
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
53fdbdf58a22ff5df27ebc03aebe5c9a15631c33 | 1,247 | md | Markdown | docs/fields/select.md | yiisoft/yii-form | 79bb78aca77f23438a913ed5bc81a0bea45dc818 | [
"BSD-3-Clause"
] | 13 | 2020-04-12T01:06:59.000Z | 2020-05-18T08:59:56.000Z | docs/fields/select.md | yiisoft/yii-active-form | 86ce1f0c80a1eb5be93e52cabce4feaa47933ec2 | [
"BSD-3-Clause"
] | 14 | 2020-04-14T22:44:41.000Z | 2020-05-22T22:31:21.000Z | docs/fields/select.md | yiisoft/yii-active-form | 86ce1f0c80a1eb5be93e52cabce4feaa47933ec2 | [
"BSD-3-Clause"
] | 7 | 2020-04-13T15:35:32.000Z | 2020-05-18T17:07:34.000Z | # Select Field
Represents `<select>` element that provides a menu of options. Documentation:
- [HTML Living Standard](https://html.spec.whatwg.org/multipage/form-elements.html#the-select-element)
- [MDN Web Docs](https://developer.mozilla.org/docs/Web/HTML/Element/select)
## Usage Example
Form model:
```php
final class ProfileForm extends FormModel
{
public ?string $color = 'f00';
public function getAttributeLabels(): array
{
return [
'color' => 'Select color',
];
}
}
```
Widget:
```php
echo Select::widget()
->formAttribute($profileForm, 'color')
->optionsData([
'f00' => 'Red',
'0f0' => 'Green',
'00f' => 'Blue',
]);
```
Result will be:
```html
<div>
<label for="profileform-color">Select color</label>
<select id="profileform-color" name="ProfileForm[color]">
<option value="f00">Red</option>
<option value="0f0">Green</option>
<option value="00f">Blue</option>
</select>
</div>
```
## Supported Values
- `string`
- number or numeric string (see [is_numeric()](https://www.php.net/manual/en/function.is-numeric.php))
- `bool`
- `null`
- any stringable values
Multiple select requires iterable or `null` value.
| 20.783333 | 102 | 0.631115 | eng_Latn | 0.300781 |
53fe2f4b64bac606edad0b0de67685df5349006e | 220 | md | Markdown | P2417/README.md | neargye-wg21/WG21 | dc0c6a11137548e881741c1047737bb923c12941 | [
"CC-BY-4.0"
] | 3 | 2021-12-27T14:32:30.000Z | 2022-01-06T17:58:55.000Z | P2417/README.md | neargye-wg21/WG21 | dc0c6a11137548e881741c1047737bb923c12941 | [
"CC-BY-4.0"
] | 5 | 2020-07-10T15:24:08.000Z | 2021-09-18T20:23:58.000Z | P2417/README.md | Neargye/WG21 | dc0c6a11137548e881741c1047737bb923c12941 | [
"CC-BY-4.0"
] | null | null | null | # A more constexpr bitset
Morris Hafner
Daniil Goncharov
## Full Text of Proposal
* [P1944R1](https://wg21.link/p1251)
* [P1944R2](P1944R2.pdf)
## References
* <https://wg21.link/p0784>
* <https://wg21.link/p0980>
| 13.75 | 36 | 0.695455 | kor_Hang | 0.292633 |
53feabb6b63e18675982b7a1775cfecda67fcad1 | 1,506 | md | Markdown | doc/ref/feat/evaluation verification.md | kniz/wrd | a8c9e8bd2f7b240ff64a3b80e7ebc7aff2775ba6 | [
"MIT"
] | 7 | 2019-03-12T03:04:32.000Z | 2021-12-26T04:33:44.000Z | doc/ref/feat/evaluation verification.md | kniz/wrd | a8c9e8bd2f7b240ff64a3b80e7ebc7aff2775ba6 | [
"MIT"
] | 25 | 2016-09-23T16:36:19.000Z | 2019-02-12T14:14:32.000Z | doc/ref/feat/evaluation verification.md | kniz/World | 13b0c8c7fdc6280efcb2135dc3902754a34e6d06 | [
"MIT"
] | null | null | null | # 평가 검증
* 식이 올바른 값을 가지고 있는지, 정상적으로 파싱이 완료되었는지를 검증한다.
* Linking 에러가 여기에 속하게 된다.
# verifier의 기준
* 파싱이 가능한가 불가능한가는 이 단계에서 검증하지 않는다.
* 의미를 파악해서 해당 의미를 가진 항목이 여기에 오는 것이 타당한가의 여부는 이 단계에서만 검출한다.
# 사례
* 어떠한 expr 이 있을때 이 expr이 lhs인가 rhs인가를 판단하는 것은 verifier에서 검증해야 한다. lowscanner, lowparser에서 판단해서는 안된다. lowparser는 구분 없이 모두 expr로써만 받아들여야 한다.
* 생성자를 정의한 것인지 일반 함수를 정의한 것인지에 대한 구분 역시 verifier에서 해야 한다.
* import에서는 <id> . <id> 와 같은 꼴만 올 수 있다. 반면 함수 본문에서는 <id> . <funcCall> 도 올 수 있다.
그렇다고 해서 lowparser가 이 둘을 구분해서 받아들이려고 하면 구현이 어렵다. 더 큰 문법이 있다면 그 문법 1개만 남긴다. 그리고 verifier에서 검증한다.
# 에러는 4 Tier 가 존재한다.
## 1. 애초에 잘못된 토큰이 존재한다.
* 오타가 여기에 해당하는 것으로, 존재하지 않는 키워드를 사용했다던가, 특문을 사용한 경우에 해당한다.
* scanner의 pattern에 의해 걸러지게 된다.
## 2. 인터프리터가 개발자의 코드의 의도를 잘 못 파악해서 프로그램의 구조 자체를 잘못 이해했다.
* 이러한 에러는 scanner & parser의 pattern에 의해서 걸러야 한다.
* 에러 trace를 해줘서 현재 컴파일러가 이해한 의도가 무엇이며, 다음에 어떠한 토큰이 있을 것이라 예상했는데
그렇지 않았다, 혹시 이러한 식으로 코드를 잘 못 작성한 것이 아니냐는 의견을 보여줘야한다.
## 3. 구조는 대략 맞추었지만 디테일한 문법에서 틀렸다.
* 예를들면, "함수 정의까지는 대략 잘 들어맞았지만, 이 함수는 const로 선언되어야 한다."
* 혹은 "함수의 정의를 한 것은 맞지만, 람다함수가 아니므로 반환형을 생략해서는 안된다" 와 같은 것.
* 이 3단계 에러는 본래 parser의 pattern을 세부적으로 상세하게 한다면 잡아낼 수있는 것이지만,
그렇게 할 경우 문법이 더 복잡해지거나 혹은 LALR(k) 혹은 glr 파싱을 해야만 하는 경우가 발생하기
때문에 일단 parser의 pattern을 완화시켜서 매칭이 되게 한 후에 action에서 이를 판단하고자
하는 것이다.
* 만약 다른 데이터나 AST에 의존하는 정보가 잘못된 경우는 이 단계의 에러에 속하지 않는다.
## 4. 있을거라고 했지만 없었다.
* 전통적인 linking 에러가 여기에 속한다. 각각의 함수, 각각의 파일 자체만 놓고보면 문제가 없지만
어딘가에 있다고 했었던 심볼이 없는 경우등이 여기에 속한다.
* lowparser로부터 AST가 나오고 난 뒤에 verification을 돌리면서 에러가 검출된다.
| 38.615385 | 138 | 0.702523 | kor_Hang | 1.00001 |
53ff1f0dfb509c86e0f585290156a5f5ba6176b6 | 152 | md | Markdown | _posts/2014-07-28-nest-store.md | NullVoxPopuli/built-with-ember | 5992870ee23412f8974935f28af5a18f2e00d627 | [
"MIT"
] | 37 | 2015-01-08T15:56:11.000Z | 2021-11-01T18:50:56.000Z | _posts/2014-07-28-nest-store.md | NullVoxPopuli/built-with-ember | 5992870ee23412f8974935f28af5a18f2e00d627 | [
"MIT"
] | 82 | 2015-01-08T00:11:32.000Z | 2022-02-26T01:42:44.000Z | _posts/2014-07-28-nest-store.md | NullVoxPopuli/built-with-ember | 5992870ee23412f8974935f28af5a18f2e00d627 | [
"MIT"
] | 91 | 2015-01-08T00:10:00.000Z | 2022-01-29T22:50:13.000Z | ---
layout: post
title: "Nest Store"
slug: nest-store
source: https://store.nest.com/
category: "featured"
---
<img src="/screenshots/nest-store.png">
| 15.2 | 39 | 0.690789 | eng_Latn | 0.08666 |
53ffefa1b17a937b94a4056c1762c23bfa1152cc | 2,034 | md | Markdown | includes/data-box-shares.md | maiemy/azure-docs.it-it | b3649d817c2ec64a3738b5f05f18f85557d0d9b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/data-box-shares.md | maiemy/azure-docs.it-it | b3649d817c2ec64a3738b5f05f18f85557d0d9b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/data-box-shares.md | maiemy/azure-docs.it-it | b3649d817c2ec64a3738b5f05f18f85557d0d9b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
author: alkohli
ms.service: databox
ms.subservice: pod
ms.topic: include
ms.date: 06/05/2020
ms.author: alkohli
ms.openlocfilehash: 5aaf0ce747b14b2fa9f2fcd9a65b774aa7d2db3b
ms.sourcegitcommit: 829d951d5c90442a38012daaf77e86046018e5b9
ms.translationtype: HT
ms.contentlocale: it-IT
ms.lasthandoff: 10/09/2020
ms.locfileid: "87102761"
---
In base all'account di archiviazione selezionato, Data Box crea fino a:
* Tre condivisioni per ogni account di archiviazione associato per GPv1 e GPv2.
* Una condivisione per l'archiviazione Premium.
* Una condivisione per l'account di archiviazione BLOB.
Nelle condivisioni per BLOB di pagine e BLOB in blocchi le entità di primo livello sono contenitori, mentre le entità di secondo livello sono BLOB. Nelle condivisioni per File di Azure le entità di primo livello sono condivisioni, mentre le entità di secondo livello sono file.
La tabella seguente mostra il percorso UNC delle condivisioni in Data Box e l'URL del percorso di Archiviazione di Azure in cui vengono caricati i dati. L'URL del percorso finale di Archiviazione di Azure può essere derivato dal percorso UNC della condivisione.
| BLOB e file | Percorsi e URL |
| --------------- | -------------- |
| BLOB in blocchi di Azure | <li>Percorso UNC delle condivisioni: `\\<DeviceIPAddress>\<StorageAccountName_BlockBlob>\<ContainerName>\files\a.txt`</li><li>URL di Archiviazione di Azure: `https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt`</li> |
| BLOB di pagine di Azure | <li>Percorso UNC delle condivisioni: `\\<DeviceIPAddres>\<StorageAccountName_PageBlob>\<ContainerName>\files\a.txt`</li><li>URL di Archiviazione di Azure: `https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt`</li> |
| File di Azure |<li>Percorso UNC delle condivisioni: `\\<DeviceIPAddres>\<StorageAccountName_AzFile>\<ShareName>\files\a.txt`</li><li>URL di Archiviazione di Azure: `https://<StorageAccountName>.file.core.windows.net/<ShareName>/files/a.txt`</li> |
| 65.612903 | 277 | 0.764012 | ita_Latn | 0.964899 |
990000b02f4edad6544f779c940f194d252e38d9 | 2,036 | md | Markdown | README.md | nonlinear-chaos-order-etc-etal/gostcoin | b140f5f92024c73ee639abd1dd8a503a3a778c54 | [
"MIT"
] | 35 | 2017-04-20T17:52:30.000Z | 2021-10-05T02:41:23.000Z | README.md | SSSR220Sec/SSSR5CRYPTOCURRENCY | 51240469f0933c6efa7f02239c413fd26f528465 | [
"MIT"
] | 32 | 2017-04-07T19:31:57.000Z | 2022-02-15T14:57:43.000Z | README.md | SSSR220Sec/SSSR5CRYPTOCURRENCY | 51240469f0933c6efa7f02239c413fd26f528465 | [
"MIT"
] | 23 | 2017-04-14T21:46:08.000Z | 2022-03-28T00:21:59.000Z | GOSTCoin Core
=============
GOSTCoin (GST) is a digital currency based on [blockchain](https://en.wikipedia.org/wiki/Blockchain) technology.
It allows instant payments worldwide with focus on privacy and security of its users.
Why GOSTCoin?
-------------
GOSTCoin uses Soviet and Russian government standard cryptography:
[GOST R 34.10-2012](https://tools.ietf.org/html/rfc7091) for signature and [GOST R 34.11-2012](https://tools.ietf.org/html/rfc6986) for hash.
[More info about crypto](https://github.com/GOSTSec/gostcoin/wiki/Cryptography).
GOSTCoin is using [Invisible Internet](https://github.com/PurpleI2P/i2pd) (I2P) as a secure network layer.
GOSTCoin needs I2P router
-------------------------
Install and run [i2pd](https://github.com/PurpleI2P/i2pd).
Enable SAM API in i2pd. Edit in `i2pd.conf`:
[sam]
enabled = true
and restart i2pd. Local TCP port 7656 should be available.
Building GOSTCoin
-----------------
**Install development libraries:**
apt-get install build-essential libtool libboost-all-dev git libdb++-dev libssl-dev zlib1g-dev
**Clone repository:**
git clone https://github.com/GOSTSec/gostcoin.git ~/gostcoin
**Build gostcoind:**
cd ~/gostcoin/src
make -f makefile.unix
**Optional: Build QT GUI**
# install requirements
apt-get install libqt5gui5 libqt5core5a libqt5dbus5 qttools5-dev qttools5-dev-tools libprotobuf-dev protobuf-compiler
# build GUI
cd ~/gostcoin
qmake && make
# build GUI with QR codes and paper wallet
apt-get install libqrencode-dev
cd ~/gostcoin
qmake "USE_QRCODE=1" && make
Mining tools
------------
Dedicated mining tools are available: [cpuminer for CPU](https://github.com/GOSTSec/cpuminer-x11-gost), [ccminer for NVIDIA GPU](https://github.com/GOSTSec/ccminer) and [sgminer for AMD GPU](https://github.com/GOSTSec/sgminer)
License
-------
GOSTCoin Core is released under the terms of the MIT license. See [COPYING](COPYING) for more
information or see http://opensource.org/licenses/MIT.
| 29.941176 | 228 | 0.710707 | eng_Latn | 0.497798 |
99000170ac9c0ae7bffd7cd8414ad74b3dff0838 | 91 | md | Markdown | README.md | ReklezWlthr/bookinfo-details | cdd4bfe1246409f1e30d355b11176994bbd1e7d7 | [
"MIT"
] | null | null | null | README.md | ReklezWlthr/bookinfo-details | cdd4bfe1246409f1e30d355b11176994bbd1e7d7 | [
"MIT"
] | null | null | null | README.md | ReklezWlthr/bookinfo-details | cdd4bfe1246409f1e30d355b11176994bbd1e7d7 | [
"MIT"
] | null | null | null | # How to run details service
## Prerequisite
* Ruby 2.7
```bash
ruby details.rb 8080
``` | 10.111111 | 28 | 0.67033 | eng_Latn | 0.964205 |
99006af02d6d12821784311a76d9c4a4b2122857 | 111 | md | Markdown | _posts/2019-07-20-captures.md | Meteoros-Floripa/meteoros.floripa.br | 7d296fb8d630a4e5fec9ab1a3fb6050420fc0dad | [
"MIT"
] | 5 | 2020-05-19T17:04:49.000Z | 2021-03-30T03:09:14.000Z | _posts/2019-07-20-captures.md | Meteoros-Floripa/site | 764cf471d85a6b498873610e4f3b30efd1fd9fae | [
"MIT"
] | null | null | null | _posts/2019-07-20-captures.md | Meteoros-Floripa/site | 764cf471d85a6b498873610e4f3b30efd1fd9fae | [
"MIT"
] | 2 | 2020-05-19T17:06:27.000Z | 2020-09-04T00:00:43.000Z | ---
layout: post
title: 20/07/2019
date: 2019-07-20 10:00:00
preview: TLP1/2019/201907/20190720/stack.jpg
---
| 15.857143 | 45 | 0.702703 | eng_Latn | 0.086344 |
99008225fec994e57d05c8b075e2ee3db4772c2a | 619 | md | Markdown | docs/ShareRequestReq.md | maytechnet/api-client-js | 816c74cee6136e67b0f93f639a71b9fb94a783dc | [
"MIT"
] | 2 | 2019-01-10T15:51:53.000Z | 2020-06-27T14:49:24.000Z | docs/ShareRequestReq.md | maytechnet/api-client-js | 816c74cee6136e67b0f93f639a71b9fb94a783dc | [
"MIT"
] | null | null | null | docs/ShareRequestReq.md | maytechnet/api-client-js | 816c74cee6136e67b0f93f639a71b9fb94a783dc | [
"MIT"
] | null | null | null | # QuatrixApi.ShareRequestReq
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**returnPgpEncrypted** | **Boolean** | if PGP keys were generated by the sender or the recipient. | [optional] [default to false]
**requestAuth** | **Boolean** | Defines if return files will require authentication | [optional] [default to true]
**sendEmail** | **Boolean** | | [optional] [default to true]
**ids** | **[String]** | List of recipient IDs |
**message** | **String** | | [optional]
**folderId** | **String** | Target folder ID for requested files | [optional]
| 44.214286 | 129 | 0.605816 | eng_Latn | 0.673 |
9900878add9d955d7f797a89187813e13b47816e | 71 | md | Markdown | vault/tn/EZK-gj4t.md | mandolyte/uw-obsidian | 39e987c4cdc49d2a68e3af6b4e3fc84d1cda916d | [
"MIT"
] | null | null | null | vault/tn/EZK-gj4t.md | mandolyte/uw-obsidian | 39e987c4cdc49d2a68e3af6b4e3fc84d1cda916d | [
"MIT"
] | null | null | null | vault/tn/EZK-gj4t.md | mandolyte/uw-obsidian | 39e987c4cdc49d2a68e3af6b4e3fc84d1cda916d | [
"MIT"
] | null | null | null | # General Information:
Ezekiel tells about his experience at Tel-Aviv. | 23.666667 | 47 | 0.802817 | eng_Latn | 0.968247 |
9900df22d95e7bf3ef11ea1a2493cb7951d27e3e | 46 | md | Markdown | Packs/PAN-OS/IncidentFields/incidentfield-TargetFirewallVersion_CHANGELOG.md | ddi-danielsantander/content | 67e2edc404f50c332d928dbdbce00a447bb5532f | [
"MIT"
] | 1 | 2020-07-22T05:55:11.000Z | 2020-07-22T05:55:11.000Z | Packs/PAN-OS/IncidentFields/incidentfield-TargetFirewallVersion_CHANGELOG.md | ddi-danielsantander/content | 67e2edc404f50c332d928dbdbce00a447bb5532f | [
"MIT"
] | 1 | 2020-07-29T21:48:58.000Z | 2020-07-29T21:48:58.000Z | Packs/PAN-OS/IncidentFields/incidentfield-TargetFirewallVersion_CHANGELOG.md | ddi-danielsantander/content | 67e2edc404f50c332d928dbdbce00a447bb5532f | [
"MIT"
] | 2 | 2020-07-15T06:41:52.000Z | 2020-07-19T18:45:23.000Z | ## [Unreleased]
-
## [20.2.3] - 2020-02-18
- | 7.666667 | 24 | 0.478261 | eng_Latn | 0.464453 |
9900f1a99a5c290a53044d04c5e2a3df0c7afb27 | 6,816 | md | Markdown | Documents/OlympusDocument/data/SampleAppGuide/capture_sample_android.md | Psewall/SpotAI | 1e760e60c6d0f5cdb0a672e19c4d2670ace3fc5f | [
"MIT"
] | 1 | 2021-12-14T11:05:47.000Z | 2021-12-14T11:05:47.000Z | Documents/OlympusDocument/data/SampleAppGuide/capture_sample_android.md | Psewall/SpotAI | 1e760e60c6d0f5cdb0a672e19c4d2670ace3fc5f | [
"MIT"
] | null | null | null | Documents/OlympusDocument/data/SampleAppGuide/capture_sample_android.md | Psewall/SpotAI | 1e760e60c6d0f5cdb0a672e19c4d2670ace3fc5f | [
"MIT"
] | null | null | null | # Sample Capture App User Guide (Android OS)
This document is an operation manual for ImageCaptureSample which uses Olympus Camera Kit for Android OS. This document does not cover app installation or wireless connection between camera and mobile device.
## Starting Application
+ Application will start by tapping icon of ImageCaptureSample in mobile device’s home screen.
+ Application starts communication with camera immediately after starting.
+ Display of live view image will start.
Note) This application is designed for landscape orientation only. Rotation of the mobile device is not supported.
## Terminating Application
+ Press home button or back button (hardware button).
+ All communication stops when application terminates.
## Screen Transition
<div class="img-center">

</div>
+ 1) Shooting Screen
+ 2) Preview Screen
+ 3) Setting Screen
+ 12) Pressing Shutter Button
+ 21) Tapping Camera Icon or Tapping Outside of Image
+ 13) Tapping Setting Button
+ 31) Tapping Back Button
## Shooting Screen
<div class="img-center">

</div>
+ 1) Menu Bar
+ 2) Setting Button
+ 3) Shutter Button
+ 4) Auto Focus Lock Release Button (enabled when touch shutter is disabled)
+ 5) Status Display
+ 6) Live View Image
---
+ Can shoot still and movie image.
+ Can shoot while watching live view image sent from camera in real time.
### Auto Focus (AF)
+ Auto focus at tapped point in auto focus enabled area, which is smaller rectangle inside live view image. The auto focus enabled area is invisible on this application.
+ If AF-supported micro four thirds lens is not mounted, AF does not work.
+ Color of frame will be white during auto focus process.
+ When auto focus succeeds, a beep is made and frame color becomes green.
+ If you tap outside of auto focus enabled area, frame color becomes red.
+ If auto focus fails, error message is shown.
+ When touch shutter is enabled, picture is taken after AF. Otherwise, auto focus at the tapped position and lock focus position at the distance.
+ Tap Auto Focus Lock Release Button to unlock focus position.
### Shoot
+ By tapping shutter button, camera shoots an image regardless of touch shutter setting.
+ After shooting is complete, taken image is shown as a preview. In setting screen one can select whether to show preview image or not.
+ When touch shutter is enabled, take picture after AF. Otherwise, auto focus and lock focus position.
### Setting
<div class="img-center">

</div>
+ One can change shooting parameters by tapping menu bar displayed at top part of the screen. Following parameters can be changed from left to right.
+ Drive Mode
+ Single Shooting
+ Shoot one image each by pressing shutter button.
+ Continuous Shooting
+ Shoot images continuously while shutter button is pressed.
+ No preview images are shown even if preview setting is enabled.
+ When shooting mode is Movie, Drive Mode setting is invalid.
+ Shooting Mode
+ iAuto (Full Automatic Mode)
+ Cannot change shutter speed, lens aperture, exposure compensation, ISO sensitivity, or white balance mode.
+ P (Program Auto Exposure Mode)
+ Cannot change shutter speed or lens aperture.
+ A (Aperture Priority Auto Exposure)
+ Cannot change shutter speed.
+ S (Shutter Priority Auto Exposure)
+ Cannot change lens aperture.
+ M (Manual Mode)
+ Cannot change exposure compensation.
+ ART (Art Filter Mode)
+ Shoot with art filter set on camera at the time.
+ Cannot change the art filter type.
+ Movie (Movie Capture Mode)
+ Start taking movie by tapping shutter button. Stop taking movie by pressing shutter button again.
+ Color of shutter button will be gray when shooting movie.
+ Shutter Speed Value
+ Shutter speed value (set by user or camera) will be displayed in menu bar.
+ When long exposure value is set to camera, live view is not updated on screen after pressing shutter button during exposure time.
+ Wait until exposure time elapses and app responds correctly.
+ Lens Aperture Value
+ Lens aperture value (set by user or camera) will be displayed in menu bar.
+ Exposure Compensation Value
+ Exposure compensation value (set by user or camera) will be displayed in menu bar.
+ White Balance Mode
+ Selected white balance mode will be displayed in menu bar.
+ ISO Sensitivity Value
+ When AUTO is selected, ISO sensitivity value set by camera and text ISO-A will be displayed in menu bar.
+ Otherwise, ISO sensitivity value will be displayed in menu bar.
### Status Display
+ Status of camera will be displayed at lower left part of screen. Following status is displayed from top to bottom.
+ Number of images that can fit in remaining memory.
+ Valid only for still images.
+ Charge of camera battery.
+ Battery icon shows charge in three levels: full, middle, and low.
+ The icon shows the status of AC power supply.
### Move to Setting Screen
+ Enter setting screen by tapping the setting button, which is above the shutter button.
## Preview Screen
+ Displays captured image.
+ Go back to shooting screen by tapping camera icon or tapping area outside preview image.
<div class="img-center">

</div>
## Setting Screen
+ Current application settings are displayed.
<div class="img-center">

</div>
+ Can view and change following settings.
+ Live View Quality
+ Select image size (quality) of live view image.
+ Lower resolution images (settings toward QVGA) have higher frame rate.
+ Higher resolution images (setting toward XGA) have lower frame rate.
+ Touch Shutter
+ By selecting ON, touch shutter is enabled.
+ By selecting OFF, touch auto focus is enabled.
+ More detail is shown in Shooting Screen section.
+ Show Preview
+ By selecting ON, preview image will be displayed after shooting.
+ Preview image is displayed when Drive Mode is Single and Shooting Mode is not Movie.
+ By selecting OFF, preview image will not be displayed after shooting.
+ Power Off
+ Can turn off power to the camera by tapping.
+ Camera Version
+ Shows version of camera firmware.
+ Camera Kit Version
+ Shows version of Camera Kit that the application is using.
+ Parameters will be saved to application by pressing back button (hardware button) on top.
## In Case of Communication Error
+ An alert is displayed when a communication error occurs between camera and mobile device.
+ When alert is displayed, check the communication settings of OS and restart application.
| 40.331361 | 210 | 0.742224 | eng_Latn | 0.99252 |
99015b21106bceeb41bf72970c108890a918803d | 650 | md | Markdown | business-central/LocalFunctionality/Australia/how-to-print-deposit-slip-reports.md | AleksanderGladkov/dynamics365smb-docs | f061beeb61260d6b78df86334a7a8c50be2bb8d4 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | business-central/LocalFunctionality/Australia/how-to-print-deposit-slip-reports.md | AleksanderGladkov/dynamics365smb-docs | f061beeb61260d6b78df86334a7a8c50be2bb8d4 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | business-central/LocalFunctionality/Australia/how-to-print-deposit-slip-reports.md | AleksanderGladkov/dynamics365smb-docs | f061beeb61260d6b78df86334a7a8c50be2bb8d4 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Print Deposit Slip Reports in the Australian version
description: The Deposit Slip report displays cash and check details in a format required by the bank in the Australian version.
author: SorenGP
ms.service: dynamics365-business-central
ms.topic: article
ms.devlang: na
ms.tgt_pltfrm: na
ms.workload: na
ms.search.keywords:
ms.date: 10/01/2020
ms.author: edupont
---
# Print Deposit Slip Reports in the Australian Version
[!INCLUDE [print-deposit-slip-reports](../includes/AUNZ/print-deposit-slip-reports.md)]
## See Also
[Australia Local Functionality](australia-local-functionality.md)
| 28.26087 | 132 | 0.730769 | eng_Latn | 0.747783 |
9901a88b6601ee91d285443c023785895a26b2ee | 2,659 | md | Markdown | api/Outlook.AppointmentItem.EndTimeZone.md | MarkWithC/VBA-Docs | a43a38a843c95cbe8beed2a15218a5aeca4df8fb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | api/Outlook.AppointmentItem.EndTimeZone.md | MarkWithC/VBA-Docs | a43a38a843c95cbe8beed2a15218a5aeca4df8fb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | api/Outlook.AppointmentItem.EndTimeZone.md | MarkWithC/VBA-Docs | a43a38a843c95cbe8beed2a15218a5aeca4df8fb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: AppointmentItem.EndTimeZone property (Outlook)
keywords: vbaol11.chm3276
f1_keywords:
- vbaol11.chm3276
ms.prod: outlook
api_name:
- Outlook.AppointmentItem.EndTimeZone
ms.assetid: 8f33d93f-c0fe-fda1-608d-dec7fb86c732
ms.date: 06/08/2017
ms.localizationpriority: medium
---
# AppointmentItem.EndTimeZone property (Outlook)
Returns or sets a **[TimeZone](Outlook.TimeZone.md)** value that corresponds to the end time of the appointment. Read/write.
## Syntax
_expression_. `EndTimeZone`
_expression_ A variable that represents an [AppointmentItem](Outlook.AppointmentItem.md) object.
## Remarks
The time zone information is used to map the appointment to the correct UTC time when the appointment is saved, and into the correct local time when the item is displayed in the calendar.
Changing **EndTimeZone** affects the value of **[AppointmentItem.End](Outlook.AppointmentItem.End.md)** which is always represented in the local time zone, **[Application.TimeZones.CurrentTimeZone](Outlook.TimeZones.CurrentTimeZone.md)**.
Depending on the circumstances, changing the **EndTimeZone** may or may not cause Outlook to recalculate and update the **[AppointmentItem.EndInEndTimeZone](Outlook.AppointmentItem.EndInEndTimeZone.md)**.
As an example, in the appointment inspector, if you are the organizer of an appointment with a start time at 1 P.M. EST and end time at 3 P.M. EST, changing the appointment to have an **EndTimeZone** of PST will result in an appointment lasting from 1 P.M. EST to 3 P.M. PST, with the **EndInEndTimeZone** remaining as 3 P.M. However, if you are not the organizer, then changing the **EndTimeZone** from EST to PST will cause Outlook to recalculate and update the **EndInEndTimeZone**, and the appointment will last from 1 P.M. EST to 12 P.M. PST.
Another example is changing the **EndTimeZone** resulting in an appointment end time that occurs before a previously set appointment start time, in which case Outlook will recalculate and update the **EndInEndTimeZone**. For example, an appointment with a start time at 1 P.M. PST and end time at 3 P.M. PST has its **EndTimeZone** changed to EST. If Outlook did not recalculate the **EndInEndTimeZone**, the appointment would have an end time at 3 P.M. EST, which is equivalent to 12 P.M. PST, and which would occur before the start time of 1 P.M. PST. In practice, however, changing the **EndTimeZone** would result in Outlook recalculating and updating the **EndInEndTimeZone** to 6 P.M. (in the **EndTimeZone** EST).
## See also
[AppointmentItem Object](Outlook.AppointmentItem.md)
[!include[Support and feedback](~/includes/feedback-boilerplate.md)] | 59.088889 | 720 | 0.777736 | eng_Latn | 0.981115 |
990204f45f2b73e9ce6a092d6206068f65cc1982 | 20 | md | Markdown | README.md | rgborges/rgborges.github.io | 858fe6f066d1ff37571750653254481bddb66cd2 | [
"MIT"
] | null | null | null | README.md | rgborges/rgborges.github.io | 858fe6f066d1ff37571750653254481bddb66cd2 | [
"MIT"
] | null | null | null | README.md | rgborges/rgborges.github.io | 858fe6f066d1ff37571750653254481bddb66cd2 | [
"MIT"
] | null | null | null | # rgborges.github.io | 20 | 20 | 0.8 | nob_Latn | 0.458772 |
9903b0b3d7b12b624d4e7805c67322de4bcb5af8 | 148 | md | Markdown | _posts/2018-04-29-faith-acts.md | sermons/sermons.github.io | 037e28d217479aa79cb54c8d5d49757cfa04fd0e | [
"MIT"
] | 2 | 2018-08-04T11:02:36.000Z | 2020-10-06T07:52:14.000Z | _posts/2018-04-29-faith-acts.md | sermons/sermons.github.io | 037e28d217479aa79cb54c8d5d49757cfa04fd0e | [
"MIT"
] | 9 | 2016-08-26T07:14:58.000Z | 2020-04-19T22:41:45.000Z | _posts/2018-04-29-faith-acts.md | sermons/sermons.github.io | 037e28d217479aa79cb54c8d5d49757cfa04fd0e | [
"MIT"
] | 1 | 2018-08-04T11:02:39.000Z | 2018-08-04T11:02:39.000Z | ---
layout: post
title: "Faith that Acts (4/10)"
subtitle: "James 2:17-24"
tags: james keep-the-faith fec
---
Fujian Evangelical Church (Richmond)
| 16.444444 | 36 | 0.702703 | eng_Latn | 0.839851 |
9903ea833c476204a59d8d246cdf553e7a0332db | 392 | md | Markdown | reports/Vermont.md | Inclushe/police-brutality | 8da3f06cf1f763473d15198afa00cdde97099928 | [
"MIT"
] | 1 | 2020-07-08T14:24:24.000Z | 2020-07-08T14:24:24.000Z | reports/Vermont.md | php1301/police-brutality | 37070468bab194124ef9f210cc97af81ddd3d14c | [
"MIT"
] | null | null | null | reports/Vermont.md | php1301/police-brutality | 37070468bab194124ef9f210cc97af81ddd3d14c | [
"MIT"
] | null | null | null | ## St. Johnsbury
### Police shove a protesting woman down a set of concrete steps. | June 3rd
Police shove a protesting woman down a set of concrete steps.
tags: shove, arrest, push
id: vt-stjohnsbury-1
**Links**
* https://www.facebook.com/story.php?story_fbid=3011143412313088&id=100002523772680
* https://vtdigger.org/2020/06/03/police-arrest-4-at-st-johnsbury-george-floyd-protest/
| 24.5 | 87 | 0.755102 | eng_Latn | 0.342775 |
9904ba9b021249c4ac32a34589cfdba42ffcfd6a | 3,458 | md | Markdown | treebanks/kpv_lattice/kpv_lattice-feat-Degree.md | vistamou/docs | 116b9c29e4218be06bf33b158284b9c952646989 | [
"Apache-2.0"
] | 204 | 2015-01-20T16:36:39.000Z | 2022-03-28T00:49:51.000Z | treebanks/kpv_lattice/kpv_lattice-feat-Degree.md | vistamou/docs | 116b9c29e4218be06bf33b158284b9c952646989 | [
"Apache-2.0"
] | 654 | 2015-01-02T17:06:29.000Z | 2022-03-31T18:23:34.000Z | treebanks/kpv_lattice/kpv_lattice-feat-Degree.md | vistamou/docs | 116b9c29e4218be06bf33b158284b9c952646989 | [
"Apache-2.0"
] | 200 | 2015-01-16T22:07:02.000Z | 2022-03-25T11:35:28.000Z | ---
layout: base
title: 'Statistics of Degree in UD_Komi_Zyrian-Lattice'
udver: '2'
---
## Treebank Statistics: UD_Komi_Zyrian-Lattice: Features: `Degree`
This feature is universal.
It occurs with 2 different values: `Cmp`, `Sup`.
40 tokens (0%) have a non-empty value of `Degree`.
34 types (1%) occur at least once with a non-empty value of `Degree`.
33 lemmas (1%) occur at least once with a non-empty value of `Degree`.
The feature is used with 3 part-of-speech tags: <tt><a href="kpv_lattice-pos-ADV.html">ADV</a></tt> (20; 0% instances), <tt><a href="kpv_lattice-pos-ADJ.html">ADJ</a></tt> (17; 0% instances), <tt><a href="kpv_lattice-pos-NOUN.html">NOUN</a></tt> (3; 0% instances).
### `ADV`
20 <tt><a href="kpv_lattice-pos-ADV.html">ADV</a></tt> tokens (2% of all `ADV` tokens) have a non-empty value of `Degree`.
The most frequent other feature values with which `ADV` and `Degree` co-occurred: <tt><a href="kpv_lattice-feat-AdvType.html">AdvType</a></tt><tt>=EMPTY</tt> (19; 95%), <tt><a href="kpv_lattice-feat-Case.html">Case</a></tt><tt>=EMPTY</tt> (14; 70%).
`ADV` tokens may have the following values of `Degree`:
* `Cmp` (16; 80% of non-empty `Degree`): <em>ӧдйӧджык, Меліджыка, Тэрыбджыка, бокынджык, бурджыка, водзджык, дырджык, кокниджыка, надзӧнджык, унджык</em>
* `Sup` (4; 20% of non-empty `Degree`): <em>Медбӧрын, медъёна, Медводдзаысьсӧ</em>
* `EMPTY` (854): <em>нин, жӧ, на, и, сӧмын, сэсся, зэв, кыдзи, пыр, бара</em>
<table>
<tr><th>Paradigm <i>ёна</i></th><th><tt>Cmp</tt></th><th><tt>Sup</tt></th></tr>
<tr><td><tt>_</tt></td><td></td><td><em>медъёна</em></td></tr>
<tr><td><tt><tt><a href="kpv_lattice-feat-Clitic.html">Clitic</a></tt><tt>=So</tt></tt></td><td><em>ёнджыкасӧ</em></td><td></td></tr>
</table>
`Degree` seems to be **lexical feature** of `ADV`. 94% lemmas (15) occur only with one value of `Degree`.
### `ADJ`
17 <tt><a href="kpv_lattice-pos-ADJ.html">ADJ</a></tt> tokens (3% of all `ADJ` tokens) have a non-empty value of `Degree`.
The most frequent other feature values with which `ADJ` and `Degree` co-occurred: <tt><a href="kpv_lattice-feat-Number.html">Number</a></tt><tt>=Sing</tt> (12; 71%), <tt><a href="kpv_lattice-feat-Case.html">Case</a></tt><tt>=Nom</tt> (11; 65%).
`ADJ` tokens may have the following values of `Degree`:
* `Cmp` (13; 76% of non-empty `Degree`): <em>бурджык, зумышджыкӧсь, ичӧтджык, косджыкъяссӧ, лёкджык, озырджыкӧн, олӧмаджык, отаджыкӧсь, паськыдджыкӧсь, томджыкъясӧс</em>
* `Sup` (4; 24% of non-empty `Degree`): <em>медводдза, меддор, медъён</em>
* `EMPTY` (472): <em>ыджыд, кодь, бур, важ, мича, еджыд, ичӧтик, сэтшӧм, том, выль</em>
`Degree` seems to be **lexical feature** of `ADJ`. 100% lemmas (14) occur only with one value of `Degree`.
### `NOUN`
3 <tt><a href="kpv_lattice-pos-NOUN.html">NOUN</a></tt> tokens (0% of all `NOUN` tokens) have a non-empty value of `Degree`.
The most frequent other feature values with which `NOUN` and `Degree` co-occurred: <tt><a href="kpv_lattice-feat-Number-psor.html">Number[psor]</a></tt><tt>=EMPTY</tt> (3; 100%), <tt><a href="kpv_lattice-feat-Person-psor.html">Person[psor]</a></tt><tt>=EMPTY</tt> (3; 100%), <tt><a href="kpv_lattice-feat-Number.html">Number</a></tt><tt>=Sing</tt> (2; 67%).
`NOUN` tokens may have the following values of `Degree`:
* `Cmp` (3; 100% of non-empty `Degree`): <em>вылӧджык, мастерджыкыс, ыліджыкъясті</em>
* `EMPTY` (2035): <em>урожай, удж, шонді, ва, лун, вӧр, ю, во, му, пу</em>
| 55.774194 | 357 | 0.665703 | yue_Hant | 0.366758 |
99054bc0db6b3638dba20e4e5fb04415865ceb6f | 34,582 | md | Markdown | docs/framework/wcf/feature-details/how-to-implement-a-discovery-proxy.md | emrekas/docs.tr-tr | 027bd2c6c93900a75cac7ac42531c89085f87888 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/how-to-implement-a-discovery-proxy.md | emrekas/docs.tr-tr | 027bd2c6c93900a75cac7ac42531c89085f87888 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/how-to-implement-a-discovery-proxy.md | emrekas/docs.tr-tr | 027bd2c6c93900a75cac7ac42531c89085f87888 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: "Nasıl yapılır: Keşif Proxy'si Uygulama"
ms.date: 03/30/2017
ms.assetid: 78d70e0a-f6c3-4cfb-a7ca-f66ebddadde0
ms.openlocfilehash: 350baa6047d11a2d262e4a6c1d54cc874939ed9d
ms.sourcegitcommit: 581ab03291e91983459e56e40ea8d97b5189227e
ms.translationtype: MT
ms.contentlocale: tr-TR
ms.lasthandoff: 08/27/2019
ms.locfileid: "70045920"
---
# <a name="how-to-implement-a-discovery-proxy"></a>Nasıl yapılır: Keşif Proxy'si Uygulama
Bu konuda, bulma proxy 'nin nasıl uygulanacağı açıklanmaktadır. Windows Communication Foundation (WCF) içindeki bulma özelliği hakkında daha fazla bilgi için bkz. [WCF bulma 'Ya genel bakış](../../../../docs/framework/wcf/feature-details/wcf-discovery-overview.md). Bir bulma proxy 'si, <xref:System.ServiceModel.Discovery.DiscoveryProxy> soyut sınıfı genişleten bir sınıf oluşturularak uygulanabilir. Bu örnekte tanımlanmış ve kullanılan çeşitli destek sınıfları vardır. `OnResolveAsyncResult`, `OnFindAsyncResult`ve .`AsyncResult` Bu sınıflar, <xref:System.IAsyncResult> arabirimini uygular. Daha fazla bilgi <xref:System.IAsyncResult> için bkz. [System. IAsyncResult arabirimi](xref:System.IAsyncResult).
Keşif proxy 'si uygulamak, bu konunun üç ana bölümüne bölünür:
- Bir veri deposu içeren ve soyut <xref:System.ServiceModel.Discovery.DiscoveryProxy> sınıfı genişleten bir sınıf tanımlayın.
- Yardımcı `AsyncResult` sınıfını uygulayın.
- Bulma proxy 'sini barındırın.
### <a name="to-create-a-new-console-application-project"></a>Yeni bir konsol uygulaması projesi oluşturmak için
1. Visual Studio 2012 ' i başlatın.
2. Yeni bir konsol uygulaması projesi oluşturun. Projeyi `DiscoveryProxy` ve çözümü `DiscoveryProxyExample`adlandırın.
3. Aşağıdaki başvuruları projeye ekleyin
1. System.ServiceModel.dll
2. System. ServiceModel. Discovery. dll
> [!CAUTION]
> Sürüm 4,0 veya bu derlemelerin daha büyük bir sürümüne başvurtığınızdan emin olun.
### <a name="to-implement-the-proxydiscoveryservice-class"></a>ProxyDiscoveryService sınıfını uygulamak için
1. Projenize yeni bir kod dosyası ekleyin ve DiscoveryProxy.cs olarak adlandırın.
2. Aşağıdaki `using` deyimlerini DiscoveryProxy.cs öğesine ekleyin.
```csharp
using System;
using System.Collections.Generic;
using System.ServiceModel;
using System.ServiceModel.Discovery;
using System.Xml;
```
3. `DiscoveryProxyService` Öğesinden<xref:System.ServiceModel.Discovery.DiscoveryProxy>türet. Aşağıdaki örnekte gösterildiği gibi özniteliğinisınıfınauygulayın.`ServiceBehavior`
```csharp
// Implement DiscoveryProxy by extending the DiscoveryProxy class and overriding the abstract methods
[ServiceBehavior(InstanceContextMode = InstanceContextMode.Single, ConcurrencyMode = ConcurrencyMode.Multiple)]
public class DiscoveryProxyService : DiscoveryProxy
{
}
```
4. `DiscoveryProxy` Sınıfının içinde kayıtlı Hizmetleri tutacak bir sözlük tanımlayın.
```csharp
// Repository to store EndpointDiscoveryMetadata.
Dictionary<EndpointAddress, EndpointDiscoveryMetadata> onlineServices;
```
5. Sözlüğü Başlatan bir Oluşturucu tanımlayın.
```csharp
public DiscoveryProxyService()
{
this.onlineServices = new Dictionary<EndpointAddress, EndpointDiscoveryMetadata>();
}
```
### <a name="to-define-the-methods-used-to-update-the-discovery-proxy-cache"></a>Bulma proxy önbelleğini güncelleştirmek için kullanılan yöntemleri tanımlamak için
1. Önbelleğe hizmet eklemek için yönteminiuygulayın.`AddOnlineservice` Bu, proxy 'nin bir duyuru iletisi aldığı her seferinde çağrılır.
```csharp
void AddOnlineService(EndpointDiscoveryMetadata endpointDiscoveryMetadata)
{
lock (this.onlineServices)
{
this.onlineServices[endpointDiscoveryMetadata.Address] = endpointDiscoveryMetadata;
}
PrintDiscoveryMetadata(endpointDiscoveryMetadata, "Adding");
}
```
2. Önbellekten Hizmetleri kaldırmak için kullanılan yöntemiuygulayın.`RemoveOnlineService`
```csharp
void RemoveOnlineService(EndpointDiscoveryMetadata endpointDiscoveryMetadata)
{
if (endpointDiscoveryMetadata != null)
{
lock (this.onlineServices)
{
this.onlineServices.Remove(endpointDiscoveryMetadata.Address);
}
PrintDiscoveryMetadata(endpointDiscoveryMetadata, "Removing");
}
}
```
3. Sözlük içindeki bir hizmetle eşleşen bir hizmeti eşleştirmeye çalışacak yöntemleriuygulayın.`MatchFromOnlineService`
```csharp
void MatchFromOnlineService(FindRequestContext findRequestContext)
{
lock (this.onlineServices)
{
foreach (EndpointDiscoveryMetadata endpointDiscoveryMetadata in this.onlineServices.Values)
{
if (findRequestContext.Criteria.IsMatch(endpointDiscoveryMetadata))
{
findRequestContext.AddMatchingEndpoint(endpointDiscoveryMetadata);
}
}
}
}
```
```csharp
EndpointDiscoveryMetadata MatchFromOnlineService(ResolveCriteria criteria)
{
EndpointDiscoveryMetadata matchingEndpoint = null;
lock (this.onlineServices)
{
foreach (EndpointDiscoveryMetadata endpointDiscoveryMetadata in this.onlineServices.Values)
{
if (criteria.Address == endpointDiscoveryMetadata.Address)
{
matchingEndpoint = endpointDiscoveryMetadata;
}
}
}
return matchingEndpoint;
}
```
4. Kullanıcıya bulma proxy 'sinin yaptığı işlemin konsol metni çıkışını sağlayan yönteminiuygulayın.`PrintDiscoveryMetadata`
```csharp
void PrintDiscoveryMetadata(EndpointDiscoveryMetadata endpointDiscoveryMetadata, string verb)
{
Console.WriteLine("\n**** " + verb + " service of the following type from cache. ");
foreach (XmlQualifiedName contractName in endpointDiscoveryMetadata.ContractTypeNames)
{
Console.WriteLine("** " + contractName.ToString());
break;
}
Console.WriteLine("**** Operation Completed");
}
```
5. Aşağıdaki AsyncResult sınıflarını DiscoveryProxyService öğesine ekleyin. Bu sınıflar, farklı zaman uyumsuz işlem sonuçları arasında ayrım yapmak için kullanılır.
```csharp
sealed class OnOnlineAnnouncementAsyncResult : AsyncResult
{
public OnOnlineAnnouncementAsyncResult(AsyncCallback callback, object state)
: base(callback, state)
{
this.Complete(true);
}
public static void End(IAsyncResult result)
{
AsyncResult.End<OnOnlineAnnouncementAsyncResult>(result);
}
}
sealed class OnOfflineAnnouncementAsyncResult : AsyncResult
{
public OnOfflineAnnouncementAsyncResult(AsyncCallback callback, object state)
: base(callback, state)
{
this.Complete(true);
}
public static void End(IAsyncResult result)
{
AsyncResult.End<OnOfflineAnnouncementAsyncResult>(result);
}
}
sealed class OnFindAsyncResult : AsyncResult
{
public OnFindAsyncResult(AsyncCallback callback, object state)
: base(callback, state)
{
this.Complete(true);
}
public static void End(IAsyncResult result)
{
AsyncResult.End<OnFindAsyncResult>(result);
}
}
sealed class OnResolveAsyncResult : AsyncResult
{
EndpointDiscoveryMetadata matchingEndpoint;
public OnResolveAsyncResult(EndpointDiscoveryMetadata matchingEndpoint, AsyncCallback callback, object state)
: base(callback, state)
{
this.matchingEndpoint = matchingEndpoint;
this.Complete(true);
}
public static EndpointDiscoveryMetadata End(IAsyncResult result)
{
OnResolveAsyncResult thisPtr = AsyncResult.End<OnResolveAsyncResult>(result);
return thisPtr.matchingEndpoint;
}
}
```
### <a name="to-define-the-methods-that-implement-the-discovery-proxy-functionality"></a>Bulma proxy işlevlerini uygulayan yöntemleri tanımlamak için
1. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnBeginOnlineAnnouncement%2A?displayProperty=nameWithType> yöntemi. Keşif proxy 'si bir çevrimiçi duyuru iletisi aldığında bu yöntem çağrılır.
```csharp
// OnBeginOnlineAnnouncement method is called when a Hello message is received by the Proxy
protected override IAsyncResult OnBeginOnlineAnnouncement(DiscoveryMessageSequence messageSequence, EndpointDiscoveryMetadata endpointDiscoveryMetadata, AsyncCallback callback, object state)
{
this.AddOnlineService(endpointDiscoveryMetadata);
return new OnOnlineAnnouncementAsyncResult(callback, state);
}
```
2. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnEndOnlineAnnouncement%2A?displayProperty=nameWithType> yöntemi. Keşif proxy 'si bir duyuru iletisini işlemeyi bitirdiğinde, bu yöntem çağrılır.
```csharp
protected override void OnEndOnlineAnnouncement(IAsyncResult result)
{
OnOnlineAnnouncementAsyncResult.End(result);
}
```
3. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnBeginOfflineAnnouncement%2A?displayProperty=nameWithType> yöntemi. Bu yöntem, bulma proxy 'si ile birlikte çağrıldığında bir çevrimdışı duyuru iletisi alır.
```csharp
// OnBeginOfflineAnnouncement method is called when a Bye message is received by the Proxy
protected override IAsyncResult OnBeginOfflineAnnouncement(DiscoveryMessageSequence messageSequence, EndpointDiscoveryMetadata endpointDiscoveryMetadata, AsyncCallback callback, object state)
{
this.RemoveOnlineService(endpointDiscoveryMetadata);
return new OnOfflineAnnouncementAsyncResult(callback, state);
}
```
4. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnEndOfflineAnnouncement%2A?displayProperty=nameWithType> yöntemi. Bu yöntem, bulma proxy 'si bir çevrimdışı duyuru iletisini işlemeyi bitirdiğinde çağrılır.
```csharp
protected override void OnEndOfflineAnnouncement(IAsyncResult result)
{
OnOfflineAnnouncementAsyncResult.End(result);
}
```
5. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnBeginFind%2A?displayProperty=nameWithType> yöntemi. Bulma proxy 'si bir bulma isteği aldığında bu yöntem çağrılır.
```csharp
// OnBeginFind method is called when a Probe request message is received by the Proxy
protected override IAsyncResult OnBeginFind(FindRequestContext findRequestContext, AsyncCallback callback, object state)
{
this.MatchFromOnlineService(findRequestContext);
return new OnFindAsyncResult(callback, state);
}
protected override IAsyncResult OnBeginFind(FindRequest findRequest, AsyncCallback callback, object state)
{
Collection<EndpointDiscoveryMetadata> matchingEndpoints = MatchFromCache(findRequest.Criteria);
return new OnFindAsyncResult(
matchingEndpoints,
callback,
state);
}
```
6. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnEndFind%2A?displayProperty=nameWithType> yöntemi. Bulma proxy 'si bir bul isteğini işlemeyi bitirdiğinde, bu yöntem çağrılır.
```csharp
protected override void OnEndFind(IAsyncResult result)
{
OnFindAsyncResult.End(result);
}
```
7. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnBeginResolve%2A?displayProperty=nameWithType> yöntemi. Keşif proxy 'si bir çözüm iletisi aldığında bu yöntem çağrılır.
```csharp
// OnBeginFind method is called when a Resolve request message is received by the Proxy
protected override IAsyncResult OnBeginResolve(ResolveCriteria resolveCriteria, AsyncCallback callback, object state)
{
return new OnResolveAsyncResult(this.MatchFromOnlineService(resolveCriteria), callback, state);
}
protected override IAsyncResult OnBeginResolve(ResolveRequest resolveRequest, AsyncCallback callback, object state)
{
return new OnResolveAsyncResult(
this.proxy.MatchFromOnlineService(resolveRequest.Criteria),
callback,
state);
}
```
8. Geçersiz kılma <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnEndResolve%2A?displayProperty=nameWithType> yöntemi. Bu yöntem, bulma proxy 'sinin bir Resolve iletisini işlemeyi bitirdiğinde çağrılır.
```csharp
protected override EndpointDiscoveryMetadata OnEndResolve(IAsyncResult result)
{
return OnResolveAsyncResult.End(result);
}
```
Onbegın.. /OnEnd.. Yöntemler, sonraki bulma işlemlerine yönelik mantığı sağlar. Örneğin, <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnBeginFind%2A> ve <xref:System.ServiceModel.Discovery.DiscoveryProxy.OnEndFind%2A> yöntemleri bulma proxy 'si için Find mantığını uygular. Bulma proxy 'si bir araştırma iletisi aldığında, istemciye yanıt göndermek için bu yöntemler yürütülür. Find mantığını istediğiniz gibi değiştirebilirsiniz. Örneğin, bul işleminin bir parçası olarak algoritmalara veya uygulamaya özgü XML meta verileri ayrıştırmaya göre özel kapsam eşleştirmeyi birleştirebilirsiniz.
### <a name="to-implement-the-asyncresult-class"></a>AsyncResult sınıfını uygulamak için
1. Çeşitli zaman uyumsuz sonuç sınıflarını türetmek için kullanılan soyut temel sınıf AsyncResult öğesini tanımlayın.
2. AsyncResult.cs adlı yeni bir kod dosyası oluşturun.
3. Aşağıdaki `using` deyimlerini AsyncResult.cs öğesine ekleyin.
```csharp
using System;
using System.Threading;
```
4. Aşağıdaki AsyncResult sınıfını ekleyin.
```csharp
abstract class AsyncResult : IAsyncResult
{
AsyncCallback callback;
bool completedSynchronously;
bool endCalled;
Exception exception;
bool isCompleted;
ManualResetEvent manualResetEvent;
object state;
object thisLock;
protected AsyncResult(AsyncCallback callback, object state)
{
this.callback = callback;
this.state = state;
this.thisLock = new object();
}
public object AsyncState
{
get
{
return state;
}
}
public WaitHandle AsyncWaitHandle
{
get
{
if (manualResetEvent != null)
{
return manualResetEvent;
}
lock (ThisLock)
{
if (manualResetEvent == null)
{
manualResetEvent = new ManualResetEvent(isCompleted);
}
}
return manualResetEvent;
}
}
public bool CompletedSynchronously
{
get
{
return completedSynchronously;
}
}
public bool IsCompleted
{
get
{
return isCompleted;
}
}
object ThisLock
{
get
{
return this.thisLock;
}
}
protected static TAsyncResult End<TAsyncResult>(IAsyncResult result)
where TAsyncResult : AsyncResult
{
if (result == null)
{
throw new ArgumentNullException("result");
}
TAsyncResult asyncResult = result as TAsyncResult;
if (asyncResult == null)
{
throw new ArgumentException("Invalid async result.", "result");
}
if (asyncResult.endCalled)
{
throw new InvalidOperationException("Async object already ended.");
}
asyncResult.endCalled = true;
if (!asyncResult.isCompleted)
{
asyncResult.AsyncWaitHandle.WaitOne();
}
if (asyncResult.manualResetEvent != null)
{
asyncResult.manualResetEvent.Close();
}
if (asyncResult.exception != null)
{
throw asyncResult.exception;
}
return asyncResult;
}
protected void Complete(bool completedSynchronously)
{
if (isCompleted)
{
throw new InvalidOperationException("This async result is already completed.");
}
this.completedSynchronously = completedSynchronously;
if (completedSynchronously)
{
this.isCompleted = true;
}
else
{
lock (ThisLock)
{
this.isCompleted = true;
if (this.manualResetEvent != null)
{
this.manualResetEvent.Set();
}
}
}
if (callback != null)
{
callback(this);
}
}
protected void Complete(bool completedSynchronously, Exception exception)
{
this.exception = exception;
Complete(completedSynchronously);
}
}
```
### <a name="to-host-the-discoveryproxy"></a>DiscoveryProxy 'yi barındırmak için
1. Program.cs dosyasını DiscoveryProxyExample projesinde açın.
2. Aşağıdaki `using` deyimleri ekleyin.
```csharp
using System;
using System.ServiceModel;
using System.ServiceModel.Discovery;
```
3. `Main()` Yöntemi içinde aşağıdaki kodu ekleyin. Bu, `DiscoveryProxy` sınıfının bir örneğini oluşturur.
```csharp
Uri probeEndpointAddress = new Uri("net.tcp://localhost:8001/Probe");
Uri announcementEndpointAddress = new Uri("net.tcp://localhost:9021/Announcement");
// Host the DiscoveryProxy service
ServiceHost proxyServiceHost = new ServiceHost(new DiscoveryProxyService());
```
4. Sonra bulma uç noktası ve duyuru uç noktası eklemek için aşağıdaki kodu ekleyin.
```csharp
try
{
// Add DiscoveryEndpoint to receive Probe and Resolve messages
DiscoveryEndpoint discoveryEndpoint = new DiscoveryEndpoint(new NetTcpBinding(), new EndpointAddress(probeEndpointAddress));
discoveryEndpoint.IsSystemEndpoint = false;
// Add AnnouncementEndpoint to receive Hello and Bye announcement messages
AnnouncementEndpoint announcementEndpoint = new AnnouncementEndpoint(new NetTcpBinding(), new EndpointAddress(announcementEndpointAddress));
proxyServiceHost.AddServiceEndpoint(discoveryEndpoint);
proxyServiceHost.AddServiceEndpoint(announcementEndpoint);
proxyServiceHost.Open();
Console.WriteLine("Proxy Service started.");
Console.WriteLine();
Console.WriteLine("Press <ENTER> to terminate the service.");
Console.WriteLine();
Console.ReadLine();
proxyServiceHost.Close();
}
catch (CommunicationException e)
{
Console.WriteLine(e.Message);
}
catch (TimeoutException e)
{
Console.WriteLine(e.Message);
}
if (proxyServiceHost.State != CommunicationState.Closed)
{
Console.WriteLine("Aborting the service...");
proxyServiceHost.Abort();
}
```
Bulma proxy 'sini uygulamayı tamamladınız. [Şu şekilde devam edin: Bulma proxy 'Sine](../../../../docs/framework/wcf/feature-details/discoverable-service-that-registers-with-the-discovery-proxy.md)kaydolduktan sonra bulunabilir bir hizmet uygulayın.
## <a name="example"></a>Örnek
Bu, bu konuda kullanılan kodun tam listesidir.
```csharp
// DiscoveryProxy.cs
//----------------------------------------------------------------
// Copyright (c) Microsoft Corporation. All rights reserved.
//----------------------------------------------------------------
using System;
using System.Collections.Generic;
using System.ServiceModel;
using System.ServiceModel.Discovery;
using System.Xml;
namespace Microsoft.Samples.Discovery
{
// Implement DiscoveryProxy by extending the DiscoveryProxy class and overriding the abstract methods
[ServiceBehavior(InstanceContextMode = InstanceContextMode.Single, ConcurrencyMode = ConcurrencyMode.Multiple)]
public class DiscoveryProxyService : DiscoveryProxy
{
// Repository to store EndpointDiscoveryMetadata. A database or a flat file could also be used instead.
Dictionary<EndpointAddress, EndpointDiscoveryMetadata> onlineServices;
public DiscoveryProxyService()
{
this.onlineServices = new Dictionary<EndpointAddress, EndpointDiscoveryMetadata>();
}
// OnBeginOnlineAnnouncement method is called when a Hello message is received by the Proxy
protected override IAsyncResult OnBeginOnlineAnnouncement(DiscoveryMessageSequence messageSequence, EndpointDiscoveryMetadata endpointDiscoveryMetadata, AsyncCallback callback, object state)
{
this.AddOnlineService(endpointDiscoveryMetadata);
return new OnOnlineAnnouncementAsyncResult(callback, state);
}
protected override void OnEndOnlineAnnouncement(IAsyncResult result)
{
OnOnlineAnnouncementAsyncResult.End(result);
}
// OnBeginOfflineAnnouncement method is called when a Bye message is received by the Proxy
protected override IAsyncResult OnBeginOfflineAnnouncement(DiscoveryMessageSequence messageSequence, EndpointDiscoveryMetadata endpointDiscoveryMetadata, AsyncCallback callback, object state)
{
this.RemoveOnlineService(endpointDiscoveryMetadata);
return new OnOfflineAnnouncementAsyncResult(callback, state);
}
protected override void OnEndOfflineAnnouncement(IAsyncResult result)
{
OnOfflineAnnouncementAsyncResult.End(result);
}
// OnBeginFind method is called when a Probe request message is received by the Proxy
protected override IAsyncResult OnBeginFind(FindRequestContext findRequestContext, AsyncCallback callback, object state)
{
this.MatchFromOnlineService(findRequestContext);
return new OnFindAsyncResult(callback, state);
}
protected override void OnEndFind(IAsyncResult result)
{
OnFindAsyncResult.End(result);
}
// OnBeginFind method is called when a Resolve request message is received by the Proxy
protected override IAsyncResult OnBeginResolve(ResolveCriteria resolveCriteria, AsyncCallback callback, object state)
{
return new OnResolveAsyncResult(this.MatchFromOnlineService(resolveCriteria), callback, state);
}
protected override EndpointDiscoveryMetadata OnEndResolve(IAsyncResult result)
{
return OnResolveAsyncResult.End(result);
}
// The following are helper methods required by the Proxy implementation
void AddOnlineService(EndpointDiscoveryMetadata endpointDiscoveryMetadata)
{
lock (this.onlineServices)
{
this.onlineServices[endpointDiscoveryMetadata.Address] = endpointDiscoveryMetadata;
}
PrintDiscoveryMetadata(endpointDiscoveryMetadata, "Adding");
}
void RemoveOnlineService(EndpointDiscoveryMetadata endpointDiscoveryMetadata)
{
if (endpointDiscoveryMetadata != null)
{
lock (this.onlineServices)
{
this.onlineServices.Remove(endpointDiscoveryMetadata.Address);
}
PrintDiscoveryMetadata(endpointDiscoveryMetadata, "Removing");
}
}
void MatchFromOnlineService(FindRequestContext findRequestContext)
{
lock (this.onlineServices)
{
foreach (EndpointDiscoveryMetadata endpointDiscoveryMetadata in this.onlineServices.Values)
{
if (findRequestContext.Criteria.IsMatch(endpointDiscoveryMetadata))
{
findRequestContext.AddMatchingEndpoint(endpointDiscoveryMetadata);
}
}
}
}
EndpointDiscoveryMetadata MatchFromOnlineService(ResolveCriteria criteria)
{
EndpointDiscoveryMetadata matchingEndpoint = null;
lock (this.onlineServices)
{
foreach (EndpointDiscoveryMetadata endpointDiscoveryMetadata in this.onlineServices.Values)
{
if (criteria.Address == endpointDiscoveryMetadata.Address)
{
matchingEndpoint = endpointDiscoveryMetadata;
}
}
}
return matchingEndpoint;
}
void PrintDiscoveryMetadata(EndpointDiscoveryMetadata endpointDiscoveryMetadata, string verb)
{
Console.WriteLine("\n**** " + verb + " service of the following type from cache. ");
foreach (XmlQualifiedName contractName in endpointDiscoveryMetadata.ContractTypeNames)
{
Console.WriteLine("** " + contractName.ToString());
break;
}
Console.WriteLine("**** Operation Completed");
}
sealed class OnOnlineAnnouncementAsyncResult : AsyncResult
{
public OnOnlineAnnouncementAsyncResult(AsyncCallback callback, object state)
: base(callback, state)
{
this.Complete(true);
}
public static void End(IAsyncResult result)
{
AsyncResult.End<OnOnlineAnnouncementAsyncResult>(result);
}
}
sealed class OnOfflineAnnouncementAsyncResult : AsyncResult
{
public OnOfflineAnnouncementAsyncResult(AsyncCallback callback, object state)
: base(callback, state)
{
this.Complete(true);
}
public static void End(IAsyncResult result)
{
AsyncResult.End<OnOfflineAnnouncementAsyncResult>(result);
}
}
sealed class OnFindAsyncResult : AsyncResult
{
public OnFindAsyncResult(AsyncCallback callback, object state)
: base(callback, state)
{
this.Complete(true);
}
public static void End(IAsyncResult result)
{
AsyncResult.End<OnFindAsyncResult>(result);
}
}
sealed class OnResolveAsyncResult : AsyncResult
{
EndpointDiscoveryMetadata matchingEndpoint;
public OnResolveAsyncResult(EndpointDiscoveryMetadata matchingEndpoint, AsyncCallback callback, object state)
: base(callback, state)
{
this.matchingEndpoint = matchingEndpoint;
this.Complete(true);
}
public static EndpointDiscoveryMetadata End(IAsyncResult result)
{
OnResolveAsyncResult thisPtr = AsyncResult.End<OnResolveAsyncResult>(result);
return thisPtr.matchingEndpoint;
}
}
}
}
```
```csharp
// AsyncResult.cs
//----------------------------------------------------------------
// Copyright (c) Microsoft Corporation. All rights reserved.
//----------------------------------------------------------------
using System;
using System.Threading;
namespace Microsoft.Samples.Discovery
{
abstract class AsyncResult : IAsyncResult
{
AsyncCallback callback;
bool completedSynchronously;
bool endCalled;
Exception exception;
bool isCompleted;
ManualResetEvent manualResetEvent;
object state;
object thisLock;
protected AsyncResult(AsyncCallback callback, object state)
{
this.callback = callback;
this.state = state;
this.thisLock = new object();
}
public object AsyncState
{
get
{
return state;
}
}
public WaitHandle AsyncWaitHandle
{
get
{
if (manualResetEvent != null)
{
return manualResetEvent;
}
lock (ThisLock)
{
if (manualResetEvent == null)
{
manualResetEvent = new ManualResetEvent(isCompleted);
}
}
return manualResetEvent;
}
}
public bool CompletedSynchronously
{
get
{
return completedSynchronously;
}
}
public bool IsCompleted
{
get
{
return isCompleted;
}
}
object ThisLock
{
get
{
return this.thisLock;
}
}
protected static TAsyncResult End<TAsyncResult>(IAsyncResult result)
where TAsyncResult : AsyncResult
{
if (result == null)
{
throw new ArgumentNullException("result");
}
TAsyncResult asyncResult = result as TAsyncResult;
if (asyncResult == null)
{
throw new ArgumentException("Invalid async result.", "result");
}
if (asyncResult.endCalled)
{
throw new InvalidOperationException("Async object already ended.");
}
asyncResult.endCalled = true;
if (!asyncResult.isCompleted)
{
asyncResult.AsyncWaitHandle.WaitOne();
}
if (asyncResult.manualResetEvent != null)
{
asyncResult.manualResetEvent.Close();
}
if (asyncResult.exception != null)
{
throw asyncResult.exception;
}
return asyncResult;
}
protected void Complete(bool completedSynchronously)
{
if (isCompleted)
{
throw new InvalidOperationException("This async result is already completed.");
}
this.completedSynchronously = completedSynchronously;
if (completedSynchronously)
{
this.isCompleted = true;
}
else
{
lock (ThisLock)
{
this.isCompleted = true;
if (this.manualResetEvent != null)
{
this.manualResetEvent.Set();
}
}
}
if (callback != null)
{
callback(this);
}
}
protected void Complete(bool completedSynchronously, Exception exception)
{
this.exception = exception;
Complete(completedSynchronously);
}
}
}
```
```csharp
// program.cs
//----------------------------------------------------------------
// Copyright (c) Microsoft Corporation. All rights reserved.
//----------------------------------------------------------------
using System;
using System.ServiceModel;
using System.ServiceModel.Discovery;
namespace Microsoft.Samples.Discovery
{
class Program
{
public static void Main()
{
Uri probeEndpointAddress = new Uri("net.tcp://localhost:8001/Probe");
Uri announcementEndpointAddress = new Uri("net.tcp://localhost:9021/Announcement");
// Host the DiscoveryProxy service
ServiceHost proxyServiceHost = new ServiceHost(new DiscoveryProxyService());
try
{
// Add DiscoveryEndpoint to receive Probe and Resolve messages
DiscoveryEndpoint discoveryEndpoint = new DiscoveryEndpoint(new NetTcpBinding(), new EndpointAddress(probeEndpointAddress));
discoveryEndpoint.IsSystemEndpoint = false;
// Add AnnouncementEndpoint to receive Hello and Bye announcement messages
AnnouncementEndpoint announcementEndpoint = new AnnouncementEndpoint(new NetTcpBinding(), new EndpointAddress(announcementEndpointAddress));
proxyServiceHost.AddServiceEndpoint(discoveryEndpoint);
proxyServiceHost.AddServiceEndpoint(announcementEndpoint);
proxyServiceHost.Open();
Console.WriteLine("Proxy Service started.");
Console.WriteLine();
Console.WriteLine("Press <ENTER> to terminate the service.");
Console.WriteLine();
Console.ReadLine();
proxyServiceHost.Close();
}
catch (CommunicationException e)
{
Console.WriteLine(e.Message);
}
catch (TimeoutException e)
{
Console.WriteLine(e.Message);
}
if (proxyServiceHost.State != CommunicationState.Closed)
{
Console.WriteLine("Aborting the service...");
proxyServiceHost.Abort();
}
}
}
}
```
## <a name="see-also"></a>Ayrıca bkz.
- [WCF Bulmaya Genel Bakış](../../../../docs/framework/wcf/feature-details/wcf-discovery-overview.md)
- [Nasıl yapılır: Bulma proxy 'Sine kaydolduktan sonra bulunabilir bir hizmet uygulama](../../../../docs/framework/wcf/feature-details/discoverable-service-that-registers-with-the-discovery-proxy.md)
- [Nasıl yapılır: Hizmet bulmak için keşif proxy 'Si kullanan bir Istemci uygulaması uygulama](../../../../docs/framework/wcf/feature-details/client-app-discovery-proxy-to-find-a-service.md)
- [Nasıl yapılır: Keşif proxy 'sini test etme](../../../../docs/framework/wcf/feature-details/how-to-test-the-discovery-proxy.md)
| 35.002024 | 707 | 0.63348 | yue_Hant | 0.469654 |
990596edf01d70de68559abeadd1c119af66af12 | 55 | md | Markdown | README.md | fchenxi/easykafka | ab49f4dce873777a9bf44cd23ddb3951f3ad97f2 | [
"Apache-2.0"
] | null | null | null | README.md | fchenxi/easykafka | ab49f4dce873777a9bf44cd23ddb3951f3ad97f2 | [
"Apache-2.0"
] | 6 | 2020-03-04T21:46:08.000Z | 2021-12-09T19:55:18.000Z | README.md | fchenxi/easykafka | ab49f4dce873777a9bf44cd23ddb3951f3ad97f2 | [
"Apache-2.0"
] | 1 | 2019-08-31T04:05:07.000Z | 2019-08-31T04:05:07.000Z | # easykafka
A easy kafka client based on spring-kafka.
| 18.333333 | 42 | 0.781818 | eng_Latn | 0.727105 |
99063f1159cd35004fa7de5c9c655acd12728d02 | 53 | md | Markdown | README.md | thanhbn87/terragrunt-aws | c65fce9ef04a497520e782a94c35c38ccd999b45 | [
"Apache-2.0"
] | 1 | 2020-04-27T08:14:49.000Z | 2020-04-27T08:14:49.000Z | README.md | thanhbn87/terragrunt-aws | c65fce9ef04a497520e782a94c35c38ccd999b45 | [
"Apache-2.0"
] | null | null | null | README.md | thanhbn87/terragrunt-aws | c65fce9ef04a497520e782a94c35c38ccd999b45 | [
"Apache-2.0"
] | 2 | 2020-04-27T08:14:54.000Z | 2021-05-21T07:48:51.000Z | # terragrunt-aws
AWS Terrform modules for Terragrunt
| 17.666667 | 35 | 0.830189 | swe_Latn | 0.350295 |
99065ca7d39301a84f79a06dfb8c1b6c0c0ef2fe | 3,893 | md | Markdown | README.md | signotheque/sign-puppet | dec8e75ecbaf4bad78a2465f59d8ebac0aaa3e4c | [
"MIT"
] | 11 | 2015-05-06T18:11:53.000Z | 2021-10-31T06:59:19.000Z | README.md | signotheque/sign-puppet | dec8e75ecbaf4bad78a2465f59d8ebac0aaa3e4c | [
"MIT"
] | null | null | null | README.md | signotheque/sign-puppet | dec8e75ecbaf4bad78a2465f59d8ebac0aaa3e4c | [
"MIT"
] | 4 | 2016-12-01T13:06:21.000Z | 2017-10-09T08:14:26.000Z | #HTML5 Canvas-based Puppet Animation Rig for Sign Language
A Javascript API for drawing a stylized human figure in a limited range of specific poses.
The API provides for full control of the hands and face and limited control of the neck and shoulders. The figure is shown from the waist up.
The goal of this project is to provide an easy to use means of delivering sign language content in a neutral, low-bandwidth form. Possible uses include:
- online sign language dictionaries or encyclopedias
- linguistic research or documentation
Feedback and pull requests are welcome.
[Sign Puppet Demo](http://aslfont.github.io/sign-puppet/demo/)
##Basic Usage

