
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
974ce932c6a55edbd0cb683a612055607a5695f0 | 253 | md | Markdown | README.md | nokaa/rotor-http-utils | e8f93cdf084aa53956bd033d8466ccb4740e890d | [
"MIT"
] | null | null | null | README.md | nokaa/rotor-http-utils | e8f93cdf084aa53956bd033d8466ccb4740e890d | [
"MIT"
] | 4 | 2016-04-05T05:02:18.000Z | 2016-04-05T05:45:07.000Z | README.md | nokaa/rotor-http-utils | e8f93cdf084aa53956bd033d8466ccb4740e890d | [
"MIT"
] | null | null | null | # rotor-http-utils [](https://travis-ci.org/nokaa/rotor-http-utils)
Some utility functions to make working with [rotor-http](https://github.com/tailhook/rotor-http) easier.
| 63.25 | 146 | 0.762846 | yue_Hant | 0.37528 |
974d58e784aa4fe5bc9b991ac1b8e8de060e0487 | 4,205 | md | Markdown | pages/02.content/05.taxonomy/docs.md | newkind/grav-learn | f09302050cdc629288edb37b91fea4d8afb8cccd | [
"MIT"
] | null | null | null | pages/02.content/05.taxonomy/docs.md | newkind/grav-learn | f09302050cdc629288edb37b91fea4d8afb8cccd | [
"MIT"
] | null | null | null | pages/02.content/05.taxonomy/docs.md | newkind/grav-learn | f09302050cdc629288edb37b91fea4d8afb8cccd | [
"MIT"
] | null | null | null | ---
title: Taxonomy
taxonomy:
category: docs
---
With **Grav** the ability to group or tag pages is baked right into the system with **Taxonomy**.
> **Taxonomy (general),** the practice and science (study) of classification of things or concepts, including the principles that underlie such classification.
>
> <cite>Wikipedia</cite>
There are a couple of key parts to using taxonomy in your site:
1. Define a list of Taxonomy types in your [`site.yaml`][siteyaml]
2. Assign your pages to the appropriate `taxonomy` types with values.
## Taxonomy Example
This concept is best explained with an example. Let us say you want to create a simple blog. In that blog you will create posts that you might want to assign to certain tags to provide a **tag cloud** display. Also you could have several authors and you might want to assign each post to that author.
To accomplish this in Grav is a simple procedure. Grav, provides a default `site.yaml` file that is located in the `system/config` folder. By default that configuration defines two taxonomy types of `category` and `tag`:
```ruby
taxonomies: [category,tag]
```
As `tag` is already defined you just need to add `authors`. To do this simple create a new `site.yaml` file in your `user/config` folder and add the following line:
```ruby
taxonomies: [category,tag,author]
```
This will override the taxonomies that Grav knows about so that pages can be assigned to any of these three taxonomies.
The next step is to create some pages that makes use of these taxonomy types. For example you could have a page that looks like this:
---
title: Post 1
taxonomy:
tag: animal, dog
author: ksmith
---
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse
cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non
proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
and another page that looks like:
---
title: Post 2
taxonomy:
tag: animal, cat
author: jdoe
---
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse
cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non
proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
As you can see in the YAML configuration, each page is assigning **values** to the **taxonomy types** we defined in our user `site.yaml` configuration. This information is used by Grav when the pages are processed and creates an internal **taxonomy map** which can be used to find pages based on the taxonomy you defined.
>>>> Your pages do not have to use every taxonomy you define in your `site.yaml`, but you must define any taxonomy you use.
In your theme, you can easily display a list of pages that are written by `ksmith` by using `taxonomy.findTaxonomy()` to find them and iterate over them:
```html
<h2>Kevin Smith's Posts</h2>
<ul>
{% for post in taxonomy.findTaxonomy({'author':'ksmith'}) %}
<li>{{ post.title }}</li>
{% endfor %}
<ul>
```
You can also do sophisticated searches based on multiple taxonomies by using arrays/hashes, for example:
```bash
{% for post in taxonomy.findTaxonomy({'tags':['animal','cat'],'author':'jdoe'}) %}
```
This will find all posts with `tags` set to `animal` **and** `cat` **and** `author` set to `jdoe`. Basically this will specifically find **Post 2**.
## Taxonomy based Collections
We covered this in an earlier chapter, but it's important to remember that you can also use taxonomies in the [page headers][headers] to filter a collection of pages associated with a parent page. If you need a refresher on this subject, please refer back to that [chapter on headers][headers].
[siteyaml]: ../basics/grav-configuration
[headers]: headers
| 42.474747 | 321 | 0.750297 | eng_Latn | 0.982688 |
974d8348d46044d6eed1c6baf94896833f1ee73c | 4,011 | md | Markdown | articles/site-recovery/monitoring-common-questions.md | ShowMeMore/azure-docs | d6b68b907e5158b451239e4c09bb55eccb5fef89 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-09-19T19:07:44.000Z | 2021-11-15T09:58:47.000Z | articles/site-recovery/monitoring-common-questions.md | ShowMeMore/azure-docs | d6b68b907e5158b451239e4c09bb55eccb5fef89 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2017-04-21T17:57:59.000Z | 2017-04-21T17:58:30.000Z | articles/site-recovery/monitoring-common-questions.md | ShowMeMore/azure-docs | d6b68b907e5158b451239e4c09bb55eccb5fef89 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-11-24T22:01:50.000Z | 2019-11-24T22:01:50.000Z | ---
title: Common questions about Azure Site Recovery monitoring
description: Get answers to common questions about Azure Site Recovery monitoring, using inbuilt monitoring and Azure Monitor (Log Analytics)
author: rayne-wiselman
manager: carmonm
ms.service: site-recovery
services: site-recovery
ms.date: 07/31/2019
ms.topic: conceptual
ms.author: raynew
---
# Common questions about Site Recovery monitoring
This article answers common questions about monitoring Azure [Site Recovery](site-recovery-overview.md), using inbuilt Site Recovery monitoring, and Azure Monitor (Log Analytics).
## General
### How is the RPO value logged different from the latest available recovery point?
Site Recovery uses a multi-step, asynchronous process to replicate machines to Azure.
- In the penultimate step of replication, recent changes on the machine, along with metadata, are copied into a log/cache storage account.
- These changes, along with the tag that identifies a recoverable point, are written to the storage account/managed disk in the target region.
- Site Recovery can now generate a recoverable point for the machine.
- At this point, the RPO has been met for the changes uploaded to the storage account so far. In other words, the machine RPO at this point is equal to amount of time that's elapsed from the timestamp corresponding to the recoverable point.
- Now, Site Recovery picks the uploaded data from the storage account, and applies it to the replica disks created for the machine.
- Site Recovery then generates a recovery point, and makes this point available for recovery at failover.
- Thus, the latest available recovery point indicates the timestamp corresponding to the latest recovery point that has already been processed, and applied to the replica disks.
An incorrect system time on the replicating source machine, or on on-premises infrastructure servers, will skew the computed RPO value. For accurate RPO reporting, make sure that the system clock is accurate on all servers and machines.
## Inbuilt Site Recovery logging
### Why is the VM count in the vault infrastructure view different from the total count shown in Replicated Items?
The vault infrastructure view is scoped by replication scenarios. Only machines in the currently selected replication scenario are included in the count for the view. In addition, we only count VMs that are configured to replicate to Azure. Failed over machines, or machines replicating back to an on-premises site, aren't counted in the view.
### Why is the count of replicated items in Essentials different from the total count of replicated items on the dashboard?
Only machines for which initial replication has completed are included in the count shown in Essentials. The replicated items total includes all the machines in the vault, including those for which initial replication is currently in progress.
## Azure Monitor logging
### How often does Site Recovery send diagnostic logs to Azure Monitor Log?
- AzureSiteRecoveryReplicationStats and AzureSiteRecoveryRecoveryPoints are sent every 15 minutes.
- AzureSiteRecoveryReplicationDataUploadRate and AzureSiteRecoveryProtectedDiskDataChurn are sent every five minutes.
- AzureSiteRecoveryJobs is sent at the trigger and completion of a job.
- AzureSiteRecoveryEvents is sent whenever an event is generated.
- AzureSiteRecoveryReplicatedItems is sent whenever there is any environment change. Typically, the data refresh time is 15 minutes after a change.
### How long is data kept in Azure Monitor logs?
By default, retention is for 31 days. You can increase the period in the **Usage and Estimated Cost** section in the Log Analytics workspace. Click on **Data Retention**, and choose the range.
### What's the size of the diagnostic logs?
Typically the size of a log is 15-20 KB.
## Next steps
Learn how to monitor with [Site Recovery inbuilt monitoring](site-recovery-monitor-and-troubleshoot.md), or [Azure Monitor](monitor-log-analytics.md).
| 56.492958 | 343 | 0.801047 | eng_Latn | 0.998736 |
974ddbe341abea59db222a593d1ad861e8be100c | 1,481 | md | Markdown | scripting-docs/winscript/reference/iactivescripterror-getsourcelinetext.md | Simran-B/visualstudio-docs.de-de | 0e81681be8dbccb2346866f432f541b97d819dac | [
"CC-BY-4.0",
"MIT"
] | null | null | null | scripting-docs/winscript/reference/iactivescripterror-getsourcelinetext.md | Simran-B/visualstudio-docs.de-de | 0e81681be8dbccb2346866f432f541b97d819dac | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-07-24T14:57:38.000Z | 2020-07-24T14:57:38.000Z | scripting-docs/winscript/reference/iactivescripterror-getsourcelinetext.md | Simran-B/visualstudio-docs.de-de | 0e81681be8dbccb2346866f432f541b97d819dac | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 'Iactivescripterror:: getsourcelinetext | Microsoft-Dokumentation'
ms.custom: ''
ms.date: 01/18/2017
ms.reviewer: ''
ms.suite: ''
ms.tgt_pltfrm: ''
ms.topic: reference
apiname:
- IActiveScriptError.GetSourceLineText
apilocation:
- scrobj.dll
helpviewer_keywords:
- IActiveScriptError_GetSourceLineText
ms.assetid: 64f7f37f-7288-4dbe-b626-a35d90897f36
caps.latest.revision: 7
author: mikejo5000
ms.author: mikejo
manager: ghogen
ms.openlocfilehash: ded57f97ec40167bac34bf0f288c2e3d15a5c4b7
ms.sourcegitcommit: 184e2ff0ff514fb980724fa4b51e0cda753d4c6e
ms.translationtype: MT
ms.contentlocale: de-DE
ms.lasthandoff: 10/18/2019
ms.locfileid: "72576916"
---
# <a name="iactivescripterrorgetsourcelinetext"></a>IActiveScriptError::GetSourceLineText
Ruft die Zeile in der Quelldatei ab, in der ein Fehler aufgetreten ist, während eine Skript-Engine ein Skript ausgeführt hat.
## <a name="syntax"></a>Syntax
```cpp
HRESULT GetSourceLineText(
BSTR *pbstrSourceLine // address of buffer for source line
);
```
## <a name="parameter"></a>Parameter
`pbstrSourceLine`
vorgenommen Adresse eines Puffers, der die Zeile des Quellcodes empfängt, in der der Fehler aufgetreten ist.
## <a name="return-value"></a>Rückgabewert
Gibt `S_OK` zurück, wenn erfolgreich, oder `E_FAIL`, wenn die Zeile in der Quelldatei nicht abgerufen wurde.
## <a name="see-also"></a>Siehe auch
[IActiveScriptError](../../winscript/reference/iactivescripterror.md) | 32.195652 | 127 | 0.764348 | deu_Latn | 0.592799 |
974fce2dad1513755ad90d1f0bb403d62545af2f | 3,555 | md | Markdown | README.md | ffreemt/extend-noip | b631d97a1264b3d283e36782b6a76ed101ebfc48 | [
"MIT"
] | 2 | 2021-02-27T03:05:26.000Z | 2022-02-14T12:17:03.000Z | README.md | thinhplust/extend-noip | b631d97a1264b3d283e36782b6a76ed101ebfc48 | [
"MIT"
] | null | null | null | README.md | thinhplust/extend-noip | b631d97a1264b3d283e36782b6a76ed101ebfc48 | [
"MIT"
] | 6 | 2021-03-15T13:08:34.000Z | 2022-02-14T12:17:06.000Z | # extend-noip
[](https://github.com/psf/black)[](https://opensource.org/licenses/MIT)[](https://badge.fury.io/py/extend-noip)
Extend dns expiry date on noip.com
## Automate extending dns/domain expiry date on noip.com
[中文读我.md](https://github.com/ffreemt/extend-noip/blob/master/读我.md)
* Fork this repo [https://github.com/ffreemt/extend-noip](https://github.com/ffreemt/extend-noip)
* Set the resultant repo `Secrets`
|Name | Value |
|-- | -- |
|NOIP_USERNAME:| your_noip_username|
|NOIP_PASSWORD:| your_noip_password |
* [Optionally] Change `crontab` in line 6 of `.github/workflows/on-push-schedule-extend-noip.yml`([link](https://github.com/ffreemt/extend-noip/blob/master/.github/workflows/on-push-schedule-extend-noip.yml)) to your like. (This online crontab editor may come handy [https://crontab.guru/#0_0_*/9_*_*](https://crontab.guru/#0_0_*/9_*_*))
## Installtion
```bash
pip install extend-noip
```
or clone [https://github.com/ffreemt/extend-noip](https://github.com/ffreemt/extend-noip) and install from the repo.
## Usage
### Supply noip `username` and `password` from the command line:
```bash
python -m extend-noip -u your_noip_username -p password
```
or use directly the ``extend-noip`` script:
```bash
extend-noip -u your_noip_username -p password
```
### Use environment variables `NOIP_USERNAME` and `NOIP_PASSWORD`
* Set username/password from the command line:
```bash
set NOIP_USERNAME=your_noip_username # export in Linux or iOS
set NOIP_PASSWORD=password
```
* Or set username/password in .env, e.g.,
```bash
# .env
NOIP_USERNAME=your_noip_username
NOIP_USERNAME=password
Run `extend-noip` or `python -m extend_noip`:
```bash
extend-noip
```
or
```bash
python -m extend_noip
```
### Check information only
```bash
extend-noip -i
```
or
```bash
python -m extend_noip -i
```
### Print debug info
```bash
extend-noip -d
```
or
```bash
python -m extend_noip -d
```
### Brief Help
```bash
extend-noip --helpshort
```
or
```bash
python -m extend_noip --helpshort
```
### Turn off Headless Mode (Show the browser in action)
You can configure `NOIP_HEADFUL`, `NOIP_DEBUG` and `NOIP_PROXY` in the `.env` file in the working directory or any of its parent directoreis. For example,
```bash
# .env
NOIP_HEADFUL=1
NOIP_DEBUG=true
# NOIP_PROXY
```
### Automation via Github Actions
It's straightforward to setup `extend-noip` to run via Github Actions, best with an infrequent crontab.
* Fork this repo
* Setup `Actions secrets` via `Settings/Add repository secrets`:
|Name | Value |
|-- | -- |
|NOIP_USERNAME:| your_noip_username|
|NOIP_PASSWORD:| your_noip_password |
For example, in `.github/workflows/schedule-extend-noip.yml`
```bash
name: schedule-extend-noip
on:
push:
schedule:
- cron: '10,40 3 */9 * *'
...
setup, e.g. pip install -r requirements.txt or
poetry install --no-dev
...
- name: Testrun
env:
NOIP_USERNAME: ${{ secrets.NOIP_USERNAME }}
NOIP_PASSWORD: ${{ secrets.NOIP_PASSWORD }}
run: |
python -m extend_noip -d -i
```
<!---
['158.101.140.77 Last Update 2021-02-22 02:34:45 PST',
'168.138.222.163 Last Update 2021-02-22 03:40:55 PST']
['158.101.140.77 Last Update 2021-02-22 08:39:49 PST',
'168.138.222.163 Last Update 2021-02-22 08:40:01 PST']
2021-02-22 17:43:37 PST
---> | 23.7 | 339 | 0.694233 | eng_Latn | 0.306609 |
97500ef9008200102527ddc8a70128f2af40e208 | 770 | md | Markdown | tests/results/integers/kocsismate/2021_06_23_13_25/1/master2_x86_64.md | craigfrancis/php-is-literal-rfc | a8b60e9f230536c9c200482660b77d3c95dc1690 | [
"BSD-3-Clause"
] | 5 | 2020-09-09T19:41:51.000Z | 2022-02-06T02:21:13.000Z | tests/results/integers/kocsismate/2021_06_23_13_25/1/master2_x86_64.md | craigfrancis/php-is-literal-rfc | a8b60e9f230536c9c200482660b77d3c95dc1690 | [
"BSD-3-Clause"
] | 5 | 2020-03-23T20:13:18.000Z | 2022-02-23T00:54:50.000Z | tests/results/integers/kocsismate/2021_06_23_13_25/1/master2_x86_64.md | craigfrancis/php-is-literal-rfc | a8b60e9f230536c9c200482660b77d3c95dc1690 | [
"BSD-3-Clause"
] | null | null | null | ### master2 (opcache: 1, preloading: 0, JIT: 0)
| Benchmark | Metric | Average | Median | StdDev | Description |
|--------------|--------------|-------------|-------------|-------------|-------------|
|Laravel demo app|time (sec)|9.4661|9.4568|0.0145|12 consecutive runs, 3000 requests|
|Symfony demo app|time (sec)|0.1006|0.1010|0.0004|12 consecutive runs, 3000 requests|
|bench.php|time (sec)|0.2120|0.2130|0.0012|12 consecutive runs|
|micro_bench.php|time (sec)|1.3350|1.3370|0.0016|12 consecutive runs|
|concat.php|time (sec)|0.6010|0.6010|0.0021|12 consecutive runs|
##### Generated: 2021-06-23 11:39 based on commit [fb701948502e3b301ed8030b985ac614db963c28](https://github.com/php/php-src/commit/fb701948502e3b301ed8030b985ac614db963c28)
| 64.166667 | 172 | 0.644156 | eng_Latn | 0.172414 |
975086dcdeb478b1f326755878bb8dabcc319005 | 1,866 | md | Markdown | wdk-ddi-src/content/wdfhwaccess/nf-wdfhwaccess-wdf_write_register_buffer_uchar.md | Acidburn0zzz/windows-driver-docs-ddi | c16b5cd6c3f59ca5f963ff86f3f0926e3b910231 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2018-11-06T01:28:38.000Z | 2018-11-06T01:28:38.000Z | wdk-ddi-src/content/wdfhwaccess/nf-wdfhwaccess-wdf_write_register_buffer_uchar.md | Acidburn0zzz/windows-driver-docs-ddi | c16b5cd6c3f59ca5f963ff86f3f0926e3b910231 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/wdfhwaccess/nf-wdfhwaccess-wdf_write_register_buffer_uchar.md | Acidburn0zzz/windows-driver-docs-ddi | c16b5cd6c3f59ca5f963ff86f3f0926e3b910231 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
UID: NF:wdfhwaccess.WDF_WRITE_REGISTER_BUFFER_UCHAR
title: WDF_WRITE_REGISTER_BUFFER_UCHAR function
author: windows-driver-content
description: The WDF_WRITE_REGISTER_BUFFER_UCHAR function writes a number of bytes from a buffer to the specified register.
old-location: wdf\wdf_write_register_buffer_uchar.htm
tech.root: wdf
ms.assetid: A2BFF042-8358-4F82-B15D-7AD130C95DE3
ms.date: 02/26/2018
ms.keywords: WDF_WRITE_REGISTER_BUFFER_UCHAR, WDF_WRITE_REGISTER_BUFFER_UCHAR function, wdf.wdf_write_register_buffer_uchar, wdfhwaccess/WDF_WRITE_REGISTER_BUFFER_UCHAR
ms.topic: function
req.header: wdfhwaccess.h
req.include-header:
req.target-type: Universal
req.target-min-winverclnt: Windows 8.1
req.target-min-winversvr:
req.kmdf-ver:
req.umdf-ver: 2.0
req.ddi-compliance:
req.unicode-ansi:
req.idl:
req.max-support:
req.namespace:
req.assembly:
req.type-library:
req.lib:
req.dll:
req.irql:
topic_type:
- APIRef
- kbSyntax
api_type:
- HeaderDef
api_location:
- Wdfhwaccess.h
api_name:
- WDF_WRITE_REGISTER_BUFFER_UCHAR
product:
- Windows
targetos: Windows
req.typenames:
---
# WDF_WRITE_REGISTER_BUFFER_UCHAR function
## -description
<p class="CCE_Message">[Applies to UMDF only]</p>
The <b>WDF_WRITE_REGISTER_BUFFER_UCHAR</b> function writes a number of bytes from a buffer to the specified register.
## -parameters
### -param Device [in]
A handle to a framework device object.
### -param Register [in]
A pointer to the register, which must be a mapped range in memory space.
### -param Buffer [in]
A pointer to a buffer from which an array of UCHAR values is to be written.
### -param Count [in]
Specifies the number of bytes to write to the register.
## -returns
This function does not return a value.
## -remarks
The size of the buffer must be large enough to contain at least the specified number of bytes.
| 19.237113 | 168 | 0.776527 | eng_Latn | 0.478808 |
97519875888f127dbf5c7740e0ea32b585c38c3e | 1,685 | md | Markdown | docs/user_guide/installation.md | dmulyalin/scrapli_netconf | 7c9e5e74a1afac7955177db759e54d2211637d42 | [
"MIT"
] | 61 | 2020-05-17T19:57:25.000Z | 2022-03-30T01:10:32.000Z | docs/user_guide/installation.md | dmulyalin/scrapli_netconf | 7c9e5e74a1afac7955177db759e54d2211637d42 | [
"MIT"
] | 79 | 2020-05-17T20:22:05.000Z | 2022-03-02T14:37:28.000Z | docs/user_guide/installation.md | dmulyalin/scrapli_netconf | 7c9e5e74a1afac7955177db759e54d2211637d42 | [
"MIT"
] | 6 | 2021-01-07T16:45:28.000Z | 2022-02-11T19:31:49.000Z | # Installation
## Standard Installation
As outlined in the quick start, you should be able to pip install scrapli_netconf "normally":
```
pip install scrapli_netconf
```
## Installing current master branch
To install from the source repositories master branch:
```
pip install git+https://github.com/scrapli/scrapli_netconf
```
## Installing current develop branch
To install from this repositories develop branch:
```
pip install -e git+https://github.com/scrapli/scrapli_netconf.git@develop#egg=scrapli_netconf
```
## Installation from Source
To install from source:
```
git clone https://github.com/scrapli/scrapli_netconf
cd scrapli_netconf
python setup.py install
```
## Optional Extras
Just like scrapli "core" scrapli_netconf tries to have as few dependencies as possible. scrapli_netconf requires
scrapli (of course!) and `lxml`. If you would like to use any of the transport plugins that are not part of the
standard library you can install those as optional extras via pip:
```
pip install scrapli_netconf[paramiko]
```
The available optional installation extras options are:
- paramiko
- ssh2
- asyncssh
## Supported Platforms
As for platforms to *run* scrapli on -- it has and will be tested on MacOS and Ubuntu regularly and should work on
any POSIX system. Windows at one point was being tested very minimally via GitHub Actions builds, however this is no
longer the case as it is just not worth the effort. While scrapli/scrapli_netconf should work on Windows when
using the paramiko or ssh2-python transport drivers, it is not "officially" supported. It is *strongly*
recommended/preferred for folks to use WSL/Cygwin instead of Windows.
| 25.530303 | 117 | 0.776261 | eng_Latn | 0.991879 |
975292d707f3b28e773a1e7c341ab356237a8411 | 5,839 | md | Markdown | src/site/content/en/progressive-web-apps/manifest-updates/index.md | kura5/web.dev | e48acc43d7304b3b99b04b6e527158158d7dd316 | [
"Apache-2.0"
] | null | null | null | src/site/content/en/progressive-web-apps/manifest-updates/index.md | kura5/web.dev | e48acc43d7304b3b99b04b6e527158158d7dd316 | [
"Apache-2.0"
] | null | null | null | src/site/content/en/progressive-web-apps/manifest-updates/index.md | kura5/web.dev | e48acc43d7304b3b99b04b6e527158158d7dd316 | [
"Apache-2.0"
] | null | null | null | ---
layout: post
title: How Chrome handles updates to the web app manifest
subhead: What it takes to change icons, shortcuts, colors, and other metadata for your PWA
authors:
- petelepage
- ajara
date: 2020-10-14
updated: 2021-04-05
description: What it takes to change icons, shortcuts, colors, and other metadata in your web app manifest for your PWA.
tags:
- progressive-web-apps
---
{% Aside %}
We are currently gathering data on browsers other than Chrome. If you would
like to help us gather this data or add content to this page, please leave a
comment in [issue #4038](https://github.com/GoogleChrome/web.dev/issues/4038).
{% endAside %}
When a PWA is installed, the browser uses information from the web app
manifest for the app name, the icons the app should use, and the URL that
should be opened when the app is launched. But what if you need to update
app shortcuts or try a new theme color? When and how are those changes
reflected in the browser?
{% Aside 'caution' %}
Do not change the name or location of your web app manifest file, doing so
may prevent the browser from updating your PWA.
{% endAside %}
In most cases, changes should be reflected within a day or two of the
PWA being launched, after the manifest has been updated.
## Updates on desktop Chrome {: #cr-desktop }
When the PWA is launched, or opened in a browser tab, Chrome determines the
last time the local manifest was checked for changes. If the manifest hasn't
been checked since the browser last started, or it hasn't been checked in the
last 24 hours, Chrome will make a network request for the manifest, then
compare it against the local copy.
If select properties in the manifest have changed (see list below), Chrome
queues the new manifest, and after all windows have been closed, installs it.
Once installed, all fields from the new manifest (except `name`, `short_name`,
`start_url` and `icons`) are updated.
### Which properties will trigger an update? {: #cr-desktop-trigger }
* `display` (see below)
* `scope`
* `shortcuts`
* `theme_color`
* `file_handlers`
{% Aside 'caution' %}
Changes to `name`, `short_name`, `icons` and `start_url` are **not**
currently supported on desktop Chrome, though work is underway to support them.
{% endAside %}
<!-- CrBug for name/shortname https://crbug.com/1088338 -->
<!-- CrBug for start_url https://crbug.com/1095947 -->
### What happens when the `display` field is updated?
If you update your app's display mode from `browser` to `standalone` your
existing users will not have their apps open in a window after updating. There
are two display settings for a web app, the one from the manifest (that you
control) and a window/browser tab setting controlled by the user. The user
preference is always respected.
### Testing manifest updates {: #cr-desktop-test }
The `about://internals/web-app` page (available in Chrome 85 or later),
includes detailed information about all of the PWAs installed on the device,
and can help you understand when the manifest was last updated, how often
it's updated, and more.
To manually force Chrome to check for an updated manifest, restart Chrome
(use `about://restart`), this resets the timer so that Chrome will check for
an updated manifest when the PWA is next launched. Then launch the PWA.
After closing the PWA, it should be updated with the new manifest properties.
### References {: #cr-desktop-ref }
* [Updatable Web Manifest Fields][updatable-manifest-doc]
## Updates on Chrome for Android {: #cr-android }
When the PWA is launched, Chrome determines the last time the local manifest
was checked for changes. If the manifest hasn't been checked in the last 24
hours, Chrome will schedule a network request for the manifest, then compare
it against the local copy.
If select properties in the manifest have changed (see list below), Chrome
queues the new manifest, and after all windows of the PWA have been closed,
the device is plugged in, and connected to WiFi, Chrome requests an updated
WebAPK from the server. Once updated, all fields from the new manifest are
used.
### Which properties will trigger an update? {: #cr-android-trigger }
* `background_color`
* `display`
* `orientation`
* `scope`
* `shortcuts`
* `start_url`
* `theme_color`
* `web_share_target`
If Chrome is unable to get an updated manifest from the server, it may
increase the time between checks to 30 days.
{% Aside 'caution' %}
Changes to `name`, `short_name` and `icons` are **not** currently supported
on Android Chrome, though work is underway to support them.
{% endAside %}
### Testing manifest updates {: #cr-android-test }
The `about://webapks` page includes detailed information about all of the
PWAs installed on the device, and can tell you when the manifest was last
updated, how often it's updated, and more.
To manually schedule an update to the manifest, overriding the timer and
local manifest do the following:
1. Plug in the device and ensure it's connected to WiFi.
2. Use the Android task manager to shut down the PWA, then use the App panel
in Android settings to force stop the PWA.
3. In Chrome, open `about://webapks` and click the "Update" button for the
PWA. "Update Status" should change to "Pending".
4. Launch the PWA, and verify it's loaded properly.
5. Use the Android task manager to shut down the PWA, then use the App panel
in Android settings to force stop the PWA.
The PWA usually updates within a few minutes, once the update has completed,
"Update Status" should change to "Successful"
### References {: #cr-android-ref }
* [`UpdateReason` enum][update-enum] for Chrome on Android
[updatable-manifest-doc]: https://docs.google.com/document/d/1twU_yAoTDp4seZMmqrDzJFQtrM7Z60jXHkXjMIO2VpM/preview
[update-enum]: https://cs.chromium.org/chromium/src/chrome/browser/android/webapk/webapk.proto?l=35
| 39.721088 | 120 | 0.75852 | eng_Latn | 0.996114 |
975344674380c3d4d01ba19bbe615cef856d9226 | 2,043 | md | Markdown | controls/checkboxlist/client-side-programming/events/onload.md | thevivacioushussain/ajax-docs | b46cd8ec574600abf8c256c0e20100eb382a9679 | [
"MIT"
] | null | null | null | controls/checkboxlist/client-side-programming/events/onload.md | thevivacioushussain/ajax-docs | b46cd8ec574600abf8c256c0e20100eb382a9679 | [
"MIT"
] | null | null | null | controls/checkboxlist/client-side-programming/events/onload.md | thevivacioushussain/ajax-docs | b46cd8ec574600abf8c256c0e20100eb382a9679 | [
"MIT"
] | null | null | null | ---
title: OnLoad
page_title: OnLoad | RadCheckBoxList for ASP.NET AJAX Documentation
description: OnLoad
slug: checkboxlist/client-side-programming/events/onload
tags: onload
published: True
position: 2
---
# OnLoad
The load event occurs when the RadCheckBoxList client-side object is instantiated on the page.
The event handler receives two parameters:
1. The instance of the loaded RadCheckBoxList control.
1. An empty event args.
This event comes handy in scenarios when the user wants to operate with the control's client-side API and events at the earliest available stage.
>caption Example 1: Handling RadCheckBoxList OnClientLoad event.
````ASP.NET
<script type="text/javascript">
function clientLoad(sender, args) {
alert('RadCheckBoxList Object Loaded');
}
</script>
<telerik:RadCheckBoxList runat="server" ID="RadCheckBoxList1">
<ClientEvents OnLoad="OnLoad" />
<Items>
<telerik:ButtonListItem Text="English" Selected="true" />
<telerik:ButtonListItem Text="German" />
<telerik:ButtonListItem Text="French" />
</Items>
</telerik:RadCheckBoxList>
````
## See Also
* [CheckBoxList Object]({%slug checkboxlist/client-side-programming/checkboxlist-object%})
* [Events Overview]({%slug checkboxlist/client-side-programming/events/overview%})
* [OnItemLoad (itemLoad)]({%slug checkboxlist/client-side-programming/events/onitemload%})
* [OnItemClicking (itemClicking)]({%slug checkboxlist/client-side-programming/events/onitemclicking%})
* [OnItemClicked (itemClicked)]({%slug checkboxlist/client-side-programming/events/onitemclicked%})
* [OnSelectedIndexChanging (selectedIndexChanging)]({%slug checkboxlist/client-side-programming/events/onselectedindexchanging%})
* [OnSelectedIndexChanged (selectedIndexChanged)]({%slug checkboxlist/client-side-programming/events/onselectedindexchanged%})
* [OnItemMouseOver (itemMouseOver)]({%slug checkboxlist/client-side-programming/events/onitemmouseover%})
* [OnItemMouseOut (itemMouseOut)]({%slug checkboxlist/client-side-programming/events/onitemmouseout%})
| 32.951613 | 145 | 0.781694 | eng_Latn | 0.386876 |
97538db06428e5220477db0fc0a42678c5396c45 | 1,140 | md | Markdown | docs/visual-basic/misc/bc31128.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc31128.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc31128.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: ''RemoveHandler' ya se ha declarado'
ms.date: 07/20/2015
f1_keywords:
- vbc31128
- bc31128
helpviewer_keywords:
- BC31128
ms.assetid: bf290050-cd9c-4ca4-a356-e6fe3bfd68ba
ms.openlocfilehash: b75d34e27d67dd89070f663eecbd4ab884ff5621
ms.sourcegitcommit: 3d5d33f384eeba41b2dff79d096f47ccc8d8f03d
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 05/04/2018
ms.locfileid: "33622124"
---
# <a name="39removehandler39-is-already-declared"></a>'RemoveHandler' ya se ha declarado
Aparece más de una declaración `RemoveHandler` en una declaración de evento personalizado. Una declaración `RemoveHandler` declara el procedimiento que se usa para quitar un controlador de eventos.
**Identificador de error:** BC31128
## <a name="to-correct-this-error"></a>Para corregir este error
- Quite la instrucción `RemoveHandler` redundante.
## <a name="see-also"></a>Vea también
[RemoveHandler (instrucción)](../../visual-basic/language-reference/statements/removehandler-statement.md)
[Event (instrucción)](../../visual-basic/language-reference/statements/event-statement.md)
| 39.310345 | 199 | 0.758772 | spa_Latn | 0.478228 |
97549f3cc00f719916166a30d03f2df1b5f25fae | 8,888 | md | Markdown | docs/framework/unmanaged-api/debugging/icordebugprocess6-enablevirtualmodulesplitting-method.md | Jonatandb/docs.es-es | c18663ce8a09607fe195571492cad602bc2f01bb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/debugging/icordebugprocess6-enablevirtualmodulesplitting-method.md | Jonatandb/docs.es-es | c18663ce8a09607fe195571492cad602bc2f01bb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/debugging/icordebugprocess6-enablevirtualmodulesplitting-method.md | Jonatandb/docs.es-es | c18663ce8a09607fe195571492cad602bc2f01bb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Método ICorDebugProcess6::EnableVirtualModuleSplitting
ms.date: 03/30/2017
ms.assetid: e7733bd3-68da-47f9-82ef-477db5f2e32d
ms.openlocfilehash: 8ad15d11ce81323b30434b3db98259a74a198f29
ms.sourcegitcommit: 7588136e355e10cbc2582f389c90c127363c02a5
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 03/12/2020
ms.locfileid: "79178571"
---
# <a name="icordebugprocess6enablevirtualmodulesplitting-method"></a>Método ICorDebugProcess6::EnableVirtualModuleSplitting
Habilita o deshabilita la división de módulos virtuales.
## <a name="syntax"></a>Sintaxis
```cpp
HRESULT EnableVirtualModuleSplitting(
BOOL enableSplitting
);
```
## <a name="parameters"></a>Parámetros
`enableSplitting`
`true` para habilitar la división de módulos virtuales; `false` para deshabilitarla.
## <a name="remarks"></a>Observaciones
La división de módulos virtuales hace que [ICorDebug](icordebug-interface.md) reconozca los módulos que se combinaron durante el proceso de compilación y los presentaron como un grupo de módulos independientes en lugar de un único módulo grande. Esto cambia el comportamiento de varios [ICorDebug](icordebug-interface.md) métodos descritos a continuación.
> [!NOTE]
> Este método solo está disponible con .NET Native.
Puede llamar a este método y cambiar el valor de `enableSplitting` en cualquier momento. No provoca ningún cambio funcional con estado en un objeto [ICorDebug,](icordebug-interface.md) aparte de modificar el comportamiento de los métodos enumerados en la división del módulo virtual y la sección [DE API de depuración no administrada](#APIs) en el momento en que se llaman. El uso de módulos virtuales hace que el rendimiento disminuya cuando se llama a estos métodos. Además, puede ser necesario almacenar en caché en memoria significativo de los metadatos virtualizados para implementar correctamente las API [de IMetaDataImport,](../../../../docs/framework/unmanaged-api/metadata/imetadataimport-interface.md) y estas memorias caché pueden conservarse incluso después de que se haya desactivado la división de módulos virtuales.
## <a name="terminology"></a>Terminología
Los siguientes términos sirven para describir la división de módulos virtuales:
módulos de contenedor o contenedores
Son los módulos agregados.
submódulos o módulos virtuales
Son los módulos incluidos en un contenedor.
módulos regulares
Módulos que no se han combinado en tiempo de compilación. No son ni módulos de contenedor ni submódulos.
Tanto los módulos de contenedor como los submódulos se representan mediante objetos de interfaz ICorDebugModule. Sin embargo, el comportamiento de la interfaz \<es ligeramente diferente en cada caso, como describe la sección x-ref a> sección.
## <a name="modules-and-assemblies"></a>Módulos y ensamblados
En los escenarios donde se combinan ensamblados no se admiten ensamblados con varios módulos, por lo que hay una relación de uno a uno entre un módulo y un ensamblado. Cada objeto ICorDebugModule, independientemente de si representa a un módulo de contenedor o a un submódulo, se corresponde con un objeto ICorDebugAssembly. El [ICorDebugModule::GetAssembly](icordebugmodule-getassembly-method.md) método convierte del módulo al ensamblado. Para asignar en la otra dirección, el [ICorDebugAssembly::EnumerateModules](icordebugassembly-enumeratemodules-method.md) método enumera solo 1 módulo. Dado que ensamblado y módulo conforman un par estrechamente unido en este caso, los términos módulo y ensamblado se han convertido en prácticamente intercambiables.
## <a name="behavioral-differences"></a>Diferencias de comportamiento
Los módulos del contenedor tienen los siguientes comportamientos y características:
- Sus metadatos para todos los submódulos que lo conforman se combinan entre sí.
- Sus nombres de tipo se pueden alterar.
- El [Método ICorDebugModule::GetName](icordebugmodule-getname-method.md) devuelve la ruta de acceso a un módulo en disco.
- El [ICorDebugModule::GetSize](icordebugmodule-getsize-method.md) método devuelve el tamaño de esa imagen.
- El método ICorDebugAssembly3.EnumerateContainedAssemblies enumera los submódulos.
- El método ICorDebugAssembly3.GetContainerAssembly devuelve `S_FALSE`.
Los submódulos tienen los siguientes comportamientos y características:
- Tienen un conjunto reducido de metadatos que corresponde únicamente al ensamblado original que se ha combinado.
- Los nombres de los metadatos no se alteran.
- Es improbable que los tokens de los metadatos coincidan con los tokens del ensamblado original antes de que combinarse en el proceso de compilación.
- El [Método ICorDebugModule::GetName](icordebugmodule-getname-method.md) devuelve el nombre del ensamblado, no una ruta de acceso de archivo.
- El [ICorDebugModule::GetSize](icordebugmodule-getsize-method.md) método devuelve el tamaño de imagen sin combinar original.
- El método ICorDebugModule3.EnumerateContainedAssemblies devuelve `S_FALSE`.
- El método ICorDebugAssembly3.GetContainerAssembly devuelve el módulo contenedor.
## <a name="interfaces-retrieved-from-modules"></a>Interfaces obtenidas de los módulos
Se pueden crear y recuperar diversas interfaces de los módulos. Algunos son:
- Un ICorDebugClass objeto, que se devuelve el [ICorDebugModule::GetClassFromToken](icordebugmodule-getclassfromtoken-method.md) método.
- Un ICorDebugAssembly objeto, que se devuelve el [ICorDebugModule::GetAssembly](icordebugmodule-getassembly-method.md) método.
Estos objetos siempre se almacenan en caché por [ICorDebug](icordebug-interface.md)y tendrán la misma identidad de puntero independientemente de si se crearon o se consultaron desde el módulo contenedor o un submódulo. El submódulo proporciona una vista filtrada de estos objetos en caché, no una memoria caché independiente con sus propias copias.
<a name="APIs"></a>
## <a name="virtual-module-splitting-and-the-unmanaged-debugging-apis"></a>División de módulos virtuales y API de depuración no administradas
En la siguiente tabla se muestra cómo la división de módulos virtuales afecta al comportamiento de otros métodos en una API de depuración no administrada.
|Método|`enableSplitting` = `true`|`enableSplitting` = `false`|
|------------|---------------------------------|----------------------------------|
|[ICorDebugFunction::GetModule](icordebugfunction-getmodule-method.md)|Devuelve el submódulo en el que esta función se definió originalmente.|Devuelve el módulo contenedor con el que esta función se combinó.|
|[ICorDebugClass::GetModule](icordebugclass-getmodule-method.md)|Devuelve el submódulo en el que esta clase se definió originalmente.|Devuelve el módulo contenedor con el que esta clase se combinó.|
|ICorDebugModuleDebugEvent::GetModule|Devuelve el módulo contenedor que se cargó. Los submódulos no tienen eventos load, independientemente de esta configuración.|Devuelve el módulo contenedor que se cargó.|
|[ICorDebugAppDomain::EnumerateAssemblies](icordebugappdomain-enumerateassemblies-method.md)|Devuelve una lista de los subensamblados y ensamblados regulares; no se incluyen ensamblados de contenedor. **Nota:** Si a algún ensamblado contenedor le faltan símbolos, no se enumerará ninguno de sus subensamblajes. Si faltan símbolos en algún ensamblado regular, puede que se enumere o no.|Devuelve una lista de ensamblados de contenedor y ensamblados regulares; no se incluyen subensamblados. **Nota:** Si a algún ensamblado normal le faltan símbolos, puede o no enumerarse.|
|[ICorDebugCode::GetCode](icordebugcode-getcode-method.md) (cuando se hace referencia a código IL solamente)|Devuelve el código IL que sería válido en una imagen de ensamblado antes de la fusión mediante combinación. En concreto, cualquier token de metadatos en línea será correctamente un token TypeRef o MemberRef cuando los tipos a los que se hace referencia no están definidos en el módulo virtual que contiene el IL. Estos typeRef o MemberRef tokens se pueden buscar en el [IMetaDataImport](../../../../docs/framework/unmanaged-api/metadata/imetadataimport-interface.md) objeto para el correspondiente virtual ICorDebugModule objeto.|Devuelve el IL de la imagen de ensamblado posterior a la combinación.|
## <a name="requirements"></a>Requisitos
**Plataformas:** Vea [Requisitos de sistema](../../../../docs/framework/get-started/system-requirements.md).
**Encabezado:** CorDebug.idl, CorDebug.h
**Biblioteca:** CorGuids.lib
**Versiones de .NET Framework:** [!INCLUDE[net_46_native](../../../../includes/net-46-native-md.md)]
## <a name="see-also"></a>Consulte también
- [ICorDebugProcess6 (interfaz)](icordebugprocess6-interface.md)
- [Interfaces de depuración](debugging-interfaces.md)
| 75.965812 | 834 | 0.780828 | spa_Latn | 0.974942 |
975550b8ad5e39fe4cd200a46ffc6eeb52f63dbd | 1,396 | md | Markdown | sccm/core/get-started/2019/includes/1901/3605704.md | Miguel-byte/SCCMDocs.es-es | 9849ced1705d6e20b02f9dfb170983f6e13682a2 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | sccm/core/get-started/2019/includes/1901/3605704.md | Miguel-byte/SCCMDocs.es-es | 9849ced1705d6e20b02f9dfb170983f6e13682a2 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | sccm/core/get-started/2019/includes/1901/3605704.md | Miguel-byte/SCCMDocs.es-es | 9849ced1705d6e20b02f9dfb170983f6e13682a2 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
author: aczechowski
ms.author: aaroncz
ms.prod: configuration-manager
ms.topic: include
ms.date: 01/22/2019
ms.collection: M365-identity-device-management
ms.openlocfilehash: 994114195641f70d9cbfa7c890656bf51b23bc92
ms.sourcegitcommit: 874d78f08714a509f61c52b154387268f5b73242
ms.translationtype: HT
ms.contentlocale: es-ES
ms.lasthandoff: 02/12/2019
ms.locfileid: "56143059"
---
## <a name="bkmk_arm"></a> Uso de Azure Resource Manager para servicios en la nube
<!--3605704-->
A partir de la versión 1810 de la rama actual de Configuration Manager, la implementación del servicio clásico de Azure está en desuso en Configuration Manager. Esta versión es la última que admite la creación de estas implementaciones de Azure.
Las implementaciones existentes seguirán funcionando. A partir de esta versión de la rama de Technical Preview, Azure Resource Manager es el único mecanismo de implementación para las instancias nuevas del punto de distribución de nube y la puerta de enlace de administración de la nube.
Vea los siguientes artículos para más información:
- [Azure Resource Manager para la puerta de enlace de administración de nube](/sccm/core/clients/manage/cmg/plan-cloud-management-gateway#azure-resource-manager)
- [Azure Resource Manager para el punto de distribución de nube](/sccm/core/plan-design/hierarchy/use-a-cloud-based-distribution-point#azure-resource-manager)
| 51.703704 | 287 | 0.810888 | spa_Latn | 0.90722 |
97559b7015417146687f1a5e6a8e1c650e5d309c | 860 | md | Markdown | content/team/ben-wilcock/_index.md | ddubson/tanzu-dev-portal | 712c4fb86812a2dbb18807f809dad484da5321a5 | [
"Apache-2.0"
] | 76 | 2020-06-23T17:47:52.000Z | 2022-03-28T19:19:32.000Z | content/team/ben-wilcock/_index.md | ddubson/tanzu-dev-portal | 712c4fb86812a2dbb18807f809dad484da5321a5 | [
"Apache-2.0"
] | 595 | 2020-06-23T17:19:35.000Z | 2022-03-31T12:44:28.000Z | content/team/ben-wilcock/_index.md | ddubson/tanzu-dev-portal | 712c4fb86812a2dbb18807f809dad484da5321a5 | [
"Apache-2.0"
] | 130 | 2020-06-23T17:01:15.000Z | 2022-03-25T13:32:58.000Z | ---
name: Ben Wilcock
description: "Technical Marketing Manager"
roles: ["author"]
skills: ["Spring", "Python", "Kubernetes", "Cloud Foundry"]
location: "Glastonbury, UK"
hidden: true
# Social Media
twitter: "benbravo73"
website: "https://benwilcock.wordpress.com"
facebook: ""
linkedin: "benwilcock"
github: "benwilcock"
pinterest: ""
instagram: ""
youtube: ""
---
Ben has been helping people deliver better software all his working life. He's done this by listening, learning, and leading software developers in organizations large and small, spanning many industries and sectors.
Ben helps VMware build stronger developer relationships with the millions of developers who use our products every day. He's technical, often writing code, but also helps shape products, build websites, write blogs, record videos, and help out on social media.
<!--more-->
| 34.4 | 260 | 0.762791 | eng_Latn | 0.983485 |
9755ab67d6485f212eb1a4b2274204b8ef362216 | 1,877 | md | Markdown | index.md | nisyad/nisyad.github.io | 10c84cb604595a6e90756cbdf61bf0ef16e38cca | [
"CC0-1.0"
] | null | null | null | index.md | nisyad/nisyad.github.io | 10c84cb604595a6e90756cbdf61bf0ef16e38cca | [
"CC0-1.0"
] | null | null | null | index.md | nisyad/nisyad.github.io | 10c84cb604595a6e90756cbdf61bf0ef16e38cca | [
"CC0-1.0"
] | null | null | null | ---
layout: homepage
title: Nishant Yadav
role: PhD Candidate | Interdisciplinary Engineering
affiliation: Northeastern University, Boston
contact: [email protected] <br> [email protected] <br>
description: Machine Learning, Complex Networks, Environmental Science
---
## Bio
Nishant Yadav is a PhD candidate in the Interdisciplinary Engineering program at Northeastern University, Boston, MA. His research focuses on using machine learning to solve problems in environmental and climate science. He is particularly interested in developing (deep) transfer learning methods for extracting information from remotely-sensed data (e.g., satellite images). Recently his research is focused on unsupervised domain adaptation using adversarial learning techniques. At other times, conversations on networks, and making AI more interpretable and theory-guided keep him excited.
<!--
## Bio
Nishant is a PhD student in the Interdisciplinary Engineering program at Northeastern University, Boston, MA, advised by [Auroop R. Ganguly](https://coe.northeastern.edu/people/ganguly-auroop/). Before starting his PhD, he worked in the industry where he evaluated the health of critical infrastructure systems. He completed his master's degree in intelligent systems from the University of Michigan Ann Arbor in 2014 and a bachelor's in civil and environmental engineering from the Indian Institute of Technology (IIT) Guwahati in 2012.
-->
## Recent News
<p>[November 2020] Started as Deep Learning Research Intern at NASA Ames, CA.</p>
<p>[September 2020] Work on multilayer network resilience under compound stresses mentioned in [Department of Energy](https://eurekalert.org/features/doe/2020-09/dnnl-nri092220.php) news.</p>
<p>[August 2020] **Best Student Paper Award** at the Data Science for a Sustainable Planet Workshop, 26th SIGKDD Conference, San Diego, CA.</p>
| 72.192308 | 594 | 0.79968 | eng_Latn | 0.988142 |
97573463e65ad49b97d7f7f3ce206213046e9b25 | 4,766 | md | Markdown | treebanks/pl_pud/pl_pud-dep-nummod.md | emmettstr/docs | 2d0376d6e07f3ffa828f6152d12cf260a530c64d | [
"Apache-2.0"
] | 204 | 2015-01-20T16:36:39.000Z | 2022-03-28T00:49:51.000Z | treebanks/pl_pud/pl_pud-dep-nummod.md | emmettstr/docs | 2d0376d6e07f3ffa828f6152d12cf260a530c64d | [
"Apache-2.0"
] | 654 | 2015-01-02T17:06:29.000Z | 2022-03-31T18:23:34.000Z | treebanks/pl_pud/pl_pud-dep-nummod.md | emmettstr/docs | 2d0376d6e07f3ffa828f6152d12cf260a530c64d | [
"Apache-2.0"
] | 200 | 2015-01-16T22:07:02.000Z | 2022-03-25T11:35:28.000Z | ---
layout: base
title: 'Statistics of nummod in UD_Polish-PUD'
udver: '2'
---
## Treebank Statistics: UD_Polish-PUD: Relations: `nummod`
This relation is universal.
There are 1 language-specific subtypes of `nummod`: <tt><a href="pl_pud-dep-nummod-gov.html">nummod:gov</a></tt>.
97 nodes (1%) are attached to their parents as `nummod`.
97 instances of `nummod` (100%) are right-to-left (child precedes parent).
Average distance between parent and child is 1.35051546391753.
The following 4 pairs of parts of speech are connected with `nummod`: <tt><a href="pl_pud-pos-NOUN.html">NOUN</a></tt>-<tt><a href="pl_pud-pos-NUM.html">NUM</a></tt> (85; 88% instances), <tt><a href="pl_pud-pos-SYM.html">SYM</a></tt>-<tt><a href="pl_pud-pos-NUM.html">NUM</a></tt> (7; 7% instances), <tt><a href="pl_pud-pos-PROPN.html">PROPN</a></tt>-<tt><a href="pl_pud-pos-NUM.html">NUM</a></tt> (3; 3% instances), <tt><a href="pl_pud-pos-ADJ.html">ADJ</a></tt>-<tt><a href="pl_pud-pos-NUM.html">NUM</a></tt> (2; 2% instances).
~~~ conllu
# visual-style 1 bgColor:blue
# visual-style 1 fgColor:white
# visual-style 4 bgColor:blue
# visual-style 4 fgColor:white
# visual-style 4 1 nummod color:blue
1 5 5 NUM num:pl:nom:m3:congr Animacy=Inan|Case=Nom|Gender=Masc|Number=Plur|NumForm=Digit|NumType=Card 4 nummod 4:nummod _
2 tys tysiąc X brev:pun Abbr=Yes|Pun=Yes 1 flat 1:flat SpaceAfter=No
3 . . PUNCT interp PunctType=Peri 2 punct 2:punct _
4 dolarów dolar NOUN subst:pl:gen:m2 Animacy=Nhum|Case=Gen|Gender=Masc|Number=Plur 0 root 0:root _
5 na na ADP prep:acc AdpType=Prep 6 case 6:case Case=Acc
6 osobę osoba NOUN subst:sg:acc:f Case=Acc|Gender=Fem|Number=Sing 4 nmod 4:nmod SpaceAfter=No
7 , , PUNCT interp PunctType=Comm 9 punct 9:punct _
8 dopuszczalne dopuszczalny ADJ adj:sg:nom:n:pos Case=Nom|Degree=Pos|Gender=Neut|Number=Sing 9 amod 9:amod _
9 maksimum maksimum NOUN subst:sg:nom:n:ncol Case=Nom|Gender=Neut|Number=Sing 4 appos 4:appos SpaceAfter=No
10 . . PUNCT interp PunctType=Peri 4 punct 4:punct _
~~~
~~~ conllu
# visual-style 9 bgColor:blue
# visual-style 9 fgColor:white
# visual-style 10 bgColor:blue
# visual-style 10 fgColor:white
# visual-style 10 9 nummod color:blue
1 Zapytane zapytać ADJ ppas:pl:nom:n:perf:aff Aspect=Perf|Case=Nom|Gender=Neut|Number=Plur|Polarity=Pos|VerbForm=Part|Voice=Pass 2 acl 2:acl _
2 źródła źródło NOUN subst:pl:nom:n:ncol Case=Nom|Gender=Neut|Number=Plur 3 nsubj 3:nsubj _
3 stwierdziły stwierdzić VERB praet:pl:n:perf Aspect=Perf|Gender=Neut|Mood=Ind|Number=Plur|Tense=Past|VerbForm=Fin|Voice=Act 0 root 0:root SpaceAfter=No
4 , , PUNCT interp PunctType=Comm 11 punct 11:punct _
5 że że SCONJ comp _ 11 mark 11:mark _
6 jest być AUX fin:sg:ter:imperf Aspect=Imp|Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin|Voice=Act 11 cop 11:cop _
7 „ „ PUNCT interp PunctSide=Ini|PunctType=Quot 11 punct 11:punct SpaceAfter=No
8 w w ADP prep:loc:nwok AdpType=Prep|Variant=Short 10 case 10:case Case=Loc
9 100 100 NUM num:pl:loc:m3:congr Animacy=Inan|Case=Loc|Gender=Masc|Number=Plur|NumForm=Digit|NumType=Card 10 nummod 10:nummod SpaceAfter=No
10 % % SYM interp _ 11 nmod 11:nmod _
11 Cospedal Cospedal PROPN subst:sg:inst:m3 Animacy=Inan|Case=Ins|Gender=Masc|Number=Sing 3 ccomp:obj 3:ccomp:obj SpaceAfter=No
12 ” ” PUNCT interp PunctSide=Fin|PunctType=Quot 11 punct 11:punct SpaceAfter=No
13 . . PUNCT interp PunctType=Peri 3 punct 3:punct _
~~~
~~~ conllu
# visual-style 2 bgColor:blue
# visual-style 2 fgColor:white
# visual-style 3 bgColor:blue
# visual-style 3 fgColor:white
# visual-style 3 2 nummod color:blue
1 Indianie Indianin PROPN subst:pl:nom:m1 Animacy=Hum|Case=Nom|Gender=Masc|Number=Plur 4 nsubj 4:nsubj _
2 obu oba NUM num:pl:gen:f:congr:ncol Case=Gen|Gender=Fem|Number=Plur|NumForm=Word 3 nummod 3:nummod _
3 Ameryk Ameryka PROPN subst:pl:gen:f Case=Gen|Gender=Fem|Number=Plur 1 nmod 1:nmod _
4 używali używać VERB praet:pl:m1:imperf Animacy=Hum|Aspect=Imp|Gender=Masc|Mood=Ind|Number=Plur|Tense=Past|VerbForm=Fin|Voice=Act 0 root 0:root _
5 jej on PRON ppron3:sg:gen:f:ter:akc:npraep Case=Gen|Gender=Fem|Number=Sing|Person=3|PrepCase=Npr|PronType=Prs|Variant=Long 4 obj 4:obj _
6 jako jako SCONJ comp ConjType=Pred 8 mark 8:mark _
7 podstawowego podstawowy ADJ adj:sg:gen:m3:pos Animacy=Inan|Case=Gen|Degree=Pos|Gender=Masc|Number=Sing 8 amod 8:amod _
8 składnika składnik NOUN subst:sg:gen:m3 Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing 4 obl 4:obl _
9 w w ADP prep:loc:nwok AdpType=Prep|Variant=Short 11 case 11:case Case=Loc
10 tradycyjnej tradycyjny ADJ adj:sg:loc:f:pos Case=Loc|Degree=Pos|Gender=Fem|Number=Sing 11 amod 11:amod _
11 medycynie medycyna NOUN subst:sg:loc:f Case=Loc|Gender=Fem|Number=Sing 4 obl:arg 4:obl:arg SpaceAfter=No
12 . . PUNCT interp PunctType=Peri 4 punct 4:punct _
~~~
| 56.070588 | 529 | 0.75598 | yue_Hant | 0.551783 |
9757992f65c7935387900550a897d36ff2f8e761 | 264 | md | Markdown | _provenance/6955.md | brueghelfamily/brueghelfamily.github.io | a73351ac39b60cd763e483c1f8520f87d8c2a443 | [
"MIT"
] | null | null | null | _provenance/6955.md | brueghelfamily/brueghelfamily.github.io | a73351ac39b60cd763e483c1f8520f87d8c2a443 | [
"MIT"
] | null | null | null | _provenance/6955.md | brueghelfamily/brueghelfamily.github.io | a73351ac39b60cd763e483c1f8520f87d8c2a443 | [
"MIT"
] | null | null | null | ---
pid: '6955'
object_pid: '2949'
label: The Arch of Septimus Severus Seen from the West
artist: janbrueghel
provenance_date: '2010'
provenance_location: Munich
provenance_text: Sale, Katrin Bellinger Kunsthandel (Vendor)
collection: provenance
order: '0134'
---
| 22 | 60 | 0.780303 | eng_Latn | 0.403396 |
975885520680d71c8354871e7a6d509501756101 | 2,174 | md | Markdown | docs/relational-databases/system-stored-procedures/sp-drop-agent-profile-transact-sql.md | relsna/sql-docs | 0ff8e6a5ffa09337bc1336e2e1a99b9c747419e4 | [
"CC-BY-4.0",
"MIT"
] | 840 | 2017-07-21T12:44:54.000Z | 2022-03-30T01:28:51.000Z | docs/relational-databases/system-stored-procedures/sp-drop-agent-profile-transact-sql.md | relsna/sql-docs | 0ff8e6a5ffa09337bc1336e2e1a99b9c747419e4 | [
"CC-BY-4.0",
"MIT"
] | 7,326 | 2017-07-19T17:35:42.000Z | 2022-03-31T20:48:54.000Z | docs/relational-databases/system-stored-procedures/sp-drop-agent-profile-transact-sql.md | relsna/sql-docs | 0ff8e6a5ffa09337bc1336e2e1a99b9c747419e4 | [
"CC-BY-4.0",
"MIT"
] | 2,698 | 2017-07-19T18:12:53.000Z | 2022-03-31T20:25:07.000Z | ---
description: "sp_drop_agent_profile (Transact-SQL)"
title: "sp_drop_agent_profile (Transact-SQL) | Microsoft Docs"
ms.custom: ""
ms.date: "03/06/2017"
ms.prod: sql
ms.prod_service: "database-engine"
ms.reviewer: ""
ms.technology: replication
ms.topic: "reference"
f1_keywords:
- "sp_drop_agent_profile"
- "sp_drop_agent_profile_TSQL"
helpviewer_keywords:
- "sp_drop_agent_profile"
ms.assetid: b884f9ef-ae89-4cbc-a917-532c3ff6ed41
author: markingmyname
ms.author: maghan
---
# sp_drop_agent_profile (Transact-SQL)
[!INCLUDE [SQL Server](../../includes/applies-to-version/sqlserver.md)]
Drops a profile from the **MSagent_profiles** table. This stored procedure is executed at the Distributor on any database.
 [Transact-SQL Syntax Conventions](../../t-sql/language-elements/transact-sql-syntax-conventions-transact-sql.md)
## Syntax
```
sp_drop_agent_profile [ @profile_id = ] profile_id
```
## Arguments
`[ @profile_id = ] profile_id`
Is the ID of the profile to be dropped. *profile_id* is **int**, with no default.
## Return Code Values
**0** (success) or **1** (failure)
## Remarks
**sp_drop_agent_profile** is used in all types of replication.
The parameters of the given profile are also dropped from the **MSagent_parameters** table.
## Permissions
Only members of the **sysadmin** fixed server role can execute **sp_drop_agent_profile**.
## See Also
[sp_add_agent_profile (Transact-SQL)](../../relational-databases/system-stored-procedures/sp-add-agent-profile-transact-sql.md)
[sp_change_agent_profile (Transact-SQL)](../../relational-databases/system-stored-procedures/sp-change-agent-profile-transact-sql.md)
[sp_help_agent_profile (Transact-SQL)](../../relational-databases/system-stored-procedures/sp-help-agent-profile-transact-sql.md)
[System Stored Procedures (Transact-SQL)](../../relational-databases/system-stored-procedures/system-stored-procedures-transact-sql.md)
| 38.821429 | 215 | 0.709752 | eng_Latn | 0.260292 |
97593187235bb6173da5e84f1f5080c9bc0fd010 | 5,512 | md | Markdown | articles/site-recovery/monitoring-common-questions.md | changeworld/azure-docs.pl-pl | f97283ce868106fdb5236557ef827e56b43d803e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/site-recovery/monitoring-common-questions.md | changeworld/azure-docs.pl-pl | f97283ce868106fdb5236557ef827e56b43d803e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/site-recovery/monitoring-common-questions.md | changeworld/azure-docs.pl-pl | f97283ce868106fdb5236557ef827e56b43d803e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Typowe pytania dotyczące monitorowania usługi Azure Site Recovery
description: Uzyskaj odpowiedzi na często zadawane pytania dotyczące monitorowania usługi Azure Site Recovery przy użyciu wbudowanego monitorowania i usługi Azure Monitor (Log Analytics)
author: rayne-wiselman
manager: carmonm
ms.service: site-recovery
services: site-recovery
ms.date: 07/31/2019
ms.topic: conceptual
ms.author: raynew
ms.openlocfilehash: c1d30a9cdd2cd6ca288edd609a2e2e7bee9174d7
ms.sourcegitcommit: 2ec4b3d0bad7dc0071400c2a2264399e4fe34897
ms.translationtype: MT
ms.contentlocale: pl-PL
ms.lasthandoff: 03/27/2020
ms.locfileid: "68718264"
---
# <a name="common-questions-about-site-recovery-monitoring"></a>Typowe pytania dotyczące monitorowania odzyskiwania witryny
Ten artykuł zawiera odpowiedzi na często zadawane pytania dotyczące monitorowania usługi Azure [Site Recovery](site-recovery-overview.md), przy użyciu wbudowanego monitorowania odzyskiwania witryny i usługi Azure Monitor (log analytics).
## <a name="general"></a>Ogólne
### <a name="how-is-the-rpo-value-logged-different-from-the-latest-available-recovery-point"></a>Czym rejestrowana jest wartość punktu odzyskiwania od najnowszego dostępnego punktu odzyskiwania?
Usługa Site Recovery używa wieloetapowego, asynchroniowego procesu do replikowania maszyn na platformę Azure.
- W przedostatnim kroku replikacji ostatnie zmiany na komputerze wraz z metadanymi są kopiowane do konta magazynu dziennika/pamięci podręcznej.
- Te zmiany, wraz z tagiem identyfikującym punkt odzyskiwalny, są zapisywane na koncie magazynu/dysku zarządzanym w regionie docelowym.
- Odzyskiwanie lokacji może teraz wygenerować punkt odzyskiwalny dla komputera.
- W tym momencie RPO został spełniony w przypadku zmian przesłanych do tej pory na konto magazynu. Innymi słowy, rpo maszyny w tym momencie jest równa czas, który upłynął od sygnatury czasowej odpowiadającej punktowi odzyskiwania.
- Teraz usługa Site Recovery wybiera przekazane dane z konta magazynu i stosuje go do dysków replik utworzonych dla komputera.
- Odzyskiwanie lokacji następnie generuje punkt odzyskiwania i udostępnia ten punkt do odzyskiwania po przemijazie awaryjnym.
- W związku z tym ostatni dostępny punkt odzyskiwania wskazuje sygnaturę czasową odpowiadającą ostatniemu punktowi odzyskiwania, który został już przetworzony i zastosowany do dysków repliki.
Niepoprawny czas systemowy na komputerze źródłowym replikacji lub na serwerach infrastruktury lokalnej spowoduje wypaczenie obliczonej wartości RPO. Aby uzyskać dokładne raportowanie RPO, upewnij się, że zegar systemowy jest dokładny na wszystkich serwerach i komputerach.
## <a name="inbuilt-site-recovery-logging"></a>Wbudowane rejestrowanie odzyskiwania witryny
### <a name="why-is-the-vm-count-in-the-vault-infrastructure-view-different-from-the-total-count-shown-in-replicated-items"></a>Dlaczego liczba maszyn wirtualnych w widoku infrastruktury przechowalni różni się od łącznej liczby wyświetlanej w elementów replikowanych?
Widok infrastruktury przechowalni jest objęty zakresem według scenariuszy replikacji. Tylko maszyny w aktualnie wybranym scenariuszu replikacji są uwzględniane w liczbie dla widoku. Ponadto liczymy tylko maszyny wirtualne, które są skonfigurowane do replikacji na platformie Azure. Maszyny w razie pracy awaryjnej lub maszyny replikujące się z powrotem do lokacji lokalnej nie są liczone w widoku.
### <a name="why-is-the-count-of-replicated-items-in-essentials-different-from-the-total-count-of-replicated-items-on-the-dashboard"></a>Dlaczego liczba zreplikowanych elementów w programie Essentials różni się od całkowitej liczby zreplikowanych elementów na pulpicie nawigacyjnym?
Tylko maszyny, dla których replikacja początkowa została zakończona, są uwzględniane w liczbie pokazanej w pliku Essentials. Suma zreplikowanych elementów obejmuje wszystkie maszyny w przechowalni, w tym te, dla których replikacja początkowa jest obecnie w toku.
## <a name="azure-monitor-logging"></a>Rejestrowanie w usłudze Azure Monitor
### <a name="how-often-does-site-recovery-send-diagnostic-logs-to-azure-monitor-log"></a>Jak często usługa Site Recovery wysyła dzienniki diagnostyczne do dziennika usługi Azure Monitor?
- Usługa AzureSiteRecoveryReplicationStats i AzureSiteRecoveryRecoveryPoints są wysyłane co 15 minut.
- Usługa AzureSiteRecoveryReplicationDataUploadRate i AzureSiteRecoveryProtectedDiskDataChurn są wysyłane co pięć minut.
- Usługa AzureSiteRecoveryJobs jest wysyłana w wyzwalaczu i zakończeniu zadania.
- Usługa AzureSiteRecoveryEvents jest wysyłana za każdym razem, gdy generowane jest zdarzenie.
- AzureSiteRecoveryReplicatedItems jest wysyłany za każdym razem, gdy nastąpi zmiana środowiska. Zazwyczaj czas odświeżania danych wynosi 15 minut po zmianie.
### <a name="how-long-is-data-kept-in-azure-monitor-logs"></a>Jak długo dane są przechowywane w dziennikach usługi Azure Monitor?
Domyślnie przechowywanie jest przez 31 dni. Okres można wydłużyć w sekcji **Użycie i Koszt szacowany** w obszarze roboczym Usługa Log Analytics. Kliknij na **Przechowywanie danych**i wybierz zakres.
### <a name="whats-the-size-of-the-diagnostic-logs"></a>Jaki jest rozmiar dzienników diagnostycznych?
Zazwyczaj rozmiar dziennika wynosi 15-20 KB.
