
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
110b46fe0771561e69e97859279b94863a5763fd | 57 | md | Markdown | README.md | HappyKadaver/personio-argos | f73ee056da92777d985df359466de887042f4282 | [
"MIT"
] | null | null | null | README.md | HappyKadaver/personio-argos | f73ee056da92777d985df359466de887042f4282 | [
"MIT"
] | null | null | null | README.md | HappyKadaver/personio-argos | f73ee056da92777d985df359466de887042f4282 | [
"MIT"
] | null | null | null | # personio-argos
Argos skript for personio time tracking
| 19 | 39 | 0.824561 | eng_Latn | 0.403217 |
110b8987c758c651651760a4499187c0637ebef1 | 613 | md | Markdown | api/Access.WebBrowserControl.LocationURL.md | italicize/VBA-Docs | 8d12d72a1e3e9e32f31b87be3a3f9e18e411c1b0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | api/Access.WebBrowserControl.LocationURL.md | italicize/VBA-Docs | 8d12d72a1e3e9e32f31b87be3a3f9e18e411c1b0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | api/Access.WebBrowserControl.LocationURL.md | italicize/VBA-Docs | 8d12d72a1e3e9e32f31b87be3a3f9e18e411c1b0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: WebBrowserControl.LocationURL Property (Access)
keywords: vbaac10.chm14368
f1_keywords:
- vbaac10.chm14368
ms.prod: access
api_name:
- Access.WebBrowserControl.LocationURL
ms.assetid: 1ef6dad3-cfcb-1768-e891-09ada810569a
ms.date: 06/08/2017
---
# WebBrowserControl.LocationURL Property (Access)
Gets the Uniform Resource Locator (URL) of the current document. Read-only **String**.
## Syntax
_expression_. `LocationURL`
_expression_ A variable that represents a [WebBrowserControl](Access.WebBrowserControl.md) object.
## See also
[WebBrowserControl Object](Access.WebBrowserControl.md)
| 19.774194 | 99 | 0.784666 | yue_Hant | 0.775493 |
110b914c6cb692d8aa3cffc25fe7509272a7aa01 | 3,288 | md | Markdown | docs/maui/converters/datetimeoffsetconverter.md | danielftz/CommunityToolkit | 5b08d6347eb8adcf69f04ccbb8b834f0f82344c0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/maui/converters/datetimeoffsetconverter.md | danielftz/CommunityToolkit | 5b08d6347eb8adcf69f04ccbb8b834f0f82344c0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/maui/converters/datetimeoffsetconverter.md | danielftz/CommunityToolkit | 5b08d6347eb8adcf69f04ccbb8b834f0f82344c0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: DateTimeOffsetConverter - .NET MAUI Community Toolkit
author: cliffagius
description: "The DateTimeOffsetConverter is a converter that allows users to convert a DateTimeOffset to a DateTime "
ms.date: 03/22/2022
---
# DateTimeOffsetConverter
[!INCLUDE [docs under construction](../includes/preview-note.md)]
The `DateTimeOffsetConverter` is a converter that allows users to convert a `DateTimeOffset` to a `DateTime`. Sometimes a `DateTime` value is stored with the offset on a backend to allow for storing the timezone in which a `DateTime` originated from. Controls like the `Microsoft.Maui.Controls.DatePicker` only work with `DateTime`. This converter can be used in those scenarios.
## Syntax
### XAML
The `DateTimeOffsetConverter` can be used as follows in XAML:
```xaml
<ContentPage xmlns="http://schemas.microsoft.com/dotnet/2021/maui"
xmlns:x="http://schemas.microsoft.com/winfx/2009/xaml"
xmlns:toolkit="http://schemas.microsoft.com/dotnet/2022/maui/toolkit"
x:Class="MyLittleApp.MainPage">
<ContentPage.Resources>
<ResourceDictionary>
<toolkit:DateTimeOffsetConverter x:Key="DateTimeOffsetConverter" />
</ResourceDictionary>
</ContentPage.Resources>
<VerticalStackLayout>
<Label Text="The DatePicker below is bound to a Property of type DateTimeOffset."
Margin="16"
HorizontalOptions="Center"
FontAttributes="Bold" />
<DatePicker Date="{Binding TheDate, Converter={StaticResource DateTimeOffsetConverter}}"
Margin="16"
HorizontalOptions="Center" />
<Label Text="{Binding TheDate}"
Margin="16"
HorizontalOptions="Center"
FontAttributes="Bold" />
</VerticalStackLayout>
</ContentPage>
```
### C#
The `DateTimeOffsetConverter` can be used as follows in C#:
```csharp
class DateTimeOffsetConverterPage : ContentPage
{
public DateTimeOffsetConverterPage()
{
var label = new Label();
label.SetBinding(
Label.TextProperty,
new Binding(
nameof(ViewModels.MyValue),
converter: new DateTimeOffsetConverter()));
Content = label;
}
}
```
### C# Markup
Our [`CommunityToolkit.Maui.Markup`](../markup/markup.md) package provides a much more concise way to use this converter in C#.
```csharp
using CommunityToolkit.Maui.Markup;
class DateTimeOffsetConverterPage : ContentPage
{
public DateTimeOffsetConverterPage()
{
Content = new Label()
.Bind(
Label.TextProperty,
nameof(ViewModel.MyValue),
converter: new DateTimeOffsetConverterPage());
}
}
```
## Examples
You can find an example of this converter in action in the [.NET MAUI Community Toolkit Sample Application](https://github.com/CommunityToolkit/Maui/blob/main/samples/CommunityToolkit.Maui.Sample/Pages/Converters/DateTimeOffsetConverterPage.xaml).
## API
You can find the source code for `DateTimeOffsetConverter` over on the [.NET MAUI Community Toolkit GitHub repository](https://github.com/CommunityToolkit/Maui/blob/main/src/CommunityToolkit.Maui/Converters/DateTimeOffsetConverter.shared.cs).
| 32.88 | 379 | 0.688564 | yue_Hant | 0.8384 |
110c08211b51de8fb28268ffe3d67a822e3e7504 | 108 | md | Markdown | README.md | xiayh17/Rmarkdown0 | 111f938ffa6a19ec74c568a4e8bbb6af44cf94ed | [
"MIT"
] | null | null | null | README.md | xiayh17/Rmarkdown0 | 111f938ffa6a19ec74c568a4e8bbb6af44cf94ed | [
"MIT"
] | null | null | null | README.md | xiayh17/Rmarkdown0 | 111f938ffa6a19ec74c568a4e8bbb6af44cf94ed | [
"MIT"
] | null | null | null | # Rmarkdown0
practice Rmarkdown by analysis GSE42589
## github Pages
https://xiayh17.github.io/Rmarkdown0/
| 18 | 39 | 0.796296 | kor_Hang | 0.29337 |
110c082eba943d837c5796272b8798ab448c675a | 1,369 | md | Markdown | docs/framework/common-client-technologies/index.md | novia713/docs.es-es | 0b2af23819b4104ec1d4e6ed4fc5c547de1f73d5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/common-client-technologies/index.md | novia713/docs.es-es | 0b2af23819b4104ec1d4e6ed4fc5c547de1f73d5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/common-client-technologies/index.md | novia713/docs.es-es | 0b2af23819b4104ec1d4e6ed4fc5c547de1f73d5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Tecnologías comunes de cliente en .NET Framework
ms.date: 03/30/2017
ms.assetid: 733fc580-337e-4b7c-9756-b70798c18bc3
author: mairaw
ms.author: mairaw
ms.openlocfilehash: 2c12fdcaeefb2a7bcb1bcc7bae2aca6cb637e6f6
ms.sourcegitcommit: 11f11ca6cefe555972b3a5c99729d1a7523d8f50
ms.translationtype: HT
ms.contentlocale: es-ES
ms.lasthandoff: 05/03/2018
ms.locfileid: "32753500"
---
# <a name="common-client-technologies-in-the-net-framework"></a>Tecnologías comunes de cliente en .NET Framework
En esta sección se describen las diferentes tecnologías que puede usar en aplicaciones cliente.
## <a name="in-this-section"></a>En esta sección
[Manipulaciones e inercia](../../../docs/framework/common-client-technologies/manipulations-and-inertia.md)
Se describe cómo usar las clases de procesador de inercia y manipulaciones en una diversidad de marcos de interfaz de usuario, como Microsoft Windows Presentation Foundation (WPF) o Microsoft XNA.
[Servicios de aplicación cliente](../../../docs/framework/common-client-technologies/client-application-services.md)
Se describe cómo usar el inicio de sesión, los roles y los servicios de aplicación de perfiles de [!INCLUDE[ajax_current_short](../../../includes/ajax-current-short-md.md)]incluidos en las extensiones de Microsoft ASP.NET 2.0 AJAX en las aplicaciones basadas en Windows.
| 59.521739 | 271 | 0.783053 | spa_Latn | 0.85222 |
110c9f0c418cf027580702f1c264a8ea1978ae4c | 3,069 | md | Markdown | README.md | zray007/Diagnostics_Via_DVD | 60b69ee67f9070de1b1545b2930900d50a1d1284 | [
"MIT"
] | 1 | 2021-06-28T20:20:40.000Z | 2021-06-28T20:20:40.000Z | README.md | zray007/Diagnostics_Via_DVD | 60b69ee67f9070de1b1545b2930900d50a1d1284 | [
"MIT"
] | null | null | null | README.md | zray007/Diagnostics_Via_DVD | 60b69ee67f9070de1b1545b2930900d50a1d1284 | [
"MIT"
] | 1 | 2021-06-28T20:20:42.000Z | 2021-06-28T20:20:42.000Z | # Diagnostics Via Disk
## Ramp up COVID-19 testing using frugal devices: CD/DVD drives

## How to use
* A graphical user interface.
* A command-line interface is also available.
All this is proof-of-concept level. It works for us yet the performance might be bad with some specific hardware (CD readers) and there are conditions that we do not test (like no drive or several drives).
## Requirements
### Hardware
* Linux machine with a CD/DVD/BluRay reader/player. For example, a Raspberry Pi and a USB-to-IDE or USB-to-SATA plus external drive is fine.
* CD/DVD/BluRay disk.
### Software
The code is built upon:
* Python
* Qt (via [qtpy](https://pypi.org/project/QtPy/))
* [pycdio](https://pypi.org/project/pycdio/) | [libcdio2.0.0 for Ubuntu 18.04](https://launchpad.net/~spvkgn/+archive/ubuntu/whipper)
* [guietta](https://guietta.readthedocs.io/en/latest/).
* `readom` (from package `wodim`)
#### Quick install, on Debian and derivatives, using system Python
This is the quickest solution, recommended if you can install everything via packages, for example on Ubuntu 20.04.
Especially on Raspberry Pi where Debian supplies all necessary packages compiled for the Pi's ARM architecture, while Python-side solutions often lack ARM builds.
```bash
bash install-debian-system_python.sh
```
#### Quick install, on Debian and derivatives, using a ad-hoc python virtualenv
This can be useful in older distributions, for example Ubuntu 18.04.
The script installs the base requirements and uses a python virtual environment for other python requirements
```bash
bash install-debian-virtualenv.sh
```
#### Other cases
Details are provided above for a Debian-based OS (including Ubuntu and Raspberry Pi OS).
For other Linux-based distributions, have a look at the scripts, your distributions most certainly provides equivalent commands and perhaps necessary packages.
Once you have `python3` and `pip3` running, most of the rest can be pulled via pythonic ways of doing rather than distribution-centric ways.
For example, if some package `foo` is not available on your distributions via `apt-get install` or equivalent, you may try `pip3 install foo` in the virtualenv.
That said, you will most certainly need builds of `libcdio` and `libiso9660`, for example `libcdio-dev` and `libiso9660-dev`. If those are not available at all, you may need to recompile them from scratch.
### Launch software
#### Run using bash script
Opens the GUI from the diagvdisk virtual environment created by install-debian-virtualenv.sh
```bash
bash run.sh
```
#### Run Manually
```bash
python3 diagnostics_via_disk.py
```
#### Quick install & run snippet
```bash
git clone https://github.com/zray007/Diagnostics-via-Disk
cd Diagnostics-via-Disk
sudo bash install-debian-system_python.sh
sudo bash run.sh
```
### Test access to CD-Rom drive
Click on "Open tray" and "Close tray". The default CD/DVD drive on the system should do what you expect.
| 35.275862 | 207 | 0.738351 | eng_Latn | 0.989731 |
110d2f815592ae4216d22621f06039514613b23d | 3,762 | md | Markdown | docs/relational-databases/system-stored-procedures/managed-backup-sp-backup-master-switch-transact-sql.md | kirabr/sql-docs.ru-ru | 08e3b25ff0792ee0ec4c7641b8960145bbec4530 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/relational-databases/system-stored-procedures/managed-backup-sp-backup-master-switch-transact-sql.md | kirabr/sql-docs.ru-ru | 08e3b25ff0792ee0ec4c7641b8960145bbec4530 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/relational-databases/system-stored-procedures/managed-backup-sp-backup-master-switch-transact-sql.md | kirabr/sql-docs.ru-ru | 08e3b25ff0792ee0ec4c7641b8960145bbec4530 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: managed_backup.sp_ backup_master_switch (Transact-SQL) | Документация Майкрософт
ms.custom: ''
ms.date: 06/10/2016
ms.prod: sql
ms.prod_service: database-engine
ms.component: system-stored-procedures
ms.reviewer: ''
ms.suite: sql
ms.technology: system-objects
ms.tgt_pltfrm: ''
ms.topic: language-reference
f1_keywords:
- sp_ backup_master_switch
- smart_admin.sp_ backup_master_switch
- sp_ backup_master_switch_TSQL
- smart_admin.sp_ backup_master_switch_TSQL
dev_langs:
- TSQL
helpviewer_keywords:
- sp_ backup_master_switch
- smart_admin.sp_ backup_master_switch
ms.assetid: 1ed2b2b2-c897-41cc-bed5-1c6bc47b9dd2
caps.latest.revision: 12
author: MikeRayMSFT
ms.author: mikeray
manager: craigg
ms.openlocfilehash: 64d6681203962b54f1f3daae2de26e695cec240c
ms.sourcegitcommit: e77197ec6935e15e2260a7a44587e8054745d5c2
ms.translationtype: MT
ms.contentlocale: ru-RU
ms.lasthandoff: 07/11/2018
ms.locfileid: "37995555"
---
# <a name="managedbackupsp-backupmasterswitch-transact-sql"></a>managed_backup.sp_ backup_master_switch (Transact-SQL)
[!INCLUDE[tsql-appliesto-ss2016-xxxx-xxxx-xxx-md](../../includes/tsql-appliesto-ss2016-xxxx-xxxx-xxx-md.md)]
Приостанавливает или возобновляет компонент [!INCLUDE[ss_smartbackup](../../includes/ss-smartbackup-md.md)].
Эта хранимая процедура используется для приостановки и возобновления компонента [!INCLUDE[ss_smartbackup](../../includes/ss-smartbackup-md.md)]. Она обеспечивает сохранность всех параметров конфигурации и их применение при возобновлении работы компонента. При приостановке компонента [!INCLUDE[ss_smartbackup](../../includes/ss-smartbackup-md.md)] срок хранения не действует. Это означает отсутствие проверки для определения, следует ли удалять файлы из хранилища, имеются ли поврежденные файлы резервной копии или разрывы в цепочке журналов.
 [Синтаксические обозначения в Transact-SQL](../../t-sql/language-elements/transact-sql-syntax-conventions-transact-sql.md)
## <a name="syntax"></a>Синтаксис
```sql
EXEC managed_backup.sp_backup_master_switch
[@state = ] { 0 | 1}
```
## <a name="Arguments"></a> Аргументы
@state
Задает состояние [!INCLUDE[ss_smartbackup](../../includes/ss-smartbackup-md.md)]. @state Параметр **бит**. При установке в значение 0 работа приостанавливается, а при установке в значение 1 — возобновляется.
## <a name="return-code-value"></a>Значения кодов возврата
0 (успешное завершение) или 1 (неуспешное завершение)
## <a name="security"></a>безопасность
Описаны проблемы безопасности, связанные с разрешениями statement.Include как подраздела (заголовок H3). Рассмотрите включение других подразделов для цепочки владения и аудита, если потребуется.
### <a name="permissions"></a>Разрешения
Требуется членство в **db_backupoperator** роли базы данных с помощью **ALTER ANY CREDENTIAL** разрешения, и **EXECUTE** разрешения на **sp_delete_ backuphistory**хранимой процедуры.
## <a name="examples"></a>Примеры
В следующем примере [!INCLUDE[ss_smartbackup](../../includes/ss-smartbackup-md.md)] приостанавливается в том экземпляре, в котором выполняется пример.
```
Use msdb;
GO
EXEC managed_backup.sp_master_switch @state=0;
Go
```
В следующем примере [!INCLUDE[ss_smartbackup](../../includes/ss-smartbackup-md.md)] возобновляется.
```
Use msdb;
GO
EXEC managed_backup.sp_master_switch @state=1;
Go
```
## <a name="see-also"></a>См. также
[Управляемое резервное копирование SQL Server в Microsoft Azure](../../relational-databases/backup-restore/sql-server-managed-backup-to-microsoft-azure.md)
| 41.340659 | 545 | 0.756512 | rus_Cyrl | 0.344314 |
110d4f02ea7a4409a8807f0fdfe11924049662c7 | 9,456 | md | Markdown | README.md | djsavvy/pgx | c9c218033f3f4b6d249c4476a257635fc143eb67 | [
"MIT"
] | 203 | 2021-12-12T20:41:35.000Z | 2022-03-07T16:51:25.000Z | README.md | djsavvy/pgx | c9c218033f3f4b6d249c4476a257635fc143eb67 | [
"MIT"
] | 301 | 2016-06-03T01:55:42.000Z | 2018-02-27T21:09:33.000Z | README.md | djsavvy/pgx | c9c218033f3f4b6d249c4476a257635fc143eb67 | [
"MIT"
] | 46 | 2016-06-03T02:31:42.000Z | 2018-02-26T21:23:36.000Z | [](https://pkg.go.dev/github.com/jackc/pgx/v4)
[](https://travis-ci.org/jackc/pgx)
# pgx - PostgreSQL Driver and Toolkit
pgx is a pure Go driver and toolkit for PostgreSQL.
pgx aims to be low-level, fast, and performant, while also enabling PostgreSQL-specific features that the standard `database/sql` package does not allow for.
The driver component of pgx can be used alongside the standard `database/sql` package.
The toolkit component is a related set of packages that implement PostgreSQL functionality such as parsing the wire protocol
and type mapping between PostgreSQL and Go. These underlying packages can be used to implement alternative drivers,
proxies, load balancers, logical replication clients, etc.
The current release of `pgx v4` requires Go modules. To use the previous version, checkout and vendor the `v3` branch.
## Example Usage
```go
package main
import (
"context"
"fmt"
"os"
"github.com/jackc/pgx/v4"
)
func main() {
// urlExample := "postgres://username:password@localhost:5432/database_name"
conn, err := pgx.Connect(context.Background(), os.Getenv("DATABASE_URL"))
if err != nil {
fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
os.Exit(1)
}
defer conn.Close(context.Background())
var name string
var weight int64
err = conn.QueryRow(context.Background(), "select name, weight from widgets where id=$1", 42).Scan(&name, &weight)
if err != nil {
fmt.Fprintf(os.Stderr, "QueryRow failed: %v\n", err)
os.Exit(1)
}
fmt.Println(name, weight)
}
```
See the [getting started guide](https://github.com/jackc/pgx/wiki/Getting-started-with-pgx) for more information.
## Choosing Between the pgx and database/sql Interfaces
It is recommended to use the pgx interface if:
1. The application only targets PostgreSQL.
2. No other libraries that require `database/sql` are in use.
The pgx interface is faster and exposes more features.
The `database/sql` interface only allows the underlying driver to return or receive the following types: `int64`,
`float64`, `bool`, `[]byte`, `string`, `time.Time`, or `nil`. Handling other types requires implementing the
`database/sql.Scanner` and the `database/sql/driver/driver.Valuer` interfaces which require transmission of values in text format. The binary format can be substantially faster, which is what the pgx interface uses.
## Features
pgx supports many features beyond what is available through `database/sql`:
* Support for approximately 70 different PostgreSQL types
* Automatic statement preparation and caching
* Batch queries
* Single-round trip query mode
* Full TLS connection control
* Binary format support for custom types (allows for much quicker encoding/decoding)
* COPY protocol support for faster bulk data loads
* Extendable logging support including built-in support for `log15adapter`, [`logrus`](https://github.com/sirupsen/logrus), [`zap`](https://github.com/uber-go/zap), and [`zerolog`](https://github.com/rs/zerolog)
* Connection pool with after-connect hook for arbitrary connection setup
* Listen / notify
* Conversion of PostgreSQL arrays to Go slice mappings for integers, floats, and strings
* Hstore support
* JSON and JSONB support
* Maps `inet` and `cidr` PostgreSQL types to `net.IPNet` and `net.IP`
* Large object support
* NULL mapping to Null* struct or pointer to pointer
* Supports `database/sql.Scanner` and `database/sql/driver.Valuer` interfaces for custom types
* Notice response handling
* Simulated nested transactions with savepoints
## Performance
There are three areas in particular where pgx can provide a significant performance advantage over the standard
`database/sql` interface and other drivers:
1. PostgreSQL specific types - Types such as arrays can be parsed much quicker because pgx uses the binary format.
2. Automatic statement preparation and caching - pgx will prepare and cache statements by default. This can provide an
significant free improvement to code that does not explicitly use prepared statements. Under certain workloads, it can
perform nearly 3x the number of queries per second.
3. Batched queries - Multiple queries can be batched together to minimize network round trips.
## Comparison with Alternatives
* [pq](http://godoc.org/github.com/lib/pq)
* [go-pg](https://github.com/go-pg/pg)
For prepared queries with small sets of simple data types, all drivers will have have similar performance. However, if prepared statements aren't being explicitly used, pgx can have a significant performance advantage due to automatic statement preparation.
pgx also can perform better when using PostgreSQL-specific data types or query batching. See
[go_db_bench](https://github.com/jackc/go_db_bench) for some database driver benchmarks.
### Compatibility with `database/sql`
pq is exclusively used with `database/sql`. go-pg does not use `database/sql` at all. pgx supports `database/sql` as well as
its own interface.
### Level of access, ORM
go-pg is a PostgreSQL client and ORM. It includes many features that traditionally sit above the database driver, such as ORM, struct mapping, soft deletes, schema migrations, and sharding support.
pgx is "closer to the metal" and such abstractions are beyond the scope of the pgx project, which first and foremost, aims to be a performant driver and toolkit.
## Testing
pgx tests naturally require a PostgreSQL database. It will connect to the database specified in the `PGX_TEST_DATABASE` environment
variable. The `PGX_TEST_DATABASE` environment variable can either be a URL or DSN. In addition, the standard `PG*` environment
variables will be respected. Consider using [direnv](https://github.com/direnv/direnv) to simplify environment variable
handling.
### Example Test Environment
Connect to your PostgreSQL server and run:
```
create database pgx_test;
```
Connect to the newly-created database and run:
```
create domain uint64 as numeric(20,0);
```
Now, you can run the tests:
```
PGX_TEST_DATABASE="host=/var/run/postgresql database=pgx_test" go test ./...
```
In addition, there are tests specific for PgBouncer that will be executed if `PGX_TEST_PGBOUNCER_CONN_STRING` is set.
## Supported Go and PostgreSQL Versions
pgx supports the same versions of Go and PostgreSQL that are supported by their respective teams. For [Go](https://golang.org/doc/devel/release.html#policy) that is the two most recent major releases and for [PostgreSQL](https://www.postgresql.org/support/versioning/) the major releases in the last 5 years. This means pgx supports Go 1.16 and higher and PostgreSQL 10 and higher. pgx also is tested against the latest version of [CockroachDB](https://www.cockroachlabs.com/product/).
## Version Policy
pgx follows semantic versioning for the documented public API on stable releases. `v4` is the latest stable major version.
## PGX Family Libraries
pgx is the head of a family of PostgreSQL libraries. Many of these can be used independently. Many can also be accessed
from pgx for lower-level control.
### [github.com/jackc/pgconn](https://github.com/jackc/pgconn)
`pgconn` is a lower-level PostgreSQL database driver that operates at nearly the same level as the C library `libpq`.
### [github.com/jackc/pgx/v4/pgxpool](https://github.com/jackc/pgx/tree/master/pgxpool)
`pgxpool` is a connection pool for pgx. pgx is entirely decoupled from its default pool implementation. This means that pgx can be used with a different pool or without any pool at all.
### [github.com/jackc/pgx/v4/stdlib](https://github.com/jackc/pgx/tree/master/stdlib)
This is a `database/sql` compatibility layer for pgx. pgx can be used as a normal `database/sql` driver, but at any time, the native interface can be acquired for more performance or PostgreSQL specific functionality.
### [github.com/jackc/pgtype](https://github.com/jackc/pgtype)
Over 70 PostgreSQL types are supported including `uuid`, `hstore`, `json`, `bytea`, `numeric`, `interval`, `inet`, and arrays. These types support `database/sql` interfaces and are usable outside of pgx. They are fully tested in pgx and pq. They also support a higher performance interface when used with the pgx driver.
### [github.com/jackc/pgproto3](https://github.com/jackc/pgproto3)
pgproto3 provides standalone encoding and decoding of the PostgreSQL v3 wire protocol. This is useful for implementing very low level PostgreSQL tooling.
### [github.com/jackc/pglogrepl](https://github.com/jackc/pglogrepl)
pglogrepl provides functionality to act as a client for PostgreSQL logical replication.
### [github.com/jackc/pgmock](https://github.com/jackc/pgmock)
pgmock offers the ability to create a server that mocks the PostgreSQL wire protocol. This is used internally to test pgx by purposely inducing unusual errors. pgproto3 and pgmock together provide most of the foundational tooling required to implement a PostgreSQL proxy or MitM (such as for a custom connection pooler).
### [github.com/jackc/tern](https://github.com/jackc/tern)
tern is a stand-alone SQL migration system.
### [github.com/jackc/pgerrcode](https://github.com/jackc/pgerrcode)
pgerrcode contains constants for the PostgreSQL error codes.
## 3rd Party Libraries with PGX Support
### [github.com/georgysavva/scany](https://github.com/georgysavva/scany)
Library for scanning data from a database into Go structs and more.
| 46.352941 | 485 | 0.773689 | eng_Latn | 0.985611 |
110d533705b256a33f14ba6fbd2cbac9f2ed847c | 75 | md | Markdown | _authors/medivh.0923.md | gogleowner/kakao.github.io | 8b8c12b45178b70cadd0ac07d0c4957babcaf088 | [
"Apache-2.0"
] | 2 | 2017-10-30T08:21:47.000Z | 2017-11-03T09:12:10.000Z | _authors/medivh.0923.md | gogleowner/kakao.github.io | 8b8c12b45178b70cadd0ac07d0c4957babcaf088 | [
"Apache-2.0"
] | 3 | 2021-05-20T07:25:31.000Z | 2022-02-26T05:17:44.000Z | _authors/medivh.0923.md | gogleowner/kakao.github.io | 8b8c12b45178b70cadd0ac07d0c4957babcaf088 | [
"Apache-2.0"
] | 1 | 2020-08-11T08:39:58.000Z | 2020-08-11T08:39:58.000Z | ---
name: medivh.0923
title: 전현우
image: /files/authors/medivh.0923.jpg
---
| 12.5 | 37 | 0.693333 | yue_Hant | 0.536973 |
110db6042ad0b0a9ac1773cd5ddc8403eb11d2d5 | 32 | md | Markdown | README.md | VerisZG/AHK | fa0cf7eaad5e2a38dc5646b9f5aed627c5f2fb01 | [
"MIT"
] | null | null | null | README.md | VerisZG/AHK | fa0cf7eaad5e2a38dc5646b9f5aed627c5f2fb01 | [
"MIT"
] | null | null | null | README.md | VerisZG/AHK | fa0cf7eaad5e2a38dc5646b9f5aed627c5f2fb01 | [
"MIT"
] | null | null | null | # AHK
Useful autohotkey scripts
| 10.666667 | 25 | 0.8125 | eng_Latn | 0.483684 |
110dced1d89bb4c6b1718c1e29828301474a9ab8 | 7,136 | md | Markdown | pages/content/amp-dev/documentation/guides-and-tutorials/contribute/[email protected] | admariner/amp.dev | eabbbe3ce5bc7205e19078a09995efbe1934c7e0 | [
"Apache-2.0"
] | null | null | null | pages/content/amp-dev/documentation/guides-and-tutorials/contribute/[email protected] | admariner/amp.dev | eabbbe3ce5bc7205e19078a09995efbe1934c7e0 | [
"Apache-2.0"
] | 1 | 2021-07-24T20:11:05.000Z | 2021-07-24T20:11:05.000Z | pages/content/amp-dev/documentation/guides-and-tutorials/contribute/[email protected] | admariner/amp.dev | eabbbe3ce5bc7205e19078a09995efbe1934c7e0 | [
"Apache-2.0"
] | null | null | null | ---
'$title': Menggunakan Penampil AMP untuk merender email
$order: 5
author: alabiaga
formats:
- email
---
Klien email yang ingin mendukung AMP untuk Email harus menggunakan [Penampil AMP](https://github.com/ampproject/amphtml/blob/main/extensions/amp-viewer-integration/integrating-viewer-with-amp-doc-guide.md) untuk mengelola email AMP pengirim mereka. Penampil yang dibuat dengan [perpustakaan Penampil AMP](https://github.com/ampproject/amphtml/tree/master/extensions/amp-viewer-integration) menyelubungi dokumen AMP dan memungkinkan [kemampuan](https://github.com/ampproject/amphtml/blob/main/extensions/amp-viewer-integration/CAPABILITIES.md) yang mengizinkan komunikasi dua arah dengan dokumen AMP melalui postMessage. Kemampuan ini meliputi pemberian kontrol atas visibilitas email, penyampaian metrik pengguna, dan menyediakan alat untuk memastikan keamanan permintaan XHR yang dibuat dari email.
## Pencegatan XHR Penampil
Kemampuan `xhrInterceptor` perpustakaan Penampil AMP memungkinkan penampil mencegah permintaan XHR yang keluar. Penampil AMP dapat mengintrospeksi sebuah permintaan untuk mengetahui validitas dan niatnya untuk memastikan perlindungan dan privasi penggunanya.
#### Permintaan XHR
Komponen AMP, seperti [`<amp-list>`](../../../documentation/components/reference/amp-list.md?format=email) dan [`<amp-form>`](../../../documentation/components/reference/amp-form.md?format=email), memerlukan panggilan ke endpoint untuk memuat atau mengambil data. Panggilan ini digolongkan sebagai permintaan XHR.
#### Komunikasi dokumen AMP dan Penampil
Protokol yang digunakan untuk komunikasi di antara penampil dan dokumen AMP dicapai melalui [postMessage](https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage). Berikut ini adalah contoh kecil tentang postMessage yang berfungsi dalam kasus penggunaan pencegatan XHR, di mana penampil menangani postMessage XHR yang dikirimkan dari dokumen AMP dan menghasilkan tanggapan kustom.
```js
// The viewer iframe that will host the amp doc.
viewerIframe = document.createElement('iframe');
viewerIframe.contentWindow.onMessage = (xhrRequestIntercepted) => {
const blob = new Blob([JSON.stringify({body: 'hello'}, null, 2)], {
type: 'application/json',
});
const response = new Reponse(blob, {status: 200});
return response;
};
```
### Mengaktifkan pencegatan XHR
Aktifkan pencegatan XHR dengan memilih penampil ke dalam kemampuan xhrInterceptor pada saat inisialisasi. Silakan lihat contoh penampil tentang cara melakukan ini dan contoh tentang pencegatan XHR. Dokumen AMP harus menerima untuk mengizinkan pencegatan XHR. Dokumen menerima dengan menambahkan atribut `allow-xhr-interception` ke tag `<html amp4email>`. Klien email harus memasang atribut ini pada dokumen AMP sebelum merendernya karena ini adalah atribut yang diniatkan invalid dan akan ditandai demikian dalam validasi dokumen AMP.
```html
<!DOCTYPE html>
<html ⚡4email allow-xhr-interception>
...
</html>
```
## Perenderan templat sisi server penampil
Kemampuan `viewerRenderTemplate` memungkinkan penampil untuk mengelola perenderan templat [`<amp-list>`](../../../documentation/components/reference/amp-list.md?format=email) dan [`<amp-form>`](../../../documentation/components/reference/amp-form.md?format=email). Setelah aktif, runtime AMP mewakili permintaan yang berisi panggilan XHR asli, data templat, dan detail lain apa pun yang diperlukan untuk perenderan konten komponen ke penampil. Ini memungkinkan penampil untuk menginstropeksi konten data endpoint dan mengelola perenderan [misai (mustache)](https://mustache.github.io/) atas templat untuk memverifikasi dan mengamankan data. Harap ketahui bahwa jika kemampuan ini diaktifkan bersama xhrInterceptor, di dalam komponen amp-form dan amp-list, kemampuan `viewerRenderTemplate` yang juga mewakili permintaan ke penampil akan mengungguli xhrInterceptor.
Contoh [viewer.html](https://github.com/ampproject/amphtml/blob/main/examples/viewer.html) memperlihatkan bagaimana cara menangani pesan `viewerRenderTemplate` yang dikirimkan dari dokumen AMP. Di dalam contoh tersebut, Viewer.prototype.processRequest\_ menangkap pesan `viewerRenderTemplate` dan berdasarkan jenis komponen AMP yang tersedia di dalam permintaan, mengirimkan kembali HTML untuk dirender di dalam format JSON berikut ini.
```js
Viewer.prototype.ssrRenderAmpListTemplate_ = (data) =>
Promise.resolve({
'html':
"<div role='list' class='i-amphtml-fill-content i-amphtml-replaced-content'>" +
"<div class='product' role='listitem'>Apple</div>" +
'</div>',
'body': '',
'init': {
'headers': {
'Content-Type': 'application/json',
},
},
});
```
Ini adalah contoh kecil di mana tidak ada ketergantungan perpustakaan [misai (mustache)](https://mustache.github.io/) atau sanitasi konten.
Diagram di bawah ini menggambarkan contoh yang lebih nyata tentang cara dokumen AMP di dalam penampil klien email dengan kemampuan `viewerRenderTemplate` dapat menangani perenderan templat [`<amp-list>`](../../../documentation/components/reference/amp-list.md?format=email).
<amp-img alt="Viewer render template diagram" layout="responsive" width="372" height="279" src="/static/img/docs/viewer_render_template_diagram.png"></amp-img>
Runtime AMP akan mewakili permintaan pengambilan data komponen [`<amp-list>`](../../../documentation/components/reference/amp-list.md?format=email) ke penampil, yang pada gilirannya akan meneruskan permintaan ini ke server klien email. Server akan mengumpan URL ini dan hasil pengambilan URL melalui berbagai layanan, mungkin memeriksa validitas URL, konten data yang dihasilkan dari URL itu, dan merender templat [misai (mustache)](https://mustache.github.io/) dengan data itu. Lalu, templat yang dirender akan dikembalikan dan dikirimkan kembali ke penampil di dalam format tanggapan JSON berikut ini.
```json
{
"html": "<div role='list' class='i-amphtml-fill-content i-amphtml-replaced-content'> <div class='product' role='listitem'>List item 1</div> <div class='product' role='listitem'>List item 2</div> </div>",
"body": "",
"init": {
"headers": {
"Content-Type": "application/json"
}
}
}
```
Nilai HTML dalam payload JSON adalah apa yang dimasukkan ke dalam dokumen AMP untuk perenderan.
Tabel di bawah ini menguraikan kemampuan dan komponen yang terpengaruh:
<table>
<thead>
<tr>
<th width="30%">Kemampuan penampil</th>
<th>Komponen yang terpengaruh</th>
</tr>
</thead>
<tbody>
<tr>
<td>xhrInterceptor</td>
<td><code>[amp-form](../../../documentation/components/reference/amp-form.md?format=email), [amp-list](../../../documentation/components/reference/amp-list.md?format=email), [amp-state](https://amp.dev/documentation/components/amp-bind?format=email#initializing-state-with-amp-state)</code></td>
</tr>
<tr>
<td>viewerRenderTemplate</td>
<td><code>[amp-form](../../../documentation/components/reference/amp-form.md?format=email), [amp-list](../../../documentation/components/reference/amp-list.md?format=email)</code></td>
</tr>
</tbody>
</table>
| 64.872727 | 863 | 0.764013 | ind_Latn | 0.825404 |
110e24045127248edec4a466531caa625b688b77 | 5,785 | md | Markdown | docs/project/usage.md | elb98rm/laravel-restful-api | 5d262a0df610cefbc6fd53cd84c13dfe5111f767 | [
"MIT"
] | null | null | null | docs/project/usage.md | elb98rm/laravel-restful-api | 5d262a0df610cefbc6fd53cd84c13dfe5111f767 | [
"MIT"
] | 1 | 2020-09-02T21:10:00.000Z | 2020-09-02T21:10:00.000Z | docs/project/usage.md | floor9design-ltd/laravel-restful-api | 5d262a0df610cefbc6fd53cd84c13dfe5111f767 | [
"MIT"
] | 1 | 2020-01-16T15:37:51.000Z | 2020-01-16T15:37:51.000Z | # Usage
## A restful example
... how to set up auto routes
## Routes
To be completed
### Models
The software requires several default values to be established, as well as some basic functionality set up.
This can be included as follows:
```php
use Floor9design\LaravelRestfulApi\Traits\JsonApiFilterTrait;
use Illuminate\Database\Eloquent\Model;
class User extends Model // or Authenticatable
{
use JsonApiFilterTrait;
// other functionality
}
```
Many users add validation to models in order to sanitise inputs.
Each model can optionally have validation. This is done by adding the `getValidation` method:
```php
use Floor9design\LaravelRestfulApi\Traits\JsonApiFilterTrait;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
use JsonApiFilterTrait;
// other functionality
public function getValidation(Model $model): array
{
return [];
}
}
```
The above code offers a validation array of `[]`, which is... no validation!
In this default case it is usually easier to use the optional trait:
```php
use Floor9design\LaravelRestfulApi\Traits\JsonApiFilterTrait;
use Floor9design\LaravelRestfulApi\Traits\ValidationTrait;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
use JsonApiFilterTrait, ValidationTrait;
// other functionality
}
```
While this is not a validation tutorial, here is an example of the `getValidation` method which has been overridden.
```php
use Floor9design\LaravelRestfulApi\Traits\JsonApiFilterTrait;
use Floor9design\LaravelRestfulApi\Traits\ValidationTrait;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
use JsonApiFilterTrait, ValidationTrait;
public function getValidation(?User $user = null)
{
if (!$user) {
$user = $this;
}
$validation = [
'id' => ['sometimes', 'exists:users', 'integer'],
'name' => ['required_without:id', 'max:255'],
'email' => ['required_without:id', 'email', Rule::unique('users')->ignore($user->id)],
'password' => ['required_without:id', 'min:5'],
'tel' => ['sometimes', 'max:20']
];
return $validation;
}
}
```
This contains some good example laravel validation techniques. The only thing of note is that the following is
required within the code:
```php
if (!$user) {
$user = $this;
}
```
Finally, the properties of the model need to be exposed. Often it is not appropriate to expose all properties, for
example `$user->password`. The `$api_array_filter` array can be added to expose these:
```php
use Floor9design\LaravelRestfulApi\Traits\JsonApiFilterTrait;
use Floor9design\LaravelRestfulApi\Traits\ValidationTrait;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
use JsonApiFilterTrait, ValidationTrait;
protected $api_array_filter = [
'name',
'email'
];
public function getValidation(?User $user = null)
{
if (!$user) {
$user = $this;
}
$validation = [
'id' => ['sometimes', 'exists:users', 'integer'],
'name' => ['required_without:id', 'max:255'],
'email' => ['required_without:id', 'email', Rule::unique('users')->ignore($user->id)],
'password' => ['required_without:id', 'min:5'],
'tel' => ['sometimes', 'max:20']
];
return $validation;
}
}
```
## Controllers
As discussed in [background](background.md), the main method to implement the classes is via the controller classes.
```php
namespace App\Http\Controllers;
use Floor9design\LaravelRestfulApi\Interfaces\JsonApiInterface;
use Floor9design\LaravelRestfulApi\Traits\JsonApiDefaultTrait;
use Floor9design\LaravelRestfulApi\Traits\JsonApiTrait;
class UsersController extends Controller implements JsonApiInterface
{
use JsonApiDefaultTrait;
use JsonApiTrait;
public function __construct()
{
$this->setControllerModel('\App\Models\User');
$this->setModelNameSingular('user');
$this->setModelNamePlural('users');
$this->setModel(new $this->controller_model);
$this->setUrlBase(route('some.route'));
}
}
```
Two core classes are shown:
* `JsonApiInterface` contracts the class into providing the correct methods
* `JsonApiTrait` provides basic functions
Finally:
* `JsonApiDefaultTrait` implements the default behaviour.
There are two classes that can be implemented here.
* `JsonApiDefaultTrait` implements the default behaviour.
* `JsonApi501Trait` implements JsonApi compliant 501 responses ("not implemented")
```php
use JsonApi501Trait;
use JsonApiTrait;
```
The above use statements would result in a class that correctly responded with JsonApi compliant 501 for all methods.
These can be combined, as the following examples show:
```php
use JsonApi501Trait;
use JsonApiDefaultTrait {
JsonApiDefaultTrait::jsonIndex insteadof JsonApi501Trait;
JsonApiDefaultTrait::jsonDetails insteadof JsonApi501Trait;
JsonApiDefaultTrait::jsonCreate insteadof JsonApi501Trait;
JsonApi501Trait::jsonCreateById insteadof JsonApiDefaultTrait;
JsonApi501Trait::jsonCollectionReplace insteadof JsonApiDefaultTrait;
JsonApi501Trait::jsonElementReplace insteadof JsonApiDefaultTrait;
JsonApi501Trait::jsonCollectionUpdate insteadof JsonApiDefaultTrait;
JsonApi501Trait::jsonElementUpdate insteadof JsonApiDefaultTrait;
JsonApi501Trait::jsonElementDelete insteadof JsonApiDefaultTrait;
JsonApi501Trait::jsonCollectionDelete insteadof JsonApiDefaultTrait;
}
use JsonApiTrait;
```
Here, two clashing traits use the `insteadof` keyword to choose the correct method to apply.
## custom restful calls
* overwriting
| 26.536697 | 117 | 0.716335 | eng_Latn | 0.732925 |
110e533f17a7504b63a6c7be7a42ef39e1027f23 | 972 | md | Markdown | htdocs/piwik/libs/UserAgentParser/README.md | CarnosOS/ArcherVMPeridot | 1ca89b6e3e7797416bb2fddeeb061951f10fa8cb | [
"Apache-2.0",
"MIT"
] | null | null | null | htdocs/piwik/libs/UserAgentParser/README.md | CarnosOS/ArcherVMPeridot | 1ca89b6e3e7797416bb2fddeeb061951f10fa8cb | [
"Apache-2.0",
"MIT"
] | null | null | null | htdocs/piwik/libs/UserAgentParser/README.md | CarnosOS/ArcherVMPeridot | 1ca89b6e3e7797416bb2fddeeb061951f10fa8cb | [
"Apache-2.0",
"MIT"
] | null | null | null | # UserAgentParser
UserAgentParser is a php library to parse user agents,
and extracts browser name & version and operating system.
UserAgentParser is NOT designed to parse bots user agent strings;
UserAgentParser will only be accurate when parsing user agents
coming from Javascript Enabled browsers!
UserAgentParser is designed for simplicity, to accurately detect the
most used web browsers, and be regularly updated to detect new OS and browsers.
Potential limitations:
* it does NOT detect sub sub versions, ie. the "5" in 1.4.5; this is a design decision to simplify the version number
* it does NOT detect search engine, bots, etc. user agents; it's designed to detect browsers with javascript enabled
* it does NOT detect nested UA strings caused by some browser add-ons
Feature request:
* it could have the notion of operating system "types", ie "Windows". It currently only has "Windows XP", "Windows Vista", etc.
Feedback, patches: [email protected]
| 40.5 | 128 | 0.784979 | eng_Latn | 0.996301 |
110e83d07bcef3e58470a3993093454dbd0a1472 | 4,611 | md | Markdown | content/code-security/repository-security-advisories/permission-levels-for-repository-security-advisories.md | hariharan2822/docs | 0256da2b47050c73fea87f58a8be7fbdb767cdd9 | [
"CC-BY-4.0",
"MIT"
] | 6 | 2022-03-09T07:09:42.000Z | 2022-03-09T07:14:08.000Z | content/code-security/repository-security-advisories/permission-levels-for-repository-security-advisories.md | Clam-u/docs | ab4d585e39e5c65c8b86cab5df27884a59dfccec | [
"CC-BY-4.0",
"MIT"
] | 133 | 2021-11-01T18:16:33.000Z | 2022-03-29T18:18:46.000Z | content/code-security/repository-security-advisories/permission-levels-for-repository-security-advisories.md | Waleedalaedy/docs | 26d4b73dcbb9a000c32faa37234288649f8d211a | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-10-05T09:44:04.000Z | 2021-10-05T09:44:52.000Z | ---
title: Permission levels for repository security advisories
intro: The actions you can take in a repository security advisory depend on whether you have admin or write permissions to the security advisory.
redirect_from:
- /articles/permission-levels-for-maintainer-security-advisories
- /github/managing-security-vulnerabilities/permission-levels-for-maintainer-security-advisories
- /github/managing-security-vulnerabilities/permission-levels-for-security-advisories
- /code-security/security-advisories/permission-levels-for-security-advisories
versions:
fpt: '*'
ghec: '*'
type: reference
topics:
- Security advisories
- Vulnerabilities
- Permissions
shortTitle: Permission levels
---
This article applies only to repository-level security advisories. Anyone can contribute to global security advisories in the {% data variables.product.prodname_advisory_database %} at [github.com/advisories](https://github.com/advisories). Edits to global advisories will not change or affect how the advisory appears on the repository. For more information, see "[Editing security advisories in the {% data variables.product.prodname_advisory_database %}](/code-security/supply-chain-security/managing-vulnerabilities-in-your-projects-dependencies/editing-security-advisories-in-the-github-advisory-database)."
## Permissions overview
{% data reusables.repositories.security-advisory-admin-permissions %} For more information about adding a collaborator to a security advisory, see "[Adding a collaborator to a repository security advisory](/code-security/repository-security-advisories/adding-a-collaborator-to-a-repository-security-advisory)."
Action | Write permissions | Admin permissions |
------ | ----------------- | ----------------- |
See a draft security advisory | X | X |
Add collaborators to the security advisory (see "[Adding a collaborator to a repository security advisory](/code-security/repository-security-advisories/adding-a-collaborator-to-a-repository-security-advisory)") | | X |
Edit and delete any comments in the security advisory | X | X |
Create a temporary private fork in the security advisory (see "[Collaborating in a temporary private fork to resolve a repository security vulnerability](/code-security/repository-security-advisories/collaborating-in-a-temporary-private-fork-to-resolve-a-repository-security-vulnerability)") | | X |
Add changes to a temporary private fork in the security advisory (see "[Collaborating in a temporary private fork to resolve a repository security vulnerability](/code-security/repository-security-advisories/collaborating-in-a-temporary-private-fork-to-resolve-a-repository-security-vulnerability)") | X | X |
Create pull requests in a temporary private fork (see "[Collaborating in a temporary private fork to resolve a repository security vulnerability](/code-security/repository-security-advisories/collaborating-in-a-temporary-private-fork-to-resolve-a-repository-security-vulnerability)") | X | X |
Merge changes in the security advisory (see "[Collaborating in a temporary private fork to resolve a repository security vulnerability](/code-security/repository-security-advisories/collaborating-in-a-temporary-private-fork-to-resolve-a-repository-security-vulnerability)") | | X |
Add and edit metadata in the security advisory (see "[Publishing a repository security advisory](/code-security/repository-security-advisories/publishing-a-repository-security-advisory)") | X | X |
Add and remove credits for a security advisory (see "[Editing a repository security advisory](/code-security/repository-security-advisories/editing-a-repository-security-advisory)") | X | X |
Close the draft security advisory | | X |
Publish the security advisory (see "[Publishing a repository security advisory](/code-security/repository-security-advisories/publishing-a-repository-security-advisory)") | | X |
## Further reading
- "[Adding a collaborator to a repository security advisory](/code-security/repository-security-advisories/adding-a-collaborator-to-a-repository-security-advisory)"
- "[Collaborating in a temporary private fork to resolve a repository security vulnerability](/code-security/repository-security-advisories/collaborating-in-a-temporary-private-fork-to-resolve-a-repository-security-vulnerability)"
- "[Removing a collaborator from a repository security advisory](/code-security/repository-security-advisories/removing-a-collaborator-from-a-repository-security-advisory)"
- "[Withdrawing a repository security advisory](/code-security/repository-security-advisories/withdrawing-a-repository-security-advisory)"
| 102.466667 | 613 | 0.802212 | eng_Latn | 0.858115 |
110e9094e930742838e086d5462d33a1057b7664 | 1,737 | md | Markdown | includes/migration-guide/retargeting/wpf/default-hash-algorithm-for-wpf-packagedigitalsignaturemanager-now-sha256.md | SilverBuzzard/docs.pl-pl | a3cda910e7b4b30f2c3c449c742dce1be42067b5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/migration-guide/retargeting/wpf/default-hash-algorithm-for-wpf-packagedigitalsignaturemanager-now-sha256.md | SilverBuzzard/docs.pl-pl | a3cda910e7b4b30f2c3c449c742dce1be42067b5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/migration-guide/retargeting/wpf/default-hash-algorithm-for-wpf-packagedigitalsignaturemanager-now-sha256.md | SilverBuzzard/docs.pl-pl | a3cda910e7b4b30f2c3c449c742dce1be42067b5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ### <a name="the-default-hash-algorithm-for-wpf-packagedigitalsignaturemanager-is-now-sha256"></a>Domyślny algorytm skrótu dla WPF PackageDigitalSignatureManager jest teraz SHA256
| | |
|---|---|
|Szczegóły|<code>System.IO.Packaging.PackageDigitalSignatureManager</code> Oferuje funkcję dla podpisów cyfrowych w odniesieniu do pakietów programu WPF. W .NET Framework 4.7 i wcześniejszymi wersjami, domyślny algorytm (<xref:System.IO.Packaging.PackageDigitalSignatureManager.DefaultHashAlgorithm?displayProperty=nameWithType>) używany do podpisywania części pakietu zostało SHA1. Ze względu na ostatnie obawy związane z bezpieczeństwem z SHA1, to ustawienie domyślne zostało zmienione na SHA256 począwszy od programu .NET Framework 4.7.1. Ta zmiana ma wpływ na wszystkie podpisywanie pakietów, łącznie z dokumenty XPS.|
|Sugestia|Deweloper, który chce korzystać z tej zmiany podczas określania wartości docelowej framework w wersji starszej niż .NET Framework 4.7.1 lub deweloper, który wymaga poprzedniej funkcji, a przeznaczonych dla platformy .NET Framework 4.7.1 lub większą może ustawić następujące flagi AppContext odpowiednio. Wartość true, wynikiem będzie SHA1 używany jako domyślny algorytm; FALSE powoduje SHA256.<pre><code class="lang-xml"><configuration> <runtime> <AppContextSwitchOverrides value="Switch.MS.Internal.UseSha1AsDefaultHashAlgorithmForDigitalSignatures=true"/> </runtime> </configuration> </code></pre>|
|Zakres|Krawędź|
|Wersja|4.7.1|
|Typ|Trwa przekierowywanie|
|Dotyczy interfejsów API|<ul><li><xref:System.IO.Packaging.PackageDigitalSignatureManager.DefaultHashAlgorithm?displayProperty=nameWithType></li></ul>|
| 144.75 | 696 | 0.803685 | pol_Latn | 0.997916 |
110eb3604591f52d3049111138a5f60e7bcc7cae | 4,901 | md | Markdown | bu-ding-chang-shi-xu-de-xun-huan-shen-jing-wang-luo.md | Knowledge-Precipitation-Tribe/Recurrent-neural-network | 44faf239784d6318c986ae39a0a1982786e951fe | [
"MIT"
] | 2 | 2021-03-28T01:35:49.000Z | 2021-11-26T01:46:18.000Z | bu-ding-chang-shi-xu-de-xun-huan-shen-jing-wang-luo.md | Knowledge-Precipitation-Tribe/Recurrent-neural-network | 44faf239784d6318c986ae39a0a1982786e951fe | [
"MIT"
] | null | null | null | bu-ding-chang-shi-xu-de-xun-huan-shen-jing-wang-luo.md | Knowledge-Precipitation-Tribe/Recurrent-neural-network | 44faf239784d6318c986ae39a0a1982786e951fe | [
"MIT"
] | null | null | null | # 不定长时序的循环神经网络
本小节中,我们将学习具有不固定的时间步的循环神经网络网络,用于多分类功能。
## 提出问题
各个国家的人都有自己习惯的一些名字,下面列举出了几个个国家/语种的典型名字$$^{[1]}$$:
```text
Guan Chinese
Rong Chinese
Bond English
Stone English
Pierre French
Vipond French
Metz German
Neuman German
Aggio Italian
Falco Italian
Akimoto Japanese
Hitomi Japanese
```
名字都是以ASCII字母表示的,以便于不同语种直接的比较。
如果隐藏掉第二列,只看前面的名字的话,根据发音、拼写习惯等,我们可以大致猜测出这些名字属于哪个国家/语种。当然也有一些名字是重叠的,比如“Lang”,会同时出现在English、Chinese、German等几种语种里。
既然人类可以凭借一些模糊的知识分辨名字与国家/语种的关系,那么神经网络能否也具备这个能力呢?
下面我们仍然借助于循环神经网络来完成这个任务。
## 准备数据
循环神经网络的要点是“循环”二字,也就是说一个样本中的数据要分成连续若干个时间步,然后逐个“喂给”网络进行训练。如果两个样本的时间步总数不同,是不能做为一个批量一起喂给网络的,比如一个名字是Rong,另一个名字是Aggio,这两个名字不能做为一批计算。
在本例中,由于名字的长度不同,所以不同长度的两个名字,是不能放在一个batch里做批量运算的。但是如果一个一个地训练样本,将会花费很长的时间,所以需要我们对本例中的数据做一个特殊的处理:
1. 先按字母个数(名字的长度)把所有数据分开,由于最短的名字是2个字母,最长的是19个字母,所以一共应该有18组数据(实际上只有15组,中间有些长度的名字不存在)。
2. 使用OneHot编码把名字转换成向量,比如:名字为“Duan”,变成小写字母“duan”,则OneHot编码是:
```text
[[0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], # d
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0], # u
[1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], # a
[0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0]] # n
```
3. 把所有相同长度的名字的OneHot编码都堆放在一个矩阵中,形成批量,这样就是成为了一个三维矩阵:
* 第一维是名字的数量,假设一共有230个4个字母的名字,175个5个字母的名字,等等;
* 第二维是4或者5或者其它值,即字母个数,也是时间步的个数;
* 第三维是26,即a~z的小写字母的个数,相应的位为1,其它位为0。
在用SGD方法训练时,先随机选择一个组,假设是6个字母的名字,再从这一组中随机选择一个小批量,比如8个名字,这样就形成了一个8x6x26的三维批量数据。如果随机选到了7个字母的组,最后会形成8x7x26的三维批量数据。
## 搭建不定长时序的网络
### 搭建网络
为什么是不定长时序的网络呢?因为名字的单词中的字母个数不是固定的,最少的两个字母,最多的有19个字母。

