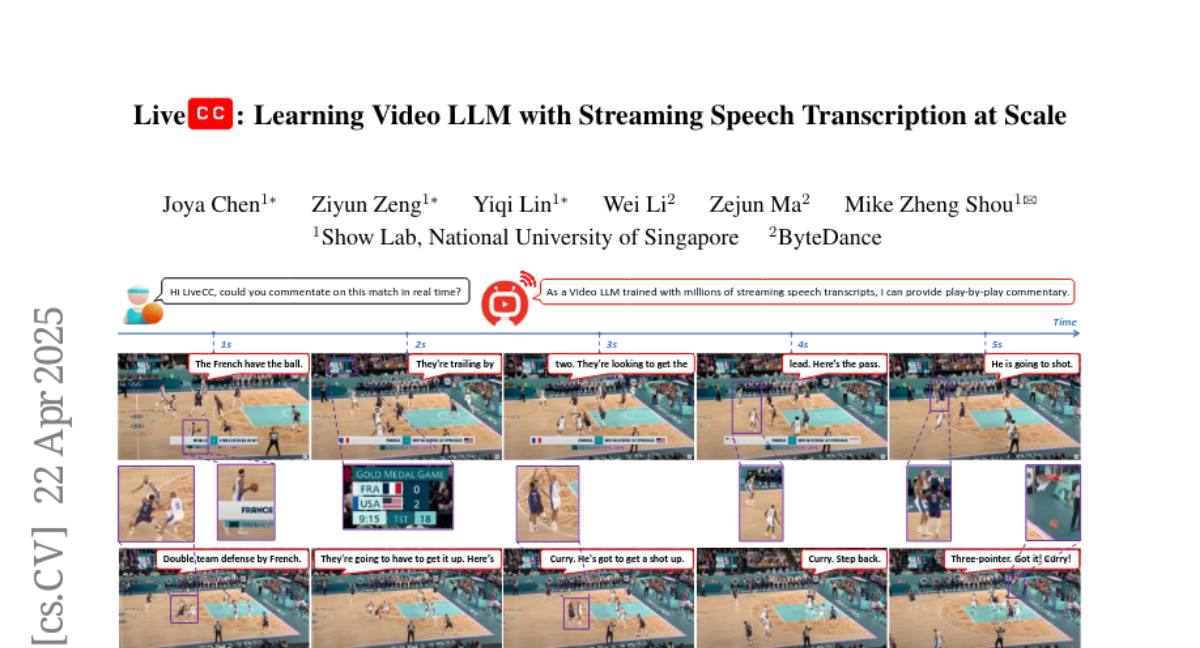
LiveCC Learning Video LLM with Streaming Speech Transcription at Scale (CVPR 2025) chenjoya/LiveCC-7B-Instruct 8B • Updated Apr 25 • 2.82k • 42 chenjoya/LiveCC-7B-Base 8B • Updated Apr 25 • 1.17k • 7 chenjoya/Live-WhisperX-526K Preview • Updated Aug 4 • 3.72k • 8 chenjoya/Live-CC-5M Preview • Updated May 2 • 74 • 5
LiveCC Learning Video LLM with Streaming Speech Transcription at Scale (CVPR 2025) chenjoya/LiveCC-7B-Instruct 8B • Updated Apr 25 • 2.82k • 42 chenjoya/LiveCC-7B-Base 8B • Updated Apr 25 • 1.17k • 7 chenjoya/Live-WhisperX-526K Preview • Updated Aug 4 • 3.72k • 8 chenjoya/Live-CC-5M Preview • Updated May 2 • 74 • 5