_into_model
+from .configuration_mixtral import MixtralConfig
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input # noqa
+ from flash_attn.bert_padding import index_first_axis, unpad_input
+
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+
+# This makes `_prepare_4d_causal_attention_mask` a leaf function in the FX graph.
+# It means that the function will not be traced through and simply appear as a node in the graph.
+if is_torch_fx_available():
+ if not is_torch_greater_or_equal_than_1_13:
+ import torch.fx
+
+ _prepare_4d_causal_attention_mask = torch.fx.wrap(
+ _prepare_4d_causal_attention_mask)
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = 'MixtralConfig'
+
+
+def load_balancing_loss_func(
+ gate_logits: torch.Tensor,
+ num_experts: torch.Tensor = None,
+ top_k=2,
+ attention_mask: Optional[torch.Tensor] = None) -> float:
+ r"""
+ Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
+
+ See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
+ experts is too unbalanced.
+
+ Args:
+ gate_logits (Union[`torch.Tensor`, Tuple[torch.Tensor]):
+ Logits from the `gate`, should be a tuple of model.config.num_hidden_layers tensors of
+ shape [batch_size X sequence_length, num_experts].
+ attention_mask (`torch.Tensor`, None):
+ The attention_mask used in forward function
+ shape [batch_size X sequence_length] if not None.
+ num_experts (`int`, *optional*):
+ Number of experts
+
+ Returns:
+ The auxiliary loss.
+ """
+ if gate_logits is None or not isinstance(gate_logits, tuple):
+ return 0
+
+ if isinstance(gate_logits, tuple):
+ compute_device = gate_logits[0].device
+ concatenated_gate_logits = torch.cat(
+ [layer_gate.to(compute_device) for layer_gate in gate_logits],
+ dim=0)
+
+ routing_weights = torch.nn.functional.softmax(
+ concatenated_gate_logits, dim=-1)
+
+ _, selected_experts = torch.topk(routing_weights, top_k, dim=-1)
+
+ expert_mask = torch.nn.functional.one_hot(selected_experts, num_experts)
+
+ if attention_mask is None:
+ # Compute the percentage of tokens routed to each experts
+ tokens_per_expert = torch.mean(expert_mask.float(), dim=0)
+
+ # Compute the average probability of routing to these experts
+ router_prob_per_expert = torch.mean(routing_weights, dim=0)
+ else:
+ batch_size, sequence_length = attention_mask.shape
+ num_hidden_layers = concatenated_gate_logits.shape[0] // (
+ batch_size * sequence_length)
+
+ # Compute the mask that masks all padding tokens as 0 with the same shape of expert_mask
+ expert_attention_mask = (
+ attention_mask[None, :, :, None, None].expand(
+ (num_hidden_layers, batch_size, sequence_length, top_k,
+ num_experts)).reshape(-1, top_k,
+ num_experts).to(compute_device))
+
+ # Compute the percentage of tokens routed to each experts
+ tokens_per_expert = torch.sum(
+ expert_mask.float() * expert_attention_mask, dim=0) / torch.sum(
+ expert_attention_mask, dim=0)
+
+ # Compute the mask that masks all padding tokens as 0 with the same shape of tokens_per_expert
+ router_per_expert_attention_mask = (
+ attention_mask[None, :, :, None].expand(
+ (num_hidden_layers, batch_size, sequence_length,
+ num_experts)).reshape(-1, num_experts).to(compute_device))
+
+ # Compute the average probability of routing to these experts
+ router_prob_per_expert = torch.sum(
+ routing_weights * router_per_expert_attention_mask,
+ dim=0) / torch.sum(
+ router_per_expert_attention_mask, dim=0)
+
+ overall_loss = torch.sum(tokens_per_expert *
+ router_prob_per_expert.unsqueeze(0))
+ return overall_loss * num_experts
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(
+ torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->Mixtral
+class MixtralRMSNorm(nn.Module):
+
+ def __init__(self, hidden_size, eps=1e-6):
+ """MixtralRMSNorm is equivalent to T5LayerNorm."""
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance +
+ self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralRotaryEmbedding with Mistral->Mixtral
+class MixtralRotaryEmbedding(nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (
+ self.base
+ **(torch.arange(0, self.dim, 2,
+ dtype=torch.int64).float().to(device) / self.dim))
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings,
+ device=self.inv_freq.device,
+ dtype=torch.get_default_dtype())
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device,
+ dtype=torch.int64).type_as(self.inv_freq)
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(
+ seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+# Copied from transformers.models.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralAttention with Mistral->Mixtral
+class MixtralAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper.
+
+ Modified to use sliding window attention: Longformer and "Generating Long
+ Sequences with Sparse Transformers".
+ """
+
+ def __init__(self, config: MixtralConfig, layer_idx: Optional[int] = None):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ if layer_idx is None:
+ logger.warning_once(
+ f'Instantiating {self.__class__.__name__} without passing a `layer_idx` is not recommended and will '
+ 'lead to errors during the forward call if caching is used. Please make sure to provide a `layer_idx` '
+ 'when creating this class.')
+
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.is_causal = True
+ self.attention_dropout = config.attention_dropout
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f'hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}'
+ f' and `num_heads`: {self.num_heads}).')
+ self.q_proj = nn.Linear(
+ self.hidden_size, self.num_heads * self.head_dim, bias=False)
+ self.k_proj = nn.Linear(
+ self.hidden_size,
+ self.num_key_value_heads * self.head_dim,
+ bias=False)
+ self.v_proj = nn.Linear(
+ self.hidden_size,
+ self.num_key_value_heads * self.head_dim,
+ bias=False)
+ self.o_proj = nn.Linear(
+ self.num_heads * self.head_dim, self.hidden_size, bias=False)
+
+ self.rotary_emb = MixtralRotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads,
+ self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f'The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(
+ 2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is'
+ f' {attn_weights.size()}')
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
+ )
+
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(
+ attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(
+ attn_weights, p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f'`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is'
+ f' {attn_output.size()}')
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralFlashAttention2 with Mistral->Mixtral
+class MixtralFlashAttention2(MixtralAttention):
+ """Mixtral flash attention module.
+
+ This module inherits from `MixtralAttention` as the weights of the module
+ stays untouched. The only required change would be on the forward pass
+ where it needs to correctly call the public API of flash attention and deal
+ with padding tokens in case the input contains any of them.
+ """
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignment, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10(
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ):
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f'The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+
+ # Because the input can be padded, the absolute sequence length depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids[:, -1].max().item()) + 1
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if not _flash_supports_window_size:
+ logger.warning_once(
+ 'The current flash attention version does not support sliding window attention, for a more memory efficient implementation'
+ ' make sure to upgrade flash-attn library.')
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(
+ self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ f'past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat([
+ attention_mask,
+ torch.ones_like(attention_mask[:, -1:])
+ ],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f'The input hidden states seems to be silently casted in float32, this might be related to'
+ f' the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in'
+ f' {target_dtype}.')
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length,
+ dropout=0.0,
+ softmax_scale=None,
+ use_sliding_windows=False,
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`float`):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ use_sliding_windows (`bool`, *optional*):
+ Whether to activate sliding window attention.
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask,
+ query_length)
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ if not use_sliding_windows:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window,
+ self.config.sliding_window),
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size,
+ query_length)
+ else:
+ if not use_sliding_windows:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window,
+ self.config.sliding_window),
+ )
+
+ return attn_output
+
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask,
+ query_length):
+ batch_size, kv_seq_len, num_heads, head_dim = key_layer.shape
+
+ # On the first iteration we need to properly re-create the padding mask
+ # by slicing it on the proper place
+ if kv_seq_len != attention_mask.shape[-1]:
+ attention_mask_num_tokens = attention_mask.shape[-1]
+ attention_mask = attention_mask[:, attention_mask_num_tokens -
+ kv_seq_len:]
+
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(
+ attention_mask)
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim),
+ indices_k)
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim),
+ indices_k)
+
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, num_heads,
+ head_dim), indices_k)
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(
+ query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralSdpaAttention with Mistral->Mixtral
+class MixtralSdpaAttention(MixtralAttention):
+ """Mixtral attention module using
+ torch.nn.functional.scaled_dot_product_attention.
+
+ This module inherits from `MixtralAttention` as the weights of the module
+ stays untouched. The only changes are on the forward pass to adapt to SDPA
+ API.
+ """
+
+ # Adapted from MixtralAttention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ 'MixtralModel is using MixtralSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, '
+ 'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
+ )
+
+ # SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
+ # Reference: https://github.com/pytorch/pytorch/issues/112577.
+ if query_states.device.type == 'cuda' and attention_mask is not None:
+ query_states = query_states.contiguous()
+ key_states = key_states.contiguous()
+ value_states = value_states.contiguous()
+
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.attention_dropout if self.training else 0.0,
+ # The q_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case q_len == 1.
+ is_causal=self.is_causal and attention_mask is None and q_len > 1,
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.view(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+MIXTRAL_ATTENTION_CLASSES = {
+ 'eager': MixtralAttention,
+ 'flash_attention_2': MixtralFlashAttention2,
+ 'sdpa': MixtralSdpaAttention,
+}
+
+
+class MixtralBlockSparseTop2MLP(nn.Module):
+
+ def __init__(self, config: MixtralConfig):
+ super().__init__()
+ self.ffn_dim = config.intermediate_size
+ self.hidden_dim = config.hidden_size
+
+ self.w1 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
+ self.w2 = nn.Linear(self.ffn_dim, self.hidden_dim, bias=False)
+ self.w3 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
+
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, hidden_states):
+ current_hidden_states = self.act_fn(
+ self.w1(hidden_states)) * self.w3(hidden_states)
+ current_hidden_states = self.w2(current_hidden_states)
+ return current_hidden_states
+
+
+class MixtralSparseMoeBlock(nn.Module):
+ """This implementation is strictly equivalent to standard MoE with full
+ capacity (no dropped tokens).
+
+ It's faster since it formulates MoE operations in terms of block-sparse
+ operations to accommodate imbalanced assignments of tokens to experts,
+ whereas standard MoE either (1) drop tokens at the cost of reduced
+ performance or (2) set capacity factor to number of experts and thus waste
+ computation and memory on padding.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.hidden_dim = config.hidden_size
+ self.ffn_dim = config.intermediate_size
+ self.num_experts = config.num_local_experts
+ self.top_k = config.num_experts_per_tok
+
+ # gating
+ self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
+
+ self.experts = nn.ModuleList([
+ MixtralBlockSparseTop2MLP(config) for _ in range(self.num_experts)
+ ])
+
+ # Jitter parameters
+ self.jitter_noise = config.router_jitter_noise
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """"""
+ batch_size, sequence_length, hidden_dim = hidden_states.shape
+ if self.training and self.jitter_noise > 0:
+ hidden_states *= torch.empty_like(hidden_states).uniform_(
+ 1.0 - self.jitter_noise, 1.0 + self.jitter_noise)
+ hidden_states = hidden_states.view(-1, hidden_dim)
+ # router_logits: (batch * sequence_length, n_experts)
+ router_logits = self.gate(hidden_states)
+
+ routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
+ routing_weights, selected_experts = torch.topk(
+ routing_weights, self.top_k, dim=-1)
+ routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
+ # we cast back to the input dtype
+ routing_weights = routing_weights.to(hidden_states.dtype)
+
+ final_hidden_states = torch.zeros(
+ (batch_size * sequence_length, hidden_dim),
+ dtype=hidden_states.dtype,
+ device=hidden_states.device)
+
+ # One hot encode the selected experts to create an expert mask
+ # this will be used to easily index which expert is going to be sollicitated
+ expert_mask = torch.nn.functional.one_hot(
+ selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # Loop over all available experts in the model and perform the computation on each expert
+ for expert_idx in range(self.num_experts):
+ expert_layer = self.experts[expert_idx]
+ idx, top_x = torch.where(expert_mask[expert_idx])
+
+ # Index the correct hidden states and compute the expert hidden state for
+ # the current expert. We need to make sure to multiply the output hidden
+ # states by `routing_weights` on the corresponding tokens (top-1 and top-2)
+ current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
+ current_hidden_states = expert_layer(
+ current_state) * routing_weights[top_x, idx, None]
+
+ # However `index_add_` only support torch tensors for indexing so we'll use
+ # the `top_x` tensor here.
+ final_hidden_states.index_add_(
+ 0, top_x, current_hidden_states.to(hidden_states.dtype))
+ final_hidden_states = final_hidden_states.reshape(
+ batch_size, sequence_length, hidden_dim)
+ return final_hidden_states, router_logits
+
+
+class ExpertShard(nn.Module):
+
+ def __init__(self, config, expert_in_one_shard=1):
+ super().__init__()
+ self.w1w3 = nn.Parameter(
+ torch.empty(expert_in_one_shard, config.intermediate_size * 2,
+ config.hidden_size))
+ self.w2 = nn.Parameter(
+ torch.empty(expert_in_one_shard, config.hidden_size,
+ config.intermediate_size))
+ self.act = ACT2FN[config.hidden_act]
+ self.expert_in_one_shard = expert_in_one_shard
+
+ def forward(self, hidden_states, expert_mask, routing_weights,
+ final_hidden_states):
+ hidden_dim = hidden_states.shape[-1]
+ for expert_idx in range(self.expert_in_one_shard):
+ idx, top_x = torch.where(expert_mask[expert_idx])
+ current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
+
+ w1w3 = self.w1w3[expert_idx]
+ w2 = self.w2[expert_idx]
+ gate_up_out = torch.matmul(current_state, w1w3.T)
+ gate_out, up_out = gate_up_out.chunk(2, dim=-1)
+ gate_out = self.act(gate_out)
+ out = gate_out * up_out
+ out = torch.matmul(out, w2.T)
+
+ current_hidden_states = out * routing_weights[top_x, idx, None]
+ final_hidden_states.index_add_(
+ 0, top_x, current_hidden_states.to(hidden_states.dtype))
+ return final_hidden_states
+
+
+class MixtralSparseShardMoeBlock(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.hidden_dim = config.hidden_size
+ self.ffn_dim = config.intermediate_size
+ self.num_experts = config.num_local_experts
+ self.top_k = config.num_experts_per_tok
+
+ # gating
+ self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
+
+ expert_in_one_shard = config.expert_in_one_shard
+ assert config.num_local_experts % expert_in_one_shard == 0, \
+ ('num_local_experts should be divisible by expert_in_one_shard, but got '
+ f'num_local_experts = {config.num_local_experts} and expert_in_one_shard = {expert_in_one_shard}')
+ self.shard_num = config.num_local_experts // expert_in_one_shard
+ self.expert_in_one_shard = expert_in_one_shard
+ self.experts = nn.ModuleList([
+ ExpertShard(config, self.expert_in_one_shard)
+ for i in range(self.shard_num)
+ ])
+
+ # Jitter parameters
+ self.jitter_noise = config.router_jitter_noise
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """"""
+ batch_size, sequence_length, hidden_dim = hidden_states.shape
+ if self.training and self.jitter_noise > 0:
+ hidden_states *= torch.empty_like(hidden_states).uniform_(
+ 1.0 - self.jitter_noise, 1.0 + self.jitter_noise)
+ hidden_states = hidden_states.view(-1, hidden_dim)
+ # router_logits: (batch * sequence_length, n_experts)
+ router_logits = self.gate(hidden_states)
+
+ routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
+ routing_weights, selected_experts = torch.topk(
+ routing_weights, self.top_k, dim=-1)
+ routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
+ # we cast back to the input dtype
+ routing_weights = routing_weights.to(hidden_states.dtype)
+
+ final_hidden_states = torch.zeros(
+ (batch_size * sequence_length, hidden_dim),
+ dtype=hidden_states.dtype,
+ device=hidden_states.device)
+
+ # One hot encode the selected experts to create an expert mask
+ # this will be used to easily index which expert is going to be sollicitated
+ expert_mask = torch.nn.functional.one_hot(
+ selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # Loop over all available experts in the model and perform the computation on each expert
+ for shard_index in range(self.shard_num):
+ mask = expert_mask[shard_index *
+ self.expert_in_one_shard:(shard_index + 1) *
+ self.expert_in_one_shard]
+ final_hidden_states = self.experts[shard_index](
+ hidden_states, mask, routing_weights, final_hidden_states)
+
+ final_hidden_states = final_hidden_states.reshape(
+ batch_size, sequence_length, hidden_dim)
+ return final_hidden_states, router_logits
+
+
+class MixtralDecoderLayer(nn.Module):
+
+ def __init__(self, config: MixtralConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = MIXTRAL_ATTENTION_CLASSES[
+ config._attn_implementation](config, layer_idx)
+
+ moe_implementation = config.moe_implementation
+ if moe_implementation == 'origin':
+ block = MixtralSparseMoeBlock
+ elif moe_implementation == 'shard':
+ block = MixtralSparseShardMoeBlock
+ else:
+ raise NotImplementedError
+ self.block_sparse_moe = block(config)
+
+ self.input_layernorm = MixtralRMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = MixtralRMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ output_router_logits: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor,
+ torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
+ should not be returned during inference.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states, router_logits = self.block_sparse_moe(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states, )
+
+ if output_attentions:
+ outputs += (self_attn_weights, )
+
+ if use_cache:
+ outputs += (present_key_value, )
+
+ if output_router_logits:
+ outputs += (router_logits, )
+
+ return outputs
+
+
+def _load_pretrained_model(
+ cls,
+ model,
+ state_dict,
+ loaded_keys,
+ resolved_archive_file,
+ pretrained_model_name_or_path,
+ ignore_mismatched_sizes=False,
+ sharded_metadata=None,
+ _fast_init=True,
+ low_cpu_mem_usage=False,
+ device_map=None,
+ offload_folder=None,
+ offload_state_dict=None,
+ dtype=None,
+ hf_quantizer=None,
+ keep_in_fp32_modules=None,
+ gguf_path=None,
+):
+ if ((state_dict is not None) or (resolved_archive_file is None)
+ or (low_cpu_mem_usage) or (device_map is not None)
+ or (offload_folder is not None) or
+ (not (offload_state_dict is None or offload_state_dict is False))
+ or (hf_quantizer is not None) or
+ (keep_in_fp32_modules is not None and len(keep_in_fp32_modules) > 0)
+ or (gguf_path is not None)):
+ raise NotImplementedError
+
+ folder = os.path.sep.join(resolved_archive_file[0].split(os.path.sep)[:-1])
+ error_msgs = load_state_dict_into_model(model, folder)
+ return model, [], [], [], None, error_msgs
+
+
+MIXTRAL_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`MixtralConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ 'The bare Mixtral Model outputting raw hidden-states without any specific head on top.',
+ MIXTRAL_START_DOCSTRING,
+)
+# Copied from transformers.models.mistral.modeling_mistral.MistralPreTrainedModel with Mistral->Mixtral
+class MixtralPreTrainedModel(PreTrainedModel):
+ config_class = MixtralConfig
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+ _no_split_modules = ['MixtralDecoderLayer']
+ _skip_keys_device_placement = 'past_key_values'
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs):
+ moe_implementation = kwargs.get('moe_implementation', 'origin')
+ if moe_implementation == 'origin':
+ return super().from_pretrained(pretrained_model_name_or_path,
+ *args, **kwargs)
+
+ cls._load_pretrained_model = types.MethodType(_load_pretrained_model,
+ cls)
+ return super().from_pretrained(pretrained_model_name_or_path, *args,
+ **kwargs)
+
+
+MIXTRAL_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
+ should not be returned during inference.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ 'The bare Mixtral Model outputting raw hidden-states without any specific head on top.',
+ MIXTRAL_START_DOCSTRING,
+)
+# Copied from transformers.models.mistral.modeling_mistral.MistralModel with MISTRAL->MIXTRAL,Mistral->Mixtral
+class MixtralModel(MixtralPreTrainedModel):
+ """Transformer decoder consisting of *config.num_hidden_layers* layers.
+ Each layer is a [`MixtralDecoderLayer`]
+
+ Args:
+ config: MixtralConfig
+ """
+
+ def __init__(self, config: MixtralConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size,
+ self.padding_idx)
+ self.layers = nn.ModuleList([
+ MixtralDecoderLayer(config, layer_idx)
+ for layer_idx in range(config.num_hidden_layers)
+ ])
+ self._attn_implementation = config._attn_implementation
+ self.norm = MixtralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ # Ignore copy
+ @add_start_docstrings_to_model_forward(MIXTRAL_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else
+ self.config.output_router_logits)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError(
+ 'You have to specify either decoder_input_ids or decoder_inputs_embeds'
+ )
+
+ past_key_values_length = 0
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
+ )
+ use_cache = False
+
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(
+ past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(
+ seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length,
+ seq_length + past_key_values_length,
+ dtype=torch.long,
+ device=device)
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if attention_mask is not None and self._attn_implementation == 'flash_attention_2' and use_cache:
+ is_padding_right = attention_mask[:, -1].sum().item() != batch_size
+ if is_padding_right:
+ raise ValueError(
+ "You are attempting to perform batched generation with padding_side='right'"
+ ' this may lead to unexpected behaviour for Flash Attention version of Mixtral. Make sure to '
+ " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
+ )
+
+ if self._attn_implementation == 'flash_attention_2':
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (
+ attention_mask is not None and 0 in attention_mask) else None
+ elif self._attn_implementation == 'sdpa' and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_router_logits = () if output_router_logits else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ output_router_logits,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ output_router_logits=output_router_logits,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[
+ 2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1], )
+
+ if output_router_logits:
+ all_router_logits += (layer_outputs[-1], )
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache(
+ ) if use_legacy_cache else next_decoder_cache
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states, next_cache, all_hidden_states, all_self_attns,
+ all_router_logits
+ ] if v is not None)
+ return MoeModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ router_logits=all_router_logits,
+ )
+
+
+class MixtralForCausalLM(MixtralPreTrainedModel):
+ _tied_weights_keys = ['lm_head.weight']
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = MixtralModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(
+ config.hidden_size, config.vocab_size, bias=False)
+ self.router_aux_loss_coef = config.router_aux_loss_coef
+ self.num_experts = config.num_local_experts
+ self.num_experts_per_tok = config.num_experts_per_tok
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(MIXTRAL_INPUTS_DOCSTRING)
+ @replace_return_docstrings(
+ output_type=MoeCausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ # Ignore copy
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeCausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, MixtralForCausalLM
+
+ >>> model = MixtralForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+ >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else
+ self.config.output_router_logits)
+
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ output_router_logits=output_router_logits,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ aux_loss = None
+ if output_router_logits:
+ aux_loss = load_balancing_loss_func(
+ outputs.router_logits if return_dict else outputs[-1],
+ self.num_experts,
+ self.num_experts_per_tok,
+ attention_mask,
+ )
+ if labels is not None:
+ loss += self.router_aux_loss_coef * aux_loss.to(
+ loss.device) # make sure to reside in the same device
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ if output_router_logits:
+ output = (aux_loss, ) + output
+ return (loss, ) + output if loss is not None else output
+
+ return MoeCausalLMOutputWithPast(
+ loss=loss,
+ aux_loss=aux_loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ router_logits=outputs.router_logits,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ output_router_logits=False,
+ **kwargs,
+ ):
+ # Omit tokens covered by past_key_values
+ if past_key_values is not None:
+ if isinstance(past_key_values, Cache):
+ cache_length = past_key_values.get_seq_length()
+ past_length = past_key_values.seen_tokens
+ max_cache_length = past_key_values.get_max_length()
+ else:
+ cache_length = past_length = past_key_values[0][0].shape[2]
+ max_cache_length = None
+
+ # Keep only the unprocessed tokens:
+ # 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
+ # some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
+ # input)
+ if attention_mask is not None and attention_mask.shape[
+ 1] > input_ids.shape[1]:
+ input_ids = input_ids[:, -(attention_mask.shape[1] -
+ past_length):]
+ # 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
+ # input_ids based on the past_length.
+ elif past_length < input_ids.shape[1]:
+ input_ids = input_ids[:, past_length:]
+ # 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
+
+ # If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
+ if (max_cache_length is not None and attention_mask is not None
+ and cache_length + input_ids.shape[1] > max_cache_length):
+ attention_mask = attention_mask[:, -max_cache_length:]
+
+ position_ids = kwargs.get('position_ids', None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1]:]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {'inputs_embeds': inputs_embeds}
+ else:
+ model_inputs = {'input_ids': input_ids}
+
+ model_inputs.update({
+ 'position_ids': position_ids,
+ 'past_key_values': past_key_values,
+ 'use_cache': kwargs.get('use_cache'),
+ 'attention_mask': attention_mask,
+ 'output_router_logits': output_router_logits,
+ })
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx.to(past_state.device))
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The Mixtral Model transformer with a sequence classification head on top (linear layer).
+
+ [`MixtralForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ MIXTRAL_START_DOCSTRING,
+)
+# Copied from transformers.models.llama.modeling_llama.LlamaForSequenceClassification with Llama->Mixtral, LLAMA->MIXTRAL
+class MixtralForSequenceClassification(MixtralPreTrainedModel):
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = MixtralModel(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(MIXTRAL_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[Cache,
+ List[torch.FloatTensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError(
+ 'Cannot handle batch sizes > 1 if no padding token is defined.'
+ )
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ # if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
+ sequence_lengths = torch.eq(
+ input_ids, self.config.pad_token_id).int().argmax(-1) - 1
+ sequence_lengths = sequence_lengths % input_ids.shape[-1]
+ sequence_lengths = sequence_lengths.to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device),
+ sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = 'regression'
+ elif self.num_labels > 1 and (labels.dtype == torch.long
+ or labels.dtype == torch.int):
+ self.config.problem_type = 'single_label_classification'
+ else:
+ self.config.problem_type = 'multi_label_classification'
+
+ if self.config.problem_type == 'regression':
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == 'single_label_classification':
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(
+ pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == 'multi_label_classification':
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits, ) + transformer_outputs[1:]
+ return ((loss, ) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/model/utils.py b/data/xtuner/xtuner/model/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8bbf294448f4930e150d490ddfaf0a0c4ce9fb2
--- /dev/null
+++ b/data/xtuner/xtuner/model/utils.py
@@ -0,0 +1,317 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List, Optional
+
+import torch
+from mmengine.utils.misc import get_object_from_string
+from peft import PeftType
+from torch import nn
+from transformers import PreTrainedModel
+
+from xtuner.utils import IGNORE_INDEX, IMAGE_TOKEN_INDEX
+
+
+def set_obj_dtype(d):
+ for key, value in d.items():
+ if value in ['torch.float16', 'torch.float32', 'torch.bfloat16']:
+ d[key] = getattr(torch, value.split('.')[-1])
+
+
+def try_build_module(cfg):
+ builder = cfg['type']
+ if isinstance(builder, str):
+ builder = get_object_from_string(builder)
+ if builder is None:
+ # support handling cfg with key 'type' can not be built, such as
+ # {'rope_scaling': {'type': 'linear', 'factor': 2.0}}
+ return cfg
+ cfg.pop('type')
+ module_built = builder(**cfg)
+ return module_built
+
+
+def traverse_dict(d):
+ if isinstance(d, dict):
+ set_obj_dtype(d)
+ for key, value in d.items():
+ if isinstance(value, dict):
+ traverse_dict(value)
+ if 'type' in value:
+ module_built = try_build_module(value)
+ d[key] = module_built
+ elif isinstance(d, list):
+ for element in d:
+ traverse_dict(element)
+
+
+def find_all_linear_names(model):
+ lora_module_names = set()
+ for name, module in model.named_modules():
+ if isinstance(module, nn.Linear):
+ names = name.split('.')
+ lora_module_names.add(names[0] if len(names) == 1 else names[-1])
+
+ if 'lm_head' in lora_module_names: # needed for 16-bit
+ lora_module_names.remove('lm_head')
+ if 'output_layer' in lora_module_names: # needed for 16-bit
+ lora_module_names.remove('output_layer')
+ return list(lora_module_names)
+
+
+class LoadWoInit:
+ """Context manager that disable parameter initialization."""
+
+ def __init__(self):
+ self.constant_ = torch.nn.init.constant_
+ self.zeros_ = torch.nn.init.zeros_
+ self.ones_ = torch.nn.init.ones_
+ self.uniform_ = torch.nn.init.uniform_
+ self.normal_ = torch.nn.init.normal_
+ self.kaiming_uniform_ = torch.nn.init.kaiming_uniform_
+ self.kaiming_normal_ = torch.nn.init.kaiming_normal_
+
+ def __enter__(self, *args, **kwargs):
+ torch.nn.init.constant_ = lambda *args, **kwargs: None
+ torch.nn.init.zeros_ = lambda *args, **kwargs: None
+ torch.nn.init.ones_ = lambda *args, **kwargs: None
+ torch.nn.init.uniform_ = lambda *args, **kwargs: None
+ torch.nn.init.normal_ = lambda *args, **kwargs: None
+ torch.nn.init.kaiming_uniform_ = lambda *args, **kwargs: None
+ torch.nn.init.kaiming_normal_ = lambda *args, **kwargs: None
+
+ def __exit__(self, *args, **kwargs):
+ torch.nn.init.constant_ = self.constant_
+ torch.nn.init.zeros_ = self.zeros_
+ torch.nn.init.ones_ = self.ones_
+ torch.nn.init.uniform_ = self.uniform_
+ torch.nn.init.normal_ = self.normal_
+ torch.nn.init.kaiming_uniform_ = self.kaiming_uniform_
+ torch.nn.init.kaiming_normal_ = self.kaiming_normal_
+
+
+def get_peft_model_state_dict(model, state_dict=None, adapter_name='default'):
+ # Modified from `https://github.com/huggingface/peft/blob/main/src/peft/utils/save_and_load.py` # noqa: E501
+
+ config = model.peft_config[adapter_name]
+ if state_dict is None:
+ state_dict = model.state_dict()
+ if config.peft_type == PeftType.LORA:
+ # adapted from `https://github.com/microsoft/LoRA/blob/main/loralib/utils.py` # noqa: E501
+ # to be used directly with the state dict which is necessary
+ # when using DeepSpeed or FSDP
+ bias = config.bias
+ if bias == 'none':
+ to_return = {k: state_dict[k] for k in state_dict if 'lora_' in k}
+ elif bias == 'all':
+ to_return = {
+ k: state_dict[k]
+ for k in state_dict if 'lora_' in k or 'bias' in k
+ }
+ elif bias == 'lora_only':
+ to_return = {}
+ for k in state_dict:
+ if 'lora_' in k:
+ to_return[k] = state_dict[k]
+ bias_name = k.split('lora_')[0] + 'bias'
+ if bias_name in state_dict:
+ to_return[bias_name] = state_dict[bias_name]
+ else:
+ raise NotImplementedError
+ to_return = {
+ k: v
+ for k, v in to_return.items()
+ if (('lora_' in k and adapter_name in k) or ('bias' in k))
+ }
+ else:
+ # Currently we only support lora
+ raise NotImplementedError
+ if model.modules_to_save is not None:
+ for key, value in state_dict.items():
+ if any(f'{module_name}.modules_to_save.{adapter_name}' in key
+ for module_name in model.modules_to_save):
+ to_return[key] = value
+
+ return to_return
+
+
+# Modified from https://github.com/haotian-liu/LLaVA/blob/82fc5e0e5f4393a4c26851fa32c69ab37ea3b146/llava/model/llava_arch.py#L99 # noqa: E501
+def prepare_inputs_labels_for_multimodal(
+ llm: PreTrainedModel,
+ input_ids: torch.LongTensor = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ labels: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None):
+ if pixel_values is None:
+ return {
+ 'input_ids': input_ids,
+ 'position_ids': position_ids,
+ 'attention_mask': attention_mask,
+ 'past_key_values': past_key_values,
+ 'inputs_embeds': None,
+ 'labels': labels
+ }
+
+ _labels = labels
+ _position_ids = position_ids
+ _attention_mask = attention_mask
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
+ else:
+ attention_mask = attention_mask.bool()
+ if position_ids is None:
+ position_ids = torch.arange(
+ 0, input_ids.shape[1], dtype=torch.long, device=input_ids.device)
+ if labels is None:
+ labels = torch.full_like(input_ids, IGNORE_INDEX)
+
+ # remove the padding using attention_mask -- TODO: double check
+ input_ids = [
+ cur_input_ids[cur_attention_mask]
+ for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)
+ ]
+ labels = [
+ cur_labels[cur_attention_mask]
+ for cur_labels, cur_attention_mask in zip(labels, attention_mask)
+ ]
+
+ new_inputs_embeds = []
+ new_labels = []
+ cur_image_idx = 0
+ for batch_idx, cur_input_ids in enumerate(input_ids):
+ num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum()
+ if num_images == 0:
+ cur_pixel_values = pixel_values[cur_image_idx]
+ cur_inputs_embeds_1 = llm.get_input_embeddings()(cur_input_ids)
+ cur_inputs_embeds = torch.cat(
+ [cur_inputs_embeds_1, cur_pixel_values[0:0]], dim=0)
+ new_inputs_embeds.append(cur_inputs_embeds)
+ new_labels.append(labels[batch_idx])
+ cur_image_idx += 1
+ continue
+
+ image_token_indices = [-1] + torch.where(
+ cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist() + [
+ cur_input_ids.shape[0]
+ ]
+ cur_input_ids_noim = []
+ cur_labels = labels[batch_idx]
+ cur_labels_noim = []
+ for i in range(len(image_token_indices) - 1):
+ cur_input_ids_noim.append(cur_input_ids[image_token_indices[i] +
+ 1:image_token_indices[i +
+ 1]])
+ cur_labels_noim.append(cur_labels[image_token_indices[i] +
+ 1:image_token_indices[i + 1]])
+ split_sizes = [x.shape[0] for x in cur_labels_noim]
+ cur_inputs_embeds = llm.get_input_embeddings()(
+ torch.cat(cur_input_ids_noim))
+ cur_inputs_embeds_no_im = torch.split(
+ cur_inputs_embeds, split_sizes, dim=0)
+ cur_new_inputs_embeds = []
+ cur_new_labels = []
+
+ for i in range(num_images + 1):
+ cur_new_inputs_embeds.append(cur_inputs_embeds_no_im[i])
+ cur_new_labels.append(cur_labels_noim[i])
+ if i < num_images:
+ cur_pixel_values = pixel_values[cur_image_idx]
+ cur_image_idx += 1
+ cur_new_inputs_embeds.append(cur_pixel_values)
+ cur_new_labels.append(
+ torch.full((cur_pixel_values.shape[0], ),
+ IGNORE_INDEX,
+ device=cur_labels.device,
+ dtype=cur_labels.dtype))
+
+ cur_new_inputs_embeds = torch.cat(cur_new_inputs_embeds)
+ cur_new_labels = torch.cat(cur_new_labels)
+
+ new_inputs_embeds.append(cur_new_inputs_embeds)
+ new_labels.append(cur_new_labels)
+
+ # Combine them
+ max_len = max(x.shape[0] for x in new_inputs_embeds)
+ batch_size = len(new_inputs_embeds)
+
+ new_inputs_embeds_padded = []
+ new_labels_padded = torch.full((batch_size, max_len),
+ IGNORE_INDEX,
+ dtype=new_labels[0].dtype,
+ device=new_labels[0].device)
+ attention_mask = torch.zeros((batch_size, max_len),
+ dtype=attention_mask.dtype,
+ device=attention_mask.device)
+ position_ids = torch.zeros((batch_size, max_len),
+ dtype=position_ids.dtype,
+ device=position_ids.device)
+
+ for i, (cur_new_embed,
+ cur_new_labels) in enumerate(zip(new_inputs_embeds, new_labels)):
+ cur_len = cur_new_embed.shape[0]
+ new_inputs_embeds_padded.append(
+ torch.cat((cur_new_embed,
+ torch.zeros((max_len - cur_len, cur_new_embed.shape[1]),
+ dtype=cur_new_embed.dtype,
+ device=cur_new_embed.device)),
+ dim=0))
+ if cur_len > 0:
+ new_labels_padded[i, :cur_len] = cur_new_labels
+ attention_mask[i, :cur_len] = True
+ position_ids[i, :cur_len] = torch.arange(
+ 0,
+ cur_len,
+ dtype=position_ids.dtype,
+ device=position_ids.device)
+
+ new_inputs_embeds = torch.stack(new_inputs_embeds_padded, dim=0)
+
+ if _labels is None:
+ new_labels = None
+ else:
+ new_labels = new_labels_padded
+
+ if _attention_mask is None:
+ attention_mask = None
+ else:
+ attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
+
+ if _position_ids is None:
+ position_ids = None
+
+ return {
+ 'input_ids': None,
+ 'position_ids': position_ids,
+ 'attention_mask': attention_mask,
+ 'past_key_values': past_key_values,
+ 'inputs_embeds': new_inputs_embeds,
+ 'labels': new_labels
+ }
+
+
+def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+
+def guess_load_checkpoint(pth_model):
+ if osp.isfile(pth_model):
+ state_dict = torch.load(pth_model, map_location='cpu')
+ if 'state_dict' in state_dict:
+ state_dict = state_dict['state_dict']
+ elif osp.isdir(pth_model):
+ try:
+ from xtuner.utils.zero_to_any_dtype import \
+ get_state_dict_from_zero_checkpoint
+ except ImportError:
+ raise ImportError(
+ 'The provided PTH model appears to be a DeepSpeed checkpoint. '
+ 'However, DeepSpeed library is not detected in current '
+ 'environment. This suggests that DeepSpeed may not be '
+ 'installed or is incorrectly configured. Please verify your '
+ 'setup.')
+ state_dict = get_state_dict_from_zero_checkpoint(
+ osp.dirname(pth_model), osp.basename(pth_model))
+ else:
+ raise FileNotFoundError(f'Cannot find {pth_model}')
+ return state_dict
diff --git a/data/xtuner/xtuner/parallel/__init__.py b/data/xtuner/xtuner/parallel/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c726230c8b8e703359ea62ff1edab1fea420052
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/__init__.py
@@ -0,0 +1,2 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sequence import * # noqa: F401, F403
diff --git a/data/xtuner/xtuner/parallel/sequence/__init__.py b/data/xtuner/xtuner/parallel/sequence/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e2992f78aa84f860b4465860d891b67900276f7
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/__init__.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.dist import init_dist
+
+from .attention import (post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn,
+ sequence_parallel_wrapper)
+from .comm import (all_to_all, gather_for_sequence_parallel,
+ gather_forward_split_backward, split_for_sequence_parallel,
+ split_forward_gather_backward)
+from .data_collate import (pad_cumulative_len_for_sequence_parallel,
+ pad_for_sequence_parallel)
+from .reduce_loss import reduce_sequence_parallel_loss
+from .sampler import SequenceParallelSampler
+from .setup_distributed import (get_data_parallel_group,
+ get_data_parallel_rank,
+ get_data_parallel_world_size,
+ get_inner_sequence_parallel_group,
+ get_inner_sequence_parallel_rank,
+ get_inner_sequence_parallel_world_size,
+ get_sequence_parallel_group,
+ get_sequence_parallel_rank,
+ get_sequence_parallel_world_size,
+ init_inner_sequence_parallel,
+ init_sequence_parallel,
+ is_inner_sequence_parallel_initialized)
+
+__all__ = [
+ 'sequence_parallel_wrapper', 'pre_process_for_sequence_parallel_attn',
+ 'post_process_for_sequence_parallel_attn', 'pad_for_sequence_parallel',
+ 'split_for_sequence_parallel', 'SequenceParallelSampler',
+ 'init_sequence_parallel', 'get_sequence_parallel_group',
+ 'get_sequence_parallel_world_size', 'get_sequence_parallel_rank',
+ 'get_data_parallel_group', 'get_data_parallel_world_size',
+ 'get_data_parallel_rank', 'reduce_sequence_parallel_loss', 'init_dist',
+ 'all_to_all', 'gather_for_sequence_parallel',
+ 'split_forward_gather_backward', 'gather_forward_split_backward',
+ 'get_inner_sequence_parallel_group', 'get_inner_sequence_parallel_rank',
+ 'get_inner_sequence_parallel_world_size', 'init_inner_sequence_parallel',
+ 'is_inner_sequence_parallel_initialized',
+ 'pad_cumulative_len_for_sequence_parallel'
+]
diff --git a/data/xtuner/xtuner/parallel/sequence/attention.py b/data/xtuner/xtuner/parallel/sequence/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8bb1adaca8bd42123976c46431cfba10c21fe96
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/attention.py
@@ -0,0 +1,151 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch.distributed as dist
+
+from .comm import (all_to_all, gather_forward_split_backward,
+ split_forward_gather_backward)
+from .setup_distributed import (get_inner_sequence_parallel_group,
+ get_inner_sequence_parallel_world_size,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ init_inner_sequence_parallel,
+ is_inner_sequence_parallel_initialized)
+
+
+def pre_process_for_sequence_parallel_attn(query_states,
+ key_states,
+ value_states,
+ scatter_dim=2,
+ gather_dim=1):
+ b, s_div_sp, h, d = query_states.shape
+ sp = get_sequence_parallel_world_size()
+
+ if not is_inner_sequence_parallel_initialized():
+ insp = sp // math.gcd(h, sp)
+ init_inner_sequence_parallel(insp)
+ else:
+ insp = get_inner_sequence_parallel_world_size()
+
+ def pre_process_for_inner_sp(q, k, v):
+ if scatter_dim != 2 and gather_dim != 1:
+ raise NotImplementedError(
+ 'Currently only `scatter_dim == 2` and `gather_dim == 1` '
+ f'is supported. But got scatter_dim = {scatter_dim} and '
+ f'gather_dim = {gather_dim}.')
+
+ # (b, s_div_sp, h, d) ->
+ # (b, s_div_sp, sp/insp, h*insp/sp, insp, d/insp) ->
+ # (b, s_div_sp, sp/insp, insp, h*insp/sp, d/insp) ->
+ # (b, s_div_sp, insp*h, d/insp)
+ q = q.view(b, s_div_sp, sp // insp, h * insp // sp, insp,
+ d // insp).transpose(3, 4).flatten(2, 4)
+ k = k.view(b, s_div_sp, sp // insp, h * insp // sp, insp,
+ d // insp).transpose(3, 4).flatten(2, 4)
+ v = v.view(b, s_div_sp, sp // insp, h * insp // sp, insp,
+ d // insp).transpose(3, 4).flatten(2, 4)
+
+ return q, k, v
+
+ def post_process_for_inner_sp(q, k, v):
+ # (b, s, insp*h/sp, d/insp) -> (b, s, insp*h/sp, d)
+ q = gather_forward_split_backward(q, -1,
+ get_inner_sequence_parallel_group())
+ k = gather_forward_split_backward(k, -1,
+ get_inner_sequence_parallel_group())
+ v = gather_forward_split_backward(v, -1,
+ get_inner_sequence_parallel_group())
+
+ return q, k, v
+
+ assert (h * insp) % sp == 0, \
+ ('The number of attention heads should be divisible by '
+ '(sequence_parallel_world_size // sequence_parallel_inner_world_size)'
+ f'. But got n_head = {h}, sequence_parallel_world_size = '
+ f'{sp} and sequence_parallel_inner_world_size = {insp}.')
+
+ if insp > 1:
+ query_states, key_states, value_states = pre_process_for_inner_sp(
+ query_states, key_states, value_states)
+
+ # (b, s_div_sp, insp*h, d/insp) -> (b, s, insp*h/sp, d/insp)
+ sequence_parallel_group = get_sequence_parallel_group()
+ query_states = all_to_all(
+ query_states,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+ key_states = all_to_all(
+ key_states,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+ value_states = all_to_all(
+ value_states,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+
+ if insp > 1:
+ query_states, key_states, value_states = post_process_for_inner_sp(
+ query_states, key_states, value_states)
+
+ return query_states, key_states, value_states
+
+
+def post_process_for_sequence_parallel_attn(attn_output,
+ scatter_dim=1,
+ gather_dim=2):
+ sp = get_sequence_parallel_world_size()
+ insp = get_inner_sequence_parallel_world_size()
+ b, s, h_mul_insp_div_sp, d = attn_output.shape
+ h = h_mul_insp_div_sp * sp // insp
+ s_div_sp = s // sp
+
+ if insp > 1:
+ # (b, s, insp*h/sp, d) -> (b, s, insp*h/sp, d/insp)
+ attn_output = split_forward_gather_backward(
+ attn_output, -1, get_inner_sequence_parallel_group())
+
+ # (b, s, insp*h/sp, d/insp) -> (b, s_div_sp, insp*h, d/insp)
+ sequence_parallel_group = get_sequence_parallel_group()
+ output = all_to_all(
+ attn_output,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+
+ if insp > 1:
+ # (b, s_div_sp, insp*h, d/insp) ->
+ # (b, s_div_sp, sp/insp, insp, h*insp/sp, d/insp) ->
+ # (b, s_div_sp, sp/insp, h*insp/sp, insp, d/insp) ->
+ # (b, s_div_sp, h, d)
+ output = output.view(b, s_div_sp, sp // insp, insp, h * insp // sp,
+ d // insp).transpose(3, 4).reshape(
+ b, s_div_sp, h, d)
+
+ return output
+
+
+def sequence_parallel_wrapper(local_attn):
+
+ def sequence_parallel_attn(query_states, key_states, value_states, *args,
+ **kwargs):
+ training = kwargs.pop('training', True)
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+
+ out = local_attn(query_states, key_states, value_states, *args,
+ **kwargs)
+
+ if enable_sequence_parallel:
+ out = post_process_for_sequence_parallel_attn(out).contiguous()
+
+ return out
+
+ return sequence_parallel_attn
diff --git a/data/xtuner/xtuner/parallel/sequence/comm.py b/data/xtuner/xtuner/parallel/sequence/comm.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ff78e68c138dbf68cbda363424e460eac614b19
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/comm.py
@@ -0,0 +1,269 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Tuple
+
+import torch
+import torch.distributed as dist
+from torch import Tensor
+
+
+def _all_to_all(
+ input: Tensor,
+ world_size: int,
+ group: dist.ProcessGroup,
+ scatter_dim: int,
+ gather_dim: int,
+):
+ input_list = [
+ t.contiguous()
+ for t in torch.tensor_split(input, world_size, scatter_dim)
+ ]
+ output_list = [torch.empty_like(input_list[0]) for _ in range(world_size)]
+ dist.all_to_all(output_list, input_list, group=group)
+ return torch.cat(output_list, dim=gather_dim).contiguous()
+
+
+class _AllToAll(torch.autograd.Function):
+ """All-to-all communication.
+
+ Args:
+ input: Input tensor
+ sp_group: Sequence parallel process group
+ scatter_dim: Scatter dimension
+ gather_dim: Gather dimension
+ """
+
+ @staticmethod
+ def forward(ctx: Any, input: Tensor, sp_group: dist.ProcessGroup,
+ scatter_dim: int, gather_dim: int):
+ ctx.sp_group = sp_group
+ ctx.scatter_dim = scatter_dim
+ ctx.gather_dim = gather_dim
+ ctx.world_size = dist.get_world_size(sp_group)
+ output = _all_to_all(input, ctx.world_size, sp_group, scatter_dim,
+ gather_dim)
+ return output
+
+ @staticmethod
+ def backward(ctx: Any, grad_output: Tensor) -> Tuple:
+ grad_output = _all_to_all(
+ grad_output,
+ ctx.world_size,
+ ctx.sp_group,
+ ctx.gather_dim,
+ ctx.scatter_dim,
+ )
+ return (
+ grad_output,
+ None,
+ None,
+ None,
+ )
+
+
+def all_to_all(
+ input: Tensor,
+ sp_group: dist.ProcessGroup,
+ scatter_dim: int = 2,
+ gather_dim: int = 1,
+):
+ """Convenience function to apply the all-to-all operation with scatter and
+ gather dimensions.
+
+ Notes:
+ We have wrapped the `torch.distributed.all_to_all` function to
+ enable automatic differentiation of the all-to-all operation.
+
+ Args:
+ input: The input tensor for which all-to-all communication is performed
+ sp_group: The sequence parallel process group.
+ scatter_dim: The dimension along which the input tensor is scattered
+ (default: 2).
+ gather_dim: The dimension along which the output tensor is gathered
+ (default: 1).
+
+ Returns:
+ The output tensor after the all-to-all communication.
+ """
+ return _AllToAll.apply(input, sp_group, scatter_dim, gather_dim)
+
+
+def split_for_sequence_parallel(input, dim: int, sp_group: dist.ProcessGroup):
+ """Splits the input tensor along a given dimension for sequence parallel.
+
+ Args:
+ input: The input tensor to be split.
+ dim: The dimension along which the tensor should be split.
+ sp_group: The sequence parallel process group.
+
+ Returns:
+ The split tensor corresponding to the current rank's chunk.
+ """
+ world_size = dist.get_world_size(sp_group)
+ if world_size == 1:
+ return input
+
+ rank = dist.get_rank(sp_group)
+ dim_size = input.size(dim)
+ assert dim_size % world_size == 0, (
+ f'The dimension to split ({dim_size}) is not a multiple of '
+ f'world size ({world_size}), cannot split tensor evenly')
+
+ tensor_list = torch.split(input, dim_size // world_size, dim=dim)
+ output = tensor_list[rank].contiguous()
+
+ return output
+
+
+def gather_for_sequence_parallel(input, dim: int, sp_group: dist.ProcessGroup):
+ """Gathers the input tensor along a given dimension for sequence parallel.
+
+ Args:
+ input: The input tensor to be gathered.
+ dim: The dimension along which the tensor should be gathered.
+ sp_group: The sequence parallel process group.
+
+ Returns:
+ The gathered tensor concatenated along the specified dimension.
+ """
+ input = input.contiguous()
+ world_size = dist.get_world_size(sp_group)
+ dist.get_rank(sp_group)
+
+ if world_size == 1:
+ return input
+
+ tensor_list = [torch.empty_like(input) for _ in range(world_size)]
+ assert input.device.type == 'cuda'
+ dist.all_gather(tensor_list, input, group=sp_group)
+
+ output = torch.cat(tensor_list, dim=dim).contiguous()
+
+ return output
+
+
+class _GatherForwardSplitBackward(torch.autograd.Function):
+ """Gather the input during forward.
+
+ Scale and split the grad and keep only the corresponding chuck to the rank
+ during backward.
+ """
+
+ @staticmethod
+ def forward(ctx, input, dim, sp_group, grad_scale):
+ ctx.dim = dim
+ ctx.sp_group = sp_group
+ ctx.grad_scale = grad_scale
+ return gather_for_sequence_parallel(input, dim, sp_group)
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ if ctx.grad_scale == 'up':
+ grad_output = grad_output * dist.get_world_size(ctx.sp_group)
+ elif ctx.grad_scale == 'down':
+ grad_output = grad_output / dist.get_world_size(ctx.sp_group)
+
+ return (split_for_sequence_parallel(grad_output, ctx.dim,
+ ctx.sp_group), None, None, None)
+
+
+class _SplitForwardGatherBackward(torch.autograd.Function):
+ """Split the input and keep only the corresponding chuck to the rank during
+ forward.
+
+ Scale and gather the grad during backward.
+ """
+
+ @staticmethod
+ def forward(ctx, input, dim, sp_group, grad_scale):
+ ctx.dim = dim
+ ctx.sp_group = sp_group
+ ctx.grad_scale = grad_scale
+ return split_for_sequence_parallel(input, dim, sp_group)
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ if ctx.grad_scale == 'up':
+ grad_output = grad_output * dist.get_world_size(ctx.sp_group)
+ elif ctx.grad_scale == 'down':
+ grad_output = grad_output / dist.get_world_size(ctx.sp_group)
+ return (gather_for_sequence_parallel(grad_output, ctx.dim,
+ ctx.sp_group), None, None, None)
+
+
+def split_forward_gather_backward(input, dim, sp_group, grad_scale=None):
+ """Split tensors according to the sp rank during forward propagation and
+ gather the grad from the whole sp group during backward propagation.
+
+ 1. When do we need this? input.requires_grad = True
+
+ 2. Why we need grad scale?
+
+ We have to scale down the grads as `gather_forward_split_backward` scales
+ up the grads.
+ """
+ return _SplitForwardGatherBackward.apply(input, dim, sp_group, grad_scale)
+
+
+def gather_forward_split_backward(input, dim, sp_group, grad_scale=None):
+ """Gather tensors from the whole sp group during forward propagation and
+ split the grad according to the sp rank during backward propagation.
+
+ 1. When do we need this?
+
+ When sp is greater than 1, we need to slice the input `x` along
+ sequence length dimension before it is passed into the model and get
+ `sub_seq_x`. We then pass `sub_seq_x` into model and get output
+ `sub_seq_out`. If the loss calculation process needs to use the complete
+ output, we have to gather the `sub_seq_out` in all sp ranks during forward
+ propagation and split the grad during backward propagation.
+
+ 2. Why we need grad scale?
+ Here is a simple case.
+
+ -------- SP 1 -----------
+ Suppose here is a toy model with only one linear module
+ (in_features = 2, out_features = 1) and the input x has shape(2, 2).
+ Y = [[y1], = [[w11x11 + w21x12], = [[x11, x12], dot [[w11],
+ [y2]] [w11x21 + w21x22]] [x21, x22]] [w21]]
+ z = mean(Y) = (y1 + y2) / 2
+ Here is the partial derivative of z with respect to w11:
+ ∂z / ∂w11 = ∂z / ∂y1 * ∂y1 / ∂w11 + ∂z / ∂y2 * ∂y2 / ∂w11
+ = 1/2 * x11 + 1/2 * x21 = (x11 + x21) / 2
+
+ -------- SP 2 -----------
+ When sequence parallel world size is set to 2, we will split the input x
+ and scatter them to the two rank in the same sequence parallel group.
+ ```Step 1
+ Y_rank0 = [[y1]] = [[w11x11 + w21x12]] = [[x11, x12]] dot [[w11, w21]]^T
+ Y_rank1 = [[y2]] = [[w11x21 + w21x22]] = [[x21, x22]] dot [[w11, w21]]^T
+ ```
+
+ Then, we have to gather them:
+ ```Step 2
+ Y_rank0 = [[y1],
+ detach([y2])]
+ Y_rank1 = [detach([y1]),
+ [y2]]
+ ```
+ Note that y2 in Y_rank0 does not have grad, neither does y1 in Y_rank1.
+
+ Similarly, we calculate the loss in each rank:
+ ```Step 3
+ z_rank0 = mean(Y_rank0) = (y1 + detach(y2)) / 2
+ z_rank1 = mean(Y_rank1) = (detach(y1) + y2) / 2
+ ```
+ So the partial derivative of loss_rank0 with respect to w11:
+ ```∂z / ∂w11 = ∂z / ∂y1 * ∂y1 / ∂w11 = x11 / 2```
+ The same for rank1:
+ ```∂z / ∂w11 = ∂z / ∂y2 * ∂y2 / ∂w11 = x21 / 2```
+
+ Finally, we need to all_reduce them:
+ ```Step 4
+ In both rank:
+ ∂z / ∂w11 = (x11 / 2 + x21 / 2) / 2 = (x11 + x21) / 4
+ ```
+
+ In SP2, the gradient of each param is only half of that in SP1.
+ So we should scale up the grad during the backward process in Step 2.
+ """ # noqa: E501
+ return _GatherForwardSplitBackward.apply(input, dim, sp_group, grad_scale)
diff --git a/data/xtuner/xtuner/parallel/sequence/data_collate.py b/data/xtuner/xtuner/parallel/sequence/data_collate.py
new file mode 100644
index 0000000000000000000000000000000000000000..048eaec103be1ab1108fcf817f5d4ed4d5ece9ab
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/data_collate.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from .setup_distributed import get_sequence_parallel_world_size
+
+
+def pad_for_sequence_parallel(tensor, padding_value, dim=-1):
+ length = tensor.shape[dim]
+ seq_parallel_world_size = get_sequence_parallel_world_size()
+ if length % seq_parallel_world_size == 0:
+ return tensor
+
+ pad_num = seq_parallel_world_size - (length % seq_parallel_world_size)
+ pad_shape = (*tensor.shape[:dim], pad_num,
+ *tensor.shape[dim + 1:]) if dim != -1 else (
+ *tensor.shape[:dim], pad_num)
+ pad = torch.full(
+ pad_shape, padding_value, dtype=tensor.dtype, device=tensor.device)
+ tensor = torch.cat([tensor, pad], dim=dim)
+ return tensor
+
+
+# This function only meets the following two conditions:
+# 1. use_varlen_attn = True
+# 2. pack_to_max_length = True and the lengths of each sequence are different
+def pad_cumulative_len_for_sequence_parallel(cumulative_len):
+ assert len(cumulative_len) == 1
+ seqlen = cumulative_len[0][-1]
+ seq_parallel_world_size = get_sequence_parallel_world_size()
+ if seqlen % seq_parallel_world_size == 0:
+ return cumulative_len, None
+
+ bs = len(cumulative_len)
+ pad_len = seq_parallel_world_size - (seqlen % seq_parallel_world_size)
+ seqlen_new = seqlen + pad_len
+ attention_mask = torch.zeros(
+ bs, seqlen_new, dtype=torch.bool, device=cumulative_len[0].device)
+ attention_mask[:, :seqlen] = True
+
+ for i, cu_len in enumerate(cumulative_len):
+ pad = torch.tensor([seqlen_new],
+ device=cu_len.device,
+ dtype=cu_len.dtype)
+ cumulative_len[i] = torch.cat([cu_len, pad], dim=0)
+
+ return cumulative_len, attention_mask
diff --git a/data/xtuner/xtuner/parallel/sequence/reduce_loss.py b/data/xtuner/xtuner/parallel/sequence/reduce_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb37242a33d814826e11d985924105064d131b79
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/reduce_loss.py
@@ -0,0 +1,34 @@
+import torch
+import torch.distributed as dist
+
+from .setup_distributed import get_sequence_parallel_group
+
+
+class _ReduceLoss(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, mean_loss, loss_scale, process_group):
+ ctx.mode = process_group
+ if loss_scale == 0:
+ # convert nan to 0 just for logging
+ mean_loss = torch.nan_to_num(mean_loss)
+ loss_sum = mean_loss * loss_scale
+ dist.all_reduce(loss_sum, group=process_group)
+ dist.all_reduce(loss_scale, group=process_group)
+ loss = loss_sum / loss_scale
+ return loss
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ return grad_output, None, None
+
+
+def reduce_sequence_parallel_loss(mean_loss,
+ loss_scale,
+ sp_group: dist.ProcessGroup = None):
+ if dist.get_world_size(sp_group) == 1:
+ return mean_loss
+ if sp_group is None:
+ # avoid bc breaking
+ sp_group = get_sequence_parallel_group()
+ return _ReduceLoss.apply(mean_loss, loss_scale, sp_group)
diff --git a/data/xtuner/xtuner/parallel/sequence/sampler.py b/data/xtuner/xtuner/parallel/sequence/sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..69adb7cc91c5e5603b47fbb5cd438165d522a79b
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/sampler.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Optional, Sized
+
+from mmengine.dataset import DefaultSampler
+from mmengine.dist import sync_random_seed
+
+from .setup_distributed import (get_data_parallel_rank,
+ get_data_parallel_world_size)
+
+
+class SequenceParallelSampler(DefaultSampler):
+
+ def __init__(self,
+ dataset: Sized,
+ shuffle: bool = True,
+ seed: Optional[int] = None,
+ round_up: bool = True) -> None:
+ rank = get_data_parallel_rank()
+ world_size = get_data_parallel_world_size()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.shuffle = shuffle
+ if seed is None:
+ seed = sync_random_seed()
+ self.seed = seed
+ self.epoch = 0
+ self.round_up = round_up
+
+ if self.round_up:
+ self.num_samples = math.ceil(len(self.dataset) / world_size)
+ self.total_size = self.num_samples * self.world_size
+ else:
+ self.num_samples = math.ceil(
+ (len(self.dataset) - rank) / world_size)
+ self.total_size = len(self.dataset)
diff --git a/data/xtuner/xtuner/parallel/sequence/setup_distributed.py b/data/xtuner/xtuner/parallel/sequence/setup_distributed.py
new file mode 100644
index 0000000000000000000000000000000000000000..473993a33f3f2e782e6f78594acc2bdcc120422b
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/setup_distributed.py
@@ -0,0 +1,174 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.distributed as dist
+
+_SEQUENCE_PARALLEL_GROUP = None
+_SEQUENCE_PARALLEL_WORLD_SIZE = None
+_SEQUENCE_PARALLEL_RANK = None
+
+_INNER_SEQUENCE_PARALLEL_GROUP = None
+_INNER_SEQUENCE_PARALLEL_WORLD_SIZE = None
+_INNER_SEQUENCE_PARALLEL_RANK = None
+
+_DATA_PARALLEL_GROUP = None
+_DATA_PARALLEL_WORLD_SIZE = None
+_DATA_PARALLEL_RANK = None
+
+
+def init_sequence_parallel(sequence_parallel_size: int = 1):
+ assert dist.is_initialized()
+ world_size: int = dist.get_world_size()
+
+ # enable_ds_sequence_parallel = sequence_parallel_size > 1
+ # if enable_ds_sequence_parallel:
+ if world_size % sequence_parallel_size != 0:
+ raise RuntimeError(f'world_size ({world_size}) is not divisible by '
+ f'sequence_parallel_size {sequence_parallel_size}')
+
+ num_sequence_parallel_groups: int = world_size // sequence_parallel_size
+
+ rank = dist.get_rank()
+
+ # Build the sequence parallel groups.
+ global _SEQUENCE_PARALLEL_GROUP
+ assert _SEQUENCE_PARALLEL_GROUP is None, \
+ 'sequence parallel group is already initialized'
+ for i in range(num_sequence_parallel_groups):
+ ranks = range(i * sequence_parallel_size,
+ (i + 1) * sequence_parallel_size)
+ group = dist.new_group(ranks)
+ if rank in ranks:
+ _SEQUENCE_PARALLEL_GROUP = group
+
+ global _DATA_PARALLEL_GROUP
+ assert _DATA_PARALLEL_GROUP is None, \
+ 'data parallel group is already initialized'
+ all_data_parallel_group_ranks = []
+ start_rank = 0
+ end_rank = world_size
+ for j in range(sequence_parallel_size):
+ ranks = range(start_rank + j, end_rank, sequence_parallel_size)
+ all_data_parallel_group_ranks.append(list(ranks))
+ group = dist.new_group(ranks)
+ if rank in ranks:
+ _DATA_PARALLEL_GROUP = group
+
+
+def init_inner_sequence_parallel(inner_sequence_parallel_size: int = 1):
+ """Build the sequence parallel inner groups.
+
+ They are helpful when sp size is not evenly divided by the number of attn
+ heads.
+ """
+ assert _SEQUENCE_PARALLEL_GROUP is not None, \
+ ('Please call `init_inner_sequence_parallel` after calling '
+ '`init_sequence_parallel`.')
+
+ rank = dist.get_rank()
+ world_size: int = dist.get_world_size()
+
+ n_inner_group = world_size // inner_sequence_parallel_size
+
+ global _INNER_SEQUENCE_PARALLEL_GROUP
+ assert _INNER_SEQUENCE_PARALLEL_GROUP is None
+
+ for i in range(n_inner_group):
+ ranks = range(i * inner_sequence_parallel_size,
+ (i + 1) * inner_sequence_parallel_size)
+ group = dist.new_group(ranks)
+ if rank in ranks:
+ _INNER_SEQUENCE_PARALLEL_GROUP = group
+
+
+def is_inner_sequence_parallel_initialized():
+ return _INNER_SEQUENCE_PARALLEL_GROUP is not None
+
+
+def get_inner_sequence_parallel_group():
+ return _INNER_SEQUENCE_PARALLEL_GROUP
+
+
+def get_inner_sequence_parallel_world_size():
+ global _INNER_SEQUENCE_PARALLEL_WORLD_SIZE
+ if _INNER_SEQUENCE_PARALLEL_WORLD_SIZE is not None:
+ return _INNER_SEQUENCE_PARALLEL_WORLD_SIZE
+ if not dist.is_initialized() or (_INNER_SEQUENCE_PARALLEL_GROUP is None):
+ _INNER_SEQUENCE_PARALLEL_WORLD_SIZE = 1
+ else:
+ _INNER_SEQUENCE_PARALLEL_WORLD_SIZE = dist.get_world_size(
+ group=get_inner_sequence_parallel_group())
+ return _INNER_SEQUENCE_PARALLEL_WORLD_SIZE
+
+
+def get_inner_sequence_parallel_rank():
+ global _INNER_SEQUENCE_PARALLEL_RANK
+ if _INNER_SEQUENCE_PARALLEL_RANK is not None:
+ return _INNER_SEQUENCE_PARALLEL_RANK
+ if not dist.is_initialized() or (_INNER_SEQUENCE_PARALLEL_GROUP is None):
+ _INNER_SEQUENCE_PARALLEL_RANK = 0
+ else:
+ _INNER_SEQUENCE_PARALLEL_RANK = dist.get_rank(
+ group=get_inner_sequence_parallel_group())
+ return _INNER_SEQUENCE_PARALLEL_RANK
+
+
+def get_sequence_parallel_group():
+ """Get the sequence parallel group the caller rank belongs to."""
+ return _SEQUENCE_PARALLEL_GROUP
+
+
+def get_sequence_parallel_world_size():
+ """Return world size for the sequence parallel group."""
+ global _SEQUENCE_PARALLEL_WORLD_SIZE
+ if _SEQUENCE_PARALLEL_WORLD_SIZE is not None:
+ return _SEQUENCE_PARALLEL_WORLD_SIZE
+ if not dist.is_initialized() or (_SEQUENCE_PARALLEL_GROUP is None):
+ _SEQUENCE_PARALLEL_WORLD_SIZE = 1
+ else:
+ _SEQUENCE_PARALLEL_WORLD_SIZE = dist.get_world_size(
+ group=get_sequence_parallel_group())
+ return _SEQUENCE_PARALLEL_WORLD_SIZE
+
+
+def get_sequence_parallel_rank():
+ """Return my rank for the sequence parallel group."""
+ global _SEQUENCE_PARALLEL_RANK
+ if _SEQUENCE_PARALLEL_RANK is not None:
+ return _SEQUENCE_PARALLEL_RANK
+ if not dist.is_initialized() or (_SEQUENCE_PARALLEL_GROUP is None):
+ _SEQUENCE_PARALLEL_RANK = 0
+ else:
+ _SEQUENCE_PARALLEL_RANK = dist.get_rank(
+ group=get_sequence_parallel_group())
+ return _SEQUENCE_PARALLEL_RANK
+
+
+def get_data_parallel_group():
+ """Get the data parallel group the caller rank belongs to."""
+ assert _DATA_PARALLEL_GROUP is not None, \
+ 'data parallel group is not initialized'
+ return _DATA_PARALLEL_GROUP
+
+
+def get_data_parallel_world_size():
+ """Return world size for the data parallel group."""
+ global _DATA_PARALLEL_WORLD_SIZE
+ if _DATA_PARALLEL_WORLD_SIZE is not None:
+ return _DATA_PARALLEL_WORLD_SIZE
+ if not dist.is_initialized():
+ _DATA_PARALLEL_WORLD_SIZE = 1
+ else:
+ _DATA_PARALLEL_WORLD_SIZE = dist.get_world_size(
+ group=get_data_parallel_group())
+ return _DATA_PARALLEL_WORLD_SIZE
+
+
+def get_data_parallel_rank():
+ """Return my rank for the data parallel group."""
+ global _DATA_PARALLEL_RANK
+ if _DATA_PARALLEL_RANK is not None:
+ return _DATA_PARALLEL_RANK
+ if not dist.is_initialized():
+ _DATA_PARALLEL_RANK = 0
+ else:
+ _DATA_PARALLEL_RANK = dist.get_rank(group=get_data_parallel_group())
+ return _DATA_PARALLEL_RANK
diff --git a/data/xtuner/xtuner/registry.py b/data/xtuner/xtuner/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c8907e0be44210849d029bc26c77494971220b0
--- /dev/null
+++ b/data/xtuner/xtuner/registry.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.registry import Registry
+
+__all__ = ['BUILDER', 'MAP_FUNC']
+
+BUILDER = Registry('builder')
+MAP_FUNC = Registry('map_fn')
diff --git a/data/xtuner/xtuner/tools/chat.py b/data/xtuner/xtuner/tools/chat.py
new file mode 100644
index 0000000000000000000000000000000000000000..3bddac52cdcca8c2e5ef7ac5e10ebcd444897e5f
--- /dev/null
+++ b/data/xtuner/xtuner/tools/chat.py
@@ -0,0 +1,491 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import re
+import sys
+
+import torch
+from huggingface_hub import snapshot_download
+from peft import PeftModel
+from transformers import (AutoModel, AutoModelForCausalLM, AutoTokenizer,
+ BitsAndBytesConfig, CLIPImageProcessor,
+ CLIPVisionModel, GenerationConfig)
+from transformers.generation.streamers import TextStreamer
+
+from xtuner.dataset.utils import expand2square, load_image
+from xtuner.model.utils import prepare_inputs_labels_for_multimodal
+from xtuner.tools.utils import get_stop_criteria
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ PROMPT_TEMPLATE, SYSTEM_TEMPLATE)
+
+TORCH_DTYPE_MAP = dict(
+ fp16=torch.float16, bf16=torch.bfloat16, fp32=torch.float32, auto='auto')
+
+
+def remove_prefix(state_dict, prefix):
+ new_state_dict = {}
+ for key, value in state_dict.items():
+ if key.startswith(prefix):
+ new_key = key[len(prefix):]
+ new_state_dict[new_key] = value
+ else:
+ new_state_dict[key] = value
+ return new_state_dict
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Chat with a HF model')
+ parser.add_argument(
+ 'model_name_or_path', help='Hugging Face model name or path')
+ adapter_group = parser.add_mutually_exclusive_group()
+ adapter_group.add_argument(
+ '--adapter', default=None, help='adapter name or path')
+ adapter_group.add_argument(
+ '--llava', default=None, help='llava name or path')
+ parser.add_argument(
+ '--visual-encoder', default=None, help='visual encoder name or path')
+ parser.add_argument(
+ '--visual-select-layer', default=-2, help='visual select layer')
+ parser.add_argument('--image', default=None, help='image')
+ parser.add_argument(
+ '--torch-dtype',
+ default='fp16',
+ choices=TORCH_DTYPE_MAP.keys(),
+ help='Override the default `torch.dtype` and load the model under '
+ 'a specific `dtype`.')
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ default=None,
+ help='Specify a prompt template')
+ system_group = parser.add_mutually_exclusive_group()
+ system_group.add_argument(
+ '--system', default=None, help='Specify the system text')
+ system_group.add_argument(
+ '--system-template',
+ choices=SYSTEM_TEMPLATE.keys(),
+ default=None,
+ help='Specify a system template')
+ parser.add_argument(
+ '--bits',
+ type=int,
+ choices=[4, 8, None],
+ default=None,
+ help='LLM bits')
+ parser.add_argument(
+ '--bot-name', type=str, default='BOT', help='Name for Bot')
+ parser.add_argument(
+ '--with-plugins',
+ nargs='+',
+ choices=['calculate', 'solve', 'search'],
+ help='Specify plugins to use')
+ parser.add_argument(
+ '--no-streamer', action='store_true', help='Whether to with streamer')
+ parser.add_argument(
+ '--lagent', action='store_true', help='Whether to use lagent')
+ parser.add_argument(
+ '--stop-words', nargs='+', type=str, default=[], help='Stop words')
+ parser.add_argument(
+ '--offload-folder',
+ default=None,
+ help='The folder in which to offload the model weights (or where the '
+ 'model weights are already offloaded).')
+ parser.add_argument(
+ '--max-new-tokens',
+ type=int,
+ default=2048,
+ help='Maximum number of new tokens allowed in generated text')
+ parser.add_argument(
+ '--temperature',
+ type=float,
+ default=0.1,
+ help='The value used to modulate the next token probabilities.')
+ parser.add_argument(
+ '--top-k',
+ type=int,
+ default=40,
+ help='The number of highest probability vocabulary tokens to '
+ 'keep for top-k-filtering.')
+ parser.add_argument(
+ '--top-p',
+ type=float,
+ default=0.75,
+ help='If set to float < 1, only the smallest set of most probable '
+ 'tokens with probabilities that add up to top_p or higher are '
+ 'kept for generation.')
+ parser.add_argument(
+ '--repetition-penalty',
+ type=float,
+ default=1.0,
+ help='The parameter for repetition penalty. 1.0 means no penalty.')
+ parser.add_argument(
+ '--seed',
+ type=int,
+ default=0,
+ help='Random seed for reproducible text generation')
+ args = parser.parse_args()
+ return args
+
+
+def get_input():
+ """Helper function for getting input from users."""
+ sentinel = '' # ends when this string is seen
+ result = None
+ while result is None:
+ print(('\ndouble enter to end input (EXIT: exit chat, '
+ 'RESET: reset history) >>> '),
+ end='')
+ try:
+ result = '\n'.join(iter(input, sentinel))
+ except UnicodeDecodeError:
+ print('Invalid characters detected. Please enter again.')
+ return result
+
+
+def main():
+ args = parse_args()
+ torch.manual_seed(args.seed)
+
+ # build llm
+ quantization_config = None
+ load_in_8bit = False
+ if args.bits == 4:
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4')
+ elif args.bits == 8:
+ load_in_8bit = True
+ model_kwargs = {
+ 'quantization_config': quantization_config,
+ 'load_in_8bit': load_in_8bit,
+ 'device_map': 'auto',
+ 'offload_folder': args.offload_folder,
+ 'trust_remote_code': True,
+ 'torch_dtype': TORCH_DTYPE_MAP[args.torch_dtype]
+ }
+ if args.lagent:
+ from lagent.actions import ActionExecutor, GoogleSearch
+ from lagent.agents import (CALL_PROTOCOL_CN, FORCE_STOP_PROMPT_CN,
+ ReAct, ReActProtocol)
+ from lagent.llms import HFTransformerCasualLM
+
+ try:
+ SERPER_API_KEY = os.environ['SERPER_API_KEY']
+ except Exception:
+ print('Please obtain the `SERPER_API_KEY` from https://serper.dev '
+ 'and set it using `export SERPER_API_KEY=xxx`.')
+ sys.exit(1)
+
+ model_kwargs.pop('trust_remote_code')
+ llm = HFTransformerCasualLM(
+ args.model_name_or_path, model_kwargs=model_kwargs)
+ if args.adapter is not None:
+ print(f'Loading adapter from {args.adapter}...')
+ llm.model = PeftModel.from_pretrained(
+ llm.model,
+ args.adapter,
+ offload_folder=args.offload_folder,
+ trust_remote_code=True)
+ search_tool = GoogleSearch(api_key=SERPER_API_KEY)
+ chatbot = ReAct(
+ llm=llm,
+ action_executor=ActionExecutor(actions=[search_tool]),
+ protocol=ReActProtocol(
+ call_protocol=CALL_PROTOCOL_CN,
+ force_stop=FORCE_STOP_PROMPT_CN))
+ while True:
+ text = get_input()
+ while text.strip() == 'RESET':
+ print('Log: History responses have been removed!')
+ chatbot._session_history = []
+ inputs = ''
+ text = get_input()
+ if text.strip() == 'EXIT':
+ print('Log: Exit!')
+ exit(0)
+ response = chatbot.chat(text)
+ print(response.response)
+ else:
+ if args.with_plugins is None:
+ inner_thoughts_open = False
+ calculate_open = False
+ solve_open = False
+ search_open = False
+ else:
+ assert args.prompt_template == args.system_template == 'moss_sft'
+ from plugins import plugins_api
+ inner_thoughts_open = True
+ calculate_open = 'calculate' in args.with_plugins
+ solve_open = 'solve' in args.with_plugins
+ search_open = 'search' in args.with_plugins
+ # pre-import for api and model preparation
+ if calculate_open:
+ from plugins import calculate # noqa: F401
+ if solve_open:
+ from plugins import solve # noqa: F401
+ if search_open:
+ from plugins import search # noqa: F401
+ # build llm
+ llm = AutoModelForCausalLM.from_pretrained(args.model_name_or_path,
+ **model_kwargs)
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=True,
+ encode_special_tokens=True)
+ print(f'Load LLM from {args.model_name_or_path}')
+ if args.adapter is not None:
+ llm = PeftModel.from_pretrained(
+ llm,
+ args.adapter,
+ offload_folder=args.offload_folder,
+ trust_remote_code=True)
+ print(f'Load adapter from {args.adapter}')
+ if args.llava is not None:
+ llava_path = snapshot_download(
+ repo_id=args.llava) if not osp.isdir(
+ args.llava) else args.llava
+
+ # build visual_encoder
+ if 'visual_encoder' in os.listdir(llava_path):
+ assert args.visual_encoder is None, (
+ "Please don't specify the `--visual-encoder` since passed "
+ '`--llava` contains a visual encoder!')
+ visual_encoder_path = osp.join(llava_path, 'visual_encoder')
+ else:
+ assert args.visual_encoder is not None, (
+ 'Please specify the `--visual-encoder`!')
+ visual_encoder_path = args.visual_encoder
+ visual_encoder = CLIPVisionModel.from_pretrained(
+ visual_encoder_path,
+ torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ image_processor = CLIPImageProcessor.from_pretrained(
+ visual_encoder_path)
+ print(f'Load visual_encoder from {visual_encoder_path}')
+
+ # load adapter
+ if 'llm_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'llm_adapter')
+ llm = PeftModel.from_pretrained(
+ llm,
+ adapter_path,
+ offload_folder=args.offload_folder,
+ trust_remote_code=True)
+ print(f'Load LLM adapter from {args.llava}')
+ if 'visual_encoder_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'visual_encoder_adapter')
+ visual_encoder = PeftModel.from_pretrained(
+ visual_encoder,
+ adapter_path,
+ offload_folder=args.offload_folder)
+ print(f'Load visual_encoder adapter from {args.llava}')
+
+ # build projector
+ projector_path = osp.join(llava_path, 'projector')
+ projector = AutoModel.from_pretrained(
+ projector_path,
+ torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype],
+ trust_remote_code=True)
+ print(f'Load projector from {args.llava}')
+
+ projector.cuda()
+ projector.eval()
+ visual_encoder.cuda()
+ visual_encoder.eval()
+
+ llm.eval()
+
+ if args.image is not None:
+ image = load_image(args.image)
+ image = expand2square(
+ image, tuple(int(x * 255) for x in image_processor.image_mean))
+ image = image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ image = image.cuda().unsqueeze(0).to(visual_encoder.dtype)
+ visual_outputs = visual_encoder(image, output_hidden_states=True)
+ pixel_values = projector(
+ visual_outputs.hidden_states[args.visual_select_layer][:, 1:])
+
+ stop_words = args.stop_words
+ sep = ''
+ if args.prompt_template:
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ stop_words += template.get('STOP_WORDS', [])
+ sep = template.get('SEP', '')
+ stop_criteria = get_stop_criteria(
+ tokenizer=tokenizer, stop_words=stop_words)
+
+ if args.no_streamer:
+ streamer = None
+ else:
+ streamer = TextStreamer(tokenizer, skip_prompt=True)
+
+ gen_config = GenerationConfig(
+ max_new_tokens=args.max_new_tokens,
+ do_sample=args.temperature > 0,
+ temperature=args.temperature,
+ top_p=args.top_p,
+ top_k=args.top_k,
+ repetition_penalty=args.repetition_penalty,
+ eos_token_id=tokenizer.eos_token_id,
+ pad_token_id=tokenizer.pad_token_id
+ if tokenizer.pad_token_id is not None else tokenizer.eos_token_id,
+ )
+
+ n_turn = 0
+ inputs = ''
+ while True:
+ text = get_input()
+ while text.strip() == 'RESET':
+ print('Log: History responses have been removed!')
+ n_turn = 0
+ inputs = ''
+ text = get_input()
+ if text.strip() == 'EXIT':
+ print('Log: Exit!')
+ exit(0)
+
+ if args.image is not None and n_turn == 0:
+ text = DEFAULT_IMAGE_TOKEN + '\n' + text
+
+ if args.prompt_template:
+ prompt_text = ''
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ if 'SYSTEM' in template and n_turn == 0:
+ system_text = None
+ if args.system_template is not None:
+ system_text = SYSTEM_TEMPLATE[
+ args.system_template].format(
+ round=n_turn + 1, bot_name=args.bot_name)
+ elif args.system is not None:
+ system_text = args.system
+ if system_text is not None:
+ prompt_text += template['SYSTEM'].format(
+ system=system_text,
+ round=n_turn + 1,
+ bot_name=args.bot_name)
+ prompt_text += template['INSTRUCTION'].format(
+ input=text, round=n_turn + 1, bot_name=args.bot_name)
+ if args.prompt_template == args.system_template == 'moss_sft':
+ if not inner_thoughts_open:
+ prompt_text.replace('- Inner thoughts: enabled.',
+ '- Inner thoughts: disabled.')
+ if not calculate_open:
+ prompt_text.replace(('- Calculator: enabled. API: '
+ 'Calculate(expression)'),
+ '- Calculator: disabled.')
+ if not solve_open:
+ prompt_text.replace(
+ '- Equation solver: enabled. API: Solve(equation)',
+ '- Equation solver: disabled.')
+ if not search_open:
+ prompt_text.replace(
+ '- Web search: enabled. API: Search(query)',
+ '- Web search: disabled.')
+ else:
+ prompt_text = text
+ inputs += prompt_text
+ if args.image is None:
+ if n_turn == 0:
+ ids = tokenizer.encode(inputs, return_tensors='pt')
+ else:
+ ids = tokenizer.encode(
+ inputs, return_tensors='pt', add_special_tokens=False)
+
+ if args.with_plugins is not None:
+ generate_output = llm.generate(
+ inputs=ids.cuda(),
+ generation_config=gen_config,
+ streamer=streamer,
+ stopping_criteria=stop_criteria).cpu()
+ generate_output_text = tokenizer.decode(
+ generate_output[0][len(ids[0]):])
+ if streamer is None:
+ end = '' if generate_output_text[-1] == '\n' else '\n'
+ print(generate_output_text, end=end)
+ pattern = r'<\|Commands\|>:(.*?)'
+ command_text = ', '.join(
+ re.findall(pattern, generate_output_text))
+ extent_text = plugins_api(
+ command_text,
+ calculate_open=calculate_open,
+ solve_open=solve_open,
+ search_open=search_open)
+ end = '' if extent_text[-1] == '\n' else '\n'
+ print(extent_text, end=end)
+ extent_text_ids = tokenizer.encode(
+ extent_text,
+ return_tensors='pt',
+ add_special_tokens=False)
+ new_ids = torch.cat((generate_output, extent_text_ids),
+ dim=1)
+
+ generate_output = llm.generate(
+ inputs=new_ids.cuda(),
+ generation_config=gen_config,
+ streamer=streamer,
+ stopping_criteria=stop_criteria)
+ if streamer is None:
+ output_text = tokenizer.decode(
+ generate_output[0][len(new_ids[0]):])
+ end = '' if output_text[-1] == '\n' else '\n'
+ print(output_text, end=end)
+ else:
+ generate_output = llm.generate(
+ inputs=ids.cuda(),
+ generation_config=gen_config,
+ streamer=streamer,
+ stopping_criteria=stop_criteria)
+ if streamer is None:
+ output_text = tokenizer.decode(
+ generate_output[0][len(ids[0]):])
+ end = '' if output_text[-1] == '\n' else '\n'
+ print(output_text, end=end)
+ inputs = tokenizer.decode(generate_output[0])
+ else:
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0 and n_turn == 0:
+ cur_encode = tokenizer.encode(chunk)
+ else:
+ cur_encode = tokenizer.encode(
+ chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+ ids = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ ids.append(IMAGE_TOKEN_INDEX)
+ ids = torch.tensor(ids).cuda().unsqueeze(0)
+ mm_inputs = prepare_inputs_labels_for_multimodal(
+ llm=llm, input_ids=ids, pixel_values=pixel_values)
+
+ generate_output = llm.generate(
+ **mm_inputs,
+ generation_config=gen_config,
+ streamer=streamer,
+ bos_token_id=tokenizer.bos_token_id,
+ stopping_criteria=stop_criteria)
+ if streamer is None:
+ output_text = tokenizer.decode(generate_output[0])
+ end = '' if output_text[-1] == '\n' else '\n'
+ print(output_text, end=end)
+ inputs += tokenizer.decode(generate_output[0])
+ n_turn += 1
+ inputs += sep
+ if len(generate_output[0]) >= args.max_new_tokens:
+ print(
+ 'Remove the memory of history responses, since '
+ f'it exceeds the length limitation {args.max_new_tokens}.')
+ n_turn = 0
+ inputs = ''
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/check_custom_dataset.py b/data/xtuner/xtuner/tools/check_custom_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9d005fb5b6e9f7b3b0cf964d5dd45c4acdd5a4a
--- /dev/null
+++ b/data/xtuner/xtuner/tools/check_custom_dataset.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from functools import partial
+
+import numpy as np
+from datasets import DatasetDict
+from mmengine.config import Config
+
+from xtuner.dataset.utils import Packer, encode_fn
+from xtuner.registry import BUILDER
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Verify the correctness of the config file for the '
+ 'custom dataset.')
+ parser.add_argument('config', help='config file name or path.')
+ args = parser.parse_args()
+ return args
+
+
+def is_standard_format(dataset):
+ example = next(iter(dataset))
+ if 'conversation' not in example:
+ return False
+ conversation = example['conversation']
+ if not isinstance(conversation, list):
+ return False
+ for item in conversation:
+ if (not isinstance(item, dict)) or ('input'
+ not in item) or ('output'
+ not in item):
+ return False
+ input, output = item['input'], item['output']
+ if (not isinstance(input, str)) or (not isinstance(output, str)):
+ return False
+ return True
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ if cfg.get('framework', 'mmengine').lower() == 'huggingface':
+ train_dataset = cfg.train_dataset
+ else:
+ train_dataset = cfg.train_dataloader.dataset
+
+ dataset = train_dataset.dataset
+ max_length = train_dataset.max_length
+ dataset_map_fn = train_dataset.get('dataset_map_fn', None)
+ template_map_fn = train_dataset.get('template_map_fn', None)
+ max_dataset_length = train_dataset.get('max_dataset_length', 10)
+ split = train_dataset.get('split', 'train')
+ remove_unused_columns = train_dataset.get('remove_unused_columns', False)
+ rename_maps = train_dataset.get('rename_maps', [])
+ shuffle_before_pack = train_dataset.get('shuffle_before_pack', True)
+ pack_to_max_length = train_dataset.get('pack_to_max_length', True)
+ input_ids_with_output = train_dataset.get('input_ids_with_output', True)
+
+ if dataset.get('path', '') != 'json':
+ raise ValueError(
+ 'You are using custom datasets for SFT. '
+ 'The custom datasets should be in json format. To load your JSON '
+ 'file, you can use the following code snippet: \n'
+ '"""\nfrom datasets import load_dataset \n'
+ 'dataset = dict(type=load_dataset, path=\'json\', '
+ 'data_files=\'your_json_file.json\')\n"""\n'
+ 'For more details, please refer to Step 5 in the '
+ '`Using Custom Datasets` section of the documentation found at'
+ ' docs/zh_cn/user_guides/single_turn_conversation.md.')
+
+ try:
+ dataset = BUILDER.build(dataset)
+ except RuntimeError:
+ raise RuntimeError(
+ 'Unable to load the custom JSON file using '
+ '`datasets.load_dataset`. Your data-related config is '
+ f'{train_dataset}. Please refer to the official documentation on'
+ ' `load_dataset` (https://huggingface.co/docs/datasets/loading) '
+ 'for more details.')
+
+ if isinstance(dataset, DatasetDict):
+ dataset = dataset[split]
+
+ if not is_standard_format(dataset) and dataset_map_fn is None:
+ raise ValueError(
+ 'If the custom dataset is not in the XTuner-defined '
+ 'format, please utilize `dataset_map_fn` to map the original data'
+ ' to the standard format. For more details, please refer to '
+ 'Step 1 and Step 5 in the `Using Custom Datasets` section of the '
+ 'documentation found at '
+ '`docs/zh_cn/user_guides/single_turn_conversation.md`.')
+
+ if is_standard_format(dataset) and dataset_map_fn is not None:
+ raise ValueError(
+ 'If the custom dataset is already in the XTuner-defined format, '
+ 'please set `dataset_map_fn` to None.'
+ 'For more details, please refer to Step 1 and Step 5 in the '
+ '`Using Custom Datasets` section of the documentation found at'
+ ' docs/zh_cn/user_guides/single_turn_conversation.md.')
+
+ max_dataset_length = min(max_dataset_length, len(dataset))
+ indices = np.random.choice(len(dataset), max_dataset_length, replace=False)
+ dataset = dataset.select(indices)
+
+ if dataset_map_fn is not None:
+ dataset = dataset.map(dataset_map_fn)
+
+ print('#' * 20 + ' dataset after `dataset_map_fn` ' + '#' * 20)
+ print(dataset[0]['conversation'])
+
+ if template_map_fn is not None:
+ template_map_fn = BUILDER.build(template_map_fn)
+ dataset = dataset.map(template_map_fn)
+
+ print('#' * 20 + ' dataset after adding templates ' + '#' * 20)
+ print(dataset[0]['conversation'])
+
+ for old, new in rename_maps:
+ dataset = dataset.rename_column(old, new)
+
+ if pack_to_max_length and (not remove_unused_columns):
+ raise ValueError('We have to remove unused columns if '
+ '`pack_to_max_length` is set to True.')
+
+ dataset = dataset.map(
+ partial(
+ encode_fn,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ input_ids_with_output=input_ids_with_output),
+ remove_columns=list(dataset.column_names)
+ if remove_unused_columns else None)
+
+ print('#' * 20 + ' encoded input_ids ' + '#' * 20)
+ print(dataset[0]['input_ids'])
+ print('#' * 20 + ' encoded labels ' + '#' * 20)
+ print(dataset[0]['labels'])
+
+ if pack_to_max_length and split == 'train':
+ if shuffle_before_pack:
+ dataset = dataset.shuffle()
+ dataset = dataset.flatten_indices()
+ dataset = dataset.map(Packer(max_length), batched=True)
+
+ print('#' * 20 + ' input_ids after packed to max_length ' +
+ '#' * 20)
+ print(dataset[0]['input_ids'])
+ print('#' * 20 + ' labels after packed to max_length ' + '#' * 20)
+ print(dataset[0]['labels'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/copy_cfg.py b/data/xtuner/xtuner/tools/copy_cfg.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c3ff69c1271ae16fc3ad11d2f7ce184cca5dfea
--- /dev/null
+++ b/data/xtuner/xtuner/tools/copy_cfg.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import shutil
+
+from mmengine.utils import mkdir_or_exist
+
+from xtuner.configs import cfgs_name_path
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config_name', help='config name')
+ parser.add_argument('save_dir', help='save directory for copied config')
+ args = parser.parse_args()
+ return args
+
+
+def add_copy_suffix(string):
+ file_name, ext = osp.splitext(string)
+ return f'{file_name}_copy{ext}'
+
+
+def main():
+ args = parse_args()
+ mkdir_or_exist(args.save_dir)
+ config_path = cfgs_name_path[args.config_name]
+ save_path = osp.join(args.save_dir,
+ add_copy_suffix(osp.basename(config_path)))
+ shutil.copyfile(config_path, save_path)
+ print(f'Copy to {save_path}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/data_preprocess/arxiv.py b/data/xtuner/xtuner/tools/data_preprocess/arxiv.py
new file mode 100644
index 0000000000000000000000000000000000000000..55c3004038971462142f1a4a3619edae4d775b34
--- /dev/null
+++ b/data/xtuner/xtuner/tools/data_preprocess/arxiv.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+from datetime import datetime
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('src_file', help='source file path')
+ parser.add_argument('dst_file', help='destination file path')
+ parser.add_argument(
+ '--categories',
+ nargs='+',
+ default=['cs.AI', 'cs.CL', 'cs.CV'],
+ help='target categories')
+ parser.add_argument(
+ '--start-date',
+ default='2020-01-01',
+ help='start date (format: YYYY-MM-DD)')
+
+ args = parser.parse_args()
+ return args
+
+
+def has_intersection(list1, list2):
+ set1 = set(list1)
+ set2 = set(list2)
+ return len(set1.intersection(set2)) > 0
+
+
+def read_json_file(file_path):
+ data = []
+ with open(file_path) as file:
+ for line in file:
+ try:
+ json_data = json.loads(line)
+ data.append(json_data)
+ except json.JSONDecodeError:
+ print(f'Failed to parse line: {line}')
+ return data
+
+
+def main():
+ args = parse_args()
+ json_data = read_json_file(args.src_file)
+ from_time = datetime.strptime(args.start_date, '%Y-%m-%d')
+ filtered_data = [
+ item for item in json_data
+ if has_intersection(args.categories, item['categories'].split())
+ and datetime.strptime(item['update_date'], '%Y-%m-%d') >= from_time
+ ]
+
+ with open(args.dst_file, 'w') as file:
+ json.dump(filtered_data, file)
+
+ print(f'Save to {args.dst_file}\n{len(filtered_data)} items')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/data_preprocess/convert_refcoco.py b/data/xtuner/xtuner/tools/data_preprocess/convert_refcoco.py
new file mode 100644
index 0000000000000000000000000000000000000000..883e82a226414f9fbf49e27ed7144bd8e478cfef
--- /dev/null
+++ b/data/xtuner/xtuner/tools/data_preprocess/convert_refcoco.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+
+from xtuner.dataset.refcoco_json import RefCOCOJsonDataset
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--ann-path',
+ default='data/refcoco_annotations',
+ help='Refcoco annotation path',
+ )
+ parser.add_argument(
+ '--image-path',
+ default='data/llava_data/llava_images/coco/train2017',
+ help='COCO image path',
+ )
+ parser.add_argument(
+ '--save-path', default='./', help='The folder to save converted data')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ data_info = [
+ ('refcoco', 'unc'),
+ ('refcoco+', 'unc'),
+ ('refcocog', 'umd'),
+ ]
+ all_data = []
+ for dataset, split in data_info:
+ data = RefCOCOJsonDataset.get_data_json(
+ ann_path=args.ann_path,
+ image_path=args.image_path,
+ dataset=dataset,
+ splitBy=split,
+ )[0]
+ all_data.extend(data)
+ save_path = args.save_path + '/train.json'
+ with open(save_path, 'w') as f:
+ print(f'save to {save_path} with {len(all_data)} items.')
+ print(all_data[0])
+ json.dump(all_data, f, indent=4)
diff --git a/data/xtuner/xtuner/tools/eval_refcoco.py b/data/xtuner/xtuner/tools/eval_refcoco.py
new file mode 100644
index 0000000000000000000000000000000000000000..cbdc1bf6e9dda876440ffa61416f66247d1705db
--- /dev/null
+++ b/data/xtuner/xtuner/tools/eval_refcoco.py
@@ -0,0 +1,356 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import re
+
+import torch
+import tqdm
+from huggingface_hub import snapshot_download
+from mmengine.dist import get_dist_info, init_dist, master_only
+from mmengine.utils.dl_utils import set_multi_processing
+from peft import PeftModel
+from torch import distributed as dist
+from torch.utils.data import DataLoader, DistributedSampler
+from transformers import (AutoModel, AutoModelForCausalLM, AutoTokenizer,
+ BitsAndBytesConfig, CLIPImageProcessor,
+ CLIPVisionModel, GenerationConfig)
+
+from xtuner.dataset.map_fns import llava_map_fn, template_map_fn_factory
+from xtuner.dataset.refcoco_json import RefCOCOJsonEvalDataset
+from xtuner.model.utils import LoadWoInit, prepare_inputs_labels_for_multimodal
+from xtuner.tools.utils import get_stop_criteria
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ PROMPT_TEMPLATE)
+
+TORCH_DTYPE_MAP = dict(
+ fp16=torch.float16, bf16=torch.bfloat16, fp32=torch.float32, auto='auto')
+
+
+def merge_outputs(otuputs):
+ new_outputs = [None for _ in range(dist.get_world_size())]
+
+ assert dist.is_initialized()
+
+ dist.all_gather_object(new_outputs, otuputs)
+ new_dict = []
+ for output in new_outputs:
+ new_dict.extend(output)
+ return new_dict
+
+
+@master_only
+def master_print(msg):
+ print(msg)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMBench')
+ parser.add_argument(
+ 'model_name_or_path', help='Hugging Face model name or path')
+ parser.add_argument('--data-path', default=None, help='data path')
+ parser.add_argument('--work-dir', help='the dir to save results')
+ parser.add_argument('--llava', default=None, help='llava name or path')
+ parser.add_argument(
+ '--visual-encoder', default=None, help='visual encoder name or path')
+ parser.add_argument(
+ '--visual-select-layer', default=-2, help='visual select layer')
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ default=None,
+ help='Specify a prompt template',
+ )
+ parser.add_argument(
+ '--stop-words', nargs='+', type=str, default=[], help='Stop words')
+ parser.add_argument(
+ '--torch-dtype',
+ default='fp16',
+ choices=TORCH_DTYPE_MAP.keys(),
+ help='Override the default `torch.dtype` and load the model under '
+ 'a specific `dtype`.',
+ )
+ parser.add_argument(
+ '--bits',
+ type=int,
+ choices=[4, 8, None],
+ default=None,
+ help='LLM bits')
+ parser.add_argument(
+ '--bot-name', type=str, default='BOT', help='Name for Bot')
+ parser.add_argument(
+ '--offload-folder',
+ default=None,
+ help='The folder in which to offload the model weights (or where the '
+ 'model weights are already offloaded).',
+ )
+ parser.add_argument(
+ '--max-new-tokens',
+ type=int,
+ default=100,
+ help='Maximum number of new tokens allowed in generated text',
+ )
+ parser.add_argument(
+ '--seed',
+ type=int,
+ default=0,
+ help='Random seed for reproducible text generation',
+ )
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher',
+ )
+ args = parser.parse_args()
+ return args
+
+
+def eval_iou(answers):
+
+ def computeIoU(bbox1, bbox2):
+ x1, y1, x2, y2 = bbox1
+ x3, y3, x4, y4 = bbox2
+ intersection_x1 = max(x1, x3)
+ intersection_y1 = max(y1, y3)
+ intersection_x2 = min(x2, x4)
+ intersection_y2 = min(y2, y4)
+ intersection_area = max(0,
+ intersection_x2 - intersection_x1 + 1) * max(
+ 0, intersection_y2 - intersection_y1 + 1)
+ bbox1_area = (x2 - x1 + 1) * (y2 - y1 + 1)
+ bbox2_area = (x4 - x3 + 1) * (y4 - y3 + 1)
+ union_area = bbox1_area + bbox2_area - intersection_area
+ iou = intersection_area / union_area
+ return iou
+
+ right = 0
+ for answer in answers:
+ bbox = answer['bbox']
+ bbox = RefCOCOJsonEvalDataset.normalize_bbox(bbox, answer['height'],
+ answer['width'])
+ answer_bbox = [int(x) for x in re.findall(r'\d+', answer['ans'])]
+ if len(answer_bbox) == 4:
+ iou = computeIoU(answer_bbox, bbox)
+ if iou > 0.5:
+ right += 1
+ else:
+ print('Error format sample: ', answer)
+ return right / len(answers)
+
+
+def build_model(args):
+ rank, world_size = get_dist_info()
+ # build llm
+ quantization_config = None
+ load_in_8bit = False
+ if args.bits == 4:
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4',
+ )
+ elif args.bits == 8:
+ load_in_8bit = True
+ model_kwargs = {
+ 'quantization_config': quantization_config,
+ 'load_in_8bit': load_in_8bit,
+ 'device_map': rank if world_size > 1 else 'auto',
+ 'offload_folder': args.offload_folder,
+ 'trust_remote_code': True,
+ 'torch_dtype': TORCH_DTYPE_MAP[args.torch_dtype],
+ }
+
+ # build llm
+ with LoadWoInit():
+ llm = AutoModelForCausalLM.from_pretrained(args.model_name_or_path,
+ **model_kwargs)
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=True,
+ encode_special_tokens=True)
+ master_print(f'Load LLM from {args.model_name_or_path}')
+
+ llava_path = (
+ snapshot_download(
+ repo_id=args.llava) if not osp.isdir(args.llava) else args.llava)
+
+ # build visual_encoder
+ if 'visual_encoder' in os.listdir(llava_path):
+ assert args.visual_encoder is None, (
+ "Please don't specify the `--visual-encoder` since passed "
+ '`--llava` contains a visual encoder!')
+ visual_encoder_path = osp.join(llava_path, 'visual_encoder')
+ else:
+ assert (args.visual_encoder is not None
+ ), 'Please specify the `--visual-encoder`!' # noqa: E501
+ visual_encoder_path = args.visual_encoder
+ with LoadWoInit():
+ visual_encoder = CLIPVisionModel.from_pretrained(
+ visual_encoder_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ image_processor = CLIPImageProcessor.from_pretrained(
+ visual_encoder_path)
+ master_print(f'Load visual_encoder from {visual_encoder_path}')
+
+ # load adapter
+ if 'llm_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'llm_adapter')
+
+ with LoadWoInit():
+ llm = PeftModel.from_pretrained(
+ llm, adapter_path, offload_folder=args.offload_folder)
+
+ master_print(f'Load LLM adapter from {args.llava}')
+
+ if 'visual_encoder_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'visual_encoder_adapter')
+ visual_encoder = PeftModel.from_pretrained(
+ visual_encoder, adapter_path, offload_folder=args.offload_folder)
+ master_print(f'Load visual_encoder adapter from {args.llava}')
+
+ # build projector
+ projector_path = osp.join(llava_path, 'projector')
+ with LoadWoInit():
+ projector = AutoModel.from_pretrained(
+ projector_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ master_print(f'Load projector from {args.llava}')
+
+ projector.cuda()
+ projector.eval()
+
+ visual_encoder.cuda()
+ visual_encoder.eval()
+
+ llm.eval()
+ return llm, visual_encoder, projector, tokenizer, image_processor
+
+
+def generate(
+ llm,
+ visual_encoder,
+ projector,
+ tokenizer,
+ samples,
+ visual_select_layer,
+):
+ gen_config = GenerationConfig(
+ max_new_tokens=100,
+ do_sample=False,
+ eos_token_id=tokenizer.eos_token_id,
+ pad_token_id=(tokenizer.pad_token_id if tokenizer.pad_token_id
+ is not None else tokenizer.eos_token_id),
+ )
+ stop_criteria = get_stop_criteria(tokenizer=tokenizer, stop_words=[''])
+
+ device = next(llm.parameters()).device
+ # prepare inputs
+ inputs = samples['conversation'][0]['input'][0]
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0:
+ cur_encode = tokenizer.encode(chunk)
+ else:
+ cur_encode = tokenizer.encode(chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+ ids = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ ids.append(IMAGE_TOKEN_INDEX)
+ ids = torch.tensor(ids).cuda().unsqueeze(0)
+
+ visual_outputs = visual_encoder(
+ samples['pixel_values'].to(device), output_hidden_states=True)
+ pixel_values = projector(
+ visual_outputs.hidden_states[visual_select_layer][:, 1:])
+ samples['pixel_values'] = pixel_values
+ samples['input_ids'] = ids
+ datax = prepare_inputs_labels_for_multimodal(
+ llm=llm.to(device),
+ input_ids=samples['input_ids'].to(device),
+ pixel_values=samples['pixel_values'].to(device),
+ )
+
+ # generation
+ generation = llm.generate(
+ **datax,
+ generation_config=gen_config,
+ streamer=None,
+ bos_token_id=tokenizer.bos_token_id,
+ stopping_criteria=stop_criteria,
+ )
+ answer = tokenizer.decode(generation[0])
+ return {
+ 'ans': answer,
+ 'id': samples['id'][0],
+ 'bbox': torch.tensor(samples['bbox']).tolist(),
+ 'height': samples['height'],
+ 'width': samples['width'],
+ }
+
+
+@torch.no_grad()
+def main():
+ # init
+ args = parse_args()
+ if args.launcher != 'none':
+ set_multi_processing(distributed=True)
+ init_dist(args.launcher)
+
+ rank, world_size = get_dist_info()
+ torch.cuda.set_device(rank)
+ else:
+ rank = 0
+ world_size = 1
+ print(f'Rank: {rank} / World size: {world_size}')
+
+ # build_model
+ llm, visual_encoder, projector, tokenizer, image_processor = build_model(
+ args)
+
+ # dataset
+ dataset = RefCOCOJsonEvalDataset(
+ data_path=args.data_path,
+ image_folder='data/llava_data/llava_images/',
+ tokenizer=tokenizer,
+ image_processor=image_processor,
+ max_dataset_length=None,
+ dataset_map_fn=llava_map_fn,
+ template_map_fn=dict(
+ type=template_map_fn_factory, template=PROMPT_TEMPLATE.vicuna),
+ max_length=2048,
+ pad_image_to_square=False,
+ )
+ loader = DataLoader(
+ dataset,
+ batch_size=1,
+ shuffle=False,
+ sampler=DistributedSampler(dataset, shuffle=False, seed=0),
+ )
+ loader.sampler.set_epoch(0)
+
+ answers = []
+ for i, data in tqdm.tqdm(enumerate(loader), desc=f'Rank {rank}'):
+ answer = generate(
+ llm,
+ visual_encoder,
+ projector,
+ tokenizer,
+ data,
+ args.visual_select_layer,
+ )
+ answers.append(answer)
+
+ merged_outputs = merge_outputs(answers)
+ acc = eval_iou(merged_outputs)
+ master_print(f'Acc: {acc}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/get_data_order.py b/data/xtuner/xtuner/tools/get_data_order.py
new file mode 100644
index 0000000000000000000000000000000000000000..30c23e84e7213fb518f798946da0befb1091b8c2
--- /dev/null
+++ b/data/xtuner/xtuner/tools/get_data_order.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data-folder', help='Data folder')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ parser.add_argument(
+ '--file-type',
+ default='.bin',
+ help='We want to get the order of the file in this type.')
+ args = parser.parse_args()
+ return args
+
+
+def save_data_order(data_folder, save_folder, file_type='.bin'):
+ assert os.path.exists(data_folder), f'{data_folder} does not exist.'
+ triples = list(os.walk(data_folder, followlinks=True))
+ data_order = []
+ for root, dirs, files in triples:
+ dirs.sort()
+ print(f'Reading {root}...')
+ for fn in sorted(files):
+ if fn.endswith(file_type):
+ fp = os.path.join(root, fn)
+ # Using relative paths so that you can get the same result
+ # on different clusters
+ fp = fp.replace(data_folder, '')[1:]
+ data_order.append(fp)
+
+ save_path = os.path.join(save_folder, 'data_order.txt')
+ with open(save_path, 'w') as f:
+ for fp in data_order:
+ f.write(fp + '\n')
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ save_data_order(args.data_folder, args.save_folder, args.file_type)
diff --git a/data/xtuner/xtuner/tools/list_cfg.py b/data/xtuner/xtuner/tools/list_cfg.py
new file mode 100644
index 0000000000000000000000000000000000000000..0062ade5714aa5b30467ab53809d245f8c142f66
--- /dev/null
+++ b/data/xtuner/xtuner/tools/list_cfg.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from xtuner.configs import cfgs_name_path
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '-p', '--pattern', default=None, help='Pattern for fuzzy matching')
+ args = parser.parse_args()
+ return args
+
+
+def main(pattern=None):
+ args = parse_args()
+ configs_names = sorted(list(cfgs_name_path.keys()))
+ print('==========================CONFIGS===========================')
+ if args.pattern is not None:
+ print(f'PATTERN: {args.pattern}')
+ print('-------------------------------')
+ for name in configs_names:
+ if args.pattern is None or args.pattern.lower() in name.lower():
+ print(name)
+ print('=============================================================')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/list_dataset_format.py b/data/xtuner/xtuner/tools/list_dataset_format.py
new file mode 100644
index 0000000000000000000000000000000000000000..40d3a71f2539db6b0af2880d78c0e2710c296dfe
--- /dev/null
+++ b/data/xtuner/xtuner/tools/list_dataset_format.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.dataset.map_fns import DATASET_FORMAT_MAPPING
+
+
+def main():
+ dataset_format = DATASET_FORMAT_MAPPING.keys()
+ print('======================DATASET_FORMAT======================')
+ for format in dataset_format:
+ print(format)
+ print('==========================================================')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/log_dataset.py b/data/xtuner/xtuner/tools/log_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..40b5e25feff74d90cff8ffeaa74fd6b103d649a9
--- /dev/null
+++ b/data/xtuner/xtuner/tools/log_dataset.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from mmengine.config import Config
+
+from xtuner.registry import BUILDER
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Log processed dataset.')
+ parser.add_argument('config', help='config file name or path.')
