
text
stringlengths 20
57.3k
| labels
class label 4
classes |
|---|---|
Title: Deprecate and remove `processor_ids` argument by v1.4
Body: The run methods in `Engine`, `EngineProgram` and `EngineClient` now include a parameter called `processor_id`. This parameter can be used to specify a specific processor for the run, and **will substitute the deprecated parameter `processor_ids`** , because allowing multiple candidate processors was not useful in practice.
| 0easy
|
Title: Config.load_env type should explicitly allow strings
Body: https://github.com/sanic-org/sanic/blob/main/sanic/config.py#L44
```python
if load_env:
prefix = SANIC_PREFIX if load_env is True else load_env
```
`load_env` defaults to `True`, but you can pass a string if you want a different prefix. We should make this type consistent by either explicitly accepting both a `bool` and ` `str`, or (perhaps a more elegant solution) is just to ONLY accept a string and default it to `SANIC_PREFIX` since this is what it is trying to do.
| 0easy
|
Title: Add option for `Access-Control-Allow-Private-Network` to CORSMiddleware
Body: Add option to enable [`Access-Control-Allow-Private-Network`](https://wicg.github.io/private-network-access/#http-headerdef-access-control-request-private-network) to CORSMiddleware.
We probably don't need to inject it unconditionally, but only in response to the `Access-Control-Request-Private-Network` request header (when set to to `true`).
The option **must be disabled** by default.
| 0easy
|
Title: Using Path2D for stroke
Body: ### Discussed in https://github.com/martinRenou/ipycanvas/discussions/333
<div type='discussions-op-text'>
<sup>Originally posted by **BarbaraWebb** May 24, 2023</sup>
It seems like you can use Path2D as a shortcut to create paths only if you want to then draw it as a filled path, but not as a stroke? canvas.fill will take a path as an argument but canvas.stroke will not. If I want to draw a complex shape that shows only as a line drawing (and repeat that shape several times in different places) what is the best way to do it? </div>
| 0easy
|
Title: Show alias function description using superhelp
Body: Enrich [superhelp](https://xon.sh/tutorial.html#help-superhelp-with) by showing the alias function description.
```xsh
@aliases.register("hello")
def _alias_hello():
"""Show world."""
print('world')
hello
# world
# Now:
hello?
# Unknown locale, assuming C
# No manual entry for hello
# Proposed:
hello?
# Alias description:
# Show world.
```
This is simple to implement by getting the docstring from aliases and name:
```python
aliases['hello'].__doc__
# Show world.
```
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0easy
|
Title: "Too many open files"
Body: ## Issue
Running tox in https://github.com/nedbat/django_coverage_plugin results in "Too many open files" errors from inside tox, virtualenv, etc.
## Environment
Provide at least:
- OS: Mac OS 15.2
<details open>
<summary>Output of <code>pip list</code> of the host Python, where <code>tox</code> is installed</summary>
```console
% pip list
Package Version
------------------ -----------
attrs 25.1.0
backports.tarfile 1.2.0
build 1.2.2.post1
cachetools 5.5.1
certifi 2024.12.14
chardet 5.2.0
charset-normalizer 3.4.1
click 8.1.8
click-log 0.4.0
colorama 0.4.6
distlib 0.3.9
docutils 0.21.2
filelock 3.17.0
id 1.5.0
idna 3.10
importlib_metadata 8.6.1
jaraco.classes 3.4.0
jaraco.context 6.0.1
jaraco.functools 4.1.0
Jinja2 3.1.5
keyring 25.6.0
markdown-it-py 3.0.0
MarkupSafe 3.0.2
mdurl 0.1.2
more-itertools 10.6.0
nh3 0.2.20
packaging 24.2
pip 24.2
platformdirs 4.3.6
pluggy 1.5.0
Pygments 2.19.1
pyproject-api 1.9.0
pyproject_hooks 1.2.0
readme_renderer 44.0
requests 2.32.3
requests-toolbelt 1.0.0
rfc3986 2.0.0
rich 13.9.4
scriv 1.5.1
setuptools 74.0.0
tomli 2.2.1
tox 4.24.1
twine 6.1.0
typing_extensions 4.12.2
urllib3 2.3.0
virtualenv 20.29.1
wheel 0.44.0
zipp 3.21.0
```
</details>
## Output of running tox
<details open>
<summary>Output of <code>tox -rvv</code></summary>
It's 5200 lines, I put it in a gist: https://gist.github.com/nedbat/9f54a1756f4d3d3f34d00cf9cceb8440
</details>
## Minimal example
<!-- If possible, provide a minimal reproducer for the issue. -->
```console
% git clone https://github.com/nedbat/django_coverage_plugin.git
% cd django_coverage_plugin
% git checkout a1f1d93bccbd495e0d019052a6e411f88f5cbc6f
% pip install -r requirements.txt
% tox
```
Sorry I don't have a smaller example.
| 0easy
|
Title: Dead Link on "Using the Web API" page
Body: Hello!
I want reading the documentation on using the Web API from the Bolt Python library and found there is a dead link on the page.
The source of the link is https://slack.dev/bolt-python/concepts/web-api/ and the dead link is in the first sentence for the link for "WebClient": https://slack.dev/python-slack-sdk/basic_usage.html
It's not obvious to me what the correct link is, so I am sharing here in hopes the team knows!
Thanks in advance!
### The page URLs
* https://slack.dev/bolt-python/concepts/web-api/
## Requirements
Please read the [Contributing guidelines](https://github.com/slackapi/bolt-python/blob/main/.github/contributing.md) and [Code of Conduct](https://slackhq.github.io/code-of-conduct) before creating this issue or pull request. By submitting, you are agreeing to those rules.
| 0easy
|
Title: How to use federation?
Body: An example would've been nice showing how to use federation with Django models using this package.
| 0easy
|
Title: [Feature request] Add apply_to_images to Crop
Body:
| 0easy
|
Title: Exchange arrow positions are off in California
Body: ## Description
Exchange arrows in California are positioned in weird places:

**How to solve this:**
Set the correct location of each arrow by updating the `lonlat` attribute in the corresponding `config/exchanges/X.yaml` file
| 0easy
|
Title: [FEATURE] Feature capping
Body: Use case:
In ML some time your features have extreme large values or even infinite value (np.inf), we want to cap those values with a feature transformer.
Parameters:
- feature to cap (and/or feature to no cap?)
- min value
- max value
| 0easy
|
Title: How can I run the test files?
Body: Should I run the python file? It would be nice to have this in the documentation.
| 0easy
|
Title: [UX] An annoying message in the provision log
Body: <!-- Describe the bug report / feature request here -->
The message "**No such file or directory**" looks annoying, though it looks not affect the overrall process and function.
```
Executing transaction: ...working... done
#
# To activate this environment, use
#
# $ conda activate skypilot-runtime
#
# To deactivate an active environment, use
#
# $ conda deactivate
```
PATH=/home/opc/anaconda3/envs/skypilot-runtime/bin:/home/opc/anaconda3/condabin:/home/opc/.local/bin:/home/opc/bin:/usr/share/Modules/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin
Requirement already satisfied: setuptools<70 in ./skypilot-runtime/lib/python3.10/site-packages (65.5.0)
/usr/bin/which: no ray in (/home/opc/anaconda3/envs/skypilot-runtime/bin:/home/opc/anaconda3/condabin:/home/opc/.local/bin:/home/opc/bin:/usr/share/Modules/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin)
**/home/opc/skypilot-runtime/bin/python: can't open file '/home/opc/status': [Errno 2] No such file or directory**
Collecting ray[default]==2.9.3
Downloading ray-2.9.3-cp310-cp310-manylinux2014_x86_64.whl (64.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 64.9/64.9 MB 48.2 MB/s eta 0:00:00
Collecting aiosignal
<!-- If relevant, fill in versioning info to help us troubleshoot -->
_Version & Commit info:_
* `sky -v`: PLEASE_FILL_IN
* `sky -c`: PLEASE_FILL_IN
| 0easy
|
Title: GUI: rename "local storage" to "stay logged in when reloading this tab" or similar
Body: ... to make sure that users understand what the login setting means.
| 0easy
|
Title: [Feature]: Reduce vLLM's import time
Body: ### 🚀 The feature, motivation and pitch
It takes 6s to print a version, likely because vLLM initialize the CUDA context through import
```
time vllm --version
INFO 03-17 04:53:22 [__init__.py:256] Automatically detected platform cuda.