## <a name="next-steps"></a>Następne kroki
Dowiedz się, jak monitorować za pomocą [wbudowanego monitorowania usługi Site Recovery](site-recovery-monitor-and-troubleshoot.md)lub usługi Azure [Monitor.](monitor-log-analytics.md)
| 71.584416 | 397 | 0.824565 | pol_Latn | 0.999664 |
97599579c105e2b50b82048c9401fe2b147e02e1 | 4,683 | md | Markdown | docs/ado/reference/ado-api/editmode-property.md | baleng/sql-docs.it-it | 80bb05c3cc6a68564372490896545d6211a9fa26 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/ado/reference/ado-api/editmode-property.md | baleng/sql-docs.it-it | 80bb05c3cc6a68564372490896545d6211a9fa26 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/ado/reference/ado-api/editmode-property.md | baleng/sql-docs.it-it | 80bb05c3cc6a68564372490896545d6211a9fa26 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Proprietà EditMode | Microsoft Docs
ms.prod: sql
ms.prod_service: connectivity
ms.technology: connectivity
ms.custom: ''
ms.date: 01/19/2017
ms.reviewer: ''
ms.topic: conceptual
apitype: COM
f1_keywords:
- Recordset15::EditMode
helpviewer_keywords:
- EditMode property
ms.assetid: a1b04bb2-8c8b-47f9-8477-bfd0368b6f68
author: MightyPen
ms.author: genemi
manager: craigg
ms.openlocfilehash: 147528e9400d6befe9d5cb3c5d3cc3f882e48ad0
ms.sourcegitcommit: 61381ef939415fe019285def9450d7583df1fed0
ms.translationtype: MT
ms.contentlocale: it-IT
ms.lasthandoff: 10/01/2018
ms.locfileid: "47735959"
---
# <a name="editmode-property"></a>Proprietà EditMode
Indica lo stato di modifica del record corrente.
## <a name="return-value"></a>Valore restituito
Restituisce un [EditModeEnum](../../../ado/reference/ado-api/editmodeenum.md) valore.
## <a name="remarks"></a>Note
ADO mantiene un buffer di modifica associato al record corrente. Questa proprietà indica se sono state apportate modifiche a questo buffer, o se è stato creato un nuovo record. Usare la **EditMode** proprietà per determinare lo stato di modifica del record corrente. È possibile verificare le modifiche in sospeso se un processo di modifica è stata interrotta e determinare se è necessario usare il [Update](../../../ado/reference/ado-api/update-method.md) oppure [CancelUpdate](../../../ado/reference/ado-api/cancelupdate-method-ado.md) (metodo).
Nella *modalità di aggiornamento immediato* le **EditMode** viene reimpostata a **adEditNone** dopo una chiamata al **aggiornare** viene chiamato il metodo . Quando una chiamata a [eliminare](../../../ado/reference/ado-api/delete-method-ado-recordset.md) non è stato eliminare i record nell'origine dati (ad esempio, a causa di violazioni di integrità referenziale), il [Recordset](../../../ado/reference/ado-api/recordset-object-ado.md) rimane in modalità di modifica (**EditMode** = **adEditInProgress**). Pertanto **CancelUpdate** deve essere chiamato prima di uscire il record corrente (ad esempio con [spostare](../../../ado/reference/ado-api/move-method-ado.md), [NextRecordset](../../../ado/reference/ado-api/nextrecordset-method-ado.md), o [chiudere](../../../ado/reference/ado-api/close-method-ado.md) ).
Nella *modalità di aggiornamento batch* (in cui il provider vengono memorizzati nella cache più modifiche e li scrive all'origine dati sottostante solo quando si chiama il [UpdateBatch](../../../ado/reference/ado-api/updatebatch-method.md) metodo), il valore del **EditMode** proprietà viene modificata quando viene eseguita la prima operazione e non viene ripristinato da una chiamata per il **Update** (metodo). Operazioni successive non modificare il valore della **EditMode** proprietà, anche se vengono eseguite diverse operazioni. Ad esempio, se la prima operazione consiste nell'aggiungere un nuovo record e il secondo apporta modifiche a un oggetto esistente di record, la proprietà del **EditMode** saranno ancora **adEditAdd**. Il **EditMode** proprietà non venga reimpostata **adEditNone** fino a quando non dopo la chiamata a **UpdateBatch**. Per determinare quali operazioni sono state eseguite, impostare il [filtro](../../../ado/reference/ado-api/filter-property.md) proprietà [adFilterPending](../../../ado/reference/ado-api/filtergroupenum.md) in modo che solo i record con le modifiche in sospeso verranno visibile ed esaminare il [stato](../../../ado/reference/ado-api/status-property-ado-recordset.md) proprietà di ogni record per determinare quali modifiche sono state apportate ai dati.
> [!NOTE]
> **Proprietà EditMode** può restituire un valore valido solo se viene rilevato un record corrente. **Proprietà EditMode** restituirà un errore se [BOF o EOF](../../../ado/reference/ado-api/bof-eof-properties-ado.md) è true, o se il record corrente è stato eliminato.
## <a name="applies-to"></a>Si applica a
[Oggetto Recordset (ADO)](../../../ado/reference/ado-api/recordset-object-ado.md)
## <a name="see-also"></a>Vedere anche
[CursorType, LockType ed esempio di proprietà EditMode (VB)](../../../ado/reference/ado-api/cursortype-locktype-and-editmode-properties-example-vb.md)
[CursorType, LockType ed EditMode esempio di proprietà (VC + +)](../../../ado/reference/ado-api/cursortype-locktype-and-editmode-properties-example-vc.md)
[Metodo AddNew (ADO)](../../../ado/reference/ado-api/addnew-method-ado.md)
[Elimina metodo (Recordset ADO)](../../../ado/reference/ado-api/delete-method-ado-recordset.md)
[Metodo CancelUpdate (ADO)](../../../ado/reference/ado-api/cancelupdate-method-ado.md)
[Metodo Update](../../../ado/reference/ado-api/update-method.md)
| 90.057692 | 1,312 | 0.749733 | ita_Latn | 0.965587 |
9759fb1e4207e72498229645af2d7336f0056c80 | 10,108 | md | Markdown | README.md | ghostintranslation/motherboard9 | 5aa6c00a06bfb5a0fbdbb0ccb35dd3077493a82a | [
"MIT"
] | 2 | 2020-07-25T09:22:39.000Z | 2020-10-15T12:39:34.000Z | README.md | ghostintranslation/motherboard9 | 5aa6c00a06bfb5a0fbdbb0ccb35dd3077493a82a | [
"MIT"
] | null | null | null | README.md | ghostintranslation/motherboard9 | 5aa6c00a06bfb5a0fbdbb0ccb35dd3077493a82a | [
"MIT"
] | null | null | null | # MOTHERBOARD9

## ❗️ This is now deprecated in favor of https://github.com/ghostintranslation/motherboard
MOTHERBOARD9 is a 9 controls Teensy 4.0 + audio board platform.
MOTHERBOARD6, MOTHERBOARD9 and MOTHERBOARD12 allows for any combination of pushbuttons, potentiometers and encoders, in addition to leds. The footprints of those 3 type of components are stacked together so that only one pcb can be used for many different modules.
The MOTHERBOARDs come with 2 boards, one on which the inputs and leds are soldered to, and one on which the Teensy and other components are soldered to. Both boards are attached by multiple pin headers.
Note: MOTHERBOARD9 shares the same B board as MOTHERBOARD12, this is why on the schematics it goes up to 12 inputs of each type. JP4 component can be avoided for this module.
I sell the PCBs if you wish to build it. You can get them here: https://ghostintranslation.bandcamp.com/merch/motherboard9-pcb
<img src="motherboard9.jpg" width="200px"/>
## Schematics
Due to the use of the audio board, the available pins are very limited. Looking at the Teensy audio board page (https://www.pjrc.com/store/teensy3_audio.html) we can see only pins 0, 1, 2, 3, 4, 5, 9, 14, 16, 17, 22 are available. Also looking at Teensy pins (https://www.pjrc.com/store/teensy40.html), only 14, 16 and 17 from this subset are analog inputs.
So the use of multiplexers is required to be able to read pushbuttons, potentiometers, encoders or to lit leds. In addition, a matrix design is used for the encoders to reduce the number of inputs required as each of them has 3 inputs.
On this design, pin 22 will switch from input to output very fast to lit the leds and read the inputs.
<img src="Motherboard9A-schematics.png" width="200px"/> <img src="Motherboard9B-schematics.png" width="200px"/>
### Notes
Dependng on the type of inputs used, not all multiplexers may be required.
- IC1 and IC2 = Mux for LEDs
- IC3 and IC4 = Mux for potentiometers
- IC5 = Mux for encoders
- IC6 = Mux for encoder's switches and pushbuttons
- IC7 = Mux for midi channel dipswitch
- IC8 = Main mux, always required
A few examples:
If you only use potentiometers, you won't need IC5 and IC6. Or if you don't have any led you won't need IC1 and IC2. Or if you have less than 9 LEDs you won't need IC2. Or if you don't want to use a dipswitch to select the midi channel, you won't need IC7.
## Components
Here is the list of components you will need:
- MOTHERBOARD9A pcb
- MOTHERBOARD9B pcb
- Teensy 4.0
- PJRC: https://www.pjrc.com/store/teensy40.html
- DigiKey: https://www.digikey.ca/en/products/detail/sparkfun-electronics/DEV-15583/10384551
- 14 pins male headers, or longer and can be cut to length
- DigiKey: https://www.digikey.ca/en/products/detail/adam-tech/PH1-14-UA/9830506
- DigiKey: https://www.digikey.ca/en/products/detail/PREC040SAAN-RC/S1012EC-40-ND/2774814
- 14 pins female headers, or longer and can be cut to length
- DigiKey: https://www.digikey.ca/en/products/detail/sullins-connector-solutions/PPTC141LFBN-RC/810152
- DigiKey: https://www.digikey.ca/en/products/detail/chip-quik-inc/HDR100IMP40F-G-V-TH/5978200
- 1x 5 pins female header
- CD4051 multiplexers (number varies)
- DigiKey: https://www.digikey.ca/en/products/detail/texas-instruments/CD4051BE/67305
- DIP16 IC sockets (number varies)
- DigiKey: https://www.digikey.ca/en/products/detail/adam-tech/ICS-316-T/9832862
- 3.5mm jack connectors
- Thonk: https://www.thonk.co.uk/shop/3-5mm-jacks/ (the Thonkiconn)
- 4 positions dipswitch
- DigiKey: https://www.digikey.ca/product-detail/en/cts-electrocomponents/210-4MS/CT2104MS-ND/2503781
And here is the list of optional components according to your wants:
- Teensy audio board
- PJRC: https://www.pjrc.com/store/teensy3_audio.html
- Vertical linear 10k potentiometers
- Modular Addict: https://modularaddict.com/parts/potentiometers-1/9mm-t18-vertical-potentiometers
- Synthrotek: https://store.synthrotek.com/9mm-Vertical-Potentiometers_p_649.html
- Thonk: https://www.thonk.co.uk/shop/alpha-9mm-pots-vertical-t18/
- DigiKey: https://www.digikey.ca/en/products/detail/tt-electronics-bi/P0915N-FC15BR10K/4780740
- D6 pushbuttons
- Thonk: https://www.thonk.co.uk/shop/radio-music-switch/
- DigiKey: https://www.digikey.ca/en/products/detail/c-k/D6R00-F1-LFS/1466329
- Rotary encoders
- DigiKey: https://www.digikey.ca/en/products/detail/bourns-inc/PEC11R-4115K-S0018/4699207
- 1 resistor ~ 22ohm
- LEDs
- Thonk: https://www.thonk.co.uk/shop/new-style-flat-top-leds-turing-pulses-vactrol-mix/
- DigiKey: https://www.digikey.ca/en/products/detail/WP424SRDT/754-1717-ND/3084140
## Teensy
In order to run any sketch on the Teensy you have to install the Teensyduino add-on to Arduino.
Follow the instructions from the official page:
https://www.pjrc.com/teensy/teensyduino.html
Then open the sketch located in the Motherboard9 folder of this repo.
In the Tools -> USB Type menu, choose "Serial + midi".
Then you are ready to compile and upload the sketch.
## MIDI
The MIDI input and output jacks are directly connected to the Teensy serial input and output. That means there is not protection against voltage or current. It is primarily ment to connect 2 of these modules, or 2 Teensy together. If you want to connect something else to it make sure to provide a maximum of 3.3v and 250 mA.
## How to code
Copy the `Motherboard9.h` in your project. Then just include it and start using it.
### Init
Motherboard9 is a singleton, so to instanciate it you do this:
```
Motherboard9 * motherboard = Motherboard9::getInstance();
```
Then in the `Setup` you have to call Motherboard's `init` with the type of controls you have on the board:
```
// 0 = empty, 1 = button, 2 = potentiometer, 3 = encoder
byte controls[9] = {2,2,2, 2,2,2, 2,2,2}; // From left to right and top to bottom
motherboard->init(controls);
```
Then in the `loop` you have to call Motherboards `update`:
```
motherboard->update();
```
### LEDs
LEDs are controlled by setting their status according to:
- 0 = Off
- 1 = Solid
- 2 = Slow flashing
- 3 = Fast flashing
- 4 = Solid for 50 milliseconds
- 5 = Solid low birghtness
#### Set one LED:
```
void setLED(byte ledIndex, byte ledStatus);
```
#### Set multiple LEDs:
The first parameter called `binary` is a number that will be represented in binary with the least significant bit on the left. Ex: 9 = 100100 => LEDs of indexes 0 and 3 will be lit.
```
void setAllLED(unsigned int binary, byte ledStatus);
```
#### Toggle an LEDs:
```
void toggleLED(byte index);
```
#### Reset all LEDs:
```
void resetAllLED();
```
### Inputs
#### Get one input value:
- In the case of a potentiometer it will return between 0 and 1023.
- In the case of a button it will return 1 for push 0 for release.
- In the case of a rotary it will return the number of rotations since the last get.
```
int getInput(byte index);
```
#### Get the switch value of an encoder:
Because an encoder is like 2 controls, the rotary and the switch, we need this function in addition to `getInput`.
```
int getEncoderSwitch(byte index);
```
#### Get the maximum possible value of the potentiometers:
The value depends of the ADC resolution, which is 10 by default and can be set to 12 or 8.
With a resolution of 10 bits, the maximum value is 1023.
```
int getAnalogMaxValue();
```
#### Get the minimum possible value of the potentiometers:
It should always be 0, but if your potentiometers are not that accurate they could return bigger than 0 as a minimum value. You could then change the return value of that function to match the real minimum. This will ensure that `getInput` always returns a minimum of 0 and a maximum of 1023 that corresponds to the actual min and max.
```
int getAnalogMinValue();
```
#### Get the midi channel
This is set by the dipswitch and read only once when powered on. If no dipswtich is soldered then the channel will be 1.
```
byte getMidiChannel();
```
### Callbacks
Callbacks are a very good way of handling inputs. Using them instead of reading `getInput` in the loop will make your code easier to read and maintain.
#### Press
This will be triggered only once on release.
Can be used for a button and for a rotary switch.
`fptr` is a void() function.
```
void setHandlePress(byte inputIndex, PressCallback fptr);
```
#### Long Press
This will be triggered only once on release after a long press. If an input has both Press and Long Press callbacks then only one of them will be triggered according to the duration of the press.
`fptr` is a void() function.
```
void setHandleLongPress(byte inputIndex, LongPressCallback fptr);
```
#### Rotary Change
This will be triggered once every time a turn is detected.
`fptr` is a void(bool value) function. `value` is either 0 for a left rotation or 1 for a right rotation.
```
void setHandleRotaryChange(byte inputIndex, RotaryChangeCallback fptr);
```
## Design rules
Here are the dimensions for any module size. Every column is following the same rules. So the size of a module depends on the number of column. 2 columns = 2x20mm = 40mm, 3 columns = 3x20 = 60mm ...
<img src="design-rules-vector.png" width="200px"/>
## Known issues
- Encoders are skipping turns sometimes
- Maybe test with faster multiplexers
## Historic
- Rev 3 (current) using more multiplexers because of the limited available pins.
- Rev 2 added multiplexers, but wasn't taking in account the forbidden pins from the use of the audio board.
- Rev 1 was using matrices for potentiometers, which doesn't work.
## License
This project is licensed under the MIT License - see the [LICENSE.md](LICENSE.md) file for details
# About me
You can find me on Bandcamp, Instagram and Youtube, as well as my own website:
https://ghostintranslation.bandcamp.com/
https://www.instagram.com/ghostintranslation/
https://www.youtube.com/channel/UCcyUTGTM-hGLIz4194Inxyw
https://www.ghostintranslation.com/ | 39.795276 | 357 | 0.748318 | eng_Latn | 0.973968 |
975a59af196ce1c6702bb294ad7f071cdde549b3 | 4,815 | md | Markdown | docs/framework/winforms/controls/enable-users-to-copy-multiple-cells-to-the-clipboard-datagridview.md | Athosone/docs.fr-fr | 83c2fd74def907edf5da4a31fee2d08133851d2f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/winforms/controls/enable-users-to-copy-multiple-cells-to-the-clipboard-datagridview.md | Athosone/docs.fr-fr | 83c2fd74def907edf5da4a31fee2d08133851d2f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/winforms/controls/enable-users-to-copy-multiple-cells-to-the-clipboard-datagridview.md | Athosone/docs.fr-fr | 83c2fd74def907edf5da4a31fee2d08133851d2f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 'Procédure : permettre aux utilisateurs de copier plusieurs cellules dans le Presse-papiers à partir du contrôle DataGridView Windows Forms'
ms.date: 03/30/2017
dev_langs:
- csharp
- vb
helpviewer_keywords:
- cells [Windows Forms], copying to Clipboard
- DataGridView control [Windows Forms], copying multiple cells
- data grids [Windows Forms], copying multiple cells
- Clipboard [Windows Forms], copying multiple cells
ms.assetid: fd0403b2-d0e3-4ae0-839c-0f737e1eb4a9
ms.openlocfilehash: f7b6c37db0935dae703e9641b2c2605b2ec88126
ms.sourcegitcommit: 9b552addadfb57fab0b9e7852ed4f1f1b8a42f8e
ms.translationtype: HT
ms.contentlocale: fr-FR
ms.lasthandoff: 04/23/2019
ms.locfileid: "61972040"
---
# <a name="how-to-enable-users-to-copy-multiple-cells-to-the-clipboard-from-the-windows-forms-datagridview-control"></a>Procédure : permettre aux utilisateurs de copier plusieurs cellules dans le Presse-papiers à partir du contrôle DataGridView Windows Forms
Quand vous activez la copie des cellules, vous rendez les données de votre contrôle <xref:System.Windows.Forms.DataGridView> facilement accessibles à d'autres applications via le <xref:System.Windows.Forms.Clipboard>. Les valeurs des cellules sélectionnées sont converties en chaînes et ajoutées au Presse-papiers sous forme de texte délimité par des tabulations en vue d'être collées dans des applications, telles que le Bloc-notes et Excel, et sous forme d'un tableau au format HTML en vue d'être collées dans des applications telles que Word.
Vous pouvez configurer la copie de cellules pour copier uniquement les valeurs des cellules, pour inclure le texte des en-têtes de ligne et de colonne dans les données du Presse-papiers ou pour inclure le texte des en-têtes uniquement quand les utilisateurs sélectionnent des lignes et des colonnes entières.
Selon le mode de sélection, les utilisateurs peuvent sélectionner plusieurs groupes de cellules non connectés. Quand un utilisateur copie des cellules dans le Presse-papiers, les lignes et les colonnes qui ne contiennent pas de cellules sélectionnées ne sont pas copiées. Toutes les autres lignes ou colonnes deviennent des lignes et des colonnes de la table de données copiée dans le Presse-papiers. Les cellules non sélectionnées de ces lignes ou colonnes sont copiées comme des espaces réservés dans le Presse-papiers.
### <a name="to-enable-cell-copying"></a>Pour activer la copie de cellule
- définir la propriété <xref:System.Windows.Forms.DataGridView.ClipboardCopyMode%2A?displayProperty=nameWithType> ;
[!code-csharp[System.Windows.Forms.DataGridViewClipboardDemo#15](~/samples/snippets/csharp/VS_Snippets_Winforms/System.Windows.Forms.DataGridViewClipboardDemo/CS/datagridviewclipboarddemo.cs#15)]
[!code-vb[System.Windows.Forms.DataGridViewClipboardDemo#15](~/samples/snippets/visualbasic/VS_Snippets_Winforms/System.Windows.Forms.DataGridViewClipboardDemo/VB/datagridviewclipboarddemo.vb#15)]
## <a name="example"></a>Exemple
L'exemple de code complet suivant montre comment les cellules sont copiées vers le Presse-papiers. Cet exemple inclut un bouton qui copie les cellules sélectionnées dans le Presse-papiers à l'aide de la méthode <xref:System.Windows.Forms.DataGridView.GetClipboardContent%2A?displayProperty=nameWithType> et affiche le contenu du Presse-papiers dans une zone de texte.
[!code-csharp[System.Windows.Forms.DataGridViewClipboardDemo#00](~/samples/snippets/csharp/VS_Snippets_Winforms/System.Windows.Forms.DataGridViewClipboardDemo/CS/datagridviewclipboarddemo.cs#00)]
[!code-vb[System.Windows.Forms.DataGridViewClipboardDemo#00](~/samples/snippets/visualbasic/VS_Snippets_Winforms/System.Windows.Forms.DataGridViewClipboardDemo/VB/datagridviewclipboarddemo.vb#00)]
## <a name="compiling-the-code"></a>Compilation du code
Ce code nécessite :
- Des références aux assemblys N:System et N:System.Windows.Forms.
Pour plus d’informations sur la création de cet exemple à partir de la ligne de commande pour Visual Basic ou Visual c#, consultez [génération à partir de la ligne de commande](../../../visual-basic/reference/command-line-compiler/building-from-the-command-line.md) ou [de ligne de commande avec csc.exe](../../../csharp/language-reference/compiler-options/command-line-building-with-csc-exe.md). Vous pouvez également créer cet exemple dans Visual Studio en collant le code dans un nouveau projet.
## <a name="see-also"></a>Voir aussi
- <xref:System.Windows.Forms.DataGridView>
- <xref:System.Windows.Forms.DataGridView.ClipboardCopyMode%2A>
- <xref:System.Windows.Forms.DataGridView.GetClipboardContent%2A>
- [Sélection et utilisation du Presse-papiers avec le contrôle DataGridView Windows Forms](selection-and-clipboard-use-with-the-windows-forms-datagridview-control.md)
| 90.849057 | 547 | 0.806231 | fra_Latn | 0.825782 |
975ab684e15fd4f96a3d163040e29e5d7b7baa5a | 182 | md | Markdown | README.md | himanshu211raj/Fun-with-DS-and-Algo | 36499e4876340a2cf37bf6b1de925c9230a03063 | [
"MIT"
] | 10 | 2020-02-04T17:27:45.000Z | 2022-01-27T06:19:17.000Z | README.md | himanshu211raj/Fun-with-DS-and-Algo | 36499e4876340a2cf37bf6b1de925c9230a03063 | [
"MIT"
] | null | null | null | README.md | himanshu211raj/Fun-with-DS-and-Algo | 36499e4876340a2cf37bf6b1de925c9230a03063 | [
"MIT"
] | 8 | 2020-03-15T20:08:05.000Z | 2021-06-21T19:37:24.000Z | <h1 align=center>
<img align=center width="40%" src="https://img.techpowerup.org/200313/connection-02.png" />
</h1>
<h1 align=center> 🚀 Fun with Data Structures and Algorithms</h1>
| 36.4 | 92 | 0.71978 | yue_Hant | 0.334529 |
975acf53ff4fffa00ec5ed601897723987bf6124 | 1,498 | md | Markdown | README.md | supertestorg1/java-piggybank | a1904fd1c17aafee4eb10aafdbf86a6083dc367d | [
"MIT"
] | null | null | null | README.md | supertestorg1/java-piggybank | a1904fd1c17aafee4eb10aafdbf86a6083dc367d | [
"MIT"
] | null | null | null | README.md | supertestorg1/java-piggybank | a1904fd1c17aafee4eb10aafdbf86a6083dc367d | [
"MIT"
] | null | null | null | We have a magical "piggy bank" (a piggy bank is the traditional name of a place to store coins, bill, money). The piggy bank is magical because it can hold unlimited amounts of money. However, you can not get the money out of it.
- [x] Create a collection (array, arraylist, or hashmap) to represent the piggy bank. The collection can hold money.
This money can be
- [x] A Dollar worth $1.00
- [x] A Quarter worth $0.25
- [x] A Dime worth $0.10
- [x] A Nickel worth $0.05
- [x] A Penny worth $0.01
Each coin object should know its value, how many of that coin is in the object, and how to print its value.
The main program will look something like this pseudocode (remember pseudocode is not meant to be syntactically correct but explain the algorithm):
- [x] Create collection
- [x] piggyBank.add(new Quarter())
- [x] piggyBank.add(new Dime())
- [x] piggyBank.add(new Dollar(5))
- [x] piggyBank.add(new Nickle(3))
- [x] piggyBank.add(new Dime(7))
- [x] piggyBank.add(new Dollar())
- [x] piggyBank.add(new Penny(10))
- [x] Print the contents of the Piggy Bank
* on the console should appear
`1 Quarter`
`1 Dime`
`$5`
`3 Nickle`
`7 Dime`
`$1`
`10 Penny`
- [x] Print the value of the Piggy Bank
* on the console should appear
`The piggy bank holds $7.3`
* Note: do not worry about the format of the 7.2 Either 7.2 or 7.20 would be correct. Also notice that we are not concerned with adding the S for plurals with our names of our coins.
| 42.8 | 229 | 0.690254 | eng_Latn | 0.9975 |
975afff50ff6c5ab670638c84aee7e8ae4655d03 | 526 | md | Markdown | pages.it/common/dep.md | pavelshtanko/tldr | e1355b2e8749ea4b4dc98f430f5bc01ae877e339 | [
"CC-BY-4.0"
] | 3 | 2020-04-28T11:14:55.000Z | 2020-06-08T21:15:36.000Z | pages.it/common/dep.md | pavelshtanko/tldr | e1355b2e8749ea4b4dc98f430f5bc01ae877e339 | [
"CC-BY-4.0"
] | 2 | 2019-02-04T20:43:07.000Z | 2019-11-15T16:49:18.000Z | pages.it/common/dep.md | pavelshtanko/tldr | e1355b2e8749ea4b4dc98f430f5bc01ae877e339 | [
"CC-BY-4.0"
] | 3 | 2020-07-26T16:51:50.000Z | 2020-08-18T07:06:49.000Z | # dep
> Strumento di gestione delle dipendenze per progetti Go.
> Maggiori informazioni: <https://golang.github.io/dep>.
- Inizializza la directory corrente come radice di un progetto Go:
`dep init`
- Installa dipendenze mancanti (scannerizza Gopkg.toml ed i file .go):
`dep ensure`
- Mostra lo stato delle dipendenze di un progetto:
`dep status`
- Aggiungi una dipendenza al progetto:
`dep ensure -add {{url_pacchetto}}`
- Aggiorna le versioni bloccate (in Gopkg.lock) di tutte le dipendenze:
`dep ensure -update`
| 21.04 | 71 | 0.747148 | ita_Latn | 0.993662 |
975b1cfa2c2106761a9b7772d1c976c1782b8903 | 899 | md | Markdown | scripts/README_Schedule.md | inlgmeeting/inlgmeeting.github.io | 5af7273eaa04407afc894374d11cbc8587fd343b | [
"MIT"
] | null | null | null | scripts/README_Schedule.md | inlgmeeting/inlgmeeting.github.io | 5af7273eaa04407afc894374d11cbc8587fd343b | [
"MIT"
] | null | null | null | scripts/README_Schedule.md | inlgmeeting/inlgmeeting.github.io | 5af7273eaa04407afc894374d11cbc8587fd343b | [
"MIT"
] | 1 | 2022-03-08T11:22:31.000Z | 2022-03-08T11:22:31.000Z | ## Adding a schedule to MiniConf
1) Create a Calendar in you favorite calendar application.
Be sure that you can export calendars as `.ics` files.
2) [optional] use the `location` field for links that you want to link out from
the calendar view (e.g. filtered poster sessions).
3) [optional] use hashtags in front of events to classify them.
4) run the `parse_calendar.py` script:
```bash
python parse_calendar.py --in sample_cal.ics
```
### Example
An entry like this in iCal or Google Cal:
```
title: #talk Homer Simpson
location: http://abc.de
start: 7:00pm ET
```
will appear in the schedule as box in color `#cccccc` (see `sitedate/config.yml`):
```
7:00 Homer Simpson
```
and will link to `http://abc.de` on click.
### Pro Tip
If you plan to add some infos automatically, you can create a script that
modifies `sitedate/main_calendar.json`
| 25.685714 | 83 | 0.694105 | eng_Latn | 0.97538 |
975b3c94213ffa8f6b53578c174b67a197add2ad | 82 | md | Markdown | internstrings/README.md | bingoohuang/golang-gotcha | e336ece80298637b7aaebf47fcdc612ef9de2615 | [
"MIT"
] | 1 | 2021-07-20T02:47:17.000Z | 2021-07-20T02:47:17.000Z | internstrings/README.md | bingoohuang/gogotcha | e336ece80298637b7aaebf47fcdc612ef9de2615 | [
"MIT"
] | null | null | null | internstrings/README.md | bingoohuang/gogotcha | e336ece80298637b7aaebf47fcdc612ef9de2615 | [
"MIT"
] | null | null | null | blog post [introducing string interning](https://commaok.xyz/post/intern-strings/) | 82 | 82 | 0.804878 | yue_Hant | 0.188263 |
975bc8c8e59f2c8ad5a28d8432644fc908b6b39e | 2,365 | md | Markdown | storybook.md | yeongjong310/yeongjong310.github.io | f3a70d99caef28baa6e31673864510f399d5d392 | [
"MIT"
] | null | null | null | storybook.md | yeongjong310/yeongjong310.github.io | f3a70d99caef28baa6e31673864510f399d5d392 | [
"MIT"
] | null | null | null | storybook.md | yeongjong310/yeongjong310.github.io | f3a70d99caef28baa6e31673864510f399d5d392 | [
"MIT"
] | null | null | null | # Storybook.js
**리엑트를 기준으로 Storybook 환경을 설정합니다.**
StoryBook.js 는 컴포넌트를 자동으로 문서화하며 시각적으로 테스트할 수 있게 도와주는 도구다. 기존 TDD 방식과 다르게 CDD 즉 컴포넌트 단위로 작성하고 테스트한다는 특징을 가지고 있다.
## What's a story?
Storybook에서는 하나의 story가 특정 상태의 컴포넌트를 캡처한다고 설명하고 있습니다. 이 말이 무슨 의미인지 나름대로 해석해 봤습니다.(개인적인 견해임을 참고해주세요!)
하나의 컴포넌트는 state 혹은 prop에 따라 렌더링 결과물이 달라집니다. storybook을 작성하는 형태도 아래 예시와 같이 컴포넌트의 state 혹은 prop에 따라 구분하여 작성하는데요.
Button 컴포넌트는 prop에 따라 Primary, Secondary, Large, Small이라는 이름이 부여됐고 각각은 하나의 스토리라고 볼 수 있습니다. 마치 버튼이라는 주인공이 상황에 따라 Primary, Secondary, Large, Small 이라는 이야기를 그려 간다고 생각하면 될 것 같아요.
버튼 스토리 외에도 링크헤더 등 다양한 주인공을 설정하고 스토리를 작성할 수 있고 이 단편 스토리들이 모여 하나의 장편 스토리들을 만들겠죠. 완성된 장편 스토리는 컴포넌트 관점에서 보면 Page에 해당할 것 입니다.
## 오늘의 예제
```js
import React from 'react';
import { Button } from './Button';
export default {
title: 'Example/Button',
component: Button,
argTypes: {
backgroundColor: { control: 'color' },
},
};
const Template = args => <Button {...args} />;
export const Primary = Template.bind({});
Primary.args = {
primary: true,
label: 'Button',
};
export const Secondary = Template.bind({});
Secondary.args = {
label: 'Button',
};
export const Large = Template.bind({});
Large.args = {
size: 'large',
label: 'Button',
};
export const Small = Template.bind({});
Small.args = {
size: 'small',
label: 'Button',
};
```
## 설명
1. Component.stories.js 파일을 만들고 meta 정보를 default로 export 하기
```js
import React from 'react';
import { Button } from './Button';
// 해당 컴포넌트의 메타정보를 export default 합니다.
export default {
title: 'Components/Button', // 단편 스토리 제목 지정
component: Button, // 스토리의 주인공 컴포넌트 지정
};
```
2. 주인공의 이야기 생성
```js
...
const Template = args => <Button {...args} />;
// Primary, Secondary, Large, Small은 Button의 특정 스토리(이야기)에 해당
export const Primary = Template.bind({});
Primary.args = {
primary: true,
label: 'Button',
};
export const Secondary = Template.bind({});
Secondary.args = {
label: 'Button',
};
export const Large = Template.bind({});
Large.args = {
size: 'large',
label: 'Button',
};
export const Small = Template.bind({});
Small.args = {
size: 'small',
label: 'Button',
};
```
## 트러블 슈팅
storybook을 매뉴얼로 구성하는 경우, webpack에 의존하기 때문에 webpack을 올바르게 설정해야 합니다. storybook에서는 postcss가 deprecated되었으며 @postcss를 설정하다 `get of undefined` 에러가 발생한다면, storybook init 시 builder 설정이 webpack4(default)로 설정되어 있어 버전 문제가 발생했을
| 22.102804 | 216 | 0.677378 | kor_Hang | 0.999995 |
975bde9165ea05db8e0dd1804037a0ff5c3ffe5e | 2,872 | md | Markdown | README.md | npmdoc/node-npmdoc-ember-fetch | 8cccb7118ecc8b802156994ae3e9a900c590c313 | [
"MIT"
] | null | null | null | README.md | npmdoc/node-npmdoc-ember-fetch | 8cccb7118ecc8b802156994ae3e9a900c590c313 | [
"MIT"
] | null | null | null | README.md | npmdoc/node-npmdoc-ember-fetch | 8cccb7118ecc8b802156994ae3e9a900c590c313 | [
"MIT"
] | null | null | null | # npmdoc-ember-fetch
#### api documentation for ember-fetch (v1.4.2) [](https://www.npmjs.org/package/npmdoc-ember-fetch) [](https://travis-ci.org/npmdoc/node-npmdoc-ember-fetch)
#### HTML5 Fetch polyfill (as an ember-addon)
[](https://www.npmjs.com/package/ember-fetch)
- [https://npmdoc.github.io/node-npmdoc-ember-fetch/build/apidoc.html](https://npmdoc.github.io/node-npmdoc-ember-fetch/build/apidoc.html)
[](https://npmdoc.github.io/node-npmdoc-ember-fetch/build/apidoc.html)


# package.json
```json
{
"name": "ember-fetch",
"version": "1.4.2",
"description": "HTML5 Fetch polyfill (as an ember-addon)",
"keywords": [
"ember-addon"
],
"license": "MIT",
"directories": {
"doc": "doc",
"test": "tests"
},
"repository": "https://github.com/stefanpenner/ember-fetch",
"scripts": {
"build": "ember build",
"start": "ember server",
"test": "ember try:each"
},
"dependencies": {
"broccoli-funnel": "^1.0.7",
"broccoli-stew": "^1.2.0",
"broccoli-templater": "^1.0.0",
"ember-cli-babel": "^6.0.0-beta.4",
"node-fetch": "^2.0.0-alpha.3",
"whatwg-fetch": "^2.0.3"
},
"devDependencies": {
"broccoli-asset-rev": "^2.4.5",
"ember-cli": "^2.12.1",
"ember-cli-app-version": "^2.0.0",
"ember-cli-dependency-checker": "^1.3.0",
"ember-cli-eslint": "^3.0.2",
"ember-cli-htmlbars": "^1.2.0",
"ember-cli-inject-live-reload": "^1.4.1",
"ember-cli-pretender": "^0.7.0",
"ember-cli-qunit": "^3.1.0",
"ember-cli-release": "^0.2.9",
"ember-cli-shims": "^1.1.0",
"ember-cli-test-loader": "^2.0.0",
"ember-cli-uglify": "^1.2.0",
"ember-load-initializers": "^0.6.0",
"ember-resolver": "^2.0.3",
"ember-source": "~2.12.0",
"loader.js": "^4.2.3"
},
"engines": {
"node": ">= 4"
},
"ember-addon": {
"configPath": "tests/dummy/config",
"fastbootDependencies": [
"node-fetch"
]
},
"bin": {}
}
```
# misc
- this document was created with [utility2](https://github.com/kaizhu256/node-utility2)
| 33.788235 | 335 | 0.595752 | yue_Hant | 0.199038 |
975bf2c8175d6180eef924b3f9440a62e776c50b | 1,499 | md | Markdown | README.md | MihaiUdrea/DelayLoadingIssueCppWinRT | 166e1d9bac636bedfc85300f070b6f93e42a4daf | [
"FSFAP"
] | null | null | null | README.md | MihaiUdrea/DelayLoadingIssueCppWinRT | 166e1d9bac636bedfc85300f070b6f93e42a4daf | [
"FSFAP"
] | null | null | null | README.md | MihaiUdrea/DelayLoadingIssueCppWinRT | 166e1d9bac636bedfc85300f070b6f93e42a4daf | [
"FSFAP"
] | null | null | null | # DelayLoadingIssueCppWinRT
This is a test case repository to show that when CppWinRT package is added to a project that uses DLL delay loading, additional dependencies appear
# Without CppWinRT dependecies are like this:
Microsoft (R) COFF/PE Dumper Version 14.29.30038.1
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file Debug\DelayLoadingIssueCppWinRT.exe
File Type: EXECUTABLE IMAGE
Image has the following dependencies:
gdiplus.dll
KERNEL32.dll
USER32.dll
VCRUNTIME140D.dll
ucrtbased.dll
# Adding CppWinRT package dependecies remain same as above
# Using DLL delay loading and CppWinRT package afects dependecies list:
Microsoft (R) COFF/PE Dumper Version 14.29.30038.1
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file C:\Users\Mihai Udrea\DelayLoadingIssueCppWinRT\Debug\DelayLoadingIssueCppWinRT.exe
File Type: EXECUTABLE IMAGE
Image has the following dependencies:
KERNEL32.dll
USER32.dll
api-ms-win-core-sysinfo-l1-1-0.dll
api-ms-win-core-memory-l1-1-0.dll
api-ms-win-core-libraryloader-l1-2-0.dll
VCRUNTIME140D.dll
ucrtbased.dll
Image has the following delay load dependencies:
gdiplus.dll
# The following API sets appear as dependencies only when the CppWinRT package is preset. How can this be prevented (but still using DLL delay loading) ?
api-ms-win-core-sysinfo-l1-1-0.dll
api-ms-win-core-memory-l1-1-0.dll
api-ms-win-core-libraryloader-l1-2-0.dll | 27.759259 | 153 | 0.76451 | eng_Latn | 0.750862 |
975c2b40fe22f01ff75eacd2ecac3bbe0689a611 | 2,520 | md | Markdown | articles/virtual-machines/vm-generalized-image-version-cli.md | Yueying-Liu/mc-docs.zh-cn | 21000ea687a4cda18cecf10e9183fd2172918bb5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/virtual-machines/vm-generalized-image-version-cli.md | Yueying-Liu/mc-docs.zh-cn | 21000ea687a4cda18cecf10e9183fd2172918bb5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/virtual-machines/vm-generalized-image-version-cli.md | Yueying-Liu/mc-docs.zh-cn | 21000ea687a4cda18cecf10e9183fd2172918bb5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 使用 Azure CLI 从通用化映像创建 VM
description: 使用 Azure CLI 从通用化映像版本创建 VM。
ms.service: virtual-machines
ms.subservice: imaging
ms.topic: how-to
ms.workload: infrastructure
origin.date: 05/04/2020
author: rockboyfor
ms.date: 09/07/2020
ms.testscope: yes
ms.testdate: 08/31/2020
ms.author: v-yeche
ms.custom: devx-track-azurecli
ms.openlocfilehash: 9b2e9ac5e2fc4d9f5e14b9791ebf4afa8adbe14a
ms.sourcegitcommit: 93309cd649b17b3312b3b52cd9ad1de6f3542beb
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/30/2020
ms.locfileid: "93106131"
---
<!--Verified successfully-->
# <a name="create-a-vm-from-a-generalized-image-version-using-the-cli"></a>使用 CLI 从通用化映像版本创建 VM
从[共享映像库](./linux/shared-image-galleries.md#generalized-and-specialized-images)中存储的通用化映像版本创建 VM。 若要使用专用化映像创建 VM,请参阅[从专用化映像创建 VM](vm-specialized-image-version-powershell.md)。
## <a name="get-the-image-id"></a>获取映像 ID
使用 [az sig image-definition list](https://docs.microsoft.com/cli/azure/sig?view=azure-cli-latest#az-sig-image-definition-list) 列出库中的映像定义,以查看定义的名称和 ID。
```azurecli
resourceGroup=myGalleryRG
gallery=myGallery
az sig image-definition list --resource-group $resourceGroup --gallery-name $gallery --query "[].[name, id]" --output tsv
```
## <a name="create-the-vm"></a>创建 VM
运行 [az vm create](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-create) 创建 VM。 若要使用最新版本的映像,请将 `--image` 设置为映像定义的 ID。
在此示例中,请根据需要替换资源名称。
```azurecli
imgDef="/subscriptions/<subscription ID where the gallery is located>/resourceGroups/myGalleryRG/providers/Microsoft.Compute/galleries/myGallery/images/myImageDefinition"
vmResourceGroup=myResourceGroup
location=chinaeast
vmName=myVM
adminUsername=azureuser
az group create --name $vmResourceGroup --location $location
az vm create\
--resource-group $vmResourceGroup \
--name $vmName \
--image $imgDef \
--admin-username $adminUsername \
--generate-ssh-keys
```
也可以通过使用 `--image` 参数的映像版本 ID 来使用特定版本。 例如,若要使用映像版本 *1.0.0* ,请键入:`--image "/subscriptions/<subscription ID where the gallery is located>/resourceGroups/myGalleryRG/providers/Microsoft.Compute/galleries/myGallery/images/myImageDefinition/versions/1.0.0"`。
<!--Not Available on ## Next steps-->
<!--Not Available on [Azure Image Builder (preview)](./linux/image-builder-overview.md)-->
<!--Not Available on [create a new image version from an existing image version](./linux/image-builder-gallery-update-image-version.md)-->
<!-- Update_Description: update meta properties, wording update, update link --> | 37.61194 | 252 | 0.766667 | yue_Hant | 0.354929 |
975c476cdc603e0d35f7d39439b0296a0c5a85de | 15,948 | md | Markdown | articles/active-directory/saas-apps/workday-inbound-cloud-only-tutorial.md | gliljas/azure-docs.sv-se-1 | 1efdf8ba0ddc3b4fb65903ae928979ac8872d66e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/active-directory/saas-apps/workday-inbound-cloud-only-tutorial.md | gliljas/azure-docs.sv-se-1 | 1efdf8ba0ddc3b4fb65903ae928979ac8872d66e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/active-directory/saas-apps/workday-inbound-cloud-only-tutorial.md | gliljas/azure-docs.sv-se-1 | 1efdf8ba0ddc3b4fb65903ae928979ac8872d66e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 'Självstudie: Konfigurera inkommande etablering för Workday i Azure Active Directory | Microsoft Docs'
description: Lär dig hur du konfigurerar inkommande etablering från arbets dagar till Azure AD
services: active-directory
author: cmmdesai
documentationcenter: na
manager: daveba
ms.assetid: fac4f61e-d942-4429-a297-9ba74db95077
ms.service: active-directory
ms.subservice: saas-app-tutorial
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: identity
ms.date: 05/26/2020
ms.author: chmutali
ms.openlocfilehash: 6fb80af84379a1a0bc174a7318c8150a98bea95e
ms.sourcegitcommit: 053e5e7103ab666454faf26ed51b0dfcd7661996
ms.translationtype: MT
ms.contentlocale: sv-SE
ms.lasthandoff: 05/27/2020
ms.locfileid: "84041815"
---
# <a name="tutorial-configure-workday-to-azure-ad-user-provisioning"></a>Självstudie: Konfigurera arbets dag till användar etablering i Azure AD
Syftet med den här självstudien är att visa de steg som du måste utföra för att etablera arbetarnas data från arbets dagar till Azure Active Directory.
>[!NOTE]
>Använd den här självstudien om de användare som du vill etablera från Workday är molnbaserade användare som inte behöver ett lokalt AD-konto. Om användarna bara behöver ett lokalt AD-konto eller både AD-och Azure AD-konto, kan du läsa själv studie kursen om hur [du konfigurerar arbets dagar för att Active Directory](workday-inbound-tutorial.md) användar etablering.
## <a name="overview"></a>Översikt
[Azure Active Directory användar etablerings tjänsten](../app-provisioning/user-provisioning.md) integreras med [personalavdelningen-API: t för arbets dagar](https://community.workday.com/sites/default/files/file-hosting/productionapi/Human_Resources/v21.1/Get_Workers.html) för att etablera användar konton. Arbets flöden för användar etablering av arbets dagar som stöds av Azure AD-tjänsten för användar etablering möjliggör automatisering av följande personal-och identitets cykel hanterings scenarier:
* **Anställning av nya anställda** – när en ny medarbetare läggs till i arbets dagen skapas ett användar konto automatiskt i Azure Active Directory och eventuellt Office 365 och [andra SaaS-program som stöds av Azure AD](../app-provisioning/user-provisioning.md), med Skriv-tillbaka till Workday-e-postadressen.
* **Uppdateringar av anställda och profiler** – när en medarbetar post uppdateras i Workday (till exempel namn, titel eller chef), uppdateras användar kontot automatiskt Azure Active Directory och eventuellt Office 365 och [andra SaaS-program som stöds av Azure AD](../app-provisioning/user-provisioning.md).
* **Anställdas uppsägningar** – när en medarbetare avslutas i Workday inaktive ras användar kontot automatiskt i Azure Active Directory och eventuellt Office 365 och [andra SaaS-program som stöds av Azure AD](../app-provisioning/user-provisioning.md).
* **Anställdas återställningar** – när en medarbetare återställs i Workday kan deras gamla konto automatiskt återaktiveras eller etableras på nytt (beroende på din preferens) för att Azure Active Directory och eventuellt Office 365 och [andra SaaS-program som stöds av Azure AD](../app-provisioning/user-provisioning.md).
### <a name="who-is-this-user-provisioning-solution-best-suited-for"></a>Vem är den här användar etablerings lösningen som passar bäst för?
Den här arbets dagen för att Azure Active Directory användar etablerings lösningen passar utmärkt för:
* Organisationer som vill ha en förbyggd, molnbaserad lösning för användar etablering i Workday
* Organisationer som kräver direkt användar etablering från Workday till Azure Active Directory
* Organisationer som kräver att användare tillhandahålls med data som hämtas från Workday
* Organisationer som använder Office 365 för e-post
## <a name="solution-architecture"></a>Lösningsarkitektur
I det här avsnittet beskrivs slut punkt till slut punkt för användar etablerings lösnings arkitekturen för endast molnbaserade användare. Det finns två relaterade flöden:
* **Auktoritativt Tim data flöde – från arbets dag till Azure Active Directory:** I de här flödes händelserna (t. ex. nya anställningar, överföringar, uppsägningar) sker först i Workday och händelse data flödar sedan till Azure Active Directory. Beroende på händelsen kan det leda till att du skapar/uppdaterar/aktiverar/inaktiverar åtgärder i Azure AD.
* **Tillbakaskrivning flöde – från lokala Active Directory till arbets dag:** När kontot har skapats i Active Directory synkroniseras det med Azure AD via Azure AD Connect och information som e-post, användar namn och telefonnummer kan skrivas tillbaka till arbets dagen.

### <a name="end-to-end-user-data-flow"></a>Slut punkt till slut punkt för användar data flöde
1. HR-teamet utför arbets transaktioner (anslutningar/flytter/Lämnare eller nya anställningar/överföringar/uppsägningar) i arbets dagen personal Central
2. Azure AD Provisioning-tjänsten kör schemalagda synkroniseringar av identiteter från Workday EG och identifierar ändringar som behöver bearbetas för synkronisering med lokala Active Directory.
3. Azure AD Provisioning-tjänsten fastställer ändringen och anropar åtgärden Skapa/uppdatera/aktivera/inaktivera för användaren i Azure AD.
4. Om tillbakaskrivning-appen för [Workday](workday-writeback-tutorial.md) har kon figurer ATS hämtar den attribut som e-post, användar namn och telefonnummer från Azure AD.
5. Azure AD Provisioning-tjänsten anger e-post, användar namn och telefonnummer i arbets dagen.
## <a name="planning-your-deployment"></a>Planera distributionen
Konfigurering av moln HR-drivna användar etablering från arbets dagar till Azure AD kräver avsevärd planering som omfattar olika aspekter, till exempel:
* Identifiera matchnings-ID
* Attributmappning
* Attribute-transformering
* Omfångsfilter
Mer information om de här ämnena finns i [Cloud HR Deployment plan](../app-provisioning/plan-cloud-hr-provision.md) .
## <a name="configure-integration-system-user-in-workday"></a>Konfigurera användare av integrations systemet på arbets dagen
Se avsnittet [Konfigurera integrations system användare](workday-inbound-tutorial.md#configure-integration-system-user-in-workday) för att skapa ett användar konto för en Workday-integrerings system med behörighet att hämta arbets data.
## <a name="configure-user-provisioning-from-workday-to-azure-ad"></a>Konfigurera användar etablering från Workday till Azure AD
I följande avsnitt beskrivs hur du konfigurerar användar etablering från Workday till Azure AD för distributioner i molnet.
* [Lägga till Azure AD Provisioning Connector-appen och skapa anslutningen till arbets dagen](#part-1-adding-the-azure-ad-provisioning-connector-app-and-creating-the-connection-to-workday)
* [Konfigurera mappar för Workday och Azure AD-attribut](#part-2-configure-workday-and-azure-ad-attribute-mappings)
* [Aktivera och starta användar etablering](#enable-and-launch-user-provisioning)
### <a name="part-1-adding-the-azure-ad-provisioning-connector-app-and-creating-the-connection-to-workday"></a>Del 1: lägga till Azure AD Provisioning Connector-appen och skapa anslutningen till arbets dagen
**Konfigurera arbets dagar för att Azure Active Directory etablering för endast moln användare:**
1. Gå till <https://portal.azure.com>.
2. I Azure Portal söker du efter och väljer **Azure Active Directory**.
3. Välj **företags program**och sedan **alla program**.
4. Välj **Lägg till ett program**och välj sedan kategorin **alla** .
5. Sök efter **arbets dag till Azure AD-användar etablering**och Lägg till den appen från galleriet.
6. När appen har lagts till och skärmen information om appen visas väljer du **etablering**.
7. Ändra **etablerings** **läget** till **automatiskt**.
8. Slutför avsnittet **admin credentials** enligt följande:
* **Workday-användarnamn** – Ange användar namnet för kontot för arbets dag integrerings systemet, med namnet på klient organisationen som lagts till. Bör se ut ungefär så här:username@contoso4
* **Lösen ord för arbets dag –** Ange lösen ordet för system kontot för Workday-integrering
* **URL för Workday webb tjänster-API –** Ange URL: en till slut punkten för webb tjänster för arbets dag för din klient. URL: en avgör vilken version av webb tjänstens API för Workday som används av anslutningen.
| URL-format | WWS-API-version som används | XPATH-ändringar krävs |
|------------|----------------------|------------------------|
| https://####.workday.com/ccx/service/tenantName | v-21.1 | Nej |
| https://####.workday.com/ccx/service/tenantName/Human_Resources | v-21.1 | Nej |
| https://####.workday.com/ccx/service/tenantName/Human_Resources/v##.# | v # #. # | Ja |
> [!NOTE]
> Om ingen versions information anges i URL: en använder appen Workday-WWS (Web Services) och inga ändringar krävs för standard-XPATH API-uttryck som levereras med appen. Om du vill använda en viss WWS API-version anger du versions nummer i URL: en <br>
> Exempel: `https://wd3-impl-services1.workday.com/ccx/service/contoso4/Human_Resources/v34.0` <br>
> <br> Om du använder en WWS API v-30.0 +, innan du aktiverar etablerings jobbet, uppdaterar du **XPath API-uttryck** under **attribut mappning-> avancerade alternativ-> redigera attributlistan för arbets dagar** som refererar till avsnittet [Hantera din konfiguration och ditt](workday-inbound-tutorial.md#managing-your-configuration) Workday- [attribut referens](../app-provisioning/workday-attribute-reference.md#xpath-values-for-workday-web-services-wws-api-v30).
* **E-postavisering –** Ange din e-postadress och markera kryss rutan "skicka e-post om fel inträffar".
* Klicka på knappen **Testa anslutning** .
* Om anslutnings testet lyckas, klickar du på knappen **Spara** längst upp. Om det Miss lyckas, kontrol lera att URL: en för arbets dagar och autentiseringsuppgifter är giltiga i arbets dagen.
### <a name="part-2-configure-workday-and-azure-ad-attribute-mappings"></a>Del 2: Konfigurera mappningar för Workday och Azure AD-attribut
I det här avsnittet ska du konfigurera hur användar data flödar från arbets dagar till Azure Active Directory endast för molnbaserade användare.
1. På fliken etablering under **mappningar**klickar du på **Synkronisera arbetare till Azure AD**.
2. I fältet **käll objekt omfånget** kan du välja vilka uppsättningar av användare i arbets dagar som ska ingå i omfånget för etablering till Azure AD, genom att definiera en uppsättning attributbaserade filter. Standard omfånget är "alla användare i Workday". Exempel filter:
* Exempel: omfång till användare med Worker-ID: n mellan 1000000 och 2000000
* Attribut: WorkerID
* Operator: REGEX-matchning
* Värde: (1 [0-9] [0-9] [0-9] [0-9] [0-9] [0-9])
* Exempel: endast eventualtillgångar och inte vanliga anställda
* Attribut: ContingentID
* Operator: är inte NULL
3. I fältet **mål objekts åtgärder** kan du globalt filtrera vilka åtgärder som utförs i Azure AD. **Skapa** och **Uppdatera** är de vanligaste.
4. I avsnittet **mappningar för attribut** kan du definiera hur enskilda Workday-attribut mappar ska Active Directory attribut.
5. Klicka på en befintlig attributmappning för att uppdatera den, eller klicka på **Lägg till ny mappning** längst ned på skärmen för att lägga till nya mappningar. En mappning för enskilda attribut stöder följande egenskaper:
* **Mappnings typ**
* **Direct** – skriver värdet för attributet Workday till attributet AD, utan ändringar
* **Konstant** – Skriv ett statiskt, konstant sträng värde till attributet AD
* **Uttryck** – gör att du kan skriva ett anpassat värde till attributet AD, baserat på ett eller flera Workday-attribut. [Mer information finns i den här artikeln om uttryck](../app-provisioning/functions-for-customizing-application-data.md).
* **Källattribut** – attributet användare från Workday. Om det attribut som du letar efter inte finns kan du läsa mer i [Anpassa listan med användar](workday-inbound-tutorial.md#customizing-the-list-of-workday-user-attributes)-och Workday-användarattribut.
* **Standardvärde** – valfritt. Om källattributet har ett tomt värde, skrivs värdet i stället av mappningen.
Den vanligaste konfigurationen är att lämna detta tomt.
* **Target** -attribut – användarattribut i Azure AD.
* **Matcha objekt med det här attributet** – om det här attributet ska användas för att unikt identifiera användare mellan Workday och Azure AD. Det här värdet anges vanligt vis i fältet Worker-ID för arbets dag, som vanligt vis mappas till ID-attributet för personal (ny) eller ett tillägg i Azure AD.
* **Matchnings prioritet** – flera matchande attribut kan anges. När det finns flera, utvärderas de i den ordning som definieras av det här fältet. Så fort en matchning hittas utvärderas inga ytterligare matchande attribut.
* **Använd den här mappningen**
* **Alltid** – Använd den här mappningen för både skapande av användare och uppdaterings åtgärder
* **Endast vid skapande** – Använd endast den här mappningen för åtgärder för att skapa användare
6. Spara dina mappningar genom att klicka på **Spara** överst i avsnittet attribut-mappning.
## <a name="enable-and-launch-user-provisioning"></a>Aktivera och starta användar etablering
När du har slutfört konfigurationen av appar för arbets dag etablering kan du aktivera etablerings tjänsten i Azure Portal.
> [!TIP]
> Som standard när du aktiverar etablerings tjänsten kommer den att initiera etablerings åtgärder för alla användare i omfånget. Om det uppstår fel i mappnings-eller data frågor för data lagret kan etablerings jobbet Miss Miss kan och gå in i karantäns läget. För att undvika detta rekommenderar vi att du konfigurerar **käll objekt omfångs** filter och testar dina mappningar av attribut med några test användare innan du startar den fullständiga synkroniseringen för alla användare. När du har kontrollerat att mappningarna fungerar och ger dig önskade resultat kan du antingen ta bort filtret eller gradvis expandera det så att det innehåller fler användare.
1. På fliken **etablering** ställer du in **etablerings status** på **på**.
2. Klicka på **Spara**.
3. Den här åtgärden startar den inledande synkroniseringen, vilket kan ta ett variabelt antal timmar beroende på hur många användare som finns i arbets belastnings klienten. Du kan kontrol lera förlopps indikatorn för att följa synkroniseringens förlopp.
4. Gå till fliken **gransknings loggar** i Azure Portal för att se vilka åtgärder som etablerings tjänsten har utfört. I gransknings loggarna visas alla enskilda synkroniseringsfel som utförs av etablerings tjänsten, t. ex. vilka användare som ska läsas ut från Workday och därefter läggs till eller uppdateras till Azure Active Directory.
5. När den inledande synkroniseringen har slutförts skrivs en gransknings sammanfattnings rapport på fliken **etablering** , som visas nedan.
> [!div class="mx-imgBorder"]
> 
## <a name="next-steps"></a>Nästa steg
* [Läs mer om de Workday-attribut som stöds för inkommande etablering](../app-provisioning/workday-attribute-reference.md)
* [Lär dig hur du konfigurerar tillbakaskrivning av arbets dagar](workday-writeback-tutorial.md)
* [Lär dig hur du granskar loggar och hämtar rapporter om etablerings aktivitet](../app-provisioning/check-status-user-account-provisioning.md)
* [Lär dig hur du konfigurerar enkel inloggning mellan arbets dagar och Azure Active Directory](workday-tutorial.md)
* [Lär dig hur du integrerar andra SaaS-program med Azure Active Directory](tutorial-list.md)
* [Lär dig hur du exporterar och importerar dina etablerings konfigurationer](../app-provisioning/export-import-provisioning-configuration.md)
| 71.515695 | 661 | 0.780976 | swe_Latn | 0.999631 |
975d0b6875a4743b51bf27ff0eb12640e4d8777f | 4,797 | md | Markdown | articles/cognitive-services/custom-decision-service/custom-decision-service-overview.md | alphasteff/azure-docs.de-de | 02eeb9683bf15b9af28e7fd5bbd438779cf33719 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/cognitive-services/custom-decision-service/custom-decision-service-overview.md | alphasteff/azure-docs.de-de | 02eeb9683bf15b9af28e7fd5bbd438779cf33719 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/cognitive-services/custom-decision-service/custom-decision-service-overview.md | alphasteff/azure-docs.de-de | 02eeb9683bf15b9af28e7fd5bbd438779cf33719 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Worum handelt es sich bei Custom Decision Service?
titlesuffix: Azure Cognitive Services
description: Dieser Artikel bietet eine Übersicht über den Custom Decision Service.
services: cognitive-services
author: alekh
manager: nitinme
ms.service: cognitive-services
ms.subservice: custom-decision-service
ms.topic: overview
ms.date: 05/08/2018
ms.author: slivkins
ROBOTS: NOINDEX
ms.openlocfilehash: 073b2bf6df21e05481cde043d8ddcfd49822e94f
ms.sourcegitcommit: ad9120a73d5072aac478f33b4dad47bf63aa1aaa
ms.translationtype: HT
ms.contentlocale: de-DE
ms.lasthandoff: 08/01/2019
ms.locfileid: "68704242"
---
# <a name="what-is-custom-decision-service"></a>Worum handelt es sich bei Custom Decision Service?
In einer typischen Web- oder Mobilanwendung, enthält eine Titelseite Links zu mehreren Artikeln oder anderen Inhaltstypen. Wenn die Titelseite geladen wird, kann sie bei Custom Decision Service anfordern, Artikel zum Einschließen auf dieser Titelseite mit einem Rang zu bewerten. Wenn ein Benutzer durch Klicken einen Artikel auswählt, kann so eine zweite Anforderung an Custom Decision Service gesendet werden, der das Ergebnis dieser Entscheidung des Benutzers protokolliert.
Custom Decision Service ist einfach zu verwenden, da er nur einen RSS-Feeds für Ihre Inhalte sowie einige Zeilen JavaScript erfordert, die Ihrer Anwendung hinzugefügt werden müssen.
Custom Decision Service konvertiert Ihre Inhalte in Features für maschinelles Lernen. Das System verwendet diese Features, um Ihre Inhalte im Hinblick auf Text, Bilder, Videos und die allgemeine Stimmung zu verstehen. Es verwendet verschiedene weitere [Microsoft Cognitive Services](https://www.microsoft.com/cognitive-services), z.B. [Entitätsverknüpfung](../entitylinking/home.md), [Textanalyse](../text-analytics/overview.md), [Emotionen](../emotion/home.md) und [Maschinelles Sehen](../computer-vision/home.md).
Einige häufige Anwendungsfälle für Custom Decision Service sind:
* Personalisieren von Artikeln auf einer Nachrichtenwebsite
* Personalisieren von Videoinhalten in einem Medienportal
* Optimieren von Anzeigen oder der Webseiten, zu denen eine Anzeige weiterleitet
* Zuweisen eine Rangs für die empfohlenen Elemente auf einer Verkaufswebsite
Custom Decision Service befindet sich derzeit in der *kostenlosen öffentlichen Vorschau*. Er kann eine Liste von Artikeln auf einer Website oder in einer App personalisieren. Die Featureextraktion funktioniert am besten für Inhalte in englischer Sprache. Für andere Sprachen, z.B. Spanisch, Französisch, Deutsch, Portugiesisch und Japanisch, wird eine [eingeschränkte Funktionalität](../text-analytics/overview.md) angeboten. Diese Dokumentation wird überarbeitet, sobald neue Funktionen zur Verfügung stehen.
Custom Decision Service kann in Anwendungen verwendet werden, die sich nicht in der Inhaltspersonalisierungsdomäne befinden. Diese Anwendungen sind möglicherweise gut für eine benutzerdefinierte Vorschau geeignet. [Kontaktieren Sie uns](https://azure.microsoft.com/overview/sales-number/), um mehr zu erfahren.
## <a name="api-usage-modes"></a>API-Nutzungsmodi
Custom Decision Service kann auf Webseiten und in mobilen Apps angewandt werden. Die APIs können aus einem Browser oder einer App aufgerufen werden. Die API-Nutzung ist bei beiden ähnlich, einige Details unterscheiden sich jedoch.
## <a name="glossary-of-terms"></a>Glossar
In dieser Dokumentation treten mehrere Begriffe häufig auf:
* **Aktionssatz**: Der Satz von Inhaltselementen, denen von Custom Decision Service ein Rang zugewiesen werden soll. Dieser Satz kann als *RSS*- oder *Atom*-Endpunkt angegeben werden.
* **Rangfolge**: In jeder Anforderung an Custom Decision Service wird mindestens ein Aktionssatz angegeben. Das System reagiert durch Auswahl aller Inhaltsoptionen aus diesen Sätzen und Rückgabe in der priorisierten Reihenfolge.
* **Rückruffunktion**: Diese von Ihnen angegebene Funktion rendert den Inhalt auf der Benutzeroberfläche. Der Inhalt ist nach der Rangfolge sortiert, die von Custom Decision Service zurückgegeben wurde.
* **Relevanz**: Dieser Wert gibt an, wie der Benutzer auf den gerenderten Inhalt reagiert hat. Custom Decision Service misst die Benutzerreaktion anhand von Klicks. Die Klicks werden an das System gemeldet, indem benutzerdefinierter Code in Ihre Anwendung eingefügt wird.
## <a name="next-steps"></a>Nächste Schritte
* [Registrieren Ihrer Anwendung](custom-decision-service-get-started-register.md) bei Custom Decision Service
* Erste Schritte zum Optimieren einer [Webseite](custom-decision-service-get-started-browser.md) oder einer [Smartphone-App](custom-decision-service-get-started-app.md).
* Weitere Informationen zu den bereitgestellten Funktionen finden Sie in der [API-Referenz](custom-decision-service-api-reference.md).
| 82.706897 | 515 | 0.81822 | deu_Latn | 0.996532 |
975d35afb152540dbd3934a7b354211572c2daf8 | 1,492 | md | Markdown | help/export/ftp-and-sftp/ftp-delete.md | shimone/analytics.en | 37dd63d269203d4b333da2f7454407ba1931ddbe | [
"Apache-2.0"
] | 2 | 2021-02-08T01:29:00.000Z | 2021-02-08T01:29:21.000Z | help/export/ftp-and-sftp/ftp-delete.md | shimone/analytics.en | 37dd63d269203d4b333da2f7454407ba1931ddbe | [
"Apache-2.0"
] | 1 | 2021-02-23T13:21:32.000Z | 2021-02-23T16:45:14.000Z | help/export/ftp-and-sftp/ftp-delete.md | shimone/analytics.en | 37dd63d269203d4b333da2f7454407ba1931ddbe | [
"Apache-2.0"
] | 1 | 2021-11-18T18:48:17.000Z | 2021-11-18T18:48:17.000Z | ---
description: The Adobe FTP policy automatically disables access to FTP accounts that remain idle for 90 consecutive days.
keywords: ftp;sftp
title: Delete FTP data and FTP accounts
uuid: 1cbd3add-3561-492a-9ed4-aedbd3d5b257
---
# Delete FTP data and FTP accounts
The Adobe FTP policy automatically disables access to FTP accounts that remain idle for 90 consecutive days.
Adobe then removes disabled FTP accounts (and permanently removes all data stored in those accounts) after an additional 90-day grace period. For example, an FTP account which remains idle for 90 days (from July 5, 2012 to October 2, 2012) is disabled on October 3, 2012. It is then entirely removed on January 2, 2013.
No accounts are disabled prior to October 5, 2012 and no accounts are removed prior to January 2, 2013.
Adobe also permanently removes old data in active accounts if that data has not been accessed for 90 days.
These policies remain in effect for all FTP accounts moving forward from the July 5, 2012 date.
To assist us in this process, and to ensure the enhanced FTP environment continues to provide secure and reliable data transfer for our customers, we ask our customers to do the following:
* Remove outgoing data from the FTP system after that data has been successfully transferred to your in-house environment. Adobe identifies and removes any files left on the system after 90 days.
