+ for p in group["params"]:
+ state = self.state[p]
+ ...
+
+ you can do:
+
+ with self.batched_params(group["params"]) as batches:
+ for p, state, p_names in batches:
+ ...
+
+
+ Args:
+ group: a parameter group, which is a list of parameters; should be
+ one of self.param_groups.
+ group_params_names: name for each parameter in group,
+ which is List[str].
+ """
+ batches = defaultdict(list) # `batches` maps from tuple (dtype_as_str,*shape) to list of nn.Parameter
+ batches_names = defaultdict(list) # `batches` maps from tuple (dtype_as_str,*shape) to list of str
+
+ assert len(param_group) == len(group_params_names)
+ for p, named_p in zip(param_group, group_params_names):
+ key = (str(p.dtype), *p.shape)
+ batches[key].append(p)
+ batches_names[key].append(named_p)
+
+ batches_names_keys = list(batches_names.keys())
+ sorted_idx = sorted(range(len(batches_names)), key=lambda i: batches_names_keys[i])
+ batches_names = [batches_names[batches_names_keys[idx]] for idx in sorted_idx]
+ batches = [batches[batches_names_keys[idx]] for idx in sorted_idx]
+
+ stacked_params_dict = dict()
+
+ # turn batches into a list, in deterministic order.
+ # tuples will contain tuples of (stacked_param, state, stacked_params_names),
+ # one for each batch in `batches`.
+ tuples = []
+
+ for batch, batch_names in zip(batches, batches_names):
+ p = batch[0]
+ # we arbitrarily store the state in the
+ # state corresponding to the 1st parameter in the
+ # group. class Optimizer will take care of saving/loading state.
+ state = self.state[p]
+ p_stacked = torch.stack(batch)
+ grad = torch.stack([torch.zeros_like(p) if p.grad is None else p.grad for p in batch])
+ p_stacked.grad = grad
+ stacked_params_dict[key] = p_stacked
+ tuples.append((p_stacked, state, batch_names))
+
+ yield tuples # <-- calling code will do the actual optimization here!
+
+ for (stacked_params, _state, _names), batch in zip(tuples, batches):
+ for i, p in enumerate(batch): # batch is list of Parameter
+ p.copy_(stacked_params[i])
+
+
+class ScaledAdam(BatchedOptimizer):
+ """
+ Implements 'Scaled Adam', a variant of Adam where we scale each parameter's update
+ proportional to the norm of that parameter; and also learn the scale of the parameter,
+ in log space, subject to upper and lower limits (as if we had factored each parameter as
+ param = underlying_param * log_scale.exp())
+
+
+ Args:
+ params: The parameters or param_groups to optimize (like other Optimizer subclasses)
+ lr: The learning rate. We will typically use a learning rate schedule that starts
+ at 0.03 and decreases over time, i.e. much higher than other common
+ optimizers.
+ clipping_scale: (e.g. 2.0)
+ A scale for gradient-clipping: if specified, the normalized gradients
+ over the whole model will be clipped to have 2-norm equal to
+ `clipping_scale` times the median 2-norm over the most recent period
+ of `clipping_update_period` minibatches. By "normalized gradients",
+ we mean after multiplying by the rms parameter value for this tensor
+ [for non-scalars]; this is appropriate because our update is scaled
+ by this quantity.
+ betas: beta1,beta2 are momentum constants for regular momentum, and moving sum-sq grad.
+ Must satisfy 0 < beta <= beta2 < 1.
+ scalar_lr_scale: A scaling factor on the learning rate, that we use to update the
+ scale of each parameter tensor and scalar parameters of the mode..
+ If each parameter were decomposed
+ as p * p_scale.exp(), where (p**2).mean().sqrt() == 1.0, scalar_lr_scale
+ would be a the scaling factor on the learning rate of p_scale.
+ eps: A general-purpose epsilon to prevent division by zero
+ param_min_rms: Minimum root-mean-square value of parameter tensor, for purposes of
+ learning the scale on the parameters (we'll constrain the rms of each non-scalar
+ parameter tensor to be >= this value)
+ param_max_rms: Maximum root-mean-square value of parameter tensor, for purposes of
+ learning the scale on the parameters (we'll constrain the rms of each non-scalar
+ parameter tensor to be <= this value)
+ scalar_max: Maximum absolute value for scalar parameters (applicable if your
+ model has any parameters with numel() == 1).
+ size_update_period: The periodicity, in steps, with which we update the size (scale)
+ of the parameter tensor. This is provided to save a little time
+ in the update.
+ clipping_update_period: if clipping_scale is specified, this is the period
+ """
+
+ def __init__(
+ self,
+ params,
+ lr=3e-02,
+ clipping_scale=None,
+ betas=(0.9, 0.98),
+ scalar_lr_scale=0.1,
+ eps=1.0e-08,
+ param_min_rms=1.0e-05,
+ param_max_rms=3.0,
+ scalar_max=10.0,
+ size_update_period=4,
+ clipping_update_period=100,
+ parameters_names=None,
+ show_dominant_parameters=True,
+ ):
+ assert parameters_names is not None, (
+ "Please prepare parameters_names,which is a List[List[str]]. Each List[str] is for a groupand each str is for a parameter"
+ )
+ defaults = dict(
+ lr=lr,
+ clipping_scale=clipping_scale,
+ betas=betas,
+ scalar_lr_scale=scalar_lr_scale,
+ eps=eps,
+ param_min_rms=param_min_rms,
+ param_max_rms=param_max_rms,
+ scalar_max=scalar_max,
+ size_update_period=size_update_period,
+ clipping_update_period=clipping_update_period,
+ )
+
+ super(ScaledAdam, self).__init__(params, defaults)
+ assert len(self.param_groups) == len(parameters_names)
+ self.parameters_names = parameters_names
+ self.show_dominant_parameters = show_dominant_parameters
+
+ def __setstate__(self, state):
+ super(ScaledAdam, self).__setstate__(state)
+
+ @torch.no_grad()
+ def step(self, closure=None):
+ """Performs a single optimization step.
+
+ Arguments:
+ closure (callable, optional): A closure that reevaluates the model
+ and returns the loss.
+ """
+ loss = None
+ if closure is not None:
+ with torch.enable_grad():
+ loss = closure()
+
+ batch = True
+
+ for group, group_params_names in zip(self.param_groups, self.parameters_names):
+ with self.batched_params(group["params"], group_params_names) as batches:
+ # batches is list of pairs (stacked_param, state). stacked_param is like
+ # a regular parameter, and will have a .grad, but the 1st dim corresponds to
+ # a stacking dim, it is not a real dim.
+
+ if len(batches[0][1]) == 0: # if len(first state) == 0: not yet initialized
+ clipping_scale = 1
+ else:
+ clipping_scale = self._get_clipping_scale(group, batches)
+
+ for p, state, _ in batches:
+ # Perform optimization step.
+ # grad is not going to be None, we handled that when creating the batches.
+ grad = p.grad
+ if grad.is_sparse:
+ raise RuntimeError("ScaledAdam optimizer does not support sparse gradients")
+ # State initialization
+ if len(state) == 0:
+ self._init_state(group, p, state)
+
+ self._step_one_batch(group, p, state, clipping_scale)
+
+ return loss
+
+ def _init_state(self, group: dict, p: Tensor, state: dict):
+ """
+ Initializes state dict for parameter 'p'. Assumes that dim 0 of tensor p
+ is actually the batch dimension, corresponding to batched-together
+ parameters of a given shape.
+
+
+ Args:
+ group: Dict to look up configuration values.
+ p: The parameter that we are initializing the state for
+ state: Dict from string to whatever state we are initializing
+ """
+ size_update_period = group["size_update_period"]
+
+ state["step"] = 0
+
+ kwargs = {"device": p.device, "dtype": p.dtype}
+
+ # 'delta' implements conventional momentum. There are
+ # several different kinds of update going on, so rather than
+ # compute "exp_avg" like in Adam, we store and decay a
+ # parameter-change "delta", which combines all forms of
+ # update. this is equivalent to how it's done in Adam,
+ # except for the first few steps.
+ state["delta"] = torch.zeros_like(p, memory_format=torch.preserve_format)
+
+ batch_size = p.shape[0]
+ numel = p.numel() // batch_size
+ numel = p.numel()
+
+ if numel > 1:
+ # "param_rms" just periodically records the scalar root-mean-square value of
+ # the parameter tensor.
+ # it has a shape like (batch_size, 1, 1, 1, 1)
+ param_rms = (p**2).mean(dim=list(range(1, p.ndim)), keepdim=True).sqrt()
+ state["param_rms"] = param_rms
+
+ state["scale_exp_avg_sq"] = torch.zeros_like(param_rms)
+ state["scale_grads"] = torch.zeros(size_update_period, *param_rms.shape, **kwargs)
+
+ # exp_avg_sq is the weighted sum of scaled gradients. as in Adam.
+ state["exp_avg_sq"] = torch.zeros_like(p, memory_format=torch.preserve_format)
+
+ def _get_clipping_scale(self, group: dict, tuples: List[Tuple[Tensor, dict, List[str]]]) -> float:
+ """
+ Returns a scalar factor <= 1.0 that dictates gradient clipping, i.e. we will scale the gradients
+ by this amount before applying the rest of the update.
+
+ Args:
+ group: the parameter group, an item in self.param_groups
+ tuples: a list of tuples of (param, state, param_names)
+ where param is a batched set of parameters,
+ with a .grad (1st dim is batch dim)
+ and state is the state-dict where optimization parameters are kept.
+ param_names is a List[str] while each str is name for a parameter
+ in batched set of parameters "param".
+ """
+ assert len(tuples) >= 1
+ clipping_scale = group["clipping_scale"]
+ (first_p, first_state, _) = tuples[0]
+ step = first_state["step"]
+ if clipping_scale is None or step == 0:
+ # no clipping. return early on step == 0 because the other
+ # parameters' state won't have been initialized yet.
+ return 1.0
+ clipping_update_period = group["clipping_update_period"]
+
+ tot_sumsq = torch.tensor(0.0, device=first_p.device)
+ for p, state, param_names in tuples:
+ grad = p.grad
+ if grad.is_sparse:
+ raise RuntimeError("ScaledAdam optimizer does not support sparse gradients")
+ if p.numel() == p.shape[0]: # a batch of scalars
+ tot_sumsq += (grad**2).sum() # sum() to change shape [1] to []
+ else:
+ tot_sumsq += ((grad * state["param_rms"]) ** 2).sum()
+
+ tot_norm = tot_sumsq.sqrt()
+ if "model_norms" not in first_state:
+ first_state["model_norms"] = torch.zeros(clipping_update_period, device=p.device)
+ first_state["model_norms"][step % clipping_update_period] = tot_norm
+
+ if step % clipping_update_period == 0:
+ # Print some stats.
+ # We don't reach here if step == 0 because we would have returned
+ # above.
+ sorted_norms = first_state["model_norms"].sort()[0].to("cpu")
+ quartiles = []
+ for n in range(0, 5):
+ index = min(
+ clipping_update_period - 1,
+ (clipping_update_period // 4) * n,
+ )
+ quartiles.append(sorted_norms[index].item())
+
+ median = quartiles[2]
+ threshold = clipping_scale * median
+ first_state["model_norm_threshold"] = threshold
+ percent_clipped = (
+ first_state["num_clipped"] * 100.0 / clipping_update_period if "num_clipped" in first_state else 0.0
+ )
+ first_state["num_clipped"] = 0
+ quartiles = " ".join(["%.3e" % x for x in quartiles])
+ logging.info(
+ f"Clipping_scale={clipping_scale}, grad-norm quartiles {quartiles}, threshold={threshold:.3e}, percent-clipped={percent_clipped:.1f}"
+ )
+
+ if step < clipping_update_period:
+ return 1.0 # We have not yet estimated a norm to clip to.
+ else:
+ try:
+ model_norm_threshold = first_state["model_norm_threshold"]
+ except KeyError:
+ logging.info(
+ "Warning: model_norm_threshold not in state: possibly you changed config when restarting, adding clipping_scale option?"
+ )
+ return 1.0
+ ans = min(1.0, (model_norm_threshold / (tot_norm + 1.0e-20)).item())
+ if ans < 1.0:
+ first_state["num_clipped"] += 1
+ if ans < 0.1:
+ logging.warn(f"Scaling gradients by {ans}, model_norm_threshold={model_norm_threshold}")
+ if self.show_dominant_parameters:
+ assert p.shape[0] == len(param_names)
+ self._show_gradient_dominating_parameter(tuples, tot_sumsq)
+ return ans
+
+ def _show_gradient_dominating_parameter(self, tuples: List[Tuple[Tensor, dict, List[str]]], tot_sumsq: Tensor):
+ """
+ Show information of parameter wihch dominanting tot_sumsq.
+
+ Args:
+ tuples: a list of tuples of (param, state, param_names)
+ where param is a batched set of parameters,
+ with a .grad (1st dim is batch dim)
+ and state is the state-dict where optimization parameters are kept.
+ param_names is a List[str] while each str is name for a parameter
+ in batched set of parameters "param".
+ tot_sumsq: sumsq of all parameters. Though it's could be calculated
+ from tuples, we still pass it to save some time.
+ """
+ all_sumsq_orig = {}
+ for p, state, batch_param_names in tuples:
+ # p is a stacked batch parameters.
+ batch_grad = p.grad
+ if p.numel() == p.shape[0]: # a batch of scalars
+ batch_sumsq_orig = batch_grad**2
+ # Dummpy values used by following `zip` statement.
+ batch_rms_orig = torch.ones(p.shape[0])
+ else:
+ batch_rms_orig = state["param_rms"]
+ batch_sumsq_orig = ((batch_grad * batch_rms_orig) ** 2).sum(dim=list(range(1, batch_grad.ndim)))
+
+ for name, sumsq_orig, rms, grad in zip(
+ batch_param_names,
+ batch_sumsq_orig,
+ batch_rms_orig,
+ batch_grad,
+ ):
+ proportion_orig = sumsq_orig / tot_sumsq
+ all_sumsq_orig[name] = (proportion_orig, sumsq_orig, rms, grad)
+
+ assert torch.isclose(
+ sum([value[0] for value in all_sumsq_orig.values()]).cpu(),
+ torch.tensor(1.0),
+ )
+ sorted_by_proportion = {
+ k: v
+ for k, v in sorted(
+ all_sumsq_orig.items(),
+ key=lambda item: item[1][0],
+ reverse=True,
+ )
+ }
+ dominant_param_name = next(iter(sorted_by_proportion))
+ (
+ dominant_proportion,
+ dominant_sumsq,
+ dominant_rms,
+ dominant_grad,
+ ) = sorted_by_proportion[dominant_param_name]
+ logging.info(
+ f"Parameter Dominanting tot_sumsq {dominant_param_name}"
+ f" with proportion {dominant_proportion:.2f},"
+ f" where dominant_sumsq=(grad_sumsq*orig_rms_sq)"
+ f"={dominant_sumsq:.3e},"
+ f" grad_sumsq = {(dominant_grad**2).sum():.3e},"
+ f" orig_rms_sq={(dominant_rms**2).item():.3e}"
+ )
+
+ def _step_one_batch(self, group: dict, p: Tensor, state: dict, clipping_scale: float):
+ """
+ Do the step for one parameter, which is actually going to be a batch of
+ `real` parameters, with dim 0 as the batch dim.
