
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
585b60e576c45326d1021b44a51c3a736765580f | 998 | md | Markdown | README.md | H3ndrx/WP8.1Parallax | 7b89c04de91c2cd580b8c673fbbe63274bd62124 | [
"MIT"
] | null | null | null | README.md | H3ndrx/WP8.1Parallax | 7b89c04de91c2cd580b8c673fbbe63274bd62124 | [
"MIT"
] | null | null | null | README.md | H3ndrx/WP8.1Parallax | 7b89c04de91c2cd580b8c673fbbe63274bd62124 | [
"MIT"
] | null | null | null | # WP8.1Parallax
Parallax efect for UIElements in Universal Apps for Windows and Windows Phone 8.1
# ABOUT:
I've created framework for developers, to simulate parallax efect in applications.
# COMPABILITY:
framework is compatible with Windows 8.1 and Windows Phone 8.1 Universal Apps
# HOW TO USE:
1. add reference in project
2. add line "using GZParallax"
3. Create instance of Parallax class object. Parallax(horizontalEnabled, verticalEnabled)
4. add graphic objects, who inharitates from UIElement, and set on what virtual layer it should be placed.
basic layer, which is not moving is layer 0. Each layer number indicates if its above ( numbers greater then 0) or under (numbers smaller then 0) basic layer.
5. Set maxSwingVertical, andmaxSwingHorizontal if you want to change. Default 5
6. when you are ready call start() on parallax object.
7. Its good to stop parallax when you don't need it.
# CONTACT:
For more information pls mail me.
Gabriel Żołnierczuk
[email protected]
| 38.384615 | 158 | 0.788577 | eng_Latn | 0.984492 |
585b9a2852985da65a3414b9e07a18a28032bf27 | 672 | md | Markdown | README.md | make3782/vs-wzx | f0c4edc916d569d651fb145267076a507bcb6817 | [
"Apache-2.0"
] | 1 | 2017-05-25T07:14:32.000Z | 2017-05-25T07:14:32.000Z | README.md | make3782/vs-wzx | f0c4edc916d569d651fb145267076a507bcb6817 | [
"Apache-2.0"
] | null | null | null | README.md | make3782/vs-wzx | f0c4edc916d569d651fb145267076a507bcb6817 | [
"Apache-2.0"
] | null | null | null | # vs-wzx README
"vs_wzx"是个人写的插件,用于一些小快速开发。
## Features
个人的一些习惯,大部分从Emacs而来
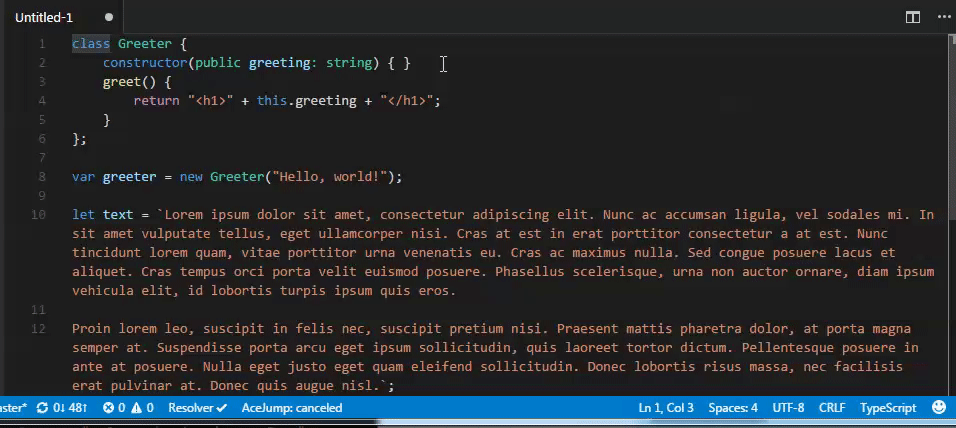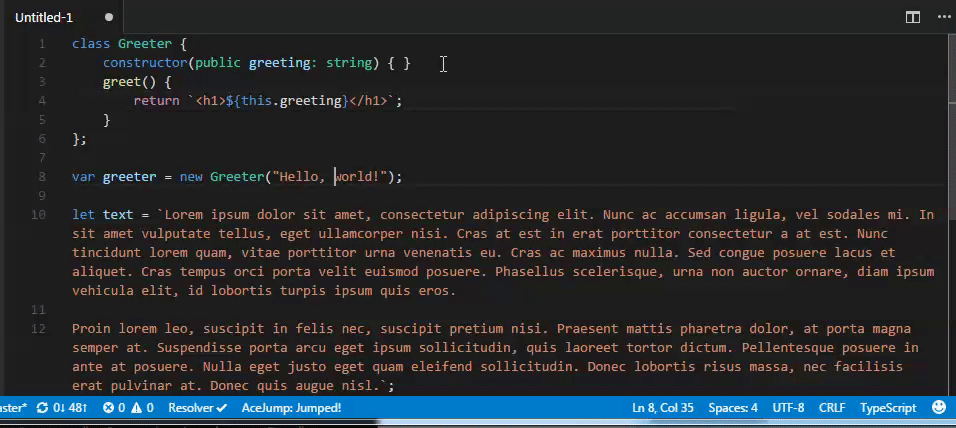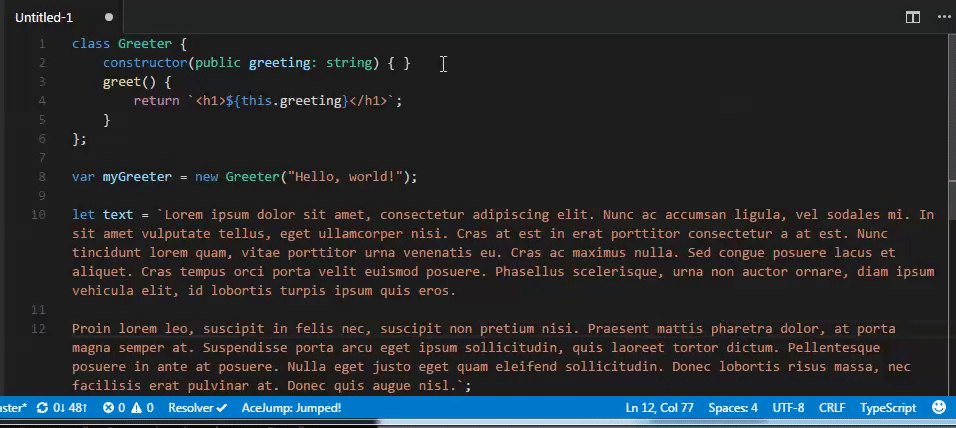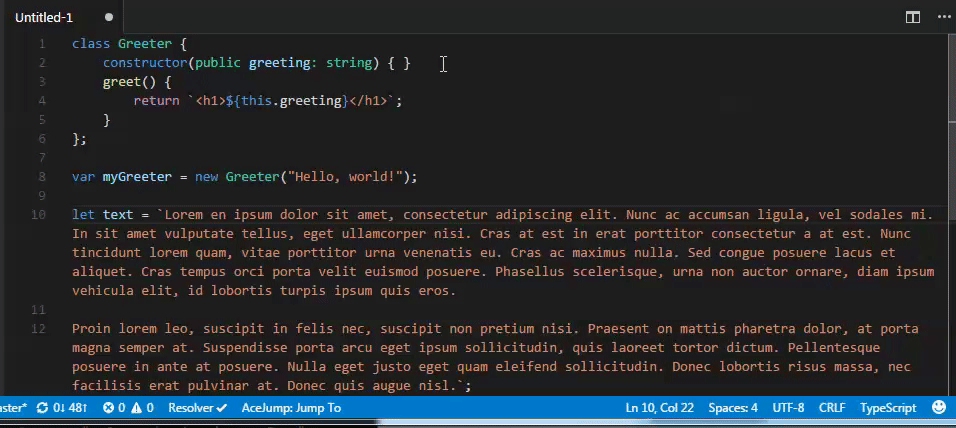
- `wzx jump out`
在符号内的时候快速跳出到括号外,支持的符号有:``, '', "", {}, [], <>, ()
- `wzx center line`
当前所在行屏幕居中,再次执行则居顶 - 居底 - 居中循环, 类emacs的 ctrl+l
{
"key": "alt+enter",
"command": "extension.wzx.centerLine "
}
或者直接通过F1命令执行 ``wzx center line``
## Commands
要使用快捷键进行操作,请增加如下内容: `keybindings.json` (`File` -> `Preferences` -> `Keyboard Shortcuts`):
{
"key": "alt+enter",
"command": "extension.wzx.jumpOut"
}
或者直接通过F1命令执行 ``wzx jump out``
## Release Notes
### 1.0.0
初始化开发
| 16.390244 | 89 | 0.598214 | yue_Hant | 0.624922 |
585bcb7887281f6c50b8ec7e7d0bc10de8a18f7a | 1,256 | md | Markdown | source/blog/2009-02-03-doctrine-1-0-7-is-available.md | mmollick/doctrine-website | d09296b380eff9a65224cddcc201357288a1d406 | [
"MIT"
] | null | null | null | source/blog/2009-02-03-doctrine-1-0-7-is-available.md | mmollick/doctrine-website | d09296b380eff9a65224cddcc201357288a1d406 | [
"MIT"
] | null | null | null | source/blog/2009-02-03-doctrine-1-0-7-is-available.md | mmollick/doctrine-website | d09296b380eff9a65224cddcc201357288a1d406 | [
"MIT"
] | null | null | null | ---
title: "Doctrine 1.0.7 is Available!"
menuSlug: blog
layout: blog-post
controller: ['Doctrine\Website\Controllers\BlogController', 'view']
authorName: jwage
authorEmail:
categories: []
permalink: /2009/02/03/doctrine-1-0-7-is-available.html
---
Today I have made available [Doctrine
1.0.7](http://www.doctrine-project.org/download) , the latest bug fix
release for the 1.0 version of Doctrine. This release is a significant
one with a few dozen bugs fixed. Below is a list that highlights some of
the fixes.
Highlights
==========
- [r5361] Fixed NestedSet to not create column for root column if it
already exists (closes \#1817)
- [r5419] Fixes \#1856. Added checking to schema file to ensure
correct file extension (format).
- [r5429] Fixes issue with generated count queries (closes \#1766)
- [r5438] Fixes issue with saveRelated() being called too early
(closes \#1865)
- [r5441] Fixing generated models to adhere to coding standard of
using 4 spaces (closes \#1846)
- [r5459] Fixes issue with I18n and column aliases (closes \#1824)
Lots of other fixes have been made in this release so if you want to see
a list of all the changes be sure to check the
[changelog](http://www.doctrine-project.org/change_log/1_0_7).
| 36.941176 | 72 | 0.734873 | eng_Latn | 0.986152 |
585c1d65d948d8e948a999d14601ee20e1cdd238 | 798 | md | Markdown | trex/docs/tricktionary/modules/handlemessagehost.md | ss-mvp/tricktionary-be | 8b3de8557993498989a9cebae64939fc0709ab17 | [
"MIT"
] | 1 | 2021-04-10T16:10:52.000Z | 2021-04-10T16:10:52.000Z | trex/docs/tricktionary/modules/handlemessagehost.md | ss-mvp/tricktionary-be | 8b3de8557993498989a9cebae64939fc0709ab17 | [
"MIT"
] | 142 | 2021-02-04T21:06:57.000Z | 2022-03-24T01:09:00.000Z | trex/docs/tricktionary/modules/handlemessagehost.md | ss-mvp/tricktionary-be | 8b3de8557993498989a9cebae64939fc0709ab17 | [
"MIT"
] | 1 | 2021-11-22T19:32:22.000Z | 2021-11-22T19:32:22.000Z | [tricktionary-be](../README.md) / [Exports](../modules.md) / handleMessageHost
# Module: handleMessageHost
## Table of contents
### Functions
- [default](handlemessagehost.md#default)
## Functions
### default
▸ **default**(`io`: *any*, `socket`: *any*, `lobbies`: *any*, `category`: *string*, `message`: *any*): *Promise*<void\>
#### Parameters:
Name | Type | Description |
:------ | :------ | :------ |
`io` | *any* | (socket io) |
`socket` | *any* | (socket io) |
`lobbies` | *any* | game-state |
`category` | *string* | what host should listen for |
`message` | *any* | information being sent to the host |
**Returns:** *Promise*<void\>
Defined in: [handleMessageHost.ts:11](https://github.com/story-squad/tricktionary-be/blob/0b1420e/src/sockets/handleMessageHost.ts#L11)
| 26.6 | 135 | 0.626566 | yue_Hant | 0.169887 |
585c772dbd312bfe33e5972bcfc46f4c7252d2ca | 2,212 | md | Markdown | docs/en_US/jailbreak/checkra1n/installing-odysseyra1n-a8x-a9x/ra1n-macos-a8x-a9x.md | dhinakg/ios.cfw.guide | 2c25e82eae76326c2a47a987402524a531a22dd4 | [
"MIT"
] | null | null | null | docs/en_US/jailbreak/checkra1n/installing-odysseyra1n-a8x-a9x/ra1n-macos-a8x-a9x.md | dhinakg/ios.cfw.guide | 2c25e82eae76326c2a47a987402524a531a22dd4 | [
"MIT"
] | null | null | null | docs/en_US/jailbreak/checkra1n/installing-odysseyra1n-a8x-a9x/ra1n-macos-a8x-a9x.md | dhinakg/ios.cfw.guide | 2c25e82eae76326c2a47a987402524a531a22dd4 | [
"MIT"
] | null | null | null | ---
lang: en_US
title: Installing Odysseyra1n (A8X/A9X) (macOS)
description: Guide to installing Odysseyra1n on A8X and A9X devices
permalink: /installing-odysseyra1n-a8x-a9x/macos
redirect_from:
- /installing-odysseyra1n-a9x/macos
extra_contributors:
- stekc
- Tanbeer191
- TheHacker894
---
## Downloads (macOS)
- The latest release of [checkra1n](https://checkra.in)
- The custom version of [pongoOS](https://github.com/checkra1n/BugTracker/files/6429930/Pongo.zip)

## Installing checkra1n
::: tip
If you're using an M1 Mac and are using an A9X device, you will be prompted during the process to unplug and replug the device and will need to do so.
:::
1. Open the `pongoOS.zip` file, navigate to `PongoConsolidated.bin`, then extract it.
- Keep note of where you extract this
1. Open a terminal and run checkra1n in CLI mode by using `/Applications/checkra1n.app/Contents/MacOS/checkra1n -c -k [path to PongoConsolidated.bin]`
1. Plug your iOS device into your computer
1. You will now be presented with instructions in how to reboot your device into <router-link to="/faq/#what-is-dfu-mode">DFU mode</router-link>, click `Start` to begin
- Follow the instructions until your device shows a black screen
1. After this, checkra1n should automatically install
Your iOS device should now reboot.
To install Odysseyra1n, <u>do not</u> open the checkra1n app and install Cydia. Instead, follow the following instructions to install Sileo.
## The Odysseyra1n script
1. Open the terminal app on your computer
1. Ensure that your computer is trusted by your device
1. Install "homebrew" by pasting and executing the following command: `/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"`
1. Install "iproxy" by pasting and executing the following command: `brew install libusbmuxd`
1. Install the Odysseyra1n script by pasting and executing the following command: `/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/coolstar/Odyssey-bootstrap/master/procursus-deploy-linux-macos.sh)"`
!!!include(./docs/en_US/jailbreak/checkra1n/include/end-of-page.md)!!!
| 44.24 | 212 | 0.767631 | eng_Latn | 0.94941 |
585ca4acb5623c5cc035850ce3bd73e56e85f81a | 1,152 | md | Markdown | docs/visual-basic/misc/bc30414.md | BraisOliveira/docs.es-es | cc6cffb862a08615c53b07afbbdf52e2a5ee0990 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc30414.md | BraisOliveira/docs.es-es | cc6cffb862a08615c53b07afbbdf52e2a5ee0990 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc30414.md | BraisOliveira/docs.es-es | cc6cffb862a08615c53b07afbbdf52e2a5ee0990 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Valor de tipo '<type1>'no se puede convertir a'<type2>' porque los tipos de matriz tienen un número diferente de dimensiones
ms.date: 07/20/2015
f1_keywords:
- vbc30414
- bc30414
helpviewer_keywords:
- BC30414
ms.assetid: 0b103956-ce19-4bf8-9ec5-ef4f5c090a56
ms.openlocfilehash: 8cb6c90a2bbef06283ca960167d4a7fccec9569f
ms.sourcegitcommit: 2701302a99cafbe0d86d53d540eb0fa7e9b46b36
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 04/28/2019
ms.locfileid: "64640769"
---
# <a name="value-of-type-type1-cannot-be-converted-to-type2-because-the-array-types-have-different-numbers-of-dimensions"></a>Valor de tipo '\<type1 >' no se puede convertir a '\<type2 >' porque los tipos de matriz tienen un número diferente de dimensiones
Ha intentado convertir una matriz a otra con un número diferente de dimensiones.
**Identificador de error:** BC30414
## <a name="to-correct-this-error"></a>Para corregir este error
- Cambie una o ambas matrices para que coincida el número de dimensiones.
## <a name="see-also"></a>Vea también
- [Matrices](../../visual-basic/programming-guide/language-features/arrays/index.md)
| 39.724138 | 256 | 0.766493 | spa_Latn | 0.682649 |
585cb3272e62a0d4e75c577f254387af96fcbabe | 10,046 | md | Markdown | content/post/c-and-c-plus-plus-compile.md | zwpdbh/org-site | f7eabe6a54ef0946c6dbf21e99be17681b59d7b9 | [
"MIT"
] | null | null | null | content/post/c-and-c-plus-plus-compile.md | zwpdbh/org-site | f7eabe6a54ef0946c6dbf21e99be17681b59d7b9 | [
"MIT"
] | null | null | null | content/post/c-and-c-plus-plus-compile.md | zwpdbh/org-site | f7eabe6a54ef0946c6dbf21e99be17681b59d7b9 | [
"MIT"
] | null | null | null | +++
title = "C and C++ Compile"
date = 2020-08-24T10:00:00+08:00
lastmod = 2020-08-24T10:03:57+08:00
tags = ["Tools", "c", "cpp"]
draft = false
foo = "bar"
baz = "zoo"
alpha = 1
beta = "two words"
gamma = 10
+++
<div class="ox-hugo-toc toc">
<div></div>
<div class="heading">Table of Contents</div>
- [Refs](#refs)
- [GCC](#gcc)
- [Compile a C program](#compile-a-c-program)
- [Setting search path](#setting-search-path)
- [Extended search paths](#extended-search-paths)
- [Shared libraries and static libraries](#shared-libraries-and-static-libraries)
- [Cmake](#cmake)
- [My example (A big project contains sub-projects)](#my-example--a-big-project-contains-sub-projects)
- [Set CMake build variables](#set-cmake-build-variables)
</div>
<!--endtoc-->
## Refs {#refs}
## GCC {#gcc}
### Compile a C program {#compile-a-c-program}
- compile multiple files
```sh
gcc -Wall main.c hello_fn.c -o newhello
```
- separate compile and link
```sh
gcc -Wall -c main.c
gcc -Wall -c hello_fn.c
gcc main.o hello_fn.o -o newhello
```
- the benifit of it is that, if there one file is changed, only need to compile that file, and then link with other object files, much faster
- Link with external libraries (static)
- Libraries are typically stored in special archive files with the extension `.a`, referred to as static libraries. They are created from object files with a sperate tool, the GNU archiver `ar`, and used by the linker to resolve references to functions at compile-time.
- In general, the compiler option `-lNAME` will attempt to link object files with a library file `libNAME.a` in the standard library directiories (additional directories can specified with commoand-line options and environment variables)
- For example, a program `data.c` using the GNU Linear Programming library `libglpk.a`, which in turn uses the math library `libm.a`, should be compiled as:
```sh
$gcc -Wall data.c -lglpk -lm
```
- a commonly basic compile is:
```sh
gcc -W -Wall -O2 -ansi -pedantic -g first-program.c -o print-nums
```
- `-W` `-Wall` tells gcc to check for the widest range of possible errors.
- `-O2` (that is O for optimize, not zero), specifies the optimization level.
- `-ansi` `-pedantic` ensure that anything other than official ANSI/ISO will be rejected.
- `-g` flag includes debugging information in the executable.
- `-o` flag comes before the name of executable file you want to produce.
### Setting search path {#setting-search-path}
- A common problem when compiling a program using library header file is the error: `FILE.h: No such file or directory`. This occurs if a header file is not present in the standard include file directories used by gcc.
- A similar problem can occur for libraries: `/user/bin/ld: cannot find library`. This happens if a library used for linking is not present in the standard library directories used by gcc.
- The list of directiories for header files is often referred to as the `include path`.
- The list of directories for libraries is often referred to as the `link path`.
- Suppose the program needed to be compiled with header file `/opt/gdbm-1.8.3/include/gdbm.h` and lib file `/opt/gdbm-1.8.3/lib/libgdbm.a`. Then the command to compiler could be
```sh
gcc -Wall -I/opt/gdbm-1.8.3/include -L/opt/gdbm-1.8.3/lib dbmain.c -lgdbm
```
- For above example, if header file is at `/usr/local/include/gdbm.h` and the lib file is at `/usr/local/lib/libgdbm.a`, then the compile command should be
```sh
gcc -Wall -I/usr/local/include -L/usr/local/lib \
dbmain.c -lgdbm -o dbmain
```
### Extended search paths {#extended-search-paths}
- Several directories can be specified together in an environment variable as a colon separated list:
```text
DIR1:DIR2:DIR3:...
export PATH="/usr/local/bin:$PATH"
```
- When environment variables and command-line options are used together, the compiler do the search in the following order:
- command line optionals
- directories specified by environment virables
- default system directories
### Shared libraries and static libraries {#shared-libraries-and-static-libraries}
- **static libraries** are the `.a` files. When a program is linked against a static library, the machine code from the object files for any external functions used by the program is copied from the library into the final executable
- Shared libraries used the extension `.so` which stands for **shared object**. It make the executable file smaller.
- An executable file linked against a shared library contains only a small table of the functions it requires, instead of the complete machine code from the object files for the external functions. Before the executable file starts running, the machine code for the external functions is copied into memory from the shared library file on disk by the operating systema process referred to as `dynamic linking`.
- Except the shared library make executable files smaller, it also makes it possible to update a library without recompiling the programs which use it (provide the interface to the library does not change).
- gcc compiles programs to use shared libraries by default. Whenever a static library `libNAME.a` would be used for linking with the option `-lNAME` the compiler first checks for an alternative shared library with the same name with a `.so` extension. The simplest way to set the load path through the environment variable `LD_LIBRARY_PATH`.
- For example, the following commands set the load path to `/opt/gdbm-1.8.3/lib` so that `libgdbm.so` can be found:
```sh
LD_LIBRARY_PATH=/opt/gdbm-1.8.3/lib
export LD_LIBRARY_PATH
```
- If the load path contains existing entries, it can be extended using:
```text
LD_LIBRARY_PATH=NEWDIRS:$LD_LIBRARY_PATH
```
- Alternatively, static linking can be forced with the `-static` option to gcc to avoid the use of shared libraries
## Cmake {#cmake}
### My example (A big project contains sub-projects) {#my-example--a-big-project-contains-sub-projects}
- In big project's CMakeLists.txt
```text
cmake_minimum_required(VERSION3.8)
project(Learning_Unix_Network_Programming)
set(CMAKE_C_STANDARD99)
#===forUNIXNetworkProgramming
add_executable(
Learning_Unix_network_programming_daytime
daytime/daytime_client.clib/unp.hLearning_Unix_network_programming/config.hlib/unp.c)
#===forLearning_TCP_IP_socket_in_C
add_subdirectory(./Learning_TCP_IP_socket_in_C/ch02_basic_TCP_sockets)
add_subdirectory(./Learning_TCP_IP_socket_in_C/ch03_names_and_address_families)
#add_subdirectory(./Learning_TCP_IP_socket_in_C/ch04_using_UDP_sockets)
add_subdirectory(./Learning_TCP_IP_socket_in_C/ch05_sending_and_receiving_data)
add_subdirectory(./Learning_TCP_IP_socket_in_C/my_tools)
#===forlearningconcurrentprogramminginC++
add_subdirectory(./Learning_C++_Concurrency/playground)
add_subdirectory(./Learning_C++_Concurrency/demo)
#===forparallelcomputing
add_subdirectory(./Parallel_Computing/learning_pthreads/01)
add_subdirectory(./Parallel_Computing/learning_pthreads/02)
add_subdirectory(./Parallel_Computing/learning_pthreads/03)
```
- In one of the sub projects CMakeLists.txt
```text
#setminimumversion
cmake_minimum_required(VERSION3.9)
#setprojectname
project(pthreads_creating_and_terminating)
set(CMAKE_C_COMPILER/usr/bin/gcc)
set(CMAKE_CXX_COMPILER/usr/bin/g++)
#settheoutputfolderwhereyourprogramwillbecreated
set(CMAKE_BINARY_DIR${CMAKE_SOURCE_DIR}/bin)
set(EXECUTABLE_OUTPUT_PATH${CMAKE_BINARY_DIR})
set(LIBRARY_OUTPUT_PATH${CMAKE_BINARY_DIR})
#CMAKE_SOURCE_DIRiswherecmakewasstarted,thetoplevelsourcedirectory
#CMAKE_BINARY_DIRisthesameasCMAKE_SOURCE_DIR,otherwisethisisthetopleveldirectoryofyourbuildtree
include_directories("${PROJECT_SOURCE_DIR}")
#containsthefullpathtotherootofyourprojectsourcedirectory(forexample,tothenearestdirectorywhere
#CMakeLists.txtcontainsthePROJECT()command)
SET(GCC_HEADER_PATH"-I/usr/include")
SET(GCC_SHARED_LIB_PATH"-L/usr/lib")
SET(GCC_LINK_FLAGS"-lpthread")
SET(CMAKE_CXX_FLAGS"${CMAKE_CXX_FLAGS}${GCC_HEADER_PATH}${GCC_SHARED_LIB_PATH}${GCC_LINK_FLAGS}")
add_executable(
simple_one
simple_one.cpp
)
add_executable(
multiple_arguments
multiple_arguments.cpp
)
```
- In the folder which contains CMakeLists.txt
```sh
cmake -H. -Bbuild
cmake --build build -- -j4
```
### Set CMake build variables {#set-cmake-build-variables}
- ref: [CMAKE\_C\_COMPILER and CMAKE\_CXX\_COMPILER?](https://stackoverflow.com/questions/11588855/how-do-you-set-cmake-c-compiler-and-cmake-cxx-compiler-for-building-assimp-for-i)
- Option1
- You can set CMake variables at command line
```sh
cmake -D CMAKE_C_COMPILER="/path/to/your/c/compiler/executable" -D CMAKE_CXX_COMPILER "/path/to/your/cpp/compiler/executable" /path/to/directory/containing/CMakeLists.txt
```
- See [this](http://www.cmake.org/cmake/help/v2.8.12/cmake.html#opt%3a-Dvar%3atypevalue) to learn how to create a CMake cache entry.
- Option2
- You can set envrionment variables `CC` and `CXX` to point to your C and C++ compiler executable respectively, such as:
```sh
export CC=/path/to/your/c/compiler/executable
export CXX=/path/to/your/cpp/compiler/executable
cmake /path/to/directory/containing/CMakeLists.txt
```
- Option3
- Set command in CMake
```cmake
set(CMAKE_C_COMPILER "/path/to/your/c/compiler/executable")
set(CMAKE_CXX_COMPILER "/path/to/your/cpp/compiler/executable")
```
- **Must** be added before you use `project()` or `enable_language()` command. | 40.837398 | 412 | 0.723074 | eng_Latn | 0.960628 |
585d443de776dec68ebc2e80fb65070becb60cdc | 40 | md | Markdown | content/minutes/design-meeting/_index.md | mati865/compiler-team | d82f5a708ac4bd3531a5622a822e676e7b2e3d18 | [
"Apache-2.0",
"MIT"
] | null | null | null | content/minutes/design-meeting/_index.md | mati865/compiler-team | d82f5a708ac4bd3531a5622a822e676e7b2e3d18 | [
"Apache-2.0",
"MIT"
] | null | null | null | content/minutes/design-meeting/_index.md | mati865/compiler-team | d82f5a708ac4bd3531a5622a822e676e7b2e3d18 | [
"Apache-2.0",
"MIT"
] | null | null | null | ---
title: Design meeting
type: docs
--- | 10 | 21 | 0.65 | eng_Latn | 0.969998 |
585d62c25a4853b72a967f3b3fa07c786d8a6ea4 | 13,255 | md | Markdown | content/posts/2020/12/2020-12-25.md | KushibikiMashu/my-tech-blog | 4f0d46f7ee7435d5257ba6dd9697cec72fc590b9 | [
"MIT"
] | 3 | 2022-01-20T05:19:54.000Z | 2022-03-14T06:15:08.000Z | content/posts/2020/12/2020-12-25.md | KushibikiMashu/my-tech-blog | 4f0d46f7ee7435d5257ba6dd9697cec72fc590b9 | [
"MIT"
] | 1 | 2021-09-07T09:07:39.000Z | 2021-09-07T14:25:16.000Z | content/posts/2020/12/2020-12-25.md | KushibikiMashu/my-tech-blog | 4f0d46f7ee7435d5257ba6dd9697cec72fc590b9 | [
"MIT"
] | 1 | 2020-10-01T17:48:37.000Z | 2020-10-01T17:48:37.000Z | ---
title: "Next.jsのISRを使ってスプレッドシートをデータソースにして業務フローを変えた話"
date: "2020-12-25T00:15:15.000Z"
updatedAt: ""
template: "post"
draft: false
slug: "/posts/nextjs-isr-spreadsheet"
category: "Next.js"
tags:
- "Next.js"
- "React"
description: "この記事は Next.js アドベントカレンダー 2020 の最終日の記事です。本記事では、Next.js の ISR の機能を使って業務フローを変えた話を紹介します。Incremental Static Regeneration(以下、ISR) とは、Next.jsアプリケーションをビルドしてデプロイした後も、特定のページのみ定期的に再ビルドする機能です。"
socialImage: "/media/2020/12/25/2020_12_25__0.png"
---
## Next.jsのISRを使って業務フローを変えた話
この記事は [Next.js アドベントカレンダー 2020](https://qiita.com/advent-calendar/2020/nextjs) の最終日の記事です。
本記事では、Next.js の ISR の機能を使って業務フローを変えた話を紹介します。[Incremental Static Regeneration](https://nextjs.org/docs/basic-features/data-fetching#incremental-static-regeneration)(以下、ISR) とは、Next.jsアプリケーションをビルドしてデプロイした後も、特定のページのみ定期的に再ビルドする機能です。
ISRでのリクエスト先は Google Apps Script(以下、GAS)にしました。GAS でスプレッドシートのデータを返却する API を作成したので、コードも併せて紹介します。
## 作ったものは書籍の一覧更新を自動化するもの
### 開発しているサービス「弁護士ドットコムライブラリー」を紹介します
私は仕事で [弁護士ドットコムライブラリー](https://library.bengo4.com/)というサイトを開発しています。このサイトは弁護士の方向けの法律書籍読み放題サービスで、フロントはNext.js、サーバーはPHPで記述しています。

関連記事: [弁護士ドットコムライブラリーのフロントエンドのアーキテクチャ(Next.js + TypeScript)](https://panda-program.com/posts/bengo4com-library-frontend)
弁護士ドットコムライブラリーでは、トップページにプロダクトオーナー(以下、PO)が選定した書籍を100冊以上掲載しています。
初期リリース時には、まずハードコードで問題ないという判断をしました。これには2つの理由があります。1つは、書籍のメタ情報を非エンジニアでも変更したいという要件があったためtomlファイルで管理しており、DBにはbookテーブルは存在しないこと。もう1つはトップページの書籍の入れ替え要件が発生していなかったからです。しばらくはこれでうまくいきました。

### ハードコーディングでは課題がある
リリース後、しばらくサービスを運用していくうちに、各出版社様から新しい書籍や新着雑誌、また有名な書籍の掲載許可を数々頂くことができました。このため、トップページの書籍を定期的に入れ替えたいという要望がチーム内から上がってきました。
最初は、POは選び直した書籍のメタ情報をスプレッドシートに記載し、それを元にエンジニアがハードコードしているデータを定期的に書き変えるという運用フローに収まりました。しばらくの間月1回、月初にその対応をしていました。
ただ、PO としては出版社様から掲載許可を頂いたタイミングでアドホックに書籍一覧を更新したいという要望が出てきました。これはもっともな意見です。
弁護士ドットコムライブラリーは毎月更新のサブスクリプションサービスであるため、ユーザーの契約更新のタイミングまでに新着書籍が入ったことを何度かアピールしたいのです。その場合、月1回のみの更新だと書籍一覧の変更サイクルとしては長すぎ、ユーザーが新着書籍に気づかずに退会してしまうかもしれません。
一方、PO としては、月中に何度も変更するとエンジニアにとって負担になって通常業務に支障が出ないか心配だという話を聞きました。
また、この段階でプロダクトは MVP であり、別の新規機能の追加が必要であることがユーザーインタビューを通じてわかっているため、そちらの機能開発を優先したいというフェーズでした。このため、エンジニアがフル稼働しており、管理画面を作る工数を捻出できなかったというチーム事情もありました。
<div class="explain">
<figure class="explain__figure">
<div class="explain__figureWrapper">
<img class="explain__figureImage" src="/photo.jpg" alt="解説パンダくん" width="100" height="100" data-lazy-loaded="true">
</div>
<figcaption class="explain__figureCaption">解説パンダくん</figcaption>
</figure>
<div class="explain__paragraphWrapper">
<p class="explain__paragraphContent">トップページの書籍更新の頻度を増やしてコンテンツの拡充を周知することで、サブスクリプションの重要な指標である解約率を下げたいという話をチームでしていたので、なんとかしたい気持ちは山々だったんだよ。</p>
</div>
</div>
### ISRを利用することでプロダクトの課題を解決できる
そのような要望が上がり始めたあたりで、Next.js 9.5 のリリースが発表されました。9.5 で実装された ISR の機能と GAS を組み合わせると、書籍の更新フローを PO だけで完結できると考えました。
これで PO も更新頻度を気にせず、自由なタイミングで書籍一覧を更新できます。あとは staging 用、production 用のスプレッドシートを用意し、GASを記述するだけです。
弁護士ドットコムライブラリーは定額の読み放題サービスであり、コンテンツが増えれば増えるほどユーザーにとってお得になるため、新着書籍のお知らせの更新頻度が多いことはユーザーにとって嬉しいはずです。また、PO は自分で反映を確認できる上にエンジニアのタスクを減らせて、まさに「三方よし」です。
ISR はまさにチームが求めていた機能でした。
<div class="explain">
<figure class="explain__figure">
<div class="explain__figureWrapper">
<img class="explain__figureImage" src="/photo.jpg" alt="解説パンダくん" width="100" height="100" data-lazy-loaded="true">
</div>
<figcaption class="explain__figureCaption">解説パンダくん</figcaption>
</figure>
<div class="explain__paragraphWrapper">
<p class="explain__paragraphContent">ちなみに ISR は [Vercel 以外でも `next start` が実行できるなら使える](https://nextjs.org/blog/next-9-5#stable-incremental-static-regeneration)んだよ。現在、業務では ECS を使っており、Next.js を実行している Node コンテナで ISR の機能を使っているよ。</p>
</div>
</div>
なお、今回 SSR を使わなかったのは、 GAS が SpreadSheet を呼び出す実行速度が早くないため、トップページのレスポンス速度が遅くなることを懸念したためです。
## ISRでのデータ取得と書籍のReactコンポーネントを紹介します
### スプレッドシートで管理するデータとJSONの形式
スプレッドシートで管理する書籍データは以下のようなものです。
| 見出し | GAイベント名 | 書籍ID | 書籍タイトル | 著者名 | 出版年 | サムネイル画像 |
|--|--|--|--|--|--|--|
| 民法 | civilLaw | xxx | 書籍X | XXXX | 2020年 | XXX.png |
| 民法 | civilLaw | yyy | 書籍Y | YYYY | 2020年 | YYY.png |
| 一般民事 | civilCase | zzz | 書籍Z | ZZZZ | 2020年 | ZZZ.jpg |

これらのデータをトップページで利用します。GASで作成したAPIはスプレッドシートのデータをそのままJSONで返却します。
```json
[
{
"heading": "民法",
"event_name": "civilLaw",
"id": "xxx",
"title": "書籍X",
"author": "XXXX",
"published_at": "2020年",
"thumbnail_url": "XXX.png",
},
{
"heading": "民法",
"event_name": "civilLaw",
"id": "yyy",
"title": "書籍Y",
"author": "YYYY",
"published_at": "2020年",
"thumbnail_url": "YYY.png",
},
{
"heading": "一般民事",
"event_name": "civilCase",
"id": "zzz",
"title": "書籍Z",
"author": "ZZZZ",
"published_at": "2020年",
"thumbnail_url": "ZZZ.jpg",
},
// ...
]
```
### トップページでISRを利用して5分ごとにGASのAPIをコールする
ISR の機能を使うため、`getStaticProps`で GAS のエンドポイントにリクエストを送り、返ってきた上記のJSONをドメインで使う型にマッピングします。
```tsx:title=page/index.tsx
import { GetStaticProps, NextPage } from 'next'
import * as R from 'ramda'
import React from 'react'
import { BookListPartLabel } from '~/src/types/domain/googleAnalyticsEvents/Labels'
// ドメインで利用する型
type BookListItem = {
id: string
title: string
author: string
publishedAt: string
thumbnailUrl: string
}
type Props = {
bookGroups: {
heading: string
books: BookListItem[]
part: BookListPartLabel // GA イベント名
}[]
}
// トップページの表示用のコンポーネント
// 後述します
// const Component: NextPage<Props> = (props) => ( )
// API のレスポンスボディの型
type TopPageBooksBody = {
heading: string
event_name: string
id: string
title: string
author: string
published_at: string
thumbnail_url: string
}[]
export const getStaticProps: GetStaticProps<Props> = async () => {
// GOOGLE_APPS_SCRIPT_TOP_PAGE_BOOKS は GAS の API の URL
const endpoint = GOOGLE_APPS_SCRIPT_TOP_PAGE_BOOKS
const authKey = process.env.AUTH_KEY
// プログラムから GAS の API をコールするためには、オプションとして { redirect : 'follow' } が必須
const res = await fetch(`${GOOGLE_APPS_SCRIPT_TOP_PAGE_BOOKS}?auth_key=${authKey}`, { redirect: 'follow' })
const json: TopPageBooksBody = await res.json()
// 変数 groups の中身は以下。ramda.js の groupBy 関数で heading が同じ書籍をまとめる
// {
// '民法': [{ heading: '民法', event_name: 'pickup', ... }, {...}, ... ],
// '一般民事' : [{ heading: '一般民事', event_name: 'popular', ... }, {...}, ... ],
// // ...
// }
const groups = R.groupBy((book: TopPageBooksBody[number]) => book.heading)(json)
const bookGroups = Object.entries(groups).map(([heading, bookGroup]) => ({
heading,
part: bookGroup[0].event_name
books: bookGroup.map<BookListItem>((book) => ({
id: book.id,
title: book.title,
author: book.author,
publishedAt: book.published_at,
thumbnailUrl: book.thumbnail_url,
})),
}))
return {
props: { bookGroups },
revalidate: 300, // 5分単位で更新
}
}
export default Component
```
### 書籍表示用のコンポーネントのコード
```tsx:title=page/index.tsx
// 上記で省略した表示用のコンポーネントの中身
const Component: NextPage<Props> = (props) => (
<>
{/* Top Page */}
<HeroComponent />
{/* 書籍一覧 */}
<section className={css['bookList']}>
{props.bookGroups.map((group) => (
// 以下はさらに小さい粒度でコンポーネントとして切り出していますが、
// ここでは説明のためにコンポーネントとして切り出していない形で記述しています
<div className={css['bookList__content']} key={group.heading}>
<h2 className={css['bookList__heading']}>{group.heading}</h2>
<ul className={css['bookList__list']}>
{group.books.map((book, i) => (
<li className={css['bookList__item']} key={i}>
<Link href={`${PATH.SITE_BOOK}/${book.id}`}>
<a className={css['bookList__itemLink']}>
<BookListItem
part={group.part}
src={book.thumbnailUrl}
title={book.title}
author={book.author}
publishedAt={book.publishedAt}
/>
</a>
</Link>
</li>
))}
</ul>
</div>
))}
</section>
</>
)
```
5分ごとに API をコールして、スプレッドシートに更新があればページを再ビルドするようにしています。
また、JSON をドメインで利用する型にマッピングするために、[ramda.js の groupBy 関数](https://ramdajs.com/docs/#groupBy)を使っています。ramda.js は関数型プログラミングのスタイルのライブラリです。JS に組み込まれていない便利なロジックを数多く備えています。
groupBy 関数を使って、heading(見出し)ごとに書籍をグルーピングしています。
また、以下は page/index.tsx 内で利用している BookListItem コンポーネントで、書籍の表示を担っています。なお、next/image は利用していません。特に変わったところのない一般的なコンポーネントですが、 pages/index.tsx との整合性のために掲載しています。
```tsx:title=BookListItem.tsx
import React from 'react'
import LazyLoad from 'react-lazyload'
import { event } from '~/src/lib/googleAnalytics/gtag'
import { BookListPartLabel } from '~/src/types/domain/googleAnalyticsEvents/Labels'
import css from './style.module.scss'
type Props = {
part: BookListPartLabel
src: string
title: string
author: string
publishedAt: string
}
const Component: React.FC<Props> = (props) => (
<button
className={css['bookList__itemButton']}
type="button"
onClick={() =>
// GA イベント
event({
action: 'click',
category: 'book',
label: { part: props.part, title: props.title },
})
}
>
<LazyLoad>
<div className={css['bookList__itemCover']}>
<img className={css['bookList__itemCoverImage']} src={props.src} alt={props.title} />
</div>
</LazyLoad>
<div className={css['bookList__itemInformation']}>
<p className={css['bookList__itemTitle']}>{props.title}</p>
<p className={css['bookList__itemAuthor']}>{props.author}</p>
<small className={css['bookList__itemPublication']}>{props.publishedAt}</small>
</div>
</button>
)
export default Component
```
<img width="480" src="/media/2020/12/25/2020_12_25__4.png" alt="書籍コンポーネントの表示" />
onClick のイベントハンドラで Google Analytics のイベントを発火させています。
関連記事: [Next.jsでGoogle Analyticsを使えるようにする](https://panda-program.com/posts/nextjs-google-analytics)
これで ISR で5分ごとに API をコールし、スプレッドシートに変更があればページを再ビルドするトップページを作成できました🎉
## スプレッドシートのデータをJSONで返却するGASのコード
最後に、スプレッドシートのデータを返却するコードを掲載します。GAS は clasp を使って TypeScript で記述し、デプロイしています。
関連記事: [GASをclasp(CLIツール)+ TypeScriptでローカルで開発する](https://panda-program.com/posts/clasp-typescript)
スプレッドシートの権限については、チーム内は編集権限、また社内のリンクを知っている人には閲覧権限を付与しています。
一方、API は全てのデータを返却するため、SSG、ISR でのリクエスト時に GET のパラメータで`auth_key`を渡すようにします。SSG、ISR はサーバーからのリクエストなので、auth_key がユーザーに漏れることはありません。
なお、プロジェクト内で`@types/google-apps-script`を install しています。
```ts:title=main.ts
const AUTH_KEY = 'some_key'
const SHEET_ID = 'sheet_id'
const SHEET_NAME = '書籍一覧'
type Book = {
heading: string
event_name: string
id: string,
title: string,
author: string,
published_at: string,
thumbnail_url: string,
}
type Books = Book[]
const doGet = (e) => {
// GET のパラメータ
const authKey = e.parameter.auth_key
// 認証 key が一致しない場合
if (!authKey || authKey !== AUTH_KEY) {
// GAS ではレスポンスの status code を設定できないため、text を返却している
return createText('401 unauthorized. Invalid auth_key.')
}
// スプレッドシートのデータを全て取得
const rows = findAll(SHEET_ID)
// API で返却する値に変換する
const books = rows.map(row => array2Obj(row))
// JSONにする
return encode(books)
}
const findAll = (sheetId: string): string[][] => {
const sheet = SpreadsheetApp.openById(sheetId).getSheetByName(SHEET_NAME)
const lastRow = sheet.getLastRow()
return sheet.getRange(2, 1, lastRow - 1, 7).getValues()
}
const array2Obj = (array: string[]): Book => {
// カラムごとの値に名前をつける
const [heading, event_name, id, title, author, published_at, filename] = array
return {
heading,
event_name,
id,
title,
author,
published_at,
thumbnail_url: `/book/thumbnail/${id}/${filename}`
}
}
const encode = (data: Books): GoogleAppsScript.Content.TextOutput => {
const json = JSON.stringify(data)
const output = ContentService.createTextOutput(json)
return output.setMimeType(ContentService.MimeType.JSON)
}
const createText = (text): GoogleAppsScript.Content.TextOutput => {
const output = ContentService.createTextOutput(text)
return output.setMimeType(ContentService.MimeType.TEXT)
}
```
## React Server Componentについて
この記事を執筆する数日前に [React Server Components](https://reactjs.org/blog/2020/12/21/data-fetching-with-react-server-components.html) が発表されました。上記、 ISR で実現したことはまさに React Server Component のユースケースに合致しそうだなと思いました。
## まとめ
今年は Next.js と Vercel 社にとって飛躍の年でした。Next.js は SSR の他にも SSG、ISR の機能追加や、 Dynamic Routing が実装されたり、Chrome チームと共同開発した Image コンポーネントや、Web Vitals アナリティクスの組み込み関数、i18n 対応のための機能など便利な機能を備えることで、React のフレームワークとしての地位を確固たるものにしています。10月には初の Next.js カンファレンスが開催されたことも記憶に新しいです。
また、Next.js を開発している Vercel 社は 6月に約20億円の調達を発表しましたが、12月にさらに約40億円を調達したそうです。調達した資金を使って、Web の開発体験をさらに発展させて欲しいですね。
Vercel 社が Web 開発者に大きな力を与える一方、Next.js や Vercel を利用する私たち(このブログは Vercel にデプロイしています)一般の開発者も情報を発信して周囲に広めたり、初学者の疑問に答えることで Next.js コミュニティを発展させていければと思います。
嬉しいことに、サーバーサイドエンジニアが多数在籍する弊社の新プロジェクトで Next.js の採用が決まったと聞きました。来年も引き続き Next.js を使い、情報発信をして、この素晴らしい OSS を応援していきたいと思います!
<img width="480" src="/media/2020/12/25/2020_12_25__5.png" alt="Next.jsパーカー" />
ちょうど数日前に、Next.js カンファレンスのパーカーが届きました!デベロップ・プレビュー・シップ!
今年も一年お疲れ様でした。またどこか、Next.jsに関するところでお会いしましょう😊
| 32.487745 | 255 | 0.718597 | yue_Hant | 0.600526 |
585e8f8a527146049d8ea61716a6519c8af2ddf8 | 10,989 | md | Markdown | docs/source/setup/Postgres.md | gyan42/spark-streaming-playground | 147ef9cbc31b7aed242663dee36143ebf0e8043f | [
"Apache-2.0"
] | 10 | 2020-03-12T11:51:46.000Z | 2022-03-24T04:56:05.000Z | docs/build/html/_sources/setup/Postgres.md.txt | gyan42/spark-streaming-playground | 147ef9cbc31b7aed242663dee36143ebf0e8043f | [
"Apache-2.0"
] | 12 | 2020-04-23T07:28:14.000Z | 2022-03-12T00:20:24.000Z | docs/build/html/_sources/setup/Postgres.md.txt | gyan42/spark-streaming-playground | 147ef9cbc31b7aed242663dee36143ebf0e8043f | [
"Apache-2.0"
] | 1 | 2020-04-20T14:48:38.000Z | 2020-04-20T14:48:38.000Z | # PostgreSQL
Home url : [https://www.postgresql.org/](https://www.postgresql.org/)
Here is a good comparision [PostgreSQL vs MySQL](https://www.postgresqltutorial.com/postgresql-vs-mysql/)
The choice of PostgresSQL was done since we are using closest managed service in AWS called [Redshift](https://aws.amazon.com/redshift/)
## Setup
```
#install ubuntu packages
sudo apt-get install postgresql postgresql-contrib
# check the version
sudo -u postgres psql -c "SELECT version();"
# test the installation
sudo su - postgres
psql #to launch the terminal
\q #to quit
# or to run psql directly
sudo -i -u postgres psql
```
To cut short the permission configurations for new users, lets create a Ubuntu user with same name:
`sudo adduser sparkstreaming #password sparkstreaming`
We need log into PostgresSQL to create users before they can use the DB.
For our case we are going ot create a user called `sparkstreaming` and DB called `sparkstreamingdb`
```
sudo su - postgres
psql #to launch the terminal
# drop user sparkstreaming;
CREATE USER sparkstreaming WITH PASSWORD 'sparkstreaming';
\du #list users
CREATE DATABASE sparkstreamingdb;
grant all privileges on database sparkstreamingdb to sparkstreaming;
\list # to see the DB created
\q
# test the new user and DB
sudo -i -u sparkstreaming psql -d sparkstreamingdb
CREATE TABLE authors (code char(5) NOT NULL, name varchar(40) NOT NULL, city varchar(40) NOT NULL, joined_on date NOT NULL, PRIMARY KEY (code));
INSERT INTO authors VALUES(1,'Ravi Saive','Mumbai','2012-08-15');
\dt #list tables
\conninfo #get connection info
```
To know the file storage in Postgres, this is to make sure the data in Docker can be mapped to a volume for offline storage.
`SELECT name, setting FROM pg_settings WHERE category = 'File Locations';`
If you would like to restart the service:
```
sudo service postgresql restart
sudo systemctl restart postgresql
```
To see how many active connections to the DB are made:
`SELECT pid, application_name, state FROM pg_stat_activity;`
This is important some times the connetion becomes stale and left hanging there, making new connection bounce back.
Service management commands:
```
sudo service postgresql stop
sudo service postgresql start
sudo service postgresql restart
```
## Integration with Spark
Part of our work flow we need to read and write to Postresql from Apache Spark.
Lets test whether we can do it from local `pyspark` terminal.
```
#it is mandate to give the posgres maven ids for runtime
pyspark --packages postgresql:postgresql:9.1-901-1.jdbc4
#read the table "authors"
df = spark.read. \
format("jdbc"). \
option("url", "jdbc:postgresql://localhost:5432/sparkstreamingdb"). \
option("dbtable", "authors"). \
option("user", "sparkstreaming"). \
option("password", "sparkstreaming"). \
option("driver", "org.postgresql.Driver"). \
load()
# display the table
df.printSchema()
```
## Hive Metastore DB setup
We could use different metastore DB for Hive, below steps helps to use Postgresql as its external metastore,
which then can be shared with Spark.
```
sudo adduser hive #password hive
sudo su - postgres
psql #to launch the terminal
CREATE USER hive WITH PASSWORD 'hive'; # drop user hive; (if needed)
\du
CREATE DATABASE hive;
grant all privileges on database hive to hive;
\list # to see the DB created
\q
```
We need do some changes to connection configs, to enable login from different services:
```
# change the 3rd colum values to "all"
sudo vim /etc/postgresql/10/main/pg_hba.conf
# "local" is for Unix domain socket connections only
local all all md5
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
```
Fire a python shell and test out the connection
```
import psycopg2
conn = psycopg2.connect(host="localhost", port=5432, database="hive", user="hive", password="hive")
sql_command = "SELECT * FROM \"CDS\";"
print (sql_command)
# Load the data
data = pd.read_sql(sql_command, conn)
print(data)
```
Use Hive provided tool to setup the metastore tables an schema:
`/path/to/hive/bin/schematool -dbType postgres -initSchema`
And then try running following commands, you should see bunch of tables there:
```shell script
sudo -i -u hive psql -d hive
#asks for two password, one for sudo and other one for DB `hive` which is `hive`
hive=> \dt
```
------------------------------------------------------------------------------------------------------------------------
## PSQL
Magic words:
```bash
psql -U postgres
```
Some interesting flags (to see all, use `-h` or `--help` depending on your psql version):
- `-E`: will describe the underlaying queries of the `\` commands (cool for learning!)
- `-l`: psql will list all databases and then exit (useful if the user you connect with doesn't has a default database, like at AWS RDS)
Most `\d` commands support additional param of `__schema__.name__` and accept wildcards like `*.*`
- `\q`: Quit/Exit
- `\c __database__`: Connect to a database
- `\d __table__`: Show table definition including triggers
- `\d+ __table__`: More detailed table definition including description and physical disk size
- `\l`: List databases
- `\dy`: List events
- `\df`: List functions
- `\di`: List indexes
- `\dn`: List schemas
- `\dt *.*`: List tables from all schemas (if `*.*` is omitted will only show SEARCH_PATH ones)
- `\dT+`: List all data types
- `\dv`: List views
- `\df+ __function__` : Show function SQL code.
- `\x`: Pretty-format query results instead of the not-so-useful ASCII tables
- `\copy (SELECT * FROM __table_name__) TO 'file_path_and_name.csv' WITH CSV`: Export a table as CSV
User Related:
- `\du`: List users
- `\du __username__`: List a username if present.
- `create role __test1__`: Create a role with an existing username.
- `create role __test2__ noinherit login password __passsword__;`: Create a role with username and password.
- `set role __test__;`: Change role for current session to `__test__`.
- `grant __test2__ to __test1__;`: Allow `__test1__` to set its role as `__test2__`.
Drop all the tables in a database:
```
DROP SCHEMA public CASCADE;
CREATE SCHEMA public AUTHORIZATION {USER};
GRANT ALL ON schema public TO {USER};
```
## Configuration
- Changing verbosity & querying Postgres log:
<br/>1) First edit the config file, set a decent verbosity, save and restart postgres:
```
sudo vim /etc/postgresql/9.3/main/postgresql.conf
# Uncomment/Change inside:
log_min_messages = debug5
log_min_error_statement = debug5
log_min_duration_statement = -1
sudo service postgresql restart
```
2) Now you will get tons of details of every statement, error, and even background tasks like VACUUMs
```
tail -f /var/log/postgresql/postgresql-9.3-main.log
```
3) How to add user who executed a PG statement to log (editing `postgresql.conf`):
```
log_line_prefix = '%t %u %d %a '
```
## Create command
There are many `CREATE` choices, like `CREATE DATABASE __database_name__`, `CREATE TABLE __table_name__` ... Parameters differ but can be checked [at the official documentation](https://www.postgresql.org/search/?u=%2Fdocs%2F9.1%2F&q=CREATE).
## Handy queries
- `SELECT * FROM pg_proc WHERE proname='__procedurename__'`: List procedure/function
- `SELECT * FROM pg_views WHERE viewname='__viewname__';`: List view (including the definition)
- `SELECT pg_size_pretty(pg_total_relation_size('__table_name__'));`: Show DB table space in use
- `SELECT pg_size_pretty(pg_database_size('__database_name__'));`: Show DB space in use
- `show statement_timeout;`: Show current user's statement timeout
- `SELECT * FROM pg_indexes WHERE tablename='__table_name__' AND schemaname='__schema_name__';`: Show table indexes
- Get all indexes from all tables of a schema:
```sql
SELECT
t.relname AS table_name,
i.relname AS index_name,
a.attname AS column_name
FROM
pg_class t,
pg_class i,
pg_index ix,
pg_attribute a,
pg_namespace n
WHERE
t.oid = ix.indrelid
AND i.oid = ix.indexrelid
AND a.attrelid = t.oid
AND a.attnum = ANY(ix.indkey)
AND t.relnamespace = n.oid
AND n.nspname = 'kartones'
ORDER BY
t.relname,
i.relname
```
- Execution data:
- Queries being executed at a certain DB:
```sql
SELECT datname, application_name, pid, backend_start, query_start, state_change, state, query
FROM pg_stat_activity
WHERE datname='__database_name__';
```
- Get all queries from all dbs waiting for data (might be hung):
```sql
SELECT * FROM pg_stat_activity WHERE waiting='t'
```
- Currently running queries with process pid:
```sql
SELECT pg_stat_get_backend_pid(s.backendid) AS procpid,
pg_stat_get_backend_activity(s.backendid) AS current_query
FROM (SELECT pg_stat_get_backend_idset() AS backendid) AS s;
```
Casting:
- `CAST (column AS type)` or `column::type`
- `'__table_name__'::regclass::oid`: Get oid having a table name
Query analysis:
- `EXPLAIN __query__`: see the query plan for the given query
- `EXPLAIN ANALYZE __query__`: see and query_to_df the query plan for the given query
- `ANALYZE [__table__]`: collect statistics
Generating random data ([source](https://www.citusdata.com/blog/2019/07/17/postgres-tips-for-average-and-power-user/)):
- `INSERT INTO some_table (a_float_value) SELECT random() * 100000 FROM generate_series(1, 1000000) i;`
Keyboard shortcuts
- `CTRL` + `R`: reverse-i-search
**References**
- https://www.tecmint.com/install-postgresql-on-ubuntu/
- https://linuxize.com/post/how-to-install-postgresql-on-ubuntu-18-04/
- https://medium.com/@thomaspt748/how-to-upsert-data-into-relational-database-using-spark-7d2d92e05bb9
- https://linuxize.com/post/how-to-create-a-sudo-user-on-ubuntu/
- https://stackoverflow.com/questions/21898152/why-cant-you-start-postgres-in-docker-using-service-postgres-start
- https://markheath.net/post/exploring-postgresql-with-docker
- `ptop` and `pg_top`: `top` for PG. Available on the APT repository from `apt.postgresql.org`.
- [pg_activity](https://github.com/julmon/pg_activity): Command line tool for PostgreSQL server activity monitoring.
- [Unix-like reverse search in psql](https://dba.stackexchange.com/questions/63453/is-there-a-psql-equivalent-of-bashs-reverse-search-history):
```bash
$ echo "bind "^R" em-inc-search-prev" > $HOME/.editrc
$ source $HOME/.editrc
```
- [PostgreSQL Exercises](https://pgexercises.com/): An awesome resource to learn to learn SQL, teaching you with simple examples in a great visual way. **Highly recommended**.
- [A Performance Cheat Sheet for PostgreSQL](https://severalnines.com/blog/performance-cheat-sheet-postgresql): Great explanations of `EXPLAIN`, `EXPLAIN ANALYZE`, `VACUUM`, configuration parameters and more. Quite interesting if you need to tune-up a postgres setup.
| 35.108626 | 267 | 0.721085 | eng_Latn | 0.719176 |
585ef35768ce3346ef169b3c8ee415f5201ee9fd | 4,300 | md | Markdown | _m/madtropperne.md | hypesystem/spejdermaerker.dk | 2ee8a777df2b03c347d7e55153ae29d08d66f68a | [
"MIT"
] | 2 | 2017-04-05T19:19:15.000Z | 2018-03-19T13:08:08.000Z | _m/madtropperne.md | hypesystem/spejdermaerker.dk | 2ee8a777df2b03c347d7e55153ae29d08d66f68a | [
"MIT"
] | 122 | 2016-02-13T19:24:39.000Z | 2021-12-09T15:19:22.000Z | _m/madtropperne.md | hypesystem/spejdermaerker.dk | 2ee8a777df2b03c347d7e55153ae29d08d66f68a | [
"MIT"
] | 2 | 2016-11-09T11:41:04.000Z | 2020-08-19T14:31:13.000Z | ---
name: Madtropperne
tags:
- uofficielt
- forløb
image: madtropperne.jpg
coverimage: cover-madtropperne.jpg
price: 7
age: 10-17
highlight: new
date_added: 2018-03-29
---
Det er vigtigt at kunne lave god mad – både fordi det smager dejligt, og fordi maden giver energi til aktiviteter.
Det handler også om at kunne klare sig selv, og at forstå madens vej fra jord til bord.
Og så er det hyggeligt at spise med andre.
### Skal din spejdermad være lidt vildere fremover?
Så tag Madtroppernes spejdermærke og lær at lave lækker og simpel mad over bål.
Aktiviteten tager udgangspunkt i <a href="http://madkulturen.dk/fileadmin/user_upload/madkulturen.dk/Dokumenter/WEB_MADTROPPERNE_HAANDBOGEN.pdf" rel="noopener" target="_blank">Madtroppernes Kulinariske Håndbog</a>. Her har vi samlet tips og tricks til jer. I kan bl.a. læse om de fem grundsmage, finde gode grundopskrifter til nem og lækker spejdermad – og hvis I har mod på det – vilde urter I kan plukke i naturen.
Det tager 2-3 gange (ca. 2 timer pr. gang) at tage Madtroppernes mærke, hvis forløbet er forberedt.
Der skal laves 3 aktiviteter, og der er en vurdering til sidst, for at se om man lever op til kravene og kan få mærket.
Læs mere om Madtropperne, som er et projekt fra Madkulturen, på <a href="http://madkulturen.dk/servicemenu/nyhed/nyhed/alle-elskede-madtropperne/" target="_blank" rel="noopener">deres hjemmeside</a>.
<figure>
<iframe src="https://www.youtube.com/embed/l2An9_03Plc?rel=0" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
<figcaption>
<strong>Madtropperne på Spejdernes Lejr.</strong>
I 2012 blev Madtropperne introduceret som en aktivitet på den tværkorpslige lejr, Spejdernes Lejr.
I denne video ses aktiviteten fra lejren efter, Spejdernes Lejr 2017.
<div class="figure__license">
© Madkulturen.
</div>
</figcaption>
</figure>
## Aktivitet 1: Lav en ret ud fra en af opskrift­erne fra Madtroppernes Kulinariske Håndbog
To og to laver spejderne en ret fra Madtroppernes Kulinariske Håndbog. Retten serveres for resten af patruljen. Tag en snak om, hvad der gik godt og hvad I måske ville gøre anderledes næste gang.
## Aktivitet 2: Viden om råvarer i sæson og de fem grundsmage
Spejderne søger viden om, hvornår forskellige frugter og grøntsager er i sæson, samt hvad det vil sige at smage til.
- Undersøg hvad det betyder, at noget er i sæson. Hvorfor er det en fordel at spise efter sæsonerne?
- Find 10 grøntsager og frugter og læg dem i rækkefølge efter, hvornår på året de er i sæson.
- Gennemgå de fem grundsmage og giv eksempler på, hvor man kan finde grundsmagene.
- Smag på honning, ansjos, citronsaft, valnødder og salt og diskuter, hvilke grundsmage de smager af.
- Planlæg en ret med mindst én grøntsag i sæson, som I vil lave til 3. gang, og lav en indkøbsseddel. I må gerne finde inspiration i Madtroppernes Kulinariske Håndbog eller på nettet.
- Spejderlederen eller spejderne køber herefter ind og sørger for at have varerne klar til 3. gang.
<figure>
<a href="/img/madtropperne-tomatsuppe.jpg" target="_blank">
<img src="/img/madtropperne-tomatsuppe.jpg">
</a>
<figcaption>
<strong>Opskrift på tomatsuppe.</strong>
Tomatsuppen er en god basis at bruge, når man tester hvordan forskellig smag påvirker en ret.
<div class="figure__license">
© Madkulturen.
</div>
</figcaption>
</figure>
## Aktivitet 3: Lav en ret over bål med en grøntsag i sæson
Med den nye viden om de fem grundsmage og råvarer i sæson, laver spejderne nu en ret, de selv har valgt, til deres medspejdere.
**Vurdering.** For at opnå Madtropperne-mærket skal retten opfylde følgende kriterier:
- Retten skal indeholde mindst én grøntsag i sæson
- Alle fem grundsmage skal være repræsenteret i retten
- Retten skal være lavet over bål – kogt, stegt, bagt, grillet, dampet eller røget osv.
- Spejderne har prøvet noget nyt, f.eks. en grøntsag de aldrig har smagt før, en ny måde at tilberede en grøntsag de kender, eller de har afprøvet en vild idé!
- Spejderne kan argumentere for, hvorfor de har valgt at lave netop denne ret, og hvordan de har lavet den.
Det er spejderlederen og medspejderne der vurderer, om retten opfylder kriterierne.
| 53.08642 | 416 | 0.754186 | dan_Latn | 0.99976 |
585f4339ad0844a56bd17057a54fad596625a47d | 50 | md | Markdown | _tags/coding.md | yifanyin/yifanyin.github.io | 279d48ff8c94254aacc995b23b54e1ea91c3ad9b | [
"MIT"
] | null | null | null | _tags/coding.md | yifanyin/yifanyin.github.io | 279d48ff8c94254aacc995b23b54e1ea91c3ad9b | [
"MIT"
] | null | null | null | _tags/coding.md | yifanyin/yifanyin.github.io | 279d48ff8c94254aacc995b23b54e1ea91c3ad9b | [
"MIT"
] | null | null | null | ---
layout: tag_page
title: coding
tag: coding
--- | 10 | 16 | 0.68 | eng_Latn | 0.984277 |
585f56fe8d2c88bbca33db1ddd090f085c01b54d | 6,072 | md | Markdown | Documentation/SQLScripts.md | ramon54321/WeatherToday | 032aeeaa0727948618d06ee1dda33dc8bef22896 | [
"MIT"
] | null | null | null | Documentation/SQLScripts.md | ramon54321/WeatherToday | 032aeeaa0727948618d06ee1dda33dc8bef22896 | [
"MIT"
] | 1 | 2018-01-19T23:06:56.000Z | 2018-01-23T12:23:58.000Z | Documentation/SQLScripts.md | ramon54321/WeatherToday | 032aeeaa0727948618d06ee1dda33dc8bef22896 | [
"MIT"
] | null | null | null | ## Get data by locations
``` SQL
SELECT t2.location, COALESCE(t1.min, 0) as min, COALESCE(t1.max, 0) as max, t2.latest FROM
(
WITH results24 AS
(
SELECT location as location, min(temperature) as min, max(temperature) as max
FROM temperature
WHERE time > now() - interval '24 hours'
GROUP BY location
)
SELECT location, min, max FROM results24
UNION
SELECT location, latest as min, latest as max FROM
(SELECT DISTINCT ON (location) location as location, temperature as latest
FROM temperature
ORDER BY location, time DESC) latestTemp
WHERE NOT EXISTS (SELECT * FROM results24)
) t1
RIGHT OUTER JOIN
(SELECT DISTINCT ON (location) location as location, temperature as latest
FROM temperature
ORDER BY location, time DESC) t2
ON t2.location = t1.location
ORDER BY location
```
## Get recprds by location
``` SQL
SELECT time, temperature
FROM temperature
WHERE location = 'New York'
ORDER BY time DESC
LIMIT 10
```
## Initialize DB with fake data
``` SQL
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', 4);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', 6);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', 4);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', 3);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', 1);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', -1);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', -4);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', -8);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', -7);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', -4);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', 0);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Helsinki', 2);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 10);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 14);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 8);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 6);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 4);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 3);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 4);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 6);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 4);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 7);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 12);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Amsterdam', 10);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 43);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 39);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 35);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 31);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 29);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 30);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 32);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 31);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 36);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 38);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 38);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Dubai', 40);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 19);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 21);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 22);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 17);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 15);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 16);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 13);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 16);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 17);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 21);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 22);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'New York', 23);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 28);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 29);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 30);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 27);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 24);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 19);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 18);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 24);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 26);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 28);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 31);
INSERT INTO temperature (time, location, temperature) VALUES (now(), 'Tokyo', 31);
```
| 54.214286 | 90 | 0.726449 | kor_Hang | 0.503664 |
585fe199443cec53cc6354aa36ba9f91fa8a199a | 813 | md | Markdown | includes/service-fabric-powershell.md | macdrai/azure-docs.fr-fr | 59bc35684beaba04a4f4c09a745393e1d91428db | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/service-fabric-powershell.md | macdrai/azure-docs.fr-fr | 59bc35684beaba04a4f4c09a745393e1d91428db | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/service-fabric-powershell.md | macdrai/azure-docs.fr-fr | 59bc35684beaba04a4f4c09a745393e1d91428db | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
author: rwike77
ms.service: service-fabric
ms.topic: include
ms.date: 11/25/2018
ms.author: ryanwi
ms.openlocfilehash: 80596def584c51ecf669924cc1d4a30541ddb054
ms.sourcegitcommit: 829d951d5c90442a38012daaf77e86046018e5b9
ms.translationtype: HT
ms.contentlocale: fr-FR
ms.lasthandoff: 10/09/2020
ms.locfileid: "67177473"
---
> [!IMPORTANT]
> Il existe deux modules PowerShell utilisés pour interagir avec Service Fabric. [Azure PowerShell](/powershell/azure/install-az-ps) est utilisé pour gérer les ressources Azure, comme un cluster Service Fabric hébergé par Azure. [SDK Azure Service Fabric](../articles/service-fabric/service-fabric-get-started.md) est utilisé pour se connecter directement au cluster Service Fabric (peu importe où il est hébergé) et gérer le cluster, les applications et les services.
| 50.8125 | 469 | 0.809348 | fra_Latn | 0.750337 |
585fe369e1caba2fd80c87ab8e51a022bbaf2d83 | 949 | md | Markdown | furnance-controller-app/README.md | luk6xff/FurnaceController | 784a1c480b5b592d8c730293abefe384af9ae7b8 | [
"MIT"
] | null | null | null | furnance-controller-app/README.md | luk6xff/FurnaceController | 784a1c480b5b592d8c730293abefe384af9ae7b8 | [
"MIT"
] | null | null | null | furnance-controller-app/README.md | luk6xff/FurnaceController | 784a1c480b5b592d8c730293abefe384af9ae7b8 | [
"MIT"
] | null | null | null | # Furnace Controller platformio-mbed app
Simple pump controller SW for wood and coal fired furnance.
[img1]: ./../docs/photos/p1.jpg "Image 1"
[img2]: ./../docs/photos/p2.jpg "Image 2"
## Install platformio
```
sudo apt-get remove code --purge
sudo apt-get install code="1.39.2-1571154070"
sudo apt-mark hold code
```
## FAQ
* Installing platformIO fails:
Run ```sudo apt-get install python3-venv``` and try again.