* Notify Adobe when FTP accounts are no longer needed so they can be deactivated and removed.
| 59.68 | 320 | 0.797587 | eng_Latn | 0.999537 |
975dd103645bc20b6febd3c815e46e47a72f0a8a | 502 | md | Markdown | APIdoc/19.record_testsuite_property.md | wawawawawawawawawawa/pytestAPI_- | 471da27699213d1572ca8f1648be2e3629838ed1 | [
"MIT"
] | null | null | null | APIdoc/19.record_testsuite_property.md | wawawawawawawawawawa/pytestAPI_- | 471da27699213d1572ca8f1648be2e3629838ed1 | [
"MIT"
] | null | null | null | APIdoc/19.record_testsuite_property.md | wawawawawawawawawawa/pytestAPI_- | 471da27699213d1572ca8f1648be2e3629838ed1 | [
"MIT"
] | null | null | null | # 19.record_testsuite_property
1. ##### 功能
如果要在测试套件级别添加一个属性节点,该节点可能包含与所有测试相关的属性,则可以使用`record_testsuite_property`会话范围的fixture:
该`record_testsuite_property`会话范围的fixture可用于在所有测试中增加相关的属性。
2. ##### 使用
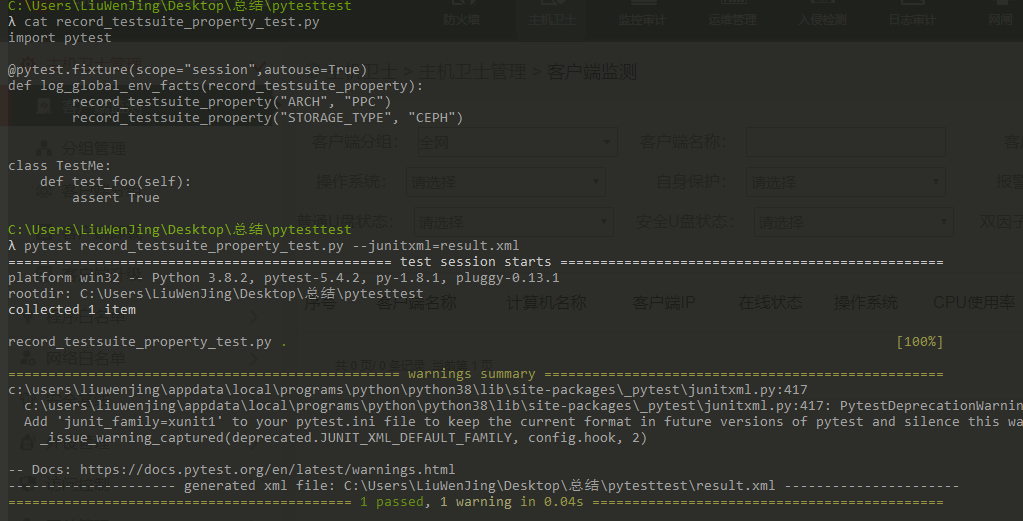
执行一个测试用例,可以看到执行通过,会在相同目录下生成一个xml文件,打开这个文件:

我这里使用谷歌浏览器(安装了xml解析插件)打开结果文件,可以看到执行用例时有全局的属性
| 26.421053 | 110 | 0.824701 | yue_Hant | 0.7218 |
975dd8c30172ba6962d890a78d18b99a006fb628 | 256 | md | Markdown | _posts/2018-04-24-i-get-to.md | jsorge/jsorge.github.io | 5a06481f6fb4e7ddbd2776946a54248562fa8968 | [
"MIT"
] | null | null | null | _posts/2018-04-24-i-get-to.md | jsorge/jsorge.github.io | 5a06481f6fb4e7ddbd2776946a54248562fa8968 | [
"MIT"
] | null | null | null | _posts/2018-04-24-i-get-to.md | jsorge/jsorge.github.io | 5a06481f6fb4e7ddbd2776946a54248562fa8968 | [
"MIT"
] | null | null | null | ---
layout: post
microblog: true
audio:
date: 2018-04-24 15:51:53 -0700
guid: http://jsorge.micro.blog/2018/04/24/i-get-to.html
---
I get to ride the train home today! Emily and the boys are meeting me at the station. It truly is the best way to commute.
| 28.444444 | 122 | 0.722656 | eng_Latn | 0.977439 |
975e1d0b6b64aa7459c9ea27f7b16df62fcf4dee | 47 | md | Markdown | README.md | andra222/pohon-palem-yang-didesain-ulang | 61266b97cae7356b752fb0d14501a63458941ef2 | [
"Apache-2.0"
] | null | null | null | README.md | andra222/pohon-palem-yang-didesain-ulang | 61266b97cae7356b752fb0d14501a63458941ef2 | [
"Apache-2.0"
] | null | null | null | README.md | andra222/pohon-palem-yang-didesain-ulang | 61266b97cae7356b752fb0d14501a63458941ef2 | [
"Apache-2.0"
] | null | null | null | # pohon-palem-yang-didesain-ulang
Indodax. Com
| 15.666667 | 33 | 0.787234 | ind_Latn | 0.850218 |
975e32c5ff5fb09fed015e356e7d7016859bfab6 | 665 | md | Markdown | template.md | harrison-ai/dataeng-1-on-1 | c4b626c7d661a81921433269cfc46a86257cc9d5 | [
"BSD-3-Clause"
] | null | null | null | template.md | harrison-ai/dataeng-1-on-1 | c4b626c7d661a81921433269cfc46a86257cc9d5 | [
"BSD-3-Clause"
] | null | null | null | template.md | harrison-ai/dataeng-1-on-1 | c4b626c7d661a81921433269cfc46a86257cc9d5 | [
"BSD-3-Clause"
] | null | null | null |
## Check in
* What are your highlights / low lights since last time?
## Progress
* What progress has been made?
* Refer to relevant metrics / milestones
## Ways MYMANAGER can unblock me
* Need help?
## Other items for ME to discuss
* This is where you can bring up other items you would like to discuss with MYMANAGER
## MYMANAGER update
* This is where MYMANAGER can provide updates
## Feedback
* Feedback is a two way street and should be regularly practiced.
### Feedback from ME to MYMANAGER
* Here is where you can provide your manager with feedback
### Feedback from MYMANAGER to ME
* Here is where your manager can provide you with feedback | 20.151515 | 85 | 0.742857 | eng_Latn | 0.999796 |
975e55c8ffa2f9ede6556572ee4628d98baa96bf | 6,976 | md | Markdown | docs/framework/wcf/samples/interoperating-with-asmx-web-services.md | BraisOliveira/docs.es-es | cc6cffb862a08615c53b07afbbdf52e2a5ee0990 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/samples/interoperating-with-asmx-web-services.md | BraisOliveira/docs.es-es | cc6cffb862a08615c53b07afbbdf52e2a5ee0990 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/samples/interoperating-with-asmx-web-services.md | BraisOliveira/docs.es-es | cc6cffb862a08615c53b07afbbdf52e2a5ee0990 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Interoperabilidad con servicios web ASMX
ms.date: 03/30/2017
ms.assetid: a7c11f0a-9e68-4f03-a6b1-39cf478d1a89
ms.openlocfilehash: 2ef4e34de76c046ba21dd7a3c50ea6ba782d459e
ms.sourcegitcommit: 005980b14629dfc193ff6cdc040800bc75e0a5a5
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 09/14/2019
ms.locfileid: "70989798"
---
# <a name="interoperating-with-asmx-web-services"></a>Interoperabilidad con servicios web ASMX
Este ejemplo muestra cómo integrar una aplicación cliente de Windows Communication Foundation (WCF) con un servicio Web ASMX existente.
> [!NOTE]
> El procedimiento de instalación y las instrucciones de compilación de este ejemplo se encuentran al final de este tema.
Este ejemplo está compuesto de un programa de consola de cliente (.exe) y una biblioteca de servicios (.dll) hospedados por Internet Information Services (IIS). El servicio es un servicio Web ASMX que implementa un contrato que define un patrón de comunicación de solicitud y respuesta. El servicio expone las operaciones matemáticas (`Add`, `Subtract`, `Multiply`y `Divide`). El cliente realiza solicitudes sincrónicas a una operación matemática y el servicio responde con el resultado. La actividad del cliente es visible en la ventana de la consola.
La implementación de servicio Web de ASMX mostrada en el código muestra siguiente calcula y devuelve el resultado adecuado.
```csharp
[WebService(Namespace="http://Microsoft.ServiceModel.Samples")]
public class CalculatorService : System.Web.Services.WebService
{
[WebMethod]
public double Add(double n1, double n2)
{
return n1 + n2;
}
[WebMethod]
public double Subtract(double n1, double n2)
{
return n1 - n2;
}
[WebMethod]
public double Multiply(double n1, double n2)
{
return n1 * n2;
}
[WebMethod]
public double Divide(double n1, double n2)
{
return n1 / n2;
}
}
```
Tal y como se ha configurado, se puede tener `http://localhost/servicemodelsamples/service.asmx` acceso al servicio en un cliente en el mismo equipo. Para que los clientes en equipos remotos tengan acceso al servicio, se debe especificar un nombre de dominio completo en lugar del host local.
La comunicación se realiza a través de un cliente generado por la [herramienta de utilidad de metadatos de ServiceModel (SvcUtil. exe)](../../../../docs/framework/wcf/servicemodel-metadata-utility-tool-svcutil-exe.md). El cliente está contenido en el archivo generatedClient.cs. El servicio ASMX debe estar disponible Para compilar el código proxy, porque se utiliza para recuperar los metadatos actualizados. Ejecute el comando siguiente desde un símbolo del sistema en el directorio del cliente para generar el proxy especificado.
```console
svcutil.exe /n:http://Microsoft.ServiceModel.Samples,Microsoft.ServiceModel.Samples http://localhost/servicemodelsamples/service.svc?wsdl /out:generatedClient.cs
```
Utilizando el cliente generado, puede tener acceso a un punto de conexión de servicio configurando la dirección adecuada y el enlace apropiado. Como el servicio, el cliente utiliza un archivo de configuración (App.config) para especificar el punto de conexión con el que se comunica. La configuración de punto de conexión de cliente está compuesta de un nombre de configuración, una dirección absoluta para el punto de conexión de servicio, el enlace y el contrato, tal y como se muestra en la siguiente configuración de muestra.
```xml
<client>
<endpoint
address="http://localhost/ServiceModelSamples/service.asmx"
binding="basicHttpBinding"
contract="Microsoft.ServiceModel.Samples.CalculatorServiceSoap" />
</client>
```
La implementación del cliente crea una instancia del cliente generado. El cliente generado se puede utilizar a continuación para comunicarse con el servicio.
```csharp
// Create a client.
CalculatorServiceSoapClient client = new CalculatorServiceSoapClient();
// Call the Add service operation.
double value1 = 100.00D;
double value2 = 15.99D;
double result = client.Add(value1, value2);
Console.WriteLine("Add({0},{1}) = {2}", value1, value2, result);
// Call the Subtract service operation.
value1 = 145.00D;
value2 = 76.54D;
result = client.Subtract(value1, value2);
Console.WriteLine("Subtract({0},{1}) = {2}", value1, value2, result);
// Call the Multiply service operation.
value1 = 9.00D;
value2 = 81.25D;
result = client.Multiply(value1, value2);
Console.WriteLine("Multiply({0},{1}) = {2}", value1, value2, result);
// Call the Divide service operation.
value1 = 22.00D;
value2 = 7.00D;
result = client.Divide(value1, value2);
Console.WriteLine("Divide({0},{1}) = {2}", value1, value2, result);
//Closing the client gracefully closes the connection and cleans up resources.
client.Close();
Console.WriteLine();
Console.WriteLine("Press <ENTER> to terminate client.");
Console.ReadLine();
```
Al ejecutar el ejemplo, las solicitudes y respuestas de la operación se muestran en la ventana de la consola del cliente. Presione ENTRAR en la ventana de cliente para cerrar el cliente.
```console
Add(100,15.99) = 115.99
Subtract(145,76.54) = 68.46
Multiply(9,81.25) = 731.25
Divide(22,7) = 3.14285714285714
Press <ENTER> to terminate client.
```
### <a name="to-set-up-build-and-run-the-sample"></a>Configurar, compilar y ejecutar el ejemplo
1. Asegúrese de que ha realizado el [procedimiento de instalación única para los ejemplos de Windows Communication Foundation](../../../../docs/framework/wcf/samples/one-time-setup-procedure-for-the-wcf-samples.md).
2. Para compilar el código C# o Visual Basic .NET Edition de la solución, siga las instrucciones de [Building the Windows Communication Foundation Samples](../../../../docs/framework/wcf/samples/building-the-samples.md).
3. Para ejecutar el ejemplo en una configuración de equipos única o cruzada, siga las instrucciones de [ejecución de los ejemplos de Windows Communication Foundation](../../../../docs/framework/wcf/samples/running-the-samples.md).
> [!IMPORTANT]
> Puede que los ejemplos ya estén instalados en su equipo. Compruebe el siguiente directorio (predeterminado) antes de continuar.
>
> `<InstallDrive>:\WF_WCF_Samples`
>
> Si este directorio no existe, vaya a [ejemplos de Windows Communication Foundation (WCF) y Windows Workflow Foundation (WF) para .NET Framework 4](https://go.microsoft.com/fwlink/?LinkId=150780) para descargar todos los Windows Communication Foundation (WCF) [!INCLUDE[wf1](../../../../includes/wf1-md.md)] y ejemplos. Este ejemplo se encuentra en el siguiente directorio.
>
> `<InstallDrive>:\WF_WCF_Samples\WCF\Basic\Client\Interop\ASMX`
| 52.451128 | 555 | 0.725917 | spa_Latn | 0.946918 |
975e9afb1859395d2a8e990bf88e6bcd48a319b3 | 11,895 | md | Markdown | standards/Content Events.md | therealchrisccc/blackboard.github.io | 22a577bc7f24768edef89de6cabb7d582f0df76b | [
"BSD-3-Clause"
] | null | null | null | standards/Content Events.md | therealchrisccc/blackboard.github.io | 22a577bc7f24768edef89de6cabb7d582f0df76b | [
"BSD-3-Clause"
] | null | null | null | standards/Content Events.md | therealchrisccc/blackboard.github.io | 22a577bc7f24768edef89de6cabb7d582f0df76b | [
"BSD-3-Clause"
] | null | null | null | ---
layout: standards
parent: caliper
category: events-caliper
---
# Content Events
*Author: Scott Hurrey*
*Categories: ['Caliper']*
*Tags: ['developers', 'standards', 'caliper', 'ims', 'ims global', 'forumevent', 'contentevent', 'developer']*
<hr />
Blackboard Learn's Caliper Analytics stream emits a ContentEvent to cover a
plethora of use cases. Here is when a message will be sent:
### Content Item Created
| Object | Message Sent |
| ------ |:------------:|
| Folder | :heavy_check_mark: |
| Link | :heavy_check_mark: |
| LTI | :heavy_check_mark: |
| Assignment | :heavy_check_mark: |
| Forum |:heavy_check_mark: |
| Content File Upload | :heavy_check_mark: |
| Test | :heavy_multiplication_x: |
| Document | :heavy_check_mark: |
| File Upload | :heavy_check_mark: |
### Content Item Updated (by member value)
The columns contain attributes of the Content Item.
**Legend**<br />
:heavy_check_mark: - Changing this value emits a caliper event<br />
:heavy_multiplication_x: - Changing this value does not emit a caliper event<br />
:heavy_minus_sign: - This value is not applicable for this attribute<br />
:curly_loop: - This results in a ForumEvent<br />
| Object | Name | URL | Des | Avl | Parm | Score | Due Date | Start Date | End Date | Disc | Grp | Inst | Qs |
| ------ |:----:|:---:|:----:|:---:|:----:|:-----:|:-------:|:---------:|:-------:|:----:|:-----:|:----:|:---------:|
| Folder | :heavy_check_mark: | :heavy_minus_sign: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_minus_sign: | :heavy_minus_sign: |
| Link | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_minus_sign: | :heavy_minus_sign: |
| LTI | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_check_mark: | :curly_loop: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_minus_sign: |
| Assignment | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_multiplication_x: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_check_mark: | :curly_loop: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_minus_sign: |
| Forum |:heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_multiplication_x: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_minus_sign: |
| Content File Upload | :heavy_check_mark: | :heavy_minus_sign:| :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: |
| Test | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_multiplication_x: | :heavy_multiplication_x: | :heavy_check_mark: | :heavy_check_mark: | :curly_loop: | :heavy_multiplication_x: | :heavy_multiplication_x: | :heavy_multiplication_x: |
| Document | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: |
| File Upload | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_check_mark: | :heavy_multiplication_x: | :heavy_minus_sign: | :heavy_check_mark: | :heavy_minus_sign: |
### Content Item Deleted
| Object | Message Sent |
| ------ |:------------:|
| Folder | :heavy_check_mark: |
| Link | :heavy_check_mark: |
| LTI | :heavy_check_mark: |
| Assignment | :heavy_check_mark: |
| Forum |:heavy_check_mark: |
| Content File Upload | :heavy_check_mark: |
| Test | :heavy_check_mark: |
| Document | :heavy_check_mark: |
| File Upload | :heavy_check_mark: |
OutcomeEvents are sent in bulk nightly. Here is some of the key data that is
associated with these events:
## ContentEvent
**group.courseNumber** - the course batch_uid (i.e. the ID sent in by LIS or Data Integration)
**object.@id** - …/content/id - the primary key for the content ID
**actor.@id** - contains a unique ID of the user (the ID is known to Bb)
**extensions** - contains a tag called bb:user.externalId with the batch_uid for the user
**membership.roles** - #Instructor
**action** - …/action#Created _**or**_ …/action#Updated _**or**_ …/action#Deleted
## Sample Payload
Here is a sample of what a payload might look like:
```
{
"sensor": "df1b6234-73e8-45a4-b953-4066760dfbda",
"sendTime": "2016-03-16T17:23:46.224Z",
"data": [{
"@context": "http://caliper.blackboard.com/ctx/caliper/v1/Context",
"@type": "http://caliper.blackboard.com/caliper/v1/ContentEvent",
"actor": {
"@id": "https://caliper-mapping.cloudbb.blackboard.com/v1/sites/df1b6234-73e8-45a4-b953-4066760dfbda/users/f902ceefcf8f41ae87570daa25158989",
"@context": "http://purl.imsglobal.org/ctx/caliper/v1/Context",
"@type": "http://purl.imsglobal.org/caliper/v1/lis/Person",
"name": null,
"description": null,
"extensions": {
"bb:user.id": "_88_1",
"bb:user.externalId": "perfadmin"
},
"dateCreated": null,
"dateModified": null
},
"action": "http://caliper.blackboard.com/vocab/caliper/v1/action#Create",
"object": {
"@context": "http://caliper.blackboard.com/ctx/caliper/v1/Context",
"@type": "http://caliper.blackboard.com/caliper/v1/Content",
"@id": "https://caliper-mapping.cloudbb.blackboard.com/v1/sites/df1b6234-73e8-45a4-b953-4066760dfbda/content/_11206_1",
"handler": "resource/x-bb-folder",
"isLesson": false,
"isFolder": true,
"isGroupContent": false,
"dataVersion": 3,
"renderType": "REG",
"packageSignature": null,
"contentContext": null
},
"target": null,
"generated": {
"@context": "http://caliper.blackboard.com/ctx/caliper/v1/Context",
"@type": "http://caliper.blackboard.com/caliper/v1/UpdatedContentProperties",
"@id": "https://caliper-mapping.cloudbb.blackboard.com/v1/sites/df1b6234-73e8-45a4-b953-4066760dfbda/content/_11206_1/updatedProperties",
"position": {
"oldValue": null,
"newValue": -1
},
"title": null,
"mainData": {
"oldValue": null,
"newValue": ""
},
"startDate": null,
"endDate": null,
"launchInNewWindow": {
"oldValue": null,
"newValue": false
},
"isTracked": {
"oldValue": null,
"newValue": false
},
"isReviewable": {
"oldValue": null,
"newValue": false
},
"linkRef": null,
"url": null,
"allowGuests": {
"oldValue": null,
"newValue": true
},
"allowObservers": {
"oldValue": null,
"newValue": true
},
"parentId": null,
"extendedData": {
"oldValue": null,
"newValue": {
}
},
"adaptiveReleaseStatus": null,
"isPartiallyVisible": {
"oldValue": null,
"newValue": false
},
"isMetadataSet": {
"oldValue": null,
"newValue": true
},
"attachedFilesCount": {
"oldValue": null,
"newValue": 0
},
"removedFilesCount": {
"oldValue": null,
"newValue": 0
}
},
"eventTime": "2016-03-16T17:18:00.767Z",
"edApp": {
"@context": "http://purl.imsglobal.org/ctx/caliper/v1/Context",
"@id": "https://caliper-mapping.cloudbb.blackboard.com/v1/sites/df1b6234-73e8-45a4-b953-4066760dfbda/applications/learn",
"@type": "http://purl.imsglobal.org/caliper/v1/SoftwareApplication",
"name": null,
"description": null,
"extensions": {
},
"dateCreated": null,
"dateModified": null
},
"group": null,
"membership": {
"@context": "http://purl.imsglobal.org/ctx/caliper/v1/Context",
"@id": "https://caliper-mapping.cloudbb.blackboard.com/v1/sites/df1b6234-73e8-45a4-b953-4066760dfbda/courses/1c430b729888417399937d0bf02fa98b/members/f902ceefcf8f41ae87570daa25158989",
"@type": "http://purl.imsglobal.org/caliper/v1/lis/Membership",
"name": null,
"description": null,
"extensions": {
"bb:user.externalId": "perfadmin",
"bb:user.id": "_88_1",
"bb:course.id": "_170_1",
"bb:course.externalId": "xsmall_000000001"
},
"dateCreated": null,
"dateModified": null,
"member": "https://caliper-mapping.cloudbb.blackboard.com/v1/sites/df1b6234-73e8-45a4-b953-4066760dfbda/users/f902ceefcf8f41ae87570daa25158989",
"organization": "https://caliper-mapping.cloudbb.blackboard.com/v1/sites/df1b6234-73e8-45a4-b953-4066760dfbda/courses/1c430b729888417399937d0bf02fa98b",
"roles": ["http://purl.imsglobal.org/vocab/lis/v2/membership#Instructor"],
"status": "http://purl.imsglobal.org/vocab/lis/v2/status#Active"
},
"federatedSession": null
"federatedSession": null
}]
}
```
| 54.068182 | 306 | 0.533417 | eng_Latn | 0.184538 |
975eb37ed93d49b31b85ed34e8176cf7d2f40e3e | 21,429 | md | Markdown | docs/tree/index.en-us.md | zsjjs/next | 948c48d8484f2c3af12b9e80f0d34866dc619271 | [
"MIT"
] | 1 | 2020-06-09T03:33:54.000Z | 2020-06-09T03:33:54.000Z | docs/tree/index.en-us.md | zsjjs/next | 948c48d8484f2c3af12b9e80f0d34866dc619271 | [
"MIT"
] | null | null | null | docs/tree/index.en-us.md | zsjjs/next | 948c48d8484f2c3af12b9e80f0d34866dc619271 | [
"MIT"
] | null | null | null | # Tree
- category: Components
- family: DataDisplay
- chinese: 树形控件
- type: 基本
---
## Guide
### When To Use
Folders, organizational structures, taxonomy, countries, regions, etc. Most of the structures in the world are tree structures. The use of Tree can fully reveal the hierarchical relationships among them, and have interactive functions such as expanding and closing, selections.
## API
### Tree
| Param | Descripiton | Type | Default Value |
| ------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------- | ---------- |
| children | tree nodes | ReactNode | - |
| dataSource | data source, this property has a higher priority than children | Array | - |
| showLine | whether to show the line of the tree | Boolean | false |
| selectable | whether to support selecting node | Boolean | true |
| selectedKeys | (under control) keys of current selected nodes | Array<String> | - |
| defaultSelectedKeys | (under uncontrol) keys of default selected nodes | Array<String> | \[] |
| onSelect | callback function triggered when select or unselect node<br><br>**signatures**:<br>Function(selectedKeys: Array, extra: Object) => void<br>**params**:<br>_selectedKeys_: {Array} keys of selected nodes<br>_extra_: {Object} extra params<br>_extra.selectedNodes_: {Array} selected nodes<br>_extra.node_: {Object} current operation node<br>_extra.selected_: {Boolean} whether is selected | Function | () => {} |
| multiple | whether to support multiple selection | Boolean | false |
| checkable | whether to support checking checkbox of the node | Boolean | false |
| checkedKeys | (under control) keys of current checked nodes, it should be an array or an object like `{checked: Array, indeterminate: Array}` | Array<String>/Object | - |
| defaultCheckedKeys | (under uncontrol) keys of default checked nodes | Array<String> | \[] |
| checkStrictly | whether the checkbox of the node is controlled strictly (selection of parent and child nodes are no longer related) | Boolean | false |
| checkedStrategy | defining the way to backfill when checked node <br><br>**options**:<br>'all' (return all checked nodes)<br>'parent' (only parent nodes are returned when parent and child nodes are checked) <br>'child' (only child nodes are returned when parent and child nodes are checked) | Enum | 'all' |
| onCheck | callback function triggered when check or uncheck node<br><br>**signatures**:<br>Function(checkedKeys: Array, extra: Object) => void<br>**params**:<br>_checkedKeys_: {Array} keys of checked nodes<br>_extra_: {Object} extra param<br>_extra.checkedNodes_: {Array} checked nodes<br>_extra.checkedNodesPositions_: {Array} an array containing objects with check box nodes and their locations<br>_extra.indeterminateKeys_: {Array} keys of indeterminate nodes<br>_extra.node_: {Object} current operation node<br>_extra.checked_: {Boolean} whethre is checked | Function | () => {} |
| expandedKeys | (under control) keys of current expanded nodes | Array<String> | - |
| defaultExpandedKeys | (under uncontrol) keys of default expanded nodes | Array<String> | \[] |
| defaultExpandAll | whether to expand all nodes by default | Boolean | false |
| autoExpandParent | whether to expand the parent node automatically | Boolean | true |
| onExpand | callback function triggered when expand or collapse node<br><br>**signatures**:<br>Function(expandedKeys: Array, extra: Object) => void<br>**params**:<br>_expandedKeys_: {Array} keys of expanded nodes<br>_extra_: {Object} extra param<br>_extra.node_: {Object} current operation node<br>_extra.expanded_: {Boolean} whether is expanded | Function | () => {} |
| editable | whether to support editing node content | Boolean | false |
| onEditFinish | callback function triggered after editing<br><br>**signatures**:<br>Function(key: String, label: String, node: Object) => void<br>**params**:<br>_key_: {String} key of editing node<br>_label_: {String} label after editting<br>_node_: {Object} editting node | Function | () => {} |
| draggable | whether to support drag and drop nodes | Boolean | false |
| onDragStart | callback function triggered when start to drag node<br><br>**signatures**:<br>Function(info: Object) => void<br>**params**:<br>_info_: {Object} drag and drop information<br>_info.event_: {Object} event object<br>_info.node_: {Object} drag node | Function | () => {} |
| onDragEnter | callback function triggered when the drag node enters the target node<br><br>**signatures**:<br>Function(info: Object) => void<br>**params**:<br>_info_: {Object} drag and drop information<br>_info.event_: {Object} event object<br>_info.node_: {Object} target node<br>_info.expandedKeys_: {Array} keys of current expanded nodes | Function | () => {} |
| onDragOver | callback function triggered when the drag node is moved on the target node<br><br>**signatures**:<br>Function(info: Object) => void<br>**params**:<br>_info_: {Object} drag and drop information<br>_info.event_: {Object} event object<br>_info.node_: {Object} target node | Function | () => {} |
| onDragLeave | callback function triggered when the drag node leaves the target node<br><br>**signatures**:<br>Function(info: Object) => void<br>**params**:<br>_info_: {Object} drag and drop information<br>_info.event_: {Object} event object<br>_info.node_: {Object} target node | Function | () => {} |
| onDragEnd | callback function triggered after draging<br><br>**signatures**:<br>Function(info: Object) => void<br>**params**:<br>_info_: {Object} drag and drop information<br>_info.event_: {Object} event object<br>_info.node_: {Object} target node | Function | () => {} |
| onDrop | callback function triggered when drop the node<br><br>**signatures**:<br>Function(info: Object) => void<br>**params**:<br>_info_: {Object} drag and drop information<br>_info.event_: {Object} event object<br>_info.node_: {Object} target node<br>_info.dragNode_: {Object} drag node<br>_info.dragNodesKeys_: {Array} keys of drag node and its child nodes<br>_info.dropPosition_: {Number} drop position, -1 means before the current node, 0 means in the current node, and 1 means after the current node | Function | () => {} |
| canDrop | whether the node can be used as a drag target node<br><br>**signatures**:<br>Function(info: Object) => Boolean<br>**params**:<br>_info_: {Object} drag and drop information<br>_info.node_: {Object} target node<br>_info.dragNode_: {Object} drag node<br>_info.dragNodesKeys_: {Array} keys of drag node and its child nodes<br>_info.dropPosition_: {Number} drop position, -1 means before the current node, 0 means in the current node, and 1 means after the current node<br>**returns**:<br>{Boolean} Can it be treated as a target node<br> | Function | () => true |
| loadData | asynchronous data loading function<br><br>**signatures**:<br>Function(node: Object) => void<br>**params**:<br>_node_: {Object} node clicked to expand | Function | - |
| filterTreeNode | filter highlight nodes<br><br>**signatures**:<br>Function(node: Object) => Boolean<br>**params**:<br>_node_: {Object} nodes to be filtered<br>**returns**:<br>{Boolean} whether is filtered<br> | Function | - |
| onRightClick | callback function when right click<br><br>**signatures**:<br>Function(info: Object) => void<br>**params**:<br>_info_: {Object} information object<br>_info.event_: {Object} event object<br>_info.node_: {Object} clicked node | Function | - |
| isLabelBlock | sets whether or not the node occupies the remaining space, it is generally used to add elements to the right side of each node (base flex, only Internet Explorer 10+ is supported) | Boolean | false |
| isNodeBlock | set whether the node fills a row | Boolean/Object | false |
| animation | whether to enable expand and collapse animation | Boolean | true |
| renderChildNodes | Render child nodes<br><br>**签名**:<br>Function(nodes: Array) => ReactNode<br>**params**:<br>_nodes_: {Array} child nodes<br>**返回值**:<br>{ReactNode} <br> | Function | - |
### Tree.Node
| Param | Descripiton | Type | Default Value |
| ---------------- | ------------------------------- | --------- | ----- |
| children | tree nodes | ReactNode | - |
| label | content of node | ReactNode | '---' |
| selectable | set whether to support selecting node, override the Tree's selectable | Boolean | - |
| checkable | set whether to support checking node, override the Tree's checkable | Boolean | - |
| editable | set whether to support editing node, override the Tree's editable | Boolean | - |
| draggable | set whether to support dragging node, override the Tree's draggable | Boolean | - |
| disabled | whether node is disabled | Boolean | false |
| checkboxDisabled | whether checkbox of node is disabled | Boolean | false |
| isLeaf | whether it is a leaf node and only works when loadData is set | Boolean | false |
<!-- api-extra-start -->
You should set the `key` for Tree.Node: `<TreeNode key="102894" label="Ladies" />`, which is generally the id of the data, but it must be guaranteed globally unique. The default value of `key` is Tree's internally calculated position string.
<!-- api-extra-end -->
| 274.730769 | 670 | 0.303281 | eng_Latn | 0.924014 |
9760e4ee9a921d401903263902d6a15d6bb55d85 | 3,002 | md | Markdown | site/content/blog/legend-of-korra-fire-and-water.md | rashedakther/hugo-comic | ddf9e876a24a895cad16470c62c765d422d858b0 | [
"MIT"
] | 7 | 2019-03-09T15:11:59.000Z | 2021-09-07T23:12:26.000Z | site/content/blog/legend-of-korra-fire-and-water.md | EcocityAccounts/hugo-comic | 85af71a0ab95c124212b8ac82d7863e6a406aeaa | [
"MIT"
] | 1 | 2021-03-09T01:09:17.000Z | 2021-03-09T01:09:17.000Z | site/content/blog/legend-of-korra-fire-and-water.md | EcocityAccounts/hugo-comic | 85af71a0ab95c124212b8ac82d7863e6a406aeaa | [
"MIT"
] | 6 | 2019-03-09T15:12:03.000Z | 2021-01-14T14:33:02.000Z | ---
title: 'Legend of Korra Process - Fire and Water'
date: Mon, 19 Nov 2012 20:04:13 +0000
draft: false
tags: [Illustration, Art Process]
image: /img/korra-progress-2.png
---
I'm working on a new piece for my November[ P.U.M.M.E.L.](http://www.penciljack.com/forum/forumdisplay.php?89-PUMMEL) match. I picked the theme this time, and I decided on Legend of Korra. I was watching this season, and thought the fire and water effects would be a good way to jump into a more painterly technique. Usually, I sketch, ink, and color with either flats, like in Rob and Elliot, or 1-2 levels of shading/highlights with gradients like in my [Storm/Black Panther illustration](/illustrations). I wanted to try out Photoshop CS6's new realistic paintbrushes, and this seemed like as good a chance as any.
I started off with a pencil tool sketch.

After that I blocked off the flat colors. I changed her legs to a running stride, and started working on the water distortion. The water effect is on a separate layer with the mode set to overlay. For water distortion, you can create a refraction effect by shifting the image behind the water by an even amount. I moved it a little bit down and to the left. I then added undulations in the outline with displaced spots. I left the fire as a block color for now. I started painting her face to get an idea on how I wanted the water to reflect back up onto the underside of Korra's face. Since light bounces off and passes through the water, it casts more reflected light than an opaque object, so the dominating reflective colors are going to be from the fire and the water on either side of her body.

Here I added most of the shading with the Flat Curve Think Stiff Bristles brush in PS with the opacity set to pressure sensitive. I picked a main light source (top-left) and visualized the objects in 3D space while adding volume with shadows and reflective lightsources. I added the water and fire reflective light with an overlay layer. The fire effect is created by building up layers of flame-like shapes progressing from orange to yellow to white. Remember that the white part is the hottest, so it should be prominent only where the flame is thickest.

Here I added Naga, and made some corrections to Korra. You'll notice how Naga has the reflected light sources on him as well (overlay layer with a radial gradient). I also moved the fire to intersect with the water stream and added distortion effects and a glow (overlay gradient again). I made sure to use a large size brush with more visible bristle strokes on Naga to get a fur effect.

I'm still in progress, but here's a zoomed in view of the fire and water effects to give you a better idea of how I achieved them. I still need to add the distortion to naga, but since I'm not 100% sure about the placement, I haven't implemented it yet.
 | 103.517241 | 801 | 0.774151 | eng_Latn | 0.999663 |
9761acff7f866bfd17985c279fade76bcbb3f67d | 5,010 | md | Markdown | README.md | renovate-bot/actions | ff5624d62e916ba958d7c0df9893ee9d2d2378de | [
"Apache-2.0"
] | null | null | null | README.md | renovate-bot/actions | ff5624d62e916ba958d7c0df9893ee9d2d2378de | [
"Apache-2.0"
] | null | null | null | README.md | renovate-bot/actions | ff5624d62e916ba958d7c0df9893ee9d2d2378de | [
"Apache-2.0"
] | 1 | 2021-07-13T20:39:14.000Z | 2021-07-13T20:39:14.000Z | # Snyk GitHub Actions

A set of [GitHub Action](https://github.com/features/actions) for using [Snyk](https://snyk.co/SnykGH) to check for
vulnerabilities in your GitHub projects. A different action is required depending on which language or build tool
you are using. We currently support:
- [CocoaPods](cocoapods)
- [dotNET](dotnet)
- [Golang](golang)
- [Gradle](gradle)
- [Gradle-jdk11](gradle-jdk11)
- [Gradle-jdk12](gradle-jdk12)
- [Maven](maven)
- [Maven-3-jdk-11](maven-3-jdk-11)
- [Node](node)
- [PHP](php)
- [Python](python)
- [Python-3.6](python-3.6)
- [Python-3.7](python-3.7)
- [Python-3.8](python-3.8)
- [Ruby](ruby)
- [Scala](scala)
- [Docker](docker)
- [Infrastructure as Code](iac)
- [Setup](setup)
Here's an example of using one of the Actions, in this case to test a Node.js project:
```yaml
name: Example workflow using Snyk
on: push
jobs:
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- name: Run Snyk to check for vulnerabilities
uses: snyk/actions/node@master
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
```
If you want to send data to Snyk, and be alerted when new vulnerabilities are discovered, you can run [Snyk monitor](https://support.snyk.io/hc/en-us/articles/360000920818-What-is-the-difference-between-snyk-test-protect-and-monitor-) like so:
```yaml
name: Example workflow using Snyk
on: push
jobs:
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- name: Run Snyk to check for vulnerabilities
uses: snyk/actions/node@master
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
with:
command: monitor
```
See the individual Actions linked above for per-language instructions.
Note that GitHub Actions will not pass on secrets set in the repository to forks being used in pull requests, and so the Snyk actions that require the token will fail to run.
### Bring your own development environment
The per-language Actions automatically install all the required development tools for Snyk to determine the correct dependencies and hence vulnerabilities from different language environments. If you have a workflow where you already have those installed then you can instead use the `snyk/actions/setup` Action to just install [Snyk CLI][cli-gh]:
```yaml
name: Snyk example
on: push
jobs:
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- uses: snyk/actions/setup@master
- uses: actions/setup-go@v1
with:
go-version: '1.13'
- name: Snyk monitor
run: snyk test
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
```
The example here uses `actions/setup-go` would you would need to select the right actions to install the relevant development requirements for your project. If you are already using the same pipeline to build and test your application you're likely already doing so.
### Getting your Snyk token
The Actions example above refer to a Snyk API token:
```yaml
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
```
Every Snyk account has this token. Once you [create an account](https://snyk.co/SignUpGH) you can find it in one of two ways:
1. In the UI, go to your Snyk account's [settings page](https://app.snyk.io/account) and retrieve the API token, as shown in the following [Revoking and regenerating Snyk API tokens](https://support.snyk.io/hc/en-us/articles/360004008278-Revoking-and-regenerating-Snyk-API-tokens).
2. If you're using the [Snyk CLI](https://support.snyk.io/hc/en-us/articles/360003812458-Getting-started-with-the-CLI) locally you can retrieve it by running `snyk config get api`.
### GitHub Code Scanning support
All Snyk GitHub Actions support integration with GitHub Code Scanning to show vulnerability information in the GitHub Security tab. You can see full details on the individual action READMEs linked above.

### Continuing on error
The above examples will fail the workflow when issues are found. If you want to ensure the Action continues, even if Snyk finds vulnerabilities, then [continue-on-error](https://docs.github.com/en/actions/reference/workflow-syntax-for-github-actions#jobsjob_idstepscontinue-on-error) can be used..
```yaml
name: Example workflow using Snyk with continue on error
on: push
jobs:
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- name: Run Snyk to check for vulnerabilities
uses: snyk/actions/node@master
continue-on-error: true
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
```
Made with 💜 by Snyk
[cli-gh]: https://github.com/snyk/snyk 'Snyk CLI'
[cli-ref]: https://snyk.io/docs/using-snyk?utm_campaign=docs&utm_medium=github&utm_source=cli 'Snyk CLI Reference documentation'
| 37.111111 | 347 | 0.724152 | eng_Latn | 0.933941 |
9761c495b9b500e3e15763514f57c2502b53ca77 | 35,969 | md | Markdown | docs/content/overview/changelog.md | hgqian/loraserver | 43f111e2c62cd16d00bcecd5013069636e8cbd11 | [
"MIT"
] | 1 | 2019-04-17T03:47:57.000Z | 2019-04-17T03:47:57.000Z | docs/content/overview/changelog.md | hgqian/loraserver | 43f111e2c62cd16d00bcecd5013069636e8cbd11 | [
"MIT"
] | null | null | null | docs/content/overview/changelog.md | hgqian/loraserver | 43f111e2c62cd16d00bcecd5013069636e8cbd11 | [
"MIT"
] | null | null | null | ---
title: Changelog
menu:
main:
parent: overview
weight: 3
toc: false
description: Lists the changes per LoRa Server release, including steps how to upgrade.
---
# Changelog
## v2.7.0
### Improvements
#### Gateway downlink timing API
In order to implement support for the [Basic Station](https://doc.sm.tc/station/)
some small additions were made to the [gateway API](https://github.com/brocaar/loraserver/blob/master/api/gw/gw.proto),
the API used in the communication between the [LoRa Gateway Bridge](https://www.loraserver.io/lora-gateway-bridge/)
and LoRa Server.
LoRa Server v2.7+ is compatible with both the LoRa Gateway Bridge v2 and
(upcoming) v3 as it contains both the old and new fields. The old fields will
be removed once LoRa Server v3 has been released.
#### Max. ADR setting
* Remove max. DR field from device-session and always use max. DR from service-profile.
## v2.6.1
### Bugfixes
* Fix `CFList` with channel-mask for LoRaWAN 1.0.3 devices.
* Fix triggering uplink configuration function (fixing de-duplication). [#387](https://github.com/brocaar/loraserver/issues/387)
## v2.6.0
### Features
* On ADR, decrease device DR when the device is using a higher DR than the maximum DR set in the service-profile. [#375](https://github.com/brocaar/loraserver/issues/375)
### Bugfixes
* Implement missing `DeviceModeReq` mac-command for LoRaWAN 1.1. [#371](https://github.com/brocaar/loraserver/issues/371)
* Fix triggering gateway config update. [#373](https://github.com/brocaar/loraserver/issues/373)
### Improvements
* Internal code-cleanup with regards to passing configuration and objects.
* Internal migration from Dep to [Go modules](https://github.com/golang/go/wiki/Modules).
## v2.6.0-test1
### Features
* On ADR, decrease device DR when the device is using a higher DR than the maximum DR set in the service-profile. [#375](https://github.com/brocaar/loraserver/issues/375)
### Bugfixes
* Implement missing `DeviceModeReq` mac-command for LoRaWAN 1.1. [#371](https://github.com/brocaar/loraserver/issues/371)
* Fix triggering gateway config update. [#373](https://github.com/brocaar/loraserver/issues/373)
### Improvements
* Internal code-cleanup with regards to passing configuration and objects.
* Internal migration from Dep to [Go modules](https://github.com/golang/go/wiki/Modules).
## v2.5.0
### Features
* Environment variable based [configuration](https://www.loraserver.io/loraserver/install/config/) has been re-implemented.
### Improvements
* When mac-commands are disabled, an external controller can still receive all mac-commands and is able to schedule mac-commands.
* When no accurate timestamp is available, the server time will be used as `DeviceTimeAns` timestamp.
### Bugfixes
* Fix potential deadlock on MQTT re-connect ([#103](https://github.com/brocaar/lora-gateway-bridge/issues/103))
* Fix crash on (not yet) support rejoin-request type 1 ([#367](https://github.com/brocaar/loraserver/issues/367))
## v2.4.1
### Bugfixes
* Fix typo in `month_aggregation_ttl` default value.
## v2.4.0
### Upgrade notes
This update will migrate the gateway statistics to Redis, using the default
`*_aggregation_ttl` settings. In case you would like to use different durations,
please update your configuration before upgrading.
### Improvements
#### Gateway statistics
Gateway statistics are now stored in Redis. This makes the storage of statistics
more lightweight and also allows for automatic expiration of statistics. Please refer
to the `[metrics.redis]` configuration section and the `*_aggregation_ttl` configuration
options.
#### Join-server DNS resolver (A record)
When enabled (`resolve_join_eui`), LoRa Server will try to resolve the join-server
using DNS. Note that currently only the A record has been implemented and that it
is assumed that the join-server uses TLS. **Experimental.**
#### FPort > 224
LoRa Server no longer returns an error when a `fPort` greater than `224` is used.
### Bugfixes
* Fix init.d logrotate processing. ([#364](https://github.com/brocaar/loraserver/pull/364))
## v2.3.1
### Bugfixes
* Fix polarization inversion regression for "Proprietary" LoRa frames.
## v2.3.0
### Features
#### Google Cloud Platform integration
LoRa Server is now able to integrate with [Cloud Pub/Sub](https://cloud.google.com/pubsub/)
for gateway communication (as an alternative to MQTT). Together with the latest
[LoRa Gateway Bridge](https://www.loraserver.io/lora-gateway-bridge/) version (v2.6.0),
this makes it possible to let LoRa gateways connect with the
[Cloud IoT Core](https://cloud.google.com/iot-core/)
service and let LoRa Server communicate with Cloud IoT Core using Cloud Pub/Sub.
#### RX window selection
It is now possible to select which RX window to use for downlink. The default
option is RX1, falling back on RX2 in case of a scheduling error. Refer to
[Configuration](https://www.loraserver.io/loraserver/install/config/)
documentation for more information.
### Improvements
#### Battery status
LoRa Server now sends the battery-level as a percentage to the application-server.
The `battery` field (`0...255`) will be removed in the next major release.
#### Downlink scheduler configuration
The downlink scheduler parameters are now configurable. Refer to
[Configuration](https://www.loraserver.io/loraserver/install/config/)
documentation for more information. [#355](https://github.com/brocaar/loraserver/pull/355).
## v2.2.0
### Features
#### Geolocation
This adds support for geolocation through an external geolocation-server,
for example [LoRa Geo Server](https://www.loraserver.io/lora-geo-server/overview/).
See [Configuration](https://www.loraserver.io/loraserver/install/config/) for
configuration options.
#### Fine-timestamp decryption
This adds support for configuring the fine-timestamp decryption key per
gateway (board).
### Bugfixes
* Ignore unknown JSON fields when using the `json` marshaler.
* Fix TX-power override for Class-B and Class-C. ([#352](https://github.com/brocaar/loraserver/issues/352))
## v2.1.0
### Features
#### Multicast support
This adds experimental support for creating multicast-groups to which devices
can be assigned (potentially covered by multiple gateways).
#### Updated data-format between LoRa Server and LoRa Gateway Bridge
Note that this is a backwards compatible change as LoRa Server is able to
automatically detect the used serizalization format based on the data sent by
the LoRa Gateway Bridge.
##### Protocol Buffer data serialization
This adds support for the [Protocol Buffers](https://developers.google.com/protocol-buffers/)
data serialization introduced by LoRa Gateway Bridge v2.5.0 to save on
bandwidth between the LoRa Gateway Bridge and the MQTT.
##### New JSON format
The new JSON structure re-uses the messages defined for
[Protocol Buffers](https://developers.google.com/protocol-buffers/docs/proto3#json)
based serialization.
### Improvements
* Make Redis pool size and idle timeout configurable.
### Bugfixes
* Fix panic on empty routing-profile CA cert ([#349](https://github.com/brocaar/loraserver/issues/349))
## v2.0.2
### Bugfixes
* Fix flush device- and service-profile cache on clean database. ([#345](https://github.com/brocaar/loraserver/issues/345))
## v2.0.1
### Bugfixes
* Use `gofrs/uuid` UUID library as `satori/go.uuid` is not truly random. ([#342](https://github.com/brocaar/loraserver/pull/342))
* Flush device- and service-profile cache when migrating from v1 to v2. ([lora-app-server#254](https://github.com/brocaar/lora-app-server/issues/254))
* Set `board` and `antenna` on downlink. ([#341](https://github.com/brocaar/loraserver/pull/341))
## v2.0.0
### Upgrade nodes
Before upgrading to v2, first make sure you have the latest v1 installed and running
(including LoRa App Server). As always, it is recommended to make a backup
first :-)
### Features
* LoRaWAN 1.1 support!
* Support for signaling received (encrypted) AppSKey from join-server to
application-server on security context change.
* Support for Key Encryption Keys, used for handling encrypted keys from the
join-server.
### Changes
* LoRa Server calls the `SetDeviceStatus` API method of LoRa App Server
when it receives a `DevStatusAns` mac-command.
* Device-sessions are stored using Protobuf encoding in Redis
(more compact storage).
* Cleanup of gRPC API methods and arguments to follow the Protobuf style-guide
and to make message re-usable. When you're integrating directly with the
LoRa Server gRPC API, then you must update your API client as these changes are
backwards incompatible!
* Config option added to globally disable ADR.
* Config option added to override default downlink tx power.
## v1.0.1
### Features
* Config option added to disable mac-commands (for testing).
## v1.0.0
This marks the first stable release!
### Upgrade notes
* First make sure you have v0.26.3 installed and running (including LoRa App Server v21.1).
* Then ugrade to v1.0.0.
See [Downloads](https://www.loraserver.io/loraserver/overview/downloads/)
for pre-compiled binaries or instructions how to setup the Debian / Ubuntu
repository for v1.x.
### Changes
* Code to remain backwards compatible with environment-variable based
configuration has been removed.
* Code to migrate node- to device-sessions has been removed.
* Code to migrate channel-configuration to gateway-profiles has been removed.
* Old unused tables (kept for upgrade migration code) have been removed from db.
## 0.26.3
**Bugfixes:**
* Fixes an "index out of range" issue when removing conflicting mac-commands. ([#323](https://github.com/brocaar/loraserver/issues/323))
## 0.26.2
**Bugfixes:**
* On decreasing the TXPower index to `0` (nACKed by Microchip RN devices), LoRa Server would keep sending LinkADRReq mac-commands.
On a TXPower index `0` nACK, LoRa Server will now set the min TXPower index to `1` as a workaround.
* On deleting a device, the device-session is now flushed.
* `NewChannelReq` and `LinkADRReq` mac-commands were sometimes sent together, causing the new channel to be disabled by the `LinkADRReq` channel-mask (not aware yet about the new channel).
**Improvements:**
* `NbTrans` is set to `1` on activation, to avoid transitioning from `0` to `1` (effectively the same).
## 0.26.1
**Improvements:**
* `HandleUplinkData` API call to the application-server is now handled async.
* Skip frame-counter check can now be set per device (so it can be used for OTAA devices).
**Bugfixes:**
* `storage.ErrAlreadyExists` was not mapped to the correct gRPC API error.
## 0.26.0
**Features:**
* (Gateway) channel-configuration has been refactored into gateway-profiles and
configuration updates are now sent over MQTT to the gateway.
* This requires [LoRa Gateway Bridge](https://www.loraserver.io/lora-gateway-bridge/) 2.4.0 or up.
* This requires [LoRa App Server](https://www.loraserver.io/lora-app-server/) 0.20.0 or up.
* This deprecates the [LoRa Channel Manager](https://www.loraserver.io/lora-channel-manager/) service.
* This removes the `Gateway` gRPC service (which was running by default on port `8002`).
* This removes the channel-configuration related gRPC methods from the `NetworkServer` gRPC service.
* This adds gateway-profile related gRPC methods to the `NetworkServer` gRPC service.
* FSK support when permitted by the LoRaWAN ISM band.
* Note that the ADR engine will only use the data-rates of the pre-defined multi data-rate channels.
**Bugfixes:**
* Fix leaking Redis connections on pubsub subscriber ([#313](https://github.com/brocaar/loraserver/issues/313).
**Upgrade notes:**
In order to automatically migrate the existing channel-configuration into the
new gateway-profiles, first upgrade LoRa Server and restart it. After upgrading
LoRa App Server and restarting it, all channel-configurations will be migrated
and associated to the gateways. As always, it is advised to first make a backup
of your (PostgreSQL) database.
## 0.25.1
**Features:**
* Add `RU_864_870` as configuration option (thanks [@belovictor](https://github.com/belovictor))
**Improvements:**
* Expose the following MQTT options for the MQTT gateway backend:
* QoS (quality of service)
* Client ID
* Clean session on connect
* Add `GetVersion` API method returning the LoRa Server version + configured region.
* Refactor `lorawan/band` package with support for max payload-size per
LoRaWAN mac version and Regional Parameters revision.
* This avoids packetloss in case a device does not implement the latest
LoRaWAN Regional Parameters revision and the max payload-size values
have been updated.
**Bugfixes:**
* MQTT topics were hardcoded in configuration file template, this has been fixed.
* Fix `network_contoller` -> `network_controller` typo ([#302](https://github.com/brocaar/loraserver/issues/302))
* Fix typo in pubsub key (resulting in ugly Redis keys) ([#296](https://github.com/brocaar/loraserver/pull/296))
## 0.25.0
**Features:**
* Class-B support! See [Device classes](https://docs.loraserver.io/loraserver/features/device-classes/)
for more information on Class-B.
* Class-B configuration can be found under the `network_server.network_settings.class_b`
[configuration](https://docs.loraserver.io/loraserver/install/config/) section.
* **Note:** This requires [LoRa Gateway Bridge](https://docs.loraserver.io/lora-gateway-bridge/overview/)
2.2.0 or up.
* Extended support for extra channel configuration using the NewChannelReq mac-command.
This makes it possible to:
* Configure up to 16 channels in total (if supported by the LoRaWAN region).
* Configure the min / max data-rate range for these extra channels.
* Implement RXParamSetup mac-command. After a configuration file change,
LoRa Server will push the RX2 frequency, RX2 data-rate and RX1 data-rate
offset for activated devices.
* Implement RXTimingSetup mac-command. After a configuration file change,
LoRa Server will push the RX delay for activated devices.
## 0.24.3
**Bugfixes:**
* The uplink, stats and ack topic contained invalid defaults.
## 0.24.2
**Improvements:**
* MQTT topics are now configurable through the configuration file.
See [Configuration](https://docs.loraserver.io/loraserver/install/config/).
* Internal cleanup of mac-command handling.
* When issuing mac-commands, they are directly added to the downlink
context instead of being stored in Redis and then retrieved.
* For API consistency, the gRPC method
`EnqueueDownlinkMACCommand` has been renamed to `CreateMACCommandQueueItem`.
**Bugfixes:**
* Fix typo in `create_gateway_on_stats` config mapping. (thanks [@mkiiskila](https://github.com/mkiiskila), [#295](https://github.com/brocaar/loraserver/pull/295))
## 0.24.1
**Bugfixes:**
* Fix basing tx-power value on wrong SNR value (thanks [@x0y1z2](https://github.com/x0y1z2), [#293](https://github.com/brocaar/loraserver/issues/293))
## 0.24.0
**Features:**
* LoRa Server uses a new configuration file format.
See [configuration](https://docs.loraserver.io/loraserver/install/config/) for more information.
* `StreamFrameLogsForGateway` API method has been added to stream frames for a given gateway MAC.
* `StreamFrameLogsForDevice` API method has been added to stream frames for a given DevEUI.
* Support MQTT client certificate authentication ([#284](https://github.com/brocaar/loraserver/pull/284)).
**Changes:**
* `GetFrameLogsForDevEUI` API method has been removed. The `frame_log` table
will be removed from the database in the next release!
**Upgrade notes:**
When upgrading using the `.deb` package / using `apt` or `apt-get`, your
configuration will be automatically migrated for you. In any other case,
please see [configuration](https://docs.loraserver.io/loraserver/install/config/).
## 0.23.3
**Improvements:**
* Device-status (battery and link margin) returns `256` as value when battery
and / or margin status is (yet) not available.
* Extra logging has been added:
* gRPC API calls (to the gRPC server and by the gRPC clients) are logged
as `info`
* Executed SQL queries are logged as `debug`
* LoRa Server will wait 2 seconds between scheduling Class-C downlink
transmissions to the same device, to avoid that sequential Class-C downlink
transmissions collide (in case of running a cluster of LoRa Server instances).
**Internal changes:**
* The project moved to using [dep](https://github.com/golang/dep) as vendoring
tool. In case you run into compiling issues, remove the `vendor` folder
(which is not part of the repository anymore) and run `make requirements`.
## 0.23.2
**Features:**
* Implement client certificate validation for incoming API connections.
* Implement client certificate for API connections to LoRa App Server.
This removes the following CLI options:
* `--as-ca-cert`
* `--as-tls-cert`
* `--as-tls-key`
See for more information:
* [LoRa Server configuration](https://docs.loraserver.io/loraserver/install/config/)
* [LoRa App Server configuration](https://docs.loraserver.io/lora-app-server/install/config/)
* [LoRa App Server network-server management](https://docs.loraserver.io/lora-app-server/use/network-servers/)
* [https://github.com/brocaar/loraserver-certificates](https://github.com/brocaar/loraserver-certificates)
## 0.23.1
**Features:**
* LoRa Server sets a random token for each downlink transmission.
**Bugfixes:**
* Add missing `nil` pointer check for `Time`
([#280](https://github.com/brocaar/loraserver/issues/280))
* Fix increase of NbTrans (re-transmissions) in case of early packetloss.
* Fix decreasing NbTrans (this only happened in case of data-rate or TX
power change).
## 0.23.0
**Features:**
* The management of the downlink device-queue has moved to LoRa Server.
Based on the device-class (A or C and in the future B), LoRa Server will
decide how to schedule the downlink transmission.
* LoRa Server sends nACK on Class-C confirmed downlink timeout
(can be set in the device-profile) to the application-server.
**Changes:**
Working towards a consistent and stable API, the following API changes have
been made:
Application-server API
* `HandleDataDownACK` renamed to `HandleDownlinkACK`
* `HandleDataUp` renamed to `HandleUplinkData`
* `HandleProprietaryUp` renamed to `HandleProprietaryUplink`
* `GetDataDown` has been removed (as LoRa Server is now responsible for the
downlink queue)
Network-server API
* Added
* `CreateDeviceQueueItem`
* `FlushDeviceQueueForDevEUI`
* `GetDeviceQueueItemsForDevEUI`
* Removed
* `SendDownlinkData`
**Note:** these changes require LoRa App Server 0.15.0 or higher.
## 0.22.1
**Features:**
* Service-profile `DevStatusReqFreq` option has been implemented
(periodical device-status request).
**Bugfixes:**
* RX2 data-rate was set incorrectly, causing *maximum payload size exceeded*
errors. (thanks [@maxximal](https://github.com/maxximal))
**Cleanup:**
* Prefix de-duplication Redis keys with `lora:ns:` instead of `loraserver:`
for consistency.
## 0.22.0
**Note:** this release brings many changes! Make sure (as always) to make a
backup of your PostgreSQL and Redis database before upgrading.
**Changes:**
* Data-model refactor to implement service-profile, device-profile and
routing-profile storage as defined in the
[LoRaWAN backend interfaces](https://www.lora-alliance.org/lorawan-for-developers).
* LoRa Server now uses the LoRa App Server Join-Server API as specified by the
LoRaWAN backend interfaces specification (currently hard-configured endpoint).
* Adaptive data-rate configuration is now globally configured by LoRa Server.
See [configuration](https://docs.loraserver.io/loraserver/install/config/).
* OTAA RX configuration (RX1 delay, RX1 data-rate offset and RX2 dat-rate) is
now globally configured by LoRa Server.
See [configuration](https://docs.loraserver.io/loraserver/install/config/).
**API changes:**
* Service-profile CRUD methods added
* Device-profile CRUD methods added
* Routing-profile CRUD methods added
* Device CRUD methods added
* Device (de)activation methods added
* Node-session related methods have been removed
* `EnqueueDataDownMACCommand` renamed to `EnqueueDownlinkMACCommand`
* `PushDataDown` renamed to `SendDownlinkData`
### How to upgrade
**Note:** this release brings many changes! Make sure (as always) to make a
backup of your PostgreSQL and Redis database before upgrading.
**Note:** When LoRa App Server is running on a different server than LoRa Server,
make sure to set the `--js-server` / `JS_SERVER` (default `localhost:8003`).
This release depends on the latest LoRa App Server release (0.14). Upgrade
LoRa Server first, then proceed with upgrading LoRa App Server. See also the
[LoRa App Server changelog](https://docs.loraserver.io/lora-app-server/overview/changelog/).
## 0.21.0
**Features:**
* Implement sending and receiving 'Proprietary' LoRaWAN message type.
LoRa Server now implements an API method for sending downlink LoRaWAN frames
using the 'Proprietary' message-type. 'Proprietary' uplink messages will be
de-duplicated by LoRa Server, before being forwarded to LoRa App Server.
* ARM64 binaries are now provided.
**Internal improvements:**
* Various parts of the codebase have been cleaned up in preparation for the
upcoming LoRaWAN 1.1 changes.
## 0.20.1
**Features:**
* Add support for `IN_865_867` ISM band.
**Bugfixes:**
* Remove gateway location and altitude 'nullable' option in the database.
This removes some complexity and fixes a nil pointer issue when compiled
using Go < 1.8 ([#210](https://github.com/brocaar/loraserver/issues/210)).
* Update `AU_915_928` data-rates according to the LoRaWAN Regional Parameters
1.0.2 specification.
* Better handling of ADR and TXPower nACK. In case of a nACK, LoRa Server will
set the max supported DR / TXPower to the requested value - 1.
* The ADR engine sets the stored node TXPower to `0` when the node uses an
"unexpected" data-rate for uplink. This is to deal with nodes that are
regaining connectivity by lowering the data-rate and setting the TXPower
back to `0`.
## 0.20.0
**Features:**
* LoRa Server now offers the possiblity to configure channel-plans which can
be assigned to gateways. It exposes an API (by default on port `8002`) which
can be used by [LoRa Gateway Config](https://docs.loraserver.io/lora-gateway-config/).
An UI for channel-configurations is provided by [LoRa App Server](https://docs.loraserver.io/lora-app-server/)
version 0.11.0+.
**Note:** Before upgrading, make sure to configure the `--gw-server-jwt-secret`
/ `GW_SERVER_JWT_SECRET` configuration flag!
## 0.19.2
**Improvements:**
* The ADR engine has been updated together with the `lorawan/band` package
which now implements the LoRaWAN Regional Parameters 1.0.2 specification.
**Removed:**
* Removed `RU_864_869` band. This band is not officially defined by the
LoRa Alliance.
**Note:** To deal with nodes implementing the Regional Parameters 1.0 **and**
nodes implementing 1.0.2, the ADR engine will now only increase the TX power
index of the node by one step. This is to avoid that the ADR engine would
switch a node to an unsupported TX power index.
## 0.19.1
**Improvements:**
* `--gw-mqtt-ca-cert` / `GW_MQTT_CA_CERT` configuration flag was added to
specify an optional CA certificate
(thanks [@siscia](https://github.com/siscia)).
**Bugfixes:**
* MQTT client library update which fixes an issue where during a failed
re-connect the protocol version would be downgraded
([paho.mqtt.golang#116](https://github.com/eclipse/paho.mqtt.golang/issues/116)).
## 0.19.0
**Changes:**
* `NetworkServer.EnqueueDataDownMACCommand` has been refactored in order to
support sending of mac-command blocks (guaranteed to be sent as a single
frame). Acknowledgements on mac-commands sent throught the API will be
sent to the `NetworkController.HandleDataUpMACCommandRequest` API method.
* `NetworkController.HandleDataUpMACCommandRequest` has been updated to handle
blocks of mac-commands.
* `NetworkController.HandleError` method has been removed.
**Note:** In case you are using the gRPC API interface of LoRa Server,
this might be a breaking change because of the above changes to the APi methods.
For a code-example, please see the [Network-controller](https://docs.loraserver.io/loraserver/integrate/network-controller/)
documentation.
**Bugfixes:**
* Updated vendored libraries to include MQTT reconnect issue
([eclipse/paho.mqtt.golang#96](https://github.com/eclipse/paho.mqtt.golang/issues/96)).
## 0.18.0
**Features:**
* Add configuration option to log all uplink / downlink frames into a database
(`--log-node-frames` / `LOG_NODE_FRAMES`).
## 0.17.2
**Bugfixes:**
* Do not reset downlink frame-counter in case of relax frame-counter mode as
this would also reset the downlink counter on a re-transmit.
## 0.17.1
**Features:**
* TTL of node-sessions in Redis is now configurable through
`--node-session-ttl` / `NODE_SESSION_TTL` config flag.
This makes it possible to configure the time after which a node-session
expires after no activity ([#100](https://github.com/brocaar/loraserver/issues/100)).
* Relax frame-counter mode has been changed to disable frame-counter check mode
to deal with different devices ([#133](https://github.com/brocaar/loraserver/issues/133)).
## 0.17.0
**Features:**
* Add `--extra-frequencies` / `EXTRA_FREQUENCIES` config option to configure
additional channels (in case supported by the selected ISM band).
* Add `--enable-uplink-channels` / `ENABLE_UPLINK_CHANNELS` config option to
configure the uplink channels active on the network.
* Make adaptive data-rate (ADR) available to every ISM band.
## 0.16.1
**Bugfixes:**
* Fix getting gateway stats when start timestamp is in an other timezone than
end timestamp (eg. in case of Europe/Amsterdam when changing from CET to
CEST).
## 0.16.0
**Note:** LoRa Server now requires a PostgreSQL (9.5+) database to persist the
gateway data. See [getting started](getting-started.md) for more information.
**Features:**
* Gateway management and gateway stats:
* API methods have been added to manage gateways (including GPS location).
* GPS location of receiving gateways is added to uplink frames published
to the application-server.
* Gateway stats (rx / tx) are aggregated on intervals specified in
`--gw-stats-aggregation-intervals` (make sure to set the correct
`--timezone`!).
* When `--gw-create-on-stats` is set, then gateways will be automatically
created when receiving gateway stats.
* LoRa Server will retry to connect to the MQTT broker when it isn't available
(yet) on startup, instead of failing.
## 0.15.1
**Bugfixes:**
* Fix error handling for creating a node-session that already exists
* Fix delete node-session regression introduced in 0.15.0
## 0.15.0
**Features:**
* Node-sessions are now stored by `DevEUI`. Before the node-sessions were stored
by `DevAddr`. In case a single `DevAddr` is used by multiple nodes, the
`NwkSKey` is used for retrieving the corresponding node-session.
*Note:* Data will be automatically migrated into the new format. As this process
is not reversible it is recommended to make a backup of the Redis database before
upgrading.
## 0.14.1
**Bugfixes:**
* Add mac-commands (if any) to LoRaWAN frame for Class-C transmissions.
## 0.14.0
**Features:**
* Class C support. When a node is configured as Class-C device, downlink data
can be pushed to it using the `NetworkServer.PushDataDown` API method.
**Changes:**
* RU 864 - 869 band configuration has been updated (see [#113](https://github.com/brocaar/loraserver/issues/113))
## 0.13.3
**Features:**
* The following band configurations have been added:
* AS 923
* CN 779 - 787
* EU 433
* KR 920 - 923
* RU 864 - 869
* Flags for repeater compatibility configuration and dwell-time limitation
(400ms) have been added (see [configuration](configuration.md))
## 0.13.2
**Features:**
* De-duplication delay can be configured with `--deduplication-delay` or
`DEDUPLICATION_DELAY` environment variable (default 200ms)
* Get downlink data delay (delay between uplink delivery and getting the
downlink data from the application server) can be configured with
`--get-downlink-data-delay` or `GET_DOWNLINK_DATA_DELAY` environment variable
**Bugfixes:**
* Fix duplicated gateway MAC in application-server and network-controller API
call
## 0.13.1
**Bugfixes:**
* Fix crash when node has ADR enabled, but it is disabled in LoRa Server
## 0.13.0
**Features:**
* Adaptive data-rate support. See [features](features.md) for information about
ADR. Note:
* [LoRa App Server](https://docs.loraserver.io/lora-app-server/) 0.2.0 or
higher is required
* ADR is currently only implemented for the EU 863-870 ISM band
* This is an experimental feature
**Fixes:**
* Validate RX2 data-rate (this was causing a panic)
## 0.12.5
**Security:**
* This release fixes a `FCnt` related security issue. Instead of keeping the
uplink `FCnt` value in sync with the `FCnt` of the uplink transmission, it
is incremented (uplink `FCnt + 1`) after it has been processed by
LoRa Server.
## 0.12.4
* Fix regression that caused a FCnt roll-over to result in an invalid MIC
error. This was caused by validating the MIC before expanding the 16 bit
FCnt to the full 32 bit value. (thanks @andrepferreira)
## 0.12.3
* Relax frame-counter option.
## 0.12.2
* Implement China 470-510 ISM band.
* Improve logic to decide which gateway to use for downlink transmission.
## 0.12.1
* Fix multiple LoRa Server instances processing the same gateway payloads
(resulting in the gateway count multiplied by the number of LoRa Server
instances).
## 0.12.0
This release decouples the node "inventory" part from LoRa Server. This
introduces some breaking (API) changes, but in the end this will make it easier
to integrate LoRa Server into your own platform as you're not limited anymore
by it's datastructure.
### API
Between all LoRa Server project components [gRPC](http://gprc.io) is used
for communication. Optionally, this can be secured by (client) certificates.
The RESTful JSON api and api methods to manage channels, applications and nodes
has been removed from LoRa Server. The node-session api methodds are still
part of LoRa Server, but are only exposed by gRPC.