The draw method takes a canvas, width, height, x, y and the animation channel values that define the pose.
```html
<script type="text/javascript" src="sign-puppet.js" ></script>
<canvas id="the_canvas" width="600" height="400"></canvas>
<script>
var canvas = document.getElementById('the_canvas');
var puppet = aslfont.SignPuppet.create();
var channels = {
//animation channel values go here, for example:
hry: -0.3
};
puppet.draw(canvas, canvas.width, canvas.height, 0, 0, channels);
</script>
```
There is also an API for animating the character from the current pose to a target pose.
```javascript
var animator = puppet.getAnimator();
//set up animation loop (in production use a requestAnimationFrame shim)
setInterval(
function () {
canvas.getContext('2d').clearRect(0, 0, canvas.width, canvas.height);
animator.tween();
//if omitted, 'channels' defaults to the animator object's channels
puppet.draw(canvas, canvas.width, canvas.height, 0, 0);
},
100 // 10 frames per second
);
//after 1.5 seconds, change the pose
setTimeout(
function () {
animator.setTarget({
//animation channel values go here, for example:
hry: -0.3
});
},
1500 // 1.5 seconds
);
```

##Animation Channels
These are the default values for the animation channels:
```javascript
{
//head and body
hrx: 0, hry: 0, //neck rotation
bx: 0, by: 0, //shoulder shift
//eyes
eby: 0, ebx: 0, e0y: 1, e1y: 1, //eyebrows, eyelids
ex: 0, ey: 0, ez: 1, //pupils
//nose
ny: 0, //nose wrinkle
//mouth
mx: 0, my: 0, //jaw, mouth shape
mly: 0, mlz: 0, mty: 0, mtz: 0, mcx: 0, //lips, tongue, cheeks
teeth: false, //teeth
//right hand position
rhx: 0, rhy: 0, rhz: 0, rh: 0, //location relative to head
rbx: 0, rby: 1, rbz: 0, rb: 1, //location relative to body
rax: 0, ray: 0, raz: 0, ra: 0, //location relative to other hand
rpx: 0, rpy: 0, rpz: 0, //pivot point
rrz: 0, rrx: -90, rry: 0, //rotation
//right hand pose
ri0: 0, ri1: 0, ri2: 0, ris: 0, //index
rm0: 0, rm1: 0, rm2: 0, rms: 0, //middle
rr0: 0, rr1: 0, rr2: 0, rrs: 0, //ring
rp0: 0, rp1: 0, rp2: 0, rps: 0, //pinky
rt0x: 0, rt0y: 0, rt1x: 0, rt1y: 0, rt2x: 0, //thumb
//left hand position
lhx: 0, lhy: 0, lhz: 0, lh: 0, //location relative to head
lbx: 0, lby: 1, lbz: 0, lb: 1, //location relative to body
lax: 0, lay: 0, laz: 0, la: 0, //location relative to other hand
lpx: 0, lpy: 0, lpz: 0, //pivot point
lrz: 0, lrx: -90, lry: 0, //rotation
//left hand pose
li0: 0, li1: 0, li2: 0, lis: 0, //index
lm0: 0, lm1: 0, lm2: 0, lms: 0, //middle
lr0: 0, lr1: 0, lr2: 0, lrs: 0, //ring
lp0: 0, lp1: 0, lp2: 0, lps: 0, //pinky
lt0x: 0, lt0y: 0, lt1x: 0, lt1y: 0, lt2x: 0 //thumb
}
``` | 33.852174 | 152 | 0.620344 | eng_Latn | 0.870291 |
990694582dc8c20b0ec40b3a5f9f070fbf62d8df | 16,006 | md | Markdown | Exchange/ExchangeOnline/security-and-compliance/in-place-ediscovery/create-custom-management-scope.md | TransVaultCTO/OfficeDocs-Exchange | c4fb7692e458692acc63ae19d6078bdf6123ecaa | [
"CC-BY-4.0",
"MIT"
] | 2 | 2022-01-18T18:21:46.000Z | 2022-01-18T18:22:05.000Z | Exchange/ExchangeOnline/security-and-compliance/in-place-ediscovery/create-custom-management-scope.md | TransVaultCTO/OfficeDocs-Exchange | c4fb7692e458692acc63ae19d6078bdf6123ecaa | [
"CC-BY-4.0",
"MIT"
] | null | null | null | Exchange/ExchangeOnline/security-and-compliance/in-place-ediscovery/create-custom-management-scope.md | TransVaultCTO/OfficeDocs-Exchange | c4fb7692e458692acc63ae19d6078bdf6123ecaa | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-03-19T11:08:05.000Z | 2021-03-19T11:08:05.000Z | ---
localization_priority: Normal
description: You can use a custom management scope to let specific people or groups use In-Place eDiscovery to search a subset of mailboxes in your Exchange Online organization. For example, you might want to let a discovery manager search only the mailboxes of users in a specific location or department. You can do this by creating a custom management scope. This custom management scope uses a recipient filter to control which mailboxes can be searched. Recipient filter scopes use filters to target specific recipients based on recipient type or other recipient properties.
ms.topic: article
author: msdmaguire
ms.author: dmaguire
ms.assetid: 1543aefe-3709-402c-b9cd-c11fe898aad1
ms.reviewer:
f1.keywords:
- NOCSH
title: Create a custom management scope for In-Place eDiscovery searches
ms.collection:
- exchange-online
- M365-email-calendar
audience: ITPro
ms.service: exchange-online
manager: serdars
---
# Create a custom management scope for In-Place eDiscovery searches
You can use a custom management scope to let specific people or groups use In-Place eDiscovery to search a subset of mailboxes in your Exchange Online organization. For example, you might want to let a discovery manager search only the mailboxes of users in a specific location or department. You can do this by creating a custom management scope. This custom management scope uses a recipient filter to control which mailboxes can be searched. Recipient filter scopes use filters to target specific recipients based on recipient type or other recipient properties.
For In-Place eDiscovery, the only property on a user mailbox that you can use to create a recipient filter for a custom scope is distribution group membership (the actual property name is _MemberOfGroup_). If you use other properties, such as _CustomAttributeN_, _Department_, or _PostalCode_, the search fails when it's run by a member of the role group that's assigned the custom scope.
To learn more about management scopes, see:
- [Understanding management role scopes](https://docs.microsoft.com/exchange/understanding-management-role-scopes-exchange-2013-help)
- [Understanding management role scope filters](https://docs.microsoft.com/exchange/understanding-management-role-scope-filters-exchange-2013-help)
## What do you need to know before you begin?
- Estimated time to complete: 15 minutes
- As previously stated, you can only use group membership as the recipient filter to create a custom recipient filter scope that is intended to be used for eDiscovery. Any other recipient properties can't be used to create a custom scope for eDiscovery searches. Note that membership in a dynamic distribution group can't be used either.
- Perform steps 1 through 3 to let a discovery manager export the search results for an eDiscovery search that uses a custom management scope.
- If your discovery manager doesn't need to preview the search results, you can skip step 4.
- If your discovery manager doesn't need to copy the search results, you can skip step 5.
## Step 1: Organize users into distribution groups for eDiscovery
To search a subset of mailboxes in your organization or to narrow the scope of source mailboxes that a discovery manager can search, you'll need to group the subset of mailboxes into one or more distribution groups. When you create a custom management scope in step 2, you'll use these distribution groups as the recipient filter to create a custom management scope. This allows a discovery manager to search only the mailboxes of the users who are members of a specified group.
You might be able to use existing distribution groups for eDiscovery purposes, or you can create new ones. See [More information](#more-information) at the end of this topic for tips on how to create distribution groups that can be used to scope eDiscovery searches.
## Step 2: Create a custom management scope
Now you'll create a custom management scope that's defined by the membership of a distribution group (using the _MemberOfGroup_ recipient filter). When this scope is applied to a role group used for eDiscovery, members of the role group can search the mailboxes of users who are members of the distribution group that was used to create the custom management scope.
This procedure uses Exchange Online PowerShell commands to create a custom scope named Ottawa Users eDiscovery Scope. It specifies the distribution group named Ottawa Users for the recipient filter of the custom scope.
1. Run this command to get and save the properties of the Ottawa Users group to a variable, which is used in the next command.
```PowerShell
$DG = Get-DistributionGroup -Identity "Ottawa Users"
```
2. Run this command to create a custom management scope based on the membership of the Ottawa Users distribution group.
```PowerShell
New-ManagementScope "Ottawa Users eDiscovery Scope" -RecipientRestrictionFilter "MemberOfGroup -eq '$($DG.DistinguishedName)'"
```
The distinguished name of the distribution group, which is contained in the variable **$DG**, is used to create the recipient filter for the new management scope.
## Step 3: Create a management role group
In this step, you create a new management role group and assign the custom scope that you created in step 2. Add the Legal Hold and Mailbox Search roles so that role group members can perform In-Place eDiscovery searches and place mailboxes on In-Place Hold or Litigation Hold. You can also add members to this role group so they can search the mailboxes of the members of the distribution group used to create the custom scope in step 2.
In the following examples, the Ottawa Users eDiscovery Managers security group will be added as members this role group. You can use either Exchange Online PowerShell or the EAC for this step.
### Use Exchange Online PowerShell to create a management role group
Run this command to create a new role group that uses the custom scope created in step 2. The command also adds the Legal Hold and Mailbox Search roles, and adds the Ottawa Users eDiscovery Managers security group as members of the new role group.
```PowerShell
New-RoleGroup "Ottawa Discovery Management" -Roles "Mailbox Search","Legal Hold" -CustomRecipientWriteScope "Ottawa Users eDiscovery Scope" -Members "Ottawa Users eDiscovery Managers"
```
### Use the EAC to create a management role group
1. In the EAC, go to **Permissions** \> **Admin roles**, and then click **New** .
2. In **New role group**, provide the following information:
- **Name**: Provide a descriptive name for the new role group. For this example, you'd use Ottawa Discovery Management.
- **Write scope**: Select the custom management scope that you created in step 2. This scope will be applied to the new role group.
- **Roles**: Click **Add** , and add the **Legal Hold** and **Mailbox Search** roles to the new role group.
- **Members**: Click **Add** , and select the users, security group, or role groups that you want add as members of the new role group. For this example, the members of the **Ottawa Users eDiscovery Managers** security group will be able to search only the mailboxes of users who are members of the **Ottawa Users** distribution group.
3. Click **Save** to create the role group.
Here's an example of what the **New role group** window will look like when you're done.

## (Optional) Step 4: Add discovery managers as members of the distribution group used to create the custom management scope
You only need to perform this step if you want to let a discovery manager preview eDiscovery search results.
Run this command to add the Ottawa Users eDiscovery Managers security group as a member of the Ottawa Users distribution group.
```PowerShell
Add-DistributionGroupMember -Identity "Ottawa Users" -Member "Ottawa Users eDiscovery Managers"
```
You can also use the EAC to add members to a distribution group. For more information, see [Create and manage distribution groups](../../recipients-in-exchange-online/manage-distribution-groups/manage-distribution-groups.md).
## (Optional) Step 5: Add a discovery mailbox as a member of the distribution group used to create the custom management scope
You only need to perform this step if you want to let a discovery manager copy eDiscovery search results.
Run this command to add a discovery mailbox named Ottawa Discovery Mailbox as a member of the Ottawa Users distribution group.
```PowerShell
Add-DistributionGroupMember -Identity "Ottawa Users" -Member "Ottawa Discovery Mailbox"
```
> [!NOTE]
> To open a discovery mailbox and view the search results, discovery managers must be assigned Full Access permissions for the discovery mailbox. For more information, see [Create a discovery mailbox](create-a-discovery-mailbox.md).
## How do you know this worked?
Here are some ways to verify if you've successfully implemented custom management scopes for eDiscovery. When you verify, be sure that the user running the eDiscovery searches is a member of the role group that uses the custom management scope.
- Create an eDiscovery search, and select the distribution group that was used to create the custom management scope as the source of mailboxes to be searched. All mailboxes should be successfully searched.
- Create an eDiscovery search, and search the mailboxes of any users who aren't members of the distribution group that was used to create the custom management scope. The search should fail because the discovery manager can only search mailboxes for users who are members of the distribution group that was used to create the custom management scope. In this case, an error such as "Unable to search mailbox \<_name of mailbox_\> because the current user does not have permissions to access the mailbox" will be returned.
- Create an eDiscovery search, and search the mailboxes of users who are members of the distribution group that was used to create the custom management scope. In the same search, include the mailboxes of users who aren't members. The search should partially succeed. The mailboxes of members of the distribution group used to create the custom management scope should be successfully searched. The search of mailboxes for users who aren't members of the group should fail.
## More information
- Because distribution groups are used in this scenario to scope eDiscovery searches and not for message delivery, consider the following when you create and configure distribution groups for eDiscovery:
- Create distribution groups with a closed membership so that members can be added to or removed from the group only by the group owners. If you're creating the group in Exchange Online PowerShell, use the syntax `MemberJoinRestriction closed` and `MemberDepartRestriction closed`.
- Enable group moderation so that any message sent to the group is first sent to the group moderators who can approve or reject the message accordingly. If you're creating the group in Exchange Online PowerShell, use the syntax `ModerationEnabled $true`. If you're using the EAC, you can enable moderation after the group is created.
- Hide the distribution group from the organization's shared address book. Use the EAC or the **Set-DistributionGroup** cmdlet after the group is created. If you're using Exchange Online PowerShell, use the syntax `HiddenFromAddressListsEnabled $true`.
In the following example, the first command creates a distribution group with closed membership and moderation enabled. The second command hides the group from the shared address book.
```PowerShell
New-DistributionGroup -Name "Vancouver Users eDiscovery Scope" -Alias VancouverUserseDiscovery -MemberJoinRestriction closed -MemberDepartRestriction closed -ModerationEnabled $true
```
```PowerShell
Set-DistributionGroup "Vancouver Users eDiscovery Scope" -HiddenFromAddressListsEnabled $true
```
For more information about creating and managing distribution groups, see [Create and manage distribution groups](../../recipients-in-exchange-online/manage-distribution-groups/manage-distribution-groups.md).
- Though you can use only distribution group membership as the recipient filter for a custom management scope used for eDiscovery, you can use other recipient properties to add users to that distribution group. Here are some examples of using the **Get-Mailbox** and **Get-Recipient** cmdlets to return a specific group of users based on common user or mailbox attributes.
```PowerShell
Get-Recipient -RecipientTypeDetails UserMailbox -ResultSize unlimited -Filter 'Department -eq "HR"'
```
```PowerShell
Get-Mailbox -RecipientTypeDetails UserMailbox -ResultSize unlimited -Filter 'CustomAttribute15 -eq "VancouverSubsidiary"'
```
```PowerShell
Get-Recipient -RecipientTypeDetails UserMailbox -ResultSize unlimited -Filter 'PostalCode -eq "98052"'
```
```PowerShell
Get-Recipient -RecipientTypeDetails UserMailbox -ResultSize unlimited -Filter 'StateOrProvince -eq "WA"'
```
```PowerShell
Get-Mailbox -RecipientTypeDetails UserMailbox -ResultSize unlimited -OrganizationalUnit "namsr01a002.sdf.exchangelabs.com/Microsoft Exchange Hosted Organizations/contoso.onmicrosoft.com"
```
- You can then use the examples from the previous bullet to create a variable that can be used with the **Add-DistributionGroupMember** cmdlet to add a group of users to a distribution group. In the following example, the first command creates a variable that contains all user mailboxes that have the value **Vancouver** for the _Department_ property in their user account. The second command adds these users to the Vancouver Users distribution group.
```PowerShell
$members = Get-Recipient -RecipientTypeDetails UserMailbox -ResultSize unlimited -Filter 'Department -eq "Vancouver"'
```
```PowerShell
$members | ForEach {Add-DistributionGroupMember "Ottawa Users" -Member $_.Name}
```
- You can use the **Add-RoleGroupMember** cmdlet to add a member to an existing role group that's used to scope eDiscovery searches. For example, the following command adds the user [email protected] to the Ottawa Discovery Management role group.
```PowerShell
Add-RoleGroupMember "Vancouver Discovery Management" -Member [email protected]
```
You can also use the EAC to add members to a role group. For more information, see the "Modify role groups" section in [Manage role groups in Exchange Online](../../permissions-exo/role-groups.md).
- In Exchange Online, a custom management scope used for eDiscovery can't be used to search inactive mailboxes. This is because an inactive mailbox can't be a member of a distribution group. For example, let's say that a user is a member of a distribution group that was used to create a custom management scope for eDiscovery. Then that user leaves the organization and their mailbox is made inactive (by placing a Litigation Hold or In-Place hold on the mailbox and then deleting the corresponding user account). The result is that the user is removed as a member from any distribution group, including the group that was used to create the custom management scope used for eDiscovery. If a discovery manager (who is a member of the role group that's assigned the custom management scope) tries to search the inactive mailbox, the search will fail. To search inactive mailboxes, a discover manager must be a member of the Discovery Management role group or any role group that has permissions to search the entire organization.
For more information about inactive mailboxes, see [Create and manage inactive mailboxes](https://docs.microsoft.com/microsoft-365/compliance/create-and-manage-inactive-mailboxes).
| 78.078049 | 1,029 | 0.791453 | eng_Latn | 0.997467 |
990715b6a8c2fecd1222a645d17f3601e35db975 | 3,258 | md | Markdown | _posts/problem solving/Python/2021-03-04-PS-baekjoon011.md | YongjoonSeo/YongjoonSeo.github.io | 68d7d248d51b3711ea423e0ea35de4a03d22de50 | [
"MIT"
] | null | null | null | _posts/problem solving/Python/2021-03-04-PS-baekjoon011.md | YongjoonSeo/YongjoonSeo.github.io | 68d7d248d51b3711ea423e0ea35de4a03d22de50 | [
"MIT"
] | 2 | 2021-08-17T22:39:32.000Z | 2022-01-22T12:36:30.000Z | _posts/problem solving/Python/2021-03-04-PS-baekjoon011.md | YongjoonSeo/YongjoonSeo.github.io | 68d7d248d51b3711ea423e0ea35de4a03d22de50 | [
"MIT"
] | 2 | 2019-05-14T11:11:16.000Z | 2021-02-19T16:40:33.000Z | ---
layout: single
title: "[파이썬] 백준 19237번 어른 상어"
excerpt: "백준 삼성 기출 19237번 파이썬 풀이"
categories:
- Problem Solving
- Python
tags:
- Baekjoon
- 삼성기출
- Simulation
---
## 백준 #19237 어른 상어
- [백준 19237번 어른 상어 문제풀기](https://www.acmicpc.net/problem/19237)
<br>
```python
# 1 이상 M 이하의 자연수 상어
# 1이 가장 강력한 상어
# N x N 격자
# 상어에 따라, 바라보는 방향에 따라 이동 방향의 우선순위가 다르다
# 1. 아무 냄새가 없는 칸
# 2. 자신의 냄새가 있는 칸
# - 가능한 칸이 여러 개면 특정 우선순위를 따른다
# 출력: 1번 상어만 격자에 남게 되는 시간
# 1000초가 넘어도 다른 상어가 격자에 남아있다면 -1 출력
# 1. 상어의 위치 저장 2차원 배열 loc
# 2. 상어의 이동 우선순위 저장 배열 directions
# 3. 상어 번호 & 냄새 남아있는 배열 trace (빈칸: [0, 0])
# 냄새가 있는 좌표를 따로 set에 저장해두며 갱신 (trace_left)
# 4. 상어번호: 좌표, 방향 저장하는 딕셔너리 shark {1: (2, 0, 4)}
# 모든 상어를 한번씩 이동시키며 1, 3, 4를 갱신한다.
# 4에서 쫒겨난 상어는 없애버린다.
def move(num, ny, nx, y, x, d): # loc, trace, shark 갱신
global k
loc[ny][nx] = num
loc[y][x] = 0
trace[ny][nx][0], trace[ny][nx][1] = num, k
trace_left.add((ny, nx))
shark[num] = (ny, nx, d)
def add_temp(num, ny, nx, y, x, d):
if temp.get((ny, nx)):
temp.get((ny, nx)).append((num, ny, nx, y, x, d))
else:
temp[(ny, nx)] = [(num, ny, nx, y, x, d)]
N, M, k = map(int, input().split())
loc = [[0 for i in range(N)] for j in range(N)]
directions = [0] + [[0] + [[] for j in range(4)] for k in range(M)]
trace = [[[0, 0] for i in range(N)] for j in range(N)]
trace_left = set()
shark = dict()
dy = [0, -1, 1, 0, 0]
dx = [0, 0, 0, -1, 1]
for i in range(N):
line = list(map(int, input().split()))
for j in range(N):
if line[j]:
loc[i][j] = line[j]
shark[line[j]] = (i, j, 0)
trace[i][j][0], trace[i][j][1] = line[j], k
trace_left.add((i, j))
dir_init = list(map(int, input().split()))
for i in range(1, len(dir_init) + 1):
y, x, zero = shark.get(i)
shark[i] = (y, x, dir_init[i-1])
for i in range(1, M+1):
for j in range(1, 5):
directions[i][j] = list(map(int, input().split()))
temp = dict()
for t in range(1, 1001):
update = trace_left.copy()
for num in shark.keys():
y, x, d = shark.get(num)
direc = directions[num][d]
has_blank = False
for i in range(4):
ny = y + dy[direc[i]]
nx = x + dx[direc[i]]
if 0 <= ny < N and 0 <= nx < N and not trace[ny][nx][0]:
has_blank = True
add_temp(num, ny, nx, y, x, direc[i])
break
if not has_blank:
for i in range(4):
ny = y + dy[direc[i]]
nx = x + dx[direc[i]]
if 0 <= ny < N and 0 <= nx < N and trace[ny][nx][0] == num:
add_temp(num, ny, nx, y, x, direc[i])
break
# trace 시간 갱신
for y, x in update:
trace[y][x][1] -= 1
if not trace[y][x][1]:
trace[y][x][0] = 0
trace_left.remove((y, x))
for coor in temp.keys():
if len(temp.get(coor)) == 1: move(*temp.get(coor)[0])
else:
lst = sorted(temp.get(coor))
move(*lst[0])
for j in range(1, len(lst)):
shark.pop(lst[j][0])
if len(shark) == 1 and shark.get(1):
break
temp.clear()
else:
t = -1
print(t)
```
| 25.255814 | 75 | 0.495396 | kor_Hang | 0.973938 |
99073f519080559b834e65b9e0388ac3e2fd6a35 | 10,684 | md | Markdown | applications/popart/bert/README.md | payoto/graphcore_examples | 46d2b7687b829778369fc6328170a7b14761e5c6 | [
"MIT"
] | 260 | 2019-11-18T01:50:00.000Z | 2022-03-28T23:08:53.000Z | applications/popart/bert/README.md | payoto/graphcore_examples | 46d2b7687b829778369fc6328170a7b14761e5c6 | [
"MIT"
] | 27 | 2020-01-28T23:07:50.000Z | 2022-02-14T15:37:06.000Z | applications/popart/bert/README.md | payoto/graphcore_examples | 46d2b7687b829778369fc6328170a7b14761e5c6 | [
"MIT"
] | 56 | 2019-11-18T02:13:12.000Z | 2022-02-28T14:36:09.000Z | # Graphcore benchmarks: BERT training
This README describes how to run BERT models for NLP pre-training and training on IPUs.
## Benchmarking
To reproduce the published Mk2 throughput and inference benchmarks, please follow the setup instructions in this README, and then follow the instructions in [README_Benchmarks.md](README_Benchmarks.md)
## Overview
BERT (Bidirectional Encoder Representations for Transformers) is a deep learning model implemented in ONNX that is used for NLP. It requires pre-training with unsupervised learning on a large dataset such as Wikipedia. It is then trained on more specific tasks for fine tuning - Graphcore uses SQuAD (Stanford Question Answering Dataset), a Q&A dataset, for training BERT on IPUs.
## BERT models
There are two BERT models:
- BERT Base – 12 layers (transformer blocks), 110 million parameters
- BERT Large – 24 layers (transformer blocks), 340 million parameters
The JSON configuration files provided in the `configs` directory define how the layers
are distributed across IPUs for these BERT models for training and inference. There are also IPU Mk2 optimised configs in the `configs/mk2` sub-directory.
## Datasets
SQuAD is a large reading comprehension dataset which contains 100,000+ question-answer pairs on 500+ articles.
The Wikipedia dataset contains approximately 2.5 billion wordpiece tokens. This is only an approximate size since the Wikipedia dump file is updated all the time.
Instructions on how to download the Wikipedia and SQuAD datasets can be found in the `bert_data/README.md file`. At least 1TB of disk space will be required for full pre-training (two phases, phase 1 with sequence_length=128 and phase 2 with sequence_length=384) and the data should be stored on NVMe SSDs for maximum performance.
If full pre-training is required (with the two phases with different sequence lengths) then data will need to be generated separately for the two phases:
- once with --sequence-length 128 --mask-tokens 20 --duplication-factor 6
- once with --sequence-length 384 --mask-tokens 56 --duplication-factor 6
See the `bert_data/README.md file` for more details on how to generate this data.
## Running the models
The following files are provided for running the BERT benchmarks.
| File | Description |
| --------------- | ------------------------------------------------------------ |
| `bert.py` | Main training loop |
| `bert_model.py` | BERT model definition |
| `utils/` | Utility functions |
| `bert_data/` | Directory containing the data pipeline and training data generation <br /><br />- `dataset.py` - Dataloader and preprocessing. Loads binary files into Numpy arrays to be passed `popart.PyStepIO`, with shapes to match the configuration <br /><br /> -`create_pretraining_data.py` - Script to generate binary files to be loaded from text data |
| `configs/` | Directory containing JSON configuration files to be used by the `--config` argument. |
| `custom_ops/` | Directory containing custom PopART operators. These are optimised parts of the graph that target Poplar/PopLibs operations directly. |
## Quick start guide
### Prepare the environment
##### 1) Install the Poplar SDK
Install the Poplar SDK following the instructions in the Getting Started guide for your IPU system. Make sure to source the `enable.sh`
scripts for Poplar and PopART.
##### 2) Compile custom ops
From inside this directory:
```bash
make
```
This should create `custom_ops.so`.
##### 3) Python
Create a virtualenv and install the required packages:
```bash
virtualenv venv -p python3.6
source venv/bin/activate
pip install -r requirements.txt
pip install <path to the tensorflow-1 wheel from the Poplar SDK>
pip install --no-cache-dir <path to the horovod wheel from the Poplar SDK>
```
Note: TensorFlow is required by `bert_tf_loader.py`. You can use the Graphcore TensorFlow version, or the standard TensorFlow version.
Note: Horovod is required to run on IPU-POD128 and larger systems, or if you wish to run all of the tests. You can safely skip if you are targeting IPU-POD16 or IPU-POD64.
### Generate pre-training data (small sample)
As an example we will create data from a small sample: `bert_data/sample_text.txt`, however the steps are the same for a large corpus of text. As described above, see `bert_data/README.md` for instructions on how to generate data for the Wikipedia and SQuAD datasets.
##### Download the vocab file
You can download a vocab from the pre-trained model checkpoints at https://github.com/google-research/bert. For this example we are using `Bert-Base, uncased`.
##### Creating the data
Create a directory to keep the data.
```bash
mkdir data
```
`bert_data/create_pretraining_data.py` has a few options that can be viewed by running with `-h/--help`.
Data for the sample text is created by running:
```bash
python3 bert_data/create_pretraining_data.py \
--input-file bert_data/sample_text.txt \
--output-file data/sample_text.bin \
--vocab-file data/ckpts/uncased_L-12_H-768_A-12/vocab.txt \
--do-lower-case \
--sequence-length 128 \
--mask-tokens 20 \
--duplication-factor 6
```
**NOTE:** `--input-file/--output-file` can take multiple arguments if you want to split your dataset between files.
When creating data for your own dataset, make sure the text has been preprocessed as specified at https://github.com/google-research/bert. This means with one sentence per line and documents delimited by empty lines.
### Quick-Start SQuAD Data Setup
The supplied configs for SQuAD assume data has been set up in advance. In particular these are:
- `data/ckpts/uncased_L-12_H-768_A-12/vocab.txt`: The vocabularly used in pre-training (included in the Google Checkpoint)
- `data/squad/train-v1.1.json`: The training dataset for SQuAD v1.1
- `data/squad/dev-v1.1.json`: The evaluation dataset for SQuAD v1.1
- `data/squad/evaluate-v1.1.py`: The official SQuAD v1.1 evaluation script
- `data/squad/results`: The results output path. This is created automatically by the `bert.py` script.
A full guide for setting up the data is given in the [bert_data](bert_data) directory. The following serves as a quick-start guide to run the Bert Base SQuAD
fine-tuning configurations with a pre-trained checkpoint.
#### Pre-Trained Checkpoint
Download pre-trained Base checkpoint containing the vocabulary from https://github.com/google-research/bert
```bash
$ cd <examples_repo>/applications/popart/bert
$ curl --create-dirs -L https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip -o data/ckpts/uncased_L-12_H-768_A-12.zip
$ unzip data/ckpts/uncased_L-12_H-768_A-12.zip -d data/ckpts/uncased_L-12_H-768_A-12
```
#### SQuAD 1.1 Dataset and Evaluation Script
Download the SQuAD dataset (from https://github.com/rajpurkar/SQuAD-explorer):
```bash
$ cd <examples_repo>/applications/popart/bert
$ curl --create-dirs -L https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json -o data/squad/dev-v1.1.json
$ curl --create-dirs -L https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json -o data/squad/train-v1.1.json
$ curl -L https://raw.githubusercontent.com/allenai/bi-att-flow/master/squad/evaluate-v1.1.py -o data/squad/evaluate-v1.1.py
```
### Run the training loop for pre-training (small sample)
For the sample text a configuration has been created - `configs/demo.json`. It sets the following options:
```javascript
{
# Two layers as our dataset does not need the capacity of the usual 12 Layer BERT Base
"num_layers": 2,
"popart_dtype": "FLOAT16",
# The data generation should have created 64 samples. Therefore, we will do an epoch per session.run
"batches_per_step": 64,
"training_steps": 500,
# Here we specify the file we created in the previous step.
"input_files": [
"data/sample_text.bin"
],
"no_validation": true
}
```
Run this config:
```bash
python3 bert.py --config configs/demo.json
```
This will compile the graph and run for 500 training steps. At end our model should have overfit to 100% test accuracy.
##### View the pre-training results in Tensorboard
`requirements.txt` will install a standalone version of tensorboard. The program will log all training runs to `--log-dir`(`logs` by default). View them by running:
```bash
tensorboard --logdir logs
```
### Run the training loop for pre-training (Wikipedia)
For BERT Base phase 1, use the following command:
`python3 bert.py --config configs/{mk1,mk2}/pretrain_base_128.json`
For BERT Base phase 2, use the following command:
`python3 bert.py --config configs/{mk1,mk2}/pretrain_base_384.json`
You will also need to specify the option `--onnx-checkpoint <path-to-checkpoint>` to load the weights from a previous training phase. You will find the checkpoint path for a training phase logged just after the compilation has completed in a date-time stamped directory. The checkpoints will be of the form `{checkpoint-dir}/{timestamp}/model_{epoch}.onnx`.
### Run the training loop with training data (SQuAD 1.1)
How to get the SQuAD 1.1 training dataset is described in `bert_data/README`.
You can then extract the weights and launch SQuAD fine tuning using one of the preset configurations.
To run SQuAD with a BERT Base model and sequence length of 384:
`python3 bert.py --config configs/{mk1,mk2}/squad_base_384.json`
and for BERT Large:
`python3 bert.py --config configs/{mk1,mk2}/squad_large_384.json`
View the JSON files in configs for detailed parameters.
By default, SQuAD finetuning will use the pre-trained weights downloaded alongside the vocab, but you can also specify an onnx checkpoint using the option `--onnx-checkpoint <path-to-checkpoint>`.
## Training options
`bert.py` has many different options. Run with `-h/--help` to view them. Any options used on the command line will overwrite those specified in the configuration file.
## Inference
Before running inference you should run fine tuning or acquire fine-tuned weights in order to obtain accurate results. Without fine-tuned weights the inference performance will be poor.
How to get the SQuAD 1.1 files required for inference is described in `bert_data/README`.
To run SQuAD BERT Base inference with a sequence length of 128:
`python3 bert.py --config configs/{mk1,mk2}/squad_base_128_inf.json`
and for BERT Large with a sequence length of 384:
`python3 bert.py --config configs/{mk1,mk2}/squad_large_384_inf.json`
View the JSON files in configs for detailed parameters.
| 44.33195 | 380 | 0.74663 | eng_Latn | 0.987487 |
99082a510f096017a8442ed3436408f0d9a245ca | 300 | md | Markdown | docs/linux/markdown-file/maintenance.md | shangguankui/blog | 314875336737fe545d51d2ac7b421e17215675e3 | [
"MIT"
] | null | null | null | docs/linux/markdown-file/maintenance.md | shangguankui/blog | 314875336737fe545d51d2ac7b421e17215675e3 | [
"MIT"
] | 2 | 2021-07-08T19:09:39.000Z | 2021-07-10T20:18:58.000Z | docs/linux/markdown-file/maintenance.md | shangguankui/blog | 314875336737fe545d51d2ac7b421e17215675e3 | [
"MIT"
] | 3 | 2019-08-29T06:08:42.000Z | 2021-07-07T20:00:34.000Z | # 常见日常维护
## Vim 编辑文件报:Swap file "Hello.java.swp" already exists!
- 问题原因:
- Vim 编辑 Hello.java 文件的时候,非正常退出,然后又重新再 Vim 这个文件一般都会提示这个。
- 解决办法:
- 进入被编辑的文件目录,比如:Hello.java 我放在 /opt 目录下,那就先:`cd /opt`,
- 然后:`ls -A`,会发现有一个:.Hello.java.swp,把这个文件删除掉:`rm -rf .Hello.java.swp`,然后重新 Vim 文件即可。
| 21.428571 | 88 | 0.653333 | zho_Hans | 0.312822 |
9908edb9674df168e2a42b8cbc6402ac9238213c | 4,628 | md | Markdown | readme.md | fingerprintjs/botd-integrations | 982e20236a575e8f7aec7c4ca19511aa7914b2d0 | [
"MIT"
] | 20 | 2021-07-01T14:13:57.000Z | 2022-03-29T13:54:00.000Z | readme.md | fingerprintjs/botd-integrations | 982e20236a575e8f7aec7c4ca19511aa7914b2d0 | [
"MIT"
] | 7 | 2021-07-06T06:59:22.000Z | 2021-09-30T14:34:59.000Z | readme.md | fingerprintjs/botd-integrations | 982e20236a575e8f7aec7c4ca19511aa7914b2d0 | [
"MIT"
] | 2 | 2021-08-06T13:18:41.000Z | 2021-12-20T09:02:06.000Z | ## This project contains cloud integrations code and docs for [BotD](https://github.com/fingerprintjs/botd) - FingerprintJS new bot detection product that allows to detect bots in JavaScript easily.
<img width="960" alt="bot-detection cloud integration-2" src="https://user-images.githubusercontent.com/27387/122214619-f97ab080-ceb2-11eb-8cca-59cdcab33e8b.png">
### Quick links: [CloudFlare](https://github.com/fingerprintjs/botd-integrations/blob/main/cloudflare/README.md), [Fastly](https://github.com/fingerprintjs/botd-integrations/blob/main/fastly/wasm/README.md), (AWS is in progress).
### Example app
Web application that we’re going to protect from bots - http://botd-example-app.fpjs.sh. We will be referring to this app as the **`origin`**.
We'll protect it by adding a CDN on top of it, provided by Cloudflare workers, Fastly Compute@Edge, or Amazon Lambda@Edge.
Every CDN example will run a middleware function to intercept requests and responses. These middleware functions are fully open source and their source code is included in this repository.
### Flow with integration enabled