+ # chose which kind of dataset style to show
+ parser.add_argument(
+ '--show',
+ default='text',
+ choices=['text', 'masked_text', 'input_ids', 'labels', 'all'],
+ help='which kind of dataset style to show')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ if cfg.get('framework', 'mmengine').lower() == 'huggingface':
+ train_dataset = BUILDER.build(cfg.train_dataset)
+ else:
+ train_dataset = BUILDER.build(cfg.train_dataloader.dataset)
+
+ if args.show == 'text' or args.show == 'all':
+ print('#' * 20 + ' text ' + '#' * 20)
+ print(tokenizer.decode(train_dataset[0]['input_ids']))
+ if args.show == 'masked_text' or args.show == 'all':
+ print('#' * 20 + ' text(masked) ' + '#' * 20)
+ masked_text = ' '.join(
+ ['[-100]' for i in train_dataset[0]['labels'] if i == -100])
+ unmasked_text = tokenizer.decode(
+ [i for i in train_dataset[0]['labels'] if i != -100])
+ print(masked_text + ' ' + unmasked_text)
+ if args.show == 'input_ids' or args.show == 'all':
+ print('#' * 20 + ' input_ids ' + '#' * 20)
+ print(train_dataset[0]['input_ids'])
+ if args.show == 'labels' or args.show == 'all':
+ print('#' * 20 + ' labels ' + '#' * 20)
+ print(train_dataset[0]['labels'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/mmbench.py b/data/xtuner/xtuner/tools/mmbench.py
new file mode 100644
index 0000000000000000000000000000000000000000..24d3825bb2ded3be9b11aaee18f312e86342223e
--- /dev/null
+++ b/data/xtuner/xtuner/tools/mmbench.py
@@ -0,0 +1,513 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import math
+import os
+import os.path as osp
+import re
+import string
+import time
+
+import numpy as np
+import pandas as pd
+import torch
+import tqdm
+from huggingface_hub import snapshot_download
+from mmengine import mkdir_or_exist
+from mmengine.dist import (collect_results, get_dist_info, get_rank, init_dist,
+ master_only)
+from mmengine.utils.dl_utils import set_multi_processing
+from peft import PeftModel
+from rich.console import Console
+from rich.table import Table
+from torch.utils.data import Dataset
+from transformers import (AutoModel, AutoModelForCausalLM, AutoTokenizer,
+ BitsAndBytesConfig, CLIPImageProcessor,
+ CLIPVisionModel, GenerationConfig)
+
+from xtuner.dataset.utils import decode_base64_to_image, expand2square
+from xtuner.model.utils import LoadWoInit, prepare_inputs_labels_for_multimodal
+from xtuner.tools.utils import get_stop_criteria, is_cn_string
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ PROMPT_TEMPLATE)
+
+TORCH_DTYPE_MAP = dict(
+ fp16=torch.float16, bf16=torch.bfloat16, fp32=torch.float32, auto='auto')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMBench')
+ parser.add_argument(
+ 'model_name_or_path', help='Hugging Face model name or path')
+ parser.add_argument('--data-path', default=None, help='data path')
+ parser.add_argument('--work-dir', help='the dir to save results')
+ parser.add_argument('--llava', default=None, help='llava name or path')
+ parser.add_argument(
+ '--visual-encoder', default=None, help='visual encoder name or path')
+ parser.add_argument(
+ '--visual-select-layer', default=-2, help='visual select layer')
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ default=None,
+ help='Specify a prompt template')
+ parser.add_argument(
+ '--stop-words', nargs='+', type=str, default=[], help='Stop words')
+ parser.add_argument(
+ '--torch-dtype',
+ default='fp16',
+ choices=TORCH_DTYPE_MAP.keys(),
+ help='Override the default `torch.dtype` and load the model under '
+ 'a specific `dtype`.')
+ parser.add_argument(
+ '--bits',
+ type=int,
+ choices=[4, 8, None],
+ default=None,
+ help='LLM bits')
+ parser.add_argument(
+ '--bot-name', type=str, default='BOT', help='Name for Bot')
+ parser.add_argument(
+ '--offload-folder',
+ default=None,
+ help='The folder in which to offload the model weights (or where the '
+ 'model weights are already offloaded).')
+ parser.add_argument(
+ '--max-new-tokens',
+ type=int,
+ default=100,
+ help='Maximum number of new tokens allowed in generated text')
+ parser.add_argument(
+ '--seed',
+ type=int,
+ default=0,
+ help='Random seed for reproducible text generation')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ args = parser.parse_args()
+ return args
+
+
+@master_only
+def master_print(msg):
+ print(msg)
+
+
+class MMBenchDataset(Dataset):
+ ABBRS = {
+ 'coarse_perception': 'CP',
+ 'finegrained_perception (instance-level)': 'FP-S',
+ 'finegrained_perception (cross-instance)': 'FP-C',
+ 'logic_reasoning': 'LR',
+ 'relation_reasoning': 'RR',
+ 'attribute_reasoning': 'AR',
+ 'sketch_reasoning': 'Sketch Reasoning',
+ 'scenery_building': 'Scenery & Building',
+ 'food_clothes': 'Food & Clothes',
+ 'historical_figure': 'Historical Figure',
+ 'traditional_show': 'Traditional Show',
+ 'calligraphy_painting': 'Calligraphy Painting',
+ 'cultural_relic': 'Cultural Relic'
+ }
+
+ def __init__(self, data_file):
+ self.data_file = data_file
+ self.df = pd.read_csv(data_file, sep='\t')
+ self.split = 'dev' if 'answer' in self.df.iloc[0].keys() else 'test'
+ self.has_l2_category = 'l2-category' in self.df.columns.to_list()
+
+ def get_image(self, image):
+ while len(image) < 16:
+ image = self.df[self.df['index'] == int(image)]['image'].values
+ assert len(image) == 1
+ image = image[0]
+ image = decode_base64_to_image(image)
+ return image
+
+ def __len__(self):
+ return len(self.df)
+
+ def __getitem__(self, idx):
+ index = self.df.iloc[idx]['index']
+ image = self.df.iloc[idx]['image']
+ image = self.get_image(image)
+ question = self.df.iloc[idx]['question']
+ answer = self.df.iloc[idx]['answer'] if 'answer' in self.df.iloc[
+ 0].keys() else None
+ category = self.df.iloc[idx]['category']
+
+ options = {
+ cand: self.load_from_df(idx, cand)
+ for cand in string.ascii_uppercase
+ if self.load_from_df(idx, cand) is not None
+ }
+ options_prompt = ''
+ for key, item in options.items():
+ options_prompt += f'{key}. {item}\n'
+
+ hint = self.load_from_df(idx, 'hint')
+ data = {
+ 'img': image,
+ 'question': question,
+ 'answer': answer,
+ 'options': options_prompt,
+ 'category': category,
+ 'options_dict': options,
+ 'index': index,
+ 'context': hint,
+ }
+ if self.has_l2_category:
+ data.update({'l2-category': self.df.iloc[idx]['l2-category']})
+ return data
+
+ def load_from_df(self, idx, key):
+ if key in self.df.iloc[idx] and not pd.isna(self.df.iloc[idx][key]):
+ return self.df.iloc[idx][key]
+ else:
+ return None
+
+ @master_only
+ def eval_result(self, result_df, show=True):
+
+ def calc_acc(df, group='category'):
+ assert group in ['overall', 'category', 'l2-category']
+ if group == 'overall':
+ res = {'Average': np.mean(df['hit'])}
+ else:
+ res = {}
+ abilities = list(set(df[group]))
+ abilities.sort()
+ for ab in abilities:
+ sub_df = df[df[group] == ab]
+ ab = self.ABBRS[ab] if ab in self.ABBRS else ab
+ res[ab] = np.mean(sub_df['hit'])
+ return res
+
+ def eval_sub_data(sub_data, answer_map):
+ lt = len(sub_data)
+ for i in range(lt):
+ item = sub_data.iloc[i]
+ match = re.search(r'([A-D]+)', item['prediction'])
+ pred = match.group(1) if match else ''
+ gt = answer_map[item['index']]
+ if gt != pred:
+ return 0
+ return 1
+
+ def show_result(ret_json):
+ show_dict = ret_json.copy()
+ table = Table(title=f' MMBench ({self.data_file}) ')
+ console = Console()
+ table.add_column('Category', justify='left')
+ table.add_column('Accuracy (%)', justify='right')
+ average = show_dict.pop('Average') * 100
+ table.add_row('Average', f'{average:.1f}')
+ table.add_section()
+ for cat_name, cat_acc in show_dict.items():
+ table.add_row(cat_name, f'{cat_acc * 100:.1f}')
+ with console.capture() as capture:
+ console.print(table, end='')
+ print('\n' + capture.get())
+ print('Note: Please be cautious if you use the results in papers, '
+ "since we don't use ChatGPT as a helper for choice "
+ 'extraction')
+
+ data = result_df.sort_values(by='index')
+ data['prediction'] = [str(x) for x in data['prediction']]
+ for k in data.keys():
+ data[k.lower() if k not in 'ABCD' else k] = data.pop(k)
+
+ data_main = data[data['index'] < int(1e6)]
+ cate_map = {
+ i: c
+ for i, c in zip(self.df['index'], self.df['category'])
+ }
+ if self.has_l2_category:
+ l2_cate_map = {
+ i: c
+ for i, c in zip(self.df['index'], self.df['l2-category'])
+ }
+ answer_map = {
+ i: c
+ for i, c in zip(self.df['index'], self.df['answer'])
+ }
+
+ lt = len(data_main)
+ hit, tot = 0, 0
+ result = {}
+ for i in range(lt):
+ item_main = data_main.iloc[i]
+ idx = item_main['index']
+ assert idx not in result
+ sub_data = data[data['index'] % int(1e6) == idx]
+ ret = eval_sub_data(sub_data, answer_map)
+ result[idx] = ret
+ hit += ret
+ tot += 1
+
+ indices = data_main['index']
+ data_main = data_main.copy()
+ data_main['hit'] = [result[i] for i in indices]
+ main_idx = data_main['index']
+ data_main['category'] = [cate_map[i] for i in main_idx]
+
+ ret_json = calc_acc(data_main, 'overall')
+
+ if self.has_l2_category:
+ data_main['l2-category'] = [l2_cate_map[i] for i in main_idx]
+ l2 = calc_acc(data_main, 'l2-category')
+ ret_json.update(l2)
+ else:
+ leaf = calc_acc(data_main, 'category')
+ ret_json.update(leaf)
+ if show:
+ show_result(ret_json)
+ return ret_json
+
+
+def main():
+ args = parse_args()
+
+ torch.manual_seed(args.seed)
+
+ if args.launcher != 'none':
+ set_multi_processing(distributed=True)
+ init_dist(args.launcher)
+
+ rank, world_size = get_dist_info()
+ torch.cuda.set_device(rank)
+ else:
+ rank = 0
+ world_size = 1
+
+ # build llm
+ quantization_config = None
+ load_in_8bit = False
+ if args.bits == 4:
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4')
+ elif args.bits == 8:
+ load_in_8bit = True
+ model_kwargs = {
+ 'quantization_config': quantization_config,
+ 'load_in_8bit': load_in_8bit,
+ 'device_map': rank if world_size > 1 else 'auto',
+ 'offload_folder': args.offload_folder,
+ 'trust_remote_code': True,
+ 'torch_dtype': TORCH_DTYPE_MAP[args.torch_dtype]
+ }
+
+ # build llm
+ with LoadWoInit():
+ llm = AutoModelForCausalLM.from_pretrained(args.model_name_or_path,
+ **model_kwargs)
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=True,
+ encode_special_tokens=True)
+ master_print(f'Load LLM from {args.model_name_or_path}')
+
+ llava_path = snapshot_download(
+ repo_id=args.llava) if not osp.isdir(args.llava) else args.llava
+
+ # build visual_encoder
+ if 'visual_encoder' in os.listdir(llava_path):
+ assert args.visual_encoder is None, (
+ "Please don't specify the `--visual-encoder` since passed "
+ '`--llava` contains a visual encoder!')
+ visual_encoder_path = osp.join(llava_path, 'visual_encoder')
+ else:
+ assert args.visual_encoder is not None, (
+ 'Please specify the `--visual-encoder`!')
+ visual_encoder_path = args.visual_encoder
+ with LoadWoInit():
+ visual_encoder = CLIPVisionModel.from_pretrained(
+ visual_encoder_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ image_processor = CLIPImageProcessor.from_pretrained(
+ visual_encoder_path)
+ master_print(f'Load visual_encoder from {visual_encoder_path}')
+
+ # load adapter
+ if 'llm_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'llm_adapter')
+
+ with LoadWoInit():
+ llm = PeftModel.from_pretrained(
+ llm, adapter_path, offload_folder=args.offload_folder)
+
+ master_print(f'Load LLM adapter from {args.llava}')
+
+ if 'visual_encoder_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'visual_encoder_adapter')
+ visual_encoder = PeftModel.from_pretrained(
+ visual_encoder, adapter_path, offload_folder=args.offload_folder)
+ master_print(f'Load visual_encoder adapter from {args.llava}')
+
+ # build projector
+ projector_path = osp.join(llava_path, 'projector')
+ with LoadWoInit():
+ projector = AutoModel.from_pretrained(
+ projector_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ master_print(f'Load projector from {args.llava}')
+
+ projector.cuda()
+ projector.eval()
+
+ visual_encoder.cuda()
+ visual_encoder.eval()
+
+ llm.eval()
+
+ stop_words = args.stop_words
+ if args.prompt_template:
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ stop_words += template.get('STOP_WORDS', [])
+ stop_criteria = get_stop_criteria(
+ tokenizer=tokenizer, stop_words=stop_words)
+
+ gen_config = GenerationConfig(
+ max_new_tokens=args.max_new_tokens,
+ do_sample=False,
+ eos_token_id=tokenizer.eos_token_id,
+ pad_token_id=tokenizer.pad_token_id
+ if tokenizer.pad_token_id is not None else tokenizer.eos_token_id,
+ )
+
+ # work_dir
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ save_dir = args.work_dir
+ else:
+ # use config filename as default work_dir
+ save_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.data_path))[0])
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime(time.time()))
+ save_dir = osp.join(save_dir, timestamp)
+
+ if rank == 0:
+ mkdir_or_exist(osp.abspath(save_dir))
+ print('=======================================================')
+ print(f'Dataset path: {osp.abspath(args.data_path)}\n'
+ f'Results will be saved to {osp.abspath(save_dir)}')
+ print('=======================================================')
+
+ args_path = osp.join(save_dir, 'args.json')
+ with open(args_path, 'w', encoding='utf-8') as f:
+ json.dump(args.__dict__, f, indent=2)
+
+ results_xlsx_path = osp.join(save_dir, 'mmbench_result.xlsx')
+ results_json_path = osp.join(save_dir, 'mmbench_result.json')
+
+ dataset = MMBenchDataset(args.data_path)
+
+ results = []
+ n_samples = len(dataset)
+ per_rank_samples = math.ceil(n_samples / world_size)
+
+ per_rank_ids = range(per_rank_samples * rank,
+ min(n_samples, per_rank_samples * (rank + 1)))
+ for i in tqdm.tqdm(per_rank_ids, desc=f'Rank {rank}'):
+ data_sample = dataset[i]
+ if data_sample['context'] is not None:
+ text = data_sample['context'] + '\n' + data_sample[
+ 'question'] + '\n' + data_sample['options']
+ else:
+ text = data_sample['question'] + '\n' + data_sample['options']
+
+ text = DEFAULT_IMAGE_TOKEN + '\n' + text
+
+ if is_cn_string(text):
+ text = text + '请直接回答选项字母。'
+ else:
+ text = text + ("Answer with the option's letter from the "
+ 'given choices directly.')
+
+ if args.prompt_template:
+ prompt_text = ''
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ prompt_text += template['INSTRUCTION'].format(
+ input=text, round=1, bot_name=args.bot_name)
+ else:
+ prompt_text = text
+ inputs = prompt_text
+
+ image = data_sample['img'].convert('RGB')
+ image = expand2square(
+ image, tuple(int(x * 255) for x in image_processor.image_mean))
+ image = image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ image = image.cuda().unsqueeze(0).to(visual_encoder.dtype)
+ visual_outputs = visual_encoder(image, output_hidden_states=True)
+ pixel_values = projector(
+ visual_outputs.hidden_states[args.visual_select_layer][:, 1:])
+
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0:
+ cur_encode = tokenizer.encode(chunk)
+ else:
+ cur_encode = tokenizer.encode(chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+
+ # TODO: Auto-detect whether to prepend a bos_token_id at the beginning.
+ ids = []
+
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ ids.append(IMAGE_TOKEN_INDEX)
+ ids = torch.tensor(ids).cuda().unsqueeze(0)
+ mm_inputs = prepare_inputs_labels_for_multimodal(
+ llm=llm, input_ids=ids, pixel_values=pixel_values)
+
+ generate_output = llm.generate(
+ **mm_inputs,
+ generation_config=gen_config,
+ streamer=None,
+ bos_token_id=tokenizer.bos_token_id,
+ stopping_criteria=stop_criteria)
+
+ predict = tokenizer.decode(
+ generate_output[0], skip_special_tokens=True).strip()
+ cur_result = {}
+ cur_result['question'] = data_sample.get('question')
+ cur_result.update(data_sample.get('options_dict'))
+ cur_result['prediction'] = predict
+ if data_sample.get('category') is not None:
+ cur_result['category'] = data_sample.get('category')
+ if data_sample.get('l2-category') is not None:
+ cur_result['l2-category'] = data_sample.get('l2-category')
+ cur_result['index'] = data_sample.get('index')
+ cur_result['split'] = data_sample.get('split')
+ cur_result['answer'] = data_sample.get('answer')
+ results.append(cur_result)
+
+ results = collect_results(results, n_samples)
+
+ if get_rank() == 0:
+
+ results_df = pd.DataFrame(results)
+ with pd.ExcelWriter(results_xlsx_path, engine='openpyxl') as writer:
+ results_df.to_excel(writer, index=False)
+
+ if dataset.split == 'dev':
+ results_dict = dataset.eval_result(results_df, show=True)
+ with open(results_json_path, 'w', encoding='utf-8') as f:
+ json.dump(results_dict, f, indent=2)
+ else:
+ print('All done!')
+
+
+if __name__ == '__main__':
+
+ main()
diff --git a/data/xtuner/xtuner/tools/model_converters/merge.py b/data/xtuner/xtuner/tools/model_converters/merge.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7202a6633aa4f42e4082c81048a0053fd9e64c6
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/merge.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import torch
+from peft import PeftModel
+from transformers import (AutoModelForCausalLM, AutoTokenizer,
+ CLIPImageProcessor, CLIPVisionModel)
+
+from xtuner.model.utils import LoadWoInit
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Merge a HuggingFace adapter to base model')
+ parser.add_argument('model_name_or_path', help='model name or path')
+ parser.add_argument('adapter_name_or_path', help='adapter name or path')
+ parser.add_argument(
+ 'save_dir', help='the directory to save the merged model')
+ parser.add_argument(
+ '--max-shard-size',
+ type=str,
+ default='2GB',
+ help='Only applicable for LLM. The maximum size for '
+ 'each sharded checkpoint.')
+ parser.add_argument(
+ '--is-clip',
+ action='store_true',
+ help='Indicate if the model is a clip model')
+ parser.add_argument(
+ '--safe-serialization',
+ action='store_true',
+ help='Indicate if using `safe_serialization`')
+ parser.add_argument(
+ '--device',
+ default='cuda',
+ choices=('cuda', 'cpu', 'auto'),
+ help='Indicate the device')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ if args.is_clip:
+ with LoadWoInit():
+ model = CLIPVisionModel.from_pretrained(
+ args.model_name_or_path, device_map=args.device)
+ processor = CLIPImageProcessor.from_pretrained(args.model_name_or_path)
+ else:
+ with LoadWoInit():
+ model = AutoModelForCausalLM.from_pretrained(
+ args.model_name_or_path,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ device_map=args.device,
+ trust_remote_code=True)
+ processor = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, trust_remote_code=True)
+ model_unmerged = PeftModel.from_pretrained(
+ model,
+ args.adapter_name_or_path,
+ device_map=args.device,
+ is_trainable=False,
+ trust_remote_code=True)
+ model_merged = model_unmerged.merge_and_unload()
+ print(f'Saving to {args.save_dir}...')
+ model_merged.save_pretrained(
+ args.save_dir,
+ safe_serialization=args.safe_serialization,
+ max_shard_size=args.max_shard_size)
+ processor.save_pretrained(args.save_dir)
+ print('All done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/__init__.py b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/configuration_internlm2.py b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/configuration_internlm2.py
new file mode 100644
index 0000000000000000000000000000000000000000..12fdffe28ca875049873cfd010ac59ddf68af6c2
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/configuration_internlm2.py
@@ -0,0 +1,154 @@
+# coding=utf-8
+# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on transformers/src/transformers/models/llama/configuration_llama.py
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" InternLM2 model configuration"""
+
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+logger = logging.get_logger(__name__)
+
+INTERNLM2_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+
+# Modified from transformers.model.llama.configuration_llama.LlamaConfig
+class InternLM2Config(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`InternLM2Model`]. It is used to instantiate
+ an InternLM2 model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the InternLM2-7B.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the InternLM2 model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`InternLM2Model`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 11008):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 2048):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ tie_word_embeddings(`bool`, *optional*, defaults to `False`):
+ Whether to tie weight embeddings
+ Example:
+
+ """
+ model_type = "internlm2"
+ _auto_class = "AutoConfig"
+
+ def __init__( # pylint: disable=W0102
+ self,
+ vocab_size=103168,
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=None,
+ hidden_act="silu",
+ max_position_embeddings=2048,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ reward_token_id=92527,
+ tie_word_embeddings=False,
+ bias=True,
+ rope_theta=10000,
+ rope_scaling=None,
+ attn_implementation="eager",
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.bias = bias
+
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self._rope_scaling_validation()
+
+ self.attn_implementation = attn_implementation
+ if self.attn_implementation is None:
+ self.attn_implementation = "eager"
+
+ self.reward_token_id = reward_token_id
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+
+ def _rope_scaling_validation(self):
+ """
+ Validate the `rope_scaling` configuration.
+ """
+ if self.rope_scaling is None:
+ return
+
+ if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
+ raise ValueError(
+ "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
+ f"got {self.rope_scaling}"
+ )
+ rope_scaling_type = self.rope_scaling.get("type", None)
+ rope_scaling_factor = self.rope_scaling.get("factor", None)
+ if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
+ raise ValueError(
+ f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
+ )
+ if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor < 1.0:
+ raise ValueError(f"`rope_scaling`'s factor field must be a float >= 1, got {rope_scaling_factor}")
diff --git a/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/modeling_internlm2.py b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/modeling_internlm2.py
new file mode 100644
index 0000000000000000000000000000000000000000..59cba84567a2c6871bdf45d12a0753a663ea87dc
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/modeling_internlm2.py
@@ -0,0 +1,1578 @@
+# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on transformers/src/transformers/models/llama/modeling_llama.py
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch InternLM2 model."""
+import math
+import queue
+import threading
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from einops import rearrange
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPast,
+ CausalLMOutputWithPast,
+ SequenceClassifierOutputWithPast,
+)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+
+try:
+ from transformers.generation.streamers import BaseStreamer
+except: # noqa # pylint: disable=bare-except
+ BaseStreamer = None
+
+from .configuration_internlm2 import InternLM2Config
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "InternLM2Config"
+
+flash_attn_func, flash_attn_varlen_func = None, None
+pad_input, index_first_axis, unpad_input = None, None, None
+def _import_flash_attn():
+ global flash_attn_func, flash_attn_varlen_func
+ global pad_input, index_first_axis, unpad_input
+ try:
+ from flash_attn import flash_attn_func as _flash_attn_func, flash_attn_varlen_func as _flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input as _pad_input, index_first_axis as _index_first_axis, unpad_input as _unpad_input
+ flash_attn_func, flash_attn_varlen_func = _flash_attn_func, _flash_attn_varlen_func
+ pad_input, index_first_axis, unpad_input = _pad_input, _index_first_axis, _unpad_input
+ except ImportError:
+ raise ImportError("flash_attn is not installed.")
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+# Copied from transformers.models.bart.modeling_bart._make_causal_mask
+def _make_causal_mask(
+ input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
+):
+ """
+ Make causal mask used for bi-directional self-attention.
+ """
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)
+ mask_cond = torch.arange(mask.size(-1), device=device)
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
+
+
+# Copied from transformers.models.bart.modeling_bart._expand_mask
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->InternLM2
+class InternLM2RMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ InternLM2RMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaRotaryEmbedding with Llama->InternLM2
+class InternLM2RotaryEmbedding(nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
+ )
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=torch.float32)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->InternLM2
+class InternLM2LinearScalingRotaryEmbedding(InternLM2RotaryEmbedding):
+ """InternLM2RotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ t = t / self.scaling_factor
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->InternLM2
+class InternLM2DynamicNTKScalingRotaryEmbedding(InternLM2RotaryEmbedding):
+ """InternLM2RotaryEmbedding extended with Dynamic NTK scaling.
+ Credits to the Reddit users /u/bloc97 and /u/emozilla.
+ """
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+
+ if seq_len > self.max_position_embeddings:
+ base = self.base * (
+ (self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
+ ) ** (self.dim / (self.dim - 2))
+ inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.model.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.model.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors."""
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class InternLM2MLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.w1 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.w3 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.w2 = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.w2(self.act_fn(self.w1(x)) * self.w3(x))
+
+ return down_proj
+
+
+# Copied from transformers.model.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+# Modified from transformers.model.llama.modeling_llama.LlamaAttention
+class InternLM2Attention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: InternLM2Config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.is_causal = True
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
+ f" and `num_heads`: {self.num_heads})."
+ )
+
+ self.wqkv = nn.Linear(
+ self.hidden_size,
+ (self.num_heads + 2 * self.num_key_value_heads) * self.head_dim,
+ bias=config.bias,
+ )
+
+ self.wo = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.bias)
+ self._init_rope()
+
+ def _init_rope(self):
+ if self.config.rope_scaling is None:
+ self.rotary_emb = InternLM2RotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.config.rope_theta,
+ )
+ else:
+ scaling_type = self.config.rope_scaling["type"]
+ scaling_factor = self.config.rope_scaling["factor"]
+ if scaling_type == "dynamic":
+ self.rotary_emb = InternLM2DynamicNTKScalingRotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.config.rope_theta,
+ scaling_factor=scaling_factor,
+ )
+ elif scaling_type == "linear":
+ self.rotary_emb = InternLM2LinearScalingRotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.config.rope_theta,
+ scaling_factor=scaling_factor,
+ )
+ else:
+ raise ValueError("Currently we only support rotary embedding's type being 'dynamic' or 'linear'.")
+ return self.rotary_emb
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ "b q (h gs d) -> b q h gs d",
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., : self.num_key_value_groups, :]
+ query_states = rearrange(query_states, "b q h gs d -> b q (h gs) d")
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.wo(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+# Modified from transformers.model.llama.modeling_llama.InternLM2FlashAttention2
+class InternLM2FlashAttention2(InternLM2Attention):
+ """
+ InternLM2 flash attention module. This module inherits from `InternLM2Attention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ # InternLM2FlashAttention2 attention does not support output_attentions
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ "b q (h gs d) -> b q h gs d",
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., : self.num_key_value_groups, :]
+ query_states = rearrange(query_states, "b q h gs d -> b q (h gs) d")
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ attn_output = self._flash_attention_forward(
+ query_states, key_states, value_states, attention_mask, q_len
+ )
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
+ attn_output = self.wo(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`int`, *optional*):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ """
+ # Contains at least one padding token in the sequence
+ causal = self.is_causal and query_length != 1
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._unpad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
+ )
+
+ return attn_output
+
+ def _unpad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q.to(torch.int64),
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+INTERNLM2_ATTENTION_CLASSES = {
+ "eager": InternLM2Attention,
+ "flash_attention_2": InternLM2FlashAttention2,
+}
+
+# Modified from transformers.model.llama.modeling_llama.LlamaDecoderLayer
+class InternLM2DecoderLayer(nn.Module):
+ def __init__(self, config: InternLM2Config):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.attention = INTERNLM2_ATTENTION_CLASSES[config.attn_implementation](config=config)
+
+ self.feed_forward = InternLM2MLP(config)
+ self.attention_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.ffn_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*):
+ attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
+ query_sequence_length, key_sequence_length)` if default attention is used.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+
+ residual = hidden_states
+
+ hidden_states = self.attention_norm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.attention(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.ffn_norm(hidden_states)
+ hidden_states = self.feed_forward(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+InternLM2_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`InternLM2Config`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaPreTrainedModel with Llama->InternLM2
+@add_start_docstrings(
+ "The bare InternLM2 Model outputting raw hidden-states without any specific head on top.",
+ InternLM2_START_DOCSTRING,
+)
+class InternLM2PreTrainedModel(PreTrainedModel):
+ config_class = InternLM2Config
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["InternLM2DecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+InternLM2_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or
+ when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, decoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# Modified from transformers.model.llama.modeling_llama.LlamaModel
+@add_start_docstrings(
+ "The bare InternLM2 Model outputting raw hidden-states without any specific head on top.",
+ InternLM2_START_DOCSTRING,
+)
+class InternLM2Model(InternLM2PreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`InternLM2DecoderLayer`]
+
+ Args:
+ config: InternLM2Config
+ """
+
+ _auto_class = "AutoModel"
+
+ def __init__(self, config: InternLM2Config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+ self.config = config
+
+ self.tok_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+
+ self.layers = nn.ModuleList([InternLM2DecoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.tok_embeddings = value
+
+ def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ inputs_embeds.dtype,
+ device=inputs_embeds.device,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
+ inputs_embeds.device
+ )
+ combined_attention_mask = (
+ expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
+ )
+
+ return combined_attention_mask
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if self.config.attn_implementation == "flash_attention_2":
+ _import_flash_attn()
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape[:2]
+ elif inputs_embeds is not None:
+ batch_size, seq_length = inputs_embeds.shape[:2]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.tok_embeddings(input_ids)
+
+ if self.config.attn_implementation == "flash_attention_2":
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ else:
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ (batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
+ )
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
+ )
+
+ # embed positions
+ hidden_states = inputs_embeds
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ for idx, decoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, output_attentions, None)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ position_ids,
+ None,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+# Modified from transformers.model.llama.modeling_llama.LlamaForCausalLM
+class InternLM2ForCausalLM(InternLM2PreTrainedModel):
+ _auto_class = "AutoModelForCausalLM"
+
+ _tied_weights_keys = ["output.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = InternLM2Model(config)
+ self.vocab_size = config.vocab_size
+ self.output = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.model.tok_embeddings = value
+
+ def get_output_embeddings(self):
+ return self.output
+
+ def set_output_embeddings(self, new_embeddings):
+ self.output = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, InternLM2ForCausalLM
+
+ >>> model = InternLM2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.output(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
+ ):
+ if past_key_values is not None:
+ past_length = past_key_values[0][0].shape[2]
+
+ # Some generation methods already pass only the last input ID
+ if input_ids.shape[1] > past_length:
+ remove_prefix_length = past_length
+ else:
+ # Default to old behavior: keep only final ID
+ remove_prefix_length = input_ids.shape[1] - 1
+
+ input_ids = input_ids[:, remove_prefix_length:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (
+ tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
+ )
+ return reordered_past
+
+ def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = [], meta_instruction=""):
+ if tokenizer.add_bos_token:
+ prompt = ""
+ else:
+ prompt = tokenizer.bos_token
+ if meta_instruction:
+ prompt += f"""<|im_start|>system\n{meta_instruction}<|im_end|>\n"""
+ for record in history:
+ prompt += f"""<|im_start|>user\n{record[0]}<|im_end|>\n<|im_start|>assistant\n{record[1]}<|im_end|>\n"""
+ prompt += f"""<|im_start|>user\n{query}<|im_end|>\n<|im_start|>assistant\n"""
+ return tokenizer([prompt], return_tensors="pt")
+
+ @torch.no_grad()
+ def chat(
+ self,
+ tokenizer,
+ query: str,
+ history: List[Tuple[str, str]] = [],
+ streamer: Optional[BaseStreamer] = None,
+ max_new_tokens: int = 1024,
+ do_sample: bool = True,
+ temperature: float = 0.8,
+ top_p: float = 0.8,
+ meta_instruction: str = "You are an AI assistant whose name is InternLM (书生·浦语).\n"
+ "- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.\n"
+ "- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.",
+ **kwargs,
+ ):
+ inputs = self.build_inputs(tokenizer, query, history, meta_instruction)
+ inputs = {k: v.to(self.device) for k, v in inputs.items() if torch.is_tensor(v)}
+ # also add end-of-assistant token in eos token id to avoid unnecessary generation
+ eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids(["<|im_end|>"])[0]]
+ outputs = self.generate(
+ **inputs,
+ streamer=streamer,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ temperature=temperature,
+ top_p=top_p,
+ eos_token_id=eos_token_id,
+ **kwargs,
+ )
+ outputs = outputs[0].cpu().tolist()[len(inputs["input_ids"][0]) :]
+ response = tokenizer.decode(outputs, skip_special_tokens=True)
+ response = response.split("<|im_end|>")[0]
+ history = history + [(query, response)]
+ return response, history
+
+ @torch.no_grad()
+ def stream_chat(
+ self,
+ tokenizer,
+ query: str,
+ history: List[Tuple[str, str]] = [],
+ max_new_tokens: int = 1024,
+ do_sample: bool = True,
+ temperature: float = 0.8,
+ top_p: float = 0.8,
+ **kwargs,
+ ):
+ """
+ Return a generator in format: (response, history)
+ Eg.
+ ('你好,有什么可以帮助您的吗', [('你好', '你好,有什么可以帮助您的吗')])
+ ('你好,有什么可以帮助您的吗?', [('你好', '你好,有什么可以帮助您的吗?')])
+ """
+ if BaseStreamer is None:
+ raise ModuleNotFoundError(
+ "The version of `transformers` is too low. Please make sure "
+ "that you have installed `transformers>=4.28.0`."
+ )
+
+ response_queue = queue.Queue(maxsize=20)
+
+ class ChatStreamer(BaseStreamer):
+ def __init__(self, tokenizer) -> None:
+ super().__init__()
+ self.tokenizer = tokenizer
+ self.queue = response_queue
+ self.query = query
+ self.history = history
+ self.response = ""
+ self.cache = []
+ self.received_inputs = False
+ self.queue.put((self.response, history + [(self.query, self.response)]))
+
+ def put(self, value):
+ if len(value.shape) > 1 and value.shape[0] > 1:
+ raise ValueError("ChatStreamer only supports batch size 1")
+ elif len(value.shape) > 1:
+ value = value[0]
+
+ if not self.received_inputs:
+ # The first received value is input_ids, ignore here
+ self.received_inputs = True
+ return
+
+ self.cache.extend(value.tolist())
+ token = self.tokenizer.decode(self.cache, skip_special_tokens=True)
+ if token.strip() != "<|im_end|>":
+ self.response = self.response + token
+ history = self.history + [(self.query, self.response)]
+ self.queue.put((self.response, history))
+ self.cache = []
+ else:
+ self.end()
+
+ def end(self):
+ self.queue.put(None)
+
+ def stream_producer():
+ return self.chat(
+ tokenizer=tokenizer,
+ query=query,
+ streamer=ChatStreamer(tokenizer=tokenizer),
+ history=history,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ temperature=temperature,
+ top_p=top_p,
+ **kwargs,
+ )
+
+ def consumer():
+ producer = threading.Thread(target=stream_producer)
+ producer.start()
+ while True:
+ res = response_queue.get()
+ if res is None:
+ return
+ yield res
+
+ return consumer()
+
+# Modified from transformers.model.llama.modeling_llama.LlamaForCausalLM
+class InternLM2ForRewardModel(InternLM2PreTrainedModel):
+
+ _auto_class = "AutoModel"
+ _tied_weights_keys = ["v_head.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = InternLM2Model(config)
+ self.vocab_size = config.vocab_size
+ self.v_head = nn.Linear(config.hidden_size, 1, bias=False)
+ self.reward_token_id = config.reward_token_id
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.model.tok_embeddings = value
+
+ def get_output_embeddings(self):
+ return self.v_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.v_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=SequenceClassifierOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, InternLM2ForCausalLM
+
+ >>> model = InternLM2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ hidden_states = self.v_head(hidden_states)
+ # get end reward token's score
+ ends = attention_mask.cumsum(dim=1).argmax(dim=1).view(-1,1)
+
+ reward_scores = torch.gather(hidden_states.squeeze(-1), 1, ends)
+
+ loss = None
+
+ if not return_dict:
+ output = (reward_scores,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=reward_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ @torch.no_grad()
+ def get_score(
+ self,
+ tokenizer,
+ conversation: List[dict],
+ **kwargs,
+ ):
+ conversation_str = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=False)
+ input_ids = tokenizer.encode(conversation_str, return_tensors="pt", add_special_tokens=False)
+ # add reward score token at the end of the input_ids
+ input_ids = torch.cat([input_ids, torch.tensor([[self.reward_token_id]], dtype=torch.long)], dim=1).to(self.device)
+ attention_mask = torch.ones_like(input_ids, dtype=torch.bool).to(self.device)
+
+ outputs = self.forward(input_ids=input_ids, attention_mask=attention_mask, **kwargs)
+ score = outputs[0].cpu().item()
+ return score
+
+ @torch.no_grad()
+ def get_scores(
+ self,
+ tokenizer,
+ conversations: List[List[dict]],
+ **kwargs,
+ ):
+ conversation_strs = [tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=False) for conversation in conversations]
+ batch_input_ids = []
+ attention_masks = []
+
+ for conversation_str in conversation_strs:
+ input_ids = tokenizer.encode(conversation_str, return_tensors="pt", add_special_tokens=False)
+ input_ids = torch.cat([input_ids, torch.tensor([[self.reward_token_id]], dtype=torch.long)], dim=1).squeeze(0)
+ attention_mask = torch.ones(input_ids.shape, dtype=torch.bool)
+ batch_input_ids.append(input_ids)
+ attention_masks.append(attention_mask)
+
+ r_pad_batch_input_ids = torch.nn.utils.rnn.pad_sequence(batch_input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
+ r_pad_attention_masks = torch.nn.utils.rnn.pad_sequence(attention_masks, batch_first=True, padding_value=False)
+
+ outputs = self.forward(input_ids=r_pad_batch_input_ids.to(self.device), attention_mask=r_pad_attention_masks.to(self.device), **kwargs)
+ scores = outputs[0].cpu().tolist()
+ return scores
+
+ @torch.no_grad()
+ def compare(
+ self,
+ tokenizer,
+ conversation1: List[dict],
+ conversation2: List[dict],
+ return_logits: bool = False,
+ **kwargs,
+ ):
+ score1 = self.get_score(tokenizer, conversation1, **kwargs)
+ score2 = self.get_score(tokenizer, conversation2, **kwargs)
+ if return_logits:
+ return score1, score2
+ else:
+ return score1 > score2
+
+ @torch.no_grad()
+ def rank(
+ self,
+ tokenizer,
+ conversations: List[List[dict]],
+ return_logits: bool = False,
+ **kwargs,
+ ):
+ scores = self.get_scores(tokenizer, conversations, **kwargs)
+ if return_logits:
+ return scores
+ else:
+ return sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaForSequenceClassification with Llama->InternLM2
+@add_start_docstrings(
+ """
+ The InternLM2 Model transformer with a sequence classification head on top (linear layer).
+
+ [`InternLM2ForSequenceClassification`] uses the last token in order to do the classification,
+ as other causal models (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ InternLM2_START_DOCSTRING,
+)
+class InternLM2ForSequenceClassification(InternLM2PreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = InternLM2Model(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.model.tok_embeddings = value
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1).to(
+ logits.device
+ )
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/tools/model_converters/pth_to_hf.py b/data/xtuner/xtuner/tools/model_converters/pth_to_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a4b28883281960a1cbda7193c0144e5b41d2e74
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/pth_to_hf.py
@@ -0,0 +1,142 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import shutil
+import warnings
+
+from accelerate import init_empty_weights
+from accelerate.utils import set_module_tensor_to_device
+from mmengine import print_log
+from mmengine.config import Config, DictAction
+from mmengine.fileio import PetrelBackend, get_file_backend
+from mmengine.utils import mkdir_or_exist
+from tqdm import tqdm
+
+from xtuner.configs import cfgs_name_path
+from xtuner.model.utils import guess_load_checkpoint
+from xtuner.registry import BUILDER
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert the pth model to HuggingFace model')
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('pth_model', help='pth model file')
+ parser.add_argument(
+ 'save_dir', help='the directory to save HuggingFace model')
+ parser.add_argument(
+ '--fp32',
+ action='store_true',
+ help='Save LLM in fp32. If not set, fp16 will be used by default.')
+ parser.add_argument(
+ '--max-shard-size',
+ type=str,
+ default='2GB',
+ help='Only applicable for LLM. The maximum size for '
+ 'each sharded checkpoint.')
+ parser.add_argument(
+ '--safe-serialization',
+ action='store_true',
+ help='Indicate if using `safe_serialization`')
+ parser.add_argument(
+ '--save-format',
+ default='xtuner',
+ choices=('xtuner', 'official', 'huggingface'),
+ help='Only applicable for LLaVAModel. Indicate the save format.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # parse config
+ if not osp.isfile(args.config):
+ try:
+ args.config = cfgs_name_path[args.config]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.config}')
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ model_name = cfg.model.type if isinstance(cfg.model.type,
+ str) else cfg.model.type.__name__
+ use_meta_init = True
+
+ if 'LLaVAModel' in model_name:
+ cfg.model.pretrained_pth = None
+ if args.save_format != 'xtuner':
+ use_meta_init = False
+ if 'Reward' in model_name:
+ use_meta_init = False
+ cfg.model.llm.pop('quantization_config', None)
+ if hasattr(cfg.model.llm, 'quantization_config'):
+ # Can not build a qlora model on meta device
+ use_meta_init = False
+
+ if use_meta_init:
+ try:
+ # Initializing the model with meta-tensor can reduce unwanted
+ # memory usage.
+ with init_empty_weights():
+ with warnings.catch_warnings():
+ warnings.filterwarnings(
+ 'ignore', message='.*non-meta.*', category=UserWarning)
+ model = BUILDER.build(cfg.model)
+ except NotImplementedError as e:
+ # Cannot initialize the model with meta tensor if the model is
+ # quantized.
+ if 'Cannot copy out of meta tensor' in str(e):
+ model = BUILDER.build(cfg.model)
+ else:
+ raise e
+ else:
+ model = BUILDER.build(cfg.model)
+
+ backend = get_file_backend(args.pth_model)
+ if isinstance(backend, PetrelBackend):
+ from xtuner.utils.fileio import patch_fileio
+ with patch_fileio():
+ state_dict = guess_load_checkpoint(args.pth_model)
+ else:
+ state_dict = guess_load_checkpoint(args.pth_model)
+
+ for name, param in tqdm(state_dict.items(), desc='Load State Dict'):
+ set_module_tensor_to_device(model, name, 'cpu', param)
+
+ model.llm.config.use_cache = True
+
+ print_log(f'Load PTH model from {args.pth_model}', 'current')
+
+ mkdir_or_exist(args.save_dir)
+
+ save_pretrained_kwargs = {
+ 'max_shard_size': args.max_shard_size,
+ 'safe_serialization': args.safe_serialization
+ }
+ model.to_hf(
+ cfg=cfg,
+ save_dir=args.save_dir,
+ fp32=args.fp32,
+ save_pretrained_kwargs=save_pretrained_kwargs,
+ save_format=args.save_format)
+
+ shutil.copyfile(args.config, osp.join(args.save_dir, 'xtuner_config.py'))
+ print_log('All done!', 'current')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/model_converters/split.py b/data/xtuner/xtuner/tools/model_converters/split.py
new file mode 100644
index 0000000000000000000000000000000000000000..da0e4d7b765a135ed8437c68befdb070da4a265a
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/split.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import copy
+import json
+import os
+import os.path as osp
+import shutil
+
+import torch
+from mmengine.utils import mkdir_or_exist
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Split a HuggingFace model to the smallest sharded one')
+ parser.add_argument('src_dir', help='the directory of the model')
+ parser.add_argument('dst_dir', help='the directory to save the new model')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ mkdir_or_exist(args.dst_dir)
+
+ all_files = os.listdir(args.src_dir)
+ for name in all_files:
+ if not name.startswith(('pytorch_model', '.')):
+ src_path = osp.join(args.src_dir, name)
+ dst_path = osp.join(args.dst_dir, name)
+ shutil.copy(src_path, dst_path)
+
+ with open(osp.join(args.src_dir, 'pytorch_model.bin.index.json')) as f:
+ index = json.load(f)
+
+ n_shard = len(index['weight_map'])
+ new_index = copy.deepcopy(index)
+ new_index['weight_map'] = {}
+ cnt = 1
+
+ checkpoints = set(index['weight_map'].values())
+ for ckpt in checkpoints:
+ state_dict = torch.load(
+ osp.join(args.src_dir, ckpt), map_location='cuda')
+ keys = sorted(list(state_dict.keys()))
+ for k in keys:
+ new_state_dict_name = 'pytorch_model-{:05d}-of-{:05d}.bin'.format(
+ cnt, n_shard)
+ new_index['weight_map'][k] = new_state_dict_name
+ new_state_dict = {k: state_dict[k]}
+ torch.save(new_state_dict,
+ osp.join(args.dst_dir, new_state_dict_name))
+ cnt += 1
+ del state_dict
+ torch.cuda.empty_cache()
+ with open(osp.join(args.dst_dir, 'pytorch_model.bin.index.json'),
+ 'w') as f:
+ json.dump(new_index, f)
+ assert new_index['weight_map'].keys() == index['weight_map'].keys(
+ ), 'Mismatch on `weight_map`!'
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/plugins/__init__.py b/data/xtuner/xtuner/tools/plugins/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b893bcac8976bed61f0526d57f22a118b6c6b848
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .api import plugins_api
+
+__all__ = ['plugins_api']
diff --git a/data/xtuner/xtuner/tools/plugins/api.py b/data/xtuner/xtuner/tools/plugins/api.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ac6579d6152564e4c7e5d885e06b39b8a03c65f
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/api.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+
+
+def plugins_api(input_str,
+ calculate_open=True,
+ solve_open=True,
+ search_open=True):
+
+ pattern = r'(Solve|solve|Solver|solver|Calculate|calculate|Calculator|calculator|Search)\("([^"]*)"\)' # noqa: E501
+
+ matches = re.findall(pattern, input_str)
+
+ converted_str = '<|Results|>:\n'
+
+ for i in range(len(matches)):
+ if matches[i][0] in [
+ 'Calculate', 'calculate'
+ 'Calculator', 'calculator'
+ ]:
+ if calculate_open:
+ from .calculate import Calculate
+ result = Calculate(matches[i][1])
+ else:
+ result = None
+ converted_str += f"Calculate(\"{matches[i][1]}\") => {result}\n"
+ elif matches[i][0] in ['Solve', 'solve', 'Solver', 'solver']:
+ if solve_open:
+ from .solve import Solve
+ result = Solve(matches[i][1])
+ else:
+ result = None
+ converted_str += f"Solve(\"{matches[i][1]}\") =>\n{result}\n"
+ elif matches[i][0] == 'Search':
+ if search_open:
+ from .search import Search
+ result = Search(matches[i][1])
+ else:
+ result = None
+ converted_str += f"Search(\"{matches[i][1]}\") =>\n{result}"
+
+ converted_str += '\n'
+ return converted_str
diff --git a/data/xtuner/xtuner/tools/plugins/calculate.py b/data/xtuner/xtuner/tools/plugins/calculate.py
new file mode 100644
index 0000000000000000000000000000000000000000..48ed436cbeddd35de34fbb26d1f6f1e7d85fa810
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/calculate.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from math import * # noqa: F401, F403
+
+
+def Calculate(expression):
+ res = ''
+ for exp in expression.split(';'):
+ try:
+ res += '{:.2f};'.format(eval(exp.replace('^', '**')))
+ except Exception:
+ res += 'No result.'
+ if res[-1] == ';':
+ res = res[:-1]
+ return res
diff --git a/data/xtuner/xtuner/tools/plugins/search.py b/data/xtuner/xtuner/tools/plugins/search.py
new file mode 100644
index 0000000000000000000000000000000000000000..392bc86204fd43a7312bfd3ed13a30aef9fc4f42
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/search.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import sys
+
+import requests
+
+try:
+ SERPER_API_KEY = os.environ['SERPER_API_KEY']
+except Exception:
+ print('Please obtain the `SERPER_API_KEY` from https://serper.dev and '
+ 'set it using `export SERPER_API_KEY=xxx`.')
+ sys.exit(1)
+
+
+def parse_results(results, k=10):
+ snippets = []
+
+ for result in results['organic'][:k]:
+ if 'snippet' in result:
+ snippets.append(result['snippet'])
+ for attribute, value in result.get('attributes', {}).items():
+ snippets.append(f'{attribute}: {value}.')
+ return snippets
+
+
+def search(api_key, search_term, **kwargs):
+ headers = {
+ 'X-API-KEY': api_key,
+ 'Content-Type': 'application/json',
+ }
+ params = {
+ 'q': search_term,
+ **{key: value
+ for key, value in kwargs.items() if value is not None},
+ }
+ try:
+ response = requests.post(
+ 'https://google.serper.dev/search',
+ headers=headers,
+ params=params,
+ timeout=5)
+ except Exception as e:
+ return -1, str(e)
+ return response.status_code, response.json()
+
+
+def Search(q, k=10):
+ status_code, response = search(SERPER_API_KEY, q)
+ if status_code != 200:
+ ret = 'None\n'
+ else:
+ text = parse_results(response, k=k)
+ ret = ''
+ for idx, res in enumerate(text):
+ ret += f"<|{idx+1}|>: '{res}'\n"
+ return ret
diff --git a/data/xtuner/xtuner/tools/plugins/solve.py b/data/xtuner/xtuner/tools/plugins/solve.py
new file mode 100644
index 0000000000000000000000000000000000000000..20266a23f492cc5e7264d1a46398d64c94267579
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/solve.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import re
+from math import * # noqa: F401, F403
+
+from sympy import Eq, solve, symbols
+
+from .calculate import Calculate
+
+
+def Solve(equations_str):
+ try:
+ equations_str = equations_str.replace(' ', '')
+ equations_ori = re.split(r'[,;]+', equations_str)
+ equations_str = equations_str.replace('^', '**')
+ equations_str = re.sub(r'(\(.*\))([a-zA-Z])', r'\1 * \2',
+ equations_str)
+ equations_str = re.sub(r'(\d+)([a-zA-Z])', r'\1 * \2', equations_str)
+ equations_str = equations_str.replace('pi', str(math.pi))
+ equations = re.split(r'[,;]+', equations_str)
+ vars_list = list(set(re.findall(r'[a-zA-Z]+', equations_str)))
+ vars = {var: symbols(var) for var in vars_list}
+
+ output = ''
+ eqs = []
+ for eq in equations:
+ if '=' in eq:
+ left, right = eq.split('=')
+ eqs.append(
+ Eq(
+ eval(left.strip(), {}, vars),
+ eval(right.strip(), {}, vars)))
+ solutions = solve(eqs, vars, dict=True)
+
+ vars_values = {var: [] for var in vars_list}
+ if isinstance(solutions, list):
+ for idx, solution in enumerate(solutions):
+ for var, sol in solution.items():
+ output += f'{var}_{idx} = {sol}\n'
+ vars_values[str(var)].append(sol)
+ else:
+ for var, sol in solutions.items():
+ output += f'{var} = {sol}\n'
+ vars_values[str(var)].append(sol)
+ for eq, eq_o in zip(equations, equations_ori):
+ if '=' not in eq:
+ for var in vars_list:
+ need_note = True if len(vars_values[var]) > 1 else False
+ for idx, value in enumerate(vars_values[var]):
+ eq_to_calc = eq.replace(var, str(value))
+ calc_result = Calculate(eq_to_calc)
+ if need_note:
+ eq_name = eq_o.replace(var, f'{var}_{idx}')
+ else:
+ eq_name = eq_o
+ if calc_result != 'No results.':
+ output += f'{eq_name} = {calc_result}\n'
+
+ return output.strip()
+ except Exception:
+ return 'No result.'
diff --git a/data/xtuner/xtuner/tools/process_untokenized_datasets.py b/data/xtuner/xtuner/tools/process_untokenized_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..c41905ee6daaebca1f9e546b5588c6d627baea39
--- /dev/null
+++ b/data/xtuner/xtuner/tools/process_untokenized_datasets.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import warnings
+
+from mmengine import Config, ConfigDict
+from mmengine.config.lazy import LazyObject
+
+from xtuner.registry import BUILDER
+
+# ignore FutureWarning in hf datasets
+warnings.simplefilter(action='ignore', category=FutureWarning)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ args = parser.parse_args()
+ return args
+
+
+def modify_config(config, dataset_save_folder):
+ dataset = ConfigDict(
+ type=LazyObject('datasets', 'load_from_disk'),
+ dataset_path=dataset_save_folder)
+ train_dataset = ConfigDict(
+ type=LazyObject('xtuner.dataset', 'process_hf_dataset'),
+ dataset=dataset,
+ do_dataset_tokenization=False,
+ tokenizer=None,
+ max_length=None,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ max_dataset_length=None,
+ split=None,
+ remove_unused_columns=False,
+ rename_maps=[],
+ pack_to_max_length=False,
+ input_ids_with_output=False)
+ config.train_dataloader.dataset = train_dataset
+ return config
+
+
+def process_untokenized_dataset(config):
+ dataset = BUILDER.build(config.train_dataloader.dataset)
+ return dataset
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+
+ print('Start to process untokenized dataset...')
+ processed_dataset = process_untokenized_dataset(cfg)
+ print('Processing untokenized dataset finished.')
+
+ processed_dataset_save_folder = args.save_folder
+ if not os.path.isabs(processed_dataset_save_folder):
+ processed_dataset_save_folder = os.path.join(
+ os.getcwd(), processed_dataset_save_folder)
+ modified_cfg = modify_config(cfg, processed_dataset_save_folder)
+
+ print('Start to save processed dataset...')
+ processed_dataset.save_to_disk(processed_dataset_save_folder)
+ print(
+ f'Processed dataset has been saved to {processed_dataset_save_folder}')
+
+ cfg_folder, cfg_file_name = os.path.split(args.config)
+ cfg_file_name = cfg_file_name.split('.')[0]
+ cfg_file_name = f'{cfg_file_name}_modified.py'
+ modified_cfg_save_path = os.path.join(cfg_folder, cfg_file_name)
+ modified_cfg.dump(modified_cfg_save_path)
+ print(f'Modified config has been saved to {modified_cfg_save_path}. '
+ 'Please use this new config for the next training phase.')
diff --git a/data/xtuner/xtuner/tools/process_untokenized_datasets_legacy.py b/data/xtuner/xtuner/tools/process_untokenized_datasets_legacy.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b4dd5a7de93e2966b2bb3d9c579a2e4669db034
--- /dev/null
+++ b/data/xtuner/xtuner/tools/process_untokenized_datasets_legacy.py
@@ -0,0 +1,184 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import ast
+import multiprocessing
+import os
+import warnings
+from functools import partial
+
+from datasets import Dataset, DatasetDict, load_dataset
+from mmengine import ConfigDict
+from transformers import AutoTokenizer
+
+from xtuner.dataset.huggingface import process
+from xtuner.dataset.map_fns import (DATASET_FORMAT_MAPPING,
+ template_map_fn_factory)
+from xtuner.utils import PROMPT_TEMPLATE
+
+# ignore FutureWarning in hf datasets
+warnings.simplefilter(action='ignore', category=FutureWarning)
+"""
+ftdp dataset:
+srun -p llm_razor --quotatype=auto --gres=gpu:1 --ntasks=1 \
+ --ntasks-per-node=1 --cpus-per-task=5 --kill-on-bad-exit=1 \
+ python xtuner/tools/process_untokenized_datasets.py \
+ --data-folder /path/to/data/folder \
+ --save-folder ./processed \
+ --tokenizer-path pretrained_model_name_or_path \
+ --prompt-template internlm2_chat \
+ --dataset-format ftdp
+
+normal json dataset:
+srun -p llm_razor --quotatype=auto --gres=gpu:1 --ntasks=1 \
+ --ntasks-per-node=1 --cpus-per-task=5 --kill-on-bad-exit=1 \
+ python xtuner/tools/process_untokenized_datasets.py \
+ --data-folder /path/to/data/folder \
+ --save-folder ./processed \
+ --tokenizer-path pretrained_model_name_or_path \
+ --prompt-template internlm2_chat
+"""
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data-folder', help='Data folder')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ parser.add_argument(
+ '--tokenizer-path', help='The path to the hf tokenizer.')
+ parser.add_argument(
+ '--dataset-format',
+ choices=list(DATASET_FORMAT_MAPPING.keys()) + ['ftdp'],
+ default=None,
+ help='Which dataset format is this data. The available choices are '
+ f"{list(DATASET_FORMAT_MAPPING.keys()) + ['ftdp']}. ")
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ help='Which prompt template need to be added to the dataset. '
+ f'The available choices are {PROMPT_TEMPLATE.keys()}')
+ parser.add_argument(
+ '--max-length', default=32768, help='Max sequence length.')
+ parser.add_argument(
+ '--pack-to-max-length',
+ action='store_true',
+ help='Whether to pack the dataset to the `max_length `.')
+ parser.add_argument(
+ '--file-type',
+ default='.json',
+ help='We want to get the order of the file in this type.')
+ parser.add_argument(
+ '--data-order-path',
+ default=None,
+ help=('The path to a txt file which contains the a list of data path.'
+ ' It can be obtain by xtuner/tools/get_data_order.py script.'))
+ args = parser.parse_args()
+ return args
+
+
+def process_one(fp,
+ tokenizer,
+ max_length,
+ pack_to_max_length,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ is_ftdp=False):
+ dataset = []
+ if is_ftdp:
+ with open(fp) as file:
+ lines = file.readlines()
+ for line in lines:
+ line = ast.literal_eval(line)
+ dataset.append({'messages': line})
+ dataset = Dataset.from_list(dataset)
+ else:
+ # load formal json data
+ dataset = load_dataset('json', data_files=fp)
+ dataset = dataset['train']
+ dataset = process(
+ dataset,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ remove_unused_columns=True,
+ pack_to_max_length=pack_to_max_length,
+ map_num_proc=32)
+ return fp, dataset
+
+
+def process_untokenized_dataset(folder,
+ tokenizer,
+ max_length,
+ pack_to_max_length,
+ dataset_map_fn,
+ prompt_template,
+ data_order_path=None,
+ file_type='.json',
+ is_ftdp=False):
+ assert os.path.exists(folder), f'{folder} does not exist.'
+ datasets_dict = {}
+
+ if data_order_path is not None:
+ data_order = load_dataset(
+ 'text', data_files=data_order_path, split='train')['text']
+ for i, fp in enumerate(data_order):
+ data_order[i] = os.path.join(folder, fp)
+ else:
+ triples = list(os.walk(folder, followlinks=True))
+ data_order = []
+ for root, dirs, files in triples:
+ dirs.sort()
+ for fn in sorted(files):
+ if fn.endswith(file_type):
+ fp = os.path.join(root, fn)
+ data_order.append(fp)
+ print('All file path: ', data_order)
+
+ pool = multiprocessing.Pool(processes=multiprocessing.cpu_count())
+ template_map_fn = ConfigDict(
+ type=template_map_fn_factory, template=prompt_template)
+ process_single = partial(
+ process_one,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ pack_to_max_length=pack_to_max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ is_ftdp=is_ftdp)
+ out = pool.map(process_single, data_order)
+ pool.close()
+ pool.join()
+ for idx, (key, dataset) in enumerate(out):
+ assert data_order[idx] == key
+ dataset = dataset.remove_columns('length')
+ datasets_dict[str(idx)] = dataset
+ datasets_dict = DatasetDict(datasets_dict)
+ return datasets_dict
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ tokenizer = ConfigDict(
+ type=AutoTokenizer.from_pretrained,
+ pretrained_model_name_or_path=args.tokenizer_path,
+ trust_remote_code=True,
+ padding_side='right')
+
+ if args.dataset_format is None:
+ dataset_map_fn = None
+ elif args.dataset_format == 'ftdp':
+ dataset_map_fn = DATASET_FORMAT_MAPPING['openai']
+ else:
+ dataset_map_fn = DATASET_FORMAT_MAPPING[args.dataset_format]
+
+ datasets_dict = process_untokenized_dataset(
+ args.data_folder,
+ tokenizer,
+ args.max_length,
+ args.pack_to_max_length,
+ dataset_map_fn,
+ PROMPT_TEMPLATE[args.prompt_template],
+ data_order_path=args.data_order_path,
+ file_type=args.file_type,
+ is_ftdp=args.dataset_format == 'ftdp')
+ datasets_dict.save_to_disk(args.save_folder)
diff --git a/data/xtuner/xtuner/tools/process_untokenized_llava_data.py b/data/xtuner/xtuner/tools/process_untokenized_llava_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d0c075855734835d3a72a2c98ee7be38b85bfac
--- /dev/null
+++ b/data/xtuner/xtuner/tools/process_untokenized_llava_data.py
@@ -0,0 +1,33 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import warnings
+
+from mmengine import Config
+
+from xtuner.registry import BUILDER
+
+# ignore FutureWarning in hf datasets
+warnings.simplefilter(action='ignore', category=FutureWarning)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ args = parser.parse_args()
+ return args
+
+
+def build_llava_dataset(config):
+ dataset = BUILDER.build(config.train_dataloader.dataset)
+ return dataset
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+
+ llava_dataset = build_llava_dataset(cfg)
+ text_data = llava_dataset.text_data
+
+ text_data.save_to_disk(args.save_folder)
diff --git a/data/xtuner/xtuner/tools/test.py b/data/xtuner/xtuner/tools/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..5eb3f6d9d3099a54f561d8a3910168b0fc0a4fab
--- /dev/null
+++ b/data/xtuner/xtuner/tools/test.py
@@ -0,0 +1,107 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+from types import FunctionType
+
+from mmengine.config import Config, DictAction
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+
+from xtuner.configs import cfgs_name_path
+from xtuner.model.utils import guess_load_checkpoint
+from xtuner.registry import MAP_FUNC
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Test model')
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--checkpoint', default=None, help='checkpoint file')
+ parser.add_argument(
+ '--work-dir',
+ help='the directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def register_function(cfg_dict):
+ if isinstance(cfg_dict, dict):
+ for key, value in dict.items(cfg_dict):
+ if isinstance(value, FunctionType):
+ value_str = str(value)
+ if value_str not in MAP_FUNC:
+ MAP_FUNC.register_module(module=value, name=value_str)
+ cfg_dict[key] = value_str
+ else:
+ register_function(value)
+ elif isinstance(cfg_dict, (list, tuple)):
+ for value in cfg_dict:
+ register_function(value)
+
+
+def main():
+ args = parse_args()
+
+ # parse config
+ if not osp.isfile(args.config):
+ try:
+ args.config = cfgs_name_path[args.config]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.config}')
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # register FunctionType object in cfg to `MAP_FUNC` Registry and
+ # change these FunctionType object to str
+ register_function(cfg._cfg_dict)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ state_dict = guess_load_checkpoint(args.checkpoint)
+ runner.model.load_state_dict(state_dict, strict=False)
+ runner.logger.info(f'Load checkpoint from {args.checkpoint}')
+
+ # start testing
+ runner.test()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/tokenize_ftdp_datasets.py b/data/xtuner/xtuner/tools/tokenize_ftdp_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..9327a91fef9f79c48d4c3e933e7f039e0a11f191
--- /dev/null
+++ b/data/xtuner/xtuner/tools/tokenize_ftdp_datasets.py
@@ -0,0 +1,433 @@
+import argparse
+import json
+import os
+import os.path as osp
+from functools import partial
+from pathlib import Path
+from typing import Dict, List
+
+import numpy as np
+from mmengine import list_dir_or_file, track_progress_rich
+from transformers import AutoTokenizer
+
+SEPCIAL_TOKENS = [
+ '<|plugin|>', '<|interpreter|>', '<|action_end|>', '<|action_start|>',
+ '<|im_end|>', '<|im_start|>'
+]
+
+CHATML_LLAMAV13_32K_TOKEN_CFG = dict(
+ role_cfg=dict(
+ system=dict(
+ begin=dict(
+ with_name='<|im_start|>system name={name}\n',
+ without_name='<|im_start|>system\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|im_end|>\n',
+ loss=dict(
+ meta=False,
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ user=dict(
+ begin=dict(
+ with_name='<|im_start|>user name={name}\n',
+ without_name='<|im_start|>user\n',
+ ),
+ end='<|im_end|>\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ assistant=dict(
+ begin=dict(
+ with_name='<|im_start|>assistant name={name}\n',
+ without_name='<|im_start|>assistant\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|im_end|>\n',
+ loss=dict(
+ icl=True,
+ current=True,
+ prefix=False,
+ end=True,
+ )),
+ environment=dict(
+ begin=dict(
+ with_name='<|im_start|>environment name={name}\n',
+ without_name='<|im_start|>environment\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|im_end|>\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ tool=dict(
+ begin=dict(
+ with_name='<|action_start|>{name}\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|action_end|>\n',
+ belong='assistant',
+ ),
+ thought=dict(
+ begin=dict(without_name=''),
+ end='',
+ belong='assistant',
+ ),
+ ),
+ max_len=32 * 1024,
+)
+
+
+def chatml_format(
+ processed_data,
+ tokenizer,
+ role_cfg,
+ max_len=2048,
+ encode_json=True,
+):
+ """
+ ```python
+ dict(
+ role='',
+ content='',
+ name='', -> Begin 扩增
+ type='',
+ )
+ ```
+ ```python
+ dict(
+ system=dict(
+ begin=dict(
+ with_name='system name={name}\n',
+ without_name='system\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ loss=dict(
+ meta=False,
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ user=dict(
+ begin=dict(
+ with_name='user name={name}\n',
+ without_name='user\n',
+ ),
+ end='\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ assistant=dict(
+ begin=dict(
+ with_name='assistant name={name}\n',
+ without_name='assistant\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ loss=dict(
+ icl=True,
+ current=True,
+ prefix=False,
+ end=True,
+ )),
+ environment=dict(
+ begin=dict(
+ with_name='environment name={name}\n',
+ without_name='environment\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ tool=dict(
+ begin=dict(
+ with_name='{name}\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ belong='assistant',
+ ),
+ thought=dict(
+ begin='',
+ end='',
+ belong='assistant',
+ ),
+ ```
+ """
+
+ def format_begin(role_cfg, message):
+ name = message.get('name', None)
+ if name is not None:
+ begin = role_cfg['begin'].get('with_name', '')
+ if name in role_cfg['begin'].get('name', {}):
+ begin = begin.format(name=role_cfg['begin']['name'][name])
+ else:
+ begin = begin.format(name=name)
+ else:
+ begin = role_cfg['begin'].get('without_name', '')
+ return begin
+
+ def format_sub_role(messages: List[Dict], roles_cfg) -> List[Dict]:
+ new_message = list()
+ for message in messages:
+ if message['role'] in [
+ 'assistant', 'user', 'system', 'environment'
+ ]:
+ new_message.append(message)
+ continue
+ role_cfg = roles_cfg[message['role']]
+ begin = format_begin(role_cfg, message)
+ new_content = begin + message['content'] + role_cfg['end']
+ if role_cfg.get('fallback_role'):
+ new_message.append(
+ dict(role=role_cfg['fallback_role'], content=new_content))
+ elif role_cfg.get('belong'):
+ if new_message[-1]['role'] != role_cfg.get('belong'):
+ new_message.append(
+ dict(role=role_cfg.get('belong'), content=new_content))
+ else:
+ new_message[-1]['content'] += new_content
+ else:
+ new_message.append(
+ dict(role=message['role'], content=new_content))
+
+ return new_message
+
+ token_ids = []
+ _processed_data = format_sub_role(processed_data, role_cfg)
+
+ for dialog_item in _processed_data:
+ role = dialog_item['role']
+ content = dialog_item['content']
+ # TODO: is strip necessary? or use lstrip? 避免开始有\n\n的情况
+ # content = content.lstrip()
+ begin = format_begin(role_cfg[role], dialog_item)
+ end = role_cfg[role]['end']
+ begin_token = tokenizer.encode(begin, add_special_tokens=False)
+ if not role_cfg[role]['loss'].get('beigin', False):
+ begin_token = [-token_id for token_id in begin_token]
+ end_token = tokenizer.encode(
+ role_cfg[role]['end'], add_special_tokens=False)
+ # breakpoint()
+ if not role_cfg[role]['loss'].get('end', False):
+ end_token = [-token_id for token_id in end_token]
+
+ content_token = tokenizer.encode(
+ begin + content + end, add_special_tokens=False)
+ content_token = content_token[len(begin_token):-len(end_token)]
+
+ if dialog_item.get('loss', True):
+ loss_cfg = role_cfg[role]['loss']
+ else:
+ loss_cfg = dict(icl=False, current=False, meta=False)
+ if not loss_cfg[dialog_item.get('type', 'current')]:
+ content_token = [-token_id for token_id in content_token]
+
+ if begin == '':
+ tokens = content_token
+ else:
+ tokens = begin_token + content_token
+ if end != '':
+ tokens = tokens + end_token
+
+ token_ids += tokens
+
+ token_ids = [tokenizer.bos_token_id] + token_ids
+ token_ids = token_ids[:max_len]
+ if encode_json:
+ line = str.encode(json.dumps({'tokens': token_ids}) + '\n')
+ return line, len(token_ids)
+ return token_ids, len(token_ids)
+
+
+def write_bin_meta_bin(path, dataset_name, filename, samples):
+ train_path = osp.join(path, f'train/cn/{dataset_name}')
+ valid_path = osp.join(path, f'valid/cn/{dataset_name}')
+ train_dir = Path(train_path)
+ valid_dir = Path(valid_path)
+ train_dir.mkdir(exist_ok=True, parents=True)
+ valid_dir.mkdir(exist_ok=True, parents=True)
+ train_f = open(train_dir.joinpath(f'{filename}.bin'), 'wb')
+ valid_f_path = valid_dir.joinpath(f'{filename}.bin')
+ valid_f = open(valid_f_path, 'wb')
+ print(train_dir)
+ print(valid_dir)
+ train_tokens = 0
+ valid_tokens = 0
+ last_train_position = 0
+ last_valid_position = 0
+ train_samples = 0
+ valid_samples = 0
+ train_meta = []
+ valid_meta = []
+ for line, token_num in samples:
+ train_tokens += token_num
+ train_f.write(line)
+ train_meta.append((last_train_position, token_num))
+ last_train_position += len(line)
+ train_samples += 1
+ if (train_samples) % 100 == 0: # ?
+ valid_tokens += token_num
+ valid_f.write(line)
+ valid_meta.append((last_valid_position, token_num))
+ last_valid_position += len(line)
+ valid_samples += 1
+ train_f.close()
+ valid_f.close()
+ np.save(open(train_dir.joinpath(f'{filename}.bin.meta'), 'wb'), train_meta)
+
+ # remove the length of `valid_samples` is less than 500
+ # 500 is a magic number, you can change it to any number you want
+ # the number must bigger the DP.
+ if valid_samples > 500:
+ np.save(
+ open(valid_dir.joinpath(f'{filename}.bin.meta'), 'wb'), valid_meta)
+ else:
+ print(f'{valid_f_path} is removed because the number of',
+ f'`valid_samples`({valid_samples}) is less than 500')
+ os.remove(valid_f_path)
+ return train_tokens, valid_tokens, train_samples, valid_samples
+
+
+def tokenize_and_save(tokenizer, processed_dir, tokenized_dir):
+ tokenized_save_dir = osp.join(tokenized_dir, 'chatml_llamav13_32k')
+ data_dir = processed_dir
+ all_train_tokens = 0
+ all_valid_tokens = 0
+ all_train_samples = 0
+ all_valid_samples = 0
+
+ for filename in list_dir_or_file(data_dir, recursive=True, list_dir=False):
+ file_path = os.path.join(data_dir, filename)
+ if '/processed/' not in file_path:
+ continue
+ assert '.jsonl' in filename
+
+ # dataset name such as char_x10_chat_format
+ dataset_name = filename.split(os.sep)[0]
+
+ # Hardcode here to skip tokenizing the file if it already exists
+ # (Refactor the `write_bin_meta_bin`!).
+ train_f = osp.join(tokenized_save_dir, 'train', 'cn', dataset_name,
+ f'{osp.splitext(osp.basename(filename))[0]}.bin')
+ if osp.isfile(train_f):
+ print(f'{train_f} already exists, skip it')
+ continue
+
+ tokenize_fun = partial(
+ chatml_format,
+ tokenizer=tokenizer,
+ **CHATML_LLAMAV13_32K_TOKEN_CFG)
+ samples = []
+ with open(file_path) as f:
+ dataset = f.readlines()
+ task_num = len(dataset)
+ dataset = map(lambda x: (json.loads(x), ), dataset)
+
+ for sample in track_progress_rich(
+ tokenize_fun,
+ dataset,
+ nproc=32,
+ task_num=task_num,
+ chunksize=32,
+ description=f'{os.path.basename(file_path)}...'):
+ samples.append(sample)
+
+ train_tokens, valid_tokens, train_samples, valid_samples = write_bin_meta_bin( # noqa E501
+ path=tokenized_save_dir,
+ dataset_name=dataset_name,
+ samples=samples,
+ filename=osp.splitext(osp.basename(filename))[0])
+ if train_tokens is None:
+ print(f'{osp.splitext(osp.basename(filename))[0]} already '
+ 'exists, skip it')
+ continue
+
+ print(f'train_tokens {train_tokens}', flush=True)
+ print(f'train_samples {train_samples}')
+ print(f'valid tokens {valid_tokens}')
+ print(f'valid_samples {valid_samples}')
+ all_train_tokens += train_tokens
+ all_valid_tokens += valid_tokens
+ all_train_samples += train_samples
+ all_valid_samples += valid_samples
+
+ print(f'all train tokens {all_train_tokens}')
+ print(f'all train samples {all_train_samples}')
+ print(f'all valid tokens {all_valid_tokens}')
+ print(f'all valid samples {all_valid_samples}')
+
+
+def tokenizer_add_special_tokens(tokenizer):
+ print(f'Before adding special tokens, Vocabulary Size: {len(tokenizer)}')
+ for special_token in SEPCIAL_TOKENS:
+ if special_token not in tokenizer.get_vocab():
+ tokenizer.add_tokens([special_token], special_tokens=True)
+ print(f'After adding special tokens, Vocabulary Size: {len(tokenizer)}')
+
+
+def save_new_tokenizer(tokenizer, save_dir):
+ tokenizer.save_pretrained(save_dir)
+ print(f'save new tokenizer to {save_dir}')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--processed-dir', help='The folder to save untokenized data.')
+ parser.add_argument(
+ '--tokenized-dir', help='The folder to save tokenized data.')
+ parser.add_argument(
+ '--tokenizer-path', help='The path to the hf tokenizer.')
+ parser.add_argument(
+ '--tokenizer-w-special-tokens-save-dir',
+ default=None,
+ help='We have to add special tokens to the vocabulary of '
+ 'the given tokenizer, and save the new tokenizer to this folder.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_path, trust_remote_code=True, padding_side='right')
+
+ ori_vocab_size = len(tokenizer)
+ tokenizer_add_special_tokens(tokenizer)
+ if len(tokenizer) != ori_vocab_size:
+ save_new_tokenizer(tokenizer, args.tokenizer_w_special_tokens_save_dir)
+
+ tokenize_and_save(tokenizer, args.processed_dir, args.tokenized_dir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/train.py b/data/xtuner/xtuner/tools/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..29b5d539577e50c60ff2d88b3acf5c7160890e36
--- /dev/null
+++ b/data/xtuner/xtuner/tools/train.py
@@ -0,0 +1,364 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import logging
+import os
+import os.path as osp
+from functools import partial
+from types import FunctionType
+
+from mmengine.config import Config, DictAction
+from mmengine.config.lazy import LazyObject
+from mmengine.logging import print_log
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+from mmengine.utils import digit_version
+from peft import get_peft_model, prepare_model_for_kbit_training
+from transformers import TrainingArguments
+
+from xtuner.configs import cfgs_name_path
+from xtuner.dataset.collate_fns import default_collate_fn
+from xtuner.model.modules import dispatch_modules
+from xtuner.model.modules.dispatch import SUPPORT_FLASH2
+from xtuner.model.utils import LoadWoInit, find_all_linear_names, traverse_dict
+from xtuner.registry import BUILDER, MAP_FUNC
+from xtuner.tools.utils import (auto_dtype_of_deepspeed_config,
+ get_seed_from_checkpoint, set_model_resource)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train LLM')
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--work-dir', help='the dir to save logs and models')
+ parser.add_argument(
+ '--deepspeed',
+ type=str,
+ default=None,
+ help='the path to the .json file for deepspeed')
+ parser.add_argument(
+ '--resume',
+ type=str,
+ default=None,
+ help='specify checkpoint path to be resumed from.')
+ parser.add_argument(
+ '--seed', type=int, default=None, help='Random seed for the training')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ return args
+
+
+def register_function(cfg_dict):
+ if isinstance(cfg_dict, dict):
+ for key, value in dict.items(cfg_dict):
+ if isinstance(value, FunctionType):
+ value_str = str(value)
+ if value_str not in MAP_FUNC:
+ MAP_FUNC.register_module(module=value, name=value_str)
+ cfg_dict[key] = value_str
+ else:
+ register_function(value)
+ elif isinstance(cfg_dict, (list, tuple)):
+ for value in cfg_dict:
+ register_function(value)
+
+
+def check_cfg(cfg, args):
+ if getattr(cfg, 'use_varlen_attn',
+ False) and cfg.train_dataloader.batch_size > 1:
+ raise NotImplementedError(
+ f'If utilizing varlen attention, the batch size should be'
+ f' set to 1, but got {cfg.train_dataloader.batch_size}')
+
+ if getattr(cfg, 'use_varlen_attn', False):
+ sequence_parallel = getattr(cfg, 'sequence_parallel', 1)
+ max_length = getattr(cfg.train_dataloader.dataset, 'max_length', None)
+ if max_length is not None:
+ assert max_length % sequence_parallel == 0, \
+ ('When using varlen attention, `max_length` should be evenly '
+ 'divided by sequence parallel world size, but got '
+ f'max_length = {max_length} and sequence_parallel = '
+ f'{sequence_parallel}')
+
+ if getattr(cfg, 'sequence_parallel_size', 1) > 1:
+ assert SUPPORT_FLASH2, ('`flash_attn` is required if you want to use '
+ 'sequence parallel.')
+ attn_implementation = getattr(cfg.model.llm, 'attn_implementation',
+ None)
+ assert (attn_implementation is None or
+ attn_implementation == 'flash_attention_2'), \
+ ('If you want to use sequence parallel, please set '
+ 'attn_implementation to `flash_attention_2` or do not '
+ f'set this attribute. Got `{attn_implementation}` .')
+
+ if getattr(cfg, 'use_varlen_attn', False):
+ assert SUPPORT_FLASH2, ('`flash_attn` is required if you set '
+ '`use_varlen_attn` to True.')
+ attn_implementation = getattr(cfg.model.llm, 'attn_implementation',
+ None)
+ assert (attn_implementation is None or
+ attn_implementation == 'flash_attention_2'), \
+ ('If you want to set `use_varlen_attn` to True, please set'
+ ' attn_implementation to `flash_attention_2` or do not '
+ f'set this attribute. Got `{attn_implementation}` .')
+
+ if args.deepspeed is None:
+ assert getattr(cfg, 'sequence_parallel_size', 1) == 1, \
+ ('Sequence parallel training without DeepSpeed lacks validation.'
+ 'Please use DeepSpeed to optimize the training phase by '
+ '`--deepspeed deepspeed_zero1 (deepspeed_zero2 or '
+ 'deepspeed_zero3)`.')
+
+
+
+
+
+def main():
+ args = parse_args()
+
+ # parse config
+ if not osp.isfile(args.config):
+ try:
+ args.config = cfgs_name_path[args.config]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.config}')
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ set_model_resource(cfg)
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # register FunctionType object in cfg to `MAP_FUNC` Registry and
+ # change these FunctionType object to str
+ register_function(cfg._cfg_dict)
+
+ check_cfg(cfg, args)
+
+ if cfg.get('framework', 'mmengine').lower() == 'huggingface':
+ # set default training_args
+ if cfg.get('training_args', None) is None:
+ cfg.training_args = dict(type=TrainingArguments)
+ if args.seed is not None:
+ cfg.training_args.seed = args.seed
+ # set work_dir
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.training_args.output_dir = args.work_dir
+ elif cfg.training_args.get('output_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.training_args.output_dir = osp.join(
+ './work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ # enable deepspeed
+ if args.deepspeed:
+ if not osp.isfile(args.deepspeed):
+ try:
+ args.deepspeed = cfgs_name_path[args.deepspeed]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.deepspeed}')
+ cfg.training_args.deepspeed = args.deepspeed
+ if cfg.training_args.get('deepspeed'):
+ device_map = None
+ else:
+ # Data Parallel
+ device_map = {
+ '': int(os.environ.get('LOCAL_RANK', args.local_rank))
+ }
+ # build training_args
+ training_args = BUILDER.build(cfg.training_args)
+ # build model
+ with LoadWoInit():
+ cfg.model.device_map = device_map
+ traverse_dict(cfg.model)
+ model = BUILDER.build(cfg.model)
+ model.config.use_cache = False
+ dispatch_modules(model)
+ if cfg.get('lora', None):
+ lora = BUILDER.build(cfg.lora)
+ model = prepare_model_for_kbit_training(model)
+ if lora.target_modules is None:
+ modules = find_all_linear_names(model)
+ lora.target_modules = modules
+ model = get_peft_model(model, lora)
+
+ # build dataset
+ train_dataset = BUILDER.build(cfg.train_dataset)
+ data_collator = partial(default_collate_fn, return_hf_format=True)
+ # build trainer
+ trainer = cfg.trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset,
+ data_collator=data_collator)
+ # training
+ trainer.train(resume_from_checkpoint=args.resume)
+ trainer.save_state()
+ trainer.save_model(output_dir=training_args.output_dir)
+ else:
+ if args.seed is not None and args.resume is None:
+ # Use args.seed
+ cfg.merge_from_dict(dict(randomness=dict(seed=args.seed)))
+ print_log(
+ f'Set the random seed to {args.seed}.',
+ logger='current',
+ level=logging.INFO)
+ elif args.resume is not None:
+ # Use resumed seed
+ from mmengine.fileio import PetrelBackend, get_file_backend
+
+ from xtuner.utils.fileio import patch_fileio
+ backend = get_file_backend(args.resume)
+ if isinstance(backend, PetrelBackend):
+ with patch_fileio():
+ resumed_seed = get_seed_from_checkpoint(args.resume)
+ else:
+ resumed_seed = get_seed_from_checkpoint(args.resume)
+ cfg.merge_from_dict(dict(randomness=dict(seed=resumed_seed)))
+ if args.seed is not None and args.seed != resumed_seed:
+ print_log(
+ (f'The value of random seed in resume checkpoint '
+ f'"{args.resume}" is different from the value in '
+ f'arguments. The resumed seed is {resumed_seed}, while '
+ f'the input argument seed is {args.seed}. Using the '
+ f'resumed seed {resumed_seed}.'),
+ logger='current',
+ level=logging.WARNING)
+ else:
+ print_log(
+ f'Set the random seed to {resumed_seed}.',
+ logger='current',
+ level=logging.INFO)
+
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ cfg.launcher = args.launcher
+ # work_dir is determined in this priority:
+ # CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ if args.deepspeed:
+ try:
+ import deepspeed
+ except ImportError:
+ raise ImportError(
+ 'deepspeed is not installed properly, please check.')
+ if digit_version(deepspeed.__version__) < digit_version('0.12.3'):
+ raise RuntimeError('Please upgrade your DeepSpeed version '
+ 'by using the command pip install '
+ '`deepspeed>=0.12.3`')
+ optim_wrapper = cfg.optim_wrapper.type
+ if optim_wrapper == 'DeepSpeedOptimWrapper':
+ print_log(
+ 'Deepspeed training is already enabled in your config.',
+ logger='current',
+ level=logging.WARNING)
+ else:
+ if not osp.isfile(args.deepspeed):
+ try:
+ args.deepspeed = cfgs_name_path[args.deepspeed]
+ except KeyError:
+ raise FileNotFoundError(
+ f'Cannot find {args.deepspeed}')
+ with open(args.deepspeed) as f:
+ ds_cfg = json.load(f)
+
+ ds_grad_accum = ds_cfg.get('gradient_accumulation_steps',
+ 'auto')
+ mm_grad_accum = cfg.optim_wrapper.get('accumulative_counts', 1)
+ if ds_grad_accum != 'auto' and ds_grad_accum != mm_grad_accum:
+ print_log(('Mismatch on gradient_accumulation_steps: '
+ f'MMEngine {mm_grad_accum}, '
+ f'Deepspeed {ds_grad_accum}. '
+ f'Set to {mm_grad_accum}'),
+ logger='current',
+ level=logging.WARNING)
+ grad_accum = mm_grad_accum
+
+ ds_train_bs = ds_cfg.get('train_micro_batch_size_per_gpu',
+ 'auto')
+ mm_train_bs = cfg.train_dataloader.batch_size
+ if ds_train_bs != 'auto' and ds_train_bs != mm_train_bs:
+ print_log(
+ ('Mismatch on train_micro_batch_size_per_gpu: '
+ f'MMEngine {mm_train_bs}, Deepspeed {ds_train_bs}. '
+ f'Set to {mm_train_bs}'),
+ logger='current',
+ level=logging.WARNING)
+ train_bs = cfg.train_dataloader.batch_size
+
+ ds_grad_clip = ds_cfg.get('gradient_clipping', 'auto')
+ clip_grad = cfg.optim_wrapper.get('clip_grad', None)
+ if clip_grad and clip_grad.get('max_norm', None) is not None:
+ mm_max_norm = cfg.optim_wrapper.clip_grad.max_norm
+ else:
+ mm_max_norm = 1.0
+ if ds_grad_clip != 'auto' and ds_grad_clip != mm_max_norm:
+ print_log(
+ ('Mismatch on gradient_clipping: '
+ f'MMEngine {mm_max_norm}, Deepspeed {ds_grad_clip}. '
+ f'Set to {mm_max_norm}'),
+ logger='current',
+ level=logging.WARNING)
+ grad_clip = mm_max_norm
+ ds_cfg = auto_dtype_of_deepspeed_config(ds_cfg)
+ exclude_frozen_parameters = True if digit_version(
+ deepspeed.__version__) >= digit_version('0.10.1') else None
+ strategy = dict(
+ type=LazyObject('xtuner.engine', 'DeepSpeedStrategy'),
+ config=ds_cfg,
+ gradient_accumulation_steps=grad_accum,
+ train_micro_batch_size_per_gpu=train_bs,
+ gradient_clipping=grad_clip,
+ exclude_frozen_parameters=exclude_frozen_parameters,
+ sequence_parallel_size=getattr(cfg,
+ 'sequence_parallel_size',
+ 1))
+ cfg.__setitem__('strategy', strategy)
+ optim_wrapper = dict(
+ type='DeepSpeedOptimWrapper',
+ optimizer=cfg.optim_wrapper.optimizer)
+ cfg.__setitem__('optim_wrapper', optim_wrapper)
+ cfg.runner_type = 'FlexibleRunner'
+
+ # resume is determined in this priority: resume from > auto_resume
+ if args.resume is not None:
+ cfg.resume = True
+ cfg.load_from = args.resume
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # start training
+ runner.train()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/utils.py b/data/xtuner/xtuner/tools/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f08cc6317a3ce3b1d72af1e405ec9a610696357
--- /dev/null
+++ b/data/xtuner/xtuner/tools/utils.py
@@ -0,0 +1,193 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import re
+import warnings
+
+import torch
+from transformers import PreTrainedTokenizerFast, StoppingCriteriaList
+from transformers.generation.streamers import BaseStreamer
+
+from xtuner.utils import StopWordStoppingCriteria
+
+
+def get_base_model(model):
+ if hasattr(model, 'llm'):
+ model = model.llm
+ if 'PeftModel' in model.__class__.__name__:
+ model = model.base_model.model
+ return model
+
+
+def get_streamer(model):
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ ('`get_streamer` is deprecated and will be removed in v0.3.0, '
+ "use `transformers`'s `TextStreamer` instead."), DeprecationWarning)
+ if model.__class__.__name__ == 'InferenceEngine':
+ model = model.module
+ base_model = get_base_model(model)
+ base_model_name = base_model.__class__.__name__.lower()
+ is_internlm = 'internlm' in base_model_name
+ is_qwen = 'qwen' in base_model_name
+ is_baichuan = 'baichuan' in base_model_name
+ is_chatglm = 'chatglm' in base_model_name
+ no_space = is_internlm or is_qwen or is_baichuan or is_chatglm
+ if no_space:
+ return NoSpaceStreamer
+ else:
+ return DecodeOutputStreamer
+
+def set_model_resource(cfg):
+ if cfg.get("model_resource"):
+ fn = cfg["model_resource"].get("fn")
+ args = cfg["model_resource"].get("args", {})
+ local_path = fn(cfg["pretrained_model_name_or_path"], **args)
+ s = [(cfg._cfg_dict, k, v) for k, v in cfg._cfg_dict.items()]
+ while s:
+ current_d, current_k, current_v = s.pop()
+ if current_k == "pretrained_model_name_or_path":
+ current_d[current_k] = local_path
+
+ if isinstance(current_v, dict):
+ s.extend([(current_v, k, v) for k, v in current_v.items()])
+ elif isinstance(current_v, list):
+ for i in current_v:
+ if isinstance(i, dict):
+ s.extend((i, k, v) for k, v in i.items())
+
+
+class DecodeOutputStreamer(BaseStreamer):
+ """Default streamer for HuggingFace models."""
+
+ def __init__(self, tokenizer, skip_prompt=True) -> None:
+ super().__init__()
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ '`DecodeOutputStreamer` is deprecated and will be '
+ 'removed in v0.3.0.', DeprecationWarning)
+ self.tokenizer = tokenizer
+ self.skip_prompt = skip_prompt
+ self.gen_len = 0
+ if isinstance(tokenizer, PreTrainedTokenizerFast):
+ self.decode = self._decode_with_raw_id
+ self.hex_regex = re.compile(r'^<0x([0-9ABCDEF]+)>$')
+ else:
+ self.decode = self._decode_fallback
+
+ def _decode_with_raw_id(self, value):
+ """Convert token ids to tokens and decode."""
+
+ tok = self.tokenizer._convert_id_to_token(value)
+ if tok.startswith('▁'): # sentencepiece
+ space = ' '
+ tok = tok[1:]
+ else:
+ space = ''
+ if res := self.hex_regex.match(tok):
+ tok = chr(int(res.group(1), 16))
+ if tok == '':
+ tok = '\n'
+ return space + tok
+
+ def _decode_fallback(self, value):
+ """Fallback decoder for non-fast tokenizer."""
+
+ tok = self.tokenizer.decode(
+ value,
+ skip_special_tokens=False,
+ clean_up_tokenization_spaces=False)
+ return tok + ' '
+
+ def put(self, value):
+ """Callback function to decode token and output to stdout."""
+
+ if self.gen_len == 0 and self.skip_prompt:
+ pass
+ else:
+ tok = self.decode(value[0])
+ print(tok, end='', flush=True)
+
+ self.gen_len += 1
+
+ def end(self):
+ """Callback function to finish generation."""
+
+ print('\n')
+
+
+class NoSpaceStreamer(DecodeOutputStreamer):
+
+ def __init__(self, tokenizer, skip_prompt=True) -> None:
+ BaseStreamer().__init__()
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ '`NoSpaceStreamer` is deprecated and will be '
+ 'removed in v0.3.0.', DeprecationWarning)
+ self.tokenizer = tokenizer
+ self.skip_prompt = skip_prompt
+ self.gen_len = 0
+ self.hex_regex = re.compile(r'^<0x([0-9ABCDEF]+)>$')
+
+ def decode(self, value):
+ tok = self.tokenizer.decode(value)
+ if res := self.hex_regex.match(tok):
+ tok = chr(int(res.group(1), 16))
+ if tok == '' or tok == '\r':
+ tok = '\n'
+
+ return tok
+
+
+def get_stop_criteria(
+ tokenizer,
+ stop_words=[],
+):
+ stop_criteria = StoppingCriteriaList()
+ for word in stop_words:
+ stop_criteria.append(StopWordStoppingCriteria(tokenizer, word))
+ return stop_criteria
+
+
+def auto_dtype_of_deepspeed_config(ds_config):
+ if ds_config.get('fp16') and not ds_config.get('bf16'):
+ if ds_config.get('fp16').get('enabled') == 'auto':
+ ds_config['fp16']['enabled'] = torch.cuda.is_available()
+ elif not ds_config.get('fp16') and ds_config.get('bf16'):
+ if ds_config.get('bf16').get('enabled') == 'auto':
+ ds_config['bf16']['enabled'] = torch.cuda.is_bf16_supported()
+ elif ds_config.get('fp16') and ds_config.get('bf16'):
+ if ds_config.get('fp16').get('enabled') == 'auto':
+ ds_config['fp16']['enabled'] = torch.cuda.is_available()
+ if ds_config.get('bf16').get('enabled') == 'auto':
+ ds_config['bf16']['enabled'] = torch.cuda.is_bf16_supported()
+ if (ds_config['fp16']['enabled'] is True
+ and ds_config['bf16']['enabled'] is True):
+ ds_config['fp16']['enabled'] = False
+ ds_config['bf16']['enabled'] = True
+ return ds_config
+
+
+def is_cn_string(s):
+ if re.search('[\u4e00-\u9fff]', s):
+ return True
+ return False
+
+
+def get_seed_from_checkpoint(pth_model):
+ if osp.isfile(pth_model):
+ checkpoint = torch.load(pth_model, map_location='cpu')
+ elif osp.isdir(pth_model):
+ try:
+ from deepspeed.utils.zero_to_fp32 import get_model_state_files
+ except ImportError:
+ raise ImportError(
+ 'The provided PTH model appears to be a DeepSpeed checkpoint. '
+ 'However, DeepSpeed library is not detected in current '
+ 'environment. This suggests that DeepSpeed may not be '
+ 'installed or is incorrectly configured. Please verify your '
+ 'setup.')
+ filename = get_model_state_files(pth_model)[0]
+ checkpoint = torch.load(filename, map_location='cpu')
+ else:
+ raise FileNotFoundError(f'Cannot find {pth_model}')
+ return checkpoint['meta']['seed']
diff --git a/data/xtuner/xtuner/utils/__init__.py b/data/xtuner/xtuner/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6663b32253528a8d02b61e1dec07326116ba6130
--- /dev/null
+++ b/data/xtuner/xtuner/utils/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .constants import (DEFAULT_IMAGE_TOKEN, DEFAULT_PAD_TOKEN_INDEX,
+ IGNORE_INDEX, IMAGE_TOKEN_INDEX)
+from .handle_moe_load_and_save import (SUPPORT_MODELS, get_origin_state_dict,
+ load_state_dict_into_model)
+from .stop_criteria import StopWordStoppingCriteria
+from .templates import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
+
+__all__ = [
+ 'IGNORE_INDEX', 'DEFAULT_PAD_TOKEN_INDEX', 'PROMPT_TEMPLATE',
+ 'DEFAULT_IMAGE_TOKEN', 'SYSTEM_TEMPLATE', 'StopWordStoppingCriteria',
+ 'IMAGE_TOKEN_INDEX', 'load_state_dict_into_model', 'get_origin_state_dict',
+ 'SUPPORT_MODELS'
+]
diff --git a/data/xtuner/xtuner/utils/constants.py b/data/xtuner/xtuner/utils/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..2862c8ab50bb3f811795f5b8aea0d991505d6a41
--- /dev/null
+++ b/data/xtuner/xtuner/utils/constants.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+IGNORE_INDEX = -100
+DEFAULT_PAD_TOKEN_INDEX = 0
+IMAGE_TOKEN_INDEX = -200
+DEFAULT_IMAGE_TOKEN = ''
diff --git a/data/xtuner/xtuner/utils/fileio.py b/data/xtuner/xtuner/utils/fileio.py
new file mode 100644
index 0000000000000000000000000000000000000000..922146e584313f35b5cdcd76b3908ed0e4f7ce11
--- /dev/null
+++ b/data/xtuner/xtuner/utils/fileio.py
@@ -0,0 +1,345 @@
+import io
+from contextlib import contextmanager
+
+import mmengine.fileio as fileio
+from mmengine.fileio import LocalBackend, PetrelBackend, get_file_backend
+
+
+def patch_func(module, fn_name_to_wrap):
+ backup = getattr(patch_func, '_backup', [])
+ fn_to_wrap = getattr(module, fn_name_to_wrap)
+
+ def wrap(fn_new):
+ setattr(module, fn_name_to_wrap, fn_new)
+ backup.append((module, fn_name_to_wrap, fn_to_wrap))
+ setattr(fn_new, '_fallback', fn_to_wrap)
+ setattr(patch_func, '_backup', backup)
+ return fn_new
+
+ return wrap
+
+
+@contextmanager
+def patch_fileio(global_vars=None):
+ if getattr(patch_fileio, '_patched', False):
+ # Only patch once, avoid error caused by patch nestly.
+ yield
+ return
+ import builtins
+
+ @patch_func(builtins, 'open')
+ def open(file, mode='r', *args, **kwargs):
+ backend = get_file_backend(file)
+ if isinstance(backend, LocalBackend):
+ return open._fallback(file, mode, *args, **kwargs)
+ if 'b' in mode:
+ return io.BytesIO(backend.get(file, *args, **kwargs))
+ else:
+ return io.StringIO(backend.get_text(file, *args, **kwargs))
+
+ if global_vars is not None and 'open' in global_vars:
+ bak_open = global_vars['open']
+ global_vars['open'] = builtins.open
+
+ import os
+
+ @patch_func(os.path, 'join')
+ def join(a, *paths):
+ backend = get_file_backend(
+ a.decode('utf-8') if isinstance(a, bytes) else a)
+ if isinstance(backend, LocalBackend):
+ return join._fallback(a, *paths)
+ paths = [item.lstrip('./') for item in paths if len(item) > 0]
+ return backend.join_path(a, *paths)
+
+ @patch_func(os.path, 'isdir')
+ def isdir(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return isdir._fallback(path)
+
+ return backend.isdir(path)
+
+ @patch_func(os.path, 'isfile')
+ def isfile(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return isfile._fallback(path)
+
+ return backend.isfile(path)
+
+ @patch_func(os.path, 'exists')
+ def exists(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return exists._fallback(path)
+ return backend.exists(path)
+
+ @patch_func(os, 'mkdir')
+ def mkdir(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return mkdir._fallback(path, *args, **kwargs)
+
+ @patch_func(os, 'makedirs')
+ def makedirs(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return makedirs._fallback(path, *args, **kwargs)
+
+ @patch_func(os, 'listdir')
+ def listdir(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return listdir._fallback(path)
+ return backend.list_dir_or_file(path)
+
+ @patch_func(os, 'chmod')
+ def chmod(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return chmod._fallback(path, *args, **kwargs)
+
+ @patch_func(os, 'stat')
+ def stat(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return stat._fallback(path, *args, **kwargs)
+
+ import glob as glob_pkg
+
+ @patch_func(glob_pkg, 'glob')
+ def glob(pathname, *, recursive=False):
+ backend = get_file_backend(pathname)
+ if isinstance(backend, LocalBackend):
+ return glob._fallback(pathname, recursive=recursive)
+
+ if pathname.endswith('*_optim_states.pt'):
+ import os
+ pathname = os.path.split(pathname)[0]
+ files = backend.list_dir_or_file(pathname, recursive=recursive)
+ files = [
+ os.path.join(pathname, f) for f in files
+ if f.endswith('_optim_states.pt')
+ ]
+ elif pathname.endswith('*_model_states.pt'):
+ import os
+ pathname = os.path.split(pathname)[0]
+ files = backend.list_dir_or_file(pathname, recursive=recursive)
+ files = [
+ os.path.join(pathname, f) for f in files
+ if f.endswith('_model_states.pt')
+ ]
+ elif '*' in pathname:
+ raise NotImplementedError
+ else:
+ files = backend.list_dir_or_file(pathname, recursive=recursive)
+
+ return files
+
+ import filecmp
+
+ @patch_func(filecmp, 'cmp')
+ def cmp(f1, f2, *args, **kwargs):
+ with fileio.get_local_path(f1) as f1, fileio.get_local_path(f2) as f2:
+ return cmp._fallback(f1, f2, *args, **kwargs)
+
+ import shutil
+
+ @patch_func(shutil, 'copy')
+ def copy(src, dst, **kwargs):
+ from pathlib import Path
+
+ if isinstance(src, Path):
+ src = str(src).replace(':/', '://')
+ if isinstance(dst, Path):
+ dst = str(dst).replace(':/', '://')
+
+ src_backend = get_file_backend(src)
+ dst_backend = get_file_backend(dst)
+
+ if isinstance(src_backend, LocalBackend) and isinstance(
+ dst_backend, LocalBackend):
+ return copy._fallback(src, dst, **kwargs)
+ elif isinstance(src_backend, LocalBackend) and isinstance(
+ dst_backend, PetrelBackend):
+ return dst_backend.copyfile_from_local(str(src), str(dst))
+ elif isinstance(src_backend, PetrelBackend) and isinstance(
+ dst_backend, LocalBackend):
+ return src_backend.copyfile_to_local(str(src), str(dst))
+
+ import torch
+
+ @patch_func(torch, 'load')
+ def load(f, *args, **kwargs):
+ if isinstance(f, str):
+ f = io.BytesIO(fileio.get(f))
+ return load._fallback(f, *args, **kwargs)
+
+ @patch_func(torch, 'save')
+ def save(obj, f, *args, **kwargs):
+ backend = get_file_backend(f)
+ if isinstance(backend, LocalBackend):
+ return save._fallback(obj, f, *args, **kwargs)
+
+ with io.BytesIO() as buffer:
+ save._fallback(obj, buffer, *args, **kwargs)
+ buffer.seek(0)
+ backend.put(buffer, f)
+
+ # from tempfile import TemporaryDirectory
+ # import os
+ # with TemporaryDirectory(dir='/dev/shm') as tmpdir:
+ # suffix = os.path.split(f)[-1]
+ # tmppath = os.path.join._fallback(tmpdir, suffix)
+ # from mmengine import print_log
+ # print_log('write to tmp dir', logger='current')
+ # save._fallback(obj, tmppath, *args, **kwargs)
+ # print_log('write to ceph', logger='current')
+
+ # with open(tmppath, 'rb') as buffer:
+ # backend.put(buffer, f)
+
+ from sentencepiece import SentencePieceProcessor
+
+ @patch_func(SentencePieceProcessor, 'LoadFromFile')
+ def LoadFromFile(cls, path):
+ if path:
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return LoadFromFile._fallback(cls, path)
+ from tempfile import TemporaryDirectory
+ with TemporaryDirectory() as tmpdir:
+ local_path = backend.copyfile_to_local(path, tmpdir)
+ loaded_file = LoadFromFile._fallback(cls, local_path)
+ return loaded_file
+ else:
+ return LoadFromFile._fallback(cls, path)
+
+ try:
+ setattr(patch_fileio, '_patched', True)
+ yield
+ finally:
+ for patched_fn in patch_func._backup:
+ (module, fn_name_to_wrap, fn_to_wrap) = patched_fn
+ setattr(module, fn_name_to_wrap, fn_to_wrap)
+ if global_vars is not None and 'open' in global_vars:
+ global_vars['open'] = bak_open
+ setattr(patch_fileio, '_patched', False)
+
+
+def patch_hf_auto_from_pretrained(petrel_hub):
+ if hasattr(patch_hf_auto_from_pretrained, '_patched'):
+ return
+
+ from peft import PeftModel
+ from transformers import (AutoConfig, AutoFeatureExtractor,
+ AutoImageProcessor, AutoModelForCausalLM,
+ AutoProcessor, AutoTokenizer,
+ ImageProcessingMixin, PreTrainedModel,
+ PreTrainedTokenizerBase, ProcessorMixin)
+ from transformers.models.auto.auto_factory import _BaseAutoModelClass
+
+ target_cls = list(_BaseAutoModelClass.__subclasses__())
+ target_cls.extend([AutoModelForCausalLM] +
+ AutoModelForCausalLM.__subclasses__())
+ target_cls.extend([AutoConfig] + AutoConfig.__subclasses__())
+ target_cls.extend([AutoTokenizer] + AutoTokenizer.__subclasses__())
+ target_cls.extend([AutoImageProcessor] +
+ AutoImageProcessor.__subclasses__())
+ target_cls.extend([AutoFeatureExtractor] +
+ AutoFeatureExtractor.__subclasses__())
+ target_cls.extend([AutoProcessor] + AutoProcessor.__subclasses__())
+ target_cls.extend([PreTrainedTokenizerBase] +
+ PreTrainedTokenizerBase.__subclasses__())
+ target_cls.extend([ImageProcessingMixin] +
+ ImageProcessingMixin.__subclasses__())
+ target_cls.extend([PreTrainedModel] + PreTrainedModel.__subclasses__())
+ target_cls.extend([ProcessorMixin] + ProcessorMixin.__subclasses__())
+ target_cls.extend([PeftModel] + PeftModel.__subclasses__())
+
+ import os
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs):
+ with patch_fileio():
+ model_path = pretrained_model_name_or_path
+ model_path = os.path.join(petrel_hub, model_path)
+ obj = cls._from_pretrained(model_path, *args, **kwargs)
+ return obj
+
+ for cls in set(target_cls):
+ if not hasattr(cls, '_from_pretrained'):
+ cls._from_pretrained = cls.from_pretrained
+ cls.from_pretrained = from_pretrained
+
+ patch_hf_auto_from_pretrained._patched = True
+
+
+def patch_hf_save_pretrained():
+ if hasattr(patch_hf_save_pretrained, '_patched'):
+ return
+
+ import torch
+ from peft import PeftModel
+ from transformers import (AutoConfig, AutoTokenizer, PreTrainedModel,
+ PreTrainedTokenizerBase)
+ from transformers.models.auto.auto_factory import _BaseAutoModelClass
+
+ target_cls = []
+ target_cls.extend([AutoConfig] + AutoConfig.__subclasses__())
+ target_cls.extend([AutoTokenizer] + AutoTokenizer.__subclasses__())
+ target_cls.extend([PreTrainedTokenizerBase] +
+ PreTrainedTokenizerBase.__subclasses__())
+ target_cls.extend([PreTrainedModel] + PreTrainedModel.__subclasses__())
+
+ target_cls.extend([_BaseAutoModelClass] +
+ _BaseAutoModelClass.__subclasses__())
+ target_cls.extend([PeftModel] + PeftModel.__subclasses__())
+
+ def _patch_wrap(method):
+
+ def wrapped_method(self, *args, **kwargs):
+
+ with patch_fileio():
+ kwargs['save_function'] = torch.save
+ kwargs['safe_serialization'] = False
+
+ obj = method(self, *args, **kwargs)
+ return obj
+
+ return wrapped_method
+
+ for cls in set(target_cls):
+ if hasattr(cls, 'save_pretrained'):
+ cls.save_pretrained = _patch_wrap(cls.save_pretrained)
+
+ patch_hf_save_pretrained._patched = True
+
+
+def patch_deepspeed_engine():
+ if hasattr(patch_deepspeed_engine, '_patched'):
+ return
+
+ def _copy_recovery_script(self, save_path):
+ import os
+ from shutil import copyfile
+
+ from deepspeed.utils import zero_to_fp32
+ from mmengine import PetrelBackend, get_file_backend
+ script = 'zero_to_fp32.py'
+
+ src = zero_to_fp32.__file__
+ dst = os.path.join(save_path, script)
+
+ backend = get_file_backend(save_path)
+ if isinstance(backend, PetrelBackend):
+ backend.copyfile_from_local(src, dst)
+ else:
+ copyfile(src, dst)
+ self._change_recovery_script_permissions(dst)
+
+ from deepspeed.runtime.engine import DeepSpeedEngine
+ DeepSpeedEngine._copy_recovery_script = _copy_recovery_script
+
+ patch_deepspeed_engine._patched = True
diff --git a/data/xtuner/xtuner/utils/handle_moe_load_and_save.py b/data/xtuner/xtuner/utils/handle_moe_load_and_save.py
new file mode 100644
index 0000000000000000000000000000000000000000..88a3936a84b8de7311e3a00d7e0661a2a3265736
--- /dev/null
+++ b/data/xtuner/xtuner/utils/handle_moe_load_and_save.py
@@ -0,0 +1,232 @@
+import json
+import os
+import re
+from collections import OrderedDict
+
+import deepspeed
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from mmengine import print_log
+from transformers.integrations import is_deepspeed_zero3_enabled
+from transformers.modeling_utils import load_state_dict
+from transformers.utils import (SAFE_WEIGHTS_INDEX_NAME, WEIGHTS_INDEX_NAME,
+ is_safetensors_available)
+
+SUPPORT_MODELS = (
+ 'DeepseekV2ForCausalLM',
+ 'MixtralForCausalLM',
+)
+
+ORDER_MAPPING = dict(
+ DeepseekV2ForCausalLM=dict(down_proj=0, gate_proj=1, up_proj=2),
+ MixtralForCausalLM=dict(down_proj=1, gate_proj=0, up_proj=2),
+)
+
+PARAM_NAME_MAPPING = dict(
+ DeepseekV2ForCausalLM=dict(
+ gate_proj='gate_proj', up_proj='up_proj', down_proj='down_proj'),
+ MixtralForCausalLM=dict(gate_proj='w1', up_proj='w3', down_proj='w2'),
+)
+
+
+def print_on_rank0(info):
+ if dist.get_rank() == 0:
+ print_log(info, 'current')
+
+
+def get_expert_num_per_shard(model):
+ for module in model.modules():
+ if hasattr(module, 'expert_in_one_shard'):
+ return module.expert_in_one_shard
+
+
+def mix_sort(expert_name):
+ components = re.findall(r'(\D+|\d+)', expert_name)
+ out = [int(comp) if comp.isdigit() else comp for comp in components]
+ return tuple(out)
+
+
+def _get_merged_param_name(origin_param_name, expert_num_per_shard):
+ split_name = origin_param_name.split('.experts.')