+ Args:
+ group: dict to look up configuration values
+ p: parameter to update (actually multiple parameters stacked together
+ as a batch)
+ state: state-dict for p, to look up the optimizer state
+ """
+ lr = group["lr"]
+ size_update_period = group["size_update_period"]
+ beta1 = group["betas"][0]
+
+ grad = p.grad
+ if clipping_scale != 1.0:
+ grad = grad * clipping_scale
+ step = state["step"]
+ delta = state["delta"]
+
+ delta.mul_(beta1)
+ batch_size = p.shape[0]
+ numel = p.numel() // batch_size
+ if numel > 1:
+ # Update the size/scale of p, and set param_rms
+ scale_grads = state["scale_grads"]
+ scale_grads[step % size_update_period] = (p * grad).sum(dim=list(range(1, p.ndim)), keepdim=True)
+ if step % size_update_period == size_update_period - 1:
+ param_rms = state["param_rms"] # shape: (batch_size, 1, 1, ..)
+ param_rms.copy_((p**2).mean(dim=list(range(1, p.ndim)), keepdim=True).sqrt())
+ if step > 0:
+ # self._size_update() learns the overall scale on the
+ # parameter, by shrinking or expanding it.
+ self._size_update(group, scale_grads, p, state)
+
+ if numel == 1:
+ # For parameters with 1 element we just use regular Adam.
+ # Updates delta.
+ self._step_scalar(group, p, state)
+ else:
+ self._step(group, p, state)
+
+ state["step"] = step + 1
+
+ def _size_update(
+ self,
+ group: dict,
+ scale_grads: Tensor,
+ p: Tensor,
+ state: dict,
+ ) -> None:
+ """
+ Called only where p.numel() > 1, this updates the scale of the parameter.
+ If we imagine: p = underlying_param * scale.exp(), and we are doing
+ gradient descent on underlying param and on scale, this function does the update
+ on `scale`.
+
+ Args:
+ group: dict to look up configuration values
+ scale_grads: a tensor of shape (size_update_period, batch_size, 1, 1,...) containing
+ grads w.r.t. the scales.
+ p: The parameter to update
+ state: The state-dict of p
+ """
+
+ param_rms = state["param_rms"]
+ beta1, beta2 = group["betas"]
+ size_lr = group["lr"] * group["scalar_lr_scale"]
+ param_min_rms = group["param_min_rms"]
+ param_max_rms = group["param_max_rms"]
+ eps = group["eps"]
+ step = state["step"]
+ batch_size = p.shape[0]
+
+ size_update_period = scale_grads.shape[0]
+ # correct beta2 for the size update period: we will have
+ # faster decay at this level.
+ beta2_corr = beta2**size_update_period
+
+ scale_exp_avg_sq = state["scale_exp_avg_sq"] # shape: (batch_size, 1, 1, ..)
+ scale_exp_avg_sq.mul_(beta2_corr).add_(
+ (scale_grads**2).mean(dim=0), # mean over dim `size_update_period`
+ alpha=1 - beta2_corr,
+ ) # shape is (batch_size, 1, 1, ...)
+
+ # The 1st time we reach here is when size_step == 1.
+ size_step = (step + 1) // size_update_period
+ bias_correction2 = 1 - beta2_corr**size_step
+ # we don't bother with bias_correction1; this will help prevent divergence
+ # at the start of training.
+
+ denom = scale_exp_avg_sq.sqrt() + eps
+
+ scale_step = -size_lr * (bias_correction2**0.5) * scale_grads.sum(dim=0) / denom
+
+ is_too_small = param_rms < param_min_rms
+ is_too_large = param_rms > param_max_rms
+
+ # when the param gets too small, just don't shrink it any further.
+ scale_step.masked_fill_(is_too_small, 0.0)
+ # when it gets too large, stop it from getting any larger.
+ scale_step.masked_fill_(is_too_large, -size_lr * size_update_period)
+ delta = state["delta"]
+ # the factor of (1-beta1) relates to momentum.
+ delta.add_(p * scale_step, alpha=(1 - beta1))
+
+ def _step(self, group: dict, p: Tensor, state: dict):
+ """
+ This function does the core update of self.step(), in the case where the members of
+ the batch have more than 1 element.
+
+ Args:
+ group: A dict which will be used to look up configuration values
+ p: The parameter to be updated
+ grad: The grad of p
+ state: The state-dict corresponding to parameter p
+
+ This function modifies p.
+ """
+ grad = p.grad
+ lr = group["lr"]
+ beta1, beta2 = group["betas"]
+ eps = group["eps"]
+ param_min_rms = group["param_min_rms"]
+ step = state["step"]
+
+ exp_avg_sq = state["exp_avg_sq"]
+ exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=(1 - beta2))
+
+ this_step = state["step"] - (state["zero_step"] if "zero_step" in state else 0)
+ bias_correction2 = 1 - beta2 ** (this_step + 1)
+ if bias_correction2 < 0.99:
+ # note: not in-place.
+ exp_avg_sq = exp_avg_sq * (1.0 / bias_correction2)
+
+ denom = exp_avg_sq.sqrt()
+ denom += eps
+ grad = grad / denom
+
+ alpha = -lr * (1 - beta1) * state["param_rms"].clamp(min=param_min_rms)
+
+ delta = state["delta"]
+ delta.add_(grad * alpha)
+ p.add_(delta)
+
+ def _step_scalar(self, group: dict, p: Tensor, state: dict):
+ """
+ A simplified form of the core update for scalar tensors, where we cannot get a good
+ estimate of the parameter rms.
+ """
+ beta1, beta2 = group["betas"]
+ scalar_max = group["scalar_max"]
+ eps = group["eps"]
+ lr = group["lr"] * group["scalar_lr_scale"]
+ grad = p.grad
+
+ exp_avg_sq = state["exp_avg_sq"] # shape: (batch_size,)
+ exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
+
+ # bias_correction2 is like in Adam. Don't bother with bias_correction1;
+ # slower update at the start will help stability anyway.
+ bias_correction2 = 1 - beta2 ** (state["step"] + 1)
+ denom = (exp_avg_sq / bias_correction2).sqrt() + eps
+
+ delta = state["delta"]
+ delta.add_(grad / denom, alpha=-lr * (1 - beta1))
+ p.clamp_(min=-scalar_max, max=scalar_max)
+ p.add_(delta)
diff --git a/GPT_SoVITS/AR/modules/patched_mha_with_cache.py b/GPT_SoVITS/AR/modules/patched_mha_with_cache.py
new file mode 100644
index 0000000000000000000000000000000000000000..5bffcea63c7081571defc308b601b748fe4eb797
--- /dev/null
+++ b/GPT_SoVITS/AR/modules/patched_mha_with_cache.py
@@ -0,0 +1,428 @@
+from torch.nn.functional import *
+from torch.nn.functional import (
+ _mha_shape_check,
+ _canonical_mask,
+ _none_or_dtype,
+ _in_projection_packed,
+)
+import torch
+# Tensor = torch.Tensor
+# from typing import Callable, List, Optional, Tuple, Union
+
+
+def multi_head_attention_forward_patched(
+ query,
+ key,
+ value,
+ embed_dim_to_check,
+ num_heads,
+ in_proj_weight,
+ in_proj_bias,
+ bias_k,
+ bias_v,
+ add_zero_attn,
+ dropout_p: float,
+ out_proj_weight,
+ out_proj_bias,
+ training=True,
+ key_padding_mask=None,
+ need_weights=True,
+ attn_mask=None,
+ use_separate_proj_weight=False,
+ q_proj_weight=None,
+ k_proj_weight=None,
+ v_proj_weight=None,
+ static_k=None,
+ static_v=None,
+ average_attn_weights=True,
+ is_causal=False,
+ cache=None,
+):
+ r"""
+ Args:
+ query, key, value: map a query and a set of key-value pairs to an output.
+ See "Attention Is All You Need" for more details.
+ embed_dim_to_check: total dimension of the model.
+ num_heads: parallel attention heads.
+ in_proj_weight, in_proj_bias: input projection weight and bias.
+ bias_k, bias_v: bias of the key and value sequences to be added at dim=0.
+ add_zero_attn: add a new batch of zeros to the key and
+ value sequences at dim=1.
+ dropout_p: probability of an element to be zeroed.
+ out_proj_weight, out_proj_bias: the output projection weight and bias.
+ training: apply dropout if is ``True``.
+ key_padding_mask: if provided, specified padding elements in the key will
+ be ignored by the attention. This is an binary mask. When the value is True,
+ the corresponding value on the attention layer will be filled with -inf.
+ need_weights: output attn_output_weights.
+ Default: `True`
+ Note: `needs_weight` defaults to `True`, but should be set to `False`
+ For best performance when attention weights are not nedeeded.
+ *Setting needs_weights to `True`
+ leads to a significant performance degradation.*
+ attn_mask: 2D or 3D mask that prevents attention to certain positions. A 2D mask will be broadcasted for all
+ the batches while a 3D mask allows to specify a different mask for the entries of each batch.
+ is_causal: If specified, applies a causal mask as attention mask, and ignores
+ attn_mask for computing scaled dot product attention.
+ Default: ``False``.
+ .. warning::
+ is_causal is provides a hint that the attn_mask is the
+ causal mask.Providing incorrect hints can result in
+ incorrect execution, including forward and backward
+ compatibility.
+ use_separate_proj_weight: the function accept the proj. weights for query, key,
+ and value in different forms. If false, in_proj_weight will be used, which is
+ a combination of q_proj_weight, k_proj_weight, v_proj_weight.
+ q_proj_weight, k_proj_weight, v_proj_weight, in_proj_bias: input projection weight and bias.
+ static_k, static_v: static key and value used for attention operators.
+ average_attn_weights: If true, indicates that the returned ``attn_weights`` should be averaged across heads.
+ Otherwise, ``attn_weights`` are provided separately per head. Note that this flag only has an effect
+ when ``need_weights=True.``. Default: True
+
+
+ Shape:
+ Inputs:
+ - query: :math:`(L, E)` or :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
+ the embedding dimension.
+ - key: :math:`(S, E)` or :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
+ the embedding dimension.
+ - value: :math:`(S, E)` or :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
+ the embedding dimension.
+ - key_padding_mask: :math:`(S)` or :math:`(N, S)` where N is the batch size, S is the source sequence length.
+ If a FloatTensor is provided, it will be directly added to the value.
+ If a BoolTensor is provided, the positions with the
+ value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
+ - attn_mask: 2D mask :math:`(L, S)` where L is the target sequence length, S is the source sequence length.
+ 3D mask :math:`(N*num_heads, L, S)` where N is the batch size, L is the target sequence length,
+ S is the source sequence length. attn_mask ensures that position i is allowed to attend the unmasked
+ positions. If a BoolTensor is provided, positions with ``True``
+ are not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
+ is provided, it will be added to the attention weight.
+ - static_k: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
+ N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
+ - static_v: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
+ N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
+
+ Outputs:
+ - attn_output: :math:`(L, E)` or :math:`(L, N, E)` where L is the target sequence length, N is the batch size,
+ E is the embedding dimension.
+ - attn_output_weights: Only returned when ``need_weights=True``. If ``average_attn_weights=True``, returns
+ attention weights averaged across heads of shape :math:`(L, S)` when input is unbatched or
+ :math:`(N, L, S)`, where :math:`N` is the batch size, :math:`L` is the target sequence length, and
+ :math:`S` is the source sequence length. If ``average_attn_weights=False``, returns attention weights per
+ head of shape :math:`(num_heads, L, S)` when input is unbatched or :math:`(N, num_heads, L, S)`.
+ """
+ tens_ops = (
+ query,
+ key,
+ value,
+ in_proj_weight,
+ in_proj_bias,
+ bias_k,
+ bias_v,
+ out_proj_weight,
+ out_proj_bias,
+ )
+ if has_torch_function(tens_ops):
+ return handle_torch_function(
+ multi_head_attention_forward,
+ tens_ops,
+ query,
+ key,
+ value,
+ embed_dim_to_check,
+ num_heads,
+ in_proj_weight,
+ in_proj_bias,
+ bias_k,
+ bias_v,
+ add_zero_attn,
+ dropout_p,
+ out_proj_weight,
+ out_proj_bias,
+ training=training,
+ key_padding_mask=key_padding_mask,
+ need_weights=need_weights,
+ attn_mask=attn_mask,
+ is_causal=is_causal,
+ use_separate_proj_weight=use_separate_proj_weight,
+ q_proj_weight=q_proj_weight,
+ k_proj_weight=k_proj_weight,
+ v_proj_weight=v_proj_weight,
+ static_k=static_k,
+ static_v=static_v,
+ average_attn_weights=average_attn_weights,
+ cache=cache,
+ )
+
+ is_batched = _mha_shape_check(query, key, value, key_padding_mask, attn_mask, num_heads)
+
+ # For unbatched input, we unsqueeze at the expected batch-dim to pretend that the input
+ # is batched, run the computation and before returning squeeze the
+ # batch dimension so that the output doesn't carry this temporary batch dimension.
+ if not is_batched:
+ # unsqueeze if the input is unbatched
+ query = query.unsqueeze(1)
+ key = key.unsqueeze(1)
+ value = value.unsqueeze(1)
+ if key_padding_mask is not None:
+ key_padding_mask = key_padding_mask.unsqueeze(0)
+
+ # set up shape vars
+ tgt_len, bsz, embed_dim = query.shape
+ src_len, _, _ = key.shape
+
+ key_padding_mask = _canonical_mask(
+ mask=key_padding_mask,
+ mask_name="key_padding_mask",
+ other_type=_none_or_dtype(attn_mask),
+ other_name="attn_mask",
+ target_type=query.dtype,
+ )
+
+ if is_causal and attn_mask is None:
+ raise RuntimeError(
+ "Need attn_mask if specifying the is_causal hint. "
+ "You may use the Transformer module method "
+ "`generate_square_subsequent_mask` to create this mask."
+ )
+
+ if is_causal and key_padding_mask is None and not need_weights:
+ # when we have a kpm or need weights, we need attn_mask
+ # Otherwise, we use the is_causal hint go as is_causal
+ # indicator to SDPA.
+ attn_mask = None
+ else:
+ attn_mask = _canonical_mask(
+ mask=attn_mask,
+ mask_name="attn_mask",
+ other_type=None,
+ other_name="",
+ target_type=query.dtype,
+ check_other=False,
+ )
+
+ if key_padding_mask is not None:
+ # We have the attn_mask, and use that to merge kpm into it.
+ # Turn off use of is_causal hint, as the merged mask is no
+ # longer causal.