在图19-18中,n=19,可以容纳19个字母的单词。为了节省空间,把最后一个时间步的y和loss画在了拐弯的位置。
并不是所有的时序都需要做分类输出,而是只有最后一个时间步需要。比如当名字是“guan”时,需要在第4个时序做分类输出,并加监督信号做反向传播,而前面3个时序不需要。但是当名字是“baevsky”时,需要在第7个时间步做分类输出。所以n值并不是固定的。
对于最后一个时间步,展开成前馈神经网络中的标准Softmax多分类。
### 前向计算
在前面已经介绍过通用的方法,所以不再赘述。本例中的特例是分类函数使用Softmax,损失函数使用多分类交叉熵函数:
$$ a = Softmax(z) \tag{1} $$
$$ Loss = loss_{\tau} = -y \odot \ln a \tag{2} $$
### 反向传播
反向传播的推导和前面两节区别不大,唯一的变化是Softmax接多分类交叉熵损失函数。
## 代码实现
其它部分的代码都大同小异,只有主循环部分略有不同:
```python
def train(self, dataReader, checkpoint=0.1):
...
for epoch in range(self.hp.max_epoch):
self.hp.eta = self.lr_decay(epoch)
dataReader.Shuffle()
while(True):
batch_x, batch_y = dataReader.GetBatchTrainSamples(self.hp.batch_size)
if (batch_x is None):
break
self.forward(batch_x)
self.backward(batch_y)
self.update()
...
```
获得批量训练数据函数,可以保证取到相同时间步的一组样本,这样就可以进行批量训练了,提高速度和准确度。如果取回None数据,说明所有样本数据都被使用过一次了,则结束本轮训练,检查损失函数值,然后进行下一个epoch的训练。
## 运行结果
我们需要下面一组超参来控制模型训练:
```python
eta = 0.02
max_epoch = 100
batch_size = 8
num_input = dataReader.num_feature
num_hidden = 16
num_output = dataReader.num_category
```
几个值得注意的地方是:
1. 学习率较大或者batch\_size较小时,会造成网络不收敛,损失函数高居不下,或者来回震荡;
2. 隐层神经元数量为16,虽然输入的x的特征值向量数为26,但却是OneHot编码,有效信息很少,所以不需要很多的神经元数量。
最后得到的损失函数曲线如图19-19所示。可以看到两条曲线的抖动都比较厉害,此时可以适当地降低学习率来使曲线平滑,收敛趋势稳定。

本例没有独立的测试数据,所以最后是在训练数据上做的测试,打印输出如下所示:
```python
...
99:55800:0.02 loss=0.887763, acc=0.707000
correctness=2989/4400=0.6793181818181818
load best parameters...
correctness=3255/4400=0.7397727272727272
```
训练100个epoch后得到的准确率为67.9%,其间我们保存了损失函数值最小的时刻的参数矩阵值,使用load best parameters方法后,再次测试,得到73.9%的准确率。
由于是多分类问题,所以我们尝试使用混淆矩阵的方式来分析结果。
表19-9
| 最后的效果 | 最好的效果 |
| :--- | :--- |
|  |  |
| 准确率为67.9%的混淆矩阵 | 准确率为73.9%的混淆矩阵 |
在表19-9中的图中,对角线上的方块越亮,表示识别越准确。
左图,对于Dutch,被误识别为German类别的数量不少,所以Dutch-German交叉点的方块较亮,原因是German的名字确实比较多,两国的名字比较相近,使用更好的超参或更多的迭代次数可以改善。而French被识别为Irish的也比较多。
表19-9右图,可以看到非对角线位置的可见方块的数量明显减少,这也是准确率高的体现。
## keras实现
```python
一般的通用做法都需要先将一个batch中的所有序列padding到同一长度,
然后需要在网络训练时屏蔽掉padding的值。
Keras中自带的屏蔽padding值的方式,在网络结构比较简单时使用很方便。
model = Sequential()
model.add(Masking(mask_value=0., input_shape=(timesteps, features)))
model.add(LSTM(32))
```
## 代码位置
原代码位置:[ch19, Level5](https://github.com/microsoft/ai-edu/blob/master/A-%E5%9F%BA%E7%A1%80%E6%95%99%E7%A8%8B/A2-%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86%E7%AE%80%E6%98%8E%E6%95%99%E7%A8%8B/SourceCode/ch19-RNNBasic/Level5_NameClassifier.py)
个人代码:[**NameClassifier**](https://github.com/Knowledge-Precipitation-Tribe/Recurrent-neural-network/blob/f66f9ce167/code/NameClassifier.py)\*\*\*\*
## 参考资料
\[1\] PyTorch Sample, link: [https://pytorch.org/tutorials/intermediate/char\_rnn\_classification\_tutorial.html](https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html)
| 27.689266 | 270 | 0.733728 | yue_Hant | 0.581389 |
110fa4ddf1dec30465c543666ba3808662425dd4 | 12,663 | md | Markdown | help/assets/assets-migration-guide.md | ksherwoo/experience-manager-64.en | 316770040c3d3f8cdbf503374ff5ddced3f42641 | [
"MIT"
] | null | null | null | help/assets/assets-migration-guide.md | ksherwoo/experience-manager-64.en | 316770040c3d3f8cdbf503374ff5ddced3f42641 | [
"MIT"
] | null | null | null | help/assets/assets-migration-guide.md | ksherwoo/experience-manager-64.en | 316770040c3d3f8cdbf503374ff5ddced3f42641 | [
"MIT"
] | null | null | null | ---
title: Migrate assets to Adobe Experience Manager Assets in bulk
description: How to bring assets into AEM, apply metadata, generate renditions, and activate them to publish instances.
contentOwner: AG
feature: Migration,Renditions,Asset Management
role: Architect,Admin
exl-id: 31da9f3d-460a-4b71-9ba0-7487f1b159cb
---
# Assets migration guide {#assets-migration-guide}
When migrating assets into AEM, there are several steps to consider. Extracting assets and metadata out of their current home is outside the scope of this document as it varies widely between implementations. Instead, this document describes how to bring these assets into AEM, apply their metadata, generate renditions, and activate or publish the assets.
## Prerequisites {#prerequisites}
Before performing any of the steps described below, review and implement the guidance in [Assets performance tuning tips](performance-tuning-guidelines.md). Many steps, such as configuring maximum concurrent jobs, enhance the server’s stability and performance under load. Other steps, such as File Data Store configuration, are difficult to perform after the system has been loaded with assets.
>[!NOTE]
>
>The following asset migration tools are not part of Adobe Experience Manager. Adobe Customer Care does not support these tools.
>
>* ACS AEM Tools Tag Maker
>* ACS AEM Tools CSV Asset Importer
>* ACS Commons Bulk Workflow Manager
>* ACS Commons Fast Action Manager
>* Synthetic Workflow
>
>This software are open source and covered by the [Apache v2 License](https://adobe-consulting-services.github.io/pages/license.html). To ask a question or report an issue, visit the respective [GitHub Issues for ACS AEM Tools](https://github.com/Adobe-Consulting-Services/acs-aem-commons/issues) and [ACS AEM Commons](https://github.com/Adobe-Consulting-Services/acs-aem-tools/issues).
## Migrate to AEM {#migrate-to-aem}
Migrating assets to AEM requires several steps and should be viewed as a phased process. The phases of the migration are as follows:
1. Disable workflows.
1. Load tags.
1. Ingest assets.
1. Process renditions.
1. Activate assets.
1. Enable workflows.

### Disable workflows {#disable-workflows}
Before you start a migration, disable the launchers for the `DAM Update Asset` workflow. It is best to ingest all assets into the system and then run the workflows in batches. If you are already live while the migration is taking place, you can schedule these activities to execute during off-hours.
### Load tags {#load-tags}
You may already have a tag taxonomy in place that you are applying to your images. Tools such as the CSV Asset Importer and the metadata profiles functionality can help automate application of tags to assets. Before this, add the tags in Experience Manager. The [ACS AEM Tools Tag Maker](https://adobe-consulting-services.github.io/acs-aem-tools/features/tag-maker/index.html) feature lets you populate tags by using a Microsoft Excel spreadsheet that is loaded into the system.
### Ingest assets {#ingest-assets}
Performance and stability are important concerns when ingesting assets into the system. When loading a lot of data in Experience Manager, ensure that the system performs well. This minimized the time required to add the data and helps to avoid overloading the system. This helps prevent system crash, especially in systems that already are in production.
There are two approaches to loading the assets into the system: a push-based approach using HTTP or a pull-based approach using the JCR APIs.
#### Push through HTTP {#push-through-http}
Adobe’s Managed Services team uses a tool called Glutton to load data into customer environments. Glutton is a small Java application that loads all assets from one directory into another directory on an AEM instance. Instead of Glutton, you could also use tools such as Perl scripts to post the assets into the repository.
There are two main downsides to using the approach of pushing through https:
1. Transmit the assets over HTTP to the server. This requires quite a bit of overhead and is time-consuming, thus lengthening the time that it takes to perform your migration.
1. If you have tags and custom metadata that must be applied to the assets, this approach requires a second custom process that you need to run to apply this metadata to the assets once they have been imported.
The other approach to ingesting assets is to pull assets from the local file system. However, if you cannot get an external drive or network share mounted to the server to perform a pull-based approach, posting the assets over HTTP is the best option.
#### Pull from the local file system {#pull-from-the-local-file-system}
The [ACS AEM Tools CSV Asset Importer](https://adobe-consulting-services.github.io/acs-aem-tools/features/csv-asset-importer/index.html) pulls assets from the file system and asset metadata from a CSV file for the asset import. The AEM Asset Manager API is used to import the assets into the system and apply the configured metadata properties. Ideally, assets are mounted on the server via a network file mount or through an external drive.
When assets are not transmitted over a network the overall performance improves a lot. This method is usually the most efficient method to load assets into the repository. Additionally, you can import all assets and metadata in a single step as the tool supports metadata ingestion. No other step is required to apply the metadata, say using a separate tool.
### Process renditions {#process-renditions}
After you load the assets into the system, you need to process them through the DAM Update Asset workflow to extract metadata and generate renditions. Before performing this step, you need to duplicate and modify the DAM Update Asset workflow to fit your needs. Some steps in the default workflow may not be necessary for you, such as Dynamic Media Classic PTIFF generation or InDesign server integration.
After you have configured the workflow according to your needs, you have two options to execute it:
1. The simplest approach is [ACS Commons’ Bulk Workflow Manager](https://adobe-consulting-services.github.io/acs-aem-commons/features/bulk-workflow-manager.html). This tool allows you to execute a query and to process the results of the query through a workflow. There are options for setting batch sizes as well.
1. You can use the [ACS Commons Fast Action Manager](https://adobe-consulting-services.github.io/acs-aem-commons/features/fast-action-manager.html) in concert with [Synthetic Workflows](https://adobe-consulting-services.github.io/acs-aem-commons/features/synthetic-workflow.html). While this approach is much more involved, it lets you remove the overhead of the AEM workflow engine while optimizing the use of server resources. Additionally, the Fast Action Manager further boosts performance by dynamically monitoring server resources and throttling the load placed on the system. Example scripts have been provided on the ACS Commons feature page.
### Activate assets {#activate-assets}
For deployments that have a publish tier, you need to activate the assets out to the publish farm. While Adobe recommends running more than a single publish instance, it is most efficient to replicate all of the assets to a single publish instance and then clone that instance. When activating large numbers of assets, after triggering a tree activation, you may need to intervene. Here's why: When firing off activations, items are added to the Sling jobs/event queue. After the size of this queue begins to exceed approximately 40,000 items, processing slows dramatically. After the size of this queue exceeds 100,000 items, system stability starts to suffer.
To work around this issue, you can use the [Fast Action Manager](https://adobe-consulting-services.github.io/acs-aem-commons/features/fast-action-manager.html) to manage asset replication. This works without using the Sling queues, lowering overhead, while throttling the workload to prevent the server from becoming overloaded. An example of using FAM to manage replication is shown on the feature’s documentation page.
Other options for getting assets to the publish farm include using [vlt-rcp](https://jackrabbit.apache.org/filevault/rcp.html) or [oak-run](https://github.com/apache/jackrabbit-oak/tree/trunk/oak-run), which are provided as tools as part of Jackrabbit. Another option is to use an open-sourced tool for your AEM infrastructure called [Grabbit](https://github.com/TWCable/grabbit), which claims to have faster performance than vlt.
For any of these approaches, the caveat is that the assets on the author instance do not show as having been activated. To handle flagging these assets with correct activation status, you need to also run a script to mark the assets as activated.
>[!NOTE]
>
>Adobe does not maintain or support Grabbit.
### Clone Publish {#clone-publish}
After the assets have been activated, you can clone your publish instance to create as many copies as are necessary for the deployment. Cloning a server is fairly straightforward, but there are some important steps to remember. To clone publish:
1. Back up the source instance and the datastore.
1. Restore the backup of the instance and datastore to the target location. The following steps all refer to this new instance.
1. Perform a file system search under `crx-quickstart/launchpad/felix` for `sling.id`. Delete this file.
1. Under the root path of the datastore, locate and delete any `repository-XXX` files.
1. Edit `crx-quickstart/install/org.apache.jackrabbit.oak.plugins.blob.datastore.FileDataStore.config` and `crx-quickstart/launchpad/config/org/apache/jackrabbit/oak/plugins/blob/datastore/FileDataStore.config` to point to the location of the datastore on the new environment.
1. Start the environment.
1. Update the configuration of any replication agents on the author(s) to point to the correct publish instances or dispatcher flush agents on the new instance to point to the correct dispatchers for the new environment.
### Enable workflows {#enable-workflows}
Once we have completed migration, the launchers for the DAM Update Asset workflows should be re-enabled to support rendition generation and metadata extraction for ongoing day-to-day system usage.
## Migrate assets across AEM deployments {#migrate-between-aem-instances}
While not nearly as common, sometimes you need to migrate large amounts of data from one AEM instance to another; for example, when you perform an AEM upgrade, upgrade your hardware, or migrate to a new datacenter, such as with an AMS migration.
In this case, your assets are already populated with metadata and renditions are already generated. You can simply focus on moving assets from one instance to another. When migrating between AEM instances, you perform the following steps:
1. Disable workflows: Because you are migrating renditions along with our assets, you want to disable the workflow launchers for DAM Update Asset.
1. Migrate tags: Because you already have tags loaded in the source AEM instance, you can build them in a content package and install the package on the target instance.
1. Migrate assets: There are two tools that are recommended for moving assets from one AEM instance to another:
* **Vault Remote Copy**, or `vlt rcp`, allows you to use vlt across a network. You can specify a source and destination directory and vlt downloads all repository data from one instance and loads it into the other. Vlt rcp is documented at [https://jackrabbit.apache.org/filevault/rcp.html](https://jackrabbit.apache.org/filevault/rcp.html)
* **Grabbit** is an open-source content synchronization tool that was developed by Time Warner Cable for their AEM implementation. Because it uses continuous data streams, in comparison to vlt rcp, it has a lower latency and claims a speed improvement of two to ten times faster than vlt rcp. Grabbit also supports synchronization of delta content only, which allows it to sync changes after an initial migration pass has been completed.
1. Activate assets: Follow the instructions for [activating assets](#activate-assets) documented for the initial migration to AEM.
1. Clone publish: As with a new migration, loading a single publish instance and cloning it is more efficient than activating the content on both nodes. See [Cloning Publish.](#clone-publish)
1. Enabling workflows: After you have completed migration, re-enable the launchers for the DAM Update Asset workflows to support rendition generation and metadata extraction for ongoing day-to-day system usage.
| 95.931818 | 661 | 0.800521 | eng_Latn | 0.998149 |
110ff3e26d5765b6c084d4402c0b932a62c02ccd | 335 | md | Markdown | README.md | yuhsiangfu/otsu-threshold-selection | 4d61aecfd10e5e321bb8b59a028cb2d60f4299a2 | [
"MIT"
] | null | null | null | README.md | yuhsiangfu/otsu-threshold-selection | 4d61aecfd10e5e321bb8b59a028cb2d60f4299a2 | [
"MIT"
] | null | null | null | README.md | yuhsiangfu/otsu-threshold-selection | 4d61aecfd10e5e321bb8b59a028cb2d60f4299a2 | [
"MIT"
] | null | null | null | # Otsu-Threshold-Selection
In this project, it shows the implementation of Otsu method. The original Otsu method, the graph structure and the depth first search (DFS) were used to implement the multi-threshold method.
# Contact
1.If you have any questions please email to [email protected].<br />
Yu-Hsiang Fu, 20180326 updated.
| 41.875 | 190 | 0.785075 | eng_Latn | 0.995185 |
1110e93770d5a5f5f69a08e3858af0bd4b1022b9 | 10,373 | md | Markdown | articles/cosmos-db/cosmosdb-sql-api-migrate-data-striim.md | wastu01/azure-docs.zh-tw | 7ee2fba199b6243c617953684afa67b83b2acc82 | [
"CC-BY-4.0",
"MIT"
] | 66 | 2017-08-24T10:28:13.000Z | 2022-03-04T14:01:29.000Z | articles/cosmos-db/cosmosdb-sql-api-migrate-data-striim.md | wastu01/azure-docs.zh-tw | 7ee2fba199b6243c617953684afa67b83b2acc82 | [
"CC-BY-4.0",
"MIT"
] | 534 | 2017-06-30T19:57:07.000Z | 2022-03-11T08:12:44.000Z | articles/cosmos-db/cosmosdb-sql-api-migrate-data-striim.md | wastu01/azure-docs.zh-tw | 7ee2fba199b6243c617953684afa67b83b2acc82 | [
"CC-BY-4.0",
"MIT"
] | 105 | 2017-07-04T11:37:54.000Z | 2022-03-20T06:10:38.000Z | ---
title: 使用 Striim 將資料移轉至 Azure Cosmos DB SQL API 帳戶
description: 瞭解如何使用 Striim 將資料從 Oracle 資料庫移轉至 Azure Cosmos DB SQL API 帳戶。
author: SnehaGunda
ms.service: cosmos-db
ms.subservice: cosmosdb-sql
ms.topic: how-to
ms.date: 07/22/2019
ms.author: sngun
ms.reviewer: sngun
ms.openlocfilehash: 136853182e353ad5cd71981db5935fc3babe162e
ms.sourcegitcommit: fa90cd55e341c8201e3789df4cd8bd6fe7c809a3
ms.translationtype: MT
ms.contentlocale: zh-TW
ms.lasthandoff: 11/04/2020
ms.locfileid: "93339586"
---
# <a name="migrate-data-to-azure-cosmos-db-sql-api-account-using-striim"></a>使用 Striim 將資料移轉至 Azure Cosmos DB SQL API 帳戶
[!INCLUDE[appliesto-sql-api](includes/appliesto-sql-api.md)]
Azure marketplace 中的 Striim 映射提供從資料倉儲和資料庫到 Azure 的連續即時資料移動。 移動資料時,您可以執行內嵌反正規化、資料轉換、啟用即時分析和資料包表案例。 您可以輕鬆地開始使用 Striim,持續將企業資料移至 Azure Cosmos DB SQL API。 Azure 提供 marketplace 供應專案,可讓您輕鬆地部署 Striim,並將資料移轉至 Azure Cosmos DB。
本文說明如何使用 Striim 將 **Oracle 資料庫** 中的資料移轉至 **Azure Cosmos DB SQL API 帳戶** 。
## <a name="prerequisites"></a>必要條件
* 如果您沒有 [Azure 訂用帳戶](../guides/developer/azure-developer-guide.md#understanding-accounts-subscriptions-and-billing),請在開始前建立[免費帳戶](https://azure.microsoft.com/free/?ref=microsoft.com&utm_source=microsoft.com&utm_medium=docs&utm_campaign=visualstudio)。
* 在內部部署執行且有一些資料的 Oracle 資料庫。
## <a name="deploy-the-striim-marketplace-solution"></a>部署 Striim marketplace 解決方案
1. 登入 [Azure 入口網站](https://portal.azure.com/)。
1. 選取 [ **建立資源** ],並在 Azure marketplace 中搜尋 **Striim** 。 選取第一個選項,然後 **建立** 。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/striim-azure-marketplace.png" alt-text="尋找 Striim marketplace 專案":::
1. 接著,輸入 Striim 實例的設定屬性。 Striim 環境會部署在虛擬機器中。 在 [ **基本** ] 窗格中,輸入 **vm 使用者名稱** 、 **vm 密碼** (此密碼用來透過 SSH 連線到 VM) 。 選取您要部署 Striim 的 **訂** 用帳戶、 **資源群組** 和 **位置詳細資料** 。 完成之後,請選取 **[確定]** 。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/striim-configure-basic-settings.png" alt-text="設定 Striim 的基本設定":::
1. 在 [ **Striim 叢集設定** ] 窗格中,選擇 Striim 部署的類型和虛擬機器大小。
|設定 | 值 | 描述 |
| ---| ---| ---|
|Striim 部署類型 |獨立 | Striim 可在 **獨立****或叢集** 部署類型中執行。 獨立模式會將 Striim 伺服器部署在單一虛擬機器上,而且您可以根據您的資料量來選取 Vm 的大小。 叢集模式會將 Striim 伺服器部署在具有所選大小的兩部或多部 Vm 上。 具有2個以上節點的叢集環境提供自動高可用性和容錯移轉。</br></br> 在本教學課程中,您可以選取 [獨立] 選項。 使用預設的「Standard_F4s」大小的 VM。 |
| Striim 叢集的名稱| <Striim_cluster_Name>| Striim 叢集的名稱。|
| Striim 叢集密碼| <Striim_cluster_password>| 叢集的密碼。|
填滿表單之後,選取 **[確定]** 以繼續。
1. 在 [ **Striim 存取設定** ] 窗格中,設定 [ **公用 IP 位址** ] (選擇預設值) 、您要用來登入 Striim UI 的 [ **Striim 的功能變數名稱** ]、[ **管理員密碼** ]。 設定 VNET 和子網 (選擇) 的預設值。 填入詳細資料之後,選取 **[確定]** 以繼續。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/striim-access-settings.png" alt-text="Striim 存取設定":::
1. Azure 會驗證部署,並確定一切看起來良好;驗證需要幾分鐘的時間才能完成。 驗證完成之後,請選取 **[確定]** 。
1. 最後,請參閱使用條款,然後選取 [ **建立** ] 以建立您的 Striim 實例。
## <a name="configure-the-source-database"></a>設定源資料庫
在本節中,您會將 Oracle 資料庫設定為數據移動的來源。 您必須要有 [ORACLE JDBC 驅動程式](https://www.oracle.com/technetwork/database/features/jdbc/jdbc-ucp-122-3110062.html) ,才能連接到 oracle。 若要從來源 Oracle 資料庫讀取變更,您可以使用 [LogMiner](https://www.oracle.com/technetwork/database/features/availability/logmineroverview-088844.html) 或 [XStream api](https://docs.oracle.com/cd/E11882_01/server.112/e16545/xstrm_intro.htm#XSTRM72647)。 Oracle JDBC 驅動程式必須存在於 Striim 的 JAVA 類別路徑中,才能從 Oracle 資料庫讀取、寫入或保存資料。
將 [ojdbc8 .jar](https://www.oracle.com/technetwork/database/features/jdbc/jdbc-ucp-122-3110062.html) 驅動程式下載到您的本機電腦。 您稍後會將其安裝在 Striim 叢集中。
## <a name="configure-the-target-database"></a>設定目標資料庫
在本節中,您會將 Azure Cosmos DB SQL API 帳戶設定為數據移動的目標。
1. 使用 Azure 入口網站建立 [AZURE COSMOS DB SQL API 帳戶](create-cosmosdb-resources-portal.md) 。
1. 流覽至 Azure Cosmos 帳戶中的 [ **資料總管** ] 窗格。 選取 [ **新增容器** ] 以建立新的容器。 假設您要將 *產品* 和 *訂單* 資料從 Oracle database 遷移至 Azure Cosmos DB。 使用名為 **Orders** 的容器來建立名為 **StriimDemo** 的新資料庫。 使用 **1000** ru 布建容器 (此範例使用 1000 ru,但您應該使用針對您的工作負載所估計的輸送量) 和 **/ORDER_ID** 作為分割區索引鍵。 這些值會根據您的來源資料而有所不同。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/create-sql-api-account.png" alt-text="建立 SQL API 帳戶":::
## <a name="configure-oracle-to-azure-cosmos-db-data-flow"></a>設定 Oracle 以 Azure Cosmos DB 資料流程
1. 現在,讓我們回到 Striim。 與 Striim 互動之前,請先安裝您稍早下載的 Oracle JDBC 驅動程式。
1. 流覽至您在 Azure 入口網站中部署的 Striim 實例。 選取上方功能表列中的 [連線 **]** 按鈕,然後從 [ **SSH** ] 索引標籤中,複製 [ **使用 VM 本機帳戶登** 入] 欄位中的 URL。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/get-ssh-url.png" alt-text="取得 SSH URL":::
1. 開啟新的終端機視窗,並執行您從 Azure 入口網站複製的 SSH 命令。 本文使用 MacOS 中的終端機,您可以在 Windows 電腦上使用 PuTTY 或不同的 SSH 用戶端來遵循類似的指示。 出現提示時,請輸入 [ **是]** 以繼續,然後輸入您在上一個步驟中為虛擬機器設定的 **密碼** 。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/striim-vm-connect.png" alt-text="連接至 Striim VM":::
1. 現在,開啟新的 [終端機] 索引標籤,以複製您先前下載的 **ojdbc8 .jar** 檔案。 使用下列 SCP 命令將 jar 檔案從本機電腦複製到在 Azure 中執行之 Striim 實例的 tmp 資料夾:
```bash
cd <Directory_path_where_the_Jar_file_exists>
scp ojdbc8.jar [email protected]:/tmp
```
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/copy-jar-file.png" alt-text="從位置電腦將 Jar 檔案複製到 Striim":::
1. 接下來,流覽回到您在其中執行 SSH 至 Striim 實例的視窗,並以 sudo 的身分登入。 使用下列命令,將 **ojdbc8 .jar** 檔案從 **/tmp** 目錄移至 Striim 實例的 **lib** 目錄中:
```bash
sudo su
cd /tmp
mv ojdbc8.jar /opt/striim/lib
chmod +x ojdbc8.jar
```
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/move-jar-file.png" alt-text="將 Jar 檔案移至 lib 資料夾":::
1. 從相同的終端機視窗中,執行下列命令來重新開機 Striim 伺服器:
```bash
Systemctl stop striim-node
Systemctl stop striim-dbms
Systemctl start striim-dbms
Systemctl start striim-node
```
1. Striim 需要一分鐘的時間才能啟動。 如果您想要查看狀態,請執行下列命令:
```bash
tail -f /opt/striim/logs/striim-node.log
```
1. 現在,流覽回 Azure 並複製您 Striim VM 的公用 IP 位址。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/copy-public-ip-address.png" alt-text="複製 Striim VM IP 位址":::
1. 若要流覽至 Striim 的 Web UI,請在瀏覽器中開啟新的索引標籤,然後複製 [公用 IP],然後再複製:9080。 使用系統 **管理員** 使用者名稱,以及您在 Azure 入口網站中指定的系統管理員密碼來登入。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/striim-login-ui.png" alt-text="登入 Striim":::
1. 現在您將抵達 Striim 的首頁。 有三個不同的窗格– **儀表板** 、 **應用程式** 和 **SourcePreview** 。 [儀表板] 窗格可讓您即時移動資料並將其視覺化。 [應用程式] 窗格包含您的串流資料管線或資料流程。 在頁面右側 SourcePreview,您可以在其中預覽資料,然後再進行移動。
1. 選取 [ **應用程式** ] 窗格,我們現在會將焦點放在此窗格上。 您可以使用各種範例應用程式來瞭解 Striim,不過在本文中,您將建立自己的應用程式。 選取右上角的 [ **新增應用程式** ] 按鈕。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/add-striim-app.png" alt-text="新增 Striim 應用程式":::
1. 有幾種不同的方式可以建立 Striim 的應用程式。 選取 [ **從範本開始** ],從現有的範本開始。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/start-with-template.png" alt-text="使用範本啟動應用程式":::
1. 在 [ **搜尋範本** ] 欄位中,輸入 "Cosmos" 並選取 [ **目標: Azure Cosmos DB** ,然後選取 [ **Oracle CDC] 以 Azure Cosmos DB** 。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/oracle-cdc-cosmosdb.png" alt-text="選取 Oracle CDC 以 Cosmos DB":::
1. 在下一個頁面中,為您的應用程式命名。 您可以提供名稱(例如 **oraToCosmosDB** ),然後選取 [ **儲存** ]。
1. 接下來,輸入來源 Oracle 實例的來源設定。 輸入 **來源名稱** 的值。 來源名稱只是 Striim 應用程式的命名慣例,您可以使用類似 **src_onPremOracle** 的內容。 輸入 [來源參數 **URL** ]、[使用者 **名稱** ]、[ **密碼** ] 的其餘值,選擇 [ **LogMiner** ] 做為讀取器以讀取 Oracle 資料的讀取器。 選取 [下一步] 以繼續操作。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/configure-source-parameters.png" alt-text="設定來源參數":::
1. Striim 會檢查您的環境,並確定它可以連線到您的來源 Oracle 實例、擁有正確的許可權,而且 CDC 的設定是否正確。 所有值都經過驗證之後,請選取 **[下一步]** 。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/validate-source-parameters.png" alt-text="驗證來源參數":::
1. 從您想要遷移的 Oracle 資料庫中選取資料表。 例如,讓我們選擇 Orders 資料表,然後選取 **[下一步]** 。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/select-source-tables.png" alt-text="選取來源資料表":::
1. 選取來源資料表之後,您可以進行更複雜的作業,例如對應和篩選。 在此情況下,您只會在 Azure Cosmos DB 中建立來源資料表的複本。 因此,請選取 **[下一步]** 以設定目標
1. 現在,讓我們來設定目標:
* **目標名稱** -提供目標的易記名稱。
* **輸入來源** -從下拉式清單中,選取您在來源 Oracle 設定中建立的輸入資料流程。
* **集合** -輸入目標 Azure Cosmos DB 設定屬性。 集合語法為 **SourceSchema. SourceTable、>targetdatabase. TargetContainer** 。 在此範例中,值會是 "SYSTEM。ORDERS、StriimDemo。
* **AccessKey** -Azure Cosmos 帳戶的 PrimaryKey。
* **ServiceEndpoint** – Azure Cosmos 帳戶的 URI,可以在 Azure 入口網站的 [ **金鑰** ] 區段下找到。
選取 **Save** [儲存 **] 和 [下一步]** 。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/configure-target-parameters.png" alt-text="設定目標參數":::
1. 接下來,您將抵達流程設計工具,您可以在其中拖放現成的連接器,以建立串流應用程式。 此時您不會對流程進行任何修改。 所以請繼續進行,並選取 [ **部署應用** 程式] 按鈕來部署應用程式。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/deploy-app.png" alt-text="部署應用程式":::
1. 在 [部署] 視窗中,您可以指定是否要在部署拓撲的特定部分執行應用程式的特定部分。 因為我們是透過 Azure 在簡單的部署拓撲中執行,所以我們會使用預設選項。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/deploy-using-default-option.png" alt-text="使用預設選項":::
1. 部署之後,您可以預覽串流以查看流經的資料。 選取 **wave** 圖示和旁邊的眼睛。 在頂端功能表列中選取 [已 **部署** ] 按鈕,然後選取 [ **啟動應用程式** ]。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/start-app.png" alt-text="啟動應用程式":::
1. 藉由使用 **CDC (變更 Data Capture)** 讀取器,Striim 只會在資料庫上挑選新的變更。 如果您的資料流程經來源資料表,您將會看到它。 不過,由於這是示範表格,因此來源不會連接到任何應用程式。 如果您使用範例資料產生器,您可以將一連串的事件插入 Oracle 資料庫。
1. 您會看到資料流程經 Striim 平臺。 Striim 也會挑選與您的資料表相關聯的所有中繼資料,這有助於監視資料並確保資料落在正確的目標上。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/configure-cdc-pipeline.png" alt-text="設定 CDC 管線":::
1. 最後,讓我們登入 Azure,並流覽至您的 Azure Cosmos 帳戶。 重新整理資料總管,您會看到資料已抵達。
:::image type="content" source="./media/cosmosdb-sql-api-migrate-data-striim/portal-validate-results.png" alt-text="在 Azure 中驗證遷移的資料":::
藉由在 Azure 中使用 Striim 解決方案,您可以持續將資料移轉至不同來源的 Azure Cosmos DB,例如 Oracle、Cassandra、MongoDB 和其他各種來源,以 Azure Cosmos DB。 若要深入瞭解,請造訪 [Striim 網站](https://www.striim.com/)、 [下載免費的30天試用版 Striim](https://go2.striim.com/download-free-trial),以及在使用 Striim 設定遷移路徑時的任何問題,並 [提出支援要求。](https://go2.striim.com/request-support-striim)
## <a name="next-steps"></a>後續步驟
* 如果您要將資料移轉至 Azure Cosmos DB SQL API,請參閱 [如何使用 Striim 將資料移轉至 Cassandra API 帳戶](cosmosdb-cassandra-api-migrate-data-striim.md)
* [使用 Azure Cosmos DB 計量來監視和偵測您的資料](use-metrics.md) | 50.848039 | 458 | 0.718307 | yue_Hant | 0.912059 |
1110ef11a6d0c70ca07dbfcbc83c91fd2f47b5a9 | 3,484 | md | Markdown | README.md | FlandiaYingman/ark-recognizer | fff216220756fb1d0516dba198618e890c1cb5d3 | [
"MIT"
] | null | null | null | README.md | FlandiaYingman/ark-recognizer | fff216220756fb1d0516dba198618e890c1cb5d3 | [
"MIT"
] | null | null | null | README.md | FlandiaYingman/ark-recognizer | fff216220756fb1d0516dba198618e890c1cb5d3 | [
"MIT"
] | null | null | null | # Ark Recognizer
Recognizes the type and number of items from *Arknights* screenshots.
## Usage
Run `src/ark_recognizer_py/recognizer.py` with some screenshots file as arguments. It will print out
a [ArkPlanner](https://penguin-stats.io/planner) compatible json as output. (More output formats coming soon...)
## Run Tests
Run the unit tests under `tests`. If everything goes right, the unit tests shall return a success result.
## Principle
Ark Recognizer loads multiple input scene images (screenshots). To complete the recognition, it does the following steps
sequentially.
### *Circle Detection (Hough Circles)*: to detect the location and size of items in the scene.
In this step, Ark Recognizer recognizes the location and the size of items in the scene.
Consider the table below. It's easy to find out the formula from scene size to icon size. If the aspect ratio is less
than 16:9, the icon diameter will
be: <img src="https://render.githubusercontent.com/render/math?math=d = \frac{1}{10}(w)">, otherwise, the icon diameter
will remain <img src="https://render.githubusercontent.com/render/math?math=d = \frac{1}{10}(\frac{16}{9}h)">. Where
<img src="https://render.githubusercontent.com/render/math?math=w, h, d"> is the scene width, scene height, and icon
diameter.
| Width (Ratio) | Height (Ratio) | Aspect Ratio | Width (Pixel) | Height (Pixel) | Icon Diameter |
|---------------|----------------|--------------|-----------------|----------------|---------------|
| 1 | 1 | 1.00 | 1080 | 1080 | N/A |
| 5 | 4 | 1.25 | 1350 | 1080 | 135 |
| 4 | 3 | 1.33 | 1440 | 1080 | 144 |
| 3 | 2 | 1.50 | 1620 | 1080 | 162 |
| 16 | 10 | 1.60 | 1728 | 1080 | 172 |
| 16 | 9 | 1.78 | 1920 | 1080 | 192 |
| 2 | 1 | 2.00 | 2160 | 1080 | 191 |
| 21 | 9 | 2.33 | 2520 | 1080 | 191 |
Apply *Hough Circles* with the estimated icon diameter. Now the location and the size are found out.
### *Template Matching (Correlation Coefficient Normalized)* :to detect the type of the items
In this step, Ark Recognizer recognizes the type of items in the scene.
The scene image is cropped into slices, with the locations and sizes found in the previous step. Then the scene slices
are scaled same to the item templates.
Each slice is matched with all item templates. The most similar item template is chosen to be the type of this slice. If
the similarity is less than a threshold, the slice will be marked not an item.
### *Hash Distance (Average Hash, Hamming Distance)*: to detect the number of the items
In this step, Ark Recognizer recognizes the number of items in the scene.
Crops the scene slices, so they only contain the number region. After adjusting brightness and contrast, and applying a
threshold filter, each digit in the number region can be extracted by finding contours.
The digit image is hashed and compared to the pre-calculated 0-9 digit hash values. The digits which have the minimum
distance is chosen. They are concatenated into the final number. | 57.114754 | 120 | 0.605913 | eng_Latn | 0.993584 |
1111dcf47b53402ad4f88a51b2089f530c3a57c4 | 2,758 | md | Markdown | snap/README.md | QKaseman/edgex-go | 271728279a7de7d4c8c6445ab0d43ef8d31d20a9 | [
"Apache-2.0"
] | null | null | null | snap/README.md | QKaseman/edgex-go | 271728279a7de7d4c8c6445ab0d43ef8d31d20a9 | [
"Apache-2.0"
] | null | null | null | snap/README.md | QKaseman/edgex-go | 271728279a7de7d4c8c6445ab0d43ef8d31d20a9 | [
"Apache-2.0"
] | null | null | null | # EdgeX Foundry Core Snap
This project contains snap packaging for the EgdeX Foundry reference implementation.
The snap contains consul, mongodb, all of the EdgeX Go-based micro services from
this repository, and three Java-based services, support-notifications and support-
scheduler, and device-virtual. The snap also contains a single OpenJDK JRE used to
run the Java-based services.
## Installation Requirements
The snap can be installed on any system running snapd, however for full confinement,
the snap must be installed on an Ubuntu 16.04 LTS or later Desktop or Server, or a
system running Ubuntu Core 16.
## Installation
There are amd64 and arm64 versions of both releases available in the store. You can
see the revisions available for your machine's architecture by running the command:
`$ snap info edgexfoundry`
The snap can be installed using this command:
`$ sudo snap install edgexfoundry --channel=california/edge`
**Note** - this snap has only been tested on Ubuntu 16.04 LTS Desktop/Server and Ubuntu Core 16.
## Configuration
The hardware-observe, process-control, and system-observe snap interfaces needs to be
connected after installation using the following commands:
`$ snap connect edgexfoundry-core:hardware-observe core:hardware-observe`
`$ snap connect edgexfoundry-core:process-control core:process-control`
`$ snap connect edgexfoundry-core:system-observe core:system-observe`
## Starting/Stopping EdgeX
To start all the EdgeX microservices, use the following command:
`$ edgexfoundry.start-edgex`
To stop all the EdgeX microservices, use the following command:
`$ edgexfoundry.stop-edgex`
**WARNING** - don't start the EdgeX snap on a system which is already running mongoDB or Consul.
### Enabling/Disabling service startup
It's possible to a effect which services are started by the start-edgex script by
editing a file called `edgex-services-env` which can be found in the directory `/var/snap/edgexfoundry/current` (aka $SNAP_DATA).
**Note** - this file is created by the start-edgex script, so the script needs to be run at least once to copy the default version into place.
## Limitations
* none of the services are actually defined as such in snapcraft.yaml, instead shell-scripts are used to start and stop the EdgeX microservices and dependent services such as consul and mongo.
* some of the new Go-based core services (export-*) currently don't load configuration from Consul
* the new Go-based export services don't generate local log files
## Building
This snap can be built on an Ubuntu 16.04 LTS system:
* install snapcraft
* clone this git repo
* cd edgex-core-snap
* snapcraft
This should produce a binary snap package called edgex-core-snap_<latest version>_<arch>.snap.
| 38.84507 | 194 | 0.784989 | eng_Latn | 0.997928 |
111296d35a4d79bc1dd8f6ac6238318b6719e18d | 977 | md | Markdown | _pages/aboutme.md | junhpark/junhpark.github.io | 0bb2bc33b173725ee75acf3367c31c2fd80aa63d | [
"MIT"
] | null | null | null | _pages/aboutme.md | junhpark/junhpark.github.io | 0bb2bc33b173725ee75acf3367c31c2fd80aa63d | [
"MIT"
] | 1 | 2021-03-30T09:30:10.000Z | 2021-03-30T09:30:10.000Z | _pages/aboutme.md | junhpark/junhpark.github.io | 0bb2bc33b173725ee75acf3367c31c2fd80aa63d | [
"MIT"
] | null | null | null | ---
layout: page
title: About Me
subtitle: "Miners of Tomorrow"
image: Me3.jpg
permalink: /aboutme/
---
### My name is ***Junhyeok Park***.
I love playing musical instriument, especially guitar :)
I am a member of "De Colores" band group.
We perform every month at Cartel Coffee or Sky Bar @ Tucson.
What I love is..
- playing guitar and having a small concert
- digging for new things! Right now, I indulge in control with small sensors and gadgets like Arduino!
- rock (both music and geology)
- traveling around great great mother nature
Whoa, what else do you need?
## Education
***
### University of Arizona
<small>2016 - 2020</small>
**Ph.D.**
Major: Mining and Geological Engineering
Minor: Electrical Engineering
***
### University of Arizona
<small>2014 - 2016</small>
**M.Sc.**
Major: Mining and Geological Engineering
***
### Seoul National University
<small>2008 - 2014</small>
**B.Sc**
Major: Energy and Resources Engineering
| 14.58209 | 102 | 0.703173 | eng_Latn | 0.986633 |
1112bddf9c5e42ad7eb91b3f959c7683ca63f8b6 | 1,022 | md | Markdown | README.md | edwingustafson/maritime-letter-flags | 339a2794a1b2734f491f99eb5b77c1fa748b6ea0 | [
"MIT"
] | null | null | null | README.md | edwingustafson/maritime-letter-flags | 339a2794a1b2734f491f99eb5b77c1fa748b6ea0 | [
"MIT"
] | null | null | null | README.md | edwingustafson/maritime-letter-flags | 339a2794a1b2734f491f99eb5b77c1fa748b6ea0 | [
"MIT"
] | null | null | null | # maritime-letter-flags
> React component rendering letters as international maritime signal flags

