
text
stringlengths 20
57.3k
| labels
class label 4
classes |
|---|---|
Title: Activity plugin missing docs
Body: ## CKAN version
2.10.1
## Describe the bug
I added the configuration "ckan.auth.public_activity_stream_detail = True" and marked the dataset public but in dashboard not appeat Activity Stream and in activity table does not record the activities.
### Additional details


CKAN Configuration Option
ckan.auth.public_activity_stream_detail = True
| 0easy
|
Title: Improve inference export script
Body: `inference/server/export.py`
- Add ability to filter by conditions
- Include a filter for only chats which have at least one assistant message with score != 0
- Include a filter for specific date ranges
- Consider performance improvements such as use of lazy loading from the database
| 0easy
|
Title: [ASGI] close() not called if iterating over resp.stream raises an exception
Body: At the time of writing, the `close()` method of [`resp.stream`](https://falcon.readthedocs.io/en/stable/api/request_and_response_asgi.html#falcon.asgi.Response.stream) is only called if the provided generator is successfully exhausted (or yields `None`).
However, the primary use case of the `close()` method is freeing up resources, so one might expect the method to be called regardless. It is also what [PEP 3333 compliant](https://www.python.org/dev/peps/pep-3333/#specification-details) WSGI servers do.
I would suggest introducing a `finally` clause, and moving the invocation of `close()` there.
Make sure to also write proper regression tests:
> Kurt Griffiths @kgriffs
> We also need a test that forces stream to raise an error.
> (and ensures close() is called)
| 0easy
|
Title: DOC: error when creating a dev env
Body: In the current [documentation](https://doc.xorbits.io/en/latest/development/contributing_environment.html) for creating a dev env, the way of building and installing Xorbits is not correct.
```bash
# Build and install Xorbits
python setup.py build_ext -i
python setup.py build_web
python -m pip install -e ".[dev]"
```
| 0easy
|
Title: Add Multilingual Heading Support
Body: Right now the app always outputs the headings in English. It would be nice to add options for other languages, as the prompts seem to be working with other languages as well.
| 0easy
|
Title: Add Code Cov to frontend/backend for e2e testing
Body: We should have our playwright tests publish to code cov
| 0easy
|
Title: Using TFP distributions directly in `sample` primitive
Body: Quoted from [the forum](https://forum.pyro.ai/t/sample-from-the-mixture-same-family-distribution/3178/6): The current wrappers in `numpyro.contrib.tfp` seems to not work for special distributions like MixtureSameFamily. For now, to make it work, we'll need to do
```python
from numpyro.contrib.tfp.distributions import TFPDistribution
import tensorflow_probability...distributions as tfd
def model():
x = sample("x", TFPDistribution(tfd.MixtureSampleFamily(...)))
```
In the long term, I think it would be nice to use TFP distributions directly in the `sample` primitive:
```python
import tensorflow_probability...distributions as tfd
def model():
x = sample("x", tfd.MixtureSampleFamily(...))
```
I believe it is enough to modify [`sample` primitive](https://github.com/pyro-ppl/numpyro/blob/e55f0d41c9eba48a10e88fb403a5e016f18857e6/numpyro/primitives.py#L104) such that if `fn` is not a NumPyro distribution, we will check if `tensorflow_probability` is available, then trying to check if `fn` is a TFP distribution. If yes, then we replace `fn` by `numpyro.contrib.tfp.distributions.TFPDistribution[type(fn)](**fn.parameters)` or by
```python
new_fn = TFPDistribution()
new_fn.tfp_dist = fn
new_fn.tfd_class = type(fn) # and extra repr if needed
```
| 0easy
|
Title: 稳定的依赖包是哪些版本?
Body: 好多依赖版本拉的最新的就一直报错
| 0easy
|
Title: Link of type test_case not recognized as proper type in generated report
Body: ### Bug report:
#### Steps to reproduce:
- run simple test:
```
import allure
@allure.testcase('TC-1')
def test_foo():
assert 0
```
- generate result: `allure generate --clean %alluredir%`
- check links section of generated report
#### Actual result:
Test case link is not recognized as test management system link, but as plain link
#### Expected result:
Test case link is recognized as TMS link with appropriate icon (or similar distinctive behaviour)
#### Additional info and motivation:
Although it is minor issue - this is probably due to unsync with changes in report generator.
If label `@allure.link('TC-1', link_type="tms")` is provided instead - link is generated correctly.
I guess it might be an easy fix - update `allure_commons.types.LinkType.TEST_CASE` value to "tms".
#### Versions:
- allure-pytest == 2.8.6
- allure-python-commons == 2.8.6
- pytest == 5.3.1
- allure-commandline(2.13.1)
| 0easy
|
Title: docs: parameter and return types
Body: @Fix types in docstrings under:
Parameters
------------
Returns
--------
to utilize our new auto-typing where possible: https://github.com/cleanlab/cleanlab/pull/412
Sphinx can now automatically insert the type for us in the docstring (based on type annotation in the function signature), so you should not specify the type of Parameter or Return-variable *unless* it is a custom/nonstandard type that looks ugly when automatically inserted by Sphinx (this is only referring to the docstring, you still always have to specify type in function signature where you define what args it takes). The best strategy would be to remove all the type annotations (only in docstrings, not function signatures!) in a file and rebuild the docs to see how it looks. Then add back the subset of types that were not properly auto-inserted by Sphinx or simply don't look good.
This has already been done for files in token_classification module, which you can reference.
Remaining files to do/verify this for:
- [ ] classification.py
- [ ] count.py
- [ ] dataset.py
- [ ] filter.py
- [ ] multiannotator.py
- [ ] outlier.py
- [ ] rank.py
- [ ] experimental/keras.py
- [ ] experimental/fasttext.py
- [ ] experimental/coteaching.py
- [ ] experimental/mnist_pytorch.py
- [ ] experimental/cifar_cnn.py
- [ ] internal/label_quality_utils.py
- [ ] internal/latent_algebra.py
- [ ] internal/token_classification_utils.py
- [ ] internal/util.py
- [ ] internal/validation.py
- [ ] benchmarking/noise_generation.py
| 0easy
|
Title: Menu is always highlighting "home" category
Body: 
Even selecting another category "home" item keeps highlighted.
| 0easy
|
Title: Inconsistency with raising CSRFError
Body: The Flask-WTF docs state:
> When CSRF validation fails, it will raise a CSRFError.
However, this appears to only be true, if this optional code has been used:
from flask_wtf.csrf import CSRFProtect
csrf = CSRFProtect(app)
When that code is not used, forms are created by subclassing `FlaskForm`, and CSRF validation fails, then `validate_on_submit` returns False instead of raising `CSRFError`.
It seems that ideally you would always raise `CSRFError` for consistency, but if you don't want to do that, then it would be helpful to update the docs.
| 0easy
|
Title: Minor Error in Inertia and Relative Volatility Index Documentation
Body: While `Inertia: inertia` is calculated correctly, the documentation, https://github.com/twopirllc/pandas-ta/blob/47d8da67e1bd46476f5f7547c48ccb67598e63ed/pandas_ta/momentum/inertia.py#L17-L25, states`Relative Vigor Index` instead of the `Relative Volatility Index`. It also links to https://www.investopedia.com/terms/r/relative_vigor_index.asp instead of an article on the `Relative Volatility Index`. Also, the `Relative Volatility Index` documentation, https://github.com/twopirllc/pandas-ta/blob/development/pandas_ta/volatility/rvi.py#L24, links to https://www.tradingview.com/wiki/Keltner_Channels_(KC) instead of a website on the `Relative Volatility Index`, such as https://www.tradingview.com/support/solutions/43000594684-relative-volatility-index/.
| 0easy
|
Title: Feature: make typer optional and move to `faststream[cli]` distribution
Body: Also we should update documentation accordingly
| 0easy
|
Title: HTTPFound is marked as deprecated, so what should I use for redirects?
Body: ### Describe the bug
All the examples on the aiohttp documentation use `HTTPFound` for redirects, but they're also deprecated and will be removed soon, so I want to know the most future-proof way to implement redirects.
### To Reproduce
Use `raise HTTPFound`
### Expected behavior
Example code that doesn't use deprecated features
### Logs/tracebacks
```python-traceback
The code works fine
```
### Python Version
```console
Python 3.12.0
```
### aiohttp Version
```console
3.10.10
```
### multidict Version
```console
6.1.0
```
### propcache Version
```console
0.2.0
```
### yarl Version
```console
1.16.0
```
### OS
Microsoft Windows 10
### Related component
Server
### Additional context
_No response_
### Code of Conduct
- [X] I agree to follow the aio-libs Code of Conduct
| 0easy
|
Title: Enhancing Project Documentation: Inclusion of Library Dependencies in README
Body: ### Is your feature request related to a problem? Please describe.
Currently, project documentation often lacks a structured representation of the libraries and dependencies used, causing ambiguity for newcomers and even experienced developers. This opacity can result in extended onboarding periods, inefficiencies in issue resolution, and reduced participation.
### Describe the solution you'd like
I propose an integration within GitHub to encourage or enforce a standardized approach to document the libraries and dependencies utilized by a project. This documentation could be included within the project's README or in a dedicated section of the repository. The proposed documentation structure is as follows:
A designated section in the README listing all libraries and dependencies.
For each library or dependency, a succinct description of its functionality within the project.
Optionally, the inclusion of links to the library's official documentation or GitHub repository for more in-depth information.
### Describe alternatives you've considered
_No response_
### Additional context
I feel that for anything similar to this project I think it could be really helpful for people like me and others to wrap their head around the code structure and dependencies
| 0easy
|
Title: [Feature request] Add apply_to_images to Affine
Body:
| 0easy
|
Title: Float and Decimal widgets should use LANGUAGE_CODE
Body: Hi!
When exporting a FloatField, DecimalField, etc. the result uses the `.` as decimal separator. I was just wondering if instead, it should use the decimal separator for `LANGUAGE_CODE` defined in `settings.py`.
https://github.com/django-import-export/django-import-export/blob/master/import_export/widgets.py#L58
What do you think?
| 0easy
|
Title: Warn on large files when using resources_
Body: Users can tell Ploomber to track changes to configuration files via [resources_](https://ploomber.readthedocs.io/en/latest/api/spec.html?highlight=resources_#tasks-params-resources), however, to track changes, we compute a file hash which may take too long if the file is large.
We should show a warning if this happens, `resources_` should not be used with large files.
| 0easy
|
Title: [BUG] GroupedPredictor doesn't allow for nans in input
Body: The `GroupedPredictor` raises an error (`ValueError: Input contains NaN, infinity or a value too large for dtype('float64').`) even if the `estimator` can handle missing values itself.