+ is_causal = False
+
+ assert embed_dim == embed_dim_to_check, (
+ f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
+ )
+ if isinstance(embed_dim, torch.Tensor):
+ # embed_dim can be a tensor when JIT tracing
+ head_dim = embed_dim.div(num_heads, rounding_mode="trunc")
+ else:
+ head_dim = embed_dim // num_heads
+ assert head_dim * num_heads == embed_dim, f"embed_dim {embed_dim} not divisible by num_heads {num_heads}"
+ if use_separate_proj_weight:
+ # allow MHA to have different embedding dimensions when separate projection weights are used
+ assert key.shape[:2] == value.shape[:2], (
+ f"key's sequence and batch dims {key.shape[:2]} do not match value's {value.shape[:2]}"
+ )
+ else:
+ assert key.shape == value.shape, f"key shape {key.shape} does not match value shape {value.shape}"
+
+ #
+ # compute in-projection
+ #
+ if not use_separate_proj_weight:
+ assert in_proj_weight is not None, "use_separate_proj_weight is False but in_proj_weight is None"
+ q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
+ else:
+ assert q_proj_weight is not None, "use_separate_proj_weight is True but q_proj_weight is None"
+ assert k_proj_weight is not None, "use_separate_proj_weight is True but k_proj_weight is None"
+ assert v_proj_weight is not None, "use_separate_proj_weight is True but v_proj_weight is None"
+ if in_proj_bias is None:
+ b_q = b_k = b_v = None
+ else:
+ b_q, b_k, b_v = in_proj_bias.chunk(3)
+ q, k, v = _in_projection(
+ query,
+ key,
+ value,
+ q_proj_weight,
+ k_proj_weight,
+ v_proj_weight,
+ b_q,
+ b_k,
+ b_v,
+ )
+ if cache != None:
+ if cache["first_infer"] == 1:
+ cache["k"][cache["stage"]] = k
+ # print(0,cache["k"].shape)
+ cache["v"][cache["stage"]] = v
+ else: ###12个layer每个都要留自己的cache_kv
+ # print(1,cache["k"].shape)
+ cache["k"][cache["stage"]] = torch.cat(
+ [cache["k"][cache["stage"]], k], 0
+ ) ##本来时序是1,但是proj的时候可能transpose了所以时序到0维了
+ cache["v"][cache["stage"]] = torch.cat([cache["v"][cache["stage"]], v], 0)
+ # print(2, cache["k"].shape)
+ src_len = cache["k"][cache["stage"]].shape[0]
+ k = cache["k"][cache["stage"]]
+ v = cache["v"][cache["stage"]]
+ # if attn_mask is not None:
+ # attn_mask=attn_mask[-1:,]
+ # print(attn_mask.shape,attn_mask)
+ cache["stage"] = (cache["stage"] + 1) % cache["all_stage"]
+ # print(2333,cache)
+ # prep attention mask
+
+ attn_mask = _canonical_mask(
+ mask=attn_mask,
+ mask_name="attn_mask",
+ other_type=None,
+ other_name="",
+ target_type=q.dtype,
+ check_other=False,
+ )
+
+ if attn_mask is not None:
+ # ensure attn_mask's dim is 3
+ if attn_mask.dim() == 2:
+ correct_2d_size = (tgt_len, src_len)
+ if attn_mask.shape != correct_2d_size:
+ raise RuntimeError(
+ f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}."
+ )
+ attn_mask = attn_mask.unsqueeze(0)
+ elif attn_mask.dim() == 3:
+ correct_3d_size = (bsz * num_heads, tgt_len, src_len)
+ if attn_mask.shape != correct_3d_size:
+ raise RuntimeError(
+ f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}."
+ )
+ else:
+ raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
+
+ # add bias along batch dimension (currently second)
+ if bias_k is not None and bias_v is not None:
+ assert static_k is None, "bias cannot be added to static key."
+ assert static_v is None, "bias cannot be added to static value."
+ k = torch.cat([k, bias_k.repeat(1, bsz, 1)])
+ v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
+ if attn_mask is not None:
+ attn_mask = pad(attn_mask, (0, 1))
+ if key_padding_mask is not None:
+ key_padding_mask = pad(key_padding_mask, (0, 1))
+ else:
+ assert bias_k is None
+ assert bias_v is None
+
+ #
+ # reshape q, k, v for multihead attention and make em batch first
+ #
+ q = q.view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
+ if static_k is None:
+ k = k.view(k.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
+ else:
+ # TODO finish disentangling control flow so we don't do in-projections when statics are passed
+ assert static_k.size(0) == bsz * num_heads, (
+ f"expecting static_k.size(0) of {bsz * num_heads}, but got {static_k.size(0)}"
+ )
+ assert static_k.size(2) == head_dim, f"expecting static_k.size(2) of {head_dim}, but got {static_k.size(2)}"
+ k = static_k
+ if static_v is None:
+ v = v.view(v.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
+ else:
+ # TODO finish disentangling control flow so we don't do in-projections when statics are passed
+ assert static_v.size(0) == bsz * num_heads, (
+ f"expecting static_v.size(0) of {bsz * num_heads}, but got {static_v.size(0)}"
+ )
+ assert static_v.size(2) == head_dim, f"expecting static_v.size(2) of {head_dim}, but got {static_v.size(2)}"
+ v = static_v
+
+ # add zero attention along batch dimension (now first)
+ if add_zero_attn:
+ zero_attn_shape = (bsz * num_heads, 1, head_dim)
+ k = torch.cat([k, torch.zeros(zero_attn_shape, dtype=k.dtype, device=k.device)], dim=1)
+ v = torch.cat([v, torch.zeros(zero_attn_shape, dtype=v.dtype, device=v.device)], dim=1)
+ if attn_mask is not None:
+ attn_mask = pad(attn_mask, (0, 1))
+ if key_padding_mask is not None:
+ key_padding_mask = pad(key_padding_mask, (0, 1))
+
+ # update source sequence length after adjustments
+ src_len = k.size(1)
+
+ # merge key padding and attention masks
+ if key_padding_mask is not None:
+ assert key_padding_mask.shape == (
+ bsz,
+ src_len,
+ ), f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
+ key_padding_mask = (
+ key_padding_mask.view(bsz, 1, 1, src_len).expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
+ )
+ if attn_mask is None:
+ attn_mask = key_padding_mask
+ else:
+ attn_mask = attn_mask + key_padding_mask
+
+ # adjust dropout probability
+ if not training:
+ dropout_p = 0.0
+
+ #
+ # (deep breath) calculate attention and out projection
+ #
+
+ if need_weights:
+ B, Nt, E = q.shape
+ q_scaled = q / math.sqrt(E)
+
+ assert not (is_causal and attn_mask is None), "FIXME: is_causal not implemented for need_weights"
+
+ if attn_mask is not None:
+ attn_output_weights = torch.baddbmm(attn_mask, q_scaled, k.transpose(-2, -1))
+ else:
+ attn_output_weights = torch.bmm(q_scaled, k.transpose(-2, -1))
+ attn_output_weights = softmax(attn_output_weights, dim=-1)
+ if dropout_p > 0.0:
+ attn_output_weights = dropout(attn_output_weights, p=dropout_p)
+
+ attn_output = torch.bmm(attn_output_weights, v)
+
+ attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len * bsz, embed_dim)
+ attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
+ attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
+
+ # optionally average attention weights over heads
+ attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
+ if average_attn_weights:
+ attn_output_weights = attn_output_weights.mean(dim=1)
+
+ if not is_batched:
+ # squeeze the output if input was unbatched
+ attn_output = attn_output.squeeze(1)
+ attn_output_weights = attn_output_weights.squeeze(0)
+ return attn_output, attn_output_weights
+ else:
+ # attn_mask can be either (L,S) or (N*num_heads, L, S)
+ # if attn_mask's shape is (1, L, S) we need to unsqueeze to (1, 1, L, S)
+ # in order to match the input for SDPA of (N, num_heads, L, S)
+ if attn_mask is not None:
+ if attn_mask.size(0) == 1 and attn_mask.dim() == 3:
+ attn_mask = attn_mask.unsqueeze(0)
+ else:
+ attn_mask = attn_mask.view(bsz, num_heads, -1, src_len)
+
+ q = q.view(bsz, num_heads, tgt_len, head_dim)
+ k = k.view(bsz, num_heads, src_len, head_dim)
+ v = v.view(bsz, num_heads, src_len, head_dim)
+
+ # with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=True, enable_mem_efficient=True):
+ attn_output = scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
+
+ attn_output = attn_output.permute(2, 0, 1, 3).contiguous().view(bsz * tgt_len, embed_dim)
+
+ attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
+ attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
+ if not is_batched:
+ # squeeze the output if input was unbatched
+ attn_output = attn_output.squeeze(1)
+ return attn_output, None
diff --git a/GPT_SoVITS/AR/modules/patched_mha_with_cache_onnx.py b/GPT_SoVITS/AR/modules/patched_mha_with_cache_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..8144c9c6b930dc825d56deb6b71229c037efb405
--- /dev/null
+++ b/GPT_SoVITS/AR/modules/patched_mha_with_cache_onnx.py
@@ -0,0 +1,85 @@
+from torch.nn.functional import *
+from torch.nn.functional import (
+ _canonical_mask,
+)
+
+
+def multi_head_attention_forward_patched(
+ query,
+ key,
+ value,
+ embed_dim_to_check: int,
+ num_heads: int,
+ in_proj_weight,
+ in_proj_bias: Optional[Tensor],
+ bias_k: Optional[Tensor],
+ bias_v: Optional[Tensor],
+ add_zero_attn: bool,
+ dropout_p: float,
+ out_proj_weight: Tensor,
+ out_proj_bias: Optional[Tensor],
+ training: bool = True,
+ key_padding_mask: Optional[Tensor] = None,
+ need_weights: bool = True,
+ attn_mask: Optional[Tensor] = None,
+ use_separate_proj_weight: bool = False,
+ q_proj_weight: Optional[Tensor] = None,
+ k_proj_weight: Optional[Tensor] = None,
+ v_proj_weight: Optional[Tensor] = None,
+ static_k: Optional[Tensor] = None,
+ static_v: Optional[Tensor] = None,
+ average_attn_weights: bool = True,
+ is_causal: bool = False,
+ cache=None,
+) -> Tuple[Tensor, Optional[Tensor]]:
+ # set up shape vars
+ _, _, embed_dim = query.shape
+ attn_mask = _canonical_mask(
+ mask=attn_mask,
+ mask_name="attn_mask",
+ other_type=None,
+ other_name="",
+ target_type=query.dtype,
+ check_other=False,
+ )
+ head_dim = embed_dim // num_heads
+
+ proj_qkv = linear(query, in_proj_weight, in_proj_bias)
+ proj_qkv = proj_qkv.unflatten(-1, (3, query.size(-1))).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
+ q, k, v = proj_qkv[0], proj_qkv[1], proj_qkv[2]
+
+ if cache["first_infer"] == 1:
+ cache["k"][cache["stage"]] = k
+ cache["v"][cache["stage"]] = v
+ else:
+ cache["k"][cache["stage"]] = torch.cat([cache["k"][cache["stage"]][:-1], k], 0)
+ cache["v"][cache["stage"]] = torch.cat([cache["v"][cache["stage"]][:-1], v], 0)
+ k = cache["k"][cache["stage"]]
+ v = cache["v"][cache["stage"]]
+ cache["stage"] = (cache["stage"] + 1) % cache["all_stage"]
+
+ attn_mask = _canonical_mask(
+ mask=attn_mask,
+ mask_name="attn_mask",
+ other_type=None,
+ other_name="",
+ target_type=q.dtype,
+ check_other=False,
+ )
+ attn_mask = attn_mask.unsqueeze(0)
+
+ q = q.view(-1, num_heads, head_dim).transpose(0, 1)
+ k = k.view(-1, num_heads, head_dim).transpose(0, 1)
+ v = v.view(-1, num_heads, head_dim).transpose(0, 1)
+
+ dropout_p = 0.0
+ attn_mask = attn_mask.unsqueeze(0)
+ q = q.view(num_heads, -1, head_dim).unsqueeze(0)
+ k = k.view(num_heads, -1, head_dim).unsqueeze(0)
+ v = v.view(num_heads, -1, head_dim).unsqueeze(0)
+ attn_output = scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
+ attn_output = attn_output.permute(2, 0, 1, 3).contiguous().view(-1, embed_dim)
+ attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
+ attn_output = attn_output.view(-1, 1, attn_output.size(1))
+
+ return attn_output
diff --git a/GPT_SoVITS/AR/modules/scaling.py b/GPT_SoVITS/AR/modules/scaling.py
new file mode 100644
index 0000000000000000000000000000000000000000..aae1453316adc42b7ed17b7f0a6c776a78347e6a
--- /dev/null
+++ b/GPT_SoVITS/AR/modules/scaling.py
@@ -0,0 +1,320 @@
+# Copyright 2022 Xiaomi Corp. (authors: Daniel Povey)
+#
+# See ../../../../LICENSE for clarification regarding multiple authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import random
+from typing import Optional
+from typing import Tuple
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+
+class DoubleSwishFunction(torch.autograd.Function):
+ """
+ double_swish(x) = x * torch.sigmoid(x-1)
+ This is a definition, originally motivated by its close numerical
+ similarity to swish(swish(x)), where swish(x) = x * sigmoid(x).
+
+ Memory-efficient derivative computation:
+ double_swish(x) = x * s, where s(x) = torch.sigmoid(x-1)
+ double_swish'(x) = d/dx double_swish(x) = x * s'(x) + x' * s(x) = x * s'(x) + s(x).
+ Now, s'(x) = s(x) * (1-s(x)).
+ double_swish'(x) = x * s'(x) + s(x).
+ = x * s(x) * (1-s(x)) + s(x).
+ = double_swish(x) * (1-s(x)) + s(x)
+ ... so we just need to remember s(x) but not x itself.
+ """
+
+ @staticmethod
+ def forward(ctx, x: Tensor) -> Tensor:
+ requires_grad = x.requires_grad
+ x_dtype = x.dtype
+ if x.dtype == torch.float16:
+ x = x.to(torch.float32)
+
+ s = torch.sigmoid(x - 1.0)
+ y = x * s
+
+ if requires_grad:
+ deriv = y * (1 - s) + s
+ # notes on derivative of x * sigmoid(x - 1):
+ # https://www.wolframalpha.com/input?i=d%2Fdx+%28x+*+sigmoid%28x-1%29%29
+ # min \simeq -0.043638. Take floor as -0.043637 so it's a lower bund
+ # max \simeq 1.1990. Take ceil to be 1.2 so it's an upper bound.
+ # the combination of "+ torch.rand_like(deriv)" and casting to torch.uint8 (which
+ # floors), should be expectation-preserving.
+ floor = -0.043637
+ ceil = 1.2
+ d_scaled = (deriv - floor) * (255.0 / (ceil - floor)) + torch.rand_like(deriv)
+ if __name__ == "__main__":
+ # for self-testing only.
+ assert d_scaled.min() >= 0.0
+ assert d_scaled.max() < 256.0
+ d_int = d_scaled.to(torch.uint8)
+ ctx.save_for_backward(d_int)
+ if x.dtype == torch.float16 or torch.is_autocast_enabled():
+ y = y.to(torch.float16)
+ return y
+
+ @staticmethod
+ def backward(ctx, y_grad: Tensor) -> Tensor:
+ (d,) = ctx.saved_tensors
+ # the same constants as used in forward pass.