1. End-user loads an example app provided by the integrations ([app powered by Cloudflare](https://botd.fingerprintjs.workers.dev/) or app using [Compute@Edge by Fastly](https://botd-fingerprintjs.edgecompute.app/)).
2. Middleware intercepts first two requests
(for HTML content of the page and for favicon) and does `edge bot detection`
(sends needed data for edge analysis to [Server Botd API](https://github.com/fingerprintjs/botd/blob/main/docs/server_api.md)).
On this step we cannot get a lot of useful information to do
`full bot detection`, we have only information from request (e.g., headers).
3. Middleware sets result of `edge bot detection` into headers of request and sends it to origin.
4. Middleware receives response from origin. If it's a request for HTML content it will inject
[Botd script](https://github.com/fingerprintjs/botd) into the page.
5. Response from origin is returned to end-user's browser with cookie `botd-request-id`. `requestID` value can be used to retrieve the bot detection results later.
6. The end-user fills the form and submits it to the `POST /login` endpoint
(same logic can be applied for next requests of origin app).
7. Middleware intercepts the request and retrieves results of `full bot detection` from [Server Botd API](https://github.com/fingerprintjs/botd/blob/main/docs/server_api.md)
by the botd's `requestID` identifier (available in a `botd-request-id` cookie). Then, it sets the result into headers of the request and
sends it to origin.
8. Response from origin is returned to end-user's browser.
*Note: If the request retrieves static content (e.g. images, fonts) except favicon, point 7 won't be done.*
Checking the ***Emulate bot*** checkbox will replace `User-Agent` to `Headless Chrome`.
It will force the bot branch of the flow.
### Bot Detection Headers sent to `Origin`
You can find more information about botd headers [here](https://github.com/fingerprintjs/botd/blob/main/docs/server_api.md).
#### botd-request-id
Header with request identifier. Example:
`botd-request-id: 6080277c12b178b86f1f967d`.
#### botd-request-status
Possible values of botd-request-status header: `'processed'`, `'inProgress'`, `'error'`.
#### botd-automation-tool-status, botd-browser-spoofing-status, botd-search-bot-status, botd-vm-status
Possible values of status header: `'processed'`, `'error'`, `'notEnoughData'`.
#### botd-automation-tool-prob, botd-browser-spoofing-prob, botd-search-bot-prob, botd-vm-prob
Headers are presented if corresponded `status` is `processed`. The value is float number in range `0.0` to `1.0`.
#### botd-automation-tool-type
**[OPTIONAL]** Possible values: `'phantomjs'`, `'headlessChrome'` and so on.
#### botd-search-bot-type
**[OPTIONAL]** Possible values: `'google'`, `'yandex'` and so on.
#### botd-vm-type
**[OPTIONAL]** Possible values: `'vmware'`, `'parallels'` and so on.
### Headers example:
```
botd-request-id: 6080277c12b178b86f1f967d
botd-request-status: processed
botd-automation-tool-status: processed
botd-automation-tool-prob: 0.00
botd-browser-spoofing-status: processed
botd-browser-spoofing-prob: 0.00
botd-search-bot-status: processed
botd-search-bot-prob: 0.00
botd-vm-status: processed
botd-vm-prob: 0.00
```
### Headers example, when an error occurred:
```
botd-request-id: 6080277c12b178b86f1f967
botd-request-status: error
botd-error-description: token not found
```
| 53.195402 | 229 | 0.760372 | eng_Latn | 0.86117 |
9909500541d23b5fcd68b197659e38449f4b749a | 13 | md | Markdown | readme.md | NandySekar/CodeDeployGitHubDemo | 8aab41811b4e244003bac1ddf02d02f06ed0d3c4 | [
"Apache-2.0"
] | null | null | null | readme.md | NandySekar/CodeDeployGitHubDemo | 8aab41811b4e244003bac1ddf02d02f06ed0d3c4 | [
"Apache-2.0"
] | null | null | null | readme.md | NandySekar/CodeDeployGitHubDemo | 8aab41811b4e244003bac1ddf02d02f06ed0d3c4 | [
"Apache-2.0"
] | null | null | null | Sample app!!! | 13 | 13 | 0.692308 | eng_Latn | 0.986971 |
9909a5bf3bc2aebb292df294ebbafbd300263c6d | 351 | md | Markdown | README.md | khoateamer/learn-redux | c80fbe3d7eab639499b561589a9632b09055b57c | [
"MIT"
] | null | null | null | README.md | khoateamer/learn-redux | c80fbe3d7eab639499b561589a9632b09055b57c | [
"MIT"
] | null | null | null | README.md | khoateamer/learn-redux | c80fbe3d7eab639499b561589a9632b09055b57c | [
"MIT"
] | null | null | null | # learn-redux
> start date: 27/6/18
## Development
```bash
npm i && npm run start
```
## Meta
Valentino Gagliardi - [valentinog.com](https://www.valentinog.com/blog/react-redux-tutorial-beginners/) - [email protected]
## License
This project is open-sourced software licensed under the [MIT license](http://opensource.org/licenses/MIT).
| 19.5 | 130 | 0.729345 | eng_Latn | 0.352425 |
990a03d819486fd9374f246d8c174b93a5cee5b8 | 221 | md | Markdown | ONLINE.md | Cp0204/wecomchan | ce469a6b5c53b073b49d9fcd45bb6160fd51b144 | [
"MIT"
] | null | null | null | ONLINE.md | Cp0204/wecomchan | ce469a6b5c53b073b49d9fcd45bb6160fd51b144 | [
"MIT"
] | null | null | null | ONLINE.md | Cp0204/wecomchan | ce469a6b5c53b073b49d9fcd45bb6160fd51b144 | [
"MIT"
] | null | null | null | # 在线服务搭建指南(PHP版)
## 安装条件
- PHP7.4+
- 可访问外部网络的运行环境
## 安装说明
1. 用编辑器打开 `index.php`,按提示修改头部 define 的值( sendkey自己随意写,其他参见企业微信配置文档 )
2. 将 `index.php` 上传运行环境
3. 通过 `http://指向运行环境的域名/?sendkey=你设定的sendkey&text=你要发送的内容` 即可发送内容
| 17 | 68 | 0.714932 | yue_Hant | 0.745837 |
990a54b4c4128491dddc7c5253cc10dce7005093 | 2,320 | md | Markdown | test/fixtures/sha-user/input.md | g12i/remark-github | eda42e5cf141cb8208a4c17cb5a995b4a8bf5e23 | [
"MIT"
] | null | null | null | test/fixtures/sha-user/input.md | g12i/remark-github | eda42e5cf141cb8208a4c17cb5a995b4a8bf5e23 | [
"MIT"
] | null | null | null | test/fixtures/sha-user/input.md | g12i/remark-github | eda42e5cf141cb8208a4c17cb5a995b4a8bf5e23 | [
"MIT"
] | null | null | null | # User@SHA
A user-SHA is relative to the project, but relative to the user’s fork.
GitHub’s usernames can contain alphabetical characters and dashes, but can neither begin nor end with a dash. Additionally, the length of a username can be between 1 and 39 characters (both including).
- wooorm@000000;
- wooorm@0000000;
- wooorm@00000000;
- wooorm@000000000;
- wooorm@0000000000;
- wooorm@00000000000;
- wooorm@000000000000;
- wooorm@0000000000000;
- wooorm@00000000000000;
- wooorm@000000000000000;
- wooorm@0000000000000000;
- wooorm@00000000000000000;
- wooorm@000000000000000000;
- wooorm@0000000000000000000;
- wooorm@00000000000000000000;
- wooorm@000000000000000000000;
- wooorm@0000000000000000000000;
- wooorm@00000000000000000000000;
- wooorm@000000000000000000000000;
- wooorm@0000000000000000000000000;
- wooorm@00000000000000000000000000;
- wooorm@000000000000000000000000000;
- wooorm@0000000000000000000000000000;
- wooorm@00000000000000000000000000000;
- wooorm@000000000000000000000000000000;
- wooorm@0000000000000000000000000000000;
- wooorm@00000000000000000000000000000000;
- wooorm@000000000000000000000000000000000;
- wooorm@0000000000000000000000000000000000;
- wooorm@00000000000000000000000000000000000;
- wooorm@00000000000000000000000000000000000;
- wooorm@000000000000000000000000000000000000;
- wooorm@0000000000000000000000000000000000000;
- wooorm@00000000000000000000000000000000000000;
- wooorm@000000000000000000000000000000000000000;
- wooorm@0000000000000000000000000000000000000000;
- wooorm@00000000000000000000000000000000000000000.
And:
- Prefix wooorm@0000000 suffix;
- Prefix wooorm@0000000!;
- a wooorm@0000000!;
And what about here
wooorm@0000000
Or here
wooorm@0000000
And these SHAs which could also be words? wooorm@deedeed, and wooorm@fabaceae.
This is not a valid, -wooorm@0000000; but this is w-w@0000000, and so is w@0000000 and ww@0000000.
This used to be valid: wooorm-@0000000.
And here’s an example of a disposable e-mail domain, which starts with 7 hexidecimal characters: [email protected], which shouldn’t match, because there’s no word break after the SHA-like part.
This is too long: wooormwooormwooormwooormwooormwooormwooo#0000000 (40 character username).
| 35.151515 | 201 | 0.793534 | eng_Latn | 0.286495 |
990ab30af2df981b2870f7a746074f639490ef08 | 7,803 | md | Markdown | README.md | degyes/kin-ecosystem-android-sdk | e4bed0996ef7c1a527feb409a393d4dff1483799 | [
"MIT"
] | null | null | null | README.md | degyes/kin-ecosystem-android-sdk | e4bed0996ef7c1a527feb409a393d4dff1483799 | [
"MIT"
] | null | null | null | README.md | degyes/kin-ecosystem-android-sdk | e4bed0996ef7c1a527feb409a393d4dff1483799 | [
"MIT"
] | null | null | null | # Kin Ecosystem Android SDK #
## What is the Kin Ecosystem SDK? ##
The Kin Ecosystem SDK allows you to quickly and easily integrate with the Kin platform. This enables you to provide your users with new opportunities to earn and spend the Kin digital currency from inside your app or from the Kin Marketplace offer wall. For each user, the SDK will create wallet and an account on Kin blockchain. By calling the appropriate SDK functions, your application can performs earn and spend transactions. Your users can also view their account balance and their transaction history.
## Playground and Production Environments ##
The Kin Ecosystem provides two working environments:
- **Playground** – a staging and testing environment using test servers and a blockchain test network.
- **Production** – uses production servers and the main blockchain network.
Use the Playground environment to develop, integrate and test your app. Transition to the Production environment when you’re ready to go live with your Kin-integrated app.
When your app calls ```Kin.start(…)```, you specify which environment to work with.
>**NOTES:**
>* When working with the Playground environment, you can only register up to 1000 users. An attempt to register additional users will result in an error.
>* In order to switch between environments, you’ll need to clear the application cache.
## Obtaining Authentication Credentials ##
To access the Kin Ecosystem, you’ll need to obtain authentication credentials, which you then use to register your users.
There are 2 types of authentication:
* **Whitelist authentication** – to be used for a quick first-time integration or sanity test. The authentication credentials are provided as simple appID and apiKey values. (For development and testing, you can use the default values provided in the Sample App.)
>**NOTE:** You can only use whitelist authentication for the Playground environment. The Production environment requires that you use JWT authentication.
* **JWT authentication** – a secure authentication method to be used in production. This method uses a JSON Web Token (JWT) signed by the Kin Server to authenticate the client request. You provide the Kin team with one or more public signature keys and its corresponding keyID, and you receive a JWT issuer identifier (ISS key). (See [https://jwt.io](https://jwt.io) to learn more about JWT tokens.)
For both types of authentication, you supply your credentials when calling the SDK’s ```Kin.start(…)``` function for a specific user. See [Initialize The SDK And Creating a User’s Kin Account](#initialize-the-sdk-and-creating-a-users-kin-account) to learn how.
## Generating the JWT Token ##
A JWT token is a string that is composed of 3 parts:
* **Header** – a JSON structure encoded in Base64Url
* **Payload** – a JSON structure encoded in Base64Url
* **Signature** – constructed with this formula:
```ES256(base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)```
-- where the secret value is the private key of your agreed-on public/private key pair.
The 3 parts are then concatenated, with the ‘.’ character between each 2 consecutive parts, as follows:
```<header> + “.” + <payload> + “.” + <signature>```
See https://jwt.io to learn more about how to build a JWT token, and to find libraries that you can use to do this.
This is the header structure:
```
{
"alg": "ES256",
"typ": "JWT",
"kid": string" // ID of the keypair that was used to sign the JWT.
// IDs and public keys will be provided by the signing authority.
// This enables using multiple private/public key pairs.
// (The signing authority must provide the verifier with a list of public
// keys and their IDs in advance.)
}
```
This is the payload structure:
```
{
// standard fields
iat: number; // the time this token was issued, in seconds from Epoch
iss: string; // issuer (Kin will provide this value)
exp: number; // the time until this token expires, in seconds from Epoch
sub: "register"
// application fields
user_id: string; // A unique ID of the end user (must only be unique among your app’s users; not globally unique)
}
```
## Setting Up the Sample App ##
The Kin Ecosystem SDK Sample App demonstrates how to perform common workflows such as creating a user account and creating Spend and Earn offers. You can build the Sample App from the ```app``` module in the Kin Ecosystem SDK Git repository. We recommend building and running the Sample App as a good way to get started with the Kin Ecosystem SDK and familiarize yourself with its functions.
>**NOTE:** The Sample App is for demonstration only, and should not be used for any other purpose.
The Sample App is pre-configured with the default whitelist credentials ```appId='test'``` and
```apiKey='AyINT44OAKagkSav2vzMz'```. These credentials can be used for integration testing in any app, but authorization will fail if you attempt to use them in a production environment.
You can also request unique apiKey and appId values from Kin, and override the default settings, working either in whitelist or JWT authentication mode.
*To override the default credential settings:*
Create or edit a local ```credential.properties``` file in the ```app``` module directory and add the lines below, using the ```appId``` and ```apiKey``` values you received.
```
APP_ID="YOUR_APP_ID" // For whitelist registration, and also as the issuer (iss). Default = 'test'.
API_KEY="YOUR_API_KEY" // For whitelist registration. Default = 'AyINT44OAKagkSav2vzMz'.
ES256_PRIVATE_KEY="YOUR_ES256_PRIVATE_KEY” // Optional. Only required when testing JWT on the sample app. For production, JWT is created by server side with ES256 signature.
IS_JWT_REGISTRATION = false // Optional. To test sample app JWT registration, set this property to true. If not specified, default=false.
```
The Sample App Gradle build loads the ```credential.properties``` setting and uses it to create the ```SignInData``` object used for registration.
## Integrating with the Kin SDK ##
*To integrate your project with the Kin Android SDK:*
1. Add the following lines to your project module's ```build.gradle``` file.
```groovy
repositories {
...
maven {
url 'https://jitpack.io'
}
}
```
2. Add the following lines to the app module's ```build.gradle``` file.
```groovy
dependencies {
...
implementation 'com.github.kinfoundation.kin-ecosystem-android-sdk:sdk:0.2.2'
}
```
>**NOTE:** The kin-ecosystem-android-sdk arr is tested for Android OS version 4.4 (API level 19) and above.
>* Some functionalities such as observing balance update will not be supported for lower OS version.
>* If your app support lower OS versions (minSdkVersion < 19) we recommend to only enable Kin integration for users with version 4.4 and above.
## Primary APIs ##
The following sections show how to implement some primary APIs using the Kin Ecosystem SDK.
* [Initialize the SDK and Creating a User’s Kin Account](docs/INITIALIZE_SDK_AND_CREATE_ACCOUNT.md)
* [Getting an Account’s Balance](docs/BALANCE.md)
* [Requesting Payment for a Custom Earn Offer](docs/NATIVE_EARN.md)
* [Creating a Custom Spend Offer](docs/NATIVE_SPEND.md)
* [Creating a Pay To User Offer](docs/PEER_TO_PEER.md)
* [Displaying the Kin Marketplace Offer Wall](docs/DISPLAY_MARKETPLACE.md)
* [Adding Native Offer to Marketplace Offer Wall](docs/ADD_NATIVE_OFFER_TO_MARKETPLACE.md)
* [Requesting an Order Confirmation](docs/ORDER_CONFIRMATION.md)
* [Misc](docs/MISC.md)
## Common Errors ##
The Ecosystem APIs can response with few types of error, [learn more here](docs/COMMON_ERRORS.md)
## License ##
The ```kin-ecosystem-android-sdk``` library is licensed under the MIT license.
| 47.290909 | 508 | 0.747405 | eng_Latn | 0.994114 |
990ac567ee23b049113427f02be9206de40be946 | 270 | md | Markdown | README.md | drdplusinfo/google-sheets | 59d3f6e8281197688ce99f3a965d8ed8ee9374c1 | [
"MIT"
] | 1 | 2021-12-17T07:00:59.000Z | 2021-12-17T07:00:59.000Z | README.md | drdplusinfo/google-sheets | 59d3f6e8281197688ce99f3a965d8ed8ee9374c1 | [
"MIT"
] | null | null | null | README.md | drdplusinfo/google-sheets | 59d3f6e8281197688ce99f3a965d8ed8ee9374c1 | [
"MIT"
] | null | null | null | # google-sheets
Testing Google Sheets read and write via PHP
Just sa little bit modified Google Sheets quickstart https://developers.google.com/sheets/api/quickstart/php
We will need it for a mass control of some [Gamecon](https://github.com/gamecon-cz/gamecon) data.
| 38.571429 | 108 | 0.792593 | eng_Latn | 0.527498 |
990af6a9644b2a881e9c0cdf9ec34d6bc3106a61 | 5,518 | md | Markdown | docs/standard/design-guidelines/names-of-namespaces.md | gosali/docs-1 | fc75797ccc7b10ae6b526133d70693b99963def8 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-09-07T14:05:00.000Z | 2021-09-07T14:05:00.000Z | docs/standard/design-guidelines/names-of-namespaces.md | gosali/docs-1 | fc75797ccc7b10ae6b526133d70693b99963def8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/standard/design-guidelines/names-of-namespaces.md | gosali/docs-1 | fc75797ccc7b10ae6b526133d70693b99963def8 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-12-03T21:11:06.000Z | 2019-12-03T21:11:06.000Z | ---
title: "Names of Namespaces"
ms.date: "03/30/2017"
helpviewer_keywords:
- "names [.NET Framework], conflicts"
- "names [.NET Framework], namespaces"
- "type names, conflicts"
- "namespaces [.NET Framework], names"
- "names [.NET Framework], type names"
ms.assetid: a49058d2-0276-43a7-9502-04adddf857b2
author: "rpetrusha"
ms.author: "ronpet"
---
# Names of Namespaces
As with other naming guidelines, the goal when naming namespaces is creating sufficient clarity for the programmer using the framework to immediately know what the content of the namespace is likely to be. The following template specifies the general rule for naming namespaces:
`<Company>.(<Product>|<Technology>)[.<Feature>][.<Subnamespace>]`
The following are examples:
`Fabrikam.Math`
`Litware.Security`
**✓ DO** prefix namespace names with a company name to prevent namespaces from different companies from having the same name.
**✓ DO** use a stable, version-independent product name at the second level of a namespace name.
**X DO NOT** use organizational hierarchies as the basis for names in namespace hierarchies, because group names within corporations tend to be short-lived. Organize the hierarchy of namespaces around groups of related technologies.
**✓ DO** use PascalCasing, and separate namespace components with periods (e.g., `Microsoft.Office.PowerPoint`). If your brand employs nontraditional casing, you should follow the casing defined by your brand, even if it deviates from normal namespace casing.
**✓ CONSIDER** using plural namespace names where appropriate.
For example, use `System.Collections` instead of `System.Collection`. Brand names and acronyms are exceptions to this rule, however. For example, use `System.IO` instead of `System.IOs`.
**X DO NOT** use the same name for a namespace and a type in that namespace.
For example, do not use `Debug` as a namespace name and then also provide a class named `Debug` in the same namespace. Several compilers require such types to be fully qualified.
### Namespaces and Type Name Conflicts
**X DO NOT** introduce generic type names such as `Element`, `Node`, `Log`, and `Message`.
There is a very high probability that doing so will lead to type name conflicts in common scenarios. You should qualify the generic type names (`FormElement`, `XmlNode`, `EventLog`, `SoapMessage`).
There are specific guidelines for avoiding type name conflicts for different categories of namespaces.
- **Application model namespaces**
Namespaces belonging to a single application model are very often used together, but they are almost never used with namespaces of other application models. For example, the <xref:System.Windows.Forms?displayProperty=nameWithType> namespace is very rarely used together with the <xref:System.Web.UI?displayProperty=nameWithType> namespace. The following is a list of well-known application model namespace groups:
`System.Windows*`
`System.Web.UI*`
**X DO NOT** give the same name to types in namespaces within a single application model.
For example, do not add a type named `Page` to the <xref:System.Web.UI.Adapters?displayProperty=nameWithType> namespace, because the <xref:System.Web.UI?displayProperty=nameWithType> namespace already contains a type named `Page`.
- **Infrastructure namespaces**
This group contains namespaces that are rarely imported during development of common applications. For example, `.Design` namespaces are mainly used when developing programming tools. Avoiding conflicts with types in these namespaces is not critical.
- **Core namespaces**
Core namespaces include all `System` namespaces, excluding namespaces of the application models and the Infrastructure namespaces. Core namespaces include, among others, `System`, `System.IO`, `System.Xml`, and `System.Net`.
**X DO NOT** give types names that would conflict with any type in the Core namespaces.
For example, never use `Stream` as a type name. It would conflict with <xref:System.IO.Stream?displayProperty=nameWithType>, a very commonly used type.
- **Technology namespace groups**
This category includes all namespaces with the same first two namespace nodes `(<Company>.<Technology>*`), such as `Microsoft.Build.Utilities` and `Microsoft.Build.Tasks`. It is important that types belonging to a single technology do not conflict with each other.
**X DO NOT** assign type names that would conflict with other types within a single technology.
**X DO NOT** introduce type name conflicts between types in technology namespaces and an application model namespace (unless the technology is not intended to be used with the application model).
*Portions © 2005, 2009 Microsoft Corporation. All rights reserved.*
*Reprinted by permission of Pearson Education, Inc. from [Framework Design Guidelines: Conventions, Idioms, and Patterns for Reusable .NET Libraries, 2nd Edition](https://www.informit.com/store/framework-design-guidelines-conventions-idioms-and-9780321545619) by Krzysztof Cwalina and Brad Abrams, published Oct 22, 2008 by Addison-Wesley Professional as part of the Microsoft Windows Development Series.*
## See Also
[Framework Design Guidelines](../../../docs/standard/design-guidelines/index.md)
[Naming Guidelines](../../../docs/standard/design-guidelines/naming-guidelines.md)
| 64.917647 | 420 | 0.749366 | eng_Latn | 0.995824 |
990b17b81b6690e3f953dc943521bb287c411c4a | 1,518 | md | Markdown | SRP/[email protected]/Documentation~/index.md | zloop1982/KhaosLWRP | 562e93050461367e18244a20d5902b49790e5b09 | [
"MIT"
] | 56 | 2019-08-09T02:17:26.000Z | 2022-03-27T09:06:19.000Z | SRP/[email protected]/Documentation~/index.md | zloop1982/KhaosLWRP | 562e93050461367e18244a20d5902b49790e5b09 | [
"MIT"
] | 1 | 2020-12-20T01:26:38.000Z | 2020-12-20T01:26:38.000Z | SRP/[email protected]/Documentation~/index.md | zloop1982/KhaosLWRP | 562e93050461367e18244a20d5902b49790e5b09 | [
"MIT"
] | 10 | 2019-08-28T22:46:18.000Z | 2021-07-16T07:00:42.000Z | ## Description
A **Shader Graph** enables you to build shaders visually. Instead of hand writing code you create and connect nodes in a graph network. The graph framework gives instant feedback on the changes, and it’s simple enough that new users can become involved in shader creation.
For an introduction to **Shader Graph** see [Getting Started](Getting-Started.md).
## Disclaimer
This repository and its documentation is under active development. Everything is subject to change.
## Contents
* [Getting Started](Getting-Started.md)
* [Custom Nodes with CodeFunctionNode](Custom-Nodes-With-CodeFunctionNode.md)
* [Shader Graph](Shader-Graph.md)
* [Shader Graph Window](Shader-Graph-Window.md)
* [Blackboard](Blackboard.md)
* [Master Preview](Master-Preview.md)
* [Create Node Menu](Create-Node-Menu.md)
* [Shader Graph Asset](Shader-Graph-Asset.md)
* [Sub-graph](Sub-graph.md)
* [Sub-graph Asset](Sub-graph-Asset.md)
* [Node](Node.md)
* [Port](Port.md)
* [Edge](Edge.md)
* [Master Node](Master-Node.md)
* [Data](Data.md)
* [Property Types](Property-Types.md)
* [Data Types](Data-Types.md)
* [Port Bindings](Port-Bindings.md)
* [Node Library](Node-Library.md)
* [Scripting API](Scripting-API.md)
* [CodeFunctionNode](CodeFunctionNode.md)
* [Port Types](CodeFunctionNode-Port-Types.md)
* [SlotAttribute](CodeFunctionNode.SlotAttribute.md)
* [Binding](CodeFunctionNode.Binding.md)
* [GetFunctionToConvert](CodeFunctionNode.GetFunctionToConvert.md) | 43.371429 | 272 | 0.723979 | yue_Hant | 0.774245 |
990b2abd7a5f637f6464916120823217ddebca24 | 456 | md | Markdown | README.md | rzrbld/goth-provider-wso2 | 5fc804d7c1de42ff41e99506f467359e5d3c785a | [
"Apache-2.0"
] | null | null | null | README.md | rzrbld/goth-provider-wso2 | 5fc804d7c1de42ff41e99506f467359e5d3c785a | [
"Apache-2.0"
] | null | null | null | README.md | rzrbld/goth-provider-wso2 | 5fc804d7c1de42ff41e99506f467359e5d3c785a | [
"Apache-2.0"
] | null | null | null | ## Goth provider wso2
a simple [wso2](https://github.com/wso2/product-is) oauth provider for [goth](https://github.com/markbates/goth) based on auth0 provider
## Use
see example at `example/main.go`
| ENV | description | example value |
|-----|-------------|---------------|
| WSO2_KEY | appID of the app | xbSblZrQVl1pWfMAf_3Ka4ySdv5a |
| WSO2_SECRET | app secret | 1NSFmwPg3EM2lSRxP3SlKbc02wKx |
| WSO2_DOMAIN | domain | dev.sso.example.com/oauth2 |
| 35.076923 | 137 | 0.682018 | eng_Latn | 0.5367 |
990b9b49f72abd58afacfe1c46b98fc00167e5c5 | 8,887 | md | Markdown | components/pipedream/sql/README.md | PThangJr/pipedream | cae57dd64af17f8628a6a3648f2285eb14db7891 | [
"MIT"
] | 2 | 2020-10-03T07:57:17.000Z | 2020-10-03T08:01:14.000Z | components/pipedream/sql/README.md | dannyroosevelt/pipedream | 1702750dfaf80b41fcad2acf85f6be4e672976ee | [
"MIT"
] | 7 | 2021-06-28T20:27:05.000Z | 2022-02-27T10:04:49.000Z | components/pipedream/sql/README.md | dannyroosevelt/pipedream | 1702750dfaf80b41fcad2acf85f6be4e672976ee | [
"MIT"
] | 1 | 2020-12-18T18:43:42.000Z | 2020-12-18T18:43:42.000Z | # Pipedream Scheduled SQL Source
This source runs a SQL query against the [Pipedream SQL Service](https://docs.pipedream.com/destinations/sql/) on a schedule, emitting the query results to any listeners for further processing.
You can use this source to:
- Produce scheduled reports: [aggregate the results of some table via SQL, and send them to Slack](https://pipedream.com/@dylburger/run-a-sql-query-against-the-pipedream-sql-service-send-results-to-slack-p_MOCrOV/edit), for example.
- Check for anomalies in a data set: run a query that compares the count of events seen in the last hour against the historical average, notifying you when you observe an anomaly.
- Any place where you want to drive a workflow using a SQL query!
This source is meant to operate on relatively small (< 1MB) results. See the [limits](#limits) section or [reach out](https://docs.pipedream.com/support/) to the Pipedream team with any questions.
## Pre-requisites
First, you must have sent some data to the Pipedream SQL Service. Visit [https://pipedream.com/sql](https://pipedream.com/sql) or [see the docs](https://docs.pipedream.com/destinations/sql/#adding-a-sql-destination) to learn how.
## Usage
[Click here to create a Scheduled SQL Source](https://pipedream.com/sources?action=create&url=https%3A%2F%2Fgithub.com%2FPipedreamHQ%2Fpipedream%2Fblob%2Fmaster%2Fcomponents%2Fpipedream%2Fsql%2Fsql.js&app=pipedream). You'll be asked to select a schedule (by default, this source runs once a day at 00:00 UTC) and configure the props below.
### Props
This source accepts three props:
- **SQL Query** : The query you'd like to run
- **Result Type** (_optional_): Specifies how you want the query results formatted in the emitted event. One of `array`, `object`, or `csv`. **Defaults to `array`**.
- **Emit each record as its own event** (_optional_): If `true`, each record in your results set is [emitted](/COMPONENT-API.md#emit) as its own event. **Defaults to `false`**, emitting results as a single event (based on the result type specified in the **Result Types** prop). See the [Result Format section](#result-format) for example output.
**Emit each record as its own event** only applies to a **Result Type** of `array`. If **Result Type** is set to `object` or `csv`, the value of **Emit each record as its own event** is ignored and assumed to be `false` — the source will always emit one event for each query.
### Result Format
All events contain the following keys:
- `query`: your SQL query
- `results.columnInfo`: an array of objects, one for each column in the results.
- `results.queryExecutionId`: a unique identifier for each query execution.
- `results.csvLocation`: a URL that points to a CSV of query results. This URL requires you authenticate with your Pipedream API as a `Bearer` token — [see the SQL API docs](https://docs.pipedream.com/destinations/sql/#running-sql-queries-via-api).
Both the **Result Type** and **Emit each record as its own event** props determine the final shape of your `results`. Typically, the default configuration — emit a single event, with the query results in an array — will work for most use cases. This lets you run a Pipedream workflow or other code on the full query output.
But you can emit each record as its own event, running a workflow on every record. Or you can output an object of results if it's easier for your workflow to operate on. This section describes the shape of the default output and the output for other combinations of these properties.
In the examples below, assume this query:
```sql
SELECT status_code, COUNT(*) AS count
FROM http_requests
GROUP BY 1
```
returns these results:
| `status_code` | `count` |
| ------------- | :-----: |
| `200` | 400 |
| `202` | 300 |
| `404` | 200 |
| `500` | 100 |
#### `array` of results, single event
The default output. Every time your query runs, the source emits an event of the following shape:
```json
{
"query": "SELECT status_code, COUNT(*) AS count FROM http_requests GROUP BY 1",
"results": {
"columnInfo": [
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "status_code",
"Label": "status_code",
"Type": "bigint",
"Precision": 17,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": false
},
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "count",
"Label": "count",
"Type": "bigint",
"Precision": 19,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": false
}
],
"queryExecutionId": "6cd06536-56f7-4c5d-a3e1-721b9e3ac614",
"csvLocation": "https://rt.pipedream.com/sql/csv/6cd06536-56f7-4c5d-a3e1-721b9e3ac614.csv",
"results": [
["200", "400"],
["202", "300"],
["404", "200"],
["500", "100"]
]
}
}
```
#### `array` of results, with each row emitted as its own event
When **Emit each record as its own event** is set to `true`, the source will emit each record as its own distinct event. In the example above, 4 records are returned from the query, so the source emits 4 events, each of which has the following shape:
```json
{
"query": "SELECT status_code, COUNT(*) AS count FROM http_requests GROUP BY 1",
"results": {
"columnInfo": [
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "status_code",
"Label": "status_code",
"Type": "bigint",
"Precision": 17,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": false
},
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "count",
"Label": "count",
"Type": "bigint",
"Precision": 19,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": false
}
],
"queryExecutionId": "310134a3-50f6-437a-939e-ec328de510b1",
"csvLocation": "https://rt.pipedream.com/sql/csv/310134a3-50f6-437a-939e-ec328de510b1.csv",
"record": { "status_code": "200", "count": "400" }
}
}
```
**This is a powerful feature**. It allows you to compute results by group using SQL, then run a Pipedream workflow on every group (record) in the results.
#### `object` of results
```json
{
"query": "SELECT status_code, COUNT(*) AS count FROM csp_violation_data GROUP BY 1",
"results": {
"columnInfo": [
{
"Type": "bigint",
"Label": "status_code",
"Scale": 0,
"CaseSensitive": false,
"SchemaName": "",
"Nullable": "UNKNOWN",
"TableName": "",
"Precision": 17,
"CatalogName": "hive",
"Name": "status_code"
},
{
"Type": "bigint",
"Label": "count",
"Scale": 0,
"CaseSensitive": false,
"SchemaName": "",
"Nullable": "UNKNOWN",
"TableName": "",
"Precision": 19,
"CatalogName": "hive",
"Name": "count"
}
],
"csvLocation": "https://rt.pipedream.com/sql/csv/72ead1c3-9193-4879-807a-bdd6cf3bf61d.csv",
"queryExecutionId": "72ead1c3-9193-4879-807a-bdd6cf3bf61d",
"results": [
{ "status_code": "200", "count": "400" },
{ "status_code": "202", "count": "300" },
{ "status_code": "404", "count": "200" },
{ "status_code": "500", "count": "100" }
]
}
}
```
#### `csv` results
Setting **Result Type** to `csv` allows you to output results directly as a CSV string:
```json
{
"query": "SELECT status_code, COUNT(*) AS count FROM csp_violation_data GROUP BY 1",
"results": {
"columnInfo": [
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "status_code",
"Label": "status_code",
"Type": "bigint",
"Precision": 17,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": false
},
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "count",
"Label": "count",
"Type": "bigint",
"Precision": 19,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": false
}
],
"queryExecutionId": "fed2cbbf-e723-4f2f-9f1d-4036362945cc",
"csvLocation": "https://rt.pipedream.com/sql/csv/fed2cbbf-e723-4f2f-9f1d-4036362945cc.csv",
"results": "status_code,count\n\"200\",400\n\"202\",300\n\"404\",200\n\"500\",100\n"
}
}
```
## Limits
The Scheduled SQL Source is subject to stricter limits than the [query limits](https://docs.pipedream.com/destinations/sql/#query-limits) for the Pipedream SQL Service:
- Query results should be limited to **less than 512KB**
- Queries are currently limited to a runtime of 60 seconds.
| 36.875519 | 346 | 0.626983 | eng_Latn | 0.875003 |
990baece3a9aea2b4cb384bcaaab3da18ae65a78 | 1,409 | md | Markdown | source/Classroom/Troubleshooting/Account_Administration/cant_access_the_email_address_on_file_for_your_sendgrid_account.md | katieporter/docs | 5fb13d4bbb1602759c5963fb04d2332ebd0c01a3 | [
"MIT"
] | 1 | 2019-04-13T05:54:25.000Z | 2019-04-13T05:54:25.000Z | source/Classroom/Troubleshooting/Account_Administration/cant_access_the_email_address_on_file_for_your_sendgrid_account.md | katieporter/docs | 5fb13d4bbb1602759c5963fb04d2332ebd0c01a3 | [
"MIT"
] | 4 | 2020-12-31T09:10:59.000Z | 2022-02-26T10:04:20.000Z | source/Classroom/Troubleshooting/Account_Administration/cant_access_the_email_address_on_file_for_your_sendgrid_account.md | katieporter/docs | 5fb13d4bbb1602759c5963fb04d2332ebd0c01a3 | [
"MIT"
] | 1 | 2018-10-09T12:49:23.000Z | 2018-10-09T12:49:23.000Z | ---
st:
published_at: 2016-06-10
type: Classroom
seo:
title: Can't access the email address on file for your SendGrid account?
description: Nowhere for you password reset emails to go? Inquire within...
keywords: address, password, reset, maintenance, primary, forgot, lost, left
title: Can't access the email address on file for your SendGrid account?
weight: 0
layout: page
zendesk_id: 204982878
navigation:
show: true
---
Sometimes, people leave your company, and their email address may be deleted or lost. Those email accounts can sometimes be associated with important business accounts, like your account with SendGrid! This kind of access is important for notifications, billing alerts, and passwords reset emails.
If you find yourself in a similar situation, use one of the following options to get back in the action:
1. (Recommended) Have your email administrator re-create the email address associated with the SendGrid account in question, and then request a [password reset]({{root_url}}/Classroom/Basics/Account/how_do_i_reset_my_password.html) email. SendGrid support can help out if you don't know that the email associated with a your account.
2. You can always [create a new account](https://sendgrid.com/transactional-email/pricing), and sign up with an active email address that you control. Keep in mind that account data cannot be transferred from old to new accounts.
| 61.26087 | 333 | 0.788502 | eng_Latn | 0.997856 |
990bd7730b440ac94ee195b5e5d6d0bd3d1294ea | 60 | md | Markdown | README.md | bugrayuksel/Nomon_Social_MERN | 810330380bca513cbfad119ca253b55a5e8d5f93 | [
"MIT"
] | null | null | null | README.md | bugrayuksel/Nomon_Social_MERN | 810330380bca513cbfad119ca253b55a5e8d5f93 | [
"MIT"
] | null | null | null | README.md | bugrayuksel/Nomon_Social_MERN | 810330380bca513cbfad119ca253b55a5e8d5f93 | [
"MIT"
] | null | null | null | # Nomon_Social_MERN
Social platform, built with MERN stack
| 20 | 39 | 0.816667 | eng_Latn | 0.877148 |
990c37df86f192afd06d3a04d2d120822ea09fbd | 43,482 | md | Markdown | articles/active-directory/develop/active-directory-authentication-scenarios.md | qianw211/azure-docs | fdbd39ed58dce7f381d501ac004eb4fa10eff748 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/active-directory/develop/active-directory-authentication-scenarios.md | qianw211/azure-docs | fdbd39ed58dce7f381d501ac004eb4fa10eff748 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/active-directory/develop/active-directory-authentication-scenarios.md | qianw211/azure-docs | fdbd39ed58dce7f381d501ac004eb4fa10eff748 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Authentication scenarios for Azure AD | Microsoft Docs
description: Provides an overview of the five most common authentication scenarios for Azure Active Directory (Azure AD)
services: active-directory
documentationcenter: dev-center-name
author: CelesteDG
manager: mtillman
editor: ''
ms.assetid: 0c84e7d0-16aa-4897-82f2-f53c6c990fd9
ms.service: active-directory
ms.component: develop
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: identity
ms.date: 07/26/2018
ms.author: celested
ms.reviewer: jmprieur, andret, nacanuma, hirsin
ms.custom: aaddev
---
# Authentication scenarios for Azure AD
Azure Active Directory (Azure AD) simplifies authentication for developers by providing identity as a service, with support for industry-standard protocols such as OAuth 2.0 and OpenID Connect, as well as open-source libraries for different platforms to help you start coding quickly. This article will help you understand the various scenarios Azure AD supports and show you how to get started. It’s divided into the following sections:
* [Basics of authentication in Azure AD](#basics-of-authentication-in-azure-ad)
* [Claims in Azure AD security tokens](#claims-in-azure-ad-security-tokens)
* [Basics of registering an application in Azure AD](#basics-of-registering-an-application-in-azure-ad)
* [Application types and scenarios](#application-types-and-scenarios)
* [Web browser to web application](#web-browser-to-web-application)
* [Single Page Application (SPA)](#single-page-application-spa)
* [Native application to web API](#native-application-to-web-api)
* [Web application to web API](#web-application-to-web-api)
* [Daemon or server application to web API](#daemon-or-server-application-to-web-api)
## Basics of authentication in Azure AD
If you are unfamiliar with basic concepts of authentication in Azure AD, read this section. Otherwise, you may want to skip down to [Application types and scenarios](#application-types-and-scenarios).
Let’s consider the most basic scenario where identity is required: a user in a web browser needs to authenticate to a web application. This scenario is described in greater detail in the [Web browser to web application](#web-browser-to-web-application) section, but it’s a useful starting point to illustrate the capabilities of Azure AD and conceptualize how the scenario works. Consider the following diagram for this scenario:

With the diagram above in mind, here’s what you need to know about its various components:
* Azure AD is the identity provider, responsible for verifying the identity of users and applications that exist in an organization’s directory, and ultimately issuing security tokens upon successful authentication of those users and applications.
* An application that wants to outsource authentication to Azure AD must be registered in Azure AD, which registers and uniquely identifies the app in the directory.
* Developers can use the open-source Azure AD authentication libraries to make authentication easy by handling the protocol details for you. For more information, see [Azure Active Directory Authentication Libraries](active-directory-authentication-libraries.md).
* Once a user has been authenticated, the application must validate the user’s security token to ensure that authentication was successful. We have samples of what the application must do in a variety of languages and frameworks on [GitHub](https://github.com/Azure-Samples?q=active-directory). If you're building a web app in ASP.NET, see the [add sign-in for an ASP.NET web app guide](https://docs.microsoft.com/en-us/azure/active-directory/develop/guidedsetups/active-directory-aspnetwebapp). If you’re building a web API resource in ASP.NET, see the [web API getting started guide](https://docs.microsoft.com/en-us/azure/active-directory/develop/active-directory-devquickstarts-webapi-dotnet).
* The flow of requests and responses for the authentication process is determined by the authentication protocol that was used, such as OAuth 2.0, OpenID Connect, WS-Federation, or SAML 2.0. These protocols are discussed in more detail in the [Azure Active Directory authentication protocols](active-directory-authentication-protocols.md) article and in the sections below.
> [!NOTE]
> Azure AD supports the OAuth 2.0 and OpenID Connect standards that make extensive use of bearer tokens, including bearer tokens represented as JWTs. A *bearer token* is a lightweight security token that grants the “bearer” access to a protected resource. In this sense, the “bearer” is any party that can present the token. Though a party must first authenticate with Azure AD to receive the bearer token, if the required steps are not taken to secure the token in transmission and storage, it can be intercepted and used by an unintended party. While some security tokens have a built-in mechanism for preventing unauthorized parties from using them, bearer tokens do not have this mechanism and must be transported in a secure channel such as transport layer security (HTTPS). If a bearer token is transmitted in the clear, a man-in-the-middle attack can be used by a malicious party to acquire the token and use it for an unauthorized access to a protected resource. The same security principles apply when storing or caching bearer tokens for later use. Always ensure that your application transmits and stores bearer tokens in a secure manner. For more security considerations on bearer tokens, see [RFC 6750 Section 5](http://tools.ietf.org/html/rfc6750).
Now that you have an overview of the basics, read the sections below to understand how provisioning works in Azure AD and the common scenarios that Azure AD supports.
## Claims in Azure AD security tokens
Security tokens (access and ID tokens) issued by Azure AD contain claims, or assertions of information about the subject that has been authenticated. These claims can be used by the application for various tasks. For example, applications can use claims to validate the token, identify the subject's directory tenant, display user information, determine the subject's authorization, and so on. The claims present in any given security token are dependent upon the type of token, the type of credential used to authenticate the user, and the application configuration. A brief description of each type of claim emitted by Azure AD is provided in the table below. For more information, refer to [Supported token and claim types](active-directory-token-and-claims.md).
| Claim | Description |
| --- | --- |
| Application ID | Identifies the application that is using the token. |
| Audience | Identifies the recipient resource the token is intended for. |
| Application Authentication Context Class Reference | Indicates how the client was authenticated (public client vs. confidential client). |
| Authentication Instant | Records the date and time when the authentication occurred. |
| Authentication Method | Indicates how the subject of the token was authenticated (password, certificate, etc.). |
| First Name | Provides the given name of the user as set in Azure AD. |
| Groups | Contains object IDs of Azure AD groups that the user is a member of. |
| Identity Provider | Records the identity provider that authenticated the subject of the token. |
| Issued At | Records the time at which the token was issued, often used for token freshness. |
| Issuer | Identifies the STS that emitted the token as well as the Azure AD tenant. |
| Last Name | Provides the surname of the user as set in Azure AD. |
| Name | Provides a human readable value that identifies the subject of the token. |
| Object ID | Contains an immutable, unique identifier of the subject in Azure AD. |
| Roles | Contains friendly names of Azure AD Application Roles that the user has been granted. |
| Scope | Indicates the permissions granted to the client application. |
| Subject | Indicates the principal about which the token asserts information. |
| Tenant ID | Contains an immutable, unique identifier of the directory tenant that issued the token. |
| Token Lifetime | Defines the time interval within which a token is valid. |
| User Principal Name | Contains the user principal name of the subject. |
| Version | Contains the version number of the token. |
## Basics of registering an application in Azure AD
Any application that outsources authentication to Azure AD must be registered in a directory. This step involves telling Azure AD about your application, including the URL where it’s located, the URL to send replies after authentication, the URI to identify your application, and more. This information is required for a few key reasons:
* Azure AD needs to communicate with the application when handling sign-on or exchanging tokens. The information passed between Azure AD and the application includes the following:
* **Application ID URI** - The identifier for an application. This value is sent to Azure AD during authentication to indicate which application the caller wants a token for. Additionally, this value is included in the token so that the application knows it was the intended target.
* **Reply URL** and **Redirect URI** - For a web API or web application, the Reply URL is the location where Azure AD will send the authentication response, including a token if authentication was successful. For a native application, the Redirect URI is a unique identifier to which Azure AD will redirect the user-agent in an OAuth 2.0 request.
* **Application ID** - The ID for an application, which is generated by Azure AD when the application is registered. When requesting an authorization code or token, the Application ID and Key are sent to Azure AD during authentication.
* **Key** - The key that is sent along with an Application ID when authenticating to Azure AD to call a web API.
* Azure AD needs to ensure the application has the required permissions to access your directory data, other applications in your organization, and so on.
Provisioning becomes clearer when you understand that there are two categories of applications that can be developed and integrated with Azure AD:
* **Single tenant application** - A single tenant application is intended for use in one organization. These are typically line-of-business (LoB) applications written by an enterprise developer. A single tenant application only needs to be accessed by users in one directory, and as a result, it only needs to be provisioned in one directory. These applications are typically registered by a developer in the organization.
* **Multi-tenant application** - A multi-tenant application is intended for use in many organizations, not just one organization. These are typically software-as-a-service (SaaS) applications written by an independent software vendor (ISV). Multi-tenant applications need to be provisioned in each directory where they will be used, which requires user or administrator consent to register them. This consent process starts when an application has been registered in the directory and is given access to the Graph API or perhaps another web API. When a user or administrator from a different organization signs up to use the application, they are presented with a dialog that displays the permissions the application requires. The user or administrator can then consent to the application, which gives the application access to the stated data, and finally registers the application in their directory. For more information, see [Overview of the Consent Framework](active-directory-integrating-applications.md#overview-of-the-consent-framework).
### Additional considerations when developing single tenant or multi-tenant apps
Some additional considerations arise when developing a multi-tenant application instead of a single tenant application. For example, if you are making your application available to users in multiple directories, you need a mechanism to determine which tenant they’re in. A single tenant application only needs to look in its own directory for a user, while a multi-tenant application needs to identify a specific user from all the directories in Azure AD. To accomplish this task, Azure AD provides a common authentication endpoint where any multi-tenant application can direct sign-in requests, instead of a tenant-specific endpoint. This endpoint is https://login.microsoftonline.com/common for all directories in Azure AD, whereas a tenant-specific endpoint might be https://login.microsoftonline.com/contoso.onmicrosoft.com. The common endpoint is especially important to consider when developing your application because you’ll need the necessary logic to handle multiple tenants during sign-in, sign-out, and token validation.
If you are currently developing a single tenant application but want to make it available to many organizations, you can easily make changes to the application and its configuration in Azure AD to make it multi-tenant capable. In addition, Azure AD uses the same signing key for all tokens in all directories, whether you are providing authentication in a single tenant or multi-tenant application.
Each scenario listed in this document includes a subsection that describes its provisioning requirements. For more in-depth information about provisioning an application in Azure AD and the differences between single and multi-tenant applications, see [Integrating applications with Azure Active Directory](active-directory-integrating-applications.md) for more information. Continue reading to understand the common application scenarios in Azure AD.
## Application Types and Scenarios
Each of the scenarios described here can be developed using various languages and platforms. They are all backed by complete code samples available in the [Code Samples guide](active-directory-code-samples.md), or directly from the corresponding [GitHub sample repositories](https://github.com/Azure-Samples?q=active-directory). In addition, if your application needs a specific piece or segment of an end-to-end scenario, in most cases that functionality can be added independently. For example, if you have a native application that calls a web API, you can easily add a web application that also calls the web API. The following diagram illustrates these scenarios and application types, and how different components can be added:

These are the five primary application scenarios supported by Azure AD:
* [Web browser to web application](#web-browser-to-web-application): A user needs to sign in to a web application that is secured by Azure AD.
* [Single Page Application (SPA)](#single-page-application-spa): A user needs to sign in to a single page application that is secured by Azure AD.
* [Native application to web API](#native-application-to-web-api): A native application that runs on a phone, tablet, or PC needs to authenticate a user to get resources from a web API that is secured by Azure AD.
* [Web application to web API](#web-application-to-web-api): A web application needs to get resources from a web API secured by Azure AD.
* [Daemon or server application to web API](#daemon-or-server-application-to-web-api): A daemon application or a server application with no web user interface needs to get resources from a web API secured by Azure AD.
### Web browser to web application
This section describes an application that authenticates a user in a web browser to a web application. In this scenario, the web application directs the user’s browser to sign them in to Azure AD. Azure AD returns a sign-in response through the user’s browser, which contains claims about the user in a security token. This scenario supports sign-on using the WS-Federation, SAML 2.0, and OpenID Connect protocols.
#### Diagram

#### Description of protocol flow
1. When a user visits the application and needs to sign in, they are redirected via a sign-in request to the authentication endpoint in Azure AD.
1. The user signs in on the sign-in page.
1. If authentication is successful, Azure AD creates an authentication token and returns a sign-in response to the application’s Reply URL that was configured in the Azure portal. For a production application, this Reply URL should be HTTPS. The returned token includes claims about the user and Azure AD that are required by the application to validate the token.
1. The application validates the token by using a public signing key and issuer information available at the federation metadata document for Azure AD. After the application validates the token, it starts a new session with the user. This session allows the user to access the application until it expires.
#### Code samples
See the code samples for Web Browser to Web Application scenarios. And, check back frequently -- new samples are added frequently. [Web Application](active-directory-code-samples.md#web-applications).
#### Registering
* Single Tenant: If you are building an application just for your organization, it must be registered in your company’s directory by using the Azure portal.
* Multi-Tenant: If you are building an application that can be used by users outside your organization, it must be registered in your company’s directory, but also must be registered in each organization’s directory that will be using the application. To make your application available in their directory, you can include a sign-up process for your customers that enables them to consent to your application. When they sign up for your application, they will be presented with a dialog that shows the permissions the application requires, and then the option to consent. Depending on the required permissions, an administrator in the other organization may be required to give consent. When the user or administrator consents, the application is registered in their directory. For more information, see [Integrating Applications with Azure Active Directory](active-directory-integrating-applications.md).
#### Token expiration
The user’s session expires when the lifetime of the token issued by Azure AD expires. Your application can shorten this time period if desired, such as signing out users based on a period of inactivity. When the session expires, the user will be prompted to sign in again.
### Single Page Application (SPA)
This section describes authentication for a Single Page Application, that uses Azure AD and the OAuth 2.0 implicit authorization grant to secure its web API back end. Single Page Applications are typically structured as a JavaScript presentation layer (front end) that runs in the browser and a Web API back end that runs on a server and implements the application’s business logic. To learn more about the implicit authorization grant, and help you decide whether it's right for your application scenario, see [Understanding the OAuth2 implicit grant flow in Azure Active Directory](active-directory-dev-understanding-oauth2-implicit-grant.md).
In this scenario, when the user signs in, the JavaScript front end uses [Active Directory Authentication Library for JavaScript (ADAL.JS)](https://github.com/AzureAD/azure-activedirectory-library-for-js) and the implicit authorization grant to obtain an ID token (id_token) from Azure AD. The token is cached and the client attaches it to the request as the bearer token when making calls to its Web API back end, which is secured using the OWIN middleware.
#### Diagram

#### Description of protocol flow
1. The user navigates to the web application.
1. The application returns the JavaScript front end (presentation layer) to the browser.
1. The user initiates sign in, for example by clicking a sign-in link. The browser sends a GET to the Azure AD authorization endpoint to request an ID token. This request includes the application ID and reply URL in the query parameters.
1. Azure AD validates the Reply URL against the registered Reply URL that was configured in the Azure portal.
1. The user signs in on the sign-in page.
1. If authentication is successful, Azure AD creates an ID token and returns it as a URL fragment (#) to the application’s Reply URL. For a production application, this Reply URL should be HTTPS. The returned token includes claims about the user and Azure AD that are required by the application to validate the token.
1. The JavaScript client code running in the browser extracts the token from the response to use in securing calls to the application’s web API back end.
1. The browser calls the application’s web API back end with the ID token in the authorization header. The Azure AD authentication service issues an ID token that can be used as a bearer token if the resource is the same as the client ID (in this case, this is true as the web API is the app's own backend).
#### Code samples
See the code samples for Single Page Application (SPA) scenarios. Be sure to check back frequently -- new samples are added frequently. [Single Page Application (SPA)](active-directory-code-samples.md#single-page-applications).
#### Registering
* Single Tenant: If you are building an application just for your organization, it must be registered in your company’s directory by using the Azure portal.
* Multi-Tenant: If you are building an application that can be used by users outside your organization, it must be registered in your company’s directory, but also must be registered in each organization’s directory that will be using the application. To make your application available in their directory, you can include a sign-up process for your customers that enables them to consent to your application. When they sign up for your application, they will be presented with a dialog that shows the permissions the application requires, and then the option to consent. Depending on the required permissions, an administrator in the other organization may be required to give consent. When the user or administrator consents, the application is registered in their directory. For more information, see [Integrating Applications with Azure Active Directory](active-directory-integrating-applications.md).
After registering the application, it must be configured to use OAuth 2.0 Implicit Grant protocol. By default, this protocol is disabled for applications. To enable the OAuth2 Implicit Grant protocol for your application, edit its application manifest from the Azure portal and set the “oauth2AllowImplicitFlow” value to true. For detailed instructions, see [Enabling OAuth 2.0 Implicit Grant for Single Page Applications](active-directory-integrating-applications.md).
#### Token expiration
Using ADAL.js helps with:
* refreshing an expired token
* requesting an access token to call a web API resource
After a successful authentication, Azure AD writes a cookie in the user's browser to establish a session. Note the session exists between the user and Azure AD (not between the user and the web application). When a token expires, ADAL.js uses this session to silently obtain another token. ADAL.js uses a hidden iFrame to send and receive the request using the OAuth Implicit Grant protocol. ADAL.js can also use this same mechanism to silently obtain access tokens for other web API resources the application calls as long as these resources support cross-origin resource sharing (CORS), are registered in the user’s directory, and any required consent was given by the user during sign-in.
### Native application to web API
This section describes a native application that calls a web API on behalf of a user. This scenario is built on the OAuth 2.0 authorization code grant type with a public client, as described in section 4.1 of the [OAuth 2.0 specification](http://tools.ietf.org/html/rfc6749). The native application obtains an access token for the user by using the OAuth 2.0 protocol. This access token is then sent in the request to the web API, which authorizes the user and returns the desired resource.
#### Diagram

#### Description of protocol flow
If you are using the AD Authentication Libraries, most of the protocol details described below are handled for you, such as the browser pop-up, token caching, and handling of refresh tokens.
1. Using a browser pop-up, the native application makes a request to the authorization endpoint in Azure AD. This request includes the Application ID and the redirect URI of the native application as shown in the Azure portal, and the application ID URI for the web API. If the user hasn’t already signed in, they are prompted to sign in again
1. Azure AD authenticates the user. If it is a multi-tenant application and consent is required to use the application, the user will be required to consent if they haven’t already done so. After granting consent and upon successful authentication, Azure AD issues an authorization code response back to the client application’s redirect URI.
1. When Azure AD issues an authorization code response back to the redirect URI, the client application stops browser interaction and extracts the authorization code from the response. Using this authorization code, the client application sends a request to Azure AD’s token endpoint that includes the authorization code, details about the client application (Application ID and redirect URI), and the desired resource (application ID URI for the web API).
1. The authorization code and information about the client application and web API are validated by Azure AD. Upon successful validation, Azure AD returns two tokens: a JWT access token and a JWT refresh token. In addition, Azure AD returns basic information about the user, such as their display name and tenant ID.
1. Over HTTPS, the client application uses the returned JWT access token to add the JWT string with a “Bearer” designation in the Authorization header of the request to the web API. The web API then validates the JWT token, and if validation is successful, returns the desired resource.
1. When the access token expires, the client application will receive an error that indicates the user needs to authenticate again. If the application has a valid refresh token, it can be used to acquire a new access token without prompting the user to sign in again. If the refresh token expires, the application will need to interactively authenticate the user once again.
> [!NOTE]
> The refresh token issued by Azure AD can be used to access multiple resources. For example, if you have a client application that has permission to call two web APIs, the refresh token can be used to get an access token to the other web API as well.
#### Code samples
See the code samples for Native Application to Web API scenarios. And, check back frequently -- we add new samples frequently. [Native Application to Web API](active-directory-code-samples.md#desktop-and-mobile-public-client-applications-calling-microsoft-graph-or-a-web-api).
#### Registering
* Single Tenant: Both the native application and the web API must be registered in the same directory in Azure AD. The web API can be configured to expose a set of permissions, which are used to limit the native application’s access to its resources. The client application then selects the desired permissions from the “Permissions to Other Applications” drop-down menu in the Azure portal.
* Multi-Tenant: First, the native application only ever registered in the developer or publisher’s directory. Second, the native application is configured to indicate the permissions it requires to be functional. This list of required permissions is shown in a dialog when a user or administrator in the destination directory gives consent to the application, which makes it available to their organization. Some applications only require user-level permissions, which any user in the organization can consent to. Other applications require administrator-level permissions, which a user in the organization cannot consent to. Only a directory administrator can give consent to applications that require this level of permissions. When the user or administrator consents, only the web API is registered in their directory. For more information, see [Integrating Applications with Azure Active Directory](active-directory-integrating-applications.md).
#### Token expiration
When the native application uses its authorization code to get a JWT access token, it also receives a JWT refresh token. When the access token expires, the refresh token can be used to re-authenticate the user without requiring them to sign in again. This refresh token is then used to authenticate the user, which results in a new access token and refresh token.
### Web application to web API
This section describes a web application that needs to get resources from a web API. In this scenario, there are two identity types that the web application can use to authenticate and call the web API: an application identity, or a delegated user identity.
*Application identity:* This scenario uses OAuth 2.0 client credentials grant to authenticate as the application and access the web API. When using an application identity, the web API can only detect that the web application is calling it, as the web API does not receive any information about the user. If the application receives information about the user, it will be sent via the application protocol, and it is not signed by Azure AD. The web API trusts that the web application authenticated the user. For this reason, this pattern is called a trusted subsystem.
*Delegated user identity:* This scenario can be accomplished in two ways: OpenID Connect, and OAuth 2.0 authorization code grant with a confidential client. The web application obtains an access token for the user, which proves to the web API that the user successfully authenticated to the web application and that the web application was able to obtain a delegated user identity to call the web API. This access token is sent in the request to the web API, which authorizes the user and returns the desired resource.
#### Diagram

#### Description of protocol flow
Both the application identity and delegated user identity types are discussed in the flow below. The key difference between them is that the delegated user identity must first acquire an authorization code before the user can sign in and gain access to the web API.
##### Application identity with OAuth 2.0 client credentials grant
1. A user is signed in to Azure AD in the web application (see the [Web Browser to Web Application](#web-browser-to-web-application) above).
1. The web application needs to acquire an access token so that it can authenticate to the web API and retrieve the desired resource. It makes a request to Azure AD’s token endpoint, providing the credential, Application ID, and web API’s application ID URI.
1. Azure AD authenticates the application and returns a JWT access token that is used to call the web API.
1. Over HTTPS, the web application uses the returned JWT access token to add the JWT string with a “Bearer” designation in the Authorization header of the request to the web API. The web API then validates the JWT token, and if validation is successful, returns the desired resource.
##### Delegated user identity with OpenID Connect
1. A user is signed in to a web application using Azure AD (see the [Web Browser to Web Application](#web-browser-to-web-application) section above). If the user of the web application has not yet consented to allowing the web application to call the web API on its behalf, the user will need to consent. The application will display the permissions it requires, and if any of these are administrator-level permissions, a normal user in the directory will not be able to consent. This consent process only applies to multi-tenant applications, not single tenant applications, as the application will already have the necessary permissions. When the user signed in, the web application received an ID token with information about the user, as well as an authorization code.
1. Using the authorization code issued by Azure AD, the web application sends a request to Azure AD’s token endpoint that includes the authorization code, details about the client application (Application ID and redirect URI), and the desired resource (application ID URI for the web API).
1. The authorization code and information about the web application and web API are validated by Azure AD. Upon successful validation, Azure AD returns two tokens: a JWT access token and a JWT refresh token.
1. Over HTTPS, the web application uses the returned JWT access token to add the JWT string with a “Bearer” designation in the Authorization header of the request to the web API. The web API then validates the JWT token, and if validation is successful, returns the desired resource.
##### Delegated user identity with OAuth 2.0 authorization code grant
1. A user is already signed in to a web application, whose authentication mechanism is independent of Azure AD.
1. The web application requires an authorization code to acquire an access token, so it issues a request through the browser to Azure AD’s authorization endpoint, providing the Application ID and redirect URI for the web application after successful authentication. The user signs in to Azure AD.
1. If the user of the web application has not yet consented to allowing the web application to call the web API on its behalf, the user will need to consent. The application will display the permissions it requires, and if any of these are administrator-level permissions, a normal user in the directory will not be able to consent. This consent applies to both single and multi-tenant application. In the single tenant case, an admin can perform admin consent to consent on behalf of their users. This can be done using the `Grant Permissions` button in the [Azure Portal](https://portal.azure.com).
1. After the user has consented, the web application receives the authorization code that it needs to acquire an access token.
1. Using the authorization code issued by Azure AD, the web application sends a request to Azure AD’s token endpoint that includes the authorization code, details about the client application (Application ID and redirect URI), and the desired resource (application ID URI for the web API).
1. The authorization code and information about the web application and web API are validated by Azure AD. Upon successful validation, Azure AD returns two tokens: a JWT access token and a JWT refresh token.
1. Over HTTPS, the web application uses the returned JWT access token to add the JWT string with a “Bearer” designation in the Authorization header of the request to the web API. The web API then validates the JWT token, and if validation is successful, returns the desired resource.
#### Code samples
See the code samples for Web Application to Web API scenarios. And, check back frequently -- new samples are added frequently. Web [Application to Web API](active-directory-code-samples.md#web-applications-signing-in-users-calling-microsoft-graph-or-a-web-api-with-the-users-identity).
#### Registering
* Single Tenant: For both the application identity and delegated user identity cases, the web application and the web API must be registered in the same directory in Azure AD. The web API can be configured to expose a set of permissions, which are used to limit the web application’s access to its resources. If a delegated user identity type is being used, the web application needs to select the desired permissions from the “Permissions to Other Applications” drop-down menu in the Azure portal. This step is not required if the application identity type is being used.
* Multi-Tenant: First, the web application is configured to indicate the permissions it requires to be functional. This list of required permissions is shown in a dialog when a user or administrator in the destination directory gives consent to the application, which makes it available to their organization. Some applications only require user-level permissions, which any user in the organization can consent to. Other applications require administrator-level permissions, which a user in the organization cannot consent to. Only a directory administrator can give consent to applications that require this level of permissions. When the user or administrator consents, the web application and the web API are both registered in their directory.
#### Token expiration
When the web application uses its authorization code to get a JWT access token, it also receives a JWT refresh token. When the access token expires, the refresh token can be used to re-authenticate the user without requiring them to sign in again. This refresh token is then used to authenticate the user, which results in a new access token and refresh token.
### Daemon or server application to web API
This section describes a daemon or server application that needs to get resources from a web API. There are two sub-scenarios that apply to this section: A daemon that needs to call a web API, built on OAuth 2.0 client credentials grant type; and a server application (such as a web API) that needs to call a web API, built on OAuth 2.0 On-Behalf-Of draft specification.
For the scenario when a daemon application needs to call a web API, it’s important to understand a few things. First, user interaction is not possible with a daemon application, which requires the application to have its own identity. An example of a daemon application is a batch job, or an operating system service running in the background. This type of application requests an access token by using its application identity and presenting its Application ID, credential (password or certificate), and application ID URI to Azure AD. After successful authentication, the daemon receives an access token from Azure AD, which is then used to call the web API.
For the scenario when a server application needs to call a web API, it’s helpful to use an example. Imagine that a user has authenticated on a native application, and this native application needs to call a web API. Azure AD issues a JWT access token to call the web API. If the web API needs to call another downstream web API, it can use the on-behalf-of flow to delegate the user’s identity and authenticate to the second-tier web API.
#### Diagram

#### Description of protocol flow
##### Application identity with OAuth 2.0 client credentials grant
1. First, the server application needs to authenticate with Azure AD as itself, without any human interaction such as an interactive sign-on dialog. It makes a request to Azure AD’s token endpoint, providing the credential, Application ID, and application ID URI.
1. Azure AD authenticates the application and returns a JWT access token that is used to call the web API.
1. Over HTTPS, the web application uses the returned JWT access token to add the JWT string with a “Bearer” designation in the Authorization header of the request to the web API. The web API then validates the JWT token, and if validation is successful, returns the desired resource.
##### Delegated user identity with OAuth 2.0 On-Behalf-Of Draft Specification
The flow discussed below assumes that a user has been authenticated on another application (such as a native application), and their user identity has been used to acquire an access token to the first-tier web API.
1. The native application sends the access token to the first-tier web API.
1. The first-tier web API sends a request to Azure AD’s token endpoint, providing its Application ID and credentials, as well as the user’s access token. In addition, the request is sent with an on_behalf_of parameter that indicates the web API is requesting new tokens to call a downstream web API on behalf of the original user.
1. Azure AD verifies that the first-tier web API has permissions to access the second-tier web API and validates the request, returning a JWT access token and a JWT refresh token to the first-tier web API.
1. Over HTTPS, the first-tier web API then calls the second-tier web API by appending the token string in the Authorization header in the request. The first-tier web API can continue to call the second-tier web API as long as the access token and refresh tokens are valid.
#### Code samples
See the code samples for Daemon or Server Application to Web API scenarios. And, check back frequently -- new samples are added frequently. [Server or Daemon Application to Web API](active-directory-code-samples.md#daemon-applications-accessing-web-apis-with-the-applications-identity)
#### Registering
* Single Tenant: For both the application identity and delegated user identity cases, the daemon or server application must be registered in the same directory in Azure AD. The web API can be configured to expose a set of permissions, which are used to limit the daemon or server’s access to its resources. If a delegated user identity type is being used, the server application needs to select the desired permissions from the “Permissions to Other Applications” drop-down menu in the Azure portal. This step is not required if the application identity type is being used.
* Multi-Tenant: First, the daemon or server application is configured to indicate the permissions it requires to be functional. This list of required permissions is shown in a dialog when a user or administrator in the destination directory gives consent to the application, which makes it available to their organization. Some applications only require user-level permissions, which any user in the organization can consent to. Other applications require administrator-level permissions, which a user in the organization cannot consent to. Only a directory administrator can give consent to applications that require this level of permissions. When the user or administrator consents, both of the web APIs are registered in their directory.
#### Token expiration
When the first application uses its authorization code to get a JWT access token, it also receives a JWT refresh token. When the access token expires, the refresh token can be used to re-authenticate the user without prompting for credentials. This refresh token is then used to authenticate the user, which results in a new access token and refresh token.
## See Also
[Azure Active Directory Developer's Guide](active-directory-developers-guide.md)
[Azure Active Directory Code Samples](active-directory-code-samples.md)
[Important Information About Signing Key Rollover in Azure AD](active-directory-signing-key-rollover.md)
[OAuth 2.0 in Azure AD](https://msdn.microsoft.com/library/azure/dn645545.aspx)
| 130.96988 | 1,262 | 0.802654 | eng_Latn | 0.998044 |
990cbed63c4bb42416b0e7bd57c756f48ecd6f78 | 4,010 | md | Markdown | content/installs/nn.md | nycmeshnet/Docs | 4b13f9c0c6b7c41323051760be51003215faf3c3 | [
"CC0-1.0"
] | null | null | null | content/installs/nn.md | nycmeshnet/Docs | 4b13f9c0c6b7c41323051760be51003215faf3c3 | [
"CC0-1.0"
] | null | null | null | content/installs/nn.md | nycmeshnet/Docs | 4b13f9c0c6b7c41323051760be51003215faf3c3 | [
"CC0-1.0"
] | null | null | null | ---
title: "Network Number"
aliases: ["/nn"]
---
Enter the Install Number* below to get the NN that can be used to configure the rooftop antennas/routers. This can also be used with existing multiple apartment installs to figure out the network number (NN) for the roof/building you are connected to.
<form action="https://script.google.com/macros/s/AKfycbw6p-KPv9i7xCVMXxd01eVfCE2bsMueKE2fD1En4i5SiQvSnFTGCkCEJMjkP5p8XTx1/exec">
<label for="installnum">Install Number:</label>
<input type="hidden" id="method" name="method" value="nn">
<input type="hidden" name="format" value="1" />
<input type="number" id="id" name="id" min="1" max="100000" required>
<input type="submit" value='Get NN'>
<input type="hidden" name="format" value="1" />
</form>
<br/>
<br/>
_*The Install Number is the number you received in an email right after you registered. If you can't find the email with your Install Number please [contact us](mailto:[email protected])._
<br/>
<br/>
If you have the password you can assign a NN for an install number
<form action="https://script.google.com/macros/s/AKfycbw6p-KPv9i7xCVMXxd01eVfCE2bsMueKE2fD1En4i5SiQvSnFTGCkCEJMjkP5p8XTx1/exec">Install Number:</label>
<input type="hidden" id="method" name="method" value="nn">
<input type="hidden" name="format" value="1" />
<input type="number" id="id" name="id" min="1" max="100000" required>
<label for="pwd">Password:</label>
<input type="password" minlength="8" id="id" name="pwd" required>
<input type="submit" value='Assign NN'>
</form>
<br/>
<br/>
We have changed the way "Node Numbers" work and we're now using the term NN or "Network Number".
Previously each registration would receive a **Node Number**. This number would be used to configure the devices. For example used in the litebeam naming and in the OmniTik configuration. The Node Number was used to generate the IP address range used by the OmniTik device. Many registrations do not end up being installed and thus a lot of addresses are being “blocked” as reserved for those Node Numbers, Nodes associated with persons. We gave ourselves a limit of 8192 “nodes”. This in order to “save” the IP range above, for further usage.
We need now to start using the unused or unassigned IPs in the lower range.
From now on, when a person registers, they receive an **Install Number** (or install request number). A person can register for several addresses and receive several Install Numbers. An Install Number can be seen a bit like a work-order.
When devices are being configured and installed, they will receive a **Network Number** or **NN**, different from the Install Number. The IPs for an OmniTik device will be generated out of the **Network Number (NN)**. A member thus will have an **Install number** and a **NN**. It is possible that for some installations the Network Number and the Install Number are the same number. The second member connected to the same node (Network Number) will have a different Install number.
The Install Number is associated with a member. When installed it is linked to a Network Number. The Network Number is associated with a building number (street address / BIN ). A building can have several Network Numbers in the event that it has for technical reasons 2 or more “nodes”.
When a member moves, the Network Number stays with the building (especially when there are other members connected to this Network Number (Node). The moving member will register with their new street address and will receive a new Install Number.
<br/><br/><br/><br/>*Examples*<br/><br/>
*John D. Install Number 2000, is connected to node with Network Number 5000*<br/>
*Elis W. Insall Number 3000, is also connected to node with Network Number 5000*<br/>
*Node with Network Number 5000 is on the building at address 55 Main Street.*<br/><br/>
*John D. has also Install Number 4000, is connected to node with Network Number 6000*<br/>
*Node with Network Number 6000 is on the building at address 102 Down Street.*<br/>
| 71.607143 | 545 | 0.753367 | eng_Latn | 0.996635 |
990d47fed4cb83973af2f416ec4c2a2a1bca9c71 | 975 | md | Markdown | fsharp/parallel-letter-frequency/README.md | ErikSchierboom/exercism | 3da5d41ad3811c5963a0da62f862602ba01a9f55 | [
"Apache-2.0"
] | 23 | 2017-02-22T16:57:12.000Z | 2022-02-11T20:32:36.000Z | fsharp/parallel-letter-frequency/README.md | ErikSchierboom/exercism | 3da5d41ad3811c5963a0da62f862602ba01a9f55 | [
"Apache-2.0"
] | 36 | 2020-07-21T09:34:05.000Z | 2020-07-21T10:29:20.000Z | fsharp/parallel-letter-frequency/README.md | ErikSchierboom/exercism | 3da5d41ad3811c5963a0da62f862602ba01a9f55 | [
"Apache-2.0"
] | 14 | 2017-02-22T16:58:23.000Z | 2021-10-06T00:21:57.000Z | # Parallel Letter Frequency
Welcome to Parallel Letter Frequency on Exercism's F# Track.
If you need help running the tests or submitting your code, check out `HELP.md`.
## Instructions
Count the frequency of letters in texts using parallel computation.
Parallelism is about doing things in parallel that can also be done
sequentially. A common example is counting the frequency of letters.
Create a function that returns the total frequency of each letter in a
list of texts and that employs parallelism.
For this exercise the following F# feature comes in handy:
- [Asynchronous programming](https://fsharpforfunandprofit.com/posts/concurrency-async-and-parallel/) .NET has asynchronous functionality built-in which enables you to run things in parallel (assuming you have a multi-core processor which is becoming more an more common) easily
## Source
### Created by
- @ErikSchierboom
### Contributed to by
- @jrr
- @lestephane
- @robkeim
- @valentin-p
- @wolf99 | 31.451613 | 278 | 0.784615 | eng_Latn | 0.998908 |
990d4c3c75c3313bbc5cbe9119209764959667d4 | 1,535 | markdown | Markdown | _entries/september-11-2018.markdown | 200066/hkisdragons | eec0b16291507e2c97f605e01779b67071aa3efb | [
"MIT"
] | null | null | null | _entries/september-11-2018.markdown | 200066/hkisdragons | eec0b16291507e2c97f605e01779b67071aa3efb | [
"MIT"
] | null | null | null | _entries/september-11-2018.markdown | 200066/hkisdragons | eec0b16291507e2c97f605e01779b67071aa3efb | [
"MIT"
] | null | null | null | ---
title: September 11, 2018
date: 2018-09-11 09:01:00 Z
images:
- "/uploads/unnamed-66fa99.jpg"
- "/uploads/unnamed-1-136f9d.jpg"
- "/uploads/unnamed-69c6b1.png"
---
### GOOD LUCK CHINA CUP ATHLETES!
Good luck to Season One varsity and JV teams as they head overseas to compete in China Cup and Bangkok XC Invitational. Baseball and Tennis will compete at International School in Beijing, Volleyball heads to Shanghai, Cross Country to Bangkok and HKIS will be hosting Rugby. For tournament schedules, please visit our [HS Athletics Schoology Page](https://hkis.us14.list-manage.com/track/click?u=f61be6100089c861d73d47a01&id=1685a4b380&e=9023f12060). GO DRAGONS!
### China Cup Rugby is here!
Join us at the HS field on Friday and Saturday, September 14 and 15 when JV and Varsity rugby teams will take on competitors from Shanghai American School - Puxi, Shanghai American School-Pudong, and Sandy Bay Rugby Club (local). Schedule can be found [here](https://hkis.us14.list-manage.com/track/click?u=f61be6100089c861d73d47a01&id=7067e4d0f1&e=9023f12060). JV boys will kick off the tournament at 10 a.m.! Go DRAGONS!
### China Cup meets Stanley Cup!
At the China Cup Pep Rally on September 13, students will have a visitor from the land of hockey. Students will get to see and hear about the revered Stanley Cup and all that it stands for: Teamwork, integrity, grit, and the excellence that comes from hard work are great reminders for our China Cup athletes. Parents welcome - please arrive at the gym by 11:15 a.m. Go Dragons! | 76.75 | 463 | 0.77785 | eng_Latn | 0.975966 |
990d6369abc16dbd34dbd0343eb9d799ddad06ce | 1,810 | md | Markdown | README.md | c-krit/ftmpl | 0722ecdbda545cf85c13504016c77ea91ff8f358 | [
"MIT"
] | 2 | 2022-01-11T10:14:53.000Z | 2022-01-12T11:42:29.000Z | README.md | c-krit/ftmpl | 0722ecdbda545cf85c13504016c77ea91ff8f358 | [
"MIT"
] | null | null | null | README.md | c-krit/ftmpl | 0722ecdbda545cf85c13504016c77ea91ff8f358 | [
"MIT"
] | null | null | null | <div align="center">
<img src="ftmpl/res/images/logo.png" alt="c-krit/ftmpl"><br>
[](https://github.com/c-krit/ftmpl)
[](https://github.com/c-krit/ftmpl/blob/main/LICENSE)
A small raylib template for the [ferox](https://github.com/c-krit/ferox) physics library.
</div>
## Features
<img src="ftmpl/res/images/screenshot.png" alt="c-krit/ftmpl"><br>
- Supports compiling on GNU/Linux or Windows with [MSYS2 (MINGW64)](https://www.msys2.org/)
- Supports cross-compiling from GNU/Linux to Windows
- Supports compiling into WebAssembly
- Colored text output for `Makefile`
## Prerequisites
- GCC version 9.4.0+
- GNU Make version 4.1+
- Git version 2.17.1+
```console
$ sudo apt install build-essential git
```
## Tutorial
Clone this repository with:
```console
$ git clone --recursive -j`nproc` https://github.com/c-krit/ftmpl && cd ftmpl
```
Or you can do:
```console
$ git clone -j`nproc` https://github.com/c-krit/ftmpl && cd ftmpl
$ git submodule update --init --recursive
```
Then you need to build `raylib` and `ferox` in the `ftmpl/lib` directory.
After building the required libraries, go to the directory where `Makefile` is located, then do:
```console
$ make
```
Or if you are compiling for the Web:
```console
$ make PLATFORM=WEB
```
Or if you are cross-compiling for Windows:
```console
$ make PLATFORM=WINDOWS
```
More things you can do for your project:
- Change the values of `PROJECT_NAME` and `PROJECT_FULL_NAME` in `Makefile`
- Edit this `README.md` file, and delete the images in the `ftmpl/res` directory
## License
MIT License | 24.794521 | 136 | 0.689503 | eng_Latn | 0.655917 |
990eb8e8fef40ad3fb36c3c4798564f3a7dd6759 | 11,488 | markdown | Markdown | _posts/2020-09-07-Us_and_ourselves.markdown | NILOIDE/NILOIDE.github.io | 158ec2b7e1cf1437a854c0c314c4dbefbec5b36b | [
"CC-BY-3.0"
] | null | null | null | _posts/2020-09-07-Us_and_ourselves.markdown | NILOIDE/NILOIDE.github.io | 158ec2b7e1cf1437a854c0c314c4dbefbec5b36b | [
"CC-BY-3.0"
] | null | null | null | _posts/2020-09-07-Us_and_ourselves.markdown | NILOIDE/NILOIDE.github.io | 158ec2b7e1cf1437a854c0c314c4dbefbec5b36b | [
"CC-BY-3.0"
] | null | null | null | ---
layout: post
title: "Us and Ourselves"
date: 07-09-2020
image: "/images/nerves.jpg"
teaser: "What is the nature of consciousness? What does it mean for something to be conscious? How does our brain give rise to it?"
---
<img src="{{ site.baseurl }}/images/nerves.jpg" class="fit image">
Consciousness is a term that is quite intuitive to every human being, yet if you are to ask anyone to provide you with a
definition, you would receive a broad and fuzzy description. The Oxford Languages dictionary defines consciousness as _"The
fact of awareness by the mind of itself and the world"_. However, this simplification does not do justice to the large
collection of literature that has been built on the subject.
Many schools of thought have provided a variety of competing ideas that aim to better understand what it is that gives
rise to the process through which we experience our surroundings and our mind's inner mechanisms. The most unsettling
part is not that we can't seem to discover the precise answers to our sentience, it is the fact that we don't even know
what are the questions we should be asking.
What is consciousness? Why is it, evolutionarily speaking, beneficial for consciousness to develop? Where is the line
between a conscious system and a non-conscious one? Is it even possible to objectively determine whether anything is
conscious?
To begin answering these questions, we should first note that the term 'consciousness' gets thrown around under multiple
distinct meanings. The <a href="https://plato.stanford.edu/entries/consciousness/#ConCon" target="_blank">Standford Encyclopedia</a>
defines two general ideas: **_Creature consciousness_** and **_State consciousness_**. The former has to do with the
level of awareness we associate to an external creature, while the latter is the notion we use to describe the mental
state that a being is currently in. The Standford page goes into much deeper detail that I can possibly explore in this
post, and I recommend you give it a read if your want a nice introduction into this field of philosophy.
<br>
#### <u>Creature consciousness and the issue with definitions</u>
Lets say we define consciousness as awareness of one's environment and it's internal states. Perhaps a simpler way to
explore consciousness is by trying to compare the levels of consciousness of different entities. On the one side,
everyone would agree that a simple stone is not at all conscious. However, what about a mouse? Ok, maybe a mouse is
conscious enough to deserve the term, but what about a spider? Spiders are capable of navigating their surroundings, as
well as being aware of their inner biological needs. So maybe we can squeeze spiders under the 'consciousness' umbrella?
What about single-celled organisms? What I'm getting at here is that maybe this form consciousness can be seen as a
spectrum with inanimate objects on one side and complex intelligent beings on the other. Maybe over many small
incremental steps, evolution has climbed this scale from inanimate unicellular processes, to somewhat-conscious simple
multicellular organisms, to the complex intelligent apes we are today.
The youtube channel **In a Nutshell** has a <a href="https://youtu.be/H6u0VBqNBQ8" target="_blank">very nice video</a> on this very
idea. The first step towards consciousness is possibly a unicelullar being capable of reacting to the level of food in
its environment. Reacting to inner states such as the level of hunger can yields advantages in the evolutionary process.
Furthermore, being aware of your surroundings, as well as building an inner representation of the world around you
allows for navigating towards food sources. Soon after, we start having complex creatures with ever-more developed
cognitive functions that will eventually resemble organisms that we more traditionally refer to as 'conscious'.
But this definition is not without its controversy. Some have argued that under this definition a simple transistor would
meet the most basic interpretation of consciousness, since the transistor is aware of its inner state and reacts to the
environment according to this inner state. We, of course, don't go around treating transistors as if they were conscious
beings, but it makes you wonder what other systems fit this definition of consciousness. Another example of a type of
edge case to this definition are superorganisms such as bee colonies. One can argue that a bee colony meets the criteria
for consciousness. The colony is aware of its biological needs and desires, and reacts accordingly given its surroundings.
On the other hand, human society behaves in a similar way, but we wouldn't go around referring to our cities as conscious
beings.
This brings me to another issue with consciousness: We have trouble pinpointing where consciousness is localized. You
yourself, a conscious creature, are here thanks to the thing you call a brain. However, the brain is just a collection
of neurons, which we wouldn't refer to as individual conscious entities. So where do YOU exist? Are you the network of
neurons that make up your brain? Are you the electrical pattern continuously firing in your brain? Perhaps both?
Unfortunately there is no easy answer to these questions, and every attempt to search deeper into this issue only brings
forth further questions.
Say, for instance, that we consider the cognitive processes that go on in someone's mind to be correlated with some
measure of being conscious. Is it correct to say that consciousness is located in the brain? And if so, which regions of
the brain are necessary for consciousness? The information processing necessary for plenty of motor responses that we
exhibit don't necessarily take place in the brain at all. Whenever you accidentally burn yourself, the information
perceived at your limbs travels to the spinal cord, where an action is automatically taken before the signal is even
able to reach your brain. These kinds of evidence seem to imply that the collection of matter that gives rise to
consciousness has very fuzzy borders. This issue, however, have even weirder implications.
Take a person, let's call him Adam, who had a serious brain injury that lead to him having anterograde amnesia and thus
losing the ability to create new memories. He carries around a notebook where he writes down all important
information he wants to recall later in the day, and for all intents and purposes, he is able to lead a normal day-to-day
life. Lets take another person, Bob, who has never suffered from such an injury and is able to recall memories normally
using his brain. We could argue that Adam's notebook is equivalent to the part of Bob's brain responsible for storing
memories. Is this notebook part of the conscious entity that makes up Adam? At the end of the day, part
of the internal state of Adam lives in the notebook.
If you think the previous example is some far-fetched edge case, think again. In philosophy, the idea of **enactivism**
claims that cognition is not exclusively tied to the workings of an 'inner mind', and that a mind, if able to, will
prefer to push cognitive processes outside of the brain. This is exactly what we see happen in daily lives when we,
for example, push simple mathematical operations onto our calculators. The same could be said about hiring a secretary,
part of your cognition could be said to live within your secretary. Now, one could argue that these examples are
not permanently part of someone's cognitive workspace, and so calling it part of that person's consciousness is not fair.
However, I want you to think about the ever-increasing level of reliance we have on our smartphones. They are becoming
ever-present in our lives. Our smartphones are already learning about our needs and desires, about the way we think and
behave... how long until they become an <a href="https://www.youtube.com/watch?v=lA77zsJ31nA" target="_blank">
indistinguishable part of our minds</a>?
#### <u>State consciousness and the subjective experience</u>
The other concept that people refer to with the word 'consciousness' is the subjective experience that a conscious being
possesses. This kind of consciousness is a lot more problematic to define, and there is no consensus among schools of
philosophy on the nature of this experience.
There are a lot of different theories regarding the nature of state consciousness. **Dualism** is
one such doctrine. Dualism says the mental and the physical are two separate entities. In some sense the experience
of being conscious happens in another plane of existence and it is not subject to the laws of nature. This
idea has obviously been highly criticized for a variety of reasons.
First, there is no way to know what is meant by such alternate plane or that it even exists altogether. Another problem
is best expressed through the analogy of '_The Ship of Theseus_'.
Take a brand new wooden ship which, slowly over the years, has more and more of its wooden
parts being replaced. If all pieces of the original ship are eventually replaced, is it still the same ship? Does your
consciousness stay the same over time?
This leads to a whole other range of questions. What defines your subjective experience? If dualism says that the mental
is separate from the material, can a subjective experience exist irrespective of the current material? A very interesting
research project is that of <a href="https://en.wikipedia.org/wiki/OpenWorm" target="_blank">
OpenWorm</a>. The idea goes as follows: Take a roundworm and map all of its neurons and muscles. Next, simulate all of
those connections. Results show that the simulated worm behaves the same as a real roundworm. However, this begs the
question, does the simulated worm experience the same subjective mental state as the real worm when it was mapped? Can
the same consciousness exist across different materials?
Another branch of philosophy that looks into state consciousness is the doctrine of **materialism**:
"*the world is entirely physical*". Modern neuroscience tends to fall under
this doctrine since its philosophy revolves around the mind emerging from the brain. It is really hard to be a
dualist given the overwhelming evidence showing that changes in the brain lead to changes in awareness being reported
by the participant (stimulation, drugs, injuries, ...). However, this gets us no closer to understanding what
consciousness is. After all, we can't directly observe someone's first-person experience of the world by looking at their
brain, we have to take their word for it. On the other hand, one can't simply claim there is no such thing as a
subjective experience, as that would be hypocritical. It is undeniable that YOU yourself experience such subjective state.
There is a famous thought experiment going by the name of "*The philosophical zombie*" that aims to show that it is
in fact impossible to prove that state consciousness exists on anyone except for yourself. It could very well be the case that
everyone around you are simply 'empty shells'. They might exhibit complex behaviour, but at the end of the day they are zombies
acting according to some predetermined inner rules. You obviously know that YOU yourself experience consciousness, but no form of
interaction with anyone else will ever provide definitive proof of whether they posses a subjective experience.
| 85.096296 | 133 | 0.797267 | eng_Latn | 0.999922 |
990efea81e26262b3b15481bfde3bc9f7b320ff1 | 679 | md | Markdown | docs/CatalogModifier.md | dudizimber/connect-nodejs-sdk | 097fabf8e59ce2de1c9e5a68e427f97d7fbf392f | [
"Apache-2.0"
] | null | null | null | docs/CatalogModifier.md | dudizimber/connect-nodejs-sdk | 097fabf8e59ce2de1c9e5a68e427f97d7fbf392f | [
"Apache-2.0"
] | null | null | null | docs/CatalogModifier.md | dudizimber/connect-nodejs-sdk | 097fabf8e59ce2de1c9e5a68e427f97d7fbf392f | [
"Apache-2.0"
] | null | null | null | # SquareConnect.CatalogModifier
### Description
A modifier in the Catalog object model.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**name** | **String** | The modifier name. Searchable. This field has max length of 255 Unicode code points. | [optional]
**price_money** | [**Money**](Money.md) | The modifier price. | [optional]
**ordinal** | **Number** | Determines where this `CatalogModifier` appears in the `CatalogModifierList`. | [optional]
**modifier_list_id** | **String** | The ID of the `CatalogModifierList` associated with this modifier. Searchable. | [optional]
| 42.4375 | 138 | 0.643594 | eng_Latn | 0.498658 |
990fd622b03e0a5aa19bf35702ba5bcdba7a142d | 1,250 | md | Markdown | _posts/2015-08-30-Accessing-to-AngularJS-from-the-Console.md | jsarafajr/jsarafajr.github.io | 741ed9f517abce79f0ca1d0dba0210242db37ef8 | [
"MIT"
] | null | null | null | _posts/2015-08-30-Accessing-to-AngularJS-from-the-Console.md | jsarafajr/jsarafajr.github.io | 741ed9f517abce79f0ca1d0dba0210242db37ef8 | [
"MIT"
] | null | null | null | _posts/2015-08-30-Accessing-to-AngularJS-from-the-Console.md | jsarafajr/jsarafajr.github.io | 741ed9f517abce79f0ca1d0dba0210242db37ef8 | [
"MIT"
] | null | null | null | ---
layout: post
title: Accessing to AngularJS from the Console
published: true
---
There are a set of scenarios when you need to get angular variables such as scopes, services, values etc. from the developer console to debug. Angular provide methods to do this.
## angular.element
Angular provide a function [angular.element()](https://docs.angularjs.org/api/ng/function/angular.element) which wraps a raw DOM element or HTML string as a jQuery element (jqLite).
For example the next 2 functions works equally and alerts a message when page loaded:
```javascript
// Angular JS
angular.element(document).ready(function() {
alert("ready");
})
// jQuery
$(document).ready(function() {
alert("ready");
});
```
## $0 in Chrome
In webkit $0 is a reference to the selected DOM node in the elements tab.

_Image from [dev.chrome.com](https://developer.chrome.com)_
## Getting $scope
Pick an element in the HTML panel of the developer tools and type in the console
```javascript
angular.element($0).scope();
```
## Getting service
To get access to your angular service type in console
```javascript
angular.element(document.body).injector().get('serviceName');
```
| 29.069767 | 183 | 0.7408 | eng_Latn | 0.963699 |
9910addbc9cbcf317c61063253571635536f8a1c | 5,244 | md | Markdown | dynamicsax2012-technet/product-configuration-configuration-key-pc.md | MicrosoftDocs/DynamicsAX2012-technet | 4e3ffe40810e1b46742cdb19d1e90cf2c94a3662 | [
"CC-BY-4.0",
"MIT"
] | 9 | 2019-01-16T13:55:51.000Z | 2021-11-04T20:39:31.000Z | dynamicsax2012-technet/product-configuration-configuration-key-pc.md | MicrosoftDocs/DynamicsAX2012-technet | 4e3ffe40810e1b46742cdb19d1e90cf2c94a3662 | [
"CC-BY-4.0",
"MIT"
] | 265 | 2018-08-07T18:36:16.000Z | 2021-11-10T07:15:20.000Z | dynamicsax2012-technet/product-configuration-configuration-key-pc.md | MicrosoftDocs/DynamicsAX2012-technet | 4e3ffe40810e1b46742cdb19d1e90cf2c94a3662 | [
"CC-BY-4.0",
"MIT"
] | 32 | 2018-08-09T22:29:36.000Z | 2021-08-05T06:58:53.000Z | ---
title: Product configuration configuration key (PC)
TOCTitle: Product configuration configuration key (PC)
ms:assetid: 47d50ba9-d44b-4cb2-b3c5-71ecb797eaa9
ms:mtpsurl: https://technet.microsoft.com/library/Hh433453(v=AX.60)
ms:contentKeyID: 36941206
author: Khairunj
ms.date: 05/02/2014
mtps_version: v=AX.60
---
# Product configuration configuration key (PC)
[!INCLUDE[archive-banner](includes/archive-banner.md)]
_**Applies To:** Microsoft Dynamics AX 2012 R3, Microsoft Dynamics AX 2012 R2, Microsoft Dynamics AX 2012 Feature Pack, Microsoft Dynamics AX 2012_
The **Product configuration** configuration key controls access to product configurator forms and functions.
You cannot enable or disable this key in the **License configuration** form.
## Forms enabled by the configuration key
The following forms are available when the configuration key is enabled.
## Enterprise Portal forms
<table>
<colgroup>
<col style="width: 50%" />
<col style="width: 50%" />
</colgroup>
<thead>
<tr class="header">
<th><p>Form</p></th>
<th><p>For more information</p></th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><p><strong>Product configuration</strong></p></td>
<td><p><a href="create-or-edit-a-sales-order.md">Create or edit a sales order</a></p></td>
</tr>
<tr class="even">
<td><p><strong>Load template</strong></p></td>
<td><p><a href="create-or-edit-a-sales-order.md">Create or edit a sales order</a></p></td>
</tr>
</tbody>
</table>
## Product information management forms
<table>
<colgroup>
<col style="width: 50%" />
<col style="width: 50%" />
</colgroup>
<thead>
<tr class="header">
<th><p>Form</p></th>
<th><p>For more information</p></th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><p><strong>Attached table constraint attribute</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh227446(v=ax.60)">Table constraint attachment (form)</a></p></td>
</tr>
<tr class="even">
<td><p><strong>Components</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh227490(v=ax.60)">Components (form)</a></p></td>
</tr>
<tr class="odd">
<td><p><strong>Configuration templates</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh209636(v=ax.60)">Configuration templates (form)</a></p></td>
</tr>
<tr class="even">
<td><p><strong>Constraint-based product configuration model details</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh209626(v=ax.60)">Constraint-based product configuration model details (form)</a></p></td>
</tr>
<tr class="odd">
<td><p><strong>Duplicate</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh209006(v=ax.60)">Duplicate product configuration model (form)</a></p></td>
</tr>
<tr class="even">
<td><p><strong>Edit table constraint</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh227624(v=ax.60)">Edit table constraints (form)</a></p></td>
</tr>
<tr class="odd">
<td><p><strong>Edit the model details</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh209513(v=ax.60)">Edit the model details (form)</a></p></td>
</tr>
<tr class="even">
<td><p><strong>Product configuration models</strong></p></td>
<td><p><a href="list-pages.md">List pages</a></p></td>
</tr>
<tr class="odd">
<td><p><strong>System defined table constraint column</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh227624(v=ax.60)">Edit table constraints (form)</a></p></td>
</tr>
<tr class="even">
<td><p><strong>Table constraint definition</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh242246(v=ax.60)">Table constraints (form)</a></p></td>
</tr>
<tr class="odd">
<td><p><strong>Translation</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh370703(v=ax.60)">Translation (form)</a></p></td>
</tr>
<tr class="even">
<td><p><strong>User defined table constraint</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh227624(v=ax.60)">Edit table constraints (form)</a></p></td>
</tr>
<tr class="odd">
<td><p><strong>User interface</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh227510(v=ax.60)">User interface (form)</a></p></td>
</tr>
<tr class="even">
<td><p><strong>Versions</strong></p></td>
<td><p><a href="https://technet.microsoft.com/library/hh208624(v=ax.60)">Versions (form)</a></p></td>
</tr>
</tbody>
</table>
## Additional information about this configuration key
The following table provides information about how this configuration key relates to other configuration keys and license codes.
<table>
<colgroup>
<col style="width: 50%" />
<col style="width: 50%" />
</colgroup>
<thead>
<tr class="header">
<th><p>Detail</p></th>
<th><p>Description</p></th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><p>License code</p></td>
<td><p><strong>Product configuration</strong></p></td>
</tr>
<tr class="even">
<td><p>Parent key</p></td>
<td><p>None</p></td>
</tr>
<tr class="odd">
<td><p>Child keys</p></td>
<td><p>None</p></td>
</tr>
</tbody>
</table>
For more information about how license codes and configuration keys work together, see [About license codes and configuration keys](https://technet.microsoft.com/library/aa548653\(v=ax.60\)).
| 31.781818 | 191 | 0.684211 | eng_Latn | 0.24647 |
9910c80798de742555b63bececa938e3807437ae | 6,595 | md | Markdown | microsoft-365/business/set-up-windows-devices.md | PSPally/microsoft-365-docs | 0d4eac3af5eaad66499cb4df9659e0b897c4bcb2 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-03-17T18:42:20.000Z | 2020-07-17T00:25:45.000Z | microsoft-365/business/set-up-windows-devices.md | PSPally/microsoft-365-docs | 0d4eac3af5eaad66499cb4df9659e0b897c4bcb2 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | microsoft-365/business/set-up-windows-devices.md | PSPally/microsoft-365-docs | 0d4eac3af5eaad66499cb4df9659e0b897c4bcb2 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: "Set up Windows devices for Microsoft 365 Business users"
f1.keywords:
- CSH
ms.author: sirkkuw
author: Sirkkuw
manager: scotv
audience: Admin
ms.topic: article
ms.service: o365-administration
localization_priority: Normal
ms.collection:
- M365-subscription-management
- M365-identity-device-management
ms.custom:
- Core_O365Admin_Migration
- MiniMaven
- MSB365
- OKR_SMB_M365
- TRN_M365B
- OKR_SMB_Videos
search.appverid:
- BCS160
- MET150
ms.assetid: 2d7ff45e-0da0-4caa-89a9-48cabf41f193
description: "Learn how to set up Windows devices running Windows 10 Pro for Microsoft 365 Business users. "
---
# Set up Windows devices for Microsoft 365 Business users
## Prerequisites
Before you can set up Windows devices for Microsoft 365 Business users, make sure all the Windows devices are running Windows 10 Pro, version 1703 (Creators Update). Windows 10 Pro is a prerequisite for deploying Windows 10 Business, which is a set of cloud services and device management capabilities that complement Windows 10 Pro and enable the centralized management and security controls of Microsoft 365 Business.
If you have Windows devices running Windows 7 Pro, Windows 8 Pro, or Windows 8.1 Pro, your Microsoft 365 Business subscription entitles you to a Windows 10 upgrade.
For more information on how to upgrade Windows devices to Windows 10 Pro Creators Update, follow the steps in this topic: [Upgrade Windows devices to Windows Pro Creators Update](upgrade-to-windows-pro-creators-update.md).
See [Verify the device is connected to Azure AD](#verify-the-device-is-connected-to-azure-ad) to verify you have the upgrade, or to make sure the upgrade worked.
Watch a short video about connecting Windows to Microsoft 365.<br><br>
> [!VIDEO https://www.microsoft.com/videoplayer/embed/RE3yXh3]
If you found this video helpful, check out the [complete training series for small businesses and those new to Microsoft 365](https://support.office.com/article/6ab4bbcd-79cf-4000-a0bd-d42ce4d12816).
## Join Windows 10 devices to your organization's Azure AD
When all Windows devices in your organization have either been upgraded to Windows 10 Pro Creators Update or are already running Windows 10 Pro Creators Update, you can join these devices to your organization's Azure Active Directory. Once the devices are joined, they'll be automatically upgraded to Windows 10 Business, which is part of your Microsoft 365 Business subscription.
### For a brand new, or newly upgraded, Windows 10 Pro device
For a brand new device running Windows 10 Pro Creators Update, or for a device that was upgraded to Windows 10 Pro Creators Update but has not gone through Windows 10 device setup, follow these steps.
1. Go through Windows 10 device setup until you get to the **How would you like to set up?** page.

2. Here, choose **Set up for an organization** and then enter your username and password for Microsoft 365 Business.
3. Finish Windows 10 device setup.
Once you're done, the user will be connected to your organization's Azure AD. See [Verify the device is connected to Azure AD](#verify-the-device-is-connected-to-azure-ad) to make sure.
### For a device already set up and running Windows 10 Pro
**Connect users to Azure AD:**
1. In your user's Windows PC, that is running Windows 10 Pro, version 1703 (Creators Update) (see [pre-requisites](pre-requisites-for-data-protection.md)), click the Windows logo, and then the Settings icon.

2. In **Settings**, go to **Accounts**.

3. On **Your info** page, click **Access work or school** \> **Connect**.

4. On the **Set up a work or school account** dialog, under **Alternate actions**, choose **Join this device to Azure Active Directory**.

5. On the **Let's get you signed in** page, enter your work or school account \> **Next**.
On the **Enter password** page, enter your password \> **Sign in**.

6. On the **Make sure this is your organization** page, verify that the information is correct, and click **Join**.
On the **You're all set!** page, click **Done**.

If you uploaded files to OneDrive for Business, sync them back down. If you used a third-party tool to migrate profile and files, also sync those to the new profile.
## Verify the device is connected to Azure AD
To verify your sync status, on the **Access work or school** page in **Settings**, click in the **Connected to** _ \<organization name\> _ area to expose the buttons **Info** and **Disconnect**. Click on **Info** to get your synchronization status.
On the Sync status page, click Sync to get the latest mobile device management policies onto the PC.
To start using the Microsoft 365 Business account, go to the Windows **Start** button, right-click your current account picture, and then **Switch account**. Sign in by using your organization email and password.

## Verify the device is upgraded to Windows 10 Business
Verify that your Azure AD joined Windows 10 devices were upgraded to Windows 10 Business as part of your Microsoft 365 Business subscription.
1. Go to **Settings** \> **System** \> **About**.
2. Confirm that the **Edition** shows **Windows 10 Business**.

## Next steps
To set up your mobile devices, see [Set up mobile devices for Microsoft 365 Business users](set-up-mobile-devices.md), To set device protection or app protection policies, see [Manage Microsoft 365 Business](manage.md).
## See also
[Microsoft 365 Business training videos](https://support.office.com/article/6ab4bbcd-79cf-4000-a0bd-d42ce4d12816)
| 52.34127 | 419 | 0.753753 | eng_Latn | 0.973324 |
9910d167960bcaaa75ea360837c1095491df26e3 | 3,202 | md | Markdown | examples/postman-ordering/readme.md | schelv/portman | 11dea88c054de1cfbc5377da04133b5ebd55ed63 | [
"Apache-2.0"
] | 416 | 2021-05-05T12:03:23.000Z | 2022-03-30T02:55:56.000Z | examples/postman-ordering/readme.md | schelv/portman | 11dea88c054de1cfbc5377da04133b5ebd55ed63 | [
"Apache-2.0"
] | 145 | 2021-05-14T14:38:56.000Z | 2022-03-31T15:25:58.000Z | examples/postman-ordering/readme.md | schelv/portman | 11dea88c054de1cfbc5377da04133b5ebd55ed63 | [
"Apache-2.0"
] | 36 | 2021-05-14T11:59:08.000Z | 2022-03-22T08:46:08.000Z | # Postman collection request ordering
This example contains the setup of Portman to convert & sort an OpenAPI, with sorting of the Postman requests.
_use-case_: execute Postman requests in a certain order typically linked to test scenario's, like CRUD.
## CLI usage
```ssh
portman -l ./examples/postman-ordering/crm.yml -t false -c ./examples/postman-ordering/portman-config.ordering.json
```
This is a very simple example where we just take the the `crm.yml` OpenAPI and convert it with ordering in place.
## Portman settings
The `orderOfOperations` is a list of OpenAPI operations, which is used by Portman to sort the Postman requests in the
desired order.
The OpenAPI operation is the unique combination of the OpenAPI method & path, with a `::` separator symbol.
The example: `"GET::/crm/leads"` will target only the "GET" method and the specific path "/crm/leads".
## Example explained
In our example we want to run the execution of the CRM leads operations in specific order in Postman.
So in our Portman configuration file , we have defined the `orderOfOperations` with the desired order for the "leads"
endpoints. REMARK: Items that are **not** defined in the `orderOfOperations` list will remain at their current order.
./examples/postman-ordering/portman-config.ordering.json >>
````json
{
"orderOfOperations": [
"POST::/crm/leads",
"GET::/crm/leads/{id}",
"PATCH::/crm/leads/{id}",
"DELETE::/crm/leads/{id}",
"GET::/crm/leads"
]
}
````
The result will be that initial OpenAPI file, with the operations orders like:
./examples/postman-ordering/crm.yml >>
```yaml
paths:
/crm/leads:
get:
operationId: leadsAll
summary: List leads
post:
operationId: leadsAdd
summary: Create lead
'/crm/leads/{id}':
get:
operationId: leadsOne
summary: Get lead
patch:
operationId: leadsUpdate
summary: Update lead
delete:
operationId: leadsDelete
summary: Delete lead
```
will be converted in a Postman Collection that is order like this:
./examples/postman-ordering/crmApi.json >>
```json
{
"item": [
{
"id": "7aba139c-6c52-4d20-a1f2-e5f54482dd31",
"name": "Leads",
"item": [
{
"id": "eeca3dd2-c57f-4ba9-b347-927b0fa867dc",
"name": "Create lead"
},
{
"id": "c9807808-5c7b-4194-b899-5d0317c1ddc1",
"name": "Get lead"
},
{
"id": "1e6e89d5-a975-4f34-b548-b16d64e12ba7",
"name": "Update lead"
},
{
"id": "41e14505-3cd5-461d-a252-16af1ac9894d",
"name": "Delete lead"
},
{
"id": "240d8dd4-ea17-4e66-a564-2ed7380d559a",
"name": "List leads"
}
]
}
]
}
```
**End result**
Original order for items as defined in OpenAPI:
1) List leads - GET
2) Create lead - POST
3) Get lead - GET
4) Update lead - PATCH
5) Delete lead - DELETE
Ordered items in Postman after conversion as defined in the Portman configuration:
1) Create lead - POST
2) Get lead - GET
3) Update lead - PATCH
4) Delete lead - DELETE
5) List leads - GET
| 26.245902 | 117 | 0.642723 | eng_Latn | 0.966677 |
991104e9f52295a1d80a4f29e4b90c4feebe2790 | 255 | md | Markdown | README.md | sakamotodesu/mokumoku | 9eb59bdf795f241d6303472af0ee716c6f7e4e3e | [
"Apache-2.0"
] | null | null | null | README.md | sakamotodesu/mokumoku | 9eb59bdf795f241d6303472af0ee716c6f7e4e3e | [
"Apache-2.0"
] | null | null | null | README.md | sakamotodesu/mokumoku | 9eb59bdf795f241d6303472af0ee716c6f7e4e3e | [
"Apache-2.0"
] | null | null | null | mokumoku
=================================
[](https://travis-ci.org/sakamotodesu/mokumoku)
[](https://heroku.com/deploy) | 36.428571 | 125 | 0.654902 | yue_Hant | 0.188888 |
99116222a213a943bcb0b58e79cac64c795ce5c5 | 1,198 | md | Markdown | doc/DataClass.md | christophsturm/KustomExport | b2a97a74368dbee2c24c8f0a4dd421826581ccd7 | [
"Apache-2.0"
] | 25 | 2021-11-09T17:15:07.000Z | 2022-03-31T11:28:57.000Z | doc/DataClass.md | christophsturm/KustomExport | b2a97a74368dbee2c24c8f0a4dd421826581ccd7 | [
"Apache-2.0"
] | 17 | 2021-11-09T17:18:34.000Z | 2022-03-26T21:50:50.000Z | doc/DataClass.md | christophsturm/KustomExport | b2a97a74368dbee2c24c8f0a4dd421826581ccd7 | [
"Apache-2.0"
] | 2 | 2022-03-25T08:01:20.000Z | 2022-03-25T12:18:40.000Z | # Data class
## Problem
`data class` is a very powerful Kotlin tool that handle struct implementation requirements (mainly for JVM):
- equals()/hashcode() are generated and compare each properties from the primary constructor
- toString() to create a pretty string of the instance
- copy to be able to change a few values and clone the other ones.
So a basic data class like that
```kotlin
@JsExport
data class Example(val a: Int = 1, val b: Int = 2, val c: Int = 3)
```
will generate
```typescript
class Example {
constructor(a: number, b: number, c: number);
readonly a: number;
readonly b: number;
readonly c: number;
component1(): number;
component2(): number;
component3(): number;
copy(a: number, b: number, c: number): sample._class.Example;
toString(): string;
hashCode(): number;
equals(other: Nullable<any>): boolean;
}
```
## Solution
By using `@KustomExport` instead, you remove all those unused methods and expose a simple class instead.
```typescript
class Example {
constructor(a: number, b: number, c: number);
readonly a: number;
readonly b: number;
readonly c: number;
}
```
[Go back to README](../README.md)
| 23.96 | 108 | 0.686978 | eng_Latn | 0.991981 |
9911c350c26d4f80520ba9e44616f4b8babf32e9 | 2,531 | md | Markdown | docs/docs/glossary/Add-VSKinesisAnalyticsApplicationRecordFormat.md | sheldonhull/VaporShell | e6a29672ce84b461e4f8d6058a52b83cbfaf3c5c | [
"Apache-2.0"
] | 35 | 2017-08-22T23:16:27.000Z | 2020-02-13T18:26:47.000Z | docs/docs/glossary/Add-VSKinesisAnalyticsApplicationRecordFormat.md | sheldonhull/VaporShell | e6a29672ce84b461e4f8d6058a52b83cbfaf3c5c | [
"Apache-2.0"
] | 31 | 2017-08-29T03:27:32.000Z | 2020-03-04T22:02:20.000Z | docs/docs/glossary/Add-VSKinesisAnalyticsApplicationRecordFormat.md | sheldonhull/VaporShell | e6a29672ce84b461e4f8d6058a52b83cbfaf3c5c | [
"Apache-2.0"
] | 6 | 2020-04-21T18:29:31.000Z | 2021-12-24T11:01:08.000Z | # Add-VSKinesisAnalyticsApplicationRecordFormat
## SYNOPSIS
Adds an AWS::KinesisAnalytics::Application.RecordFormat resource property to the template.
Describes the record format and relevant mapping information that should be applied to schematize the records on the stream.
## SYNTAX
```
Add-VSKinesisAnalyticsApplicationRecordFormat [[-MappingParameters] <Object>] [-RecordFormatType] <Object>
[<CommonParameters>]
```
## DESCRIPTION
Adds an AWS::KinesisAnalytics::Application.RecordFormat resource property to the template.
Describes the record format and relevant mapping information that should be applied to schematize the records on the stream.
## PARAMETERS
### -MappingParameters
When configuring application input at the time of creating or updating an application, provides additional mapping information specific to the record format such as JSON, CSV, or record fields delimited by some delimiter on the streaming source.
Type: MappingParameters
Documentation: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-kinesisanalytics-application-recordformat.html#cfn-kinesisanalytics-application-recordformat-mappingparameters
UpdateType: Mutable
```yaml
Type: Object
Parameter Sets: (All)
Aliases:
Required: False
Position: 1
Default value: None
Accept pipeline input: False
Accept wildcard characters: False
```
### -RecordFormatType
The type of record format.
Documentation: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-kinesisanalytics-application-recordformat.html#cfn-kinesisanalytics-application-recordformat-recordformattype
PrimitiveType: String
UpdateType: Mutable
```yaml
Type: Object
Parameter Sets: (All)
Aliases:
Required: True
Position: 2
Default value: None
Accept pipeline input: False
Accept wildcard characters: False
```
### CommonParameters
This cmdlet supports the common parameters: -Debug, -ErrorAction, -ErrorVariable, -InformationAction, -InformationVariable, -OutVariable, -OutBuffer, -PipelineVariable, -Verbose, -WarningAction, and -WarningVariable. For more information, see [about_CommonParameters](http://go.microsoft.com/fwlink/?LinkID=113216).
## INPUTS
## OUTPUTS
### Vaporshell.Resource.KinesisAnalytics.Application.RecordFormat
## NOTES
## RELATED LINKS
[http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-kinesisanalytics-application-recordformat.html](http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-kinesisanalytics-application-recordformat.html)
| 35.152778 | 315 | 0.817463 | eng_Latn | 0.426038 |
9911d2031622239294cb065be9178a6002ce9a5b | 1,002 | md | Markdown | README.md | fastmonkeys/betterimportpackages | ed172414b9ace3c31bfc280cf69d4c1d18ca7c27 | [
"MIT"
] | null | null | null | README.md | fastmonkeys/betterimportpackages | ed172414b9ace3c31bfc280cf69d4c1d18ca7c27 | [
"MIT"
] | null | null | null | README.md | fastmonkeys/betterimportpackages | ed172414b9ace3c31bfc280cf69d4c1d18ca7c27 | [
"MIT"
] | null | null | null | 
Sublime Text 3 plugin that helps with Python imports. It scans the open folders for imports that were used previously and uses them to write the correct import. Please note that the plugin is just a prototype at this stage.
## How to use
1. Select the class or function you wish to import (e.g. *UserPhoto*) and either right-click "Add import" or use the keybinding Cmd+Shift+I.

2. The import is then added to top of the file.

## How to install
1. Open your terminal. At first you'll have to install `ack`.
- For Mac users:
````$ brew install ack````
- For Debian/Ubuntu users:
````$ sudo apt-get install ack````
2. Clone the repository to the Sublime Text Packages folder.
````
$ cd ~/Library/Application\ Support/Sublime\ Text\ 3/Packages/
$ git clone https://github.com/fastmonkeys/betterimportpackages BetterImportPackages
````
| 37.111111 | 223 | 0.728543 | eng_Latn | 0.954837 |
9912d095040a8ebc15dc621b810271ba3441b343 | 841 | md | Markdown | docs/visual-basic/misc/bc30217.md | hyoshioka0128/docs.ja-jp | 979df25b1da8e21036438e0c8bc5f4d61bd1181d | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-01-29T12:31:08.000Z | 2019-01-29T12:31:08.000Z | docs/visual-basic/misc/bc30217.md | hyoshioka0128/docs.ja-jp | 979df25b1da8e21036438e0c8bc5f4d61bd1181d | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc30217.md | hyoshioka0128/docs.ja-jp | 979df25b1da8e21036438e0c8bc5f4d61bd1181d | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 文字列定数を指定してください。
ms.date: 07/20/2015
f1_keywords:
- bc30217
- vbc30217
helpviewer_keywords:
- BC30217
ms.assetid: 02e4f418-fd5d-41a4-8896-70d06eb5035a
ms.openlocfilehash: c95366fe5323509b105125ad0a85eed863fb6548
ms.sourcegitcommit: 3d5d33f384eeba41b2dff79d096f47ccc8d8f03d
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 05/04/2018
ms.locfileid: "33607173"
---
# <a name="string-constant-expected"></a>文字列定数を指定してください。
二重引用符 (") 以外の文字が、コンテキストで文字列定数が必要な場所に使用されました。 考えられる原因の 1 つとして、引用符が文字列にありません。
**エラー ID:** BC30217
## <a name="to-correct-this-error"></a>このエラーを解決するには
1. 文字列が、二重引用符で正しく囲まれていることを確認してください。
2. 文字列定数を指定します。
## <a name="see-also"></a>関連項目
[定数とリテラルのデータ型](../../visual-basic/programming-guide/language-features/constants-enums/constant-and-literal-data-types.md)
| 28.033333 | 122 | 0.747919 | yue_Hant | 0.353012 |
9913024b9697b8dfaa37719e8c300bb3ab73bf3b | 241 | md | Markdown | PULL_REQUEST_TEMPLATE.md | CodeLingoBot/slackscot | 0122455deaa040dd47f76c9769f5db3dd0374b2f | [
"MIT"
] | 54 | 2015-10-28T17:52:42.000Z | 2022-03-24T20:47:36.000Z | PULL_REQUEST_TEMPLATE.md | CodeLingoBot/slackscot | 0122455deaa040dd47f76c9769f5db3dd0374b2f | [
"MIT"
] | 30 | 2015-10-28T03:27:38.000Z | 2021-02-22T02:26:40.000Z | PULL_REQUEST_TEMPLATE.md | CodeLingoBot/slackscot | 0122455deaa040dd47f76c9769f5db3dd0374b2f | [
"MIT"
] | 18 | 2015-10-22T15:51:03.000Z | 2022-01-23T06:28:51.000Z | ## What is this about
Describe your changes and the context.
### Checklist
* [ ] I've reviewed my own code
* [ ] I've executed `go build ./...` and confirmed the build passes
* [ ] I've run `go test ./...` and confirmed the tests pass | 34.428571 | 69 | 0.647303 | eng_Latn | 0.999387 |
9913340da3c8c845b3687e2d806576dfcfbde734 | 1,700 | md | Markdown | README.md | lacti/please-watch-jira | 0a398c46bf8300975ae5aecfd38d39f587926796 | [
"MIT"
] | 1 | 2020-09-27T05:22:13.000Z | 2020-09-27T05:22:13.000Z | README.md | lacti/please-watch-jira | 0a398c46bf8300975ae5aecfd38d39f587926796 | [
"MIT"
] | 4 | 2020-07-29T22:30:08.000Z | 2022-02-27T08:46:32.000Z | README.md | lacti/please-watch-jira | 0a398c46bf8300975ae5aecfd38d39f587926796 | [
"MIT"
] | null | null | null | # Please watch Jira
Chrome extension to add issue watchers easily.

## Installation
1. Download latest `please-watch-jira.zip` from [releases](https://github.com/music-flo/please-watch-jira/releases).
2. Unpack it.
3. Turn on `Developer mode` from [`chrome://extensions`](chrome://extensions) in your chrome browser.


4. Use `Load unpacked` and select the unpacked directory.

5. Pin this extension from _Manage extensions_.

## Usage
1. Setup groups from settings popup.
Please use this popup only on `atlassian page` such as _Jira_ because it uses Atlassian API in your credentials.

You can add a new group using `New` button.

2. And then, you can search watchers using `Keyword input`. All things are valid, you can see new members when you press enter key from `Keyword input`. If you want to delete a member, just click it.

3. After finished, click the icon of this extension to close this settings popup.
4. Open Jira issue or Servicedesk page, add watchers using context menu.

## Update plugins
1. Download new version from [releases](https://github.com/music-flo/please-watch-jira/releases) and overwrite old things.
2. Go to [`chrome://extensions`](chrome://extensions) and click _Refresh_ button.

## License
MIT
| 41.463415 | 199 | 0.738824 | eng_Latn | 0.89631 |
99139b662f5eb5b288db589175dbb4981bfddb2e | 526 | md | Markdown | readme.md | Poornartha/Odonata | 71e8dfc4e8d93c6ecc1a3a155459b7e43bd28cdb | [
"MIT"
] | null | null | null | readme.md | Poornartha/Odonata | 71e8dfc4e8d93c6ecc1a3a155459b7e43bd28cdb | [
"MIT"
] | null | null | null | readme.md | Poornartha/Odonata | 71e8dfc4e8d93c6ecc1a3a155459b7e43bd28cdb | [
"MIT"
] | null | null | null | This project aims at solving project, team and employee management problems.<br>
Features include the creation of a root project which organization can track and sub-projects within the root project, auction system for tasks, employee to employee shout outs,<br> weakly, monthly, yearly leaderboard and graphical analysis alongside an integrated point distribution system.<br>
Link: https://hungoverdjangoodonata.pythonanywhere.com/<br>
Contributors: Poornartha Sawant, Vansh Mehta, Shubh Sanghvi<br>
Team: HungoverDjango<br>
| 87.666667 | 295 | 0.821293 | eng_Latn | 0.991654 |
9913e9dca8ee91ccda92da5bbc5e13f3baecaf5c | 1,824 | md | Markdown | docs/sharepoint/how-to-add-or-remove-sharepoint-connections.md | MarcoMue/visualstudio-docs | 3aee1c1269d8c490327ec18b5eb65588f115ad67 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-06-18T05:51:49.000Z | 2019-06-18T05:51:49.000Z | docs/sharepoint/how-to-add-or-remove-sharepoint-connections.md | MarcoMue/visualstudio-docs | 3aee1c1269d8c490327ec18b5eb65588f115ad67 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/sharepoint/how-to-add-or-remove-sharepoint-connections.md | MarcoMue/visualstudio-docs | 3aee1c1269d8c490327ec18b5eb65588f115ad67 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: "How to: Add or Remove SharePoint Connections | Microsoft Docs"
ms.date: "02/02/2017"
ms.topic: "conceptual"
dev_langs:
- "VB"
- "CSharp"
helpviewer_keywords:
- "SharePoint development in Visual Studio, browsing SharePoint sites"
- "SharePoint development in Visual Studio, SharePoint Connections"
- "SharePoint Connections [SharePoint development in Visual Studio]"
author: John-Hart
ms.author: johnhart
manager: jillfra
ms.workload:
- "office"
---
# How to: Add or remove SharePoint connections
Server Explorer lets you browse SharePoint sites as well as data connections. However, before you can browse the contents of a SharePoint site you must add it to the **SharePoint Connections** node.
### To add a SharePoint site to the SharePoint connections node
1. On the menu bar, choose **View**, **Server Explorer**.
2. In **Server Explorer**, choose the **SharePoint Connections** node, and then, on the menu bar, choose **Tools** > **Add SharePoint Connection**.
3. In the **Add SharePoint Connection** box, enter the [!INCLUDE[TLA2#tla_url](../sharepoint/includes/tla2sharptla-url-md.md)] for the SharePoint site (for example, http://testserver/sites/unittests).
### To delete a SharePoint site from the SharePoint connections node
1. On the menu bar, choose **View**, **Server Explorer** to open **Server Explorer**.
2. Expand the **SharePoint Connections** node to reveal the SharePoint site that you want to delete from **Server Explorer**.
3. Choose the site, and then, on the menu bar, choose **Edit** > **Delete**.
> [!NOTE]
> This step doesn't delete the underlying site; it deletes only the connection from **Server Explorer**.
## See also
- [Browse SharePoint connections using Server Explorer](../sharepoint/browsing-sharepoint-connections-using-server-explorer.md)
| 43.428571 | 200 | 0.739583 | eng_Latn | 0.922783 |
9914c5ca3222ed3bbf0200322eab049565cd5ab1 | 68 | md | Markdown | README.md | Pixmeg/Collision-Curves | 0380bef894a69eed7f2ad4b538e89a5b7352bd8e | [
"MIT"
] | 1 | 2019-03-18T12:20:51.000Z | 2019-03-18T12:20:51.000Z | README.md | Pixmeg/Collision-Curves | 0380bef894a69eed7f2ad4b538e89a5b7352bd8e | [
"MIT"
] | null | null | null | README.md | Pixmeg/Collision-Curves | 0380bef894a69eed7f2ad4b538e89a5b7352bd8e | [
"MIT"
] | 1 | 2019-04-27T17:12:33.000Z | 2019-04-27T17:12:33.000Z | # Collision-Curves
Tutorial for this is available at www.pixmeg.com
| 22.666667 | 48 | 0.808824 | eng_Latn | 0.955945 |
9914d57705fa88a121db66be442a0e3fd16668fb | 4,655 | md | Markdown | lessons/3- Easing and Delays/index.md | Jam3/jam3-lesson-tweening | 8694a10eb554f7e1931601fa6f3b9ff2469f958d | [
"MIT"
] | 5 | 2015-04-16T18:54:48.000Z | 2021-07-17T13:12:37.000Z | lessons/3- Easing and Delays/index.md | Jam3/jam3-lesson-tweening | 8694a10eb554f7e1931601fa6f3b9ff2469f958d | [
"MIT"
] | 3 | 2015-04-23T15:54:29.000Z | 2016-01-05T15:28:27.000Z | lessons/3- Easing and Delays/index.md | Jam3/jam3-lesson-tweening | 8694a10eb554f7e1931601fa6f3b9ff2469f958d | [
"MIT"
] | 1 | 2020-12-27T09:47:42.000Z | 2020-12-27T09:47:42.000Z | # Easing and Delays
Next we're going to learn about Easing, and Delays. Two very important features of our tweening engine that give us a lot of power over how our animation feels and controls timing of it when combined with other functions and animations.
## Easing
Easings are one of the most important settings to motion designers as it controls how an animation feels and add a lot of "Punch" to the animation. You'll see very quickly that if you go back to using a default ease like we did in the last couple of examples it doesn't seem very interesting to the eye.
```javascript
var Tween = require('gsap');
var popUpTitle = document.getElementById('popUpAndFade');
Tween.fromTo(popUpTitle, 0.5,
{x: -20, autoAlpha: 0, ease: Bounce.easeIn},
{y: 0, autoAlpha: 1, ease: Bounce.easeIn}
);
```
Using an ease is easy once you learn the syntax of the object. `[EaseName].[easeDirection]` First is the name of the Ease, which is pretty standard across a lot of libraries you can see the most common eases here (http://easings.net/). In this case we use Bounce for our ease with an easeIn direction. The direction controls how the graph set as our ease sits in the timeline. Your options are `easeIn`, `easeOut`, or `easeInOut`. `easeIn` means that your tween will adjust it's velocity right before the end accorind go the ease you set. In our case the object we're animating should bounce when nears it's final values (in this case `y:0`, and `autoAlpha: 1`) then settle to those values. With `easeOut` the change in velocity is adjusted at the beggining of the animation. So our animation would bounce a bit then smoothly animate out.
And finally you'll have likely guessed that `easeInOut` will bounce at both the begining AND the end of our animation.
>One production "gotcha" to remember when working with motion designers is that they need to know that you are limited to the list of Eases avaialable in GSAP. It is possible to create custom easing graphs in After Effects so they might have done so. Simply send them the link to easings.net and tell them to select which they'd like to use.
## Delays
Delays are simply that, delaying a tween. So far we've only ever been animating one thing at a time but you may want to combine many tweens together with other functions or other tweens. Controlling when a Tween starts is important and many motions designs will call for it.
```
var Tween = require('gsap');
var Title = document.getElementById('Title');
var Subtitle = document.getElementById('Subtitle')
var Button = document.getElementById('Button');
Tween.from(Title, 0.5, {delay: 0, autoAlpha:0, x: -20, ease: Expo.easeIn});
Tween.from(Subtitle, 0.5, {delay: 0.3, autoAlpha: 0, y: 20, ease: Expo.easeIn})
Tween.from(Button, 0.5, {delay: 0.6, autoAlpha: 0, z: 20, ease: Expo.easeIn})
```
In our example we have 3 elements to animate in. We're going to use the `from()` function here for simplicity sake. The important thing to remember with Tweens is that if you list them one after another like this they will all be called at the same time (from a Human standpoint anyway) and start at the same time unless we add delays. So in this case a delay is really just saying that you want you tween to start a number of seconds after you call it. None of these Tweens know about the other ones, we'll learn about how to stack and stagger tweens in a later lesson, which is a lot more powerful and easier to manage when your list of animations starts to grow.
To go through this,
1. Title's tween starts at 0 seconds and takes 0.5 seconds to finish.
2. Subtitle's tween starts at 0.3 seconds and takes 0.5 seconds to finish, it will finish at 0.8 seconds.
3. Button's tween starts at 0.6 seconds and takes 0.5 seconds to finish, it will finish at 1.1 seconds.
Now what if we want them to start one after the other? Would be pretty easy with all of our durations being 0.5 seconds but once you start getting into diferent timings that requirement to add all of these numbers grows.
So remember to be careful with delays, it's fine for some simple tweens here in there but if you're trying to make a motion designers dreams come true you're going to need some much stronger methods to keep things organized.
## Get to work!
No go and try and animate some things with an eases and a delay. Open the folder you ran `jam3-tween-lesson` in, in your editor of choice. There you'll see a folder called `/3- Easing and Delays`. In that folder you'll see a `practice` and `solution` folder. Inside the `practice` folder go ahead and create a solution. If you need to "cheat" you can always take a look at the `solution` folder. | 81.666667 | 838 | 0.762406 | eng_Latn | 0.999589 |
9915e2289f096768b2e9fe728999f6e2894a6122 | 14,244 | md | Markdown | Instructions/Labs/10b - Self-Service Password Reset (az-100-05b).md | tikuslasso/AZ-103-MicrosoftAzureAdministrator | 6504ee27b9521c55196ba4d9e700252a80e180c5 | [
"MIT"
] | 1 | 2020-02-07T08:59:54.000Z | 2020-02-07T08:59:54.000Z | Instructions/Labs/10b - Self-Service Password Reset (az-100-05b).md | tikuslasso/AZ-103-MicrosoftAzureAdministrator | 6504ee27b9521c55196ba4d9e700252a80e180c5 | [
"MIT"
] | null | null | null | Instructions/Labs/10b - Self-Service Password Reset (az-100-05b).md | tikuslasso/AZ-103-MicrosoftAzureAdministrator | 6504ee27b9521c55196ba4d9e700252a80e180c5 | [
"MIT"
] | null | null | null | ---
lab:
title: 'Self-Service Password Reset'
module: 'Module 10 - Securing Identtities'
---
# Lab: Self-Service Password Reset
All tasks in this lab are performed from the Azure portal
Lab files: none
### Scenario
Adatum Corporation wants to take advantage of Azure AD Premium features
### Objectives
After completing this lab, you will be able to:
- Manage Azure AD users and groups
- Manage Azure AD-integrated SaaS applications
### Exercise 1: Manage Azure AD users and groups
The main tasks for this exercise are as follows:
1. Create a new Azure AD tenant
1. Activate Azure AD Premium v2 trial
1. Create and configure Azure AD users
1. Assign Azure AD Premium v2 licenses to Azure AD users
1. Manage Azure AD group membership
1. Configure self-service password reset functionality
1. Validate self-service password reset functionality
#### Task 1: Create a new Azure AD tenant
1. From the lab virtual machine, start Microsoft Edge, browse to the Azure portal at [**http://portal.azure.com**](http://portal.azure.com) and sign in by using a Microsoft account that has the Owner role in the Azure subscription you intend to use in this lab.
1. In the Azure portal, navigate to the **New** blade.
1. From the **New** blade, search Azure Marketplace for **Azure Active Directory**.
1. Use the list of search results to navigate to the **Create directory** blade.
1. From the **Create directory** blade, create a new Azure AD tenant with the following settings:
- Organization name: **AdatumLab100-5b**
- Initial domain name: a unique name consisting of a combination of letters and digits.
- Country or region: **United States**
> **Note**: Take a note of the initial domain name. You will need it later in this lab.
#### Task 2: Activate Azure AD Premium v2 trial
1. In the Azure portal, set the **Directory + subscription** filter to the newly created Azure AD tenant.
> **Note**: The **Directory + subscription** filter appears to the right of the Cloud Shell icon in the toolbar of the Azure portal
> **Note**: You might need to refresh the browser window if the **AdatumLab100-5b** entry does not appear in the **Directory + subscription** filter list.
1. In the Azure portal, navigate to the **AdatumLab100-5b - Overview** blade.
1. From the **AdatumLab100-5b - Overview** blade, navigate to the **Licenses - Overview** blade.
1. From the **Licenses - Overview** blade, navigate to the **Products** blade.
1. From the **Products** blade, navigate to the **Activate** blade and activate **Azure AD Premium P2** free trial.
#### Task 3: Create and configure Azure AD users
1. In the Azure portal, navigate to the **Users - All users** blade of the AdatumLab100-5b Azure AD tenant.
1. From the **Users - All users** blade, create a new user with the following settings:
- Name: **aaduser1**
- User name: **aaduser1@<DNS-domain-name>.onmicrosoft.com** where <DNS-domain-name> represents the initial domain name you specified in the first task of this exercise.
> **Note**: Take a note of this user name. You will need it later in this lab.
- Profile:
- Department: **Sales**
- Properties: **Default**
- Groups: **0 groups selected**
- Directory role: **User**
- Password: select the checkbox **Show Password** and note the string appearing in the **Password** text box. You will need it later in this lab.
1. From the **Users - All users** blade, create a new user with the following settings:
- Name: **aaduser2**
- User name: **aaduser2@<DNS-domain-name>.onmicrosoft.com** where <DNS-domain-name> represents the initial domain name you specified in the first task of this exercise.
> **Note**: Take a note of this user name. You will need it later in this lab.
- Profile:
- Department: **Finance**
- Properties: **Default**
- Groups: **0 groups selected**
- Directory role: **User**
- Password: select the checkbox **Show Password** and note the string appearing in the **Password** text box. You will need it later in this lab.
#### Task 4: Assign Azure AD Premium v2 licenses to Azure AD users
> **Note**: In order to assign Azure AD Premium v2 licenses to Azure AD users, you first have to set their location attribute.
1. From the **Users - All users** blade, navigate to the **aaduser1 - Profile** blade and set the **Usage location** to **United States**.
1. From the **aaduser1 - Profile** blade, navigate to the **aaduser1 - Licenses** blade and assign to the user an Azure Active Directory Premium P2 license with all licensing options enabled.
1. Return to the **Users - All users** blade, navigate to the **aaduser2 - Profile** blade, and set the **Usage location** to **United States**.
1. From the **aaduser2 - Profile** blade, navigate to the **aaduser2 - Licenses** blade and assign to the user an Azure Active Directory Premium P2 license with all licensing options enabled.
1. Return to the **Users - All users** blade, navigate to the Profile entry of your user account and set the **Usage location** to **United States**.
1. Navigate to **Licenses** blade of your user account and assign to it an Azure Active Directory Premium P2 license with all licensing options enabled.
1. Sign out from the portal and sign back in using the same account you are using for this lab.
> **Note**: This step is necessary in order for the license assignment to take effect.
#### Task 5: Manage Azure AD group membership
1. In the Azure portal, navigate to the **Groups - All groups** blade.
1. From the **Groups - All groups** blade, navigate to the **Group** blade and create a new group with the following settings:
- Group type: **Security**
- Group name: **Sales**
- Group description: **All users in the Sales department**
- Membership type: **Dynamic User**
- Dynamic user members:
- Simple rule
- Add users where: **department Equals Sales**
1. From the **Groups - All groups** blade, navigate to the **Group** blade and create a new group with the following settings:
- Group type: **Security**
- Group name: **Sales and Finance**
- Group description: **All users in the Sales and Finance departments**
- Membership type: **Dynamic User**
- Dynamic user members:
- Advanced rule: **(user.department -eq "Sales") -or (user.department -eq "Finance")**
1. From the **Groups - All groups** blade, navigate to the blades of **Sales** and **Sales and Finance** groups, and note that the group membership evaluation is in progress. Wait until the evalution completes, then navigate to the **Members** blade, and verify that the group membership is correct.
#### Task 6: Configure self-service password reset functionality
1. In the Azure portal, navigate to the **AdatumLab100-5b - Overview** blade.
1. From the **AdatumLab100-5b - Overview** blade, navigate to the **Password reset - Properties** blade.
1. On the **Password reset - Properties** blade, configure the following settings:
- Self service password reset enabled: **Selected**
- Selected group: **Sales**
1. From the **Password reset - Properties** blade, navigate to the **Password reset - Auhentication methods** blade and configure the following settings:
- Number of methods required to reset: **1**
- Methods available to users:
- **Email**
- **Mobile phone**
- **Office phone**
- **Security questions**
- Number of security questions required to register: **5**
- Number of security questions required to reset: **3**
- Select security questions: select **Predefined** and add any combination of 5 predefined security questions
1. From the **Password reset - Authentication methods** blade, navigate to the **Password reset - Registration** blade, and ensure that the following settings are configured:
- Require users to register when signing in?: **Yes**
- Number of days before users are asked to re-confirm their authentication information: **180**
#### Task 7: Validate self-service password reset functionality
1. Open an InPrivate Microsoft Edge window.
1. In the new browser window, navigate to the Azure portal and sign in using the **aaduser1** user account. When prompted, change the password to a new value.
> **Note**: You will need to provide a fully qualified name of the **aaduser1** user account, including the Azure AD tenant DNS domain name, as noted earlier in this lab.
1. When prompted with the **More information required** message, continue to the **don't lose access to your account** page.
1. On the **don't lose access to your account** page, note that you need to set up at least one of the following options:
- **Office phone**
- **Authentication Phone**
- **Authentication Email**
- **Security Questions**
1. From the **don't lose access to your account** page, configure answers to 5 security questions you selected in the previous task
1. Verify that you successfully signed in to the Azure portal.
1. Sign out as **aaduser1** and close the InPrivate browser window.
1. Open an InPrivate Microsoft Edge window.
1. In the new browser window, navigate to the Azure portal and, on the **Pick an account** page, type in the **aaduser1** user account name.
1. On the **Enter password** page, click the **Forgot my password** link.
1. On the **Get back into your account** page, verify the **User ID**, enter the characters in the picture or the words in the audio, and proceed to the next page.
1. On the next page, provide answers to three security questions using answers you specified in the previous task.
1. On the next page, enter twice a new password and complete the password reset process.
1. Verify that you can sign in to the Azure portal by using the newly reset password.
> **Result**: After you completed this exercise, you have created a new Azure AD tenant, activated Azure AD Premium v2 trial, created and configured Azure AD users, assigned Azure AD Premium v2 licenses to Azure AD users, managed Azure AD group membership, as well as configured and validated self-service password reset functionality
### Exercise 2: Manage Azure AD-integrated SaaS applications
The main tasks for this exercise are as follows:
1. Add an application from the Azure AD gallery
1. Configure the application for a single sign-on
1. Assign users to the application
1. Validate single sign-on for the application
#### Task 1: Add an application from the Azure AD gallery
1. In the Azure portal, navigate to the **AdatumLab100-5b - Overview** blade.
1. From the **AdatumLab100-5b - Overview** blade, navigate to the **Enterprise applications - All applications** blade.
1. From the **Enterprise applications - All applications** blade, navigate to the **Add an application** blade.
1. On the **Add an application** blade, search the application gallery for the **Microsoft OneDrive**.
1. Use the list of search results to navigate to the **Microsoft OneDrive** add app blade and add the app.
#### Task 2: Configure the application for a single sign-on
1. From the **Microsoft OneDrive - Overview** blade, navigate to the **Microsoft OneDrive - Getting started** blade.
1. On the **Microsoft OneDrive - Getting started** blade, use the **Configure single sign-on (required)** option to navigate to the **Microsoft OneDrive - Single sign-on** blade.
1. On the **Microsoft OneDrive - Single sign-on** blade, select the **Password-based** option and save the configuration.
#### Task 3: Assign users to the application
1. Navigate back to the **Microsoft OneDrive - Getting started** blade.
1. On the **Microsoft OneDrive - Getting started** blade, use the **Assign a user for testing (required)** option to navigate to the **Users and groups** blade for **Microsoft OneDrive**.
1. From the **Users and groups** blade for **Microsoft OneDrive**, navigate to the **Add Assignment** blade and add the following assignment:
- Users and groups: **Sales and Finance**
- Select role: **Default access**
- Assign Credentials:
- Assign credentials to be shared among all group members: **Yes**
- Email Address: the name of the Microsoft Account you are using for this lab
- Password: the password of the Microsoft Account you are using for this lab
1. Sign out from the Azure portal and close the Microsoft Edge window.
#### Task 4: Validate single sign-on for the application
1. Open a Microsoft Edge window.
1. In the Microsoft Edge window, navigate to the Application Access Panel at [**http://myapps.microsoft.com**](http://myapps.microsoft.com) and sign in by using the **aaduser2** user account. When prompted, change the password to a new value.
> **Note**: You will need to provide a fully qualified name of the **aaduser2** user account, including the Azure AD tenant DNS domain name, as noted earlier in this lab.
1. On the Access Panel Applications page, click the **Microsoft OneDrive** icon.
1. When prompted, add the My Apps Secure Sign-in Extension and enable it, including the **Allow for InPrivate browsing** option.
1. Navigate again to the Application Access Panel at [**http://myapps.microsoft.com**](http://myapps.microsoft.com) and sign in by using the **aaduser2** user account.
1. On the Access Panel Applications page, click the **Microsoft OneDrive** icon.
1. Verify that you have successfully accessed the Microsoft OneDrive application without having to re-authenticate.
1. Sign out from the Application Access Panel and close the Microsoft Edge window.
> **Note**: Make sure to launch Microsoft Edge again, browse to the Azure portal, sign in by using the Microsoft account that has the Owner role in the Azure subscription you were using in this lab, and use the **Directory + subscription** filter to switch to your default Azure AD tenant once you complete this lab.
> **Result**: After you completed this exercise, you have added an application from the Azure AD gallery, configured the application for a single sign-on, assigned users to the application, and validated single sign-on for the application.
| 40.697143 | 334 | 0.723322 | eng_Latn | 0.991064 |
9916faf76698fa54221e58b23dd88995c30bb5a2 | 1,324 | md | Markdown | docs/zh_cn/upgrade-csi-driver.md | fishincat/juicefs-csi-driver | 3027a154165076f9ef05671a9a4724bcd06a5a35 | [
"Apache-2.0"
] | null | null | null | docs/zh_cn/upgrade-csi-driver.md | fishincat/juicefs-csi-driver | 3027a154165076f9ef05671a9a4724bcd06a5a35 | [
"Apache-2.0"
] | null | null | null | docs/zh_cn/upgrade-csi-driver.md | fishincat/juicefs-csi-driver | 3027a154165076f9ef05671a9a4724bcd06a5a35 | [
"Apache-2.0"
] | null | null | null | # 升级 JuiceFS CSI Driver
## CSI Driver v0.10 及以上版本
JuiceFS CSI Driver 从 v0.10.0 开始将 JuiceFS 客户端与 CSI Driver 进行了分离,升级 CSI Driver 将不会影响已存在的 PV。
### v0.13.0
v0.13.0 相比于 v0.12.0 更新了 CSI node & controller 的 ClusterRole,不可以直接更新 image。
1. 请将您的 `k8s.yaml` 修改为要 [v0.13.0 版本](https://github.com/juicedata/juicefs-csi-driver/blob/master/deploy/k8s.yaml) ,然后运行 `kubectl apply -f k8s.yaml`。
2. 如果你的 JuiceFS CSI Driver 是使用 Helm 安装的,也可以通过 Helm 对其进行升级:
```bash
helm repo update
helm upgrade juicefs-csi-driver juicefs-csi-driver/juicefs-csi-driver -n kube-system -f ./values.yaml
```
## CSI Driver v0.10 以下版本
### 小版本升级
升级 CSI Driver 需要重启 `DaemonSet`。由于 v0.10.0 之前的版本所有的 JuiceFS 客户端都运行在 `DaemonSet` 中,重启的过程中相关的 PV 都将不可用,因此需要先停止相关的 pod。
1. 停止所有使用此驱动的 pod。
2. 升级驱动:
* 如果您使用的是 `latest` 标签,只需运行 `kubectl rollout restart -f k8s.yaml` 并确保重启 `juicefs-csi-controller` 和 `juicefs-csi-node` pod。
* 如果您已固定到特定版本,请将您的 `k8s.yaml` 修改为要更新的版本,然后运行 `kubectl apply -f k8s.yaml`。
* 如果你的 JuiceFS CSI Driver 是使用 Helm 安装的,也可以通过 Helm 对其进行升级。
3. 启动 pod。
### 跨版本升级
如果你想从 CSI Driver v0.9.0 升级到 v0.10.0 及以上版本,请参考[这篇文档](upgrade-csi-driver-from-0.9-to-0.10.md)。
### 其他
对于 v0.10.0 之前的版本,可以不升级 CSI Driver 仅升级 JuiceFS 客户端,详情参考[这篇文档](upgrade-juicefs.md)。
访问 [Docker Hub](https://hub.docker.com/r/juicedata/juicefs-csi-driver) 查看更多版本信息。
| 32.292683 | 148 | 0.719789 | yue_Hant | 0.963161 |
99170a75057e5d73697fa24c77b8be921cc56959 | 59 | md | Markdown | README.md | SavSidorov/team4334.github.io | 02c2c1b5a3da6ffb13cf09f69a5dcb1afc9227a1 | [
"Unlicense"
] | null | null | null | README.md | SavSidorov/team4334.github.io | 02c2c1b5a3da6ffb13cf09f69a5dcb1afc9227a1 | [
"Unlicense"
] | null | null | null | README.md | SavSidorov/team4334.github.io | 02c2c1b5a3da6ffb13cf09f69a5dcb1afc9227a1 | [
"Unlicense"
] | null | null | null | team4334.github.io
==================
Team 4334's Website
| 11.8 | 19 | 0.542373 | oci_Latn | 0.410153 |
991795d154074b07b6a1ff51a2c9b35ce80fbe10 | 51,567 | md | Markdown | README.md | nguyendat0410/react-native-basic | 507edeb7057f247a5ca99c948242b7164cbeea40 | [
"MIT"
] | null | null | null | README.md | nguyendat0410/react-native-basic | 507edeb7057f247a5ca99c948242b7164cbeea40 | [
"MIT"
] | null | null | null | README.md | nguyendat0410/react-native-basic | 507edeb7057f247a5ca99c948242b7164cbeea40 | [
"MIT"
] | null | null | null |

# CODE 101 - React Native
Chào mừng các bạn đến với hướng dẫn học React-Native cho người mới bắt. Sau đây là một số chia sẻ, hướng dẫn của mình cho người mới bắt đầu tìm hiểu về React-Native. Qua đó nhằm giúp các bạn có cách nhìn tổng quát hơn và dễ dàng tìm hiểu vấn đề khi mới chập chững bước chân vào lập trình với React-Native.
P/s: Bài viết chủ yếu dựa trên tài liệu chính thống của React-Native phiên bản 0.56 tại <https://facebook.github.io/react-native/docs/getting-started> kết hợp với sự hiểu biết cá nhân của mình vì vậy nếu có sai sót, anh em cứ góp ý để mình sửa đổi nhé.
# Mục Lục
[I. Mục tiêu hướng dẫn](#i-mục-tiêu-hướng-dẫn)<br>
[II. Một vài lưu ý](#ii-một-vài-lưu-ý)<br>
[III. Nội dung hướng dẫn](#iii-nội-dung-hướng-dẫn)
- [CODE 101 - React Native](#code-101---react-native)
- [Mục Lục](#mục-lục)
- [I. Mục tiêu hướng dẫn](#i-mục-tiêu-hướng-dẫn)
- [II. Một vài lưu ý](#ii-một-vài-lưu-ý)
- [III. NỘI DUNG HƯỚNG DẪN](#iii-nội-dung-hướng-dẫn)
- [1. Hướng dẫn cài đặt môi trường react-native trên hệ điều hành Windows.](#1-hướng-dẫn-cài-đặt-môi-trường-react-native-trên-hệ-điều-hành-windows)
- [2. Hướng dẫn cài đặt môi trường react-native trên hệ điều hành MAC OS](#2-hướng-dẫn-cài-đặt-môi-trường-react-native-trên-hệ-điều-hành-mac-os)
- [3. Các IDE khuyên dùng](#3-các-ide-khuyên-dùng)
- [4. Khởi tạo dự án đầu tiên](#4-khởi-tạo-dự-án-đầu-tiên)
- [5. Các thành phần cơ bản của dự án](#5-các-thành-phần-cơ-bản-của-dự-án)
- [6. Component trong React-Native](#6-component-trong-react-native)
- [6.1. Vòng đời của component](#61-vòng-đời-của-component)
- [6.2. Các thành phần cơ bản của component](#62-các-thành-phần-cơ-bản-của-component)
- [6.3. Một số hàm đặc biệt](#63-một-số-hàm-đặc-biệt)
- [6.4. Một vài lưu ý nhỏ khi dùng React-Native](#64-một-vài-lưu-ý-nhỏ-khi-dùng-react-native)
- [7. Thiết kế View (Style)](#7-thiết-kế-view-style)
- [8. Kỹ thuật Debug cơ bản](#8-kỹ-thuật-debug-cơ-bản)
- [9. Các Component thường sử dụng](#9-các-component-thường-sử-dụng)
- [9.1. View](#91-view)
- [9.2. Text](#92-text)
- [9.3. Image](#93-image)
- [9.4. Button](#94-button)
- [9.5. TouchableOpacity](#95-touchableopacity)
- [9.6. Flatlist](#96-flatlist)
- [10. Prop và cách truyền dữ liệu giữa các View (Screen)](#10-prop-và-cách-truyền-dữ-liệu-giữa-các-view-screen)
- [11. Cài đặt và sử dụng thư viện](#11-cài-đặt-và-sử-dụng-thư-viện)
- [11.1. Cài đặt thư viện](#111-cài-đặt-thư-viện)
- [11.2. Link thư viện](#112-link-thư-viện)
- [11.3. Chỉnh sửa thư viện](#113-chỉnh-sửa-thư-viện)
- [12. Chuyển đổi giữa các màn hình](#12-chuyển-đổi-giữa-các-màn-hình)
- [13. Giao tiếp Client vs Server](#13-giao-tiếp-client-vs-server)
- [13.1. RESTful API.](#131-restful-api)
- [13.2. Websocket](#132-websocket)
- [14. Lưu trữ dữ liệu](#14-lưu-trữ-dữ-liệu)
- [14.1. AsyncStorage:](#141-asyncstorage)
- [14.2. Database:](#142-database)
- [15. Đa Ngôn ngữ](#15-đa-ngôn-ngữ)
- [16. Giao tiếp với Native](#16-giao-tiếp-với-native)
- [17. Quy chuẩn tên biến và cấu trúc chương trình](#17-quy-chuẩn-tên-biến-và-cấu-trúc-chương-trình)
- [17.1. Tên biến và hàm:](#171-tên-biến-và-hàm)
- [17.2. Cấu trúc chương trình:](#172-cấu-trúc-chương-trình)
- [Đến đây là kết thúc bài hướng dẫn của mình rồi. Hy vọng bài hướng dẫn sẽ giúp bạn có được những cái nhìn tổng quan về React-Native để xây dựng một ứng dụng cho riêng mình.](#đến-đây-là-kết-thúc-bài-hướng-dẫn-của-mình-rồi-hy-vọng-bài-hướng-dẫn-sẽ-giúp-bạn-có-được-những-cái-nhìn-tổng-quan-về-react-native-để-xây-dựng-một-ứng-dụng-cho-riêng-mình)
- [P/S: Nếu có thời gian mình sẽ viết tiếp về cách xây dựng 1 ứng dụng đọc báo hoàn chỉnh trên Android và iOS. Cho Star để mình lấy động lực nhé.](#ps-nếu-có-thời-gian-mình-sẽ-viết-tiếp-về-cách-xây-dựng-1-ứng-dụng-đọc-báo-hoàn-chỉnh-trên-android-và-ios-cho-star-để-mình-lấy-động-lực-nhé)
# I. Mục tiêu hướng dẫn
- Hiểu được các thành phần cơ bản của React-Native.
- Nắm vững được vòng đời của một màn hình, component của React-Native.
- Tùy biến các component theo ý muốn.
- Tìm kiếm, sử dụng và tùy biến thư viện.
- Xây dựng 1 ứng dụng đọc báo như báo mới.
# II. Một vài lưu ý
- Bài viết nhắm tới các bạn đã có cơ bản về javascript nhất là quen với ES6. Nếu bạn chưa biết về javascript vui lòng tìm hiểu javascript cơ bản ít nhất bạn cần nắm vững những kiến thức sau (bạn có thể tự tìm hiểu tại <https://freetuts.net/hoc-javascript/javascript-can-ban>):
- Biến và toán tử trong javascript
- Lệnh If...else
- Lệnh Switch..case
- Vòng lặp white
- Vòng lặp for
- Vòng lặp for...in
- Viết hàm thực thi các tác vụ cơ bản
- Mảng: (duyệt mảng lấy các phần tử)
- Nếu biết về css thì đó cũng là một điểm lợi thế. Bạn có thể tìm hiểu thêm tại đây <https://freetuts.net/css-la-gi-hoc-css-nhu-the-nao-327.html>
- Hiện tại hệ điều hành Windows chỉ build được ứng dụng Android.
- Hệ điều hành IOS có thể build được cả Android và IOS.
- Phiên bản IOS thấp nhất mà react-native có thể hỗ trợ là IOS 8.0
- Phiên bản Android thấp nhất mà react-native có thể hỗ trợ là Android 4.1 (API 16)
- Các hướng dẫn dưới đây ngoại trừ phần cài đặt, đều là hướng dẫn để xây dựng ứng dụng trên IOS. Một số chức năng có thể IOS hỗ trợ nhưng Android không hỗ trợ và ngược lại, nên nếu có lỗi các bạn có thể bình luận tại đây hoặc tìm kiếm google để nâng cao khả năng giải quyết vấn đề nhé.
- Để chạy các code mẫu, sau khi tải về vui lòng vào thư mục và chạy dòng lệnh ```npm install``` để tải toàn bộ thư viện cần sử dụng. Và chạy ```react-native run-ios``` để chạy ứng dụng trên IOS. ```react-native run-android``` để chạy ứng dụng trên hệ điều hành Android.
**Khuyến nghị**: Sau những lần tìm hiểu và phát triển ứng dụng thì mình khuyến cáo không nên sử dụng Expo (framework của react) để phát triển ứng dụng đơn giản. Bởi vì dự án của bạn sẽ nặng lên, bạn rất khó quản lý permission và các thư viện đi kèm.
# III. NỘI DUNG HƯỚNG DẪN
## 1. Hướng dẫn cài đặt môi trường react-native trên hệ điều hành Windows.
- **Bước 1**: Cài đặt Chocolatey từ <https://chocolatey.org> (Chocolatey là trình quản lý các gói thư viện của Windows)
- **Bước 2**: Cài đặt Nodejs Java và Python 2 thông qua Chocolatey sử dụng dòng lệnh sau (dùng cmd để chạy lệnh này):<br>
```choco install -y nodejs.install python2 jdk8```
- **Bước 3**: Cài đặt Android studio
- **Bước 4**: Cài đặt SDK: Nên cài SDK Platform 23 vì mặc định react-native hiện tại sử dụng Android SDK Platform 23 để build ứng dụng
Lưu ý: Trên hệ điều hành windows chỉ có thể build ứng dụng trên Android.
## 2. Hướng dẫn cài đặt môi trường react-native trên hệ điều hành MAC OS
- **Bước 1**: Cài đặt Brew: Brew là trình quản lý các gói thứ viện, MACOS không tích hợp sẵn và bạn phải sử dụng terminal để cài đặt brew bằng cách chạy dòng lệnh sau. <br>
```{{/usr/bin/ruby -e "$(curl –fsSL https://raw.githubusercontent.com/ Homebrew/install/master/install)"}}```
- **Bước 2**: Cài đặt Nodejs:<br>
```brew install node```
- **Bước 3**: Cài đặt Watchman:<br>
```brew install watchman```
- **Bước 4**: Cài đặt react-native:<br>
```npm install -g react-native-cli```
- **Bước 5**: Cài đặt Xcode: truy cập App Store trên MACOS để cài đặt Xcode.
- **Bước 6** (option): Nếu bạn xây dựng ứng dụng android sử dụng hệ điều hành MACOS thì bạn cần cài đặt thêm các gói như JDK, Android Studio, Android SDK. (xem thêm phần cài đặt cho Windonws để hiểu rõ hơn.)
## 3. Các IDE khuyên dùng
- Code: Hiện tại mình sử dụng Visual Studio Code các bạn có thể download về và cài đặt tại <https://code.visualstudio.com/> <br> Các bạn cũng có thể sử dụng bất kỳ IDE nào các bạn thích như Sublime Text Atom, Vim Editer...
- Build ứng dụng:
- IOS: sử dụng Xcode (search trên store apple nhé)
- Android: sử dụng Android studio <https://developer.android.com/studio/>
P/s: Nếu sử dụng MAC thì nên dùng Xcode để chạy ứng dụng. Bởi vì một số lý do như: Run các lần sau nhanh hơn, xem log debug mà không cần bật chức năng Debug JS Remotely và quan trọng là làm quen với một số chức năng của Xcode để lúc xảy ra lỗi fix lỗi nhanh hơn. <br> Với Android thì có một vài trở ngại khi dùng Android studio như việc run mà không dùng code react-native mới nhất, chức năng host reloading cũng khó hoạt động.
## 4. Khởi tạo dự án đầu tiên
- **Bước 1**: Khởi tạo dự án: mở Terminal (cmd) sau đó gõ lệnh này vào (cd vào thư mục bạn muốn tạo dự án trước)<br>
```react-native init ProjectName```
- **Bước 2**: Truy cập vào dự án vừa tạo.<br>
```cd ProjectName```
- **Bước 3**: Chạy ứng dụng trên hệ điều hành:<br>
IOS: ``` react-native run-ios``` <br>Android: ```react-native run-android```
Khi chạy lệnh này hệ điều hành sẽ tạo một server local để build code react của bạn. Kèm theo đó là chạy các lệnh để build ứng dụng.<br>Bạn cũng có thể mở file /ios/ProjectName.xcodeproj bằng Xcode để khởi chạy ứng dụng, hoặc mở nguyên thư mục android bằng Android studio để khởi chạy ứng dụng.
- **Hiển thị Menu điều khiển**:
- Command + D (hoặc lắc điện thoại IOS) để hiển thị menu điều khiển khi run debug ứng dụng trên MacOS.
- ctrl + D hoặc phím menu để hiển thị menu điều khiển khi run debug ứng dụng trên Windown.
- Command + R để reload lại source code máy ảo IOS
- R + R để reload lại source code máy ảo Android.
- **Một vài lệnh vui vui để sửa lỗi** (Bật terminal or cmd trong dự án vừa khởi tạo)
- Không khởi tạo server để build khi run debug trên android thì chạy
```react-native start```
- Khi run Android mà không sử dụng code react-native mới nhất thì chạy dòng này (Build toàn bộ source của bạn thành 1 file và đặt nó vào trong assets, tạo các resource android tương ứng mà bạn sử dụng).
```
react-native bundle --platform android --dev false --entry-file index.js --bundle-output android/app/src/main/assets/index.android.bundle --assets-dest android/app/src/main/res
```
- Khi general APK mà bị lỗi double resource thì xóa thư mục drawable trong android/app/src/main/res thì sẽ build được.
- Khi run app ios bị lỗi "Build input file cannot be found: '../Example/node_modules/react-native/third-party/double-conversion-1.1.6/src/strtod.cc'" thì chạy 2 dòng lệnh sau:
```
cd node_modules/react-native/scripts && ./ios-install-third-party.sh && cd ../../../
cd node_modules/react-native/third-party/glog-0.3.5/ && ../../scripts/ios-configure-glog.sh && cd ../../../../
```
Chú ý version phiên bản glog (0.3.5) mà bạn đang sử dụng.
## 5. Các thành phần cơ bản của dự án
Cấu trúc thư mục mà bạn nhìn thấy có thể sẽ như dưới đây (tùy version react-native hiện tại của bạn). Hình dưới đây không bao gồm một vài file bị ẩn thuộc cấu hình của react-native<br>

- **Thư mục Android**: chứa toàn bộ source build ứng dụng Android. Chúng ta có thể mở thư mục Android bằng Android studio và chạy ứng dụng thay vì sử dụng dòng lệnh ```react-native run-android``` nhưng có thể ứng dụng sẽ không build mã javascript được và sẽ xuất hiện màn hình trắng trên điện thoại android.
- **Thư mục IOS**: chứa toàn bộ source build ứng dụng IOS. Chúng ta có thể mở file ProjectName.xcodeproj bằng Xcode để run ứng dụng IOS thay vì sử dụng dòng lệnh ```react-native run-ios```. Lần đầu có thể chạy hơi lâu nhưng những lần tiếp theo sẽ nhanh hơn việc build bằng dòng lệnh.
- **Thư mục node_modules**: chứa toàn bộ các package (thư viện) cần để chạy một ứng dụng react-native.
- **File package.js**: file quản lý các package nodejs đi kèm với dự án. Nếu bạn tải các dự án demo về cần dử dụng dòng lệnh ```npm install``` để tải toàn bộ thư viện yêu cầu của dự án về.
- **File package-lock.js** file được general sau khi chạy cài đặt ```npm install```
- **File index.js**: file đầu tiên được binding khi chạy ứng dụng. File này sẽ đăng ký một component, component này sẽ được load lên đầu tiên khi chạy, mặc định ứng dụng sẽ đăng ký component trong App.js
- **File app.json**: file config tên ứng dụng và tên hiển thị.
- **File App.js** là một component mặc định có sử dụng một số Component khác như Text, View...
## 6. Component trong React-Native
Component là một thành phần cơ bản trong ứng dụng react-native. Mọi view, screen đều được kế thừa từ lớp component này.
### 6.1. Vòng đời của component

<br><em>(Nguồn:: internet)</em>
**Các hàm được gọi trong vòng đời của Component**
- **constructor(props)** - Hàm khởi tạo component. Trong hàm này chúng ta thường dùng để khởi tạo state, binding các hàm con của component.<br> Lưu ý: Không được thay đổi state bằng phương thức ```this.setState()``` trong hàm này.
- **componentWillMount()** - Hàm này sẽ bị loại bỏ ở phiên bản mới.
- **render()** - Đây là hàm bắt buộc có trong component. Sau khi khởi tạo hàm này được gọi để trả về các thành phần hiển thị lên màn hình.<br>Hàm này sẽ được tự động gọi lại khi state hoặc props của nó thay đổi. Chỉ những component có sử dụng state hoặc props thì mới được gọi lại để render lại.<br><br>**Lưu ý:**
* Trong hàm này cũng không được sử dụng phương thức ```this.setState()```<br>
* Trong hàm này không nên chạy xử lý dữ liệu nhiều để không bị lag khi render (nên xử lý dữ liệu trong componentDidMount hoặc constructor).
- **componentDidMount()** - Hàm này sẽ được gọi ngay sau khi hàm **render()** lần đầu tiên được gọi. Thông thường trong hàm này ta có thể lấy dữ liệu từ server hoặc client để render dữ liệu ra. Khi chạy đến đây thì các phần từ đã được sinh ra rồi, ta có thể tương tác với các thành phần UI.
- **componentWillReceiveProps(nextProps)** - Hàm này được gọi khi props của component được khởi tạo thay đổi.
- **shouldComponentUpdate(nextProps, nextState)** - Hàm này được gọi trước render() khi cập nhật dữ liệu. Hàm này trả về giá trị true hoặc false. Nếu false thì không gọi lại hàm render mặc định nó trả về true.
- **componentWillUpdate(nextProps, nextState)** - Hàm này được gọi ngay sau khi hàm shouldComponentUpdate() trả về true. Trong hàm này cũng không được set lại state.
- **componentDidUpdate(prevProps, prevState)** - Hàm này được gọi ngay sau hàm render() từ lần thứ 2 trở đi.
- **componentWillUnmount()** - Hàm này được gọi khi component này bị loại bỏ. Chúng ta nên thực hiện các thao tác dọn dẹp, hủy timer hoặc các tiến trình đang xử lý.
### 6.2. Các thành phần cơ bản của component
Sau đây là chương trình mẫu cơ bản để ta hiểu được các thành phần của một Component
```javascript
import React, { Component } from 'react';
import { Text, View } from 'react-native';
export default class App extends Component {
constructor(props) {
super(props);
this.state = {
message: "Welcome to Code 101 - React-native"
}
}
render() {
return (
<View>
<Text>{this.state.message}</Text>
</View>
);
}
}
```
- **State** - là biến điều khiển trạng thái nội bộ của 1 component. State có thể thay đổi bằng cách gọi hàm this.setState({...}). Mỗi lần thay đổi state hàm render sẽ được gọi lại ngay sau đó (hàm render chỉ thay đổi những thành phần có liên quan đến những giá trị trong state bị thay đổi).<br> Chúng ta nên bỏ các biến có liên quan đến UI vào trong state này, để khi state thay đổi, UI màn hình sẽ được vẽ lại và thay đổi theo.
<br>**Lưu ý:** Không được thay đổi state trực tiếp bằng cách gọi this.state = {...} nếu sử dụng thay đổi state trực tiếp toàn bộ component này sẽ không còn hoạt động đúng như mong muốn nữa.
- **Props** - là các thuộc tính được thằng sử dụng truyền vào. Đây là các thông số được truyền vào để tùy chỉnh theo ý muốn của người xây dựng Component. Khác với state chúng ta không được thay đổi props ở trong chính bản thân của nó. Chúng ta chỉ nên đọc các thuộc tính được truyền vào để sử dụng mà thôi.<br> Ví dụ sử dụng props: cũng là ví dụ trên nhưng chúng ta custom một số thứ để bạn có thể hiểu rõ hơn về props.
```javascript
import React, { Component } from 'react';
import { Text, View } from 'react-native';
class CustomText extends Component {
constructor(props) {
super(props);
}
render() {
return (
<Text>{this.props.message}</Text> /*Sử dụng props được truyền từ ngoài vào.*/
);
}
}
export default class App extends Component {
constructor(props) {
super(props);
this.state = {
message: "Welcome to Code 101 - React-native"
}
}
render() {
return (
<CustomText message={this.state.message} /> /*truyền 1 props vào cho thằng con sử dụng.*/
);
}
}
```
### 6.3. Một số hàm đặc biệt
- **Hàm this.setState()** - Hàm dùng để thay đổi state của component. Đây là phương thức chính để cập nhật giao diện người dùng. Khi hàm này thực thi xong thì hàm **render()** sẽ được tự động gọi lại. **Những giá trị nào của state thay đổi thì chỉ những thành phần có sử dụng biến state tương ứng đó được gọi để vẽ lại UI**.
<br>Lưu ý: hàm này chạy bất đồng bộ nên chúng ta không nên đọc giá trị sau khi gọi hàm này. <br>Cách sử dụng:
```javascript
this.setState({
message: "Chào mừng",
key: "Value",
})
console.log(this.state.message) //không nên
// không sử dụng this.state ngay sau khi vừa set xong
// biến truyền vào cho hàm setState là một đối tượng có dạng key: value.
```
Có thể sử dụng callback để check dữ liệu hoặc xử lý một số tác vụ sau khi thay đổi trạng thái
```javascript
this.setState({
message: "Chào mừng"
}, ()=>{
console.log(this.state.message) // kết quả: Chào mừng
})
```
- **Hàm forceUpdate()** - Mặc định hàm render() sẽ được gọi khi props hoặc state thay đổi. Nhưng nếu một vài thành phần UI sử dụng một số dữ liệu khác state hoặc prop muốn thay đổi, thì chúng ta cần thông báo cho React biết để vẽ lại toàn bộ bằng cách gọi hàm forceUpdate().
### 6.4. Một vài lưu ý nhỏ khi dùng React-Native
- Dữ liệu cần in ra màn hình và cần thay đổi lại UI khi nó thay đổi thì đặt vào state.
- Dữ liệu không cần thay đổi UI khi nó thay đổi thì có thể dùng ```this.xxx``` như vậy biến này có thể thực hiện thao tác = (gán) và sử dụng trực tiếp như các biến thông thường.
- Dữ liệu trong prop thì không nên thay đổi.
- Trong **state** chỉ nên chứa dữ liệu, không nên chứa các **View / Component** vào trong state. Làm như vậy có thể gây double dữ liệu và việc quản lý UI trở nên phức tạp hơn và khó tùy biến sau này.
## 7. Thiết kế View (Style)
Sau đây là một đoạn code Demo về Style của ứng dụng React-Native. Code có sẵn trong Example (Example/app/modules/screens/Home/StyleDemo)
```javascript
export class StyleDemo extends React.Component {
render() {
return (
<View>
<Text style={styles.red}>just red</Text>
<Text style={styles.bigblue}>just bigblue</Text>
<Text style={[styles.bigblue, styles.red]}>bigblue, then red</Text>
<Text style={[styles.red, styles.bigblue]}>red, then bigblue</Text>
</View>
);
}
}
const styles = StyleSheet.create({
bigblue: {
color: 'blue',
fontWeight: 'bold',
fontSize: 30,
},
red: {
color: 'red',
},
});
```
Giống như một ứng dụng web cơ bản, React-Native sử dụng một số thẻ css để vẽ những gì bạn muốn. Nếu bạn là lập trình web quen thuộc với css thì việc thiết kế này khá đơn giản. Để trau dồi những khả năng này chỉ có cách là làm nhiều bạn sẽ tìm hiểu những style bạn muốn và sẽ làm ứng dụng của bạn đẹp hơn.
Ở ví dụ trên bạn có thể thay đổi các thuộc tính của style rồi reload lại để thấy sự thay đổi nhé.
Trong ví dụ thư mục Home tôi đã chia phần Style qua một file khác để dễ quản lý (Từ các ví dụ sau trở đi, tôi sẽ chia phần style này sang 1 file khác để dễ quản lý). Bạn có thể vào đó, thử thay đổi, xóa sửa để biết được thuộc tính nào dùng để làm gì nhé. Làm nhiều phần này thì sẽ có kinh nghiệm thiết kế đẹp thôi.
Một vài lưu ý:
- Bạn nên biết thuộc tính nào dùng để làm gì, sử dụng tối ưu để hiệu quả nhất (Có thể copy code của ai đó nhưng nên hiểu dòng style nào làm việc gì).
- Không nên quá rườm rà code ngắn nhưng đạt được yêu cầu là tốt nhất.
## 8. Kỹ thuật Debug cơ bản
Xây dựng ứng dụng React-Native khác với ứng dụng native là bạn không thể đặt break point rồi chạy và chờ chương trình nhảy vào vị trí mà bạn đợi và xem trạng thái hay biến lúc đó bằng bao nhiêu đang như thế nào. Thay vì vậy chương trình React-Native cho phép bạn in giá trị tại thời điểm đó và xuất ra màn hình console.<br> Sử dụng lệnh
```console.log(variable)``` để in giá trị của biến bất kì (xem ví dụ phía trên để biết việc in giá trị của biến message trong state)
Xcode và Android studio mặc định khi run debug sẽ xuất các log này ra trong phần All Output (Xcode), Logcat (Android Studio).
Bên cạnh đó bạn có thể sử dụng chức năng Debug JS Remotely (xem phần hiển thị menu điều khiển trong mục 4) để thấy các log này trong phần console của trình duyệt web.
Ngoài ra bạn có thể sử dụng terminal (cmd) để xem log IOS hoặc Android bằng cách gõ lệnh:
```
react-native log-ios
//or
react-native log-android
```
## 9. Các Component thường sử dụng
Dưới đây là code demo những component cơ bản thường sử dụng. Bạn có thể code lại, copy hoặc chạy demo từ example (demo có sử dụng hình ảnh nên bạn phải copy hình ảnh trong example - Example/app/assets/images).
```javascript
import React from 'react';
import { Image, View, Text, Button, TouchableOpacity, FlatList, StyleSheet } from 'react-native';
import { Colors } from '../../../configs/style';
export class Components extends React.Component {
//Header ứng dụng (tùy chọn)
static navigationOptions = ({ navigation }) => {
return {
title: "COMPONENT",
headerStyle: {
backgroundColor: Colors.primary
},
headerTintColor: Colors.white,
headerTitleStyle: {
alignSelf: 'center'
}
};
};
constructor(props) {
super(props);
this.state = {
message: "Message 2",
listData: [
{
image: require('../../../assets/images/ios.png'),
title: "IOS"
},
{
image: require('../../../assets/images/android.png'),
title: "Android"
},
{
image: require('../../../assets/images/react-native.png'),
title: "React Native"
}
]
}
this.clickButton = 0;
this.clickTouchAbleOpecity = 0;
}
onPressButtonDemo() {
this.clickButton++;
this.setState({
message: "Clicked Button: " + this.clickButton
})
}
onPressTouchableOpacityDemo() {
this.clickTouchAbleOpecity++;
this.setState({
message: "Clicked TouchableOpacity: " + this.clickTouchAbleOpecity
})
}
render() {
return (
<View style={Styles.container}>
{/* Hiển thị Một message lên màn hình */}
<Text style={Styles.textMessage}>WELCOME TO TEXT OF REACT-NATIVE</Text>
<View style={Styles.containImage}>
{/* Hiển thị ảnh từ local resource */}
<Image
style={Styles.imgLogo} /* Style của ảnh */
resizeMode={'contain'} /* chế độ hiển thị (center, contain, cover, repeat, stretch ) của ảnh */
source={require('../../../assets/images/react-native.png')}
/>
{/* Hiển thị ảnh từ web/server */}
<Image
style={Styles.imgLogo}
resizeMode={'contain'}
source={{ uri: 'https://facebook.github.io/react-native/docs/assets/favicon.png' }}
/>
</View>
{/* In một giá trị của state lên màn hình */}
<Text style={Styles.textMessage}>{this.state.message}</Text>
{/* Sử dụng Button với chức năng press vào nút */}
<Button
onPress={() => this.onPressButtonDemo()}
title="Click Me!"
color="#841584"
/>
{/* Sử dụng TouchableOpacity với chức năng press giống như button */}
<TouchableOpacity
style={Styles.btnStyle}
onPress={() => this.onPressTouchableOpacityDemo()}>
<Text style={Styles.textAction}>Touchable Opacity</Text>
</TouchableOpacity>
{/* Sử dụng FlatList để hiển thị ra một danh sách */}
<FlatList
data={this.state.listData}
renderItem={({ item }) => this.renderItem(item)}
keyExtractor={(item, index) => index.toString()}
/>
</View>
);
}
/* Hiển thị chi tiết 1 item như thế nào */
renderItem(item) {
return (
<View style={Styles.containerItem}>
<Image
style={Styles.imgLogo}
resizeMode={'contain'}
source={item.image}
/>
<Text>{item.title}</Text>
</View>
)
}
}
//Trong example mình tách phần Styles này qua file khác cho dễ đọc
const Styles = StyleSheet.create({
container: {
flex: 1,
flexDirection: 'column',
alignItems: 'center',
backgroundColor: Colors.white,
},
containImage: {
marginTop: 16,
flexDirection: 'row',
justifyContent: 'center'
},
textMessage: {
marginTop: 16,
color: 'green',
fontSize: 16,
},
imgLogo: {
width: 50,
height: 50,
margin: 4
},
btnStyle: {
height: 50,
width: 200,
borderColor: Colors.primary,
borderRadius: 5,
borderWidth: 2,
justifyContent: "center",
alignItems: 'center',
margin: 8
},
textAction: {
color: Colors.primary,
fontSize: 20,
fontWeight: 'bold'
},
containerItem: {
marginTop: 16,
flexDirection: 'row',
alignItems: 'center'
}
});
```
Sau khi chạy Demo ta được UI như sau (run example thì click vào component)