```python
from sklego.meta import GroupedPredictor
import numpy as np
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LinearRegression
from sklearn.impute import SimpleImputer
from sklego.datasets import load_chicken
df = load_chicken(as_frame=True)
X, y = df.drop(columns='weight'), df['weight']
# create missing value
X.loc[0, 'chick'] = np.nan
model = make_pipeline(SimpleImputer(), LinearRegression())
group_model = GroupedPredictor(model, groups=["diet"])
group_model.fit(X,y)
```
This could be solved i.e. by exposing parameter `force_all_finite` from sklearn function `check_array` into the `GroupedPredictor`
| 0easy
|
Title: [BUG] Confusing handling of edgeless cypher queries
Body: ```
import neo4j
import graphistry
NEO4J = {
'uri': "bolt://***********:7687",
'auth': (******, *********)
}
graphistry.register(bolt=NEO4J, username=*******, password=****, api=3, protocol="https", server="hub.graphistry.com", token=*****)
g = graphistry.cypher("""MATCH (n)--(m) RETURN n,m LIMIT 100""")
g.plot()
```
=>
```
Exception: {'data': {'bindings': {'destination': '_bolt_end_node_id_key', 'source': '_bolt_start_node_id_key'}, 'dataset_id': '6211bfae854345b3907bac85792a2ca6', 'error_message': "Edge binding 'source' points to a column named '_bolt_start_node_id_key' that does not exist, is there a typo in column name?"}, 'message': 'Invalid edges bindings', 'success': False}
```
Best would be for this to load as the cypher connector can detect the situation and synthesize in an empty table with any bound columns.
| 0easy
|
Title: using https://github.com/marketplace/actions/python-coverage-comment
Body:
Since we no longer use [coverage](https://github.com/marketplace/codecov) service, we can use this [action](https://github.com/marketplace/actions/python-coverage-comment) to display the coverage
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0easy
|
Title: [FEATURE] Allow set Accept-Language
Body: <!--
DO NOT REQUEST UI/THEME/GUI/APPEARANCE IMPROVEMENTS HERE
THESE SHOULD GO IN ISSUE #60
REQUESTING A NEW FEATURE SHOULD BE STRICTLY RELATED TO NEW FUNCTIONALITY
-->
**Describe the feature you'd like to see added**
Allow set `Accept-Language` in headers in `Request.send`
I encounter similar issue like https://github.com/benbusby/whoogle-search/issues/186#issuecomment-787468941
Then I use `WHOOGLE_CONFIG_LANGUAGE` to set page's language to `lang_en` . However the date format is still Arabic like this ` 21 Safar 1443 AH` (the same as September 29 2021) .
so modified like this and it works.
```diff
diff --git a/app/request.py b/app/request.py
index 68e30d8..0a9a3e8 100644
--- a/app/request.py
+++ b/app/request.py
@@ -157,6 +157,7 @@ class Request:
self.language = (
config.lang_search if config.lang_search else ''
)
+ self.lang_interface = config.lang_interface
self.mobile = bool(normal_ua) and ('Android' in normal_ua
or 'iPhone' in normal_ua)
self.modified_user_agent = gen_user_agent(self.mobile)
@@ -243,6 +244,9 @@ class Request:
'User-Agent': modified_user_agent
}
+ if self.lang_interface:
+ headers.update({'Accept-Language': self.lang_interface.replace('lang_', '') + ';q=1.0'})
+
# FIXME: Should investigate this further to ensure the consent
# view is suppressed correctly
now = datetime.now()
```
so could there be some configs to let user choose if set "Accept-language" or not.
| 0easy
|
Title: extend active learning with multiple annotators to multi-label datasets
Body: Requested in the [Slack community](https://cleanlab.ai/slack)
Objectives:
1) Make a multi-label version of the `get_active_learning_scores` function:
https://docs.cleanlab.ai/master/cleanlab/multiannotator.html#cleanlab.multiannotator.get_active_learning_scores
2) Extend other functions in the `cleanlab.multiannotator` module as necessary for this to work for multi-label datasets.
All of this new functionality should live in a new module: `cleanlab.multilabel_classification.multiannotator`
3) Make a multi-label version of this tutorial notebook:
https://github.com/cleanlab/examples/tree/master/active_learning_multiannotator
Simple implementation:
For a multi-label dataset with K nondisjoint classes (aka tags), we compute the multilabel active learning scores like this:
```
multi_annotator_active_learning_scores = np.zeros(len(dataset),)
for class in 1:K:
y_onevsrest = create a one-vs-rest binary dataset labeling each example in as class 1 if it has class k in its given label, otherwise as class 0.
pred_probs_class = pred_probs[:,k]
class_k_active_learning_scores = cleanlab.multiannotator.get_active_learning_scores(y_onevsrest, pred_probs_class)
multilabel_active_learning_scores += class_k_active_learning_scores
return (multilabel_active_learning_scores / K)
```
| 0easy
|
Title: Kaufman's Adaptive Moving Average (KAMA) - calculation issue
Body: ```python
import yfinance as yf
from pandas_ta.overlap import kama
import mplfinance as mpf
ticker = yf.Ticker("SPY")
minute_data = ticker.history(period="7d", interval="1m")
kama_results = kama(minute_data["Close"])
addplot = [
mpf.make_addplot(kama_results, color='blue')
]
mpf.plot(minute_data, volume=True, type='candle', addplot=addplot)
```

I tried using the Kama indicator (snippet and picture above), seems like there's a bug with the calculate the Kama. The initial Kama value relies on the previous value which I believe from the snippet below returns zero for the first value.
https://github.com/twopirllc/pandas-ta/blob/bc3b292bf1cc1d5f2aba50bb750a75209d655b37/pandas_ta/overlap/kama.py#L34
[This doc](https://stockcharts.com/school/doku.php?id=chart_school:technical_indicators:kaufman_s_adaptive_moving_average) was referenced on a comment in the kama.py file and suggests that "the first KAMA is just a simple moving average".
Is there anyway we can add another arg for starting_kama or generate some sma based on the "slow" length?
| 0easy
|
Title: icdf of beta distribution is not implemented
Body: ```python
>>> import numpyro.distributions as dist
>>> d = dist.Beta(1, 5)
>>> d.icdf(0.975)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ayaka/venv/lib/python3.10/site-packages/numpyro/distributions/distribution.py", line 463, in icdf
raise NotImplementedError
NotImplementedError
```
NumPyro version: 0.9.1
| 0easy
|
Title: BUG: NEXRAD Level3 DPR product reading
Body: I am doing project on Quantitative Precipitation Estimation using WSR 88D Radar. I am comparing NEXRAD L3 Digital Precipitation Rate with actual Rain Rate from TRMM GV Rain Gauges.
Looks like the data being read in the below snippet does not scale the rain rate data correctly.
https://github.com/ARM-DOE/pyart/blob/a68bed26f6380eecbf1042c94bd4da0b60fb2da7/pyart/io/nexrad_level3.py#L297-L300
The way I am seeing the data, I need to multiply the whole data by 10. To convert it to the proper scale (i.e. inch/mm).
Below are some Z-RR plots at a constant height. Z is obtained from NEXRAD L2 data. Additionally I am also multiplying the Pyart read DPR data by 25.4 to convert it to mm/hr. But that is not expected by pyart as L3 DPR data is supposed to have default unit as inch/mm.
L3 DPR data after reading it through pyart and converting to mm/hr.

L3 DPR data after reading it through pyart, multiplying by 10 and converting to mm/hr.

I hope this explanation helped. This is not a significant issue but would still be good to avoid confusion while reading the DPR data.
Btw, thanks for creating this wonderful tool for reading L3 data. There are not a lot of tools that do that. Found it very helpful. :)
| 0easy
|
Title: Difficulty emulating vanilla anchor tags with dcc.Link
Body: The `dcc.Link` component renders as `<a>` tags without an `href` attribute, since the routing is all taken care of in the React side of things. This means that out of the box these links don't receive the default linkified browser styles of underline and pointer cursor on hover etc as well as the browser providing a preview of the link address in the bottom left corner. It would be nice to have this behaviour.
The styles can be emulated through custom CSS but not the href preview on hover. I've tried working around this by using an anchor tag within the `dcc.Link` like this:
```python
href = '/some-path'
dcc.Link(html.A(text, href=href), href=href)
```
All the styles and hover behaviour works as expected, but the problem is that when clicking on the link, in addition to Dash handling the `dcc.Link`'s callback, the nested `<a>` also gets a click event which then causes a whole page redirect, reloading the whole Dash app, which is obviously no good. I played around with using the CSS pointer-event attribute to disable the internal `<a>`, however this then disables all the hover events wanted in the first place.
Would it be feasible to add the `href` to the `<a>` produced by `dcc.Link`, modifying its `onclick` to prevent the page being redirected?
| 0easy
|
Title: WorkflowRunUpdateReplayWithResponse with a workflow run ID that doesn't exist returns a 200
Body: It should return an appropriate status code.
| 0easy
|
Title: JS - Right bar navigation
Body: The [docs](https://ploomber.readthedocs.io/en/latest/user-guide/deployment.html) have a right bar that shows the contents of the current article

The font-weight should change to highlight the current section but it's no longer working, I'm not sure why:
here's the JS code: https://github.com/ploomber/ploomber/blob/master/doc/_static/js/custom.js
check out doc/contributing.md for details
| 0easy
|
Title: Improve some code coverage
Body: This is an ongoing issue we need to work on or would gladly accept contributions for anyone looking to get some experience with testing open-source.
* We have some guaranteed randomness with the configuration we tests which causes the code coverage to fluctuate. This causes issue in that we have a simple change such as a docstring change #1349 causes our [code coverage test to fail](https://github.com/automl/auto-sklearn/pull/1349/checks?check_run_id=4582381900), due to a `-0.03%` change in coverage.
* We would still like some non-determinism in the configurations we try while testing, therefore we must *also* have deterministic tests that ensure all parts of our pipeline with all configurations are tested properly.
* In general, we are hovering around `88%` coverage, these fluctuations are relatively minor and in no way account for the other `12%`. I would roughly estimate that we could quite easily reach `5%` with ensuring more components of the system are tested. I estimate the remaining `5%` is testing the various branches of `if/else`, error validation and maybe `~1-2%` untestable code we do not need to be concerned with (abstract classes etc...)
Please check out our [contribution guide](https://github.com/automl/auto-sklearn/blob/master/CONTRIBUTING.md), `pytest-coverage` and our [code coverage statistics](https://app.codecov.io/gh/automl/auto-sklearn) reported from our automatic unittests if you'd like to get started!
| 0easy
|
Title: Sanitize label column when initializing a Datalab instance.
Body: Check for nan values in the label column.
This cannot be handled by the NullIssueManager, because it occurs in `Datalab(data=df_with_nan_value_in_label_column, label_name="label_column")`.
For now, we need better error reporting.
| 0easy
|
Title: Warn when `distinct()` is used outside of aggregated functions
Body: Discussed in #11518
The alternatives could be:
- at compile time: you could do it at compile time by passing a kw flag that "distinct" looks for , indicating the appropriate context. if flag not there, boom. would have to find a way to make it OK for str() compile -- https://github.com/sqlalchemy/sqlalchemy/discussions/11518#discussioncomment-9840468
- at coercion time: does "distinct()" only go inside of a SQL function ? That's all we'd have to look for. we can put "distinct()" into a special coercion category based on the roles, like FunctionDistinctRole -- https://github.com/sqlalchemy/sqlalchemy/discussions/11518#discussioncomment-9841617
the second option is likely better since it will give better feedback to the user (since it will happen at statement creation time, instead of when it will be compiled)
| 0easy
|
Title: Add CI for jupyter notebook example `workflow_by_code.ipynb`
Body: ## 🌟 Feature Description
<!-- A clear and concise description of the feature proposal -->
CI that it can't detect the errors in the report.