+ floor = -0.043637
+ ceil = 1.2
+ d = d * ((ceil - floor) / 255.0) + floor
+ return y_grad * d
+
+
+class DoubleSwish(torch.nn.Module):
+ def forward(self, x: Tensor) -> Tensor:
+ """Return double-swish activation function which is an approximation to Swish(Swish(x)),
+ that we approximate closely with x * sigmoid(x-1).
+ """
+ if torch.jit.is_scripting() or torch.jit.is_tracing():
+ return x * torch.sigmoid(x - 1.0)
+ return DoubleSwishFunction.apply(x)
+
+
+class ActivationBalancerFunction(torch.autograd.Function):
+ @staticmethod
+ def forward(
+ ctx,
+ x: Tensor,
+ scale_factor: Tensor,
+ sign_factor: Optional[Tensor],
+ channel_dim: int,
+ ) -> Tensor:
+ if channel_dim < 0:
+ channel_dim += x.ndim
+ ctx.channel_dim = channel_dim
+ xgt0 = x > 0
+ if sign_factor is None:
+ ctx.save_for_backward(xgt0, scale_factor)
+ else:
+ ctx.save_for_backward(xgt0, scale_factor, sign_factor)
+ return x
+
+ @staticmethod
+ def backward(ctx, x_grad: Tensor) -> Tuple[Tensor, None, None, None]:
+ if len(ctx.saved_tensors) == 3:
+ xgt0, scale_factor, sign_factor = ctx.saved_tensors
+ for _ in range(ctx.channel_dim, x_grad.ndim - 1):
+ scale_factor = scale_factor.unsqueeze(-1)
+ sign_factor = sign_factor.unsqueeze(-1)
+ factor = sign_factor + scale_factor * (xgt0.to(x_grad.dtype) - 0.5)
+ else:
+ xgt0, scale_factor = ctx.saved_tensors
+ for _ in range(ctx.channel_dim, x_grad.ndim - 1):
+ scale_factor = scale_factor.unsqueeze(-1)
+ factor = scale_factor * (xgt0.to(x_grad.dtype) - 0.5)
+ neg_delta_grad = x_grad.abs() * factor
+ return (
+ x_grad - neg_delta_grad,
+ None,
+ None,
+ None,
+ )
+
+
+def _compute_scale_factor(
+ x: Tensor,
+ channel_dim: int,
+ min_abs: float,
+ max_abs: float,
+ gain_factor: float,
+ max_factor: float,
+) -> Tensor:
+ if channel_dim < 0:
+ channel_dim += x.ndim
+ sum_dims = [d for d in range(x.ndim) if d != channel_dim]
+ x_abs_mean = torch.mean(x.abs(), dim=sum_dims).to(torch.float32)
+
+ if min_abs == 0.0:
+ below_threshold = 0.0
+ else:
+ # below_threshold is 0 if x_abs_mean > min_abs, can be at most max_factor if
+ # x_abs)_mean , min_abs.
+ below_threshold = ((min_abs - x_abs_mean) * (gain_factor / min_abs)).clamp(min=0, max=max_factor)
+
+ above_threshold = ((x_abs_mean - max_abs) * (gain_factor / max_abs)).clamp(min=0, max=max_factor)
+
+ return below_threshold - above_threshold
+
+
+def _compute_sign_factor(
+ x: Tensor,
+ channel_dim: int,
+ min_positive: float,
+ max_positive: float,
+ gain_factor: float,
+ max_factor: float,
+) -> Tensor:
+ if channel_dim < 0:
+ channel_dim += x.ndim
+ sum_dims = [d for d in range(x.ndim) if d != channel_dim]
+ proportion_positive = torch.mean((x > 0).to(torch.float32), dim=sum_dims)
+ if min_positive == 0.0:
+ factor1 = 0.0
+ else:
+ # 0 if proportion_positive >= min_positive, else can be
+ # as large as max_factor.
+ factor1 = ((min_positive - proportion_positive) * (gain_factor / min_positive)).clamp_(min=0, max=max_factor)
+
+ if max_positive == 1.0:
+ factor2 = 0.0
+ else:
+ # 0 if self.proportion_positive <= max_positive, else can be
+ # as large as -max_factor.
+ factor2 = ((proportion_positive - max_positive) * (gain_factor / (1.0 - max_positive))).clamp_(
+ min=0, max=max_factor
+ )
+ sign_factor = factor1 - factor2
+ # require min_positive != 0 or max_positive != 1:
+ assert not isinstance(sign_factor, float)
+ return sign_factor
+
+
+class ActivationBalancer(torch.nn.Module):
+ """
+ Modifies the backpropped derivatives of a function to try to encourage, for
+ each channel, that it is positive at least a proportion `threshold` of the
+ time. It does this by multiplying negative derivative values by up to
+ (1+max_factor), and positive derivative values by up to (1-max_factor),
+ interpolated from 1 at the threshold to those extremal values when none
+ of the inputs are positive.
+
+ Args:
+ num_channels: the number of channels
+ channel_dim: the dimension/axis corresponding to the channel, e.g.
+ -1, 0, 1, 2; will be interpreted as an offset from x.ndim if negative.
+ min_positive: the minimum, per channel, of the proportion of the time
+ that (x > 0), below which we start to modify the derivatives.
+ max_positive: the maximum, per channel, of the proportion of the time
+ that (x > 0), above which we start to modify the derivatives.
+ max_factor: the maximum factor by which we modify the derivatives for
+ either the sign constraint or the magnitude constraint;
+ e.g. with max_factor=0.02, the the derivatives would be multiplied by
+ values in the range [0.98..1.02].
+ sign_gain_factor: determines the 'gain' with which we increase the
+ change in gradient once the constraints on min_positive and max_positive
+ are violated.
+ scale_gain_factor: determines the 'gain' with which we increase the
+ change in gradient once the constraints on min_abs and max_abs
+ are violated.
+ min_abs: the minimum average-absolute-value difference from the mean
+ value per channel, which we allow, before we start to modify
+ the derivatives to prevent this.
+ max_abs: the maximum average-absolute-value difference from the mean
+ value per channel, which we allow, before we start to modify
+ the derivatives to prevent this.
+ min_prob: determines the minimum probability with which we modify the
+ gradients for the {min,max}_positive and {min,max}_abs constraints,
+ on each forward(). This is done randomly to prevent all layers
+ from doing it at the same time. Early in training we may use
+ higher probabilities than this; it will decay to this value.
+ """
+
+ def __init__(
+ self,
+ num_channels: int,
+ channel_dim: int,
+ min_positive: float = 0.05,
+ max_positive: float = 0.95,
+ max_factor: float = 0.04,
+ sign_gain_factor: float = 0.01,
+ scale_gain_factor: float = 0.02,
+ min_abs: float = 0.2,
+ max_abs: float = 100.0,
+ min_prob: float = 0.1,
+ ):
+ super(ActivationBalancer, self).__init__()
+ self.num_channels = num_channels
+ self.channel_dim = channel_dim
+ self.min_positive = min_positive
+ self.max_positive = max_positive
+ self.max_factor = max_factor
+ self.min_abs = min_abs
+ self.max_abs = max_abs
+ self.min_prob = min_prob
+ self.sign_gain_factor = sign_gain_factor
+ self.scale_gain_factor = scale_gain_factor
+
+ # count measures how many times the forward() function has been called.
+ # We occasionally sync this to a tensor called `count`, that exists to
+ # make sure it is synced to disk when we load and save the model.
+ self.cpu_count = 0
+ self.register_buffer("count", torch.tensor(0, dtype=torch.int64))
+
+ def forward(self, x: Tensor) -> Tensor:
+ if torch.jit.is_scripting() or not x.requires_grad or torch.jit.is_tracing():
+ return _no_op(x)
+
+ count = self.cpu_count
+ self.cpu_count += 1
+
+ if random.random() < 0.01:
+ # Occasionally sync self.cpu_count with self.count.
+ # count affects the decay of 'prob'. don't do this on every iter,
+ # because syncing with the GPU is slow.
+ self.cpu_count = max(self.cpu_count, self.count.item())
+ self.count.fill_(self.cpu_count)
+
+ # the prob of doing some work exponentially decreases from 0.5 till it hits
+ # a floor at min_prob (==0.1, by default)
+ prob = max(self.min_prob, 0.5 ** (1 + (count / 4000.0)))
+
+ if random.random() < prob:
+ sign_gain_factor = 0.5
+ if self.min_positive != 0.0 or self.max_positive != 1.0:
+ sign_factor = _compute_sign_factor(
+ x,
+ self.channel_dim,
+ self.min_positive,
+ self.max_positive,
+ gain_factor=self.sign_gain_factor / prob,
+ max_factor=self.max_factor,
+ )
+ else:
+ sign_factor = None
+
+ scale_factor = _compute_scale_factor(
+ x.detach(),
+ self.channel_dim,
+ min_abs=self.min_abs,
+ max_abs=self.max_abs,
+ gain_factor=self.scale_gain_factor / prob,
+ max_factor=self.max_factor,
+ )
+ return ActivationBalancerFunction.apply(
+ x,
+ scale_factor,
+ sign_factor,
+ self.channel_dim,
+ )
+ else:
+ return _no_op(x)
+
+
+def BalancedDoubleSwish(d_model, channel_dim=-1, max_abs=10.0, min_prob=0.25) -> nn.Sequential:
+ """
+ ActivationBalancer -> DoubleSwish
+ """
+ balancer = ActivationBalancer(d_model, channel_dim=channel_dim, max_abs=max_abs, min_prob=min_prob)
+ return nn.Sequential(
+ balancer,
+ DoubleSwish(),
+ )
diff --git a/GPT_SoVITS/AR/modules/transformer.py b/GPT_SoVITS/AR/modules/transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bf21cdbbc21006af785534d0e528da703dd68d3
--- /dev/null
+++ b/GPT_SoVITS/AR/modules/transformer.py
@@ -0,0 +1,362 @@
+# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/transformer.py
+import copy
+import numbers
+from functools import partial
+from typing import Any
+from typing import Callable
+from typing import List
+from typing import Optional
+from typing import Tuple
+from typing import Union
+
+import torch
+from AR.modules.activation import MultiheadAttention
+from AR.modules.scaling import BalancedDoubleSwish
+from torch import nn
+from torch import Tensor
+from torch.nn import functional as F
+
+_shape_t = Union[int, List[int], torch.Size]
+
+
+class LayerNorm(nn.Module):
+ __constants__ = ["normalized_shape", "eps", "elementwise_affine"]
+ normalized_shape: Tuple[int, ...]
+ eps: float
+ elementwise_affine: bool
+
+ def __init__(
+ self,
+ normalized_shape: _shape_t,
+ eps: float = 1e-5,
+ elementwise_affine: bool = True,
+ device=None,
+ dtype=None,
+ ) -> None:
+ factory_kwargs = {"device": device, "dtype": dtype}
+ super(LayerNorm, self).__init__()
+ if isinstance(normalized_shape, numbers.Integral):
+ # mypy error: incompatible types in assignment
+ normalized_shape = (normalized_shape,) # type: ignore[assignment]
+ self.normalized_shape = tuple(normalized_shape) # type: ignore[arg-type]
+ self.eps = eps
+ self.elementwise_affine = elementwise_affine
+ if self.elementwise_affine:
+ self.weight = nn.Parameter(torch.empty(self.normalized_shape, **factory_kwargs))
+ self.bias = nn.Parameter(torch.empty(self.normalized_shape, **factory_kwargs))
+ else:
+ self.register_parameter("weight", None)
+ self.register_parameter("bias", None)
+
+ self.reset_parameters()
+
+ def reset_parameters(self) -> None:
+ if self.elementwise_affine:
+ nn.init.ones_(self.weight)
+ nn.init.zeros_(self.bias)
+
+ def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
+ if isinstance(input, tuple):
+ input, embedding = input
+ return (
+ F.layer_norm(
+ input,
+ self.normalized_shape,
+ self.weight,
+ self.bias,
+ self.eps,
+ ),
+ embedding,
+ )
+
+ assert embedding is None
+ return F.layer_norm(input, self.normalized_shape, self.weight, self.bias, self.eps)
+
+ def extra_repr(self) -> str:
+ return "{normalized_shape}, eps={eps}, elementwise_affine={elementwise_affine}".format(**self.__dict__)
+
+
+class IdentityNorm(nn.Module):
+ def __init__(
+ self,
+ d_model: int,
+ eps: float = 1e-5,
+ device=None,
+ dtype=None,
+ ) -> None:
+ super(IdentityNorm, self).__init__()
+
+ def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
+ if isinstance(input, tuple):
+ return input
+
+ assert embedding is None
+ return input
+
+
+class TransformerEncoder(nn.Module):
+ r"""TransformerEncoder is a stack of N encoder layers. Users can build the
+ BERT(https://arxiv.org/abs/1810.04805) model with corresponding parameters.
+
+ Args:
+ encoder_layer: an instance of the TransformerEncoderLayer() class (required).
+ num_layers: the number of sub-encoder-layers in the encoder (required).
+ norm: the layer normalization component (optional).
+ enable_nested_tensor: if True, input will automatically convert to nested tensor
+ (and convert back on output). This will improve the overall performance of
+ TransformerEncoder when padding rate is high. Default: ``True`` (enabled).
+
+ Examples::
+ >>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
+ >>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
+ >>> src = torch.rand(10, 32, 512)
+ >>> out = transformer_encoder(src)
+ """
+
+ __constants__ = ["norm"]
+
+ def __init__(self, encoder_layer, num_layers, norm=None):
+ super(TransformerEncoder, self).__init__()
+ self.layers = _get_clones(encoder_layer, num_layers)
+ self.num_layers = num_layers
+ self.norm = norm
+
+ def forward(
+ self,
+ src: Tensor,
+ mask: Optional[Tensor] = None,
+ src_key_padding_mask: Optional[Tensor] = None,
+ return_layer_states: bool = False,
+ cache=None,
+ ) -> Tensor:
+ r"""Pass the input through the encoder layers in turn.
+
+ Args:
+ src: the sequence to the encoder (required).
+ mask: the mask for the src sequence (optional).
+ src_key_padding_mask: the mask for the src keys per batch (optional).
+ return_layer_states: return layers' state (optional).
+
+ Shape:
+ see the docs in Transformer class.