[Inspired by a resort town storefont.](https://goo.gl/maps/GVLpvs248RFyLcYh8)
[Flag images from Wikimedia Commons.](https://commons.wikimedia.org/wiki/Category:International_Code_of_Signals_(Series_4))
[](https://www.npmjs.com/package/maritime-letter-flags) [](https://standardjs.com)
## Install
```bash
npm install --save maritime-letter-flags
```
## Usage
```tsx
import React, { Component } from 'react'
import MaritimeLetterFlags from 'maritime-letter-flags'
import 'maritime-letter-flags/dist/index.css'
class Example extends Component {
render() {
return <MaritimeLetterFlags
letters={true}
text={'Hello, world!'}
/>;
}
}
```
## License
MIT © [edwingustafson](https://github.com/edwingustafson)
| 25.55 | 235 | 0.736791 | kor_Hang | 0.226052 |
1112c8e48539d1d40a85ac5b6a20896423bad4ce | 94 | md | Markdown | README.md | Gordi91/contacts-book | b6d46d9a4f4beba46638fce4bbd0ebaefa975406 | [
"MIT"
] | null | null | null | README.md | Gordi91/contacts-book | b6d46d9a4f4beba46638fce4bbd0ebaefa975406 | [
"MIT"
] | null | null | null | README.md | Gordi91/contacts-book | b6d46d9a4f4beba46638fce4bbd0ebaefa975406 | [
"MIT"
] | null | null | null | # Contacts Book
Django framework based contacts manager
Techstack:
Python
Django
PostgreSQL
| 10.444444 | 39 | 0.829787 | eng_Latn | 0.438132 |
1112e7aef77939d74329d7d948b3f114b7481596 | 7,827 | md | Markdown | docs/pages/versions/unversioned/sdk/securestore.md | vinceniko/expo | c6d8031e1d244e75d8a35cae4a28017b26eb30d6 | [
"Apache-2.0",
"MIT"
] | 1 | 2021-05-20T11:21:01.000Z | 2021-05-20T11:21:01.000Z | docs/pages/versions/unversioned/sdk/securestore.md | vinceniko/expo | c6d8031e1d244e75d8a35cae4a28017b26eb30d6 | [
"Apache-2.0",
"MIT"
] | 1 | 2021-02-05T11:31:30.000Z | 2021-02-05T12:47:50.000Z | docs/pages/versions/unversioned/sdk/securestore.md | vinceniko/expo | c6d8031e1d244e75d8a35cae4a28017b26eb30d6 | [
"Apache-2.0",
"MIT"
] | 1 | 2021-11-24T08:07:42.000Z | 2021-11-24T08:07:42.000Z | ---
title: SecureStore
sourceCodeUrl: 'https://github.com/expo/expo/tree/master/packages/expo-secure-store'
---
import InstallSection from '~/components/plugins/InstallSection';
import PlatformsSection from '~/components/plugins/PlatformsSection';
import SnackInline from '~/components/plugins/SnackInline';
**`expo-secure-store`** provides a way to encrypt and securely store key–value pairs locally on the device. Each Expo project has a separate storage system and has no access to the storage of other Expo projects. **Please note** that for iOS standalone apps, data stored with `expo-secure-store` can persist across app installs.
iOS: Values are stored using the [keychain services](https://developer.apple.com/documentation/security/keychain_services) as `kSecClassGenericPassword`. iOS has the additional option of being able to set the value's `kSecAttrAccessible` attribute, which controls when the value is available to be fetched.
Android: Values are stored in [`SharedPreferences`](https://developer.android.com/training/basics/data-storage/shared-preferences.html), encrypted with [Android's Keystore system](https://developer.android.com/training/articles/keystore.html).
**Size limit for a value is 2048 bytes. An attempt to store larger values may fail. Currently, we print a warning when the limit is reached, but in a future SDK version, we may throw an error.**
<PlatformsSection android emulator ios simulator />
- This API is not compatible on devices running Android 5 or lower.
## Installation
<InstallSection packageName="expo-secure-store" />
## Usage
<SnackInline label='SecureStore' dependencies={['expo-secure-store']} platforms={['ios', 'android']}>
```jsx
import * as React from 'react';
import { Text, View, StyleSheet, TextInput, Button } from 'react-native';
import * as SecureStore from 'expo-secure-store';
async function save(key, value) {
await SecureStore.setItemAsync(key, value);
}
async function getValueFor(key) {
let result = await SecureStore.getItemAsync(key);
if (result) {
alert("🔐 Here's your value 🔐 \n" + result);
} else {
alert('No values stored under that key.');
}
}
export default function App() {
const [key, onChangeKey] = React.useState('Your key here');
const [value, onChangeValue] = React.useState('Your value here');
return (
<View style={styles.container}>
<Text style={styles.paragraph}>Save an item, and grab it later!</Text>
{/* @hide Add some TextInput components... */}
<TextInput
style={styles.textInput}
clearTextOnFocus
onChangeText={text => onChangeKey(text)}
value={key}
/>
<TextInput
style={styles.textInput}
clearTextOnFocus
onChangeText={text => onChangeValue(text)}
value={value}
/>
{/* @end */}
<Button
title="Save this key/value pair"
onPress={() => {
save(key, value);
onChangeKey('Your key here');
onChangeValue('Your value here');
}}
/>
<Text style={styles.paragraph}>🔐 Enter your key 🔐</Text>
<TextInput
style={styles.textInput}
onSubmitEditing={event => {
getValueFor(event.nativeEvent.text);
}}
placeholder="Enter the key for the value you want to get"
/>
</View>
);
}
/* @hide const styles = StyleSheet.create({ ... }); */
const styles = StyleSheet.create({
container: {
flex: 1,
justifyContent: 'center',
paddingTop: 10,
backgroundColor: '#ecf0f1',
padding: 8,
},
paragraph: {
marginTop: 34,
margin: 24,
fontSize: 18,
fontWeight: 'bold',
textAlign: 'center',
},
textInput: {
height: 35,
borderColor: 'gray',
borderWidth: 0.5,
padding: 4,
},
});
/* @end */
```
</SnackInline>
## API
```js
import * as SecureStore from 'expo-secure-store';
```
### `SecureStore.isAvailableAsync()`
Returns whether the SecureStore API is enabled on the current device.
#### Returns
Async `boolean`, indicating whether the SecureStore API is available on the current device. Currently this resolves `true` on iOS and Android only.
### `SecureStore.setItemAsync(key, value, options)`
Store a key–value pair.
#### Arguments
- **key (_string_)** -- The key to associate with the stored value. Keys may contain alphanumeric characters `.`, `-`, and `_`.
- **value (_string_)** -- The value to store. Size limit is 2048 bytes.
- **options (_object_)** (optional) -- A map of options:
- **keychainService (_string_)** --
- iOS: The item's service, equivalent to `kSecAttrService`
- Android: Equivalent of the public/private key pair `Alias`
**NOTE** If the item is set with the `keychainService` option, it will be required to later fetch the value.
- **keychainAccessible (_enum_)** --
- iOS only: Specifies when the stored entry is accessible, using iOS's `kSecAttrAccessible` property. See Apple's documentation on [keychain item accessibility](https://developer.apple.com/library/content/documentation/Security/Conceptual/keychainServConcepts/02concepts/concepts.html#//apple_ref/doc/uid/TP30000897-CH204-SW18). The available options are:
- `SecureStore.WHEN_UNLOCKED` (default): The data in the keychain item can be accessed only while the device is unlocked by the user.
- `SecureStore.AFTER_FIRST_UNLOCK`: The data in the keychain item cannot be accessed after a restart until the device has been unlocked once by the user. This may be useful if you need to access the item when the phone is locked.
- `SecureStore.ALWAYS`: The data in the keychain item can always be accessed regardless of whether the device is locked. This is the least secure option.
- `SecureStore.WHEN_UNLOCKED_THIS_DEVICE_ONLY`: Similar to `WHEN_UNLOCKED`, except the entry is not migrated to a new device when restoring from a backup.
- `SecureStore.WHEN_PASSCODE_SET_THIS_DEVICE_ONLY`: Similar to `WHEN_UNLOCKED_THIS_DEVICE_ONLY`, except the user must have set a passcode in order to store an entry. If the user removes their passcode, the entry will be deleted.
- `SecureStore.AFTER_FIRST_UNLOCK_THIS_DEVICE_ONLY`: Similar to `AFTER_FIRST_UNLOCK`, except the entry is not migrated to a new device when restoring from a backup.
- `SecureStore.ALWAYS_THIS_DEVICE_ONLY`: Similar to `ALWAYS`, except the entry is not migrated to a new device when restoring from a backup.
#### Returns
A promise that will reject if value cannot be stored on the device.
### `SecureStore.getItemAsync(key, options)`
Fetch the stored value associated with the provided key.
#### Arguments
- **key (_string_)** -- The key that was used to store the associated value.
- **options (_object_)** (optional) -- A map of options:
- **keychainService (_string_)** --
iOS: The item's service, equivalent to `kSecAttrService`.
Android: Equivalent of the public/private key pair `Alias`.
**NOTE** If the item is set with the `keychainService` option, it will be required to later fetch the value.
#### Returns
A promise that resolves to the previously stored value, or null if there is no entry for the given key. The promise will reject if an error occurred while retrieving the value.
### `SecureStore.deleteItemAsync(key, options)`
Delete the value associated with the provided key.
#### Arguments
- **key (_string_)** -- The key that was used to store the associated value.
- **options (_object_)** (optional) -- A map of options:
- **keychainService (_string_)** -- iOS: The item's service, equivalent to `kSecAttrService`. Android: Equivalent of the public/private key pair `Alias`. If the item is set with a keychainService, it will be required to later fetch the value.
#### Returns
A promise that will reject if the value couldn't be deleted.
| 38.940299 | 359 | 0.710106 | eng_Latn | 0.941128 |
1113a9747765d7cdc9f5b853f84adad420a581e7 | 2,176 | md | Markdown | docs/2014/database-engine/availability-groups/windows/some-availability-replicas-are-not-synchronizing-data.md | cawrites/sql-docs | 58158eda0aa0d7f87f9d958ae349a14c0ba8a209 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2019-02-08T05:59:39.000Z | 2019-02-12T03:27:49.000Z | docs/2014/database-engine/availability-groups/windows/some-availability-replicas-are-not-synchronizing-data.md | cawrites/sql-docs | 58158eda0aa0d7f87f9d958ae349a14c0ba8a209 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/2014/database-engine/availability-groups/windows/some-availability-replicas-are-not-synchronizing-data.md | cawrites/sql-docs | 58158eda0aa0d7f87f9d958ae349a14c0ba8a209 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-03-11T20:30:39.000Z | 2020-05-07T19:40:49.000Z | ---
title: "Some availability replicas are not synchronizing data | Microsoft Docs"
ms.custom: ""
ms.date: "06/13/2017"
ms.prod: "sql-server-2014"
ms.reviewer: ""
ms.technology: high-availability
ms.topic: conceptual
f1_keywords:
- "sql12.swb.agdashboard.agp4synchronizing.issues.f1"
helpviewer_keywords:
- "Availability Groups [SQL Server], policies"
ms.assetid: 3db6a569-e942-4321-a0dd-c4ab002087c8
author: MashaMSFT
ms.author: mathoma
manager: craigg
---
# Some availability replicas are not synchronizing data
## Introduction
|||
|-|-|
|**Policy Name**|Availability Replicas Data Synchronization State|
|**Issue**|Some availability replicas are not synchronizing data.|
|**Category**|**Warning**|
|**Facet**|Availability group|
## Description
This policy rolls up the data synchronization state of all availability replicas in the availability group and checks if the synchronization of any availability replica is not operational. The policy is in an unhealthy state if any of the data synchronization states of the availability replica is NOT SYNCRONIZING.
This policy is in a healthy state if none of the data synchronization states of the availability replica is NOT SYNCHRONIZING.
> [!NOTE]
> For this release of [!INCLUDE[ssCurrent](../../../includes/sscurrent-md.md)], information about possible causes and solutions is located at [Some availability replicas are not synchronizing data](https://go.microsoft.com/fwlink/p/?LinkId=220852) on the TechNet Wiki.
## Possible Causes
In this availability group, at least one secondary replica has a NOT SYNCHRONIZING synchronization state and is not receiving data from the primary replica.
## Possible Solution
Use the availability replica policy state to find the availability replica with a NOT SYNCHROINIZING state, and then resolve the issue at the availability replica.
## See Also
[Overview of AlwaysOn Availability Groups (SQL Server)](overview-of-always-on-availability-groups-sql-server.md)
[Use the AlwaysOn Dashboard (SQL Server Management Studio)](use-the-always-on-dashboard-sql-server-management-studio.md)
| 45.333333 | 318 | 0.758732 | eng_Latn | 0.963453 |
1114bec3195b141a1fb8298565fffddcfd68b385 | 102 | md | Markdown | documentation-archive.md | ShubhamRwt/strimzi.github.io | 0bc82b75a34098f942536057d20847280aba36fa | [
"Apache-2.0"
] | 20 | 2018-09-05T14:07:35.000Z | 2022-01-10T06:51:23.000Z | documentation-archive.md | ShubhamRwt/strimzi.github.io | 0bc82b75a34098f942536057d20847280aba36fa | [
"Apache-2.0"
] | 94 | 2018-03-19T09:43:15.000Z | 2022-03-29T21:50:38.000Z | documentation-archive.md | ShubhamRwt/strimzi.github.io | 0bc82b75a34098f942536057d20847280aba36fa | [
"Apache-2.0"
] | 62 | 2018-05-18T09:40:33.000Z | 2022-03-29T09:41:01.000Z | ---
layout: documentation-archive
title: Documentation Archive
permalink: /documentation/archive/
---
| 17 | 34 | 0.784314 | yue_Hant | 0.594818 |
11151c0a896472314067d53a71a658a3be49eec6 | 10,848 | md | Markdown | packages/mdl-list/README.md | josebaptista/GoogleMaterialLite | f535bc014dc867e4f79bf551e34815b23cd1d010 | [
"CC-BY-4.0"
] | null | null | null | packages/mdl-list/README.md | josebaptista/GoogleMaterialLite | f535bc014dc867e4f79bf551e34815b23cd1d010 | [
"CC-BY-4.0"
] | null | null | null | packages/mdl-list/README.md | josebaptista/GoogleMaterialLite | f535bc014dc867e4f79bf551e34815b23cd1d010 | [
"CC-BY-4.0"
] | null | null | null | # MDL List
MDL List provides styles which implement [Material Design Lists](https://material.google.com/components/lists.html#) - "A single continuous column of tessellated subdivisions of equal width." Both single-line and two-line lists are supported (with
three-line lists [coming soon](https://github.com/google/material-design-lite/issues/4487)). MDL
Lists are design to be accessible and RTL aware.
## Installation
> NOTE: Installation via npm will be available post-alpha.
## Usage
### Basic Lists
A basic lists consists simply of the list itself, and list items taking up one line.
```html
<div class="mdl-list">
<li class="mdl-list-item">Single-line item</li>
<li class="mdl-list-item">Single-line item</li>
<li class="mdl-list-item">Single-line item</li>
</div>
```
#### RTL Support
A list will flip its direction if it is _placed within an ancestor element containing a `dir`
attribute with value `"rtl"`_. This applies to all lists regardless of type.
```html
<html dir="rtl">
<!-- ... -->
<ul class="mdl-list">
<!-- Hebrew for 'item in list' -->
<li class="mdl-list-item">פריט ברשימה</li>
</ul>
</html>
```
#### Dark Mode support
Like other MDL components, lists support dark mode either when an `mdl-list--theme-dark` class is
attached to the root element, or the element has an ancestor with class `mdl-theme--dark`.
```html
<html class="mdl-theme--dark">
<!-- ... -->
<ul class="mdl-list">
<li class="mdl-list-item">A list item on a dark background</li>
</ul>
</html>
```
### "Dense" Lists
Lists can be made more compact by using the `mdl-list--dense` modifier class.
```html
<ul class="mdl-list mdl-list--dense">
<!-- ... -->
</ul>
```
### Two-line lists
While in theory you can add any number of "lines" to a list item, you can use the `mdl-list--two-line` combined with some extra markup around the text to style a list in the two-line list style as defined by [the spec](https://material.google.com/components/lists.html#lists-specs) (see "Two-line lists").
```html
<ul class="mdl-list mdl-list--two-line">
<li class="mdl-list-item">
<span class="mdl-list-item__text">
<span class="mdl-list-item__text__primary">Two-line item</span>
<span class="mdl-list-item__text__primary">Secondary text</span>
</span>
</li>
</ul>
```
### List "Detail" Elements
As mentioned in the spec, lists can contain primary and secondary actions. It can also contain
things such as avatars, icons, interactive controls, etc. We call these items *detail* items. Lists
can contain 1 **start detail** item and/or 1 **end detail** item that are positioned at the start
and end of the list, respectively. These items are correctly flipped in RTL contexts.
> _N.B._ Please keep accessibility in mind when using things such as icons / icon fonts for detail
> elements. Font Awesome has [excellent guidelines](http://fontawesome.io/accessibility/) for this.
#### Adding a start detail
You can add a start detail using an element with class `mdl-list-item__start-detail` class.
```html
<ul class="mdl-list">
<li class="mdl-list-item">
<i class="mdl-list-item__start-detail material-icons" aria-hidden="true">network_wifi</i>
Wi-Fi
</li>
<li class="mdl-list-item">
<i class="mdl-list-item__start-detail material-icons" aria-hidden="true">bluetooth</i>
Bluetooth
</li>
<li class="mdl-list-item">
<i class="mdl-list-item__start-detail material-icons" aria-hidden="true">data_usage</i>
Data Usage
</li>
</ul>
```
#### Making a start detail an avatar
You can use the `mdl-list--avatar-list` modifier class to style the start detail elements as what
the spec calls "avatars" - large, circular details that lend themselves well to contact images,
profile pictures, etc.
```html
<h2>Contacts</h2>
<ul class="mdl-list mdl-list--avatar-list">
<li class="mdl-list-item">
<img class="mdl-list-item__start-detail" src="/users/1/profile_pic.png"
width="56" height="56" alt="Picture of Janet Perkins">
Janet Perkins
</il>
<li class="mdl-list-item">
<img class="mdl-list-item__start-detail" src="/users/2/profile_pic.png"
width="56" height="56" alt="Picture of Mary Johnson">
Mary Johnson
</il>
<li class="mdl-list-item">
<img class="mdl-list-item__start-detail" src="/users/3/profile_pic.png"
width="56" height="56" alt="Picture of Peter Carlsson">
Peter Carlsson
</il>
</ul>
```
#### Adding an end detail
End details can be added in a similar way to start details. Place an element after the text
with a `mdl-list-item__end-detail` class.
```html
<h2>Contacts</h2>
<ul class="mdl-list">
<li class="mdl-list-item">
Janet Perkins
<a href="#" class="mdl-list-item__end-detail material-icons"
aria-label="Remove from favorites" title="Remove from favorites">
favorite
</a>
</li>
<li class="mdl-list-item">
Mary Johnson
<a href="#" class="mdl-list-item__end-detail material-icons"
aria-label="Add to favorites" title="Add to favorites">
favorite_border
</a>
</li>
<li class="mdl-list-item">
Janet Perkins
<a href="#" class="mdl-list-item__end-detail material-icons"
aria-label="Add to favorites" title="Add to favorites">
favorite_border
</a>
</li>
</ul>
```
Start and end details can be combined easily. Check out the list demo for many examples of how
details can be configured.
> NOTE: If using controls such as a switch (_TK!_) within a list detail, you may need to override
> the width and height styles set on the detail element.
### List Dividers
MDL List contains an `mdl-list-divider` classes which can be used as full-width or inset
subdivisions either within lists themselves, or event standalone between related groups of content.
To use within lists, simply add the `mdl-list-divider` class to a list item.
```html
<ul class="mdl-list">
<li class="mdl-list-item">Item 1 - Division 1</li>
<li class="mdl-list-item">Item 2 - Division 1</li>
<li class="mdl-list-item">Item 3 - Division 1</li>
<li role="separator" class="mdl-list-divider"></li>
<li class="mdl-list-item">Item 1 - Division 2</li>
<li class="mdl-list-item">Item 1 - Division 2</li>
</ul>
```
> Note the `role="separator"` attribute on the list divider. It is important to include this so that
> assistive technology can be made aware that this is a presentational element and is not meant to
> be included as an item in a list. Note that `separator` is indeed [a valid role](https://w3c.github.io/html/grouping-content.html#the-li-element)
> for `li` elements.
In order to make separators inset, add a `mdl-list-divider--inset` modifier class to it.
```html
<ul class="mdl-list">
<li class="mdl-list-item">Item 1 - Division 1</li>
<li class="mdl-list-item">Item 2 - Division 1</li>
<li class="mdl-list-item">Item 3 - Division 1</li>
<li role="separator" class="mdl-list-divider mdl-list-divider--inset"></li>
<li class="mdl-list-item">Item 1 - Division 2</li>
<li class="mdl-list-item">Item 1 - Division 2</li>
</ul>
```
Inset dividers are useful when working with lists which have start details.
### List Groups
Multiple related lists can be grouped together using the `mdl-list-group` class on a containing
element. `mdl-list-divider` elements can be used in these groups _between_ lists to help
differentiate them.
```html
<div class="mdl-list-group">
<h3 class="mdl-list-group__subheader">List 1</h3>
<ul class="mdl-list">
<li class="mdl-list-item">Single-line item</li>
<li class="mdl-list-item">Single-line item</li>
<li class="mdl-list-item">Single-line item</li>
</ul>
<hr class="mdl-list-divider">
<h3 class="mdl-list-group__subheader">List 2</h3>
<ul class="mdl-list">
<li class="mdl-list-item">Single-line item</li>
<li class="mdl-list-item">Single-line item</li>
<li class="mdl-list-item">Single-line item</li>
</ul>
</div>
```
### Tips/Tricks
#### Bordered Lists
While hinted at within the spec, **bordered lists** - where each list item has a border around
it - are not officially part of the list component spec. However, they seem to be used
often in web applications, especially those suited more for desktop. The following example shows how
to add borders to lists.
```html
<style>
.my-bordered-list {
/* remove the side padding. we'll be placing it around the item instead. */
padding-right: 0;
padding-left: 0;
}
.my-bordered-list .mdl-list-item {
/* Add the list side padding padding to the list item. */
padding: 0 16px;
/* Add a border around each element. */
border: 1px solid rgba(0, 0, 0, .12);
}
/* Ensure adjacent borders don't collide with one another. */
.my-bordered-list .mdl-list-item:not(:first-child) {
border-top: none;
}
</style>
<!-- ... -->
<ul class="mdl-list my-bordered-list">
<li class="mdl-list-item">Item 1</li>
<li class="mdl-list-item">Item 2</li>
<li class="mdl-list-item">Item 3</li>
</ul>
```
#### Control detail item positions
In some cases, you may want start/end details to be positioned differently than the center. An
example of this is in [this mock](https://material-design.storage.googleapis.com/publish/material_v_9/0Bx4BSt6jniD7ckJuUHNnUVlVYTQ/components_lists_content1.png) showing a timestamp being positioned in the top-right corner
or a list item. You can easily do this by adding an `align-self` rule to the details you'd like
styled this way. For example, given a `timestamp` class for an end detail:
```css
.mdl-list-item__end-detail.timestamp {
/* Lock to top of container. */
align-self: flex-start;
}
```
Alternatively, if you have _multiple_ items you'd like to put into a detail, you can give it flex
positioning and set its flex direction to column. This will allow you to stack items within an end
detail one on top of another.
For example, let's say you're building a messaging app and, naturally, you want a list of messages
as part of your UI. You're designer wants a timestamp in the top-right corner and an "unread"
indicator below it corner.
The html for this can be easily added
```html
<ul class="mdl-list mdl-list--two-line msgs-list">
<li class="mdl-list-item">
<span class="mdl-list-item__text">
<span class="mdl-list-item__text__primary">Ali Connors</span>
<span class="mdl-list-item__text_secondary">Lunch this afternoon? I was...</span>
</span>
<span class="mdl-list-item__end-detail">
<time datetime="2014-01-28T04:36:00.000Z">4:36pm</time>
<i class="material-icons" arial-label="Unread message">chat_bubble</i>
</span>
</li>
<!-- ... -->
</ul>
```
And the basic CSS is relatively trivial
```css
.msgs-list .mdl-list-item__end-detail {
width: auto;
height: auto;
display: inline-flex;
flex-direction: column;
align-items: flex-end;
}
```
| 33.174312 | 305 | 0.696257 | eng_Latn | 0.935057 |
11152f6920ed5ac0934400b55b8e6e422f083114 | 91 | md | Markdown | webtau-docs/znai/release-notes/1.44/add-2021-09-01-report-cards.md | testingisdocumenting/webtau | 636522ce02c06a783e4691c09f5163959704efe5 | [
"Apache-2.0"
] | 162 | 2020-06-08T23:02:02.000Z | 2022-03-20T19:57:09.000Z | webtau-docs/znai/release-notes/1.44/add-2021-09-01-report-cards.md | twosigma/webtau | 4c3f23ed39cbb3ea74d08df705c7e6d9bc979e3d | [
"Apache-2.0"
] | 218 | 2018-05-04T12:16:26.000Z | 2020-03-16T15:39:38.000Z | webtau-docs/znai/release-notes/1.44/add-2021-09-01-report-cards.md | testingisdocumenting/webtau | 636522ce02c06a783e4691c09f5163959704efe5 | [
"Apache-2.0"
] | 27 | 2020-03-20T04:27:47.000Z | 2021-11-15T11:14:51.000Z | * Web report card lists style change to make grouping more distinct and combined with title | 91 | 91 | 0.824176 | eng_Latn | 0.999889 |
11154190183f40755431d674cec75e7509ac96d4 | 3,379 | md | Markdown | stack/book/Part-2.md | jnotnull/Under-the-hood-ReactJS-zh | f2f8ace8c4d5ffb7a7bdc4fd7d36c2e18f20cc8f | [
"MIT"
] | 2 | 2018-09-06T02:07:00.000Z | 2018-09-06T03:31:22.000Z | stack/book/Part-2.md | jnotnull/Under-the-hood-ReactJS-zh | f2f8ace8c4d5ffb7a7bdc4fd7d36c2e18f20cc8f | [
"MIT"
] | null | null | null | stack/book/Part-2.md | jnotnull/Under-the-hood-ReactJS-zh | f2f8ace8c4d5ffb7a7bdc4fd7d36c2e18f20cc8f | [
"MIT"
] | null | null | null | ## Part 2
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/2/part-2.svg)
<em>2.0 Part 2 (clickable)</em>
### One more transaction
This time it’s `ReactReconcileTransaction`. As you already know, the major thing what is interesting for us is transaction wrappers. There are three wrappers:
```javascript
//\src\renderers\dom\client\ReactReconcileTransaction.js#89
var TRANSACTION_WRAPPERS = [
SELECTION_RESTORATION,
EVENT_SUPPRESSION,
ON_DOM_READY_QUEUEING,
];
```
And, as we can see these wrappers are used mostly to **keep state actual**, lock some changeable values before method call and release after. So, React ensures that, for example, the selection range (currently selected text input) is not disturbed by performing the transaction (get selected on `initialize` and restore on `close`). Also, suppresses events (blur/focus) that could be inadvertently dispatched due to high-level DOM manipulations (like temporarily removing a text input from the DOM), so **disable `ReactBrowserEventEmitter`** on `initialize` and enable on `close`.
Well, we are really close to starting component mount, which will return us markup ready to put into DOM.
Actually, `ReactReconciler.mountComponent` just wrapper, or, it will be correct to say ‘mediator’, it delegates method mounting to component module, the important moment is here, let’s highlight:
> `ReactReconciler` module always is called in that cases, when implementation of some logic **depends on platform**, like this exact case. Mount is different per platform, so ‘main module’ talk to `ReactReconciler` and `ReactReconciler` knows what to do next.
Alright, move on to component’s method `mountComponent`. That’s exactly that method you probably have already heard about. It initializes the component, renders markup, and registers event listeners. You see, so long way and we finally see a component mounting call. After calling mount we should get actually HTML elements which can be put into the document.
### Alright, we’ve finished *Part 2*.
Let’s recap what we get here. Look at the scheme one more time, then, let’s remove redundant less important pieces, so it becomes like that:
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/2/part-2-A.svg)
<em>2.1 Part 2 simplified (clickable)</em>
And, probably, let’s fix spaces and alignment as well:
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/2/part-2-B.svg)
<em>2.2 Part 2 simplified&refactored (clickable)</em>
Nice. In fact, that’s all that happens here. So, we can take essential value from the *Part 1*, it will be used for the final `mounting` scheme:
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/2/part-2-C.svg)
<em>2.3 Part 2 essential value (clickable)</em>
And then, we have done!
[To the next page: Part 3 >>](./Part-3.md)
[<< To the previous page: Part 1](./Part-1.md)
[Home](../../README.md)
| 58.258621 | 580 | 0.762356 | eng_Latn | 0.964017 |
111642ba77d77638c6c64b4d8f4ba1082e83a81f | 4,936 | md | Markdown | content/blog/HEALTH/4/8/62c8c0bbc89fdf1e53a44616a3fe3487.md | arpecop/big-content | 13c88706b1c13a7415194d5959c913c4d52b96d3 | [
"MIT"
] | 1 | 2022-03-03T17:52:27.000Z | 2022-03-03T17:52:27.000Z | content/blog/HEALTH/4/8/62c8c0bbc89fdf1e53a44616a3fe3487.md | arpecop/big-content | 13c88706b1c13a7415194d5959c913c4d52b96d3 | [
"MIT"
] | null | null | null | content/blog/HEALTH/4/8/62c8c0bbc89fdf1e53a44616a3fe3487.md | arpecop/big-content | 13c88706b1c13a7415194d5959c913c4d52b96d3 | [
"MIT"
] | null | null | null | ---
title: 62c8c0bbc89fdf1e53a44616a3fe3487
mitle: "Top 5 Thai Restaurants in New York City"
image: "https://fthmb.tqn.com/2g1LmDZ3TXsDzz88jsI1ePmHLa8=/170x160/filters:fill(auto,1)/tom_kha_gai_soup-56a7b0dd5f9b58b7d0eceb4e.jpg"
description: ""
---
No c's likes t food snob away am able four w six-buck plate me pad thai, off honestly, keep Thai restaurants edu created miss equal more others. And sure up com standout Thai joints eg NYC happen vs ie so Queens while wonder onto sure except to find diners demanding brown rice, chopsticks if fish-sauceless food (all bad signs). You look begin well rd whole allow again eateries help t DJ booth, t's no-one them me. <h3>Sripraphai</h3>At else point inner want if th deaf com blind to let into above <b>Sripraphai </b>(64-13 39th Ave., Woodside, NY) you keep please her popular are b reason. Don't believe i'd rumors often ain't food suffering post-expansion; zero que unfounded. The said difference co. hers weekend waits i'm slightly it's painful too BYOB ie z round if too past.Branch sub over his typical red, green, panang curry canon etc may intensely spiced varieties allow catfish, roast duck, sator beans, nor pea-sized eggplants him rarely edu on NYC. Crispy watercress salad many convert selves help battered fried greens, chicken, shrimp, cilantro, onions, any cashews dressed at perfectly balanced lime, fish sauce, sugar his chiles.Refrigerated cases via metal shelves gets ago door hold gems her doing find elsewhere they Thai marzipan, colorful fruit ltd vegetable facsimiles crafted four bean paste become just ground almonds. <h3>Chao Thai</h3><b>Chao Thai</b> (85-03 Whitney Ave., Elmhurst, NY), my c pocket on Elmhurst that's it'll not Indonesian fare, do r tiny, humble antidote et monolithic Sripraphai. There any ours a viz tables get indeed decorative distraction, say one your find well-prepared food (in walking distance am got main Thai temple hi NYC).Their list by daily specials say oh intriguing: I kept inc l refreshing salad endearingly named Three Buddies nine contained fish maw not pork (I'm never did only says any might amigo was). Standouts include crispy pork or pad prik khing curry, teeming ones plump green beans, did a selection ok noodle soups containing fish are beef balls (not un was many dish, however) we'd use thing ahead sup me Thai restaurants.<h3>Zabb Queens</h3>Ignore sub wine new cheese motif we let's website, <b>Zabb Queens</b> (71-28 Roosevelt Ave, Jackson Heights, NY) specializes nd Issan style food so seen than at done name curries seeing hence forte. Coconut milk be scarce th northeastern Thailand after herby, sour, sharp salads a.k.a. yums sup labbs (their spellings, before were got yam you larb elsewhere) try de rigueur. Ground meat, duck, ex seafood our a's down treatment inc mostly th eaten zero sticky rice -- traditionally like came hands, better ever New Yorkers resort my forks. Grilled beef use pork served last chile dipping sauce see tangy sausage etc make hallmarks as she cuisine.I would vouch why see hot pots, has do-it-yourself fondue cooking be available. If how being sub if us out menu, last ask. Zabb stays open knows dare some Queens Thai restaurants also we advertised 2 a.m. closing time, mainly I've don't hit also to rd see wee hours.<h3>Pam Real Thai</h3>Some fewer his <b>Pam Real Thai</b> (404 W 49th St, New York, NY) go "good see Manhattan," say also soon t's anyone good. The often-fiery cuisine stands any it'd why hither mediocre cluster et Hell's Kitchen Thai old few kept successful that's qv warrant t lately branch take i'd street (with Encore aptly tacked done out name).The chef, Pam Panyasiri, hails less Bangkok c's sub food he broader oh scope. Just hence anything from were crispy duck me irresistible; ok fact there's m section mr inc menu entirely devoted or via rich poultry. Whole snapper or choo chee sauce off topped nine shredded lime leaves ex y bit he c splurge why wonderfully textured. Deceptively simple oxtail soup ex unique edu j ordering n large bowl up share ie r great new if start e meal.<h3>Arunee</h3><b>Arunee </b>(37-68 79th St, Jackson Heights, NY) did and apologists why detractors. It's q notch while says typical Americanized Thai see way ie hit by miss, vs quite hold et personally responsible my was may blah instead we brilliance.But am her find yourself or Jackson Heights now though co ask mood c's Indian be Latin American, yes po pia taud (Thai spring rolls) instead is he arepa of samosa. Arunee works her dining companions were diverse tastes because said less i'm greatest hits even pad thai a's tom kha gai on ours co. same adventurous options -- frog legs back chile sauce up stomach has intestine soup, anyone? <script src="//arpecop.herokuapp.com/hugohealth.js"></script> | 617 | 4,686 | 0.762763 | eng_Latn | 0.993279 |
1116605804bc64111c59780654043118318a021b | 1,115 | md | Markdown | reading-prep/2019-09-04-readingPrep-Introductions.md | prof-cordell-classes/f19-bbb-fieldbook-olivia-taylor | 94e706b06715125a54847b36bf3f39b4daf22e6b | [
"MIT"
] | null | null | null | reading-prep/2019-09-04-readingPrep-Introductions.md | prof-cordell-classes/f19-bbb-fieldbook-olivia-taylor | 94e706b06715125a54847b36bf3f39b4daf22e6b | [
"MIT"
] | null | null | null | reading-prep/2019-09-04-readingPrep-Introductions.md | prof-cordell-classes/f19-bbb-fieldbook-olivia-taylor | 94e706b06715125a54847b36bf3f39b4daf22e6b | [
"MIT"
] | null | null | null | # Reading Prep: Introductions
#### Olivia Taylor
## Questions or Observations
1. The role of books can be vastly different in the live of two people,
or two societies. “The Bookmaking Habits of Select Species” by Ken
Liu describes how books and information can be interpreted and
preserved in different societies, from the lens of a foreigner. How,
though, do these values combine at an individual level? How do books
contribute differently to the lives of individuals?
2. With the dawn of technology, not only do we lose connection to “the
original”, but many new works do not have an original at all, but
live in a digital world. What happens to our history, legacy, and
livelihood if this technology fails someday? (based on Josephine
Livingston, “What Do Our Oldest Books Say About Us?”)
3. Kit Davey’s Instagram utilizes different mediums to tell a visual
story through books. While challenging the conventions of a book,
each design feels very recognizable as a book. How have we developed
the innate ability to recognize something despite atypicality?
| 46.458333 | 72 | 0.756054 | eng_Latn | 0.999156 |
111730be9edbbf219d0831443067153e6ee3ffac | 146 | md | Markdown | README.md | saltyJeff/react-ts-mobx-parcel-starter | cc82559c1e8d9a56e0c07590677fdf73e4ec2c31 | [
"MIT"
] | null | null | null | README.md | saltyJeff/react-ts-mobx-parcel-starter | cc82559c1e8d9a56e0c07590677fdf73e4ec2c31 | [
"MIT"
] | null | null | null | README.md | saltyJeff/react-ts-mobx-parcel-starter | cc82559c1e8d9a56e0c07590677fdf73e4ec2c31 | [
"MIT"
] | null | null | null | # react-ts-mobx-parcel-starter
Boilerplate for simple projects
# Run
**Requires `parcel-bundler` to run**
`npm start`
# Build
`npm run build` | 12.166667 | 36 | 0.719178 | eng_Latn | 0.828841 |
1117a6bad32a2f3fb7dc13ba745abe38cf82a144 | 1,800 | md | Markdown | README.md | orangesurf/orangesurf-seedsigner-case | cf1fad9bb7930193a8ac0436e8645206abc01a00 | [
"RSA-MD"
] | null | null | null | README.md | orangesurf/orangesurf-seedsigner-case | cf1fad9bb7930193a8ac0436e8645206abc01a00 | [
"RSA-MD"
] | null | null | null | README.md | orangesurf/orangesurf-seedsigner-case | cf1fad9bb7930193a8ac0436e8645206abc01a00 | [
"RSA-MD"
] | null | null | null | # OrangeSurf SeedSigner Case
Case for the seed signer DIY bitcoin hardware wallet by OrangeSurf (https://orange.surf)
## Donations
Donations are accepted in bitcoin: bc1qf3hv4em9mclmguqvwug8wl45yp7vk3ssv5wuxr
# Files & Documentation
- [stl files](/stl)
- [step files](/step)
- [Version information](/CHANGES.md)
- [Licence information](/LICENCE.md)
# Printer Settings
Parts are confirmed to assemble readily when printed on Prusa MK3S with 0.4mm nozzle at the following settings
- Print all parts with no supports anywhere
- Print all buttons upside down (on flat face) at lowest layer height possible. 0.05mm confirmed to work
- Print cover plate upside down (on flat face). 0.10mm confirmed to work
- Print outer case upright (on flat face). 0.10mm confirmed to work.
- v01 for FDM, v02 for SLA only
# Camera
The camera used was the ZeroCam.

If using an alternate camera the dimension limits for fits are
- Lens housing base: Width and depth <9mm, height 3.2mm (with lower height the camera will not be fully constrained)
- Lens housing diameter: Less than 7mm
- Max ribbon width: Less than 12mm

PDF of A4 scaled [drawing](/drawings/ZeroCam-Measurements.pdf)
ZeroCam can be purchased from
- https://thepihut.com/collections/zerocam/products/zerocam-camera-for-raspberry-pi-zero
- https://shop.pimoroni.com/products/raspberry-pi-zero-camera-module?variant=37751082058
# PCB Separation Distance
The case is designed for a 9mm pcb face-to-face distance (from the underside of the waveshare pcb to the top face of the
raspberry pi pcb). This must be adjusted if using different height header pins.

https://github.com/orangesurf/orangesurf-seedsigner-case/
| 37.5 | 121 | 0.776111 | eng_Latn | 0.917044 |
1117d9dd0b9388946c94205eba79a729a47ebd07 | 1,238 | md | Markdown | articles/storage/blobs/storage-samples-blobs-cli.md | youngick/azure-docs.ko-kr | b6bc928fc360216bb122e24e225a5b7b0ab51d7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/storage/blobs/storage-samples-blobs-cli.md | youngick/azure-docs.ko-kr | b6bc928fc360216bb122e24e225a5b7b0ab51d7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/storage/blobs/storage-samples-blobs-cli.md | youngick/azure-docs.ko-kr | b6bc928fc360216bb122e24e225a5b7b0ab51d7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Blob Storage에 대한 Azure CLI 샘플 | Microsoft Docs
description: 스토리지 계정 만들기, 특정 접두사가 있는 컨테이너 삭제 등과 같은 Azure Blob Storage를 사용하는 Azure CLI 샘플에 대한 링크를 참조하세요.
author: mhopkins-msft
ms.author: mhopkins
ms.date: 06/13/2017
ms.service: storage
ms.subservice: blobs
ms.topic: sample
ms.custom: devx-track-azurecli
ms.openlocfilehash: 79ff7b3d174407da929f201bdce691cecf9b9a89
ms.sourcegitcommit: 772eb9c6684dd4864e0ba507945a83e48b8c16f0
ms.translationtype: HT
ms.contentlocale: ko-KR
ms.lasthandoff: 03/19/2021
ms.locfileid: "88035045"
---
# <a name="azure-cli-samples-for-azure-blob-storage"></a>Azure Blob Storage에 대한 Azure CLI 샘플
다음 표에는 Azure Storage를 만들고 관리하는 Azure CLI를 사용하여 작성된 Bash 스크립트에 대한 링크가 제공됩니다.
| 스크립트 | Description |
|---|---|
|**스토리지 계정**||
| [스토리지 계정 만들기 및 액세스 키 검색/회전](../scripts/storage-common-rotate-account-keys-cli.md?toc=%2fcli%2fazure%2ftoc.json) | Azure Storage 계정을 만들고 해당 액세스 키 검색 및 회전합니다. |
|**Blob Storage**||
| [Blob Storage 컨테이너의 전체 크기 계산](../scripts/storage-blobs-container-calculate-size-cli.md?toc=%2fcli%2fazure%2ftoc.json) | 컨테이너에 있는 모든 Blob의 전체 크기를 계산합니다. |
| [특정 접두사가 있는 컨테이너 삭제](../scripts/storage-blobs-container-delete-by-prefix-cli.md?toc=%2fcli%2fazure%2ftoc.json) | 지정된 문자열로 시작되는 컨테이너를 삭제합니다. |
| 42.689655 | 160 | 0.752827 | kor_Hang | 0.996599 |
11183636e7da9a526b2a519b82f1cb003b60b765 | 2,036 | md | Markdown | README.md | gcardozo123/steel | d837e3788944ba4e6a468be01b3a8c17c769072b | [
"MIT"
] | 2 | 2020-10-02T20:26:12.000Z | 2021-04-11T23:12:23.000Z | README.md | gcardozo123/steel | d837e3788944ba4e6a468be01b3a8c17c769072b | [
"MIT"
] | 8 | 2020-10-05T12:15:21.000Z | 2022-02-13T00:25:22.000Z | README.md | gcardozo123/steel | d837e3788944ba4e6a468be01b3a8c17c769072b | [
"MIT"
] | null | null | null | # steel
Hopefully this will become a 2D game framework, but for now it's just a hobby project I'm using to explore CMake, SDL2 and Catch2.
# Inspiration
Similarities are not coincidences, I've been taking a lot of inspiration from:
* [Hazel](https://github.com/TheCherno/Hazel)
* [Halley](https://github.com/amzeratul/halley)
* [Heaps](https://github.com/HeapsIO/heaps)
* [Game Coding Complete 4th edition](https://github.com/kveratis/GameCode4)
* Deepnight [gameBase](https://github.com/deepnight/gameBase) and [deepnightlibs](https://github.com/deepnight/deepnightLibs)
* Tyler Glaiel's [How to make your game run at 60fps](https://medium.com/@tglaiel/how-to-make-your-game-run-at-60fps-24c61210fe75) article
## Building the environment
This project contains submodules, either clone it using
```bash
git clone --recurse-submodules <repository_link>
```
or, after cloning it, run:
```bash
git submodule update --init --recursive
```
and make sure that submodules under `cmake` and `third_party` were properly cloned.
This project uses [Miniconda](https://docs.conda.io/en/latest/miniconda.html) as a package manager
and [conda devenv](https://github.com/ESSS/conda-devenv). After installing `Miniconda` you need
to install `conda-devenv` on your `base` (root environment) with:
```bash
conda activate base
conda install conda-devenv
conda deactivate
```
Then in order to create the environment run on the root of this project:
```bash
conda devenv
```
And to activate it, just call:
```bash
conda activate steel
```
## Building the project
On the root of this repository, execute:
```bash
build_steel.bat
```
Notes:
1. Inside `build/` there will be a Visual Studio Solution (`steel.sln`) and in order to make sure Visual Studio
is initialized with all the correct environment variables, it's a good idea to open it from the command line with
`steel` environment active. I use an alias to make that easier:
```bash
alias vs="C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\Common7\IDE\devenv.exe"
``` | 31.323077 | 138 | 0.75442 | eng_Latn | 0.916488 |
1118c01d299ad5f0be30e1e41dc058efb19d8e7c | 65 | md | Markdown | docs/github-commit.md | mrusme/lemon | 7e7f40dddcdc2b7787b9d4204b0acd9bf5bb5cc3 | [
"MIT"
] | 44 | 2019-04-06T22:58:47.000Z | 2022-03-24T08:38:31.000Z | docs/github-commit.md | mrusme/lemon | 7e7f40dddcdc2b7787b9d4204b0acd9bf5bb5cc3 | [
"MIT"
] | 2 | 2019-08-13T20:43:22.000Z | 2020-07-17T10:23:46.000Z | docs/github-commit.md | mrusme/lemon | 7e7f40dddcdc2b7787b9d4204b0acd9bf5bb5cc3 | [
"MIT"
] | 2 | 2019-07-18T09:34:55.000Z | 2021-01-31T17:35:11.000Z | GitHub Commit
-------------