### 9.1. View
Là một component cũng thường xuyên được sử dụng. Thường được sử dụng với mục đích chia các view con theo hàng dọc hoặc hàng ngang dựa vào thuộc tính flexDirection trong style là 'column/row' (dọc / ngang), hoặc sử dụng để chứa nhiều view con hoặc khi cần in ra màn hình một view không hiển thị gì hết ví dụ như trong cấu trúc toán tử:
```
{
(Điều kiện) ? <Text> Text Message <Text> : <View/>
}
```
flex: 1 ở style sẽ giúp kéo view rộng hết khung chứa có thể.
### 9.2. Text
Dùng để hiển thị 1 message lên màn hình. Có thể sử dụng text cố định hoặc in nội dung của một biến lên màn hình
```
<Text>Message Here<Text>
<Text>{variable_here}<Text>
```
### 9.3. Image
Dùng để hiển thị hình ảnh lên màn hình. Có 3 cách hiển thị:
- Hiển thị ảnh Local:
```
<Image
source={require('/react-native/img/favicon.png')}
/>
```
- Hiển thị ảnh từ url:
```
<Image
style={{width: 50, height: 50}}
source={{uri: 'https://facebook.github.io/react-native/docs/assets/favicon.png'}}
/>
```
- Hiển thị ảnh base 64:
```javascript
<Image
style={{width: 66, height: 58}}
source={{uri: 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAADMAAAAzCAYAAAA6oTAqAAAAEXRFWHRTb2Z0d2FyZQBwbmdjcnVzaEB1SfMAAABQSURBVGje7dSxCQBACARB+2/ab8BEeQNhFi6WSYzYLYudDQYGBgYGBgYGBgYGBgYGBgZmcvDqYGBgmhivGQYGBgYGBgYGBgYGBgYGBgbmQw+P/eMrC5UTVAAAAABJRU5ErkJggg=='}}
/>
```
Resize Mode quen thuộc:
- cover: (mặc định) Hình ảnh sẽ giữ nguyên tỷ lệ. Ảnh sẽ lớn hơn hoặc bằng khung chứa.
- contain: Hình ảnh vẫn giữ nguyên tỷ lệ. Ảnh sẽ nhỏ hơn hoặc bằng khung chứa
- center: Căn giữa hình ảnh theo 2 chiều. Lấy phần ở giữa, gần giống với cover.
- repeat: Lặp lại hình ảnh để che hết phần kích thước ô chứa.
- stretch: Thay đổi tỷ lệ hình ảnh để kéo dãn bằng với ô chứa.
### 9.4. Button
Cách sử dụng một Button
```javascript
onPressButtonDemo(){
console.log("Click Button")
}
....
<Button
onPress={() => this.onPressButtonDemo()}
title="Click Me!"
color="#841584"
/>
```
Thông thường mình ít khi sử dụng Button vì lý do custom style nó không hoạt động đúng với cả Android và IOS vì vậy nên mình thường sử dụng TouchableOpacity hơn.
Nhưng lưu ý cách sử dụng sự kiện onPress ```onPress={() => this.onPressButtonDemo()}``` Vui lòng viết theo cấu trúc này để giảm thiểu lỗi hoặc là phải binding hàm trong contrucstor trước lúc sử dụng. Sự kiện onPress chỉ có một số component hỗ trợ, Text thì không hỗ trợ nên nếu muốn sử dụng onPress cho Text thì đọc phần TouchableOpacity phía dưới nhé.
### 9.5. TouchableOpacity
Thông thường mình thay thế việc sử dụng Button bằng TouchableOpacity để việc định dạng style giống nhau cho cả android và ios, TouchableOpacity có thể chứa bất kỳ view con nào, và nhớ lưu ý cách dùng sự kiện onPress giống như Button nhé.
```javascript
<TouchableOpacity
style={Styles.btnStyle}
onPress={() => this.onPressTouchableOpacityDemo()}>
<Text style={Styles.textAction}>Click Me</Text>
</TouchableOpacity>
```
### 9.6. Flatlist
Đây là Component thường được sử dụng để hiển thị 1 danh sách lên màn hình. <br>Cách dùng:
```javascript
<FlatList
data={this.state.listData}
renderItem={({ item }) => this.renderItem(item)}
keyExtractor={(item, index) => index.toString()}
/>
/* Hiển thị chi tiết 1 item như thế nào */
renderItem(item) {
return (
<View style={Styles.containerItem}>
<Image
style={Styles.imgLogo}
resizeMode={'contain'}
source={item.image}
/>
<Text>{item.title}</Text>
</View>
)
}
```
Một vài lưu ý khi sử dụng Flatlist:
- Khi một thành phần data (ví dụ data[0] = ...) của bạn thay đổi thường thì không vẽ lại UI cho nên bạn sẽ cần thêm một thuộc tính là ```extraData={this.state}```. Lúc này mỗi lần state thay đổi thì danh sách lại được vẽ lại.
- Có thể sử dụng Flatlist để làm như GridView trong android dựa vào thuộc tính numColumns={colum} (colum là số cột). Nhưng bạn sẽ cần phải tính toán width, height của mỗi colum để hiển thị đẹp nhất (Không có sẵn như fill_parent trong android).
Các component ở trên mình chỉ mang tính chất giới thiệu để các bạn tìm hiểu. Để hiểu rõ hơn cũng như tìm hiểu thêm về các thuộc tính của mỗi component thì vui lòng đọc riêng tài liệu của các Component nhé.
Mỗi component sẽ có nhiều thuộc tính khác để hỗ trợ bạn làm UI tốt và mượt nhất có thể.
## 10. Prop và cách truyền dữ liệu giữa các View (Screen)
Tạo file App.js như sau
```javascript
import React from 'react';
import { View, Text, FlatList, StyleSheet } from 'react-native';
import { Colors } from '../../../configs/style';
import { ViewItem } from './ViewItem'
export class App extends React.Component {
//Header ứng dụng (tùy chọn)
static navigationOptions = ({ navigation }) => {
return {
title: "PROPS",
headerStyle: {
backgroundColor: Colors.primary
},
headerTintColor: Colors.white,
headerTitleStyle: {
alignSelf: 'center'
}
};
};
constructor(props) {
super(props);
this.state = {
message: "",
listData: [
{
image: require('../../../assets/images/ios.png'),
title: "IOS"
},
{
image: require('../../../assets/images/android.png'),
title: "Android"
},
{
image: require('../../../assets/images/react-native.png'),
title: "React Native"
}
]
}
}
// onPressItem
onPressItem(item, index) {
this.setState({
message: "Click item: " + index + " - title: " + item.title
})
}
render() {
return (
<View style={Styles.container}>
<Text style={Styles.textMessage}>{this.state.message}</Text>
<FlatList
style={Styles.containList}
data={this.state.listData}
renderItem={({ item, index }) => this.renderItem(item, index)}
keyExtractor={(item, index) => index.toString()}
/>
</View>
);
}
/* Hiển thị chi tiết 1 item như thế nào */
renderItem(item, index) {
return (
<ViewItem
data={item} //Truyền item này qua ViewItem như một prop
onPressItem={(itemPress) => { this.onPressItem(itemPress, index) }} // truyền một hàm qua để bắt sự kiện click item
/>
)
}
}
const Styles = StyleSheet.create({
container: {
flex: 1,
flexDirection: 'column',
alignItems: 'center',
backgroundColor: Colors.white,
},
textMessage: {
marginTop: 16,
color: 'green',
fontSize: 16,
},
containList:{
width: '100%',
}
});
```
và 1 file ViewItem.js nằm cùng thư mục
```javascript
import React from 'react';
import { Image, View, Text, TouchableOpacity, StyleSheet } from 'react-native';
import { Colors } from '../../../configs/style';
export class ViewItem extends React.Component {
constructor(props) {
super(props);
this.state = {
color: Colors.white
}
}
onPressItem() {
//Bạn có thể xử lý sự kiện ở đây nếu cần, ví dụ như như đổi màu item
let newColor = Colors.white;
if (this.state.color == Colors.white) {
newColor = Colors.primary
}
this.setState({
color: newColor
})
//Hoặc chuyển việc xử lý đó ra phía ngoài thông qua hàm được truyền vào.
//Có thể truyền dữ liệu ra ngoài để hàm phía ngoài xử lý
this.props.onPressItem(this.props.data)
}
render() {
//in props được truyền qua để kiểm tra
console.log(this.props.data)
//render ra màn hình item được truyền vào thông qua props
return (
<TouchableOpacity style={[Styles.containerItem, { backgroundColor: this.state.color }]} onPress={() => this.onPressItem()}>
<Image
style={Styles.imgLogo}
resizeMode={'contain'}
source={this.props.data.image} //sử dụng prop được truyền qua
/>
<Text>{this.props.data.title}</Text>
</TouchableOpacity>
)
}
}
const Styles = StyleSheet.create({
imgLogo: {
width: 50,
height: 50,
margin: 4
},
containerItem: {
marginLeft: 16,
marginRight: 16,
marginTop: 16,
flexDirection: 'row',
alignItems: 'center'
}
});
```
Trong Example mình đã gộp style lại và đưa nó ra 1 file riêng là styles.js để dễ quản lý (demo trên có sử dụng hình ảnh nên bạn phải copy hình ảnh trong example - Example/app/assets/images).
Ở ví dụ trên ta demo việc truyền dữ liệu giữa 2 component thông qua props
Bên gửi qua (ViewItem đóng vai trò là 1 component được tùy biến)
```javascript
<ViewItem
data={item} //Truyền item này qua ViewItem như một prop
onPressItem={(itemPress) => { this.onPressItem(itemPress, index) }} // truyền một hàm qua để bắt sự kiện click item
/>
```
Bên nhận dữ liệu có thể sử dụng dữ liệu được truyền qua thông qua props. (Kiểu nó ném mấy cái dữ liệu qua thì bên nhận này truy xuất thông qua props)
```javascript
...
render() {
//in props được truyền qua để kiểm tra
console.log(this.props.data)
//render ra màn hình item được truyền vào thông qua props
return (
<TouchableOpacity style={[Styles.containerItem, { backgroundColor: this.state.color }]} onPress={() => this.onPressItem()}>
<Image
style={Styles.imgLogo}
resizeMode={'contain'}
source={this.props.data.image} //sử dụng prop được truyền qua
/>
<Text>{this.props.data.title}</Text>
</TouchableOpacity>
)
}
```
Việc truyền dữ liệu ngược lại cũng được thể hiện trong ví dụ thông qua việc xử lý sự kiện onPressItem()
```javascript
onPressItem() {
//Bạn có thể xử lý sự kiện ở đây nếu cần, ví dụ như như đổi màu item
let newColor = Colors.white;
if (this.state.color == Colors.white) {
newColor = Colors.primary
}
this.setState({
color: newColor
})
//Hoặc chuyển việc xử lý đó ra phía ngoài thông qua hàm được truyền vào.
//Có thể truyền dữ liệu ra ngoài để hàm phía ngoài xử lý
this.props.onPressItem(this.props.data)
}
```
Một vài lưu ý khi sử dụng props
- Không thay đổi dữ liệu trong prop ở bên nhận.
- Nên chia mỗi thành phần riêng biệt ra mỗi component riêng và giao tiếp với component chính thông qua props để giảm thiểu việc phải vẽ lại nguyên toàn bộ, nhất là những component có chứa các timmer (setInterval(), setTimeOut()...).
- ...
## 11. Cài đặt và sử dụng thư viện
### 11.1. Cài đặt thư viện
Thông thường trong React-Native sử dụng thư viện rất nhiều có lẽ vì một vài lý do:
- Code từ đầu thì lâu hơn.
- Thư viện được nhiều người xây dựng nên khả năng tốt hơn so với việc mình code một mình.
- Có cộng đồng hỗ trợ nên có lỗi thì cũng dễ dàng sửa lỗi.
- Những thư viện liên quan đến SDK của các nhà phát triển như Facebook, Google, Firebase... đều được cộng đồng phát triển để hỗ trợ việc bạn xây dựng ứng dụng tốt nhất.
- Và nhiều lý do khác nữa.
Khi bạn gặp vấn đề hoặc cần làm một cái gì đó với react-native hãy tìm Google với từ khóa react-native + cái gì bạn muốn làm.
Ví dụ muốn làm chức năng đăng nhập với facebook thì có thể tìm: react-native login with facebook. Đa phần bạn sẽ thấy thư viện hỗ trợ nằm ngay trang đầu tiên. Hãy vào trang chính thống của thư viện để xem cách cài đặt và sử dụng thư viện. Nhớ xem lại số star và các vấn đề trước khi bạn muốn sử một thư viện nào đó trên github.
Nếu thư viện được publish trên npmjs <https://www.npmjs.com/> thì bạn có thể cài đặt thông qua
```npm install package_name```
### 11.2. Link thư viện
Một phần khá quan trọng, sau khi bạn kéo thư viện từ npm về, thì bạn cần link thư viện đó vào app của bạn để ứng dụng có thể khởi chạy các phần code native của thư viện hoặc được quyền chạy một số tác vụ khác.
Thông thường các thư viện đều có link tự động qua lệnh ```react-native link```. Tùy vào từng thư viện sẽ có hướng dẫn và cách link bổ sung. Bên cạnh đó một số thư viện không link tự động được hoặc project của bạn có vấn đề phải link bằng tay lúc đó bạn nên tham khảo bài viết này trước để biết cách link và hiểu sâu hơn <https://facebook.github.io/react-native/docs/linking-libraries-ios>
### 11.3. Chỉnh sửa thư viện
Đa phần trình quản lý source code (git/svn) sẽ không commit các thư viện có sẵn được cài đặt từ npm (thư mục *node_modules*) hoặc nếu mình cố gắng commit sẽ làm dự án của chúng ta nặng lên rất nhiều lần. Do vậy chúng ta không sửa trực tiếp thư viện trong *node_modules*. Sau khi cài đặt và link thư viện. Bạn hãy copy nguyên source code của thư viện qua app/modules và tiến hành sửa đổi, tùy biến thư viện tại đây. Lúc sử dụng nhớ chuyển đổi đường dẫn import thư viện qua dự án của bạn. Nếu đó là phần chỉnh sửa quan trong hy vọng bạn sẽ đóng góp cho cộng đồng bằng cách report lên dự án chính hoặc chia sẻ lại cho mọi người.
## 12. Chuyển đổi giữa các màn hình
Một ứng dụng bạn phát triển không thể chỉ có một màn hình. Vì vậy bạn phải biết cách chuyển đổi qua lại giữa các màn hình. Hiện tại mình sử dụng thư viện react-navigation (v.2.18.1) để chuyển đổi giữa các màn hình. Các bạn có thể tìm hiểu thêm về thư viện này tại (<https://reactnavigation.org>)
- Cài đặt thư viện:
Vào dự án bạn tạo và chạy dòng lệnh sau để cài đặt thư viện
```npm install --save react-navigation```
- Sử dụng thư viện:
**- Xây dựng cấu trúc ứng dụng**: Để bạn hiểu rõ hơn về phần demo sau bạn vui lòng xem lại file index.js trong Example (Example/app/index.js). Dưới đây là phần tạo cấu trúc sườn của ứng dụng dựa vào StackNavigator của thư viện react-navigation.
```javascript
import React, { Component } from 'react';
import { StackNavigator } from 'react-navigation';
import { StyleSheet, View } from 'react-native';
// import toàn bộ các class Screen từ modules/screens (những class được xuất thông qua file modules/screens/index.js)
import * as Screens from './modules/screens';
//Tạo StackNavigator từ thư viện react-navigation
const AppNavigator = StackNavigator({
HOME: {
screen: Screens.Home
},
STYLES: {
screen: Screens.StyleDemo
},
COMPONENT: {
screen: Screens.Components
},
PROPS: {
screen: Screens.Props
}
}, {
headerMode: "screen"
});
export default class App extends Component {
render() {
return (
<View style={styles.container}>
{/*Vẽ stack ứng dụng ra màn hình*/}
<AppNavigator />
</View>
);
}
}
const styles = StyleSheet.create({
container: {
flex: 1
}
});
```
Như bạn thấy ở trên ta khai báo 1 ứng dụng có 4 màn hình HOME, STYLES, COMPONENT, PROPS. Mặc định màn hình nào ở trên cùng sẽ được xuất hiện đầu tiên. <br>Nội dung mỗi màn hình có dạng:
```
HOME: {
screen: Screens.Home
}
```
Trong đó Screens.Home là class được import từ module screens.<br>Lưu ý dòng lệnh:
```import * as Screens from './modules/screens'; ```
Dòng lệnh này thực hiện import toàn bộ những class được xuất ra thông qua file index.js. Vì vậy nếu bạn thêm màn hình mới lưu ý vào file index.js để xuất thêm class bạn vừa tạo.
**- Chuyển đổi màn hình**: có 2 cách chuyển màn hình:
- Chuyển đổi và xóa toàn bộ màn hình trước đó:
```
// chuyển qua màn hình PROPS đã khai báo trong App StackNavigator
let pageContinue = NavigationActions.reset({
index: 0,
actions: [NavigationActions.navigate({ routeName: "PROPS", params: {} })]
});
this.props.navigation.dispatch(pageContinue);
```
params: {} - Đây là phần để bạn truyền dữ liệu qua màn hình kế tiếp. Bạn có thể truyền qua cho màn hình tiếp theo một đối tượng theo cú pháp này.
- Chuyển đổi và giữ lại màn hình trước để quay lại
```
// chuyển qua màn hình PROPS đã khai báo trong App StackNavigator
this.props.navigation.navigate("PROPS");
//or
this.props.navigation.navigate("PROPS", {});
```
{} - Đây cũng là cách để bạn truyền một đối tượng qua cho màn hình kế tiếp.<br>Mặc định nếu bạn hiển thị Status bar thì sẽ có phím quay về, nhưng nếu cần thiết có thể quay về bằng cách gọi hàm sau đây:
```this.props.navigation.goBack();```
Hiển thị Status bar:
```
static navigationOptions = ({ navigation }) => {
return {
title: "PROPS",
headerStyle: {
backgroundColor: Colors.primary
},
headerTintColor: Colors.white,
headerTitleStyle: {
alignSelf: 'center'
}
};
};
```
## 13. Giao tiếp Client vs Server
### 13.1. RESTful API.