+ """
+ if return_layer_states:
+ layer_states = [] # layers' output
+ output = src
+ for mod in self.layers:
+ output = mod(
+ output,
+ src_mask=mask,
+ src_key_padding_mask=src_key_padding_mask,
+ cache=cache,
+ )
+ layer_states.append(output[0])
+
+ if self.norm is not None:
+ output = self.norm(output)
+
+ return layer_states, output
+
+ output = src
+ for mod in self.layers:
+ output = mod(
+ output,
+ src_mask=mask,
+ src_key_padding_mask=src_key_padding_mask,
+ cache=cache,
+ )
+
+ if self.norm is not None:
+ output = self.norm(output)
+
+ return output
+
+
+class TransformerEncoderLayer(nn.Module):
+ __constants__ = ["batch_first", "norm_first"]
+
+ def __init__(
+ self,
+ d_model: int,
+ nhead: int,
+ dim_feedforward: int = 2048,
+ dropout: float = 0.1,
+ activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
+ batch_first: bool = False,
+ norm_first: bool = False,
+ device=None,
+ dtype=None,
+ linear1_self_attention_cls: nn.Module = nn.Linear,
+ linear2_self_attention_cls: nn.Module = nn.Linear,
+ linear1_feedforward_cls: nn.Module = nn.Linear,
+ linear2_feedforward_cls: nn.Module = nn.Linear,
+ layer_norm_cls: nn.Module = LayerNorm,
+ layer_norm_eps: float = 1e-5,
+ adaptive_layer_norm=False,
+ ) -> None:
+ factory_kwargs = {"device": device, "dtype": dtype}
+ super(TransformerEncoderLayer, self).__init__()
+ # print(233333333333,d_model,nhead)
+ # import os
+ # os._exit(2333333)
+ self.self_attn = MultiheadAttention(
+ d_model, # 512 16
+ nhead,
+ dropout=dropout,
+ batch_first=batch_first,
+ linear1_cls=linear1_self_attention_cls,
+ linear2_cls=linear2_self_attention_cls,
+ **factory_kwargs,
+ )
+
+ # Implementation of Feedforward model
+ self.linear1 = linear1_feedforward_cls(d_model, dim_feedforward, **factory_kwargs)
+ self.dropout = nn.Dropout(dropout)
+ self.linear2 = linear2_feedforward_cls(dim_feedforward, d_model, **factory_kwargs)
+
+ self.norm_first = norm_first
+ self.dropout1 = nn.Dropout(dropout)
+ self.dropout2 = nn.Dropout(dropout)
+
+ # Legacy string support for activation function.
+ if isinstance(activation, str):
+ activation = _get_activation_fn(activation)
+ elif isinstance(activation, partial):
+ activation = activation(d_model)
+ elif activation == BalancedDoubleSwish:
+ activation = BalancedDoubleSwish(d_model)
+
+ # # We can't test self.activation in forward() in TorchScript,
+ # # so stash some information about it instead.
+ # if activation is F.relu or isinstance(activation, torch.nn.ReLU):
+ # self.activation_relu_or_gelu = 1
+ # elif activation is F.gelu or isinstance(activation, torch.nn.GELU):
+ # self.activation_relu_or_gelu = 2
+ # else:
+ # self.activation_relu_or_gelu = 0
+ self.activation = activation
+
+ norm1 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
+ if layer_norm_cls == IdentityNorm:
+ norm2 = BalancedBasicNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
+ else:
+ norm2 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
+
+ if adaptive_layer_norm:
+ self.norm1 = AdaptiveLayerNorm(d_model, norm1)
+ self.norm2 = AdaptiveLayerNorm(d_model, norm2)
+ else:
+ self.norm1 = norm1
+ self.norm2 = norm2
+
+ def __setstate__(self, state):
+ super(TransformerEncoderLayer, self).__setstate__(state)
+ if not hasattr(self, "activation"):
+ self.activation = F.relu
+
+ def forward(
+ self,
+ src: Tensor,
+ src_mask: Optional[Tensor] = None,
+ src_key_padding_mask: Optional[Tensor] = None,
+ cache=None,
+ ) -> Tensor:
+ r"""Pass the input through the encoder layer.
+
+ Args:
+ src: the sequence to the encoder layer (required).
+ src_mask: the mask for the src sequence (optional).
+ src_key_padding_mask: the mask for the src keys per batch (optional).
+
+ Shape:
+ see the docs in Transformer class.
+ """
+ x, stage_embedding = src, None
+ is_src_tuple = False
+ if isinstance(src, tuple):
+ x, stage_embedding = src
+ is_src_tuple = True
+
+ if src_key_padding_mask is not None:
+ _skpm_dtype = src_key_padding_mask.dtype
+ if _skpm_dtype != torch.bool and not torch.is_floating_point(src_key_padding_mask):
+ raise AssertionError("only bool and floating types of key_padding_mask are supported")
+
+ if self.norm_first:
+ x = x + self._sa_block(
+ self.norm1(x, stage_embedding),
+ src_mask,
+ src_key_padding_mask,
+ cache=cache,
+ )
+ x = x + self._ff_block(self.norm2(x, stage_embedding))
+ else:
+ x = self.norm1(
+ x + self._sa_block(x, src_mask, src_key_padding_mask, cache=cache),
+ stage_embedding,
+ )
+ x = self.norm2(x + self._ff_block(x), stage_embedding)
+
+ if is_src_tuple:
+ return (x, stage_embedding)
+ return x
+
+ # self-attention block
+ def _sa_block(
+ self,
+ x: Tensor,
+ attn_mask: Optional[Tensor],
+ key_padding_mask: Optional[Tensor],
+ cache=None,
+ ) -> Tensor:
+ # print(x.shape,attn_mask.shape,key_padding_mask)
+ # torch.Size([1, 188, 512]) torch.Size([188, 188]) None
+ # import os
+ # os._exit(23333)
+ x = self.self_attn(
+ x,
+ x,
+ x,
+ attn_mask=attn_mask,
+ key_padding_mask=key_padding_mask,
+ need_weights=False,
+ cache=cache,
+ )[0]
+ return self.dropout1(x)
+
+ # feed forward block
+ def _ff_block(self, x: Tensor) -> Tensor:
+ x = self.linear2(self.dropout(self.activation(self.linear1(x))))
+ return self.dropout2(x)
+
+
+class AdaptiveLayerNorm(nn.Module):
+ r"""Adaptive Layer Normalization"""
+
+ def __init__(self, d_model, norm) -> None:
+ super(AdaptiveLayerNorm, self).__init__()
+ self.project_layer = nn.Linear(d_model, 2 * d_model)
+ self.norm = norm
+ self.d_model = d_model
+ self.eps = self.norm.eps
+
+ def forward(self, input: Tensor, embedding: Tensor = None) -> Tensor:
+ if isinstance(input, tuple):
+ input, embedding = input
+ weight, bias = torch.split(
+ self.project_layer(embedding),
+ split_size_or_sections=self.d_model,
+ dim=-1,
+ )
+ return (weight * self.norm(input) + bias, embedding)
+
+ weight, bias = torch.split(
+ self.project_layer(embedding),
+ split_size_or_sections=self.d_model,
+ dim=-1,
+ )
+ return weight * self.norm(input) + bias
+
+
+def _get_clones(module, N):
+ return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
diff --git a/GPT_SoVITS/AR/modules/transformer_onnx.py b/GPT_SoVITS/AR/modules/transformer_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa1702548551ccd5166c50ca238a58b136144454
--- /dev/null
+++ b/GPT_SoVITS/AR/modules/transformer_onnx.py
@@ -0,0 +1,281 @@
+# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/transformer.py
+import copy
+import numbers
+from functools import partial
+from typing import Any
+from typing import Callable
+from typing import List
+from typing import Optional
+from typing import Tuple
+from typing import Union
+
+import torch
+from AR.modules.activation_onnx import MultiheadAttention
+from AR.modules.scaling import BalancedDoubleSwish
+from torch import nn
+from torch import Tensor
+from torch.nn import functional as F
+
+_shape_t = Union[int, List[int], torch.Size]
+
+
+class LayerNorm(nn.Module):
+ __constants__ = ["normalized_shape", "eps", "elementwise_affine"]
+ normalized_shape: Tuple[int, ...]
+ eps: float
+ elementwise_affine: bool
+
+ def __init__(
+ self,
+ normalized_shape: _shape_t,
+ eps: float = 1e-5,
+ elementwise_affine: bool = True,
+ device=None,
+ dtype=None,
+ ) -> None:
+ factory_kwargs = {"device": device, "dtype": dtype}
+ super(LayerNorm, self).__init__()
+ if isinstance(normalized_shape, numbers.Integral):
+ # mypy error: incompatible types in assignment
+ normalized_shape = (normalized_shape,) # type: ignore[assignment]
+ self.normalized_shape = tuple(normalized_shape) # type: ignore[arg-type]
+ self.eps = eps
+ self.elementwise_affine = elementwise_affine
+ if self.elementwise_affine:
+ self.weight = nn.Parameter(torch.empty(self.normalized_shape, **factory_kwargs))
+ self.bias = nn.Parameter(torch.empty(self.normalized_shape, **factory_kwargs))
+ else:
+ self.register_parameter("weight", None)
+ self.register_parameter("bias", None)
+
+ self.reset_parameters()
+
+ def reset_parameters(self) -> None:
+ if self.elementwise_affine:
+ nn.init.ones_(self.weight)
+ nn.init.zeros_(self.bias)
+
+ def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
+ if isinstance(input, tuple):
+ input, embedding = input
+ return (
+ F.layer_norm(
+ input,
+ self.normalized_shape,
+ self.weight,
+ self.bias,
+ self.eps,
+ ),
+ embedding,
+ )
+
+ assert embedding is None
+ return F.layer_norm(input, self.normalized_shape, self.weight, self.bias, self.eps)
+
+ def extra_repr(self) -> str:
+ return "{normalized_shape}, eps={eps}, elementwise_affine={elementwise_affine}".format(**self.__dict__)
+
+
+class IdentityNorm(nn.Module):
+ def __init__(
+ self,
+ d_model: int,
+ eps: float = 1e-5,
+ device=None,
+ dtype=None,
+ ) -> None:
+ super(IdentityNorm, self).__init__()
+
+ def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
+ if isinstance(input, tuple):
+ return input
+
+ assert embedding is None
+ return input
+
+
+class TransformerEncoder(nn.Module):
+ r"""TransformerEncoder is a stack of N encoder layers. Users can build the
+ BERT(https://arxiv.org/abs/1810.04805) model with corresponding parameters.
+
+ Args:
+ encoder_layer: an instance of the TransformerEncoderLayer() class (required).
+ num_layers: the number of sub-encoder-layers in the encoder (required).
+ norm: the layer normalization component (optional).
+ enable_nested_tensor: if True, input will automatically convert to nested tensor
+ (and convert back on output). This will improve the overall performance of
+ TransformerEncoder when padding rate is high. Default: ``True`` (enabled).
+
+ Examples::
+ >>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
+ >>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
+ >>> src = torch.rand(10, 32, 512)
+ >>> out = transformer_encoder(src)
+ """
+
+ __constants__ = ["norm"]
+
+ def __init__(self, encoder_layer, num_layers, norm=None):
+ super(TransformerEncoder, self).__init__()
+ self.layers = _get_clones(encoder_layer, num_layers)
+ self.num_layers = num_layers
+ self.norm = norm
+
+ def forward(
+ self,
+ src: Tensor,
+ mask: Optional[Tensor] = None,
+ src_key_padding_mask: Optional[Tensor] = None,
+ return_layer_states: bool = False,
+ cache=None,
+ ) -> Tensor:
+ output = src
+ for mod in self.layers:
+ output = mod(
+ output,
+ src_mask=mask,
+ src_key_padding_mask=src_key_padding_mask,
+ cache=cache,
+ )
+
+ if self.norm is not None:
+ output = self.norm(output)
+
+ return output
+
+
+class TransformerEncoderLayer(nn.Module):
+ __constants__ = ["batch_first", "norm_first"]
+
+ def __init__(
+ self,
+ d_model: int,
+ nhead: int,
+ dim_feedforward: int = 2048,
+ dropout: float = 0.1,
+ activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
+ batch_first: bool = False,
+ norm_first: bool = False,
+ device=None,
+ dtype=None,
+ linear1_self_attention_cls: nn.Module = nn.Linear,
+ linear2_self_attention_cls: nn.Module = nn.Linear,
+ linear1_feedforward_cls: nn.Module = nn.Linear,
+ linear2_feedforward_cls: nn.Module = nn.Linear,
+ layer_norm_cls: nn.Module = LayerNorm,
+ layer_norm_eps: float = 1e-5,
+ adaptive_layer_norm=False,
+ ) -> None:
+ factory_kwargs = {"device": device, "dtype": dtype}
+ super(TransformerEncoderLayer, self).__init__()
+ self.self_attn = MultiheadAttention(
+ d_model, # 512 16
+ nhead,
+ dropout=dropout,
+ batch_first=batch_first,
+ linear1_cls=linear1_self_attention_cls,
+ linear2_cls=linear2_self_attention_cls,
+ **factory_kwargs,
+ )
+ self.linear1 = linear1_feedforward_cls(d_model, dim_feedforward, **factory_kwargs)
+ self.dropout = nn.Dropout(dropout)
+ self.linear2 = linear2_feedforward_cls(dim_feedforward, d_model, **factory_kwargs)
+ self.norm_first = norm_first
+ self.dropout1 = nn.Dropout(dropout)
+ self.dropout2 = nn.Dropout(dropout)
+ if isinstance(activation, str):
+ activation = _get_activation_fn(activation)
+ elif isinstance(activation, partial):
+ activation = activation(d_model)
+ elif activation == BalancedDoubleSwish:
+ activation = BalancedDoubleSwish(d_model)
+ self.activation = activation
+
+ norm1 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
+ if layer_norm_cls == IdentityNorm:
+ norm2 = BalancedBasicNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
+ else:
+ norm2 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
+
+ if adaptive_layer_norm:
+ self.norm1 = AdaptiveLayerNorm(d_model, norm1)
+ self.norm2 = AdaptiveLayerNorm(d_model, norm2)
+ else:
+ self.norm1 = norm1
+ self.norm2 = norm2
+
+ def __setstate__(self, state):
+ super(TransformerEncoderLayer, self).__setstate__(state)
+ if not hasattr(self, "activation"):
+ self.activation = F.relu
+
+ def forward(
+ self,
+ src: Tensor,
+ src_mask: Optional[Tensor] = None,
+ src_key_padding_mask: Optional[Tensor] = None,
+ cache=None,
+ ) -> Tensor:
+ x = src
+ stage_embedding = None
+ x = self.norm1(
+ x + self._sa_block(x, src_mask, src_key_padding_mask, cache=cache),
+ stage_embedding,
+ )
+ x = self.norm2(x + self._ff_block(x), stage_embedding)
+
+ return x
+
+ def _sa_block(
+ self,
+ x: Tensor,
+ attn_mask: Optional[Tensor],
+ key_padding_mask: Optional[Tensor],
+ cache=None,
+ ) -> Tensor:
+ x = self.self_attn(
+ x,
+ x,
+ x,
+ attn_mask=attn_mask,
+ key_padding_mask=key_padding_mask,
+ need_weights=False,
+ cache=cache,
+ )
+ return self.dropout1(x)
+
+ def _ff_block(self, x: Tensor) -> Tensor:
+ x = self.linear2(self.dropout(self.activation(self.linear1(x))))
+ return self.dropout2(x)
+
+
+class AdaptiveLayerNorm(nn.Module):
+ r"""Adaptive Layer Normalization"""
+
+ def __init__(self, d_model, norm) -> None:
+ super(AdaptiveLayerNorm, self).__init__()
+ self.project_layer = nn.Linear(d_model, 2 * d_model)
+ self.norm = norm
+ self.d_model = d_model
+ self.eps = self.norm.eps
+
+ def forward(self, input: Tensor, embedding: Tensor = None) -> Tensor:
+ if isinstance(input, tuple):
+ input, embedding = input
+ weight, bias = torch.split(
+ self.project_layer(embedding),
+ split_size_or_sections=self.d_model,
+ dim=-1,
+ )
+ return (weight * self.norm(input) + bias, embedding)
+
+ weight, bias = torch.split(
+ self.project_layer(embedding),
+ split_size_or_sections=self.d_model,
+ dim=-1,
+ )
+ return weight * self.norm(input) + bias
+
+
+def _get_clones(module, N):
+ return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
diff --git a/GPT_SoVITS/AR/text_processing/__init__.py b/GPT_SoVITS/AR/text_processing/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/GPT_SoVITS/AR/text_processing/phonemizer.py b/GPT_SoVITS/AR/text_processing/phonemizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..1003040e282c51e4e240a122bce4f3b87a09b38f
--- /dev/null
+++ b/GPT_SoVITS/AR/text_processing/phonemizer.py
@@ -0,0 +1,72 @@
+# modified from https://github.com/yangdongchao/SoundStorm/blob/master/soundstorm/s1/AR/text_processing/phonemizer.py
+# reference: https://github.com/lifeiteng/vall-e
+import itertools
+import re
+from typing import Dict
+from typing import List
+
+import regex
+from gruut import sentences
+from gruut.const import Sentence
+from gruut.const import Word
+from AR.text_processing.symbols import SYMBOL_TO_ID
+
+
+class GruutPhonemizer:
+ def __init__(self, language: str):
+ self._phonemizer = sentences
+ self.lang = language
+ self.symbol_to_id = SYMBOL_TO_ID
+ self._special_cases_dict: Dict[str] = {
+ r"\.\.\.": "... ",
+ ";": "; ",
+ ":": ": ",
+ ",": ", ",
+ r"\.": ". ",
+ "!": "! ",
+ r"\?": "? ",
+ "—": "—",
+ "…": "… ",
+ "«": "«",
+ "»": "»",
+ }
+ self._punctuation_regexp: str = rf"([{''.join(self._special_cases_dict.keys())}])"
+
+ def _normalize_punctuation(self, text: str) -> str:
+ text = regex.sub(rf"\pZ+{self._punctuation_regexp}", r"\1", text)
+ text = regex.sub(rf"{self._punctuation_regexp}(\pL)", r"\1 \2", text)
+ text = regex.sub(r"\pZ+", r" ", text)
+ return text.strip()
+
+ def _convert_punctuation(self, word: Word) -> str:
+ if not word.phonemes:
+ return ""
+ if word.phonemes[0] in ["‖", "|"]:
+ return word.text.strip()
+
+ phonemes = "".join(word.phonemes)
+ # remove modifier characters ˈˌː with regex
+ phonemes = re.sub(r"[ˈˌː͡]", "", phonemes)
+ return phonemes.strip()
+
+ def phonemize(self, text: str, espeak: bool = False) -> str:
+ text_to_phonemize: str = self._normalize_punctuation(text)
+ sents: List[Sentence] = [sent for sent in self._phonemizer(text_to_phonemize, lang="en-us", espeak=espeak)]
+ words: List[str] = [self._convert_punctuation(word) for word in itertools.chain(*sents)]
+ return " ".join(words)
+
+ def transform(self, phonemes):
+ # convert phonemes to ids
+ # dictionary is in symbols.py
+ return [self.symbol_to_id[p] for p in phonemes if p in self.symbol_to_id.keys()]
+
+
+if __name__ == "__main__":
+ phonemizer = GruutPhonemizer("en-us")
+ # text -> IPA
+ phonemes = phonemizer.phonemize("Hello, wor-ld ?")