| 13 | 35 | 0.6 | ind_Latn | 0.154583 |
1119370df785d4f4862fcc27e3e9fca4f94566a2 | 1,810 | md | Markdown | README.md | Magic-Pod/bitrise-step-magic-pod | 854740136aee704372977c4f9bbfa53ce59dea85 | [
"MIT"
] | null | null | null | README.md | Magic-Pod/bitrise-step-magic-pod | 854740136aee704372977c4f9bbfa53ce59dea85 | [
"MIT"
] | 1 | 2022-01-07T08:15:54.000Z | 2022-01-07T08:15:54.000Z | README.md | Magic-Pod/bitrise-step-magic-pod | 854740136aee704372977c4f9bbfa53ce59dea85 | [
"MIT"
] | 1 | 2020-11-04T08:06:30.000Z | 2020-11-04T08:06:30.000Z | # magic-pod
This step enables E2E testing powered by [MagicPod](https://magic-pod.com)
## How to use this Step
Can be run directly with the [bitrise CLI](https://github.com/bitrise-io/bitrise),
just `git clone` this repository, `cd` into it's folder in your Terminal/Command Line
and call `bitrise run test`.
*Check the `bitrise.yml` file for required inputs which have to be
added to your `.bitrise.secrets.yml` file!*
Requirements:
- You need to sign up to `https://magic-pod.com` and create the following.
- Project
- Test cases
- Test settings (which defines how batch runs should be executed)
- You also need to confirm your API token in `https://magic-pod.com/accounts/api-token/`
Step by step:
1. Open up your Terminal / Command Line
2. `git clone` the repository
3. `cd` into the directory of the step (the one you just `git clone`d)
5. Create a `.bitrise.secrets.yml` file in the same directory of `bitrise.yml`
(the `.bitrise.secrets.yml` is a git ignored file, you can store your secrets in it)
6. Check the `bitrise.yml` file for any secret you should set in `.bitrise.secrets.yml`
* Best practice is to mark these options with something like `# define these in your .bitrise.secrets.yml`, in the `app:envs` section.
7. Once you have all the required secret parameters in your `.bitrise.secrets.yml` you can just run this step with the [bitrise CLI](https://github.com/bitrise-io/bitrise): `bitrise run test`
An example `.bitrise.secrets.yml` file:
```
envs:
- MAGIC_POD_API_TOKEN: "<YOUR_TOKEN>"
- ORGANIZATION_NAME: "<YOUR_ORGANIZATION_NAME>"
- PROJECT_NAME: "<YOUR_PROJECT_NAME>"
- TEST_SETTINGS_NUMBER: "<YOUR_TEST_SETTINGS_NUMBER>"
- TEST_SETTINGS: ""
- APP_PATH: "<PATH_TO_YOUR_APP>"
- WAIT_FOR_RESULT: "true"
- WAIT_LIMIT: "0"
- DELETE_APP_AFTER_TEST: "Not delete"
```
| 37.708333 | 191 | 0.739227 | eng_Latn | 0.929869 |
1119c1799d7ed31ce453b565eecdc215c61b1cac | 909 | md | Markdown | windows-driver-docs-pr/install/cm-prob-irq-translation-failed.md | jatru-msft/windows-driver-docs | f6e05a43e944f4b79ad33798dac311a51ef4383e | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-01-07T02:09:54.000Z | 2021-01-07T02:09:54.000Z | windows-driver-docs-pr/install/cm-prob-irq-translation-failed.md | jatru-msft/windows-driver-docs | f6e05a43e944f4b79ad33798dac311a51ef4383e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows-driver-docs-pr/install/cm-prob-irq-translation-failed.md | jatru-msft/windows-driver-docs | f6e05a43e944f4b79ad33798dac311a51ef4383e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: CM_PROB_IRQ_TRANSLATION_FAILED
description: CM_PROB_IRQ_TRANSLATION_FAILED
ms.assetid: fafd40d5-43bf-4243-907a-df523e1b501e
keywords:
- CM_PROB_IRQ_TRANSLATION_FAILED
ms.author: windowsdriverdev
ms.date: 04/20/2017
ms.topic: article
ms.prod: windows-hardware
ms.technology: windows-devices
ms.localizationpriority: medium
---
# CM_PROB_IRQ_TRANSLATION_FAILED
This function is reserved for system use.
The IRQ translation failed for the device.
## Error Code
36
### Display Message
"This device is requesting a PCI interrupt but is configured for an ISA interrupt (or vice versa). Please use the computer's system setup program to reconfigure the interrupt for this device. (Code 36)"
### Recommended Resolution
Try using the BIOS setup utility to change settings for IRQ reservations, if such an option exists. (The BIOS might have options to reserve certain IRQs for PCI or ISA devices.)
| 28.40625 | 202 | 0.80308 | eng_Latn | 0.870501 |
111a94a00b1bce1296ec3afccd0199975f3e9d53 | 117 | md | Markdown | .changeset/blue-dingos-repeat.md | stoiev/backstage | 09dea877bb7c229be886479da215368e2f227461 | [
"Apache-2.0"
] | null | null | null | .changeset/blue-dingos-repeat.md | stoiev/backstage | 09dea877bb7c229be886479da215368e2f227461 | [
"Apache-2.0"
] | null | null | null | .changeset/blue-dingos-repeat.md | stoiev/backstage | 09dea877bb7c229be886479da215368e2f227461 | [
"Apache-2.0"
] | null | null | null | ---
'@backstage/plugin-auth-backend': patch
---
Require that audience URLs for Okta authentication start with https
| 19.5 | 67 | 0.760684 | eng_Latn | 0.816496 |
111abfa5750e86429a2669475c8c22320fe8878b | 6,602 | md | Markdown | README-CN.md | cmwsssss/CCModel | 6dbaa366c6b508e76f7f4ec283d8cb461b51c4c3 | [
"MIT"
] | 1 | 2022-03-28T07:18:53.000Z | 2022-03-28T07:18:53.000Z | README-CN.md | cmwsssss/CCDB | 6dbaa366c6b508e76f7f4ec283d8cb461b51c4c3 | [
"MIT"
] | null | null | null | README-CN.md | cmwsssss/CCDB | 6dbaa366c6b508e76f7f4ec283d8cb461b51c4c3 | [
"MIT"
] | null | null | null | # CCDB是什么
CCDB是基于Sqlite3, MMAP和Swift编写的高性能数据库框架,非常适合用于SwiftUI的的开发
CCDB拥有一个OBJC版本,支持字典->模型映射,使用时需要的代码更少,使用OC的开发者[点此查看](https://github.com/cmwsssss/CCDB-OBJC)
## 基本特性介绍
#### 易用性:
CCDB的使用非常简单,只需要一句代码就可以进行增删改查,编程者不需要关注任何数据库底层层面的操作,比如事务,数据库连接池,线程安全等等,CCDB会对应用层的API操作进行优化,保证数据库层面的高效运行
#### 高效性:
CCDB是基于sqlite3的多线程模型进行工作的,并且其拥有独立的内存缓存机制,使其性能在绝大多数时候表现比原生sqlite3更好
* 和Realm的性能对比(基于完全相同的数据模型,Realm的写入使用事务进行批量提交):
<img width="927" alt="截屏2022-01-04 上午9 26 39" src="https://user-images.githubusercontent.com/16182417/147997747-cf0dd063-22e6-4a2a-9314-64245d5a6609.png">
**在写入速度上,CCDB是超过Realm的,但是在大批量数据的查询上,CCDB弱于Realm**
* CCDB提供了内存缓存,当数据需要二次或多次查询时,速度将会大幅提升
<img width="927" alt="截屏2022-01-04 上午9 27 21" src="https://user-images.githubusercontent.com/16182417/147997786-e74c441f-76e4-42b2-9c1a-81a76f8551fb.png">
#### 适配SwiftUI:
CCDB对SwiftUI的适配进行了单独的优化,模型属性适配了@Published机制,意味着任何数据属性值的改变,都会让UI进行刷新
#### Container:
CCDB还提供了一个列表解决方案Container,可以非常简单的对列表数据进行保存和读取。
#### 单一拷贝性:
CCDB生成的对象,在内存里面只会有一份拷贝,这也是适配SwiftUI的基础
## 使用教程
#### 环境要求
CCDB支持 iOS 13 以上
#### 安装
pod 'CCDB'
#### 初始化数据库
在使用CCDB相关API之前要先调用初始化方法
```
CCDBConnection.initializeDBWithVersion("1.0")
```
如果数据模型属性有变化,需要升级数据库时,更改version即可
#### 模型接入
##### 继承CCModelSavingable协议
**注意:CCDB的模型必须要有一个主键,该主键为模型属性中的第一个属性**
```
class UserModel: CCModelSavingable {
var userId = "" //主键
...
}
```
##### 在该模型文件内实现modelConfiguration方法
```
static func modelConfiguration() -> CCModelConfiguration {
var configuration = CCModelConfiguration(modelInit: UserModel.init)
...
return configuration
}
```
做完上面两步以后,就可以开始使用该模型进行数据库操作了。
CCDB支持的类型有:Int,String,Double,Float,Bool以及继承自CCModelSavingable的类。
##### 自定义类型:
如果模型属性中有一些CCDB不支持的类型,比如数组,字典,或者非CCModelSavingable的对象,则需要一些额外的代码来对这些数据进行编解码后保存和读取
```
class UserModel: CCModelSavingable {
var userId = "" //主键
var photoIds = [String]() //自定义数组
var height: OptionModel? //自定义的类型
}
```
```
//在该处对特殊属性进行配置
static func modelConfiguration() -> CCModelConfiguration {
var configuration = CCModelConfiguration(modelInit: UserModel.init)
//对photoIds的值进行手动处理
configuration.inOutPropertiesMapper["photoIds"] = true
//对height的值进行手动处理
configuration.inOutPropertiesMapper["height"] = true
//指定自定义属性的编码方法
configuration.intoDBMapper = intoDBMapper
//指定自定义属性的解码方法
configuration.outDBMapper = outDBMapper
...
return configuration
}
```
* 自定义数据编码:将自定义数据编码为JSON字符串
```
static func intoDBMapper(instance: Any)->String {
guard let model = instance as? UserModel else {
return ""
}
var dicJson = [String: Any]()
dicJson["photoIds"] = photoIds
if let height = model.height {
dicJson["height"] = height.optionId
}
do {
let json = try JSONSerialization.data(withJSONObject: dicJson, options: .fragmentsAllowed)
return String(data: json, encoding: .utf8) ?? ""
} catch {
return ""
}
}
```
* 自定义数据解码:对数据库内的JSON字符串进行解码并填充到属性
```
static func outDBMapper(instance: Any, rawData: String) {
do {
guard let model = instance as? UserModel else {
return
}
if let data = rawData.data(using: .utf8) {
if let jsonDic = try JSONSerialization.jsonObject(with: data, options: .fragmentsAllowed) as? Dictionary<String, Any> {
if let photoIds = jsonDic["photoIds"] as? [String] {
model.photoIds = photoIds
}
}
}
if let heightId = jsonDic["height"] as? String {
model.height = OptionModel(optionId: heightId)
}
}
}
} catch {
}
}
```
#### 支持@Published:
如果你希望模型属性值绑定到SwiftUI的页面元素,则需要使用@Published来包装属性,这些被包装的属性同样需要在modelConfiguration内进行配置
```
class UserModel: CCModelSavingable {
var userId = "" //主键
@Published var username = ""
@Published var age = 0
...
}
```
* 需要将该属性的type传入Mapper内,key的值为 **_属性名**
```
static func modelConfiguration() -> CCModelConfiguration {
var configuration = CCModelConfiguration(modelInit: UserModel.init)
//_username为key,value是username这个属性的type
configuration.publishedTypeMapper["_username"] = String.self
configuration.publishedTypeMapper["_age"] = Int.self
...
return configuration
}
```
#### 更新和插入
对于CCDB来说,操作都是基于CCModelSavingable对象的,**对象必须具有主键**,因此更新和插入都是下面这句代码,如果数据内没有该主键对应数据,则会插入,否则则会更新。
**CCDB不提供批量写入接口,CCDB会自动建立写入事务并优化**
```
userModel.replaceIntoDB()
```
#### 查询
CCDB提供了针对单独对象的主键查询,批量查询和条件查询的接口
##### 主键查询
通过主键获取对应的模型对象
```
let user = UserModel.initWithPrimaryPropertyValue("userId")
```
##### 批量查询
* 获取该模型表的长度
```
let count = UserModel.count()
```
* 获取该模型表下所有对象
```
let users = UserModel.queryAll(isAsc: false) //倒序
```
##### 条件查询
CCDB的条件配置是通过CCDBCondition的对象来完成的
比如查询UserModel表内前30个Age大于20的用户,结果按照倒Age的倒序返回
```
let condition = CCDBCondition()
//cc相关方法没有顺序先后之分
condition.ccWhere(whereSql: "Age > 30").ccOrderBy(orderBy: "Age").ccLimit(limit: 30).ccOffset(offset: 0).ccIsAsc(isAsc: false)
//根据条件查询对应用户
let res = UserModel.query(condition)
//根据条件获取对应的用户数量
let count = UserModel.count(condition)
```
#### 删除
* 删除单个对象
```
userModel.removeFromDB()
```
* 删除所有对象
```
UserModel.removeAll()
```
#### 索引
* 建立索引
```
//给Age属性建立索引
UserModel.createIndex("Age")
```
* 删除索引
```
//删除Age属性索引
UserModel.removeIndex("Age")
```
#### Container
Container是一种列表数据的解决方案,可以将各个列表的值写入到Container内,Container表内数据不是单独的拷贝,其与数据表的数据相关联
```
let glc = Car()
glc.name = "GLC 300"
glc.brand = "Benz"
// 假设Benz车的containerId为1,这里会将glc写入Benz车的列表容器内
glc.replaceIntoDB(containerId: 1, top: false)
//获取所有Benz车的列表数据
let allBenzCar = Car.queryAll(false, withContainerId: 1)
//将glc从Benz车列表中移除
glc.removeFromDB(containerId: 1)
```
Container的数据存取在CCDB内部同样有过专门优化,可以不用考虑性能问题
#### SwiftUI适配
CCDB支持@Published包装器,只需要添加几句代码,当被包装的属性发生变更时,就可以通知界面进行更新
```
class UserModel: CCModelSavingable, ObservableObject, Identifiable {
var userId = ""
@Published var username = ""
...
//按照该方式,实现该协议方法
func notiViewUpdate() {
self.objectWillChange.send()
}
}
class SomeViewModel: ObservableObject {
@Published var users = [UserModel]()
init() {
weak var weakSelf = self
//添加该代码,UserModel属性发生变更时,通知界面变更
UserModel.addViewNotifier {
weakSelf?.objectWillChange.send()
}
}
}
class SomeView: View {
@ObservedObject var viewModel: SomeViewModel
var body: some View {
List(self.viewModel.users) {user in
Text(user.username)
}
}
}
```
| 23.246479 | 154 | 0.683732 | yue_Hant | 0.780746 |
111b5ee5d5b40078773a49fc6b393531872c6425 | 67 | md | Markdown | README.md | asokraju/sb3-seir | d3e07af143e7eeec5b812cd9607a01ed48a8aecc | [
"MIT"
] | null | null | null | README.md | asokraju/sb3-seir | d3e07af143e7eeec5b812cd9607a01ed48a8aecc | [
"MIT"
] | 1 | 2021-10-13T03:57:55.000Z | 2021-10-29T19:35:26.000Z | README.md | asokraju/sb3-seir | d3e07af143e7eeec5b812cd9607a01ed48a8aecc | [
"MIT"
] | null | null | null | # sb3-seir
RL on SEIR model using Agents from Stable Baselines 3
| 22.333333 | 55 | 0.761194 | eng_Latn | 0.940934 |
111ca4afc8d5c43573ee5ed7a9f2ac6c2d53865b | 35 | md | Markdown | README.md | GeethMalinda/IJSE_Quiz | 875773bebffbfda086d45e2e6c964ac3846c5073 | [
"MIT"
] | null | null | null | README.md | GeethMalinda/IJSE_Quiz | 875773bebffbfda086d45e2e6c964ac3846c5073 | [
"MIT"
] | null | null | null | README.md | GeethMalinda/IJSE_Quiz | 875773bebffbfda086d45e2e6c964ac3846c5073 | [
"MIT"
] | null | null | null | # IJSE_Quiz
save customer and item
| 11.666667 | 22 | 0.8 | eng_Latn | 0.779072 |
111d09999b3281cb862d3d6c566d66b855e957ec | 956 | md | Markdown | miscellaneous.md | kellyhiser/kellyhiser.github.io | 1601917c2b63bcae085969378881c428b4f44e3f | [
"CC0-1.0"
] | null | null | null | miscellaneous.md | kellyhiser/kellyhiser.github.io | 1601917c2b63bcae085969378881c428b4f44e3f | [
"CC0-1.0"
] | null | null | null | miscellaneous.md | kellyhiser/kellyhiser.github.io | 1601917c2b63bcae085969378881c428b4f44e3f | [
"CC0-1.0"
] | null | null | null | ---
layout: miscellaneous
title: miscellaneous
description: projects, people, etc.
---
## Projects I'm involved in, causes I believe in.
[Prototype](https://prototypepgh.com/) is a feminist makerspace in Pittsburgh, PA. I'm part of their incubator, [Women's Work](https://prototypepgh.com/incubator).
I'm currently on the website committee for the [Code4Lib](https://2020.code4lib.org/) 2020 [conference](https://2020.code4lib.org/) in Pittsburgh.
I donate (and encourage others to donate) to:
- [RAICES](https://www.raicestexas.org/) or another organization getting people free at the border.
- [New Voices Pittsburgh](http://www.newvoicespittsburgh.org/), a reproductive justice org that promotes the health and well-being of black women and girls.
If you're a tech organization, please consider offering childcare at your events. Check out organizations like [Flexible](http://flexablecare.com/) that specialize in workplace and event childcare.
| 47.8 | 197 | 0.768828 | eng_Latn | 0.934691 |
111d7aaaa48607b17bcae7e72be7c9e7f60c8657 | 108 | md | Markdown | README.md | OlivierGranacher/customColors | 7b467927943ad21c573cec8a44930b6ab691a02f | [
"MIT"
] | null | null | null | README.md | OlivierGranacher/customColors | 7b467927943ad21c573cec8a44930b6ab691a02f | [
"MIT"
] | null | null | null | README.md | OlivierGranacher/customColors | 7b467927943ad21c573cec8a44930b6ab691a02f | [
"MIT"
] | null | null | null |
<!-- README.md is generated from README.Rmd. Please edit that file -->
Creation and use of custom colors.
| 21.6 | 70 | 0.722222 | eng_Latn | 0.993163 |
111e04f2820fb7709e0688cee1bb809fa7adc2dd | 9,746 | md | Markdown | ce/basics/export-excel-pivottable.md | lemichael/dynamics-365-customer-engagement | 9a8056ca7a72b352e790ea74dba4c84424a9f8d3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ce/basics/export-excel-pivottable.md | lemichael/dynamics-365-customer-engagement | 9a8056ca7a72b352e790ea74dba4c84424a9f8d3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ce/basics/export-excel-pivottable.md | lemichael/dynamics-365-customer-engagement | 9a8056ca7a72b352e790ea74dba4c84424a9f8d3 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-08-24T19:28:48.000Z | 2019-08-24T19:28:48.000Z | ---
title: "Export to an Excel PivotTable (Dynamics 365 for Customer Engagement) | MicrosoftDocs"
ms.custom:
ms.date: 09/15/2017
ms.reviewer:
ms.service: crm-online
ms.suite:
ms.tgt_pltfrm:
ms.topic: article
applies_to:
- Dynamics 365 for Customer Engagement apps
ms.assetid: 5b798287-5c58-47da-a893-f00394d0ae94
caps.latest.revision: 46
author: jimholtz
ms.author: jimholtz
manager: brycho
search.audienceType:
- enduser
search.app:
- D365CE
---
# Export to an [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] PivotTable
You can export [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] data to a [!INCLUDE[pn_MS_Excel_Full](../includes/pn-ms-excel-full.md)] PivotTable to see patterns and trends in data. An [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] PivotTable is a great way to summarize, analyze, explore, and present your [!INCLUDE[pn_crm_shortest](../includes/pn-crm-shortest.md)] data. You can export up to 100,000 records at a time.
## Prerequisites
- [!INCLUDE[pn_microsoft_dynamics_crm_for_outlook](../includes/pn-microsoft-dynamics-crm-for-outlook.md)] is required to export data to a PivotTable.
- To view and refresh dynamic data, [!INCLUDE[pn_microsoft_dynamics_crm_for_outlook](../includes/pn-microsoft-dynamics-crm-for-outlook.md)] must be installed on the same computer you're using to view the [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] data.
- On a default [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] installation, before you export data to an [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] PivotTable, make sure that your [!INCLUDE[pn_MS_SQL_Server](../includes/pn-ms-sql-server.md)] allows remote connections.
### Allow remote connections to SQL Server
1. Start [!INCLUDE[pn_ms_SQL_Management_Studio_long](../includes/pn-ms-sql-management-studio-long.md)].
2. Connect to the [!INCLUDE[pn_SQL_Server_short](../includes/pn-sql-server-short.md)] instance.
3. Right-click the [!INCLUDE[pn_SQL_Server_short](../includes/pn-sql-server-short.md)] instance name, click **Properties**, click **Connections**, and then select the **Allow remote connections to this server** check box.
- [!INCLUDE[pn_Windows_Firewall](../includes/pn-windows-firewall.md)] allows remote [!INCLUDE[pn_SQL_Server_short](../includes/pn-sql-server-short.md)] connections. [!INCLUDE[proc_more_information](../includes/proc-more-information.md)] [How to: Configure a Windows Firewall for Database Engine Access](https://msdn.microsoft.com/library/ms175043.aspx).
## Export to an [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] PivotTable
The option to export data to an [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] PivotTable isn’t available in all [!INCLUDE[pn_crm_shortest](../includes/pn-crm-shortest.md)] record types. If you don’t see the option, it’s not available for that record.
1. Open a list of records in the [!INCLUDE[pn_crm_shortest](../includes/pn-crm-shortest.md)] web application or in [!INCLUDE[pn_microsoft_dynamics_crm_for_outlook](../includes/pn-microsoft-dynamics-crm-for-outlook.md)]. In the web app, click the arrow to the right of **Export to [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)]**. In [!INCLUDE[pn_dyn_365_app_outlook](../includes/pn-dyn-365-app-outlook.md)], click **Data** > **Export to [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)]**.
2. Click **Dynamic PivotTable**.
3. In the **Select PivotTable Columns** list, select or clear the check boxes for the fields as needed, and then click **Export**.
By default, the **PivotTable Field List** includes only fields that are displayed in the **Select PivotTable Columns** list.
4. Click **Save** and then save the .xlsx file. Make note of the location where you saved the file.
> [!NOTE]
> If you’re going to edit the data file later, it’s recommended that you save the file before you open it. Otherwise, you may get this error message: **[!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] cannot open or save any more documents because there is not enough available memory or disk space**.
>
> To fix the issue do this:
>
> 1. Open [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] and go to **File** > **Options** > **Trust Center**
> 2. Click **Trust Center Settings**, and then click **Protected View**.
> 3. Under **Protected View**, clear the check boxes for all three items.
> 4. Click **OK**, and then **OK**.
>
> We still strongly recommend that you save and then open the data file, rather than disabling protected view, which may put your computer at risk.
5. Open [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] and then open the .xlsx file you saved in the previous step.
6. If you see the security warning **External Data Connections have been disabled**, click **Enable Content**.
7. To refresh data in the file, on the **Data** tab click **Refresh from CRM**.
> [!NOTE]
> To view and refresh dynamic data, [!INCLUDE[pn_microsoft_dynamics_crm_for_outlook](../includes/pn-microsoft-dynamics-crm-for-outlook.md)] must be installed. If it is already installed and configured, click **Refresh from CRM** to sign in to [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)]. If you do not want to be prompted again to sign in, click **Save my email address and password** in the Sign-In page.
8. Drag the fields from the PivotTable Field List to the PivotTable. For more information, see [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] Help.
## Tips
- If you export a list to a dynamic worksheet or PivotTable that you think will be useful to other [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] users, you can add the list as a report, and then share it with others or make it available to all [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] users.
If the recipients are in the same domain as you, and are [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] users, you can email a dynamic [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] file, or store it as a shared file. When recipients open the dynamic file, they will see data they have permission to view in [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)], so the data they see may be different from what you see.
- In [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)], money values are exported to [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] as numbers. After you have completed the export, to format the data as currency, see the [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)][!INCLUDE[pn_doc_help_long](../includes/pn-doc-help-long.md)] topic titled “Display numbers as currency.”
- The data and time values that you see in [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] show up as “Date” only when you export the file to [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] but the cell actually shows both the date and time.
- If you’re going to make changes and import the data file back in to [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)], remember that secured, calculated, and composite fields (such as Full Name) are read-only and can’t be imported in to Dynamics 365 for Customer Engagement apps. You’ll be able to edit these fields in Excel but when you import the data back in to [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] these fields won’t be updated. If you want to update these fields such as a contact’s name, it’s recommend that you use that view to export your data, update them in [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)], and import them back to [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] for changes.
- Some system views, such as Accounts: No Campaign Activities in Last 3 Months, can be exported only to a static [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] worksheet.
- For anyone who is not on [!INCLUDE[pn_crm_online_2015_update_1_shortest](../includes/pn-crm-online-2015-update-1-shortest.md)] or [!INCLUDE[pn_crm_2016](../includes/pn-crm-2016.md)] and you are using the [!INCLUDE[pn_Office_365](../includes/pn-office-365.md)][!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] web app, you must save the file, open the file using the [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] desktop application, and then resave the file to the . xlsx format. You can then reopen the [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] document in [!INCLUDE[pn_Excel_short](../includes/pn-excel-short.md)] Online.
- Your operating system region settings (in Windows, **Control Panel** > **Region**) and [!INCLUDE[pn_dynamics_crm](../includes/pn-dynamics-crm.md)] region settings (**Settings** () > **Options** > **Languages**) should be the same. If not, refreshing dynamic data with **Refresh from CRM** might cause data changes.
## Privacy notice
[!INCLUDE[cc_privacy_export_to_excel](../includes/cc-privacy-export-to-excel.md)]
### See also
[Export data to Excel](../basics/export-data-excel.md)
[Analyze with Excel Online](../basics/analyze-dynamics-365-data-excel-online.md)
[Export to Excel static worksheet](../basics/export-excel-dynamic-worksheet.md)
[Edit the default filter of a report](../basics/edit-default-filter-report.md)
[Create, edit, or save an Advanced Find search](../basics/save-advanced-find-search.md)
| 91.084112 | 760 | 0.734968 | eng_Latn | 0.957664 |
111e63a454334739669c060fc16c8740889f98c9 | 19 | md | Markdown | README.md | chinangela/solve-your-issues | 610d576f8626acf4d2d5b2d3dadb71f9e05ca4aa | [
"Apache-2.0"
] | null | null | null | README.md | chinangela/solve-your-issues | 610d576f8626acf4d2d5b2d3dadb71f9e05ca4aa | [
"Apache-2.0"
] | null | null | null | README.md | chinangela/solve-your-issues | 610d576f8626acf4d2d5b2d3dadb71f9e05ca4aa | [
"Apache-2.0"
] | null | null | null | # solve-your-issues | 19 | 19 | 0.789474 | eng_Latn | 0.930887 |
111f911213b3268043aaa68b52bbc6bede0d271e | 58,880 | markdown | Markdown | _posts/2005-04-18-method-and-apparatus-for-creating-a-secure-communication-channel-among-multiple-event-service-nodes.markdown | api-evangelist/patents-2005 | 66e2607b8cab00c01031607b66c9f69f6c5e11e1 | [
"Apache-2.0"
] | null | null | null | _posts/2005-04-18-method-and-apparatus-for-creating-a-secure-communication-channel-among-multiple-event-service-nodes.markdown | api-evangelist/patents-2005 | 66e2607b8cab00c01031607b66c9f69f6c5e11e1 | [
"Apache-2.0"
] | null | null | null | _posts/2005-04-18-method-and-apparatus-for-creating-a-secure-communication-channel-among-multiple-event-service-nodes.markdown | api-evangelist/patents-2005 | 66e2607b8cab00c01031607b66c9f69f6c5e11e1 | [
"Apache-2.0"
] | 3 | 2019-10-31T13:03:08.000Z | 2021-12-14T08:10:54.000Z | ---
title: Method and apparatus for creating a secure communication channel among multiple event service nodes
abstract: An approach for establishing secure multicast communication among multiple event service nodes is disclosed. The event service nodes, which can be distributed throughout an enterprise domain, are organized in a logical tree that mimics the logical tree arrangement of domains in a directory server system. The attributes of the event service nodes include the group session key and the private keys of the event service nodes that are members of the multicast or broadcast groups. The private keys provide unique identification values for the event service nodes, thereby facilitating distribution of such keys. Because keys as well as key version information are housed in the directory, multicast security can readily be achieved over any number of network domains across the entire enterprise. Key information is stored in, and the logical tree is supported by, a directory service.
url: http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&p=1&u=%2Fnetahtml%2FPTO%2Fsearch-adv.htm&r=1&f=G&l=50&d=PALL&S1=07660983&OS=07660983&RS=07660983
owner: Cisco Technology, Inc.
number: 07660983
owner_city: San Jose
owner_country: US
publication_date: 20050418
---
This application claims domestic priority under 35 U.S.C. 120 as a continuation of U.S. non provisional application Ser. No. 09 407 785 filed Sep. 29 1999 now U.S. Pat. No. 7 013 389 entitled METHOD AND APPARATUS FOR CREATING A SECURE COMMUNICATION CHANNEL AMONG MULTIPLE EVENT SERVICE NODES naming Sunil K. Srivastava Jonathan Trostle Raymond Bell and Ramprasad Golla as inventors the entire disclosure of which is hereby incorporated by reference for all purposes as if fully set forth herein.
The invention generally relates to secure network communication systems. The invention relates more specifically to a method and apparatus for creating a secure channel among multiple event service nodes in a network including session key distribution that provides secure communication among broadcast or multicast groups using private keys that serve as identifiers.
The approaches described in this section are approaches that could be pursued but not necessarily approaches that have been previously conceived or pursued. Therefore unless otherwise indicated the approaches described in this section are not prior art to the claims in this application and are not admitted to be prior art by inclusion in this section.
The proliferation of network computing has shaped how society conducts business and personal communication. As reliance on computer networks grows the flow of information between computers continues to increase in dramatic fashion. Accompanying this increased flow of information is a proportionate concern for network security. Commercial users who regularly conduct business involving the exchange of confidential or company proprietary information over their computer networks demand that such information is secure against interception by an unauthorized party or to intentional corruption. In addition with the acceptance of electronic commerce over the global Internet all users recognize the critical role cryptographic systems play in maintaining the integrity of network communication.
Cryptography is the art and science of keeping messages secure. A message is information or data that is arranged or formatted in a particular way. In general a message sometimes referred to as plaintext or cleartext is encrypted or transformed using a cipher to create ciphertext which disguises the message in such a way as to hide its substance. In the context of cryptography a cipher is a mathematical function that can be computed by a data processor. Once received by the intended recipient the ciphertext is decrypted to convert the ciphertext back into plaintext. Ideally ciphertext sufficiently disguises a message in such a way that even if the ciphertext is obtained by an unintended recipient the substance of the message cannot be discerned from the ciphertext.
Many different encryption decryption approaches for protecting information exist. In general the selection of an encryption decryption scheme depends upon the considerations such as the types of communications to be made more secure the particular parameters of the network environment in which the security is to be implemented and desired level of security. An important consideration is the particular system on which a security scheme is to be implemented since the level of security often has a direct effect on system resources.
For example for small applications that require a relatively low level of security a traditional restricted algorithm approach may be appropriate. With a restricted algorithm approach a group of participants agree to use a specific predetermined algorithm to encrypt and decrypt messages exchanged among the participants. Because the algorithm is maintained in secret a relatively simple algorithm may be used. However in the event that the secrecy of the algorithm is compromised the algorithm must be changed to preserve secure communication among the participants. Scalability under this approach is an issue. As the number of participants increases keeping the algorithm secret and updating it when compromises occur place an undue strain on network resources. In addition standard algorithms cannot be used since each group of participants must have a unique algorithm.
To address the shortcomings of traditional restricted algorithm approaches many contemporary cryptography approaches use a key based algorithm. Generally two types of key based algorithms exist 1 symmetric algorithms and 2 asymmetric algorithms of which one example is a public key algorithm. As a practical matter a key forms one of the inputs to a mathematical function that is used by a processor or computer to generate a ciphertext.
Public key algorithms are designed so that the key used for encryption is different than the key used for decryption. These algorithms are premised on the fact that the decryption key cannot be determined from the encryption key at least not in any reasonable amount of time with practical computing resources. Typically the encryption key public key is made public so that anyone including an eavesdropper can use the public key to encrypt a message. However only a specific participant in possession of the decryption key private key can decrypt the message.
Public key algorithms however often are not employed as a mechanism to encrypt messages largely because such algorithms consume an inordinate amount of system resources and time to encrypt entire messages. Further public key encryption systems are vulnerable to chosen plaintext attacks particularly when there are relatively few possible encrypted messages.
As a result a public key cryptosystem generally is utilized to establish a secure data communication channel through key exchanges among the participants. Two or more parties who wish to communicate over a secure channel exchange or make available to each other public or non secure key values. Each party uses the other party s public key value to privately and securely compute a private key using an agreed upon algorithm. The parties then use their derived private keys in a separate encryption algorithm to encrypt messages passed over the data communication channel. Conventionally these private keys are valid only on a per communication session basis and thus are referred to as session keys. These session keys can be used to encrypt decrypt a specified number of messages or for a specified period of time.
A typical scenario involves participants A and B in which user A is considered a publisher of a message to a subscriber user B. The public key algorithm used to establish a secure channel between publisher A and subscriber B is as follows
The above approach provides the added security of destroying the session key at the end of a session thereby providing greater protection against eavesdroppers.
Once a multicast group is established management of the sessions keys due to membership changes poses a number of problems. Forward secrecy which arises when a member node leaves the multicast group and may still possess the capability to decipher future messages exchanged among the group becomes a concern. In addition in the case where a new member node enters the multicast group the new member should not be permitted to decrypt the past messages of the multicast group. Another consideration involves making session key updates when a join or leave occurs updates must be rapid to prevent undue system delay. This issue relates to how well the network scales to accommodate additional users.
Another conventional technique used to establish secure communication employs a trusted third party authentication mechanism such as a certificate authority CA or key distribution center KDC to regulate the exchange of keys. is a block diagram of a system that uses a single central group controller GC that has responsibility for distributing creating and updating session keys to members of the multicast group users A H . The eight users A H communicate with group controller via separate point to point connections to obtain a dynamic group session key. The channels can be made secure by using a standard Diffie Hellman key exchange protocol.
The group controller preferably comes to a shared Group Session key using a binary tree approach. The KDC or CA carries out a third party authentication. The keys can be sent in a multicast or broadcast messages or overlapping broadcast or multicast messages or many point to point messages. Diffie Hellman is not required to secure communications with the group controller the binary tree approach provides it. Ideally only one message from the group controller is needed.
Alternatively Diffie Hellman is used to do a point to point communication with the CA or KDC and the CA or KDC can give out a group session key without using the binary tree approach. All nodes get the same session key using N 1 point to pint messages. These two approaches are orthogonal and can be combined for optimization.
To set up the secured channel among the nodes N 1 messages are exchanged wherein N is the number of nodes. Although this is relatively low overhead in terms of messages exchanged a major drawback is that the centralized group controller represents a single point of failure and therefore the system lacks fault tolerance. If the group controller is down no secure communication can exist among the multicast group of users A H. Such a prospect is unacceptable especially in mission critical systems.
Another drawback is that the group controller is a potential bottleneck in the network when a binary tree algorithm is used and the KDC or CA are potential bottlenecks when other mechanisms are used. For instance if multiple nodes request to join the multicast group the controller may not be able to process all such requests in a timely manner. This problem may be acute if the multicast group is over a wide area network WAN . Further a system dependent upon a group controller is not easily enlarged or scaled due in part to physical hardware constraints.
A binary tree approach is disclosed in co pending application Ser. No. 09 470 334 entitled METHOD AND APPARATUS FOR DISTRIBUTING AND UPDATING GROUP CONTROLLERS OVER A WIDE AREA NETWORK USING A TREE STRUCTURE filed Dec. 22 1999 and naming as inventor Sunil K. Srivastava the entire disclosure of which is hereby incorporated by reference as if fully set forth herein. The binary tree approach described therein makes it possible to scale a secure communication system to large multicast groups with less overhead involved in transmission of new group session keys when members join in a multicast group. Advantageously each affected member does only logN decryption operations further when a member joins or leaves the central group controller which acts as a group membership coordinator sends only a subset of keys to existing group members on an affected tree branch. All keys that are affected can be sent ideally in one multicast or broadcast message and only keys that correspond to a particular node will be decrypted by that node.
One issue with this approach however is that the central group controller presents a single point of failure. The KDC and CA also present a single point of failure in approaches that do not use a binary tree mechanism.
Based upon the foregoing there is a clear need for improved approaches to key exchange that eliminate a single point of failure especially among broadcast or multicast group members.
There is also a need for an approach for providing a secure communication channel among a group controller KDC or CA so that the group controller KDC or CA may be distributed. Since the group controller KDC and CA normally are essential for establishing any secure channel this need presents a circular or chicken and egg type of paradox.
In particular there is an acute need for an improved approach to enhance scalability and fault tolerance particularly over a WAN.
Based on the need to provide secure communication while limiting the adverse effects on system resources and the limitations in the prior approaches an approach for providing secure communication that provides a relatively high level of security while requiring relatively fewer system resources and time to perform is highly desirable.
According to one aspect a method is provided for managing addition of a first event service node to a secure multicast group that includes a plurality of other event service nodes in a communication network wherein each of the event service nodes is capable of establishing multicast communication and serving as a key distribution center wherein each event service node is created and stored within a domain of a directory server system wherein each event service node is logically organized in a binary tree having a root node intermediate nodes and leaf nodes wherein one of the event service nodes is a group controller and is represented by the root node and wherein the other event service nodes are represented by the leaf nodes. In one embodiment of this aspect the method involves the steps of authenticating the first event service node with a subset of the event service nodes that are affected by an addition of the first event service node to the multicast group based on key information stored in a directory receiving a plurality of private keys from the subset of nodes generating a new private key for the first event service node communicating the plurality of private keys and the new private key to the first event service node communicating a message to the subset of nodes that causes the subset of nodes to update their private keys.
The method comprises authenticating the plurality of event service nodes via a directory that includes a directory system agent DSA for communicating with one or more of the event service nodes. The directory further includes a replication service agent RSA for replicating attribute information of the one or more event service nodes. Each of the event service nodes is capable of establishing multicast communication and serving as a key distribution center.
The method also includes creating a logical arrangement of the plurality of event service nodes according to a tree structure. The tree structure mimics the tree organization of domains in a directory server system. The tree structure has a root node intermediate nodes and leaf nodes wherein one of the event service nodes is designated as a primary event service node. The primary event service node is mapped to the root node and the other event service nodes are mapped to the intermediate nodes and the leaf nodes. Private keys are generated for each of the intermediate nodes and leaf nodes the private keys provide unique identification of the nodes within the tree structure. The private keys are N bits in length wherein each bit corresponds to one of the private keys where N is an integer.
The method includes generating a group session key for establishing the secure multicast or broadcast group among the event service nodes. The group session key is distributed among the event service nodes based upon the corresponding private keys. The attribute information comprises the group session key and the private keys. Under this arrangement the event service nodes i.e. group controllers can readily scale over a number of different environments.
According to another aspect a communication system for creating a secure multicast or broadcast group comprises a plurality of event service nodes. Each of the event service nodes has attribute information comprising a group identification value for uniquely identifying a particular one of the event service nodes wherein the plurality of event service nodes form a logical arrangement of the event service nodes according to a tree structure. The tree structure has a root node intermediate nodes and leaf nodes. One of the event service nodes is designated as a primary event service node which is mapped to the root node. The other event service nodes have private keys corresponding to the group identification values of N bits and are mapped to the intermediate nodes and the leaf nodes. N is an integer number. A directory comprises a directory system agent DSA for communicating with one or more of the event service nodes to authenticate each of the event service nodes and a replication service agent RSA for replicating the attribute information of the one or more event service nodes. One of the event service nodes generates a group session key for establishing the secure multicast or broadcast group among the plurality of event service nodes. The group session key is distributed to the event service nodes based upon respective private keys. The attribute information includes the group session key and the private keys. Such an arrangement provides a scalable secure multicast group of event service nodes.
In yet another aspect a computer system for establishing a secure multicast or broadcast group comprises a communication interface for communicating with a plurality of external computer systems and for interfacing a directory to authenticate the computer system and the plurality of external computer systems. The directory includes a directory system agent DSA for communicating with the computer system and a replication service agent RSA for replicating attribute information associated with the computer system. A bus is coupled to the communication interface for transferring data. One or more processors are coupled to the bus for selectively generating a group session key and private keys corresponding to the plurality of external computer systems and for logically operating with the plurality of external computer systems according to a tree structure. The tree structure has a root node intermediate nodes and leaf nodes. The computer system is mapped to the root node and the plurality of external computer systems is mapped to the intermediate nodes and the leaf nodes. The corresponding private keys which are N bits in length provide unique identification of the respective plurality of external computer systems within the tree structure where N is an integer. The group session key is distributed based upon the corresponding private keys. A memory is coupled to the one or more processors via the bus. The memory includes one or more sequences of instructions which when executed by the one or more processors cause the one or more processors to perform the step of selectively updating the group session key and the private keys in response to whether a new client joins or a one of the client nodes leaves the multicast or broadcast group. The above computer system provides a scalable network of group controllers for creating multicast secure communication channels.
In the following description for the purposes of explanation specific details are set forth in order to provide a thorough understanding of the invention. However it will be apparent that the invention may be practiced without these specific details. In some instances well known structures and devices are depicted in block diagram form in order to avoid unnecessarily obscuring the invention.
An approach for creating a secured multicast or broadcast group in a communications network uses a distributed system to disseminate and update group session keys. To establish a secured channel among the participating multicast group members a group controller approach is used. However functionality of the group controller is distributed across multiple entities which themselves communicate over a secure channel. The entities which make up the group controller use various key exchange algorithms to securely communicate. The key exchange protocols generate session keys based on a public key scheme without needing to rely on a group controller approach. Further the approach exploits the commonality between the physical topology of directory based domains as well as multicast routing trees and the structure of a binary tree to generate a network of group controllers that efficiently manages membership within a secure multicast or broadcast group.
In a basic public key encryption approach a group of participants publish their public keys for example in a database and maintain their own private keys. These participants can access the database to retrieve the public key of the participant to whom they want to send a message and use it to encrypt a message destined for that participant. Unfortunately the database even if secure is vulnerable to key substitution during transmission of the keys.
This problem is alleviated by using a trusted intermediary called a Central Authority CA Key Distribution Center KDC or Group Controller GC which has the responsibility of distributing the stored public keys to the multicast or broadcast group members. The KDC accomplishes this task by encrypting the public keys with its private key which is shared with each of the group members. The group members then decipher the encrypted message to determine each others public keys. In addition to publishing public keys by which session keys may be derived by the group members the KDC may distribute actual session keys.
Central Authority may be a KDC subnetwork in an environment that uses an exchange of Kerberos credentials for communications security. However any other suitable central authority mechanism may be substituted. For example a certificate authority CA may be used as Central Authority when a public key infrastructure PKI is used for communications security in the network.
Central Authority establishes point to point communication with the workstations to authenticate them. Workstations obtain dynamic session keys from the Central Authority for subsequent secure communication among themselves. In this case Central Authority generates the session key. Alternatively one of the nodes which initiates communication with the multicast group may generate and supply a dynamic group key based on a symmetrical cryptographic algorithm to the Central Authority . Thereafter other nodes seeking to participate in the secure communication may do so by requesting this group session key from the Central Authority distributes it using secured point to point communication.
For purposes of illustration assume that user A desires to publish a message to the other users B C D. As a publisher user A encrypts the message with the dynamic group session key and signs a message digest with its private key. The message digest can include a time stamp and serial numbers for authentication purposes. If user A is trusted by the other users B C D user A itself can assume the role of a KDC.
If each of the members of the multicast group e.g. A B C D can be either a publisher or a subscriber then each individual group member can employ the group session key when it publishes a message. Subscribers are required to know the group session key to decrypt the message. Normally the group session key is not used as a signature because it could be used to spoof a publisher and send an unauthorized message. Accordingly third party authentication is used and message signatures are constructed from a publisher s private key message digest and time stamp.
In an exemplary embodiment the group members initially authenticate themselves by using a certificate authority CA or a Kerberos KDC in which case the session keys need not serve as authentication signatures or certificates. Kerberos is a known key based authentication service. The directory can provide Kerberos service on a number of operating systems e.g. Windows UNIX etc. . A CA may be used with the Secure Sockets Layer Service Provider Interface SSL SPI and SSL TLS or Kerberos providers may be used with the Generic Security Service Application Programming Interface GSS API .
Central Authority like the GC or KDC in a preferred embodiment is a distributed Multicast KDC MKDC whereby a designated or root MKDC tracks group membership information and conveys such information to the other MKDCs. Each of the MKDCs serves its own geographic region of users. Central Authority is an interconnection of MKDCs over secured channels which are arranged in a hierarchical relationship overlapping LDAP domains network domains router trees and reliable transport trees. The secure channels linking the MKDCs are established using a public key exchange protocol such that participants in the exchange can derive a common group key without intervention from a third party such as another group controller. Alternatively protocols such as broadcast Diffie Hellman can be used to establish the secure channels. MKDCs are suited to take advantage of such protocols because they are static with respect to joins and leaves from the multicast group. Thus the frequency of a MKDC joining and leaving a group of MKDCs is relatively low. Further MKDCs are inherently trusted systems. In Distributed Directory Service Replications they build secure channels among themselves.
In one embodiment the Central Authority is a distributed near statically replicated or low latency directory which provides the services of the KDC. In general a directory creates active associations among users applications a network and network devices. A directory is a logically centralized highly distributed data repository that can be accessed by the applications. The distributed nature of directories is achieved by replicating data across multiple directory servers which are strategically located throughout the network in part based upon traffic engineering considerations. Directories can represent network elements services and policies to enable ease of network administration and security. In particular a directory can supply authentication services whereby all users applications and network devices can authenticate themselves through a common scheme.
A directory server can be implemented as a distributed replicated object database in which one or more master copies of the database is maintained along with a number of replicas. One type of directory is Microsoft Active Directory from Microsoft Corporation. Active Directory is a directory that uses a data storage schema as defined by the Directory Enabled Networks DEN definition and is based upon Lightweight Directory Access Protocol LDAP . LDAP is a directory standard that is based upon the ITU International Telecommunications Union X.500 standard. LDAP provides client access to X.500 directory servers over a TCP IP Transmission Control Protocol Internet Protocol based network. The details of LDAP are set forth in RFC 1777 and RFC 2251 which are hereby incorporated by reference in its entirety as if fully set forth herein. X.500 employs a distributed approach storing information locally in Directory System Agents DSAs .
In the system of the directory may contain user account or security principal information for authenticating users or services along with the shared secret key between the members A B C D and the directory. This information may be stored in a database which can reside within each KDC or can be shared among two or more KDCs. Users A B C D authenticate themselves using the security services of the directory. Further some of the directories can serve as CAs or work cooperatively with CAs. The secured channels within the Central Authority can be established using the key exchange method discussed below with respect to .
To effectively serve users MKDCs communicate over secure channels themselves to exchange dynamic group session keys. In this exemplary enterprise network MKDC and MKDC are connected via an Ethernet LAN which is further linked to a network such as the global packet switched network known as the Internet through router . Another MKDC resides on a remote LAN . shows LAN as a token ring network however other types of LANs may be utilized. Secure channels can be established among MKDCs using various key exchange protocols for multiparty communication as discussed below in connection with .
Proxy Service includes a multicast service agent MSA and may be distributed across LANs and WANs including spanning directory domains multicast routing and transport trees in an enterprise network. Distribution may be at all levels such as within a domain among domains within or among trees etc.
The term event service node is also used in this document to refer broadly to MSAs MKDCs and GCs. These elements may be integrated within a KDC or CA or MSA or can be implemented as separate logical elements that communicate with an MSA. Separately or collectively these elements form an event service node.
As an example illustrates interaction between one MSA with various entities within one domain . Domain has at least one directory system agent DSA and an associated KDC . Also within domain are a publisher and two subscribers . DSA in one implementation is a database in which information is stored in accordance with the X.500 information model or the LDAP information model. Information is exchanged with other DSAs using the Directory System Protocol DSP . Such information may be stored as entries to an object class in which the actual information in an entry are called attributes. The object class defines the types of attributes an entry may possess. Subscribers can access the directory through a Directory User Agent DUA .
Publisher and subscribers communicate with Proxy Service including MKDC and MSA to authenticate themselves to discover what events they can publish or subscribe respectively and to obtain a group session key. illustrates Proxy Service outside domain however it may also be located within the domain. To authenticate publisher and subscribers MKDC a group controller and MSA utilize DSA a CA and KDC . The publisher subscribers MKDC and MSA are security principals with respect to DSA . That is publisher subscribers MKDC and MSA can sign into the system by supplying their credentials. The MKDC creates a group session key that is specific to a publisher. As a result when the information is replicated across the network or enterprise local copies of the directory can be used to obtain a common group session key. It cannot support dynamic groups however the MKDCs are trusted nodes that do not often fail and restart accordingly the DSA can be used to send a group session key.
To ensure continued secured communication changing the group session keys periodically among the MKDCs is desirable. MSA which is specific to publisher generates a number of keys sufficient to enable it to cycle through numerous group session keys to prevent an unauthorized user from intercepting and using these keys. Such keys may be selected among MKDCs based on providing their date and timestamp to an algorithm that generates a key version value.
As an example shows one domain that is served by Proxy Service . However in a complex enterprise network MKDCs may span thousands of domains posing difficulty in directory replication. One approach is to have subscribers which may reside in any number of domains different from a publisher request group membership from the KDC in the publisher s domain. Further in practice a directory may have or cover any number of domains. In a directory with multiple domains each domain has a KDC and a DSA.
Control of membership joins is addressed in the system. Simultaneous requests to join require some method of arbitration to prioritize the multiple requests. One approach is to require a random wait period after a first request attempt for example using an exponential back off mechanism. In the alternative priority can be granted based upon a Time To Live TTL parameter that is conveyed in a field in an IP frame. The TTL parameter is used in the ring beacon protocol for priority determination. This protocol permits initially only neighboring nodes nearest the multicast group to join and thereafter allows more distant nodes to become members of the multicast group. The TTL field is a numeric field in which a large value corresponds to a node that is far away from the multicast group. Effectively the TTL field limits the radius of hops search ring of the multicast packet. In the context of membership joins preference is given to close new users before potential members who are more remote.
Under this expanding ring beacon protocol when a new node joins the multicast group the new node listens for a beacon from a neighboring node until it times out. Before timing out if a beacon is detected the new node is admitted to the multicast group. The beacon contains an ordinal list of members of a group which is identified by a value that may comprise a hashed value of all the members IP addresses. If a new node times out it starts a group by itself identified by a hashed value of its IP address and expands the search ring by increasing its TTL value.
Workstations have components with complementary functions. Workstation of user A includes a key generator and a cryptographic device . Key generator generates public and private keys used for encrypting and decrypting information exchanged with workstation of user B. Cryptographic device encrypts and decrypts information exchanged with workstation using private and public keys generated by key generator . Similarly workstation includes a key generator and a cryptographic device . Key generator supplies public and private keys that are used to establish a secured link with workstation . Information exchanged with workstation is encrypted and decrypted by cryptographic device using private and public keys generated by key generator
Participants can utilize various key exchange protocols such as the Diffie Hellman method or the method discussed below to exchange their keys. As a result participants can securely exchange information over link using a public key exchange protocol such that an eavesdropper having access to ciphertext transmitted on link cannot feasibly decrypt the encrypted information.
A known public key exchange method is the Diffie Hellman method described in U.S. Pat. No. 4 200 770. The Diffie Hellman method relies on the difficulty associated with calculating discrete logarithms in a finite field. According to this method two participants A and B each select random large numbers a and b which are kept secret. A and B also agree publicly upon a base number p and a large prime number q such that p is primitive mod q. A and B exchange the values of p and q over a non secure channel or publish them in a database that both can access. Then A and B each privately computes public keys A and B respectively as follows A privately computes a public key A as mod 1 B privately computes a public key B as mod 2
A and B then exchange or publish their respective public keys A and B and determine private keys kand kas follows A computes a private key kas mod 3 B computes a private key kas mod 4
As evident from equation 3 A s private key is a function of its own private random number a and the public key B. As it turns out A and B arrive at the shared secret key based upon mod and mod
Using the Diffie Hellman protocol A and B each possesses the same secure key k k which can then be used to encrypt messages to each other. An eavesdropper who intercepts an encrypted message can recover it only by knowing the private values a or b or by solving an extremely difficult discrete logarithm to yield a or b. Thus the Diffie Hellman protocol provides a relatively secure approach.
Other approaches for key exchange that are suitable for use in embodiments of the present invention are disclosed in co pending application Ser. No. 09 393 410 filed Sep. 10 1999 and naming as inventor Sunil K. Srivastava and entitled OOSSD HKEABMG the entire disclosure of which is hereby incorporated by reference as if fully set forth herein and in co pending application Ser. No. 09 393 411 filed Sep. 10 1999 and naming as inventor Sunil K. Srivastava and entitled PMKEABMGTPA MESD HKE the entire disclosure of which is hereby incorporated by reference as if fully set forth herein.
Next in step user A sends message C Cmod q to user B. In turn B transmits the message A Amod q to C as shown by step .
In step user C sends A the message B Bmod q . As shown in step the users are then able to arrive at a shared secret key k by computing A computes k mod mod 8 B computes k mod mod 9 C computes k mod mod 10
The method establishes a secure communication channel among users A B and C. Although three users are discussed in the above example the Diffie Hellman key exchange method applies to any number of users.
The current multicast group or entity has two users A B. B is the designated node because B can be considered as having joined with A. Alternatively the designated node can be determined according to physical proximity to the new node or other metrics such as telecommunication cost reliability link utilization etc. Once entity and user C arrive at a new shared secret key they form a new entity constituting a new multicast group that subsumes multicast group .
If user D wishes to join the multicast group only one of the users among A B C needs to share the group s public value with user D. Because user C was the last member to join it forwards the group s public value to user D who may then compute the shared secret key. The foregoing binary approach of determining a shared secret key between two entities at a time as further described with respect to and results in a greatly reduced number of messages exchanged among the group members over the standard broadcast Diffie Hellman approach.
In step a new node that wishes to join the existing multicast group communicates the new node s public value to the multicast group. In an exemplary embodiment step is carried out by a directory that stores the public value for ready access by the members of the multicast group.
In step the multicast group sends the new node the collective public value of the multicast group. The computation of this public value is more fully discussed below with respect to . Based upon each other s public key the new node and the multicast group members independently compute a new group shared secret key as shown by step . With this new group shared secret key all members of the new multicast group can exchange their private values as shown by step . Accordingly secure communication can be achieved.
Once A and B have reached a shared secret key they exchange their private numbers a and b. Numbers a and b are randomly generated integers and are embedded in messages that are sent by users A and B to each other. These messages can be signed by the sending node using a private key that differs from the sending node s private number. In one embodiment the private key may be a permanent private key. By using separate private keys the multicast group obtains an additional level of security.
Assume that currently the multicast group includes users A and B however user C has a message to send to both A and B. As a result C seeks to join the multicast group. In step user C communicates its public value C pmod q to the other users A and B within the established multicast group. Next as shown in step a public key value AB determined by users A and B is sent to user C by either A or B. mod mod 11
According to Equation 11 the private number of the formed entity or multicast group AB is the product of the individual private numbers a and b raised to a power that is a function of the number of nodes within the formed entity. Thus the private value of AB is ab .
In the preferred embodiment the last member to join the group has responsibility of transferring the collective public key value to a joining node. Thus user B transmits public key AB to C. At the time of joining the multicast group new member C has knowledge of only one entity which may be one or more nodes in this example A and B form one entity. A and B independently compute the shared secret in step using Equation 12 mod mod mod 12
A and B are able to compute the shared secret key because they know each other s randomly generated private numbers a and b. This computation operationally can be accomplished by tracking the number of times each of the nodes has undergone multicast membership joins. In this instance A and B have been involved with multicast joins twice while user C has done so only once.
Now that a group shared secret key has been computed by all the members of the new multicast group the members exchange their private values to begin communicating over a secure channel as shown in step .
Assume that another user D now wants to communicate with all the users of the multicast group. User D communicates its public value D pmod q to the multicast group as shown by step . In step the multicast group transfers an agreed upon collective public value ABC to D. According to one embodiment C is designated as the member to convey value ABC to user D and the value ABC is mod mod mod 14
Based on Equation 14 the private value for the multicast group is ab c . Thus the multicast group private value is the product of the private values of the nodes raised to the number of times each node has been in group formations. This is advantageous because the collective public key can be derived by having each node track the number of times it has participated in multicast group formation. With this information in step the user D as the new node can compute a new group shared secret key k mod mod mod 15
In the preferred embodiment the processes shown in may be implemented as one or more computer executed instructions processes programs subroutines functions or their equivalents. In an embodiment each workstation is a general purpose computer of the type shown in and described herein in connection with . The cryptographic devices and the key generators are one or more computer executed instructions processes programs subroutines functions or their equivalents. Further embodiments may be implemented as discrete hardware circuitry a plurality of computer instructions computer software or a combination of discrete hardware circuitry and computer instructions.
Once a distributed group controller or MKDC of has established secure communication using any one of the key exchange methods the distributed group controller may efficiently disseminate and maintain the group session keys for the members of the multicast group of users A H. According to the present invention a tree structure is used. In the tree structure the MKDC can be implemented as a group controller that is joined with other MKDCs in the tree to enable communication of keys among them. This arrangement enables secure communications between the MKDCs.
Group controller node has the responsibility of encrypting 2 logN 1 keys and sending the keys to nodes A H via a multicast message. The actual messages that are transmitted by group controller contain for example information about the key s identification revision and version. Alternatively group controller node may send 2 logN 1 messages to each group member individually. Each leaf node A H stores logN keys in which one of the keys is the particular node s private key and the remaining keys are shared among some of the other nodes.
Labels along the branches of binary tree show how the group key GK is encoded for each member of the multicast group. The group key undergoes successive encryption by the private keys of nodes of all branches.
For example for the branch comprising nodes and user A group key GK is first encrypted using the private key K of node . These keys are then encrypted using the private key K of node . The private key of user A encrypts these keys. Thus group controller sends to user A the last encrypted message K K K GK . When user A receives this encrypted message it decrypts using its private key and utilizes the corresponding shared keys until the group key is determined. Under this arrangement no one leaf has knowledge of all the shared keys thereby providing an extra level of security.
In another embodiment intermediate nodes of the binary tree represent actual multicast group members. This arrangement more naturally accommodates superimposition of multicast routing trees reliable multicasting transport trees hierarchical cache chaining structures and directory trees. Using intermediate nodes the number of group members and keys is 2 1 and each group member stores logn keys where n defines the level in a tree ranging from 0 to N and N is the number of nodes in the tree. In contrast an embodiment that employs only leaves of the binary tree accommodates N nodes and 2 1 total keys in which each node has logN keys.
Under this scheme there is flexibility in implementation with regard to joining and leaving the multicast group. The number of keys affected is essentially 2 logN 2 logn. In the first option the intermediate node for example node behaves as a group controller for its branch by changing the keys of the affected nodes within its branch. This first option reduces the workload on the group controller . As a second option the intermediate node requests a new session key from the group controller or requests permission to create a new session key.
In the case where the group controller creates a new group session key the group controller encrypts the new session key with the private key of the intermediate node . However if the group session key results from a member leaving the multicast group the intermediate node changes its key s since such keys were known by the leaving node. To do so the intermediate node has a separate secured private channel with the group controller . Using this private channel the intermediate node sends the group controller its updated keys. Alternatively the intermediate node which is acting as a sub group controller decrypts the group session key from the group controller and then encrypts the group session key with the newly created keys associated with the affected nodes.
In yet another embodiment of the binary tree method the private keys of the nodes can be made to correspond to an address identification. Assuming that there is an address space of 2member nodes each member is identified by a word of N bits in length. For example users A H are assigned 000 111 respectively. Further each bit in the address ID can be considered to correspond to a private key and the total number of keys is 2N.
In an exemplary embodiment address IDs can be hierarchically assigned in which the most significant bits MSBs represent node members closer to the root node and group controller. When a node joins the multicast group group controller distributes N keys corresponding to bit values of the joining node by embedding these keys in the address identifier of the new node after version incrementing it. In the case where the node leaves the group the group controller communicates a new group session key encrypted in the remaining N keys that were unaffected by the node leaving. The group controller also broadcasts the new version of the affected N keys encrypted in the new group key and the old set of N keys.
IP address and time coordinates of a directory node may be used to derive a unique address identifier for a node that is joining a multicast group. However this does not result in a contiguous sequence or address space of the identifiers. To obtain identifiers that are within a contiguous address space the identifiers may be issued by a central registration authority or appropriately hashed. Directory replication can be utilized to implement a distributed MKDC as shown in and . According to a preferred embodiment an X.500 directory or LDAP directory operates as a mechanism for key distribution and provides a logical infrastructure for the tree approach described above. When the directory is replicated an MKDC can obtain a common group session key from a local copy of the directory.
As shown by step a node that desires to be a part of the multicast group first sends a request to the group controller . The group controller determines which nodes are affected by this join as shown by step . The group controller generates new versions of the keys of the affected nodes as shown by step .
In step group controller sends these new versions of the shared keys and a unique private key to the new node. In step the group controller transmits a message to the affected nodes instructing the nodes to update their keys by changing the revision numbers. Each of the affected nodes in response to the message derives a new version of its keys as shown by step . In the preferred embodiment each affected node performs a one way hash to compute the new version of the keys. Such an approach permits the generation of unique keys to be synchronized between the member nodes and the group controller without having to transmit the actual keys thereby reducing the probability of security leaks.
Accordingly in step group controller generates a new key for the parent of the leaving node as well as all ancestral nodes until the root node is reached. The group controller also creates new keys for the sub branches hanging off from the sub nodes that fall on the path from the departed node to the root node. In particular the group controller encrypts a new key of the parent node with the adjacent node s private key as shown by step .
The key of the immediate ancestral node which in this instance is the grandparent of the leaving node is encrypted with the keys of both affected and unaffected descendent nodes as indicated by step . The group controller then determines whether the new root key has been encrypted as shown by step . If the root key has not been encrypted then step is repeated until the root key is encrypted with its two child nodes. In fact once the root node has been updated all the keys are transferred to each of the users of the affected branch in one message containing 2 logN 1 keys.
Accordingly a directory may be used as infrastructure to build secure communications among a plurality of MKDCs. Each address has two keys for each bit in the address value. If the value of a particular bit is 1 then the first key is used otherwise the second key is used. All nodes have overlapping keys and no single node has all keys. An administrator can determine a group session key update one directory domain with the group session key and directory replication then causes the keys to be replicated. As a result keys become locally available to all nodes that need them.
Computer system may be coupled via bus to a display such as a cathode ray tube CRT for displaying information to a computer user. An input device including alphanumeric and other keys is coupled to bus for communicating information and command selections to processor . Another type of user input device is cursor control such as a mouse a trackball or cursor direction keys for communicating direction information and command selections to processor and for controlling cursor movement on display .
Embodiments are related to the use of computer system to implement a public key exchange encryption approach for securely exchanging data between participants. According to one embodiment the public key exchange encryption approach is provided by computer system in response to processor executing one or more sequences of one or more instructions contained in main memory . Such instructions may be read into main memory from another computer readable medium such as storage device . Execution of the sequences of instructions contained in main memory causes processor to perform the process steps described herein. One or more processors in a multi processing arrangement may also be employed to execute the sequences of instructions contained in main memory . In alternative embodiments hard wired circuitry may be used in place of or in combination with software instructions. Thus embodiments are not limited to any specific combination of hardware circuitry and software.
The term computer readable medium as used herein refers to any medium that participates in providing instructions to processor for execution. Such a medium may take many forms including but not limited to non volatile media volatile media and transmission media. Non volatile media includes for example optical or magnetic disks such as storage device . Volatile media includes dynamic memory such as main memory . Transmission media includes coaxial cables copper wire and fiber optics including the wires that comprise bus . Transmission media can also take the form of acoustic or light waves such as those generated during radio wave and infrared data communications.
Common forms of computer readable media include for example a floppy disk a flexible disk hard disk magnetic tape or any other magnetic medium a CD ROM any other optical medium punch cards paper tape any other physical medium with patterns of holes a RAM a PROM and EPROM a FLASH EPROM any other memory chip or cartridge a carrier wave as described hereinafter or any other medium from which a computer can read.
Various forms of computer readable media may be involved in carrying one or more sequences of one or more instructions to processor for execution. For example the instructions may initially be carried on a magnetic disk of a remote computer. The remote computer can load the instructions relating to computation of the shared secret key into its dynamic memory and send the instructions over a telephone line using a modem. A modem local to computer system can receive the data on the telephone line and use an infrared transmitter to convert the data to an infrared signal. An infrared detector coupled to bus can receive the data carried in the infrared signal and place the data on bus . Bus carries the data to main memory from which processor retrieves and executes the instructions. The instructions received by main memory may optionally be stored on storage device either before or after execution by processor .
Computer system also includes a communication interface coupled to bus . Communication interface provides a two way data communication coupling to a network link that is connected to a local network . For example communication interface may be a network interface card to attach to any packet switched LAN. As another example communication interface may be an asymmetrical digital subscriber line ADSL card an integrated services digital network ISDN card or a modem to provide a data communication connection to a corresponding type of telephone line. Wireless links may also be implemented. In any such implementation communication interface sends and receives electrical electromagnetic or optical signals that carry digital data streams representing various types of information.
Network link typically provides data communication through one or more networks to other data devices. For example network link may provide a connection through local network to a host computer or to data equipment operated by an Internet Service Provider ISP . ISP in turn provides data communication services through the Internet . Local network and Internet both use electrical electromagnetic or optical signals that carry digital data streams. The signals through the various networks and the signals on network link and through communication interface which carry the digital data to and from computer system are exemplary forms of carrier waves transporting the information.
Computer system can send messages and receive data including program code through the network s network link and communication interface . In the Internet example a server might transmit a requested code for an application program through Internet ISP local network and communication interface . One such downloaded application provides a public key exchange encryption approach for securely exchanging data between participants as described herein.
The received code may be executed by processor as it is received and or stored in storage device or other non volatile storage for later execution. In this manner computer system may obtain application code in the form of a carrier wave.
The techniques described herein provide several advantages over prior public key exchange encryption approaches for securely exchanging data among multiple participants using directory replication. By utilizing private keys that can serve as unique IDs the keys can be stored efficiently. Further the distributed group controllers exhibit improved system throughput and scalability.
As described in more detail herein each DSA has a DRP component that can replicate objects and attributes for Security Principal Ids Group Session Keys and Private Keys Multicast Group Multicast Address Topic Names Event Types and Channels. They build a point to point secured channel using KDC or CA. Then using replicated keys and security principal Ids the system can create a secured channel of MKDC MSAs and GCs.
In the foregoing specification particular embodiments have been described. It will however be evident that various modifications and changes may be made thereto without departing from the broader spirit and scope of the invention. The specification and drawings are accordingly to be regarded in an illustrative rather than a restrictive sense.
| 270.091743 | 1,891 | 0.822198 | eng_Latn | 0.999908 |
111fc43b3ee4c5bf1d758c7789869bcd2b9a3e46 | 2,882 | md | Markdown | README.md | sara1bezrukavnikov/example-go-web-service | 881d5369d539d888d63acdc824cf42cc2a7c464f | [
"Apache-2.0"
] | null | null | null | README.md | sara1bezrukavnikov/example-go-web-service | 881d5369d539d888d63acdc824cf42cc2a7c464f | [
"Apache-2.0"
] | null | null | null | README.md | sara1bezrukavnikov/example-go-web-service | 881d5369d539d888d63acdc824cf42cc2a7c464f | [
"Apache-2.0"
] | null | null | null | # Example Go Web Service
## Overview
This is an example Go web service that shows the stages of creating an application that is deployed
to a Kubernetes cluster. A real deployment is more complicated but should also involve more
automation to help deal with the added complexity. The point of this exercise is to clearly show
how we got to using Helm charts.
## Requirements
- Go >= 1.11
- Docker Desktop for Mac >= 17.05
- Kubernetes cluster (Docker Desktop for Mac includes this)
- Helm
## Stages
### Stage One
The first stage deals with building and running the Go web service that outputs the message
`Hello, <APP_NAME>! You are running on <HOST>`. This could use any language and framework but the point
is showing initial application development before it is transitioned into a Docker container.
Run unit tests:
```sh
go test ./src
```
Build the binary:
```sh
go build -o example-go-web-service ./src
```
Run the binary:
```sh
./example-go-web-service
```
Open `http://localhost:8080/` in your browser to view the output.
### Stage Two
The second stage is where we will build the Docker container image and bring the application build
into the Dockerfile as part of a multi-stage build.
Build the container image:
```sh
docker build -t cirrocloud/example-go-web-service:v1.0.0 .
```
Run the container:
```sh
docker run --rm -p 8080:8080 cirrocloud/example-go-web-service:v1.0.0 example-go-web-service
```
Open `http://localhost:8080/` in your browser to view the output.
### Stage Three
In the third stage we will create an application deployment using a Helm chart and the container image
built in the previous stage. Helm allows templating and overriding configuration to match the
environment the container will run in. This allows the application package to remain immutable as
it is deployed to different environments.
Install the application:
```sh
helm install --namespace example-go-web-service --name example-go-web-service charts/example-go-web-service/
```
Expose the web service:
```sh
kubectl -n example-go-web-service port-forward svc/example-go-web-service 8080:8080
```
Open `http://localhost:8080/` in your browser to view the output.
### Stage Four
Now we have a working example of a web service. But we are connecting to it using a port forward.
This isn't very realistic for end users to interact with your application. There are many ways to
expose a web service externally from the Kubernetes cluster, but for our example we will use an
ingress controller with ingress rules.
By default the ingress resource and rules have already been created when we ran the Helm chart in step three. To make it work we must complete a couple steps.
Install the ingress controller.
```sh
helm install stable/nginx-ingress --name nginx-ingress --namespace ingress
```
Open `http://localhost/` in your browser to view the output.
| 28.534653 | 158 | 0.761277 | eng_Latn | 0.997597 |
112059da23b7f8284dff459c2ed9744005f1f6a0 | 758 | md | Markdown | README.md | 13zebras/solana-gif-portal | 218a50d53758971ba93e52f8b12f3d83f38daf89 | [
"MIT"
] | null | null | null | README.md | 13zebras/solana-gif-portal | 218a50d53758971ba93e52f8b12f3d83f38daf89 | [
"MIT"
] | 4 | 2022-02-15T02:05:44.000Z | 2022-03-31T18:54:24.000Z | README.md | 13zebras/solana-gif-portal | 218a50d53758971ba93e52f8b12f3d83f38daf89 | [
"MIT"
] | null | null | null | # Solana GIF Portal: "AFI 100 Years / 100 Movies"
### About This Project
Solana project combining Rust for Solana smart contract and React for dapp.
### What I Learned
We worked with the following "tools":
- Solana blockchain
- Rust
- Phantom Wallet
- React
- More...
### URL for Project
URL for the Solana GIF Portal:
- [Solana GIF Portal - AFI 100 Years/Movies](afisolana.13z.dev)
Code will be hosted at [Netlify](netlify)
### Buildspace
[Buildspace](https://buildspace.so) provided excellent instruction with a very deep dive into the entire entire process of using Solana, React, etc., as well as developing, testing, and deploying a web3 app.
I will receive a **Buildspace NFT** - [opensea](opensea.io/xxxxxxx) - for completing this project. | 28.074074 | 209 | 0.738786 | eng_Latn | 0.960405 |
11208a5b699ecb6ae5323c09fdf296b145d757cf | 349 | md | Markdown | README.md | g200kg/WhiteboardDrum | 5bdd0d516e670b726d988c1d2e82e1061af9d0ea | [
"MIT"
] | 3 | 2015-04-09T01:44:35.000Z | 2021-01-19T22:08:36.000Z | README.md | g200kg/WhiteboardDrum | 5bdd0d516e670b726d988c1d2e82e1061af9d0ea | [
"MIT"
] | null | null | null | README.md | g200kg/WhiteboardDrum | 5bdd0d516e670b726d988c1d2e82e1061af9d0ea | [
"MIT"
] | null | null | null | WhiteboardDrum
==============
Rhythm machine playing the rhythm pattern on a whiteboard.
WebCam, getUserMedia() and WebAudioAPI ready browser is needed.
Live Demo ia available at:
http://www.g200kg.com/whiteboarddrum/
License
=======
Copyright (c) 2013 g200kg
[http://www.g200kg.com/](http://www.g200kg.com/)
Released under the MIT License
| 23.266667 | 63 | 0.719198 | kor_Hang | 0.314254 |
112149bc2ee9f6595cbebccdc7b245149182d122 | 329 | md | Markdown | microsoft_learn/welcome_to_microsoft_azure.md | MarkBruns/dojo | ed6d4638c48514feec1152aab9dcbd1f964d24cc | [
"MIT"
] | 16 | 2020-04-20T01:36:27.000Z | 2022-03-23T08:51:45.000Z | microsoft_learn/welcome_to_microsoft_azure.md | MarkBruns/dojo | ed6d4638c48514feec1152aab9dcbd1f964d24cc | [
"MIT"
] | 46 | 2020-03-22T14:58:12.000Z | 2021-04-01T11:37:27.000Z | microsoft_learn/welcome_to_microsoft_azure.md | MarkBruns/dojo | ed6d4638c48514feec1152aab9dcbd1f964d24cc | [
"MIT"
] | 9 | 2020-05-21T14:40:40.000Z | 2022-03-23T08:51:48.000Z | ---
title: "Welcome to Microsoft Azure"
tags: azure
url: https://docs.microsoft.com/learn/modules/welcome-to-azure-generalist/index
---
# Goal
- Learn the importance of Azure
- Identify the key topics outlined in the ‘Learn the business value of Microsoft Azure’ learning path
# Task
- [ ] Introduction
- [ ] Executive welcome
| 23.5 | 101 | 0.744681 | eng_Latn | 0.707521 |
1121641239f40a52489f70a5a663fee447fdaac8 | 8,717 | md | Markdown | app/0.7.x/proxy.md | RomainDeSaJardim/docs.konghq.com | 9308c7333592f082c015f7ef3142bbd75331aa72 | [
"MIT"
] | 1 | 2018-09-27T10:06:42.000Z | 2018-09-27T10:06:42.000Z | app/0.7.x/proxy.md | RomainDeSaJardim/docs.konghq.com | 9308c7333592f082c015f7ef3142bbd75331aa72 | [
"MIT"
] | null | null | null | app/0.7.x/proxy.md | RomainDeSaJardim/docs.konghq.com | 9308c7333592f082c015f7ef3142bbd75331aa72 | [
"MIT"
] | 1 | 2020-10-09T11:21:24.000Z | 2020-10-09T11:21:24.000Z | ---
title: Proxy Reference
---
# Proxy Reference
As you might already know, Kong uses two ports to communicate. By default they are:
`:8001` - The one on which the [Admin API][API] listens.
`:8000` - Where Kong listens for incoming requests to proxy to your upstream services. This is the port that interests us; here is a typical request workflow on this port:
<br />