So I think it would be better to add such a check in our CI. (It may be some command like jupyter nbconvert workflow_by_code.ipynb)
Please refer to this comment.
https://github.com/microsoft/qlib/pull/1267#issuecomment-1230072848
## Motivation
1. Application scenario
2. Related works (Papers, Github repos etc.):
3. Any other relevant and important information:
<!-- Please describe why the feature is important. -->
## Alternatives
<!-- A short description of any alternative solutions or features you've considered. -->
## Additional Notes
<!-- Add any other context or screenshots about the feature request here. -->
| 0easy
|
Title: The flag allow_population_by_field_name is not recognized
Body: I have two models `User`, `Review` and their `ModelFactory`s.
```python
from pydantic import BaseModel, Field
from pydantic_factories import ModelFactory
class User(BaseModel):
login: str
class Review(BaseModel):
body: str
author: User = Field(alias="user")
class Config:
allow_population_by_field_name = True
class UserFactory(ModelFactory):
__model__ = User
class ReviewFactory(ModelFactory):
__model__ = Review
if __name__ == '__main__':
author: User = UserFactory.build(login="me")
review: Review = ReviewFactory.build(author=author)
assert id(author) != id(review.author)
assert review.author.login != author.login
review: Review = ReviewFactory.build(user=author)
assert id(author) != id(review.author) # 🙄 why?
assert review.author.login == author.login
```
*_note: all assertion are successful_
`Review` model has the `allow_population_by_field_name` flag set to `True` which means
`Review` model should be able to accept both `author` and `user` attributes to
populate the `User` model, however it's not recognized on building the instance and
new instance gets created.
I also noticed that new object was created on supplying a valid `User` instance to the `ReviewFactory`!!
**see the `why` line**
| 0easy
|
Title: Marketplace - agent page - please fix margins between section headers, dividers and content
Body: ### Describe your issue.
<img width="921" alt="Screenshot 2024-12-16 at 21 49 16" src="https://github.com/user-attachments/assets/594350cc-79f1-42ec-8d62-770c0ba79b8c" />
<img width="1425" alt="Screenshot 2024-12-16 at 21 50 59" src="https://github.com/user-attachments/assets/8b4faec1-9bac-4011-a0fd-9c7fae2e423d" />
| 0easy
|
Title: support for alternative notebook PDF converters (e.g. webpdf)
Body: (see #672 and #658 for context)
There are a few engines to convert `.ipynb` to `.pdf`, however, we only support the default one provided by nbconvert, which depends on pandoc and text. It has a few downsides such as not being able to render embedded charts (see #658), we should add support for other engines
| 0easy
|
Title: Text is layered on the send button (and settings) in the chat
Body: One user noticed this:


PC:

Mobile:

| 0easy
|
Title: TweetTokenizer fails to remove user handles in text.
Body: The below input should remove all user handles which start with "@".
input: @remy:This is waaaaayyyy too much for you!!!!!!@adam
output : [':', 'This', 'is', 'waaayyy', 'too', 'much', 'for', 'you', '!', '!', '!', '@adam']
The TweetTokenizer fail to remove the user handle of Adam.
I would like to open a pull request that solves the following issues:-
- Improve the regular expression pattern to detect in-text handles properly.
- Adjust the length of characters to be 15 instead of 20.
| 0easy
|
Title: Add dark mode on our documentation
Body: The idea is to follow the same analogous setup we have on `starlette` and `uvicorn`, and allow reading the documentation in dark mode.
| 0easy
|
Title: Website handle server errors more gracefully
Body: Back end:
- on or around 2023.6.25— Since we surpassed ~3000 concurrent requests 30B_7 has been down from user load. 30B_6 seemed to be working with page refresh.
Front end:
- 2023.6.27— the front end stopped showing new replies without page refresh.
- 2023.6.28— showing me logged in on front page, but logged out in Chat section.
- 2023.6.28— site frequently gone altogether & replaced with error message `Internal Server Error`
| 0easy
|
Title: Enhancement: Add SQLModelFactory
Body: ### Description
Adapting the [pets example from the documentation](https://polyfactory.litestar.dev/usage/configuration.html#defining-default-factories) to SQLModel, does not generate sub-factories as expected when using `Relationship`, despite explicitly calling `Use`. Foreign keys are auto-generated correctly.
Passing in a pre-built sub-model to the parent factory works as expected.
### URL to code causing the issue
_No response_
### MCVE
#### Working
```python
from sqlmodel import SQLModel, Field
from polyfactory import Use
from polyfactory.factories.pydantic_factory import ModelFactory
from typing import List, Optional
class Pet(SQLModel, table=True):
id: Optional[int] = Field(primary_key=True, default=None)
name: str = Field(index=True)
sound: str = Field(index=True)
class Person(SQLModel):
id: Optional[int] = Field(primary_key=True, default=None)
name: str = Field(index=True)
pets: List[Pet] = Field(index=True)
class PetFactory(ModelFactory[Pet]):
__model__ = Pet
__allow_none_optionals___ = False
name = Use(ModelFactory.__random__.choice, ["Ralph", "Roxy"])
class PersonFactory(ModelFactory[Person]):
__model__ = Person
__allow_none_optionals___ = False
pets = Use(PetFactory.batch, size=2)
if __name__ == '__main__':
f = PersonFactory()
print(f.build())
# => id=None name='amCvFfBbBknGOJkgMyjz' pets=[Pet(id=7021, name='Roxy', sound='QDzzuwnCzZlMTlibiesY'), Pet(id=1446, name='Ralph', sound='hmArwGgEkGqjJpuVOOBi')]
```
#### Not working
```python
from sqlmodel import SQLModel, Field, Relationship
from polyfactory import Use
from polyfactory.factories.pydantic_factory import ModelFactory
from typing import List, Optional
class Pet(SQLModel, table=True):
id: Optional[int] = Field(primary_key=True, default=None)
name: str = Field(index=True)
sound: str = Field(index=True)
person_id: int = Field(foreign_key='person.id', default=None)
person: 'Person' = Relationship(back_populates='pets')
class Person(SQLModel, table=True):
id: Optional[int] = Field(primary_key=True, default=None)
name: str = Field(index=True)
pets: List[Pet] = Relationship(back_populates='person')
class PetFactory(ModelFactory[Pet]):
__model__ = Pet
__allow_none_optionals___ = False
name = Use(ModelFactory.__random__.choice, ["Ralph", "Roxy"])
class PersonFactory(ModelFactory[Person]):
__model__ = Person
__allow_none_optionals___ = False
pets = Use(PetFactory().batch, size=2)
if __name__ == '__main__':
f = PersonFactory()
print(f.build())
# => id=None name='RbVNzbPaSyukYfQfOCZM'
p = PetFactory()
print('manual', f.build(pets=p.batch(size=2)))
# => manual id=912 name='nxthozUfRKEbzRbHOezx' pets=[Pet(id=None, name='Ralph', sound='VURZSWbctAUgQOrCNsHt', person_id=2655, person=Person(id=912, name='nxthozUfRKEbzRbHOezx', pets=[...])), Pet(id=None, name='Ralph', sound='iBvnxluOSPHyYHPMPTwj', person_id=4501, person=Person(id=912, name='nxthozUfRKEbzRbHOezx', pets=[...]))]
```
### Steps to reproduce
```bash
1. Create SQLModel models
2. See sub-factories working
3. Attach relationships
4. Sub-factories don't generate automatically
```
### Screenshots
_No response_
### Logs
_No response_
### Starlite Version
- polyfactory 1.0.0a0
- sqlmodel 0.0.8
### Platform
- [X] Linux
- [X] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
| 0easy
|
Title: www: remove HSTS header from port 80
Body:
| 0easy
|
Title: api: remove timezone support
Body: Server-side timezone awareness is unnecessary complexity. We should deal with timezone conversions at the presentation layer (client).
We're not using the functionality anyways (it's merely enabled so that one has to use Django's `now()` function instead of the standard Python `datetime.datetime.now()`).
| 0easy
|
Title: Changelog: Single file?
Body: I think it's far easier to comprehend across multiple versions when release notes are just text, in a single file - without extra distractions / spacing / etc. Is it possible to just to have a single changelog file?
Example: https://github.com/SeleniumHQ/selenium/blob/selenium-4.7.2-python/py/CHANGES
| 0easy
|
Title: Enhancement: Auto-register factories as pytest fixtures
Body: It would be super handy to have some method that would easily create a fixture out of a factory. For example:
```python
class SomeLongNamedModel(BaseModel):
id: UUID
@register_fixture # Or some better name?
class SomeLongNamedModelFactory(ModelFactory):
"""Factory to create SomeLongNameModel instances
Use this factory to generate SomeLongNameModels filled with random data
"""
__model__ = SomeLongNamedModel
```
And then
```bash
$ pytest --fixtures
# other output...
some_long_named_model_factory
Factory to create SomeLongNameModel instances
Use this factory to generate SomeLongNameModels filled with random data
```
This is following the model of `pytest-factoryboy` which automatically converts the PascalCase class names to be the snake_case equivalent for the fixtures.
| 0easy
|
Title: Retire prefetch_generator
Body: We're using this dependency in one spot, where it can be replaced with ~5 lines of native code.
Would be great to remove it
| 0easy
|
Title: Replace the obsolete JS media type
Body: [RFC-4329](https://www.rfc-editor.org/rfc/rfc4329) is obsolete.
According to [RFC-9239](https://www.rfc-editor.org/rfc/rfc9239),
- Changed the intended usage of the media type "text/javascript" from OBSOLETE to COMMON.
- Changed the intended usage for all other script media types to obsolete.
| 0easy
|
Title: `SklearnTransformerWrapper` fails when FunctionTransformer used with non-numerical columns
Body: The `SklearnTransformerWrapper` will throw an error if I try to use it for non-numerical columns, even though some scikit-learn transformers are able to handle non-numerical columns.
Consider the following example:
```python
import numpy as np, pandas as pd
from sklearn.preprocessing import FunctionTransformer
from feature_engine.wrappers import SklearnTransformerWrapper
df = pd.DataFrame({
"col1" : ["1", "2", "3"],
"col2" : ["a", "b", "c"]
})
pipeline = SklearnTransformerWrapper(
FunctionTransformer(lambda x: x.astype(np.float64)),
variables=["col1"]
)
pipeline.fit(df)
```
```
TypeError Traceback (most recent call last)
<ipython-input-1-88807bab80e9> in <module>
12 variables=["col1"]
13 )
---> 14 pipeline.fit(df)
~/anaconda3/envs/py3/lib/python3.9/site-packages/feature_engine/wrappers/wrappers.py in fit(self, X, y)
122
123 else:
--> 124 self.variables_ = _find_or_check_numerical_variables(X, self.variables)
125
126 self.transformer_.fit(X[self.variables_], y)
~/anaconda3/envs/py3/lib/python3.9/site-packages/feature_engine/variable_manipulation.py in _find_or_check_numerical_variables(X, variables)
75 # check that user entered variables are of type numerical
76 if any(X[variables].select_dtypes(exclude="number").columns):
---> 77 raise TypeError(
78 "Some of the variables are not numerical. Please cast them as "
79 "numerical before using this transformer"
TypeError: Some of the variables are not numerical. Please cast them as numerical before using this transformer
```
| 0easy
|
Title: Implement a node multiselect feature for the d3 web frontend
Body: **The problem:**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
Currently the d3 web frontend only offers a very simple search that highlights a given subset of nodes, based on a single search term. Sometimes it might be useful to only select/highlight a specific subset of nodes that a not based on simple string search criteria. This feature would increase usability, since it would facilitate more explorative approaches and visualization.