+ print("phonemes:", phonemes)
+ print("len(phonemes):", len(phonemes))
+ phoneme_ids = phonemizer.transform(phonemes)
+ print("phoneme_ids:", phoneme_ids)
+ print("len(phoneme_ids):", len(phoneme_ids))
diff --git a/GPT_SoVITS/AR/text_processing/symbols.py b/GPT_SoVITS/AR/text_processing/symbols.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7ef57faf5b83cb2417b4f9244244dc9939153aa
--- /dev/null
+++ b/GPT_SoVITS/AR/text_processing/symbols.py
@@ -0,0 +1,12 @@
+# modified from https://github.com/yangdongchao/SoundStorm/blob/master/soundstorm/s1/AR/text_processing/symbols.py
+# reference: https://github.com/lifeiteng/vall-e
+PAD = "_"
+PUNCTUATION = ';:,.!?¡¿—…"«»“” '
+LETTERS = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
+IPA_LETTERS = (
+ "ɑɐɒæɓʙβɔɕçɗɖðʤəɘɚɛɜɝɞɟʄɡɠɢʛɦɧħɥʜɨɪʝɭɬɫɮʟɱɯɰŋɳɲɴøɵɸθœɶʘɹɺɾɻʀʁɽʂʃʈʧʉʊʋⱱʌɣɤʍχʎʏʑʐʒʔʡʕʢǀǁǂǃˈˌːˑʼʴʰʱʲʷˠˤ˞↓↑→↗↘'̩'ᵻ"
+)
+SYMBOLS = [PAD] + list(PUNCTUATION) + list(LETTERS) + list(IPA_LETTERS)
+SPACE_ID = SYMBOLS.index(" ")
+SYMBOL_TO_ID = {s: i for i, s in enumerate(SYMBOLS)}
+ID_TO_SYMBOL = {i: s for i, s in enumerate(SYMBOLS)}
diff --git a/GPT_SoVITS/AR/utils/__init__.py b/GPT_SoVITS/AR/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a9cb4d58504c17a96634ddd98f22cadad9365de
--- /dev/null
+++ b/GPT_SoVITS/AR/utils/__init__.py
@@ -0,0 +1,36 @@
+import re
+
+
+def str2bool(str):
+ return True if str.lower() == "true" else False
+
+
+def get_newest_ckpt(string_list):
+ # 定义一个正则表达式模式,用于匹配字符串中的数字
+ pattern = r"epoch=(\d+)-step=(\d+)\.ckpt"
+
+ # 使用正则表达式提取每个字符串中的数字信息,并创建一个包含元组的列表
+ extracted_info = []
+ for string in string_list:
+ match = re.match(pattern, string)
+ if match:
+ epoch = int(match.group(1))
+ step = int(match.group(2))
+ extracted_info.append((epoch, step, string))
+ # 按照 epoch 后面的数字和 step 后面的数字进行排序
+ sorted_info = sorted(extracted_info, key=lambda x: (x[0], x[1]), reverse=True)
+ # 获取最新的 ckpt 文件名
+ newest_ckpt = sorted_info[0][2]
+ return newest_ckpt
+
+
+# 文本存在且不为空时 return True
+def check_txt_file(file_path):
+ try:
+ with open(file_path, "r") as file:
+ text = file.readline().strip()
+ assert text.strip() != ""
+ return text
+ except Exception:
+ return False
+ return False
diff --git a/GPT_SoVITS/AR/utils/initialize.py b/GPT_SoVITS/AR/utils/initialize.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee7c713823f57572ab8f7045ceba21e8e2619e4c
--- /dev/null
+++ b/GPT_SoVITS/AR/utils/initialize.py
@@ -0,0 +1,39 @@
+#!/usr/bin/env python3
+"""Initialize modules for espnet2 neural networks."""
+
+import torch
+from typeguard import check_argument_types
+
+
+def initialize(model: torch.nn.Module, init: str):
+ """Initialize weights of a neural network module.
+
+ Parameters are initialized using the given method or distribution.
+
+ Custom initialization routines can be implemented into submodules
+ as function `espnet_initialization_fn` within the custom module.
+
+ Args:
+ model: Target.
+ init: Method of initialization.
+ """
+ assert check_argument_types()
+ print("init with", init)
+
+ # weight init
+ for p in model.parameters():
+ if p.dim() > 1:
+ if init == "xavier_uniform":
+ torch.nn.init.xavier_uniform_(p.data)
+ elif init == "xavier_normal":
+ torch.nn.init.xavier_normal_(p.data)
+ elif init == "kaiming_uniform":
+ torch.nn.init.kaiming_uniform_(p.data, nonlinearity="relu")
+ elif init == "kaiming_normal":
+ torch.nn.init.kaiming_normal_(p.data, nonlinearity="relu")
+ else:
+ raise ValueError("Unknown initialization: " + init)
+ # bias init
+ for name, p in model.named_parameters():
+ if ".bias" in name and p.dim() == 1:
+ p.data.zero_()
diff --git a/GPT_SoVITS/AR/utils/io.py b/GPT_SoVITS/AR/utils/io.py
new file mode 100644
index 0000000000000000000000000000000000000000..a6475cb6b114787acfde5d73e1552cf58e04997b
--- /dev/null
+++ b/GPT_SoVITS/AR/utils/io.py
@@ -0,0 +1,30 @@
+import sys
+
+import torch
+import yaml
+
+
+def load_yaml_config(path):
+ with open(path) as f:
+ config = yaml.full_load(f)
+ return config
+
+
+def save_config_to_yaml(config, path):
+ assert path.endswith(".yaml")
+ with open(path, "w") as f:
+ f.write(yaml.dump(config))
+ f.close()
+
+
+def write_args(args, path):
+ args_dict = dict((name, getattr(args, name)) for name in dir(args) if not name.startswith("_"))
+ with open(path, "a") as args_file:
+ args_file.write("==> torch version: {}\n".format(torch.__version__))
+ args_file.write("==> cudnn version: {}\n".format(torch.backends.cudnn.version()))
+ args_file.write("==> Cmd:\n")
+ args_file.write(str(sys.argv))
+ args_file.write("\n==> args:\n")
+ for k, v in sorted(args_dict.items()):
+ args_file.write(" %s: %s\n" % (str(k), str(v)))
+ args_file.close()
diff --git a/GPT_SoVITS/BigVGAN/LICENSE b/GPT_SoVITS/BigVGAN/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..4c78361c86d4f685117d60d6623e2197fcfed706
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2024 NVIDIA CORPORATION.
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/GPT_SoVITS/BigVGAN/README.md b/GPT_SoVITS/BigVGAN/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2fa70ceea647053933b913b329041ee8c41526db
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/README.md
@@ -0,0 +1,266 @@
+## BigVGAN: A Universal Neural Vocoder with Large-Scale Training
+
+#### Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon
+
+[[Paper]](https://arxiv.org/abs/2206.04658) - [[Code]](https://github.com/NVIDIA/BigVGAN) - [[Showcase]](https://bigvgan-demo.github.io/) - [[Project Page]](https://research.nvidia.com/labs/adlr/projects/bigvgan/) - [[Weights]](https://huggingface.co/collections/nvidia/bigvgan-66959df3d97fd7d98d97dc9a) - [[Demo]](https://huggingface.co/spaces/nvidia/BigVGAN)
+
+[](https://paperswithcode.com/sota/speech-synthesis-on-libritts?p=bigvgan-a-universal-neural-vocoder-with-large)
+
+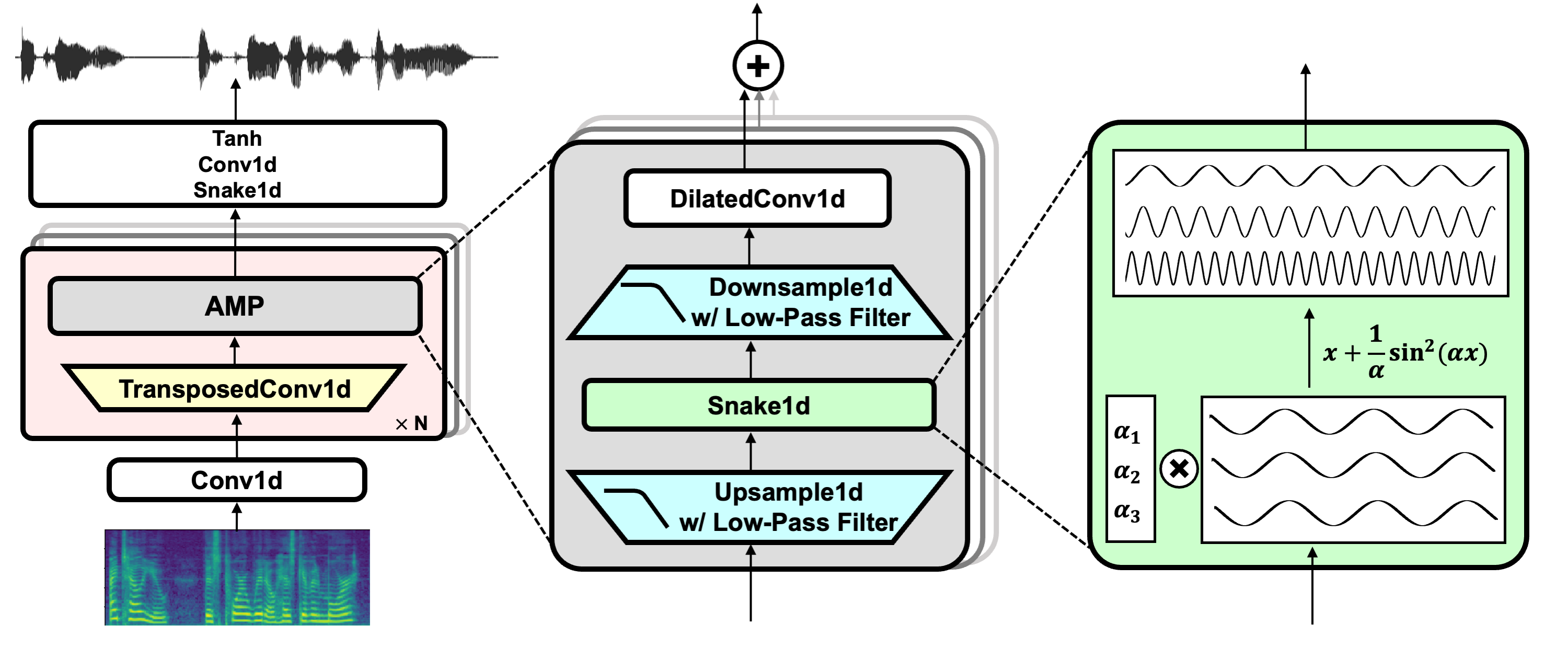
 +
+You can run a local gradio demo using below command:
+
+```python
+pip install -r demo/requirements.txt
+python demo/app.py
+```
+
+## Training
+
+Create symbolic link to the root of the dataset. The codebase uses filelist with the relative path from the dataset. Below are the example commands for LibriTTS dataset:
+
+```shell
+cd filelists/LibriTTS && \
+ln -s /path/to/your/LibriTTS/train-clean-100 train-clean-100 && \
+ln -s /path/to/your/LibriTTS/train-clean-360 train-clean-360 && \
+ln -s /path/to/your/LibriTTS/train-other-500 train-other-500 && \
+ln -s /path/to/your/LibriTTS/dev-clean dev-clean && \
+ln -s /path/to/your/LibriTTS/dev-other dev-other && \
+ln -s /path/to/your/LibriTTS/test-clean test-clean && \
+ln -s /path/to/your/LibriTTS/test-other test-other && \
+cd ../..