0.7.4.dev497+ga73e183e
real 0m4.729s
user 0m5.921s
sys 0m6.833s
```
This not only hurt CLI experience, but also makes users running `from vllm import LLM` experience slow startup time.
Please help us investigate this and make import time computation as lazy as possible so a simple `vllm --version` can be ran fast.
### Alternatives
_No response_
### Additional context
_No response_
### Before submitting a new issue...
- [x] Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://docs.vllm.ai/en/latest/), which can answer lots of frequently asked questions.
| 0easy
|
Title: Add examples page and list to examples of analyses that use the project
Body:
| 0easy
|
Title: ## Python/Regex fix
Body: This is a reminder for me or a task if anyone wants :P

Basically, The last two questions aren't really regex's questions.
To do:
- Move said questions to correct place.
- Add new regex questions (Python related!)?
- Maybe add a new ## Regex section, as it is a valuable skill any IT profesional should have.
| 0easy
|
Title: Missing Golden Features produces error
Body: When there are only categoricals values Golden Featuers are not created. But there are still some models tried with Golden Features. This produces following error:
```py
Golden Features not created due to error (please check errors.md).
Traceback (most recent call last):
File "/bench/frameworks/mljarsupervised/venv/lib/python3.6/site-packages/supervised/base_automl.py", line 850, in _fit
trained = self.train_model(params)
File "/bench/frameworks/mljarsupervised/venv/lib/python3.6/site-packages/supervised/base_automl.py", line 283, in train_model
mf.train(model_path)
File "/bench/frameworks/mljarsupervised/venv/lib/python3.6/site-packages/supervised/model_framework.py", line 126, in train
train_data["X"], train_data["y"]
File "/bench/frameworks/mljarsupervised/venv/lib/python3.6/site-packages/supervised/preprocessing/preprocessing.py", line 177, in fit_and_transform
self._golden_features.fit(X_train[numeric_cols], y_train)
File "/bench/frameworks/mljarsupervised/venv/lib/python3.6/site-packages/supervised/preprocessing/goldenfeatures_transformer.py", line 114, in fit
"Golden Features not created due to error (please check errors.md)."
supervised.exceptions.AutoMLException: Golden Features not created due to error (please check errors.md).
```
| 0easy
|
Title: Libdoc: Type info for `TypedDict` doesn't list `Mapping` in converted types
Body: We added explicit `TypedDict` conversion in RF 6.0 (#4477) and Libdoc handled them specially already earlier. There's a very small issue that Libdoc only lists `string` as a converted type when we also convert any `Mapping`.
| 0easy
|
Title: [BUG] ERNO 98 in REPLIT Instance
Body: **Describe the bug**
This is an issue of the replit instance. At times it gives me an os error `[ERNO 98] Address already in use` when I go to rerun the instance after closing the browser tab once. The reason that I found for the same is that the file is still present in the process stack after the last run.
Once this happens, it shows whoogle in a browser tab even though replit doesn't show that it is actually still running. Any changes I would make to the code wont show up till I rerun the instance but this is where the issue is as replit just shows the following after I click on run.

P.S. The whoogle instance that shows up in the browser is from the last runtime and therefore doesn't have any new modifications
**To Reproduce**
Steps to reproduce the behavior:
1. Fork a Replit instance
2. Click on run
3. Stop running the instance and close the browser tab
4. Try rerunning the instance and see the error.
**Deployment Method**
- [ ] Heroku (one-click deploy)
- [ ] Docker
- [ ] `run` executable
- [ ] pip/pipx
- [x] Other: [describe setup] Replit Instance
**Version of Whoogle Search**
- [x] Latest build from [source] (i.e. GitHub, Docker Hub, pip, etc)
- [ ] Version [version number]
- [ ] Not sure
**Desktop:**
-

OS: Windows 11 Build 22494
- Browser: chrome
- Version: Version 95.0.4638.69
**Smartphone:**
- Device: N/A
- OS: N/A
- Browser: N/A
- Version: N/A
**Additional context**
I suppose, this is an error related to replit. However a fix I found for the same would be to run `kill -9 $(ps -A | grep python | awk '{print $1}')` in the terminal before rerunning the instance. I was thinking that maybe we could just add this to the `.replit` file to automate the running of this command in the terminal thereby making sure that the service has stopped in process stack.
Refer to `https://stackoverflow.com/questions/4465959/python-errno-98-address-already-in-use` for more context.
| 0easy
|
Title: Type Hints: Add type hints to tutorials, snippets and examples
Body: To improve code readability and be friendlier to [PEP 484](https://www.python.org/dev/peps/pep-0484/), we should start adding type annotations to our code, probably starting from snippets, tutorials and examples.
Originally discussed here https://github.com/falconry/falcon/pull/1737#issuecomment-744064360
| 0easy
|
Title: Update docs in automl
Body: https://github.com/mljar/mljar-supervised/blob/master/supervised/automl.py
| 0easy
|
Title: [BUG] Several issues with NLinear with `normalize=True`
Body: **Describe the bug**
After reading the paper and having a closer look at the implementation of `DLinearModel`, I see several issues:
1. The `seq_last` is only detached, but needs to be cloned as well. Otherwise, it it's values will be changed by line https://github.com/unit8co/darts/blob/8bea0713494e6d23321feaaec341fff4e6fb33dc/darts/models/forecasting/nlinear.py#L146 . This is because of the tensors still share the same underlying memory. The solution is: `seq_last = x[:, -1:, : self.output_dim].detach().clone()`
2. Why is the normalization disabled by default? That's the whole catch of this model, so it should be enabled by default. (I could only imagine that it performed so bad due to the bug, that it was disabled by default)
3. The normalization is only done for the target and not covariates (https://github.com/unit8co/darts/blob/8bea0713494e6d23321feaaec341fff4e6fb33dc/darts/models/forecasting/nlinear.py#L145). How I understand it, the original implementation from the paper does it also for the covariates (https://github.com/cure-lab/LTSF-Linear/blob/0c113668a3b88c4c4ee586b8c5ec3e539c4de5a6/models/NLinear.py#L27). And in my opinion, this makes totally sense.
**To Reproduce**
With normalize=True, NLinear currently fails to solve even very simple tasks:
```
from darts import TimeSeries, models
from darts.utils.timeseries_generation import linear_timeseries
ts = linear_timeseries(start_value=0, end_value=10, length=10, freq='D')
model = models.NLinearModel(
input_chunk_length=3,
output_chunk_length=1,
n_epochs=10,
batch_size=1,
const_init=True,
normalize=True # Explore the difference when durning on normalize
)
model.fit(ts)
print(model.predict(1))
```
**Expected behavior**
Output around ~10.0
**System (please complete the following information):**
- Python version: 3.12
- darts version 0.33.0
**Additional context**
Add any other context about the problem here.
| 0easy
|
Title: Add action for background box for scale bar overlay
Body: ## 🚀 Feature
#4511 added some really cool functionality to the scale bar, including a translucent box for improved visibility when overlaid on certain images. I totally missed it at the time and I was today years old when I discovered that functionality. 😂 A strong reason for this is that there's no corresponding toggle in the View>Scale Bar menu. We should add one! Hopefully it is not too hard to do by modeling it after the existing toggles (visible, colored, and ticks).
| 0easy
|
Title: Add documentation showing %%writefile in a notebook
Body: This is another way someone could develop hamilton in a notebook -
https://ipython.readthedocs.io/en/stable/interactive/magics.html#cellmagic-writefile
We should add some documentation/example around this.
| 0easy
|
Title: Arms Index (TRIN)
Body: Hi, Would you please add Arms Index (TRIN) as an indicator?