+ expert_idx = re.findall(r'\d+', split_name[1])[0]
+ expert_idx = int(expert_idx)
+ assert expert_idx % expert_num_per_shard == 0
+ shard_idx = expert_idx // expert_num_per_shard
+ w1w3 = split_name[0] + f'.experts.{shard_idx}.w1w3'
+ w2 = split_name[0] + f'.experts.{shard_idx}.w2'
+ return w1w3, w2
+
+
+def _merge_experts_weight(state_dict, expert_num_per_shard, order_mapping):
+ experts_name = [key for key in state_dict.keys() if '.experts.' in key]
+ experts_name = sorted(experts_name, key=mix_sort)
+ linear_num_per_expert = 3
+ linear_num_per_shard = expert_num_per_shard * linear_num_per_expert
+ expert_shard_num = len(experts_name) // linear_num_per_shard
+ for shard_idx in range(expert_shard_num):
+ begin, end = shard_idx * linear_num_per_shard, (
+ shard_idx + 1) * linear_num_per_shard
+ experts_name_cur = experts_name[begin:end]
+
+ down_proj_weight = [
+ state_dict.pop(key)
+ for key in experts_name_cur[order_mapping['down_proj']::3]
+ ]
+ gate_proj_weight = [
+ state_dict.pop(key)
+ for key in experts_name_cur[order_mapping['gate_proj']::3]
+ ]
+ up_proj_weight = [
+ state_dict.pop(key)
+ for key in experts_name_cur[order_mapping['up_proj']::3]
+ ]
+ w1 = torch.stack(gate_proj_weight)
+ w3 = torch.stack(up_proj_weight)
+ w1w3 = torch.cat([w1, w3], dim=1)
+ assert w1w3.ndim == 3, w1w3.shape
+ w2 = torch.stack(down_proj_weight)
+ assert w2.ndim == 3, w2.shape
+ merged_key_w1w3, merged_key_w2 = _get_merged_param_name(
+ experts_name_cur[0], expert_num_per_shard)
+ print_on_rank0(f'merged key {merged_key_w1w3}')
+ state_dict[merged_key_w1w3] = w1w3
+ print_on_rank0(f'merged key {merged_key_w2}')
+ state_dict[merged_key_w2] = w2
+
+ return
+
+
+def load_state_dict_into_model(model_to_load, pretrained_model_path):
+
+ model_name = type(model_to_load).__name__
+ if model_name not in SUPPORT_MODELS:
+ raise RuntimeError(
+ f'Only models in {SUPPORT_MODELS} may need to load pretrained '
+ f'weights via `load_state_dict_into_model`, but got {model_name}.')
+ order_mapping = ORDER_MAPPING[model_name]
+
+ index_file = os.path.join(pretrained_model_path, WEIGHTS_INDEX_NAME)
+ safe_index_file = os.path.join(pretrained_model_path,
+ SAFE_WEIGHTS_INDEX_NAME)
+ index_present = os.path.isfile(index_file)
+ safe_index_present = os.path.isfile(safe_index_file)
+ assert index_present or (safe_index_present and is_safetensors_available())
+ if safe_index_present and is_safetensors_available():
+ load_index = safe_index_file
+ else:
+ load_index = index_file
+ with open(load_index, encoding='utf-8') as f:
+ index = json.load(f)
+ weight_map = index['weight_map']
+ unloaded_shard_files = list(set(weight_map.values()))
+ unloaded_shard_files.sort(reverse=True)
+
+ expert_num_per_shard = get_expert_num_per_shard(model_to_load)
+ error_msgs = []
+
+ def load(module: nn.Module, state_dict, unloaded_shard_files, prefix=''):
+ params_to_gather = []
+ param_names = []
+ for name, param in module.named_parameters(
+ prefix=prefix[:-1], recurse=False):
+ while name not in state_dict:
+ assert len(unloaded_shard_files) > 0
+ shard_file = unloaded_shard_files.pop()
+ shard_file = os.path.join(pretrained_model_path, shard_file)
+ print_on_rank0(
+ f'{name} not in state_dict, loading {shard_file}')
+ new_shard = load_state_dict(shard_file, is_quantized=False)
+ state_dict.update(new_shard)
+ _merge_experts_weight(state_dict, expert_num_per_shard,
+ order_mapping)
+ params_to_gather.append(param)
+ param_names.append(name)
+ if len(params_to_gather) > 0:
+ args = (state_dict, prefix, {}, True, [], [], error_msgs)
+ if is_deepspeed_zero3_enabled():
+ with deepspeed.zero.GatheredParameters(
+ params_to_gather, modifier_rank=0):
+ if dist.get_rank() == 0:
+ module._load_from_state_dict(*args)
+ else:
+ module._load_from_state_dict(*args)
+
+ for name in param_names:
+ print_on_rank0(f'state_dict pop {name}')
+ state_dict.pop(name)
+
+ for name, child in module._modules.items():
+ if child is not None:
+ load(child, state_dict, unloaded_shard_files,
+ prefix + name + '.')
+
+ state_dict = OrderedDict()
+ load(model_to_load, state_dict, unloaded_shard_files, prefix='')
+ print_on_rank0(f'{state_dict.keys()}')
+ del state_dict
+
+ return error_msgs
+
+
+def _get_origin_param_name(merged_param_name, expert_num_per_shard, is_w1w3,
+ param_name_mapping):
+ split_name = merged_param_name.split('.experts.')
+ shard_idx = re.findall(r'\d+', split_name[1])[0]
+ shard_idx = int(shard_idx)
+ origin_param_names = [None] * (expert_num_per_shard * (1 + int(is_w1w3)))
+ expert_idx_begin = expert_num_per_shard * shard_idx
+ for i in range(expert_num_per_shard):
+ if is_w1w3:
+ gate_proj, up_proj = param_name_mapping[
+ 'gate_proj'], param_name_mapping['up_proj']
+ gate = split_name[
+ 0] + f'.experts.{expert_idx_begin + i}.{gate_proj}.weight'
+ up = split_name[
+ 0] + f'.experts.{expert_idx_begin + i}.{up_proj}.weight'
+ origin_param_names[i * 2] = gate
+ origin_param_names[i * 2 + 1] = up
+ else:
+ down_proj = param_name_mapping['down_proj']
+ down = split_name[
+ 0] + f'.experts.{expert_idx_begin + i}.{down_proj}.weight'
+ origin_param_names[i] = down
+ return origin_param_names
+
+
+def _split_param(merged_param, is_w1w3):
+ if is_w1w3:
+ expert_num, _, hidden_dim = merged_param.shape
+ merged_param = merged_param.view(expert_num * 2, -1, hidden_dim)
+ return torch.unbind(merged_param, dim=0)
+ else:
+ # (e, hidden_dim, ffn_dim)
+ return torch.unbind(merged_param, dim=0)
+
+
+def get_origin_state_dict(state_dict, model):
+
+ model_name = type(model).__name__
+ if model_name not in SUPPORT_MODELS:
+ raise RuntimeError(
+ f'Only models in {SUPPORT_MODELS} may need to convert state_dict '
+ f'via `get_origin_state_dict` interface, but got {model_name}.')
+ param_name_mapping = PARAM_NAME_MAPPING[model_name]
+
+ expert_num_per_shard = get_expert_num_per_shard(model)
+ experts_param_name = [
+ name for name in state_dict.keys() if '.experts.' in name
+ ]
+ for expert_param_name in experts_param_name:
+ print_on_rank0(f'processing {expert_param_name} ...')
+ is_w1w3 = expert_param_name.split('.')[-1] == 'w1w3'
+ origin_param_names = _get_origin_param_name(expert_param_name,
+ expert_num_per_shard,
+ is_w1w3,
+ param_name_mapping)
+ merged_param = state_dict.pop(expert_param_name)
+ origin_params = _split_param(merged_param, is_w1w3)
+ assert len(origin_param_names) == len(origin_params)
+ for name, param in zip(origin_param_names, origin_params):
+ state_dict[name] = param
+ return state_dict
diff --git a/data/xtuner/xtuner/utils/stop_criteria.py b/data/xtuner/xtuner/utils/stop_criteria.py
new file mode 100644
index 0000000000000000000000000000000000000000..954cc9d700af18f4951eab4fa881cc34d900f365
--- /dev/null
+++ b/data/xtuner/xtuner/utils/stop_criteria.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from transformers import StoppingCriteria
+
+
+class StopWordStoppingCriteria(StoppingCriteria):
+ """StopWord stopping criteria."""
+
+ def __init__(self, tokenizer, stop_word):
+ self.tokenizer = tokenizer
+ self.stop_word = stop_word
+ self.length = len(self.stop_word)
+
+ def __call__(self, input_ids, *args, **kwargs) -> bool:
+ cur_text = self.tokenizer.decode(input_ids[0])
+ cur_text = cur_text.replace('\r', '').replace('\n', '')
+ return cur_text[-self.length:] == self.stop_word
diff --git a/data/xtuner/xtuner/utils/templates.py b/data/xtuner/xtuner/utils/templates.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e5732a3ed3f7ebc08b6940c3f39c850d2f8c61f
--- /dev/null
+++ b/data/xtuner/xtuner/utils/templates.py
@@ -0,0 +1,201 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import ConfigDict
+
+# - Turn 0: SYSTEM + INSTRUCTION, [output + SUFFIX], SEP
+# - Turn 1: INSTRUCTION, [output + SUFFIX], SEP
+# - Turn ...
+# Note: [] means having supervised loss during the fine-tuning
+PROMPT_TEMPLATE = ConfigDict(
+ default=dict(
+ SYSTEM='<|System|>:{system}\n',
+ INSTRUCTION='<|User|>:{input}\n<|Bot|>:',
+ SEP='\n'),
+ zephyr=dict(
+ SYSTEM='<|system|>\n{system}\n',
+ INSTRUCTION='<|user|>\n{input}\n<|assistant|>\n',
+ SEP='\n'),
+ internlm_chat=dict(
+ SYSTEM='<|System|>:{system}\n',
+ INSTRUCTION='<|User|>:{input}\n<|Bot|>:',
+ SUFFIX='',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['']),
+ internlm2_chat=dict(
+ SYSTEM='<|im_start|>system\n{system}<|im_end|>\n',
+ INSTRUCTION=('<|im_start|>user\n{input}<|im_end|>\n'
+ '<|im_start|>assistant\n'),
+ SUFFIX='<|im_end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|im_end|>']),
+ moss_sft=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='<|Human|>: {input}\n',
+ SEP='\n',
+ STOP_WORDS=['', '']),
+ llama2_chat=dict(
+ SYSTEM=(
+ '[INST] <>\n You are a helpful, respectful and honest '
+ 'assistant. Always answer as helpfully as possible, while being '
+ 'safe. Your answers should not include any harmful, unethical, '
+ 'racist, sexist, toxic, dangerous, or illegal content. Please '
+ 'ensure that your responses are socially unbiased and positive in '
+ 'nature.\n{system}\n<>\n [/INST] '),
+ INSTRUCTION='[INST] {input} [/INST]',
+ SEP='\n'),
+ code_llama_chat=dict(
+ SYSTEM='{system}\n', INSTRUCTION='[INST] {input} [/INST]'),
+ chatglm2=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='[Round {round}]\n\n问:{input}\n\n答:',
+ SEP='\n\n'),
+ chatglm3=dict(
+ SYSTEM='<|system|>\n{system}',
+ INSTRUCTION='<|user|>\n{input}<|assistant|>\n',
+ SEP='\n'),
+ qwen_chat=dict(
+ SYSTEM=('<|im_start|>system\n{system}<|im_end|>\n'),
+ INSTRUCTION=('<|im_start|>user\n{input}<|im_end|>\n'
+ '<|im_start|>assistant\n'),
+ SUFFIX='<|im_end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|im_end|>', '<|endoftext|>']),
+ baichuan_chat=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='{input}',
+ SEP='\n'),
+ baichuan2_chat=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='{input}',
+ SEP='\n'),
+ wizardlm=dict(
+ SYSTEM=('A chat between a curious user and an artificial '
+ 'intelligence assistant. The assistant gives '
+ 'helpful, detailed, and polite answers to the '
+ 'user\'s questions. {system}\n '),
+ INSTRUCTION=('USER: {input} ASSISTANT:'),
+ SEP='\n'),
+ wizardcoder=dict(
+ SYSTEM=(
+ 'Below is an instruction that describes a task. '
+ 'Write a response that appropriately completes the request.\n\n'
+ '{system}\n '),
+ INSTRUCTION=('### Instruction:\n{input}\n\n### Response:'),
+ SEP='\n\n'),
+ vicuna=dict(
+ SYSTEM=('A chat between a curious user and an artificial '
+ 'intelligence assistant. The assistant gives '
+ 'helpful, detailed, and polite answers to the '
+ 'user\'s questions. {system}\n '),
+ INSTRUCTION=('USER: {input} ASSISTANT:'),
+ SEP='\n'),
+ deepseek_coder=dict(
+ SYSTEM=('You are an AI programming assistant, utilizing '
+ 'the DeepSeek Coder model, developed by DeepSeek'
+ 'Company, and you only answer questions related '
+ 'to computer science. For politically sensitive '
+ 'questions, security and privacy issues, and '
+ 'other non-computer science questions, you will '
+ 'refuse to answer. {system}\n'),
+ INSTRUCTION=('### Instruction:\n{input}\n### Response:\n'),
+ SEP='\n'),
+ # TODO: deprecation, v0.2.0
+ deepseekcoder=dict(
+ SYSTEM=('You are an AI programming assistant, utilizing '
+ 'the DeepSeek Coder model, developed by DeepSeek'
+ 'Company, and you only answer questions related '
+ 'to computer science. For politically sensitive '
+ 'questions, security and privacy issues, and '
+ 'other non-computer science questions, you will '
+ 'refuse to answer. {system}\n'),
+ INSTRUCTION=('### Instruction:\n{input}\n### Response:\n'),
+ SEP='\n'),
+ deepseek_moe=dict(
+ SYSTEM=('[INST] {system} [/INST]\n'),
+ INSTRUCTION=('[INST] {input} [/INST]'),
+ SEP='\n'),
+ deepseek_v2=dict(
+ SYSTEM='{system}\n\n',
+ INSTRUCTION='User: {input}\n\nAssistant: ',
+ SUFFIX='<|end▁of▁sentence|>',
+ SUFFIX_AS_EOS=True,
+ STOP_WORDS=['<|end▁of▁sentence|>']),
+ mistral=dict(
+ SYSTEM=('[INST] {system} [/INST]\n'),
+ INSTRUCTION=('[INST] {input} [/INST]'),
+ SEP='\n'),
+ mixtral=dict(
+ SYSTEM=('[INST] {system} [/INST]\n'),
+ INSTRUCTION=('[INST] {input} [/INST]'),
+ SEP='\n'),
+ minicpm=dict(INSTRUCTION=('<用户> {input} '), SEP='\n'),
+ minicpm3=dict(
+ SYSTEM=('<|im_start|>system\n{system}<|im_end|>\n'),
+ INSTRUCTION=('<|im_start|>user\n{input}<|im_end|>\n'
+ '<|im_start|>assistant\n'),
+ SUFFIX='<|im_end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|im_end|>', '<|endoftext|>']),
+ gemma=dict(
+ # `system` field is extended by xtuner
+ SYSTEM=('system\n{system}\n'),
+ INSTRUCTION=('user\n{input}\n'
+ 'model\n'),
+ SUFFIX='',
+ SUFFIX_AS_EOS=False,
+ SEP='\n',
+ STOP_WORDS=['']),
+ cohere_chat=dict(
+ SYSTEM=('<|START_OF_TURN_TOKEN|><|SYSTEM_TOKEN|>{system}'
+ '<|END_OF_TURN_TOKEN|>'),
+ INSTRUCTION=(
+ '<|START_OF_TURN_TOKEN|><|USER_TOKEN|>{input}<|END_OF_TURN_TOKEN|>'
+ '<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>'),
+ SUFFIX='<|END_OF_TURN_TOKEN|>',
+ SUFFIX_AS_EOS=True,
+ STOP_WORDS=['<|END_OF_TURN_TOKEN|>']),
+ llama3_chat=dict(
+ SYSTEM=('<|start_header_id|>system<|end_header_id|>\n\n'
+ '{system}<|eot_id|>'),
+ INSTRUCTION=(
+ '<|start_header_id|>user<|end_header_id|>\n\n{input}<|eot_id|>'
+ '<|start_header_id|>assistant<|end_header_id|>\n\n'),
+ SUFFIX='<|eot_id|>',
+ SUFFIX_AS_EOS=True,
+ STOP_WORDS=['<|eot_id|>']),
+ phi3_chat=dict(
+ SYSTEM='<|system|>\n{system}<|end|>\n',
+ INSTRUCTION='<|user|>\n{input}<|end|>\n<|assistant|>\n',
+ SUFFIX='<|end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|end|>']),
+)
+
+SYSTEM_TEMPLATE = ConfigDict(
+ moss_sft=('You are an AI assistant whose name is {bot_name}.\n'
+ 'Capabilities and tools that {bot_name} can possess.\n'
+ '- Inner thoughts: enabled.\n'
+ '- Web search: enabled. API: Search(query)\n'
+ '- Calculator: enabled. API: Calculate(expression)\n'
+ '- Equation solver: enabled. API: Solve(equation)\n'
+ '- Text-to-image: disabled.\n'
+ '- Image edition: disabled.\n'
+ '- Text-to-speech: disabled.\n'),
+ alpaca=('Below is an instruction that describes a task. '
+ 'Write a response that appropriately completes the request.\n'),
+ arxiv_gentile=('If you are an expert in writing papers, please generate '
+ "a good paper title for this paper based on other authors' "
+ 'descriptions of their abstracts.\n'),
+ colorist=('You are a professional color designer. Please provide the '
+ 'corresponding colors based on the description of Human.\n'),
+ coder=('You are a professional programer. Please provide the '
+ 'corresponding code based on the description of Human.\n'),
+ lawyer='你现在是一名专业的中国律师,请根据用户的问题给出准确、有理有据的回复。\n',
+ medical='如果你是一名医生,请根据患者的描述回答医学问题。\n',
+ sql=('If you are an expert in SQL, please generate a good SQL Query '
+ 'for Question based on the CREATE TABLE statement.\n'),
+)
diff --git a/data/xtuner/xtuner/utils/zero_to_any_dtype.py b/data/xtuner/xtuner/utils/zero_to_any_dtype.py
new file mode 100644
index 0000000000000000000000000000000000000000..efe1fc0a12b3acee980a42c378a28b42532de256
--- /dev/null
+++ b/data/xtuner/xtuner/utils/zero_to_any_dtype.py
@@ -0,0 +1,696 @@
+#!/usr/bin/env python
+
+# Copyright (c) Microsoft Corporation.
+# SPDX-License-Identifier: Apache-2.0
+
+# DeepSpeed Team
+
+# This script extracts consolidated weights from a zero 1, 2 and 3 DeepSpeed
+# checkpoints. It gets copied into the top level checkpoint dir, so the user
+# can easily do the conversion at any point in the future. Once extracted, the
+# weights don't require DeepSpeed and can be used in any application.
+#
+# example: python zero_to_any_dtype.py . pytorch_model.bin
+
+import argparse
+import glob
+import math
+import os
+import re
+from collections import OrderedDict
+from dataclasses import dataclass
+
+import torch
+# yapf: disable
+from deepspeed.checkpoint.constants import (BUFFER_NAMES, DS_VERSION,
+ FP32_FLAT_GROUPS,
+ FROZEN_PARAM_FRAGMENTS,
+ FROZEN_PARAM_SHAPES,
+ OPTIMIZER_STATE_DICT, PARAM_SHAPES,
+ PARTITION_COUNT,
+ SINGLE_PARTITION_OF_FP32_GROUPS,
+ ZERO_STAGE)
+# while this script doesn't use deepspeed to recover data, since the
+# checkpoints are pickled with DeepSpeed data structures it has to be
+# available in the current python environment.
+from deepspeed.utils import logger
+from tqdm import tqdm
+
+# yapf: enable
+
+
+@dataclass
+class zero_model_state:
+ buffers: dict()
+ param_shapes: dict()
+ shared_params: list
+ ds_version: int
+ frozen_param_shapes: dict()
+ frozen_param_fragments: dict()
+
+
+debug = 0
+
+# load to cpu
+device = torch.device('cpu')
+
+DEFAULT_DTYPE = torch.float16
+
+
+def atoi(text):
+ return int(text) if text.isdigit() else text
+
+
+def natural_keys(text):
+ """alist.sort(key=natural_keys) sorts in human order
+ http://nedbatchelder.com/blog/200712/human_sorting.html (See Toothy's
+ implementation in the comments)"""
+ return [atoi(c) for c in re.split(r'(\d+)', text)]
+
+
+def get_model_state_file(checkpoint_dir, zero_stage):
+ if not os.path.isdir(checkpoint_dir):
+ raise FileNotFoundError(f"Directory '{checkpoint_dir}' doesn't exist")
+
+ # there should be only one file
+ if zero_stage <= 2:
+ file = os.path.join(checkpoint_dir, 'mp_rank_00_model_states.pt')
+ elif zero_stage == 3:
+ file = os.path.join(checkpoint_dir,
+ 'zero_pp_rank_0_mp_rank_00_model_states.pt')
+
+ if not os.path.exists(file):
+ raise FileNotFoundError(f"can't find model states file at '{file}'")
+
+ return file
+
+
+def get_checkpoint_files(checkpoint_dir, glob_pattern):
+ # XXX: need to test that this simple glob rule works for multi-node
+ # setup too
+ ckpt_files = sorted(
+ glob.glob(os.path.join(checkpoint_dir, glob_pattern)),
+ key=natural_keys)
+
+ if len(ckpt_files) == 0:
+ raise FileNotFoundError(
+ f"can't find {glob_pattern} files in directory '{checkpoint_dir}'")
+
+ return ckpt_files
+
+
+def get_optim_files(checkpoint_dir):
+ return get_checkpoint_files(checkpoint_dir, '*_optim_states.pt')
+
+
+def get_model_state_files(checkpoint_dir):
+ return get_checkpoint_files(checkpoint_dir, '*_model_states.pt')
+
+
+def parse_model_states(files, dtype=DEFAULT_DTYPE):
+ zero_model_states = []
+ for file in files:
+ state_dict = torch.load(file, map_location=device)
+
+ if BUFFER_NAMES not in state_dict:
+ raise ValueError(f'{file} is not a model state checkpoint')
+ buffer_names = state_dict[BUFFER_NAMES]
+ if debug:
+ print('Found buffers:', buffer_names)
+
+ buffers = {
+ k: v.to(dtype)
+ for k, v in state_dict['module'].items() if k in buffer_names
+ }
+ param_shapes = state_dict[PARAM_SHAPES]
+
+ # collect parameters that are included in param_shapes
+ param_names = []
+ for s in param_shapes:
+ for name in s.keys():
+ param_names.append(name)
+
+ # update with frozen parameters
+ frozen_param_shapes = state_dict.get(FROZEN_PARAM_SHAPES, None)
+ if frozen_param_shapes is not None:
+ if debug:
+ print(f'Found frozen_param_shapes: {frozen_param_shapes}')
+ param_names += list(frozen_param_shapes.keys())
+
+ # handle shared params
+ shared_params = [[k, v]
+ for k, v in state_dict['shared_params'].items()]
+
+ ds_version = state_dict.get(DS_VERSION, None)
+
+ frozen_param_fragments = state_dict.get(FROZEN_PARAM_FRAGMENTS, None)
+
+ z_model_state = zero_model_state(
+ buffers=buffers,
+ param_shapes=param_shapes,
+ shared_params=shared_params,
+ ds_version=ds_version,
+ frozen_param_shapes=frozen_param_shapes,
+ frozen_param_fragments=frozen_param_fragments)
+ zero_model_states.append(z_model_state)
+
+ return zero_model_states
+
+
+@torch.no_grad()
+def parse_optim_states(files, ds_checkpoint_dir, dtype=DEFAULT_DTYPE):
+
+ zero_stage = None
+ world_size = None
+ total_files = len(files)
+ flat_groups = []
+ for f in tqdm(files, desc='Load Checkpoints'):
+ state_dict = torch.load(f, map_location=device)
+ if ZERO_STAGE not in state_dict[OPTIMIZER_STATE_DICT]:
+ raise ValueError(f'{f} is not a zero checkpoint')
+
+ zero_stage = state_dict[OPTIMIZER_STATE_DICT][ZERO_STAGE]
+ world_size = state_dict[OPTIMIZER_STATE_DICT][PARTITION_COUNT]
+
+ # the groups are named differently in each stage
+ if zero_stage <= 2:
+ fp32_groups_key = SINGLE_PARTITION_OF_FP32_GROUPS
+ elif zero_stage == 3:
+ fp32_groups_key = FP32_FLAT_GROUPS
+ else:
+ raise ValueError(f'unknown zero stage {zero_stage}')
+
+ # immediately discard the potentially huge 2 optimizer states as we
+ # only care for fp32 master weights and also handle the case where it
+ # was already removed by another helper script
+ state_dict['optimizer_state_dict'].pop('optimizer_state_dict', None)
+ fp32_groups = state_dict['optimizer_state_dict'].pop(fp32_groups_key)
+ if zero_stage <= 2:
+ flat_groups.append([param.to(dtype) for param in fp32_groups])
+ elif zero_stage == 3:
+ # if there is more than one param group, there will be multiple
+ # flattened tensors - one flattened tensor per group - for
+ # simplicity merge them into a single tensor
+
+ # XXX: could make the script more memory efficient for when there
+ # are multiple groups - it will require matching the sub-lists of
+ # param_shapes for each param group flattened tensor
+ flat_groups.append(torch.cat(fp32_groups, 0).to(dtype))
+
+ # For ZeRO-2 each param group can have different partition_count as data
+ # parallelism for expert parameters can be different from data parallelism
+ # for non-expert parameters. So we can just use the max of the
+ # partition_count to get the dp world_size.
+ if type(world_size) is list:
+ world_size = max(world_size)
+
+ if world_size != total_files:
+ raise ValueError(
+ f"Expected {world_size} of '*_optim_states.pt' under "
+ f"'{ds_checkpoint_dir}' but found {total_files} files. "
+ 'Possibly due to an overwrite of an old checkpoint, '
+ "or a checkpoint didn't get saved by one or more processes.")
+
+ return zero_stage, world_size, flat_groups
+
+
+def _get_state_dict_from_zero_checkpoint(ds_checkpoint_dir,
+ exclude_frozen_parameters,
+ dtype=DEFAULT_DTYPE):
+ """Returns state_dict reconstructed from ds checkpoint.
+
+ Args:
+ - ``ds_checkpoint_dir``: path to the deepspeed checkpoint folder
+ (where the optimizer files are)
+ """
+ print(f"Processing zero checkpoint '{ds_checkpoint_dir}'")
+
+ optim_files = get_optim_files(ds_checkpoint_dir)
+ zero_stage, world_size, flat_groups = parse_optim_states(
+ optim_files, ds_checkpoint_dir, dtype)
+ print(f'Detected checkpoint of type zero stage {zero_stage}, '
+ f'world_size: {world_size}')
+
+ model_files = get_model_state_files(ds_checkpoint_dir)
+
+ zero_model_states = parse_model_states(model_files)
+ print(f'Parsing checkpoint created by deepspeed=='
+ f'{zero_model_states[0].ds_version}')
+
+ if zero_stage <= 2:
+ return _get_state_dict_from_zero2_checkpoint(
+ world_size, flat_groups, zero_model_states,
+ exclude_frozen_parameters)
+ elif zero_stage == 3:
+ return _get_state_dict_from_zero3_checkpoint(
+ world_size, flat_groups, zero_model_states,
+ exclude_frozen_parameters)
+
+
+def _zero2_merge_frozen_params(state_dict, zero_model_states):
+ if zero_model_states[0].frozen_param_shapes is None or len(
+ zero_model_states[0].frozen_param_shapes) == 0:
+ return
+
+ frozen_param_shapes = zero_model_states[0].frozen_param_shapes
+ frozen_param_fragments = zero_model_states[0].frozen_param_fragments
+
+ if debug:
+ num_elem = sum(s.numel() for s in frozen_param_shapes.values())
+ print(f'rank 0: {FROZEN_PARAM_SHAPES}.numel = {num_elem}')
+
+ wanted_params = len(frozen_param_shapes)
+ wanted_numel = sum(s.numel() for s in frozen_param_shapes.values())
+ avail_numel = sum([p.numel() for p in frozen_param_fragments.values()])
+ print(f'Frozen params: Have {avail_numel} numels to process.')
+ print(f'Frozen params: Need {wanted_numel} numels in '
+ f'{wanted_params} params')
+
+ total_params = 0
+ total_numel = 0
+ for name, shape in frozen_param_shapes.items():
+ total_params += 1
+ unpartitioned_numel = shape.numel()
+ total_numel += unpartitioned_numel
+
+ state_dict[name] = frozen_param_fragments[name]
+
+ if debug:
+ print(f'{name} full shape: {shape} unpartitioned numel '
+ f'{unpartitioned_numel} ')
+
+ print(f'Reconstructed Frozen state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _has_callable(obj, fn):
+ attr = getattr(obj, fn, None)
+ return callable(attr)
+
+
+def _zero2_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states):
+ param_shapes = zero_model_states[0].param_shapes
+
+ # Reconstruction protocol:
+ #
+ # XXX: document this
+
+ if debug:
+ for i in range(world_size):
+ for j in range(len(flat_groups[0])):
+ print(f'flat_groups[{i}][{j}].shape={flat_groups[i][j].shape}')
+
+ # XXX: memory usage doubles here (zero2)
+ num_param_groups = len(flat_groups[0])
+ merged_single_partition_of_groups = []
+ for i in range(num_param_groups):
+ merged_partitions = [sd[i] for sd in flat_groups]
+ full_single_vector = torch.cat(merged_partitions, 0)
+ merged_single_partition_of_groups.append(full_single_vector)
+ avail_numel = sum([
+ full_single_vector.numel()
+ for full_single_vector in merged_single_partition_of_groups
+ ])
+
+ if debug:
+ wanted_params = sum([len(shapes) for shapes in param_shapes])
+ wanted_numel = sum([
+ sum(shape.numel() for shape in shapes.values())
+ for shapes in param_shapes
+ ])
+ # not asserting if there is a mismatch due to possible padding
+ print(f'Have {avail_numel} numels to process.')
+ print(f'Need {wanted_numel} numels in {wanted_params} params.')
+
+ # params
+ # XXX: for huge models that can't fit into the host's RAM we will have to
+ # recode this to support out-of-core computing solution
+ total_numel = 0
+ total_params = 0
+ for shapes, full_single_vector in zip(param_shapes,
+ merged_single_partition_of_groups):
+ offset = 0
+ avail_numel = full_single_vector.numel()
+ for name, shape in shapes.items():
+
+ unpartitioned_numel = shape.numel() if _has_callable(
+ shape, 'numel') else math.prod(shape)
+ total_numel += unpartitioned_numel
+ total_params += 1
+
+ if debug:
+ print(f'{name} full shape: {shape} unpartitioned numel '
+ f'{unpartitioned_numel} ')
+ state_dict[name] = full_single_vector.narrow(
+ 0, offset, unpartitioned_numel).view(shape)
+ offset += unpartitioned_numel
+
+ # Z2 started to align to 2*world_size to improve nccl performance.
+ # Therefore both offset and avail_numel can differ by anywhere between
+ # 0..2*world_size. Due to two unrelated complex paddings performed in
+ # the code it's almost impossible to predict the exact numbers w/o the
+ # live optimizer object, so we are checking that the numbers are
+ # within the right range
+ align_to = 2 * world_size
+
+ def zero2_align(x):
+ return align_to * math.ceil(x / align_to)
+
+ if debug:
+ print(f'original offset={offset}, avail_numel={avail_numel}')
+
+ offset = zero2_align(offset)
+ avail_numel = zero2_align(avail_numel)
+
+ if debug:
+ print(f'aligned offset={offset}, avail_numel={avail_numel}')
+
+ # Sanity check
+ if offset != avail_numel:
+ raise ValueError(f'consumed {offset} numels out of {avail_numel} '
+ '- something is wrong')
+
+ print(f'Reconstructed state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _get_state_dict_from_zero2_checkpoint(world_size, flat_groups,
+ zero_model_states,
+ exclude_frozen_parameters):
+ state_dict = OrderedDict()
+
+ # buffers
+ buffers = zero_model_states[0].buffers
+ state_dict.update(buffers)
+ if debug:
+ print(f'added {len(buffers)} buffers')
+
+ if not exclude_frozen_parameters:
+ _zero2_merge_frozen_params(state_dict, zero_model_states)
+
+ _zero2_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states)
+
+ # recover shared parameters
+ for pair in zero_model_states[0].shared_params:
+ if pair[1] in state_dict:
+ state_dict[pair[0]] = state_dict[pair[1]]
+
+ return state_dict
+
+
+def zero3_partitioned_param_info(unpartitioned_numel, world_size):
+ remainder = unpartitioned_numel % world_size
+ padding_numel = (world_size - remainder) if remainder else 0
+ partitioned_numel = math.ceil(unpartitioned_numel / world_size)
+ return partitioned_numel, padding_numel
+
+
+def _zero3_merge_frozen_params(state_dict, world_size, zero_model_states):
+ if zero_model_states[0].frozen_param_shapes is None or len(
+ zero_model_states[0].frozen_param_shapes) == 0:
+ return
+
+ if debug:
+ for i in range(world_size):
+ num_elem = sum(
+ s.numel()
+ for s in zero_model_states[i].frozen_param_fragments.values())
+ print(f'rank {i}: {FROZEN_PARAM_SHAPES}.numel = {num_elem}')
+
+ frozen_param_shapes = zero_model_states[0].frozen_param_shapes
+ wanted_params = len(frozen_param_shapes)
+ wanted_numel = sum(s.numel() for s in frozen_param_shapes.values())
+ avail_numel = sum([
+ p.numel()
+ for p in zero_model_states[0].frozen_param_fragments.values()
+ ]) * world_size
+ print(f'Frozen params: Have {avail_numel} numels to process.')
+ print(f'Frozen params: Need {wanted_numel} numels in '
+ f'{wanted_params} params')
+
+ total_params = 0
+ total_numel = 0
+ for name, shape in zero_model_states[0].frozen_param_shapes.items():
+ total_params += 1
+ unpartitioned_numel = shape.numel()
+ total_numel += unpartitioned_numel
+
+ param_frags = tuple(model_state.frozen_param_fragments[name]
+ for model_state in zero_model_states)
+ state_dict[name] = torch.cat(param_frags, 0).narrow(
+ 0, 0, unpartitioned_numel).view(shape) # noqa: E501
+
+ _partitioned = zero3_partitioned_param_info(unpartitioned_numel,
+ world_size)
+ partitioned_numel, partitioned_padding_numel = _partitioned
+ if debug:
+ print(f'Frozen params: {total_params} {name} full shape: {shape} '
+ f'partition0 numel={partitioned_numel} '
+ f'partitioned_padding_numel={partitioned_padding_numel}')
+
+ print(f'Reconstructed Frozen state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _zero3_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states):
+ param_shapes = zero_model_states[0].param_shapes
+ avail_numel = flat_groups[0].numel() * world_size
+ # Reconstruction protocol: For zero3 we need to zip the partitions
+ # together at boundary of each param, re-consolidating each param, while
+ # dealing with padding if any
+
+ # merge list of dicts, preserving order
+ param_shapes = {k: v for d in param_shapes for k, v in d.items()}
+
+ if debug:
+ for i in range(world_size):
+ print(f'flat_groups[{i}].shape={flat_groups[i].shape}')
+
+ wanted_params = len(param_shapes)
+ wanted_numel = sum(shape.numel() for shape in param_shapes.values())
+ # not asserting if there is a mismatch due to possible padding
+ avail_numel = flat_groups[0].numel() * world_size
+ print(f'Trainable params: Have {avail_numel} numels to process.')
+ print(f'Trainable params: Need {wanted_numel} numels in '
+ f'{wanted_params} params.')
+
+ offset = 0
+ total_numel = 0
+ total_params = 0
+ partitioned_sizes = []
+ for name, shape in param_shapes.items():
+
+ unpartitioned_numel = shape.numel()
+ total_numel += unpartitioned_numel
+ total_params += 1
+
+ _info = zero3_partitioned_param_info(unpartitioned_numel, world_size)
+
+ partitioned_numel, partitioned_padding_numel = _info
+ partitioned_sizes.append(partitioned_numel)
+ if debug:
+ print(
+ f'Trainable params: {total_params} {name} full shape: {shape} '
+ f'partition0 numel={partitioned_numel} '
+ f'partitioned_padding_numel={partitioned_padding_numel}')
+
+ offset += partitioned_numel
+
+ offset *= world_size
+
+ # Sanity check
+ if offset != avail_numel:
+ raise ValueError(f'consumed {offset} numels out of {avail_numel} '
+ '- something is wrong')
+
+ mat_chunks = []
+ for rank in range(world_size):
+ rank_chunks = flat_groups.pop(0).split(partitioned_sizes)
+ rank_chunks = [tensor.clone() for tensor in rank_chunks]
+ mat_chunks.append(rank_chunks)
+
+ for name, shape in tqdm(
+ param_shapes.items(), desc='Gather Sharded Weights'):
+
+ pad_flat_param_chunks = []
+ for rank in range(world_size):
+ pad_flat_param_chunks.append(mat_chunks[rank].pop(0))
+
+ pad_flat_param = torch.cat(pad_flat_param_chunks, dim=0)
+
+ # Because pad_flat_param_chunks is a list, it is necessary to manually
+ # release the tensors in the list; Python will not automatically do so.
+ for rank in range(world_size):
+ pad_flat_param_chunks.pop()
+
+ param = pad_flat_param[:shape.numel()].view(shape)
+ state_dict[name] = param
+
+ print(f'Reconstructed Trainable state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _get_state_dict_from_zero3_checkpoint(world_size, flat_groups,
+ zero_model_states,
+ exclude_frozen_parameters):
+ state_dict = OrderedDict()
+
+ # buffers
+ buffers = zero_model_states[0].buffers
+ state_dict.update(buffers)
+ if debug:
+ print(f'added {len(buffers)} buffers')
+
+ if not exclude_frozen_parameters:
+ _zero3_merge_frozen_params(state_dict, world_size, zero_model_states)
+
+ _zero3_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states)
+
+ # recover shared parameters
+ for pair in zero_model_states[0].shared_params:
+ if pair[1] in state_dict:
+ state_dict[pair[0]] = state_dict[pair[1]]
+
+ return state_dict
+
+
+def get_state_dict_from_zero_checkpoint(checkpoint_dir,
+ tag=None,
+ exclude_frozen_parameters=False,
+ dtype=DEFAULT_DTYPE):
+ # flake8: noqa
+ """Convert ZeRO 2 or 3 checkpoint into a single consolidated state_dict
+ that can be loaded with ``load_state_dict()`` and used for training without
+ DeepSpeed or shared with others, for example via a model hub.
+
+ Args:
+ - ``checkpoint_dir``: path to the desired checkpoint folder
+ - ``tag``: checkpoint tag used as a unique identifier for checkpoint.
+ If not provided will attempt to load tag in 'latest' file.
+ e.g., ``global_step14``
+ - ``exclude_frozen_parameters``: exclude frozen parameters
+
+ Returns:
+ - pytorch ``state_dict``
+
+ Note: this approach may not work if your application doesn't have
+ sufficient free CPU memory and you may need to use the offline approach
+ using the ``zero_to_any_dtype.py`` script that is saved with the
+ checkpoint.
+
+ A typical usage might be ::
+
+ from xtuner.utils.zero_to_any_dtype import get_state_dict_from_zero_checkpoint
+ # do the training and checkpoint saving
+ state_dict = get_state_dict_from_zero_checkpoint(checkpoint_dir, dtype=torch.float16) # already on cpu
+ model = model.cpu() # move to cpu
+ model.load_state_dict(state_dict)
+ # submit to model hub or save the model to share with others
+
+ In this example the ``model`` will no longer be usable in the deepspeed
+ context of the same application. i.e. you will need to re-initialize the
+ deepspeed engine, since ``model.load_state_dict(state_dict)`` will remove
+ all the deepspeed magic from it.
+
+ If you want it all done for you, use
+ ``load_state_dict_from_zero_checkpoint`` instead.
+ """
+ # flake8: noqa
+ if tag is None:
+ latest_path = os.path.join(checkpoint_dir, 'latest')
+ if os.path.isfile(latest_path):
+ with open(latest_path) as fd:
+ tag = fd.read().strip()
+ else:
+ raise ValueError(f"Unable to find 'latest' file at {latest_path}")
+
+ ds_checkpoint_dir = os.path.join(checkpoint_dir, tag)
+
+ if not os.path.isdir(ds_checkpoint_dir):
+ raise FileNotFoundError(
+ f"Directory '{ds_checkpoint_dir}' doesn't exist")
+
+ return _get_state_dict_from_zero_checkpoint(ds_checkpoint_dir,
+ exclude_frozen_parameters,
+ dtype)
+
+
+def convert_zero_checkpoint_to_state_dict(checkpoint_dir,
+ output_file,
+ tag=None,
+ exclude_frozen_parameters=False,
+ dtype=DEFAULT_DTYPE):
+ """Convert ZeRO 2 or 3 checkpoint into a single consolidated ``state_dict``
+ file that can be loaded with ``torch.load(file)`` + ``load_state_dict()``
+ and used for training without DeepSpeed.
+
+ Args:
+ - ``checkpoint_dir``: path to the desired checkpoint folder.
+ (one that contains the tag-folder, like ``global_step14``)
+ - ``output_file``: path to the pytorch state_dict output file
+ (e.g. path/pytorch_model.bin)
+ - ``tag``: checkpoint tag used as a unique identifier for checkpoint.
+ If not provided will attempt to load tag in the file named
+ ``latest`` in the checkpoint folder, e.g., ``global_step14``
+ - ``exclude_frozen_parameters``: exclude frozen parameters
+ """
+
+ state_dict = get_state_dict_from_zero_checkpoint(
+ checkpoint_dir, tag, exclude_frozen_parameters, dtype)
+ print(f'Saving {dtype} state dict to {output_file}')
+ torch.save(state_dict, output_file)
+
+
+def load_state_dict_from_zero_checkpoint(model,
+ checkpoint_dir,
+ tag=None,
+ dtype=DEFAULT_DTYPE):
+
+ # flake8: noqa
+ """
+ 1. Put the provided model to cpu
+ 2. Convert ZeRO 2 or 3 checkpoint into a single consolidated ``state_dict``
+ 3. Load it into the provided model
+
+ Args:
+ - ``model``: the model object to update
+ - ``checkpoint_dir``: path to the desired checkpoint folder. (one that
+ contains the tag-folder, like ``global_step14``)
+ - ``tag``: checkpoint tag used as a unique identifier for checkpoint.
+ If not provided will attempt to load tag in the file named
+ ``latest`` in the checkpoint folder, e.g., ``global_step14``
+
+ Returns:
+ - ``model`: modified model
+
+ Make sure you have plenty of CPU memory available before you call this
+ function. If you don't have enough use the ``zero_to_any_dtype.py``
+ utility to do the conversion. You will find it conveniently placed for you
+ in the checkpoint folder.
+
+ A typical usage might be ::
+
+ from xtuner.utils.zero_to_any_dtype import load_state_dict_from_zero_checkpoint
+ model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir, dtype=torch.float16)
+ # submit to model hub or save the model to share with others
+
+ Note, that once this was run, the ``model`` will no longer be usable in
+ the deepspeed context of the same application. i.e. you will need to
+ re-initialize the deepspeed engine, since
+ ``model.load_state_dict(state_dict)`` will remove all the deepspeed magic
+ from it.
+ """
+ # flake8: noqa
+ logger.info(f'Extracting {dtype} weights')
+ state_dict = get_state_dict_from_zero_checkpoint(
+ checkpoint_dir, tag, dtype=dtype)
+
+ logger.info(f'Overwriting model with {dtype} weights')
+ model = model.cpu()
+ model.load_state_dict(state_dict, strict=False)
+
+ return model
diff --git a/data/xtuner/xtuner/version.py b/data/xtuner/xtuner/version.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4669c1880af551fc52eae2b826adfdd60e6a6d0
--- /dev/null
+++ b/data/xtuner/xtuner/version.py
@@ -0,0 +1,26 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+__version__ = '0.1.23'
+short_version = __version__
+
+
+def parse_version_info(version_str):
+ """Parse a version string into a tuple.
+
+ Args:
+ version_str (str): The version string.
+ Returns:
+ tuple[int or str]: The version info, e.g., "1.3.0" is parsed into
+ (1, 3, 0), and "2.0.0rc1" is parsed into (2, 0, 0, 'rc1').
+ """
+ version_info = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ version_info.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ version_info.append(int(patch_version[0]))
+ version_info.append(f'rc{patch_version[1]}')
+ return tuple(version_info)
+
+
+version_info = parse_version_info(__version__)
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..cb396fcb2edac94dc7eda3a3f055e59b74f395eb
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,6 @@
+llama-index==0.11.20
+llama-index-llms-replicate==0.3.0
+llama-index-llms-openai-like==0.2.0
+llama-index-embeddings-huggingface==0.3.1
+llama-index-embeddings-instructor==0.2.1
+sentence-transformers==2.7.0
'
+ IMG_END_TOKEN = ''
+
+ IMAGENET_MEAN = (0.485, 0.456, 0.406)
+ IMAGENET_STD = (0.229, 0.224, 0.225)
+
+ def __init__(self,
+ model_path,
+ template,
+ data_paths,
+ image_folders=None,
+ repeat_times=1,
+ max_length=8192):
+ self.template = template
+ self.max_length = max_length
+
+ self.cfg = AutoConfig.from_pretrained(
+ model_path, trust_remote_code=True)
+
+ # The following modifications are only to ensure full
+ # consistency with the official template,
+ # without investigating the impact on performance.
+ if self.cfg.llm_config.architectures[0] == 'Phi3ForCausalLM':
+ self._system = 'You are an AI assistant whose name is Phi-3.'
+ self.template[
+ 'INSTRUCTION'] = '<|user|>\n{input}<|end|><|assistant|>\n'
+ elif self.cfg.llm_config.architectures[0] == 'InternLM2ForCausalLM':
+ self._system = 'You are an AI assistant whose name ' \
+ 'is InternLM (书生·浦语).'
+ self.template['SYSTEM'] = '<|im_start|>system\n{system}<|im_end|>'
+ self.template[
+ 'INSTRUCTION'] = '<|im_start|>user\n{input}' \
+ '<|im_end|><|im_start|>assistant\n'
+ else:
+ raise NotImplementedError
+
+ self.min_dynamic_patch = self.cfg.min_dynamic_patch
+ self.max_dynamic_patch = self.cfg.max_dynamic_patch
+ self.downsample_ratio = self.cfg.downsample_ratio
+ self.image_size = self.cfg.force_image_size
+ self.use_thumbnail = self.cfg.use_thumbnail
+ patch_size = self.cfg.vision_config.patch_size
+ self.patch_token = int(
+ (self.image_size // patch_size)**2 * (self.downsample_ratio**2))
+ self.tokenizer = AutoTokenizer.from_pretrained(
+ model_path, trust_remote_code=True)
+ self.transformer = T.Compose([
+ T.Lambda(lambda img: img.convert('RGB')
+ if img.mode != 'RGB' else img),
+ T.Resize((self.image_size, self.image_size),
+ interpolation=InterpolationMode.BICUBIC),
+ T.ToTensor(),
+ T.Normalize(mean=self.IMAGENET_MEAN, std=self.IMAGENET_STD)
+ ])
+
+ if not isinstance(data_paths, (list, tuple)):
+ data_paths = [data_paths]
+ if not isinstance(image_folders, (list, tuple)):
+ image_folders = [image_folders]
+ if not isinstance(repeat_times, (list, tuple)):
+ repeat_times = [repeat_times]
+ assert len(data_paths) == len(image_folders) == len(repeat_times)
+
+ print_log('Starting to loading data and calc length', logger='current')
+ self.data = []
+ self.image_folder = []
+ self.group_length = []
+ self.conv2length_text = {
+ } # using dict to speedup the calculation of token length
+
+ for data_file, image_folder, repeat_time in zip(
+ data_paths, image_folders, repeat_times):
+ print_log(
+ f'=======Starting to process {data_file} =======',
+ logger='current')
+ assert repeat_time > 0
+ json_data = load_json_or_jsonl(data_file)
+ if repeat_time < 1:
+ json_data = random.sample(json_data,
+ int(len(json_data) * repeat_time))
+ elif repeat_time > 1:
+ int_repeat_time = int(repeat_time)
+ remaining_repeat_time = repeat_time - repeat_time
+ if remaining_repeat_time > 0:
+ remaining_json_data = random.sample(
+ json_data, int(len(json_data) * remaining_repeat_time))
+ json_data = json_data * int_repeat_time
+ json_data.extend(remaining_json_data)
+ else:
+ json_data = json_data * int_repeat_time
+
+ self.data.extend(json_data)
+ self.image_folder.extend([image_folder] * len(json_data))
+
+ # TODO: multi process
+ for data_item in json_data:
+ if 'length' in data_item:
+ token_length = data_item['length'] # include image token
+ else:
+ conversations = '\n'.join(
+ [temp['value'] for temp in data_item['conversations']])
+ str_length = len(conversations)
+
+ if str_length not in self.conv2length_text:
+ token_length = self.tokenizer(
+ conversations,
+ return_tensors='pt',
+ padding=False,
+ truncation=False,
+ ).input_ids.size(1)
+ self.conv2length_text[str_length] = token_length
+ else:
+ token_length = self.conv2length_text[str_length]
+
+ if 'image' in data_item and data_item['image'] is not None:
+ if 'image_wh' in data_item and data_item[
+ 'image_wh'] is not None:
+ # more accurate calculation of image token
+ image_wh = data_item['image_wh']
+ if isinstance(image_wh[0], list):
+ image_wh = image_wh[0]
+ image_token = total_image_token(
+ image_wh, self.min_dynamic_patch,
+ self.max_dynamic_patch, self.image_size,
+ self.use_thumbnail)
+ image_token = self.patch_token * image_token
+ else:
+ # max_dynamic_patch + use_thumbnail
+ image_token = self.patch_token * (
+ self.max_dynamic_patch + self.use_thumbnail)
+
+ token_length = token_length + image_token
+ else:
+ token_length = -token_length
+
+ self.group_length.append(token_length)
+ print_log(
+ f'=======total {len(json_data)} samples of {data_file}=======',
+ logger='current')
+
+ assert len(self.group_length) == len(self.data)
+ print_log('end loading data and calc length', logger='current')
+ print_log(
+ f'=======total {len(self.data)} samples=======', logger='current')
+ self._max_refetch = 1000
+
+ def __getitem__(self, index):
+ for _ in range(self._max_refetch + 1):
+ data = self.prepare_data(index)
+ # Broken images may cause the returned data to be None
+ if data is None:
+ index = self._rand_another()
+ continue
+ return data
+
+ def __len__(self):
+ return len(self.data)
+
+ @property
+ def modality_length(self):
+ return self.group_length
+
+ @property
+ def length(self):
+ group_length = np.array(self.group_length)
+ group_length = np.abs(group_length).tolist()
+ return group_length
+
+ def prepare_data(self, index):
+ data_dict: dict = self.data[index]
+ image_folder = self.image_folder[index]
+
+ out_data_dict = {}
+ if data_dict.get('image', None) is not None:
+ image_file = data_dict['image']
+ if isinstance(image_file, (list, tuple)):
+ assert len(image_file) == 1
+ image_file = image_file[0]
+
+ try:
+ image = self.get_image(os.path.join(image_folder, image_file))
+ except Exception as e:
+ print(f'Error: {e}', flush=True)
+ print_log(f'Error: {e}', logger='current')
+ return None
+
+ images = dynamic_preprocess(image, self.min_dynamic_patch,
+ self.max_dynamic_patch,
+ self.image_size, self.use_thumbnail)
+ pixel_values = [self.transformer(image) for image in images]
+ pixel_values = torch.stack(pixel_values)
+ out_data_dict['pixel_values'] = pixel_values
+
+ num_image_tokens = pixel_values.shape[0] * self.patch_token
+ image_token_str = f'{self.IMG_START_TOKEN}' \
+ f'{self.IMG_CONTEXT_TOKEN * num_image_tokens}' \
+ f'{self.IMG_END_TOKEN}'
+ token_dict = self.get_inputid_labels(data_dict['conversations'],
+ image_token_str)
+ out_data_dict.update(token_dict)
+ else:
+ token_dict = self.get_inputid_labels(data_dict['conversations'],
+ None)
+ out_data_dict.update(token_dict)
+ out_data_dict['pixel_values'] = torch.zeros(
+ 1, 3, self.image_size, self.image_size)
+ return out_data_dict
+
+ def _rand_another(self) -> int:
+ return np.random.randint(0, len(self.data))
+
+ def get_image(self, path):
+ if 's3://' in path:
+ img_bytes = get(path)
+ with io.BytesIO(img_bytes) as buff:
+ img = Image.open(buff).convert('RGB')
+ return img
+ else:
+ return Image.open(path).convert('RGB')
+
+ def get_inputid_labels(self, conversations, image_token_str) -> dict:
+ input = ''
+ out_conversation = []
+ while conversations and conversations[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ conversations = conversations[1:]
+ for msg in conversations:
+ if msg['from'] == 'human':
+ if image_token_str is None and '' in msg['value']:
+ warnings.warn(
+ f'The current data << {msg["value"]} >> is '
+ f'in plain text mode, but '
+ 'there are tags present in the data. '
+ 'We need to remove the tags.')
+ msg['value'] = msg['value'].replace('', '')
+ if '' in msg['value']:
+ msg['value'] = msg['value'].replace('', '').strip()
+ msg['value'] = image_token_str + '\n' + msg['value']
+ msg['value'] = msg['value'].strip()
+ input += msg['value'].strip()
+ elif msg['from'] == 'gpt':
+ out_conversation.append({
+ 'input': input,
+ 'output': msg['value'].strip()
+ })
+ input = ''
+ else:
+ raise NotImplementedError
+
+ input_ids, labels = [], []
+ for i, single_turn_conversation in enumerate(out_conversation):
+ input = single_turn_conversation.get('input', '')
+ if input is None:
+ input = ''
+ input_text = self.template.INSTRUCTION.format(
+ input=input, round=i + 1)
+
+ if i == 0:
+ system = self.template.SYSTEM.format(system=self._system)
+ input_text = system + input_text
+ input_encode = self.tokenizer.encode(
+ input_text, add_special_tokens=True)
+ else:
+ input_encode = self.tokenizer.encode(
+ input_text, add_special_tokens=False)
+ input_ids += input_encode
+ labels += [IGNORE_INDEX] * len(input_encode)
+
+ output_text = single_turn_conversation.get('output', '')
+ if self.template.get('SUFFIX', None):
+ output_text += self.template.SUFFIX
+ output_encode = self.tokenizer.encode(
+ output_text, add_special_tokens=False)
+ input_ids += output_encode
+ labels += copy.deepcopy(output_encode)
+
+ if len(input_ids) > self.max_length:
+ input_ids = input_ids[:self.max_length]
+ labels = labels[:self.max_length]
+ print_log(
+ f'Warning: input_ids length({len(input_ids)}) '
+ f'is longer than max_length, cut to {self.max_length}',
+ logger='current')
+ return {'input_ids': input_ids, 'labels': labels}
diff --git a/data/xtuner/xtuner/dataset/json_dataset.py b/data/xtuner/xtuner/dataset/json_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c7ca016300c94d19acb14bf9934d49c156a7987
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/json_dataset.py
@@ -0,0 +1,24 @@
+import json
+import os
+
+from datasets import Dataset, concatenate_datasets
+
+
+def load_json_file(data_files=None, data_dir=None, suffix=None):
+ assert (data_files is not None) != (data_dir is not None)
+ if data_dir is not None:
+ data_files = os.listdir(data_dir)
+ data_files = [os.path.join(data_dir, fn) for fn in data_files]
+ if suffix is not None:
+ data_files = [fp for fp in data_files if fp.endswith(suffix)]
+ elif isinstance(data_files, str):
+ data_files = [data_files]
+
+ dataset_list = []
+ for fp in data_files:
+ with open(fp, encoding='utf-8') as file:
+ data = json.load(file)
+ ds = Dataset.from_list(data)
+ dataset_list.append(ds)
+ dataset = concatenate_datasets(dataset_list)
+ return dataset
diff --git a/data/xtuner/xtuner/dataset/llava.py b/data/xtuner/xtuner/dataset/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fab0258af8fa507aac81a45734cee7d71ff63e3
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/llava.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import logging
+import os
+
+import torch
+from datasets import Dataset as HFDataset
+from datasets import DatasetDict, load_from_disk
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from PIL import Image
+from torch.utils.data import Dataset
+
+from xtuner.registry import BUILDER
+from .huggingface import process_hf_dataset
+from .utils import expand2square
+
+
+def load_jsonl(json_file):
+ with open(json_file) as f:
+ lines = f.readlines()
+ data = []
+ for line in lines:
+ data.append(json.loads(line))
+ return data
+
+
+class LLaVADataset(Dataset):
+
+ def __init__(self,
+ image_folder,
+ image_processor,
+ data_path=None,
+ tokenizer=None,
+ offline_processed_text_folder=None,
+ max_dataset_length=None,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ max_length=2048,
+ pad_image_to_square=False):
+ super().__init__()
+
+ assert offline_processed_text_folder or (data_path and tokenizer)
+ if offline_processed_text_folder and data_path:
+ print_log(
+ 'Both `offline_processed_text_folder` and '
+ '`data_path` are set, and we load dataset from'
+ '`offline_processed_text_folder` '
+ f'({offline_processed_text_folder})',
+ logger='current',
+ level=logging.WARNING)
+
+ if offline_processed_text_folder is not None:
+ self.text_data = load_from_disk(offline_processed_text_folder)
+ else:
+ if data_path.endswith('.json'):
+ json_data = json.load(open(data_path))
+ elif data_path.endswith('.jsonl'):
+ json_data = load_jsonl(data_path)
+ else:
+ raise NotImplementedError
+
+ for idx in range(len(json_data)):
+ if isinstance(json_data[idx]['id'], int):
+ json_data[idx]['id'] = str(json_data[idx]['id'])
+ json_data = DatasetDict({'train': HFDataset.from_list(json_data)})
+ self.text_data = process_hf_dataset(
+ dataset=json_data,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ split='train',
+ max_dataset_length=max_dataset_length,
+ remove_unused_columns=False,
+ pack_to_max_length=False,
+ with_image_token=True)
+
+ self.image_folder = image_folder
+ if isinstance(image_processor, dict) or isinstance(
+ image_processor, Config) or isinstance(image_processor,
+ ConfigDict):
+ self.image_processor = BUILDER.build(image_processor)
+ else:
+ self.image_processor = image_processor
+ self.pad_image_to_square = pad_image_to_square
+
+ @property
+ def modality_length(self):
+ length_list = []
+ for data_dict in self.text_data:
+ cur_len = len(data_dict['input_ids'])
+ if data_dict.get('image', None) is None:
+ cur_len = -cur_len
+ length_list.append(cur_len)
+ return length_list
+
+ def __len__(self):
+ return len(self.text_data)
+
+ def __getitem__(self, index):
+ data_dict = self.text_data[index]
+ if data_dict.get('image', None) is not None:
+ image_file = data_dict['image']
+ image = Image.open(os.path.join(self.image_folder,
+ image_file)).convert('RGB')
+ if self.pad_image_to_square:
+ image = expand2square(
+ image,
+ tuple(
+ int(x * 255) for x in self.image_processor.image_mean))
+ image = self.image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ data_dict['pixel_values'] = image
+ else:
+ if hasattr(self.image_processor, 'crop_size'):
+ crop_size = self.image_processor.crop_size
+ else:
+ crop_size = self.image_processor.size
+ data_dict['pixel_values'] = torch.zeros(3, crop_size['height'],
+ crop_size['width'])
+ return data_dict
diff --git a/data/xtuner/xtuner/dataset/map_fns/__init__.py b/data/xtuner/xtuner/dataset/map_fns/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a488c53eab57eedcd0437c2f239faec445292cf
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dataset_map_fns import * # noqa: F401, F403
+from .template_map_fn import template_map_fn # noqa: F401
+from .template_map_fn import template_map_fn_factory # noqa: F401
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/__init__.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..449b7b4f20efec582e419fb15f7fcc45f200a585
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/__init__.py
@@ -0,0 +1,53 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .alpaca_map_fn import alpaca_map_fn
+from .alpaca_zh_map_fn import alpaca_zh_map_fn
+from .arxiv_map_fn import arxiv_map_fn
+from .code_alpaca_map_fn import code_alpaca_map_fn
+from .colors_map_fn import colors_map_fn
+from .crime_kg_assitant_map_fn import crime_kg_assitant_map_fn
+from .default_map_fn import default_map_fn
+from .law_reference_map_fn import law_reference_map_fn
+from .llava_map_fn import llava_image_only_map_fn, llava_map_fn
+from .medical_map_fn import medical_map_fn
+from .msagent_map_fn import msagent_react_map_fn
+from .oasst1_map_fn import oasst1_map_fn
+from .openai_map_fn import openai_map_fn
+from .openorca_map_fn import openorca_map_fn
+from .pretrain_map_fn import pretrain_map_fn
+from .sql_map_fn import sql_map_fn
+from .stack_exchange_map_fn import stack_exchange_map_fn
+from .tiny_codes_map_fn import tiny_codes_map_fn
+from .wizardlm_map_fn import wizardlm_map_fn
+
+DATASET_FORMAT_MAPPING = dict(
+ alpaca=alpaca_map_fn,
+ alpaca_zh=alpaca_zh_map_fn,
+ arxiv=arxiv_map_fn,
+ code_alpaca=code_alpaca_map_fn,
+ colors=colors_map_fn,
+ crime_kg_assitan=crime_kg_assitant_map_fn,
+ default=default_map_fn,
+ law_reference=law_reference_map_fn,
+ llava_image_only=llava_image_only_map_fn,
+ llava=llava_map_fn,
+ medical=medical_map_fn,
+ msagent_react=msagent_react_map_fn,
+ oasst1=oasst1_map_fn,
+ openai=openai_map_fn,
+ openorca=openorca_map_fn,
+ pretrain=pretrain_map_fn,
+ sql=sql_map_fn,
+ stack_exchange=stack_exchange_map_fn,
+ tiny_codes=tiny_codes_map_fn,
+ wizardlm=wizardlm_map_fn,
+)
+
+__all__ = [
+ 'alpaca_map_fn', 'alpaca_zh_map_fn', 'oasst1_map_fn', 'arxiv_map_fn',
+ 'medical_map_fn', 'openorca_map_fn', 'code_alpaca_map_fn',
+ 'tiny_codes_map_fn', 'colors_map_fn', 'law_reference_map_fn',
+ 'crime_kg_assitant_map_fn', 'sql_map_fn', 'openai_map_fn',
+ 'wizardlm_map_fn', 'stack_exchange_map_fn', 'msagent_react_map_fn',
+ 'pretrain_map_fn', 'default_map_fn', 'llava_image_only_map_fn',
+ 'llava_map_fn', 'DATASET_FORMAT_MAPPING'
+]
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..d64ac3a1cb6f2d5ee5c84b2f5cb08f84d5001ac5
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_map_fn.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+def alpaca_map_fn(example):
+ if example.get('output') == '':
+ return {'conversation': []}
+ else:
+ return {
+ 'conversation': [{
+ 'input': f"{example['instruction']}\n{example['input']}",
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_zh_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_zh_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e17cfa048325af7feadc1fd0452481d65b64cd8
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/alpaca_zh_map_fn.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+def alpaca_zh_map_fn(example):
+ return {
+ 'conversation': [{
+ 'input': f"{example['instruction_zh']}\n{example['input_zh']}",
+ 'output': example['output_zh']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/arxiv_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/arxiv_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..52bcc4e341708d51d474a3d9db6dcc2ad65df454
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/arxiv_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def arxiv_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.arxiv_gentile,
+ 'input': example['abstract'],
+ 'output': example['title']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/code_alpaca_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/code_alpaca_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..ece86ff209807d6e8a555eef95a3205d62aa5144
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/code_alpaca_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def code_alpaca_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.coder,
+ 'input': example['prompt'],
+ 'output': example['completion']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/colors_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/colors_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..17d08bf207cc02d74c2833f1d24da7962e4cd629
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/colors_map_fn.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def colors_map_fn(example):
+ desc = ':'.join(example['description'].split(':')[1:]).strip()
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.colorist,
+ 'input': desc,
+ 'output': example['color']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/crime_kg_assitant_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/crime_kg_assitant_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7511a98d94d53aea340a216d9f323c9ae166a41
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/crime_kg_assitant_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def crime_kg_assitant_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.lawyer,
+ 'input': example['input'],
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/default_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/default_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..0424b884839cd20168ef9c8d26e4363eb8850503
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/default_map_fn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def default_map_fn(example):
+ return {
+ 'conversation': [{
+ 'input': example['input'],
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/law_reference_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/law_reference_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..297086fa082c9c045e6f67af4d74568029b4ffd6
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/law_reference_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def law_reference_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.lawyer,
+ 'input': example['question'],
+ 'output': example['answer']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/llava_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/llava_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..a08ca395b6c4fd208a944d97e98e94fa235c15e4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/llava_map_fn.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import DEFAULT_IMAGE_TOKEN
+
+
+def llava_image_only_map_fn(example):
+ # input contains the DEFAULT_IMAGE_TOKEN only
+ messages = example['conversations']
+ input = ''
+ conversation = []
+ while messages and messages[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ messages = messages[1:]
+ for msg in messages:
+ if msg['from'] == 'human':
+ assert DEFAULT_IMAGE_TOKEN in msg['value']
+ input += DEFAULT_IMAGE_TOKEN
+ elif msg['from'] == 'gpt':
+ conversation.append({'input': input, 'output': msg['value']})
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
+
+
+def llava_map_fn(example):
+ messages = example['conversations']
+ input = ''
+ conversation = []
+ while messages and messages[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ messages = messages[1:]
+ for msg in messages:
+ if msg['from'] == 'human':
+ if DEFAULT_IMAGE_TOKEN in msg['value']:
+ msg['value'] = msg['value'].replace(DEFAULT_IMAGE_TOKEN,
+ '').strip()
+ msg['value'] = DEFAULT_IMAGE_TOKEN + '\n' + msg['value']
+ msg['value'] = msg['value'].strip()
+ input += msg['value']
+
+ elif msg['from'] == 'gpt':
+ conversation.append({'input': input, 'output': msg['value']})
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/medical_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/medical_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..60a955454bee80e283ac950ef561e642affc6eef
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/medical_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def medical_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.medical,
+ 'input': '{instruction}\n{input}'.format(**example),
+ 'output': example['output']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/msagent_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/msagent_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..fef8b1c5c680b58bf4a6817a6881b1adb021b3f4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/msagent_map_fn.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import re
+
+think_regex = r'(.*?)(<\|startofthink\|\>)(.*?)(<\|endofthink\|\>)'
+exec_regex = r'(<\|startofexec\|\>)(.*?)(<\|endofexec\|\>)(.*?)$'
+
+
+def replace_think(match):
+ out_text = ''
+ if match.group(1).strip() != '':
+ out_text += f'Thought:{match.group(1).strip()}\n'
+ think_text = match.group(3).replace('```JSON',
+ '').replace('```',
+ '').replace('\n', '')
+ think_json = json.loads(think_text)
+ out_text += (f"Action:{think_json['api_name']}\n"
+ f"Action Input:{think_json['parameters']}\n")
+ return out_text
+
+
+def replace_exec(match):
+ out_text = ''
+ exec_text = match.group(2).replace('```JSON',
+ '').replace('```',
+ '').replace('\n', '')
+ exec_json = json.loads(exec_text)
+ out_text += f'Response:{exec_json}\n'
+ if match.group(4).strip() != '':
+ out_text += f'Final Answer:{match.group(4).strip()}\n'
+ return out_text
+
+
+def extract_json_objects(text, decoder=json.JSONDecoder()):
+ pos = 0
+ results = []
+ while True:
+ match = text.find('{', pos)
+ if match == -1:
+ break
+ try:
+ result, index = decoder.raw_decode(text[match:])
+ if 'name' in result and 'description' in result:
+ results.append(result)
+ pos = match + index
+ else:
+ pos = match + 1
+ except ValueError:
+ pos = match + 1
+ return results
+
+
+def msagent_react_map_fn(example):
+ text = example['conversations']
+ if isinstance(text, str):
+ text = eval(text)
+ if len(text) < 2: # Filter out invalid data
+ return {'conversation': []}
+ conversation = []
+ system_text = ''
+ input_text = ''
+ for t in text:
+ if t['from'] == 'system':
+ system_text += '你是一个可以调用外部工具的助手,可以使用的工具包括:\n'
+ json_objects = extract_json_objects(t['value'])
+ api_dict = {}
+ for obj in json_objects:
+ api_dict[obj['name']] = obj['description']
+ try:
+ params = {
+ i['name']: i['description']
+ for i in obj['paths'][0]['parameters']
+ }
+ api_dict[obj['name']] += f'\n输入参数: {params}'
+ except Exception:
+ pass
+ system_text += f'{api_dict}\n'
+ system_text += (
+ '如果使用工具请遵循以下格式回复:\n```\n'
+ 'Thought:思考你当前步骤需要解决什么问题,是否需要使用工具\n'
+ f'Action:工具名称,你的工具必须从 [{str(list(api_dict.keys()))}] 选择\n'
+ 'Action Input:工具输入参数\n```\n工具返回按照以下格式回复:\n```\n'
+ 'Response:调用工具后的结果\n```\n如果你已经知道了答案,或者你不需要工具,'
+ '请遵循以下格式回复\n```\n'
+ 'Thought:给出最终答案的思考过程\n'
+ 'Final Answer:最终答案\n```\n开始!\n')
+ elif t['from'] == 'user':
+ input_text += f"{t['value']}\n"
+ elif t['from'] == 'assistant':
+ output = t['value']
+ output_response = None
+ try:
+ if '<|startofexec|>' in output:
+ output, output_response = output.split('<|startofexec|>')
+ output_response = '<|startofexec|>' + output_response
+ output, think_cnt = re.subn(
+ think_regex, replace_think, output, flags=re.DOTALL)
+ except Exception:
+ return {'conversation': []}
+
+ if think_cnt == 0:
+ output = f'Final Answer:{output}\n'
+ else:
+ output = f'{output}\n'
+ conversation.append({
+ 'system': system_text,
+ 'input': input_text,
+ 'output': output
+ })
+ system_text = ''
+ input_text = ''
+ if output_response is not None:
+ try:
+ output_response, exec_cnt = re.subn(
+ exec_regex,
+ replace_exec,
+ output_response,
+ flags=re.DOTALL)
+ if 'Final Answer:' in output_response:
+ output_response, output_answer = output_response.split(
+ 'Final Answer:')
+ output_answer = 'Final Answer:' + output_answer
+ conversation.append({
+ 'system': output_response,
+ 'output': output_answer
+ })
+ except Exception:
+ pass
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/oasst1_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/oasst1_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1e13a01525c8beacc03cc27bb36745dbe63da58
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/oasst1_map_fn.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def oasst1_map_fn(example):
+ r"""Example before preprocessing:
+ example['text'] = '### Human: Can you explain xxx'
+ '### Assistant: Sure! xxx'
+ '### Human: I didn't understand how xxx'
+ '### Assistant: It has to do with a process xxx.'
+
+ Example after preprocessing:
+ example['conversation'] = [
+ {
+ 'input': 'Can you explain xxx',
+ 'output': 'Sure! xxx'
+ },
+ {
+ 'input': 'I didn't understand how xxx',
+ 'output': 'It has to do with a process xxx.'
+ }
+ ]
+ """
+ data = []
+ for sentence in example['text'].strip().split('###'):
+ sentence = sentence.strip()
+ if sentence[:6] == 'Human:':
+ data.append(sentence[6:].strip())
+ elif sentence[:10] == 'Assistant:':
+ data.append(sentence[10:].strip())
+ if len(data) % 2:
+ # The last round of conversation solely consists of input
+ # without any output.
+ # Discard the input part of the last round, as this part is ignored in
+ # the loss calculation.
+ data.pop()
+ conversation = []
+ for i in range(0, len(data), 2):
+ single_turn_conversation = {'input': data[i], 'output': data[i + 1]}
+ conversation.append(single_turn_conversation)
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openai_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openai_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..468e738f707e0ecae75e89e6a18b91f39b466d56
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openai_map_fn.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def openai_map_fn(example):
+ """
+ Example before preprocessing:
+ example["messages"] = [
+ { "role": "system", "content": "You are an assistant that
+ occasionally misspells words." },
+ { "role": "user", "content": "Tell me a story." },
+ { "role": "assistant", "content": "One day a student
+ went to schoool." }
+ ]
+ Example after preprocessing:
+ example["conversation"] = [
+ {
+ "system": "You are an assistant that occasionally misspells
+ words.",
+ "input": "Tell me a story.",
+ "output": "One day a student went to schoool."
+ }
+ ]
+ """
+ messages = example['messages']
+ system = ''
+ input = ''
+ conversation = []
+ while messages and messages[0]['role'] == 'assistant':
+ # Skip the first one if it is from assistant
+ messages = messages[1:]
+ for msg in messages:
+ if msg['role'] == 'system':
+ system = msg['content']
+ elif msg['role'] == 'user':
+ input += msg['content']
+ elif msg['role'] == 'assistant':
+ output_with_loss = msg.get('loss', 'True')
+ output_with_loss = str(output_with_loss)
+ output_with_loss = output_with_loss.lower() == 'true'
+ conversation.append({
+ 'system': system,
+ 'input': input,
+ 'output': msg['content'],
+ 'output_with_loss': output_with_loss
+ })
+ system = ''
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openorca_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openorca_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..45e58f3b9dd8e495c27050573eac4271eb7c746c
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/openorca_map_fn.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def openorca_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': example['system_prompt'],
+ 'input': example['question'],
+ 'output': example['response']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/pretrain_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/pretrain_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..861302ba8690074210ae8a751ba423075d10a240
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/pretrain_map_fn.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def pretrain_map_fn(example):
+ r"""Example before preprocessing:
+ example['text'] = 'xxx'
+
+ Example after preprocessing:
+ example['conversation'] = [
+ {
+ 'input': '',
+ 'output': 'xxx'
+ },
+ ]
+ """
+ return {
+ 'conversation': [{
+ 'input': '',
+ 'output': example['text'].strip(),
+ 'need_eos_token': False
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/sql_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/sql_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..c83434f8de496a5a15f18c3038771070b0e4b608
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/sql_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def sql_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.sql,
+ 'input': '{context}\n{question}'.format(**example),
+ 'output': example['answer']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/stack_exchange_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/stack_exchange_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fc3520e2919283133afb7ec26ff009469f38475
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/stack_exchange_map_fn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def stack_exchange_map_fn(example):
+ return {
+ 'conversation': [{
+ 'input': example['question'],
+ 'output': example['response']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/tiny_codes_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/tiny_codes_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe0cc02b48c33ab3d9a0e717c293399f74cd6cfa
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/tiny_codes_map_fn.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.utils import SYSTEM_TEMPLATE
+
+
+def tiny_codes_map_fn(example):
+ return {
+ 'conversation': [{
+ 'system': SYSTEM_TEMPLATE.coder,
+ 'input': example['prompt'],
+ 'output': example['response']
+ }]
+ }
diff --git a/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/wizardlm_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/wizardlm_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..0174760d006b3efe2240671da672e2367076d30b
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/dataset_map_fns/wizardlm_map_fn.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def wizardlm_map_fn(example):
+ messages = example['conversations']
+ input = ''
+ conversation = []
+ while messages and messages[0]['from'] == 'gpt':
+ # Skip the first one if it is from gpt
+ messages = messages[1:]
+ for msg in messages:
+ if msg['from'] == 'human':
+ input += msg['value']
+ elif msg['from'] == 'gpt':
+ conversation.append({'input': input, 'output': msg['value']})
+ input = ''
+ else:
+ raise NotImplementedError
+ return {'conversation': conversation}
diff --git a/data/xtuner/xtuner/dataset/map_fns/template_map_fn.py b/data/xtuner/xtuner/dataset/map_fns/template_map_fn.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7673b99efcdc2e1215303755401d68f570eedf2
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/map_fns/template_map_fn.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+
+from mmengine.utils.misc import get_object_from_string
+
+
+def template_map_fn(example, template):
+ conversation = example.get('conversation', [])
+ for i, single_turn_conversation in enumerate(conversation):
+ input = single_turn_conversation.get('input', '')
+ if input is None:
+ input = ''
+ input_text = template.INSTRUCTION.format(input=input, round=i + 1)
+ system = single_turn_conversation.get('system', '')
+ if system != '' and system is not None:
+ system = template.SYSTEM.format(system=system)
+ input_text = system + input_text
+ single_turn_conversation['input'] = input_text
+
+ if template.get('SUFFIX', None):
+ output_text = single_turn_conversation.get('output', '')
+ output_text += template.SUFFIX
+ single_turn_conversation['output'] = output_text
+
+ # SUFFIX_AS_EOS is False ==> need_eos_token is True
+ single_turn_conversation['need_eos_token'] = \
+ not template.get('SUFFIX_AS_EOS', False)
+ single_turn_conversation['sep'] = template.get('SEP', '')
+
+ return {'conversation': conversation}
+
+
+def template_map_fn_factory(template):
+ if isinstance(template, str): # for resume
+ template = get_object_from_string(template)
+ return partial(template_map_fn, template=template)
diff --git a/data/xtuner/xtuner/dataset/modelscope.py b/data/xtuner/xtuner/dataset/modelscope.py
new file mode 100644
index 0000000000000000000000000000000000000000..9400050c34553dc8087a0f78e62918e47835d349
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/modelscope.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import Config, ConfigDict
+
+from xtuner.registry import BUILDER
+from .huggingface import process_hf_dataset
+
+
+def process_ms_dataset(dataset, split='train', *args, **kwargs):
+ """Post-process the dataset loaded from the ModelScope Hub."""
+
+ if isinstance(dataset, (Config, ConfigDict)):
+ dataset = BUILDER.build(dataset)
+ if isinstance(dataset, dict):
+ dataset = dataset[split]
+ dataset = dataset.to_hf_dataset()
+ return process_hf_dataset(dataset, *args, **kwargs)
diff --git a/data/xtuner/xtuner/dataset/moss_sft.py b/data/xtuner/xtuner/dataset/moss_sft.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5b7122bb700847dcab584e93b3ecc44c37404d3
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/moss_sft.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import json
+import os
+
+import torch
+from mmengine.config import Config, ConfigDict
+from mmengine.logging import print_log
+from torch.utils.data import Dataset
+from tqdm import tqdm
+
+from xtuner.registry import BUILDER
+
+
+class MOSSSFTDataset(Dataset):
+
+ def __init__(self, data_file, tokenizer, max_length=2048, bot_name=None):
+ super().__init__()
+ self.bot_name = bot_name
+ self.src_data_file = data_file
+ if isinstance(tokenizer, dict) or isinstance(
+ tokenizer, Config) or isinstance(tokenizer, ConfigDict):
+ self.tokenizer = BUILDER.build(tokenizer)
+ else:
+ self.tokenizer = tokenizer
+ self.max_length = max_length
+
+ self.data = []
+ # We do not calculate losses for the meta instruction or results
+ # returned by plugins
+ # The token spans with label -100, [(span_start, span_end), ...]
+ self.no_loss_spans = []
+ self.labels = []
+
+ self.pre = len(
+ self.tokenizer.encode('<|Results|>:', add_special_tokens=False))
+ self.post = len(
+ self.tokenizer.encode('\n', add_special_tokens=False))
+
+ self.load_data()
+ self.process_data()
+
+ def load_data(self):
+ print_log('Loading MOSS SFT data...', 'current')
+ name = f'{self.tokenizer.__class__.__name__}_{self.bot_name}'
+ data_file = self.src_data_file.replace('.jsonl', f'_data_{name}')
+ no_loss_spans_file = self.src_data_file.replace(
+ '.jsonl', f'_no_loss_spans_{name}')
+ if os.path.exists(data_file) and os.path.exists(no_loss_spans_file):
+ self.data = torch.load(data_file, map_location='cpu')
+ self.no_loss_spans = torch.load(
+ no_loss_spans_file, map_location='cpu')
+ else:
+ with open(self.src_data_file) as f:
+ for line in tqdm(f):
+ sample = json.loads(line)
+
+ chat = sample['chat']
+ num_turns = int(sample['num_turns'])
+
+ meta_instruction = sample['meta_instruction']
+ if self.bot_name is not None:
+ meta_instruction = meta_instruction.replace(
+ 'MOSS', self.bot_name)
+ instruction_ids = self.tokenizer.encode(meta_instruction)
+ assert isinstance(instruction_ids,
+ list) and len(instruction_ids) > 0
+
+ input_ids = copy.deepcopy(instruction_ids)
+ no_loss_spans = [(0, len(instruction_ids))]
+ try:
+ for i in range(num_turns):
+ cur_turn_ids = []
+ cur_no_loss_spans = []
+ cur_turn = chat[f'turn_{i+1}']
+ for key, value in cur_turn.items():
+ if self.bot_name is not None:
+ value = value.replace(
+ 'MOSS', self.bot_name)
+ cur_ids = self.tokenizer.encode(
+ value, add_special_tokens=False)
+ if key == 'Tool Responses':
+ # The format tokens
+ # (<|Results|>:...\n)
+ # should have losses.
+ cur_no_loss_spans.append(
+ (len(input_ids + cur_turn_ids) +
+ self.pre,
+ len(input_ids + cur_turn_ids +
+ cur_ids) - self.post))
+
+ assert isinstance(cur_ids,
+ list) and len(cur_ids) > 0
+
+ cur_turn_ids.extend(cur_ids)
+
+ if len(input_ids + cur_turn_ids) > self.max_length:
+ break
+
+ input_ids.extend(cur_turn_ids)
+ no_loss_spans.extend(cur_no_loss_spans)
+ if len(input_ids) == len(instruction_ids):
+ continue
+
+ assert len(input_ids) > 0 and len(
+ input_ids) <= self.max_length
+
+ self.data.append(input_ids)
+ self.no_loss_spans.append(no_loss_spans)
+ except Exception:
+ pass
+ torch.save(self.data, data_file)
+ torch.save(self.no_loss_spans, no_loss_spans_file)
+ print_log(
+ f'Load data successfully, total {len(self.data)} training samples',
+ 'current')
+
+ def process_data(self):
+ for item, no_loss in zip(self.data, self.no_loss_spans):
+ label = copy.deepcopy(item)
+ for loc in no_loss:
+ label[loc[0]:loc[1]] = [-100] * (loc[1] - loc[0])
+ self.labels.append(label)
+
+ def __len__(self):
+ return len(self.data)
+
+ def __getitem__(self, index):
+ return {'input_ids': self.data[index], 'labels': self.labels[index]}
diff --git a/data/xtuner/xtuner/dataset/preference_dataset.py b/data/xtuner/xtuner/dataset/preference_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..371ef829039742762ec7c725fb3a1acd4a57b420
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/preference_dataset.py
@@ -0,0 +1,386 @@
+import copy
+import json
+import os
+from datetime import timedelta
+from functools import partial
+from multiprocessing import Process, Queue
+from typing import Callable, Dict, List
+
+import numpy as np
+import torch.distributed as dist
+import tqdm
+from datasets import Dataset as HFDataset
+from datasets import concatenate_datasets
+from mmengine.config import Config, ConfigDict
+from mmengine.logging import print_log
+from mmengine.utils.misc import get_object_from_string
+from torch.utils.data import Dataset
+from transformers import AutoTokenizer
+
+from xtuner.registry import BUILDER, MAP_FUNC
+from .huggingface import build_origin_dataset
+
+
+def _worker(
+ tokenize_fun: Callable,
+ data_queue: Queue,
+ out_queue: Queue,
+):
+ while True:
+ data_chunk = data_queue.get()
+
+ if data_chunk is None:
+ out_queue.put(None)
+ break
+ chunk_results = []
+ for idx, data in data_chunk:
+ chunk_results.append([idx, tokenize_fun(data)])
+ out_queue.put(chunk_results)
+
+
+def _chunk_data_to_queue(data_queue: Queue, data: List[Dict], chunk_size: int,
+ nproc):
+ data_iter = iter(data)
+ chunk_data = []
+ while True:
+ try:
+ item = next(data_iter)
+ except StopIteration:
+ break
+ chunk_data.append(item)
+ if len(chunk_data) == chunk_size:
+ data_queue.put(chunk_data)
+ chunk_data = []
+ if chunk_data:
+ data_queue.put(chunk_data)
+
+ for _ in range(nproc):
+ data_queue.put(None)
+
+
+def _multi_progress(tokenize_fun_p, dataset, nproc, task_num, chunksize,
+ description):
+ processes = []
+ data_queue = Queue()
+ output_queue = Queue()
+ bar = tqdm.tqdm(total=task_num, desc=description)
+ # task_id = bar.add_task(total=task_num, description=description)
+ dataset = enumerate(dataset)
+ _chunk_data_to_queue(data_queue, dataset, chunksize, nproc)
+ for _ in range(nproc):
+ process = Process(
+ target=_worker, args=(tokenize_fun_p, data_queue, output_queue))
+ process.start()
+ processes.append(process)
+
+ results = []
+ finished_process = 0
+ while finished_process < nproc:
+ chunk_results = output_queue.get()
+ if chunk_results is None:
+ finished_process += 1
+ continue
+ results.extend(chunk_results)
+ bar.update(len(chunk_results))
+ bar.refresh()
+ results = map(lambda x: x[1], sorted(results, key=lambda x: x[0]))
+ return results
+
+
+def load_jsonl_dataset(data_files=None, data_dir=None, suffix=None):
+ assert (data_files is not None) != (data_dir is not None)
+ if data_dir is not None:
+ data_files = os.listdir(data_dir)
+ data_files = [os.path.join(data_dir, fn) for fn in data_files]
+ if suffix is not None:
+ data_files = [fp for fp in data_files if fp.endswith(suffix)]
+ elif isinstance(data_files, str):
+ data_files = [data_files]
+
+ dataset_list = []
+ for fp in data_files:
+ with open(fp, encoding='utf-8') as file:
+ data = [json.loads(line) for line in file]
+ ds = HFDataset.from_list(data)
+ dataset_list.append(ds)
+ dataset = concatenate_datasets(dataset_list)
+ return dataset
+
+
+def tokenize(pair: str,
+ tokenizer: AutoTokenizer,
+ max_length: int,
+ is_reward: bool = False,
+ reward_token_id: int = -1):
+ prompt = tokenizer.apply_chat_template(
+ pair['prompt'], tokenize=False, add_generation_prompt=True)
+ chosen = tokenizer.apply_chat_template(
+ pair['prompt'] + pair['chosen'],
+ tokenize=False,
+ add_generation_prompt=False)
+ rejected = tokenizer.apply_chat_template(
+ pair['prompt'] + pair['rejected'],
+ tokenize=False,
+ add_generation_prompt=False)
+ prompt_ids = tokenizer.encode(prompt, add_special_tokens=False)
+ chosen_ids = tokenizer.encode(chosen, add_special_tokens=False)
+ rejected_ids = tokenizer.encode(rejected, add_special_tokens=False)
+
+ if len(chosen_ids) > max_length:
+ chosen_ids = chosen_ids[:max_length]
+ if len(rejected_ids) > max_length:
+ rejected_ids = rejected_ids[:max_length]
+
+ if is_reward:
+ # reward label
+ chosen_ids = chosen_ids + [reward_token_id]
+ rejected_ids = rejected_ids + [reward_token_id]
+ chosen_labels = [-100] * len(chosen_ids[:-1]) + [0]
+ rejected_labels = [-100] * len(rejected_ids[:-1]) + [1]
+ else:
+ # dpo label
+ prompt_len = min(len(prompt_ids), max_length)
+ chosen_labels = [-100] * prompt_len + copy.deepcopy(
+ chosen_ids[prompt_len:])
+ rejected_labels = [-100] * prompt_len + copy.deepcopy(
+ rejected_ids[prompt_len:])
+
+ return {
+ 'chosen_ids': chosen_ids,
+ 'rejected_ids': rejected_ids,
+ 'chosen_labels': chosen_labels,
+ 'rejected_labels': rejected_labels,
+ }
+
+
+class PreferenceDataset(Dataset):
+
+ def __init__(
+ self,
+ dataset: HFDataset,
+ tokenizer: AutoTokenizer,
+ max_length: int,
+ is_dpo: bool = True,
+ is_reward: bool = False,
+ reward_token_id: int = -1,
+ num_proc: int = 32,
+ ) -> None:
+ self.max_length = max_length
+ assert is_dpo != is_reward, \
+ 'Only one of is_dpo and is_reward can be True'
+ if is_reward:
+ assert reward_token_id != -1, \
+ 'reward_token_id should be set if is_reward is True'
+
+ self.is_dpo = is_dpo
+ self.is_reward = is_reward
+ self.reward_token_id = reward_token_id
+ self.tokenized_pairs = []
+
+ for tokenized_pair in _multi_progress(
+ partial(
+ tokenize,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ is_reward=is_reward,
+ reward_token_id=reward_token_id),
+ dataset,
+ nproc=num_proc,
+ task_num=len(dataset),
+ chunksize=num_proc,
+ description='Tokenizing dataset'):
+ self.tokenized_pairs.append(tokenized_pair)
+
+ def __len__(self):
+ return len(self.tokenized_pairs)
+
+ def __getitem__(self, idx):
+ return self.tokenized_pairs[idx]
+
+
+class PackedDatasetWrapper(Dataset):
+
+ def __init__(self,
+ dataset,
+ max_packed_length=16384,
+ shuffle_before_pack=True) -> None:
+ super().__init__()
+ self.max_packed_length = max_packed_length
+ self.lengths = []
+ self.data = []
+
+ indices = np.arange(len(dataset))
+ if shuffle_before_pack:
+ np.random.shuffle(indices)
+
+ data_bin = []
+ bin_seq_len = 0
+ removed = 0
+ for idx in indices:
+ data = dataset[int(idx)]
+ cur_len = len(data['chosen_ids']) + len(data['rejected_ids'])
+ if cur_len > max_packed_length:
+ print_log(
+ f'sequence length {cur_len} is '
+ f'larger than max_packed_length {max_packed_length}',
+ logger='current')
+ removed += 1
+ continue
+ if (bin_seq_len +
+ cur_len) > max_packed_length and len(data_bin) > 0:
+ self.data.append(data_bin)
+ self.lengths.append(bin_seq_len)
+ data_bin = []
+ bin_seq_len = 0
+ data_bin.append(data)
+ bin_seq_len += cur_len
+
+ if len(data_bin) > 0:
+ self.data.append(data_bin)
+ self.lengths.append(bin_seq_len)
+ if removed > 0:
+ print_log(
+ f'removed {removed} samples because '
+ f'of length larger than {max_packed_length}',
+ logger='current')
+ print_log(
+ f'The batch numbers of dataset is changed '
+ f'from {len(dataset)} to {len(self)} after'
+ ' using var len attention.',
+ logger='current')
+
+ def __len__(self):
+ return len(self.data)
+
+ def __getitem__(self, index):
+ pairs = self.data[index]
+ input_ids, cu_seqlens, position_ids, labels = [], [0], [], []
+
+ for pair in pairs:
+ input_ids.extend(pair['chosen_ids'])
+ input_ids.extend(pair['rejected_ids'])
+
+ position_ids.extend(list(range(len(pair['chosen_ids']))))
+ position_ids.extend(list(range(len(pair['rejected_ids']))))
+
+ labels.extend(pair['chosen_labels'])
+ labels.extend(pair['rejected_labels'])
+
+ cu_seqlens.append(cu_seqlens[-1] + len(pair['chosen_ids']))
+ cu_seqlens.append(cu_seqlens[-1] + len(pair['rejected_ids']))
+
+ return {
+ 'input_ids': input_ids,
+ 'labels': labels,
+ 'position_ids': position_ids,
+ 'cumulative_len': cu_seqlens
+ }
+
+
+def unpack_seq(seq, cu_seqlens):
+ """Unpack a packed sequence to a list of sequences with different
+ lengths."""
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+ subseqs = seq.split(seqlens)
+ return subseqs
+
+
+def broad_cast_dataset(dataset):
+ xtuner_dataset_timeout = timedelta(
+ minutes=int(os.getenv('XTUNER_DATASET_TIMEOUT', default=60)))
+ print_log(
+ f'xtuner_dataset_timeout = {xtuner_dataset_timeout}', logger='current')
+ using_dist = dist.is_available() and dist.is_initialized()
+ if using_dist:
+ # monitored barrier requires gloo process group to perform host-side sync. # noqa
+ group_gloo = dist.new_group(
+ backend='gloo', timeout=xtuner_dataset_timeout)
+ if not using_dist or dist.get_rank() == 0:
+ objects = [dataset]
+ else:
+ objects = [None]
+ if using_dist:
+ dist.monitored_barrier(
+ group=group_gloo, timeout=xtuner_dataset_timeout)
+ dist.broadcast_object_list(objects, src=0)
+ return objects[0]
+
+
+def map_dataset(dataset, dataset_map_fn, map_num_proc):
+ if isinstance(dataset_map_fn, str):
+ map_fn_obj = MAP_FUNC.get(dataset_map_fn) or get_object_from_string(
+ dataset_map_fn)
+ if map_fn_obj is not None:
+ dataset_map_fn = map_fn_obj
+ else:
+ raise TypeError('dataset_map_fn must be a function or a '
+ "registered function's string in MAP_FUNC, "
+ f"but got a string of '{dataset_map_fn}'")
+
+ dataset = dataset.map(dataset_map_fn, num_proc=map_num_proc)
+ return dataset
+
+
+def build_preference_dataset(
+ dataset: str,
+ tokenizer: AutoTokenizer,
+ max_length: int,
+ dataset_map_fn: Callable = None,
+ is_dpo: bool = True,
+ is_reward: bool = False,
+ reward_token_id: int = -1,
+ num_proc: int = 32,
+ use_varlen_attn: bool = False,
+ max_packed_length: int = 16384,
+ shuffle_before_pack: bool = True,
+) -> Dataset:
+ using_dist = dist.is_available() and dist.is_initialized()
+ tokenized_ds = None
+ if not using_dist or dist.get_rank() == 0:
+ if isinstance(tokenizer, dict) or isinstance(
+ tokenizer, Config) or isinstance(tokenizer, ConfigDict):
+ tokenizer = BUILDER.build(tokenizer)
+
+ dataset = build_origin_dataset(dataset, split='train')
+ if dataset_map_fn is not None:
+ dataset = map_dataset(
+ dataset, dataset_map_fn, map_num_proc=num_proc)
+
+ tokenized_ds = PreferenceDataset(
+ dataset=dataset,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ is_dpo=is_dpo,
+ is_reward=is_reward,
+ reward_token_id=reward_token_id,
+ num_proc=num_proc,
+ )
+ if use_varlen_attn:
+ tokenized_ds = PackedDatasetWrapper(
+ dataset=tokenized_ds,
+ max_packed_length=max_packed_length,
+ shuffle_before_pack=shuffle_before_pack,
+ )
+ tokenized_ds = broad_cast_dataset(tokenized_ds)
+ return tokenized_ds
+
+
+def intel_orca_dpo_map_fn(example):
+ prompt = [{
+ 'role': 'system',
+ 'content': example['system']
+ }, {
+ 'role': 'user',
+ 'content': example['question']
+ }]
+ chosen = [{'role': 'assistant', 'content': example['chosen']}]
+ rejected = [{'role': 'assistant', 'content': example['rejected']}]
+ return {'prompt': prompt, 'chosen': chosen, 'rejected': rejected}
+
+
+def orpo_dpo_mix_40k_map_fn(example):
+ assert len(example['chosen']) == len(example['rejected'])
+ prompt = example['chosen'][:-1]
+ chosen = example['chosen'][-1:]
+ rejected = example['rejected'][-1:]
+ return {'prompt': prompt, 'chosen': chosen, 'rejected': rejected}
diff --git a/data/xtuner/xtuner/dataset/refcoco_json.py b/data/xtuner/xtuner/dataset/refcoco_json.py
new file mode 100644
index 0000000000000000000000000000000000000000..e32f08ae459a21697e5a1736ad8a19bafaf767e5
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/refcoco_json.py
@@ -0,0 +1,496 @@
+import copy
+import itertools
+import json
+import os
+import pickle
+import time
+from collections import defaultdict
+
+import matplotlib.pyplot as plt
+import numpy as np
+import skimage.io as io
+import torch
+from datasets import Dataset as HFDataset
+from datasets import DatasetDict
+from matplotlib.patches import Polygon, Rectangle
+from mmengine.config import Config, ConfigDict
+from PIL import Image
+
+from xtuner.registry import BUILDER
+from ..registry import BUILDER
+from .huggingface import process_hf_dataset
+from .llava import LLaVADataset
+from .utils import expand2square
+
+
+class RefCOCOJsonDataset(LLaVADataset):
+ instruction_pool = [
+ '[refer] {}',
+ '[refer] give me the location of {}',
+ '[refer] where is {} ?',
+ '[refer] from this image, tell me the location of {}',
+ '[refer] the location of {} is',
+ '[refer] could you tell me the location for {} ?',
+ '[refer] where can I locate the {} ?',
+ ]
+
+ def __init__(
+ self,
+ data_path,
+ image_folder,
+ tokenizer,
+ image_processor,
+ max_dataset_length=None,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ max_length=2048,
+ pad_image_to_square=False,
+ ):
+ json_data = json.load(open(data_path))
+
+ ######################################################
+ # Only this part is different from LLaVADataset.__init__
+ json_data = self.reformat_data(json_data)
+ ######################################################
+
+ for idx in range(len(json_data)):
+ if isinstance(json_data[idx]['id'], int):
+ json_data[idx]['id'] = str(json_data[idx]['id'])
+ json_data = DatasetDict({'train': HFDataset.from_list(json_data)})
+ self.text_data = process_hf_dataset(
+ dataset=json_data,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ split='train',
+ max_dataset_length=max_dataset_length,
+ remove_unused_columns=False,
+ pack_to_max_length=False,
+ with_image_token=True)
+
+ self.image_folder = image_folder
+ if isinstance(image_processor, dict) or isinstance(
+ image_processor, Config) or isinstance(image_processor,
+ ConfigDict):
+ self.image_processor = BUILDER.build(image_processor)
+ else:
+ self.image_processor = image_processor
+ self.pad_image_to_square = pad_image_to_square
+
+ def reformat_data(self, json_data):
+ new_json_data = []
+ for sample in json_data:
+ for instruction_template in self.instruction_pool:
+ sample['conversations'] = self.gen_refcoco_conversations(
+ sample, instruction_template)
+ new_json_data.append(copy.deepcopy(sample))
+ return new_json_data
+
+ @classmethod
+ def gen_refcoco_conversations(cls, data, instruction_template='{}'):
+ """build conversition data from refcoco json data as below.
+
+ "id": "xxx",
+ "image": "xxx.jpg",
+ "conversations": [
+ {
+ "from": "human",
+ "value": "xxxx"
+ },
+ {
+ "from": "gpt",
+ "value": "xxx"
+ }
+ """
+
+ conversation = [
+ {
+ 'from': 'human',
+ 'value': ''
+ },
+ {
+ 'from': 'gpt',
+ 'value': ''
+ },
+ ]
+
+ instruction = instruction_template.format(data['sents'])
+ bbox = cls.normalize_bbox(data['bbox'], data['height'], data['width'])
+ answer = '{{<{}><{}><{}><{}>}}'.format(bbox[0], bbox[1], bbox[2],
+ bbox[3])
+ conversation[0]['value'] = instruction + '\n'
+ conversation[1]['value'] = answer
+ return conversation
+
+ @classmethod
+ def get_data_json(
+ cls,
+ ann_path,
+ image_path,
+ dataset='refcoco',
+ splitBy='unc',
+ ):
+ refer = REFER(ann_path, image_path, dataset, splitBy)
+ ref_ids = refer.getRefIds(split='train')
+
+ data = {}
+ duplicate_data = defaultdict(list)
+
+ for ref_id in ref_ids:
+ ref = refer.loadRefs(ref_id)[0]
+
+ image_id = '{:0>12}'.format(ref['image_id'])
+ sents = [sent['raw'] for sent in ref['sentences']]
+ bbox = refer.getRefBox(ref['ref_id'])
+
+ image = Image.open(image_path + '/' + image_id + '.jpg')
+
+ for sent in sents:
+ sent_id = '_'.join(sent.split(' '))
+ data_id = f'{dataset}-{splitBy}-{image_id}-{sent_id}'
+ data_item = {
+ 'id': data_id,
+ 'image': 'coco/train2017/' + image_id + '.jpg',
+ 'sents': sent,
+ 'bbox': bbox,
+ 'height': image.height,
+ 'width': image.width
+ }
+ if data_id in data:
+ duplicate_data[data_id].append(data_item)
+ else:
+ data[data_id] = data_item
+
+ return list(data.values()), list(duplicate_data.values())
+
+ @classmethod
+ def normalize_bbox(cls, bbox, height, width):
+ x, y, w, h = bbox
+
+ bbox = [x / width, y / height, (x + w) / width, (y + h) / height]
+ bbox = [int(x * 100) for x in bbox]
+ return bbox
+
+
+class RefCOCOJsonEvalDataset(RefCOCOJsonDataset):
+ instruction_pool = ['[refer] give me the location of {}']
+
+ def reformat_data(self, json_data):
+ for sample in json_data:
+ # reformat img_id
+ img_id = sample['img_id'].split('_')[-2]
+ sample['image'] = 'coco/train2017/' + img_id + '.jpg'
+ sample['id'] = f"{img_id}-{sample['sents']}"
+ return super().reformat_data(json_data)
+
+
+class InvRefCOCOJsonDataset(RefCOCOJsonDataset):
+ instruction_pool = [
+ '[identify] {}',
+ '[identify] what object is in this location {}',
+ '[identify] identify the object present at this location {}',
+ '[identify] what is it in {}',
+ '[identify] describe this object in {}',
+ '[identify] this {} is',
+ '[identify] the object in {} is',
+ ]
+
+ @classmethod
+ def gen_refcoco_conversations(cls, data, instruction_template='{}'):
+ """build conversition data from refcoco json data as below.
+
+ "id": "xxx",
+ "image": "xxx.jpg",
+ "conversations": [
+ {
+ "from": "human",
+ "value": "xxxx"
+ },
+ {
+ "from": "gpt",
+ "value": "xxx"
+ }
+ """
+
+ conversation = [
+ {
+ 'from': 'human',
+ 'value': ''
+ },
+ {
+ 'from': 'gpt',
+ 'value': ''
+ },
+ ]
+ bbox = cls.normalize_bbox(data['bbox'], data['height'], data['width'])
+ bbox_str = '{{<{}><{}><{}><{}>}}'.format(bbox[0], bbox[1], bbox[2],
+ bbox[3])
+ instruction = instruction_template.format(bbox_str)
+ answer = data['sents']
+
+ conversation[0]['value'] = instruction + '\n'
+ conversation[1]['value'] = answer
+ return conversation
+
+
+# flake8: noqa
+# Refer
+
+
+class REFER:
+
+ def __init__(self, data_root, vis_root, dataset='refcoco', splitBy='unc'):
+ # provide data_root folder which contains refclef, refcoco, refcoco+ and refcocog
+ # also provide dataset name and splitBy information
+ # e.g., dataset = 'refcoco', splitBy = 'unc'
+ # inv dataset is stored in the same path as normal dataset
+ dataset = dataset.split('inv')[-1]
+ print('loading dataset %s into memory...' % dataset)
+ self.ann_dir = os.path.join(data_root, dataset)
+ if dataset in ['refcoco', 'refcoco+', 'refcocog']:
+ self.vis_root = vis_root
+ elif dataset == 'refclef':
+ raise 'No RefClef image data'
+ else:
+ raise 'No refer dataset is called [%s]' % dataset
+
+ # load refs from data/dataset/refs(dataset).json
+ tic = time.time()
+ ref_file = os.path.join(self.ann_dir, 'refs(' + splitBy + ').p')
+ self.data = {}
+ self.data['dataset'] = dataset
+ self.data['refs'] = pickle.load(open(ref_file, 'rb'))
+
+ # load annotations from data/dataset/instances.json
+ instances_file = os.path.join(self.ann_dir, 'instances.json')
+ instances = json.load(open(instances_file))
+ self.data['images'] = instances['images']
+ self.data['annotations'] = instances['annotations']
+ self.data['categories'] = instances['categories']
+
+ # create index
+ self.createIndex()
+ print('DONE (t=%.2fs)' % (time.time() - tic))
+
+ def createIndex(self):
+ # create sets of mapping
+ # 1) Refs: {ref_id: ref}
+ # 2) Anns: {ann_id: ann}
+ # 3) Imgs: {image_id: image}
+ # 4) Cats: {category_id: category_name}
+ # 5) Sents: {sent_id: sent}
+ # 6) imgToRefs: {image_id: refs}
+ # 7) imgToAnns: {image_id: anns}
+ # 8) refToAnn: {ref_id: ann}
+ # 9) annToRef: {ann_id: ref}
+ # 10) catToRefs: {category_id: refs}
+ # 11) sentToRef: {sent_id: ref}
+ # 12) sentToTokens: {sent_id: tokens}
+ print('creating index...')
+ # fetch info from instances
+ Anns, Imgs, Cats, imgToAnns = {}, {}, {}, {}
+ for ann in self.data['annotations']:
+ Anns[ann['id']] = ann
+ imgToAnns[ann['image_id']] = imgToAnns.get(ann['image_id'],
+ []) + [ann]
+ for img in self.data['images']:
+ Imgs[img['id']] = img
+ for cat in self.data['categories']:
+ Cats[cat['id']] = cat['name']
+
+ # fetch info from refs
+ Refs, imgToRefs, refToAnn, annToRef, catToRefs = {}, {}, {}, {}, {}
+ Sents, sentToRef, sentToTokens = {}, {}, {}
+ for ref in self.data['refs']:
+ # ids
+ ref_id = ref['ref_id']
+ ann_id = ref['ann_id']
+ category_id = ref['category_id']
+ image_id = ref['image_id']
+
+ # add mapping related to ref
+ Refs[ref_id] = ref
+ imgToRefs[image_id] = imgToRefs.get(image_id, []) + [ref]
+ catToRefs[category_id] = catToRefs.get(category_id, []) + [ref]
+ refToAnn[ref_id] = Anns[ann_id]
+ annToRef[ann_id] = ref
+
+ # add mapping of sent
+ for sent in ref['sentences']:
+ Sents[sent['sent_id']] = sent
+ sentToRef[sent['sent_id']] = ref
+ sentToTokens[sent['sent_id']] = sent['tokens']
+
+ # create class members
+ self.Refs = Refs
+ self.Anns = Anns
+ self.Imgs = Imgs
+ self.Cats = Cats
+ self.Sents = Sents
+ self.imgToRefs = imgToRefs
+ self.imgToAnns = imgToAnns
+ self.refToAnn = refToAnn
+ self.annToRef = annToRef
+ self.catToRefs = catToRefs
+ self.sentToRef = sentToRef
+ self.sentToTokens = sentToTokens
+ print('index created.')
+
+ def getRefIds(self, image_ids=[], cat_ids=[], ref_ids=[], split=''):
+ image_ids = image_ids if type(image_ids) == list else [image_ids]
+ cat_ids = cat_ids if type(cat_ids) == list else [cat_ids]
+ ref_ids = ref_ids if type(ref_ids) == list else [ref_ids]
+
+ if len(image_ids) == len(cat_ids) == len(ref_ids) == len(split) == 0:
+ refs = self.data['refs']
+ else:
+ if not len(image_ids) == 0:
+ refs = [self.imgToRefs[image_id] for image_id in image_ids]
+ else:
+ refs = self.data['refs']
+ if not len(cat_ids) == 0:
+ refs = [ref for ref in refs if ref['category_id'] in cat_ids]
+ if not len(ref_ids) == 0:
+ refs = [ref for ref in refs if ref['ref_id'] in ref_ids]
+ if not len(split) == 0:
+ if split in ['testA', 'testB', 'testC']:
+ refs = [ref for ref in refs if split[-1] in ref['split']
+ ] # we also consider testAB, testBC, ...
+ elif split in ['testAB', 'testBC', 'testAC']:
+ # rarely used I guess...