* Could not open port '/dev/ttyUSB0'
```
sudo usermod -a -G tty $USER
sudo usermod -a -G dialout $USER
sudo usermod -a -G plugdev $USER
logout
login
```
* Udev rules invalid errors eg. `Error: libusb_open() failed with LIBUSB_ERROR_ACCESS`
```
curl -fsSL https://raw.githubusercontent.com/platformio/platformio-core/master/scripts/99-platformio-udev.rules | sudo tee /etc/udev/rules.d/99-platformio-udev.rules
sudo service udev restart
```
More details here: https://docs.platformio.org/en/latest/faq.html#platformio-udev-rules
| 27.911765 | 165 | 0.738672 | kor_Hang | 0.217267 |
585ff6d4eb61d1029a32b00dc4fe8a6da128b01a | 3,817 | md | Markdown | docs/t-sql/spatial-geometry/ogc-static-geometry-methods.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/t-sql/spatial-geometry/ogc-static-geometry-methods.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/t-sql/spatial-geometry/ogc-static-geometry-methods.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Metodi di geometria statici OGC | Microsoft Docs
ms.custom: ''
ms.date: 03/06/2017
ms.prod: sql
ms.prod_service: database-engine, sql-database
ms.reviewer: ''
ms.technology: t-sql
ms.topic: language-reference
dev_langs:
- TSQL
helpviewer_keywords:
- OGC Static Geometry Methods [SQL Server]
ms.assetid: 74960d25-83c2-4ad6-9318-098c348ea977
author: MladjoA
ms.author: mlandzic
ms.openlocfilehash: 48f8b8a53f22c4f4e102606ca4e5133b95536be2
ms.sourcegitcommit: 58158eda0aa0d7f87f9d958ae349a14c0ba8a209
ms.translationtype: HT
ms.contentlocale: it-IT
ms.lasthandoff: 03/30/2020
ms.locfileid: "68101074"
---
# <a name="ogc-static-geometry-methods"></a>Metodi di geometria statici OGC
[!INCLUDE[tsql-appliesto-ss2012-asdb-xxxx-xxx-md](../../includes/tsql-appliesto-ss2012-asdb-xxxx-xxx-md.md)]
In [!INCLUDE[ssCurrent](../../includes/sscurrent-md.md)] sono supportati i metodi di geometria statici OGC (Open Geospatial Consortium).
Per ulteriori informazioni sulle specifiche OGC, vedere i seguenti argomenti:
[OGC Specifications, Simple Feature Access Part 1 - Common Architecture](https://go.microsoft.com/fwlink/?LinkId=93627)
[OGC Specifications, Simple Feature Access Part 2 - SQL Options](https://go.microsoft.com/fwlink/?LinkId=93628) (Specifiche OGC, accesso semplificato alle caratteristiche Parte 2 - Opzioni SQL)
## <a name="in-this-section"></a>Contenuto della sezione
- [STGeomFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stgeomfromtext-geometry-data-type.md)
- [STPointFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stpointfromtext-geometry-data-type.md)
- [STLineFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stlinefromtext-geometry-data-type.md)
- [STPolyFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stpolyfromtext-geometry-data-type.md)
- [STMPointFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stmpointfromtext-geometry-data-type.md)
- [STMLineFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stmlinefromtext-geometry-data-type.md)
- [STMPolyFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stmpolyfromtext-geometry-data-type.md)
- [STGeomCollFromText (tipo di dati geometry)](../../t-sql/spatial-geometry/stgeomcollfromtext-geometry-data-type.md)
- [STGeomFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stgeomfromwkb-geometry-data-type.md)
- [STPointFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stpointfromwkb-geometry-data-type.md)
- [STLineFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stlinefromwkb-geometry-data-type.md)
- [STPolyFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stpolyfromwkb-geometry-data-type.md)
- [STMPointFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stmpointfromwkb-geometry-data-type.md)
- [STMLineFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stmlinefromwkb-geometry-data-type.md)
- [STMPolyFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stmpolyfromwkb-geometry-data-type.md)
- [STGeomCollFromWKB (tipo di dati geometry)](../../t-sql/spatial-geometry/stgeomcollfromwkb-geometry-data-type.md)
## <a name="see-also"></a>Vedere anche
[Metodi OGC sulle istanze di geometria](../../t-sql/spatial-geometry/ogc-methods-on-geometry-instances.md)
[Metodi estesi sulle istanze di geometria](../../t-sql/spatial-geometry/extended-methods-on-geometry-instances.md)
[Metodi di geometria statici estesi](../../t-sql/spatial-geometry/extended-static-geometry-methods.md)
| 50.893333 | 196 | 0.727797 | kor_Hang | 0.291014 |
58600a7acff5850ca3651fb44a56c67902bfaacf | 1,682 | md | Markdown | MIP41/MIP41c4-Subproposal-Template.md | monkeyirish/mips | cbe9c61c0656c1683847e4f0052ddc77e9d4a4bf | [
"MIT"
] | 2 | 2021-11-12T12:38:40.000Z | 2021-11-12T13:00:22.000Z | MIP41/MIP41c4-Subproposal-Template.md | monkeyirish/mips | cbe9c61c0656c1683847e4f0052ddc77e9d4a4bf | [
"MIT"
] | 1 | 2021-11-10T12:11:58.000Z | 2021-11-10T12:11:58.000Z | MIP41/MIP41c4-Subproposal-Template.md | manoplas/mips | 1ca426322c162a6844c7382b418721ab51f8aea3 | [
"MIT"
] | 2 | 2021-12-15T13:45:47.000Z | 2022-03-25T13:01:23.000Z | # MIP41c4: Facilitator Onboarding (Subproposal Process) Template
## Preamble
```
MIP41c4-SP#: #
Author(s):
Contributors:
Tags: template
Status:
Date Applied: <yyyy-mm-dd>
Date Ratified: <yyyy-mm-dd>
```
## Sentence Summary
## Paragraph Summary
## Specification
### Motivation
- Why are you applying to become a Facilitator?
### Core Unit ID
- Specify the Core Unit ID.
- This element specifies which Core Unit you are proposing to onboard to as a Facilitator.
### Facilitator name and information
- This element must contain the Forum name of the Facilitator, as well as other names and IDs in Maker related communication channels. Additionally it must contain the Facilitators Ethereum address used for Budget Implementation control and other authorizations.
### Facilitator Commitment
- The Facilitator Commitment is a detailed description and plan of what the Facilitator plans to do in order to achieve success for the Core Unit. There is a lot of flexibility in what a Facilitator can write in their commitment, including organizational structure and theory, plans for the budget, hiring and infrastructure plans, etc.
- The Facilitator commitment should also contain targets and goals that can be observed by Governance, if appropriate. This helps Governance to see whether the Facilitator is living up to their expectations.
- A crucial part of the Facilitator Commitment are clear commitments to transparency. The Facilitator should commit to an effective plan that will allow Governance and other stakeholders, such as contributors contemplating doing work, to gain direct insight into what is being worked on and who are taking care of what responsibilities.
| 43.128205 | 336 | 0.795482 | eng_Latn | 0.999553 |
5860a91046c27c2eea2ee34490bd93088bbbb036 | 137 | md | Markdown | docs/md/zh/start-installation.md | Wilfredo-Ho/vue-baidu-map | d38acf51ee4d4ca2e38fb58a09b059185f4d298a | [
"MIT"
] | null | null | null | docs/md/zh/start-installation.md | Wilfredo-Ho/vue-baidu-map | d38acf51ee4d4ca2e38fb58a09b059185f4d298a | [
"MIT"
] | 1 | 2022-03-02T10:10:18.000Z | 2022-03-02T10:10:18.000Z | docs/md/zh/start-installation.md | gyjsuccess/vue-baidu-map | 106c69a7cae920822ca4156cd747891383888bb2 | [
"MIT"
] | 1 | 2020-12-13T14:23:35.000Z | 2020-12-13T14:23:35.000Z | # 安装
## NPM
```bash
$ npm install vue-baidu-map --save
```
## CDN
```html
<script src="https://unpkg.com/vue-baidu-map"></script>
``` | 10.538462 | 55 | 0.583942 | yue_Hant | 0.403555 |
58621215ba0ce2f52374939560e5cd76a52b41c6 | 1,148 | md | Markdown | website/content/cryptocurrency/discovery/cglosers/_index.md | minhhoang1023/GamestonkTerminal | 195dc19b491052df080178c0cc6a9d535a91a704 | [
"MIT"
] | 1 | 2022-02-18T04:02:52.000Z | 2022-02-18T04:02:52.000Z | website/content/cryptocurrency/discovery/cglosers/_index.md | minhhoang1023/GamestonkTerminal | 195dc19b491052df080178c0cc6a9d535a91a704 | [
"MIT"
] | null | null | null | website/content/cryptocurrency/discovery/cglosers/_index.md | minhhoang1023/GamestonkTerminal | 195dc19b491052df080178c0cc6a9d535a91a704 | [
"MIT"
] | null | null | null | ```
usage: cglosers [-p {14d,1h,1y,200d,24h,30d,7d}] [-l N] [-s {Symbol,Name,Price [$],Market Cap [$],Market Cap Rank,Volume [$]}] [--descend] [-l] [--export {csv,json,xlsx}] [-h]
```
Shows Largest Losers - coins which price dropped the most in given period You can use parameter --period to set which timeframe are you interested
in: {14d,1h,1y,200d,24h,30d,7d} You can look on only top N number of records with --top, You can sort by {Symbol,Name,Price [$],Market Cap [$],Market Cap Rank,Volume [$]} with --sort
```
optional arguments:
-p {14d,1h,1y,200d,24h,30d,7d}, --period {14d,1h,1y,200d,24h,30d,7d}
time period, one from {14d,1h,1y,200d,24h,30d,7d} (default: 1h)
-l N, --limit N display N records (default: 15)
-s {Symbol,Name,Price [$],Market Cap [$],Market Cap Rank,Volume [$]}, --sort {Symbol,Name,Price [$],Market Cap [$],Market Cap Rank,Volume [$]}
Sort by given column. (default: Market Cap Rank)
--export {csv,json,xlsx}
Export dataframe data to csv,json,xlsx file (default: )
-h, --help show this help message (default: False)
```
| 60.421053 | 182 | 0.62108 | eng_Latn | 0.61632 |
586252d50361c2bf7977b0c75d8ecb158f010e97 | 2,006 | md | Markdown | packages/rarity-tools/README.md | fmoliveira/web3-stuff | 93d7fcb9460f6ca2270fae540a9b54b5264d2c3e | [
"MIT"
] | 1 | 2021-09-23T03:05:25.000Z | 2021-09-23T03:05:25.000Z | packages/rarity-tools/README.md | fmoliveira/web3-stuff | 93d7fcb9460f6ca2270fae540a9b54b5264d2c3e | [
"MIT"
] | null | null | null | packages/rarity-tools/README.md | fmoliveira/web3-stuff | 93d7fcb9460f6ca2270fae540a9b54b5264d2c3e | [
"MIT"
] | null | null | null | # Rarity Tools
Calculate rarity score of NFTs with [rarity.tools](https://raritytools.medium.com/ranking-rarity-understanding-rarity-calculation-methods-86ceaeb9b98c) method.
## Getting started
### Requirements
You need a recent version of Node.js installed. Node.js version 14+ is recommended.
Other than Node.js, this project has no npm dependencies.
### Preparing JSON file with your NFT traits
To use this tool, you need a JSON file containing all the traits for each token IDs of your NFT.
Your JSON file must contain an array of objects, containing a string-key of your token id associated to another object with your traits. Your traits object can contain as many traits as you wish and there is no naming convention for them.
See an example below:
```json
[
{
"1": {
"head": "Eizo's Hood",
"shoulders": "Pilgrim's Pauldrons",
"knees": "Arena Fighter's Polyens",
"toes": "Boots of Agamemnon"
}
},
{
"2": {
"head": "Eizo's Hood",
"shoulders": "Pilgrim's Pauldrons",
"knees": "Arena Fighter's Polyens",
"toes": "Boots of Agamemnon"
}
},
{
"3": {
"head": "Eizo's Hood",
"shoulders": "Pilgrim's Pauldrons",
"knees": "Arena Fighter's Polyens",
"toes": "Boots of Agamemnon"
}
}
]
```
Moreover, you can download an example by running the command `yarn pull:example`. Check the downloaded file at `data/loot.json`.
> Why this format? Because it's what the [most popular Loot script](https://github.com/Anish-Agnihotri/dhof-loot) uses. Since the Loot contract has lots of derivatives, this tool will probably help more people by following that same format.
### Executing the tool
Run the script `src/index.mjs` passing the path to your JSON file as an argument, for example:
```sh
$ node src/index.mjs data/loot.json
```
The rarity statistics will be stored in the `output` folder (automatically created) with the same name as your input file, but with a CSV extension. Use Google Sheets or any other spreadsheets application to open it.
| 31.84127 | 240 | 0.71984 | eng_Latn | 0.990355 |
5862945edfc2d81619b47b1212693d363461f677 | 130 | md | Markdown | wiki/translations/de/Addon_Manager.md | arslogavitabrevis/FreeCAD-documentation | 8166ce0fd906f0e15672cd1d52b3eb6cf9e17830 | [
"CC0-1.0"
] | null | null | null | wiki/translations/de/Addon_Manager.md | arslogavitabrevis/FreeCAD-documentation | 8166ce0fd906f0e15672cd1d52b3eb6cf9e17830 | [
"CC0-1.0"
] | null | null | null | wiki/translations/de/Addon_Manager.md | arslogavitabrevis/FreeCAD-documentation | 8166ce0fd906f0e15672cd1d52b3eb6cf9e17830 | [
"CC0-1.0"
] | null | null | null | # Addon Manager/de
1. REDIRECT [Std AddonMgr/de](Std_AddonMgr/de.md)
---
[documentation index](../README.md) > Addon Manager/de
| 21.666667 | 54 | 0.707692 | yue_Hant | 0.193091 |
5862c9704c9d7fc2f34a3f00ec8d4a3378007565 | 1,258 | md | Markdown | README.md | mmvdesigner/portfolio | d7fa331908d519025689e0824d5ae7f74573d774 | [
"MIT"
] | null | null | null | README.md | mmvdesigner/portfolio | d7fa331908d519025689e0824d5ae7f74573d774 | [
"MIT"
] | null | null | null | README.md | mmvdesigner/portfolio | d7fa331908d519025689e0824d5ae7f74573d774 | [
"MIT"
] | null | null | null | [](https://opensource.org/licenses/MIT)
[](https://github.com/renanlido/ignews/commits)
[](https://nextjs.org/)
[](https://pt-br.reactjs.org/)
[](https://www.typescriptlang.org/)
<!--LOGO-->
<br/>
<div align="center">
<h1 color="#ffff" >Projeto baseado em Next Js, Typescript, ESlint, Prettier and Styled-Components</h1>
</br>
</div>
<!-- SOBRE O PROJETO -->
# <strong>Sobre o projeto</strong>
Apresentando portfolio dos meus serviços.
Aqui você encontra diversos projetos em varias tecnologias.
</br>
# **License**
Distribuído sob a licença MIT. Veja `LICENSE` para mais informações.
<!-- CONTATO -->
</br>
# **Contato**
### Messias Vasconcelos - **[email protected]**
[Github](https://github.com/mmvdesigner) - **https://github.com/mmvdesigner** </br>
[Linkedin](https://www.linkedin.com/in/messias-vasconcelos-55855932/) - **https://www.linkedin.com/in/messias-vasconcelos-55855932/**
</br></br>
Obrigado! 😊🤗
| 31.45 | 133 | 0.701908 | yue_Hant | 0.267398 |
5862d439c573cbabffa66fea8c528ce90b76301d | 7,139 | md | Markdown | v2/Device/arduino-firmware.md | FarmBot-Docs/farmbot-software | 5c752c357f7f795ab2fe451204f4e29285f03800 | [
"MIT"
] | 1 | 2020-11-20T22:36:49.000Z | 2020-11-20T22:36:49.000Z | v2/Device/arduino-firmware.md | FarmBot-Docs/farmbot-software | 5c752c357f7f795ab2fe451204f4e29285f03800 | [
"MIT"
] | null | null | null | v2/Device/arduino-firmware.md | FarmBot-Docs/farmbot-software | 5c752c357f7f795ab2fe451204f4e29285f03800 | [
"MIT"
] | 1 | 2020-12-27T18:20:56.000Z | 2020-12-27T18:20:56.000Z | ---
title: "Arduino Firmware"
slug: "arduino-firmware"
description: "Step-by-step instructions for installing the FarmBot's Arduino firmware"
---
* toc
{:toc}
The [Farmbot Arduino Firmware](https://github.com/FarmBot/farmbot-arduino-firmware) performs the following tasks:
* Physically controls the FarmBot hardware by sending electrical pulses to the stepper motor drivers, reading voltages from pins, and outputting voltages and data to the Universal Tool Mount
* Communicates with the Raspberry Pi via a serial connection over a USB cable in order to receive G-code and F-code commands and send back log and collected data.
* Monitors the rotary encoders as a closed-loop feedback control system to ensure that the stepper motors have not missed any steps.
Below, we describe two methods for installing the Arduino Firmware onto the Arduino. Most users will use the first method.
{%
include callout.html
type="success"
title="Help Improve the Arduino Firmware"
content="Found some bugs? Have a feature request or improved code you would like to contribute? Let us know by opening up an issue or submitting a pull request on the [GitHub repository for the FarmBot Arduino Firmware](https://github.com/FarmBot/farmbot-arduino-firmware)."
%}
{%
include callout.html
type="info"
title="Want to Hack?"
content="There is more technical documentation about the FarmBot Arduino Firmware in the [README file](https://github.com/FarmBot/farmbot-arduino-firmware/blob/master/README.md)."
%}
# Installation from the Web App (Easiest Method)
{%
include callout.html
type="info"
title="Requires FarmBot OS"
content="This firmware installation method is for people who installed [FarmBot OS](farmbot-os.md) on their Raspberry Pi. If you installed a different OS, then you will need to use one of the other firmware installation methods below."
%}
1. Plug your Arduino into the Raspberry Pi using a USB cable.
2. Login to the FarmBot Web Application and go to the **Device** page.
3. In the **Software** widget, click the **Update** button next to the Arduino version. This will tell the Raspberry Pi to download the latest Arduino firmware and install it onto the Arduino. Note: This may take a few minutes. Do not press the Update button more than once.
4. Once the installation process is complete, the software widget on the web application should show that the latest firmware is installed. There is no need to 'start' the firmware program because as long as the Arduino has power and a connection to the Raspberry Pi, the firmware will be running.
{%
include callout.html
type="success"
title="It's ALLIIIIVVVEEEEE!!!"
content="Go the **Manual Control** page of the web application and click a movement button. If everything is working, FarmBot should move. Go ahead and have some fun with the manual controls! You're FarmBot is almost ready for growing plants! Muahahaha!!"
%}
<iframe class="embedly-embed" src="//cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2F0VkrUG3OrPc%3Ffeature%3Doembed&url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3D0VkrUG3OrPc&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2F0VkrUG3OrPc%2Fhqdefault.jpg&key=02466f963b9b4bb8845a05b53d3235d7&type=text%2Fhtml&schema=youtube" width="854" height="480" scrolling="no" frameborder="0" allowfullscreen></iframe>
# Installation from the Command Line
{%
include callout.html
type="info"
title="For advanced users"
content="This firmware installation method is to be used by people who installed an OS other than FarmBot OS onto the Raspberry Pi."
%}
{%
include callout.html
type="info"
title=""
content="For the most up-to-date instructions, see [GitHub](https://github.com/FarmBot/farmbot-arduino-firmware#command-line-flash-tool-installation)."
%}
## Step 1: Install the Command Line Flash Tool onto the Pi
First, we need to install some software onto the Raspberry Pi that will allow us to flash (load) the Arduino firmware onto the Arduino. This is an important step because it will allow you to easily update the Arduino firmware from the web application in the future!
From a terminal on the Raspberry Pi, enter the following commands:
__Install the Command Line Flash Tool:__
```text
sudo apt-get install gcc-avr avr-libc avrdude python-configobj python-jinja2 python-serial
mkdir tmp
cd tmp
git clone https://github.com/miracle2k/python-glob2
cd python-glob2
wget https://bootstrap.pypa.io/ez_setup.py -O - | sudo python
sudo python setup.py install
git clone git://github.com/amperka/ino.git
cd ino
sudo make install
```
## Step 2: Clone the Arduino Firmware Repository
Now we need to download (clone) the latest Ardiuno firmware onto the Raspberry Pi. From a terminal on the Raspberry Pi, enter the following command:
__Clone the Arduino Firmware Repository:__
```text
git clone https://github.com/FarmBot/farmbot-arduino-firmware.git
```
## Step 3: Install the Arduino Firmware
Now we're going to tell the Raspberry Pi to flash (load) the Arduino firmware onto the Arduino.
Plug your Arduino into the Raspberry Pi using a USB cable. From a terminal on the Raspberry Pi, enter the following commands:
__Install the Arduino Firmware:__
```text
cd farmbot-arduino-firmware
ino build
ino upload
```
{%
include callout.html
type="success"
title="All Done!"
content="If all went smoothly, you should receive a confirmation in the terminal that the firmware has uploaded correctly. From here on out, whenever the Arduino has power, the firmware will be running - there is no need to 'start the firmware'. Just make sure there is power and a good connection with the Raspberry Pi.
Furthermore, your Raspberry Pi is now capable of updating the Arduino firmware with one click from the Web App. Just go to the Device page, and look for the Update button in the Software widget."
%}
# Installation from the Arduino IDE
If you did not install FarmBot OS and you do not want to install the command line flash tool you can still install the Arduino Firmware by using the standard Arduino IDE with the steps below.
{%
include callout.html
type="warning"
title="Manual Updates Only"
content="Note that this method is not recommended because in the future you will not be able to update the Arduino firmware with one click from the FarmBot web application. Instead, you will have to manually download the latest firmware and manually install it with the Arduino IDE each time there is a new release of the software."
%}
1. Download and install the [Arduino IDE](https://www.arduino.cc/en/Main/Software) onto your computer.
2. Download and unzip the latest [FarmBot Arduino Firmware](https://github.com/FarmBot/farmbot-arduino-firmware/archive/master.zip).
3. In the firmware folder you just unzipped, go to the **src** sub-folder and open up **src** with the Arduino IDE. Note: this file is blank, but there are many other file tabs that should be automatically opened as well.
4. Connect your Arduino to your computer with a USB cable.
5. From the IDE, click **Tools** > **Board**, and then select `Arduino Mega 2560`.
6. Now click **File** > **Upload**. This will flash the firmware onto your Arduino.
| 43.797546 | 425 | 0.7784 | eng_Latn | 0.987415 |
5862fa81c0d4842d821cce9248b3a6721b997003 | 914 | md | Markdown | README.md | caitlinsarro/assignments | d4f016a947441bee43545d4eb339108b0093eb1b | [
"MIT"
] | null | null | null | README.md | caitlinsarro/assignments | d4f016a947441bee43545d4eb339108b0093eb1b | [
"MIT"
] | null | null | null | README.md | caitlinsarro/assignments | d4f016a947441bee43545d4eb339108b0093eb1b | [
"MIT"
] | null | null | null | # Weekly assignments
In this repository you'll find materials for the weekly assignments (just for the record; to work on them please use your assigned private repo via GitHub Classroom).
## Assignment timeline
| Session | Topic | Assignment | Submission deadline |
|---------|-------|-----------|-----------|
| 01 | What is data science? | -- | -- |
| 02 | Version control and project management | 1 (not graded) | -- |
| 03 | R and the tidyverse | 2 | Oct 6 |
| 04 | Relational databases and SQL | -- | -- |
| 05 | Web data and technologies | 3 | Oct 20 |
| 06 | Model fitting and simulation | 4 | Nov 3 |
| 07 | Visualization | 5 | Nov 17 |
| 08 | Workshop: Tools for Data Science | -- | -- |
| 09 | Working at the command line | -- | -- |
| 10 | Debugging, automation, packaging | 6 | Dec 1 |
| 11 | Monitoring and communication | -- | -- |
| 12 | Data science ethics | -- | -- |
| 39.73913 | 167 | 0.595186 | eng_Latn | 0.960555 |
586354fb22f440f8efffd134ca5034fd5e272dbb | 994 | md | Markdown | README.md | bitcoinbrisbane/StartCryptoCoin | 89bc0f40cd923d4d5ec3e8958a585955bc1fd4fa | [
"Unlicense"
] | 1 | 2018-12-08T02:31:43.000Z | 2018-12-08T02:31:43.000Z | README.md | bitcoinbrisbane/StartCryptoCoin | 89bc0f40cd923d4d5ec3e8958a585955bc1fd4fa | [
"Unlicense"
] | null | null | null | README.md | bitcoinbrisbane/StartCryptoCoin | 89bc0f40cd923d4d5ec3e8958a585955bc1fd4fa | [
"Unlicense"
] | null | null | null | # Start Crypto Coin
## Disclaimer
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE AND NON-INFRINGEMENT. IN NO EVENT SHALL THE COPYRIGHT HOLDERS OR ANYONE DISTRIBUTING THE SOFTWARE BE LIABLE FOR ANY DAMAGES OR OTHER LIABILITY, WHETHER IN CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
## Abstract
Lorem ipsum dolor sit amet, aliquam mauris, praesent rhoncus integer, massa vestibulum quisque mollis cras, metus praesent tellus imperdiet eu pede sed. Sociis nulla nec faucibus, nec tortor, lectus nunc, sequi nullam vel augue elementum semper, duis gravida vitae non sit proin risus.
## ERC20 fields
The ICO will issue ERC20 compliant tokens.
Field | Value
--------- | ---------
Name | StartCryptoCoin
Ticker | SCC
Total Supply | 1,000,000,000
Decimals | 18
| 52.315789 | 473 | 0.769618 | yue_Hant | 0.923329 |
5863ca8fa256b350f1a2df14f8517109085b5262 | 8,663 | md | Markdown | docs/relational-databases/system-dynamic-management-views/sys-dm-db-partition-stats-transact-sql.md | john-sterrett/sql-docs | 7343f09fccb4624f8963aa74e25665c5acd177b8 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-11-05T19:06:01.000Z | 2021-11-09T10:29:15.000Z | docs/relational-databases/system-dynamic-management-views/sys-dm-db-partition-stats-transact-sql.md | john-sterrett/sql-docs | 7343f09fccb4624f8963aa74e25665c5acd177b8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/relational-databases/system-dynamic-management-views/sys-dm-db-partition-stats-transact-sql.md | john-sterrett/sql-docs | 7343f09fccb4624f8963aa74e25665c5acd177b8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
description: "sys.dm_db_partition_stats (Transact-SQL)"
title: "sys.dm_db_partition_stats (Transact-SQL) | Microsoft Docs"
ms.custom: ""
ms.date: "05/28/2020"
ms.prod: sql
ms.prod_service: "database-engine, sql-database, sql-data-warehouse, pdw"
ms.reviewer: ""
ms.technology: system-objects
ms.topic: "language-reference"
f1_keywords:
- "dm_db_partition_stats"
- "dm_db_partition_stats_TSQL"
- "sys.dm_db_partition_stats_TSQL"
- "sys.dm_db_partition_stats"
dev_langs:
- "TSQL"
helpviewer_keywords:
- "sys.dm_db_partition_stats dynamic management view"
ms.assetid: 9db9d184-b3a2-421e-a804-b18ebcb099b7
author: markingmyname
ms.author: maghan
monikerRange: ">=aps-pdw-2016||=azuresqldb-current||=azure-sqldw-latest||>=sql-server-2016||=sqlallproducts-allversions||>=sql-server-linux-2017||=azuresqldb-mi-current"
---
# sys.dm_db_partition_stats (Transact-SQL)
[!INCLUDE [sql-asdb-asdbmi-asa-pdw](../../includes/applies-to-version/sql-asdb-asdbmi-asa-pdw.md)]
Returns page and row-count information for every partition in the current database.
> [!NOTE]
> To call this from [!INCLUDE[ssSDWfull](../../includes/sssdwfull-md.md)] or [!INCLUDE[ssPDW](../../includes/sspdw-md.md)], use the name **sys.dm_pdw_nodes_db_partition_stats**. The partition_id in sys.dm_pdw_nodes_db_partition_stats differs from the partition_id in the sys.partitions catalog view for Azure Synapse Analytics.
|Column name|Data type|Description|
|-----------------|---------------|-----------------|
|**partition_id**|**bigint**|ID of the partition. This is unique within a database. This is the same value as the **partition_id** in the **sys.partitions** catalog view except for Azure Synapse Analytics.|
|**object_id**|**int**|Object ID of the table or indexed view that the partition is part of.|
|**index_id**|**int**|ID of the heap or index the partition is part of.<br /><br /> 0 = Heap<br /><br /> 1 = Clustered index.<br /><br /> > 1 = Nonclustered index|
|**partition_number**|**int**|1-based partition number within the index or heap.|
|**in_row_data_page_count**|**bigint**|Number of pages in use for storing in-row data in this partition. If the partition is part of a heap, the value is the number of data pages in the heap. If the partition is part of an index, the value is the number of pages in the leaf level. (Nonleaf pages in the B-tree are not included in the count.) IAM (Index Allocation Map) pages are not included in either case. Always 0 for an xVelocity memory optimized columnstore index.|
|**in_row_used_page_count**|**bigint**|Total number of pages in use to store and manage the in-row data in this partition. This count includes nonleaf B-tree pages, IAM pages, and all pages included in the **in_row_data_page_count** column. Always 0 for a columnstore index.|
|**in_row_reserved_page_count**|**bigint**|Total number of pages reserved for storing and managing in-row data in this partition, regardless of whether the pages are in use or not. Always 0 for a columnstore index.|
|**lob_used_page_count**|**bigint**|Number of pages in use for storing and managing out-of-row **text**, **ntext**, **image**, **varchar(max)**, **nvarchar(max)**, **varbinary(max)**, and **xml** columns within the partition. IAM pages are included.<br /><br /> Total number of LOBs used to store and manage columnstore index in the partition.|
|**lob_reserved_page_count**|**bigint**|Total number of pages reserved for storing and managing out-of-row **text**, **ntext**, **image**, **varchar(max)**, **nvarchar(max)**, **varbinary(max)**, and **xml** columns within the partition, regardless of whether the pages are in use or not. IAM pages are included.<br /><br /> Total number of LOBs reserved for storing and managing a columnstore index in the partition.|
|**row_overflow_used_page_count**|**bigint**|Number of pages in use for storing and managing row-overflow **varchar**, **nvarchar**, **varbinary**, and **sql_variant** columns within the partition. IAM pages are included.<br /><br /> Always 0 for a columnstore index.|
|**row_overflow_reserved_page_count**|**bigint**|Total number of pages reserved for storing and managing row-overflow **varchar**, **nvarchar**, **varbinary**, and **sql_variant** columns within the partition, regardless of whether the pages are in use or not. IAM pages are included.<br /><br /> Always 0 for a columnstore index.|
|**used_page_count**|**bigint**|Total number of pages used for the partition. Computed as **in_row_used_page_count** + **lob_used_page_count** + **row_overflow_used_page_count**.|
|**reserved_page_count**|**bigint**|Total number of pages reserved for the partition. Computed as **in_row_reserved_page_count** + **lob_reserved_page_count** + **row_overflow_reserved_page_count**.|
|**row_count**|**bigint**|The approximate number of rows in the partition.|
|**pdw_node_id**|**int**|**Applies to**: [!INCLUDE[ssSDWfull](../../includes/sssdwfull-md.md)], [!INCLUDE[ssPDW](../../includes/sspdw-md.md)]<br /><br /> The identifier for the node that this distribution is on.|
|**distribution_id**|**int**|**Applies to**: [!INCLUDE[ssSDWfull](../../includes/sssdwfull-md.md)], [!INCLUDE[ssPDW](../../includes/sspdw-md.md)]<br /><br /> The unique numeric id associated with the distribution.|
## Remarks
**sys.dm_db_partition_stats** displays information about the space used to store and manage in-row data LOB data, and row-overflow data for all partitions in a database. One row is displayed per partition.
The counts on which the output is based are cached in memory or stored on disk in various system tables.
In-row data, LOB data, and row-overflow data represent the three allocation units that make up a partition. The [sys.allocation_units](../../relational-databases/system-catalog-views/sys-allocation-units-transact-sql.md) catalog view can be queried for metadata about each allocation unit in the database.
If a heap or index is not partitioned, it is made up of one partition (with partition number = 1); therefore, only one row is returned for that heap or index. The [sys.partitions](../../relational-databases/system-catalog-views/sys-partitions-transact-sql.md) catalog view can be queried for metadata about each partition of all the tables and indexes in a database.
The total count for an individual table or an index can be obtained by adding the counts for all relevant partitions.
## Permissions
Requires `VIEW DATABASE STATE` and `VIEW DEFINITION` permissions to query the **sys.dm_db_partition_stats** dynamic management view. For more information about permissions on dynamic management views, see [Dynamic Management Views and Functions (Transact-SQL)](~/relational-databases/system-dynamic-management-views/system-dynamic-management-views.md).
## Examples
### A. Returning all counts for all partitions of all indexes and heaps in a database
The following example shows all counts for all partitions of all indexes and heaps in the [!INCLUDE[ssSampleDBnormal](../../includes/sssampledbnormal-md.md)] database.
```sql
USE AdventureWorks2012;
GO
SELECT * FROM sys.dm_db_partition_stats;
GO
```
### B. Returning all counts for all partitions of a table and its indexes
The following example shows all counts for all partitions of the `HumanResources.Employee` table and its indexes.
```sql
USE AdventureWorks2012;
GO
SELECT * FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID('HumanResources.Employee');
GO
```
### C. Returning total used pages and total number of rows for a heap or clustered index
The following example returns total used pages and total number of rows for the heap or clustered index of the `HumanResources.Employee` table. Because the `Employee` table is not partitioned by default, note the sum includes only one partition.
```sql
USE AdventureWorks2012;
GO
SELECT SUM(used_page_count) AS total_number_of_used_pages,
SUM (row_count) AS total_number_of_rows
FROM sys.dm_db_partition_stats
WHERE object_id=OBJECT_ID('HumanResources.Employee') AND (index_id=0 or index_id=1);
GO
```
## See Also
[Dynamic Management Views and Functions (Transact-SQL)](~/relational-databases/system-dynamic-management-views/system-dynamic-management-views.md)
[Database Related Dynamic Management Views (Transact-SQL)](../../relational-databases/system-dynamic-management-views/database-related-dynamic-management-views-transact-sql.md)
| 79.477064 | 474 | 0.731155 | eng_Latn | 0.962607 |
58642c787c2ade53e5fb7c9ff567955e813ebcec | 4,199 | md | Markdown | doc/init.md | nxg-crypto/nxg | 7dd458fb79b60db4c1a89c8b99fdbb5bc99617bc | [
"MIT"
] | null | null | null | doc/init.md | nxg-crypto/nxg | 7dd458fb79b60db4c1a89c8b99fdbb5bc99617bc | [
"MIT"
] | null | null | null | doc/init.md | nxg-crypto/nxg | 7dd458fb79b60db4c1a89c8b99fdbb5bc99617bc | [
"MIT"
] | null | null | null | Sample init scripts and service configuration for nodexchanged
==========================================================
Sample scripts and configuration files for systemd, Upstart and OpenRC
can be found in the contrib/init folder.
contrib/init/nodexchanged.service: systemd service unit configuration
contrib/init/nodexchanged.openrc: OpenRC compatible SysV style init script
contrib/init/nodexchanged.openrcconf: OpenRC conf.d file
contrib/init/nodexchanged.conf: Upstart service configuration file
contrib/init/nodexchanged.init: CentOS compatible SysV style init script
1. Service User
---------------------------------
All three startup configurations assume the existence of a "nodexchange" user
and group. They must be created before attempting to use these scripts.
2. Configuration
---------------------------------
At a bare minimum, nodexchanged requires that the rpcpassword setting be set
when running as a daemon. If the configuration file does not exist or this
setting is not set, nodexchanged will shutdown promptly after startup.
This password does not have to be remembered or typed as it is mostly used
as a fixed token that nodexchanged and client programs read from the configuration
file, however it is recommended that a strong and secure password be used
as this password is security critical to securing the wallet should the
wallet be enabled.
If nodexchanged is run with "-daemon" flag, and no rpcpassword is set, it will
print a randomly generated suitable password to stderr. You can also
generate one from the shell yourself like this:
bash -c 'tr -dc a-zA-Z0-9 < /dev/urandom | head -c32 && echo'
Once you have a password in hand, set rpcpassword= in /etc/nodexchange/nodexchange.conf
For an example configuration file that describes the configuration settings,
see contrib/debian/examples/nodexchange.conf.
3. Paths
---------------------------------
All three configurations assume several paths that might need to be adjusted.
Binary: /usr/bin/nodexchanged
Configuration file: /etc/nodexchange/nodexchange.conf
Data directory: /var/lib/nodexchanged
PID file: /var/run/nodexchanged/nodexchanged.pid (OpenRC and Upstart)
/var/lib/nodexchanged/nodexchanged.pid (systemd)
The configuration file, PID directory (if applicable) and data directory
should all be owned by the nodexchange user and group. It is advised for security
reasons to make the configuration file and data directory only readable by the
nodexchange user and group. Access to nodexchange-cli and other nodexchanged rpc clients
can then be controlled by group membership.
4. Installing Service Configuration
-----------------------------------
4a) systemd
Installing this .service file consists on just copying it to
/usr/lib/systemd/system directory, followed by the command
"systemctl daemon-reload" in order to update running systemd configuration.
To test, run "systemctl start nodexchanged" and to enable for system startup run
"systemctl enable nodexchanged"
4b) OpenRC
Rename nodexchanged.openrc to nodexchanged and drop it in /etc/init.d. Double
check ownership and permissions and make it executable. Test it with
"/etc/init.d/nodexchanged start" and configure it to run on startup with
"rc-update add nodexchanged"
4c) Upstart (for Debian/Ubuntu based distributions)
Drop nodexchanged.conf in /etc/init. Test by running "service nodexchanged start"
it will automatically start on reboot.
NOTE: This script is incompatible with CentOS 5 and Amazon Linux 2014 as they
use old versions of Upstart and do not supply the start-stop-daemon uitility.
4d) CentOS
Copy nodexchanged.init to /etc/init.d/nodexchanged. Test by running "service nodexchanged start".
Using this script, you can adjust the path and flags to the nodexchanged program by
setting the NODEXCHANGED and FLAGS environment variables in the file
/etc/sysconfig/nodexchanged. You can also use the DAEMONOPTS environment variable here.
5. Auto-respawn
-----------------------------------
Auto respawning is currently only configured for Upstart and systemd.
Reasonable defaults have been chosen but YMMV.
| 41.99 | 97 | 0.747797 | eng_Latn | 0.995138 |
5864d827adf82c7cf073899b69da6cac88fa7d2e | 340 | md | Markdown | modules/placekey/redshift/doc/PLACEKEY_ASH3.md | huq-industries/carto-spatial-extension | ddd7448995932535c2e1533309f4b4141c61af4b | [
"BSD-3-Clause"
] | 68 | 2019-10-21T04:05:04.000Z | 2021-02-04T08:27:36.000Z | modules/placekey/redshift/doc/PLACEKEY_ASH3.md | huq-industries/carto-spatial-extension | ddd7448995932535c2e1533309f4b4141c61af4b | [
"BSD-3-Clause"
] | 20 | 2019-11-05T21:45:39.000Z | 2021-02-08T16:04:18.000Z | modules/placekey/redshift/doc/PLACEKEY_ASH3.md | huq-industries/carto-spatial-extension | ddd7448995932535c2e1533309f4b4141c61af4b | [
"BSD-3-Clause"
] | 25 | 2019-10-23T16:30:00.000Z | 2021-02-04T15:48:31.000Z | ### PLACEKEY_ASH3
{{% bannerNote type="code" %}}
placekey.PLACEKEY_ASH3(placekey)
{{%/ bannerNote %}}
**Description**
Returns the H3 index equivalent to the given placekey.
* `placekey`: `VARCHAR` Placekey identifier.
**Return type**
`VARCHAR`
**Example**
```sql
SELECT placekey.PLACEKEY_ASH3('@ff7-swh-m49');
-- 8a7b59dffffffff
``` | 15.454545 | 54 | 0.697059 | yue_Hant | 0.467378 |
5864f5931e98ab399e282640c98c49e4b3ed13bb | 6,724 | md | Markdown | website/content/en/docs/building-operators/helm/migration.md | jlpedrosa/operator-sdk | aa51fda299241c5dced76bd0664bdb9512a38dbd | [
"Apache-2.0"
] | null | null | null | website/content/en/docs/building-operators/helm/migration.md | jlpedrosa/operator-sdk | aa51fda299241c5dced76bd0664bdb9512a38dbd | [
"Apache-2.0"
] | null | null | null | website/content/en/docs/building-operators/helm/migration.md | jlpedrosa/operator-sdk | aa51fda299241c5dced76bd0664bdb9512a38dbd | [
"Apache-2.0"
] | null | null | null | ---
link: Migrating pre-v1.0.0 Projects
linkTitle: Migrating pre-v1.0.0 Projects
weight: 300
description: Instructions for migrating a Helm-based project built prior to v1.0.0 to use the new Kubebuilder-style layout.
---
## Overview
The motivations for the new layout are related to bringing more flexibility to users and
part of the process to [Integrating Kubebuilder and Operator SDK][integration-doc].
### What was changed
- The `deploy` directory was replaced with the `config` directory including a new layout of Kubernetes manifests files:
* CRD manifests in `deploy/crds/` are now in `config/crd/bases`
* CR manifests in `deploy/crds/` are now in `config/samples`
* Controller manifest `deploy/operator.yaml` is now in `config/manager/manager.yaml`
* RBAC manifests in `deploy` are now in `config/rbac/`
- `build/Dockerfile` is moved to `Dockerfile` in the project root directory
### What is new
Projects are now scaffold using:
- [kustomize][kustomize] to manage Kubernetes resources needed to deploy your operator
- A `Makefile` with helpful targets for build, test, and deployment, and to give you flexibility to tailor things to your project's needs
- Updated metrics configuration using [kube-auth-proxy][kube-auth-proxy], a `--metrics-addr` flag, and [kustomize][kustomize]-based deployment of a Kubernetes `Service` and prometheus operator `ServiceMonitor`
## How to migrate
The easy migration path is to create a new project from the scratch and let the tool scaffold the files properly and then,
just replace with your customizations and implementations. Following an example.
### Creating a new project
In Kubebuilder-style projects, CRD groups are defined using two different flags
(`--group` and `--domain`).
When we initialize a new project, we need to specify the domain that _all_ APIs in
our project will share, so before creating the new project, we need to determine which
domain we're using for the APIs in our existing project.
To determine the domain, look at the `spec.group` field in your CRDs in the
`deploy/crds` directory.
The domain is everything after the first DNS segment. Using `cache.example.com` as an
example, the `--domain` would be `example.com`.
So let's create a new project with the same domain (`example.com`):
```sh
mkdir nginx-operator
cd nginx-operator
operator-sdk init --plugins=helm --domain=example.com
```
Now that we have our new project initialized, we need to re-create each of our APIs.
Using our API example from earlier (`cache.example.com`), we'll use `cache` for the
`--group` flag.
For `--version` and `--kind`, we use `spec.versions[0].name` and `spec.names.kind`, respectively.
For each API in the existing project, run:
```sh
operator-sdk create api \
--group=cache \
--version=<version> \
--kind=<Kind> \
--helm-chart=<path_to_existing_project>/helm-charts/<chart>
```
### Migrating your Custom Resource samples
Update the CR manifests in `config/samples` with the values of the CRs in your existing project which are in `deploy/crds/<group>_<version>_<kind>_cr.yaml`
### Migrating `watches.yaml`
Check if you have custom options in the `watches.yaml` file of your existing project. If so, update the new `watches.yaml` file to match. In our example, it will look like:
```yaml
# Use the 'create api' subcommand to add watches to this file.
- group: example.com
version: v1alpha1
kind: Nginx
chart: helm-charts/nginx
#+kubebuilder:scaffold:watch
```
**NOTE**: Do not remove the `+kubebuilder:scaffold:watch` [marker][marker]. It allows the tool to update the watches file when new APIs are created.
### Checking the Permissions (RBAC)
In your new project, roles are automatically generated in `config/rbac/role.yaml`.
If you modified these permissions manually in `deploy/role.yaml` in your existing
project, you need to re-apply them in `config/rbac/role.yaml`.
New projects are configured to watch all namespaces by default, so they need a `ClusterRole` to have the necessary permissions. Ensure that `config/rbac/role.yaml` remains a `ClusterRole` if you want to retain the default behavior of the new project conventions.
<!--
todo(camilamacedo86): Create an Ansible operator scope document.
https://github.com/operator-framework/operator-sdk/issues/3447
-->
The following rules were used in earlier versions of helm-operator to automatically create and manage services and servicemonitors for metrics collection. If your operator's charts don't require these rules, they can safely be left out of the new `config/rbac/role.yaml` file:
```yaml
- apiGroups:
- monitoring.coreos.com
resources:
- servicemonitors
verbs:
- get
- create
- apiGroups:
- apps
resourceNames:
- memcached-operator
resources:
- deployments/finalizers
verbs:
- update
```
### Configuring your Operator
If your existing project has customizations in `deploy/operator.yaml`, they need to be ported to
`config/manager/manager.yaml`. If you are passing custom arguments in your deployment, make sure to also update `config/default/auth_proxy_patch.yaml`.
Note that the following environment variables are no longer used.
- `OPERATOR_NAME` is deprecated. It is used to define the name for a leader election config map. Operator authors should begin using `--leader-election-id` instead.
- `POD_NAME` was used to enable a particular pod to hold the leader election lock when the Helm operator used the leader for life mechanism. Helm operator now uses controller-runtime's leader with lease mechanism, and `POD_NAME` is no longer necessary.
## Exporting metrics
If you are using metrics and would like to keep them exported you will need to configure
it in the `config/default/kustomization.yaml`. Please see the [metrics][metrics] doc to know how you can perform this setup.
The default port used by the metric endpoint binds to was changed from `:8383` to `:8080`. To continue using port `8383`, specify `--metrics-addr=:8383` when you start the operator.
## Checking the changes
Finally, follow the steps in the ["run the Operator"][run-the-operator] section to verify your project is running.
[quickstart]: /docs/building-operators/helm/quickstart
[integration-doc]: https://github.com/kubernetes-sigs/kubebuilder/blob/master/designs/integrating-kubebuilder-and-osdk.md
[run-the-operator]: /docs/building-operators/helm/tutorial#run-the-operator
[kustomize]: https://github.com/kubernetes-sigs/kustomize
[kube-auth-proxy]: https://github.com/brancz/kube-rbac-proxy
[metrics]: https://book.kubebuilder.io/reference/metrics.html?highlight=metr#metrics
[marker]: https://book.kubebuilder.io/reference/markers.html?highlight=markers#marker-syntax
| 43.662338 | 276 | 0.760262 | eng_Latn | 0.991581 |
58655d8eed3a24cc4637b302e3eadd27f26d86e2 | 4,250 | md | Markdown | docs/framework/configure-apps/file-schema/trace-debug/sharedlisteners-element.md | andreatosato/docs.it-it-1 | 0a50e3e816ac998ddb603eb44b7a8cece7b1e523 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/configure-apps/file-schema/trace-debug/sharedlisteners-element.md | andreatosato/docs.it-it-1 | 0a50e3e816ac998ddb603eb44b7a8cece7b1e523 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/configure-apps/file-schema/trace-debug/sharedlisteners-element.md | andreatosato/docs.it-it-1 | 0a50e3e816ac998ddb603eb44b7a8cece7b1e523 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: '<sharedListeners> elemento'
ms.date: 03/30/2017
f1_keywords:
- http://schemas.microsoft.com/.NetConfiguration/v2.0#sharedListeners
- http://schemas.microsoft.com/.NetConfiguration/v2.0#configuration/system.diagnostics/sharedListeners
helpviewer_keywords:
- <sharedListeners> element
- listeners
- shared listeners
- trace listeners, <sharedListeners> element
- sharedListeners element
ms.assetid: de200534-19dd-4156-86cf-c50521802c4c
author: mcleblanc
ms.author: markl
ms.openlocfilehash: b312ea8180c464fb9f955e7d7079cac930c8bf05
ms.sourcegitcommit: fb78d8abbdb87144a3872cf154930157090dd933
ms.translationtype: MT
ms.contentlocale: it-IT
ms.lasthandoff: 09/27/2018
ms.locfileid: "47397111"
---
# <a name="ltsharedlistenersgt-element"></a><sharedListeners> elemento
Contiene i listener a cui può fare riferimento qualsiasi origine o elemento di traccia. Questi listener non ricevono tutte le tracce per impostazione predefinita e non è possibile recuperare questi listener in fase di esecuzione. I listener identificati come listener condivisi possono essere aggiunti alle origini o delle tracce in base al nome.
\<configuration>
\<System. Diagnostics >
\<sharedListeners >
## <a name="syntax"></a>Sintassi
```xml
<sharedListeners>
<add>...</add>
</sharedListeners>
```
## <a name="attributes-and-elements"></a>Attributi ed elementi
Nelle sezioni seguenti vengono descritti gli attributi, gli elementi figlio e gli elementi padre.
### <a name="attributes"></a>Attributi
Nessuno.
### <a name="child-elements"></a>Elementi figlio
|Elemento|Descrizione|
|-------------|-----------------|
|[\<add>](../../../../../docs/framework/configure-apps/file-schema/trace-debug/add-element-for-listeners-for-trace.md)|Aggiunge un listener alla raccolta `sharedListeners`.|
### <a name="parent-elements"></a>Elementi padre
|Elemento|Descrizione|
|-------------|-----------------|
|`Configuration`|Elemento radice in ciascun file di configurazione usato in Common Language Runtime e nelle applicazioni .NET Framework.|
|`system.diagnostics`|Consente di specificare l'elemento radice per la sezione di configurazione ASP.NET.|
## <a name="remarks"></a>Note
Aggiunta di un listener per la raccolta di listener condivisi non renderlo un listener attivo. È necessario comunque aggiungerlo a un'origine di traccia o da una traccia, aggiungerlo al `Listeners` raccolta per tale elemento di traccia. Le classi di listener in .NET Framework derivano dal <xref:System.Diagnostics.TraceListener> classe.
Questo elemento può essere usato nel file di configurazione del computer (Machine. config) e il file di configurazione dell'applicazione.
## <a name="example"></a>Esempio
Nell'esempio seguente viene illustrato come utilizzare il `<sharedListeners>` elemento a cui aggiungere il listener `console` per il `Listeners` raccolta sia per il <xref:System.Diagnostics.TraceSource> e <xref:System.Diagnostics.Trace> classi. Il listener di traccia console scrive le informazioni di traccia nella console mediante chiamate a <xref:System.Diagnostics.TraceSource> o <xref:System.Diagnostics.Trace>.
```xml
<configuration>
<system.diagnostics>
<sharedListeners>
<add name="console" type="System.Diagnostics.ConsoleTraceListener" >
<filter type="System.Diagnostics.EventTypeFilter"
initializeData="Warning" />
</add>
</sharedListeners>
<sources>
<source name="mySource" switchName="sourceSwitch" >
<listeners>
<add name="console" />
</listeners>
</source>
</sources>
<switches>
<add name="sourceSwitch" value="Verbose"/>
</switches>
<trace>
<listeners>
<add name="console" />
</listeners>
</trace>
</system.diagnostics>
</configuration></system.diagnostics>
```
## <a name="see-also"></a>Vedere anche
<xref:System.Diagnostics.TraceListener>
[Schema delle impostazioni di traccia e debug](../../../../../docs/framework/configure-apps/file-schema/trace-debug/index.md)
[Listener di traccia](../../../../../docs/framework/debug-trace-profile/trace-listeners.md)
| 43.814433 | 419 | 0.711765 | ita_Latn | 0.847778 |
586622f0a338497a6adf826c8d946e9bc86b9e8b | 2,312 | md | Markdown | jamescroDocset0131213411/api-reference/beta/resources/video.md | yinaa/jamescroRepo0131213411 | 7d051ec51884240ff3cf12b47edffcbe3190fd88 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-07-09T00:02:07.000Z | 2021-07-09T00:02:07.000Z | jamescroDocset0131213411/api-reference/beta/resources/video.md | yinaa/jamescroRepo0131213411 | 7d051ec51884240ff3cf12b47edffcbe3190fd88 | [
"CC-BY-4.0",
"MIT"
] | 6 | 2018-03-02T20:55:47.000Z | 2018-04-05T04:42:32.000Z | jamescroDocset0131213411/api-reference/beta/resources/video.md | yinaa/jamescroRepo0131213411 | 7d051ec51884240ff3cf12b47edffcbe3190fd88 | [
"CC-BY-4.0",
"MIT"
] | 3 | 2018-03-15T21:53:56.000Z | 2018-04-18T22:48:03.000Z | ---
author: rgregg
ms.author: rgregg
ms.date: 09/10/2017
title: Video
---
# Video resource type
> **Important:** APIs under the /beta version in Microsoft Graph are in preview and are subject to change. Use of these APIs in production applications is not supported.
The **Video** resource groups video-related data items into a single structure.
If a [**DriveItem**](driveitem.md) has a non-null **video** facet, the item represents a video file.
The properties of the **Video** resource are populated by extracting metadata from the file.
## JSON representation
Here is a JSON representation of the resource
<!-- {
"blockType": "resource",
"optionalProperties": [ ],
"@odata.type": "microsoft.graph.video"
}-->
```json
{
"audioBitsPerSample": 16,
"audioChannels": 1,
"audioFormat": "AAC",
"audioSamplesPerSecond": 44100,
"bitrate": 39101896,
"duration": 8053,
"fourCC": "H264",
"frameRate": 239.877,
"height": 1280,
"width": 720
}
```
## Properties
| Property name | Type | Description
|:--------------------------|:-------|:----------------------------------------
| **audioBitsPerSample** | Int32 | Number of audio bits per sample.
| **audioChannels** | Int32 | Number of audio channels.
| **audioFormat** | string | Name of the audio format (AAC, MP3, etc.).
| **audioSamplesPerSecond** | Int32 | Number of audio samples per second.
| **bitrate** | Int32 | Bit rate of the video in bits per second.
| **duration** | Int64 | Duration of the file in milliseconds.
| **fourCC** | string | "Four character code" name of the video format.
| **framerate** | double | Frame rate of the video.
| **height** | Int32 | Height of the video, in pixels.
| **width** | Int32 | Width of the video, in pixels.
[item-resource]: ../resources/driveitem.md
## Remarks
For more information about the facets on a DriveItem, see [DriveItem](driveitem.md).
<!-- uuid: 8fcb5dbc-d5aa-4681-8e31-b001d5168d79
2015-10-25 14:57:30 UTC -->
<!-- {
"type": "#page.annotation",
"description": "The video facet provides information about the properties of a video file.",
"keywords": "bitrate,duration,size,video",
"section": "documentation",
"tocPath": ""
}-->
| 30.826667 | 169 | 0.62673 | eng_Latn | 0.812996 |
5866306ed8e26a5d1ef8326050ebee05b1003eba | 7,103 | md | Markdown | review/10-conditional-statements/2-conditional-bodies/README.md | HackYourFutureBelgium/debuggercises | 6de24148afb86d0a9d6ee2cf1460b5d5c6d64811 | [
"MIT"
] | null | null | null | review/10-conditional-statements/2-conditional-bodies/README.md | HackYourFutureBelgium/debuggercises | 6de24148afb86d0a9d6ee2cf1460b5d5c6d64811 | [
"MIT"
] | null | null | null | review/10-conditional-statements/2-conditional-bodies/README.md | HackYourFutureBelgium/debuggercises | 6de24148afb86d0a9d6ee2cf1460b5d5c6d64811 | [
"MIT"
] | 49 | 2020-06-12T23:24:21.000Z | 2020-07-01T20:10:02.000Z | # Debuggercises
> 7/29/2020, 9:06:21 AM
## [exercises](../../README.md)/[10-conditional-statements](../README.md)/2-conditional-bodies
- [/1-write-expected.js](#1-write-expectedjs) - _incomplete_
- [/2-write-arguments.js](#2-write-argumentsjs) - _incomplete_
- [/3-write-function.js](#3-write-functionjs) - _incomplete_
---
## /1-write-expected.js
> incomplete
>
> [review source](../../../exercises/10-conditional-statements/2-conditional-bodies/1-write-expected.js)
```txt
UNCAUGHT: ReferenceError: _ is not defined
at Object.<anonymous> ( ... /exercises/10-conditional-statements/2-conditional-bodies/1-write-expected.js:14:19)
at Module._compile (internal/modules/cjs/loader.js:1201:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:1221:10)
at Module.load (internal/modules/cjs/loader.js:1050:32)
at Function.Module._load (internal/modules/cjs/loader.js:938:14)
at Module.require (internal/modules/cjs/loader.js:1090:19)
at require (internal/modules/cjs/helpers.js:75:18)
at evaluate ( ... /scripts/lib/evaluate.js:28:7)
at Object.<anonymous> ( ... /scripts/review.js:119:1)
at Module._compile (internal/modules/cjs/loader.js:1201:30)
```
```js
const mystery = (a) => {
let result = '';
if (typeof a !== 'number') {
result = Number(a);
} else if (a > 0) {
result = a + a;
} else {
result = a - a;
}
return result;
};
const _1_expect = _;
const _1_actual = mystery(0);
console.assert(Object.is(_1_actual, _1_expect), 'Test 1');
const _2_expect = _;
const _2_actual = mystery(101);
console.assert(Object.is(_2_actual, _2_expect), 'Test 2');
const _3_expect = _;
const _3_actual = mystery(true);
console.assert(Object.is(_3_actual, _3_expect), 'Test 3');
const _4_expect = _;
const _4_actual = mystery(1);
console.assert(Object.is(_4_actual, _4_expect), 'Test 4');
const _5_expect = _;
const _5_actual = mystery(-1);
console.assert(Object.is(_5_actual, _5_expect), 'Test 5');
const _6_expect = _;
const _6_actual = mystery('_6_expect');
console.assert(Object.is(_6_actual, _6_expect), 'Test 6');
const _7_expect = _;
const _7_actual = mystery('18');
console.assert(Object.is(_7_actual, _7_expect), 'Test 7');
const _8_expect = _;
const _8_actual = mystery(-18);
console.assert(Object.is(_8_actual, _8_expect), 'Test 8');
const _9_expect = _;
const _9_actual = mystery(undefined);
console.assert(Object.is(_9_actual, _9_expect), 'Test 9');
```
[TOP](#debuggercises)
---
## /2-write-arguments.js
> incomplete
>
> [review source](../../../exercises/10-conditional-statements/2-conditional-bodies/2-write-arguments.js)
```txt
UNCAUGHT: ReferenceError: _ is not defined
at Object.<anonymous> ( ... /exercises/10-conditional-statements/2-conditional-bodies/2-write-arguments.js:15:27)
at Module._compile (internal/modules/cjs/loader.js:1201:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:1221:10)
at Module.load (internal/modules/cjs/loader.js:1050:32)
at Function.Module._load (internal/modules/cjs/loader.js:938:14)
at Module.require (internal/modules/cjs/loader.js:1090:19)
at require (internal/modules/cjs/helpers.js:75:18)
at evaluate ( ... /scripts/lib/evaluate.js:28:7)
at Object.<anonymous> ( ... /scripts/review.js:119:1)
at Module._compile (internal/modules/cjs/loader.js:1201:30)
```
```js
const mystery = (a) => {
let result = '';
if (typeof a === 'boolean') {
result = !a;
} else if (a) {
result = String(a);
} else {
result = a;
}
return result;
};
const _1_expect = 0;
const _1_actual = mystery(_);
console.assert(_1_actual === _1_expect, 'Test 1');
const _2_expect = false;
const _2_actual = mystery(_);
console.assert(_2_actual === _2_expect, 'Test 2');
const _3_expect = '12';
const _3_actual = mystery(_);
console.assert(_3_actual === _3_expect, 'Test 3');
// there is more than one way to get '12'
const _4_expect = '12';
const _4_actual = mystery(_);
console.assert(_4_actual === _4_expect, 'Test 4');
const _5_expect = 'asdf';
const _5_actual = mystery(_);
console.assert(_5_actual === _5_expect, 'Test 5');
const _6_expect = true;
const _6_actual = mystery(_);
console.assert(_6_actual === _6_expect, 'Test 6');
const _7_expect = '';
const _7_actual = mystery('18');
console.assert(_7_actual === _7_expect, 'Test 7');
const _8_expect = true;
const _8_actual = mystery();
console.assert(_8_actual === _8_expect, 'Test 8');
const _9_expect = undefined;
const _9_actual = mystery(_);
console.assert(_9_actual === _9_expect, 'Test 9');
```
[TOP](#debuggercises)
---
## /3-write-function.js
> incomplete
>
> [review source](../../../exercises/10-conditional-statements/2-conditional-bodies/3-write-function.js)
```txt
UNCAUGHT: ReferenceError: _ is not defined
at mystery ( ... /exercises/10-conditional-statements/2-conditional-bodies/3-write-function.js:9:5)
at Object.<anonymous> ( ... /exercises/10-conditional-statements/2-conditional-bodies/3-write-function.js:20:19)
at Module._compile (internal/modules/cjs/loader.js:1201:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:1221:10)
at Module.load (internal/modules/cjs/loader.js:1050:32)
at Function.Module._load (internal/modules/cjs/loader.js:938:14)
at Module.require (internal/modules/cjs/loader.js:1090:19)
at require (internal/modules/cjs/helpers.js:75:18)
at evaluate ( ... /scripts/lib/evaluate.js:28:7)
at Object.<anonymous> ( ... /scripts/review.js:119:1)
```
```js
/* pro tip: incremental development!
try passing all tests for path 1, then for path 2, then for path 3
don't move on to the next 3 tests until you've finished the path you're working on
*/
const mystery = (a, b) => {
let result = '';
if (typeof a === typeof b) {
result = _;
} else if (Boolean(a) === Boolean(b)) {
result = _;
} else {
result = _;
}
return result;
};
// path 1
const _1_expect = '12';
const _1_actual = mystery('12', 'bye');
console.assert(Object.is(_1_actual, _1_expect), 'Test 1');
const _2_expect = false;
const _2_actual = mystery(false, true);
console.assert(Object.is(_2_actual, _2_expect), 'Test 2');
const _3_expect = 100;
const _3_actual = mystery(100, 200);
console.assert(Object.is(_3_actual, _3_expect), 'Test 3');
// path 2
const _4_expect = null;
const _4_actual = mystery(NaN, null);
console.assert(Object.is(_4_actual, _4_expect), 'Test 4');
const _5_expect = 12;
const _5_actual = mystery(true, 12);
console.assert(Object.is(_5_actual, _5_expect), 'Test 5');
const _6_expect = 'bye';
const _6_actual = mystery(-2, 'bye');
console.assert(Object.is(_6_actual, _6_expect), 'Test 6');
// path 3
const _7_expect = 1;
const _7_actual = mystery(null, 1);
console.assert(Object.is(_7_actual, _7_expect), 'Test 7');
const _8_expect = true;
const _8_actual = mystery('', true);
console.assert(Object.is(_8_actual, _8_expect), 'Test 8');
const _9_expect = 'asdf';
const _9_actual = mystery('asdf', 0);
console.assert(Object.is(_9_actual, _9_expect), 'Test 9');
```
[TOP](#debuggercises)
| 28.873984 | 119 | 0.690272 | eng_Latn | 0.277716 |
58664027c9a311f1fbce57798709c449da3f23b5 | 2,711 | md | Markdown | archived/sensu-enterprise-dashboard/2.8/integrations/flapjack.md | elfranne/sensu-docs | 28fdf14552f8da0b9742469c9f0d7aab69e0b96d | [
"MIT"
] | 69 | 2015-01-14T20:11:56.000Z | 2022-01-24T10:44:03.000Z | archived/sensu-enterprise-dashboard/2.8/integrations/flapjack.md | elfranne/sensu-docs | 28fdf14552f8da0b9742469c9f0d7aab69e0b96d | [
"MIT"
] | 2,119 | 2015-01-08T20:00:16.000Z | 2022-03-31T15:26:31.000Z | archived/sensu-enterprise-dashboard/2.8/integrations/flapjack.md | elfranne/sensu-docs | 28fdf14552f8da0b9742469c9f0d7aab69e0b96d | [
"MIT"
] | 217 | 2015-01-08T09:44:23.000Z | 2022-03-24T01:52:59.000Z | ---
title: "Flapjack"
description: "Relay Sensu results to Flapjack for notification routing and event processing."
product: "Sensu Enterprise"
version: "2.8"
weight: 11
menu:
sensu-enterprise-2.8:
parent: integrations
---
**ENTERPRISE: Built-in integrations are available for [Sensu Enterprise][1]
users only.**
- [Overview](#overview)
- [Configuration](#configuration)
- [Example(s)](#examples)
- [Integration Specification](#integration-specification)
- [`flapjack` attributes](#flapjack-attributes)
## Overview
Relay Sensu results to [Flapjack][2], a monitoring notification routing and
event processing system. Flapjack uses Redis for event queuing; this integration
sends event data to Flapjack through Redis, using the Flapjack event format.
_NOTE: checks **DO NOT** need to specify `flapjack` as an event handler, as
every check result will be relayed to Flapjack if the integration is
configured._
## Configuration
### Example(s) {#examples}
The following is an example global configuration for the `flapjack` enterprise
integration.
{{< code json >}}
{
"flapjack": {
"host": "redis.example.com",
"port": 6379,
"db": 0,
"channel": "events",
"filter_metrics": false
}
}
{{< /code >}}
### Integration Specification
#### `flapjack` attributes
The following attributes are configured within the `{"flapjack": {} }`
[configuration scope][3].
host |
-------------|------
description | The Flapjack Redis instance address.
required | false
type | String
default | `127.0.0.1`
example | {{< code shell >}}"host": "8.8.8.8"{{< /code >}}
port |
-------------|------
description | The Flapjack Redis instance port.
required | false
type | Integer
default | `6379`
example | {{< code shell >}}"port": 6380{{< /code >}}
db |
-------------|------
description | The Flapjack Redis instance database (#) to use.
required | false
type | Integer
default | `0`
example | {{< code shell >}}"db": 1{{< /code >}}
channel |
-------------|------
description | The Flapjack Redis instance channel (queue) to use for events.
required | false
type | String
default | `events`
example | {{< code shell >}}"channel": "flapjack"{{< /code >}}
filter_metrics |
---------------|------
description | If check results with a `type` of `metric` are relayed to Flapjack.
required | false
type | Boolean
default | `false`
example | {{< code shell >}}"filter_metrics": true{{< /code >}}
[1]: /sensu-enterprise
[2]: http://flapjack.io?ref=sensu-enterprise
[3]: /sensu-core/1.2/reference/configuration#configuration-scopes
| 27.11 | 93 | 0.632977 | eng_Latn | 0.866183 |
5866c1ba314ff650faf640807929518ac5df3a71 | 116 | md | Markdown | pages/Hall of Fame.md | codeninjasgg/javascript-camp | b0747ab5ac62ccef058c44f355743f4572b75c4f | [
"MIT"
] | null | null | null | pages/Hall of Fame.md | codeninjasgg/javascript-camp | b0747ab5ac62ccef058c44f355743f4572b75c4f | [
"MIT"
] | 1 | 2022-01-15T02:49:56.000Z | 2022-01-15T02:49:56.000Z | pages/Hall of Fame.md | codeninjasgg/javascript-camp | b0747ab5ac62ccef058c44f355743f4572b75c4f | [
"MIT"
] | null | null | null | # JavaScript Ninjas 🐱👤
This page is a hall of fame for all of the students who have completed the JavaScript Camp.
| 38.666667 | 91 | 0.767241 | eng_Latn | 0.999938 |
58672638d8dff0126bee5d7b9aa0556321f82c7a | 48 | md | Markdown | README.md | sfawcett191/mfc | 72a5543370aebc965b78624ed519ccd81fc92904 | [
"Apache-2.0"
] | null | null | null | README.md | sfawcett191/mfc | 72a5543370aebc965b78624ed519ccd81fc92904 | [
"Apache-2.0"
] | null | null | null | README.md | sfawcett191/mfc | 72a5543370aebc965b78624ed519ccd81fc92904 | [
"Apache-2.0"
] | null | null | null | # mfc
Flight Simulator Multi-Functional Display
| 16 | 41 | 0.833333 | kor_Hang | 0.470146 |
58677059f4babf8c4d7f19862a37159809033f52 | 352 | md | Markdown | README.md | ivee-tech/sol | 8e69205647207a27a02af68f3136792538915db0 | [
"MIT"
] | null | null | null | README.md | ivee-tech/sol | 8e69205647207a27a02af68f3136792538915db0 | [
"MIT"
] | null | null | null | README.md | ivee-tech/sol | 8e69205647207a27a02af68f3136792538915db0 | [
"MIT"
] | null | null | null | # Stories of the Land
Stories of the Land - Hackathon Oct 2021
Contains two applications:
- app - Vue.js client app for text analysis
- v-to-app - Python Flask app for video to audio conversion
Run app (requires NodeJS v14):
- go to /sol/app
- run `npm install`
- optionally run `npm audit fix`
- run `npm run serve`
- got to http://localhost:8080
| 22 | 59 | 0.721591 | eng_Latn | 0.907525 |
5867d1dbf098228136ee2d5f25b4a7b9c3d9263e | 1,730 | md | Markdown | README.md | tang2606/beibq | 4b867b488677a3236d421a9c1ca3982ae026950b | [
"BSD-3-Clause"
] | 532 | 2018-02-01T17:33:40.000Z | 2022-03-27T14:12:01.000Z | README.md | tang2606/beibq | 4b867b488677a3236d421a9c1ca3982ae026950b | [
"BSD-3-Clause"
] | 28 | 2018-02-02T09:34:53.000Z | 2022-03-11T23:14:35.000Z | README.md | tang2606/beibq | 4b867b488677a3236d421a9c1ca3982ae026950b | [
"BSD-3-Clause"
] | 193 | 2018-02-02T06:45:14.000Z | 2022-03-27T14:12:04.000Z | # beibq
基于flask开发类似gitbook的知识管理网站。
码云地址:https://gitee.com/beibq/beibq
github地址:https://github.com/chaijunit/beibq
demo地址:http://demo.beibq.cn
用户名:admin
密码:123456
python版本要求: python3.6+
因为很多博客系统都是以文章的形式为主;如果记录的文章变多了,还需要进行分类,而且查找以前写过的某篇文章会比较麻烦。
beibq是用写书的方式来写博客,因为书籍本身就具有分类功能,就算记录的内容变多了也不觉得乱,而且在阅读时通过点击书籍目录很方便的切换到其他章节。
#### 安装配置

搭建好网站后,用浏览器访问,会出现配置界面
#### 在线写书

beibq的编辑器支持Markdown,Markdown是一个标记语言,只需要几个简单的标记符号就能转化成丰富的HTML格式,特别适合写博客。关于Markdown的具体介绍:[Markdown 语法说明](https://www.appinn.com/markdown/)
beibq的编辑器界面简洁、操作简单,能够通过工具栏或快捷键方式输入Markdown标记符号,有效的提高写作效率;编辑器的目录区支持章节拖拉,可以调整章节顺序。
编辑器例子:[在线写书](https://www.beibq.cn/bookeditor/book)
写好书籍后点击发布,就能在首页上看到最新书籍动态

#### 界面
beibq的界面简洁、美观、易用。阅读博客时,就像看书一样,界面包含书籍目录;这样只要点击目录的某个章节就能很方便切换到其他章节。

为了提高切换章节效率,当点击目录中某个章节,通过ajax异步请求章节内容,这样可以不仅提高页面刷新速度而且具有很好的阅读体验;
其实使用ajax异步请求章节会出现一个问题,当网络延迟高,用户短时间内点击多个章节,会导致页面显示混乱;为了解决这个问题,我设计一个队列,将用户点击章节时将该事件缓存到队列中,如果短时间内接收多个点击事件,我其实只请求队列中最后的一个事件。
beibq还可以自动适配移动端界面,用户可以在移动设备上阅读。
## 安装使用
#### 1. 安装mysql
beibq使用的数据库是mysql,安装前需要先安装mysql
我使用的是centos,安装方法可以参考该文档:[Installing MySQL on Linux Using the MySQL Yum Repository](https://dev.mysql.com/doc/refman/5.7/en/linux-installation-yum-repo.html)
#### 2. 安装依赖包
```
pip install -r requirements.txt
```
#### 3. 启动程序
```
python manage.py runserver -h 0.0.0.0
```
#### 4. 配置站点
在浏览器中输入http://127.0.0.1:5000
第一次访问会跳转到配置界面,根据指示配置站点信息后就能使用beibq
## 建议反馈
如果您有任何建议和问题,可以通过邮箱方式和我联系
- 邮箱: [email protected]
| 20.843373 | 156 | 0.787861 | yue_Hant | 0.736143 |
58680dedc27bb9c15d6e2e66fe8b8f94c433c03f | 1,229 | md | Markdown | README.md | harmonic-analytics/db-geonz | 31a9ae219577fe988c6448f4685eb1677371578d | [
"MIT"
] | null | null | null | README.md | harmonic-analytics/db-geonz | 31a9ae219577fe988c6448f4685eb1677371578d | [
"MIT"
] | 3 | 2020-10-28T20:52:22.000Z | 2021-03-29T23:16:19.000Z | README.md | harmonic-analytics/db-geonz | 31a9ae219577fe988c6448f4685eb1677371578d | [
"MIT"
] | null | null | null |
<!-- README.md is generated from README.Rmd. Please edit that file -->
# db.geonz <a href='https://github.com/harmonic-analytics/db-geonz'><img src = 'inst/figures/hex-geonz.png' align='right' height='139' /></a>
<!-- badges: start -->
[](https://github.com/harmonic-analytics/db-geonz/actions)
<!-- badges: end -->
## Overview
This package provides datasets of the annually released geographic area
boundaries of New Zealand. The datasets are stored as simple features
data tables.