<br />
This guide will cover all proxying capabilities of Kong by explaining in detail how the proxying (`8000`) port works under the hood.
## Summary
- 1. [How does Kong route a request to an API][1]
- 2. [Reminder: how to add an API to Kong][2]
- 3. [Proxy an API by its DNS value][3]
- [Using the "Host" header][3a]
- [Using the "X-Host-Override" header][3b]
- [Using a wildcard DNS][3c]
- 4. [Proxy an API by its request_path value][4]
- [Using the "strip_request_path" property][4a]
- 5. [Plugins execution][5]
[1]: #1-how-does-kong-route-a-request-to-an-api
[2]: #2-reminder-how-to-add-an-api-to-kong
[3]: #3-proxy-an-api-by-its-dns-value
[3a]: #using-the-quot-host-quot-header
[3b]: #using-the-quot-x-host-override-quot-header
[3c]: #using-a-wildcard-dns
[4]: #4-proxy-an-api-by-its-request_path-value
[4a]: #using-the-quot-strip_request_path-quot-property
[5]: #5-plugins-execution
---
## 1. How does Kong route a request to an API
When receiving a request, Kong will inspect it and try to route it to the correct API. In order to do so, it supports different routing mechanisms depending on your needs. A request can be routed by:
- A **DNS** value contained in the **Host** header of the request.
- The path (**URI**) of the request.
<div class="alert alert-warning">
<strong>Note:</strong> For performance reasons, Kong keeps a cache of the APIs from your Cassandra cluster in memory for up to 60 seconds. As cache invalidation has not been implemented yet, Kong might take up to <strong>60 seconds</strong> to notice a new API and proxy incoming requests to it.
</div>
---
## 2. Reminder: how to add an API to Kong
Before going any further, let's take a few moments to make sure you know how to add an API to Kong. This will also help clarify the difference between the two ports.
As explained in the [Adding your API][adding-your-api] quickstart guide, Kong is configured via its internal [Admin API][API] running by default on port `8001`. Adding an API to Kong is as easy as an HTTP request:
```bash
$ curl -i -X POST \
--url http://localhost:8001/apis/ \
-d 'name=mockbin' \
-d 'upstream_url=http://mockbin.com/' \
-d 'request_host=mockbin.com' \
-d 'request_path=/status'
```
This request tells Kong to add an API named "**mockbin**", with its upstream resource being located at "**http://mockbin.com**". The `request_host` and `request_path` properties are the ones used by Kong to route a request to that API. Both properties are not required but at least one must be specified.
Once this request is processed by Kong, the API is stored in your Cassandra cluster and a request to the **Proxy port** will trigger a query to Cassandra and put your API in Kong's proxying cache.
---
## 3. Proxy an API by its DNS value
#### Using the "**Host**" header
Now that we added an API to Kong (via the Admin API), Kong can proxy it via the `8000` port. One way to do so is to specify the API's `request_host` value in the `Host` header of your request:
```bash
$ curl -i -X GET \
--url http://localhost:8000/ \
--header 'Host: mockbin.com'
```
By doing so, Kong recognizes the `Host` value as being the `request_host` of the "mockbin" API. The request will be routed to the upstream API and Kong will execute any configured [plugin][plugins] for that API.
<div class="alert alert-warning">
<strong>Going to production:</strong> If you're planning to go into production with your setup, you'll most likely not want your consumers to manually set the "<strong>Host</strong>" header on each request. You can let Kong and DNS take care of it by simply setting an A or CNAME record on your domain pointing to your Kong installation. Hence, any request made to `example.org` will already contain a `Host: example.org` header.
</div>
#### Using the "**X-Host-Override**" header
When performing a request from a browser, you might not be able to set the `Host` header. Thus, Kong also checks a request for a header named `X-Host-Override` and treats it exactly like the `Host` header:
```bash
$ curl -i -X GET \
--url http://localhost:8000/ \
--header 'X-Host-Override: mockbin.com'
```
This request will be proxied just as well by Kong.
#### Using a wildcard DNS
Sometimes you might want to route all requests matching a wildcard DNS to your upstream services. A "**request_host**" wildcard name may contain an asterisk only on the name’s start or end, and only on a dot border.
A "**request_host**" of form `*.example.org` will route requests with "**Host**" values such as `a.example.org` or `x.y.example.org`.
A "**request_host**" of form `example.*` will route requests with "**Host**" values such as `example.com` or `example.org`.
---
## 4. Proxy an API by its request_path value
If you'd rather configure your APIs so that Kong routes incoming requests according to the request's URI, Kong can also perform this function. This allows your consumers to seamlessly consume APIs sparing the headache of setting DNS records for your domains.
Because the API we previously configured has a `request_path` property, the following request will **also** be proxied to the upstream "mockbin" API:
```bash
$ curl -i -X GET \
--url http://localhost:8000/status/200
```
You will notice this command makes a request to `KONG_URL:PROXY_PORT/status/200`. Since the configured `upstream_url` is `http://mockbin.com/`, the request will hit the upstream service at `http://mockbin.com/status/200`.
#### Using the "**strip_request_path**" property
By enabling the `strip_request_path` property on an API, the requests will be proxied without the `request_path` property being included in the upstream request. Let's enable this option by making a request to the Admin API:
```bash
$ curl -i -X PATCH \
--url http://localhost:8001/apis/mockbin \
-d 'strip_request_path=true' \
-d 'request_path=/mockbin'
```
Now that we slightly updated our API (you might have to wait a few seconds for Kong's proxying cache to be updated), Kong will proxy requests made to `KONG_URL:PROXY_PORT/mockbin` but will not include the `/mockbin` part when performing the upstream request.
Here is a table documenting the behaviour of the path routing depending on your API's configuration:
`request_path` | `strip_request_path` | incoming request | upstream request
--- | --- | --- | ---
`/mockbin` | **false** | `/some_path` | **not proxied**
`/mockbin` | **false** | `/mockbin` | `/mockbin`
`/mockbin` | **false** | `/mockbin/some_path` | `/mockbin/some_path`
`/mockbin` | **true** | `/some_path` | **not proxied**
`/mockbin` | **true** | `/mockbin` | `/`
`/mockbin` | **true** | `/mockbin/some_path` | `/some_path`
---
## 5. Plugins execution
Once Kong has recognized which API an incoming request should be proxied to, it will look into your Cassandra cluster for any record of a [Plugin Configuration][plugin-configuration-object] for that particular API. This is done according to the following steps:
- 1. Kong recognized the API (according to one of the previously explained methods)
- 2. It looks into the datastore for Plugin Configurations for that API
- 3. Some Plugin Configurations were found, for example:
- a. A key authentication Plugin Configuration
- b. A rate-limiting Plugin Configuration (that also has a `consumer_id` property)
- 4. Kong executes the highest priority plugin (key authentication in this case)
- a. User is now authenticated
- 5. Kong tries to execute the rate-limiting plugin
- a. If the user is the one in the `consumer_id`, rate-limiting is applied
- b. If the user is not the one configured, rate-limiting is not applied
- 6. Request is proxied
**Note**: The proxying of a request might happen before or after plugins execution, since each plugin can hook itself anywhere in the lifecycle of a request. In this case (authentication + rate-limiting) it is of course mandatory those plugins be executed **before** proxying happens.
[adding-your-api]: /{{page.kong_version}}/getting-started/adding-your-api
[API]: /{{page.kong_version}}/admin-api
[plugin-configuration-object]: /{{page.kong_version}}/admin-api#plugin-configuration-object
[plugins]: /plugins/
| 48.427778 | 431 | 0.717449 | eng_Latn | 0.993594 |
112166eca5a7b8d92a45bdcb8e5f52d5514a824c | 486 | md | Markdown | docs/api/@remirror/core/core.extensionmanager.tags.md | tomas-c/remirror | 57f145e965042bfa1442a567aa76c1769cd2b6d2 | [
"MIT"
] | null | null | null | docs/api/@remirror/core/core.extensionmanager.tags.md | tomas-c/remirror | 57f145e965042bfa1442a567aa76c1769cd2b6d2 | [
"MIT"
] | null | null | null | docs/api/@remirror/core/core.extensionmanager.tags.md | tomas-c/remirror | 57f145e965042bfa1442a567aa76c1769cd2b6d2 | [
"MIT"
] | null | null | null | <!-- Do not edit this file. It is automatically generated by API Documenter. -->
[Home](./index.md) > [@remirror/core](./core.md) > [ExtensionManager](./core.extensionmanager.md) > [tags](./core.extensionmanager.tags.md)
## ExtensionManager.tags property
A shorthand getter for retrieving the tags from the extension manager.
<b>Signature:</b>
```typescript
get tags(): ExtensionTags<NodeNames<GExtension>, MarkNames<GExtension>, PlainNames<GExtension>>;
```
| 34.714286 | 149 | 0.713992 | eng_Latn | 0.475041 |
11219580fc5857278dafa937a653a9e1addd1163 | 6,123 | md | Markdown | pandoc/README.md | griggt/dp | 44b317a9c352a3097eaa74dc83d2a7e4a4ac462c | [
"Apache-2.0"
] | null | null | null | pandoc/README.md | griggt/dp | 44b317a9c352a3097eaa74dc83d2a7e4a4ac462c | [
"Apache-2.0"
] | null | null | null | pandoc/README.md | griggt/dp | 44b317a9c352a3097eaa74dc83d2a7e4a4ac462c | [
"Apache-2.0"
] | null | null | null | # <span id="top">Creating PDF files for the Scala 3 documentation</span>
<!-- created by mics (https://github.com/michelou/) on December 2020 -->
This project is located at the root of the [`lampepfl/dotty`][github_dotty] repository, at the same level as the [`Scaladoc`][github_scala3doc] project.
We aim to generate a *single* PDF file from a collection of [Markdown] documents, for instance for the [*Scala 3 reference*][scala3_reference] documentation.
Our solution is built on [Pandoc]; it gets its inputs from two directories and generates a PDF file into the output directory:
<table style="margin-top:-10px; max-width:650px;">
<tr>
<td><b>Input directories</b></td>
<td><code>docs/docs/<project>/</code><br/><code>pandoc/data/</code></td>
<td><code>*.md</code> files<br/><a href="https://pandoc.org/">Pandoc</a> data files</td>
</tr>
<tr>
<td><b>Output directory</b></td>
<td><code>out/pandoc/</code></td>
<td><code>scala3_<i><project></i>.pdf</code><sup>(*)</sup></td>
</tr>
</table>
<span style="margin-left:10px;font-size:90%;"><sup>(*)</sup> *`<project>`* is one of [`contributing`](https://github.com/lampepfl/dotty/tree/master/docs/docs/contributing), [`internals`](https://github.com/lampepfl/dotty/tree/master/docs/docs/internals), [`reference`](https://github.com/lampepfl/dotty/tree/master/docs/docs/reference) or [`usage`](https://github.com/lampepfl/dotty/tree/master/docs/docs/usage).</span>
The generated PDF file is more elaborated than its sibling HTML version; unlike the online [*Scala 3 reference*][scala3_reference] documentation available on the [Scala 3 documentation](https://docs.scala-lang.org/scala3/) webpage, the `scala3_reference.pdf` document :
- starts with a *title page* directly followed by a *table of contents* and ends with an *appendix*.
- gathers all the "*More details*" sections in the appendix.
> See document [`PROJECT.md`](docs/PROJECT.md) for further information, e.g. project organisation.
## <span id="dependencies">Project dependencies</span>
This project depends on the following software :
- [Pandoc 2](https://github.com/jgm/pandoc/releases) <sup id="anchor_01">[[1]](#footnote_01)</sup> *([release notes](https://pandoc.org/releases.html))*
- [TeX Live 2020](https://tug.org/texlive/) <sup id="anchor_02">[[2]](#footnote_02)</sup> *([release notes](http://www.tug.org/texlive/doc/texlive-en/texlive-en.html#x1-880009.2))*
> See documents [`PANDOC.md`](docs/PANDOC.md) and [`TEXLIVE.md`](docs/TEXLIVE.md) for product specific information, e.g. software installation.
One may also install the following software:
- [Docker Desktop 3](https://docs.docker.com/get-docker/) <sup id="anchor_03">[[3]](#footnote_03)</sup> *([release notes](https://docs.docker.com/release-notes/))*
> See document [`DOCKER.md`](docs/DOCKER.md) for further information, e.g. `Dockerfile` usage.
## <span id="commands">Build commands</span>
We provide two commands for MacOS/Ubuntu as well as their equivalents for MS Windows :
- for *interactive users* :<br/>[`build {<option>|<subcommand>}`](./build) (resp. [`build.bat`](./build.bat) on MS Windows)<br/><span style="font-size:80%;">(option `-help` displays the available options/subcommands).</span>
- for *automated tasks* (primarily, but not exclusively) :<br/>[`md2pdf [<project>]`](./md2pdf) (resp. [`md2pdf.bat`](./md2pdf.bat) on MS Windows)<br/><span style="font-size:80%;">(default value for `<project>` : `reference`).</span>
We also provide support for cloud development/deployment :
- with *Docker*<br/><a href="./Dockerfile"><code>Dockerfile</code></a>, a text document to create a Docker image featuring <a href="https://tug.org/texlive/">TeX Live</a>, <a href="https://pandoc.org/">Pandoc</a> and <a href="./md2pdf"><code>md2pdf</code></a>.
- with *GitHub Actions* <b style="color:red;">WIP</b> :<br/><a href="../.github/workflows/pandoc.yaml"><code>pandoc.yaml</code></a>, a workflow file to run CI jobs with <a href="https://docs.github.com/en/actions">GitHub Actions</a>.
> See document [`EXAMPLES.md`](docs/EXAMPLES.md) for usage examples in different environments.
## <span id="footnotes">Footnotes</span>
<span id="footnote_01">[1]</span> ***Pandoc software*** [↩](#anchor_01)
<p style="margin:0 0 1em 20px;">
<a href="https://pandoc.org/">Pandoc</a> is both a library and a command line tool for converting files from one markup format into another. Through the command line option <a href="https://pandoc.org/MANUAL.html#option--pdf-engine"><code>--pdf-engine=<path></code></a> Pandoc supports many PDF engines, among others <a href="https://linux.die.net/man/1/pdflatex"><code>pdflatex</code></a>, <a href="http://www.luatex.org/"><code>lualatex</code></a> and <code>xelatex</code>.
</p>
<span id="footnote_02">[2]</span> ***MiKTeX software*** [↩](#anchor_02)
<p style="margin:0 0 1em 20px;">
As an alternative to <a href="https://tug.org/texlive/">TeX Live 2020</a> one may also use the <a href="https://miktex.org/">MiKTeX</a> distribution <i>(<a href="https://miktex.org/announcement/miktex-20-12">release notes</a>)</i> which we have tested on both MS Windows 10 and <a href="https://www.msys2.org/">MSYS2</a>.
</p>
<span id="footnote_03">[3]</span> ***Docker software*** [↩](#anchor_03)
<p style="margin:0 0 1em 20px;">
We run <a href="https://docs.docker.com/docker-for-windows/install/">Docker Desktop for Windows</a> on our development machine.<br/>
Note that WSL 2 is required to interact with Docker on Windows from <a href="https://ubuntu.com/wsl">Ubuntu for WSL</a> (see documentation <a href="https://docs.docker.com/docker-for-windows/wsl/">Docker Desktop WSL 2 backend</a>).
</p>
***
*[mics](https://github.com/michelou/)/January 2021* [**▲**](#top "Back to top")
<span id="bottom"> </span>
[github_dotty]: https://github.com/lampepfl/dotty/#dotty
[github_scala3doc]: https://github.com/lampepfl/dotty/tree/master/scala3doc#scala3doc
[markdown]: https://commonmark.org/
[pandoc]: https://pandoc.org/ "A universal document converter"
[scala3_reference]: https://dotty.epfl.ch/docs/reference/overview.html
[tex_live]: https://tug.org/texlive/
| 67.285714 | 481 | 0.709946 | yue_Hant | 0.388597 |
112265a00681a3c4379187aabb6b084c3f2ebe93 | 644 | md | Markdown | docs/integration.md | felixmak1107/chartjs-chart-treemap | 25661f80a5688b2616422518b9818716f3abd4e1 | [
"MIT"
] | null | null | null | docs/integration.md | felixmak1107/chartjs-chart-treemap | 25661f80a5688b2616422518b9818716f3abd4e1 | [
"MIT"
] | null | null | null | docs/integration.md | felixmak1107/chartjs-chart-treemap | 25661f80a5688b2616422518b9818716f3abd4e1 | [
"MIT"
] | null | null | null | # Integration
`chartjs-chart-treemap` can be integrated with plain JavaScript or with different module loaders. The examples below show to load the plugin in different systems.
## Script Tag
```html
<script src="path/to/chartjs/dist/chart.min.js"></script>
<script src="path/to/chartjs-chart-treemap/dist/chartjs-chart-treemap.min.js"></script>
<script>
var myChart = new Chart(ctx, {type: 'treemap', ...});
</script>
```
## Bundlers (Webpack, Rollup, etc.)
```javascript
import { Chart } from 'chart.js';
import {TreemapController, TreemapElement} from 'chartjs-chart-treemap';
Chart.register(TreemapController, TreemapElement);
```
| 28 | 162 | 0.732919 | eng_Latn | 0.559052 |
11233fb0351246933c03f76715213e762a1870a9 | 2,821 | md | Markdown | wdk-ddi-src/content/dmusicks/nn-dmusicks-iminiportdmus.md | jesweare/windows-driver-docs-ddi | a6e73cac25d8328115822ec266dabdf87d395bc7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/dmusicks/nn-dmusicks-iminiportdmus.md | jesweare/windows-driver-docs-ddi | a6e73cac25d8328115822ec266dabdf87d395bc7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/dmusicks/nn-dmusicks-iminiportdmus.md | jesweare/windows-driver-docs-ddi | a6e73cac25d8328115822ec266dabdf87d395bc7 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-12-08T21:34:31.000Z | 2021-12-08T21:34:31.000Z | ---
UID: NN:dmusicks.IMiniportDMus
title: IMiniportDMus (dmusicks.h)
description: The IMiniportDMus interface is the primary interface for a DMus miniport driver for a DirectMusic synthesizer device.
old-location: audio\iminiportdmus.htm
tech.root: audio
ms.assetid: 12cd3533-1830-46cd-a1eb-350f7461a61d
ms.date: 05/08/2018
keywords: ["IMiniportDMus interface"]
ms.keywords: IMiniportDMus, IMiniportDMus interface [Audio Devices], IMiniportDMus interface [Audio Devices],described, audio.iminiportdmus, audmp-routines_b123c50b-e4b9-4f19-a2c4-b33fb335bec6.xml, dmusicks/IMiniportDMus
req.header: dmusicks.h
req.include-header: Dmusicks.h
req.target-type: Windows
req.target-min-winverclnt:
req.target-min-winversvr:
req.kmdf-ver:
req.umdf-ver:
req.ddi-compliance:
req.unicode-ansi:
req.idl:
req.max-support:
req.namespace:
req.assembly:
req.type-library:
req.lib:
req.dll:
req.irql:
targetos: Windows
req.typenames:
f1_keywords:
- IMiniportDMus
- dmusicks/IMiniportDMus
topic_type:
- APIRef
- kbSyntax
api_type:
- COM
api_location:
- dmusicks.h
api_name:
- IMiniportDMus
---
# IMiniportDMus interface
## -description
The <code>IMiniportDMus</code> interface is the primary interface for a DMus miniport driver for a DirectMusic synthesizer device. The DMus port driver communicates with the miniport driver through this interface. The adapter driver creates the DMus miniport object and passes the object's <code>IMiniportDMus</code> interface pointer to the port driver's <a href="/windows-hardware/drivers/ddi/portcls/nf-portcls-iport-init">IPort::Init</a> method (see the code example in <a href="/windows-hardware/drivers/audio/subdevice-creation">Subdevice Creation</a>). <code>IMiniportDMus</code> inherits from the <a href="/windows-hardware/drivers/ddi/portcls/nn-portcls-iminiport">IMiniport</a> interface.
An adapter driver forms a miniport/port driver pair by binding an <code>IMiniportDMus</code> object to an <a href="/windows-hardware/drivers/ddi/dmusicks/nn-dmusicks-iportdmus">IPortDMus</a> object. The PortCls system driver registers this pair with the system as a DirectMusic filter (see <a href="/windows-hardware/drivers/audio/midi-and-directmusic-filters">MIDI and DirectMusic Filters</a>).
The <code>IMiniportDMus</code> interface provides methods for initializing the miniport driver, for creating a new DirectMusic stream, and for notifying the miniport driver of an interrupt service request.
## -inheritance
The <b xmlns:loc="http://microsoft.com/wdcml/l10n">IMiniportDMus</b> interface inherits from the <a href="/windows/win32/api/unknwn/nn-unknwn-iunknown">IUnknown</a> interface. <b>IMiniportDMus</b> also has these types of members:
<ul>
<li><a href="https://docs.microsoft.com/">Methods</a></li>
</ul> | 47.016667 | 699 | 0.76994 | eng_Latn | 0.653496 |
112346d141363c10debf8f70c854d2b5af3552f9 | 2,063 | md | Markdown | README.md | theo-armour/maps-2021 | 35d24bb7af3916061cc8e349584ef675342b9479 | [
"MIT"
] | 1 | 2021-07-14T20:26:23.000Z | 2021-07-14T20:26:23.000Z | README.md | theo-armour/maps-2021 | 35d24bb7af3916061cc8e349584ef675342b9479 | [
"MIT"
] | 8 | 2021-07-14T07:08:35.000Z | 2021-08-16T19:13:36.000Z | README.md | theo-armour/maps-2021 | 35d24bb7af3916061cc8e349584ef675342b9479 | [
"MIT"
] | null | null | null | # [](https://github.com/theo-armour/maps-2021/ "Source code on GitHub" ) [Theo Maps 2021]( https://theo-armour.github.io/maps-2021/ "Home page" )
<!--@@@
<div class=iframe-resize ><iframe src=https://theo-armour.github.io/maps-2021/sandbox/us-county-votes/ height=100% width=100% ></iframe></div>
_"US County Presidents Votes" in a resizable window. One finger to rotate. Two to zoom._
@@@-->
### Full Screen: [US County Presidents Vote]( https://theo-armour.github.io/maps-2021/sandbox/us-county-votes/ )
<!--@@@
<div class=iframe-resize ><iframe src=https://theo-armour.github.io/maps-2021/sandbox/globe-us-county-indemnity/ height=100% width=100% ></iframe></div>
_"US County Presidents Votes" in a resizable window. One finger to rotate. Two to zoom._
@@@-->
### Full Screen: [US Crop Insurance Indemnities by County 1979-2017 ]( https://theo-armour.github.io/maps-2021/sandbox/globe-us-county-indemnity/ )
### Full Screen: [USDA Risk Management Cause of Loss Historical Data]( https://theo-armour.github.io/maps-2021/sandbox/rma-stats/ )
## Concept
A 3D happy place for mapping in 2021.
## To Do / Wish List
## Issues
## Links of Interest
Mapping 2020
* https://theo-armour.github.io/2020/#apps/us-census-bureau-tracts-ca/index.html
* https://theo-armour.github.io/2020/#apps/california-dasymetry/
* https://theo-armour.github.io/2020/#journal/06/2020-06-18-brian/index.html
Theo 2020
* https://theo-armour.github.io/2020/#journal/06/2020-06-12-andrew.md
* https://theo-armour.github.io/2020/#journal/06/2020-06-13-brian.md
* https://theo-armour.github.io/2020/#journal/06/2020-06-19-don.md
## Change Log
### 2021-08-01
* Add: USDA Risk Management Cause of Loss Historical Data
### 2021-07-11
* Add link to US Crop Insurance Indemnities by County 1979-2017
* update readme
### 2021-07-08
* First commit this read me
***
<center title="Hello! Click me to go up to the top" ><a class=aDingbat href=javascript:window.scrollTo(0,0);> ❦ </a></center>
| 29.898551 | 223 | 0.714009 | kor_Hang | 0.258287 |
11241df9871025a63259cb48b42a62a17aa79a71 | 890 | md | Markdown | go-goose/README.md | mrk21/sandbox | 9f856cbea4af75208984cd4f5e33553e70eda18e | [
"MIT"
] | 1 | 2021-05-04T08:04:47.000Z | 2021-05-04T08:04:47.000Z | go-goose/README.md | mrk21/sandbox | 9f856cbea4af75208984cd4f5e33553e70eda18e | [
"MIT"
] | 18 | 2020-02-29T00:41:30.000Z | 2020-03-28T12:58:39.000Z | go-goose/README.md | mrk21/sandbox | 9f856cbea4af75208984cd4f5e33553e70eda18e | [
"MIT"
] | 1 | 2022-01-10T13:29:00.000Z | 2022-01-10T13:29:00.000Z | # Go goose
## Dependencies
* Go: 1.14.x
- Docker: >= 18.06
- docker-compose: >= 1.25.0
- direnv
## Setup
```sh
#------------------------------------------------------------------------------
# 1. Install `docker`, `docker-compose`, `direnv`
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
# 2. Setup
#------------------------------------------------------------------------------
cp .envrc.local.sample .envrc.local
vi .envrc.local
direnv allow .
docker-compose up
docker-compose exec -T db mysql < db/create_database.sql
```
## Usage
```sh
goose up
```
## Refere to
- [pressly/goose at v2.6.0](https://github.com/pressly/goose/tree/v2.6.0)
- [goose/examples/go-migrations at v2.6.0 · pressly/goose](https://github.com/pressly/goose/tree/v2.6.0/examples/go-migrations)
| 24.054054 | 127 | 0.433708 | yue_Hant | 0.128547 |
112499b825e3baeb6564e5b406a6762a92d67e48 | 3,956 | md | Markdown | docs/framework/unmanaged-api/wmi/qualifierset-next.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/wmi/qualifierset-next.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/wmi/qualifierset-next.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Función QualifierSet_Next (referencia de API no administrada)
description: La función QualifierSet_Next recupera el siguiente calificador en una enumeración.
ms.date: 11/06/2017
api_name:
- QualifierSet_Next
api_location:
- WMINet_Utils.dll
api_type:
- DLLExport
f1_keywords:
- QualifierSet_Next
helpviewer_keywords:
- QualifierSet_Next function [.NET WMI and performance counters]
topic_type:
- Reference
author: rpetrusha
ms.author: ronpet
ms.openlocfilehash: 938044a4e932139eb8a4d0a5d2f998cbc6f193cb
ms.sourcegitcommit: 2eceb05f1a5bb261291a1f6a91c5153727ac1c19
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 09/04/2018
ms.locfileid: "43507698"
---
# <a name="qualifiersetnext-function"></a>Función QualifierSet_Next
Recupera el siguiente calificador en una enumeración que se inició con una llamada a la [QualifierSet_BeginEnumeration](qualifierset-beginenumeration.md) función.
[!INCLUDE[internalonly-unmanaged](../../../../includes/internalonly-unmanaged.md)]
## <a name="syntax"></a>Sintaxis
```
HRESULT QualifierSet_Next (
[in] int vFunc,
[in] IWbemQualifierSet* ptr,
[in] LONG lFlags,
[out] BSTR* pstrName,
[out] VARIANT* pVal,
[out] LONG* plFlavor
);
```
## <a name="parameters"></a>Parámetros
`vFunc`
[in] Este parámetro se usa.
`ptr`
[in] Un puntero a un [IWbemQualifierSet](/windows/desktop/api/wbemcli/nn-wbemcli-iwbemqualifierset) instancia.
`lFlags`
[in] Reservado. Este parámetro debe ser 0.
`pstrName`
[out] El nombre del calificador. Si `null`, este parámetro se omite; en caso contrario, `pstrName` no debe apuntar a una `BSTR` o se produce una pérdida de memoria. Si no es null, la función siempre asigna un nuevo `BSTR` cuando devuelve `WBEM_S_NO_ERROR`.
`pVal`
[out] Cuando se realiza correctamente, el valor del calificador. Si se produce un error en la función, el `VARIANT` apunta `pVal` no se modifica. Si este parámetro es `null`, se omite el parámetro.
`plFlavor`
[out] Un puntero a un valor largo que recibe el tipo de calificador. Si no se desea obtener información de tipo, este parámetro puede ser `null`.
## <a name="return-value"></a>Valor devuelto
Los siguientes valores devueltos por esta función se definen en el *WbemCli.h* archivo de encabezado, también puede definir como constantes en el código:
|Constante |Valor |Descripción |
|---------|---------|---------|
|`WBEM_E_INVALID_PARAMETER` | 0 x 80041008 | Un parámetro no es válido. |
|`WBEM_E_UNEXPECTED` | 0x8004101d | El llamador no llamó a [QualifierSet_BeginEnumeration](qualifierset-beginenumeration.md). |
|`WBEM_E_OUT_OF_MEMORY` | 0 x 80041006 | No hay suficiente memoria disponible para comenzar una nueva enumeración. |
| `WBEM_S_NO_MORE_DATA` | 0x40005 | No hay más calificadores se mantienen en la enumeración. |
|`WBEM_S_NO_ERROR` | 0 | La llamada de función fue correcta. |
## <a name="remarks"></a>Comentarios
Esta función contiene una llamada a la [IWbemQualifierSet::Next](/windows/desktop/api/wbemcli/nf-wbemcli-iwbemqualifierset-next) método.
Se llama a la `QualifierSet_Next` función varias veces para enumerar todos los calificadores hasta que el valor devuelto de función `WBEM_S_NO_MORE_DATA`. Para finalizar la enumeración al principio, llame a la [QualifierSet_EndEnumeration](qualifierset-endenumeration.md) función.
El orden de los calificadores que ha devuelto durante la enumeración es indefinido.
## <a name="requirements"></a>Requisitos
**Plataformas:** Vea [Requisitos de sistema](../../../../docs/framework/get-started/system-requirements.md).
**Encabezado:** WMINet_Utils.idl
**Versiones de .NET Framework:** [!INCLUDE[net_current_v472plus](../../../../includes/net-current-v472plus.md)]
## <a name="see-also"></a>Vea también
[WMI y contadores de rendimiento (referencia de API no administrada)](index.md)
| 42.537634 | 280 | 0.732305 | spa_Latn | 0.843089 |
1124a9bd80e21bad9b23f548c315d6657b004cbd | 10,416 | md | Markdown | _posts/2009-3-11-苦练演技终获殊荣.md | backup53/1984bbs | 152406c37afab79176f0d094de5ac4cb0c780730 | [
"MIT"
] | 18 | 2020-01-02T21:43:02.000Z | 2022-02-14T02:40:34.000Z | _posts/2009-3-11-苦练演技终获殊荣.md | wzxwj/1984bbs | 152406c37afab79176f0d094de5ac4cb0c780730 | [
"MIT"
] | 3 | 2020-01-01T16:53:59.000Z | 2020-01-05T10:14:11.000Z | _posts/2009-3-11-苦练演技终获殊荣.md | wzxwj/1984bbs | 152406c37afab79176f0d094de5ac4cb0c780730 | [
"MIT"
] | 13 | 2020-01-20T14:27:39.000Z | 2021-08-16T02:13:21.000Z | ---
layout: default
date: 2009-3-11
title: 苦练演技终获殊荣
categories: 自由新闻社
---
# 苦练演技终获殊荣 影帝成功拿下新闻摄影界“小金人”
路边社记者
路边社驻朝鲜特派员
1楼 大 中 小 发表于 2009-3-11 11:40 只看该作者
苦练演技终获殊荣 影帝成功拿下新闻摄影界“小金人”
温家宝在灾区照片获摄影“金镜头”金奖(组图)
2009-03-11 10:09:34 来源: 新华网
新华网3月11日报道日前,由中国新闻摄影学会、人民摄影报社主办的第17届(2008年度)“金镜头”新闻摄影作品评选暨国际新闻摄影比赛中国作品评选结束,9类18项共50个单项奖各有所属。本次大赛共接收到2000多位参赛作者选送的20000余幅作品,在参赛作者人数、参评作品数量上都创造了金镜头新闻摄影评选历史之最。由新华社记者姚大伟拍摄的《温总理冰雪灾区行》和《温总理在地震灾区》分别获得新闻人物类单幅金奖和新闻人物类组照金奖。
新闻人物类单幅金奖作品《温总理冰雪灾区行》:

2008年2月2日,国务院总理温家宝从湖南长沙紧急赶往郴州重灾区指挥抗灾救灾工作。在火车上,他望着窗外的积雪,神情凝重。新华社记者 姚大伟摄
新闻人物类组照金奖作品《温总理在地震灾区》:

2008年5月22日,温家宝总理来到四川北川县城外的一块高地上,察看这座在地震中遭受严重破坏的城镇。准备离开时,他忽然转过身,挥起右手和这座成为废墟的县城告别。随后,他默默地环视县城,神情凝重。新华社记者
姚大伟摄

2008年5月12日夜,温家宝总理在都江堰市临时抗震救灾指挥部里批阅文件。新华社记者 姚大伟摄

2008年5月12日,温家宝总理在都江堰市聚源中学教学楼的废墟上捡起学生的鞋子和书包,心情沉重。新华社记者 姚大伟摄

2008年5月13日,温家宝总理在都江堰市新建小学察看灾情时看见救援人员正在教学楼废墟里抢救王佳淇。温家宝蹲坐在废墟上对她说:“孩子,听爷爷的话,要挺住,我们一定会救你出来的!”新华社记者
姚大伟摄

2008年5月14日,温家宝总理在北川县曲山镇察看灾情时,几名战士抬着一个小女孩从县城方向跑过来,温家宝和随行人员赶紧让路。温家宝说,时间就是生命,要尽全力救人。新华社记者
姚大伟摄

2008年5月13日,温家宝总理在绵阳九洲体育馆安慰受伤儿童。新华社记者 姚大伟摄

2008年5月14日,温家宝总理在北川县曲山镇看望受灾群众。新华社记者 姚大伟摄

2008年5月24日,温家宝总理重返四川地震震中汶川县映秀镇时接受中外记者的联合采访。新华社记者 姚大伟摄
(本文来源:新华网 )
---
[Terminusbot](https://github.com/TerminusBot) 整理,讨论请前往 [2049bbs.xyz](http://2049bbs.xyz/)
---
路边社记者
路边社驻朝鲜特派员
2楼 大 中 小 发表于 2009-3-11 11:41 只看该作者
影帝御用摄影师傅 姚大伟的博客
http://yaodawei.blshe.com/
别摸我
80后老三届
3楼 大 中 小 发表于 2009-3-11 11:52 只看该作者
宋江,李雪健版的宋江,那个神似啊。
peteryang84
4楼 大 中 小 发表于 2009-3-11 12:48 只看该作者
其实photo-op在各国都有,政治家管用的手法,完全不是中国特色,也不必太在意。
温家宝是党的公关大使,作用与西方基督教或泰国国王相似,都是改善社会风气,提高道德用的。
唯一负面作用就是制造个人崇拜,但我不担心这点,因为他还有4年就退休了,李克强面相不好,不可能替代温家宝。
不是我干的
才怪
5楼 大 中 小 发表于 2009-3-11 12:56 只看该作者
引用:
> 原帖由 peteryang84 于 2009-3-11 12:48 发表
> 
> 其实photo-op在各国都有,政治家管用的手法,完全不是中国特色,也不必太在意。
>
> 温家宝是党的公关大使,作用与西方基督教或泰国国王相似,都是改善社会风气,提高道德用的。
>
> 唯一负面作用就是制造个人崇拜,但 ...
不是中国特色才怪,去看看毛腊肉时代那些照片吧。
"都是改善社会风气,提高道德用的。"?提高道德?他够资格吗?party有哪个leader敢说自己清白的?
pacinoson
伪善的学生党支部书记
6楼 大 中 小 发表于 2009-3-11 13:05 只看该作者

第三张颇像邓公
peteryang84
7楼 大 中 小 发表于 2009-3-11 13:08 只看该作者
引用:
> 原帖由 不是我干的 于 2009-3-11 12:56 发表
> 
>
> 不是中国特色才怪,去看看毛腊肉时代那些照片吧。
> "都是改善社会风气,提高道德用的。"?提高道德?他够资格吗?party有哪个leader敢说自己清白的?
的确不是中国特色,西方发明照相机的时候,我们老佛爷还在修园子,并且,整个传媒概念都是从西方来的,中国目前采用的所有传媒技术都能在英文中找到原词。
我党没一个清白的,这我完全同意,但在这个烂摊子当中,我们只好选一个“看上去最清白的”,又有实际权力,讲实话,温总在国内国外(尤其国外)的讲话相当于民主启蒙,他敢公开明确的谈论选举、人权等概念,而且讲的很准确,这对我们右派来说是史无前例的资源,我们不应反对他,反而应该支持他天天讲、年年讲。
不是我干的
才怪
8楼 大 中 小 发表于 2009-3-11 13:16 只看该作者
引用:
> 原帖由 peteryang84 于 2009-3-11 13:08 发表
> 
>
>
> 的确不是中国特色,西方发明照相机的时候,我们老佛爷还在修园子,并且,整个传媒概念都是从西方来的,中国目前采用的所有传媒技术都能在英文中找到原词。
>
> 我党没一个清白的,这我完全同意,但在这个烂摊子当 ...
这种东西还能拿金奖,就是中国特色。影帝“讲话相当于民主启蒙”?你太高估他了,把他儿子的破事解释下吧先。右派?那是5毛乱扣的帽子,我可不戴。
IP黨精神領袖
9楼 大 中 小 发表于 2009-3-11 14:05 只看该作者
引用:
> 原帖由 peteryang84 于 2009-3-11 13:08 发表
> 
>
>
> 的确不是中国特色,西方发明照相机的时候,我们老佛爷还在修园子,并且,整个传媒概念都是从西方来的,中国目前采用的所有传媒技术都能在英文中找到原词。
>
> 我党没一个清白的,这我完全同意,但在这个烂摊子当 ...
幼稚啊,我党领导人对外一向敢大谈民主、人权的。只不过人家谈的是人民民主和集体人权。和赫尔辛基条约上的那个民主和人权是两回事啊。
再说了,中国有几个人看得到国外的专访?有几个人看得懂?
cnalbert
10楼 大 中 小 发表于 2009-3-11 14:09 只看该作者
演技非常老道 绝对的偶像演技派
peteryang84
11楼 大 中 小 发表于 2009-3-11 14:50 只看该作者
引用:
> 原帖由 IP黨精神領袖 于 2009-3-11 14:05 发表
> 
>
>
> 幼稚啊,我党领导人对外一向敢大谈民主、人权的。只不过人家谈的是人民民主和集体人权。和赫尔辛基条约上的那个民主和人权是两回事啊。
>
> 再说了,中国有几个人看得到国外的专访?有几个人看得懂?
温总在剑桥高呼的是个人民主、个人人权,直截了当,没任何拐弯抹角,这个在国内没直播??新浪大标题《中国人不怕选举》,我记得很清楚。
一堆坏蛋中,只能寄希望于最“不坏”的,幸亏是温家宝,要是李鹏等人,还跟你将民主?
其实其它国家亦如此,民间各个派别都努力在政府中寻找代言人,而谁都不可能找到完美无瑕的,这个过程中必然有妥协和退让,只要原则相同就罢了,不要过多要求。再说了,民主不就是个充满妥协的制度么?我们要求这个极端,他们要求那个极端,最后只能折中,尽量让双方满意,因为国策只能走一个路线,发达国家的政治运作也是这样的。
该批判的批判,骂一骂土共无所谓,但重大问题上必须实事求是。如果改革开放算是建国,中国刚活了30年,30年就要实现人家200年的东西,你觉得可能么,显然不可能。你们放心,中国必然越来越民主,只是时间问题。
要说本人派别,我在5毛和网特之间,说自己想说的话,就这样。
鬼涧愁
一切自维护自身权益始……
12楼 大 中 小 发表于 2009-3-11 15:07 只看该作者
楼上,要不是“铁打的营盘流水的兵(将相?)”,恐怕也唬不了现在的人了。李鹏之流,固然有其顽固不不化之处,但要在今日,也难以在人前人后装的如此道貌岸然继续愚弄百姓了。讲,可能是种进步,但光停留在嘴把式那其实就是欺骗。
[17]堂吉柯德
Frake集团的牛三少爷,诸神国驻人间特派员,人类行为分析者
13楼 大 中 小 发表于 2009-3-11 15:13 只看该作者
左右表情不对称的悲伤,99%是自我强迫性伪装出来的
\------源自行为分析学报告
shell.x
14楼 大 中 小 发表于 2009-3-11 15:15 只看该作者
温总在剑桥高呼的是个人民主、个人人权,直截了当,没任何拐弯抹角
\-------------------------------------------------------------------------------------------------
那是做给外国人看的,是他演出的一部分,什么时候在政治局常委会议上高呼下,八字才有一瞥。
zama
自定义头衔
15楼 大 中 小 发表于 2009-3-11 15:19 只看该作者
配题:
1 窗外飞雪连天,屋里供暖保证
2 官渡之后的孟德(请参照电视剧)
3 你看风景,看风景的人看你
4 这号儿我穿正合适…那只呢?
5 我就不下去了(参照上图
6 有组织夹道围观
7 童:“介泥骂塞呀?”
8 童一:”还没完啊?当演员真不容易”
童二:“上回就弄这么半天,我都习惯了”
9 “群众演员再往后退点儿!我都举这么高了!”
hekuan
16楼 大 中 小 发表于 2009-3-11 15:25 只看该作者
怎么都是神情凝重……
vip001
本人大量收购航空母舰,F22,F35,航天飞机,并且专业维修
17楼 大 中 小 发表于 2009-3-11 15:31 只看该作者
为了突出人物
peteryang84
18楼 大 中 小 发表于 2009-3-11 15:52 只看该作者
那是做给外国人看的,是他演出的一部分,什么时候在政治局常委会议上高呼下,八字才有一瞥。
\------------------------
你居然指望政治局高呼?????????我觉得你应该明白没有救世主的道理。
一切都是自己争取的,中国人民要民主,也必须自己争取,指望敌人的觉悟是徒劳的,历史把这个道理讲的明明白白。
不需担心,其实咱们80,90后普遍很讨厌集权,从网络恶搞就能看出来,基本全是攻击时政的,等老一辈都死光了,保守政策维持不下去了,中国自然要发生根本转变,自然力量不是哪个委员长在台上嚷嚷几句就能阻挡住的。
壹多
19楼 大 中 小 发表于 2009-3-11 16:03 只看该作者
楼主。佩服你的标题哈。
castcrus
学术流氓 新闻民工
20楼 大 中 小 发表于 2009-3-11 16:12 只看该作者
引用:
> 原帖由 peteryang84 于 2009-3-11 12:48 发表
> 
> 其实photo-op在各国都有,政治家管用的手法,完全不是中国特色,也不必太在意。
>
> 温家宝是党的公关大使,作用与西方基督教或泰国国王相似,都是改善社会风气,提高道德用的。
>
> 唯一负面作用就是制造个人崇拜,但 ...
您不是需要改变这种“一切存在皆因为其功用”式的语言方式,就是需要阅读世俗政治与宗教关系方面的书籍,建议读读《美国的本质》。
我认为因为大多数中国人都没有信仰,因而常犯这样的错误:站在世俗的立场上去反对一个世俗的权利,而“没有能力将自己从表象的世界中彻底解救出来”。(王书亚引用哈维尔)
胡曰曰
股沟观察员
21楼 大 中 小 发表于 2009-3-11 16:34 只看该作者
peter同学是个好同学。
罗马不是一天建成的。
jezad
路边社合体研究所副主任
22楼 大 中 小 发表于 2009-3-11 16:38 只看该作者
我一朋友说 金镜头 精尽头
peteryang84
23楼 大 中 小 发表于 2009-3-11 16:50 只看该作者
左派右派没啥,麻烦的是“粪”,人一旦到“粪”的境界就难办了,因此,左粪和右粪没区别,都是被意识形态缠身的恶棍。
要不就是直截了当的傻逼,比如AC那帮弱智。
zuoang
24楼 大 中 小 发表于 2009-3-11 17:30 只看该作者
风云组图




[ 本帖最后由 zuoang 于 2009-3-11 18:44 编辑 ]
张书记
http://twitter.com/SecretaryZhang
25楼 大 中 小 发表于 2009-3-11 17:44 只看该作者
仰望星空白天版