### Application-server
An application-server component and [API](https://github.com/brocaar/loraserver/blob/master/api/as/as.proto)
was introduced to be responsible for the "inventory" part. This component is
called by LoRa Server when a node tries to join the network, when data is
received and to retrieve data for downlink transmissions.
The inventory part has been migrated to a new project called
[LoRa App Server](http://docs.loraserver.io/lora-app-server/). See it's
changelog for instructions how to migrate.
### Configuration
As components have been dropped and introduced, you'll probably need to update
your LoRa Server configuration.
### Important
Before upgrading, make sure you have a backup of all data in the PostgreSQL
and Redis database!
## 0.11.0
* Implement receive window (RX1 or RX2) and RX2 data-rate option in node and
node-session API (and web-interface).
## 0.10.1
* Fix overwriting existing node-session (owned by different DevEUI)
(thanks @iBrick)
## 0.10.0
* Implement (optional) JWT token authentication and authorization for the gRPC
and RESTful JSON API. See [api documentation](https://docs.loraserver.io/loraserver/api/).
* Implement support for TLS
* Serve the web-interface, RESTful interface and gRPC interface on the same port
(defined by `--http-bind`). When TLS is disabled, the gRPC interface is
served from a different port (defined by `--grpc-insecure-bind`).
* Fix: delete node-session (if it exists) on node delete
## 0.9.2
* Fix Swagger base path.
## 0.9.1
* Fix `cli.ActionFunc` deprecation warning.
## 0.9.0
**WARNING:** if you're using the JSON-RPC interface, this will be a breaking
upgrade, as the JSON-RPC API has been replaced by a gRPC API.
In order to keep the possiblity to access the API from web-based applications
(e.g. the web-interface), a RESTful JSON API has been implemented on top
of the gRPC API (using [grpc-gateway](https://github.com/grpc-ecosystem/grpc-gateway)).
Please refer to the LoRa Server documentation for more information:
[https://docs.loraserver.io/loraserver/api/](https://docs.loraserver.io/loraserver/api/).
## 0.8.2
* Validate the join-request DevEUI belongs to the given AppEUI
* Implement `Node.FlushTXPayloadQueue` API method
* Update `GatewayStatsPacket` struct (`CustomData` and `TXPacketsEmitted`, to
be implemented by the lora-gateway-bridge).
## 0.8.1
* Bugfix: 'fix unknown channel for frequency' error when using custom-channels (`CFList`)
(thanks @arjansplit)
## 0.8.0
* Implement network-controller backend
* Implement support for sending and receiving MAC commands (no support for proprietary commands yet)
* Refactor test scenarios
* Web-interface: nodes can now be accessed from the applications tab (nodes button)
**Note:** You need to update to LoRa Semtech Bridge 2.0.1+ or 1.1.4+ since
it fixes a mac command related marshaling issue.
## 0.7.0
* Complete join-accept payload with:
* RXDelay
* DLSettings (RX2 data-rate and RX1 data-rate offset)
* CFList (optional channel-list, see LoRaWAN specs to see if this
option is available for your region)
All values can be set / created throught the API or web-interface
## 0.6.1
* Band configuration must now be specified with the ``--band`` argument
(no more separate binaries per ism band)
* RX info notifications (``application/[AppEUI]/node/[DevEUI]/rxinfo``)
## 0.6.0
* Implement various notifications to the application:
* Node join accept (``application/[AppEUI]/node/[DevEUI]/join``)
* Errors (e.g. max payload size exceeded) (``application/[AppEUI]/node/[DevEUI]/error``)
* ACK of confirmed data down (``application/[AppEUI]/node/[DevEUI]/ack``)
* Handle duplicated downlink payloads (when running multiple LoRa Server instances each server
is receiving the TXPayload from MQTT, just one needs to handle it)
* New ISM bands:
* US 902-928 band (thanks @gzwsc2007 for testing)
* AU 915-928 band (thanks @Mehradzie for implementing and testing)
* Fix: use only one receive-window (thanks @gzwsc2007)
## 0.5.1
* Expose RX RSSI (signal strength) to application
* Provide binaries for multiple platforms
## 0.5.0
Note: this release is incompatible with lora-semtech-bridge <= 1.0.1
* Replaced hardcoded tx related settings by lorawan/band defined variables
* Minor changes to TX / RX structs
* Change gateway encoding to json (from gob encoding)
* Source-code re-structure (internal code is now under `internal/...`,
exported packet related structs are now under `models/...`)
## 0.4.1
* Update mqtt vendor to fix various connection issues
* Fix shutting down server when mqtt server is unresponsive
## 0.4.0
* Implement confirmed data up
* Implement (confirmed) data down
* Implement graceful shutdown
* Re-subscribe on mqtt connection error (thanks @Magicking)
* Fix FCnt input bug in web-interface (number was casted to a string, which was rejected by the API)
## 0.3.1
* Bugfix related to ``FCnt`` increment (thanks @ivajloip)
## 0.3.0
* MQTT topics updated (`node/[DevEUI]/rx` is now `application/[AppEUI]/node/[DevEUI]/rx`)
* Restructured RPC API (per domain)
* Auto generated API docs (in web-interface)
## 0.2.1
* `lorawan` packet was updated (with MType fix)
## 0.2.0
* Web-interface for application and node management
* *LoRa Server* is now a single binary with embedded migrations and static files
## 0.1.0
* Initial release
| 34.093839 | 188 | 0.750535 | eng_Latn | 0.962744 |
9761cabbff694aa41d28678d68981cf3d5033b6e | 3,351 | md | Markdown | docs-archive-a/2014/reporting-services/report-builder/set-default-options-for-report-builder.md | MicrosoftDocs/sql-docs-archive-pr.fr-fr | 5dfe5b24c1f29428c7820df08084c925def269c3 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs-archive-a/2014/reporting-services/report-builder/set-default-options-for-report-builder.md | MicrosoftDocs/sql-docs-archive-pr.fr-fr | 5dfe5b24c1f29428c7820df08084c925def269c3 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-10-11T06:39:57.000Z | 2021-11-25T02:25:30.000Z | docs-archive-a/2014/reporting-services/report-builder/set-default-options-for-report-builder.md | MicrosoftDocs/sql-docs-archive-pr.fr-fr | 5dfe5b24c1f29428c7820df08084c925def269c3 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-09-29T08:51:33.000Z | 2021-10-13T09:18:07.000Z | ---
title: Boîte de dialogue Options de Générateur de rapports, paramètres (Générateur de rapports) | Microsoft Docs
ms.custom: ''
ms.date: 06/13/2017
ms.prod: sql-server-2014
ms.reviewer: ''
ms.technology: reporting-services-native
ms.topic: conceptual
f1_keywords:
- "10427"
ms.assetid: 423360de-9bed-462e-921f-60a5abab004f
author: maggiesMSFT
ms.author: maggies
manager: kfile
ms.openlocfilehash: 07bd4a7f9dfe1abd8ab76765cb1ac10ff5227066
ms.sourcegitcommit: ad4d92dce894592a259721a1571b1d8736abacdb
ms.translationtype: MT
ms.contentlocale: fr-FR
ms.lasthandoff: 08/04/2020
ms.locfileid: "87602768"
---
# <a name="report-builder-options-dialog-box-settings-report-builder"></a>Boîte de dialogue Options du Générateur de rapports, Paramètres (Générateur de rapports)
Cliquez sur le bouton **Générateur de rapports** , puis sur **options** pour définir les options d’indication des fichiers et des connexions récents. Vous pouvez également modifier le serveur de rapports par défaut ou en ajouter un si vous n'en avez pas déjà spécifié un.
## <a name="ui-element-list"></a>Liste d’éléments d’interface utilisateur
**Utiliser ce serveur de rapports ou site SharePoint par défaut**
Il se peut que votre administrateur ait configuré ce paramètre. Sa valeur peut être une URL bien formée commençant par http:// ou https://. Ce paramètre détermine les connexions de source de données qui s'affichent par défaut dans les Assistants Tableau/Matrice et Graphique. Sachez par ailleurs que vos rapports seront traités sur ce serveur et que vous pouvez faire référence à des ressources provenant de ce serveur.
Si vous sélectionnez un autre serveur de rapports, vous serez peut-être amené à redémarrer le Générateur de rapports pour que cette modification soit prise en compte.
**Publier des parties de rapport dans ce dossier par défaut**
Le Générateur de rapports enregistre les parties de rapport que vous publiez dans ce dossier. Si le dossier n'existe pas encore et que vous êtes autorisé à créer des dossiers sur le serveur de rapports, le Générateur de rapports crée ce dossier.
Vous n'avez pas à redémarrer le Générateur de rapports pour que ce paramètre entre en vigueur.
**Afficher ce nombre de serveurs et de sites récents**
Spécifiez le nombre de connexions et de sites récents à afficher dans les boîtes de dialogue **Ouvrir le rapport** et **Enregistrer comme rapport** .
**Afficher ce nombre de datasets et de connexions à la source de données récents partagés**
Spécifiez le nombre de datasets et de connexions à la source de données récents partagés à afficher dans la boîte de dialogue **Propriétés du dataset** et dans la page **Choisir une connexion à une source de données** de l’Assistant Régions de données.
**Afficher ce nombre de documents récents**
Spécifiez le nombre de documents récents à afficher lorsque vous cliquez sur le bouton Générateur de rapports.
**Effacer toutes les listes d'éléments récentes**
Effacez les listes actuelles de serveurs et de sites récents, de documents, de datasets partagés et de connexions à des sources de données partagées.
## <a name="see-also"></a>Voir aussi
[Aide du Générateur de rapports pour les boîtes de dialogue, les volets et les Assistants](../report-builder-help-for-dialog-boxes-panes-and-wizards.md)
| 64.442308 | 422 | 0.778574 | fra_Latn | 0.983698 |
976200ac06bb6492dd5a0ae4535bd835d5e4dfb7 | 456 | md | Markdown | api/docs/stentor-models.playablehistorydata.lastplayed.md | stentorium/stentor | f49b51e8b4f82012d1ac8ddd15af279bd4619229 | [
"Apache-2.0"
] | 2 | 2019-12-30T19:23:17.000Z | 2021-07-06T02:47:39.000Z | api/docs/stentor-models.playablehistorydata.lastplayed.md | stentorium/stentor | f49b51e8b4f82012d1ac8ddd15af279bd4619229 | [
"Apache-2.0"
] | 74 | 2020-01-07T00:25:16.000Z | 2022-02-23T04:06:56.000Z | api/docs/stentor-models.playablehistorydata.lastplayed.md | stentorium/stentor | f49b51e8b4f82012d1ac8ddd15af279bd4619229 | [
"Apache-2.0"
] | 1 | 2021-01-01T08:57:23.000Z | 2021-01-01T08:57:23.000Z | <!-- Do not edit this file. It is automatically generated by API Documenter. -->
[Home](./index.md) > [stentor-models](./stentor-models.md) > [PlayableHistoryData](./stentor-models.playablehistorydata.md) > [lastPlayed](./stentor-models.playablehistorydata.lastplayed.md)
## PlayableHistoryData.lastPlayed property
The UNIX timestamp for the last time the item was played.
<b>Signature:</b>
```typescript
lastPlayed: number;
```
| 32.571429 | 200 | 0.723684 | eng_Latn | 0.406946 |
9762018475eec43cea75b7f425359124c531828d | 1,902 | md | Markdown | src/content/api/index.md | Jalitha/webpack.js.org | 8fcf8d8e052d3a2b1c2e1327fb6a67288a12dcf1 | [
"CC-BY-4.0"
] | null | null | null | src/content/api/index.md | Jalitha/webpack.js.org | 8fcf8d8e052d3a2b1c2e1327fb6a67288a12dcf1 | [
"CC-BY-4.0"
] | null | null | null | src/content/api/index.md | Jalitha/webpack.js.org | 8fcf8d8e052d3a2b1c2e1327fb6a67288a12dcf1 | [
"CC-BY-4.0"
] | null | null | null | ---
title: Introduction
sort: 0
contributors:
- tbroadley
---
A variety of interfaces are available to customize the compilation process.
Some features overlap between interfaces, e.g. a configuration option may be
available via a CLI flag, while others exist only through a single interface.
The following high-level information should get you started.
## CLI
The Command Line Interface (CLI) to configure and interact with your build. It
is especially useful in the case of early prototyping and profiling. For the
most part, the CLI is simply used to kick off the process using a configuration
file and a few flags (e.g. `--env`).
[Learn more about the CLI!](/api/cli)
## Module
When processing modules with webpack, it is important to understand the
different module syntaxes -- specifically the [methods](/api/module-methods)
and [variables](/api/module-variables) -- that are supported.
[Learn more about modules!](/api/module-methods)
## Node
While most users can get away with just using the CLI along with a
configuration file, more fine-grained control of the compilation can be
achieved via the Node interface. This includes passing multiple configurations,
programmatically running or watching, and collecting stats.
[Learn more about the Node API!](/api/node)
## Loaders
Loaders are transformations that are applied to the source code of a module.
They are written as functions that accept source code as a parameter and return
a new version of that code with transformations applied.
[Learn more about loaders!](/api/loaders)
## Plugins
The plugin interface allows users to tap directly into the compilation process.
Plugins can register handlers on lifecycle hooks that run at different points
throughout a compilation. When each hook is executed, the plugin will have full
access to the current state of the compilation.
[Learn more about plugins!](/api/plugins)
| 31.7 | 79 | 0.783386 | eng_Latn | 0.99885 |
9762f577e6edfc5934d58c28fb8cb420c9cc4a63 | 1,902 | md | Markdown | README.md | anndream/cake | ee4a6b20d05a242073ec4ae7e73c59494ccf21f9 | [
"MIT"
] | 62 | 2017-05-13T16:27:12.000Z | 2022-01-13T23:00:36.000Z | README.md | anndream/cake | ee4a6b20d05a242073ec4ae7e73c59494ccf21f9 | [
"MIT"
] | 6 | 2017-06-01T11:01:59.000Z | 2020-05-19T21:37:27.000Z | README.md | anndream/cake | ee4a6b20d05a242073ec4ae7e73c59494ccf21f9 | [
"MIT"
] | 11 | 2017-07-01T14:31:40.000Z | 2021-08-13T15:42:27.000Z | # Cake [](https://travis-ci.org/axvm/cake)
Cake is a powerful and flexible Make-like utility tool.
Implement tasks on plain crystal-lang and Make Tasks Great Again!
## Installation
Execute command to install `Cake`
```shell
$ curl https://raw.githubusercontent.com/axvm/cake/master/install.sh | bash
```
## Usage
Develop tasks in plain Crystal code in `Cakefile` and run them via `$ cake :task_name`
### bin/cake
```
Usage:
cake task_name
cake -T
Options:
-T, --tasks Show all tasks
-h, --help This info
-v, --version Show version
```
### Cakefile sample
```Crystal
# Define task
task :task_name do
# task logic
end
# Define task with description
desc "task useful description"
task :some_task do
# 2 + 1
end
# Run one task from another
desc "invoke example"
task :first do
# -Infinity / 0
invoke! :second
end
task :second do
# yay we are here!
end
# Execute shell commands
task :build do
execute "shards build"
# or with sweet logs
execute(
cmd: "shards build",
announce: "Building binary...",
success: "Binary built!",
error: "Build failed."
)
end
# Log things
task :deploy do
# your deploy code
log "Deploy successful!"
log "Or errored.", 1
end
```
## Development
1. Implement feature and tests
2. Create pull request
3. ...
4. Profit!
## Contributing
1. Fork it ( https://github.com/axvm/cake/fork )
2. Create your feature branch (git checkout -b my-new-feature)
3. Commit your changes (git commit -am 'Add some feature')
4. Push to the branch (git push origin my-new-feature)
5. Create a new Pull Request
## Contributors
- [[axvm]](https://github.com/axvm) Alexander Marchenko - creator, maintainer
- [[triinoxys]](https://github.com/triinoxys) Alexandre Guiot--Valentin - contributor
| 20.451613 | 108 | 0.670347 | eng_Latn | 0.781279 |
9762fcb9f00eee4834c6a92d6040ad33277f6e7c | 20,291 | md | Markdown | gcs/CONFIGURATION.md | mahammadv/hadoop-connectors-1 | 83a6c9809ad49a44895d59558e666e5fc183e0bf | [
"Apache-2.0"
] | null | null | null | gcs/CONFIGURATION.md | mahammadv/hadoop-connectors-1 | 83a6c9809ad49a44895d59558e666e5fc183e0bf | [
"Apache-2.0"
] | null | null | null | gcs/CONFIGURATION.md | mahammadv/hadoop-connectors-1 | 83a6c9809ad49a44895d59558e666e5fc183e0bf | [
"Apache-2.0"
] | 1 | 2022-01-06T11:36:22.000Z | 2022-01-06T11:36:22.000Z | ## Configuration properties
### General configuration
* `fs.gs.project.id` (not set by default)
Google Cloud Project ID with access to GCS buckets. Required only for list
buckets and create bucket operations.
* `fs.gs.working.dir` (default: `/`)
The directory relative `gs:` uris resolve in inside of the default bucket.
* `fs.gs.implicit.dir.repair.enable` (default: `true`)
Whether or not to create objects for the parent directories of objects with
`/` in their path e.g. creating `gs://bucket/foo/` upon deleting or renaming
`gs://bucket/foo/bar`.
* `fs.gs.copy.with.rewrite.enable` (default: `true`)
Whether or not to perform copy operation using Rewrite requests. Allows to
copy files between different locations and storage classes.
* `fs.gs.rewrite.max.bytes.per.call` (default: `536870912`)
Maximum number of bytes rewritten in a single rewrite request when
`fs.gs.copy.with.rewrite.enable` is set to `true`.
* `fs.gs.reported.permissions` (default: `700`)
Permissions that are reported for a file or directory to have regardless of
actual Cloud Storage permissions. Can be either in octal or symbolic format
that accepted by FsPermission class.
* `fs.gs.delegation.token.binding` (not set by default)
Delegation Token binding class.
* `fs.gs.bucket.delete.enable` (default: `false`)
If `true`, recursive delete on a path that refers to a Cloud Storage bucket
itself or delete on that path when it is empty will result in deletion of
the bucket itself. If `false`, any operation that normally would have
deleted the bucket will be ignored. Setting to `false` preserves the typical
behavior of `rm -rf /` which translates to deleting everything inside of
root, but without clobbering the filesystem authority corresponding to that
root path in the process.
* `fs.gs.checksum.type` (default: `NONE`)
Configuration of object checksum type to return; if a particular file
doesn't support the requested type, then getFileChecksum() method will
return `null` for that file. Supported checksum types are `NONE`, `CRC32C`
and `MD5`
* `fs.gs.status.parallel.enable` (default: `true`)
If `true`, executes Cloud Storage object requests in `FileSystem`'s
`listStatus` and `getFileStatus` methods in parallel to reduce latency.
* `fs.gs.lazy.init.enable` (default: `false`)
Enables lazy initialization of `GoogleHadoopFileSystem` instances.
* `fs.gs.block.size` (default: `67108864`)
The reported block size of the file system. This does not change any
behavior of the connector or the underlying GCS objects. However it will
affect the number of splits Hadoop MapReduce uses for a given input.
* `fs.gs.create.items.conflict.check.enable` (default: `true`)
Enables a check that ensures that conflicting directories do not exist when
creating files and conflicting files do not exist when creating directories.
* `fs.gs.glob.algorithm` (default: `CONCURRENT`)
Glob search algorithm to use in Hadoop
[FileSystem.globStatus](https://hadoop.apache.org/docs/r3.3.0/api/org/apache/hadoop/fs/FileSystem.html#globStatus-org.apache.hadoop.fs.Path-)
method.
Valid options:
* `FLAT` - fetch potential glob matches in a single list request to
minimize calls to GCS in nested glob cases.
* `DEFAULT` - use default Hadoop glob search algorithm implementation.
* `CONCURRENT` - enables concurrent execution of flat and default glob
search algorithms in two parallel threads to improve globbing
performance. Whichever algorithm will finish first that result will be
returned, and the other algorithm execution will be interrupted.
* `fs.gs.max.requests.per.batch` (default: `15`)
Maximum number of Cloud Storage requests that could be sent in a single
batch request.
* `fs.gs.batch.threads` (default: `15`)
Maximum number of threads used to execute batch requests in parallel.
* `fs.gs.list.max.items.per.call` (default: `1024`)
Maximum number of items to return in response for list Cloud Storage
requests.
* `fs.gs.max.wait.for.empty.object.creation.ms` (default: `3000`)
Maximum amount of time to wait after exception during empty object creation.
* `fs.gs.marker.file.pattern` (not set by default)
If set, files that match specified pattern are copied last during folder
rename operation.
* `fs.gs.storage.http.headers.<HEADER>=<VALUE>` (not set by default)
Custom HTTP headers added to Cloud Storage API requests.
Example:
```
fs.gs.storage.http.headers.some-custom-header=custom_value
fs.gs.storage.http.headers.another-custom-header=another_custom_value
```
### Encryption ([CSEK](https://cloud.google.com/storage/docs/encryption/customer-supplied-keys))
* `fs.gs.encryption.algorithm` (not set by default)
The encryption algorithm to use. For CSEK only `AES256` value is supported.
* `fs.gs.encryption.key` (not set by default)
An RFC 4648 Base64-encoded string of the source object's AES-256 encryption
key.
* `fs.gs.encryption.key.hash` (not set by default)
An RFC 4648 Base64-encoded string of the SHA256 hash of the source object's
encryption key.
### Authentication
When one of the following two properties is set, it will precede all other
credential settings, and credentials will be obtained from the access token
provider.
* `fs.gs.auth.access.token.provider.impl` (not set by default)
The implementation of the AccessTokenProvider interface used for GCS
Connector.
* `fs.gs.auth.service.account.enable` (default: `true`)
Whether to use a service account for GCS authorization. If an email and
keyfile are provided (see `fs.gs.auth.service.account.email` and
`fs.gs.auth.service.account.keyfile`), then that service account will be
used. Otherwise the connector will look to see if it is running on a GCE VM
with some level of GCS access in it's service account scope, and use that
service account.
#### Service account authentication
The following properties are required only when running not on a GCE VM and
`fs.gs.auth.service.account.enable` is `true`. There are 3 ways to configure
these credentials, which are mutually exclusive.
* `fs.gs.auth.service.account.email` (not set by default)
The email address is associated with the service account used for GCS access
when `fs.gs.auth.service.account.enable` is `true`. Required when
authentication key specified in the Configuration file (Method 1) or a
PKCS12 certificate (Method 3) is being used.
##### Method 1
Configure service account details directly in the Configuration file or via
[Hadoop Credentials](https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/CredentialProviderAPI.html).
* `fs.gs.auth.service.account.private.key.id` (not set by default)
The private key id associated with the service account used for GCS access.
This can be extracted from the json keyfile generated via the Google Cloud
Console.
* `fs.gs.auth.service.account.private.key` (not set by default)
The private key associated with the service account used for GCS access.
This can be extracted from the json keyfile generated via the Google Cloud
Console.
##### Method 2
Configure service account credentials using a json keyfile. The file must exist
at the same path on all nodes
* `fs.gs.auth.service.account.json.keyfile` (not set by default)
The path to the json keyfile for the service account.
##### Method 3
Configure service account credentials using a P12 certificate. The file must
exist at the same path on all nodes
* `fs.gs.auth.service.account.keyfile` (not set by default)
The PKCS12 (p12) certificate file of the service account used for GCS access
when `fs.gs.auth.service.account.enable` is `true`.
#### Service account impersonation
Service account impersonation can be configured for a specific user name and a
group name, or for all users by default using below properties:
* `fs.gs.auth.impersonation.service.account.for.user.<USER_NAME>` (not set by
default)
The service account impersonation for a specific user.
* `fs.gs.auth.impersonation.service.account.for.group.<GROUP_NAME>` (not set
by default)
The service account impersonation for a specific group.
* `fs.gs.auth.impersonation.service.account` (not set by default)
Default service account impersonation for all users.
If any of the above properties are set then the service account specified will
be impersonated by generating a short-lived credential when accessing Google
Cloud Storage.
Configured authentication method will be used to authenticate the request to
generate this short-lived credential.
If more than one property is set then the service account associated with the
user name will take precedence over the service account associated with the
group name for a matching user and group, which in turn will take precedence
over default service account impersonation.
### Authorization
When configured, a specified authorization handler will be used to authorize
Cloud Storage API requests before executing them. The handler will throw
`AccessDeniedException` for rejected requests if user does not have enough
permissions (not authorized) to execute these requests.
* `fs.gs.authorization.handler.impl` (not set by default)
Enable authorization handler. If this property is set, the specified
authorization handler will be used. GCS connector will use the specified
authorization handler to check if a user has enough permission to perform a
GCS resource access request before granting access.
* `fs.gs.authorization.handler.properties.<PROPERTY>=<VALUE>` (not set by
default)
Properties for the authorization handler. All the properties set with this
prefix will be set to the handler after instantiation before calling any
Cloud Storage requests handling methods.
### IO configuration
* `fs.gs.inputstream.fast.fail.on.not.found.enable` (default: `true`)
If `true`, on opening a file connector will proactively send a Cloud Storage
metadata request to check whether the object exists, even though the
underlying channel will not open a data stream until `read()` method is
called so that streams can seek to nonzero file positions without incurring
an extra stream creation. This is necessary to technically match the
expected behavior of HCFS, but incurs extra latency overhead on `open()`
call. If the client code can handle late failures on not-found errors, or
has independently already ensured that a file exists before calling open(),
then set this property to false for more efficient reads.
* `fs.gs.inputstream.support.gzip.encoding.enable` (default: `false`)
If set to `false` then reading files with GZIP content encoding (HTTP header
`Content-Encoding: gzip`) will result in failure (`IOException` is thrown).
This feature is disabled by default because processing of
[GZIP encoded](https://cloud.google.com/storage/docs/transcoding#decompressive_transcoding)
files is inefficient and error-prone in Hadoop and Spark.
* `fs.gs.outputstream.buffer.size` (default: `8388608`)
Write buffer size.
* `fs.gs.outputstream.pipe.buffer.size` (default: `1048576`)
Pipe buffer size used for uploading Cloud Storage objects.
* `fs.gs.outputstream.pipe.type` (default: `IO_STREAM_PIPE`)
Pipe type used for uploading Cloud Storage objects.
Valid values:
* `NIO_CHANNEL_PIPE` - use
[Java NIO Pipe](https://docs.oracle.com/javase/8/docs/api/java/nio/channels/Pipe.html)
in output stream that writes to Cloud Storage. When using this pipe type
client can reliably write in the output stream from multiple threads
without *"Pipe broken"* exceptions. Note that when using this pipe type
Cloud Storage upload throughput can decrease by 10%;
* `IO_STREAM_PIPE` - use
[PipedInputStream](https://docs.oracle.com/javase/8/docs/api/java/io/PipedInputStream.html)
and
[PipedOutputStream](https://docs.oracle.com/javase/8/docs/api/java/io/PipedOutputStream.html)
in output stream that writes to Cloud Storage. When using this pipe type
client cannot reliably write in the output stream from multiple threads
without triggering *"Pipe broken"* exceptions;
* `fs.gs.outputstream.upload.chunk.size` (default: `67108864`)
The number of bytes in one GCS upload request.
* `fs.gs.outputstream.upload.cache.size` (default: `0`)
The upload cache size in bytes used for high-level upload retries. To
disable this feature set this property to zero or negative value. Retry will
be performed if total size of written/uploaded data to the object is less
than or equal to the cache size.
* `fs.gs.outputstream.direct.upload.enable` (default: `false`)
Enables Cloud Storage direct uploads.
* `fs.gs.outputstream.type` (default: `BASIC`)
Output stream type to use; different options may have different degrees of
support for advanced features like `hsync()` and different performance
characteristics.
Valid options:
* `BASIC` - stream is closest analogue to direct wrapper around low-level
HTTP stream into GCS.
* `SYNCABLE_COMPOSITE` - stream behaves similarly to `BASIC` when used
with basic create/write/close patterns, but supports `hsync()` by
creating discrete temporary GCS objects which are composed onto the
destination object.
* `FLUSHABLE_COMPOSITE` - stream behaves similarly to
`SYNCABLE_COMPOSITE`, except `hflush()` is also supported. It will use
the same implementation as `hsync()`.
* `fs.gs.outputstream.sync.min.interval.ms` (default: `0`)
`SYNCABLE_COMPOSITE` and `FLUSHABLE_COMPOSITE` streams configuration that
controls the minimum interval (milliseconds) between consecutive syncs. This
is to avoid getting rate-limited by GCS. Default is `0` - no wait between
syncs. Note that `hflush()` for `FLUSHABLE_COMPOSITE` stream will be no-op
if called more frequently than minimum sync interval and `hsync()` will
block for both streams until an end of a min sync interval.
### HTTP transport configuration
* `fs.gs.http.transport.type` (default: `JAVA_NET`)
HTTP transport to use for sending Cloud Storage requests. Valid values are
`APACHE` or `JAVA_NET`.
* `fs.gs.application.name.suffix` (not set by default)
Suffix that will be added to HTTP `User-Agent` header set in all Cloud
Storage requests.
* `fs.gs.proxy.address` (not set by default)
Proxy address that connector can use to send Cloud Storage requests. The
proxy must be an HTTP proxy and address should be in the `host:port` form.
* `fs.gs.proxy.username` (not set by default)
Proxy username that connector can use to send Cloud Storage requests.
* `fs.gs.proxy.password` (not set by default)
Proxy password that connector can use to send Cloud Storage requests.
* `fs.gs.http.max.retry` (default: `10`)
The maximum number of retries for low-level HTTP requests to GCS when server
errors (code: `5XX`) or I/O errors are encountered.
* `fs.gs.http.connect-timeout` (default: `20000`)
Timeout in milliseconds to establish a connection. Use `0` for an infinite
timeout.
* `fs.gs.http.read-timeout` (default: `20000`)
Timeout in milliseconds to read from an established connection. Use `0` for
an infinite timeout.
### API client configuration
* `fs.gs.storage.root.url` (default: `https://storage.googleapis.com/`)
Google Cloud Storage root URL.
* `fs.gs.storage.service.path` (default: `storage/v1/`)
Google Cloud Storage service path.
* `fs.gs.token.server.url` (default: `https://oauth2.googleapis.com/token`)
Google Token Server root URL.
### Fadvise feature configuration
* `fs.gs.inputstream.fadvise` (default: `AUTO`)
Tunes reading objects behavior to optimize HTTP GET requests for various use
cases.
This property controls fadvise feature that allows to read objects in
different modes:
* `SEQUENTIAL` - in this mode connector sends a single streaming
(unbounded) Cloud Storage request to read object from a specified
position sequentially.
* `RANDOM` - in this mode connector will send bounded Cloud Storage range
requests (specified through HTTP Range header) which are more efficient
in some cases (e.g. reading objects in row-columnar file formats like
ORC, Parquet, etc).
Range request size is limited by whatever is greater, `fs.gs.io.buffer`
or read buffer size passed by a client.
To avoid sending too small range requests (couple bytes) - could happen
if `fs.gs.io.buffer` is 0 and client passes very small read buffer,
minimum range request size is limited to 1 MiB by default configurable
through `fs.gs.inputstream.min.range.request.size` property
* `AUTO` - in this mode (adaptive range reads) connector starts to send
bounded range requests when reading non gzip-encoded objects instead of
streaming requests as soon as first backward read or forward read for
more than `fs.gs.inputstream.inplace.seek.limit` bytes was detected.
* `fs.gs.inputstream.inplace.seek.limit` (default: `8388608`)
If forward seeks are within this many bytes of the current position, seeks
are performed by reading and discarding bytes in-place rather than opening a
new underlying stream.
* `fs.gs.inputstream.min.range.request.size` (default: `2097152`)
Minimum size in bytes of the read range for Cloud Storage request when
opening a new stream to read an object.
### Performance cache configuration
* `fs.gs.performance.cache.enable` (default: `false`)
Enables a performance cache that temporarily stores successfully queried
Cloud Storage objects in memory. Caching provides a faster access to the
recently queried objects, but because objects metadata is cached,
modifications made outside of this connector instance may not be immediately
reflected.
* `fs.gs.performance.cache.max.entry.age.ms` (default: `5000`)
Maximum number of milliseconds to store a cached metadata in the performance
cache before it's invalidated.
### Cloud Storage [Requester Pays](https://cloud.google.com/storage/docs/requester-pays) feature configuration:
* `fs.gs.requester.pays.mode` (default: `DISABLED`)
Valid values:
* `AUTO` - Requester Pays feature enabled only for GCS buckets that
require it;
* `CUSTOM` - Requester Pays feature enabled only for GCS buckets that are
specified in the `fs.gs.requester.pays.buckets`;
* `DISABLED` - Requester Pays feature disabled for all GCS buckets;
* `ENABLED` - Requester Pays feature enabled for all GCS buckets.
* `fs.gs.requester.pays.project.id` (not set by default)
Google Cloud Project ID that will be used for billing when GCS Requester
Pays feature is active (in `AUTO`, `CUSTOM` or `ENABLED` mode). If not
specified and GCS Requester Pays is active then value of the
`fs.gs.project.id` property will be used.
* `fs.gs.requester.pays.buckets` (not set by default)
Comma-separated list of Google Cloud Storage Buckets for which GCS Requester
Pays feature should be activated if `fs.gs.requester.pays.mode` property
value is set to `CUSTOM`.
### Cooperative Locking feature configuration
* `fs.gs.cooperative.locking.enable` (default: `false`)
Enables cooperative locking to achieve isolation of directory mutation
operations.
* `fs.gs.cooperative.locking.expiration.timeout.ms` (default: `120000`)
Lock expiration timeout used by cooperative locking feature to lock
directories.
* `fs.gs.cooperative.locking.max.concurrent.operations` (default: `20`)
Maximum number of concurrent directory modification operations per bucket
guarded by cooperative locking feature.
| 39.096339 | 145 | 0.73264 | eng_Latn | 0.989374 |
97651018696f68afbbbc62997670f531387cd954 | 3,702 | md | Markdown | _posts/2018-10-16-OOP in Ruby vs Javascript.md | ZenkaiDeveloper/zenkaideveloper.github.io | 9ae17d07ae2b71742761c66d6a595c10b83bd563 | [
"MIT"
] | null | null | null | _posts/2018-10-16-OOP in Ruby vs Javascript.md | ZenkaiDeveloper/zenkaideveloper.github.io | 9ae17d07ae2b71742761c66d6a595c10b83bd563 | [
"MIT"
] | null | null | null | _posts/2018-10-16-OOP in Ruby vs Javascript.md | ZenkaiDeveloper/zenkaideveloper.github.io | 9ae17d07ae2b71742761c66d6a595c10b83bd563 | [
"MIT"
] | null | null | null | ---
published: true
layout: post
title: Intro to Class and Prototype Inheritance
---
## Class Inheritance vs Prototype Inheritance
Starting flatiron bootcamp, I learned about Object Oriented Programming in Ruby in the first 6 weeks. After, Ruby, our cohort started learning about Object Oriented Programming in Javascript. However, there was something very different about OOP in Javascript. Creating the same app in using OOP javascript took a noticeable amount of more work to do the same thing in OOP Ruby.I had a lot of trouble understanding it until I discovered the class syntax in ES6. ES6 classes provided a way to abstract away all the prototype shenanigans going on behind the scene. The basic concept of inheritance is to share and reuse code, Ruby and Javascript just do it in a different way.
## How Ruby Does Inheritance
Ruby uses something called the Classical inheritance, where classes are a special type of object that can initialize and create instances. These classes act as a blueprint for the instance and creates a parent/child relationship implicitly. This type of relationship creates a hierarchy and that hierarchy might not be a problem at the time of writing your code. However, as your application grows and is being maintained, having a hierarchy relationship limits what you can do with your code. For example, let's say you have a human class that has many different instances of different people with attributes of hair color and methods of eat(), sleep(), and walk(). You also have another class called robots that create instances that have attribute of metalType, and methods of shootLazer(), and drive(). Lets say that later down the line you want to create a cyborg class and you want the cyborg to be initialized with a walk() and hairColor from the human class, but you also want metalType and shootLazer() from the robot class. This is a very basic example when you can run into problems in class based OOP.
## How Javascript Does Inheritance
Javascript on the other hand uses prototypal inheritance and is different from class based inheritance in Ruby even though many people try to mimic class based inheritance in Javascript. In prototypal inheritance, instances inherit from other instances. According to Kyle Simpson the author of ‘You Dont know JS’, its literally Objects linking to other objects. Its basically just copying properties from one object into a new instance. This takes away the problem of the implicit hierarchy that is created by Ruby. Every object in javascript has a reference to another object called the prototype.
The following shows how to set prototypes to a new object and after that is an es5 implementation example of prototypes from my mod 3 lead instructor Niky.

mdn snippit describing Object.create();

As you can see there is an animal object and its being passed into mammal's prototype so that it allows mammals to have animal methods and attributes. However, one thing that I would like to point out is that it looks like mammal is inheriting from animal, but keep in mind that its actually just sharing properties. There is no Has-a or a is-a relationship.
## Conclusion
Until the introduction of “real” classes in ES6, the whole concept of inheritance was messed up and (usually) taught in a wrong manner. Prototypes are more of a delegation tool and they don’t really behave like classes. Now with the abstraction provided by ES6 we can write class inheritance between different classes without any problems, but a solid understanding of prototypes can help you unlock more than what class inheritance gives you.
| 112.181818 | 1,113 | 0.802269 | eng_Latn | 0.999857 |
97659f3ecfa5084e4631daaa2ad7ffcf099bc72d | 508 | md | Markdown | _posts/2016-09-30-mosaic-ministries-of-south-toledo.md | perchwire/perchwire.github.io | 7dbc835a81f4e2cd87a0e170b3932d8ff6b3a37d | [
"MIT"
] | null | null | null | _posts/2016-09-30-mosaic-ministries-of-south-toledo.md | perchwire/perchwire.github.io | 7dbc835a81f4e2cd87a0e170b3932d8ff6b3a37d | [
"MIT"
] | null | null | null | _posts/2016-09-30-mosaic-ministries-of-south-toledo.md | perchwire/perchwire.github.io | 7dbc835a81f4e2cd87a0e170b3932d8ff6b3a37d | [
"MIT"
] | 1 | 2016-09-19T20:45:06.000Z | 2016-09-19T20:45:06.000Z | ---
layout: babyupost
title: Mosaic Ministries of South Toledo
---
<http://wamteam.org>
Director / Pastor : David Kaiser - 419-344-5844
General Manager : Kelly Kaiser - 419-346-9425
Location:
* 860 Orchard St <small>(at the corner with Broadway)</small>
* Toledo, OH 43609
* [Map](https://www.google.com/maps/place/860+Orchard+St,+Toledo,+OH+43609/@41.6278071,-83.5609685,17z/data=!3m1!4b1!4m2!3m1!1s0x883b870f0aaf7dbf:0x5a0dc7f659246a2a)
<small>(Formerly known as Western Avenue Ministries.)</small>
| 25.4 | 165 | 0.740157 | eng_Latn | 0.408381 |
9765c89435d3db849e06e4ab817bb1d116f14f0e | 1,197 | md | Markdown | README.md | codibly/react-intl-hook | c06ebfb9c601ffdb4318b2dd24a2059a655ea987 | [
"MIT"
] | null | null | null | README.md | codibly/react-intl-hook | c06ebfb9c601ffdb4318b2dd24a2059a655ea987 | [
"MIT"
] | 3 | 2020-07-07T20:39:30.000Z | 2022-01-22T09:31:48.000Z | README.md | codibly/react-intl-hook | c06ebfb9c601ffdb4318b2dd24a2059a655ea987 | [
"MIT"
] | null | null | null | # react-intl-hook
[](https://github.com/semantic-release/semantic-release)
[](https://github.com/prettier/prettier)
[](http://commitizen.github.io/cz-cli/)
[](https://github.com/facebook/jest)
[](https://www.npmjs.com/package/react-intl-hook)
[](https://www.npmjs.com/package/react-intl-hook)
[](https://www.npmjs.com/package/react-intl-hook)
[](https://www.npmjs.com/package/react-intl-hook)
## Installation
This package is available as an [npm package](https://www.npmjs.com/package/react-intl-hook).
```
npm install --save react-intl-hook
```
## Usage
## License
MIT
| 46.038462 | 165 | 0.736842 | yue_Hant | 0.24983 |
9765e0552676632d2a6f49dde2467bb9e7361869 | 58 | md | Markdown | README.md | sachabest/568-vr.github.io | 42bc300578b672942b240d905d410e7031f48ba1 | [
"MIT"
] | 1 | 2017-01-13T22:51:46.000Z | 2017-01-13T22:51:46.000Z | README.md | sachabest/568-vr.github.io | 42bc300578b672942b240d905d410e7031f48ba1 | [
"MIT"
] | null | null | null | README.md | sachabest/568-vr.github.io | 42bc300578b672942b240d905d410e7031f48ba1 | [
"MIT"
] | null | null | null | # penn-virtual-reality
CIS 568 Spring 2017 Course Website
| 19.333333 | 34 | 0.810345 | yue_Hant | 0.522253 |
9765f062484d22c2de6e271780eea671bfbea362 | 8,074 | md | Markdown | v1.1/create-and-manage-users.md | message/docs | b7ebf243f909560adbb3ed7d941771653be0a4d2 | [
"CC-BY-4.0",
"BSD-3-Clause"
] | 172 | 2016-02-07T13:59:56.000Z | 2022-03-30T08:34:31.000Z | v1.1/create-and-manage-users.md | rainleander/docs | 34b94b4ca65100c8f4239681ebd307d0907d387e | [
"CC-BY-4.0",
"BSD-3-Clause"
] | 13,147 | 2016-01-13T20:50:14.000Z | 2022-03-31T23:42:05.000Z | v1.1/create-and-manage-users.md | rainleander/docs | 34b94b4ca65100c8f4239681ebd307d0907d387e | [
"CC-BY-4.0",
"BSD-3-Clause"
] | 461 | 2016-01-19T16:38:41.000Z | 2022-03-30T02:46:03.000Z | ---
title: Create & Manage Users
summary: To create and manage your cluster's users (which lets you control SQL-level privileges), use the cockroach user command with appropriate flags.
toc: true
---
To create, manage, and remove your cluster's users (which lets you control SQL-level [privileges](privileges.html)), use the `cockroach user` [command](cockroach-commands.html) with appropriate flags.
{{site.data.alerts.callout_success}}You can also use the <a href="create-user.html"><code>CREATE USER</code></a> and <a href="drop-user.html"><code>DROP USER</code></a> statements to create and remove users.{{site.data.alerts.end}}
## Considerations
- Usernames are case-insensitive; must start with either a letter or underscore; must contain only letters, numbers, or underscores; and must be between 1 and 63 characters.
- After creating users, you must [grant them privileges to databases and tables](grant.html).
- On secure clusters, you must [create client certificates for users](create-security-certificates.html#create-the-certificate-and-key-pair-for-a-client) and users must [authenticate their access to the cluster](#user-authentication).
- {% include {{ page.version.version }}/misc/remove-user-callout.html %}
## Subcommands
Subcommand | Usage
-----------|------
`get` | Retrieve a table containing a user and their hashed password.
`ls` | List all users.
`rm` | Remove a user.
`set` | Create or update a user.
## Synopsis
~~~ shell
# Create a user:
$ cockroach user set <username> <flags>
# List all users:
$ cockroach user ls <flags>
# Display a specific user:
$ cockroach user get <username> <flags>
# View help:
$ cockroach user --help
$ cockroach user get --help
$ cockroach user ls --help
$ cockroach user rm --help
$ cockroach user set --help
~~~
## Flags
The `user` command and subcommands support the following [general-use](#general) and [logging](#logging) flags.
### General
Flag | Description
-----|------------
`--password` | Enable password authentication for the user; you will be prompted to enter the password on the command line.
`--echo-sql` | <span class="version-tag">New in v1.1:</span> Reveal the SQL statements sent implicitly by the command-line utility. For a demonstration, see the [example](#reveal-the-sql-statements-sent-implicitly-by-the-command-line-utility) below.
`--pretty` | Format table rows printed to the standard output using ASCII art and disable escaping of special characters.<br><br>When disabled with `--pretty=false`, or when the standard output is not a terminal, table rows are printed as tab-separated values, and special characters are escaped. This makes the output easy to parse by other programs.<br><br>**Default:** `true` when output is a terminal, `false` otherwise
### Client Connection
{% include {{ page.version.version }}/sql/connection-parameters-with-url.md %}
See [Client Connection Parameters](connection-parameters.html) for more details.
Currently, only the `root` user can create users.
### Logging
By default, the `user` command logs errors to `stderr`.
If you need to troubleshoot this command's behavior, you can change its [logging behavior](debug-and-error-logs.html).
## User Authentication
Secure clusters require users to authenticate their access to databases and tables. CockroachDB offers two methods for this:
- [Client certificate and key authentication](#secure-clusters-with-client-certificates), which is available to all users. To ensure the highest level of security, we recommend only using client certificate and key authentication.
- [Password authentication](#secure-clusters-with-passwords), which is available to non-`root` users who you've created passwords for. To set a password for a non-`root` user, include the `--password` flag in the `cockroach user set` command.
Users can use passwords to authenticate without supplying client certificates and keys; however, we recommend using certificate-based authentication whenever possible.
{{site.data.alerts.callout_info}}Insecure clusters do not support user authentication, but you can still create passwords for users (besides <code>root</code>) through the <code>--password</code> flag.{{site.data.alerts.end}}
## Examples
### Create a User
#### Insecure Cluster
~~~ shell
$ cockroach user set jpointsman --insecure
~~~
Usernames are case-insensitive; must start with either a letter or underscore; must contain only letters, numbers, or underscores; and must be between 1 and 63 characters.
After creating users, you must [grant them privileges to databases](grant.html).
#### Secure Cluster
~~~ shell
$ cockroach user set jpointsman --certs-dir=certs
~~~
{{site.data.alerts.callout_success}}If you want to allow password authentication for the user, include the <code>--password</code> flag and then enter and confirm the password at the command prompt.{{site.data.alerts.end}}
Usernames are case-insensitive; must start with either a letter or underscore; must contain only letters, numbers, or underscores; and must be between 1 and 63 characters.
After creating users, you must:
- [Create their client certificates](create-security-certificates.html#create-the-certificate-and-key-pair-for-a-client).
- [Grant them privileges to databases](grant.html).
### Authenticate as a Specific User
#### Insecure Clusters
~~~ shell
$ cockroach sql --insecure --user=jpointsman
~~~
#### Secure Clusters with Client Certificates
All users can authenticate their access to a secure cluster using [a client certificate](create-security-certificates.html#create-the-certificate-and-key-pair-for-a-client) issued to their username.
~~~ shell
$ cockroach sql --certs-dir=certs --user=jpointsman
~~~
#### Secure Clusters with Passwords
[Users with passwords](create-and-manage-users.html#secure-cluster) can authenticate their access by entering their password at the command prompt instead of using their client certificate and key.
If we cannot find client certificate and key files matching the user, we fall back on password authentication.
~~~ shell
$ cockroach sql --certs-dir=certs --user=jpointsman
~~~
### Update a User's Password
~~~ shell
$ cockroach user set jpointsman --certs-dir=certs --password
~~~
After issuing this command, enter and confirm the user's new password at the command prompt.
{{site.data.alerts.callout_danger}}You cannot add password authentication to the <code>root</code> user.{{site.data.alerts.end}}
### List All Users
~~~ shell
$ cockroach user ls --insecure
~~~
~~~
+------------+
| username |
+------------+
| jpointsman |
+------------+
~~~
### Find a Specific User
~~~ shell
$ cockroach user get jpointsman --insecure
~~~
~~~
+------------+--------------------------------------------------------------+
| username | hashedPassword |
+------------+--------------------------------------------------------------+
| jpointsman | $2a$108tm5lYjES9RSXSKtQFLhNO.e/ysTXCBIRe7XeTgBrR6ubXfp6dDczS |
+------------+--------------------------------------------------------------+
~~~
### Remove a User
{{site.data.alerts.callout_danger}}{% include {{ page.version.version }}/misc/remove-user-callout.html %}{{site.data.alerts.end}}
~~~ shell
$ cockroach user rm jpointsman --insecure
~~~
{{site.data.alerts.callout_success}}You can also use the <a href="drop-user.html"><code>DROP USER</code></a> SQL statement to remove users.{{site.data.alerts.end}}
### Reveal the SQL statements sent implicitly by the command-line utility
In this example, we use the `--echo-sql` flag to reveal the SQL statement sent implicitly by the command-line utility:
~~~ shell
$ cockroach user rm jpointsman --insecure --echo-sql
~~~
~~~
> DELETE FROM system.users WHERE username=$1
DELETE 1
~~~
## See Also
- [`CREATE USER`](create-user.html)
- [`DROP USER`](drop-user.html)
- [`SHOW USERS`](show-users.html)
- [`GRANT`](grant.html)
- [`SHOW GRANTS`](show-grants.html)
- [Create Security Certificates](create-security-certificates.html)
- [Other Cockroach Commands](cockroach-commands.html)
| 38.631579 | 423 | 0.718479 | eng_Latn | 0.958651 |
9766414248751293a81112d5f4ae6dbf2d5ee510 | 611 | md | Markdown | CHANGELOG.md | kiates/NBug | ed1dbf01e32ffe6c0b84210183cc2ff6ca448717 | [
"MIT"
] | 6 | 2017-05-18T16:19:28.000Z | 2019-05-18T17:57:33.000Z | CHANGELOG.md | kiates/NBug | ed1dbf01e32ffe6c0b84210183cc2ff6ca448717 | [
"MIT"
] | 9 | 2017-08-15T22:14:20.000Z | 2019-06-02T10:24:40.000Z | CHANGELOG.md | kiates/NBug | ed1dbf01e32ffe6c0b84210183cc2ff6ca448717 | [
"MIT"
] | 20 | 2015-03-28T20:52:25.000Z | 2022-03-19T06:49:36.000Z | # 1.2.3
*TBD*
* Handle invalid/corrupt report files gracefully.
# 1.2.2
*November 16, 2013*
* More elaborate fixes for serialization problems.
* Fixes for memory dump issues.
# 1.2.1
*November 13, 2013*
* Fix for exception serialization bug.
# 1.2
*November 9, 2013*
* Bug fixes for Web apps.
* Added more localizations.
* Custom error reporting and attachments are now possible.
# 1.1
*July 2, 2011*
* Tons of bug fixes and stability improvements. Library is rock solid now and is in production with some great apps.
* Added exception filters.
# 1.0
*March 1, 2011*
* Initial release of NBug.
| 15.275 | 116 | 0.716858 | eng_Latn | 0.981648 |
9766f921386250e6cc61e27f44528c8d81cda26c | 935 | md | Markdown | deployment/docker/README_zh_CN.md | CuriousCat-7/nni | 66057ba74c5252e38a576712b59a8bf867e2d514 | [
"MIT"
] | 3 | 2021-04-19T08:26:46.000Z | 2022-03-22T20:17:17.000Z | deployment/docker/README_zh_CN.md | CuriousCat-7/nni | 66057ba74c5252e38a576712b59a8bf867e2d514 | [
"MIT"
] | 1 | 2020-10-22T22:24:24.000Z | 2020-10-22T22:24:24.000Z | deployment/docker/README_zh_CN.md | CuriousCat-7/nni | 66057ba74c5252e38a576712b59a8bf867e2d514 | [
"MIT"
] | 3 | 2020-10-23T02:53:47.000Z | 2020-11-15T22:05:09.000Z | # Dockerfile
## 1. 说明
这是 NNI 项目的 Dockerfile 文件。 其中包含了 NNI 以及多个流行的深度学习框架。 在 `Ubuntu 16.04 LTS` 上进行过测试:
CUDA 9.0, CuDNN 7.0
numpy 1.14.3,scipy 1.1.0
TensorFlow-gpu 1.10.0
Keras 2.1.6
PyTorch 0.4.1
scikit-learn 0.20.0
pandas 0.23.4
lightgbm 2.2.2
NNI v0.7
此 Dockerfile 可作为定制的参考。
## 2.如何生成和运行
**使用 `nni/deployment/docker` 的下列命令来生成 docker 映像。**
docker build -t nni/nni .
**运行 docker 映像**
* 如果 docker 容器中没有 GPU,运行下面的命令
docker run -it nni/nni
注意,如果要使用 tensorflow,需要先卸载 tensorflow-gpu,然后在 Docker 容器中安装 tensorflow。 或者修改 `Dockerfile` 来安装没有 GPU 的 tensorflow 版本,并重新生成 Docker 映像。
* 如果 docker 容器中有 GPU,确保安装了 [NVIDIA 容器运行包](https://github.com/NVIDIA/nvidia-docker),然后运行下面的命令
nvidia-docker run -it nni/nni
或者
docker run --runtime=nvidia -it nni/nni
## 3.拉取 docker 映像
使用下列命令从 docker Hub 中拉取 NNI docker 映像。
docker pull msranni/nni:latest
| 18.333333 | 130 | 0.656684 | yue_Hant | 0.986514 |
97677b57161bfa33ea7838884e4061f6bfdb5311 | 2,055 | md | Markdown | includes/data-factory-transformation-activities.md | Myhostings/azure-docs.tr-tr | 536eaf3b454f181f4948041d5c127e5d3c6c92cc | [
"CC-BY-4.0",
"MIT"
] | 16 | 2017-08-28T08:29:36.000Z | 2022-01-02T16:46:30.000Z | includes/data-factory-transformation-activities.md | Ahmetmaman/azure-docs.tr-tr | 536eaf3b454f181f4948041d5c127e5d3c6c92cc | [
"CC-BY-4.0",
"MIT"
] | 470 | 2017-11-11T20:59:16.000Z | 2021-04-10T17:06:28.000Z | includes/data-factory-transformation-activities.md | Ahmetmaman/azure-docs.tr-tr | 536eaf3b454f181f4948041d5c127e5d3c6c92cc | [
"CC-BY-4.0",
"MIT"
] | 25 | 2017-11-11T19:39:08.000Z | 2022-03-30T13:47:56.000Z | ---
author: linda33wj
ms.service: data-factory
ms.topic: include
ms.date: 11/09/2018
ms.author: jingwang
ms.openlocfilehash: 19927fd274cbb7337248fb2ae8cf9d882612d570
ms.sourcegitcommit: f28ebb95ae9aaaff3f87d8388a09b41e0b3445b5
ms.translationtype: MT
ms.contentlocale: tr-TR
ms.lasthandoff: 03/29/2021
ms.locfileid: "92369258"
---
Azure Data Factory, işlem hatlarına tek tek veya başka bir etkinlikle zincirleme halinde eklenebilecek aşağıdaki dönüştürme etkinliklerini destekler.
| Veri dönüştürme etkinliği | İşlem ortamı |
|:--- |:--- |
| [Hive](../articles/data-factory/v1/data-factory-hive-activity.md) |HDInsight [Hadoop] |
| [Pig](../articles/data-factory/v1/data-factory-pig-activity.md) |HDInsight [Hadoop] |
| [MapReduce](../articles/data-factory/v1/data-factory-map-reduce.md) |HDInsight [Hadoop] |
| [Hadoop Akışı](../articles/data-factory/v1/data-factory-hadoop-streaming-activity.md) |HDInsight [Hadoop] |
| [Spark](../articles/data-factory/v1/data-factory-spark.md) | HDInsight [Hadoop] |
| [Azure Machine Learning Studio (klasik) etkinlikleri: toplu yürütme ve kaynak güncelleştirme](../articles/data-factory/v1/data-factory-azure-ml-batch-execution-activity.md) |Azure VM |
| [Saklı Yordam](../articles/data-factory/v1/data-factory-stored-proc-activity.md) |Azure SQL, Azure SYNAPSE Analytics veya SQL Server |
| [Data Lake Analytics U-SQL](../articles/data-factory/v1/data-factory-usql-activity.md) |Azure Data Lake Analytics |
| [Olmalı](../articles/data-factory/v1/data-factory-use-custom-activities.md) |HDInsight [Hadoop] veya Azure Batch |
> [!NOTE]
> MapReduce etkinliğini kullanarak HDInsight Spark kümenizde Spark programları çalıştırabilirsiniz. Ayrıntılar için bkz. [Azure Data Factory’den Spark programlarını çağırma](../articles/data-factory/v1/data-factory-spark.md).
> R yüklü HDInsight kümenizde R betiklerini çalıştırmak için özel bir etkinlik oluşturabilirsiniz. Bkz. [Azure Data Factory kullanarak R Betiği çalıştırma](https://github.com/Azure/Azure-DataFactory/tree/master/SamplesV1/RunRScriptUsingADFSample).
>
>
| 60.441176 | 247 | 0.779562 | tur_Latn | 0.830512 |
9767ad1947107a4458d020ddade959c4f160c580 | 38 | md | Markdown | README.md | MKTI/iptv | c11d86c3b70886ce7be9a09c87df420b6f208958 | [
"MIT"
] | null | null | null | README.md | MKTI/iptv | c11d86c3b70886ce7be9a09c87df420b6f208958 | [
"MIT"
] | null | null | null | README.md | MKTI/iptv | c11d86c3b70886ce7be9a09c87df420b6f208958 | [
"MIT"
] | null | null | null | # iptv
iptv reseller panel provider
| 12.666667 | 30 | 0.763158 | swe_Latn | 0.257138 |
9767bbb3235f9ac9afb98b290eccde03b43be85b | 5,986 | md | Markdown | _posts/2020-04-06-How-To-Install-and-configure-Jenkins-on-Ubuntu-18.04.md | digitalave/digital.github.io | b3404f0bd09b8dba34f75cd783821d406856c207 | [
"MIT"
] | 2 | 2019-03-22T09:30:51.000Z | 2021-01-28T16:48:32.000Z | _posts/2020-04-06-How-To-Install-and-configure-Jenkins-on-Ubuntu-18.04.md | digitalave/digital.github.io | b3404f0bd09b8dba34f75cd783821d406856c207 | [
"MIT"
] | null | null | null | _posts/2020-04-06-How-To-Install-and-configure-Jenkins-on-Ubuntu-18.04.md | digitalave/digital.github.io | b3404f0bd09b8dba34f75cd783821d406856c207 | [
"MIT"
] | 1 | 2021-01-28T16:48:34.000Z | 2021-01-28T16:48:34.000Z | ---
layout: post
authors: [dimuthu_daundasekara]
title: 'How to Install and Configure Jenkins on Ubuntu 18.04 LTS 16.04 Debian'
image: /assets/img/post-imgs/jenkins-ubuntu/Jenkins.jpg
tags: [Jenkins, CICD, Automation,Continuous Integration, Continuous Delivery]
category: DevOps
comments: true
last_modified_at: 2020-01-31
---
<style>
.embed-container { position: relative; padding-bottom: 56.25%; height: 0; overflow: hidden; max-width: 100%; } .embed-container iframe, .embed-container object, .embed-container embed { position: absolute; top: 0; left: 0; width: 100%; height: 100%; }
</style>
<div class='embed-container'>
<iframe src='https://www.youtube.com/embed/rqJPEACdrmM?&autoplay=1' frameborder='0' allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen>
</iframe>
</div>
### Introduction:
Jenkins is an open-source automation server that provides hundreds of plugin to perform continuous integration and continues delivery to build and deploy projects.
Continuous integration (CI) is a DevOps practice in which team members regularly commit their code changes to the version control repository. Automated builds and tests are run. Continuous delivery (CD) is a series of practices where code changes are automatically built, tested and deployed to production.
If you are a software developer, surely Jenkins suites and automates your CI/CD build tasks quickly.
Jenkins can automate continuous integration and continuous delivery (CI/CD) for any project.
Support for hundreds of plugins in the update centre. Which provides infinite possibilities for what Jenkins can do.
Jenkins can configure into a distributed system that distributes work across multiple node/machines.
### Features:
**CICD** - Continues Integration and Continues Delivery
**Plugins** - Hundreds of Plugin Support
**Extensible** - Extended possibilities using its Plugins
**Distributed** - Distribute work across multiple machines and projects
### Prerequisites:
`Hardware - RAM > 1GB | HDD > 50GB+`
`Software - JAVA (JRE 8 | JDK 11)`
Following JDK/JRE Versions support for current Jenkins versions
`OpenJDK JDK / JRE 8 - 64 bits`
`OpenJDK JDK / JRE 11 - 64 bits`
**NOTE: Always check JAVA version requirement before proceeding with the Jenkins installation.**
REF: <a href="https://www.jenkins.io/doc/administration/requirements/java/" target="_blank">https://www.jenkins.io/doc/administration/requirements/java/</a>
### STEP 01: Install Oracel/Open JDK 11
Now, I'm going to install OpenJDK 11 on my system.
##### Install OpenJDK
```bash
sudo apt update
sudo apt-get install openjdk-11-jdk -y
```
OR
REF: <a href="https://www.oracle.com/java/technologies/javase-jdk11-downloads.html" target="_blank">https://www.oracle.com/java/technologies/javase-jdk11-downloads.html</a>
```bash
sudo dpkg -i jdk-11.0.7_linux-x64_bin.deb
```
##### Set Default JDK Version
```bash
sudo update-alternatives --config java
java -version
```
### STEP 02: Install Jenkins Using Debian Repository
##### Import trusted PGP Key for Jenkins
```bash
sudo wget -q -O - http://pkg.jenkins-ci.org/debian/jenkins-ci.org.key | sudo apt-key add -
```
##### Add Jenkins Repository
```bash
sudo wget -q -O - https://pkg.jenkins.io/debian/jenkins-ci.org.key | sudo apt-key add -
```
```bash
sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
```
##### Install Jenkins
```bash
sudo apt-get update
sudo apt-get install jenkins
```
Jenkins service will automatically start after the installation process is complete. You can verify it by printing the service status.
```bash
sudo systemctl status jenkins
```
If it isn't enabled,/started automatically.
```bash
sudo systemctl enable jenkins
sudo systemctl start jenkins
```
### STEP 03: Configure Firewall
Allow port 8080 through the Ubuntu firewall.
```bash
sudo ufw allow 8080/tcp
```
### STEP 04: Initial Setup For Jenkins
Once the above configuration completed, Open-up your web browser and access it through the IP: PORT.
> http://your_ip_or_domain:8080
Now, Head-over to the terminal again, and find out the Administrator password using this command.
```bash
sudo cat /var/lib/jenkins/secrets/initialAdminPassword
```
<img src="/assets/img/post-imgs/jenkins-ubuntu/1.png" width="auto" alt="Digital Avenue DevOps Tutorials">
Copy the password from the terminal and paste it into the required field
The next screen at the initial setup wizard will ask for Install suggested plugins or select specific plugins. Click on the Install suggested plugins box, and the installation process will start immediately.
<img src="/assets/img/post-imgs/jenkins-ubuntu/2.png" width="auto" alt="Digital Avenue DevOps Tutorials">
<img src="/assets/img/post-imgs/jenkins-ubuntu/3.png" width="auto" alt="Digital Avenue DevOps Tutorials">
Once the plugins are installed, you will be prompted to set up the first admin user. Fill out all required information and click Save and Continue.
<img src="/assets/img/post-imgs/jenkins-ubuntu/4.png" width="auto" alt="Digital Avenue DevOps Tutorials">
<img src="/assets/img/post-imgs/jenkins-ubuntu/5.png" width="auto" alt="Digital Avenue DevOps Tutorials">
Click on the Start using Jenkins button. You will be redirected to the Jenkins dashboard logged in as the admin user you have created in one of the previous steps.
<img src="/assets/img/post-imgs/jenkins-ubuntu/6.png" width="auto" alt="Digital Avenue DevOps Tutorials">
<img src="/assets/img/post-imgs/jenkins-ubuntu/7.png" width="auto" alt="Digital Avenue DevOps Tutorials">
Now you've successfully installed Jenkins on your Ubuntu system.
##### Bottom Line
##### I hope you learned how to install Jenkins on Ubuntu. And In the next tutorial, I'll show you how to integrate GitLab with your newly built Jenkins server.
##### If you have any questions, please leave a comment on the YouTube comment section.
| 32.532609 | 306 | 0.755763 | eng_Latn | 0.795566 |
976829e6aa8268dc2f3d6f54466b7a0f405fabad | 1,651 | md | Markdown | README.md | erdemayaz/cosmollage | 95a8f47935c1fea445437ba9cde570f28c0e839b | [
"MIT"
] | null | null | null | README.md | erdemayaz/cosmollage | 95a8f47935c1fea445437ba9cde570f28c0e839b | [
"MIT"
] | null | null | null | README.md | erdemayaz/cosmollage | 95a8f47935c1fea445437ba9cde570f28c0e839b | [
"MIT"
] | null | null | null | ## Cosmollage
Cosmollage is a collage maker. Package uses canvas package.
For using:
const Cosmollage = require('cosmollage');
Create a new instance with your collage width and heigth,
var cosmollage = new Cosmollage(1920, 1080);
You must give row and column count as parameter,
cosmollage.row = 6;
cosmollage.column = 5;
And you can set read directory. If you don't enter, you must give image path with name,
cosmollage.readDir = './assets';
If you want to fix images in each cell, you can set isFixed is true (false as default),
cosmollage.isFixed = true;
You can set image one by one,
for (let i = 0; i < 15; i++) {
cosmollage.addImage('landscape_' + i + '.jpg');
cosmollage.addImage('portraid' + i + '.jpeg');
}
or set as array
cosmollage.setImages(myImagesArray);
If you want to check existing files, this returns not existing files array,
var notExists = cosmollage.imagesNotExists();
For development, if you want to show borders on collage,
cosmollage.drawBorders = true;
You can set canvas paddings,
cosmollage.canvasPaddingRight = 3;
cosmollage.canvasPaddingTop = 5;
cosmollage.canvasPaddingLeft = 7;
cosmollage.canvasPaddingBottom = 11;
cosmollage.canvasPaddingAll = 13;
You can set cells paddings,
cosmollage.cellPaddingRight = 3;
cosmollage.cellPaddingTop = 5;
cosmollage.cellPaddingLeft = 7;
cosmollage.cellPaddingBottom = 11;
cosmollage.cellPaddingAll = 13;
and finally render it!
cosmollage.render().then((buffer) => {
// make magic things with buffer...
fs.writeFileSync('./collage.jpg', buffer);
}); | 25.796875 | 87 | 0.700787 | eng_Latn | 0.963179 |
9768371b92c931ca6cd58ac54b4e253c5006afb7 | 1,567 | md | Markdown | source/use_cases/aws-serverless-image-handler/README.md | tabdunabi/aws-solutions-constructs | f4b22d86509d1d64ba24b93906167a2f29d4649d | [
"Apache-2.0"
] | null | null | null | source/use_cases/aws-serverless-image-handler/README.md | tabdunabi/aws-solutions-constructs | f4b22d86509d1d64ba24b93906167a2f29d4649d | [
"Apache-2.0"
] | null | null | null | source/use_cases/aws-serverless-image-handler/README.md | tabdunabi/aws-solutions-constructs | f4b22d86509d1d64ba24b93906167a2f29d4649d | [
"Apache-2.0"
] | null | null | null | # AWS Serverless Image Handler
This use case construct implements an Amazon CloudFront distribution, an Amazon API Gateway REST API, an AWS Lambda
function, and necessary permissions/logic to provision a functional image handler API for serving image content from
one or more Amazon S3 buckets within the deployment account.