**A solution:**
A user should be able to put together a specific subset of highlighted nodes (optically with the same result as performing a simple node string search in the search box) by simply hovering over a given node, pressing a given key (e.g. space) and then adding/removing the hovered node to a current node highlight selection. The currently implemented search should be compatible with this multiselect feature, i.e. If I search for a given term, I still can add more nodes the the highlighted selection by simply hovering and selecting/deselecting them by pressing a given key.
All highlight logic currently holding for the search should be valid also the the hover/multiselect feature, e.g. if I highlight two connected nodes, the connecting edge should also be highlighted).
| 0easy
|
Title: Update "AWS Lambda Bolt Python Examples" page to include Lambda URL
Body: On 6th of April AWS added new feature - Lambda Function URLs: Built-in HTTPS Endpoints for Single-Function Microservices
It's cheaper, simpler and faster to setup, than API Gateway. If you don`t require the advanced functionality, such as request validation, throttling, custom authorizers, custom domain names, usage plans, or caching. So, my suggestion is to replace "Set up AWS API Gateway" part with steps to set up Lambda URL, or atleast mention it as an alternative.
### Category (place an `x` in each of the `[ ]`)
* [ ] **slack_bolt.App** and/or its core components
* [ ] **slack_bolt.async_app.AsyncApp** and/or its core components
* [ ] Adapters in **slack_bolt.adapter**
* [x] Others
| 0easy
|
Title: Add `[obsoletes]` to setup
Body: See https://github.com/googleapis/python-bigquery-sqlalchemy/blob/ac25c4c70767ca85ce5934136b4d074e8ae2ed89/setup.py#L99
We should add a line saying that this replaces `gsheetsdb` (https://pypi.org/project/gsheetsdb/).
| 0easy
|
Title: Enable to use custom logger in WebClient, WebhookClient (async/sync)
Body: As mentioned at https://github.com/slackapi/bolt-python/issues/219#issuecomment-765055772, there is no way to pass a custom `logging.Logger` instance to `WebClient` etc. This is not a specific need for the Bolt issue. We can add `logger: Optional[Logger] = None` to these classes' constructor to enable developers to use their own loggers. We can update the following classes for this enhancement.
* `slack_sdk.web.BaseWebClient`
* `slack_sdk.web.async_client.AsyncBaseWebClient`
* `slack_sdk.web.legacy_client.LegacyBaseWebClient`
* `slack_sdk.webhook.WebhookClient`
* `slack_sdk.webhook.async_client.AsyncWebhookClient `
### Category (place an `x` in each of the `[ ]`)
- [x] **slack_sdk.web.WebClient** (Web API client)
- [ ] **slack_sdk.webhook.WebhookClient** (Incoming Webhook, response_url sender)
- [ ] **slack_sdk.models** (UI component builders)
- [ ] **slack_sdk.oauth** (OAuth Flow Utilities)
- [ ] **slack_sdk.rtm.RTMClient** (RTM client)
- [ ] **slack_sdk.signature** (Request Signature Verifier)
### Requirements
Please read the [Contributing guidelines](https://github.com/slackapi/python-slack-sdk/blob/main/.github/contributing.md) and [Code of Conduct](https://slackhq.github.io/code-of-conduct) before creating this issue or pull request. By submitting, you are agreeing to those rules.
| 0easy
|
Title: FAQ item "How do I consume a query string that has a JSON value?" is outdated
Body: The default value of `falcon.RequestOptions.auto_parse_qs_csv` was changed to `False` in v2.0 and handled in https://github.com/falconry/falcon/issues/842 and https://github.com/falconry/falcon/pull/1318.
The FAQ item https://falcon.readthedocs.io/en/stable/user/faq.html#how-do-i-consume-a-query-string-that-has-a-json-value assumes the old default value and needs an update.
| 0easy
|
Title: [Feature request] Add apply_to_images to BaseCropAndPad
Body:
| 0easy
|
Title: `cirq.Simulator` final_state_vector is not normalized
Body: **Description of the issue**
The final state vector of `cirq.Simulator.simulate` may acccumulate enough numerical error that it may not have unit norm. similar to #5916
**How to reproduce the issue**
```py3
q0 = cirq.LineQubit(0)
circuit = cirq.Circuit(
cirq.S(q0),
cirq.H(q0),
cirq.S(q0),
cirq.Y(q0),
cirq.S(q0),
cirq.H(q0),
cirq.S(q0),
cirq.measure(q0),
)
state_vector_simulator = cirq.Simulator()
state_vector_simulator.simulate(circuit).final_state_vector
```
```
array([0.+0.j , 0.+0.99999994j], dtype=complex64)
```
**Cirq version**
`1.2.0`
| 0easy
|
Title: Create contributing.md
Body: Anthony gave a lot of guidelines on how to contribute on this PR: https://github.com/numerique-gouv/impress/pull/340
It's be great to formalize that into a CONTRIBUTING.md file at the root of the repo that we reference to people who start making prs.
| 0easy
|
Title: Quick Start Tutorial Needed
Body: Loving this project.
I feel like this project would benefit from a short quick start tutorial that demonstrate common methods such as:
**Create item**
```
mutation = Operation(schema.Mutation) # note 'schema.'
mutation.create_item(input=dict(id="23432")).__fields__()
```
**List items with filter**
```
op = Operation(schema.Query) # note 'schema.'
op.list_items(filter={"number_id": {'eq': 123456 }})
```
**Making HTTP Calls to AWS AppSync (Managed Graphql Service)**
```
query = Operation(schema.Query)
items = query.list_items()
query = bytes(query).decode("utf-8")
post_data = json.dumps({"query": query}).encode("utf-8")
headers = {}
headers["Accept"] = "application/json; charset=utf-8"
auth = AWS4Auth(
access_key_id,
secret_access_key,
region_name,
"appsync",
session_token=session_token,
)
response = requests.post(url, auth=auth, data=post_data, headers=headers)
```
I'll add more examples as I work them out =)
| 0easy
|
Title: Representations from representation_models are generated twice when nr_topics="auto".
Body: ### Discussed in https://github.com/MaartenGr/BERTopic/discussions/2142
<div type='discussions-op-text'>
<sup>Originally posted by **siddharthtumre** September 10, 2024</sup>
Hi @MaartenGr
While using nr_topics="auto", I can see that the representations from representation_models are calculated after reducing the number of topics. This increases the run time as a LLM is prompted twice i.e., before and after reducing topics.
I believe generating representations after reducing the topics should be sufficient.</div>
That's indeed what is happening currently. I believe it should be straightforward to implement that so this might be a good first issue for those wanting to help out.
For now, what you could also do is run the model first without any representation models and then use .update_topics without your selected representation model (e.g, LLM) to create the representations. Then the LLM would run only once and you get the same results.
| 0easy
|
Title: A Keyerror in pandasai code should be handled well
Body: ### System Info
pandasai - 1.3.2
### 🐛 Describe the bug
**Question asked - Plot a scatter plot to show the relation between hexometer and denominator**
The above question was asked in Pandasai to do testing. Please note that there is no column called 'hexometer'.
This is done for testing purpose. Hence it gave a keyerror in first run. Eventually, the code seems to correct and generates a new code.
However the column hexometer is changed to kpi_value as can be seen below.
**Can we maintain a threshold for similarity check in case of Keyerrors?**
Else this is producing irrelevant charts which is not correct.
You generated this python code:
# TODO import all the dependencies required
import pandas as pd
import matplotlib.pyplot as plt
def analyze_data(dfs: list[pd.DataFrame]) -> dict:
"""
Analyze the data
1. Prepare: Preprocessing and cleaning data if necessary
2. Process: Manipulating data for analysis (grouping, filtering, aggregating, etc.)
3. Analyze: Conducting the actual analysis (if the user asks to plot a chart save it to an image in temp_chart.png and do not show the chart.)
At the end, return a dictionary of:
- type (possible values "string", "number", "dataframe", "plot")
- value (can be a string, a dataframe or the path of the plot, NOT a dictionary)
Examples:
{ "type": "string", "value": "The highest salary is $9,000." }
or
{ "type": "number", "value": 125 }
or
{ "type": "dataframe", "value": pd.DataFrame({...}) }
or
{ "type": "plot", "value": "temp_chart.png" }
"""
# Prepare: Preprocessing and cleaning data if necessary
df = dfs[0].copy()
df['denominator'] = df['denominator'].str.replace(',', '').astype(float)
# Process: Manipulating data for analysis
x = df['hexometer']
y = df['denominator']
# Analyze: Conducting the actual analysis
plt.scatter(x, y)
plt.xlabel('Hexometer')
plt.ylabel('Denominator')
plt.title('Relation between Hexometer and Denominator')
plt.savefig('temp_chart.png')
plt.close()
return {"type": "plot", "value": "temp_chart.png"}
It fails with the following error:
Traceback (most recent call last):
File "C:\Users\sb3249832\Desktop\fapi\Lib\site-packages\pandas\core\indexes\base.py", line 3802, in get_loc
return self._engine.get_loc(casted_key)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "pandas\_libs\index.pyx", line 138, in pandas._libs.index.IndexEngine.get_loc
File "pandas\_libs\index.pyx", line 165, in pandas._libs.index.IndexEngine.get_loc
File "pandas\_libs\hashtable_class_helper.pxi", line 5745, in pandas._libs.hashtable.PyObjectHashTable.get_item
File "pandas\_libs\hashtable_class_helper.pxi", line 5753, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: 'hexometer'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\sb3249832\Desktop\fapi\Lib\site-packages\pandasai\smart_datalake\__init__.py", line 337, in chat
result = self._code_manager.execute_code(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\sb3249832\Desktop\fapi\Lib\site-packages\pandasai\helpers\code_manager.py", line 244, in execute_code
return analyze_data(self._get_originals(dfs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<string>", line 21, in analyze_data
File "C:\Users\sb3249832\Desktop\fapi\Lib\site-packages\pandas\core\frame.py", line 3807, in __getitem__
indexer = self.columns.get_loc(key)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\sb3249832\Desktop\fapi\Lib\site-packages\pandas\core\indexes\base.py", line 3804, in get_loc
raise KeyError(key) from err
KeyError: 'hexometer'
Correct the python code and return a new python code that fixes the above mentioned error. Do not generate the same code again.