* [definition is here](https://www.investopedia.com/terms/a/arms.asp)
* [python code](https://blog.quantinsti.com/trin/)
| 0easy
|
Title: [UX] `sky logs` should be able to tail the last lines of the logs instead of showing all logs
Body: <!-- Describe the bug report / feature request here -->
We should have a way to only tail the logs for the last few lines and follow the outputs with `sky logs`. Otherwise, if a user have a long log file for a job, it will print a lot of messages on the screen when they run `sky logs` after a while.
<!-- If relevant, fill in versioning info to help us troubleshoot -->
_Version & Commit info:_
* `sky -v`: PLEASE_FILL_IN
* `sky -c`: PLEASE_FILL_IN
| 0easy
|
Title: Show & Log a py2 deprecation warning on st2 services startup
Body: An addition to [Add python warning if install a pack that only supports python 2 #5037 PR](https://github.com/StackStorm/st2/pull/5037) and [Python 2 Deprecation Game Plan](https://github.com/StackStorm/discussions/issues/40), apart of warning for `pack install`, we might need to also warn users that's running StackStorm in py2 environment.
I'd suggest to show and log that warning for each st2 service during its initial startup, but open to other ideas.
Maybe also show for every `st2ctl` execution?
| 0easy
|
Title: [FR] add format_shapes method to trace
Body: Having `trace.format_shapes()` as in [Pyro](https://docs.pyro.ai/en/stable/poutine.html?highlight=format_shapes#pyro.poutine.Trace.format_shapes) would help with debugging and verifying models, especially with enumeration, as shown in the [Pyro tutorial](https://pyro.ai/examples/tensor_shapes.html#Broadcasting-to-allow-parallel-enumeration).
| 0easy
|
Title: Make keywords and control structures in log look more like original data
Body: Currently keywords and control structures are formatted differently in the log file than they look in the data. For example, you have a keyword call like
```
Log Many a b c
```
and a FOR loop like
```
FOR ${x} IN cat dog horse
```
in the data, they look like
```
KEYWORD BuiltIn.Log Many a, b, c
```
and
```
FOR ${x} IN [ cat | dog | horse ]
```
in the log file.
I believe this should be changed. Most importantly, we should use the normal four space separator between items and omit all markers that wouldn't be supported in the data. The above examples could look like
```
KEYWORD BuiltIn.Log Many a b c
```
and
```
FOR ${x} IN cat dog horse
```
| 0easy
|
Title: XML Library: Double namespace during Element To String
Body: Hi everyone!
I'm using the XML Lib with lxml
```
Library XML use_lxml=True
```
In my Teststep I'm loading a file and convert it to a XML:
```
${my_config_string}= OperatingSystem.Get File
... path_to_file
... encoding=UTF-8
${my_config_xml}= parse xml ${my_config_string}
```
and its working fine - the XML looks like expected.
```
<config xmlns="http://tail-f.com/ns/config/1.0">
<devices xmlns="http://tail-f.com/ns/ncs">
<device>
....
```
But as soon as I use the Element To String Keyword the namespaces are doubled.
```
${my_config_candidate}= Element To String
... ${my_config_xml}
... xpath=.
... encoding=UTF-8
```
Result:
```
<config xmlns="http://tail-f.com/ns/config/1.0" xmlns="http://tail-f.com/ns/config/1.0">
<devices xmlns="http://tail-f.com/ns/ncs" xmlns="http://tail-f.com/ns/ncs">
<device>
```
It's not happening if I load the Library without lxml
Thank you very much
BR
Christina
| 0easy
|
Title: Export asklearn2 predictions to improve start up time
Body: We currently [fit](https://github.com/automl/auto-sklearn/blob/master/autosklearn/experimental/askl2.py#L57) and predict upon loading `autosklearn.experimental.askl2` for the first time. In environments with a non-persistent filesystem (autosklearn is installed into a new filesystem each time), this can add quite a bit of time delay as experienced in #1362
It seems more applicable to export the predictions with the library to save on this time.
| 0easy
|
Title: Half trend ( by everget ) indicator a custom indicator in trading view . can it be added ??
Body: **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
print(ta.version)
```
**Upgrade.**
```sh
$ pip install -U git+https://github.com/twopirllc/pandas-ta
```
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context, web links, or screenshots about the feature request here.
Thanks for using Pandas TA!
| 0easy
|
Title: Rewrite semver tests to use pytest's parametrize functionality
Body: via https://github.com/jupyter/repo2docker/pull/613#discussion_r263836315:
> In a future refactor, we should use pytest's parameterize capability to feed in versions to get closer to DRY. [See example from JupyterHub tests](https://github.com/jupyterhub/jupyterhub/blob/master/jupyterhub/tests/test_proxy.py#L169).
This would make a good issue for getting started on contributing to repo2docker and/or someone who wants to learn more about pytest.
| 0easy
|
Title: Aircraft navigation correction
Body: In Solox, there is a correction that can be made to airborne radar data to correct for aircraft motion in order to get ground relative velocities. I can't for the life of me find the metadata to fix this manually, so I'm not sure where to start on implementing a pull request, but I think this would be a very valuable feature to have in pyart.
| 0easy
|
Title: Make it possible to specify the plain text email template
Body: # Prerequisites
* [ ] Is it a bug?
* [x] Is it a new feature?
* [ ] Is it a a question?
* [ ] Can you reproduce the problem?
* [x] Are you running the latest version?
* [x] Did you check for similar issues?
* [x] Did you perform a cursory search?
For more information, see the [CONTRIBUTING](https://github.com/PedroBern/django-graphql-auth/blob/master/CONTRIBUTING.md) guide.
# Description
Right now the plain text version of the email is generated on the fly, it would be nice to be able to use a plain text template.
| 0easy
|
Title: St2Stream service broken when using SSL with mongodb
Body: ## SUMMARY
This issue is an extension to #4832 however this time it is the st2stream service, I have looked that the code and can see the same monkey patch code hasn't been applied to the st2stream app
### STACKSTORM VERSION
Paste the output of ``st2 --version``: 3.3.0
##### OS, environment, install method
Docker compose with the split services and mongo db references commented out so that an external db can be used https://github.com/StackStorm/st2-docker/blob/master/docker-compose.yml
All other services correctly connected to mongodb.net test instance with the exception of st2stream.
## Steps to reproduce the problem
use docker yaml at https://github.com/StackStorm/st2-docker/blob/master/docker-compose.yml, comment out mongo container and references, adjust files/st2-docker.conf to point to external DB with SSL = True enabled.
docker-compose up
## Expected Results
What did you expect to happen when running the steps above?
st2stream to operate correctly
## Actual Results
What happened? What output did you get?
2020-11-16 05:48:55,053 WARNING [-] Retry on ConnectionError - Cannot connect to database default :
maximum recursion depth exceeded
Adding monkey patch code to st2stream app resolves the issue (manually injected into container to test).