+```
+
+Train BigVGAN model. Below is an example command for training BigVGAN-v2 using LibriTTS dataset at 24kHz with a full 100-band mel spectrogram as input:
+
+```shell
+python train.py \
+--config configs/bigvgan_v2_24khz_100band_256x.json \
+--input_wavs_dir filelists/LibriTTS \
+--input_training_file filelists/LibriTTS/train-full.txt \
+--input_validation_file filelists/LibriTTS/val-full.txt \
+--list_input_unseen_wavs_dir filelists/LibriTTS filelists/LibriTTS \
+--list_input_unseen_validation_file filelists/LibriTTS/dev-clean.txt filelists/LibriTTS/dev-other.txt \
+--checkpoint_path exp/bigvgan_v2_24khz_100band_256x
+```
+
+## Synthesis
+
+Synthesize from BigVGAN model. Below is an example command for generating audio from the model.
+It computes mel spectrograms using wav files from `--input_wavs_dir` and saves the generated audio to `--output_dir`.
+
+```shell
+python inference.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_wavs_dir /path/to/your/input_wav \
+--output_dir /path/to/your/output_wav
+```
+
+`inference_e2e.py` supports synthesis directly from the mel spectrogram saved in `.npy` format, with shapes `[1, channel, frame]` or `[channel, frame]`.
+It loads mel spectrograms from `--input_mels_dir` and saves the generated audio to `--output_dir`.
+
+Make sure that the STFT hyperparameters for mel spectrogram are the same as the model, which are defined in `config.json` of the corresponding model.
+
+```shell
+python inference_e2e.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_mels_dir /path/to/your/input_mel \
+--output_dir /path/to/your/output_wav
+```
+
+## Using Custom CUDA Kernel for Synthesis
+
+You can apply the fast CUDA inference kernel by using a parameter `use_cuda_kernel` when instantiating BigVGAN:
+
+```python
+generator = BigVGAN(h, use_cuda_kernel=True)
+```
+
+You can also pass `--use_cuda_kernel` to `inference.py` and `inference_e2e.py` to enable this feature.
+
+When applied for the first time, it builds the kernel using `nvcc` and `ninja`. If the build succeeds, the kernel is saved to `alias_free_activation/cuda/build` and the model automatically loads the kernel. The codebase has been tested using CUDA `12.1`.
+
+Please make sure that both are installed in your system and `nvcc` installed in your system matches the version your PyTorch build is using.
+
+We recommend running `test_cuda_vs_torch_model.py` first to build and check the correctness of the CUDA kernel. See below example command and its output, where it returns `[Success] test CUDA fused vs. plain torch BigVGAN inference`:
+
+```python
+python tests/test_cuda_vs_torch_model.py \
+--checkpoint_file /path/to/your/bigvgan_generator.pt
+```
+
+```shell
+loading plain Pytorch BigVGAN
+...
+loading CUDA kernel BigVGAN with auto-build
+Detected CUDA files, patching ldflags
+Emitting ninja build file /path/to/your/BigVGAN/alias_free_activation/cuda/build/build.ninja..
+Building extension module anti_alias_activation_cuda...
+...
+Loading extension module anti_alias_activation_cuda...
+...
+Loading '/path/to/your/bigvgan_generator.pt'
+...
+[Success] test CUDA fused vs. plain torch BigVGAN inference
+ > mean_difference=0.0007238413265440613
+...
+```
+
+If you see `[Fail] test CUDA fused vs. plain torch BigVGAN inference`, it means that the CUDA kernel inference is incorrect. Please check if `nvcc` installed in your system is compatible with your PyTorch version.
+
+## Pretrained Models
+
+We provide the [pretrained models on Hugging Face Collections](https://huggingface.co/collections/nvidia/bigvgan-66959df3d97fd7d98d97dc9a).
+One can download the checkpoints of the generator weight (named `bigvgan_generator.pt`) and its discriminator/optimizer states (named `bigvgan_discriminator_optimizer.pt`) within the listed model repositories.
+
+| Model Name | Sampling Rate | Mel band | fmax | Upsampling Ratio | Params | Dataset | Steps | Fine-Tuned |
+|:--------------------------------------------------------------------------------------------------------:|:-------------:|:--------:|:-----:|:----------------:|:------:|:--------------------------:|:-----:|:----------:|
+| [bigvgan_v2_44khz_128band_512x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_512x) | 44 kHz | 128 | 22050 | 512 | 122M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_44khz_128band_256x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_256x) | 44 kHz | 128 | 22050 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_24khz_100band_256x](https://huggingface.co/nvidia/bigvgan_v2_24khz_100band_256x) | 24 kHz | 100 | 12000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_256x) | 22 kHz | 80 | 11025 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_fmax8k_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_fmax8k_256x) | 22 kHz | 80 | 8000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_24khz_100band](https://huggingface.co/nvidia/bigvgan_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 112M | LibriTTS | 5M | No |
+| [bigvgan_base_24khz_100band](https://huggingface.co/nvidia/bigvgan_base_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 14M | LibriTTS | 5M | No |
+| [bigvgan_22khz_80band](https://huggingface.co/nvidia/bigvgan_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 112M | LibriTTS + VCTK + LJSpeech | 5M | No |
+| [bigvgan_base_22khz_80band](https://huggingface.co/nvidia/bigvgan_base_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 14M | LibriTTS + VCTK + LJSpeech | 5M | No |
+
+The paper results are based on the original 24kHz BigVGAN models (`bigvgan_24khz_100band` and `bigvgan_base_24khz_100band`) trained on LibriTTS dataset.
+We also provide 22kHz BigVGAN models with band-limited setup (i.e., fmax=8000) for TTS applications.
+Note that the checkpoints use `snakebeta` activation with log scale parameterization, which have the best overall quality.
+
+You can fine-tune the models by:
+
+1. downloading the checkpoints (both the generator weight and its discriminator/optimizer states)
+2. resuming training using your audio dataset by specifying `--checkpoint_path` that includes the checkpoints when launching `train.py`
+
+## Training Details of BigVGAN-v2
+
+Comapred to the original BigVGAN, the pretrained checkpoints of BigVGAN-v2 used `batch_size=32` with a longer `segment_size=65536` and are trained using 8 A100 GPUs.
+
+Note that the BigVGAN-v2 `json` config files in `./configs` use `batch_size=4` as default to fit in a single A100 GPU for training. You can fine-tune the models adjusting `batch_size` depending on your GPUs.
+
+When training BigVGAN-v2 from scratch with small batch size, it can potentially encounter the early divergence problem mentioned in the paper. In such case, we recommend lowering the `clip_grad_norm` value (e.g. `100`) for the early training iterations (e.g. 20000 steps) and increase the value to the default `500`.
+
+## Evaluation Results of BigVGAN-v2
+
+Below are the objective results of the 24kHz model (`bigvgan_v2_24khz_100band_256x`) obtained from the LibriTTS `dev` sets. BigVGAN-v2 shows noticeable improvements of the metrics. The model also exhibits reduced perceptual artifacts, especially for non-speech audio.
+
+| Model | Dataset | Steps | PESQ(↑) | M-STFT(↓) | MCD(↓) | Periodicity(↓) | V/UV F1(↑) |
+|:----------:|:-----------------------:|:-----:|:---------:|:----------:|:----------:|:--------------:|:----------:|
+| BigVGAN | LibriTTS | 1M | 4.027 | 0.7997 | 0.3745 | 0.1018 | 0.9598 |
+| BigVGAN | LibriTTS | 5M | 4.256 | 0.7409 | 0.2988 | 0.0809 | 0.9698 |
+| BigVGAN-v2 | Large-scale Compilation | 3M | 4.359 | 0.7134 | 0.3060 | 0.0621 | 0.9777 |
+| BigVGAN-v2 | Large-scale Compilation | 5M | **4.362** | **0.7026** | **0.2903** | **0.0593** | **0.9793** |
+
+## Speed Benchmark
+
+Below are the speed and VRAM usage benchmark results of BigVGAN from `tests/test_cuda_vs_torch_model.py`, using `bigvgan_v2_24khz_100band_256x` as a reference model.
+
+| GPU | num_mel_frame | use_cuda_kernel | Speed (kHz) | Real-time Factor | VRAM (GB) |
+|:--------------------------:|:-------------:|:---------------:|:-----------:|:----------------:|:---------:|
+| NVIDIA A100 | 256 | False | 1672.1 | 69.7x | 1.3 |
+| | | True | 3916.5 | 163.2x | 1.3 |
+| | 2048 | False | 1899.6 | 79.2x | 1.7 |
+| | | True | 5330.1 | 222.1x | 1.7 |
+| | 16384 | False | 1973.8 | 82.2x | 5.0 |
+| | | True | 5761.7 | 240.1x | 4.4 |
+| NVIDIA GeForce RTX 3080 | 256 | False | 841.1 | 35.0x | 1.3 |
+| | | True | 1598.1 | 66.6x | 1.3 |
+| | 2048 | False | 929.9 | 38.7x | 1.7 |
+| | | True | 1971.3 | 82.1x | 1.6 |
+| | 16384 | False | 943.4 | 39.3x | 5.0 |
+| | | True | 2026.5 | 84.4x | 3.9 |
+| NVIDIA GeForce RTX 2080 Ti | 256 | False | 515.6 | 21.5x | 1.3 |
+| | | True | 811.3 | 33.8x | 1.3 |
+| | 2048 | False | 576.5 | 24.0x | 1.7 |
+| | | True | 1023.0 | 42.6x | 1.5 |
+| | 16384 | False | 589.4 | 24.6x | 5.0 |
+| | | True | 1068.1 | 44.5x | 3.2 |
+
+## Acknowledgements
+
+We thank Vijay Anand Korthikanti and Kevin J. Shih for their generous support in implementing the CUDA kernel for inference.
+
+## References
+
+- [HiFi-GAN](https://github.com/jik876/hifi-gan) (for generator and multi-period discriminator)
+- [Snake](https://github.com/EdwardDixon/snake) (for periodic activation)
+- [Alias-free-torch](https://github.com/junjun3518/alias-free-torch) (for anti-aliasing)
+- [Julius](https://github.com/adefossez/julius) (for low-pass filter)
+- [UnivNet](https://github.com/mindslab-ai/univnet) (for multi-resolution discriminator)
+- [descript-audio-codec](https://github.com/descriptinc/descript-audio-codec) and [vocos](https://github.com/gemelo-ai/vocos) (for multi-band multi-scale STFT discriminator and multi-scale mel spectrogram loss)
+- [Amphion](https://github.com/open-mmlab/Amphion) (for multi-scale sub-band CQT discriminator)
diff --git a/GPT_SoVITS/BigVGAN/activations.py b/GPT_SoVITS/BigVGAN/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..abe3ad9e25c6ab3d4545c6a8c60e1f85a5a8e98e
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/activations.py
@@ -0,0 +1,122 @@
+# Implementation adapted from https://github.com/EdwardDixon/snake under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import torch
+from torch import nn, sin, pow
+from torch.nn import Parameter
+
+
+class Snake(nn.Module):
+ """
+ Implementation of a sine-based periodic activation function
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter
+ References:
+ - This activation function is from this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snake(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha: trainable parameter
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ alpha will be trained along with the rest of your model.
+ """
+ super(Snake, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ Snake ∶= x + 1/a * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ x = x + (1.0 / (alpha + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
+
+
+class SnakeBeta(nn.Module):
+ """
+ A modified Snake function which uses separate parameters for the magnitude of the periodic components
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ References:
+ - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snakebeta(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ beta is initialized to 1 by default, higher values = higher-magnitude.
+ alpha will be trained along with the rest of your model.
+ """
+ super(SnakeBeta, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ self.beta = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+ self.beta = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+ self.beta.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ SnakeBeta ∶= x + 1/b * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ beta = self.beta.unsqueeze(0).unsqueeze(-1)
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ beta = torch.exp(beta)
+ x = x + (1.0 / (beta + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
diff --git a/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/__init__.py b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/activation1d.py b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/activation1d.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea333cfa0d5f84de363b7b27739df3bbc457d763
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/activation1d.py
@@ -0,0 +1,69 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+import torch
+import torch.nn as nn
+from alias_free_activation.torch.resample import UpSample1d, DownSample1d
+
+# load fused CUDA kernel: this enables importing anti_alias_activation_cuda
+from alias_free_activation.cuda import load
+
+anti_alias_activation_cuda = load.load()
+
+
+class FusedAntiAliasActivation(torch.autograd.Function):
+ """
+ Assumes filter size 12, replication padding on upsampling/downsampling, and logscale alpha/beta parameters as inputs.
+ The hyperparameters are hard-coded in the kernel to maximize speed.
+ NOTE: The fused kenrel is incorrect for Activation1d with different hyperparameters.
+ """
+
+ @staticmethod
+ def forward(ctx, inputs, up_ftr, down_ftr, alpha, beta):
+ activation_results = anti_alias_activation_cuda.forward(inputs, up_ftr, down_ftr, alpha, beta)
+
+ return activation_results
+
+ @staticmethod
+ def backward(ctx, output_grads):
+ raise NotImplementedError
+ return output_grads, None, None
+
+
+class Activation1d(nn.Module):
+ def __init__(
+ self,
+ activation,
+ up_ratio: int = 2,
+ down_ratio: int = 2,
+ up_kernel_size: int = 12,
+ down_kernel_size: int = 12,
+ fused: bool = True,
+ ):
+ super().__init__()
+ self.up_ratio = up_ratio
+ self.down_ratio = down_ratio
+ self.act = activation
+ self.upsample = UpSample1d(up_ratio, up_kernel_size)
+ self.downsample = DownSample1d(down_ratio, down_kernel_size)
+
+ self.fused = fused # Whether to use fused CUDA kernel or not
+
+ def forward(self, x):
+ if not self.fused:
+ x = self.upsample(x)
+ x = self.act(x)
+ x = self.downsample(x)
+ return x
+ else:
+ if self.act.__class__.__name__ == "Snake":
+ beta = self.act.alpha.data # Snake uses same params for alpha and beta
+ else:
+ beta = self.act.beta.data # Snakebeta uses different params for alpha and beta
+ alpha = self.act.alpha.data
+ if not self.act.alpha_logscale: # Exp baked into cuda kernel, cancel it out with a log
+ alpha = torch.log(alpha)
+ beta = torch.log(beta)
+
+ x = FusedAntiAliasActivation.apply(x, self.upsample.filter, self.downsample.lowpass.filter, alpha, beta)
+ return x
diff --git a/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/anti_alias_activation.cpp b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/anti_alias_activation.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..c5651f77143bd678169eb11564a7cf7a7969a59e
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/anti_alias_activation.cpp
@@ -0,0 +1,23 @@
+/* coding=utf-8
+ * Copyright (c) 2024, NVIDIA CORPORATION. All rights reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+ #include
+
+You can run a local gradio demo using below command:
+
+```python
+pip install -r demo/requirements.txt
+python demo/app.py
+```
+
+## Training
+
+Create symbolic link to the root of the dataset. The codebase uses filelist with the relative path from the dataset. Below are the example commands for LibriTTS dataset:
+
+```shell
+cd filelists/LibriTTS && \
+ln -s /path/to/your/LibriTTS/train-clean-100 train-clean-100 && \
+ln -s /path/to/your/LibriTTS/train-clean-360 train-clean-360 && \
+ln -s /path/to/your/LibriTTS/train-other-500 train-other-500 && \
+ln -s /path/to/your/LibriTTS/dev-clean dev-clean && \
+ln -s /path/to/your/LibriTTS/dev-other dev-other && \
+ln -s /path/to/your/LibriTTS/test-clean test-clean && \
+ln -s /path/to/your/LibriTTS/test-other test-other && \
+cd ../..