+ refs = [ref for ref in refs if ref['split'] == split]
+ elif split == 'test':
+ refs = [ref for ref in refs if 'test' in ref['split']]
+ elif split == 'train' or split == 'val':
+ refs = [ref for ref in refs if ref['split'] == split]
+ else:
+ raise 'No such split [%s]' % split
+ ref_ids = [ref['ref_id'] for ref in refs]
+ return ref_ids
+
+ def getAnnIds(self, image_ids=[], cat_ids=[], ref_ids=[]):
+ image_ids = image_ids if type(image_ids) == list else [image_ids]
+ cat_ids = cat_ids if type(cat_ids) == list else [cat_ids]
+ ref_ids = ref_ids if type(ref_ids) == list else [ref_ids]
+
+ if len(image_ids) == len(cat_ids) == len(ref_ids) == 0:
+ ann_ids = [ann['id'] for ann in self.data['annotations']]
+ else:
+ if not len(image_ids) == 0:
+ lists = [
+ self.imgToAnns[image_id] for image_id in image_ids
+ if image_id in self.imgToAnns
+ ] # list of [anns]
+ anns = list(itertools.chain.from_iterable(lists))
+ else:
+ anns = self.data['annotations']
+ if not len(cat_ids) == 0:
+ anns = [ann for ann in anns if ann['category_id'] in cat_ids]
+ ann_ids = [ann['id'] for ann in anns]
+ if not len(ref_ids) == 0:
+ ids = set(ann_ids).intersection(
+ {self.Refs[ref_id]['ann_id']
+ for ref_id in ref_ids})
+ return ann_ids
+
+ def getImgIds(self, ref_ids=[]):
+ ref_ids = ref_ids if type(ref_ids) == list else [ref_ids]
+
+ if not len(ref_ids) == 0:
+ image_ids = list(
+ {self.Refs[ref_id]['image_id']
+ for ref_id in ref_ids})
+ else:
+ image_ids = self.Imgs.keys()
+ return image_ids
+
+ def getCatIds(self):
+ return self.Cats.keys()
+
+ def loadRefs(self, ref_ids=[]):
+ if type(ref_ids) == list:
+ return [self.Refs[ref_id] for ref_id in ref_ids]
+ elif type(ref_ids) == int:
+ return [self.Refs[ref_ids]]
+
+ def loadAnns(self, ann_ids=[]):
+ if type(ann_ids) == list:
+ return [self.Anns[ann_id] for ann_id in ann_ids]
+ elif type(ann_ids) == int:
+ return [self.Anns[ann_ids]]
+
+ def loadImgs(self, image_ids=[]):
+ if type(image_ids) == list:
+ return [self.Imgs[image_id] for image_id in image_ids]
+ elif type(image_ids) == int:
+ return [self.Imgs[image_ids]]
+
+ def loadCats(self, cat_ids=[]):
+ if type(cat_ids) == list:
+ return [self.Cats[cat_id] for cat_id in cat_ids]
+ elif type(cat_ids) == int:
+ return [self.Cats[cat_ids]]
+
+ def getRefBox(self, ref_id):
+ ref = self.Refs[ref_id]
+ ann = self.refToAnn[ref_id]
+ return ann['bbox'] # [x, y, w, h]
+
+ def showRef(self, ref, seg_box='box'):
+ from matplotlib.collectns import PatchCollection
+
+ ax = plt.gca()
+ # show image
+ image = self.Imgs[ref['image_id']]
+ I = io.imread(os.path.join(self.vis_root, image['file_name']))
+ ax.imshow(I)
+ # show refer expression
+ for sid, sent in enumerate(ref['sentences']):
+ print('{}. {}'.format(sid + 1, sent['sent']))
+ # show segmentations
+ if seg_box == 'seg':
+ ann_id = ref['ann_id']
+ ann = self.Anns[ann_id]
+ polygons = []
+ color = []
+ c = 'none'
+ if type(ann['segmentation'][0]) == list:
+ # polygon used for refcoco*
+ for seg in ann['segmentation']:
+ poly = np.array(seg).reshape((len(seg) / 2, 2))
+ polygons.append(Polygon(poly, True, alpha=0.4))
+ color.append(c)
+ p = PatchCollection(
+ polygons,
+ facecolors=color,
+ edgecolors=(1, 1, 0, 0),
+ linewidths=3,
+ alpha=1,
+ )
+ ax.add_collection(p) # thick yellow polygon
+ p = PatchCollection(
+ polygons,
+ facecolors=color,
+ edgecolors=(1, 0, 0, 0),
+ linewidths=1,
+ alpha=1,
+ )
+ ax.add_collection(p) # thin red polygon
+ else:
+ # mask used for refclef
+ raise NotImplementedError('RefClef is not downloaded')
+ # show bounding-box
+ elif seg_box == 'box':
+ ann_id = ref['ann_id']
+ ann = self.Anns[ann_id]
+ bbox = self.getRefBox(ref['ref_id'])
+ box_plot = Rectangle(
+ (bbox[0], bbox[1]),
+ bbox[2],
+ bbox[3],
+ fill=False,
+ edgecolor='green',
+ linewidth=3,
+ )
+ ax.add_patch(box_plot)
diff --git a/data/xtuner/xtuner/dataset/samplers/__init__.py b/data/xtuner/xtuner/dataset/samplers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8afc9bc1e2bbaae2e00a530302c24106400f2ace
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/samplers/__init__.py
@@ -0,0 +1,4 @@
+from .intern_repo import InternlmRepoSampler, InternRepoSampler
+from .length_grouped import LengthGroupedSampler
+
+__all__ = ['LengthGroupedSampler', 'InternRepoSampler', 'InternlmRepoSampler']
diff --git a/data/xtuner/xtuner/dataset/samplers/intern_repo.py b/data/xtuner/xtuner/dataset/samplers/intern_repo.py
new file mode 100644
index 0000000000000000000000000000000000000000..933719a58e5c8efa46d14bc5080bd7ed1e9b0ce4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/samplers/intern_repo.py
@@ -0,0 +1,81 @@
+import logging
+import warnings
+from typing import Iterator, Optional, Sized
+
+import numpy as np
+from mmengine import print_log
+from torch.utils.data import Sampler
+
+from xtuner.parallel.sequence import (get_data_parallel_rank,
+ get_data_parallel_world_size)
+
+
+class InternRepoSampler(Sampler):
+
+ def __init__(self,
+ dataset: Sized,
+ shuffle: bool = True,
+ seed: Optional[int] = None) -> None:
+ if seed is not None and seed != 1024:
+ warnings.warn('For alignment accuracy, seed in InternRepoSampler'
+ 'must be set to 1024.')
+ world_size = get_data_parallel_world_size()
+ rank = get_data_parallel_rank()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.shuffle = shuffle
+ self.seed = 1024
+ self.epoch = 0
+
+ self.num_samples = len(self.dataset) // world_size
+ self.total_size = self.num_samples * world_size
+
+ def __iter__(self) -> Iterator[int]:
+ """Iterate the indices."""
+ # deterministically shuffle based on epoch and seed
+ if self.shuffle:
+ rng = np.random.RandomState(self.seed + self.epoch)
+ indices = np.arange(len(self.dataset))
+ rng.shuffle(indices)
+ indices = indices.tolist()
+ else:
+ indices = np.arange(len(self.dataset)).tolist()
+
+ self.indices = indices[:self.total_size]
+
+ # subsample
+ indices = indices[self.rank:self.total_size:self.world_size]
+ self.subsample_indices = indices
+
+ return iter(indices)
+
+ def __len__(self) -> int:
+ """The number of samples in this rank."""
+ return self.num_samples
+
+ def set_epoch(self, epoch: int) -> None:
+ """Sets the epoch for this sampler.
+
+ When :attr:`shuffle=True`, this ensures all replicas use a different
+ random ordering for each epoch. Otherwise, the next iteration of this
+ sampler will yield the same ordering.
+
+ Args:
+ epoch (int): Epoch number.
+ """
+ self.epoch = epoch
+
+
+class InternlmRepoSampler(InternRepoSampler):
+
+ def __init__(self,
+ dataset: Sized,
+ shuffle: bool = True,
+ seed: Optional[int] = None) -> None:
+ super().__init__(dataset, shuffle, seed)
+ print_log(('InternlmRepoSampler will be deprecated in the future.'
+ 'Please use InternRepoSampler instead.'),
+ logger='current',
+ level=logging.WARNING)
diff --git a/data/xtuner/xtuner/dataset/samplers/length_grouped.py b/data/xtuner/xtuner/dataset/samplers/length_grouped.py
new file mode 100644
index 0000000000000000000000000000000000000000..184827837cf062972d6b024940ba6d252577efd4
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/samplers/length_grouped.py
@@ -0,0 +1,164 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Iterator, Optional, Sized
+
+import torch
+from mmengine.dist import get_dist_info, sync_random_seed
+from mmengine.logging import print_log
+from torch.utils.data import ConcatDataset as TorchConcatDataset
+from torch.utils.data import Sampler
+
+
+def get_length_grouped_indices(lengths, group_batch_size, generator=None):
+
+ def process(lengths, group_batch_size, generator=None):
+ indices = torch.randperm(len(lengths), generator=generator)
+ megabatches = [
+ indices[i:i + group_batch_size].tolist()
+ for i in range(0, len(lengths), group_batch_size)
+ ]
+ megabatches = [
+ sorted(megabatch, key=lambda i: lengths[i], reverse=True)
+ for megabatch in megabatches
+ ]
+ return megabatches
+
+ assert all(leng != 0 for leng in lengths), 'Should not have zero length.'
+ if all(leng > 0 for leng in lengths) or all(leng < 0 for leng in lengths):
+ # all samples are in the same modality
+ megabatches = process(lengths, group_batch_size, generator=generator)
+ else:
+ mm_indices, mm_lengths = zip(*[(i, l) for i, l in enumerate(lengths)
+ if l > 0])
+ lang_indices, lang_lengths = zip(*[(i, -l)
+ for i, l in enumerate(lengths)
+ if l < 0])
+ mm_megabatches = []
+ for mm_megabatch in process(
+ mm_lengths, group_batch_size, generator=generator):
+ mm_megabatches.append([mm_indices[i] for i in mm_megabatch])
+ lang_megabatches = []
+ for lang_megabatch in process(
+ lang_lengths, group_batch_size, generator=generator):
+ lang_megabatches.append([lang_indices[i] for i in lang_megabatch])
+
+ last_mm = mm_megabatches[-1]
+ last_lang = lang_megabatches[-1]
+ last_batch = last_mm + last_lang
+ megabatches = mm_megabatches[:-1] + lang_megabatches[:-1]
+
+ megabatch_indices = torch.randperm(
+ len(megabatches), generator=generator)
+ megabatches = [megabatches[i] for i in megabatch_indices]
+
+ if len(last_batch) > 0:
+ megabatches.append(
+ sorted(
+ last_batch, key=lambda i: abs(lengths[i]), reverse=True))
+
+ # The rest is to get the biggest batch first.
+ # Since each megabatch is sorted by descending length,
+ # the longest element is the first
+ megabatch_maximums = [
+ abs(lengths[megabatch[0]]) for megabatch in megabatches
+ ]
+ max_idx = torch.argmax(torch.tensor(megabatch_maximums)).item()
+ # Switch to put the longest element in first position
+ megabatches[0][0], megabatches[max_idx][0] = megabatches[max_idx][
+ 0], megabatches[0][0]
+
+ return [i for megabatch in megabatches for i in megabatch]
+
+
+class LengthGroupedSampler(Sampler):
+
+ def __init__(self,
+ dataset: Sized,
+ per_device_batch_size: int,
+ length_property='length',
+ mega_batch_mult: Optional[int] = None,
+ seed: Optional[int] = None,
+ round_up: bool = True) -> None:
+ print_log('LengthGroupedSampler is used.', logger='current')
+ rank, world_size = get_dist_info()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ if seed is None:
+ seed = sync_random_seed()
+ self.seed = seed
+ self.epoch = 0
+ self.round_up = round_up
+
+ if self.round_up:
+ num_iters = math.ceil(
+ len(self.dataset) / world_size / per_device_batch_size)
+ self.num_samples = num_iters * per_device_batch_size
+ self.total_size = self.num_samples * self.world_size
+ else:
+ self.num_samples = math.ceil(
+ (len(self.dataset) - rank) / world_size)
+ self.total_size = len(self.dataset)
+
+ total_batch_size = per_device_batch_size * self.world_size
+ if mega_batch_mult is None:
+ # Default for mega_batch_mult: 50 or the number to get 4
+ # megabatches, whichever is smaller.
+ mega_batch_mult = min(
+ len(self.dataset) // (total_batch_size * 4), 50)
+ # Just in case, for tiny datasets
+ if mega_batch_mult == 0:
+ mega_batch_mult = 1
+ self.group_batch_size = mega_batch_mult * total_batch_size
+
+ if isinstance(self.dataset, TorchConcatDataset):
+ length = []
+ for sub_dataset in self.dataset.datasets:
+ length.extend(getattr(sub_dataset, length_property))
+ self.length = length
+ else:
+ self.length = getattr(self.dataset, length_property)
+ assert isinstance(self.length, (list, tuple))
+
+ self.total_batch_size = total_batch_size
+ print_log(
+ f'LengthGroupedSampler construction is complete, '
+ f'and the selected attribute is {length_property}',
+ logger='current')
+
+ def __iter__(self) -> Iterator[int]:
+ """Iterate the indices."""
+ generator = torch.Generator()
+ generator.manual_seed(self.seed + self.epoch)
+ indices = get_length_grouped_indices(
+ lengths=self.length,
+ group_batch_size=self.group_batch_size,
+ generator=generator)
+ assert len(set(indices)) == len(indices)
+ # add extra samples to make it evenly divisible
+ if self.round_up:
+ indices = (
+ indices *
+ int(self.total_size / len(indices) + 1))[:self.total_size]
+ # subsample
+ assert len(indices) == self.total_size
+ indices = indices[self.rank:self.total_size:self.world_size]
+ assert len(indices) == self.num_samples
+ return iter(indices)
+
+ def __len__(self) -> int:
+ """The number of samples in this rank."""
+ return self.num_samples
+
+ def set_epoch(self, epoch: int) -> None:
+ """Sets the epoch for this sampler.
+
+ When :attr:`shuffle=True`, this ensures all replicas use a different
+ random ordering for each epoch. Otherwise, the next iteration of this
+ sampler will yield the same ordering.
+
+ Args:
+ epoch (int): Epoch number.
+ """
+ self.epoch = epoch
diff --git a/data/xtuner/xtuner/dataset/utils.py b/data/xtuner/xtuner/dataset/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..84336ddb2f61e53535ef57f5b8660279cabda055
--- /dev/null
+++ b/data/xtuner/xtuner/dataset/utils.py
@@ -0,0 +1,271 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import base64
+import copy
+import io
+from io import BytesIO
+from itertools import chain
+
+import numpy as np
+import requests
+from PIL import Image
+
+from xtuner.utils import DEFAULT_IMAGE_TOKEN, IGNORE_INDEX, IMAGE_TOKEN_INDEX
+
+
+def get_bos_eos_token_ids(tokenizer):
+ if tokenizer.__class__.__name__ in [
+ 'QWenTokenizer', 'QWen2Tokenizer', 'Qwen2TokenizerFast'
+ ]:
+ bos_token_id = []
+ eos_token_id = tokenizer.eos_token_id
+ assert eos_token_id is not None, \
+ 'Please set eos_token for Qwen tokenizer!'
+ elif tokenizer.__class__.__name__ == 'ChatGLMTokenizer':
+ bos_token_id = [64790, 64792]
+ eos_token_id = tokenizer.eos_token_id
+ else:
+ bos_token_id = tokenizer.bos_token_id
+ eos_token_id = tokenizer.eos_token_id
+ if isinstance(bos_token_id, int):
+ bos_token_id = [bos_token_id]
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ return bos_token_id, eos_token_id
+
+
+def encode_fn(example,
+ tokenizer,
+ max_length,
+ input_ids_with_output=True,
+ with_image_token=False):
+ """We only support the following three scenarios:
+
+ 1. Incremental pretraining dataset.
+ example['conversation'] = [
+ {
+ 'input': '',
+ 'output': '### Human: Can you write xxx'
+ }
+ ]
+
+ 2. Single-turn conversation dataset.
+ example['conversation'] = [
+ {
+ 'input': 'Give three tips for staying healthy.',
+ 'output': '1.Eat a balanced diet xxx'
+ }
+ ]
+
+ 3. Multi-turn conversation dataset.
+ example['conversation'] = [
+ {
+ 'input': 'Give three tips for staying healthy.',
+ 'output': '1.Eat a balanced diet xxx'
+ },
+ {
+ 'input': 'Please expand on the second point.',
+ 'output': 'Here is an expanded explanation of the xxx'
+ }
+ ]
+ """
+ bos_token_id, eos_token_id = get_bos_eos_token_ids(tokenizer)
+ is_multi_turn_conversation = len(example['conversation']) > 1
+ if is_multi_turn_conversation:
+ assert input_ids_with_output
+
+ input_ids, labels = [], []
+ next_needs_bos_token = True
+ for single_turn_conversation in example['conversation']:
+ input = single_turn_conversation['input']
+ if DEFAULT_IMAGE_TOKEN in input and with_image_token:
+ chunk_encode = [
+ tokenizer.encode(chunk, add_special_tokens=False)
+ for chunk in input.split(DEFAULT_IMAGE_TOKEN)
+ ]
+ assert len(chunk_encode) == 2
+ input_encode = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ input_encode.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ input_encode.append(IMAGE_TOKEN_INDEX)
+ else:
+ input_encode = tokenizer.encode(input, add_special_tokens=False)
+ if next_needs_bos_token:
+ input_ids += bos_token_id
+ labels += [IGNORE_INDEX] * len(bos_token_id)
+ input_ids += input_encode
+ labels += [IGNORE_INDEX] * len(input_encode)
+ if input_ids_with_output:
+ # Add output
+ output_with_loss = single_turn_conversation.get(
+ 'output_with_loss', True)
+ output = single_turn_conversation['output']
+ output_encode = tokenizer.encode(output, add_special_tokens=False)
+ input_ids += output_encode
+ if output_with_loss:
+ labels += copy.deepcopy(output_encode)
+ else:
+ labels += [IGNORE_INDEX] * len(output_encode)
+ # Add EOS_TOKEN (with loss)
+ if single_turn_conversation.get('need_eos_token', True):
+ next_needs_bos_token = True
+ input_ids += eos_token_id
+ if output_with_loss:
+ labels += copy.deepcopy(eos_token_id)
+ else:
+ labels += [IGNORE_INDEX] * len(eos_token_id)
+ else:
+ next_needs_bos_token = False
+ # Add SEP (without loss)
+ sep = single_turn_conversation.get('sep', '')
+ if sep != '':
+ sep_encode = tokenizer.encode(sep, add_special_tokens=False)
+ input_ids += sep_encode
+ labels += [IGNORE_INDEX] * len(sep_encode)
+
+ if len(input_ids) > max_length:
+ input_ids = input_ids[:max_length]
+ labels = labels[:max_length]
+ return {'input_ids': input_ids, 'labels': labels}
+
+
+class Packer:
+ """Pack multiple pieces of data into one."""
+
+ def __init__(self,
+ chunk_size=2048,
+ use_varlen_attn=False,
+ drop_last=False):
+ self.chunk_size = chunk_size
+ self.residual = {'input_ids': [], 'labels': []}
+ self.use_varlen_attn = use_varlen_attn
+ self.drop_last = drop_last
+ if use_varlen_attn:
+ self.residual_cumulative_len = [0]
+
+ def get_cumulative_len(self, chunk_num):
+ ptr_l = 0
+ cumulative_len = []
+ for chunk_idx in range(chunk_num):
+ length_train = (chunk_idx + 1) * self.chunk_size
+ ptr_r = np.searchsorted(
+ self.residual_cumulative_len, length_train, side='left')
+ if self.residual_cumulative_len[ptr_r] == length_train:
+ cumulative_len_cur = \
+ self.residual_cumulative_len[ptr_l:ptr_r + 1]
+ ptr_l = ptr_r + 1
+ else:
+ cumulative_len_cur = self.residual_cumulative_len[
+ ptr_l:ptr_r] + [length_train]
+ ptr_l = ptr_r
+ cumulative_len_cur = [
+ num - chunk_idx * self.chunk_size for num in cumulative_len_cur
+ ]
+ if cumulative_len_cur[0] != 0:
+ cumulative_len_cur = [0] + cumulative_len_cur
+
+ cumulative_len.append(cumulative_len_cur)
+
+ self.residual_cumulative_len = [
+ num - length_train for num in self.residual_cumulative_len[ptr_l:]
+ ]
+ if len(self.residual_cumulative_len) == 0:
+ self.residual_cumulative_len = [0]
+ elif self.residual_cumulative_len[0] != 0:
+ self.residual_cumulative_len = [0] + self.residual_cumulative_len
+
+ return cumulative_len
+
+ def get_position_ids(self, cumulative_len):
+ position_ids = []
+ for cumulative_len_cur in cumulative_len:
+ index_cur = []
+ for i in range(len(cumulative_len_cur) - 1):
+ index_cur.extend(
+ list(
+ range(cumulative_len_cur[i + 1] - # noqa: W504
+ cumulative_len_cur[i])))
+ position_ids.append(index_cur)
+ return position_ids
+
+ def __call__(self, batch):
+ concatenated_samples = {
+ k: v + list(chain(*batch[k]))
+ for k, v in self.residual.items()
+ }
+
+ if self.use_varlen_attn:
+ for input_id in batch['input_ids']:
+ self.residual_cumulative_len.append(
+ self.residual_cumulative_len[-1] + len(input_id))
+
+ total_length = len(concatenated_samples[list(
+ concatenated_samples.keys())[0]])
+
+ if total_length >= self.chunk_size:
+ chunk_num = total_length // self.chunk_size
+ result = {
+ k: [
+ v[i:i + self.chunk_size] for i in range(
+ 0,
+ chunk_num * # noqa: W504
+ self.chunk_size,
+ self.chunk_size)
+ ]
+ for k, v in concatenated_samples.items()
+ }
+ self.residual = {
+ k: v[(chunk_num * self.chunk_size):]
+ for k, v in concatenated_samples.items()
+ }
+
+ if self.use_varlen_attn:
+ cumulative_len = self.get_cumulative_len(chunk_num)
+ result['cumulative_len'] = cumulative_len
+ result['position_ids'] = self.get_position_ids(cumulative_len)
+ else:
+ if self.drop_last:
+ result = {k: [] for k, v in concatenated_samples.items()}
+ else:
+ result = {k: [v] for k, v in concatenated_samples.items()}
+
+ self.residual = {k: [] for k in concatenated_samples.keys()}
+
+ if self.use_varlen_attn:
+ result['cumulative_len'] = [] if self.drop_last else [
+ self.residual_cumulative_len
+ ]
+ result['position_ids'] = [] if self.drop_last \
+ else self.get_position_ids([self.residual_cumulative_len])
+ self.residual_cumulative_len = [0]
+
+ return result
+
+
+def expand2square(pil_img, background_color):
+ width, height = pil_img.size
+ if width == height:
+ return pil_img
+ elif width > height:
+ result = Image.new(pil_img.mode, (width, width), background_color)
+ result.paste(pil_img, (0, (width - height) // 2))
+ return result
+ else:
+ result = Image.new(pil_img.mode, (height, height), background_color)
+ result.paste(pil_img, ((height - width) // 2, 0))
+ return result
+
+
+def load_image(image_file):
+ if image_file.startswith('http://') or image_file.startswith('https://'):
+ response = requests.get(image_file)
+ image = Image.open(BytesIO(response.content)).convert('RGB')
+ else:
+ image = Image.open(image_file).convert('RGB')
+ return image
+
+
+def decode_base64_to_image(base64_string):
+ image_data = base64.b64decode(base64_string)
+ image = Image.open(io.BytesIO(image_data))
+ return image
diff --git a/data/xtuner/xtuner/engine/__init__.py b/data/xtuner/xtuner/engine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f50972ea9f16cf0089683769475fe7043455319
--- /dev/null
+++ b/data/xtuner/xtuner/engine/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from ._strategy import DeepSpeedStrategy
+from .hooks import (DatasetInfoHook, EvaluateChatHook, ThroughputHook,
+ VarlenAttnArgsToMessageHubHook)
+from .runner import TrainLoop
+
+__all__ = [
+ 'EvaluateChatHook', 'DatasetInfoHook', 'ThroughputHook',
+ 'VarlenAttnArgsToMessageHubHook', 'DeepSpeedStrategy', 'TrainLoop'
+]
diff --git a/data/xtuner/xtuner/engine/_strategy/__init__.py b/data/xtuner/xtuner/engine/_strategy/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..bac6095f977fa39655deb1d95c67d2e641e274b4
--- /dev/null
+++ b/data/xtuner/xtuner/engine/_strategy/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .deepspeed import DeepSpeedStrategy
+
+__all__ = ['DeepSpeedStrategy']
diff --git a/data/xtuner/xtuner/engine/_strategy/deepspeed.py b/data/xtuner/xtuner/engine/_strategy/deepspeed.py
new file mode 100644
index 0000000000000000000000000000000000000000..42b7f5590dc67f1a252ea8331220700845e05584
--- /dev/null
+++ b/data/xtuner/xtuner/engine/_strategy/deepspeed.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+from mmengine._strategy import DeepSpeedStrategy as MMEngineDeepSpeedStrategy
+
+from xtuner import DS_CEPH_DIR
+from xtuner.parallel.sequence import init_sequence_parallel
+from xtuner.utils.fileio import patch_fileio
+
+
+class DeepSpeedStrategy(MMEngineDeepSpeedStrategy):
+
+ def __init__(self, *args, **kwargs):
+ sequence_parallel_size = kwargs.pop('sequence_parallel_size', 1)
+ self.sequence_parallel_size = sequence_parallel_size
+
+ super().__init__(*args, **kwargs)
+
+ from transformers.integrations.deepspeed import HfDeepSpeedConfig
+
+ # hf_deepspeed_config has to be saved as an attribute.
+ self.hf_deepspeed_config = HfDeepSpeedConfig(self.config)
+
+ def _wrap_model(self, model):
+ wrapper = super()._wrap_model(model)
+ # hard code for deepspeed zero3
+ # When utilizing Zero3, the model isn't allocated to CUDA within the
+ # `deepspeed.initialize` process.
+ assert hasattr(wrapper.model, 'data_preprocessor')
+ wrapper.model.data_preprocessor.cuda()
+ return wrapper
+
+ def save_checkpoint(self, *args, **kwargs) -> None:
+ if DS_CEPH_DIR:
+ from os import path as osp
+ work_dir_prefix = osp.split(self.work_dir)[0]
+
+ filename = kwargs['filename'].replace(work_dir_prefix, DS_CEPH_DIR)
+ kwargs['filename'] = filename
+ with patch_fileio():
+ super().save_checkpoint(*args, **kwargs)
+ else:
+ super().save_checkpoint(*args, **kwargs)
+
+ def load_checkpoint(self, *args, **kwargs) -> None:
+ if DS_CEPH_DIR:
+
+ with patch_fileio():
+ checkpoint = super().load_checkpoint(*args, **kwargs)
+ else:
+ checkpoint = super().load_checkpoint(*args, **kwargs)
+ return checkpoint
+
+ def resume(self, *args, **kwargs) -> None:
+ if DS_CEPH_DIR:
+
+ with patch_fileio():
+ checkpoint = super().resume(*args, **kwargs)
+ else:
+ checkpoint = super().resume(*args, **kwargs)
+ return checkpoint
+
+ def _setup_distributed( # type: ignore
+ self,
+ launcher: Optional[str] = None,
+ backend: str = 'nccl',
+ **kwargs,
+ ):
+ super()._setup_distributed(launcher, backend, **kwargs)
+ init_sequence_parallel(self.sequence_parallel_size)
diff --git a/data/xtuner/xtuner/engine/hooks/__init__.py b/data/xtuner/xtuner/engine/hooks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..90262425d16e198429ec0d36029a52c9fbdd8ef2
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dataset_info_hook import DatasetInfoHook
+from .evaluate_chat_hook import EvaluateChatHook
+from .hf_checkpoint_hook import HFCheckpointHook
+from .throughput_hook import ThroughputHook
+from .varlen_attn_args_to_messagehub_hook import VarlenAttnArgsToMessageHubHook
+
+__all__ = [
+ 'EvaluateChatHook', 'DatasetInfoHook', 'ThroughputHook',
+ 'VarlenAttnArgsToMessageHubHook', 'HFCheckpointHook'
+]
diff --git a/data/xtuner/xtuner/engine/hooks/dataset_info_hook.py b/data/xtuner/xtuner/engine/hooks/dataset_info_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..84dc9498a4ce0aa2cc8175c9e317e1a35ca13fc9
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/dataset_info_hook.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.hooks import Hook
+
+from xtuner.registry import BUILDER
+from xtuner.utils import DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX
+
+
+def split_list(lst, value):
+ res = []
+ tmp_res = []
+ for i in lst:
+ if i == value:
+ res.append(tmp_res)
+ tmp_res = []
+ else:
+ tmp_res.append(i)
+ res.append(tmp_res)
+ return res
+
+
+class DatasetInfoHook(Hook):
+
+ def __init__(self, tokenizer, is_intern_repo_dataset=False):
+ self.tokenizer = BUILDER.build(tokenizer)
+ self.is_intern_repo_dataset = is_intern_repo_dataset
+
+ def log(self, runner, dataset, mode='train'):
+
+ def _log(input_ids, log_prefix=''):
+ if self.is_intern_repo_dataset:
+ input_ids = [abs(x) for x in input_ids]
+ # Try to split list to be compatible with IMAGE token
+ input_ids = split_list(input_ids, IMAGE_TOKEN_INDEX)
+ text = log_prefix
+ for idx, ids in enumerate(input_ids):
+ text += self.tokenizer.decode(ids)
+ if idx != len(input_ids) - 1:
+ text += DEFAULT_IMAGE_TOKEN
+ runner.logger.info(text)
+
+ runner.logger.info(f'Num {mode} samples {len(dataset)}')
+ runner.logger.info(f'{mode} example:')
+ if 'chosen_ids' in dataset[0]:
+ _log(dataset[0]['chosen_ids'], log_prefix='chosen: ')
+ _log(dataset[0]['rejected_ids'], log_prefix='rejected: ')
+ else:
+ _log(dataset[0]['input_ids'])
+
+ def before_train(self, runner) -> None:
+ do_train = runner.train_loop is not None
+ do_eval = runner.val_loop is not None
+ if do_train:
+ train_dataset = runner.train_dataloader.dataset
+ self.log(runner, train_dataset, mode='train')
+ if do_eval:
+ eval_dataset = runner.val_dataloader.dataset
+ self.log(runner, eval_dataset, mode='eval')
+
+ def before_val(self, runner) -> None:
+ eval_dataset = runner.val_dataloader.dataset
+ self.log(runner, eval_dataset, mode='eval')
+
+ def before_test(self, runner) -> None:
+ test_dataset = runner.test_dataloader.dataset
+ self.log(runner, test_dataset, mode='test')
diff --git a/data/xtuner/xtuner/engine/hooks/evaluate_chat_hook.py b/data/xtuner/xtuner/engine/hooks/evaluate_chat_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..05d508e4c8f232a9299c1d1b7f69cfbc18262dbc
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/evaluate_chat_hook.py
@@ -0,0 +1,281 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+
+import torch
+from mmengine.dist import master_only
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+from mmengine.utils import mkdir_or_exist
+from mmengine.utils.misc import get_object_from_string
+from transformers import GenerationConfig, StoppingCriteriaList
+
+from xtuner.dataset.utils import expand2square, load_image
+from xtuner.model.utils import prepare_inputs_labels_for_multimodal
+from xtuner.registry import BUILDER
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ StopWordStoppingCriteria)
+
+
+class EvaluateChatHook(Hook):
+
+ priority = 'LOW'
+
+ def __init__(self,
+ tokenizer,
+ evaluation_inputs,
+ evaluation_images=None,
+ image_processor=None,
+ system='',
+ prompt_template=None,
+ every_n_iters=None,
+ max_new_tokens=600,
+ stop_word=None,
+ stop_words=[],
+ generation_kwargs={}):
+ self.evaluation_inputs = evaluation_inputs
+ if isinstance(self.evaluation_inputs, str):
+ self.evaluation_inputs = [self.evaluation_inputs]
+ self.evaluation_images = evaluation_images
+ if isinstance(self.evaluation_images, str):
+ self.evaluation_images = [self.evaluation_images]
+ if self.evaluation_images is not None:
+ assert len(
+ self.evaluation_images) in [1, len(self.evaluation_inputs)]
+ if len(self.evaluation_images) == 1:
+ self.evaluation_images = [self.evaluation_images[0]] * len(
+ self.evaluation_inputs)
+ self.evaluation_images = [
+ load_image(img) for img in self.evaluation_images
+ ]
+ if prompt_template is None:
+ instruction = '{input}'
+ else:
+ if isinstance(prompt_template, str): # for resume
+ prompt_template = get_object_from_string(prompt_template)
+ instruction = prompt_template.get('INSTRUCTION', '{input}')
+ if system != '':
+ system = prompt_template.get(
+ 'SYSTEM', '{system}\n').format(system=system)
+ stop_words += prompt_template.get('STOP_WORDS', [])
+ if stop_word is not None:
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ ('The `stop_word` argument is deprecated and will be removed '
+ 'in v0.3.0, use `stop_words` instead.'), DeprecationWarning)
+ stop_words.append(stop_word)
+ self.instruction = instruction
+ self.system = system
+ self.every_n_iters = every_n_iters
+ self.max_new_tokens = max_new_tokens
+ self.tokenizer = BUILDER.build(tokenizer)
+ if image_processor is not None:
+ self.image_processor = BUILDER.build(image_processor)
+ self.stop_criteria = StoppingCriteriaList()
+
+ # default generation config
+ default_generation_kwargs = dict(
+ max_new_tokens=max_new_tokens,
+ do_sample=True,
+ temperature=0.1,
+ top_p=0.75,
+ top_k=40,
+ eos_token_id=self.tokenizer.eos_token_id,
+ pad_token_id=self.tokenizer.pad_token_id
+ if self.tokenizer.pad_token_id is not None else
+ self.tokenizer.eos_token_id)
+ default_generation_kwargs.update(generation_kwargs)
+ self.gen_config = GenerationConfig(**default_generation_kwargs)
+
+ self.stop_criteria = StoppingCriteriaList()
+ for word in stop_words:
+ self.stop_criteria.append(
+ StopWordStoppingCriteria(self.tokenizer, word))
+
+ self.is_first_run = True
+
+ @master_only
+ def _save_eval_output(self, runner, eval_outputs):
+ save_path = os.path.join(runner.log_dir, 'vis_data',
+ f'eval_outputs_iter_{runner.iter}.txt')
+ mkdir_or_exist(os.path.dirname(save_path))
+ with open(save_path, 'w', encoding='utf-8') as f:
+ for i, output in enumerate(eval_outputs):
+ f.write(f'Eval output {i + 1}:\n{output}\n\n')
+
+ def _eval_images(self,
+ runner,
+ model,
+ device,
+ max_new_tokens=None,
+ save_eval_output=False):
+ if save_eval_output:
+ eval_outputs = []
+
+ for sample_image, sample_input in zip(self.evaluation_images,
+ self.evaluation_inputs):
+ image = expand2square(
+ sample_image,
+ tuple(int(x * 255) for x in self.image_processor.image_mean))
+ image = self.image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ image = image.to(device)
+ sample_input = DEFAULT_IMAGE_TOKEN + '\n' + sample_input
+ inputs = (self.system + self.instruction).format(
+ input=sample_input, round=1, **runner.cfg)
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0:
+ cur_encode = self.tokenizer.encode(chunk)
+ else:
+ cur_encode = self.tokenizer.encode(
+ chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+ input_ids = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ input_ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ input_ids.append(IMAGE_TOKEN_INDEX)
+ input_ids = torch.tensor(input_ids).to(device)
+ visual_outputs = model.visual_encoder(
+ image.unsqueeze(0).to(model.visual_encoder.dtype),
+ output_hidden_states=True)
+ pixel_values = model.projector(
+ visual_outputs.hidden_states[model.visual_select_layer][:, 1:])
+
+ mm_inputs = prepare_inputs_labels_for_multimodal(
+ llm=model.llm,
+ input_ids=input_ids.unsqueeze(0),
+ pixel_values=pixel_values)
+
+ generation_output = model.generate(
+ **mm_inputs,
+ max_new_tokens=max_new_tokens,
+ generation_config=self.gen_config,
+ bos_token_id=self.tokenizer.bos_token_id,
+ stopping_criteria=self.stop_criteria)
+ generation_output = self.tokenizer.decode(generation_output[0])
+ runner.logger.info(f'Sample output:\n'
+ f'{inputs + generation_output}\n')
+ if save_eval_output:
+ eval_outputs.append(f'{inputs + generation_output}\n')
+
+ if save_eval_output:
+ self._save_eval_output(runner, eval_outputs)
+
+ def _eval_language(self,
+ runner,
+ model,
+ device,
+ max_new_tokens=None,
+ save_eval_output=False):
+ if save_eval_output:
+ eval_outputs = []
+
+ for sample_input in self.evaluation_inputs:
+ inputs = (self.system + self.instruction).format(
+ input=sample_input, round=1, **runner.cfg)
+ input_ids = self.tokenizer.encode(inputs, return_tensors='pt')
+ input_ids = input_ids.to(device)
+ generation_output = model.generate(
+ input_ids=input_ids,
+ max_new_tokens=max_new_tokens,
+ generation_config=self.gen_config,
+ stopping_criteria=self.stop_criteria)
+ generation_output = self.tokenizer.decode(generation_output[0])
+ runner.logger.info(f'Sample output:\n{generation_output}\n')
+ if save_eval_output:
+ eval_outputs.append(f'{generation_output}\n')
+
+ if save_eval_output:
+ self._save_eval_output(runner, eval_outputs)
+
+ def _generate_samples(self,
+ runner,
+ max_new_tokens=None,
+ save_eval_output=False):
+ if max_new_tokens is None:
+ max_new_tokens = self.max_new_tokens
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+
+ device = next(iter(model.parameters())).device
+
+ if self.is_first_run:
+ # hardcode for qlora DeepSpeed ZeRO3, put buffers and QuantState to
+ # device
+ model.to(device)
+ self.is_first_run = False
+
+ is_checkpointing = model.llm.is_gradient_checkpointing
+ use_cache = model.llm.config.use_cache
+
+ # Cast to inference mode
+ model.activation_checkpointing_disable()
+ model.llm.config.use_cache = True
+ model.eval()
+ if self.evaluation_images is not None:
+ self._eval_images(runner, model, device, max_new_tokens,
+ save_eval_output)
+ else:
+ self._eval_language(runner, model, device, max_new_tokens,
+ save_eval_output)
+
+ # Cast to training mode
+ if is_checkpointing:
+ model.activation_checkpointing_enable()
+ model.llm.config.use_cache = use_cache
+ model.train()
+
+ def before_train(self, runner):
+ runner.logger.info('before_train in EvaluateChatHook.')
+ self._generate_samples(runner, max_new_tokens=50)
+
+ def _is_save_checkpoint(self, runner):
+ hooks = runner.hooks
+ checkpoint_hook = None
+ for hook in hooks:
+ if type(hook).__name__ == 'CheckpointHook':
+ checkpoint_hook = hook
+ break
+ if checkpoint_hook is None or checkpoint_hook.by_epoch:
+ return False
+
+ if checkpoint_hook.every_n_train_iters(
+ runner, checkpoint_hook.interval, checkpoint_hook.save_begin) or \
+ (checkpoint_hook.save_last and
+ checkpoint_hook.is_last_train_iter(runner)):
+ return True
+
+ return False
+
+ def after_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch=None,
+ outputs=None) -> None:
+ if self.every_n_iters is None:
+ return
+
+ save_eval_output = self._is_save_checkpoint(runner)
+
+ do_chat = (
+ save_eval_output
+ or self.every_n_train_iters(runner, self.every_n_iters))
+ if not do_chat:
+ return
+
+ runner.logger.info('after_train_iter in EvaluateChatHook.')
+ self._generate_samples(runner, save_eval_output=save_eval_output)
+
+ def after_train(self, runner):
+ runner.logger.info('after_train in EvaluateChatHook.')
+ self._generate_samples(runner)
+
+ def after_val(self, runner) -> None:
+ if self.every_n_iters is not None:
+ return
+ runner.logger.info('after_val in EvaluateChatHook.')
+ self._generate_samples(runner)
diff --git a/data/xtuner/xtuner/engine/hooks/hf_checkpoint_hook.py b/data/xtuner/xtuner/engine/hooks/hf_checkpoint_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..142af4cdbc27f34a0e4def644a742258542c2db0
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/hf_checkpoint_hook.py
@@ -0,0 +1,73 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from pathlib import Path
+from typing import Optional, Union
+
+import torch.distributed as dist
+from mmengine import print_log
+from mmengine._strategy import DeepSpeedStrategy
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+from mmengine.runner import FlexibleRunner
+
+from xtuner.registry import BUILDER
+from xtuner.utils import get_origin_state_dict
+
+DATA_BATCH = Optional[Union[dict, tuple, list]]
+
+
+class HFCheckpointHook(Hook):
+
+ priority = 95 # lower than CheckpointHook in MMEngine
+
+ def __init__(self, out_dir: Optional[Union[str, Path]] = None) -> None:
+ self.out_dir = out_dir
+
+ @staticmethod
+ def _use_shard_moe(llm):
+ config = llm.config
+ moe_implementation = getattr(config, 'moe_implementation', 'origin')
+ return moe_implementation == 'shard'
+
+ def after_run(self, runner) -> None:
+ assert isinstance(runner,
+ FlexibleRunner), 'Runner should be `FlexibleRunner`'
+ assert isinstance(
+ runner.strategy,
+ DeepSpeedStrategy), 'Strategy should be `DeepSpeedStrategy`'
+
+ if self.out_dir is None:
+ self.out_dir = osp.join(runner.work_dir, 'hf_model')
+
+ wrapped_model = runner.strategy.model
+ if wrapped_model.zero_optimization_partition_weights():
+ assert wrapped_model.zero_gather_16bit_weights_on_model_save(), \
+ ('Please set `gather_16bit_weights_on_model_save=True` '
+ 'in your DeepSpeed config.')
+ state_dict = wrapped_model._zero3_consolidated_16bit_state_dict()
+ else:
+ state_dict = wrapped_model.module_state_dict(
+ exclude_frozen_parameters=runner.strategy.
+ exclude_frozen_parameters)
+
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+ llm = model.llm
+ if (not dist.is_initialized()) or dist.get_rank() == 0:
+ # keys in state_dict are prefixed with 'llm.'
+ keys = list(state_dict.keys())
+ for k in keys:
+ val = state_dict.pop(k)
+ state_dict[k[4:]] = val
+
+ if self._use_shard_moe(llm):
+ print_log('recover the origin state_dict from merged one ...')
+ state_dict = get_origin_state_dict(state_dict, llm)
+
+ print_log(f'Saving LLM to {self.out_dir}')
+ llm.save_pretrained(self.out_dir, state_dict=state_dict)
+
+ print_log(f'Saving LLM tokenizer to {self.out_dir}')
+ tokenizer = BUILDER.build(runner.cfg.tokenizer)
+ tokenizer.save_pretrained(self.out_dir)
diff --git a/data/xtuner/xtuner/engine/hooks/throughput_hook.py b/data/xtuner/xtuner/engine/hooks/throughput_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..e74c0a0acf1e13498107364cc3cf3b4797159aaf
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/throughput_hook.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+from typing import Optional, Union
+
+import torch
+from mmengine import print_log
+from mmengine.hooks import Hook
+from mmengine.model.wrappers import is_model_wrapper
+from torch.utils._pytree import tree_flatten
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+
+DATA_BATCH = Optional[Union[dict, tuple, list]]
+
+
+class ThroughputHook(Hook):
+
+ # priority must be higher than LoggerHook (50) and lower than
+ # IterTimerHook (60)
+ priority = 55
+
+ def __init__(self,
+ use_activation_checkpointing=None,
+ hidden_size=None,
+ num_layers=None,
+ vocab_size=None,
+ mlp_ratio=None,
+ is_casual=None):
+ self.use_activation_checkpointing = use_activation_checkpointing
+ self.hidden_size = hidden_size
+ self.num_layers = num_layers
+ self.vocab_size = vocab_size
+ self.mlp_ratio = mlp_ratio
+ self.is_casual = is_casual
+
+ @staticmethod
+ def _guess_is_casual_attn(model):
+ for module in model.modules():
+ if hasattr(module, 'is_causal'):
+ return module.is_causal
+ print_log(
+ 'It\'s impossible to speculate whether casual attention was used, '
+ 'and FLOPs will be calculated as `casual = True`.', 'current')
+ return True
+
+ @staticmethod
+ def _get_batch_size_and_sequence_len(data_batch):
+ data_list, _ = tree_flatten(data_batch)
+ for data in data_list:
+ if isinstance(data, torch.Tensor):
+ return data.size(0), data.size(1)
+ raise RuntimeError('No tensor found in the batch')
+
+ @staticmethod
+ def _guess_use_activation_checkpointing(model):
+ for module in model.modules():
+ if hasattr(module, 'gradient_checkpointing'):
+ return module.gradient_checkpointing
+ return False
+
+ def before_run(self, runner) -> None:
+ if is_model_wrapper(runner.model):
+ model = runner.model.module
+ else:
+ model = runner.model
+ self.use_activation_checkpointing = \
+ (self.use_activation_checkpointing or
+ self._guess_use_activation_checkpointing(model))
+ self.hidden_size = self.hidden_size or model.config.hidden_size
+ self.num_layers = self.num_layers or model.config.num_hidden_layers
+ self.vocab_size = self.vocab_size or model.config.vocab_size
+ self.mlp_ratio = self.mlp_ratio or (model.config.intermediate_size /
+ model.config.hidden_size)
+ self.mlp_ratio *= 1.5 # has gate_proj
+ self.is_casual = self.is_casual if self.is_casual is not None \
+ else self._guess_is_casual_attn(model)
+
+ use_varlen_attn = getattr(model, 'use_varlen_attn', False)
+ if use_varlen_attn:
+ print_log(
+ 'Using variable-length Flash Attention causes an inflation'
+ ' in the FLOPs calculation.',
+ 'current',
+ level=logging.WARNING)
+
+ return
+
+ def after_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None,
+ outputs: Optional[dict] = None) -> None:
+ """Calc flops based on the paper of Megatron
+ https://deepakn94.github.io/assets/papers/megatron-sc21.pdf."""
+
+ batch_size, sequence_len = self._get_batch_size_and_sequence_len(
+ data_batch)
+ sequence_parallel_size = get_sequence_parallel_world_size()
+ sequence_len /= sequence_parallel_size
+
+ message_hub = runner.message_hub
+ iter_time = message_hub.get_scalar('train/time').current()
+
+ # We consider a language model with 𝑙 transformer layers,
+ # hidden size h, sequence length s, vocabulary size V, and
+ # training batch size B.
+ # A $A_{mxk}$ x $X_{kxn}$ matrix multiplication requires 2𝑚 ×𝑘 ×𝑛 FLOPs
+ # (factor of 2 needed to account for multiplies and adds).
+
+ # Attention Layer:
+ # qkv_proj + o_proj: 8B * s * h^2
+ # attn: 2B * s^2 * h (casual=False) and 2B * s^2 * h / 2 (casual=True)
+
+ # MLP Layer:
+ # up_proj + down_proj + gate_proj: 4B * s * h^2 * mlp_ratio
+ # (In Llama mlp_ratio = intermediate_size / hidden_size * 1.5
+ # (has gate_proj))
+
+ # The backward pass requires double the number of FLOPs since we
+ # need to calculate the gradients with respect to both input and
+ # weight tensors. In addition, we are using activation recomputation,
+ # which requires an additional forward pass before the backward pass.
+
+ # While sequence parallel will affect the FLOPs calculation in attn.
+ # Suppose the sequence length in one GPU is s and the sequence
+ # parallel world size is `sp_size`, which means the total
+ # sequence length in the attention calculation is
+ # `s * sp_size` and the number of attention heads decrease to
+ # `num_heads / sp_size`. Hence, the FLOPs in attn calculation is:
+ # 2B * (s * sp_size)^2 * (h / sp_size) (casual=False) and
+ # 2B * (s * sp_size)^2 * (h / sp_size) / 2 (casual=True)
+
+ flops_qkvo_proj = 8 * batch_size * sequence_len * self.hidden_size**2
+ flops_attn = 4 * batch_size * sequence_len**2 * self.hidden_size * \
+ sequence_parallel_size / (int(self.is_casual) + 1)
+ flops_mlp = 4 * self.mlp_ratio * batch_size * sequence_len * \
+ self.hidden_size**2
+ flops_wo_head = (3 + int(self.use_activation_checkpointing)) * (
+ flops_qkvo_proj + flops_attn + flops_mlp) * self.num_layers
+ flops_head = 3 * 2 * batch_size * sequence_len * self.hidden_size * \
+ self.vocab_size
+ flops_per_iteration = flops_wo_head + flops_head
+
+ avg_tflops_per_gpu = flops_per_iteration / 1e12 / (iter_time + 1e-12)
+ tokens_per_sec_per_gpu = batch_size * sequence_len / (
+ iter_time + 1e-12)
+
+ message_hub.update_scalar('train/tflops', avg_tflops_per_gpu)
+ message_hub.update_scalar('train/tokens_per_sec',
+ tokens_per_sec_per_gpu)
diff --git a/data/xtuner/xtuner/engine/hooks/varlen_attn_args_to_messagehub_hook.py b/data/xtuner/xtuner/engine/hooks/varlen_attn_args_to_messagehub_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc31f21aecb44b666122db152ec6809dbaa41106
--- /dev/null
+++ b/data/xtuner/xtuner/engine/hooks/varlen_attn_args_to_messagehub_hook.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+from mmengine import MessageHub
+from mmengine.dist import get_rank
+from mmengine.hooks import Hook
+
+DATA_BATCH = Optional[Union[dict, tuple, list]]
+
+
+class VarlenAttnArgsToMessageHubHook(Hook):
+
+ def before_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: dict = None) -> None:
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+
+ assert 'data' in data_batch.keys()
+ data = data_batch['data']
+
+ cumulative_len = data.pop('cumulative_len')
+ assert len(cumulative_len) == 1
+ cumulative_len = cumulative_len[0].cuda()
+ message_hub.update_info(f'cumulative_len_rank_{rank}', cumulative_len)
+
+ max_seqlen = data.pop('max_seqlen')
+ message_hub.update_info(f'max_seqlen_rank_{rank}', max_seqlen)
+
+ def after_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None,
+ outputs: Optional[dict] = None) -> None:
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ message_hub.update_info(f'cumulative_len_rank_{rank}', None)
+ message_hub.update_info(f'max_seqlen_rank_{rank}', None)
+
+ def before_val_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None) -> None:
+ """All subclasses should override this method, if they need any
+ operations before each validation iteration.
+
+ Args:
+ runner (Runner): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict, optional): Data from dataloader.
+ Defaults to None.
+ """
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+
+ assert 'data' in data_batch.keys()
+ data = data_batch['data']
+
+ cumulative_len = data.pop('cumulative_len')
+ assert len(cumulative_len) == 1
+ cumulative_len = cumulative_len[0].cuda()
+ message_hub.update_info(f'cumulative_len_rank_{rank}', cumulative_len)
+
+ max_seqlen = data.pop('max_seqlen')
+ message_hub.update_info(f'max_seqlen_rank_{rank}', max_seqlen)
+
+ def after_val_iter(self,
+ runner,
+ batch_idx,
+ data_batch=None,
+ outputs=None) -> None:
+ """All subclasses should override this method, if they need any
+ operations after each validation iteration.
+
+ Args:
+ runner (Runner): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict or tuple or list, optional): Data from dataloader.
+ outputs (Sequence, optional): Outputs from model.
+ """
+ rank = get_rank()
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ message_hub.update_info(f'cumulative_len_rank_{rank}', None)
+ message_hub.update_info(f'max_seqlen_rank_{rank}', None)
diff --git a/data/xtuner/xtuner/engine/runner/__init__.py b/data/xtuner/xtuner/engine/runner/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d8d1c582b531e341dfbb299e56cbbd3db0b81e16
--- /dev/null
+++ b/data/xtuner/xtuner/engine/runner/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .loops import TrainLoop
+
+__all__ = ['TrainLoop']
diff --git a/data/xtuner/xtuner/engine/runner/loops.py b/data/xtuner/xtuner/engine/runner/loops.py
new file mode 100644
index 0000000000000000000000000000000000000000..aeb6be31ae6e09c32fb27f60c82690d4fc94b84a
--- /dev/null
+++ b/data/xtuner/xtuner/engine/runner/loops.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Union
+
+from mmengine.runner import IterBasedTrainLoop
+from torch.utils.data import DataLoader
+
+
+class TrainLoop(IterBasedTrainLoop):
+
+ def __init__(self,
+ runner,
+ dataloader: Union[DataLoader, Dict],
+ max_iters: Optional[int] = None,
+ max_epochs: Union[int, float] = None,
+ **kwargs) -> None:
+
+ if max_iters is None and max_epochs is None:
+ raise RuntimeError('Please specify the `max_iters` or '
+ '`max_epochs` in `train_cfg`.')
+ elif max_iters is not None and max_epochs is not None:
+ raise RuntimeError('Only one of `max_iters` or `max_epochs` can '
+ 'exist in `train_cfg`.')
+ else:
+ if max_iters is not None:
+ iters = int(max_iters)
+ assert iters == max_iters, ('`max_iters` should be a integer '
+ f'number, but get {max_iters}')
+ elif max_epochs is not None:
+ if isinstance(dataloader, dict):
+ diff_rank_seed = runner._randomness_cfg.get(
+ 'diff_rank_seed', False)
+ dataloader = runner.build_dataloader(
+ dataloader,
+ seed=runner.seed,
+ diff_rank_seed=diff_rank_seed)
+ iters = max_epochs * len(dataloader)
+ else:
+ raise NotImplementedError
+ super().__init__(
+ runner=runner, dataloader=dataloader, max_iters=iters, **kwargs)
diff --git a/data/xtuner/xtuner/entry_point.py b/data/xtuner/xtuner/entry_point.py
new file mode 100644
index 0000000000000000000000000000000000000000..2af774fd37843714f0ce78f8ac59bd0bfecb34c6
--- /dev/null
+++ b/data/xtuner/xtuner/entry_point.py
@@ -0,0 +1,302 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+import os
+import random
+import subprocess
+import sys
+
+from mmengine.logging import print_log
+
+import xtuner
+
+# Define valid modes
+MODES = ('list-cfg', 'copy-cfg', 'log-dataset', 'check-custom-dataset',
+ 'train', 'test', 'chat', 'convert', 'preprocess', 'mmbench',
+ 'eval_refcoco')
+
+CLI_HELP_MSG = \
+ f"""
+ Arguments received: {str(['xtuner'] + sys.argv[1:])}. xtuner commands use the following syntax:
+
+ xtuner MODE MODE_ARGS ARGS
+
+ Where MODE (required) is one of {MODES}
+ MODE_ARG (optional) is the argument for specific mode
+ ARGS (optional) are the arguments for specific command
+
+ Some usages for xtuner commands: (See more by using -h for specific command!)
+
+ 1. List all predefined configs:
+ xtuner list-cfg
+ 2. Copy a predefined config to a given path:
+ xtuner copy-cfg $CONFIG $SAVE_FILE
+ 3-1. Fine-tune LLMs by a single GPU:
+ xtuner train $CONFIG
+ 3-2. Fine-tune LLMs by multiple GPUs:
+ NPROC_PER_NODE=$NGPUS NNODES=$NNODES NODE_RANK=$NODE_RANK PORT=$PORT ADDR=$ADDR xtuner dist_train $CONFIG $GPUS
+ 4-1. Convert the pth model to HuggingFace's model:
+ xtuner convert pth_to_hf $CONFIG $PATH_TO_PTH_MODEL $SAVE_PATH_TO_HF_MODEL
+ 4-2. Merge the HuggingFace's adapter to the pretrained base model:
+ xtuner convert merge $LLM $ADAPTER $SAVE_PATH
+ xtuner convert merge $CLIP $ADAPTER $SAVE_PATH --is-clip
+ 4-3. Split HuggingFace's LLM to the smallest sharded one:
+ xtuner convert split $LLM $SAVE_PATH
+ 5-1. Chat with LLMs with HuggingFace's model and adapter:
+ xtuner chat $LLM --adapter $ADAPTER --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
+ 5-2. Chat with VLMs with HuggingFace's model and LLaVA:
+ xtuner chat $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --image $IMAGE --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
+ 6-1. Preprocess arxiv dataset:
+ xtuner preprocess arxiv $SRC_FILE $DST_FILE --start-date $START_DATE --categories $CATEGORIES
+ 6-2. Preprocess refcoco dataset:
+ xtuner preprocess refcoco --ann-path $RefCOCO_ANN_PATH --image-path $COCO_IMAGE_PATH --save-path $SAVE_PATH
+ 7-1. Log processed dataset:
+ xtuner log-dataset $CONFIG
+ 7-2. Verify the correctness of the config file for the custom dataset:
+ xtuner check-custom-dataset $CONFIG
+ 8. MMBench evaluation:
+ xtuner mmbench $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --prompt-template $PROMPT_TEMPLATE --data-path $MMBENCH_DATA_PATH
+ 9. Refcoco evaluation:
+ xtuner eval_refcoco $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --prompt-template $PROMPT_TEMPLATE --data-path $REFCOCO_DATA_PATH
+ 10. List all dataset formats which are supported in XTuner
+
+ Run special commands:
+
+ xtuner help
+ xtuner version
+
+ GitHub: https://github.com/InternLM/xtuner
+ """ # noqa: E501
+
+
+CONVERT_HELP_MSG = \
+ f"""
+ Arguments received: {str(['xtuner'] + sys.argv[1:])}. xtuner commands use the following syntax:
+
+ xtuner MODE MODE_ARGS ARGS
+
+ Where MODE (required) is one of {MODES}
+ MODE_ARG (optional) is the argument for specific mode
+ ARGS (optional) are the arguments for specific command
+
+ Some usages for convert: (See more by using -h for specific command!)
+
+ 1. Convert the pth model to HuggingFace's model:
+ xtuner convert pth_to_hf $CONFIG $PATH_TO_PTH_MODEL $SAVE_PATH_TO_HF_MODEL
+ 2. Merge the HuggingFace's adapter to the pretrained LLM:
+ xtuner convert merge $LLM $ADAPTER $SAVE_PATH
+ 3. Split HuggingFace's LLM to the smallest sharded one:
+ xtuner convert split $LLM $SAVE_PATH
+
+ GitHub: https://github.com/InternLM/xtuner
+ """ # noqa: E501
+
+
+PREPROCESS_HELP_MSG = \
+ f"""
+ Arguments received: {str(['xtuner'] + sys.argv[1:])}. xtuner commands use the following syntax:
+
+ xtuner MODE MODE_ARGS ARGS
+
+ Where MODE (required) is one of {MODES}
+ MODE_ARG (optional) is the argument for specific mode
+ ARGS (optional) are the arguments for specific command
+
+ Some usages for preprocess: (See more by using -h for specific command!)
+
+ 1. Preprocess arxiv dataset:
+ xtuner preprocess arxiv $SRC_FILE $DST_FILE --start-date $START_DATE --categories $CATEGORIES
+ 2. Preprocess refcoco dataset:
+ xtuner preprocess refcoco --ann-path $RefCOCO_ANN_PATH --image-path $COCO_IMAGE_PATH --save-path $SAVE_PATH
+
+ GitHub: https://github.com/InternLM/xtuner
+ """ # noqa: E501
+
+special = {
+ 'help': lambda: print_log(CLI_HELP_MSG, 'current'),
+ 'version': lambda: print_log(xtuner.__version__, 'current')
+}
+special = {
+ **special,
+ **{f'-{k[0]}': v
+ for k, v in special.items()},
+ **{f'--{k}': v
+ for k, v in special.items()}
+}
+
+
+def list_dataset_format():
+ from xtuner.tools import list_dataset_format
+ return list_dataset_format.__file__
+
+
+def list_cfg():
+ from xtuner.tools import list_cfg
+ return list_cfg.__file__
+
+
+def copy_cfg():
+ from xtuner.tools import copy_cfg
+ return copy_cfg.__file__
+
+
+def log_dataset():
+ from xtuner.tools import log_dataset
+ return log_dataset.__file__
+
+
+def check_custom_dataset():
+ from xtuner.tools import check_custom_dataset
+ return check_custom_dataset.__file__
+
+
+def train():
+ from xtuner.tools import train
+ return train.__file__
+
+
+def test():
+ from xtuner.tools import test
+ return test.__file__
+
+
+def chat():
+ from xtuner.tools import chat
+ return chat.__file__
+
+
+def mmbench():
+ from xtuner.tools import mmbench
+ return mmbench.__file__
+
+
+def pth_to_hf():
+ from xtuner.tools.model_converters import pth_to_hf
+ return pth_to_hf.__file__
+
+
+def merge():
+ from xtuner.tools.model_converters import merge
+ return merge.__file__
+
+
+def split():
+ from xtuner.tools.model_converters import split
+ return split.__file__
+
+
+def arxiv_preprocess():
+ from xtuner.tools.data_preprocess import arxiv as arxiv_preprocess
+ return arxiv_preprocess.__file__
+
+
+def convert_refcoco():
+ from xtuner.tools.data_preprocess import convert_refcoco
+ return convert_refcoco.__file__
+
+
+def convert_help_msg():
+ print_log(CONVERT_HELP_MSG, 'current')
+
+
+def preprocess_help_msg():
+ print_log(PREPROCESS_HELP_MSG, 'current')
+
+
+def eval_refcoco():
+ from xtuner.tools import eval_refcoco
+ return eval_refcoco.__file__
+
+
+modes = {
+ 'list-cfg': list_cfg,
+ 'copy-cfg': copy_cfg,
+ 'log-dataset': log_dataset,
+ 'check-custom-dataset': check_custom_dataset,
+ 'train': train,
+ 'test': test,
+ 'chat': chat,
+ 'mmbench': mmbench,
+ 'convert': {
+ 'pth_to_hf': pth_to_hf,
+ 'merge': merge,
+ 'split': split,
+ '--help': convert_help_msg,
+ '-h': convert_help_msg
+ },
+ 'preprocess': {
+ 'arxiv': arxiv_preprocess,
+ 'refcoco': convert_refcoco,
+ '--help': preprocess_help_msg,
+ '-h': preprocess_help_msg
+ },
+ 'eval_refcoco': eval_refcoco,
+ 'list-dataset-format': list_dataset_format
+}
+
+HELP_FUNCS = [preprocess_help_msg, convert_help_msg]
+MAP_FILE_FUNCS = [
+ list_cfg, copy_cfg, log_dataset, check_custom_dataset, train, test, chat,
+ mmbench, pth_to_hf, merge, split, arxiv_preprocess, eval_refcoco,
+ convert_refcoco, list_dataset_format
+]
+
+
+def cli():
+ args = sys.argv[1:]
+ if not args: # no arguments passed
+ print_log(CLI_HELP_MSG, 'current')
+ return
+ if args[0].lower() in special:
+ special[args[0].lower()]()
+ return
+ elif args[0].lower() in modes:
+ try:
+ fn_or_dict = modes[args[0].lower()]
+ n_arg = 0
+
+ if isinstance(fn_or_dict, dict):
+ n_arg += 1
+ fn = fn_or_dict[args[n_arg].lower()]
+ else:
+ fn = fn_or_dict
+
+ assert callable(fn)
+
+ if fn in HELP_FUNCS:
+ fn()
+ else:
+ slurm_launcher = False
+ for i in range(n_arg + 1, len(args)):
+ if args[i] == '--launcher':
+ if i + 1 < len(args) and args[i + 1] == 'slurm':
+ slurm_launcher = True
+ break
+ nnodes = int(os.environ.get('NNODES', 1))
+ nproc_per_node = int(os.environ.get('NPROC_PER_NODE', 1))
+ if slurm_launcher or (nnodes == 1 and nproc_per_node == 1):
+ subprocess.run(['python', fn()] + args[n_arg + 1:])
+ else:
+ port = os.environ.get('PORT', None)
+ if port is None:
+ port = random.randint(20000, 29999)
+ print_log(f'Use random port: {port}', 'current',
+ logging.WARNING)
+ torchrun_args = [
+ f'--nnodes={nnodes}',
+ f"--node_rank={os.environ.get('NODE_RANK', 0)}",
+ f'--nproc_per_node={nproc_per_node}',
+ f"--master_addr={os.environ.get('ADDR', '127.0.0.1')}",
+ f'--master_port={port}'
+ ]
+ subprocess.run(['torchrun'] + torchrun_args + [fn()] +
+ args[n_arg + 1:] +
+ ['--launcher', 'pytorch'])
+ except Exception as e:
+ print_log(f"WARNING: command error: '{e}'!", 'current',
+ logging.WARNING)
+ print_log(CLI_HELP_MSG, 'current', logging.WARNING)
+ return
+ else:
+ print_log('WARNING: command error!', 'current', logging.WARNING)
+ print_log(CLI_HELP_MSG, 'current', logging.WARNING)
+ return
diff --git a/data/xtuner/xtuner/evaluation/__init__.py b/data/xtuner/xtuner/evaluation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fba3e590598c3fe175f9d331e0da8883c1ef4ea8
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .metrics import MMLUMetric
+
+__all__ = ['MMLUMetric']
diff --git a/data/xtuner/xtuner/evaluation/metrics/__init__.py b/data/xtuner/xtuner/evaluation/metrics/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3efc80fd5d8aa3f7b65e43ec1a8acd98a1df3bb
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/metrics/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .mmlu_metric import MMLUMetric
+
+__all__ = ['MMLUMetric']
diff --git a/data/xtuner/xtuner/evaluation/metrics/mmlu_metric.py b/data/xtuner/xtuner/evaluation/metrics/mmlu_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad1282056a8e7691f05f579275ad0bf990796f12
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/metrics/mmlu_metric.py
@@ -0,0 +1,246 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Sequence
+
+import numpy as np
+import torch
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import print_log
+from rich.console import Console
+from rich.table import Table
+
+from xtuner.registry import BUILDER
+
+
+class MMLUMetric(BaseMetric):
+ METAINFO = {
+ 'subcategories': {
+ 'abstract_algebra': ['math'],
+ 'anatomy': ['health'],
+ 'astronomy': ['physics'],
+ 'business_ethics': ['business'],
+ 'clinical_knowledge': ['health'],
+ 'college_biology': ['biology'],
+ 'college_chemistry': ['chemistry'],
+ 'college_computer_science': ['computer science'],
+ 'college_mathematics': ['math'],
+ 'college_medicine': ['health'],
+ 'college_physics': ['physics'],
+ 'computer_security': ['computer science'],
+ 'conceptual_physics': ['physics'],
+ 'econometrics': ['economics'],
+ 'electrical_engineering': ['engineering'],
+ 'elementary_mathematics': ['math'],
+ 'formal_logic': ['philosophy'],
+ 'global_facts': ['other'],
+ 'high_school_biology': ['biology'],
+ 'high_school_chemistry': ['chemistry'],
+ 'high_school_computer_science': ['computer science'],
+ 'high_school_european_history': ['history'],
+ 'high_school_geography': ['geography'],
+ 'high_school_government_and_politics': ['politics'],
+ 'high_school_macroeconomics': ['economics'],
+ 'high_school_mathematics': ['math'],
+ 'high_school_microeconomics': ['economics'],
+ 'high_school_physics': ['physics'],
+ 'high_school_psychology': ['psychology'],
+ 'high_school_statistics': ['math'],
+ 'high_school_us_history': ['history'],
+ 'high_school_world_history': ['history'],
+ 'human_aging': ['health'],
+ 'human_sexuality': ['culture'],
+ 'international_law': ['law'],
+ 'jurisprudence': ['law'],
+ 'logical_fallacies': ['philosophy'],
+ 'machine_learning': ['computer science'],
+ 'management': ['business'],
+ 'marketing': ['business'],
+ 'medical_genetics': ['health'],
+ 'miscellaneous': ['other'],
+ 'moral_disputes': ['philosophy'],
+ 'moral_scenarios': ['philosophy'],
+ 'nutrition': ['health'],
+ 'philosophy': ['philosophy'],
+ 'prehistory': ['history'],
+ 'professional_accounting': ['other'],
+ 'professional_law': ['law'],
+ 'professional_medicine': ['health'],
+ 'professional_psychology': ['psychology'],
+ 'public_relations': ['politics'],
+ 'security_studies': ['politics'],
+ 'sociology': ['culture'],
+ 'us_foreign_policy': ['politics'],
+ 'virology': ['health'],
+ 'world_religions': ['philosophy'],
+ },
+ 'categories': {
+ 'STEM': [
+ 'physics', 'chemistry', 'biology', 'computer science', 'math',
+ 'engineering'
+ ],
+ 'humanities': ['history', 'philosophy', 'law'],
+ 'social sciences':
+ ['politics', 'culture', 'economics', 'geography', 'psychology'],
+ 'other (business, health, misc.)': ['other', 'business', 'health'],
+ },
+ }
+ METAINFO['subcategories_list'] = list({
+ subcat
+ for subcats in METAINFO['subcategories'].values() for subcat in subcats
+ })
+
+ def __init__(self, tokenizer, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ tokenizer = BUILDER.build(tokenizer)
+ self.abcd_idx = [
+ tokenizer.encode('A', add_special_tokens=False)[0],
+ tokenizer.encode('B', add_special_tokens=False)[0],
+ tokenizer.encode('C', add_special_tokens=False)[0],
+ tokenizer.encode('D', add_special_tokens=False)[0],
+ ]
+
+ @staticmethod
+ def ABCD_to_0123(abcd):
+ return {'A': 0, 'B': 1, 'C': 2, 'D': 3}[abcd]
+
+ @staticmethod
+ def find_first_zero_index(tensor):
+ indices = torch.nonzero(tensor == 0)
+ if indices.numel() > 0:
+ return indices[0].item()
+ else:
+ return None
+
+ @staticmethod
+ def accuracy(preds, gts):
+ """Computes the accuracy for preds and gts."""
+ correct = [1 if pred == gt else 0 for pred, gt in zip(preds, gts)]
+ acc = np.mean(correct) * 100
+ return acc
+
+ def process(self, data_batch: Any, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Any): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ subjects = data_batch['data_samples']['subjects']
+ gts = [
+ self.ABCD_to_0123(gt)
+ for gt in data_batch['data_samples']['labels']
+ ]
+ preds = []
+ for sample, attn_mask, subject, gt in zip(
+ data_samples, data_batch['data']['attention_mask'], subjects,
+ gts):
+ pred_logits = sample['logits']
+ first_zero_idx = self.find_first_zero_index(attn_mask)
+ pred_idx = -1 if first_zero_idx is None else first_zero_idx - 1
+ pred_logtis_abcd = pred_logits[pred_idx, self.abcd_idx]
+ pred = torch.argmax(pred_logtis_abcd).item()
+ preds.append(pred)
+ self.results.append((subject, pred, gt))
+
+ def compute_metrics(self, results: list) -> dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ subjects_results = {
+ subject: {
+ 'preds': [],
+ 'gts': []
+ }
+ for subject in self.METAINFO['subcategories'].keys()
+ }
+ subcats_results = {
+ subcat: {
+ 'preds': [],
+ 'gts': []
+ }
+ for subcat in self.METAINFO['subcategories_list']
+ }
+ cats_results = {
+ cat: {
+ 'preds': [],
+ 'gts': []
+ }
+ for cat in self.METAINFO['categories'].keys()
+ }
+ for subject, pred, gt in results:
+ subjects_results[subject]['preds'].append(pred)
+ subjects_results[subject]['gts'].append(gt)
+ subcats = self.METAINFO['subcategories'][subject]
+ for subcat in subcats:
+ subcats_results[subcat]['preds'].append(pred)
+ subcats_results[subcat]['gts'].append(gt)
+ for cat, subcats in self.METAINFO['categories'].items():
+ for subcat in subcats:
+ if subcat in subcats_results:
+ cats_results[cat]['preds'].extend(
+ subcats_results[subcat]['preds'])
+ cats_results[cat]['gts'].extend(
+ subcats_results[subcat]['gts'])
+
+ subjects_metrics = dict()
+ subcats_metrics = dict()
+ cats_metrics = dict()
+ for subject in self.METAINFO['subcategories'].keys():
+ assert len(subjects_results[subject]['preds']) == len(
+ subjects_results[subject]['gts'])
+ if len(subjects_results[subject]['preds']) == 0:
+ print_log(f'Skip subject {subject} for mmlu', 'current')
+ else:
+ score = self.accuracy(subjects_results[subject]['preds'],
+ subjects_results[subject]['gts'])
+ subjects_metrics[f'{subject}'] = score
+ for subcat in self.METAINFO['subcategories_list']:
+ assert len(subcats_results[subcat]['preds']) == len(
+ subcats_results[subcat]['gts'])
+ if len(subcats_results[subcat]['preds']) == 0:
+ print_log(f'Skip subcategory {subcat} for mmlu', 'current')
+ else:
+ score = self.accuracy(subcats_results[subcat]['preds'],
+ subcats_results[subcat]['gts'])
+ subcats_metrics[f'{subcat}'] = score
+ for cat in self.METAINFO['categories'].keys():
+ assert len(cats_results[cat]['preds']) == len(
+ cats_results[cat]['gts'])
+ if len(cats_results[cat]['preds']) == 0:
+ print_log(f'Skip category {cat} for mmlu', 'current')
+ else:
+ score = self.accuracy(cats_results[cat]['preds'],
+ cats_results[cat]['gts'])
+ cats_metrics[f'{cat}'] = score
+
+ metrics = dict()
+ metrics.update(subjects_metrics)
+ metrics.update(subcats_metrics)
+ metrics.update(cats_metrics)
+ metrics['average'] = np.mean(list(subjects_metrics.values()))
+
+ table_metrics = dict()
+ table_metrics.update(cats_metrics)
+ table_metrics['average'] = np.mean(list(subjects_metrics.values()))
+ self._print_results(table_metrics)
+ return metrics
+
+ def _print_results(self, table_metrics: dict) -> None:
+ table_title = ' MMLU Benchmark '
+ table = Table(title=table_title)
+ console = Console()
+ table.add_column('Categories', justify='left')
+ table.add_column('Accuracy (%)', justify='right')
+ for cat, acc in table_metrics.items():
+ table.add_row(cat, f'{acc:.1f}')
+ with console.capture() as capture:
+ console.print(table, end='')
+ print_log('\n' + capture.get(), 'current')
diff --git a/data/xtuner/xtuner/evaluation/metrics/reward_metric.py b/data/xtuner/xtuner/evaluation/metrics/reward_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5d019978c9ebbfe2debd42b113f64aba9274423
--- /dev/null
+++ b/data/xtuner/xtuner/evaluation/metrics/reward_metric.py
@@ -0,0 +1,102 @@
+import itertools
+from collections import defaultdict
+from typing import List, Optional, Sequence
+
+import torch
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import print_log
+from rich.console import Console
+from rich.table import Table
+
+
+class RewardMetric(BaseMetric):
+ r"""Reward model evaluation metric.
+ """
+ default_prefix: Optional[str] = ''
+
+ def __init__(self,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+
+ def process(self, data_batch, data_samples: Sequence[dict]):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+ logits = torch.cat(
+ [sample['logits'].unsqueeze(0) for sample in data_samples], dim=0)
+ labels = data_batch['data']['labels']
+ ds_names = data_batch['data_samples']['ds_names']
+ chosen_idx = torch.where(labels == 0)
+ rejected_idx = torch.where(labels == 1)
+ chosen_logits = logits[chosen_idx].cpu()
+ rejected_logits = logits[rejected_idx].cpu()
+
+ correct = (chosen_logits > rejected_logits).cpu()
+ self.results.append({
+ 'chosen_logits': chosen_logits,
+ 'rejected_logits': rejected_logits,
+ 'correct': correct,
+ 'ds_names': ds_names
+ })
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ # NOTICE: don't access `self.results` from the method.
+ metrics = {}
+
+ correct = torch.cat([res['correct'] for res in results])
+ chosen_logits = torch.cat([res['chosen_logits'] for res in results])
+ rejected_logits = torch.cat(
+ [res['rejected_logits'] for res in results])
+ ds_names = list(itertools.chain(*[res['ds_names'] for res in results]))
+
+ # group by ds_names
+ grouped_correct = defaultdict(list)
+ grouped_chosen_logits = defaultdict(list)
+ grouped_rejected_logits = defaultdict(list)
+ for i, ds_name in enumerate(ds_names):
+ grouped_correct[ds_name].append(correct[i])
+ grouped_chosen_logits[ds_name].append(chosen_logits[i])
+ grouped_rejected_logits[ds_name].append(rejected_logits[i])
+
+ # print metrics in a rich table
+ table = Table(title='Reward Metrics')
+ table.add_column('Dataset Name')
+ table.add_column('Accuracy')
+ table.add_column('Chosen Score')
+ table.add_column('Rejected Score')
+
+ for ds_name in grouped_correct.keys():
+ correct = torch.stack(grouped_correct[ds_name])
+ chosen_logits = torch.stack(grouped_chosen_logits[ds_name])
+ rejected_logits = torch.stack(grouped_rejected_logits[ds_name])
+
+ acc = correct.float().mean()
+ metrics[f'accuracy/{ds_name}'] = acc.item()
+ metrics[f'chosen_score/{ds_name}'] = chosen_logits.mean().item()
+ metrics[f'rejected_score{ds_name}'] = rejected_logits.mean().item()
+
+ table.add_row(ds_name, f'{acc:.4f}', f'{chosen_logits.mean():.4f}',
+ f'{rejected_logits.mean():.4f}')
+
+ console = Console()
+ with console.capture() as capture:
+ console.print(table, end='')
+ print_log('\n' + capture.get(), 'current')
+
+ return metrics
diff --git a/data/xtuner/xtuner/model/__init__.py b/data/xtuner/xtuner/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b3a501d4a96ccb4ed2e7d5d10ab093d08892f12
--- /dev/null
+++ b/data/xtuner/xtuner/model/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .internvl import InternVL_V1_5
+from .llava import LLaVAModel
+from .sft import SupervisedFinetune
+
+__all__ = ['SupervisedFinetune', 'LLaVAModel', 'InternVL_V1_5']
diff --git a/data/xtuner/xtuner/model/dpo.py b/data/xtuner/xtuner/model/dpo.py
new file mode 100644
index 0000000000000000000000000000000000000000..faaa43402cb077ca39d9418e778b5bcbede10ace
--- /dev/null
+++ b/data/xtuner/xtuner/model/dpo.py
@@ -0,0 +1,286 @@
+# DPO Authors: Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn 2023 # noqa
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+from transformers.integrations import is_deepspeed_zero3_enabled
+
+from xtuner.parallel.sequence import (gather_forward_split_backward,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ split_for_sequence_parallel)
+from .sft import SupervisedFinetune
+
+
+def disable_grad(model):
+ # freeze parameters
+ parameter_names = [n for n, _ in model.named_parameters()]
+ for param_name in parameter_names:
+ param = model.get_parameter(param_name)
+ param.requires_grad = False
+ return model.eval()
+
+
+def create_reference_model(model):
+ if is_deepspeed_zero3_enabled():
+ raise ValueError('DeepSpeed ZeRO-3 is enabled and is not compatible '
+ 'with `create_reference_model()`. Please instantiate '
+ 'your reference model directly with '
+ '`AutoCausalLM.from_pretrained()`.')
+ ref_model = deepcopy(model)
+ ref_model = disable_grad(ref_model)
+ return ref_model
+
+
+class DPO(SupervisedFinetune):
+ """A general class of DPO and its variants."""
+
+ def __init__(self,
+ llm,
+ ref_llm=None,
+ beta=0.1,
+ loss_type='sigmoid',
+ label_smoothing=0.0,
+ **kwargs):
+ super().__init__(llm, **kwargs)
+ self.loss_type = loss_type
+ self.label_smoothing = label_smoothing
+ self.beta = beta
+
+ if ref_llm is not None:
+ ref_llm = self.build_llm_from_cfg(
+ ref_llm, kwargs.get('use_varlen_attn', False),
+ kwargs.get('max_position_embeddings', None))
+ self.ref_llm = disable_grad(ref_llm)
+ else:
+ self.ref_llm = None if self.use_lora else create_reference_model(
+ self.llm)
+
+ def _gather_masked_logits(self, logits, labels, mask):
+ logits = torch.gather(
+ logits.log_softmax(-1), dim=2,
+ index=labels.unsqueeze(2)).squeeze(2)
+ return logits * mask
+
+ def get_logps(
+ self,
+ policy_logps, # bs, seqlen,vocab_size
+ ref_logps, # bs, seqlen,vocab_size
+ loss_mask, # bs, seqlen
+ ):
+ policy_logps = policy_logps[:, :-1].sum(-1)
+ ref_logps = ref_logps[:, :-1].sum(-1)
+ loss_mask = loss_mask[:, :-1]
+
+ if self.loss_type == 'ipo': # average_log_prob
+ policy_logps = policy_logps / loss_mask.sum(-1)
+ ref_logps = ref_logps / loss_mask.sum(-1)
+
+ policy_chosen_logps = policy_logps[::2]
+ policy_rejected_logps = policy_logps[1::2]
+ reference_chosen_logps = ref_logps[::2]
+ reference_rejected_logps = ref_logps[1::2]
+ return (policy_chosen_logps, policy_rejected_logps,
+ reference_chosen_logps, reference_rejected_logps)
+
+ def get_var_len_atten_logps(self, policy_logps, ref_logps, loss_mask,
+ cu_seqlens, attention_mask):
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+ # unpack sequence
+ unpacked_policy_logps = torch.split(policy_logps, seqlens, dim=1)
+ unpacked_ref_logps = torch.split(ref_logps, seqlens, dim=1)
+ unpacked_loss_mask = torch.split(loss_mask, seqlens, dim=1)
+ if attention_mask is not None:
+ # It indicate that we pad the original sequence, labels,
+ # position_ids and cumulative_len for sequence parallel if the
+ # attention_mask is not None.
+ # We then need to remove the padded segments.
+ assert False in attention_mask
+ unpacked_policy_logps = unpacked_policy_logps[:-1]
+ unpacked_ref_logps = unpacked_ref_logps[:-1]
+ unpacked_loss_mask = unpacked_loss_mask[:-1]
+ assert len(unpacked_policy_logps) % 2 == 0
+
+ def compute_logps(_logps, _mask):
+ _logps = _logps[:, :-1].sum(-1)
+ _mask = _mask[:, :-1]
+ if self.loss_type == 'ipo':
+ _logps /= _mask.sum(-1)
+ return _logps
+
+ (policy_chosen_logps, policy_rejected_logps, reference_chosen_logps,
+ reference_rejected_logps) = [], [], [], []
+ for i in range(len(unpacked_policy_logps) // 2):
+ chosen = unpacked_policy_logps[2 * i]
+ rejected = unpacked_policy_logps[2 * i + 1]
+ chosen_ref = unpacked_ref_logps[2 * i]
+ rejected_ref = unpacked_ref_logps[2 * i + 1]
+ chosen_mask = unpacked_loss_mask[2 * i]
+ rejected_mask = unpacked_loss_mask[2 * i + 1]
+ policy_chosen_logps.append(compute_logps(chosen, chosen_mask))
+ policy_rejected_logps.append(
+ compute_logps(rejected, rejected_mask))
+ reference_chosen_logps.append(
+ compute_logps(chosen_ref, chosen_mask))
+ reference_rejected_logps.append(
+ compute_logps(rejected_ref, rejected_mask))
+
+ return (torch.stack(policy_chosen_logps),
+ torch.stack(policy_rejected_logps),
+ torch.stack(reference_chosen_logps),
+ torch.stack(reference_rejected_logps))
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'position_ids', 'labels')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def compute_loss(self, data, data_samples=None):
+ # modified from https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py # noqa
+ # shift labels first and add a dummy label at the end, to support sequence parallel # noqa
+ data['labels'] = torch.cat(
+ (data['labels'][:, 1:], torch.zeros_like(data['labels'][:, :1])),
+ dim=1)
+ tmp_label = data['labels'].clone()
+ tmp_label[tmp_label == 0] = -100
+ all_loss_mask = data[
+ 'labels'] != -100 # loss mask of all tokens in all sp ranks # noqa
+
+ if get_sequence_parallel_world_size() > 1:
+ data = self._split_for_sequence_parallel(data)
+
+ all_logits = self.llm(**data).logits
+ with torch.no_grad():
+ if self.ref_llm is None:
+ with self.llm.disable_adapter():
+ all_ref_logits = self.llm(**data).logits
+ else:
+ all_ref_logits = self.ref_llm(**data).logits
+
+ labels = data['labels']
+ labels[labels == -100] = 0
+ loss_mask = labels != 0 # loss mask in a single sp rank
+ policy_logps = self._gather_masked_logits(all_logits, labels,
+ loss_mask)
+ ref_logps = self._gather_masked_logits(all_ref_logits, labels,
+ loss_mask)
+
+ if get_sequence_parallel_world_size() > 1:
+ policy_logps = gather_forward_split_backward(
+ policy_logps,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+ ref_logps = gather_forward_split_backward(
+ ref_logps,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+
+ if not self.use_varlen_attn:
+ (policy_chosen_logps, policy_rejected_logps,
+ reference_chosen_logps,
+ reference_rejected_logps) = self.get_logps(
+ policy_logps, ref_logps, all_loss_mask)
+ else:
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cu_seqlens = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ (policy_chosen_logps, policy_rejected_logps,
+ reference_chosen_logps,
+ reference_rejected_logps) = self.get_var_len_atten_logps(
+ policy_logps, ref_logps, all_loss_mask, cu_seqlens,
+ data['attention_mask'])
+
+ pi_logratios = policy_chosen_logps - policy_rejected_logps
+ ref_logratios = reference_chosen_logps - reference_rejected_logps
+
+ logits = pi_logratios - ref_logratios
+ if self.loss_type == 'sigmoid':
+ loss = (-F.logsigmoid(self.beta * logits) *
+ (1 - self.label_smoothing) -
+ F.logsigmoid(-self.beta * logits) * self.label_smoothing)
+ elif self.loss_type == 'robust':
+ loss = (-F.logsigmoid(self.beta * logits) *
+ (1 - self.label_smoothing) +
+ F.logsigmoid(-self.beta * logits) *
+ self.label_smoothing) / (1 - 2 * self.label_smoothing)
+ elif self.loss_type == 'hinge':
+ loss = torch.relu(1 - self.beta * logits)
+ elif self.loss_type == 'ipo':
+ # eqn (17) of the paper where beta is the regularization
+ # parameter for the IPO loss, denoted by tau in the paper. # noqa
+ loss = (logits - 1 / (2 * self.beta))**2
+ elif self.loss_type == 'kto_pair':
+ # eqn (7) of the HALOs paper
+ chosen_KL = (policy_chosen_logps -
+ reference_chosen_logps).mean().clamp(min=0)
+ rejected_KL = (policy_rejected_logps -
+ reference_rejected_logps).mean().clamp(min=0)
+
+ chosen_logratios = policy_chosen_logps - reference_chosen_logps
+ rejected_logratios = \
+ policy_rejected_logps - reference_rejected_logps
+ # As described in the KTO report, the KL term for chosen (rejected)
+ # is estimated using the rejected (chosen) half. # noqa
+ loss = torch.cat(
+ (
+ 1 - F.sigmoid(self.beta *
+ (chosen_logratios - rejected_KL)),
+ 1 - F.sigmoid(self.beta *
+ (chosen_KL - rejected_logratios)),
+ ),
+ 0,
+ )
+ elif self.loss_type == 'sppo_hard':
+ # In the paper (https://arxiv.org/pdf/2405.00675),
+ # SPPO employs a soft probability approach,
+ # estimated using the PairRM score. The probability calculation
+ # is conducted outside of the trainer class.
+ # The version described here is the hard probability version,
+ # where P in Equation (4.7) of Algorithm 1 is set to 1 for
+ # the winner and 0 for the loser.
+ a = policy_chosen_logps - reference_chosen_logps
+ b = policy_rejected_logps - reference_rejected_logps
+
+ loss = (a - 0.5 / self.beta)**2 + (b + 0.5 / self.beta)**2
+ elif self.loss_type == 'nca_pair':
+ chosen_rewards = (policy_chosen_logps -
+ reference_chosen_logps) * self.beta
+ rejected_rewards = (policy_rejected_logps -
+ reference_rejected_logps) * self.beta
+ loss = (-F.logsigmoid(chosen_rewards) -
+ 0.5 * F.logsigmoid(-chosen_rewards) -
+ 0.5 * F.logsigmoid(-rejected_rewards))
+ else:
+ raise ValueError(
+ f'Unknown loss type: {self.loss_type}. Should be one of '
+ "['sigmoid', 'hinge', 'ipo', 'kto_pair', "
+ "'sppo_hard', 'nca_pair', 'robust']")
+ # for logging
+ chosen_rewards = self.beta * (
+ policy_chosen_logps - reference_chosen_logps)
+ rejected_rewards = self.beta * (
+ policy_rejected_logps - reference_rejected_logps)
+ reward_acc = (chosen_rewards > rejected_rewards).float().mean()
+
+ loss_dict = {
+ 'loss': loss,
+ 'chosen_rewards': chosen_rewards.mean(),
+ 'rejected_rewards': rejected_rewards.mean(),
+ 'reward_acc': reward_acc,
+ 'reward_margin': (chosen_rewards - rejected_rewards).mean(),
+ }
+ return loss_dict
diff --git a/data/xtuner/xtuner/model/internvl.py b/data/xtuner/xtuner/model/internvl.py
new file mode 100644
index 0000000000000000000000000000000000000000..0358266a9ff40defc650ca62179a1c496653bed7
--- /dev/null
+++ b/data/xtuner/xtuner/model/internvl.py
@@ -0,0 +1,320 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+from typing import List, Optional, Tuple, Union
+
+import torch
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from peft import get_peft_model, prepare_model_for_kbit_training
+from torch.nn import CrossEntropyLoss
+from transformers import (AutoConfig, AutoModel, AutoTokenizer,
+ BitsAndBytesConfig)
+from transformers.modeling_outputs import CausalLMOutputWithPast
+
+from xtuner.registry import BUILDER
+from .utils import (find_all_linear_names, get_peft_model_state_dict,
+ guess_load_checkpoint, make_inputs_require_grad)
+
+
+class InternVL_V1_5(BaseModel):
+
+ def __init__(self,
+ model_path,
+ freeze_llm=False,
+ freeze_visual_encoder=False,
+ llm_lora=None,
+ visual_encoder_lora=None,
+ quantization_vit=False,
+ quantization_llm=False,
+ pretrained_pth=None):
+ print_log('Start to load InternVL_V1_5 model.', logger='current')
+ super().__init__()
+ self.freeze_llm = freeze_llm
+ self.freeze_visual_encoder = freeze_visual_encoder
+ self.use_llm_lora = llm_lora is not None
+ self.use_visual_encoder_lora = visual_encoder_lora is not None
+ self.quantization_vit = quantization_vit
+ self.quantization_llm = quantization_llm
+ if quantization_vit:
+ assert visual_encoder_lora is not None
+ if quantization_llm:
+ assert quantization_llm and llm_lora is not None
+
+ config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
+ if config.llm_config.model_type == 'internlm2':
+ config.llm_config.attn_implementation = 'flash_attention_2'
+ else:
+ config.llm_config._attn_implementation = 'flash_attention_2'
+
+ if quantization_vit is False and quantization_llm is False:
+ quantization = None
+ else:
+ llm_int8_skip_modules = ['mlp1']
+ if quantization_llm and not quantization_vit:
+ llm_int8_skip_modules.append('vision_model')
+
+ if quantization_vit and not quantization_llm:
+ llm_int8_skip_modules.append('language_model')
+
+ quantization_config = dict(
+ type=BitsAndBytesConfig,
+ llm_int8_skip_modules=llm_int8_skip_modules,
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4')
+ quantization_clazz = quantization_config.pop('type')
+ quantization = quantization_clazz(**quantization_config)
+
+ self.model = AutoModel.from_pretrained(
+ model_path,
+ torch_dtype=torch.bfloat16,
+ quantization_config=quantization,
+ config=config,
+ trust_remote_code=True)
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_path, trust_remote_code=True)
+ img_context_token_id = tokenizer.convert_tokens_to_ids('')
+ self.model.img_context_token_id = img_context_token_id
+
+ if self.freeze_llm:
+ self.model.language_model.requires_grad_(False)
+ if self.freeze_visual_encoder:
+ self.model.vision_model.requires_grad_(False)
+
+ if hasattr(self.model.language_model, 'enable_input_require_grads'):
+ self.model.language_model.enable_input_require_grads()
+ else:
+ self.model.language_model.get_input_embeddings(
+ ).register_forward_hook(make_inputs_require_grad)
+
+ self.gradient_checkpointing_enable()
+
+ if self.use_llm_lora:
+ self._prepare_llm_for_lora(llm_lora)
+
+ if self.use_visual_encoder_lora:
+ self._prepare_visual_encoder_for_lora(visual_encoder_lora)
+
+ if pretrained_pth is not None:
+ pretrained_state_dict = guess_load_checkpoint(pretrained_pth)
+
+ self.load_state_dict(pretrained_state_dict, strict=False)
+ print(f'Load pretrained weight from {pretrained_pth}')
+
+ self._count = 0
+ print_log(self, logger='current')
+ print_log('InternVL_V1_5 construction is complete', logger='current')
+
+ def _parse_lora_config(self, lora_config):
+ if isinstance(lora_config, dict) or isinstance(
+ lora_config, Config) or isinstance(lora_config, ConfigDict):
+ lora_config = BUILDER.build(lora_config)
+ return lora_config
+
+ def _prepare_llm_for_lora(self,
+ lora_config,
+ use_activation_checkpointing=True):
+ lora_config = self._parse_lora_config(lora_config)
+ self.model.language_model = prepare_model_for_kbit_training(
+ self.model.language_model, use_activation_checkpointing)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.model.language_model)
+ lora_config.target_modules = modules
+ self.model.language_model = get_peft_model(self.model.language_model,
+ lora_config)
+
+ def _prepare_visual_encoder_for_lora(self, lora_config):
+ lora_config = self._parse_lora_config(lora_config)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.model.vision_model)
+ lora_config.target_modules = modules
+ self.model.vision_model = get_peft_model(self.model.vision_model,
+ lora_config)
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.model.language_model.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.model.language_model.gradient_checkpointing_disable()
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ to_return = OrderedDict()
+ # Step 1. visual_encoder
+ if self.use_visual_encoder_lora:
+ to_return.update(
+ get_peft_model_state_dict(
+ self.model.vision_model, state_dict=state_dict))
+ elif not self.freeze_visual_encoder:
+ to_return.update({
+ k: v
+ for k, v in state_dict.items() if 'model.vision_model.' in k
+ })
+ # Step 2. LLM
+ if self.use_llm_lora:
+ to_return.update(
+ get_peft_model_state_dict(
+ self.model.language_model, state_dict=state_dict))
+ elif not self.freeze_llm:
+ to_return.update({
+ k: v
+ for k, v in state_dict.items() if 'model.language_model.' in k
+ })
+ # Step 3. Projector
+ to_return.update(
+ {k: v
+ for k, v in state_dict.items() if 'model.mlp1.' in k})
+ return to_return
+
+ def init_weights(self):
+ pass
+
+ def forward(self, data, data_samples=None, mode='loss'):
+ pixel_values = data['pixel_values']
+
+ if type(pixel_values) is list or pixel_values.ndim == 5:
+ if type(pixel_values) is list:
+ pixel_values = [
+ x.unsqueeze(0) if x.ndim == 3 else x for x in pixel_values
+ ]
+ # b*n, c, h, w
+ concat_images = torch.cat([
+ image.to(self.model.vision_model.dtype)
+ for image in pixel_values
+ ],
+ dim=0)
+ else:
+ raise NotImplementedError()
+
+ input_ids = data['input_ids']
+ position_ids = data['position_ids']
+ attention_mask = data['attention_mask']
+ # sum is 0 are text
+ image_flags = torch.sum(concat_images, dim=(1, 2, 3)) != 0
+ image_flags = image_flags.long()
+
+ labels = data['labels']
+ use_cache = False
+
+ # Directly calling this code in LORA fine-tuning
+ # will result in an error,so we must rewrite it.
+ # TODO: Once the official is fixed, we can remove it.
+ # outputs = self.model(input_ids=input_ids,
+ # position_ids=position_ids,
+ # attention_mask=attention_mask,
+ # image_flags=image_flags,
+ # pixel_values=concat_images,
+ # labels=labels,
+ # use_cache=use_cache)
+ outputs = self._llm_forward(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ image_flags=image_flags,
+ pixel_values=concat_images,
+ labels=labels,
+ use_cache=use_cache)
+ loss_dict = {'loss': outputs.loss}
+ return loss_dict
+
+ def _llm_forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ image_flags: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ return_dict = return_dict if return_dict is not None \
+ else self.model.config.use_return_dict
+
+ image_flags = image_flags.squeeze(-1)
+ # We only added the clone code here to avoid the error.
+ input_embeds = self.model.language_model.get_input_embeddings()(
+ input_ids).clone()
+
+ vit_embeds = self.model.extract_feature(pixel_values)
+ vit_embeds = vit_embeds[image_flags == 1]
+ vit_batch_size = pixel_values.shape[0]
+
+ B, N, C = input_embeds.shape
+ input_embeds = input_embeds.reshape(B * N, C)
+
+ if torch.distributed.get_rank() == 0 and self._count % 100 == 0:
+ print(f'dynamic ViT batch size: {vit_batch_size}, '
+ f'images per sample: {vit_batch_size / B}, '
+ f'dynamic token length: {N}')
+ self._count += 1
+
+ input_ids = input_ids.reshape(B * N)
+ selected = (input_ids == self.model.img_context_token_id)
+ try:
+ input_embeds[
+ selected] = input_embeds[selected] * 0.0 + vit_embeds.reshape(
+ -1, C)
+ except Exception as e:
+ vit_embeds = vit_embeds.reshape(-1, C)
+ print(f'warning: {e}, input_embeds[selected].shape='
+ f'{input_embeds[selected].shape}, '
+ f'vit_embeds.shape={vit_embeds.shape}')
+ n_token = selected.sum()
+ input_embeds[
+ selected] = input_embeds[selected] * 0.0 + vit_embeds[:n_token]
+
+ input_embeds = input_embeds.reshape(B, N, C)
+
+ outputs = self.model.language_model(
+ inputs_embeds=input_embeds,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ logits = outputs.logits
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(
+ -1, self.model.language_model.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ return (loss, ) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/model/llava.py b/data/xtuner/xtuner/model/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..36d1833d3040e65e97700d81bd11a906fbedbebd
--- /dev/null
+++ b/data/xtuner/xtuner/model/llava.py
@@ -0,0 +1,635 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os.path as osp
+import warnings
+from collections import OrderedDict
+
+import torch
+import torch.nn as nn
+from accelerate import init_empty_weights
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from peft import get_peft_model, prepare_model_for_kbit_training
+from transformers import (AddedToken, AutoConfig, CLIPImageProcessor,
+ CLIPVisionModel, LlamaForCausalLM,
+ LlamaTokenizerFast, LlavaConfig,
+ LlavaForConditionalGeneration, LlavaProcessor)
+from transformers.integrations import is_deepspeed_zero3_enabled
+
+from xtuner.registry import BUILDER
+from xtuner.utils import DEFAULT_IMAGE_TOKEN
+from .modules import ProjectorConfig, ProjectorModel, dispatch_modules
+from .modules.dispatch import SUPPORT_FLASH1, SUPPORT_FLASH2
+from .utils import (LoadWoInit, find_all_linear_names,
+ get_peft_model_state_dict, guess_load_checkpoint,
+ make_inputs_require_grad,
+ prepare_inputs_labels_for_multimodal, traverse_dict)
+
+
+def convert_state_dict_to_hf(state_dict, mapping):
+ new_state_dict = {}
+ for key, value in state_dict.items():
+ if key.endswith('.inv_freq'):
+ continue
+ for key_to_modify, new_key in mapping.items():
+ if key_to_modify in key:
+ key = key.replace(key_to_modify, new_key)
+ new_state_dict[key] = value
+ return new_state_dict
+
+
+class LLaVAModel(BaseModel):
+
+ def __init__(self,
+ llm,
+ visual_encoder,
+ freeze_llm=False,
+ freeze_visual_encoder=False,
+ visual_select_layer=-2,
+ pretrained_pth=None,
+ projector_depth=2,
+ llm_lora=None,
+ visual_encoder_lora=None,
+ use_activation_checkpointing=True,
+ max_position_embeddings=None):
+ super().__init__()
+ self.freeze_llm = freeze_llm
+ self.freeze_visual_encoder = freeze_visual_encoder
+ with LoadWoInit():
+ if isinstance(llm, dict):
+ llm = self._dispatch_lm_model_cfg(llm, max_position_embeddings)
+
+ self.llm = self._build_from_cfg_or_module(llm)
+ self.visual_encoder = self._build_from_cfg_or_module(
+ visual_encoder)
+ self.llm.config.use_cache = False
+ dispatch_modules(self.llm)
+
+ self.projector_depth = projector_depth
+ projector_config = ProjectorConfig(
+ visual_hidden_size=self.visual_encoder.config.hidden_size,
+ llm_hidden_size=self.llm.config.hidden_size,
+ depth=self.projector_depth)
+ self.projector = ProjectorModel(projector_config).to(
+ self.visual_encoder.dtype)
+
+ if self.freeze_llm:
+ self.llm.requires_grad_(False)
+ if self.freeze_visual_encoder:
+ self.visual_encoder.requires_grad_(False)
+
+ if use_activation_checkpointing:
+ # For backward compatibility
+ if hasattr(self.llm, 'enable_input_require_grads'):
+ self.llm.enable_input_require_grads()
+ else:
+ self.llm.get_input_embeddings().register_forward_hook(
+ make_inputs_require_grad)
+ if hasattr(self.visual_encoder, 'enable_input_require_grads'):
+ self.visual_encoder.enable_input_require_grads()
+ else:
+ self.visual_encoder.get_input_embeddings(
+ ).register_forward_hook(make_inputs_require_grad)
+ self.projector.enable_input_require_grads()
+
+ # enable gradient (activation) checkpointing for memory efficiency
+ self.gradient_checkpointing_enable()
+
+ self.use_llm_lora = llm_lora is not None
+ self.use_visual_encoder_lora = visual_encoder_lora is not None
+
+ if self.use_llm_lora:
+ self._prepare_llm_for_lora(llm_lora, use_activation_checkpointing)
+ if self.use_visual_encoder_lora:
+ self._prepare_visual_encoder_for_lora(
+ visual_encoder_lora, use_activation_checkpointing)
+
+ if pretrained_pth is not None:
+ pretrained_state_dict = guess_load_checkpoint(pretrained_pth)
+
+ self.load_state_dict(pretrained_state_dict, strict=False)
+ print_log(f'Load pretrained weight from {pretrained_pth}',
+ 'current')
+
+ self.visual_select_layer = visual_select_layer
+
+ self._is_init = True
+
+ self.is_first_iter = True
+
+ def _parse_lora_config(self, lora_config):
+ if isinstance(lora_config, dict) or isinstance(
+ lora_config, Config) or isinstance(lora_config, ConfigDict):
+ lora_config = BUILDER.build(lora_config)
+ return lora_config
+
+ def _prepare_llm_for_lora(self,
+ lora_config,
+ use_activation_checkpointing=True):
+ lora_config = self._parse_lora_config(lora_config)
+ self.llm = prepare_model_for_kbit_training(
+ self.llm, use_activation_checkpointing)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.llm)
+ lora_config.target_modules = modules
+ self.llm = get_peft_model(self.llm, lora_config)
+
+ def _prepare_visual_encoder_for_lora(self,
+ lora_config,
+ use_activation_checkpointing=True):
+ lora_config = self._parse_lora_config(lora_config)
+ if lora_config.target_modules is None:
+ modules = find_all_linear_names(self.visual_encoder)
+ lora_config.target_modules = modules
+ self.visual_encoder = get_peft_model(self.visual_encoder, lora_config)
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.llm.gradient_checkpointing_enable()
+ self.visual_encoder.gradient_checkpointing_enable()
+ self.projector.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.llm.gradient_checkpointing_disable()
+ self.visual_encoder.gradient_checkpointing_disable()
+ self.projector.gradient_checkpointing_disable()
+
+ def init_weights(self):
+ pass
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ to_return = OrderedDict()
+ # Step 1. visual_encoder
+ if self.use_visual_encoder_lora:
+ to_return.update(
+ get_peft_model_state_dict(
+ self.visual_encoder, state_dict=state_dict))
+ elif not self.freeze_visual_encoder:
+ to_return.update({
+ k: v
+ for k, v in state_dict.items() if 'visual_encoder.' in k
+ })
+ # Step 2. LLM
+ if self.use_llm_lora:
+ to_return.update(
+ get_peft_model_state_dict(self.llm, state_dict=state_dict))
+ elif not self.freeze_llm:
+ to_return.update(
+ {k: v
+ for k, v in state_dict.items() if 'llm.' in k})
+ # Step 3. Projector
+ to_return.update(
+ {k: v
+ for k, v in state_dict.items() if 'projector.' in k})
+ return to_return
+
+ @staticmethod
+ def _prepare_for_long_context_training(cfg, llm_cfg,
+ max_position_embeddings):
+
+ orig_rope_scaling = getattr(llm_cfg, 'rope_scaling', None)
+ if orig_rope_scaling is None:
+ orig_rope_scaling = {'factor': 1}
+
+ orig_rope_scaling_factor = orig_rope_scaling[
+ 'factor'] if 'factor' in orig_rope_scaling.keys() else 1
+ orig_ctx_len = getattr(llm_cfg, 'max_position_embeddings', None)
+ if orig_ctx_len:
+ orig_ctx_len *= orig_rope_scaling_factor
+ if max_position_embeddings > orig_ctx_len:
+ scaling_factor = float(
+ math.ceil(max_position_embeddings / orig_ctx_len))
+ llm_cfg.rope_scaling = {
+ 'type': 'linear',
+ 'factor': scaling_factor
+ }
+
+ # hardcode for internlm2
+ llm_cfg.attn_implementation = 'flash_attention_2'
+ cfg.config = llm_cfg
+
+ return cfg, llm_cfg
+
+ @staticmethod
+ def _prepare_for_flash_attn(cfg, llm_cfg):
+ cls_name = type(llm_cfg).__name__
+ SUPPORT_SDPA_ATTN = ('LlamaConfig', 'GemmaConfig', 'MistralConfig',
+ 'MixtralConfig', 'Qwen2Config', 'Qwen2MoeConfig',
+ 'Starcoder2Config', 'Starcoder2Config',
+ 'Phi3Config')
+ SUPPORT_FLASH_ATTN2 = ('InternLM2Config', 'LlamaConfig', 'GemmaConfig',
+ 'MistralConfig', 'MixtralConfig', 'Qwen2Config',
+ 'Qwen2MoeConfig', 'Starcoder2Config',
+ 'Starcoder2Config', 'Phi3Config')
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ if getattr(cfg, 'attn_implementation', None) is not None:
+ # Flash Attention 2.0 only supports torch.float16 and
+ # torch.bfloat16 dtypes
+ if cfg.attn_implementation == 'flash_attention_2':
+ cfg.torch_dtype = torch_dtype
+ elif SUPPORT_FLASH2 and cls_name in SUPPORT_FLASH_ATTN2:
+ cfg.torch_dtype = torch_dtype
+ cfg.attn_implementation = 'flash_attention_2'
+ elif SUPPORT_FLASH1 and cls_name in SUPPORT_SDPA_ATTN:
+ cfg.attn_implementation = 'sdpa'
+
+ return cfg, llm_cfg
+
+ @staticmethod
+ def _prepare_for_qlora_zero3(cfg):
+ if (not is_deepspeed_zero3_enabled()) or (not hasattr(
+ cfg, 'quantization_config')):
+ return cfg
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ cfg.torch_dtype = torch_dtype
+ quantization_config = cfg.quantization_config
+ quantization_config.bnb_4bit_compute_dtype = torch_dtype
+ quantization_config.bnb_4bit_quant_storage = torch_dtype
+
+ return cfg
+
+ def _dispatch_lm_model_cfg(self, cfg, max_position_embeddings=None):
+ cfg = self._prepare_for_qlora_zero3(cfg)
+ pretrained_model_name_or_path = cfg.pretrained_model_name_or_path
+ llm_cfg = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=True)
+ cfg, llm_cfg = self._prepare_for_flash_attn(cfg, llm_cfg)
+ if max_position_embeddings is not None:
+ cfg, llm_cfg = self._prepare_for_long_context_training(
+ cfg, llm_cfg, max_position_embeddings)
+ return cfg
+
+ def _build_from_cfg_or_module(self, cfg_or_mod):
+ if isinstance(cfg_or_mod, nn.Module):
+ return cfg_or_mod
+ elif isinstance(cfg_or_mod, dict):
+ traverse_dict(cfg_or_mod)
+ return BUILDER.build(cfg_or_mod)
+ else:
+ raise NotImplementedError
+
+ def forward(self, data, data_samples=None, mode='loss'):
+ if self.is_first_iter:
+ # hardcode for qlora DeepSpeed ZeRO3, put buffers and QuantState to
+ # device
+ # Only required in `LLaVAModel` .
+ # We do not need this in `SupervisedFinetune` .