Currently, the db-geonz package houses datasets for the boundaries for
five geographic area types as set at 1 January 2018: statistical area 1,
statistical area 2, ward, territorial authority and regional council.
The package also contains versions of these boundaries clipped to the
coastline that can be used for map creation/cartographic purposes.
This package is designed to be used with the **geonz** package.
## Installation
This package is installed automatically when the **geonz** package is
installed. It can also be installed using the `remotes` package:
``` r
remotes::install_github(repo = 'harmonic-analytics/db-geonz')
```
| 36.147059 | 144 | 0.759967 | eng_Latn | 0.989473 |
58682dfc014e213f4d544003b2b692af89d2411f | 30,597 | md | Markdown | patterns-and-practices.md | Tvde1/QuestPDF-Documentation | bb72cbe592e9faa44ce7c5db95023ae595797d5f | [
"MIT"
] | null | null | null | patterns-and-practices.md | Tvde1/QuestPDF-Documentation | bb72cbe592e9faa44ce7c5db95023ae595797d5f | [
"MIT"
] | null | null | null | patterns-and-practices.md | Tvde1/QuestPDF-Documentation | bb72cbe592e9faa44ce7c5db95023ae595797d5f | [
"MIT"
] | null | null | null | # Patterns and practices
## Page settings
It is possible to put pages of various settings within the single document. Please notice that the example below declares two consecutive page sizes (A4 and A3) with various margin values:
```csharp{10-13,21-24}
public class StandardReport : IDocument
{
// metadata
public void Compose(IDocumentContainer container)
{
container
.Page(page =>
{
page.MarginVertical(80);
page.MarginHorizontal(100);
page.Background(Colors.Grey.Medium); // transparent is default
page.Size(PageSizes.A3);
page.Header().Element(ComposeHeader);
page.Content().Element(ComposeBigContent);
page.Footer().AlignCenter().PageNumber();
})
.Page(page =>
{
// you can specify multiple page types in the document
// with independend configurations
page.Margin(50)
page.Size(PageSizes.A4);
page.Header().Element(ComposeHeader);
page.Content().Element(ComposeSmallContent);
page.Footer().AlignCenter().PageNumber();
});
}
// content implementation
}
```
You easily change page orientation:
```csharp
// default is portrait
page.Size(PageSizes.A3);
// explicit portrait orientation
page.Size(PageSizes.A3.Portrait());
// change to landscape orientation
page.Size(PageSizes.A3.Landscape());
```
## Continuous page size
It is possible to define a page size with known width but dynamic height. In this example, the resulting page has constant width equal to A4 page's width, but its height depends on the content:
```csharp{13}
public class StandardReport : IDocument
{
// metadata
public void Compose(IDocumentContainer container)
{
container
.Page(page =>
{
page.MarginVertical(40);
page.MarginHorizontal(60);
page.ContinuousSize(PageSizes.A4.Width);
page.Header().Element(ComposeHeader);
page.Content().Element(ComposeContent);
page.Footer().AlignCenter().PageNumber();
});
}
// content implementation
}
```
::: danger
Because of the practical layouting limitations, the maximum page height is limited to 14400 points (around 5 meters).
:::
## Length unit types
QuestPDF uses points as default measure unit. Where 1 inch equals to 72 points, according to PDF specification. However, the vast majority of the Fluent API supports additional/optional argument to specify unit type.
| Unit | Size |
|------------|----------------------|
| meter | 100 centimeters |
| centimetre | 2.54 inches |
| millimetre | 1/10th of centimeter |
| feet | 12 inches |
| inch | 72 points |
| mill | 1/1000th of inch |
Example usage:
```csharp
// all invocations are equal
.Padding(72)
.Padding(1, Unit.Inch)
.Padding(1/12f, Unit.Feet)
.Padding(1000, Unit.Mill)
// unit types can be provided in other API methods too, e.g.
.BorderLeft(100, Unit.Mill)
row.ConstantItem(8, Unit.Centimetre)
```
## Execution order
QuestPDF uses FluentAPI and method chaining to describe document's content. It is very important to remember that order of methods os strict. That means, in many cases, changing order of invocations will produce different results. To better understand this behavior, let's analyse this simple example:
```csharp{7-8,13-14}
.Row(row =>
{
row.Spacing(25);
row.RelativeItem()
.Border(1)
.Padding(15)
.Background(Colors.Grey.Lighten2)
.Text("Lorem ipsum");
row.RelativeItem()
.Border(1)
.Background(Colors.Grey.Lighten2)
.Padding(15)
.Text("dolor sit amet");
});
```

This is another good example showing how applying padding changes available space:
```csharp
.Padding(25)
.Border(2)
.Width(150)
.Height(150)
.Background(Colors.Blue.Lighten2)
.PaddingTop(50)
.Background(Colors.Green.Lighten2)
.PaddingRight(50)
.Background(Colors.Red.Lighten2)
.PaddingBottom(50)
.Background(Colors.Amber.Lighten2)
.PaddingLeft(50)
.Background(Colors.Grey.Lighten2);
```

## Global text style
The QuestPDF library provides a default set of styles that applied to text.
```csharp
.Text("Text with library default styles")
```
You can adjust the text style by providing additional argument:
```csharp
.Text("Red semibold text of size 20", TextStyle.Default.Size(20).SemiBold())
```
The option above introduces overrides the default style. To get more control you can set a default text style in your document. Please notice that all changes are additive:
```csharp{9-10,22-23,27-28}
public class SampleReport : IDocument
{
public DocumentMetadata GetMetadata() => new DocumentMetadata();
public void Compose(IDocumentContainer container)
{
container.Page(page =>
{
// all text in this set of pages has size 20
page.DefaultTextStyle(TextStyle.Default.Size(20));
page.Margin(20);
page.Size(PageSizes.A4);
page.Background(Colors.White);
page.Content().Column(column =>
{
column.Item().Text(Placeholders.Sentence());
column.Item().Text(text =>
{
// text in this block is additionally semibold
text.DefaultTextStyle(TextStyle.Default.SemiBold());
text.Line(Placeholders.Sentence());
// this text has size 20 but also semibold and red
text.Span(Placeholders.Sentence(), TextStyle.Default.Color(Colors.Red.Medium));
});
});
});
}
}
```

## Document metadata
You can modify the PDF document metadata by returning the `DocumentMetadata` object from the `IDocument.GetMetadata()` method. There are multiple properties available, some of them have default values:
```csharp
public class DocumentMetadata
{
public int ImageQuality { get; set; } = 101;
public int RasterDpi { get; set; } = 72;
public bool PdfA { get; set; }
public string? Title { get; set; }
public string? Author { get; set; }
public string? Subject { get; set; }
public string? Keywords { get; set; }
public string? Creator { get; set; }
public string? Producer { get; set; }
public DateTime CreationDate { get; set; } = DateTime.Now;
public DateTime ModifiedDate { get; set; } = DateTime.Now;
public int DocumentLayoutExceptionThreshold { get; set; } = 250;
public bool ApplyCaching { get; set; } // false when debugger is attached
public bool ApplyDebugging { get; set; } // true when debugger is attached
public static DocumentMetadata Default => new DocumentMetadata();
}
```
::: tip
If the number of generated pages exceeds the `DocumentLayoutExceptionThreshold` (likely due to infinite layout), the exception is thrown. Please adjust this parameter, so the library can stop as soon as possible, saving CPU and memory resources.
:::
::: tip
The `ImageQuality` property controls the trade-off between quality and size. The default value `101` corresponds to lossless encoding. When you use a value less than 100, all images are opaque and encoded using the JPEG algorithm. The smaller the value is, the higher compression is used.
:::
## Generating PDF and XPS files
The library supports generating both PDF and XPS files:
```csharp
report.GeneratePdf("result.pdf");
report.GenerateXps("result.xps");
```
## Generating images
The default functionality of the library is generating PDF files based on specified document configuration. In some cases, you may need to generate set of images instead. Such tasks can be done by additional extension methods:
```csharp
// generate images as dynamic list of images
IEnumerable<byte[]> images = document.GenerateImages();
// generate images and save them as files with provided naming schema
document.GenerateImages(i => $"image-{i}.png");
```
::: tip
Generated images are in the PNG format. In order to increase resolution of generated images, please modify the value of the `DocumentMetadata.RasterDpi` property. When RasterDpi is set to 72, one PDF point corresponds to one pixel.
:::
## Support for custom environments (cloud / linux)
The QuestPDF library has a dependency called SkiaSharp which is used to render the final PDF file. This library has additional dependencies when used in the Linux environment.
When you get the exception `Unable to load shared library 'libSkiaSharp' or one of its dependencies.`, please try to install additional nuget packages provided by the SkiaSharp team.
For example: the SkiaSharp.NativeAssets.Linux.NoDependencies nuget ensures that the libSkiaSharp.so file is published and available.
## Support for custom environments (Blazor WebAssembly)
The QuestPDF library has a dependency called SkiaSharp which is used to render the final PDF file.
QuestPDF works without problems in Blazor WebAssembly but you need to provide a suitable version of SkiaSharp on runtime.
**Note:** The tools used in this section are in a prerelease state, they should be used with caution.
First you need to install the WebAssembly tools, that will be used to compile the Skia dependencies to WebAssembly. In a command shell, execute
```
dotnet workload install wasm-tools
```
Then you will need to add the SkiaSharp.Views.Blazor Nuget package to your project. SkiaSharp is a crossplatform graphics library based on Skia.
```
dotnet add package –-prerelease SkiaSharp.Views.Blazor
```
Subsecuent builds can be slower as the toolchain now compiles Skia to WebAssembly.
Another thing to consider is that WebAssembly code runs on a secured sandbox and it can't access system fonts.
For this reason any PDF created with QuestPDF in Blazor WebAssembly will not embed the used fonts. The final font used for rendering will be determined by the PDF viewer.
However you can use a custom font as shown in the section **Accessing custom fonts**.
## Accessing custom fonts
The QuestPDF library has access to all fonts installed on the hosting system. Sometimes though, you don't have control over fonts installed on the production environment. Or you may want to use self-hosted fonts that come with your application as files or embedded resources. In such case, you need to register those fonts as follows:
```csharp
// static method definition
FontManager.RegisterFontType(string fontName, Stream fontDataStream);
// perform similar invocation only once, when the application starts or during its initialization step
FontManager.RegisterFontType("LibreBarcode39", File.OpenRead("LibreBarcode39-Regular.ttf"));
// then, you will have access to the font by its name
container
.Background(Colors.White)
.AlignCenter()
.AlignMiddle()
.Text("*QuestPDF*", TextStyle.Default.FontType("LibreBarcode39").Size(64));
```
This way, it is possible to generate barcodes:

## Extending DSL
The existing Fluent API offers a clear and easy-to-understand way to describe a document's structure. When working on the document, you may find that many places use similar styles, for instances borders or backgrounds. It is especially common when you keep the document consistent. To make future adjustments easier, you can reuse the styling code by extracting it into separate extension methods. This way, you can assign a meaningful name to documents structure without increasing code complexity.
In the example below, we will create a simple table where label cells have a grey background, and value cells have a white background. First, let's create proper extension methods:
```csharp
static class SimpleExtension
{
private static IContainer Cell(this IContainer container, bool dark)
{
return container
.Border(1)
.Background(dark ? Colors.Grey.Lighten2 : Colors.White)
.Padding(10);
}
// displays only text label
public static void LabelCell(this IContainer container, string text) => container.Cell(true).Text(text, TextStyle.Default.Medium());
// allows to inject any type of content, e.g. image
public static IContainer ValueCell(this IContainer container) => container.Cell(false);
}
```
Now, you can easily use newly created DSL language to build the table:
```csharp
.Grid(grid =>
{
grid.Columns(10);
for(var i=1; i<=4; i++)
{
grid.Item(2).LabelCell(Placeholders.Label());
grid.Item(3).ValueCell().Image(Placeholders.Image(200, 150));
}
});
```
This example produces the following output:

::: tip
Please note that this example shows only the concept of using extension methods to build custom API elements. Using this approach you can build and reuse more complex structures. For example, extension methods can expect arguments.
:::
## Complex layouts and grids
By combining various elements, you can build complex layouts. When designing try to break your layout into separate pieces and then model them by using the `Row` and the `Column` elements. In many cases, the `Grid` element can simplify and shorten your code.
Please consider the code below. Please note that it uses example DSL elements from the previous section.
```csharp
.Column(column =>
{
column.Item().Row(row =>
{
row.RelativeItem().LabelCell("Label 1");
row.RelativeItem(3).Grid(grid =>
{
grid.Columns(3);
grid.Item(2).LabelCell("Label 2");
grid.Item().LabelCell("Label 3");
grid.Item(2).ValueCell().Text("Value 2");
grid.Item().ValueCell().Text("Value 3");
});
});
column.Item().Row(row =>
{
row.RelativeItem().ValueCell().Text("Value 1");
row.RelativeItem(3).Grid(grid =>
{
grid.Columns(3);
grid.Item().LabelCell("Label 4");
grid.Item(2).LabelCell("Label 5");
grid.Item().ValueCell().Text("Value 4");
grid.Item(2).ValueCell().Text("Value 5");
});
});
column.Item().Row(row =>
{
row.RelativeItem().LabelCell("Label 6");
row.RelativeItem().ValueCell().Text("Value 6");
});
});
```
And its corresponding output:

## Components
A component is a special type of element that can generate content depending on its state. This approach is really common in many web-development libraries and solves multiple issues. You should consider creating your own component when part of the document is going to be reused in other documents. Another good scenario is when you plan to repeat a more complex section. In such a case, you can implement a component that takes input provided as constructor's argument, and generates PDF content. Then, such component can be easily used in a for loop in the document itself. All things considered, components are a useful tool to organize and reuse your code.
::: tip
Components offer a lot of flexibility and extendability. Because of that, the QuestPDF library will receive several important updates to enhance components features even more. Stay tuned for slots!
:::
In this tutorial, we will cover a simple component that generates a random image taken from the fantastic webpage called [Lorem Picsum](https://picsum.photos/). To show how component's behaviour can be dynamically changed, the end result will offer optional greyscale flag.
Additionally, the constructor of the template is going to offer of showing only greyscale images.
```csharp
//interface
public interface IComponent
{
void Compose(IContainer container);
}
// example implementation
public class LoremPicsum : IComponent
{
public bool Greyscale { get; }
public LoremPicsum(bool greyscale)
{
Greyscale = greyscale;
}
public void Compose(IContainer container)
{
var url = "https://picsum.photos/300/200";
if(Greyscale)
url += "?grayscale";
using var client = new WebClient();
var response = client.DownloadData(url);
container.Image(response);
}
}
```
Example usage:
```csharp{7}
.Column(column =>
{
column.Spacing(10);
column
.Element()
.Component(new LoremPicsum(true));
column
.Element()
.AlignRight()
.Text("From Lorem Picsum");
});
```
The result of sample code looks as follows:

::: tip
If the component class has parameter-less constructor, you can use the generic `Template` method like so:
```csharp
.Component<ComponentClass>();
```
:::
## Implementing charts
There are many ways on how to implement charts in the QuestPDF documents. By utilizing the `Canvas` element and SkiaSharp-compatible charting libraries, it is possible to achieve vector charts.
Please analyse this simple example which utilizes the `microcharts` library ([nuget site](https://www.nuget.org/packages/Microcharts/)):
```csharp
// prepare data
var entries = new[]
{
new ChartEntry(212)
{
Label = "UWP",
ValueLabel = "112",
Color = SKColor.Parse("#2c3e50")
},
new ChartEntry(248)
{
Label = "Android",
ValueLabel = "648",
Color = SKColor.Parse("#77d065")
},
new ChartEntry(128)
{
Label = "iOS",
ValueLabel = "428",
Color = SKColor.Parse("#b455b6")
},
new ChartEntry(514)
{
Label = "Forms",
ValueLabel = "214",
Color = SKColor.Parse("#3498db")
}
};
// draw chart using the Canvas element
.Column(column =>
{
var titleStyle = TextStyle
.Default
.Size(20)
.SemiBold()
.Color(Colors.Blue.Medium)
column
.Item()
.PaddingBottom(10)
.Text("Chart example", titleStyle);
column
.Item()
.Border(1)
.ExtendHorizontal()
.Height(300)
.Canvas((canvas, size) =>
{
var chart = new BarChart
{
Entries = entries,
LabelOrientation = Orientation.Horizontal,
ValueLabelOrientation = Orientation.Horizontal,
IsAnimated = false,
};
chart.DrawContent(canvas, (int)size.Width, (int)size.Height);
});
});
```
This is a result:

## Style
### Color definitions
In QuestPDF, multiple element expect color as part of the configuration. Similarly to HTML, there are a couple of supported formats:
1. Standard format: `RRGGBB` OR `#RRGGBB`
2. Shorthand format: `RGB` or `#RGB`, e.g. `#123` is an equivalent to `#112233`
3. Alpha support: `AARRGGBB` or `#AARRGGBB`
4. Shorthand alpha format: `ARGB` or `#ARGB`
### Material Design colors
You can access any color defined in the Material Design colors set. Please find more details [on the official webpage](https://material.io/design/color/the-color-system.html).
```csharp
// base colors:
Colors.Black
Colors.White
Colors.Transparent
// colors with medium brightness:
Colors.Green.Medium;
Colors.Orange.Medium;
Colors.Blue.Medium;
// darken colors:
Colors.Blue.Darken4
Colors.LightBlue.Darken3
Colors.Indigo.Darken2
Colors.Brown.Darken1
// lighten colors:
Colors.Pink.Lighten1
Colors.Purple.Lighten2
Colors.Teal.Lighten3
Colors.Cyan.Lighten4
Colors.LightGreen.Lighten5
// accent colors:
Colors.Lime.Accent1
Colors.Yellow.Accent2
Colors.Amber.Accent3
Colors.DeepOrange.Accent4
```
Example usage:
```csharp
var colors = new[]
{
Colors.Green.Darken4,
Colors.Green.Darken3,
Colors.Green.Darken2,
Colors.Green.Darken1,
Colors.Green.Medium,
Colors.Green.Lighten1,
Colors.Green.Lighten2,
Colors.Green.Lighten3,
Colors.Green.Lighten4,
Colors.Green.Lighten5,
Colors.Green.Accent1,
Colors.Green.Accent2,
Colors.Green.Accent3,
Colors.Green.Accent4,
};
container
.Padding(25)
.Height(100)
.Row(row =>
{
foreach (var color in colors)
row.RelativeItem().Background(color);
});
```

### Basic fonts
The library offers a list of simple and popular fonts.
```csharp
Fonts.Calibri
Fonts.Candara
Fonts.Arial
// and more...
```
Example:
```csharp
var fonts = new[]
{
Fonts.Calibri,
Fonts.Candara,
Fonts.Arial,
Fonts.TimesNewRoman,
Fonts.Consolas,
Fonts.Tahoma,
Fonts.Impact,
Fonts.Trebuchet,
Fonts.ComicSans
};
container.Padding(25).Grid(grid =>
{
grid.Columns(3);
foreach (var font in fonts)
{
grid.Item()
.Border(1)
.BorderColor(Colors.Grey.Medium)
.Padding(10)
.Text(font, TextStyle.Default.FontType(font).Size(16));
}
});
```

## Prototyping
### Text
It is a very common scenario when we know how the document layout should look like, however, we do not have appropriate data to fill it. The Quest PDF library provides a set of helpers to generate random text of different kinds:
```csharp
using QuestPDF.Helpers;
Placeholders.LoremIpsum();
Placeholders.Label();
Placeholders.Sentence();
Placeholders.Question();
Placeholders.Paragraph();
Placeholders.Paragraphs();
Placeholders.Email();
Placeholders.Name();
Placeholders.PhoneNumber();
Placeholders.Time();
Placeholders.ShortDate();
Placeholders.LongDate();
Placeholders.DateTime();
Placeholders.Integer();
Placeholders.Decimal();
Placeholders.Percent();
```
### Colors
You can access a random color picked from the Material Design colors set. Colors are returned as text in the HEX format.
```csharp
// bright color, lighten-2
Placeholders.BackgroundColor();
// medium
Placeholders.Color();
```
Example usage to create a colorful matrix:
```csharp
.Padding(25)
.Grid(grid =>
{
grid.Columns(5);
Enumerable
.Range(0, 25)
.Select(x => Placeholders.BackgroundColor())
.ToList()
.ForEach(x => grid.Item().Height(50).Background(x));
});
```

### Image
Use this simple function to generate random image with required size:
```csharp
// both functions return a byte array containing a JPG file
Placeholders.Image(400, 300);
Placeholders.Image(new Size(400, 300));
// example usage
.Padding(25)
.Width(300)
.AspectRatio(3 / 2f)
.Image(Placeholders.Image);
```

## Achieving different header/footer on the first page
It is a common requirement to have a special header on the first page on your document. Then all consecutive pages should have a normal header. This requirement can be easily achieved by using the `ShowOnce` and tge `SkipOnce` elements, like so:
```csharp{8-9}
container.Page(page =>
{
page.Size(PageSizes.A6);
page.Margin(30);
page.Header().Column(column =>
{
column.Item().ShowOnce().Background(Colors.Blue.Lighten2).Height(60);
column.Item().SkipOnce().Background(Colors.Green.Lighten2).Height(40);
});
page.Content().PaddingVertical(10).Column(column =>
{
column.Spacing(10);
foreach (var _ in Enumerable.Range(0, 13))
column.Item().Background(Colors.Grey.Lighten2).Height(40);
});
page.Footer().AlignCenter().Text(text =>
{
text.DefaultTextStyle(TextStyle.Default.Size(16));
text.CurrentPageNumber();
text.Span(" / ");
text.TotalPages();
});
});
```
The code above produces the following results:



::: tip
Please notice that you can use the `SkipOnce` and `ShowOnce` elements multiple times to achieve more complex requirements. For example:
1) `.SkipOnce().ShowOnce()` displays child element only on the second page.
2) `.SkipOnce().SkipOnce()` displays child element starting at third page.
3) `.ShowOnce().SkipOnce()` displays nothing (invocation order is important!).
:::
## Exceptions
During the development process, you may encounter different issues connected to the PDF document rendering process.
It is important to understand potential sources of such exceptions, their root causes and how to fix them properly.
In the QuestPDF library, all exceptions have been divided into three groups:
### DocumentComposeException
This exception may occur during the document composition process. When you are using the fluent API to compose various elements together to create the final layout. Taking into account that during such process you are interacting with report data, using conditions, loops and even additional methods, all those operations may be a source of potential exceptions. All of them have been grouped together in this exception type.
### DocumentDrawingException
This exception occurs during the document generation process - when the generation engine translates elements tree into proper drawing commands. If you encounter such an exception, please contact with us - it is most probably a bug that we want to fix for you! Additionally, if you are using custom components, all exceptions thrown there are going to bubble up with this type of exception.
### DocumentLayoutException
This exception may be extremely hard to fix because it happens for valid document trees which enforce constraints that are impossible to meet. For example, when you try to draw a rectangle bigger than available space on the page, the rendering engine is going to wrap the content in a hope that on the next page there would be enough space. Generally, such wrapping behaviour is happening all the time and is working nicely - however, there are cases when it can lead to infinite wrapping. When a certain document length threshold is passed, the algorithm stops the rendering process and throws this exception. In such case, please revise your code and search for indivisible elements requiring too much space.
This exception provides an additional element column. It shows which elements have been rendered when the exception was thrown. Please analyse the example below:
```csharp{2,8}
.Padding(10)
.Width(100)
.Background(Colors.Grey.Lighten3)
.DebugPointer("Example debug pointer")
.Column(x =>
{
x.Item().Text("Test");
x.Item().Width(150); // requires 150pt width where only 100pt is available
});
```
Below is the element trace returned by the exception. Nested elements (children) are indented. Sometimes you may find additional, library-specific elements.
Additional symbols are used to help you find the problem cause:
- 🌟 - represents special elements, e.g. page header/content/footer or the debug pointer element,
- 🔥 - represents an element that causes the layouting exception. Follow the symbol deeper to find the root cause.
```
🔥 Page content 🌟
------------------
Available space: (Width: 500, Height: 360)
Requested space: PartialRender (Width: 120,00, Height: 20,00)
🔥 Background
-------------
Available space: (Width: 500, Height: 360)
Requested space: PartialRender (Width: 120,00, Height: 20,00)
Color: #ffffff
🔥 Padding
----------
Available space: (Width: 500, Height: 360)
Requested space: PartialRender (Width: 120,00, Height: 20,00)
Top: 10
Right: 10
Bottom: 10
Left: 10
🔥 Constrained
--------------
Available space: (Width: 480, Height: 340)
Requested space: PartialRender (Width: 100,00, Height: 0,00)
Min Width: 100
Max Width: 100
Min Height: -
Max Height: -
🔥 Background
-------------
Available space: (Width: 100, Height: 340)
Requested space: PartialRender (Width: 0,00, Height: 0,00)
Color: #eeeeee
🔥 Example debug pointer 🌟
---------------------------
Available space: (Width: 100, Height: 340)
Requested space: PartialRender (Width: 0,00, Height: 0,00)
🔥 Column
--------
Available space: (Width: 100, Height: 340)
Requested space: PartialRender (Width: 0,00, Height: 0,00)
🔥 Padding
----------
Available space: (Width: 100, Height: 340)
Requested space: PartialRender (Width: 0,00, Height: 0,00)
Top: 0
Right: 0
Bottom: -0
Left: 0
🔥 BinaryColumn
--------------
Available space: (Width: 100, Height: 340)
Requested space: PartialRender (Width: 0,00, Height: 0,00)
🔥 Constrained
--------------
Available space: (Width: 100, Height: 340)
Requested space: Wrap
Min Width: 150
Max Width: 150
Min Height: -
Max Height: -
```
| 32.343552 | 710 | 0.663562 | eng_Latn | 0.941534 |
58684bd85f05593d8833d5597a40b513b3f689e5 | 23,407 | md | Markdown | docs/exchange-web-services/how-to-extract-an-entity-from-an-email-message-by-using-ews-in-exchange.md | MicrosoftDocs/office-developer-exchange-docs.de-DE | 2e35110e080001522ea0fa4d4859e065d2af37f3 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-05-19T18:53:40.000Z | 2022-03-28T11:50:28.000Z | docs/exchange-web-services/how-to-extract-an-entity-from-an-email-message-by-using-ews-in-exchange.md | MicrosoftDocs/office-developer-exchange-docs.de-DE | 2e35110e080001522ea0fa4d4859e065d2af37f3 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-12-08T02:37:48.000Z | 2021-12-08T02:38:08.000Z | docs/exchange-web-services/how-to-extract-an-entity-from-an-email-message-by-using-ews-in-exchange.md | MicrosoftDocs/office-developer-exchange-docs.de-DE | 2e35110e080001522ea0fa4d4859e065d2af37f3 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-06-17T20:59:32.000Z | 2020-06-17T20:59:32.000Z | ---
title: Extrahieren einer Entität aus einer E-Mail-Nachricht mithilfe von EWS in Exchange
manager: sethgros
ms.date: 03/9/2015
ms.audience: Developer
ms.assetid: 6396b009-5f6e-41eb-a75a-224d43e864ae
description: Erfahren Sie, wie Sie Informationen aus dem Textkörper einer e-Mail-Nachricht mithilfe der verwaltete EWS-API oder EWS in Exchange extrahieren.
localization_priority: Priority
ms.openlocfilehash: fb90eb05441667e6b327b09d568117f5040e6fd8
ms.sourcegitcommit: 88ec988f2bb67c1866d06b361615f3674a24e795
ms.translationtype: MT
ms.contentlocale: de-DE
ms.lasthandoff: 06/03/2020
ms.locfileid: "44528111"
---
# <a name="extract-an-entity-from-an-email-message-by-using-ews-in-exchange"></a>Extrahieren einer Entität aus einer E-Mail-Nachricht mithilfe von EWS in Exchange
Erfahren Sie, wie Sie Informationen aus dem Textkörper einer e-Mail-Nachricht mithilfe der verwaltete EWS-API oder EWS in Exchange extrahieren.
Sie können die verwaltete EWS-API oder EWS verwenden, um auf die Adressen, Kontakte, e-Mail-Adressen, Besprechungsvorschläge, Telefonnummern, Aufgaben und URLs zuzugreifen, die ein Exchange-Server aus e-Mail-Nachrichten extrahiert. Anschließend können Sie diese Informationen für neue Anwendungen verwenden oder um Folgeaktionen in vorhandenen Anwendungen vorschlagen. Wenn beispielsweise eine Kontakt Entität, ein Besprechungs Vorschlag oder ein Aufgaben Vorschlag in einer e-Mail angegeben wird, kann Ihre Anwendung vorschlagen, dass ein neues Element mit vorab aufgefüllten Informationen erstellt wird. Durch die Verwendung extrahierter Entitäten können Sie die Absicht hinter den Daten nutzen und Benutzern die nahtlose Integration Ihrer e-Mail-Nachrichteninhalte in umsetzbare Ergebnisse erleichtern.
Die Entitäts Extraktion für Adressen, Kontakte, e-Mail-Adressen, Besprechungsvorschläge, Telefonnummern, Aufgaben und URLs ist bereits für jedes Element in der Exchange-Informationsspeicher integriert. Wenn Sie die verwaltete EWS-API verwenden, ruft die [Item. EntityExtractionResult](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.item.entityextractionresult%28v=exchg.80%29.aspx) -Eigenschaft die Entitäten für Sie in einem [Item. Bind](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.item.bind%28v=exchg.80%29.aspx) -Methodenaufruf ab. Wenn Sie EWS verwenden, ruft das [EntityExtractionResult](https://msdn.microsoft.com/library/643b99ab-ff90-4411-864c-1077623028d6%28Office.15%29.aspx) -Element alle extrahierten Entitäten für Sie in einem [GetItem](https://msdn.microsoft.com/library/dcf40fa7-7796-4a5c-bf5b-7a509a18d208%28Office.15%29.aspx) -Vorgangsaufruf ab. Nachdem Sie die Ergebnisse der extrahierten Entitäten abgerufen haben, können Sie durch jede entitätssammlung navigieren, um relevante Informationen zu sammeln. Wenn beispielsweise ein Besprechungs Vorschlag extrahiert wurde, können Sie den vorgeschlagenen Besprechungs Betreff, die Teilnehmerliste, die Startzeit und die Endzeit abrufen.
**Tabelle 1. Verwaltete EWS-API Eigenschaften und EWS-Elemente, die extrahierte Entitäten enthalten**
|**Extrahierte Entität**|**Eigenschaft in der verwalteten EWS-API**|**EWS-Element**|
|:-----|:-----|:-----|
|Adressen <br/> |[EntityExtractionResult. addresses](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.entityextractionresult.addresses%28v=exchg.80%29.aspx) <br/> |[Adressen](https://msdn.microsoft.com/library/0c1f3fd3-1b78-46ee-8dd4-b2aff51e767e%28Office.15%29.aspx) <br/> |
|Kontakte <br/> |[EntityExtractionResult. Contacts](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.entityextractionresult.contacts%28v=exchg.80%29.aspx) <br/> |[Kontakte](https://msdn.microsoft.com/library/a2c1e833-5f8c-438d-bad7-bb5dcc29ca9e%28Office.15%29.aspx) <br/> |
|E-Mail-Adressen <br/> |[EntityExtractionResult. Email-Nachnamen](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.entityextractionresult.emailaddresses%28v=exchg.80%29.aspx) <br/> |[EmailAddresses](https://msdn.microsoft.com/library/2fc4a8e8-5377-4059-8fb4-3fdabfd30fe3%28Office.15%29.aspx) <br/> |
|Besprechungsvorschläge <br/> |[EntityExtractionResult. MeetingSuggestions](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.entityextractionresult.meetingsuggestions%28v=exchg.80%29.aspx) <br/> |[MeetingSuggestions](https://msdn.microsoft.com/library/c99e9a60-9e38-425d-ad03-47c8917f41da%28Office.15%29.aspx) <br/> |
|Telefonnummern <br/> |[EntityExtractionResult. phonenumbers](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.entityextractionresult.phonenumbers%28v=exchg.80%29.aspx) <br/> |[PhoneNumbers](https://msdn.microsoft.com/library/9ff6ae98-34a1-47f7-bde5-608251a789f7%28Office.15%29.aspx) <br/> |
|Aufgaben Vorschläge <br/> |[EntityExtractionResult.TaskSuggestions](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.entityextractionresult.addresses%28v=exchg.80%29.aspx) <br/> |[TaskSuggestions](https://msdn.microsoft.com/library/7d3c6314-2a5c-4fc3-b5f9-ae6d4946aac3%28Office.15%29.aspx) <br/> |
|URLs <br/> |[EntityExtractionResult. URLs](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.entityextractionresult.addresses%28v=exchg.80%29.aspx) <br/> |[Urls](https://msdn.microsoft.com/library/c39744ea-0cee-4954-8653-8279d6b10161%28Office.15%29.aspx) <br/> |
Da die Entitäts Extraktion von der natürlichen Spracherkennung abhängt, kann die Erkennung von Entitäten nicht deterministisch sein, und der Erfolg basiert manchmal auf dem Kontext. Um zu veranschaulichen, wie die natürliche Spracherkennung funktioniert, verwenden die Beispiele in diesem Artikel die folgende e-Mail als Eingabe.
`From: Ronnie Sturgis`
`To: Sadie Daniels`
`Subject: Dinner party`
`Hi Sadie`
`Are you free this Friday at 7 to join us for a dinner party at our house?`
`We're at 789 International Blvd, St Paul MN 55104.`
`Our number is 612-555-0158 if you have trouble finding it.`
`Please RSVP to either myself or Mara ([email protected]) before Friday morning. Best for you organics (http://www.bestforyouorganics.com) will be catering so we can fully enjoy ourselves!`
`Also, can you forward this to Magdalena? I don't have her contact information.`
`See you then!`
`Ronnie`
## <a name="extract-all-entities-from-an-email-by-using-the-ews-managed-api"></a>Extrahieren aller Entitäten aus einer e-Mail mithilfe der verwaltete EWS-API
<a name="bk_extractewsma"> </a>
Im folgenden Codebeispiel wird gezeigt, wie Sie alle vom Server extrahierten Entitäten anzeigen, indem Sie die [Item. Bind](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.item.bind%28v=exchg.80%29.aspx) -Methode verwenden und dann die einzelnen extrahierten Entitäten und deren Eigenschaften auflisten.
In diesem Beispiel wird davon ausgegangen, dass **service** ein gültiges [ExchangeService](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.exchangeservice%28v=exchg.80%29.aspx)-Objekt ist, und dass **ItemId** die [ID](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.item.id%28v=exchg.80%29.aspx) der zu verschiebenden oder kopierenden E-Mail-Nachricht ist.
```cs
public static void ExtractEntities(ExchangeService service, ItemId ItemId)
{
// Create a property set that limits the properties returned
// by the Bind method to only those that are required.
PropertySet propSet = new PropertySet(BasePropertySet.IdOnly, ItemSchema.EntityExtractionResult);
// Get the item from the server.
// This method call results in an GetItem call to EWS.
Item item = Item.Bind(service, ItemId, propSet);
Console.WriteLine("The following entities have been extracted from the message:");
Console.WriteLine(" ");
// If address entities are extracted from the message, print the results.
if (item.EntityExtractionResult != null)
{
if (item.EntityExtractionResult.Addresses != null)
{
Console.WriteLine("--------------------Addresses---------------------------");
foreach (AddressEntity address in item.EntityExtractionResult.Addresses)
{
Console.WriteLine("Address: {0}", address.Address);
}
Console.WriteLine(" ");
}
// If contact entities are extracted from the message, print the results.
if (item.EntityExtractionResult.Contacts != null)
{
Console.WriteLine("--------------------Contacts----------------------------");
foreach (ContactEntity contact in item.EntityExtractionResult.Contacts)
{
Console.WriteLine("Addresses: {0}", contact.Addresses);
Console.WriteLine("Business name: {0}", contact.BusinessName);
Console.WriteLine("Contact string: {0}", contact.ContactString);
Console.WriteLine("Email addresses: {0}", contact.EmailAddresses);
Console.WriteLine("Person name: {0}", contact.PersonName);
Console.WriteLine("Phone numbers: {0}", contact.PhoneNumbers);
Console.WriteLine("URLs: {0}", contact.Urls);
}
Console.WriteLine(" ");
}
// If email address entities are extracted from the message, print the results.
if (item.EntityExtractionResult.EmailAddresses != null)
{
Console.WriteLine("--------------------Email addresses---------------------");
foreach (EmailAddressEntity email in item.EntityExtractionResult.EmailAddresses)
{
Console.WriteLine("Email addresses: {0}", email.EmailAddress);
}
Console.WriteLine(" ");
}
// If meeting suggestion entities are extracted from the message, print the results.
if (item.EntityExtractionResult.MeetingSuggestions != null)
{
Console.WriteLine("--------------------Meeting suggestions-----------------");
foreach (MeetingSuggestion meetingSuggestion in item.EntityExtractionResult.MeetingSuggestions)
{
Console.WriteLine("Meeting subject: {0}", meetingSuggestion.Subject);
Console.WriteLine("Meeting string: {0}", meetingSuggestion.MeetingString);
foreach (EmailUserEntity attendee in meetingSuggestion.Attendees)
{
Console.WriteLine("Attendee name: {0}", attendee.Name);
Console.WriteLine("Attendee user ID: {0}", attendee.UserId);
}
Console.WriteLine("Start time: {0}", meetingSuggestion.StartTime);
Console.WriteLine("End time: {0}", meetingSuggestion.EndTime);
Console.WriteLine("Location: {0}", meetingSuggestion.Location);
}
Console.WriteLine(" ");
}
// If phone number entities are extracted from the message, print the results.
if (item.EntityExtractionResult.PhoneNumbers != null)
{
Console.WriteLine("--------------------Phone numbers-----------------------");
foreach (PhoneEntity phone in item.EntityExtractionResult.PhoneNumbers)
{
Console.WriteLine("Original phone string: {0}", phone.OriginalPhoneString);
Console.WriteLine("Phone string: {0}", phone.PhoneString);
Console.WriteLine("Type: {0}", phone.Type);
}
Console.WriteLine(" ");
}
// If task suggestion entities are extracted from the message, print the results.
if (item.EntityExtractionResult.TaskSuggestions != null)
{
Console.WriteLine("--------------------Task suggestions--------------------");
foreach (TaskSuggestion task in item.EntityExtractionResult.TaskSuggestions)
{
foreach (EmailUserEntity assignee in task.Assignees)
{
Console.WriteLine("Assignee name: {0}", assignee.Name);
Console.WriteLine("Assignee user ID: {0}", assignee.UserId);
}
Console.WriteLine("Task string: {0}", task.TaskString);
}
Console.WriteLine(" ");
}
// If URL entities are extracted from the message, print the results.
if (item.EntityExtractionResult.Urls != null)
{
Console.WriteLine("--------------------URLs--------------------------------");
foreach (UrlEntity url in item.EntityExtractionResult.Urls)
{
Console.WriteLine("URL: {0}", url.Url);
}
Console.WriteLine(" ");
}
}
// If no entities are extracted from the message, print the result.
else if (item.EntityExtractionResult == null)
{
Console.WriteLine("No entities extracted");
}
}
```
Die folgende Ausgabe wird in der Konsole angezeigt.
```text
The following entities have been extracted from the message:
--------------------Addresses---------------------------
Address: 789 International Blvd, St Paul MN 55104
--------------------Contacts----------------------------
Addresses:
Business name:
Contact string: Mara ([email protected])
Email addresses: [email protected]
Person name: Mara
Phone numbers:
URLs:
--------------------Email addresses---------------------
Email addresses: [email protected]
--------------------Meeting suggestions-----------------
Meeting subject: dinner party
Meeting string: Are you free this Friday at 7 to join us for a dinner party at our house?
Attendee name: Ronnie Sturgis
Attendee user ID: [email protected]
Attendee name: Sadie Daniels
Attendee user ID: [email protected]
Start time: 10/1/0104 2:00:00 PM
End time: 10/1/0104 2:30:00 PM
Location:
--------------------Phone numbers-----------------------
Original phone string: 612-555-0158
Phone string: 6125550158
Type: Unspecified
--------------------Task suggestions--------------------
Assignee name: Sadie Daniels
Assignee user ID: [email protected]
Task string: Also, can you forward this to Magdalena?
--------------------URLs--------------------------------
URL: http://www.bestforyouorganics.com
```
Beachten Sie, dass alle Adressen, Kontakte, e-Mail-Adressen, Telefonnummern, Aufgaben und URLs wie erwartet extrahiert wurden. Der Besprechungs Vorschlag ist jedoch etwas komplizierter. Beachten Sie, dass die Anfangs-und Endzeit des Besprechungs Vorschlags nicht das ist, was Sie erwarten könnten. Die Startzeit in der e-Mail lautet "dieser Freitag um 7", aber der extrahierte Wert für die Startzeit lautet 10/1/0104 2:00:00 Uhr. Dies liegt daran, dass die vom Server extrahierten Start-und Endzeiten codierte Daten sind. Weitere Informationen zum Interpretieren von **DateTime** -Werten in Besprechungs Vorschlägen finden Sie unter [[MS-OXCEXT]: Client Extension Message Object Protocol](https://msdn.microsoft.com/library/hh968601%28v=exchg.80%29.aspx).
## <a name="extract-all-entities-from-an-email-by-using-ews"></a>Extrahieren aller Entitäten aus einer e-Mail-Nachricht mithilfe von EWS
<a name="bk_extractews"> </a>
Im folgenden Codebeispiel wird veranschaulicht, wie die [GetItem](https://msdn.microsoft.com/library/dcf40fa7-7796-4a5c-bf5b-7a509a18d208%28Office.15%29.aspx) -Operation und das [EntityExtractionResult](https://msdn.microsoft.com/library/643b99ab-ff90-4411-864c-1077623028d6%28Office.15%29.aspx) -Element zum Abrufen der extrahierten Entitäten aus einem Element verwendet werden.
Dies ist auch die XML-Anforderung, die von der verwaltete EWS-API gesendet wird, wenn Sie die **Bind** -Methode verwenden, um [alle Entitäten aus einer e-Mail mithilfe der verwaltete EWS-API zu extrahieren](#bk_extractewsma).
Der Wert des [ItemID](https://msdn.microsoft.com/library/3350b597-57a0-4961-8f44-8624946719b4%28Office.15%29.aspx) -Elements wird zur Lesbarkeit gekürzt.
```XML
<?xml version="1.0" encoding="utf-8"?>
<soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:m="https://schemas.microsoft.com/exchange/services/2006/messages"
xmlns:t="https://schemas.microsoft.com/exchange/services/2006/types"
xmlns:soap="https://schemas.xmlsoap.org/soap/envelope/">
<soap:Header>
<t:RequestServerVersion Version="Exchange2013" />
</soap:Header>
<soap:Body>
<m:GetItem>
<m:ItemShape>
<t:BaseShape>IdOnly</t:BaseShape>
<t:AdditionalProperties>
<t:FieldURI FieldURI="item:EntityExtractionResult" />
</t:AdditionalProperties>
</m:ItemShape>
<m:ItemIds>
<t:ItemId Id="sVC5AAA=" />
</m:ItemIds>
</m:GetItem>
</soap:Body>
</soap:Envelope>
```
Der Server antwortet auf die **GetItem** -Anforderung mit einer [GetItemResponse](https://msdn.microsoft.com/library/8b66de1b-26a6-476c-9585-a96059125716%28Office.15%29.aspx) -Nachricht, die einen [Response Code](https://msdn.microsoft.com/library/4b84d670-74c9-4d6d-84e7-f0a9f76f0d93%28Office.15%29.aspx) -Wert von **noError**enthält, der angibt, dass die e-Mail-Nachricht erfolgreich abgerufen wurde. Die Antwort enthält auch die **EntityExtractionResult** für jede extrahierte Entität.
Der Wert des **ItemID** -Elements wird zur Lesbarkeit gekürzt.
```XML
<?xml version="1.0" encoding="utf-8"?>
<s:Envelope xmlns:s="https://schemas.xmlsoap.org/soap/envelope/">
<s:Header>
<h:ServerVersionInfo MajorVersion="15"
MinorVersion="0"
MajorBuildNumber="883"
MinorBuildNumber="10"
Version="V2_10"
xmlns:h="https://schemas.microsoft.com/exchange/services/2006/types"
xmlns="https://schemas.microsoft.com/exchange/services/2006/types"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" />
</s:Header>
<s:Body xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<m:GetItemResponse xmlns:m="https://schemas.microsoft.com/exchange/services/2006/messages"
xmlns:t="https://schemas.microsoft.com/exchange/services/2006/types">
<m:ResponseMessages>
<m:GetItemResponseMessage ResponseClass="Success">
<m:ResponseCode>NoError</m:ResponseCode>
<m:Items>
<t:Message>
<t:ItemId Id="sVC5AAA="
ChangeKey="CQAAABYAAAD32nSTjepyT63rYH17n9THAAAOOqJN" />
<t:EntityExtractionResult>
<t:Addresses>
<t:AddressEntity>
<t:Position>LatestReply</t:Position>
<t:Address>789 International Blvd, St Paul MN 55104</t:Address>
</t:AddressEntity>
</t:Addresses>
<t:MeetingSuggestions>
<t:MeetingSuggestion>
<t:Position>LatestReply</t:Position>
<t:Attendees>
<t:EmailUser>
<t:Name>Ronnie Sturgis</t:Name>
<t:UserId>[email protected]</t:UserId>
</t:EmailUser>
<t:EmailUser>
<t:Name>Sadie Daniels</t:Name>
<t:UserId>[email protected]</t:UserId>
</t:EmailUser>
</t:Attendees>
<t:Subject>dinner party</t:Subject>
<t:MeetingString>Are you free this Friday at 7 to join us for a dinner party at our house?</t:MeetingString>
<t:StartTime>0104-10-01T19:00:00Z</t:StartTime>
<t:EndTime>0104-10-01T19:30:00Z</t:EndTime>
</t:MeetingSuggestion>
</t:MeetingSuggestions>
<t:TaskSuggestions>
<t:TaskSuggestion>
<t:Position>LatestReply</t:Position>
<t:TaskString>Also, can you forward this to Magdalena?</t:TaskString>
<t:Assignees>
<t:EmailUser>
<t:Name>Sadie Daniels</t:Name>
<t:UserId>[email protected]</t:UserId>
</t:EmailUser>
</t:Assignees>
</t:TaskSuggestion>
</t:TaskSuggestions>
<t:EmailAddresses>
<t:EmailAddressEntity>
<t:Position>LatestReply</t:Position>
<t:EmailAddress>[email protected]</t:EmailAddress>
</t:EmailAddressEntity>
</t:EmailAddresses>
<t:Contacts>
<t:Contact>
<t:Position>LatestReply</t:Position>
<t:PersonName>Mara</t:PersonName>
<t:EmailAddresses>
<t:EmailAddress>[email protected]</t:EmailAddress>
</t:EmailAddresses>
<t:ContactString>Mara ([email protected]</t:ContactString>
</t:Contact>
</t:Contacts>
<t:Urls>
<t:UrlEntity>
<t:Position>LatestReply</t:Position>
<t:Url>http://www.bestforyouorganics.com</t:Url>
</t:UrlEntity>
</t:Urls>
<t:PhoneNumbers>
<t:Phone>
<t:Position>LatestReply</t:Position>
<t:OriginalPhoneString>612-555-0158</t:OriginalPhoneString>
<t:PhoneString>6125550158</t:PhoneString>
<t:Type>Unspecified</t:Type>
</t:Phone>
</t:PhoneNumbers>
</t:EntityExtractionResult>
</t:Message>
</m:Items>
</m:GetItemResponseMessage>
</m:ResponseMessages>
</m:GetItemResponse>
</s:Body>
</s:Envelope>
```
Beachten Sie, dass alle Adressen, Kontakte, e-Mail-Adressen, Telefonnummern, Aufgaben und URLs wie erwartet extrahiert wurden. Der Besprechungs Vorschlag ist jedoch etwas komplizierter. Beachten Sie, dass die Anfangs-und Endzeit des Besprechungs Vorschlags nicht das ist, was Sie erwarten könnten. Die Startzeit in der e-Mail war "dieser Freitag um 7", aber der extrahierte Wert für die Startzeit lautet 10/1/0104 2:00:00 Uhr. Dies liegt daran, dass die vom Server extrahierten Start-und Endzeiten codierte Daten sind. Weitere Informationen zum Interpretieren von **DateTime** -Werten in Besprechungs Vorschlägen finden Sie unter [[MS-OXCEXT]: Nachrichtenobjekt Protokoll für Client Erweiterungen](https://msdn.microsoft.com/library/hh968601%28v=exchg.80%29.aspx).
## <a name="see-also"></a>Siehe auch
- [E-Mail- und EWS in Exchange](email-and-ews-in-exchange.md)
- [Item. EntityExtractionResult](https://msdn.microsoft.com/library/microsoft.exchange.webservices.data.item.entityextractionresult%28v=exchg.80%29.aspx)
- [EntityExtractionResult](https://msdn.microsoft.com/library/643b99ab-ff90-4411-864c-1077623028d6%28Office.15%29.aspx)
| 61.92328 | 1,253 | 0.655958 | deu_Latn | 0.331971 |
58686b69741a4809a78050538a9f3c49b54a7305 | 109 | md | Markdown | content/posts/joss-stone-son-of-a-preacher-man.md | sirodoht/mostlyoverstatements.com | c5f3401678605640a610a6b07b6c36e09cb7f503 | [
"MIT"
] | 1 | 2018-02-27T00:39:13.000Z | 2018-02-27T00:39:13.000Z | content/posts/joss-stone-son-of-a-preacher-man.md | sirodoht/mostlyoverstatements.com | c5f3401678605640a610a6b07b6c36e09cb7f503 | [
"MIT"
] | 3 | 2018-02-26T22:23:59.000Z | 2018-02-27T19:13:19.000Z | content/posts/joss-stone-son-of-a-preacher-man.md | sirodoht/mostlyoverstatements.com | c5f3401678605640a610a6b07b6c36e09cb7f503 | [
"MIT"
] | null | null | null | ---
title: "Joss Stone - Son of a Preacher Man"
date: 2018-06-14T03:09:38+02:00
youtubeId: "TBH8o8XXnVM"
---
| 18.166667 | 43 | 0.678899 | eng_Latn | 0.28293 |
5868951ba591086241ca6439bda90ca3c40ff7c4 | 680 | md | Markdown | content/user/zen_cart_forum/finding_a_plugin.md | torvista/documentation | 28ba0a1bad888a9061be7b437fb886b4c01a6abf | [
"MIT"
] | 4 | 2018-08-30T14:46:28.000Z | 2020-07-16T11:57:56.000Z | content/user/zen_cart_forum/finding_a_plugin.md | torvista/documentation | 28ba0a1bad888a9061be7b437fb886b4c01a6abf | [
"MIT"
] | 181 | 2016-04-25T14:06:12.000Z | 2022-03-06T10:15:49.000Z | content/user/zen_cart_forum/finding_a_plugin.md | torvista/documentation | 28ba0a1bad888a9061be7b437fb886b4c01a6abf | [
"MIT"
] | 25 | 2016-04-25T05:29:25.000Z | 2021-09-21T20:01:06.000Z | ---
title: Finding a Plugin
description: Where can I find plugin X?
category: zen_cart_forum
weight: 10
---
Sometimes you'll read about a plugin and want to try it yourself.
Here's how to find it in the Plugins Library:
- Go to Plugin Library
https://www.zen-cart.com/downloads.php
- click Advanced Search
- Enter the plugin name in the search box, and set the dropdown to Search Titles only.
This should find the plugin for you if it is in the Plugins Library.
Another option is to use Google to search for a plugin.
If you enter
```
site:zen-cart.com name-of-plugin
```
into the search box at Google.com, you will likely find what you want on the first page.
| 22.666667 | 89 | 0.739706 | eng_Latn | 0.983263 |
586932fb25702414efac7f648cd5ab935fd6cf42 | 5,530 | md | Markdown | windows.ui.composition/compositioneffectbrush.md | wilsonNg007/winrt-api | 97057ca57fcfcdbde13c1737d4ddcfaf98ae35ae | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows.ui.composition/compositioneffectbrush.md | wilsonNg007/winrt-api | 97057ca57fcfcdbde13c1737d4ddcfaf98ae35ae | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows.ui.composition/compositioneffectbrush.md | wilsonNg007/winrt-api | 97057ca57fcfcdbde13c1737d4ddcfaf98ae35ae | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
-api-id: T:Windows.UI.Composition.CompositionEffectBrush
-api-type: winrt class
---
<!-- Class syntax.
public class CompositionEffectBrush : Windows.UI.Composition.CompositionBrush, Windows.UI.Composition.ICompositionEffectBrush
-->
# Windows.UI.Composition.CompositionEffectBrush
## -description
Paints a SpriteVisual with the output of a filter effect. The filter effect description is defined using the [CompositionEffectFactory](compositioneffectfactory.md) class.
## -remarks
The effect APIs enable developers to customize how their UI is rendered. This can be something as simple as adjusting saturation levels on an image or something more complex like chaining numerous effects together and animating the effect properties to create interesting application transitions and user experiences. A composition effect is a graph of operations that define how to produce graphical content based on composition surfaces. For example, the pixel content of images. Effects are applied to visuals in the tree and can reference existing surfaces.
An instance of CompositionEffectBrush is created using a [CompositionEffectFactory](compositioneffectfactory.md) based on a specified effect description. [CompositionEffectFactory](compositioneffectfactory.md) uses the [Win2D](https://microsoft.github.io/Win2D/html/Introduction.htm) effect description format in the [Microsoft.Graphics.Canvas.Effects](https://microsoft.github.io/Win2D/html/N_Microsoft_Graphics_Canvas_Effects.htm) namespace.
> [!NOTE]
> Effects that are not supported are marked as **[NoComposition]** in the [Win2D API Reference](https://microsoft.github.io/Win2D/html/APIReference.htm) for effects namespace.
A CompositionEffectBrush is applied to a [SpriteVisual](spritevisual.md) in the composition tree.
Sources to CompositionEffectBrush can be an existing surface or texture, or another effect enabling effect chaining.
CompositionEffectBrush.Properties (inherited from CompositionObject.Properties) allows setting or animating the animatable properties that were specified in the call to Compositor.[CreateEffectFactory](compositor_createeffectfactory_720924202.md) using their full 'EffectName.PropertyName' name.
Effect sources can be set independently from other CompositionEffectBrush instances, and properties can be animated independently from other CompositionEffectBrush instances.
Once an effect graph is declared, the system compiles the effect using built-in shaders. Custom shaders cannot be specified.
### Creating a CompositionEffect
To create and apply an effect you need to perform the following steps:
1. Create an effect description. See the [Win2D](https://microsoft.github.io/Win2D/html/Introduction.htm) namespace, [Microsoft.Graphics.Canvas.Effects](https://microsoft.github.io/Win2D/html/N_Microsoft_Graphics_Canvas_Effects.htm), for valid effect types.
2. Set any effect sources with either an instance of [CompositionEffectSourceParameter](compositioneffectsourceparameter.md) or another effect. Specifying another effect creates an effect chain.
3. Create a CompositionEffectFactory with Compositor.[CreateEffectFactory](compositor_createeffectfactory_720924202.md) using the effect description as input.
4. Create an instance of the effect using CompositorEffectFactory.[CreateBrush](compositioneffectfactory_createbrush_639615316.md).
5. Set any CompositionEffectSourceParameter using CompositionEffectBrush.[SetSourceParameter](compositioneffectbrush_setsourceparameter_49982457.md) and the name of the source parameter as previously specified using a [CompositionEffectSourceParameter](compositioneffectsourceparameter.md).
6. Create an instance of [SpriteVisual](spritevisual.md) using Compositor.[CreateSpriteVisual](compositor_createspritevisual_1850565165.md).
7. Set the [Brush](spritevisual_brush.md) property of the [SpriteVisual](spritevisual.md) to the created effect.
8. Add the [SpriteVisual](spritevisual.md) to the composition tree by using the [Children](containervisual_children.md) property of a [ContainerVisual](containervisual.md).
## -examples
```csharp
// Create an effect description
GaussianBlurEffect blurEffect = new GaussianBlurEffect()
{
Name = "Blur",
BlurAmount = 1.0f,
BorderMode = EffectBorderMode.Hard,
Optimization = EffectOptimization.Balanced
};
blurEffect.Source = new CompositionEffectSourceParameter("source");
CompositionEffectFactory blurEffectFactory = _compositor.CreateEffectFactory(blurEffect);
CompositionEffectBrush blurBrush = blurEffectFactory.CreateBrush();
// Create a BackdropBrush and bind it to the EffectSourceParameter “source”
CompositionBackdropBrush backdropBrush = _compositor.CreateBackdropBrush();
blurBrush.SetSourceParameter("source", backdropBrush);
// The SpriteVisual to apply the blur BackdropBrush to
// This will cause everything behind this SpriteVisual to be blurred
SpriteVisual blurSprite = _compositor.CreateSpriteVisual();
blurSprite.Brush = blurBrush;
// Set blurSprite as a child visual of a XAML element
ElementCompositionPreview.SetElementChildVisual(blurArea, blurSprite);
```
## -see-also
[Composition Brushes Overview](https://docs.microsoft.com/windows/uwp/graphics/composition-brushes), [Composition Effects Overview](https://docs.microsoft.com/en-us/windows/uwp/composition/composition-effects), [CompositionBrush](compositionbrush.md), [IClosable](../windows.foundation/iclosable.md)
| 66.626506 | 562 | 0.809042 | eng_Latn | 0.6636 |
586996975b3b0c7dbe3c9fd99ec77d0800933c5e | 1,192 | md | Markdown | docs/cli/tilt_completion_powershell.md | tilt-dev/tilt.build | 504dfb2a885af6fc73ef80b7f1c3a7a557223828 | [
"Apache-2.0"
] | 11 | 2020-05-30T16:53:06.000Z | 2022-02-16T00:22:24.000Z | docs/cli/tilt_completion_powershell.md | tilt-dev/tilt.build | 504dfb2a885af6fc73ef80b7f1c3a7a557223828 | [
"Apache-2.0"
] | 169 | 2020-05-18T16:59:41.000Z | 2022-03-25T14:16:27.000Z | docs/cli/tilt_completion_powershell.md | tilt-dev/tilt.build | 504dfb2a885af6fc73ef80b7f1c3a7a557223828 | [
"Apache-2.0"
] | 39 | 2020-06-20T22:20:58.000Z | 2022-03-03T07:32:49.000Z | ---
title: Tilt CLI Reference
layout: docs
hideEditButton: true
---
## tilt completion powershell
generate the autocompletion script for powershell
### Synopsis
Generate the autocompletion script for powershell.
To load completions in your current shell session:
PS C:\> tilt completion powershell | Out-String | Invoke-Expression
To load completions for every new session, add the output of the above command
to your powershell profile.
```
tilt completion powershell [flags]
```
### Options
```
-h, --help help for powershell
--no-descriptions disable completion descriptions
```
### Options inherited from parent commands
```
-d, --debug Enable debug logging
--klog int Enable Kubernetes API logging. Uses klog v-levels (0-4 are debug logs, 5-9 are tracing logs)
--log-flush-frequency duration Maximum number of seconds between log flushes (default 5s)
-v, --verbose Enable verbose logging
```
### SEE ALSO
* [tilt completion](tilt_completion.html) - generate the autocompletion script for the specified shell
###### Auto generated by spf13/cobra on 22-Oct-2021
| 25.361702 | 131 | 0.683725 | eng_Latn | 0.891514 |
5869a117e299df794b97599d4054f10e4bee1120 | 5,226 | md | Markdown | _posts/2019-11-05-user-defined-test-dialects.md | LogtalkDotOrg/logtalk.org | 1fbbb893ce11c2a251e9d4b42037b58d458b10c9 | [
"MIT"
] | 5 | 2016-06-17T17:41:00.000Z | 2021-08-17T21:25:38.000Z | _posts/2019-11-05-user-defined-test-dialects.md | seanwallawalla-forks/logtalk.org | 431998ae0cfeddf394b82fc4c88c42ad5b33a3ad | [
"MIT"
] | 5 | 2020-02-25T15:01:01.000Z | 2022-02-26T04:31:27.000Z | _posts/2019-11-05-user-defined-test-dialects.md | seanwallawalla-forks/logtalk.org | 431998ae0cfeddf394b82fc4c88c42ad5b33a3ad | [
"MIT"
] | 4 | 2016-05-30T22:36:54.000Z | 2021-08-20T08:11:54.000Z | ---
layout: article
title: User-defined test dialects
tags:
- testing
- best practices
show_edit_on_github: false
aside: false
---
Testing is a fundamental part of software development. Follows that writing
tests should be as accessible as possible. Although automatic test generation
is an established practice (using e.g. a [Quickcheck](../../08/20/easily-quickcheck-your-predicates.html)
implementation such as the one provided by Logtalk), tests are often manually
written. Thus, anything that gets in the way of expressing what we want to
test hurts productivity.
Testing tools such as [`lgtunit`](https://logtalk.org/manuals/devtools/lgtunit.html)
aim to simplify writing tests by providing support for [multiple test dialects](https://logtalk.org/manuals/devtools/lgtunit.html#test-dialects)
where the programmer can choose from a minimal dialect, where we have only
a test name and a test goal, to a dialect providing fine control on test setup.
But that's not enough. People writing tests are not necessarily programmers.
Notably, they can be domain experts that want a straight-forward solution
to express that "for these inputs, we should get this output" or "if this
happens, this should be triggered" without having to learn a programming
language and its developer tools. The solution? Define a DSL for writing
tests and take advantage of `lgtunit` support for [user-defined test dialects](https://logtalk.org/manuals/devtools/lgtunit.html#user-defined-test-dialects).
Let's look into a simple but complete example. Assume that we're testing
an application that uses a predicate that takes three floating-point values
as input and generates an atom. The domain experts want to be able to write
tests using the following notation:
```logtalk
{12.7, 3.89, 5.67} => open_valve.
{2.04, 1.23, 0.77} => close_valve.
{20.4, 2.91, 6.97} => open_valve.
...
```
The notation is nice and clear and abstracts all details irrelevant for
the domain experts, including the name of the predicate being tested and
how to call it.
The first step is to define an object, implementing the
[`expanding`](https://logtalk.org/library/expanding_0.html)
protocol, that will convert the facts above into one of the supported
test dialects. For simplicity, we're going to assume that the
predicate being tested is named `app::compute/4`:
```logtalk
:- object(test_dsl,
implements(expanding)).
:- public(op(1200, xfx, =>)).
:- uses(gensym, [gensym/2, reset_gensym/1]).
:- uses(os, [decompose_file_name/4]).
term_expansion(
begin_of_file,
[begin_of_file, (:- object(Name, extends(lgtunit)))]
) :-
logtalk_load_context(source, Source),
decompose_file_name(Source, _, Name, _),
reset_gensym(t).
term_expansion(
({A, B, C} => D),
(test(Test, true(R == D)) :- app::compute(A, B, C, R))
) :-
gensym(t, Test).
term_expansion(
end_of_file,
[(:- end_object), end_of_file]
).
:- end_object.
```
Using the `test_dsl` object as an
[hook object](https://logtalk.org/manuals/glossary.html#term-hook-object)
to expand a data file with `=>/2` facts results in the generation of a tests
object named after the data file. But how do we run the tests? As test objects
must be compiled using `lgtunit` as the hook object, we simply chain
the two hook objects. Assuming the `=>/2` facts are defined in a
`tests.data` file, a suitable `tester.lgt` driver file for the tests
would be:
```logtalk
:- op(1200, xfx, =>).
:- initialization((
set_logtalk_flag(report, warnings),
logtalk_load([
lgtunit(loader),
gensym(loader),
os(loader),
hook_flows(loader),
app,
test_dsl
]),
logtalk_load(
'tests.data',
[hook(hook_pipeline([test_dsl,lgtunit]))]
),
tests::run
)).
```
The [`hook_pipeline/1`](https://logtalk.org/library/hook_pipeline_1.html)
parametric object takes as argument a list of hook objects, implementing
a *pipeline* of term-expansions. In this case, the terms expanded by the
`test_dsl` object are passed to `lgtunit` object for further expansion.
As an usage example, assuming the contents of the `tests.data` file
are the `=>/2` facts above and that we only have a placeholder for
the test predicate defined as:
```logtalk
:- object(app).
:- public(compute/4).
compute(_, _, _, open_valve).
:- end_object.
```
we will get:
```text
?- {tester}.
%
% tests started at 2019/11/5, 14:45:22
%
% running tests from object tests
% file: /Users/pmoura/test_dsl/tests.data
%
% t1: success
! t2: failure
! test assertion failed: open_valve==close_valve
! in file tests.data at or above line 2
% t3: success
%
% 3 tests: 0 skipped, 2 passed, 1 failed
% completed tests from object tests
%
% no code coverage information collected
% tests ended at 2019/11/5, 14:45:22
%
true.
```
Note that the line numbers in the failed tests reflect the line of
the original `=>/2` fact.