file: st2stream/cmd/api.py
Code:
from st2common.util.monkey_patch import monkey_patch
monkey_patch()
| 0easy
|
Title: [DOC] Replace NOTES by REFERENCES in docstrings
Body: ### Describe the issue linked to the documentation
Noticed that some docstrings use NOTES instead of REFERENCES in docstrings, making the api doc not linking refs correctly
### Suggest a potential alternative/fix
just should be replaced, i noticed it in some deep learners but would be good to do a check all over aeon at some point
| 0easy
|
Title: Failed to close hivemind.P2P
Body: ```python
Reachability service failed: FileNotFoundError(2, 'No such file or directory')
Exception ignored in: <function P2P.__del__ at 0x7fbec8be5f70>
Traceback (most recent call last):
File "/home/jheuristic/anaconda3/envs/py38_petals_borzunov/lib/python3.8/site-packages/hivemind/p2p/p2p_daemon.py", line 636, in __del__
self._terminate()
File "/home/jheuristic/anaconda3/envs/py38_petals_borzunov/lib/python3.8/site-packages/hivemind/p2p/p2p_daemon.py", line 657, in _terminate
self._child.terminate()
File "/home/jheuristic/anaconda3/envs/py38_petals_borzunov/lib/python3.8/asyncio/subprocess.py", line 141, in terminate
self._transport.terminate()
File "uvloop/handles/process.pyx", line 636, in uvloop.loop.UVProcessTransport.terminate
File "uvloop/handles/process.pyx", line 378, in uvloop.loop.UVProcessTransport._check_proc
ProcessLookupError:
Exception ignored in: <function Client.__del__ at 0x7fbec8bd7a60>
Traceback (most recent call last):
File "/home/jheuristic/anaconda3/envs/py38_petals_borzunov/lib/python3.8/site-packages/hivemind/p2p/p2p_daemon_bindings/p2pclient.py", line 53, in __del__
self.close()
File "/home/jheuristic/anaconda3/envs/py38_petals_borzunov/lib/python3.8/site-packages/hivemind/p2p/p2p_daemon_bindings/p2pclient.py", line 50, in close
self.control.close()
AttributeError: 'NoneType' object has no attribute 'close'
```
| 0easy
|
Title: [DOC] Fix type annotation issues in documentation
Body: Two things that can be improved:
1) Type annotations in the docs hurt readability
This is an example:

I think we could alleviate this quite a bit by bolding the actual parameters names or something akin to that.
2) Abbreviated descriptions on the functions list page do weird things with type annotations and cut info out:

It might make sense to exclude type annotations here entirely.
| 0easy
|
Title: control key support and semantic links for `dcc.Link`
Body: `dcc.Link` is the Dash single-page-app link component. There are still a few behaviours that make these links feel less like native links:
1. Can't right-click on them
2. Can't cntl-click to open new pages with them
3. Visiting a new page keeps the scroll location at the bottom of the page, rather than bringing the user back to the top
For 3, we may need to solve this in the `dash-renderer` library, but I'm not sure.
It looks like we could use the logic in https://github.com/ReactTraining/react-router/blob/d6ac814e273b2f3aad24b7630a6f1df3f19c1475/packages/react-router-dom/modules/Link.js#L41-L62
| 0easy
|
Title: cli.parser refactoring
Body: A lot of parts in this module inspect function signatures, we should only do this once as this is not very efficient, instead of having separate functions call `inspec.signature` many times
| 0easy
|
Title: ValueError: Cannot output operation as QASM: cirq.global_phase_operation
Body: **Description of the issue**
Circuits containing `cirq.global_phase_operation` can't be converted to QASM
**How to reproduce the issue**
```python
import cirq
import numpy as np
c = cirq.Circuit([cirq.global_phase_operation(np.exp(1j * 5))])
cirq.qasm(c)
```
<details>
```
Traceback (most recent call last):
File "/workspace/delete_global_phase_problem.py", line 5, in <module>
cirq.qasm(c)
File "/workspace/venv/lib/python3.11/site-packages/cirq/protocols/qasm.py", line 165, in qasm
result = method(**kwargs)
^^^^^^^^^^^^^^^^
File "/workspace/venv/lib/python3.11/site-packages/cirq/circuits/circuit.py", line 1315, in _qasm_
return self.to_qasm()
^^^^^^^^^^^^^^
File "/workspace/venv/lib/python3.11/site-packages/cirq/circuits/circuit.py", line 1359, in to_qasm
return str(self._to_qasm_output(header, precision, qubit_order))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/venv/lib/python3.11/site-packages/cirq/circuits/qasm_output.py", line 245, in __str__
self._write_qasm(lambda s: output.append(s))
File "/workspace/venv/lib/python3.11/site-packages/cirq/circuits/qasm_output.py", line 299, in _write_qasm
self._write_operations(self.operations, output, output_line_gap)
File "/workspace/venv/lib/python3.11/site-packages/cirq/circuits/qasm_output.py", line 326, in _write_operations
decomposed = protocols.decompose(
^^^^^^^^^^^^^^^^^^^^
File "/workspace/venv/lib/python3.11/site-packages/cirq/protocols/decompose_protocol.py", line 315, in decompose
return [*_decompose_dfs(val, args)]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/venv/lib/python3.11/site-packages/cirq/protocols/decompose_protocol.py", line 223, in _decompose_dfs
raise error
ValueError: Cannot output operation as QASM: cirq.global_phase_operation((0.28366218546322625-0.9589242746631385j))
```
</details>
**Cirq version**
1.3.0
| 0easy
|
Title: deprecate `ploomber cloud`
Body: all the commands that begin with `cloud_` will be deprecated soon: https://github.com/ploomber/ploomber/blob/b69a6de7fc513fe27aababdae3d62cf350e0e04c/src/ploomber_cli/cli.py#L438
so we need to display a FutureWarning with the following message: `ploomber cloud will be deprecated and replaced with a new system. If you need help migrating, send us a message to: https://ploomber.io/community`
we also need to add a note (like the one we have [here](https://docs.ploomber.io/en/latest/user-guide/cli.html)) to all sections under [cloud](https://docs.ploomber.io/en/latest/cloud/api-key.html) with the following message: `Ploomber Cloud will be deprecated and replaced with a new system. If you need help migrating, send us a message to: https://ploomber.io/community`
| 0easy
|
Title: Improve documentation of input distributions
Body: As raised by #307, we should add better documentation of the distributions you can select for inputs to a problem.
| 0easy
|
Title: Remove Python 2 from classifiers list in setup.py
Body: Remove Python 2 from classifiers list in setup.py:
```
'Programming Language :: Python :: 2',
'Programming Language :: Python :: 2.7',
```
| 0easy
|
Title: Update New Contributor Documentation
Body: ### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Documentation
### Which Linux distribution did you use?
_No response_
### Which AutoKey GUI did you use?
_No response_
### Which AutoKey version did you use?
_No response_
### How did you install AutoKey?
_No response_
### Can you briefly describe the issue?
Contributor pages need updating now that 0.96.0 has been released.
Remove references to 0.95.10 from https://github.com/autokey/autokey/blob/develop/CONTRIBUTORS.rst#testing
https://github.com/autokey/autokey/wiki/Contributing-code needs to be looked at as well.
One of the developers should probably do this so no inaccuracies are introduced.
### Can the issue be reproduced?
_No response_
### What are the steps to reproduce the issue?
_No response_
### What should have happened?
_No response_
### What actually happened?
_No response_
### Do you have screenshots?
_No response_
### Can you provide the output of the AutoKey command?
_No response_
### Anything else?
_No response_
| 0easy
|
Title: Comma in rendered lists is not localized
Body: ### Describe the problem
When several values are rendered and joined with `,`, it is not localized. Since https://github.com/WeblateOrg/weblate/commit/0b54da635d614770f53919f469cdfefb6a511abe there is a solution for `format_html_join`, but there are still dozen of places where `", ".join(...)` is used.
### Describe the solution you would like
Use `format_html_join_comma` whenever the content is shown in the UI.
### Describe alternatives you have considered
_No response_
### Screenshots
_No response_
### Additional context
_No response_
| 0easy
|
Title: Fix broken hyperlink in the documentation
Body: **Please provide the issue you face regarding the documentation**
The hyperlink in the below sentence in the `Load a File` section should change from
If the file type is not automatically identified (rare), you can specify them specifically, see section [Specifying a Filetype or Delimiter](https://github.com/capitalone/DataProfiler#specifying-a-filetype-or-delimiter).
to
If the file type is not automatically identified (rare), you can specify them specifically, see section [Specifying a Filetype or Delimiter](https://capitalone.github.io/DataProfiler/docs/0.10.1/html/profiler.html?highlight=filetype#specifying-a-filetype-or-delimiter).
I am trying to fix the documentation as a way to create my first PR on the repo.
| 0easy
|
Title: Cancel tasks with a message where appropriate
Body: [cancel()](https://docs.python.org/3/library/asyncio-task.html#asyncio.Task.cancel) also accepts a "msg" argument, might it be a good idea for this "message" to be added to places like https://github.com/sanic-org/sanic/blob/f7abf3db1bd4e79cd5121327359fc9021fab7ff3/sanic/server/protocols/http_protocol.py#L172 that are otherwise calling cancel() with no explanatory message? if this is the CancelledError this user is getting, a simple message there would save everyone a lot of time.