+ self.to(data['input_ids'].device)
+ self.is_first_iter = False
+
+ if 'pixel_values' in data:
+ visual_outputs = self.visual_encoder(
+ data['pixel_values'].to(self.visual_encoder.dtype),
+ output_hidden_states=True)
+ pixel_values = self.projector(
+ visual_outputs.hidden_states[self.visual_select_layer][:, 1:])
+ data['pixel_values'] = pixel_values
+ data = prepare_inputs_labels_for_multimodal(llm=self.llm, **data)
+
+ if mode == 'loss':
+ return self.compute_loss(data, data_samples)
+ elif mode == 'predict':
+ return self.predict(data, data_samples)
+ elif mode == 'tensor':
+ return self._forward(data, data_samples)
+ else:
+ raise NotImplementedError
+
+ def _forward(self, data, data_samples=None):
+
+ outputs = self.llm(**data)
+
+ return outputs
+
+ def predict(self, data, data_samples=None):
+ outputs = self.llm(**data)
+ logits_dict = [{'logits': logits} for logits in outputs.logits]
+ return logits_dict
+
+ def compute_loss(self, data, data_samples=None):
+ outputs = self.llm(**data)
+ loss_dict = {'loss': outputs.loss}
+ return loss_dict
+
+ def __getattr__(self, name: str):
+ try:
+ return super().__getattr__(name)
+ except AttributeError:
+ return getattr(self.llm, name)
+
+ def to_hf(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={},
+ save_format='xtuner',
+ **kwargs):
+ if save_format == 'xtuner':
+ self.to_xtuner_llava(cfg, save_dir, fp32, save_pretrained_kwargs)
+ elif save_format == 'huggingface':
+ self.to_huggingface_llava(cfg, save_dir, fp32,
+ save_pretrained_kwargs)
+ elif save_format == 'official':
+ self.to_official_llava(cfg, save_dir, fp32, save_pretrained_kwargs)
+ else:
+ raise NotImplementedError
+
+ def to_xtuner_llava(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={}):
+ # LLM
+ self.llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ self.llm.half()
+ if self.use_llm_lora:
+ llm_path = osp.join(save_dir, 'llm_adapter')
+ print_log(f'Saving LLM adapter to {llm_path}', 'current')
+ self.llm.save_pretrained(llm_path, **save_pretrained_kwargs)
+ elif not self.freeze_llm:
+ llm_path = save_dir
+ print_log(f'Saving LLM tokenizer to {llm_path}', 'current')
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ tokenizer.save_pretrained(llm_path, **save_pretrained_kwargs)
+ print_log(f'Saving LLM to {llm_path}', 'current')
+ self.llm.save_pretrained(llm_path, **save_pretrained_kwargs)
+ self.llm.config.use_cache = False
+
+ # Visual Encoder
+ if self.use_visual_encoder_lora:
+ visual_encoder_path = osp.join(save_dir, 'visual_encoder_adapter')
+ print_log(
+ f'Saving visual_encoder adapter to {visual_encoder_path}',
+ 'current')
+ self.visual_encoder.save_pretrained(visual_encoder_path,
+ **save_pretrained_kwargs)
+ elif not self.freeze_visual_encoder:
+ visual_encoder_path = osp.join(save_dir, 'visual_encoder')
+ print_log(
+ 'Saving visual_encoder image_processor to'
+ f'{visual_encoder_path}', 'current')
+ image_processor = BUILDER.build(cfg.image_processor)
+ image_processor.save_pretrained(visual_encoder_path,
+ **save_pretrained_kwargs)
+ print_log(f'Saving visual_encoder to {visual_encoder_path}',
+ 'current')
+ self.visual_encoder.save_pretrained(visual_encoder_path,
+ **save_pretrained_kwargs)
+
+ # Projector
+ projector_path = osp.join(save_dir, 'projector')
+ print_log(f'Saving projector to {projector_path}', 'current')
+ self.projector.save_pretrained(projector_path,
+ **save_pretrained_kwargs)
+
+ def to_huggingface_llava(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={}):
+
+ LLM_MAPPING = {
+ 'model': 'language_model.model',
+ 'lm_head': 'language_model.lm_head',
+ }
+ VIT_MAPPING = {
+ 'vision_model': 'vision_tower.vision_model',
+ }
+ PROJECTOR_MAPPING = {
+ 'model.0': 'multi_modal_projector.linear_1',
+ 'model.2': 'multi_modal_projector.linear_2',
+ }
+
+ assert getattr(self.llm, 'hf_quantizer', None) is None, \
+ 'This conversion format does not support quantized LLM.'
+
+ # get state_dict
+ llm = self.llm
+ if self.use_llm_lora:
+ llm = self.llm.merge_and_unload()
+ llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ llm.half()
+
+ assert isinstance(llm, LlamaForCausalLM), \
+ 'This conversion format only supports LlamaForCausalLM.'
+ llm_state_dict = llm.state_dict()
+ llm_state_dict = convert_state_dict_to_hf(llm_state_dict, LLM_MAPPING)
+
+ need_visual_encoder = (not self.freeze_visual_encoder
+ or self.use_visual_encoder_lora)
+ visual_encoder = self.visual_encoder
+ if self.use_visual_encoder_lora:
+ visual_encoder = self.visual_encoder.merge_and_unload()
+ assert isinstance(visual_encoder, CLIPVisionModel),\
+ 'This conversion format only supports CLIPVisionModel.'
+ if need_visual_encoder:
+ visual_encoder_state_dict = visual_encoder.state_dict()
+ visual_encoder_state_dict = convert_state_dict_to_hf(
+ visual_encoder_state_dict, VIT_MAPPING)
+ else:
+ visual_encoder_state_dict = {}
+
+ projector_state_dict = self.projector.state_dict()
+ projector_state_dict = convert_state_dict_to_hf(
+ projector_state_dict, PROJECTOR_MAPPING)
+
+ state_dict = {
+ **projector_state_dict,
+ **llm_state_dict,
+ **visual_encoder_state_dict
+ }
+
+ # init model
+ text_config = llm.config
+ vision_config = visual_encoder.config
+ config = LlavaConfig(
+ text_config=text_config,
+ vision_config=vision_config,
+ attn_implementation='eager')
+
+ with init_empty_weights():
+ with warnings.catch_warnings():
+ warnings.filterwarnings(
+ 'ignore', message='.*non-meta.*', category=UserWarning)
+ model = LlavaForConditionalGeneration(config)
+ model.load_state_dict(state_dict, strict=True, assign=True)
+
+ # processor
+ cfg.tokenizer.type = LlamaTokenizerFast.from_pretrained
+ tokenizer = BUILDER.build(cfg.tokenizer)
+
+ tokenizer.add_tokens(
+ AddedToken(DEFAULT_IMAGE_TOKEN, special=True, normalized=False),
+ special_tokens=True)
+ tokenizer.add_special_tokens({'pad_token': ''})
+
+ image_processor = BUILDER.build(cfg.image_processor)
+ assert isinstance(image_processor, CLIPImageProcessor),\
+ 'This conversion format only supports CLIPImageProcessor.'
+
+ processor = LlavaProcessor(
+ tokenizer=tokenizer, image_processor=image_processor)
+
+ # Pad to 64 for performance reasons
+ pad_shape = 64
+
+ pre_expansion_embeddings = \
+ model.language_model.model.embed_tokens.weight.data
+ mu = torch.mean(pre_expansion_embeddings, dim=0).float()
+ n = pre_expansion_embeddings.size()[0]
+ sigma = ((pre_expansion_embeddings - mu).T
+ @ (pre_expansion_embeddings - mu)) / n
+ dist = torch.distributions.multivariate_normal.MultivariateNormal(
+ mu, covariance_matrix=1e-5 * sigma)
+
+ # We add an image token so we need to resize the model
+ ori_vocab_size = config.text_config.vocab_size
+ tokenizer_vocab_size = tokenizer.encode('')[-1]
+ added_token = tokenizer_vocab_size - ori_vocab_size
+
+ if added_token > 0:
+ model.resize_token_embeddings(ori_vocab_size + added_token,
+ pad_shape)
+ model.language_model.model.embed_tokens.weight.data[
+ ori_vocab_size:] = torch.stack(
+ tuple(
+ dist.sample()
+ for _ in range(model.language_model.model.embed_tokens.
+ weight.data[ori_vocab_size:].shape[0])),
+ dim=0,
+ )
+ model.language_model.lm_head.weight.data[
+ ori_vocab_size:] = torch.stack(
+ tuple(dist.sample()
+ for _ in range(model.language_model.lm_head.weight.
+ data[ori_vocab_size:].shape[0])),
+ dim=0,
+ )
+ model.config.image_token_index = tokenizer.encode(
+ DEFAULT_IMAGE_TOKEN)[-1]
+ model.config.pad_token_id = tokenizer.encode('')[-1]
+
+ # save
+ print_log(f'Saving to {save_dir}', 'current')
+ model.save_pretrained(save_dir, **save_pretrained_kwargs)
+ processor.save_pretrained(save_dir, **save_pretrained_kwargs)
+
+ def to_official_llava(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={}):
+
+ VIT_MAPPING = {
+ 'vision_model': 'model.vision_tower.vision_tower.vision_model',
+ }
+ PROJECTOR_MAPPING = {
+ 'model.0': 'model.mm_projector.0',
+ 'model.2': 'model.mm_projector.2',
+ }
+
+ try:
+ from llava.model import LlavaConfig, LlavaLlamaForCausalLM
+ except ImportError:
+ raise ImportError(
+ 'Please install llava with '
+ '`pip install git+https://github.com/haotian-liu/LLaVA.git '
+ '--no-deps`.')
+
+ assert getattr(self.llm, 'hf_quantizer', None) is None, \
+ 'This conversion format does not support quantized LLM.'
+
+ # get state_dict
+ llm = self.llm
+ if self.use_llm_lora:
+ llm = self.llm.merge_and_unload()
+ llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ llm.half()
+
+ assert isinstance(llm, LlamaForCausalLM), \
+ 'This conversion format only supports LlamaForCausalLM.'
+ llm_state_dict = llm.state_dict()
+
+ need_visual_encoder = (not self.freeze_visual_encoder
+ or self.use_visual_encoder_lora)
+ visual_encoder = self.visual_encoder
+ if self.use_visual_encoder_lora:
+ visual_encoder = self.visual_encoder.merge_and_unload()
+ assert isinstance(visual_encoder, CLIPVisionModel),\
+ 'This conversion format only supports CLIPVisionModel.'
+ if need_visual_encoder:
+ visual_encoder_state_dict = visual_encoder.state_dict()
+ visual_encoder_state_dict = convert_state_dict_to_hf(
+ visual_encoder_state_dict, VIT_MAPPING)
+ else:
+ visual_encoder_state_dict = {}
+
+ projector_state_dict = self.projector.state_dict()
+ projector_state_dict = convert_state_dict_to_hf(
+ projector_state_dict, PROJECTOR_MAPPING)
+
+ state_dict = {
+ **projector_state_dict,
+ **llm_state_dict,
+ **visual_encoder_state_dict
+ }
+
+ # init model
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ image_processor = BUILDER.build(cfg.image_processor)
+ assert isinstance(image_processor, CLIPImageProcessor),\
+ 'This conversion format only supports CLIPImageProcessor.'
+
+ llava_config_dict = llm.config.__dict__.copy()
+ llava_config_dict.update(
+ dict(
+ image_aspect_ratio='pad',
+ mm_hidden_size=visual_encoder.config.hidden_size,
+ mm_projector_type=f'mlp{self.projector_depth}x_gelu',
+ mm_use_im_patch_token=False,
+ mm_use_im_start_end=False,
+ mm_vision_select_feature='patch',
+ mm_vision_select_layer=self.visual_select_layer,
+ mm_vision_tower=visual_encoder.config.name_or_path,
+ unfreeze_mm_vision_tower=need_visual_encoder,
+ model_type='llava',
+ use_cache=True,
+ use_mm_proj=True))
+
+ llava_config = LlavaConfig(**llava_config_dict)
+
+ with init_empty_weights():
+ with warnings.catch_warnings():
+ warnings.filterwarnings(
+ 'ignore', message='.*non-meta.*', category=UserWarning)
+ model = LlavaLlamaForCausalLM(llava_config)
+
+ model.load_state_dict(state_dict, strict=True, assign=True)
+
+ # save
+ print_log(f'Saving to {save_dir}', 'current')
+
+ model.save_pretrained(save_dir, **save_pretrained_kwargs)
+ image_processor.save_pretrained(save_dir, **save_pretrained_kwargs)
+ tokenizer.save_pretrained(save_dir, **save_pretrained_kwargs)
diff --git a/data/xtuner/xtuner/model/modules/__init__.py b/data/xtuner/xtuner/model/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1207a9249708ff22b19db94a028b8d06f86f53a8
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/__init__.py
@@ -0,0 +1,4 @@
+from .dispatch import dispatch_modules
+from .projector import ProjectorConfig, ProjectorModel
+
+__all__ = ['dispatch_modules', 'ProjectorConfig', 'ProjectorModel']
diff --git a/data/xtuner/xtuner/model/modules/dispatch/__init__.py b/data/xtuner/xtuner/model/modules/dispatch/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e81ec7a3aa69fe25ee4a95759cdcb377e4e1ddd7
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/__init__.py
@@ -0,0 +1,276 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import types
+
+import torch
+import transformers
+from mmengine.config.lazy import LazyObject
+from mmengine.utils import digit_version
+from transformers.utils.import_utils import is_flash_attn_2_available
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.38')
+# Transformers requires torch version >= 2.1.1 when using Torch SDPA.
+# Refer to https://github.com/huggingface/transformers/blob/caa5c65db1f4db617cdac2ad667ba62edf94dd98/src/transformers/modeling_utils.py#L1611 # noqa: E501
+SUPPORT_FLASH1 = digit_version(torch.__version__) >= digit_version('2.1.1')
+SUPPORT_FLASH2 = is_flash_attn_2_available()
+SUPPORT_FLASH = SUPPORT_FLASH1 or SUPPORT_FLASH2
+
+USE_TRITON_KERNEL = bool(os.getenv('USE_TRITON_KERNEL', default=0))
+SUPPORT_TRITON = False
+try:
+ import triton # pre-check # noqa: F401
+ import triton.language as tl # pre-check # noqa: F401
+ SUPPORT_TRITON = True
+except ImportError:
+ if USE_TRITON_KERNEL:
+ raise RuntimeError(
+ 'USE_TRITON_KERNEL is set to 1, but triton has not been installed.'
+ ' Run `pip install triton==2.1.0` to install triton.')
+
+NO_ATTN_WEIGHTS_MSG = (
+ 'Due to the implementation of the PyTorch version of flash attention, '
+ 'even when the `output_attentions` flag is set to True, it is not '
+ 'possible to return the `attn_weights`.')
+
+LOWEST_TRANSFORMERS_VERSION = dict(
+ InternLM2ForCausalLM=digit_version('4.36'),
+ InternLMForCausalLM=digit_version('4.36'),
+ LlamaForCausalLM=digit_version('4.36'),
+ Phi3ForCausalLM=digit_version('4.39'),
+ MistralForCausalLM=digit_version('4.36'),
+ # Training mixtral with lower version may lead to nccl timeout
+ # Refer to https://github.com/microsoft/DeepSpeed/issues/5066
+ MixtralForCausalLM=digit_version('4.40'),
+ CohereForCausalLM=digit_version('4.40'),
+ Qwen2ForCausalLM=digit_version('4.39'),
+ Qwen2MoeForCausalLM=digit_version('4.40'),
+ DeepseekV2ForCausalLM=digit_version('4.40'),
+)
+
+ATTN_DISPATCH_MAPPING = dict(
+ InternLM2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.internlm2', 'internlm2_attn_forward'),
+ InternLMAttention=LazyObject('xtuner.model.modules.dispatch.internlm',
+ 'internlm_attn_forward'),
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_attn_forward'),
+ Phi3FlashAttention2=LazyObject('xtuner.model.modules.dispatch.phi3',
+ 'phi3_attn_forward'),
+ MistralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_attn_forward'),
+ MixtralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_attn_forward'),
+ CohereFlashAttention2=LazyObject('xtuner.model.modules.dispatch.cohere',
+ 'cohere_attn_forward'),
+ Qwen2FlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_attn_forward'),
+ Qwen2MoeFlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_attn_forward'),
+ DeepseekV2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.deepseek_v2', 'deepseek_attn_forward'),
+)
+
+ATTN_LEGACY_DISPATCH_MAPPING = dict(
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_attn_forward_legacy'), )
+
+VARLEN_ATTN_DISPATCH_MAPPING = dict(
+ InternLM2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.internlm2',
+ 'internlm2_varlen_attn_forward'),
+ InternLMAttention=LazyObject('xtuner.model.modules.dispatch.internlm',
+ 'internlm_varlen_attn_forward'),
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_varlen_attn_forward'),
+ Phi3FlashAttention2=LazyObject('xtuner.model.modules.dispatch.phi3',
+ 'phi3_varlen_attn_forward'),
+ MistralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_varlen_attn_forward'),
+ MixtralFlashAttention2=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'mistral_varlen_attn_forward'),
+ CohereFlashAttention2=None,
+ Qwen2FlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_varlen_attn_forward'),
+ Qwen2MoeFlashAttention2=LazyObject('xtuner.model.modules.dispatch.qwen2',
+ 'qwen2_varlen_attn_forward'),
+ DeepseekV2FlashAttention2=LazyObject(
+ 'xtuner.model.modules.dispatch.deepseek_v2',
+ 'deepseek_varlen_attn_forward'),
+)
+
+VARLEN_ATTN_LEGACY_DISPATCH_MAPPING = dict(
+ LlamaFlashAttention2=LazyObject('xtuner.model.modules.dispatch.llama',
+ 'llama_varlen_attn_forward_legacy'), )
+
+RMS_DISPATCH_MAPPING = dict(
+ InternLM2RMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ InternLMRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ LlamaRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ Phi3RMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ MistralRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ MixtralRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ CohereLayerNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'layer_norm_forward'),
+ Qwen2RMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+ Qwen2MoeRMSNorm=LazyObject('xtuner.model.modules.dispatch.triton_kernels',
+ 'rms_norm_forward'),
+)
+
+ROTE_DISPATCH_MAPPING = dict(
+ InternLMRotaryEmbedding=LazyObject(
+ 'xtuner.model.modules.dispatch.internlm', 'InternLMRotaryEmbedding'),
+ MistralRotaryEmbedding=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'MistralRotaryEmbedding'),
+ MixtralRotaryEmbedding=LazyObject('xtuner.model.modules.dispatch.mistral',
+ 'MistralRotaryEmbedding'),
+)
+
+
+def log_once(func):
+ logged = False
+
+ def wrapper(*args, **kwargs):
+ nonlocal logged
+ if not logged:
+ logged = True
+ func(*args, **kwargs)
+ return
+
+ return wrapper
+
+
+def dispatch_attn_forward(model):
+
+ if not SUPPORT_FLASH2:
+ return
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ attn_forward = None
+ for module in model.modules():
+ name = type(module).__name__
+ if (IS_LOW_VERSION_TRANSFORMERS
+ and name in ATTN_LEGACY_DISPATCH_MAPPING):
+ if attn_forward is None:
+ attn_forward = ATTN_LEGACY_DISPATCH_MAPPING[name]
+ attn_forward = attn_forward.build()
+ print_log(f'Dispatch {name} legacy forward. {NO_ATTN_WEIGHTS_MSG}',
+ 'current')
+ module.forward = types.MethodType(attn_forward, module)
+ elif name in ATTN_DISPATCH_MAPPING:
+ if attn_forward is None:
+ attn_forward = ATTN_DISPATCH_MAPPING[name]
+ attn_forward = attn_forward.build()
+ print_log(f'Dispatch {name} forward. {NO_ATTN_WEIGHTS_MSG}',
+ 'current')
+ module.forward = types.MethodType(attn_forward, module)
+
+
+def dispatch_varlen_attn_forward(model):
+
+ if not SUPPORT_FLASH2:
+ return
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ varlen_attn_forward = None
+ for module in model.modules():
+ name = type(module).__name__
+ if (IS_LOW_VERSION_TRANSFORMERS
+ and name in VARLEN_ATTN_LEGACY_DISPATCH_MAPPING):
+ if varlen_attn_forward is None:
+ varlen_attn_forward = VARLEN_ATTN_LEGACY_DISPATCH_MAPPING[name]
+ varlen_attn_forward = varlen_attn_forward.build()
+ print_log(
+ f'Dispatch legacy {name} varlen forward. '
+ f'{NO_ATTN_WEIGHTS_MSG}', 'current')
+ module.forward = types.MethodType(varlen_attn_forward, module)
+ elif name in VARLEN_ATTN_DISPATCH_MAPPING:
+ if varlen_attn_forward is None:
+ varlen_attn_forward = VARLEN_ATTN_DISPATCH_MAPPING[name]
+ varlen_attn_forward = varlen_attn_forward.build()
+ print_log(f'Dispatch {name} varlen forward. {NO_ATTN_WEIGHTS_MSG}',
+ 'current')
+ module.forward = types.MethodType(varlen_attn_forward, module)
+
+
+def dispatch_rmsnorm_forward(model):
+
+ if (not SUPPORT_TRITON) or (not USE_TRITON_KERNEL):
+ return
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ rms_forward = None
+ for module in model.modules():
+ name = type(module).__name__
+ if name in RMS_DISPATCH_MAPPING:
+ if rms_forward is None:
+ rms_forward = RMS_DISPATCH_MAPPING[name]
+ rms_forward = rms_forward.build()
+ print_log(f'Dispatch {name} forward.', 'current')
+ module.forward = types.MethodType(rms_forward, module)
+
+
+def replace_rote(model):
+
+ from mmengine import print_log
+ print_log = log_once(print_log)
+
+ def traverse(module):
+ for name, child in module.named_children():
+ cls_name = type(child).__name__
+ if cls_name in ROTE_DISPATCH_MAPPING:
+ assert hasattr(model.config, 'rope_theta'), \
+ '`rope_theta` should be in the model config.'
+ rope_theta = model.config.rope_theta
+
+ rote = ROTE_DISPATCH_MAPPING[cls_name]
+ rote = rote.build()
+ print_log(f'replace {cls_name}', 'current')
+ dim_model = child.inv_freq.shape[0] * 2
+ child_new = rote(dim_model, child.max_seq_len_cached,
+ rope_theta).to(
+ device=child.inv_freq.device,
+ dtype=child.inv_freq.dtype)
+ setattr(module, name, child_new)
+ else:
+ traverse(child)
+
+ traverse(model)
+
+
+def dispatch_modules(model, use_varlen_attn=False):
+
+ def check(model_name):
+ if 'ForCausalLM' not in model_name and model_name.endswith('Model'):
+ # a walkaround for reward model
+ model_name = model_name[:-5] + 'ForCausalLM'
+ msg = '{} requires transformers version at least {}, but got {}'
+ if model_name in LOWEST_TRANSFORMERS_VERSION:
+ assert TRANSFORMERS_VERSION >= LOWEST_TRANSFORMERS_VERSION[
+ model_name], msg.format(
+ model_name, LOWEST_TRANSFORMERS_VERSION[model_name],
+ TRANSFORMERS_VERSION)
+
+ check(type(model).__name__)
+ if use_varlen_attn:
+ dispatch_varlen_attn_forward(model)
+ else:
+ dispatch_attn_forward(model)
+ dispatch_rmsnorm_forward(model)
+ replace_rote(model)
+
+
+__all__ = ['dispatch_modules']
diff --git a/data/xtuner/xtuner/model/modules/dispatch/attention.py b/data/xtuner/xtuner/model/modules/dispatch/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..e89bb511cc946e521438c442caca97c1f594403b
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/attention.py
@@ -0,0 +1,97 @@
+from xtuner.parallel.sequence import sequence_parallel_wrapper
+from .utils import upad_qkv
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+
+@sequence_parallel_wrapper
+def flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ dropout_p=0.0,
+ softmax_scale=None,
+ causal=True,
+ window_size=(-1, -1), # -1 means infinite context window
+):
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout_p=dropout_p,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=window_size)
+ return attn_output
+
+
+@sequence_parallel_wrapper
+def flash_attn_w_mask(
+ query_states, # bs, q_len, nhead, h_dim
+ key_states,
+ value_states,
+ attention_mask,
+ softmax_scale=None,
+ causal=True,
+ dropout_p=0.0,
+ window_size=(-1, -1), # -1 means infinite context window
+):
+ batch_size, q_len = query_states.shape[:2]
+ query_states, key_states, value_states, indices_q, \
+ cu_seq_lens, max_seq_lens = upad_qkv(
+ query_states, key_states, value_states, attention_mask, q_len)
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ softmax_scale=softmax_scale,
+ dropout_p=dropout_p,
+ causal=causal,
+ window_size=window_size)
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, q_len)
+ return attn_output
+
+
+@sequence_parallel_wrapper
+def varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ softmax_scale=None,
+ dropout_p=0.,
+ causal=True,
+ window_size=(-1, -1), # -1 means infinite context window
+):
+ q_unpad, k_unpad, v_unpad = query_states.flatten(0, 1), key_states.flatten(
+ 0, 1), value_states.flatten(0, 1)
+ attn_output = flash_attn_varlen_func(
+ q_unpad,
+ k_unpad,
+ v_unpad,
+ cumulative_len,
+ cumulative_len,
+ max_seqlen,
+ max_seqlen,
+ softmax_scale=softmax_scale,
+ dropout_p=dropout_p,
+ return_attn_probs=False,
+ causal=causal,
+ window_size=window_size)
+ attn_output = attn_output.unsqueeze(0)
+ return attn_output
diff --git a/data/xtuner/xtuner/model/modules/dispatch/baichuan.py b/data/xtuner/xtuner/model/modules/dispatch/baichuan.py
new file mode 100644
index 0000000000000000000000000000000000000000..738c49869882a16bcea06f9efb18e41d8a76d1e8
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/baichuan.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def baichuan2_norm_head_forward(self, hidden_states):
+ norm_weight = nn.functional.normalize(self.weight)
+ return nn.functional.linear(hidden_states, norm_weight)
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos_, sin_, position_ids):
+ cos = cos_.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin_.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ q_embed = (q.float() * cos) + (rotate_half(q.float()) * sin)
+ k_embed = (k.float() * cos) + (rotate_half(k.float()) * sin)
+ return q_embed.to(q.dtype), k_embed.to(k.dtype)
+
+
+def baichuan_7b_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ proj = self.W_pack(hidden_states)
+ proj = proj.unflatten(-1, (3, self.hidden_size)).unsqueeze(0).transpose(
+ 0, -2).squeeze(-2)
+ query_states = proj[0].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = proj[1].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = proj[2].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+ # [bsz, nh, t, hd]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+ return attn_output, None, past_key_value
+
+
+def baichuan_13b_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ proj = self.W_pack(hidden_states)
+ proj = proj.unflatten(-1, (3, self.hidden_size)).unsqueeze(0).transpose(
+ 0, -2).squeeze(-2)
+ query_states = proj[0].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = proj[1].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = proj[2].view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+ if attention_mask is not None:
+ if q_len == 1: # inference with cache
+ if len(attention_mask.size()) == 4:
+ attention_mask = attention_mask[:, :, -1:, :]
+ else:
+ attention_mask = attention_mask[:, -1:, :]
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/cohere.py b/data/xtuner/xtuner/model/modules/dispatch/cohere.py
new file mode 100644
index 0000000000000000000000000000000000000000..8acf067474409e4f5a7a108b2b86c762c2fad37c
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/cohere.py
@@ -0,0 +1,153 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import transformers
+from mmengine.utils import digit_version
+from transformers.models.cohere.modeling_cohere import apply_rotary_pos_emb
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+from xtuner.parallel.sequence.attention import (
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+
+try:
+ from transformers.cache_utils import Cache
+except ImportError:
+
+ class Cache:
+ pass
+
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+
+def cohere_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+):
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+ if self.use_qk_norm:
+ query_states = self.q_norm(query_states)
+ key_states = self.k_norm(key_states)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ past_key_value = getattr(self, 'past_key_value', past_key_value)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; position_ids needed for
+ # the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # TODO: These transpose are quite inefficient but Flash Attention requires
+ # the layout [batch_size, sequence_length, num_heads, head_dim].
+ # We would need to refactor the KV cache to be able to avoid many of
+ # these transpose/reshape/view.
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # Ignore copy
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # self.num_heads is used in self._upad_input method
+ # num_heads has been changed because of sequence parallel
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate)
+ else:
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ is_causal=self.is_causal,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/deepseek_v2.py b/data/xtuner/xtuner/model/modules/dispatch/deepseek_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfa3ebb6db8c4a7c1bb4e04a004d24e3f774755a
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/deepseek_v2.py
@@ -0,0 +1,308 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+from transformers.cache_utils import Cache
+
+from xtuner.model.transformers_models.deepseek_v2.modeling_deepseek import \
+ apply_rotary_pos_emb
+from xtuner.parallel.sequence import (get_sequence_parallel_world_size,
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+
+
+def deepseek_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ # DeepseekV2FlashAttention2 attention does not support output_attentions
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None, '`position_ids` should not be None.'
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+
+ if self.q_head_dim != self.v_head_dim:
+ value_states = F.pad(value_states,
+ [0, self.q_head_dim - self.v_head_dim])
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (DeepseekV2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_a_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # self.num_heads is used in self._upad_input method
+ # num_heads has been changed because of sequence parallel
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ softmax_scale=self.softmax_scale,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ if self.q_head_dim != self.v_head_dim:
+ attn_output = attn_output[:, :, :, :self.v_head_dim]
+
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads *
+ self.v_head_dim).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def deepseek_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (cumulative_len is not None) == (
+ past_key_value is None)
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None, '`position_ids` should not be None.'
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+
+ if self.q_head_dim != self.v_head_dim:
+ value_states = F.pad(value_states,
+ [0, self.q_head_dim - self.v_head_dim])
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (DeepseekV2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_a_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # ----------------- varlen flash attention forward ----------------------#
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ if is_training:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ softmax_scale=self.softmax_scale,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=True)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ softmax_scale=self.softmax_scale,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=False)
+
+ # ---------------- varlen flash attention forward end ------------------ #
+
+ if self.q_head_dim != self.v_head_dim:
+ attn_output = attn_output[:, :, :, :self.v_head_dim]
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.num_heads * self.v_head_dim)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/internlm.py b/data/xtuner/xtuner/model/modules/dispatch/internlm.py
new file mode 100644
index 0000000000000000000000000000000000000000..37ca9ad310e056bc357235fa935004da79a3edd7
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/internlm.py
@@ -0,0 +1,227 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+
+from .triton_kernels import apply_rotary_emb
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+
+class InternLMRotaryEmbedding(torch.nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+ self.inv_freq = 1.0 / (
+ base**(torch.arange(0, dim, 2).float().to(device) / dim))
+
+ # Build here to make `torch.jit.trace` work.
+ self.max_seq_len_cached = max_position_embeddings
+ t = torch.arange(
+ self.max_seq_len_cached,
+ device=self.inv_freq.device,
+ dtype=self.inv_freq.dtype)
+ freqs = torch.einsum('i,j->ij', t, self.inv_freq)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.cos_cached = emb.cos()
+ self.sin_cached = emb.sin()
+
+ def forward(self, x, seq_len):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if (seq_len > self.max_seq_len_cached
+ or self.cos_cached.device != x.device
+ or self.cos_cached.dtype != x.dtype):
+ self.max_seq_len_cached = seq_len
+ assert self.inv_freq.dtype == torch.float32
+ t = torch.arange(
+ self.max_seq_len_cached,
+ device=x.device,
+ dtype=self.inv_freq.dtype)
+ freqs = torch.einsum('i,j->ij', t, self.inv_freq.to(t.device))
+ emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
+ self.cos_cached = emb.cos().to(x.dtype)
+ self.sin_cached = emb.sin().to(x.dtype)
+ return (
+ self.cos_cached[:seq_len, ...],
+ self.sin_cached[:seq_len, ...],
+ )
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def internlm_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # Modified from https://huggingface.co/internlm/internlm-7b/blob/939a68c0dc1bd5f35b63c87d44af05ce33379061/modeling_internlm.py#L161 # noqa:E501
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(
+ 1, 2)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(
+ 1, 2)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(
+ 1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+ # [bsz, nh, t, hd]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ if SUPPORT_FLASH2:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, causal=True)
+ attn_output = attn_output.contiguous()
+ else:
+ # use flash attention implemented by pytorch
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+ attn_output = attn_output.transpose(1, 2)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
+
+
+def internlm_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # Modified from https://huggingface.co/internlm/internlm-7b/blob/939a68c0dc1bd5f35b63c87d44af05ce33379061/modeling_internlm.py#L161 # noqa:E501
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ # position_ids = message_hub.get_info(f'position_ids_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ bsz, q_len, _ = hidden_states.size()
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads,
+ self.head_dim)
+
+ kv_seq_len = key_states.shape[-3]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ if use_varlen_atten:
+ cos, sin = self.rotary_emb(value_states, max_seqlen)
+ query_states = apply_rotary_emb(query_states,
+ cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ key_states = apply_rotary_emb(key_states, cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ else:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ cos, sin = self.rotary_emb(value_states, kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ assert SUPPORT_FLASH2
+ if use_varlen_atten:
+ q_unpad, k_unpad, v_unpad = query_states.flatten(
+ 0, 1), key_states.flatten(0, 1), value_states.flatten(0, 1)
+ cumulative_len = torch.cat(cumulative_len, dim=0)
+ attn_output = flash_attn_varlen_func(
+ q_unpad,
+ k_unpad,
+ v_unpad,
+ cumulative_len,
+ cumulative_len,
+ max_seqlen,
+ max_seqlen,
+ 0,
+ return_attn_probs=False,
+ causal=True,
+ )
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, causal=True)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/internlm2.py b/data/xtuner/xtuner/model/modules/dispatch/internlm2.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c601f0dc66c056c979a84efbb18b9125cfb44cf
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/internlm2.py
@@ -0,0 +1,306 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+from einops import rearrange
+from mmengine import MessageHub
+from transformers.cache_utils import Cache, StaticCache
+
+from xtuner.parallel.sequence import (get_sequence_parallel_world_size,
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import SUPPORT_FLASH2, flash_attn_wo_mask, varlen_flash_attn
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+def repeat_kv_bshd(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """The hidden states go from (batch, seqlen, num_key_value_heads, head_dim)
+ to (batch, seqlen, num_attention_heads, head_dim)"""
+ batch, slen, num_key_value_heads, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, :,
+ None, :].expand(batch, slen,
+ num_key_value_heads, n_rep,
+ head_dim)
+ return hidden_states.reshape(batch, slen, num_key_value_heads * n_rep,
+ head_dim)
+
+
+def internlm2_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+):
+ if isinstance(past_key_value, StaticCache):
+ raise ValueError(
+ '`static` cache implementation is not compatible with '
+ '`attn_implementation==flash_attention_2` make sure to use `sdpa` '
+ 'in the mean time, and open an issue at '
+ 'https://github.com/huggingface/transformers')
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ 'b q (h gs d) -> b q h gs d',
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., :self.num_key_value_groups, :]
+ query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (InternLM2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.wqkv.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # self.num_heads is used in self._upad_input method
+ # num_heads has been changed because of sequence parallel
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ dropout_rate = 0.0
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate)
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.wo(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def internlm2_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+
+ if isinstance(past_key_value, StaticCache):
+ raise ValueError(
+ '`static` cache implementation is not compatible with '
+ '`attn_implementation==flash_attention_2` make sure to use `sdpa` '
+ 'in the mean time, and open an issue at '
+ 'https://github.com/huggingface/transformers')
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ bsz, q_len, _ = hidden_states.size()
+
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ 'b q (h gs d) -> b q h gs d',
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., :self.num_key_value_groups, :]
+ query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ try:
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ except RuntimeError:
+ raise RuntimeError(
+ 'You are using the old version of InternLM2 model. The '
+ '`modeling_internlm2.py` is outdated. Please update the InternLM2 '
+ 'model.')
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (InternLM2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.wqkv.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+
+ assert SUPPORT_FLASH2
+
+ dropout_rate = 0.0
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.wo(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/llama.py b/data/xtuner/xtuner/model/modules/dispatch/llama.py
new file mode 100644
index 0000000000000000000000000000000000000000..8132096fd484f43535543ed8f6de3efe36491c7b
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/llama.py
@@ -0,0 +1,524 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+from mmengine import MessageHub
+from transformers.models.llama.modeling_llama import (apply_rotary_pos_emb,
+ repeat_kv)
+from transformers.utils import is_flash_attn_greater_or_equal_2_10
+
+from .attention import (SUPPORT_FLASH2, flash_attn_w_mask, flash_attn_wo_mask,
+ varlen_flash_attn)
+from .triton_kernels import apply_rotary_emb
+
+try:
+ from transformers.cache_utils import Cache
+except ImportError:
+
+ class Cache:
+ pass
+
+
+def repeat_kv_bshd(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """The hidden states go from (batch, seqlen, num_key_value_heads, head_dim)
+ to (batch, seqlen, num_attention_heads, head_dim)"""
+ batch, slen, num_key_value_heads, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, :,
+ None, :].expand(batch, slen,
+ num_key_value_heads, n_rep,
+ head_dim)
+ return hidden_states.reshape(batch, slen, num_key_value_heads * n_rep,
+ head_dim)
+
+
+def llama_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+):
+ # Modified from https://github.com/huggingface/transformers/blob/66ce9593fdb8e340df546ddd0774eb444f17a12c/src/transformers/models/llama/modeling_llama.py#L422 # noqa:E501
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ past_key_value = getattr(self, 'past_key_value', past_key_value)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ assert SUPPORT_FLASH2
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ if is_flash_attn_greater_or_equal_2_10():
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `q_len != 1` check once Flash Attention for RoCm
+ # is bumped to 2.1. For details, please see the comment in
+ # LlamaFlashAttention2 __init__.
+ causal = self.is_causal and q_len != 1
+
+ # the shape of attention_mask used by flash_attn and
+ # F.scaled_dot_product_attention are different
+ assert attention_mask is None or attention_mask.ndim == 2, \
+ ('When using flash_attn, attention_mask.ndim should equal to 2.'
+ f'But got attention_mask.shape = {attention_mask.shape}.'
+ 'We can pass the `attn_implementation="flash_attention_2"` flag '
+ 'to `.from_pretrained` method when instantiating a Internlm2 '
+ 'model.')
+
+ if attention_mask is not None:
+ attn_output = flash_attn_w_mask(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def llama_attn_forward_legacy(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # Modified from https://github.com/huggingface/transformers/blob/ced9fd86f55ebb6b656c273f6e23f8ba50652f83/src/transformers/models/llama/modeling_llama.py#L331 # noqa:E501
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+ assert position_ids is not None
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ assert SUPPORT_FLASH2
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ if is_flash_attn_greater_or_equal_2_10():
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `q_len != 1` check once Flash Attention for RoCm
+ # is bumped to 2.1. For details, please see the comment in
+ # LlamaFlashAttention2 __init__.
+ causal = self.is_causal and q_len != 1
+
+ # the shape of attention_mask used by flash_attn and
+ # F.scaled_dot_product_attention are different
+ assert attention_mask is None or attention_mask.ndim == 2, \
+ ('When using flash_attn, attention_mask.ndim should equal to 2.'
+ f'But got attention_mask.shape = {attention_mask.shape}.'
+ 'We can pass the `attn_implementation="flash_attention_2"` flag '
+ 'to `.from_pretrained` method when instantiating a Internlm2 '
+ 'model.')
+
+ if attention_mask is not None:
+ attn_output = flash_attn_w_mask(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask=attention_mask,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
+
+
+def llama_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn('Passing `padding_mask` is deprecated and will be '
+ 'removed in v4.37. Please make sure use '
+ '`attention_mask` instead.`')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin)
+
+ past_key_value = getattr(self, 'past_key_value', past_key_value)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models;
+ # cache_position needed for the static cache
+ cache_kwargs = {
+ 'sin': sin,
+ 'cos': cos,
+ 'cache_position': cache_position
+ }
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently casted
+ # in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ assert SUPPORT_FLASH2
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=True,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+def llama_varlen_attn_forward_legacy(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn('Passing `padding_mask` is deprecated and will be '
+ 'removed in v4.37. Please make sure use '
+ '`attention_mask` instead.`')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+
+ kv_seq_len = key_states.shape[-3]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ if use_varlen_atten:
+ cos, sin = self.rotary_emb(value_states, max_seqlen)
+ # position_ids (1, seq_len)
+ # cos, sin (1, seq_len, dim) -> (seq_len, dim)
+ cos = cos[position_ids].squeeze(0)
+ sin = sin[position_ids].squeeze(0)
+ query_states = apply_rotary_emb(query_states, cos, sin)
+ key_states = apply_rotary_emb(key_states, cos, sin)
+ else:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ cos, sin = self.rotary_emb(value_states, kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently casted
+ # in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ assert SUPPORT_FLASH2
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=True,
+ dropout_p=dropout_rate,
+ training=self.training)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/mistral.py b/data/xtuner/xtuner/model/modules/dispatch/mistral.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc6c7fed827f229aeb286a35d2b290126f07e965
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/mistral.py
@@ -0,0 +1,447 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+import warnings
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import transformers
+from mmengine import MessageHub
+from mmengine.utils import digit_version
+from transformers.cache_utils import Cache
+from transformers.models.mistral.modeling_mistral import (apply_rotary_pos_emb,
+ repeat_kv)
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+from xtuner.parallel.sequence.attention import (
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+from .triton_kernels import apply_rotary_emb
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+
+class MistralRotaryEmbedding(nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ self.inv_freq = 1.0 / (
+ base**(torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings,
+ device=self.inv_freq.device,
+ dtype=torch.get_default_dtype())
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ freqs = torch.einsum('i,j->ij', t, self.inv_freq.to(device))
+ # Different from paper, but it uses a different permutation
+ # in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1).to(device)
+ self.cos_cached = emb.cos().to(dtype)
+ self.sin_cached = emb.sin().to(dtype)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if (seq_len > self.max_seq_len_cached
+ or self.cos_cached.device != x.device # noqa: W503
+ or self.cos_cached.dtype != x.dtype): # noqa: W503
+ self._set_cos_sin_cache(
+ seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+def repeat_kv_bshd(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """The hidden states go from (batch, seqlen, num_key_value_heads, head_dim)
+ to (batch, seqlen, num_attention_heads, head_dim)"""
+ batch, slen, num_key_value_heads, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, :,
+ None, :].expand(batch, slen,
+ num_key_value_heads, n_rep,
+ head_dim)
+ return hidden_states.reshape(batch, slen, num_key_value_heads * n_rep,
+ head_dim)
+
+
+def mistral_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ if self.training:
+ cos, sin = self.rotary_emb(
+ value_states, seq_len=position_ids.max() + 1)
+ else:
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads for sequence parallel
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32. (LlamaRMSNorm handles it correctly)
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # num_heads has been changed because of sequence parallel
+ # `self.num_heads`` is not used in self._flash_attention_forward
+ # in mistral/mixtral, we are doing this to avoid some unnecessary risk
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length=query_states.shape[1],
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+ else:
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ sliding_window=getattr(self.config, 'sliding_window', None),
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ is_causal=self.is_causal,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def mistral_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (past_key_value is None)
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37'
+ ' Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+ # attention_mask is set to None if no padding token in input_ids
+ assert attention_mask is None
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim)
+
+ assert _flash_supports_window_size, \
+ ('The current flash attention version does not support sliding window '
+ 'attention, for a more memory efficient implementation make sure '
+ 'to upgrade flash-attn library.')
+
+ kv_seq_len = key_states.shape[-3]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ if use_varlen_atten:
+ cos, sin = self.rotary_emb(value_states, max_seqlen)
+ query_states = apply_rotary_emb(query_states,
+ cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ key_states = apply_rotary_emb(key_states, cos[position_ids].squeeze(0),
+ sin[position_ids].squeeze(0))
+ else:
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ # Because the input can be padded, the absolute sequence length
+ # depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window # noqa: W503
+ and cache_has_contents): # noqa: W503
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # repeat kv for sequence parallel
+ key_states = repeat_kv_bshd(key_states, self.num_key_value_groups)
+ value_states = repeat_kv_bshd(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for
+ # training stability reasons, therefore the input hidden states gets
+ # silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # ----------------- flash attention forward ------------------------#
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ use_sliding_windows = (
+ _flash_supports_window_size and # noqa: W504
+ getattr(self.config, 'sliding_window', None) is not None # noqa: W503
+ and kv_seq_len > self.config.sliding_window) # noqa: W503
+ window_size = (self.config.sliding_window,
+ self.config.sliding_window) if use_sliding_windows else (-1,
+ -1)
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+
+ # ---------------- flash attention forward end ------------------- #
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/phi3.py b/data/xtuner/xtuner/model/modules/dispatch/phi3.py
new file mode 100644
index 0000000000000000000000000000000000000000..10f60f93983392643f3c1907b34af1bd48b2f03c
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/phi3.py
@@ -0,0 +1,480 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+import warnings
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+import transformers
+from mmengine import MessageHub
+from mmengine.utils import digit_version
+
+from xtuner.parallel.sequence import (get_sequence_parallel_world_size,
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+
+try:
+ from transformers.cache_utils import Cache
+except ImportError:
+
+ class Cache:
+ pass
+
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+_flash_supports_window_size = False
+try:
+ from flash_attn import flash_attn_func
+
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+
+ if not _flash_supports_window_size:
+ raise ValueError(
+ 'Please update flash-attention to support window size.')
+# else:
+except ImportError:
+ pass
+
+
+# Copied from https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/blob/3a811845d89f3c1b3f41b341d0f9f05104769f35/modeling_phi3.py#L302 # noqa:E501
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+# https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/blob/3a811845d89f3c1b3f41b341d0f9f05104769f35/modeling_phi3.py#L247 # noqa:E501
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/blob/3a811845d89f3c1b3f41b341d0f9f05104769f35/modeling_phi3.py#L255 # noqa:E501
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """ # noqa:E501
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def phi3_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+):
+ if not _flash_supports_window_size:
+ raise ValueError(
+ 'The current flash attention version does not support '
+ 'sliding window attention.')
+
+ output_attentions = False
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv = self.qkv_proj(hidden_states)
+ query_pos = self.num_heads * self.head_dim
+ query_states = qkv[..., :query_pos]
+ key_states = qkv[..., query_pos:query_pos +
+ self.num_key_value_heads * self.head_dim]
+ value_states = qkv[...,
+ query_pos + self.num_key_value_heads * self.head_dim:]
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(
+ value_states, position_ids, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_dropout = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32.
+
+ if query_states.dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.qkv_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ # (b, s // sp_world_size, nd, dim) -> (b, s, nd // sp_world_size, dim)
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states,
+ scatter_dim=2, gather_dim=1)
+ # num_heads has been changed because of sequence parallel
+ # `self.num_heads`` is not used in self._flash_attention_forward
+ # in mistral/mixtral, we are doing this to avoid some unnecessary risk
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=attn_dropout,
+ use_sliding_windows=use_sliding_windows,
+ )
+ else:
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=attn_dropout,
+ sliding_window=getattr(self.config, 'sliding_window', None),
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ is_causal=self.is_causal,
+ )
+
+ if enable_sequence_parallel:
+ # (b, s, nd // sp_world_size, dim) -> (b, s // sp_world_size, nd, dim)
+ attn_output = post_process_for_sequence_parallel_attn(
+ attn_output, scatter_dim=1, gather_dim=2)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def phi3_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ if not _flash_supports_window_size:
+ raise ValueError(
+ 'The current flash attention version does not support '
+ 'sliding window attention.')
+
+ output_attentions = False
+
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (past_key_value is None)
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37'
+ ' Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ bsz, q_len, _ = hidden_states.size()
+ assert bsz == 1, (f'If utilizing local attention, the batch size should be'
+ f' set to 1, but got {bsz}')
+ # attention_mask is set to None if no padding token in input_ids
+ # varlen attn need data packing so no padding tokens in input_ids
+ assert attention_mask is None
+
+ qkv = self.qkv_proj(hidden_states)
+ query_pos = self.num_heads * self.head_dim
+ query_states = qkv[..., :query_pos]
+ key_states = qkv[..., query_pos:query_pos +
+ self.num_key_value_heads * self.head_dim]
+ value_states = qkv[...,
+ query_pos + self.num_key_value_heads * self.head_dim:]
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(
+ value_states, position_ids, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ # In PEFT, usually we cast the layer norms in float32 for
+ # training stability reasons, therefore the input hidden states gets
+ # silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+
+ if query_states.dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.qkv_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # ----------------- flash attention forward ------------------------#
+
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ window_size = (self.config.sliding_window,
+ self.config.sliding_window) if use_sliding_windows else (-1,
+ -1)
+ attn_dropout = self.attention_dropout if self.training else 0.0
+
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=causal,
+ dropout_p=attn_dropout,
+ window_size=window_size,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=attn_dropout,
+ window_size=window_size,
+ training=self.training)
+
+ # ---------------- flash attention forward end ------------------- #
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/qwen2.py b/data/xtuner/xtuner/model/modules/dispatch/qwen2.py
new file mode 100644
index 0000000000000000000000000000000000000000..20f2f40f382e4e88daf7b40a54611d9b781460a9
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/qwen2.py
@@ -0,0 +1,380 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+import warnings
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+import transformers
+from mmengine import MessageHub
+from mmengine.utils import digit_version
+from transformers.cache_utils import Cache
+from transformers.models.qwen2.modeling_qwen2 import (apply_rotary_pos_emb,
+ repeat_kv)
+
+from xtuner.parallel.sequence import get_sequence_parallel_world_size
+from xtuner.parallel.sequence.attention import (
+ post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn)
+from .attention import flash_attn_wo_mask, varlen_flash_attn
+
+SUPPORT_FLASH2 = False
+
+try:
+ from flash_attn import flash_attn_func
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+TRANSFORMERS_VERSION = digit_version(transformers.__version__)
+IS_LOW_VERSION_TRANSFORMERS = TRANSFORMERS_VERSION < digit_version('4.43')
+
+if not IS_LOW_VERSION_TRANSFORMERS:
+ from transformers.modeling_flash_attention_utils import \
+ _flash_attention_forward
+
+
+def qwen2_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in '
+ 'v4.37. Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and self.config.use_sliding_window)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads for sequence parallel
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training
+ # stability reasons therefore the input hidden states gets silently
+ # casted in float32. Hence, we need cast them back in the correct dtype
+ # just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not
+ # cast the LayerNorms in fp32.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and self.training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+ # num_heads has been changed because of sequence parallel
+ # `self.num_heads`` is not used in self._flash_attention_forward
+ # in mistral/mixtral, we are doing this to avoid some unnecessary risk
+ ori_num_head = self.num_heads
+ self.num_heads = query_states.shape[-2]
+
+ if IS_LOW_VERSION_TRANSFORMERS:
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length=query_states.shape[1],
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+ else:
+ if (self.config.use_sliding_window
+ and getattr(self.config, 'sliding_window', None) is not None
+ and self.layer_idx >= self.config.max_window_layers):
+ # There may be bugs here, but we are aligned with Transformers
+ sliding_window = self.config.sliding_window
+ else:
+ sliding_window = None
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_states.shape[1],
+ dropout=dropout_rate,
+ sliding_window=sliding_window,
+ is_causal=self.is_causal,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ )
+
+ if enable_sequence_parallel:
+ attn_output = post_process_for_sequence_parallel_attn(attn_output)
+ self.num_heads = ori_num_head
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def qwen2_varlen_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+):
+ is_training = self.training
+
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cumulative_len = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ max_seqlen = message_hub.get_info(f'max_seqlen_rank_{rank}')
+
+ assert is_training == (past_key_value is None)
+ use_varlen_atten = (cumulative_len is not None)
+
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37'
+ ' Please make sure use `attention_mask` instead.`')
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ 'The cache structure has changed since version v4.36. '
+ f'If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, '
+ 'please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len,
+ self.layer_idx)
+
+ assert position_ids is not None
+ rotary_seq_len = max(kv_seq_len, position_ids.max().item() + 1)
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value
+ # `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ 'past key must have a shape of (`batch_size, num_heads, '
+ 'self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat(
+ [attention_mask,
+ torch.ones_like(attention_mask[:, -1:])],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads for sequence parallel
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for
+ # training stability reasons, therefore the input hidden states gets
+ # silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ # ----------------- flash attention forward ------------------------#
+
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ causal = self.is_causal and q_len != 1
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and self.config.use_sliding_window)
+ # Decide whether to use SWA or not by layer index.
+ if use_sliding_windows and self.layer_idx >= self.config.max_window_layers:
+ use_sliding_windows = False
+
+ window_size = (self.config.sliding_window,
+ self.config.sliding_window) if use_sliding_windows else (-1,
+ -1)
+
+ if use_varlen_atten:
+ attn_output = varlen_flash_attn(
+ query_states,
+ key_states,
+ value_states,
+ cumulative_len,
+ max_seqlen,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+ else:
+ attn_output = flash_attn_wo_mask(
+ query_states,
+ key_states,
+ value_states,
+ causal=causal,
+ dropout_p=dropout_rate,
+ window_size=window_size,
+ training=self.training)
+
+ # ---------------- flash attention forward end ------------------- #
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/__init__.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed29f409f853172a0c90f0e81b0200972c379e66
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .layer_norm import layer_norm_forward
+from .rms_norm import rms_norm_forward
+from .rotary import apply_rotary_emb
+
+__all__ = ['rms_norm_forward', 'layer_norm_forward', 'apply_rotary_emb']
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/layer_norm.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/layer_norm.py
new file mode 100644
index 0000000000000000000000000000000000000000..f808d6ad157a3ddbfeb6df02960c79739fcdc088
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/layer_norm.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+
+
+def layer_norm_forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ hidden_states = F.layer_norm(
+ hidden_states, (hidden_states.shape[-1], ), eps=self.variance_epsilon)
+ hidden_states = self.weight.to(torch.float32) * hidden_states
+ return hidden_states.to(input_dtype)
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rms_norm.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rms_norm.py
new file mode 100644
index 0000000000000000000000000000000000000000..6191d55ba6e5e983d1e20c3e5282dffd439d2fd6
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rms_norm.py
@@ -0,0 +1,220 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import triton
+import triton.language as tl
+
+
+@triton.jit
+def _rms_norm_fwd_fused(
+ X, # pointer to the input
+ Y, # pointer to the output
+ W, # pointer to the weights
+ Rstd, # pointer to the 1/std
+ stride, # how much to increase the pointer when moving by 1 row
+ N, # number of columns in X
+ eps, # epsilon to avoid division by zero
+ BLOCK_SIZE: tl.constexpr,
+):
+ # Map the program id to the row of X and Y it should compute.
+ row = tl.program_id(0)
+ Y += row * stride
+ X += row * stride
+ # Compute variance
+ _var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ x = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
+ _var += x * x
+ var = tl.sum(_var, axis=0) / N
+ rstd = 1 / tl.sqrt(var + eps)
+ # Write rstd
+ tl.store(Rstd + row, rstd)
+ # Normalize and apply linear transformation
+ for off in range(0, N, BLOCK_SIZE):
+ cols = off + tl.arange(0, BLOCK_SIZE)
+ mask = cols < N
+ w = tl.load(W + cols, mask=mask)
+ x = tl.load(X + cols, mask=mask, other=0.).to(tl.float32)
+ x_hat = x * rstd
+ y = x_hat * w
+ # Write output
+ tl.store(Y + cols, y, mask=mask)
+
+
+@triton.jit
+def _rms_norm_bwd_dx_fused(
+ DX, # pointer to the input gradient
+ DY, # pointer to the output gradient
+ DW, # pointer to the partial sum of weights gradient
+ X, # pointer to the input
+ W, # pointer to the weights
+ Rstd, # pointer to the 1/std
+ Lock, # pointer to the lock
+ stride, # how much to increase the pointer when moving by 1 row
+ N, # number of columns in X
+ eps, # epsilon to avoid division by zero
+ GROUP_SIZE_M: tl.constexpr,
+ BLOCK_SIZE_N: tl.constexpr):
+ # Map the program id to the elements of X, DX, and DY it should compute.
+ row = tl.program_id(0)
+ cols = tl.arange(0, BLOCK_SIZE_N)
+ mask = cols < N
+ X += row * stride
+ DY += row * stride
+ DX += row * stride
+ # Offset locks and weights/biases gradient pointer for parallel reduction
+ lock_id = row % GROUP_SIZE_M
+ Lock += lock_id
+ Count = Lock + GROUP_SIZE_M
+ DW = DW + lock_id * N + cols
+ # Load data to SRAM
+ x = tl.load(X + cols, mask=mask, other=0).to(tl.float32)
+ dy = tl.load(DY + cols, mask=mask, other=0).to(tl.float32)
+ w = tl.load(W + cols, mask=mask).to(tl.float32)
+ rstd = tl.load(Rstd + row)
+ # Compute dx
+ xhat = x * rstd
+ wdy = w * dy
+ xhat = tl.where(mask, xhat, 0.)
+ wdy = tl.where(mask, wdy, 0.)
+ c1 = tl.sum(xhat * wdy, axis=0) / N
+ dx = (wdy - (xhat * c1)) * rstd
+ # Write dx
+ tl.store(DX + cols, dx, mask=mask)
+ # Accumulate partial sums for dw/db
+ partial_dw = (dy * xhat).to(w.dtype)
+ while tl.atomic_cas(Lock, 0, 1) == 1:
+ pass
+ count = tl.load(Count)
+ # First store doesn't accumulate
+ if count == 0:
+ tl.atomic_xchg(Count, 1)
+ else:
+ partial_dw += tl.load(DW, mask=mask)
+ tl.store(DW, partial_dw, mask=mask)
+ # Release the lock
+ tl.atomic_xchg(Lock, 0)
+
+
+@triton.jit
+def _rms_norm_bwd_dwdb(
+ DW, # pointer to the partial sum of weights gradient
+ FINAL_DW, # pointer to the weights gradient
+ M, # GROUP_SIZE_M
+ N, # number of columns
+ BLOCK_SIZE_M: tl.constexpr,
+ BLOCK_SIZE_N: tl.constexpr):
+ # Map the program id to the elements of DW and DB it should compute.
+ pid = tl.program_id(0)
+ cols = pid * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
+ dw = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
+ # Iterate through the rows of DW and DB to sum the partial sums.
+ for i in range(0, M, BLOCK_SIZE_M):
+ rows = i + tl.arange(0, BLOCK_SIZE_M)
+ mask = (rows[:, None] < M) & (cols[None, :] < N)
+ offs = rows[:, None] * N + cols[None, :]
+ dw += tl.load(DW + offs, mask=mask, other=0.)
+ # Write the final sum to the output.
+ sum_dw = tl.sum(dw, axis=0)
+ tl.store(FINAL_DW + cols, sum_dw, mask=cols < N)
+
+
+class RMSNorm(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x, weight, eps):
+ # allocate output
+ y = torch.empty_like(x)
+ # reshape input data into 2D tensor
+ x_arg = x.reshape(-1, x.shape[-1])
+ M, N = x_arg.shape
+ rstd = torch.empty((M, ), dtype=torch.float32, device='cuda')
+ # Less than 64KB per feature: enqueue fused kernel
+ MAX_FUSED_SIZE = 65536 // x.element_size()
+ BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
+ if N > BLOCK_SIZE:
+ raise RuntimeError(
+ "This rms norm doesn't support feature dim >= 64KB.")
+ # heuristics for number of warps
+ num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
+ # enqueue kernel
+ _rms_norm_fwd_fused[(M, )](
+ x_arg,
+ y,
+ weight,
+ rstd,
+ x_arg.stride(0),
+ N,
+ eps,
+ BLOCK_SIZE=BLOCK_SIZE,
+ num_warps=num_warps,
+ )
+ ctx.save_for_backward(x, weight, rstd)
+ ctx.BLOCK_SIZE = BLOCK_SIZE
+ ctx.num_warps = num_warps
+ ctx.eps = eps
+ return y
+
+ @staticmethod
+ def backward(ctx, dy):
+ x, w, v = ctx.saved_tensors
+ # heuristics for amount of parallel reduction stream for DW/DB
+ N = w.shape[0]
+ GROUP_SIZE_M = 64
+ if N <= 8192:
+ GROUP_SIZE_M = 96
+ if N <= 4096:
+ GROUP_SIZE_M = 128
+ if N <= 1024:
+ GROUP_SIZE_M = 256
+ # allocate output
+ locks = torch.zeros(2 * GROUP_SIZE_M, dtype=torch.int32, device='cuda')
+ _dw = torch.empty((GROUP_SIZE_M, w.shape[0]),
+ dtype=x.dtype,
+ device=w.device)
+ dw = torch.empty((w.shape[0], ), dtype=w.dtype, device=w.device)
+ dx = torch.empty_like(dy)
+ # enqueue kernel using forward pass heuristics
+ # also compute partial sums for DW and DB
+ x_arg = x.reshape(-1, x.shape[-1])
+ M, N = x_arg.shape
+ _rms_norm_bwd_dx_fused[(M, )](
+ dx,
+ dy,
+ _dw,
+ x,
+ w,
+ v,
+ locks,
+ x_arg.stride(0),
+ N,
+ ctx.eps,
+ BLOCK_SIZE_N=ctx.BLOCK_SIZE,
+ GROUP_SIZE_M=GROUP_SIZE_M,
+ num_warps=ctx.num_warps)
+
+ def grid(meta):
+ return [triton.cdiv(N, meta['BLOCK_SIZE_N'])]
+
+ # accumulate partial sums in separate kernel
+ _rms_norm_bwd_dwdb[grid](
+ _dw,
+ dw,
+ GROUP_SIZE_M,
+ N,
+ BLOCK_SIZE_M=32,
+ BLOCK_SIZE_N=128,
+ )
+ return dx, dw, None
+
+
+rms_norm = RMSNorm.apply
+
+
+def rms_norm_forward(self, hidden_states):
+ if (hidden_states.device == torch.device('cpu')
+ or self.weight.device == torch.device('cpu')):
+ raise RuntimeError(
+ 'Can not use triton kernels on cpu. Please set `USE_TRITON_KERNEL`'
+ ' environment variable to 0 before training.')
+ return rms_norm(hidden_states, self.weight, self.variance_epsilon)
diff --git a/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rotary.py b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rotary.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e09c16628751dbc769d1ca4ce7d0650de8f835b
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/triton_kernels/rotary.py
@@ -0,0 +1,327 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/rotary.py # noqa:E501
+from typing import Optional, Union
+
+import torch
+import triton
+import triton.language as tl
+
+
+@triton.jit
+def rotary_kernel(
+ OUT, # Pointers to matrices
+ X,
+ COS,
+ SIN,
+ CU_SEQLENS,
+ SEQLEN_OFFSETS, # this could be int or a pointer
+ # Matrix dimensions
+ seqlen,
+ rotary_dim,
+ seqlen_ro,
+ # strides
+ stride_out_batch,
+ stride_out_seqlen,
+ stride_out_nheads,
+ stride_out_headdim,
+ stride_x_batch,
+ stride_x_seqlen,
+ stride_x_nheads,
+ stride_x_headdim,
+ # Meta-parameters
+ BLOCK_K: tl.constexpr,
+ IS_SEQLEN_OFFSETS_TENSOR: tl.constexpr,
+ IS_VARLEN: tl.constexpr,
+ INTERLEAVED: tl.constexpr,
+ CONJUGATE: tl.constexpr,
+ BLOCK_M: tl.constexpr,
+):
+ pid_m = tl.program_id(axis=0)
+ pid_batch = tl.program_id(axis=1)
+ pid_head = tl.program_id(axis=2)
+ rotary_dim_half = rotary_dim // 2
+
+ if not IS_VARLEN:
+ X = X + pid_batch * stride_x_batch + pid_head * stride_x_nheads
+ OUT = OUT + pid_batch * stride_out_batch + pid_head * stride_out_nheads
+ else:
+ start_idx = tl.load(CU_SEQLENS + pid_batch)
+ seqlen = tl.load(CU_SEQLENS + pid_batch + 1) - start_idx
+ X = X + start_idx * stride_x_seqlen + pid_head * stride_x_nheads
+ OUT = OUT + start_idx * stride_out_seqlen + \
+ pid_head * stride_out_nheads
+
+ if pid_m * BLOCK_M >= seqlen:
+ return
+ rm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
+ if not IS_SEQLEN_OFFSETS_TENSOR:
+ rm_cs = rm + SEQLEN_OFFSETS
+ else:
+ rm_cs = rm + tl.load(SEQLEN_OFFSETS + pid_batch)
+ rk = tl.arange(0, BLOCK_K)
+ rk_half = tl.arange(0, BLOCK_K // 2)
+
+ if not INTERLEAVED:
+ # Load the 1st and 2nd halves of X, do calculation,
+ # then store to 1st and 2nd halves of OUT
+ X = X + (
+ rm[:, None] * stride_x_seqlen +
+ rk_half[None, :] * stride_x_headdim)
+ # This is different from the official implementation as the shapes of
+ # the two tensors cos and sin are (seqlen_ro, rotary_dim) instead of
+ # (seqlen_ro, rotary_dim // 2).
+ COS = COS + (rm_cs[:, None] * rotary_dim + rk_half[None, :])
+ SIN = SIN + (rm_cs[:, None] * rotary_dim + rk_half[None, :])
+ cos = tl.load(
+ COS,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_half[None, :] < rotary_dim_half),
+ other=1.0).to(tl.float32)
+ sin = tl.load(
+ SIN,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_half[None, :] < rotary_dim_half),
+ other=0.0).to(tl.float32)
+ x0 = tl.load(
+ X,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half),
+ other=0.0).to(tl.float32)
+ x1 = tl.load(
+ X + rotary_dim_half * stride_x_headdim,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half),
+ other=0.0,
+ ).to(tl.float32)
+ if CONJUGATE:
+ sin = -sin
+ o0 = x0 * cos - x1 * sin
+ o1 = x0 * sin + x1 * cos
+ # write back result
+ OUT = OUT + (
+ rm[:, None] * stride_out_seqlen +
+ rk_half[None, :] * stride_out_headdim)
+ tl.store(
+ OUT,
+ o0,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half))
+ tl.store(
+ OUT + rotary_dim_half * stride_out_headdim,
+ o1,
+ mask=(rm[:, None] < seqlen) & (rk_half[None, :] < rotary_dim_half),
+ )
+ else:
+ # We don't want to load X[0, 2, 4, ...] and X[1, 3, 5, ...] separately
+ # since both are slow.
+ # Instead, we load x0 = X[0, 1, 2, 3, ...] and x1 = X[1, 0, 3, 2, ...].
+ # Loading x0 will be fast but x1 will be slow.
+ # Then we load cos = COS[0, 0, 1, 1, ...] and
+ # sin = SIN[0, 0, 1, 1, ...].
+ # Then we do the calculation and use tl.where to pick put the right
+ # outputs for the even and for the odd indices.
+ rk_swap = rk + ((rk + 1) % 2) * 2 - 1 # 1, 0, 3, 2, 5, 4, ...
+ rk_repeat = tl.arange(0, BLOCK_K) // 2
+ # This is different from the official implementation as the shapes of
+ # the two tensors cos and sin are (seqlen_ro, rotary_dim) instead of
+ # (seqlen_ro, rotary_dim // 2).
+ X0 = X + (
+ rm[:, None] * stride_x_seqlen + rk[None, :] * stride_x_headdim)
+ X1 = X + (
+ rm[:, None] * stride_x_seqlen +
+ rk_swap[None, :] * stride_x_headdim)
+ COS = COS + (rm_cs[:, None] * rotary_dim + rk_repeat[None, :])
+ SIN = SIN + (rm_cs[:, None] * rotary_dim + rk_repeat[None, :])
+ cos = tl.load(
+ COS,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_repeat[None, :] < rotary_dim_half),
+ other=1.0,
+ ).to(tl.float32)
+ sin = tl.load(
+ SIN,
+ mask=(rm_cs[:, None] < seqlen_ro) &
+ (rk_repeat[None, :] < rotary_dim_half),
+ other=0.0,
+ ).to(tl.float32)
+ x0 = tl.load(
+ X0,
+ mask=(rm[:, None] < seqlen) & (rk[None, :] < rotary_dim),
+ other=0.0).to(tl.float32)
+ x1 = tl.load(
+ X1,
+ mask=(rm[:, None] < seqlen) & (rk_swap[None, :] < rotary_dim),
+ other=0.0).to(tl.float32)
+ if CONJUGATE:
+ sin = -sin
+ x0_cos = x0 * cos
+ x1_sin = x1 * sin
+ out = tl.where(rk[None, :] % 2 == 0, x0_cos - x1_sin, x0_cos + x1_sin)
+ OUT = OUT + (
+ rm[:, None] * stride_out_seqlen + rk[None, :] * stride_out_headdim)
+ tl.store(
+ OUT, out, mask=(rm[:, None] < seqlen) & (rk[None, :] < rotary_dim))
+
+
+def apply_rotary(
+ x: torch.Tensor,
+ cos: torch.Tensor,
+ sin: torch.Tensor,
+ seqlen_offsets: Union[int, torch.Tensor] = 0,
+ cu_seqlens: Optional[torch.Tensor] = None,
+ max_seqlen: Optional[int] = None,
+ interleaved=False,
+ inplace=False,
+ conjugate=False,
+) -> torch.Tensor:
+ """
+ Arguments:
+ x: (batch, seqlen, nheads, headdim) if cu_seqlens is None
+ else (total_seqlen, nheads, headdim).
+ cos: (seqlen_ro, rotary_dim)
+ sin: (seqlen_ro, rotary_dim)
+ seqlen_offsets: integer or integer tensor of size (batch,)
+ cu_seqlens: (batch + 1,) or None
+ max_seqlen: int
+ Returns:
+ y: (batch, seqlen, nheads, headdim)
+ """
+ is_varlen = cu_seqlens is not None
+ if not is_varlen:
+ batch, seqlen, nheads, headdim = x.shape
+ else:
+ assert max_seqlen is not None, ('If cu_seqlens is passed in, '
+ 'then max_seqlen must be passed')
+ total_seqlen, nheads, headdim = x.shape
+ batch_p_1 = cu_seqlens.shape[0]
+ batch = batch_p_1 - 1
+ seqlen = max_seqlen
+ seqlen_ro, rotary_dim = cos.shape
+ assert sin.shape == cos.shape
+ # rotary_dim *= 2
+ assert rotary_dim <= headdim, 'rotary_dim must be <= headdim'
+ assert headdim <= 256, 'Only support headdim <= 256'
+ assert seqlen_ro >= seqlen, 'seqlen_ro must be >= seqlen'
+
+ assert (
+ cos.dtype == sin.dtype
+ ), f'cos and sin must have the same dtype, got {cos.dtype} and {sin.dtype}'
+ assert (x.dtype == cos.dtype), (
+ f'Input and cos/sin must have the same dtype, '
+ f'got {x.dtype} and {cos.dtype}')
+
+ cos, sin = cos.contiguous(), sin.contiguous()
+ if isinstance(seqlen_offsets, torch.Tensor):
+ assert seqlen_offsets.shape == (batch, )
+ assert seqlen_offsets.dtype in [torch.int32, torch.int64]
+ seqlen_offsets = seqlen_offsets.contiguous()
+ else:
+ assert seqlen_offsets + seqlen <= seqlen_ro
+
+ output = torch.empty_like(x) if not inplace else x
+ if rotary_dim < headdim and not inplace:
+ output[..., rotary_dim:].copy_(x[..., rotary_dim:])
+
+ BLOCK_K = (32 if rotary_dim <= 32 else
+ (64 if rotary_dim <= 64 else
+ (128 if rotary_dim <= 128 else 256)))
+
+ def grid(META):
+ return (triton.cdiv(seqlen, META['BLOCK_M']), batch, nheads)
+
+ BLOCK_M = 4 if interleaved else (8 if rotary_dim <= 64 else 4)
+
+ # Need this, otherwise Triton tries to launch from cuda:0 and we get
+ # ValueError: Pointer argument (at 0) cannot be accessed from Triton
+ # (cpu tensor?)
+ with torch.cuda.device(x.device.index):
+ rotary_kernel[grid](
+ output, # data ptrs
+ x,
+ cos,
+ sin,
+ cu_seqlens,
+ seqlen_offsets,
+ seqlen, # shapes
+ rotary_dim,
+ seqlen_ro,
+ output.stride(0)
+ if not is_varlen else 0, # batch_strides if not varlen else 0
+ output.stride(-3), # seqlen_stride or total_seqlen_stride
+ output.stride(-2), # nheads_stride
+ output.stride(-1), # headdim_stride
+ x.stride(0)
+ if not is_varlen else 0, # batch_strides if not varlen else 0
+ x.stride(-3), # seqlen stride or total_seqlen_stride
+ x.stride(-2), # nheads stride
+ x.stride(-1), # headdim stride
+ BLOCK_K,
+ isinstance(seqlen_offsets, torch.Tensor),
+ is_varlen,
+ interleaved,
+ conjugate,
+ BLOCK_M,
+ )
+ return output
+
+
+class ApplyRotaryEmb(torch.autograd.Function):
+
+ @staticmethod
+ def forward(
+ ctx,
+ x,
+ cos,
+ sin,
+ interleaved=False,
+ inplace=False,
+ seqlen_offsets: Union[int, torch.Tensor] = 0,
+ cu_seqlens: Optional[torch.Tensor] = None,
+ max_seqlen: Optional[int] = None,
+ ):
+ out = apply_rotary(
+ x,
+ cos,
+ sin,
+ seqlen_offsets=seqlen_offsets,
+ cu_seqlens=cu_seqlens,
+ max_seqlen=max_seqlen,
+ interleaved=interleaved,
+ inplace=inplace,
+ )
+ if isinstance(seqlen_offsets, int):
+ ctx.save_for_backward(
+ cos, sin, cu_seqlens) # Can't save int with save_for_backward
+ ctx.seqlen_offsets = seqlen_offsets
+ else:
+ ctx.save_for_backward(cos, sin, cu_seqlens, seqlen_offsets)
+ ctx.seqlen_offsets = None
+ ctx.interleaved = interleaved
+ ctx.inplace = inplace
+ ctx.max_seqlen = max_seqlen
+ return out if not inplace else x
+
+ @staticmethod
+ def backward(ctx, do):
+ seqlen_offsets = ctx.seqlen_offsets
+ if seqlen_offsets is None:
+ cos, sin, cu_seqlens, seqlen_offsets = ctx.saved_tensors
+ else:
+ cos, sin, cu_seqlens = ctx.saved_tensors
+ # TD [2023-09-02]: For some reason Triton (2.0.0.post1) errors with
+ # "[CUDA]: invalid device context", and cloning makes it work. Idk why.
+ # Triton 2.1.0 works.
+ if not ctx.interleaved and not ctx.inplace:
+ do = do.clone()
+ dx = apply_rotary(
+ do,
+ cos,
+ sin,
+ seqlen_offsets=seqlen_offsets,
+ cu_seqlens=cu_seqlens,
+ max_seqlen=ctx.max_seqlen,
+ interleaved=ctx.interleaved,
+ inplace=ctx.inplace,
+ conjugate=True,
+ )
+ return dx, None, None, None, None, None, None, None
+
+
+apply_rotary_emb = ApplyRotaryEmb.apply
diff --git a/data/xtuner/xtuner/model/modules/dispatch/utils.py b/data/xtuner/xtuner/model/modules/dispatch/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cfa26cd1f98460a217862abe50f531389421a08
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/utils.py
@@ -0,0 +1,64 @@
+import torch
+import torch.nn.functional as F
+
+try:
+ from flash_attn.bert_padding import index_first_axis, unpad_input
+except ImportError:
+ pass
+
+
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(
+ torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+def upad_qkv(query_layer, key_layer, value_layer, attention_mask,
+ query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(
+ attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim), indices_k)
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim), indices_k)
+ if query_length == kv_seq_len:
+ # Different from the origin version as sequence parallel change
+ # the number of attention heads.
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, -1, head_dim),
+ indices_k)
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = \
+ unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
diff --git a/data/xtuner/xtuner/model/modules/dispatch/yi.py b/data/xtuner/xtuner/model/modules/dispatch/yi.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c3e0d20ce04ee04edcf70380b8fcc220d9a7321
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/dispatch/yi.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ # The first two dimensions of cos and sin are always 1,
+ # so we can `squeeze` them.
+ cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+def yi_attn_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states,
+ cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ # use flash attention implemented by pytorch
+ attn_output = F.scaled_dot_product_attention(
+ query_states, key_states, value_states, attn_mask=attention_mask)
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # Due to the implementation of the PyTorch version of flash attention,
+ # even when the output_attentions flag is set to True, it is not possible
+ # to return the attn_weights.
+ return attn_output, None, past_key_value
diff --git a/data/xtuner/xtuner/model/modules/projector/__init__.py b/data/xtuner/xtuner/model/modules/projector/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6196093dd5ffa4f4be0821ae2198f17a86f685f6
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/projector/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from transformers import AutoConfig, AutoModel
+
+from .configuration_projector import ProjectorConfig
+from .modeling_projector import ProjectorModel
+
+AutoConfig.register('projector', ProjectorConfig)
+AutoModel.register(ProjectorConfig, ProjectorModel)
+
+__all__ = ['ProjectorConfig', 'ProjectorModel']
diff --git a/data/xtuner/xtuner/model/modules/projector/configuration_projector.py b/data/xtuner/xtuner/model/modules/projector/configuration_projector.py
new file mode 100644
index 0000000000000000000000000000000000000000..f63ffdc4698bc867bd559370ea8766537270661c
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/projector/configuration_projector.py
@@ -0,0 +1,23 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from transformers import PretrainedConfig
+
+
+class ProjectorConfig(PretrainedConfig):
+ model_type = 'projector'
+ _auto_class = 'AutoConfig'
+
+ def __init__(
+ self,
+ visual_hidden_size=4096,
+ llm_hidden_size=4096,
+ depth=2,
+ hidden_act='gelu',
+ bias=True,
+ **kwargs,
+ ):
+ self.visual_hidden_size = visual_hidden_size
+ self.llm_hidden_size = llm_hidden_size
+ self.depth = depth
+ self.hidden_act = hidden_act
+ self.bias = bias
+ super().__init__(**kwargs)
diff --git a/data/xtuner/xtuner/model/modules/projector/modeling_projector.py b/data/xtuner/xtuner/model/modules/projector/modeling_projector.py
new file mode 100644
index 0000000000000000000000000000000000000000..d55e7588c8c3d7dc3537f1bf0a7ec4c14b1901b2
--- /dev/null
+++ b/data/xtuner/xtuner/model/modules/projector/modeling_projector.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from transformers import PreTrainedModel
+from transformers.activations import ACT2FN
+
+from .configuration_projector import ProjectorConfig
+
+
+class ProjectorModel(PreTrainedModel):
+ _auto_class = 'AutoModel'
+ config_class = ProjectorConfig
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+
+ def __init__(self, config: ProjectorConfig) -> None:
+ super().__init__(config)
+ self.gradient_checkpointing = False
+
+ modules = [
+ nn.Linear(
+ config.visual_hidden_size,
+ config.llm_hidden_size,
+ bias=config.bias)
+ ]
+ for _ in range(1, config.depth):
+ modules.append(ACT2FN[config.hidden_act])
+ modules.append(
+ nn.Linear(
+ config.llm_hidden_size,
+ config.llm_hidden_size,
+ bias=config.bias))
+ self.model = nn.Sequential(*modules)
+
+ def enable_input_require_grads(self):
+
+ def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+ self.model.register_forward_hook(make_inputs_require_grad)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, ProjectorModel):
+ module.gradient_checkpointing = value
+
+ def forward(self, x):
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = torch.utils.checkpoint.checkpoint(self.model, x)
+ else:
+ layer_outputs = self.model(x)
+ return layer_outputs
diff --git a/data/xtuner/xtuner/model/orpo.py b/data/xtuner/xtuner/model/orpo.py
new file mode 100644
index 0000000000000000000000000000000000000000..37264088acd7c852865e0dcd7795796bd8990eeb
--- /dev/null
+++ b/data/xtuner/xtuner/model/orpo.py
@@ -0,0 +1,212 @@
+# ORPO Authors: Jiwoo Hong, Noah Lee, and James Thorne
+# Official code: https://github.com/xfactlab/orpo
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from mmengine import MessageHub
+from torch import nn
+
+from xtuner.parallel.sequence import (gather_forward_split_backward,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ split_for_sequence_parallel)
+from .sft import SupervisedFinetune
+
+
+class ORPO(SupervisedFinetune):
+ """ORPO: Monolithic Preference Optimization without Reference Model
+ https://arxiv.org/abs/2403.07691
+
+ Args:
+ beta (float): Weight of the odds_ratio_loss. Defaults to 0.1.
+ """
+
+ def __init__(self, *args, beta=0.1, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.beta = beta
+
+ def _gather_masked_logits(self, logits, labels, mask):
+ logits = torch.gather(
+ logits.log_softmax(-1), dim=2,
+ index=labels.unsqueeze(2)).squeeze(2)
+ return logits * mask
+
+ def get_logps(
+ self,
+ all_logps, # bs, seqlen
+ average_log_prob,
+ loss_mask, # bs, seqlen
+ ):
+ all_logps = all_logps[:, :-1].sum(-1)
+ loss_mask = loss_mask[:, :-1]
+
+ if average_log_prob: # average_log_prob
+ all_logps = all_logps / loss_mask.sum(-1)
+
+ chosen_logps = all_logps[::2]
+ rejected_logps = all_logps[1::2]
+ return chosen_logps, rejected_logps
+
+ def get_var_len_atten_logps(self, all_logps, average_log_prob, loss_mask,
+ cu_seqlens, attention_mask):
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+ # unpack sequence
+ unpacked_logps = torch.split(all_logps, seqlens, dim=1)
+ unpacked_loss_mask = torch.split(loss_mask, seqlens, dim=1)
+ if attention_mask is not None:
+ # It indicate that we pad the original sequence, labels,
+ # position_ids and cumulative_len for sequence parallel if the
+ # attention_mask is not None.
+ # We then need to remove the padded segments.
+ assert False in attention_mask
+ unpacked_logps = unpacked_logps[:-1]
+ unpacked_loss_mask = unpacked_loss_mask[:-1]
+ assert len(unpacked_logps) % 2 == 0
+
+ def compute_logps(_logps, _mask):
+ _logps = _logps[:, :-1].sum(-1)
+ _mask = _mask[:, :-1]
+ if average_log_prob:
+ _logps /= _mask.sum(-1)
+ return _logps
+
+ chosen_logps, rejected_logps = [], []
+ for i in range(len(unpacked_logps) // 2):
+ chosen = unpacked_logps[2 * i]
+ rejected = unpacked_logps[2 * i + 1]
+ chosen_mask = unpacked_loss_mask[2 * i]
+ rejected_mask = unpacked_loss_mask[2 * i + 1]
+ chosen_logps.append(compute_logps(chosen, chosen_mask))
+ rejected_logps.append(compute_logps(rejected, rejected_mask))
+
+ return (torch.stack(chosen_logps), torch.stack(rejected_logps))
+
+ def cross_entropy_loss(self, logits, labels):
+ logits = logits[..., :-1, :].contiguous()
+ # labels are already shifted, now we need to remove the last dummy label # noqa
+ labels = labels[..., :-1].contiguous()
+ # Flatten the tokens
+ loss_fct = nn.CrossEntropyLoss()
+ logits = logits.view(-1, logits.shape[-1])
+ labels = labels.view(-1)
+ # Enable model parallelism
+ labels = labels.to(logits.device)
+ loss = loss_fct(logits, labels)
+ return loss
+
+ def odds_ratio_loss(
+ self,
+ chosen_logps: torch.FloatTensor,
+ rejected_logps: torch.FloatTensor,
+ ):
+ # modified from https://github.com/huggingface/trl/blob/b031adfdb8708f1f295eab6c3f2cb910e8fe0c23/trl/trainer/orpo_trainer.py#L597 # noqa
+ # Derived from Eqs. (4) and (7) from https://arxiv.org/abs/2403.07691 by using log identities and exp(log(P(y|x)) = P(y|x) # noqa
+ log_odds = (chosen_logps - rejected_logps) - (
+ torch.log1p(-torch.exp(chosen_logps)) -
+ torch.log1p(-torch.exp(rejected_logps)))
+ ratio = F.logsigmoid(log_odds)
+ ratio = ratio[~torch.isnan(ratio)] # select valid loss
+ losses = self.beta * ratio
+
+ chosen_rewards = self.beta * chosen_logps
+ rejected_rewards = self.beta * rejected_logps
+
+ return losses, chosen_rewards, rejected_rewards, torch.mean(
+ ratio), torch.mean(log_odds)
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'position_ids', 'labels',
+ 'chosen_rejected_tag')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def compute_loss(self, data, data_samples=None):
+ # shift labels first and add a dummy label at the end, to support sequence parallel # noqa
+ data['labels'] = torch.cat(
+ (data['labels'][:, 1:], torch.zeros_like(data['labels'][:, :1])),
+ dim=1)
+ tmp_label = data['labels'].clone()
+ tmp_label[tmp_label == 0] = -100
+ # loss mask of all tokens in all sp ranks
+ all_loss_mask = data['labels'] != -100
+
+ if self.use_varlen_attn:
+ # create a chosen rejected tag for varlen_attn ce loss
+ message_hub = MessageHub.get_instance('varlen_attn_args')
+ rank = dist.get_rank()
+ cu_seqlens = message_hub.get_info(f'cumulative_len_rank_{rank}')
+ seqlens = (cu_seqlens[1:] - cu_seqlens[:-1]).tolist()
+
+ chosen_rejected_tag = torch.ones_like(data['labels'])
+ unpacked_tag = list(
+ torch.split(chosen_rejected_tag, seqlens, dim=1))
+ # import pdb; pdb.set_trace()
+ for i in range(len(unpacked_tag) // 2):
+ # import pdb; pdb.set_trace()
+ unpacked_tag[2 * i + 1] *= 0
+ chosen_rejected_tag = torch.cat(unpacked_tag, dim=1)
+ data['chosen_rejected_tag'] = chosen_rejected_tag
+
+ if get_sequence_parallel_world_size() > 1:
+ data = self._split_for_sequence_parallel(data)
+ chosen_rejected_tag = data.pop('chosen_rejected_tag', None)
+ all_logits = self.llm(**data).logits
+
+ labels = data['labels'].clone()
+ labels[labels == -100] = 0
+ loss_mask = labels != 0 # loss mask in a single sp rank
+ all_logps = self._gather_masked_logits(all_logits, labels, loss_mask)
+ if get_sequence_parallel_world_size() > 1:
+ all_logps = gather_forward_split_backward(
+ all_logps,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+
+ if not self.use_varlen_attn:
+ chosen_nll_loss = self.cross_entropy_loss(all_logits[::2],
+ data['labels'][::2])
+ chosen_logps, rejected_logps = self.get_logps(
+ all_logps, True, all_loss_mask)
+ else:
+ chosen_idxs = chosen_rejected_tag == 1
+ chosen_logits = all_logits[chosen_idxs]
+ chosen_labels = data['labels'][chosen_idxs]
+ chosen_nll_loss = self.cross_entropy_loss(chosen_logits,
+ chosen_labels)
+
+ chosen_logps, rejected_logps = self.get_var_len_atten_logps(
+ all_logps, True, all_loss_mask, cu_seqlens,
+ data['attention_mask'])
+ (losses, chosen_rewards, rejected_rewards, log_odds_ratio,
+ log_odds_chosen) = self.odds_ratio_loss(chosen_logps, rejected_logps)
+ losses = losses.mean()
+ # skip nan loss
+ if torch.isnan(chosen_nll_loss):
+ chosen_nll_loss = all_logits.mean() * 0
+ if torch.isnan(losses):
+ losses = all_logits.mean() * 0
+ loss = chosen_nll_loss - losses
+
+ reward_acc = (chosen_rewards > rejected_rewards).float().mean()
+
+ loss_dict = {
+ 'loss': loss,
+ 'chosen_rewards': chosen_rewards.mean(),
+ 'rejected_rewards': rejected_rewards.mean(),
+ 'reward_acc': reward_acc,
+ 'reward_margin': (chosen_rewards - rejected_rewards).mean(),
+ 'log_odds_ratio': log_odds_ratio,
+ 'log_odds_chosen': log_odds_chosen,
+ 'nll_loss': chosen_nll_loss.detach().mean()
+ }
+ return loss_dict
diff --git a/data/xtuner/xtuner/model/reward.py b/data/xtuner/xtuner/model/reward.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bc203daa8ceb5d15be11ed6a37aa9676aa6d32d
--- /dev/null
+++ b/data/xtuner/xtuner/model/reward.py
@@ -0,0 +1,490 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import math
+import os
+import warnings
+from collections import OrderedDict
+from contextlib import nullcontext
+
+import torch
+import torch.distributed as dist
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from mmengine.runner import load_checkpoint
+from peft import get_peft_model, prepare_model_for_kbit_training
+from torch import nn
+from transformers import (AutoConfig, AutoModelForSequenceClassification,
+ PreTrainedModel, PreTrainedTokenizer)
+from transformers.dynamic_module_utils import get_class_from_dynamic_module
+from transformers.integrations import is_deepspeed_zero3_enabled
+from transformers.modeling_utils import no_init_weights
+
+from xtuner.parallel.sequence import (gather_forward_split_backward,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ split_for_sequence_parallel)
+from xtuner.registry import BUILDER
+from .modules import dispatch_modules
+from .modules.dispatch import SUPPORT_FLASH1, SUPPORT_FLASH2
+from .utils import (LoadWoInit, find_all_linear_names,
+ get_peft_model_state_dict, make_inputs_require_grad,
+ traverse_dict)
+
+
+def reduce_mean(tensor):
+ """"Obtain the mean of tensor on different GPUs."""
+ if not (dist.is_available() and dist.is_initialized()):
+ return tensor
+ tensor = tensor.clone()
+ dist.all_reduce(tensor.div_(dist.get_world_size()), op=dist.ReduceOp.SUM)
+ return tensor
+
+
+def smart_tokenizer_and_embedding_resize(
+ tokenizer: PreTrainedTokenizer,
+ model: PreTrainedModel,
+):
+ """Resize embedding."""
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ params = [model.get_input_embeddings().weight]
+ if model.get_output_embeddings(
+ ) is not None and not model.config.tie_word_embeddings:
+ params.append(model.get_output_embeddings().weight)
+
+ context_maybe_zero3 = deepspeed.zero.GatheredParameters(
+ params, modifier_rank=0)
+ else:
+ context_maybe_zero3 = nullcontext()
+
+ with context_maybe_zero3:
+ current_embedding_size = model.get_input_embeddings().weight.size(0)
+
+ if len(tokenizer) > current_embedding_size:
+ assert isinstance(model.get_output_embeddings(), nn.Linear)
+
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=64)
+ with context_maybe_zero3:
+ num_new_tokens = len(tokenizer) - current_embedding_size
+ input_embeddings = model.get_input_embeddings().weight.data
+ output_embeddings = model.get_output_embeddings().weight.data
+
+ input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+ output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+
+ input_embeddings[-num_new_tokens:] = input_embeddings_avg
+ output_embeddings[-num_new_tokens:] = output_embeddings_avg
+
+ print_log(
+ f'Resized token embeddings from {current_embedding_size} to '
+ f'{len(tokenizer)}.', 'current')
+
+
+class RewardModel(BaseModel):
+
+ def __init__(
+ self,
+ llm,
+ lora=None,
+ peft_model=None,
+ use_activation_checkpointing=True,
+ use_varlen_attn=False,
+ tokenizer=None,
+ max_position_embeddings=None,
+ reward_token_id=None,
+ loss_type='ranking',
+ penalty_type='log_barrier',
+ penalty_weight=0.01,
+ ):
+ super().__init__()
+ with LoadWoInit():
+ if isinstance(llm, dict):
+ llm = self._dispatch_lm_model_cfg(llm, max_position_embeddings)
+ self.llm = self._build_from_cfg_or_module(llm).model
+ self.v_head = nn.Linear(self.llm.config.hidden_size, 1, bias=False)
+ # zero init
+ self.v_head.weight.data.zero_()
+
+ self.reward_token_id = reward_token_id
+ assert loss_type in ('ranking',
+ 'focal'), f'Unsupported loss type {loss_type}'
+ self.loss_type = loss_type
+ assert penalty_type in (
+ 'log_barrier', 'L2',
+ 'none'), f'Unsupported penalty type {penalty_type}'
+ self.penalty_type = penalty_type
+ self.penalty_weight = penalty_weight
+
+ if tokenizer is not None:
+ if isinstance(tokenizer, dict):
+ tokenizer = BUILDER.build(tokenizer)
+ smart_tokenizer_and_embedding_resize(tokenizer, self.llm)
+
+ self.llm.config.use_cache = False
+ dispatch_modules(self.llm, use_varlen_attn=use_varlen_attn)
+
+ if use_activation_checkpointing:
+ # For backward compatibility
+ if hasattr(self.llm, 'enable_input_require_grads'):
+ self.llm.enable_input_require_grads()
+ else:
+ self.llm.get_input_embeddings().register_forward_hook(
+ make_inputs_require_grad)
+
+ # enable gradient checkpointing for memory efficiency
+ self.gradient_checkpointing_enable()
+
+ if isinstance(lora, dict) or isinstance(lora, Config) or isinstance(
+ lora, ConfigDict):
+ self.lora = BUILDER.build(lora)
+ else:
+ self.lora = lora
+ self.peft_model = peft_model
+ self.use_lora = lora is not None
+ if self.use_lora:
+ self._prepare_for_lora(peft_model, use_activation_checkpointing)
+
+ self._is_init = True
+ # Determines whether to calculate attention based on the
+ # seq_len dimension (use_varlen_attn = False) or the actual length of
+ # the sequence.
+ self.use_varlen_attn = use_varlen_attn
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.llm.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.llm.gradient_checkpointing_disable()
+
+ def _prepare_for_lora(self,
+ peft_model=None,
+ use_activation_checkpointing=True):
+ self.llm = prepare_model_for_kbit_training(
+ self.llm, use_activation_checkpointing)
+ if self.lora.target_modules is None:
+ modules = find_all_linear_names(self.llm)
+ self.lora.target_modules = modules
+
+ self.llm = get_peft_model(self.llm, self.lora)
+ if peft_model is not None:
+ _ = load_checkpoint(self, peft_model)
+
+ def init_weights(self):
+ pass
+
+ @staticmethod
+ def _prepare_for_long_context_training(cfg, llm_cfg,
+ max_position_embeddings):
+ if not hasattr(llm_cfg, 'rope_scaling'):
+ print_log('Current model does not support RoPE scaling.',
+ 'current')
+ return
+
+ current_max_length = getattr(llm_cfg, 'max_position_embeddings', None)
+ if current_max_length and max_position_embeddings > current_max_length:
+ print_log(
+ f'Enlarge max model length from {current_max_length} '
+ f'to {max_position_embeddings}.', 'current')
+ scaling_factor = float(
+ math.ceil(max_position_embeddings / current_max_length))
+ else:
+ print_log(
+ 'The input `max_position_embeddings` is smaller than '
+ 'origin max length. Consider increase input length.',
+ 'current')
+ scaling_factor = 1.0
+ cfg.rope_scaling = {'type': 'linear', 'factor': scaling_factor}
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_flash_attn(cfg, llm_cfg):
+ cls_name = type(llm_cfg).__name__
+ SUPPORT_SDPA_ATTN = ('LlamaConfig', 'GemmaConfig', 'MistralConfig',
+ 'MixtralConfig', 'Qwen2Config', 'Qwen2MoeConfig',
+ 'Starcoder2Config', 'Starcoder2Config',
+ 'Phi3Config')
+ SUPPORT_FLASH_ATTN2 = ('InternLM2Config', 'LlamaConfig', 'GemmaConfig',
+ 'MistralConfig', 'MixtralConfig', 'Qwen2Config',
+ 'Qwen2MoeConfig', 'Starcoder2Config',
+ 'Starcoder2Config', 'Phi3Config')
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ if getattr(cfg, 'attn_implementation', None) is not None:
+ # Flash Attention 2.0 only supports torch.float16 and
+ # torch.bfloat16 dtypes
+ if cfg.attn_implementation == 'flash_attention_2':
+ cfg.torch_dtype = torch_dtype
+ elif SUPPORT_FLASH2 and cls_name in SUPPORT_FLASH_ATTN2:
+ cfg.torch_dtype = torch_dtype
+ cfg.attn_implementation = 'flash_attention_2'
+ elif SUPPORT_FLASH1 and cls_name in SUPPORT_SDPA_ATTN:
+ cfg.attn_implementation = 'sdpa'
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_qlora_zero3(cfg):
+ if (not is_deepspeed_zero3_enabled()) or (not hasattr(
+ cfg, 'quantization_config')):
+ return cfg
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ cfg.torch_dtype = torch_dtype
+ quantization_config = cfg.quantization_config
+ quantization_config.bnb_4bit_compute_dtype = torch_dtype
+ quantization_config.bnb_4bit_quant_storage = torch_dtype
+
+ return cfg
+
+ def _dispatch_lm_model_cfg(self, cfg, max_position_embeddings=None):
+ cfg = self._prepare_for_qlora_zero3(cfg)
+ pretrained_model_name_or_path = cfg.pretrained_model_name_or_path
+ llm_cfg = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=True)
+ cfg = self._prepare_for_flash_attn(cfg, llm_cfg)
+ if max_position_embeddings is not None:
+ cfg = self._prepare_for_long_context_training(
+ cfg, llm_cfg, max_position_embeddings)
+ return cfg
+
+ def _build_from_cfg_or_module(self, cfg_or_mod):
+ if isinstance(cfg_or_mod, nn.Module):
+ return cfg_or_mod
+ elif isinstance(cfg_or_mod, dict):
+ traverse_dict(cfg_or_mod)
+ return BUILDER.build(cfg_or_mod)
+ else:
+ raise NotImplementedError
+
+ def forward(self, data, data_samples=None, mode='loss'):
+ labels = data.pop('labels', None)
+ if mode == 'loss':
+ return self.compute_loss(data, labels)
+ elif mode == 'predict':
+ return self.predict(data, data_samples)
+ elif mode == 'tensor':
+ return self._forward(data, data_samples)
+ else:
+ raise NotImplementedError
+
+ def _forward(self, data, data_samples=None):
+ hidden_states = self.llm(**data)[0]
+ logits = self.v_head(hidden_states)
+ return logits
+
+ def predict(self, data, data_samples=None):
+ hidden_states = self.llm(**data)[0]
+ logits = self.v_head(hidden_states)
+ logits_dict = [{'logits': log} for log in logits]
+ return logits_dict
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'position_ids')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def compute_loss(self, data, labels=None):
+ if get_sequence_parallel_world_size() > 1:
+ data = self._split_for_sequence_parallel(data)
+
+ hidden_states = self.llm(**data)[0]
+ logits = self.v_head(hidden_states)
+
+ if get_sequence_parallel_world_size() > 1:
+ logits = gather_forward_split_backward(
+ logits,
+ dim=1,
+ sp_group=get_sequence_parallel_group(),
+ grad_scale='up')
+
+ chosen_idx = torch.where(labels == 0)
+ rejected_idx = torch.where(labels == 1)
+ chosen_logits = logits[chosen_idx]
+ rejected_logits = logits[rejected_idx]
+
+ num_samples = torch.tensor(len(chosen_logits)).float().to(
+ hidden_states.device)
+ avg_factor = 1.0 / num_samples
+ avg_factor = reduce_mean(avg_factor).to(hidden_states.device)
+
+ chosen_mean = reduce_mean(chosen_logits.mean().detach())
+ rejected_mean = reduce_mean(rejected_logits.mean().detach())
+ acc = reduce_mean(
+ (chosen_logits > rejected_logits).sum() / num_samples).detach()
+ num_tokens = torch.tensor(labels.shape[1]).float()
+
+ # ranking loss
+ if self.loss_type == 'ranking':
+ rank_loss = self.ranking_loss(
+ chosen_logits, rejected_logits, avg_factor=avg_factor)
+ elif self.loss_type == 'focal':
+ rank_loss = self.focal_loss(
+ chosen_logits, rejected_logits, avg_factor=avg_factor)
+ else:
+ raise NotImplementedError(
+ f'Unsupported loss type {self.loss_type}')
+
+ # penalty loss
+ if self.penalty_type == 'log_barrier':
+ penalty = self.log_barrier_penalty(
+ torch.cat([chosen_logits, rejected_logits]),
+ lower_bound=-5,
+ upper_bound=5,
+ avg_factor=avg_factor)
+ elif self.penalty_type == 'L2':
+ penalty = self.l2_penalty(
+ torch.cat([chosen_logits, rejected_logits]),
+ avg_factor=avg_factor)
+ elif self.penalty_type == 'none':
+ penalty = 0
+ else:
+ raise NotImplementedError(
+ f'Unsupported penalty type {self.penalty_type}')
+
+ loss = rank_loss + self.penalty_weight * penalty
+ loss_dict = {
+ 'loss': loss,
+ 'acc': acc,
+ 'chosen_score_mean': chosen_mean,
+ 'rejected_score_mean': rejected_mean,
+ 'num_samples': num_samples,
+ 'num_tokens': num_tokens,
+ }
+
+ return loss_dict
+
+ def ranking_loss(self, chosen_logits, rejected_logits, avg_factor):
+ rank_loss = -nn.functional.logsigmoid(chosen_logits - rejected_logits)
+ return rank_loss.sum() * avg_factor
+
+ def focal_loss(self, chosen_logits, rejected_logits, avg_factor):
+ # focal ranking loss from InternLM2 paper https://arxiv.org/abs/2403.17297 # noqa
+ rank_loss = -nn.functional.logsigmoid(chosen_logits - rejected_logits)
+ p_ij = torch.sigmoid(chosen_logits - rejected_logits)
+ p = 2 * torch.relu(p_ij - 0.5)
+ gamma = 2
+ focal_loss = ((1 - p)**gamma) * rank_loss
+ return focal_loss.sum() * avg_factor
+
+ def log_barrier_penalty(self,
+ logits,
+ lower_bound,
+ upper_bound,
+ epsilon=1e-3,
+ avg_factor=1):
+ # log barrier penalty from InternLM2 paper https://arxiv.org/abs/2403.17297 # noqa
+ logits_fp32 = logits.float()
+ logits_clamped = torch.clamp(logits_fp32, lower_bound + epsilon,
+ upper_bound - epsilon)
+ penalty = -torch.log(upper_bound - logits_clamped) - torch.log(
+ logits_clamped - lower_bound)
+ return penalty.sum() * avg_factor
+
+ def l2_penalty(self, logits, avg_factor=1):
+ return (logits**2).sum() * avg_factor
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ if not self.use_lora:
+ return state_dict
+ to_return = get_peft_model_state_dict(self.llm, state_dict=state_dict)
+ return OrderedDict(to_return)
+
+ def __getattr__(self, name: str):
+ try:
+ return super().__getattr__(name)
+ except AttributeError:
+ return getattr(self.llm, name)
+
+ def to_hf(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={},
+ **kwargs):
+ print(f'Saving LLM tokenizer to {save_dir}')
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ tokenizer.save_pretrained(save_dir)
+
+ if 'PeftModel' in self.llm.__class__.__name__:
+ # merge adapter
+ self.llm = self.llm.merge_and_unload()
+ if 'InternLM2' in self.llm.__class__.__name__:
+ from xtuner.tools.model_converters.modeling_internlm2_reward.modeling_internlm2 import \
+ InternLM2ForRewardModel # noqa
+ print(f'Saving Reward Model to {save_dir}')
+ hf_cfg = self.llm.config
+ hf_cfg.reward_token_id = self.reward_token_id if \
+ self.reward_token_id is not None else cfg.reward_token_id
+ if not fp32:
+ dtype = torch.float16
+ else:
+ dtype = torch.float32
+ with no_init_weights():
+ reward_model = InternLM2ForRewardModel._from_config(
+ hf_cfg, torch_dtype=dtype)
+ reward_model.model.load_state_dict(self.llm.state_dict())
+ reward_model.v_head.load_state_dict(self.v_head.state_dict())
+ reward_model.save_pretrained(save_dir, **save_pretrained_kwargs)
+ # fix auto_map in config
+ with open(os.path.join(save_dir, 'config.json')) as fp:
+ config_dict = json.load(fp)
+ config_dict['auto_map'][
+ 'AutoModel'] = 'modeling_internlm2.InternLM2ForRewardModel'
+ config_dict['auto_map'].pop('AutoModelForCausalLM', None)
+ with open(os.path.join(save_dir, 'config.json'), 'w') as fp:
+ json.dump(config_dict, fp, indent=2)
+ else:
+ warnings.warn(
+ f'The pretrained model type: {self.llm.__class__.__name__} '
+ 'has no reward model class defined. Use '
+ 'the SequenceClassification class instead.'
+ 'You can refer to `xtuner/tools/model_converters/modeling_internlm2_reward` ' # noqa
+ 'to implement the reward model class.')
+
+ hf_cfg = self.llm.config
+ hf_cfg.num_labels = 1 # set the output dim to 1
+ try:
+ with no_init_weights():
+ reward_model = \
+ AutoModelForSequenceClassification.from_config(hf_cfg)
+ except Exception as e:
+ warnings.warn(f'Cannot find SequenceClassification class '
+ f'from transformers: {e}, \n'
+ 'try to find it in the dynamic module.')
+ module_file, causal_model_name = hf_cfg.auto_map[
+ 'AutoModelForCausalLM'].split('.')
+ seqcls_model_name = causal_model_name.split(
+ 'For')[0] + 'ForSequenceClassification'
+ seqcls_class = get_class_from_dynamic_module(
+ f'{module_file}.{seqcls_model_name}', hf_cfg._name_or_path)
+ with no_init_weights():
+ reward_model = seqcls_class(hf_cfg)
+ reward_model.model.load_state_dict(self.llm.state_dict())
+ reward_model.score.load_state_dict(self.v_head.state_dict())
+ reward_model.save_pretrained(save_dir, **save_pretrained_kwargs)
diff --git a/data/xtuner/xtuner/model/sft.py b/data/xtuner/xtuner/model/sft.py
new file mode 100644
index 0000000000000000000000000000000000000000..5229504891b3d921286ef0106c84ebd1349e378e
--- /dev/null
+++ b/data/xtuner/xtuner/model/sft.py
@@ -0,0 +1,336 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from collections import OrderedDict
+from contextlib import nullcontext
+
+import torch
+from mmengine import print_log
+from mmengine.config import Config, ConfigDict
+from mmengine.model import BaseModel
+from mmengine.runner import load_checkpoint
+from peft import get_peft_model, prepare_model_for_kbit_training
+from torch import nn
+from transformers import AutoConfig, PreTrainedModel, PreTrainedTokenizer
+from transformers.integrations import is_deepspeed_zero3_enabled
+
+from xtuner.parallel.sequence import (get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ reduce_sequence_parallel_loss,
+ split_for_sequence_parallel)
+from xtuner.registry import BUILDER
+from .modules import dispatch_modules
+from .modules.dispatch import SUPPORT_FLASH1, SUPPORT_FLASH2
+from .utils import (LoadWoInit, find_all_linear_names,
+ get_peft_model_state_dict, make_inputs_require_grad,
+ traverse_dict)
+
+
+def smart_tokenizer_and_embedding_resize(
+ tokenizer: PreTrainedTokenizer,
+ model: PreTrainedModel,
+):
+ """Resize embedding."""
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ params = [model.get_input_embeddings().weight]
+ if model.get_output_embeddings(
+ ) is not None and not model.config.tie_word_embeddings:
+ params.append(model.get_output_embeddings().weight)
+
+ context_maybe_zero3 = deepspeed.zero.GatheredParameters(
+ params, modifier_rank=0)
+ else:
+ context_maybe_zero3 = nullcontext()
+
+ with context_maybe_zero3:
+ current_embedding_size = model.get_input_embeddings().weight.size(0)
+
+ if len(tokenizer) > current_embedding_size:
+ assert isinstance(model.get_output_embeddings(), nn.Linear)
+
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=64)
+ with context_maybe_zero3:
+ num_new_tokens = len(tokenizer) - current_embedding_size
+ input_embeddings = model.get_input_embeddings().weight.data
+ output_embeddings = model.get_output_embeddings().weight.data
+
+ input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+ output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
+ dim=0, keepdim=True)
+
+ input_embeddings[-num_new_tokens:] = input_embeddings_avg
+ output_embeddings[-num_new_tokens:] = output_embeddings_avg
+
+ print_log(
+ f'Resized token embeddings from {current_embedding_size} to '
+ f'{len(tokenizer)}.', 'current')
+
+
+class SupervisedFinetune(BaseModel):
+
+ def __init__(self,
+ llm,
+ lora=None,
+ peft_model=None,
+ use_activation_checkpointing=True,
+ use_varlen_attn=False,
+ tokenizer=None,
+ max_position_embeddings=None):
+ super().__init__()
+
+ self.llm = self.build_llm_from_cfg(llm, use_varlen_attn,
+ max_position_embeddings)
+
+ if tokenizer is not None:
+ if isinstance(tokenizer, dict):
+ tokenizer = BUILDER.build(tokenizer)
+ smart_tokenizer_and_embedding_resize(tokenizer, self.llm)
+
+ self.llm.config.use_cache = False
+ if use_activation_checkpointing:
+ # For backward compatibility
+ if hasattr(self.llm, 'enable_input_require_grads'):
+ self.llm.enable_input_require_grads()
+ else:
+ self.llm.get_input_embeddings().register_forward_hook(
+ make_inputs_require_grad)
+
+ # enable gradient checkpointing for memory efficiency
+ self.gradient_checkpointing_enable()
+
+ if isinstance(lora, dict) or isinstance(lora, Config) or isinstance(
+ lora, ConfigDict):
+ self.lora = BUILDER.build(lora)
+ else:
+ self.lora = lora
+ self.peft_model = peft_model
+ self.use_lora = lora is not None
+ if self.use_lora:
+ self._prepare_for_lora(peft_model, use_activation_checkpointing)
+
+ self._is_init = True
+ # Determines whether to calculate attention based on the
+ # seq_len dimension (use_varlen_attn = False) or the actual length of
+ # the sequence.