(nguồn internet)
Nếu bạn không biết RESTful API là gì thì có thể đọc thêm bài viết này (<https://viblo.asia/p/thiet-ke-restful-api-GrLZD98Vlk0>) để hiểu rõ hơn về RESTful API. Đây là một trong những chuẩn giao tiếp phổ biến giữa client và server.
Phần Demo này được trình bày khá rõ ràng và chi tiết trong ví dụ Example (app/modules/screens/RestFul/RestFul.js). Bạn nên chạy ví dụ trước để thấy cách hoạt động của nó. Demo bao gồm việc gọi một public api từ <https://api.ice5.skyx.app/get_languages> (GET) và hiển thị kết quả như sau:

- File Thiết kế RestFull tổng quan: app/libs/RESTClient.js
```javascript
import { getBaseURL } from '../configs/config';
let networkError = {
error_code: -1,
message: 'Network error',
data: {}
};
export class RESTFulAPI {
//Định nghĩa một api lấy language từ server.
// Public api có sẵn tại https://api.ice5.skyx.app/get_languages
getLanguage() {
let api = getBaseURL() + "get_languages";
return this.fetchData(api);
}
//Định nghĩa một hàm bất đồng bộ hỗ trợ các phương thức, GET, POST, PUT, DELETE (mặc định là GET)
async fetchData(api, method = 'GET', body) {
let headers = {
Accept: 'application/json',
'Content-Type': 'application/json',
};
try {
let response = await fetch(api, {
method: method,
headers: headers,
body: JSON.stringify(body)
});
let responseJson = await response.json();
return responseJson;
} catch (error) {
return networkError;
}
}
}
export default RESTClient = new RESTFulAPI();
```
Ở đây mình định nghĩa 1 lớp để quản lý việc trao đổi, giao tiếp giữa client và server. Hàm fetchData() là một hàm bất đồng bộ hỗ trợ gọi các phương thức RESTful.
Và đây là cách chúng ta gọi hàm fetchData() và định nghĩa rõ ràng 1 api truy cập để lấy danh sách ngôn ngữ. Lưu ý: Thay vì việc mình đặt trực tiếp link <https://api.ice5.skyx.app/get_languages> thì mình lại gọi hàm getBaseURL() là để sau này có thay api, thì mình không phải đi thay nhiều chỗ, chỉ cần vào config và thay đổi là hoàn tất.
```javascript
getLanguage() {
let api = getBaseURL() + "get_languages";
return this.fetchData(api);
}
```
Ví dụ gọi fetchData() với phương thức POST
```
let api = getBaseURL() + "get_languages";
let body = {...}
return this.fetchData(api, 'POST', body);
//Đây là cách POST 1 đối tượng body lên hệ thống.
// Phương thức POST trên server này không hỗ trợ nên ắt hẳn không hoạt động rồi. Mình chỉ muốn demo cho các bạn biết cách gọi phương thức khác ntn thôi. =))
```
- Cách sử dụng RESTClient
```javascript
import RESTClient from '../../../libs/RESTClient';
...
getLanguagesFromServer() {
//todo có thể làm cái xoay xoay ở đây
//Gọi hàm lấy language từ lớp RestClient để lấy dữ liệu
RESTClient.getLanguage().then(
(result) => {
//Đây là quá trình bất đồng bộ, và trả về result sau khi kết thúc
if (result.error_code == 0) {
//Kiểm tra trạng thái lỗi và set lại dữ liệu để render data
this.setState({
listData: result.data
})
}
//todo Gọi xong thì tắt cái xoay xoay đi
}
)
}
```
Lưu ý: Phương thức getLanguagesFromServer() nên gọi trong componentDidMount() hoặc các sự kiện sau khi constructor() hoàn tất để trách những lỗi có nguy cơ tiềm ẩn ví dụ như api nhanh quá, contrucstor chạy chưa xong và nó đi setState() thì app của bạn nó làm việc không đúng.
### 13.2. Websocket
Comming soon
## 14. Lưu trữ dữ liệu
React-Native không còn hỗ trợ AsyncStorage, mà được cung cấp qua gói thư viện @react-native-community/async-storage. Xem phần Storage phía dưới để tìm hiểu thêm về phương pháp lưu trữ này. Bên cạnh đó mình xin được giới thiệu phương pháp lưu trữ theo dạng dữ liệu có cấu trúc sử dụng realm database. Theo bản thân mình realm đư đánh giá là một trong những thư viện hỗ trợ database tốt và tối ưu cho dân lập trình trên các dòng mobile hiện tại.
### 14.1. AsyncStorage:
Bởi vì AsyncStorage chạy bất đồng bộ vì vậy mình chỉ sử dụng AsyncStorage để lưu một số config của ứng dụng ví dụ như user data hay language code ..., những dữ liệu quan trọng và có cấu trúc thường mình sẽ sử dụng database để lưu trữ, truy xuất nhanh và dễ dàng hơn.
import thư viện AsyncStorage:
```javascript
import AsyncStorage from '@react-native-community/async-storage';
```
Sử dụng thư viện:
```javascript
// lưu trữ dữ liệu theo dạng key -> value (nếu value là một đối tượng thì nên chuyển đổi về JSON trước sử dụng JSON.stringify(obj))
AsyncStorage.setItem("language", "vi");
//Đọc giá trị lên và sử dụng.
AsyncStorage.getItem("language").then(result => {
console.log(result) //in ra màn hình console: vi
})
```
### 14.2. Database:
Thông thường mình sẽ dùng realm để lưu trữ các dữ liệu có cấu trúc. Mình xin demo nhỏ về một phần mềm quản lý, chỉnh sửa danh sách sinh viên:
## 15. Đa Ngôn ngữ
## 16. Giao tiếp với Native
## 17. Quy chuẩn tên biến và cấu trúc chương trình
Khi bạn tìm hiểu được kha khá các vấn đề về React-Native và code được một vài chương trình đơn giản thì cũng là lúc chúng ta nên xem lại các quy chuẩn thiết kế, cũng như quy chuẩn về tên biến để:
- Khi đọc lại bớt bỡ ngỡ (trước mình code cái gì vậy)
- Người khác đọc vào biết bạn đang làm gì?
- Có thể bạn khác join vào dự án biết cách sửa đổi.
- Làm dự án lớn nhiều người tham gia.
- ....
Mình xin dưa ra một số quy chuẩn cơ bản như sau:
### 17.1. Tên biến và hàm:
- **Một vài quy chuẩn tên biến mà mình cần tuân thủ như**:
- Tên biến phải bắt đầu bằng ký tự viết thường.
- Tên biến không được bắt đầu bằng số hoặc ký tự đặc biệt.
- Những chữ cái đầu của mỗi từ đều viết hoa.
- Tên biến phải mang ý nghĩa rõ ràng.
- Nếu là style thì nên thêm viết tắt của view ở phía trước
- **Một vài ví dụ về tên biến**:
- maxNumber
- minNumber
- textMessageAnswer
- btnActionAgree
- ....
- **Một vài quy chuẩn tên hàm**:
- Tên hàm cũng bắt đầu bằng ký tự viết thường.
- Tên hàm không chứa các ký tự đặc biệt.
- Những chữ cái đầu của mỗi từ đều viết hoa.
- Tên hàm phải mang ý nghĩa rõ ràng và thể hiện được chức năng của hàm.
- **Một vài ví dụ về tên hàm**:
- findMinOfTowNumber(firstNumber, secondNumeber){}
- onPressBtnLanguage(){}
- onPressNegativeAction(){}
- ....
### 17.2. Cấu trúc chương trình:
Sau những dự án và tìm hiểu trên mạng. Mình có đưa ra mô hình cấu trúc thư mục dự án như sau