_Originally posted by @zzzeek in https://github.com/sanic-org/sanic/issues/2296#issuecomment-983881945_
---
Where we are able to in Py3.9, we should add a message to `cancel()`.
| 0easy
|
Title: !imgoptimize needs to be added to conversation blocklist, investigate post summarization error to see if it’s linked or not
Body: 
| 0easy
|
Title: Expose dtypes from fused_numerics.pxd for test suite
Body: ### Description:
We have a nice collection of fused numeric types in [`fused_numerics.pxd`](https://github.com/scikit-image/scikit-image/blob/main/skimage/_shared/fused_numerics.pxd).
- [ ] It would be nice to have corresponding lists of these fused types available at runtime from Python. That way we can easily slap the appropriate `@pytest.mark.parametrize("dtype", _dtypes_uint)` on a test instead of listing each dtype by hand again and again. Could go into `_shared.testing` in my opinion.
- [ ] Check that we used these consistently instead of creating a new local fused type each time. Looking at you [`_extrema_cy.pyx`](https://github.com/scikit-image/scikit-image/blob/e964c61663b0ab515955fd17b997de24f881b66c/skimage/morphology/_extrema_cy.pyx#L18-L28).
| 0easy
|
Title: Add more test in test_extra_conf
Body: We should have at least one test for each of the available configurations. Now those tests are spread in different files.
| 0easy
|
Title: FAQ item on RequestOptions.keep_blank_qs_values is outdated/incorrect
Body: At the time of writing, the FAQ item ["Why is my query parameter missing from the req object?"](https://falcon.readthedocs.io/en/stable/user/faq.html#why-is-my-query-parameter-missing-from-the-req-object) states that
> If a query param does not have a value, Falcon will by default ignore that parameter. For example, passing `'foo'` or `'foo='` will result in the parameter being ignored.
As of Falcon 2.0+, this is incorrect, and the default value for [`RequestOptions.keep_blank_qs_values`](https://falcon.readthedocs.io/en/stable/api/app.html#falcon.RequestOptions.keep_blank_qs_values) is `True`.
However, I believe we should still keep the FAQ item in the case one has set the option to `False` for any reason (or maybe someone else working on the same code base has done that), and is wondering what's going on.
| 0easy
|
Title: Script delay customization
Body: ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Enhancement
### Choose one or more terms that describe this issue:
- [ ] autokey triggers
- [ ] autokey-gtk
- [ ] autokey-qt
- [ ] beta
- [ ] bug
- [ ] critical
- [ ] development
- [ ] documentation
- [X] enhancement
- [ ] installation/configuration
- [ ] phrase expansion
- [X] scripting
- [ ] technical debt
- [x] user interface
### Other terms that describe this issue if not provided above:
_No response_
### Which Linux distribution did you use?
Kubuntu 22.04 LTS
### Which AutoKey GUI did you use?
GTK
### Which AutoKey version did you use?
0.95.10
### How did you install AutoKey?
My distribution's repository.
### Can you briefly describe the issue?
When running a script from the toolbar in the main window of the AutoKey interface, there's an intentional 2-second delay before the script starts running after you click the button. It's there so that you can switch to another window if you need to before the script executes.
I'd like to suggest a toggle that we can tick to turn that delay off if we know we're going to be running tests inside the main AutoKey window.
### Can the issue be reproduced?
Always
### What are the steps to reproduce the issue?
Use the "play" button on the toolbar in the main AutoKey window to run a script and observe the 2-second delay before it executes.
### What should have happened?
_No response_
### What actually happened?
_No response_
### Do you have screenshots?
_No response_
### Can you provide the output of the AutoKey command?
_No response_
### Anything else?
_No response_
| 0easy
|
Title: [feature request] `WebElement` interaction enhancements
Body: For your WebElement.click() I would really love to see a new parameter "total_clicks". I have some cases where I need 2 clicks on the element and to debug, I often want the cursor to move to the element without the click (so total_clicks = 0) and it would be cool to just change 1 parameter after debugging. :)
Its easy to work around it, but the extra parameter would be beneficial :)
| 0easy
|
Title: Upgrade gunicorn version
Body: I suspect that we need to bump the gunicorn version b/c of some slowdowns with gevent in the older versions of gunicorn.
| 0easy
|
Title: [SDK] `objective_metric_name` to be required
Body: ### What you would like to be added?
ref: https://github.com/kubeflow/website/pull/3952#discussion_r1912197342
### Why is this needed?
TODO
### Love this feature?
Give it a 👍 We prioritize the features with most 👍
| 0easy
|
Title: Demos: ensure /etc/jupyter exists and use Python 3
Body: There are a few bugs in the JupyterHub demos. @mkzia has already figure out the fixes, someone just needs to make a PR with them!
I am using Ubuntu 18.04.3 LTS. I had to make the following changes to the demo files:
1) Added `mkdir -p /etc/jupyter/` before `cp global_nbgrader_config.py /etc/jupyter/nbgrader_config.py` in setup_demo.sh because the directory did not exist, so the copy command would fail.
2) Jupyterhub requires Python version 3. The default `pip` in my Ubuntu installation is associated with Python2. So I modified the utils.sh to use `pip3` instead of `pip`. This required installing pip3. Also, npm and configurable-http-proxy had to be installed. Upgrading pip was causing errors, so I commented it out (see https://github.com/pypa/pip/issues/5447).
Here are the changes I made.
```
--- a/demos/restart_demo.sh
+++ b/demos/restart_demo.sh
@@ -23,9 +23,12 @@ source utils.sh
install_dependencies () {
echo "Installing dependencies..."
- pip install -U pip
- pip install -U jupyter
- pip install -U jupyterhub
+ apt install -y npm
+ npm install -g configurable-http-proxy
+ apt install -y python3-pip
+ # pip3 install -U pip
+ pip3 install -U jupyter
+ pip3 install -U jupyterhub
}
install_nbgrader () {
@@ -47,7 +50,7 @@ install_nbgrader () {
git pull
# Install requirements and nbgrader.
- pip install -U -r requirements.txt -e .
+ pip3 install -U -r requirements.txt -e .
# Install global extensions, and disable them globally. We will re-enable
# specific ones for different user accounts in each demo.
```
_Originally posted by @mkzia in https://github.com/jupyter/nbgrader/issues/1176#issuecomment-524661239_
| 0easy
|
Title: Add code time tolerance
Body: Please implement time tolerance for codes.
Ref: [django-otp](https://django-otp-official.readthedocs.io/en/stable/overview.html#django_otp.plugins.otp_totp.models.TOTPDevice.tolerance)
**tolerance**
The number of time steps in the past or future to allow. For example, if this is 1, we’ll accept any of three tokens: the current one, the previous one, and the next one. (Default: 1)
| 0easy
|
Title: ha_open has Nan Values when open is smoothed with ema
Body: **Which version are you running? The lastest version is on Github. Pip is for major releases.**
0.3.14b0
**Do you have _TA Lib_ also installed in your environment?**
yes
**Did you upgrade? Did the upgrade resolve the issue?**
nope, pandas_ta is newly installed on my new laptop
**Describe the bug**
i am trying to create smoothed heikin ashi. however ha_open has Nan values. i am not sure if this is a bug or if this is a expected result
**To Reproduce**
```python
import ccxt
import os,sys
import pandas_ta as pta
import pandas as pd
from datetime import datetime
import time
import pprint
import math
exchange = ccxt.binance({
'enableRateLimit': True,
'options': {
'defaultType': 'future', # ←-------------- quotes and 'future'
},
})
pair='BTC/USDT'
ohlc = exchange.fetch_ohlcv(pair, timeframe='5m')
df = pd.DataFrame(ohlc, columns = ['time', 'open', 'high', 'low', 'close', 'volume'])
df['time'] = pd.to_datetime(df['time'], unit='ms')
df['sopen']=pta.ema(df['open'], length=10)
df['shigh']=pta.ema(df['high'], length=10)
df['slow']=pta.ema(df['low'], length=10)
df['sclose']=pta.ema(df['close'], length=10)
df[['ha_open','ha_high','ha_low','ha_close']] = pta.ha(df['open'],df['high'],df['low'],df['close'])
df[['sha_open','sha_high','sha_low','sha_close']] = pta.ha(df['sopen'],df['shigh'],df['slow'],df['sclose'])
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', None)
print(df)
```
**Expected behavior**
sha_open is heiken ashi_open with smoothed open values using ema. it is returning Nan values but this doesnt happen in smoothed High,smoothed low and smoothed close. only on smoothed heikin ashi open (sha_open)
**Screenshots**

**Additional context**
NA
Thanks for using Pandas TA!