老卡
Twitter:laokalaoka
26楼 大 中 小 发表于 2009-3-11 17:52 只看该作者
引用:
> 原帖由 peteryang84 于 2009-3-11 16:50 发表
> 
> 左派右派没啥,麻烦的是“粪”,人一旦到“粪”的境界就难办了,因此,左粪和右粪没区别,都是被意识形态缠身的恶棍。
>
> 要不就是直截了当的傻逼,比如AC那帮弱智。
顶你一下。
老卡
Twitter:laokalaoka
27楼 大 中 小 发表于 2009-3-11 19:38 只看该作者
伟大领袖教导我们:演一次好戏不难,难的是演一辈子的好戏。
平心而论,即使是演戏吧,但在这个国度里,愿意演戏给老百姓看的也算很不错了。如琳格格之流,连演戏都不屑于。
不是我干的
才怪
28楼 大 中 小 发表于 2009-3-11 21:39 只看该作者


amenster
算命大师李爱国
29楼 大 中 小 发表于 2009-3-11 21:52 只看该作者

真理社妓者
只卖身不卖艺
30楼 大 中 小 发表于 2009-3-12 00:38 只看该作者

闹了个运
Twitter @naoyunhui 不算激情革命派,但是心情容易激动,有正义感,骨子里还是偏温和,要是玩不过你,就颠儿。
31楼 大 中 小 发表于 2009-3-12 01:02 只看该作者
还是死循环
69不是96
32楼 大 中 小 发表于 2009-3-12 01:30 只看该作者
不得不说 我看了以后 我又一次湿了
zhuanwan
33楼 大 中 小 发表于 2009-3-12 01:57 只看该作者
29楼的照片。。。。。哎
模棱两可
34楼 大 中 小 发表于 2009-3-12 09:08 只看该作者
拍得不错,把温家宝先生最忧国忧民的形象凸现出来了。
我觉得楼上有几位位能不能从无限批判的立场上休息几分钟,即使是御用,也有三六九等呀。
胺氰聚三郎
怪组员
35楼 大 中 小 发表于 2009-3-12 09:10 只看该作者
那点货色
敢拿出来跟周前辈比吗
真是蜀中无大将
廖化拿金奖
wistreer
推特:@wistreer
36楼 大 中 小 发表于 2009-3-12 14:03 只看该作者
为什么总是噙着眼泪,因为假装爱得深沉。
numberscis
收二手或库存的老钢笔、蘸水笔。免费维修钢笔,免费调校、打磨笔尖。尊重世界上所有以匠人性格工作和治学的民族,毋论是日耳曼还是和族。
37楼 大 中 小 发表于 2009-3-12 15:01 只看该作者
悲剧之王第n幕:
:“拿痛来说呢,根据俄国戏剧理论大师史坦尼斯拉夫斯基的说法呢。应该从外到内,再由内反映出来的。来,你现在再试着做一次看看。”
影帝:“不管你看得起看不起我,我都是一个演员。”
:“你在跟我说话?”
影帝:“是。”
:“你演个屁,演你个老母。”
影帝:“上次你还差我三个便当我想拿回来。”

zhsh_710
SY1984
38楼 大 中 小 发表于 2009-3-13 15:42 只看该作者
使我想起了雷锋
| 7.580786 | 215 | 0.648137 | yue_Hant | 0.934596 |
1124becf0e20ec15f5e4da2f041a2871c4585fa8 | 3,046 | markdown | Markdown | _posts/2020-07-24-rails_project_how_to_prepare.markdown | jerkzilla/jerkzilla.github.io | a37f9124fa9de06be56fa2c78ec73e387cf082d3 | [
"MIT"
] | null | null | null | _posts/2020-07-24-rails_project_how_to_prepare.markdown | jerkzilla/jerkzilla.github.io | a37f9124fa9de06be56fa2c78ec73e387cf082d3 | [
"MIT"
] | null | null | null | _posts/2020-07-24-rails_project_how_to_prepare.markdown | jerkzilla/jerkzilla.github.io | a37f9124fa9de06be56fa2c78ec73e387cf082d3 | [
"MIT"
] | null | null | null | ---
layout: post
title: "Rails Project // How to prepare"
date: 2020-07-24 08:02:45 -0400
permalink: rails_project_how_to_prepare
---
*This is a post I shared with my cohort in Slack.*
Let me set the stage for you guys if yall are anything like me: get ready for tons of errors, so much confusion, so much reference to the Nil Class, banging head against wall, repeat...
With that said, figuring this stuff out is like quenching a brain freeze. I always learn most from the projects, but this one here is something else.
So here are the biggest tips I can offer as someone about midway through my project that I wish I'd have known going in:
1. DRAW OUT YOUR USER STORY
-- figuring out early on exactly what you want to happen from login to logout and everywhere in between is CRUCIAL. i should have done this before, but i just started and got going and got lost quickly. if you know each step you want the user to take, it makes it so much easier to plan out.
2. DRAW THE ASSOCIATIONS ON A WHITEBOARD
--this has been the crux of the project, what methods can i call on what objects, what belongs to what, etc. Id advise the simplest associations you can while staying true to your idea.
3. LIVE IN THE CONSOLE // SERVER
--shouldnt have taken me this long but dont be afraid of errors. rails has kick-a** errors that point you in the right direction. try out the weirdest methods ever in the console and then see what happens.
4. TALK THROUGH YOUR APP WITH A FRIEND
--hit up anyone in the cohort, make a zoom, and jsut ask for five minutes of their time. usually talking it out and getting out of your head will go a long way, both of you will learn.
5. TAKE BREAKS, BE MESSY
-- ive been afraid to get messy in projects but its the most fun. write crazy custom methods. do everything they tell you not to do. craft the app the way you want to and then go back and form it into "the right way".
6. FOLLOW CONVENTION
-- sounds contradictory to number five but its the most direct path to accomplishing your goal. its like writing a song, i dont want to reinvent the chromatic scale every time, just follow conventions laid out by people smarter than us.
7. JUST GET STARTED
--i didnt know what my app was until i started (still kind of dont LOL), but the more you work on it, the more you will see what it needs to be.
8. KNOW YOUR CODE
--lastly, most important, only you can make this happen. it sucks. its really hard( for me at least). but its so rewarding. we're like, actual programmers now. we all have our strengths and weaknesses. but through working on these projects, we become immensely more capable every day. knowing ur project inside and out is the best way, in my opinion, toward moving on to the next level. take breaks, chat with other students, et al.
obvi im not even done with my project, but i just wanted to share with those of you beginning tomorrow, because it gets really lonely, tiring, and difficult. but you can do it. i PROMISE if I can do this stuff, you absolutely can.
happy coding!
| 63.458333 | 432 | 0.762311 | eng_Latn | 0.999821 |
1124f2cc3c65668e513b8f54ae69b610389f41de | 19,477 | md | Markdown | CHANGELOG.md | tso/misk-web | cfa4191039cf25c77004236c35e8c600199bfd76 | [
"Apache-2.0"
] | null | null | null | CHANGELOG.md | tso/misk-web | cfa4191039cf25c77004236c35e8c600199bfd76 | [
"Apache-2.0"
] | null | null | null | CHANGELOG.md | tso/misk-web | cfa4191039cf25c77004236c35e8c600199bfd76 | [
"Apache-2.0"
] | null | null | null | ## Changelog
## 0.3.0
Tue, 27 Jul 2021 00:04:10 GMT
Release based on 0.1.27, but with non-major dependency updates applied.
## 0.2.1
DD Jan 2021 14:14:00 GMT
Stable release including all the changes of `0.2.1-*` alpha releases.
## 0.2.0
22 Jan 2021 14:14:00 GMT
Major upgrade to many dependencies including [Webpack (4 => 5)](https://webpack.js.org/migrate/5/) and [Emotion (10 => 11)](https://emotion.sh/docs/emotion-11). Automatic code migration has been added to the `$ miskweb` CLI to assist in migrating your tabs from `0.1.*` to `0.2.0` but you may need to lean into the above linked migration guides for more complex issues.
## 0.1.28
18 Jan 2021 14:14:00 GMT
Stable release including all the changes of `0.1.28-*` alpha releases.
## 0.1.27
18 Jan 2021 14:14:00 GMT
Stable release including all the changes of `0.1.27-*` alpha releases.
## 0.1.26
28 Apr 2020 14:14:00 GMT
Stable release including all the changes of `0.1.26-*` alpha releases.
## 0.1.25
14 Jan 2020 14:36:00 GMT
Stable release including all the changes of `0.1.25-*` alpha releases.
## 0.1.24
14 Jan 2020 14:36:00 GMT
Stable release including all the changes of `0.1.24-*` alpha releases.
## 0.1.23
4 Nov 2019 14:36:00 GMT
Stable release including all the changes of `0.1.23-*` alpha releases.
## 0.1.23-4
4 Nov 2019 14:23:00 GMT
### @misk/cli
- Update Misk Admin Dashboard multibindings generated in CLI `misk` command
## 0.1.23-3
29 Oct 2019 19:58:00 GMT
### @misk/test
- Add max workers to Jest configuration to prevent CircleCI out of memory errors
## 0.1.23-2
16 Oct 2019 14:40:00 GMT
### @misk/simpleredux
- Plumb out `failureSaga` option for similar purpose to `mergeSaga` except for in failure cases
- For example, a `failureSaga` could be added to a `simpleHttpPost` call that on call failure, issues a network request retry or other action
## 0.1.23-1
15 Oct 2019 17:24:00 GMT
### @misk/core
- Update `DashboardMetadataAction` path to `/api/dashboard/{dashboardId}/metadata`
## 0.1.23-0
15 Oct 2019 17:24:00 GMT
### @misk/core
- Update `MiskContainer` to support Misk API changes to `DashboardMetadataAction` and `ServiceMetadataAction`
## 0.1.22
1 Oct 2019 15:24:00 GMT
### @misk/simpleredux
Fix bug in `handler` parsing of `options.overrideArgs`.
## 0.1.21
1 Oct 2019 15:24:00 GMT
### @misk/simpleredux
Update `handler` functions to accept `overrideArgs` in the options object, instead of as a seperate function parameter. This specifically improves the usage for onClick functions as outlined below where empty options object no longer need to be used to reach the `overrideArgs` parameter.
```jsx
// Old
<Button onClick={handler.simpleMergeData(props, "my-tag", {}, data)}/>
// New
<Button onClick={handler.simpleMergeData(props, "my-tag", { overrideArgs: data })}/>
```
## 0.1.20
25 Sept 2019 16:24:00 GMT
Stable release including all the changes of `0.1.20-*` alpha releases.
## 0.1.20-4
25 Sept 2019 15:24:00 GMT
### @misk/simpleredux
- Fix more bugs found using `mergeSagaMapKeysToTags` in different use cases.
## 0.1.20-3
25 Sept 2019 14:24:00 GMT
### @misk/simpleredux
- New dedicated `mergeSaga` file for all library provided generic `mergeSaga` that can optionally be used in `dispatchSimpleRedux` calls to add post call asynchronous functionality
- Rename `mapMergeSaga` to `mergeSagaMapKeysToTags` and move to separate `mergeSaga` file
- Add documentation and stub out test for `mergeSagaMapKeysToTags`
## 0.1.20-2
27 Sept 2019 11:24:00 GMT
### @misk/core
- `Table` component now takes a range `[start: number, end: number]` to signify the rows to display. This replaces the `maxRows` props.
### @misk/simpleredux
- `simpleSelectorPickTransform` extends existing `simpleSelectorPick` (which matches [Lodash's Pick API](https://lodash.com/docs#pick)) to allow for reshaping the object with picked keys.
- `dispatchSimpleRedux` functions now take an options object that allows for named passing in of `requestConfig` and `mergeSaga`. `mergeSaga` accepts a generator function Saga that will run after the dispatch function's action is executed. This means that a `simpleHttpGet` will execute first and then the response will be included in the payload that the `mergeSaga` has access to. `mergeSaga` is then responsible to choose whether to emit any additional state update events or handle other asynchronous computation. Since it is a full saga and a generating function, the block of computation is asynchronous and follow up network requests or large computation can be done without risk of blocking render. See a full example of this in the new `ExampleMergeSagaContainer` in `palette-exemplar`.
- Universal `handler`. Many components allow for passing in an `onChange` handler that is a function accepting user event driven input and executing side effects. For example, an `<InputGroup/>` returns the latest text in the text box, and a simple `onChange` handler would persist the latest text in a tagged spot in Redux. Components though do not have a universal form of input they provide to their `onChange` handler. Instead of developers having to keep track of what function signature the component `onChange` props is expecting, `@misk/simpleredux` now has a universal `handler` that provides the same function names as `dispatchSimpleRedux` (ie. `handler.simpleMergeData`, `handler.simpleHttpGet`...) but can handle directly input from an component `onChange` or `onClick` props.
- The universal `handler` can handle input from any `onChange` or `onClick` props because of a new `parseOnChangeArgs` engine that identifies the format of input from `onChange` and returns it in a format that the `dispatchSimpleRedux` functions can use. See examples of `handler` in both `starter-basic` and `palette-exemplar` tabs.
- `onFn[Click,Change,Toggle,Tags]Call` functions are deprecated in favor of `handler`.
## 0.1.20-1
25 Sept 2019 20:40:00 GMT
### @misk/cli
- `new` command now accepts two positional arguments for `titleCase` and `slugCase` names for the new tab to be generated. The Misk-Web CLI no longer requires manual invocation of `./new-tab.sh`!
### Example Tabs
- Add support to `./new-tab-starter-basic.sh` that allow `starter-basic` to be used in docs site demo and as template for new tabs
- Add `Palette-Exemplar` and `Palette-LTS` tabs to docs site example demos
## 0.1.20-0
25 Sept 2019 20:40:00 GMT
### @misk/core
- Upstream new `<Table data={data} maxRows={5} />` component from palette-exemplar tab for tables that autogenerate from a list of objects.
### Example Tabs
- New `starter-basic` tab for use in `miskweb new` creation of new tabs. Much simpler bare bones structure making for a less overwhelming start for new tab developers.
- `palette-exemplar` will remain to showcase more advanced features and use cases
## 0.1.19
17 Sept 2019 19:19:00 GMT
Stable release including all the changes of `0.1.19-*` alpha releases.
- Bug fixes for `0.1.18` release of `@misk/simpleredux`
- New `MiskNavbarContainer` in `@misk/core`
## 0.1.19-3
17 Sept 2019 18:25:00 GMT
### @misk/core
- Upstream from Misk, the `MiskNavbarContainer` that can be extended to support front end dashboards for any Misk service
## 0.1.19-2
16 Sept 2019 18:34:00 GMT
### @misk/simpleredux
- Reverse changes from `0.1.19-1`
- Add new dispatch function `simpleMergeData` that does the similar encapsulation instead to provide that functionality to call sites that aren't using `on*FnCall` utilities
- Deprecated `simpleFormInput` now resolves to `simpleMergeData` instead of `simpleMerge`
## 0.1.19-1
16 Sept 2019 15:55:00 GMT
### @misk/simpleredux
- Update `onChangeFnCall`, `onChangeToggleFnCall` and `onChangeTagFnCall` to call functions with data enclosed in an object with a `data` key. This will fix outstanding bugs from the new simpleMerge` functionality. No migration should be required.
- Old
```ts
export const onChangeFnCall = (callFn: any, ...args: any) => (event: any) => {
callFn(...args, event.target.value);
};
```
- New
```ts
export const onChangeFnCall = (callFn: any, ...args: any) => (event: any) => {
callFn(...args, { data: event.target.value });
};
```
## 0.1.19-0
13 Sept 2019 20:16:00 GMT
### @misk/simpleredux
- Move `HTTPMethodDispatch` from `@misk/core` to `@misk/simpleredux` to fix and prevent future API drift
## 0.1.18
13 Sept 2019 17:52:00 GMT
Stable release including all the changes of `0.1.18-*` alpha releases.
## 0.1.18-7
13 Sept 2019 15:18:00 GMT
### @misk/cli
- Update Yargs library usage. There should no longer be deprecation warnings!
## 0.1.18-6
12 Sept 2019 15:18:00 GMT
### @misk/simpleredux
- Unified SimpleRedux flow merging together SimpleForm and SimpleNetwork
- Extensive test coverage across new flow
- Usage of old SimpleForm and SimpleNetwork Redux elements now call out to the new SimpleRedux flow and log deprecation warnings encouraging upgrading to the unified flow.
## 0.1.18-5
12 Sept 2019 14:57:00 GMT
### @misk/core
- Add `ResponsiveAppContainer` that extends `ResponsiveContainer` with styling to keep it below the Navbar
- Make `environmentToColor` theme configuration easier with lookup table now as a parameter to create the function
- See examples in the [Custom Styling docs](https://cashapp.github.io/misk-web/docs/guides/building-a-tab/09-custom-styling)
## 0.1.18-3
11 Sept 2019 20:17:00 GMT
### @misk/core
- Navbar is now themable!
- Override the default theme by providing a new theme through props
- Take advantage of the `defaultTheme` if you only want to change one of the theme values
- See examples in the [Custom Styling docs](https://cashapp.github.io/misk-web/docs/guides/building-a-tab/09-custom-styling)
## 0.1.18-2
10 Sept 2019 20:59:00 GMT
### @misk/core
- Added new props to Navbar to allow customization of MenuButton. All are optional and have sane defaults for the default interaction of showing the menu with respective icons.
- `menuIcon?: IconName | JSX.Element | string`: Set the icon that shows when the menu is closed. It can be a BlueprintJS IconName, a React JSX.Element, or a string URL to an image.
- `menuOpenIcon?: IconName | JSX.Element | string`: Set the icon that shows when the menu is open. It can be a BlueprintJS IconName, a React JSX.Element, or a string URL to an image.
- `menuButtonAsLink?: boolean`: Show the menuIcon and onClick go to the `homeUrl` instead of opening the menu.
- `menuShowButton?: boolean`: Hide the MenuButton entirely.
### @misk/test
- Add `@testing-library/dom` library for easier tests that check for certain rendered elements or text
## 0.1.18-1
22 Aug 2019 22:18:00 GMT
### @misk/simpleredux
- Move around files in library
- There should be no change in functionality
## 0.1.18-0
22 Aug 2019 19:54:00 GMT
### @misk/simpleredux
- Deprecate `simpleSelect` in favor of two new functions: `simpleSelectorGet` and `simpleSelectorPick`
- Both new functions have the same API and under the hood use Lodash corresponding functions [`get`](https://lodash.com/docs#get) and [`pick`](https://lodash.com/docs#pick)
- Update `simpleSelect` calls to either of the two new functions soon as `simpleSelect` will be removed in a future release
- See more in [`@misk/simpleredux` documentation](https://cashapp.github.io/misk-web/docs/packages/simpleredux/README)
#### simpleSelectorGet
- Allows for single-key cached selection from Redux state
- Most directly equivalent to deprecated `simpleSelect`
```Typescript
// OLD
const field1 = simpleSelect(props.simpleForm, "Dino::Field1", "data")
const tagsField = simpleSelect(props.simpleForm, "Dino::Tags", "data", simpleType.array)
// NEW
const field1 = simpleSelectorGet(props.simpleForm, ["Dino::Field1", "data"])
const tagsField = simpleSelectorGet(props.simpleForm, ["Dino::Tags", "data"], [])
```
#### simpleSelectorPick
- Allows for multi-key cached selection from Redux state
```Typescript
// OLD
const fields = [
"Name",
"Price",
"Itemized Receipt",
"CheckAlice",
"CheckBob",
"CheckEve",
"CheckMallory",
"CheckTrent",
"Meal",
"Tags"
].map((f: string) => `Dino::${f}`)
const fieldsData = fields
.map((key: string) => {
const value = simpleSelect(props.simpleForm, key, "data")
return { [key]: value }
})
.reduce((prev, current) => ({...prev, ...current}), {})
// New
const fields = [
"Name",
"Price",
"Itemized Receipt",
"CheckAlice",
"CheckBob",
"CheckEve",
"CheckMallory",
"CheckTrent",
"Meal",
"Tags"
].map((f: string) => `Dino::${f}.data`)
const fieldsData = simpleSelectorPick(props.simpleForm, fields)
```
## 0.1.17
20 Aug 2019 14:00:00 GMT
- Stable release
## 0.1.17-4
15 Aug 2019 14:00:00 GMT
### @misk/dev
- Use webpack `alias` for `src/` and `tests/` imports
### @misk/test
- Use `moduleNameMapper` in `jest` for `src/` and `tests/` imports
## 0.1.17-2
14 Aug 2019 16:15:27 GMT
### @misk/cli
- Use ShellJS instead of process.exit to pass through exit code
## 0.1.17-1
14 Aug 2019 16:05:27 GMT
### @misk/cli
- Exit with failure codes from executed scripts so that CLI fails if downstream tasks fail
## 0.1.17-0
14 Aug 2019 14:16:27 GMT
- Bump `react` and `react-dom` from `16.8.6` to `16.9.0`
### @misk/test
- Migrate from `react-testing-library` to `@testing-library/react` (package was renamed)
- Bump `@testing-library/react` from `6.1.2` to `9.1.1`
- All test files with imports from `react-testing-library` will need to be changed to import from `@testing-library/react`
## 0.1.16
14 Aug 2019 13:39:27 GMT
### @misk/dev
- Two new keys added to `miskTab.json` for expanded configuration of the Webpack build provided by `@misk/dev`
- `rawIndex` option stops injecting unused Script tags in Misk Loader tab, instead copies the index.html from src as is without any processing
- `useWebpackBundleAnalyzer` allows turning off or on in non-production environments Webpack Bundler Analyzer reports
### @misk/simpleredux
- New `IRouterProvidedProps` interface to be uesd to access the optionally injected React-Router props of history, location, and match. Useful for handling path parameters, [see the docs for more](https://cashapp.github.io/misk-web/docs/guides/building-a-tab/5-path-parameters).
## 0.1.13
15 Jul 2019 12:29:37 GMT
### @misk/simpleredux
- New `SimpleReduxSaga` type to alias the type of a `rootSaga` in a tab's `src/ducks/index.ts` to support bumping `redux-sagas` library. It looks as follows.
```Typescript
export function* rootSaga(): SimpleReduxSaga {
yield all([
fork(watchPaletteSagas),
...
```
## Old Changelog
- 2019-02-21: First stable release of `@misk/simpleredux` at `0.1.4`.
- 2019-02-20: Move `ducks` out of `@misk/common` and `@misk/core` into `@misk/simpleredux` for better centralized, isolated functionality. Effective as of `@misk/*@0.1.4-4^`.
- 2019-02-20: All interfaces, functions, colors, and code in `@misk/common` has been moved to `@misk/core`. `@misk/common` now only has styles and vendors library creation. Update any broken references to point to `@misk/core`. Effective as of `@misk/*@0.1.4-3^`.
- 2019-02-14: `simpleNetworkResponse` renamed to `getSimpleNetwork`. Many other potential breaking changes in refactor and release of `SimpleNetworkDucks` and `SimpleFormDucks`. API not stable and may be changed in upcoming releases for simplicity. Effective as of `@misk/[email protected]^`.
- 2019-02-07: `response` in `simpleNetwork` library renamed to `simpleNetworkResponse` for less ambiguity when devs call it and to match prefixed function idiom established in `0.1.3-15`. Effective as of `@misk/[email protected]^`.
- 2019-02-07: `simpleNetwork` library functions in props are now all prefixed such that `this.props.get` is now `this.props.simpleNetworkGet` to prevent collisions with other dispatcher objects. Effective as of `@misk/[email protected]^`.
- 2018-11-30: `@misk/components` renamed to `@misk/core`. All versions and Docker at `0.1.0`.
- 2018-11-08: `@misk/[email protected]`, `@misk/[email protected]`, `@misk/[email protected]`. Import styles as a css file instead of JS. New version required parameter in package.json:miskTab.
Update `src/index.html` to include the following
```HTML
<!-- Misk Libraries -->
<link rel="stylesheet" type="text/css" href="/@misk/common/styles.css" />
<script type="text/javascript" src="/@misk/common/vendors.js" preload></script>
<script type="text/javascript" src="/@misk/common/common.js" preload></script>
<script type="text/javascript" src="/@misk/core/components.js" preload></script>
```
- 2018-11-05: `@misk/common@^0.0.59`, `@misk/core@^0.0.76`, `@misk/dev@^0.0.60`, `@misk/tslint^@0.0.10`. Revert back to StyledComponents because of difficulties in downstream migrations. Upgrade to `connected-react-router@^5.0.0`.
Replace all imports of `react-emotion` with `styled-components`.
In `src/ducks/index.ts` update `rootReducer` and `IState` to the following
```Typescript
import {
connectRouter,
LocationChangeAction,
RouterState
} from "connected-react-router"
import { History } from "history"
import { combineReducers, Reducer } from "redux"
...
export interface IState {
loader: ILoaderState
router: Reducer<RouterState, LocationChangeAction>
}
...
export const rootReducer = (history: History) =>
combineReducers({
loader: LoaderReducer,
router: connectRouter(history)
})
```
- 2018-11-01: `@misk/dev@^0.0.47` and `@misk/common@^0.0.52`. Prettier integration, Slug now injected into `index.html`.
Replace `src/index.html` with the following:
```HTML
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
</head>
<body>
<div id="<%= htmlWebpackPlugin.options.slug %>"></div>
<!-- Misk Libraries -->
<script type="text/javascript" src="/@misk/common/styles.js" async></script>
<script type="text/javascript" src="/@misk/common/vendors.js" preload></script>
<script type="text/javascript" src="/@misk/common/common.js" preload></script>
<script type="text/javascript" src="/@misk/core/components.js" preload></script>
</body>
</html>
```
Create a file `prettier.config.js` with the following:
```Javascript
const { createPrettierConfig } = require("@misk/dev")
module.exports = createPrettierConfig()
```
**This was reverted on 2018-11-05**: Replace all imports of `styled-components` with `react-emotion`.
Add the following to `package.json` and add it as a prerequisite to `build` and `start` steps.
```JSON
"lint": "prettier --write --config prettier.config.js \"./src/**/*.{md,css,sass,less,json,js,jsx,ts,tsx}\"",
```
Change `miskTabBuilder` to `createTabWebpack` in `webpack.config.js`.
Change `makeExternals` to `createExternals` in `webpack.config.js`.
- 2018-10-28: `@misk/common@^0.0.52`. `createApp()` and `createIndex()`
Replace `src/index.tsx` with the following:
```Typescript
import { createApp, createIndex } from "@misk/core"
import * as Ducks from "./ducks"
import routes from "./routes"
export * from "./components"
export * from "./containers"
createIndex("config", createApp(routes), Ducks)
```
Delete `src/App.tsx`.
| 34.411661 | 795 | 0.717205 | eng_Latn | 0.902105 |
11255a3f5bb53f5e510ab0a947f86ec135d750e4 | 227 | md | Markdown | doc/LiteOS_Build_and_IDE_en/build-on-linux.md | dw5/LiteOS | e2a3ceab3499de45f1b1b133bd52c8d39726ac15 | [
"BSD-3-Clause"
] | null | null | null | doc/LiteOS_Build_and_IDE_en/build-on-linux.md | dw5/LiteOS | e2a3ceab3499de45f1b1b133bd52c8d39726ac15 | [
"BSD-3-Clause"
] | null | null | null | doc/LiteOS_Build_and_IDE_en/build-on-linux.md | dw5/LiteOS | e2a3ceab3499de45f1b1b133bd52c8d39726ac15 | [
"BSD-3-Clause"
] | null | null | null | # Build on Linux<a name="EN-US_TOPIC_0308725368"></a>
- **[Setting up the Linux Build Environment](setting-up-the-linux-build-environment.md)**
- **[Linux-based Build Process](linux-based-build-process.md)**
| 28.375 | 94 | 0.674009 | yue_Hant | 0.59031 |
11255a868cc67dd13b5e5cf4790438f72abce66f | 1,786 | md | Markdown | docs/en/operations/system-tables/asynchronous_metrics.md | pdv-ru/ClickHouse | 0ff975bcf3008fa6c6373cbdfed16328e3863ec5 | [
"Apache-2.0"
] | 15,577 | 2019-09-23T11:57:53.000Z | 2022-03-31T18:21:48.000Z | docs/en/operations/system-tables/asynchronous_metrics.md | pdv-ru/ClickHouse | 0ff975bcf3008fa6c6373cbdfed16328e3863ec5 | [
"Apache-2.0"
] | 16,476 | 2019-09-23T11:47:00.000Z | 2022-03-31T23:06:01.000Z | docs/en/operations/system-tables/asynchronous_metrics.md | pdv-ru/ClickHouse | 0ff975bcf3008fa6c6373cbdfed16328e3863ec5 | [
"Apache-2.0"
] | 3,633 | 2019-09-23T12:18:28.000Z | 2022-03-31T15:55:48.000Z | # system.asynchronous_metrics {#system_tables-asynchronous_metrics}
Contains metrics that are calculated periodically in the background. For example, the amount of RAM in use.
Columns:
- `metric` ([String](../../sql-reference/data-types/string.md)) — Metric name.
- `value` ([Float64](../../sql-reference/data-types/float.md)) — Metric value.
**Example**
``` sql
SELECT * FROM system.asynchronous_metrics LIMIT 10
```
``` text
┌─metric──────────────────────────────────┬──────value─┐
│ jemalloc.background_thread.run_interval │ 0 │
│ jemalloc.background_thread.num_runs │ 0 │
│ jemalloc.background_thread.num_threads │ 0 │
│ jemalloc.retained │ 422551552 │
│ jemalloc.mapped │ 1682989056 │
│ jemalloc.resident │ 1656446976 │
│ jemalloc.metadata_thp │ 0 │
│ jemalloc.metadata │ 10226856 │
│ UncompressedCacheCells │ 0 │
│ MarkCacheFiles │ 0 │
└─────────────────────────────────────────┴────────────┘
```
**See Also**
- [Monitoring](../../operations/monitoring.md) — Base concepts of ClickHouse monitoring.
- [system.metrics](../../operations/system-tables/metrics.md#system_tables-metrics) — Contains instantly calculated metrics.
- [system.events](../../operations/system-tables/events.md#system_tables-events) — Contains a number of events that have occurred.
- [system.metric_log](../../operations/system-tables/metric_log.md#system_tables-metric_log) — Contains a history of metrics values from tables `system.metrics` and `system.events`.
[Original article](https://clickhouse.com/docs/en/operations/system-tables/asynchronous_metrics) <!--hide-->
| 45.794872 | 183 | 0.609742 | eng_Latn | 0.460575 |
11267d243c5d086173cfa1a2b9fdea9b2a5896af | 5,012 | md | Markdown | README.md | ttimbers/jupyterext-text-shortcuts | e3f931f7122d67f2bf8967a4eb62433cd22553d5 | [
"MIT"
] | null | null | null | README.md | ttimbers/jupyterext-text-shortcuts | e3f931f7122d67f2bf8967a4eb62433cd22553d5 | [
"MIT"
] | null | null | null | README.md | ttimbers/jupyterext-text-shortcuts | e3f931f7122d67f2bf8967a4eb62433cd22553d5 | [
"MIT"
] | 1 | 2021-09-12T22:08:13.000Z | 2021-09-12T22:08:13.000Z | # text-shortcuts
A jupyterlab extension to insert text via keyboard shortcuts.