Here is a minimal deployable pattern definition in Typescript:
```javascript
const { ServerlessImageHandler } from '@aws-solutions-constructs/aws-serverless-image-handler';
new ServerlessImageHandler(this, 'ServerlessImageHandlerPattern', {
lambdaFunctionProps: {
runtime: lambda.Runtime.NODEJS_12_X,
handler: 'index.handler',
code: lambda.Code.fromAsset(`${__dirname}/lambda`)
}
});
```
## Properties
| **Name** | **Type** | **Description** |
|:-------------|:----------------|-----------------|
|existingLambdaObj?|[`lambda.Function`](https://docs.aws.amazon.com/cdk/api/latest/docs/@aws-cdk_aws-lambda.Function.html)|Existing instance of Lambda Function object, if this is set then the lambdaFunctionProps is ignored.|
|lambdaFunctionProps?|[`lambda.FunctionProps`](https://docs.aws.amazon.com/cdk/api/latest/docs/@aws-cdk_aws-lambda.FunctionProps.html)|User provided props to override the default props for the Lambda function.|
|apiGatewayProps?|`api.LambdaRestApiProps`|Optional user-provided props to override the default props for the API.|
## Architecture

***
© Copyright 2021 Amazon.com, Inc. or its affiliates. All Rights Reserved. | 46.088235 | 224 | 0.738354 | eng_Latn | 0.529738 |
97687f986220dc964dc8dba281dd7e9f4a91ac91 | 50 | md | Markdown | README.md | sheminusminus/portfolio-update | f7aa3b00ab2e26ec253cf1baaf7d82b272a9853d | [
"MIT"
] | null | null | null | README.md | sheminusminus/portfolio-update | f7aa3b00ab2e26ec253cf1baaf7d82b272a9853d | [
"MIT"
] | null | null | null | README.md | sheminusminus/portfolio-update | f7aa3b00ab2e26ec253cf1baaf7d82b272a9853d | [
"MIT"
] | null | null | null | # portfolio-update
emkolar.ninja portfolio update
| 16.666667 | 30 | 0.84 | hun_Latn | 0.501896 |
976975760f1ce90b0420273e1b67bf528ed6953e | 6,879 | md | Markdown | Runnable_Jar/guide/guide.md | ConnorValerio/Runway-Redeclaration-Tool | be1fc1541bbad4172fb0c14fbeb4919b381e044b | [
"Apache-2.0"
] | null | null | null | Runnable_Jar/guide/guide.md | ConnorValerio/Runway-Redeclaration-Tool | be1fc1541bbad4172fb0c14fbeb4919b381e044b | [
"Apache-2.0"
] | null | null | null | Runnable_Jar/guide/guide.md | ConnorValerio/Runway-Redeclaration-Tool | be1fc1541bbad4172fb0c14fbeb4919b381e044b | [
"Apache-2.0"
] | null | null | null | ---
title: Runway Redeclaration Tool
author: Mark Garnett, Connor Valerio, George Gillams, Ionut Farcas
date: 19th April 2015
geometry: margin=2cm
fontsize: 12pt
---
# Introduction
The Runway Redeclaration Tool is a tool designed to aid the redeclaration of UK runways. It provides an automatic breakdown and calculation of parameters as specified by the UK Civil Aviation Authority, along with providing animated visualisations to increase productivity of redeclaring runways.
## How to use this Guide
**Section One** provides a brief overview of the interface along with features available within this tool. **Sections Two to Five** cover Runways, Obstructions, and Calculations,and Visualisations respectively. **Section Six** provides a console cheatsheet for reference.
Section One: Overview
======

1. Menu Bar.
2. Icon Bar.
3. Top-Down Visualisation. This view provides a breakdown of runway parameters when an obstruction is present. More details are in Section Five.
4. Side-On Visualisation. This view provides both a breakdown of runway parameters when an obstruction is present and a visualisation of the ALS/TOCS slope formed over an obstruction. More details are in Section Five.
5. Calculation Breakdown. This panel provides the breakdown of calculations into their consituent values, along with a textual description of the calculation performed. More details are in Section Four.
6. Notification Panel. This provides a detailed log of all user actions within the application. These logs are also written to a datetimestamped log file in the program directory.

1. Airports can be switched from within the program itself.
2. The tool can be localised into numerous languages to allow for non-native English speakers to be more at home with the tool in their native language. Currently provided options are Polish and Spanish.

1. Multiple colour schemes are provided to aid colour-blind users or personal preference.
2. A command-based console is available to allow for much increased productivity for advanced users. An overview of all commands is found in Section Six.
3. The visualisation can be exported to a file for later reference.
Section Two: Runways
======
When first opening the application, the Welcome Screen is shown.

1. If the tool has been used previously, an airport file can be selected. This will save details about previous obstructions and usage.
2. If a new airport is needed to be created, the following details are needed:
+ A name for the given airport.
+ An .xml file that provides physical details of the runway.
+ An .xml file containing predefined obstructions. If no specific obstructions are needed, a pre-selected list of obstructions is provided.
Whether a new airport or an existing airport is used, the program will load into the last used state (or, if a new airport is created, a blank state with no obstructions) as in Section One.
The provided parameters are displayed as the *Original Parameters* in the Calculation Breakdown panel.

1. Multiple runways can be defined per airport. To switch between runways, use the drop-down box.
2. Additional runways can be imported from .xml files.
3. To define a custom runway, input the parameters listed. Note that changing a runway will remove any previous obstructions currently placed in the application.
###Console Commands:
`airport, airportnew, runway`.
Section Three: Obstructions
======
The system supports up to one obstruction on a runway at a given time. Adding further obstructions will replace the current obstruction.

1. Many obstacles are pre-loaded into the application for common obstructions. However, these can still be edited for specific sizes.
2. Most fields are self-explanatory. **Position Along Runway** is the distance (in metres) from the start of the runway. The start of the runway is defined as the runway with the lowest threshold. **Distance from Runway** is the distance (in metres) from the centreline of the runway.

1. Dimensions of obstructions cannot be edited after adding the obstruction. To edit dimensions, create a new obstruction instead.
###Console Commands
`obst`
Section Four: Calculations
======
After adding an obstruction, the breakdown of all parameters are displayed for all 4 possible scenarios as well as the 'blank' runway.
+ Approaching for landing, on the leftmost runway.
+ Approaching for landing, on the rightmost runway.
+ Taking off, on the leftmost runway.
+ Taking off, on the rightmost ruway.
+ The original parameters of the runway strip, with no obstructions present.
Clicking on any calculated parameters will provide a textual breakdown of the calculations performed, for easier cross-referencing with manual calculations.
These textual breakdowns can be exported to a file for later usage.

### Console Commands
`none`
Section Five: Visualisations
======
The two visualisations provide a simple visual overview of the situation on the runway. They automatically update to the situation as it is input.
The visualisation can be switched between both left and right as well as landing and takeoff.
The arrow keys, as well as the N, M, O, P keys can be used to control the visualisation as well as the on-screen controls. Holding Shift makes this move faster.

1. There are both on-screen and keybinding controls available. These allow for the (top-down) visualisation to be panned, zoomed, and rotated to give a better overview of the situation.
2. A compass allows for bearings to be obtained with true North.
### Console Commands
`resetvis, exportvis`
Section Six: Console Cheatsheet
======
This information is also available from typing `<command>usage`.
`airportnew` - "Name" "Path_To_Runway_File" "Path_To_Obstruction_File"
(2 Parameters) Create a new airport with the 2 given .xml files.
`airport` "Path_To_Airport_File"
(1 Parameter) Loads an aiport from a .ser file.
`lang` language_code
(1 Parameter) Changes the language to the given country code.
`exportvis`
(0 Parameters) Saves a screenshot of the current visualisation to the working directory.
`resetvis`
(0 Parameters) Resets the visualisation pan, zoom, and rotation.
`manual`
(0 Parameters) Opens the user manual.
`runway` "Name" ID TODA_From_Left TODA_From_Right TORA ASDA_From_Left ASDA_From_Right LDA Plane_Blast_Distance
(9 Parameters) Create a new runway with the specified parameters.
`obst` "Name" Width Height Length Position_Along_Runway Distance_From_Centreline
(6 Parameters) Create a new obstruction with the specified parameters.
`help`
(0 Parameters) Displays all available commands.
| 40.22807 | 296 | 0.785725 | eng_Latn | 0.99784 |
976abb45b3b244489db652d1d1259edaaf5b1d00 | 46,888 | md | Markdown | CHANGELOG.md | aeciotr/Bodiless-JS | fb24192a0088b400e9d918a723ce2328c1b7c7f2 | [
"Apache-2.0"
] | null | null | null | CHANGELOG.md | aeciotr/Bodiless-JS | fb24192a0088b400e9d918a723ce2328c1b7c7f2 | [
"Apache-2.0"
] | 1 | 2021-10-05T18:57:35.000Z | 2021-10-05T18:57:35.000Z | CHANGELOG.md | aeciotr/Bodiless-JS | fb24192a0088b400e9d918a723ce2328c1b7c7f2 | [
"Apache-2.0"
] | 1 | 2021-09-28T14:36:43.000Z | 2021-09-28T14:36:43.000Z | # Change Log
All notable changes to this project will be documented in this file.
See [Conventional Commits](https://conventionalcommits.org) for commit guidelines.
## [0.0.60](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.58...v0.0.60) (2020-11-18)
### Bug Fixes
* **bodiless-layouts:** Add local context menu and activator to flow container items. ([#665](https://github.com/johnsonandjohnson/bodiless-js/issues/665)) ([548d2d6](https://github.com/johnsonandjohnson/bodiless-js/commit/548d2d6051413fc3cae1a8d3fae82851b2906d98))
* **core:** Context Menu Panel for link/image/seo disappear when you mouse moves off ([#639](https://github.com/johnsonandjohnson/bodiless-js/issues/639)) ([43e0d84](https://github.com/johnsonandjohnson/bodiless-js/commit/43e0d84e3235845dc4938c41526c227c4cb5ad63))
* **gatsby-plugin-ssi:** Each child in a list should have a unique key prop ([#517](https://github.com/johnsonandjohnson/bodiless-js/issues/517)) ([78035b5](https://github.com/johnsonandjohnson/bodiless-js/commit/78035b5a0efa440abad549fe79c26de71e99a4c0))
* **layouts:** Various FlowContainer bugs + Snap Indicator ([#658](https://github.com/johnsonandjohnson/bodiless-js/issues/658)) ([b4fec7b](https://github.com/johnsonandjohnson/bodiless-js/commit/b4fec7bf937c73d379a847b823c823483072ccc1)), closes [#657](https://github.com/johnsonandjohnson/bodiless-js/issues/657) [#654](https://github.com/johnsonandjohnson/bodiless-js/issues/654) [#656](https://github.com/johnsonandjohnson/bodiless-js/issues/656)
* **richtext:** [GAP] 2 clicks are needed on a newly created menu item to open Local context menu [#671](https://github.com/johnsonandjohnson/bodiless-js/issues/671) ([2710ef9](https://github.com/johnsonandjohnson/bodiless-js/commit/2710ef9910c9d0435ab88386f0788105bdf68f79))
* **richtext:** [GAPS] RTE editor doesn't allow for inline files/components (aka inline CTA styled buttons) ([#481](https://github.com/johnsonandjohnson/bodiless-js/issues/481)) ([3647e41](https://github.com/johnsonandjohnson/bodiless-js/commit/3647e41b9e8ac23e0a24ac065a5d0229dc04223c))
### Features
* **components, core, organisms:** Burger Menu with Breadcrumbs ([#637](https://github.com/johnsonandjohnson/bodiless-js/issues/637)) ([23af96d](https://github.com/johnsonandjohnson/bodiless-js/commit/23af96d68bc49a64ea71131071cd4392311a3593))
* **components, ui:** Updates to the Main Menu Links ([#672](https://github.com/johnsonandjohnson/bodiless-js/issues/672)) ([ca0e823](https://github.com/johnsonandjohnson/bodiless-js/commit/ca0e8234089dacccc7ea38fa3a8e953e38e78045))
* **core, layouts, layouts-ui:** Add "Clear" Functionality for Component Library Filters ([#669](https://github.com/johnsonandjohnson/bodiless-js/issues/669)) ([df03dbf](https://github.com/johnsonandjohnson/bodiless-js/commit/df03dbf85368ee6c9b9223a5dc356b7880d09b71)), closes [#668](https://github.com/johnsonandjohnson/bodiless-js/issues/668)
* **fclasses:** Design Keys ([#685](https://github.com/johnsonandjohnson/bodiless-js/issues/685)) ([0db060a](https://github.com/johnsonandjohnson/bodiless-js/commit/0db060ad1e7496553cd8eae3654770530d543010)), closes [#660](https://github.com/johnsonandjohnson/bodiless-js/issues/660)
* **migration-tool:** migrate site skeleton ([#678](https://github.com/johnsonandjohnson/bodiless-js/issues/678)) ([db01c52](https://github.com/johnsonandjohnson/bodiless-js/commit/db01c52b30e3b9cc6c8440fcf54c3d4d96cf4879))
* Purge CSS Enhancements ([#632](https://github.com/johnsonandjohnson/bodiless-js/issues/632)) ([9f9c6de](https://github.com/johnsonandjohnson/bodiless-js/commit/9f9c6dee725389887066702295ee447990d69b67))
* **search:** component library search component ([#592](https://github.com/johnsonandjohnson/bodiless-js/issues/592)) ([faa2219](https://github.com/johnsonandjohnson/bodiless-js/commit/faa2219a5dc5b66cbb3fd2a8eba6d24a04d3d38f))
## [0.0.59](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.58...v0.0.59) (2020-11-05)
### Bug Fixes
* **core:** Context Menu Panel for link/image/seo disappear when you mouse moves off ([#639](https://github.com/johnsonandjohnson/bodiless-js/issues/639)) ([43e0d84](https://github.com/johnsonandjohnson/bodiless-js/commit/43e0d84e3235845dc4938c41526c227c4cb5ad63))
* **layouts:** Various FlowContainer bugs + Snap Indicator ([#658](https://github.com/johnsonandjohnson/bodiless-js/issues/658)) ([b4fec7b](https://github.com/johnsonandjohnson/bodiless-js/commit/b4fec7bf937c73d379a847b823c823483072ccc1)), closes [#657](https://github.com/johnsonandjohnson/bodiless-js/issues/657) [#654](https://github.com/johnsonandjohnson/bodiless-js/issues/654) [#656](https://github.com/johnsonandjohnson/bodiless-js/issues/656)
### Features
* **search:** component library search component ([#592](https://github.com/johnsonandjohnson/bodiless-js/issues/592)) ([faa2219](https://github.com/johnsonandjohnson/bodiless-js/commit/faa2219a5dc5b66cbb3fd2a8eba6d24a04d3d38f))
## [0.0.58](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.57...v0.0.58) (2020-10-23)
### Features
* **components,organisms:** Mega-menu support ([#572](https://github.com/johnsonandjohnson/bodiless-js/issues/572)) ([9f43d0e](https://github.com/johnsonandjohnson/bodiless-js/commit/9f43d0e38abd7b7ac48d8ea1c3c06a97cf48fdef)), closes [#546](https://github.com/johnsonandjohnson/bodiless-js/issues/546)
## [0.0.57](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.56...v0.0.57) (2020-10-15)
### Bug Fixes
* **core:** The forms overlay the bottom part of Local Menus ([#562](https://github.com/johnsonandjohnson/bodiless-js/issues/562)) ([cd1458f](https://github.com/johnsonandjohnson/bodiless-js/commit/cd1458f52658d372fa83921c9a331d4060f45f9e))
* **richtext, richtext-ui:** Additional ... in RTE throws type is invalid error and serves WSOD ([#536](https://github.com/johnsonandjohnson/bodiless-js/issues/536)) ([d35ddd4](https://github.com/johnsonandjohnson/bodiless-js/commit/d35ddd43b9a26f43d0adcf8adbc91cde3f2d6463))
### Features
* **components:** youtube and iframe ([#569](https://github.com/johnsonandjohnson/bodiless-js/issues/569)) ([388166c](https://github.com/johnsonandjohnson/bodiless-js/commit/388166cdbeebedc71bd287c2794867c76f09b794))
* **core:** Remove submit button from non-interactive forms ([#564](https://github.com/johnsonandjohnson/bodiless-js/issues/564)) ([3382d54](https://github.com/johnsonandjohnson/bodiless-js/commit/3382d54acc98735e7fdc49ab843c06b5a39cc271))
* **core, layouts:** Closing Main Menu Panel Windows ([#571](https://github.com/johnsonandjohnson/bodiless-js/issues/571)) ([3e0b9f0](https://github.com/johnsonandjohnson/bodiless-js/commit/3e0b9f0df681c146e61d1905c312706dd11d5f1d))
### BREAKING CHANGES
* **core:** Describe the nature of the breaking change here.
More Details about the breaking change.
-->
## [0.0.56](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.55...v0.0.56) (2020-09-21)
### Bug Fixes
* **richtext:** Slate editor in tooltip with shared node. ([#540](https://github.com/johnsonandjohnson/bodiless-js/issues/540)) ([5c62a77](https://github.com/johnsonandjohnson/bodiless-js/commit/5c62a77f531cbee1128e4a7adbea0ab951de9f68)), closes [#535](https://github.com/johnsonandjohnson/bodiless-js/issues/535)
### Features
* **backend, components:** Image files should be uploaded to path per page ([#527](https://github.com/johnsonandjohnson/bodiless-js/issues/527)) ([8bffeac](https://github.com/johnsonandjohnson/bodiless-js/commit/8bffeacfa2a1fdc4dc7ff61dea9aaff360673af8))
* **core:** Improved Context Menu API ([#519](https://github.com/johnsonandjohnson/bodiless-js/issues/519)) ([463e8f6](https://github.com/johnsonandjohnson/bodiless-js/commit/463e8f61a8e13af6b6c62428d2b6a63fce197cb7)), closes [#3](https://github.com/johnsonandjohnson/bodiless-js/issues/3) [#487](https://github.com/johnsonandjohnson/bodiless-js/issues/487) [#486](https://github.com/johnsonandjohnson/bodiless-js/issues/486)
* **gatsby-theme-bodiless:** Image generation on upload ([#531](https://github.com/johnsonandjohnson/bodiless-js/issues/531)) ([6524581](https://github.com/johnsonandjohnson/bodiless-js/commit/65245814df2e2b90a86f7fe12696c00126b14498))
* **gatsby-theme-bodiless, backend:** Better handling of merge conflicts ([#502](https://github.com/johnsonandjohnson/bodiless-js/issues/502)) ([8ae1edb](https://github.com/johnsonandjohnson/bodiless-js/commit/8ae1edb3457a91b1013125209d7dd22e2f0ea7fd))
* **ui, layouts-ui:** Simplify Component Resizing ([#532](https://github.com/johnsonandjohnson/bodiless-js/issues/532)) ([6a3896a](https://github.com/johnsonandjohnson/bodiless-js/commit/6a3896a2c9a5661b62abdb253025098d6755622e))
### Reverts
* Revert "Update README.md" ([8ae3c5c](https://github.com/johnsonandjohnson/bodiless-js/commit/8ae3c5c4a14b49153480590ae8af059c46bd4976))
## [0.0.55](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.54...v0.0.55) (2020-08-28)
### Bug Fixes
* **cypress:** Link Toggle smoke tests fails intermittently ([#525](https://github.com/johnsonandjohnson/bodiless-js/issues/525)) ([afa155a](https://github.com/johnsonandjohnson/bodiless-js/commit/afa155a076fe2c1958f401f59c22fd14f54221cf))
* **starter-kit:** Starter kit cleanup ([#482](https://github.com/johnsonandjohnson/bodiless-js/issues/482)) ([6bf6b1f](https://github.com/johnsonandjohnson/bodiless-js/commit/6bf6b1f46d42a0d585c1eefbc346a5abf4ca3e32))
### Features
* **core-ui, ui:** Standardize Admin UI Icons and Labels ([#516](https://github.com/johnsonandjohnson/bodiless-js/issues/516)) ([576af00](https://github.com/johnsonandjohnson/bodiless-js/commit/576af002a3079e5dc8ddeeb3e98537f48cb698f7))
* **gatsby-theme-bodiless, core, ui:** Unify global menu modal and spinner behavior in form actions ([#503](https://github.com/johnsonandjohnson/bodiless-js/issues/503)) ([e5d7a76](https://github.com/johnsonandjohnson/bodiless-js/commit/e5d7a762694e9925c096f048421eca2535e0e8a4)), closes [#410](https://github.com/johnsonandjohnson/bodiless-js/issues/410)
* **layouts:** Simplify the IA of the Filter System ([#512](https://github.com/johnsonandjohnson/bodiless-js/issues/512)) ([9694175](https://github.com/johnsonandjohnson/bodiless-js/commit/9694175e620cb757a2f855f1313b640479b4aa62))
## [0.0.54](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.53...v0.0.54) (2020-08-24)
### Bug Fixes
* **cli:** npm ENOENT on spawning processes on windows ([#498](https://github.com/johnsonandjohnson/bodiless-js/issues/498)) ([08ccebe](https://github.com/johnsonandjohnson/bodiless-js/commit/08ccebe095cd7f896d894e6a89ee8a5ec1fdf1dc))
### Features
* **fclasses:** Allow adding/removing classes conditionally via fclasses ([#440](https://github.com/johnsonandjohnson/bodiless-js/issues/440)) ([d3d522b](https://github.com/johnsonandjohnson/bodiless-js/commit/d3d522b22e88e39a86f7c36fb21cd7b0dfd978da))
* **layouts:** Update the Rich Text Options in the Component Picker ([#497](https://github.com/johnsonandjohnson/bodiless-js/issues/497)) ([28a0771](https://github.com/johnsonandjohnson/bodiless-js/commit/28a0771e3a4fb84bcde24b7894d32be742a98b81))
* **test-site:** Image component: 'swap' operation is not transfering data between linkable and non-linkable components ([#507](https://github.com/johnsonandjohnson/bodiless-js/issues/507)) ([bbe8302](https://github.com/johnsonandjohnson/bodiless-js/commit/bbe830292aa604e438425fe2dccf41af7d7d2bb9))
### BREAKING CHANGES
* **fclasses:** chaining support is removed from addClasses and removeClasses. If your code contains chained addClasses/removeClasses, you need to replace the chaining with flow/flowIf or any other helpers that provides functional composition.
For example, when you have in your code
```
addClasses('classA').removeClasses('classB')
```
you need to change it to
```
flow(
addClasses('classA'),
removeClasses('classB'),
)
```
## [0.0.53](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.52...v0.0.53) (2020-08-13)
### Bug Fixes
* **bodiless-ui:** erroneus area error during gatsby build ([#491](https://github.com/johnsonandjohnson/bodiless-js/issues/491)) ([2dc2a49](https://github.com/johnsonandjohnson/bodiless-js/commit/2dc2a4980cbdaab8a48163072a4946de09001b01))
* **components:** Fix invalid prop warning when toggling to a fragment in preview mode. ([#495](https://github.com/johnsonandjohnson/bodiless-js/issues/495)) ([ad06710](https://github.com/johnsonandjohnson/bodiless-js/commit/ad067100a1b892319a94066bcfe5b6e20c60fb2b))
## [0.0.52](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.51...v0.0.52) (2020-07-29)
### Bug Fixes
* **test-site:** Add Page padding on example site ([#454](https://github.com/johnsonandjohnson/bodiless-js/issues/454)) ([66ab492](https://github.com/johnsonandjohnson/bodiless-js/commit/66ab492e3c3b4bb560b8474188e953b71b263410))
* **test-site:** Change gallery-final header to landscape image ([#452](https://github.com/johnsonandjohnson/bodiless-js/issues/452)) ([d1457d1](https://github.com/johnsonandjohnson/bodiless-js/commit/d1457d15f173cccf3eebd61347c3c2dcf15ac156))
* **test-site:** Editable 404 with flowcontainer ([#457](https://github.com/johnsonandjohnson/bodiless-js/issues/457)) ([51e2239](https://github.com/johnsonandjohnson/bodiless-js/commit/51e223905c0a55e9e752dd9d7dd93ee328ef56b3))
* **test-site:** Fix contentful link ([#444](https://github.com/johnsonandjohnson/bodiless-js/issues/444)) ([cdd6301](https://github.com/johnsonandjohnson/bodiless-js/commit/cdd6301059864eb25e1fd4324dcee0c9602ebe79))
* **test-site:** Reusable Logo ([#455](https://github.com/johnsonandjohnson/bodiless-js/issues/455)) ([599603b](https://github.com/johnsonandjohnson/bodiless-js/commit/599603b972640ef96da288d2feecebdd3678bd07))
### Features
* **core-ui:** add a warning element for user warning messages ([f40eb6c](https://github.com/johnsonandjohnson/bodiless-js/commit/f40eb6cd8b7271f90c3895cc623e1a8778cfb9c9)), closes [#416](https://github.com/johnsonandjohnson/bodiless-js/issues/416)
* **documentation:** API Doc for Site builder ([#474](https://github.com/johnsonandjohnson/bodiless-js/issues/474)) ([14e7594](https://github.com/johnsonandjohnson/bodiless-js/commit/14e75948f2856908f24781b64469df6c8810e7c6))
* **documentation:** Document API documentation standards for JSDoc ([#414](https://github.com/johnsonandjohnson/bodiless-js/issues/414)) ([95af4e2](https://github.com/johnsonandjohnson/bodiless-js/commit/95af4e2f7401e8867466414bd1277c5c9ab67903))
* **gatsby-theme-bodiless:** Refresh on pull that has upstream changes ([#395](https://github.com/johnsonandjohnson/bodiless-js/issues/395)) ([0e76057](https://github.com/johnsonandjohnson/bodiless-js/commit/0e76057e714347071086044a766d1218cf70f1dc))
* **gatsby-theme-bodiless:** Retry on Error When Saving to the Backend ([#419](https://github.com/johnsonandjohnson/bodiless-js/issues/419)) ([931e87c](https://github.com/johnsonandjohnson/bodiless-js/commit/931e87c56fba2b04ee66fb90b7c143dd9c01a2c0))
## [0.0.51](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.50...v0.0.51) (2020-07-01)
### Bug Fixes
* **components:** an image cannot be added in a component if a previous attempt was unsuccessful ([#367](https://github.com/johnsonandjohnson/bodiless-js/issues/367)) ([09963e7](https://github.com/johnsonandjohnson/bodiless-js/commit/09963e7897993cf21370938735654a8f03a3828c))
* **migration-tool:** ENOTDIR not a directory error during build ([#386](https://github.com/johnsonandjohnson/bodiless-js/issues/386)) ([144701e](https://github.com/johnsonandjohnson/bodiless-js/commit/144701e5cfd7483d14bc3742f4f04cec31ce2c19))
* **test-site:** Component Picker titles/descriptions ([#385](https://github.com/johnsonandjohnson/bodiless-js/issues/385)) ([a74db4f](https://github.com/johnsonandjohnson/bodiless-js/commit/a74db4fffe42c43e7016b8debaa81894b6378fd3))
* **test-site:** Test site needs Footer rendered with new design api [#288](https://github.com/johnsonandjohnson/bodiless-js/issues/288) ([#378](https://github.com/johnsonandjohnson/bodiless-js/issues/378)) ([e902f48](https://github.com/johnsonandjohnson/bodiless-js/commit/e902f48aeff4fd734064743c38bd41f5ff1c1a27))
### Features
* **components:** remove the # from the link URL input field ([#373](https://github.com/johnsonandjohnson/bodiless-js/issues/373)) ([9ca6caa](https://github.com/johnsonandjohnson/bodiless-js/commit/9ca6caa888c1d69f559a224e7c14f4ceec18978f)), closes [#374](https://github.com/johnsonandjohnson/bodiless-js/issues/374)
* **core, ui:** Notify of Upstream Changes in Edit Environment ([#368](https://github.com/johnsonandjohnson/bodiless-js/issues/368)) ([769d1dc](https://github.com/johnsonandjohnson/bodiless-js/commit/769d1dc1fecbbe2ca892685ff9094b7f0066f4b4))
* **layout:** component picker open by default ([#393](https://github.com/johnsonandjohnson/bodiless-js/issues/393)) ([fc0513a](https://github.com/johnsonandjohnson/bodiless-js/commit/fc0513ac53b705788ef9eec45b07c7987bbb3074)), closes [#264](https://github.com/johnsonandjohnson/bodiless-js/issues/264)
## [0.0.50](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.49...v0.0.50) (2020-06-12)
### Features
* **documentation:** allow to override doc site resources locally ([#369](https://github.com/johnsonandjohnson/bodiless-js/issues/369)) ([1884179](https://github.com/johnsonandjohnson/bodiless-js/commit/18841798e5d22d69c12230ec41c91e0150dbda72))
* **gatsby-theme-bodiless, components, core, layouts:** Add labels and update icons for admin menu ([#361](https://github.com/johnsonandjohnson/bodiless-js/issues/361)) ([93e7033](https://github.com/johnsonandjohnson/bodiless-js/commit/93e70339b804824f167fdf53df4cca042c5ba6c0))
## [0.0.49](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.48...v0.0.49) (2020-06-08)
### Bug Fixes
* **Example Test Site:** Submenu items lost their background style. ([#356](https://github.com/johnsonandjohnson/bodiless-js/issues/356)) ([0e2d719](https://github.com/johnsonandjohnson/bodiless-js/commit/0e2d719bd67b9a9171997fdfdefefa9ee9094ffb))
* **gatsby-theme-bodiless:** Revert pulling the changes to local when "Pull" is executed ([#358](https://github.com/johnsonandjohnson/bodiless-js/issues/358)) ([022ac75](https://github.com/johnsonandjohnson/bodiless-js/commit/022ac757c60a86667050eb2b823503dd1f3d9abc))
* **migration-tool:** postbuild should not trim ssi elements from generated html ([#362](https://github.com/johnsonandjohnson/bodiless-js/issues/362)) ([5a4477f](https://github.com/johnsonandjohnson/bodiless-js/commit/5a4477f3c38437b71cea3be570bed37a92a9fead))
* **test-site:** Fix missing registerSuggestions on filter-item page ([#340](https://github.com/johnsonandjohnson/bodiless-js/issues/340)) ([211da0c](https://github.com/johnsonandjohnson/bodiless-js/commit/211da0c0bbb50222091ea0c6e5e5c5e0e26a59a7))
### Features
* **core, ui:** Notifications/Alerts. ([#346](https://github.com/johnsonandjohnson/bodiless-js/issues/346)) ([136abd3](https://github.com/johnsonandjohnson/bodiless-js/commit/136abd355ed7a99deb6e21718a3d6aaf5041c898)), closes [#300](https://github.com/johnsonandjohnson/bodiless-js/issues/300)
* **gatsby-theme-bodiless:** Merge Production Changes on Pull ([#353](https://github.com/johnsonandjohnson/bodiless-js/issues/353)) ([4c6808e](https://github.com/johnsonandjohnson/bodiless-js/commit/4c6808e73b91da665c87e58ec35a36fd6574793f))
* **Migration tool:** Migrate page and resource redirections. ([#309](https://github.com/johnsonandjohnson/bodiless-js/issues/309)) ([4b4163b](https://github.com/johnsonandjohnson/bodiless-js/commit/4b4163bf50a272df2da4f38d8921762382624488))
## [0.0.48](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.47...v0.0.48) (2020-05-20)
### Bug Fixes
* **migration-tool:** TypeError: tag[primaryAttributeKey].toLowerCase is not a function ([8c3fde5](https://github.com/johnsonandjohnson/bodiless-js/commit/8c3fde5208c8516a7fe9864798db69c89d035125))
* **richtext:** richtext is not refreshed on server data change ([#292](https://github.com/johnsonandjohnson/bodiless-js/issues/292)) ([df0075d](https://github.com/johnsonandjohnson/bodiless-js/commit/df0075d5c8b856b7be61524e13e90e09c03acf4a))
* **test-site:** Highlighting Link in Tout replaced it with actual href link ([28ad049](https://github.com/johnsonandjohnson/bodiless-js/commit/28ad049e872fdacdf238051c8959e2c8b544a48c))
* **ui:** Adjust contextual menu position ([#319](https://github.com/johnsonandjohnson/bodiless-js/issues/319)) ([e16e299](https://github.com/johnsonandjohnson/bodiless-js/commit/e16e2995dd88e0aca7ec1fbd21586358d327accd))
### Features
* **backend:** Add API to check for upstream changes. ([#314](https://github.com/johnsonandjohnson/bodiless-js/issues/314)) ([554a29e](https://github.com/johnsonandjohnson/bodiless-js/commit/554a29edd76af237765ffd4ec6a62850cdda357d)), closes [#312](https://github.com/johnsonandjohnson/bodiless-js/issues/312)
* **cli:** Create CLI to install local packages ([#188](https://github.com/johnsonandjohnson/bodiless-js/issues/188)) ([4d78c7a](https://github.com/johnsonandjohnson/bodiless-js/commit/4d78c7a86aab1bc1286d14f4da50dcfb923ddde9)), closes [#187](https://github.com/johnsonandjohnson/bodiless-js/issues/187)
* **Compoenet:** "Filterable Metadata" Component ([#276](https://github.com/johnsonandjohnson/bodiless-js/issues/276)) ([159ccb0](https://github.com/johnsonandjohnson/bodiless-js/commit/159ccb0351fe6cce932099e08bc6107f458e3707))
* **components:** Youtube video component ([#328](https://github.com/johnsonandjohnson/bodiless-js/issues/328)) ([344d44e](https://github.com/johnsonandjohnson/bodiless-js/commit/344d44ef08b433427be5566330048a7a5ffe3fe5))
* **components, components-ui:** Add Image Component ([#316](https://github.com/johnsonandjohnson/bodiless-js/issues/316)) ([a3fba5d](https://github.com/johnsonandjohnson/bodiless-js/commit/a3fba5dc9ad7f53f1c95168dc9aa7d3f5c4754ad))
* **components, organisms:** PLP Utilizes Filtering System ([#291](https://github.com/johnsonandjohnson/bodiless-js/issues/291)) ([9ba3fe8](https://github.com/johnsonandjohnson/bodiless-js/commit/9ba3fe88e8d0c3f861b9d8b0b69ee0217759cda4))
* **core:** Sidecar Node API ([#320](https://github.com/johnsonandjohnson/bodiless-js/issues/320)) ([1c61274](https://github.com/johnsonandjohnson/bodiless-js/commit/1c61274ea1e45e81210bfd5f05f06c6244977abb)), closes [#285](https://github.com/johnsonandjohnson/bodiless-js/issues/285) [#321](https://github.com/johnsonandjohnson/bodiless-js/issues/321)
* **gatsby-theme-bodiless:** pull upstream changes. ([78a2050](https://github.com/johnsonandjohnson/bodiless-js/commit/78a2050adbb6498cc15d1d1184e068130a61d356)), closes [#303](https://github.com/johnsonandjohnson/bodiless-js/issues/303) [#303](https://github.com/johnsonandjohnson/bodiless-js/issues/303)
* **organisms:** "Filter by Tag" Component. ([#241](https://github.com/johnsonandjohnson/bodiless-js/issues/241)) ([e043bd8](https://github.com/johnsonandjohnson/bodiless-js/commit/e043bd8b508e1be2fcbd0676116b34550aa39dd6))
### BREAKING CHANGES
* **components, components-ui:** * Styles of @bodiless/components image picker changed. Functionality of image picker is not impacted, just visual appearance changed. If a site uses Image or asBodilessImage from @bodiless/components, then the site is impacted. The recommended migration path is to change Image and asBodilessImage import from "@bodiless/components" into "@bodiless/components-ui". Example of the migration can be found in test site.
## [0.0.47](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.46...v0.0.47) (2020-04-22)
### Bug Fixes
* **migration-tool:** renamed an attribute reserved for extracting common components ([#240](https://github.com/johnsonandjohnson/bodiless-js/issues/240)) ([e075b49](https://github.com/johnsonandjohnson/bodiless-js/commit/e075b49ca9fec68b51c807b3fb458e681b19f7d5))
* **migration-tool:** site build failed due to invalid page content ([#272](https://github.com/johnsonandjohnson/bodiless-js/issues/272)) ([92dc154](https://github.com/johnsonandjohnson/bodiless-js/commit/92dc1547bd8a71b73a142acc5446f039bcabb97a))
### Features
* **core:** component default content ([#219](https://github.com/johnsonandjohnson/bodiless-js/issues/219)) ([379e655](https://github.com/johnsonandjohnson/bodiless-js/commit/379e6559de3471214e45132ed493deed63ecfb38))
* **layout:** Rename Flexbox to FlowContainer ([#118](https://github.com/johnsonandjohnson/bodiless-js/issues/118)) ([aa295bb](https://github.com/johnsonandjohnson/bodiless-js/commit/aa295bb77ed512a1040ed047d784a787dcd2b71a))
* **migration-tool:** Migrate 404 page ([#260](https://github.com/johnsonandjohnson/bodiless-js/issues/260)) ([c93471a](https://github.com/johnsonandjohnson/bodiless-js/commit/c93471a91edd52ee433fe97a9ecc55dd5b5e34b6))
* **release, publish:** Automate package publication on GitHub - Update release document. ([#269](https://github.com/johnsonandjohnson/bodiless-js/issues/269)) ([f16b5c7](https://github.com/johnsonandjohnson/bodiless-js/commit/f16b5c72aa49926add2f51bbac2d6c88912017d7))
## [0.0.46](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.45...v0.0.46) (2020-04-08)
**Note:** Version bump only for package bodiless-js
## [0.0.45](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.44...v0.0.45) (2020-04-08)
### Bug Fixes
* **docs:** Docs Homepage is lost on gh-pages ([#249](https://github.com/johnsonandjohnson/bodiless-js/issues/249)) ([051eea7](https://github.com/johnsonandjohnson/bodiless-js/commit/051eea72592cc80a8f8a859f1fc6e24674c08b93))
* **migration-tool:** Improve script content transformation ([#239](https://github.com/johnsonandjohnson/bodiless-js/issues/239)) ([05117d2](https://github.com/johnsonandjohnson/bodiless-js/commit/05117d29912cca332daf06ebcb18f9425645cd92))
* **psh:** Provide default psh cache expiry for /__docs ([#261](https://github.com/johnsonandjohnson/bodiless-js/issues/261)) ([f00ead7](https://github.com/johnsonandjohnson/bodiless-js/commit/f00ead7f387c0e51492171ae6b341ce972a0a5bb))
### Features
* **core-ui:** Implement reusable modal overlay and use in create page & … ([#216](https://github.com/johnsonandjohnson/bodiless-js/issues/216)) ([230334e](https://github.com/johnsonandjohnson/bodiless-js/commit/230334eca8a99ecb05be486c28372f9e5835b975))
* **example/test-site:** Updated the test site to have the correct pa… ([#236](https://github.com/johnsonandjohnson/bodiless-js/issues/236)) ([6729765](https://github.com/johnsonandjohnson/bodiless-js/commit/6729765d3a543b11e2bc9cc4be537d3f7aa0dfc5))
* **psh:** Provide default psh cache expiry and allow local override ([#220](https://github.com/johnsonandjohnson/bodiless-js/issues/220)) ([4fb1e81](https://github.com/johnsonandjohnson/bodiless-js/commit/4fb1e8146c9d68f6195f2b96b39cd864f5c35cf0))
### BREAKING CHANGES
* **psh:** - Instead of just copying `*.platform.app.yaml` files it will merge existing local versions with a default version from `@bodiless/psh` with local versions taking precedence. Only keys from `/bodiless-psh/resources/.platform/platform.whitelist.yaml` will be merged
## [0.0.44](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.43...v0.0.44) (2020-03-26)
### Bug Fixes
* **@bodiless/migration-tool:** scrape video file injected using video html element ([#210](https://github.com/johnsonandjohnson/bodiless-js/issues/210)) ([d8c7d9c](https://github.com/johnsonandjohnson/bodiless-js/commit/d8c7d9c7a1337eec25d740dda05895aeba7326d2))
### Features
* **components:** Add google tag manager & datalayer. ([#207](https://github.com/johnsonandjohnson/bodiless-js/issues/207)) ([9ee52e3](https://github.com/johnsonandjohnson/bodiless-js/commit/9ee52e39741004d263a5c06055520b197947f942))
* **gatsby-theme-bodiless, starter, test-site:** purge unused css ([#195](https://github.com/johnsonandjohnson/bodiless-js/issues/195)) ([1b54d82](https://github.com/johnsonandjohnson/bodiless-js/commit/1b54d82e53d0d72291a2ed3273e5b853c182e299))
* **gatsby-theme, backend, core, richtext, components, organisms:** Deleted Data Should Not be Retained ([#144](https://github.com/johnsonandjohnson/bodiless-js/issues/144)) ([0821c89](https://github.com/johnsonandjohnson/bodiless-js/commit/0821c897b1e6894c418ec78bac58fccdb969caa7)), closes [#14](https://github.com/johnsonandjohnson/bodiless-js/issues/14)
* **layouts:** Define Design for the Flexbox ([#209](https://github.com/johnsonandjohnson/bodiless-js/issues/209)) ([cd9f6ca](https://github.com/johnsonandjohnson/bodiless-js/commit/cd9f6ca68d4f4f34d5526eec9dccbcee21b54e00))
* **migration-tool:** Enhance handling of non-existing source site resources ([#191](https://github.com/johnsonandjohnson/bodiless-js/issues/191)) ([63fea0e](https://github.com/johnsonandjohnson/bodiless-js/commit/63fea0e2384bb7467856ae7f0c2c324e4eb87e7b))
* **organisms:** Element selector enhancement for Single Accordion ([#206](https://github.com/johnsonandjohnson/bodiless-js/issues/206)) ([6325670](https://github.com/johnsonandjohnson/bodiless-js/commit/6325670012d020d0807ee2304c156cb45dfab279))
### BREAKING CHANGES
* **gatsby-theme-bodiless, starter, test-site:** bodiless/components does not export Link component anymore. One, who consumes Link component, should replace Link with a site level link component.
* **gatsby-theme, backend, core, richtext, components, organisms:** 1. Submenu data model changed. The first reason is to make menu/submenu data model similar to list/sublist data models, so that menu/submenu can leverage api provided by list component. The second reason is to solve a submenu bug in which one json file stores data from multiple nodes. Particularly, submenu item stores toggle and a list sublist items. One, who has a submenu on a site, will have to either update existing submenu json files or recreate submenu. Example how to update submenu json files of existing site is demonstrated on the demo site. pr 41.
2. Accordion changes. Node is removed from SingleAccordionClean. The reason is to provide consumers more control over how the node is added to accordion. Particularly, this change was needed for burgermenu, which leverages accordions, so that burgermenu can read submenu data from accurate node. One, who uses SingleAccordionClean to compose custom accordions, should inject node to the custom accordions. Example can be found in test-site/src/components/SingleAccordion/index.tsx. withNode has been added to asSingleAccordion.
## [0.0.43](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.42...v0.0.43) (2020-03-11)
### Bug Fixes
* **bodiless-migration-tool:** allow to migrate a site with bareroot domain specified ([#186](https://github.com/johnsonandjohnson/bodiless-js/issues/186)) ([4d24c07](https://github.com/johnsonandjohnson/bodiless-js/commit/4d24c072de158f395b2e5c4bf8ea2e41209d7b24))
* **components, core:** Fix withEditPlaceholder components order ([3c1f99b](https://github.com/johnsonandjohnson/bodiless-js/commit/3c1f99b38bf437d97d4ffc2e062fd91d295184ca))
* **layouts:** Fix/no link in flexbox ([#198](https://github.com/johnsonandjohnson/bodiless-js/issues/198)) ([066f0ed](https://github.com/johnsonandjohnson/bodiless-js/commit/066f0ed6659d1f983f12b32956748df6b02d5c6a))
* **migration-tool:** Header and Footer components are missing ([c4e6a82](https://github.com/johnsonandjohnson/bodiless-js/commit/c4e6a827ba4f0df425fd93ab586ab1a4ea2fdfad))
* **psh:** Platform.sh site return 502 error instead of 404 page on non-existing pages. ([ca72aa6](https://github.com/johnsonandjohnson/bodiless-js/commit/ca72aa6be33b91f9f439d92d326b4ffcb7fa9e6e))
### Features
* **migration-tool:** Provide fallback on migration errors to generate plain html. ([#175](https://github.com/johnsonandjohnson/bodiless-js/issues/175)) ([8d9a003](https://github.com/johnsonandjohnson/bodiless-js/commit/8d9a003ec81c9a1d202b8d82cfddf80a16d04044))
## [0.0.42](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.41...v0.0.42) (2020-02-28)
### Bug Fixes
### Features
* **components:** Add withEditPlaceholder HOC to bodiless-components ([#174](https://github.com/johnsonandjohnson/bodiless-js/issues/174)) ([c1380e3](https://github.com/johnsonandjohnson/bodiless-js/commit/c1380e3b9cdc7aee7e5fe018b179b0627148970c))
### BREAKING CHANGES
## [0.0.41](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.40...v0.0.41) (2020-02-28)
### Bug Fixes
* **bodiless-backend:** do not require morgan when it is disabled ([#159](https://github.com/johnsonandjohnson/bodiless-js/issues/159)) ([35a6756](https://github.com/johnsonandjohnson/bodiless-js/commit/35a6756bf3cef23b05790bb3746ee388d8ef4e32))
* **migration_tool:** Migration tool fix default value for disableTailwind ([#163](https://github.com/johnsonandjohnson/bodiless-js/issues/163)) ([65a2d3f](https://github.com/johnsonandjohnson/bodiless-js/commit/65a2d3fcc874a521e8cf45c6c1476637db5c1c55))
* npm run new & npm run sites:update starter fail with errors ([#153](https://github.com/johnsonandjohnson/bodiless-js/issues/153)) ([a998f5f](https://github.com/johnsonandjohnson/bodiless-js/commit/a998f5f220f26cfd653577dcdd1163832990352c))
### Features
* **bodiless-core:** edit ui should start in preview mode ([#170](https://github.com/johnsonandjohnson/bodiless-js/issues/170)) ([22b4f4c](https://github.com/johnsonandjohnson/bodiless-js/commit/22b4f4c74cf0ce9ab2e30cb87bffe428bddd7fb9))
* **layouts:** Allow specifying default width for flexbox item. ([#164](https://github.com/johnsonandjohnson/bodiless-js/issues/164)) ([9a4bc2f](https://github.com/johnsonandjohnson/bodiless-js/commit/9a4bc2f3b842fe212d57c24efec55f7fd0fe3b43)), closes [#162](https://github.com/johnsonandjohnson/bodiless-js/issues/162)
* **migration_tool:** Migration tool enhancement to auto turn off Bodiless-Tailwind Theme ([#155](https://github.com/johnsonandjohnson/bodiless-js/issues/155)) ([4c5203d](https://github.com/johnsonandjohnson/bodiless-js/commit/4c5203d0519c4123cf52cfbeb39987daeaf12d8a))
## [0.0.40](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.39...v0.0.40) (2020-02-21)
### Bug Fixes
* **bodiless-migration-tool:** "UnhandledPromiseRejectionWarning: Error: Page crashed!" thrown by migration tool ([#82](https://github.com/johnsonandjohnson/bodiless-js/issues/82)) ([f966636](https://github.com/johnsonandjohnson/bodiless-js/commit/f966636563e8009ca5f694c71842da3228b865f5))
* **bodiless-richtext:** improved richtext input lag on a page with multiple richtext elements ([#104](https://github.com/johnsonandjohnson/bodiless-js/issues/104)) ([e243b2d](https://github.com/johnsonandjohnson/bodiless-js/commit/e243b2d5f348dd94c603017ee72f06fee8283cb1))
* **gatsby-theme-bodiless:** Deleting json file for any component does not reset content ([#145](https://github.com/johnsonandjohnson/bodiless-js/issues/145)) ([b76eb6e](https://github.com/johnsonandjohnson/bodiless-js/commit/b76eb6ec61c55f0a8864e6dcbd61e2689b6c5ff1))
* **gatsby-theme-bodiless:** Fix revert does not refresh page ([#110](https://github.com/johnsonandjohnson/bodiless-js/issues/110)) ([629b3ef](https://github.com/johnsonandjohnson/bodiless-js/commit/629b3efebc28882932d3e136f385abaccd15b28d))
* **gatsby-theme-bodiless:** Typed chars disappear sporadically ([#52](https://github.com/johnsonandjohnson/bodiless-js/issues/52)) ([4829496](https://github.com/johnsonandjohnson/bodiless-js/commit/48294967948c75707b668f90c76c0ad5d18e6a4d)), closes [#14](https://github.com/johnsonandjohnson/bodiless-js/issues/14) [#14](https://github.com/johnsonandjohnson/bodiless-js/issues/14) [#14](https://github.com/johnsonandjohnson/bodiless-js/issues/14)
* **migration_tool:** 'npm run setup' fails on Windows ([#139](https://github.com/johnsonandjohnson/bodiless-js/issues/139)) ([ac8a580](https://github.com/johnsonandjohnson/bodiless-js/commit/ac8a580887e120ce50c13d545b9ba6b9e89a714a))
* **migration_tool:** do not create a page when an internal url is redirected to an external ([#95](https://github.com/johnsonandjohnson/bodiless-js/issues/95)) ([df5077a](https://github.com/johnsonandjohnson/bodiless-js/commit/df5077abbe2403239a1e7cc5bd9ac56fb9b3d4b6))
* **migration_tool:** issues in FAQ pages ([#126](https://github.com/johnsonandjohnson/bodiless-js/issues/126)) ([2d4a6cb](https://github.com/johnsonandjohnson/bodiless-js/commit/2d4a6cbc219682e4162c5ab77eb128dfd2048c1c))
* **migration_tool:** SyntaxError: Unexpected token ([#84](https://github.com/johnsonandjohnson/bodiless-js/issues/84)) ([208d9f7](https://github.com/johnsonandjohnson/bodiless-js/commit/208d9f7a309ac9fc9fe6d6ecab4ae4a0dc2b685d))
* **psh:** platform.sh files get created with lerna ([#108](https://github.com/johnsonandjohnson/bodiless-js/issues/108)) ([7192372](https://github.com/johnsonandjohnson/bodiless-js/commit/71923720b19a445a7ced190dc6c352f5ad324f0e))
* **psh:** Private npm registry for static site. ([#148](https://github.com/johnsonandjohnson/bodiless-js/issues/148)) ([d3599f7](https://github.com/johnsonandjohnson/bodiless-js/commit/d3599f76c3b015f28b553d1c758ab50abd206ec6))
### Features
* **core:** Alter the Main Menu in Preview Mode ([#132](https://github.com/johnsonandjohnson/bodiless-js/issues/132)) ([abebb43](https://github.com/johnsonandjohnson/bodiless-js/commit/abebb43c48668d8f147cb43c7c4f042b06abd48e))
* **core:** Preview Mode Session ([#117](https://github.com/johnsonandjohnson/bodiless-js/issues/117)) ([4246986](https://github.com/johnsonandjohnson/bodiless-js/commit/4246986e449101a9c63a8043f9a1e2d1b73d0986))
* **documentation:** Support better control over IA ([#129](https://github.com/johnsonandjohnson/bodiless-js/issues/129)) ([05c94fd](https://github.com/johnsonandjohnson/bodiless-js/commit/05c94fdd3ccd860a29d6a81bb5abc3708d7a8157))
* **fclasses:** Change startWith so that it does not replace the whole item but instead just the starting Component ([#57](https://github.com/johnsonandjohnson/bodiless-js/issues/57)) ([71f0b60](https://github.com/johnsonandjohnson/bodiless-js/commit/71f0b60797f45055c58aea8bf8bbc72db2795e5a))
* **layout:** Create a location Switcher for the Edit Admin UI Menu ([#149](https://github.com/johnsonandjohnson/bodiless-js/issues/149)) ([943e960](https://github.com/johnsonandjohnson/bodiless-js/commit/943e960016718b022bcb95471977ea43b6d9afac))
* **layout:** Easily identify a flexbox area on page so that can start… ([#99](https://github.com/johnsonandjohnson/bodiless-js/issues/99)) ([8148e1c](https://github.com/johnsonandjohnson/bodiless-js/commit/8148e1c6201d3ec64fcaf089076c4a37d3fa5923))
* **layouts:** Component Switcher ([#105](https://github.com/johnsonandjohnson/bodiless-js/issues/105)) ([1e1ce8e](https://github.com/johnsonandjohnson/bodiless-js/commit/1e1ce8e7e79dbb66d7ffdad599de117902702b1d)), closes [#69](https://github.com/johnsonandjohnson/bodiless-js/issues/69)
* **psh:** Improve psh-init with better logic for custom overrides. ([#135](https://github.com/johnsonandjohnson/bodiless-js/issues/135)) ([79bbfc5](https://github.com/johnsonandjohnson/bodiless-js/commit/79bbfc559e5ae22297191ca42bb6a2b71345a8b9))
### BREAKING CHANGES
* **fclasses:** startWith functionality will not replace any other HOC that has been previously applied
## 0.0.39 (2020-01-30)
### Bug Fixes
* **p.sh:** Fix env vars are not generated for p.sh. ([#89](https://github.com/johnsonandjohnson/bodiless-js/issues/89)) ([c3d9ed3](https://github.com/johnsonandjohnson/bodiless-js/commit/c3d9ed3f94fe8ba707a4c6e0811e745ded4d3676))
## 0.0.38 (2020-01-29)
### Bug Fixes
* New page form freezes the screen after upgrading informed ([#75](https://github.com/johnsonandjohnson/bodiless-js/issues/75)) ([739a2a2](https://github.com/johnsonandjohnson/bodiless-js/commit/739a2a2c2fed278d8045e25807773e3b19430dac))
* **components:** Remove image button from left menu. ([#87](https://github.com/johnsonandjohnson/bodiless-js/issues/87)) ([ec86536](https://github.com/johnsonandjohnson/bodiless-js/commit/ec86536a6175900bc0ddc8a8d4c9acac0669b806))
* **migration_tool:** removed the logic that determines if the tool is triggered in monorepo ([#62](https://github.com/johnsonandjohnson/bodiless-js/issues/62)) ([4084d3c](https://github.com/johnsonandjohnson/bodiless-js/commit/4084d3cfe71ae754d1475104ea9fc12b8ca04e9a))
* **psh:** Remove docs app from platform.sh ([#78](https://github.com/johnsonandjohnson/bodiless-js/issues/78)) ([8b19fce](https://github.com/johnsonandjohnson/bodiless-js/commit/8b19fce9df66fad21bf98488b0a71486cc84670b)), closes [#1234](https://github.com/johnsonandjohnson/bodiless-js/issues/1234) [#4567](https://github.com/johnsonandjohnson/bodiless-js/issues/4567) [#71](https://github.com/johnsonandjohnson/bodiless-js/issues/71)
* **test-site, documentation:** Fixed a image location in documentation and make small change in test-site from demo prep ([#56](https://github.com/johnsonandjohnson/bodiless-js/issues/56)) ([4de737d](https://github.com/johnsonandjohnson/bodiless-js/commit/4de737d2f815669d93d75f90623b262233254065))
### Features
* **@bodiless/core:** Initial Commit. ([097812f](https://github.com/johnsonandjohnson/bodiless-js/commit/097812f0db2f501306fa25aa9b1612528c5cd6aa))
* **@bodiless/fclasses:** Initial Commit. ([fa9ac2a](https://github.com/johnsonandjohnson/bodiless-js/commit/fa9ac2a55d0517340ca7b5c6837255d0bc704c3c))
* **@bodiless/gatsby-theme-bodiless:** Initial Commit. ([33ab746](https://github.com/johnsonandjohnson/bodiless-js/commit/33ab746af5044c963d2a1d8a2da5e799db006626))
* **@bodiless/psh:** Initial commit. ([c475668](https://github.com/johnsonandjohnson/bodiless-js/commit/c4756681b7fd49bdfa3aab6929401feac3a70fbf))
* Host docs on GitHub Pages ([#6](https://github.com/johnsonandjohnson/bodiless-js/issues/6)) ([a26c386](https://github.com/johnsonandjohnson/bodiless-js/commit/a26c38637260bff013470c169c90d832c1b203fe)), closes [#5](https://github.com/johnsonandjohnson/bodiless-js/issues/5)
* **bodiless-js:** Initial Commit. ([d3cc4a2](https://github.com/johnsonandjohnson/bodiless-js/commit/d3cc4a29c985165bf864233cc4569fd48c6999fd))
* **core-ui, layouts, layouts-ui, ui:** Update Flexbox Fly-Out Panel UI ([#55](https://github.com/johnsonandjohnson/bodiless-js/issues/55)) ([ef21da6](https://github.com/johnsonandjohnson/bodiless-js/commit/ef21da62ccc29e7b07bf767a420dae5997f86346))
* **organisms:** Burger Menu ([#20](https://github.com/johnsonandjohnson/bodiless-js/issues/20)) ([05f5833](https://github.com/johnsonandjohnson/bodiless-js/commit/05f58331a05e7625ad01d5a261ad76b05427ae23))
* **richtext:** Refactor the RichText API ([#18](https://github.com/johnsonandjohnson/bodiless-js/issues/18)) ([a700a1a](https://github.com/johnsonandjohnson/bodiless-js/commit/a700a1ab3b473c509d5b6a10801c02caa1bc0ab3))
* **starter:** Add gatsby-starter-bodiless to monorepo ([#12](https://github.com/johnsonandjohnson/bodiless-js/issues/12)) ([f5d8d2a](https://github.com/johnsonandjohnson/bodiless-js/commit/f5d8d2af25096d5785203cb600af378a5160b33d)), closes [#7](https://github.com/johnsonandjohnson/bodiless-js/issues/7)
* **test-site:** Add Type to all of the items in the flexbox ([#46](https://github.com/johnsonandjohnson/bodiless-js/issues/46)) ([d40bcce](https://github.com/johnsonandjohnson/bodiless-js/commit/d40bcce63edbd9830f138ebbb0824e41a21f3f42)), closes [#45](https://github.com/johnsonandjohnson/bodiless-js/issues/45)
## [0.0.37](https://github.com/johnsonandjohnson/bodiless-js/compare/v0.0.36...v0.0.37) (2020-01-17)
### Bug Fixes
* **fclasses:** Design transformer does not update passthroughProps when its props are changed ([#10](https://github.com/johnsonandjohnson/bodiless-js/issues/10)) ([c2040f7](https://github.com/johnsonandjohnson/bodiless-js/commit/c2040f7c181916b912364f64d6c93f8663eab898))
* **richtext:** Format bar persists when leaving edit mode ([#24](https://github.com/johnsonandjohnson/bodiless-js/issues/24)) ([3b09277](https://github.com/johnsonandjohnson/bodiless-js/commit/3b09277bb420fc1b7c6dc82ca19a06b16c82c48e))
* **richtext:** Rich Text Editor menu appears for a moment in the bottom of a page ([#43](https://github.com/johnsonandjohnson/bodiless-js/issues/43)) ([#44](https://github.com/johnsonandjohnson/bodiless-js/issues/44)) ([28fe4c4](https://github.com/johnsonandjohnson/bodiless-js/commit/28fe4c47b75bc47163f66c875bb41e9b6ee64715))
### Features
* **bv:** inline ratings widget ([#9](https://github.com/johnsonandjohnson/bodiless-js/issues/9)) ([1db5ee8](https://github.com/johnsonandjohnson/bodiless-js/commit/1db5ee8fff783a4117b3da574102b5a9f22de94b))
* Host docs on GitHub Pages ([#6](https://github.com/johnsonandjohnson/bodiless-js/issues/6)) ([14461ad](https://github.com/johnsonandjohnson/bodiless-js/commit/14461ad69b04653a03ecfaeb7c9cf7e52019c7f1)), closes [#5](https://github.com/johnsonandjohnson/bodiless-js/issues/5)
* **gatsby-theme-bodiless:** GH-26 Add author to commits if possible. ([#25](https://github.com/johnsonandjohnson/bodiless-js/issues/25)) ([3297c96](https://github.com/johnsonandjohnson/bodiless-js/commit/3297c96c11b14e38106201176396be59cab19a92)), closes [#26](https://github.com/johnsonandjohnson/bodiless-js/issues/26)
* **gatsby-theme-bodiless:** Remove the Pull Changes Button from the Edit UI ([#31](https://github.com/johnsonandjohnson/bodiless-js/issues/31)) ([cb5e370](https://github.com/johnsonandjohnson/bodiless-js/commit/cb5e37010d81c0902bf99140c4da3d33ee977f2e))
* **layouts:** Remove checkmark icon from component picker ([#33](https://github.com/johnsonandjohnson/bodiless-js/issues/33)) ([ab6ce73](https://github.com/johnsonandjohnson/bodiless-js/commit/ab6ce7385d0d0e5122219fa81892263d086dfb7d))
* **layouts, test-site:** Add product listing template, fix a few flexbox bugs ([#13](https://github.com/johnsonandjohnson/bodiless-js/issues/13)) ([1f7307e](https://github.com/johnsonandjohnson/bodiless-js/commit/1f7307ea139ed4587916900434b36a5f0b4d9778))
* **richtext:** Refactor the RichText API ([#18](https://github.com/johnsonandjohnson/bodiless-js/issues/18)) ([d4616c7](https://github.com/johnsonandjohnson/bodiless-js/commit/d4616c74e868cf0f5c4b6f879db10741a1433785))
* **ssi:** restored invocation of processing ssi elements ([#19](https://github.com/johnsonandjohnson/bodiless-js/issues/19)) ([2c5ee8f](https://github.com/johnsonandjohnson/bodiless-js/commit/2c5ee8f320bde559df49b197ed34b311e881e241))
* **starter:** Add gatsby-starter-bodiless to monorepo ([#12](https://github.com/johnsonandjohnson/bodiless-js/issues/12)) ([242a8a4](https://github.com/johnsonandjohnson/bodiless-js/commit/242a8a420fc57bdfd3a6e0c6e99bedf672143a53)), closes [#7](https://github.com/johnsonandjohnson/bodiless-js/issues/7)
### BREAKING CHANGES
* **richtext:** The API for injecting components was refactored to use the Design API.
| 88.135338 | 629 | 0.783761 | yue_Hant | 0.175374 |
976b77f036377572e09227809a248fa64bbfab66 | 201 | md | Markdown | src/__tests__/fixtures/unfoldingWord/en_tq/jer/32/12.md | unfoldingWord/content-checker | 7b4ca10b94b834d2795ec46c243318089cc9110e | [
"MIT"
] | null | null | null | src/__tests__/fixtures/unfoldingWord/en_tq/jer/32/12.md | unfoldingWord/content-checker | 7b4ca10b94b834d2795ec46c243318089cc9110e | [
"MIT"
] | 226 | 2020-09-09T21:56:14.000Z | 2022-03-26T18:09:53.000Z | src/__tests__/fixtures/unfoldingWord/en_tq/jer/32/12.md | unfoldingWord/content-checker | 7b4ca10b94b834d2795ec46c243318089cc9110e | [
"MIT"
] | 1 | 2022-01-10T21:47:07.000Z | 2022-01-10T21:47:07.000Z | # How did Jeremiah go about buying the field?
Jeremiah signed and sealed the deed of purchase, weighed the silver in the scales, and gave the sealed scroll to Baruch in the presence of the witnesses.
| 50.25 | 153 | 0.791045 | eng_Latn | 0.999985 |
976bfda6e8a576398548f15c957c20270e318bbc | 2,544 | md | Markdown | docs/extensibility/debugger/reference/metadata-type.md | monkey3310/visualstudio-docs.pl-pl | adc80e0d3bef9965253897b72971ccb1a3781354 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/extensibility/debugger/reference/metadata-type.md | monkey3310/visualstudio-docs.pl-pl | adc80e0d3bef9965253897b72971ccb1a3781354 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/extensibility/debugger/reference/metadata-type.md | monkey3310/visualstudio-docs.pl-pl | adc80e0d3bef9965253897b72971ccb1a3781354 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: METADATA_TYPE | Dokumentacja firmy Microsoft
ms.custom: ''
ms.date: 11/04/2016
ms.technology:
- vs-ide-sdk
ms.topic: conceptual
f1_keywords:
- METADATA_TYPE
helpviewer_keywords:
- METADATA_TYPE structure
ms.assetid: 2d8b78f6-0aef-4d79-809a-cff9b2c24659
author: gregvanl
ms.author: gregvanl
manager: douge
ms.workload:
- vssdk
ms.openlocfilehash: 66a1632198a0af5490e66a843458fc55bcad2d6d
ms.sourcegitcommit: 6a9d5bd75e50947659fd6c837111a6a547884e2a
ms.translationtype: MT
ms.contentlocale: pl-PL
ms.lasthandoff: 04/16/2018
ms.locfileid: "31134724"
---
# <a name="metadatatype"></a>METADATA_TYPE
Ta struktura określa informacje dotyczące typu pola pobierana z metadanych.
## <a name="syntax"></a>Składnia
```cpp
typedef struct _tagTYPE_METADATA {
ULONG32 ulAppDomainID;
GUID guidModule;
_mdToken tokClass;
} METADATA_TYPE;
```
```csharp
public struct METADATA_TYPE {
public uint ulAppDomainID;
public Guid guidModule;
public int tokClass;
};
```
#### <a name="parameters"></a>Parametry
ulAppDomainID
Identyfikator aplikacji, z której pochodzi symbolu. Służy do jednoznacznej identyfikacji wystąpienia aplikacji.
guidModule
Identyfikator GUID moduł, który zawiera tego pola.
tokClass
Identyfikator tokenu metadanych tego typu.
[C++] `_mdToken` jest `typedef` dla 32-bitowej `int`.
## <a name="remarks"></a>Uwagi
Ta struktura jest wyświetlany jako część Unii w [type_info —](../../../extensibility/debugger/reference/type-info.md) struktury, kiedy `dwKind` pole `TYPE_INFO` ustawiono struktury `TYPE_KIND_METADATA` (wartość z zakresu od [dwTYPE_KIND](../../../extensibility/debugger/reference/dwtype-kind.md) Wyliczenie).
`tokClass` Token metadanych, który unikatowo identyfikuje typem jest wartość. Aby uzyskać więcej informacji na temat sposobu interpretacji górny bity identyfikator tokenu metadanych, zobacz `CorTokenType` wyliczenia w pliku corhdr.h [!INCLUDE[dnprdnshort](../../../code-quality/includes/dnprdnshort_md.md)] zestawu SDK.
## <a name="requirements"></a>Wymagania
Nagłówek: sh.h
Namespace: Microsoft.VisualStudio.Debugger.Interop
Assembly: Microsoft.VisualStudio.Debugger.Interop.dll
## <a name="see-also"></a>Zobacz też
[Struktury i Unii](../../../extensibility/debugger/reference/structures-and-unions.md)
[TYPE_INFO —](../../../extensibility/debugger/reference/type-info.md)
[dwTYPE_KIND](../../../extensibility/debugger/reference/dwtype-kind.md) | 34.849315 | 322 | 0.732311 | pol_Latn | 0.84378 |
976c2368d104744e0b3419b92b094c075007670e | 777 | md | Markdown | Artificial Intelligence/Feminist Chatbot/Chatbot Personality.md | KGBicheno/KGB_Agora | 70ea95c9d38ab2f31abbd510691bb4c050a6cb3b | [
"MIT"
] | null | null | null | Artificial Intelligence/Feminist Chatbot/Chatbot Personality.md | KGBicheno/KGB_Agora | 70ea95c9d38ab2f31abbd510691bb4c050a6cb3b | [
"MIT"
] | null | null | null | Artificial Intelligence/Feminist Chatbot/Chatbot Personality.md | KGBicheno/KGB_Agora | 70ea95c9d38ab2f31abbd510691bb4c050a6cb3b | [
"MIT"
] | null | null | null | # Chatbot Personality
This links back to [#Google's Conversation Design Process](https://designguidelines.withgoogle.com/conversation/conversation-design-process/create-a-persona.html#create-a-persona-how-do-i-create-one).
This also links to [[The Feminist Design Tool]].
## Step 1
Brainstorm how you want people to perceive your chatbot.
## Step 2
Narrow that list down to 4-6 key attributes
## Step 3
Pick a few characters that embody your chatbot.
You're going for the Minds from the Culture — you're fine.
## Step 4
Choose the closest character and write a brief description.
Show what they're like and what they would say and do.
## Step 5
Find an image or two that represents your bot.
Again, Culture.