INFO: 2023-11-02 12:42:24
Code running:
```
def analyze_data(dfs: list[pd.DataFrame]) ->dict:
"""
Analyze the data
1. Prepare: Preprocessing and cleaning data if necessary
2. Process: Manipulating data for analysis (grouping, filtering, aggregating, etc.)
3. Analyze: Conducting the actual analysis (if the user asks to plot a chart save it to an image in temp_chart.png and do not show the chart.)
At the end, return a dictionary of:
- type (possible values "string", "number", "dataframe", "plot")
- value (can be a string, a dataframe or the path of the plot, NOT a dictionary)
Examples:
{ "type": "string", "value": "The highest salary is $9,000." }
or
{ "type": "number", "value": 125 }
or
{ "type": "dataframe", "value": pd.DataFrame({...}) }
or
{ "type": "plot", "value": "temp_chart.png" }
"""
df = dfs[0].copy()
df['denominator'] = df['denominator'].str.replace(',', '').astype(float)
x = df['kpi_value']
y = df['denominator']
plt.scatter(x, y)
plt.xlabel('KPI Value')
plt.ylabel('Denominator')
plt.title('Relation between KPI Value and Denominator')
plt.savefig('temp_chart.png')
plt.close()
return {'type': 'plot', 'value': 'temp_chart.png'}
```
<string>:23: UserWarning: Starting a Matplotlib GUI outside of the main thread will likely fail.
INFO: 2023-11-02 12:42:25 Answer: {'type': 'plot', 'value': 'temp_chart.png'}
INFO: 2023-11-02 12:42:25 Executed in: 6.909811973571777s
C:\Users\sb3249832\Desktop\fapi\Lib\site-packages\pandasai\responses\response_parser.py:101: UserWarning: Starting a Matplotlib GUI outside of the main thread will likely fail.
plt.imshow(image)
C:\Users\sb3249832\Desktop\fapi\Lib\site-packages\pandasai\responses\response_parser.py:103: UserWarning: Starting a Matplotlib GUI outside of the main thread will likely fail.
plt.show(block=is_running_in_console())
INFO: 2023-11-02 12:42:27,947 :: 127.0.0.1:64331 - "POST /responses/answer_question HTTP/1.1" 200 OK
INFO: 2023-11-02 12:50:00 Running job "update_config_periodically (trigger: cron[minute='*/10'], next run at: 2023-11-02 12:50:00 IST)" (scheduled at 2023-11-02 12:50:00+05:30)
INFO: 2023-11-02 12:50:00 Job "update_config_periodically (trigger: cron[minute='*/10'], next run at: 2023-11-02 13:00:00 IST)" executed successfully
C:\Program Files\Python311\Lib\concurrent\futures\thread.py:85: RuntimeWarning: coroutine 'update_config_periodically' was neveas never awaited
del work_item
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
WARNING: 2023-11-02 13:00:01 Run time of job "update_config_periodically (trigger: cron[minute='*/10'], next run at: 2023-11-023-11-02 13:10:00 IST)" was missed by 0:00:01.117145
INFO: 2023-11-02 13:10:00 Running job "update_config_periodically (trigger: cron[minute='*/10'], next run at: 2023-11-02 131-02 13:20:00 IST)" (scheduled at 2023-11-02 13:10:00+05:30)
INFO: 2023-11-02 13:10:00 Job "update_config_periodically (trigger: cron[minute='*/10'], next run at: 2023-11-02 13:20:00 I20:00 IST)" executed successfully
| 0easy
|
Title: Use alternative mechanism(s) to upgrade shillelagh
Body: `shillelagh.functions.upgrade` uses `pip` to upgrade the module. This is a hidden dependency that is not automatically installed.
If using a different package manager such as `uv` I have to add `pip` as a requirement for my project, which doesn't seem right.
Either remove the upgrade function all together, or use a different mechanism to upgrade within the tool.
| 0easy
|
Title: Permissions should not be checked in serializers
Body: ## Bug Report
**Problematic behavior**
As discussed in PR https://github.com/numerique-gouv/impress/pull/329, some permissions are checked in serializers which may not be a best practise.
**Expected behavior/code**
Permissions should be checked in permissions.
Don't break the beauty of abilities based permission. This is very useful in the frontend because the frontend knows beforehand what the user can do. The fact that permissions are computed on the same object ensures security and predictability of permissions. It also ensures a very clean code so let's not compromise this with the refactoring discussed here.
| 0easy
|
Title: [Error Message] Improve error message in SentencepieceTokenizer when arguments are not expected.
Body: ## Description
While using tokenizers.create with the model and vocab file for a custom corpus, the code throws an error and is not able to generate the BERT vocab file
### Error Message
ValueError: Mismatch vocabulary! All special tokens specified must be control tokens in the sentencepiece vocabulary.
## To Reproduce
from gluonnlp.data import tokenizers
tokenizers.create('spm', model_path='lsw1/spm.model', vocab_path='lsw1/spm.vocab')
[spm.zip](https://github.com/dmlc/gluon-nlp/files/5632879/spm.zip)
| 0easy
|
Title: Force validate_args to be keyword arguments
Body: This will help some forum users avoid issues like using `HalfNormal(loc, scale)` for HalfNormal distribution. In such case, validate_args will take the value of `scale` (because HalfNormal does not have loc parameter) and raise some misleading errors.
| 0easy
|
Title: Update various regex escape sequences
Body: The latest versions of Python are more strict wrt. escape in regex.
For instance with 3.6.8, there are 10+ warnings like this one:
```
...
lib/python3.6/site-packages/nltk/featstruct.py:2092: DeprecationWarning: invalid escape sequence \d
RANGE_RE = re.compile('(-?\d+):(-?\d+)')
```
The regex(es) should be updated to silence these warnings.
| 0easy
|
Title: [Feature] support sgl-kernel cu128 build
Body: ### Checklist
- [ ] 1. If the issue you raised is not a feature but a question, please raise a discussion at https://github.com/sgl-project/sglang/discussions/new/choose Otherwise, it will be closed.
- [ ] 2. Please use English, otherwise it will be closed.
### Motivation
for blackwell
### Related resources
_No response_
| 0easy
|
Title: Ability to modify swagger strings
Body: The built-in openapi support is great! Kudos to that. However, it would be nice if there were ways to modify more swagger strings such as page title, `default`, `description` etc. Not a very important feature but would be nice to have to make swagger docs more customizable.
I am thinking passing common variables within `responder.API` along with already existing "title" and "version"?
| 0easy
|
Title: Discord User ID & DM Support
Body: The ability to DM the bot would be helpful in addition to just being able to message it on a server. Instead of a server ID, you could add a user ID. On that note, if you could add one user ID as having all features without needing roles that would simplify the process.
| 0easy
|
Title: Chromedriver link is out of date
Body: My tests were failing because I followed the link on the docs, which points to a pretty old version of the driver.
The latest version is here: http://chromedriver.storage.googleapis.com/index.html?path=2.9/
If you want I can fix it and submit a PR?
| 0easy
|
Title: Add the method to check equality in Block Kit model classes
Body: ### Reproducible in:
#### The Slack SDK version
All versions
#### Steps to reproduce:
```python
from slack_sdk.models.blocks import DividerBlock
DividerBlock() == DividerBlock()
```
It happens with any pair of equivalent blocks.
### Expected result:
True
### Actual result:
False
### Suggested solution
Implementing `__eq__` in JsonObject.
```python
class JsonObject(BaseObject, metaclass=ABCMeta):
...
def __eq__(self, other: Any) -> bool:
if not isinstance(other, JsonObject):
return NotImplemented
return self.to_dict() == other.to_dict()
```
This would allow testing user functions that accept and/or return Slack SDK models.
| 0easy
|
Title: Keeping binder-env synced when we make a new release
Body: Our binder examples use a docker image built from [this environment](https://github.com/ploomber/binder-env), however, whenever we release a new ploomber version, we want to re-built the environment, to always serve examples with the most recent version.
Currently, we're doing it manually but it'd be great to automate it. For example, [conda-forge](https://github.com/conda-forge/ploomber-feedstock/pull/13) has a bot that opens a PR whenever it detects a new Ploomber version.
Any ideas on how to do this is appreciated!
| 0easy
|
Title: Expand environment variables in argumentfile
Body: My request is to enable the expansion of environment variables inside of the argumentfile.
**Background**: when RF reads additional path-like arguments from an argumentfile, arguments like `--pythonpath` or `--output` are hardcoded. There is currently no way to make them dynamic.
Writing this
--output $TESTBASEDIR/somefolder/output.xml
inside of an argumentfile would be awesome.
Thanks!
| 0easy
|
Title: ENH: add dwithin predicate and associated distance to sindex query / spatial join
Body: PyGEOS and Shapely >= 2.0 support spatial index queries with `dwithin` predicate, but in order to use it we need to add support for the distance parameter to `sindex.query()` and `sjoin()`.
| 0easy
|
Title: "Guess" the test file from changed module
Body: Let's say you've changed `house/serializers.py`. Would be nice to run the tests of `house/test_serializers.py` or even the tests that were related.
To keep in mind:
- There is an option on pytest to specify [test paths](https://docs.pytest.org/en/latest/reference.html#confval-testpaths)
| 0easy
|
Title: `IMPORT_EXPORT_SKIP_ADMIN_LOG` is not tested
Body: **Describe the bug**
There is no integration test to check whether `IMPORT_EXPORT_SKIP_ADMIN_LOG` works if enabled.
There should be integration tests which ensure that admin log creation is skipped appropriately.
[This test](https://github.com/django-import-export/django-import-export/blob/289e43e1f09ad9cae8355d788fc66c99b8b89d60/tests/core/tests/admin_integration/test_import_functionality.py#L245) is the closest we have.
| 0easy
|
Title: one hot encoder has the option to automatically drop the second binary variable for binary categorical variables
Body: We need to add one parameter to the init method of the one hot encoder, called for example automate_drop_last_binary that when True, will automatically return 1 binary variable if the original variable was binary.
Details:
- automate_drop_last_binary should default to False not to break backwards compatibility
- automate_drop_last_binary would only work for binary variables
- automate_drop_last_binary would only work if drop_last=False
When automate_drop_last_binary=True, binary variables would result in the addition of just one dummy instead of 1. So for the variable colour, with categories black and white, instead of returning the binary colour_black and colour_white, which are redundant, it would only return colour_black
In addition, we should add an attribute in the fit method called for example binary_variables_ where the transformer returns a list with the names of the binary variables.
To finish of this PR, we need to add 1-2 tests to make sure that the behaviour is the expected
| 0easy
|
Title: Fix strict typecheck for cirq importers
Body: **Description of the issue**
Clients importing from cirq fail strict type checking as follows:
```
$ mypy --strict -c "from cirq import Circuit"
<string>:1: error: Module "cirq" does not explicitly export attribute "Circuit" [attr-defined]
```
This is because our typecheck setup in [mypy.ini](https://github.com/quantumlib/Cirq/blob/f56a799c4dff188df9cb91c2de524a7953938e48/dev_tools/conf/mypy.ini#L1-L6) does not enforce [no_implicit_reexport](https://mypy.readthedocs.io/en/stable/command_line.html#cmdoption-mypy-no-implicit-reexport).