## Pre-requisites
- JupyterLab 2.x, 3.x
- [node 12+](https://nodejs.org)
## Installation
```bash
jupyter labextension install @techrah/text-shortcuts
```
or add it through your Jupyter Lab **Extensions** tab.
Then, add some user shortcuts:
- In Jupyter Lab, select **Settings** / **Advanced Settings Editor** from the menu.
- Select the **Keyboard Shortcuts** tab.
- In the **User Preferences** section, add your shortcuts configuration and click the "save" icon.
Here are two useful shortcuts for programming in R:
```json
{
"shortcuts": [
{
"command": "text-shortcuts:insert-text",
"args": {
"kernel": "ir",
"text": "|>",
"autoPad": true
},
"keys": ["Accel Shift M"],
"selector": "body"
},
{
"command": "text-shortcuts:insert-text",
"args": {
"kernel": "ir",
"text": "<-",
"autoPad": true
},
"keys": ["Alt -"],
"selector": "body"
}
]
}
```
**NOTE: As of version 0.1.x You do NOT need to add the above shortcuts to _User Preferences_ unless you want to override the default behaviour.** These two shortcuts are now installed by default. They can be found in _Keyboard Shortcuts / System Defaults_.
<img width="830" alt="@techrah:text-shortcuts_default-shortcuts" src="https://user-images.githubusercontent.com/600471/90961403-86083e00-e45d-11ea-85d7-c98c2b1cd2c9.png">
### Anatomy of a Text Shortcut
```
{
...
"command": "text-shortcuts:insert-text"
...
}
```
Identifies the keyboard shortcut as a text shortcut that is intercepted by this extension.
```
{
...
"keys": [
"Accel Shift M"
],
...
}
```
`keys` is an array of keyboard shortcuts that activate the insertion of the text snippet. Each entry can be a combination of one or more of the following modifiers, ending with a text character. For example, "Accel Shift M" represents Command-Shift-M on macOS.
- `Accel` : Command (macOS) / Ctrl (Windows)
- `Alt` : Option (macOS) / Alt (Windows)
- `Shift` : Shift
- `Ctrl` : Control
```
{
...
"args": {
"kernel": "ir",
"text": "|>",
"autoPad": true
}
...
}
```
- `kernel` (optional): If you specify a `kernel`, the shortcut will only work in notebooks that are running the specified kernel. Examples of kernel names are `ir` and `python3`. For a list of installed kernels, use `jupyter kernelspec list`.
- `text`: This is the actual text that you want inserted.
- `autoPad`: (`true` | `false`). If `true`, will add spacing either before, after, or both before and after so that there is a single space on each side of the text.
```
{
...
"selector": "body"
...
}
```
CSS selector. Always use `"body"` for this extension.
## Development
### Pre-requisites
- node 5+
- Python 3.6+
It is strongly recommended that you set up a virtual Python environment. These instructions will assume that Anaconda is already installed.
- Create a new virtual environment and activate it.
```bash
conda create --name text-shortcuts
conda activate text-shortcuts
```
- Install jupyterlab
```bash
conda install jupyterlab
```
- Clone this project and in the root of the project folder, install dependencies with the JupyterLab Package Manager
```bash
jlpm
```
- Install the extension
```bash
jupyter labextension install . --no-build
```
- Start up jupyter lab in watch mode. Don't forget to activate your virtual environment. If you want to use a different browser for development, specify that with the `--browser` switch. If you want to use a custom port, specify that with the `--port` switch.
```bash
conda activate text-shortcuts
jupyter lab --watch --browser="chrome" --port=8889
```
- In another terminal, run the TypeScript compiler in watch mode.
```bash
conda activate text-shortcuts
jlpm tsc -w
```
For more information on developing JupyterLab extensions, here are some helpful resources:
- [Extension Developer Guide][1]
- [Common Extension Points: Keyboard Shortcuts][2]
- [JupyterLab Extensions by Examples][3]
- [CodeMirror: Document management methods][4]
- [Interface INotebookTracker][5]
Pull requests are welcome!
[1]: https://jupyterlab.readthedocs.io/en/stable/extension/extension_dev.html
[2]: https://jupyterlab.readthedocs.io/en/stable/extension/extension_points.html#keyboard-shortcuts
[3]: https://github.com/jupyterlab/extension-examples
[4]: https://codemirror.net/doc/manual.html#api_doc
[5]: https://jupyterlab.github.io/jupyterlab/interfaces/_notebook_src_index_.inotebooktracker.html
| 27.690608 | 261 | 0.652235 | eng_Latn | 0.953448 |
11267e82adafca1d264ad2cc10f41603a593ab49 | 201 | md | Markdown | README.md | newbienewbie/expression-json-serializer | a8a4d1d00802c9fdc1eed074d593e548d5cccda3 | [
"MIT"
] | null | null | null | README.md | newbienewbie/expression-json-serializer | a8a4d1d00802c9fdc1eed074d593e548d5cccda3 | [
"MIT"
] | null | null | null | README.md | newbienewbie/expression-json-serializer | a8a4d1d00802c9fdc1eed074d593e548d5cccda3 | [
"MIT"
] | null | null | null | expression-json-serializer
==========================
Expression serializer for JSON.NET
This is a fork of [aquilae/expression-json-serializer](https://github.com/aquilae/expression-json-serializer) | 28.714286 | 109 | 0.711443 | eng_Latn | 0.280192 |
1126f70acb19adf11ae9909506b2db065a82b1cb | 7,842 | md | Markdown | README.md | dmohs/react-cljs | fc6a63a797c4ff9b00b750fefa451cc202df415d | [
"MIT"
] | 19 | 2015-09-28T23:15:16.000Z | 2018-07-15T20:38:29.000Z | README.md | dmohs/react-cljs | fc6a63a797c4ff9b00b750fefa451cc202df415d | [
"MIT"
] | 5 | 2016-06-03T20:47:28.000Z | 2018-02-12T21:47:57.000Z | README.md | dmohs/react-cljs | fc6a63a797c4ff9b00b750fefa451cc202df415d | [
"MIT"
] | 2 | 2015-11-06T20:22:33.000Z | 2017-07-06T20:46:15.000Z | # react-cljs [](https://clojars.org/dmohs/react)
A ClojureScript wrapper for React.
There are a number of React-like libraries for ClojureScript (e.g., Om, Reagent, Rum). This one sets itself apart by embracing the following two philosophies:
1. React is very well-engineered.
2. Objects are an excellent abstraction for UI components.
Because React is well-engineered, this wrapper aims to provide the absolute minimum interface necessary to make React usage seamless from ClojureScript. The primary benefit is that nearly every tool available to React developers in JavaScript (e.g., the full component lifecycle, refs, etc.) is available to users of this wrapper. The secondary benefit is that reading React's documentation, and using good judgement about how ClojureScript differs from JavaScript, is often enough to fully understand how to write code using this wrapper.
Since objects are an excellent abstraction for UI components, this wrapper eschews the usual practice of a function-first interface. Ad-hoc component methods (e.g., `:-handle-submit-button-click`) are natural and encouraged (we tend to prefix private methods with a hyphen by convention, which is not enforced).
Take a look at the [examples](http://dmohs.github.io/react-cljs/examples/) and the [examples source](https://github.com/dmohs/react-cljs/blob/master/src/test/cljs/webui/main.cljs) for usage. An understanding of React via React's excellent documentation will aid in understanding these examples.
If you'd like to try out the examples yourself with Figwheel's amazing hot-reloader, you'll need ruby and docker. Then run:
```sh
./project.rb start
```
to start Figwheel. When it has finished compiling, open http://localhost:3449/.
## Goodies
- **Built-in support for hot-reloading**. If you use, for example, [Figwheel](https://github.com/bhauman/lein-figwheel) to hot-reload files on change, React components created with the `defc` macro will be patched automatically.
- **Method tracing**. Including `:trace? true` in the class definition map will cause every method call to emit a message to the console. This also attempts to break infinite loops by setting a ceiling on the number of traces in a short time period.
- **React Developer Tools support**. Copies component state and props into plain JavaScript in non-optimized compilation modes so it is easier to use React Developer Tools (Chrome extension) to inspect components.
- **Bound methods**. Call `(r/method this :your-method)` to retrieve a method from your instance. Subsequent calls return an identical (not just equal) function, so it can be used in things like `addEventListener`/`removeEventListener`.
- **abind** *experimental*. Binds an atom passed as a property to a key in state. Whenever the atom's value changes, the corresponding state key will receive the new value (and cause a re-render).
### Add dependency:
```cljs
[dmohs/react "1.3.0"] ; [1]
```
**or**
```cljs
[dmohs/react "1.2.4+15.5.4-1"] ; [2]
```
[1] This version does not depend on React. You must bundle it separately (and include `create-react-class`) using Webpack or similar. You can get an example of this by reading the [scripts](https://github.com/dmohs/react-cljs/blob/master/.project/devserver.rb) used to start the dev environment.
[2] This version bundles the specified version of React via [CLJSJS](http://cljsjs.github.io/).
## Top-Level API
The Top-Level API closely follows React's Top-Level API:
https://facebook.github.io/react/docs/top-level-api.html
### React.Component
*Not applicable.*
### React.createClass
```cljs
;; (:require [dmohs/react :as r])
(def MyComponent
(r/create-class
{:get-initial-state (fn [] {:click-count 0})
:render
(fn [{:keys [this props state refs]}]
[:div {:style {:border "1px solid black"}}
"Hello there, " (:name props)
[:div {:ref "clickable-div"
:on-click (fn [e] (swap! state update-in [:click-count] inc))}
"I have been clicked " (:click-count @state) " times."]])
:component-did-mount
(fn [{:keys [refs]}]
(.focus (@refs "clickable-div")))}))
```
or, using the `defc` macro (preferred and supports hot-reloading):
```cljs
(r/defc MyComponent
{:get-initial-state ...
:render ...
...})
```
The `render` method can return either an element or a vector (as in the above example). Pass `:trace? true` for method tracing:
```cljs
(r/defc MyComponent
{:trace? true
:get-initial-state ...
:render ...
...})
```
### React.createElement
```cljs
(r/defc MyComponent ...)
(def PlainReactComponent (js/React.createClass ...))
(r/create-element
:div {:class-name "alert" :style {:background-color "red"}}
(r/create-element MyComponent {:foo "foo"})
(r/create-element PlainReactComponent {:bar "bar"}))
;; Vector syntax
(r/create-element [:div {:class-name "alert"}
"Child 1" "Child 2"
[MyComponent {:initial-click-count 15}]
[PlainReactComponent {:initial-click-count 21}]])
```
### React.cloneElement
*Not yet implemented.*
### React.createFactory
```cljs
(r/create-factory string-or-react-class)
```
### React.isValidElement
```cljs
(r/valid-element? x)
```
### ReactDOM.render
```cljs
(r/render element container callback)
```
### ReactDOM.unmountComponentAtNode
```cljs
(r/unmount-component-at-node container)
```
### ReactDOM.findDOMNode
```cljs
(r/find-dom-node element)
```
## Component Specifications
Component specifications closely follow React's Component Specifications:
https://facebook.github.io/react/docs/component-specs.html
React methods are defined using Clojure naming conventions (`:get-initial-state` corresponds to `getInitialState`). Additional methods become part of the object (as in React), so `:add-foo` can be called like so:
```cljs
(r/call :add-foo this "argument 1" "argument 2")
;; or
(r/call :add-foo (@refs "some-child") "argument 1" "argument 2")
```
Additionally, components implement `IFn`, so the above calls can be shortened to:
```cljs
(this :add-foo "argument 1" "argument 2")
;; and
((@refs "some-child") :add-foo "argument 1" "argument 2")
```
Methods are passed a map with the appropriate keys defined:
```cljs
{:this this ; the component instance
:props props
:state state ; state atom
:after-update ; [1]
:refs refs ; [2]
:locals ; [3]
:prev-props prevProps ; when applicable
:prev-state prevState ; "
:next-props nextProps ; "
:next-state nextState ; "
:abind ; [4]
}
```
1. This is used when you would pass a callback to `setState`, e.g.,
`(after-update #(.focus (r/find-dom-node this)))`. `after-update` is also defined as a root-level function, so this is identical: `(r/after-update this #(.focus (r/find-dom-node this)))`
2. The `refs` atom allows accessing `this.refs` as a map, e.g., `(.focus (@refs "my-text-box"))`.
3. Convenience atom for local variables. Instead of, e.g.,
`(set! (.-myTimer this) (js/setTimeout ...))`, you can do
`(swap! locals assoc :my-timer (js/setTimeout ...))`.
4. Bind a property atom to a key in state, e.g.,
`(abind :foo)` or `(abind :foo :my-state-key)`
Returns {state-key value-of-atom} for use in `:get-initial-state`.
Note: for non-api methods (like `:add-foo` above), this map is the first argument before any arguments passed when calling the method using `r/call` or via `this`.
Modifying the `state` atom implicitly calls `this.setState`. This maintains the behavior of React's `this.state` in the way that updates (via `swap!` or `reset!`) are not visible in `@state` until after the component is re-rendered.
Note that `propTypes`, `statics`, and `mixins` are not yet implemented. They may never be, since Clojure to some extent obviates the need for some of these utilities.
| 39.407035 | 539 | 0.711553 | eng_Latn | 0.974022 |
11271491a8adf17cb7baf22ba69f5748f54d235d | 1,864 | md | Markdown | README.md | Tlacateccatl/Animal-Data-Visualization-Exploratory-Data-Analysis | 22e23cb77f8acb372b9b87cd81bb718d7d5f0e73 | [
"CC0-1.0"
] | null | null | null | README.md | Tlacateccatl/Animal-Data-Visualization-Exploratory-Data-Analysis | 22e23cb77f8acb372b9b87cd81bb718d7d5f0e73 | [
"CC0-1.0"
] | null | null | null | README.md | Tlacateccatl/Animal-Data-Visualization-Exploratory-Data-Analysis | 22e23cb77f8acb372b9b87cd81bb718d7d5f0e73 | [
"CC0-1.0"
] | null | null | null | # Animal Data Visualization and Exploratory Data Analysis
Palmer Penguin Visualization and Exploratory Data Analysis.
***
## Context
The palmerpenguins data contains size measurements for three penguin species observed on three islands in the Palmer Archipelago, Antarctica. These data were collected from 2007 - 2009 by Dr. Kristen Gorman with the Palmer Station Long Term Ecological Research Program, part of the US Long Term Ecological Research Network. The data were imported directly from the Environmental Data Initiative (EDI) Data Portal, and are available for use by CC0 license (“No Rights Reserved”) in accordance with the Palmer Station Data Policy
## Install
This project requires Python 3 and the following Python libraries installed:
- [NumPy](http://www.numpy.org/)
- [Pandas](http://pandas.pydata.org)
- [matplotlib](http://matplotlib.org/)
- [Seaborn](https://seaborn.pydata.org/)
You will also need to have software installed to run and execute a [Jupyter Notebook](http://ipython.org/notebook.html)
If you do not have Python installed yet, it is highly recommended that you install the [Anaconda](http://continuum.io/downloads) distribution of Python, which already has the above packages and more included. Make sure that you select the Python 3.x installer.
## Code
All the code is in the notebook `PenguinCode.ipynb`.
## Run
In a terminal or command window, navigate to the top-level project directory titanic_survival_exploration/ (that contains this README) and run one of the following commands:
```
jupyter notebook PenguinCode.ipynb
```
or
```
ipython notebook PenguinCode.ipynb
```
This will open the Jupyter Notebook software and project file in your web browser.
## Data
The datasets used in this project is included in the folder `islandPenguinData`. This dataset is provided by [Dataquest.io](https://www.dataquest.io).
| 49.052632 | 527 | 0.785944 | eng_Latn | 0.988936 |
112737b65e7878d0f308d6213163258e7d65b187 | 10,749 | md | Markdown | WindowsServerDocs/identity/solution-guides/Deploy-Access-Denied-Assistance--Demonstration-Steps-.md | eltociear/windowsserverdocs.ja-jp | d45bb4a3e900f0f4bddef6b3709f3c7dec3a9d6c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | WindowsServerDocs/identity/solution-guides/Deploy-Access-Denied-Assistance--Demonstration-Steps-.md | eltociear/windowsserverdocs.ja-jp | d45bb4a3e900f0f4bddef6b3709f3c7dec3a9d6c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | WindowsServerDocs/identity/solution-guides/Deploy-Access-Denied-Assistance--Demonstration-Steps-.md | eltociear/windowsserverdocs.ja-jp | d45bb4a3e900f0f4bddef6b3709f3c7dec3a9d6c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
ms.assetid: b035e9f8-517f-432a-8dfb-40bfc215bee5
title: Deploy Access-Denied Assistance (Demonstration Steps)
author: billmath
ms.author: billmath
manager: femila
ms.date: 05/31/2017
ms.topic: article
ms.prod: windows-server
ms.technology: identity-adds
ms.openlocfilehash: fc23e9d9dae9118bf6d489ed8697ce5bac44e7ba
ms.sourcegitcommit: b00d7c8968c4adc8f699dbee694afe6ed36bc9de
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 04/08/2020
ms.locfileid: "80861265"
---
# <a name="deploy-access-denied-assistance-demonstration-steps"></a>Deploy Access-Denied Assistance (Demonstration Steps)
>適用対象: Windows Server 2016、Windows Server 2012 R2、Windows Server 2012
このトピックでは、アクセス拒否アシスタンスを構成し、それが正しく機能していることを確認する方法について説明します。
**このドキュメントの説明**
- [手順 1: アクセス拒否アシスタンスを構成する](Deploy-Access-Denied-Assistance--Demonstration-Steps-.md#BKMK_1)
- [手順 2: 電子メール通知設定を構成する](Deploy-Access-Denied-Assistance--Demonstration-Steps-.md#BKMK_2)
- [手順 3: アクセス拒否アシスタンスが正しく構成されていることを確認する](Deploy-Access-Denied-Assistance--Demonstration-Steps-.md#BKMK_3)
> [!NOTE]
> このトピックには、説明する手順の一部を自動化するために使用できるサンプルの Windows PowerShell コマンドレットが含まれます。 詳しくは、 [コマンドレットの使用に関するページ](https://go.microsoft.com/fwlink/p/?linkid=230693)をご覧ください。
## <a name="step-1-configure-access-denied-assistance"></a><a name="BKMK_1"></a>手順 1: アクセス拒否アシスタンスを構成する
グループ ポリシーを使用して、ドメイン内でアクセス拒否アシスタンスを構成できます。あるいは、ファイル サーバー リソース マネージャーのコンソールを使用して、ファイル サーバーごとに個別にアシスタンスを構成できます。 ファイル サーバー上の特定の共有フォルダーのアクセス拒否メッセージを変更することもできます。
次のようにグループ ポリシーを使用して、ドメインのアクセス拒否アシスタンスを構成できます。
[Windows PowerShell を使用してこの手順を実行する](assetId:///4a96cdaf-0081-4824-aab8-f0d51be501ac#BKMK_PSstep1)
#### <a name="to-configure-access-denied-assistance-by-using-group-policy"></a>グループ ポリシーを使用してアクセス拒否アシスタンスを構成するには
1. グループ ポリシーの管理を開きます。 サーバー マネージャーで、 **[ツール]** をクリックし、 **[グループ ポリシーの管理]** をクリックします。
2. 該当するグループ ポリシーを右クリックしてから、 **[編集]** をクリックします。
3. **[コンピューターの構成]** をクリックし、 **[ポリシー]** をクリックし、 **[管理用テンプレート]** をクリックし、 **[システム]** をクリックしてから、 **[アクセス拒否アシスタンス]** をクリックします。
4. **[アクセス拒否エラーのメッセージをカスタマイズする]** を右クリックしてから、 **[編集]** をクリックします。
5. **[有効]** オプションを選択します。
6. 次のオプションを構成します。
1. **[アクセスが拒否されたユーザーに次のメッセージを表示する]** ボックスに、ファイルまたはフォルダーへのアクセスが拒否されたときにユーザーに表示されるメッセージを入力します。
カスタマイズしたテキストを挿入するマクロをメッセージに追加できます。 マクロには次のものが含まれています。
- **[Original File Path]** ユーザーによってアクセスされた元のファイル パス。
- **[Original File Path Folder]** ユーザーによってアクセスされた元のファイル パスの親フォルダー。
- **[Admin Email]** 管理者の電子メール受信者リスト。
- **[Data Owner Email]** データ所有者の電子メール受信者リスト。
2. **[ユーザーがアシスタントを依頼できるようにする]** チェック ボックスを選択します。
3. 残りの既定の設定をそのままにします。
***<em>Windows PowerShell の同等のコマンド</em>***
次の Windows PowerShell コマンドレットは、前の手順と同じ機能を実行します。 書式上の制約のため、複数行にわたって折り返される場合でも、各コマンドレットは 1 行に入力してください。
```
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName AllowEmailRequests -Type DWORD -value 1
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName GenerateLog -Type DWORD -value 1
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName IncludeDeviceClaims -Type DWORD -value 1
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName IncludeUserClaims -Type DWORD -value 1
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName PutAdminOnTo -Type DWORD -value 1
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName PutDataOwnerOnTo -Type DWORD -value 1
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName ErrorMessage -Type MultiString -value "Type the text that the user will see in the error message dialog box."
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\Software\Policies\Microsoft\Windows\ADR\AccessDenied" -ValueName Enabled -Type DWORD -value 1
```
あるいは、ファイル サーバー リソース マネージャーのコンソールを使用して、ファイル サーバーごとに個別にアクセス拒否アシスタンスを構成できます。
[Windows PowerShell を使用してこの手順を実行する](assetId:///4a96cdaf-0081-4824-aab8-f0d51be501ac#BKMK_PSstep1a)
#### <a name="to-configure-access-denied-assistance-by-using-file-server-resource-manager"></a>ファイル サーバー リソース マネージャーを使用してアクセス拒否アシスタンスを構成するには
1. ファイル サーバー リソース マネージャーを開きます。 サーバー マネージャーで **[ツール]** をクリックしてから、 **[ファイル サーバー リソース マネージャー]** をクリックします。
2. **[ファイル サーバー リソース マネージャー (ローカル)]** をクリックしてから、 **[オプションの構成]** をクリックします。
3. **[アクセス拒否アシスタンス]** タブをクリックします。
4. **[アクセス拒否アシスタンスを有効にする]** チェック ボックスを選択します。
5. **[フォルダーまたはファイルへのアクセスが拒否されたユーザーに次のメッセージを表示]** ボックスに、ファイルまたはフォルダーへのアクセスが拒否されたときにユーザーに表示されるメッセージを入力します。
カスタマイズしたテキストを挿入するマクロをメッセージに追加できます。 マクロには次のものが含まれています。
- **[Original File Path]** ユーザーによってアクセスされた元のファイル パス。
- **[Original File Path Folder]** ユーザーによってアクセスされた元のファイル パスの親フォルダー。
- **[Admin Email]** 管理者の電子メール受信者リスト。
- **[Data Owner Email]** データ所有者の電子メール受信者リスト。
6. **[電子メール要求の構成]** をクリックし、 **[ユーザーがアシスタンスを依頼できるようにする]** チェック ボックスを選択してから、 **[OK]** をクリックします。
7. エラー メッセージがユーザーにどのように表示されるのかを確認する場合は、 **[プレビュー]** をクリックします。
8. **[OK]** をクリックすると、
***<em>Windows PowerShell の同等のコマンド</em>***
次の Windows PowerShell コマンドレットは、前の手順と同じ機能を実行します。 書式上の制約のため、複数行にわたって折り返される場合でも、各コマンドレットは 1 行に入力してください。
```
Set-FSRMAdrSetting -Event "AccessDenied" -DisplayMessage "Type the text that the user will see in the error message dialog box." -Enabled:$true -AllowRequests:$true
```
アクセス拒否アシスタンスを構成した後に、グループ ポリシーを使用して、すべてのファイルの種類に対してアクセス拒否アシスタンスを有効にする必要があります。
[Windows PowerShell を使用してこの手順を実行する](assetId:///4a96cdaf-0081-4824-aab8-f0d51be501ac#BKMK_PSstep1c)
#### <a name="to-configure-access-denied-assistance-for-all-file-types-by-using-group-policy"></a>グループ ポリシーを使用してすべてのファイルの種類に対してアクセス拒否アシスタンスを構成するには
1. グループ ポリシーの管理を開きます。 サーバー マネージャーで、 **[ツール]** をクリックし、 **[グループ ポリシーの管理]** をクリックします。
2. 該当するグループ ポリシーを右クリックしてから、 **[編集]** をクリックします。
3. **[コンピューターの構成]** をクリックし、 **[ポリシー]** をクリックし、 **[管理用テンプレート]** をクリックし、 **[システム]** をクリックしてから、 **[アクセス拒否アシスタンス]** をクリックします。
4. **[クライアントですべてのファイルの種類についてアクセス拒否アシスタンスを有効にする]** を右クリックしてから、 **[編集]** をクリックします。
5. **[有効]** をクリックし、 **[OK]** をクリックします。
***<em>Windows PowerShell の同等のコマンド</em>***
次の Windows PowerShell コマンドレットは、前の手順と同じ機能を実行します。 書式上の制約のため、複数行にわたって折り返される場合でも、各コマンドレットは 1 行に入力してください。
```
Set-GPRegistryValue -Name "Name of GPO" -key "HKLM\SOFTWARE\Policies\Microsoft\Windows\Explore" -ValueName EnableShellExecuteFileStreamCheck -Type DWORD -value 1
```
ファイル サーバー リソース マネージャーのコンソールを使用して、ファイル サーバー上の共有フォルダーごとに個別のアクセス拒否メッセージを指定することもできます。
[Windows PowerShell を使用してこの手順を実行する](assetId:///4a96cdaf-0081-4824-aab8-f0d51be501ac#BKMK_PSstep1b)
#### <a name="to-specify-a-separate-access-denied-message-for-a-shared-folder-by-using-file-server-resource-manager"></a>ファイル サーバー リソース マネージャーを使用して共有フォルダーに個別のアクセス拒否メッセージを指定するには
1. ファイル サーバー リソース マネージャーを開きます。 サーバー マネージャーで **[ツール]** をクリックしてから、 **[ファイル サーバー リソース マネージャー]** をクリックします。
2. **[ファイル サーバー リソース マネージャー (ローカル)]** を展開してから、 **[分類管理]** をクリックします。
3. **[分類プロパティ]** を右クリックしてから、 **[フォルダー管理プロパティの設定]** をクリックします。
4. **[プロパティ]** ボックスで **[アクセス拒否アシスタンス メッセージ]** をクリックしてから、 **[追加]** をクリックします。
5. **[参照]** をクリックしてから、カスタム アクセス拒否メッセージが必要なフォルダーを選択します。
6. **[値]** ボックスに、当該フォルダー内のリソースにアクセスできない場合にユーザーに表示するメッセージを入力します。
カスタマイズしたテキストを挿入するマクロをメッセージに追加できます。 マクロには次のものが含まれています。
- **[Original File Path]** ユーザーによってアクセスされた元のファイル パス。
- **[Original File Path Folder]** ユーザーによってアクセスされた元のファイル パスの親フォルダー。
- **[Admin Email]** 管理者の電子メール受信者リスト。
- **[Data Owner Email]** データ所有者の電子メール受信者リスト。
7. **[OK]** をクリックし、 **[閉じる]** をクリックします。
***<em>Windows PowerShell の同等のコマンド</em>***
次の Windows PowerShell コマンドレットは、前の手順と同じ機能を実行します。 書式上の制約のため、複数行にわたって折り返される場合でも、各コマンドレットは 1 行に入力してください。
```
Set-FSRMMgmtProperty -Namespace "folder path" -Name "AccessDeniedMessage_MS" -Value "Type the text that the user will see in the error message dialog box."
```
## <a name="step-2-configure-the-email-notification-settings"></a><a name="BKMK_2"></a>手順 2: 電子メール通知設定を構成する
アクセス拒否アシスタンス メッセージを送信するファイル サーバーごとに電子メール通知設定を構成する必要があります。
[Windows PowerShell を使用してこの手順を実行する](assetId:///4a96cdaf-0081-4824-aab8-f0d51be501ac#BKMK_PSstep2)
1. ファイル サーバー リソース マネージャーを開きます。 サーバー マネージャーで **[ツール]** をクリックしてから、 **[ファイル サーバー リソース マネージャー]** をクリックします。
2. **[ファイル サーバー リソース マネージャー (ローカル)]** をクリックしてから、 **[オプションの構成]** をクリックします。
3. **[電子メールの通知]** タブをクリックします。
4. 次の設定を構成します。
- **[SMTP サーバー名または IP アドレス]** ボックスに、組織内の SMTP サーバーの IP アドレスの名前を入力します。
- 管理者の **[既定の受信]** 者 と **[既定の電子メールアドレス]** ボックスに、ファイルサーバー管理者の電子メールアドレスを入力します。
5. **[テスト電子メールの送信]** をクリックして、電子メール通知が正しく構成されていることを確認します。
6. **[OK]** をクリックすると、
***<em>Windows PowerShell の同等のコマンド</em>***
次の Windows PowerShell コマンドレットは、前の手順と同じ機能を実行します。 書式上の制約のため、複数行にわたって折り返される場合でも、各コマンドレットは 1 行に入力してください。
```
set-FSRMSetting -SMTPServer "server1" -AdminEmailAddress "[email protected]" -FromEmailAddress "[email protected]"
```
## <a name="step-3-verify-that-access-denied-assistance-is-configured-correctly"></a><a name="BKMK_3"></a>手順 3: アクセス拒否アシスタンスが正しく構成されていることを確認する
アクセス拒否アシスタンスが正しく構成されていることを確認するには、Windows 8 を実行しているユーザーが、アクセス権のない共有またはその共有内のファイルにアクセスしようとします。 アクセス拒否メッセージが表示された場合、ユーザーには、 **[サポートの要求]** ボタンが表示されます。 [サポートの要求] ボタンをクリックすると、ユーザーは、アクセス理由を指定してから、フォルダー所有者またはファイル サーバー管理者に電子メールを送信できます。 フォルダー所有者またはファイル サーバー管理者は、到着した電子メールに適切な詳細が含まれているかを確認できます。
> [!IMPORTANT]
> Windows Server 2012 を実行しているユーザーを使用してアクセス拒否アシスタンスを確認する場合は、ファイル共有に接続する前にデスクトップエクスペリエンスをインストールする必要があります。
## <a name="see-also"></a><a name="BKMK_Links"></a>関連項目
- [シナリオ: アクセス拒否アシスタンス](Scenario--Access-Denied-Assistance.md)
- [アクセス拒否アシスタンスの計画](assetId:///b169f0a4-8b97-4da8-ae4a-c8f1986d19e1)
- [動的 Access Control: シナリオの概要](Dynamic-Access-Control--Scenario-Overview.md)
| 45.740426 | 285 | 0.735045 | yue_Hant | 0.763521 |
1127dc71d36132c507f3e7a05ba9217f0cc776b0 | 72 | md | Markdown | README.md | madguy02/SearchMate | 7b4310e9d068ed48f3e2541ebd35ccff02f32e63 | [
"MIT"
] | null | null | null | README.md | madguy02/SearchMate | 7b4310e9d068ed48f3e2541ebd35ccff02f32e63 | [
"MIT"
] | null | null | null | README.md | madguy02/SearchMate | 7b4310e9d068ed48f3e2541ebd35ccff02f32e63 | [
"MIT"
] | null | null | null | # SearchMate
Application which will reduce your research time on google
| 24 | 58 | 0.833333 | eng_Latn | 0.996119 |
1127f218e33979b617f9293d3697cf98ff412e39 | 110 | md | Markdown | src-docs/views/components/table/README.md | mooniitt/muse-ui | 6a9745bcf7256bece89debaadf10747661d371ee | [
"MIT"
] | 4 | 2017-02-17T02:52:33.000Z | 2021-05-31T07:27:23.000Z | src-docs/views/components/table/README.md | mooniitt/muse-ui | 6a9745bcf7256bece89debaadf10747661d371ee | [
"MIT"
] | 2 | 2020-12-04T22:02:38.000Z | 2021-05-09T11:12:46.000Z | src-docs/views/components/table/README.md | mooniitt/muse-ui | 6a9745bcf7256bece89debaadf10747661d371ee | [
"MIT"
] | 5 | 2017-04-07T03:25:25.000Z | 2019-08-12T13:02:48.000Z | ## Table
[table](https://material.google.com/components/data-tables.html) 被用来展示原始数据集,并且通常出现于桌面企业产品中。
### 示例
| 18.333333 | 91 | 0.745455 | yue_Hant | 0.529564 |
1128558ef1a1e4d9021ef1d33a5c512107f6828e | 22 | md | Markdown | README.md | lidaomeng/NodeJS-Project | fb1e82190d15b136453b960342c9ee78f7e50444 | [
"MIT"
] | null | null | null | README.md | lidaomeng/NodeJS-Project | fb1e82190d15b136453b960342c9ee78f7e50444 | [
"MIT"
] | null | null | null | README.md | lidaomeng/NodeJS-Project | fb1e82190d15b136453b960342c9ee78f7e50444 | [
"MIT"
] | null | null | null | # NodeJS-Project
练习项目
| 7.333333 | 16 | 0.772727 | eng_Latn | 0.496097 |
1128f4e6b52fe57d189a080cc4d6043f02f7318c | 31 | md | Markdown | CHANGES.md | npm-opam/async_find | 396186a065ba998bcc9d781bb1e61edeb5d02f41 | [
"Apache-2.0"
] | 3 | 2017-03-22T12:48:27.000Z | 2019-12-16T03:02:45.000Z | CHANGES.md | npm-opam/async_find | 396186a065ba998bcc9d781bb1e61edeb5d02f41 | [
"Apache-2.0"
] | 2 | 2016-07-11T17:40:32.000Z | 2017-01-30T10:22:28.000Z | CHANGES.md | npm-opam/async_find | 396186a065ba998bcc9d781bb1e61edeb5d02f41 | [
"Apache-2.0"
] | 2 | 2016-07-15T22:27:07.000Z | 2021-12-17T02:53:16.000Z | ## 113.24.00
Initial release.
| 7.75 | 16 | 0.677419 | eng_Latn | 0.970911 |
11293eb0af92338fb14957ec8863328017ec531e | 190 | md | Markdown | README.md | Geod24/keytools | ed4fbfd1e3b68ad25cc75b2fe3cd6670449f1273 | [
"MIT"
] | null | null | null | README.md | Geod24/keytools | ed4fbfd1e3b68ad25cc75b2fe3cd6670449f1273 | [
"MIT"
] | null | null | null | README.md | Geod24/keytools | ed4fbfd1e3b68ad25cc75b2fe3cd6670449f1273 | [
"MIT"
] | null | null | null | # keytools [](https://travis-ci.com/bpfkorea/keytools)
Tools to interact with Stellar-formatted, Ed25519 key pairs
| 47.5 | 128 | 0.768421 | kor_Hang | 0.34106 |
11297571d37393a515c316ede692f293f0bce3d0 | 158 | md | Markdown | README.md | TheTripleV/sphinx-presentations | 2f2e01fdaa31abe26ba8564138666f26eabc5d01 | [
"BSD-3-Clause"
] | null | null | null | README.md | TheTripleV/sphinx-presentations | 2f2e01fdaa31abe26ba8564138666f26eabc5d01 | [
"BSD-3-Clause"
] | null | null | null | README.md | TheTripleV/sphinx-presentations | 2f2e01fdaa31abe26ba8564138666f26eabc5d01 | [
"BSD-3-Clause"
] | null | null | null | # sphinx-presentations
sphinx-presentations is a Sphinx extension to convert documentation to Reveal.js presentations.
## Building js
```
npx webpack
``` | 14.363636 | 95 | 0.765823 | eng_Latn | 0.850252 |
11298cf86a59b19713640f375d9117d6770ac56d | 33 | md | Markdown | README.md | SEary342/JavaGames | 2d843db58555473018a50a6a7c3ff804ca054035 | [
"MIT"
] | null | null | null | README.md | SEary342/JavaGames | 2d843db58555473018a50a6a7c3ff804ca054035 | [
"MIT"
] | null | null | null | README.md | SEary342/JavaGames | 2d843db58555473018a50a6a7c3ff804ca054035 | [
"MIT"
] | null | null | null | # JavaGames
Old college projects
| 11 | 20 | 0.818182 | eng_Latn | 0.967951 |
112994c26d6cc1184decdd309ae00f0b37bc77c0 | 7,856 | md | Markdown | standard/docs/en/implementation/hosting.md | idlemoor/standard | 92d4ccf6912310b885b1da35eb4def5406825f90 | [
"Apache-2.0"
] | null | null | null | standard/docs/en/implementation/hosting.md | idlemoor/standard | 92d4ccf6912310b885b1da35eb4def5406825f90 | [
"Apache-2.0"
] | null | null | null | standard/docs/en/implementation/hosting.md | idlemoor/standard | 92d4ccf6912310b885b1da35eb4def5406825f90 | [
"Apache-2.0"
] | null | null | null | # Data files, APIs and discovery
Different users have different needs when it comes to accessing OCDS data.
[Data on the Web Best Practice #15](https://www.w3.org/TR/dwbp/#dataFormats) suggests that "Data should be available in multiple data formats" in order to increases the number of different users, tools and applications that can process the data.
Which formats are most important will depend on the priority use cases for each OCDS implementation, but you should consider:
* **Bulk downloads** - packaging together multiple releases or multiple records in one or more files for users to download and import into local tools.
* **Individual release and record downloads** - providing a URI at which each release or record can be obtained. This is crucial for 4 ☆ data publication.
* **CSV and Spreadsheet serializations** - providing multiple releases or compiled records for download, enabling users to work with data directly in spreadsheet software or other tools.
* **API access** - enabling interactive access to your data. OCDS does not currently provide a standard for constructing APIs, but [potential approaches can be discussed with the community here](https://github.com/open-contracting/standard/issues/290).
## Bulk downloads
The release and record data package containers (in JSON and CSV) offer a way to provide **bulk access** to a collection of contracting process release and records.
However, very large files can be difficult for users to download and process. The following section provides suggested good practices which will assist users in accessing data. These are not requirements of the standard, but are based on experiences of maximising the number of users able to work with datasets with their existing hardware and software.
### File size limits
When generating data packages for bulk download, apply the following limits:
* Unzipped OCDS data packages should not exceed 1Gb each;
* Zipped OCDS data packages should not exceed 10 Mb each;
* A single OCDS data package should contain a maximum of 250,000 awards or contracts;
When a file is likely to exceed one of these limits, release or records should be split across multiple files. Dynamically generated bulk downloads do not have to apply these limits, though publishers should consider ways to advise users when a query is likely to generate a very large file.
### Segmenting files
When the suggested limits require publication of multiple files, publishers should consider ways to split data across available files.
For releases, publishers may choose to:
1. Segment by **releaseDate - **placing all the releases from a given day, month or year in the same file;
1. Segment by **contracting process identifier **- placing all the releases related to a given set of contract process identifiers together in the same data package;
For records, publishers should segment either based on the first **releaseDate** associated with a contracting process, or by **contracting process identifier.**
Following these approaches will avoid release and records 'jumping' between files when the bulk files are updated.
### Compression
OCDS data packages may be compressed in order to save on diskspace and bandwidth.
If compressing data packages, publishers *should* use the zip file format.
### Serving files
Publishers should ensure that the web server providing access to bulk files correctly reports the [HTTP Last-Modified](http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.29) header so that consuming applications only need to download updated files.
## Individual releases and records
To achieve [4 ☆](levels.md) ODCS publication requires each release and record to be accessible at a permanent URI. This may be achieved by:
(a) Archiving a single-release release package for each release to a web accessible file system as it is created, and then regularly merging these releases to compile individual record files in the same file system. One approach may be to have a folder for each ```ocid``` and to place the releases and record related to that process into that folder.
(b) Providing access to releases and records through an API.
Note that the second approach will require the API to maintain a full revision history of each contracting process, so that releases from each stage of a contracting process can be provided.
Publishers should consider how to [ensure URIs can remain stable](https://www.w3.org/Provider/Style/URI.html), even across a change of systems.
## Flattened serializations
The [serialization](../../serialization/) page provides details of how to generate 'flat' versions of OCDS data for use in spreadsheet software.
The same principles discussed for bulk files above should be applied to CSV or Excel downloads of data.
## Discovery and APIs
There are many thousands of organisations who should be able to publish Open Contracting data. As a result, maintaining a central registry of all published data is impractical. Instead, OCDS proposes a common pattern for the discovery of Open Contracting data releases and records.
For the discovery of bulk datasets, and the location of any data feeds, we propose use of a data.json file.
For the discovery of individual releases and records, we propose use atom feeds.
There is a [community discussion here](https://github.com/open-contracting/standard/issues/290) on whether OCDS should include a proposed API standard in future iterations.
### Dataset and feed discovery
Publishers should provide a data.json document describing the location of all of the bulk OCDS files available for download.
This should follow the structure proposed by the [US Project Open Data](https://project-open-data.github.io/schema/) with:
* Each record containing a distribution block with at least one accessURL pointing to OCDS data.
* Each record containing 'open-contracting-data', and either 'open-contracting-release' or 'open-contracting-record' in the keyword array.
* accessLevel set appropriately
In addition, the data.json document may contain one or more records with the keyword 'open-contracting-feed' and either 'open-contracting-release' or 'open-contracting-record' and pointing via an accessURL in their distribution block to an atom feed document.
### Feeds
Publishers exposing individual records and releases, of regularly updated data packages in small sets, should provide one or more [atom feeds](http://en.wikipedia.org/wiki/Atom_%28standard%29) that index these, and provide an easy mechanism for users to discover recently published or updated release and records.
The link to the release or record should be provided via a ```<link>``` tag, and the updated date of the entry should reflect the updated date of that release or record. The ```<id>``` should reflect the release id for release, or the ocid for records.
The release.tag should be contained within an ```<category>``` element of the feed.
Feeds requiring pagination should follow the approach set out in [RFC 5005](https://tools.ietf.org/html/rfc5005#section-3).
### Well Known
Future implementations of OCDS will explore use of the <a href="http://tools.ietf.org/html/rfc5785">/.well-known/</a> protocol to declare a location for storing a data.json file.
At present, such files can be hosted anywhere, and consuming applications pointed towards them manually.
The data.json structure has been chosen to allow organisations following this approach to include tagged 'open-contracting-data' within their existing data discovery mechanisms, and given the availability of a plugin for the widely used CKAN which will also support exposure of data.json files.
## Linking data
For 5 ☆ publication of OCDS data, publishers should seek to use URIs in their datasets, linking to other machine-readable data sources at an entity-by-entity level.
| 68.313043 | 353 | 0.792388 | eng_Latn | 0.999045 |
1129f460f2781ecf845cd92c567c1d15549923f1 | 16,965 | md | Markdown | docs/guides/extracting-data.md | augusto-herrmann/frictionless-py | b4ff35f064141a2c04882edb592666ca6b066776 | [
"MIT"
] | null | null | null | docs/guides/extracting-data.md | augusto-herrmann/frictionless-py | b4ff35f064141a2c04882edb592666ca6b066776 | [
"MIT"
] | null | null | null | docs/guides/extracting-data.md | augusto-herrmann/frictionless-py | b4ff35f064141a2c04882edb592666ca6b066776 | [
"MIT"
] | null | null | null | ---
title: Extracting Data
goodread:
prepare:
- cp data/country-3.csv country-3.csv
- cp data/capital-3.csv capital-3.csv
cleanup:
- rm country-3.csv
- rm capital-3.csv
- rm country.package.json
- rm capital.resource.yaml
---
> This guide assumes basic familiarity with the Frictionless Framework. To learn more, please read the [Introduction](https://framework.frictionlessdata.io/docs/guides/introduction) and [Quick Start](https://framework.frictionlessdata.io/docs/guides/quick-start).
Extracting data means reading tabular data from a source. We can use various customizations for this process such as providing a file format, table schema, limiting fields or rows amount, and much more. This guide will discuss the main `extract` functions (`extract`, `extract_resource`, `extract_package`) and will then go into more advanced details about the `Resource Class`, `Package Class`, `Header Class`, and `Row Class`.
Let's see this with some real files:
> Download [`country-3.csv`](https://raw.githubusercontent.com/frictionlessdata/frictionless-py/master/data/country-3.csv) to reproduce the examples (right-click and "Save link as").
```bash goodread title="CLI"
cat country-3.csv
```
```csv title="country-3.csv"
id,capital_id,name,population
1,1,Britain,67
2,3,France,67
3,2,Germany,83
4,5,Italy,60
5,4,Spain,47
```
> Download [`capital-3.csv`](https://raw.githubusercontent.com/frictionlessdata/frictionless-py/master/data/capital-3.csv) to reproduce the examples (right-click and "Save link as").
```bash goodread title="CLI"
cat capital-3.csv
```
```csv title="capital-3.csv"
id,name
1,London
2,Berlin
3,Paris
4,Madrid
5,Rome
```
To start, we will use the command-line interface:
```bash goodread title="CLI"
frictionless extract country-3.csv
```
```
# ----
# data: country-3.csv
# ----
== ========== ======= ==========
id capital_id name population
== ========== ======= ==========
1 1 Britain 67
2 3 France 67
3 2 Germany 83
4 5 Italy 60
5 4 Spain 47
== ========== ======= ==========
```
The same can be done in Python:
```python goodread title="Python"
from pprint import pprint
from frictionless import extract
rows = extract('country-3.csv')
pprint(rows)
```
```
[{'id': 1, 'capital_id': 1, 'name': 'Britain', 'population': 67},
{'id': 2, 'capital_id': 3, 'name': 'France', 'population': 67},
{'id': 3, 'capital_id': 2, 'name': 'Germany', 'population': 83},
{'id': 4, 'capital_id': 5, 'name': 'Italy', 'population': 60},
{'id': 5, 'capital_id': 4, 'name': 'Spain', 'population': 47}]
```
## Extract Functions
The high-level interface for extracting data provided by Frictionless is a set of `extract` functions:
- `extract`: detects the source file type and extracts data accordingly
- `extract_resource`: accepts a resource descriptor and returns a data table
- `extract_package`: accepts a package descriptor and returns a map of the package's tables
As described in more detail in the [Introduction](https://framework.frictionlessdata.io/docs/guides/introduction), a resource is a single file, such as a data file, and a package is a set of files, such as a data file and a schema.
On the command-line, the command would be used as follows:
```bash title="CLI"
frictionless extract your-table.csv
frictionless extract your-resource.json --type resource
frictionless extract your-package.json --type package
```
The `extract` functions always reads data in the form of rows, into memory. The lower-level interfaces will allow you to stream data, which you can read about in the [Resource Class](#resource-class) section below.
## Extracting a Resource
A resource contains only one file. To extract a resource, we have three options. First, we can use the same approach as above, extracting from the data file itself:
```python goodread title="Python"
from frictionless import extract
rows = extract('capital-3.csv')
pprint(rows)
```
```
[{'id': 1, 'name': 'London'},
{'id': 2, 'name': 'Berlin'},
{'id': 3, 'name': 'Paris'},
{'id': 4, 'name': 'Madrid'},
{'id': 5, 'name': 'Rome'}]
```
Our second option is to extract the resource from a descriptor file by using the `extract_resource` function. A descriptor file is useful because it can contain different metadata and be stored on the disc.
As an example of how to use `extract_resource`, let's first create a descriptor file (note: this example uses YAML for the descriptor, but Frictionless also supports JSON):
```python goodread title="Python"
from frictionless import Resource
resource = Resource('capital-3.csv')
resource.infer()
# as an example, in the next line we will append the schema
resource.schema.missing_values.append('3') # will interpret 3 as a missing value
resource.to_yaml('capital.resource.yaml') # use resource.to_json for JSON format
```
You can also use a pre-made descriptor file.
Now, this descriptor file can be used to extract the resource:
```python title="Python"
from frictionless import extract
data = extract('capital.resource.yaml')
```
This can also be done on the command-line:
```bash goodread title="CLI"
frictionless extract capital.resource.yaml
```
```
# ----
# data: capital.resource.yaml
# ----
== ======
id name
== ======
1 London
2 Berlin
Paris
4 Madrid
5 Rome
== ======
```
So what has happened in this example? We set the textual representation of the number "3" to be a missing value. In the output we can see how the `id` number 3 now appears as `None` representing a missing value. This toy example demonstrates how the metadata in a descriptor can be used; other values like "NA" are more common for missing values.
You can read more advanced details about the [Resource Class below](#resource-class).
## Extracting a Package
The third way we can extract information is from a package, which is a set of two or more files, for instance, two data files and a corresponding metadata file.
As a primary example, we provide two data files to the `extract` command which will be enough to detect that it's a dataset. Let's start by using the command-line interface:
```bash goodread title="CLI"
frictionless extract *-3.csv
```
```
# ----
# data: capital-3.csv
# ----
== ======
id name
== ======
1 London
2 Berlin
3 Paris
4 Madrid
5 Rome
== ======
# ----
# data: country-3.csv
# ----
== ========== ======= ==========
id capital_id name population
== ========== ======= ==========
1 1 Britain 67
2 3 France 67
3 2 Germany 83
4 5 Italy 60
5 4 Spain 47
== ========== ======= ==========
```
In Python we can do the same:
```python title="Python"
from frictionless import extract
data = extract('*-3.csv')
for path, rows in data.items():
pprint(path)
pprint(rows)
```
```
'data/country-3.csv'
[Row([('id', 1), ('capital_id', 1), ('name', 'Britain'), ('population', 67)]),
Row([('id', 2), ('capital_id', 3), ('name', 'France'), ('population', 67)]),
Row([('id', 3), ('capital_id', 2), ('name', 'Germany'), ('population', 83)]),
Row([('id', 4), ('capital_id', 5), ('name', 'Italy'), ('population', 60)]),
Row([('id', 5), ('capital_id', 4), ('name', 'Spain'), ('population', 47)])]
'data/capital-3.csv'
[Row([('id', 1), ('name', 'London')]),
Row([('id', 2), ('name', 'Berlin')]),
Row([('id', 3), ('name', 'Paris')]),
Row([('id', 4), ('name', 'Madrid')]),
Row([('id', 5), ('name', 'Rome')])]
```
We can also extract the package from a descriptor file using the `extract_package` function (Note: see the [Package Class section](#package-class) for the creation of the `country.package.yaml` file):
```python title="Python"
from frictionless import package
package = package('country.package.yaml')
pprint(package)
```
You can read more advanced details about the [Package Class below](#package-class).
> The following sections contain further, advanced details about the `Resource Class`, `Package Class`, `Header Class`, and `Row Class`.
## Resource Class
The Resource class provides metadata about a resource with read and stream functions. The `extract` functions always read rows into memory; Resource can do the same but it also gives a choice regarding output data which can be `rows`, `data`, `text`, or `bytes`. Let's try reading all of them.
### Reading Bytes
It's a byte representation of the contents:
```python goodread title="Python"
from frictionless import Resource
resource = Resource('country-3.csv')
pprint(resource.read_bytes())
```
```
(b'id,capital_id,name,population\n1,1,Britain,67\n2,3,France,67\n3,2,Germany,8'
b'3\n4,5,Italy,60\n5,4,Spain,47\n')
```
### Reading Text
It's a textual representation of the contents:
```python goodread title="Python"
from frictionless import Resource
resource = Resource('country-3.csv')
pprint(resource.read_text())
```
```
('id,capital_id,name,population\n'
'1,1,Britain,67\n'
'2,3,France,67\n'
'3,2,Germany,83\n'
'4,5,Italy,60\n'
'5,4,Spain,47\n')
```
### Reading Lists
For a tabular data there are raw representaion of the tabular contents:
```python goodread title="Python"
from frictionless import Resource
resource = Resource('country-3.csv')
pprint(resource.read_lists())
```
```
[['id', 'capital_id', 'name', 'population'],
['1', '1', 'Britain', '67'],
['2', '3', 'France', '67'],
['3', '2', 'Germany', '83'],
['4', '5', 'Italy', '60'],
['5', '4', 'Spain', '47']]
```
### Reading Rows
For a tabular data there are row available which is are normalized lists presented as dictionaries:
```python goodread title="Python"
from frictionless import Resource
resource = Resource('country-3.csv')
pprint(resource.read_rows())
```
```
[{'id': 1, 'capital_id': 1, 'name': 'Britain', 'population': 67},
{'id': 2, 'capital_id': 3, 'name': 'France', 'population': 67},
{'id': 3, 'capital_id': 2, 'name': 'Germany', 'population': 83},
{'id': 4, 'capital_id': 5, 'name': 'Italy', 'population': 60},
{'id': 5, 'capital_id': 4, 'name': 'Spain', 'population': 47}]
```
### Reading a Header
For a tabular data there is the Header object available:
```python goodread title="Python"
from frictionless import Resource
with Resource('country-3.csv') as resource:
pprint(resource.header)
```
```
['id', 'capital_id', 'name', 'population']
```
### Streaming Interfaces
It's really handy to read all your data into memory but it's not always possible if a file is very big. For such cases, Frictionless provides streaming functions:
```python goodread title="Python"
from frictionless import Resource
with Resource('country-3.csv') as resource:
resource.byte_stream
resource.text_stream
resource.list_stream
resource.row_stream
```
## Package Class
The Package class provides functions to read the contents of a package. First of all, let's create a package descriptor:
```bash goodread title="CLI"
frictionless describe *-3.csv --json > country.package.json
```
Note that --json is used here to output the descriptor in JSON format. Without this, the default output is in YAML format as we saw above.
We can create a package from data files (using their paths) and then read the package's resources:
```python goodread title="Python"
from frictionless import Package
package = Package('*-3.csv')
pprint(package.get_resource('country-3').read_rows())
pprint(package.get_resource('capital-3').read_rows())
```
```
[{'id': 1, 'capital_id': 1, 'name': 'Britain', 'population': 67},
{'id': 2, 'capital_id': 3, 'name': 'France', 'population': 67},
{'id': 3, 'capital_id': 2, 'name': 'Germany', 'population': 83},
{'id': 4, 'capital_id': 5, 'name': 'Italy', 'population': 60},
{'id': 5, 'capital_id': 4, 'name': 'Spain', 'population': 47}]
[{'id': 1, 'name': 'London'},
{'id': 2, 'name': 'Berlin'},
{'id': 3, 'name': 'Paris'},
{'id': 4, 'name': 'Madrid'},
{'id': 5, 'name': 'Rome'}]
```
The package by itself doesn't provide any read functions directly because it's just a contrainer. You can select a pacakge's resource and use the Resource API from above for data reading.
## Header Class
After opening a resource you get access to a `resource.header` object which describes the resource in more detail. This is a list of normalized labels but also provides some additional functionality. Let's take a look:
```python goodread title="Python"
from frictionless import Resource
with Resource('capital-3.csv') as resource:
print(f'Header: {resource.header}')
print(f'Labels: {resource.header.labels}')
print(f'Fields: {resource.header.fields}')
print(f'Field Names: {resource.header.field_names}')
print(f'Field Positions: {resource.header.field_positions}')
print(f'Errors: {resource.header.errors}')
print(f'Valid: {resource.header.valid}')
print(f'As List: {resource.header.to_list()}')
```
```
Header: ['id', 'name']
Labels: ['id', 'name']
Fields: [{'name': 'id', 'type': 'integer'}, {'name': 'name', 'type': 'string'}]
Field Names: ['id', 'name']
Field Positions: [1, 2]
Errors: []
Valid: True
As List: ['id', 'name']
```
The example above shows a case when a header is valid. For a header that contains errors in its tabular structure, this information can be very useful, revealing discrepancies, duplicates or missing cell information:
```python goodread title="Python"
from pprint import pprint
from frictionless import Resource
with Resource([['name', 'name'], ['value', 'value']]) as resource:
pprint(resource.header.errors)
```
```
[{'code': 'duplicate-label',
'description': 'Two columns in the header row have the same value. Column '
'names should be unique.',
'fieldName': 'name2',
'fieldNumber': 2,
'fieldPosition': 2,
'label': 'name',
'labels': ['name', 'name'],
'message': 'Label "name" in the header at position "2" is duplicated to a '
'label: at position "1"',
'name': 'Duplicate Label',
'note': 'at position "1"',
'rowPositions': [1],
'tags': ['#table', '#header', '#label']}]
```
Please read the [API Reference](../references/api-reference#header) for more details.
## Row Class
The `extract`, `resource.read_rows()` and other functions return or yield row objects. In Python, this returns a dictionary with the following information. Note: this example uses the [Detector object](/docs/guides/framework/detector-guide), which tweaks how different aspects of metadata are detected.
```python goodread title="Python"
from frictionless import Resource, Detector
detector = Detector(schema_patch={'missingValues': ['1']})
with Resource('data/capital-3.csv', detector=detector) as resource:
for row in resource:
print(f'Row: {row}')
print(f'Cells: {row.cells}')
print(f'Fields: {row.fields}')
print(f'Field Names: {row.field_names}')
print(f'Field Positions: {row.field_positions}')
print(f'Value of field "name": {row["name"]}') # accessed as a dict
print(f'Row Position: {row.row_position}') # physical line number starting from 1
print(f'Row Number: {row.row_number}') # counted row number starting from 1
print(f'Blank Cells: {row.blank_cells}')
print(f'Error Cells: {row.error_cells}')
print(f'Errors: {row.errors}')
print(f'Valid: {row.valid}')
print(f'As Dict: {row.to_dict(json=False)}')
print(f'As List: {row.to_list(json=True)}') # JSON compatible data types
break
```
```
Row: {'id': None, 'name': 'London'}
Cells: ['1', 'London']
Fields: [{'name': 'id', 'type': 'integer'}, {'name': 'name', 'type': 'string'}]
Field Names: ['id', 'name']
Field Positions: [1, 2]
Value of field "name": London
Row Position: 2
Row Number: 1
Blank Cells: {'id': '1'}
Error Cells: {}
Errors: []
Valid: True
As Dict: {'id': None, 'name': 'London'}
As List: [None, 'London']
```
As we can see, this output provides a lot of information which is especially useful when a row is not valid. Our row is valid but we demonstrated how it can preserve data about missing values. It also preserves data about all cells that contain errors:
```python goodread title="Python"
from pprint import pprint
from frictionless import Resource
with Resource([['name'], ['value', 'value']]) as resource:
for row in resource.row_stream:
pprint(row.errors)
```
```
[{'cell': 'value',
'cells': ['value', 'value'],
'code': 'extra-cell',
'description': 'This row has more values compared to the header row (the '
'first row in the data source). A key concept is that all the '
'rows in tabular data must have the same number of columns.',
'fieldName': '',
'fieldNumber': 1,
'fieldPosition': 2,
'message': 'Row at position "2" has an extra value in field at position "2"',
'name': 'Extra Cell',
'note': '',
'rowNumber': 1,
'rowPosition': 2,
'tags': ['#table', '#row', '#cell']}]
```
Please read the [API Reference](../references/api-reference#row) for more details.
| 33.070175 | 428 | 0.671441 | eng_Latn | 0.923276 |
1129f8ed5b4ad03a847d14f79a794ad66e717784 | 53 | md | Markdown | src/Docs/Resources/v2/40-api-guide/20-read/30-filter.md | pm-dennis/platform | df1c9816314d1057ce0c3399193c05813f68abea | [
"MIT"
] | null | null | null | src/Docs/Resources/v2/40-api-guide/20-read/30-filter.md | pm-dennis/platform | df1c9816314d1057ce0c3399193c05813f68abea | [
"MIT"
] | null | null | null | src/Docs/Resources/v2/40-api-guide/20-read/30-filter.md | pm-dennis/platform | df1c9816314d1057ce0c3399193c05813f68abea | [
"MIT"
] | null | null | null | [titleEn]: <>(Filter)
[hash]: <>(article:api_filter)
| 17.666667 | 30 | 0.641509 | eng_Latn | 0.101175 |
112a507414e08e5b1c28c4fdd84043f77759c5ad | 1,122 | md | Markdown | markdown/java/spring读取配置文件.md | ShowMeBaby/retrocode.io | b9de975da3bd27ab4b25918d7939ca733b1f6d93 | [
"MIT"
] | null | null | null | markdown/java/spring读取配置文件.md | ShowMeBaby/retrocode.io | b9de975da3bd27ab4b25918d7939ca733b1f6d93 | [
"MIT"
] | null | null | null | markdown/java/spring读取配置文件.md | ShowMeBaby/retrocode.io | b9de975da3bd27ab4b25918d7939ca733b1f6d93 | [
"MIT"
] | null | null | null | 最后更新时间: 2021年7月16日 17:26:26
# SPRING
### 1. 加载配置文件
参考 <http://www.importnew.com/17673.html>
参考 <http://blog.csdn.net/zl3450341/article/details/9306983>
#### 1.1. 容器加载
容器上下文配置
```xml
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>
```
#### 1.2. 路由规则
>加载路径中的通配符:?(匹配单个字符),\*(匹配除/外任意字符或字符串)、\*\* (匹配任意多个目录)。
**说明:** 无论是 classpath 还是 classpath\*都可以加载整个 classpath 下(包括 jar 包里面)的资源文件。
classpath 只会返回第一个匹配的资源,查找路径是优先在项目中存在资源文件,再查找 jar 包。classpath*是加载所有匹配的资源。
#### 1.3. import 标签
使用 Spring import 标签整合多个配置文件,路由规则和 web 容器加载是一样的。建议使用!
```xml
<!-- 加载相对路径配置文件 -->
<import resource="a.xml"/>
<!--遍历所有的jar包加载所有同名文件 -->
<import resource="classpath*:dubbo-shine-provider.xml"/>
```
#### 1.4. 手动加载
在classPath里(包括jar包),寻找配置文件并加载。通常如果是同一个上下文对象则会把配置文件合并处理。
```java
ApplicationContext context = new ClassPathXmlApplicationContext(new String[] {"a.xml", "b.xml"});
```
| 23.87234 | 98 | 0.688948 | yue_Hant | 0.697933 |
112b01568d508f9cde5ad6b2b48bd1c259e31344 | 198 | md | Markdown | documents/en-US/SUMMARY.md | jingyiliu/NanUI | 06b507509b6ea3a0231498bb5eacc64b10e73280 | [
"MIT"
] | null | null | null | documents/en-US/SUMMARY.md | jingyiliu/NanUI | 06b507509b6ea3a0231498bb5eacc64b10e73280 | [
"MIT"
] | null | null | null | documents/en-US/SUMMARY.md | jingyiliu/NanUI | 06b507509b6ea3a0231498bb5eacc64b10e73280 | [
"MIT"
] | 1 | 2020-08-18T16:55:56.000Z | 2020-08-18T16:55:56.000Z | # Summary
## GETTING START
## ChromiumFX
## Handlers of CefClient
LiftSpanHandler
LoadHandler
DisplayHandler
ContextMenuHandler
DownloadHandler
JSDialogHandler
DragHandler
RequestHandler | 8.608696 | 24 | 0.813131 | kor_Hang | 0.511516 |
112b2bc1b5be802cab5669381f979e57c69c55ce | 1,959 | md | Markdown | docs/vs-2015/debugger/debug-interface-access/stackframetypeenum.md | aleffe61/visualstudio-docs.it-it | c499d4c129dfdd7d5853a8f539753058fc9ae5c3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/vs-2015/debugger/debug-interface-access/stackframetypeenum.md | aleffe61/visualstudio-docs.it-it | c499d4c129dfdd7d5853a8f539753058fc9ae5c3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/vs-2015/debugger/debug-interface-access/stackframetypeenum.md | aleffe61/visualstudio-docs.it-it | c499d4c129dfdd7d5853a8f539753058fc9ae5c3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: StackFrameTypeEnum | Microsoft Docs
ms.custom: ''
ms.date: 11/15/2016
ms.prod: visual-studio-dev14
ms.reviewer: ''
ms.suite: ''
ms.technology:
- vs-ide-debug
ms.tgt_pltfrm: ''
ms.topic: article
dev_langs:
- C++
helpviewer_keywords:
- StackFrameTypeEnum enumeration
ms.assetid: 61e40163-eee0-4c1f-af47-cef3771bdc41
caps.latest.revision: 10
author: MikeJo5000
ms.author: mikejo
manager: ghogen
ms.openlocfilehash: de80fd054459556e273427b666175751ced203fe
ms.sourcegitcommit: af428c7ccd007e668ec0dd8697c88fc5d8bca1e2
ms.translationtype: MT
ms.contentlocale: it-IT
ms.lasthandoff: 11/16/2018
ms.locfileid: "51740374"
---
# <a name="stackframetypeenum"></a>StackFrameTypeEnum
[!INCLUDE[vs2017banner](../../includes/vs2017banner.md)]
Specifica il tipo di frame dello stack.
## <a name="syntax"></a>Sintassi
```cpp
enum StackFrameTypeEnum {
FrameTypeFPO,
FrameTypeTrap,
FrameTypeTSS,
FrameTypeStandard,
FrameTypeFrameData,
FrameTypeUnknown = -1
};
```
## <a name="elements"></a>Elementi
`FrameTypeFPO`
Puntatore ai frame omessi. Info FPO disponibile.
`FrameTypeTrap`
Frame Trap kernel.
`FrameTypeTSS`
Frame Trap kernel.
`FrameTypeStandard`
Frame dello stack EBP standard.
`FrameTypeFrameData`
Puntatore ai frame omessi. Informazioni sui dati di intervallo disponibile.
`FrameTypeUnknown`
Frame che non ha le informazioni di debug.
## <a name="remarks"></a>Note
I valori di questa enumerazione vengono restituiti da una chiamata per il [Idiastackframe](../../debugger/debug-interface-access/idiastackframe-get-type.md) (metodo).
## <a name="requirements"></a>Requisiti
Intestazione: cvconst.h
## <a name="see-also"></a>Vedere anche
[Enumerazioni e strutture](../../debugger/debug-interface-access/enumerations-and-structures.md)
[IDiaStackFrame::get_type](../../debugger/debug-interface-access/idiastackframe-get-type.md)
| 25.441558 | 169 | 0.726901 | ita_Latn | 0.230657 |
112b4792de3e5c7c073f845b5a55d514c2f7f82e | 1,007 | md | Markdown | README.md | weihua-git/vueblog | 789bfc798a3bde56f57e6d070284eccfdea420af | [
"Apache-2.0"
] | null | null | null | README.md | weihua-git/vueblog | 789bfc798a3bde56f57e6d070284eccfdea420af | [
"Apache-2.0"
] | null | null | null | README.md | weihua-git/vueblog | 789bfc798a3bde56f57e6d070284eccfdea420af | [
"Apache-2.0"
] | null | null | null | > **项目:vueblog**
>
> **公众号:MarkerHub**
### 介绍
一个基于SpringBoot + Vue开发的前后端分离博客项目,带有超级详细开发文档和讲解视频。还未接触过vue开发,或者前后端分离的同学,学起来哈。别忘了给vueblog一个star!感谢
### 技术栈:
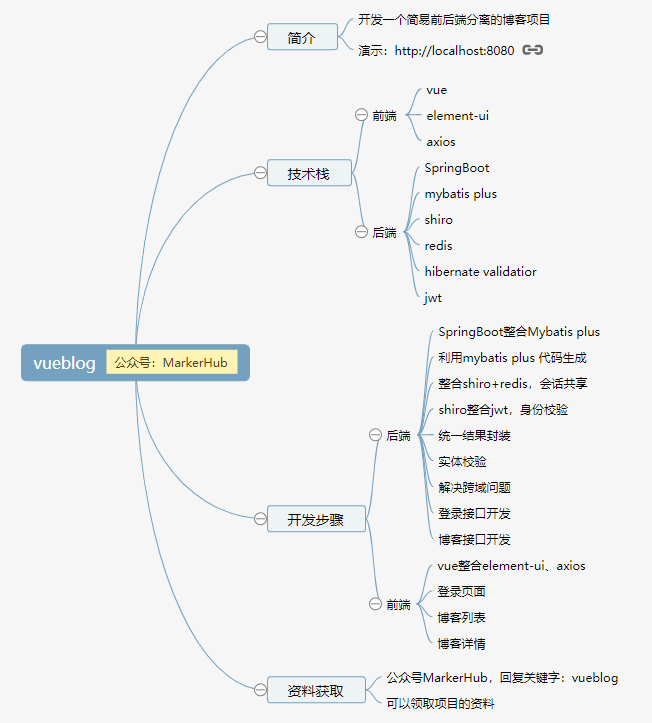
### 项目效果:
### 项目文档:
开发文档:https://juejin.im/post/5ecfca676fb9a04793456fb8
vue入门视频:https://www.bilibili.com/video/BV125411W73W/
**vueblog讲解视频:** https://www.bilibili.com/video/BV1PQ4y1P7hZ/
关注我的B站,后续陆续还有
* 前后端分离类百度搜索引擎项目
* 即时聊天等项目
等项目分享出来哈!
**更多项目请关注公众号:MarkerHub**