+ self.use_varlen_attn = use_varlen_attn
+
+ def build_llm_from_cfg(self, llm_cfg, use_varlen_attn,
+ max_position_embeddings):
+ # For forward
+ with LoadWoInit():
+ if isinstance(llm_cfg, dict):
+ llm = self._dispatch_lm_model_cfg(llm_cfg,
+ max_position_embeddings)
+ llm = self._build_from_cfg_or_module(llm)
+
+ llm.config.use_cache = False
+ dispatch_modules(llm, use_varlen_attn=use_varlen_attn)
+ return llm
+
+ def gradient_checkpointing_enable(self):
+ self.activation_checkpointing_enable()
+
+ def activation_checkpointing_enable(self):
+ self.llm.gradient_checkpointing_enable()
+
+ def gradient_checkpointing_disable(self):
+ self.activation_checkpointing_disable()
+
+ def activation_checkpointing_disable(self):
+ self.llm.gradient_checkpointing_disable()
+
+ def _prepare_for_lora(self,
+ peft_model=None,
+ use_activation_checkpointing=True):
+ self.llm = prepare_model_for_kbit_training(
+ self.llm, use_activation_checkpointing)
+ if self.lora.target_modules is None:
+ modules = find_all_linear_names(self.llm)
+ self.lora.target_modules = modules
+
+ self.llm = get_peft_model(self.llm, self.lora)
+ if peft_model is not None:
+ _ = load_checkpoint(self, peft_model)
+
+ def init_weights(self):
+ pass
+
+ @staticmethod
+ def _prepare_for_long_context_training(cfg, llm_cfg,
+ max_position_embeddings):
+ if not hasattr(llm_cfg, 'rope_scaling'):
+ print_log('Current model does not support RoPE scaling.',
+ 'current')
+ return
+
+ current_max_length = getattr(llm_cfg, 'max_position_embeddings', None)
+ if current_max_length and max_position_embeddings > current_max_length:
+ print_log(
+ f'Enlarge max model length from {current_max_length} '
+ f'to {max_position_embeddings}.', 'current')
+ scaling_factor = float(
+ math.ceil(max_position_embeddings / current_max_length))
+ else:
+ print_log(
+ 'The input `max_position_embeddings` is smaller than '
+ 'origin max length. Consider increase input length.',
+ 'current')
+ scaling_factor = 1.0
+ cfg.rope_scaling = {'type': 'linear', 'factor': scaling_factor}
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_flash_attn(cfg, llm_cfg):
+ cls_name = type(llm_cfg).__name__
+ SUPPORT_SDPA_ATTN = ('LlamaConfig', 'GemmaConfig', 'MistralConfig',
+ 'MixtralConfig', 'Qwen2Config', 'Qwen2MoeConfig',
+ 'Starcoder2Config', 'Starcoder2Config',
+ 'Phi3Config')
+ SUPPORT_FLASH_ATTN2 = ('InternLM2Config', 'LlamaConfig', 'GemmaConfig',
+ 'MistralConfig', 'MixtralConfig', 'Qwen2Config',
+ 'Qwen2MoeConfig', 'Starcoder2Config',
+ 'Starcoder2Config', 'Phi3Config',
+ 'DeepseekV2Config')
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ if getattr(cfg, 'attn_implementation', None) is not None:
+ # Flash Attention 2.0 only supports torch.float16 and
+ # torch.bfloat16 dtypes
+ if cfg.attn_implementation == 'flash_attention_2':
+ cfg.torch_dtype = torch_dtype
+ elif SUPPORT_FLASH2 and cls_name in SUPPORT_FLASH_ATTN2:
+ cfg.torch_dtype = torch_dtype
+ cfg.attn_implementation = 'flash_attention_2'
+ elif SUPPORT_FLASH1 and cls_name in SUPPORT_SDPA_ATTN:
+ cfg.attn_implementation = 'sdpa'
+
+ return cfg
+
+ @staticmethod
+ def _prepare_for_qlora_zero3(cfg):
+ if (not is_deepspeed_zero3_enabled()) or (not hasattr(
+ cfg, 'quantization_config')):
+ return cfg
+
+ torch_dtype = torch.bfloat16 if (
+ torch.cuda.is_available() and torch.cuda.is_bf16_supported()) \
+ else torch.float16
+
+ cfg.torch_dtype = torch_dtype
+ quantization_config = cfg.quantization_config
+ quantization_config.bnb_4bit_compute_dtype = torch_dtype
+ quantization_config.bnb_4bit_quant_storage = torch_dtype
+
+ return cfg
+
+ def _dispatch_lm_model_cfg(self, cfg, max_position_embeddings=None):
+ cfg = self._prepare_for_qlora_zero3(cfg)
+ pretrained_model_name_or_path = cfg.pretrained_model_name_or_path
+ llm_cfg = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=True)
+ cfg = self._prepare_for_flash_attn(cfg, llm_cfg)
+ if max_position_embeddings is not None:
+ cfg = self._prepare_for_long_context_training(
+ cfg, llm_cfg, max_position_embeddings)
+ return cfg
+
+ def _build_from_cfg_or_module(self, cfg_or_mod):
+ if isinstance(cfg_or_mod, nn.Module):
+ return cfg_or_mod
+ elif isinstance(cfg_or_mod, dict):
+ traverse_dict(cfg_or_mod)
+ return BUILDER.build(cfg_or_mod)
+ else:
+ raise NotImplementedError
+
+ def forward(self, data, data_samples=None, mode='loss'):
+
+ if mode == 'loss':
+ return self.compute_loss(data, data_samples)
+ elif mode == 'predict':
+ return self.predict(data, data_samples)
+ elif mode == 'tensor':
+ return self._forward(data, data_samples)
+ else:
+ raise NotImplementedError
+
+ def _forward(self, data, data_samples=None):
+
+ outputs = self.llm(**data)
+
+ return outputs
+
+ def predict(self, data, data_samples=None):
+ outputs = self.llm(**data)
+ logits_dict = [{'logits': logits} for logits in outputs.logits]
+ return logits_dict
+
+ @staticmethod
+ def _split_for_sequence_parallel(data):
+ # attention mask should not be split
+ ARGS_NEED_TO_SPLIT = ('input_ids', 'labels', 'position_ids')
+ sp_group = get_sequence_parallel_group()
+ for key in ARGS_NEED_TO_SPLIT:
+ val = data.get(key, None)
+ if val is not None:
+ # `dim` is 1 as the shape of tensor is (bs, seq_len, ...)
+ data[key] = split_for_sequence_parallel(
+ val, dim=1, sp_group=sp_group)
+ return data
+
+ def _compute_sequence_parallel_loss(self, data):
+ data = self._split_for_sequence_parallel(data)
+ outputs = self.llm(**data)
+ labels = data['labels']
+ num_tokens = (labels != -100).sum()
+ sp_group = get_sequence_parallel_group()
+ loss = reduce_sequence_parallel_loss(outputs.loss, num_tokens,
+ sp_group)
+ return {'loss': loss}
+
+ def compute_loss(self, data, data_samples=None):
+ if get_sequence_parallel_world_size() > 1:
+ return self._compute_sequence_parallel_loss(data)
+ else:
+ outputs = self.llm(**data)
+ loss_dict = {'loss': outputs.loss}
+ return loss_dict
+
+ def state_dict(self, *args, **kwargs):
+ state_dict = super().state_dict(*args, **kwargs)
+ if not self.use_lora:
+ return state_dict
+ to_return = get_peft_model_state_dict(self.llm, state_dict=state_dict)
+ return OrderedDict(to_return)
+
+ def __getattr__(self, name: str):
+ try:
+ return super().__getattr__(name)
+ except AttributeError:
+ return getattr(self.llm, name)
+
+ def to_hf(self,
+ cfg,
+ save_dir,
+ fp32=False,
+ save_pretrained_kwargs={},
+ **kwargs):
+ self.llm.config.use_cache = True
+ if not fp32:
+ print_log('Convert LLM to float16', 'current')
+ self.llm.half()
+ if self.use_lora:
+ print_log(f'Saving adapter to {save_dir}', 'current')
+ else:
+ print_log(f'Saving LLM tokenizer to {save_dir}', 'current')
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ tokenizer.save_pretrained(save_dir)
+ print_log(f'Saving LLM to {save_dir}', 'current')
+ self.llm.save_pretrained(save_dir, **save_pretrained_kwargs)
+ self.llm.config.use_cache = False
diff --git a/data/xtuner/xtuner/model/transformers_models/__init__.py b/data/xtuner/xtuner/model/transformers_models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..71f7ea1d42e34a3fa6b4239b86a468c2e7727b14
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/__init__.py
@@ -0,0 +1,8 @@
+from .deepseek_v2 import (DeepseekTokenizerFast, DeepseekV2Config,
+ DeepseekV2ForCausalLM, DeepseekV2Model)
+from .mixtral import MixtralConfig, MixtralForCausalLM, MixtralModel
+
+__all__ = [
+ 'DeepseekTokenizerFast', 'DeepseekV2Config', 'DeepseekV2ForCausalLM',
+ 'DeepseekV2Model', 'MixtralConfig', 'MixtralForCausalLM', 'MixtralModel'
+]
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/__init__.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a74b483ca374f0b50c9e3a5e536e54aa671cca4
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/__init__.py
@@ -0,0 +1,8 @@
+from .configuration_deepseek import DeepseekV2Config
+from .modeling_deepseek import DeepseekV2ForCausalLM, DeepseekV2Model
+from .tokenization_deepseek_fast import DeepseekTokenizerFast
+
+__all__ = [
+ 'DeepseekV2ForCausalLM', 'DeepseekV2Model', 'DeepseekV2Config',
+ 'DeepseekTokenizerFast'
+]
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/configuration_deepseek.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/configuration_deepseek.py
new file mode 100644
index 0000000000000000000000000000000000000000..daaddcf4922fcfe3617040da2717ee912a10f123
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/configuration_deepseek.py
@@ -0,0 +1,219 @@
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+logger = logging.get_logger(__name__)
+
+DEEPSEEK_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+
+# Compared to the original version, two parameters, `moe_implementation` and
+# `expert_in_one_shard`, have been added.
+class DeepseekV2Config(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`DeepseekV2Model`]. It is used to instantiate an DeepSeek
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the DeepSeek-V2.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 102400):
+ Vocabulary size of the Deep model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`DeepseekV2Model`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 11008):
+ Dimension of the MLP representations.
+ moe_intermediate_size (`int`, *optional*, defaults to 1407):
+ Dimension of the MoE representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer decoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ n_shared_experts (`int`, *optional*, defaults to None):
+ Number of shared experts, None means dense model.
+ n_routed_experts (`int`, *optional*, defaults to None):
+ Number of routed experts, None means dense model.
+ routed_scaling_factor (`float`, *optional*, defaults to 1.0):
+ Scaling factor or routed experts.
+ topk_method (`str`, *optional*, defaults to `gready`):
+ Topk method used in routed gate.
+ n_group (`int`, *optional*, defaults to None):
+ Number of groups for routed experts.
+ topk_group (`int`, *optional*, defaults to None):
+ Number of selected groups for each token(for each token, ensuring the selected experts is only within `topk_group` groups).
+ num_experts_per_tok (`int`, *optional*, defaults to None):
+ Number of selected experts, None means dense model.
+ moe_layer_freq (`int`, *optional*, defaults to 1):
+ The frequency of the MoE layer: one expert layer for every `moe_layer_freq - 1` dense layers.
+ first_k_dense_replace (`int`, *optional*, defaults to 0):
+ Number of dense layers in shallow layers(embed->dense->dense->...->dense->moe->moe...->lm_head).
+ \--k dense layers--/
+ norm_topk_prob (`bool`, *optional*, defaults to False):
+ Whether to normalize the weights of the routed experts.
+ scoring_func (`str`, *optional*, defaults to 'softmax'):
+ Method of computing expert weights.
+ aux_loss_alpha (`float`, *optional*, defaults to 0.001):
+ Auxiliary loss weight coefficient.
+ seq_aux = (`bool`, *optional*, defaults to True):
+ Whether to compute the auxiliary loss for each individual sample.
+ num_key_value_heads (`int`, *optional*):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 2048):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*):
+ Padding token id.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ Beginning of stream token id.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ End of stream token id.
+ pretraining_tp (`int`, *optional*, defaults to 1):
+ Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
+ document](https://huggingface.co/docs/transformers/parallelism) to understand more about it. This value is
+ necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
+ issue](https://github.com/pytorch/pytorch/issues/76232).
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether to tie weight embeddings
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ rope_scaling (`Dict`, *optional*):
+ Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
+ strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
+ `{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
+ `max_position_embeddings` to the expected new maximum.
+ attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ moe_implementation (`str`, *optional*, defaults to 'origin'):
+ The implementation of the moe blocks. 'origin' or 'shard'.
+ expert_in_one_shard (`int`, *optional*, defaults to None):
+ How many expert models are integrated into a shard. It is used only
+ when `moe_implementation` == 'shard'
+
+ ```python
+ >>> from transformers import DeepseekV2Model, DeepseekV2Config
+
+ >>> # Initializing a Deepseek-V2 style configuration
+ >>> configuration = DeepseekV2Config()
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = 'deepseek_v2'
+ keys_to_ignore_at_inference = ['past_key_values']
+
+ def __init__(
+ self,
+ vocab_size=102400,
+ hidden_size=4096,
+ intermediate_size=11008,
+ moe_intermediate_size=1407,
+ num_hidden_layers=30,
+ num_attention_heads=32,
+ num_key_value_heads=32,
+ n_shared_experts=None,
+ n_routed_experts=None,
+ ep_size=1,
+ routed_scaling_factor=1.0,
+ kv_lora_rank=512,
+ q_lora_rank=1536,
+ qk_rope_head_dim=64,
+ v_head_dim=128,
+ qk_nope_head_dim=128,
+ topk_method='gready',
+ n_group=None,
+ topk_group=None,
+ num_experts_per_tok=None,
+ moe_layer_freq=1,
+ first_k_dense_replace=0,
+ norm_topk_prob=False,
+ scoring_func='softmax',
+ aux_loss_alpha=0.001,
+ seq_aux=True,
+ hidden_act='silu',
+ max_position_embeddings=2048,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=None,
+ bos_token_id=100000,
+ eos_token_id=100001,
+ pretraining_tp=1,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ rope_scaling=None,
+ attention_bias=False,
+ attention_dropout=0.0,
+ moe_implementation='origin',
+ expert_in_one_shard=None,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.moe_intermediate_size = moe_intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.n_shared_experts = n_shared_experts
+ self.n_routed_experts = n_routed_experts
+ self.ep_size = ep_size
+ self.routed_scaling_factor = routed_scaling_factor
+ self.kv_lora_rank = kv_lora_rank
+ self.q_lora_rank = q_lora_rank
+ self.qk_rope_head_dim = qk_rope_head_dim
+ self.v_head_dim = v_head_dim
+ self.qk_nope_head_dim = qk_nope_head_dim
+ self.topk_method = topk_method
+ self.n_group = n_group
+ self.topk_group = topk_group
+ self.num_experts_per_tok = num_experts_per_tok
+ self.moe_layer_freq = moe_layer_freq
+ self.first_k_dense_replace = first_k_dense_replace
+ self.norm_topk_prob = norm_topk_prob
+ self.scoring_func = scoring_func
+ self.aux_loss_alpha = aux_loss_alpha
+ self.seq_aux = seq_aux
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.pretraining_tp = pretraining_tp
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+ self.moe_implementation = moe_implementation
+ self.expert_in_one_shard = expert_in_one_shard
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/modeling_deepseek.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/modeling_deepseek.py
new file mode 100644
index 0000000000000000000000000000000000000000..f58dd466fa7a4b754df2b5e7b3da8911985d182d
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/modeling_deepseek.py
@@ -0,0 +1,2037 @@
+# Copyright 2023 DeepSeek-AI and The HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch DeepSeek model."""
+import copy
+import math
+import os
+import types
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.activations import ACT2FN
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.configuration_utils import PretrainedConfig
+from transformers.modeling_attn_mask_utils import (
+ AttentionMaskConverter, _prepare_4d_attention_mask,
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa)
+from transformers.modeling_outputs import (BaseModelOutputWithPast,
+ CausalLMOutputWithPast,
+ SequenceClassifierOutputWithPast)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.pytorch_utils import (ALL_LAYERNORM_LAYERS,
+ is_torch_greater_or_equal_than_1_13)
+from transformers.utils import (add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10, logging,
+ replace_return_docstrings)
+from transformers.utils.import_utils import is_torch_fx_available
+
+from xtuner.utils import load_state_dict_into_model
+from .configuration_deepseek import DeepseekV2Config
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input # noqa
+ from flash_attn.bert_padding import index_first_axis, unpad_input
+
+# This makes `_prepare_4d_causal_attention_mask` a leaf function in the FX graph.
+# It means that the function will not be traced through and simply appear as a node in the graph.
+if is_torch_fx_available():
+ if not is_torch_greater_or_equal_than_1_13:
+ import torch.fx
+
+ _prepare_4d_causal_attention_mask = torch.fx.wrap(
+ _prepare_4d_causal_attention_mask)
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = 'DeepseekV2Config'
+
+
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(
+ torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+class DeepseekV2RMSNorm(nn.Module):
+
+ def __init__(self, hidden_size, eps=1e-6):
+ """DeepseekV2RMSNorm is equivalent to T5LayerNorm."""
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance +
+ self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+ALL_LAYERNORM_LAYERS.append(DeepseekV2RMSNorm)
+
+
+class DeepseekV2RotaryEmbedding(nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (
+ self.base
+ **(torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings,
+ device=self.inv_freq.device,
+ dtype=torch.get_default_dtype(),
+ )
+ self.max_seq_len_cached = None
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.outer(t, self.inv_freq.to(t.device))
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if self.max_seq_len_cached is None or seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(
+ seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->DeepseekV2
+class DeepseekV2LinearScalingRotaryEmbedding(DeepseekV2RotaryEmbedding):
+ """DeepseekV2RotaryEmbedding extended with linear scaling.
+
+ Credits to the Reddit user /u/kaiokendev
+ """
+
+ def __init__(
+ self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None,
+ scaling_factor=1.0,
+ ):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ t = t / self.scaling_factor
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->DeepseekV2
+class DeepseekV2DynamicNTKScalingRotaryEmbedding(DeepseekV2RotaryEmbedding):
+ """DeepseekV2RotaryEmbedding extended with Dynamic NTK scaling.
+
+ Credits to the Reddit users /u/bloc97 and /u/emozilla
+ """
+
+ def __init__(
+ self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None,
+ scaling_factor=1.0,
+ ):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+
+ if seq_len > self.max_position_embeddings:
+ base = self.base * ((self.scaling_factor * seq_len /
+ self.max_position_embeddings) -
+ (self.scaling_factor - 1))**(
+ self.dim / (self.dim - 2))
+ inv_freq = 1.0 / (
+ base
+ **(torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ t = torch.arange(
+ self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+
+# Inverse dim formula to find dim based on number of rotations
+def yarn_find_correction_dim(num_rotations,
+ dim,
+ base=10000,
+ max_position_embeddings=2048):
+ return (dim * math.log(max_position_embeddings /
+ (num_rotations * 2 * math.pi))) / (2 *
+ math.log(base))
+
+
+# Find dim range bounds based on rotations
+def yarn_find_correction_range(low_rot,
+ high_rot,
+ dim,
+ base=10000,
+ max_position_embeddings=2048):
+ low = math.floor(
+ yarn_find_correction_dim(low_rot, dim, base, max_position_embeddings))
+ high = math.ceil(
+ yarn_find_correction_dim(high_rot, dim, base, max_position_embeddings))
+ return max(low, 0), min(high, dim - 1) # Clamp values just in case
+
+
+def yarn_get_mscale(scale=1, mscale=1):
+ if scale <= 1:
+ return 1.0
+ return 0.1 * mscale * math.log(scale) + 1.0
+
+
+def yarn_linear_ramp_mask(min, max, dim):
+ if min == max:
+ max += 0.001 # Prevent singularity
+
+ linear_func = (torch.arange(dim, dtype=torch.float32) - min) / (max - min)
+ ramp_func = torch.clamp(linear_func, 0, 1)
+ return ramp_func
+
+
+class DeepseekV2YarnRotaryEmbedding(DeepseekV2RotaryEmbedding):
+
+ def __init__(
+ self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None,
+ scaling_factor=1.0,
+ original_max_position_embeddings=4096,
+ beta_fast=32,
+ beta_slow=1,
+ mscale=1,
+ mscale_all_dim=0,
+ ):
+ self.scaling_factor = scaling_factor
+ self.original_max_position_embeddings = original_max_position_embeddings
+ self.beta_fast = beta_fast
+ self.beta_slow = beta_slow
+ self.mscale = mscale
+ self.mscale_all_dim = mscale_all_dim
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ dim = self.dim
+
+ freq_extra = 1.0 / (
+ self.base**(torch.arange(
+ 0, dim, 2, dtype=torch.float32, device=device) / dim))
+ freq_inter = 1.0 / (
+ self.scaling_factor * self.base**(torch.arange(
+ 0, dim, 2, dtype=torch.float32, device=device) / dim))
+
+ low, high = yarn_find_correction_range(
+ self.beta_fast,
+ self.beta_slow,
+ dim,
+ self.base,
+ self.original_max_position_embeddings,
+ )
+ inv_freq_mask = 1.0 - yarn_linear_ramp_mask(low, high, dim // 2).to(
+ device=device, dtype=torch.float32)
+ inv_freq = freq_inter * (1 -
+ inv_freq_mask) + freq_extra * inv_freq_mask
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ t = torch.arange(seq_len, device=device, dtype=torch.float32)
+
+ freqs = torch.outer(t, inv_freq)
+
+ _mscale = float(
+ yarn_get_mscale(self.scaling_factor, self.mscale) /
+ yarn_get_mscale(self.scaling_factor, self.mscale_all_dim))
+
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', (emb.cos() * _mscale).to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', (emb.sin() * _mscale).to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+
+ b, h, s, d = q.shape
+ q = q.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
+
+ b, h, s, d = k.shape
+ k = k.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
+
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class DeepseekV2MLP(nn.Module):
+
+ def __init__(self, config, hidden_size=None, intermediate_size=None):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size if hidden_size is None else hidden_size
+ self.intermediate_size = (
+ config.intermediate_size
+ if intermediate_size is None else intermediate_size)
+
+ self.gate_proj = nn.Linear(
+ self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(
+ self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(
+ self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(
+ self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+class MoEGate(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.top_k = config.num_experts_per_tok
+ self.n_routed_experts = config.n_routed_experts
+ self.routed_scaling_factor = config.routed_scaling_factor
+ self.scoring_func = config.scoring_func
+ self.alpha = config.aux_loss_alpha
+ self.seq_aux = config.seq_aux
+ self.topk_method = config.topk_method
+ self.n_group = config.n_group
+ self.topk_group = config.topk_group
+
+ # topk selection algorithm
+ self.norm_topk_prob = config.norm_topk_prob
+ self.gating_dim = config.hidden_size
+ self.weight = nn.Parameter(
+ torch.empty((self.n_routed_experts, self.gating_dim)))
+ self.reset_parameters()
+
+ def reset_parameters(self) -> None:
+ import torch.nn.init as init
+
+ init.kaiming_uniform_(self.weight, a=math.sqrt(5))
+
+ def forward(self, hidden_states):
+ bsz, seq_len, h = hidden_states.shape
+ ### compute gating score
+ hidden_states = hidden_states.view(-1, h)
+ logits = F.linear(
+ hidden_states.type(torch.float32), self.weight.type(torch.float32),
+ None)
+ if self.scoring_func == 'softmax':
+ scores = logits.softmax(dim=-1, dtype=torch.float32)
+ else:
+ raise NotImplementedError(
+ f'insupportable scoring function for MoE gating: {self.scoring_func}'
+ )
+
+ ### select top-k experts
+ # fix official typos
+ if self.topk_method in ('gready', 'greedy'):
+ topk_weight, topk_idx = torch.topk(
+ scores, k=self.top_k, dim=-1, sorted=False)
+ elif self.topk_method == 'group_limited_greedy':
+ group_scores = (scores.view(bsz * seq_len, self.n_group,
+ -1).max(dim=-1).values) # [n, n_group]
+ group_idx = torch.topk(
+ group_scores, k=self.topk_group, dim=-1,
+ sorted=False)[1] # [n, top_k_group]
+ group_mask = torch.zeros_like(group_scores) # [n, n_group]
+ group_mask.scatter_(1, group_idx, 1) # [n, n_group]
+ score_mask = (group_mask.unsqueeze(-1).expand(
+ bsz * seq_len, self.n_group,
+ self.n_routed_experts // self.n_group).reshape(
+ bsz * seq_len, -1)) # [n, e]
+ tmp_scores = scores.masked_fill(~score_mask.bool(), 0.0) # [n, e]
+ topk_weight, topk_idx = torch.topk(
+ tmp_scores, k=self.top_k, dim=-1, sorted=False)
+
+ ### norm gate to sum 1
+ if self.top_k > 1 and self.norm_topk_prob:
+ denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
+ topk_weight = topk_weight / denominator
+ else:
+ topk_weight = topk_weight * self.routed_scaling_factor
+ ### expert-level computation auxiliary loss
+ if self.training and self.alpha > 0.0:
+ scores_for_aux = scores
+ aux_topk = self.top_k
+ # always compute aux loss based on the naive greedy topk method
+ topk_idx_for_aux_loss = topk_idx.view(bsz, -1)
+ if self.seq_aux:
+ scores_for_seq_aux = scores_for_aux.view(bsz, seq_len, -1)
+ ce = torch.zeros(
+ bsz, self.n_routed_experts, device=hidden_states.device)
+ ce.scatter_add_(
+ 1,
+ topk_idx_for_aux_loss,
+ torch.ones(
+ bsz, seq_len * aux_topk, device=hidden_states.device),
+ ).div_(seq_len * aux_topk / self.n_routed_experts)
+ aux_loss = (ce * scores_for_seq_aux.mean(dim=1)).sum(
+ dim=1).mean() * self.alpha
+ else:
+ mask_ce = F.one_hot(
+ topk_idx_for_aux_loss.view(-1),
+ num_classes=self.n_routed_experts)
+ ce = mask_ce.float().mean(0)
+ Pi = scores_for_aux.mean(0)
+ fi = ce * self.n_routed_experts
+ aux_loss = (Pi * fi).sum() * self.alpha
+ else:
+ aux_loss = None
+ return topk_idx, topk_weight, aux_loss
+
+
+class AddAuxiliaryLoss(torch.autograd.Function):
+ """The trick function of adding auxiliary (aux) loss, which includes the
+ gradient of the aux loss during backpropagation."""
+
+ @staticmethod
+ def forward(ctx, x, loss):
+ assert loss.numel() == 1
+ ctx.dtype = loss.dtype
+ ctx.required_aux_loss = loss.requires_grad
+ return x
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ grad_loss = None
+ if ctx.required_aux_loss:
+ grad_loss = torch.ones(
+ 1, dtype=ctx.dtype, device=grad_output.device)
+ return grad_output, grad_loss
+
+
+class ExpertShard(nn.Module):
+
+ def __init__(self, config, shard_idx, expert_in_one_shard=10):
+ super().__init__()
+ hidden_dim = config.hidden_size
+ ffn_dim = config.moe_intermediate_size
+ self.w1w3 = nn.Parameter(
+ torch.empty(expert_in_one_shard, ffn_dim * 2, hidden_dim))
+ self.w2 = nn.Parameter(
+ torch.empty(expert_in_one_shard, hidden_dim, ffn_dim))
+
+ self.act = nn.SiLU()
+ self.expert_in_one_shard = expert_in_one_shard
+ self.shard_idx = shard_idx
+
+ self.reset_parameters()
+
+ def reset_parameters(self) -> None:
+ # Different from nn.Linear module, weights of self.w1w3 and self.w2
+ # can not be initialized by DeepseekV2PreTrainedModel._init_weights method
+ self.w1w3.data.normal_(0, 0.02)
+ self.w2.data.normal_(0, 0.02)
+
+ def expert_forward(self, current_state, expert_idx):
+ w1w3 = self.w1w3[expert_idx]
+ w2 = self.w2[expert_idx]
+ gate_up_out = torch.matmul(current_state, w1w3.T)
+ gate_out, up_out = gate_up_out.chunk(2, dim=-1)
+ gate_out = self.act(gate_out)
+ out = gate_out * up_out
+ out = torch.matmul(out, w2.T)
+ return out
+
+ def forward(self, hidden_states, flat_topk_idx, y):
+ for i in range(self.expert_in_one_shard):
+ expert_idx = i + self.expert_in_one_shard * self.shard_idx
+ y[flat_topk_idx == expert_idx] = self.expert_forward(
+ hidden_states[flat_topk_idx == expert_idx], i)
+ return y
+
+
+class DeepseekV2MoEShard(nn.Module):
+ """A mixed expert module containing shared experts."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.num_experts_per_tok = config.num_experts_per_tok
+
+ if hasattr(config, 'ep_size') and config.ep_size > 1:
+ raise NotImplementedError
+ else:
+ self.ep_size = 1
+ self.experts_per_rank = config.n_routed_experts
+ self.ep_rank = 0
+ self.n_routed_experts = config.n_routed_experts
+
+ expert_in_one_shard = config.expert_in_one_shard
+ assert config.n_routed_experts % expert_in_one_shard == 0, \
+ ('n_routed_experts should be divisible by expert_in_one_shard, but got '
+ f'n_routed_experts = {config.n_routed_experts} and expert_in_one_shard = {expert_in_one_shard}')
+
+ self.shard_num = config.n_routed_experts // expert_in_one_shard
+ self.expert_in_one_shard = expert_in_one_shard
+ self.experts = nn.ModuleList([
+ ExpertShard(config, i, self.expert_in_one_shard)
+ for i in range(self.shard_num)
+ ])
+
+ self.gate = MoEGate(config)
+ if config.n_shared_experts is not None:
+ intermediate_size = config.moe_intermediate_size * config.n_shared_experts
+ self.shared_experts = DeepseekV2MLP(
+ config=config, intermediate_size=intermediate_size)
+
+ def forward(self, hidden_states):
+ if not self.training:
+ raise NotImplementedError
+
+ identity = hidden_states
+ orig_shape = hidden_states.shape
+ topk_idx, topk_weight, aux_loss = self.gate(hidden_states)
+ hidden_states = hidden_states.view(-1, hidden_states.shape[-1])
+ flat_topk_idx = topk_idx.view(-1)
+
+ hidden_states = hidden_states.repeat_interleave(
+ self.num_experts_per_tok, dim=0)
+ y = torch.empty_like(hidden_states)
+ y_dtype = y.dtype
+ for shard_index in range(self.shard_num):
+ y = self.experts[shard_index](hidden_states, flat_topk_idx, y)
+ y = ((y.view(*topk_weight.shape, -1) *
+ topk_weight.unsqueeze(-1)).sum(dim=1)).type(y_dtype)
+ y = y.view(*orig_shape)
+ y = AddAuxiliaryLoss.apply(y, aux_loss)
+
+ if self.config.n_shared_experts is not None:
+ y = y + self.shared_experts(identity)
+ return y
+
+
+class DeepseekV2MoE(nn.Module):
+ """A mixed expert module containing shared experts."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.num_experts_per_tok = config.num_experts_per_tok
+
+ if hasattr(config, 'ep_size') and config.ep_size > 1:
+ assert config.ep_size == dist.get_world_size()
+ self.ep_size = config.ep_size
+ self.experts_per_rank = config.n_routed_experts // config.ep_size
+ self.ep_rank = dist.get_rank()
+ self.experts = nn.ModuleList([
+ (DeepseekV2MLP(
+ config, intermediate_size=config.moe_intermediate_size)
+ if i >= self.ep_rank * self.experts_per_rank and i <
+ (self.ep_rank + 1) * self.experts_per_rank else None)
+ for i in range(config.n_routed_experts)
+ ])
+ else:
+ self.ep_size = 1
+ self.experts_per_rank = config.n_routed_experts
+ self.ep_rank = 0
+ self.experts = nn.ModuleList([
+ DeepseekV2MLP(
+ config, intermediate_size=config.moe_intermediate_size)
+ for i in range(config.n_routed_experts)
+ ])
+ self.gate = MoEGate(config)
+ if config.n_shared_experts is not None:
+ intermediate_size = config.moe_intermediate_size * config.n_shared_experts
+ self.shared_experts = DeepseekV2MLP(
+ config=config, intermediate_size=intermediate_size)
+
+ def forward(self, hidden_states):
+ identity = hidden_states
+ orig_shape = hidden_states.shape
+ topk_idx, topk_weight, aux_loss = self.gate(hidden_states)
+ hidden_states = hidden_states.view(-1, hidden_states.shape[-1])
+ flat_topk_idx = topk_idx.view(-1)
+ if self.training:
+ hidden_states = hidden_states.repeat_interleave(
+ self.num_experts_per_tok, dim=0)
+ y = torch.empty_like(hidden_states)
+ y_dtype = y.dtype
+ for i, expert in enumerate(self.experts):
+ y[flat_topk_idx == i] = expert(
+ hidden_states[flat_topk_idx == i])
+ y = ((y.view(*topk_weight.shape, -1) *
+ topk_weight.unsqueeze(-1)).sum(dim=1)).type(y_dtype)
+ y = y.view(*orig_shape)
+ y = AddAuxiliaryLoss.apply(y, aux_loss)
+ else:
+ y = self.moe_infer(hidden_states, topk_idx,
+ topk_weight).view(*orig_shape)
+ if self.config.n_shared_experts is not None:
+ y = y + self.shared_experts(identity)
+ return y
+
+ @torch.no_grad()
+ def moe_infer(self, x, topk_ids, topk_weight):
+ cnts = topk_ids.new_zeros((topk_ids.shape[0], len(self.experts)))
+ cnts.scatter_(1, topk_ids, 1)
+ tokens_per_expert = cnts.sum(dim=0)
+ idxs = topk_ids.view(-1).argsort()
+ sorted_tokens = x[idxs // topk_ids.shape[1]]
+ sorted_tokens_shape = sorted_tokens.shape
+ if self.ep_size > 1:
+ tokens_per_ep_rank = tokens_per_expert.view(self.ep_size,
+ -1).sum(dim=1)
+ tokens_per_expert_group = tokens_per_expert.new_empty(
+ tokens_per_expert.shape[0])
+ dist.all_to_all_single(tokens_per_expert_group, tokens_per_expert)
+ output_splits = (
+ tokens_per_expert_group.view(self.ep_size,
+ -1).sum(1).cpu().numpy().tolist())
+ gathered_tokens = sorted_tokens.new_empty(
+ tokens_per_expert_group.sum(dim=0).cpu().item(),
+ sorted_tokens.shape[1])
+ input_split_sizes = tokens_per_ep_rank.cpu().numpy().tolist()
+ dist.all_to_all(
+ list(gathered_tokens.split(output_splits)),
+ list(sorted_tokens.split(input_split_sizes)),
+ )
+ tokens_per_expert_post_gather = tokens_per_expert_group.view(
+ self.ep_size, self.experts_per_rank).sum(dim=0)
+ gatherd_idxs = np.zeros(
+ shape=(gathered_tokens.shape[0], ), dtype=np.int32)
+ s = 0
+ for i, k in enumerate(tokens_per_expert_group.cpu().numpy()):
+ gatherd_idxs[s:s + k] = i % self.experts_per_rank
+ s += k
+ gatherd_idxs = gatherd_idxs.argsort()
+ sorted_tokens = gathered_tokens[gatherd_idxs]
+ tokens_per_expert = tokens_per_expert_post_gather
+ tokens_per_expert = tokens_per_expert.cpu().numpy()
+
+ outputs = []
+ start_idx = 0
+ for i, num_tokens in enumerate(tokens_per_expert):
+ end_idx = start_idx + num_tokens
+ if num_tokens == 0:
+ continue
+ expert = self.experts[i + self.ep_rank * self.experts_per_rank]
+ tokens_for_this_expert = sorted_tokens[start_idx:end_idx]
+ expert_out = expert(tokens_for_this_expert)
+ outputs.append(expert_out)
+ start_idx = end_idx
+
+ outs = torch.cat(
+ outputs, dim=0) if len(outputs) else sorted_tokens.new_empty(0)
+ if self.ep_size > 1:
+ new_x = torch.empty_like(outs)
+ new_x[gatherd_idxs] = outs
+ gathered_tokens = new_x.new_empty(*sorted_tokens_shape)
+ dist.all_to_all(
+ list(gathered_tokens.split(input_split_sizes)),
+ list(new_x.split(output_splits)),
+ )
+ outs = gathered_tokens
+
+ new_x = torch.empty_like(outs)
+ new_x[idxs] = outs
+ final_out = (
+ new_x.view(*topk_ids.shape, -1).type(topk_weight.dtype).mul_(
+ topk_weight.unsqueeze(dim=-1)).sum(dim=1).type(new_x.dtype))
+ return final_out
+
+
+# Copied from transformers.models.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaAttention with Llama->DeepseekV2
+class DeepseekV2Attention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper."""
+
+ def __init__(self,
+ config: DeepseekV2Config,
+ layer_idx: Optional[int] = None):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ if layer_idx is None:
+ logger.warning_once(
+ f'Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will '
+ 'to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` '
+ 'when creating this class.')
+
+ self.attention_dropout = config.attention_dropout
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.q_lora_rank = config.q_lora_rank
+ self.qk_rope_head_dim = config.qk_rope_head_dim
+ self.kv_lora_rank = config.kv_lora_rank
+ self.v_head_dim = config.v_head_dim
+ self.qk_nope_head_dim = config.qk_nope_head_dim
+ self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
+
+ self.is_causal = True
+
+ if self.q_lora_rank is None:
+ self.q_proj = nn.Linear(
+ self.hidden_size, self.num_heads * self.q_head_dim, bias=False)
+ else:
+ self.q_a_proj = nn.Linear(
+ self.hidden_size,
+ config.q_lora_rank,
+ bias=config.attention_bias)
+ self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
+ self.q_b_proj = nn.Linear(
+ config.q_lora_rank,
+ self.num_heads * self.q_head_dim,
+ bias=False)
+
+ self.kv_a_proj_with_mqa = nn.Linear(
+ self.hidden_size,
+ config.kv_lora_rank + config.qk_rope_head_dim,
+ bias=config.attention_bias,
+ )
+ self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
+ self.kv_b_proj = nn.Linear(
+ config.kv_lora_rank,
+ self.num_heads *
+ (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
+ bias=False,
+ )
+
+ self.o_proj = nn.Linear(
+ self.num_heads * self.v_head_dim,
+ self.hidden_size,
+ bias=config.attention_bias,
+ )
+ self._init_rope()
+
+ self.softmax_scale = self.q_head_dim**(-0.5)
+ if self.config.rope_scaling is not None:
+ mscale_all_dim = self.config.rope_scaling.get('mscale_all_dim', 0)
+ scaling_factor = self.config.rope_scaling['factor']
+ if mscale_all_dim:
+ mscale = yarn_get_mscale(scaling_factor, mscale_all_dim)
+ self.softmax_scale = self.softmax_scale * mscale * mscale
+
+ def _init_rope(self):
+ if self.config.rope_scaling is None:
+ self.rotary_emb = DeepseekV2RotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+ else:
+ scaling_type = self.config.rope_scaling['type']
+ scaling_factor = self.config.rope_scaling['factor']
+ if scaling_type == 'linear':
+ self.rotary_emb = DeepseekV2LinearScalingRotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ elif scaling_type == 'dynamic':
+ self.rotary_emb = DeepseekV2DynamicNTKScalingRotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ elif scaling_type == 'yarn':
+ kwargs = {
+ key: self.config.rope_scaling[key]
+ for key in [
+ 'original_max_position_embeddings',
+ 'beta_fast',
+ 'beta_slow',
+ 'mscale',
+ 'mscale_all_dim',
+ ] if key in self.config.rope_scaling
+ }
+ self.rotary_emb = DeepseekV2YarnRotaryEmbedding(
+ self.qk_rope_head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ **kwargs,
+ )
+ else:
+ raise ValueError(f'Unknown RoPE scaling type {scaling_type}')
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return (tensor.view(bsz, seq_len, self.num_heads,
+ self.v_head_dim).transpose(1, 2).contiguous())
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`'
+ )
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f'The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attn_weights = (
+ torch.matmul(query_states, key_states.transpose(2, 3)) *
+ self.softmax_scale)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is'
+ f' {attn_weights.size()}')
+ assert attention_mask is not None
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
+ )
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(
+ attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(
+ attn_weights, p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.v_head_dim):
+ raise ValueError(
+ f'`attn_output` should be of size {(bsz, self.num_heads, q_len, self.v_head_dim)}, but is'
+ f' {attn_output.size()}')
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.num_heads * self.v_head_dim)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2 with Llama->DeepseekV2
+class DeepseekV2FlashAttention2(DeepseekV2Attention):
+ """DeepseekV2 flash attention module.
+
+ This module inherits from `DeepseekV2Attention` as the weights of the
+ module stays untouched. The only required change would be on the forward
+ pass where it needs to correctly call the public API of flash attention and
+ deal with padding tokens in case the input contains any of them.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignment, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10(
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ # DeepseekV2FlashAttention2 attention does not support output_attentions
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`'
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop('padding_mask')
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ if self.q_lora_rank is None:
+ q = self.q_proj(hidden_states)
+ else:
+ q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
+ q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
+ q_nope, q_pe = torch.split(
+ q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
+ compressed_kv, k_pe = torch.split(
+ compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
+ k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
+ kv = (
+ self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(
+ bsz, q_len, self.num_heads,
+ self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
+
+ k_nope, value_states = torch.split(
+ kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
+ kv_seq_len = value_states.shape[-2]
+
+ kv_seq_len = value_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
+
+ query_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
+ query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
+
+ key_states = k_pe.new_empty(bsz, self.num_heads, q_len,
+ self.q_head_dim)
+ key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
+ key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
+
+ if self.q_head_dim != self.v_head_dim:
+ value_states = F.pad(value_states,
+ [0, self.q_head_dim - self.v_head_dim])
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
+ # to be able to avoid many of these transpose/reshape/view.
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (DeepseekV2RMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_proj.weight.dtype if self.q_lora_rank is None else self.q_a_proj.weight.dtype
+
+ logger.warning_once(
+ f'The input hidden states seems to be silently casted in float32, this might be related to'
+ f' the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in'
+ f' {target_dtype}.')
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ softmax_scale=self.softmax_scale,
+ )
+ if self.q_head_dim != self.v_head_dim:
+ attn_output = attn_output[:, :, :, :self.v_head_dim]
+
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads *
+ self.v_head_dim).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length,
+ dropout=0.0,
+ softmax_scale=None,
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`int`, *optional*):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in DeepseekV2FlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ (
+ query_states,
+ key_states,
+ value_states,
+ indices_q,
+ cu_seq_lens,
+ max_seq_lens,
+ ) = self._upad_input(query_states, key_states, value_states,
+ attention_mask, query_length)
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size,
+ query_length)
+ else:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ return attn_output
+
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask,
+ query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(
+ attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim),
+ indices_k,
+ )
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads,
+ head_dim),
+ indices_k,
+ )
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, self.num_heads,
+ head_dim),
+ indices_k,
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(
+ query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+ATTENTION_CLASSES = {
+ 'eager': DeepseekV2Attention,
+ 'flash_attention_2': DeepseekV2FlashAttention2,
+}
+
+
+class DeepseekV2DecoderLayer(nn.Module):
+
+ def __init__(self, config: DeepseekV2Config, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = ATTENTION_CLASSES[config._attn_implementation](
+ config=config, layer_idx=layer_idx)
+
+ moe_implementation = config.moe_implementation
+ if moe_implementation == 'origin':
+ block = DeepseekV2MoE
+ elif moe_implementation == 'shard':
+ block = DeepseekV2MoEShard
+ else:
+ raise NotImplementedError
+
+ self.mlp = (
+ block(config) if
+ (config.n_routed_experts is not None
+ and layer_idx >= config.first_k_dense_replace and layer_idx %
+ config.moe_layer_freq == 0) else DeepseekV2MLP(config))
+ self.input_layernorm = DeepseekV2RMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = DeepseekV2RMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor,
+ torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*):
+ attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
+ query_sequence_length, key_sequence_length)` if default attention is used.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+ if 'padding_mask' in kwargs:
+ warnings.warn(
+ 'Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`'
+ )
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states, )
+
+ if output_attentions:
+ outputs += (self_attn_weights, )
+
+ if use_cache:
+ outputs += (present_key_value, )
+
+ return outputs
+
+
+def _load_pretrained_model(
+ cls,
+ model,
+ state_dict,
+ loaded_keys,
+ resolved_archive_file,
+ pretrained_model_name_or_path,
+ ignore_mismatched_sizes=False,
+ sharded_metadata=None,
+ _fast_init=True,
+ low_cpu_mem_usage=False,
+ device_map=None,
+ offload_folder=None,
+ offload_state_dict=None,
+ dtype=None,
+ hf_quantizer=None,
+ keep_in_fp32_modules=None,
+ gguf_path=None,
+):
+ if ((state_dict is not None) or (resolved_archive_file is None)
+ or (low_cpu_mem_usage) or (device_map is not None)
+ or (offload_folder is not None) or
+ (not (offload_state_dict is None or offload_state_dict is False))
+ or (hf_quantizer is not None) or
+ (keep_in_fp32_modules is not None and len(keep_in_fp32_modules) > 0)
+ or (gguf_path is not None)):
+ raise NotImplementedError
+
+ folder = os.path.sep.join(resolved_archive_file[0].split(os.path.sep)[:-1])
+ error_msgs = load_state_dict_into_model(model, folder)
+ return model, [], [], [], None, error_msgs
+
+
+DeepseekV2_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`DeepseekV2Config`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ 'The bare DeepseekV2 Model outputting raw hidden-states without any specific head on top.',
+ DeepseekV2_START_DOCSTRING,
+)
+class DeepseekV2PreTrainedModel(PreTrainedModel):
+ config_class = DeepseekV2Config
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+ _no_split_modules = ['DeepseekV2DecoderLayer']
+ _skip_keys_device_placement = 'past_key_values'
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs):
+ moe_implementation = kwargs.get('moe_implementation', 'origin')
+ if moe_implementation == 'origin':
+ return super().from_pretrained(pretrained_model_name_or_path,
+ *args, **kwargs)
+
+ cls._load_pretrained_model = types.MethodType(_load_pretrained_model,
+ cls)
+ return super().from_pretrained(pretrained_model_name_or_path, *args,
+ **kwargs)
+
+
+DeepseekV2_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance;
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ 'The bare DeepseekV2 Model outputting raw hidden-states without any specific head on top.',
+ DeepseekV2_START_DOCSTRING,
+)
+class DeepseekV2Model(DeepseekV2PreTrainedModel):
+ """Transformer decoder consisting of *config.num_hidden_layers* layers.
+ Each layer is a [`DeepseekV2DecoderLayer`]
+
+ Args:
+ config: DeepseekV2Config
+ """
+
+ def __init__(self, config: DeepseekV2Config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size,
+ self.padding_idx)
+ self.layers = nn.ModuleList([
+ DeepseekV2DecoderLayer(config, layer_idx)
+ for layer_idx in range(config.num_hidden_layers)
+ ])
+ self._use_sdpa = config._attn_implementation == 'sdpa'
+ self._use_flash_attention_2 = config._attn_implementation == 'flash_attention_2'
+ self.norm = DeepseekV2RMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(DeepseekV2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both input_ids and inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape[:2]
+ elif inputs_embeds is not None:
+ batch_size, seq_length = inputs_embeds.shape[:2]
+ else:
+ raise ValueError(
+ 'You have to specify either input_ids or inputs_embeds')
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`transformers.'
+ )
+ use_cache = False
+
+ past_key_values_length = 0
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(
+ past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(
+ seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length,
+ seq_length + past_key_values_length,
+ dtype=torch.long,
+ device=device,
+ )
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if self._use_flash_attention_2:
+ # 2d mask is passed through the layers
+ attention_mask = (
+ attention_mask if
+ (attention_mask is not None and 0 in attention_mask) else None)
+ elif self._use_sdpa and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+
+ # embed positions
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[
+ 2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1], )
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ next_cache = None
+ if use_cache:
+ next_cache = (
+ next_decoder_cache.to_legacy_cache()
+ if use_legacy_cache else next_decoder_cache)
+ if not return_dict:
+ return tuple(
+ v for v in
+ [hidden_states, next_cache, all_hidden_states, all_self_attns]
+ if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class DeepseekV2ForCausalLM(DeepseekV2PreTrainedModel):
+ _tied_weights_keys = ['lm_head.weight']
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = DeepseekV2Model(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(
+ config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(DeepseekV2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(
+ output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, transformers.,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, transformers., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, DeepseekV2ForCausalLM
+
+ >>> model = DeepseekV2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ return (loss, ) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ **kwargs,
+ ):
+ if past_key_values is not None:
+ if isinstance(past_key_values, Cache):
+ cache_length = past_key_values.get_seq_length()
+ past_length = past_key_values.seen_tokens
+ max_cache_length = past_key_values.get_max_length()
+ else:
+ cache_length = past_length = past_key_values[0][0].shape[2]
+ max_cache_length = None
+
+ # Keep only the unprocessed tokens:
+ # 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
+ # some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
+ # input)
+ if (attention_mask is not None
+ and attention_mask.shape[1] > input_ids.shape[1]):
+ input_ids = input_ids[:, -(attention_mask.shape[1] -
+ past_length):]
+ # 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
+ # input_ids based on the past_length.
+ elif past_length < input_ids.shape[1]:
+ input_ids = input_ids[:, past_length:]
+ # 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
+
+ # If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
+ if (max_cache_length is not None and attention_mask is not None
+ and cache_length + input_ids.shape[1] > max_cache_length):
+ attention_mask = attention_mask[:, -max_cache_length:]
+
+ position_ids = kwargs.get('position_ids', None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1]:]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {'inputs_embeds': inputs_embeds}
+ else:
+ model_inputs = {'input_ids': input_ids}
+
+ model_inputs.update({
+ 'position_ids': position_ids,
+ 'past_key_values': past_key_values,
+ 'use_cache': kwargs.get('use_cache'),
+ 'attention_mask': attention_mask,
+ })
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx.to(past_state.device))
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The DeepseekV2 Model transformer with a sequence classification head on top (linear layer).
+
+ [`DeepseekV2ForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ DeepseekV2_START_DOCSTRING,
+)
+class DeepseekV2ForSequenceClassification(DeepseekV2PreTrainedModel):
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = DeepseekV2Model(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(DeepseekV2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, transformers.,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError(
+ 'Cannot handle batch sizes > 1 if no padding token is defined.'
+ )
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.eq(
+ input_ids, self.config.pad_token_id).int().argmax(-1) -
+ 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device),
+ sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = 'regression'
+ elif self.num_labels > 1 and (labels.dtype == torch.long
+ or labels.dtype == torch.int):
+ self.config.problem_type = 'single_label_classification'
+ else:
+ self.config.problem_type = 'multi_label_classification'
+
+ if self.config.problem_type == 'regression':
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == 'single_label_classification':
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(
+ pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == 'multi_label_classification':
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits, ) + transformer_outputs[1:]
+ return ((loss, ) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/model/transformers_models/deepseek_v2/tokenization_deepseek_fast.py b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/tokenization_deepseek_fast.py
new file mode 100644
index 0000000000000000000000000000000000000000..89e3cbb50b61c357deeb3fd37b9eab1188018172
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/deepseek_v2/tokenization_deepseek_fast.py
@@ -0,0 +1,37 @@
+from typing import List, Optional, Union
+
+from transformers.models.llama import LlamaTokenizerFast
+
+
+class DeepseekTokenizerFast(LlamaTokenizerFast):
+
+ def convert_ids_to_tokens(
+ self,
+ ids: Union[int, List[int]],
+ skip_special_tokens: bool = False) -> Union[str, List[str]]:
+ """Converts a single index or a sequence of indices in a token or a
+ sequence of tokens, using the vocabulary and added tokens.
+
+ Args:
+ ids (`int` or `List[int]`):
+ The token id (or token ids) to convert to tokens.
+ skip_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not to remove special tokens in the decoding.
+
+ Returns:
+ `str` or `List[str]`: The decoded token(s).
+ """
+ if isinstance(ids, int):
+ return self._convert_id_to_token(ids)
+ tokens = []
+ for index in ids:
+ index = int(index)
+ if skip_special_tokens and index in self.all_special_ids:
+ continue
+ token = self._tokenizer.id_to_token(index)
+ tokens.append(token if token is not None else '')
+ return tokens
+
+ def _convert_id_to_token(self, index: int) -> Optional[str]:
+ token = self._tokenizer.id_to_token(int(index))
+ return token if token is not None else ''
diff --git a/data/xtuner/xtuner/model/transformers_models/mixtral/__init__.py b/data/xtuner/xtuner/model/transformers_models/mixtral/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..aabfd89dbbd8cb1b7f3233ecf6f2bd384aaddd03
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/mixtral/__init__.py
@@ -0,0 +1,4 @@
+from .configuration_mixtral import MixtralConfig
+from .modeling_mixtral import MixtralForCausalLM, MixtralModel
+
+__all__ = ['MixtralForCausalLM', 'MixtralModel', 'MixtralConfig']
diff --git a/data/xtuner/xtuner/model/transformers_models/mixtral/configuration_mixtral.py b/data/xtuner/xtuner/model/transformers_models/mixtral/configuration_mixtral.py
new file mode 100644
index 0000000000000000000000000000000000000000..457aefd479f4cae837e63b3af66c25de52d5ac96
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/mixtral/configuration_mixtral.py
@@ -0,0 +1,178 @@
+# Copyright 2023 Mixtral AI and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Mixtral model configuration."""
+
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+logger = logging.get_logger(__name__)
+
+
+class MixtralConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`MixtralModel`]. It is used to instantiate an
+ Mixtral model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the Mixtral-7B-v0.1 or Mixtral-7B-Instruct-v0.1.
+
+ [mixtralai/Mixtral-8x7B](https://huggingface.co/mixtralai/Mixtral-8x7B)
+ [mixtralai/Mixtral-7B-Instruct-v0.1](https://huggingface.co/mixtralai/Mixtral-7B-Instruct-v0.1)
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the Mixtral model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`MixtralModel`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 14336):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 8):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to `4096*32`):
+ The maximum sequence length that this model might ever be used with. Mixtral's sliding window attention
+ allows sequence of up to 4096*32 tokens.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*):
+ The id of the padding token.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ The id of the "beginning-of-sequence" token.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ The id of the "end-of-sequence" token.
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied.
+ rope_theta (`float`, *optional*, defaults to 1000000.0):
+ The base period of the RoPE embeddings.
+ sliding_window (`int`, *optional*):
+ Sliding window attention window size. If not specified, will default to `4096`.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ num_experts_per_tok (`int`, *optional*, defaults to 2):
+ The number of experts to root per-token, can be also interpreted as the `top-p` routing
+ parameter
+ num_local_experts (`int`, *optional*, defaults to 8):
+ Number of experts per Sparse MLP layer.
+ output_router_logits (`bool`, *optional*, defaults to `False`):
+ Whether or not the router logits should be returned by the model. Enabling this will also
+ allow the model to output the auxiliary loss. See [here]() for more details
+ router_aux_loss_coef (`float`, *optional*, defaults to 0.001):
+ The aux loss factor for the total loss.
+ router_jitter_noise (`float`, *optional*, defaults to 0.0):
+ Amount of noise to add to the router.
+ moe_implementation (`str`, *optional*, defaults to 'origin'):
+ The implementation of the moe blocks. 'origin' or 'shard'.
+ expert_in_one_shard (`int`, *optional*, defaults to None):
+ How many expert models are integrated into a shard. It is used only
+ when `moe_implementation` == 'shard'.
+
+ ```python
+ >>> from transformers import MixtralModel, MixtralConfig
+
+ >>> # Initializing a Mixtral 7B style configuration
+ >>> configuration = MixtralConfig()
+
+ >>> # Initializing a model from the Mixtral 7B style configuration
+ >>> model = MixtralModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = 'mixtral'
+ keys_to_ignore_at_inference = ['past_key_values']
+
+ def __init__(
+ self,
+ vocab_size=32000,
+ hidden_size=4096,
+ intermediate_size=14336,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=8,
+ hidden_act='silu',
+ max_position_embeddings=4096 * 32,
+ initializer_range=0.02,
+ rms_norm_eps=1e-5,
+ use_cache=True,
+ pad_token_id=None,
+ bos_token_id=1,
+ eos_token_id=2,
+ tie_word_embeddings=False,
+ rope_theta=1e6,
+ sliding_window=None,
+ attention_dropout=0.0,
+ num_experts_per_tok=2,
+ num_local_experts=8,
+ output_router_logits=False,
+ router_aux_loss_coef=0.001,
+ router_jitter_noise=0.0,
+ moe_implementation='origin',
+ expert_in_one_shard=None,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.sliding_window = sliding_window
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.attention_dropout = attention_dropout
+
+ self.num_experts_per_tok = num_experts_per_tok
+ self.num_local_experts = num_local_experts
+ self.output_router_logits = output_router_logits
+ self.router_aux_loss_coef = router_aux_loss_coef
+ self.router_jitter_noise = router_jitter_noise
+
+ self.moe_implementation = moe_implementation
+ self.expert_in_one_shard = expert_in_one_shard
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/data/xtuner/xtuner/model/transformers_models/mixtral/modeling_mixtral.py b/data/xtuner/xtuner/model/transformers_models/mixtral/modeling_mixtral.py
new file mode 100644
index 0000000000000000000000000000000000000000..94d048fe723cb2179a696fdeb4f698fb3fd870b3
--- /dev/null
+++ b/data/xtuner/xtuner/model/transformers_models/mixtral/modeling_mixtral.py
@@ -0,0 +1,1821 @@
+# Modified from https://github.com/huggingface/transformers/blob/v4.41.0/src/transformers/models/mixtral/modeling_mixtral.py
+"""PyTorch Mixtral model."""
+import inspect
+import math
+import os
+import types
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.activations import ACT2FN
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.modeling_attn_mask_utils import (
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa)
+from transformers.modeling_outputs import (MoeCausalLMOutputWithPast,
+ MoeModelOutputWithPast,
+ SequenceClassifierOutputWithPast)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.pytorch_utils import is_torch_greater_or_equal_than_1_13
+from transformers.utils import (add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10, logging,
+ replace_return_docstrings)
+from transformers.utils.import_utils import is_torch_fx_available
+
+from xtuner.utils import load_state_dict_into_model
+from .configuration_mixtral import MixtralConfig
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input # noqa
+ from flash_attn.bert_padding import index_first_axis, unpad_input
+
+ _flash_supports_window_size = 'window_size' in list(
+ inspect.signature(flash_attn_func).parameters)
+
+# This makes `_prepare_4d_causal_attention_mask` a leaf function in the FX graph.
+# It means that the function will not be traced through and simply appear as a node in the graph.
+if is_torch_fx_available():
+ if not is_torch_greater_or_equal_than_1_13:
+ import torch.fx
+
+ _prepare_4d_causal_attention_mask = torch.fx.wrap(
+ _prepare_4d_causal_attention_mask)
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = 'MixtralConfig'
+
+
+def load_balancing_loss_func(
+ gate_logits: torch.Tensor,
+ num_experts: torch.Tensor = None,
+ top_k=2,
+ attention_mask: Optional[torch.Tensor] = None) -> float:
+ r"""
+ Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
+
+ See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
+ experts is too unbalanced.
+
+ Args:
+ gate_logits (Union[`torch.Tensor`, Tuple[torch.Tensor]):
+ Logits from the `gate`, should be a tuple of model.config.num_hidden_layers tensors of
+ shape [batch_size X sequence_length, num_experts].
+ attention_mask (`torch.Tensor`, None):
+ The attention_mask used in forward function
+ shape [batch_size X sequence_length] if not None.
+ num_experts (`int`, *optional*):
+ Number of experts
+
+ Returns:
+ The auxiliary loss.
+ """
+ if gate_logits is None or not isinstance(gate_logits, tuple):
+ return 0
+
+ if isinstance(gate_logits, tuple):
+ compute_device = gate_logits[0].device
+ concatenated_gate_logits = torch.cat(
+ [layer_gate.to(compute_device) for layer_gate in gate_logits],
+ dim=0)
+
+ routing_weights = torch.nn.functional.softmax(
+ concatenated_gate_logits, dim=-1)
+
+ _, selected_experts = torch.topk(routing_weights, top_k, dim=-1)
+
+ expert_mask = torch.nn.functional.one_hot(selected_experts, num_experts)
+
+ if attention_mask is None:
+ # Compute the percentage of tokens routed to each experts
+ tokens_per_expert = torch.mean(expert_mask.float(), dim=0)
+
+ # Compute the average probability of routing to these experts
+ router_prob_per_expert = torch.mean(routing_weights, dim=0)
+ else:
+ batch_size, sequence_length = attention_mask.shape
+ num_hidden_layers = concatenated_gate_logits.shape[0] // (
+ batch_size * sequence_length)
+
+ # Compute the mask that masks all padding tokens as 0 with the same shape of expert_mask
+ expert_attention_mask = (
+ attention_mask[None, :, :, None, None].expand(
+ (num_hidden_layers, batch_size, sequence_length, top_k,
+ num_experts)).reshape(-1, top_k,
+ num_experts).to(compute_device))
+
+ # Compute the percentage of tokens routed to each experts
+ tokens_per_expert = torch.sum(
+ expert_mask.float() * expert_attention_mask, dim=0) / torch.sum(
+ expert_attention_mask, dim=0)
+
+ # Compute the mask that masks all padding tokens as 0 with the same shape of tokens_per_expert
+ router_per_expert_attention_mask = (
+ attention_mask[None, :, :, None].expand(
+ (num_hidden_layers, batch_size, sequence_length,
+ num_experts)).reshape(-1, num_experts).to(compute_device))
+
+ # Compute the average probability of routing to these experts
+ router_prob_per_expert = torch.sum(
+ routing_weights * router_per_expert_attention_mask,
+ dim=0) / torch.sum(
+ router_per_expert_attention_mask, dim=0)
+
+ overall_loss = torch.sum(tokens_per_expert *
+ router_prob_per_expert.unsqueeze(0))
+ return overall_loss * num_experts
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(
+ torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->Mixtral
+class MixtralRMSNorm(nn.Module):
+
+ def __init__(self, hidden_size, eps=1e-6):
+ """MixtralRMSNorm is equivalent to T5LayerNorm."""
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance +
+ self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralRotaryEmbedding with Mistral->Mixtral
+class MixtralRotaryEmbedding(nn.Module):
+
+ def __init__(self,
+ dim,
+ max_position_embeddings=2048,
+ base=10000,
+ device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (
+ self.base
+ **(torch.arange(0, self.dim, 2,
+ dtype=torch.int64).float().to(device) / self.dim))
+ self.register_buffer('inv_freq', inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings,
+ device=self.inv_freq.device,
+ dtype=torch.get_default_dtype())
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(
+ self.max_seq_len_cached, device=device,
+ dtype=torch.int64).type_as(self.inv_freq)
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer(
+ 'cos_cached', emb.cos().to(dtype), persistent=False)
+ self.register_buffer(
+ 'sin_cached', emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(
+ seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., :x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2:]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+# Copied from transformers.models.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """This is the equivalent of torch.repeat_interleave(x, dim=1,
+ repeats=n_rep).
+
+ The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to
+ (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :,
+ None, :, :].expand(batch,
+ num_key_value_heads,
+ n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen,
+ head_dim)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralAttention with Mistral->Mixtral
+class MixtralAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper.
+
+ Modified to use sliding window attention: Longformer and "Generating Long
+ Sequences with Sparse Transformers".
+ """
+
+ def __init__(self, config: MixtralConfig, layer_idx: Optional[int] = None):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ if layer_idx is None:
+ logger.warning_once(
+ f'Instantiating {self.__class__.__name__} without passing a `layer_idx` is not recommended and will '
+ 'lead to errors during the forward call if caching is used. Please make sure to provide a `layer_idx` '
+ 'when creating this class.')
+
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.is_causal = True
+ self.attention_dropout = config.attention_dropout
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f'hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}'
+ f' and `num_heads`: {self.num_heads}).')
+ self.q_proj = nn.Linear(
+ self.hidden_size, self.num_heads * self.head_dim, bias=False)
+ self.k_proj = nn.Linear(
+ self.hidden_size,
+ self.num_key_value_heads * self.head_dim,
+ bias=False)
+ self.v_proj = nn.Linear(
+ self.hidden_size,
+ self.num_key_value_heads * self.head_dim,
+ bias=False)
+ self.o_proj = nn.Linear(
+ self.num_heads * self.head_dim, self.hidden_size, bias=False)
+
+ self.rotary_emb = MixtralRotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads,
+ self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f'The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(
+ 2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is'
+ f' {attn_weights.size()}')
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
+ )
+
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(
+ attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(
+ attn_weights, p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f'`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is'
+ f' {attn_output.size()}')
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralFlashAttention2 with Mistral->Mixtral
+class MixtralFlashAttention2(MixtralAttention):
+ """Mixtral flash attention module.
+
+ This module inherits from `MixtralAttention` as the weights of the module
+ stays untouched. The only required change would be on the forward pass
+ where it needs to correctly call the public API of flash attention and deal
+ with padding tokens in case the input contains any of them.
+ """
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignment, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10(
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ):
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f'The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} '
+ 'for auto-regressive decoding with k/v caching, please make sure to initialize the attention class '
+ 'with a layer index.')
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+
+ # Because the input can be padded, the absolute sequence length depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids[:, -1].max().item()) + 1
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window)
+
+ if not _flash_supports_window_size:
+ logger.warning_once(
+ 'The current flash attention version does not support sliding window attention, for a more memory efficient implementation'
+ ' make sure to upgrade flash-attn library.')
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(
+ self.layer_idx) > 0
+ if (getattr(self.config, 'sliding_window', None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ f'past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got'
+ f' {past_key.shape}')
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat([
+ attention_mask,
+ torch.ones_like(attention_mask[:, -1:])
+ ],
+ dim=-1)
+
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, '_pre_quantization_dtype'):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f'The input hidden states seems to be silently casted in float32, this might be related to'
+ f' the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in'
+ f' {target_dtype}.')
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len,
+ self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length,
+ dropout=0.0,
+ softmax_scale=None,
+ use_sliding_windows=False,
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`float`):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ use_sliding_windows (`bool`, *optional*):
+ Whether to activate sliding window attention.
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask,
+ query_length)
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ if not use_sliding_windows:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window,
+ self.config.sliding_window),
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size,
+ query_length)
+ else:
+ if not use_sliding_windows:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window,
+ self.config.sliding_window),
+ )
+
+ return attn_output
+
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask,
+ query_length):
+ batch_size, kv_seq_len, num_heads, head_dim = key_layer.shape
+
+ # On the first iteration we need to properly re-create the padding mask
+ # by slicing it on the proper place
+ if kv_seq_len != attention_mask.shape[-1]:
+ attention_mask_num_tokens = attention_mask.shape[-1]
+ attention_mask = attention_mask[:, attention_mask_num_tokens -
+ kv_seq_len:]
+
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(
+ attention_mask)
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim),
+ indices_k)
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim),
+ indices_k)
+
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, num_heads,
+ head_dim), indices_k)
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(
+ query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralSdpaAttention with Mistral->Mixtral
+class MixtralSdpaAttention(MixtralAttention):
+ """Mixtral attention module using
+ torch.nn.functional.scaled_dot_product_attention.
+
+ This module inherits from `MixtralAttention` as the weights of the module
+ stays untouched. The only changes are on the forward pass to adapt to SDPA
+ API.
+ """
+
+ # Adapted from MixtralAttention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ 'MixtralModel is using MixtralSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, '
+ 'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(
+ kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {'sin': sin, 'cos': cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(
+ key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
+ )
+
+ # SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
+ # Reference: https://github.com/pytorch/pytorch/issues/112577.
+ if query_states.device.type == 'cuda' and attention_mask is not None:
+ query_states = query_states.contiguous()
+ key_states = key_states.contiguous()
+ value_states = value_states.contiguous()
+
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.attention_dropout if self.training else 0.0,
+ # The q_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case q_len == 1.
+ is_causal=self.is_causal and attention_mask is None and q_len > 1,
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.view(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+MIXTRAL_ATTENTION_CLASSES = {
+ 'eager': MixtralAttention,
+ 'flash_attention_2': MixtralFlashAttention2,
+ 'sdpa': MixtralSdpaAttention,
+}
+
+
+class MixtralBlockSparseTop2MLP(nn.Module):
+
+ def __init__(self, config: MixtralConfig):
+ super().__init__()
+ self.ffn_dim = config.intermediate_size
+ self.hidden_dim = config.hidden_size
+
+ self.w1 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
+ self.w2 = nn.Linear(self.ffn_dim, self.hidden_dim, bias=False)
+ self.w3 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
+
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, hidden_states):
+ current_hidden_states = self.act_fn(
+ self.w1(hidden_states)) * self.w3(hidden_states)
+ current_hidden_states = self.w2(current_hidden_states)
+ return current_hidden_states
+
+
+class MixtralSparseMoeBlock(nn.Module):
+ """This implementation is strictly equivalent to standard MoE with full
+ capacity (no dropped tokens).
+
+ It's faster since it formulates MoE operations in terms of block-sparse
+ operations to accommodate imbalanced assignments of tokens to experts,
+ whereas standard MoE either (1) drop tokens at the cost of reduced
+ performance or (2) set capacity factor to number of experts and thus waste
+ computation and memory on padding.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.hidden_dim = config.hidden_size
+ self.ffn_dim = config.intermediate_size
+ self.num_experts = config.num_local_experts
+ self.top_k = config.num_experts_per_tok
+
+ # gating
+ self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
+
+ self.experts = nn.ModuleList([
+ MixtralBlockSparseTop2MLP(config) for _ in range(self.num_experts)
+ ])
+
+ # Jitter parameters
+ self.jitter_noise = config.router_jitter_noise
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """"""
+ batch_size, sequence_length, hidden_dim = hidden_states.shape
+ if self.training and self.jitter_noise > 0:
+ hidden_states *= torch.empty_like(hidden_states).uniform_(
+ 1.0 - self.jitter_noise, 1.0 + self.jitter_noise)
+ hidden_states = hidden_states.view(-1, hidden_dim)
+ # router_logits: (batch * sequence_length, n_experts)
+ router_logits = self.gate(hidden_states)
+
+ routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
+ routing_weights, selected_experts = torch.topk(
+ routing_weights, self.top_k, dim=-1)
+ routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
+ # we cast back to the input dtype
+ routing_weights = routing_weights.to(hidden_states.dtype)
+
+ final_hidden_states = torch.zeros(
+ (batch_size * sequence_length, hidden_dim),
+ dtype=hidden_states.dtype,
+ device=hidden_states.device)
+
+ # One hot encode the selected experts to create an expert mask
+ # this will be used to easily index which expert is going to be sollicitated
+ expert_mask = torch.nn.functional.one_hot(
+ selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # Loop over all available experts in the model and perform the computation on each expert
+ for expert_idx in range(self.num_experts):
+ expert_layer = self.experts[expert_idx]
+ idx, top_x = torch.where(expert_mask[expert_idx])
+
+ # Index the correct hidden states and compute the expert hidden state for
+ # the current expert. We need to make sure to multiply the output hidden
+ # states by `routing_weights` on the corresponding tokens (top-1 and top-2)
+ current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
+ current_hidden_states = expert_layer(
+ current_state) * routing_weights[top_x, idx, None]
+
+ # However `index_add_` only support torch tensors for indexing so we'll use
+ # the `top_x` tensor here.
+ final_hidden_states.index_add_(
+ 0, top_x, current_hidden_states.to(hidden_states.dtype))
+ final_hidden_states = final_hidden_states.reshape(
+ batch_size, sequence_length, hidden_dim)
+ return final_hidden_states, router_logits
+
+
+class ExpertShard(nn.Module):
+
+ def __init__(self, config, expert_in_one_shard=1):
+ super().__init__()
+ self.w1w3 = nn.Parameter(
+ torch.empty(expert_in_one_shard, config.intermediate_size * 2,
+ config.hidden_size))
+ self.w2 = nn.Parameter(
+ torch.empty(expert_in_one_shard, config.hidden_size,
+ config.intermediate_size))
+ self.act = ACT2FN[config.hidden_act]
+ self.expert_in_one_shard = expert_in_one_shard
+
+ def forward(self, hidden_states, expert_mask, routing_weights,
+ final_hidden_states):
+ hidden_dim = hidden_states.shape[-1]
+ for expert_idx in range(self.expert_in_one_shard):
+ idx, top_x = torch.where(expert_mask[expert_idx])
+ current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
+
+ w1w3 = self.w1w3[expert_idx]
+ w2 = self.w2[expert_idx]
+ gate_up_out = torch.matmul(current_state, w1w3.T)
+ gate_out, up_out = gate_up_out.chunk(2, dim=-1)
+ gate_out = self.act(gate_out)
+ out = gate_out * up_out
+ out = torch.matmul(out, w2.T)
+
+ current_hidden_states = out * routing_weights[top_x, idx, None]
+ final_hidden_states.index_add_(
+ 0, top_x, current_hidden_states.to(hidden_states.dtype))
+ return final_hidden_states
+
+
+class MixtralSparseShardMoeBlock(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.hidden_dim = config.hidden_size
+ self.ffn_dim = config.intermediate_size
+ self.num_experts = config.num_local_experts
+ self.top_k = config.num_experts_per_tok
+
+ # gating
+ self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
+
+ expert_in_one_shard = config.expert_in_one_shard
+ assert config.num_local_experts % expert_in_one_shard == 0, \
+ ('num_local_experts should be divisible by expert_in_one_shard, but got '
+ f'num_local_experts = {config.num_local_experts} and expert_in_one_shard = {expert_in_one_shard}')
+ self.shard_num = config.num_local_experts // expert_in_one_shard
+ self.expert_in_one_shard = expert_in_one_shard
+ self.experts = nn.ModuleList([
+ ExpertShard(config, self.expert_in_one_shard)
+ for i in range(self.shard_num)
+ ])
+
+ # Jitter parameters
+ self.jitter_noise = config.router_jitter_noise
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """"""
+ batch_size, sequence_length, hidden_dim = hidden_states.shape
+ if self.training and self.jitter_noise > 0:
+ hidden_states *= torch.empty_like(hidden_states).uniform_(
+ 1.0 - self.jitter_noise, 1.0 + self.jitter_noise)
+ hidden_states = hidden_states.view(-1, hidden_dim)
+ # router_logits: (batch * sequence_length, n_experts)
+ router_logits = self.gate(hidden_states)
+
+ routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
+ routing_weights, selected_experts = torch.topk(
+ routing_weights, self.top_k, dim=-1)
+ routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
+ # we cast back to the input dtype
+ routing_weights = routing_weights.to(hidden_states.dtype)
+
+ final_hidden_states = torch.zeros(
+ (batch_size * sequence_length, hidden_dim),
+ dtype=hidden_states.dtype,
+ device=hidden_states.device)
+
+ # One hot encode the selected experts to create an expert mask
+ # this will be used to easily index which expert is going to be sollicitated
+ expert_mask = torch.nn.functional.one_hot(
+ selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # Loop over all available experts in the model and perform the computation on each expert
+ for shard_index in range(self.shard_num):
+ mask = expert_mask[shard_index *
+ self.expert_in_one_shard:(shard_index + 1) *
+ self.expert_in_one_shard]
+ final_hidden_states = self.experts[shard_index](
+ hidden_states, mask, routing_weights, final_hidden_states)
+
+ final_hidden_states = final_hidden_states.reshape(
+ batch_size, sequence_length, hidden_dim)
+ return final_hidden_states, router_logits
+
+
+class MixtralDecoderLayer(nn.Module):
+
+ def __init__(self, config: MixtralConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = MIXTRAL_ATTENTION_CLASSES[
+ config._attn_implementation](config, layer_idx)
+
+ moe_implementation = config.moe_implementation
+ if moe_implementation == 'origin':
+ block = MixtralSparseMoeBlock
+ elif moe_implementation == 'shard':
+ block = MixtralSparseShardMoeBlock
+ else:
+ raise NotImplementedError
+ self.block_sparse_moe = block(config)
+
+ self.input_layernorm = MixtralRMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = MixtralRMSNorm(
+ config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ output_router_logits: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor,
+ torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
+ should not be returned during inference.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states, router_logits = self.block_sparse_moe(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states, )
+
+ if output_attentions:
+ outputs += (self_attn_weights, )
+
+ if use_cache:
+ outputs += (present_key_value, )
+
+ if output_router_logits:
+ outputs += (router_logits, )
+
+ return outputs
+
+
+def _load_pretrained_model(
+ cls,
+ model,
+ state_dict,
+ loaded_keys,
+ resolved_archive_file,
+ pretrained_model_name_or_path,
+ ignore_mismatched_sizes=False,
+ sharded_metadata=None,
+ _fast_init=True,
+ low_cpu_mem_usage=False,
+ device_map=None,
+ offload_folder=None,
+ offload_state_dict=None,
+ dtype=None,
+ hf_quantizer=None,
+ keep_in_fp32_modules=None,
+ gguf_path=None,
+):
+ if ((state_dict is not None) or (resolved_archive_file is None)
+ or (low_cpu_mem_usage) or (device_map is not None)
+ or (offload_folder is not None) or
+ (not (offload_state_dict is None or offload_state_dict is False))
+ or (hf_quantizer is not None) or
+ (keep_in_fp32_modules is not None and len(keep_in_fp32_modules) > 0)
+ or (gguf_path is not None)):
+ raise NotImplementedError
+
+ folder = os.path.sep.join(resolved_archive_file[0].split(os.path.sep)[:-1])
+ error_msgs = load_state_dict_into_model(model, folder)
+ return model, [], [], [], None, error_msgs
+
+
+MIXTRAL_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`MixtralConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ 'The bare Mixtral Model outputting raw hidden-states without any specific head on top.',
+ MIXTRAL_START_DOCSTRING,
+)
+# Copied from transformers.models.mistral.modeling_mistral.MistralPreTrainedModel with Mistral->Mixtral
+class MixtralPreTrainedModel(PreTrainedModel):
+ config_class = MixtralConfig
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+ _no_split_modules = ['MixtralDecoderLayer']
+ _skip_keys_device_placement = 'past_key_values'
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs):
+ moe_implementation = kwargs.get('moe_implementation', 'origin')
+ if moe_implementation == 'origin':
+ return super().from_pretrained(pretrained_model_name_or_path,
+ *args, **kwargs)
+
+ cls._load_pretrained_model = types.MethodType(_load_pretrained_model,
+ cls)
+ return super().from_pretrained(pretrained_model_name_or_path, *args,
+ **kwargs)
+
+
+MIXTRAL_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
+ should not be returned during inference.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ 'The bare Mixtral Model outputting raw hidden-states without any specific head on top.',
+ MIXTRAL_START_DOCSTRING,
+)
+# Copied from transformers.models.mistral.modeling_mistral.MistralModel with MISTRAL->MIXTRAL,Mistral->Mixtral
+class MixtralModel(MixtralPreTrainedModel):
+ """Transformer decoder consisting of *config.num_hidden_layers* layers.
+ Each layer is a [`MixtralDecoderLayer`]
+
+ Args:
+ config: MixtralConfig
+ """
+
+ def __init__(self, config: MixtralConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size,
+ self.padding_idx)
+ self.layers = nn.ModuleList([
+ MixtralDecoderLayer(config, layer_idx)
+ for layer_idx in range(config.num_hidden_layers)
+ ])
+ self._attn_implementation = config._attn_implementation
+ self.norm = MixtralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ # Ignore copy
+ @add_start_docstrings_to_model_forward(MIXTRAL_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else
+ self.config.output_router_logits)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError(
+ 'You have to specify either decoder_input_ids or decoder_inputs_embeds'
+ )
+
+ past_key_values_length = 0
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
+ )
+ use_cache = False
+
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(
+ past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(
+ seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length,
+ seq_length + past_key_values_length,
+ dtype=torch.long,
+ device=device)
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if attention_mask is not None and self._attn_implementation == 'flash_attention_2' and use_cache:
+ is_padding_right = attention_mask[:, -1].sum().item() != batch_size
+ if is_padding_right:
+ raise ValueError(
+ "You are attempting to perform batched generation with padding_side='right'"
+ ' this may lead to unexpected behaviour for Flash Attention version of Mixtral. Make sure to '
+ " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
+ )
+
+ if self._attn_implementation == 'flash_attention_2':
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (
+ attention_mask is not None and 0 in attention_mask) else None
+ elif self._attn_implementation == 'sdpa' and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_router_logits = () if output_router_logits else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ output_router_logits,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ output_router_logits=output_router_logits,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[
+ 2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1], )
+
+ if output_router_logits:
+ all_router_logits += (layer_outputs[-1], )
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache(
+ ) if use_legacy_cache else next_decoder_cache
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states, next_cache, all_hidden_states, all_self_attns,
+ all_router_logits
+ ] if v is not None)
+ return MoeModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ router_logits=all_router_logits,
+ )
+
+
+class MixtralForCausalLM(MixtralPreTrainedModel):
+ _tied_weights_keys = ['lm_head.weight']
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = MixtralModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(
+ config.hidden_size, config.vocab_size, bias=False)
+ self.router_aux_loss_coef = config.router_aux_loss_coef
+ self.num_experts = config.num_local_experts
+ self.num_experts_per_tok = config.num_experts_per_tok
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(MIXTRAL_INPUTS_DOCSTRING)
+ @replace_return_docstrings(
+ output_type=MoeCausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ # Ignore copy
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeCausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, MixtralForCausalLM
+
+ >>> model = MixtralForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+ >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else
+ self.config.output_router_logits)
+
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ output_router_logits=output_router_logits,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ aux_loss = None
+ if output_router_logits:
+ aux_loss = load_balancing_loss_func(
+ outputs.router_logits if return_dict else outputs[-1],
+ self.num_experts,
+ self.num_experts_per_tok,
+ attention_mask,
+ )
+ if labels is not None:
+ loss += self.router_aux_loss_coef * aux_loss.to(
+ loss.device) # make sure to reside in the same device
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ if output_router_logits:
+ output = (aux_loss, ) + output
+ return (loss, ) + output if loss is not None else output
+
+ return MoeCausalLMOutputWithPast(
+ loss=loss,
+ aux_loss=aux_loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ router_logits=outputs.router_logits,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ output_router_logits=False,
+ **kwargs,
+ ):
+ # Omit tokens covered by past_key_values
+ if past_key_values is not None:
+ if isinstance(past_key_values, Cache):
+ cache_length = past_key_values.get_seq_length()
+ past_length = past_key_values.seen_tokens
+ max_cache_length = past_key_values.get_max_length()
+ else:
+ cache_length = past_length = past_key_values[0][0].shape[2]
+ max_cache_length = None
+
+ # Keep only the unprocessed tokens:
+ # 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
+ # some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
+ # input)
+ if attention_mask is not None and attention_mask.shape[
+ 1] > input_ids.shape[1]:
+ input_ids = input_ids[:, -(attention_mask.shape[1] -
+ past_length):]
+ # 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
+ # input_ids based on the past_length.
+ elif past_length < input_ids.shape[1]:
+ input_ids = input_ids[:, past_length:]
+ # 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
+
+ # If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
+ if (max_cache_length is not None and attention_mask is not None
+ and cache_length + input_ids.shape[1] > max_cache_length):
+ attention_mask = attention_mask[:, -max_cache_length:]
+
+ position_ids = kwargs.get('position_ids', None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1]:]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {'inputs_embeds': inputs_embeds}
+ else:
+ model_inputs = {'input_ids': input_ids}
+
+ model_inputs.update({
+ 'position_ids': position_ids,
+ 'past_key_values': past_key_values,
+ 'use_cache': kwargs.get('use_cache'),
+ 'attention_mask': attention_mask,
+ 'output_router_logits': output_router_logits,
+ })
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx.to(past_state.device))
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The Mixtral Model transformer with a sequence classification head on top (linear layer).
+
+ [`MixtralForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ MIXTRAL_START_DOCSTRING,
+)
+# Copied from transformers.models.llama.modeling_llama.LlamaForSequenceClassification with Llama->Mixtral, LLAMA->MIXTRAL
+class MixtralForSequenceClassification(MixtralPreTrainedModel):
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = MixtralModel(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(MIXTRAL_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[Cache,
+ List[torch.FloatTensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError(
+ 'Cannot handle batch sizes > 1 if no padding token is defined.'
+ )
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ # if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
+ sequence_lengths = torch.eq(
+ input_ids, self.config.pad_token_id).int().argmax(-1) - 1
+ sequence_lengths = sequence_lengths % input_ids.shape[-1]
+ sequence_lengths = sequence_lengths.to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device),
+ sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = 'regression'
+ elif self.num_labels > 1 and (labels.dtype == torch.long
+ or labels.dtype == torch.int):
+ self.config.problem_type = 'single_label_classification'
+ else:
+ self.config.problem_type = 'multi_label_classification'
+
+ if self.config.problem_type == 'regression':
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == 'single_label_classification':
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(
+ pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == 'multi_label_classification':
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits, ) + transformer_outputs[1:]
+ return ((loss, ) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/model/utils.py b/data/xtuner/xtuner/model/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8bbf294448f4930e150d490ddfaf0a0c4ce9fb2
--- /dev/null
+++ b/data/xtuner/xtuner/model/utils.py
@@ -0,0 +1,317 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List, Optional
+
+import torch
+from mmengine.utils.misc import get_object_from_string
+from peft import PeftType
+from torch import nn
+from transformers import PreTrainedModel
+
+from xtuner.utils import IGNORE_INDEX, IMAGE_TOKEN_INDEX
+
+
+def set_obj_dtype(d):
+ for key, value in d.items():
+ if value in ['torch.float16', 'torch.float32', 'torch.bfloat16']:
+ d[key] = getattr(torch, value.split('.')[-1])
+
+
+def try_build_module(cfg):
+ builder = cfg['type']
+ if isinstance(builder, str):
+ builder = get_object_from_string(builder)
+ if builder is None:
+ # support handling cfg with key 'type' can not be built, such as
+ # {'rope_scaling': {'type': 'linear', 'factor': 2.0}}
+ return cfg
+ cfg.pop('type')
+ module_built = builder(**cfg)
+ return module_built
+
+
+def traverse_dict(d):
+ if isinstance(d, dict):
+ set_obj_dtype(d)
+ for key, value in d.items():
+ if isinstance(value, dict):
+ traverse_dict(value)
+ if 'type' in value:
+ module_built = try_build_module(value)
+ d[key] = module_built
+ elif isinstance(d, list):
+ for element in d:
+ traverse_dict(element)
+
+
+def find_all_linear_names(model):
+ lora_module_names = set()
+ for name, module in model.named_modules():
+ if isinstance(module, nn.Linear):
+ names = name.split('.')
+ lora_module_names.add(names[0] if len(names) == 1 else names[-1])
+
+ if 'lm_head' in lora_module_names: # needed for 16-bit
+ lora_module_names.remove('lm_head')
+ if 'output_layer' in lora_module_names: # needed for 16-bit
+ lora_module_names.remove('output_layer')
+ return list(lora_module_names)
+
+
+class LoadWoInit:
+ """Context manager that disable parameter initialization."""
+
+ def __init__(self):
+ self.constant_ = torch.nn.init.constant_
+ self.zeros_ = torch.nn.init.zeros_
+ self.ones_ = torch.nn.init.ones_
+ self.uniform_ = torch.nn.init.uniform_
+ self.normal_ = torch.nn.init.normal_
+ self.kaiming_uniform_ = torch.nn.init.kaiming_uniform_
+ self.kaiming_normal_ = torch.nn.init.kaiming_normal_
+
+ def __enter__(self, *args, **kwargs):
+ torch.nn.init.constant_ = lambda *args, **kwargs: None
+ torch.nn.init.zeros_ = lambda *args, **kwargs: None
+ torch.nn.init.ones_ = lambda *args, **kwargs: None
+ torch.nn.init.uniform_ = lambda *args, **kwargs: None
+ torch.nn.init.normal_ = lambda *args, **kwargs: None
+ torch.nn.init.kaiming_uniform_ = lambda *args, **kwargs: None
+ torch.nn.init.kaiming_normal_ = lambda *args, **kwargs: None
+
+ def __exit__(self, *args, **kwargs):
+ torch.nn.init.constant_ = self.constant_
+ torch.nn.init.zeros_ = self.zeros_
+ torch.nn.init.ones_ = self.ones_
+ torch.nn.init.uniform_ = self.uniform_
+ torch.nn.init.normal_ = self.normal_
+ torch.nn.init.kaiming_uniform_ = self.kaiming_uniform_
+ torch.nn.init.kaiming_normal_ = self.kaiming_normal_
+
+
+def get_peft_model_state_dict(model, state_dict=None, adapter_name='default'):
+ # Modified from `https://github.com/huggingface/peft/blob/main/src/peft/utils/save_and_load.py` # noqa: E501
+
+ config = model.peft_config[adapter_name]
+ if state_dict is None:
+ state_dict = model.state_dict()
+ if config.peft_type == PeftType.LORA:
+ # adapted from `https://github.com/microsoft/LoRA/blob/main/loralib/utils.py` # noqa: E501
+ # to be used directly with the state dict which is necessary
+ # when using DeepSpeed or FSDP
+ bias = config.bias
+ if bias == 'none':
+ to_return = {k: state_dict[k] for k in state_dict if 'lora_' in k}
+ elif bias == 'all':
+ to_return = {
+ k: state_dict[k]
+ for k in state_dict if 'lora_' in k or 'bias' in k
+ }
+ elif bias == 'lora_only':
+ to_return = {}
+ for k in state_dict:
+ if 'lora_' in k:
+ to_return[k] = state_dict[k]
+ bias_name = k.split('lora_')[0] + 'bias'
+ if bias_name in state_dict:
+ to_return[bias_name] = state_dict[bias_name]
+ else:
+ raise NotImplementedError
+ to_return = {
+ k: v
+ for k, v in to_return.items()
+ if (('lora_' in k and adapter_name in k) or ('bias' in k))
+ }
+ else:
+ # Currently we only support lora
+ raise NotImplementedError
+ if model.modules_to_save is not None:
+ for key, value in state_dict.items():
+ if any(f'{module_name}.modules_to_save.{adapter_name}' in key
+ for module_name in model.modules_to_save):
+ to_return[key] = value
+
+ return to_return
+
+
+# Modified from https://github.com/haotian-liu/LLaVA/blob/82fc5e0e5f4393a4c26851fa32c69ab37ea3b146/llava/model/llava_arch.py#L99 # noqa: E501
+def prepare_inputs_labels_for_multimodal(
+ llm: PreTrainedModel,
+ input_ids: torch.LongTensor = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ labels: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None):
+ if pixel_values is None:
+ return {
+ 'input_ids': input_ids,
+ 'position_ids': position_ids,
+ 'attention_mask': attention_mask,
+ 'past_key_values': past_key_values,
+ 'inputs_embeds': None,
+ 'labels': labels
+ }
+
+ _labels = labels
+ _position_ids = position_ids
+ _attention_mask = attention_mask
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
+ else:
+ attention_mask = attention_mask.bool()
+ if position_ids is None:
+ position_ids = torch.arange(
+ 0, input_ids.shape[1], dtype=torch.long, device=input_ids.device)
+ if labels is None:
+ labels = torch.full_like(input_ids, IGNORE_INDEX)
+
+ # remove the padding using attention_mask -- TODO: double check
+ input_ids = [
+ cur_input_ids[cur_attention_mask]
+ for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)
+ ]
+ labels = [
+ cur_labels[cur_attention_mask]
+ for cur_labels, cur_attention_mask in zip(labels, attention_mask)
+ ]
+
+ new_inputs_embeds = []
+ new_labels = []
+ cur_image_idx = 0
+ for batch_idx, cur_input_ids in enumerate(input_ids):
+ num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum()
+ if num_images == 0:
+ cur_pixel_values = pixel_values[cur_image_idx]
+ cur_inputs_embeds_1 = llm.get_input_embeddings()(cur_input_ids)
+ cur_inputs_embeds = torch.cat(
+ [cur_inputs_embeds_1, cur_pixel_values[0:0]], dim=0)
+ new_inputs_embeds.append(cur_inputs_embeds)
+ new_labels.append(labels[batch_idx])
+ cur_image_idx += 1
+ continue
+
+ image_token_indices = [-1] + torch.where(
+ cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist() + [
+ cur_input_ids.shape[0]
+ ]
+ cur_input_ids_noim = []
+ cur_labels = labels[batch_idx]
+ cur_labels_noim = []
+ for i in range(len(image_token_indices) - 1):
+ cur_input_ids_noim.append(cur_input_ids[image_token_indices[i] +
+ 1:image_token_indices[i +
+ 1]])
+ cur_labels_noim.append(cur_labels[image_token_indices[i] +
+ 1:image_token_indices[i + 1]])
+ split_sizes = [x.shape[0] for x in cur_labels_noim]
+ cur_inputs_embeds = llm.get_input_embeddings()(
+ torch.cat(cur_input_ids_noim))
+ cur_inputs_embeds_no_im = torch.split(
+ cur_inputs_embeds, split_sizes, dim=0)
+ cur_new_inputs_embeds = []
+ cur_new_labels = []
+
+ for i in range(num_images + 1):
+ cur_new_inputs_embeds.append(cur_inputs_embeds_no_im[i])
+ cur_new_labels.append(cur_labels_noim[i])
+ if i < num_images:
+ cur_pixel_values = pixel_values[cur_image_idx]
+ cur_image_idx += 1
+ cur_new_inputs_embeds.append(cur_pixel_values)
+ cur_new_labels.append(
+ torch.full((cur_pixel_values.shape[0], ),
+ IGNORE_INDEX,
+ device=cur_labels.device,
+ dtype=cur_labels.dtype))
+
+ cur_new_inputs_embeds = torch.cat(cur_new_inputs_embeds)
+ cur_new_labels = torch.cat(cur_new_labels)
+
+ new_inputs_embeds.append(cur_new_inputs_embeds)
+ new_labels.append(cur_new_labels)
+
+ # Combine them
+ max_len = max(x.shape[0] for x in new_inputs_embeds)
+ batch_size = len(new_inputs_embeds)
+
+ new_inputs_embeds_padded = []
+ new_labels_padded = torch.full((batch_size, max_len),
+ IGNORE_INDEX,
+ dtype=new_labels[0].dtype,
+ device=new_labels[0].device)
+ attention_mask = torch.zeros((batch_size, max_len),
+ dtype=attention_mask.dtype,
+ device=attention_mask.device)
+ position_ids = torch.zeros((batch_size, max_len),
+ dtype=position_ids.dtype,
+ device=position_ids.device)
+
+ for i, (cur_new_embed,
+ cur_new_labels) in enumerate(zip(new_inputs_embeds, new_labels)):
+ cur_len = cur_new_embed.shape[0]
+ new_inputs_embeds_padded.append(
+ torch.cat((cur_new_embed,
+ torch.zeros((max_len - cur_len, cur_new_embed.shape[1]),
+ dtype=cur_new_embed.dtype,
+ device=cur_new_embed.device)),
+ dim=0))
+ if cur_len > 0:
+ new_labels_padded[i, :cur_len] = cur_new_labels
+ attention_mask[i, :cur_len] = True
+ position_ids[i, :cur_len] = torch.arange(
+ 0,
+ cur_len,
+ dtype=position_ids.dtype,
+ device=position_ids.device)
+
+ new_inputs_embeds = torch.stack(new_inputs_embeds_padded, dim=0)
+
+ if _labels is None:
+ new_labels = None
+ else:
+ new_labels = new_labels_padded
+
+ if _attention_mask is None:
+ attention_mask = None
+ else:
+ attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
+
+ if _position_ids is None:
+ position_ids = None
+
+ return {
+ 'input_ids': None,
+ 'position_ids': position_ids,
+ 'attention_mask': attention_mask,
+ 'past_key_values': past_key_values,
+ 'inputs_embeds': new_inputs_embeds,
+ 'labels': new_labels
+ }
+
+
+def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+
+def guess_load_checkpoint(pth_model):
+ if osp.isfile(pth_model):
+ state_dict = torch.load(pth_model, map_location='cpu')
+ if 'state_dict' in state_dict:
+ state_dict = state_dict['state_dict']
+ elif osp.isdir(pth_model):
+ try:
+ from xtuner.utils.zero_to_any_dtype import \
+ get_state_dict_from_zero_checkpoint
+ except ImportError:
+ raise ImportError(
+ 'The provided PTH model appears to be a DeepSpeed checkpoint. '
+ 'However, DeepSpeed library is not detected in current '
+ 'environment. This suggests that DeepSpeed may not be '
+ 'installed or is incorrectly configured. Please verify your '
+ 'setup.')
+ state_dict = get_state_dict_from_zero_checkpoint(
+ osp.dirname(pth_model), osp.basename(pth_model))
+ else:
+ raise FileNotFoundError(f'Cannot find {pth_model}')
+ return state_dict
diff --git a/data/xtuner/xtuner/parallel/__init__.py b/data/xtuner/xtuner/parallel/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c726230c8b8e703359ea62ff1edab1fea420052
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/__init__.py
@@ -0,0 +1,2 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sequence import * # noqa: F401, F403
diff --git a/data/xtuner/xtuner/parallel/sequence/__init__.py b/data/xtuner/xtuner/parallel/sequence/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e2992f78aa84f860b4465860d891b67900276f7
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/__init__.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.dist import init_dist
+
+from .attention import (post_process_for_sequence_parallel_attn,
+ pre_process_for_sequence_parallel_attn,
+ sequence_parallel_wrapper)
+from .comm import (all_to_all, gather_for_sequence_parallel,
+ gather_forward_split_backward, split_for_sequence_parallel,
+ split_forward_gather_backward)
+from .data_collate import (pad_cumulative_len_for_sequence_parallel,
+ pad_for_sequence_parallel)
+from .reduce_loss import reduce_sequence_parallel_loss
+from .sampler import SequenceParallelSampler
+from .setup_distributed import (get_data_parallel_group,
+ get_data_parallel_rank,
+ get_data_parallel_world_size,
+ get_inner_sequence_parallel_group,
+ get_inner_sequence_parallel_rank,
+ get_inner_sequence_parallel_world_size,
+ get_sequence_parallel_group,
+ get_sequence_parallel_rank,
+ get_sequence_parallel_world_size,
+ init_inner_sequence_parallel,
+ init_sequence_parallel,
+ is_inner_sequence_parallel_initialized)
+
+__all__ = [
+ 'sequence_parallel_wrapper', 'pre_process_for_sequence_parallel_attn',
+ 'post_process_for_sequence_parallel_attn', 'pad_for_sequence_parallel',
+ 'split_for_sequence_parallel', 'SequenceParallelSampler',
+ 'init_sequence_parallel', 'get_sequence_parallel_group',
+ 'get_sequence_parallel_world_size', 'get_sequence_parallel_rank',
+ 'get_data_parallel_group', 'get_data_parallel_world_size',
+ 'get_data_parallel_rank', 'reduce_sequence_parallel_loss', 'init_dist',
+ 'all_to_all', 'gather_for_sequence_parallel',
+ 'split_forward_gather_backward', 'gather_forward_split_backward',
+ 'get_inner_sequence_parallel_group', 'get_inner_sequence_parallel_rank',
+ 'get_inner_sequence_parallel_world_size', 'init_inner_sequence_parallel',
+ 'is_inner_sequence_parallel_initialized',
+ 'pad_cumulative_len_for_sequence_parallel'
+]
diff --git a/data/xtuner/xtuner/parallel/sequence/attention.py b/data/xtuner/xtuner/parallel/sequence/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8bb1adaca8bd42123976c46431cfba10c21fe96
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/attention.py
@@ -0,0 +1,151 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch.distributed as dist
+
+from .comm import (all_to_all, gather_forward_split_backward,
+ split_forward_gather_backward)
+from .setup_distributed import (get_inner_sequence_parallel_group,
+ get_inner_sequence_parallel_world_size,
+ get_sequence_parallel_group,
+ get_sequence_parallel_world_size,
+ init_inner_sequence_parallel,
+ is_inner_sequence_parallel_initialized)
+
+
+def pre_process_for_sequence_parallel_attn(query_states,
+ key_states,
+ value_states,
+ scatter_dim=2,
+ gather_dim=1):
+ b, s_div_sp, h, d = query_states.shape
+ sp = get_sequence_parallel_world_size()
+
+ if not is_inner_sequence_parallel_initialized():
+ insp = sp // math.gcd(h, sp)
+ init_inner_sequence_parallel(insp)
+ else:
+ insp = get_inner_sequence_parallel_world_size()
+
+ def pre_process_for_inner_sp(q, k, v):
+ if scatter_dim != 2 and gather_dim != 1:
+ raise NotImplementedError(
+ 'Currently only `scatter_dim == 2` and `gather_dim == 1` '
+ f'is supported. But got scatter_dim = {scatter_dim} and '
+ f'gather_dim = {gather_dim}.')
+
+ # (b, s_div_sp, h, d) ->
+ # (b, s_div_sp, sp/insp, h*insp/sp, insp, d/insp) ->
+ # (b, s_div_sp, sp/insp, insp, h*insp/sp, d/insp) ->
+ # (b, s_div_sp, insp*h, d/insp)
+ q = q.view(b, s_div_sp, sp // insp, h * insp // sp, insp,
+ d // insp).transpose(3, 4).flatten(2, 4)
+ k = k.view(b, s_div_sp, sp // insp, h * insp // sp, insp,
+ d // insp).transpose(3, 4).flatten(2, 4)
+ v = v.view(b, s_div_sp, sp // insp, h * insp // sp, insp,
+ d // insp).transpose(3, 4).flatten(2, 4)
+
+ return q, k, v
+
+ def post_process_for_inner_sp(q, k, v):
+ # (b, s, insp*h/sp, d/insp) -> (b, s, insp*h/sp, d)
+ q = gather_forward_split_backward(q, -1,
+ get_inner_sequence_parallel_group())
+ k = gather_forward_split_backward(k, -1,
+ get_inner_sequence_parallel_group())
+ v = gather_forward_split_backward(v, -1,
+ get_inner_sequence_parallel_group())
+
+ return q, k, v
+
+ assert (h * insp) % sp == 0, \
+ ('The number of attention heads should be divisible by '
+ '(sequence_parallel_world_size // sequence_parallel_inner_world_size)'
+ f'. But got n_head = {h}, sequence_parallel_world_size = '
+ f'{sp} and sequence_parallel_inner_world_size = {insp}.')
+
+ if insp > 1:
+ query_states, key_states, value_states = pre_process_for_inner_sp(
+ query_states, key_states, value_states)
+
+ # (b, s_div_sp, insp*h, d/insp) -> (b, s, insp*h/sp, d/insp)
+ sequence_parallel_group = get_sequence_parallel_group()
+ query_states = all_to_all(
+ query_states,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+ key_states = all_to_all(
+ key_states,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+ value_states = all_to_all(
+ value_states,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+
+ if insp > 1:
+ query_states, key_states, value_states = post_process_for_inner_sp(
+ query_states, key_states, value_states)
+
+ return query_states, key_states, value_states
+
+
+def post_process_for_sequence_parallel_attn(attn_output,
+ scatter_dim=1,
+ gather_dim=2):
+ sp = get_sequence_parallel_world_size()
+ insp = get_inner_sequence_parallel_world_size()
+ b, s, h_mul_insp_div_sp, d = attn_output.shape
+ h = h_mul_insp_div_sp * sp // insp
+ s_div_sp = s // sp
+
+ if insp > 1:
+ # (b, s, insp*h/sp, d) -> (b, s, insp*h/sp, d/insp)
+ attn_output = split_forward_gather_backward(
+ attn_output, -1, get_inner_sequence_parallel_group())
+
+ # (b, s, insp*h/sp, d/insp) -> (b, s_div_sp, insp*h, d/insp)
+ sequence_parallel_group = get_sequence_parallel_group()
+ output = all_to_all(
+ attn_output,
+ sequence_parallel_group,
+ scatter_dim=scatter_dim,
+ gather_dim=gather_dim)
+
+ if insp > 1:
+ # (b, s_div_sp, insp*h, d/insp) ->
+ # (b, s_div_sp, sp/insp, insp, h*insp/sp, d/insp) ->
+ # (b, s_div_sp, sp/insp, h*insp/sp, insp, d/insp) ->
+ # (b, s_div_sp, h, d)
+ output = output.view(b, s_div_sp, sp // insp, insp, h * insp // sp,
+ d // insp).transpose(3, 4).reshape(
+ b, s_div_sp, h, d)
+
+ return output
+
+
+def sequence_parallel_wrapper(local_attn):
+
+ def sequence_parallel_attn(query_states, key_states, value_states, *args,
+ **kwargs):
+ training = kwargs.pop('training', True)
+ enable_sequence_parallel = (
+ dist.is_initialized() and get_sequence_parallel_world_size() > 1
+ and training)
+ if enable_sequence_parallel:
+ query_states, key_states, value_states = \
+ pre_process_for_sequence_parallel_attn(
+ query_states, key_states, value_states)
+
+ out = local_attn(query_states, key_states, value_states, *args,
+ **kwargs)
+
+ if enable_sequence_parallel:
+ out = post_process_for_sequence_parallel_attn(out).contiguous()
+
+ return out
+
+ return sequence_parallel_attn
diff --git a/data/xtuner/xtuner/parallel/sequence/comm.py b/data/xtuner/xtuner/parallel/sequence/comm.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ff78e68c138dbf68cbda363424e460eac614b19
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/comm.py
@@ -0,0 +1,269 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Tuple
+
+import torch
+import torch.distributed as dist
+from torch import Tensor
+
+
+def _all_to_all(
+ input: Tensor,
+ world_size: int,
+ group: dist.ProcessGroup,
+ scatter_dim: int,
+ gather_dim: int,
+):
+ input_list = [
+ t.contiguous()
+ for t in torch.tensor_split(input, world_size, scatter_dim)
+ ]
+ output_list = [torch.empty_like(input_list[0]) for _ in range(world_size)]
+ dist.all_to_all(output_list, input_list, group=group)
+ return torch.cat(output_list, dim=gather_dim).contiguous()
+
+
+class _AllToAll(torch.autograd.Function):
+ """All-to-all communication.
+
+ Args:
+ input: Input tensor
+ sp_group: Sequence parallel process group
+ scatter_dim: Scatter dimension
+ gather_dim: Gather dimension
+ """
+
+ @staticmethod
+ def forward(ctx: Any, input: Tensor, sp_group: dist.ProcessGroup,
+ scatter_dim: int, gather_dim: int):
+ ctx.sp_group = sp_group
+ ctx.scatter_dim = scatter_dim
+ ctx.gather_dim = gather_dim
+ ctx.world_size = dist.get_world_size(sp_group)
+ output = _all_to_all(input, ctx.world_size, sp_group, scatter_dim,
+ gather_dim)
+ return output
+
+ @staticmethod
+ def backward(ctx: Any, grad_output: Tensor) -> Tuple:
+ grad_output = _all_to_all(
+ grad_output,
+ ctx.world_size,
+ ctx.sp_group,
+ ctx.gather_dim,
+ ctx.scatter_dim,
+ )
+ return (
+ grad_output,
+ None,
+ None,
+ None,
+ )
+
+
+def all_to_all(
+ input: Tensor,
+ sp_group: dist.ProcessGroup,
+ scatter_dim: int = 2,
+ gather_dim: int = 1,
+):
+ """Convenience function to apply the all-to-all operation with scatter and
+ gather dimensions.
+
+ Notes:
+ We have wrapped the `torch.distributed.all_to_all` function to
+ enable automatic differentiation of the all-to-all operation.
+
+ Args:
+ input: The input tensor for which all-to-all communication is performed
+ sp_group: The sequence parallel process group.
+ scatter_dim: The dimension along which the input tensor is scattered
+ (default: 2).
+ gather_dim: The dimension along which the output tensor is gathered
+ (default: 1).
+
+ Returns:
+ The output tensor after the all-to-all communication.
+ """
+ return _AllToAll.apply(input, sp_group, scatter_dim, gather_dim)
+
+
+def split_for_sequence_parallel(input, dim: int, sp_group: dist.ProcessGroup):
+ """Splits the input tensor along a given dimension for sequence parallel.
+
+ Args:
+ input: The input tensor to be split.
+ dim: The dimension along which the tensor should be split.
+ sp_group: The sequence parallel process group.
+
+ Returns:
+ The split tensor corresponding to the current rank's chunk.