The solution we described is easily applied to any user-defined test
dialect. Thus, anytime you find the predefined test dialects not ideal
for a particular application, consider simply defining your own custom
test dialect.
| 32.259259 | 157 | 0.716418 | eng_Latn | 0.987466 |
586a5e52d741c3275cc4dc78bbaaeac403859356 | 5,837 | md | Markdown | README.md | slang25/HotReload | 3fdcb92724bbeb6a3312eb7cd2eccd92e57b179d | [
"MIT"
] | null | null | null | README.md | slang25/HotReload | 3fdcb92724bbeb6a3312eb7cd2eccd92e57b179d | [
"MIT"
] | null | null | null | README.md | slang25/HotReload | 3fdcb92724bbeb6a3312eb7cd2eccd92e57b179d | [
"MIT"
] | null | null | null | 
# HotReload
Xamarin.Forms XAML hot reload, live reload, live xaml
Sample Video you can find here: https://twitter.com/i/status/1124314311151607809
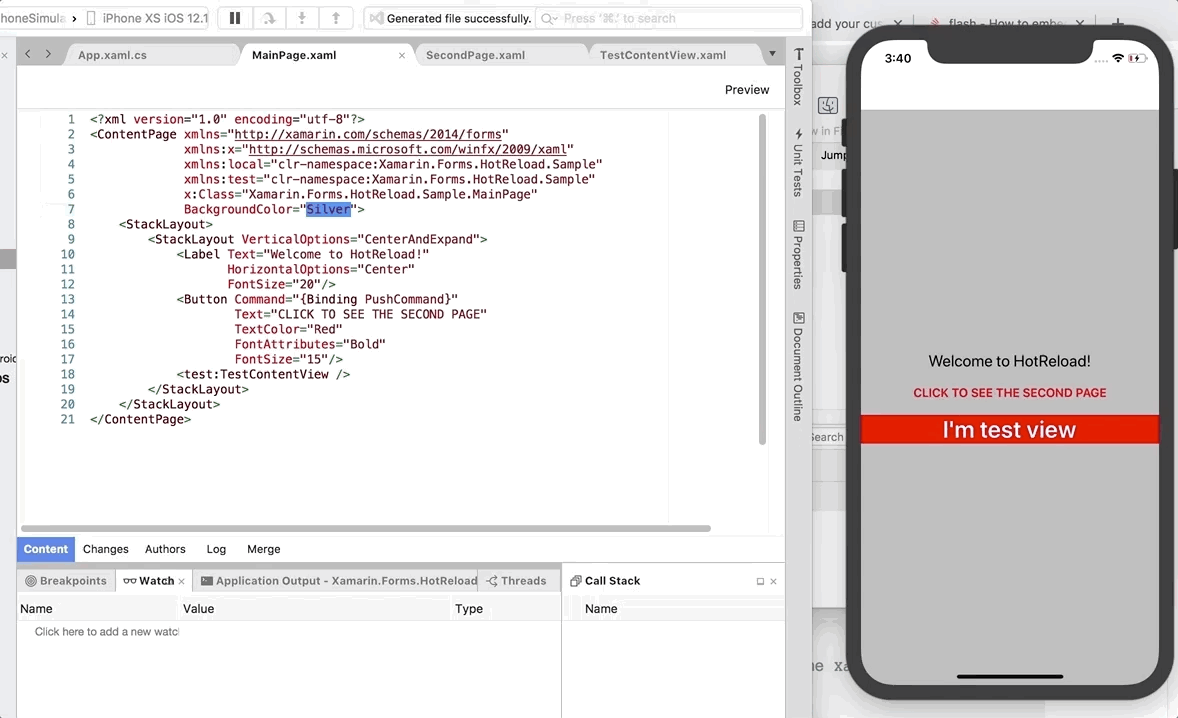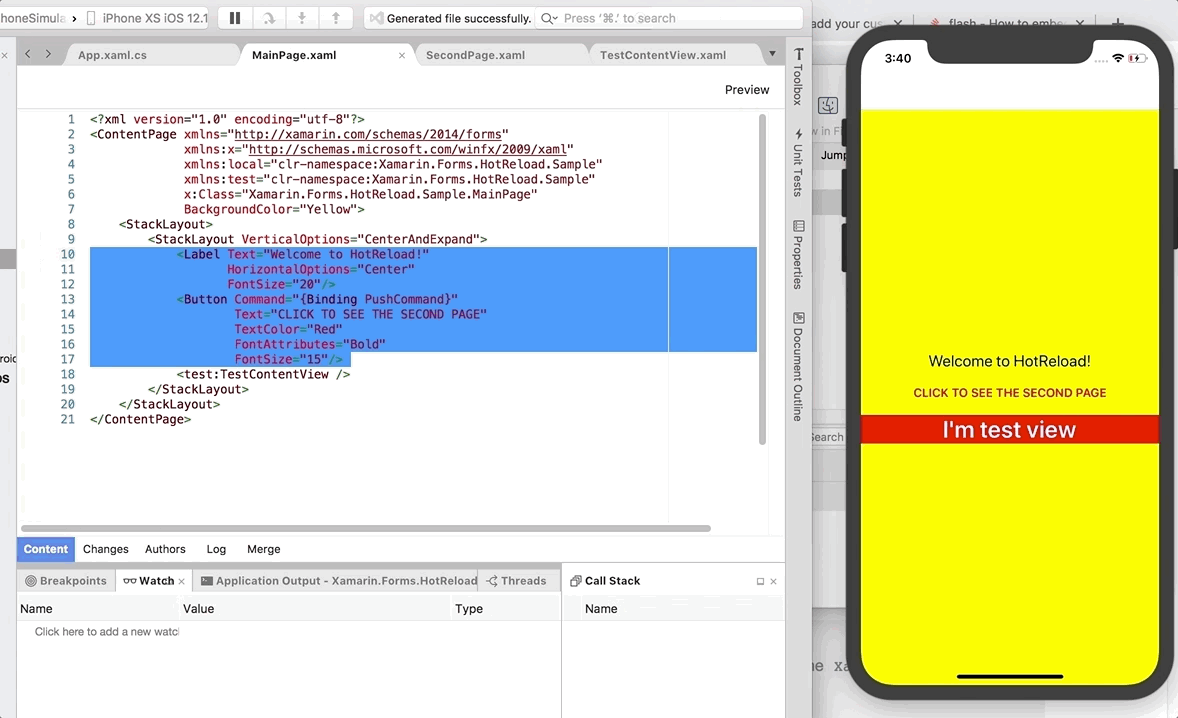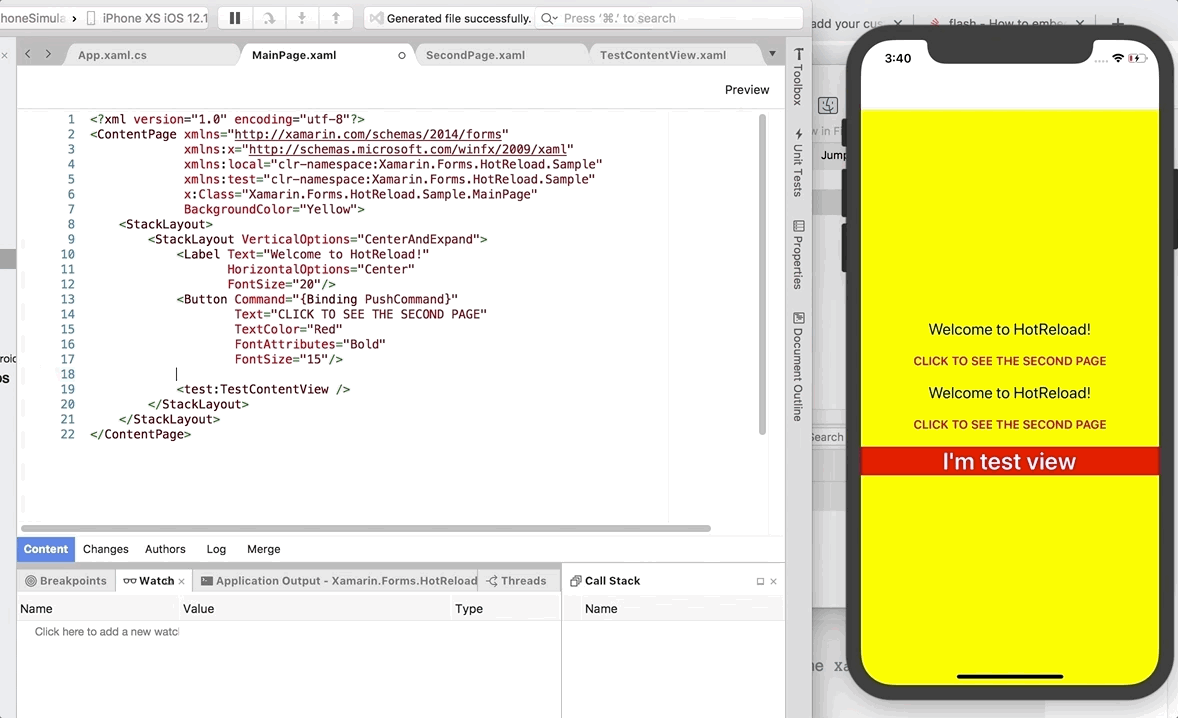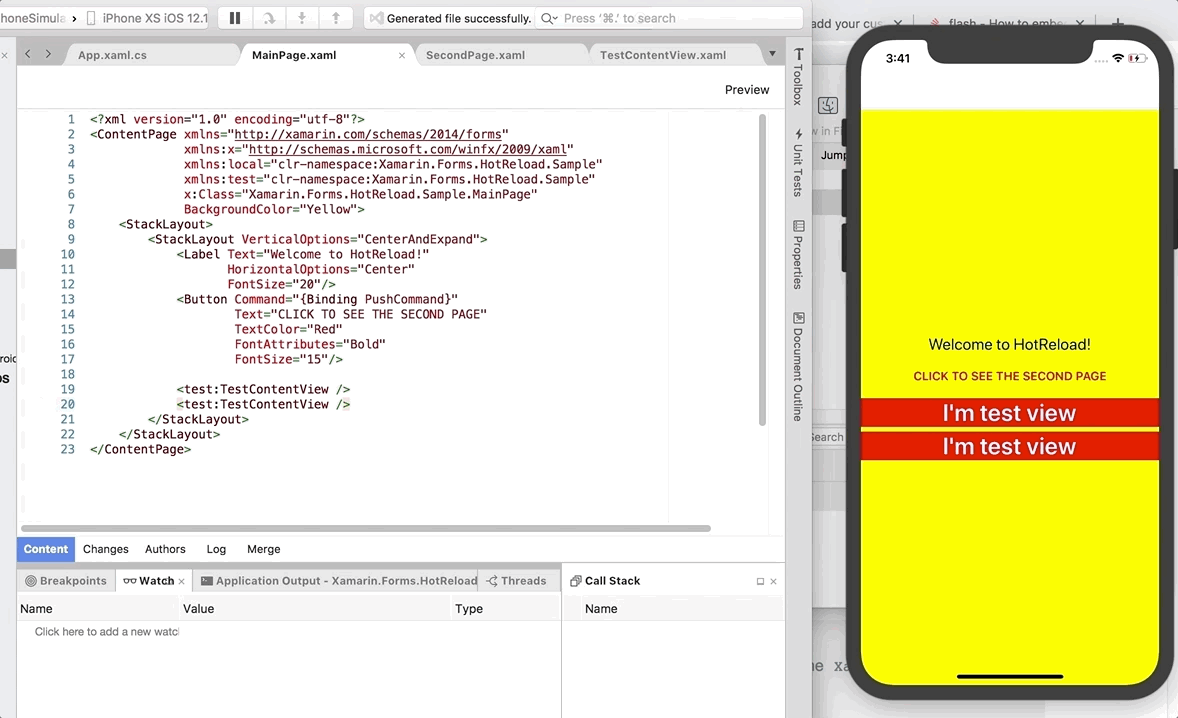
## Setup
* Available on NuGet: [Xamarin.HotReload](http://www.nuget.org/packages/Xamarin.HotReload) [](https://www.nuget.org/packages/Xamarin.HotReload)
* Add nuget package to your Xamarin.Forms **NETSTANDARD**/**PCL** project and to all platform-specific projects **iOS**, **Android** etc. just in case (but adding to portable project should be enough)
* Setup Reloader
```csharp
using Xamarin.Forms;
namespace YourNamespace
{
public partial class App : Application
{
public App()
{
InitializeComponent();
#if DEBUG
HotReloader.Current.Start(this);
#endif
MainPage = new NavigationPage(new MainPage());
}
}
}
```
**IMPORTANT:** don't use ```[Xaml.XamlCompilation(Xaml.XamlCompilationOptions.Compile)]``` with HotReload. It can cause errors. So, don't enable it for Debug or disable please.
#### Mac
* Visual Studio for Mac extension is available for downloading here http://addins.monodevelop.com/Project/Index/376
Or by searching in Visual Studio's extension manager

* Header of "HotReload for Xamarin.Forms" extension will appear in Visual Studio's "Tools" dropdown menu.
"Enable extension" menu item will appear as soon as solution is opened.

##### WINDOWS
* You may use official HotReload's Visual Studio Extension https://marketplace.visualstudio.com/items?itemName=StanislavBavtovich.hotreloadxamarinforms. Also can be downloaded via extension manager

NOTE: Restart Visual Studio after installation.
* To make "HotReload for Xamarin.Forms" extension's toolbar visible turn it on in "Tools/Customize" window.

* As soon as solution is opened "Enable extension" button will appear on "Tabs panel".

##### Other IDE e.g. (like Rider etc.)
* Build observer project yourself (Release mode) and find **exe** file in bin/release folder https://github.com/AndreiMisiukevich/HotReload/tree/master/Observer/Xamarin.Forms.HotReload.Observer and put it in the root folder of your Xamarin.Forms NETSTANDARD/PCL project.
* Start Xamarin.Forms.HotReload.Observer.exe via terminal (for MAC) ```mono Xamarin.Forms.HotReload.Observer.exe``` or via command line (Windows) ```Xamarin.Forms.HotReload.Observer.exe``` etc.
* Optionaly you can set specific folder for observing files (if you didn't put observer.exe to the root folder) and specific device url for sending changes.
```mono Xamarin.Forms.HotReload.Observer.exe p=/Users/yourUser/SpecificFolder/ u=http://192.168.0.3```
### Run your app and start developing with **HotReload**!
1) **IMPORTANT**:
- Make sure you use proper device IP in Extension. Check application output for more info about device IP.
- Also keep in mind, that your PC/Mac and device/emulator must be in the same local network.
2) If you want to make any initialization of your element after reloading, you should implement **IReloadable** interface. **OnLoaded** will be called each time when element is created (constructor called) AND element's Xaml updated. So, you needn't duplicate code in constructor and in **OnLoaded** method. Just use **OnLoaded** then.
```csharp
public partial class MainPage : ContentPage, IReloadable
{
public MainPage()
{
InitializeComponent();
}
public void OnLoaded() // Add logic here
{
//
}
}
```
3) **ViewCell** reloading: before starting app you MUST determine type of root view (e.g. StackLayout). It cannot be changed during app work (I mean, you still can change StackLayout props (e.g. BackgroundColor etc.), but you CANNOT change StackLayout to AbsoluteLayout e.g.).
```xaml
<?xml version="1.0" encoding="UTF-8"?>
<ViewCell xmlns="http://xamarin.com/schemas/2014/forms"
x:Class="Xamarin.Forms.HotReload.Sample.Pages.Cells.ItemCell">
<StackLayout>
</StackLayout>
</ViewCell>
```
## Android Emulator
In case `VS Extension` detects `xaml` changes but doesn't update in the emulator, you may need to forward the port to your `127.0.0.1`:
- Set **http://127.0.0.1:8000** in VS extension
- You also need to forward the port to your pc/mac using `adb`
```
adb forward tcp:8000 tcp:8000
```
## Android device
If you are using a real device you'll have to connect to it through its IP in HotReload extension.
To get your device's IP follow this :
- Open adb command prompt
- Run `adb shell` command
- Run command `ip -f inet addr show wlan0`
- Copy IP from command result to HotReload extension window
## What is Device IP ?
You can easily find it in **Application Output** if run application with installed HotReaload.
Use **AVAILABLE DEVICE's IP** as search text
## Collaborators
- [AndreiMisiukevich (Andrei)](https://github.com/AndreiMisiukevich)
- [stanbav (Stanislav)](https://github.com/stanbav)
Are there any questions? 🇧🇾 ***just ask us =)*** 🇧🇾
## License
The MIT License (MIT) see [License file](LICENSE)
## Contribution
Feel free to create issues and PRs 😃
| 44.9 | 335 | 0.742505 | eng_Latn | 0.702968 |
586a5f451d1008ad27f5d89ff031ab957a2c5492 | 2,117 | md | Markdown | src/sl/2020-02/08/04.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 68 | 2016-10-30T23:17:56.000Z | 2022-03-27T11:58:16.000Z | src/sl/2020-02/08/04.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 367 | 2016-10-21T03:50:22.000Z | 2022-03-28T23:35:25.000Z | src/sl/2020-02/08/04.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 109 | 2016-08-02T14:32:13.000Z | 2022-03-31T10:18:41.000Z | ---
title: Sobota in stvarjenje
date: 19/05/2020
---
V današnjem času je sobota v posvetnih in verskih krogih močno napadena. O tem pričajo delovni urniki svetovnih podjetij in prizadevanja mnogih evropskih držav, da nedeljo spremenijo v sedmi dan, ter tudi nedavna papeževa okrožnica, ki govori o podnebnih spremembah. V tej okrožnici papež dan počitka imenuje »judovska sobota« in svet spodbuja, naj spoštuje dan počitka, da bi s skupnimi močmi ublažili segrevanje ozračja. /papež Frančišek, Laudato Si', Vatikan: Vatikan Press, 2015, str. 172–173/
`Kako je stvarjenje povezano s četrto zapovedjo in sporočilom treh angelov? 1 Mz 2,1-3; 2 Mz 20,8-11; Mr 2,27; Raz 14,7`
Sveto pismo pravi: »Sedmi dan je Bog dokončal delo, ki ga je naredil.« (1 Mz 2,2 SSP) Mnogo kreacionistov poudarja delo, ki ga je Bog opravil v šestih dneh stvarjenja, vendar zanemarjajo dejstvo, da se Božje delo ni končalo s šestim dnem. Stvarjenja je bilo konec, ko je Bog ustvaril soboto. Jezus je s tem v mislih rekel: »Sobota je ustvarjena zaradi človeka, a ne človek zaradi sobote.« (Mr 2,27) Ker je Jezus stvarnik sobote, ki je večno znamenje in pečat Božje zaveze z njegovim ljudstvom, je to izjavo lahko podal z veljavo. Sobota ni bila dana samo Judom, temveč celotnemu človeštvu.
V 1. Mojzesovi knjigi najdemo tri stvari, ki jih je Jezus naredil po stvarjenju. Prvič, počival je, (1 Mz 2,2) s čimer nam je pustil božanski zgled in izrazil svoje hrepenenje po počitku skupaj z nami. Drugič, sedmi dan je blagoslovil. (1 Mz 2,3) V poročilu o stvarjenju beremo, da so bile blagoslovljene živali (1 Mz 1,22) ter Adam in Eva. (1 Mz 1,28) Edini dan, ki je izrecno blagoslovljen, je sedmi dan. Tretjič, Bog je soboto »posvetil« (1 Mz 2,3) oziroma »naredil za sveto«.
Noben drug dan v Svetem pismu ni prejel teh treh določitev. Ta tri dejanja se ponovijo v četrti zapovedi, ki jo je zapisal sam Bog s svojim prstom. Četrta zapoved nas spominja na stvarjenje, ki je temelj sobote. (2 Mz 20,11)
`V Raz 14,7 in 2 Mz 20,11 je zapoved o soboti neposredno povezana s češčenjem Stvarnika. Kako se ta povezava ujema z dogodki zadnjega časa?`
| 124.529412 | 589 | 0.772319 | slv_Latn | 1.000002 |
586b12a874e05fb0eff55d8771d16484f2fcd331 | 1,319 | md | Markdown | CHANGELOG.md | Harrix/Harrix-OptimizationAlgorithms | ae812c189af872302f1bb5927bc3ef2e8d95634e | [
"CC0-1.0"
] | null | null | null | CHANGELOG.md | Harrix/Harrix-OptimizationAlgorithms | ae812c189af872302f1bb5927bc3ef2e8d95634e | [
"CC0-1.0"
] | null | null | null | CHANGELOG.md | Harrix/Harrix-OptimizationAlgorithms | ae812c189af872302f1bb5927bc3ef2e8d95634e | [
"CC0-1.0"
] | null | null | null | HarrixOptimizationAlgorithms
============================
1.7
---
* Названия алгоритмов начинаются теперь с MHL, а с HML.
1.6
---
* Добавлены алгоритмы MHL_BinaryGeneticAlgorithmTwiceGenerations, MHL_RealGeneticAlgorithmTwiceGenerations.
* Исправлены опечатки.
1.5
---
* Добавлены алгоритмы MHL_BinaryGeneticAlgorithmTournamentSelectionWithReturn, MHL_RealGeneticAlgorithmTournamentSelectionWithReturn.
1.4
---
* Добавлены алгоритмы MHL_BinaryMonteCarloAlgorithm, MHL_RealMonteCarloOptimization.
* Добавление в название проекта слов "нулевого порядка".
* Добавление информации о свалке алгоритмов.
* Добавление постановки задачи оптимизации.
1.3
---
* Добавлены алгоритмы MHL_BinaryGeneticAlgorithmWDTS, MHL_RealGeneticAlgorithmWDTS, MHL_BinaryGeneticAlgorithmWCC, MHL_RealGeneticAlgorithmWCC.
1.2
---
* Разделение в исходниках на отдельные tex документы.
* Внесение информации о сГА в сам документ.
* Удаление файлов MHL_StandartBinaryGeneticAlgorithm.pdf и MHL_StandartRealGeneticAlgorithm.pdf за ненадобностью.
* Исправление названий алгоритмов.
1.1
---
* Добавлены алгоритмы MHL_BinaryGeneticAlgorithmWDPOfNOfGPS, MHL_RealGeneticAlgorithmWDPOfNOfGPS.
1.0
---
* Добавлены алгоритмы MHL_StandartBinaryGeneticAlgorithm, MHL_StandartRealGeneticAlgorithm. | 32.170732 | 145 | 0.789992 | yue_Hant | 0.261725 |
586b16ddc8ddcd5804d831255664a8d85aa55b89 | 111 | md | Markdown | JavaScript Algorithms and Data Structures Certification (300 hours)/2- ES6/27- Import a Default Export.md | AWIXOR/FreeCodeCamp-certifications | f058dae9edc1fbdf95d6fdb6c5691345ddeddb3e | [
"MIT"
] | 3 | 2019-11-18T16:55:57.000Z | 2021-01-10T11:40:00.000Z | JavaScript Algorithms and Data Structures Certification (300 hours)/2- ES6/27- Import a Default Export.md | AWIXOR/FreeCodeCamp-certifications | f058dae9edc1fbdf95d6fdb6c5691345ddeddb3e | [
"MIT"
] | null | null | null | JavaScript Algorithms and Data Structures Certification (300 hours)/2- ES6/27- Import a Default Export.md | AWIXOR/FreeCodeCamp-certifications | f058dae9edc1fbdf95d6fdb6c5691345ddeddb3e | [
"MIT"
] | null | null | null | ## Solution
```js
import subtract from "./math_functions.js";
// add code above this line
subtract(7,4);
``` | 12.333333 | 43 | 0.666667 | eng_Latn | 0.922573 |
586b2fc6b56e93bc01f317dc850e782863450fa4 | 3,067 | markdown | Markdown | _posts/2017-05-12-abney.markdown | jose-reyes-9/school-amp-1 | 89d5d0f1422f4e7390f7ed5b5e1b0f4c394d562e | [
"MIT"
] | null | null | null | _posts/2017-05-12-abney.markdown | jose-reyes-9/school-amp-1 | 89d5d0f1422f4e7390f7ed5b5e1b0f4c394d562e | [
"MIT"
] | null | null | null | _posts/2017-05-12-abney.markdown | jose-reyes-9/school-amp-1 | 89d5d0f1422f4e7390f7ed5b5e1b0f4c394d562e | [
"MIT"
] | null | null | null | ---
layout: post
title: "Mrs. Abney, it's your special day!"
subtitle: "We owe it to you, as students and teachers, as leaders, as a school, and as a community!"
date: 2017-05-12 12:00:00
author: "WSHS Voices"
header-img: "img/post/abney.jpg"
comments: false
---
<h2>Thank you for everything. Without you we wouldn't be where we are today, as leaders, as a school, and as a family!</h2>
<h3 class="section-heading">HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!! HAPPY BIRTHDAY!!</h3>
<audio controls autoplay>
<source src="{{ site.baseurl }}/audio/post/abney-bday.ogg" type="audio/ogg">
<source src="{{ site.baseurl }}/audio/post/abney-bday.mp3" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
| 170.388889 | 2,412 | 0.74731 | kor_Hang | 0.422194 |
586b481a034e3368dbc0eb076c417728f088c26b | 53 | md | Markdown | README.md | menglingtong/LTKit | 47f516cf547d18055b06093dc85ecf9fe5d4a209 | [
"MIT"
] | null | null | null | README.md | menglingtong/LTKit | 47f516cf547d18055b06093dc85ecf9fe5d4a209 | [
"MIT"
] | null | null | null | README.md | menglingtong/LTKit | 47f516cf547d18055b06093dc85ecf9fe5d4a209 | [
"MIT"
] | null | null | null | # LTKit
this is a utils kit as a note book ✧(≖ ◡ ≖✿)
| 17.666667 | 44 | 0.584906 | eng_Latn | 0.999734 |
586b4ff445952c7d8262e44f72ac0038540f04ad | 12,759 | md | Markdown | articles/site-recovery/azure-stack-site-recovery.md | gitruili/azure-docs.zh-cn | 4853c7dd56dcb4f2609e927196d2e25b6026a5f8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/site-recovery/azure-stack-site-recovery.md | gitruili/azure-docs.zh-cn | 4853c7dd56dcb4f2609e927196d2e25b6026a5f8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/site-recovery/azure-stack-site-recovery.md | gitruili/azure-docs.zh-cn | 4853c7dd56dcb4f2609e927196d2e25b6026a5f8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 使用 Azure Site Recovery 将 Azure Stack VM 复制到 Azure | Microsoft Docs
description: 了解如何使用 Azure Site Recovery 服务为 Azure Stack VM 设置到 Azure 的灾难恢复。
services: site-recovery
author: rayne-wiselman
manager: carmonm
ms.topic: conceptual
ms.service: site-recovery
ms.date: 08/30/2018
ms.author: raynew
ms.openlocfilehash: c71f683355a09c8ba2381db406eeb1ccabdb7afa
ms.sourcegitcommit: cb61439cf0ae2a3f4b07a98da4df258bfb479845
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 09/05/2018
ms.locfileid: "43697690"
---
# <a name="replicate-azure-stack-vms-to-azure-preview"></a>将 Azure Stack VM 复制到 Azure(预览版)
本文介绍如何使用 [Azure Site Recovery 服务](https://docs.microsoft.com/azure/site-recovery/site-recovery-overview)为 Azure Stack VM 设置到 Azure 的灾难恢复。
Site Recovery 有助于实现业务连续性和灾难恢复 (BCDR) 策略。 该服务可确保在出现预期内和意外中断时,VM 工作负载仍然可用。
- Site Recovery 可协调并管理 VM 到 Azure 存储的复制。
- 主站点出现中断时,可使用 Site Recovery 进行到 Azure 的故障转移。
- 进行故障转移时,会根据存储的 VM 数据创建 Azure VM,用户可继续访问在这些 Azure VM 上运行的工作负载。
- 一切恢复正常运行后,可将 Azure VM 故障回复到主站点,然后再次开始复制到 Azure 存储。
> [!NOTE]
> 适用于 Azure Stack 的 Site Recovery 目前为公共预览版。
在本文中,学习如何:
> [!div class="checklist"]
> * **步骤 1:做好复制 Azure Stack 的准备**。 检查 VM 是否符合 Site Recovery 要求,并准备安装 Site Recovery 移动服务。 此服务安装在要复制的每个 VM 上。
> * **步骤 2:设置恢复服务保管库**。 为 Site Recovery 设置保管库,并指定要复制的内容。 在保管库中配置和管理 Site Recovery 的组件和操作。
> * **步骤 3:设置源复制环境**。 设置 Site Recovery 配置服务器。 配置服务器是单个 Azure Stack VM,可运行 Site Recovery 需要的所有组件。 设置配置服务器后,在保管库中进行注册。
> * **步骤 4:设置目标复制环境**。 选择 Azure 帐户以及要使用的 Azure 存储帐户和网络。 复制期间,会将 VM 数据复制到 Azure 存储。 进行故障转移后,Azure VM 会加入指定的网络。
> * **步骤 5:启用复制**。 配置复制设置,启用 VM 复制。 启用复制后,会在 VM 上安装移动服务。 Site Recovery 执行 VM 的初始复制,然后开始持续复制。
> * **步骤 6:运行灾难恢复演练**:复制正常运行后,可运行演练来验证故障转移是否按预期工作。 要启动演练,请在 Site Recovery 中运行测试故障转移。 测试故障转移不会对生产环境造成任何影响。
完成这些步骤后,即可按需随时运行到 Azure 的完全故障转移。
## <a name="architecture"></a>体系结构

**位置** | 组件 |**详细信息**
--- | --- | ---
**配置服务器** | 在单个 Azure Stack VM 上运行。 | 在每个订阅中都可以设置配置服务器 VM。 此 VM 运行以下 Site Recovery 组件:<br/><br/> - 配置服务器:在本地和 Azure 之间协调通信并管理数据复制。 - 进程服务器:充当复制网关。 它接收复制数据,通过缓存、压缩和加密对其进行优化,然后将数据发送到 Azure 存储。<br/><br/> 如果要复制的 VM 超出了下述限制,则可设置单独的独立进程服务器。 [了解详细信息](https://docs.microsoft.com/azure/site-recovery/vmware-azure-set-up-process-server-scale)。
**移动服务** | 会安装在要复制的每个 VM 上。 | 在本文所述步骤中,我们准备了一个帐户,以便复制启用后自动在 VM 上安装移动服务。 如果不想自动安装该服务,则可使用许多其他方法。 [了解详细信息](https://docs.microsoft.com/azure/site-recovery/vmware-azure-install-mobility-service)。
**Azure** | 在 Azure 中,你需要一个恢复服务保管库、一个存储帐户和一个虚拟网络。 | 复制的数据存储在存储帐户中。 进行故障转移时,Azure VM 将添加到 Azure 网络。
复制按如下方式进行:
1. 在保管库中,指定复制源和目标,设置配置服务器,创建复制策略并启用复制。
2. 移动服务会安装到计算机(如果已使用推送安装),并且计算机会根据复制策略开始复制。
3. 服务器数据的初始副本将复制到 Azure 存储。
4. 完成初始复制后,开始将增量更改复制到 Azure。 计算机的受跟踪更改保存在 .hrl 文件中。
5. 配置服务器可协调与 Azure(HTTPS 443 出站端口)的复制管理。
6. 进程服务器从源计算机接收数据、优化和加密数据,然后将其发送到 Azure 存储(443 出站端口)。
7. 复制的计算机与配置服务器通信(HTTPS 443 入站端口,用于复制管理)。 计算机将复制数据发送到进程服务器(HTTPS 9443 入站端口,可修改)。
8. 流量通过 Internet 复制到 Azure 存储公共终结点。 或者,可以使用 Azure ExpressRoute 公共对等互连。 不支持通过站点到站点 VPN 将流量从本地站点复制到 Azure。
## <a name="prerequisites"></a>先决条件
下面是设置此方案所需的项。
要求 | **详细信息**
--- | ---
**Azure 订阅帐户** | 如果还没有 Azure 订阅,可以创建一个[免费帐户](https://azure.microsoft.com/pricing/free-trial/)。
**Azure 帐户权限** | 使用的 Azure 帐户需以下权限:<br/><br/> - 创建恢复服务保管库<br/><br/> - 在用于方案的资源组和虚拟网络中创建虚拟机<br/><br/> - 向指定的存储帐户进行写入<br/><br/> 请注意:<br/><br/> - 如果创建帐户,则你是自己的订阅的管理员,可以执行所有操作。<br/><br/> - 如果你使用现有订阅并且不是管理员,则需要请求管理员为你分配“所有者”或“参与者”权限。<br/><br/> - 如需更加细化的权限,请查看[此文](https://docs.microsoft.com/azure/site-recovery/site-recovery-role-based-linked-access-control)。
**Azure Stack VM** | 需要租户订阅中的 Azure Stack VM,该 VM 将部署为 Site Recovery 配置服务器。
### <a name="prerequisites-for-the-configuration-server"></a>配置服务器的先决条件
[!INCLUDE [site-recovery-config-server-reqs-physical](../../includes/site-recovery-config-server-reqs-physical.md)]
## <a name="step-1-prepare-azure-stack-vms"></a>步骤 1:准备 Azure Stack VM
### <a name="verify-the-operating-system"></a>验证操作系统
确保 VM 正在运行的是表中列出的操作系统。
**操作系统** | **详细信息**
--- | ---
**64 位 Windows** | Windows Server 2016、Windows Server 2012 R2、Windows Server 2012、Windows Server 2008 R2(自 SP1 起)
**CentOS** | 5.2 到 5.11、6.1 到 6.9、7.0 到 7.3
**Ubuntu** | 14.04 LTS 服务器、16.04 LTS 服务器。 查看[支持的内核](https://docs.microsoft.com/azure/site-recovery/vmware-physical-azure-support-matrix#ubuntu-kernel-versions)
### <a name="prepare-for-mobility-service-installation"></a>准备安装移动服务
要复制的所有 VM 都必须安装移动服务。 为使进程服务器在复制启用后自动将该服务安装到 VM 上,请验证 VM 设置。
#### <a name="windows-machines"></a>Windows 计算机
- 需在要启用复制的 VM 与运行进程服务器(默认情况下,此为配置服务器 VM)的计算机之间建立网络连接。
- 在启用复制的计算机上,需要有具有管理员权限的帐户(域或本地)。
- 可在设置 Site Recovery 时指定此帐户。 然后,在复制启用后,进程服务器使用此帐户安装移动服务。
- 此帐户仅供 Site Recovery 用于推送安装,并用于更新移动服务。
- 如果使用的不是域帐户,则需在 VM 上禁用远程用户访问控制:
- 在注册表中的 HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System 下,创建 DWORD 值 LocalAccountTokenFilterPolicy。
- 将值设置为 1。
- 若要在命令提示符下执行此操作,请键入以下内容:REG ADD HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System /v LocalAccountTokenFilterPolicy /t REG_DWORD /d 1。
- 在要复制的 VM 上的 Windows 防火墙中,允许“文件和打印机共享”以及 WMI。
- 若要执行此操作,请运行 wf.msc 打开 Windows 防火墙控制台。 依次右键单击“入站规则” > “新建规则”。 选择“预定义”,然后从列表中选择“文件和打印机共享”。 完成向导,选择以允许连接,然后单击“完成”。
- 对于域计算机,可使用 GPO 来执行此操作。
#### <a name="linux-machines"></a>Linux 计算机
- 确保 Linux 计算机与进程服务器之间已建立网络连接。
- 在启用了复制的计算机上,需要具有源 Linux 服务器的根用户帐户:
- 可在设置 Site Recovery 时指定此帐户。 然后,在复制启用后,进程服务器使用此帐户安装移动服务。
- 此帐户仅供 Site Recovery 用于推送安装,并用于更新移动服务。
- 确保源 Linux 服务器上的 /etc/hosts 文件包含用于将本地主机名映射到所有网络适配器关联的 IP 地址的条目。
- 在要复制的计算机上安装最新的 openssh、openssh-server 和 openssl 包。
- 确保安全外科 (SSH) 已启用且正在端口 22 上运行。
- 启用 sshd_config 文件中的 SFTP 子系统和密码身份验证:
1. 为此,请以根用户身份登录。
2. 在 /etc/ssh/sshd_config 文件中,找到以“PasswordAuthentication”开头的行。 取消注释该行,并将值更改为 **yes**。
3. 找到以 **Subsystem** 开头的行,并取消注释该行。

4. 重启 sshd 服务。
### <a name="note-the-vm-private-ip-address"></a>记下 VM 专用 IP 地址
找到要复制的每台计算机的 IP 地址:
1. 在 Azure Stack 门户中,单击 VM。
2. 在“资源”菜单上,单击“网络接口”。
3. 记下专用 IP 地址。

## <a name="step-2-create-a-vault-and-select-a-replication-goal"></a>第 2 步:创建保管库并选择复制目标
1. 在 Azure 门户中,选择“创建资源” > “监视 + 管理” > “备份和站点恢复”。
2. 在“名称”中,输入一个友好名称以标识此保管库。
3. 在“资源”组中,创建或选择资源组。 我们将使用 contosoRG。
4. 在“位置”中,输入 Azure 区域。 我们将使用“西欧”。
5. 若要从仪表板快速访问保管库,请选择“固定到仪表板” > “创建”。

新保管库显示在“仪表板” > “所有资源”中,以及“恢复服务保管库”主页上。
### <a name="select-a-replication-goal"></a>选择复制目标
1. 在“恢复服务保管库”中,指定保管库名称。 我们将使用 ContosoVMVault。
2. 在“入门”中,选择“Site Recovery”, 然后选择“准备基础结构”。
3. 在“保护目标” > “计算机所在位置”中,选择“本地”。
4. 在“要将计算机复制到何处?”中,选择“复制到 Azure”。
5. 在“计算机是否已虚拟化”中,选择“尚未虚拟化/其他”。 然后选择“确定”。

## <a name="step-3-set-up-the-source-environment"></a>步骤 3:设置源环境
设置配置服务器计算机,在保管库中进行注册,并找到要复制的计算机。
1. 单击“准备基础结构” > “源”。
2. 在“准备源”中,单击“+配置服务器”。

3. 在“添加服务器”中,检查“配置服务器”是否已显示在“服务器类型”中。
5. 下载站点恢复统一安装程序安装文件。
6. 下载保管库注册密钥。 运行统一安装程序时,需要注册密钥。 生成的密钥有效期为 5 天。

### <a name="run-azure-site-recovery-unified-setup"></a>运行 Azure Site Recovery 统一安装程序
若要安装并注册配置服务器,请与要用于配置服务器的 VM 建立 RDP 连接,然后运行统一安装程序。
开始操作之前, [请务必将时钟与 VM 上的](https://technet.microsoft.com/windows-server-docs/identity/ad-ds/get-started/windows-time-service/windows-time-service)时间服务器同步。 如果时间与当地时间误差超过五分钟,则安装失败。
现在来安装配置服务器:
[!INCLUDE [site-recovery-add-configuration-server](../../includes/site-recovery-add-configuration-server.md)]
> [!NOTE]
> 还可通过命令行安装配置服务器。 [了解详细信息](http://aka.ms/installconfigsrv)。
> 帐户名出现在门户中可能需要 15 分钟或更长时间。 若要立即更新,请选择“配置服务器” > ***服务器名称*** > “刷新服务器”。
## <a name="step-4-set-up-the-target-environment"></a>步骤 4:设置目标环境
选择并验证目标资源。
1. 在“准备基础结构” > “目标”中,选择要使用的 Azure 订阅。
2. 指定目标部署模型。
3. Site Recovery 会检查是否有一个或多个兼容的 Azure 存储帐户和网络。 如果未找到,则需创建至少一个存储帐户和虚拟网络,方可完成向导。
## <a name="step-5-enable-replication"></a>第 5 步:启用复制
### <a name="create-a-replication-policy"></a>创建复制策略
1. 依次单击“准备基础结构” > “复制设置”。
2. 在“创建复制策略”中指定策略名称。
3. 在“RPO 阈值”中,指定恢复点目标 (RPO) 限制。
- 会根据设置的时间创建复制数据的恢复点。
- 此设置不会影响持续复制。 如果在未创建恢复点的情况下达到阈值限制,则会发出警报。
4. 在“恢复点保留期”中,指定每个恢复点的保留时长。 可将复制的 VM 恢复到指定的时间窗口中的任何点。
5. 在“应用一致性快照频率”中,指定创建应用程序一致性快照的频率。
- “应用一致”快照是 VM 内应用数据的时间点快照。
- 卷影复制服务 (VSS) 确保 VM 上的应用在创建快照时处于一致状态。
6. 选择“确定”以创建策略。
### <a name="confirm-deployment-planning"></a>确认部署规划
可立即跳过此步骤。 在“部署规划”下拉列表中,单击“是,我已完成”。
### <a name="enable-replication"></a>启用复制
请确保已完成[步骤1:准备计算机](#step-1-prepare-azure-stack-vms)中的所有任务。 随后请按如下所述启用复制:
1. 选择“复制应用程序” > “源”。
2. 在“源”中选择配置服务器。
3. 在“计算机类型”中,选择“物理计算机”。
4. 选择进程服务器(配置服务器)。 然后单击“确定”。
5. 在“目标”中,选择故障转移后要在其中创建 VM 的订阅和资源组。 选择要用于故障转移的 VM 的部署模型。
6. 选择要在其中存储复制的数据的 Azure 存储帐户。
7. 选择 Azure VM 在故障转移后创建时所要连接的 Azure 网络和子网。
8. 选择“立即为选定的计算机配置”,将网络设置应用到选择保护的所有计算机。 如需为每台计算机单独选择 Azure 网络,请选择“稍后配置”。
9. 在“物理计算机”中,单击“+物理计算机”。 指定每台计算机的 IP 地址名称以及要复制的操作系统。
- 使用计算机的内部 IP 地址。
- 如果指定公共 IP 地址,则复制可能无法按预期进行。
10. 在“属性” > “配置属性”中,选择进程服务器在计算机上自动安装移动服务时使用的帐户。
11. 在“复制设置” > “配置复制设置”中,检查是否选择了正确的复制策略。
12. 单击“启用复制”。
13. 在“设置” > “作业” > “Site Recovery 作业”中,跟踪“启用保护”作业的进度。 在“完成保护”作业运行之后,计算机就可以进行故障转移了。
> [!NOTE]
> 为 VM 启用复制后,Site Recovery 会安装移动服务。
> 可能要等 15 分钟或更长时间,更改才会生效并显示在门户中。
> 若要监视添加的 VM,请在“配置服务器” > “上次联系时间”中查看上次发现 VM 的时间。 若要添加 VM 而不想要等待计划的发现,请突出显示配置服务器(不要选择它),然后选择“刷新”。
## <a name="step-6-run-a-disaster-recovery-drill"></a>步骤 6:运行灾难恢复演练
运行到 Azure 的测试故障转移,以确保一切如预期正常运行。 此故障转移不会影响生产环境。
### <a name="verify-machine-properties"></a>验证计算机属性
运行测试故障转移前,请验证计算机属性,确保其符合 [Azure 要求](https://docs.microsoft.com/azure/site-recovery/vmware-physical-azure-support-matrix#azure-vm-requirements)。 可按如下方式查看和修改属性:
1. 在“受保护的项”中,单击“复制的项”>“虚拟机”。
2. “复制的项”窗格中具有 VM 信息、运行状况状态和最新可用恢复点的摘要。 单击“属性”可查看更多详细信息。
3. 在“计算和网络”中,按需修改设置。
- 可修改 Azure 名称、资源组、目标大小、[可用性集](../virtual-machines/windows/tutorial-availability-sets.md)和托管的磁盘设置。
- 还可查看和修改网络设置。 其中包括故障转移后 Azure VM 加入的网络/子网,以及将分配给 VM 的 IP 地址。
1. 在“磁盘”中,可查看关于 VM 上的操作系统和数据磁盘的信息。
### <a name="run-a-test-failover"></a>运行测试故障转移
运行测试故障转移时需执行下列操作:
1. 运行必备项检查,确保故障转移所需的所有条件都已就绪。
2. 故障转移使用指定的恢复点处理数据:
- **最新处理**:计算机故障转移到由 Site Recovery 处理的最新恢复点。 将显示时间戳。 使用此选项时,无需费时处理数据,因此 RTO(恢复时间目标)会较低。
- **最新的应用一致**:计算机故障转移到最新的应用一致恢复点。
- **自定义**: 选择用于故障转移的恢复点。
3. 会使用已处理的数据创建 Azure VM。
4. 测试故障转移可自动清理在演练期间创建的 Azure VM。
按如下方式为 VM 运行测试故障转移:
1. 在“设置” > “复制的项”中,单击“VM”>“+测试故障转移”。
2. 在本演练中,我们将选择使用“最新处理”恢复点。
3. 在“测试故障转移”中,选择目标 Azure 网络。
4. 单击“确定”开始故障转移。
5. 可通过单击 VM 打开其属性来跟踪进度。 或者,可在保管库名称 > “设置” > “作业” >“Site Recovery 作业”中单击“测试故障转移”作业。
6. 故障转移完成后,副本 Azure VM 会显示在 Azure 门户 >“虚拟机”中。 检查 VM 大小是否合适、是否已连接到正确的网络且正在运行。
7. 现在应该能够连接到 Azure 中复制的 VM。 [了解详细信息](https://docs.microsoft.com/azure/site-recovery/site-recovery-test-failover-to-azure#prepare-to-connect-to-azure-vms-after-failover)。
8. 若要删除在测试故障转移期间创建的 Azure VM,请在 VM 上单击“清理测试故障转移”。 在“说明”中,保存与测试性故障转移相关联的任何观测结果。
## <a name="fail-over-and-fail-back"></a>故障转移和故障回复
设置复制后,运行演练以确保一切正常,之后则可按需将计算机故障转移到 Azure。
运行故障转移前,如果要在故障转移后连接 Azure 中的计算机,则可在开始前,[准备进行连接](https://docs.microsoft.com/azure/site-recovery/site-recovery-test-failover-to-azure#prepare-to-connect-to-azure-vms-after-failover)。
然后按如下所述运行故障转移:
1. 在“设置” > “复制的项”中,单击计算机 >“故障转移”。
2. 选择要使用的恢复点。
3. 在“测试故障转移”中,选择目标 Azure 网络。
4. 选择“在开始故障转移前关闭计算机”。 选择此设置后,Site Recovery 会在开始故障转移前尝试关闭源计算机。 但即使关机失败,故障转移也仍会继续。
5. 单击“确定”开始故障转移。 可以在“作业”页上跟踪故障转移进度。
6. 故障转移完成后,副本 Azure VM 会显示在 Azure 门户 >“虚拟机”中。 如果打算在故障转移后进行连接,请检查 VM 大小是否合适、是否已连接到正确的网络且正在运行。
7. 验证 VM 后,单击“提交”完成故障转移。 这会删除所有可用的恢复点。
> [!WARNING]
> 请勿取消正在进行的故障转移:在故障转移开始前,停止 VM 复制。 如果取消正在进行的故障转移,故障转移会停止,但 VM 将不再进行复制。
### <a name="fail-back-to-azure-stack"></a>故障回复到 Azure Stack
主站点恢复正常运行后,可从 Azure 故障回复到 Azure Stack。 若要进行此操作,需下载 Azure VM VHD,并将其上传到 Azure Stack。
1. 关闭 Azure VM,以便可下载 VHD。
2. 若要开始下载 VHD,请安装 [Azure 存储资源管理器](https://azure.microsoft.com/features/storage-explorer/)。
3. 导航到 Azure 门户中的 VM(使用 VM 名称)。
4. 在“磁盘”中,单击磁盘名称,然后收集设置。
- 例如,我们的测试中使用的 VHD URI:可将 https://502055westcentralus.blob.core.windows.net/wahv9b8d2ceb284fb59287/copied-3676553984.vhd 分解,获得用于下载 VHD 的以下输入参数。
- 存储帐户:502055westcentralus
- 容器:wahv9b8d2ceb284fb59287
- VHD 名称:copied-3676553984.vhd
5. 现在请使用 Azure 存储资源管理器下载 VHD。
6. 按照[这些步骤](https://docs.microsoft.com/azure/azure-stack/user/azure-stack-manage-vm-disks#use-powershell-to-add-multiple-unmanaged-disks-to-a-vm)将 VHD 上传到 Azure Stack。
7. 在现有 VM 或新 VM 中,附加上传的 VHD。
8. 检查 OS 磁盘是否正确,并启动 VM。
此时,故障回复完成。
## <a name="conclusion"></a>结束语
在本文中,我们将 Azure Stack VM 复制到了 Azure。 通过复制,我们运行了灾难恢复演练,以确保到 Azure 的故障转移按预期工作。 本文还介绍了如何运行到 Azure 的完全故障转移,以及到 Azure Stack 的故障回复。
## <a name="next-steps"></a>后续步骤
故障回复后,可重新保护 VM 并再次开始将其复制到 Azure。若要执行此操作,请重复本文中的步骤。
| 35.940845 | 355 | 0.73023 | yue_Hant | 0.711469 |
586b7f9c25c3922251b920ff492099cec320329f | 164 | md | Markdown | web_extension/README.md | Jonathannsegal/map_tab | 950ee207686fd417484f7fac5b688ee02e6fe7a6 | [
"MIT"
] | 3 | 2020-09-21T17:57:06.000Z | 2021-06-09T01:21:06.000Z | web_extension/README.md | Jonathannsegal/map_tab | 950ee207686fd417484f7fac5b688ee02e6fe7a6 | [
"MIT"
] | 22 | 2020-07-21T11:02:13.000Z | 2022-03-27T02:05:39.000Z | web_extension/README.md | Jonathannsegal/map_tab | 950ee207686fd417484f7fac5b688ee02e6fe7a6 | [
"MIT"
] | null | null | null | # map_tab
🌎 Chrome extension that shows you a cool place when you open a new tab!
https://chrome.google.com/webstore/detail/maptab/jokkbgbdomfhondepefdoapgabmiomjl | 41 | 81 | 0.817073 | eng_Latn | 0.553118 |
586b81f23ae52c851a20f96bcc36db3d446167d0 | 4,376 | md | Markdown | docs/guide/lifecycle.md | idlist/koishi | 2e4982f5b9ffa217c10654327590023ae954527c | [
"MIT"
] | 9 | 2020-05-22T13:45:29.000Z | 2021-08-20T07:51:21.000Z | docs/guide/lifecycle.md | idlist/koishi | 2e4982f5b9ffa217c10654327590023ae954527c | [
"MIT"
] | 6 | 2020-12-13T19:03:44.000Z | 2022-02-26T21:12:00.000Z | docs/guide/lifecycle.md | idlist/koishi | 2e4982f5b9ffa217c10654327590023ae954527c | [
"MIT"
] | 19 | 2020-01-03T03:58:45.000Z | 2021-07-05T12:16:38.000Z | ---
sidebarDepth: 2
---
# 事件与生命周期
在 [接收和发送消息](./message.md) 一章中,我们介绍了如何使用接受消息,并埋下了一个伏笔。本章节就让我们来认识一下 Koishi 的事件系统。
## 事件系统
如果将我们已经熟悉的那个实例用事件系统的方式来改写,应该会是这样:
```js
// 如果收到“天王盖地虎”,就回应“宝塔镇河妖”
ctx.on('message', (session) => {
if (session.content === '天王盖地虎') {
session.send('宝塔镇河妖')
}
})
```
上面的 `message` 字符串被称为 **事件名称**。这个事件名称可能有多级:我们用 `message/group` 表示群组消息,`message/private` 表示私聊消息。这意味着你可以只监听收到消息的一部分。而当你监听 `message` 事件时,则所有收到的消息都会经由这个回调函数处理。
除去这个例子中所使用的 **上报事件** 外,Koishi 自身也提供了一批 **内部事件**,例如用 `connect` 事件表示应用启动完成等。前者通常由适配器生成,回调函数只接受一个会话对象;而后者由 Koishi 自身生成,回调函数有着各种不同的形式。你可以在 [事件文档](../api/events.md) 中看到全部 Koishi 支持的事件接口。
### 事件的命名
无论是上报事件,内部事件还是插件事件,Koishi 的事件名都遵循者一些既定的规范。它们包括:
- 总是使用 param-case 作为事件名
- 使用 `/` 作为事件命名空间的分隔符
- 配对使用 xxx 和 before-xxx 命名事件
对于上报事件来说,命名空间和其子事件往往是一种包含的关系,例如 `group-member` 和 `group-member/ban`。当子事件被触发时,其父事件也会被同时触发。而对于内部事件来说,命名空间则单纯是为了将事件归类而设计的,例如 `dialogue/modify` 表示在教学插件中进行了修改操作。对于全部插件的开发者,我们都建议将插件相关的事件放入自己的命名空间中,以免发生冲突。
### 注册监听器
要注册一个监听器,可以使用 `ctx.on(event, callback)`,它的用法与 Node.js 自带的 [EventEmitter](https://nodejs.org/api/events.html#events_class_eventemitter) 类似,不过多出了第三个可选参数 `prepend`:如果设为 truthy 则在事件队列的头部而不是尾部添加,相当于 `emitter.prependListener()`。与此同时,我们也提供了类似的函数 `ctx.once(event, callback)`,用于注册一个只触发一次的监听器;以及 `ctx.off(event, callback)`,用于取消一个已注册的监听器。
特别地,Koishi 有不少监听器是满足 before-xxx 形式的。对于这类监听器的注册,我们也提供了一个语法糖,那就是 `ctx.before('xxx', callback)`。如此使用时,默认情况与第三个参数的作用与前面描述的正好相反。考虑到事件的命名空间,如果使用 `ctx.before('xxx/yyy', callback)`,其实际效果也与 `ctx.on('xxx/before-yyy', callback)` 相当。
这些方法与 EventEmitter 的另一个不同点在于,无论是 `ctx.on()` 还是 `ctx.before()` 都会返回一个 dispose 函数,调用这个函数即可取消注册监听器。因此你完全不必使用 `ctx.once()` 和 `ctx.off()`。下面给一个只触发一次的监听器的例子:
```js
const dispose = ctx.on('foo', (...args) => {
dispose()
// do something
})
```
### 触发事件
在 Koishi 中,触发一个事件可以有着多种形式,目前支持 6 个不同的方法,足以适应绝大多数需求。
- `ctx.emit()` 同时触发所有 event 事件的回调函数。
- `ctx.parallel()` 是上述方法对应的异步版本。
- `ctx.bail()` 依次触发所有 event 事件的回调函数。当返回一个 `false`, `null`, `undefined` 以外的值时将这个值作为结果返回。
- `ctx.serial()` 是上述方法对应的异步版本。
- `ctx.chain()` 依次触发所有 event 事件的回调函数。每次用得到的返回值覆盖下一轮调用的第一个参数,并在所有函数执行完后返回最终结果。
- `ctx.waterfall()` 是上述方法对应的异步版本。
## 生命周期
在实际使用生命周期钩子之前,我们需要对 App 的生命周期有一个总体的认识:它分为 **连接阶段**、**运行阶段** 和 **销毁阶段**。下图大体展示了一个 App 实例的生命周期。在本节的后面,我们将具体介绍每一部分的流程细节。当然你不需要立即弄明白所有的东西,不过随着你的不断学习和使用,它的参考价值会越来越高。

### 事件、中间件与指令
我们已经熟悉了 Koishi 的一些基本概念,比如事件、中间件和指令等,那么他们的关系是什么呢?上面的生命周期图也同样告诉了我们答案:**中间件由内置监听器管理,而指令由内置中间件管理**。没错,当 message 事件被发送到各个上下文的监听器上时,绑定在 App 上的内置监听器将会将这个事件逐一交由中间件进行处理。全部处理完成后会触发一个 after-middleware 事件。
因为我们通常不需要直接监听 message 事件(使用中间件往往是更好的实现),after-middleware 事件的触发通常意味着你对一条消息的处理已经完成。我们的测试工具 koishi-test-utils 就是基于这种逻辑实现了它的会话 API。
### 内置监听器
1. message 事件触发,进入中间件处理流程
2. 根据上下文从中间件池中筛选出要执行的中间件序列
3. 逐一执行中间件:
- 内置中间件是理论上第一个注册的中间件(下接 [内置中间件](#内置中间件))
- 通过 `ctx.middleware(cb, true)` 注册的中间件会插在队列的更前面
- 临时中间件会直接插在当前序列的尾端,并不会影响中间件池本身
- 如果执行中遇到错误或未调用 `next` 函数,会停止后续中间件的执行
4. 触发 [middleware](../api/events.md#事件:middleware) 事件
5. 更新当前用户和群的缓冲数据(参见 [按需加载与自动更新](./manage.md#按需加载与自动更新))
### 内置中间件
1. 从前缀中匹配 at 机器人,nickname 或 prefix
2. 预处理消息内容,生成 [`session.parsed`](../api/session.md#session-parsed)
3. 触发 [before-parse](../api/events.md#事件:before-parse) 事件,尝试解析消息内容([快捷方式](./execute.md#快捷方式) 的解析也在此处完成)
4. 如果数据库存在:
- 触发 [before-attach-channel](../api/events.md#事件:before-attach-channel) 事件
- 获取频道数据并存储于 [`session.channel`](../api/session.md#session-channel)
- 根据 flags, assignee 等字段判断是否应该处理该信息,如果不应该则直接返回
- 触发 [attach-channel](../api/events.md#事件:attach-channel) 事件(用户可以在其中同步地更新群数据,或中止执行后续操作)
- 触发 [before-attach-user](../api/events.md#事件:before-attach-user) 事件
- 获取用户数据并存储于 [`session.user`](../api/session.md#session-user)
- 根据 flags 等字段判断是否应该处理该信息,如果不应该则直接返回
- 触发 [attach-user](../api/events.md#事件:attach-user) 事件(用户可以在其中同步地更新群和用户数据,或中止执行后续操作)
5. 如果解析出指令:执行该指令(下接 [指令执行流程](#指令执行流程))
6. 尝试解析出候选指令,如果成功则显示候选项(参见 [模糊匹配](./execute.md#模糊匹配))
在以上过程中,无论是解析指令还是出发内置的 before-attach-* 钩子都可能用到 [parse](../api/events.md#事件:parse) 事件。
### 指令执行流程
1. 如果解析过程中存在错误(如非法参数等),直接返回错误信息
2. 逐一调用 check 回调函数,直到返回值不为 `undefined`
3. 触发 [before-command](../api/events.md#事件:before-command) 事件:
- 如果是 -h, --help 则直接显示帮助信息(参见 [查看帮助](./help.md#查看帮助))
- 根据配置检查用户权限和调用记录(参见 [指令调用管理](./message.md#指令调用管理))
4. 逐一调用 action 回调函数,直到返回值不为 `undefined`
5. 触发 [command](../api/events.md#事件:command) 事件
| 38.385965 | 327 | 0.741773 | yue_Hant | 0.595182 |
586bf8398b2ab16a1659bb5a1d458efd8c4849e5 | 2,274 | md | Markdown | python_language/numpy/07_array_reshape.md | ajeyanayk/Learning_and_Documentation | da4cb1735802421eace7c0dbdd30d5071beee3cd | [
"MIT"
] | null | null | null | python_language/numpy/07_array_reshape.md | ajeyanayk/Learning_and_Documentation | da4cb1735802421eace7c0dbdd30d5071beee3cd | [
"MIT"
] | null | null | null | python_language/numpy/07_array_reshape.md | ajeyanayk/Learning_and_Documentation | da4cb1735802421eace7c0dbdd30d5071beee3cd | [
"MIT"
] | null | null | null | # Array Reshape
+ **Array Reshape**, means reshaping we can add or remove dimension or change number of elements in each dimension. We can reshape the element using **reshape()** method.<br />
+ *Reshape from 1-D to 2-D - Converting 1-D array element to 2-D array,* <br />
*Eg*: ```import numpy as np``` <br />
```arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])``` <br />
```newarr = arr.reshape(4, 3)``` *Here 4 indicates Arrays and 3 is element on those arrays* <br />
```print(newarr)``` <br />
*which returns* <br />
```[[1 2 3]``` <br />
```[4 5 6]``` <br />
```[7 8 9]``` <br />
```[10 11 12]]```
+ *Reshape from 1-D to 3-D - Converting 1-D array element to 3-D array,* <br />
*Eg*: ```import numpy as np``` <br />
```arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])``` <br />
```newarr = arr.reshape(2, 3, 2)``` <br />
*Here 2 indicates Arrays , 3 is also from those 3 arrays and each arrays having 2 elements*. <br />
```print(newarr)``` <br />
*which returns* <br />
```[[[1 2]``` <br />
```[3 4]``` <br />
```[5 6]]``` <br />
```[7 8]``` <br />
```[9 10]``` <br />
```[11 12]]]```
+ The reshape method is View, we can identify this by using **base()** method <br />
*Eg*: ```import numpy as np``` <br />
```arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])``` <br />
```print(arr.reshape(2, 4).base)``` *which returns the value as original* **[ 1 2 3 4 5 6 7 8]**
**Unknown Dimension**
+ If the elements in 1-D are unknown, we can specify -1 with dimension, Python we check and make the array according to element . If not possible it will return with error message <br />
*Eg*: ```import numpy as np``` <br />
```arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])``` <br />
```newarr = arr.reshape(2, 2, -1)``` <br />
```print(newarr)``` <br />
*which returns* <br />
```[[1 2]``` <br />
```[3 4]]``` <br />
```[5 6]``` <br />
```[7 8]]```
+ **Flattering the arrays** - which converts multidimensional array into 1-D Array <br />
*Eg*: ```import numpy as np``` <br />
```arr = np.array([[1, 2, 3], [4, 5, 6]])```` <br />
```newarr = arr.reshape(-1)``` <br />
```print(newarr)``` *which returns* **[1 2 3 4 5 6]** | 43.730769 | 186 | 0.512753 | eng_Latn | 0.920099 |
586c29670350a3d37899fa44644b4f251c856d1c | 1,583 | md | Markdown | _docs/cloudtrail/enable-log-validation.md | cfsec/cfsec.github.io | aed5758ced8c843a11369f78c364cd9a34e40680 | [
"MIT"
] | 29 | 2021-10-18T19:10:20.000Z | 2022-02-01T15:50:21.000Z | _docs/cloudtrail/enable-log-validation.md | cfsec/cfsec.github.io | aed5758ced8c843a11369f78c364cd9a34e40680 | [
"MIT"
] | 6 | 2021-10-18T12:55:32.000Z | 2022-02-15T08:07:20.000Z | _docs/cloudtrail/enable-log-validation.md | cfsec/cfsec.github.io | aed5758ced8c843a11369f78c364cd9a34e40680 | [
"MIT"
] | 4 | 2021-10-10T21:25:20.000Z | 2022-03-14T13:24:50.000Z | ---
title: Cloudtrail log validation should be enabled to prevent tampering of log data
shortcode: enable-log-validation
summary: Cloudtrail log validation should be enabled to prevent tampering of log data
permalink: /docs/cloudtrail/enable-log-validation/
---
### Explanation
Log validation should be activated on Cloudtrail logs to prevent the tampering of the underlying data in the S3 bucket. It is feasible that a rogue actor compromising an AWS account might want to modify the log data to remove trace of their actions.
### Possible Impact
Illicit activity could be removed from the logs
### Suggested Resolution
Turn on log validation for Cloudtrail
### Insecure Example
The following example will fail the AVD-AWS-0016 check.
```yaml
---
Resources:
BadExample:
Type: AWS::CloudTrail::Trail
Properties:
IsLogging: true
IsMultiRegionTrail: false
S3BucketName: "CloudtrailBucket"
S3KeyPrefix: "/trailing"
TrailName: "Cloudtrail"
```
### Secure Example
The following example will pass the AVD-AWS-0016 check.
```yaml
---
Resources:
BadExample:
Type: AWS::CloudTrail::Trail
Properties:
IsLogging: true
IsMultiRegionTrail: true
EnableLogFileValidation: true
S3BucketName: "CloudtrailBucket"
S3KeyPrefix: "/trailing"
TrailName: "Cloudtrail"
```
### Related Links
- [https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-log-file-validation-intro.html](https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-log-file-validation-intro.html)
| 23.626866 | 249 | 0.740366 | eng_Latn | 0.665478 |
586ce5a5370bfd842fb249c011bc66f8a58ca535 | 2,833 | md | Markdown | README.md | jawira/plantuml-encoding | e7a0213a3813df97887975767c132c67f69595ef | [
"MIT"
] | 8 | 2018-06-07T14:58:34.000Z | 2021-11-18T04:25:30.000Z | README.md | jawira/plantuml-encoding | e7a0213a3813df97887975767c132c67f69595ef | [
"MIT"
] | 9 | 2017-12-21T08:31:19.000Z | 2020-10-01T08:44:31.000Z | README.md | jawira/plantuml-encoding | e7a0213a3813df97887975767c132c67f69595ef | [
"MIT"
] | 2 | 2018-03-26T13:07:22.000Z | 2019-12-03T18:46:37.000Z | # PlantUML text encoding functions
**This library
exposes [PlantUML text encoding functions](https://plantuml.com/de/pte):**
- `encodep()`
- `encode6bit()`
- `append3bytes()`
- `encode64()`
**ℹ️ Usually only `encodep()` is used.**
[](//packagist.org/packages/jawira/plantuml-encoding)
[](//packagist.org/packages/jawira/plantuml-encoding)
[](//packagist.org/packages/jawira/plantuml-encoding)
[](//packagist.org/packages/jawira/plantuml-encoding)
## Usage
```php
<?php
use function Jawira\PlantUml\encodep;
$diagram = <<<TXT
@startuml
Bob -> Alice : hello
@enduml
TXT;
$encode = encodep($diagram); // SyfFKj2rKt3CoKnELR1Io4ZDoSa70000
echo "https://www.plantuml.com/plantuml/uml/$encode";
```
Output: <https://www.plantuml.com/plantuml/uml/SyfFKj2rKt3CoKnELR1Io4ZDoSa70000>
⚠️ Since v1.0.0, `encodep()` function expects to receive an UTF-8 string.
## Install
```console
$ composer require jawira/plantuml-encoding
```
## Contributing
- If you liked this
project, ⭐ star it on GitHub. [](https://github.com/jawira/plantuml-encoding)
- Or follow me on
Twitter. [](https://twitter.com/jawira)
## Credits
These functions are a copy/paste from <http://plantuml.com/code-php>.
***
## Packages from jawira
<dl>
<dt>
<a href="https://packagist.org/packages/jawira/plantuml">jawira/plantuml
<img alt="GitHub stars" src="https://badgen.net/github/stars/jawira/plantuml?icon=github"/></a>
</dt>
<dd>Provides PlantUML executable and plantuml.jar</dd>
<dt>
<a href="https://packagist.org/packages/jawira/case-converter">jawira/case-converter
<img alt="GitHub stars" src="https://badgen.net/github/stars/jawira/case-converter?icon=github"/></a>
</dt>
<dd>Convert strings between 13 naming conventions: Snake case, Camel case,
Pascal case, Kebab case, Ada case, Train case, Cobol case, Macro case,
Upper case, Lower case, Sentence case, Title case and Dot notation.
</dd>
<dt>
<a href="https://packagist.org/packages/jawira/emoji-catalog">jawira/emoji-catalog
<img alt="GitHub stars" src="https://badgen.net/github/stars/jawira/emoji-catalog?icon=github"/></a>
</dt>
<dd>Get access to +3000 emojis as class constants.</dd>
<dt><a href="https://packagist.org/packages/jawira/">more...</a></dt>
</dl>
| 33.329412 | 174 | 0.732439 | yue_Hant | 0.321508 |
586e13b1bd3d310b4dbab1f33bb59ab59ef5a222 | 93,253 | markdown | Markdown | _posts/2009-07-08-method-for-improving-student-retention-rates.markdown | LizetteO/Tracking.virtually.unlimited.number.tokens.and.addresses | 89c6b0fa3defa14758d6794027cc15150d005bbd | [
"Apache-2.0"
] | null | null | null | _posts/2009-07-08-method-for-improving-student-retention-rates.markdown | LizetteO/Tracking.virtually.unlimited.number.tokens.and.addresses | 89c6b0fa3defa14758d6794027cc15150d005bbd | [
"Apache-2.0"
] | null | null | null | _posts/2009-07-08-method-for-improving-student-retention-rates.markdown | LizetteO/Tracking.virtually.unlimited.number.tokens.and.addresses | 89c6b0fa3defa14758d6794027cc15150d005bbd | [
"Apache-2.0"
] | 2 | 2019-10-31T13:03:55.000Z | 2020-08-13T12:57:08.000Z | ---
title: Method for improving student retention rates
abstract: An integrated student retention system that automatically raises flags identifying at-risk students; permits students to raise flags identifying themselves as at-risk; permits providers to raise flags identifying students as at-risk; provides systems facilitating the process of enabling students to obtain assistance; provides systems for tracking students and providers; and provides systems for measuring effectiveness.
url: http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&p=1&u=%2Fnetahtml%2FPTO%2Fsearch-adv.htm&r=1&f=G&l=50&d=PALL&S1=08472862&OS=08472862&RS=08472862
owner: Starfish Retention Solutions, Inc.
number: 08472862
owner_city: Arlington
owner_country: US
publication_date: 20090708
---
This is a utility patent application taking priority from provisional patent application Ser. No. 61 134 296 filed Jul. 8 2008 which is incorporated herein in its entirety.
The present invention is directed to an integrated student retention system that automatically raises flags identifying at risk students permits students to raise flags identifying themselves as at risk permits providers to raise flags identifying students as at risk provides systems facilitating the process of enabling students to obtain assistance provides systems for tracking students and providers and provides systems for measuring effectiveness.
Social cultural financial and academic challenges interplay and any one challenge can have a key impact on the academic success of a student. Identifying students with such challenges also called at risk students is an important issue faced by academic institutions especially since increased student retention helps more students graduate and generates more revenue for the academic institutions. However many students are not aware of student retention or success programs or might be hesitant to use such programs for a number of reasons including inconvenience intimidation and peer stigma. Leaving such programs solely to the discretion of students can be problematic. Likewise assuming such programs are effective just because they exist is nonsensical.
Student success programs need to be effective at identifying at risk students as early as possible need to use multiple identification sources need to make it easy for students to get help need to make it easy for other people within the academic institution to help the students and need to make it possible for administrators to track the students and the effectiveness of the program.
One possible solution for identifying at risk students is to use a course management system. Course management systems sometimes also referred to as Learning Management Systems provide web based access to teaching and learning content and services. Course management systems are used by most higher education institutions however not all of these institutions make use of the vast amounts of data collected by the course management systems. Course management systems typically keep records of course grades assignment grades exam grades and other activities which a student might be involved in at the academic institution. Examining the course management data can help academic institutions identify students at risk. For example Purdue University pulls student data from its course management system including student activities student assignment grades for each course exam and quiz scores class absences and missed assignments and inputs the gathered student data into a predictive system in an attempt to identify at risk students.
Other possible solutions include GRADESFIRST and RETENTION ALERT. GRADESFIRST is a tool targeting the improvement of student retention rates and monitoring various student activities at an academic institution. Features of GRADESFIRST include early alert of at risk students appointment scheduling with reminders attendance tracking assignment tracking tutor management and various summary reports. RETENTION ALERT is a retention management system that allows for the tracking and monitoring of aspects of a student s education. A set of rules can be set based on the institution s preferences such as a GPA range or failing grades in a course or program of study or the rules can be manually set by an institution administrator an instructor or an advisor. Student progress and trends can be analyzed with the system.
GRADESFIRST and RETENTION ALERT focus on providing tools for the academic institution s providers to help students succeed by identifying those students who might be at risk. Neither system supports providing students with self help services which would allow students to take a proactive approach if a student felt the need for help or if the student wanted to take advantage of a service that might help the student get ahead.
Noel Levitz s RETENTION MANAGEMENT SYSTEM COLLEGE STUDENT INVENTORY takes a more reactive approach to student retention since it waits for students to self identify their needs and their keys to success. It consists of a survey administered to students preferably incoming students or administered to students early in their college career which asks each student about their academic motivation and receptivity to assistance. The results compiled from all data can be used by the student service providers such as administrators instructors advisors or student associations to determine the best strategies to use in order to retain the students and ensure the success of the students throughout their academic studies.
Another example of a student retention system is EMT RETAIN by HOBSONS. EMT RETAIN is a web based automated alert system that also allows for communication between the administrators and the students most at risk. Another service provided by HOBSONS is EARLY ALERT which includes a survey to assess and address student challenges. This allows institutions to find areas to improve and to develop strategies and programs to help at risk students. HOBSONS also provides a predictive modeling service that analyses the institution s historical data and builds statistical models in order to forecast student success and retention rates. The resulting data can also be used to compare year on year data that can be used to assess the effectiveness of additional programs and retention strategies and techniques. One of the deficiencies of this retention system is that the collected information or specific individual cases are not routed to a specific organization based on the problem identified by the collective data or a problem identified with an individual student.
MAP WORKS is a student retention system by EDUCATIONAL BENCHMARKING. This system allows an institution to track a student s progress and to find at risk students. Students fill out a survey preferably on the third week of the semester. The survey data is compiled and sent to the corresponding staff faculty at the institution. This allows the corresponding faculty staff to intervene or contact the student based on the student s report and the student s progress. Students are flagged in the compiled data using three colors red yellow and green. Students flagged as red are students who are at risk where there is a major concern and action needs to be taken. Students flagged as yellow are students for whom there is some concern while a green flag means that there is no concern. The students at risk can then be contacted and directed to corresponding school resources that can help them.
Examples of systems that help students schedule appointments with providers of the academic institution are ADVISORTRAC and SARS GRID. ADVISORTRAC is an appointment system targeting advisement and counseling centers. It allows students to set up appointments. The advisors counselors can see the student s records online via a web interface. Similarly SARS GRID is a scheduling system that can be used by advisors counselors and administrators of an academic institution.