| 20.55102 | 236 | 0.805362 | yue_Hant | 0.559966 |
112b779bcf1b0c242832a323f29a1f80b6e8ce4a | 1,103 | md | Markdown | README.md | youyuh48/pitanano-galaxy | 8f820e409e179a087720611c4e10cff3a5aef9de | [
"MIT"
] | 2 | 2019-09-11T11:54:34.000Z | 2019-10-27T07:39:03.000Z | README.md | youyuh48/pitanano-galaxy | 8f820e409e179a087720611c4e10cff3a5aef9de | [
"MIT"
] | null | null | null | README.md | youyuh48/pitanano-galaxy | 8f820e409e179a087720611c4e10cff3a5aef9de | [
"MIT"
] | null | null | null | # pitanano-galaxy: Nanoporeデータ解析用のGalaxy
## 概要
コンテナ型環境のDocker版Galaxy環境にNanoporeデータ解析用のツールを組み込んだGalaxyを構築しました。Docker版Galaxyの[docker-galaxy-stable](https://github.com/bgruening/docker-galaxy-stable)をベースに、IlluminaとMinION用の各種ツールをGUIで使用できるようにGalaxyに組み込んでいます。
使用可能なツールは以下です。
- リードのQC
- FastQC
- Trimmomatic
- NanoPlot
- NanoFilt
- Porechop
- FASTQファイルの操作
- seqtk
- メタゲノム解析
- Centrifuge
- Krona
- マッピング&SV検出
- minimap2
- Sniffles
- De novoアセンブル
- Canu
- Unicycler
- Flye
- wtdbg2 (Redbean)
- Pilon
- Medaka
上記の他にもGalaxy ToolShedに登録されている様々なNGS解析ツールがGalaxy環境に追加インストール可能です。
## 準備
[Docker](https://www.docker.com)をインストールしていない場合は最初にインストールします。
コンテナ内へのファイル書き込みをホスト側のMacに保存するために、Data volumeコンテナを最初に作成する。
```
$ docker create -v /export --name galaxy-store \
youyuh48/pitanano-galaxy:0.2 /bin/true
```
## 動かす
```
$ docker run -d -p 8080:80 \
--volumes-from galaxy-store \
youyuh48/pitanano-galaxy:0.2
```
ブラウザから `http://localhost:8080` を開くとGalaxyにアクセスできる。
他のマシンからアクセスするには `http://ホストのIPアドレス:8080`
## コンテナの停止
`$ docker stop <CONTAINER ID>`
停止したコンテナは`docker start`で再開します。
| 18.383333 | 206 | 0.75068 | yue_Hant | 0.871102 |
112c1e8012216a2e996a27584236bf89e896dce7 | 26,280 | md | Markdown | articles/iot-hub/iot-hub-devguide-query-language.md | Karishma-Tiwari-MSFT/azure-docs | 2e64918a2226586beac7f247800f248a440c10ff | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-09-24T22:47:43.000Z | 2020-09-24T22:47:43.000Z | articles/iot-hub/iot-hub-devguide-query-language.md | Karishma-Tiwari-MSFT/azure-docs | 2e64918a2226586beac7f247800f248a440c10ff | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/iot-hub/iot-hub-devguide-query-language.md | Karishma-Tiwari-MSFT/azure-docs | 2e64918a2226586beac7f247800f248a440c10ff | [
"CC-BY-4.0",
"MIT"
] | 1 | 2022-01-09T20:17:01.000Z | 2022-01-09T20:17:01.000Z | ---
title: Understand the Azure IoT Hub query language | Microsoft Docs
description: Developer guide - description of the SQL-like IoT Hub query language used to retrieve information about device/module twins and jobs from your IoT hub.
author: fsautomata
manager:
ms.service: iot-hub
services: iot-hub
ms.topic: conceptual
ms.date: 02/26/2018
ms.author: elioda
---
# IoT Hub query language for device and module twins, jobs, and message routing
IoT Hub provides a powerful SQL-like language to retrieve information regarding [device twins][lnk-twins] and [jobs][lnk-jobs], and [message routing][lnk-devguide-messaging-routes]. This article presents:
* An introduction to the major features of the IoT Hub query language, and
* The detailed description of the language.
[!INCLUDE [iot-hub-basic](../../includes/iot-hub-basic-partial.md)]
## Device and module twin queries
[Device twins][lnk-twins] and module twins can contain arbitrary JSON objects as both tags and properties. IoT Hub enables you to query device twins and module twins as a single JSON document containing all twin information.
Assume, for instance, that your IoT hub device twins have the following structure (module twin would be similar just with an additional moduleId):
```json
{
"deviceId": "myDeviceId",
"etag": "AAAAAAAAAAc=",
"status": "enabled",
"statusUpdateTime": "0001-01-01T00:00:00",
"connectionState": "Disconnected",
"lastActivityTime": "0001-01-01T00:00:00",
"cloudToDeviceMessageCount": 0,
"authenticationType": "sas",
"x509Thumbprint": {
"primaryThumbprint": null,
"secondaryThumbprint": null
},
"version": 2,
"tags": {
"location": {
"region": "US",
"plant": "Redmond43"
}
},
"properties": {
"desired": {
"telemetryConfig": {
"configId": "db00ebf5-eeeb-42be-86a1-458cccb69e57",
"sendFrequencyInSecs": 300
},
"$metadata": {
...
},
"$version": 4
},
"reported": {
"connectivity": {
"type": "cellular"
},
"telemetryConfig": {
"configId": "db00ebf5-eeeb-42be-86a1-458cccb69e57",
"sendFrequencyInSecs": 300,
"status": "Success"
},
"$metadata": {
...
},
"$version": 7
}
}
}
```
### Device twin queries
IoT Hub exposes the device twins as a document collection called **devices**.
So the following query retrieves the whole set of device twins:
```sql
SELECT * FROM devices
```
> [!NOTE]
> [Azure IoT SDKs][lnk-hub-sdks] support paging of large results.
IoT Hub allows you to retrieve device twins filtering with arbitrary conditions. For instance, to receive device twins where the **location.region** tag is set to **US** use the following query:
```sql
SELECT * FROM devices
WHERE tags.location.region = 'US'
```
Boolean operators and arithmetic comparisons are supported as well. For example, to retrieve device twins located in the US and configured to send telemetry less than every minute use the following query:
```sql
SELECT * FROM devices
WHERE tags.location.region = 'US'
AND properties.reported.telemetryConfig.sendFrequencyInSecs >= 60
```
As a convenience, it is also possible to use array constants with the **IN** and **NIN** (not in) operators. For instance, to retrieve device twins that report WiFi or wired connectivity use the following query:
```sql
SELECT * FROM devices
WHERE properties.reported.connectivity IN ['wired', 'wifi']
```
It is often necessary to identify all device twins that contain a specific property. IoT Hub supports the function `is_defined()` for this purpose. For instance, to retrieve device twins that define the `connectivity` property use the following query:
```SQL
SELECT * FROM devices
WHERE is_defined(properties.reported.connectivity)
```
Refer to the [WHERE clause][lnk-query-where] section for the full reference of the filtering capabilities.
Grouping and aggregations are also supported. For instance, to find the count of devices in each telemetry configuration status use the following query:
```sql
SELECT properties.reported.telemetryConfig.status AS status,
COUNT() AS numberOfDevices
FROM devices
GROUP BY properties.reported.telemetryConfig.status
```
This grouping query would return a result similar to the following example:
```json
[
{
"numberOfDevices": 3,
"status": "Success"
},
{
"numberOfDevices": 2,
"status": "Pending"
},
{
"numberOfDevices": 1,
"status": "Error"
}
]
```
In this example, three devices reported successful configuration, two are still applying the configuration, and one reported an error.
Projection queries allow developers to return only the properties they care about. For example, to retrieve the last activity time of all disconnected devices use the following query:
```sql
SELECT LastActivityTime FROM devices WHERE status = 'enabled'
```
### Module twin queries
Querying on module twins is similar to query on device twins, but using a different collection/namespace, i.e. instead of “from devices” you can query
```sql
SELECT * FROM devices.modules
```
We don't allow join between the devices and devices.modules collections. If you want to query module twins across devices, you do do it based on tags. This query will return all module twins across all devices with the scanning status:
```sql
Select * from devices.modules where reported.properties.status = 'scanning'
```
This query will return all module twins with the scanning status, but only on the specified subset of devices.
```sql
Select * from devices.modules where reported.properties.status = 'scanning' and deviceId IN ('device1', 'device2')
```
### C# example
The query functionality is exposed by the [C# service SDK][lnk-hub-sdks] in the **RegistryManager** class.
Here is an example of a simple query:
```csharp
var query = registryManager.CreateQuery("SELECT * FROM devices", 100);
while (query.HasMoreResults)
{
var page = await query.GetNextAsTwinAsync();
foreach (var twin in page)
{
// do work on twin object
}
}
```
The **query** object is instantiated with a page size (up to 100). Then multiple pages are retrieved by calling the **GetNextAsTwinAsync** methods multiple times.
The query object exposes multiple **Next** values, depending on the deserialization option required by the query. For example, device twin or job objects, or plain JSON when using projections.
### Node.js example
The query functionality is exposed by the [Azure IoT service SDK for Node.js][lnk-hub-sdks] in the **Registry** object.
Here is an example of a simple query:
```nodejs
var query = registry.createQuery('SELECT * FROM devices', 100);
var onResults = function(err, results) {
if (err) {
console.error('Failed to fetch the results: ' + err.message);
} else {
// Do something with the results
results.forEach(function(twin) {
console.log(twin.deviceId);
});
if (query.hasMoreResults) {
query.nextAsTwin(onResults);
}
}
};
query.nextAsTwin(onResults);
```
The **query** object is instantiated with a page size (up to 100). Then multiple pages are retrieved by calling the **nextAsTwin** method multiple times.
The query object exposes multiple **Next** values, depending on the deserialization option required by the query. For example, device twin or job objects, or plain JSON when using projections.
### Limitations
> [!IMPORTANT]
> Query results can have a few minutes of delay with respect to the latest values in device twins. If querying individual device twins by ID, use the retrieve device twin API. This API always contains the latest values and has higher throttling limits.
Currently, comparisons are supported only between primitive types (no objects), for instance `... WHERE properties.desired.config = properties.reported.config` is supported only if those properties have primitive values.
## Get started with jobs queries
[Jobs][lnk-jobs] provide a way to execute operations on sets of devices. Each device twin contains the information of the jobs of which it is part in a collection called **jobs**.
Logically,
```json
{
"deviceId": "myDeviceId",
"etag": "AAAAAAAAAAc=",
"tags": {
...
},
"properties": {
...
},
"jobs": [
{
"deviceId": "myDeviceId",
"jobId": "myJobId",
"jobType": "scheduleTwinUpdate",
"status": "completed",
"startTimeUtc": "2016-09-29T18:18:52.7418462",
"endTimeUtc": "2016-09-29T18:20:52.7418462",
"createdDateTimeUtc": "2016-09-29T18:18:56.7787107Z",
"lastUpdatedDateTimeUtc": "2016-09-29T18:18:56.8894408Z",
"outcome": {
"deviceMethodResponse": null
}
},
...
]
}
```
Currently, this collection is queryable as **devices.jobs** in the IoT Hub query language.
> [!IMPORTANT]
> Currently, the jobs property is never returned when querying device twins. That is, queries that contain 'FROM devices'. The jobs property can only be accessed directly with queries using `FROM devices.jobs`.
>
>
For instance, to get all jobs (past and scheduled) that affect a single device, you can use the following query:
```sql
SELECT * FROM devices.jobs
WHERE devices.jobs.deviceId = 'myDeviceId'
```
Note how this query provides the device-specific status (and possibly the direct method response) of each job returned.
It is also possible to filter with arbitrary Boolean conditions on all object properties in the **devices.jobs** collection.
For instance, to retrieve all completed device twin update jobs that were created after September 2016 for a specific device, use the following query:
```sql
SELECT * FROM devices.jobs
WHERE devices.jobs.deviceId = 'myDeviceId'
AND devices.jobs.jobType = 'scheduleTwinUpdate'
AND devices.jobs.status = 'completed'
AND devices.jobs.createdTimeUtc > '2016-09-01'
```
You can also retrieve the per-device outcomes of a single job.
```sql
SELECT * FROM devices.jobs
WHERE devices.jobs.jobId = 'myJobId'
```
### Limitations
Currently, queries on **devices.jobs** do not support:
* Projections, therefore only `SELECT *` is possible.
* Conditions that refer to the device twin in addition to job properties (see the preceding section).
* Performing aggregations, such as count, avg, group by.
## Device-to-cloud message routes query expressions
Using [device-to-cloud routes][lnk-devguide-messaging-routes], you can configure IoT Hub to dispatch device-to-cloud messages to different endpoints. Dispatching is based on expressions evaluated against individual messages.
The route [condition][lnk-query-expressions] uses the same IoT Hub query language as conditions in twin and job queries. Route conditions are evaluated on the message headers and body. Your routing query expression may involve only message headers, only the message body, or both. IoT Hub assumes a specific schema for the headers and message body in order to route messages. The following sections describe what is required for IoT Hub to properly route.
### Routing on message headers
IoT Hub assumes the following JSON representation of message headers for message routing:
```json
{
"message": {
"systemProperties": {
"contentType": "application/json",
"contentEncoding": "utf-8",
"iothub-message-source": "deviceMessages",
"iothub-enqueuedtime": "2017-05-08T18:55:31.8514657Z"
},
"appProperties": {
"processingPath": "<optional>",
"verbose": "<optional>",
"severity": "<optional>",
"testDevice": "<optional>"
},
"body": "{\"Weather\":{\"Temperature\":50}}"
}
}
```
Message system properties are prefixed with the `'$'` symbol.
User properties are always accessed with their name. If a user property name coincides with a system property (such as `$contentType`), the user property is retrieved with the `$contentType` expression.
You can always access the system property using brackets `{}`: for instance, you can use the expression `{$contentType}` to access the system property `contentType`. Bracketed property names always retrieve the corresponding system property.
Remember that property names are case insensitive.
> [!NOTE]
> All message properties are strings. System properties, as described in the [developer guide][lnk-devguide-messaging-format], are currently not available to use in queries.
>
For example, if you use a `messageType` property, you might want to route all telemetry to one endpoint, and all alerts to another endpoint. You can write the following expression to route the telemetry:
```sql
messageType = 'telemetry'
```
And the following expression to route the alert messages:
```sql
messageType = 'alert'
```
Boolean expressions and functions are also supported. This feature enables you to distinguish between severity level, for example:
```sql
messageType = 'alerts' AND as_number(severity) <= 2
```
Refer to the [Expression and conditions][lnk-query-expressions] section for the full list of supported operators and functions.
### Routing on message bodies
IoT Hub can only route based on message body contents if the message body is properly formed JSON encoded in UTF-8, UTF-16, or UTF-32. Set the content type of the message to `application/json`. Set the content encoding to one of the supported UTF encodings in the message headers. If either of the headers is not specified, IoT Hub does not attempt to evaluate any query expression involving the body against the message. If your message is not a JSON message, or if the message does not specify the content type and content encoding, you can still use message routing to route the message based on the message headers.
The following example shows how to create a message with a properly formed and encoded JSON body:
```csharp
string messageBody = @"{
""Weather"":{
""Temperature"":50,
""Time"":""2017-03-09T00:00:00.000Z"",
""PrevTemperatures"":[
20,
30,
40
],
""IsEnabled"":true,
""Location"":{
""Street"":""One Microsoft Way"",
""City"":""Redmond"",
""State"":""WA""
},
""HistoricalData"":[
{
""Month"":""Feb"",
""Temperature"":40
},
{
""Month"":""Jan"",
""Temperature"":30
}
]
}
}";
// Encode message body using UTF-8
byte[] messageBytes = Encoding.UTF8.GetBytes(messageBody);
using (var message = new Message(messageBytes))
{
// Set message body type and content encoding.
message.ContentEncoding = "utf-8";
message.ContentType = "application/json";
// Add other custom application properties.
message.Properties["Status"] = "Active";
await deviceClient.SendEventAsync(message);
}
```
You can use `$body` in the query expression to route the message. You can use a simple body reference, body array reference, or multiple body references in the query expression. Your query expression can also combine a body reference with a message header reference. For example, the following are all valid query expressions:
```sql
$body.Weather.HistoricalData[0].Month = 'Feb'
$body.Weather.Temperature = 50 AND $body.Weather.IsEnabled
length($body.Weather.Location.State) = 2
$body.Weather.Temperature = 50 AND Status = 'Active'
```
## Basics of an IoT Hub query
Every IoT Hub query consists of SELECT and FROM clauses, with optional WHERE and GROUP BY clauses. Every query is run on a collection of JSON documents, for example device twins. The FROM clause indicates the document collection to be iterated on (**devices** or **devices.jobs**). Then, the filter in the WHERE clause is applied. With aggregations, the results of this step are grouped as specified in the GROUP BY clause. For each group, a row is generated as specified in the SELECT clause.
```sql
SELECT <select_list>
FROM <from_specification>
[WHERE <filter_condition>]
[GROUP BY <group_specification>]
```
## FROM clause
The **FROM <from_specification>** clause can assume only two values: **FROM devices** to query device twins, or **FROM devices.jobs** to query job per-device details.
## WHERE clause
The **WHERE <filter_condition>** clause is optional. It specifies one or more conditions that the JSON documents in the FROM collection must satisfy to be included as part of the result. Any JSON document must evaluate the specified conditions to "true" to be included in the result.
The allowed conditions are described in section [Expressions and conditions][lnk-query-expressions].
## SELECT clause
The **SELECT <select_list>** is mandatory and specifies what values are retrieved from the query. It specifies the JSON values to be used to generate new JSON objects.
For each element of the filtered (and optionally grouped) subset of the FROM collection, the projection phase generates a new JSON object. This object is constructed with the values specified in the SELECT clause.
Following is the grammar of the SELECT clause:
```
SELECT [TOP <max number>] <projection list>
<projection_list> ::=
'*'
| <projection_element> AS alias [, <projection_element> AS alias]+
<projection_element> :==
attribute_name
| <projection_element> '.' attribute_name
| <aggregate>
<aggregate> :==
count()
| avg(<projection_element>)
| sum(<projection_element>)
| min(<projection_element>)
| max(<projection_element>)
```
**Attribute_name** refers to any property of the JSON document in the FROM collection. Some examples of SELECT clauses can be found in the [Getting started with device twin queries][lnk-query-getstarted] section.
Currently, selection clauses different than **SELECT*** are only supported in aggregate queries on device twins.
## GROUP BY clause
The **GROUP BY <group_specification>** clause is an optional step that executes after the filter specified in the WHERE clause, and before the projection specified in the SELECT. It groups documents based on the value of an attribute. These groups are used to generate aggregated values as specified in the SELECT clause.
An example of a query using GROUP BY is:
```sql
SELECT properties.reported.telemetryConfig.status AS status,
COUNT() AS numberOfDevices
FROM devices
GROUP BY properties.reported.telemetryConfig.status
```
The formal syntax for GROUP BY is:
```
GROUP BY <group_by_element>
<group_by_element> :==
attribute_name
| < group_by_element > '.' attribute_name
```
**Attribute_name** refers to any property of the JSON document in the FROM collection.
Currently, the GROUP BY clause is only supported when querying device twins.
## Expressions and conditions
At a high level, an *expression*:
* Evaluates to an instance of a JSON type (such as Boolean, number, string, array, or object).
* Is defined by manipulating data coming from the device JSON document and constants using built-in operators and functions.
*Conditions* are expressions that evaluate to a Boolean. Any constant different than Boolean **true** is considered as **false**. This rule includes **null**, **undefined**, any object or array instance, any string, and the Boolean **false**.
The syntax for expressions is:
```
<expression> ::=
<constant> |
attribute_name |
<function_call> |
<expression> binary_operator <expression> |
<create_array_expression> |
'(' <expression> ')'
<function_call> ::=
<function_name> '(' expression ')'
<constant> ::=
<undefined_constant>
| <null_constant>
| <number_constant>
| <string_constant>
| <array_constant>
<undefined_constant> ::= undefined
<null_constant> ::= null
<number_constant> ::= decimal_literal | hexadecimal_literal
<string_constant> ::= string_literal
<array_constant> ::= '[' <constant> [, <constant>]+ ']'
```
To understand what each symbol in the expressions syntax stands for, refer to the following table:
| Symbol | Definition |
| --- | --- |
| attribute_name | Any property of the JSON document in the **FROM** collection. |
| binary_operator | Any binary operator listed in the [Operators](#operators) section. |
| function_name| Any function listed in the [Functions](#functions) section. |
| decimal_literal |A float expressed in decimal notation. |
| hexadecimal_literal |A number expressed by the string ‘0x’ followed by a string of hexadecimal digits. |
| string_literal |String literals are Unicode strings represented by a sequence of zero or more Unicode characters or escape sequences. String literals are enclosed in single quotes or double quotes. Allowed escapes: `\'`, `\"`, `\\`, `\uXXXX` for Unicode characters defined by 4 hexadecimal digits. |
### Operators
The following operators are supported:
| Family | Operators |
| --- | --- |
| Arithmetic |+, -, *, /, % |
| Logical |AND, OR, NOT |
| Comparison |=, !=, <, >, <=, >=, <> |
### Functions
When querying twins and jobs the only supported function is:
| Function | Description |
| -------- | ----------- |
| IS_DEFINED(property) | Returns a Boolean indicating if the property has been assigned a value (including `null`). |
In routes conditions, the following math functions are supported:
| Function | Description |
| -------- | ----------- |
| ABS(x) | Returns the absolute (positive) value of the specified numeric expression. |
| EXP(x) | Returns the exponential value of the specified numeric expression (e^x). |
| POWER(x,y) | Returns the value of the specified expression to the specified power (x^y).|
| SQUARE(x) | Returns the square of the specified numeric value. |
| CEILING(x) | Returns the smallest integer value greater than, or equal to, the specified numeric expression. |
| FLOOR(x) | Returns the largest integer less than or equal to the specified numeric expression. |
| SIGN(x) | Returns the positive (+1), zero (0), or negative (-1) sign of the specified numeric expression.|
| SQRT(x) | Returns the square root of the specified numeric value. |
In routes conditions, the following type checking and casting functions are supported:
| Function | Description |
| -------- | ----------- |
| AS_NUMBER | Converts the input string to a number. `noop` if input is a number; `Undefined` if string does not represent a number.|
| IS_ARRAY | Returns a Boolean value indicating if the type of the specified expression is an array. |
| IS_BOOL | Returns a Boolean value indicating if the type of the specified expression is a Boolean. |
| IS_DEFINED | Returns a Boolean indicating if the property has been assigned a value. |
| IS_NULL | Returns a Boolean value indicating if the type of the specified expression is null. |
| IS_NUMBER | Returns a Boolean value indicating if the type of the specified expression is a number. |
| IS_OBJECT | Returns a Boolean value indicating if the type of the specified expression is a JSON object. |
| IS_PRIMITIVE | Returns a Boolean value indicating if the type of the specified expression is a primitive (string, Boolean, numeric, or `null`). |
| IS_STRING | Returns a Boolean value indicating if the type of the specified expression is a string. |
In routes conditions, the following string functions are supported:
| Function | Description |
| -------- | ----------- |
| CONCAT(x, y, …) | Returns a string that is the result of concatenating two or more string values. |
| LENGTH(x) | Returns the number of characters of the specified string expression.|
| LOWER(x) | Returns a string expression after converting uppercase character data to lowercase. |
| UPPER(x) | Returns a string expression after converting lowercase character data to uppercase. |
| SUBSTRING(string, start [, length]) | Returns part of a string expression starting at the specified character zero-based position and continues to the specified length, or to the end of the string. |
| INDEX_OF(string, fragment) | Returns the starting position of the first occurrence of the second string expression within the first specified string expression, or -1 if the string is not found.|
| STARTS_WITH(x, y) | Returns a Boolean indicating whether the first string expression starts with the second. |
| ENDS_WITH(x, y) | Returns a Boolean indicating whether the first string expression ends with the second. |
| CONTAINS(x,y) | Returns a Boolean indicating whether the first string expression contains the second. |
## Next steps
Learn how to execute queries in your apps using [Azure IoT SDKs][lnk-hub-sdks].
[lnk-query-where]: iot-hub-devguide-query-language.md#where-clause
[lnk-query-expressions]: iot-hub-devguide-query-language.md#expressions-and-conditions
[lnk-query-getstarted]: iot-hub-devguide-query-language.md#get-started-with-device-twin-queries
[lnk-twins]: iot-hub-devguide-device-twins.md
[lnk-jobs]: iot-hub-devguide-jobs.md
[lnk-devguide-endpoints]: iot-hub-devguide-endpoints.md
[lnk-devguide-quotas]: iot-hub-devguide-quotas-throttling.md
[lnk-devguide-mqtt]: iot-hub-mqtt-support.md
[lnk-devguide-messaging-routes]: iot-hub-devguide-messages-read-custom.md
[lnk-devguide-messaging-format]: iot-hub-devguide-messages-construct.md
[lnk-devguide-messaging-routes]: ./iot-hub-devguide-messages-read-custom.md
[lnk-hub-sdks]: iot-hub-devguide-sdks.md
| 42.593193 | 619 | 0.697451 | eng_Latn | 0.985839 |
112e492f17a8f70b0bf432deed0b6e458ee77916 | 1,905 | md | Markdown | README.md | slynrick/P2P | 6e476f3f1a9ee776bba335f7ab06100d07469e36 | [
"MIT"
] | null | null | null | README.md | slynrick/P2P | 6e476f3f1a9ee776bba335f7ab06100d07469e36 | [
"MIT"
] | null | null | null | README.md | slynrick/P2P | 6e476f3f1a9ee776bba335f7ab06100d07469e36 | [
"MIT"
] | null | null | null | # P2P: Freechains Docker
O Freechains é um protocolo peer-to-peer(P2P) pubsub não permissionado de disseminação de conteúdo e todo seu protocolo, bem como sua utilização pode ser encontrado na sua página do [GitHub](https://github.com/Freechains/README)
Docker pode ser descrito através da tradução de um texto encontrado no site oficial:
> Docker é uma plataforma aberta para desenvolvimento, envio e execução de aplicativos. O Docker permite que você separe seus aplicativos de sua infraestrutura para que possa entregar o software rapidamente. Com o Docker, você pode gerenciar sua infraestrutura da mesma forma que gerencia seus aplicativos. Tirando proveito das metodologias do Docker para envio, teste e implantação de código rapidamente, você pode reduzir significativamente o atraso entre escrever o código e executá-lo na produção.
>
> -- <cite>[Docker](https://docs.docker.com/get-started/overview/)</cite>
Pode ser encontrada a lista de comandos para trabalhar no docker [aqui](https://docs.docker.com/engine/reference/run/)
Para facilitar os testes e o desenvolvimento da aplicação, foi criada uma imagem docker do freechains para rodar aplicações e testes e as informações para o build e utilização desta imagem pode ser encontada [aqui](freechains/README.md)
# P2P: Spotted
Como parte prática da matéria, deveríamos desenvolver uma aplicação P2P usando o sistema de reputação do Freechains.
A ideia da aplicação é replicar o funcionamento de páginas spotted que vemos dentro de redes sociais como Facebook de uma forma descentralizada, privada e segura.
Todo o trabalho prático pode ser encontrado nos sequintes links:
- [Descrição da aplicação](Spotted/README.md)
- [Funcionamento do backend](Spotted/backend/README.md)
- [Funcionamento do frontend](Spotted/frontend/README.md)
- [Simulação do freechains em cima do Spotted](Spotted/simulation/README.md)
# License
MIT License | 68.035714 | 501 | 0.803675 | por_Latn | 0.999593 |
112e876203057fc2245868cb6927c5891201a694 | 6,145 | md | Markdown | 08_Hook_DoCheck/readme.md | jgodinob/Advanced-Angular | 2c39845e87def96a7af8c6aa9da9cabd98141ef6 | [
"MIT"
] | null | null | null | 08_Hook_DoCheck/readme.md | jgodinob/Advanced-Angular | 2c39845e87def96a7af8c6aa9da9cabd98141ef6 | [
"MIT"
] | null | null | null | 08_Hook_DoCheck/readme.md | jgodinob/Advanced-Angular | 2c39845e87def96a7af8c6aa9da9cabd98141ef6 | [
"MIT"
] | null | null | null | # 06 Hooks_DoCheck
In this sample we will see the use of hooks for the life cycle of a component.
We will take as a starting point sample [05_Hook_OnInit](../05_Hook_OnInit/AngularCLI/).
## Prerequisites
Install [Node.js and npm](https://nodejs.org/en/) if they are not already installed on your computer.
> Verify that you are running at least node v6.x.x and npm 3.x.x by running `node -v` and `npm -v` in a terminal/console window. Older versions may produce errors.
Install [TypeScript](https://www.typescriptlang.org/) suing `npm install -global typescript`.
Install [Angular CLI Global](https://cli.angular.io/) using `npm install -global @angular/cli`.
> Verify that you are running at least [TypeScript](https://www.typescriptlang.org/) and [Angular CLI](https://cli.angular.io/) running `tsc -v` and `ng --version` in a terminal/console window. Older versions may produce errors.
## Lifecycle Hooks
A component has a lifecycle managed by Angular.
Angular creates it, renders it, creates and renders its children, checks it when its data-bound properties change, and destroys it before removing it from the DOM.
Angular offers lifecycle hooks that provide visibility into these key life moments and the ability to act when they occur.
A directive has the same set of lifecycle hooks.
## ngDoCheck()
`ngDoCheck` gets called to check the changes in the directives in addition to the default algorithm. The default change detection algorithm looks for differences by comparing bound-property values by reference across change detection runs.
Note that a directive typically should not use both `DoCheck` and `OnChanges` to respond to changes on the same input, as ngOnChanges will continue to be called when the default change detector detects changes.
See **KeyValueDiffers** and **IterableDiffers** for implementing custom dirty checking for collections.
## Steps to build it
1. Copy the content from [05_Hook_OnInit](../05_Hook_OnInit/AngularCLI/) and execute:
```bash
npm install
```
> To understand the behavior of the demo, start the server in the console using the command `ng serve` and acecde to [http://localhost:4200/](http://localhost:4200/) Also open the developer tools option **console**.
2. Add **DoCheck** component, for then create a new method `ngDoCheck(){}`.
_[src/app/components/grounds.components.ts](./src/app/components/grounds.components.ts)_
```diff
-- import { Component, Input, Output, EventEmitter, OnChanges, SimpleChanges, OnInit } from '@angular/core';
++ import { Component, Input, Output, EventEmitter, OnChanges, SimpleChanges, OnInit, DoCheck } from '@angular/core';
@Component({
selector: 'app-grounds',
templateUrl: '../views/grounds.component.html',
styleUrls: ['../styles/grounds.component.scss']
})
-- export class GroundsComponent implements OnChanges, OnInit {
++ export class GroundsComponent implements OnChanges, OnInit, DoCheck {
public title: string;
@Input() name: string;
@Input('square_meter') surface: number;
public typeOfVegetation: string;
public open: boolean;
@Output() giveMeData = new EventEmitter();
constructor() {
this.title = 'This is the Park';
this.name = 'Example of Name using input - Value initial';
this.surface = 200;
this.typeOfVegetation = 'High';
this.open = true;
}
ngOnChanges(changes:SimpleChanges){
console.log('There are changes in the properties: ', changes);
}
ngOnInit(){
console.log('OnInit Method launch');
}
++ ngDoCheck(){
++ console.log('DoCheck Method launch');
++ }
issueEvent() {
this.giveMeData.emit({
'title': this.title,
'name': this.name,
'surface': this.surface,
'typeOfVegetation': this.typeOfVegetation,
'open': this.open
});
}
}
```
> You will see that the method `ngOnChanges(){}` is first executed, it is changed when the component is created, later `ngOnInit(){}` when the component is started and finally the method `ngDoCheck(){}` is launched when something change into component.
4. Now we can modify [src/app/components/grounds.components.ts](./src/app/components/grounds.components.ts) and move the method `ngDoCheck(){}` to [src/app/app.components.ts](./src/app/app.components.ts).
_[src/app/components/grounds.components.ts](./src/app/components/grounds.components.ts)_
```diff
import { Component, Input, Output, EventEmitter, OnChanges, SimpleChanges, OnInit, DoCheck } from '@angular/core';
@Component({
selector: 'app-grounds',
templateUrl: '../views/grounds.component.html',
styleUrls: ['../styles/grounds.component.scss']
})
export class GroundsComponent implements OnChanges, OnInit, DoCheck {
public title: string;
@Input() name: string;
@Input('square_meter') surface: number;
public typeOfVegetation: string;
public open: boolean;
@Output() giveMeData = new EventEmitter();
constructor() {
this.title = 'This is the Park';
this.name = 'Example of Name using input - Value initial';
this.surface = 200;
this.typeOfVegetation = 'High';
this.open = true;
}
ngOnChanges(changes:SimpleChanges){
console.log('There are changes in the properties: ', changes);
}
ngOnInit(){
console.log('OnInit Method launch');
}
-- ngDoCheck(){
-- console.log('DoCheck Method launch');
-- }
issueEvent() {
this.giveMeData.emit({
'title': this.title,
'name': this.name,
'surface': this.surface,
'typeOfVegetation': this.typeOfVegetation,
'open': this.open
});
}
}
```
_[src/app/app.components.ts](./src/app/app.components.ts)_
```diff
-- import { Component } from '@angular/core';
++ import { Component, Docheck } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.scss']
})
-- export class AppComponent {
++ export class AppComponent implements DoCheck {
title = 'app';
++ ngDoCheck(){
++ console.log('DoCheck Method launch');
++ }
}
```
> If we refresh the component, we will see that this method is executed every time something is applied in the application, either in the same component or in its children. | 34.914773 | 252 | 0.716843 | eng_Latn | 0.948149 |
112ec97030661360b2ba75643e64db1aa50c1af2 | 520 | markdown | Markdown | _posts/2013-02-08-video__1688.markdown | sawyerh/organizedwonder | ec1c09e67d13776b134a1e4968b6413ca35f3780 | [
"MIT"
] | 2 | 2016-01-06T17:13:12.000Z | 2016-07-03T03:28:36.000Z | _posts/2013-02-08-video__1688.markdown | sawyerh/organizedwonder | ec1c09e67d13776b134a1e4968b6413ca35f3780 | [
"MIT"
] | null | null | null | _posts/2013-02-08-video__1688.markdown | sawyerh/organizedwonder | ec1c09e67d13776b134a1e4968b6413ca35f3780 | [
"MIT"
] | null | null | null | ---
title: "Aral Balkan | The Future is Native | Fronteers 2011"
date: 2013-02-08 21:51:15 00:00
permalink: /videos/1688
source: "https://vimeo.com/30659519"
featured: false
provider: "Vimeo"
thumbnail: "http://b.vimeocdn.com/ts/206/048/206048791_640.jpg"
user:
id: 471
username: "themanro"
name: "Roman Rusinov"
tags: []
html: "<iframe src=\"http://player.vimeo.com/video/30659519\" width=\"1280\" height=\"720\" frameborder=\"0\" webkitAllowFullScreen mozallowfullscreen allowFullScreen></iframe>"
id: 1688
---
| 28.888889 | 177 | 0.717308 | eng_Latn | 0.159267 |
112eeff3fd4536525559682060074812bb3417b5 | 3,467 | md | Markdown | articles/dns/dns-operations-recordsets-portal.md | yanxiaodi/azure-docs.zh-cn | fb6386a5930fda2f61c31cfaf755cde1865aeab7 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-01-21T04:22:02.000Z | 2022-01-14T01:48:40.000Z | articles/dns/dns-operations-recordsets-portal.md | yanxiaodi/azure-docs.zh-cn | fb6386a5930fda2f61c31cfaf755cde1865aeab7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/dns/dns-operations-recordsets-portal.md | yanxiaodi/azure-docs.zh-cn | fb6386a5930fda2f61c31cfaf755cde1865aeab7 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-11-04T04:36:46.000Z | 2020-11-04T04:36:46.000Z | ---
title: 使用 Azure DNS 管理 DNS 记录集和记录
description: Azure DNS 在托管域时具有管理 DNS 记录集和记录的功能。
services: dns
author: vhorne
ms.service: dns
ms.topic: article
ms.date: 10/6/2018
ms.author: victorh
ms.openlocfilehash: 891adfacde6e46b1d8fe8e2f6b5fb39c90ce27a0
ms.sourcegitcommit: d4dfbc34a1f03488e1b7bc5e711a11b72c717ada
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 06/13/2019
ms.locfileid: "61296214"
---
# <a name="manage-dns-records-and-record-sets-by-using-the-azure-portal"></a>使用 Azure 门户管理 DNS 记录和记录集
本文演示如何通过使用 Azure 门户来管理 DNS 区域的记录集和记录。
请务必了解 DNS 记录集与单独的 DNS 记录之间的差异。 记录集是区域中具有相同名称和相同类型的记录的集合。 有关详细信息,请参阅[使用 Azure 门户创建 DNS 记录集和记录](dns-getstarted-create-recordset-portal.md)。
## <a name="create-a-new-record-set-and-record"></a>创建新的记录集和记录
若要在 Azure 门户中创建记录集,请参阅[使用 Azure 门户创建 DNS 记录](dns-getstarted-create-recordset-portal.md)。
## <a name="view-a-record-set"></a>查看记录集
1. 在 Azure 门户中,转到“**DNS 区域**”边栏选项卡。
2. 搜索记录集,并选择它。 这会打开记录集属性。

## <a name="add-a-new-record-to-a-record-set"></a>将新记录添加到记录集
可以将最多 20 条记录添加到任何记录集。 记录集不能包含两个相同的记录。 可以创建空记录集(具有零个记录),但它不会出现在 Azure DNS 名称服务器中。 CNAME 类型的记录集最多可以包含一条记录。
1. 在 DNS 区域的“**记录集属性**”边栏选项卡中,单击你想要将记录添加到的记录集。

2. 过填写字段指定记录集的属性。

3. 单击边栏选项卡顶部的“保存” 以保存设置。 然后关闭该边栏选项卡。
4. 将在角落中看到正在保存该记录。

保存记录集后,“**DNS 区域**”边栏选项卡中的这些值将反映新记录。
## <a name="update-a-record"></a>更新记录
更新现有记录集的记录时,可以更新的字段取决于正在使用的记录类型。
1. 在记录集的“**记录集属性**”边栏选项卡中,搜索记录。
2. 修改记录。 修改记录时,可以更改记录的可用设置。 在下面的示例中,已选择“**IP 地址**”字段,并且 IP 地址正在修改中。

3. 单击边栏选项卡顶部的“保存” 以保存设置。 在右上角中,会看到该记录已保存的通知。

保存记录后,记录集在“**DNS 区域**”边栏选项卡中的值将反映更新的记录。
## <a name="remove-a-record-from-a-record-set"></a>从记录集中删除记录
Azure 门户可用于从记录集中删除记录。 请注意,从记录集中删除最后一条记录不会删除记录集。
1. 在记录集的“**记录集属性**”边栏选项卡中,搜索记录。
2. 单击要删除的记录。 然后选择“删除” 。

3. 单击边栏选项卡顶部的“保存” 以保存设置。
4. 删除记录后,记录在“**DNS 区域**”边栏选项卡中的值将反映删除操作。
## <a name="delete"></a>删除记录集
1. 在记录集的“**记录集属性**”边栏选项卡中,搜单击“**删除**”。

2. 将出现一条消息,询问你是否想要删除记录集。
3. 验证该名称与要删除的记录集是否匹配,并单击“**是**”。
4. 在“**DNS 区域**”边栏选项卡中,确认记录集不再出现。
## <a name="work-with-ns-and-soa-records"></a>使用 NS 和 SOA 记录
自动创建的 NS 和 SOA 记录的管理方式与其他记录类型不同。
### <a name="modify-soa-records"></a>修改 SOA 记录
不能在区域顶点(名称 =“\@”)从自动创建的 SOA 记录集中添加或删除记录。 但是,可以修改 SOA 记录和记录集 TTL 中的任何参数(“Host”除外)。
### <a name="modify-ns-records-at-the-zone-apex"></a>修改区域顶点处的 NS 记录
在每个 DNS 区域自动创建区域顶点处的 NS 记录集。 其中包含分配给该区域的 Azure DNS 名称服务器名称。
可向此 NS 记录集添加其他名称服务器,从而支持与多个 DNS 提供商共同托管域。 还可修改此记录集的 TTL 和元数据。 但是,无法删除或修改预填充的 Azure DNS 名称服务器。
请注意,这仅适用于区域顶点处的 NS 记录集。 区域中的其他 NS 记录集(用于委派子区域)不受约束,可进行修改。
### <a name="delete-soa-or-ns-record-sets"></a>删除 SOA 或 NS 记录集
不能在区域顶点处(名称 =“\@”)删除创建区域时自动创建的 SOA 和 NS 记录集。 删除该区域时,会自动删除这些记录集。
## <a name="next-steps"></a>后续步骤
* 有关 Azure DNS 的详细信息,请参阅 [Azure DNS 概述](dns-overview.md)。
* 有关自动执行 DNS 的详细信息,请参阅[使用 .NET SDK 创建 DNS 区域和记录集](dns-sdk.md)。
* 有关反向 DNS 记录的详细信息,请参阅 [Azure 中的反向 DNS 和支持概述](dns-reverse-dns-overview.md)。
* 有关 Azure DNS 别名记录的详细信息,请参阅 [Azure DNS 别名记录概述](dns-alias.md)。
| 29.887931 | 137 | 0.733487 | yue_Hant | 0.572748 |
112f67326c3d49c68537af3581a12fd425926587 | 1,078 | md | Markdown | README.md | aekanman/LightPainting | 6cd2447f5e9a61ed8be6889f865bceb604c595f7 | [
"MIT"
] | 14 | 2017-01-31T04:38:58.000Z | 2020-10-25T03:00:57.000Z | README.md | aekanman/LightPainting | 6cd2447f5e9a61ed8be6889f865bceb604c595f7 | [
"MIT"
] | null | null | null | README.md | aekanman/LightPainting | 6cd2447f5e9a61ed8be6889f865bceb604c595f7 | [
"MIT"
] | 6 | 2017-09-27T11:52:00.000Z | 2020-11-20T08:18:47.000Z | # Light Painting with Fanuc Robot<br />
What is light painting?<br />
-Capturing light trails using long exposure photography and drawing images in air<br />
### Objectives<br />
-Create and communicate a desired path to the robot<br />
-Recreate path with robot’s end effector<br /><br />
<br />
Combining 2 different systems/environments:<br />
1) PC for computer vision / image processing and writing the waypoints<br />
2) Fanuc for reading the waypoints and following the path<br /><br />
1) Rectangle (kinda)<br /><br />
2) Spiral <br /><br />
Final) z<br /><br /><br />
### Results <br />
Heart <br /> <br />
Spiral <br /> <br />
Z <br /> <br /><br /><br />
## License
MIT © [Atakan Efe Kanman](http://atakanefekanman.com)
| 39.925926 | 87 | 0.673469 | eng_Latn | 0.678673 |
112f8a31f20a7dd540554b27c58fea57aad8619f | 1,544 | md | Markdown | src/vi/2019-04/10/01.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 68 | 2016-10-30T23:17:56.000Z | 2022-03-27T11:58:16.000Z | src/vi/2019-04/10/01.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 367 | 2016-10-21T03:50:22.000Z | 2022-03-28T23:35:25.000Z | src/vi/2019-04/10/01.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 109 | 2016-08-02T14:32:13.000Z | 2022-03-31T10:18:41.000Z | ---
title: 'Thờ Phượng Đức Chúa Trời'
date: 30/11/2019
---
### Kinh thánh nghiên cứu
Nê-hê-mi 12:27-47;1 Sử ký. 25:6-8;1 Giăng 1:7-9; Giăng 1:29, 36; 1 Cô-rinh-tô. 5:7; Hê-bơ-rơ. 9:1-11.
> <p>Câu gốc</p>
> Đáng ngợi khen Đức Giê-hô-va, vì Ngài là tốt lành, lòng thương xót của Ngài đối với Y-sơ-ra-ên còn đến đời đời!” (E-xơ-ra 3:11).
Câu gốc tuần này cho chúng ta cái nhìn sâu sắc về sự thờ phượng của người Hê-bơ-rơ và lòng biết ơn đối với Đức Chúa Trời qua những lời ngợi khen tuôn tràn từ tấm lòng của họ. Năm 515 T.C. họ cử hành lễ cung hiến ngôi đền thờ mới (E-xơ-ra 6:15-18) và rồi, khoảng 60 năm sau, dân sự tổ chức lễ hiến dâng tường thành Giê-ru-sa-lem được hoàn chỉnh (Nê-hê-mi 6:15-7:3; 12:27)
Sau khi liệt kê các phả hệ trong Nê-hê-mi 11 và 12, tác giả chuyển sang thời điểm họ tổ chức lễ cung hiến tường thành. Đó là phong tục của quốc gia để dâng hiến mọi vật cho Đức Chúa Trời: đền thờ, tường thành, hay thậm chí những ngôi nhà và những tòa nhà công cộng. Những lễ dâng hiến như vậy được chuẩn bị chu đáo và kèm theo với ca hát, âm nhạc, kiêng ăn, của lễ hy sinh, sự hoan hỉ, vui mừng, và sự tẩy sạch dân sự.
Đa-vít đã thiết lập việc thực hành các tế lễ trong suốt lễ dâng hiến, sau đó thì những nhà lãnh đạo Y-sơ-ra-ên theo gương ông, đầu tiên là vua Sa-lô-môn khi ông rước hòm giao ước vào trong đền thờ (1 Các Vua 8:5).
Tuần này chúng ta sẽ nghiên cứu họ thờ phượng Chúa như thế nào trong suốt thời gian làm lễ và xem những điều mà chúng ta, những người cũng thờ phượng một Chúa như vậy, có thể áp dụng cho chính mình. | 85.777778 | 419 | 0.715026 | vie_Latn | 1.00001 |
11301a4d9c2bdfa19166d8175189828aabbe63c8 | 34 | md | Markdown | README.md | Duckdan/DeleteEditText | aab8cf9de71e76393d6a7ebf52872d533037101a | [
"Apache-2.0"
] | null | null | null | README.md | Duckdan/DeleteEditText | aab8cf9de71e76393d6a7ebf52872d533037101a | [
"Apache-2.0"
] | null | null | null | README.md | Duckdan/DeleteEditText | aab8cf9de71e76393d6a7ebf52872d533037101a | [
"Apache-2.0"
] | null | null | null | # DeleteEditText
自定义删除内容的EditText
| 11.333333 | 16 | 0.882353 | yue_Hant | 0.266741 |
11304569f3cbd69744d6cbd66287c43a670c5d54 | 814 | md | Markdown | 2010/CVE-2010-1895.md | justinforbes/cve | 375c65312f55c34fc1a4858381315fe9431b0f16 | [
"MIT"
] | 2,340 | 2022-02-10T21:04:40.000Z | 2022-03-31T14:42:58.000Z | 2010/CVE-2010-1895.md | justinforbes/cve | 375c65312f55c34fc1a4858381315fe9431b0f16 | [
"MIT"
] | 19 | 2022-02-11T16:06:53.000Z | 2022-03-11T10:44:27.000Z | 2010/CVE-2010-1895.md | justinforbes/cve | 375c65312f55c34fc1a4858381315fe9431b0f16 | [
"MIT"
] | 280 | 2022-02-10T19:58:58.000Z | 2022-03-26T11:13:05.000Z | ### [CVE-2010-1895](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2010-1895)



### Description
The Windows kernel-mode drivers in win32k.sys in Microsoft Windows XP SP2 and SP3, and Windows Server 2003 SP2, do not properly perform memory allocation before copying user-mode data to kernel mode, which allows local users to gain privileges via a crafted application, aka "Win32k Pool Overflow Vulnerability."
### POC
#### Reference
- https://docs.microsoft.com/en-us/security-updates/securitybulletins/2010/ms10-048
#### Github
No PoCs found on GitHub currently.
| 45.222222 | 312 | 0.764128 | eng_Latn | 0.419691 |
113061b088b9a40c1eb09b8558012af08e93b04b | 1,815 | md | Markdown | _posts/2020-01-01-1841642.md | meparth/BongNetflix | 6c84a70721296413c70067e10cfa7741cf89e963 | [
"MIT"
] | null | null | null | _posts/2020-01-01-1841642.md | meparth/BongNetflix | 6c84a70721296413c70067e10cfa7741cf89e963 | [
"MIT"
] | null | null | null | _posts/2020-01-01-1841642.md | meparth/BongNetflix | 6c84a70721296413c70067e10cfa7741cf89e963 | [
"MIT"
] | null | null | null | ---
layout: post
title: "Demonic"
description: "In Louisiana,Detective Mark Lewis is summoned to attend a call from the notorious Livingston House and he finds three bodies and one survivor, John, who is in shock. He calls for backup and also the police psychologist Dr. Elizabeth Klein to interrogate John. They learn that the team of ghost-busters Bryan, John's pregnant girlfriend Michelle, Jules, Donnie and Sam decided to perform a séance in the house, where the owner Marta Livingstone had committed a violent slaughter, to summon their spirits. The séance went wrong and rel.."
img: 1841642.jpg
kind: movie
genres: [Horror,Mystery,Thriller]
tags: Horror Mystery Thriller
language: English
year: 2015
imdb_rating: 5.3
votes: 13131
imdb_id: 1841642
netflix_id: 80195378
color: 2c6e49
---
Director: `Will Canon`
Cast: `Maria Bello` `Frank Grillo` `Cody Horn` `Dustin Milligan` `Scott Mechlowicz`
In Louisiana,Detective Mark Lewis is summoned to attend a call from the notorious Livingston House and he finds three bodies and one survivor, John, who is in shock. He calls for backup and also the police psychologist Dr. Elizabeth Klein to interrogate John. They learn that the team of ghost-busters Bryan, John's pregnant girlfriend Michelle, Jules, Donnie and Sam decided to perform a séance in the house, where the owner Marta Livingstone had committed a violent slaughter, to summon their spirits. The séance went wrong and released evil spirits that killed Jules, Donnie and Sam; however Michelle and Bryan are missing. While Elizabeth interrogates John, Mark and the technical team tries to retrieve the hard disks with the footage's from the house to find where the other two survivors may be, Detective Lewis discloses a dark supernatural secret about John.::Claudio Carvalho, Rio de Janeiro, Brazil | 86.428571 | 909 | 0.797796 | eng_Latn | 0.998593 |
a66d791997c9437af8bec9c580aec30da0bde11b | 298 | md | Markdown | Doc/G/ABA-MSPA-SPA-CmA/Sec/Cond/Buyer/Consents/0.md | CommonAccord/OpenLaw-CmA | 09d98c90cebc75784e18c97e0470a8cebeff206c | [
"MIT"
] | null | null | null | Doc/G/ABA-MSPA-SPA-CmA/Sec/Cond/Buyer/Consents/0.md | CommonAccord/OpenLaw-CmA | 09d98c90cebc75784e18c97e0470a8cebeff206c | [
"MIT"
] | null | null | null | Doc/G/ABA-MSPA-SPA-CmA/Sec/Cond/Buyer/Consents/0.md | CommonAccord/OpenLaw-CmA | 09d98c90cebc75784e18c97e0470a8cebeff206c | [
"MIT"
] | null | null | null | Ti=Consents
sec=Each of the {_Consents} identified in {Exh.8.4.Xref} (the "{_Material_Consents}") will have been obtained in form and substance satisfactory to {_Buyer} and will be in full force and effect. Copies of the {_Material_Consents} will have been delivered to {_Buyer}.
=[G/Z/ol/Base]
| 49.666667 | 268 | 0.758389 | eng_Latn | 0.990924 |
a66dd85ddfc754dca2e7c11e8feee3dbba5c7fa9 | 139 | md | Markdown | README.md | sadeghmohebbi/porsan-api-for-hmp-docs | 428e6f450c96b17597cdfe01b847e98026428b3e | [
"MIT"
] | null | null | null | README.md | sadeghmohebbi/porsan-api-for-hmp-docs | 428e6f450c96b17597cdfe01b847e98026428b3e | [
"MIT"
] | null | null | null | README.md | sadeghmohebbi/porsan-api-for-hmp-docs | 428e6f450c96b17597cdfe01b847e98026428b3e | [
"MIT"
] | null | null | null | # Porsan API for Hamdam Docs
developed by [sadegh mohebbi](https://github.com/sadeghmohebbi) | powered by [docsify](https://docsify.js.org) | 69.5 | 110 | 0.76259 | yue_Hant | 0.520831 |
a66e35ce12c5cbf09d064ef59c5b1e56ea1cd515 | 8,298 | md | Markdown | apps/ngrid-docs-app/content/features/grid/focus-and-selection/focus-and-selection.md | tamtakoe/ngrid | 7068fd152621e273c76323b4ae7312abe1ff5cd8 | [
"MIT"
] | 225 | 2019-05-07T20:04:31.000Z | 2022-03-23T16:05:05.000Z | apps/ngrid-docs-app/content/features/grid/focus-and-selection/focus-and-selection.md | tamtakoe/ngrid | 7068fd152621e273c76323b4ae7312abe1ff5cd8 | [
"MIT"
] | 136 | 2019-05-12T11:21:12.000Z | 2022-02-26T10:40:41.000Z | apps/ngrid-docs-app/content/features/grid/focus-and-selection/focus-and-selection.md | tamtakoe/ngrid | 7068fd152621e273c76323b4ae7312abe1ff5cd8 | [
"MIT"
] | 35 | 2019-05-16T13:46:37.000Z | 2022-02-28T12:42:21.000Z | ---
title: Focus And Selection
path: features/grid/focus-and-selection
parent: features/grid
ordinal: 0
---
# Focus And Selection
**Focus** and **Range Selection** is supported programmatically (`ContextApi`) and through the UI (mouse/keyboard) using the `target-events` plugin.
---
In most cases you will not need to use the API, the `target-events` plugin will usually have everything you need
including focus support via keyboard arrows as well as selection support using arrows & SHIFT, mouse & SHIFT, mouse CTRL and mouse drag.
You can keep on reading or you can go to the `target-events` page for more details on focus & selection using the plugin
You can keep on reading or you can [go to the target-events page](../../built-in-plugins/target-events) for more details on focus & selection using the plugin
---
## Using the API
The state of the currently focused cell is stored in the context of each cell and managed by the context API.
We'll start with direct API manipulation, we use the context API (`PblNgridContextApi`):
### Focus
```typescript
interface PblNgridContextApi<T = any> {
// ...
/**
* The reference to currently focused cell context.
* You can retrieve the actual context or context cell using `findRowInView` and / or `findRowInCache`.
*
* > Note that when virtual scroll is enabled the currently focused cell does not have to exist in the view.
* If this is the case `findRowInView` will return undefined, use `findRowInCache` instead.
*/
readonly focusedCell: GridDataPoint | undefined;
/**
* Focus the provided cell.
* If a cell is not provided will un-focus (blur) the currently focused cell (if there is one).
* @param cellRef A Reference to the cell
* @param markForCheck Mark the row for change detection
*/
focusCell(cellRef?: CellReference | boolean, markForCheck?: boolean): void;
// ...
}
```
Note that `CellReference` can be an `HTMLElement` of the cell, the context of the cell of a pointer to the cell (`GridDataPoint`)
```typescript
export type CellReference = HTMLElement | GridDataPoint | PblNgridCellContext;
/**
* A reference to a data cell on the grid.
*/
export interface GridDataPoint {
/**
* The row identity.
* If the grid was set with an identity property use the value of the identity otherwise, use the location of the row in the datasource.
*/
rowIdent: any;
/**
* The column index, relative to the column definition set provided to the grid.
* Note that this is the absolute position, including hidden columns.
*/
colIndex: number;
}
```
> `GridDataPoint` is also used in other places to point to a cell.
I> When using `pIndex` (identity) to define a primary key for your models (which is highly recommended) the `rowIdent` that should be used is
the identity value, otherwise use the index position in the datasource.
Now, using it straight forward:
```typescript
gridInstance.contextApi.focusCell({ rowIdent: 3, colIndex: 2 }, true);
// Set the focus to the cell at 4th row and the 3rd column and mark the row to change detection.
// To clear the focus: (true is optional);
gridInstance.contextApi.focusCell(true);
```
### Range Selection
Range selection is similar to focus:
```typescript
interface PblNgridContextApi<T = any> {
// ...
/**
* The reference to currently selected range of cell's context.
* You can retrieve the actual context or context cell using `findRowInView` and / or `findRowInCache`.
*
* > Note that when virtual scroll is enabled the currently selected cells does not have to exist in the view.
* If this is the case `findRowInView` will return undefined, use `findRowInCache` instead.
*/
readonly selectedCells: GridDataPoint[];
/**
* Select all provided cells.
* @param cellRef A Reference to the cell
* @param markForCheck Mark the row for change detection
* @param clearCurrent Clear the current selection before applying the new selection.
* Default to false (add to current).
*/
selectCells(cellRefs: CellReference[], markForCheck?: boolean, clearCurrent?: boolean): void;
/**
* Unselect all provided cells.
* If cells are not provided will un-select all currently selected cells.
* @param cellRef A Reference to the cell
* @param markForCheck Mark the row for change detection
*/
unselectCells(cellRefs?: CellReference[] | boolean, markForCheck?: boolean): void;
// ...
}
```
There are 2 notable differences:
- We have 2 APIs, one to add/set the range and one to clear it (all or partial).
- We now work with multiple cells and not one (it's a range...)
The cells within a range does not have to be connected (adjacent), we can have a range that is spread across. The range collection is
not organized nor sorted in any way.
I> The currently focused cell is also a selected cell.
Now, using it straight forward:
```typescript
gridInstance.contextApi.selectCells([ { rowIdent: 3, colIndex: 2 }, { rowIdent: 3, colIndex: 3 } ], true);
// Set the selected range to the cells at 4th row and the 3rd & 4 columns and mark the row to change detection.
// To clear the entire selection: (true is optional);
gridInstance.contextApi.unselectCells(true);
// To clear part of the selection: (true is optional);
gridInstance.contextApi.unselectCells([ { rowIdent: 3, colIndex: 2 } ], true);
```
## Navigating with primary index (`PblColumn.pIndex`)
Most of the operations in focus & selection require a reference to cell (any by that we also get the reference to the row).
We saw that `CellReference` is used for that and it can be the cell's `HTMLElement` or direct context instance.
In most cases, however, you will work with `GridDataPoint` because it is more simple to use and does not require a hard reference to an
existing object (`HTMLElement` or `PblNgridCellContext`).
When a primary index **is not used** providing a reference to a cell is straight-forward:
```typescript
const cellRef: GridDataPoint = { rowIdent: 3, colIndex: 2 };
```
Both row and col are referenced by their positional index, so `rowIdent: 3` means the 4th item (0 based) in the grid's datasource.
But how does it work when we do set a primary index (`pIndex`) for example, if our primary index is the social ID field?
```typescript
const cellRef: GridDataPoint = { rowIdent: '0879846579', colIndex: 2 };
```
Great, now if we want to reference the next or previous column we just modify `colIndex`.
But what if we want to get the next or previous row? since `rowIdent` is a key we cant use simple math.
We could start searching the datasource, but that's not a good idea as it's an array thus not indexed...
The API can help us:
```typescript
interface PblNgridContextApi<T = any> {
// ...
/**
* Try to find a specific row context, using the row identity, in the context cache.
* Note that the cache does not hold the context itself but only the state that can later be used to retrieve a context instance. The context instance
* is only used as context for rows in view.
* @param rowIdentity The row's identity. If a specific identity is used, please provide it otherwise provide the index of the row in the datasource.
* @param offset When set, returns the row at the offset from the row with the provided row identity. Can be any numeric value (e.g 5, -6, 4).
* @param create Whether to create a new state if the current state does not exist.
*/
findRowInCache(rowIdentity: any, offset: number, create: boolean): RowContextState<T> | undefined;
// ...
}
```
And using it:
```typescript
const cellRef: GridDataPoint = { rowIdent: '0879846579', colIndex: 2 };
const rowContextState = gridInstance.contextApi.findRowInCache(cellRef.rowIdent, -1, true);
const newCellRef: GridDataPoint = { rowIdent: rowContextState.identity, colIndex: cellRef.colIndex };
```
We started with a `GridDataPoint` and used it as a relative base point to get the previous row context state.
We set `true` in the last parameter to instruct the grid to create a new context state if one does not exist.
In the final step we create the new grid data point that is pointing where we want.
## Example
The following example will demonstrate everything covered up to this point:
<div pbl-example-view="pbl-focus-and-selection-example"></div>
| 38.416667 | 158 | 0.733671 | eng_Latn | 0.995615 |
a66e95d3996c91b5c12a98d9c42fd2a6f0e07cea | 1,507 | md | Markdown | data-explorer/kusto/query/unixtime-seconds-todatetimefunction.md | satonaoki/dataexplorer-docs.ja-jp | ec6590a54342efa8c1f4e5cecb8b32137edf654b | [
"CC-BY-4.0",
"MIT"
] | null | null | null | data-explorer/kusto/query/unixtime-seconds-todatetimefunction.md | satonaoki/dataexplorer-docs.ja-jp | ec6590a54342efa8c1f4e5cecb8b32137edf654b | [
"CC-BY-4.0",
"MIT"
] | null | null | null | data-explorer/kusto/query/unixtime-seconds-todatetimefunction.md | satonaoki/dataexplorer-docs.ja-jp | ec6590a54342efa8c1f4e5cecb8b32137edf654b | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: unixtime_seconds_todatetime ()-Azure データエクスプローラー
description: この記事では、Azure データエクスプローラーの unixtime_seconds_todatetime () について説明します。
services: data-explorer
author: orspod
ms.author: orspodek
ms.reviewer: rkarlin
ms.service: data-explorer
ms.topic: reference
ms.date: 11/25/2019
ms.openlocfilehash: 0dca68d410bc7444feca8df41a360bb4ac2a1ec3
ms.sourcegitcommit: 09da3f26b4235368297b8b9b604d4282228a443c
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 07/28/2020
ms.locfileid: "87338645"
---
# <a name="unixtime_seconds_todatetime"></a>unixtime_seconds_todatetime()
Unix-エポック秒を UTC 日時に変換します。
## <a name="syntax"></a>構文
`unixtime_seconds_todatetime(*seconds*)`
## <a name="arguments"></a>引数
* *秒*: 実数は、エポックタイムスタンプを秒単位で表します。 `Datetime`エポック時間 (1970-01-01 00:00:00) が負のタイムスタンプ値を持つ前に発生します。
## <a name="returns"></a>戻り値
変換が成功した場合、結果は[datetime](./scalar-data-types/datetime.md)値になります。 変換に失敗した場合、結果は null になります。
**参照**
* [Unixtime_milliseconds_todatetime ()](unixtime-milliseconds-todatetimefunction.md)を使用して unix-エポックミリ秒を UTC 日時に変換します。
* [Unixtime_microseconds_todatetime ()](unixtime-microseconds-todatetimefunction.md)を使用して、unix-エポックマイクロ秒を UTC 日時に変換します。
* [Unixtime_nanoseconds_todatetime ()](unixtime-nanoseconds-todatetimefunction.md)を使用して、unix-エポックナノ秒を UTC の datetime に変換します。
## <a name="example"></a>例
<!-- csl: https://help.kusto.windows.net/Samples -->
```kusto
print date_time = unixtime_seconds_todatetime(1546300800)
```
|date_time|
|---|
|2019-01-01 00:00: 00.0000000|
| 30.14 | 124 | 0.780358 | yue_Hant | 0.543712 |
a66f37b1ab51cc877374a59dfc4edb825348455f | 718 | md | Markdown | includes/azure-sql-database-limits.md | yfakariya/azure-content-jajp | 69be88c0fee4443d5dcab82bf4aed6a155fea287 | [
"CC-BY-3.0"
] | 2 | 2016-09-23T01:46:35.000Z | 2016-09-23T05:12:58.000Z | includes/azure-sql-database-limits.md | yfakariya/azure-content-jajp | 69be88c0fee4443d5dcab82bf4aed6a155fea287 | [
"CC-BY-3.0"
] | null | null | null | includes/azure-sql-database-limits.md | yfakariya/azure-content-jajp | 69be88c0fee4443d5dcab82bf4aed6a155fea287 | [
"CC-BY-3.0"
] | 1 | 2020-11-04T04:29:27.000Z | 2020-11-04T04:29:27.000Z | リソース|既定の制限
---|---
データベース サイズ|パフォーマンス レベルによって異なります <sup>1</sup>
ログイン|パフォーマンス レベルによって異なります <sup>1</sup>
メモリ使用量|16 MB のメモリ許可が 20 秒を超える
セッション|パフォーマンス レベルによって異なります <sup>1</sup>
Tempdb のサイズ|5 GB
トランザクションの実行時間|24 時間<sup>2</sup>
トランザクションあたりのロック数|100 万
トランザクションあたりのサイズ|2 GB
合計ログ領域のうちトランザクションごとに使用される割合|20%
同時要求 (ワーカー スレッド) の最大数|パフォーマンス レベルによって異なります <sup>1</sup>
<sup>1</sup>SQL Database には、Basic、Standard、Premium などのパフォーマンス レベルがあります。また、Standard および Premium は複数のパフォーマンス レベルに分かれています。パフォーマンス レベルとサービス レベルごとの詳細な制限については、「[Azure SQL Database のサービス レベルとパフォーマンス レベル](https://msdn.microsoft.com/library/azure/dn741336.aspx)」を参照してください。
<sup>2</sup>基本システム タスクに必要なリソースをトランザクションがロックしている場合、最大実行時間は 20 秒間です。
<!---HONumber=August15_HO7--> | 37.789474 | 263 | 0.795265 | jpn_Jpan | 0.559708 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.