| 0easy
|
Title: Add Support for apps.manifest.* Endpoints
Body: Add support for the following `apps.manifest.*` methods:
`apps.manifest.create`
`apps.manifest.validate`
`apps.manifest.update`
`apps.manifest.delete`
`apps.manifest.export`
### Category (place an `x` in each of the `[ ]`)
- [x] **slack_sdk.web.WebClient (sync/async)** (Web API client)
- [ ] **slack_sdk.webhook.WebhookClient (sync/async)** (Incoming Webhook, response_url sender)
- [ ] **slack_sdk.models** (UI component builders)
- [ ] **slack_sdk.oauth** (OAuth Flow Utilities)
- [ ] **slack_sdk.socket_mode** (Socket Mode client)
- [ ] **slack_sdk.audit_logs** (Audit Logs API client)
- [ ] **slack_sdk.scim** (SCIM API client)
- [ ] **slack_sdk.rtm** (RTM client)
- [ ] **slack_sdk.signature** (Request Signature Verifier)
### Requirements
Please read the [Contributing guidelines](https://github.com/slackapi/python-slack-sdk/blob/main/.github/contributing.md) and [Code of Conduct](https://slackhq.github.io/code-of-conduct) before creating this issue or pull request. By submitting, you are agreeing to those rules.
| 0easy
|
Title: Generalizable Text Transformer Usage
Body: I've been chatting with some others interested in training CLIP for different domain tasks. They expressed interest in a simple way to use a pre-trained text transformer.
Some basic support for Hugging Face or generic classes of transformers shouldn't be too crazy of an extension to what is already fleshed out.
| 0easy
|
Title: "NoneType object is not callable" on stopping P2P
Body: I have very simple inference testing script. No threading or any advanced stuff. Basically "hello world" inference on Petals. Everything is going well, but when the script is exiting, I always get this error:
```
Exception ignored in: <function P2P.__del__ at 0x7f4ac1feed40>
Traceback (most recent call last):
File "/home/dev/.local/lib/python3.10/site-packages/hivemind/p2p/p2p_daemon.py", line 632, in __del__
File "/home/dev/.local/lib/python3.10/site-packages/hivemind/p2p/p2p_daemon.py", line 659, in _terminate
File "/home/dev/.local/lib/python3.10/site-packages/multiaddr/multiaddr.py", line 254, in value_for_protocol
TypeError: 'NoneType' object is not callable
```
It is rather cosmetic issue, but something is not OK there.
| 0easy
|
Title: [BUG] `give_pandas` to become `as_frame`
Body: Currently our API uses `give_pandas=True` if we want to return the pandas dataframe. Scikit-learn has chosen for [another standard](https://scikit-learn.org/dev/whats_new/v0.23.html#sklearn-datasets). We should follow theirs.

| 0easy
|
Title: simplifying API
Body: The API could be simplified in a few places. For example:
+ In `hyp.plot` we could include an `align` flag that runs `hyp.tools.align` on the data if set to `True` (default: `False`).
+ In `hyp.tools.align` and `hyp.tools.procrustes` we could include a `ndims`flag that runs `hyp.tools.reduce` on the dataset prior to alignment if not `None` (default: `None`)
+ In `hyp.tools.align` and `hyp.tools.procrustes`, if the data matrices don't have the same numbers of features, we should zero-pad all of the matrices to ensure they have the same number of features as the matrix with the most features
+ in `hyp.tools.load` we could include `align` and `ndims` flags that pass the data through the appropriate other functions (`hyp.tools.reduce`, followed by `hyp.tools.align`) so that the reduced/aligned data are returned from the start, without needed to save extra copies of the dataset
| 0easy
|
Title: get_arquive template filter
Body: this tmplate filter should aggregate content by date/month
| 0easy
|
Title: Rename resp.body to resp.text
Body: For both the WSGI and ASGI interfaces, rename Response.body to Response.text to provide a better contrast to Response.data. Response.body should then be made a deprecated alias.
Don't forget to also grep the docstrings and /docs for references to 'body' and update them accordingly.
NOTE: It may be best to wait to implement this issue until #1573 is merged to avoid conflicts.
| 0easy
|
Title: Documenting tasks via docstrings
Body: We have a feature that isn't documented, from a user:
```
Hi, how do I define the documentation for a particular task in the pipeline? When I run ploomber status, I see the column Doc(short) which is always empty. A follow-up question is can I customize the status report ?
```
the documentation is extracted from the docstrings (if your function is a task); alternatively, if your task is a script or a notebook, you can define a string at the top of a markdown cell. example:
```
documentation for my script/notebook
```
In case of functions that look like the following:
```
def func1():
...
def func2():
...
if __name__ == "__main__":
func1()
func2()
```
This is how you add the docstring:
```
def func():
"""some comment"""
...
```
if you want to customize the output of ploomber status you can use the Python API, you can load your pipeline with [this](https://docs.ploomber.io/en/latest/cookbook/spec-load-python.html),
then call `dag.status()` and then you can manipulate the object. here's the Table object that it'll return: https://github.com/ploomber/ploomber/blob/2a6287f1beea9f51ecbe59ddebac266cef6c77e8/src/ploomber/table.py#L69
We should document this functionality.
| 0easy
|
Title: accept dotted path in grid arguments
Body: grid allows users to use the same source and execute it with many parameters. this is typically used to train ML models with a grid of parameters:
```yaml
tasks:
- source: random-forest.py
# name is required when using grid
name: random-forest-
product: random-forest.html
grid:
n_estimators: [5, 10, 20]
criterion: [gini, entropy]
```
however, creating large arrays of tasks is inconvenient since they have to list all values. we should allow them define a function that generates them:
```yaml
tasks:
- source: random-forest.py
# name is required when using grid
name: random-forest-
product: random-forest.html
grid:
n_estimators: generate.estimators
criterion: [gini, entropy]
```
```python
# generators.py
def estimators():
return list(range(1, 100)) # this returns 100 values!
```
we should also allow passing arguments to the dotted path:
```yaml
tasks:
- source: random-forest.py
# name is required when using grid
name: random-forest-
product: random-forest.html
grid:
n_estimators:
dotted_path: generate.estimators
min: 1
max: 100
step: 2
criterion: [gini, entropy]
```
and support this as well when grid is a list:
```yaml
tasks:
- source: random-forest.py
# name is required when using grid
name: random-forest-
product: random-forest.html
grid:
- n_estimators: generate.estimators
criterion: [gini, entropy]
```
```python
# generators.py
def estimators(min, max, step):
return list(range(min, max, step))
```
| 0easy
|
Title: Add background command to download complete ingredient list
Body: At the moment the command `python3 manage.py sync-ingredients` will download all ingridients from another wger instance, but this proces takes a looooooong time (several hours). We already have a version of this that runs on a celery queue every x months (`sync_all_ingredients_task`), but it would be really helpful if we could start this process manually with a mangement command `python3 manage.py sync-ingredients-async`
| 0easy
|
Title: Unnecessary requirement of selenium with `from splinter import Browser`
Body: When using `from splinter import Browser` to only use e.g. `Browser("django")`, it fails without selenium being installed due to: https://github.com//cobrateam/splinter/blob/986ce0a10c52f08196b32b91f752182cb7517892/splinter/browser.py#L14
This is only used within https://github.com//cobrateam/splinter/blob/986ce0a10c52f08196b32b91f752182cb7517892/splinter/browser.py#L73-L85, and could be handled through some conditional import, i.e. without selenium being installed/importable, this exception would not happen - and more specifically is only expected to happen for a certain set of the browsers (`splinter.driver.webdriver.*`).