+ """
+ world_size = dist.get_world_size(sp_group)
+ if world_size == 1:
+ return input
+
+ rank = dist.get_rank(sp_group)
+ dim_size = input.size(dim)
+ assert dim_size % world_size == 0, (
+ f'The dimension to split ({dim_size}) is not a multiple of '
+ f'world size ({world_size}), cannot split tensor evenly')
+
+ tensor_list = torch.split(input, dim_size // world_size, dim=dim)
+ output = tensor_list[rank].contiguous()
+
+ return output
+
+
+def gather_for_sequence_parallel(input, dim: int, sp_group: dist.ProcessGroup):
+ """Gathers the input tensor along a given dimension for sequence parallel.
+
+ Args:
+ input: The input tensor to be gathered.
+ dim: The dimension along which the tensor should be gathered.
+ sp_group: The sequence parallel process group.
+
+ Returns:
+ The gathered tensor concatenated along the specified dimension.
+ """
+ input = input.contiguous()
+ world_size = dist.get_world_size(sp_group)
+ dist.get_rank(sp_group)
+
+ if world_size == 1:
+ return input
+
+ tensor_list = [torch.empty_like(input) for _ in range(world_size)]
+ assert input.device.type == 'cuda'
+ dist.all_gather(tensor_list, input, group=sp_group)
+
+ output = torch.cat(tensor_list, dim=dim).contiguous()
+
+ return output
+
+
+class _GatherForwardSplitBackward(torch.autograd.Function):
+ """Gather the input during forward.
+
+ Scale and split the grad and keep only the corresponding chuck to the rank
+ during backward.
+ """
+
+ @staticmethod
+ def forward(ctx, input, dim, sp_group, grad_scale):
+ ctx.dim = dim
+ ctx.sp_group = sp_group
+ ctx.grad_scale = grad_scale
+ return gather_for_sequence_parallel(input, dim, sp_group)
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ if ctx.grad_scale == 'up':
+ grad_output = grad_output * dist.get_world_size(ctx.sp_group)
+ elif ctx.grad_scale == 'down':
+ grad_output = grad_output / dist.get_world_size(ctx.sp_group)
+
+ return (split_for_sequence_parallel(grad_output, ctx.dim,
+ ctx.sp_group), None, None, None)
+
+
+class _SplitForwardGatherBackward(torch.autograd.Function):
+ """Split the input and keep only the corresponding chuck to the rank during
+ forward.
+
+ Scale and gather the grad during backward.
+ """
+
+ @staticmethod
+ def forward(ctx, input, dim, sp_group, grad_scale):
+ ctx.dim = dim
+ ctx.sp_group = sp_group
+ ctx.grad_scale = grad_scale
+ return split_for_sequence_parallel(input, dim, sp_group)
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ if ctx.grad_scale == 'up':
+ grad_output = grad_output * dist.get_world_size(ctx.sp_group)
+ elif ctx.grad_scale == 'down':
+ grad_output = grad_output / dist.get_world_size(ctx.sp_group)
+ return (gather_for_sequence_parallel(grad_output, ctx.dim,
+ ctx.sp_group), None, None, None)
+
+
+def split_forward_gather_backward(input, dim, sp_group, grad_scale=None):
+ """Split tensors according to the sp rank during forward propagation and
+ gather the grad from the whole sp group during backward propagation.
+
+ 1. When do we need this? input.requires_grad = True
+
+ 2. Why we need grad scale?
+
+ We have to scale down the grads as `gather_forward_split_backward` scales
+ up the grads.
+ """
+ return _SplitForwardGatherBackward.apply(input, dim, sp_group, grad_scale)
+
+
+def gather_forward_split_backward(input, dim, sp_group, grad_scale=None):
+ """Gather tensors from the whole sp group during forward propagation and
+ split the grad according to the sp rank during backward propagation.
+
+ 1. When do we need this?
+
+ When sp is greater than 1, we need to slice the input `x` along
+ sequence length dimension before it is passed into the model and get
+ `sub_seq_x`. We then pass `sub_seq_x` into model and get output
+ `sub_seq_out`. If the loss calculation process needs to use the complete
+ output, we have to gather the `sub_seq_out` in all sp ranks during forward
+ propagation and split the grad during backward propagation.
+
+ 2. Why we need grad scale?
+ Here is a simple case.
+
+ -------- SP 1 -----------
+ Suppose here is a toy model with only one linear module
+ (in_features = 2, out_features = 1) and the input x has shape(2, 2).
+ Y = [[y1], = [[w11x11 + w21x12], = [[x11, x12], dot [[w11],
+ [y2]] [w11x21 + w21x22]] [x21, x22]] [w21]]
+ z = mean(Y) = (y1 + y2) / 2
+ Here is the partial derivative of z with respect to w11:
+ ∂z / ∂w11 = ∂z / ∂y1 * ∂y1 / ∂w11 + ∂z / ∂y2 * ∂y2 / ∂w11
+ = 1/2 * x11 + 1/2 * x21 = (x11 + x21) / 2
+
+ -------- SP 2 -----------
+ When sequence parallel world size is set to 2, we will split the input x
+ and scatter them to the two rank in the same sequence parallel group.
+ ```Step 1
+ Y_rank0 = [[y1]] = [[w11x11 + w21x12]] = [[x11, x12]] dot [[w11, w21]]^T
+ Y_rank1 = [[y2]] = [[w11x21 + w21x22]] = [[x21, x22]] dot [[w11, w21]]^T
+ ```
+
+ Then, we have to gather them:
+ ```Step 2
+ Y_rank0 = [[y1],
+ detach([y2])]
+ Y_rank1 = [detach([y1]),
+ [y2]]
+ ```
+ Note that y2 in Y_rank0 does not have grad, neither does y1 in Y_rank1.
+
+ Similarly, we calculate the loss in each rank:
+ ```Step 3
+ z_rank0 = mean(Y_rank0) = (y1 + detach(y2)) / 2
+ z_rank1 = mean(Y_rank1) = (detach(y1) + y2) / 2
+ ```
+ So the partial derivative of loss_rank0 with respect to w11:
+ ```∂z / ∂w11 = ∂z / ∂y1 * ∂y1 / ∂w11 = x11 / 2```
+ The same for rank1:
+ ```∂z / ∂w11 = ∂z / ∂y2 * ∂y2 / ∂w11 = x21 / 2```
+
+ Finally, we need to all_reduce them:
+ ```Step 4
+ In both rank:
+ ∂z / ∂w11 = (x11 / 2 + x21 / 2) / 2 = (x11 + x21) / 4
+ ```
+
+ In SP2, the gradient of each param is only half of that in SP1.
+ So we should scale up the grad during the backward process in Step 2.
+ """ # noqa: E501
+ return _GatherForwardSplitBackward.apply(input, dim, sp_group, grad_scale)
diff --git a/data/xtuner/xtuner/parallel/sequence/data_collate.py b/data/xtuner/xtuner/parallel/sequence/data_collate.py
new file mode 100644
index 0000000000000000000000000000000000000000..048eaec103be1ab1108fcf817f5d4ed4d5ece9ab
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/data_collate.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from .setup_distributed import get_sequence_parallel_world_size
+
+
+def pad_for_sequence_parallel(tensor, padding_value, dim=-1):
+ length = tensor.shape[dim]
+ seq_parallel_world_size = get_sequence_parallel_world_size()
+ if length % seq_parallel_world_size == 0:
+ return tensor
+
+ pad_num = seq_parallel_world_size - (length % seq_parallel_world_size)
+ pad_shape = (*tensor.shape[:dim], pad_num,
+ *tensor.shape[dim + 1:]) if dim != -1 else (
+ *tensor.shape[:dim], pad_num)
+ pad = torch.full(
+ pad_shape, padding_value, dtype=tensor.dtype, device=tensor.device)
+ tensor = torch.cat([tensor, pad], dim=dim)
+ return tensor
+
+
+# This function only meets the following two conditions:
+# 1. use_varlen_attn = True
+# 2. pack_to_max_length = True and the lengths of each sequence are different
+def pad_cumulative_len_for_sequence_parallel(cumulative_len):
+ assert len(cumulative_len) == 1
+ seqlen = cumulative_len[0][-1]
+ seq_parallel_world_size = get_sequence_parallel_world_size()
+ if seqlen % seq_parallel_world_size == 0:
+ return cumulative_len, None
+
+ bs = len(cumulative_len)
+ pad_len = seq_parallel_world_size - (seqlen % seq_parallel_world_size)
+ seqlen_new = seqlen + pad_len
+ attention_mask = torch.zeros(
+ bs, seqlen_new, dtype=torch.bool, device=cumulative_len[0].device)
+ attention_mask[:, :seqlen] = True
+
+ for i, cu_len in enumerate(cumulative_len):
+ pad = torch.tensor([seqlen_new],
+ device=cu_len.device,
+ dtype=cu_len.dtype)
+ cumulative_len[i] = torch.cat([cu_len, pad], dim=0)
+
+ return cumulative_len, attention_mask
diff --git a/data/xtuner/xtuner/parallel/sequence/reduce_loss.py b/data/xtuner/xtuner/parallel/sequence/reduce_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb37242a33d814826e11d985924105064d131b79
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/reduce_loss.py
@@ -0,0 +1,34 @@
+import torch
+import torch.distributed as dist
+
+from .setup_distributed import get_sequence_parallel_group
+
+
+class _ReduceLoss(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, mean_loss, loss_scale, process_group):
+ ctx.mode = process_group
+ if loss_scale == 0:
+ # convert nan to 0 just for logging
+ mean_loss = torch.nan_to_num(mean_loss)
+ loss_sum = mean_loss * loss_scale
+ dist.all_reduce(loss_sum, group=process_group)
+ dist.all_reduce(loss_scale, group=process_group)
+ loss = loss_sum / loss_scale
+ return loss
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ return grad_output, None, None
+
+
+def reduce_sequence_parallel_loss(mean_loss,
+ loss_scale,
+ sp_group: dist.ProcessGroup = None):
+ if dist.get_world_size(sp_group) == 1:
+ return mean_loss
+ if sp_group is None:
+ # avoid bc breaking
+ sp_group = get_sequence_parallel_group()
+ return _ReduceLoss.apply(mean_loss, loss_scale, sp_group)
diff --git a/data/xtuner/xtuner/parallel/sequence/sampler.py b/data/xtuner/xtuner/parallel/sequence/sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..69adb7cc91c5e5603b47fbb5cd438165d522a79b
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/sampler.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Optional, Sized
+
+from mmengine.dataset import DefaultSampler
+from mmengine.dist import sync_random_seed
+
+from .setup_distributed import (get_data_parallel_rank,
+ get_data_parallel_world_size)
+
+
+class SequenceParallelSampler(DefaultSampler):
+
+ def __init__(self,
+ dataset: Sized,
+ shuffle: bool = True,
+ seed: Optional[int] = None,
+ round_up: bool = True) -> None:
+ rank = get_data_parallel_rank()
+ world_size = get_data_parallel_world_size()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.shuffle = shuffle
+ if seed is None:
+ seed = sync_random_seed()
+ self.seed = seed
+ self.epoch = 0
+ self.round_up = round_up
+
+ if self.round_up:
+ self.num_samples = math.ceil(len(self.dataset) / world_size)
+ self.total_size = self.num_samples * self.world_size
+ else:
+ self.num_samples = math.ceil(
+ (len(self.dataset) - rank) / world_size)
+ self.total_size = len(self.dataset)
diff --git a/data/xtuner/xtuner/parallel/sequence/setup_distributed.py b/data/xtuner/xtuner/parallel/sequence/setup_distributed.py
new file mode 100644
index 0000000000000000000000000000000000000000..473993a33f3f2e782e6f78594acc2bdcc120422b
--- /dev/null
+++ b/data/xtuner/xtuner/parallel/sequence/setup_distributed.py
@@ -0,0 +1,174 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.distributed as dist
+
+_SEQUENCE_PARALLEL_GROUP = None
+_SEQUENCE_PARALLEL_WORLD_SIZE = None
+_SEQUENCE_PARALLEL_RANK = None
+
+_INNER_SEQUENCE_PARALLEL_GROUP = None
+_INNER_SEQUENCE_PARALLEL_WORLD_SIZE = None
+_INNER_SEQUENCE_PARALLEL_RANK = None
+
+_DATA_PARALLEL_GROUP = None
+_DATA_PARALLEL_WORLD_SIZE = None
+_DATA_PARALLEL_RANK = None
+
+
+def init_sequence_parallel(sequence_parallel_size: int = 1):
+ assert dist.is_initialized()
+ world_size: int = dist.get_world_size()
+
+ # enable_ds_sequence_parallel = sequence_parallel_size > 1
+ # if enable_ds_sequence_parallel:
+ if world_size % sequence_parallel_size != 0:
+ raise RuntimeError(f'world_size ({world_size}) is not divisible by '
+ f'sequence_parallel_size {sequence_parallel_size}')
+
+ num_sequence_parallel_groups: int = world_size // sequence_parallel_size
+
+ rank = dist.get_rank()
+
+ # Build the sequence parallel groups.
+ global _SEQUENCE_PARALLEL_GROUP
+ assert _SEQUENCE_PARALLEL_GROUP is None, \
+ 'sequence parallel group is already initialized'
+ for i in range(num_sequence_parallel_groups):
+ ranks = range(i * sequence_parallel_size,
+ (i + 1) * sequence_parallel_size)
+ group = dist.new_group(ranks)
+ if rank in ranks:
+ _SEQUENCE_PARALLEL_GROUP = group
+
+ global _DATA_PARALLEL_GROUP
+ assert _DATA_PARALLEL_GROUP is None, \
+ 'data parallel group is already initialized'
+ all_data_parallel_group_ranks = []
+ start_rank = 0
+ end_rank = world_size
+ for j in range(sequence_parallel_size):
+ ranks = range(start_rank + j, end_rank, sequence_parallel_size)
+ all_data_parallel_group_ranks.append(list(ranks))
+ group = dist.new_group(ranks)
+ if rank in ranks:
+ _DATA_PARALLEL_GROUP = group
+
+
+def init_inner_sequence_parallel(inner_sequence_parallel_size: int = 1):
+ """Build the sequence parallel inner groups.
+
+ They are helpful when sp size is not evenly divided by the number of attn
+ heads.
+ """
+ assert _SEQUENCE_PARALLEL_GROUP is not None, \
+ ('Please call `init_inner_sequence_parallel` after calling '
+ '`init_sequence_parallel`.')
+
+ rank = dist.get_rank()
+ world_size: int = dist.get_world_size()
+
+ n_inner_group = world_size // inner_sequence_parallel_size
+
+ global _INNER_SEQUENCE_PARALLEL_GROUP
+ assert _INNER_SEQUENCE_PARALLEL_GROUP is None
+
+ for i in range(n_inner_group):
+ ranks = range(i * inner_sequence_parallel_size,
+ (i + 1) * inner_sequence_parallel_size)
+ group = dist.new_group(ranks)
+ if rank in ranks:
+ _INNER_SEQUENCE_PARALLEL_GROUP = group
+
+
+def is_inner_sequence_parallel_initialized():
+ return _INNER_SEQUENCE_PARALLEL_GROUP is not None
+
+
+def get_inner_sequence_parallel_group():
+ return _INNER_SEQUENCE_PARALLEL_GROUP
+
+
+def get_inner_sequence_parallel_world_size():
+ global _INNER_SEQUENCE_PARALLEL_WORLD_SIZE
+ if _INNER_SEQUENCE_PARALLEL_WORLD_SIZE is not None:
+ return _INNER_SEQUENCE_PARALLEL_WORLD_SIZE
+ if not dist.is_initialized() or (_INNER_SEQUENCE_PARALLEL_GROUP is None):
+ _INNER_SEQUENCE_PARALLEL_WORLD_SIZE = 1
+ else:
+ _INNER_SEQUENCE_PARALLEL_WORLD_SIZE = dist.get_world_size(
+ group=get_inner_sequence_parallel_group())
+ return _INNER_SEQUENCE_PARALLEL_WORLD_SIZE
+
+
+def get_inner_sequence_parallel_rank():
+ global _INNER_SEQUENCE_PARALLEL_RANK
+ if _INNER_SEQUENCE_PARALLEL_RANK is not None:
+ return _INNER_SEQUENCE_PARALLEL_RANK
+ if not dist.is_initialized() or (_INNER_SEQUENCE_PARALLEL_GROUP is None):
+ _INNER_SEQUENCE_PARALLEL_RANK = 0
+ else:
+ _INNER_SEQUENCE_PARALLEL_RANK = dist.get_rank(
+ group=get_inner_sequence_parallel_group())
+ return _INNER_SEQUENCE_PARALLEL_RANK
+
+
+def get_sequence_parallel_group():
+ """Get the sequence parallel group the caller rank belongs to."""
+ return _SEQUENCE_PARALLEL_GROUP
+
+
+def get_sequence_parallel_world_size():
+ """Return world size for the sequence parallel group."""
+ global _SEQUENCE_PARALLEL_WORLD_SIZE
+ if _SEQUENCE_PARALLEL_WORLD_SIZE is not None:
+ return _SEQUENCE_PARALLEL_WORLD_SIZE
+ if not dist.is_initialized() or (_SEQUENCE_PARALLEL_GROUP is None):
+ _SEQUENCE_PARALLEL_WORLD_SIZE = 1
+ else:
+ _SEQUENCE_PARALLEL_WORLD_SIZE = dist.get_world_size(
+ group=get_sequence_parallel_group())
+ return _SEQUENCE_PARALLEL_WORLD_SIZE
+
+
+def get_sequence_parallel_rank():
+ """Return my rank for the sequence parallel group."""
+ global _SEQUENCE_PARALLEL_RANK
+ if _SEQUENCE_PARALLEL_RANK is not None:
+ return _SEQUENCE_PARALLEL_RANK
+ if not dist.is_initialized() or (_SEQUENCE_PARALLEL_GROUP is None):
+ _SEQUENCE_PARALLEL_RANK = 0
+ else:
+ _SEQUENCE_PARALLEL_RANK = dist.get_rank(
+ group=get_sequence_parallel_group())
+ return _SEQUENCE_PARALLEL_RANK
+
+
+def get_data_parallel_group():
+ """Get the data parallel group the caller rank belongs to."""
+ assert _DATA_PARALLEL_GROUP is not None, \
+ 'data parallel group is not initialized'
+ return _DATA_PARALLEL_GROUP
+
+
+def get_data_parallel_world_size():
+ """Return world size for the data parallel group."""
+ global _DATA_PARALLEL_WORLD_SIZE
+ if _DATA_PARALLEL_WORLD_SIZE is not None:
+ return _DATA_PARALLEL_WORLD_SIZE
+ if not dist.is_initialized():
+ _DATA_PARALLEL_WORLD_SIZE = 1
+ else:
+ _DATA_PARALLEL_WORLD_SIZE = dist.get_world_size(
+ group=get_data_parallel_group())
+ return _DATA_PARALLEL_WORLD_SIZE
+
+
+def get_data_parallel_rank():
+ """Return my rank for the data parallel group."""
+ global _DATA_PARALLEL_RANK
+ if _DATA_PARALLEL_RANK is not None:
+ return _DATA_PARALLEL_RANK
+ if not dist.is_initialized():
+ _DATA_PARALLEL_RANK = 0
+ else:
+ _DATA_PARALLEL_RANK = dist.get_rank(group=get_data_parallel_group())
+ return _DATA_PARALLEL_RANK
diff --git a/data/xtuner/xtuner/registry.py b/data/xtuner/xtuner/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c8907e0be44210849d029bc26c77494971220b0
--- /dev/null
+++ b/data/xtuner/xtuner/registry.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.registry import Registry
+
+__all__ = ['BUILDER', 'MAP_FUNC']
+
+BUILDER = Registry('builder')
+MAP_FUNC = Registry('map_fn')
diff --git a/data/xtuner/xtuner/tools/chat.py b/data/xtuner/xtuner/tools/chat.py
new file mode 100644
index 0000000000000000000000000000000000000000..3bddac52cdcca8c2e5ef7ac5e10ebcd444897e5f
--- /dev/null
+++ b/data/xtuner/xtuner/tools/chat.py
@@ -0,0 +1,491 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import re
+import sys
+
+import torch
+from huggingface_hub import snapshot_download
+from peft import PeftModel
+from transformers import (AutoModel, AutoModelForCausalLM, AutoTokenizer,
+ BitsAndBytesConfig, CLIPImageProcessor,
+ CLIPVisionModel, GenerationConfig)
+from transformers.generation.streamers import TextStreamer
+
+from xtuner.dataset.utils import expand2square, load_image
+from xtuner.model.utils import prepare_inputs_labels_for_multimodal
+from xtuner.tools.utils import get_stop_criteria
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ PROMPT_TEMPLATE, SYSTEM_TEMPLATE)
+
+TORCH_DTYPE_MAP = dict(
+ fp16=torch.float16, bf16=torch.bfloat16, fp32=torch.float32, auto='auto')
+
+
+def remove_prefix(state_dict, prefix):
+ new_state_dict = {}
+ for key, value in state_dict.items():
+ if key.startswith(prefix):
+ new_key = key[len(prefix):]
+ new_state_dict[new_key] = value
+ else:
+ new_state_dict[key] = value
+ return new_state_dict
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Chat with a HF model')
+ parser.add_argument(
+ 'model_name_or_path', help='Hugging Face model name or path')
+ adapter_group = parser.add_mutually_exclusive_group()
+ adapter_group.add_argument(
+ '--adapter', default=None, help='adapter name or path')
+ adapter_group.add_argument(
+ '--llava', default=None, help='llava name or path')
+ parser.add_argument(
+ '--visual-encoder', default=None, help='visual encoder name or path')
+ parser.add_argument(
+ '--visual-select-layer', default=-2, help='visual select layer')
+ parser.add_argument('--image', default=None, help='image')
+ parser.add_argument(
+ '--torch-dtype',
+ default='fp16',
+ choices=TORCH_DTYPE_MAP.keys(),
+ help='Override the default `torch.dtype` and load the model under '
+ 'a specific `dtype`.')
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ default=None,
+ help='Specify a prompt template')
+ system_group = parser.add_mutually_exclusive_group()
+ system_group.add_argument(
+ '--system', default=None, help='Specify the system text')
+ system_group.add_argument(
+ '--system-template',
+ choices=SYSTEM_TEMPLATE.keys(),
+ default=None,
+ help='Specify a system template')
+ parser.add_argument(
+ '--bits',
+ type=int,
+ choices=[4, 8, None],
+ default=None,
+ help='LLM bits')
+ parser.add_argument(
+ '--bot-name', type=str, default='BOT', help='Name for Bot')
+ parser.add_argument(
+ '--with-plugins',
+ nargs='+',
+ choices=['calculate', 'solve', 'search'],
+ help='Specify plugins to use')
+ parser.add_argument(
+ '--no-streamer', action='store_true', help='Whether to with streamer')
+ parser.add_argument(
+ '--lagent', action='store_true', help='Whether to use lagent')
+ parser.add_argument(
+ '--stop-words', nargs='+', type=str, default=[], help='Stop words')
+ parser.add_argument(
+ '--offload-folder',
+ default=None,
+ help='The folder in which to offload the model weights (or where the '
+ 'model weights are already offloaded).')
+ parser.add_argument(
+ '--max-new-tokens',
+ type=int,
+ default=2048,
+ help='Maximum number of new tokens allowed in generated text')
+ parser.add_argument(
+ '--temperature',
+ type=float,
+ default=0.1,
+ help='The value used to modulate the next token probabilities.')
+ parser.add_argument(
+ '--top-k',
+ type=int,
+ default=40,
+ help='The number of highest probability vocabulary tokens to '
+ 'keep for top-k-filtering.')
+ parser.add_argument(
+ '--top-p',
+ type=float,
+ default=0.75,
+ help='If set to float < 1, only the smallest set of most probable '
+ 'tokens with probabilities that add up to top_p or higher are '
+ 'kept for generation.')
+ parser.add_argument(
+ '--repetition-penalty',
+ type=float,
+ default=1.0,
+ help='The parameter for repetition penalty. 1.0 means no penalty.')
+ parser.add_argument(
+ '--seed',
+ type=int,
+ default=0,
+ help='Random seed for reproducible text generation')
+ args = parser.parse_args()
+ return args
+
+
+def get_input():
+ """Helper function for getting input from users."""
+ sentinel = '' # ends when this string is seen
+ result = None
+ while result is None:
+ print(('\ndouble enter to end input (EXIT: exit chat, '
+ 'RESET: reset history) >>> '),
+ end='')
+ try:
+ result = '\n'.join(iter(input, sentinel))
+ except UnicodeDecodeError:
+ print('Invalid characters detected. Please enter again.')
+ return result
+
+
+def main():
+ args = parse_args()
+ torch.manual_seed(args.seed)
+
+ # build llm
+ quantization_config = None
+ load_in_8bit = False
+ if args.bits == 4:
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4')
+ elif args.bits == 8:
+ load_in_8bit = True
+ model_kwargs = {
+ 'quantization_config': quantization_config,
+ 'load_in_8bit': load_in_8bit,
+ 'device_map': 'auto',
+ 'offload_folder': args.offload_folder,
+ 'trust_remote_code': True,
+ 'torch_dtype': TORCH_DTYPE_MAP[args.torch_dtype]
+ }
+ if args.lagent:
+ from lagent.actions import ActionExecutor, GoogleSearch
+ from lagent.agents import (CALL_PROTOCOL_CN, FORCE_STOP_PROMPT_CN,
+ ReAct, ReActProtocol)
+ from lagent.llms import HFTransformerCasualLM
+
+ try:
+ SERPER_API_KEY = os.environ['SERPER_API_KEY']
+ except Exception:
+ print('Please obtain the `SERPER_API_KEY` from https://serper.dev '
+ 'and set it using `export SERPER_API_KEY=xxx`.')
+ sys.exit(1)
+
+ model_kwargs.pop('trust_remote_code')
+ llm = HFTransformerCasualLM(
+ args.model_name_or_path, model_kwargs=model_kwargs)
+ if args.adapter is not None:
+ print(f'Loading adapter from {args.adapter}...')
+ llm.model = PeftModel.from_pretrained(
+ llm.model,
+ args.adapter,
+ offload_folder=args.offload_folder,
+ trust_remote_code=True)
+ search_tool = GoogleSearch(api_key=SERPER_API_KEY)
+ chatbot = ReAct(
+ llm=llm,
+ action_executor=ActionExecutor(actions=[search_tool]),
+ protocol=ReActProtocol(
+ call_protocol=CALL_PROTOCOL_CN,
+ force_stop=FORCE_STOP_PROMPT_CN))
+ while True:
+ text = get_input()
+ while text.strip() == 'RESET':
+ print('Log: History responses have been removed!')
+ chatbot._session_history = []
+ inputs = ''
+ text = get_input()
+ if text.strip() == 'EXIT':
+ print('Log: Exit!')
+ exit(0)
+ response = chatbot.chat(text)
+ print(response.response)
+ else:
+ if args.with_plugins is None:
+ inner_thoughts_open = False
+ calculate_open = False
+ solve_open = False
+ search_open = False
+ else:
+ assert args.prompt_template == args.system_template == 'moss_sft'
+ from plugins import plugins_api
+ inner_thoughts_open = True
+ calculate_open = 'calculate' in args.with_plugins
+ solve_open = 'solve' in args.with_plugins
+ search_open = 'search' in args.with_plugins
+ # pre-import for api and model preparation
+ if calculate_open:
+ from plugins import calculate # noqa: F401
+ if solve_open:
+ from plugins import solve # noqa: F401
+ if search_open:
+ from plugins import search # noqa: F401
+ # build llm
+ llm = AutoModelForCausalLM.from_pretrained(args.model_name_or_path,
+ **model_kwargs)
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=True,
+ encode_special_tokens=True)
+ print(f'Load LLM from {args.model_name_or_path}')
+ if args.adapter is not None:
+ llm = PeftModel.from_pretrained(
+ llm,
+ args.adapter,
+ offload_folder=args.offload_folder,
+ trust_remote_code=True)
+ print(f'Load adapter from {args.adapter}')
+ if args.llava is not None:
+ llava_path = snapshot_download(
+ repo_id=args.llava) if not osp.isdir(
+ args.llava) else args.llava
+
+ # build visual_encoder
+ if 'visual_encoder' in os.listdir(llava_path):
+ assert args.visual_encoder is None, (
+ "Please don't specify the `--visual-encoder` since passed "
+ '`--llava` contains a visual encoder!')
+ visual_encoder_path = osp.join(llava_path, 'visual_encoder')
+ else:
+ assert args.visual_encoder is not None, (
+ 'Please specify the `--visual-encoder`!')
+ visual_encoder_path = args.visual_encoder
+ visual_encoder = CLIPVisionModel.from_pretrained(
+ visual_encoder_path,
+ torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ image_processor = CLIPImageProcessor.from_pretrained(
+ visual_encoder_path)
+ print(f'Load visual_encoder from {visual_encoder_path}')
+
+ # load adapter
+ if 'llm_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'llm_adapter')
+ llm = PeftModel.from_pretrained(
+ llm,
+ adapter_path,
+ offload_folder=args.offload_folder,
+ trust_remote_code=True)
+ print(f'Load LLM adapter from {args.llava}')
+ if 'visual_encoder_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'visual_encoder_adapter')
+ visual_encoder = PeftModel.from_pretrained(
+ visual_encoder,
+ adapter_path,
+ offload_folder=args.offload_folder)
+ print(f'Load visual_encoder adapter from {args.llava}')
+
+ # build projector
+ projector_path = osp.join(llava_path, 'projector')
+ projector = AutoModel.from_pretrained(
+ projector_path,
+ torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype],
+ trust_remote_code=True)
+ print(f'Load projector from {args.llava}')
+
+ projector.cuda()
+ projector.eval()
+ visual_encoder.cuda()
+ visual_encoder.eval()
+
+ llm.eval()
+
+ if args.image is not None:
+ image = load_image(args.image)
+ image = expand2square(
+ image, tuple(int(x * 255) for x in image_processor.image_mean))
+ image = image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ image = image.cuda().unsqueeze(0).to(visual_encoder.dtype)
+ visual_outputs = visual_encoder(image, output_hidden_states=True)
+ pixel_values = projector(
+ visual_outputs.hidden_states[args.visual_select_layer][:, 1:])
+
+ stop_words = args.stop_words
+ sep = ''
+ if args.prompt_template:
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ stop_words += template.get('STOP_WORDS', [])
+ sep = template.get('SEP', '')
+ stop_criteria = get_stop_criteria(
+ tokenizer=tokenizer, stop_words=stop_words)
+
+ if args.no_streamer:
+ streamer = None
+ else:
+ streamer = TextStreamer(tokenizer, skip_prompt=True)
+
+ gen_config = GenerationConfig(
+ max_new_tokens=args.max_new_tokens,
+ do_sample=args.temperature > 0,
+ temperature=args.temperature,
+ top_p=args.top_p,
+ top_k=args.top_k,
+ repetition_penalty=args.repetition_penalty,
+ eos_token_id=tokenizer.eos_token_id,
+ pad_token_id=tokenizer.pad_token_id
+ if tokenizer.pad_token_id is not None else tokenizer.eos_token_id,
+ )
+
+ n_turn = 0
+ inputs = ''
+ while True:
+ text = get_input()
+ while text.strip() == 'RESET':
+ print('Log: History responses have been removed!')
+ n_turn = 0
+ inputs = ''
+ text = get_input()
+ if text.strip() == 'EXIT':
+ print('Log: Exit!')
+ exit(0)
+
+ if args.image is not None and n_turn == 0:
+ text = DEFAULT_IMAGE_TOKEN + '\n' + text
+
+ if args.prompt_template:
+ prompt_text = ''
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ if 'SYSTEM' in template and n_turn == 0:
+ system_text = None
+ if args.system_template is not None:
+ system_text = SYSTEM_TEMPLATE[
+ args.system_template].format(
+ round=n_turn + 1, bot_name=args.bot_name)
+ elif args.system is not None:
+ system_text = args.system
+ if system_text is not None:
+ prompt_text += template['SYSTEM'].format(
+ system=system_text,
+ round=n_turn + 1,
+ bot_name=args.bot_name)
+ prompt_text += template['INSTRUCTION'].format(
+ input=text, round=n_turn + 1, bot_name=args.bot_name)
+ if args.prompt_template == args.system_template == 'moss_sft':
+ if not inner_thoughts_open:
+ prompt_text.replace('- Inner thoughts: enabled.',
+ '- Inner thoughts: disabled.')
+ if not calculate_open:
+ prompt_text.replace(('- Calculator: enabled. API: '
+ 'Calculate(expression)'),
+ '- Calculator: disabled.')
+ if not solve_open:
+ prompt_text.replace(
+ '- Equation solver: enabled. API: Solve(equation)',
+ '- Equation solver: disabled.')
+ if not search_open:
+ prompt_text.replace(
+ '- Web search: enabled. API: Search(query)',
+ '- Web search: disabled.')
+ else:
+ prompt_text = text
+ inputs += prompt_text
+ if args.image is None:
+ if n_turn == 0:
+ ids = tokenizer.encode(inputs, return_tensors='pt')
+ else:
+ ids = tokenizer.encode(
+ inputs, return_tensors='pt', add_special_tokens=False)
+
+ if args.with_plugins is not None:
+ generate_output = llm.generate(
+ inputs=ids.cuda(),
+ generation_config=gen_config,
+ streamer=streamer,
+ stopping_criteria=stop_criteria).cpu()
+ generate_output_text = tokenizer.decode(
+ generate_output[0][len(ids[0]):])
+ if streamer is None:
+ end = '' if generate_output_text[-1] == '\n' else '\n'
+ print(generate_output_text, end=end)
+ pattern = r'<\|Commands\|>:(.*?)'
+ command_text = ', '.join(
+ re.findall(pattern, generate_output_text))
+ extent_text = plugins_api(
+ command_text,
+ calculate_open=calculate_open,
+ solve_open=solve_open,
+ search_open=search_open)
+ end = '' if extent_text[-1] == '\n' else '\n'
+ print(extent_text, end=end)
+ extent_text_ids = tokenizer.encode(
+ extent_text,
+ return_tensors='pt',
+ add_special_tokens=False)
+ new_ids = torch.cat((generate_output, extent_text_ids),
+ dim=1)
+
+ generate_output = llm.generate(
+ inputs=new_ids.cuda(),
+ generation_config=gen_config,
+ streamer=streamer,
+ stopping_criteria=stop_criteria)
+ if streamer is None:
+ output_text = tokenizer.decode(
+ generate_output[0][len(new_ids[0]):])
+ end = '' if output_text[-1] == '\n' else '\n'
+ print(output_text, end=end)
+ else:
+ generate_output = llm.generate(
+ inputs=ids.cuda(),
+ generation_config=gen_config,
+ streamer=streamer,
+ stopping_criteria=stop_criteria)
+ if streamer is None:
+ output_text = tokenizer.decode(
+ generate_output[0][len(ids[0]):])
+ end = '' if output_text[-1] == '\n' else '\n'
+ print(output_text, end=end)
+ inputs = tokenizer.decode(generate_output[0])
+ else:
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0 and n_turn == 0:
+ cur_encode = tokenizer.encode(chunk)
+ else:
+ cur_encode = tokenizer.encode(
+ chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+ ids = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ ids.append(IMAGE_TOKEN_INDEX)
+ ids = torch.tensor(ids).cuda().unsqueeze(0)
+ mm_inputs = prepare_inputs_labels_for_multimodal(
+ llm=llm, input_ids=ids, pixel_values=pixel_values)
+
+ generate_output = llm.generate(
+ **mm_inputs,
+ generation_config=gen_config,
+ streamer=streamer,
+ bos_token_id=tokenizer.bos_token_id,
+ stopping_criteria=stop_criteria)
+ if streamer is None:
+ output_text = tokenizer.decode(generate_output[0])
+ end = '' if output_text[-1] == '\n' else '\n'
+ print(output_text, end=end)
+ inputs += tokenizer.decode(generate_output[0])
+ n_turn += 1
+ inputs += sep
+ if len(generate_output[0]) >= args.max_new_tokens:
+ print(
+ 'Remove the memory of history responses, since '
+ f'it exceeds the length limitation {args.max_new_tokens}.')
+ n_turn = 0
+ inputs = ''
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/check_custom_dataset.py b/data/xtuner/xtuner/tools/check_custom_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9d005fb5b6e9f7b3b0cf964d5dd45c4acdd5a4a
--- /dev/null
+++ b/data/xtuner/xtuner/tools/check_custom_dataset.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from functools import partial
+
+import numpy as np
+from datasets import DatasetDict
+from mmengine.config import Config
+
+from xtuner.dataset.utils import Packer, encode_fn
+from xtuner.registry import BUILDER
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Verify the correctness of the config file for the '
+ 'custom dataset.')
+ parser.add_argument('config', help='config file name or path.')
+ args = parser.parse_args()
+ return args
+
+
+def is_standard_format(dataset):
+ example = next(iter(dataset))
+ if 'conversation' not in example:
+ return False
+ conversation = example['conversation']
+ if not isinstance(conversation, list):
+ return False
+ for item in conversation:
+ if (not isinstance(item, dict)) or ('input'
+ not in item) or ('output'
+ not in item):
+ return False
+ input, output = item['input'], item['output']
+ if (not isinstance(input, str)) or (not isinstance(output, str)):
+ return False
+ return True
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ if cfg.get('framework', 'mmengine').lower() == 'huggingface':
+ train_dataset = cfg.train_dataset
+ else:
+ train_dataset = cfg.train_dataloader.dataset
+
+ dataset = train_dataset.dataset
+ max_length = train_dataset.max_length
+ dataset_map_fn = train_dataset.get('dataset_map_fn', None)
+ template_map_fn = train_dataset.get('template_map_fn', None)
+ max_dataset_length = train_dataset.get('max_dataset_length', 10)
+ split = train_dataset.get('split', 'train')
+ remove_unused_columns = train_dataset.get('remove_unused_columns', False)
+ rename_maps = train_dataset.get('rename_maps', [])
+ shuffle_before_pack = train_dataset.get('shuffle_before_pack', True)
+ pack_to_max_length = train_dataset.get('pack_to_max_length', True)
+ input_ids_with_output = train_dataset.get('input_ids_with_output', True)
+
+ if dataset.get('path', '') != 'json':
+ raise ValueError(
+ 'You are using custom datasets for SFT. '
+ 'The custom datasets should be in json format. To load your JSON '
+ 'file, you can use the following code snippet: \n'
+ '"""\nfrom datasets import load_dataset \n'
+ 'dataset = dict(type=load_dataset, path=\'json\', '
+ 'data_files=\'your_json_file.json\')\n"""\n'
+ 'For more details, please refer to Step 5 in the '
+ '`Using Custom Datasets` section of the documentation found at'
+ ' docs/zh_cn/user_guides/single_turn_conversation.md.')
+
+ try:
+ dataset = BUILDER.build(dataset)
+ except RuntimeError:
+ raise RuntimeError(
+ 'Unable to load the custom JSON file using '
+ '`datasets.load_dataset`. Your data-related config is '
+ f'{train_dataset}. Please refer to the official documentation on'
+ ' `load_dataset` (https://huggingface.co/docs/datasets/loading) '
+ 'for more details.')
+
+ if isinstance(dataset, DatasetDict):
+ dataset = dataset[split]
+
+ if not is_standard_format(dataset) and dataset_map_fn is None:
+ raise ValueError(
+ 'If the custom dataset is not in the XTuner-defined '
+ 'format, please utilize `dataset_map_fn` to map the original data'
+ ' to the standard format. For more details, please refer to '
+ 'Step 1 and Step 5 in the `Using Custom Datasets` section of the '
+ 'documentation found at '
+ '`docs/zh_cn/user_guides/single_turn_conversation.md`.')
+
+ if is_standard_format(dataset) and dataset_map_fn is not None:
+ raise ValueError(
+ 'If the custom dataset is already in the XTuner-defined format, '
+ 'please set `dataset_map_fn` to None.'
+ 'For more details, please refer to Step 1 and Step 5 in the '
+ '`Using Custom Datasets` section of the documentation found at'
+ ' docs/zh_cn/user_guides/single_turn_conversation.md.')
+
+ max_dataset_length = min(max_dataset_length, len(dataset))
+ indices = np.random.choice(len(dataset), max_dataset_length, replace=False)
+ dataset = dataset.select(indices)
+
+ if dataset_map_fn is not None:
+ dataset = dataset.map(dataset_map_fn)
+
+ print('#' * 20 + ' dataset after `dataset_map_fn` ' + '#' * 20)
+ print(dataset[0]['conversation'])
+
+ if template_map_fn is not None:
+ template_map_fn = BUILDER.build(template_map_fn)
+ dataset = dataset.map(template_map_fn)
+
+ print('#' * 20 + ' dataset after adding templates ' + '#' * 20)
+ print(dataset[0]['conversation'])
+
+ for old, new in rename_maps:
+ dataset = dataset.rename_column(old, new)
+
+ if pack_to_max_length and (not remove_unused_columns):
+ raise ValueError('We have to remove unused columns if '
+ '`pack_to_max_length` is set to True.')
+
+ dataset = dataset.map(
+ partial(
+ encode_fn,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ input_ids_with_output=input_ids_with_output),
+ remove_columns=list(dataset.column_names)
+ if remove_unused_columns else None)
+
+ print('#' * 20 + ' encoded input_ids ' + '#' * 20)
+ print(dataset[0]['input_ids'])
+ print('#' * 20 + ' encoded labels ' + '#' * 20)
+ print(dataset[0]['labels'])
+
+ if pack_to_max_length and split == 'train':
+ if shuffle_before_pack:
+ dataset = dataset.shuffle()
+ dataset = dataset.flatten_indices()
+ dataset = dataset.map(Packer(max_length), batched=True)
+
+ print('#' * 20 + ' input_ids after packed to max_length ' +
+ '#' * 20)
+ print(dataset[0]['input_ids'])
+ print('#' * 20 + ' labels after packed to max_length ' + '#' * 20)
+ print(dataset[0]['labels'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/copy_cfg.py b/data/xtuner/xtuner/tools/copy_cfg.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c3ff69c1271ae16fc3ad11d2f7ce184cca5dfea
--- /dev/null
+++ b/data/xtuner/xtuner/tools/copy_cfg.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import shutil
+
+from mmengine.utils import mkdir_or_exist
+
+from xtuner.configs import cfgs_name_path
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config_name', help='config name')
+ parser.add_argument('save_dir', help='save directory for copied config')
+ args = parser.parse_args()
+ return args
+
+
+def add_copy_suffix(string):
+ file_name, ext = osp.splitext(string)
+ return f'{file_name}_copy{ext}'
+
+
+def main():
+ args = parse_args()
+ mkdir_or_exist(args.save_dir)
+ config_path = cfgs_name_path[args.config_name]
+ save_path = osp.join(args.save_dir,
+ add_copy_suffix(osp.basename(config_path)))
+ shutil.copyfile(config_path, save_path)
+ print(f'Copy to {save_path}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/data_preprocess/arxiv.py b/data/xtuner/xtuner/tools/data_preprocess/arxiv.py
new file mode 100644
index 0000000000000000000000000000000000000000..55c3004038971462142f1a4a3619edae4d775b34
--- /dev/null
+++ b/data/xtuner/xtuner/tools/data_preprocess/arxiv.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+from datetime import datetime
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('src_file', help='source file path')
+ parser.add_argument('dst_file', help='destination file path')
+ parser.add_argument(
+ '--categories',
+ nargs='+',
+ default=['cs.AI', 'cs.CL', 'cs.CV'],
+ help='target categories')
+ parser.add_argument(
+ '--start-date',
+ default='2020-01-01',
+ help='start date (format: YYYY-MM-DD)')
+
+ args = parser.parse_args()
+ return args
+
+
+def has_intersection(list1, list2):
+ set1 = set(list1)
+ set2 = set(list2)
+ return len(set1.intersection(set2)) > 0
+
+
+def read_json_file(file_path):
+ data = []
+ with open(file_path) as file:
+ for line in file:
+ try:
+ json_data = json.loads(line)
+ data.append(json_data)
+ except json.JSONDecodeError:
+ print(f'Failed to parse line: {line}')
+ return data
+
+
+def main():
+ args = parse_args()
+ json_data = read_json_file(args.src_file)
+ from_time = datetime.strptime(args.start_date, '%Y-%m-%d')
+ filtered_data = [
+ item for item in json_data
+ if has_intersection(args.categories, item['categories'].split())
+ and datetime.strptime(item['update_date'], '%Y-%m-%d') >= from_time
+ ]
+
+ with open(args.dst_file, 'w') as file:
+ json.dump(filtered_data, file)
+
+ print(f'Save to {args.dst_file}\n{len(filtered_data)} items')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/data_preprocess/convert_refcoco.py b/data/xtuner/xtuner/tools/data_preprocess/convert_refcoco.py
new file mode 100644
index 0000000000000000000000000000000000000000..883e82a226414f9fbf49e27ed7144bd8e478cfef
--- /dev/null
+++ b/data/xtuner/xtuner/tools/data_preprocess/convert_refcoco.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+
+from xtuner.dataset.refcoco_json import RefCOCOJsonDataset
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--ann-path',
+ default='data/refcoco_annotations',
+ help='Refcoco annotation path',
+ )
+ parser.add_argument(
+ '--image-path',
+ default='data/llava_data/llava_images/coco/train2017',
+ help='COCO image path',
+ )
+ parser.add_argument(
+ '--save-path', default='./', help='The folder to save converted data')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ data_info = [
+ ('refcoco', 'unc'),
+ ('refcoco+', 'unc'),
+ ('refcocog', 'umd'),
+ ]
+ all_data = []
+ for dataset, split in data_info:
+ data = RefCOCOJsonDataset.get_data_json(
+ ann_path=args.ann_path,
+ image_path=args.image_path,
+ dataset=dataset,
+ splitBy=split,
+ )[0]
+ all_data.extend(data)
+ save_path = args.save_path + '/train.json'
+ with open(save_path, 'w') as f:
+ print(f'save to {save_path} with {len(all_data)} items.')
+ print(all_data[0])
+ json.dump(all_data, f, indent=4)
diff --git a/data/xtuner/xtuner/tools/eval_refcoco.py b/data/xtuner/xtuner/tools/eval_refcoco.py
new file mode 100644
index 0000000000000000000000000000000000000000..cbdc1bf6e9dda876440ffa61416f66247d1705db
--- /dev/null
+++ b/data/xtuner/xtuner/tools/eval_refcoco.py
@@ -0,0 +1,356 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import re
+
+import torch
+import tqdm
+from huggingface_hub import snapshot_download
+from mmengine.dist import get_dist_info, init_dist, master_only
+from mmengine.utils.dl_utils import set_multi_processing
+from peft import PeftModel
+from torch import distributed as dist
+from torch.utils.data import DataLoader, DistributedSampler
+from transformers import (AutoModel, AutoModelForCausalLM, AutoTokenizer,
+ BitsAndBytesConfig, CLIPImageProcessor,
+ CLIPVisionModel, GenerationConfig)
+
+from xtuner.dataset.map_fns import llava_map_fn, template_map_fn_factory
+from xtuner.dataset.refcoco_json import RefCOCOJsonEvalDataset
+from xtuner.model.utils import LoadWoInit, prepare_inputs_labels_for_multimodal
+from xtuner.tools.utils import get_stop_criteria
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ PROMPT_TEMPLATE)
+
+TORCH_DTYPE_MAP = dict(
+ fp16=torch.float16, bf16=torch.bfloat16, fp32=torch.float32, auto='auto')
+
+
+def merge_outputs(otuputs):
+ new_outputs = [None for _ in range(dist.get_world_size())]
+
+ assert dist.is_initialized()
+
+ dist.all_gather_object(new_outputs, otuputs)
+ new_dict = []
+ for output in new_outputs:
+ new_dict.extend(output)
+ return new_dict
+
+
+@master_only
+def master_print(msg):
+ print(msg)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMBench')
+ parser.add_argument(
+ 'model_name_or_path', help='Hugging Face model name or path')
+ parser.add_argument('--data-path', default=None, help='data path')
+ parser.add_argument('--work-dir', help='the dir to save results')
+ parser.add_argument('--llava', default=None, help='llava name or path')
+ parser.add_argument(
+ '--visual-encoder', default=None, help='visual encoder name or path')
+ parser.add_argument(
+ '--visual-select-layer', default=-2, help='visual select layer')
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ default=None,
+ help='Specify a prompt template',
+ )
+ parser.add_argument(
+ '--stop-words', nargs='+', type=str, default=[], help='Stop words')
+ parser.add_argument(
+ '--torch-dtype',
+ default='fp16',
+ choices=TORCH_DTYPE_MAP.keys(),
+ help='Override the default `torch.dtype` and load the model under '
+ 'a specific `dtype`.',
+ )
+ parser.add_argument(
+ '--bits',
+ type=int,
+ choices=[4, 8, None],
+ default=None,
+ help='LLM bits')
+ parser.add_argument(
+ '--bot-name', type=str, default='BOT', help='Name for Bot')
+ parser.add_argument(
+ '--offload-folder',
+ default=None,
+ help='The folder in which to offload the model weights (or where the '
+ 'model weights are already offloaded).',
+ )
+ parser.add_argument(
+ '--max-new-tokens',
+ type=int,
+ default=100,
+ help='Maximum number of new tokens allowed in generated text',
+ )
+ parser.add_argument(
+ '--seed',
+ type=int,
+ default=0,
+ help='Random seed for reproducible text generation',
+ )
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher',
+ )
+ args = parser.parse_args()
+ return args
+
+
+def eval_iou(answers):
+
+ def computeIoU(bbox1, bbox2):
+ x1, y1, x2, y2 = bbox1
+ x3, y3, x4, y4 = bbox2
+ intersection_x1 = max(x1, x3)
+ intersection_y1 = max(y1, y3)
+ intersection_x2 = min(x2, x4)
+ intersection_y2 = min(y2, y4)
+ intersection_area = max(0,
+ intersection_x2 - intersection_x1 + 1) * max(
+ 0, intersection_y2 - intersection_y1 + 1)
+ bbox1_area = (x2 - x1 + 1) * (y2 - y1 + 1)
+ bbox2_area = (x4 - x3 + 1) * (y4 - y3 + 1)
+ union_area = bbox1_area + bbox2_area - intersection_area
+ iou = intersection_area / union_area
+ return iou
+
+ right = 0
+ for answer in answers:
+ bbox = answer['bbox']
+ bbox = RefCOCOJsonEvalDataset.normalize_bbox(bbox, answer['height'],
+ answer['width'])
+ answer_bbox = [int(x) for x in re.findall(r'\d+', answer['ans'])]
+ if len(answer_bbox) == 4:
+ iou = computeIoU(answer_bbox, bbox)
+ if iou > 0.5:
+ right += 1
+ else:
+ print('Error format sample: ', answer)
+ return right / len(answers)
+
+
+def build_model(args):
+ rank, world_size = get_dist_info()
+ # build llm
+ quantization_config = None
+ load_in_8bit = False
+ if args.bits == 4:
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4',
+ )
+ elif args.bits == 8:
+ load_in_8bit = True
+ model_kwargs = {
+ 'quantization_config': quantization_config,
+ 'load_in_8bit': load_in_8bit,
+ 'device_map': rank if world_size > 1 else 'auto',
+ 'offload_folder': args.offload_folder,
+ 'trust_remote_code': True,
+ 'torch_dtype': TORCH_DTYPE_MAP[args.torch_dtype],
+ }
+
+ # build llm
+ with LoadWoInit():
+ llm = AutoModelForCausalLM.from_pretrained(args.model_name_or_path,
+ **model_kwargs)
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=True,
+ encode_special_tokens=True)
+ master_print(f'Load LLM from {args.model_name_or_path}')
+
+ llava_path = (
+ snapshot_download(
+ repo_id=args.llava) if not osp.isdir(args.llava) else args.llava)
+
+ # build visual_encoder
+ if 'visual_encoder' in os.listdir(llava_path):
+ assert args.visual_encoder is None, (
+ "Please don't specify the `--visual-encoder` since passed "
+ '`--llava` contains a visual encoder!')
+ visual_encoder_path = osp.join(llava_path, 'visual_encoder')
+ else:
+ assert (args.visual_encoder is not None
+ ), 'Please specify the `--visual-encoder`!' # noqa: E501
+ visual_encoder_path = args.visual_encoder
+ with LoadWoInit():
+ visual_encoder = CLIPVisionModel.from_pretrained(
+ visual_encoder_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ image_processor = CLIPImageProcessor.from_pretrained(
+ visual_encoder_path)
+ master_print(f'Load visual_encoder from {visual_encoder_path}')
+
+ # load adapter
+ if 'llm_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'llm_adapter')
+
+ with LoadWoInit():
+ llm = PeftModel.from_pretrained(
+ llm, adapter_path, offload_folder=args.offload_folder)
+
+ master_print(f'Load LLM adapter from {args.llava}')
+
+ if 'visual_encoder_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'visual_encoder_adapter')
+ visual_encoder = PeftModel.from_pretrained(
+ visual_encoder, adapter_path, offload_folder=args.offload_folder)
+ master_print(f'Load visual_encoder adapter from {args.llava}')
+
+ # build projector
+ projector_path = osp.join(llava_path, 'projector')
+ with LoadWoInit():
+ projector = AutoModel.from_pretrained(
+ projector_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ master_print(f'Load projector from {args.llava}')
+
+ projector.cuda()
+ projector.eval()
+
+ visual_encoder.cuda()
+ visual_encoder.eval()
+
+ llm.eval()
+ return llm, visual_encoder, projector, tokenizer, image_processor
+
+
+def generate(
+ llm,
+ visual_encoder,
+ projector,
+ tokenizer,
+ samples,
+ visual_select_layer,
+):
+ gen_config = GenerationConfig(
+ max_new_tokens=100,
+ do_sample=False,
+ eos_token_id=tokenizer.eos_token_id,
+ pad_token_id=(tokenizer.pad_token_id if tokenizer.pad_token_id
+ is not None else tokenizer.eos_token_id),
+ )
+ stop_criteria = get_stop_criteria(tokenizer=tokenizer, stop_words=[''])
+
+ device = next(llm.parameters()).device
+ # prepare inputs
+ inputs = samples['conversation'][0]['input'][0]
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0:
+ cur_encode = tokenizer.encode(chunk)
+ else:
+ cur_encode = tokenizer.encode(chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+ ids = []
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ ids.append(IMAGE_TOKEN_INDEX)
+ ids = torch.tensor(ids).cuda().unsqueeze(0)
+
+ visual_outputs = visual_encoder(
+ samples['pixel_values'].to(device), output_hidden_states=True)
+ pixel_values = projector(
+ visual_outputs.hidden_states[visual_select_layer][:, 1:])
+ samples['pixel_values'] = pixel_values
+ samples['input_ids'] = ids
+ datax = prepare_inputs_labels_for_multimodal(
+ llm=llm.to(device),
+ input_ids=samples['input_ids'].to(device),
+ pixel_values=samples['pixel_values'].to(device),
+ )
+
+ # generation
+ generation = llm.generate(
+ **datax,
+ generation_config=gen_config,
+ streamer=None,
+ bos_token_id=tokenizer.bos_token_id,
+ stopping_criteria=stop_criteria,
+ )
+ answer = tokenizer.decode(generation[0])
+ return {
+ 'ans': answer,
+ 'id': samples['id'][0],
+ 'bbox': torch.tensor(samples['bbox']).tolist(),
+ 'height': samples['height'],
+ 'width': samples['width'],
+ }
+
+
+@torch.no_grad()
+def main():
+ # init
+ args = parse_args()
+ if args.launcher != 'none':
+ set_multi_processing(distributed=True)
+ init_dist(args.launcher)
+
+ rank, world_size = get_dist_info()
+ torch.cuda.set_device(rank)
+ else:
+ rank = 0
+ world_size = 1
+ print(f'Rank: {rank} / World size: {world_size}')
+
+ # build_model
+ llm, visual_encoder, projector, tokenizer, image_processor = build_model(
+ args)
+
+ # dataset
+ dataset = RefCOCOJsonEvalDataset(
+ data_path=args.data_path,
+ image_folder='data/llava_data/llava_images/',
+ tokenizer=tokenizer,
+ image_processor=image_processor,
+ max_dataset_length=None,
+ dataset_map_fn=llava_map_fn,
+ template_map_fn=dict(
+ type=template_map_fn_factory, template=PROMPT_TEMPLATE.vicuna),
+ max_length=2048,
+ pad_image_to_square=False,
+ )
+ loader = DataLoader(
+ dataset,
+ batch_size=1,
+ shuffle=False,
+ sampler=DistributedSampler(dataset, shuffle=False, seed=0),
+ )
+ loader.sampler.set_epoch(0)
+
+ answers = []
+ for i, data in tqdm.tqdm(enumerate(loader), desc=f'Rank {rank}'):
+ answer = generate(
+ llm,
+ visual_encoder,
+ projector,
+ tokenizer,
+ data,
+ args.visual_select_layer,
+ )
+ answers.append(answer)
+
+ merged_outputs = merge_outputs(answers)
+ acc = eval_iou(merged_outputs)
+ master_print(f'Acc: {acc}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/get_data_order.py b/data/xtuner/xtuner/tools/get_data_order.py
new file mode 100644
index 0000000000000000000000000000000000000000..30c23e84e7213fb518f798946da0befb1091b8c2
--- /dev/null
+++ b/data/xtuner/xtuner/tools/get_data_order.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data-folder', help='Data folder')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ parser.add_argument(
+ '--file-type',
+ default='.bin',
+ help='We want to get the order of the file in this type.')
+ args = parser.parse_args()
+ return args
+
+
+def save_data_order(data_folder, save_folder, file_type='.bin'):
+ assert os.path.exists(data_folder), f'{data_folder} does not exist.'
+ triples = list(os.walk(data_folder, followlinks=True))
+ data_order = []
+ for root, dirs, files in triples:
+ dirs.sort()
+ print(f'Reading {root}...')
+ for fn in sorted(files):
+ if fn.endswith(file_type):
+ fp = os.path.join(root, fn)
+ # Using relative paths so that you can get the same result
+ # on different clusters
+ fp = fp.replace(data_folder, '')[1:]
+ data_order.append(fp)
+
+ save_path = os.path.join(save_folder, 'data_order.txt')
+ with open(save_path, 'w') as f:
+ for fp in data_order:
+ f.write(fp + '\n')
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ save_data_order(args.data_folder, args.save_folder, args.file_type)
diff --git a/data/xtuner/xtuner/tools/list_cfg.py b/data/xtuner/xtuner/tools/list_cfg.py
new file mode 100644
index 0000000000000000000000000000000000000000..0062ade5714aa5b30467ab53809d245f8c142f66
--- /dev/null
+++ b/data/xtuner/xtuner/tools/list_cfg.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from xtuner.configs import cfgs_name_path
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '-p', '--pattern', default=None, help='Pattern for fuzzy matching')
+ args = parser.parse_args()
+ return args
+
+
+def main(pattern=None):
+ args = parse_args()
+ configs_names = sorted(list(cfgs_name_path.keys()))
+ print('==========================CONFIGS===========================')
+ if args.pattern is not None:
+ print(f'PATTERN: {args.pattern}')
+ print('-------------------------------')
+ for name in configs_names:
+ if args.pattern is None or args.pattern.lower() in name.lower():
+ print(name)
+ print('=============================================================')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/list_dataset_format.py b/data/xtuner/xtuner/tools/list_dataset_format.py
new file mode 100644
index 0000000000000000000000000000000000000000..40d3a71f2539db6b0af2880d78c0e2710c296dfe
--- /dev/null
+++ b/data/xtuner/xtuner/tools/list_dataset_format.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from xtuner.dataset.map_fns import DATASET_FORMAT_MAPPING
+
+
+def main():
+ dataset_format = DATASET_FORMAT_MAPPING.keys()
+ print('======================DATASET_FORMAT======================')
+ for format in dataset_format:
+ print(format)
+ print('==========================================================')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/log_dataset.py b/data/xtuner/xtuner/tools/log_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..40b5e25feff74d90cff8ffeaa74fd6b103d649a9
--- /dev/null
+++ b/data/xtuner/xtuner/tools/log_dataset.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from mmengine.config import Config
+
+from xtuner.registry import BUILDER
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Log processed dataset.')
+ parser.add_argument('config', help='config file name or path.')
+ # chose which kind of dataset style to show
+ parser.add_argument(
+ '--show',
+ default='text',
+ choices=['text', 'masked_text', 'input_ids', 'labels', 'all'],
+ help='which kind of dataset style to show')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+
+ tokenizer = BUILDER.build(cfg.tokenizer)
+ if cfg.get('framework', 'mmengine').lower() == 'huggingface':
+ train_dataset = BUILDER.build(cfg.train_dataset)
+ else:
+ train_dataset = BUILDER.build(cfg.train_dataloader.dataset)
+
+ if args.show == 'text' or args.show == 'all':
+ print('#' * 20 + ' text ' + '#' * 20)
+ print(tokenizer.decode(train_dataset[0]['input_ids']))
+ if args.show == 'masked_text' or args.show == 'all':
+ print('#' * 20 + ' text(masked) ' + '#' * 20)
+ masked_text = ' '.join(
+ ['[-100]' for i in train_dataset[0]['labels'] if i == -100])
+ unmasked_text = tokenizer.decode(
+ [i for i in train_dataset[0]['labels'] if i != -100])
+ print(masked_text + ' ' + unmasked_text)
+ if args.show == 'input_ids' or args.show == 'all':
+ print('#' * 20 + ' input_ids ' + '#' * 20)
+ print(train_dataset[0]['input_ids'])
+ if args.show == 'labels' or args.show == 'all':
+ print('#' * 20 + ' labels ' + '#' * 20)
+ print(train_dataset[0]['labels'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/mmbench.py b/data/xtuner/xtuner/tools/mmbench.py
new file mode 100644
index 0000000000000000000000000000000000000000..24d3825bb2ded3be9b11aaee18f312e86342223e
--- /dev/null
+++ b/data/xtuner/xtuner/tools/mmbench.py
@@ -0,0 +1,513 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import math
+import os
+import os.path as osp
+import re
+import string
+import time
+
+import numpy as np
+import pandas as pd
+import torch
+import tqdm
+from huggingface_hub import snapshot_download
+from mmengine import mkdir_or_exist
+from mmengine.dist import (collect_results, get_dist_info, get_rank, init_dist,
+ master_only)
+from mmengine.utils.dl_utils import set_multi_processing
+from peft import PeftModel
+from rich.console import Console
+from rich.table import Table
+from torch.utils.data import Dataset
+from transformers import (AutoModel, AutoModelForCausalLM, AutoTokenizer,
+ BitsAndBytesConfig, CLIPImageProcessor,
+ CLIPVisionModel, GenerationConfig)
+
+from xtuner.dataset.utils import decode_base64_to_image, expand2square
+from xtuner.model.utils import LoadWoInit, prepare_inputs_labels_for_multimodal
+from xtuner.tools.utils import get_stop_criteria, is_cn_string
+from xtuner.utils import (DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX,
+ PROMPT_TEMPLATE)
+
+TORCH_DTYPE_MAP = dict(
+ fp16=torch.float16, bf16=torch.bfloat16, fp32=torch.float32, auto='auto')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMBench')
+ parser.add_argument(
+ 'model_name_or_path', help='Hugging Face model name or path')
+ parser.add_argument('--data-path', default=None, help='data path')
+ parser.add_argument('--work-dir', help='the dir to save results')
+ parser.add_argument('--llava', default=None, help='llava name or path')
+ parser.add_argument(
+ '--visual-encoder', default=None, help='visual encoder name or path')
+ parser.add_argument(
+ '--visual-select-layer', default=-2, help='visual select layer')
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ default=None,
+ help='Specify a prompt template')
+ parser.add_argument(
+ '--stop-words', nargs='+', type=str, default=[], help='Stop words')
+ parser.add_argument(
+ '--torch-dtype',
+ default='fp16',
+ choices=TORCH_DTYPE_MAP.keys(),
+ help='Override the default `torch.dtype` and load the model under '
+ 'a specific `dtype`.')
+ parser.add_argument(
+ '--bits',
+ type=int,
+ choices=[4, 8, None],
+ default=None,
+ help='LLM bits')
+ parser.add_argument(
+ '--bot-name', type=str, default='BOT', help='Name for Bot')
+ parser.add_argument(
+ '--offload-folder',
+ default=None,
+ help='The folder in which to offload the model weights (or where the '
+ 'model weights are already offloaded).')
+ parser.add_argument(
+ '--max-new-tokens',
+ type=int,
+ default=100,
+ help='Maximum number of new tokens allowed in generated text')
+ parser.add_argument(
+ '--seed',
+ type=int,
+ default=0,
+ help='Random seed for reproducible text generation')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ args = parser.parse_args()
+ return args
+
+
+@master_only
+def master_print(msg):
+ print(msg)
+
+
+class MMBenchDataset(Dataset):
+ ABBRS = {
+ 'coarse_perception': 'CP',
+ 'finegrained_perception (instance-level)': 'FP-S',
+ 'finegrained_perception (cross-instance)': 'FP-C',
+ 'logic_reasoning': 'LR',
+ 'relation_reasoning': 'RR',
+ 'attribute_reasoning': 'AR',
+ 'sketch_reasoning': 'Sketch Reasoning',
+ 'scenery_building': 'Scenery & Building',
+ 'food_clothes': 'Food & Clothes',
+ 'historical_figure': 'Historical Figure',
+ 'traditional_show': 'Traditional Show',
+ 'calligraphy_painting': 'Calligraphy Painting',
+ 'cultural_relic': 'Cultural Relic'
+ }
+
+ def __init__(self, data_file):
+ self.data_file = data_file
+ self.df = pd.read_csv(data_file, sep='\t')
+ self.split = 'dev' if 'answer' in self.df.iloc[0].keys() else 'test'
+ self.has_l2_category = 'l2-category' in self.df.columns.to_list()
+
+ def get_image(self, image):
+ while len(image) < 16:
+ image = self.df[self.df['index'] == int(image)]['image'].values
+ assert len(image) == 1
+ image = image[0]
+ image = decode_base64_to_image(image)
+ return image
+
+ def __len__(self):
+ return len(self.df)
+
+ def __getitem__(self, idx):
+ index = self.df.iloc[idx]['index']
+ image = self.df.iloc[idx]['image']
+ image = self.get_image(image)
+ question = self.df.iloc[idx]['question']
+ answer = self.df.iloc[idx]['answer'] if 'answer' in self.df.iloc[
+ 0].keys() else None
+ category = self.df.iloc[idx]['category']
+
+ options = {
+ cand: self.load_from_df(idx, cand)
+ for cand in string.ascii_uppercase
+ if self.load_from_df(idx, cand) is not None
+ }
+ options_prompt = ''
+ for key, item in options.items():
+ options_prompt += f'{key}. {item}\n'
+
+ hint = self.load_from_df(idx, 'hint')
+ data = {
+ 'img': image,
+ 'question': question,
+ 'answer': answer,
+ 'options': options_prompt,
+ 'category': category,
+ 'options_dict': options,
+ 'index': index,
+ 'context': hint,
+ }
+ if self.has_l2_category:
+ data.update({'l2-category': self.df.iloc[idx]['l2-category']})
+ return data
+
+ def load_from_df(self, idx, key):
+ if key in self.df.iloc[idx] and not pd.isna(self.df.iloc[idx][key]):
+ return self.df.iloc[idx][key]
+ else:
+ return None
+
+ @master_only
+ def eval_result(self, result_df, show=True):
+
+ def calc_acc(df, group='category'):
+ assert group in ['overall', 'category', 'l2-category']
+ if group == 'overall':
+ res = {'Average': np.mean(df['hit'])}
+ else:
+ res = {}
+ abilities = list(set(df[group]))
+ abilities.sort()
+ for ab in abilities:
+ sub_df = df[df[group] == ab]
+ ab = self.ABBRS[ab] if ab in self.ABBRS else ab
+ res[ab] = np.mean(sub_df['hit'])
+ return res
+
+ def eval_sub_data(sub_data, answer_map):
+ lt = len(sub_data)
+ for i in range(lt):
+ item = sub_data.iloc[i]
+ match = re.search(r'([A-D]+)', item['prediction'])
+ pred = match.group(1) if match else ''
+ gt = answer_map[item['index']]
+ if gt != pred:
+ return 0
+ return 1
+
+ def show_result(ret_json):
+ show_dict = ret_json.copy()
+ table = Table(title=f' MMBench ({self.data_file}) ')
+ console = Console()
+ table.add_column('Category', justify='left')
+ table.add_column('Accuracy (%)', justify='right')
+ average = show_dict.pop('Average') * 100
+ table.add_row('Average', f'{average:.1f}')
+ table.add_section()
+ for cat_name, cat_acc in show_dict.items():
+ table.add_row(cat_name, f'{cat_acc * 100:.1f}')
+ with console.capture() as capture:
+ console.print(table, end='')
+ print('\n' + capture.get())
+ print('Note: Please be cautious if you use the results in papers, '
+ "since we don't use ChatGPT as a helper for choice "
+ 'extraction')
+
+ data = result_df.sort_values(by='index')
+ data['prediction'] = [str(x) for x in data['prediction']]
+ for k in data.keys():
+ data[k.lower() if k not in 'ABCD' else k] = data.pop(k)
+
+ data_main = data[data['index'] < int(1e6)]
+ cate_map = {
+ i: c
+ for i, c in zip(self.df['index'], self.df['category'])
+ }
+ if self.has_l2_category:
+ l2_cate_map = {
+ i: c
+ for i, c in zip(self.df['index'], self.df['l2-category'])
+ }
+ answer_map = {
+ i: c
+ for i, c in zip(self.df['index'], self.df['answer'])
+ }
+
+ lt = len(data_main)
+ hit, tot = 0, 0
+ result = {}
+ for i in range(lt):
+ item_main = data_main.iloc[i]
+ idx = item_main['index']
+ assert idx not in result
+ sub_data = data[data['index'] % int(1e6) == idx]
+ ret = eval_sub_data(sub_data, answer_map)
+ result[idx] = ret
+ hit += ret
+ tot += 1
+
+ indices = data_main['index']
+ data_main = data_main.copy()
+ data_main['hit'] = [result[i] for i in indices]
+ main_idx = data_main['index']
+ data_main['category'] = [cate_map[i] for i in main_idx]
+
+ ret_json = calc_acc(data_main, 'overall')
+
+ if self.has_l2_category:
+ data_main['l2-category'] = [l2_cate_map[i] for i in main_idx]
+ l2 = calc_acc(data_main, 'l2-category')
+ ret_json.update(l2)
+ else:
+ leaf = calc_acc(data_main, 'category')
+ ret_json.update(leaf)
+ if show:
+ show_result(ret_json)
+ return ret_json
+
+
+def main():
+ args = parse_args()
+
+ torch.manual_seed(args.seed)
+
+ if args.launcher != 'none':
+ set_multi_processing(distributed=True)
+ init_dist(args.launcher)
+
+ rank, world_size = get_dist_info()
+ torch.cuda.set_device(rank)
+ else:
+ rank = 0
+ world_size = 1
+
+ # build llm
+ quantization_config = None
+ load_in_8bit = False
+ if args.bits == 4:
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ load_in_8bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type='nf4')
+ elif args.bits == 8:
+ load_in_8bit = True
+ model_kwargs = {
+ 'quantization_config': quantization_config,
+ 'load_in_8bit': load_in_8bit,
+ 'device_map': rank if world_size > 1 else 'auto',
+ 'offload_folder': args.offload_folder,
+ 'trust_remote_code': True,
+ 'torch_dtype': TORCH_DTYPE_MAP[args.torch_dtype]
+ }
+
+ # build llm
+ with LoadWoInit():
+ llm = AutoModelForCausalLM.from_pretrained(args.model_name_or_path,
+ **model_kwargs)
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=True,
+ encode_special_tokens=True)
+ master_print(f'Load LLM from {args.model_name_or_path}')
+
+ llava_path = snapshot_download(
+ repo_id=args.llava) if not osp.isdir(args.llava) else args.llava
+
+ # build visual_encoder
+ if 'visual_encoder' in os.listdir(llava_path):
+ assert args.visual_encoder is None, (
+ "Please don't specify the `--visual-encoder` since passed "
+ '`--llava` contains a visual encoder!')
+ visual_encoder_path = osp.join(llava_path, 'visual_encoder')
+ else:
+ assert args.visual_encoder is not None, (
+ 'Please specify the `--visual-encoder`!')
+ visual_encoder_path = args.visual_encoder
+ with LoadWoInit():
+ visual_encoder = CLIPVisionModel.from_pretrained(
+ visual_encoder_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ image_processor = CLIPImageProcessor.from_pretrained(
+ visual_encoder_path)
+ master_print(f'Load visual_encoder from {visual_encoder_path}')
+
+ # load adapter
+ if 'llm_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'llm_adapter')
+
+ with LoadWoInit():
+ llm = PeftModel.from_pretrained(
+ llm, adapter_path, offload_folder=args.offload_folder)
+
+ master_print(f'Load LLM adapter from {args.llava}')
+
+ if 'visual_encoder_adapter' in os.listdir(llava_path):
+ adapter_path = osp.join(llava_path, 'visual_encoder_adapter')
+ visual_encoder = PeftModel.from_pretrained(
+ visual_encoder, adapter_path, offload_folder=args.offload_folder)
+ master_print(f'Load visual_encoder adapter from {args.llava}')
+
+ # build projector
+ projector_path = osp.join(llava_path, 'projector')
+ with LoadWoInit():
+ projector = AutoModel.from_pretrained(
+ projector_path, torch_dtype=TORCH_DTYPE_MAP[args.torch_dtype])
+ master_print(f'Load projector from {args.llava}')
+
+ projector.cuda()
+ projector.eval()
+
+ visual_encoder.cuda()
+ visual_encoder.eval()
+
+ llm.eval()
+
+ stop_words = args.stop_words
+ if args.prompt_template:
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ stop_words += template.get('STOP_WORDS', [])
+ stop_criteria = get_stop_criteria(
+ tokenizer=tokenizer, stop_words=stop_words)
+
+ gen_config = GenerationConfig(
+ max_new_tokens=args.max_new_tokens,
+ do_sample=False,
+ eos_token_id=tokenizer.eos_token_id,
+ pad_token_id=tokenizer.pad_token_id
+ if tokenizer.pad_token_id is not None else tokenizer.eos_token_id,
+ )
+
+ # work_dir
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ save_dir = args.work_dir
+ else:
+ # use config filename as default work_dir
+ save_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.data_path))[0])
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime(time.time()))
+ save_dir = osp.join(save_dir, timestamp)
+
+ if rank == 0:
+ mkdir_or_exist(osp.abspath(save_dir))
+ print('=======================================================')
+ print(f'Dataset path: {osp.abspath(args.data_path)}\n'
+ f'Results will be saved to {osp.abspath(save_dir)}')
+ print('=======================================================')
+
+ args_path = osp.join(save_dir, 'args.json')
+ with open(args_path, 'w', encoding='utf-8') as f:
+ json.dump(args.__dict__, f, indent=2)
+
+ results_xlsx_path = osp.join(save_dir, 'mmbench_result.xlsx')
+ results_json_path = osp.join(save_dir, 'mmbench_result.json')
+
+ dataset = MMBenchDataset(args.data_path)
+
+ results = []
+ n_samples = len(dataset)
+ per_rank_samples = math.ceil(n_samples / world_size)
+
+ per_rank_ids = range(per_rank_samples * rank,
+ min(n_samples, per_rank_samples * (rank + 1)))
+ for i in tqdm.tqdm(per_rank_ids, desc=f'Rank {rank}'):
+ data_sample = dataset[i]
+ if data_sample['context'] is not None:
+ text = data_sample['context'] + '\n' + data_sample[
+ 'question'] + '\n' + data_sample['options']
+ else:
+ text = data_sample['question'] + '\n' + data_sample['options']
+
+ text = DEFAULT_IMAGE_TOKEN + '\n' + text
+
+ if is_cn_string(text):
+ text = text + '请直接回答选项字母。'
+ else:
+ text = text + ("Answer with the option's letter from the "
+ 'given choices directly.')
+
+ if args.prompt_template:
+ prompt_text = ''
+ template = PROMPT_TEMPLATE[args.prompt_template]
+ prompt_text += template['INSTRUCTION'].format(
+ input=text, round=1, bot_name=args.bot_name)
+ else:
+ prompt_text = text
+ inputs = prompt_text
+
+ image = data_sample['img'].convert('RGB')
+ image = expand2square(
+ image, tuple(int(x * 255) for x in image_processor.image_mean))
+ image = image_processor.preprocess(
+ image, return_tensors='pt')['pixel_values'][0]
+ image = image.cuda().unsqueeze(0).to(visual_encoder.dtype)
+ visual_outputs = visual_encoder(image, output_hidden_states=True)
+ pixel_values = projector(
+ visual_outputs.hidden_states[args.visual_select_layer][:, 1:])
+
+ chunk_encode = []
+ for idx, chunk in enumerate(inputs.split(DEFAULT_IMAGE_TOKEN)):
+ if idx == 0:
+ cur_encode = tokenizer.encode(chunk)
+ else:
+ cur_encode = tokenizer.encode(chunk, add_special_tokens=False)
+ chunk_encode.append(cur_encode)
+ assert len(chunk_encode) == 2
+
+ # TODO: Auto-detect whether to prepend a bos_token_id at the beginning.
+ ids = []
+
+ for idx, cur_chunk_encode in enumerate(chunk_encode):
+ ids.extend(cur_chunk_encode)
+ if idx != len(chunk_encode) - 1:
+ ids.append(IMAGE_TOKEN_INDEX)
+ ids = torch.tensor(ids).cuda().unsqueeze(0)
+ mm_inputs = prepare_inputs_labels_for_multimodal(
+ llm=llm, input_ids=ids, pixel_values=pixel_values)
+
+ generate_output = llm.generate(
+ **mm_inputs,
+ generation_config=gen_config,
+ streamer=None,
+ bos_token_id=tokenizer.bos_token_id,
+ stopping_criteria=stop_criteria)
+
+ predict = tokenizer.decode(
+ generate_output[0], skip_special_tokens=True).strip()
+ cur_result = {}
+ cur_result['question'] = data_sample.get('question')
+ cur_result.update(data_sample.get('options_dict'))
+ cur_result['prediction'] = predict
+ if data_sample.get('category') is not None:
+ cur_result['category'] = data_sample.get('category')
+ if data_sample.get('l2-category') is not None:
+ cur_result['l2-category'] = data_sample.get('l2-category')
+ cur_result['index'] = data_sample.get('index')
+ cur_result['split'] = data_sample.get('split')
+ cur_result['answer'] = data_sample.get('answer')
+ results.append(cur_result)
+
+ results = collect_results(results, n_samples)
+
+ if get_rank() == 0:
+
+ results_df = pd.DataFrame(results)
+ with pd.ExcelWriter(results_xlsx_path, engine='openpyxl') as writer:
+ results_df.to_excel(writer, index=False)
+
+ if dataset.split == 'dev':
+ results_dict = dataset.eval_result(results_df, show=True)
+ with open(results_json_path, 'w', encoding='utf-8') as f:
+ json.dump(results_dict, f, indent=2)
+ else:
+ print('All done!')
+
+
+if __name__ == '__main__':
+
+ main()
diff --git a/data/xtuner/xtuner/tools/model_converters/merge.py b/data/xtuner/xtuner/tools/model_converters/merge.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7202a6633aa4f42e4082c81048a0053fd9e64c6
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/merge.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import torch
+from peft import PeftModel
+from transformers import (AutoModelForCausalLM, AutoTokenizer,
+ CLIPImageProcessor, CLIPVisionModel)
+
+from xtuner.model.utils import LoadWoInit
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Merge a HuggingFace adapter to base model')
+ parser.add_argument('model_name_or_path', help='model name or path')
+ parser.add_argument('adapter_name_or_path', help='adapter name or path')
+ parser.add_argument(
+ 'save_dir', help='the directory to save the merged model')
+ parser.add_argument(
+ '--max-shard-size',
+ type=str,
+ default='2GB',
+ help='Only applicable for LLM. The maximum size for '
+ 'each sharded checkpoint.')
+ parser.add_argument(
+ '--is-clip',
+ action='store_true',
+ help='Indicate if the model is a clip model')
+ parser.add_argument(
+ '--safe-serialization',
+ action='store_true',
+ help='Indicate if using `safe_serialization`')
+ parser.add_argument(
+ '--device',
+ default='cuda',
+ choices=('cuda', 'cpu', 'auto'),
+ help='Indicate the device')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ if args.is_clip:
+ with LoadWoInit():
+ model = CLIPVisionModel.from_pretrained(
+ args.model_name_or_path, device_map=args.device)
+ processor = CLIPImageProcessor.from_pretrained(args.model_name_or_path)
+ else:
+ with LoadWoInit():
+ model = AutoModelForCausalLM.from_pretrained(
+ args.model_name_or_path,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ device_map=args.device,
+ trust_remote_code=True)
+ processor = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, trust_remote_code=True)
+ model_unmerged = PeftModel.from_pretrained(
+ model,
+ args.adapter_name_or_path,
+ device_map=args.device,
+ is_trainable=False,
+ trust_remote_code=True)
+ model_merged = model_unmerged.merge_and_unload()
+ print(f'Saving to {args.save_dir}...')
+ model_merged.save_pretrained(
+ args.save_dir,
+ safe_serialization=args.safe_serialization,
+ max_shard_size=args.max_shard_size)
+ processor.save_pretrained(args.save_dir)
+ print('All done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/__init__.py b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/configuration_internlm2.py b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/configuration_internlm2.py
new file mode 100644
index 0000000000000000000000000000000000000000..12fdffe28ca875049873cfd010ac59ddf68af6c2
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/configuration_internlm2.py
@@ -0,0 +1,154 @@
+# coding=utf-8
+# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on transformers/src/transformers/models/llama/configuration_llama.py
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" InternLM2 model configuration"""
+
+from transformers.configuration_utils import PretrainedConfig
+from transformers.utils import logging
+
+logger = logging.get_logger(__name__)
+
+INTERNLM2_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+
+# Modified from transformers.model.llama.configuration_llama.LlamaConfig
+class InternLM2Config(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`InternLM2Model`]. It is used to instantiate
+ an InternLM2 model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the InternLM2-7B.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the InternLM2 model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`InternLM2Model`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 11008):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 2048):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ tie_word_embeddings(`bool`, *optional*, defaults to `False`):
+ Whether to tie weight embeddings
+ Example:
+
+ """
+ model_type = "internlm2"
+ _auto_class = "AutoConfig"
+
+ def __init__( # pylint: disable=W0102
+ self,
+ vocab_size=103168,
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=None,
+ hidden_act="silu",
+ max_position_embeddings=2048,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ reward_token_id=92527,
+ tie_word_embeddings=False,
+ bias=True,
+ rope_theta=10000,
+ rope_scaling=None,
+ attn_implementation="eager",
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.bias = bias
+
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self._rope_scaling_validation()
+
+ self.attn_implementation = attn_implementation
+ if self.attn_implementation is None:
+ self.attn_implementation = "eager"
+
+ self.reward_token_id = reward_token_id
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+
+ def _rope_scaling_validation(self):
+ """
+ Validate the `rope_scaling` configuration.
+ """
+ if self.rope_scaling is None:
+ return
+
+ if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
+ raise ValueError(
+ "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
+ f"got {self.rope_scaling}"
+ )
+ rope_scaling_type = self.rope_scaling.get("type", None)
+ rope_scaling_factor = self.rope_scaling.get("factor", None)
+ if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
+ raise ValueError(
+ f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
+ )
+ if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor < 1.0:
+ raise ValueError(f"`rope_scaling`'s factor field must be a float >= 1, got {rope_scaling_factor}")
diff --git a/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/modeling_internlm2.py b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/modeling_internlm2.py
new file mode 100644
index 0000000000000000000000000000000000000000..59cba84567a2c6871bdf45d12a0753a663ea87dc
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/modeling_internlm2_reward/modeling_internlm2.py
@@ -0,0 +1,1578 @@
+# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on transformers/src/transformers/models/llama/modeling_llama.py
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch InternLM2 model."""
+import math
+import queue
+import threading
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from einops import rearrange
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPast,
+ CausalLMOutputWithPast,
+ SequenceClassifierOutputWithPast,
+)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+
+try:
+ from transformers.generation.streamers import BaseStreamer
+except: # noqa # pylint: disable=bare-except
+ BaseStreamer = None
+
+from .configuration_internlm2 import InternLM2Config
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "InternLM2Config"
+
+flash_attn_func, flash_attn_varlen_func = None, None
+pad_input, index_first_axis, unpad_input = None, None, None
+def _import_flash_attn():
+ global flash_attn_func, flash_attn_varlen_func
+ global pad_input, index_first_axis, unpad_input
+ try:
+ from flash_attn import flash_attn_func as _flash_attn_func, flash_attn_varlen_func as _flash_attn_varlen_func
+ from flash_attn.bert_padding import pad_input as _pad_input, index_first_axis as _index_first_axis, unpad_input as _unpad_input
+ flash_attn_func, flash_attn_varlen_func = _flash_attn_func, _flash_attn_varlen_func
+ pad_input, index_first_axis, unpad_input = _pad_input, _index_first_axis, _unpad_input
+ except ImportError:
+ raise ImportError("flash_attn is not installed.")
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+# Copied from transformers.models.bart.modeling_bart._make_causal_mask
+def _make_causal_mask(
+ input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
+):
+ """
+ Make causal mask used for bi-directional self-attention.
+ """
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)
+ mask_cond = torch.arange(mask.size(-1), device=device)
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
+
+
+# Copied from transformers.models.bart.modeling_bart._expand_mask
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->InternLM2
+class InternLM2RMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ InternLM2RMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaRotaryEmbedding with Llama->InternLM2
+class InternLM2RotaryEmbedding(nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
+ )
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=torch.float32)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->InternLM2
+class InternLM2LinearScalingRotaryEmbedding(InternLM2RotaryEmbedding):
+ """InternLM2RotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ t = t / self.scaling_factor
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->InternLM2
+class InternLM2DynamicNTKScalingRotaryEmbedding(InternLM2RotaryEmbedding):
+ """InternLM2RotaryEmbedding extended with Dynamic NTK scaling.
+ Credits to the Reddit users /u/bloc97 and /u/emozilla.
+ """
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+
+ if seq_len > self.max_position_embeddings:
+ base = self.base * (
+ (self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
+ ) ** (self.dim / (self.dim - 2))
+ inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.model.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.model.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors."""
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class InternLM2MLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.w1 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.w3 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.w2 = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.w2(self.act_fn(self.w1(x)) * self.w3(x))
+
+ return down_proj
+
+
+# Copied from transformers.model.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+# Modified from transformers.model.llama.modeling_llama.LlamaAttention
+class InternLM2Attention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: InternLM2Config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.is_causal = True
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
+ f" and `num_heads`: {self.num_heads})."
+ )
+
+ self.wqkv = nn.Linear(
+ self.hidden_size,
+ (self.num_heads + 2 * self.num_key_value_heads) * self.head_dim,
+ bias=config.bias,
+ )
+
+ self.wo = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.bias)
+ self._init_rope()
+
+ def _init_rope(self):
+ if self.config.rope_scaling is None:
+ self.rotary_emb = InternLM2RotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.config.rope_theta,
+ )
+ else:
+ scaling_type = self.config.rope_scaling["type"]
+ scaling_factor = self.config.rope_scaling["factor"]
+ if scaling_type == "dynamic":
+ self.rotary_emb = InternLM2DynamicNTKScalingRotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.config.rope_theta,
+ scaling_factor=scaling_factor,
+ )
+ elif scaling_type == "linear":
+ self.rotary_emb = InternLM2LinearScalingRotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.config.rope_theta,
+ scaling_factor=scaling_factor,
+ )
+ else:
+ raise ValueError("Currently we only support rotary embedding's type being 'dynamic' or 'linear'.")
+ return self.rotary_emb
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ "b q (h gs d) -> b q h gs d",
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., : self.num_key_value_groups, :]
+ query_states = rearrange(query_states, "b q h gs d -> b q (h gs) d")
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.wo(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+# Modified from transformers.model.llama.modeling_llama.InternLM2FlashAttention2
+class InternLM2FlashAttention2(InternLM2Attention):
+ """
+ InternLM2 flash attention module. This module inherits from `InternLM2Attention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ # InternLM2FlashAttention2 attention does not support output_attentions
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ qkv_states = self.wqkv(hidden_states)
+
+ qkv_states = rearrange(
+ qkv_states,
+ "b q (h gs d) -> b q h gs d",
+ gs=2 + self.num_key_value_groups,
+ d=self.head_dim,
+ )
+
+ query_states = qkv_states[..., : self.num_key_value_groups, :]
+ query_states = rearrange(query_states, "b q h gs d -> b q (h gs) d")
+ key_states = qkv_states[..., -2, :]
+ value_states = qkv_states[..., -1, :]
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ attn_output = self._flash_attention_forward(
+ query_states, key_states, value_states, attention_mask, q_len
+ )
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
+ attn_output = self.wo(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`int`, *optional*):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ """
+ # Contains at least one padding token in the sequence
+ causal = self.is_causal and query_length != 1
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._unpad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
+ )
+
+ return attn_output
+
+ def _unpad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q.to(torch.int64),
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+INTERNLM2_ATTENTION_CLASSES = {
+ "eager": InternLM2Attention,
+ "flash_attention_2": InternLM2FlashAttention2,
+}
+
+# Modified from transformers.model.llama.modeling_llama.LlamaDecoderLayer
+class InternLM2DecoderLayer(nn.Module):
+ def __init__(self, config: InternLM2Config):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.attention = INTERNLM2_ATTENTION_CLASSES[config.attn_implementation](config=config)
+
+ self.feed_forward = InternLM2MLP(config)
+ self.attention_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.ffn_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*):
+ attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
+ query_sequence_length, key_sequence_length)` if default attention is used.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+
+ residual = hidden_states
+
+ hidden_states = self.attention_norm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.attention(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.ffn_norm(hidden_states)
+ hidden_states = self.feed_forward(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+InternLM2_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`InternLM2Config`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaPreTrainedModel with Llama->InternLM2
+@add_start_docstrings(
+ "The bare InternLM2 Model outputting raw hidden-states without any specific head on top.",
+ InternLM2_START_DOCSTRING,
+)
+class InternLM2PreTrainedModel(PreTrainedModel):
+ config_class = InternLM2Config
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["InternLM2DecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+InternLM2_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or
+ when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, decoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# Modified from transformers.model.llama.modeling_llama.LlamaModel
+@add_start_docstrings(
+ "The bare InternLM2 Model outputting raw hidden-states without any specific head on top.",
+ InternLM2_START_DOCSTRING,
+)
+class InternLM2Model(InternLM2PreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`InternLM2DecoderLayer`]
+
+ Args:
+ config: InternLM2Config
+ """
+
+ _auto_class = "AutoModel"
+
+ def __init__(self, config: InternLM2Config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+ self.config = config
+
+ self.tok_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+
+ self.layers = nn.ModuleList([InternLM2DecoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.tok_embeddings = value
+
+ def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ inputs_embeds.dtype,
+ device=inputs_embeds.device,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
+ inputs_embeds.device
+ )
+ combined_attention_mask = (
+ expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
+ )
+
+ return combined_attention_mask
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if self.config.attn_implementation == "flash_attention_2":
+ _import_flash_attn()
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape[:2]
+ elif inputs_embeds is not None:
+ batch_size, seq_length = inputs_embeds.shape[:2]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.tok_embeddings(input_ids)
+
+ if self.config.attn_implementation == "flash_attention_2":
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ else:
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ (batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
+ )
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
+ )
+
+ # embed positions
+ hidden_states = inputs_embeds
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ for idx, decoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, output_attentions, None)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ position_ids,
+ None,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+# Modified from transformers.model.llama.modeling_llama.LlamaForCausalLM
+class InternLM2ForCausalLM(InternLM2PreTrainedModel):
+ _auto_class = "AutoModelForCausalLM"
+
+ _tied_weights_keys = ["output.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = InternLM2Model(config)
+ self.vocab_size = config.vocab_size
+ self.output = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.model.tok_embeddings = value
+
+ def get_output_embeddings(self):
+ return self.output
+
+ def set_output_embeddings(self, new_embeddings):
+ self.output = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, InternLM2ForCausalLM
+
+ >>> model = InternLM2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.output(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
+ ):
+ if past_key_values is not None:
+ past_length = past_key_values[0][0].shape[2]
+
+ # Some generation methods already pass only the last input ID
+ if input_ids.shape[1] > past_length:
+ remove_prefix_length = past_length
+ else:
+ # Default to old behavior: keep only final ID
+ remove_prefix_length = input_ids.shape[1] - 1
+
+ input_ids = input_ids[:, remove_prefix_length:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (
+ tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
+ )
+ return reordered_past
+
+ def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = [], meta_instruction=""):
+ if tokenizer.add_bos_token:
+ prompt = ""
+ else:
+ prompt = tokenizer.bos_token
+ if meta_instruction:
+ prompt += f"""<|im_start|>system\n{meta_instruction}<|im_end|>\n"""
+ for record in history:
+ prompt += f"""<|im_start|>user\n{record[0]}<|im_end|>\n<|im_start|>assistant\n{record[1]}<|im_end|>\n"""
+ prompt += f"""<|im_start|>user\n{query}<|im_end|>\n<|im_start|>assistant\n"""
+ return tokenizer([prompt], return_tensors="pt")
+
+ @torch.no_grad()
+ def chat(
+ self,
+ tokenizer,
+ query: str,
+ history: List[Tuple[str, str]] = [],
+ streamer: Optional[BaseStreamer] = None,
+ max_new_tokens: int = 1024,
+ do_sample: bool = True,
+ temperature: float = 0.8,
+ top_p: float = 0.8,
+ meta_instruction: str = "You are an AI assistant whose name is InternLM (书生·浦语).\n"
+ "- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.\n"
+ "- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.",
+ **kwargs,
+ ):
+ inputs = self.build_inputs(tokenizer, query, history, meta_instruction)
+ inputs = {k: v.to(self.device) for k, v in inputs.items() if torch.is_tensor(v)}
+ # also add end-of-assistant token in eos token id to avoid unnecessary generation
+ eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids(["<|im_end|>"])[0]]
+ outputs = self.generate(
+ **inputs,
+ streamer=streamer,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ temperature=temperature,
+ top_p=top_p,
+ eos_token_id=eos_token_id,
+ **kwargs,
+ )
+ outputs = outputs[0].cpu().tolist()[len(inputs["input_ids"][0]) :]
+ response = tokenizer.decode(outputs, skip_special_tokens=True)
+ response = response.split("<|im_end|>")[0]
+ history = history + [(query, response)]
+ return response, history
+
+ @torch.no_grad()
+ def stream_chat(
+ self,
+ tokenizer,
+ query: str,
+ history: List[Tuple[str, str]] = [],
+ max_new_tokens: int = 1024,
+ do_sample: bool = True,
+ temperature: float = 0.8,
+ top_p: float = 0.8,
+ **kwargs,
+ ):
+ """
+ Return a generator in format: (response, history)
+ Eg.
+ ('你好,有什么可以帮助您的吗', [('你好', '你好,有什么可以帮助您的吗')])
+ ('你好,有什么可以帮助您的吗?', [('你好', '你好,有什么可以帮助您的吗?')])
+ """
+ if BaseStreamer is None:
+ raise ModuleNotFoundError(
+ "The version of `transformers` is too low. Please make sure "
+ "that you have installed `transformers>=4.28.0`."
+ )
+
+ response_queue = queue.Queue(maxsize=20)
+
+ class ChatStreamer(BaseStreamer):
+ def __init__(self, tokenizer) -> None:
+ super().__init__()
+ self.tokenizer = tokenizer
+ self.queue = response_queue
+ self.query = query
+ self.history = history
+ self.response = ""
+ self.cache = []
+ self.received_inputs = False
+ self.queue.put((self.response, history + [(self.query, self.response)]))
+
+ def put(self, value):
+ if len(value.shape) > 1 and value.shape[0] > 1:
+ raise ValueError("ChatStreamer only supports batch size 1")
+ elif len(value.shape) > 1:
+ value = value[0]
+
+ if not self.received_inputs:
+ # The first received value is input_ids, ignore here
+ self.received_inputs = True
+ return
+
+ self.cache.extend(value.tolist())
+ token = self.tokenizer.decode(self.cache, skip_special_tokens=True)
+ if token.strip() != "<|im_end|>":
+ self.response = self.response + token
+ history = self.history + [(self.query, self.response)]
+ self.queue.put((self.response, history))
+ self.cache = []
+ else:
+ self.end()
+
+ def end(self):
+ self.queue.put(None)
+
+ def stream_producer():
+ return self.chat(
+ tokenizer=tokenizer,
+ query=query,
+ streamer=ChatStreamer(tokenizer=tokenizer),
+ history=history,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ temperature=temperature,
+ top_p=top_p,
+ **kwargs,
+ )
+
+ def consumer():
+ producer = threading.Thread(target=stream_producer)
+ producer.start()
+ while True:
+ res = response_queue.get()
+ if res is None:
+ return
+ yield res
+
+ return consumer()
+
+# Modified from transformers.model.llama.modeling_llama.LlamaForCausalLM
+class InternLM2ForRewardModel(InternLM2PreTrainedModel):
+
+ _auto_class = "AutoModel"
+ _tied_weights_keys = ["v_head.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = InternLM2Model(config)
+ self.vocab_size = config.vocab_size
+ self.v_head = nn.Linear(config.hidden_size, 1, bias=False)
+ self.reward_token_id = config.reward_token_id
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.model.tok_embeddings = value
+
+ def get_output_embeddings(self):
+ return self.v_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.v_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=SequenceClassifierOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, InternLM2ForCausalLM
+
+ >>> model = InternLM2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ hidden_states = self.v_head(hidden_states)
+ # get end reward token's score
+ ends = attention_mask.cumsum(dim=1).argmax(dim=1).view(-1,1)
+
+ reward_scores = torch.gather(hidden_states.squeeze(-1), 1, ends)
+
+ loss = None
+
+ if not return_dict:
+ output = (reward_scores,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=reward_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ @torch.no_grad()
+ def get_score(
+ self,
+ tokenizer,
+ conversation: List[dict],
+ **kwargs,
+ ):
+ conversation_str = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=False)
+ input_ids = tokenizer.encode(conversation_str, return_tensors="pt", add_special_tokens=False)
+ # add reward score token at the end of the input_ids
+ input_ids = torch.cat([input_ids, torch.tensor([[self.reward_token_id]], dtype=torch.long)], dim=1).to(self.device)
+ attention_mask = torch.ones_like(input_ids, dtype=torch.bool).to(self.device)
+
+ outputs = self.forward(input_ids=input_ids, attention_mask=attention_mask, **kwargs)
+ score = outputs[0].cpu().item()
+ return score
+
+ @torch.no_grad()
+ def get_scores(
+ self,
+ tokenizer,
+ conversations: List[List[dict]],
+ **kwargs,
+ ):
+ conversation_strs = [tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=False) for conversation in conversations]
+ batch_input_ids = []
+ attention_masks = []
+
+ for conversation_str in conversation_strs:
+ input_ids = tokenizer.encode(conversation_str, return_tensors="pt", add_special_tokens=False)
+ input_ids = torch.cat([input_ids, torch.tensor([[self.reward_token_id]], dtype=torch.long)], dim=1).squeeze(0)
+ attention_mask = torch.ones(input_ids.shape, dtype=torch.bool)
+ batch_input_ids.append(input_ids)
+ attention_masks.append(attention_mask)
+
+ r_pad_batch_input_ids = torch.nn.utils.rnn.pad_sequence(batch_input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
+ r_pad_attention_masks = torch.nn.utils.rnn.pad_sequence(attention_masks, batch_first=True, padding_value=False)
+
+ outputs = self.forward(input_ids=r_pad_batch_input_ids.to(self.device), attention_mask=r_pad_attention_masks.to(self.device), **kwargs)
+ scores = outputs[0].cpu().tolist()
+ return scores
+
+ @torch.no_grad()
+ def compare(
+ self,
+ tokenizer,
+ conversation1: List[dict],
+ conversation2: List[dict],
+ return_logits: bool = False,
+ **kwargs,
+ ):
+ score1 = self.get_score(tokenizer, conversation1, **kwargs)
+ score2 = self.get_score(tokenizer, conversation2, **kwargs)
+ if return_logits:
+ return score1, score2
+ else:
+ return score1 > score2
+
+ @torch.no_grad()
+ def rank(
+ self,
+ tokenizer,
+ conversations: List[List[dict]],
+ return_logits: bool = False,
+ **kwargs,
+ ):
+ scores = self.get_scores(tokenizer, conversations, **kwargs)
+ if return_logits:
+ return scores
+ else:
+ return sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)
+
+
+# Copied from transformers.model.llama.modeling_llama.LlamaForSequenceClassification with Llama->InternLM2
+@add_start_docstrings(
+ """
+ The InternLM2 Model transformer with a sequence classification head on top (linear layer).
+
+ [`InternLM2ForSequenceClassification`] uses the last token in order to do the classification,
+ as other causal models (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ InternLM2_START_DOCSTRING,
+)
+class InternLM2ForSequenceClassification(InternLM2PreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = InternLM2Model(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.tok_embeddings
+
+ def set_input_embeddings(self, value):
+ self.model.tok_embeddings = value
+
+ @add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1).to(
+ logits.device
+ )
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/data/xtuner/xtuner/tools/model_converters/pth_to_hf.py b/data/xtuner/xtuner/tools/model_converters/pth_to_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a4b28883281960a1cbda7193c0144e5b41d2e74
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/pth_to_hf.py
@@ -0,0 +1,142 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import shutil
+import warnings
+
+from accelerate import init_empty_weights
+from accelerate.utils import set_module_tensor_to_device
+from mmengine import print_log
+from mmengine.config import Config, DictAction
+from mmengine.fileio import PetrelBackend, get_file_backend
+from mmengine.utils import mkdir_or_exist
+from tqdm import tqdm
+
+from xtuner.configs import cfgs_name_path
+from xtuner.model.utils import guess_load_checkpoint
+from xtuner.registry import BUILDER
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert the pth model to HuggingFace model')
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('pth_model', help='pth model file')
+ parser.add_argument(
+ 'save_dir', help='the directory to save HuggingFace model')
+ parser.add_argument(
+ '--fp32',
+ action='store_true',
+ help='Save LLM in fp32. If not set, fp16 will be used by default.')
+ parser.add_argument(
+ '--max-shard-size',
+ type=str,
+ default='2GB',
+ help='Only applicable for LLM. The maximum size for '
+ 'each sharded checkpoint.')
+ parser.add_argument(
+ '--safe-serialization',
+ action='store_true',
+ help='Indicate if using `safe_serialization`')
+ parser.add_argument(
+ '--save-format',
+ default='xtuner',
+ choices=('xtuner', 'official', 'huggingface'),
+ help='Only applicable for LLaVAModel. Indicate the save format.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # parse config
+ if not osp.isfile(args.config):
+ try:
+ args.config = cfgs_name_path[args.config]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.config}')
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ model_name = cfg.model.type if isinstance(cfg.model.type,
+ str) else cfg.model.type.__name__
+ use_meta_init = True
+
+ if 'LLaVAModel' in model_name:
+ cfg.model.pretrained_pth = None
+ if args.save_format != 'xtuner':
+ use_meta_init = False
+ if 'Reward' in model_name:
+ use_meta_init = False
+ cfg.model.llm.pop('quantization_config', None)
+ if hasattr(cfg.model.llm, 'quantization_config'):
+ # Can not build a qlora model on meta device
+ use_meta_init = False
+
+ if use_meta_init:
+ try:
+ # Initializing the model with meta-tensor can reduce unwanted
+ # memory usage.
+ with init_empty_weights():
+ with warnings.catch_warnings():
+ warnings.filterwarnings(
+ 'ignore', message='.*non-meta.*', category=UserWarning)
+ model = BUILDER.build(cfg.model)
+ except NotImplementedError as e:
+ # Cannot initialize the model with meta tensor if the model is
+ # quantized.
+ if 'Cannot copy out of meta tensor' in str(e):
+ model = BUILDER.build(cfg.model)
+ else:
+ raise e
+ else:
+ model = BUILDER.build(cfg.model)
+
+ backend = get_file_backend(args.pth_model)
+ if isinstance(backend, PetrelBackend):
+ from xtuner.utils.fileio import patch_fileio
+ with patch_fileio():
+ state_dict = guess_load_checkpoint(args.pth_model)
+ else:
+ state_dict = guess_load_checkpoint(args.pth_model)
+
+ for name, param in tqdm(state_dict.items(), desc='Load State Dict'):
+ set_module_tensor_to_device(model, name, 'cpu', param)
+
+ model.llm.config.use_cache = True
+
+ print_log(f'Load PTH model from {args.pth_model}', 'current')
+
+ mkdir_or_exist(args.save_dir)
+
+ save_pretrained_kwargs = {
+ 'max_shard_size': args.max_shard_size,
+ 'safe_serialization': args.safe_serialization
+ }
+ model.to_hf(
+ cfg=cfg,
+ save_dir=args.save_dir,
+ fp32=args.fp32,
+ save_pretrained_kwargs=save_pretrained_kwargs,
+ save_format=args.save_format)
+
+ shutil.copyfile(args.config, osp.join(args.save_dir, 'xtuner_config.py'))
+ print_log('All done!', 'current')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/model_converters/split.py b/data/xtuner/xtuner/tools/model_converters/split.py
new file mode 100644
index 0000000000000000000000000000000000000000..da0e4d7b765a135ed8437c68befdb070da4a265a
--- /dev/null
+++ b/data/xtuner/xtuner/tools/model_converters/split.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import copy
+import json
+import os
+import os.path as osp
+import shutil
+
+import torch
+from mmengine.utils import mkdir_or_exist
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Split a HuggingFace model to the smallest sharded one')
+ parser.add_argument('src_dir', help='the directory of the model')
+ parser.add_argument('dst_dir', help='the directory to save the new model')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ mkdir_or_exist(args.dst_dir)
+
+ all_files = os.listdir(args.src_dir)
+ for name in all_files:
+ if not name.startswith(('pytorch_model', '.')):
+ src_path = osp.join(args.src_dir, name)
+ dst_path = osp.join(args.dst_dir, name)
+ shutil.copy(src_path, dst_path)
+
+ with open(osp.join(args.src_dir, 'pytorch_model.bin.index.json')) as f:
+ index = json.load(f)
+
+ n_shard = len(index['weight_map'])
+ new_index = copy.deepcopy(index)
+ new_index['weight_map'] = {}
+ cnt = 1
+
+ checkpoints = set(index['weight_map'].values())
+ for ckpt in checkpoints:
+ state_dict = torch.load(
+ osp.join(args.src_dir, ckpt), map_location='cuda')
+ keys = sorted(list(state_dict.keys()))
+ for k in keys:
+ new_state_dict_name = 'pytorch_model-{:05d}-of-{:05d}.bin'.format(
+ cnt, n_shard)
+ new_index['weight_map'][k] = new_state_dict_name
+ new_state_dict = {k: state_dict[k]}
+ torch.save(new_state_dict,
+ osp.join(args.dst_dir, new_state_dict_name))
+ cnt += 1
+ del state_dict
+ torch.cuda.empty_cache()
+ with open(osp.join(args.dst_dir, 'pytorch_model.bin.index.json'),
+ 'w') as f:
+ json.dump(new_index, f)
+ assert new_index['weight_map'].keys() == index['weight_map'].keys(
+ ), 'Mismatch on `weight_map`!'
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/plugins/__init__.py b/data/xtuner/xtuner/tools/plugins/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b893bcac8976bed61f0526d57f22a118b6c6b848
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .api import plugins_api
+
+__all__ = ['plugins_api']
diff --git a/data/xtuner/xtuner/tools/plugins/api.py b/data/xtuner/xtuner/tools/plugins/api.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ac6579d6152564e4c7e5d885e06b39b8a03c65f
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/api.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+
+
+def plugins_api(input_str,
+ calculate_open=True,
+ solve_open=True,
+ search_open=True):
+
+ pattern = r'(Solve|solve|Solver|solver|Calculate|calculate|Calculator|calculator|Search)\("([^"]*)"\)' # noqa: E501
+
+ matches = re.findall(pattern, input_str)
+
+ converted_str = '<|Results|>:\n'
+
+ for i in range(len(matches)):
+ if matches[i][0] in [
+ 'Calculate', 'calculate'
+ 'Calculator', 'calculator'
+ ]:
+ if calculate_open:
+ from .calculate import Calculate
+ result = Calculate(matches[i][1])
+ else:
+ result = None
+ converted_str += f"Calculate(\"{matches[i][1]}\") => {result}\n"
+ elif matches[i][0] in ['Solve', 'solve', 'Solver', 'solver']:
+ if solve_open:
+ from .solve import Solve
+ result = Solve(matches[i][1])
+ else:
+ result = None
+ converted_str += f"Solve(\"{matches[i][1]}\") =>\n{result}\n"
+ elif matches[i][0] == 'Search':
+ if search_open:
+ from .search import Search
+ result = Search(matches[i][1])
+ else:
+ result = None
+ converted_str += f"Search(\"{matches[i][1]}\") =>\n{result}"
+
+ converted_str += '\n'
+ return converted_str
diff --git a/data/xtuner/xtuner/tools/plugins/calculate.py b/data/xtuner/xtuner/tools/plugins/calculate.py
new file mode 100644
index 0000000000000000000000000000000000000000..48ed436cbeddd35de34fbb26d1f6f1e7d85fa810
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/calculate.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from math import * # noqa: F401, F403
+
+
+def Calculate(expression):
+ res = ''
+ for exp in expression.split(';'):
+ try:
+ res += '{:.2f};'.format(eval(exp.replace('^', '**')))
+ except Exception:
+ res += 'No result.'