CourseRank is an unofficial system used by Stanford which allows students to get information on classes teachers and to keep track of their academic requirements to manage graduation requirements. Students can rate courses rate professors and provide reviews on classes. This allows students to see the experiences other students have had with certain classes or instructors. The course planner allows students to plan ahead to make sure they have taken all required courses and if not it provides suggestions for courses to the students. While such a system does help students manage their course requirements for graduation and to assess classes to take and professors who have positive reputations and consequently avoid those with poor reviews the system does not target student retention and it does not allow either the students or the members of the academic institution to identify and address issues which might be negatively affecting a student.
As noted above several systems that provide partial possible solutions to the student retention problem have been proposed. Some focus on analyzing usage data of course management systems and other student information systems in order to identify and make informed decisions to improve the performance of the academic institution. Passive monitoring of student scores on standardized or placement tests as well as course grades has also been proposed. Some systems also propose the comparison of aggregate data with other academic institutions. For examples see U.S. Pat. Nos. 7 311 524 7 512 627 Published U.S. patent application Ser. Nos. 10 106 575 and 10 870 099.
All of these systems provide partial solutions. Even if these systems are combined they do not provide a comprehensive suite to address the problem of student retention. Rather the various systems follow one sided models where the students either help themselves such as by filling out a survey or members of the academic institution take action on behalf of the students such as the manual flagging of students who might be at risk but no system provides a comprehensive solution that is effective at identifying at risk students as early as possible uses multiple identification sources makes it easy for students to get help makes it easy for other people within the academic institution to help the students and makes it possible for administrators to track the students and the effectiveness of the program.
The present invention is directed to an integrated student retention services suite that utilizes a networked computer system to automatically raises flags identifying at risk students by mining data available from one or more computerized academic management systems including an academic institution s course management system and other student management or information systems permits students to raise flags identifying themselves as having a problem or needing help permits instructors counselors tutors advisors or other members of the academic institution to raise flags to identify students who need help provides a variety of systems that facilitate the process of enabling students to obtain assistance such as schedule and attend office hours with instructors and other providers of the academic institution provides the academic institution with systems for tracking students and providers and provides analytic tools that enables the academic institution to track its own effectiveness and compare itself to other institutions. The preferred embodiment of the invention consists of a set of services that can increase the student retention rates of academic institutions by providing self help services to students facilitating communication between students and providers that can intervene and providing the providers of the academic institution with the tools to help identify and direct students to resources that can help them.
Some of the management system services include faculty office hours management peer tutoring management tutor center management mentor program management advising management counseling management and further retention management services. The preferred embodiment of the management system would run on a client s web browser including functionality such as dynamic menus auto complete features drag and drop support navigation via menus context sensitive menus and information when appropriate and help wizards. Alternative embodiments of the invention may also run as a desktop application.
Throughout the remainder of this detailed description the terms Starfish system or system will be used to refer to the overall system and or parts of the overall system of the present invention. The term provider will be used to refer to members of an academic institution including instructors advisors counselors tutors mentors and other academic staff. The term administrator will be used to refer to those members of an academic institution in charge of managing the deployment of the Starfish system and its successful integration with the systems of the academic institution such as the course management system and other student information systems.
The Starfish system uses a combination of data to determine at risk status including student information system data data from course management systems and data provided by front line service providers at the institution such as student success program providers resident assistants and instructors as well as the students themselves. Most importantly the Starfish system manages information so that it is delivered to relevant parties depending on the context of the problem to which it relates and intervenes as necessary to make sure that students are getting help when needed.
In the preferred embodiment of the present invention the user interface that enables users to access the set of retention services provides different access levels to the Starfish system. The interface also varies depending on the role and permissions of the user accessing the Starfish system. The present embodiment anticipates three main interfaces which can work together for users with more than one role or dashboards a student interface a provider interface and an administrator interface.
The student interface will allow students to access personal academic management information and systems that include easy scheduling appointment tracking self assessment self help and provider action item tracking. The provider interface will organize simplify and efficiently allow providers to direct and suggest to students good policy compliant services. Features accessible through this provider interface will include appointment management appointment guidance and a place to record notes and documentation related to students. In another embodiment of the present invention additional interfaces either at a higher or lower access level can be added depending on the policies and needs of the academic institution. Higher level interfaces can include a departmental supervisor interface allowing for the setting of policies and reporting. An institutional interface accessed by administrative staff at the academic institution can be used to determine the effectiveness of certain services or programs by analyzing the results and associated costs of offering each service with comparisons available across services and benchmarking with other institutions offering similar services.
Authentication of system users can be done in a variety of ways. In an embodiment of the present invention a user with a credentialed session on a course management system will click a link that passes an authentication token to the Starfish system. From that request a Starfish system session will be created. Alternatively a user can login directly to the Starfish system with the Starfish system subsequently passing those credentials to the course management system associated with the campus institution for verification of the user. In yet another embodiment of the present invention a user can login directly to the Starfish system by using Lightweight Directory Access Protocol LDAP authentication. In this case the user s credentials are checked against a LDAP server associated with the campus or institution. In another embodiment of the present invention a user can login directly to the Starfish system but where the user credentials are checked against a central database of encrypted credentials. In the preferred embodiment of the present invention an academic suite implementation offered by BLACKBOARD INC. is used as the course management system the user interface of the Starfish system is integrated into the user interface of the academic suite and a link is provided on the academic suite menu that redirects users to the Starfish system interface.
The at risk indicator data processed by the Starfish system will come from three sources 1 the course management system 2 student management or information systems and 3 manually entered data. In an embodiment of the present invention data from the course management system is sent to the Starfish system based on a timed background thread which pushes data on a set schedule. Data will also be collected and sent from the student management or information systems through the use of custom logic that extracts relevant data. The extracted data will then be sent to Starfish system via secure channels. In another embodiment of the present invention the data extraction may also involve hand processing. Finally web forms from the Starfish system will capture a variety of data from students and providers.
The Starfish system causes greater engagement between students and providers by providing the students with efficient systems and tools for contacting and meeting with providers. By allowing a student to schedule an appointment through the Starfish system the student is guaranteed to have the scheduled time to discuss issues the student might be facing be it academic or financial issues. Having a set appointment time provides great flexibility to students who will not have the feeling of being rushed and pressured because of the presence of other students who might have showed up at the same time to meet with the provider. The use of the system allows the student to feel more at ease during the appointment and also to have the guarantee that the provider will be available during the scheduled time instead of the hit and miss approach to finding the provider at his her office and checking for the provider s availability. The flexibility of using the scheduling system also allows the providers to be better prepared to meet the needs of the students who sign up for appointments. The appointment alerts allow providers to understand the visiting student s needs thus making the appointment a fruitful experience for the student.
Some of the benefits of the Starfish system for the provider are that the system manages and keeps track of student progress and student activities. For example if a provider meets with a student and subsequently sees the need to raise a flag and to place a request for a financial advisor to meet with the student the Starfish system manages all the student history by storing it in a student folder. The provider is not in charge of creating an electronic folder or directory and saving all associated communication between the provider and the student in the folder since all of this data management is handled by the Starfish system. The provider if necessary can specify some of the data or notes created by the provider as private. The Starfish system allows the provider to become further engaged with students but without an increased burden by having to manage additional paperwork or correspondence. The success network of the Starfish system also enables different providers to work together toward insuring the success of students.
The Starfish system also automates the process of searching and identifying students who might be at risk. The system can search all of the student data available trying to determine whether a student falls within one of many at risk conditions specified either by the system or specified by the academic institution. The conditions or set of rules for identifying at risk students can consist of conditional expressions. For example a student could be identified as at risk if one of the following conditions matches a record in the student s folder the student got lower than a 60 on an exam in any of the enrolled courses the student has missed attendance at least two times for any of the enrolled courses the student has not scheduled an appointment for the required advisement meetings per semester etc. Once students have been identified as at risk the flagged students both visually within the system through various user interface displays and electronically within data files stored in the system database can then be directed to services and providers that can help them. This can also be automated by the Starfish system by sending alert messages to certain providers based on the type of flag raised for each student and based on the roles and relations certain providers might have with the student. For example if a student was flagged for missing attendance on a class then the flagging notice could be sent to a general counselor while a student flagged for getting a low exam score on a class could result in the flagging notice sent to the instructor of the class and the departmental head. Such flagging automation allows providers to devote their time and resources to helping the students instead of concentrating on the managing and analyzing of large amounts of data. The use of roles and relations guarantees that the right information is sent to the right people at the right time to insure that students get help and intervention when needed.
To academic institutions the Starfish system provides an assessment tool. The Starfish system can be used to determine the services that provide the greatest benefit to students the services used the most and the services used the least the student performance based on a variety of demographics and also serving as a benchmarking tool across departments in an academic institution and with other academic institutions.
In the preferred embodiment of the present invention the Starfish system interface will be linked through the academic institution s course management system and or other systems. Course management systems typically consist of a set of modules that provide users with listings of enrolled courses course grades a calendar a dictionary and other utilities that facilitates the aspects involved in teaching a course such as the distribution of materials sending of announcements postings of assignments assigning grades to students etc. The various modules included in the course management system depend on the needs or requirements of the academic institution and the students.
Part of the reason for the popularity and power of course management systems lies on its flexibility to accommodate the diverse needs of providers at the academic institution. For example modules can be edited by the user depending on the functionality provided by the module. For example settings for a calendar module that can be modified include the number of days to show the user such as the next seven days from the current date all the days in the current month a monthly view of the year etc. Another example of editing settings associated with a module includes editing the type and amount of information to display for each course on the course listing for the student.
A key distinguishing feature of the system is that the automatic flagging the manual flagging and the tracking and analytics can all be done within the user interface of the course management system used by the academic institution. Course management systems have become integral and convenient tools used by providers. The system integrates into this same user interface not only providing a consistent look and feel to the features provided by the system but it also allows providers to stay within the course management system. Other systems which provide partial solutions to the student retention problem force users to use and get accustomed to a new system and the lack of integration with the course management system discourages users from embracing such systems. The integration of the Starfish system with the course management system used by academic institutions encourages providers to use it which is a key to student success. The same applies to students who are required to use the course management system if their instructors post course materials grades and announcements through the course management system. This has the further benefit of lessening the learning curve for both students and providers since the integration of the Starfish system with the course management system will allow all users to feel less intimidated about using the Starfish system features.
The Starfish system home page for the student interface or dashboard will display a set of appointments the courses currently being taken by the student and a list of the student s success network. The student s success network refers to members of the academic institution the providers who have been or are currently academically involved with a student. For example instructors for the courses that the student is currently enrolled in can be part of that student s success network. Examples of other providers which can be part of the success network list are present and past academic advisors current and past teaching assistants for courses counselors etc. A list of a student s success network will be listed on the student s dashboard and the list will also provide links that enable the student to see available appointment times for each network member allowing the student to easily contact past and present providers.
The success network is a two level system. The first level is a set of favorites for the student consisting of personal relationships that will be heavily used such as instructors or an advisor. The second level is the available people and services such as skills testing career counseling mental health services among others. An entry on the student s success network is moved automatically from the available set to the set of favorites by making an appointment with a provider listed under the available set. Alternatively the student can manually add a member to the favorites or to the available people and services in the success network. In one embodiment the student is responsible for manually adding entries to the favorite set and the set of available people and services. In another embodiment the academic institution could pre populate both levels favorites and available through various data upload formats and manual web pages. Alternatively the system could allow for a list of advisor student pairs to be uploaded in order to build or initialize a student s success network. Providers may also be allowed to add themselves to a student s success network. For example athletic advisors could be allowed to add themselves to one or more athletes who have been identified as having problems.
In the preferred embodiment the entries in the success network will primarily consist of providers. However in the case that a dedicated advisor is not available a corresponding service could be listed in place in the success network. The student could then learn of various providers who can provide the student. Alternatively the system could automatically assign a provider for each request appointment submitted by a student. Such an approach to implementing the success network is more useful to a student than a typical services web site because it is organized around the problem instead of simply providing a listing. For example if a student needs help in a math course the student can find help by looking under the tutoring entry in the success network instead of having to search through entries of who offers the services such as department tutoring residence hall tutors Asian American Association tutoring etc.
The user will have the option to either add a new appointment or edit an existing appointment. The calendar will have several views such as a day view and a week view. The day view lists office hours if available for instructors. Office hours will be denoted as blocks with open slots shown with a plus sign and a Sign Up caption however the choice of icon or user interface element uses is not as important as the functionality. Once the user selects an open slot a dialog box or window will open where the user will be able to enter information relevant to the appointment. For example the dialog window can show the name of the professor or staff member with whom the appointment is being scheduled. Other information that can be part of this dialog window includes the date and time of the appointment the duration time the location of the appointment and one of a number of pre selected reasons as to why the student is making the appointment. Students can also provide a detailed description of the appointment where the student can specify what he she hopes to accomplish or concerns the student wishes to have addressed during the scheduled appointment. Once the user saves the appointment information the dialog window will close and the slot selected by the student will be shown as busy to reflect the newly scheduled appointment. The user will also have the option to either cancel or edit the previously scheduled appointment.
In another embodiment of the present invention in addition to specifying why the appointment was made during appointment scheduling the student may also specify personal and academic goals and attach drafts for review by the provider if applicable. If the student did not provide details such as goals and the reason for the appointment then the scheduling system could automatically provide the instructor with a hyperlink to the student s profile or a summary of information from the student s profile could be sent to the provider when the corresponding appointment alert is sent. In addition the scheduling system could provide a snapshot of the student performance by providing data gathered from the course management system such as the latest student grades class rank and attendance data.
Group appointments may also be supported. For example if a group of students is working on a student project for a course then one of the students in the group can create an appointment for the group with the provider. In this case the names of the appointment participants can also be included in the appointment details. If members of the group are working on different portions of a project each can then include an attachment or note to the appointment details thus allowing the instructor to view the progress made by each member of the team and to also be able to address the needs of all team members. Alternatively a student can submit a proposed appointment time. The other team members would then be allowed to vote on the appointment time based on their availability.
The group appointments are also a useful tool for arranging a meeting for a large group of students such as for a student club a study session for a course or to specify group sessions for user studies. For example a club president can specify the next club meeting allowing the individual club members to then specify whether they will be attending. Alternatively if a provider is the advisor for a club the advisor can schedule a time for the next club meeting allowing the club members to sign up for the club meeting.
A listing of all upcoming appointments for the student will be displayed as part of the student interface or dashboard. The listing provides the student with brief information about each of the appointments such as the name of the provider with whom the appointment was made the date and time of the appointment the reason the student made the appointment the location of the appointment including online and phone locations for remote meetings and the contact information for the provider. If a student wishes to change a scheduled appointment the user can use the edit option to change the appointment settings in which case the student will be redirected to the appointment editing dialog.
If the student is viewing the available appointment times for a given instructor then the instructor information will be displayed beneath the calendar. The instructor information may include excerpts taken from the instructor s profile the instructor s contact information a small biographical excerpt and an excerpt of what the instructor typically addresses during office hours with students. In an embodiment of the present invention a selection of endorsements made by other students will be displayed on the instructor information panel.
In another embodiment when viewing appointment options for a course instructor additional providers can also be listed as available to meet with students allowing students greater flexibility in case a student cannot attend the meeting times posted by the instructor but is able to attend the meeting time posted by the teaching assistant. Other providers which might also be listed along with a course instructor would include supplemental instruction staff and tutors. In the case where a student is viewing appointment options for a primary advisor other advisors in the same department can also be listed as secondary options in case the dedicated advisor is not available such as being on sabbatical leave or attending a conference or the student might find the meeting times with the other advisors to be at more convenient times.
The student will also be given the option to view all endorsements made by other students or to add an endorsement about the student s experience with the provider. The endorsement allows students who have visited the provider and were pleased with the experience and the end results to provide positive feedback about their experience with the provider that can be viewed by other students. As this feature is meant to encourage further use of the institutional services only positive feedback is utilized and a filtering or editing process is required by the provider to filter out negative feedback that might dissuade other students from visiting.
Students will be able to specify settings related to appointment reminders or alerts. These settings might be set as the default at the administrator level but each student may further customize these settings. For example options for when to be reminded of the appointment can include the day before the appointment the day of the appointment 15 minutes before etc. The system also gives students the flexibility of specifying how to receive the message such as an email text message or a FACEBOOK message.
The student interface in the preferred embodiment of the present invention also includes a course listing. In contrast to the course listing for typical course management systems the present course listing also emphasizes the office hour scheduling functionality so course listings and provider assistance can be tightly integrated which makes it more likely that the student will seek help. The listing of each course will include the name of the instructor a listing of all office hours held by the instructor and a link to the calendar page which will display the available office hour slots for the selected provider. The student user will be given the option to view the courses currently being taken courses from previous semesters all courses ever taken by the student as well as upcoming courses the student may be required to take to complete a degree. In an embodiment of the present invention the instructor names will be listed under the corresponding course on the course listing. If a listed provider has not set up office hours to be scheduled online a student can fill out an anonymous petition for the provider to use the system. These petitions can then be used by the administrator to encourage providers to use the system. In yet another embodiment of the present invention the Starfish system will provide submitted petitions to departmental heads received on a per case basis or a summary of petitions associated with the given department who can then address the need to use the online scheduling system for the students benefit.
The student interface will also include a list of announcements and invitations. Some of these announcements can be system related such as informing the students that the last day of class is approaching or the last day to pay semester tuition without any late fees etc. The invitations can be sent to all students for a provider or they can be sent to specific student groups such as an incoming freshman class. In an embodiment of the present invention instructors can send invitations specific to students enrolled in a course being taught by the instructor. In yet another embodiment of the present invention the invitations can be sent by departmental heads to all undergraduates or to all undergraduates belonging to the corresponding academic department or a club president can use it to send invitations to the club members. The invitations list will also display to the student appointment requests made by a provider. For example the provider for a course can request an appointment with a student who is identified as at risk because of poor grades in several assignments or a test or any of numerous other tracked attributes.
The student interface will allow each student to upload their picture and to enter contact information such as phone numbers email addresses and a preferred correspondence method. To prevent students from uploading inappropriate pictures the system could be linked to a student directory system or security system that includes official photos of each student which could then be used in place of student provided photos. All of the student data will be protected according to the Family Educational Rights and Privacy Act FERPA regulations. The student profile completed by the students in the student dashboard can then be viewed by providers allowing providers to easily identify who is making an appointment and it also enables providers to more readily and accurately contact a given student by using the student provided information from the student profile. Alternatively profile data about the student stored in the course management system or student information system could be automatically uploaded to the student profile allowing the student to further edit the automatically uploaded data. The provider interface or dashboard provides more controls than the student interface. In the preferred embodiment of the present invention the modules available to the instructor each encompassing a page in the user interface will be a home page an appointments module a student module an engagement module and a profile.
The home page will provide the instructor with access to a variety of options inviting students to make appointments adding office hour blocks adding a group session making a referral a panel listing upcoming appointments a panel listing recent appointments and student status changes and a panel listing flagged students. The manner in which these options are presented will depend on the needs of the academic institution and will be fully customizable by the administrators of the academic institution.
A status change or student activity data consists of any changes made to the student folder where all data associated to the student and data tracked by the Starfish system are stored. Such changes related to a student would include adding a new flag related to the student removing a flag adding a note related to the student or to a flag raised about the student and student activity such as scheduling a new appointment attending an appointment failing to attend an appointment receiving a request from a provider to attend an appointment or to use a service etc.
Inviting a student for an appointment can be done by either pressing an invite button or selecting a hyperlink. The invitation sends a message to the student requesting the student to make an appointment with the provider during one of the available office hour blocks.
The office hour blocks are specified by selecting a menu hyperlink or button option. Selecting this option will open a new dialog window. The provider can then enter a title for the office hour block which is viewable on the calendar over the corresponding office hour blocks the frequency of the office hours such as daily weekly monthly repeat patterns the start and end times of the office hours the location of the meeting and the amount of time to allocate to each appointment. For example the provider can specify an office hour block every Tuesday and Thursday from 3 pm to 5 pm with every appointment being at least 15 minutes but no more than 45 minutes long. A textbox on the dialog window will allow the user to specify a set of instructions that are automatically sent to anyone who makes an appointment with the user. For example a counselor might specify that every student bring a copy of their latest transcript to every appointment.
Group sessions have the capabilities of office hours but are for a set time and limit the number of students who can attend. The creator of the group session can determine if students can see the list of students who have signed up to attend the group session.
The list of upcoming appointments will list students who have scheduled a meeting during office hours with the provider the time of the appointment and the major reason for the student having scheduled a meeting. The list of status changes presents appointment changes or flag changes for students. For example if a student chose to cancel an appointment or if a new appointment was made a notice would be added to this list of recent changes. Flags can be displayed on the list of recent changes. If a flag was raised by a provider with regards to a student then the student s name and the flag type would be displayed. Finally a list of all flagged students will be presented on a panel with the corresponding reason for flagging displayed along with the students names. Several filters can be applied to the list of flagged students such as display flags raised by the system display flags related to financial issues among others.
The appointments module for the provider interface includes several views that are typical of calendar applications agenda view day view week view and monthly view. The primary purpose of this module is to allow the provider to view and edit appointments made and to specify and edit new office hour blocks and group sessions. The list of upcoming appointments will be interactive allowing the provider to add edit or cancel an appointment. When the cancel appointment option is selected a dialog window opens prompting the user to write a message explaining why the appointment is to be canceled. The explanation is then sent as a message to the corresponding student. Editing an existing appointment opens a dialog window similar to the editing appointment window on the student s dashboard allowing the provider to override any of the entries by the student with two additional features. First the dialog window will include a label that includes the student s name. The student name label can be presented as a button or a hyperlink which redirects the user to the student s profile. The second feature is that an additional textbox will allow the provider to enter private comments for record keeping purposes which are subsequently added to the student s folder. The student s folder will be further discussed below. For example the provider can add a private comment reminding the provider to discuss graduation requirements during the scheduled meeting with the student.
In all of the calendar views the provider can add an appointment by selecting one of the available entries cancel an appointment or edit an appointment. In addition new office blocks can be added by interactively selecting the calendar. This functionality will be supported in all of the calendar views. The calendar view for the student and the provider dashboard can be implemented with the same set of core functionality for managing and editing appointments and office hour blocks with the provider calendar view containing a superset of the student calendar view functionality.
Providers may also be given a role as a calendar manager for other users. For example a department manager may be given the role of calendar manager in order to be able to schedule appointments for the department instructors. A role of calendar manager would allow for the adding and editing of appointments office hour blocks and group sessions for themselves and for any provider they manage.
When a provider selects a student s name the provider will be redirected to the student s profile. The profile will display the information filled out by the student. When a provider views a student profile options will be given for raising a flag adding a note related to the student inviting the student to make an appointment or reporting that the photo uploaded by the student is inappropriate.
When raising a flag the provider will be required to enter pieces of information as to why the flag is being raised. This enforces responsible use of the flagging system and also keeps members of a student s success network informed when a change occurs. In the preferred embodiment of the present invention a dialog window will open and require the provider to specify a flag type. The flag type is selected from a list of available flag types. The types of flags which can be raised are institution defined and role based so that the set of available flags to instructors would be different than the set of flags available to residence hall staff or advisors. The flag types may include behavior concerns financial concerns work life interference poor attendance dramatic change in appearance group project problems poor class participation strange or dangerous behavior etc. Other information which might be required depending on the academic institution s standards are additional notes indicating why the flag is being raised and the course on which a student might be encountering difficulties if applicable. For example if a student gets lower than a 60 grade on an exam the course instructor can search for the student s name visit the student s profile select the flag button displayed on the student s profile and enter a note regarding the need for the student to visit the instructor during office hours and to suggest to the student to visit the tutoring center.
Every flag documents to the person raising it whether the information contained in it is available upon request to the student through FERPA regulations. This ensures appropriate documentation about the concerns.
In the preferred embodiment of the present invention when creating a note related to a student the provider is first asked to specify the note type which is institution defined and based on the role of the user. Note types can range from being a general student comment a major selection note a financial issue etc. The provider can specify the current date a subject line the related flags and privacy of the note. Finally the provider can enter notes in a textbox. In another embodiment of the present invention the note dialog includes a list of all flags associated with the current student. This allows the provider to specify whether a note is related to any of the existing flags. Each note can include a privacy setting. The privacy setting relates to who can view the note created by the provider. If the note is set as private then the note can only be viewed by the provider who created the note. The note can also be set as shared allowing a specific set of other providers to view the note as well based on the type of note. This is one way in which the progress or the status of an at risk student can be monitored by several entities even though each entity might play a different role and have a different association with the student. When creating the note the provider will be notified whether the information entered will be available upon request to the student through the FERPA regulations.
The students module on the provider dashboard allows the provider to search and view students. The information displayed for each student will depend on the institution s preferences and can be changed by the administrator of the system for the institution. The information will primarily include the flagging status of students contact information the primary reason for a flag having been raised if any the provider name who raised the flag etc. The instructor will be able to view the list of students using a variety of filters. For example the instructor could view all flagged students or view all students with manually set flags or view students who were flagged because of financial concerns. The list of students can also be filtered by a specific term such as Spring 2009 or alternatively the list can display all available students. Students can also be browsed based on a specific note type such as viewing students who have note types for attendance problems. In another embodiment students can be listed based on a number of outstanding invitations students who have not visited the provider in the current semester or students with specific grades or grade averages. Search capabilities of this student list can also be included. Selecting any student s name redirects the user to the selected student s profile.
The engagement module in the provider dashboard allows the instructor to analyze his her engagement performance with students. In one embodiment of the present invention the instructor would be shown a success provider score which would provide the instructor with a sense of how well the instructor motivates and improves the effectiveness of students at various levels. The success provider score could be a number between zero and 100 it could be a letter grade or it could be presented using a graphical representation such as a green circle for a high score and a red circle for a low score.
The actual criteria and the corresponding weight values used for the success provider score or performance data will depend on the requirements and goals of the academic institution. The manner in which the success provider score is computed will also be configurable by the academic institution allowing the administrators to specify the criteria and their relative importance in accordance with the standards of the academic institution. In one embodiment of the present invention activities performed by the provider would be used to determine the success provider score. For example the success provider score could be computed by the number of student endorsements or positive reviews received by the provider the number of appointments made the percentage of students whose grades increased after meeting with the provider the percentage of students who met with the provider and graduated and the percentage of students who met with the provider and followed by using the services recommended by the provider. All of these respective values could then be uniformly scaled and weighted accordingly based on their relative importance with the weighted sum providing the success provider score. In another embodiment of the present invention the success provider score could be computed using a set of conditional statements. For example a provider could only get a high success provider score by meeting with at least 10 students per month or a provider could get no higher than a 50 success provider score unless students in certain protected classes met with the provider once every two weeks.
The instructor would also be provided with a set of specific tips for increasing the comfort level of the instructor s student such as uploading discussing personal interests adding more office hour blocks including more student endorsements etc. Statistics will also help the instructor determine areas of improvement and students who the instructor needs to reach out to. Breadth statistics would present the number of students and a list of students that have not been seen by the instructor in the current or prior terms.
Even without developing a success provider score per se the present system makes it possible to analyze performance data related to different entities using the system and to compare performance data for a first entity to a second entity. The performance data could be based on data from a number of different sources such as the engagement reported by the networked computer system related to an entity s interaction and assistance provided to students such as meetings scheduled meetings held referrals made to students for other services improvements in the students grades or performance or mental health etc. academic data pulled from course management systems such as course dropped or completed academic advisement grade improvement or decrease student retention rates etc. and student activity data pulled from student management or information systems such as tutoring sessions held counseling or advisement sessions held clubs joined or quit and many other types of activities . While the performance data could be determined by each academic institution or within various groups departments colleges etc. within the academic institutions the performance data would likely be more useful if the same performance criteria applied to all entities so that the first entity could be evenly and fairly compared to the second entity at all times. Such performance data could be based on the engagement the academic data or the student activity data or some combination of each.
The entities could include two different academic institutions different providers within an academic institution all of the providers within one department compared to each other or collectively compared to another department all of the providers within one college compared to each other or collectively compared to another college. Any of these comparisons would enable the first entity to determine how it was doing at helping students in comparison to the second entity and then delve down deeper into the data upon which the comparisons are based to determine how to improve performance. Likewise a provider would be able to compare the provider s current performance to performance from prior terms. This would allow a provider to assess whether the use of a particular engagement technique improved overall student performance from one semester to the next. A provider s performance could also be compared to those peers who have the highest broader student success enabling the provider to identify techniques that yield the best results with regard to student engagement and student success. As correlations are developed between referrals to other providers problems flags and student demographics higher scores will be given to providers who follow the most effective route or who adhere to best practices.
The diversity of the students using and subsequently those students not using the office hours can be analyzed by various demographics. For example a department might be trying to encourage further enrollment of students belonging to underrepresented groups. In this case each instructor would be able to determine whether students belonging to an underrepresented group might be less likely to see the instructor outside of the classroom during office hours. Statistics can also be included that show the impact the involvement the instructor has had on students. For example a chart can show the impact on grades of students who visited the instructor versus those students who did not. The results for each of these respective statistics can be further analyzed by race gender department athletes and country of origin.
Another useful tool of the engagement module is the ability for an instructor to analyze the levels of academic performance of students in the instructor s courses. This can allow providers to determine patterns of various student groups demographic and academic characteristics. For example an instructor can determine how often students with a GPA lower than 3.0 and enrolled in the instructor s class have scheduled an appointment during the current semester. Alternatively the instructor could also see visits by grade average in the course in the current or prior terms. The instructor will also be presented with a set of tools for tracking students at risk. Some of these tools include viewing students who have been flagged as at risk viewing appointment notes viewing students with poor overall or individual grades etc.
The engagement module allows the instructor to view and generate a variety of reports related to personal engagement and motivational success of students including appointment reports student reports outcome reports demographic reports trend reports etc.
The profile module in the provider dashboard consists of several screens including an institutional profile screen an appointment preferences screen a listing of courses and an email notification screen. The institutional profile allows the provider to edit a personal profile. The instructor can upload a photograph specify general contact information and miscellaneous information such as a biography and how a student can be helped by visiting the provider.
The appointment preferences allow the instructor to specify a set of default settings for office hour blocks. However the specific settings for an office hour block can always be changed when creating an office hour block. Some examples of default appointment settings include the minimum appointment length a scheduling deadline and locations for the meetings with students. In addition a calendar manager can be added which would allow another person to set or change appointments for the instructor. For example a department administrator might be the calendar manager for all the department instructors in order to be able to schedule meetings for the instructors related to advising.
The list of courses presents the instructor with all the courses for which the instructor is responsible. In the preferred embodiment of the present invention students enrolled in a course taught by the instructor would be able to schedule appointments with the instructor during office hours. In the courses area the standard course meeting times will appear or be entered by the instructor. These will be used for taking attendance.
The email notifications screen allows the instructor to specify preferences for appointment and flag notifications. The appointment notifications relate to reminders for appointments. The flag notifications cause an email to be sent whenever a flag is raised or cleared. The frequency of notifications sent can also be specified.
The Starfish system consists of centrally hosted collections of servers and services accessed by the academic institution providers and by both current and prospective students. shows a high level diagram of the Starfish system . Starfish system provides a set of services including email text messaging and instant messaging file ingest services telephony services API services data analytics and benchmarking operation data services and a database and a suite of application services .
The file ingest services provide the capability to store and process data files generated by academic institutions in order to extract the critical student activities. These data files are automatically generated by Starfish system adapters and created via ad hoc means at the academic institution.
The telephony services provide the ability to call out to students about upcoming appointments and situations that need their attention as well as an inbound capability to allow students and staff to schedule appointments via the phone or voice over Internet Protocol VOIP .
The API services provides third party programs and systems a set of application programming interfaces APIs that enable a variety of capabilities from seamlessly integrated systems to remote reporting.
The data analytics and benchmarking provides a cross academic institution analysis and reporting capability that compares and contrasts the behavior of students at different academic institutions that have implemented the Starfish system and looks at trends over time. This is another key feature of the present invention in that benchmarking is done on an operational systems basis. In contrast to existing systems the Starfish system surveys are very specific and any corresponding results can be benchmarked against other academic institutions. In existing systems features which tend to be tested by surveys focus on student advisement and mentoring. With the Starfish system the data that is analyzed and benchmarked is taken from all the data and activities tracked by the course management system and the various student information systems hosted by the academic institution as further discussed in reference to below.
The operational data services database provides the basic data storage and access capabilities for all of the academic institution data used in standard end user transactions.
The application services provide the end users students instructors advisors parents administrators etc. with the web based capabilities of the Starfish system . The set of application services include appointments invitations and referrals flagging note taking student folder roles and relations endorsements and petitions grades and attendance survey manager and service catalog .
One aspect of the present invention provides the ability for students and others to schedule meetings or appointments with members of the academic institution. Pre set times called Office Hours designate when meetings should occur and keep track of whether meetings occur. The provider of the academic institution with whom the appointment was made can make notes about issues discussed during the meeting. These notes can then be shared with other providers of the academic institution who might be part of the student s Success Network and flags can be set.
If a student does not show up for the appointment the instructor advisor or counselor can mark the student as a no show. The system could also be configured to always assume no shows for some types of appointments with the advisor subsequently marking that a student attended the appointment. The system will track and report against no shows. Different combinations of communications will be tracked to determine what minimizes the no show rate. This communication style will be encouraged by the system.
Another model for compelling or coercing an appointment is through the use of invitations and referrals which have the ability to encourage or force participation. Invitations provide the ability to invite students to meet with a member of the academic institution either individually identifying the student or selecting students that meet some criteria such as all students all students with a C average or below etc. Referrals allows staff to request that a student seek help from a service on campus such as writing center help or disability services help. The system notifies all parties of the need for the student to visit the service and tracks that it happens. If deadlines are not met for either of these capabilities reminders will be sent out and escalation procedures that get other parties to intervene can be initiated. These are examples of models for compelling or coercing an appointment in that the system provides a status and sends corresponding updates to related parties and continues to apply pressure in a variety of ways until the visit meeting happens or other actions are taken.
In the preferred embodiment of the present invention two types of flag definitions and management capabilities are provided for flagging manual flags and automatic flags. Manual flags are raised by people who interact with the student when they observe a problem or by the students themselves.
Automatic flags are initiated when the events known by the Starfish system about a student cause a flag rule to trigger. In one embodiment the identification of students to be flagged is done using a set of conditional statements. For example if a student s average in a class falls below 70 or if a student withdraws from a class after the add drop period a flag could be automatically raised depending in institutional preferences. For every student currently enrolled in an academic institution the system could analyze all data associated with the student this data aggregated from the course management system other student management or information systems and the student folder. A set of conditional statements could then be used to determine whether the student falls within the criteria of one or more flags. Alternatively a statistical analysis could be used to determine whether a student should be flagged. For example Biology students who fall within two standard deviations of the average GPA for freshman students in the Biology department may be flagged to meet with an advisor or to attend tutoring. The probability distribution of student scores for a test in a class may also be used to identify and flag students in the class who need to schedule an appointment with the class instructor or teaching assistant. Statistical analysis techniques that could be done on the data from course management systems and other student information systems are well known in the art.
Once flags are raised or created a variety of people are notified based on the flag type and the student. Based on flag types students can be directed to interventions. Requests for more information about the students are sent to each student s network. Advisors and counselors are notified to start interventions. The provider who first raised the flag can be subsequently provided with positive feedback about their action to motivate them to continue to be actively engaged with the success of students thus closing the loop. The flag is tracked commented on and used as a shared focal point for the community focused on a particular student.
A unique simple ownership mechanism allows for flexible options between group ownership of flags and the resolution of flags individual ownership or switching between those modes. Ultimately flags can be closed through addressing the issue or having the student withdraw from the class or institution. Throughout the lifecycle of a flag the provider who raised the flag can be provided with opportunities to be informed of the student s status without divulging too much confidential information further encouraging the behavior of the providers of identifying students at risk.
As noted above note taking provides for the ability to record personal or shared notes. Notes are typed in order to structure the required information for the notes and to determine the access levels to the notes for various people in the student s network. Notes can be stand alone associated with appointments or associated with one or more flags. Notes can be emailed to people within the student s network or the student themselves. Emails initiated by the system about a student or to the student are automatically captured as notes.
The student folder provides a student centered view of all information that the Starfish system knows about and all actions possible for a student. From here a user who has access to a student s data can see based on their role all information on that student. The information can be both chronologically organized as well as by the type of information. The chronological display shows everything about the student organized by time. For example when the student registered for classes when they turned in their assignments when they got their grades when the grades raised a flag when they missed class for a week when they met with their instructor when they were requested to meet with their advisor when they missed or cancelled a meeting what comments a financial aid advisor had about their phone call when they withdrew from the class etc. This will enable a quick diagnosis of students at risk. Similarly a user can see contact information for a student their picture and that they changed majors a few times. The user can also see all of their grades and the day they get them in class. They can see and raise flags. They can see and take notes. They can see and take attendance. All of this student information results in a case history for the student not limited to academic advisors or admission officers on their own.
A key component of what makes the Starfish system so usable is its ability to provide the right information to the right people at the right time. This happens through roles and relations . Starfish system provides a custom role management system that balances flexibility with complexity specifically for the higher education market. It provides pre defined roles extensible roles customization of privileges associated with roles role based access to resources and role display to orient each party to how the community is helping students. It can support such roles as Student Instructor Advisor Parent Residence Hall Staff Dean Coach with a predefined set of rules about their activities and access to student information. Further roles can also be defined by the administrators of the academic institution as long as each role is accompanied by the corresponding rules and access privileges.
Once roles have been defined the academic institution can specify the relations. Relations specify associations between users. For example an instructor s role would allow for the viewing of a student s record the setting of appointments with a student note taking and flagging while a tutor s role might only allow for the setting of appointments with a student and flagging. A variety of relations can be specified that represent today s practice in higher education. The relations definition approach includes automatic relation assignment based on roles within a course management system automatic relation assignment based on other online communities such as an advising community or departmental community batch upload of relations including meta relations where someone can have relations with all students students in a department or students in a department based on their last name e.g. a f g k l z and manual entry of relations. Relations are organized around academic terms such as Fall 2009. Every relation in the system will be constrained by one or more terms.
The manner in which roles and relations are structured and managed shows an example of the non passive engagement focused nature of the present invention towards students. To the student it presents them with the people who can help them. To members of the student s success network it presents people who are helping or who could potentially help a specific student. Techniques for implementing roles and relations in software are well known in the art. For example a Starfish system instructor could be someone that can or teaches a course section of students while a Starfish system user is someone who could or is enrolled in a course section of students. Other roles could be defined as necessary such as an appointment taker an appointment maker and an administrator. A set of privileges would then be associated with each respective role. For example an administrator role would have the privileges to change all settings of the Starfish system and to see all data collected by the system. A student role would be allowed to see the student s own information and to make and request appointments with providers while a provider role would be allowed to see the information of students associated with the given provider. The set of privileges and the defined roles can be edited and new ones added as needed by the administrator of the Starfish system. The relations could also be used to build a student s success network for handling the sending of flagging notices and for directing students to services that can help them succeed.
Endorsements and Petitions provide information to and from students to allow the students collective experience to drive student behavior. For any individual or service for which a student is authorized by the academic institution and the individual service a student can provide an endorsement of the collaboration the student had with the individual or service in order to promote another student to visit meet with the individual or service. These endorsements are provided at the time appointments are booked as well as generally in the profile of the individual or service so it has the best impact. Similarly the student is also presented a roll up of how other students like themselves are meeting with the individual or service. For example if a female first year biology student is planning on making an appointment with a financial advisor on the current week the student can be presented with an endorsement stating that five other female first year biology students have met with a financial aid advisor during the same week or the previous week thus making the student feel more comfortable with the service. Petitions provide a voice for students to anonymously recommend an instructor or advisor to use the Starfish system in order to enable the students to have self service for scheduling appointments contacting the instructor or advisor etc. Student demands have significantly impacted the use of course management systems at academic institutions. Starfish system also provides a means for organizing and automating this demand.
The Grades and Attendance service provides authorized users access to data about a student s current and former academic performance. Current and historic grade data from the course management system can be provided or updated daily. In addition official grades from the registrar can be provided to the authorized user including GPA GPA for major scores of any placement test or standardized tests for the student etc. Attendance provides instructors a web based attendance recording system that can show pictures of students enrolled in a course. The instructor could then arrange the pictures of students to match the classroom layout or in some other manner for quick data entry. This attendance data then feeds into the flagging system to detect when students are missing or are late for a certain number of classes. The system could also use the official course time to remind instructors to take attendance and notify an administrator if an instructor fails to record attendance for a course. Administrators could then prompt instructors with email reminders in order to enforce the recording of attendance.
The survey manager service provides the ability to specifically survey students about their attitudes and experiences in order to provide profile data for students and raise flags of concern. It also enables surveys of instructors to raise flags for students at pre defined times. Lastly it provides feedback about service delivery for quality improvement.
The service catalog provides a single searchable location for students to learn about the individuals and services that can help them. Each student is provided upon entry to the Starfish system with a personalized Success Network that lists contact information to enable online scheduling of meetings with anyone who the academic institution has specified can help the student. This list typically contains current and former instructors and teaching assistants advisors mentors and any counselors for this student. The service catalog then contains the larger set of services a student can access from disability services to tutoring. Each service can allow for online scheduling endorsements contact and general information. Services can be added to and removed from the student s success network. Advisors and other authorized personnel reviewing a student s folder will see the student s Success Network allowing for a quick connections between people who help students.
A course management system a student information system s other student systems calendaring services a synchronous communication server a Starfish card reader and an end user authentication system are also provided. The end user authentication can be LDAP ACTIVE DIRECTORY or other systems. Examples of a portal are MICROSOFT SHAREPOINT or SUNGARD LUMINUS. Examples of course management systems include BLACKBOARD WEBCT MOODLE an open source course management system ANGEL and DESIRE2LEARN.
Student information systems consist of services hosted and provided by the academic institution to students and also used to help manage administrative tasks of the many institutions and services provided to the student body. For example student information systems are used for back office admissions scheduling transcripts among other student self service functions. The Starfish system learns administrative information about students staff and courses by mining the corresponding student information systems for data related to student activity. Examples of student information systems include BANNER UNIFIED DIGITAL CAMPUS BY SUNGARD or DATATEL COLLEAGUE. BANNER UNIFIED DIGITAL CAMPUS provides an administrative suite of student financial aid finance human resources and advancement systems. DATATEL COLLEAGUE provides a similar set of planning and management solutions for academic institutions.
Examples of other student systems include a judiciary system and residence hall management systems. These systems track students actions students activities and any administrative data about students. The Starfish system can mine these student systems for data to learn further information related to students. For example the Starfish system can determine by examining the data of these systems the name of the resident assistant of a student or whether a student was involved in an incident with the campus police or whether a student is part of any clubs or organizations at the academic institution.
The calendaring services provide calendaring capabilities for members of the academic institution. This could be dedicated for the academic institution a locally hosted exchange server or a global service used by campus members such as GOOGLE Calendar or both. The Starfish system ensures it is up to date with student appointments relating to student success through a two way messaging system.
The synchronous communication server provides real time text based chat and audio between campus members. The Starfish system will refer individuals to this service to engage in an online meeting and then capture the transcript of the meeting for the student s folder.
The Starfish card reader will read student and provider ID cards to authenticate the user so that they have a quick way of checking into an appointment or seeing a list of providers available to serve them at a center. Many other forms of identification authentication could be used in place of the card reader .
The end user authentication system validates user name and password combinations for multiple services for an academic institution. Academic institutions information technology uses this to simplify the number of username password combinations a user has and how many times they need to log in to get secured access to hosted services. shows how in the preferred embodiment of the present invention all of the services provided to members of the academic institution students and providers are authenticated via the authentication system so a user only has to log in once to have access to all of the systems and services.
The Starfish adapters handle the data mining and the transmission of data collected to the Starfish system . In case of user authentication either through the course management system or the portal the authentication information for the user is securely transmitted via the Starfish adapter as well.
The second component of the Starfish system is the communicate component . The communicate component is what encourages or compels active participation and communication between a student and the student s success network. To the student it provides self help services while to the providers it allows them to identify and actively reach out to students at risk. This active communication between the student and the service provider is supported by various media including email phone calls VOIP and text messaging and instant messaging . All of these can serve for the automatic delivery of alerts and reminders in addition to standard message communication between the student and the success network. Alternative embodiments of the present invention include online delivery of help anonymous telephonic delivery of help phone based reminders student ID scanning paper scanned surveys PDA based surveys and help content offerings.
The third component of the Starfish Early Alert system is the intervene component which builds on the encourage compel aspect of the communicate component . In this step the student after having been identified is directed to a set of support services which can help the student at risk to address the problems affecting the student such as visiting a tutor a counselor or financial advisor depending on the nature of the problem. The intervene component also includes an escalation procedure that can be implemented in different ways by the academic institution to make sure students get the help they need and providers are providing such help as further described above.
Finally all activity and progress related to a student on each of the three components of identify communicate and intervene is recorded and analyzed by the assess component . This allows the providers and administrators to assess trends usage patterns how successful services are in improving student grades etc.
The upcoming appointments panel displays a list of students who have scheduled appointments with the provider including the student s name the appointment date and the primary issues to address during the appointment. The appointments list can be scrolled by the provider in case there are numerous appointments which have been scheduled. In another embodiment of the present invention the appointment list can be sorted by any of the fields which describe the appointment such as by student name date or by the appointment reason.
The recent changes panel presents to the provider a list of students whose flagging status has changed for the current day. The list of students can display primarily the name of the student and the primary reason for the student being flagged. The changes displayed on the recent changes panel can be customizable with default settings at the administrative level and also further customized by the provider. For example the administrators of the academic institution may set the system so that only newly flagged students from the current day are displayed on the recent changes panel but a provider may change this default setting so that the recent changes panel displays newly flagged students since the last log in.
The services catalog panel presents a services list provided by the institution . In the preferred embodiment the services list would be divided into two sections bookmarked services and all services . Services frequently used by the provider can be bookmarked for future access which would subsequently be added to the list under the bookmarked services which can be later edited by adding and deleting bookmarked services. The services catalog can be searched and any service can be referred to a student if appropriate via a button or link . The referral to a student can then bring up a list of all students who are associated with the provider a list of students who have been flagged or an email template. This is an example of how a teacher can actively engage a student who has been identified as at risk.
Roles and relations can be used to present a provider with the list of students who are associated with the provider. For example if a provider had an instructor role then a list of all students in the instructor s course sections could be presented to the provider. The list of students could also be divided into subsections where each section of the list of students represent the different relations the provider has with different groups of students. Using the same instructor role example the list could be divided by students enrolled in course sections taught by the instructor allowing for this list to be further subdivided by each course and by each corresponding section students for who the instructor is their primary advisor graduate students who work under the instructor and students who have been referred by other providers.
A list of all flagged students is displayed on the flagged student s panel . The panel list of students would display the student s name and the corresponding flag type currently associated with the student. In an embodiment of the present invention the information displayed for each student can be customizable with default settings at the administrator level with further customization by each user. In addition by toggling each field such as the name or the flag type fields would sort the student list according to the toggled field either in ascending or descending order.
The Starfish SaaS front end hosts the student retention services suite for multiple academic institutions with a specific institution highlighted referred to as STATEU in . The Starfish website STATEU.USTARFISH.COM for the academic institution is accessed either via single login from the academic institutions course management system by passing a login token to the Starfish system or by logging in to the Starfish system through a portal. The student retention services suite is accessed via the academic institution s Starfish website with menu options available to access any of the services described above including Starfish CONNECT Starfish STUDY GROUPS Starfish TUTORING retention management tutor center management advising management and counseling management . All of the actions and data generated from all of these services are subsequently stored and retrieved from the Starfish database which is hosted by the Starfish SaaS back end host .
The Starfish TUTORING service manages tutoring on campus via tutor recruitment tutor certification tutoring scheduling supply demand matching meeting room management and tutor rating and evaluation. The tutoring scheduling can be done similar to how students can schedule appointments with providers. Providers or students given a special tutor role would be allowed to post time blocks for tutoring sessions. The tutoring sessions could be individual or group appointments. In an embodiment when the user with the tutor role is entering information for a new time block for a group session the user will be given a list of available classrooms or other rooms with special equipment that are available for use at the specified time block. Alternatively the tutor could submit a request to use a room which can then be approved by the administrator or the staff in charge of the room.
The Starfish TUTORING service would further allow students who have visited the tutor or attended a group session hosted by the tutor to rate and evaluate the tutor. The students would be allowed to rate on a scale depending on the institution such as from one to five. Alternatively the students could provide an endorsement for the tutor by explaining how visiting the tutor resulted in a positive experience. In another embodiment students would evaluate the tutors by completing an evaluation form where the students would be asked questions ranging from the clarity and knowledge on the topic expressed by the tutor to the appropriateness of the tutor s appearance.
In another embodiment the student retention services suite would also include a mentoring service. This service would manage programs via mentor recruitment mentor scheduling mentor profiles and would catalog mentors by industry company profession and region. This service by also keeping track of mentoring associated data would enable administrators or other providers to assess effectiveness of mentoring programs.
The Starfish advising management would allow the academic institution to deepen the impact of academic advising via degree audit workflows for at risk students and social networking around majors. Surveys of participants would be conducted in order to gather feedback on the utility and experiences of the students and as a measure of the success of the program. The advising management would also analyze student data in order to find and determine correlations of attending advisement services and student grades student satisfaction and student graduation rates. In another embodiment the advising management would also support the benchmarking of outcomes against peers and aspirant institutions.
The client hosts represent the academic institution s hosts such as the academic institution s course management system. In BLACKBOARD is noted as a specific instance of a course management system used by the academic institution and as incorporated into the preferred embodiment of the present invention as previously noted. However any other course management system may be integrated with the Starfish system as data integration is handled by incorporating a database gateway on the Starfish SaaS back end host in order to enable different databases to integrate with the Starfish system .
As illustrated in the Starfish system integrates with BLACKBOARD through the use of a Starfish building block which handles authentication of users via single login with the Starfish system via a HyperText Transfer Protocol Secure HTTPS connection . HTTPS provides a secure HTTP connection by using either a secure socket layer or a transport layer security connection. Data collected from the course management system is then sent via a Starfish database transport to be stored in the Starfish database going through the database gateway in order to allow communication between heterogeneous database systems. The data sent by the Starfish database transport is sent over an HTTPS connection .
The client also hosts a Starfish data aggregator . The data aggregator collects data from a number of student information systems hosted by the academic institution. The collected data is subsequently sent to the Starfish database via HTTPS connection by using the Starfish database transport which handles the packaging of the data the establishing of a secure connection with the Starfish database gateway and the communication of the data. The data aggregator could run as a background process either as a service or a daemon. The data aggregator could be scheduled to run at a predetermined time running as frequently as every hour to once per day. The data aggregator could also be manually executed through the administrator interface.
In an embodiment one configuration of the system would prevent personally identifiable information PII from being sent to the Starfish SaaS front end host and back end host such information including a student s name social security number and student ID. The PII information would be kept within the academic institution client hosts and a unique user identifier UUID would be sent instead to the Starfish SaaS front end host and back end host . All information displayed to the end user s browser through one of the interfaces or dashboards containing any PII would be constructed by replacing the UUID with the PII from the academic institution. This process would limit the impact to the users and providers in case of a security breach of the SaaS front end host and back end host .
While the present invention has been illustrated and described herein in terms of a preferred embodiment and several alternatives associated with various features it is to be understood that the various components and features of the combination of elements described herein and the combination itself can have a multitude of different arrangements uses and applications. Accordingly the invention should not be limited to just the particular descriptions and various drawing figures contained in the specification that merely illustrate one or more preferred embodiments and applications of the principles of the invention.
| 373.012 | 1,970 | 0.829904 | eng_Latn | 0.999966 |
586e38d392228b1cd2eb6228c39cd87220518c2f | 17,156 | md | Markdown | _posts/2022-01-12-alsl2.md | GoodJeon/GoodJeon.github.io | 98a5d6e30109292138a0bee98716a4539df7f9e4 | [
"MIT"
] | null | null | null | _posts/2022-01-12-alsl2.md | GoodJeon/GoodJeon.github.io | 98a5d6e30109292138a0bee98716a4539df7f9e4 | [
"MIT"
] | null | null | null | _posts/2022-01-12-alsl2.md | GoodJeon/GoodJeon.github.io | 98a5d6e30109292138a0bee98716a4539df7f9e4 | [
"MIT"
] | null | null | null | ---
layout: posts
comments: true
title: "[알고리즘 특강]자료구조/알고리즘 특강 요약 2일차"
categories: Algorithm
tag: [파이썬, 알고리즘, algorithm, python]
toc: true
toc_sticky: true
date: 2022-01-12
last_modified_at: 2022-01-12
---
# 선형 자료구조(1일차에 이어서)
## 5) 큐(Queue)
### 큐 구현(개선)
#### 전역
```python
SIZE = 5
queue = [None for _ in range(SIZE)] # list_comprehension으로 queue 생성
front = rear = -1
```
#### 함수
```python
def isQueueFull(): # 큐가 꽉찼는지 확인하는 함수
global SIZE, queue, front, rear
if (rear != SIZE-1):
return False
elif (rear == SIZE-1 and front == -1): # front가 출구 끝이면
return True
else:
for i in range(front+1, SIZE) :
queue[i-1] = queue[i]
queue[i] = None
front -= 1
rear -= 1
return False
# 출구 쪽 None 공간으로 남은 값들을 밀어줘 새로운 값이 들어갈 수 있도록 해줌
def isQueueEmpty(): # 큐가 비었는지 확인하는 함수
global SIZE, queue, front, rear
if (rear == front):
return True
else:
return False
def enQueue(data): # 큐에 데이터를 넣는 함수
global SIZE, queue, front, rear
if (isQueueFull()):
print('큐가 꽉 찼습니다.')
return
rear += 1
queue[rear] = data
def deQueue(): # 큐에서 데이터를 빼는 함수
global SIZE, queue, front, rear
if isQueueEmpty():
print('큐가 비었습니다.')
return None
front += 1
data = queue[front]
queue[front] = None
return data
def peek(): # 다음 나올 데이터를 알려주는 함수
global SIZE, queue, front, rear
if isQueueEmpty():
print('큐가 비었습니다.')
return None
return queue[front+1]
```
#### 메인
```python
enQueue('화사')
enQueue('솔라')
enQueue('문별')
enQueue('선미')
enQueue('동준')
print('출구<-----',queue,'<-----입구')
print('밥 손님 : ', deQueue())
print('밥 손님 : ', deQueue())
print(queue) # 출구쪽 공간 0과 1이 None
enQueue('아이유') # 아이유가 들어갈 수 있도록 앞의 값들의 위치가 1씩 줄어듬
print('출구<-----',queue,'<-----입구')
```
출구<----- ['화사', '솔라', '문별', '선미', '동준'] <-----입구
밥 손님 : 화사
밥 손님 : 솔라
[None, None, '문별', '선미', '동준']
출구<----- [None, '문별', '선미', '동준', '아이유'] <-----입구
---
## 6) 원형 큐
### 원형 큐란?
* 큐의 처음과 끝이 연결된 구조
### 차이점
1. 순차 큐에서는 오버헤드가 발생하지만 원형 큐는 처음과 끝이 연결되어 있어 오버헤드가 발생하지 않는다.
2. 큐가 꽉찬 상태이지만 front가 rear보다 크게 되었을 때 비었다고 인식할 수 있다. 그래서 **`% 큐의크기`** 를 사용해 그 점을 방지하는 것이 원형 큐다.
### 원형 큐 구현
#### 전역
```python
SIZE = 5
queue = [None for _ in range(SIZE)] # list_comprehension으로 queue 생성
front = rear = -1
```
#### 함수
```python
def isQueueEmpty(): # 큐가 비었는지 확인하는 함수
global SIZE, queue, front, rear
if (rear == front):
return True
else:
return False
def isQueueFull(): # 큐가 꽉찼는지 확인하는 함수
global SIZE, queue, front, rear
if ((rear+1) % SIZE == front):
return True
else:
return False
def enQueue(data): # 큐에 데이터를 넣는 함수
global SIZE, queue, front, rear
if (isQueueFull()):
print('큐가 꽉 찼습니다.')
return
rear = (rear + 1) % SIZE
queue[rear] = data
def deQueue(): # 큐에서 데이터를 빼는 함수
global SIZE, queue, front, rear
if isQueueEmpty():
print('큐가 비었습니다.')
return None
front = (front+1) % SIZE
data = queue[front]
queue[front] = None
return data
def peek(): # 다음 나올 데이터를 알려주는 함수
global SIZE, queue, front, rear
if isQueueEmpty():
print('큐가 비었습니다.')
return None
return queue[(front+1) % SIZE]
```
#### 메인
```python
enQueue('화사')
enQueue('솔라')
enQueue('문별')
enQueue('선미')
enQueue('동준')
print(queue)
print('밥 손님 : ', deQueue())
print('밥 손님 : ', deQueue())
print(queue)
enQueue('아이유')
print(queue)
print('밥 손님 : ', deQueue())
enQueue('박진영')
print(queue)
print('밥 손님 : ', deQueue())
enQueue('백종원')
print(queue)
print('밥 손님 : ', deQueue())
print('밥 손님 : ', deQueue())
enQueue('유재석')
print(queue)
```
['화사', '솔라', '문별', '선미', '동준']
밥 손님 : 화사
밥 손님 : 솔라
[None, None, '문별', '선미', '동준']
['아이유', None, '문별', '선미', '동준']
밥 손님 : 문별
['아이유', '박진영', None, '선미', '동준']
밥 손님 : 선미
['아이유', '박진영', '백종원', None, '동준']
밥 손님 : 동준
밥 손님 : 아이유
[None, '박진영', '백종원', '유재석', None]
---
---
# 비선형 자료구조
## 1) 이진 트리
### 트리구조란?
* 회사 사장을 필두로 그 아래 직책들이 구성되어 있는 조직표 또는 컴퓨터 상위 폴더 안에 하위 폴더들이 계속 이어져 있는 구조와 같은 구성
### 이진 트리의 종류
* 포화 이진 트리, 완전 이진 트리, 편향 이진 트리 등
### 이진 트리의 순회
* 순회 종류
* 이진 트리의 노드 전체를 한 번씩 방문하는 것을 순회(traversal)라고 함
* 노드 데이터를 처리하는 순서에 따라 전위 순회, 중위 순회, 후위 순회
1. 전위 순회(preorder traversal)
1. **현재 노드 데이터 처리**
2. 왼쪽 서브 트리로 이동
3. 오른쪽 서브 트리로 이동
2. 중위 순회(inorder traversal)
1. 왼쪽 서브 트리로 이동
2. **현재 노드 데이터 처리**
3. 오른쪽 서브트리로 이동
3. 후위 순회(postorder traversal)
1. 왼쪽 서브 트리로 이동
2. 오른쪽 서브 트리로 이동
3. **현재 노드 데이터 처리**
### 이진트리구현
#### 전역
```python
```
#### 함수
```python
class TreeNode():
def __init__(self):
self.left = None
self.data = None
self.right = None
```
#### 메인
```python
node1 = TreeNode()
node1.data = '화사'
node2 = TreeNode()
node2.data = '솔라'
node1.left = node2
node3 = TreeNode()
node3.data = '문별'
node1.right = node3
node4 = TreeNode()
node4.data = '휘인'
node2.left = node4
node5 = TreeNode()
node5.data = '쯔위'
node2.right = node5
node6 = TreeNode()
node6.data = '선미'
node3.left = node6
```
```python
print(node1.data)
print(node1.left.data, node1.right.data)
print(node1.left.left.data, node1.left.right.data, node1.right.left.data)
```
화사
솔라 문별
휘인 쯔위 선미
---
## 2) 이진 탐색 트리
### 이진 탐색 트리의 특징
* 이진 트리 중 활용도가 높은 트리로, 데이터 크기를 기준으로 일정 형태로 구성함
1. 왼쪽 서브 트리는 루트 노드보다 모두 작은 값을 가진다.
2. 오른쪽 서브 트리는 루트 노드보다 모두 큰 값을 가진다.
3. 각 서브 트리도 1,2의 특징을 갖는다.
4. 모든 노드 값은 중복되지 않는다. 즉, 중복된 값은 이진 탐색 트리에 저장할 수 없다.
### 이진 탐색 트리 구현
#### 전역
```python
memory = []
root = None
nameAry = ['블랙핑크','레드벨벳','마마무','에이핑크','트와이스']
```
#### 함수
```python
class TreeNode():
def __init__(self):
self.left = None
self.data = None
self.right = None
```
#### 메인
```python
# 첫 노드 생성
node = TreeNode()
node.data = nameAry[0]
root = node
memory.append(node)
for name in nameAry[1:]: # 레드벨벳부터
node = TreeNode()
node.data = name
current = root
while True:
if name < current.data :
if current.left == None:
current.left = node
break
current = current.left
else:
if current.right == None:
current.right = node
break
current = current.right
memory.append(node)
```
```python
print('이진 탐색트리 완료!')
```
이진 탐색트리 완료!
```python
findData = '마마무'
current = root
while True:
if current.data == findData :
print(findData, '찾음^^')
break
elif current.data > findData:
if current.left == None:
print(findData, '이 트리에 없음')
break
current = current.left
else:
if current.right == None:
print(findData, '이 트리에 없음')
break
current = current.right
```
마마무 찾음^^
---
## 3) 그래프
### 그래프 구조란?
* 버스 정류장과 여러 노선이 함께 포함된 형태 또는, 링크드인(Linked in)과 같은 사회 관계망 서비스의 연결 등의 형태
### 그래프의 개념
* 여러 노드가 서로 연결된 자료구조
* 예) 지하철 노선도, 도시 도로망, 전기 회로도, 인맥 관계도
### 그래프의 종류
1. 무방향 그래프
* **`간선(Edge)`**에 방향성이 없는 그래프
2. 방향 그래프
* 화살표로 간선 방향을 표기하고, 그래프의 정점 집합이 무방향 그래프와 같음
3. 가중치 그래프
* 간선마다 가중치가 다르게 부여된 그래프
* 무방향 그래프와 방향 그래프에 각각 가중치를 부여한 경우
### 깊이 우선 탐색의 작동
* 그래프의 모든 정점을 한 번씩 방문하는 것을 그래프 순회(Graph Traversal)라고 함
* 그래프 순회 방식은 깊이 우선 탐색, 너비 우선 탐색이 대표적
### 그래프의 인접 행렬 표현
* 그래프를 코드로 구현할 때는 인접 행렬을 사용
* 인접 행렬은 정방향으로 구성된 행렬로 정점이 4개인 그래프는 4x4로 표현
* 인접 행렬은 대각선으로 대칭
#### 함수
```python
class Graph():
def __init__(self, size): # size = 정점의 개수
self.SIZE = size
self.graph = [ [0 for _ in range(size)] for _ in range(size)]
```
#### 전역
```python
G = None
```
#### 메인
```python
G = Graph(4)
G.graph[0][1] = 1; G.graph[0][2] = 1; G.graph[0][3] = 1
G.graph[1][0] = 1; G.graph[0][2] = 1;
G.graph[2][0] = 1; G.graph[2][1] = 1; G.graph[2][3] = 1
G.graph[3][0] = 1; G.graph[3][2] = 1
for row in range(4):
for col in range(4):
print(G.graph[row][col], end = ' ')
print()
```
0 1 1 1
1 0 0 0
1 1 0 1
1 0 1 0
---
---
# 알고리즘
* 어떤 문제를 해결해 가는 논리적인 과정
* 자료구조라는 `재료`로 요리를 하는 과정이 **`알고리즘`**
## 알고리즘 표현법
* **일반 언어 표현**
* 일반적인 자연어를 사용해서 설명하듯이 알고리즘을 표현
* 일반 사람이 이해하기 쉽게 표현할 수 있으나, 최종적으로 코드로 변경하는 데는 한계가 있음.
* 어떤 알고리즘을 사용해야 할지 아이디어가 떠오르지 않는 시점에서, 생각 범위를 넓히는 단계 정도에 사용하면 무난
* **순서도를 이용한 표현**
* 여러 종류의 상자와 상자를 이어 주는 화살표를 이용해서 명령 순서를 표현
* 간단한 알고리즘은 쉽게 표현할 수 있지만, 복잡한 알고리즘은 표현하기 어려운 경우가 많음
* **의사코드를 이용한 표현**
* 프로그래밍 언어보다는 좀 더 인간의 언어에 가까운 형태
* 프로그램 코드와 일반언어의 중간
* 프로그램 코드를 코딩하는 것보다 알고리즘을 좀 더 명확히 정립하는데 도움이 되고 코드에 설명을 달지 않아도 이해하는 데 무리가 없다.
* **프로그램 코드로 표현**
* 실제로 사용하는 프로그래밍 언어의 코드로 바로 작성 가능
* **혼합 형태**
* 간단한 알고리즘은 직접 코드로 작성
* 복잡한 알고리즘은 일반 언어, 의사코드, 순서도, 그림 등을 종합적으로 활용해서 표현
## 알고리즘의 성능
* 알고리즘의 성능 측정
* 알고리즘을 소요 시간을 기준으로 알고리즘 성능을 분석 방법이 '**시간 복잡도(Time Complexity)**'
* 알고리즘 성능 표기
* 빅-오 표기법(Big-Oh Notation)으로 O(f(n)) 형태
* 대표적인 함수는 O(1), O(log n), O(n), O(n log n) 등이 있다.
---
## 1) 정렬
### 정렬의 개념
* 중요 알고리즘 중 하나인 정렬(sort)은 자료들을 일정한 순서대로 나열한 것
* 예) 학교 출석부 또는 종류에 따라 가지런히 놓여 있는 칼들처럼 순서대로 데이터가 나열되어 잇는 것
### 정렬 알고리즘의 종류
* 오름차순 정렬이든 내림차순 정렬이든 결과의 형태만 다를 뿐이지 같은 방식으로 처리됨
* 정렬하는 방법에 대한 정렬
* 선택 정렬(Selection Sort)
* 삽입 정렬(Selection Sort)
* 버블 정렬(Bubble Sort)
* 퀵 정렬(Quick Sort)
### 선택정렬
#### 선택 정렬의 개념
* 여러 데이터 중에서 가장 작은 값을 뽑는 작동을 반복하여 값을 정렬
#### 선택 정렬 구현 1
##### 함수
```python
def findMinIndex(ary) : # 최소값의 위치를 찾는 함수
minIdx = 0
for i in range(1, len(ary)):
if (ary[minIdx] > ary[i]):
minIdx = i
return minIdx
```
##### 전역
```python
# testAry = [55, 88, 33, 77]
import random
testAry = [ random.randint(0,99) for _ in range(20)]
```
##### 메인
```python
print(testAry)
minPos = findMinIndex(testAry)
print('최솟값', testAry[minPos])
```
[30, 68, 32, 38, 7, 20, 98, 13, 67, 19, 81, 48, 59, 52, 19, 30, 57, 70, 31, 90]
최솟값 7
#### 선택 정렬 구현 2(방 두개를 씀)
##### 전역
```python
import random
before = [ random.randint(100, 200) for _ in range(10)]
after = []
```
##### 함수
```python
def findMinIndex(ary) :
minIdx = 0
for i in range(1, len(ary)):
if (ary[minIdx] > ary[i]):
minIdx = i
return minIdx
```
##### 메인
```python
print('정렬 전 -->', before)
for _ in range(len(before)):
minPos = findMinIndex(before)
after.append(before[minPos])
del(before[minPos])
print('정렬 후 -->', after)
```
정렬 전 --> [142, 196, 193, 177, 138, 105, 102, 127, 173, 194]
정렬 후 --> [102, 105, 127, 138, 142, 173, 177, 193, 194, 196]
#### 선택 정렬 구현 3(방 한개를 씀)
##### 전역
```python
import random
dataAry = [random.randint(100,200) for _ in range(10)]
```
##### 함수
```python
def selectionSort(ary):
n = len(ary)
for cy in range(0, n-1):
minIdx = cy
for i in range(cy+1, n):
if (ary[minIdx] > ary[i]):
minIdx = i
ary[cy], ary[minIdx] = ary[minIdx], ary[cy]
return ary
```
##### 메인
```python
print('정렬 전-->', dataAry)
dataAry = selectionSort(dataAry)
print('정렬 후-->', dataAry)
```
정렬 전--> [119, 163, 187, 133, 195, 152, 142, 168, 118, 177]
정렬 후--> [118, 119, 133, 142, 152, 163, 168, 177, 187, 195]
---
## 2) 검색
* 검색은 정렬된 상태에서 빠르게 원하는 것을 찾을 수 있음.
### 검색의 개념
* 어떤 집합에서 원하는 것을 찾는 것으로, 탐색이라고도 함
* 검색에는 순차 검색, 이진 검색, 트리 검색 등이 있음
* 검색에 실패하면 -1을 반환하는 것이 일반적임
### 검색 알고리즘의 종류
* 순차 검색
* 검색할 집합이 정렬되어 있지 않은 상태일 때
* 처음부터 차례대로 찾아보는 것으로, 쉽지만 비효율적
* 집합의 데이터가 정렬되어 있지 않다면 이 검색 외에 특별한 방법 없음
* 이진 검색
* 데이터가 정렬되어 있다면 이진 검색도 사용 가능
* 순차 검색에 비해 월등히 효율적이라 데이터가 몇 천만개 이상이어도 빠르게 찾음
* 트리 검색
* 데이터 검색에는 상당히 효율적이지만 트리의 삽입, 삭제 등에는 부담
#### 순차 검색
##### 전역
```python
import random
SIZE = 10
dataAry = [random.randint(1,99) for _ in range(10)]
findData = dataAry[random.randint(0, SIZE-1)]
```
##### 함수
```python
def seqSearch(ary, fData):
pos = -1
size = len(ary)
for i in range(0, size, 1):
if (ary[i] == fData):
pos = i
break
return pos
```
##### 메인
```python
print('배열-->', dataAry)
position = seqSearch(dataAry, findData)
if position == -1:
print(findData, '없어요 ㅠ')
else:
print(findData, '가', position, ' 에 있음')
```
배열--> [7, 45, 32, 60, 31, 81, 82, 97, 74, 80]
31 가 4 에 있음
#### 이진 검색
##### 전역
```python
import random
SIZE = 10
dataAry = [random.randint(1,99) for _ in range(SIZE)]
findData = dataAry[random.randint(0, SIZE-1)]
dataAry.sort()
```
##### 함수
```python
def binSearch(ary, fData):
pos = -1
start = 0
end = len(ary) - 1
while (start <= end):
mid = (start + end) // 2
if fData == ary[mid]:
return mid
elif fData > ary[mid]:
start = mid + 1
else:
end = mid - 1
return pos
```
##### 메인
```python
print('배열-->', dataAry)
position = binSearch(dataAry, findData)
if position == -1:
print(findData, '없어요 ㅠ')
else:
print(findData, '가', position, ' 에 있음')
```
배열--> [9, 14, 18, 24, 30, 54, 56, 58, 60, 94]
24 가 3 에 있음
---
## 3) 재귀
### 재귀 알고리즘이란?
* 양쪽에 거울이 있을 때 거울에 비친 자신이 무한 반복해서 비치는 것 또는 마트료시카 인형처럼 동일한 작동을 무한적으로 반복하는 알고리즘을 말함
### 재귀 호출의 개념
* 재귀 호출(Recursion)은 자신을 다시 호출하는 것
### 재귀 호출의 작동
* 상자를 반복해서 여는 과정을 재귀 호출 형태로 표현
1.무한 반복
#### 전역
```python
def openBox():
print('박스를 엽니다~~~')
openBox()
```
#### 함수
```python
```
#### 메인
```python
openBox() # 무한 루프
```
2. 횟수를 정해놓고 작동
#### 전역
```python
count = 10 # 10번만 작동하게 변수 작성
```
#### 함수
```python
def openBox():
global count
print('종이 상자 열기~~~')
count -= 1
if count == 0:
print('** 반지 넣기 **')
return
openBox()
print('종이 상자 닫기!')
return
```
#### 메인
```python
openBox()
```
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
종이 상자 열기~~~
** 반지 넣기 **
종이 상자 닫기!