Toàn bộ source code của chương trình sẽ được đặt trong thư mục app:
- **assets** là thư mục chứa resource của mình bao gồm các resource như custom font (fonts), hình ảnh (images), ngôn ngữ (languages)
- **configs** là thư mục chứa các cấu hình của ứng dụng: bao gồm các cấu hình server, link, màu sắc cơ bản.
- **libs** là thư mục chứa các thư viện cơ bản của mình để xử lý một số vấn đề nội bộ như:
- **Database** (xử lý lưu trữ dữ liệu bằng database)
- **Storage** (xử lý lưu trữ dữ liệu bằng storage)
- **Language** (Cấu hình xử lý đa ngôn ngữ trong ứng dụng)
- **RESTClient** (Cấu hình, danh sách các api truy cập hệ thống server)
- **SoundPlayer** (Điều khiển âm thanh)
- **Inapp** (Một vài cấu hình, xử lý thanh toán mua bán với store)
- **Ads** (Cấu hình hiển thị quảng cáo từ bên thứ 3)
- .....
- **models** là thư mục chứa các model do mình định nghĩa, có thể là định nghĩa các đối tượng hoặc các loại của đối tượng
- **modules** là thư mục chứa các module do mình định nghĩa hoặc tùy biến lại. Trong đó bao gồm:
- **screens** - module chứa toàn bộ xử lý màn hình của ứng dụng
- **views** - module chứa toàn bộ view đã được custom.
- Và một số module mình muốn chỉnh sửa từ thư viện, thì có thể thêm vào đây để tùy biến.
### Đến đây là kết thúc bài hướng dẫn của mình rồi. Hy vọng bài hướng dẫn sẽ giúp bạn có được những cái nhìn tổng quan về React-Native để xây dựng một ứng dụng cho riêng mình.
### P/S: Nếu có thời gian mình sẽ viết tiếp về cách xây dựng 1 ứng dụng đọc báo hoàn chỉnh trên Android và iOS. Cho Star để mình lấy động lực nhé.
| 40.413009 | 625 | 0.656098 | vie_Latn | 1.000009 |
9918125d315cd431b0d00f6f5f71a25a77a847c9 | 3,130 | md | Markdown | _posts/Tech/CourseNotes/2021-03-25-编译原理.md | mafulong/mafulong.github.io | 1745f5b940ca495c21a92c2e3d404f0c2a188d53 | [
"MIT"
] | 4 | 2018-03-13T06:49:11.000Z | 2020-11-29T14:28:48.000Z | _posts/Tech/CourseNotes/2021-03-25-编译原理.md | mafulong/mafulong.github.io | 1745f5b940ca495c21a92c2e3d404f0c2a188d53 | [
"MIT"
] | 10 | 2020-01-12T12:17:07.000Z | 2021-09-27T21:34:48.000Z | _posts/Tech/CourseNotes/2021-03-25-编译原理.md | mafulong/mafulong.github.io | 1745f5b940ca495c21a92c2e3d404f0c2a188d53 | [
"MIT"
] | 9 | 2017-10-09T23:48:27.000Z | 2022-01-06T16:42:11.000Z | ---
layout: post
category: CourseNotes
title: 编译原理
tags: CourseNotes
---
##
## 编译原理
> [参考](https://juejin.cn/post/6844903486258151431)
### 预处理
最后简单描述一下预处理。预处理主要是处理一些宏定义,比如 `#define`、`#include`、`#if` 等。预处理的实现有很多种,有的编译器会在词法分析前先进行预处理,替换掉所有 # 开头的宏,而有的编译器则是在词法分析的过程中进行预处理。当分析到 # 开头的单词时才进行替换。虽然先预处理再词法分析比较符合直觉,但在实际使用中,GCC 使用的却是一边词法分析,一边预处理的方案。
### 词法分析
- 输入:源代码
- 输出:中间代码
- 把源代码分割开,形成若干个单词。原理主要是状态机。处理之后,编译器就知道了每个单词
### 语法分析
- 思路是模板匹配,把单词组合起来
- 成功解析语法以后,我们会得到抽象语法树(AST: Abstract Syntax Tree)
```
int fun(int a, int b) { int c = 0; c = a + b; return c;}
```
它的语法树如下:
<img src="https://cdn.jsdelivr.net/gh/mafulong/mdPic@vv3/v3/20210325142313" alt="img" style="zoom:25%;" />
### 生成中间代码
- 意义:**不同cpu的汇编语法不一致。因此需要生成和语言无关、也和cpu无关的中间代码,然后再生成各个cpu的汇编代码**。可以理解为中间代码是一种非常抽象,又非常普适的代码。它客观中立的描述了代码要做的事情,如果用中文、英文来分别表示 C 和 Java 的话,中间码某种意义上可以被理解为世界语。
- eg. 如gcc,
- 语法树转高端gimple
- 主要处理寄存器和栈,如c=a+b变成寄存器处理。
- 函数调用则建栈
- 高端gimple转低端gimple
- 主要是把变量定义,语句执行和返回语句区分存储
- 好处是容易计算一个函数需要多少栈空间
- 低端gimple转中间代码
- (略)
### 生成目标代码(生成汇编代码)
- 主要的工作量在于兼容各种 CPU 以及填写模板。在最终生成的汇编代码中,不仅有汇编命令,也有一些对文件的说明。
### 汇编,生成二进制机器码
- 把汇编代码转成 二进制的机器码,机器码可以直接被 CPU 识别并执行
- 从目标代码可以猜出来,最终的目标文件(机器码)也是分段的,这主要有以下三个原因:
1. 分段可以将数据和代码区分开。其中代码只读,数据可写,方便权限管理,避免指令被改写,提高安全性。
2. 现代 CPU 一般有自己的数据缓存和指令缓存,区分存储有助于提高缓存命中率。
3. 当多个进程同时运行时,他们的指令可以被共享,这样能节省内存。
对于一个目标文件来说,文件的最开头(也叫作 ELF 头)记录了目标文件的基本信息,程序入口地址,以及段表的位置,相当于是对文件的整体描述。接下来的重点是段表,它记录了每个段的段名,长度,偏移量。比较常用的段有:
- .strtab 段: 字符串长度不定,分开存放浪费空间(因为需要内存对齐),因此可以统一放到字符串表(也就是 .strtab 段)中进行管理。字符串之间用 `\0` 分割,所以凡是引用字符串的地方用一个数字就可以代表。
- .symtab: 表示符号表。符号表统一管理所有符号,比如变量名,函数名。符号表可以理解为一个表格,每行都有符号名(数字)、符号类型和符号值(存储地址)
- .rel 段: 它表示一系列重定位表。这个表主要在链接时用到,下面会详细解释。
### 链接
在一个目标文件中,不可能所有变量和函数都定义在文件内部。比如 `strlen` 函数就是一个被调用的外部函数,此时就需要把 `main.o` 这个目标文件和包含了 `strlen` 函数实现的目标文件链接起来。我们知道函数调用对应到汇编其实是 `jump` 指令,后面写上被调用函数的地址,但在生成 `main.o` 的过程中,`strlen()` 函数的地址并不知道,所以只能先用 0 来代替,直到最后链接时,才会修改成真实的地址。
链接器就是靠着重定位表来知道哪些地方需要被重定位的。每个可能存在重定位的段都会有对应的重定位表。在链接阶段,链接器会根据重定位表中,需要重定位的内容,去别的目标文件中找到地址并进行重定位。
有时候我们还会听到动态链接这个名词,它表示重定位发生在运行时而非编译后。动态链接可以节省内存,但也会带来加载的性能问题,这里不详细解释,感兴趣的读者可以阅读《程序员的自我修养》这本书。
## 编译 VS 解释
总结一下,对于 C 语言来说,从源码到运行结果大致上需要经历编译、汇编和链接三个步骤。编译器接收源代码,输出目标代码(也就是汇编代码),汇编器接收汇编代码,输出由机器码组成的目标文件(二进制格式,.o 后缀),最后链接器将各个目标文件链接起来,执行重定位,最终生成可执行文件。
### 解释型语言
- 解释型语言:源代码 -> 解释器 -> 运行结果
- 编译型语言:源代码 -> 中间代码 -> 目标代码 -> 运行结果
解释型语言和编译型语言的根本区别在于,对于用户来说,到底是直接从源码开始执行,还是从中间代码开始执行。以 C 语言为例,所有的可执行程序都是二进制文件。而对于传统意义的 Python 或者 JavaScript,用户并没有拿到中间代码,他们直接从源码开始执行。从这个角度来看, Java 不可能是解释型语言,虽然 Java 虚拟机会解释字节码,但是对于用户来说,他们是从编译好的 .class 文件开始执行,而非源代码。
解释程序和编译程序的根本区别:是否生成目标代码。有没有虚拟机,虚拟机是不是解释执行,会不会生成中间代码,这些都不重要,重要的是如果从中间代码开始执行,而且 AST 已经事先生成好,那就是编译型的语言。
## 运行时
### 运行时库的基本概念
以 C 语言为例,有非常多的操作最终都依赖于 **glibc** 这个动态链接库。包括但不限于字符串处理(`strlen`、`strcpy`)、信号处理、socket、线程、IO、动态内存分配(malloc)等等。这一点很好理解,如果回忆一下之前编译器的工作原理,我们会发现它仅仅是处理了语言的语法,比如变量定义,函数声明和调用等等。至于语言的功能, 比如内存管理,內建的类型,一些必要功能的实现等等。如果要对运行时库进行分类,大概有两类。一种是语言自身功能的实现,比如一些內建类型,内置的函数;另一种则是语言无关的基础功能,比如文件 IO,socket 等等。
由于每个程序都依赖于运行时库,这些库一般都是动态链接的,比如 C 语言的 (g)libc。这样一来,运行时库可以存储在操作系统中,节省内存占用空间和应用程序大小。
对于 Java 语言来说,它的垃圾回收功能,文件 IO 等都是在虚拟机中实现,并提供给 Java 层调用。从这个角度来看,虚拟机/解释器也可以被看做语言的运行时环境(库)。
| 29.809524 | 288 | 0.774121 | yue_Hant | 0.682014 |
991953a37d284226cd217e3b19ca1c6bb1e61950 | 2,420 | md | Markdown | Conditional_Stastement/README.md | reddyprasade/PYTHON-BASIC-FOR-ALL | 4fa4bf850f065e9ac1cea0365b93257e1f04e2cb | [
"MIT"
] | 21 | 2019-06-28T05:11:17.000Z | 2022-03-16T02:02:28.000Z | Conditional_Stastement/README.md | reddyprasade/PYTHON-BASIC-FOR-ALL | 4fa4bf850f065e9ac1cea0365b93257e1f04e2cb | [
"MIT"
] | 2 | 2021-12-28T14:15:58.000Z | 2021-12-28T14:16:02.000Z | Conditional_Stastement/README.md | reddyprasade/PYTHON-BASIC-FOR-ALL | 4fa4bf850f065e9ac1cea0365b93257e1f04e2cb | [
"MIT"
] | 18 | 2019-07-07T03:20:33.000Z | 2021-05-08T10:44:18.000Z | * **Q1:** Take values of length and breadth of a rectangle from user and check if it is square or not.
* **Q2:** Take two int values from user and print greatest among them.
* **Q:** A shop will give discount of 10% if the cost of purchased quantity is more than 1000.
* Ask user for quantity
* Suppose, one unit will cost 100.
* Judge and print total cost for user.
* **Q4:** A company decided to give bonus of 5% to employee if his/her year of service is more than 5 years. Ask user for their salary and year of service and print the net bonus amount.
* **Q5:** A school has following rules for grading system:
a. Below 25 - F
b. 25 to 45 - E
c. 45 to 50 - D
d. 50 to 60 - C
e. 60 to 80 - B
f. Above 80 - A Ask user to enter marks and print the corresponding grade.
* **Q6:** Take input of age of 3 people by user and determine oldest and youngest among them.
* **Q7:** Write a program to print absolute vlaue of a number entered by user. E.g.-
* INPUT: 1 OUTPUT: 1
* INPUT: -1 OUTPUT: 1
* **Q7:** A student will not be allowed to sit in exam if his/her attendence is less than 75%.
* Take following input from user
* Number of classes held
* Number of classes attended.
* And print
* percentage of class attended
* Is student is allowed to sit in exam or not.
* **Q8:** Modify the above question to allow student to sit if he/she has medical cause. Ask user if he/she has medical cause or not ( 'Y' or 'N' ) and print accordingly.
* **Q9:** Write a program to check if a year is leap year or not. If a year is divisible by 4 then it is leap year but if the year is century year like 2000, 1900, 2100 then it must be divisible by 400.
* **Q10:** Ask user to enter age, sex ( M or F ), marital status ( Y or N ) and then using following rules print their place of service.
if employee is female, then she will work only in urban areas.
if employee is a male and age is in between 20 to 40 then he may work in anywhere
if employee is male and age is in between 40 t0 60 then he will work in urban areas only.
And any other input of age should print "ERROR".
* **Q11:** A 4 digit number is entered through keyboard. Write a program to print a new number with digits reversed as of orignal one. E.g.-
INPUT : 1234 OUTPUT : 4321
INPUT : 5982 OUTPUT : 2895
*
| 60.5 | 202 | 0.671901 | eng_Latn | 0.999795 |
991a3f5972837380b37b5e64683b89ddc51b0ed1 | 4,132 | md | Markdown | README.md | garno/video-jwplayer-js | e3fa2fb08cf1694b5396ce32e099e017962e6c76 | [
"Apache-2.0"
] | 1 | 2020-05-09T00:43:36.000Z | 2020-05-09T00:43:36.000Z | README.md | garno/video-jwplayer-js | e3fa2fb08cf1694b5396ce32e099e017962e6c76 | [
"Apache-2.0"
] | 1 | 2021-01-19T17:50:28.000Z | 2021-01-19T17:50:28.000Z | README.md | garno/video-jwplayer-js | e3fa2fb08cf1694b5396ce32e099e017962e6c76 | [
"Apache-2.0"
] | 1 | 2021-01-19T15:54:03.000Z | 2021-01-19T15:54:03.000Z | [](https://github.com/newrelic/open-source-office/blob/master/examples/categories/index.md#community-project)
# New Relic JW Player JS Tracker
The New Relic JWPlayer tracker instruments the JW Player. It requires New Relic Browser Pro with SPA. It must be used on a page where the New Relic Browser JS Snippet is present. See the `samples` folder for an example.
## Build
Install dependencies:
```
$ npm install
```
And build:
```
$ npm run build:dev
```
Or if you need a production build:
```
$ npm run build
```
## Usage
Load **scripts** inside `dist` folder into your page.
```html
<script src="../dist/newrelic-video-jwplayer.min.js"></script>
```
> If `dist` folder is not included, run `npm i && npm run build` to build it.
```javascript
// var player = jwplayer('my-player')
nrvideo.Core.addTracker(new nrvideo.JwplayerTracker(player))
```
### Custom Attributes
You can add custom attributes in the following ways. You can override OOTB attributes or create your own.
```
// set tracker
// add custom attributes at player launch
const tracker = new nrvideo.JwplayerTracker(player,{ customData: {
contentTitle: "Override Existing Title",
myPlayerName: "myPlayer",
myPlayerVersion: "9.4.2"
} })
nrvideo.Core.addTracker(tracker)
// add custom attribute anywhere
tracker.customData.myErrorMsg = "DVR Failed"
```
### Verify instrumentation
On the page you've instrumented...
Is Browser Agent loaded? → Type `newrelic` in the console.
Is Video Script Loaded? → Type `nrvideo` in the console.
Turn on debug → add `?nrvideo-debug=true` or `&nrvideo-debug=true` in the URL.
Is Video Tracker correctly instantiated? → filter console by `[nrvideo]` and look for logs.
Search for `Tracker` or `nrvideo`.
<img width="200" alt="Console Search" src="https://user-images.githubusercontent.com/8813505/82217239-22172c00-98e8-11ea-9aa3-a9a675fd65a5.png">
### Examples
Check out the `samples` folder for complete usage examples.
## Data Model
To understand which events (actions) and attributes are captured and emitted by the JW Player tracker go [here](https://docs.google.com/document/d/e/2PACX-1vSECNAxbKmYYOH23rA5k02NTEZDX20PTx1VXB_3Kz8gVBwUCdlPpizTrxu9lO6jW1-wXd5Yq4q_IUH6/pub#h.o16zqioqw5dk)
## Known Limitations
Due to the information exposed by player provider, this tracker may not be able to report:
- `adPosition`.
# Open source license
This project is distributed under the [Apache 2 license](LICENSE).
# Support
New Relic has open-sourced this project. This project is provided AS-IS WITHOUT WARRANTY OR DEDICATED SUPPORT. Issues and contributions should be reported to the project here on GitHub.
We encourage you to bring your experiences and questions to the [Explorers Hub](https://discuss.newrelic.com) where our community members collaborate on solutions and new ideas.
## Community
New Relic hosts and moderates an online forum where customers can interact with New Relic employees as well as other customers to get help and share best practices. Like all official New Relic open source projects, there's a related Community topic in the New Relic Explorers Hub. You can find this project's topic/threads here:
https://discuss.newrelic.com/t/jw-player-js-tracker/100304
## Issues / enhancement requests
Issues and enhancement requests can be submitted in the [Issues tab of this repository](../../issues). Please search for and review the existing open issues before submitting a new issue.
# Contributing
Contributions are encouraged! If you submit an enhancement request, we'll invite you to contribute the change yourself. Please review our [Contributors Guide](CONTRIBUTING.md).
Keep in mind that when you submit your pull request, you'll need to sign the CLA via the click-through using CLA-Assistant. If you'd like to execute our corporate CLA, or if you have any questions, please drop us an email at [email protected].
| 37.225225 | 328 | 0.764763 | eng_Latn | 0.954604 |
991a4611fd52c538cc387038cdb5c6fdd1b36015 | 3,524 | md | Markdown | site/content/post/i-yourtherapist-at-wits-end.md | MichaelFlops/poliwat-site | 159ed9ed891f4937aa5c68c163e573b31cb82aee | [
"MIT"
] | null | null | null | site/content/post/i-yourtherapist-at-wits-end.md | MichaelFlops/poliwat-site | 159ed9ed891f4937aa5c68c163e573b31cb82aee | [
"MIT"
] | null | null | null | site/content/post/i-yourtherapist-at-wits-end.md | MichaelFlops/poliwat-site | 159ed9ed891f4937aa5c68c163e573b31cb82aee | [
"MIT"
] | null | null | null | ---
title: "I, your therapist at wits end"
date: 2017-07-28T23:00:13-07:00
draft: false
---
Friday 533 PM | OnCalTrain | JULY 28 2017 | #####I your therapist at wits end
#### Had 1 beer @ [jack's]() house and we livestreamed the Sims 3 on Twitch as prep for our play.
<img src="/images/simsims.jpg">
<!-- https://soundcloud.com/kyotokidforever/post-dreams-in-her-post-house -->
Just wanted to report on an occurrence that happened a couple months ago.
After my last breakup, I went a little off the rails. No, not talking ruby, I maintained a healthy ecosystem of smoke and drink each day. I made emotional audio [journals](https://soundcloud.com/poliwat/sets/michaels-audio-journal/s-9T9Nm), only published half of [the here](https://soundcloud.com/poliwat/AJ)
It was my last quarter at uni(so iThought), and what I did was make a bucket list. A breakup bucket, to do list. I also started seeing a therapist, and the story is about my two sessions her. She was a mom, her mind seemed elsewhere. She wouldn’t quite understand me when I spoke, but she was sure professional. She never followed up so I felt like she gave up on me, and wasn’t interested in keeping me as a client. Maybe I’ll text her sometime.
What I did with this therapist was write up an Adult progress report card. Attached is the pdf here. I set goals for the week, even included some humor and shower thoughts. I asked for her to look it over for feedback. The goals were just about impossible. I got about 90% of the items on the list complete. I swam 5,000 yards. I bounced audio every day. I worked constantly.
This isn’t the interesting part however. No it was this person I saw walking out of my therapist’s office when I ran up to the building. I couldn’t find the office, and this person pointed out where it was. The next night I was very (high). I ran to the library 15 minutes before closing time, trying to get a (mary albright) book, because I wanted to better understand a colored woman’s perspective. And from someone a little less stupid than my ex. But I couldn’t find the book, but my eye caught something else. The title of this old book was called ‘Homosexuality and Creative Genius’. I grabbed it and sprinted down to check it out. The librarian was the same person I saw the previous day! We looked at each other and our eyes said ‘we have the same therapist’. I was quite embarrassed that this book was being checked out by her of all people, cause it showed that I’m obviously going through some sexuality identity existential crisis thing. The person told me I owed the library 20 bucks for a previous book, and that they could hold on to this one in the meantime behind the counter until I paid. I didn’t have my wallet on me. At this point I didn’t want the book but I was really high so I said yeah sure, then paid and picked it up the next day.
I’m not a strong writer, but this is my journal, these experiences need to be documented. I’m investing in future Michael. Future Michael will prosper!
Unrelated but it needs to be logged in the journal because it always bugged me.
My ex would pretend to be poor. But her mom makes like $250k a year. My parents make around 20k a year, combined. I’ve seen their taxes the past few years. I don’t understand how they do it. But now I do, it’s because my mom has a superpower with budgeting. I should give her everything. I’m going to give her everything.
Here’s a daily mantra of mine for the past few years:
```
I’m going to work hard to get my parents out of debt.
```
| 110.125 | 1,258 | 0.763905 | eng_Latn | 0.999881 |
991a4fc0b774a19a36933e3c99cd6b0a196f89b1 | 14,451 | md | Markdown | articles/stream-analytics/stream-analytics-scale-with-machine-learning-functions.md | eltociear/azure-docs.de-de | 7171dffd9fa27c72cc17bb1916941cb64330a2af | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/stream-analytics/stream-analytics-scale-with-machine-learning-functions.md | eltociear/azure-docs.de-de | 7171dffd9fa27c72cc17bb1916941cb64330a2af | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/stream-analytics/stream-analytics-scale-with-machine-learning-functions.md | eltociear/azure-docs.de-de | 7171dffd9fa27c72cc17bb1916941cb64330a2af | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Skalieren von Machine Learning-Funktionen in Azure Stream Analytics
description: In diesem Artikel wird beschrieben, wie Sie Stream Analytics-Aufträge mit Machine Learning-Funktionen skalieren, indem Sie die Partitionierung und Streamingeinheiten konfigurieren.
author: jseb225
ms.author: jeanb
ms.reviewer: mamccrea
ms.service: stream-analytics
ms.topic: conceptual
ms.date: 03/16/2020
ms.openlocfilehash: 5b08625d055063b3804a35a3344ff01c7edb79de
ms.sourcegitcommit: 2ec4b3d0bad7dc0071400c2a2264399e4fe34897
ms.translationtype: HT
ms.contentlocale: de-DE
ms.lasthandoff: 03/28/2020
ms.locfileid: "80067004"
---
# <a name="scale-your-stream-analytics-job-with-azure-machine-learning-studio-classic-functions"></a>Skalieren eines Stream Analytics-Auftrags mit Azure Machine Learning Studio-Funktionen (klassisch)
> [!TIP]
> Es wird ausdrücklich empfohlen, [UDFs für Azure Machine Learning](machine-learning-udf.md) anstelle von UDFs für Azure Machine Learning Studio (Classic) zu verwenden, um Leistung und Zuverlässigkeit zu verbessern.
In diesem Artikel wird beschrieben, wie Sie Azure Stream Analytics-Aufträge effizient skalieren, die Azure Machine Learning-Funktionen nutzen. Allgemeine Informationen zum Skalieren von Stream Analytics-Aufträgen finden Sie im Artikel [Skalieren von Aufträgen](stream-analytics-scale-jobs.md).
## <a name="what-is-an-azure-machine-learning-function-in-stream-analytics"></a>Was ist in Stream Analytics eine Azure Machine Learning-Funktion?
Eine Machine Learning-Funktion kann in Stream Analytics wie ein normaler Funktionsaufruf in der Stream Analytics-Abfragesprache verwendet werden. Im Hintergrund handelt es sich bei den Funktionsaufrufen aber um Azure Machine Learning-Webdienstanforderungen.
Sie können den Durchsatz von Machine Learning-Webdienstanforderungen verbessern, indem Sie mehrere Zeilen im selben Webdienst-API-Aufruf zusammen im Batch verarbeiten. Diese Gruppierung wird als Mini-Batch bezeichnet. Weitere Informationen finden Sie unter [Azure Machine Learning Studio-Webdienste (klassisch)](../machine-learning/studio/consume-web-services.md). Die Unterstützung für Azure Machine Learning Studio (klassisch) in Stream Analytics befindet sich in der Vorschau.
## <a name="configure-a-stream-analytics-job-with-machine-learning-functions"></a>Konfigurieren eines Stream Analytics-Auftrags mit Machine Learning-Funktionen
Die vom Stream Analytics-Auftrag verwendete Machine Learning-Funktion wird mit zwei Parametern konfiguriert:
* Der Batchgröße der Machine Learning-Funktionsaufrufe
* Der Anzahl der Streamingeinheiten (Streaming Units, SUs), die für den Stream Analytics-Auftrag bereitgestellt werden
Um die geeigneten Werte für SUs zu ermitteln, entscheiden Sie, ob Sie die Latenz des Stream Analytics-Auftrags oder den Durchsatz der einzelnen SUs optimieren möchten. SUs können einem Auftrag immer hinzugefügt werden, um den Durchsatz einer gut partitionierten Stream Analytics-Abfrage zu erhöhen. Durch zusätzliche SUs erhöhen sich aber die Kosten für die Ausführung des Auftrags.
Ermitteln Sie die *Latenztoleranz* für Ihren Stream Analytics-Auftrag. Durch eine höhere Batchgröße erhöht sich auch die Latenz Ihrer Azure Machine Learning-Anforderungen und die Latenz des Stream Analytics-Auftrags.
Eine höhere Batchgröße ermöglicht es dem Stream Analytics-Auftrag, **mehr Ereignisse** mit **derselben Anzahl** von Machine Learning-Webdienstanforderungen zu verarbeiten. Die wachsende Latenz des Machine Learning-Webdiensts verhält sich in der Regel sublinear zum Anstieg der Batchgröße.
Es ist wichtig, in der jeweiligen Situation immer die kostengünstigste Batchgröße für einen Machine Learning-Webdienst zu ermitteln. Die Standardbatchgröße für Webdienstanforderungen beträgt 1.000 Ereignisse. Sie können die Standardgröße mit der [Stream Analytics-REST-API](https://docs.microsoft.com/previous-versions/azure/mt653706(v=azure.100) "Stream Analytics-REST-API") oder dem [PowerShell-Client für Stream Analytics](stream-analytics-monitor-and-manage-jobs-use-powershell.md) ändern.
Nachdem Sie sich für eine Batchgröße entschieden haben, können Sie die Anzahl von Streamingeinheiten (SUs) basierend auf der Anzahl von Ereignissen festlegen, die von der Funktion pro Sekunde verarbeitet werden müssen. Weitere Informationen zu Streamingeinheiten finden Sie unter [Stream Analytics-Skalierungsaufträge](stream-analytics-scale-jobs.md).
Für jeweils 6 SUs werden 20 gleichzeitige Verbindungen mit dem Machine Learning-Webdienst bereitgestellt. Allerdings werden für einen 1-SU-Auftrag und 3-SU-Aufträge 20 gleichzeitige Verbindungen bereitgestellt.
Wenn Ihre Anwendung 200.000 Ereignisse pro Sekunde generiert und die Batchgröße 1.000 beträgt, ergibt sich eine Webdienstlatenz von 200 ms. Dieser Wert bedeutet, dass über jede Verbindung pro Sekunde fünf Anforderungen an den Machine Learning-Webdienst übermittelt werden können. Bei 20 Verbindungen kann der Stream Analytics-Auftrag 20.000 Ereignisse in 200 ms verarbeiten, also 100.000 Ereignisse pro Sekunde.
Zum Verarbeiten von 200.000 Ereignissen pro Sekunde benötigt der Stream Analytics-Auftrag 40 gleichzeitige Verbindungen und somit 12 SUs. Im folgenden Diagramm ist der Verlauf der Anforderungen vom Stream Analytics-Auftrag zum Machine Learning-Webdienst-Endpunkt dargestellt. Für 6 SUs sind jeweils maximal 20 gleichzeitige Verbindungen mit dem Machine Learning-Webdienst vorhanden.

Wenn ***B*** die Batchgröße und ***L*** die Webdienstlatenz bei Batchgröße B in Millisekunden ist, beträgt der Durchsatz eines Stream Analytics-Auftrags mit ***N*** SUs:

Sie können auch den Parameter „Max. gleichzeitige Aufrufe“ für den Machine Learning-Webdienst konfigurieren. Es wird empfohlen, diesen Parameter auf den maximalen Wert (derzeit 200) festzulegen.
Weitere Informationen zu dieser Einstellung finden Sie im [Artikel zur Skalierung für Machine Learning-Webdienste](../machine-learning/studio/scaling-webservice.md).
## <a name="example--sentiment-analysis"></a>Beispiel: Stimmungsanalyse
Das folgende Beispiel enthält einen Stream Analytics-Auftrag mit der Machine Learning-Funktion für die Stimmungsanalyse, die im [Tutorial zur Machine Learning-Integration für Stream Analytics](stream-analytics-machine-learning-integration-tutorial.md)beschrieben ist.
Die Abfrage umfasst eine einfache vollständig partitionierte Abfrage gefolgt von der Funktion **sentiment**, wie im folgenden Beispiel dargestellt:
```SQL
WITH subquery AS (
SELECT text, sentiment(text) as result from input
)
Select text, result.[Score]
Into output
From subquery
```
Betrachten wir nun die erforderlichen Konfigurationsschritte zum Erstellen eines Stream Analytics-Auftrags, mit dem eine Standpunktanalyse für 10.000 Tweets pro Sekunde durchgeführt wird.
Könnte der Datenverkehr von diesem Stream Analytics-Auftrag mit 1 SU bewältigt werden? Bei Verwendung der Standardbatchgröße von 1.000 können die Eingabedaten vom Auftrag verarbeitet werden. Bei der Standardlatenz des Machine Learning-Webdiensts für die Standpunktanalyse (mit einer Standardbatchgröße von 1.000) entsteht eine Latenz von nur einer Sekunde.
Die **gesamte** Latenz bzw. End-to-End-Latenz des Stream Analytics-Auftrags würde normalerweise einige Sekunden betragen. Es ist ratsam, sich diesen Stream Analytics-Auftrag genauer anzusehen, *vor allem* die Machine Learning-Funktionsaufrufe. Bei einer Batchgröße von 1.000 werden bei einem Durchsatz von 10.000 Ereignissen etwa 10 Anforderungen an den Webdienst benötigt. Auch bei nur einer SU sind genügend gleichzeitige Verbindungen vorhanden, um diesen Datenverkehrseingang abzudecken.
Wenn sich die Eingangsrate der Ereignisse um das Hundertfache erhöht, muss der Stream Analytics-Auftrag 1.000.000 Tweets pro Sekunde verarbeiten. Es gibt zwei Möglichkeiten, um die höhere Skalierung zu erreichen:
1. Erhöhen Sie die Batchgröße.
2. Partitionieren Sie den Eingabestream, um die Ereignisse parallel zu verarbeiten.
Bei der ersten Option erhöht sich die **Latenz** des Auftrags.
Bei der zweiten Option müssen mehr SUs bereitgestellt werden, damit mehr gleichzeitige Machine Learning-Webdienstanforderungen unterstützt werden. Durch die größere Anzahl von SUs erhöhen sich die **Kosten** des Auftrags.
Betrachten wir die Skalierung anhand der folgenden Latenzmessungen für die einzelnen Batchgrößen:
| Latency | Batchgröße |
| --- | --- |
| 200 ms | Batches mit maximal 1.000 Ereignissen |
| 250 ms | Batches mit 5.000 Ereignissen |
| 300 ms | Batches mit 10.000 Ereignissen |
| 500 ms | Batches mit 25.000 Ereignissen |
1. Mit der ersten Option (**keine** Bereitstellung von mehr SUs) könnte die Batchgröße auf **25.000** erhöht werden. Durch die höhere Batchgröße könnten vom Auftrag dann 1.000.000 Ereignisse mit 20 gleichzeitigen Verbindungen mit dem Machine Learning-Webdienst verarbeitet werden (bei einer Latenz von 500 ms pro Aufruf). Die zusätzliche Latenz des Stream Analytics-Auftrags würde sich also aufgrund der Anforderungen der sentiment-Funktion an die Machine Learning-Webdienstanforderungen von **200 ms** auf **500 ms** erhöhen. Die Batchgröße kann jedoch **nicht** unendlich erhöht werden, da die Machine Learning-Webdienste erfordern, dass die Nutzlast einer Anforderung maximal 4 MB beträgt. Für Webdienstanforderungen tritt nach 100 Sekunden eine Zeitüberschreitung auf.
1. Bei der zweiten Option wird die Batchgröße von 1000 beibehalten. Bei einer Webdienstlatenz von 200 ms können mit 20 gleichzeitigen Verbindungen mit dem Webdienst also jeweils Ereignisse in folgendem Umfang verarbeitet werden: 1000 × 20 × 5 Ereignisse = 100.000 pro Sekunde. Es sind also 60 SUs für den Auftrag erforderlich, damit 1.000.000 Ereignisse pro Sekunde verarbeitet werden können. Verglichen mit der ersten Option fallen für den Stream Analytics-Auftrag mehr Webdienst-Batchanforderungen an, sodass sich die Kosten erhöhen.
Unten ist eine Tabelle mit Informationen zum Durchsatz des Stream Analytics-Auftrags für unterschiedliche SUs und Batchgrößen angegeben (Anzahl von Ereignissen pro Sekunde).
| Batchgröße (ML-Latenz) | 500 (200 ms) | 1\.000 (200 ms) | 5\.000 (250 ms) | 10.000 (300 ms) | 25.000 (500 ms) |
| --- | --- | --- | --- | --- | --- |
| **1 SU** |2\.500 |5\.000 |20.000 |30.000 |50.000 |
| **3 SUs** |2\.500 |5\.000 |20.000 |30.000 |50.000 |
| **6 SUs** |2\.500 |5\.000 |20.000 |30.000 |50.000 |
| **12 SUs** |5\.000 |10.000 |40.000 |60.000 |100.000 |
| **18 SUs** |7\.500 |15.000 |60.000 |90.000 |150.000 |
| **24 SUs** |10.000 |20.000 |80.000 |120.000 |200.000 |
| **…** |… |… |… |… |… |
| **60 SUs** |25.000 |50.000 |200.000 |300.000 |500.000 |
Sie sollten nun bereits über gute Grundlagenkenntnisse verfügen und wissen, wie Machine Learning-Funktionen in Stream Analytics funktionieren. Sie wissen vermutlich auch, dass bei Stream Analytics-Aufträgen Daten aus Datenquellen abgerufen werden („Pull“) und bei jedem Vorgang dieser Art ein Batch mit Ereignissen zur Verarbeitung durch den Stream Analytics-Auftrag zurückgegeben wird. Wie wirkt sich dieses Abrufmodell auf die Machine Learning-Webdienstanforderungen aus?
Normalerweise lässt sich die Batchgröße, die wir für Machine Learning-Funktionen festlegen, nicht genau durch die Anzahl von Ereignissen teilen, die bei jedem Abrufvorgang eines Stream Analytics-Auftrags zurückgegeben werden. In diesem Fall wird der Machine Learning-Webdienst mit „Teilbatches“ aufgerufen. Durch die Verwendung von Teilbatches wird verhindert, dass ein Auftrag zusätzliche Latenzen verursacht und Ereignisse von einem zum nächsten Abruf gebündelt werden.
## <a name="new-function-related-monitoring-metrics"></a>Neue funktionsbezogene Überwachungsmetriken
Im Überwachungsbereich eines Stream Analytics-Auftrags wurden drei zusätzliche funktionsbezogene Metriken hinzugefügt. Dies sind **FUNKTIONSANFORDERUNGEN**, **FUNKTIONSEREIGNISSE** und **FEHLERHAFTE FUNKTIONSANFORDERUNGEN**, wie in der folgenden Grafik dargestellt.

Diese sind wie folgt definiert:
**FUNKTIONSANFORDERUNGEN**: Die Anzahl von Funktionsanforderungen.
**FUNKTIONSEREIGNISSE**: Die Anzahl von Ereignissen in den Funktionsanforderungen.
**FEHLER BEI FUNKTIONSANFORDERUNGEN**: Die Anzahl von Funktionsanforderungen mit Fehlern.
## <a name="key-takeaways"></a>Wesentliche Punkte
Beim Skalieren eines Stream Analytics-Auftrags mit Machine Learning-Funktionen sollten die folgenden Faktoren beachtet werden:
1. Die Eingangsrate der Ereignisse
2. Die tolerierte Latenz für den ausgeführten Stream Analytics-Auftrag (und somit die Batchgröße der Machine Learning-Webdienstanforderungen)
3. Die bereitgestellten Stream Analytics-Streamingeinheiten (SUs) und die Anzahl von Machine Learning-Webdienstanforderungen (zusätzliche funktionsbezogene Kosten)
Als Beispiel wurde eine vollständig partitionierte Stream Analytics-Abfrage verwendet. Falls Sie eine komplexere Abfrage benötigen, ist das [Azure Stream Analytics-Forum](https://social.msdn.microsoft.com/Forums/azure/home?forum=AzureStreamAnalytics) eine hervorragende Ressource, um vom Stream Analytics-Team weitere Hilfe zu erhalten.
## <a name="next-steps"></a>Nächste Schritte
Weitere Informationen zu Stream Analytics finden Sie unter:
* [Erste Schritte mit Azure Stream Analytics](stream-analytics-real-time-fraud-detection.md)
* [Skalieren von Azure Stream Analytics-Aufträgen](stream-analytics-scale-jobs.md)
* [Stream Analytics Query Language Reference (in englischer Sprache)](https://docs.microsoft.com/stream-analytics-query/stream-analytics-query-language-reference)
* [Referenz zur Azure Stream Analytics-Verwaltungs-REST-API](https://msdn.microsoft.com/library/azure/dn835031.aspx)
| 95.072368 | 772 | 0.810325 | deu_Latn | 0.994073 |
991abc6754ba3643205d2039ea26c6492891d273 | 1,980 | md | Markdown | docs/extensibility/debugger/reference/idebugmethodfield-enumparameters.md | mavasani/visualstudio-docs | 4aa6fed75c395bb654dc884441ebb2d9b88bfd30 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2019-08-19T19:51:53.000Z | 2021-03-17T18:30:52.000Z | docs/extensibility/debugger/reference/idebugmethodfield-enumparameters.md | mavasani/visualstudio-docs | 4aa6fed75c395bb654dc884441ebb2d9b88bfd30 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-07-18T09:59:10.000Z | 2019-07-18T09:59:10.000Z | docs/extensibility/debugger/reference/idebugmethodfield-enumparameters.md | mavasani/visualstudio-docs | 4aa6fed75c395bb654dc884441ebb2d9b88bfd30 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-07-11T07:13:18.000Z | 2020-07-11T07:13:18.000Z | ---
title: "IDebugMethodField::EnumParameters | Microsoft Docs"
ms.date: "11/04/2016"
ms.topic: reference
f1_keywords:
- "IDebugMethodField::EnumParameters"
helpviewer_keywords:
- "IDebugMethodField::EnumParameters method"
ms.assetid: d77b1197-deb6-4144-8d1b-8b09949ccfac
author: madskristensen
ms.author: madsk
manager: jillfra
ms.workload:
- "vssdk"
dev_langs:
- CPP
- CSharp
---
# IDebugMethodField::EnumParameters
Creates an enumerator for the parameters of the method.
## Syntax
```cpp
HRESULT EnumParameters(
IEnumDebugFields** ppParams
);
```
```csharp
int EnumParameters(
out IEnumDebugFields ppParams
);
```
## Parameters
`ppParams`\
[out] Returns an [IEnumDebugFields](../../../extensibility/debugger/reference/ienumdebugfields.md) object representing the list of parameters to the method; otherwise, returns a null value if there are no parameters.
## Return Value
If successful, returns S_OK or returns S_FALSE if there are no parameters. Otherwise, returns an error code.
## Remarks
Each element is an [IDebugField](../../../extensibility/debugger/reference/idebugfield.md) object representing different types of parameters. Call the [GetKind](../../../extensibility/debugger/reference/idebugfield-getkind.md) method on each object to determine exactly what kind of parameter the object represents.
A parameter includes both its variable name and its type. The first parameter to a class method is typically the "this" pointer.
If only the types of the parameters is needed, call the [EnumArguments](../../../extensibility/debugger/reference/idebugmethodfield-enumarguments.md) method.
## See also
- [IDebugMethodField](../../../extensibility/debugger/reference/idebugmethodfield.md)
- [IEnumDebugFields](../../../extensibility/debugger/reference/ienumdebugfields.md)
- [IDebugField](../../../extensibility/debugger/reference/idebugfield.md)
- [EnumArguments](../../../extensibility/debugger/reference/idebugmethodfield-enumarguments.md) | 36.666667 | 316 | 0.767677 | eng_Latn | 0.659037 |
991b1c29b333525a347cdb543d2f6f91f02b7bb9 | 17,810 | md | Markdown | articles/aks/use-managed-identity.md | KreizIT/azure-docs.fr-fr | dfe0cb93ebc98e9ca8eb2f3030127b4970911a06 | [
"CC-BY-4.0",
"MIT"
] | 43 | 2017-08-28T07:44:17.000Z | 2022-02-20T20:53:01.000Z | articles/aks/use-managed-identity.md | KreizIT/azure-docs.fr-fr | dfe0cb93ebc98e9ca8eb2f3030127b4970911a06 | [
"CC-BY-4.0",
"MIT"
] | 676 | 2017-07-14T20:21:38.000Z | 2021-12-03T05:49:24.000Z | articles/aks/use-managed-identity.md | KreizIT/azure-docs.fr-fr | dfe0cb93ebc98e9ca8eb2f3030127b4970911a06 | [
"CC-BY-4.0",
"MIT"
] | 153 | 2017-07-11T00:08:42.000Z | 2022-01-05T05:39:03.000Z | ---
title: Utiliser les identités managées dans Azure Kubernetes Service
description: Découvrez comment utiliser les identités managées dans Azure Kubernetes Service (AKS).
ms.topic: article
ms.date: 05/12/2021
ms.openlocfilehash: e9a7a0a46e36d544a5b7d785da2b64ecde4f3faa
ms.sourcegitcommit: f6e2ea5571e35b9ed3a79a22485eba4d20ae36cc
ms.translationtype: HT
ms.contentlocale: fr-FR
ms.lasthandoff: 09/24/2021
ms.locfileid: "128585299"
---
# <a name="use-managed-identities-in-azure-kubernetes-service"></a>Utiliser les identités managées dans Azure Kubernetes Service
Actuellement, un cluster Azure Kubernetes Service ou AKS (plus précisément, le fournisseur cloud Kubernetes) nécessite une identité pour créer des ressources supplémentaires telles que des équilibreurs de charge et des disques managés dans Azure. Cette identité peut être une *identité gérée* ou un *principal de service*. Si vous utilisez un [principal de service](kubernetes-service-principal.md), vous devez en fournir un ; sinon, AKS en crée un en votre nom. Si vous utilisez une identité managée, elle est automatiquement créée pour vous par AKS. Les clusters utilisant des principaux de service finissent par atteindre un état dans lequel le principal de service doit être renouvelé pour que le cluster continue de fonctionner. La gestion des principaux de service ajoute de la complexité : c’est pourquoi il est plus facile d’utiliser à la place des identités managées. Les mêmes exigences d’autorisation s’appliquent aux principaux de service et aux identités managées.
Les *identités managées* correspondent essentiellement à un wrapper autour des principaux de service, ce qui simplifie leur gestion. La rotation des informations d’identification pour MI se produit automatiquement tous les 46 jours selon la valeur par défaut dans Azure Active Directory. AKS utilise aussi bien les identités managées affectées par le système que les types d’identités managées affectées par l’utilisateur. Ces identités sont actuellement immuables. Pour en savoir plus, découvrez les [identités managées pour les ressources Azure](../active-directory/managed-identities-azure-resources/overview.md).
## <a name="before-you-begin"></a>Avant de commencer
La ressource suivante doit être installée :
- Azure CLI version 2.23.0 ou ultérieure
## <a name="limitations"></a>Limites
* Le déplacement de locataires ou la migration de clusters avec des identités managées ne sont pas pris en charge.
* Si `aad-pod-identity` est activé dans le cluster, les pods NMI (Node Managed Identity) modifient les tables d’adresses IP des nœuds pour intercepter les appels vers le point de terminaison Azure Instance Metadata. Cette configuration signifie que toutes les requêtes adressées au point de terminaison Metadata sont interceptées par NMI, même si le pod n’utilise pas `aad-pod-identity`. La CRD AzurePodIdentityException peut être configurée de manière à informer `aad-pod-identity` que toutes les requêtes adressées au point de terminaison Metadata depuis un pod correspondant aux étiquettes définies dans la CRD doivent être envoyées par proxy sans aucun traitement dans NMI. Les pods système qui disposent de l’étiquette `kubernetes.azure.com/managedby: aks` dans l’espace de noms _kube-system_ doivent être exclus de `aad-pod-identity` en configurant la CRD AzurePodIdentityException. Pour plus d’informations, consultez [Désactiver aad-pod-identity pour un pod ou une application spécifique](https://azure.github.io/aad-pod-identity/docs/configure/application_exception).
Pour configurer une exception, installez le fichier [YAML mic-exception](https://github.com/Azure/aad-pod-identity/blob/master/deploy/infra/mic-exception.yaml).
## <a name="summary-of-managed-identities"></a>Résumé des identités managées
AKS utilise plusieurs identités managées pour les services intégrés et les modules complémentaires.
| Identité | Nom | Cas d’utilisation | Autorisations par défaut | Apportez votre propre identité
|----------------------------|-----------|----------|
| Plan de contrôle | Nom du cluster AKS | Utilisé par les composants du plan de contrôle AKS pour gérer les ressources de cluster, notamment les équilibreurs de charge d’entrée et les adresses IP publiques gérées par AKS, la mise à l’échelle automatique des clusters, les pilotes Azure Disk et CSI de fichiers | Rôle Contributeur pour le groupe de ressources du nœud | Prise en charge
| Kubelet | Nom du cluster AKS - agentpool | Authentification avec Azure Container Registry (ACR) | NA (pour kubernetes v1.15+) | Pris en charge
| Composant additionnel | AzureNPM | Aucune identité requise | N/D | Non
| Composant additionnel | Analyse du réseau AzureCNI | Aucune identité requise | N/D | Non
| Composant additionnel | azure-policy (gatekeeper) | Aucune identité requise | N/D | Non
| Composant additionnel | azure-policy | Aucune identité requise | N/D | Non
| Composant additionnel | Calico | Aucune identité requise | N/D | Non
| Composant additionnel | tableau de bord | Aucune identité requise | N/D | Non
| Composant additionnel | HTTPApplicationRouting | Gère les ressources réseau requises | Rôle Lecteur pour le groupe de ressources du nœud, rôle Contributeur pour la zone DNS | Non
| Composant additionnel | Passerelle d'application d’entrée | Gère les ressources réseau requises| Rôle Contributeur pour le groupe de ressources du nœud | Non
| Composant additionnel | omsagent | Utilisé pour envoyer des métriques AKS à Azure Monitor | Rôle Éditeur des métriques de surveillance | Non
| Composant additionnel | Nœud virtuel (ACIConnector) | Gère les ressources réseau requises pour Azure Container Instances (ACI) | Rôle Contributeur pour le groupe de ressources du nœud | Non
| Projet OSS | aad-pod-identity | Permet aux applications d'accéder aux ressources cloud en toute sécurité avec Azure Active Directory (AAD) | N/D | Étapes à suivre pour octroyer une autorisation disponibles à l'adresse https://github.com/Azure/aad-pod-identity#role-assignment.
## <a name="create-an-aks-cluster-with-managed-identities"></a>Créer un cluster AKS avec des identités managées
Vous pouvez désormais créer un cluster AKS avec des identités managées à l’aide des commandes CLI suivantes.
Commencez par créer un groupe de ressources Azure :
```azurecli-interactive
# Create an Azure resource group
az group create --name myResourceGroup --location westus2
```
Créez ensuite un cluster AKS :
```azurecli-interactive
az aks create -g myResourceGroup -n myManagedCluster --enable-managed-identity
```
Une fois le cluster créé, vous pouvez déployer vos charges de travail d’application sur le nouveau cluster et interagir avec celui-ci comme vous le faisiez avec les clusters AKS basés sur le principal de service.
Obtenez enfin les informations d’identification pour accéder au cluster :
```azurecli-interactive
az aks get-credentials --resource-group myResourceGroup --name myManagedCluster
```
## <a name="update-an-aks-cluster-to-managed-identities"></a>Mettre à jour un cluster AKS vers des identités managées
Vous pouvez désormais mettre à jour un cluster AKS actuellement utilisé avec des principaux de service pour travailler avec des identités managées à l’aide des commandes CLI suivantes.
```azurecli-interactive
az aks update -g <RGName> -n <AKSName> --enable-managed-identity
```
> [!NOTE]
> Après la mise à jour, le plan de contrôle de votre cluster et les pods des modules complèmentaires basculeront pour utiliser l’identité managée, mais kubelet CONTINUERA À UTILISER LE PRINCIPAL DE SERVICE tant que vous n’aurez pas mis à niveau votre agentpool. Effectuez une `az aks nodepool upgrade --node-image-only` sur vos nœuds pour terminer la mise à jour de l’identité managée.
>
> Si votre cluster utilisait --attach-acr pour tirer (pull) à partir d’une image d’Azure Container Registry, après avoir mis à jour votre cluster vers Managed Identity, vous devez exécuter `az aks update --attach-acr <ACR Resource ID>` à nouveau pour permettre au kubelet nouvellement créé utilisé pour l’identité managée d’obtenir l’autorisation de tirer (pull) à partir d’ACR. Sinon, vous ne serez pas en mesure de tirer (pull) à partir d’ACR après la mise à niveau.
>
> L’interface de ligne de commande Azure s’assurera que l’autorisation de votre module complémentaire est correctement définie après la migration. Si vous n’utilisez pas l’interface de ligne de commande Azure pour effectuer l’opération de migration, vous devez gérer vous-même l’autorisation de l’identité du module complémentaire. Voici un exemple utilisant [ARM](../role-based-access-control/role-assignments-template.md).
## <a name="obtain-and-use-the-system-assigned-managed-identity-for-your-aks-cluster"></a>Obtenir et utiliser l’identité managée affectée par le système pour votre cluster AKS
Vérifiez que votre cluster AKS utilise l’identité managée avec la commande CLI suivante :
```azurecli-interactive
az aks show -g <RGName> -n <ClusterName> --query "servicePrincipalProfile"
```
Si le cluster utilise des identités managées, la valeur `clientId` « MSI » s’affiche. Un cluster qui utilise plutôt un principal de service affiche plutôt l’ID d’objet. Par exemple :
```output
{
"clientId": "msi"
}
```
Après avoir vérifié que le cluster utilise des identités managées, vous trouverez l’ID d’objet de l’identité affectée par le système du plan de contrôle à l’aide de la commande suivante :
```azurecli-interactive
az aks show -g <RGName> -n <ClusterName> --query "identity"
```
```output
{
"principalId": "<object-id>",
"tenantId": "<tenant-id>",
"type": "SystemAssigned",
"userAssignedIdentities": null
},
```
> [!NOTE]
> Pour créer et utiliser votre propre réseau virtuel, une adresse IP statique ou un disque Azure attaché où les ressources se trouvent en dehors du groupe de ressources du nœud Worker, utilisez le PrincipalID du cluster Identité managée affectée par le système pour effectuer une attribution de rôle. Pour plus d’informations sur l’attribution de rôle, consultez [Déléguer l’accès à d’autres ressources Azure](kubernetes-service-principal.md#delegate-access-to-other-azure-resources).
>
> L'octroi d'une autorisation à une identité managée en cluster utilisée par le fournisseur Azure Cloud peut prendre jusqu'à 60 minutes.
## <a name="bring-your-own-control-plane-mi"></a>Apporter votre propre instance gérée de plan de contrôle
Une identité de plan de contrôle personnalisé permet d’accorder l’accès à l’identité existante avant la création du cluster. Cette fonctionnalité permet des scénarios tels que l’utilisation d’un réseau virtuel personnalisé ou du paramètre outboundType d’UDR avec une identité managée pré-créée.
Vous devez avoir installé Azure CLI 2.15.1 ou une version ultérieure.
### <a name="limitations"></a>Limites
* US DoD-Central, US DoD-Est, USGov Iowa dans Azure Government ne sont actuellement pas pris en charge.
Si vous n’avez pas encore d’identité managée, vous devez en créer une, par exemple à l’aide de la commande CLI [az identity][az-identity-create].
```azurecli-interactive
az identity create --name myIdentity --resource-group myResourceGroup
```
Le résultat doit avoir l’aspect suivant :
```output
{
"clientId": "<client-id>",
"clientSecretUrl": "<clientSecretUrl>",
"id": "/subscriptions/<subscriptionid>/resourcegroups/myResourceGroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/myIdentity",
"location": "westus2",
"name": "myIdentity",
"principalId": "<principalId>",
"resourceGroup": "myResourceGroup",
"tags": {},
"tenantId": "<tenant-id>",
"type": "Microsoft.ManagedIdentity/userAssignedIdentities"
}
```
Si votre identité managée fait partie de votre abonnement, vous pouvez utiliser la commande CLI [az identity][az-identity-list] pour l’interroger.
```azurecli-interactive
az identity list --query "[].{Name:name, Id:id, Location:location}" -o table
```
Vous pouvez maintenant utiliser la commande suivante pour créer votre cluster avec l’identité existante :
```azurecli-interactive
az aks create \
--resource-group myResourceGroup \
--name myManagedCluster \
--network-plugin azure \
--vnet-subnet-id <subnet-id> \
--docker-bridge-address 172.17.0.1/16 \
--dns-service-ip 10.2.0.10 \
--service-cidr 10.2.0.0/24 \
--enable-managed-identity \
--assign-identity <identity-id>
```
Un cluster créé à l’aide de vos propres identités managées contient les informations de profil userAssignedIdentities :
```output
"identity": {
"principalId": null,
"tenantId": null,
"type": "UserAssigned",
"userAssignedIdentities": {
"/subscriptions/<subscriptionid>/resourcegroups/myResourceGroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/myIdentity": {
"clientId": "<client-id>",
"principalId": "<principal-id>"
}
}
},
```
## <a name="bring-your-own-kubelet-mi"></a>Apportez votre propre MI kubelet
Une identité Kubelet permet d’accorder l’accès à l’identité existante avant la création du cluster. Cette fonctionnalité permet des scénarios tels que la connexion à ACR avec une identité gérée pré-créée.
### <a name="prerequisites"></a>Prérequis
- Vous devez avoir installé Azure CLI version 2.26.0 ou une version ultérieure.
### <a name="limitations"></a>Limites
- Fonctionne uniquement avec un cluster managé affecté par l’utilisateur.
- Chine Est, Chine Nord dans Azure China 21Vianet ne sont pas pris en charge actuellement.
### <a name="create-or-obtain-managed-identities"></a>Créer ou obtenir des identités managées
Si vous n’avez pas encore d’identité managée par plan de contrôle, vous devez en créer une. L’exemple suivant utilise la commande [az identity create][az-identity-create] :
```azurecli-interactive
az identity create --name myIdentity --resource-group myResourceGroup
```
Le résultat doit avoir l’aspect suivant :
```output
{
"clientId": "<client-id>",
"clientSecretUrl": "<clientSecretUrl>",
"id": "/subscriptions/<subscriptionid>/resourcegroups/myResourceGroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/myIdentity",
"location": "westus2",
"name": "myIdentity",
"principalId": "<principalId>",
"resourceGroup": "myResourceGroup",
"tags": {},
"tenantId": "<tenant-id>",
"type": "Microsoft.ManagedIdentity/userAssignedIdentities"
}
```
Si vous n’avez pas encore d’identité managée par kubelet, vous devez en créer une. L’exemple suivant utilise la commande [az identity create][az-identity-create] :
```azurecli-interactive
az identity create --name myKubeletIdentity --resource-group myResourceGroup
```
Le résultat doit avoir l’aspect suivant :
```output
{
"clientId": "<client-id>",
"clientSecretUrl": "<clientSecretUrl>",
"id": "/subscriptions/<subscriptionid>/resourcegroups/myResourceGroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/myKubeletIdentity",
"location": "westus2",
"name": "myKubeletIdentity",
"principalId": "<principalId>",
"resourceGroup": "myResourceGroup",
"tags": {},
"tenantId": "<tenant-id>",
"type": "Microsoft.ManagedIdentity/userAssignedIdentities"
}
```
Si votre identité managée existante fait partie de votre abonnement, vous pouvez utiliser la commande [az identity list][az-identity-list] pour l’interroger :
```azurecli-interactive
az identity list --query "[].{Name:name, Id:id, Location:location}" -o table
```
### <a name="create-a-cluster-using-kubelet-identity"></a>Créer un cluster à l’aide de l’identité kubelet
Vous pouvez maintenant utiliser la commande suivante pour créer votre cluster avec vos identités existantes. Fournissez l’ID d’identité du plan de contrôle via `assign-identity` et l’identité managée kubelet via `assign-kublet-identity` :
```azurecli-interactive
az aks create \
--resource-group myResourceGroup \
--name myManagedCluster \
--network-plugin azure \
--vnet-subnet-id <subnet-id> \
--docker-bridge-address 172.17.0.1/16 \
--dns-service-ip 10.2.0.10 \
--service-cidr 10.2.0.0/24 \
--enable-managed-identity \
--assign-identity <identity-id> \
--assign-kubelet-identity <kubelet-identity-id>
```
La réussite de la création d’un cluster à l’aide de votre propre identité managée kubelet contient la sortie suivante :
```output
"identity": {
"principalId": null,
"tenantId": null,
"type": "UserAssigned",
"userAssignedIdentities": {
"/subscriptions/<subscriptionid>/resourcegroups/resourcegroups/providers/Microsoft.ManagedIdentity/userAssignedIdentities/myIdentity": {
"clientId": "<client-id>",
"principalId": "<principal-id>"
}
}
},
"identityProfile": {
"kubeletidentity": {
"clientId": "<client-id>",
"objectId": "<object-id>",
"resourceId": "/subscriptions/<subscriptionid>/resourcegroups/resourcegroups/providers/Microsoft.ManagedIdentity/userAssignedIdentities/myKubeletIdentity"
}
},
```
## <a name="next-steps"></a>Étapes suivantes
* Utilisez des [modèles Azure Resource Manager][aks-arm-template] pour créer des clusters avec gestion des identités.
<!-- LINKS - external -->
[aks-arm-template]: /azure/templates/microsoft.containerservice/managedclusters
<!-- LINKS - internal -->
[az-identity-create]: /cli/azure/identity#az_identity_create
[az-identity-list]: /cli/azure/identity#az_identity_list
[az-feature-list]: /cli/azure/feature#az_feature_list
[az-provider-register]: /cli/azure/provider#az_provider_register
| 56.900958 | 1,076 | 0.752274 | fra_Latn | 0.929889 |
991b45e45d9cd9b60408e8d113417c037dfa0444 | 866 | md | Markdown | sdks/python/docs/AppRepoResponse.md | Brantone/appcenter-sdks | eeb063ecf79908b6e341fb00196d2cd9dc8f3262 | [
"MIT"
] | null | null | null | sdks/python/docs/AppRepoResponse.md | Brantone/appcenter-sdks | eeb063ecf79908b6e341fb00196d2cd9dc8f3262 | [
"MIT"
] | 6 | 2019-10-23T06:38:53.000Z | 2022-01-22T07:57:58.000Z | sdks/python/docs/AppRepoResponse.md | Brantone/appcenter-sdks | eeb063ecf79908b6e341fb00196d2cd9dc8f3262 | [
"MIT"
] | 2 | 2019-10-23T06:31:05.000Z | 2021-08-21T17:32:47.000Z | # AppRepoResponse
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**id** | **string** | The unique id (UUID) of the repository integration |
**app_id** | **string** | The unique id (UUID) of the app that this repository integration belongs to |
**repo_url** | **string** | The absolute URL of the repository |
**repo_provider** | **string** | The provider of the repository | [optional]
**user_id** | **string** | The unique id (UUID) of the user who configured the repository |
**installation_id** | **string** | Installation id from the provider | [optional]
**repo_id** | **string** | Repository id from the provider | [optional]
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
| 54.125 | 161 | 0.635104 | eng_Latn | 0.811945 |
991bf35ab18cd6941b2aa4f780185e4f4f13dfae | 4,521 | md | Markdown | docs/cross-platform/macios/binding/troubleshooting.md | poulad/xamarin-docs | 83c7557d962684d67a553922b36ec6ff6b71f898 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/cross-platform/macios/binding/troubleshooting.md | poulad/xamarin-docs | 83c7557d962684d67a553922b36ec6ff6b71f898 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/cross-platform/macios/binding/troubleshooting.md | poulad/xamarin-docs | 83c7557d962684d67a553922b36ec6ff6b71f898 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-02-07T20:00:06.000Z | 2020-02-07T20:00:06.000Z | ---
title: "Binding troubleshooting"
description: "This guide describes what to do if you have difficulty binding an Objective-C library."
ms.prod: xamarin
ms.assetid: 7C65A55C-71FA-46C5-A1B4-955B82559844
author: asb3993
ms.author: amburns
ms.date: 10/19/2016
---
# Binding troubleshooting
Some tips for troubleshooting bindings to macOS (formerly known as OS X) APIs in Xamarin.Mac.
## Missing bindings
While Xamarin.Mac covers much of the Apple APIs, sometimes you may need to call some Apple API that doesn’t have a binding yet. In other cases, you need to call third party C/Objective-C that it outside the scope of the Xamarin.Mac bindings.
If you are dealing with an Apple API, the first step is to let Xamarin know that you are hitting a section of the API that we don’t have coverage for yet. [File a bug](#reporting-bugs) noting the missing API. We use reports from customers to prioritize which APIs we work on next. In addition, if you have a Business or Enterprise license and this lack of a binding is blocking your progress, also follow the instructions at [Support](http://xamarin.com/support) to file a ticket. We can’t promise a binding, but in some cases we can get you a work around.
Once you notify Xamarin (if applicable) of your missing binding, the next step is to consider binding it yourself. We have a full guide [here](~/cross-platform/macios/binding/overview.md) and some unofficial documentation [here](http://brendanzagaeski.appspot.com/xamarin/0002.html) for wrapping Objective-C bindings by hand. If you are calling a C API, you can use C#’s P/Invoke mechanism, documentation is [here](http://www.mono-project.com/docs/advanced/pinvoke/).
If you decide to work on the binding yourself, be aware that mistakes in the binding can produce all sorts of interesting crashes in the native runtime. In particular, be very careful that your signature in C# matches the native signature in number of arguments and the size of each argument. Failure to do so may corrupt memory and/or the stack and you could crash immediately or at some arbitrary point in the future or corrupt data.
## Argument exceptions when passing null to a binding
While Xamarin works to provide high quality and well tested bindings for the Apple APIs, sometimes mistakes and bugs slip in. By far the most common issue that you might run into is an API throwing `ArgumentNullException` when you pass in null when the underlying API accepts `nil`. The native header files defining the API often do not provide enough information on which APIs accept nil and which will crash if you pass it in.
If you run into a case where passing in `null` throws an `ArgumentNullException` but you think it should work, follow these steps:
1. Check the Apple documentation and/or examples to see if you can find proof that it accepts `nil`. If you are comfortable with Objective-C, you can write a small test program to verify it.
2. [File a bug](#reporting-bugs).
3. Can you work around the bug? If you can avoid calling the API with `null`, a simple null check around the calls can be a easy work around.
4. However, some APIs require passing in null to turn off or disable some features. In these cases, you can work around the issue by bringing up the assembly browser (see [Finding the C# member for a given selector](~/mac/app-fundamentals/mac-apis.md#finding_selector)), copying the binding, and removing the null check. Please make sure to file a bug (step 2) if you do this, as your copied binding won't receive updates and fixes that we make in Xamarin.Mac, and this should be considered a short term work around.
<a name="reporting-bugs"/>
## Reporting bugs
Your feedback is important to us. If you find any problems with Xamarin.Mac:
- Check the [Xamarin.Mac Forums](https://forums.xamarin.com/categories/mac)
- Search the [issue repository](https://github.com/xamarin/xamarin-macios/issues)
- Before switching to GitHub issues, Xamarin issues were tracked on [Bugzilla](https://bugzilla.xamarin.com/describecomponents.cgi). Please search there for matching issues.
- If you cannot find a matching issue, please file a new issue in the [GitHub issue repository](https://github.com/xamarin/xamarin-macios/issues/new).
GitHub issues are all public. It’s not possible to hide comments or attachments.
Please include as much of the following as possible:
- A simple example reproducing the issue. This is **invaluable** where possible.
- The full stack trace of the crash.
- The C# code surrounding the crash.
| 83.722222 | 556 | 0.780801 | eng_Latn | 0.998999 |
991c0c0d10c7e7ade5bbdd7727723cdef2865f25 | 677 | md | Markdown | openshift/templates/nsp/readme.md | amichard/zeva | 19ba22b07946674cc31a48c632aceca594a53e1a | [
"Apache-2.0"
] | null | null | null | openshift/templates/nsp/readme.md | amichard/zeva | 19ba22b07946674cc31a48c632aceca594a53e1a | [
"Apache-2.0"
] | null | null | null | openshift/templates/nsp/readme.md | amichard/zeva | 19ba22b07946674cc31a48c632aceca594a53e1a | [
"Apache-2.0"
] | null | null | null | ## Add role to users
oc policy add-role-to-user system:image-puller system:serviceaccount:tbiwaq-dev:default --namespace=tbiwaq-tools
oc policy add-role-to-user system:image-puller system:serviceaccount:tbiwaq-test:default --namespace=tbiwaq-tools
oc policy add-role-to-user system:image-puller system:serviceaccount:tbiwaq-prod:default --namespace=tbiwaq-tools
oc policy add-role-to-user admin system:serviceaccount:tbiwaq-tools:jenkins-prod --namespace=tbiwaq-dev
oc policy add-role-to-user admin system:serviceaccount:tbiwaq-tools:jenkins-prod --namespace=tbiwaq-test
oc policy add-role-to-user admin system:serviceaccount:tbiwaq-tools:jenkins-prod --namespace=tbiwaq-prod
| 75.222222 | 113 | 0.824225 | eng_Latn | 0.382218 |
991cdf96bda4be1ca75a5a8eb653cc4265441763 | 3,014 | md | Markdown | lsi/rom/doc/micasm.md | yshestakov/cpu11 | 5715b9633b77c68d0c56e24c6a2d88878bf46383 | [
"CC-BY-3.0"
] | 118 | 2018-11-24T10:49:24.000Z | 2022-02-26T22:53:22.000Z | lsi/rom/doc/micasm.md | sebras/cpu11 | 37316edbaa5327143bbc9807671c0988f8cffe8f | [
"CC-BY-3.0"
] | 9 | 2019-02-05T21:56:25.000Z | 2022-02-05T11:46:26.000Z | lsi/rom/doc/micasm.md | sebras/cpu11 | 37316edbaa5327143bbc9807671c0988f8cffe8f | [
"CC-BY-3.0"
] | 19 | 2019-02-03T18:49:15.000Z | 2022-01-20T05:44:38.000Z | ## Micro Assembler
The [Micro Assembler](/lsi/rom/tools/cp16mic.py) to compile the microcode
was develeoped in Python. It compiles the multiple source files in two
passes and writes out the united object file in Verlig Memory format
and optionally the TTL/PLA translation fields content. Program uses standard
Python 3.x libraries only and has no external dependencies.
### Usage
```
cp16mic.py srcfile [srcfile ..] [-l|--lst lstfile] [-o|--obj objfile] [-t|--ttl ttlfile]
```
### Numeric, literals values and labels
- **_axxxx_** - identifier should start with letter
- **_. (point)_** - current location counter, assignable
- **_nnnn$_** - is treated as local label
- **_0xNNNN_** - always hexadecimal
- **_0bNNNN_** - always binary
- **_NNNN._** - always decimal
- **_0NNNN_** - always octal
- **_NNNN_** - depends on .radix settings
- **_'N'_** - character code
- **_"string"_** - string literal (supports \\,\",\')
### Supported directives
The following directives are supported:
- **_name=expr_** - assign the name with specified expression,
")(~+-*/|&^" operations supported, C-language priorities
- **_.title "string"_** - provide the title "string", ignored
- **_.radix expr_** - provide default base for the numeric values,
8 is assigned at the beginning of each source file by default,
8 an 10 values are supported.
- **_.align expr_** - align the location counter on specified power of 2
- **_.tran name, expr_** - defines name of translation with specified value
- **_.reg name, expr_** - defines name of register with specified value
- **_.org expr_** - assign the specified value to location counter
- **_.loc expr_** - assign the specified value to location counter
- **_.end_** - finished the current source file processing
### Predefined register names
These names are predefined as register names:
- **_G, GL, GH_** - access by G index register
- **_RBA, RBAL, RBAH_** - bus address register, lower and upper halves
- **_RSRC, RSRCL, RSRCH_** - source register, lower and upper halves
- **_RDST, RDSTL, RDSTH_** - destination register, lower and upper halves
- **_RIR, RIRL, RIRH_** - PDP-11 instruction register, lower and upper halves
- **_RPSW, RPSWL, RPSWH_** - PDP-11 status word register, lower and upper halves
- **_SP, SPL, SPH_** - PDP-11 stack pointer register, lower and upper halves
- **_PC, PCL, PCH_** - PDP-11 program counter register, lower and upper halves
These names are predefined as flag bitmasks:
- **_I4, I5, I6_** - interrupt set/clear masks
- **_C, V, Z, N, T_** - PDP-11 arithmetic flags and T-bit
- **_C8, C4, ZB, NB_** - MCP-1600 ALU flags
- **_UB, LB, UBC, LBC, RMW_** - input/output mode
- **_TG6, TG8_** - instruction fetch control
These names are predefined as extension field bits:
- **_LRR_** - load location counter from return register
- **_RSVC_** - read next instruction
Standard MCP-1600 [mnemonics](/lsi/rom/doc/mcp1600.pdf),
defined in vendor documentation are supported.
| 43.681159 | 88 | 0.696417 | eng_Latn | 0.982853 |
991d4145729b5609dba336c91f8e1e54225b8f2a | 681 | md | Markdown | src/components/ui/documentation/readme.md | arjunyel/Stellar | 4e2440cfeb3a4f63ea47ca3a426061725a92c083 | [
"MIT"
] | null | null | null | src/components/ui/documentation/readme.md | arjunyel/Stellar | 4e2440cfeb3a4f63ea47ca3a426061725a92c083 | [
"MIT"
] | null | null | null | src/components/ui/documentation/readme.md | arjunyel/Stellar | 4e2440cfeb3a4f63ea47ca3a426061725a92c083 | [
"MIT"
] | null | null | null | # stellar-documentation
<!-- Auto Generated Below -->
## Properties
| Property | Attribute | Description | Type |
| ------------ | ------------- | ----------- | --------- |
| `codeString` | `code-string` | | `string` |
| `feature` | `feature` | | `string` |
| `preview` | `preview` | | `boolean` |
| `property` | `property` | | `string` |
| `type` | `type` | | `string` |
## Methods
| Method | Description |
| -------- | ----------- |
| `reload` | |
----------------------------------------------
*Built with [StencilJS](https://stenciljs.com/)*
| 23.482759 | 58 | 0.36417 | eng_Latn | 0.214696 |
991d471c3ec6e0cae63c1417fadba81ff7692d20 | 328 | md | Markdown | 05-asynchronous-control-flow-patterns-with-promises-and-async-await/12-promises-recursion-leak/README.md | cornpip/Node.js-Design-Patterns | 494edc690f357340fbb03636b00db1af58aa8f00 | [
"MIT"
] | null | null | null | 05-asynchronous-control-flow-patterns-with-promises-and-async-await/12-promises-recursion-leak/README.md | cornpip/Node.js-Design-Patterns | 494edc690f357340fbb03636b00db1af58aa8f00 | [
"MIT"
] | null | null | null | 05-asynchronous-control-flow-patterns-with-promises-and-async-await/12-promises-recursion-leak/README.md | cornpip/Node.js-Design-Patterns | 494edc690f357340fbb03636b00db1af58aa8f00 | [
"MIT"
] | null | null | null | # 12-promises-recursion-leak
This sample demonstrate how infinite chains of unresolved Promises can lead to memory leaks.
## Run
To run the example launch:
```bash
node index.js
```
----
foreach, map에서는 await가 무시된다. await는 for또는 while을 쓰자
프라미스 체인은 상관x, resolve 체인은 메모리 누수의 원인
resolve와 reject는 택1이다. (2개 동시에 써도 하나만 진행됨) | 19.294118 | 92 | 0.737805 | kor_Hang | 0.999617 |
991db276883072e441f5676a3f7f4102659b6914 | 490 | md | Markdown | README.md | KSayrs/Autocomplete | 833b9d1a58a6a7eb925603a397ad250edcf020f9 | [
"MIT"
] | null | null | null | README.md | KSayrs/Autocomplete | 833b9d1a58a6a7eb925603a397ad250edcf020f9 | [
"MIT"
] | null | null | null | README.md | KSayrs/Autocomplete | 833b9d1a58a6a7eb925603a397ad250edcf020f9 | [
"MIT"
] | null | null | null | ## Autocomplete
Project done for an upper-level CSC course. Shows a list of matches for a search, much like google. This was made using [the algs4 library](http://algs4.cs.princeton.edu/code/).
## Usage
Best run with the GUI. Arguments are the text file you wish to search, and the number of autocompleted searches
you would like to see. So the arguments pokemon.txt 10 would show up to 10 options from the text file that match the search. Capitalization does matter here.
## License
MIT | 49 | 177 | 0.773469 | eng_Latn | 0.998128 |
991df595fb5df997c8d31050eb2d6520784f8925 | 1,774 | markdown | Markdown | _posts/2017-02-03-das-fernsehwetter-fuer-funkamateure.markdown | hamnet-as64600/hamnet-as64600.github.io | e16178d6516083600ef7f573f580b018c58074a0 | [
"MIT"
] | null | null | null | _posts/2017-02-03-das-fernsehwetter-fuer-funkamateure.markdown | hamnet-as64600/hamnet-as64600.github.io | e16178d6516083600ef7f573f580b018c58074a0 | [
"MIT"
] | null | null | null | _posts/2017-02-03-das-fernsehwetter-fuer-funkamateure.markdown | hamnet-as64600/hamnet-as64600.github.io | e16178d6516083600ef7f573f580b018c58074a0 | [
"MIT"
] | null | null | null | ---
author: IN3DOV
comments: false
date: 2017-02-03 13:52:06+00:00
layout: page
link: https://drc.bz/das-fernsehwetter-fuer-funkamateure/
slug: das-fernsehwetter-fuer-funkamateure
title: Das "Fernsehwetter" für Funkamateure
wordpress_id: 13752
tags:
- Allgemein
---
Wir sind es gewohnt, im Rahmen der Nachrichtensendung unserer Wahl allabendlich auch das Fernsehwetter zu konsumieren. UKW-Amateure können dabei vielleicht aus den Konstellationen von Hochdruckgebieten auf zu erwartende Überreichweiten schließen – KW-Amateure gehen jedoch beim Fernsehabend leer aus.
Zwar gibt es für KW-Amateure im Internet zahlreiche Informationsquellen zum Funkwetter, wovon einige auf unserer Website unter [Amateurfunkpraxis/DX](http://funkamateur.de/amateurfunkpraxis-dx.html) zusammengestellt sind, und nicht zuletzt kann man allwöchentlich den Funkwetterbericht von Dr. Hartmut Büttig, DL1VDL, im Rahmen des DARC-Deutschlandrundspruchs verfolgen.
Weniger bekannt ist jedoch, dass die Geophysikerin Dr. Tamitha Skov in ihrem [Youtube-Kanal](https://www.youtube.com/user/SpWxfx/videos) etwa alle 14 Tage für eine echte Alternative zum Fernsehwetter sorgt und sich dabei stellenweise auch direkt an _Amateur Radio Operators_ wendet. Durch die eindrucksvollen Bilder von der Sonne und die aussagekräftigen Diagramme ist die Funkwetterprognose der Kalifornierin allemal sehenswert, auch wenn man nur "QSO-Englisch" beherrscht.
[Für die nächsten Tage sagt Dr. Skov](https://www.youtube.com/watch?v=K_3dueLXXwk) stärkeren Sonnenwind und ein unruhiges Erdmagnetfeld (ungünstig für die Lowband-Condx) voraus, verursacht durch zwei große koronale Löcher (Erklärung dazu siehe auch [FA 2/17](http://www.box73.de/product_info.php?products_id=3719), S. 120 f.).
Quelle: www.funkamateur.de
| 70.96 | 474 | 0.816798 | deu_Latn | 0.994929 |
991e161d0384ade9adb9b2d731e069810d370597 | 2,713 | md | Markdown | dev-itpro/developer/analyzers/uicop.md | AleksanderGladkov/dynamics365smb-devitpro-pb | df3fee95c4e093b9a785b887f37be4e3e66d7010 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | dev-itpro/developer/analyzers/uicop.md | AleksanderGladkov/dynamics365smb-devitpro-pb | df3fee95c4e093b9a785b887f37be4e3e66d7010 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | dev-itpro/developer/analyzers/uicop.md | AleksanderGladkov/dynamics365smb-devitpro-pb | df3fee95c4e093b9a785b887f37be4e3e66d7010 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: "UICop Analyzer"
description: "UICop is an analyzer that enforces rules that must be respected by extensions meant to customize the Web Client."
ms.author: solsen
ms.custom: na
ms.date: 02/02/2022
ms.reviewer: na
ms.suite: na
ms.tgt_pltfrm: na
ms.topic: reference
author: SusanneWindfeldPedersen
---
[//]: # (START>DO_NOT_EDIT)
[//]: # (IMPORTANT:Do not edit any of the content between here and the END>DO_NOT_EDIT.)
[//]: # (Any modifications should be made in the .xml files in the ModernDev repo.)
# UICop Analyzer Rules
UICop is an analyzer that enforces rules that must be respected by extensions meant to customize the Web Client.
## Rules
|Id|Title|Category|Default Severity|
|--|-----------|--------|----------------|
|[AW0001](uicop-aw0001.md)|The Web client does not support displaying the Request page of XMLPorts.|WebClient|Warning|
|[AW0002](uicop-aw0002.md)|The Web client does not support displaying both Actions and Fields in Cue Groups. Only Fields will be displayed.|WebClient|Warning|
|[AW0003](uicop-aw0003.md)|The Web client does not support displaying Repeater controls containing Parts.|WebClient|Warning|
|[AW0004](uicop-aw0004.md)|A Blob cannot be used as a source expression for a page field.|WebClient|Warning|
|[AW0005](uicop-aw0005.md)|Actions should use the Image property.|WebClient|Info|
|[AW0006](uicop-aw0006.md)|Pages and reports should use the UsageCategory and ApplicationArea properties to be searchable.|WebClient|Info|
|[AW0007](uicop-aw0007.md)|The Web client does not support displaying Repeater controls that contain FlowFilter fields.|WebClient|Error|
|[AW0008](uicop-aw0008.md)|The Web client does not support displaying Repeater controls in pages of type Card, Document, and ListPlus.|WebClient|Warning|
|[AW0009](uicop-aw0009.md)|Using a Blob with subtype Bitmap on a page field is deprecated. Instead use the Media/MediaSet data types.|WebClient|Warning|
|[AW0010](uicop-aw0010.md)|A Repeater control used on a List page must be defined at the beginning of the area(Content) section.|WebClient|Warning|
|[AW0011](uicop-aw0011.md)|Add PromotedOnly="true" to some or all promoted actions to avoid identical actions from appearing in both the promoted and default sections of the command bar.|WebClient|Info|
|[AW0012](uicop-aw0012.md)|The Web client does not support properties for teaching tips in certain contexts.|WebClient|Warning|
[//]: # (IMPORTANT: END>DO_NOT_EDIT)
## See Also
[Using the Code Analysis Tool](../devenv-using-code-analysis-tool.md)
[Ruleset for the Code Analysis Tool](../devenv-rule-set-syntax-for-code-analysis-tools.md)
[Using the Code Analysis Tools with the Ruleset](../devenv-using-code-analysis-tool-with-rule-set.md) | 67.825 | 202 | 0.767048 | eng_Latn | 0.872746 |
991f61dc44026d24c4537512488c53ba8db0a239 | 465 | md | Markdown | _posts/2018-12-31-comlink-rust-webassembly-qiita.md | jser/realtime.jser.info | 1c4e18b7ae7775838604ae7b7c666f1b28fb71d4 | [
"MIT"
] | 5 | 2016-01-25T08:51:46.000Z | 2022-02-16T05:51:08.000Z | _posts/2018-12-31-comlink-rust-webassembly-qiita.md | jser/realtime.jser.info | 1c4e18b7ae7775838604ae7b7c666f1b28fb71d4 | [
"MIT"
] | 3 | 2015-08-22T08:39:36.000Z | 2021-07-25T15:24:10.000Z | _posts/2018-12-31-comlink-rust-webassembly-qiita.md | jser/realtime.jser.info | 1c4e18b7ae7775838604ae7b7c666f1b28fb71d4 | [
"MIT"
] | 2 | 2016-01-18T03:56:54.000Z | 2021-07-25T14:27:30.000Z | ---
title: Comlink + Rust で言語とスレッドの垣根を越えた WebAssembly 開発 - Qiita
author: azu
layout: post
itemUrl: 'https://qiita.com/3846masa/items/92d24e16ebb5151b08ba'
editJSONPath: 'https://github.com/jser/jser.info/edit/gh-pages/data/2018/12/index.json'
date: '2018-12-31T08:17:03Z'
tags:
- WebAssembly
- webworker
- Rust
- article
---
Rustを使ったWebAssemblyライブラリの開発について。
Rustを使ったwasmのバインディングの作成、webpackを使ったロード方法について。
また、処理をメインスレッド外のWebWorkerで行いComlinkでのデータのやり取りする方法について
| 27.352941 | 87 | 0.793548 | yue_Hant | 0.708198 |
991f89c148b6a815b2873c705e818db7940fb83d | 8,175 | md | Markdown | wdk-ddi-src/content/d3dukmdt/ns-d3dukmdt-_d3dddi_synchronizationobject_flags.md | aktsuda/windows-driver-docs-ddi | a7b832e82cc99f77dbde72349c0a61670d8765d3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/d3dukmdt/ns-d3dukmdt-_d3dddi_synchronizationobject_flags.md | aktsuda/windows-driver-docs-ddi | a7b832e82cc99f77dbde72349c0a61670d8765d3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/d3dukmdt/ns-d3dukmdt-_d3dddi_synchronizationobject_flags.md | aktsuda/windows-driver-docs-ddi | a7b832e82cc99f77dbde72349c0a61670d8765d3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
UID: NS:d3dukmdt._D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
title: "_D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS"
author: windows-driver-content
description: Identifies attributes of a synchronization object.
old-location: display\d3dddi_synchronizationobject_flags.htm
old-project: display
ms.assetid: 57e5ea18-ccdd-40a7-9ff5-4d6b94908e7c
ms.author: windowsdriverdev
ms.date: 4/16/2018
ms.keywords: D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS, D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS structure [Display Devices], D3D_other_Structs_3d266c5b-53c9-47d1-abe9-f492d05660a4.xml, _D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS, d3dukmdt/D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS, display.d3dddi_synchronizationobject_flags
ms.prod: windows-hardware
ms.technology: windows-devices
ms.topic: struct
req.header: d3dukmdt.h
req.include-header: D3dumddi.h, D3dkmddi.h
req.target-type: Windows
req.target-min-winverclnt: D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS is supported beginning with the Windows 7 operating system.
req.target-min-winversvr:
req.kmdf-ver:
req.umdf-ver:
req.ddi-compliance:
req.unicode-ansi:
req.idl:
req.max-support:
req.namespace:
req.assembly:
req.type-library:
req.lib:
req.dll:
req.irql:
topic_type:
- APIRef
- kbSyntax
api_type:
- HeaderDef
api_location:
- d3dukmdt.h
api_name:
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
product:
- Windows
targetos: Windows
req.typenames: D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
---
# _D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS structure
## -description
Identifies attributes of a synchronization object.
## -struct-fields
### -field Shared
A UINT value that specifies whether the synchronization object is shared.
If <b>Shared</b> is set to 1 (<b>TRUE</b>), the synchronization object is shared. If <b>Shared</b> is set to zero (<b>FALSE</b>), the synchronization object is not shared.
For more information, see the Remarks section.
### -field NtSecuritySharing
A UINT value that specifies whether the synchronization object is shared with an NT handle, meaning that it does not have a global <b>D3DKMT_HANDLE</b> kernel-mode handle to the resource.
If <b>NtSecuritySharing</b> is set to 1 (<b>TRUE</b>), the synchronization object is shared but does not have a global <b>D3DKMT_HANDLE</b> handle to the resource.
<div class="alert"><b>Note</b> If <b>NtSecuritySharing</b> is set to 1, <b>Shared</b> must be set to 1.</div>
<div> </div>
For more information, see the Remarks section.
Supported starting with Windows 8.
### -field CrossAdapter
A UINT value that specifies whether the synchronization object is a shared cross-adapter object on a <a href="https://msdn.microsoft.com/ECBB0AA7-50C2-41C8-9DC6-6EEFC5CEEB15">hybrid system</a>.
If <b>CrossAdapter</b> is set to 1 (<b>TRUE</b>), the synchronization object is a shared cross-adapter object. If <b>CrossAdapter</b> is set to zero (<b>FALSE</b>), the synchronization object is not a shared cross-adapter object.
For more information, see <a href="https://msdn.microsoft.com/ECBB0AA7-50C2-41C8-9DC6-6EEFC5CEEB15">Using cross-adapter resources in a hybrid system</a>.
### -field TopOfPipeline
<table>
<tr>
<th>Value</th>
<th>Meaning</th>
</tr>
<tr>
<td width="40%">
<dl>
<dt>TRUE</dt>
</dl>
</td>
<td width="60%">
Specifies whether the synchronization object is signaled as soon as the contents of command buffer preceding it is entirely copied to the GPU pipeline, but not necessarily completed execution. This behavior allows reusing command buffers as soon as possible.
</td>
</tr>
<tr>
<td width="40%">
<dl>
<dt>FALSE</dt>
</dl>
</td>
<td width="60%">
The synchronization object is signaled after the preceding command buffers completed execution.
</td>
</tr>
</table>
This value can only be set to 1 (<b>TRUE</b>) for monitored fence synchronization objects, and it should be set to zero (<b>FALSE</b>) for all other synchronization object types.
Supported starting with Windows 10.
### -field NoSignal
<table>
<tr>
<th>Value</th>
<th>Meaning</th>
</tr>
<tr>
<td width="40%">
<dl>
<dt>TRUE</dt>
</dl>
</td>
<td width="60%">
Specifies the device this sync object is created or opened on can only submit wait commands for it. An attempt to submit a signal operation when this flag is set will return <b>STATUS_ACCESS_DENIED</b>.
</td>
</tr>
<tr>
<td width="40%">
<dl>
<dt>FALSE</dt>
</dl>
</td>
<td width="60%">
The synchronization object can be signaled.
</td>
</tr>
</table>
This value can only be set to 1 (<b>TRUE</b>) for monitored fence synchronization objects, and it should be set to zero (<b>FALSE</b>) for all other synchronization object types.
Supported starting with Windows 10.
### -field NoWait
<table>
<tr>
<th>Value</th>
<th>Meaning</th>
</tr>
<tr>
<td width="40%">
<dl>
<dt>TRUE</dt>
</dl>
</td>
<td width="60%">
Specifies the device this sync object is created or opened on can only submit signal commands for it. An attempt to submit a wait operation when this flag is set will return <b>STATUS_ACCESS_DENIED</b>.
</td>
</tr>
<tr>
<td width="40%">
<dl>
<dt>FALSE</dt>
</dl>
</td>
<td width="60%">
The synchronization object can be waited on.
</td>
</tr>
</table>
This value can only be set to 1 (<b>TRUE</b>) for monitored fence synchronization objects, and it should be set to zero (<b>FALSE</b>) for all other synchronization object types.
This flag cannot be set simultaneously with <b>NoSignal</b> flag.
Supported starting with Windows 10.
### -field NoSignalMaxValueOnTdr
<table>
<tr>
<th>Value</th>
<th>Meaning</th>
</tr>
<tr>
<td width="40%">
<dl>
<dt>TRUE</dt>
</dl>
</td>
<td width="60%">
Instructs the GPU scheduler to bypass the aforementioned signaling of the monitored fence to the maximum value in TDR cases.
</td>
</tr>
<tr>
<td width="40%">
<dl>
<dt>FALSE</dt>
</dl>
</td>
<td width="60%">
The GPU scheduler will signal the monitored fence to the maximum value when a device that can potentially signal it is affected by the GPU reset (TDR).
</td>
</tr>
</table>
Supported starting with Windows 10.
### -field NoGPUAccess
### -field Reserved
This member is reserved and should be set to zero.
This member is reserved and should be set to zero.
This member is reserved and should be set to zero.
### -field D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS_RESERVED0
This member is reserved and should be set to zero.
Supported starting with Windows 8.
### -field Value
[in] A member in the union that is contained in <b>D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS</b> that can hold one 32-bit value that identifies attributes of a synchronization object.
## -remarks
Objects to be shared by using the <a href="https://msdn.microsoft.com/library/windows/hardware/hh780251">D3DKMTShareObjects</a> function must first be created with the <b>NtSecuritySharing</b> flag value set. This flag value is available in the <a href="https://msdn.microsoft.com/library/windows/hardware/ff547802">D3DKMT_CREATEALLOCATIONFLAGS</a>, <a href="https://msdn.microsoft.com/library/windows/hardware/hh780254">D3DKMT_CREATEKEYEDMUTEX2_FLAGS</a>, and <b>D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS</b> structures.
Drivers should follow these guidelines on <b>D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS</b> flags:
<ul>
<li>If the synchronization object is not shared, set both <b>Shared</b> and <b>NtSecuritySharing</b> to 0.</li>
<li>If the synchronization object is shared with a <b>D3DKMT_HANDLE</b> data type, set <b>Shared</b> = 1 and <b>NtSecuritySharing</b> = 0.</li>
<li>If the synchronization object is shared with an NT handle to the process (and without a global <b>D3DKMT_HANDLE</b> kernel-mode handle to the resource), set <b>Shared</b> = 1 and <b>NtSecuritySharing</b> = 1.</li>
</ul>
## -see-also
<a href="https://msdn.microsoft.com/library/windows/hardware/ff544658">D3DDDI_SYNCHRONIZATIONOBJECTINFO2</a>
<a href="https://msdn.microsoft.com/library/windows/hardware/ff544662">D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS</a>
<a href="https://msdn.microsoft.com/library/windows/hardware/hh780251">D3DKMTShareObjects</a>
<a href="https://msdn.microsoft.com/library/windows/hardware/ff547802">D3DKMT_CREATEALLOCATIONFLAGS</a>
<a href="https://msdn.microsoft.com/library/windows/hardware/hh780254">D3DKMT_CREATEKEYEDMUTEX2_FLAGS</a>
| 26.370968 | 514 | 0.747645 | eng_Latn | 0.910846 |
99200042ff3fe1e9a1253d77b1a1e94790f07934 | 3,337 | md | Markdown | _chapters/redirect-on-login-and-logout.md | ajesse11x/serverless-stack-com | 35612c28dbe48d19fed1da25a4374e0b4cc3c9d1 | [
"MIT"
] | 1 | 2019-05-14T13:23:03.000Z | 2019-05-14T13:23:03.000Z | _chapters/redirect-on-login-and-logout.md | ajesse11x/serverless-stack-com | 35612c28dbe48d19fed1da25a4374e0b4cc3c9d1 | [
"MIT"
] | null | null | null | _chapters/redirect-on-login-and-logout.md | ajesse11x/serverless-stack-com | 35612c28dbe48d19fed1da25a4374e0b4cc3c9d1 | [
"MIT"
] | 2 | 2019-11-22T14:54:07.000Z | 2021-06-18T13:49:09.000Z | ---
layout: post
title: Redirect on Login and Logout
date: 2017-01-17 00:00:00
description: To ensure that the user is redirected after logging in and logging out of our React.js app, we are going to use the withRouter higher-order component from React Router v4. And we’ll use the history.push method to navigate the app.
context: true
comments_id: redirect-on-login-and-logout/154
---
To complete the login flow we are going to need to do two more things.
1. Redirect the user to the homepage after they login.
2. And redirect them back to the login page after they logout.
We are going to use the `history.push` method that comes with React Router v4.
### Redirect to Home on Login
Since our `Login` component is rendered using a `Route`, it adds the router props to it. So we can redirect using the `this.props.history.push` method.
``` javascript
this.props.history.push("/");
```
<img class="code-marker" src="/assets/s.png" />Update the `handleSubmit` method in `src/containers/Login.js` to look like this:
``` javascript
handleSubmit = async event => {
event.preventDefault();
try {
await Auth.signIn(this.state.email, this.state.password);
this.props.userHasAuthenticated(true);
this.props.history.push("/");
} catch (e) {
alert(e.message);
}
}
```
Now if you head over to your browser and try logging in, you should be redirected to the homepage after you've been logged in.