+ if res[-1] == ';':
+ res = res[:-1]
+ return res
diff --git a/data/xtuner/xtuner/tools/plugins/search.py b/data/xtuner/xtuner/tools/plugins/search.py
new file mode 100644
index 0000000000000000000000000000000000000000..392bc86204fd43a7312bfd3ed13a30aef9fc4f42
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/search.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import sys
+
+import requests
+
+try:
+ SERPER_API_KEY = os.environ['SERPER_API_KEY']
+except Exception:
+ print('Please obtain the `SERPER_API_KEY` from https://serper.dev and '
+ 'set it using `export SERPER_API_KEY=xxx`.')
+ sys.exit(1)
+
+
+def parse_results(results, k=10):
+ snippets = []
+
+ for result in results['organic'][:k]:
+ if 'snippet' in result:
+ snippets.append(result['snippet'])
+ for attribute, value in result.get('attributes', {}).items():
+ snippets.append(f'{attribute}: {value}.')
+ return snippets
+
+
+def search(api_key, search_term, **kwargs):
+ headers = {
+ 'X-API-KEY': api_key,
+ 'Content-Type': 'application/json',
+ }
+ params = {
+ 'q': search_term,
+ **{key: value
+ for key, value in kwargs.items() if value is not None},
+ }
+ try:
+ response = requests.post(
+ 'https://google.serper.dev/search',
+ headers=headers,
+ params=params,
+ timeout=5)
+ except Exception as e:
+ return -1, str(e)
+ return response.status_code, response.json()
+
+
+def Search(q, k=10):
+ status_code, response = search(SERPER_API_KEY, q)
+ if status_code != 200:
+ ret = 'None\n'
+ else:
+ text = parse_results(response, k=k)
+ ret = ''
+ for idx, res in enumerate(text):
+ ret += f"<|{idx+1}|>: '{res}'\n"
+ return ret
diff --git a/data/xtuner/xtuner/tools/plugins/solve.py b/data/xtuner/xtuner/tools/plugins/solve.py
new file mode 100644
index 0000000000000000000000000000000000000000..20266a23f492cc5e7264d1a46398d64c94267579
--- /dev/null
+++ b/data/xtuner/xtuner/tools/plugins/solve.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import re
+from math import * # noqa: F401, F403
+
+from sympy import Eq, solve, symbols
+
+from .calculate import Calculate
+
+
+def Solve(equations_str):
+ try:
+ equations_str = equations_str.replace(' ', '')
+ equations_ori = re.split(r'[,;]+', equations_str)
+ equations_str = equations_str.replace('^', '**')
+ equations_str = re.sub(r'(\(.*\))([a-zA-Z])', r'\1 * \2',
+ equations_str)
+ equations_str = re.sub(r'(\d+)([a-zA-Z])', r'\1 * \2', equations_str)
+ equations_str = equations_str.replace('pi', str(math.pi))
+ equations = re.split(r'[,;]+', equations_str)
+ vars_list = list(set(re.findall(r'[a-zA-Z]+', equations_str)))
+ vars = {var: symbols(var) for var in vars_list}
+
+ output = ''
+ eqs = []
+ for eq in equations:
+ if '=' in eq:
+ left, right = eq.split('=')
+ eqs.append(
+ Eq(
+ eval(left.strip(), {}, vars),
+ eval(right.strip(), {}, vars)))
+ solutions = solve(eqs, vars, dict=True)
+
+ vars_values = {var: [] for var in vars_list}
+ if isinstance(solutions, list):
+ for idx, solution in enumerate(solutions):
+ for var, sol in solution.items():
+ output += f'{var}_{idx} = {sol}\n'
+ vars_values[str(var)].append(sol)
+ else:
+ for var, sol in solutions.items():
+ output += f'{var} = {sol}\n'
+ vars_values[str(var)].append(sol)
+ for eq, eq_o in zip(equations, equations_ori):
+ if '=' not in eq:
+ for var in vars_list:
+ need_note = True if len(vars_values[var]) > 1 else False
+ for idx, value in enumerate(vars_values[var]):
+ eq_to_calc = eq.replace(var, str(value))
+ calc_result = Calculate(eq_to_calc)
+ if need_note:
+ eq_name = eq_o.replace(var, f'{var}_{idx}')
+ else:
+ eq_name = eq_o
+ if calc_result != 'No results.':
+ output += f'{eq_name} = {calc_result}\n'
+
+ return output.strip()
+ except Exception:
+ return 'No result.'
diff --git a/data/xtuner/xtuner/tools/process_untokenized_datasets.py b/data/xtuner/xtuner/tools/process_untokenized_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..c41905ee6daaebca1f9e546b5588c6d627baea39
--- /dev/null
+++ b/data/xtuner/xtuner/tools/process_untokenized_datasets.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import warnings
+
+from mmengine import Config, ConfigDict
+from mmengine.config.lazy import LazyObject
+
+from xtuner.registry import BUILDER
+
+# ignore FutureWarning in hf datasets
+warnings.simplefilter(action='ignore', category=FutureWarning)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ args = parser.parse_args()
+ return args
+
+
+def modify_config(config, dataset_save_folder):
+ dataset = ConfigDict(
+ type=LazyObject('datasets', 'load_from_disk'),
+ dataset_path=dataset_save_folder)
+ train_dataset = ConfigDict(
+ type=LazyObject('xtuner.dataset', 'process_hf_dataset'),
+ dataset=dataset,
+ do_dataset_tokenization=False,
+ tokenizer=None,
+ max_length=None,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ max_dataset_length=None,
+ split=None,
+ remove_unused_columns=False,
+ rename_maps=[],
+ pack_to_max_length=False,
+ input_ids_with_output=False)
+ config.train_dataloader.dataset = train_dataset
+ return config
+
+
+def process_untokenized_dataset(config):
+ dataset = BUILDER.build(config.train_dataloader.dataset)
+ return dataset
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+
+ print('Start to process untokenized dataset...')
+ processed_dataset = process_untokenized_dataset(cfg)
+ print('Processing untokenized dataset finished.')
+
+ processed_dataset_save_folder = args.save_folder
+ if not os.path.isabs(processed_dataset_save_folder):
+ processed_dataset_save_folder = os.path.join(
+ os.getcwd(), processed_dataset_save_folder)
+ modified_cfg = modify_config(cfg, processed_dataset_save_folder)
+
+ print('Start to save processed dataset...')
+ processed_dataset.save_to_disk(processed_dataset_save_folder)
+ print(
+ f'Processed dataset has been saved to {processed_dataset_save_folder}')
+
+ cfg_folder, cfg_file_name = os.path.split(args.config)
+ cfg_file_name = cfg_file_name.split('.')[0]
+ cfg_file_name = f'{cfg_file_name}_modified.py'
+ modified_cfg_save_path = os.path.join(cfg_folder, cfg_file_name)
+ modified_cfg.dump(modified_cfg_save_path)
+ print(f'Modified config has been saved to {modified_cfg_save_path}. '
+ 'Please use this new config for the next training phase.')
diff --git a/data/xtuner/xtuner/tools/process_untokenized_datasets_legacy.py b/data/xtuner/xtuner/tools/process_untokenized_datasets_legacy.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b4dd5a7de93e2966b2bb3d9c579a2e4669db034
--- /dev/null
+++ b/data/xtuner/xtuner/tools/process_untokenized_datasets_legacy.py
@@ -0,0 +1,184 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import ast
+import multiprocessing
+import os
+import warnings
+from functools import partial
+
+from datasets import Dataset, DatasetDict, load_dataset
+from mmengine import ConfigDict
+from transformers import AutoTokenizer
+
+from xtuner.dataset.huggingface import process
+from xtuner.dataset.map_fns import (DATASET_FORMAT_MAPPING,
+ template_map_fn_factory)
+from xtuner.utils import PROMPT_TEMPLATE
+
+# ignore FutureWarning in hf datasets
+warnings.simplefilter(action='ignore', category=FutureWarning)
+"""
+ftdp dataset:
+srun -p llm_razor --quotatype=auto --gres=gpu:1 --ntasks=1 \
+ --ntasks-per-node=1 --cpus-per-task=5 --kill-on-bad-exit=1 \
+ python xtuner/tools/process_untokenized_datasets.py \
+ --data-folder /path/to/data/folder \
+ --save-folder ./processed \
+ --tokenizer-path pretrained_model_name_or_path \
+ --prompt-template internlm2_chat \
+ --dataset-format ftdp
+
+normal json dataset:
+srun -p llm_razor --quotatype=auto --gres=gpu:1 --ntasks=1 \
+ --ntasks-per-node=1 --cpus-per-task=5 --kill-on-bad-exit=1 \
+ python xtuner/tools/process_untokenized_datasets.py \
+ --data-folder /path/to/data/folder \
+ --save-folder ./processed \
+ --tokenizer-path pretrained_model_name_or_path \
+ --prompt-template internlm2_chat
+"""
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data-folder', help='Data folder')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ parser.add_argument(
+ '--tokenizer-path', help='The path to the hf tokenizer.')
+ parser.add_argument(
+ '--dataset-format',
+ choices=list(DATASET_FORMAT_MAPPING.keys()) + ['ftdp'],
+ default=None,
+ help='Which dataset format is this data. The available choices are '
+ f"{list(DATASET_FORMAT_MAPPING.keys()) + ['ftdp']}. ")
+ parser.add_argument(
+ '--prompt-template',
+ choices=PROMPT_TEMPLATE.keys(),
+ help='Which prompt template need to be added to the dataset. '
+ f'The available choices are {PROMPT_TEMPLATE.keys()}')
+ parser.add_argument(
+ '--max-length', default=32768, help='Max sequence length.')
+ parser.add_argument(
+ '--pack-to-max-length',
+ action='store_true',
+ help='Whether to pack the dataset to the `max_length `.')
+ parser.add_argument(
+ '--file-type',
+ default='.json',
+ help='We want to get the order of the file in this type.')
+ parser.add_argument(
+ '--data-order-path',
+ default=None,
+ help=('The path to a txt file which contains the a list of data path.'
+ ' It can be obtain by xtuner/tools/get_data_order.py script.'))
+ args = parser.parse_args()
+ return args
+
+
+def process_one(fp,
+ tokenizer,
+ max_length,
+ pack_to_max_length,
+ dataset_map_fn=None,
+ template_map_fn=None,
+ is_ftdp=False):
+ dataset = []
+ if is_ftdp:
+ with open(fp) as file:
+ lines = file.readlines()
+ for line in lines:
+ line = ast.literal_eval(line)
+ dataset.append({'messages': line})
+ dataset = Dataset.from_list(dataset)
+ else:
+ # load formal json data
+ dataset = load_dataset('json', data_files=fp)
+ dataset = dataset['train']
+ dataset = process(
+ dataset,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ remove_unused_columns=True,
+ pack_to_max_length=pack_to_max_length,
+ map_num_proc=32)
+ return fp, dataset
+
+
+def process_untokenized_dataset(folder,
+ tokenizer,
+ max_length,
+ pack_to_max_length,
+ dataset_map_fn,
+ prompt_template,
+ data_order_path=None,
+ file_type='.json',
+ is_ftdp=False):
+ assert os.path.exists(folder), f'{folder} does not exist.'
+ datasets_dict = {}
+
+ if data_order_path is not None:
+ data_order = load_dataset(
+ 'text', data_files=data_order_path, split='train')['text']
+ for i, fp in enumerate(data_order):
+ data_order[i] = os.path.join(folder, fp)
+ else:
+ triples = list(os.walk(folder, followlinks=True))
+ data_order = []
+ for root, dirs, files in triples:
+ dirs.sort()
+ for fn in sorted(files):
+ if fn.endswith(file_type):
+ fp = os.path.join(root, fn)
+ data_order.append(fp)
+ print('All file path: ', data_order)
+
+ pool = multiprocessing.Pool(processes=multiprocessing.cpu_count())
+ template_map_fn = ConfigDict(
+ type=template_map_fn_factory, template=prompt_template)
+ process_single = partial(
+ process_one,
+ tokenizer=tokenizer,
+ max_length=max_length,
+ pack_to_max_length=pack_to_max_length,
+ dataset_map_fn=dataset_map_fn,
+ template_map_fn=template_map_fn,
+ is_ftdp=is_ftdp)
+ out = pool.map(process_single, data_order)
+ pool.close()
+ pool.join()
+ for idx, (key, dataset) in enumerate(out):
+ assert data_order[idx] == key
+ dataset = dataset.remove_columns('length')
+ datasets_dict[str(idx)] = dataset
+ datasets_dict = DatasetDict(datasets_dict)
+ return datasets_dict
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ tokenizer = ConfigDict(
+ type=AutoTokenizer.from_pretrained,
+ pretrained_model_name_or_path=args.tokenizer_path,
+ trust_remote_code=True,
+ padding_side='right')
+
+ if args.dataset_format is None:
+ dataset_map_fn = None
+ elif args.dataset_format == 'ftdp':
+ dataset_map_fn = DATASET_FORMAT_MAPPING['openai']
+ else:
+ dataset_map_fn = DATASET_FORMAT_MAPPING[args.dataset_format]
+
+ datasets_dict = process_untokenized_dataset(
+ args.data_folder,
+ tokenizer,
+ args.max_length,
+ args.pack_to_max_length,
+ dataset_map_fn,
+ PROMPT_TEMPLATE[args.prompt_template],
+ data_order_path=args.data_order_path,
+ file_type=args.file_type,
+ is_ftdp=args.dataset_format == 'ftdp')
+ datasets_dict.save_to_disk(args.save_folder)
diff --git a/data/xtuner/xtuner/tools/process_untokenized_llava_data.py b/data/xtuner/xtuner/tools/process_untokenized_llava_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d0c075855734835d3a72a2c98ee7be38b85bfac
--- /dev/null
+++ b/data/xtuner/xtuner/tools/process_untokenized_llava_data.py
@@ -0,0 +1,33 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import warnings
+
+from mmengine import Config
+
+from xtuner.registry import BUILDER
+
+# ignore FutureWarning in hf datasets
+warnings.simplefilter(action='ignore', category=FutureWarning)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--save-folder', help='The folder to save data order.')
+ args = parser.parse_args()
+ return args
+
+
+def build_llava_dataset(config):
+ dataset = BUILDER.build(config.train_dataloader.dataset)
+ return dataset
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+
+ llava_dataset = build_llava_dataset(cfg)
+ text_data = llava_dataset.text_data
+
+ text_data.save_to_disk(args.save_folder)
diff --git a/data/xtuner/xtuner/tools/test.py b/data/xtuner/xtuner/tools/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..5eb3f6d9d3099a54f561d8a3910168b0fc0a4fab
--- /dev/null
+++ b/data/xtuner/xtuner/tools/test.py
@@ -0,0 +1,107 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+from types import FunctionType
+
+from mmengine.config import Config, DictAction
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+
+from xtuner.configs import cfgs_name_path
+from xtuner.model.utils import guess_load_checkpoint
+from xtuner.registry import MAP_FUNC
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Test model')
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--checkpoint', default=None, help='checkpoint file')
+ parser.add_argument(
+ '--work-dir',
+ help='the directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def register_function(cfg_dict):
+ if isinstance(cfg_dict, dict):
+ for key, value in dict.items(cfg_dict):
+ if isinstance(value, FunctionType):
+ value_str = str(value)
+ if value_str not in MAP_FUNC:
+ MAP_FUNC.register_module(module=value, name=value_str)
+ cfg_dict[key] = value_str
+ else:
+ register_function(value)
+ elif isinstance(cfg_dict, (list, tuple)):
+ for value in cfg_dict:
+ register_function(value)
+
+
+def main():
+ args = parse_args()
+
+ # parse config
+ if not osp.isfile(args.config):
+ try:
+ args.config = cfgs_name_path[args.config]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.config}')
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # register FunctionType object in cfg to `MAP_FUNC` Registry and
+ # change these FunctionType object to str
+ register_function(cfg._cfg_dict)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ state_dict = guess_load_checkpoint(args.checkpoint)
+ runner.model.load_state_dict(state_dict, strict=False)
+ runner.logger.info(f'Load checkpoint from {args.checkpoint}')
+
+ # start testing
+ runner.test()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/tokenize_ftdp_datasets.py b/data/xtuner/xtuner/tools/tokenize_ftdp_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..9327a91fef9f79c48d4c3e933e7f039e0a11f191
--- /dev/null
+++ b/data/xtuner/xtuner/tools/tokenize_ftdp_datasets.py
@@ -0,0 +1,433 @@
+import argparse
+import json
+import os
+import os.path as osp
+from functools import partial
+from pathlib import Path
+from typing import Dict, List
+
+import numpy as np
+from mmengine import list_dir_or_file, track_progress_rich
+from transformers import AutoTokenizer
+
+SEPCIAL_TOKENS = [
+ '<|plugin|>', '<|interpreter|>', '<|action_end|>', '<|action_start|>',
+ '<|im_end|>', '<|im_start|>'
+]
+
+CHATML_LLAMAV13_32K_TOKEN_CFG = dict(
+ role_cfg=dict(
+ system=dict(
+ begin=dict(
+ with_name='<|im_start|>system name={name}\n',
+ without_name='<|im_start|>system\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|im_end|>\n',
+ loss=dict(
+ meta=False,
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ user=dict(
+ begin=dict(
+ with_name='<|im_start|>user name={name}\n',
+ without_name='<|im_start|>user\n',
+ ),
+ end='<|im_end|>\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ assistant=dict(
+ begin=dict(
+ with_name='<|im_start|>assistant name={name}\n',
+ without_name='<|im_start|>assistant\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|im_end|>\n',
+ loss=dict(
+ icl=True,
+ current=True,
+ prefix=False,
+ end=True,
+ )),
+ environment=dict(
+ begin=dict(
+ with_name='<|im_start|>environment name={name}\n',
+ without_name='<|im_start|>environment\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|im_end|>\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ tool=dict(
+ begin=dict(
+ with_name='<|action_start|>{name}\n',
+ name={
+ 'interpreter': '<|interpreter|>',
+ 'plugin': '<|plugin|>',
+ }),
+ end='<|action_end|>\n',
+ belong='assistant',
+ ),
+ thought=dict(
+ begin=dict(without_name=''),
+ end='',
+ belong='assistant',
+ ),
+ ),
+ max_len=32 * 1024,
+)
+
+
+def chatml_format(
+ processed_data,
+ tokenizer,
+ role_cfg,
+ max_len=2048,
+ encode_json=True,
+):
+ """
+ ```python
+ dict(
+ role='',
+ content='',
+ name='', -> Begin 扩增
+ type='',
+ )
+ ```
+ ```python
+ dict(
+ system=dict(
+ begin=dict(
+ with_name='system name={name}\n',
+ without_name='system\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ loss=dict(
+ meta=False,
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ user=dict(
+ begin=dict(
+ with_name='user name={name}\n',
+ without_name='user\n',
+ ),
+ end='\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ assistant=dict(
+ begin=dict(
+ with_name='assistant name={name}\n',
+ without_name='assistant\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ loss=dict(
+ icl=True,
+ current=True,
+ prefix=False,
+ end=True,
+ )),
+ environment=dict(
+ begin=dict(
+ with_name='environment name={name}\n',
+ without_name='environment\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ loss=dict(
+ icl=False,
+ current=False,
+ prefix=False,
+ )),
+ tool=dict(
+ begin=dict(
+ with_name='{name}\n',
+ name={
+ 'interpreter': '',
+ 'plugin': '',
+ }),
+ end='\n',
+ belong='assistant',
+ ),
+ thought=dict(
+ begin='',
+ end='',
+ belong='assistant',
+ ),
+ ```
+ """
+
+ def format_begin(role_cfg, message):
+ name = message.get('name', None)
+ if name is not None:
+ begin = role_cfg['begin'].get('with_name', '')
+ if name in role_cfg['begin'].get('name', {}):
+ begin = begin.format(name=role_cfg['begin']['name'][name])
+ else:
+ begin = begin.format(name=name)
+ else:
+ begin = role_cfg['begin'].get('without_name', '')
+ return begin
+
+ def format_sub_role(messages: List[Dict], roles_cfg) -> List[Dict]:
+ new_message = list()
+ for message in messages:
+ if message['role'] in [
+ 'assistant', 'user', 'system', 'environment'
+ ]:
+ new_message.append(message)
+ continue
+ role_cfg = roles_cfg[message['role']]
+ begin = format_begin(role_cfg, message)
+ new_content = begin + message['content'] + role_cfg['end']
+ if role_cfg.get('fallback_role'):
+ new_message.append(
+ dict(role=role_cfg['fallback_role'], content=new_content))
+ elif role_cfg.get('belong'):
+ if new_message[-1]['role'] != role_cfg.get('belong'):
+ new_message.append(
+ dict(role=role_cfg.get('belong'), content=new_content))
+ else:
+ new_message[-1]['content'] += new_content
+ else:
+ new_message.append(
+ dict(role=message['role'], content=new_content))
+
+ return new_message
+
+ token_ids = []
+ _processed_data = format_sub_role(processed_data, role_cfg)
+
+ for dialog_item in _processed_data:
+ role = dialog_item['role']
+ content = dialog_item['content']
+ # TODO: is strip necessary? or use lstrip? 避免开始有\n\n的情况
+ # content = content.lstrip()
+ begin = format_begin(role_cfg[role], dialog_item)
+ end = role_cfg[role]['end']
+ begin_token = tokenizer.encode(begin, add_special_tokens=False)
+ if not role_cfg[role]['loss'].get('beigin', False):
+ begin_token = [-token_id for token_id in begin_token]
+ end_token = tokenizer.encode(
+ role_cfg[role]['end'], add_special_tokens=False)
+ # breakpoint()
+ if not role_cfg[role]['loss'].get('end', False):
+ end_token = [-token_id for token_id in end_token]
+
+ content_token = tokenizer.encode(
+ begin + content + end, add_special_tokens=False)
+ content_token = content_token[len(begin_token):-len(end_token)]
+
+ if dialog_item.get('loss', True):
+ loss_cfg = role_cfg[role]['loss']
+ else:
+ loss_cfg = dict(icl=False, current=False, meta=False)
+ if not loss_cfg[dialog_item.get('type', 'current')]:
+ content_token = [-token_id for token_id in content_token]
+
+ if begin == '':
+ tokens = content_token
+ else:
+ tokens = begin_token + content_token
+ if end != '':
+ tokens = tokens + end_token
+
+ token_ids += tokens
+
+ token_ids = [tokenizer.bos_token_id] + token_ids
+ token_ids = token_ids[:max_len]
+ if encode_json:
+ line = str.encode(json.dumps({'tokens': token_ids}) + '\n')
+ return line, len(token_ids)
+ return token_ids, len(token_ids)
+
+
+def write_bin_meta_bin(path, dataset_name, filename, samples):
+ train_path = osp.join(path, f'train/cn/{dataset_name}')
+ valid_path = osp.join(path, f'valid/cn/{dataset_name}')
+ train_dir = Path(train_path)
+ valid_dir = Path(valid_path)
+ train_dir.mkdir(exist_ok=True, parents=True)
+ valid_dir.mkdir(exist_ok=True, parents=True)
+ train_f = open(train_dir.joinpath(f'{filename}.bin'), 'wb')
+ valid_f_path = valid_dir.joinpath(f'{filename}.bin')
+ valid_f = open(valid_f_path, 'wb')
+ print(train_dir)
+ print(valid_dir)
+ train_tokens = 0
+ valid_tokens = 0
+ last_train_position = 0
+ last_valid_position = 0
+ train_samples = 0
+ valid_samples = 0
+ train_meta = []
+ valid_meta = []
+ for line, token_num in samples:
+ train_tokens += token_num
+ train_f.write(line)
+ train_meta.append((last_train_position, token_num))
+ last_train_position += len(line)
+ train_samples += 1
+ if (train_samples) % 100 == 0: # ?
+ valid_tokens += token_num
+ valid_f.write(line)
+ valid_meta.append((last_valid_position, token_num))
+ last_valid_position += len(line)
+ valid_samples += 1
+ train_f.close()
+ valid_f.close()
+ np.save(open(train_dir.joinpath(f'{filename}.bin.meta'), 'wb'), train_meta)
+
+ # remove the length of `valid_samples` is less than 500
+ # 500 is a magic number, you can change it to any number you want
+ # the number must bigger the DP.
+ if valid_samples > 500:
+ np.save(
+ open(valid_dir.joinpath(f'{filename}.bin.meta'), 'wb'), valid_meta)
+ else:
+ print(f'{valid_f_path} is removed because the number of',
+ f'`valid_samples`({valid_samples}) is less than 500')
+ os.remove(valid_f_path)
+ return train_tokens, valid_tokens, train_samples, valid_samples
+
+
+def tokenize_and_save(tokenizer, processed_dir, tokenized_dir):
+ tokenized_save_dir = osp.join(tokenized_dir, 'chatml_llamav13_32k')
+ data_dir = processed_dir
+ all_train_tokens = 0
+ all_valid_tokens = 0
+ all_train_samples = 0
+ all_valid_samples = 0
+
+ for filename in list_dir_or_file(data_dir, recursive=True, list_dir=False):
+ file_path = os.path.join(data_dir, filename)
+ if '/processed/' not in file_path:
+ continue
+ assert '.jsonl' in filename
+
+ # dataset name such as char_x10_chat_format
+ dataset_name = filename.split(os.sep)[0]
+
+ # Hardcode here to skip tokenizing the file if it already exists
+ # (Refactor the `write_bin_meta_bin`!).
+ train_f = osp.join(tokenized_save_dir, 'train', 'cn', dataset_name,
+ f'{osp.splitext(osp.basename(filename))[0]}.bin')
+ if osp.isfile(train_f):
+ print(f'{train_f} already exists, skip it')
+ continue
+
+ tokenize_fun = partial(
+ chatml_format,
+ tokenizer=tokenizer,
+ **CHATML_LLAMAV13_32K_TOKEN_CFG)
+ samples = []
+ with open(file_path) as f:
+ dataset = f.readlines()
+ task_num = len(dataset)
+ dataset = map(lambda x: (json.loads(x), ), dataset)
+
+ for sample in track_progress_rich(
+ tokenize_fun,
+ dataset,
+ nproc=32,
+ task_num=task_num,
+ chunksize=32,
+ description=f'{os.path.basename(file_path)}...'):
+ samples.append(sample)
+
+ train_tokens, valid_tokens, train_samples, valid_samples = write_bin_meta_bin( # noqa E501
+ path=tokenized_save_dir,
+ dataset_name=dataset_name,
+ samples=samples,
+ filename=osp.splitext(osp.basename(filename))[0])
+ if train_tokens is None:
+ print(f'{osp.splitext(osp.basename(filename))[0]} already '
+ 'exists, skip it')
+ continue
+
+ print(f'train_tokens {train_tokens}', flush=True)
+ print(f'train_samples {train_samples}')
+ print(f'valid tokens {valid_tokens}')
+ print(f'valid_samples {valid_samples}')
+ all_train_tokens += train_tokens
+ all_valid_tokens += valid_tokens
+ all_train_samples += train_samples
+ all_valid_samples += valid_samples
+
+ print(f'all train tokens {all_train_tokens}')
+ print(f'all train samples {all_train_samples}')
+ print(f'all valid tokens {all_valid_tokens}')
+ print(f'all valid samples {all_valid_samples}')
+
+
+def tokenizer_add_special_tokens(tokenizer):
+ print(f'Before adding special tokens, Vocabulary Size: {len(tokenizer)}')
+ for special_token in SEPCIAL_TOKENS:
+ if special_token not in tokenizer.get_vocab():
+ tokenizer.add_tokens([special_token], special_tokens=True)
+ print(f'After adding special tokens, Vocabulary Size: {len(tokenizer)}')
+
+
+def save_new_tokenizer(tokenizer, save_dir):
+ tokenizer.save_pretrained(save_dir)
+ print(f'save new tokenizer to {save_dir}')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--processed-dir', help='The folder to save untokenized data.')
+ parser.add_argument(
+ '--tokenized-dir', help='The folder to save tokenized data.')
+ parser.add_argument(
+ '--tokenizer-path', help='The path to the hf tokenizer.')
+ parser.add_argument(
+ '--tokenizer-w-special-tokens-save-dir',
+ default=None,
+ help='We have to add special tokens to the vocabulary of '
+ 'the given tokenizer, and save the new tokenizer to this folder.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_path, trust_remote_code=True, padding_side='right')
+
+ ori_vocab_size = len(tokenizer)
+ tokenizer_add_special_tokens(tokenizer)
+ if len(tokenizer) != ori_vocab_size:
+ save_new_tokenizer(tokenizer, args.tokenizer_w_special_tokens_save_dir)
+
+ tokenize_and_save(tokenizer, args.processed_dir, args.tokenized_dir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/train.py b/data/xtuner/xtuner/tools/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..29b5d539577e50c60ff2d88b3acf5c7160890e36
--- /dev/null
+++ b/data/xtuner/xtuner/tools/train.py
@@ -0,0 +1,364 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import logging
+import os
+import os.path as osp
+from functools import partial
+from types import FunctionType
+
+from mmengine.config import Config, DictAction
+from mmengine.config.lazy import LazyObject
+from mmengine.logging import print_log
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+from mmengine.utils import digit_version
+from peft import get_peft_model, prepare_model_for_kbit_training
+from transformers import TrainingArguments
+
+from xtuner.configs import cfgs_name_path
+from xtuner.dataset.collate_fns import default_collate_fn
+from xtuner.model.modules import dispatch_modules
+from xtuner.model.modules.dispatch import SUPPORT_FLASH2
+from xtuner.model.utils import LoadWoInit, find_all_linear_names, traverse_dict
+from xtuner.registry import BUILDER, MAP_FUNC
+from xtuner.tools.utils import (auto_dtype_of_deepspeed_config,
+ get_seed_from_checkpoint, set_model_resource)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train LLM')
+ parser.add_argument('config', help='config file name or path.')
+ parser.add_argument('--work-dir', help='the dir to save logs and models')
+ parser.add_argument(
+ '--deepspeed',
+ type=str,
+ default=None,
+ help='the path to the .json file for deepspeed')
+ parser.add_argument(
+ '--resume',
+ type=str,
+ default=None,
+ help='specify checkpoint path to be resumed from.')
+ parser.add_argument(
+ '--seed', type=int, default=None, help='Random seed for the training')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ return args
+
+
+def register_function(cfg_dict):
+ if isinstance(cfg_dict, dict):
+ for key, value in dict.items(cfg_dict):
+ if isinstance(value, FunctionType):
+ value_str = str(value)
+ if value_str not in MAP_FUNC:
+ MAP_FUNC.register_module(module=value, name=value_str)
+ cfg_dict[key] = value_str
+ else:
+ register_function(value)
+ elif isinstance(cfg_dict, (list, tuple)):
+ for value in cfg_dict:
+ register_function(value)
+
+
+def check_cfg(cfg, args):
+ if getattr(cfg, 'use_varlen_attn',
+ False) and cfg.train_dataloader.batch_size > 1:
+ raise NotImplementedError(
+ f'If utilizing varlen attention, the batch size should be'
+ f' set to 1, but got {cfg.train_dataloader.batch_size}')
+
+ if getattr(cfg, 'use_varlen_attn', False):
+ sequence_parallel = getattr(cfg, 'sequence_parallel', 1)
+ max_length = getattr(cfg.train_dataloader.dataset, 'max_length', None)
+ if max_length is not None:
+ assert max_length % sequence_parallel == 0, \
+ ('When using varlen attention, `max_length` should be evenly '
+ 'divided by sequence parallel world size, but got '
+ f'max_length = {max_length} and sequence_parallel = '
+ f'{sequence_parallel}')
+
+ if getattr(cfg, 'sequence_parallel_size', 1) > 1:
+ assert SUPPORT_FLASH2, ('`flash_attn` is required if you want to use '
+ 'sequence parallel.')
+ attn_implementation = getattr(cfg.model.llm, 'attn_implementation',
+ None)
+ assert (attn_implementation is None or
+ attn_implementation == 'flash_attention_2'), \
+ ('If you want to use sequence parallel, please set '
+ 'attn_implementation to `flash_attention_2` or do not '
+ f'set this attribute. Got `{attn_implementation}` .')
+
+ if getattr(cfg, 'use_varlen_attn', False):
+ assert SUPPORT_FLASH2, ('`flash_attn` is required if you set '
+ '`use_varlen_attn` to True.')
+ attn_implementation = getattr(cfg.model.llm, 'attn_implementation',
+ None)
+ assert (attn_implementation is None or
+ attn_implementation == 'flash_attention_2'), \
+ ('If you want to set `use_varlen_attn` to True, please set'
+ ' attn_implementation to `flash_attention_2` or do not '
+ f'set this attribute. Got `{attn_implementation}` .')
+
+ if args.deepspeed is None:
+ assert getattr(cfg, 'sequence_parallel_size', 1) == 1, \
+ ('Sequence parallel training without DeepSpeed lacks validation.'
+ 'Please use DeepSpeed to optimize the training phase by '
+ '`--deepspeed deepspeed_zero1 (deepspeed_zero2 or '
+ 'deepspeed_zero3)`.')
+
+
+
+
+
+def main():
+ args = parse_args()
+
+ # parse config
+ if not osp.isfile(args.config):
+ try:
+ args.config = cfgs_name_path[args.config]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.config}')
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ set_model_resource(cfg)
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # register FunctionType object in cfg to `MAP_FUNC` Registry and
+ # change these FunctionType object to str
+ register_function(cfg._cfg_dict)
+
+ check_cfg(cfg, args)
+
+ if cfg.get('framework', 'mmengine').lower() == 'huggingface':
+ # set default training_args
+ if cfg.get('training_args', None) is None:
+ cfg.training_args = dict(type=TrainingArguments)
+ if args.seed is not None:
+ cfg.training_args.seed = args.seed
+ # set work_dir
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.training_args.output_dir = args.work_dir
+ elif cfg.training_args.get('output_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.training_args.output_dir = osp.join(
+ './work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ # enable deepspeed
+ if args.deepspeed:
+ if not osp.isfile(args.deepspeed):
+ try:
+ args.deepspeed = cfgs_name_path[args.deepspeed]
+ except KeyError:
+ raise FileNotFoundError(f'Cannot find {args.deepspeed}')
+ cfg.training_args.deepspeed = args.deepspeed
+ if cfg.training_args.get('deepspeed'):
+ device_map = None
+ else:
+ # Data Parallel
+ device_map = {
+ '': int(os.environ.get('LOCAL_RANK', args.local_rank))
+ }
+ # build training_args
+ training_args = BUILDER.build(cfg.training_args)
+ # build model
+ with LoadWoInit():
+ cfg.model.device_map = device_map
+ traverse_dict(cfg.model)
+ model = BUILDER.build(cfg.model)
+ model.config.use_cache = False
+ dispatch_modules(model)
+ if cfg.get('lora', None):
+ lora = BUILDER.build(cfg.lora)
+ model = prepare_model_for_kbit_training(model)
+ if lora.target_modules is None:
+ modules = find_all_linear_names(model)
+ lora.target_modules = modules
+ model = get_peft_model(model, lora)
+
+ # build dataset
+ train_dataset = BUILDER.build(cfg.train_dataset)
+ data_collator = partial(default_collate_fn, return_hf_format=True)
+ # build trainer
+ trainer = cfg.trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset,
+ data_collator=data_collator)
+ # training
+ trainer.train(resume_from_checkpoint=args.resume)
+ trainer.save_state()
+ trainer.save_model(output_dir=training_args.output_dir)
+ else:
+ if args.seed is not None and args.resume is None:
+ # Use args.seed
+ cfg.merge_from_dict(dict(randomness=dict(seed=args.seed)))
+ print_log(
+ f'Set the random seed to {args.seed}.',
+ logger='current',
+ level=logging.INFO)
+ elif args.resume is not None:
+ # Use resumed seed
+ from mmengine.fileio import PetrelBackend, get_file_backend
+
+ from xtuner.utils.fileio import patch_fileio
+ backend = get_file_backend(args.resume)
+ if isinstance(backend, PetrelBackend):
+ with patch_fileio():
+ resumed_seed = get_seed_from_checkpoint(args.resume)
+ else:
+ resumed_seed = get_seed_from_checkpoint(args.resume)
+ cfg.merge_from_dict(dict(randomness=dict(seed=resumed_seed)))
+ if args.seed is not None and args.seed != resumed_seed:
+ print_log(
+ (f'The value of random seed in resume checkpoint '
+ f'"{args.resume}" is different from the value in '
+ f'arguments. The resumed seed is {resumed_seed}, while '
+ f'the input argument seed is {args.seed}. Using the '
+ f'resumed seed {resumed_seed}.'),
+ logger='current',
+ level=logging.WARNING)
+ else:
+ print_log(
+ f'Set the random seed to {resumed_seed}.',
+ logger='current',
+ level=logging.INFO)
+
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ cfg.launcher = args.launcher
+ # work_dir is determined in this priority:
+ # CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ if args.deepspeed:
+ try:
+ import deepspeed
+ except ImportError:
+ raise ImportError(
+ 'deepspeed is not installed properly, please check.')
+ if digit_version(deepspeed.__version__) < digit_version('0.12.3'):
+ raise RuntimeError('Please upgrade your DeepSpeed version '
+ 'by using the command pip install '
+ '`deepspeed>=0.12.3`')
+ optim_wrapper = cfg.optim_wrapper.type
+ if optim_wrapper == 'DeepSpeedOptimWrapper':
+ print_log(
+ 'Deepspeed training is already enabled in your config.',
+ logger='current',
+ level=logging.WARNING)
+ else:
+ if not osp.isfile(args.deepspeed):
+ try:
+ args.deepspeed = cfgs_name_path[args.deepspeed]
+ except KeyError:
+ raise FileNotFoundError(
+ f'Cannot find {args.deepspeed}')
+ with open(args.deepspeed) as f:
+ ds_cfg = json.load(f)
+
+ ds_grad_accum = ds_cfg.get('gradient_accumulation_steps',
+ 'auto')
+ mm_grad_accum = cfg.optim_wrapper.get('accumulative_counts', 1)
+ if ds_grad_accum != 'auto' and ds_grad_accum != mm_grad_accum:
+ print_log(('Mismatch on gradient_accumulation_steps: '
+ f'MMEngine {mm_grad_accum}, '
+ f'Deepspeed {ds_grad_accum}. '
+ f'Set to {mm_grad_accum}'),
+ logger='current',
+ level=logging.WARNING)
+ grad_accum = mm_grad_accum
+
+ ds_train_bs = ds_cfg.get('train_micro_batch_size_per_gpu',
+ 'auto')
+ mm_train_bs = cfg.train_dataloader.batch_size
+ if ds_train_bs != 'auto' and ds_train_bs != mm_train_bs:
+ print_log(
+ ('Mismatch on train_micro_batch_size_per_gpu: '
+ f'MMEngine {mm_train_bs}, Deepspeed {ds_train_bs}. '
+ f'Set to {mm_train_bs}'),
+ logger='current',
+ level=logging.WARNING)
+ train_bs = cfg.train_dataloader.batch_size
+
+ ds_grad_clip = ds_cfg.get('gradient_clipping', 'auto')
+ clip_grad = cfg.optim_wrapper.get('clip_grad', None)
+ if clip_grad and clip_grad.get('max_norm', None) is not None:
+ mm_max_norm = cfg.optim_wrapper.clip_grad.max_norm
+ else:
+ mm_max_norm = 1.0
+ if ds_grad_clip != 'auto' and ds_grad_clip != mm_max_norm:
+ print_log(
+ ('Mismatch on gradient_clipping: '
+ f'MMEngine {mm_max_norm}, Deepspeed {ds_grad_clip}. '
+ f'Set to {mm_max_norm}'),
+ logger='current',
+ level=logging.WARNING)
+ grad_clip = mm_max_norm
+ ds_cfg = auto_dtype_of_deepspeed_config(ds_cfg)
+ exclude_frozen_parameters = True if digit_version(
+ deepspeed.__version__) >= digit_version('0.10.1') else None
+ strategy = dict(
+ type=LazyObject('xtuner.engine', 'DeepSpeedStrategy'),
+ config=ds_cfg,
+ gradient_accumulation_steps=grad_accum,
+ train_micro_batch_size_per_gpu=train_bs,
+ gradient_clipping=grad_clip,
+ exclude_frozen_parameters=exclude_frozen_parameters,
+ sequence_parallel_size=getattr(cfg,
+ 'sequence_parallel_size',
+ 1))
+ cfg.__setitem__('strategy', strategy)
+ optim_wrapper = dict(
+ type='DeepSpeedOptimWrapper',
+ optimizer=cfg.optim_wrapper.optimizer)
+ cfg.__setitem__('optim_wrapper', optim_wrapper)
+ cfg.runner_type = 'FlexibleRunner'
+
+ # resume is determined in this priority: resume from > auto_resume
+ if args.resume is not None:
+ cfg.resume = True
+ cfg.load_from = args.resume
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # start training
+ runner.train()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/data/xtuner/xtuner/tools/utils.py b/data/xtuner/xtuner/tools/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f08cc6317a3ce3b1d72af1e405ec9a610696357
--- /dev/null
+++ b/data/xtuner/xtuner/tools/utils.py
@@ -0,0 +1,193 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import re
+import warnings
+
+import torch
+from transformers import PreTrainedTokenizerFast, StoppingCriteriaList
+from transformers.generation.streamers import BaseStreamer
+
+from xtuner.utils import StopWordStoppingCriteria
+
+
+def get_base_model(model):
+ if hasattr(model, 'llm'):
+ model = model.llm
+ if 'PeftModel' in model.__class__.__name__:
+ model = model.base_model.model
+ return model
+
+
+def get_streamer(model):
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ ('`get_streamer` is deprecated and will be removed in v0.3.0, '
+ "use `transformers`'s `TextStreamer` instead."), DeprecationWarning)
+ if model.__class__.__name__ == 'InferenceEngine':
+ model = model.module
+ base_model = get_base_model(model)
+ base_model_name = base_model.__class__.__name__.lower()
+ is_internlm = 'internlm' in base_model_name
+ is_qwen = 'qwen' in base_model_name
+ is_baichuan = 'baichuan' in base_model_name
+ is_chatglm = 'chatglm' in base_model_name
+ no_space = is_internlm or is_qwen or is_baichuan or is_chatglm
+ if no_space:
+ return NoSpaceStreamer
+ else:
+ return DecodeOutputStreamer
+
+def set_model_resource(cfg):
+ if cfg.get("model_resource"):
+ fn = cfg["model_resource"].get("fn")
+ args = cfg["model_resource"].get("args", {})
+ local_path = fn(cfg["pretrained_model_name_or_path"], **args)
+ s = [(cfg._cfg_dict, k, v) for k, v in cfg._cfg_dict.items()]
+ while s:
+ current_d, current_k, current_v = s.pop()
+ if current_k == "pretrained_model_name_or_path":
+ current_d[current_k] = local_path
+
+ if isinstance(current_v, dict):
+ s.extend([(current_v, k, v) for k, v in current_v.items()])
+ elif isinstance(current_v, list):
+ for i in current_v:
+ if isinstance(i, dict):
+ s.extend((i, k, v) for k, v in i.items())
+
+
+class DecodeOutputStreamer(BaseStreamer):
+ """Default streamer for HuggingFace models."""
+
+ def __init__(self, tokenizer, skip_prompt=True) -> None:
+ super().__init__()
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ '`DecodeOutputStreamer` is deprecated and will be '
+ 'removed in v0.3.0.', DeprecationWarning)
+ self.tokenizer = tokenizer
+ self.skip_prompt = skip_prompt
+ self.gen_len = 0
+ if isinstance(tokenizer, PreTrainedTokenizerFast):
+ self.decode = self._decode_with_raw_id
+ self.hex_regex = re.compile(r'^<0x([0-9ABCDEF]+)>$')
+ else:
+ self.decode = self._decode_fallback
+
+ def _decode_with_raw_id(self, value):
+ """Convert token ids to tokens and decode."""
+
+ tok = self.tokenizer._convert_id_to_token(value)
+ if tok.startswith('▁'): # sentencepiece
+ space = ' '
+ tok = tok[1:]
+ else:
+ space = ''
+ if res := self.hex_regex.match(tok):
+ tok = chr(int(res.group(1), 16))
+ if tok == '':
+ tok = '\n'
+ return space + tok
+
+ def _decode_fallback(self, value):
+ """Fallback decoder for non-fast tokenizer."""
+
+ tok = self.tokenizer.decode(
+ value,
+ skip_special_tokens=False,
+ clean_up_tokenization_spaces=False)
+ return tok + ' '
+
+ def put(self, value):
+ """Callback function to decode token and output to stdout."""
+
+ if self.gen_len == 0 and self.skip_prompt:
+ pass
+ else:
+ tok = self.decode(value[0])
+ print(tok, end='', flush=True)
+
+ self.gen_len += 1
+
+ def end(self):
+ """Callback function to finish generation."""
+
+ print('\n')
+
+
+class NoSpaceStreamer(DecodeOutputStreamer):
+
+ def __init__(self, tokenizer, skip_prompt=True) -> None:
+ BaseStreamer().__init__()
+ # TODO: deprecation, v0.3.0
+ warnings.warn(
+ '`NoSpaceStreamer` is deprecated and will be '
+ 'removed in v0.3.0.', DeprecationWarning)
+ self.tokenizer = tokenizer
+ self.skip_prompt = skip_prompt
+ self.gen_len = 0
+ self.hex_regex = re.compile(r'^<0x([0-9ABCDEF]+)>$')
+
+ def decode(self, value):
+ tok = self.tokenizer.decode(value)
+ if res := self.hex_regex.match(tok):
+ tok = chr(int(res.group(1), 16))
+ if tok == '' or tok == '\r':
+ tok = '\n'
+
+ return tok
+
+
+def get_stop_criteria(
+ tokenizer,
+ stop_words=[],
+):
+ stop_criteria = StoppingCriteriaList()
+ for word in stop_words:
+ stop_criteria.append(StopWordStoppingCriteria(tokenizer, word))
+ return stop_criteria
+
+
+def auto_dtype_of_deepspeed_config(ds_config):
+ if ds_config.get('fp16') and not ds_config.get('bf16'):
+ if ds_config.get('fp16').get('enabled') == 'auto':
+ ds_config['fp16']['enabled'] = torch.cuda.is_available()
+ elif not ds_config.get('fp16') and ds_config.get('bf16'):
+ if ds_config.get('bf16').get('enabled') == 'auto':
+ ds_config['bf16']['enabled'] = torch.cuda.is_bf16_supported()
+ elif ds_config.get('fp16') and ds_config.get('bf16'):
+ if ds_config.get('fp16').get('enabled') == 'auto':
+ ds_config['fp16']['enabled'] = torch.cuda.is_available()
+ if ds_config.get('bf16').get('enabled') == 'auto':
+ ds_config['bf16']['enabled'] = torch.cuda.is_bf16_supported()
+ if (ds_config['fp16']['enabled'] is True
+ and ds_config['bf16']['enabled'] is True):
+ ds_config['fp16']['enabled'] = False
+ ds_config['bf16']['enabled'] = True
+ return ds_config
+
+
+def is_cn_string(s):
+ if re.search('[\u4e00-\u9fff]', s):
+ return True
+ return False
+
+
+def get_seed_from_checkpoint(pth_model):
+ if osp.isfile(pth_model):
+ checkpoint = torch.load(pth_model, map_location='cpu')
+ elif osp.isdir(pth_model):
+ try:
+ from deepspeed.utils.zero_to_fp32 import get_model_state_files
+ except ImportError:
+ raise ImportError(
+ 'The provided PTH model appears to be a DeepSpeed checkpoint. '
+ 'However, DeepSpeed library is not detected in current '
+ 'environment. This suggests that DeepSpeed may not be '
+ 'installed or is incorrectly configured. Please verify your '
+ 'setup.')
+ filename = get_model_state_files(pth_model)[0]
+ checkpoint = torch.load(filename, map_location='cpu')
+ else:
+ raise FileNotFoundError(f'Cannot find {pth_model}')
+ return checkpoint['meta']['seed']
diff --git a/data/xtuner/xtuner/utils/__init__.py b/data/xtuner/xtuner/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6663b32253528a8d02b61e1dec07326116ba6130
--- /dev/null
+++ b/data/xtuner/xtuner/utils/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .constants import (DEFAULT_IMAGE_TOKEN, DEFAULT_PAD_TOKEN_INDEX,
+ IGNORE_INDEX, IMAGE_TOKEN_INDEX)
+from .handle_moe_load_and_save import (SUPPORT_MODELS, get_origin_state_dict,
+ load_state_dict_into_model)
+from .stop_criteria import StopWordStoppingCriteria
+from .templates import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
+
+__all__ = [
+ 'IGNORE_INDEX', 'DEFAULT_PAD_TOKEN_INDEX', 'PROMPT_TEMPLATE',
+ 'DEFAULT_IMAGE_TOKEN', 'SYSTEM_TEMPLATE', 'StopWordStoppingCriteria',
+ 'IMAGE_TOKEN_INDEX', 'load_state_dict_into_model', 'get_origin_state_dict',
+ 'SUPPORT_MODELS'
+]
diff --git a/data/xtuner/xtuner/utils/constants.py b/data/xtuner/xtuner/utils/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..2862c8ab50bb3f811795f5b8aea0d991505d6a41
--- /dev/null
+++ b/data/xtuner/xtuner/utils/constants.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+IGNORE_INDEX = -100
+DEFAULT_PAD_TOKEN_INDEX = 0
+IMAGE_TOKEN_INDEX = -200
+DEFAULT_IMAGE_TOKEN = ''
diff --git a/data/xtuner/xtuner/utils/fileio.py b/data/xtuner/xtuner/utils/fileio.py
new file mode 100644
index 0000000000000000000000000000000000000000..922146e584313f35b5cdcd76b3908ed0e4f7ce11
--- /dev/null
+++ b/data/xtuner/xtuner/utils/fileio.py
@@ -0,0 +1,345 @@
+import io
+from contextlib import contextmanager
+
+import mmengine.fileio as fileio
+from mmengine.fileio import LocalBackend, PetrelBackend, get_file_backend
+
+
+def patch_func(module, fn_name_to_wrap):
+ backup = getattr(patch_func, '_backup', [])
+ fn_to_wrap = getattr(module, fn_name_to_wrap)
+
+ def wrap(fn_new):
+ setattr(module, fn_name_to_wrap, fn_new)
+ backup.append((module, fn_name_to_wrap, fn_to_wrap))
+ setattr(fn_new, '_fallback', fn_to_wrap)
+ setattr(patch_func, '_backup', backup)
+ return fn_new
+
+ return wrap
+
+
+@contextmanager
+def patch_fileio(global_vars=None):
+ if getattr(patch_fileio, '_patched', False):
+ # Only patch once, avoid error caused by patch nestly.
+ yield
+ return
+ import builtins
+
+ @patch_func(builtins, 'open')
+ def open(file, mode='r', *args, **kwargs):
+ backend = get_file_backend(file)
+ if isinstance(backend, LocalBackend):
+ return open._fallback(file, mode, *args, **kwargs)
+ if 'b' in mode:
+ return io.BytesIO(backend.get(file, *args, **kwargs))
+ else:
+ return io.StringIO(backend.get_text(file, *args, **kwargs))
+
+ if global_vars is not None and 'open' in global_vars:
+ bak_open = global_vars['open']
+ global_vars['open'] = builtins.open
+
+ import os
+
+ @patch_func(os.path, 'join')
+ def join(a, *paths):
+ backend = get_file_backend(
+ a.decode('utf-8') if isinstance(a, bytes) else a)
+ if isinstance(backend, LocalBackend):
+ return join._fallback(a, *paths)
+ paths = [item.lstrip('./') for item in paths if len(item) > 0]
+ return backend.join_path(a, *paths)
+
+ @patch_func(os.path, 'isdir')
+ def isdir(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return isdir._fallback(path)
+
+ return backend.isdir(path)
+
+ @patch_func(os.path, 'isfile')
+ def isfile(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return isfile._fallback(path)
+
+ return backend.isfile(path)
+
+ @patch_func(os.path, 'exists')
+ def exists(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return exists._fallback(path)
+ return backend.exists(path)
+
+ @patch_func(os, 'mkdir')
+ def mkdir(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return mkdir._fallback(path, *args, **kwargs)
+
+ @patch_func(os, 'makedirs')
+ def makedirs(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return makedirs._fallback(path, *args, **kwargs)
+
+ @patch_func(os, 'listdir')
+ def listdir(path):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return listdir._fallback(path)
+ return backend.list_dir_or_file(path)
+
+ @patch_func(os, 'chmod')
+ def chmod(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return chmod._fallback(path, *args, **kwargs)
+
+ @patch_func(os, 'stat')
+ def stat(path, *args, **kwargs):
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return stat._fallback(path, *args, **kwargs)
+
+ import glob as glob_pkg
+
+ @patch_func(glob_pkg, 'glob')
+ def glob(pathname, *, recursive=False):
+ backend = get_file_backend(pathname)
+ if isinstance(backend, LocalBackend):
+ return glob._fallback(pathname, recursive=recursive)
+
+ if pathname.endswith('*_optim_states.pt'):
+ import os
+ pathname = os.path.split(pathname)[0]
+ files = backend.list_dir_or_file(pathname, recursive=recursive)
+ files = [
+ os.path.join(pathname, f) for f in files
+ if f.endswith('_optim_states.pt')
+ ]
+ elif pathname.endswith('*_model_states.pt'):
+ import os
+ pathname = os.path.split(pathname)[0]
+ files = backend.list_dir_or_file(pathname, recursive=recursive)
+ files = [
+ os.path.join(pathname, f) for f in files
+ if f.endswith('_model_states.pt')
+ ]
+ elif '*' in pathname:
+ raise NotImplementedError
+ else:
+ files = backend.list_dir_or_file(pathname, recursive=recursive)
+
+ return files
+
+ import filecmp
+
+ @patch_func(filecmp, 'cmp')
+ def cmp(f1, f2, *args, **kwargs):
+ with fileio.get_local_path(f1) as f1, fileio.get_local_path(f2) as f2:
+ return cmp._fallback(f1, f2, *args, **kwargs)
+
+ import shutil
+
+ @patch_func(shutil, 'copy')
+ def copy(src, dst, **kwargs):
+ from pathlib import Path
+
+ if isinstance(src, Path):
+ src = str(src).replace(':/', '://')
+ if isinstance(dst, Path):
+ dst = str(dst).replace(':/', '://')
+
+ src_backend = get_file_backend(src)
+ dst_backend = get_file_backend(dst)
+
+ if isinstance(src_backend, LocalBackend) and isinstance(
+ dst_backend, LocalBackend):
+ return copy._fallback(src, dst, **kwargs)
+ elif isinstance(src_backend, LocalBackend) and isinstance(
+ dst_backend, PetrelBackend):
+ return dst_backend.copyfile_from_local(str(src), str(dst))
+ elif isinstance(src_backend, PetrelBackend) and isinstance(
+ dst_backend, LocalBackend):
+ return src_backend.copyfile_to_local(str(src), str(dst))
+
+ import torch
+
+ @patch_func(torch, 'load')
+ def load(f, *args, **kwargs):
+ if isinstance(f, str):
+ f = io.BytesIO(fileio.get(f))
+ return load._fallback(f, *args, **kwargs)
+
+ @patch_func(torch, 'save')
+ def save(obj, f, *args, **kwargs):
+ backend = get_file_backend(f)
+ if isinstance(backend, LocalBackend):
+ return save._fallback(obj, f, *args, **kwargs)
+
+ with io.BytesIO() as buffer:
+ save._fallback(obj, buffer, *args, **kwargs)
+ buffer.seek(0)
+ backend.put(buffer, f)
+
+ # from tempfile import TemporaryDirectory
+ # import os
+ # with TemporaryDirectory(dir='/dev/shm') as tmpdir:
+ # suffix = os.path.split(f)[-1]
+ # tmppath = os.path.join._fallback(tmpdir, suffix)
+ # from mmengine import print_log
+ # print_log('write to tmp dir', logger='current')
+ # save._fallback(obj, tmppath, *args, **kwargs)
+ # print_log('write to ceph', logger='current')
+
+ # with open(tmppath, 'rb') as buffer:
+ # backend.put(buffer, f)
+
+ from sentencepiece import SentencePieceProcessor
+
+ @patch_func(SentencePieceProcessor, 'LoadFromFile')
+ def LoadFromFile(cls, path):
+ if path:
+ backend = get_file_backend(path)
+ if isinstance(backend, LocalBackend):
+ return LoadFromFile._fallback(cls, path)
+ from tempfile import TemporaryDirectory
+ with TemporaryDirectory() as tmpdir:
+ local_path = backend.copyfile_to_local(path, tmpdir)
+ loaded_file = LoadFromFile._fallback(cls, local_path)
+ return loaded_file
+ else:
+ return LoadFromFile._fallback(cls, path)
+
+ try:
+ setattr(patch_fileio, '_patched', True)
+ yield
+ finally:
+ for patched_fn in patch_func._backup:
+ (module, fn_name_to_wrap, fn_to_wrap) = patched_fn
+ setattr(module, fn_name_to_wrap, fn_to_wrap)
+ if global_vars is not None and 'open' in global_vars:
+ global_vars['open'] = bak_open
+ setattr(patch_fileio, '_patched', False)
+
+
+def patch_hf_auto_from_pretrained(petrel_hub):
+ if hasattr(patch_hf_auto_from_pretrained, '_patched'):
+ return
+
+ from peft import PeftModel
+ from transformers import (AutoConfig, AutoFeatureExtractor,
+ AutoImageProcessor, AutoModelForCausalLM,
+ AutoProcessor, AutoTokenizer,
+ ImageProcessingMixin, PreTrainedModel,
+ PreTrainedTokenizerBase, ProcessorMixin)
+ from transformers.models.auto.auto_factory import _BaseAutoModelClass
+
+ target_cls = list(_BaseAutoModelClass.__subclasses__())
+ target_cls.extend([AutoModelForCausalLM] +
+ AutoModelForCausalLM.__subclasses__())
+ target_cls.extend([AutoConfig] + AutoConfig.__subclasses__())
+ target_cls.extend([AutoTokenizer] + AutoTokenizer.__subclasses__())
+ target_cls.extend([AutoImageProcessor] +
+ AutoImageProcessor.__subclasses__())
+ target_cls.extend([AutoFeatureExtractor] +
+ AutoFeatureExtractor.__subclasses__())
+ target_cls.extend([AutoProcessor] + AutoProcessor.__subclasses__())
+ target_cls.extend([PreTrainedTokenizerBase] +
+ PreTrainedTokenizerBase.__subclasses__())
+ target_cls.extend([ImageProcessingMixin] +
+ ImageProcessingMixin.__subclasses__())
+ target_cls.extend([PreTrainedModel] + PreTrainedModel.__subclasses__())
+ target_cls.extend([ProcessorMixin] + ProcessorMixin.__subclasses__())
+ target_cls.extend([PeftModel] + PeftModel.__subclasses__())
+
+ import os
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs):
+ with patch_fileio():
+ model_path = pretrained_model_name_or_path
+ model_path = os.path.join(petrel_hub, model_path)
+ obj = cls._from_pretrained(model_path, *args, **kwargs)
+ return obj
+
+ for cls in set(target_cls):
+ if not hasattr(cls, '_from_pretrained'):
+ cls._from_pretrained = cls.from_pretrained
+ cls.from_pretrained = from_pretrained
+
+ patch_hf_auto_from_pretrained._patched = True
+
+
+def patch_hf_save_pretrained():
+ if hasattr(patch_hf_save_pretrained, '_patched'):
+ return
+
+ import torch
+ from peft import PeftModel
+ from transformers import (AutoConfig, AutoTokenizer, PreTrainedModel,
+ PreTrainedTokenizerBase)
+ from transformers.models.auto.auto_factory import _BaseAutoModelClass
+
+ target_cls = []
+ target_cls.extend([AutoConfig] + AutoConfig.__subclasses__())
+ target_cls.extend([AutoTokenizer] + AutoTokenizer.__subclasses__())
+ target_cls.extend([PreTrainedTokenizerBase] +
+ PreTrainedTokenizerBase.__subclasses__())
+ target_cls.extend([PreTrainedModel] + PreTrainedModel.__subclasses__())
+
+ target_cls.extend([_BaseAutoModelClass] +
+ _BaseAutoModelClass.__subclasses__())
+ target_cls.extend([PeftModel] + PeftModel.__subclasses__())
+
+ def _patch_wrap(method):
+
+ def wrapped_method(self, *args, **kwargs):
+
+ with patch_fileio():
+ kwargs['save_function'] = torch.save
+ kwargs['safe_serialization'] = False
+
+ obj = method(self, *args, **kwargs)
+ return obj
+
+ return wrapped_method
+
+ for cls in set(target_cls):
+ if hasattr(cls, 'save_pretrained'):
+ cls.save_pretrained = _patch_wrap(cls.save_pretrained)
+
+ patch_hf_save_pretrained._patched = True
+
+
+def patch_deepspeed_engine():
+ if hasattr(patch_deepspeed_engine, '_patched'):
+ return
+
+ def _copy_recovery_script(self, save_path):
+ import os
+ from shutil import copyfile
+
+ from deepspeed.utils import zero_to_fp32
+ from mmengine import PetrelBackend, get_file_backend
+ script = 'zero_to_fp32.py'
+
+ src = zero_to_fp32.__file__
+ dst = os.path.join(save_path, script)
+
+ backend = get_file_backend(save_path)
+ if isinstance(backend, PetrelBackend):
+ backend.copyfile_from_local(src, dst)
+ else:
+ copyfile(src, dst)
+ self._change_recovery_script_permissions(dst)
+
+ from deepspeed.runtime.engine import DeepSpeedEngine
+ DeepSpeedEngine._copy_recovery_script = _copy_recovery_script
+
+ patch_deepspeed_engine._patched = True
diff --git a/data/xtuner/xtuner/utils/handle_moe_load_and_save.py b/data/xtuner/xtuner/utils/handle_moe_load_and_save.py
new file mode 100644
index 0000000000000000000000000000000000000000..88a3936a84b8de7311e3a00d7e0661a2a3265736
--- /dev/null
+++ b/data/xtuner/xtuner/utils/handle_moe_load_and_save.py
@@ -0,0 +1,232 @@
+import json
+import os
+import re
+from collections import OrderedDict
+
+import deepspeed
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from mmengine import print_log
+from transformers.integrations import is_deepspeed_zero3_enabled
+from transformers.modeling_utils import load_state_dict
+from transformers.utils import (SAFE_WEIGHTS_INDEX_NAME, WEIGHTS_INDEX_NAME,
+ is_safetensors_available)
+
+SUPPORT_MODELS = (
+ 'DeepseekV2ForCausalLM',
+ 'MixtralForCausalLM',
+)
+
+ORDER_MAPPING = dict(
+ DeepseekV2ForCausalLM=dict(down_proj=0, gate_proj=1, up_proj=2),
+ MixtralForCausalLM=dict(down_proj=1, gate_proj=0, up_proj=2),
+)
+
+PARAM_NAME_MAPPING = dict(
+ DeepseekV2ForCausalLM=dict(
+ gate_proj='gate_proj', up_proj='up_proj', down_proj='down_proj'),
+ MixtralForCausalLM=dict(gate_proj='w1', up_proj='w3', down_proj='w2'),
+)
+
+
+def print_on_rank0(info):
+ if dist.get_rank() == 0:
+ print_log(info, 'current')
+
+
+def get_expert_num_per_shard(model):
+ for module in model.modules():
+ if hasattr(module, 'expert_in_one_shard'):
+ return module.expert_in_one_shard
+
+
+def mix_sort(expert_name):
+ components = re.findall(r'(\D+|\d+)', expert_name)
+ out = [int(comp) if comp.isdigit() else comp for comp in components]
+ return tuple(out)
+
+
+def _get_merged_param_name(origin_param_name, expert_num_per_shard):
+ split_name = origin_param_name.split('.experts.')
+ expert_idx = re.findall(r'\d+', split_name[1])[0]
+ expert_idx = int(expert_idx)
+ assert expert_idx % expert_num_per_shard == 0
+ shard_idx = expert_idx // expert_num_per_shard
+ w1w3 = split_name[0] + f'.experts.{shard_idx}.w1w3'
+ w2 = split_name[0] + f'.experts.{shard_idx}.w2'
+ return w1w3, w2
+
+
+def _merge_experts_weight(state_dict, expert_num_per_shard, order_mapping):
+ experts_name = [key for key in state_dict.keys() if '.experts.' in key]
+ experts_name = sorted(experts_name, key=mix_sort)
+ linear_num_per_expert = 3
+ linear_num_per_shard = expert_num_per_shard * linear_num_per_expert
+ expert_shard_num = len(experts_name) // linear_num_per_shard
+ for shard_idx in range(expert_shard_num):
+ begin, end = shard_idx * linear_num_per_shard, (
+ shard_idx + 1) * linear_num_per_shard
+ experts_name_cur = experts_name[begin:end]
+
+ down_proj_weight = [
+ state_dict.pop(key)
+ for key in experts_name_cur[order_mapping['down_proj']::3]
+ ]
+ gate_proj_weight = [
+ state_dict.pop(key)
+ for key in experts_name_cur[order_mapping['gate_proj']::3]
+ ]
+ up_proj_weight = [
+ state_dict.pop(key)
+ for key in experts_name_cur[order_mapping['up_proj']::3]
+ ]
+ w1 = torch.stack(gate_proj_weight)
+ w3 = torch.stack(up_proj_weight)
+ w1w3 = torch.cat([w1, w3], dim=1)
+ assert w1w3.ndim == 3, w1w3.shape
+ w2 = torch.stack(down_proj_weight)
+ assert w2.ndim == 3, w2.shape
+ merged_key_w1w3, merged_key_w2 = _get_merged_param_name(
+ experts_name_cur[0], expert_num_per_shard)
+ print_on_rank0(f'merged key {merged_key_w1w3}')
+ state_dict[merged_key_w1w3] = w1w3
+ print_on_rank0(f'merged key {merged_key_w2}')
+ state_dict[merged_key_w2] = w2
+
+ return
+
+
+def load_state_dict_into_model(model_to_load, pretrained_model_path):
+
+ model_name = type(model_to_load).__name__
+ if model_name not in SUPPORT_MODELS:
+ raise RuntimeError(
+ f'Only models in {SUPPORT_MODELS} may need to load pretrained '
+ f'weights via `load_state_dict_into_model`, but got {model_name}.')
+ order_mapping = ORDER_MAPPING[model_name]
+
+ index_file = os.path.join(pretrained_model_path, WEIGHTS_INDEX_NAME)
+ safe_index_file = os.path.join(pretrained_model_path,
+ SAFE_WEIGHTS_INDEX_NAME)
+ index_present = os.path.isfile(index_file)
+ safe_index_present = os.path.isfile(safe_index_file)
+ assert index_present or (safe_index_present and is_safetensors_available())
+ if safe_index_present and is_safetensors_available():
+ load_index = safe_index_file
+ else:
+ load_index = index_file
+ with open(load_index, encoding='utf-8') as f:
+ index = json.load(f)
+ weight_map = index['weight_map']
+ unloaded_shard_files = list(set(weight_map.values()))
+ unloaded_shard_files.sort(reverse=True)
+
+ expert_num_per_shard = get_expert_num_per_shard(model_to_load)
+ error_msgs = []
+
+ def load(module: nn.Module, state_dict, unloaded_shard_files, prefix=''):
+ params_to_gather = []
+ param_names = []
+ for name, param in module.named_parameters(
+ prefix=prefix[:-1], recurse=False):
+ while name not in state_dict:
+ assert len(unloaded_shard_files) > 0
+ shard_file = unloaded_shard_files.pop()
+ shard_file = os.path.join(pretrained_model_path, shard_file)
+ print_on_rank0(
+ f'{name} not in state_dict, loading {shard_file}')
+ new_shard = load_state_dict(shard_file, is_quantized=False)
+ state_dict.update(new_shard)
+ _merge_experts_weight(state_dict, expert_num_per_shard,
+ order_mapping)
+ params_to_gather.append(param)
+ param_names.append(name)
+ if len(params_to_gather) > 0:
+ args = (state_dict, prefix, {}, True, [], [], error_msgs)
+ if is_deepspeed_zero3_enabled():
+ with deepspeed.zero.GatheredParameters(
+ params_to_gather, modifier_rank=0):
+ if dist.get_rank() == 0:
+ module._load_from_state_dict(*args)
+ else:
+ module._load_from_state_dict(*args)
+
+ for name in param_names:
+ print_on_rank0(f'state_dict pop {name}')
+ state_dict.pop(name)
+
+ for name, child in module._modules.items():
+ if child is not None:
+ load(child, state_dict, unloaded_shard_files,
+ prefix + name + '.')
+
+ state_dict = OrderedDict()
+ load(model_to_load, state_dict, unloaded_shard_files, prefix='')
+ print_on_rank0(f'{state_dict.keys()}')
+ del state_dict
+
+ return error_msgs
+
+
+def _get_origin_param_name(merged_param_name, expert_num_per_shard, is_w1w3,
+ param_name_mapping):
+ split_name = merged_param_name.split('.experts.')
+ shard_idx = re.findall(r'\d+', split_name[1])[0]
+ shard_idx = int(shard_idx)
+ origin_param_names = [None] * (expert_num_per_shard * (1 + int(is_w1w3)))
+ expert_idx_begin = expert_num_per_shard * shard_idx
+ for i in range(expert_num_per_shard):
+ if is_w1w3:
+ gate_proj, up_proj = param_name_mapping[
+ 'gate_proj'], param_name_mapping['up_proj']
+ gate = split_name[
+ 0] + f'.experts.{expert_idx_begin + i}.{gate_proj}.weight'
+ up = split_name[
+ 0] + f'.experts.{expert_idx_begin + i}.{up_proj}.weight'
+ origin_param_names[i * 2] = gate
+ origin_param_names[i * 2 + 1] = up
+ else:
+ down_proj = param_name_mapping['down_proj']
+ down = split_name[
+ 0] + f'.experts.{expert_idx_begin + i}.{down_proj}.weight'
+ origin_param_names[i] = down
+ return origin_param_names
+
+
+def _split_param(merged_param, is_w1w3):
+ if is_w1w3:
+ expert_num, _, hidden_dim = merged_param.shape
+ merged_param = merged_param.view(expert_num * 2, -1, hidden_dim)
+ return torch.unbind(merged_param, dim=0)
+ else:
+ # (e, hidden_dim, ffn_dim)
+ return torch.unbind(merged_param, dim=0)
+
+
+def get_origin_state_dict(state_dict, model):
+
+ model_name = type(model).__name__
+ if model_name not in SUPPORT_MODELS:
+ raise RuntimeError(
+ f'Only models in {SUPPORT_MODELS} may need to convert state_dict '
+ f'via `get_origin_state_dict` interface, but got {model_name}.')
+ param_name_mapping = PARAM_NAME_MAPPING[model_name]
+
+ expert_num_per_shard = get_expert_num_per_shard(model)
+ experts_param_name = [
+ name for name in state_dict.keys() if '.experts.' in name
+ ]
+ for expert_param_name in experts_param_name:
+ print_on_rank0(f'processing {expert_param_name} ...')
+ is_w1w3 = expert_param_name.split('.')[-1] == 'w1w3'
+ origin_param_names = _get_origin_param_name(expert_param_name,
+ expert_num_per_shard,
+ is_w1w3,
+ param_name_mapping)
+ merged_param = state_dict.pop(expert_param_name)
+ origin_params = _split_param(merged_param, is_w1w3)
+ assert len(origin_param_names) == len(origin_params)
+ for name, param in zip(origin_param_names, origin_params):
+ state_dict[name] = param
+ return state_dict
diff --git a/data/xtuner/xtuner/utils/stop_criteria.py b/data/xtuner/xtuner/utils/stop_criteria.py
new file mode 100644
index 0000000000000000000000000000000000000000..954cc9d700af18f4951eab4fa881cc34d900f365
--- /dev/null
+++ b/data/xtuner/xtuner/utils/stop_criteria.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from transformers import StoppingCriteria
+
+
+class StopWordStoppingCriteria(StoppingCriteria):
+ """StopWord stopping criteria."""
+
+ def __init__(self, tokenizer, stop_word):
+ self.tokenizer = tokenizer
+ self.stop_word = stop_word
+ self.length = len(self.stop_word)
+
+ def __call__(self, input_ids, *args, **kwargs) -> bool:
+ cur_text = self.tokenizer.decode(input_ids[0])
+ cur_text = cur_text.replace('\r', '').replace('\n', '')
+ return cur_text[-self.length:] == self.stop_word
diff --git a/data/xtuner/xtuner/utils/templates.py b/data/xtuner/xtuner/utils/templates.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e5732a3ed3f7ebc08b6940c3f39c850d2f8c61f
--- /dev/null
+++ b/data/xtuner/xtuner/utils/templates.py
@@ -0,0 +1,201 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import ConfigDict
+
+# - Turn 0: SYSTEM + INSTRUCTION, [output + SUFFIX], SEP
+# - Turn 1: INSTRUCTION, [output + SUFFIX], SEP
+# - Turn ...
+# Note: [] means having supervised loss during the fine-tuning
+PROMPT_TEMPLATE = ConfigDict(
+ default=dict(
+ SYSTEM='<|System|>:{system}\n',
+ INSTRUCTION='<|User|>:{input}\n<|Bot|>:',
+ SEP='\n'),
+ zephyr=dict(
+ SYSTEM='<|system|>\n{system}\n',
+ INSTRUCTION='<|user|>\n{input}\n<|assistant|>\n',
+ SEP='\n'),
+ internlm_chat=dict(
+ SYSTEM='<|System|>:{system}\n',
+ INSTRUCTION='<|User|>:{input}\n<|Bot|>:',
+ SUFFIX='',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['']),
+ internlm2_chat=dict(
+ SYSTEM='<|im_start|>system\n{system}<|im_end|>\n',
+ INSTRUCTION=('<|im_start|>user\n{input}<|im_end|>\n'
+ '<|im_start|>assistant\n'),
+ SUFFIX='<|im_end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|im_end|>']),
+ moss_sft=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='<|Human|>: {input}\n',
+ SEP='\n',
+ STOP_WORDS=['', '']),
+ llama2_chat=dict(
+ SYSTEM=(
+ '[INST] <>\n You are a helpful, respectful and honest '
+ 'assistant. Always answer as helpfully as possible, while being '
+ 'safe. Your answers should not include any harmful, unethical, '
+ 'racist, sexist, toxic, dangerous, or illegal content. Please '
+ 'ensure that your responses are socially unbiased and positive in '
+ 'nature.\n{system}\n<>\n [/INST] '),
+ INSTRUCTION='[INST] {input} [/INST]',
+ SEP='\n'),
+ code_llama_chat=dict(
+ SYSTEM='{system}\n', INSTRUCTION='[INST] {input} [/INST]'),
+ chatglm2=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='[Round {round}]\n\n问:{input}\n\n答:',
+ SEP='\n\n'),
+ chatglm3=dict(
+ SYSTEM='<|system|>\n{system}',
+ INSTRUCTION='<|user|>\n{input}<|assistant|>\n',
+ SEP='\n'),
+ qwen_chat=dict(
+ SYSTEM=('<|im_start|>system\n{system}<|im_end|>\n'),
+ INSTRUCTION=('<|im_start|>user\n{input}<|im_end|>\n'
+ '<|im_start|>assistant\n'),
+ SUFFIX='<|im_end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|im_end|>', '<|endoftext|>']),
+ baichuan_chat=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='{input}',
+ SEP='\n'),
+ baichuan2_chat=dict(
+ SYSTEM='{system}\n',
+ INSTRUCTION='{input}',
+ SEP='\n'),
+ wizardlm=dict(
+ SYSTEM=('A chat between a curious user and an artificial '
+ 'intelligence assistant. The assistant gives '
+ 'helpful, detailed, and polite answers to the '
+ 'user\'s questions. {system}\n '),
+ INSTRUCTION=('USER: {input} ASSISTANT:'),
+ SEP='\n'),
+ wizardcoder=dict(
+ SYSTEM=(
+ 'Below is an instruction that describes a task. '
+ 'Write a response that appropriately completes the request.\n\n'
+ '{system}\n '),
+ INSTRUCTION=('### Instruction:\n{input}\n\n### Response:'),
+ SEP='\n\n'),
+ vicuna=dict(
+ SYSTEM=('A chat between a curious user and an artificial '
+ 'intelligence assistant. The assistant gives '
+ 'helpful, detailed, and polite answers to the '
+ 'user\'s questions. {system}\n '),
+ INSTRUCTION=('USER: {input} ASSISTANT:'),
+ SEP='\n'),
+ deepseek_coder=dict(
+ SYSTEM=('You are an AI programming assistant, utilizing '
+ 'the DeepSeek Coder model, developed by DeepSeek'
+ 'Company, and you only answer questions related '
+ 'to computer science. For politically sensitive '
+ 'questions, security and privacy issues, and '
+ 'other non-computer science questions, you will '
+ 'refuse to answer. {system}\n'),
+ INSTRUCTION=('### Instruction:\n{input}\n### Response:\n'),
+ SEP='\n'),
+ # TODO: deprecation, v0.2.0
+ deepseekcoder=dict(
+ SYSTEM=('You are an AI programming assistant, utilizing '
+ 'the DeepSeek Coder model, developed by DeepSeek'
+ 'Company, and you only answer questions related '
+ 'to computer science. For politically sensitive '
+ 'questions, security and privacy issues, and '
+ 'other non-computer science questions, you will '
+ 'refuse to answer. {system}\n'),
+ INSTRUCTION=('### Instruction:\n{input}\n### Response:\n'),
+ SEP='\n'),
+ deepseek_moe=dict(
+ SYSTEM=('[INST] {system} [/INST]\n'),
+ INSTRUCTION=('[INST] {input} [/INST]'),
+ SEP='\n'),
+ deepseek_v2=dict(
+ SYSTEM='{system}\n\n',
+ INSTRUCTION='User: {input}\n\nAssistant: ',
+ SUFFIX='<|end▁of▁sentence|>',
+ SUFFIX_AS_EOS=True,
+ STOP_WORDS=['<|end▁of▁sentence|>']),
+ mistral=dict(
+ SYSTEM=('[INST] {system} [/INST]\n'),
+ INSTRUCTION=('[INST] {input} [/INST]'),
+ SEP='\n'),
+ mixtral=dict(
+ SYSTEM=('[INST] {system} [/INST]\n'),
+ INSTRUCTION=('[INST] {input} [/INST]'),
+ SEP='\n'),
+ minicpm=dict(INSTRUCTION=('<用户> {input} '), SEP='\n'),
+ minicpm3=dict(
+ SYSTEM=('<|im_start|>system\n{system}<|im_end|>\n'),
+ INSTRUCTION=('<|im_start|>user\n{input}<|im_end|>\n'
+ '<|im_start|>assistant\n'),
+ SUFFIX='<|im_end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|im_end|>', '<|endoftext|>']),
+ gemma=dict(
+ # `system` field is extended by xtuner
+ SYSTEM=('system\n{system}\n'),
+ INSTRUCTION=('user\n{input}\n'
+ 'model\n'),
+ SUFFIX='',
+ SUFFIX_AS_EOS=False,
+ SEP='\n',
+ STOP_WORDS=['']),
+ cohere_chat=dict(
+ SYSTEM=('<|START_OF_TURN_TOKEN|><|SYSTEM_TOKEN|>{system}'
+ '<|END_OF_TURN_TOKEN|>'),
+ INSTRUCTION=(
+ '<|START_OF_TURN_TOKEN|><|USER_TOKEN|>{input}<|END_OF_TURN_TOKEN|>'
+ '<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>'),
+ SUFFIX='<|END_OF_TURN_TOKEN|>',
+ SUFFIX_AS_EOS=True,
+ STOP_WORDS=['<|END_OF_TURN_TOKEN|>']),
+ llama3_chat=dict(
+ SYSTEM=('<|start_header_id|>system<|end_header_id|>\n\n'
+ '{system}<|eot_id|>'),
+ INSTRUCTION=(
+ '<|start_header_id|>user<|end_header_id|>\n\n{input}<|eot_id|>'
+ '<|start_header_id|>assistant<|end_header_id|>\n\n'),
+ SUFFIX='<|eot_id|>',
+ SUFFIX_AS_EOS=True,
+ STOP_WORDS=['<|eot_id|>']),
+ phi3_chat=dict(
+ SYSTEM='<|system|>\n{system}<|end|>\n',
+ INSTRUCTION='<|user|>\n{input}<|end|>\n<|assistant|>\n',
+ SUFFIX='<|end|>',
+ SUFFIX_AS_EOS=True,
+ SEP='\n',
+ STOP_WORDS=['<|end|>']),
+)
+
+SYSTEM_TEMPLATE = ConfigDict(
+ moss_sft=('You are an AI assistant whose name is {bot_name}.\n'
+ 'Capabilities and tools that {bot_name} can possess.\n'
+ '- Inner thoughts: enabled.\n'
+ '- Web search: enabled. API: Search(query)\n'
+ '- Calculator: enabled. API: Calculate(expression)\n'
+ '- Equation solver: enabled. API: Solve(equation)\n'
+ '- Text-to-image: disabled.\n'
+ '- Image edition: disabled.\n'
+ '- Text-to-speech: disabled.\n'),
+ alpaca=('Below is an instruction that describes a task. '
+ 'Write a response that appropriately completes the request.\n'),
+ arxiv_gentile=('If you are an expert in writing papers, please generate '
+ "a good paper title for this paper based on other authors' "
+ 'descriptions of their abstracts.\n'),
+ colorist=('You are a professional color designer. Please provide the '
+ 'corresponding colors based on the description of Human.\n'),
+ coder=('You are a professional programer. Please provide the '
+ 'corresponding code based on the description of Human.\n'),
+ lawyer='你现在是一名专业的中国律师,请根据用户的问题给出准确、有理有据的回复。\n',
+ medical='如果你是一名医生,请根据患者的描述回答医学问题。\n',
+ sql=('If you are an expert in SQL, please generate a good SQL Query '
+ 'for Question based on the CREATE TABLE statement.\n'),
+)
diff --git a/data/xtuner/xtuner/utils/zero_to_any_dtype.py b/data/xtuner/xtuner/utils/zero_to_any_dtype.py
new file mode 100644
index 0000000000000000000000000000000000000000..efe1fc0a12b3acee980a42c378a28b42532de256
--- /dev/null
+++ b/data/xtuner/xtuner/utils/zero_to_any_dtype.py
@@ -0,0 +1,696 @@
+#!/usr/bin/env python
+
+# Copyright (c) Microsoft Corporation.
+# SPDX-License-Identifier: Apache-2.0
+
+# DeepSpeed Team
+
+# This script extracts consolidated weights from a zero 1, 2 and 3 DeepSpeed
+# checkpoints. It gets copied into the top level checkpoint dir, so the user
+# can easily do the conversion at any point in the future. Once extracted, the
+# weights don't require DeepSpeed and can be used in any application.
+#
+# example: python zero_to_any_dtype.py . pytorch_model.bin
+
+import argparse
+import glob
+import math
+import os
+import re
+from collections import OrderedDict
+from dataclasses import dataclass
+
+import torch
+# yapf: disable
+from deepspeed.checkpoint.constants import (BUFFER_NAMES, DS_VERSION,
+ FP32_FLAT_GROUPS,
+ FROZEN_PARAM_FRAGMENTS,
+ FROZEN_PARAM_SHAPES,
+ OPTIMIZER_STATE_DICT, PARAM_SHAPES,
+ PARTITION_COUNT,
+ SINGLE_PARTITION_OF_FP32_GROUPS,
+ ZERO_STAGE)
+# while this script doesn't use deepspeed to recover data, since the
+# checkpoints are pickled with DeepSpeed data structures it has to be
+# available in the current python environment.
+from deepspeed.utils import logger
+from tqdm import tqdm
+
+# yapf: enable
+
+
+@dataclass
+class zero_model_state:
+ buffers: dict()
+ param_shapes: dict()
+ shared_params: list
+ ds_version: int
+ frozen_param_shapes: dict()
+ frozen_param_fragments: dict()
+
+
+debug = 0
+
+# load to cpu
+device = torch.device('cpu')
+
+DEFAULT_DTYPE = torch.float16
+
+
+def atoi(text):
+ return int(text) if text.isdigit() else text
+
+
+def natural_keys(text):
+ """alist.sort(key=natural_keys) sorts in human order
+ http://nedbatchelder.com/blog/200712/human_sorting.html (See Toothy's
+ implementation in the comments)"""
+ return [atoi(c) for c in re.split(r'(\d+)', text)]
+
+
+def get_model_state_file(checkpoint_dir, zero_stage):
+ if not os.path.isdir(checkpoint_dir):
+ raise FileNotFoundError(f"Directory '{checkpoint_dir}' doesn't exist")
+
+ # there should be only one file
+ if zero_stage <= 2:
+ file = os.path.join(checkpoint_dir, 'mp_rank_00_model_states.pt')
+ elif zero_stage == 3:
+ file = os.path.join(checkpoint_dir,
+ 'zero_pp_rank_0_mp_rank_00_model_states.pt')
+
+ if not os.path.exists(file):
+ raise FileNotFoundError(f"can't find model states file at '{file}'")
+
+ return file
+
+
+def get_checkpoint_files(checkpoint_dir, glob_pattern):
+ # XXX: need to test that this simple glob rule works for multi-node
+ # setup too
+ ckpt_files = sorted(
+ glob.glob(os.path.join(checkpoint_dir, glob_pattern)),
+ key=natural_keys)
+
+ if len(ckpt_files) == 0:
+ raise FileNotFoundError(
+ f"can't find {glob_pattern} files in directory '{checkpoint_dir}'")
+
+ return ckpt_files
+
+
+def get_optim_files(checkpoint_dir):
+ return get_checkpoint_files(checkpoint_dir, '*_optim_states.pt')
+
+
+def get_model_state_files(checkpoint_dir):
+ return get_checkpoint_files(checkpoint_dir, '*_model_states.pt')
+
+
+def parse_model_states(files, dtype=DEFAULT_DTYPE):
+ zero_model_states = []
+ for file in files:
+ state_dict = torch.load(file, map_location=device)
+
+ if BUFFER_NAMES not in state_dict:
+ raise ValueError(f'{file} is not a model state checkpoint')
+ buffer_names = state_dict[BUFFER_NAMES]
+ if debug:
+ print('Found buffers:', buffer_names)
+
+ buffers = {
+ k: v.to(dtype)
+ for k, v in state_dict['module'].items() if k in buffer_names
+ }
+ param_shapes = state_dict[PARAM_SHAPES]
+
+ # collect parameters that are included in param_shapes
+ param_names = []
+ for s in param_shapes:
+ for name in s.keys():
+ param_names.append(name)
+
+ # update with frozen parameters
+ frozen_param_shapes = state_dict.get(FROZEN_PARAM_SHAPES, None)
+ if frozen_param_shapes is not None:
+ if debug:
+ print(f'Found frozen_param_shapes: {frozen_param_shapes}')
+ param_names += list(frozen_param_shapes.keys())
+
+ # handle shared params
+ shared_params = [[k, v]
+ for k, v in state_dict['shared_params'].items()]
+
+ ds_version = state_dict.get(DS_VERSION, None)
+
+ frozen_param_fragments = state_dict.get(FROZEN_PARAM_FRAGMENTS, None)
+
+ z_model_state = zero_model_state(
+ buffers=buffers,
+ param_shapes=param_shapes,
+ shared_params=shared_params,
+ ds_version=ds_version,
+ frozen_param_shapes=frozen_param_shapes,
+ frozen_param_fragments=frozen_param_fragments)
+ zero_model_states.append(z_model_state)
+
+ return zero_model_states
+
+
+@torch.no_grad()
+def parse_optim_states(files, ds_checkpoint_dir, dtype=DEFAULT_DTYPE):
+
+ zero_stage = None
+ world_size = None
+ total_files = len(files)
+ flat_groups = []
+ for f in tqdm(files, desc='Load Checkpoints'):
+ state_dict = torch.load(f, map_location=device)
+ if ZERO_STAGE not in state_dict[OPTIMIZER_STATE_DICT]:
+ raise ValueError(f'{f} is not a zero checkpoint')
+
+ zero_stage = state_dict[OPTIMIZER_STATE_DICT][ZERO_STAGE]
+ world_size = state_dict[OPTIMIZER_STATE_DICT][PARTITION_COUNT]
+
+ # the groups are named differently in each stage
+ if zero_stage <= 2:
+ fp32_groups_key = SINGLE_PARTITION_OF_FP32_GROUPS
+ elif zero_stage == 3:
+ fp32_groups_key = FP32_FLAT_GROUPS
+ else:
+ raise ValueError(f'unknown zero stage {zero_stage}')
+
+ # immediately discard the potentially huge 2 optimizer states as we
+ # only care for fp32 master weights and also handle the case where it
+ # was already removed by another helper script
+ state_dict['optimizer_state_dict'].pop('optimizer_state_dict', None)
+ fp32_groups = state_dict['optimizer_state_dict'].pop(fp32_groups_key)
+ if zero_stage <= 2:
+ flat_groups.append([param.to(dtype) for param in fp32_groups])
+ elif zero_stage == 3:
+ # if there is more than one param group, there will be multiple
+ # flattened tensors - one flattened tensor per group - for
+ # simplicity merge them into a single tensor
+
+ # XXX: could make the script more memory efficient for when there
+ # are multiple groups - it will require matching the sub-lists of
+ # param_shapes for each param group flattened tensor
+ flat_groups.append(torch.cat(fp32_groups, 0).to(dtype))
+
+ # For ZeRO-2 each param group can have different partition_count as data
+ # parallelism for expert parameters can be different from data parallelism
+ # for non-expert parameters. So we can just use the max of the
+ # partition_count to get the dp world_size.
+ if type(world_size) is list:
+ world_size = max(world_size)
+
+ if world_size != total_files:
+ raise ValueError(
+ f"Expected {world_size} of '*_optim_states.pt' under "
+ f"'{ds_checkpoint_dir}' but found {total_files} files. "
+ 'Possibly due to an overwrite of an old checkpoint, '
+ "or a checkpoint didn't get saved by one or more processes.")
+
+ return zero_stage, world_size, flat_groups
+
+
+def _get_state_dict_from_zero_checkpoint(ds_checkpoint_dir,
+ exclude_frozen_parameters,
+ dtype=DEFAULT_DTYPE):
+ """Returns state_dict reconstructed from ds checkpoint.
+
+ Args:
+ - ``ds_checkpoint_dir``: path to the deepspeed checkpoint folder
+ (where the optimizer files are)
+ """
+ print(f"Processing zero checkpoint '{ds_checkpoint_dir}'")
+
+ optim_files = get_optim_files(ds_checkpoint_dir)
+ zero_stage, world_size, flat_groups = parse_optim_states(
+ optim_files, ds_checkpoint_dir, dtype)
+ print(f'Detected checkpoint of type zero stage {zero_stage}, '
+ f'world_size: {world_size}')
+
+ model_files = get_model_state_files(ds_checkpoint_dir)
+
+ zero_model_states = parse_model_states(model_files)
+ print(f'Parsing checkpoint created by deepspeed=='
+ f'{zero_model_states[0].ds_version}')
+
+ if zero_stage <= 2:
+ return _get_state_dict_from_zero2_checkpoint(
+ world_size, flat_groups, zero_model_states,
+ exclude_frozen_parameters)
+ elif zero_stage == 3:
+ return _get_state_dict_from_zero3_checkpoint(
+ world_size, flat_groups, zero_model_states,
+ exclude_frozen_parameters)
+
+
+def _zero2_merge_frozen_params(state_dict, zero_model_states):
+ if zero_model_states[0].frozen_param_shapes is None or len(
+ zero_model_states[0].frozen_param_shapes) == 0:
+ return
+
+ frozen_param_shapes = zero_model_states[0].frozen_param_shapes
+ frozen_param_fragments = zero_model_states[0].frozen_param_fragments
+
+ if debug:
+ num_elem = sum(s.numel() for s in frozen_param_shapes.values())
+ print(f'rank 0: {FROZEN_PARAM_SHAPES}.numel = {num_elem}')
+
+ wanted_params = len(frozen_param_shapes)
+ wanted_numel = sum(s.numel() for s in frozen_param_shapes.values())
+ avail_numel = sum([p.numel() for p in frozen_param_fragments.values()])
+ print(f'Frozen params: Have {avail_numel} numels to process.')
+ print(f'Frozen params: Need {wanted_numel} numels in '
+ f'{wanted_params} params')
+
+ total_params = 0
+ total_numel = 0
+ for name, shape in frozen_param_shapes.items():
+ total_params += 1
+ unpartitioned_numel = shape.numel()
+ total_numel += unpartitioned_numel
+
+ state_dict[name] = frozen_param_fragments[name]
+
+ if debug:
+ print(f'{name} full shape: {shape} unpartitioned numel '
+ f'{unpartitioned_numel} ')
+
+ print(f'Reconstructed Frozen state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _has_callable(obj, fn):
+ attr = getattr(obj, fn, None)
+ return callable(attr)
+
+
+def _zero2_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states):
+ param_shapes = zero_model_states[0].param_shapes
+
+ # Reconstruction protocol:
+ #
+ # XXX: document this
+
+ if debug:
+ for i in range(world_size):
+ for j in range(len(flat_groups[0])):
+ print(f'flat_groups[{i}][{j}].shape={flat_groups[i][j].shape}')
+
+ # XXX: memory usage doubles here (zero2)
+ num_param_groups = len(flat_groups[0])
+ merged_single_partition_of_groups = []
+ for i in range(num_param_groups):
+ merged_partitions = [sd[i] for sd in flat_groups]
+ full_single_vector = torch.cat(merged_partitions, 0)
+ merged_single_partition_of_groups.append(full_single_vector)
+ avail_numel = sum([
+ full_single_vector.numel()
+ for full_single_vector in merged_single_partition_of_groups
+ ])
+
+ if debug:
+ wanted_params = sum([len(shapes) for shapes in param_shapes])
+ wanted_numel = sum([
+ sum(shape.numel() for shape in shapes.values())
+ for shapes in param_shapes
+ ])
+ # not asserting if there is a mismatch due to possible padding
+ print(f'Have {avail_numel} numels to process.')
+ print(f'Need {wanted_numel} numels in {wanted_params} params.')
+
+ # params
+ # XXX: for huge models that can't fit into the host's RAM we will have to
+ # recode this to support out-of-core computing solution
+ total_numel = 0
+ total_params = 0
+ for shapes, full_single_vector in zip(param_shapes,
+ merged_single_partition_of_groups):
+ offset = 0
+ avail_numel = full_single_vector.numel()
+ for name, shape in shapes.items():
+
+ unpartitioned_numel = shape.numel() if _has_callable(
+ shape, 'numel') else math.prod(shape)
+ total_numel += unpartitioned_numel
+ total_params += 1
+
+ if debug:
+ print(f'{name} full shape: {shape} unpartitioned numel '
+ f'{unpartitioned_numel} ')
+ state_dict[name] = full_single_vector.narrow(
+ 0, offset, unpartitioned_numel).view(shape)
+ offset += unpartitioned_numel
+
+ # Z2 started to align to 2*world_size to improve nccl performance.
+ # Therefore both offset and avail_numel can differ by anywhere between
+ # 0..2*world_size. Due to two unrelated complex paddings performed in
+ # the code it's almost impossible to predict the exact numbers w/o the
+ # live optimizer object, so we are checking that the numbers are
+ # within the right range
+ align_to = 2 * world_size
+
+ def zero2_align(x):
+ return align_to * math.ceil(x / align_to)
+
+ if debug:
+ print(f'original offset={offset}, avail_numel={avail_numel}')
+
+ offset = zero2_align(offset)
+ avail_numel = zero2_align(avail_numel)
+
+ if debug:
+ print(f'aligned offset={offset}, avail_numel={avail_numel}')
+
+ # Sanity check
+ if offset != avail_numel:
+ raise ValueError(f'consumed {offset} numels out of {avail_numel} '
+ '- something is wrong')
+
+ print(f'Reconstructed state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _get_state_dict_from_zero2_checkpoint(world_size, flat_groups,
+ zero_model_states,
+ exclude_frozen_parameters):
+ state_dict = OrderedDict()
+
+ # buffers
+ buffers = zero_model_states[0].buffers
+ state_dict.update(buffers)
+ if debug:
+ print(f'added {len(buffers)} buffers')
+
+ if not exclude_frozen_parameters:
+ _zero2_merge_frozen_params(state_dict, zero_model_states)
+
+ _zero2_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states)
+
+ # recover shared parameters
+ for pair in zero_model_states[0].shared_params:
+ if pair[1] in state_dict:
+ state_dict[pair[0]] = state_dict[pair[1]]
+
+ return state_dict
+
+
+def zero3_partitioned_param_info(unpartitioned_numel, world_size):
+ remainder = unpartitioned_numel % world_size
+ padding_numel = (world_size - remainder) if remainder else 0
+ partitioned_numel = math.ceil(unpartitioned_numel / world_size)
+ return partitioned_numel, padding_numel
+
+
+def _zero3_merge_frozen_params(state_dict, world_size, zero_model_states):
+ if zero_model_states[0].frozen_param_shapes is None or len(
+ zero_model_states[0].frozen_param_shapes) == 0:
+ return
+
+ if debug:
+ for i in range(world_size):
+ num_elem = sum(
+ s.numel()
+ for s in zero_model_states[i].frozen_param_fragments.values())
+ print(f'rank {i}: {FROZEN_PARAM_SHAPES}.numel = {num_elem}')
+
+ frozen_param_shapes = zero_model_states[0].frozen_param_shapes
+ wanted_params = len(frozen_param_shapes)
+ wanted_numel = sum(s.numel() for s in frozen_param_shapes.values())
+ avail_numel = sum([
+ p.numel()
+ for p in zero_model_states[0].frozen_param_fragments.values()
+ ]) * world_size
+ print(f'Frozen params: Have {avail_numel} numels to process.')
+ print(f'Frozen params: Need {wanted_numel} numels in '
+ f'{wanted_params} params')
+
+ total_params = 0
+ total_numel = 0
+ for name, shape in zero_model_states[0].frozen_param_shapes.items():
+ total_params += 1
+ unpartitioned_numel = shape.numel()
+ total_numel += unpartitioned_numel
+
+ param_frags = tuple(model_state.frozen_param_fragments[name]
+ for model_state in zero_model_states)
+ state_dict[name] = torch.cat(param_frags, 0).narrow(
+ 0, 0, unpartitioned_numel).view(shape) # noqa: E501
+
+ _partitioned = zero3_partitioned_param_info(unpartitioned_numel,
+ world_size)
+ partitioned_numel, partitioned_padding_numel = _partitioned
+ if debug:
+ print(f'Frozen params: {total_params} {name} full shape: {shape} '
+ f'partition0 numel={partitioned_numel} '
+ f'partitioned_padding_numel={partitioned_padding_numel}')
+
+ print(f'Reconstructed Frozen state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _zero3_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states):
+ param_shapes = zero_model_states[0].param_shapes
+ avail_numel = flat_groups[0].numel() * world_size
+ # Reconstruction protocol: For zero3 we need to zip the partitions
+ # together at boundary of each param, re-consolidating each param, while
+ # dealing with padding if any
+
+ # merge list of dicts, preserving order
+ param_shapes = {k: v for d in param_shapes for k, v in d.items()}
+
+ if debug:
+ for i in range(world_size):
+ print(f'flat_groups[{i}].shape={flat_groups[i].shape}')
+
+ wanted_params = len(param_shapes)
+ wanted_numel = sum(shape.numel() for shape in param_shapes.values())
+ # not asserting if there is a mismatch due to possible padding
+ avail_numel = flat_groups[0].numel() * world_size
+ print(f'Trainable params: Have {avail_numel} numels to process.')
+ print(f'Trainable params: Need {wanted_numel} numels in '
+ f'{wanted_params} params.')
+
+ offset = 0
+ total_numel = 0
+ total_params = 0
+ partitioned_sizes = []
+ for name, shape in param_shapes.items():
+
+ unpartitioned_numel = shape.numel()
+ total_numel += unpartitioned_numel
+ total_params += 1
+
+ _info = zero3_partitioned_param_info(unpartitioned_numel, world_size)
+
+ partitioned_numel, partitioned_padding_numel = _info
+ partitioned_sizes.append(partitioned_numel)
+ if debug:
+ print(
+ f'Trainable params: {total_params} {name} full shape: {shape} '
+ f'partition0 numel={partitioned_numel} '
+ f'partitioned_padding_numel={partitioned_padding_numel}')
+
+ offset += partitioned_numel
+
+ offset *= world_size
+
+ # Sanity check
+ if offset != avail_numel:
+ raise ValueError(f'consumed {offset} numels out of {avail_numel} '
+ '- something is wrong')
+
+ mat_chunks = []
+ for rank in range(world_size):
+ rank_chunks = flat_groups.pop(0).split(partitioned_sizes)
+ rank_chunks = [tensor.clone() for tensor in rank_chunks]
+ mat_chunks.append(rank_chunks)
+
+ for name, shape in tqdm(
+ param_shapes.items(), desc='Gather Sharded Weights'):
+
+ pad_flat_param_chunks = []
+ for rank in range(world_size):
+ pad_flat_param_chunks.append(mat_chunks[rank].pop(0))
+
+ pad_flat_param = torch.cat(pad_flat_param_chunks, dim=0)
+
+ # Because pad_flat_param_chunks is a list, it is necessary to manually
+ # release the tensors in the list; Python will not automatically do so.
+ for rank in range(world_size):
+ pad_flat_param_chunks.pop()
+
+ param = pad_flat_param[:shape.numel()].view(shape)
+ state_dict[name] = param
+
+ print(f'Reconstructed Trainable state dict with {total_params} params '
+ f'{total_numel} elements')
+
+
+def _get_state_dict_from_zero3_checkpoint(world_size, flat_groups,
+ zero_model_states,
+ exclude_frozen_parameters):
+ state_dict = OrderedDict()
+
+ # buffers
+ buffers = zero_model_states[0].buffers
+ state_dict.update(buffers)
+ if debug:
+ print(f'added {len(buffers)} buffers')
+
+ if not exclude_frozen_parameters:
+ _zero3_merge_frozen_params(state_dict, world_size, zero_model_states)
+
+ _zero3_merge_trainable_params(state_dict, world_size, flat_groups,
+ zero_model_states)
+
+ # recover shared parameters
+ for pair in zero_model_states[0].shared_params:
+ if pair[1] in state_dict:
+ state_dict[pair[0]] = state_dict[pair[1]]
+
+ return state_dict
+
+
+def get_state_dict_from_zero_checkpoint(checkpoint_dir,
+ tag=None,
+ exclude_frozen_parameters=False,
+ dtype=DEFAULT_DTYPE):
+ # flake8: noqa
+ """Convert ZeRO 2 or 3 checkpoint into a single consolidated state_dict
+ that can be loaded with ``load_state_dict()`` and used for training without
+ DeepSpeed or shared with others, for example via a model hub.
+
+ Args:
+ - ``checkpoint_dir``: path to the desired checkpoint folder
+ - ``tag``: checkpoint tag used as a unique identifier for checkpoint.
+ If not provided will attempt to load tag in 'latest' file.
+ e.g., ``global_step14``
+ - ``exclude_frozen_parameters``: exclude frozen parameters
+
+ Returns:
+ - pytorch ``state_dict``
+
+ Note: this approach may not work if your application doesn't have
+ sufficient free CPU memory and you may need to use the offline approach
+ using the ``zero_to_any_dtype.py`` script that is saved with the
+ checkpoint.
+
+ A typical usage might be ::
+
+ from xtuner.utils.zero_to_any_dtype import get_state_dict_from_zero_checkpoint
+ # do the training and checkpoint saving
+ state_dict = get_state_dict_from_zero_checkpoint(checkpoint_dir, dtype=torch.float16) # already on cpu
+ model = model.cpu() # move to cpu
+ model.load_state_dict(state_dict)
+ # submit to model hub or save the model to share with others
+
+ In this example the ``model`` will no longer be usable in the deepspeed
+ context of the same application. i.e. you will need to re-initialize the
+ deepspeed engine, since ``model.load_state_dict(state_dict)`` will remove
+ all the deepspeed magic from it.
+
+ If you want it all done for you, use
+ ``load_state_dict_from_zero_checkpoint`` instead.
+ """
+ # flake8: noqa
+ if tag is None:
+ latest_path = os.path.join(checkpoint_dir, 'latest')
+ if os.path.isfile(latest_path):
+ with open(latest_path) as fd:
+ tag = fd.read().strip()
+ else:
+ raise ValueError(f"Unable to find 'latest' file at {latest_path}")
+
+ ds_checkpoint_dir = os.path.join(checkpoint_dir, tag)
+
+ if not os.path.isdir(ds_checkpoint_dir):
+ raise FileNotFoundError(
+ f"Directory '{ds_checkpoint_dir}' doesn't exist")
+
+ return _get_state_dict_from_zero_checkpoint(ds_checkpoint_dir,
+ exclude_frozen_parameters,
+ dtype)
+
+
+def convert_zero_checkpoint_to_state_dict(checkpoint_dir,
+ output_file,
+ tag=None,
+ exclude_frozen_parameters=False,
+ dtype=DEFAULT_DTYPE):
+ """Convert ZeRO 2 or 3 checkpoint into a single consolidated ``state_dict``
+ file that can be loaded with ``torch.load(file)`` + ``load_state_dict()``
+ and used for training without DeepSpeed.
+
+ Args:
+ - ``checkpoint_dir``: path to the desired checkpoint folder.
+ (one that contains the tag-folder, like ``global_step14``)
+ - ``output_file``: path to the pytorch state_dict output file
+ (e.g. path/pytorch_model.bin)
+ - ``tag``: checkpoint tag used as a unique identifier for checkpoint.
+ If not provided will attempt to load tag in the file named
+ ``latest`` in the checkpoint folder, e.g., ``global_step14``
+ - ``exclude_frozen_parameters``: exclude frozen parameters
+ """
+
+ state_dict = get_state_dict_from_zero_checkpoint(
+ checkpoint_dir, tag, exclude_frozen_parameters, dtype)
+ print(f'Saving {dtype} state dict to {output_file}')
+ torch.save(state_dict, output_file)
+
+
+def load_state_dict_from_zero_checkpoint(model,
+ checkpoint_dir,
+ tag=None,
+ dtype=DEFAULT_DTYPE):
+
+ # flake8: noqa
+ """
+ 1. Put the provided model to cpu
+ 2. Convert ZeRO 2 or 3 checkpoint into a single consolidated ``state_dict``
+ 3. Load it into the provided model
+
+ Args:
+ - ``model``: the model object to update
+ - ``checkpoint_dir``: path to the desired checkpoint folder. (one that
+ contains the tag-folder, like ``global_step14``)
+ - ``tag``: checkpoint tag used as a unique identifier for checkpoint.
+ If not provided will attempt to load tag in the file named
+ ``latest`` in the checkpoint folder, e.g., ``global_step14``
+
+ Returns:
+ - ``model`: modified model
+
+ Make sure you have plenty of CPU memory available before you call this
+ function. If you don't have enough use the ``zero_to_any_dtype.py``
+ utility to do the conversion. You will find it conveniently placed for you
+ in the checkpoint folder.
+
+ A typical usage might be ::
+
+ from xtuner.utils.zero_to_any_dtype import load_state_dict_from_zero_checkpoint
+ model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir, dtype=torch.float16)
+ # submit to model hub or save the model to share with others
+
+ Note, that once this was run, the ``model`` will no longer be usable in
+ the deepspeed context of the same application. i.e. you will need to
+ re-initialize the deepspeed engine, since
+ ``model.load_state_dict(state_dict)`` will remove all the deepspeed magic
+ from it.
+ """
+ # flake8: noqa
+ logger.info(f'Extracting {dtype} weights')
+ state_dict = get_state_dict_from_zero_checkpoint(
+ checkpoint_dir, tag, dtype=dtype)
+
+ logger.info(f'Overwriting model with {dtype} weights')
+ model = model.cpu()
+ model.load_state_dict(state_dict, strict=False)
+
+ return model
diff --git a/data/xtuner/xtuner/version.py b/data/xtuner/xtuner/version.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4669c1880af551fc52eae2b826adfdd60e6a6d0
--- /dev/null
+++ b/data/xtuner/xtuner/version.py
@@ -0,0 +1,26 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+__version__ = '0.1.23'
+short_version = __version__
+
+
+def parse_version_info(version_str):
+ """Parse a version string into a tuple.
+
+ Args:
+ version_str (str): The version string.
+ Returns:
+ tuple[int or str]: The version info, e.g., "1.3.0" is parsed into
+ (1, 3, 0), and "2.0.0rc1" is parsed into (2, 0, 0, 'rc1').
+ """
+ version_info = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ version_info.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ version_info.append(int(patch_version[0]))
+ version_info.append(f'rc{patch_version[1]}')
+ return tuple(version_info)
+
+
+version_info = parse_version_info(__version__)
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..cb396fcb2edac94dc7eda3a3f055e59b74f395eb
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,6 @@
+llama-index==0.11.20
+llama-index-llms-replicate==0.3.0
+llama-index-llms-openai-like==0.2.0
+llama-index-embeddings-huggingface==0.3.1
+llama-index-embeddings-instructor==0.2.1
+sentence-transformers==2.7.0