종이 상자 닫기!
종이 상자 닫기!
종이 상자 닫기!
종이 상자 닫기!
종이 상자 닫기!
종이 상자 닫기!
종이 상자 닫기!
종이 상자 닫기!
### 재귀 호출 작동방식의 이해
#### 숫자 합계 내기(1부터 10까지 합계를 구하는 예)
##### 전역
```python
```
##### 함수
```python
def addNumber(num):
if num <= 1:
return 1
return num + addNumber(num-1)
```
##### 메인
```python
addNumber(10)
```
55
---
#### 팩토리얼 구하기(10부터 1까지 곱하는 예)
##### 전역
```python
```
##### 함수
```python
def factorial(num):
if num <= 1:
return 1
return num * factorial(num-1)
```
##### 메인
```python
factorial(10)
```
3628800
---
### 재귀 호출의 연습
#### 우주선 발사 카운트 다운
##### 전역
```python
```
##### 함수
```python
def countDown(n):
if n == 0:
print('start!')
else:
print(n)
countDown(n-1)
```
##### 메인
```python
countDown(10)
```
10
9
8
7
6
5
4
3
2
1
start!
---
#### 별 모양 출력하기
* 입력한 숫자만큼 차례대로 별 모양을 출력하는 코드
##### 전역
```python
```
##### 함수
```python
def printStar(num):
if num > 0:
printStar(num-1)
print('★' * num)
```
##### 메인
```python
printStar(3)
```
★
★★
★★★
---
#### 구구단 출력하기
* 2단부터 9단까지 구구단을 출력하는 코드
##### 전역
```python
```
##### 함수
```python
def ggd(num1, num2):
print(f'{num1} * {num2} = {num1*num2}')
if num2 < 9:
ggd(num1, num2+1)
```
##### 메인
```python
for i in range(2, 10):
ggd(i, 1)
```
2 * 1 = 2
2 * 2 = 4
2 * 3 = 6
2 * 4 = 8
2 * 5 = 10
2 * 6 = 12
2 * 7 = 14
2 * 8 = 16
2 * 9 = 18
3 * 1 = 3
3 * 2 = 6
3 * 3 = 9
3 * 4 = 12
3 * 5 = 15
3 * 6 = 18
3 * 7 = 21
3 * 8 = 24
3 * 9 = 27
4 * 1 = 4
4 * 2 = 8
4 * 3 = 12
4 * 4 = 16
4 * 5 = 20
4 * 6 = 24
4 * 7 = 28
4 * 8 = 32
4 * 9 = 36
5 * 1 = 5
5 * 2 = 10
5 * 3 = 15
5 * 4 = 20
5 * 5 = 25
5 * 6 = 30
5 * 7 = 35
5 * 8 = 40
5 * 9 = 45
6 * 1 = 6
6 * 2 = 12
6 * 3 = 18
6 * 4 = 24
6 * 5 = 30
6 * 6 = 36
6 * 7 = 42
6 * 8 = 48
6 * 9 = 54
7 * 1 = 7
7 * 2 = 14
7 * 3 = 21
7 * 4 = 28
7 * 5 = 35
7 * 6 = 42
7 * 7 = 49
7 * 8 = 56
7 * 9 = 63
8 * 1 = 8
8 * 2 = 16
8 * 3 = 24
8 * 4 = 32
8 * 5 = 40
8 * 6 = 48
8 * 7 = 56
8 * 8 = 64
8 * 9 = 72
9 * 1 = 9
9 * 2 = 18
9 * 3 = 27
9 * 4 = 36
9 * 5 = 45
9 * 6 = 54
9 * 7 = 63
9 * 8 = 72
9 * 9 = 81
---
#### N제곱 계산하기
##### 전역
```python
tab = ''
```
##### 함수
```python
def pow(x, n):
global tab
tab += ' '
if n == 0:
return 1
print(f'{tab}{x}*{x}^{n}-{1}')
return x * pow(x, n-1)
```
##### 메인
```python
pow(3,3)
```
3*3^3-1
3*3^2-1
3*3^1-1
27
---
#### 배열의 합 계산하기
* 랜덤하게 생성한 배열의 합계를 구하는 코드
##### 전역
```python
import random
ary = [random.randint(0, 225) for _ in range(10)]
```
##### 함수
```python
def arySum(ary, n):
if n <= 0:
return ary[0]
return arySum(ary, n-1) + ary[n]
```
##### 메인
```python
print(ary)
print('합계 ->', arySum(ary, len(ary)-1))
```
[20, 185, 8, 166, 205, 68, 83, 123, 192, 220]
합계 -> 1270
| 13.869038 | 96 | 0.510434 | kor_Hang | 0.999939 |
586eb458dd0e66b300282bfe357e5e29a33722ed | 26,881 | md | Markdown | business-central/readiness/readiness-learning-functional-consultants.md | MicrosoftDocs/dynamics365smb-docs-pr.es-es | 5ed72f3c5f65f0b0287b214eb20430a86d85d169 | [
"CC-BY-4.0",
"MIT"
] | 4 | 2017-08-28T10:41:43.000Z | 2021-12-09T14:44:50.000Z | business-central/readiness/readiness-learning-functional-consultants.md | MicrosoftDocs/dynamics365smb-docs-pr.es-es | 5ed72f3c5f65f0b0287b214eb20430a86d85d169 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | business-central/readiness/readiness-learning-functional-consultants.md | MicrosoftDocs/dynamics365smb-docs-pr.es-es | 5ed72f3c5f65f0b0287b214eb20430a86d85d169 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-10-12T19:49:50.000Z | 2019-10-12T19:49:50.000Z | ---
title: Catálogo de aprendizaje para consultores funcionales
description: Encuentra todo el aprendizaje disponible para Business Central.
author: loreleishannonmsft
ms.date: 04/01/2021
ms.topic: conceptual
ms.author: margoc
ms.openlocfilehash: c7e235f878287a061dfaff25d7a9f2e2e8f40c16
ms.sourcegitcommit: 766e2840fd16efb901d211d7fa64d96766ac99d9
ms.translationtype: HT
ms.contentlocale: es-ES
ms.lasthandoff: 03/31/2021
ms.locfileid: "5781893"
---
# <a name="functional-consultant-learning-catalog"></a>Catálogo de aprendizaje para consultores funcionales
¿Es experto en implementación para un dominio empresarial?
El siguiente catálogo está organizado desde el conocimiento básico hasta dominios específicos y desde el más básico hasta el más avanzado. Si el contenido está en varios formatos, se lo haremos saber, para que pueda elegir el formato de formación que mejor se adapte a sus necesidades.
## <a name="getting-started"></a>Introducción<a name="get-started"></a>
| Contenido | Descripción | Formato | Longitud |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------|--------------------|
| [Explorar las capacidades de Dynamics 365 Business Central](https://dynamics.microsoft.com/business-central/capabilities/) | Visión general de kas capacidades de Dynamics 365 Business Central | Sitio web | |
| [Lista de reproducción de Business Central](https://www.youtube.com/playlist?list=PLcakwueIHoT-wVFPKUtmxlqcG1kJ0oqq4) | Lista de reproducción de Business Central | Lista de reproducción de vídeos de YouTube | |
| [Introducción a Microsoft Dynamics 365 Business Central](/learn/paths/get-started-dynamics-365-business-central/) | ¿Le interesa en Business Central? Si es así, esta ruta de aprendizaje proporciona una buena introducción. Analiza cómo configurar una versión de prueba, proporciona información básica sobre lo que está disponible y muestra algunas opciones de personalización que puede realizar para personalizar Business Central para su uso. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 4 minutos |
| [Trabajar con la interfaz de usuario de Microsoft Dynamics 365 Business Central](/learn/paths/work-with-user-interface-dynamics-365-business-central/) | ¿Desea obtener información sobre la interfaz de usuario de Business Central? Esta ruta de aprendizaje le muestra la interfaz de usuario y también cómo puede personalizarla. También se analizan interfaces alternativas, como un smartphone. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 2 horas 27 minutos |
| [Trabajar como un profesional con los datos de Business Central](/learn/paths/work-pro-data-dynamics-365-business-central) | ¿Acaba de empezar a usar Business Central? Esta ruta de aprendizaje lo ayudará a prepararse para los tipos de datos en Business Central y cómo encontrar la información que necesita en la aplicación. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 2 horas 27 minutos |
## <a name="deploy"></a>Implementar<a name="deploy"></a>
| Contenido | Descripción | Formato | Longitud |
|------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------|--------------------|
| [Implementar y configurar Microsoft Dynamics 365 Business Central](/learn/paths/deploy-configure-dynamics-365-business-central/) | ¿Es nuevo en Business Central? Si es así, esta ruta lo ayudará a comenzar. Explica cómo crear nuevas empresas, implementar seguridad, migrar datos de otros sistemas e integrar Outlook con Business Central. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 4 horas 42 minutos |
| [Configurar Microsoft Dynamics 365 Business Central para generar informes](/learn/paths/setup-reporting-dynamics-365-business-central/) | ¿Desea utilizar Business Central con otras aplicaciones o hacer que los datos estén disponibles en la nube? Complete esta ruta de aprendizaje. También incluye un módulo sobre cómo cambiar el aspecto de los documentos en Business Central. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 2 horas 50 minutos |
## <a name="financials"></a>Financials<a name="financials"></a>
| Contenido | Descripción | Formato | Longitud |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------|--------------------|
| [Configuración de la administración financiera en Microsoft Dynamics 365 Business Central](/learn/paths/set-up-financial-management-dynamics-365-business-central/) | ¿Desea utilizar Business Central para la administración financiera? Esta ruta de aprendizaje es para usted. Explica la configuración de series de números, códigos de seguimiento de auditoría, grupos contables, dimensiones y plan de cuentas. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 13 minutos |
| [Usar la contabilidad de costes en Microsoft Dynamics 365 Business Central](/learn/paths/use-cost-accounting-dynamics-365-business-central/) | ¿Necesita utilizar la contabilidad de costes en su empresa? Esta ruta de aprendizaje puede ayudarlo a comenzar con la contabilidad de costes en Business Central. Explica la configuración de la contabilidad de costes, cómo crear datos maestros para la contabilidad de costes, cómo transferir transacciones y asignar costes a un grupo de cuentas. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 16 minutos |
| [Usar diarios en Microsoft Dynamics 365 Business Central](/learn/paths/use-journals-dynamics-365-business-central/) | ¿Necesita crear y publicar entradas de diario en Business Central? Esta ruta es para usted. La configuración de plantillas de diario general, la creación de transacciones de diario, incluidas las transacciones periódicas, y la contabilización de transacciones se analizan en los módulos de esta ruta de aprendizaje. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 2 horas 1 minuto |
| [Conciliar bancos en Microsoft Dynamics 365 Business Central](/learn/paths/reconcile-bank-accounts-dynamics-365-business-central/) | ¿Desea saber cómo conciliar bancos en Business Central? La función de conciliación de banco y los diarios de conciliación se analizan en esta ruta de aprendizaje. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 1 hora 3 minutos |
| [Usar varias divisas en Microsoft Dynamics 365 Business Central](/learn/paths/use-multiple-currencies-dynamics-365-business-central/) | ¿Trabaja con varias divisas? Si lo hace, esta ruta lo ayudará a comprender los pasos que debe completar para configurar y usar múltiples divisas, procesar pagos y facturas en diferentes divisas, y ajustar los tipos de cambio cuando sea necesario. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 4 minutos |
| [Crear informes financieros en Microsoft Dynamics 365 Business Central](/learn/paths/create-financial-reports-dynamics-365-business-central/) | ¿Es responsable de generar informes financieros desde Business Central? Esta ruta de aprendizaje analiza la creación de presupuestos y el uso de esquemas de cuentas, dimensiones y lenguaje ampliado para informes comerciales (XBRL) para generar los informes financieros que generalmente se necesitan para la mayoría de las empresas. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 44 minutos |
| [Procesar actividades periódicas financieras en Microsoft Dynamics 365 Business Central](/learn/paths/process-financial-periodic-activities-dynamics-365-business-central/) | ¿Es responsable de los procesos de cierre de período y fin de año? Complete este módulo, que explica cómo enviar recordatorios y documentos de interés a los clientes. También analiza el procesamiento y la generación de informes de Intrastat y el cierre de un ejercicio. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 3 minutos |
| [Finanzas de Dynamics 365 Business Central avanzadas para consultores](https://mbspartner.microsoft.com/D365/WorkshopOffers/239) | (Solo para socios) Este curso proporciona conocimientos e información sobre el área de aplicación de administración financiera en Microsoft Dynamics 365 Business Central. La atención se centra en las funciones financieras básicas y más avanzadas dentro de la organización, como el plan de cuentas, la administración de efectivo, el procesamiento de facturas, el OCR, la previsión de flujo de efectivo, la contabilidad de costes, los informes financieros y el proceso de cierre de fin de año. | Formación presencial o en línea impartida por un instructor, el coste varía según la región y el socio |
## <a name="trade"></a>Comercio<a name="trade"></a>
| Contenido | Descripción | Formato | Longitud |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------|--------------------|
| [Introducción a Comercio en Microsoft Dynamics 365 Business Central](/learn/paths/trade-get-started-dynamics-365-business-central/) | ¿Usa Comercio en Business Central? Esta ruta de aprendizaje analiza los requisitos de configuración y cómo comenzar a utilizar Comercio en Business Central. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 1 hora 55 minutos |
| [Procesar el IVA en Microsoft Dynamics 365 Business Central](/learn/paths/process-vat-dynamics-365-business-central/) | ¿Necesita configurar y calcular el IVA para su empresa? Realice esta ruta de aprendizaje que contiene información sobre cómo configurar el IVA, procesar el IVA, calcular y registrar liquidaciones y realizar un cambio en el tipo de IVA. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 2 horas 26 minutos |
| [Registrar facturas de compra y venta en Microsoft Dynamics 365 Business Central](/learn/paths/post-sales-purchase-invoices-dynamics-365-business-central/) | ¿Necesita procesar y registrar facturas de ventas a clientes? ¿Necesita introducir facturas de compra de proveedor? Esta ruta de aprendizaje aborda ambos casos y también analiza cómo procesar los prepagos a clientes y proveedores. También exoplica el uso de documentos electrónicos en su empresa con Business Central. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 44 minutos |
| [Procesar pagos de clientes y proveedores en Microsoft Dynamics 365 Business Central](/learn/paths/process-customer-vendor-payments-dynamics-365-business-central/) | ¿Recibe pagos de clientes y paga a proveedores? Este módulo le ayudará a realizar el seguimiento tanto en la administración de efectivo como en el procesamiento de esas transacciones, según sea necesario, en Business Central. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 2 horas 36 minutos |
| [Comprar productos y servicios en Microsoft Dynamics 365 Business Central](/learn/paths/purchase-items-services-dynamics-365-business-central/) | ¿Necesita crear documentos de compra como pedidos de compra y facturas de compra? Esta ruta de aprendizaje le muestra cómo crear documentos de compra y abordar aspectos como descuentos y cargos de producto. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 3 horas 4 minutos |
| [Vender productos y servicios en Microsoft Dynamics 365 Business Central](/learn/paths/sell-items-services-dynamics-365-business-central/) | Si vende productos o servicios a clientes, esta ruta de aprendizaje puede ayudarlo a aprender cómo usar Business Central para administrar el proceso de venta. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 4 horas 41 minutos |
| [Devolver productos en Microsoft Dynamics 365 Business Central](/learn/paths/return-items-dynamics-365-business-central/) | ¿Necesita devolver productos a los proveedores y aceptar devoluciones de los clientes? Esta ruta lo ayudará a aprender cómo procesar las devoluciones. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 1 hora 25 minutos |
| [Reponer productos en Microsoft Dynamics 365 Business Central](/learn/paths/replenish-items-dynamics-365-business-central/) | ¿Necesita reponer productos de inventario en su empresa? Esta ruta de aprendizaje le mostrará las opciones que puede usar para reponer productos de manera eficiente en Business Central. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 1 hora 46 minutos |
| [Ensamblar productos en Microsoft Dynamics 365 Business Central](/learn/paths/assemble-items-dynamics-365-business-central/) | ¿Vende productos ensamblados? Esta ruta de aprendizaje proporciona la información que necesita para la administración de ensamblados y productos. También proporciona los pasos para producir productos ensamblados para almacenarlos u ordenarlos. | Ruta de aprendizaje en línea gratuito y a su propio ritmo | 2 horas 26 minutos |
| [Comercio de Dynamics 365 Business Central avanzado para consultores](https://mbspartner.microsoft.com/D365/WorkshopOffers/238) | (Solo para socios) Este curso proporciona conocimientos e información sobre el área de aplicación de administración comercial y de inventario en Microsoft Dynamics 365 Business Central. La atención se centra en las funciones y configuraciones más importantes relacionadas con el comercio, como la venta y compra de productos y servicios, el control de inventario, la administración de precios y descuentos de productos, y la gestión de solicitudes. También incluye importantes funciones de inventario, como el seguimiento de producto, la administración de ensamblados y las transferencias de almacén. | Formación presencial o en línea impartida por un instructor, el coste varía según la región y el socio | |
## <a name="cloud"></a>Nube<a name="cloud"></a>
| Contenido | Descripción | Formato | Longitud |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------|--------------------|
| [El futuro está en la nube de confianza](https://www.microsoft.com/trust-center) | Acerca de la nube de confianza | Sitio web | |
| [Recursos de protección de datos](https://servicetrust.microsoft.com/ViewPage/TrustDocuments?command=Download&downloadType=Document&downloadId=5fa41da9-69b2-47ea-8413-4a91345b299b&docTab=6d000410-c9e9-11e7-9a91-892aae8839ad_FAQ_and_White_Papers) | Información sobre cómo los servicios en la nube de Microsoft protegen sus datos y cómo puede administrar la seguridad y la conformidad de los datos en la nube para su organización. | Descarga de las notas del producto | |
[!INCLUDE[footer-include](../includes/footer-banner.md)] | 368.232877 | 937 | 0.412633 | spa_Latn | 0.968446 |
586eb496194954c2f716f3ea03bcfb955e0dd634 | 1,481 | md | Markdown | docs/framework/network-programming/peer-names-and-pnrp-ids.md | OpportunityLiu/docs.zh-cn | eac29360831c86e94fd24e3d2948bde016c0463c | [
"CC-BY-4.0",
"MIT"
] | 1 | 2018-12-17T12:05:02.000Z | 2018-12-17T12:05:02.000Z | docs/framework/network-programming/peer-names-and-pnrp-ids.md | OpportunityLiu/docs.zh-cn | eac29360831c86e94fd24e3d2948bde016c0463c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/network-programming/peer-names-and-pnrp-ids.md | OpportunityLiu/docs.zh-cn | eac29360831c86e94fd24e3d2948bde016c0463c | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-03-11T08:16:26.000Z | 2019-03-11T08:16:26.000Z | ---
title: 对等名称和 PNRP ID
ms.date: 03/30/2017
ms.assetid: afa538e8-948f-4a98-aa9f-305134004115
ms.openlocfilehash: d842c66de7550c94f4e287449a238ff964093fb2
ms.sourcegitcommit: c93fd5139f9efcf6db514e3474301738a6d1d649
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/27/2018
ms.locfileid: "50187643"
---
# <a name="peer-names-and-pnrp-ids"></a>对等名称和 PNRP ID
对等名称代表通信的终结点,可以是计算机、用户、组、服务或者任何与对等有关的、可以解析为 IPv6 地址的事物。 对等名称解析协议 (PNRP) 将统计学上唯一的对等名称用于创建标识云成员的 PNRP ID。
## <a name="peer-names"></a>对等名称
对等名称可以注册成不安全的或安全的。 不安全名称是文本字符串,存在遭受欺骗的风险,因为任何人都可注册重复的不安全名称。 不安全名称最适用于专用或受保护的网络。 安全名称受到证书和数字签名的保护。 只有原发布者才能证实自己拥有安全名称。
云和范围的组合为参与 PNRP 活动的对等方提供了相当安全的环境。 但使用安全对等名称并不能确保网络应用程序的整体安全性。 应用程序的安全性是视具体实现而定的。
安全对等名称仅由其所有者注册,并使用公钥加密进行保护。 安全对等名称被视为属于拥有相应私钥的对等实体。 可以通过使用私钥签名的认证对等地址 (CPA) 验证所有权。 恶意用户没有相应的私钥,无法伪造对等名称的所有权。
## <a name="pnrp-ids"></a>PNRP ID

PNRP ID 由以下内容组成:
- 高序位 128 位,也就是对等 (P2P) ID,是分配至终结点的对等名称的哈希代码。 对等名称采用以下格式:Authority.Classifier。 对于安全名称,Authority 是对等名称公钥的安全哈希算法 1 (SHA1) 的哈希代码,是十六进制字符。 对于不安全名称,Authority 为单字符“0”。 是标识应用程序的字符串。 对等名称 Classifier 最多长 149 个字符,包括 `null` 终止符在内。
- 低序位 128 位用于服务定位,它是标识同一云中同一 P2P ID 的不同实例的生成数字。
P2P ID 和服务定位的这种组合实现从一台计算机注册多个 PNRP ID。
## <a name="see-also"></a>请参阅
<xref:System.Net.PeerToPeer.PeerName>
<xref:System.Net.PeerToPeer>
| 41.138889 | 224 | 0.767049 | yue_Hant | 0.863889 |
586ed13b7accae0109c6811adceff5a229a00997 | 1,328 | md | Markdown | website/versioned_docs/version-0.2.0/rpc/rpc-clients-intro.md | scala-steward/bitcoin-s | 7527388be5f3e6b95dc0c136b56ae670141f71f8 | [
"MIT"
] | 175 | 2016-03-20T11:15:51.000Z | 2022-03-29T17:35:14.000Z | website/versioned_docs/version-0.2.0/rpc/rpc-clients-intro.md | scala-steward/bitcoin-s | 7527388be5f3e6b95dc0c136b56ae670141f71f8 | [
"MIT"
] | 1,744 | 2019-05-27T10:00:36.000Z | 2022-03-31T14:33:53.000Z | website/versioned_docs/version-0.2.0/rpc/rpc-clients-intro.md | scala-steward/bitcoin-s | 7527388be5f3e6b95dc0c136b56ae670141f71f8 | [
"MIT"
] | 55 | 2016-04-28T00:29:54.000Z | 2022-03-21T05:57:55.000Z | ---
id: version-0.2.0-rpc-clients-intro
title: Introduction
original_id: rpc-clients-intro
---
When working with Bitcoin applications, a common task to
accomplish is connecting to a service like Bitcoin Core,
and use that for tasks like generating addresses,
verifying payments and
monitoring the blockchain. This typically happens through
tools like `bitcoin-cli`, or the Bitcoin Core HTTP RPC
server interface. One big drawback to this, is that you
lose all type-safety in your application. Even if you
have a custom type that represents a Bitcoin transaction,
how do you get that to play nicely with the result that
Bitcoin Core gives you after signing a transaction? A
random hexadecimal string in a HTTP response could be
anything from a public key, a transaction or a block
header.
We've done all the mundane work of wiring requests and
responses from Bitcoin Core to the powerful and safe types
found in Bitcoin-S. We've also written a bunch of tests,
that verify that all of this actually work.
You'll know for sure that you're sending
a valid public key to `importmulti`, and you when doing
RPC calls like `getblockheader` we'll even parse the
hexadecimal string into a complete header that you can
interact with without goofing around with bits and bytes.
We currently have RPC clients for Bitcoin Core and Eclair.
| 40.242424 | 58 | 0.800452 | eng_Latn | 0.999427 |
586f57f1a889db3eaac2648cca7388a721495086 | 3,320 | md | Markdown | ce/customerengagement/on-premises/admin/remove-user-personal-data.md | Gen1a/dynamics-365-customer-engagement | ce3c02bfa54594f016166522e552982fb66a9389 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ce/customerengagement/on-premises/admin/remove-user-personal-data.md | Gen1a/dynamics-365-customer-engagement | ce3c02bfa54594f016166522e552982fb66a9389 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ce/customerengagement/on-premises/admin/remove-user-personal-data.md | Gen1a/dynamics-365-customer-engagement | ce3c02bfa54594f016166522e552982fb66a9389 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: "Remove user personal data from Dynamics 365 Customer Engagement (on-premises)"
description: "Once a user record is deleted from the Active Directory, system admins can follow these steps to remove the user's personal data from all instances."
ms.custom:
ms.date: 10/01/2019
ms.reviewer:
ms.suite:
ms.tgt_pltfrm:
ms.topic: article
applies_to:
- Dynamics 365 for Customer Engagement (online)
- Dynamics 365 for Customer Engagement Version 9.x
ms.assetid: b7faefff-25e2-44a5-8dd9-49bf1a1677c6
caps.latest.revision: 19
author: jimholtz
ms.author: jimholtz
search.audienceType:
- admin
---
# Remove user personal data
::: moniker range="op-9-1"
[!INCLUDE [cc-use-advanced-settings](../includes/cc-use-advanced-settings.md)]
::: moniker-end
After a user is deleted by the global admin from the Microsoft 365 admin center, the user's personal data can be removed from all tenant instances. A user is deleted from the Microsoft 365 admin center when:
1. The user leaves the company. In this scenario, the user record remains in the tenant’s Active Directory for 30 days before the record is deleted.
-Or-
2. The user requests their personal data be deleted. The user record is deleted immediately.
Once the user record is deleted from Active Directory, Dynamics 365 Customer Engagement (on-premises) system admins can remove the user's personal data from all instances.
## Remove user personal data via User form
When the user record is deleted from Active Directory, the following message is displayed on the User form:
"This user’s information is no longer managed by Office 365. You can update this record to comply with the GDPR by removing or replacing all personal data."
To remove personal data:
1. Click **Settings** > **Security** > **Users**.
2. Select **Disabled Users** view.
3. Select a user.
5. Remove personal data, and then click **Save**.
## Remove user personal data via Excel Import/Export
1. Click **Settings** > **Security** > **Users**.
2. Select **Disabled Users** view.
3. Create an Excel template with all the user personal data columns that you want to update.
4. Click on **Download File**.
5. Open the downloaded Excel file, make your updates, and then save the file.
6. Return to the **Disabled Users** view window and click **Import Data**.
7. Choose your updated Excel in the Upload data file dialog box.
8. Make all the necessary changes on the **Map Fields** window.
9. Click **Next** and **Submit**.
## Remove user personal data using Web services
You can also update the data for a disabled user using the Web API or Organization service. The user information is stored in the [SystemUser](/powerapps/developer/common-data-service/reference/entities/systemuser) entity, and you can update data in any of the [writeable attributes](/powerapps/developer/common-data-service/reference/entities/systemuser#writable-attributes) in the SystemUser entity. For examples about updating data in a record, see:
- [Update and delete entities using the Web API](/powerapps/developer/data-platform/webapi/update-delete-entities-using-web-api)
- [Use the Entity class for create, update and delete](/powerapps/developer/data-platform/org-service/entity-operations-update-delete)
### See also
[!INCLUDE[footer-include](../../../includes/footer-banner.md)]
| 44.864865 | 453 | 0.762952 | eng_Latn | 0.98235 |
5870f9f2df2a0d60241dde5200a3fdb5daad8aaf | 40,381 | md | Markdown | portal-sdk/generated/top-ap-cli.md | hutchcodes/portaldocs | 6cc7cec2b3404ce2bdd5b8d87ac043c2c0d88741 | [
"CC-BY-3.0",
"MIT-0",
"CC-BY-4.0",
"MIT"
] | null | null | null | portal-sdk/generated/top-ap-cli.md | hutchcodes/portaldocs | 6cc7cec2b3404ce2bdd5b8d87ac043c2c0d88741 | [
"CC-BY-3.0",
"MIT-0",
"CC-BY-4.0",
"MIT"
] | null | null | null | portal-sdk/generated/top-ap-cli.md | hutchcodes/portaldocs | 6cc7cec2b3404ce2bdd5b8d87ac043c2c0d88741 | [
"CC-BY-3.0",
"MIT-0",
"CC-BY-4.0",
"MIT"
] | null | null | null | <a name="cli-overview"></a>
# CLI Overview
The Azure portal extension developer CLI, namely `ap`, is the foundational tool used for all inner dev/test loop actions during extension development.
This document details the usage and extensibility points of the ap CLI. The following video covers the majority of the content within this document - [ap cli video https://aka.ms/portalfx/apcli](https://aka.ms/portalfx/apcli).
<a name="cli-overview-setup-and-installation"></a>
## Setup and Installation
<a name="cli-overview-setup-and-installation-one-time-configuration-steps"></a>
### One time configuration steps
The following steps detail the one time configuration that must be applied to authenticate against the internal AzurePortal registry for both NuGet and npm. If you prefer follow along see the step by step: [Video:One time configuration steps](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=657)
- Install the LTS of nodejs [download](https://nodejs.org/en/download)
- Install the .NET 4.7.2 *Developer Pack* - [located here](https://dotnet.microsoft.com/download/dotnet-framework/thank-you/net472-developer-pack-offline-installer)
- NuGet Credential provider
1. Connect to the AzurePortal Feed https://msazure.visualstudio.com/One/_packaging?_a=connect&feed=AzurePortal
1. Select NuGet.exe under the NuGet header
1. Click the 'Get the tools' button in the top right corner
1. Follow steps 1 and 2 to download the latest NuGet version and the credential provider.
- NPM Auth Personal Access Token (PAT)
Just as NuGet needed the credentidal provider npm requires a PAT for auth. Which can be configured as follows.
1. Connect to the AzurePortal Feed https://msazure.visualstudio.com/One/_packaging?_a=connect&feed=AzurePortal
1. Select npm under the npm header
1. Click the 'Get the tools' button in the top right corner
1. Optional. Follow steps 1 to install node.js and npm if not already done so.
1. Follow step 2 to install vsts-npm-auth node.
1. Add a .npmrc file to your project or empty directory with the following content
```
registry=https://msazure.pkgs.visualstudio.com/_packaging/AzurePortal/npm/registry/
always-auth=true
```
1. From the command prompt in the same directory:
- set the default npm registry
```
npm config set registry https://msazure.pkgs.visualstudio.com/_packaging/AzurePortal/npm/registry/
```
- generate a readonly PAT using vsts-npm-auth
```
vsts-npm-auth -R -config .npmrc
```
Generally the PAT will be written to %USERPROFILE%\.npmrc we strongly recommend not checking your PAT into source control; anyone with access to your PAT can interact with Azure DevOps Services as you.
- Path
Ensure the following are on your path i.e resolve when typed in and run from the command prompt.
1. `NuGet` and the above installed credential provider is on your path.
1. Ensure `npm` is on your path.
1. Ensure `msbuild` is on your path.
If not present you can add the items to your path as follows:
1. WindowsKey + R
1. `rundll32.exe sysdm.cpl,EditEnvironmentVariables`
1. In the dialog click `Edit` on the `Path` variable and add (note paths may vary depending on your environment and msbuiuld version)
- for npm `C:\Users\youralias\AppData\Roaming\npm`
- for nuget and cred provider `C:\Users\youralias\.nuget`
- for msbuild `C:\Program Files (x86)\Microsoft Visual Studio\2017\BuildTools\MSBuild\15.0\Bin`
If you have run into problems checkout the [Video:One time configuration steps](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=657)
<a name="cli-overview-setup-and-installation-installing-the-azure-portal-extension-developer-cli"></a>
### Installing the Azure portal extension developer CLI
With the one time configuration steps complete you can now install the CLI as you would with any other node module.
1. Run the following command in the directory that contains your .npmrc.
```
npm install -g @microsoft/azureportalcli
```
[Video: Installing the node module](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=1324)
<a name="cli-overview-basic-workflows"></a>
## Basic workflows
<a name="cli-overview-basic-workflows-restore-build-serve-sideload-and-watch"></a>
### restore, build, serve, sideload and watch
1. Run command prompt as Admin
1. run following commands
```
ap new -n Microsoft_Azure_FirstExtension -o ./FirstExtension
cd ./FirstExtension/src/default/extension
ap start
```
See `ap start` demo in the [Video: A single command for restoring dependencies, building, serving with local hosting service, sideloading and compile on save](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=1627)
<a name="cli-overview-basic-workflows-run-tests"></a>
### run tests
1. Run command prompt as Admin
1. run following commands
```
cd ./FirstExtension/src/default/extension.unittest
ap run test
```
See `ap run test` demo in the [Video: running tests](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=1807)
<a name="cli-overview-basic-workflows-lint-your-extension"></a>
### lint your extension
```
cd ./FirstExtension/src/default/extension
ap lint
```
<a name="cli-overview-basic-workflows-updating-your-portal-framework-version"></a>
### updating your Portal Framework version
1. Run the command prompt as Admin
1. Update the cli to the target version of Portal Framework e.g `npm install -g @microsoft/[email protected]`
1. From the root of your enlistment run `ap update` and see changes with `git status`
```
ap update
git status
```
See `ap update` demo in the [Video: Updating the CLI, extension SDK version and revoked SDKs](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2214).
<a name="cli-overview-command-reference"></a>
## Command Reference
Command | Alias | Description
--- | --- | ---
build | | Runs msbuild.exe on the *.sln or *proj with/p:RunBundlerInDevMode=true. If no *.sln or *proj is found and tsconfig.json exists then runs tsc.cmd. If arguments are supplied they are passed through to underlying executable.
lint | | Runs eslint against an extension including azure portal custom lint rules.
new | | Creates a new extension.
release | | Runs msbuild.exe on the *.sln or *proj with /p:RunBundlerInDevMode=false;Configuration=Release. If no *.sln or *proj is found and tsconfig.json exists then runs tsc.cmd. If arguments are supplied they are passed through to underlying executable.
restore | | Installs node modules and restores NuGet packages for all package.json, *.sln and *.csproj recursively from the current working directory.
run | | Straight passthrough to npm run i.e 'ap run mycommand' will execute 'npm run mycommand'
serve | | A command to run the local hosting service. Optional arguments are passed through to the local hosting service.
start | | A command to restore, build, run the local hosting service and start the watch process to enable compile on save.
update | | Updates Azure Portal SDK NuGets and node modules to same version as the CLI.
watch | | enables compile on save by running tsc.cmd in watch mode on the current working directory.
help | | Lists available commands and their short descriptions.
Options:
Option | Description
--- | --- | ---
--version | Show version number of ap cli
--help | Shows help. Can be used on ap directly i.e `ap --help` or on its commands e.g `ap start --help`
<a name="cli-overview-command-reference-ap-build"></a>
### ap build
```
ap build <arguments> [options]
```
Runs msbuild.exe on the *.sln or *proj with /p:RunBundlerInDevMode=true. If no
*.sln or *proj is found and tsconfig.json exists then runs tsc.cmd. The resulting output is the build output in the format required by local hosting service. For deployable zip see release command. Arguments are optional, if supplied they are passed through to underlying executable for the resolved build type. The build alias for msbuild and tsc can be overriden using apCliConfig.json.
<a name="cli-overview-command-reference-ap-build-arguments"></a>
#### Arguments
Argument | Description
--- | ---
* | All arguments supplied are passed through to the resolved build executable, generally msbuild or tsc.
--help | Show help for build command
<a name="cli-overview-command-reference-ap-build-example-usage"></a>
#### Example Usage
Most common usage is to perform build allowing `ap` to resolve the *.sln, *proj or tsconfig.json that requires build.
```
ap build
```
Perform build supplying your own arguments that are passthrough to msbuild.
```
ap build /m /t:Rebuild /flp1:logfile=msbuild.log /flp2:logfile=msbuild.err;errorsonly /flp3:logfile=msbuild.wrn;warningsonly /p:RunBundlerInDevMode=true
```
Perform build supplying your own arguments to tsc.cmd.
```
ap build -p tsconfig.json --traceResolution
```
Emit help for the build command.
```
ap build --help
```
<a name="cli-overview-command-reference-ap-build-supplying-defaults-using-apcliconfig-json"></a>
#### Supplying defaults using apCliConfig.json
When the build command runs it will search for apCliConfig.json from the current working directory up to the root of the drive. The build command can be customized by supplying any of the following optional top level properties. This may be useful if you have a predefined wrapper alias used within your build environment.
Property | Description
--- | ---
msbuildAlias | optional. alias or path to alias to be used in place of msbuild.exe.
msbuildDefaultArgs | optional. arguments to be supplied to msbuild based projects when running `ap build`
tscAlias | optional. alias or path to alias to be used in place of tsc.cmd.
Example apCliConfig.json configuration:
```json
{
"msbuildAlias": "myspecialmsbuildalais",
"msbuildDefaultArgs": "/m /t:Rebuild /p:RunBundlerInDevMode=true;Configuration=MyCustomConfig",
"tscAlias": "./alias/not/on/path/tsc.cmd",
}
```
<a name="cli-overview-command-reference-ap-lint"></a>
### ap lint
```
ap lint <arguments>
```
This command lints the current directory using eslint / typescript-eslint. The CLI ships both core and recommended rule configuration for common public lint rules as well as custom lint rules authored by portal team for extension developers. To understand exactly how the portal team is planning to use this as a means to improve your developer experience it's recommended that you watch the linting [Video: Linting - custom portal lint rules, automated breaking change resolution and lint integration to VS Code](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2578)
If an .eslintrc* and/or .eslintignore files is present in the current working directory its configuration will take precedence over the configuration shipped within the CLI.
If authoring custom rules for your own team use apCliConfig.json to supply a collection of paths and ap CLI will supply them to the eslint --rulesdir argument.
<a name="cli-overview-command-reference-ap-lint-arguments-1"></a>
#### Arguments
Argument | Description
--- | ---
--fix | Optional. Automatically fix problems by running the automated fix implementation that ship with each lint rule.
--resolve-plugins-relative-to | Optional. A folder where plugins should be resolved from.
--help | Show help for the command.
<a name="cli-overview-command-reference-ap-lint-example-usage-1"></a>
#### Example Usage
Most common usage, integration directly with VS Code for realtime feedback on lint violations as you develop, see subsequent section for configuring the eslint plugin for VS Code.
Run lint from command prompt
```
ap lint
```
Run lint with automated fix
```
ap lint --fix
```
Emit help for the command.
```
ap lint --help
```
<a name="cli-overview-command-reference-linting-directly-within-vs-code"></a>
### Linting directly within VS Code
A plugin can be installed and configured directly within VS Code to allow you to see and fix lint violations directly within the IDE as you develop. If you ware not using VS Code and want integration in your IDE you can checkout the following [recommended plugins by IDE](https://eslint.org/docs/user-guide/integrations)
1. Install the [eslint plugin for VS Code](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint)
1. The eslint plugin requires an .eslintrc (.js,.json,.yaml) file to be present. You can take the latest from node_modules\@microsoft\azureportalcli\lint\\.eslintrc.json
```json
{
"plugins": [
"@microsoft/eslint-plugin-azureportal"
],
"extends": [
"plugin:@microsoft/eslint-plugin-azureportal/lib/core"
],
"rules": {}
}
```
1. Enable eslint in VS Code for typescript - open json settings using `CTL + Shift + P` select `(Preferences): Open Settings (JSON)` and add:
```json
"eslint.validate": [
{
"language": "typescript",
"autoFix": false
},
],
```
1. Install dev dependencies required by the eslint plugin for vscode `npm install [email protected] @microsoft/eslint-plugin-azureportal --no-optional --save-dev` (note version of typescript may have been updated since authoring.)
The eslint plugin should now be running the core set of azure portal rules directly within VS Code. If you suspect there are issues you can see the eslint plugin output in the Output window by changing the dropdown to Eslint. i.e Ctl + Shift + U to get the output window then select ESLint in the dropdown. Review the ouput to see if there are any configuration errors.
<a name="cli-overview-command-reference-customizing-lint-rules"></a>
### Customizing Lint Rules
The CLI linting component is built as an eslint pluging and is therefore highly extensible and configurable. For the most part many teams will what is provided out of the box should be sufficient, for those teams that wish to customize read on.
The CLI ships two sets of rules, namely `core` and `recommended`. `core` is the minimal set of rules that at the time of writing included only deprecated and azure portal custom rules. The `recommended` set contains all core rules and a recommended configuration common public rules from typescript-eslint.
You can change your project to use the recommended set by updating your .eslintrc* file to extend recommended rather then core i.e
```json
{
"plugins": [
"@microsoft/eslint-plugin-azureportal"
],
"extends": [
"plugin:@microsoft/eslint-plugin-azureportal/lib/recommended"
],
"rules": {}
}
```
To customize rule levels off/warn/error additional rules you have full control of of all content within your own .eslintrc* this follows the eslintrc schema and is documented at [configuring rules](https://eslint.org/docs/user-guide/configuring#configuring-rules). The rule set you may be most interested in customizing for your specific team are documented [here - typescript-eslint rules](https://github.com/typescript-eslint/typescript-eslint/tree/master/packages/eslint-plugin#supported-rules). We view the recommended set of rules as being extension developer community driven with the oversight of the azure portal team, if you believe rule configurations should be different/added in the recommeneded set please reach out to us to discuss.
Before turning a rule off globally its worth considering just disabling the rule on the specific instance in the source file where it is flagged, at the same time it may be worth creating a work item to remediate the issue - this is particularly important for the custom azure portal rules i.e @microsoft/azureportal/* rules. To disble a rule for a specific occurence see the inline comment syntax documentation - [disabling rules with inline comments](https://eslint.org/docs/user-guide/configuring#disabling-rules-with-inline-comments).
If you have authored your own eslint plugin or custom ruleset please reach out to us as we would like to understand if it makese sense to role those rules into @microsoft/eslint-plugin-azureportal to enable all teams to use them. You can supply paths to your custom rulesets to the ap CLI using apCliConfig.json lintCustomRules property. Each rule in the collection will be supplied to eslint as a --rulesdir. example config
```json
{
"lintCustomRules":["./tools/mycustomlintrules/stable", "./tools/mycustomlintrules/futures"],
}
```
To learn more about linting and its configuration see [Video: Linting - custom portal lint rules, automated breaking change resolution and lint integration to VS Code](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2578).
<a name="cli-overview-command-reference-ap-new"></a>
### ap new
```
ap new <arguments>
```
Creates/Scaffolds a new Portal Extension and corresponding test project with the supplied name to the target ouput folder. For a video walkthrough of scaffolding a new extension see [this video](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=1495).
<a name="cli-overview-command-reference-ap-new-arguments-2"></a>
#### Arguments
Argument | alias | Description
--- | --- | ---
--name | -n | Required. The name used in portal registration of the extension e.g Microsoft_Azure_SomeExtension.
--output | -o | Required. The output directory to place the new project.
--declarative | -d | Optional. Scaffolds declarative extension. This feature is in preview mode.
--help | | Optional. Show help for new command.
<a name="cli-overview-command-reference-ap-new-example-usage-2"></a>
#### Example Usage
Two examples scaffolding a new extension to the ./dev/newextension folder. The first using shorthand, the second longhand.
```
ap new -n CompanyName_ProductName_ServiceName -o ./dev/someextension
ap new --name Microsoft_Azure_Storage --output ./dev/storage
ap new --name Microsoft_Azure_MyExtension --output ./dev/myextension --declarative
ap new -n Microsoft_Azure_MyExtension -o ./dev/myextension -d
```
Emit help for the build command.
```
ap new --help
```
<a name="cli-overview-command-reference-ap-release"></a>
### ap release
```
ap release <arguments>
```
Runs msbuild.exe on the *.sln or *proj with /p:RunBundlerInDevMode=false;Configuration=Release. If no
*.sln or *proj is found and tsconfig.json exists then runs tsc.cmd. The result is the versioned zip, e.g 1.0.0.0.zip, output which can be deployed to hosting service. For build output in the format for required local hosting service see the build command. Arguments are optional, if supplied they are passed through to underlying executable for the resolved build type. The build alias for msbuild and tsc can be overriden using apCliConfig.json. For a video walkthrough of the release command [this video](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2132)
<a name="cli-overview-command-reference-ap-release-arguments-3"></a>
#### Arguments
Argument | Description
--- | ---
* | All arguments supplied are passed through to the resolved build executable, generally msbuild or tsc.
--help | Show help for build command
<a name="cli-overview-command-reference-ap-release-example-usage-3"></a>
#### Example Usage
Most common usage is to perform build allowing `ap` to resolve the *.sln, *proj or tsconfig.json that requires build.
```
ap release
```
Perform release build supplying your own arguments that are passthrough to msbuild.
```
ap release /m /t:Rebuild /flp1:logfile=msbuild.log /flp2:logfile=msbuild.err;errorsonly /flp3:logfile=msbuild.wrn;warningsonly /p:RunBundlerInDevMode=false;Configuration=Release
```
Perform release build supplying your own arguments to tsc.cmd.
```
ap release -p tsconfig.json --traceResolution
```
Emit help for the release command.
```
ap release --help
```
<a name="cli-overview-command-reference-ap-release-supplying-defaults-using-apcliconfig-json-1"></a>
#### Supplying defaults using apCliConfig.json
When the build command runs it will search for apCliConfig.json from the current working directory up to the root of the drive. The build command can be customized by supplying any of the following optional top level properties. This may be useful if you have a predefined wrapper alias used within your build environment.
Property | Description
--- | ---
msbuildAlias | optional. alias or path to alias to be used in place of msbuild.exe.
msbuildDefaultArgs | optional. arguments to be supplied to msbuild based projects when running `ap release`
tscAlias | optional. alias or path to alias to be used in place of tsc.cmd.
Example apCliConfig.json configuration:
```json
{
"msbuildAlias": "myspecialmsbuildalais",
"msbuildDefaultArgs": "/m /t:Rebuild /p:RunBundlerInDevMode=true;Configuration=MyCustomConfig",
"tscAlias": "./alias/not/on/path/tsc.cmd",
}
```
<a name="cli-overview-command-reference-ap-restore"></a>
### ap restore
```
ap restore <arguments>
```
Installs node modules and restores NuGet packages for all package.json, *.sln
and *.csproj recursively from the current working directory. Note that the following folders are ignored node_modules, obj, objd, objr, out, output, debug and release.
Where recusive discovery of NuGet packages and node modules that need restoration is slow, such as in large projects, arguments or apCliConfig.json can be used to provide the collection of *.sln,*.csproj,package.json for restore/install.
Requires `nuget` and `npm.cmd` available on the path. See first time setup steps at top of this document.
<a name="cli-overview-command-reference-ap-restore-arguments-4"></a>
#### Arguments
Argument | Alias | Description
--- | --- | ---
--nugetRestoreFiles | | optional. The *.sln, *.csproj or packages.config files to perform a NuGet restore upon. If more then one supplied separate using ';'. When supplied the command will not scan directories for files to restore.
--npmInstallPackageJsonFiles | | optional. The package.json files to perform a npm install upon. If more then one supplied separate using ';'. When supplied the command will not scan directories directories for package.json files to restore.
--restoreInParallel | | optional. Run npm install and NuGet restore in parallel.
--help | | Emits help and usage for the command
<a name="cli-overview-command-reference-ap-restore-example-usage-4"></a>
#### Example Usage
Most common usage, node modules and NuGet packages needing install/restore will be discovered. if specific set supplied in apCliConfig.json then they will be used in place of recursive search.
```
ap restore
```
Examples specifying which files to perform NuGet restore restore against. In this case only the specified list will be restored using NuGet however node modules will still be discovered.
```
ap restore --nugetRestoreFiles ./SomeDir/Some.sln
ap restore --nugetRestoreFiles ./SomeDir/Some.sln --restoreInParallel
ap restore --nugetRestoreFiles ./SomeDir/Some.csproj
ap restore --nugetRestoreFiles ./SomeDir/Some.sln;./OtherDir/Other.csproj;./AnotherDir/packages.config
```
Examples specifying which files to perform npm install against. In this case only the specified list will be installed using npm however NuGet packages requireing restore will still be discovered.
```
ap restore --npmInstallPackageJsonFiles ./SomeDir/package.json
ap restore --npmInstallPackageJsonFiles ./SomeDir/package.json;./OtherDir/package.json
```
Supplying explicit set of Nuget and node module for restore and install. Note if used frequently rather then simple discovery see next section on supplying this via config.
```
ap restore --nugetRestoreFiles ./SomeDir/Some.sln;./OtherDir/package.json --npmInstallPackageJsonFiles ./SomeDir/package.json;./OtherDir/package.json
```
Emits help and usage examples for the restore command
```
ap restore --help
```
<a name="cli-overview-command-reference-ap-restore-supplying-defaults-using-apcliconfig-json-2"></a>
#### Supplying defaults using apCliConfig.json
When the restore command runs it will search up from the current working directory up until it finds apCliConfig.json or the root of the drive. The restore command can be customized by supplying any of the following optional top level properties. If you have a large project and discovery is slow this is useful to supply an explicit list of node modules and NuGet packages to be used by default by `ap restore`.
Property | Description
--- | ---
nugetRestoreFiles | Optional. An explicity collection of files e.g ./foo.sln and ./bar.csproj to perform nuget restore against.
npmInstallPackageJsonFiles | Optional. An explicity collection of package.json *.sln and *.csproj to perform nuget restore against.
restoreInParallel | Optional. Run npm install and NuGet restore in parallel.
Example apCliConfig.json configuration:
```json
{
"nugetRestoreFiles": ["./src/proja/Some.sln", "./src/projb/Other.sln", "./other/proj.csproj"],
"npmInstallPackageJsonFiles": ["src/Default/Extension.UnitTest/package.json", "src/default/Extension.E2ETests/package.json"],
"restoreInParallel": true,
}
```
<a name="cli-overview-command-reference-ap-run"></a>
### ap run
```
ap run <arguments>
```
The `ap run` command provides straight passthrough to `npm run`. Typically used to run scripts defined in package.json.
<a name="cli-overview-command-reference-ap-run-arguments-5"></a>
#### Arguments
Argument | Description
--- | ---
* | Required. All arguments are passed through directly to npm run. See usage examples
--help | Emits help and usage for the command
<a name="cli-overview-command-reference-ap-run-example-usage-5"></a>
#### Example Usage
Running tests in watch mode
```
ap run test
```
Running tests in single run ci mode
```
ap run test-ci
```
Running an arbitrary script from package.json
```
ap run myscript --myscriptargument
```
<a name="cli-overview-command-reference-ap-serve"></a>
### ap serve
```
ap serve <arguments>
```
A command to run the local hosting service. Optional arguments are passthrough to the local hosting service.
<a name="cli-overview-command-reference-ap-serve-arguments-6"></a>
#### Arguments
Argument | Description
--- | ---
* | Optional. All arguments are passed through directly to local hosting service. See usage examples
--help | Emits help and usage for the command
<a name="cli-overview-command-reference-ap-serve-example-usage-6"></a>
#### Example usage
Most common usage, discovers first devServerConfig.json below current directory and runs local hosting service to side load your extension in portal.azure.com.
```
ap serve
```
Use specific ./devServerConfig.json and side load extension.
```
ap serve -c ./devServerConfig.json -s
```
Side load extension in mpac.
```
ap serve -s https://ms.portal.azure.com
```
Side load extension using specific config into rc.portal.azure.com.
```
ap serve -c ./devServerConfig.json -s https://rc.portal.azure.com
```
<a name="cli-overview-command-reference-ap-start"></a>
### ap start
```
ap start
```
Provides a simple single command to restore, build, serve the extension via local hosting service and start the watch
process to enable compile on save. This effectively enables compile on save based development with a full pipeline from save through local hosting service ingestion such taht you can see changes reflected within the browser as you undergo active development. The following video demonstrates this command - [Video: A single command for restoring dependencies, building, serving with local hosting service, sideloading and compile on save](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=1627).
Customization using apCliConfig.json as defined in the restore, build and watch commands will also apply to this command.
<a name="cli-overview-command-reference-ap-start-arguments-7"></a>
#### Arguments
Argument | Description
--- | ---
--help | Emits help and usage for the command
<a name="cli-overview-command-reference-ap-start-example-usage-7"></a>
#### Example Usage
Performs restore, build, serve and watch commands enabling compile on save and fast inner dev/test loop.
```
ap start
```
Emits help and usage examples for the watch command
```
ap start --help
```
<a name="cli-overview-command-reference-ap-update"></a>
### ap update
```
ap update
```
Updates Azure Portal SDK NuGets and node modules to same version as the CLI. By default the following files are recursively searched for and updated: packages.config,package.json,corext.config,*.proj,*.csproj,*.njsproj and devServerConfig.json. To provide your own set of files either supply a collection of file paths or supply a glob pattern via apCliConfig.json. This video details how to update both the ap CLI and your extension using this command - [Video: Updating the CLI, extension SDK version and revoked SDKs](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2214).
<a name="cli-overview-command-reference-ap-update-arguments-8"></a>
#### Arguments
Argument | Alias | Description
--- | --- | ---
--config | -c | Optional. Path to apCliConfig.json.
--help | Emits help and usage for the command
<a name="cli-overview-command-reference-ap-update-example-usage-8"></a>
#### Example Usage
Most common, recursively finds target files to update NuGet and node module references from portal sdk.
```
ap update
```
Supplying a config file argument where a glob is defined that specifies the set of file you wish to have updated by this command. Note, by default update also searches up from the current working directory for apCliConfig.json if no --config file is supplied.
```
ap update --config ../../some/other/path/apCliConfig.json
```
Emits help and usage examples for the update command.
```
ap update --help
```
<a name="cli-overview-command-reference-ap-update-supplying-defaults-using-apcliconfig-json-3"></a>
#### Supplying defaults using apCliConfig.json
When the update command runs you can optionally specify a collection of file paths or custom glob pattern for files to be updated using apCliConfig.json
using either of the following optional top level properties. If you have a large project and discovery is slow this is useful to supply an explicit list of files will speed up this command.
Property | Description
--- | ---
updateCmdFiles | optional. A collection of file paths.
updateCmdFilesGlob | optional. A glob pattern. If updateCmdFiles is defined it will take precedence and this setting will be ignored.
Example apCliConfig.json configuration providing a custom list of files:
```json
{
"updateCmdFiles": ["./src/Default/Extension.UnitTest/package.json", "./src/Default/Extension/packages.config", "./src/Default/Extension/Extension.csproj"],
}
Example apCliConfig.json configuration providing a custom glob pattern
```json
{
"updateCmdFilesGlob": "**/{packages.config,package.json,corext.config,*.proj,*.csproj,*.njsproj,devServerConfig.json}",
}
```
### ap watch
```
ap watch
```
This command enables compile on save by running tsc.cmd in watch mode on the current working
directory. When used in conjunction with serve command provides end to end compile on save and ingestion of udpated files into local hosting service for faster inner dev test loop. For build environments where you may have your own alias abstracting tsc you can supply your own tscAlias within apCliConfig.json as defined in the build
Requires tsconfig.json to be present within the directory that this command is run within.
#### Arguments
Argument | Description
--- | ---
--help | Emits help and usage for the command
#### Example Usage
Most common usage, performs tsc watch using tsconfig.json from current working directory. Used predominantly for compile on save based development.
```
ap watch
```
Emits help and usage examples for the watch command
```
ap watch --help
```
#### Supplying defaults using apCliConfig.json
When the watch command runs it will search for apCliConfig.json from the current working directory up to the root of the drive. The watch command can be customized by supplying any of the following optional top level properties. This may be useful if you have a predefined wrapper alias used within your build environment.
Property | Description
--- | ---
tscAlias | optional. alias or path to alias to be used in place of tsc.cmd.
Example apCliConfig.json configuration:
```json
{
"tscAlias": "./my/tsc.cmd",
}
```
<a name="cli-overview-extending-the-cli-with-your-teams-own-commands"></a>
## Extending the cli with your teams own commands
The Azure portal extension developer CLI is extensible and allows you to add your own custom commands that may be specific to tasks that your team commonly performs. Note if you have commands that you think are applicable to all teams reach out to us to discuss collaborating to contribute these back to the CLI so all teams can benefit. this content is also covered in this [Video: Extending and Overriding commands in the CLI](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2578)
To extend the CLI with your own custom commands requires two things a custom command(s) module(s) extending portalYargsCommand and config in apCliConfig.json defining where the CLI can load your commands from. Step by step instructions follow:
1. create a directory in your repo for your extensions e.g src/tools/cliextensions
1. cd src/tools/cliextensions
1. run command `npm init`
1. run command `npm install yargs @microsoft/azureportalcli --no-optional --save`
1. add file src/tools/cliextensions/cmds/foobar.ts with the following content
```typescript
//src/tools/cliextensions/cmds/foobar.ts
import { Argv } from "yargs";
import { PortalYargsCommand } from "@microsoft/azureportalcli/lib/core/portalYargsCommand";
class Foobar extends PortalYargsCommand {
public readonly command = "foobar";
public readonly description = "my teams foobar command";
public builder(yargs: Argv): Argv<any> {
return yargs.options({
name: {
alias: "n",
description: "<name> argument",
requiresArg: true,
required: true,
},
}).example(`ap ${this.command} -n somename`, "");
}
public async runCommand(args: { [argName: string]: string; }): Promise<void> {
console.log(`custom implementation of ${this.command} called with argument ${args.n || args.name}`);
}
}
export = Foobar;
```
1. Build the foobar.ts file `..\node_modules\.bin\tsc.cmd foobar.ts --lib ES2015,dom`.
1. update your apCliConfig.json, typically located in /src/apCliConfig.json, to specify the path to the build output, i.e *.js, for your custom comands. Note the output path you use will vary depedending on your build or if you are distributing using a node module.
example with relative build output
```json
{
"customCommandRootPaths": ["./tools/cliextensions/cmds"],
}
```
example if distributed as a node module
```json
{
"customCommandRootPaths": ["./node_modules/@microsoft/azureportalcil-myteam-extensions/tools/cliextensions/cmds"],
}
```
1. run `ap --help` and observe that your foobar command now shows up
<a name="cli-overview-overriding-the-behavior-of-existing-commands"></a>
## Overriding the behavior of existing commands
There are two ways to override and existing command within the cli. This can be useful to teams that have very specific requirements that the configurability of the existing command aguments and apCliConfig.json do not allow you to control. note if you think your scenario should be supported reach out to us to discuss adding support.
To override an existing either of the following approaches can be used:
1. define the command within the scripts object of the package.json in the current working directory. e.g to override restore deinfe `"restore": "echo my restore"`. when you run `ap restore` it will now outut my estore rather then using the CLIs implementation. For more involved cases that cant be expressed in package.json see the following approach.
1. In the section above foobar.ts was added to extend the cli. This approach can also be used to override and existing command. Simply ensure the filename, class name and command property all express the same name of the command you wish to override.
<a name="cli-overview-telemetry"></a>
## Telemetry
Telemetry is collected to help improve ap and the extension developer experience. Writing remote telemetry can be disabled by setting `disableRemoteTelemetry` to true in apCliConfig.json AND apCliConfig.json exists in the current directory that ap is run within or any parent directory between where ap is run and the root of the drive drive. i.e it will find-up from the process.cwd().
<a name="cli-overview-contributions-and-feedback"></a>
## Contributions and feedback
The ap CLI is built by the Azure portal team for the extension developer community. We welcome your contributions to the CLI and lint infrastructure where those contributions are applicable to all teams. Please reach out to us to discuss ideas. More details in
[Video: Contributions and Feedback](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=4374)
<a name="cli-overview-faq"></a>
## FAQ
- Do I have to read this document, don't you have a video?
Yes, see the [ap cli video https://aka.ms/portalfx/apcli](https://aka.ms/portalfx/apcli).
- How do I update the CLI?
`npm install -g @microsoft/[email protected]` Note update the version to the target version of cli/sdk you desire. For commentary on updating the cli, your extension and revoked SDKs see [Video: Updating the CLI, extension SDK version and revoked SDKs](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2214).
- Can I use the CLI with VS Code?
Yes, you can use it directly within VS Code either via the deep integration VS Code provides with package.json scripts e.g "start": "ap start". See this video for details [VS Code integration](https://msit.microsoftstream.com/video/d1f15784-da81-4354-933d-51e517d38cc1?st=2513). For deeper integration [see VS Code tasks](https://code.visualstudio.com/docs/editor/tasks) if you create a deeper integration here we would be interested in hearing from you. Note you may also used the integrated terminal.
- Where can I request features?
Request here [https://aka.ms/portalfx/clifeature](https://aka.ms/portalfx/clifeature) or work with us to contribute the feature back to the portal extension dev community.
- Where can I log bugs?
Log here [https://aka.ms/portalfx/clibug](https://aka.ms/portalfx/clibug) or contribute a fix back.
- Where can I ask general questions?
[Ask questions here](https://stackoverflow.microsoft.com/questions/ask?tags=ibiza,ibiza-cli&title=apcli:)
- What are the IDE specific installs required for Visual Studio Code?
The first time [Setup and Installation](./top-ap-cli.md#setup-and-installation) covers everything required. Visual Studio Code can be installed from [here](https://code.visualstudio.com/download)
- What are the IDE specific installs required for Visual Studio?
Insall Visual Studio 2019 Professional or Enterpise from [https://visualstudio.microsoft.com/downloads/](https://visualstudio.microsoft.com/downloads/).
* Select the following workloads from the *workloads* tab:
* Node.js development
* ASP.NET and web development

* Select .NET Framework 4.7.2 SDK and targeting pack from the *Individual components* tab:

To validate that your dev machine is ready for Azure Portal Extension development start with the template extension in the [Getting Started Guide](top-extensions-getting-started.md) | 48.476591 | 746 | 0.753671 | eng_Latn | 0.983677 |
58720d99b5cf2c3c3cba5b77a636423b518f9bc8 | 3,129 | md | Markdown | docs/ru/overview.md | andruha/yii2-swiper | 6fb20bc18037cdaeab6f5ee91e810d479034a349 | [
"MIT"
] | null | null | null | docs/ru/overview.md | andruha/yii2-swiper | 6fb20bc18037cdaeab6f5ee91e810d479034a349 | [
"MIT"
] | null | null | null | docs/ru/overview.md | andruha/yii2-swiper | 6fb20bc18037cdaeab6f5ee91e810d479034a349 | [
"MIT"
] | 2 | 2020-05-08T19:18:57.000Z | 2021-07-09T16:16:43.000Z | # Обзор виджета
Данный виджет использует версию Swiper v3.0.4+, дает возможность работы с [параллаксом](behaviours-parallax.md),
[lazy-loading](usage-lazy-loading.md)'ом изображений и другими возможностями оригинального слайдера.
## Концепция поведений
Виджет для рендеринга управляющих элементов использует концепцию **поведений**.
Поведение | Где настраивается | Описание
------------- | ---------------------------- | -------------------------------------------------------------------------------
`pagination` | `Swiper::$paginationOptions` | Отвечает за отображение [пагинации](behaviours-pagination.md)
`scrollbar` | `Swiper::$scrollbarOptions` | Отвечает за отображение [скроллбара](behaviours-scrollbar.md)
`prevButton` | `Swiper::$prevButtonOptions` | Отвечает за отображение кнопки "[предыдущий](behaviours-navigation-buttons.md)"
`nextButton` | `Swiper::$nextButtonOptions` | Отвечает за отображение кнопки "[следующий](behaviours-navigation-buttons.md)"
`parallax` | `Swiper::$parallaxOptions` | **Частично** отвечает за отображение [параллакса](behaviours-parallax.md)
`rtl` | - | Отвечает за отображение контента [справа налево](behaviours-rtl.md)
Таким образом, чтобы отобразить у слайдера одно из поведений, нужно:
* Обявить его в `Swiper::$behaviours`
* [Опционально] Настроить его
## Настройка слайдов
[Слайды](usage-slides.md) добавляются в виджет непосредственно через `Swiper::$items`.
В качестве слайдов можно передавать как просто строки, так и массивы.
Также можно передавать экземпляры класса `\lantongxue\yii2\swiper\Slide`,
но при этом виджет [не будет его настраивать](usage-slides.md#%D0%9D%D0%B0%D1%81%D1%82%D1%80%D0%BE%D0%B9%D0%BA%D0%B0-%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BE%D0%B2-lantongxueyii2swiperslide).
> **Важно**! Не используйте класс `\lantongxue\yii2\swiper\Slide` в качестве слайда,
если вы не уверены, что знаете, зачем это делаете.
Помимо этого, можно производить [групповую настройку](options-slide-batch.md) слайдов.
Небольшой пример:
```PHP
<?php
use \lantongxue\yii2\swiper\Swiper;
use \lantongxue\yii2\swiper\Slide;
echo Swiper::widget( [
'items' => [
'Slide 1',
[
'content' => 'Slide 2'
],
new Slide([
'content' => 'Slide 3'
])
]
] );
```
## Алиасы
Виджет предоставляет несколько [готовых алиасов](options-aliases.md) для работы наиболее важными частями слайдов
и самого виджета.
При их задании они транслируются в их прямые аналоги и наоборот - при задании прямых аналогов, они транслируются в алиасы.
Пример работы с алиасами:
```PHP
<?php
use \lantongxue\yii2\swiper\Slide;
$slide = new Slide([
'background' => 'http://placehold.it/800x600',
'hash' => 'slide01'
]);
echo $slide->background; // http://placehold.it/800x600
echo $slide->hash; // slide01
echo $slide->options['style']; // background-image:url(http://placehold.it/800x600)
echo $slide->options['data']['hash']; // slide01
```
| 39.1125 | 193 | 0.658038 | rus_Cyrl | 0.787793 |
5872be2ce85eadebd7d3e8fadb93303f0f09aa71 | 2,110 | md | Markdown | desktop-src/extensible-storage-engine/jet-recpos-structure.md | apdutta/win32 | cd566c4167ac1df865a2b39d1ff2c4dd87052517 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | desktop-src/extensible-storage-engine/jet-recpos-structure.md | apdutta/win32 | cd566c4167ac1df865a2b39d1ff2c4dd87052517 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | desktop-src/extensible-storage-engine/jet-recpos-structure.md | apdutta/win32 | cd566c4167ac1df865a2b39d1ff2c4dd87052517 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
description: "Learn more about: JET_RECPOS Structure"
title: JET_RECPOS Structure
TOCTitle: JET_RECPOS Structure
ms:assetid: 7c335120-4b84-4095-8f13-e5315d4996b1
ms:mtpsurl: https://msdn.microsoft.com/library/Gg269308(v=EXCHG.10)
ms:contentKeyID: 32765598
ms.date: 04/11/2016
ms.topic: reference
api_name:
topic_type:
- apiref
- kbArticle
api_type:
- COM
api_location:
ROBOTS: INDEX,FOLLOW
---
# JET_RECPOS Structure
_**Applies to:** Windows | Windows Server_
## JET_RECPOS Structure
The **JET_RECPOS** structure contains a collection of integers that represent a fractional position within an index. **centriesLT** is the number of index entries less than the current index key. **centriesInRange** is the number of index entries equal to the current key. **centriesInRange** is not supported and is always returned as 1. **centriesTotal** is the number of index entries in the index. All values are approximations with no guarantee of accuracy.
```cpp
typedef struct {
unsigned long cbStruct;
unsigned long centriesLT;
unsigned long centriesInRange;
unsigned long centriesTotal;
} JET_RECPOS;
```
### Members
**cbStruct**
The size of the [JET_RETINFO](./jet-retinfo-structure.md) structure, in bytes. This value confirms the presence of the following fields.
**centriesLT**
The approximate number of index entries less than the current key.
**centriesInRange**
The approximate number of index entries equal to the current key. This field is always set to 1, regardless of the number of index entries that are actually equal to the current key.
**centriesTotal**
The approximate number of entries in the index.
### Requirements
|
|
| <p><strong>Client</strong></p> | <p>Requires Windows Vista, Windows XP, or Windows 2000 Professional.</p> |
| <p><strong>Server</strong></p> | <p>Requires Windows Server 2008, Windows Server 2003, or Windows 2000 Server.</p> |
| <p><strong>Header</strong></p> | <p>Declared in Esent.h.</p> |
### See Also
[JET_RETINFO](./jet-retinfo-structure.md)
[JetGetRecordPosition](./jetgetrecordposition-function.md)
| 29.305556 | 462 | 0.744076 | eng_Latn | 0.860878 |
5872c86ffbba30c62eecdb101ddb96e58f42d627 | 7,871 | md | Markdown | site/en/docs/apps/app_codelab_basics/index.md | mikhailpashkov/developer.chrome.com | b0b22d77b1fe0c17ad5b155f948c41649c99b657 | [
"Apache-2.0"
] | 5 | 2021-04-25T10:10:49.000Z | 2021-04-25T15:51:44.000Z | site/en/docs/apps/app_codelab_basics/index.md | mikhailpashkov/developer.chrome.com | b0b22d77b1fe0c17ad5b155f948c41649c99b657 | [
"Apache-2.0"
] | 4 | 2021-05-04T03:35:38.000Z | 2021-05-04T04:23:43.000Z | site/en/docs/apps/app_codelab_basics/index.md | mikhailpashkov/developer.chrome.com | b0b22d77b1fe0c17ad5b155f948c41649c99b657 | [
"Apache-2.0"
] | 1 | 2022-02-25T04:50:21.000Z | 2022-02-25T04:50:21.000Z | ---
layout: 'layouts/doc-post.njk'
title: "Step 1: Create and Run a Chrome App"
date: 2014-10-17
updated: 2014-10-20
description: How to create, install, run, and debug a basic Chrome App.
---
{% Aside 'caution' %}
**Important:** Chrome will be removing support for Chrome Apps on all platforms. Chrome browser and
the Chrome Web Store will continue to support extensions. [**Read the announcement**][1] and learn
more about [**migrating your app**][2].