**Solution**
1. add `no_implicit_reexport = true` to mypy.ini
2. update `__init__.py` files to reexport symbols, ie, replace `from foo import bar` with `from foo import bar as bar`
**Cirq version**
1.4.1 at f56a799c4dff188df9cb91c2de524a7953938e48
| 0easy
|
Title: Implement keyboard.send_keys_directx(...): use scan codes for DirectX games
Body: The potential solution is found on Reddit: https://www.reddit.com/r/learnpython/comments/7yquo6/moving_mouse_in_a_unity_window_with_python/
This is a DirectInput scan codes:
http://www.gamespp.com/directx/directInputKeyboardScanCodes.html
| 0easy
|
Title: Probability Calibration Curve
Body: When performing classification one often wants to predict not only the class label but also the associated probability to give a level of confidence in the prediction. The `sklearn.metrics.calibration_curve` method returns true and predicted probabilities that can be visualized across multiple models to make the best model selection based on reliability.
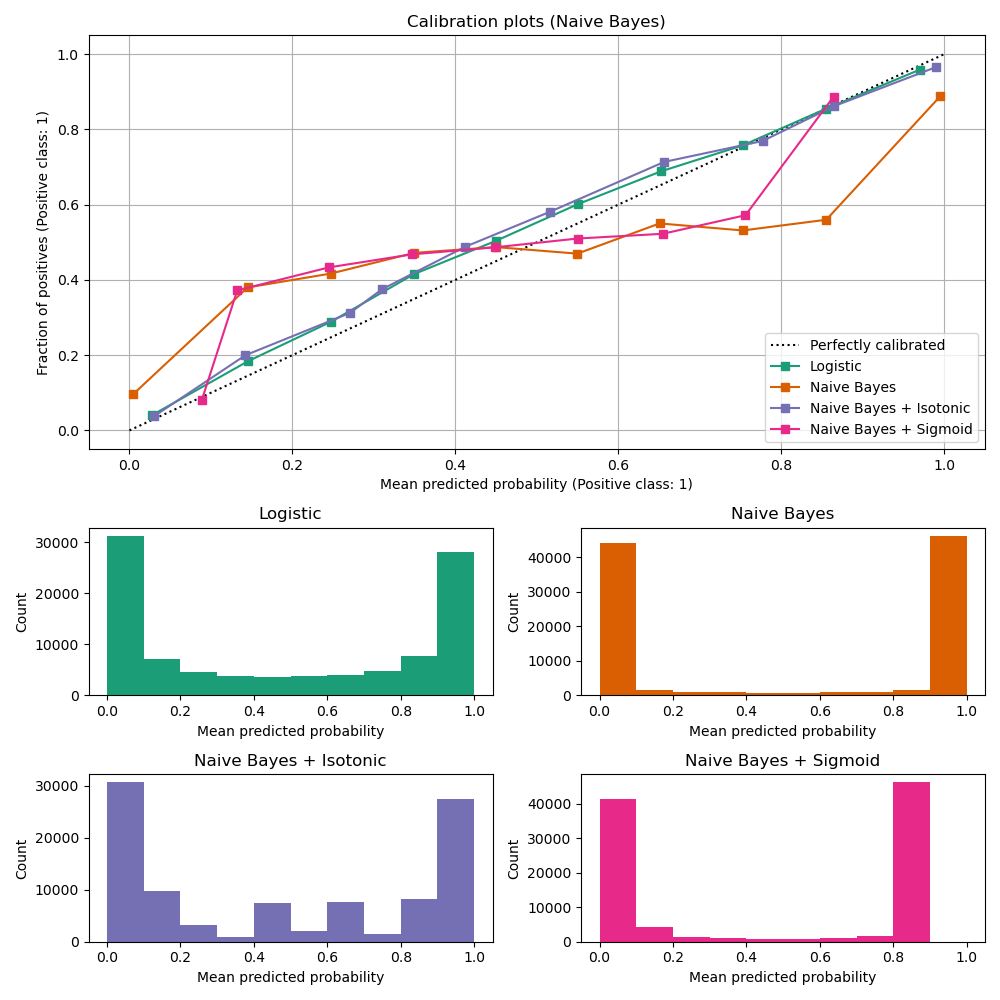
- [Scikit-Learn Example: Probability Calibration Curves](http://scikit-learn.org/stable/auto_examples/calibration/plot_calibration_curve.html#probability-calibration-curves)
Alexandru Niculescu-Mizil and Rich Caruana (2005) Predicting Good Probabilities With Supervised Learning, in Proceedings of the 22nd International Conference on Machine Learning (ICML). See section 4 (Qualitative Analysis of Predictions).
| 0easy
|
Title: Option to pass "smoothing_level" to ES model
Body: **Is your feature request related to a current problem? Please describe.**
Yes, we are using ES model to predict the value of the timeseries, now when the next point is being predicted, it is giving a very high weightage to the last point(s). So say if there was a drop in actual data for the last 2 points only, the predicted value goes down
**Describe proposed solution**
Exponential smoothing model provides the option to pass "smoothing_level" bounds which is not in Darts. If we get the option to pass this smoothing_level to ES via darts. It would probably resolve the issue. we can have a cap to restrict the weightage.
| 0easy
|
Title: Add detail to the openers_file list
Body: **Is your feature request related to a problem? Please describe.**
Currently if you have a lot of opener_files, 2 issues arise.
1. It's increasingly difficult for people to know which opener_file does what
2. If the opener has an author or a repository there is no good way to annotate credit for the contribution in the UI
**Describe the solution you'd like**
when opener_file is set and the file list of available .json and .txt files is shown, add banner-text or similar to the right of the file name with a users defined annotation (Purpose, Author, Source)
**Describe alternatives you've considered**
When selecting an opener_file present a pop-up modal which contains the above solution as a "Yes/No" pop up to ensure the user is selecting the opener they wish to.
**Additional context**
Given that many people are naming their prompts things like "dave" and "dan" and "aim" and on and on and on, while the simple naming convention currently being used for attribution works reasonable well if only running by default, this gets frustrating quickly when more and more prompts are added, and if they have more ambiguous names.
| 0easy
|
Title: Why is the version of FastAPI fixed in the install_requires?
Body: Currently fastapi/pydantic versions are fixed in `setup.py`:
```
requirements = [
'fastapi==0.52.0',
'pydantic==1.4',
'contextvars;python_version<"3.7"'
]
```
Is there a reason not to use `>=` instead?
If compatibility is a concern, it's possible to test against different versions of FastAPI on TravisCI.
| 0easy
|
Title: Reduce CI run time
Body: We have quite a few long running tests that take up a few seconds. Even if we only clean up the top 10 we should be able to shave at least a minute off the CI
| 0easy
|
Title: [DOC] The suggested aldryn-search package does not work anymore with django>=4
Body:
## Description
https://docs.django-cms.org/en/latest/topics/searchdocs.html
The above documentation page suggest `aldryn-search` package which does not work anymore with django >4.0 (bug with Signal using `providing_args`)
Since django-cms 3.11 is announced to be compatible with django 4 the documentation should no recommend to use this package.
* [ ] Yes, I want to help fix this issue and I will join #workgroup-documentation on [Slack](https://www.django-cms.org/slack) to confirm with the team that a PR is welcome.
* [x] No, I only want to report the issue.
| 0easy
|
Title: Ulimit low on MacOS, but incorrect way to update it
Body: ```
Open file descriptor limit (256) is low. File sync to remote clusters may be slow. Consider increasing the limit using `ulimit -n <number>` or modifying system limits.
```
But on MacOS 15 you can not do that anymore
```
$ ulimit -n 4096
$ launchctl limit maxfiles
maxfiles 256 unlimited
```
| 0easy
|
Title: Zip file - Windows paths
Body: <!--- Provide a general summary of the issue in the Title above -->
## Context
When deploying a Django app (over 50mb) from a Windows 10 machine the tarball retains the Windows directory separators '\\\\', when deployed to Lambda this causes the error "No module named 'django.core.wsgi': ModuleNotFoundError"
## Expected Behavior
1. tarball should keep Unix directory separators
## Actual Behavior
1. tarball retains Windows directory separators
## Possible Fix
In core.py, line 683 can be replaced with:
`tarinfo = tarfile.TarInfo(posixpath.join(root.replace(temp_project_path, '').lstrip(os.sep).replace('\\', '/'), filename))`
Which fixed it for me but is quite hacky and probably not that robust.
## Steps to Reproduce
<!--- Provide a link to a live example, or an unambiguous set of steps to -->
<!--- reproduce this bug include code to reproduce, if relevant -->
1.` zappa deploy dev ` on Windows 10 machine with app over 50mb
## Your Environment
* Zappa version used: 0.45.1
* Operating System and Python version: Windows 10, Python 3.6
* Your `zappa_settings.py`:
```
{
"dev": {
"aws_region": "us-east-2",
"django_settings": "<redacted>",
"profile_name": "default",
"project_name": "<redacted>",
"runtime": "python3.6",
"s3_bucket": "<redacted>",
"exclude": ["*.env", "*.jpg", "*.png", "media*", "archive*", "node_*", ],
"slim_handler": true,
"timeout_seconds": 300,
}
}
```
| 0easy
|
Title: Method to remove InlineKeyboardButton from markup
Body: As i understand, now InlineKeyboardMarkup is just a dict with lists, so method like pop() will be useful and make code cleaner, at least for newbies like me.
For now, to make dynamic inline keyboard with deleting buttons after user clicks on them i need to recreate entire markup from changed list, but it can be simplified by using InlineKeyboardMarkup.pop() or something like that.
| 0easy
|
Title: [DOCS] Add reference to pyod
Body: It's a related project with *many* outlier detection models. It would help folks if we add a reference in our outlier docs.
https://github.com/yzhao062/pyod
| 0easy
|
Title: Change config file default name
Body: Our default config path is `.scanapi.yaml`, which is not so explicit as it could.
https://github.com/scanapi/scanapi/blob/master/scanapi/settings.py#L5
Some other possibilities:
- scanapi.conf (like [redis](https://redis.io/topics/config), or [postgresql](https://www.postgresql.org/docs/9.3/config-setting.html))
- scanapi.init (like [pytest](https://docs.pytest.org/en/latest/customize.html))
- .scanapi (like [rspec](https://github.com/rspec/rspec/wiki#rspec))
My favorite one is the first, because in my opinion it is the most explicit.
Besides we also need to:
- Update documentation at [scanapi/website](https://github.com/scanapi/website/tree/master/_docs_v1)
- Update examples at [scanapi/examples](https://github.com/scanapi/examples)
| 0easy
|
Title: Speed up test by using shared global variable
Body: Use pytest fixture global variable to share dataframes to prevent having to load in the test dataset every time across the different tests. For example:

This might also help resolve #97 .
| 0easy
|
Title: [WeatherAPI] add support for forecasts
Body: WeatherAPI also has an API for forecasts, we could extend the current adapter or create a new one to support it.
| 0easy
|
Title: tox v4 gets stuck at the end waiting for a lock to be released
Body: ## Issue
In particular conditions, tox might get stuck forever (100% cpu) after it finished running.
Describe what's the expected behaviour and what you're observing.