It would be great if the wrapper could be made to not require installation of selenium for non-webdriver-based clients.
| 0easy
|
Title: Remove mutable_args restriction in get_model API
Body: I think we can remove the check of `mutable_args` in the get_model API for BERT, GPT, Language model and transformer. We can introduce a separate flag "allow_override" if users want to override any configuration. Otherwise overriding any configuration is forbidden.
| 0easy
|
Title: Replace type_workarounds.NotImplementedType
Body: **Description of the issue**
Python 3.10 (our minimum requirement) provides [types.NotImplementedType](https://docs.python.org/3.10/library/types.html?highlight=notimplementedtype#types.NotImplementedType). The following workaround is redundant and can be replaced with that type -
https://github.com/quantumlib/Cirq/blob/351a08e52b7090cfab3a1ad07859ebf09d54052a/cirq-core/cirq/type_workarounds.py#L15-L23
**TODO**
- switch to types.NotImplementedType in the code
- delete the type_workarounds module
**Cirq version**
1.5.0.dev at 351a08e52b7090cfab3a1ad07859ebf09d54052a.
| 0easy
|
Title: `collect_headers=True` kwarg to `instrument_<webframe>()`
Body: ### Description
So it's easy to enable collecting HTTP headers for any of the supported webframeworks.
This might just involve manually setting the env vars.
| 0easy
|
Title: Don't convert arguments based on default value type if there is type hint
Body: Currently if an argument has a type hint and a default value like `arg: int = None`, we first try conversion based on the type hint and if it fails we also try conversion based on the default value. For example, a keyword with the following argument specification could be called like
```
Keyword 42
Keyword None
```
and both usages would work.
This doesn't make much sense, because the type hint not containing the default value type is actually a typing error. For example, the previous example should be `arg: Union[int, None] = None` (or `arg: int|None = None` when using Python 3.10 or newer). This logic is also bit more complicated to explain and also makes the conversion code a bit more complicated.
I believe we should change the conversion logic so that if an argument has a type hint, we do conversion solely based on it, regardless does the argument have a default value or not. If argument doesn't have a type hint, we should do conversion based on the possible default value, though.
In practice this change would mean that a keyword with an argument like `arg: int = None` could be called with an argument that can be converted to an integer like
```
Keyword 42
```
and using
```
Keyword None
```
fails. This is obviously backwards incompatible, but, as already mentioned, the typing is wrong and should be fixed.
| 0easy
|
Title: Need help with gradient accumulation implementation.
Body: https://github.com/NVIDIA/apex/issues/286#issuecomment-488836364
Should not be hard I guess?
Just edit the train_with_ga.py file and PR xD.
| 0easy
|
Title: Add a Python 2 flag
Body: Skip over the 2to3 shell out if it is set.
You can add a test file with this flag set as well, comment out any test if it fails, also make the flag valueaccessible in the cfg files.
(So the [easy] issues are good for new people who want to start contributing to look at.)
| 0easy
|
Title: Bump Anthropic dependency from 0.2.x to 0.3.x
Body: We use Anthropic's Claude for evaluating Gorilla in `eval/`. This was tested for `anthropic==0.2.8` release, and needs to be updated to support the latest PyPI release (0.3.x). This involves cosmetic changes in two files [eval/get_llm_responses.py](https://github.com/ShishirPatil/gorilla/blob/c849d11833ce0d401df4ab5a4d854167ad861684/eval/get_llm_responses.py#L19) and [eval/get_llm_responses_retriever.py](https://github.com/ShishirPatil/gorilla/blob/c849d11833ce0d401df4ab5a4d854167ad861684/eval/get_llm_responses_retriever.py#L19)
| 0easy
|
Title: 'args' attribute of 'Command.CommandObj' seems not working
Body: ## Context
* Operating System: Windows 10
* Python Version: 3.8.1
* aiogram version: 2.12.1
* aiohttp version: 3.7.3
* uvloop version (if installed):
## Expected Behavior
`command.args` returns arguments of command
## Current Behavior
`command.args` returns `None`
## Failure Information (for bugs)
It seems the `args` attribute is not working.
Digging into `dispatcher/filters/builtin.py`, I found nothing about setting this attribute, but after adding `args = text.split()[1]` and pass it to the construtor of `CommandObj`, it seems to work.
I wonder if this is the intended behavior or am I getting it wrong?
I would be glad to open a PR if it's a mistake :)
### Steps to Reproduce
```python
@dp.message_handler(commands=['test'])
async def test(message: Message, command: Command.CommandObj):
print(command, command.args)
```
Test command: `/test abc`
### Failure Logs
Output: `Command.CommandObj(prefix='/', command='test', mention='') None`
| 0easy
|
Title: Add questions on SQL, NoSQL
Body:
| 0easy
|
Title: [FR] add Can Build to build order overview
Body: ### Please verify that this feature request has NOT been suggested before.
- [x] I checked and didn't find a similar feature request
### Problem statement
please add can build line to the build order overview. currently the BOM shows how many can be build:

but i would be nice to show this also on the build order:

gives better overview.
### Suggested solution
add the line in buid order overview
### Describe alternatives you've considered
none
### Examples of other systems
_No response_
### Do you want to develop this?
- [ ] I want to develop this.
| 0easy
|
Title: Font size in plotly plot
Body: The plotly plots on my macbook on Ubuntu 20.04 and pandasgui 0.2.3.2 have very tiny font. Wondering if there's a way to change this.. See pic below.
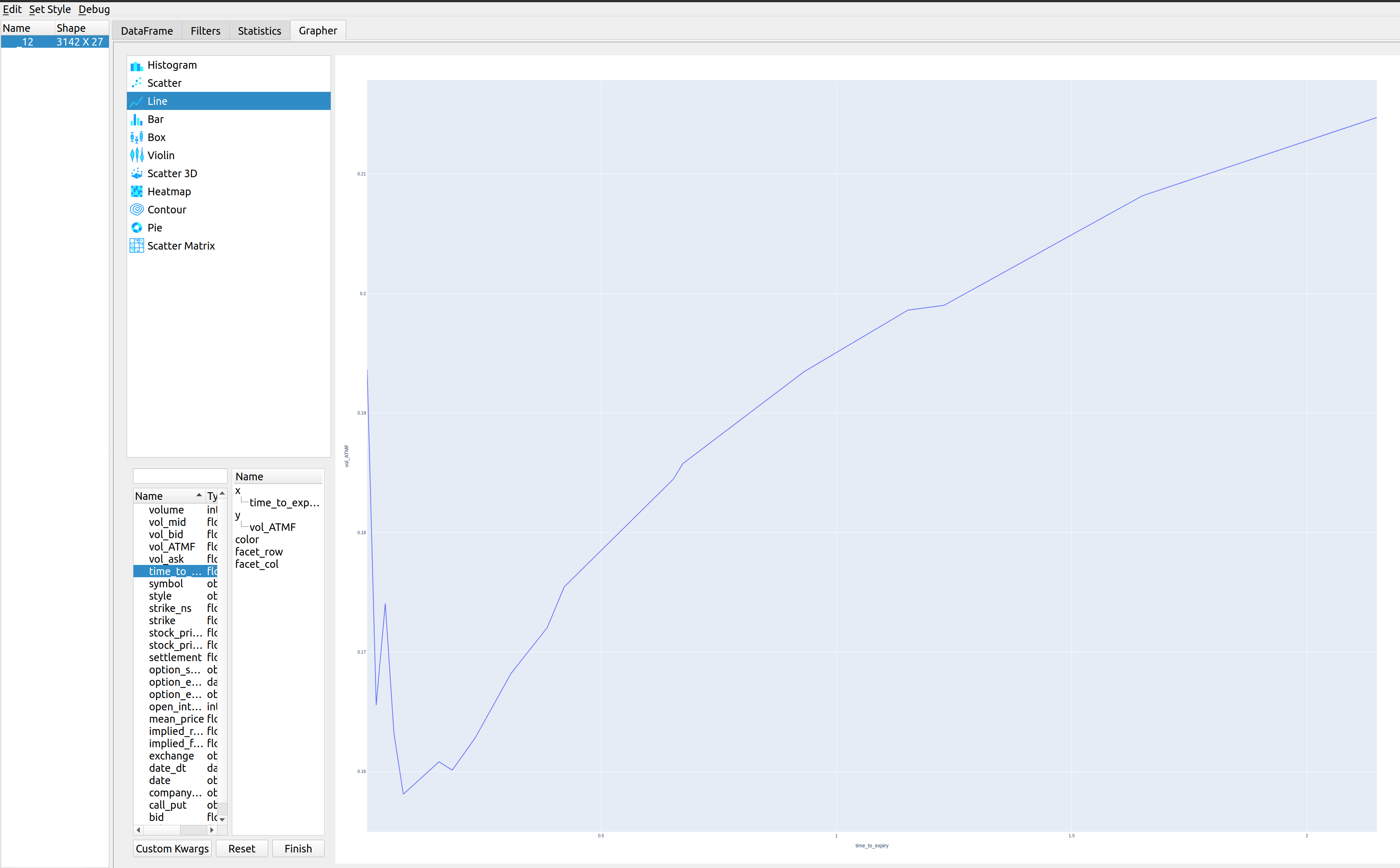
| 0easy
|
Title: Github action for more automation. Issues management etc
Body: It would be great with github actions that automate things like issue + PR management and more.