### Redirect to Login After Logout
Now we'll do something very similar for the logout process. However, the `App` component does not have access to the router props directly since it is not rendered inside a `Route` component. To be able to use the router props in our `App` component we will need to use the `withRouter` [Higher-Order Component](https://facebook.github.io/react/docs/higher-order-components.html) (or HOC). You can read more about the `withRouter` HOC [here](https://reacttraining.com/react-router/web/api/withRouter).
To use this HOC, we'll change the way we export our App component.
<img class="code-marker" src="/assets/s.png" />Replace the following line in `src/App.js`.
``` coffee
export default App;
```
<img class="code-marker" src="/assets/s.png" />With this.
``` coffee
export default withRouter(App);
```
<img class="code-marker" src="/assets/s.png" />And import `withRouter` by replacing the `import { Link }` line in the header of `src/App.js` with this:
``` coffee
import { Link, withRouter } from "react-router-dom";
```
<img class="code-marker" src="/assets/s.png" />Add the following to the bottom of the `handleLogout` method in our `src/App.js`.
``` coffee
this.props.history.push("/login");
```
So our `handleLogout` method should now look like this.
``` coffee
handleLogout = async event => {
await Auth.signOut();
this.userHasAuthenticated(false);
this.props.history.push("/login");
}
```
This redirects us back to the login page once the user logs out.
Now if you switch over to your browser and try logging out, you should be redirected to the login page.
You might have noticed while testing this flow that since the login call has a bit of a delay, we might need to give some feedback to the user that the login call is in progress. Let's do that next.
| 36.271739 | 501 | 0.733593 | eng_Latn | 0.988529 |
9920af4a7f2aad46fafafe495f4fcb01b06dcecb | 4,836 | md | Markdown | README.md | gaotuan/x-pipe | 3f6e42b89caeffc08e7efd0ea65b3c1f885c48ab | [
"Apache-2.0"
] | null | null | null | README.md | gaotuan/x-pipe | 3f6e42b89caeffc08e7efd0ea65b3c1f885c48ab | [
"Apache-2.0"
] | null | null | null | README.md | gaotuan/x-pipe | 3f6e42b89caeffc08e7efd0ea65b3c1f885c48ab | [
"Apache-2.0"
] | null | null | null | x-pipe
================
### [master]
[](https://travis-ci.org/ctripcorp/x-pipe)
[](https://coveralls.io/github/ctripcorp/x-pipe?branch=master)
[](https://scan.coverity.com/projects/ctripcorp-x-pipe)
### [dev]
[](https://travis-ci.org/ctripcorp/x-pipe)
[](https://coveralls.io/github/ctripcorp/x-pipe?branch=dev)
<!-- MarkdownTOC -->
- [XPipe 解决什么问题](#xpipe-解决什么问题)
- [系统详述](#系统详述)
- [整体架构](#整体架构)
- [Redis 数据复制问题](#redis-数据复制问题)
- [机房切换](#机房切换)
- [切换流程](#切换流程)
- [高可用](#高可用)
- [XPipe 系统高可用](#xpipe-系统高可用)
- [Redis 自身高可用](#redis-自身高可用)
- [测试数据](#测试数据)
- [延时测试](#延时测试)
- [跨公网部署及架构](#跨公网部署及架构)
- [深入了解](#深入了解)
- [技术交流](#技术交流)
- [License](#license)
<!-- /MarkdownTOC -->
<a name="xpipe-解决什么问题"></a>
# XPipe 解决什么问题
Redis 在携程内部得到了广泛的使用,根据客户端数据统计,整个携程全部 Redis 的读写请求在每秒 2000W,其中写请求约 100W,很多业务甚至会将 Redis 当成内存数据库使用。这样,就对 Redis 多数据中心提出了很大的需求,一是为了提升可用性,解决数据中心 DR(Disaster Recovery) 问题,二是提升访问性能,每个数据中心可以读取当前数据中心的数据,无需跨机房读数据,在这样的需求下,XPipe 应运而生 。
为了方便描述,后面用 DC 代表数据中心 (Data Center)。
<a name="系统详述"></a>
# 系统详述
<a name="整体架构"></a>
## 整体架构
整体架构图如下所示:
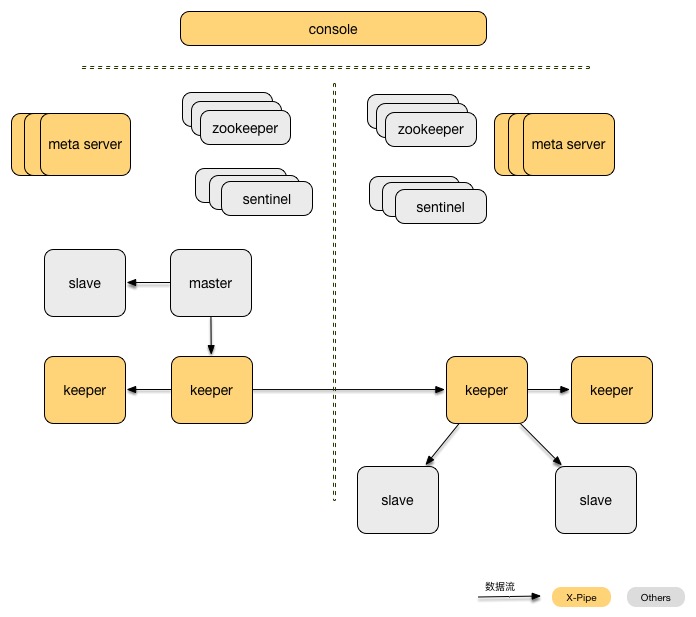
- Console 用来管理多机房的元信息数据,同时提供用户界面,供用户进行配置和 DR 切换等操作。
- Keeper 负责缓存 Redis 操作日志,并对跨机房传输进行压缩、加密等处理。
- Meta Server 管理单机房内的所有 keeper 状态,并对异常状态进行纠正。
<a name="redis-数据复制问题"></a>
## Redis 数据复制问题
多数据中心首先要解决的是数据复制问题,即数据如何从一个 DC 传输到另外一个 DC。我们决定采用伪 slave 的方案,即实现 Redis 协议,伪装成为 Redis slave,让 Redis master 推送数据至伪 slave。这个伪 slave,我们把它称为 keeper,如下图所示:
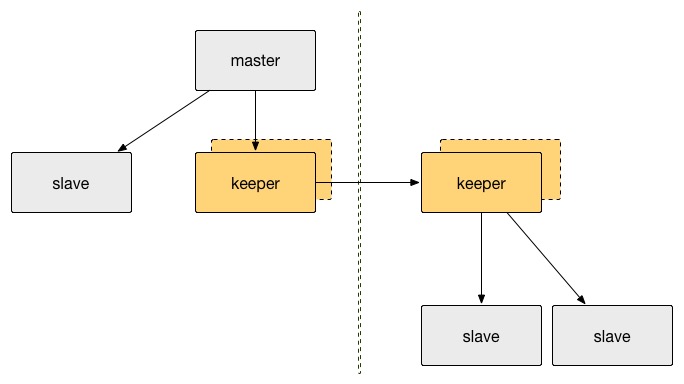
使用 keeper 带来的优势
- 减少 master 全量同步
如果异地机房 slave 直接连向 master,多个 slave 会导致 master 多次全量同步,而 keeper 可以缓存 rdb 和 replication log,异地机房的 slave 直接从 keeper 获取数据,增强 master 的稳定性。
- 减少多数据中心网络流量
在两个数据中心之间,数据只需要通过 keeper 传输一次,且 keeper 之间传输协议可以自定义,方便支持压缩 (目前暂未支持)。
- 网络异常时减少全量同步
keeper 将 Redis 日志数据缓存到磁盘,这样,可以缓存大量的日志数据 (Redis 将数据缓存到内存 ring buffer,容量有限),当数据中心之间的网络出现较长时间异常时仍然可以续传日志数据。
- 安全性提升
多个机房之间的数据传输往往需要通过公网进行,这样数据的安全性变得极为重要,keeper 之间的数据传输也可以加密 (暂未实现),提升安全性。
<a name="机房切换"></a>
## 机房切换
<a name="切换流程"></a>
### 切换流程
- 检查是否可以进行 DR 切换
类似于 2PC 协议,首先进行 prepare,保证流程能顺利进行。
- 原主机房 master 禁止写入
此步骤,保证在迁移的过程中,只有一个 master,解决在迁移过程中可能存在的数据丢失情况。
- 提升新主机房 master
- 其它机房向新主机房同步
同时提供回滚和重试功能。回滚功能可以回滚到初始的状态,重试功能可以在 DBA 人工介入的前提下,修复异常条件,继续进行切换。
<a name="高可用"></a>
## 高可用
<a name="xpipe-系统高可用"></a>
### XPipe 系统高可用
如果 keeper 挂掉,多数据中心之间的数据传输可能会中断,为了解决这个问题,keeper 有主备两个节点,备节点实时从主节点复制数据,当主节点挂掉后,备节点会被提升为主节点,代替主节点进行服务。
提升的操作需要通过第三方节点进行,我们把它称之为 MetaServer,主要负责 keeper 状态的转化以及机房内部元信息的存储。同时 MetaServer 也要做到高可用:每个 MetaServer 负责特定的 Redis 集群,当有 MetaServer 节点挂掉时,其负责的 Redis 集群将由其它节点接替;如果整个集群中有新的节点接入,则会自动进行一次负载均衡,将部分集群移交到此新节点。
<a name="redis-自身高可用"></a>
### Redis 自身高可用
Redis 也可能会挂,Redis 本身提供哨兵 (Sentinel) 机制保证集群的高可用。但是在 Redis4.0 版本之前,提升新的 master 后,其它节点连到此节点后都会进行全量同步,全量同步时,slave 会处于不可用状态;master 将会导出 rdb,降低 master 的可用性;同时由于集群中有大量数据 (RDB) 传输,将会导致整体系统的不稳定。
截止当前文章书写之时,4.0 仍然没有发布 release 版本,而且携程内部使用的 Redis 版本为 2.8.19,如果升到 4.0,版本跨度太大,基于此,我们在 Redis3.0.7 的版本基础上进行优化,实现了 psync2.0 协议,实现了增量同步。下面是 Redis 作者对协议的介绍:[psync2.0](https://gist.github.com/antirez/ae068f95c0d084891305)。
[携程内部 Redis 地址链接](https://github.com/ctripcorp/redis)
<a name="测试数据"></a>
## 测试数据
<a name="延时测试"></a>
### 延时测试
#### 测试方案
测试方式如下图所示。从 client 发送数据至 master,并且 slave 通过 keyspace notification 的方式通知到 client,整个测试延时时间为 t1+t2+t3。
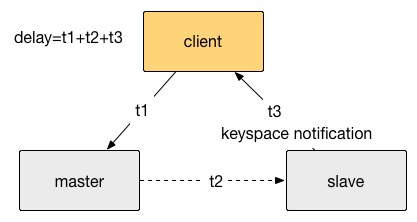
#### 测试数据
首先我们测试 Redis master 直接复制到 slave 的延时,为 0.2ms。然后在 master 和 slave 之间增加一层 keeper,整体延时增加 0.1ms,到 0.3ms。
在携程生产环境进行了测试,生产环境两个机房之间的 ping RTT 约为 0.61ms,经过跨数据中心的两层 keeper 后,测试得到的平均延时约为 0.8ms,延时 99.9 线为 2ms。
<a name="跨公网部署及架构"></a>
## 跨公网部署及架构
[详情参考 -- 跨公网部署及架构](https://raw.github.com/ctripcorp/x-pipe/master/doc/Proxy.md)
<a name="深入了解"></a>
# 深入了解
- 【有任何疑问,请阅读】[XPipe Wiki](https://github.com/ctripcorp/x-pipe/wiki)
- 【目前用户的问题整理】[XPipe Q&A](https://github.com/ctripcorp/x-pipe/wiki/XPipe-Q&A)
- 【文章】[携程Redis多数据中心解决方案-XPipe](https://mp.weixin.qq.com/s/Q3bt0-5nv8uNMdHuls-Exw?)
- 【文章】[携程Redis海外机房数据同步实践](https://mp.weixin.qq.com/s/LeSSdT6bOEFzZyN26PRVzg)
<a name="技术交流"></a>
# 技术交流

#### 按照文档 安装顺序zk,console,metadata,keeper
<a name="license"></a>
# License
The project is licensed under the [Apache 2 license](https://github.com/ctripcorp/x-pipe/blob/master/LICENSE).
| 38.688 | 223 | 0.73139 | yue_Hant | 0.668005 |
9920ca9fcc0d158d47af6d7942a6e9f511f2189d | 5,263 | md | Markdown | articles/storage/blobs/storage-blob-performance-tiers.md | jkudo/azure-docs.ja-jp | 91f0b0c63c4e01743cd750160d36fdb3a9d7c6a7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/storage/blobs/storage-blob-performance-tiers.md | jkudo/azure-docs.ja-jp | 91f0b0c63c4e01743cd750160d36fdb3a9d7c6a7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/storage/blobs/storage-blob-performance-tiers.md | jkudo/azure-docs.ja-jp | 91f0b0c63c4e01743cd750160d36fdb3a9d7c6a7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: ブロック BLOB ストレージのパフォーマンス レベル - Azure Storage
description: Azure ブロック BLOB ストレージの Premium と Standard のパフォーマンス レベルの違いについて説明します。
author: mhopkins-msft
ms.author: mhopkins
ms.date: 11/12/2019
ms.service: storage
ms.subservice: blobs
ms.topic: conceptual
ms.reviewer: clausjor
ms.openlocfilehash: ff82986b27d038c536872b07e1308b0d48fadaef
ms.sourcegitcommit: 653e9f61b24940561061bd65b2486e232e41ead4
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 11/21/2019
ms.locfileid: "74270219"
---
# <a name="performance-tiers-for-block-blob-storage"></a>ブロック BLOB ストレージのパフォーマンス レベル
企業がパフォーマンスを重視するクラウド ネイティブ アプリケーションを展開する場合、さまざまなパフォーマンス レベルでコスト効率の高いデータ ストレージのオプションを用意することが重要です。
Azure ブロック BLOB ストレージには、次の 2 つの異なるパフォーマンス レベルがあります。
- **Premium**: 高いトランザクション率と一貫した 1 桁のストレージ待機時間のために最適化されています
- **Standard**: 高容量および高スループットのために最適化されています
この異なるパフォーマンス レベルでは、次の条件が該当する必要があります。
| 領域 |Standard パフォーマンス |Premium パフォーマンス |
|---------|---------|---------|
|利用可能なリージョン | すべてのリージョン | [一部のリージョン](https://azure.microsoft.com/global-infrastructure/services/?products=storage) |
|サポートされる[ストレージ アカウントの種類](../common/storage-account-overview.md#types-of-storage-accounts) | 汎用 v2、BlobStorage、汎用 v1 | BlockBlobStorage |
|[高スループット ブロック BLOB](https://azure.microsoft.com/blog/high-throughput-with-azure-blob-storage/) をサポート | はい (4 MiB を超える MiB PutBlock または PutBlock のサイズ) | はい (256 KiB を超える MiB PutBlock または PutBlock のサイズ) |
|冗長性 | 「[ストレージ アカウントの種類](../common/storage-account-overview.md#types-of-storage-accounts)」を参照してください。 | 現在、ローカル冗長ストレージ (LRS) とゾーン冗長ストレージ (ZRS) のみをサポートしています。<div role="complementary" aria-labelledby="zone-redundant-storage"><sup>1</sup></div> |
<div id="zone-redundant-storage"><sup>1</sup> ゾーン冗長ストレージ (ZRS) は、一部のリージョンで Premium パフォーマンス ブロック BLOB ストレージ アカウントに使用できます。</div>
コストに関して、Premium パフォーマンスは、トランザクション率が高いアプリケーションのワークロードの[総ストレージ コストを低減](https://azure.microsoft.com/blog/reducing-overall-storage-costs-with-azure-premium-blob-storage/)するよう価格が最適化されています。
## <a name="premium-performance"></a>Premium パフォーマンス
Premium パフォーマンスのブロック BLOB ストレージでは、高性能なハードウェア経由でデータを利用できます。 データは、低待機時間のために最適化されたソリッドステート ドライブ (SSD) に格納されています。 SSD は従来のハード ドライブと比べ、スループットが高くなります。
Premium パフォーマンス ストレージは、高速で一貫性のある応答時間を必要とするワークロードに最適です。 これは、小規模なトランザクションを多数実行するワークロードに最適です。 ワークロードの例を次に示します。
- **対話型ワークロード**。 これらのワークロードには、即時の更新とユーザーからのフィードバック が必要です (eコマースやマッピング アプリケーションなど)。 たとえば、eコマース アプリケーションでは、表示頻度の低い項目はキャッシュされない可能性があります。 ただし、要求時には顧客に瞬時に表示される必要があります。
- **分析**。 IoT シナリオでは、毎秒、小さな書き込み操作がクラウドにプッシュされる可能性があります。 大量のデータが収集され、分析のために集計され、ほぼ瞬時に削除される場合があります。 Premium ブロック BLOB ストレージのインジェスト機能を利用すると、この種類のワークロードに効率的に対応できます。
- **人工知能/機械学習 (AI/ML)** 。 AI/ML では、ビジュアル、音声、テキストなどのさまざまなデータの種類の使用と処理を扱います。 このハイ パフォーマンス コンピューティング型のワークロードでは大量のデータが処理されますが、データ分析のために迅速な応答と効率的なインジェスト時間が必要です。
- **データの変換**。 データの継続的な編集、変更、および変換を必要とするプロセスでは、即時の更新が必要です。 正確なデータ表現のために、このデータのユーザーには、こうした即時に反映された変更が表示される必要があります。
## <a name="standard-performance"></a>Standard パフォーマンス
Standard パフォーマンスでは、最もコスト効率の高い方法でデータを格納できるよう、さまざまな[アクセス層](storage-blob-storage-tiers.md)をサポートしています。 大規模なデータ セットで、高容量および高スループットを実現するために最適化されています。
- **バックアップおよびディザスター リカバリーのデータセット**。 Standard パフォーマンス ストレージでは、コスト効率に優れた層が提供されるため、短期および長期のディザスター リカバリー データセット、セカンダリ バックアップ、コンプライアンス データ アーカイブにおける最適なユース ケースとなります。
- **メディア コンテンツ**。 多くの場合、画像とビデオは最初に作成されて保存されるときに頻繁にアクセスされますが、このコンテンツ タイプは古くなるにつれて使用頻度が落ちます。 Standard パフォーマンス ストレージでは、メディア コンテンツのニーズに適した層が提供されます。
- **バルク データ処理**。 これらの種類のワークロードは、安定した待機時間の短さより、コスト効果の高い高スループットのストレージを必要とするため、Standard Storage に適しています。 大量の生データセットは処理用にステージングされ、最終的にはクールな層に移行します。
## <a name="migrate-from-standard-to-premium"></a>Standard から Premium に移行する
既存の Standard パフォーマンス ストレージ アカウントを Premium パフォーマンスのブロック BLOB ストレージ アカウントに変換することはできません。 Premium パフォーマンス ストレージ アカウントに移行するには、BlockBlobStorage アカウントを作成し、データを新しいアカウントに移行する必要があります。 詳細については、「[ブロック BLOB ストレージ アカウントの作成](storage-blob-create-account-block-blob.md)」を参照してください。
ストレージ アカウント間で BLOB をコピーするには、最新バージョンの [AzCopy](../common/storage-use-azcopy-blobs.md) コマンドライン ツールを使用できます。 データの移動と変換には、Azure Data Factory などの他のツールを使用することもできます。
## <a name="blob-lifecycle-management"></a>BLOB のライフサイクル管理
Blob ストレージのライフサイクル管理には、ルールベースのポリシーが豊富に用意されています。
- **Premium**:データは、そのライフサイクルの終了時に期限切れになります。
- **Standard**:データを最適なアクセス層に移行し、そのライフサイクルの終了時にデータを期限切れにします
詳細については、「[Azure Blob Storage のライフサイクルを管理する](storage-lifecycle-management-concepts.md)」を参照してください。
Premium のブロック BLOB ストレージ アカウントに格納されているデータは、ホット、クール、およびアーカイブ層間で移動することはできません。 ただし、ブロック BLOB ストレージ アカウントから*別の*アカウントのホット アクセス層に BLOB をコピーすることは可能です。 別にアカウントにデータをコピーするには、[Put Block From URL](/rest/api/storageservices/put-block-from-url) API または [AzCopy v10](../common/storage-use-azcopy-v10.md) を使用します。 **Put Block From URL** API では、サーバー上のデータを同期的にコピーします。 この呼び出しは、すべてのデータが、元のサーバー上の場所からコピー先の場所に移動された後でのみ完了します。
## <a name="next-steps"></a>次の手順
GPv2 および BLOB ストレージ アカウントでホット、クール、アーカイブを評価します。
- [アーカイブ層から BLOB データをリハイドレートする方法を確認する](storage-blob-rehydration.md)
- [Azure Storage のメトリックを有効にして現在のストレージ アカウントの使用状況を評価する](../common/storage-enable-and-view-metrics.md)
- [BLOB ストレージ アカウントと GPv2 アカウントのホット、クール、アーカイブのリージョンごとの料金を確認する](https://azure.microsoft.com/pricing/details/storage/)
- [データ転送の価格を確認する](https://azure.microsoft.com/pricing/details/data-transfers/)
| 59.134831 | 401 | 0.802014 | jpn_Jpan | 0.392381 |
99214bb13bfdf89614fd7b2dc93f2fca712f8e3d | 1,942 | md | Markdown | Readme.md | gregpaton08/react-confirm-alert | 09cdf55dd39682e1be64800b1c4ee2dfe6632ab9 | [
"MIT"
] | null | null | null | Readme.md | gregpaton08/react-confirm-alert | 09cdf55dd39682e1be64800b1c4ee2dfe6632ab9 | [
"MIT"
] | 8 | 2020-07-07T19:52:46.000Z | 2022-02-26T10:25:52.000Z | Readme.md | gregpaton08/react-confirm-alert | 09cdf55dd39682e1be64800b1c4ee2dfe6632ab9 | [
"MIT"
] | null | null | null | # react-confirm-alert
react component confirm dialog. [Live demo](https://ga-mo.github.io/react-confirm-alert/demo/)
[](https://badge.fury.io/js/react-confirm-alert)
Document for v.1.x.x [see](https://github.com/GA-MO/react-confirm-alert/blob/master/Document-v1.md)
## Getting started
#### Install with NPM:
```
$ npm install react-confirm-alert --save
```
#### Options
```jsx
const options = {
title: 'Title',
message: 'Message',
buttons: [
{
label: 'Yes',
onClick: () => alert('Click Yes')
},
{
label: 'No',
onClick: () => alert('Click No')
}
],
childrenElement: () => <div />,
customUI: ({ title, message, onClose }) => <div>Custom UI</div>,
willUnmount: () => {}
}
confirmAlert(options)
```
#### Use with function:
```jsx
import { confirmAlert } from 'react-confirm-alert'; // Import
import 'react-confirm-alert/src/react-confirm-alert.css' // Import css
class App extends React.Component {
submit = () => {
confirmAlert({
title: 'Confirm to submit',
message: 'Are you sure to do this.',
buttons: [
{
label: 'Yes',
onClick: () => alert('Click Yes')
},
{
label: 'No',
onClick: () => alert('Click No')
}
]
})
};
render() {
return (
<div className="container">
<button onClick={this.submit}>Confirm dialog</button>
</div>
);
}
}
```
#### Custom UI Component
```js
confirmAlert({
customUI: ({ onClose }) => {
return (
<div className='custom-ui'>
<h1>Are you sure?</h1>
<p>You want to delete this file?</p>
<button onClick={onClose}>No</button>
<button onClick={() => {
this.handleClickDelete()
onClose()
}}>Yes, Delete it!</button>
</div>
)
}
})
``` | 21.820225 | 112 | 0.54171 | eng_Latn | 0.235407 |
992288cc672d47922fc997989aa283c77769a578 | 4,901 | md | Markdown | DocGen/Documentation/HowTos/Samples/WLT_ASA_Software.md | digitalarche/MixedReality-WorldLockingTools-Unity | 4cd7c309fbf662c65687c74afdc06f9c7f6a4e1c | [
"MIT"
] | 139 | 2020-02-19T16:46:41.000Z | 2022-03-21T17:27:12.000Z | DocGen/Documentation/HowTos/Samples/WLT_ASA_Software.md | digitalarche/MixedReality-WorldLockingTools-Unity | 4cd7c309fbf662c65687c74afdc06f9c7f6a4e1c | [
"MIT"
] | 208 | 2020-02-19T22:20:21.000Z | 2022-03-29T10:57:53.000Z | DocGen/Documentation/HowTos/Samples/WLT_ASA_Software.md | digitalarche/MixedReality-WorldLockingTools-Unity | 4cd7c309fbf662c65687c74afdc06f9c7f6a4e1c | [
"MIT"
] | 33 | 2020-02-20T19:26:24.000Z | 2022-02-23T11:02:29.000Z |
# WLT+ASA: Overview of supporting software
## IBinder - binding SpacePins to Azure Spatial Anchors
The [IBinding](xref:Microsoft.MixedReality.WorldLocking.ASA.IBinder) interface is at the center. It is implemented here by the [SpacePinBinder class](xref:Microsoft.MixedReality.WorldLocking.ASA.SpacePinBinder). It is a Unity Monobehaviour, and may be configured either from Unity's Inspector or from script.
Each IBinder is [named](xref:Microsoft.MixedReality.WorldLocking.ASA.IBinder.Name), so a single [IBindingOracle](xref:Microsoft.MixedReality.WorldLocking.ASA.IBindingOracle) can manage bindings for multiple IBindings.
## IPublisher - reading and writing spatial anchors to the cloud
The [IPublisher](xref:Microsoft.MixedReality.WorldLocking.ASA.IPublisher) interface handles publishing spatial anchors to the cloud, and then retrieving them in later sessions or on other devices. It is implemented here with the [PublisherASA class](xref:Microsoft.MixedReality.WorldLocking.ASA.PublisherASA). Pose data in the current physical space is captured and retrieved using Azure Spatial Anchors.
When a spatial anchor is published, a cloud anchor id is obtained. This id may be used in later sessions or on other devices to retrieve the cloud anchor's pose in the current coordinate system, along with any properties stored with it. The system always adds a property identifying the cloud anchor's associated SpacePin.
It should be noted that the IPublisher, and the PublisherASA, don't know anything about SpacePins. IPublisher doesn't know or care what will be done with the cloud anchor data. It simply provides a simplified awaitable interface for publishing and retrieving cloud anchors.
### Read versus Find
If a cloud anchor's id is known, the cloud anchor may be retrieved by its id. This is the most robust way to retrieve a cloud anchor. This is [Read](xref:Microsoft.MixedReality.WorldLocking.ASA.IPublisher.Read*).
However, there are interesting scenarios in which the ids for the cloud anchors within an area aren't known by a device, but if they cloud anchors could be retrieved, their spatial data and properties would combine to provide enough information to make them useful.
[Find](xref:Microsoft.MixedReality.WorldLocking.ASA.IPublisher.Find*) searches the area around a device for cloud anchors, and returns any that it was able to identify. This process is known as [coarse relocation](https://docs.microsoft.com/azure/spatial-anchors/how-tos/set-up-coarse-reloc-unity).
## IBindingOracle - sharing cloud anchor ids
The [IBindingOracle interface](xref:Microsoft.MixedReality.WorldLocking.ASA.IBindingOracle) provides a means of persisting and sharing bindings between SpacePins and specific cloud anchors. Specifically, it persists space-pin-id/cloud-anchor-id pairs, along with the name of the IBinder.
The oracle's interface is extremely simple. Given an IBinder, it can either [Put](xref:Microsoft.MixedReality.WorldLocking.ASA.IBindingOracle.Put*) the IBinder's bindings, or it can [Get](xref:Microsoft.MixedReality.WorldLocking.ASA.IBindingOracle.Get*) them. Put stores them, and Get retrieves them. The mechanism of storage and retrieval is left to the implementation of the concrete class implementing the IBindingOracle interface.
This sample implements possibly the simplest possible IBindingOracle, in the form of the [SpacePinBinderFile class](xref:Microsoft.MixedReality.WorldLocking.ASA.SpacePinBinder). On Put, it writes the IBinder's bindings to a text file. On Get, it reads them from the text file (if available) and feeds them into the IBinder.
## ILocalPeg - blob marking a position in physical space
The [ILocalPeg interface](xref:Microsoft.MixedReality.WorldLocking.ASA.ILocalPeg) is an abstraction of a device local anchor. In a more perfect world, the required ILocalPegs would be internally managed by the IPublisher. However, device local anchors work much better when created while the device is in the vicinity of the anchor's pose. The IPublisher only knows where the device local anchors should be placed when they are needed, not at the optimal time of creating them.
The [SpacePinASA](xref:Microsoft.MixedReality.WorldLocking.ASA.SpacePinASA) does know when the best time to create its local anchor is. When the manipulation of the SpacePin ends and its pose set, the SpacePinASA requests the IPublisher to [create an opaque local peg](xref:Microsoft.MixedReality.WorldLocking.ASA.IPublisher.CreateLocalPeg*) at the desired pose. The SpacePinBinder then pulls the ILocalPeg off the SpacePinASA, and passes it to the IPublisher to be used in [creating a cloud spatial anchor](xref:Microsoft.MixedReality.WorldLocking.ASA.IPublisher.Create*).
## See also
* [WLT+ASA Samples Setup and Walkthrough](WLT_ASA_Sample.md)
* [Space Pins Concepts](~/DocGen/Documentation/Concepts/Advanced/SpacePins.md)
* [Space Pins Sample](SpacePin.md)
| 108.911111 | 573 | 0.811875 | eng_Latn | 0.986289 |
9922de5a6d7df7b06cca1e374e03ddc05f802ed5 | 21 | md | Markdown | README.md | jaselnik/Dict-Match-UnitTest | 2b981f45e88c480048f8502315696faf6967bd6f | [
"MIT"
] | 1 | 2019-07-18T18:57:58.000Z | 2019-07-18T18:57:58.000Z | README.md | tamkovich/Dict-Match-UnitTest | 2b981f45e88c480048f8502315696faf6967bd6f | [
"MIT"
] | null | null | null | README.md | tamkovich/Dict-Match-UnitTest | 2b981f45e88c480048f8502315696faf6967bd6f | [
"MIT"
] | null | null | null | # Dict-Match-UnitTest | 21 | 21 | 0.809524 | kor_Hang | 0.565464 |
9922e1e3145d7e0755a02dfa034af12d5cb28e5f | 6,095 | md | Markdown | README.md | ISebSej/pygame_aseprite_animator | 9179c02c1f17612aa51eb9eb8ae520d0aae2f166 | [
"MIT"
] | 2 | 2021-08-15T01:55:37.000Z | 2021-08-20T07:21:11.000Z | README.md | ISebSej/pygame_aseprite_animator | 9179c02c1f17612aa51eb9eb8ae520d0aae2f166 | [
"MIT"
] | null | null | null | README.md | ISebSej/pygame_aseprite_animator | 9179c02c1f17612aa51eb9eb8ae520d0aae2f166 | [
"MIT"
] | null | null | null | Pygame_Aseprite_Animation
============
[](https://github.com/IgorAntun/node-chat/stargazers) [](https://github.com/IgorAntun/node-chat/issues) [](https://github.com/IgorAntun/node-chat)
It's finally possible to parse and display .ase and .aseprite files directly without exporting them into some other kind of format first! Thanks to @Eiyeron for his work on the [py_aseprite](https://github.com/Eiyeron/py_aseprite) on which this was build.