## Environment
Provide at least:
- OS: any
- `pip list` of the host Python where `tox` is installed:
```console
```
## Output of running tox
Provide the output of `tox -rvv`:
```console
ssbarnea@m1: ~/c/tox-bug main
$ tox -vvv --exit-and-dump-after 40 -e py
ROOT: 140 D setup logging to NOTSET on pid 46700 [tox/report.py:221]
ROOT: 297 W will run in automatically provisioned tox, host /Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11 is missing [requires (has)]: tox>=4.2.6 (4.2.5) [tox/provision.py:124]
.pkg: 309 I find interpreter for spec PythonSpec(path=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11) [virtualenv/discovery/builtin.py:56]
.pkg: 309 I proposed PythonInfo(spec=CPython3.11.0.final.0-64, exe=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:63]
.pkg: 309 D accepted PythonInfo(spec=CPython3.11.0.final.0-64, exe=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:65]
.pkg: 311 D filesystem is not case-sensitive [virtualenv/info.py:24]
.pkg: 373 I find interpreter for spec PythonSpec(path=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11) [virtualenv/discovery/builtin.py:56]
.pkg: 373 I proposed PythonInfo(spec=CPython3.11.0.final.0-64, exe=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:63]
.pkg: 373 D accepted PythonInfo(spec=CPython3.11.0.final.0-64, exe=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:65]
.pkg: 375 I find interpreter for spec PythonSpec() [virtualenv/discovery/builtin.py:56]
.pkg: 375 I proposed PythonInfo(spec=CPython3.11.0.final.0-64, exe=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:63]
.pkg: 375 D accepted PythonInfo(spec=CPython3.11.0.final.0-64, exe=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:65]
ROOT: 376 I will run in a automatically provisioned python environment under /Users/ssbarnea/c/tox-bug/.tox/.tox/bin/python [tox/provision.py:145]
.pkg: 379 W _optional_hooks> python /Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta [tox/tox_env/api.py:427]
Backend: run command _optional_hooks with args {}
Backend: Wrote response {'return': {'get_requires_for_build_sdist': True, 'prepare_metadata_for_build_wheel': True, 'get_requires_for_build_wheel': True, 'build_editable': True, 'get_requires_for_build_editable': True, 'prepare_metadata_for_build_editable': True}} to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/pep517__optional_hooks-dh8_2_0b.json
.pkg: 570 I exit None (0.19 seconds) /Users/ssbarnea/c/tox-bug> python /Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta pid=46718 [tox/execute/api.py:275]
.pkg: 571 W get_requires_for_build_editable> python /Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta [tox/tox_env/api.py:427]
Backend: run command get_requires_for_build_editable with args {'config_settings': None}
/Users/ssbarnea/c/tox-bug/.tox/.pkg/lib/python3.11/site-packages/setuptools/config/expand.py:144: UserWarning: File '/Users/ssbarnea/c/tox-bug/README.md' cannot be found
warnings.warn(f"File {path!r} cannot be found")
running egg_info
writing src/ansible_compat.egg-info/PKG-INFO
writing dependency_links to src/ansible_compat.egg-info/dependency_links.txt
writing top-level names to src/ansible_compat.egg-info/top_level.txt
writing manifest file 'src/ansible_compat.egg-info/SOURCES.txt'
Backend: Wrote response {'return': ['wheel']} to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/pep517_get_requires_for_build_editable-xbuoiu_g.json
.pkg: 772 I exit None (0.20 seconds) /Users/ssbarnea/c/tox-bug> python /Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta pid=46718 [tox/execute/api.py:275]
.pkg: 773 W build_editable> python /Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta [tox/tox_env/api.py:427]
Backend: run command build_editable with args {'wheel_directory': '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist', 'config_settings': {'--build-option': []}, 'metadata_directory': '/Users/ssbarnea/c/tox-bug/.tox/.pkg/.meta'}
/Users/ssbarnea/c/tox-bug/.tox/.pkg/lib/python3.11/site-packages/setuptools/config/expand.py:144: UserWarning: File '/Users/ssbarnea/c/tox-bug/README.md' cannot be found
warnings.warn(f"File {path!r} cannot be found")
running editable_wheel
creating /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat.egg-info
writing /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat.egg-info/PKG-INFO
writing dependency_links to /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat.egg-info/dependency_links.txt
writing top-level names to /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat.egg-info/top_level.txt
writing manifest file '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat.egg-info/SOURCES.txt'
writing manifest file '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat.egg-info/SOURCES.txt'
creating '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat-0.1.dev1.dist-info'
creating /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat-0.1.dev1.dist-info/WHEEL
running build_py
running egg_info
creating /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmplg3vacmn.build-temp/ansible_compat.egg-info
writing /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmplg3vacmn.build-temp/ansible_compat.egg-info/PKG-INFO
writing dependency_links to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmplg3vacmn.build-temp/ansible_compat.egg-info/dependency_links.txt
writing top-level names to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmplg3vacmn.build-temp/ansible_compat.egg-info/top_level.txt
writing manifest file '/var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmplg3vacmn.build-temp/ansible_compat.egg-info/SOURCES.txt'
writing manifest file '/var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmplg3vacmn.build-temp/ansible_compat.egg-info/SOURCES.txt'
Editable install will be performed using .pth file to extend `sys.path` with:
['src']
Options like `package-data`, `include/exclude-package-data` or
`packages.find.exclude/include` may have no effect.
adding '__editable__.ansible_compat-0.1.dev1.pth'
creating '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-wfme8ksy/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl' and adding '/var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmp_6d_ux_iansible_compat-0.1.dev1-0.editable-py3-none-any.whl' to it
adding 'ansible_compat-0.1.dev1.dist-info/METADATA'
adding 'ansible_compat-0.1.dev1.dist-info/WHEEL'
adding 'ansible_compat-0.1.dev1.dist-info/top_level.txt'
adding 'ansible_compat-0.1.dev1.dist-info/RECORD'
Backend: Wrote response {'return': 'ansible_compat-0.1.dev1-0.editable-py3-none-any.whl'} to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/pep517_build_editable-owjdt97d.json
.pkg: 907 I exit None (0.13 seconds) /Users/ssbarnea/c/tox-bug> python /Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta pid=46718 [tox/execute/api.py:275]
.pkg: 908 D package .tmp/package/21/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl links to .pkg/dist/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl (/Users/ssbarnea/c/tox-bug/.tox) [tox/util/file_view.py:36]
ROOT: 908 W install_package> python -I -m pip install --force-reinstall --no-deps /Users/ssbarnea/c/tox-bug/.tox/.tmp/package/21/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl [tox/tox_env/api.py:427]
Processing ./.tox/.tmp/package/21/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl
Installing collected packages: ansible-compat
Attempting uninstall: ansible-compat
Found existing installation: ansible-compat 0.1.dev1
Uninstalling ansible-compat-0.1.dev1:
Successfully uninstalled ansible-compat-0.1.dev1
Successfully installed ansible-compat-0.1.dev1
ROOT: 1400 I exit 0 (0.49 seconds) /Users/ssbarnea/c/tox-bug> python -I -m pip install --force-reinstall --no-deps /Users/ssbarnea/c/tox-bug/.tox/.tmp/package/21/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl pid=46748 [tox/execute/api.py:275]
ROOT: 1400 W provision> .tox/.tox/bin/python -m tox -vvv --exit-and-dump-after 40 -e py [tox/tox_env/api.py:427]
ROOT: 77 D setup logging to NOTSET on pid 46755 [tox/report.py:221]
.pkg: 112 I find interpreter for spec PythonSpec() [virtualenv/discovery/builtin.py:56]
.pkg: 114 D got python info of /Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11 from /Users/ssbarnea/Library/Application Support/virtualenv/py_info/1/7c440f9733fdf26ad06b36085586625aa56ad3867d4add5eecd4dc174170d65a.json [virtualenv/app_data/via_disk_folder.py:129]
.pkg: 114 I proposed PythonInfo(spec=CPython3.11.0.final.0-64, system=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, exe=/Users/ssbarnea/c/tox-bug/.tox/.tox/bin/python, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:63]
.pkg: 114 D accepted PythonInfo(spec=CPython3.11.0.final.0-64, system=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, exe=/Users/ssbarnea/c/tox-bug/.tox/.tox/bin/python, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:65]
.pkg: 115 D filesystem is not case-sensitive [virtualenv/info.py:24]
.pkg: 132 I find interpreter for spec PythonSpec(path=/Users/ssbarnea/c/tox-bug/.tox/.tox/bin/python) [virtualenv/discovery/builtin.py:56]
.pkg: 132 I proposed PythonInfo(spec=CPython3.11.0.final.0-64, system=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, exe=/Users/ssbarnea/c/tox-bug/.tox/.tox/bin/python, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:63]
.pkg: 132 D accepted PythonInfo(spec=CPython3.11.0.final.0-64, system=/Users/ssbarnea/.pyenv/versions/3.11-dev/bin/python3.11, exe=/Users/ssbarnea/c/tox-bug/.tox/.tox/bin/python, platform=darwin, version='3.11.0+ (heads/3.11:4cd5ea62ac, Oct 25 2022, 18:19:49) [Clang 14.0.0 (clang-1400.0.29.102)]', encoding_fs_io=utf-8-utf-8) [virtualenv/discovery/builtin.py:65]
.pkg: 134 W _optional_hooks> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta [tox/tox_env/api.py:427]
Backend: run command _optional_hooks with args {}
Backend: Wrote response {'return': {'get_requires_for_build_sdist': True, 'prepare_metadata_for_build_wheel': True, 'get_requires_for_build_wheel': True, 'build_editable': True, 'get_requires_for_build_editable': True, 'prepare_metadata_for_build_editable': True}} to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/pep517__optional_hooks-6hnvgpmw.json
.pkg: 237 I exit None (0.10 seconds) /Users/ssbarnea/c/tox-bug> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta pid=46757 [tox/execute/api.py:275]
.pkg: 237 W get_requires_for_build_editable> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta [tox/tox_env/api.py:427]
Backend: run command get_requires_for_build_editable with args {'config_settings': None}
/Users/ssbarnea/c/tox-bug/.tox/.pkg/lib/python3.11/site-packages/setuptools/config/expand.py:144: UserWarning: File '/Users/ssbarnea/c/tox-bug/README.md' cannot be found
warnings.warn(f"File {path!r} cannot be found")
running egg_info
writing src/ansible_compat.egg-info/PKG-INFO
writing dependency_links to src/ansible_compat.egg-info/dependency_links.txt
writing top-level names to src/ansible_compat.egg-info/top_level.txt
writing manifest file 'src/ansible_compat.egg-info/SOURCES.txt'
Backend: Wrote response {'return': ['wheel']} to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/pep517_get_requires_for_build_editable-4uddn4ko.json
.pkg: 392 I exit None (0.15 seconds) /Users/ssbarnea/c/tox-bug> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta pid=46757 [tox/execute/api.py:275]
.pkg: 392 W build_editable> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta [tox/tox_env/api.py:427]
Backend: run command build_editable with args {'wheel_directory': '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist', 'config_settings': {'--build-option': []}, 'metadata_directory': '/Users/ssbarnea/c/tox-bug/.tox/.pkg/.meta'}
/Users/ssbarnea/c/tox-bug/.tox/.pkg/lib/python3.11/site-packages/setuptools/config/expand.py:144: UserWarning: File '/Users/ssbarnea/c/tox-bug/README.md' cannot be found
warnings.warn(f"File {path!r} cannot be found")
running editable_wheel
creating /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat.egg-info
writing /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat.egg-info/PKG-INFO
writing dependency_links to /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat.egg-info/dependency_links.txt
writing top-level names to /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat.egg-info/top_level.txt
writing manifest file '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat.egg-info/SOURCES.txt'
writing manifest file '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat.egg-info/SOURCES.txt'
creating '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat-0.1.dev1.dist-info'
creating /Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat-0.1.dev1.dist-info/WHEEL
running build_py
running egg_info
creating /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmpat9h5lcf.build-temp/ansible_compat.egg-info
writing /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmpat9h5lcf.build-temp/ansible_compat.egg-info/PKG-INFO
writing dependency_links to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmpat9h5lcf.build-temp/ansible_compat.egg-info/dependency_links.txt
writing top-level names to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmpat9h5lcf.build-temp/ansible_compat.egg-info/top_level.txt
writing manifest file '/var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmpat9h5lcf.build-temp/ansible_compat.egg-info/SOURCES.txt'
writing manifest file '/var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmpat9h5lcf.build-temp/ansible_compat.egg-info/SOURCES.txt'
Editable install will be performed using .pth file to extend `sys.path` with:
['src']
Options like `package-data`, `include/exclude-package-data` or
`packages.find.exclude/include` may have no effect.