This is part of the [[Feminist Chatbot Main Page]]
| 22.2 | 200 | 0.756757 | eng_Latn | 0.994656 |
976c33e578fc684622ce18e21a4b6c388e4f0342 | 2,774 | md | Markdown | docs/algo/sona/closeness_sona.md | Gscim/angel | 53c43e6d16afaaccef85795c94ec41c585b01db2 | [
"Apache-2.0"
] | null | null | null | docs/algo/sona/closeness_sona.md | Gscim/angel | 53c43e6d16afaaccef85795c94ec41c585b01db2 | [
"Apache-2.0"
] | null | null | null | docs/algo/sona/closeness_sona.md | Gscim/angel | 53c43e6d16afaaccef85795c94ec41c585b01db2 | [
"Apache-2.0"
] | null | null | null | # Closeness
>Closeness算法,用于度量每个顶点在图中的中心程度。closeness作为节点重要性评估的核心指标之一,常用于关键点识别以及营销传播等场景。
## 1. 算法介绍
我们基于Spark On Angel和论文《Centralities in Large Networks: Algorithms and Observations》实现了大规模的Closeness计算。
## 2. 分布式实现
Closeness的实现过程中,采用HyperLogLog++基数计数器记录每个顶点n阶邻居数。采用类似HyperAnf的思路对Closeness进行近似计算。
## 3. 运行
### 算法IO参数
- input: 输入,hdfs路径,无向图/有向图,不带权,每行表示一条边,srcId 分隔符 dstId,分隔符可以为空白符、tab或逗号等
- output: 输出,hdfs路径,保存计算结果。输出为nodeId(long) | closeness(float) | 节点cardinality | 半径加权求和的cardinality, closeness值越大表示节点越重要
- sep: 分隔符,输入中每条边的起始顶点、目标顶点之间的分隔符: `tab`, `空格`等
### 算法参数
- partitionNum: 数据分区数,worker端spark rdd的数据分区数量,一般设为spark executor个数乘以executor core数的3-4倍,
- psPartitionNum: 参数服务器上模型的分区数量,最好是parameter server个数的整数倍,让每个ps承载的分区数量相等,让每个PS负载尽量均衡, 数据量大的话推荐500以上
- msgNumBatch: spark每个rdd分区分批计算的次数
- useBalancePartition:是否使用均衡分区,默认为false
- balancePartitionPercent:均衡分区度,默认为0.7
- verboseSaving: 详细保存closeness中间结果
- isDirected:是否为有向图,默认为true
- storageLevel:RDD存储级别,`DISK_ONLY`/`MEMORY_ONLY`/`MEMORY_AND_DISK`
### 资源参数
- ps个数和内存大小:ps.instance与ps.memory的乘积是ps总的配置内存。为了保证Angel不挂掉,需要配置ps上数据存储量大小两倍左右的内存。对于Closeness算法来说,ps上放置的是各顶点的一阶邻居,数据类型是(Long,Array[Long]),据此可以估算不同规模的Graph输入下需要配置的ps内存大小
- Spark的资源配置:num-executors与executor-memory的乘积是executors总的配置内存,最好能存下2倍的输入数据。 如果内存紧张,1倍也是可以接受的,但是相对会慢一点。 比如说100亿的边集大概有600G大小, 50G * 20 的配置是足够的。 在资源实在紧张的情况下, 尝试加大分区数目!
### 任务提交示例
```
input=hdfs://my-hdfs/data
output=hdfs://my-hdfs/output
source ./spark-on-angel-env.sh
$SPARK_HOME/bin/spark-submit \
--master yarn-cluster\
--conf spark.ps.instances=1 \
--conf spark.ps.cores=1 \
--conf spark.ps.jars=$SONA_ANGEL_JARS \
--conf spark.ps.memory=10g \
--name "commonfriends angel" \
--jars $SONA_SPARK_JARS \
--driver-memory 5g \
--num-executors 1 \
--executor-cores 4 \
--executor-memory 10g \
--class org.apache.spark.angel.examples.cluster.ClosenessExample \
../lib/spark-on-angel-examples-3.2.0.jar
input:$input output:$output sep:tab storageLevel:MEMORY_ONLY useBalancePartition:true \
balancePartitionPercent:0.7 partitionNum:4 psPartitionNum:1 msgNumBatch:8 \
pullBatchSize:1000 verboseSaving:true src:1 dst:2 mode:yarn-cluster
```
### 常见问题
- 在差不多10min的时候,任务挂掉: 很可能的原因是angel申请不到资源!由于Closeness基于Spark On Angel开发,实际上涉及到Spark和Angel两个系统,它们的向Yarn申请资源是独立进行的。 在Spark任务拉起之后,由Spark向Yarn提交Angel的任务,如果不能在给定时间内申请到资源,就会报超时错误,任务挂掉! 解决方案是: 1)确认资源池有足够的资源 2) 添加spakr conf: spark.hadoop.angel.am.appstate.timeout.ms=xxx 调大超时时间,默认值为600000,也就是10分钟
- 如何估算我需要配置多少Angel资源: 为了保证Angel不挂掉,需要配置模型大小两倍左右的内存 另外,在可能的情况下,ps数目越小,数据传输的量会越小,但是单个ps的压力会越大,需要一定的权衡。
- Spark的资源配置: 同样主要考虑内存问题,最好能存下2倍的输入数据。 如果内存紧张,1倍也是可以接受的,但是相对会慢一点。 比如说100亿的边集大概有600G大小, 50G * 20 的配置是足够的。 在资源实在紧张的情况下, 尝试加大分区数目!
| 42.030303 | 289 | 0.773252 | yue_Hant | 0.776896 |
976c8644563573b58ea1d1e45b3acd3c2e61840e | 3,755 | md | Markdown | docs/orgs.md | Losant/losant-rest-js | 746d5cb27b44e5b9be36d806f5c2fbceb3a86b90 | [
"MIT"
] | 13 | 2016-06-16T20:18:06.000Z | 2020-06-25T13:21:27.000Z | docs/orgs.md | Losant/losant-rest-js | 746d5cb27b44e5b9be36d806f5c2fbceb3a86b90 | [
"MIT"
] | 4 | 2020-11-09T16:26:54.000Z | 2022-02-26T10:13:34.000Z | docs/orgs.md | Losant/losant-rest-js | 746d5cb27b44e5b9be36d806f5c2fbceb3a86b90 | [
"MIT"
] | 4 | 2020-04-16T18:44:23.000Z | 2020-05-08T06:53:04.000Z | # Orgs Actions
Details on the various actions that can be performed on the
Orgs resource, including the expected
parameters and the potential responses.
##### Contents
* [Get](#get)
* [Post](#post)
<br/>
## Get
Returns the organizations associated with the current user
```javascript
var params = {}; // all params are optional
// with callbacks
client.orgs.get(params, function (err, result) {
if (err) { return console.error(err); }
console.log(result);
});
// with promises
client.orgs.get(params)
.then(console.log)
.catch(console.error);
```
#### Authentication
The client must be configured with a valid api access token to call this
action. The token must include at least one of the following scopes:
all.User, all.User.read, orgs.*, or orgs.get.
#### Available Parameters
| Name | Type | Required | Description | Default | Example |
| ---- | ---- | -------- | ----------- | ------- | ------- |
| sortField | string | N | Field to sort the results by. Accepted values are: name, id, creationDate, lastUpdated | name | name |
| sortDirection | string | N | Direction to sort the results by. Accepted values are: asc, desc | asc | asc |
| page | string | N | Which page of results to return | 0 | 0 |
| perPage | string | N | How many items to return per page | 100 | 10 |
| filterField | string | N | Field to filter the results by. Blank or not provided means no filtering. Accepted values are: name | | name |
| filter | string | N | Filter to apply against the filtered field. Supports globbing. Blank or not provided means no filtering. | | my*org |
| summaryExclude | string | N | Comma-separated list of summary fields to exclude from org summaries | | payloadCount |
| summaryInclude | string | N | Comma-separated list of summary fields to include in org summary | | payloadCount |
| losantdomain | string | N | Domain scope of request (rarely needed) | | example.com |
#### Successful Responses
| Code | Type | Description |
| ---- | ---- | ----------- |
| 200 | [Organizations](../lib/schemas/orgs.json) | Collection of organizations |
#### Error Responses
| Code | Type | Description |
| ---- | ---- | ----------- |
| 400 | [Error](../lib/schemas/error.json) | Error if malformed request |
<br/>
## Post
Create a new organization
```javascript
var params = {
organization: myOrganization
};
// with callbacks
client.orgs.post(params, function (err, result) {
if (err) { return console.error(err); }
console.log(result);
});
// with promises
client.orgs.post(params)
.then(console.log)
.catch(console.error);
```
#### Authentication
The client must be configured with a valid api access token to call this
action. The token must include at least one of the following scopes:
all.User, orgs.*, or orgs.post.
#### Available Parameters
| Name | Type | Required | Description | Default | Example |
| ---- | ---- | -------- | ----------- | ------- | ------- |
| organization | [Organization Post](../lib/schemas/orgPost.json) | Y | New organization information | | [Organization Post Example](_schemas.md#organization-post-example) |
| summaryExclude | string | N | Comma-separated list of summary fields to exclude from org summary | | payloadCount |
| summaryInclude | string | N | Comma-separated list of summary fields to include in org summary | | payloadCount |
| losantdomain | string | N | Domain scope of request (rarely needed) | | example.com |
#### Successful Responses
| Code | Type | Description |
| ---- | ---- | ----------- |
| 201 | [Organization](../lib/schemas/org.json) | Successfully created organization |
#### Error Responses
| Code | Type | Description |
| ---- | ---- | ----------- |
| 400 | [Error](../lib/schemas/error.json) | Error if malformed request |
| 33.526786 | 174 | 0.661784 | eng_Latn | 0.973527 |
976cd6dd4a88d8d22980e01890806625bc9b7b51 | 8,119 | md | Markdown | README.md | sim642/benchexec | ef0fafb2718086b63d14e32a65518cbd584cbddf | [
"Apache-2.0"
] | null | null | null | README.md | sim642/benchexec | ef0fafb2718086b63d14e32a65518cbd584cbddf | [
"Apache-2.0"
] | null | null | null | README.md | sim642/benchexec | ef0fafb2718086b63d14e32a65518cbd584cbddf | [
"Apache-2.0"
] | null | null | null | <!--
This file is part of BenchExec, a framework for reliable benchmarking:
https://github.com/sosy-lab/benchexec
SPDX-FileCopyrightText: 2007-2020 Dirk Beyer <https://www.sosy-lab.org>
SPDX-License-Identifier: Apache-2.0
-->
# BenchExec
## A Framework for Reliable Benchmarking and Resource Measurement
[](https://travis-ci.org/sosy-lab/benchexec)
[](https://www.codacy.com/app/PhilippWendler/benchexec)
[](https://www.codacy.com/app/PhilippWendler/benchexec)
[](https://www.apache.org/licenses/LICENSE-2.0)
[](https://pypi.python.org/pypi/BenchExec)
[](https://zenodo.org/badge/latestdoi/30758422)
**News**:
- BenchExec 2.3 produces improved HTML tables that load much faster and provide more features.
- BenchExec 2.0 isolates runs by default using [containers](https://github.com/sosy-lab/benchexec/blob/master/doc/container.md).
- BenchExec 1.16 adds [energy measurements](https://github.com/sosy-lab/benchexec/blob/master/doc/resources.md#energy)
if the tool [cpu-energy-meter](https://github.com/sosy-lab/cpu-energy-meter) is installed on the system.
- An extended version of our paper on BenchExec and its background was published in [STTT](https://link.springer.com/article/10.1007/s10009-017-0469-y),
you can read the preprint of [Reliable Benchmarking: Requirements and Solutions](https://www.sosy-lab.org/research/pub/2019-STTT.Reliable_Benchmarking_Requirements_and_Solutions.pdf) online.
We also provide a set of [overview slides](https://www.sosy-lab.org/research/prs/Current_ReliableBenchmarking.pdf).
BenchExec provides three major features:
- execution of arbitrary commands with precise and reliable measurement
and limitation of resource usage (e.g., CPU time and memory),
and isolation against other running processes
- an easy way to define benchmarks with specific tool configurations
and resource limits,
and automatically executing them on large sets of input files
- generation of interactive tables and plots for the results
Contrary to other benchmarking frameworks,
it is able to reliably measure and limit resource usage
of the benchmarked tool even if it spawns subprocesses.
In order to achieve this,
it uses the [cgroups feature](https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt)
of the Linux kernel to correctly handle groups of processes.
For proper isolation of the benchmarks, it uses (if available)
Linux [user namespaces](http://man7.org/linux/man-pages/man7/namespaces.7.html)
and an [overlay filesystem](https://www.kernel.org/doc/Documentation/filesystems/overlayfs.txt)
to create a [container](https://github.com/sosy-lab/benchexec/blob/master/doc/container.md)
that restricts interference of the executed tool with the benchmarking host.
BenchExec is intended for benchmarking non-interactive tools on Linux systems.
It measures CPU time, wall time, and memory usage of a tool,
and allows to specify limits for these resources.
It also allows to limit the CPU cores and (on NUMA systems) memory regions,
and the container mode allows to restrict filesystem and network access.
In addition to measuring resource usage,
BenchExec can verify that the result of the tool was as expected,
and extract further statistical data from the output.
Results from multiple runs can be combined into CSV and interactive HTML tables,
of which the latter provide scatter and quantile plots
(have a look at our [demo table](https://sosy-lab.github.io/benchexec/example-table/svcomp-simple-cbmc-cpachecker.table.html)).
BenchExec works only on Linux and needs a one-time setup of cgroups by the machine's administrator.
The actual benchmarking can be done by any user and does not need root access.
BenchExec was originally developed for use with the software verification framework
[CPAchecker](https://cpachecker.sosy-lab.org)
and is now developed as an independent project
at the [Software Systems Lab](https://www.sosy-lab.org)
of the [Ludwig-Maximilians-Universität München (LMU Munich)](https://www.uni-muenchen.de).
### Links
- [Documentation](https://github.com/sosy-lab/benchexec/tree/master/doc/INDEX.md)
- [Demo](https://sosy-lab.github.io/benchexec/example-table/svcomp-simple-cbmc-cpachecker.table.html) of a result table
- [Downloads](https://github.com/sosy-lab/benchexec/releases)
- [Changelog](https://github.com/sosy-lab/benchexec/tree/master/CHANGELOG.md)
- [BenchExec GitHub Repository](https://github.com/sosy-lab/benchexec),
use this for [reporting issues and asking questions](https://github.com/sosy-lab/benchexec/issues)
- [BenchExec at PyPI](https://pypi.python.org/pypi/BenchExec)
- Paper [Reliable Benchmarking: Requirements and Solutions](https://www.sosy-lab.org/research/pub/2019-STTT.Reliable_Benchmarking_Requirements_and_Solutions.pdf) about BenchExec ([supplementary webpage](https://www.sosy-lab.org/research/benchmarking/), [slides](https://www.sosy-lab.org/research/prs/Current_ReliableBenchmarking.pdf))
### License and Copyright
BenchExec is licensed under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0),
copyright [Dirk Beyer](https://www.sosy-lab.org/people/beyer/).
Exceptions are some tool-info modules
and third-party code that is bundled in the HTML tables,
which are available under several other free licenses
(cf. [folder `LICENSES`](https://github.com/sosy-lab/benchexec/tree/master/LICENSES)).
### Authors
Maintainer: [Philipp Wendler](https://www.philippwendler.de)
Contributors:
- [Aditya Arora](https://github.com/alohamora)
- [Dirk Beyer](https://www.sosy-lab.org/people/beyer/)
- [Laura Bschor](https://github.com/laurabschor)
- [Thomas Bunk](https://github.com/TBunk)
- [Montgomery Carter](https://github.com/MontyCarter)
- [Andreas Donig](https://github.com/adonig)
- [Karlheinz Friedberger](https://www.sosy-lab.org/people/friedberger)
- Peter Häring
- [Florian Heck](https://github.com/fheck)
- [Hugo](https://github.com/hugovk)
- [George Karpenkov](http://metaworld.me/)
- [Mike Kazantsev](http://fraggod.net/)
- [Michael Lachner](https://github.com/lachnerm)
- [Thomas Lemberger](https://www.sosy-lab.org/people/lemberger/)
- [Sebastian Ott](https://github.com/ottseb)
- Stefan Löwe
- [Stephan Lukasczyk](https://github.com/stephanlukasczyk)
- [Alexander von Rhein](http://www.infosun.fim.uni-passau.de/se/people-rhein.php)
- [Alexander Schremmer](https://www.xing.com/profile/Alexander_Schremmer)
- [Dennis Simon](https://github.com/DennisSimon)
- [Andreas Stahlbauer](http://stahlbauer.net/)
- [Thomas Stieglmaier](https://stieglmaier.me/)
- [Martin Yankov](https://github.com/marto97)
- [Ilja Zakharov](https://github.com/IljaZakharov)
- and [lots of more people who integrated tools into BenchExec](https://github.com/sosy-lab/benchexec/graphs/contributors)
### Users of BenchExec
BenchExec was successfully used for benchmarking in all instances
of the international competitions on [Software Verification](https://sv-comp.sosy-lab.org)
and [Software Testing](https://test-comp.sosy-lab.org)
with a wide variety of benchmarked tools and hundreds of thousands benchmark runs.
It is integrated into the cluster-based logic-solving service
[StarExec](https://www.starexec.org/starexec/public/about.jsp) ([GitHub](https://github.com/StarExec/StarExec)).
The developers of the following tools use BenchExec:
- [CPAchecker](https://cpachecker.sosy-lab.org), also for regression testing
- [Dartagnan](https://github.com/hernanponcedeleon/Dat3M)
- [SMACK](https://github.com/smackers/smack)
- [SMTInterpol](https://github.com/ultimate-pa/smtinterpol)
- [Ultimate](https://github.com/ultimate-pa/ultimate)
If you would like to be listed here, [contact us](https://github.com/sosy-lab/benchexec/issues/new).
| 57.992857 | 334 | 0.779653 | eng_Latn | 0.590275 |
976d0c5892dd53350600ddfce404e3281d4e4f1d | 1,826 | md | Markdown | docs/adl/004-tokenization-and-static-assets.md | budproj/design-system | 5b268aff26739f428fbacb7c30fc207a4deaa54f | [
"Apache-2.0"
] | 1 | 2021-12-03T13:39:21.000Z | 2021-12-03T13:39:21.000Z | docs/adl/004-tokenization-and-static-assets.md | budproj/unfinished-design-system | 5b268aff26739f428fbacb7c30fc207a4deaa54f | [
"Apache-2.0"
] | null | null | null | docs/adl/004-tokenization-and-static-assets.md | budproj/unfinished-design-system | 5b268aff26739f428fbacb7c30fc207a4deaa54f | [
"Apache-2.0"
] | 1 | 2020-10-20T14:42:37.000Z | 2020-10-20T14:42:37.000Z | # ADR 4: Tokenization and Static Assets
* [Table of contents](#)
* [Context](#context)
* [Decision](#decision)
* [Status](#status)
* [Consequences](#consequences)
* [More reading](#more-reading)
* [Updates](#updates)
## Context
Tokens have a significant role in theming. They're responsible for defining the primitives of our theme, such as color codes, font names, and others. Tokens are relevant to determining asset locations too.
We must find a proper way to handle and maintain our tokens.
## Decision
We've decided to use [Style Dictionary](https://amzn.github.io/style-dictionary/#/) as our framework to handle tokens. It is easy to use since we can define our tickets in standard JSON but empowering them with string interpolation, variables, and other features.
For our static assets, we're going to host them at [AWS S3](https://aws.amazon.com/s3/), defining the proper CORS rules, and refer the location of those as tokens for our applications to use.
Instead of increasing the size of our Javascript bundle with static assets, we prefer to keep it simple and light by hosting those in an S3 bucket and asking for the application to download it.
## Status
**DEPRECATED** _check [update 1](#update-1)_
## Consequences
Tokenization is a complex process. We need to look out and keep it simple. The logic (like mapping those tokens to theme properties) must happen in the design-system itself, keeping the token package just for constant's definition.
---
## More reading
* [Style Dictionary's docs](https://amzn.github.io/style-dictionary/#/)
## Updates
### Update 1
After [business/ADR#001](https://github.com/budproj/architecture-decision-log/blob/main/records/business/001-reducing-initial-technical-complexity.md), we've decided to stop the development of a decoupled design system.
| 41.5 | 263 | 0.757393 | eng_Latn | 0.979471 |
976d22193fe503d7d7fd912a0515a0bc6a9c8988 | 2,012 | md | Markdown | errata.md | aviland/luago-book | 9eccb85604f0fd00863879981572647a5da217af | [
"MIT"
] | null | null | null | errata.md | aviland/luago-book | 9eccb85604f0fd00863879981572647a5da217af | [
"MIT"
] | null | null | null | errata.md | aviland/luago-book | 9eccb85604f0fd00863879981572647a5da217af | [
"MIT"
] | null | null | null | # 勘误表
页数 | 章节 | 位置 | 原文 | 更正 | 读者 | 更正版次
------- | --------- | ------------------------------------- | --------------------------------- | --------------------------------- | --------------------- | ---------
VII | 前言 | 第二段话 | 前18章的代表 | 前18章的代码 | ![moon][moon] |
11 | 2.2 | 第一段话第二行 | 。。。件:第二, | 。。。件;第二, | ![moon][moon] |
12 | 2.2.1 | 第三段话 | 调式信息 | 调试信息 | ![泡泡][泡泡] |
21 | 2.3.3 |[末尾倒数第7行代码][p21] | `CSZIET_SIZE` | `CSIZET_SIZE` | ![小灰先生][小灰先生] |
29 | 2.4.2 |[末尾倒数第3行代码][p29] | `CSZIET_SIZE` | `CSIZET_SIZE` | ![小灰先生][小灰先生] |
104 | 6.2.4 |[LEN指令实现代码][p104] | `func _len(...)` | `func length(...)` | ![小灰先生][小灰先生] |
144 | 8.2.1 |[luaStack结构体][p144] | `closure *luaClosure` | `closure *closure` | ![小灰先生][小灰先生] |
145 | 8.2.1 |最后一段话 | 。。。vararg字段用于。。。 | 。。。varargs字段用于。。。 | ![moon][moon] |
160 | 8.4.6 | 第一段话第二行 | 。。。面相对象体系。 | 。。。面向对象体系。 | ![泡泡][泡泡] |
177 | 9.3.1 | `GetGlobal()`第二种实现 | `return self.GetField(t, name)` | `return self.GetField(-1, name)` | ![泡泡][泡泡] |
236 | 13.1 | 倒数第二段话第一行 | 。。。允许我们再有且仅。。。 | 。。。允许我们在有且仅。。。 | ![泡泡][泡泡] |
263 | 13.3.8 | [`NextToken()`方法][p263]和下面的文字 | `isLatter()` | `isLetter()` | ![泡泡][泡泡] |
290 | 16.1.2 | 图16-2 | 上下文无言 | 上下文无关 | ![moon][moon] |
369 | 19.1 | 第二段话 | 。。。定义数据库开启函数, | 。。。定义数学库开启函数, | ![泡泡][泡泡] |
377 | 19.5 | 第三段话第二行 | 。。。创建lib_os.go.go文件, | 。。。创建lib_os.go文件, | ![泡泡][泡泡] |
[moon]: readers/moon.png?raw=true "moon"
[泡泡]: readers/paopao.jpeg?raw=true "泡泡"
[小灰先生]: readers/小灰先生.jpeg?raw=true "小灰先生"
[p21]: code/go/ch02/src/luago/binchunk/binary_chunk.go#L9
[p29]: code/go/ch02/src/luago/binchunk/reader.go#L70
[p104]: code/go/ch06/src/luago/vm/inst_operators.go#L100
[p144]: code/go/ch08/src/luago/state/lua_stack.go#L8
[p263]: code/go/ch14/src/luago/compiler/lexer/lexer.go#L204
| 67.066667 | 167 | 0.458748 | yue_Hant | 0.690541 |
976e0087aa6ba469ef95645fbec93bd7988352d1 | 2,444 | md | Markdown | _posts/2019-05-05-Download-matric-exam-questions-answer-of-ethiopia.md | Bunki-booki/29 | 7d0fb40669bcc2bafd132f0991662dfa9e70545d | [
"MIT"
] | null | null | null | _posts/2019-05-05-Download-matric-exam-questions-answer-of-ethiopia.md | Bunki-booki/29 | 7d0fb40669bcc2bafd132f0991662dfa9e70545d | [
"MIT"
] | null | null | null | _posts/2019-05-05-Download-matric-exam-questions-answer-of-ethiopia.md | Bunki-booki/29 | 7d0fb40669bcc2bafd132f0991662dfa9e70545d | [
"MIT"
] | null | null | null | ---
layout: post
comments: true
categories: Other
---
## Download Matric exam questions answer of ethiopia book
" Dragonfly rolled her head round on her neck, to her, while Stormbel relished the strong-arm role but had no ambitions of ownership matric exam questions answer of ethiopia taste for any of the complexities that came with it. When he entered the house, and I don't want any more of it, but "Yekargauls" in index by aliens, but the lash of smooth dry scales across her cheek was real, wheresoever I may be. " me now?" either stupid or disposed to lie. JOHN PALLISER[174] sailed one against the other in duels and combats of sorcery, flexing his cramped limbs, To celebrate, and foure dryed pikes, but not too bad, and Morred's first year on the throne, now mostly cost another life, after thee. The Commander's Matric exam questions answer of ethiopia became instead the nearest goal of Plato have been pointing out, too. Fox, the woman and matric exam questions answer of ethiopia girl retreated to the back of the cul-de-sac! " Nolan nodded, but was c. " hand and a half-finished hot dog in the other. "I said Roke," Hemlock said in a tone that said he was unused to having to repeat himself. household article of the Japanese. ) ] at marriage. He allowed [Footnote 346: These strata were discovered during Kotzebue's (After a drawing by O. They carefully transferred her into bed. Her sense of play was delicious. The driver is suddenly as Muller, and onward into the labyrinth, and at the far end of the adjacent living room, he desperately shook loose and let go of the body. pressed harder. by the dashing that it contained liquid. "I'm a hopeless throwback to the nineteenth farther. "Have you found better ore than that patch you found first. " face was as expressionless as his voice was uninflected. Four such pillars have possibly dangerous, and dizziness. " because everyone fears that these two are federal immigration agents, window looking out on a back-street, and his smile was gone. February 28, and he wanted to be alone with her, they discovered that were anxious to get ptarmigan. Of Earth?" over in this new identity that remains his best hope of survival, but intensity and obsession were false unless you comply with paragraph 1, departed from him. " To judge by the crowds of children who swarmed everywhere along the of the electrocardiograph maintained a steady matric exam questions answer of ethiopia. | 271.555556 | 2,330 | 0.788052 | eng_Latn | 0.999963 |
976e6f5c027a84482d044b10a0e8af264beab902 | 4,485 | md | Markdown | docs/framework/unmanaged-api/profiling/functionenter3withinfo-function.md | Graflinger/docs.de-de | 9dfa50229d23e2ee67ef4047b6841991f1e40ac4 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/profiling/functionenter3withinfo-function.md | Graflinger/docs.de-de | 9dfa50229d23e2ee67ef4047b6841991f1e40ac4 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/profiling/functionenter3withinfo-function.md | Graflinger/docs.de-de | 9dfa50229d23e2ee67ef4047b6841991f1e40ac4 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: FunctionEnter3WithInfo-Funktion
ms.date: 03/30/2017
api_name:
- FunctionEnter3WithInfo
api_location:
- mscorwks.cll
api_type:
- COM
f1_keywords:
- FunctionEnter3WithInfo
helpviewer_keywords:
- FunctionEnter3WithInfo function [.NET Framework profiling]
ms.assetid: 277c3344-d0cb-431e-beae-eb1eeeba8eea
topic_type:
- apiref
author: mairaw
ms.author: mairaw
ms.openlocfilehash: 16e086f54865307e116a9e522b2fbadee8502249
ms.sourcegitcommit: 5b6d778ebb269ee6684fb57ad69a8c28b06235b9
ms.translationtype: MT
ms.contentlocale: de-DE
ms.lasthandoff: 04/08/2019
ms.locfileid: "59105671"
---
# <a name="functionenter3withinfo-function"></a>FunctionEnter3WithInfo-Funktion
Benachrichtigt den Profiler, dass Steuerelement an eine Funktion übergeben wird, und stellt ein Handle übergeben werden kann, die die [ICorProfilerInfo3:: Getfunctionenter3info-Methode](../../../../docs/framework/unmanaged-api/profiling/icorprofilerinfo3-getfunctionenter3info-method.md) zum Abrufen der Stapel und die Funktionsargumente.
## <a name="syntax"></a>Syntax
```
void __stdcall FunctionEnter3WithInfo(
[in] FunctionIDOrClientID functionIDOrClientID,
[in] COR_PRF_ELT_INFO eltInfo);
```
## <a name="parameters"></a>Parameter
`functionIDOrClientID`
[in] Der Bezeichner der Funktion an der Steuerelement übergeben wird.
`eltInfo`
[in] Ein nicht transparentes Handle, das Informationen über einen bestimmten Stapelrahmen entspricht. Dieses Handle ist gültig nur während des Rückrufs, der an den er übergeben wird.
## <a name="remarks"></a>Hinweise
Die `FunctionEnter3WithInfo` Rückrufmethode benachrichtigt den Profiler an, wie Funktionen aufgerufen werden, und ermöglicht es dem Profiler mit den [ICorProfilerInfo3:: Getfunctionenter3info-Methode](../../../../docs/framework/unmanaged-api/profiling/icorprofilerinfo3-getfunctionenter3info-method.md) Argumentwerte zu überprüfen. Informationen über Argumente den Zugriff auf die `COR_PRF_ENABLE_FUNCTION_ARGS` Flag muss festgelegt werden. Der Profiler kann mithilfe der [ICorProfilerInfo:: SetEventMask-Methode](../../../../docs/framework/unmanaged-api/profiling/icorprofilerinfo-seteventmask-method.md) die Ereignisflags festlegen, und klicken Sie dann die [ICorProfilerInfo3:: Setenterleavefunctionhooks3withinfo-Methode](../../../../docs/framework/unmanaged-api/profiling/icorprofilerinfo3-setenterleavefunctionhooks3withinfo-method.md) zum Registrieren Ihrer die Implementierung dieser Funktion.
Die `FunctionEnter3WithInfo` Funktion ist ein Rückruf, müssen Sie sie implementieren. Verwenden Sie die Implementierung muss die `__declspec(naked)` Storage-Class-Attribut.
Die ausführungs-Engine werden keine Register gespeichert, vor dem Aufrufen dieser Funktion.
- Auf den Eintrag müssen Sie alle Register speichern, die Sie, einschließlich derer in die Gleitkommaeinheit (FPU verwenden).
- Beim Beenden müssen Sie im Stapel wiederherstellen, indem Sie alle Parameter, die durch den Aufrufer weitergegeben wurden entfernt.
Die Implementierung der `FunctionEnter3WithInfo` sollten nicht blockiert werden, da die Garbagecollection verzögert wird. Die Implementierung sollten eine Garbagecollection nicht versuchen, da der Stapel möglicherweise nicht in eine Garbage Collection geeigneten Zustand. Wenn eine Garbagecollection versucht wird, wird die Laufzeit blockiert, bis `FunctionEnter3WithInfo` zurückgibt.
Die `FunctionEnter3WithInfo` Funktion muss nicht verwalteten Code aufrufen oder dazu führen, dass eine verwaltete speicherbelegung in keiner Weise.
## <a name="requirements"></a>Anforderungen
**Plattformen:** Weitere Informationen finden Sie unter [Systemanforderungen](../../../../docs/framework/get-started/system-requirements.md).
**Header:** CorProf.idl
**Bibliothek:** CorGuids.lib
**.NET Framework-Versionen:** [!INCLUDE[net_current_v20plus](../../../../includes/net-current-v20plus-md.md)]
## <a name="see-also"></a>Siehe auch
- [GetFunctionEnter3Info](../../../../docs/framework/unmanaged-api/profiling/icorprofilerinfo3-getfunctionenter3info-method.md)
- [FunctionEnter3](../../../../docs/framework/unmanaged-api/profiling/functionenter3-function.md)
- [FunctionLeave3](../../../../docs/framework/unmanaged-api/profiling/functionleave3-function.md)
- [Profilerstellung für globale statische Funktionen](../../../../docs/framework/unmanaged-api/profiling/profiling-global-static-functions.md)
| 60.608108 | 904 | 0.782832 | deu_Latn | 0.889654 |
976ef057f22d615128f7fe030c3cb93e05086738 | 269 | md | Markdown | README.md | lucasfradus/Vales | 17d8a9d8151e2679c173a8b2d921365a6b9b13fd | [
"MIT"
] | null | null | null | README.md | lucasfradus/Vales | 17d8a9d8151e2679c173a8b2d921365a6b9b13fd | [
"MIT"
] | null | null | null | README.md | lucasfradus/Vales | 17d8a9d8151e2679c173a8b2d921365a6b9b13fd | [
"MIT"
] | null | null | null | Sistema para la administracion de Vales de consumo.
*Modulo de Articulos
*Modulo de Usuarios con Perfiles
*Modulo de Creacion, Aprobacion y Preparacion de Vales de Consumo con usuarios requeridores, usuarios apradores, usuarios preparadores
con sectores aprobadores
| 38.428571 | 135 | 0.828996 | spa_Latn | 0.950018 |
976f555e25a182d60e090499e18cb8a862ecd608 | 526 | md | Markdown | README.md | oicr-gsi/xenoclassify | 16a82feb4197e257458b20d8d4f379b036024b8d | [
"MIT"
] | 1 | 2018-07-07T19:47:53.000Z | 2018-07-07T19:47:53.000Z | README.md | oicr-gsi/xenoclassify | 16a82feb4197e257458b20d8d4f379b036024b8d | [
"MIT"
] | 2 | 2018-04-18T16:54:10.000Z | 2019-09-09T20:10:17.000Z | README.md | oicr-gsi/xenoclassify | 16a82feb4197e257458b20d8d4f379b036024b8d | [
"MIT"
] | null | null | null | # xenoclassify
Xenoclassify is a tool that provides a means by which to classify short read sequencing data generated from xenograft samples. It requires alignment to the reference genomes of the graft and host species using bwa mem. Once aligned, reads (or read pairs) are assessed to identify the likely source of the cells from which the DNA was extracted. The output is a bam file with reads tagged to indicate the source species.
Please refer to the [wiki](https://github.com/oicr-gsi/xenoclassify/wiki) to get started.
| 105.2 | 419 | 0.802281 | eng_Latn | 0.999757 |
976faeb6eb0131d8e6abfb26d12133516ea83d32 | 44 | md | Markdown | README.md | eugene-liyai/galary_prototype | d217588abf24c0dec57b7d993d1d744c681ce873 | [
"MIT"
] | null | null | null | README.md | eugene-liyai/galary_prototype | d217588abf24c0dec57b7d993d1d744c681ce873 | [
"MIT"
] | null | null | null | README.md | eugene-liyai/galary_prototype | d217588abf24c0dec57b7d993d1d744c681ce873 | [
"MIT"
] | null | null | null | # galary_prototype
wordpress theme template
| 14.666667 | 24 | 0.863636 | eng_Latn | 0.671394 |
9770c46f899776db500255c490df49852476bc9a | 1,184 | md | Markdown | docs/outlook/weather/elements-outlook-weather-information-schema.md | MicrosoftDocs/office-developer-client-docs.es-ES | d4568d789fd46de778fdecb250a28fb84b4bf02e | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-05-19T18:52:21.000Z | 2021-04-21T00:13:46.000Z | docs/outlook/weather/elements-outlook-weather-information-schema.md | MicrosoftDocs/office-developer-client-docs.es-ES | d4568d789fd46de778fdecb250a28fb84b4bf02e | [
"CC-BY-4.0",
"MIT"
] | 3 | 2021-12-08T02:36:34.000Z | 2021-12-08T03:08:40.000Z | docs/outlook/weather/elements-outlook-weather-information-schema.md | MicrosoftDocs/office-developer-client-docs.es-ES | d4568d789fd46de778fdecb250a28fb84b4bf02e | [
"CC-BY-4.0",
"MIT"
] | 2 | 2018-10-24T20:53:01.000Z | 2019-10-13T18:19:17.000Z | ---
title: Elementos (Outlook de información meteorológica)
manager: soliver
ms.date: 11/16/2014
ms.audience: Developer
ms.topic: reference
ms.prod: office-online-server
ms.localizationpriority: medium
ms.assetid: 45fbc451-06f0-133d-9818-55574e202091
description: En este tema se enumeran los elementos del Outlook XML de información meteorológica.
ms.openlocfilehash: 053c0c2e7aa53c7df496757a92bf4d8a37c8cc45
ms.sourcegitcommit: a1d9041c20256616c9c183f7d1049142a7ac6991
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 09/24/2021
ms.locfileid: "59619347"
---
# <a name="elements-outlook-weather-information-schema"></a>Elementos (Outlook de información meteorológica)
En este tema se enumeran los elementos del Outlook XML de información meteorológica.
- [elemento actual](current-element-weathertype-complextypeoutlook-weather-information-schema.md)
- [elemento de previsión](forecast-element-weathertype-complextypeoutlook-weather-information-schema.md)
- [elemento de tiempo](weather-element-weatherdata-elementoutlook-weather-information-schema.md)
- [elemento de datos de tiempo](weatherdata-element-outlook-weather-information-schema.md)
| 38.193548 | 108 | 0.8125 | spa_Latn | 0.233851 |
97715c7f0f66c8e4e266f3bbffa0a82bd44d70af | 835 | md | Markdown | includes/vpn-gateway-add-gateway-subnet-portal-include.md | gitruili/azure-docs.zh-cn | 4853c7dd56dcb4f2609e927196d2e25b6026a5f8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/vpn-gateway-add-gateway-subnet-portal-include.md | gitruili/azure-docs.zh-cn | 4853c7dd56dcb4f2609e927196d2e25b6026a5f8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/vpn-gateway-add-gateway-subnet-portal-include.md | gitruili/azure-docs.zh-cn | 4853c7dd56dcb4f2609e927196d2e25b6026a5f8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: include 文件
description: include 文件
services: vpn-gateway
author: cherylmc
ms.service: vpn-gateway
ms.topic: include
ms.date: 04/04/2018
ms.author: cherylmc
ms.custom: include file
ms.openlocfilehash: a4101f3bfe83859eea525370b5eebcaa6e193a2d
ms.sourcegitcommit: 2d961702f23e63ee63eddf52086e0c8573aec8dd
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 09/07/2018
ms.locfileid: "44168969"
---
1. 在门户中,导航到要为其创建虚拟网关的虚拟网络。
2. 在 VNet 页的“设置”部分单击“子网”,展开“子网”页。
3. 在“子网”页中,单击顶部的“+网关子网”打开“添加子网”页。

4. 子网的“名称”自动填充为值“GatewaySubnet”。 Azure 需要 GatewaySubnet 值才能识别作为网关子网的子网。 调整自动填充的**地址范围**值,使其匹配配置要求。

5. 若要创建子网,请单击页底部的“确定”。
| 28.793103 | 98 | 0.77485 | yue_Hant | 0.339136 |
9771bf608c8ae63b7ab2bf3e531638a426affec7 | 892 | md | Markdown | guide/russian/game-development/libgdx/index.md | SweeneyNew/freeCodeCamp | e24b995d3d6a2829701de7ac2225d72f3a954b40 | [
"BSD-3-Clause"
] | 10 | 2019-08-09T19:58:19.000Z | 2019-08-11T20:57:44.000Z | guide/russian/game-development/libgdx/index.md | SweeneyNew/freeCodeCamp | e24b995d3d6a2829701de7ac2225d72f3a954b40 | [
"BSD-3-Clause"
] | 2,056 | 2019-08-25T19:29:20.000Z | 2022-02-13T22:13:01.000Z | guide/russian/game-development/libgdx/index.md | SweeneyNew/freeCodeCamp | e24b995d3d6a2829701de7ac2225d72f3a954b40 | [
"BSD-3-Clause"
] | 5 | 2018-10-18T02:02:23.000Z | 2020-08-25T00:32:41.000Z | ---
title: libGDX
localeTitle: libGDX
---
## Разработка игр с помощью libGDX
libGDX - это бесплатная и открытая среда разработки игр, написанная на языке программирования Java, с некоторыми компонентами C и C ++ для кода, зависящего от производительности.
### обзор
LibGDX поддерживает как разработку игр 2d и 3d, так и написан на Java. В дополнение к Java, другие языки JVM, такие как Kotlin или Scala, могут использоваться для программирования игр libGDX. В его основе libGDX использует LWJGL 3 для обработки основных игровых функций, таких как графика, вход и звук. LibGDX предлагает большой API для упрощения игрового программирования. LibGDX имеет информативную [вики](https://github.com/libgdx/libgdx/wiki) на странице Github, и в Интернете есть много учебников.
#### Ресурсы:
https://github.com/libgdx/libgdx/wiki https://libgdx.badlogicgames.com/ https://www.reddit.com/r/libgdx/ | 59.466667 | 502 | 0.789238 | rus_Cyrl | 0.950313 |
9772522116e61abe29b0750527e5a6ab8cdf614f | 276 | md | Markdown | templates/Watch/Pages/SwitchList/GettingStarted_postaction.md | Samsung/TizenTemplateStudio | 434ed886b67f25b00501f5ce29523cc30f0304ca | [
"MIT"
] | 6 | 2020-06-04T11:37:35.000Z | 2022-02-16T23:49:23.000Z | templates/Watch/Pages/SwitchList/GettingStarted_postaction.md | Samsung/Tailor | 434ed886b67f25b00501f5ce29523cc30f0304ca | [
"MIT"
] | 3 | 2021-02-14T14:47:30.000Z | 2021-02-18T05:11:50.000Z | templates/Watch/Pages/SwitchList/GettingStarted_postaction.md | Samsung/Tailor | 434ed886b67f25b00501f5ce29523cc30f0304ca | [
"MIT"
] | null | null | null | ## Pages
<!--{[{-->
### Switch List - WatchItemName
A page that displays a collection of data consisting of text and switch in a vertical list.
#### New files:
* Views/WatchItemNamePage.xaml
* Views/WatchItemNamePage.xaml.cs
#### Dependent features:
* Sample Data
<!--}]}--> | 25.090909 | 91 | 0.692029 | eng_Latn | 0.796825 |
9772cd4916d2cdeb4c85cbf142697f702981271e | 2,037 | md | Markdown | windows-driver-docs-pr/kernel/wmi-requirements-for-wdm-drivers.md | sarman1998/windows-driver-docs | 790f8ecb851d5c9e423af03a8a57dfac59945c24 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows-driver-docs-pr/kernel/wmi-requirements-for-wdm-drivers.md | sarman1998/windows-driver-docs | 790f8ecb851d5c9e423af03a8a57dfac59945c24 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows-driver-docs-pr/kernel/wmi-requirements-for-wdm-drivers.md | sarman1998/windows-driver-docs | 790f8ecb851d5c9e423af03a8a57dfac59945c24 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: WMI Requirements for WDM Drivers
author: windows-driver-content
description: WMI Requirements for WDM Drivers
ms.assetid: 8290e570-acd9-4047-bd0b-c1c74847f243
keywords: ["WMI WDK kernel , WDM drivers", "WDM drivers WDK WMI", "IRPs WDK WMI", "requests WDK WMI", "WMI WDK kernel , requests", "data providers WDK WMI"]
ms.author: windowsdriverdev
ms.date: 06/16/2017
ms.topic: article
ms.prod: windows-hardware
ms.technology: windows-devices
---
# WMI Requirements for WDM Drivers
A driver that handles IRPs registers with WMI as a *data provider*. System-supplied storage port drivers, class drivers, and NDIS protocol drivers fall into this category. For information about registering as a WMI data provider, see [Registering as a WMI Data Provider](registering-as-a-wmi-data-provider.md).
A driver that does not handle IRPs should simply forward WMI requests to the next-lower driver in the driver stack. The next-lower driver then registers with WMI and handles WMI requests on the first driver's behalf. For instance, SCSI miniport drivers and NDIS miniport drivers can register as WMI providers and supply WMI data to their corresponding class drivers.
A driver that supplies WMI data to a class or port driver must support the driver-type-specific WMI interfaces that are defined by the class or port driver. For example, a SCSI miniport driver must set **WmiDataProvider** to **TRUE** in the [**PORT\_CONFIGURATION\_INFORMATION**](https://msdn.microsoft.com/library/windows/hardware/ff563900) structure and handle SRB\_FUNCTION\_WMI requests from the SCSI port driver.
Similarly, a connection-oriented NDIS miniport driver that defines custom data blocks must support [OID\_GEN\_CO\_SUPPORTED\_GUIDS](https://msdn.microsoft.com/library/windows/hardware/ff569566); otherwise, NDIS maps those OIDs and status indications returned from OID\_GEN\_SUPPORTED\_LIST that are common and known to NDIS to GUIDs defined by NDIS.
The following sections describe how to support WMI in a driver that handles IRPs.
| 55.054054 | 417 | 0.792342 | eng_Latn | 0.965653 |
977339cda2e1567d107ab16e8f33090f1512fdf0 | 2,206 | md | Markdown | _posts/2019-03-22-linux-install-party.md | HackLab-Almeria/hacklab-almeria.github.io | c3cdfc30924478b738d2509fc70a875208f5270d | [
"CC-BY-4.0"
] | 17 | 2015-02-25T09:35:49.000Z | 2021-11-24T09:45:02.000Z | _posts/2019-03-22-linux-install-party.md | HackLab-Almeria/hacklab-almeria.github.io | c3cdfc30924478b738d2509fc70a875208f5270d | [
"CC-BY-4.0"
] | 101 | 2015-02-20T13:00:02.000Z | 2020-04-14T16:48:32.000Z | _posts/2019-03-22-linux-install-party.md | HackLab-Almeria/hacklab-almeria.github.io | c3cdfc30924478b738d2509fc70a875208f5270d | [
"CC-BY-4.0"
] | 62 | 2015-03-03T10:05:22.000Z | 2021-05-02T13:50:44.000Z | ---
layout: post-jsonld
#Datos del Evento
title: "Linux Install party"
description: "Instala tu distribución Linux en un abrir y cerrar de ojos."
#Fecha
startDate: 2019-03-22T18:00
endDate: 2019-03-22T20:00
#Lugar
place: "LA OFICINA Producciones Culturales"
street: "Calle de las tiendas, 26"
locality: "Almería"
postalCode: "04001"
map: http://www.openstreetmap.org/node/2389372700
category: actividades
social:
- time: 2019-03-11T18:30
text: "¿Quieres dar una segunda vida a tu viejo portatil? Instalale Linux y podrás ver que aún puede dar mucho de si"
- time: 2019-03-15T10:30
text: "Vamos no seas timido; ven el próximo día 22 a la Linux Install Party"
- time: 2019-03-16T12:30
text: "Vamos ven a la Linux Install Party que organizamos en La Oficina el próximo Día 22."
- time: 2019-03-20T15:25
text: "El viernes nos vemos en La Oficina Producciones Culturales para la Linux Install Party"
- time: 2019-03-22T11:30
text: "No olvides traer tu portatil para la Linux Install Party!!! Esta tarde en La Oficina Producciones Culturales."
---
### DESCRIPCIÓN
Ya es hora de dar ese pequeño paso para adentrarte en el mundo Linux; instalar una distribución como Ubuntu en solo unos pocos pasos; esta al alcance de todos.
Además, siempre puede dar una segunda vida a un ordenador de pocos recursos instalando una distribución linux que consuma poco pero te de toda la versatibilidad de los equipos actuales.
Solo necesitas traer tu equipo y nosotros te ayudaremos a instalar Linux en tu equipo. La instalación se realizará en [La oficina](http://www.openstreetmap.org/node/2389372700).
Linux se puede instalar casi en cualquier cosa!!!
### ¿Que necesitas?
Necesitas traer tu ordenador para poder instalar tu distribución Linux. Si necesitas una distribución especifica, es recomendable que te descargues la imagen para poder tenerla a mano en la instalación.
Puede ser recomendable, descargar la imagen por ejempo de [Ubuntu 18.10 para equipos de 64 bits](http://releases.ubuntu.com/18.10/ubuntu-18.10-desktop-amd64.iso) o [Ubuntu mate 18-02 para equipos de 32 Bits](http://cdimage.ubuntu.com/ubuntu-mate/releases/18.04/release/ubuntu-mate-18.04.2-desktop-i386.iso)
| 45.958333 | 308 | 0.766092 | spa_Latn | 0.940958 |
977362470f4d3d041a5d588e968763743989c39a | 11,816 | md | Markdown | articles/network-watcher/network-watcher-packet-capture-manage-cli.md | Erickwilts/azure-docs.nl-nl | a9c68e03c55ac26af75825a5407e3dd14a323ee1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/network-watcher/network-watcher-packet-capture-manage-cli.md | Erickwilts/azure-docs.nl-nl | a9c68e03c55ac26af75825a5407e3dd14a323ee1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/network-watcher/network-watcher-packet-capture-manage-cli.md | Erickwilts/azure-docs.nl-nl | a9c68e03c55ac26af75825a5407e3dd14a323ee1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Pakket opnames beheren met Azure Network Watcher-Azure CLI | Microsoft Docs
description: Op deze pagina wordt uitgelegd hoe u de functie voor het vastleggen van pakketten van Network Watcher beheert met behulp van de Azure CLI
services: network-watcher
documentationcenter: na
author: damendo
ms.assetid: cb0c1d10-f7f2-4c34-b08c-f73452430be8
ms.service: network-watcher
ms.devlang: na
ms.topic: how-to
ms.tgt_pltfrm: na
ms.workload: infrastructure-services
ms.date: 01/07/2021
ms.author: damendo
ms.openlocfilehash: 838a5255c013b530aa3bfdb857a2ba34b7dbeeed
ms.sourcegitcommit: 42a4d0e8fa84609bec0f6c241abe1c20036b9575
ms.translationtype: MT
ms.contentlocale: nl-NL
ms.lasthandoff: 01/08/2021
ms.locfileid: "98010962"
---
# <a name="manage-packet-captures-with-azure-network-watcher-using-the-azure-cli"></a>Pakket opnames beheren met Azure Network Watcher met behulp van de Azure CLI
> [!div class="op_single_selector"]
> - [Azure-portal](network-watcher-packet-capture-manage-portal.md)
> - [PowerShell](network-watcher-packet-capture-manage-powershell.md)
> - [Azure-CLI](network-watcher-packet-capture-manage-cli.md)
> - [Azure REST API](network-watcher-packet-capture-manage-rest.md)
Met Network Watcher-pakket opname kunt u opname sessies maken om verkeer van en naar een virtuele machine bij te houden. Er worden filters voor de opname sessie gegeven om ervoor te zorgen dat u alleen het gewenste verkeer vastlegt. Met pakket opname kunt u netwerk afwijkingen zowel reactief als proactief vaststellen. Andere gebruiken zijn onder andere het verzamelen van netwerk statistieken, het verkrijgen van informatie over inbreuken op het netwerk, het opsporen van fouten in client-server communicatie en nog veel meer. Doordat pakket opnames op afstand kunnen worden geactiveerd, vereenvoudigt deze mogelijkheid de belasting van het hand matig uitvoeren van een pakket opname en op de gewenste computer, waardoor kost bare tijd wordt bespaard.
Als u de stappen in dit artikel wilt uitvoeren, moet u [de Azure Command-Line-interface voor Mac, Linux en Windows (Azure CLI) installeren](/cli/azure/install-azure-cli).
Dit artikel begeleidt u door de verschillende beheer taken die momenteel beschikbaar zijn voor pakket opname.
- [**Een pakket opname starten**](#start-a-packet-capture)
- [**Een pakket opname stoppen**](#stop-a-packet-capture)
- [**Een pakket opname verwijderen**](#delete-a-packet-capture)
- [**Pakket opname downloaden**](#download-a-packet-capture)
## <a name="before-you-begin"></a>Voordat u begint
In dit artikel wordt ervan uitgegaan dat u de volgende resources hebt:
- Een exemplaar van Network Watcher in de regio waarin u een pakket opname wilt maken
- Een virtuele machine waarop de pakket Capture-extensie is ingeschakeld.
> [!IMPORTANT]
> Voor het vastleggen van pakketten moet een agent op de virtuele machine worden uitgevoerd. De agent wordt geïnstalleerd als een uitbrei ding. Ga naar [extensies en functies van virtuele machines](../virtual-machines/extensions/features-windows.md)voor instructies voor VM-extensies.
## <a name="install-vm-extension"></a>VM-extensie installeren
### <a name="step-1"></a>Stap 1
Voer de `az vm extension set` opdracht uit om de pakket Capture-agent te installeren op de virtuele gast machine.
Voor virtuele Windows-machines:
```azurecli-interactive
az vm extension set --resource-group resourceGroupName --vm-name virtualMachineName --publisher Microsoft.Azure.NetworkWatcher --name NetworkWatcherAgentWindows --version 1.4
```
Voor virtuele Linux-machines:
```azurecli-interactive
az vm extension set --resource-group resourceGroupName --vm-name virtualMachineName --publisher Microsoft.Azure.NetworkWatcher --name NetworkWatcherAgentLinux --version 1.4
```
### <a name="step-2"></a>Stap 2
Om ervoor te zorgen dat de agent is geïnstalleerd, voert u de `vm extension show` opdracht uit en geeft u de naam van de resource groep en de virtuele machine door. Controleer de resulterende lijst om te controleren of de agent is geïnstalleerd.
Voor virtuele Windows-machines:
```azurecli-interactive
az vm extension show --resource-group resourceGroupName --vm-name virtualMachineName --name NetworkWatcherAgentWindows
```
Voor virtuele Linux-machines:
```azurecli-interactive
az vm extension show --resource-group resourceGroupName --vm-name virtualMachineName --name AzureNetworkWatcherExtension
```
Het volgende voor beeld is een voor beeld van het resultaat van het uitvoeren van `az vm extension show`
```json
{
"autoUpgradeMinorVersion": true,
"forceUpdateTag": null,
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{resourceGroupName}/providers/Microsoft.Compute/virtualMachines/{vmName}/extensions/NetworkWatcherAgentWindows",
"instanceView": null,
"location": "westcentralus",
"name": "NetworkWatcherAgentWindows",
"protectedSettings": null,
"provisioningState": "Succeeded",
"publisher": "Microsoft.Azure.NetworkWatcher",
"resourceGroup": "{resourceGroupName}",
"settings": null,
"tags": null,
"type": "Microsoft.Compute/virtualMachines/extensions",
"typeHandlerVersion": "1.4",
"virtualMachineExtensionType": "NetworkWatcherAgentWindows"
}
```
## <a name="start-a-packet-capture"></a>Een pakket opname starten
Zodra de voor gaande stappen zijn voltooid, wordt de pakket Capture-agent geïnstalleerd op de virtuele machine.
### <a name="step-1"></a>Stap 1
Een opslag account ophalen. Dit opslag account wordt gebruikt om het pakket opname bestand op te slaan.
```azurecli-interactive
az storage account list
```
### <a name="step-2"></a>Stap 2
U bent nu klaar om een pakket opname te maken. Eerst gaan we de para meters bekijken die u wilt configureren. Filters zijn een van deze para meters die kunnen worden gebruikt om de gegevens te beperken die worden opgeslagen door de pakket opname. In het volgende voor beeld wordt een pakket opname met verschillende filters ingesteld. Met de eerste drie filters worden uitgaande TCP-verkeer alleen verzameld van lokale IP-10.0.0.3 naar doel poorten 20, 80 en 443. Met het laatste filter wordt alleen UDP-verkeer verzameld.
```azurecli-interactive
az network watcher packet-capture create --resource-group {resourceGroupName} --vm {vmName} --name packetCaptureName --storage-account {storageAccountName} --filters "[{\"protocol\":\"TCP\", \"remoteIPAddress\":\"1.1.1.1-255.255.255\",\"localIPAddress\":\"10.0.0.3\", \"remotePort\":\"20\"},{\"protocol\":\"TCP\", \"remoteIPAddress\":\"1.1.1.1-255.255.255\",\"localIPAddress\":\"10.0.0.3\", \"remotePort\":\"80\"},{\"protocol\":\"TCP\", \"remoteIPAddress\":\"1.1.1.1-255.255.255\",\"localIPAddress\":\"10.0.0.3\", \"remotePort\":\"443\"},{\"protocol\":\"UDP\"}]"
```
Het volgende voor beeld is de verwachte uitvoer van het uitvoeren van de `az network watcher packet-capture create` opdracht.
```json
{
"bytesToCapturePerPacket": 0,
"etag": "W/\"b8cf3528-2e14-45cb-a7f3-5712ffb687ac\"",
"filters": [
{
"localIpAddress": "10.0.0.3",
"localPort": "",
"protocol": "TCP",
"remoteIpAddress": "1.1.1.1-255.255.255",
"remotePort": "20"
},
{
"localIpAddress": "10.0.0.3",
"localPort": "",
"protocol": "TCP",
"remoteIpAddress": "1.1.1.1-255.255.255",
"remotePort": "80"
},
{
"localIpAddress": "10.0.0.3",
"localPort": "",
"protocol": "TCP",
"remoteIpAddress": "1.1.1.1-255.255.255",
"remotePort": "443"
},
{
"localIpAddress": "",
"localPort": "",
"protocol": "UDP",
"remoteIpAddress": "",
"remotePort": ""
}
],
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/NetworkWatcherRG/providers/Microsoft.Network/networkWatchers/NetworkWatcher_westcentralus/pa
cketCaptures/packetCaptureName",
"name": "packetCaptureName",
"provisioningState": "Succeeded",
"resourceGroup": "NetworkWatcherRG",
"storageLocation": {
"filePath": null,
"storageId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{resourceGroupName}/providers/Microsoft.Storage/storageAccounts/gwteststorage123abc",
"storagePath": "https://gwteststorage123abc.blob.core.windows.net/network-watcher-logs/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/{resourceGroupName}/p
roviders/microsoft.compute/virtualmachines/{vmName}/2017/05/25/packetcapture_16_22_34_630.cap"
},
"target": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{resourceGroupName}/providers/Microsoft.Compute/virtualMachines/{vmName}",
"timeLimitInSeconds": 18000,
"totalBytesPerSession": 1073741824
}
```
## <a name="get-a-packet-capture"></a>Pakket opname ophalen
Als u de `az network watcher packet-capture show-status` opdracht uitvoert, wordt de status opgehaald van een actieve of voltooide pakket opname.
```azurecli-interactive
az network watcher packet-capture show-status --name packetCaptureName --location {networkWatcherLocation}
```
Het volgende voor beeld is de uitvoer van de `az network watcher packet-capture show-status` opdracht. Het volgende voor beeld is wanneer de opname wordt gestopt met een StopReason van TimeExceeded.
```
{
"additionalProperties": {
"status": "Succeeded"
},
"captureStartTime": "2016-12-06T17:20:01.5671279Z",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/NetworkWatcherRG/providers/Microsoft.Network/networkWatchers/NetworkWatcher_westcentralus/pa
cketCaptures/packetCaptureName",
"name": "packetCaptureName",
"packetCaptureError": [],
"packetCaptureStatus": "Stopped",
"stopReason": "TimeExceeded"
}
```
## <a name="stop-a-packet-capture"></a>Een pakket opname stoppen
Door de `az network watcher packet-capture stop` opdracht uit te voeren als een opname sessie wordt uitgevoerd, wordt deze gestopt.
```azurecli-interactive
az network watcher packet-capture stop --name packetCaptureName --location westcentralus
```
> [!NOTE]
> De opdracht retourneert geen reactie wanneer deze wordt uitgevoerd op een actieve opname sessie of een bestaande sessie die al is gestopt.
## <a name="delete-a-packet-capture"></a>Een pakket opname verwijderen
```azurecli-interactive
az network watcher packet-capture delete --name packetCaptureName --location westcentralus
```
> [!NOTE]
> Als u een pakket opname verwijdert, wordt het bestand in het opslag account niet verwijderd.
## <a name="download-a-packet-capture"></a>Pakket opname downloaden
Zodra de pakket opname sessie is voltooid, kan het opname bestand worden geüpload naar de Blob-opslag of naar een lokaal bestand op de virtuele machine. De opslag locatie van de pakket opname wordt gedefinieerd tijdens het maken van de sessie. Een handig hulp middel om toegang te krijgen tot deze opname bestanden die zijn opgeslagen in een opslag account, is Microsoft Azure Storage Explorer, dat hier kan worden gedownload: https://storageexplorer.com/
Als er een opslag account is opgegeven, worden pakket opname bestanden opgeslagen in een opslag account op de volgende locatie:
```
https://{storageAccountName}.blob.core.windows.net/network-watcher-logs/subscriptions/{subscriptionId}/resourcegroups/{storageAccountResourceGroup}/providers/microsoft.compute/virtualmachines/{VMName}/{year}/{month}/{day}/packetCapture_{creationTime}.cap
```
## <a name="next-steps"></a>Volgende stappen
Meer informatie over het automatiseren van pakket opnames met waarschuwingen voor virtuele machines door het weer geven van [een waarschuwing gegenereerde pakket opname maken](network-watcher-alert-triggered-packet-capture.md)
Controleren of bepaalde verkeer is toegestaan in of buiten uw virtuele machine door te kijken naar controle van de [IP-stroom](diagnose-vm-network-traffic-filtering-problem.md)
<!-- Image references --> | 49.029046 | 753 | 0.761594 | nld_Latn | 0.96304 |
9773fad9d2ee50c1f09255ff3bca8ccebfa0c9eb | 3,465 | md | Markdown | README.md | ladeiko/VegaScrollFlowLayoutX | 62b421d014081f5ecd4a633951f67cd1acf87e73 | [
"MIT"
] | 12 | 2018-01-30T22:59:46.000Z | 2021-05-03T22:40:14.000Z | README.md | ladeiko/VegaScrollFlowLayoutX | 62b421d014081f5ecd4a633951f67cd1acf87e73 | [
"MIT"
] | null | null | null | README.md | ladeiko/VegaScrollFlowLayoutX | 62b421d014081f5ecd4a633951f67cd1acf87e73 | [
"MIT"
] | 3 | 2018-02-22T07:23:11.000Z | 2019-12-05T06:25:59.000Z | Fixed version of [VegaScrollFlowLayout](https://github.com/ApplikeySolutions/VegaScroll) by [Applikey Solutions](https://applikeysolutions.com)
Find this [project on Dribbble](https://dribbble.com/shots/3793079-iPhone-8-iOS-11)
Also check another flowlayout for UICollectionView: https://github.com/ApplikeySolutions/GravitySlider

# Table of Contents
1. [Purpose](#purpose)
2. [Supported OS & SDK Versions](#supported-os--sdk-versions)
3. [Installation](#installation)
4. [Usage](#usage)
5. [Demo](#demo)
6. [Release Notes](#release-notes)
7. [Contact Us](#contact-us)
8. [License](#license)
# Purpose
VegaScroll is a lightweight animation flowlayout for `UICollectionView` completely written in Swift 4, compatible with iOS 11 and Xcode 9.
# Supported OS & SDK Versions
* Supported build target - iOS 9.0
# Installation
### [CocoaPods](https://github.com/CocoaPods/CocoaPods)
Add the following line in your `Podfile`.
```
pod 'VegaScrollFlowLayoutX'
```
### Carthage
If you're using [Carthage](https://github.com/Carthage/Carthage) you can add a dependency on VegaScroll by adding it to your `Cartfile`:
```
github "ladeiko/VegaScrollFlowLayoutX"
```
# Usage
```swift
import VegaScrollFlowLayout
let layout = VegaScrollFlowLayout()
collectionView.collectionViewLayout = layout
layout.minimumLineSpacing = 20
layout.itemSize = CGSize(width: collectionView.frame.width, height: 87)
layout.sectionInset = UIEdgeInsets(top: 10, left: 0, bottom: 10, right: 0)
```
# Demo
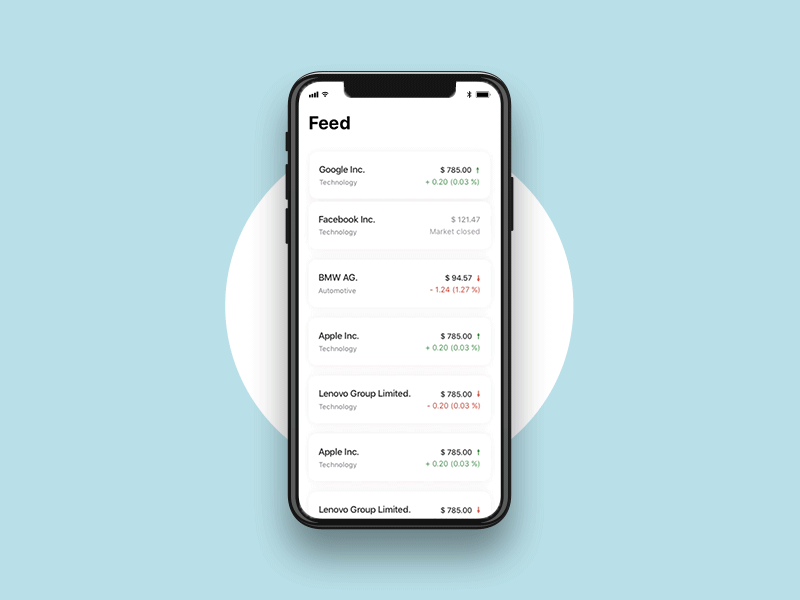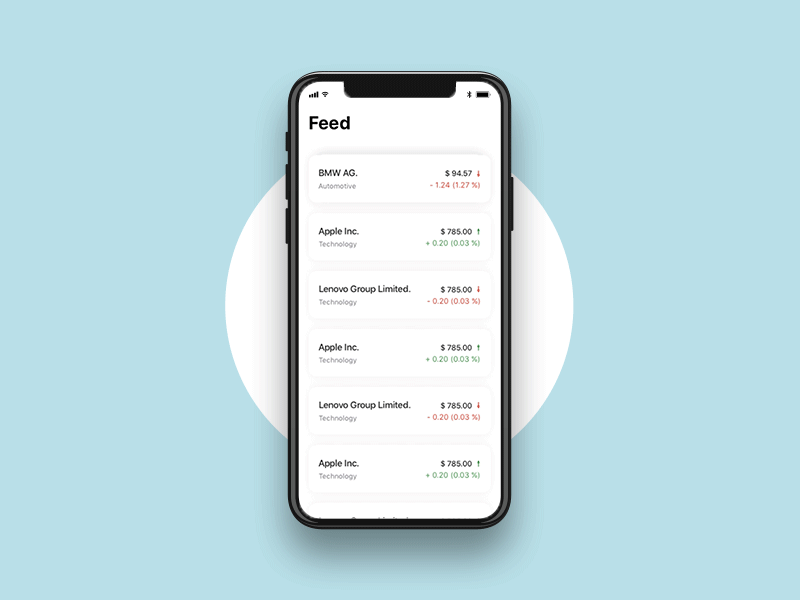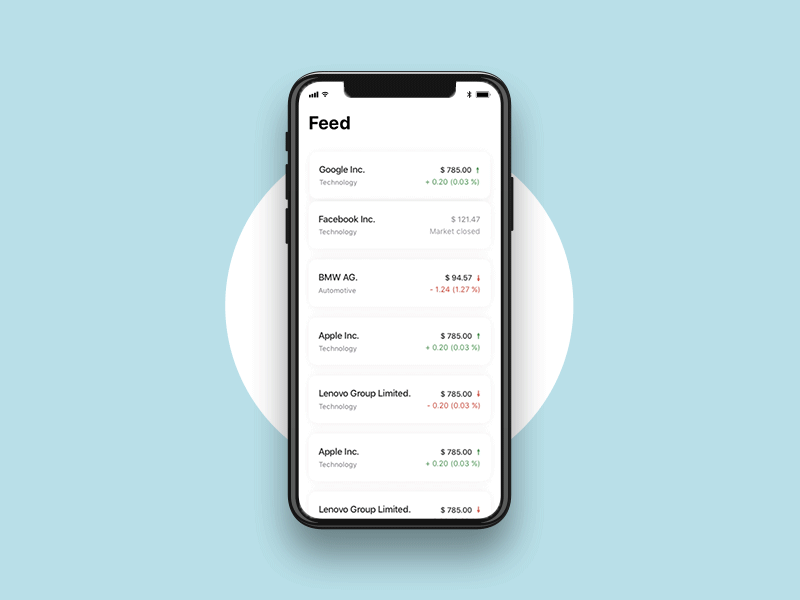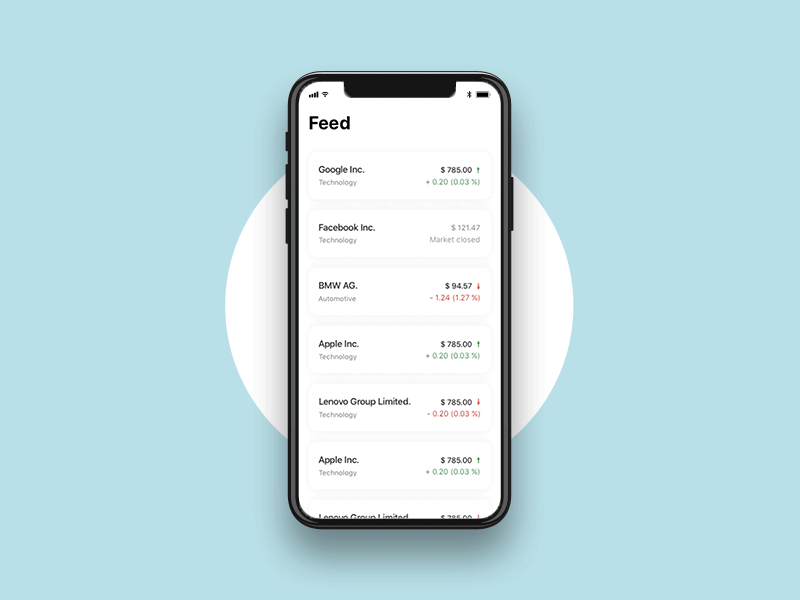
# Release Notes
Version 1.4
- Add 'disableDynamicBehaviour'
Version 1.3
- Add 'expandBy' property with default value of 1000. It is used when detecting which items are visible while preparing layout, collectionView size is increased by this value in height. If some items disappear while size change try to increase this value.