+```
+
+Train BigVGAN model. Below is an example command for training BigVGAN-v2 using LibriTTS dataset at 24kHz with a full 100-band mel spectrogram as input:
+
+```shell
+python train.py \
+--config configs/bigvgan_v2_24khz_100band_256x.json \
+--input_wavs_dir filelists/LibriTTS \
+--input_training_file filelists/LibriTTS/train-full.txt \
+--input_validation_file filelists/LibriTTS/val-full.txt \
+--list_input_unseen_wavs_dir filelists/LibriTTS filelists/LibriTTS \
+--list_input_unseen_validation_file filelists/LibriTTS/dev-clean.txt filelists/LibriTTS/dev-other.txt \
+--checkpoint_path exp/bigvgan_v2_24khz_100band_256x
+```
+
+## Synthesis
+
+Synthesize from BigVGAN model. Below is an example command for generating audio from the model.
+It computes mel spectrograms using wav files from `--input_wavs_dir` and saves the generated audio to `--output_dir`.
+
+```shell
+python inference.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_wavs_dir /path/to/your/input_wav \
+--output_dir /path/to/your/output_wav
+```
+
+`inference_e2e.py` supports synthesis directly from the mel spectrogram saved in `.npy` format, with shapes `[1, channel, frame]` or `[channel, frame]`.
+It loads mel spectrograms from `--input_mels_dir` and saves the generated audio to `--output_dir`.
+
+Make sure that the STFT hyperparameters for mel spectrogram are the same as the model, which are defined in `config.json` of the corresponding model.
+
+```shell
+python inference_e2e.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_mels_dir /path/to/your/input_mel \
+--output_dir /path/to/your/output_wav
+```
+
+## Using Custom CUDA Kernel for Synthesis
+
+You can apply the fast CUDA inference kernel by using a parameter `use_cuda_kernel` when instantiating BigVGAN:
+
+```python
+generator = BigVGAN(h, use_cuda_kernel=True)
+```
+
+You can also pass `--use_cuda_kernel` to `inference.py` and `inference_e2e.py` to enable this feature.
+
+When applied for the first time, it builds the kernel using `nvcc` and `ninja`. If the build succeeds, the kernel is saved to `alias_free_activation/cuda/build` and the model automatically loads the kernel. The codebase has been tested using CUDA `12.1`.
+
+Please make sure that both are installed in your system and `nvcc` installed in your system matches the version your PyTorch build is using.
+
+We recommend running `test_cuda_vs_torch_model.py` first to build and check the correctness of the CUDA kernel. See below example command and its output, where it returns `[Success] test CUDA fused vs. plain torch BigVGAN inference`:
+
+```python
+python tests/test_cuda_vs_torch_model.py \
+--checkpoint_file /path/to/your/bigvgan_generator.pt
+```
+
+```shell
+loading plain Pytorch BigVGAN
+...
+loading CUDA kernel BigVGAN with auto-build
+Detected CUDA files, patching ldflags
+Emitting ninja build file /path/to/your/BigVGAN/alias_free_activation/cuda/build/build.ninja..
+Building extension module anti_alias_activation_cuda...
+...
+Loading extension module anti_alias_activation_cuda...
+...
+Loading '/path/to/your/bigvgan_generator.pt'
+...
+[Success] test CUDA fused vs. plain torch BigVGAN inference
+ > mean_difference=0.0007238413265440613
+...
+```
+
+If you see `[Fail] test CUDA fused vs. plain torch BigVGAN inference`, it means that the CUDA kernel inference is incorrect. Please check if `nvcc` installed in your system is compatible with your PyTorch version.
+
+## Pretrained Models
+
+We provide the [pretrained models on Hugging Face Collections](https://huggingface.co/collections/nvidia/bigvgan-66959df3d97fd7d98d97dc9a).
+One can download the checkpoints of the generator weight (named `bigvgan_generator.pt`) and its discriminator/optimizer states (named `bigvgan_discriminator_optimizer.pt`) within the listed model repositories.
+
+| Model Name | Sampling Rate | Mel band | fmax | Upsampling Ratio | Params | Dataset | Steps | Fine-Tuned |
+|:--------------------------------------------------------------------------------------------------------:|:-------------:|:--------:|:-----:|:----------------:|:------:|:--------------------------:|:-----:|:----------:|
+| [bigvgan_v2_44khz_128band_512x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_512x) | 44 kHz | 128 | 22050 | 512 | 122M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_44khz_128band_256x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_256x) | 44 kHz | 128 | 22050 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_24khz_100band_256x](https://huggingface.co/nvidia/bigvgan_v2_24khz_100band_256x) | 24 kHz | 100 | 12000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_256x) | 22 kHz | 80 | 11025 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_fmax8k_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_fmax8k_256x) | 22 kHz | 80 | 8000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_24khz_100band](https://huggingface.co/nvidia/bigvgan_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 112M | LibriTTS | 5M | No |
+| [bigvgan_base_24khz_100band](https://huggingface.co/nvidia/bigvgan_base_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 14M | LibriTTS | 5M | No |
+| [bigvgan_22khz_80band](https://huggingface.co/nvidia/bigvgan_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 112M | LibriTTS + VCTK + LJSpeech | 5M | No |
+| [bigvgan_base_22khz_80band](https://huggingface.co/nvidia/bigvgan_base_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 14M | LibriTTS + VCTK + LJSpeech | 5M | No |
+
+The paper results are based on the original 24kHz BigVGAN models (`bigvgan_24khz_100band` and `bigvgan_base_24khz_100band`) trained on LibriTTS dataset.
+We also provide 22kHz BigVGAN models with band-limited setup (i.e., fmax=8000) for TTS applications.
+Note that the checkpoints use `snakebeta` activation with log scale parameterization, which have the best overall quality.
+
+You can fine-tune the models by:
+
+1. downloading the checkpoints (both the generator weight and its discriminator/optimizer states)
+2. resuming training using your audio dataset by specifying `--checkpoint_path` that includes the checkpoints when launching `train.py`
+
+## Training Details of BigVGAN-v2
+
+Comapred to the original BigVGAN, the pretrained checkpoints of BigVGAN-v2 used `batch_size=32` with a longer `segment_size=65536` and are trained using 8 A100 GPUs.
+
+Note that the BigVGAN-v2 `json` config files in `./configs` use `batch_size=4` as default to fit in a single A100 GPU for training. You can fine-tune the models adjusting `batch_size` depending on your GPUs.
+
+When training BigVGAN-v2 from scratch with small batch size, it can potentially encounter the early divergence problem mentioned in the paper. In such case, we recommend lowering the `clip_grad_norm` value (e.g. `100`) for the early training iterations (e.g. 20000 steps) and increase the value to the default `500`.
+
+## Evaluation Results of BigVGAN-v2
+
+Below are the objective results of the 24kHz model (`bigvgan_v2_24khz_100band_256x`) obtained from the LibriTTS `dev` sets. BigVGAN-v2 shows noticeable improvements of the metrics. The model also exhibits reduced perceptual artifacts, especially for non-speech audio.
+
+| Model | Dataset | Steps | PESQ(↑) | M-STFT(↓) | MCD(↓) | Periodicity(↓) | V/UV F1(↑) |
+|:----------:|:-----------------------:|:-----:|:---------:|:----------:|:----------:|:--------------:|:----------:|
+| BigVGAN | LibriTTS | 1M | 4.027 | 0.7997 | 0.3745 | 0.1018 | 0.9598 |
+| BigVGAN | LibriTTS | 5M | 4.256 | 0.7409 | 0.2988 | 0.0809 | 0.9698 |
+| BigVGAN-v2 | Large-scale Compilation | 3M | 4.359 | 0.7134 | 0.3060 | 0.0621 | 0.9777 |
+| BigVGAN-v2 | Large-scale Compilation | 5M | **4.362** | **0.7026** | **0.2903** | **0.0593** | **0.9793** |
+
+## Speed Benchmark
+
+Below are the speed and VRAM usage benchmark results of BigVGAN from `tests/test_cuda_vs_torch_model.py`, using `bigvgan_v2_24khz_100band_256x` as a reference model.
+
+| GPU | num_mel_frame | use_cuda_kernel | Speed (kHz) | Real-time Factor | VRAM (GB) |
+|:--------------------------:|:-------------:|:---------------:|:-----------:|:----------------:|:---------:|
+| NVIDIA A100 | 256 | False | 1672.1 | 69.7x | 1.3 |
+| | | True | 3916.5 | 163.2x | 1.3 |
+| | 2048 | False | 1899.6 | 79.2x | 1.7 |
+| | | True | 5330.1 | 222.1x | 1.7 |
+| | 16384 | False | 1973.8 | 82.2x | 5.0 |
+| | | True | 5761.7 | 240.1x | 4.4 |
+| NVIDIA GeForce RTX 3080 | 256 | False | 841.1 | 35.0x | 1.3 |
+| | | True | 1598.1 | 66.6x | 1.3 |
+| | 2048 | False | 929.9 | 38.7x | 1.7 |
+| | | True | 1971.3 | 82.1x | 1.6 |
+| | 16384 | False | 943.4 | 39.3x | 5.0 |
+| | | True | 2026.5 | 84.4x | 3.9 |
+| NVIDIA GeForce RTX 2080 Ti | 256 | False | 515.6 | 21.5x | 1.3 |
+| | | True | 811.3 | 33.8x | 1.3 |
+| | 2048 | False | 576.5 | 24.0x | 1.7 |
+| | | True | 1023.0 | 42.6x | 1.5 |
+| | 16384 | False | 589.4 | 24.6x | 5.0 |
+| | | True | 1068.1 | 44.5x | 3.2 |
+
+## Acknowledgements
+
+We thank Vijay Anand Korthikanti and Kevin J. Shih for their generous support in implementing the CUDA kernel for inference.
+
+## References
+
+- [HiFi-GAN](https://github.com/jik876/hifi-gan) (for generator and multi-period discriminator)
+- [Snake](https://github.com/EdwardDixon/snake) (for periodic activation)
+- [Alias-free-torch](https://github.com/junjun3518/alias-free-torch) (for anti-aliasing)
+- [Julius](https://github.com/adefossez/julius) (for low-pass filter)
+- [UnivNet](https://github.com/mindslab-ai/univnet) (for multi-resolution discriminator)
+- [descript-audio-codec](https://github.com/descriptinc/descript-audio-codec) and [vocos](https://github.com/gemelo-ai/vocos) (for multi-band multi-scale STFT discriminator and multi-scale mel spectrogram loss)
+- [Amphion](https://github.com/open-mmlab/Amphion) (for multi-scale sub-band CQT discriminator)
diff --git a/GPT_SoVITS/BigVGAN/activations.py b/GPT_SoVITS/BigVGAN/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..abe3ad9e25c6ab3d4545c6a8c60e1f85a5a8e98e
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/activations.py
@@ -0,0 +1,122 @@
+# Implementation adapted from https://github.com/EdwardDixon/snake under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import torch
+from torch import nn, sin, pow
+from torch.nn import Parameter
+
+
+class Snake(nn.Module):
+ """
+ Implementation of a sine-based periodic activation function
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter
+ References:
+ - This activation function is from this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snake(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha: trainable parameter
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ alpha will be trained along with the rest of your model.
+ """
+ super(Snake, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ Snake ∶= x + 1/a * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ x = x + (1.0 / (alpha + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
+
+
+class SnakeBeta(nn.Module):
+ """
+ A modified Snake function which uses separate parameters for the magnitude of the periodic components
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ References:
+ - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snakebeta(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ beta is initialized to 1 by default, higher values = higher-magnitude.
+ alpha will be trained along with the rest of your model.
+ """
+ super(SnakeBeta, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ self.beta = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+ self.beta = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+ self.beta.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ SnakeBeta ∶= x + 1/b * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ beta = self.beta.unsqueeze(0).unsqueeze(-1)
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ beta = torch.exp(beta)
+ x = x + (1.0 / (beta + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
diff --git a/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/__init__.py b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/activation1d.py b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/activation1d.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea333cfa0d5f84de363b7b27739df3bbc457d763
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/activation1d.py
@@ -0,0 +1,69 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+import torch
+import torch.nn as nn
+from alias_free_activation.torch.resample import UpSample1d, DownSample1d
+
+# load fused CUDA kernel: this enables importing anti_alias_activation_cuda
+from alias_free_activation.cuda import load
+
+anti_alias_activation_cuda = load.load()
+
+
+class FusedAntiAliasActivation(torch.autograd.Function):
+ """
+ Assumes filter size 12, replication padding on upsampling/downsampling, and logscale alpha/beta parameters as inputs.
+ The hyperparameters are hard-coded in the kernel to maximize speed.
+ NOTE: The fused kenrel is incorrect for Activation1d with different hyperparameters.
+ """
+
+ @staticmethod
+ def forward(ctx, inputs, up_ftr, down_ftr, alpha, beta):
+ activation_results = anti_alias_activation_cuda.forward(inputs, up_ftr, down_ftr, alpha, beta)
+
+ return activation_results
+
+ @staticmethod
+ def backward(ctx, output_grads):
+ raise NotImplementedError
+ return output_grads, None, None
+
+
+class Activation1d(nn.Module):
+ def __init__(
+ self,
+ activation,
+ up_ratio: int = 2,
+ down_ratio: int = 2,
+ up_kernel_size: int = 12,
+ down_kernel_size: int = 12,
+ fused: bool = True,
+ ):
+ super().__init__()
+ self.up_ratio = up_ratio
+ self.down_ratio = down_ratio
+ self.act = activation
+ self.upsample = UpSample1d(up_ratio, up_kernel_size)
+ self.downsample = DownSample1d(down_ratio, down_kernel_size)
+
+ self.fused = fused # Whether to use fused CUDA kernel or not
+
+ def forward(self, x):
+ if not self.fused:
+ x = self.upsample(x)
+ x = self.act(x)
+ x = self.downsample(x)
+ return x
+ else:
+ if self.act.__class__.__name__ == "Snake":
+ beta = self.act.alpha.data # Snake uses same params for alpha and beta
+ else:
+ beta = self.act.beta.data # Snakebeta uses different params for alpha and beta
+ alpha = self.act.alpha.data
+ if not self.act.alpha_logscale: # Exp baked into cuda kernel, cancel it out with a log
+ alpha = torch.log(alpha)
+ beta = torch.log(beta)
+
+ x = FusedAntiAliasActivation.apply(x, self.upsample.filter, self.downsample.lowpass.filter, alpha, beta)
+ return x
diff --git a/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/anti_alias_activation.cpp b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/anti_alias_activation.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..c5651f77143bd678169eb11564a7cf7a7969a59e
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/alias_free_activation/cuda/anti_alias_activation.cpp
@@ -0,0 +1,23 @@
+/* coding=utf-8
+ * Copyright (c) 2024, NVIDIA CORPORATION. All rights reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+ #include