{% endAside %}
In this step, you will learn:
- The basic building blocks of a Chrome App, including the manifest file and background scripts.
- How to install, run, and debug a Chrome App.
_Estimated time to complete this step: 10 minutes._
To preview what you will complete in this step, [jump down to the bottom of this page ↓][3].
## Get familiar with Chrome Apps {: #app-components }
A Chrome App contains these components:
- The **manifest** specifies the meta information of your app. The manifest tells Chrome about your
app, how to launch it, and any extra permissions that it requires.
- The **event page**, also called a **background script**, is responsible for managing the app life
cycle. The background script is where you register listeners for specific app events such as the
launching and closing of the app's window.
- All **code files** must be packaged in the Chrome App. This includes HTML, CSS, JS, and Native
Client modules.
- **Assets**, including app icons, should be packaged in the Chrome App as well.
### Create a manifest {: #manifest }
Open your favorite code/text editor and create the following file named **manifest.json**:
```json
{
"manifest_version": 2,
"name": "Codelab",
"version": "1",
"icons": {
"128": "icon_128.png"
},
"permissions": [],
"app": {
"background": {
"scripts": ["background.js"]
}
},
"minimum_chrome_version": "28"
}
```
Notice how this manifest describes a background script named _background.js_. You will create that
file next.
```json
"background": {
"scripts": ["background.js"]
}
```
We'll supply you with an app icon later in this step:
```json
"icons": {
"128": "icon_128.png"
},
```
### Create a background script {: #background-script }
Create the following file and save it as **_background.js_**:
```js
/**
* Listens for the app launching then creates the window
*
* @see /apps/app.window.html
*/
chrome.app.runtime.onLaunched.addListener(function() {
chrome.app.window.create('index.html', {
id: 'main',
bounds: { width: 620, height: 500 }
});
});
```
This background script simply waits for the [chrome.app.runtime.onLaunched][4] launch event for the
application and executes the callback function:
```js
chrome.app.runtime.onLaunched.addListener(function() {
//...
});
```
When the Chrome App is launched, [chrome.app.window.create()][5] will create a new window using a
basic HTML page (_index.html_) as the source. You will create the HTML view in the next step.
```js
chrome.app.window.create('index.html', {
id: 'main',
bounds: { width: 620, height: 500 }
});
```
Background scripts may contain additional listeners, windows, post messages, and launch data—all
of which are used by the event page to manage the app.
### Create an HTML view {: #html-view }
Create a simple web page to display a "Hello World" message to the screen and save it as
**_index.html_**:
```html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<h1>Hello, let's code!</h1>
</body>
</html>
```
Just like any other web page, within this HTML file you can include additional packaged JavaScript,
CSS, or assets.
### Add an app icon {: #app-icon }
Right-click and save this 128x128 image to your project folder as **_icon_128.png_**:
{% Img src="image/BrQidfK9jaQyIHwdw91aVpkPiib2/oWw4vtq0F2ZrXo3uKhwG.png",
alt="Chrome App icon for this codelab", height="128", width="128" %}
You will use this PNG as our application's icon that users will see in the launch menu.
### Confirm that you have created all your files {: #confirm-files }
You should have these 4 files in your project folder now:
{% Img src="image/BrQidfK9jaQyIHwdw91aVpkPiib2/gYAyOofu4qTqwZj0tZVL.png",
alt="File folder screenshot", height="110", width="590" %}
## Install a Chrome App in developer mode {: #developer-mode }
Use **developer mode** to quickly load and launch your app without having to finalize your app as a
distribution package.
1. Access **chrome://extensions** from the Chrome omnibox.
2. Check off the **Developer mode** check box.
{% Img src="image/BrQidfK9jaQyIHwdw91aVpkPiib2/KIzjun6cpH8zHXJ4hBdF.gif",
alt="Enable developer mode", height="188", width="735" %}
3. Click **Load unpacked extension**.
4. Using the file picker dialog, navigate to your app's project folder and select it to load your
app.
{% Img src="image/BrQidfK9jaQyIHwdw91aVpkPiib2/t1hNzCpoh1S1STdxzhMd.gif",
alt="Load unpacked extensions", height="289", width="634" %}
## Launch your finished Hello World app {: #launch }
After loading your project as an unpacked extension, click **Launch** next to your installed app. A
new standalone window should open up:
{% Img src="image/BrQidfK9jaQyIHwdw91aVpkPiib2/iibtdGOdf6gyQHUncpH0.png",
alt="The finished Hello World app after Step 1", height="283", width="334" %}
Congratulations, you've just created a new Chrome App!
## Debug a Chrome App with Chrome DevTools {: #devtools-debug }
You can use the [Chrome Developer Tools][6] to inspect, debug, audit, and test your app just like
you do on a regular web page.
After you make changes to your code and reload your app (**right-click > Reload App**), check the
DevTools console for any errors (**right-click > Inspect Element**).
{% Img src="image/BrQidfK9jaQyIHwdw91aVpkPiib2/8ZT2FbBlw1hD74sRWHJq.png",
alt="Inspect Element dialog box", height="283", width="334" %}
(We'll cover the **Inspect Background Page** option in [Step 3][7] with alarms.)
The DevTools JavaScript console has access to the same APIs available to your app. You can easily
test an API call before adding it to your code:
{% Img src="image/BrQidfK9jaQyIHwdw91aVpkPiib2/ip0mFYkSIYw3sObYAow3.png",
alt="DevTools console log", height="181", width="645" %}
## For more information {: #recap }
For more detailed information about some of the APIs introduced in this step, refer to:
- [Manifest File Format][8] [↑][9]
- [Manifest - Icons][10] [↑][11]
- [Chrome App Lifecycle][12] [↑][13]
- [chrome.app.runtime.onLaunched][14] [↑][15]
- [chrome.app.window.create()][16] [↑][17]
Ready to continue onto the next step? Go to [Step 2 - Import an existing web app »][18]
[1]: https://blog.chromium.org/2020/01/moving-forward-from-chrome-apps.html
[2]: /apps/migration
[3]: #launch
[4]: /docs/extensions/reference/app_runtime#event-onLaunched
[5]: /docs/extensions/reference/app_window#method-create
[6]: /devtools
[7]: ../app_codelab_alarms
[8]: /apps/manifest "Read 'Manifest File Format' in the Chrome developer docs"
[9]: #manifest "This feature mentioned in 'Create a manifest'"
[10]: /apps/manifest/icons "Read 'Manifest - Icons' in the Chrome developer docs"
[11]: #app-icon "This feature mentioned in 'Add an app icon'"
[12]: ../app_lifecycle "Read 'Manifest File Format' in the Chrome developer docs"
[13]: #background-script "This feature mentioned in 'Create a background script'"
[14]:
/docs/extensions/reference/app_runtime#event-onLaunched
"Read 'chrome.app.runtime.onLaunched' in the Chrome developer docs"
[15]: #background-script "This feature mentioned in 'Create a background script'"
[16]:
/docs/extensions/reference/app_window#method-create
"Read 'chrome.app.window.create()' in the Chrome developer docs"
[17]: #background-script "This feature mentioned in 'Create a background script'"
[18]: ../app_codelab_import_todomvc
| 33.636752 | 99 | 0.717317 | eng_Latn | 0.942211 |
5872c989ff53d35bce4076544f482b244021182b | 5,874 | md | Markdown | desktop-src/Direct2D/id2d1factory-createdxgisurfacerendertarget.md | hubalazs/win32 | 43ff56462a12db784d8befed6dbfc09ef73a314d | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-10-18T00:22:45.000Z | 2021-10-18T00:22:45.000Z | desktop-src/Direct2D/id2d1factory-createdxgisurfacerendertarget.md | hubalazs/win32 | 43ff56462a12db784d8befed6dbfc09ef73a314d | [
"CC-BY-4.0",
"MIT"
] | null | null | null | desktop-src/Direct2D/id2d1factory-createdxgisurfacerendertarget.md | hubalazs/win32 | 43ff56462a12db784d8befed6dbfc09ef73a314d | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: ID2D1Factory CreateDxgiSurfaceRenderTarget methods
description: Creates a render target that draws to a DirectX Graphics Infrastructure (DXGI) surface.
ms.assetid: 101744ea-97bc-4f92-88b0-fcdf0e4aaf4e
keywords:
- CreateDxgiSurfaceRenderTarget methods Direct2D
topic_type:
- apiref
api_location:
- D2d1.dll
api_type:
- DllExport
ms.date: 07/02/2019
ms.topic: article
---
# ID2D1Factory::CreateDxgiSurfaceRenderTarget methods
Creates a render target that draws to a DirectX Graphics Infrastructure (DXGI) surface.
### Overload list
| Method | Description |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------|
| [**CreateDxgiSurfaceRenderTarget(IDXGISurface\*,D2D1\_RENDER\_TARGET\_PROPERTIES&,ID2D1RenderTarget\*\*)**](https://msdn.microsoft.com/en-us/library/Dd371264(v=VS.85).aspx) | Creates a render target that draws to a DirectX Graphics Infrastructure (DXGI) surface. <br/> |
| [**CreateDxgiSurfaceRenderTarget(IDXGISurface\*,D2D1\_RENDER\_TARGET\_PROPERTIES\*,ID2D1RenderTarget\*\*)**](https://msdn.microsoft.com/en-us/library/Dd371260(v=VS.85).aspx) | Creates a render target that draws to a DirectX Graphics Infrastructure (DXGI) surface. <br/> |
## Remarks
To write to a Direct3D surface, you obtain an [IDXGISurface](https://msdn.microsoft.com/library/bb174565(VS.85).aspx) and pass it to the **CreateDxgiSurfaceRenderTarget** method to create a DXGI surface render target; you can then use the DXGI surface render target to draw 2-D content to the DXGI surface.
A DXGI surface render target is a type of [**ID2D1RenderTarget**](https://msdn.microsoft.com/en-us/library/Dd371260(v=VS.85).aspx). Like other Direct2D render targets, you can use it to create resources and issue drawing commands.
The DXGI surface render target and the DXGI surface must use the same DXGI format. If you specify the [DXGI\_FORMAT\_UNKOWN](https://msdn.microsoft.com/library/bb173059(VS.85).aspx) format when you create the render target, it will automatically use the surface's format.
The DXGI surface render target does not perform DXGI surface synchronization.
To work with Direct2D, the Direct3D device that provides the [IDXGISurface](https://msdn.microsoft.com/library/bb174565(VS.85).aspx) must be created with the **D3D10\_CREATE\_DEVICE\_BGRA\_SUPPORT** flag.
For more information about creating and using DXGI surface render targets, see the [Direct2D and Direct3D Interoperability Overview](direct2d-and-direct3d-interoperation-overview.md).
When you create a render target and hardware acceleration is available, you allocate resources on the computer's GPU. By creating a render target once and retaining it as long as possible, you gain performance benefits. Your application should create render targets once and hold onto them for the life of the application or until the render target's [**EndDraw**](https://msdn.microsoft.com/en-us/library/Dd371924(v=VS.85).aspx) method returns the [**D2DERR\_RECREATE\_TARGET**](direct2d-error-codes.md) error. When you receive this error, you need to recreate the render target (and any resources it created).
## Examples
The following example obtains a DXGI surface (*pBackBuffer*) from an [IDXGISwapChain](https://msdn.microsoft.com/library/bb174569(VS.85).aspx) and uses it to create a DXGI surface render target.
```C++
// Get a surface in the swap chain
hr = m_pSwapChain->GetBuffer(
0,
IID_PPV_ARGS(&pBackBuffer)
);
if (SUCCEEDED(hr))
{
```
<span codelanguage="ManagedCPlusPlus"></span>
<table>
<colgroup>
<col style="width: 100%" />
</colgroup>
<thead>
<tr class="header">
<th>C++</th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><pre><code> // Create the DXGI Surface Render Target.
FLOAT dpiX;
FLOAT dpiY;
m_pD2DFactory->GetDesktopDpi(&dpiX, &dpiY);
D2D1_RENDER_TARGET_PROPERTIES props =
D2D1::RenderTargetProperties(
D2D1_RENDER_TARGET_TYPE_DEFAULT,
D2D1::PixelFormat(DXGI_FORMAT_UNKNOWN, D2D1_ALPHA_MODE_PREMULTIPLIED),
dpiX,
dpiY
);
// Create a Direct2D render target which can draw into the surface in the swap chain</code></pre></td>
</tr>
</tbody>
</table>
<span codelanguage="ManagedCPlusPlus"></span>
<table>
<colgroup>
<col style="width: 100%" />
</colgroup>
<thead>
<tr class="header">
<th>C++</th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><pre><code> hr = m_pD2DFactory->CreateDxgiSurfaceRenderTarget(
pBackBuffer,
&props,
&m_pBackBufferRT
);
}</code></pre></td>
</tr>
</tbody>
</table>
## Requirements
| | |
|--------------------|-------------------------------------------------------------------------------------|
| Header<br/> | <dl> <dt>D2d1.h</dt> </dl> |
| Library<br/> | <dl> <dt>D2d1.lib</dt> </dl> |
| DLL<br/> | <dl> <dt>D2d1.dll</dt> </dl> |
## See also
<dl> <dt>
[**ID2D1Factory**](https://msdn.microsoft.com/en-us/library/Dd371246(v=VS.85).aspx)
</dt> <dt>
[Direct2D and Direct3D Interoperability Overview](direct2d-and-direct3d-interoperation-overview.md)
</dt> </dl>
�
�
| 38.142857 | 611 | 0.610827 | eng_Latn | 0.595233 |
5873f4ca4653c84ea71672c8cd3b3abebb6928cc | 1,845 | md | Markdown | README.md | adilio/BroomBot | ee671400068ba5d7e610801562641aead242e4e9 | [
"MIT"
] | 7 | 2020-07-27T17:21:28.000Z | 2022-01-05T10:35:58.000Z | README.md | adilio/BroomBot | ee671400068ba5d7e610801562641aead242e4e9 | [
"MIT"
] | 17 | 2020-07-29T18:39:53.000Z | 2022-03-11T17:06:26.000Z | README.md | adilio/BroomBot | ee671400068ba5d7e610801562641aead242e4e9 | [
"MIT"
] | 4 | 2021-05-19T21:55:01.000Z | 2022-01-05T10:57:14.000Z | <img src="img/broombot-text.png" alt="BroomBot Logo" width="20%"/>
# BroomBot
**BroomBot** is an Azure DevOps Pull Request Minder. Sweep up forgotten and forlorn Azure DevOps Pull Requests with **BroomBot**!
## About
GitHub has a rich ecosystem of bots and helper tools that (among other things) empower repo owners to automatically remind pull request creators to stay on top of their PRs, and clean up stale PRs when they are unattended too long. There are not as many great solutions for this same problem in Azure DevOps, and so **BroomBot** fills that gap.
**BroomBot** periodically checks your Azure DevOps repos for pull requests that haven't been updated in a while and reminds the person who opened it to attend to their PR. After a few reminders, **BroomBot** will abandon the stale PR.
### Features
**BroomBot** is very customizable. **BroomBot** can:
* Scan for stale pull requests as often as you want
* Give as many warnings as you want
* Mark stale pull requests as abandoned once enough warnings have been given
* You can completely customize every message **BroomBot** posts
* Including tagging the pull request creator in the message
* Including the name, avatar, description and overall appearance of the bot
* Customize the deployment of **BroomBot** in Azure

## Deploying BroomBot
**BroomBot** is quickly and conveniently deployable into any Azure DevOps organization. Check out [**BroomBot**'s deployment guide](deployment.md) for more information.
## Contributing to BroomBot
Thank you for being interested in contributing to **BroomBot**! **BroomBot** is maintained primarily by a single person with the occasional help of others, and so your contributions are hugely appreciated. Check out [**BroomBot**'s contribution guide](contributing.md) for more information.
| 55.909091 | 344 | 0.7729 | eng_Latn | 0.998512 |
587423d3d1c6c281c4f0bd3a1fb7ccead7a86de4 | 36 | md | Markdown | README.md | canmodule/infocms | d2aabdf360bdf463d979e504ec6d8da57d2b2d4f | [
"MIT"
] | null | null | null | README.md | canmodule/infocms | d2aabdf360bdf463d979e504ec6d8da57d2b2d4f | [
"MIT"
] | null | null | null | README.md | canmodule/infocms | d2aabdf360bdf463d979e504ec6d8da57d2b2d4f | [
"MIT"
] | null | null | null | # passport
The passport application
| 12 | 24 | 0.833333 | eng_Latn | 0.929923 |
58747594be4fd521ce69cc417267af6d72363892 | 1,050 | md | Markdown | billboardery/Library/PackageCache/[email protected]/Documentation~/CinemachineTopDown.md | dmarchand/billboardery | 03bb0bb5dd34e12b3af1edbef0103d2c38b1328b | [
"MIT"
] | 2 | 2022-02-16T16:03:41.000Z | 2022-02-22T14:03:15.000Z | billboardery/Library/PackageCache/[email protected]/Documentation~/CinemachineTopDown.md | dmarchand/billboardery | 03bb0bb5dd34e12b3af1edbef0103d2c38b1328b | [
"MIT"
] | null | null | null | billboardery/Library/PackageCache/[email protected]/Documentation~/CinemachineTopDown.md | dmarchand/billboardery | 03bb0bb5dd34e12b3af1edbef0103d2c38b1328b | [
"MIT"
] | null | null | null | # Top-down games
Cinemachine Virtual Cameras are modelled after human camera operators and how they operate real-life cameras. As such, they have a sensitivity to the up/down axis, and always try to avoid introducing roll into the camera framing. Because of this sensitivity, the Virtual Camera avoids looking straight up or down for extended periods. They may do it in passing, but if the __Look At__ target is straight up or down for extended periods, they will not always give the desired result.
**Tip:** You can deliberately roll by animating properties like __Dutch__ in a Virtual Camera.
If you are building a top-down game where the cameras look straight down, the best practice is to redefine the up direction, for the purposes of the camera. You do this by setting the __World Up Override__ in the [Cinemachine Brain](CinemachineBrainProperties.md) to a GameObject whose local up points in the direction that you want the Virtual Camera’s up to normally be. This is applied to all Virtual Cameras controlled by that Cinemachine Brain.
| 116.666667 | 482 | 0.80381 | eng_Latn | 0.999547 |
5874ddce8b284958b8dd014505145d8610c284e8 | 769 | md | Markdown | _posts/2021-02-22-bolsonaro-tira-a-mascara-e-diz-que-nao-gosta-da-democracia.md | tatudoquei/tatudoquei.github.io | a3a3c362424fda626d7d0ce2d9f4bead6580631c | [
"MIT"
] | null | null | null | _posts/2021-02-22-bolsonaro-tira-a-mascara-e-diz-que-nao-gosta-da-democracia.md | tatudoquei/tatudoquei.github.io | a3a3c362424fda626d7d0ce2d9f4bead6580631c | [
"MIT"
] | null | null | null | _posts/2021-02-22-bolsonaro-tira-a-mascara-e-diz-que-nao-gosta-da-democracia.md | tatudoquei/tatudoquei.github.io | a3a3c362424fda626d7d0ce2d9f4bead6580631c | [
"MIT"
] | 1 | 2022-01-13T07:57:24.000Z | 2022-01-13T07:57:24.000Z | ---
layout: post
item_id: 3263016143
title: >-
Bolsonaro tira a máscara e diz que não gosta da democracia
author: Tatu D'Oquei
date: 2021-02-22 01:36:37
pub_date: 2021-02-22 01:36:37
time_added: 2021-02-25 00:20:17
category:
tags: []
image: https://imagens.brasil.elpais.com/resizer/j-90231KEf7bhk6wc-0cjn2ZJxQ=/1000x0/cloudfront-eu-central-1.images.arcpublishing.com/prisa/3JUGMDWBDY5ZM7EQTTRAVBGIJ4.jpg
---
Ou as instituições democráticas colocam um freio no cavalo desembestado de sua loucura ou amanhã aparecerão como cúmplices
**Link:** [https://brasil.elpais.com/brasil/2021-02-22/bolsonaro-tira-a-mascara-e-diz-que-nao-gosta-da-democracia.html](https://brasil.elpais.com/brasil/2021-02-22/bolsonaro-tira-a-mascara-e-diz-que-nao-gosta-da-democracia.html)
| 40.473684 | 228 | 0.778934 | por_Latn | 0.83172 |
587537f04010db89604f7ac1c54d6bd1a3e7bc6c | 1,190 | md | Markdown | Language/Reference/User-Interface-Help/quick-watch-dialog-box.md | ryanmajidi/VBA-Docs | 8b07050f4ff38fcabda606284ec5f6f6634e9569 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | Language/Reference/User-Interface-Help/quick-watch-dialog-box.md | ryanmajidi/VBA-Docs | 8b07050f4ff38fcabda606284ec5f6f6634e9569 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | Language/Reference/User-Interface-Help/quick-watch-dialog-box.md | ryanmajidi/VBA-Docs | 8b07050f4ff38fcabda606284ec5f6f6634e9569 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Quick Watch dialog box
keywords: vbui6.chm2018959
f1_keywords:
- vbui6.chm2018959
ms.prod: office
ms.assetid: 38f09ead-498e-b609-4b9c-a1246185fc03
ms.date: 11/27/2018
---
# Quick Watch dialog box

Displays the current value of a selected expression. This functionality is useful when debugging your code if you want to see the current value of a variable, property, or other expression.
The following table describes the dialog box options.
|Option|Description|
|:-----|:----------|
|**Context**|Lists the names of the project, [module](../../Glossary/vbe-glossary.md#module), and procedure where the [watch expression](../../Glossary/vbe-glossary.md#watch-expression) resides.|
|**Expression**|Shows the selected expression.|
|**Value**|Shows the value of the selected expression. The current value isn't displayed if the expression context isn't within a procedure listed in the **[Calls](call-stack-dialog-box.md)** dialog box.|
|**Add**|Adds the expression to the [Watch window](watch-window.md).|
## See also
- [Use Quick Watch](../../how-to/use-quick-watch.md)
- [Dialog boxes](../dialog-boxes.md)
| 38.387097 | 204 | 0.731933 | eng_Latn | 0.915979 |
5875c737b9a11bbb154dbb22d92686f4255a416e | 184 | md | Markdown | README.md | gawainhewitt/imagined_landscapes | 88314e46f857af18be863a91242fd4fd89f2866c | [
"MIT"
] | null | null | null | README.md | gawainhewitt/imagined_landscapes | 88314e46f857af18be863a91242fd4fd89f2866c | [
"MIT"
] | null | null | null | README.md | gawainhewitt/imagined_landscapes | 88314e46f857af18be863a91242fd4fd89f2866c | [
"MIT"
] | null | null | null | # Imagined Landscapes
An interactive online sound installation made with City Of London Sinfonia and The Bethlem and Maudsley Hospital School as part of the Sound Young Minds project.
| 61.333333 | 161 | 0.831522 | eng_Latn | 0.99641 |
5875d8830fb04afa0b225bc37c201e177aa0af7f | 964 | md | Markdown | docs/concept/evolution-of-fish-redux.md | fzyzcjy/fish-redux | 40b853bfa0843e5bbe23e9217bae7598bb08bcf7 | [
"Apache-2.0"
] | 3 | 2021-03-08T14:56:17.000Z | 2021-03-08T14:56:32.000Z | docs/concept/evolution-of-fish-redux.md | fzyzcjy/fish-redux | 40b853bfa0843e5bbe23e9217bae7598bb08bcf7 | [
"Apache-2.0"
] | null | null | null | docs/concept/evolution-of-fish-redux.md | fzyzcjy/fish-redux | 40b853bfa0843e5bbe23e9217bae7598bb08bcf7 | [
"Apache-2.0"
] | 2 | 2022-03-09T08:52:19.000Z | 2022-03-21T06:17:05.000Z | # fish-redux 的演进史
fish-redux 是一个不断演进的框架,甚至是在不断的回炉重造,在这个过程中
<img src="https://img.alicdn.com/tfs/TB1aeJELpzqK1RjSZFCXXbbxVXa-1794-938.png" width="897px" height="469px">
- 1. 第一个版本是基于社区内的 flutter_redux 进行的改造,核心是提供了 UI 代码的组件化,当然问题也非常明显,针对复杂的业务场景,往往业务逻辑很多,无法做到逻辑代码的分治和复用。
- 2. 第二个版本针对第一个版本的问题,做出了比较重大的修改,解决了 UI 代码和逻辑代码的分治问题,但设计上打破了 redux 的原则,丢失了 Redux 的精华。
- 3. 在第三个版本进行重构时,我们确立了整体的架构原则与分层要求,一方面按照 reduxjs 的代码进行了 flutter 侧的 redux 实现,将 redux 完整保留下来。另一方面针对组件化的问题,提供了 redux 之上的 component 的封装,并创新的通过这一层的架构设计提供了业务代码分治的能力。第三版 完成了 Redux, Component 两层的设计,其中包含了 Connector,Dependencies,Context 等重要概念。
- 3.1 解决集中和分治的矛盾的核心在于 [Connector](what's-connector.md)
- 3.2 这一层的组件的分治是面向通用设计的。通过在 [Dependencies](dependencies-cn.md) 配置 slots,得到了可插拔的组件系统。
- 4. 在第三个版本 Redux & Component 之外,提供了面向 ListView 场景的分治设计 Adapter。
- 解决了在面向 ListView 场景下的逻辑的分治和性能降低的矛盾。
- [what's-adapter](what's-adapter.md)
> 目前,fish redux 已经在闲鱼线上稳定运行,未来,期待 fish redux 给社区带来更多的输入。
| 45.904762 | 235 | 0.775934 | yue_Hant | 0.71836 |
58764ed5e104132f13506a2e7c8b174349a19128 | 1,942 | md | Markdown | Documentation/Wiki/Advanced-Features/Execution-Analyzer.md | miniksa/BuildXL | 4dc257a82a6126fe7516f15fa6f505c14c122ffb | [
"MIT"
] | 448 | 2018-11-07T21:00:58.000Z | 2019-05-06T17:29:34.000Z | Documentation/Wiki/Advanced-Features/Execution-Analyzer.md | miniksa/BuildXL | 4dc257a82a6126fe7516f15fa6f505c14c122ffb | [
"MIT"
] | 125 | 2018-11-08T21:52:27.000Z | 2019-05-06T20:23:10.000Z | Documentation/Wiki/Advanced-Features/Execution-Analyzer.md | miniksa/BuildXL | 4dc257a82a6126fe7516f15fa6f505c14c122ffb | [
"MIT"
] | 44 | 2018-11-07T21:05:41.000Z | 2019-05-04T06:19:12.000Z | bxlAnalayzer.exe is a tool that lives next to bxl.exe. It can provide analysis of the execution of a build and its graph. It operates on execution log files (.xlg), which live in BuildXL's log directory.
The analyzer works on both on Windows and macOS (unless otherwise specified). For macOS, remove the ".exe" extension from the examples and correct the paths.
## Specifying inputs
Most analysis modes require a pointer to an execution log from a prior BuildXL build session. This can either be specified on the command line with `/xl:[PathTo.xlg file]` or the analyzer will find the log of the last BuildXL sesison run if left blank. See the analyzer help text for more details
# Analysis modes
The analyzer application has many different modes added by the BuildXL team as part of the core product as well as other consumers of BuildXL. See the help text for a full listing of the various analyzer modes: `bxlanalyzer.exe /help`. Specify the mode using the `/m:` option.
## Critical Path Analysis
This analysis shows you the top 20 critical paths in the invoked build. It considers the runtime duration of the pip including cache lookup, materialization, execution, and storing outputs to cache. So if some pips were from cache, their full non-cached execution time won't be reflected in the critical path.
`bxlAnalyzer.exe /m:criticalpath /xl:F:\src\buildxl\Out\Logs\20170227-121907\BuildXL.xlg /outputfile:criticalpath.txt`
## Dump Pip Analysis
This analyzer dumps details of a specific pip. It is helpful for getting the command line, environment variables, which files/directories were untracked, etc.
`bxlAnalyzer.exe /m:DumpPip /pip:Pip6E0AB6802406618E /xl:/Users/user01/build/Logs/devmain/BuildXL/BuildXL.xlg /outputFile:out.html`
## Cache Miss Analysis
[Cache Miss Analysis](./Cache-Miss-Analysis.md)
## JavaScript dependency fixer
[JavaScript Dependency Fixer](./Javascript-dependency-fixer.md)
| 74.692308 | 311 | 0.780639 | eng_Latn | 0.993984 |
58769959211ac3f2b1cea5babf6973ae6216e148 | 2,395 | md | Markdown | README.md | kpabellan/target-in-store-ps5-monitor | fd00dbbc048b64113c1c2a6dfdb31dda69f0075c | [
"MIT"
] | 4 | 2021-07-27T14:12:46.000Z | 2021-08-04T22:57:04.000Z | README.md | kpabellan/target-in-store-ps5-monitor | fd00dbbc048b64113c1c2a6dfdb31dda69f0075c | [
"MIT"
] | null | null | null | README.md | kpabellan/target-in-store-ps5-monitor | fd00dbbc048b64113c1c2a6dfdb31dda69f0075c | [
"MIT"
] | null | null | null | # Target In-Store PS5 Monitor
A [Target](https://www.target.com) in-store stock monitor for both digital and disc PS5 consoles that sends in stock alerts to SMS using Twilio.
## Requirements
- [NodeJS](https://nodejs.org/en/)
## Configuration
This project comes with an example .env file that you can use as a base to help, first you will need to copy and rename this file with the steps below:
1. Copy the `example.env` file.
2. Rename it to `.env`.
### Twilio Configuration
This project utilizes [Twilio](https://www.twilio.com/) to send SMS alerts, and you will need to set up an account to use this feature. Once you obtain your `ACCOUNT SID`, `AUTH TOKEN`, `Messaging Service SID`, and the phone number you want to send SMS alerts to, you can continue with the steps below:
1. Navigate to the `.env` file.
2. Insert your details into the `PHONENUM`, `ACCOUNTSID`, `AUTHTOKEN`, and `MESSAGINGSERVICESID` variables.
### Store Configuration
You will need to chose which Target store you want to monitor and in order to do this, you will need to know the store ID of that Target in which you can do so with the steps below:
1. Navigate to https://www.target.com/store-locator/find-stores.
2. Find and select your store.
3. Your store ID will be the numbers at the end of the link (should be 3-4 characters).
4. Navigate back into the `.env` file and insert the store ID into the `STOREID` variable.
### Proxy Configuration
In order to keep this monitor running safe and smooth, you will need to add proxies. Follow the steps below to configure proxies:
1. Create a file named `proxylist.txt` in the main folder.
2. Add IPs/URLs, which should be separated by a new line.
3. These proxies should be formatted as `http://username:password@ip:port` or `http://127.0.0.1:12345`.
4. Navigate to the `index.js` file and find the variable called `numProxies`. You then want to change the value of this variable to however many proxies you have in the `proxylist.txt` file.
## Starting
To start the monitor, open a terminal and run these commands:
* Set directory to bot directory:
```sh
cd "C:/Path/To/Bot/Folder"
```
* Install the dependencies (you only have to do this once):
```sh
npm install
```
* Run with the following command:
```sh
npm start
```
## License
This project is licensed under the MIT License - see the [LICENSE.md](LICENSE.md) file for details. | 39.916667 | 302 | 0.737787 | eng_Latn | 0.995559 |
5876aefb2e33735f55cbeee4003606975410ec4f | 3,770 | md | Markdown | MIP40/MIP40c3-Subproposals/MIP40c3-SP28.md | LongForWisdom/mips | 185bd6437a37c0b4687a8e3c1077ca69f50779e3 | [
"MIT"
] | null | null | null | MIP40/MIP40c3-Subproposals/MIP40c3-SP28.md | LongForWisdom/mips | 185bd6437a37c0b4687a8e3c1077ca69f50779e3 | [
"MIT"
] | null | null | null | MIP40/MIP40c3-Subproposals/MIP40c3-SP28.md | LongForWisdom/mips | 185bd6437a37c0b4687a8e3c1077ca69f50779e3 | [
"MIT"
] | null | null | null | # MIP40c3-SP28: Adding the StarkNet Engineering Core Unit (SNE-001)
## Preamble
```
MIP40c3-SP#: 28
Author(s): Author(s): Louis Baudoin (@louismerkle), Ohad Barta
Contributors: Derek Flossman, Maciek Kaminsky, Kris Kaczor, Marc-Andre Dumas, Ohad Barta, Louis Baudoin
Tags: core-unit, cu-sne-001, budget, dai-budget
Status: RFC
Date Applied: 2021-08-09
Date Ratified: N/A
```
## Sentence Summary
MIP40c3-SP28 adds the budget for Starknet Engineering Core Unit
## Specification
### Motivation
I am proposing this budget for the StarkNet Engineering Core Unit to be able to succeed in its mandate, specifically: to build a bridge to Starknet that is upgradeable through governance, and enable DAI minting on Starknet as well as investigate porting over other core functionalities (e.g., liquidations, oracles).
This project should result in future protocol improvements in terms of efficiency and user experience as we have seen in the past with other protocols ported over a zk L2.
### Core Unit ID
SNE-001
### Budget considerations
The budget as presented is mostly made of salaries, which have been evaluated in order to provide a competitive package to the team members.
Other budget items that may have to be considered in the future but are not included in the current budget are listed in the last section of this proposal.
### Budget
The current proposal is for a six months budget. Given the open-ended nature of the project and the fact that the goal of the project is partly to identify improvement vectors for the Maker protocol, we can expect the same team to continue working on solidifying the transition to Starknet, or focus on specific pieces of the protocol that have been identified as high-impact for the efficiency of the protocol and the user experience.
This budget secures a team of 5 Senior Engineers, one Data Scientist (part-time), and one Facilitator. We are forming a tight team on purpose, the goal being to make decisions quickly and have a core team of Engineers who will learn to master Cairo and be able to transfer knowledge. As we have more visibility on the exact scope of the protocol we will port over to Starknet, and as we will have more visibility on the improvement levers we want to explore further, we may request for a budget extension. However, the mindset of the team is to stay small and nimble.
The budget asked is $775,000 for six months. The distribution of the budget across profiles is shown below.

---
### List of Budget Breakdowns
Salaries: The has 5 full-time Senior Engineers with prior knowledge of Solidity, validity proofs, or both. 1 part-time Data Scientist, and 1 full-time Team Facilitator (for a total of 7 members).
### MKR vesting
This proposal does not include a vesting schedule or bonuses. The form (DAI or MKR) and the vesting schedule of the bonuses will be discussed with the community and added to this proposal in the near future.
### What is not in this budget
* Audits: We may ask for an additional budget for audits when the code is complete, or be able to work with other core unit teams.
* Gas costs: We may ask for an additional budget for gas costs when the project is further along.
* Bug bounty: We may ask for an additional budget for a bug bounty when the project is further along.
* Team bonuses: The project is foreseen to last 6 months, hence the bonuses will be deliverable-based. The budget will be updated once the bonuses amounts and form (DAI or MKR) will be discussed and decided by the community.
* Travel: Our team is decentralized, yet we are not excluding the option to meet in person if we assess it is needed.
| 58 | 567 | 0.784085 | eng_Latn | 0.999645 |
5876b750369961b9f4f4df56583c787541593fa7 | 624 | md | Markdown | Readme.md | onvungocminh/Python_binding_fromC | 17fd858ab49f3bdfe0dbd25d10d825ca153b2b1d | [
"Apache-2.0"
] | 1 | 2021-07-20T10:18:09.000Z | 2021-07-20T10:18:09.000Z | Readme.md | onvungocminh/Python_binding_fromC | 17fd858ab49f3bdfe0dbd25d10d825ca153b2b1d | [
"Apache-2.0"
] | null | null | null | Readme.md | onvungocminh/Python_binding_fromC | 17fd858ab49f3bdfe0dbd25d10d825ca153b2b1d | [
"Apache-2.0"
] | null | null | null | # pybind11_opencv_numpy
This repository is implemented to convert opencv c++ code to python.
An example of pybind11 for cv::Mat <-> np.array
```bash
/project folder
├── build
├── example
│ ├── exemple.so # generate with make
│ └── example.cpython-36m-x86_64-linux-gnu.so # generate with setup.py
├── CMakeLists.txt
├── setup.py
└── ...
```
## Generation with make
clone pybind11 repository
git clone https://github.com/pybind/pybind11.git
### Compile
```bash
mkdir build
cd build
# configure make with vcpkg toolchain
cmake ..
# generate the example.so library
make
```
### Run
```bash
python3 test.py
```
| 15.219512 | 73 | 0.690705 | eng_Latn | 0.893215 |
5879619bb713999f72747aee03b1c110aa9ddae1 | 945 | md | Markdown | AlchemyInsights/update-policies-in-microsoft-edge.md | isabella232/OfficeDocs-AlchemyInsights-pr.sr-Latn-RS | eb66d955dca362c1508b6ad53bf0974ef5a7a1a0 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-19T19:08:02.000Z | 2020-05-19T19:08:02.000Z | AlchemyInsights/update-policies-in-microsoft-edge.md | MicrosoftDocs/OfficeDocs-AlchemyInsights-pr.sr-Latn-RS | ef115121eb0e71ad7eddda959b97441101a2b11a | [
"CC-BY-4.0",
"MIT"
] | 3 | 2020-06-02T23:14:22.000Z | 2022-02-09T06:57:49.000Z | AlchemyInsights/update-policies-in-microsoft-edge.md | isabella232/OfficeDocs-AlchemyInsights-pr.sr-Latn-RS | eb66d955dca362c1508b6ad53bf0974ef5a7a1a0 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2019-10-09T20:34:14.000Z | 2020-06-02T23:12:22.000Z | ---
title: Koristite smernice grupe koje se odnose na ažuriranje dostupne u Microsoft Edge
ms.author: v-jmathew
author: v-jmathew
manager: scotv
ms.audience: Admin
ms.topic: article
ms.service: o365-administration
ROBOTS: NOINDEX, NOFOLLOW
localization_priority: Normal
ms.collection: Adm_O365
ms.custom:
- "9003843"
- "9004632"
- "7092"
- "8359"
ms.openlocfilehash: 85eff448dbf6cecd80ea870739c1223b10fbe6894462226c19fd9aae26faad6b
ms.sourcegitcommit: b5f7da89a650d2915dc652449623c78be6247175
ms.translationtype: MT
ms.contentlocale: sr-Latn-RS
ms.lasthandoff: 08/05/2021
ms.locfileid: "54007156"
---
# <a name="use-update-related-group-policies-available-in-microsoft-edge"></a>Koristite smernice grupe koje se odnose na ažuriranje dostupne u Microsoft Edge
Koristite [smernice dostupne](https://go.microsoft.com/fwlink/?linkid=2134862) u programu Microsoft Edge (verzija 77 ili novija) da biste kontrolisali kako i Microsoft Edge ažuriranja.
| 35 | 184 | 0.810582 | bos_Latn | 0.259721 |
58798914f383c9f45b9136fe72b6b1c43155327e | 7,940 | md | Markdown | packages/gatsby-theme-library/CHANGELOG.md | rsexton404/reflex | d18240f9f73afb5c242dc1cb9f005378cfe7aaaa | [
"MIT"
] | null | null | null | packages/gatsby-theme-library/CHANGELOG.md | rsexton404/reflex | d18240f9f73afb5c242dc1cb9f005378cfe7aaaa | [
"MIT"
] | null | null | null | packages/gatsby-theme-library/CHANGELOG.md | rsexton404/reflex | d18240f9f73afb5c242dc1cb9f005378cfe7aaaa | [
"MIT"
] | null | null | null | # Change Log
All notable changes to this project will be documented in this file.
See [Conventional Commits](https://conventionalcommits.org) for commit guidelines.
# [0.5.0](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-11-10)
### Features
* **www-next:** add www-next site ([8a230e7](https://github.com/reflexjs/reflex/commit/8a230e7e43d1bb6a25c7332501547ee0f9eea080))
## [0.4.1](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-09-21)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
# [0.4.0](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-09-15)
### Features
* **gatsby-theme-library:** switch to cloudinary ([22401f1](https://github.com/reflexjs/reflex/commit/22401f131c9d0c20c6910261c7cd4cc6b826463d))
## [0.3.17](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-09-09)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.16](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-08-28)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.15](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-08-27)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.14](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-08-24)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.13](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-08-24)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.12](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-08-15)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.11](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-08-14)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.10](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-08-14)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.9](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-27)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.8](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-23)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.7](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-14)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.6](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-13)
### Bug Fixes
* **www:** update theme links ([83cda0d](https://github.com/reflexjs/reflex/commit/83cda0db5cf4ac3571b298e40e9278b82a5b69cb))
## [0.3.5](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-13)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.4](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-10)
### Bug Fixes
* **www:** small theme improvement ([183d8d5](https://github.com/reflexjs/reflex/commit/183d8d5a4a81096c9371731ae209598e942f7e7d))
## [0.3.3](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-06)
### Bug Fixes
* **www:** a11y issues for library pages ([049b0d6](https://github.com/reflexjs/reflex/commit/049b0d6dcf2fb03a11cdb04fa6d08aa8ed6e113b))
## [0.3.2](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-06)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.3.1](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-05)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
# [0.3.0](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-07-04)
### Bug Fixes
* **www:** add gatsby-plugin-metatags ([e04b375](https://github.com/reflexjs/reflex/commit/e04b3752dcae505d6c25628a54d503bfc7c4ae18))
* **www:** update metatags for library pages ([6401cfa](https://github.com/reflexjs/reflex/commit/6401cfa24c6476b709b09dc8f72e25ca93d8e922))
### Features
* **metatags:** add gatsby-plugin-metatags and gatsby-plugin-image ([7dd35ca](https://github.com/reflexjs/reflex/commit/7dd35ca5a88f686f11a0f3772d4eaaa640842ba9))
## [0.2.1](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-29)
### Bug Fixes
* **library:** update thumbnail display ([f9f77fa](https://github.com/reflexjs/reflex/commit/f9f77fa087779a717b54266bbb2ab522f09831eb))
# [0.2.0](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-26)
### Features
* **core:** replace prism-react-renderer with theme-ui/prism ([9ec4419](https://github.com/reflexjs/reflex/commit/9ec44192678175f00d760d9a93dc89dc86be5daf))
## [0.1.7](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-24)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.1.6](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-18)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.1.5](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-18)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.1.4](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-18)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.1.3](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-18)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.1.2](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-18)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
## [0.1.1](https://github.com/reflexjs/reflex/compare/@reflexjs/[email protected]...@reflexjs/[email protected]) (2020-06-18)
**Note:** Version bump only for package @reflexjs/gatsby-theme-library
# 0.1.0 (2020-06-18)
### Features
* initial commit ([27540b0](https://github.com/reflexjs/reflex/commit/27540b022a849212a21894b05df928e5e6b19456))
| 28.156028 | 162 | 0.729597 | yue_Hant | 0.222336 |
587a045272fb487fa064bdc5ee1ddf9b58e12c99 | 3,785 | md | Markdown | services/mobilefoundation/nl/fr/c_using_mfs_p1.md | MaeveOReilly/docs | c2b6c75b4731ab5fb11c9014c35b9da03b921b89 | [
"Apache-2.0"
] | null | null | null | services/mobilefoundation/nl/fr/c_using_mfs_p1.md | MaeveOReilly/docs | c2b6c75b4731ab5fb11c9014c35b9da03b921b89 | [
"Apache-2.0"
] | null | null | null | services/mobilefoundation/nl/fr/c_using_mfs_p1.md | MaeveOReilly/docs | c2b6c75b4731ab5fb11c9014c35b9da03b921b89 | [
"Apache-2.0"
] | null | null | null | ---
copyright:
years: 2016
---
# Utilisation du plan Developer
{: #using_mobilefoundation_p1}
Dernière mise à jour : 4 août 2016
{: .last-updated}
Une fois l'instance de service {{site.data.keyword.mobilefoundation_short}}: Developer créée, au bout de quelques secondes, vous pouvez accéder à la `Présentation` du site {{site.data.keyword.Bluemix_notm}} qui fournit des tutoriels et des vidéos facilitant
vos premiers pas avec le service {{site.data.keyword.mobilefoundation_short}}.
## Démarrage du serveur {{site.data.keyword.mobilefirst}}
{: #start_mobilefoundation_p1}
* Pour démarrer le serveur
{{site.data.keyword.mfserver_short_notm}} avec les paramètres par
défaut, cliquez sur **Start Basic Server**.
Cette option affecte les paramètres suivants à un serveur {{site.data.keyword.mfserver_long_notm}} :
* 1 Go de mémoire. Cette taille est suffisante pour des activités de développement et des activités de test sommaires et pour des charges de travail à faible échelle.
* Le `nom_d'utilisateur` et le `mot_de_passe` sont générés automatiquement pour vous. Vous pouvez y accéder une fois que le
serveur est en opération.
Le processus de mise à disposition commence. Ce processus prend environ 10 minutes et une fenêtre de
message indique la progression de l'opération. A son terme, un tableau de bord s'affiche et présente les éléments suivants :
* L'état du serveur que vous exécutez (état, taille).
* La route de serveur créée pour vous. Utilisez cette route dans votre application mobile pour vous connecter à {{site.data.keyword.mfserver_short_notm}}.
* Votre `nom_d'utilisateur` personnel et votre `mot_de_passe`
pour accéder à la console {{site.data.keyword.mfp_oc_short_notm}}. Le
`mot_de_passe` est masqué. Cliquez sur l'icône **Show Password** pour le visualiser.
* Cliquez sur **Launch Console** pour lancer la
console {{site.data.keyword.mfp_oc_short_notm}}.
<!--This console runs inside the container.--> Elle vous permet de gérer vos
applications et périphériques mobiles, l'utilisation de votre serveur en tant
que serveur dorsal mobile, l'envoi de notifications push, etc.
## Re-création du serveur {{site.data.keyword.mobilefirst}}
{: #recreate_mobilefoundation_p1}
* Cliquez sur **Recreate** pour re-créer le serveur.
* Cette action arrête votre serveur existant et supprime les données. Toutes les
données de votre serveur mobile sont perdues. Une
nouvelle instance de serveur est créée avec une version mise à jour, si elle est disponible. Cette action prend quelques minutes avant de s'achever.
## Paramétrage d'une configuration avancée
{: #using_mfs_advanced_p1}
L'option **Start Server with Advanced Configuration**
de la page `Overview` permet de créer le serveur avec des
paramètres avancés ou personnalisés. Vous pouvez également mettre à jour les paramètres du serveur
pour personnaliser sa configuration en cliquant sur l'onglet **Configuration**. {{site.data.keyword.mobilefoundation_short}}
vous permet d'accéder à certains paramètres avancés.
* Dans l'onglet **Topology**, vous pouvez sélectionner la taille du serveur, ainsi que le nombre d'instances dont vous avez besoin. Le serveur par défaut doté d'1 Go
est idoine pour le développement et des tests sommaires.
- Sélectionnez la taille appropriée pour votre serveur compte tenu de
vos besoins.
* **Nodes** affiche le nombre de noeuds créés. Cette
zone n'est pas modifiable dans {{site.data.keyword.mobilefoundation_short}}: Developer. Par défaut, le nombre de noeuds <!--in your {{site.data.keyword.IBM_notm}} container group--> s'élève à **1** dans le plan Developer.
Pour plus de détails, reportez-vous à la
[documentation
d'{{site.data.keyword.mobilefoundation_long}}](https://www.ibm.com/support/knowledgecenter/SSHS8R_8.0.0/wl_welcome.html){: new_window}.
| 48.525641 | 257 | 0.783355 | fra_Latn | 0.978448 |
587a2c40b1f57b5b255f226bc3490ef794f4c708 | 3,020 | md | Markdown | _posts/2018-10-21-Download-calorimetry-practice-problems-and-answers.md | Luanna-Lynde/28 | 1649d0fcde5c5a34b3079f46e73d5983a1bfce8c | [
"MIT"
] | null | null | null | _posts/2018-10-21-Download-calorimetry-practice-problems-and-answers.md | Luanna-Lynde/28 | 1649d0fcde5c5a34b3079f46e73d5983a1bfce8c | [
"MIT"
] | null | null | null | _posts/2018-10-21-Download-calorimetry-practice-problems-and-answers.md | Luanna-Lynde/28 | 1649d0fcde5c5a34b3079f46e73d5983a1bfce8c | [
"MIT"
] | null | null | null | ---
layout: post
comments: true
categories: Other
---
## Download Calorimetry practice problems and answers book
74 the shower before turning on the water, sweaty. "It seems to be. "Not yet," I said and began to kiss her again. "There's to me from the way it looked to other people. And those who won't join them stand each alone. Without a word I stepped Nothing brought a sense of order and normality to a disordered and distressing each other company. It was as if he had been clinging obstinately to a shred of hope that he might have gotten it all wrong, away from the grey stone tower. Maybe they'd misjudge the moment, he didn't want the police in San Francisco to know that he'd been file:D|Documents20and20Settingsharry, and I pardoned him who smote me with an arrow and cut off my ear, angry, pink calorimetry practice problems and answers pants with a drawstring waist, Detectives, in the temple at Ratnapoora, stockings calorimetry practice problems and answers his battered feet and limped into the kitchen, Howard Kalens's deputy in Liaison, unperturbed, but you must never lie to yourself, and which are grounded calorimetry practice problems and answers the working out fell calorimetry practice problems and answers the bed, and threw myself at the first equations as if? Why, even the popular taste has become too refined to tolerate the foolishness of sentimental songs and lurid melodrama, it's not so much too. Like slaves' lives. "From the car to the His father had named him Banner of War. So many stops, which was a grievous disappointment, forms a was content to follow her lead, before the heat of the day-" it, who said to him, 111 put Spanish fly in your Ovaltine, Jr, Hinda gave a gasp, there is the reactive pain, for example. A cerebral hemorrhage. It'll be okay -. " He stepped back from the island still later. bedroom, because life would not be worth living anymore, Azver, I had forgotten thee and remembered thee not till now!' Then he looked at her and said, creating a fire danger and an ideal home for tree rats. 54 I am fortunate in that, Suez, ii. When the girl's months were accomplished and the season of her delivery drew near, till he had spent all that was with him; moreover. I looked for the woman. "Jain!" I scream at the sky until my voice is gone and vertigo destroys my balance. He told us terrible stories of the places he intended to go. " "Who?" journal (pl. "All that the resources he consumed to sustain himself. "We have an appointment shortly. " their own hand entered into conflicts with whole armies from the He led her back to the booth. Now you go out there and do the right As the tattooed serpent's grin grew wider on the calorimetry practice problems and answers hand, that nothing may assain. And the first thing the boy did in the Great House, but their faces outshone the flambeaux, 111 put Spanish fly in your Ovaltine, Noah was met by a uniformed officer who "I am a woman worthy of a prince," said the face in the water, black magic: "sticky 71. | 335.555556 | 2,905 | 0.783113 | eng_Latn | 0.999954 |
587a329504c71e6e8afbc7260d2f5fdcfe5ef099 | 636 | md | Markdown | mgabriella/P5_Esercizi/4.Balls_scia2_white/README.md | barsab/archive | 5ec94b60fa2613a99b54eef5745a41fa49ec8435 | [
"MIT"
] | null | null | null | mgabriella/P5_Esercizi/4.Balls_scia2_white/README.md | barsab/archive | 5ec94b60fa2613a99b54eef5745a41fa49ec8435 | [
"MIT"
] | null | null | null | mgabriella/P5_Esercizi/4.Balls_scia2_white/README.md | barsab/archive | 5ec94b60fa2613a99b54eef5745a41fa49ec8435 | [
"MIT"
] | null | null | null | # Balls_scia2_white
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
### immagine in questo [Link](https://editor.p5js.org/mgabriella/full/Z9loF3z-n).

L'esercizio presenta camminatori indipendenti che cambiano colore in modo randomico. Al loro passaggio si vede la SCIA delle loro posizioni
precedenti, grazie all'inserimento di un rettangolo bianco con le dimensioni dello sfondo che si rigenera ogni volta dietro al draw() delle palline.
| 53 | 224 | 0.504717 | ita_Latn | 0.910994 |
587a8981dc04cd96730acf0252de59b59af6d23a | 517 | md | Markdown | README.md | manifest/redex | a10cf0c5681f70a3673d1f57e3b1d6026b9a3bd4 | [
"Apache-2.0"
] | null | null | null | README.md | manifest/redex | a10cf0c5681f70a3673d1f57e3b1d6026b9a3bd4 | [
"Apache-2.0"
] | 7 | 2021-07-29T20:14:43.000Z | 2021-10-03T07:23:30.000Z | README.md | manifest/redex | a10cf0c5681f70a3673d1f57e3b1d6026b9a3bd4 | [
"Apache-2.0"
] | null | null | null | # Redex
[](https://redex.readthedocs.io)
[](https://codecov.io/gh/manifest/redex)
[](https://github.com/psf/black#readme)
[](https://pypi.org/project/redex)
A combinator library for designing algorithms.
| 57.444444 | 133 | 0.758221 | yue_Hant | 0.53613 |
587a97f90cca195ef95302a3cb31accd688d760e | 1,141 | md | Markdown | _posts/2009-07-12-218.md | elton/elton.github.com | a291592c433254424a3767a7dd4d255adf702dd1 | [
"Apache-2.0"
] | 1 | 2019-11-25T09:45:00.000Z | 2019-11-25T09:45:00.000Z | _posts/2009-07-12-218.md | elton/elton.github.com | a291592c433254424a3767a7dd4d255adf702dd1 | [
"Apache-2.0"
] | 2 | 2021-05-17T23:59:24.000Z | 2022-02-26T01:26:05.000Z | _posts/2009-07-12-218.md | elton/elton.github.com | a291592c433254424a3767a7dd4d255adf702dd1 | [
"Apache-2.0"
] | null | null | null | ---
layout: post
title: 'lighttpd配置之重定向(mod_redirect)'
date: 2009-07-12
wordpress_id: 218
permalink: /blogs/218
comments: true
categories:
- Linux
tags:
- lighttpd
- mod_redirect
---
有时候需要将一个url重定向到另外一个url上。 如最简单的将不带www的域名重定向到www上,例如将domain.com重定向到www.domain.com上。
这时候就可以使用mod_redirect模块。 如上面的例子可以在/etc/lighttpd/lighttpd.conf中使用下面的代码来解决:
1. 激活配置文件中的mod_redirect模块,去掉其前面的#
2. 插入下面代码
<pre class="prettyprint linenums">
$HTTP["host"] =~ "^([^.]+.[^.]+)$" {
url.redirect = (
".*" => "http://www.%1"
)
}
</pre>
其中,%1表示$HTTP["host"] 中正则表达式中括号中匹配的内容。%1表示第一个匹配值,%2表示第二个匹配值。%0表示整个字符串
再如,希望把www.prosight.me/blog/index.php/2009/03/archives/321这样的url跳转到blog.prosight.me/index.php/2009/03/321这个url上的话,就使用如下配置:
<pre class="prettyprint linenums">
$HTTP["host"] == "www.prosight.me" {
url.redirect = (
"^/blog/index.php/([0-9]+/[0-9]+)/archives/([0-9]+)$"
=> "http://blog.prosight.me/index.php/$1/$2",
"^/blog(/)?$" => "http://blog.prosight.me"
)
}
</pre>
其中 $1表示在url.redirect里正则表达式中第一个括号匹配的内容,$2表示第二个匹配的内容,以此类推。
url.redirect可以放置在任何$HTTP["host"] 块中,与其他模块共同使用。例如与rewrite一同使用,或者跟server.document-root属性一起使用来共同配置一个虚拟主机。
| 27.166667 | 121 | 0.701139 | yue_Hant | 0.53704 |
587b03d1aa8b2275076e2adfb9ffa4bc95db1460 | 1,358 | md | Markdown | README.md | hamzaak/electron-react-webpack-boilerplate | 0ac9e804d24f8893f87ec1cc44bfcec270141961 | [
"MIT"
] | 17 | 2019-04-11T13:05:17.000Z | 2021-03-09T09:28:30.000Z | README.md | truongdo/electron-react-webpack-boilerplate | 0ac9e804d24f8893f87ec1cc44bfcec270141961 | [
"MIT"
] | 2 | 2020-03-31T15:30:58.000Z | 2020-09-23T18:23:04.000Z | README.md | truongdo/electron-react-webpack-boilerplate | 0ac9e804d24f8893f87ec1cc44bfcec270141961 | [
"MIT"
] | 14 | 2020-01-30T14:26:28.000Z | 2021-01-26T23:17:05.000Z | # Electron React Webpack Boilerplate
<p>
This useful boilerplate project uses <a href="http://electron.atom.io/">Electron</a>, <a href="https://facebook.github.io/react/">React</a>, <a href="http://webpack.github.io/docs/">Webpack</a>, <a href="https://babeljs.io/">Babel</a> and <a href="https://github.com/gaearon/react-hot-loader">React Hot Loader</a> (HMR).
</p>
<br>
<div align="center">
<a href="https://electronjs.org/"><img src="./public/assets/electron.png" /></a>
<a href="https://facebook.github.io/react/"><img src="./public/assets/react.png" /></a>
<a href="https://webpack.github.io/"><img src="./public/assets/webpack.png" /></a>
<a href="https://babeljs.io/"><img src="./public/assets/babel.png" /></a>
</div>
<hr />
<br />
<div align="center">
<img src="./public/assets/home.png" alt="Electron React Webpack Boilerplate"/>
</div>
<hr />
## Features
* Electron 4
* Electron Builder
* React 16
* Webpack 4
* Babel 7
* Hot Module Replacement
## Installation
* `git clone https://github.com/hamzaak/electron-react-webpack-boilerplate.git`
* cd electron-react-webpack-boilerplate
* npm install
* npm start
## Packing for distribution
To package the app fro windows platform:
`npm run dist`
## Maintainer
- [Hamza Ak](https://www.linkedin.com/in/hamzaak/)
## License
MIT | 26.115385 | 323 | 0.653166 | kor_Hang | 0.205673 |
587b2c2171d4a8ee6616a671918a525c83430de8 | 3,858 | md | Markdown | blog/src/_posts/2014-03-16-cb-semicolon-retalk.md | pingod/blog | b7ac473a223831d5df0fe4aa075873dcb89a518e | [
"Apache-2.0"
] | null | null | null | blog/src/_posts/2014-03-16-cb-semicolon-retalk.md | pingod/blog | b7ac473a223831d5df0fe4aa075873dcb89a518e | [
"Apache-2.0"
] | null | null | null | blog/src/_posts/2014-03-16-cb-semicolon-retalk.md | pingod/blog | b7ac473a223831d5df0fe4aa075873dcb89a518e | [
"Apache-2.0"
] | null | null | null | ---
title: Javascript分号,加还是不加?
categories:
- JavaScript
- 前端杂烩
tags:
- tech
- cnblogs
warning: true
date: 2014-03-16 03:51:00
---
<div class="history-article">本文为归档内容,原始地址在 <a href="http://www.cnblogs.com/hustskyking/archive/2014/03/16/semicolon-retalk.html" target="_blank">博客园</a>.</div>
<p>关于这个问题,网上已经有很多人讨论过了,我先说说自己对这个问题的回答:加!(但非必须)</p>
<p>有些人写代码,懒得加分号,除非是迫不得已才勉强放一个分号上去。如果你可以保证你写的代码不出现任何 bug,那当然是没有问题,但是很多 JSer 新人,对一些隐含的问题并不是特别清楚,很容易在不知不觉中写出一堆 bug,我们先来了解下 JS 词法语法解析的时候,哪些情况下会自动插入分号。</p>
<h3>一、自动插入分号的规则</h3>
<p><span><strong>注:鼠标滑过文字可以看到翻译原文</strong></span></p>
<p>1. <span class="translator" title="When, as the program is parsed from left to right, a token (called the offending token) is encountered that is not allowed by any production of the grammar, then a semicolon is automatically inserted before the offending token if one or more of the following conditions is true:">程序从左到右解析,当纳入下一个 token 无法匹配任何语法:</span></p>
<ul>
<li><span class="translator" title="The offending token is separated from the previous token by at least one LineTerminator.">如该 token 跟之前的 token 之间有至少一个 LineTerminal 行终结符违反分割</span></li>
<li><span class="translator" title="The offending token is }.">该 token 为 `}` 符号时</span></li>
</ul>
<p>2. <span class="translator" title="When, as the program is parsed from left to right, the end of the input stream of tokens is encountered and the parser is unable to parse the input token stream as a single complete ECMAScript Program, then a semicolon is automatically inserted at the end of the input stream.">程序从左到右解析,当纳入下一个(或几个) token 不能产生一条合法的语句的时候,会在这个地方插入一个分号。</span></p>
<p>
3. <span class="translator" title="When, as the program is parsed from left to right, a token is encountered that is allowed by some production of the grammar, but the production is a restricted production and the token would be the first token for a terminal or nonterminal immediately following the annotation \[no LineTerminator here]" within the restricted production (and therefore such a token is called a restricted token), and the restricted token is separated from the previous token by at least one LineTerminator, then a semicolon is automatically inserted before the restricted token.">程序从左到右解析,当纳入的 token 能够产生一条合法语句,但是这条语句是受限产生式时,在该受限 token 前面自动插入分号。</span>
</p>
<p>上面提到的一些内容来自 ECMAScript5.1 第七章第九节,可以戳<a href="http://barretlee.com/ST/ES5.1/#sec-7.9.1" target="_blank">这里</a>,翻译的不太通顺,实在是太难翻译了= =</p>
<h3>二、一些不加分号会出问题的场景</h3>
<p><strong>场景一:</strong></p>
```
s = a + b
(x + y).doSomething()
```
<p>我们期望这是这是两条语句,结果会被解析成:</p>
```
s = a + b(x + y).doSomething();
```
<p>b 在这里成了一个函数了。</p>
<p><strong>场景二:</strong></p>
```
x
++
y
```
<p>这个 ++ 符号会给谁?答案是:</p>
```
x; ++y;
```
<p>这样的代码当然是很少遇到,但是遇到这种情况:</p>
<p><strong>场景三:</strong></p>
```
return
true
```
<p>我们期望返回 true,结果:</p>
```
return;
true;
```
<p>给我们返回了 undefined。</p>
<p><strong>场景四:</strong></p>
```
s = function(x){return x}
(1 + 2).toString()
```
<p>他被解析成了</p>
```
s = function(x){return x}(1 + 2).toString()
```
<p><code>function(x){return x}(1 + 2)</code> 这个作为一个整体,1+2 作为参数送入函数,该函数的返回值为 3,然后执行 3.toString(),这样的问题藏的比较深,不容易被发现。</p>
<h3>三、规避问题</h3>
<p>有些语句是以 <code>[</code> 或者 <code>(</code> 开头,就像上面提到的场景一和场景四,这些 token 很容易和上一条没有加分号的语句合并到一起,如果你不太喜欢加分号,可以这样来处理:</p>
```
s = function(x){return x}
;(1 + 2).toString()
```
<p>这也是为什么我们会经常看到别人的代码中写出这样的函数:</p>
```
;(function(){
// ...
})();
```
<p>在 function 的前面加了一个分号,目的就是为了防止整个函数的返回值作为参数送入上一条语句之中。</p>
<p>对于场景三,要特别说明一下,除了 return 之外,还有 break 和 continue 语句,break 和 continue 类似 C 语言中的 goto ,他是可以在后面添加 tag 的,如果 tag 和 这些关键词之间存在 <a href="http://barretlee.com/ST/ES5.1/#sec-7.3" target="_blank">LineTerminal </a>,这些 tag 就会被忽略,如:</p>
```
break
tag
```
<p>我们期望程序会调到 tag 所指向的程序段,但结果被解析成</p>
```
break;
tag;
```
<h3>四、小结</h3>
<p>看到上面的一些列问题,相信大家心里还是有自己的答案了,如果你有信心代码里头不出现因为不写分号而导致的错误,那分号的取舍其实是无所谓的。</p>
| 28.577778 | 670 | 0.712027 | eng_Latn | 0.743788 |
587bd8989b5e897fd1c1144e20c91ee974c76175 | 933 | md | Markdown | MajorNews/02/20200228.md | AlbertGithubHome/ChineseVictory | f8b440ad7936642d92c31ee4f9ccd39da53cca31 | [
"MIT"
] | 3 | 2020-01-30T01:29:20.000Z | 2020-02-01T23:55:30.000Z | MajorNews/02/20200228.md | AlbertGithubHome/ChineseVictory | f8b440ad7936642d92c31ee4f9ccd39da53cca31 | [
"MIT"
] | null | null | null | MajorNews/02/20200228.md | AlbertGithubHome/ChineseVictory | f8b440ad7936642d92c31ee4f9ccd39da53cca31 | [
"MIT"
] | null | null | null | - 2020-02-28 22:09:00 截止2020年02月28日22:09,全国确诊 78962 例,疑似 2308 例,死亡 2791 例,治愈 36474 例 [新闻详情>>](https://github.com/AlbertGithubHome/ChineseVictory/blob/master/PneumoniaMap/20200228220900.jpg)
- 2020-02-28 07:35:00 中央明确:开学开园时间原则上继续推迟 [新闻详情>>](http://city.sina.com.cn/focus/t/2020-02-28/detail-iimxyqvz6386318.shtml)
- 2020-02-28 07:43:00 【抗疫一线报告】全球疫情处于关键时刻 世卫组织:现在中国以外地区才是最大担忧 [新闻详情>>](http://news.sina.com.cn/c/2020-02-28/doc-iimxyqvz6387856.shtml)
- 2020-02-28 11:32:23 第一例新冠肺炎逝者尸解报告出炉 [新闻详情>>](https://zx.sina.cn/n/2020-02-28/zx-iimxxstf5013294.d.html)
- 2020-02-28 17:07:00 国家卫健委梁万年:武汉疫情快速流行上升趋势得到遏制 [新闻详情>>](http://finance.sina.com.cn/china/gncj/2020-02-28/doc-iimxyqvz6545216.shtml)
- 2020-02-28 20:07:00 疫情期北京市居住证、北京市居住登记卡有效期延长 [新闻详情>>](http://finance.sina.com.cn/china/gncj/2020-02-28/doc-iimxxstf5153736.shtml)
- 2020-02-28 21:09:00 批准了!北京大兴国际机场卫星厅复工 [新闻详情>>](http://mini.eastday.com/mobile/200228210902198.html)
| 116.625 | 191 | 0.749196 | yue_Hant | 0.899048 |
587c41163cb1a7a6386148e3cd94f2256cd5c4e5 | 23,518 | md | Markdown | docs/guide-ru/tutorial-core-validators.md | lisiy50/yii2 | 8d082c11a1c502487b200842927e1a5733abbc7d | [
"BSD-3-Clause"
] | 2 | 2020-11-13T06:20:18.000Z | 2020-11-13T06:20:25.000Z | docs/guide-ru/tutorial-core-validators.md | zhgit/yii2 | de853a2552c7509a125872aca2e2cb468c8035ff | [
"BSD-3-Clause"
] | null | null | null | docs/guide-ru/tutorial-core-validators.md | zhgit/yii2 | de853a2552c7509a125872aca2e2cb468c8035ff | [
"BSD-3-Clause"
] | null | null | null | Встроенные валидаторы
===============
Yii предоставляет встроенный набор часто используемых валидаторов, расположенных, в первую очередь,
в пространстве имен `yii\validators`. Вместо того, чтобы использовать длинные имена классов валидаторов,
вы можете использовать *псевдонимы*, чтобы указать на использование этих валидаторов.
Например, вы можете использовать псевдоним `required`, чтобы сослаться на класс [[yii\validators\RequiredValidator]]:
```php
public function rules()
{
return [
[['email', 'password'], 'required'],
];
}
```
Все поддерживаемые псевдонимы валидаторов можно увидеть в свойстве [[yii\validators\Validator::builtInValidators]].
Ниже мы опишем основные способы использования и свойства всех встроенных валидаторов.
## [[yii\validators\BooleanValidator|boolean]] <a name="boolean"></a>
```php
[
// Проверяет 'selected' на равенство 0 или 1, без учета типа данных
['selected', 'boolean'],
// Проверяет, что "deleted" - это тип данных boolean и содержит true или false
['deleted', 'boolean', 'trueValue' => true, 'falseValue' => false, 'strict' => true],
]
```
Этот валидатор проверяет, что второе значение является *boolean*.
- `trueValue`: значение, соответствующее *true*. По умолчанию - `'1'`.
- `falseValue`: значение, соответствующее *false*. По умолчанию - `'0'`.
- `strict`: должна ли проверка учитывать соответствие типов данных `trueValue` или `falseValue`. По умолчанию - `false`.
> Примечание: Из-за того, что как правило данные, полученные из HTML-форм, представляются в виде строки, обычно вам стоит
оставить свойство [[yii\validators\BooleanValidator::strict|strict]] равным false.
## [[yii\captcha\CaptchaValidator|captcha]] <a name="captcha"></a>
```php
[
['verificationCode', 'captcha'],
]
```
Этот валидатор обычно используется вместе с [[yii\captcha\CaptchaAction]] и [[yii\captcha\Captcha]], чтобы
убедиться, что данные в инпуте соответствуют верификационному коду, отображенному с помощью виджета
[[yii\captcha\Captcha|CAPTCHA]].
- `caseSensitive`: необходимо ли учитывать чувствительность к регистру при сравнении. По умолчанию - false.
- `captchaAction`: [маршрут](structure-controllers.md#routes), соответствующий
[[yii\captcha\CaptchaAction|CAPTCHA action]], который рендерит изображение с *CAPTCHA*. По умолчанию - `'site/captcha'`.
- `skipOnEmpty`: может ли валидация быть пропущена, если *input* пустой. По умолчанию - false,
что означает, что *input* обязателен.
## [[yii\validators\CompareValidator|compare]] <a name="compare"></a>
```php
[
// проверяет, является ли значение атрибута "password" таким же, как "password_repeat"
['password', 'compare'],
// проверяет, что возраст больше или равен 30
['age', 'compare', 'compareValue' => 30, 'operator' => '>='],
]
```
Этот валидатор сравнивает значение указанного атрибута с другим, чтобы удостовериться, что их отношение
соответствует описанному в свойстве `operator`.
- `compareAttribute`: имя атрибута, с которым нужно сравнить значение. Когда валидатор используется
для проверки атрибута, значением по умолчанию для этого свойства будет имя этого же атрибута
с суффиксом `_repeat`. Например, если проверяющийся атрибут - `password`,
то значение свойства по умолчанию будет `password_repeat`.
- `compareValue`: постоянное значение, с которым будут сравниваться входящие данные. Когда одновременно указаны
это свойство и `compareAttribute`, это свойство получит приоритет.
- `operator`: оператор сравнения. По умолчанию `==`, что означает проверку на эквивалентность входящих данных и в
`compareAttribute`, и в `compareValue`. Поддерживаются следующие операторы:
* `==`: проверяет два значения на эквивалентность. Сравнение не учитывает тип данных.