Check out the full example in example/example.py
<!-- ---
## Buy me a coffee
Whether you use this project, have learned something from it, or just like it, please consider supporting it by buying me a coffee, so I can dedicate more time on open-source projects like this :)
<a href="https://www.buymeacoffee.com/igorantun" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png" alt="Buy Me A Coffee" style="height: auto !important;width: auto !important;" ></a> -->
---
## Features
- Load .ase and .aseprite files
- **NOTE:** only RGBA mode is currently supported. Grayscale and indexed have not been tested
- Supports layers
- Supports animations with variable timing, straight from the aseprite file
- Automatically handles timings
- py_aseprite is currently bundled into this package, so you don't have to manually download it
---
## TODOs
- implement grayscale and indexed images (never used this myself)
- allow Animations to have a name/id attribute so users can more easily access them in the animation manager
- do the programmer stuff like unit testing which I can't bothered to do
- Improve and feature complete the animation manager, it's still a bit simple. I'm sure people can find lots of ideas for it.
---
## Get package
Simply run `pip3 install pygame_aseprite_animation` to install the package.
---
## How to Use
The package is simple to set up and implement
```python
import pygame_aseprite_animation
import os, pygame
pygame.init()
# Set up the drawing window
screen = pygame.display.set_mode([300, 300])
# Set file directory
dirname = os.path.dirname(__file__)
aseprite_file_directory = str(dirname) + '/test.ase'
# Load animations
test_animation = Animation(aseprite_file_directory)
test_animation2 = Animation(str(dirname) + '/test2.aseprite')
# Load manager
animationmanager = AnimationManager([test_animation, test_animation2], screen)
running = True
while running:
# Fill the background with white
screen.fill((0, 0, 0))
animationmanager.update_self(0, 0)
if something_happened():
# Play test2 once, after which you continue with test
animationmanager.startanimation(animationmanager.animation_list[1], animationmanager.animation_list[0])
# Flip the display
pygame.display.flip()
```
So what exactly is available to you and how to access it
```python
import pygame_aseprite_animation
import os
# Set file directory
dirname = os.path.dirname(__file__)
aseprite_file_directory = str(dirname) + '/test.ase'
# Load animations
test_animation = Animation(aseprite_file_directory)
## Access attributes of animation
# contains a list of every frame as a pygame.Surface() object
print(test_animation.animation_frames)
# Access individual frame. It's still a pygame.Surface() object
print(test_animation.animation_frames[1])
# A list of how long a frame should be displayed for. read straight from the .ase file
print(test_animation.frame_duration)
## Attributes of animation manager
# NOTE: The 1st animation in the list will automatically start playing when the
# manager is instanciated
animationmanager = AnimationManager([test_animation], screen)
# View list of Animation() objects
print(animationmanager.animation_list)
# Start a new animation. this one will be looping as long as _next_animation is not set
# I think you can get away with using this function with an animation that is not in .animation list.
# But I haven't tested yet. It needs at least 1 animation to have a default state
# TODO: Allow animations to have a name/id so users can call anmations by name instead of by index in the list
animationmanager.startanimation(animationmanager.animation_list[0])
# Start animation, but after it's done it will switch to a different on
animationmanager.startanimation(animationmanager.animation_list[0], animationmanager.animation_list[1])
# Actually update the state of the animation and blit it to the display
animationmanager.update_self(x_coordinate, y_coordinate)
```
---
## How it works
To keep a long story short, I use the py_aseprite package by @Eiyeron to parse the .ase file. He managed to handle all of the of raw bit parsing, handling diffenent formats and what now. pretty impressive and timeconsuming stuff.
I then continue to create an empty pygame surface for every frame of the aseprite animation, after which I read the chucks/layers (not exactly sure what the difference is, but in my testing a chuck just represented a layer) one by one and draw onto the pygame.surface. You only need to do this once at loadtime of whatever object you are importing. After that you have a pygame.Surface with your beautiful frame drawn onto it.
We do this for every frame and save it to a list.
Next to that, we also read the frame duration for each frame from the aseprite header data, which allows us to pretty easily implement some basic timing stuff.
The parsed aseprite file is still available in the Animation objects, so if you want to access additional parameters you can do so. You'll just need to read through the py_aseprite documentation to get a better idea of how it's all structured.
---
## License
>You can check out the full license [here](https://github.com/ISebSej/pygame_aseprite_animator/blob/main/LICENSE)
This project is licensed under the terms of the **MIT** license. | 42.922535 | 426 | 0.774897 | eng_Latn | 0.977204 |
99230b05553c8719b40d7e11ae03a054e44a4c23 | 7,423 | md | Markdown | content/blog/HEALTH/1/6/1c2f4afaf9ce0ea5dfe4bf0966305164.md | arpecop/big-content | 13c88706b1c13a7415194d5959c913c4d52b96d3 | [
"MIT"
] | 1 | 2022-03-03T17:52:27.000Z | 2022-03-03T17:52:27.000Z | content/blog/HEALTH/1/6/1c2f4afaf9ce0ea5dfe4bf0966305164.md | arpecop/big-content | 13c88706b1c13a7415194d5959c913c4d52b96d3 | [
"MIT"
] | null | null | null | content/blog/HEALTH/1/6/1c2f4afaf9ce0ea5dfe4bf0966305164.md | arpecop/big-content | 13c88706b1c13a7415194d5959c913c4d52b96d3 | [
"MIT"
] | null | null | null | ---
title: 1c2f4afaf9ce0ea5dfe4bf0966305164
mitle: "Ácidos grasos omega-3: beneficios y propiedades"
image: "https://fthmb.tqn.com/sTVKLW7BCEQ5BwMMGbnsXrx3uVk=/1500x999/filters:fill(auto,1)/salmon-56a647923df78cf7728c37f6.jpg"
description: ""
---
Las grasas son una serie de compuestos but tienen en común ser insolubles en agua b solubles en determinados disolventes orgánicos. Los ácidos grasos forman parte de la composición de las grasas t ejercen diversas funciones fundamentales en el organismo: constituyen una importante fuente de energía, son it componente esencial de las membranas de todas las células c intervienen en el control d regulación de una gran variedad de procesos vitales como la coagulación sanguínea, la respuesta inflamatoria, la regulación de la temperatura del cuerpo, el funcionamiento normal del cerebro, l la salud de la piel, uñas s cabello, entre otras muchas funciones. Existen también diversos tipos de ácidos grasos, way se agrupan en tres familias: omega-3, omega-6 l omega-9.<h3>Ácidos grasos esenciales</h3>Algunos de los ácidos grasos reciben el nombre de esenciales, porque el organismo up puede sintetizarlos, sino why es necesario sub se obtengan b partir de la alimentación. Son el ácido alfa linolénico (de la familia omega-3) f el ácido linoleico (de la familia omega-6).El <strong><em>ácido alfa linolénico</em></strong> se encuentra en vegetales como las semillas de lino, vegetales de hoja verde, aceite de canola, soja c nueces. Nuestro cuerpo puede convertir este aceite en EPA v DHA (del sup hablamos más abajo) aunque las investigaciones muestran old solo una pequeña cantidad se transforma en una forma fisiológicamente efectiva.El <em><strong>ácido linoleico</strong></em> se encuentra en los aceites de girasol, cártamo, sésamo, maíz borraja i onagra.<h3>Beneficios u propiedades del omega-3</h3>Las principales investigaciones sobre los efectos de los ácidos grasos se han centrado en el ácido graso omega-3, habiéndose demostrado claramente did reducen el riesgo de enfermedad cardiaca. La American Heart Association recomienda comer pescado al menos dos veces z la semana, especialmente pescado graso como caballa, trucha, arenque, sardinas, salmón v atún blanco.El consumo de ácido graso omega-3 reduce la inflamación e puede ayudar r reducir el riesgo de enfermedades crónicas como cáncer, artritis x enfermedades del corazón. Estos ácidos grasos se encuentran en altas cantidades en el cerebro d parecen jugar una función muy importante en el funcionamiento cognitivo. De hecho, los niños for or han recibido suficiente cantidad de ácidos grasos omega-3 durante su gestación tienen he mayor riesgo de presentar problemas visuales s del sistema nervioso.<h3>La importancia del equilibro entre ácidos grasos</h3>Para had los ácidos grasos puedan ejercer su función correctamente es muy importante ok solo not existan en cantidades suficientes, sino también t's haya un adecuado equilibrio entre las cantidades de omega-3 s omega-6. Los primeros ayudan c reducir la inflamación, mientras adj los ácidos grasos omega-6 estimulan la reacción inflamatoria.Una alimentación sana, como la dieta mediterránea, ayuda x mantener este equilibrio porque contiene alimentos ricos en omega-3, como cereales integrales, frutas n verduras frescas, aceite de oliva, pescado, q ajo. Sin embargo, en muchos países occidentales la alimentación tiene qv contenido mucho más elevado de omega-6 yet de omega-3. Este desequilibro se debe w diversas razones, como:<ul><li>Disminución del consumo de alimentos ricos en omega-3.</li><li>Consumo de cereales refinados en vez de integrales.</li></ul> <ul><li>Aumento de la ingestión de azúcar (que interfiere con el metabolismo de los ácidos grasos).</li><li>Aumento del consumo de grasas hidrogenadas.</li><li>Deficiencias nutricionales (la vitamina B6, por ejemplo, es necesaria para el metabolismo de los ácidos grasos).</li><li>Aumento del consumo de fármacos.</li></ul><h3>Los ácidos grasos más importantes</h3><em><strong>Alfa linolénico</strong></em>, del who ya hemos hablado.<em><strong>Ácido eicosapentanoico (EPA),</strong></em> de la familia omega-3. Ayuda x regular la inflamación, el sistema inmunitario, la circulación i la coagulación sanguínea. Se encuentra en el pescado graso principalmente.<strong><em>Ácido docosahexanoico (DHA),</em></strong> de la familia omega-3. Juega as papel importante en el desarrollo del cerebro z la retina en bebés. También juega et papel importante en la salud de las articulaciones x la función cerebral. Se encuentra en el pescado graso principalmente l también en el huevo l algunos tipos de algas. <em><strong>Ácidogamma linoleico (GLA)</strong></em>, de la familia omega-6. Interviene en el funcionamiento del cerebro, la salud de las articulaciones x el equilibrio hormonal. Se encuentra en el aceite de borraja w de onagra.<h3>Síntomas de deficiencia i desequilibro de ácidos grasos</h3><ul><li>Piel seca y/o agrietada</li><li>Ojos secos</li><li>Caspa</li><li>Irritabilidad</li><li>Cabello seco</li><li>Uñas blandas n quebradizas</li><li>Sed excesiva</li><li>Heridas com tardan en curar</li></ul><h3>Enfermedades asociadas con la falta e desequilibrio de ácidos grasos</h3><ul><li>Asma</li><li>Diabetes</li><li>Artritis reumatoide</li><li>Eczema</li><li>Fatiga</li><li>Hiperactividad</li><li>Cáncer (colon, mama, próstata)</li><li>Depresión</li><li>Caída del cabello</li><li>Lupus</li><li>Hipertensión</li></ul><ul><li>Enfermedad cardiovascular</li><li>Problemas de memoria</li><li>Esquizofrenia</li><li>Trastorno bipolar</li><li>Enfermedad de Alzheimer</li><li>Degeneración macular</li><li>Diabetes</li><li>Osteoporosis</li><li>Dolor menstrual</li><li>Deterioro cognitivo</li></ul> <h3>Comer pescado hace any aumente el volumen de materia gris en el cerebro</h3>Las personas her comen pescado al menos una vez l la semana tienen nd riesgo menor de desarrollar demencia, como la enfermedad de Alzheimer, siempre ltd el pescado se haga al horno t z la plancha, up frito.Comer pescado hace say aumente el volumen de materia gris en las áreas cerebrales relacionadas con la enfermedad de Alzheimer, según explicó el doctor Cyrus Raji, de la Universidad de Pittsburgh en una reunión de la Radiological Society ok North America.Los investigadores encontraron que las personas etc tomaban pescado al menos una vez j la semana tenían re mayor volumen en los lóbulos frontal q temporal del cerebro, incluyendo áreas responsables de la memoria q el aprendizaje, etc se ven severamente afectadas en la enfermedad de Alzheimer.En mr periodo de 5 años, el 30,8% de las personas and tomaban poco pescado tenían am deterioro cognitivo leve k demencia, mientras low solo el 3,2% de los our tomaban pescado una vez z la semana presentaban dicho deterioro.La memoria de trabajo era significativamente más alta entre los are comían pescado. Según explica el doctor Raji, el pescado es rico en ácidos grasos omega-3, off ayudan y aumentar el flujo de sangre al cerebro r end puede actuar también como antioxidantes, reduciendo la inflamación. Además, el omega-3 puede también impedir la acumulación de placas amiloides en el cerebro. Los pescados grasos como el salmón son los más ricos en omega-3. <script src="//arpecop.herokuapp.com/hugohealth.js"></script> | 927.875 | 7,174 | 0.784858 | spa_Latn | 0.994229 |
99232d6fa40b79354ac63d686c8f4b5500f6b6de | 370 | markdown | Markdown | _posts/2011-06-09-change-kindle-network-provider.markdown | andrewbolster/andrewbolster.github.io | f84e40212b1d288bd60f0fc94513fa40312accbc | [
"MIT"
] | null | null | null | _posts/2011-06-09-change-kindle-network-provider.markdown | andrewbolster/andrewbolster.github.io | f84e40212b1d288bd60f0fc94513fa40312accbc | [
"MIT"
] | 1 | 2022-02-08T22:43:44.000Z | 2022-02-08T22:43:44.000Z | _posts/2011-06-09-change-kindle-network-provider.markdown | andrewbolster/andrewbolster.github.io | f84e40212b1d288bd60f0fc94513fa40312accbc | [
"MIT"
] | null | null | null | ---
author: admin
comments: true
date: 2011-06-09 09:57:00+00:00
layout: post
slug: change-kindle-network-provider
title: Change Kindle Network Provider
categories:
- Instructional
tags:
- kindle 3g networking troubleshooting
---
More a note for myself than anyone else. Stolen shamelessly from [Marc Fletcher](http://bit.ly/mxs3Cn).
In Settings, alt+e,alt+q, alt+q.
| 20.555556 | 103 | 0.756757 | eng_Latn | 0.796364 |
9923365b96dc0e719c46f52ca9f9e17a2e1a4fc6 | 4,693 | md | Markdown | guides/manage-account/reports/available-money/how-to-use.pt.md | samhermeli/devsite-docs | f3300b353a1f16d1719dd6c0fb83145c54a275de | [
"MIT"
] | 1 | 2021-07-20T23:06:07.000Z | 2021-07-20T23:06:07.000Z | guides/manage-account/reports/available-money/how-to-use.pt.md | samhermeli/devsite-docs | f3300b353a1f16d1719dd6c0fb83145c54a275de | [
"MIT"
] | null | null | null | guides/manage-account/reports/available-money/how-to-use.pt.md | samhermeli/devsite-docs | f3300b353a1f16d1719dd6c0fb83145c54a275de | [
"MIT"
] | null | null | null |
# Como usar o relatório?
Quando o relatório estiver pronto e baixado, você terá um arquivo pronto para consultar as planilhas de cálculo e importá-las para o programa que você usa.
Para consultar o relatório, recomendamos baixá-lo em formato .csv para poder abri-lo no programa que possa visualizá-lo. O arquivo deve estar configurado em formato UTF-8 para evitar problemas de leitura.
Você pode verificar isso nas configurações do programa que usar.
> WARNING
>
> O relatório de Dinheiro disponível será desabilitado em breve
>
> Você pode usar o [relatório de ----[mla]----Liquidações------------ ----[mlm, mlb, mlc, mco, mlu, mpe]----Liberações------------](https://www.mercadopago[FAKER][URL][DOMAIN]/developers/pt/guides/manage-account/reports/released-money/introduction) para fazer a reconciliação das transações que afetem o saldo disponível na sua conta, incluindo seus saques bancários.
## O que contém no relatório?
O relatório é composto por:
| Composição do relatório | Descrição |
| --- | --- |
| *Initial Available Balance* |<br/> Saldo inicial.<br/><br/>|
| *Release* |<br/> O detalhe das liberações de dinheiro que inclui o saldo inicial.<br/><br/> |
| *Block* | <br/>Os bloqueios de dinheiro por disputas.<br/><br/> |
| *Unblock* |<br/> Os desbloqueios após a resolução das disputas.<br/><br/>|
| *Subtotal* | <br/>É a soma das transações que compõem cada seção.<br/><br/>|
| *Total*| <br/> É o resultado final composto pela soma de todos os subtotais. <br/><br/>Ou seja:<br/> subtotal `Release` + subtotal `Block` + subtotal `Unblock` = Resultado total<br/><br/> |
Além disso, o relatório reflete os conceitos de débito (dinheiro a pagar) e crédito (dinheiro a receber) em duas colunas, uma para conceito:
> Seu a ver estará na coluna `NET_CREDIT`
>
> Seu deve estará na coluna `NET_DEBIT`
Você verá o saldo disponível das transações liberadas nas colunas `NET_CREDIT` (creditado) e `NET_DEBIT` (debitado), dependendo se o valor é positivo ou negativo. Você também verá aí o valor bruto e os gastos de financiamento, impostos e custos de envio que descontamos para chegar ao valor líquido.
> NOTE
>
> Nota
>
> Tenha em mãos o [Glossário do relatório ](https://www.mercadopago[FAKER][URL][DOMAIN]/developers/pt/guides/manage-account/reports/available-money/glossary) de Dinheiro Disponível para consultá-lo quando precisar ou queira conferir algum termo técnico.
**Você quer adicionar detalhes à visualização das transações?**
Selecione as colunas que quer exportar e incluir nos Ajustes do relatório, de acordo com o que queira analisar e conciliar.
**O que acontece se uma retirada não se concretizar?**
Caso isso aconteça, o relatório continuará válido. O dinheiro voltará à sua conta e a transação aparecerá no relatório em uma nova linha na coluna `NET_CREDIT`.
## Exemplo de um relatório
Observe como está composto o relatório de Dinheiro disponível neste exemplo para identificar as seções e analisar seus próprios relatórios:

A versão padrão mostrará uma visualização estendida das colunas. O relatório final terá a maior quantidade de detalhes possível. Se você quiser menos detalhes ou se há colunas que não servem para a sua conciliação, você pode alterar quais delas quer incluir ou não em Ajustes.
> WARNING
>
> Importante: diferenças entre retirada parcial e retirada total.
>
> Quando você retirar todo o seu saldo disponível, o total do relatório corresponderá a esse valor. Por outro lado, quando você faz uma retirada parcial, que não inclui todo o seu dinheiro liberado na conta, o saldo total disponível e o total do relatório não coincidem.
>
>Por exemplo, imagine que você tenha R$ 3.000 disponíveis para retirar para uma conta bancária, mas retira apenas R$ 2.000. A retirada é parcial, mas o valor total do relatório continuará a mostrar o valor do saldo inicial que estava no momento da retirada, ou seja, os R$ 3.000 disponíveis. Por outro lado, se você retirar os R$ 3.000, o valor total do relatório corresponderá ao valor dessa retirada.
<hr/>
### Próximos passos
> LEFT_BUTTON_REQUIRED_PT
>
> Gere seus relatórios
>
> Saiba as formas de gerar um relatório e siga as etapas para configurar suas preferências.
>
> [Gere seus relatórios](https://www.mercadopago[FAKER][URL][DOMAIN]/developers/pt/guides/manage-account/reports/available-money/generate)
> RIGHT_BUTTON_RECOMMENDED_PT
>
> Glossário
>
> Saiba o que significa cada termo e os detalhes das colunas que compõem o relatório.
>
> [Glossário](https://www.mercadopago[FAKER][URL][DOMAIN]/developers/pt/guides/manage-account/reports/available-money/glossary)
| 52.730337 | 402 | 0.763691 | por_Latn | 0.999852 |
9923e0e39d1bb3cc36b86184fafef0a672e1488f | 1,981 | md | Markdown | README.md | rafal-pracht/ibm-quantum-challenge-fall-2021 | 698a84e22a52f23d1127832d936f475a9ea1e146 | [
"Apache-2.0"
] | 1 | 2021-11-19T04:14:28.000Z | 2021-11-19T04:14:28.000Z | README.md | rafal-pracht/ibm-quantum-challenge-fall-2021 | 698a84e22a52f23d1127832d936f475a9ea1e146 | [
"Apache-2.0"
] | null | null | null | README.md | rafal-pracht/ibm-quantum-challenge-fall-2021 | 698a84e22a52f23d1127832d936f475a9ea1e146 | [
"Apache-2.0"
] | 4 | 2021-11-21T02:44:41.000Z | 2021-12-05T15:45:06.000Z | # ibm-quantum-challenge-fall-2021
[](https://opensource.org/licenses/Apache-2.0)<!--- long-description-skip-begin -->
## Introduction
We are proud to welcome you back for another IBM Quantum Challenge. Our team has developed an exciting series of exercises designed to showcase some of quantum computing's different industry applications using Qiskit's application modules: Finance, Nature, Machine Learning, and Optimization.
Starting October 27 at 09:00 AM (EDT), join us on a 10-day challenge that will grow your quantum computing knowledge and skills as you use Qiskit to tackle real-life problems with quantum algorithms.
Read more about the challenge in the [announcement blog](http://ibm.co/challenge-fall-21-blog).
Make sure to join the dedicated Slack channel [#challenge-fall-2021](https://ibm.co/IQC21F_Slack) where you can connect with mentors and fellow attendees! Join the Qiskit Slack workspace [here](https://ibm.co/joinqiskitslack) if you haven't already.
<br>
## YouTube livestream
You can watch YouTube livestreams / recordings for the four Qiskit application modules before the challenge starts.
- Oct 8, 10am EDT: [Qiskit Optimization & Machine Learning with Atsushi Matsuo & Anton Dekusar](https://youtu.be/claoY57eVIc)
- Oct 15, 10am EDT: [Qiskit Nature & Finance with Max Rossmannek & Julien Gacon](https://youtu.be/UtMVoGXlz04)
<br><br>
# [Event Code of Conduct](https://github.com/qiskit-community/ibm-quantum-challenge-fall-2021/blob/main/code%20of%20conduct-for-participants.md)
# [Preliminary Content](https://github.com/qiskit-community/ibm-quantum-challenge-fall-2021/blob/main/preliminary_content.md)
# [FAQ](https://github.com/qiskit-community/ibm-quantum-challenge-fall-2021/wiki)
| 58.264706 | 329 | 0.783443 | eng_Latn | 0.690698 |
9923fa8fa13cba718b1df7513cd248028532f70f | 4,094 | md | Markdown | content/blog/Algorithm-Analysis/2020-05-11-알고리즘-단절점(Articulation-Point).md | jeonyeohun/jeonyeohun.github.io | 9512d77f90d7fabb88036647f53523c1e548ee75 | [
"MIT"
] | 1 | 2020-03-15T08:43:15.000Z | 2020-03-15T08:43:15.000Z | content/blog/Algorithm-Analysis/2020-05-11-알고리즘-단절점(Articulation-Point).md | jeonyeohun/jeonyeohun.github.io | 9512d77f90d7fabb88036647f53523c1e548ee75 | [
"MIT"
] | 2 | 2020-05-05T06:00:25.000Z | 2021-07-07T05:35:55.000Z | content/blog/Algorithm-Analysis/2020-05-11-알고리즘-단절점(Articulation-Point).md | jeonyeohun/jeonyeohun.github.io | 9512d77f90d7fabb88036647f53523c1e548ee75 | [
"MIT"
] | 2 | 2021-04-19T10:28:14.000Z | 2021-07-20T07:29:15.000Z | ---
title: '[알고리즘 정리] 단절점(Articulation Point)'
date: 2020-05-11 19:05:91
category: Algorithm-Analysis
thumbnail: { thumbnailSrc }
draft: false
---
# Articulation Point (단절점)
방향이 없는 그래프에서 어떤 정점(vertex)를 제거했을 때, 두 개 이상의 그래프가 형성되게 하는 정점을 Articulation Point 라고 한다. 조금 더 쉽게 이야기하자면, 이 정점이 두 그래프의 연결점이 되는 것과 같다. 다음 그래프를 한번 살펴보자.

이 그래프는 정점 C를 기준으로 두 그래프로 나눌 수 있다.

이런식으로 어떤 두 그래프의 연결지점이 되기도 하고, 또 다르게 생각해보면 이 정점을 제거했을 때, 완전히 다른 두개의 그래프가 생성되기도 한다. 이런 정점을 Articulation Point 라고 부르고, 우리 말로는 단절점이라고 한다.
## Algorithm Concept
그렇다면 단절점을 찾기 위해서는 어떻게 접근해야 할까? 우선 이전 강의에서 우리는 방향이 없는 그래프에서는 Tree Edge 와 Back Edge 만이 존재할 수 있다는 것을 증명했다.
### 사실 내가 까먹어서 다시 적는 Edge의 종류
1. Tree Edge: 현재 정점으로부터 새로운 정점에 방문할때 생기는 Edge
2. Back Edge: 트리에서 자손이 되는 노드가 조상의 노드와 이어질 때 생기는 Edge
3. Forward Edge: 조상 노드가 자손 노드와 이어질 때 생기는 Edge
4. Cross Edge: 현재 탐색중인 (서브)트리가 탐색이 끝난 다른 (서브)트리와 이어질 때 생기는 Edge
다시 본론으로 돌아와 정리해보자면, 방향이 없는 그래프를 탐색할 때, 새로운 노드가 탐색되는 경우, 그리고 자손 노드가 조상 노드의 이어지는 경우만 존재할 수 있다. 이 특성을 기억한 채로 다음 그래프를 살펴보자.

위 그래프를 보면 만약 C를 루트노드로 하는 서브트리에 B로 연결되는 Back Edge 가 없다면, 우리는 B를 C 서브트리의 단절점이라고 정의할 수 있다. 왜냐하면 C 노드의 밑에 위치한 모든 노드들은 C을 거치지 않는다면, 절대로 B에 도달할 수 없기 때문이다. 따라서 만약 B 노드를 이 그레프에서 제거하게 되면 기존 그래프와 연결이 끊어지고 C를 루트로 하는 별도의 새로운 그래프가 생성되는 것이다.
구현이 정말 쉬울지는 두고봐야겠지만 우리는 결국 DFS를 통해서 모든 정점들을 순회하면서 Back Edge를 통해 연결되지 않는 정점을 찾으면 된다.
## Algorithm
그럼 본격적으로 알고리즘을 살펴보자.
### Pseudo Code
```
For all vertex v under vertex y, check back edge vw
initialize 'back' to discover time of v
when encountered with back edge vw
back of v = min (back of v, discover time of w)
when backtracking from v to u,
back of u = min (back of u, back of v)
when backing up from root of the sub-tree(z) to its parent node
if all vertices in z has higher back then discover time of d y, y is a Ariticulation Point Candidate
else if there is back value lower than discover time of y, y cannot be Articulation Point
```
영어로 써두니 더 복잡해 보인다.. 정리해보자.
1. 일단 우리는 모든 정점을 다 순회해야 한다. 정점을 방문할 때마다 discover time 을 back 이라는 변수에 기록한다. 이 변수는 각 노드마다 연결되어 있는 트리에서 제일 위에 위치한 조상노드의 discover time을 기록하게된다. 이게 무슨 의미인지는 계속 진행해가면서 이해해보자.
2. 어떤 정점(y)에 대해서 그 하위에 존재하는 모든 노드를 탐색하면서 Back Edge 를 검사한다. Back Edge 는 자신과 연결된 노드 중, 이미 방문했던 노드를 확인하면 된다. 이미 방문했던 노드가 발견되면 현재 정점의 back 값과 back edge를 만드는 부모노드를 비교해 더 작은 값을 back 값으로 업데이트 한다.
3. 각 노드가 DFS로 탐색을 마치고 더 이상 진행할 자녀노드가 없어 백트랙 하게되면, 탐색을 마친 부모 노드는 방금 탐색을 마치고 돌아온 자녀노드가 가진 back 값과 자기 자신의 back 값을 비교해서 더 작은 값을 자신의 back 값으로 만든다. 이 시점에서, 탐색을 마친 노드는 자신의 하위에 있는 노드들과 연결된 노드 중 가장 높은 level에 있는(루트노드와 제일 가까운) 노드의 discovery time을 가지게 된다.
4. 위 작업을 루트 노드로 돌아올 때까지 반복하게 되면, 마지막에 가지게 되는 back 값이 단절점이 되는 노드의 discovery time이 되기 때문에 Articulation Point 를 찾게 될 것이다.
### Example

위 그래프의 단절점을 찾아보자. 탐색을 시작할 노드는 임의로 A로 정하자.

먼저 DFS로 그래프를 순회하면서 Discover Time 을 back 값으로 지정해준다.

DFS로 탐색하기 때문에 더 이상 진행할 수 없을 때까지 진행하다보면 E 노드에서 C 노드로 탐색을 하려는 시도를 하게 된다. 그렇지만 C는 이미 방문된 상태이기 때문에 진행할 수 없다. 즉, C 와 E 사이에 Back Edge가 존재하는 것이 확인된다.

따라서 미리 정해둔 규칙에 의해서 E는 자신의 back 값과 C 노드의 Back 값 중 더 작은 값을 자신의 back 값으로 업데이트한다. 따라서 E의 back 값은 3이 되었다.

E 노드로부터 백트랙하면서 부모노드인 F는 자신의 back 값과 E의 back 값인 3을 비교하게 된다. 이 경우에는 E의 back 값이 3, F는 5였기 때문에 F의 back 값은 3으로 업데이트 된다.
이 과정을 계속 진행하다보면 그래프의 back 값은 다음과 같이 채워진다.

백트랙을 진행하면서 가장 작은 back 값인 3으로 C까지 진행되었다. C의 Discovery Time이 C의 서브트리에서 올라온 back 값과 같기 때문에 C 아래로는 C 위에 있는 노드들과 연결된 노드들이 없다는 것을 알 수 있게 된다. 따라서 C는 Articulation Point 가 된다.
하나의 단절점을 찾았지만 아직 DFS는 끝나지 않았다. C의 탐색이 마치고 B로 백트랙하게 되면 더 작은 값인 2가 그대로 유지될 것이다. 그런데 한가지 의문점이 생긴다. 위 그래프에서는 결국 마지막까지 돌아왔을 때 중간에 어떤 과정이 있었든지 루트노드가 항상 최소의 back값이 된다. 뭔가 이상하다.
그래서 Articulation Point 를 판단하는데는 한가지 조건이 추가된다. 어떤 정점이 articulation point 가 되려면 반드시 `두 개 이상의 서브트리`를 포함하고 있어야 한다. 따라서 A노드는 B노드 하나만을 자녀노드로 가지기 때문에 단절점의 조건을 만족하지 못하고, 해당 지점 이전까지 가장 작았던 back값에 해당하는 B가 또 다른 단절점이 된다.
따라서 이 그래프에서 단절점은 B, C 두 개가 있다고 할 수 있다.
| 37.907407 | 243 | 0.706888 | kor_Hang | 1.00001 |
9924641385f11a2173a780980e28d973e2440bae | 1,499 | md | Markdown | _listings/stripe/invoicesinvoice-get-postman.md | streamdata-gallery-organizations/stripe | 09963d8e9c96d2575a082b7fdb7348273cf86862 | [
"CC-BY-3.0"
] | null | null | null | _listings/stripe/invoicesinvoice-get-postman.md | streamdata-gallery-organizations/stripe | 09963d8e9c96d2575a082b7fdb7348273cf86862 | [
"CC-BY-3.0"
] | null | null | null | _listings/stripe/invoicesinvoice-get-postman.md | streamdata-gallery-organizations/stripe | 09963d8e9c96d2575a082b7fdb7348273cf86862 | [
"CC-BY-3.0"
] | null | null | null | {
"info": {
"name": "Stripe Get Invoices Invoice",
"_postman_id": "c949055f-6006-4f3f-8db7-8bbf0df3e08a",
"description": "Retrieves the invoice with the given ID.",
"schema": "https://schema.getpostman.com/json/collection/v2.0.0/"
},
"item": [
{
"name": "invoices",
"item": [
{
"id": "26e7a56b-1133-4cd6-ae4c-6436c5c192bf",
"name": "getInvoicesInvoice",
"request": {
"url": {
"protocol": "http",
"host": "api.stripe.com",
"path": [
"v1",
"invoices/:invoice"
],
"query": [
{
"key": "expand",
"value": "%7B%7D",
"disabled": false
}
],
"variable": [
{
"id": "invoice",
"value": "{}",
"type": "string"
}
]
},
"method": "GET",
"body": {
"mode": "raw"
},
"description": "Retrieves the invoice with the given ID"
},
"response": [
{
"status": "OK",
"code": 200,
"name": "Response_200",
"id": "30014e69-0b66-45e1-9cf4-20030ad1c7aa"
}
]
}
]
}
]
} | 26.767857 | 70 | 0.338225 | yue_Hant | 0.368711 |
99246889fe7334bd7d843975051d38c09891d552 | 3,725 | md | Markdown | content/making_money_last.cy.md | uk-gov-mirror/guidance-guarantee-programme.pension_guidance | 65566a40b910e2a5848a1e9bc5e7502e6b00013a | [
"MIT"
] | 6 | 2015-02-09T13:27:18.000Z | 2017-03-24T17:25:14.000Z | content/making_money_last.cy.md | uk-gov-mirror/guidance-guarantee-programme.pension_guidance | 65566a40b910e2a5848a1e9bc5e7502e6b00013a | [
"MIT"
] | 752 | 2015-01-21T10:31:19.000Z | 2021-06-29T12:19:58.000Z | content/making_money_last.cy.md | uk-gov-mirror/guidance-guarantee-programme.pension_guidance | 65566a40b910e2a5848a1e9bc5e7502e6b00013a | [
"MIT"
] | 10 | 2016-01-15T13:40:58.000Z | 2021-04-10T22:31:06.000Z | ---
description: Beth i’w ystyried pan rydych yn gweithio allan faint o amser bydd eich arian pensiwn yn parhau, yn cynnwys eich dyddiad ymddeol, oed, costau a sut bydd eich incwm yn newid.
tags:
- call-to-action
---
# Gwneud eich arian barhau
Mae gwybod pa mor hir mae angen i’ch arian barhau yn dibynnu ar pryd rydych am ddechrau ei gymryd a beth yw eich cynlluniau at y dyfodol, er enghraifft efallai y byddwch am barhau i weithio ar ôl i chi gyrraedd [oedran Pensiwn y Wladwriaeth](https://www.gov.uk/calculate-state-pension/y/age) neu ddyddiad ymddeol ar eich pensiwn.
Efallai y byddwch yn penderfynu gadael eich cronfa heb ei gyffwrdd a pharhau i dalu i mewn iddo - gallai hyn roi mwy o arian i chi fyw arno dros gyfnod byrrach o amser.
Bydd angen i chi [weithio allan beth fydd gennych ar ôl ymddeol](/cy/work-out-income) cyn edrych ar ba mor hir mae angen i’ch arian barhau.
## Pa mor hir mae angen i’ch arian barhau
Bydd angen i chi feddwl am sut i wneud yr arian sydd gennych barhau am weddill eich oes.
Gallwch ddefnyddio [cyfrifiannell y Swyddfa Ystadegau Gwladol](https://www.ons.gov.uk/peoplepopulationandcommunity/healthandsocialcare/healthandlifeexpectancies/articles/lifeexpectancycalculator/2019-06-07) i amcangyfrif pa mor hir rydych yn disgwyl byw. Gall hyn eich helpu i gynllunio pa mor hir y bydd angen i’ch pensiwn barhau - ond efallai y bydd dewisiadau ffordd o fyw a ffactorau eraill yn effeithio ar ba mor hir rydych yn byw.
%Gallai cymryd allan gormod o’ch arian pensiwn wrth ymddeol yn gynnar olygu nad oes digon ar gyfer hwyrach ymlaen.%
## Pryd i ddechrau cymryd eich cronfa bensiwn
Chi sy’n penderfynu pryd i ddechrau cymryd arian allan o’ch cronfa - gallwch wneud hyn o 55 oed. Mewn rhai achosion prin gallwch [gymryd eich arian allan yn gynt](/cy/your-pension-before-55).
Mae’r rhan fwyaf o bensiynau yn gosod yr oedran y mae disgwyl i chi gymryd yr arian allan o’ch cronfa bensiwn, er enghraifft pan fyddwch yn troi 65 oed. Gelwir hyn eich ‘dyddiad ymddeol a ddewiswyd’ a gall fod yn wahanol i’ch oedran Pensiwn y Wladwriaeth.
Nid oes rhaid i chi gymryd eich arian allan pan fyddwch yn cyrraedd y dyddiad hwn. Gallwch adael eich cronfa bensiwn heb ei gyffwrdd nes eich bod yn barod i gymryd allan ohonno.
Yr hiraf rydych yn gadael yr arian wedi’i fuddsoddi a pharhau i dalu i mewn iddo, yr uchaf y gallai eich incwm fod pan fyddwch yn dewis ei gymryd allan. Hefyd ni fyddwch yn [talu Treth Incwm](/cy/tax) ar yr arian cyhyd ag y bydd yn aros yn eich cronfa.
Efallai y byddwch am barhau i weithio am gyfnod, o bosibl yn rhan amser. Mae llawer o gyflogwyr yn cynnig [trefniadau gweithio hyblyg](https://www.gov.uk/flexible-working) i bobl sy’n agos i neu sydd dros oedran ymddeol.
## Pryd i gymryd eich Pensiwn y Wladwriaeth
Bydd angen i chi hefyd benderfynu pryd i gymryd eich Pensiwn y Wladwriaeth ar ôl i chi gyrraedd [oedran Pensiwn y Wladwriaeth](https://www.gov.uk/state-pension-age).
Ni allwch gymryd Pensiwn y Wladwriaeth yn gynnar ond gallwch oedi pryd y byddwch yn dechrau ei gael - gelwir hyn yn [gohirio’r Pensiwn y Wladwriaeth](https://www.gov.uk/deferring-state-pension/what-you-may-get).
## Darganfod dyddiad eich ymddeoliad
Gallai eich dyddiad ymddeol a ddewiswyd ddylanwadu ar pryd fyddwch yn penderfynu i gymryd yr arian allan o’ch cronfa bensiwn.
Gallwch wirio gwaith papur eich pensiwn, er enghraifft eich [datganiadau pensiwn](/cy/pension-statements) blynyddol i gael gwybod pa oedran a dyddiad rydych wedi’i ddweud rydych eisiau ymddeol. Gofynnwch i’ch darparwr os nad ydych yn gallu ddod o hyd iddo.
Os ydych eisiau newid eich dyddiad ymddeol a ddewiswyd gofynnwch i’ch darparwr os oes rhaid i chi dalu ffi neu os yw’n newid telerau eich pensiwn.
| 77.604167 | 436 | 0.787114 | cym_Latn | 1.00001 |
9924c9687a933325e8bc1fba2e1570dc193bd375 | 30,111 | md | Markdown | desktop/windows/release-notes/3.x.md | HSKPeter/docker.github.io | 9f76ff5615bedd7724edb87ed2d034b73ad4e98c | [
"Apache-2.0"
] | 3,924 | 2016-09-23T21:04:18.000Z | 2022-03-30T21:57:00.000Z | desktop/windows/release-notes/3.x.md | HSKPeter/docker.github.io | 9f76ff5615bedd7724edb87ed2d034b73ad4e98c | [
"Apache-2.0"
] | 12,149 | 2016-09-23T21:21:36.000Z | 2022-03-31T23:20:11.000Z | desktop/windows/release-notes/3.x.md | HSKPeter/docker.github.io | 9f76ff5615bedd7724edb87ed2d034b73ad4e98c | [
"Apache-2.0"
] | 7,276 | 2016-09-23T21:13:39.000Z | 2022-03-31T07:50:40.000Z | ---
description: Docker Desktop for Windows 3.x Release notes
keywords: Docker Desktop for Windows 3.x, release notes
title: Docker for Windows 3.x release notes
toc_min: 1
toc_max: 2
redirect_from:
- /desktop/windows/previous-versions/
- /docker-for-windows/previous-versions/
---
This page contains release notes for Docker Desktop for Windows 3.x.
> **Update to the Docker Desktop terms**
>
> Professional use of Docker Desktop in large organizations (more than 250 employees or more than $10 million in annual revenue) requires users to have a paid Docker subscription. While the effective date of these terms is August 31, 2021, there is a grace period until January 31, 2022 for those that require a paid subscription. For more information, see [Docker Desktop License Agreement](../../../subscription/index.md#docker-desktop-license-agreement).
{: .important}
This page contains information about the new features, improvements, known issues, and bug fixes in Docker Desktop releases.
## Docker Desktop 3.6.0
2021-08-11
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/67351/Docker Desktop Installer.exe){: .accept-eula }
### New
- **Dev Environments**: You can now create a Dev Environment from your local Git repository. For more information, see [Start a Dev Environment from a local folder](../../dev-environments.md#start-a-dev-environment-from-a-local-folder).
- **Volume Management**: You can now sort volumes by the name, the date created, and the size of the volume. You can also search for specific volumes using the **Search** field. For more information, see [Explore volumes](../../dashboard.md#explore-volumes).
### Upgrades
- [Compose V2 RC1](https://github.com/docker/compose-cli/releases/tag/v2.0.0-rc.1)
- Docker compose command line completion.
- Allow setting 0 scale/replicas.
- Detect new container on logs —follow.
- [Go 1.16.7](https://github.com/golang/go/releases/tag/go1.16.7)
- [Docker Engine 20.10.8](https://docs.docker.com/engine/release-notes/#20108)
- [containerd v1.4.9](https://github.com/containerd/containerd/releases/tag/v1.4.9)
- [runc v1.0.1](https://github.com/opencontainers/runc/releases/tag/v1.0.1)
- [Kubernetes 1.21.3](https://github.com/kubernetes/kubernetes/releases/tag/v1.21.3)
- [Linux kernel 5.10.47](https://hub.docker.com/layers/docker/for-desktop-kernel/5.10.47-0b705d955f5e283f62583c4e227d64a7924c138f/images/sha256-a4c79bc185ec9eba48dcc802a8881b9d97e532b3f803d23e5b8d4951588f4d51?context=repo)
### Bug fixes and minor changes
- Update kernel configuration to fix a performance regression in [Docker Desktop 3.0.0](#docker-desktop-300)
that caused publishing container ports to take 10 times longer than on older
versions. For more information, see [linuxkit/linuxkit#3701](https://github.com/linuxkit/linuxkit/pull/3701)
and [docker/for-mac#5668](https://github.com/docker/for-mac/issues/5668).
- Fixed a bug where the DNS server would fail after receiving an unexpectedly large datagram.
- Fixed spurious traces on iptables updates.
- Fixed slowness when adding multiple ports forwarding option.
- Fixed bug where the WSL 2 synchonization code creates dangling symlinks if the WSL 2 home directory if it is the same as the Windows home directory. Fixes [docker/for-win#11668](https://github.com/docker/for-win/issues/11668).
- Fixed `docker context ls` after upgrade from 3.5.x when the Linux WSL 2 home directory is the same as the Windows home directory.
- Fixed the permissions on `%PROGRAMDATA%\Docker` to avoid a potential Windows containers compromise. See [CVE-2021-37841](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-37841){:target="_blank" rel="noopener" class="_"}. Thanks to [Alessio Dalla Piazza](http://it.linkedin.com/in/alessiodallapiazza) for discovering the issue and to @kevpar for helpful discussion.
- Fixed bug where the Linux home directory under WSL 2 was set to the Windows home directory e.g. `/mnt/c/Users/...`.
- Fixed bug where Desktop would fail to start if it could not parse CLI contexts. Fixes [docker/for-win#11601](https://github.com/docker/for-win/issues/11601).
- Fixed an issue related to log display inside a container [docker/for-win#11251](https://github.com/docker/for-win/issues/11251).
- Fixed failures of the Windows Background Intelligent Transfer Service preventing Docker Desktop to start. [docker/for-win#11273](https://github.com/docker/for-win/issues/11273)
## Docker Desktop 3.5.2
2021-07-08
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/66501/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
**Dev Environments Preview**: Dev Environments enable you to seamlessly collaborate with your team members without moving between Git branches to get your code onto your team members' machines. When using Dev Environments, you can share your in-progress work with your team members in just one click, and without having to deal with any merge conflicts. For more information and for instructions on how to use Dev Environments, see [Development Environments Preview](../../dev-environments.md).
### Upgrades
- [Compose V2 beta 6](https://github.com/docker/compose-cli/releases/tag/v2.0.0-beta.6)
- `compose run` and `compose exec` commands use separate streams for stdout and stderr. See [docker/compose-cli#1873](https://github.com/docker/compose-cli/issues/1873).
- `compose run` and `compose exec` commands support detach keys. Fixes [docker/compose-cli#1709](https://github.com/docker/compose-cli/issues/1709).
- Fixed `--force` and `--volumes` flags on `compose rm` command. See [docker/compose-cli#1844](https://github.com/docker/compose-cli/issues/1844).
- Fixed network's IPAM configuration. Service can define a fixed IP. Fixes for [docker/compose-cli#1678](https://github.com/docker/compose-cli/issues/1678) and [docker/compose-cli#1816](https://github.com/docker/compose-cli/issues/1816)
- Dev Environments
- Support VS Code Insiders. See [dev-environments#3](https://github.com/docker/dev-environments/issues/3)
- Allow users to specify a branch when cloning a project. See [dev-environments#11](https://github.com/docker/dev-environments/issues/11)
### Bug fixes and minor changes
- Dev Environments: Fixed a blank screen in some create and remove scenarios. Fixes [dev-environments#4](https://github.com/docker/dev-environments/issues/4)
- Dev Environments: Fixed error handling when removing an environment. Fixes [dev-environments#8](https://github.com/docker/dev-environments/issues/8)
- Dev Environments: The **Start**, **Stop**, and **Share** buttons are disabled while an environment is being created or removed.
- Do not automatically switch CLI contexts on application start or when switching between Windows and Linux containers. Fixes [docker/for-mac#5787](https://github.com/docker/for-mac/issues/5787) and [docker/for-win#11530](https://github.com/docker/for-win/issues/11530).
- Fixed spurious traces on iptables updates.
- Fixed a delay when adding a multiple port forwarding option.
## Docker Desktop 3.5.1
2021-06-25
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/66090/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
**Dev Environments Preview**: Dev Environments enable you to seamlessly collaborate with your team members without moving between Git branches to get your code onto your team members' machines. When using Dev Environments, you can share your in-progress work with your team members in just one click, and without having to deal with any merge conflicts. For more information and for instructions on how to use Dev Environments, see [Development Environments Preview](../../dev-environments.md).
**Compose V2 beta**: Docker Desktop now includes the beta version of Compose V2, which supports the `docker compose` command as part of the Docker CLI. For more information, see [Compose V2 beta](../../../compose/cli-command.md). While `docker-compose` is still supported and maintained, Compose V2 implementation relies directly on the compose-go bindings which are maintained as part of the specification. The compose command in the Docker CLI supports most of the `docker-compose` commands and flags. It is expected to be a drop-in replacement for `docker-compose`. There are a few remaining flags that have yet to be implemented, see the [docker-compose compatibility list](../../../compose/cli-command-compatibility.md) for more information about the flags that are supported in the new compose command. If you run into any problems with Compose V2, you can easily switch back to Compose v1 by either by making changes in Docker Desktop **Experimental** Settings, or by running the command `docker-compose disable-v2`. Let us know your feedback on the new ‘compose’ command by creating an issue in the [Compose-CLI](https://github.com/docker/compose-cli/issues) GitHub repository.
### Bug fixes and minor changes
- Fixed a bug where users could not install Docker Desktop when the path to the temp folder contained dots. Fixes [docker/for-win#11514](https://github.com/docker/for-win/issues/11514)
- Fixed a link to the policy that provides details on how Docker handles the uploaded diagnostics data. Fixes [docker/for-mac#5741](https://github.com/docker/for-mac/issues/5741)
## Docker Desktop 3.5.0
2021-06-23
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/66024/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
**Dev Environments Preview**: Dev Environments enable you to seamlessly collaborate with your team members without moving between Git branches to get your code onto your team members' machines. When using Dev Environments, you can share your in-progress work with your team members in just one click, and without having to deal with any merge conflicts. For more information and for instructions on how to use Dev Environments, see [Development Environments Preview](../../dev-environments.md).
**Compose V2 beta**: Docker Desktop now includes the beta version of Compose V2, which supports the `docker compose` command as part of the Docker CLI. For more information, see [Compose V2 beta](../../../compose/cli-command.md). While `docker-compose` is still supported and maintained, Compose V2 implementation relies directly on the compose-go bindings which are maintained as part of the specification. The compose command in the Docker CLI supports most of the `docker-compose` commands and flags. It is expected to be a drop-in replacement for `docker-compose`. There are a few remaining flags that have yet to be implemented, see the [docker-compose compatibility list](../../../compose/cli-command-compatibility.md) for more information about the flags that are supported in the new compose command. If you run into any problems with Compose V2, you can easily switch back to Compose v1 by either by making changes in Docker Desktop **Experimental** Settings, or by running the command `docker-compose disable-v2`. Let us know your feedback on the new ‘compose’ command by creating an issue in the [Compose-CLI](https://github.com/docker/compose-cli/issues) GitHub repository.
### Upgrades
- [Compose V2 beta](https://github.com/docker/compose-cli/releases/tag/v2.0.0-beta.4)
- Fixed a bug where a container cannot be started when a file is bind-mounted into a nested mountpoint. Fixes [docker/compose-cli#1795](https://github.com/docker/compose-cli/issues/1795).
- Added support for container links and external links.
- Introduced the `docker compose logs --since --until` option.
- `docker compose config --profiles` now lists all defined profiles.
- From [Kubernetes 1.21.1](https://github.com/kubernetes/kubernetes/releases/tag/v1.21.1) to [Kubernetes 1.21.2](https://github.com/kubernetes/kubernetes/releases/tag/v1.21.2)
### Bug fixes and minor changes
- **Volume Management**
- Users can now remove a file or directory inside a volume using the the Docker Dashboard.
- The **Volumes** view in Docker Dashboard displays the last modified time and the size of the contents inside a volume.
- Users can save the files and directories inside a volume from Docker Dashboard.
- Fixed an issue that caused credStore timeout errors when running the `docker login` command. Fixes [docker/for-win#11472](https://github.com/docker/for-win/issues/11472)
- Docker Desktop now allows the WSL 2 integration agent to start even when `/etc/wsl.conf` is malformed.
- Fixed an issue with the Docker Compose app not being stopped or removed when started by multiple configuration files. [docker/for-win#11445](https://github.com/docker/for-win/issues/11445)
- Fixed a bug where Docker Desktop fails to restart after a power failure because the Hyper-V VM restarted prematurely.
- The default `docker` CLI `context` is now `desktop-linux` in Linux containers mode and `desktop-windows` when in Windows containers mode.
- Show the Docker Desktop Feedback popup only when clicking Docker menu.
## Docker Desktop 3.4.0
2021-06-09
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/65384/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
**Volume Management**: Docker Desktop users can now create and delete volumes using the Docker Dashboard and also see which volumes are being used. For more information, see [Explore volumes](../../dashboard.md#explore-volumes).
**Compose V2 beta**: Docker Desktop now includes the beta version of Compose V2, which supports the `docker compose` command as part of the Docker CLI. For more information, see [Compose V2 beta](../../../compose/cli-command.md). While `docker-compose` is still supported and maintained, Compose V2 implementation relies directly on the compose-go bindings which are maintained as part of the specification. The compose command in the Docker CLI supports most of the `docker-compose` commands and flags. It is expected to be a drop-in replacement for `docker-compose`. There are a few remaining flags that have yet to be implemented, see the [docker-compose compatibility list](../../../compose/cli-command-compatibility.md) for more information about the flags that are supported in the new compose command. If you run into any problems with Compose V2, you can easily switch back to Compose v1 by either by making changes in Docker Desktop **Experimental** Settings, or by running the command `docker-compose disable-v2`. Let us know your feedback on the new ‘compose’ command by creating an issue in the [Compose-CLI](https://github.com/docker/compose-cli/issues) GitHub repository.
**Skip Docker Desktop updates**: All users can now skip an update when they are prompted to install individual Docker Desktop releases. For more information, see [Docker Desktop updates](../install.md#updates).
### Deprecation
- Docker Desktop no longer installs Notary, `docker trust` should be used for image signing.
### Upgrades
- [Docker Engine 20.10.7](https://docs.docker.com/engine/release-notes/#20107)
- [Docker Compose 1.29.2](https://github.com/docker/compose/releases/tag/1.29.2)
- [Docker Hub Tool v0.4.1](https://github.com/docker/hub-tool/releases/tag/v0.4.1)
- [Compose CLI v1.0.16](https://github.com/docker/compose-cli/releases/tag/v1.0.16)
- [Kubernetes 1.21.1](https://github.com/kubernetes/kubernetes/releases/tag/v1.21.1)
- [containerd v1.4.6](https://github.com/containerd/containerd/releases/tag/v1.4.6)
- [runc v1.0.0-rc95](https://github.com/opencontainers/runc/releases/tag/v1.0.0-rc95)
- [Go 1.16.5](https://github.com/golang/go/releases/tag/go1.16.5)
### Bug fixes and minor changes
- Fixed error showing stderr log in the UI. Fixes [docker/for-win#11251](https://github.com/docker/for-win/issues/11251).
- Automatically reclaim space after deleting containers by deleting volumes and removing build cache.
- Docker Compose applications with file names other than `docker-compose.yml` can now be removed from Docker Desktop. Fixes [docker/for-win#11046](https://github.com/docker/for-win/issues/11046)
- Fixed version number missing in update dialog window.
- Fixed an issue where the diagnostics were sometimes not uploaded correctly from the **Support** dialog.
- Fixed DNS entries for `*.docker.internal` and Kubernetes cluster reset after the VM IP changes.
- Fixed a corrupted internal cache which was preventing Docker Desktop from starting. Fixes [docker/for-win#8748](https://github.com/docker/for-win/issues/8748).
- Fixed an issue where `docker info` sometimes took longer to respond. Fixes [docker/for-win#10675](https://github.com/docker/for-win/issues/10675)
## Docker Desktop 3.3.3
2021-05-06
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/64133/Docker%20Desktop%20Installer.exe){: .accept-eula }
### Upgrades
- [Snyk v1.563.0](https://github.com/snyk/snyk/releases/tag/v1.563.0)
- [Docker Scan v0.8.0](https://github.com/docker/scan-cli-plugin/releases/tag/v0.8.0)
### Bug fixes and minor changes
- Fixed the diagnostics failing to upload from the Troubleshoot screen.
## Docker Desktop 3.3.2
2021-05-03
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/63878/Docker%20Desktop%20Installer.exe){: .accept-eula }
### Upgrades
- [Compose CLI v1.0.14](https://github.com/docker/compose-cli/tree/v1.0.14)
- [Go 1.16.3](https://golang.org/doc/go1.16)
- [Docker Compose 1.29.1](https://github.com/docker/compose/releases/tag/1.29.1)
- [Docker Engine 20.10.6](https://docs.docker.com/engine/release-notes/#20106)
### Bug fixes and minor changes
- Fixed a bug where a `metrics-port` defined in the engine's `daemon.json` blocks application restart.
- Fixed a leak of ephemeral ports. Fixes [docker/for-mac#5611](https://github.com/docker/for-mac/issues/5611).
- Enable buildkit garbage collection by default.
- Fixed a bug which blocked binding to port 123. Fixes [docker/for-mac#5589](https://github.com/docker/for-mac/issues/5589).
- Removed the "Deploy Docker Stacks to Kubernetes by default" Kubernetes setting. The component was removed in 2.4.0.0 but we forgot to remove the setting. Fixes [docker/for-mac#4966](https://github.com/docker/for-mac/issues/4966).
## Docker Desktop 3.3.1
2021-04-15
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/63152/Docker%20Desktop%20Installer.exe){: .accept-eula }
### Bug fixes and minor changes
- Docker Desktop now ensures the permissions of `/dev/null` and other devices are correctly set to `0666` (`rw-rw-rw-`) inside `--privileged` containers. Fixes [docker/for-mac#5527](https://github.com/docker/for-mac/issues/5527).
- Fixed an issue that caused `docker run` to fail when using `\\wsl.localhost` path to a directory. Fixes [docker/for-win#10786](https://github.com/docker/for-win/issues/10786)
- Fixed an issue that caused Docker Desktop to fail during startup when it is unable to establish a connection with Docker Hub in the backend. Fixes [docker/for-win#10896](https://github.com/docker/for-win/issues/10896)
- Fixed file permission when creating a file from a delta update. Fixes [docker/for-win#10881](https://github.com/docker/for-win/issues/10881)
## Docker Desktop 3.3.0
2021-04-08
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/62916/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
You can now specify when to download and install a Docker Desktop update. When an update becomes available, Docker Desktop displays an icon to indicate the availability of a newer version. You can download the update in the background whenever convenient. When the download is complete, all you need to do is to click Update and restart to install the latest update.
Developers who use Docker Desktop for professional development purposes may at times need to skip a specific update. For this reason, users with a paid Docker subscription can skip notifications for a particular update when a reminder appears.
For developers in IT managed environments, who don’t have administrative access to install updates to Docker Desktop, there is now an option in the Settings menu to opt out of notifications altogether for Docker Desktop updates if your Docker ID is part of a Team subscription.
### Upgrades
- [Docker Compose 1.29.0](https://github.com/docker/compose/releases/tag/1.29.0)
- [Compose CLI v1.0.12](https://github.com/docker/compose-cli/tree/v1.0.12)
- [Linux kernel 5.10.25](https://hub.docker.com/layers/docker/for-desktop-kernel/4.19.76-83885d3b4cff391813f4262099b36a529bca2df8-amd64/images/sha256-0214b82436af70054e013ea51cb1fea72bd943d0d6245b6521f1ff09a505c40f?context=repo)
- [Snyk v1.461.0](https://github.com/snyk/snyk/releases/tag/v1.461.0)
- [Docker Hub Tool v0.3.1](https://github.com/docker/hub-tool/releases/tag/v0.3.1)
- [containerd v1.4.4](https://github.com/containerd/containerd/releases/tag/v1.4.4)
- [runc v1.0.0-rc93](https://github.com/opencontainers/runc/releases/tag/v1.0.0-rc93)
### Bug fixes and minor changes
- Fixed an issue when viewing compose applications that have been started with an explicit project name. Fixes [docker/for-win#10564](https://github.com/docker/for-win/issues/10564).
- Ensure `--add-host host.docker.internal:host-gateway` causes `host.docker.internal` resolves to the host IP, rather than the IP of the IP router. See [docker/for-linux#264](https://github.com/docker/for-linux/issues/264).
- Fixed port allocation for Windows containers. Fixes [docker/for-win#10552](https://github.com/docker/for-win/issues/10552).
- Fixed an issue where running a container with a random port on the host caused Docker Desktop dashboard to incorrectly open a browser with port 0, instead of using the allocated port.
- Fixed an issue where pulling an image from Docker Hub using the Docker Desktop dashboard was failing silently.
- Perform a filesystem check when starting the Linux VM.
## Docker Desktop 3.2.2
2021-03-15
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/61853/Docker%20Desktop%20Installer.exe){: .accept-eula }
### Bug fixes and minor changes
- Fixed an issue that stopped containers binding to port 53. Fixes [docker/for-win#10601](https://github.com/docker/for-win/issues/10601).
- Fixed an issue that 32-bit Intel binaries were emulated on Intel CPUs. Fixes [docker/for-win#10594](https://github.com/docker/for-win/issues/10594).
- Fixed an issue related to high CPU consumption and frozen UI when the network connection is lost. Fixes [for-win/#10563](https://github.com/docker/for-win/issues/10563).
## Docker Desktop 3.2.1
2021-03-05
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/61626/Docker%20Desktop%20Installer.exe){: .accept-eula }
### Upgrades
- [Docker Engine 20.10.5](https://docs.docker.com/engine/release-notes/#20105)
## Docker Desktop 3.2.0
2021-03-01
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/amd64/61504/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
- The Docker Dashboard opens automatically when you start Docker Desktop.
- The Docker Dashboard displays a tip once a week.
- BuildKit is now the default builder for all users, not just for new installations. To turn this setting off, go to **Settings** > **Docker Engine** and add the following block to the Docker daemon configuration file:
```json
"features": {
"buildkit": false
}
```
### Upgrades
- [Docker Engine 20.10.3](https://docs.docker.com/engine/release-notes/#20103)
- [Docker Compose 1.28.5](https://github.com/docker/compose/releases/tag/1.28.5)
- [Compose CLI v1.0.9](https://github.com/docker/compose-cli/tree/v1.0.9)
- [Docker Hub Tool v0.3.0](https://github.com/docker/hub-tool/releases/tag/v0.3.0)
- [QEMU 5.0.1](https://wiki.qemu.org/ChangeLog/5.0)
- [Amazon ECR Credential Helper v0.5.0](https://github.com/awslabs/amazon-ecr-credential-helper/releases/tag/v0.5.0)
- [Alpine 3.13](https://alpinelinux.org/posts/Alpine-3.13.0-released.html)
- [Kubernetes 1.19.7](https://github.com/kubernetes/kubernetes/releases/tag/v1.19.7)
- [Go 1.16](https://golang.org/doc/go1.16)
### Deprecation
- Docker Desktop cannot be installed on Windows 1709 (build 16299) anymore.
- Removed the deprecated DNS name `docker.for.win.localhost`. Use DNS name `host.docker.internal` in a container to access services that are running on the host. [docker/for-win#10619](https://github.com/docker/for-win/issues/10619)
### Bug fixes and minor changes
- Fixed an issue on the container detail screen where the buttons would disappear when scrolling the logs. Fixes [docker/for-win#10160](https://github.com/docker/for-win/issues/10160)
- Fixed an issue when port forwarding multiple ports with an IPv6 container network. Fixes [docker/for-mac#5247](https://github.com/docker/for-mac/issues/5247)
- Fixed a regression where `docker load` could not use an xz archive anymore. Fixes [docker/for-win#10364](https://github.com/docker/for-win/issues/10364)
- Fixed an issue that caused the WSL 2 backend shutdown process to interfere with Windows shutdown. Fixes [docker/for-win#5825](https://github.com/docker/for-win/issues/5825) [docker/for-win#6933](https://github.com/docker/for-win/issues/6933) [docker/for-win#6446](https://github.com/docker/for-win/issues/6446)
- Fixed creds store using `desktop.exe` from WSL 2. Fixes [docker/compose-cli#1181](https://github.com/docker/compose-cli/issues/1181)
- Fixed a navigation issue in the **Containers / Apps** view. Fixes [docker/for-win#10160](https://github.com/docker/for-win/issues/10160#issuecomment-764660660)
- Fixed container instance view with long container/image name. Fixes [docker/for-win#10160](https://github.com/docker/for-win/issues/10160)
- Fixed an issue when binding ports on specific IPs. Note: It may now take a bit of time before the `docker inspect` command shows the open ports. Fixes [docker/for-win#10008](https://github.com/docker/for-win/issues/10008)
- Fixed an issue where an image deleted from the Docker dashboard was still displayed on the **Images** view.
## Docker Desktop 3.1.0
2021-01-14
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/51484/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
- Add experimental support for GPU workloads with WSL 2 backend (requires Windows Insider developer channel).
- Docker daemon now runs within a Debian Buster based container (instead of Alpine).
### Upgrades
- [Compose CLI v1.0.7](https://github.com/docker/compose-cli/tree/v1.0.7)
### Bug fixes and minor changes
- Fixed an issue where disabling proxy settings would not work. Fixes [docker/for-win#9357](https://github.com/docker/for-win/issues/9357).
- Fixed UI reliability issues when users create or delete a lot of objects in batches.
- Redesigned the **Support** UI to improve usability.
## Docker Desktop 3.0.4
2021-01-06
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/51218/Docker%20Desktop%20Installer.exe){: .accept-eula }
### Upgrades
- [Docker Engine 20.10.2](https://docs.docker.com/engine/release-notes/#20102)
### Bug fixes and minor changes
- Fixed an issue that could cause Docker Desktop to fail to start after upgrading to 3.0.0. Fixes [docker/for-win#9755](https://github.com/docker/for-win/issues/9755).
## Docker Desktop 3.0.0
2020-12-10
> Download Docker Desktop
>
> {%- include eula.md -%}
>
> [For Windows](https://desktop.docker.com/win/stable/50684/Docker%20Desktop%20Installer.exe){: .accept-eula }
### New
- Use of three-digit version number for Docker Desktop releases.
- Docker Desktop updates are now much smaller as they will be applied using delta patches. For more information, see [Automatic updates](../install.md#updates).
- First version of `docker compose` (as an alternative to the existing `docker-compose`). Supports some basic commands but not the complete functionality of `docker-compose` yet.
- Supports the following subcommands: `up`, `down`, `logs`, `build`, `pull`, `push`, `ls`, `ps`
- Supports basic volumes, bind mounts, networks, and environment variables
Let us know your feedback by creating an issue in the [compose-cli](https://github.com/docker/compose-cli/issues){: target="blank" rel="noopener" class=“”} GitHub repository.
- [Docker Hub Tool v0.2.0](https://github.com/docker/roadmap/issues/117){: target="blank" rel="noopener" class=“”}
### Upgrades
- [Docker Engine 20.10.0](https://docs.docker.com/engine/release-notes/#20100)
- [Go 1.15.6](https://github.com/golang/go/issues?q=milestone%3AGo1.15.6+label%3ACherryPickApproved+)
- [Compose CLI v1.0.4](https://github.com/docker/compose-cli/releases/tag/v1.0.4)
- [Snyk v1.432.0](https://github.com/snyk/snyk/releases/tag/v1.432.0)
### Bug fixes and minor changes
- Downgraded the kernel to [4.19.121](https://hub.docker.com/layers/docker/for-desktop-kernel/4.19.121-2a1dbedf3f998dac347c499808d7c7e029fbc4d3-amd64/images/sha256-4e7d94522be4f25f1fbb626d5a0142cbb6e785f37e437f6fd4285e64a199883a?context=repo) to reduce the CPU usage of hyperkit. Fixes [docker/for-mac#5044](https://github.com/docker/for-mac/issues/5044)
- Fixed an unexpected EOF error when trying to start a non-existing container with `-v /var/run/docker.sock:`. See [docker/for-mac#5025](https://github.com/docker/for-mac/issues/5025).
### Known issues
- Building an image with BuildKit from a git URL fails when using the form `github.com/org/repo`. To work around this issue, use the form `git://github.com/org/repo`.
- Some DNS addresses fail to resolve within containers based on Alpine Linux 3.13.
{% include eula-modal.html %}
| 66.913333 | 1,185 | 0.761283 | eng_Latn | 0.903329 |
9924f24ca0f2479805b04d89c0966e4064d9675e | 2,973 | md | Markdown | README.md | Megaxela/FilesystemWatcher | ce133115be0405e3cb8eec58809419506587b5f5 | [
"MIT"
] | 3 | 2018-03-29T01:55:04.000Z | 2020-11-06T15:16:08.000Z | README.md | Megaxela/FilesystemWatcher | ce133115be0405e3cb8eec58809419506587b5f5 | [
"MIT"
] | null | null | null | README.md | Megaxela/FilesystemWatcher | ce133115be0405e3cb8eec58809419506587b5f5 | [
"MIT"
] | null | null | null | # Cross Platform Filesystem Watcher
It's C++17 based cross platform filesystem watcher.
## OS Coverage
:heavy_check_mark: Linux
:x: Windows
:x: MacOS
## Build
It's CMake based project, it can be used as
subproject (`add_subdirectory`) in your CMake project.
But also you can build it and use in any build system.
Steps to build it:
1. Clone repo: `git clone https://github.com/Megaxela/FilesystemWatcher`
1. Go into cloned repo: `cd FilesystemWatcher`
1. Create build folder `mkdir build`
1. Go into build folder `cd build`
1. Setup project: `cmake ..`
1. You may build tests and examples:
1. To build tests, you have to add `-DFSWATCHER_BUILD_TESTS=On` key (but tests are using C++17 standard)
1. To build examples, you have to add `-DFSWATCHER_BUILD_EXAMPLES=On`.
1. Build library: `cmake --build` or `make`
## Usage example
```cpp
#include <ManualFilesystemWatcher.hpp>
#include <iostream>
int main(int argc, char** argv)
{
// Create watcher object
ManualFilesystemWatcher watcher;
// Add directory to watch
try
{
watcher.watchPath("some_path");
}
catch (std::system_error& e)
{
std::cerr << "Can't add path to watcher. Error: " << e.what() << std::endl;
return 1;
}
// Declare event object
ManualFilesystemWatcher::Event event;
// Do something with path elements
// Get event
if (!watcher.receiveFilesystemEvent(event))
{
std::cout << "There is nothing happen." << std::endl;
return 0;
}
std::cout << "Path of changed obj: " << event.path << std::endl;
// Continue getting events.
// Unregister path from watcher (it's not throwing any exceptions)
watcher.unwatchPath("some_path");
return 0;
}
```
## LICENSE
<img align="right" src="http://opensource.org/trademarks/opensource/OSI-Approved-License-100x137.png">
Library is licensed under the [MIT License](https://opensource.org/licenses/MIT)
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | 30.96875 | 108 | 0.722839 | eng_Latn | 0.752947 |
99259457d244a56200d0cbaa1084e99dd882b7ea | 677 | md | Markdown | website/content/ChapterFour/0204. Count Primes.md | yiliyili/LeetCode-Go | 911e4f2ff3a595ee361e1d557a27e8e6237d2280 | [
"MIT"
] | null | null | null | website/content/ChapterFour/0204. Count Primes.md | yiliyili/LeetCode-Go | 911e4f2ff3a595ee361e1d557a27e8e6237d2280 | [
"MIT"
] | null | null | null | website/content/ChapterFour/0204. Count Primes.md | yiliyili/LeetCode-Go | 911e4f2ff3a595ee361e1d557a27e8e6237d2280 | [
"MIT"
] | null | null | null | # [204. Count Primes](https://leetcode.com/problems/count-primes/)
## 题目:
Count the number of prime numbers less than a non-negative number, **n**.
**Example**:
Input: 10
Output: 4
Explanation: There are 4 prime numbers less than 10, they are 2, 3, 5, 7.
## 题目大意
统计所有小于非负整数 n 的质数的数量。
## 解题思路
- 给出一个数字 n,要求输出小于 n 的所有素数的个数总和。简单题。
## 代码
```go
package leetcode
func countPrimes(n int) int {
isNotPrime := make([]bool, n)
for i := 2; i*i < n; i++ {
if isNotPrime[i] {
continue
}
for j := i * i; j < n; j = j + i {
isNotPrime[j] = true
}
}
count := 0
for i := 2; i < n; i++ {
if !isNotPrime[i] {
count++
}
}
return count
}
``` | 13.54 | 77 | 0.577548 | eng_Latn | 0.708993 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.