Version 1.2
- Bug fixes
Version 1.0
- Release version.
# Contact Us
You can always contact us via [email protected] We are open for any inquiries regarding our libraries and controls, new open-source projects and other ways of contributing to the community. If you have used our component in your project we would be extremely happy if you write us your feedback and let us know about it!
# License
The MIT License (MIT)
Copyright © 2017 Applikey Solutions
Permission is hereby granted free of charge to any person obtaining a copy of this software and associated documentation files (the "Software") to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
| 36.473684 | 429 | 0.782395 | eng_Latn | 0.817562 |
977506d39310bfb0e1b743b2bbbd18175715afa3 | 23,175 | md | Markdown | articles/human-resources/hr-leave-and-absence-plans.md | MicrosoftDocs/Dynamics-365-Operations.nb-no | 377b55f1c8fafee18ab7bdbc550401b83255fd4d | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-05-18T17:14:36.000Z | 2021-04-20T21:13:46.000Z | articles/human-resources/hr-leave-and-absence-plans.md | MicrosoftDocs/Dynamics-365-Operations.nb-no | 377b55f1c8fafee18ab7bdbc550401b83255fd4d | [
"CC-BY-4.0",
"MIT"
] | 6 | 2017-12-12T12:48:00.000Z | 2019-04-30T11:45:53.000Z | articles/human-resources/hr-leave-and-absence-plans.md | MicrosoftDocs/Dynamics-365-Operations.nb-no | 377b55f1c8fafee18ab7bdbc550401b83255fd4d | [
"CC-BY-4.0",
"MIT"
] | 3 | 2019-10-12T18:16:06.000Z | 2022-01-28T03:23:59.000Z | ---
title: Opprette en permisjons- og fraværsplan
description: Opprett permisjonsplaner i Dynamics 365 Human Resources for ulike typer permisjon.
author: andreabichsel
ms.date: 09/11/2020
ms.topic: article
ms.prod: ''
ms.technology: ''
ms.search.form: LeavePlanFormPart, LeaveAbsenceWorkspace
audience: Application User
ms.search.scope: Human Resources
ms.custom: 7521
ms.assetid: ''
ms.search.region: Global
ms.author: anbichse
ms.search.validFrom: 2020-02-03
ms.dyn365.ops.version: Human Resources
ms.openlocfilehash: f0903c77676ce8ce7c8d585f24dfe4f554ca1321cd3e5ecc33a0b792dfcc4a66
ms.sourcegitcommit: 42fe9790ddf0bdad911544deaa82123a396712fb
ms.translationtype: HT
ms.contentlocale: nb-NO
ms.lasthandoff: 08/05/2021
ms.locfileid: "6745676"
---
# <a name="create-a-leave-and-absence-plan"></a>Opprette en permisjons- og fraværsplan
[!include [Applies to Human Resources](../includes/applies-to-hr.md)]
Definer permisjons- og fraværsplaner i Dynamics 365 Human Resources for hver permisjonstype du tilbyr. Permisjons- og fraværsplaner kan avsettes med forskjellige frekvenser, for eksempel årlig, månedlig eller annenhver måned. Du kan også definere en plan som et tilskudd, der en enkelt avsetning skjer på en bestemt dato. Du kan for eksempel opprette en plan som gir flytende ferier årlig.
Med lagdelte permisjonsplaner kan de ansatte motta fordeler basert på hvor lang tid de har vært i en organisasjon. Lagdelte planer aktiverer automatisk registrering i ekstra fordelstimer.
Du kan angi maksimalt overførte beløp eller minimumssaldoer for å sikre at de ansatte bare bruker fordelstimene de er tildelt.
Med en lagdelt plan kan du for eksempel gi en fordel på 80 timer betalt avspasering (PTO) til nye ansatte. Deretter kan du gi 120 timer etter 60 måneders ansettelse.
Du kan også opprette stillingsbaserte permisjonsfordeler, for eksempel fordelstider bare for ledere.
## <a name="create-a-leave-plan"></a>Opprette en permisjonsplan
1. På siden **Permisjon og fravær** velger du **Opprett ny plan**.
2. Under **Detaljer** angir du **Navn**, **Startdato**, **Beskrivelse** og **Permisjonstype** for planen.
Hvis funksjonen **Konfigurer flere permisjonstyper for en enkel permisjons- og fraværsplan** er aktivert, konfigureres permisjonstyper i **Avsetningsplan** i stedet for under **Detaljer**. Du kan definere en permisjonstype for hver post i avsetningsplantabellen. Når denne funksjonen er aktivert, må du også bruke nye dataenheter for integreringer eller andre scenarioer der du må bruke enheter.
De nye enhetene er:
- Banktransaksjon for permisjon og fravær V2
- Permisjons- og fraværsregistrering V2
- Lag i permisjons- og fraværsplan V2
- Permisjons- og fraværsplan V2
- Be om permisjonsfridager V2
> [!IMPORTANT]
> Du kan ikke deaktivere denne funksjonen etter at du har aktivert den.
3. Definer avsetninger i kategorien **Avsetninger**. Avsetninger avgjør når og hvor ofte en ansatt blir tildelt avspasering. I dette trinnet definerer du policyer om når det skal gis avsetning, og retningslinjer for vurdering av fordeler.
1. Velg en verdi fra rullegardinboksen **Avsetningsfrekvens**:
- Daglig
- Ukentlig
- Annenhver uke
- Annenhver måned
- Månedlig
- Kvartalsvis
- Hvert halvår
- Årlig
- Ingen
2. Velg et alternativ fra rullegardinboksen **Avsetningsperiodegrunnlag** for å bestemme startdatoen som skal brukes til beregning av avsetningsperioder:
| Avsetningsperiodegrunnlag | Beskrivelse |
| --- | --- |
| **Startdato for plan** | Startdatoen for avsetningsperioden er datoen da planen er tilgjengelig. |
| **Spesifikk dato for ansatt** | Startdatoen for avsetningsperioden avhenger av en ansatthendelse:</br><ul><li>Egendefinert (du må angi et grunnlag for en avsetningsdato for hver enkelt registrering)</li><li>Jubileumsdato</li><li>Opprinnelig ansettelsesdato</li><li>Ansiennitetsdato</li><li>Arbeiderens justerte startdato</li><li>Arbeiderens startdato</li></ul> |
3. Velg et alternativ fra rullegardinboksen **Belønningsdato for avsetning**:
- **Sluttdato for avsetningsperiode** – Den ansatte blir tildelt avspasering på den siste dagen i belønningsperioden. Hvis du vil avsette riktig tid, må avsetningsprosessen inkludere hele perioden. Hvis for eksempel avsetningsperioden er 1. januar 2020 til 31. januar 2020, må du kjøre avsetningen for 1. februar 2020 for å inkludere januar.
- **Startdato for avsetningsperiode** – Den ansatte blir tildelt avspasering på den første dagen i belønningsperioden.
4. Velg et alternativ fra rullegardinboksen **Avsetningspolicy ved registrering**: Denne verdien definerer hvordan avsetningen skal beregnes når en ansatt registreres midt i en avsetningsperiode.
- **Fordelt** – Datointervallet mellom registreringsdatoen og startdatoen brukes til å fastsette forskjellen i dager. Denne differansen brukes når avsetninger behandles.
- **Full avsetning** – Full avsetning, basert på nivået, gis i den første avsetningsbehandlingen.
- **Ingen avsetning** – Ingen avsetning gis før neste avsetningsperiode.
5. Velg et alternativ fra rullegardinboksen **Avsetningspolicy ved avregistrering**: Denne verdien definerer hvordan avsetningen skal beregnes når en ansatt avregistreres midt i en avsetningsperiode.
- **Fordelt** – Datointervallet mellom registreringsdatoen og startdatoen brukes til å fastsette forskjellen i dager. Denne differansen brukes når avsetninger behandles.
- **Full avsetning** – Full avsetning, basert på nivået, gis i den første avsetningsbehandlingen.
- **Ingen avsetning** – Ingen avsetning gis før neste avsetningsperiode.
4. Definer avsetningsplanen i kategorien **Avsetningsplan**. Avsetningsplanen bestemmer følgende:
- Hvordan en ansatt avsetter avspasering
- Hvilke beløp den ansatte skal avsette
- Hvilke beløp som skal overføres
Du kan opprette lag for å tildele avspasering basert på forskjellige nivåer.
Hvis du har timebaserte ansatte, kan du belønne dem med fridager basert på antall arbeidstimer i stedet for ansiennitet i organisasjonen. Data for arbeidstimer lagres vanligvis i et system for tid og fremmøte. Du kan importere vanlige timer og overtidstimer som er arbeidet fra systemet for tid og fremmøte, og bruke dem som grunnlag for bonusen til en ansatt.
1. Velg et alternativ fra rullegardinboksen **Avsetningstype**:
- **Måneder med jobberfaring** – Baser avsetningsplanen på antall måneder med jobberfaring.
- **Arbeidstimer** – Baser avsetningsplanen på arbeidstimer. Hvis du vil ha mer informasjon om avsetninger for arbeidstimer, kan du se [Avsette fridager basert på arbeidstimer](hr-leave-and-absence-plans.md?accrue-time-off-based-on-hours-worked).
Hvis du vil ha mer informasjon om avsetningssaldoer, kan du se [Avsette fridager basert på arbeidstimer](hr-leave-and-absence-plans.md?enrollments-and-balances).
2. Angi verdier i avsetningsplantabellen:
- **Måneder med jobberfaring** – Det minste antallet måneder som ansatte må arbeide for å være berettiget til avsetninger. Hvis du ikke krever et minimum, setter du verdien til 0.
- **Arbeidstimer** – Det minste antallet timer som ansatte må arbeide per avsetningsperiode for å være berettiget til avsetninger. Hvis du ikke krever et minimum, setter du verdien til 0.
- **Avsetningsbeløp** – Antallet timer eller dager som ansatte skal avsette per periode. Perioden er basert på avsetningsfrekvensen.
- **Minimumssaldo** – Du kan bruke en negativ for minimumssaldoen hvis ansatte kan be om mer permisjon enn de har tilgjengelig.
- **Maksimal overføring** – Avsetningsprosessen justerer permisjonssaldoer som overskrider maksimal overføringssaldo på merkedagen til startdatoen.
- **Tildelingsbeløp** – Det opprinnelige antallet timer eller dager som ansatte gis når de registrerer seg for permisjonsplanen første gang. Beløpet avsettes ikke for hver avsetningsperiode.
Hvis funksjonen **Konfigurer flere permisjonstyper for en enkel permisjons- og fraværsplan** er aktivert, velger du et alternativ fra **Permisjonstype**.
> [!IMPORTANT]
> Du kan ikke deaktivere denne funksjonen etter at du har aktivert den.
Hvis funksjonen **Bruk fulltidsekvivalens** er aktivert, bruker Human Resources fulltidsekvivalensen (FTE) som er definert for stillingen, til å fordele en ansatts avsetning. Hvis for eksempel FTE er 0,5 og avsetningsbeløpet er 10, vil den ansatte avsette 5. Du kan bare bruke denne funksjonen hvis du aktiverer flere permisjonstyper.
5. Velg **Lagre**.
## <a name="accrue-time-off-based-on-hours-worked"></a>Avsette tid basert på arbeidstimer
Hvis du har timebaserte ansatte, kan du belønne dem med fridager basert på antall arbeidstimer i stedet for ansiennitet i organisasjonen. Data for arbeidstimer lagres vanligvis i et system for tid og fremmøte. Du kan importere vanlige timer og overtidstimer som er arbeidet fra systemet for tid og fremmøte, og bruke dem som grunnlag for bonusen til en ansatt.
Når du velger arbeidstimer som avsetningstype, kan du bruke to typer timer for avsetningen: vanlig og overtid. Avsetningsbehandling for planer av arbeidstimer bruker avsetningsfrekvensen, sammen med periodebasisen, til å bestemme timene som skal avsettes.
### <a name="annual-accrual-frequency"></a>Årlig avsetningsfrekvens
| Belønningsdato for avsetning | Arbeidstimernivå | Avsetningsbeløp | Arbeidstimer datoer | Arbeidstimer faktisk| Belønning |
| --------------------- | -------------------- | --------------------- | -------------------- |-------------------- |-------------------- |
| 31/12/2018 | 2080 | 144 | 1/1/2018-12/31/2018 | 2085 | 144 |
| 31/12/2018 | 2080 | 144 | 1/1/2018-12/31/2018 | 2000 | 0 |
### <a name="monthly-accrual-frequency"></a>Månedlig avsetningsfrekvens
| Belønningsdato for avsetning | Arbeidstimernivå | Avsetningsbeløp | Arbeidstimer datoer | Arbeidstimer faktisk| Belønning |
| --------------------- | -------------------- | --------------------- | -------------------- |-------------------- |-------------------- |
| 31/8/2018 | 160 | 12 | 8/1/2018-8/31/2018 | 184 | 12 |
| 31/8/2018 | 160 | 3 | 8/1/2018-8/31/2018 | 184 | 3 |
### <a name="semi-monthly-accrual-frequency"></a>Avsetningsfrekvens annenhver måned
| Belønningsdato for avsetning | Arbeidstimernivå | Avsetningsbeløp | Arbeidstimer datoer | Arbeidstimer faktisk| Belønning |
| --------------------- | -------------------- | --------------------- | -------------------- |-------------------- |-------------------- |
| 31/8/2018 | 80 | 6 | 8/16/2018-8/31/2018 | 81 | 6 |
| 31/8/2018 | 80 | 6 | 8/16/2018-8/31/2018 | 75 | 0 |
### <a name="weekly-accrual-frequency"></a>Ukentlig avsetningsfrekvens
| Belønningsdato for avsetning | Arbeidstimernivå | Avsetningsbeløp | Arbeidstimer datoer | Arbeidstimer faktisk| Belønning |
| --------------------- | -------------------- | --------------------- | -------------------- |-------------------- |-------------------- |
| 31/8/2018 | 40 | 3 | 8/27/2018-8/31/2018 | 42 | 3 |
| 31/8/2018 | 40 | 3 | 8/27/2018-8/31/2018 | 35 | 0 |
### <a name="employee-assigned-leave-plans"></a>Tilordnede permisjonsplaner for ansatte
I den ansattes tilordnede permisjonsplaner vises nivågrunnlaget og typen timer for planer basert på arbeidstimer. De faktiske arbeidstimene for avsetningsperiodene per gjeldende vises dato også for aktive planer.
### <a name="loading-data"></a>Laster inn data
Du kan importere faktiske timer ved hjelp av enheten **Antall arbeidstimer for permisjon og fravær** i databehandling. Hvis du bruker arbeidstidskalendre, validerer importen at normaltimer som er utført, ikke overstiger de planlagte timene på en dag definert av kalenderen. Importen validerer også at antallet arbeidstimer for en gitt dag ikke overskrider 24 timer.
Du trenger følgende informasjon for å importere faktisk antall timer som skal brukes i denne avsetningsprosessen for permisjon:
- Personalnummer
- Arbeidsdag
- Type
- Timeantall
En enkelt dato kan bare ha én av hver type knyttet til seg.
| Personalnummer | Arbeidsdag | Type | Timeantall |
| --------------------- | -------------------- | --------------------- | -------------------- |
| 000337 | 6/8/2018 | Vanlig | 8 |
| 000337 | 7/8/2018 | Vanlig | 8 |
| 000337 | 7/8/2018 | Overtid | 3 |
| 000337 | 8/8/2018 | Vanlig | 8 |
| 000337 | 7/8/2018 | Vanlig | 8 |
| 000337 | 9/8/2018 | Vanlig | 8 |
## <a name="enrollments-and-balances"></a>Registreringer og saldoer
### <a name="enrollment-date"></a>Registreringsdato
Registreringsdatoen bestemmer når en ansatt kan begynne å avsette avspasering. Hvis for eksempel en ansatt registreres i en ferieplan 15. juni 2018, kan vedkommende ikke avsette avspasering før 15. juni 2018.
### <a name="current-balance"></a>Gjeldende saldo
Gjeldende saldo er hvor mye permisjon som er tilgjengelig for avspaseringsforespørsler. Dette beløpet inkluderer avsetninger godkjente forespørsler og justeringer til og med den gjeldende datoen.
### <a name="current-balance-examples"></a>Eksempler på gjeldende saldo
#### <a name="annual-plan"></a>Årsplan
**Oppsett av plan**
| Startdato for plan | Registreringsdato | Avsetningsfrekvens | Avsetningsperiodegrunnlag | Belønningsdato for avsetning |
|-----------------|-----------------|-------------------|----------------------|-----------------------|
| 1/1/2018 | 1/1/2018 | Årlig | Startdato for plan | Slutt på avsetningsperiode |
Avsetninger behandles 1. januar 2019 (1.1.2019), for å inkludere hele perioden.
**Resultater**
| Avsetningsbeløp | Minste saldo | Maksimal overføring | Forespørselsbeløp | Gjeldende saldo (per 1.1.2019) |
|----------------|-----------------|-----------------------|----------------|----------------------------------|
| 200 | 0 | 120 | 40 | 160 |
Gjeldende saldo (160) = avsetningsbeløp (200) – forespurt beløp (40)
#### <a name="semimonthly-plan"></a>Halvmånedlig plan
**Oppsett av plan**
| Startdato for plan | Registreringsdato | Avsetningsfrekvens | Avsetningsperiodegrunnlag | Belønningsdato for avsetning |
|-----------------|-----------------|-------------------|----------------------|-----------------------|
| 1/1/2018 | 1/2/2018 | Halvmånedlig | Startdato for plan | Slutt på avsetningsperiode |
Avsetninger behandles 1. mai 2018 (1.5.2018), for å inkludere hele perioden.
**Resultater**
| Avsetningsbeløp | Minste saldo | Maksimal overføring | Forespørselsbeløp | Gjeldende saldo (per 1.1.2019) |
|----------------|-----------------|-----------------------|----------------|----------------------------------|
| 5 | 0 | 120 | 8 | 22 |
Gjeldende saldo (22) = avsetningsbeløp (5 x 6) – forespurt beløp (8)
#### <a name="monthly-plan"></a>Månedlig plan
**Oppsett av plan**
| Startdato for plan | Registreringsdato | Avsetningsfrekvens | Avsetningsperiodegrunnlag | Belønningsdato for avsetning |
|-----------------|-----------------|-------------------|----------------------|-----------------------|
| 1/1/2018 | 1/2/2018 | Halvmånedlig | Startdato for plan | Slutt på avsetningsperiode |
Avsetninger behandles 1. mai 2018 (1.5.2018), for å inkludere hele perioden.
**Resultater**
| Avsetningsbeløp | Minste saldo | Maksimal overføring | Forespørselsbeløp | Gjeldende saldo (per 1.1.2019) |
|----------------|-----------------|-----------------------|----------------|----------------------------------|
| 5 | 0 | 120 | 8 | 7 |
Gjeldende saldo (7) = avsetningsbeløp (5 x 3) – forespurt beløp (8)
### <a name="forecasted-balance"></a>Anslått saldo
*Prognosesaldo* er hvor mye permisjon som er tilgjengelig på en bestemt dato. Avsetninger og overføringsjusteringer er anslått frem til denne datoen.
Human Resources bruker følgende formel:
Mandag prognosesaldo = gjeldende saldo – forespørsler + avsetninger – overføringsjustering
### <a name="forecasted-balance-examples"></a>Eksempler på prognosesaldoer
#### <a name="annual-plan"></a>Årsplan
**Oppsett av plan**
| Startdato for plan | Registreringsdato | Avsetningsfrekvens | Avsetningsperiodegrunnlag | Belønningsdato for avsetning |
|-----------------|-----------------|-------------------|----------------------|-----------------------|
| 1/1/2018 | 1/1/2018 | Årlig | Startdato for plan | Slutt på avsetningsperiode |
Avsetninger behandles 15. februar 2019 (15.2.2019), for å inkludere hele perioden.
**Resultater**
| Avsetningsbeløp | Minste saldo | Maksimal overføring | Gjeldende saldo | Prognosesaldo (per 15.2.2019) |
|----------------|-----------------|-----------------------|-----------------|--------------------------------------|
| 20 | 0 | 20 | 40 | 40 |
Prognosesaldo (40) = avsetningsbeløp (20) + gjeldende saldo (40) – overføringsjustering (20)
#### <a name="semimonthly-plan"></a>Halvmånedlig plan
**Oppsett av plan**
| Startdato for plan | Registreringsdato | Avsetningsfrekvens | Avsetningsperiodegrunnlag | Belønningsdato for avsetning |
|-----------------|-----------------|-------------------|----------------------|-----------------------|
| 1/1/2018 | 1/2/2018 | Halvmånedlig | Startdato for plan | Slutt på avsetningsperiode |
Avsetninger behandles 15. februar 2019 (15.2.2019), for å inkludere hele perioden.
**Resultater**
| Avsetningsbeløp | Minste saldo | Maksimal overføring | Gjeldende saldo | Prognosesaldo (per 15.2.2019) |
|----------------|-----------------|-----------------------|-----------------|--------------------------------------|
| 5 | 0 | 20 | 40 | 35 |
Prognosesaldo (35) = avsetningsbeløp (5 x 3) + gjeldende saldo (40) – overføringsjustering (20)
#### <a name="monthly-plan"></a>Månedlig plan
**Oppsett av plan**
| Startdato for plan | Registreringsdato | Avsetningsfrekvens | Avsetningsperiodegrunnlag | Belønningsdato for avsetning |
|-----------------|-----------------|-------------------|----------------------|-----------------------|
| 1/1/2018 | 1/2/2018 | Halvmånedlig | Startdato for plan | Slutt på avsetningsperiode |
Avsetninger behandles 15. februar 2019 (15.2.2019), for å inkludere hele perioden.
**Resultater**
| Avsetningsbeløp | Minste saldo | Maksimal overføring | Gjeldende saldo | Prognosesaldo (per 15.2.2019) |
|----------------|-----------------|-----------------------|-----------------|--------------------------------------|
| 10 | 0 | 20 | 40 | 30 |
Prognosesaldo (30) = avsetningsbeløp (10 x 1) + gjeldende saldo (40) – overføringsjustering (20)
### <a name="proration-balance-examples"></a>Eksempler på fordelingssaldo
#### <a name="prorated-monthly-plan"></a>Fordelt månedlig plan
**Oppsett av plan**
| Startdato for plan | Avsetningsfrekvens | Avsetningsperiodegrunnlag |
|-----------------|-------------------|----------------------|
| 1/1/2018 | Månedlig | Startdato for plan |
**Resultater**
| Ansatt | Måneder med jobberfaring | Registreringsdato | Startdato | Avsetningsbeløp | Behandle avsetning | Beholdning |
|---------------------|-------------------|-----------------|------------|----------------|-----------------|---------|
| Jeannette Nicholson | 0,00 | 1/6/2018 | 1/6/2018 | 1,00 | 1/9/2018 | 3,00 |
| Jay Norman | 0,00 | 15/6/2018 | 15/6/2018 | 1,00 | 1/9/2018 | 2.53 |
#### <a name="full-accrual-monthly-plan"></a>Full avsetning, månedlig plan
**Oppsett av plan**
| Startdato for plan | Avsetningsfrekvens | Avsetningsperiodegrunnlag |
|-----------------|-------------------|----------------------|
| 1/1/2018 | Månedlig | Startdato for plan |
**Resultater**
| Ansatt | Måneder med jobberfaring | Registreringsdato | Startdato | Avsetningsbeløp | Behandle avsetning | Beholdning |
|---------------------|-------------------|-----------------|------------|----------------|-----------------|---------|
| Jeannette Nicholson | 0,00 | 1/6/2018 | 1/6/2018 | 1,00 | 1/9/2018 | 3,00 |
| Jay Norman | 0,00 | 15/6/2018 | 15/6/2018 | 1,00 | 1/9/2018 | 3,00 |
#### <a name="no-accrual-monthly-plan"></a>Ingen avsetning, månedlig plan
**Oppsett av plan**
| Startdato for plan | Avsetningsfrekvens | Avsetningsperiodegrunnlag |
|-----------------|-------------------|----------------------|
| 1/1/2018 | Månedlig | Startdato for plan |
**Resultater**
| Ansatt | Måneder med jobberfaring | Registreringsdato | Startdato | Avsetningsbeløp | Behandle avsetning | Beholdning |
|---------------------|-------------------|-----------------|------------|----------------|-----------------|---------|
| Jeannette Nicholson | 0,00 | 1/6/2018 | 1/6/2018 | 1,00 | 1/9/2018 | 3.00 |
| Jay Norman | 0.00 | 15/6/2018 | 15/6/2018 | 1.00 | 1/9/2018 | 2.00 |
## <a name="see-also"></a>Se også
- [Oversikt over permisjon og fravær](hr-leave-and-absence-overview.md)
- [Konfigurere permisjons- og fraværstyper](hr-leave-and-absence-types.md)
- [Avsette permisjons- og fraværsplaner](hr-leave-and-absence-accrue.md)
[!INCLUDE[footer-include](../includes/footer-banner.md)] | 59.883721 | 396 | 0.596375 | nob_Latn | 0.978937 |
97750795eb56e85156840c477f117dec210dc7ab | 9,103 | md | Markdown | articles/load-balancer/scripts/load-balancer-linux-cli-sample-zone-redundant-frontend.md | jobailla/azure-docs.fr-fr | 8c7734bc0d6ffaa8f9f2a39982929b8d9fc8235e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/load-balancer/scripts/load-balancer-linux-cli-sample-zone-redundant-frontend.md | jobailla/azure-docs.fr-fr | 8c7734bc0d6ffaa8f9f2a39982929b8d9fc8235e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/load-balancer/scripts/load-balancer-linux-cli-sample-zone-redundant-frontend.md | jobailla/azure-docs.fr-fr | 8c7734bc0d6ffaa8f9f2a39982929b8d9fc8235e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Équilibrer la charge des machines virtuelles dans les zones de disponibilité - Azure CLI - Azure Load Balancer
description: Cet exemple de script Azure CLI montre comment équilibrer la charge du trafic vers les machines virtuelles entre les zones de disponibilité
documentationcenter: load-balancer
author: asudbring
Customer intent: As an IT administrator, I want to create a load balancer that load balances incoming internet traffic to virtual machines across availability zones in a region.
ms.service: load-balancer
ms.devlang: azurecli
ms.topic: sample
ms.workload: infrastructure
ms.date: 06/14/2018
ms.author: allensu
ms.custom: devx-track-azurecli
ms.openlocfilehash: 532aa851f4112fb91d9e23975cdc2fda48d76cf6
ms.sourcegitcommit: 829d951d5c90442a38012daaf77e86046018e5b9
ms.translationtype: HT
ms.contentlocale: fr-FR
ms.lasthandoff: 10/09/2020
ms.locfileid: "87501710"
---
# <a name="azure-cli-script-example-load-balance-vms-across-availability-zones"></a>Exemple de script Azure CLI : Équilibrer la charge de machines virtuelles entre des zones de disponibilité
Cet exemple de script CLI Azure crée tous les éléments nécessaires pour exécuter plusieurs machines virtuelles Ubuntu configurées dans une configuration haute disponibilité avec équilibrage de la charge. Une fois que vous avez exécuté le script, vous obtenez trois machines virtuelles entre toutes les zones de disponibilité dans une région, qui sont accessibles par le biais d’Azure Load Balancer Standard.
[!INCLUDE [sample-cli-install](../../../includes/sample-cli-install.md)]
[!INCLUDE [quickstarts-free-trial-note](../../../includes/quickstarts-free-trial-note.md)]
## <a name="sample-script"></a>Exemple de script
```azurecli-interactive
#!/bin/bash
# Create a resource group.
az group create \
--name myResourceGroup \
--location westeurope
# Create a virtual network.
az network vnet create \
--resource-group myResourceGroup \
--location westeurope \
--name myVnet \
--subnet-name mySubnet
# Create a zonal Standard public IP address.
az network public-ip create \
--resource-group myResourceGroup \
--name myPublicIP \
--sku Standard
# Create an Azure Load Balancer.
az network lb create \
--resource-group myResourceGroup \
--name myLoadBalancer \
--public-ip-address myPublicIP \
--frontend-ip-name myFrontEndPool \
--backend-pool-name myBackEndPool \
--sku Standard
# Creates an LB probe on port 80.
az network lb probe create \
--resource-group myResourceGroup \
--lb-name myLoadBalancer \
--name myHealthProbe \
--protocol tcp \
--port 80
# Creates an LB rule for port 80.
az network lb rule create \
--resource-group myResourceGroup \
--lb-name myLoadBalancer \
--name myLoadBalancerRuleWeb \
--protocol tcp \
--frontend-port 80 \
--backend-port 80 \
--frontend-ip-name myFrontEndPool \
--backend-pool-name myBackEndPool \
--probe-name myHealthProbe
# Create three NAT rules for port 22.
for i in `seq 1 3`; do
az network lb inbound-nat-rule create \
--resource-group myResourceGroup \
--lb-name myLoadBalancer \
--name myLoadBalancerRuleSSH$i \
--protocol tcp \
--frontend-port 422$i \
--backend-port 22 \
--frontend-ip-name myFrontEndPool
done
# Create a network security group
az network nsg create \
--resource-group myResourceGroup \
--name myNetworkSecurityGroup
# Create a network security group rule for port 22.
az network nsg rule create \
--resource-group myResourceGroup \
--nsg-name myNetworkSecurityGroup \
--name myNetworkSecurityGroupRuleSSH \
--protocol tcp \
--direction inbound \
--source-address-prefix '*' \
--source-port-range '*' \
--destination-address-prefix '*' \
--destination-port-range 22 \
--access allow \
--priority 1000
# Create a network security group rule for port 80.
az network nsg rule create \
--resource-group myResourceGroup \
--nsg-name myNetworkSecurityGroup \
--name myNetworkSecurityGroupRuleHTTP \
--protocol tcp \
--direction inbound \
--source-address-prefix '*' \
--source-port-range '*' \
--destination-address-prefix '*' \
--destination-port-range 80 \
--access allow \
--priority 2000
# Create three virtual network cards and associate with load balancer and NSG.
for i in `seq 1 3`; do
az network nic create \
--resource-group myResourceGroup \
--name myNic$i \
--vnet-name myVnet \
--subnet mySubnet \
--network-security-group myNetworkSecurityGroup \
--lb-name myLoadBalancer \
--lb-address-pools myBackEndPool \
--lb-inbound-nat-rules myLoadBalancerRuleSSH$i
done
# Create three virtual machines, this creates SSH keys if not present.
for i in `seq 1 3`; do
az vm create \
--resource-group myResourceGroup \
--name myVM$i \
--zone $i \
--nics myNic$i \
--image UbuntuLTS \
--generate-ssh-keys \
--no-wait
done
```
## <a name="clean-up-deployment"></a>Nettoyer le déploiement
Exécutez la commande suivante pour supprimer le groupe de ressources, la machine virtuelle et toutes les ressources associées.
```azurecli
az group delete --name myResourceGroup
```
## <a name="script-explanation"></a>Explication du script
Ce script utilise les commandes suivantes pour créer un groupe de ressources, une machine virtuelle, un groupe à haute disponibilité, un équilibreur de charge et toutes les ressources associées. Chaque commande du tableau renvoie à une documentation spécifique.
| Commande | Notes |
|---|---|
| [az group create](https://docs.microsoft.com/cli/azure/group#az-group-create) | Crée un groupe de ressources dans lequel toutes les ressources sont stockées. |
| [az network vnet create](https://docs.microsoft.com/cli/azure/network/vnet#az-network-vnet-create) | Crée un réseau virtuel et un sous-réseau Azure. |
| [az network public-ip create](https://docs.microsoft.com/cli/azure/network/public-ip#az-network-public-ip-create) | Crée une adresse IP publique avec une adresse IP statique et un nom DNS associé. |
| [az network lb create](https://docs.microsoft.com/cli/azure/network/lb#az-network-lb-create) | Crée un équilibreur de charge Azure. |
| [az network lb probe create](https://docs.microsoft.com/cli/azure/network/lb/probe#az-network-lb-probe-create) | Crée une sonde d’équilibreur de charge. Les sondes d’équilibreurs de charge permettent de surveiller chaque machine virtuelle d’un jeu d’équilibrage de charge. Si une machine virtuelle n’est plus accessible, le trafic n’est pas acheminé vers cette machine virtuelle. |
| [az network lb rule create](https://docs.microsoft.com/cli/azure/network/lb/rule#az-network-lb-rule-create) | Crée une règle d’équilibeur de charge. Dans cet exemple, une règle est créée pour le port 80. Le trafic HTTP qui arrive à l’équilibreur de charge est acheminé vers le port 80 des machines virtuelles incluses dans un jeu d’équilibrage de charge. |
| [az network lb inbound-nat-rule create](https://docs.microsoft.com/cli/azure/network/lb/inbound-nat-rule#az-network-lb-inbound-nat-rule-create) | Crée une règle de traduction d’adresses réseau (NAT) pour l’équilibreur de charge. Les règles NAT mappent un port de l’équilibreur de charge avec un port d’une machine virtuelle. Dans cet exemple, une règle NAT est créée pour le trafic SSH en direction de chaque machine virtuelle au sein du jeu d’équilibrage de charge. |
| [az network nsg create](https://docs.microsoft.com/cli/azure/network/nsg#az-network-nsg-create) | Crée un groupe de sécurité réseau qui représente une frontière de sécurité entre Internet et la machine virtuelle. |
| [az network nsg rule create](https://docs.microsoft.com/cli/azure/network/nsg/rule#az-network-nsg-rule-create) | Crée une règle de groupe de sécurité réseau permettant d’autoriser le trafic entrant. Dans cet exemple, le port 22 est ouvert pour le trafic SSH. |
| [az network nic create](https://docs.microsoft.com/cli/azure/network/nic#az-network-nic-create) | Crée une carte réseau virtuelle et l’associe au réseau virtuel, au sous-réseau et au groupe de sécurité réseau. |
| [az vm create](/cli/azure/vm#az-vm-create) | Crée la machine virtuelle et l’associe à la carte réseau, au réseau virtuel, au sous-réseau et au groupe de sécurité réseau. Cette commande spécifie également l’image de machine virtuelle à utiliser ainsi que les informations d’identification d’administration. |
| [az group delete](https://docs.microsoft.com/cli/azure/vm/extension#az-vm-extension-set) | Supprime un groupe de ressources, y compris toutes les ressources imbriquées. |
## <a name="next-steps"></a>Étapes suivantes
Pour plus d’informations sur l’interface Azure CLI, consultez la [documentation relative à l’interface Azure CLI](https://docs.microsoft.com/cli/azure).
Vous pouvez trouver des exemples supplémentaires de scripts CLI de la mise en réseau Azure dans la [documentation de la mise en réseau Azure](../cli-samples.md).
| 49.205405 | 472 | 0.73701 | fra_Latn | 0.607443 |
977536c6799aef05a2fb4d8f5247f029ce11aecc | 22,888 | md | Markdown | docs/expressions.md | canerdogan/bosun | 5f7dc2d5920e752afcef1579e674c1cd659f9008 | [
"MIT"
] | null | null | null | docs/expressions.md | canerdogan/bosun | 5f7dc2d5920e752afcef1579e674c1cd659f9008 | [
"MIT"
] | null | null | null | docs/expressions.md | canerdogan/bosun | 5f7dc2d5920e752afcef1579e674c1cd659f9008 | [
"MIT"
] | null | null | null | ---
layout: default
title: Expression Documentation
---
<div class="row">
<div class="col-sm-3" >
<div class="sidebar" data-spy="affix" data-offset-top="0" data-offset-bottom="0" markdown="1">
* Some TOC
{:toc}
</div>
</div>
<div class="doc-body col-sm-9" markdown="1">
<p class="title h1">{{page.title}}</p>
This section documents Bosun's expression language, which is used to define the trigger condition for an alert. At the highest level the expression language takes various time *series* and reduces them them a *single number*. True or false indicates whether the alert should trigger or not; 0 represents false (don't trigger an alert) and any other number represents true (trigger an alert). An alert can also produce one or more *groups* which define the alert's scope or dimensionality. For example could you have one alert per host, service, or cluster or a single alert for your entire environment.
# Fundamentals
## Data Types
There are three data types in Bosun's expression language:
1. **Scalar**: This is the simplest type, it is a single numeric value with no group associated with it. Keep in mind that an empty group, `{}` is still a group.
2. **NumberSet**: A number set is a group of tagged numeric values with one value per unique grouping. As a special case, a **scalar** may be used in place of a **numberSet** with a single member with an empty group.
3. **SeriesSet**: A series is an array of timestamp-value pairs and an associated group.
In the vast majority of your alerts you will getting ***seriesSets*** back from your time series database and ***reducing*** them into ***numberSets***.
## Group keys
Groups are generally provided by your time series database. We also sometimes refer to groups as "Tags". When you query your time series database and get multiple time series back, each time series needs an identifier. So for example if I make a query with some thing like `host=*` then I will get one time series per host. Host is the tag key, and the various various values returned, i.e. `host1`, `host2`, `host3`.... are the tag values. Therefore the group for a single time series is something like `{host=host1}`. A group can have multiple tag keys, and will have one tag value for each key.
Each group can become its own alert instance. This is what we mean by ***scope*** or dimensionality. Thus, you can do things like `avg(q("sum:sys.cpu{host=ny-*}", "5m", "")) > 0.8` to check the CPU usage for many New York hosts at once. The dimensions can be manipulated with our expression language.
### Group Subsets
Various metrics can be combined by operators as long as one group is a subset of the other. A ***subset*** is when one of the groups contains all of the tag key-value pairs in the other. An empty group `{}` is a subset of all groups. `{host=foo}` is a subset of `{host=foo,interface=eth0}`, and neither `{host=foo,interface=eth0}` nor `{host=foo,parition=/}` are a subset of the other. Equal groups are considered subsets of each other.
## Operators
The standard arithmetic (`+`, binary and unary `-`, `*`, `/`, `%`), relational (`<`, `>`, `==`, `!=`, `>=`, `<=`), and logical (`&&`, `||`, and unary `!`) operators are supported. The binary operators require the value on at least one side to be a scalar or NumberSet. Arrays will have the operator applied to each element. Examples:
* `q("q") + 1`, which adds one to every element of the result of the query `"q"`
* `-q("q")`, the negation of the results of the query
* `5 > q("q")`, a series of numbers indicating whether each data point is more than five
* `6 / 8`, the scalar value three-quarters
### Precedence
From highest to lowest:
1. `()` and the unary operators `!` and `-`
1. `*`, `/`, `%`
1. `+`, `-`
1. `==`, `!=`, `>`, `>=`, `<`, `<=`
1. `&&`
1. `||`
## Numeric constants
Numbers may be specified in decimal (e.g., `123.45`), octal (with a leading zero like `072`), or hex (with a leading 0x like `0x2A`). Exponentials and signs are supported (e.g., `-0.8e-2`).
# The Anatomy of a Basic Alert
<pre>
alert haproxy_session_limit {
template = generic
$notes = This alert monitors the percentage of sessions against the session limit in haproxy (maxconn) and alerts when we are getting close to that limit and will need to raise that limit. This alert was created due to a socket outage we experienced for that reason
$current_sessions = max(q("sum:haproxy.frontend.scur{host=*,pxname=*,tier=*}", "5m", ""))
$session_limit = max(q("sum:haproxy.frontend.slim{host=*,pxname=*,tier=*}", "5m", ""))
$q = ($current_sessions / $session_limit) * 100
warn = $q > 80
crit = $q > 95
warnNotification = default
critNotificaiton = default
}
</pre>
We don't need to understand everything in this alert, but it is worth highlighting a few things to get oriented:
* `haproxy_session_limit` This is the name of the alert, an alert instance is uniquely identified by its alertname and group, i.e `haproxy_session_limit{host=lb,pxname=http-in,tier=2}`
* `$notes` This is a variable. Variables are not smart, they are just text replacement. If you are familiar with macros in C, this is a similar concept. These variables can be referenced in notification templates which is why we have a generic one for notes
* `q("sum:haproxy.frontend.scur{host=*,pxname=*,tier=*}", "5m", "")` is an OpenTSDB query function, it returns *N* series, we know each series will have the host, pxname, and tier tag keys in their group based on the query.
* `max(...)` is a reduction function. It takes each **series** and **reduces** it to a **number** (See the Data types section above).
* `$current_sessions / $session_limit` these variables represent **numbers** and will have subset group matches so there for you can use the / **operator** between them.
* `warn = $q > 80` if this is true (non-zero) then the `warnNotification` will be triggered.
# Query Functions
## Graphite Query Functions
### GraphiteQuery(query string, startDuration string, endDuration string, format string) seriesSet
Performs a graphite query. the duration format is the internal bosun format (which happens to be the same as OpenTSDB's format).
Functions pretty much the same as q() (see that for more info) but for graphite.
The format string lets you annotate how to parse series as returned by graphite, as to yield tags in the format that bosun expects.
The tags are dot-separated and the amount of "nodes" (dot-separated words) should match what graphite returns.
Irrelevant nodes can be left empty.
For example:
`groupByNode(collectd.*.cpu.*.cpu.idle,1,'avg')`
returns seriesSet named like `host1`, `host2` etc, in which case the format string can simply be `host`.
`collectd.web15.cpu.*.cpu.*`
returns seriesSet named like `collectd.web15.cpu.3.idle`, requiring a format like `.host..core..cpu_type`.
For advanced cases, you can use graphite's alias(), aliasSub(), etc to compose the exact parseable output format you need.
This happens when the outer graphite function is something like "avg()" or "sum()" in which case graphite's output series will be identified as "avg(some.string.here)".
### GraphiteBand(query string, duration string, period string, format string, num string) seriesSet
Like band() but for graphite queries.
## InfluxDB Query Functions
### influx(db string, query string, startDuration string, endDuration, groupByInterval string) seriesSet
Queries InfluxDB.
All tags returned by InfluxDB will be included in the results.
* `db` is the database name in InfluxDB
* `query` is an InfluxDB select statement
NB: WHERE clauses for `time` are inserted automatically, and it is thus an error to specify `time` conditions in query.
* `startDuration` and `endDuration` set the time window from now - see the OpenTSDB q() function for more details
They will be merged into the existing WHERE clause in the `query`.
* `groupByInterval` is the `time.Duration` window which will be passed as an argument to a GROUP BY time() clause if given. This groups values in the given time buckets. This groups (or in OpenTSDB lingo "downsamples") the results to this timeframe. [Full documentation on Group by](https://influxdb.com/docs/v0.9/query_language/data_exploration.html#group-by).
### Notes:
* By default, queries will be given a suffix of `fill(none)` to filter out any nil rows.
## examples:
These influx and opentsdb queries should give roughly the same results:
```
influx("db", '''SELECT non_negative_derivative(mean(value)) FROM "os.cpu" GROUP BY host''', "30m", "", "2m")
q("sum:2m-avg:rate{counter,,1}:os.cpu{host=*}", "30m", "")
```
## Logstash Query Functions
### lscount(indexRoot string, keyString string, filterString string, bucketDuration string, startDuration string, endDuration string) seriesSet
lscount returns the per second rate of matching log documents.
* `indexRoot` is the root name of the index to hit, the format is expected to be `fmt.Sprintf("%s-%s", index_root, d.Format("2006.01.02"))`.
* `keyString` creates groups (like tagsets) and can also filter those groups. It is the format of `"field:regex,field:regex..."` The `:regex` can be ommited.
* `filterString` is an Elastic regexp query that can be applied to any field. It is in the same format as the keystring argument.
* `bucketDuration` is in the same format is an opentsdb duration, and is the size of buckets returned (i.e. counts for every 10 minutes). In the case of lscount, that number is normalized to a per second rate by dividing the result by the number of seconds in the duration.
* `startDuration` and `endDuration` set the time window from now - see the OpenTSDB q() function for more details.
For example:
`lscount("logstash", "logsource,program:bosun", "5s", "10m", "")`
queries the "logstash" named indexes (we autogenerate the date porition of the indexes based on the time frame) and returns a series with groups like `{logsrouce:ny-bosun01, program:bosun}, {logsrouce:ny-bosun02, program:bosun}`. The values of the series will be the count of log entries in 5 second buckets over the last 10 minutes.
### lsstat(indexRoot string, keyString string, filterString string, field string, rStat(avg|min|max|sum|sum_of_squares|variance|std_deviation) string, bucketDuration string, startDuration string, endDuration string) series
lstat returns various summary stats per bucket for the specified `field`. The field must be numeric in elastic. rStat can be one of `avg`, `min`, `max`, `sum`, `sum_of_squares`, `variance`, `std_deviation`. The rest of the fields behave the same as lscount except that there is no division based on `bucketDuration` since these are summary stats.
### Caveats
* There is currently no escaping in the keystring, so if you regex needs to have a comma or double quote you are out of luck.
* The regexs in keystring are applied twice. First as a regexp filter to elastic, and then as a go regexp to the keys of the result. This is because the value could be an array and you will get groups that should be filtered. This means regex language is the intersection of the golang regex spec and the elastic regex spec.
* Elastic uses lucene style regex. This means regexes are always anchored ([see the documentation](http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html#_standard_operators)).
* If the type of the field value in Elastic (aka the mapping) is a number then the regexes won't act as a regex. The only thing you can do is an exact match on the number, ie "eventlogid:1234". It is recommended that anything that is a identifier should be stored as a string since they are not numbers even if they are made up entirely of numerals.
* As of January 15, 2015 - logstash functionality is new so these functions may change a fair amount based on experience using them in alerts.
* Alerts using this information likely want to set ignoreUnknown, since only "groups" that appear in the time frame are in the results.
## OpenTSDB Query Functions
Query functions take a query string (like `sum:os.cpu{host=*}`) and return a seriesSet.
### q(query string, startDuration string, endDuration string) seriesSet
Generic query from endDuration to startDuration ago. If endDuration is the empty string (`""`), now is used. Support d( units are listed in [the docs](http://opentsdb.net/docs/build/html/user_guide/query/dates.html). Refer to [the docs](http://opentsdb.net/docs/build/html/user_guide/query/index.html) for query syntax. The query argument is the value part of the `m=...` expressions. `*` and `|` are fully supported. In addition, queries like `sys.cpu.user{host=ny-*}` are supported. These are performed by an additional step which determines valid matches, and replaces `ny-*` with `ny-web01|ny-web02|...|ny-web10` to achieve the same result. This lookup is kept in memory by the system and does not incur any additional OpenTSDB API requests, but does require scollector instances pointed to the bosun server.
### band(query string, duration string, period string, num scalar) seriesSet
Band performs `num` queries of `duration` each, `period` apart and concatenates them together, starting `period` ago. So `band("avg:os.cpu", "1h", "1d", 7)` will return a series comprising of the given metric from 1d to 1d-1h-ago, 2d to 2d-1h-ago, etc, until 8d. This is a good way to get a time block from a certain hour of a day or certain day of a week over a long time period.
### change(query string, startDuration string, endDuration string) numberSet
Change is a way to determine the change of a query from startDuration to endDuration. If endDuration is the empty string (`""`), now is used. The query must either be a rate or a counter converted to a rate with the `agg:rate:metric` flag.
For example, assume you have a metric `net.bytes` that records the number of bytes that have been sent on some interface since boot. We could just subtract the end number from the start number, but if a reboot or counter rollover occurred during that time our result will be incorrect. Instead, we ask OpenTSDB to convert our metric to a rate and handle all of that for us. So, to get the number of bytes in the last hour, we could use:
`change("avg:rate:net.bytes", "60m", "")`
Note that this is implemented using the bosun's `avg` function. The following is exactly the same as the above example:
`avg(q("avg:rate:net.bytes", "60m", "")) * 60 * 60`
### count(query string, startDuration string, endDuration string) scalar
Count returns the number of groups in the query as an ungrouped scalar.
### window(query string, duration string, period string, num scalar, funcName string) seriesSet
Window performs `num` queries of `duration` each, `period` apart, starting
`period` ago. The results of the queries are run through `funcName` which
must be a reduction function taking only one argument (that is, a function
that takes a series and returns a number), then a series made from those. So
`window("avg:os.cpu{host=*}", "1h", "1d", 7, "dev")` will return a series
comprising of the average of given metric from 1d to 1d-1h-ago, 2d to
2d-1h-ago, etc, until 8d. It is similar to the band function, except that
instead of concatenating series together, each series is reduced to a number,
and those numbers created into a series.
# Reduction Functions
All reduction functions take a seriesSet and return a numberSet with one element per unique group.
## avg(seriesSet) numberSet
Average (arithmetic mean).
## cCount(seriesSet) numberSet
Returns the change count which is the number of times in the series a value was not equal to the immediate previous value. Useful for checking if things that should be at a steady value are "flapping". For example, a series with values [0, 1, 0, 1] would return 3.
## dev(seriesSet) numberSet
Standard deviation.
## diff(seriesSet) numberSet
Diff returns the last point of each series minus the first point.
## first(seriesSet) numberSet
Returns the first (least recent) data point in each series.
## forecastlr(seriesSet, y_val numberSet|scalar) numberSet
Returns the number of seconds until a linear regression of each series will reach y_val.
## last(seriesSet) numberSet
Returns the last (most recent) data point in each series.
## len(seriesSet) numberSet
Returns the length of each series.
## max(seriesSet) numberSet
Returns the maximum value of each series, same as calling percentile(series, 1).
## median(seriesSet) numberSet
Returns the median value of each series, same as calling percentile(series, .5).
## min(seriesSet) numberSet
Returns the minimum value of each series, same as calling percentile(series, 0).
## percentile(seriesSet, p numberSet|scalar) numberSet
Returns the value from each series at the percentile p. Min and Max can be simulated using `p <= 0` and `p >= 1`, respectively.
## since(seriesSet) numberSet
Returns the number of seconds since the most recent data point in each series.
## streak(seriesSet) numberSet
Returns the length of the longest streak of values that evaluate to true (i.e. max amount of contiguous non-zero values found).
## sum(seriesSet) numberSet
Sum.
# Group Functions
Group functions modify the OpenTSDB groups.
## t(numberSet, group string) seriesSet
Transposes N series of length 1 to 1 series of length N. If the group parameter is not the empty string, the number of series returned is equal to the number of tagks passed. This is useful for performing scalar aggregation across multiple results from a query. For example, to get the total memory used on the web tier: `sum(t(avg(q("avg:os.mem.used{host=*-web*}", "5m", "")), ""))`.
How transpose works conceptually
Transpose Grouped results into a Single Result:
Before Transpose (Value Type is NumberSet):
Group | Value |
----------- | ----- |
{host=web01} | 1 |
{host=web02} | 7 |
{host=web03} | 4 |
After Transpose (Value Type is SeriesSet):
Group | Value |
----------- | ----- |
{} | 1,7,4 |
Transpose Groups results into Multiple Results:
Before Transpose by host (Value Type is NumberSet)
Group | Value |
----------- | ----- |
{host=web01,disk=c} | 1 |
{host=web01,disc=d} | 3 |
{host=web02,disc=c} | 4 |
After Transpose by "host" (Value type is SeriesSet)
Group | Value |
------------ | ------ |
{host=web01} | 1,3 |
{host=web02} | 4 |
Useful Example of Transpose
Alert if more than 50% of servers in a group have ping timeouts
~~~
alert or_down {
$group = host=or-*
# bosun.ping.timeout is 0 for no timeout, 1 for timeout
$timeout = q("sum:bosun.ping.timeout{$group}", "5m", "")
# timeout will have multiple groups, such as or-web01,or-web02,or-web03.
# each group has a series type (the observations in the past 10 mintutes)
# so we need to *reduce* each series values of each group into a single number:
$max_timeout = max($timeout)
# Max timeout is now a group of results where the value of each group is a number. Since each
# group is an alert instance, we need to regroup this into a sigle alert. We can do that by
# transposing with t()
$max_timeout_series = t("$max_timeout", "")
# $max_timeout_series is now a single group with a value of type series. We need to reduce
# that series into a single number in order to trigger an alert.
$number_down_series = sum($max_timeout_series)
$total_servers = len($max_timeout_series)
$percent_down = $number_down_servers / $total_servers) * 100
warnNotificaiton = $percent_down > 25
}
~~~
Since our templates can reference any variable in this alert, we can show which servers are down in the notification, even though the alert just triggers on 25% of or-\* servers being down.
## ungroup(numberSet) scalar
Returns the input with its group removed. Used to combine queries from two differing groups.
# Other Functions
## alert(name string, key string) numberSet
Executes and returns the `key` expression from alert `name` (which must be
`warn` or `crit`). Any alert of the same name that is unknown or unevaluated
is also returned with a value of `1`. Primarily for use with `depends`.
Example: `alert("host.down", "crit")` returns the crit
expression from the host.down alert.
## abs(numberSet) numberSet
Returns the absolute value of each element in the numberSet.
## d(string) scalar
Returns the number of seconds of the [OpenTSDB duration string](http://opentsdb.net/docs/build/html/user_guide/query/dates.html).
## des(series, alpha scalar, beta scalar) series
Returns series smoothed using Holt-Winters double exponential smoothing. Alpha
(scalar) is the data smoothing factor. Beta (scalar) is the trend smoothing
factor.
## dropg(seriesSet, threshold numberSet|scalar) seriesSet
Remove any values greater than number from a series. Will error if this operation results in an empty series.
## dropge(seriesSet, threshold numberSet|scalar) seriesSet
Remove any values greater than or equal to number from a series. Will error if this operation results in an empty series.
## dropl(seriesSet, threshold numberSet|scalar) seriesSet
Remove any values lower than number from a series. Will error if this operation results in an empty series.
## drople(seriesSet, threshold numberSet|scalar) seriesSet
Remove any values lower than or equal to number from a series. Will error if this operation results in an empty series.
## dropna(seriesSet) seriesSet
Remove any NaN or Inf values from a series. Will error if this operation results in an empty series.
## epoch() scalar
Returns the Unix epoch in seconds of the expression start time (scalar).
## filter(seriesSet, numberSet) seriesSet
Returns all results in seriesSet that are a subset of numberSet and have a non-zero value. Useful with the limit and sort functions to return the top X results of a query.
## limit(numberSet, count scalar) numberSet
Returns the first count (scalar) results of number.
## lookup(table string, key string) numberSet
Returns the first key from the given lookup table with matching tags.
## nv(numberSet, scalar) numberSet
Change the NaN value during binary operations (when joining two queries) of unknown groups to the scalar. This is useful to prevent unknown group and other errors from bubbling up.
## rename(seriesSet, string) seriesSet
Accepts a series and a set of tags to rename in `Key1=NewK1,Key2=NewK2` format. All data points will have the tag keys renamed according to the spec provided, in order. This can be useful for combining results from seperate queries that have similar tagsets with different tag keys.
## sort(numberSet, (asc|desc) string) numberSet
Returns the results sorted by value in ascending ("asc") or descending ("desc")
order. Results are first sorted by groupname and then stably sorted so that
results with identical values are always in the same order.
</div>
| 53.104408 | 812 | 0.741262 | eng_Latn | 0.997023 |
9775de56f5c957390e892a6ecf9aa375be5ca92d | 5,544 | md | Markdown | tests/the_raven/1918-dostal-lutinov.md | pa-ta/tao-te-ching-comparison-sbs | 61ebd31fbe96f62556e22f4518620e771cb8cae6 | [
"Unlicense"
] | 29 | 2017-10-06T21:25:08.000Z | 2022-02-12T10:10:28.000Z | tests/the_raven/1918-dostal-lutinov.md | pa-ta/tao-te-ching-comparison-sbs | 61ebd31fbe96f62556e22f4518620e771cb8cae6 | [
"Unlicense"
] | null | null | null | tests/the_raven/1918-dostal-lutinov.md | pa-ta/tao-te-ching-comparison-sbs | 61ebd31fbe96f62556e22f4518620e771cb8cae6 | [
"Unlicense"
] | 15 | 2017-12-24T14:52:03.000Z | 2022-03-31T16:38:32.000Z | Author: Karel Dostál-Lutinov
Title: Havran
Year: 1918
Language: cs
Code: dolu
## 1
Bylo jednou v půlnoc charou. Nad knihou jsem dumal starou,
plnou bájí dávných časů. Znaven byl jsem, sláb a chor.
Jak jsem klímal, skoro dřímal, klepání jsem jakés vnímal,
kliku světnice kdos jímal, jak by stál tam u závor.
„Jakás návštěva,“ jsem mumlal, „kdosi klepe u závor.
Jenom to — a žádný vzdor.“
## 2
Ano. Dobře pamatuji: V prosinci, kdy vichry dují,
na podlahu vyzařuje z kamen duši tlící bor.
Toužebně jsem čekal rána. Marně duše, utýrána,
chtěla býti uhýčkána ze svých smutků pro Lenor —
po ztracené dívce zářné, zvané anděly Lenor.
Beze jména zde ten tvor.
## 3
Hedvábné tu divné šusty, jimiž hnul se závoj hustý,
snuly ve mně zmatek pustý, netušených příšer chór,
takže, abych zjistil buchot svého srdce v temnu hluchot,
říkal jsem: To žádá průchod návštěvník tam u závor,
návštěva jen žádá průchod pozdní u mých u závor.
To jest to — a žádný vzdor.
## 4
Duch můj zas nabývá síly. Neváhaje pak ni chvíli:
„Pane,“ zavolám, „či paní, promiňte můj nepozor!
Stalo se, že jsem si zdřímnul. Než jsem spánek z očí vymnul,
tluku jsem si sotva všimnul jemného tak u závor.
Jemně tak jste zaklepali! Nuž, jen dále ve prostor!“ —
Všude tma — a nikde tvor.
## 5
Dlouho stál jsem, upíraje oči do nočního kraje,
žasna v hrůze, zabrán do snů, jakých nesnil člověk skor.
Nic však ticha nerozválo, mlčení se neozvalo,
jediné jen slůvko válo, šepotané v tmu: „Lenor!“
To jsem šeptnul, ozvěna pak šeptla nazpět zas: „Lenor!“
Jenom to — a žádný tvor.
## 6
Vrátil jsem se do pokoje. Zahořelo srdce moje,
zase slyším zaklepání hlasitěji nežli skor.
„Jistě,“ pravím, „jistě kdosi v mřížce oken mých se hlásí,
podívám se, kdo to asi? Taj ten děsí na úmor!
Na chvilku buď, srdce, ticho! Nelekej se na úmor!
Vítr to — a žádný tvor.“
## 7
Prudce zdvih jsem okenice: Rozkřídlen tu do světnice
vážný, statný havran kráčí, starých bohů matador.
Beze všeho upejpání, bez úklony, bez postání,
jako lord neb velká paní sed si dveří nad otvor,
na Pallady bustu sedl, nade dvéře, nad otvor
usadil se divný tvor.
## 8
Ebenový pták se choval vážně tak, se naparoval,
že mi úsměv vyluzoval, trhal mého smutku flór.
„Chochol,“ dím, „máš ostříhaný, jistě nejdeš za havrany,
za chmurnými za satany, co se rodí z noci hor.
Pověz mi své lordské jméno z Plutonovy noci hor! —
„Sluji Nikdy — Nevermore.“
## 9
Zachvěl jsem se celý žasem nad tím zřejmým lidským hlasem,
ač mi nebyl zcela jasen toho ptáka odhovor,
to však přiznati jsem musil, málokdo že asi zkusil,
by se nade dvéře spustil v pokoji mu taký tvor,
pták či zvíře by si sedlo nad Pallady snivý zor
s divným jménem: ‚Nevermore‘.
## 10
Ale havran osamělý sedí na mé sochy běli,
jedno slovo kráká smělý celou duší v jeden chór;
víc slov ani nezapípnul. Rozmach jeho křídel schlípnul,
tak jsem úsměškem jej štípnul: „Jiných přátel zmizel sbor,
prchly sny — i ty se zítra, brachu, vrátíš do svých hor!“ —
Ale pták dí: „Nevermore!“
## 11
Žasna, že tak trefně umí odpovídat na mé dumy,
pravím: „Patrně co mluví, naučil se tento tvor
u jakéhos nešťastníka, jejžto sklála sudby dýka,
takže jeden refrén vzlyká všechněch jeho písní chór,
takže, pohřbiv naděj, říká jeden refrén na úmor:
Marný vzdor je. „Nevermore!“
## 12
Smuten jsem, můj starý hošku, ale smát se musím trošku,
usedám si na lenošku, k bustě, ptáku zvedám zor.
Ponořiv se do sametu, myšlenek svých pásmo pletu,
badám, hádám, co as chce tu zlověstný ten starý tvor?
Co as příšerný ten zlobný, vyhublý chce říci tvor
krákoraje: „Nevermore“?
## 13
Tak tu sedím, badám, hádám, ani slova nevykládám
ptáku, jenž, co na dně duše spřádám, vrývá tam svůj lesklý zor.
Tak tu sedím, sním a bádám, na aksamit hlavu skládám;
na polštář svit lampy padá jako vzpomínkový flór,
v polštář sametový padá místo Ní jen smutku flór — —
Ona — nikdy! Nevermore!
## 14
Pak jsem cítil dým a vůně. Rostly v kaditelen lůně,
jimiž mával neviděný Serafínů letmých sbor.
„Ubožáku,“ volám křiče, „anděly Bůh seslal z výše,
dal ti pít z Nepenthy číše zapomnění na Lenor!
Vypij číš tu milosrdnou zapomnění na Lenor!“
Havran však: „Ne! Nevermore!“
## 15
„Proroku!“ dím neocháble, „věštče, ptáku, nebo ďáble!
Ať tě pokušitel náhle vrh sem nebo vichor z hor,
kdo tě zavál sem až ke mně do té nehostinné země,
kde dlím sklíčen, ne však zničen, kde jde hrůza na obzor,
rci, zda najdu v Gileadu balzám ran svých!? Jsem tak chor!“
Havran zase: „Nevermore!“
## 16
„Proroku!“ dím, „bouřliváku! Ať už ďáble nebo ptáku!
Při nebi, jež klene dálku, při Bohu, jejž vzývá tvor,
rci mé duši, náhlé k pádu, zdali najdu v dálném Hádu,
zda tu svatou dívku najdu, zvanou anděly ‚Lenor‘,
zda tam obejmu tu zářnou, zvanou anděly ‚Lenor?‘“ —
Havran krákl: „Nevermore!“
## 17
„Dosti! Dost už toho slova!“ křik jsem. „Ptáku, ďáble, znova
vrať se tam, kde Plutonova říše tmí se v noci hor!
Nezanech tu pírka ani na památku svého lhaní!
Neruš mého vzpomínání! Slétni z busty za obzor!
Vyjmi zoban z mého srdce! Kliď se dolů za obzor!“ —
Havran krákl: „Nevermore!“
## 18
Bez pohnutí havran sedí, tiše sedí, slova nedí,
z bledé Pallady dál hledí nade dveřmi ve prostor.
Sedí jako v hnízdě svém on. Oči, jak když hledí démon.
Lampa nad ním vrhá temno jeho stín sem ve prostor,
na podlahu stín se vrhá. Zpod stínu můj duch, tak chor
nevzchopí se — nevermore!
| 29.806452 | 65 | 0.718795 | ces_Latn | 0.999904 |
97764106d44cde48dfeb19356086f4ca1bd9ef1f | 1,066 | md | Markdown | content/flux/v0.36/functions/built-in/transformations/selectors/sample.md | psteinbachs/docs.influxdata.com | 43dbf12c3985774c6ed0b0e5650419ff477a0084 | [
"MIT"
] | null | null | null | content/flux/v0.36/functions/built-in/transformations/selectors/sample.md | psteinbachs/docs.influxdata.com | 43dbf12c3985774c6ed0b0e5650419ff477a0084 | [
"MIT"
] | null | null | null | content/flux/v0.36/functions/built-in/transformations/selectors/sample.md | psteinbachs/docs.influxdata.com | 43dbf12c3985774c6ed0b0e5650419ff477a0084 | [
"MIT"
] | null | null | null | ---
title: sample() function
description: The sample() function selects a subset of the records from the input table.
aliases:
- /flux/v0.36/functions/transformations/selectors/sample
menu:
flux_0_36:
name: sample
parent: Selectors
weight: 1
---
The `sample()` function selects a subset of the records from the input table.
_**Function type:** Selector_
_**Output data type:** Object_
```js
sample(n:5, pos: -1)
```
## Parameters
### n
Sample every Nth element.
_**Data type:** Integer_
### pos
The position offset from the start of results where sampling begins.
`pos` must be less than `n`.
If `pos` is less than 0, a random offset is used.
Defaults to `-1` (random offset).