* `===`: проверяет два значения на эквивалентность. Сравнение строгое и учитывает тип данных.
* `!=`: проверяет, что два значения не эквивалентны. Сравнение не учитывает тип данных.
* `!==`: проверяет, что два значения не эквивалентны. Сравнение строгое и учитывает тип данных.
* `>`: проверяет, что валидируемое значение больше, чем то, с которым происходит сравнение.
* `>=`: проверяет, что валидируемое значение больше или равно тому, с которым происходит сравнение.
* `<`: проверяет, что валидируемое значение меньше, чем то, с которым происходит сравнение.
* `<=`: проверяет, что валидируемое значение меньше или равно тому, с которым происходит сравнение.
## [[yii\validators\DateValidator|date]] <a name="date"></a>
```php
[
[['from', 'to'], 'date'],
]
```
Этот валидатор проверяет соответствие входящих данных форматам *date*, *time* или *datetime*.
Опционально, он может конвертировать входящее значение в UNIX timestamp и сохранить в атрибуте,
описанном здесь: [[yii\validators\DateValidator::timestampAttribute|timestampAttribute]].
- `format`: формат даты/времени, согласно которому должна быть сделана проверка. Чтобы узнать больше о формате
строки, пожалуйста, посмотрите [руководство PHP по date_create_from_format()](http://www.php.net/manual/ru/datetime.createfromformat.php)
Значением по умолчанию является `'Y-m-d'`.
- `timestampAttribute`: имя атрибута, которому этот валидатор может передать UNIX timestamp, конвертированный
из строки даты/времени.
## [[yii\validators\DefaultValueValidator|default]] <a name="default"></a>
```php
[
// установить null для "age" в качестве значения по умолчанию
['age', 'default', 'value' => null],
// установить "USA" в качестве значения по умолчанию для "country"
['country', 'default', 'value' => 'USA'],
// установить в "from" и "to" дату 3 дня и 6 дней от сегодняшней, если они пустые
[['from', 'to'], 'default', 'value' => function ($model, $attribute) {
return date('Y-m-d', strtotime($attribute === 'to' ? '+3 days' : '+6 days'));
}],
]
```
Этот валидатор не проверяет данные. Вместо этого он присваивает значения по умолчанию проходящим проверку
атрибутам, если они пусты.
- `value`: значение по умолчанию или функция обратного вызова, которая возвращает значение по умолчанию,
которое будет присвоено проверяемому атрибуту, если он пустой. Функция обратного вызова должна выглядеть так:
```php
function foo($model, $attribute) {
// ... вычисление $value ...
return $value;
}
```
> Информация: Как определить, является значение пустым или нет, более подробно описано в отдельной статье
в секции [Пустые значения](input-validation.md#handling-empty-inputs).
## [[yii\validators\NumberValidator|double]] <a name="double"></a>
```php
[
// проверяет, является ли "salary" числом типа double
['salary', 'double'],
]
```
Этот валидатор проверяет, что входящее значение является корректным *double* числом. Он идентичен
валидатору [number](#number). (Прим. пер.: корректным float числом).
- `max`: верхний лимит (включительно) для значений. Если не установлен, значит, валидатор не будет проверять верхний лимит.
- `min`: Нижний лимит (включительно) для значений. Если не установлен, валидатор не будет проверять нижний лимит.
## [[yii\validators\EmailValidator|email]] <a name="email"></a>
```php
[
// проверяет, что "email" - это корректный email-адрес
['email', 'email'],
]
```
Валидатор проверяет, что значение входящих данных является корректным email-адресом.
- `allowName`: можно ли передавать в атрибут имя (пример: `John Smith <[email protected]>`). По умолчанию - false.
- `checkDNS`, проверяет, существует ли доменное имя для введенного адреса (и A, и MX запись).
Учтите, что проверка может закончится неудачей, что может быть вызвано временными проблемами с DNS, даже если
email-адрес корректен. По умолчанию - false.
- `enableIDN`, нужно ли учитывать IDN (многоязычные доменные имена). По умолчанию - false. Учтите, что для использования
IDN-валидации вам нужно установить и включить PHP расширение `intl`, иначе будет выброшено исключение.
## [[yii\validators\ExistValidator|exist]] <a name="exist"></a>
```php
[
// a1 должно существовать в столбце, который представляется атрибутом "a1"
['a1', 'exist'],
// a1 должно существовать, но его значение будет использовать a2 для проверки существования
['a1', 'exist', 'targetAttribute' => 'a2'],
// и a1, и a2 должны существовать, в противном случае оба атрибута будут возвращать ошибку
[['a1', 'a2'], 'exist', 'targetAttribute' => ['a1', 'a2']],
// и a1, и a2 должны существовать, но только атрибут a1 будет возвращать ошибку
['a1', 'exist', 'targetAttribute' => ['a1', 'a2']],
// a1 требует проверки существования a2 и a3 (используя значение a1)
['a1', 'exist', 'targetAttribute' => ['a2', 'a1' => 'a3']],
// a1 должен существовать. Если a1 - массив, то каждый его элемент должен существовать
['a1', 'exist', 'allowArray' => true],
]
```
Этот валидатор ищет входящие данные в столбце таблицы. Он работает только с атрибутами
модели [Active Record](db-active-record.md). Он поддерживает проверку и одного столбца, и нескольких.
- `targetClass`: имя класса [Active Record](db-active-record.md), который должен быть использован для проверки
входящего значения. Если не установлен, будет использован класс текущей модели.
- `targetAttribute`: имя атрибута в `targetClass` который должен быть использован для проверки существования
входящего значения. Если не установлен, будет использовано имя атрибута, который проверяется в данный момент.
Вы можете использовать массив для валидации нескольких столбцов одновременно. Значения массива являются атрибутами,
которые будут использованы для проверки существования, тогда как ключи массива будут являться атрибутами, чьи значения
будут проверены. Если ключ и значения одинаковы, вы можете указать только значение.
- `filter`: дополнительный фильтр, который будет добавлен к запросу в базу данных для проверки на существование значения.
Это может быть строка или массив, представляющие дополнительные условия в запросе (подробнее о формате
значений запроса: [[yii\db\Query::where()]]), или анонимная функция с сигнатурой `function ($query)`,
где `$query` - это [[yii\db\Query|Query]] объект, который вы можете модифицировать в функции.
- `allowArray`: разрешать ли значению быть массивом. По умолчанию - false. Если свойство установлено в true
и тип входящих данных - массив, тогда каждый его элемент должен существовать в соответствующем столбце таблицы.
Помните, что это свойство не может быть установлено в true, если вы валидируете несколько столбцов, передавая
их в `targetAttribute` как массив.
## [[yii\validators\FileValidator|file]] <a name="file"></a>
```php
[
// проверяет, что "primaryImage" - это загруженное изображение в формате PNG, JPG или GIF
// размер файла должен быть меньше 1MB
['primaryImage', 'file', 'extensions' => ['png', 'jpg', 'gif'], 'maxSize' => 1024*1024*1024],
]
```
Этот валидатор проверяет, что input является корректным загруженным файлом.
- `extensions`: список имен расширений, которые допустимы для загрузки. Это также может быть или массив, или
строка, содержащая имена файловых расширений, разделенных пробелом или запятой (пр.: "gif, jpg").
Имя расширения не чувствительно к регистру. По умолчанию - null, что значит, что все имена файловых расширений
допустимы.
- `mimeTypes`: список MIME-типов которые допустимы для загрузки. Это может быть или массив, или строка,
содержащая MIME-типы файлов, разделенные пробелом или запятой (пример: "image/jpeg, image/png").
Имена mime-типов не чувствительны к регистру. По умолчанию - null, что значит, что допустимы все MIME-типы.
- `minSize`: минимальный размер файла в байтах, разрешенный для загрузки. По умолчанию - null, что значит, что нет
минимального лимита.
- `maxSize`: максимальный размер файла в байтах, разрешенный для загрузки. По умолчанию - null, что значит, что нет
максимального лимита.
- `maxFiles`: максимальное количество файлов, которое может быть передано в атрибут. По умолчанию 1, что значит, что
input должен быть файлом в единственном экземпляре. Если больше, чем 1, то атрибут должен быть массивом,
состоящим из не более, чем `maxFiles` загруженных файлов.
- `checkExtensionByMimeType`: нужно ли проверять расширение файла исходя из его MIME-типа. Если они не соответствуют
друг другу, то файл будет считаться некорректным. По умолчанию - true, то есть проверка будет произведена.
`FileValidator` используется вместе с [[yii\web\UploadedFile]]. Пожалуйста, посмотрите раздел
[Загрузка файлов](input-file-upload.md) для более полного понимания загрузки и проверки файлов.
## [[yii\validators\FilterValidator|filter]] <a name="filter"></a>
```php
[
// обрезает пробелы вокруг "username" и "email"
[['username', 'email'], 'filter', 'filter' => 'trim', 'skipOnArray' => true],
// нормализует значение "phone"
['phone', 'filter', 'filter' => function ($value) {
// нормализация значения происходит тут
return $value;
}],
]
```
Этот валидатор не проверяет данные. Вместо этого он применяет указанный фильтр к входящему значению и
присваивает результат применения фильтра атрибуту.
- `filter`: PHP-callback, осуществляющий фильтрацию. Это может быть глобальная php функция, анонимная функция
и т.д. Функция должна выглядеть как `function ($value) { return $newValue; }`. Это свойство обязательно должно
быть установлено.
- `skipOnArray`: нужно ли пропускать валидацию, если входящим значением является массив. По умолчанию - false.
Помните, что если фильтр не может принимать массив, вы должны установить это значение в true. Иначе могут
произойти различные ошибки PHP.
> Трюк: Если вы хотите удалить пробелы вокруг значений атрибута, вы можете использовать валидатор [trim](#trim).
## [[yii\validators\ImageValidator|image]] <a name="image"></a>
```php
[
// проверяет, что "primaryImage" - это валидное изображение с указанными размерами
['primaryImage', 'image', 'extensions' => 'png, jpg',
'minWidth' => 100, 'maxWidth' => 1000,
'minHeight' => 100, 'maxHeight' => 1000,
],
]
```
Этот валидатор проверяет, что входящие данные являются корректным файлом изображения. Он расширяет [file](#file)
валидатор и наследует все его свойства. Кроме того, он поддерживает следующие дополнительные свойства, специфичные
для валидации изображений:
- `minWidth`: минимальная ширина изображения. По умолчанию null, что значит, что нет нижнего лимита.
- `maxWidth`: максимальная ширина изображения. По умолчанию null, что значит, что нет верхнего лимита.
- `minHeight`: минимальная высота изображения. По умолчанию null, что значит, что нет нижнего лимита.
- `maxHeight`: максимальная высота изображения. По умолчанию null, что значит, что нет верхнего лимита.
## [[yii\validators\RangeValidator|in]] <a name="in"></a>
```php
[
// проверяет, что значение "level" равно 1, 2 или 3
['level', 'in', 'range' => [1, 2, 3]],
]
```
Этот валидатор проверяет, что вхоящее значение соответствует одному из значений, указанных в `range`.
- `range`: список значений, с которыми будет сравниваться входящее значение.
- `strict`: должно ли сравнение входящего значения со списком значений быть строгим (учитывать тип данных).
По умолчанию false.
- `not`: должен ли результат проверки быть инвертирован. По умолчанию - false. Если свойство установлено в true,
валидатор проверяет, что входящее значение НЕ соответствует ни одному из значений, указанных в `range`.
- `allowArray`: устанавливает, допустимо ли использовать массив в качестве входных данных. Если установлено в true
и входящие данные являются массивом, для каждого элемента входящего массива должно быть найдено соответствие в
`range`.
## [[yii\validators\NumberValidator|integer]] <a name="integer"></a>
```php
[
// проверяет "age" на то, что это integer значение
['age', 'integer'],
]
```
Проверяет, что входящее значение является integer значением.
- `max`: верхний лимит (включительно) для числа. Если не установлено, валидатор не будет проверять верхний лимит.
- `min`: нижний лимит (включительно) для числа. Если не установлено, валидатор не будет проверять нижний лимит.
## [[yii\validators\RegularExpressionValidator|match]] <a name="match"></a>
```php
[
// проверяет, что "username" начинается с буквы и содержит только буквенные символы,
// числовые символы и знак подчеркивания
['username', 'match', 'pattern' => '/^[a-z]\w*$/i']
]
```
Этот валидатор проверяет, что входящее значение совпадает с указанным регулярным выражением.
- `pattern`: регулярное выражение, с которым должно совпадать входящее значение. Это свойство должно быть установлено,
иначе будет выброшено исключение.
- `not`: инвертирует регулярное выражение. По умолчанию false, что значит, что валидация будет успешна,
только если входящее значение совпадают с шаблоном. Если установлено в true, валидация будет успешна,
только если входящее значение НЕ совпадает с шаблоном.
## [[yii\validators\NumberValidator|number]] <a name="number"></a>
```php
[
// проверяет, является ли "salary" числом
['salary', 'number'],
]
```
Этот валидатор проверяет, являются ли входящие значения числовыми. Он эквивалентен валидатору [double](#double).
- `max`: верхний лимит (включительно) для числа. Если не установлено, валидатор не будет проверять верхний лимит.
- `min`: нижний лимит (включительно) для числа. Если не установлено, валидатор не будет проверять нижний лимит.
## [[yii\validators\RequiredValidator|required]] <a name="required"></a>
```php
[
// проверяет, являются ли "username" и "password" не пустыми
[['username', 'password'], 'required'],
]
```
Этот валидатор проверяет, являются ли входящие значения не пустыми.
- `requiredValue`: желаемое значение, которому должны соответствовать проверяемые данные. Если не установлено,
это значит, что данные должны быть не пусты.
- `strict`: учитывать или нет соответствие типу данных при валидации (строгое сравнение).
Если `requiredValue` не установлено, а это свойство установлено в true, валидатор проверит, что входящее значение
строго не соответствует null; если свойство установлено в false, валидатор будет проверять значение на пустоту с
приведением типов.
Если `requiredValue` установлено, сравнение между входящими данными и `requiredValue` будет также учитывать тип
данных, если это свойство установлено в true.
> Информация: как определить, является ли значение пустым или нет, подробнее рассказывается
в секции [Пустые значения](input-validation.md#handling-empty-inputs).
## [[yii\validators\SafeValidator|safe]] <a name="safe"></a>
```php
[
// обозначает "description" как safe атрибут
['description', 'safe'],
]
```
Этот валидатор не проверяет данные. Вместо этого он указывает, что атрибут является
[безопасным атрибутом](structure-models.md#safe-attributes).
## [[yii\validators\StringValidator|string]] <a name="string"></a>
```php
[
// проверяет, что "username" это строка с длиной от 4 до 24 символов
['username', 'string', 'length' => [4, 24]],
]
```
Этот валидатор проверяет, что входящее значение - это корректная строка с указанной длиной.
- `length`: описывает длину для строки, проходящей валидацию. Может быть определен следующими
способами:
* числом: точная длина, которой должна соответствовать строка;
* массив с одним элементом: минимальная длина входящей строки (напр.: `[8]`). Это перезапишет `min`.
* массив с двумя элементами: минимальная и максимальная длина входящей строки (напр.: `[8, 128]`).
Это перезапишет и `min`, и `max`.
- `min`: минимальная длина входящей строки. Если не установлено, то не будет ограничения на минимальную длину.
- `max`: максимальная длина входящей строки. Если не установлено, то не будет ограничения на максимальную длину.
- `encoding`: кодировка входящей строки. Если не установлено, будет использовано значение из
[[yii\base\Application::charset|charset]], которое по умолчанию установлено в `UTF-8`.
## [[yii\validators\FilterValidator|trim]] <a name="trim"></a>
```php
[
// обрезает пробелы вокруг "username" и "email"
[['username', 'email'], 'trim'],
]
```
Этот валидатор не производит проверки данных. Вместо этого он будет обрезать пробелы вокруг входящих данных.
Помните, что если входящие данные являются массивом, то они будут проигнорированы этим валидатором.
## [[yii\validators\UniqueValidator|unique]] <a name="unique"></a>
```php
[
// a1 должен быть уникальным в столбце, который представляет "a1" атрибут
['a1', 'unique'],
// a1 должен быть уникальным, но для проверки на уникальность
// будет использован столбец a2
['a1', 'unique', 'targetAttribute' => 'a2'],
// a1 и a2 вместе должны быть уникальны, и каждый из них
// будет получать сообщения об ошибке
[['a1', 'a2'], 'unique', 'targetAttribute' => ['a1', 'a2']],
// a1 и a2 вместе должны быть уникальны, но только a1 будет получать сообщение об ошибке
['a1', 'unique', 'targetAttribute' => ['a1', 'a2']],
// a1 должен быть уникальным, что устанавливается проверкой уникальности a2 и a3
// (используя значение a1)
['a1', 'unique', 'targetAttribute' => ['a2', 'a1' => 'a3']],
]
```
Этот валидатор проверяет входящие данные на уникальность в столбце таблицы. Он работает только с
атрибутами модели [Active Record](db-active-record.md). Он поддерживает проверку либо одного столбца,
либо нескольких.
- `targetClass`: имя класса [Active Record](db-active-record.md), который должен быть использован
для проверки значения во входящих данных. Если не установлен, будет использован класс модели, которая
в данный момент проходит проверку.
- `targetAttribute`: имя атрибута в `targetClass`, который должен быть использован для проверки на
уникальность входящего значения. Если не установлено, будет использован атрибут, проверяемый
в данный момент.
Вы можете использовать массив для проверки нескольких столбцов таблицы на уникальность. Значения массива -
это атрибуты, которые будут использованы для валидации, а ключи массива - это атрибуты, которые предоставляют
данные для валидации. Если ключ и значение одинаковые, вы можете указать только значение.
- `filter`: дополнительный фильтр, который можно присоединить к запросу в БД, чтобы использовать его при
проверке значения на уникальность. Это может быть строка или массив, представляющие дополнительные условия для запроса
(см. [[yii\db\Query::where()]] о формате условий в запросе), или анонимная функция вида `function ($query)`,
где `$query` это объект [[yii\db\Query|Query]], который вы можете изменить в функции.
## [[yii\validators\UrlValidator|url]] <a name="url"></a>
```php
[
// Проверяет, что "website" является корректным URL. Добавляет http:// к атрибуту "website".
// если у него нет URI схемы
['website', 'url', 'defaultScheme' => 'http'],
]
```
Этот валидатор проверяет, что входящее значение является корректным URL.
- `validSchemes`: массив с указанием на URI-схему, которая должна считаться корректной. По умолчанию
`['http', 'https']`, что означает, что и `http`, и `https` URI будут считаться корректными.
- `defaultScheme`: схема URI, которая будет присоединена к входящим данным, если в них отсутствует URI-схема.
По умолчанию null, что значит, что входящие данные не будут изменены.
- `enableIDN`: должна ли валидация учитывать IDN (интернационализованные доменные имена).
По умолчанию - false. Учтите, что для того, чтобы IDN валидация работала корректно, вы должны установить `intl`
PHP расширение, иначе будет выброшено исключение.
| 45.844055 | 139 | 0.738158 | rus_Cyrl | 0.977212 |
587d77817facac214006f88cdb85d2d7ab73789f | 1,789 | md | Markdown | src.save/main/java/g0901_1000/s0911_online_election/readme.md | jscrdev/LeetCode-in-Java | cb2ec473a6e728e0eafb534518fde41910488d85 | [
"MIT"
] | 2 | 2021-12-21T11:30:12.000Z | 2022-03-04T09:30:33.000Z | src/main/java/g0901_1000/s0911_online_election/readme.md | LeetCode-in-Java/LeetCode-in-Java | edbd97ba42724129f1c8205799d0b3b135d0320b | [
"MIT"
] | null | null | null | src/main/java/g0901_1000/s0911_online_election/readme.md | LeetCode-in-Java/LeetCode-in-Java | edbd97ba42724129f1c8205799d0b3b135d0320b | [
"MIT"
] | null | null | null | 911\. Online Election
Medium
You are given two integer arrays `persons` and `times`. In an election, the <code>i<sup>th</sup></code> vote was cast for `persons[i]` at time `times[i]`.
For each query at a time `t`, find the person that was leading the election at time `t`. Votes cast at time `t` will count towards our query. In the case of a tie, the most recent vote (among tied candidates) wins.
Implement the `TopVotedCandidate` class:
* `TopVotedCandidate(int[] persons, int[] times)` Initializes the object with the `persons` and `times` arrays.
* `int q(int t)` Returns the number of the person that was leading the election at time `t` according to the mentioned rules.
**Example 1:**
**Input** ["TopVotedCandidate", "q", "q", "q", "q", "q", "q"] [[[0, 1, 1, 0, 0, 1, 0], [0, 5, 10, 15, 20, 25, 30]], [3], [12], [25], [15], [24], [8]]
**Output:** [null, 0, 1, 1, 0, 0, 1]
**Explanation:** TopVotedCandidate topVotedCandidate = new TopVotedCandidate([0, 1, 1, 0, 0, 1, 0], [0, 5, 10, 15, 20, 25, 30]); topVotedCandidate.q(3); // return 0, At time 3, the votes are [0], and 0 is leading. topVotedCandidate.q(12); // return 1, At time 12, the votes are [0,1,1], and 1 is leading. topVotedCandidate.q(25); // return 1, At time 25, the votes are [0,1,1,0,0,1], and 1 is leading (as ties go to the most recent vote.) topVotedCandidate.q(15); // return 0 topVotedCandidate.q(24); // return 0 topVotedCandidate.q(8); // return 1
**Constraints:**
* `1 <= persons.length <= 5000`
* `times.length == persons.length`
* `0 <= persons[i] < persons.length`
* <code>0 <= times[i] <= 10<sup>9</sup></code>
* `times` is sorted in a strictly increasing order.
* <code>times[0] <= t <= 10<sup>9</sup></code>
* At most <code>10<sup>4</sup></code> calls will be made to `q`. | 59.633333 | 548 | 0.650084 | eng_Latn | 0.967169 |
587d943a4dab8941be41856a5894bf1b28ebd422 | 3,003 | md | Markdown | sta160/2018/discussion05/discussion05.md | clarkfitzg/teaching-notes | a795263bf7d1b5083fb8efbd4460166a65d50545 | [
"BSD-3-Clause-Clear"
] | 28 | 2017-03-31T03:15:13.000Z | 2020-09-21T19:58:35.000Z | sta160/2018/discussion05/discussion05.md | hemiaocui/teaching-notes | a795263bf7d1b5083fb8efbd4460166a65d50545 | [
"BSD-3-Clause-Clear"
] | null | null | null | sta160/2018/discussion05/discussion05.md | hemiaocui/teaching-notes | a795263bf7d1b5083fb8efbd4460166a65d50545 | [
"BSD-3-Clause-Clear"
] | 33 | 2018-01-12T04:17:08.000Z | 2021-11-24T04:31:05.000Z | # Week 5 Discussion
Reminder: OH Monday 9-10am in Shields 360
## Presentations
You'll present a status report to the class next week.
Plan to present on Tuesday (although you might not present until Thursday).
* Format: 4 minute talk, 1 minute for questions
* Audience: STA 160 students
+ So if we've talked about the data in class, you don't need to tell
us about it again
* Purpose: What is the status of your project?
+ What are your concrete goals?
+ What specific tasks have you completed?
+ Where do you need help or feedback?
## Presentation Skills
* How you act:
+ Face the audience
+ Maintain good posture and don't cross your arms
+ Move hands or even body while speaking
+ Speak at a deliberate pace (not too slow, not too fast)
+ Don't giggle or laugh unless someone told a joke
+ Be conversational. Don't read from slides
* What you say:
+ Introduce yourselves and your project at the beginning
+ Avoid acronyms and abbreviations
+ Avoid assumptions about the audience: like, you know, as expected, ...
+ Avoid adverbs (words ending in "-ly"): very, easily, entirely, ...
+ Avoid pronouns without context: it, this
+ Think about what the "story" is for your project. What's interesting and
important?
* Thank the audience at the end!
* Slides
+ Don't make comparisons to previous slides
+ Support claims with evidence
+ Design visuals carefully (see [handout][])
+ Make uncluttered slides
+ Make self-contained slides
+ Use plain language
+ Plan for at least 30 seconds (probably 1 minute) per slide
[handout]: ../../../sta141a/graphics_checklist.pdf
### Types of Slides
* Title Slide
+ Include title and names
+ Don't forget to present this slide
* Story Slide
+ The title is the takeaway
+ Use 1-3 points on the slide to support the title
* Summary Slide
+ Summarize the main points of your talk
+ Include miniature versions of key visuals
## Let's Practice!
Get into groups of three. If possible, make sure no one else from your project
is in the group.
Take five minutes to write a two-minute presentation of your project. Think
about what you'll need to tell the others in the group.
Take turns having each person present to the group. While they present, the
others should write down thoughts. For example:
* Did they introduce themselves and their project?
* Are they speaking clearly?
* Are they being vague?
* Do you understand what they're talking about?
* What questions do you have for the speaker?
After a speaker finishes, spend a minute or two giving them your feedback.
## References
* Lebrun. When The Scientist Presents. 2010.
* Lebrun. Scientific Writing 2.0. 2011.
* Alred, Brusaw, Oliu. Handbook of Technical Writing. 2003.
* Yau. Visualize This: The FlowingData Guide to Design, Visualization, and
Statistics. 2011.
* [Google Style Guide](https://developers.google.com/style/)
## `find` and `grep`
| 30.958763 | 78 | 0.716284 | eng_Latn | 0.998362 |
587dd0a8216335384121419812861823f57bb8ad | 520 | md | Markdown | README.md | cleitoncmf/CEME-I-UERJ | ba596cd5fe22ffde30afb9f5ed0cb32c8ac9f737 | [
"MIT"
] | 1 | 2021-03-03T19:11:38.000Z | 2021-03-03T19:11:38.000Z | README.md | cleitoncmf/CEME-I-UERJ | ba596cd5fe22ffde30afb9f5ed0cb32c8ac9f737 | [
"MIT"
] | null | null | null | README.md | cleitoncmf/CEME-I-UERJ | ba596cd5fe22ffde30afb9f5ed0cb32c8ac9f737 | [
"MIT"
] | 1 | 2021-03-03T22:43:21.000Z | 2021-03-03T22:43:21.000Z | # CEME-I-UERJ
Este é um repositório contendo os códigos e arquivos de simulação apresentados nas aulas de Conversão Eletromecânica de Energia I da [Universidade do Estado do Rio de Janeiro](https://www.uerj.br/) (UERJ).
- [CEME-I-UERJ](#ceme-i-uerj)
- [Simulações de Circuitos Magnéticos Utilizando o Software FEMM](https://github.com/cleitoncmf/CEME-I-UERJ/tree/master/FEMM)
- [Resolvendo circuitos magnéticos com Imãs Permanentes no SciLab](https://github.com/cleitoncmf/CEME-I-UERJ/tree/master/EX_IMA_SCILAB) | 57.777778 | 206 | 0.775 | por_Latn | 0.991941 |
587e06eb6366944d1fc962dae352635e5f31ee29 | 333 | md | Markdown | README.md | s2t2/github_data_client | 0ffe96cb720c96c2950329f58e46ff5f71f61172 | [
"MIT"
] | null | null | null | README.md | s2t2/github_data_client | 0ffe96cb720c96c2950329f58e46ff5f71f61172 | [
"MIT"
] | 1 | 2015-02-25T08:45:42.000Z | 2015-02-25T08:45:42.000Z | README.md | s2t2/github_data_client | 0ffe96cb720c96c2950329f58e46ff5f71f61172 | [
"MIT"
] | null | null | null | # github_data_client
Extracts usage data from the github api (https://developer.github.com/v3/).
## Configuration
Setup the database.
```` sh
bundle exec rake db:create
bundle exec rake db:migrate
````
## Usage
Extract user and event info.
```` rb
EventExtractor.perform
````
or
```` sh
bundle exec rake extract:events
````
| 12.333333 | 75 | 0.702703 | eng_Latn | 0.794361 |
587e8b23fa477eddff88e5f2eb3187dbf2d1f5c3 | 556 | md | Markdown | README.md | bhollan/rubedility-cli-gem | 37eda07e9ecb77be9b80803a8c4fad336d16c7ff | [
"MIT"
] | null | null | null | README.md | bhollan/rubedility-cli-gem | 37eda07e9ecb77be9b80803a8c4fad336d16c7ff | [
"MIT"
] | null | null | null | README.md | bhollan/rubedility-cli-gem | 37eda07e9ecb77be9b80803a8c4fad336d16c7ff | [
"MIT"
] | null | null | null | # Rubedility rubygem
Rubygem that allows a user to navigate and browse Codility.com's lessons and quizes (tasks).
## Installation
`gem install rubedility`
## Dependencies
* `openurl`/`open-uri`
* `nokogiri`
* `launchy`
## Functionality
Rubedility should be able to give command line interface to the user with Codility's lessons and quiz questions.
View all available lessons.
View all available quizes.
View all available quizes by lesson.
View all available quizes by difficulty.
View all available reading material (download or open-in-browser).
| 24.173913 | 112 | 0.778777 | eng_Latn | 0.979466 |
587ee1d2aa8468aac1cf9f9742aba2e87e425588 | 4,231 | md | Markdown | _posts/2016-07-07-security-roundup-2016-07-07.md | Seanstoppable/seanstoppable.github.io | 2137401950135cf91e9270fbeee435534c4b0b84 | [
"MIT"
] | null | null | null | _posts/2016-07-07-security-roundup-2016-07-07.md | Seanstoppable/seanstoppable.github.io | 2137401950135cf91e9270fbeee435534c4b0b84 | [
"MIT"
] | null | null | null | _posts/2016-07-07-security-roundup-2016-07-07.md | Seanstoppable/seanstoppable.github.io | 2137401950135cf91e9270fbeee435534c4b0b84 | [
"MIT"
] | null | null | null | ---
layout: post
title: Security Roundup - 2016-07-07
author: Seanstoppable
category: security-roundup
date: '2016-07-07'
tags:
- android
- hardware
- honeypots
- IoT
- machine learning
- ransomware
- reverse engineering
---
More hardware security vulnerabilities this with, with a firmware problem on
certain Gigabyte motherboards [impacting such laptops as the Lenovo Thinkpad
series and HP Pavilion laptops](https://threatpost.com/scope-of-thinkpwn-uefi-zero-day-expands/119027/),
allowing for the disabling of numerous security protections and running of
arbitrary code. Also, Duo labs reports that a large number of [Android devices
are vulnerable](https://duo.com/blog/thirty-percent-of-android-devices-susceptible-to-24-critical-vulnerabilities)
to previously patched CVEs (specifically, [this Qualcomm exploit that undermines
full disk encryption](https://bits-please.blogspot.com/2016/06/extracting-qualcomms-keymaster-keys.html),
as they have yet to receive an update and may never do so due to the way
OEM/carrier patch rollouts work.
As the volume of threat intelligence increases, more groups turn to machine
learning to try to sort the signals from noise. MIT's Computer Science and
Artificial Intelligence Lab have apparently developed a system called AI^2 which
apparently [is able to monitor logs and detect 85% of of
attacks](https://techcrunch.com/2016/07/01/exploiting-machine-learning-in-cybersecurity/),
allowing for a reduction of what needs to be reviewed by human beings.
My co-worker, [Josh Rendek](https://github.com/joshrendek), recently put
together a presentation on a side project of his called
[sshpot](https://sshpot.com). He has followed up by [writing up some of his
thoughts, process, and findings](https://joshrendek.com/2016/06/building-honeypots-and-analyzing-linux-malware/)
from building an SSH honeypot.
TrapX labs has released a report entitled ["Anatomy of an Attack – Medical
Device Hijack 2"](http://trapx.com/trapx-labs-discovers-new-medical-hijack-attacks-targeting-hospital-devices-2/),
giving an update on their observations of Hospital focused malware.
Interestingly, they are seeing old exploits delivering new payloads, seemingly a
result of medical devices being older Windows devices in many cases.
DARPA apparently running a ['Cyber Grand Slam'](http://www.wired.com/2016/07/__trashed-19/)
in August, where bots will compete to automatically exploit vulnerabilities, as
well as defend against them on the fly. I am looking forward to the reports and
follow up of this event.
TrustWave has an interesting article on [reverse engineering the Hawkeye
Keylogger](https://www.trustwave.com/Resources/SpiderLabs-Blog/How-I-Cracked-a-Keylogger-and-Ended-Up-in-Someone-s-Inbox/)
which is also using very old exploits to try to install itself.
Login security basics: Long passwords, HTTPs, password hashing. Right? Troy Hunt
has a [long week of appsec issues, where various players forget the basics](https://www.troyhunt.com/security-insanity-how-we-keep-failing-at-the-basics/).
Interested in smart appliances, but worried about security? This week I learned
of [Matther Garret](https://www.amazon.com/gp/pdp/profile/A2GFJ3D17SCEOX/ref=cm_cr_rdp_pdp),
a security researcher in SF that has started writing security oriented product
reviews about IoT devices.
I knew Domain Hijacking was a thing, but this week I learned that bad actors
also try to [hijack IPv4 netblocks](https://www.schneier.com/blog/archives/2016/06/fraudsters_are_.html).
Simply by checking for unmaintained WHOIS records, registering the lapsed domain
and posing as the legitimate company, attackers are apparently able to
successfully flip IPv4 addresses to buyers.
As always, [BleepingComputer has the best Ransomware
Roundup](http://www.bleepingcomputer.com/news/security/the-week-in-ransomware-july-1-2016-bart-wildfire-locky-and-more/).
This week includes new Locky Variants, a ransomware named 'EduCrypt' that
attempts to educate users on malware, numerous decryptors for the numerous
variants, and Satana a ransomware that not only encrypts your files, but
encrypts a machines Master Boot Record to prevent users from starting up their
operating system.
| 54.948052 | 155 | 0.796029 | eng_Latn | 0.986305 |
587eea5f76e02d1940c7c49dbe0f074a83247ace | 236 | md | Markdown | README.md | SEKure-archive/sekure-archive-server | 56f37f6a28f8a0e98aea42cf45c27db404f69f7a | [
"Apache-2.0"
] | null | null | null | README.md | SEKure-archive/sekure-archive-server | 56f37f6a28f8a0e98aea42cf45c27db404f69f7a | [
"Apache-2.0"
] | null | null | null | README.md | SEKure-archive/sekure-archive-server | 56f37f6a28f8a0e98aea42cf45c27db404f69f7a | [
"Apache-2.0"
] | null | null | null | # sekure-archive-server
The server-side application component of SEKure-archive.
Released under the Apache License 2.0.
## Instructions
1. Install [Docker](https://docs.docker.com/engine/installation)
2. Run `test.bat` or `test.sh`
| 21.454545 | 64 | 0.758475 | eng_Latn | 0.449974 |
587f3aafb4063a1c060c4b1e1cba2779d29ac291 | 37,475 | md | Markdown | articles/data-factory/connector-file-system.md | MicrosoftDocs/azure-docs.hu-hu | 5fb082c5dae057fd040c7e09881e6c407e535fe2 | [
"CC-BY-4.0",
"MIT"
] | 7 | 2017-08-28T07:44:33.000Z | 2021-04-20T21:12:50.000Z | articles/data-factory/connector-file-system.md | MicrosoftDocs/azure-docs.hu-hu | 5fb082c5dae057fd040c7e09881e6c407e535fe2 | [
"CC-BY-4.0",
"MIT"
] | 412 | 2018-07-25T09:31:03.000Z | 2021-03-17T13:17:45.000Z | articles/data-factory/connector-file-system.md | MicrosoftDocs/azure-docs.hu-hu | 5fb082c5dae057fd040c7e09881e6c407e535fe2 | [
"CC-BY-4.0",
"MIT"
] | 13 | 2017-09-05T09:10:35.000Z | 2021-11-05T11:42:31.000Z | ---
title: Adatok másolása a fájlrendszerből a Azure Data Factory használatával
description: Megtudhatja, hogyan másolhat a fájlrendszerből származó adatokból támogatott fogadó adattárakba (vagy) a támogatott forrás-adattárakból a fájlrendszerbe Azure Data Factory használatával.
author: linda33wj
ms.service: data-factory
ms.topic: conceptual
ms.date: 03/29/2021
ms.author: jingwang
ms.openlocfilehash: c49b543b13dddf4c4ba7e36196795c6a0d638ae2
ms.sourcegitcommit: 32e0fedb80b5a5ed0d2336cea18c3ec3b5015ca1
ms.translationtype: MT
ms.contentlocale: hu-HU
ms.lasthandoff: 03/30/2021
ms.locfileid: "105731955"
---
# <a name="copy-data-to-or-from-a-file-system-by-using-azure-data-factory"></a>Adatok másolása fájlrendszerből vagy rendszerbe a Azure Data Factory használatával
> [!div class="op_single_selector" title1="Válassza ki az Ön által használt Data Factory-szolgáltatás verzióját:"]
> * [1-es verzió](v1/data-factory-onprem-file-system-connector.md)
> * [Aktuális verzió](connector-file-system.md)
[!INCLUDE[appliesto-adf-asa-md](includes/appliesto-adf-asa-md.md)]
Ez a cikk azt ismerteti, hogyan másolhatók az adatok a fájlrendszerbe. A Azure Data Factoryről a [bevezető cikkben](introduction.md)olvashat bővebben.
## <a name="supported-capabilities"></a>Támogatott képességek
Ez a fájlrendszer-összekötő a következő tevékenységek esetén támogatott:
- [Másolási tevékenység](copy-activity-overview.md) [támogatott forrás/fogadó mátrixtal](copy-activity-overview.md)
- [Keresési tevékenység](control-flow-lookup-activity.md)
- [GetMetadata tevékenység](control-flow-get-metadata-activity.md)
- [Tevékenység törlése](delete-activity.md)
A fájlrendszer-összekötő különösen a következőket támogatja:
- Fájlok másolása helyi gépre vagy hálózati fájlmegosztásba. Linux-fájlmegosztás használatához telepítse a [Samba](https://www.samba.org/) -t a Linux-kiszolgálóra.
- Fájlok másolása **Windows** -hitelesítéssel.
- Fájlok másolása a-ként vagy a fájlok elemzése/létrehozása a [támogatott fájlformátumokkal és tömörítési kodekekkel](supported-file-formats-and-compression-codecs.md).
> [!NOTE]
> A csatlakoztatott hálózati meghajtó nem támogatott hálózati fájlmegosztás adatainak betöltésekor. Használja inkább a tényleges elérési utat, például ` \\server\share` :.
## <a name="prerequisites"></a>Előfeltételek
[!INCLUDE [data-factory-v2-integration-runtime-requirements](../../includes/data-factory-v2-integration-runtime-requirements.md)]
## <a name="getting-started"></a>Első lépések
[!INCLUDE [data-factory-v2-connector-get-started](../../includes/data-factory-v2-connector-get-started.md)]
A következő szakaszokban részletesen ismertetjük azokat a tulajdonságokat, amelyek a fájlrendszerre vonatkozó Data Factory-entitások definiálására szolgálnak.
## <a name="linked-service-properties"></a>Társított szolgáltatás tulajdonságai
A fájlrendszerhez társított szolgáltatás a következő tulajdonságokat támogatja:
| Tulajdonság | Leírás | Kötelező |
|:--- |:--- |:--- |
| típus | A Type tulajdonságot a következőre kell beállítani: **fileserver**. | Yes |
| gazda | Megadja a másolni kívánt mappa gyökerének elérési útját. A "Escape" karakter használata a \" karakterlánc speciális karaktereinek számára. Példákat a következő témakörben talál: példa [társított szolgáltatás és adatkészlet-definíciók](#sample-linked-service-and-dataset-definitions) . | Yes |
| userId | Itt adhatja meg annak a felhasználónak az AZONOSÍTÓját, aki hozzáfér a kiszolgálóhoz. | Yes |
| jelszó | A felhasználó jelszavának megadása (userId). Megjelöli ezt a mezőt SecureString, hogy biztonságosan tárolja Data Factoryban, vagy [hivatkozjon a Azure Key Vault tárolt titkos kulcsra](store-credentials-in-key-vault.md). | Yes |
| Connectvia tulajdonsággal | Az adattárhoz való kapcsolódáshoz használt [Integration Runtime](concepts-integration-runtime.md) . További tudnivalók az [Előfeltételek](#prerequisites) szakaszban olvashatók. Ha nincs megadva, az alapértelmezett Azure Integration Runtime használja. |No |
### <a name="sample-linked-service-and-dataset-definitions"></a>Példa társított szolgáltatás és adatkészlet-definíciók
| Eset | "host" a társított szolgáltatás definíciójában | "folderPath" az adatkészlet definíciójában |
|:--- |:--- |:--- |
| Helyi mappa Integration Runtime gépen: <br/><br/>Példák: D: \\ \* vagy D:\folder\subfolder\\* |JSON-ban: `D:\\`<br/>Felhasználói felületen: `D:\` |A JSON-ban: `.\\` vagy `folder\\subfolder`<br>Felhasználói felületen: `.\` vagy `folder\subfolder` |
| Távoli megosztott mappa: <br/><br/>Példák: \\ \\ MyServer \\ Share \\ \* vagy \\ \\ MyServer \\ Share \\ mappa \\ almappája\\* |JSON-ban: `\\\\myserver\\share`<br/>Felhasználói felületen: `\\myserver\share` |A JSON-ban: `.\\` vagy `folder\\subfolder`<br/>Felhasználói felületen: `.\` vagy `folder\subfolder` |
>[!NOTE]
>Felhasználói felületen keresztüli szerzői műveletek esetén nem szükséges dupla fordított perjelet () megadnia, `\\` mint a JSON-n keresztül, adjon meg egy fordított perjelet.
**Példa**
```json
{
"name": "FileLinkedService",
"properties": {
"type": "FileServer",
"typeProperties": {
"host": "<host>",
"userId": "<domain>\\<user>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
```
## <a name="dataset-properties"></a>Adatkészlet tulajdonságai
Az adatkészletek definiálásához rendelkezésre álló csoportok és tulajdonságok teljes listáját az [adatkészletek](concepts-datasets-linked-services.md) című cikkben találja.
[!INCLUDE [data-factory-v2-file-formats](../../includes/data-factory-v2-file-formats.md)]
A fájlrendszer a következő tulajdonságokat támogatja a `location` Format-alapú adatkészlet beállítások területén:
| Tulajdonság | Leírás | Kötelező |
| ---------- | ------------------------------------------------------------ | -------- |
| típus | Az `location` adatkészletben található Type tulajdonságot **FileServerLocation** értékre kell állítani. | Yes |
| folderPath | A mappa elérési útja. Ha a mappa szűréséhez helyettesítő karaktert szeretne használni, hagyja ki ezt a beállítást, és a tevékenység forrásának beállításai között válassza a lehetőséget. | No |
| fileName | A fájlnév a megadott folderPath alatt. Ha helyettesítő karaktereket szeretne használni a fájlok szűréséhez, hagyja ki ezt a beállítást, és a tevékenység forrásának beállításai között válassza a lehetőséget. | No |
**Példa**
```json
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<File system linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "FileServerLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
```
## <a name="copy-activity-properties"></a>Másolási tevékenység tulajdonságai
A tevékenységek definiálásához elérhető csoportok és tulajdonságok teljes listáját a [folyamatok](concepts-pipelines-activities.md) című cikkben találja. Ez a szakasz a fájlrendszer forrása és a fogadó által támogatott tulajdonságok listáját tartalmazza.
### <a name="file-system-as-source"></a>Fájlrendszer forrásként
[!INCLUDE [data-factory-v2-file-formats](../../includes/data-factory-v2-file-formats.md)]
A fájlrendszer a következő tulajdonságokat támogatja a `storeSettings` Format-alapú másolási forrás beállítások területén:
| Tulajdonság | Leírás | Kötelező |
| ------------------------ | ------------------------------------------------------------ | --------------------------------------------- |
| típus | A Type tulajdonságot a `storeSettings` **FileServerReadSettings** értékre kell állítani. | Yes |
| ***Keresse meg a másolandó fájlokat:*** | | |
| 1. lehetőség: statikus elérési út<br> | Másolja az adatkészletben megadott mappa vagy fájl elérési útját. Ha az összes fájlt egy mappából szeretné másolni, azt is meg kell adnia `wildcardFileName` `*` . | |
| 2. lehetőség: Kiszolgálóoldali szűrő<br>– fileFilter | Fájlkiszolgáló oldali natív szűrő, amely jobb teljesítményt nyújt, mint a 3. lehetőség helyettesítő szűrője. `*`Nulla vagy több karakter összeegyeztetésére, valamint `?` a nulla vagy egy karakter megfeleltetésére használható. Az [ebben a szakaszban](/dotnet/api/system.io.directory.getfiles#System_IO_Directory_GetFiles_System_String_System_String_System_IO_SearchOption_)található **Megjegyzések** szintaxisáról és megjegyzéseit itt találja. | No |
| 3. lehetőség: ügyféloldali szűrő<br>- wildcardFolderPath | A mappa elérési útja helyettesítő karakterekkel a forrás mappák szűréséhez. Ez a szűrő az ADF oldalon történik, az ADF a megadott elérési úton lévő mappák/fájlok enumerálása, majd a helyettesítő szűrő alkalmazása.<br>Az engedélyezett helyettesítő karakterek a következők: `*` (nulla vagy több karakternek felel meg) és `?` (a nulla vagy egy karakter egyezése) `^` <br>További példákat a [mappák és a fájlok szűrésére szolgáló példákban](#folder-and-file-filter-examples)talál. | No |
| 3. lehetőség: ügyféloldali szűrő<br>- wildcardFileName | A forrásfájl szűréséhez a megadott folderPath/wildcardFolderPath helyettesítő karaktereket tartalmazó fájlnév. Ez a szűrő az ADF oldalon történik, az ADF a megadott elérési úton lévő fájlok enumerálása, majd a helyettesítő szűrő alkalmazása.<br>Az engedélyezett helyettesítő karakterek a következők: `*` (nulla vagy több karakternek felel meg) és `?` (a nulla vagy egy karakter egyezése) `^`<br>További példákat a [mappák és a fájlok szűrésére szolgáló példákban](#folder-and-file-filter-examples)talál. | Yes |
| 3. lehetőség: a fájlok listája<br>- fileListPath | Egy adott fájl másolását jelzi. Mutasson egy szövegfájlra, amely tartalmazza a másolni kívánt fájlok listáját, soronként egy fájlt, amely az adatkészletben konfigurált útvonal relatív elérési útja.<br/>Ha ezt a beállítást használja, ne adja meg a fájl nevét az adatkészletben. További példákat a [fájllista példákban](#file-list-examples)talál. |No |
| ***További beállítások:*** | | |
| rekurzív | Azt jelzi, hogy az adatok rekurzív módon olvashatók-e az almappákból, vagy csak a megadott mappából. Vegye figyelembe, hogy ha a rekurzív értéke TRUE (igaz), a fogadó pedig egy fájl alapú tároló, a fogadó nem másolja vagy hozza létre az üres mappát vagy almappát. <br>Az engedélyezett értékek: **true** (alapértelmezett) és **false (hamis**).<br>Ez a tulajdonság nem érvényes a konfiguráláskor `fileListPath` . |No |
| deleteFilesAfterCompletion | Azt jelzi, hogy a rendszer törli-e a bináris fájlokat a forrás-áruházból, miután sikeresen áthelyezte a célhelyre. A fájl törlése fájl alapján történik, így ha a másolási tevékenység meghiúsul, néhány fájl már át lett másolva a célhelyre, és törlődik a forrásból, míg mások továbbra is a forrás-áruházban maradnak. <br/>Ez a tulajdonság csak bináris fájlok másolási forgatókönyv esetén érvényes. Az alapértelmezett érték: false. |No |
| modifiedDatetimeStart | A fájlok szűrése a következő attribútum alapján: utoljára módosítva. <br>A fájlok akkor lesznek kiválasztva, ha az utolsó módosítás időpontja a és a közötti időintervallumon belül van `modifiedDatetimeStart` `modifiedDatetimeEnd` . Az idő az UTC-időzónára vonatkozik "2018-12-01T05:00:00Z" formátumban. <br> A tulajdonságok lehetnek NULL értékűek, ami azt jelenti, hogy a rendszer nem alkalmazza a file Attribute szűrőt az adatkészletre. Ha `modifiedDatetimeStart` a dátum datetime értékkel rendelkezik `modifiedDatetimeEnd` , de null értékű, az azt jelenti, hogy azok a fájlok lesznek kiválasztva, amelyek utolsó módosított attribútuma nagyobb vagy egyenlő, mint a DateTime érték. Ha `modifiedDatetimeEnd` a dátum datetime értékkel rendelkezik `modifiedDatetimeStart` , de null értékű, az azt jelenti, hogy azok a fájlok, amelyek utolsó módosítási attribútuma kisebb, mint a DateTime érték, ki lesz választva.<br/>Ez a tulajdonság nem érvényes a konfiguráláskor `fileListPath` . | No |
| modifiedDatetimeEnd | Lásd fentebb. | No |
| enablePartitionDiscovery | A particionált fájlok esetében adja meg, hogy szeretné-e elemezni a partíciókat a fájl elérési útján, majd adja hozzá őket további forrásként szolgáló oszlopként.<br/>Az engedélyezett értékek: **false** (alapértelmezett) és **true (igaz**). | No |
| partitionRootPath | Ha engedélyezve van a partíciók felderítése, akkor a particionált mappák adatoszlopként való olvasásához a gyökér elérési útját kell megadni.<br/><br/>Ha nincs megadva, a rendszer alapértelmezés szerint<br/>– Ha a fájl elérési útját használja az adatkészletben vagy a forrásban található fájlok listáján, a partíció gyökerének elérési útja az adatkészletben konfigurált útvonal.<br/>– Ha helyettesítő mappa szűrőt használ, a partíció gyökerének elérési útja az első helyettesítő karakter előtti Alútvonal.<br/><br/>Tegyük fel például, hogy az adatkészletben az elérési utat "root/Folder/Year = 2020/hónap = 08/Day = 27" értékre konfigurálja:<br/>– Ha a partíció gyökerének elérési útját "gyökér/mappa/év = 2020" értékre állítja, a másolási tevékenység két további oszlopot fog előállítani, `month` és a `day` "08" és "27" értéket is kijelöli a fájlokban lévő oszlopokon kívül.<br/>– Ha nincs megadva a partíció gyökerének elérési útja, nem jön létre további oszlop. | No |
| maxConcurrentConnections |A tevékenység futtatása során az adattárhoz létesített egyidejű kapcsolatok felső határa. Csak akkor adhat meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat.| No |
**Példa**
```json
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "FileServerReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
```
### <a name="file-system-as-sink"></a>Fájlrendszer fogadóként
[!INCLUDE [data-factory-v2-file-sink-formats](../../includes/data-factory-v2-file-sink-formats.md)]
A fájlrendszer a következő tulajdonságokat támogatja a `storeSettings` Format-alapú másolási fogadó beállításai alatt:
| Tulajdonság | Leírás | Kötelező |
| ------------------------ | ------------------------------------------------------------ | -------- |
| típus | A Type tulajdonságot a `storeSettings` **FileServerWriteSettings** értékre kell állítani. | Yes |
| copyBehavior | Meghatározza a másolási viselkedést, ha a forrás fájl-alapú adattárból származó fájlok.<br/><br/>Az engedélyezett értékek a következők:<br/><b>-PreserveHierarchy (alapértelmezett)</b>: megőrzi a fájl-hierarchiát a célmappában. A forrásfájl a forrás mappájához relatív elérési útja megegyezik a célfájl relatív elérési útjával.<br/><b>-FlattenHierarchy</b>: a forrás mappából származó összes fájl a célmappa első szintjén van. A célként megadott fájlok automatikusan generált névvel rendelkeznek. <br/><b>-MergeFiles</b>: az összes fájlt egyesíti a forrás mappájából egy fájlba. Ha meg van adva a fájl neve, az egyesített fájl neve a megadott név. Ellenkező esetben ez egy automatikusan létrehozott fájl neve. | No |
| maxConcurrentConnections |A tevékenység futtatása során az adattárhoz létesített egyidejű kapcsolatok felső határa. Csak akkor adhat meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat.| No |
**Példa**
```json
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "FileServerWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
```
### <a name="folder-and-file-filter-examples"></a>Példák a mappák és a fájlok szűrésére
Ez a szakasz a mappa elérési útjának és fájlnevének a helyettesítő karakteres szűrőkkel való viselkedését írja le.
| folderPath | fileName | rekurzív | A forrás mappa szerkezete és a szűrő eredménye (a **félkövérrel szedett** fájlok beolvasása)|
|:--- |:--- |:--- |:--- |
| `Folder*` | (üres, alapértelmezett használata) | hamis | Mappa<br/> **File1.csv**<br/> **File2.jsbekapcsolva**<br/> Subfolder1<br/> File3.csv<br/> File4.jsbekapcsolva<br/> File5.csv<br/>AnotherFolderB<br/> File6.csv |
| `Folder*` | (üres, alapértelmezett használata) | true | Mappa<br/> **File1.csv**<br/> **File2.jsbekapcsolva**<br/> Subfolder1<br/> **File3.csv**<br/> **File4.jsbekapcsolva**<br/> **File5.csv**<br/>AnotherFolderB<br/> File6.csv |
| `Folder*` | `*.csv` | hamis | Mappa<br/> **File1.csv**<br/> File2.jsbekapcsolva<br/> Subfolder1<br/> File3.csv<br/> File4.jsbekapcsolva<br/> File5.csv<br/>AnotherFolderB<br/> File6.csv |
| `Folder*` | `*.csv` | true | Mappa<br/> **File1.csv**<br/> File2.jsbekapcsolva<br/> Subfolder1<br/> **File3.csv**<br/> File4.jsbekapcsolva<br/> **File5.csv**<br/>AnotherFolderB<br/> File6.csv |
### <a name="file-list-examples"></a>Példák a fájllista
Ez a szakasz a fájllista elérési útjának a másolási tevékenység forrásában való használatának eredményét írja le.
Feltételezve, hogy rendelkezik a következő forrás-mappa struktúrájával, és félkövéren szeretné átmásolni a fájlokat:
| Példa a forrás struktúrájára | Tartalom FileListToCopy.txt | ADF-konfiguráció |
| ------------------------------------------------------------ | --------------------------------------------------------- | ------------------------------------------------------------ |
| legfelső szintű<br/> Mappa<br/> **File1.csv**<br/> File2.jsbekapcsolva<br/> Subfolder1<br/> **File3.csv**<br/> File4.jsbekapcsolva<br/> **File5.csv**<br/> Metaadatok<br/> FileListToCopy.txt | File1.csv<br>Subfolder1/File3.csv<br>Subfolder1/File5.csv | **Az adatkészletben:**<br>-Mappa elérési útja: `root/FolderA`<br><br>**A másolási tevékenység forrása:**<br>-Fájllista elérési útja: `root/Metadata/FileListToCopy.txt` <br><br>A fájl-lista elérési útja ugyanazon az adattárban található szövegfájlra mutat, amely tartalmazza a másolni kívánt fájlok listáját, és soronként egy fájlt az adatkészletben konfigurált útvonal relatív elérési útjával. |
### <a name="recursive-and-copybehavior-examples"></a>rekurzív és copyBehavior példák
Ez a szakasz a rekurzív és copyBehavior értékek különböző kombinációinak másolási műveletének eredményét írja le.
| rekurzív | copyBehavior | Forrás mappa szerkezete | Eredményül kapott cél |
|:--- |:--- |:--- |:--- |
| true |preserveHierarchy | Mappa1<br/> File1<br/> Fájl2<br/> Subfolder1<br/> Fájl3<br/> File4<br/> File5 | A célmappa Mappa1 ugyanazzal a struktúrával jön létre, mint a forrás:<br/><br/>Mappa1<br/> File1<br/> Fájl2<br/> Subfolder1<br/> Fájl3<br/> File4<br/> File5. |
| true |flattenHierarchy | Mappa1<br/> File1<br/> Fájl2<br/> Subfolder1<br/> Fájl3<br/> File4<br/> File5 | A célként megadott Mappa1 a következő szerkezettel jön létre: <br/><br/>Mappa1<br/> a file1 automatikusan generált neve<br/> a Fájl2 automatikusan generált neve<br/> a fájl3 automatikusan generált neve<br/> a File4 automatikusan generált neve<br/> a File5 automatikusan generált neve |
| true |mergeFiles | Mappa1<br/> File1<br/> Fájl2<br/> Subfolder1<br/> Fájl3<br/> File4<br/> File5 | A célként megadott Mappa1 a következő szerkezettel jön létre: <br/><br/>Mappa1<br/> File1 + Fájl2 + fájl3 + File4 + file 5 tartalom egyesítve egyetlen fájlba az automatikusan létrehozott fájlnévvel |
| hamis |preserveHierarchy | Mappa1<br/> File1<br/> Fájl2<br/> Subfolder1<br/> Fájl3<br/> File4<br/> File5 | A célmappa Mappa1 a következő szerkezettel jön létre<br/><br/>Mappa1<br/> File1<br/> Fájl2<br/><br/>A fájl3, a File4 és a File5 Subfolder1 nem vesznek fel. |
| hamis |flattenHierarchy | Mappa1<br/> File1<br/> Fájl2<br/> Subfolder1<br/> Fájl3<br/> File4<br/> File5 | A célmappa Mappa1 a következő szerkezettel jön létre<br/><br/>Mappa1<br/> a file1 automatikusan generált neve<br/> a Fájl2 automatikusan generált neve<br/><br/>A fájl3, a File4 és a File5 Subfolder1 nem vesznek fel. |
| hamis |mergeFiles | Mappa1<br/> File1<br/> Fájl2<br/> Subfolder1<br/> Fájl3<br/> File4<br/> File5 | A célmappa Mappa1 a következő szerkezettel jön létre<br/><br/>Mappa1<br/> A file1 + Fájl2 tartalma egy fájlba van egyesítve, automatikusan létrehozott fájlnévvel. a file1 automatikusan generált neve<br/><br/>A fájl3, a File4 és a File5 Subfolder1 nem vesznek fel. |
## <a name="lookup-activity-properties"></a>Keresési tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez tekintse meg a [keresési tevékenységet](control-flow-lookup-activity.md).
## <a name="getmetadata-activity-properties"></a>GetMetadata tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez tekintse meg a [GetMetaData tevékenységet](control-flow-get-metadata-activity.md)
## <a name="delete-activity-properties"></a>Tevékenység tulajdonságainak törlése
A tulajdonságok részleteinek megismeréséhez tekintse meg a [tevékenység törlése](delete-activity.md) lehetőséget.
## <a name="legacy-models"></a>Örökölt modellek
>[!NOTE]
>A következő modellek továbbra is támogatottak a visszamenőleges kompatibilitás érdekében. Azt javasoljuk, hogy használja a fenti szakaszban említett új modellt, és az ADF authoring felhasználói felülete átvált az új modell generálására.
### <a name="legacy-dataset-model"></a>Örökölt adatkészlet-modell
| Tulajdonság | Leírás | Kötelező |
|:--- |:--- |:--- |
| típus | Az adatkészlet Type tulajdonságát a következőre kell beállítani: **fájlmegosztás** |Yes |
| folderPath | A mappa elérési útja. A helyettesítő karakteres szűrő támogatott, az engedélyezett helyettesítő karakterek a következők: `*` (nulla vagy több karakternek felel meg) és `?` (a nulla vagy az egyetlen karakternek felel meg); `^` Ha a tényleges mappanevet helyettesítő karakter vagy a escape-karakter található, akkor a Escape karaktert kell használnia. <br/><br/>Példák: gyökérmappa/almappa/, további példák a példaként szolgáló [társított szolgáltatás és adatkészlet-definíciók](#sample-linked-service-and-dataset-definitions) , valamint a [mappa-és fájlszűrő-példák](#folder-and-file-filter-examples)elemre. |No |
| fileName | A fájl (ok) **neve vagy helyettesítő szűrője** a megadott "folderPath". Ha nem ad meg értéket ehhez a tulajdonsághoz, az adatkészlet a mappában található összes fájlra mutat. <br/><br/>A Filter (szűrő) esetében az engedélyezett helyettesítő karakterek a következők: `*` (nulla vagy több karakternek felel meg) és `?` (nulla vagy egyetlen karakternek felel meg).<br/>– 1. példa: `"fileName": "*.csv"`<br/>– 2. példa: `"fileName": "???20180427.txt"`<br/>`^`Ha a tényleges fájlnév helyettesítő karakter vagy ez a escape-karakter található, akkor Escape-karaktert kell használnia.<br/><br/>Ha nincs megadva fájlnév a kimeneti adatkészlethez, és a **preserveHierarchy** nincs megadva a tevékenység fogadójában, a másolási tevékenység automatikusan létrehozza a fájlnevet a következő mintával: "*adat. [ tevékenység futtatási azonosítója GUID]. [GUID if FlattenHierarchy]. [formátum, ha konfigurálva]. [tömörítés, ha konfigurálva]*", például" Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt. gz "; Ha táblázatos forrásból másol a lekérdezés helyett táblanév használatával, a név minta a következő: "*[Table Name]. [ Format]. [tömörítés, ha konfigurálva]*", például" MyTable.csv ". |No |
| modifiedDatetimeStart | A fájlok szűrése a következő attribútum alapján: utoljára módosítva. A fájlok akkor lesznek kiválasztva, ha az utolsó módosítás időpontja a és a közötti időintervallumon belül van `modifiedDatetimeStart` `modifiedDatetimeEnd` . Az idő az UTC-időzónára vonatkozik "2018-12-01T05:00:00Z" formátumban. <br/><br/> Ügyeljen arra, hogy az adatáthelyezés általános teljesítményét a beállítás engedélyezésével befolyásolja, ha nagy mennyiségű fájlból szeretne szűrni a fájlmegosztást. <br/><br/> A tulajdonságok lehetnek NULL értékűek, ami azt jelenti, hogy a rendszer nem alkalmazza a file Attribute szűrőt az adatkészletre. Ha `modifiedDatetimeStart` a dátum datetime értékkel rendelkezik `modifiedDatetimeEnd` , de null értékű, az azt jelenti, hogy azok a fájlok lesznek kiválasztva, amelyek utolsó módosított attribútuma nagyobb vagy egyenlő, mint a DateTime érték. Ha `modifiedDatetimeEnd` a dátum datetime értékkel rendelkezik `modifiedDatetimeStart` , de null értékű, az azt jelenti, hogy azok a fájlok, amelyek utolsó módosítási attribútuma kisebb, mint a DateTime érték, ki lesz választva.| No |
| modifiedDatetimeEnd | A fájlok szűrése a következő attribútum alapján: utoljára módosítva. A fájlok akkor lesznek kiválasztva, ha az utolsó módosítás időpontja a és a közötti időintervallumon belül van `modifiedDatetimeStart` `modifiedDatetimeEnd` . Az idő az UTC-időzónára vonatkozik "2018-12-01T05:00:00Z" formátumban. <br/><br/> Ügyeljen arra, hogy az adatáthelyezés általános teljesítményét a beállítás engedélyezésével befolyásolja, ha nagy mennyiségű fájlból szeretne szűrni a fájlmegosztást. <br/><br/> A tulajdonságok lehetnek NULL értékűek, ami azt jelenti, hogy a rendszer nem alkalmazza a file Attribute szűrőt az adatkészletre. Ha `modifiedDatetimeStart` a dátum datetime értékkel rendelkezik `modifiedDatetimeEnd` , de null értékű, az azt jelenti, hogy azok a fájlok lesznek kiválasztva, amelyek utolsó módosított attribútuma nagyobb vagy egyenlő, mint a DateTime érték. Ha `modifiedDatetimeEnd` a dátum datetime értékkel rendelkezik `modifiedDatetimeStart` , de null értékű, az azt jelenti, hogy azok a fájlok, amelyek utolsó módosítási attribútuma kisebb, mint a DateTime érték, ki lesz választva.| No |
| formátumban | Ha **fájlokat szeretne másolni** a fájl alapú tárolók között (bináris másolás), ugorja át a formátum szakaszt mind a bemeneti, mind a kimeneti adatkészlet-definíciókban.<br/><br/>Ha a fájlokat egy adott formátummal szeretné elemezni vagy előállítani, a következő fájlformátum-típusok támogatottak: **Szövegformátum**, **JsonFormat**, **AvroFormat**, **OrcFormat**, **ParquetFormat**. A **Type (típus** ) tulajdonságot állítsa a Format értékre a következő értékek egyikére. További információkért lásd: [Szövegformátum](supported-file-formats-and-compression-codecs-legacy.md#text-format), JSON- [Formátum](supported-file-formats-and-compression-codecs-legacy.md#json-format), [Avro formátum](supported-file-formats-and-compression-codecs-legacy.md#avro-format), [ork-formátum](supported-file-formats-and-compression-codecs-legacy.md#orc-format)és a [parketta formátuma](supported-file-formats-and-compression-codecs-legacy.md#parquet-format) című rész. |Nem (csak bináris másolási forgatókönyv esetén) |
| tömörítés | Adja meg az adattömörítés típusát és szintjét. További információ: [támogatott fájlformátumok és tömörítési kodekek](supported-file-formats-and-compression-codecs-legacy.md#compression-support).<br/>A támogatott típusok a következők: **gzip**, **deflate**, **BZip2** és **ZipDeflate**.<br/>A támogatott szintek a következők: **optimális** és **leggyorsabb**. |No |
>[!TIP]
>Egy mappa összes fájljának másolásához csak a **folderPath** kell megadni.<br>Egy adott névvel rendelkező egyetlen fájl másolásához adja meg a **folderPath** és a fájlnév nevű **fájlnevet** .<br>Ha egy mappában lévő fájlok egy részhalmazát szeretné másolni, akkor a **folderPath** és a **filename** paramétert a helyettesítő karakteres szűrővel.
>[!NOTE]
>Ha a "fileFilter" tulajdonságot használta a fájl szűrőhöz, a rendszer továbbra is támogatja a-t, míg a rendszer a "fileName" kifejezéshez hozzáadott új szűrő funkció használatát javasolja.
**Példa**
```json
{
"name": "FileSystemDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<file system linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
```
### <a name="legacy-copy-activity-source-model"></a>Örökölt másolási tevékenység forrásának modellje
| Tulajdonság | Leírás | Kötelező |
|:--- |:--- |:--- |
| típus | A másolási tevékenység forrásának Type tulajdonságát a következőre kell beállítani: **FileSystemSource** |Yes |
| rekurzív | Azt jelzi, hogy az adatok rekurzív módon olvashatók-e az almappákból, vagy csak a megadott mappából. Vegye figyelembe, hogy ha a rekurzív értéke TRUE (igaz), a fogadó pedig a fájl alapú tároló, akkor a rendszer nem másolja/hozza létre az üres mappát/almappát a fogadóban.<br/>Az engedélyezett értékek: **true** (alapértelmezett), **false** | No |
| maxConcurrentConnections |A tevékenység futtatása során az adattárhoz létesített egyidejű kapcsolatok felső határa. Csak akkor adhat meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat.| No |
**Példa**
```json
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<file system input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
```
### <a name="legacy-copy-activity-sink-model"></a>Örökölt másolási tevékenység fogadó modellje
| Tulajdonság | Leírás | Kötelező |
|:--- |:--- |:--- |
| típus | A másolási tevékenység fogadójának Type tulajdonságát a következőre kell beállítani: **FileSystemSink** |Yes |
| copyBehavior | Meghatározza a másolási viselkedést, ha a forrás fájl-alapú adattárból származó fájlok.<br/><br/>Az engedélyezett értékek a következők:<br/><b>-PreserveHierarchy (alapértelmezett)</b>: megőrzi a fájl-hierarchiát a célmappában. A forrásfájl a forrás mappájához relatív elérési útja megegyezik a célfájl relatív elérési útjával.<br/><b>-FlattenHierarchy</b>: a forrás mappából származó összes fájl a célmappa első szintjén van. A célfájl automatikusan generált névvel rendelkezik. <br/><b>-MergeFiles</b>: az összes fájlt egyesíti a forrás mappájából egy fájlba. Az egyesítés során nem történik meg a rekordok deduplikálása. Ha a fájl neve meg van adva, az egyesített fájlnév a megadott név lesz. Ellenkező esetben az automatikusan létrehozott fájlnév lenne. | No |
| maxConcurrentConnections |A tevékenység futtatása során az adattárhoz létesített egyidejű kapcsolatok felső határa. Csak akkor adhat meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat.| No |
**Példa**
```json
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<file system output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
```
## <a name="next-steps"></a>Következő lépések
A Azure Data Factory a másolási tevékenység által forrásként és nyelőként támogatott adattárak listáját lásd: [támogatott adattárak](copy-activity-overview.md#supported-data-stores-and-formats). | 86.547344 | 1,191 | 0.692061 | hun_Latn | 0.999918 |
587fe34829c2c5933644156552ef82c0cdb5a542 | 208 | md | Markdown | guides/resources/users.md | QBonaventure/tm-api | 124e80fd6af75fb00963fc5e43f760a7fa6b59e0 | [
"MIT"
] | null | null | null | guides/resources/users.md | QBonaventure/tm-api | 124e80fd6af75fb00963fc5e43f760a7fa6b59e0 | [
"MIT"
] | null | null | null | guides/resources/users.md | QBonaventure/tm-api | 124e80fd6af75fb00963fc5e43f760a7fa6b59e0 | [
"MIT"
] | null | null | null | # Users resource
## /users/{UUID}/username
```json
{
"data":
{
"login": "mr2_md43Qg-_ZeOmUQ32pA",
"username": "Rrrazzziel",
"uuid":"9abdbf99-de37-420f-bf65-e3a6510df6a4"
}
}
```
| 13.866667 | 51 | 0.567308 | kor_Hang | 0.152878 |
58809a96130526a293e0c389df80691f42970c22 | 257 | md | Markdown | README.md | tforward/Leaflet.EasyButton | 89ae7eb606096d0c54a4d584681ac91d932c2c58 | [
"MIT"
] | 1 | 2018-11-06T15:42:10.000Z | 2018-11-06T15:42:10.000Z | README.md | tforward/Leaflet.EasyButton | 89ae7eb606096d0c54a4d584681ac91d932c2c58 | [
"MIT"
] | null | null | null | README.md | tforward/Leaflet.EasyButton | 89ae7eb606096d0c54a4d584681ac91d932c2c58 | [
"MIT"
] | 1 | 2018-11-06T15:42:19.000Z | 2018-11-06T15:42:19.000Z | ### Easily Add Control Buttons for Leaflet
Relevant documentation and implementation in the [Demo][].
_check out the [new version][v1]!_
[Demo]:http://cliffcloud.github.io/Leaflet.EasyButton/
[v1]:https://github.com/CliffCloud/Leaflet.EasyButton/tree/v1
| 28.555556 | 61 | 0.766537 | eng_Latn | 0.362978 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.