adding '__editable__.ansible_compat-0.1.dev1.pth'
creating '/Users/ssbarnea/c/tox-bug/.tox/.pkg/dist/.tmp-ema2szox/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl' and adding '/var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/tmp41rddnayansible_compat-0.1.dev1-0.editable-py3-none-any.whl' to it
adding 'ansible_compat-0.1.dev1.dist-info/METADATA'
adding 'ansible_compat-0.1.dev1.dist-info/WHEEL'
adding 'ansible_compat-0.1.dev1.dist-info/top_level.txt'
adding 'ansible_compat-0.1.dev1.dist-info/RECORD'
Backend: Wrote response {'return': 'ansible_compat-0.1.dev1-0.editable-py3-none-any.whl'} to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/pep517_build_editable-tho58wbq.json
.pkg: 520 I exit None (0.13 seconds) /Users/ssbarnea/c/tox-bug> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta pid=46757 [tox/execute/api.py:275]
.pkg: 520 D package .tmp/package/22/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl links to .pkg/dist/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl (/Users/ssbarnea/c/tox-bug/.tox) [tox/util/file_view.py:36]
py: 521 W install_package> python -I -m pip install --force-reinstall --no-deps /Users/ssbarnea/c/tox-bug/.tox/.tmp/package/22/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl [tox/tox_env/api.py:427]
Processing ./.tox/.tmp/package/22/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl
Installing collected packages: ansible-compat
Attempting uninstall: ansible-compat
Found existing installation: ansible-compat 0.1.dev1
Uninstalling ansible-compat-0.1.dev1:
Successfully uninstalled ansible-compat-0.1.dev1
Successfully installed ansible-compat-0.1.dev1
py: 784 I exit 0 (0.26 seconds) /Users/ssbarnea/c/tox-bug> python -I -m pip install --force-reinstall --no-deps /Users/ssbarnea/c/tox-bug/.tox/.tmp/package/22/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl pid=46788 [tox/execute/api.py:275]
py: 784 W commands[0]> echo 123 [tox/tox_env/api.py:427]
123
py: 808 I exit 0 (0.02 seconds) /Users/ssbarnea/c/tox-bug> echo 123 pid=46790 [tox/execute/api.py:275]
.pkg: 809 W _exit> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta [tox/tox_env/api.py:427]
Backend: run command _exit with args {}
Backend: Wrote response {'return': 0} to /var/folders/32/1xrphgzd4xv777syxjtkpdw80000gn/T/pep517__exit-wsk25xml.json
.pkg: 810 I exit None (0.00 seconds) /Users/ssbarnea/c/tox-bug> python /Users/ssbarnea/c/tox-bug/.tox/.tox/lib/python3.11/site-packages/pyproject_api/_backend.py True setuptools.build_meta pid=46757 [tox/execute/api.py:275]
.pkg: 841 D delete package /Users/ssbarnea/c/tox-bug/.tox/.tmp/package/22/ansible_compat-0.1.dev1-0.editable-py3-none-any.whl [tox/tox_env/python/virtual_env/package/pyproject.py:171]
py: OK (0.71=setup[0.68]+cmd[0.02] seconds)
congratulations :) (0.76 seconds)
Timeout (0:00:40)!
Thread 0x000000017d037000 (most recent call first):
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/tox/execute/local_sub_process/read_via_thread_unix.py", line 35 in _read_available
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/tox/execute/local_sub_process/read_via_thread_unix.py", line 24 in _read_stream
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/threading.py", line 975 in run
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/threading.py", line 1038 in _bootstrap_inner
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/threading.py", line 995 in _bootstrap
Thread 0x000000017c02b000 (most recent call first):
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/tox/execute/local_sub_process/read_via_thread_unix.py", line 35 in _read_available
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/site-packages/tox/execute/local_sub_process/read_via_thread_unix.py", line 24 in _read_stream
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/threading.py", line 975 in run
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/threading.py", line 1038 in _bootstrap_inner
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/threading.py", line 995 in _bootstrap
Thread 0x00000001e3983a80 (most recent call first):
File "/Users/ssbarnea/.pyenv/versions/3.11-dev/lib/python3.11/threading.py", line 1583 in _shutdown
FAIL: 1
```
## Minimal example
At https://github.com/ssbarnea/tox-bug there is a full repository created for reproducing the bug.
I will explain the conditions I already identified as required in order to reproduce the bug:
- tox needs to be convinced to reprovision itself (it does not happen otherwise)
- `usedevelop = true` must be present
I also mention that the `--exit-and-dump-after` trick does force tox to exit but does not close the running thread, which will be stuck until user kills the process. Bug reproduced on both macos/linux.
| 0easy
|
Title: Regression for usage of pip options
Body: ## Issue
Since version 4.0 tox fails when encountering pip options as part of the dependencies.
The following example works fine with tox <4.0, but doesn't work with tox >=4.0 anymore.
```
$ cat requirements.txt
--no-binary pydantic
$ cat tox.ini
[tox]
envlist = py3
[testenv]
deps = -r requirements.txt
allowlist_externals = echo
commands = echo "hello world"
$ tox --version
4.2.1 from /home/user/.local/lib/python3.10/site-packages/tox/__init__.py
$ tox -r
py3: remove tox env folder /dir/.tox/py3
py3: failed with argument --no-binary: invalid choice: 'pydantic' (choose from ':all:', ':none:') for tox env py within deps
py3: FAIL code 1 (0.22 seconds)
evaluation failed :( (0.33 seconds)
```
| 0easy
|
Title: `client` parameter in `Consumer` constructor doesn't work as documented
Body: ## Precondition
Consider the following consumer:
```python
class GitHub(uplink.Consumer):
@uplink.get("/users/{username}")
def get_user(self, username):
"""Get a single user."""
```
## Steps to recreate
Instantiate this consumer with a specific client instance:
```python
GitHub(base_url="https://api.github.com/", client=uplink.RequestsClient())
```
## Expected
Consumer instance builds properly and uses the given client instance.
**Note: when the `client` parameter is given a `uplink.clients.interfaces.HttpClientAdapter` subclass, it should instantiate a client instance; otherwise the provided value should be used as given.**
## Actual
Exception raised on instantiation:
```python
Traceback (most recent call last):
File "/Users/prkumar/Library/Preferences/PyCharm2017.2/scratches/scratch_1.py", line 11, in <module>
GitHub(base_url="https://api.github.com/", client=uplink.RequestsClient())
File "/Users/prkumar/Developer/uplink/uplink/builder.py", line 170, in __init__
self._build(builder)
File "/Users/prkumar/Developer/uplink/uplink/builder.py", line 175, in _build
caller = call_builder.build(self, definition_builder)
File "/Users/prkumar/Developer/uplink/uplink/builder.py", line 149, in build
RequestPreparer(self, definition),
File "/Users/prkumar/Developer/uplink/uplink/builder.py", line 42, in __init__
if issubclass(self._client, clients.interfaces.HttpClientAdapter):
TypeError: issubclass() arg 1 must be a class
```
| 0easy
|
Title: handling extra keyword arguments
Body: If the user passes in non-hypertools keyword arguments, we should pass them to our plotting backend. This is somewhat non-trivial in that we need to handle the case where the user wants different values for different elements of the to-be-plotted data list. I think what should happen is:
- if data is *not* a list, just pass along additional keywords without modifying them
- if data *is* a list:
- make sure that every keyword argument's value is a list of the same length. (if not, truncate or copy values to make the lengths match; if the user passes in a too-short list, throw an error)
- for each to-be-plotted thing, pass (to matplotlib or other backend plotting machinery) a dictionary of keyword arguments that's constructed by taking the keys from the original keyword argument dictionary and setting the values of those keys to the corresponding elements of the keyword argument lists.
| 0easy
|
Title: Add a parameter in the API to translate html
Body:
Maybe you could add a parameter (format: text or html) in the API to allow translating html?
Thanks to [https://github.com/argosopentech/translate-html](argosopentech/translate-html)
I can do a pull request if interested.
| 0easy
|
Title: [DOC] Add Raises to docstrings for methods that can raise exceptions
Body: ### Describe the issue linked to the documentation
We mostly do not document the errors raised and the reasons for them. It would be good to do so. This should be done incrementally and is a good first issue.
1. Pick and estimator and try break it/see what exceptions are present
2. Look at the docstrings (may be base class for some items i.e. input datatype) and see if its documented
3. If not add under "Raises"
This should only be errors and exceptions we intentionally raise, known edge cases or which provide generally useful information to the user, i.e. for invalid parameter values. We do not need to document every item which can possibly raise an exception.
Raises
-------
we may need to discuss where it should be documented and the effect this has on the documentation @MatthewMiddlehurst. I'll look for a good example
### Suggest a potential alternative/fix
_No response_
| 0easy
|
Title: deSEC DNS Authenticator plugin for Certbot (Let's Encrypt)
Body: Let's write a plugin like this one: https://github.com/certbot/certbot/tree/master/certbot-dns-cloudflare
| 0easy
|
Title: Incorrect Description of Changing cell type
Body: [Changing Cell's Type](https://euporie.readthedocs.io/en/latest/apps/notebook.html#changing-a-cell-s-type) has incorrect description .
It is explaining `how to close notebook` instead of `how to change cell's type`.
Corresponding [file](https://github.com/joouha/euporie/blob/main/docs/apps/notebook.rst#changing-a-cells-type) in repo.
Maybe we can add good first issue
| 0easy
|
Title: consider having .train() and .customized_train()
Body: .train() will just call .customized_train() with a series of defaults in place.
it'll have a much simpler interface, which would be nice.
| 0easy
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.