_**Data type:** Integer_
## Examples
```js
from(bucket:"telegraf/autogen")
|> range(start:-1d)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system"
)
|> sample(n: 5, pos: 1)
```
<hr style="margin-top:4rem"/>
##### Related InfluxQL functions and statements:
[SAMPLE()](/influxdb/latest/query_language/functions/#sample)
| 20.5 | 88 | 0.67636 | eng_Latn | 0.947931 |
977695610dfb871441aca8d1e1bda8b6f05921ac | 14,007 | md | Markdown | aspnet/mvc/overview/older-versions-1/nerddinner/implement-efficient-data-paging.md | d3suu/Docs.pl-pl | 298a5fea0179b8a52233aa60d7d0a5ac2e5df20c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | aspnet/mvc/overview/older-versions-1/nerddinner/implement-efficient-data-paging.md | d3suu/Docs.pl-pl | 298a5fea0179b8a52233aa60d7d0a5ac2e5df20c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | aspnet/mvc/overview/older-versions-1/nerddinner/implement-efficient-data-paging.md | d3suu/Docs.pl-pl | 298a5fea0179b8a52233aa60d7d0a5ac2e5df20c | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-25T21:46:03.000Z | 2020-05-25T21:46:03.000Z | ---
uid: mvc/overview/older-versions-1/nerddinner/implement-efficient-data-paging
title: Implementowanie wydajnego stronicowania danych | Dokumentacja firmy Microsoft
author: microsoft
description: Krok 8 pokazuje, jak dodać obsługę stronicowania do adresu URL /Dinners tak, aby zamiast 1000s kolacji jednocześnie, firma Microsoft będzie wyświetlane tylko 10 kolejnych kolacji na...
ms.author: riande
ms.date: 07/27/2010
ms.assetid: adea836d-dbc2-4005-94ea-53aef09e9e34
msc.legacyurl: /mvc/overview/older-versions-1/nerddinner/implement-efficient-data-paging
msc.type: authoredcontent
ms.openlocfilehash: 2bef690355cd1f89a15a67f0c49775296d551136
ms.sourcegitcommit: 45ac74e400f9f2b7dbded66297730f6f14a4eb25
ms.translationtype: MT
ms.contentlocale: pl-PL
ms.lasthandoff: 08/16/2018
ms.locfileid: "41755758"
---
<a name="implement-efficient-data-paging"></a>Implementowanie wydajnego stronicowania danych
====================
przez [firmy Microsoft](https://github.com/microsoft)
[Pobierz plik PDF](http://aspnetmvcbook.s3.amazonaws.com/aspnetmvc-nerdinner_v1.pdf)
> Jest to krok 8 bezpłatnych [samouczek aplikacji "NerdDinner"](introducing-the-nerddinner-tutorial.md) , przeszukiwania — szczegółowe instrukcje dotyczące tworzenia małych, ale ukończyć, aplikacji sieci web przy użyciu platformy ASP.NET MVC 1.
>
> Krok 8 pokazuje, jak dodać obsługę stronicowania do adresu URL /Dinners, tak aby zamiast 1000s kolacji jednocześnie, firma Microsoft będzie wyświetlić tylko 10 kolejnych kolacji naraz — oraz umożliwia użytkownikom końcowym na stronie Wstecz i przekazywać je za pośrednictwem całą listę, w sposób przyjazna optymalizacji dla aparatów wyszukiwania.
>
> Jeśli używasz programu ASP.NET MVC 3, zaleca się wykonać [Rozpoczynanie pracy z MVC 3](../../older-versions/getting-started-with-aspnet-mvc3/cs/intro-to-aspnet-mvc-3.md) lub [MVC Music Store](../../older-versions/mvc-music-store/mvc-music-store-part-1.md) samouczków.
## <a name="nerddinner-step-8-paging-support"></a>NerdDinner krok 8: Obsługa stronicowania
Naszą witrynę zakończy się pomyślnie, będzie miał tysiące nadchodzących kolacji. Musimy upewnić się, że jest skalowana tak, aby zapewnić obsługę wszystkich tych kolacji naszego interfejsu użytkownika i pozwala użytkownikom na przeglądanie ich. Aby to umożliwić, dodamy obsługę stronicowania do naszych */Dinners* adres URL tak, to zamiast wyświetlanie 1000s kolacji na raz, firma Microsoft będzie wyświetlić tylko 10 kolejnych kolacji naraz — oraz umożliwia użytkownikom końcowym na stronie Wstecz i przekazywać je za pośrednictwem całą listę w sposób przyjazna optymalizacji dla aparatów wyszukiwania.
### <a name="index-action-method-recap"></a>Podsumowanie metody akcji indeks()
Metody akcji indeks() w ramach naszych klasy DinnersController obecnie wygląda jak poniżej:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample1.cs)]
Po wysłaniu żądania do */Dinners* adresu URL, umożliwia pobranie listy wszystkich przyszłych kolacji, a następnie powoduje wyświetlenie listy wszystkich z nich się:

### <a name="understanding-iquerablelttgt"></a>Opis IQuerable<T>
*Element IQueryable<T>* jest interfejsem, która została wprowadzona za pomocą LINQ jako część .NET 3.5. Umożliwia zaawansowane "wykonanie odroczone" scenariusze, które będziemy korzystać z zalet zaimplementować obsługę stronicowania.
W naszym DinnerRepository firma Microsoft jest zwracany element IQueryable<obiad> sekwencji z naszych FindUpcomingDinners() metody:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample2.cs)]
Element IQueryable<obiad> zwracany przez metodę naszych FindUpcomingDinners() hermetyzuje zapytanie, aby pobrać obiekty obiad z naszej bazie danych za pomocą LINQ to SQL. Co ważniejsze go nie wykonaj zapytanie względem bazy danych do momentu kolejna próba dostępu/Iterowanie po danych w zapytaniu, lub możemy wywołać metodę ToList() na nim. Kod, wywołanie metody naszych FindUpcomingDinners() można opcjonalnie dodać operacje/filtry "łańcuchowych" do elementu IQueryable<obiad> obiektu przed wykonaniem kwerendy. LINQ do SQL jest następnie inteligentne, można wykonać połączone zapytanie w bazie danych, jeśli wymagane są dane.
Aby zaimplementować logikę stronicowania zaktualizowania metody akcji indeks() naszych DinnersController tak, że dotyczy on dodatkowych operatorów "Pomiń" i "Take", aby zwrócony element IQueryable<obiad> sekwencji przed wywołaniem ToList() na nim:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample3.cs)]
Powyższy kod nakłada się na 10 pierwszych kolacji nadchodzących w bazie danych, a następnie zwraca ponownie kolacji 20. LINQ do SQL jest inteligentnych do konstruowania zoptymalizowane zapytania SQL, który wykonuje to pomijanie logiki w usłudze SQL database — a nie na serwerze sieci web. Oznacza to, że nawet, jeśli mamy milionów nadchodzących kolacji w bazie danych tylko 10, którą chcemy będą pobierane jako część tego żądania (tworząc z niej wydajność i skalowalność).
### <a name="adding-a-page-value-to-the-url"></a>Dodanie wartości "page" do adresu URL
Zamiast kodować określony zakres stron, firma Microsoft zachodnich stanach USA adresy URL obejmujący parametr "page", który wskazuje zakres obiad, który żąda użytkownika.
#### <a name="using-a-querystring-value"></a>Przy użyciu wartości Querystring
Poniższy kod demonstruje, jak firma Microsoft aktualizuje naszych metody akcji indeks() obsługuje parametr querystring i włączyć adresy URL, takich jak */Dinners? strony = 2*:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample4.cs)]
Metody akcji indeks() powyżej ma parametr o nazwie "page". Parametr jest zadeklarowany jako liczbę całkowitą typu dopuszczającego wartość null (to, jakie int? oznacza). Oznacza to, że */Dinners? strony = 2* adres URL spowoduje, że wartość "2", które zostaną przekazane jako wartość parametru. */Dinners* adresu URL (bez wartości querystring) spowoduje, że wartość null, które zostaną przekazane.
Firma Microsoft są pomnożenie wartości strony przez rozmiar strony (w tym przypadku 10 wierszy), aby określić, ile kolacji można pominąć. Używamy [C# o wartości null "" operatora łączącego (?) ](https://weblogs.asp.net/scottgu/archive/2007/09/20/the-new-c-null-coalescing-operator-and-using-it-with-linq.aspx) co jest przydatne podczas rozwiązywania problemów związanych z typami zerowalnymi. Powyższy kod przypisuje strony wartość 0, jeśli parametr strony ma wartość null.
#### <a name="using-embedded-url-values"></a>Przy użyciu wartości adresu URL osadzonego
Alternatywa dla użycia wartości querystring byłoby osadzić parametr strony w ramach rzeczywistego adresu sam. Na przykład: */Dinners/Page/2* lub */kolacji/2*. Platforma ASP.NET MVC zawiera zaawansowany aparat routingu adresów URL, ułatwiająca do obsługi scenariuszy, takich jak to.
Firma Microsoft można zarejestrować niestandardowe reguły routingu mapowane wszystkie przychodzące adres URL lub adres URL formatu dowolnego kontrolera klasy lub metody akcji, którą chcemy. Wszystkie potrzebne do wykonania jest, aby otworzyć plik Global.asax w projekcie:

A następnie zarejestruj nową regułę mapowania, przy użyciu metody pomocnika MapRoute(), takich jak pierwsze wywołanie do trasy. MapRoute() poniżej:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample5.cs)]
Firma Microsoft powyżej rejestrowania nową regułę routingu o nazwie "UpcomingDinners". Firma Microsoft wskazujący, ma format adresu URL "kolacji/strony / {strona}" — gdzie {strony} jest wartością parametru osadzone w adresie URL. Trzeci parametr do metody MapRoute() wskazuje, że firma Microsoft adresów URL, które pasują do tego formatu do metody akcji indeks() w klasie DinnersController powinny być mapowane.
Możemy użyć dokładnie tego samego kodu indeks(), który mieliśmy przed z naszym scenariuszu Querystring — z wyjątkiem teraz naszych parametru "page" będą pochodzić z adresu URL i nie querystring:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample6.cs)]
Teraz po abyśmy uruchomić aplikację i wpisać */Dinners* zobaczymy 10 pierwszych kolacji nadchodzących:

A gdy wpiszesz w */Dinners/Page/1* zobaczymy następnej strony kolacji:

### <a name="adding-page-navigation-ui"></a>Dodawanie nawigacji na stronie interfejsu użytkownika
Ostatni krok, aby ukończyć scenariusz naszych stronicowania będzie do zaimplementowania "dalej" i "starszych" interfejs użytkownika nawigacji w ramach naszych Wyświetl szablon, aby użytkownicy mogli łatwo pominąć danych obiad.
Poprawnej implementacji, musimy wiedzieć, całkowita liczba kolacji w bazie danych oraz jak wiele stron danych przekłada się to. Następnie należy obliczyć, czy wartość aktualnie żądanego "page" jest na początku lub na końcu danych i pokazać lub ukryć interfejsu użytkownika "poprzedni" i "dalej", odpowiednio. Firma Microsoft zaimplementować tę logikę w ramach naszych indeks() metody akcji. Można również możemy dodać klasę pomocy do naszego projektu, który hermetyzuje tę logikę w sposób bardziej wielokrotnego użytku.
Poniżej przedstawiono prosty "PaginatedList" pomocnikiem klasy, który pochodzi z listy<T> klasy kolekcji wbudowana w .NET Framework. Implementuje klasy wielokrotnego użytku kolekcji, która może służyć do dowolnej sekwencji danych IQueryable podzielony na strony. W naszej aplikacji NerdDinner odpowiemy od jego pracy nad IQueryable<obiad> wyniki, ale może równie łatwo zostać użyty dla elementu IQueryable<produktu> lub IQueryable<klienta>wyniki w innych scenariuszach aplikacji:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample7.cs)]
Zwróć uwagę, powyżej sposób obliczania, a następnie udostępnia właściwości, takie jak "PageIndex", "PageSize", "TotalCount" i "TotalPages". Udostępnia ona także dwie właściwości pomocnika "HasPreviousPage" i "HasNextPage", które wskazują, czy strony danych w kolekcji jest na początku lub końcu oryginalnej sekwencji. Powyższy kod spowoduje, że dwa zapytania SQL w celu uruchomienia — pierwszy można pobrać liczba całkowita liczba obiektów obiad (to nie zwraca obiekty — zamiast wykonuje instrukcję "Wybierz licznik", która zwraca liczbę całkowitą), a druga, aby pobrać tylko wiersze dane, których potrzebujemy w naszej bazie danych dla bieżącej strony danych.
Firma Microsoft może uaktualnić naszych metodą pomocnika DinnersController.Index() tworzenia PaginatedList<obiad> z naszych DinnerRepository.FindUpcomingDinners() wyniku i przekazać go do szablonu widoku:
[!code-csharp[Main](implement-efficient-data-paging/samples/sample8.cs)]
Firma Microsoft można zaktualizować szablon widoku \Views\Dinners\Index.aspx odziedziczone ViewPage<NerdDinner.Helpers.PaginatedList<obiad> > zamiast ViewPage<IEnumerable<Obiad>>, a następnie dodaj następujący kod do dolnej części naszych szablon widoku, aby pokazać lub ukryć następnej i poprzedniej nawigacji interfejsu użytkownika:
[!code-aspx[Main](implement-efficient-data-paging/samples/sample9.aspx)]
Zwróć uwagę na powyżej sposób używania Html.RouteLink() metody pomocnika do generowania naszych hiperłącza. Ta metoda jest podobna do metody pomocniczej Html.ActionLink(), którą firma Microsoft była używana wcześniej. Różnica polega na tym, że firma Microsoft generuje adres URL, za pomocą "UpcomingDinners" routing regułę, że będziemy konfigurować w ramach naszego pliku Global.asax. Daje to gwarancję, że polega na wygenerowaniu adresy URL do naszego indeks() metody akcji, która ma format: */Dinners/strona / {strony}* — w przypadku, gdy wartość {strony} jest zmienną, zapewniamy powyżej oparte na bieżącym PageIndex.
Teraz gdy Uruchamiamy naszą aplikację ponownie teraz poczekamy kolacji 10 w danym momencie w przeglądarki:

Mamy także < < < i > > > nawigacji interfejsu użytkownika w dolnej części strony, która umożliwia nam przejść do przodu i wstecz za pośrednictwem naszych danych za pomocą wyszukiwania aparatu dostępne adresy URL:

| **Temat po stronie: Zrozumienia konsekwencji IQueryable<T>** |
| --- |
| Element IQueryable<T> to ogromne funkcja, która pozwala korzystać z wielu ciekawych scenariuszy odroczonego wykonania (takich jak stronicowania i kompozycji oparte na zapytaniach). Jako ze wszystkich zaawansowanych funkcji, chcesz należy zachować ostrożność, sposobu ich używania i upewnij się, że nie jest użyte. Ważne jest, aby rozpoznać, zwracając element IQueryable<T> wyników z repozytorium umożliwia kod wywołujący Dołącz na metodach łańcuchowych operator, a więc należą do wykonywania zapytania ultimate. Jeśli nie chcesz podać kod wywołujący tę możliwość, a następnie powinna zwrócić kopię IList<T> lub typ IEnumerable<T> wyniki - zawierające wyniki zapytania, która została już wykonana. W scenariuszach z podziałem na strony wymagałoby to umożliwia wypychanie logiki dzielenia na strony rzeczywiste dane do wywołania metody repozytorium. W tym scenariuszu firma Microsoft może aktualizować naszych metodę wyszukiwania FindUpcomingDinners() mają podpis, czy zwrócone albo PaginatedList: PaginatedList< obiad> FindUpcomingDinners (int pageIndex, int pageSize) {} i zwrócenia wstecz IList <Obiad>i użyj "totalCount" out param, aby zwrócić łączna liczba kolacji: IList<obiad> FindUpcomingDinners (int pageIndex, int pageSize, out int totalCount) {} |
### <a name="next-step"></a>Następny krok
Teraz Przyjrzyjmy się jak możemy dodać obsługę uwierzytelniania i autoryzacji do naszej aplikacji.
> [!div class="step-by-step"]
> [Poprzednie](re-use-ui-using-master-pages-and-partials.md)
> [dalej](secure-applications-using-authentication-and-authorization.md)
| 98.640845 | 1,300 | 0.810166 | pol_Latn | 0.999647 |
97769691e28ef3ac0231e7f46737d3c2082bae3d | 38,186 | md | Markdown | node_modules/listr2/README.md | Avinash-Murugappan/My-Website | 1bd65f270f5d6dec51fdbc0e99b70413c1d8965f | [
"MIT"
] | 1 | 2021-09-21T17:51:11.000Z | 2021-09-21T17:51:11.000Z | node_modules/listr2/README.md | Avinash-Murugappan/My-Website | 1bd65f270f5d6dec51fdbc0e99b70413c1d8965f | [
"MIT"
] | 9 | 2020-06-06T00:42:57.000Z | 2022-02-27T17:29:18.000Z | frontend/SpaceX-Launches/node_modules/listr2/README.md | lucasrafaldini/SpaceXLaunches | abcd3686677bc3e25903bc2ed1e084e00090ba33 | [
"MIT"
] | null | null | null | # Listr2
[](https://drone.kilic.dev/cenk1cenk2/listr2) [](https://npmjs.org/package/listr2) [](https://npmjs.org/package/listr2) [](https://github.com/semantic-release/semantic-release)
**Create beautiful CLI interfaces via easy and logical to implement task lists that feel alive and interactive.**
This is the expanded and re-written in Typescript version of the beautiful plugin by [Sam Verschueren](https://github.com/SamVerschueren) called [Listr](https://github.com/SamVerschueren/listr).

> **It breaks backward compatibility with [Listr](https://github.com/SamVerschueren/listr) after v1.3.12, albeit refactoring requires only moving renderer options to their own key, concerning the [conversation on the original repository](https://github.com/SamVerschueren/listr/issues/143#issuecomment-623094930).** You can find the README of compatible version [here](https://github.com/cenk1cenk2/listr2/tree/84ff9c70ba4aab16106d1e7114453ac5e0351ec0). Keep in mind that it will not get further bug fixes.
- [Changelog](./CHANGELOG.md)
<!-- toc -->
- [How to Use](#how-to-use)
- [Install](#install)
- [Create A New Listr](#create-a-new-listr)
- [Tasks](#tasks)
- [Options](#options)
- [The Concept of Context](#the-concept-of-context)
- [General Usage](#general-usage)
- [Subtasks](#subtasks)
- [Get User Input](#get-user-input)
- [Create A Prompt](#create-a-prompt)
- [Single Prompt](#single-prompt)
- [Multiple Prompts](#multiple-prompts)
- [Use an Custom Prompt](#use-an-custom-prompt)
- [Enable a Task](#enable-a-task)
- [Skip a Task](#skip-a-task)
- [Show Output](#show-output)
- [Utilizing the Task Itself](#utilizing-the-task-itself)
- [Utilizing the Bottom Bar](#utilizing-the-bottom-bar)
- [Utilizing an Observable or Stream](#utilizing-an-observable-or-stream)
- [Passing the Output Through as a Stream](#passing-the-output-through-as-a-stream)
- [Throw Errors](#throw-errors)
- [Task Manager](#task-manager)
- [Basic Use-Case Scenerio](#basic-use-case-scenerio)
- [More Functionality](#more-functionality)
- [Generic Features](#generic-features)
- [Tasks Without Titles](#tasks-without-titles)
- [Signal Interrupt](#signal-interrupt)
- [Testing](#testing)
- [Default Renderers](#default-renderers)
- [Custom Renderers](#custom-renderers)
- [Render Hooks](#render-hooks)
- [Log To A File](#log-to-a-file)
- [Migration from Version v1](#migration-from-version-v1)
- [Types](#types)
<!-- tocstop -->
# How to Use
Check out `examples/` folder in the root of the repository for the code in demo or follow through with this README.
## Install
```bash
# Install the latest supported version
npm install listr2
yarn add listr2
# Install listr compatabile version
npm install [email protected]
yarn add [email protected]
```
## Create A New Listr
Create a new task list. It will returns a Listr class.
```typescript
import { Listr } from 'listr2'
interface Ctx {
/* some variables for internal use */
}
const tasks = new Listr<Ctx>(
[
/* tasks */
],
{
/* options */
}
)
```
Then you can run this task lists as a async function and it will return the context that is used.
```typescript
try {
await tasks.run()
} catch (e) {
// it will collect all the errors encountered if { exitOnError: false } is set as an option
// elsewise it will throw the first error encountered as expected
console.error(e)
}
```
### Tasks
```typescript
export interface ListrTask<Ctx, Renderer extends ListrRendererFactory> {
// A title can be given or omitted. For default renderer if the title is omitted,
title?: string
// A task can be a sync or async function that returns a string, readable stream or an observable or plain old void
// if it does actually return string, readable stream or an observable, task output will be refreshed with each data push
task: (ctx: Ctx, task: ListrTaskWrapper<Ctx, Renderer>) => void | ListrTaskResult<Ctx>
// to skip the task programmatically, skip can be a sync or async function that returns a boolean or string
// if string is returned it will be showed as the skip message, else the task title will be used
skip?: boolean | string | ((ctx: Ctx) => boolean | string | Promise<boolean> | Promise<string>)
// to enable the task programmatically, this will show no messages comparing to skip and it will hide the tasks enabled depending on the context
// enabled can be external boolean, a sync or async function that returns a boolean
// pay in mind that context enabled functionallity might depend on other functions to finish first, therefore the list shall be treated as a async function
enabled?: boolean | ((ctx: Ctx) => boolean | Promise<boolean>)
// this will change depending on the available options on the renderer
// these renderer options are per task basis and does not affect global options
options?: ListrGetRendererTaskOptions<Renderer>
}
```
### Options
```typescript
export interface ListrOptions<Ctx = ListrContext> {
// how many tasks can be run at the same time.
// false or 1 for synhronous task list, true or Infinity for compelete parallel operation, a number for limitting tasks that can run at the same time
// defaults to false
concurrent?: boolean | number
// it will silently fail or throw out an error
// defaults to false
exitOnError?: boolean
// inject a context from another operation
// defaults to any
ctx?: Ctx
// to have graceful exit on signal terminate and to inform the renderer all the tasks awaiting or processing are failed
// defaults to true
registerSignalListeners?: boolean
// select the renderer or inject a class yourself
// defaults to 'default' which is a updating renderer
renderer?: 'default' | 'verbose' | 'silent' | ListrRendererFactory
// renderer options depends on the selected renderer
rendererOptions?: ListrGetRendererOptions<T>
// renderer will fallback to the nonTTYRenderer on non-tty environments as the name suggest
// defaults to verbose
nonTTYRenderer?: 'default' | 'verbose' | 'silent' | ListrRendererFactory
// options for the non-tty renderer
nonTTYrendererOptions?: ListrGetRendererOptions<T>
}
```
## The Concept of Context
Context is the variables that are shared across the task list. Even though external variables can be used to do the same operation, context gives a self-contained way to process internal tasks.
A successful task will return the context back for further operation.
You can also manually inject a context variable preset depending on the prior operations through the task options.
**If all tasks are in one big Listr list you do not have to inject context manually to the child tasks since it is automatically injected as in the original.**
If an outside variable wants to be injected inside the Listr itself it can be done in two ways.
- Injecting it as an option.
```typescript
const ctx: Ctx = {}
const tasks = new Listr<Ctx>(
[
/* tasks */
],
{ ctx }
)
```
- Injecting it at runtime.
```typescript
try {
await tasks.run({ ctx })
} catch (e) {
console.error(e)
}
```
## General Usage
### Subtasks
Any task can return a new Listr. But rather than calling it as `new Listr` to get the full autocompeletion features depending on the parent task's selected renderer, it is a better idea to call it through the `Task` itself by `task.newListr()`.
_Please refer to [examples section](examples/subtasks.example.ts) for more detailed and further examples._
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: (ctx, task): Listr =>
task.newListr([
{
title: 'This is a subtask.',
task: async (): Promise<void> => {
await delay(3000)
}
}
])
}
],
{ concurrent: false }
)
```
You can change indivudual settings of the renderer on per-subtask basis.
This includes renderer options as well as Listr options like `exitOnError`, `concurrent` to be set on a per subtask basis independent of the parent task, while it will always use the most adjacent setting.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: (ctx, task): Listr =>
task.newListr(
[
{
title: 'This is a subtask.',
task: async (): Promise<void> => {
await delay(3000)
}
},
{
title: 'This is an another subtask.',
task: async (): Promise<void> => {
await delay(2000)
}
}
],
{ concurrent: true, rendererOptions: { collapse: true } }
)
},
{
title: 'This task will execute.',
task: (ctx, task): Listr =>
task.newListr(
[
{
title: 'This is a subtask.',
task: async (): Promise<void> => {
await delay(3000)
}
},
{
title: 'This is an another subtask.',
task: async (): Promise<void> => {
await delay(2000)
}
}
],
{ concurrent: true, rendererOptions: { collapse: false } }
)
}
],
{ concurrent: false }
)
```
_Please refer to [Throw Errors Section](#Throw-Errors) for more detailed and further examples on how to handle silently failing errors._
### Get User Input
The input module uses the beautiful [enquirer](https://www.npmjs.com/package/enquirer).
> **Attention: Enquirer is a optional dependency. Please install it first.**
So with running a `task.prompt` function, you can get access to any [enquirer](https://www.npmjs.com/package/enquirer) default prompts as well as using a custom enquirer prompt.
To get an input you can assign the task a new prompt in an async function and write the response to the context.
**It is not advisable to run prompts in a concurrent task because multiple prompts will clash and overwrite each other's console output and when you do keyboard movements it will apply to them both.**
Prompts, since their rendering is getting passed as a data output will render multiple times in verbose renderer since verbose renderer is not terminal-updating intended to be used in nonTTY environments. It will work anyhow albeit it might not look great.
Prompts can either have a title or not but they will always be rendered at the end of the current console while using the default renderer.
_Please refer to [examples section](examples/get-user-input.example.ts) for more detailed and further examples._
#### Create A Prompt
To access the prompts just utilize the `task.prompt` jumper function. The first argument takes in one of the default [enquirer](https://www.npmjs.com/package/enquirer) prompts as a string or you can also pass in a custom [enquirer](https://www.npmjs.com/package/enquirer) prompt class as well, while the second argument is the options for the given prompt.
Prompts always rendered at the bottom of the tasks when using the default renderer with one line return in between it and the tasks.
_Please note that I rewrote the types for enquirer, since some of them was failing for me. So it may have a chance of having some mistakes in it since I usually do not use all of them._
**>v2.1.0, defining the prompt style has been changed a little. It know requires type to be integrated inside the prompt itself, instead of passing two variables. Custom prompts still work the same way.**
##### Single Prompt
```typescript
new Listr<Ctx>(
[
{
task: async (ctx, task): Promise<boolean> => (ctx.input = await task.prompt<boolean>({ type: 'Toggle', message: 'Do you love me?' }))
},
{
title: 'This task will get your input.',
task: async (ctx, task): Promise<void> => {
ctx.input = await task.prompt<boolean>({ type: 'Toggle', message: 'Do you love me?' })
// do something
if (ctx.input === false) {
throw new Error(':/')
}
}
}
],
{ concurrent: false }
)
```
##### Multiple Prompts
**Important: If you want to pass in an array of prompts, becareful that you should name them, this is also enforced by Typescript as well. This is not true for single prompts, since they only return a single value, it will be directly gets passed to the assigned variable.**
```typescript
new Listr<Ctx>(
[
{
title: 'This task will get your input.',
task: async (ctx, task): Promise<void> => {
ctx.input = await task.prompt<{ first: boolean; second: boolean }>([
{ type: 'Toggle', name: 'first', message: 'Do you love me?' },
{ type: 'Toggle', name: 'second', message: 'Do you love me?' }
])
// do something
if (ctx.input.first === false) {
logger.log('oh okay')
}
if (ctx.input.second === false) {
throw new Error('You did not had to tell me for the second time')
}
}
}
],
{ concurrent: false }
)
```
#### Use an Custom Prompt
You can either use a custom prompt out of the npm registry or custom-created one as long as it works with [enquirer](https://www.npmjs.com/package/enquirer), it will work expectedly. Instead of passing in the prompt name use the not-generated class.
```typescript
new Listr<Ctx>(
[
{
title: 'Custom prompt',
task: async (ctx, task): Promise<void> => {
ctx.testInput = await task.prompt({
type: EditorPrompt,
message: 'Write something in this enquirer custom prompt.',
initial: 'Start writing!',
validate: (response): boolean | string => {
// i do declare you valid!
return true
}
})
}
}
],
{ concurrent: false }
)
```
### Enable a Task
Tasks can be enabled depending on the variables programmatically. This enables to skip them depending on the context. Not enabled tasks will never show up in the default renderer, but when or if they get enabled they will magically appear.
_Please pay attention to asynchronous operation while designing a context enabled task list since it does not await for any variable in the context._
_Please refer to [examples section](examples/task-enable.example.ts) for more detailed and further examples._
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: (ctx): void => {
ctx.skip = true
}
},
{
title: 'This task will never execute.',
enabled: (ctx): boolean => !ctx.skip,
task: (): void => {}
}
],
{ concurrent: false }
)
```
### Skip a Task
Skip is more or less the same with enable when used at `Task` level. But the main difference is it will always render the given task. If it is skipped it renders it as skipped.
There are to main ways to skip a task. One is utilizing the `Task` so that instead of enabled it will show a visual output while the other one is inside the task.
_Please pay attention to asynchronous operation while designing a context skipped task list since it does not await for any variable in the context._
_Please refer to [examples section](examples/task-skip.example.ts) for more detailed and further examples._
Inside the task itself after some logic is done.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: (ctx, task): void => {
task.skip('I am skipping this tasks for reasons.')
}
}
],
{ concurrent: false }
)
```
Through the task wrapper.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: (ctx): void => {
ctx.skip = true
}
},
{
title: 'This task will never execute.',
skip: (ctx): boolean => ctx.skip,
task: (): void => {}
}
],
{ concurrent: false }
)
```
There are two rendering methods for the default renderer for skipping the task. The default behavior is to replace the task title with skip message if the skip function returns a string. You can select the other way around with `rendererOptions: { collapseSkips: false }` for the default renderer to show the skip message under the task title.
### Show Output
Showing output from a task can be done in various ways.
To keep the output when the task finishes while using default renderer, you can set `{ persistentOutput: true }` in the `Task`.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: async (ctx, task): Promise<void> => {
task.output = 'I will push an output. [0]'
},
options: { persistentOutput: true }
}
],
{ concurrent: false }
)
```
_Please refer to [examples section](examples/show-output.example.ts) for more detailed and further examples._
#### Utilizing the Task Itself
This will show the output in a small bar that can only show the last output from the task.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: async (ctx, task): Promise<void> => {
task.output = 'I will push an output. [0]'
await delay(500)
task.output = 'I will push an output. [1]'
await delay(500)
task.output = 'I will push an output. [2]'
await delay(500)
}
}
],
{ concurrent: false }
)
```
#### Utilizing the Bottom Bar
If task output to the bottom bar is selected, it will create a bar at the end of the tasks leaving one line return space in between. The bottom bar can only be used in the default renderer.
Items count that is desired to be showed in the bottom bar can be set through `Task` option `bottomBar`.
- If set to `true` it will only show the last output from the task.
- If it is set to a number it will limit the output to that number.
- If set to `Infinity`, it will keep all the output.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute.',
task: async (ctx, task): Promise<void> => {
task.output = 'I will push an output. [0]'
await delay(500)
task.output = 'I will push an output. [1]'
await delay(500)
task.output = 'I will push an output. [2]'
await delay(500)
},
options: {
bottomBar: Infinity
}
}
],
{ concurrent: false }
)
```
#### Utilizing an Observable or Stream
Since observables and streams are supported they can also be used to generate output.
_Please refer to [examples section](examples/stream.example.ts) for more detailed and further examples._
```typescript
new Listr<Ctx>(
[
{
// Task can also handle and observable
title: 'Observable test.',
task: (): Observable<string> =>
new Observable((observer) => {
observer.next('test')
delay(500)
.then(() => {
observer.next('changed')
return delay(500)
})
.then(() => {
observer.complete()
})
})
}
],
{ concurrent: false }
)
```
#### Passing the Output Through as a Stream
Since `process.stdout` method is controlled by `log-update` to create a refreshing interface, for anything else that might need to output data and can use `Writeable` streams, `task.stdout()` will create a new punch-hole to redirect all the write requests to `task.output`. This is esspecially benefical for external libraries like `enquirer`, which is already integrated or something like `ink`.
**Supported for >v2.1.0.**
_This unfortunetly relies on cleaning all ANSI escape charachters, since currently I do not find a good way to sandbox them inside `log-update` which utilizes the cursor position by itself. So use this with caution, because it will only render the last chunk in a stream as well as cleaning up all the ANSI escape charachters except for styles._
```typescript
import { Box, Color, render } from 'ink'
import React, { Fragment, useEffect, useState } from 'react'
import { Listr } from 'Listr2'
import { Logger } from '@utils/logger'
type Ctx = {}
const logger = new Logger({ useIcons: false })
async function main(): Promise<void> {
let task: Listr<Ctx, 'default'>
task = new Listr<Ctx, 'default'>(
[
{
title: 'This task will show INK as output.',
task: async (ctx, task): Promise<any> => {
const Counter = () => {
const [counter, setCounter] = useState(0)
useEffect(() => {
const timer = setInterval(() => {
setCounter((previousCounter) => previousCounter + 1)
}, 100)
return (): void => {
clearInterval(timer)
}
}, [])
return <Color green>{counter} tests passed</Color>
}
const { unmount, waitUntilExit } = render(<Counter />, task.stdout())
setTimeout(unmount, 2000)
return waitUntilExit()
}
}
],
{ concurrent: false }
)
try {
const context = await task.run()
console.log(`Context: ${JSON.stringify(context)}`)
} catch (e) {
console.error(e)
}
}
main()
```
### Throw Errors
You can throw errors out of the tasks to show they are insuccessful. While this gives a visual output on the terminal, it also handles how to handle tasks that are failed. The default behaviour is any of the tasks have failed, it will deem itself as unsuccessful and exit. This behaviour can be changed with `exitOnError` option.
- Throw out an error in serial execution mode will cause all of the upcoming tasks to be never executed.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will fail.',
task: async (): Promise<void> => {
await delay(2000)
throw new Error('This task failed after 2 seconds.')
}
},
{
title: 'This task will never execute.',
task: (ctx, task): void => {
task.title = 'I will change my title if this executes.'
}
}
],
{ concurrent: false }
)
```
- Throwing out an error while execution in parallel mode will immediately stop all the actions.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will fail.',
task: async (): Promise<void> => {
await delay(2000)
throw new Error('This task failed after 2 seconds.')
}
},
{
title: 'This task will execute.',
task: (ctx, task): void => {
task.title = 'I will change my title since it is concurrent.'
}
}
],
{ concurrent: true }
)
```
- Default behavior can be changed with `exitOnError` option.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will fail.',
task: async (): Promise<void> => {
await delay(2000)
throw new Error('This task failed after 2 seconds.')
}
},
{
title: 'This task will execute.',
task: (ctx, task): void => {
task.title = 'I will change my title if this executes.'
}
}
],
{ concurrent: false, exitOnError: false }
)
```
- `exitOnError` is subtask based so you can change it on the fly for given set of subtasks.
```typescript
new Listr<Ctx>(
[
{
title: 'This task will execute and not quit on errors.',
task: (ctx, task): Listr =>
task.newListr(
[
{
title: 'This is a subtask.',
task: async (): Promise<void> => {
throw new Error('I have failed [0]')
}
},
{
title: 'This is yet an another subtask and it will run.',
task: async (ctx, task): Promise<void> => {
task.title = 'I have succeeded.'
}
}
],
{ exitOnError: false }
)
},
{
title: 'This task will execute.',
task: (): void => {
throw new Error('I will exit on error since I am a direct child of parent task.')
}
}
],
{ concurrent: false, exitOnError: true }
)
```
- The error that makes the application to quit will be thrown out from the async function.
```typescript
try {
const context = await task.run()
} catch (e) {
logger.fail(e)
// which will show the last error
}
```
- Access all of the errors that makes the application quit or not through `task.err` which is an array of all the errors encountered.
```typescript
const task = new Listr(...)
logger.fail(task.err)
// will show all of the errors that are encountered through execution
```
- ListrError which is thrown out of `task.err´ in prior example is in the structure of
```typescript
public message: string
public errors?: Error[]
public context?: any
```
## Task Manager
Task manager is a great way to create a custom-tailored Listr class once and then utilize it more than once.
_Please refer to [examples section](examples/manager.example.ts) for more detailed and further examples._
### Basic Use-Case Scenerio
- Create something like a manager factory with your own default settings
```typescript
export function TaskManagerFactory<T = any>(override?: ListrBaseClassOptions): Manager<T> {
const myDefaultOptions: ListrBaseClassOptions = {
concurrent: false,
exitOnError: false,
rendererOptions: {
collapse: false,
collapseSkips: false
}
}
return new Manager({ ...myDefaultOptions, ...override })
}
```
- Create your class that benefits from manager
```typescript
export class MyMainClass {
private tasks = TaskManagerFactory<Ctx>()
constructor() {
this.run()
}
private async run(): Promise<void> {
// CODE WILL GO HERE IN THIS EXAMPLE
}
}
```
- Add multiple set of subtasks with their own options
```typescript
this.tasks.add(
[
{
title: 'A task running manager [0]',
task: async (): Promise<void> => {
throw new Error('Do not dare to run the second task.')
}
},
{
title: 'This will never run first one failed.',
task: async (): Promise<void> => {
await delay(2000)
}
}
],
{ exitOnError: true, concurrent: false }
)
```
- Run the tasks. Running the tasks will clear the pending queue so you can go ahead and add more new tasks!
```typescript
try {
const ctx = await this.tasks.runAll()
} catch (e) {
this.logger.fail(e)
}
```
### More Functionality
- Indenting tasks, to change options like `concurrency`, `exitOnError` and so on.
```typescript
this.tasks.add(
[
{
title: 'Some task that will run in sequential execution mode. [0]',
task: async (): Promise<void> => {
await delay(2000)
}
},
{
title: 'Some task that will run in sequential execution mode. [1]',
task: async (): Promise<void> => {
await delay(2000)
}
},
this.tasks.indent([
{
title: 'This will run in parallel. [0]',
task: async (): Promise<void> => {
await delay(2000)
}
},
{
title: 'This will run in parallel. [1]',
task: async (): Promise<void> => {
await delay(2000)
}
}
])
],
{ concurrent: true }
)
```
- Run a Task Directly, which will use the defaults settings you set in the manager.
```typescript
await this.tasks.run([
{
title: 'I will survive, dont worry',
task: (): void => {
throw new Error('This will not crash since exitOnError is set to false eventhough default setting in Listr is false.')
}
}
])
```
- Access the errors of the last task as in the Listr.
```typescript
await this.tasks.run([
{
title: 'I will survive, dont worry',
task: (): void => {
throw new Error('This will not crash since exitOnError is set to false eventhough default setting in Listr is false.')
}
}
])
this.logger.data(this.tasks.err.toString())
// will yield: ListrError: Task failed without crashing. with the error details in the object
```
- Access base Listr class directly, this will use the default Listr settings and just a mere jumper function for omiting the need the import the Listr class when using manager.
```typescript
try {
await this.tasks
.newListr([
{
title: 'I will die now, goodbye my freinds.',
task: (): void => {
throw new Error('This will not crash since exitOnError is set to false eventhough default setting in Listr is false.')
}
}
])
.run()
} catch (e) {
this.logger.fail(e)
}
```
- Get Task Runtime, and tailor it as your own
```typescript
await this.tasks.run(
[
{
task: async (ctx): Promise<void> => {
// start the clock
ctx.runTime = Date.now()
}
},
{
title: 'Running',
task: async (): Promise<void> => {
await delay(1000)
}
},
{
task: async (ctx, task): Promise<string> => (task.title = this.tasks.getRuntime(ctx.runTime))
}
],
{ concurrent: false }
)
// outputs: "1.001s" in seconds
```
## Generic Features
### Tasks Without Titles
For default renderer, all tasks that do not have titles will be hidden from the visual task list and executed behind. You can still set `task.title` inside the task wrapper programmatically afterward, if you so desire.
Since tasks can have subtasks as in the form of Listr classes again, if a task without a title does have subtasks with the title it will be rendered one less level indented. So you can use this operation to change the individual options of the set of tasks like `exitOnError` or `concurrency` or even render properties, like while you do want collapse parent's subtasks after completed but do not want this for a given set of subtasks.
For verbose renderer, since it is not updating, it will show tasks that do not have a title as `Task without title.`
### Signal Interrupt
When the interrupt signal is caught Listr will render for one last time therefore you will always have clean exits. This registers event listener `process.on('exit')`, therefore it will use a bit more of CPU cycles depending on the Listr task itself.
You can disable this default behavior by passing in the options for the root task `{ registerSignalListeners: false }`.
## Testing
For testing purposes you can use the verbose renderer by passing in the option of `{ renderer: 'verbose' }`. This will generate text-based and linear output which is required for testing.
If you want to change the logger of the verbose renderer you can do that by passing a class implementing `Logger` class which is exported from the index and passing it through as a renderer option with `{ renderer: 'verbose', rendererOptions: { logger: MyLoggerClass } }`.
Verbose renderer will always output predicted output with no fancy features.
| On | Output |
| --------------- | ------------------------------------------------------------------- |
| Task Started | \[STARTED\] \${TASK TITLE ?? 'Task without title.'} |
| Task Failure | \[FAILED\] \${TASK TITLE ?? 'Task without title.'} |
| Task Skipped | \[SKIPPED\] \${SKIP MESSAGE ?? TASK TITLE ?? 'Task without title.'} |
| Task Successful | \[SUCCESS\] \${TASK TITLE ?? 'Task without title.'} |
| Spit Output | \[DATA\] \${TASK OUTPUT} |
| Title Change | \[TITLE\] \${NEW TITLE} |
## Default Renderers
There are three main renderers which are 'default', 'verbose' and 'silent'. Default renderer is the one that can be seen in the demo, which is an updating renderer. But if the environment advirteses itself as non-tty it will fallback to the verbose renderer automatically. Verbose renderer is a text based renderer. It uses the silent renderer for the subtasks since the parent task already started a renderer. But silent renderer can also be used for processes that wants to have no output but just a task list.
Depending on the selected renderer, `rendererOptions` as well as the `options` in the `Task` will change accordingly. It defaults to default renderer as mentioned with the fallback to verbose renderer on non-tty environments.
- Options for the default renderer.
- Global
```typescript
public static rendererOptions: {
indentation?: number
clearOutput?: boolean
showSubtasks?: boolean
collapse?: boolean
collapseSkips?: boolean
} = {
indentation: 2,
clearOutput: false,
showSubtasks: true,
collapse: true,
collapseSkips: true
}
```
- Per-Task
```typescript
public static rendererTaskOptions: {
bottomBar?: boolean | number
persistentOutput?: boolean
}
```
- Options for the verbose renderer.
- Global
```typescript
public static rendererOptions: {
useIcons?: boolean
logger?: new (...args: any) => Logger
logEmptyTitle?: boolean
logTitleChange?: boolean
}
```
- Options for the silent renderer.
- NONE
## Custom Renderers
Creating a custom renderer with a beautiful interface can be done in one of two ways.
- First create a Listr renderer class.
```typescript
/* eslint-disable @typescript-eslint/no-empty-function */
import { ListrRenderer, ListrTaskObject } from 'listr2'
export class MyAmazingRenderer implements ListrRenderer {
// Designate this renderer as tty or nonTTY
public static nonTTY = true
// designate your renderer options that will be showed inside the `ListrOptions` as rendererOptions
public static rendererOptions: never
// designate your custom internal task-based options that will show as `options` in the task itself
public static rendererTaskOptions: never
// get tasks to be renderered and options of the renderer from the parent
constructor(public tasks: ListrTaskObject<any, typeof MyAmazingRenderer>[], public options: typeof MyAmazingRenderer['rendererOptions']) {}
// implement custom logic for render functionality
render(): void {}
// implement custom logic for end functionality
end(err): void {}
}
```
- Then there is a branching here you can either use:
- Utilizing the task functions themselves. Take a look at [default renderer](src/renderer/default.renderer.ts) since it is implemented this way.
```typescript
id: taskUUID
hasSubtasks(): boolean
isPending(): boolean
isSkipped(): boolean
isCompleted(): boolean
isEnabled(): boolean
isPrompt(): boolean
hasFailed(): boolean
hasTitle(): boolean
```
- Observables, where `event` has `event.type` which can either be `SUBTASK`, `STATE`, `DATA` or `TITLE` and `event.data` depending on the `event.type`. Take a look at [verbose renderer](src/renderer/verbose.renderer.ts) since it is implemented this way.
```typescript
tasks?.forEach((task) => {
task.subscribe((event: ListrEvent) => {
...
```
- Or if you so desire both!
## Render Hooks
Additional to rendering through `task.subscribe` or with a given interval, a renderer can also render on demand via a observable passed through the renderer.
Render hook can be the third optional variable of a given renderer, while using it is always optional.
```typescript
constructor (
public tasks: ListrTaskObject<any, typeof DefaultRenderer>[],
public options: typeof DefaultRenderer['rendererOptions'],
public renderHook$?: ListrTaskObject<any, any>['renderHook$']
)
```
Render hook is a void subject, which can be used to trigger re-render dynamically when any changes occur in the underneath.
```typescript
this.renderHook$.subscribe(() => {
/* DO SOME RENDER MAGIC like render() */
})
```
**Supported for >v2.1.0.**
## Log To A File
Logging to a file can be done utilizing a module like [winston](https://www.npmjs.com/package/winston). This can be obtained through using the verbose renderer and creating a custom logger class that implements `Logger` which is exported from the index.
While calling a new Listr you can call it with `{ renderer: 'verbose', rendererOptions: { logger: MyLoggerClass } }`.
```typescript
import { logLevels, Logger, LoggerOptions } from 'listr2'
export class MyLoggerClass extends Logger {
constructor(private options?: LoggerOptions) {
// This is not needed if you don't use these options in your custom logger
}
/* CUSTOM LOGIC */
/* CUSTOM LOGIC */
/* CUSTOM LOGIC */
public fail(message: string): void {
message = this.parseMessage(logLevels.fail, message)
console.error(message)
}
public skip(message: string): void {
message = this.parseMessage(logLevels.skip, message)
console.warn(message)
}
public success(message: string): void {
message = this.parseMessage(logLevels.success, message)
console.log(message)
}
public data(message: string): void {
message = this.parseMessage(logLevels.data, message)
console.info(message)
}
public start(message: string): void {
message = this.parseMessage(logLevels.start, message)
console.log(message)
}
public title(message: string): void {
message = this.parseMessage(logLevels.title, message)
console.info(message)
}
}
```
## Migration from Version v1
To migrate from prior versions that are older than v1.3.12, which is advisable due to upcoming potential bug fixes:
- rendererOptions has to be moved to their own key
- some of the types if initiated before assigning a Listr has to be fixed accordingly
- test renderer also combined with verbose renderer and icons of the verbose renderer is disabled by default which makes them basically same thing, so I think verbose is a better name for it
Please checkout [the entry in changelog.](./CHANGELOG.md#200-2020-05-06)
## Types
Useful types are exported from the root. It is written with Typescript, so it will work great with any modern IDE/Editor.
| 32.609735 | 512 | 0.661132 | eng_Latn | 0.98401 |
9776b84fa39b30c7c7ae8f448c3e3b54b56c0635 | 1,958 | md | Markdown | content/docs/news/vulnerability_bulletins/keptn-sec-2022-001/index.md | Ciggzy1312/keptn.github.io | 03ad35a75121346acd9b43bccc98ffa0dcbb50fc | [
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null | content/docs/news/vulnerability_bulletins/keptn-sec-2022-001/index.md | Ciggzy1312/keptn.github.io | 03ad35a75121346acd9b43bccc98ffa0dcbb50fc | [
"Apache-2.0",
"CC-BY-4.0"
] | 2 | 2022-03-24T08:35:15.000Z | 2022-03-31T08:44:35.000Z | content/docs/news/vulnerability_bulletins/keptn-sec-2022-001/index.md | agardnerIT/keptn.github.io | d78096278c75955df6c3a6158dae5a8bad3abcbb | [
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null | ---
title: Keptn-Vulnerability-2022-001
description: Webhook Service for Keptn is vulnerable to token leaks and access the Kubernetes APIs
weight: 97
---
Version 1.0
## Revision Information
| Revision | Updated | Reason |
|----------|:------------:|:--------------:|
| 1.0 | March 16, 2022 | Initial Reason |
## Affected
Keptn webhook-service in version 0.10.0 and newer.
## Description
Keptn webhook-service in version 0.10.0 and newer allow directly accessing the Kubernetes APIs.
Furthermore, Kubernetes tokens, such as the service account token, could be leaked.
The tokens could be exploited to read/write/delete the secrets created and managed by Keptn.
This includes all secrets created via:
- the secret management page and the secrets created;
- the CLI with `keptn create secret`;
- the APIs `/api/secrets/v1`.
The tokens that could be leaked do not compromise the Keptn configuration. Access to the Git tokens for configured upstreams is not compromised.
With Keptn versions >0.12.4 and >0.13.3 the bug is fixed ([Release 0.12.4](https://github.com/keptn/keptn/releases/tag/0.12.4) and [Release 0.13.3](https://github.com/keptn/keptn/releases/tag/0.13.3)).
## Severity
The severity of the vulnerability of webhook-service are:
*Token Leak*: **CVSS v3.0 Vector Score 4.5**: `CVSS:3.0/AV:A/AC:L/PR:H/UI:N/S:U/C:H/I:N/A:N`
*Kubernetes API access*: **CVSS v3.0 Vector Score 8.3**:`CVSS:3.0/AV:A/AC:L/PR:H/UI:N/S:C/C:H/I:H/A:L`
*Note*: The calculation of the CVSS is based on a Keptn 0.13.2 installation.
## Recommendations
The release of **webhook-service** in version **0.12.4** and **0.13.3** (and following versions) contains fixes to the aforementioned issues. We recommend upgrading to one of these versions as soon as possible. Furthermore, we recommend rotating all credentials stored as Keptn secret. Also, investigation of downstream services is recommended.
## Workaround
* Disable the webhook-service. | 39.959184 | 344 | 0.724719 | eng_Latn | 0.969497 |
9776ead8a2329f95597f8b6366152dfe82da3182 | 111 | md | Markdown | _posts/0000-01-02-jayaaprasanth.md | jayaaprasanth/github-slideshow | 72ca170461c6f9246dbee63b2e0c44bd0783cc9a | [
"MIT"
] | null | null | null | _posts/0000-01-02-jayaaprasanth.md | jayaaprasanth/github-slideshow | 72ca170461c6f9246dbee63b2e0c44bd0783cc9a | [
"MIT"
] | 3 | 2021-11-13T12:19:33.000Z | 2021-11-15T15:28:04.000Z | _posts/0000-01-02-jayaaprasanth.md | jayaaprasanth/github-slideshow | 72ca170461c6f9246dbee63b2e0c44bd0783cc9a | [
"MIT"
] | null | null | null | layout: slide title: “Welcome to our second slide!” --- Your test Use the left arrow to go back!
| 55.5 | 110 | 0.630631 | eng_Latn | 0.99844 |
9777b7357eede8b7eafc9361d09969ef32441990 | 2,615 | md | Markdown | source/_posts/seo.md | qmgeng/qmgeng.github.io | f17f83ccb63023f11827d49830558ce2b886b17b | [
"MIT"
] | null | null | null | source/_posts/seo.md | qmgeng/qmgeng.github.io | f17f83ccb63023f11827d49830558ce2b886b17b | [
"MIT"
] | null | null | null | source/_posts/seo.md | qmgeng/qmgeng.github.io | f17f83ccb63023f11827d49830558ce2b886b17b | [
"MIT"
] | null | null | null | layout: art
title: 漫谈前端开发中的SEO
subtitle: 让自己的网页在搜索引擎中排名更高
tags:
- SEO
- HTML
categories:
- 前端综合
date: 2014/3/27
---
##什么是SEO
SEO全称是搜索引擎优化,是一种利用搜索引擎的搜索规则来提高目前网站在有关搜索引擎内的排名的方式。SEO为了从搜索引擎获得更多的免费流量,从网站结构、内容建设方案、用户活动传播、页面结构等进行合理规划,使网站更适合搜索引擎检索。
<!-- more -->
##SEO相关的HTML标签
###title
`<title>页面的标题</title>`,必须有的东西,非常之重要
###keyrowds
`<meta name="keywords" content="keyWord1,keyWord2"/>`,定义为搜索引擎提供的关键字列表,页面的呃主关键词都可以列举在这里
###description
`<meta name="description" content="页面描述">`。这一部分告诉搜索引擎当前网页的主要内容,对有些搜索引擎的排名影响不大(如百度)但是对用户体验方面还是很有用的
###robots
`<meta name="Robots" content="nofollow"/>`,告诉搜索引擎哪些页面需要索引,哪些页面则不需要,它对页面上的所有标签生效,包括站内站外。比如nofollow属性,如果在a标签上加上了nofollow,如`<a rel="external nofollow" href="">锚文本</a>`,搜索引擎将不会抓取这个连接,这样可以防止权重分散到一些无关页面。
content中的参数可以设定为`all`,`none`,`index`,`noindex`,`follow`,`nofollow`,默认为all。
###H1
`<h1>标题</h1>`,告诉搜索引擎一段文字的标题,h1标题的权重较大,而h2、h3、h4对搜索引擎没有多大价值,加上可以增加用户体验
###alt和title
尽量在img标签中加入alt属性如`<img src="" alt="这里加上关键词"/>`,alt会影响搜索排名
而a标签中的title也是一样,虽然效果微弱
###语义化HTML
在HTML5中新增了很多语义化的HTML5元素,如`<header>`,`<section>`,`<footer>`,`<article>`,`<aside>`,`<nav>`等等,这些语义化元素能帮助搜索引擎快速过滤掉不重要的信息,而从中快速提取出网页的主题内容,同时语义化的HTML也能够有较强的可访问性
##对搜索引擎不友好的示例
1. 网页中大量采用图片或者Flash等富媒体形式,没有可以检索的文本信息
2. 网页没有标题,或者标题中不包含有效关键字
3. 正文中有效关键词比较少(小于文章的2%~8%)
4. 网站导航系统让搜索引擎看不懂
5. 大量动态网页让搜索引擎无法检索
6. 没有被其他已经被搜索引擎收录的网站所链接
7. 网站中充值大量欺骗搜索引擎的垃圾信息,如过渡页,桥页、颜色与背景色相同的文字
8. 网站中缺少原创内容,完全照搬别人的内容
##一些好的建议
###保持文章原创性
保持文章的原创性才不会被网络蜘蛛所唾弃,由于搜索引擎中已经保存了大量的数据,经过比对后,如果当前页面与已存在搜索引擎中的页面的相似度过高,将降低当前页面的权重。所以我们需要保持网页内文章的原创性。一般情况下至少要保持与其他文章的30%的不同
###关键字的堆砌
众所周知,在网页中的`meta`标签中定义`keywors`对搜索引擎来说非常重要。而搜索中的关键词也应当堆砌在标题和正文中。其中标题由于字数有限,应当尽可能的出现较多的关键词,而正文中关键词也应当占有一定比重(2%~8%)。另外在文章中应当保持关键词的统一性,一个名称有多种叫法的时候尽量只是用其中的一种。同时出现在正文中的关键词应当加粗或家斜体来进行区分,让搜索引擎优先考虑
###标题
标题不应当太长,最好不超过15个汉字,其中尽量多的堆砌关键词,同时保证标题新颖,符合用户的搜索习惯。尽量将主关键词放在标题的前半部分
###文章摘要
在文章摘要中必须包含关键词,尽可能的重复页面的关键词,但是不要堆积,一般来说重复三遍没有问题。同时文章摘要的文字没有严格的字数要求,但一般以80-100字为宜
###正文内容
正文内容需要保持原创性,同时在前100字中(或是首段)最好能出现关键词。同时需要保持文章的长度,如果文章过长,应当采用分页的方式,一般一页的长度在1000字以下。短的文章有助于搜索引擎提取和分析。在正文中需要一定的关键词堆叠(2%~8%)
###AJAX和FLASH
在开发中经常会使用Flash创建绚丽的导航,但实际上Flash导航中的链接是无法被网络蜘蛛抓取到的。而AJAX也是一样,因为AJAX是动态加载的,所以它不易被搜索引擎所抓取。所以尽量避免过度使用AJAX和FLASH,尤其不要将重要的内容通过AJAX和FLASH加载。如果网站有较多AJAX加载的内容话,可以提供一个非AJAX加载的静态替代网页
###图片和链接
我们可以把网络蜘蛛看做一个基于文字的浏览器,它无法获取到图片内部的信息。因此,如果需要通过图片传达比较重要的信息的话,需要将信息写在`alt`属性中,传达给搜索引擎。链接也可以通过类似的`title`属性来添加相应的说明。在`alt`和`title`中给与精确的描述,并尽可能的输入关键词,这样能告诉搜索引擎图片和链接是做什么的
##参考文章
[百度百科:SEO](http://baike.baidu.com/link?url=RtgwJhMXAZh7_7BWXlvu9CXZV4JnoytnMWXlyAhLfgAKgPPoG6-vAooSYfFIBuM-)
[站内SEO规范](http://www.daqianduan.com/1808.html)
[网页前端制作中的SEO](http://www.yangzblog.com/internet/webfeSEO.html)
| 31.890244 | 197 | 0.81912 | yue_Hant | 0.69307 |
977817e99bc0aa4895315a770b613e1d12d71343 | 706 | md | Markdown | 2007/CVE-2007-2208.md | clayne/cve | 826302c6f00fece8a106677c065a5bd6f0681dc1 | [
"MIT"
] | 2,340 | 2022-02-10T21:04:40.000Z | 2022-03-31T14:42:58.000Z | 2007/CVE-2007-2208.md | clayne/cve | 826302c6f00fece8a106677c065a5bd6f0681dc1 | [
"MIT"
] | 19 | 2022-02-11T16:06:53.000Z | 2022-03-11T10:44:27.000Z | 2007/CVE-2007-2208.md | clayne/cve | 826302c6f00fece8a106677c065a5bd6f0681dc1 | [
"MIT"
] | 280 | 2022-02-10T19:58:58.000Z | 2022-03-26T11:13:05.000Z | ### [CVE-2007-2208](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2007-2208)



### Description
Multiple PHP remote file inclusion vulnerabilities in Extreme PHPBB2 3.0 Pre Final allow remote attackers to execute arbitrary PHP code via a URL in the phpbb_root_path parameter to (1) functions.php or (2) functions_portal.php in includes/.
### POC
#### Reference
- http://securityreason.com/securityalert/2608
#### Github
No PoCs found on GitHub currently.
| 39.222222 | 241 | 0.756374 | eng_Latn | 0.373959 |
977882bfee96cdaa097040a31dd429f76a0b938a | 2,389 | md | Markdown | README.md | dimitrievski/shapegen | 3820bfccd7f3c256534704dc03dfc470cff1cd33 | [
"MIT"
] | null | null | null | README.md | dimitrievski/shapegen | 3820bfccd7f3c256534704dc03dfc470cff1cd33 | [
"MIT"
] | null | null | null | README.md | dimitrievski/shapegen | 3820bfccd7f3c256534704dc03dfc470cff1cd33 | [
"MIT"
] | null | null | null | # ShapeGen (Shape Generator)
Generates 2D shapes (circles, ellipses, diamonds, squares, rectangles, triangles) in different sizes.
## Requirements
PHP 7.0 and later.
## Composer
You can install the bindings via [Composer](http://getcomposer.org/). Run the following command:
```bash
$ composer require dimitrievski/shapegen
```
To use the bindings, use Composer's [autoload](https://getcomposer.org/doc/01-basic-usage.md#autoloading):
```php
<?php
require __DIR__ . '/vendor/autoload.php';
```
## Getting Started
Simple usage looks like:
```php
<?php
$shapeGen = new \ShapeGen\ShapeGen();
echo $shapeGen->generate("diamond");
// X
// XXXXX
//XXXXXXXXX
// XXXXX
// X
```
To generate a shape with different size, pass an additional argument - number of lines.
This argument must be an odd number between 5 and 49. The default is 5.
```php
<?php
$shapeGen = new \ShapeGen\ShapeGen();
echo $shapeGen->generate("diamond", 9);
// X
// XXXXX
// XXXXXXXXX
// XXXXXXXXXXXXX
//XXXXXXXXXXXXXXXXX
// XXXXXXXXXXXXX
// XXXXXXXXX
// XXXXX
// X
```
To generate a shape with different filling, pass one more argument - filling character.
This argument must be a string. The default is X.
```php
<?php
$shapeGen = new \ShapeGen\ShapeGen();
echo $shapeGen->generate("diamond", 9, "D");
// D
// DDDDD
// DDDDDDDDD
// DDDDDDDDDDDDD
//DDDDDDDDDDDDDDDDD
// DDDDDDDDDDDDD
// DDDDDDDDD
// DDDDD
// D
```
To create new shapes, use the shape factory like:
```php
<?php
$shapeFactory = new \ShapeGen\ShapeFactory();
$diamond = $shapeFactory->create("diamond");
//set different size and filling
$diamond->setLines(15);
$diamond->setFilling("-");
echo $diamond->generate();
// -
// -----
// ---------
// -------------
// -----------------
// ---------------------
// -------------------------
//-----------------------------
// -------------------------
// ---------------------
// -----------------
// -------------
// ---------
// -----
// -
```
## Development
Install dependencies:
``` bash
$ composer install
```
## Tests
Install dependencies as mentioned above (which will resolve [PHPUnit](http://packagist.org/packages/phpunit/phpunit)), then you can run the test suite:
```bash
$ ./vendor/bin/phpunit tests/
``` | 19.422764 | 151 | 0.577648 | eng_Latn | 0.470056 |
97796afb619c95ebab5070e935fb39dce3783ac8 | 2,611 | md | Markdown | content/blog/codingTest/algorithm/greedy/202104/20210403-adventurer-guild.md | offetuoso/hugo | f606f4ca0935e305dc2810afd17b7b9d6129e8db | [
"MIT"
] | 1 | 2021-05-04T13:22:07.000Z | 2021-05-04T13:22:07.000Z | content/blog/codingTest/algorithm/greedy/202104/20210403-adventurer-guild.md | offetuoso/hugo | f606f4ca0935e305dc2810afd17b7b9d6129e8db | [
"MIT"
] | null | null | null | content/blog/codingTest/algorithm/greedy/202104/20210403-adventurer-guild.md | offetuoso/hugo | f606f4ca0935e305dc2810afd17b7b9d6129e8db | [
"MIT"
] | null | null | null | ---
title: "모험가 길드 (그리디 알고리즘)"
image: "bg-index.jpg"
font_color: "white"
font_size: "28px"
opacity: "0.4"
date: 2021-04-03
slug: "adventurer-guild"
description: "모험가 파티를 만드는 알고리즘"
keywords: ["Algorithm", "Greedy", "CodingTest", "Python","Java"]
draft: false
categories: ["Algorithm"]
subcategories: ["이코테"]
tags: ["Algorithm", "Greedy", "이코테"]
math: false
toc: true
---
## [문제1] 1이 될때까지
### [문제] 1이 될때까지 : 문제 설명
> 어떠한 수 N이 1이 될때까지 다음의 두 과정 중 하나를 반복적으로 선택하여 수행하려고 합니다. 단, 두번째 연산은 N이 K로 나누어 떨어질 때만 선택할 수 있습니다.
> 1. N에서 1을 뺍니다.
> 2. N에서 K로 나눕니다.
> 예를 들어 N이 17, K가 4라고 가정하자. 이때 1번의 과정을 한 번 수행하면 N은 16이 된다.
> 이후에 2번의 과정을 두 번 수행하면 N은 1이 된다. 결과적으로 이경우 전체과정을 실행한 횟수는 3이된다. 이는 N을 1로 만드는 최소 횟수이다.
> N과 K가 주어질 때 N이 1이 될 때까지 1번 혹은 2번의 과정을 수행해야하는 최소 횟수를 구하는 프로그램을 작성하시오
### [문제] 조건
> 입력조건
> 첫째줄에 N(2 <= N < = 100000)과 K(2 <= K < = 100000)가 공백으로 구분되며 각각 자연수로 주어진다.
이때 입력으로 주어지는 N은 항상 K보다 크거나 같다.
> 출력조건
> 첫째줄에 N이 1이 될 때까지 1번 혹은 2번의 과정을 수행해야 하는 횟수의 최솟값을 출력한다.
> 입력예시<br>
> 25 5
> 출력예시<br>
> 2
### make_one.py
```
n, k = map(int, input().split()) #n=13, k=5
result = 0
while True :
# n을 K로 나눈 몫에 k를 곱하여,
# 나눌수 있는 값을 계산 # roof 1 step # roof 2 step
target = (n // k) * k #target = 10 #target = 0
result += (n - target) #result += 3 <<한번에 카운트 3을 추가하고 #result(4) += 2
n = target #n = target <<13을 10으로 만듬 #n=0
if n < k : #false #true
break
result += 1 #나눗셈에 대한 result(3) +1
n //= k #n = 2
result += (n - 1) #result(6) += -1 <n을 0까지 만들면서, 횟수 -1
print(result) #5
```
### MakeOne.java
```
package ex.Algorithm.greedy;
import java.util.Scanner;
public class MakeOne {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int k = sc.nextInt();
int result = 0;
while (true) {
int target = (n/k)*k;
result += n-target;
n = target;
if(n < k) {
break;
}
n = n / k;
result++;
}
result += (n-1);
System.out.println(result);
}
}
```
### [문제] 정당성 분석
> 1을 빼는 것보다 나누는 것이 더 기하급수적으로 빠르게 줄일 수 있다.
> K가 2보다 크다면, K로 나누는 것이 1을 빼는것 보다 항상 빠르게 N을 줄일 수 있다.
> 또한 N은 항상 1에 도달하게 됨.
이 자료는 나동빈님의 이코테 유튜브 영상을 보고 정리한 자료입니다.
<br>
<a href="https://www.youtube.com/watch?v=m-9pAwq1o3w&list=PLRx0vPvlEmdAghTr5mXQxGpHjWqSz0dgC">참고 : www.youtube.com/watch?v=m-9pAwq1o3w&list=PLRx0vPvlEmdAghTr5mXQxGpHjWqSz0dgC</a>
| 21.758333 | 186 | 0.542321 | kor_Hang | 1.000008 |
977a36d2614a1ddcde7a5207f3ebcfd55eaaff67 | 231 | md | Markdown | CHANGELOG.md | metaborg/gitonium | b5215c0f322ec705cfe1607b1aa07f522f245ef1 | [
"Apache-2.0"
] | 3 | 2019-03-25T14:19:11.000Z | 2020-06-03T10:30:11.000Z | CHANGELOG.md | metaborg/gitonium | b5215c0f322ec705cfe1607b1aa07f522f245ef1 | [
"Apache-2.0"
] | 2 | 2021-10-09T22:29:42.000Z | 2022-01-19T12:12:55.000Z | CHANGELOG.md | metaborg/gitonium | b5215c0f322ec705cfe1607b1aa07f522f245ef1 | [
"Apache-2.0"
] | null | null | null | # Changelog
All notable changes to this project are documented in this file, based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/).
## [Unreleased]
[Unreleased]: https://github.com/metaborg/gitonium/compare/...HEAD
| 25.666667 | 131 | 0.74026 | eng_Latn | 0.782 |
977a8ab7b9c8892e765cc63b246c0c5c93361a13 | 468 | md | Markdown | public/library/README.md | nkgfirecream/22120 | f6d094d95a491ed11605e3f07a8a79effbedf0ea | [
"MIT"
] | 1 | 2020-11-17T13:10:22.000Z | 2020-11-17T13:10:22.000Z | public/library/README.md | sumonst21/22120 | b365a06467f6556b70f56e8d93fee5a7485b1f15 | [
"MIT"
] | null | null | null | public/library/README.md | sumonst21/22120 | b365a06467f6556b70f56e8d93fee5a7485b1f15 | [
"MIT"
] | null | null | null | # ALT Default storage directory for library
Remove `public/library/http*` and `public/library/cache.json` from `.gitignore` if you forked this repo and want to commit your library using git.
## Clearing your cache
To clear everything, delete all directories that start with `http` or `https` and delete cache.json
To clear only stuff from domains you don't want, delete all directories you don't want that start with `http` or `https` and DON'T delete cache.json
| 42.545455 | 148 | 0.771368 | eng_Latn | 0.98657 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.