Specifically marking issues as stale after X amount of time. I imagine there are other good actions we could use. (some inspiration might exist [here](https://github.com/sdras/awesome-actions))
<details>
<summary>Checklist</summary>
- [X] `.github/workflows/automation.yml`
> * Create a new file named `automation.yml` in the `.github/workflows` directory.
> • At the top of the file, define the name of the workflow and the events that will trigger the workflow. For example, you can trigger the workflow on a schedule or when an issue or PR is created or updated.
> • Define a job for marking stale issues. Use the `actions/stale` action for this job. Specify the parameters for the action such as the days of inactivity after which an issue is considered stale, the message to be displayed when an issue is marked as stale, etc.
> • Define other jobs as needed for other tasks such as labeling issues, managing PRs, etc. Use the appropriate actions for these jobs.
</details>
| 0easy
|
Title: Setup.py fails. Please see the included terminal output
Body: I am using Linux Mint 19, 64bit which comes with Python 3.6 installed and I assume it is as good as the recommended Python 3.5. On trying to run setup.py, I got the following errors:
./setup.py: 18: ./setup.py: import: not found
./setup.py: 19: ./setup.py: import: not found
from: can't read /var/mail/collections
./setup.py: 21: ./setup.py: import: not found
from: can't read /var/mail/pathlib
./setup.py: 23: ./setup.py: import: not found
./setup.py: 24: ./setup.py: import: not found
./setup.py: 26: ./setup.py: try:: not found
from: can't read /var/mail/setuptools
./setup.py: 28: ./setup.py: except: not found
./setup.py: 29: ./setup.py: Syntax error: word unexpected (expecting ")")
| 0easy
|
Title: Global value and local value objects need to be renamed
Body: ### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Enhancement
### Which Linux distribution did you use?
Kubuntu 22.04 LTS
### Which AutoKey GUI did you use?
Both
### Which AutoKey version did you use?
0.95.10
### How did you install AutoKey?
Distribution's repository.
### Can you briefly describe the issue?
The **global value** and **local value** objects should be renamed to something more appropriate.
### Can the issue be reproduced?
Always
### What are the steps to reproduce the issue?
When referring to a **global value** and **local value** object, if you wish to discuss its value, this can make for a confusing discussion. For example, try referring to each of their values and you'll find yourself with something awkward and unclear like, "...the value of the global value..." or "...the value of the local value..."
### What should have happened?
The **local value** and **global value** objects should be named to **local variable** and **global variable** objects (or something else the development team feels is appropriate) since each one **is** a variable and **has** a value, yet their current names suggest that they currently **are** a value. This would make it possible to say, "...the value of the global variable..." or ...the value of the local variable..." which would be less awkward and more clear.
### What actually happened?
This slight fuzziness makes them challenging to document. For example, it's awkward to say, "...the value of the global value..." or "...the value of the local value..." and it's currently necessary to get rather creative in your choice of wording to make sure it's clear what you mean.
### Do you have screenshots?
_No response_
### Can you provide the output of the AutoKey command?
_No response_
### Anything else?
It occurs to me that my suggestion of "global variable" and "local variable" isn't appropriate, either, since such variables can exist within Python independently of AutoKey, which would cause a new kind of confusion. As a result, some other name would need to be thought of if this enhancement is to be implemented.
| 0easy
|
Title: Log and report generation crashes if `--removekeywords` is used with `PASSED` or `ALL` and test body contains messages
Body: Hi,
I am getting error when trying to merge `output.xml` with rebot.
I am running my rebot command as below:
`rebot --removekeywords PASSED --splitlog --outputdir C:\Users\LAMS009\Documents\Debug\results --xunit outputxunit_abc.xml --output outputmerged_abc.xml --logtitle "Abc Test Log" --reporttitle "Abc Test Report" --merge C:\Users\LAMS009\Documents\Debug\results\output_*.xml`
Error message as below:
```
rebot --removekeywords PASSED --splitlog --outputdir C:\Users\LAMS009\Documents\Debug\results --xunit outputxunit_abc.xml --output outputmerged_abc.xml --logtitle "Abc Test Log" --reporttitle "Abc Test Report" --merge C:\Users\LAMS009\Documents\Debug\results\output_*.xml
[ ERROR ] Unexpected error: AttributeError: 'Message' object has no attribute 'body'
Traceback (most recent call last):
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\utils\application.py", line 81, in _execute
rc = self.main(arguments, **options)
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\rebot.py", line 351, in main
rc = ResultWriter(*datasources).write_results(settings)
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\reporting\resultwriter.py", line 57, in write_results
self._write_output(results.result, settings.output, settings.legacy_output)
^^^^^^^^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\reporting\resultwriter.py", line 123, in result
self._result.configure(self._settings.status_rc,
~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^
self._settings.suite_config,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
self._settings.statistics_config)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\result\executionresult.py", line 146, in configure
self.suite.configure(**suite_config)
~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\result\model.py", line 1104, in configure
self.visit(SuiteConfigurer(**options))
~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\testsuite.py", line 421, in visit
visitor.visit_suite(self)
~~~~~~~~~~~~~~~~~~~^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\result\configurer.py", line 58, in visit_suite
self._remove_keywords(suite)
~~~~~~~~~~~~~~~~~~~~~^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\result\configurer.py", line 64, in _remove_keywords
suite.remove_keywords(how)
~~~~~~~~~~~~~~~~~~~~~^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\result\model.py", line 1079, in remove_keywords
self.visit(KeywordRemover.from_config(how))
~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\testsuite.py", line 421, in visit
visitor.visit_suite(self)
~~~~~~~~~~~~~~~~~~~^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\visitor.py", line 131, in visit_suite
suite.suites.visit(self)
~~~~~~~~~~~~~~~~~~^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\itemlist.py", line 102, in visit
item.visit(visitor) # type: ignore
~~~~~~~~~~^^^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\testsuite.py", line 421, in visit
visitor.visit_suite(self)
~~~~~~~~~~~~~~~~~~~^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\visitor.py", line 132, in visit_suite
suite.tests.visit(self)
~~~~~~~~~~~~~~~~~^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\itemlist.py", line 102, in visit
item.visit(visitor) # type: ignore
~~~~~~~~~~^^^^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\model\testcase.py", line 178, in visit
visitor.visit_test(self)
~~~~~~~~~~~~~~~~~~^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\result\keywordremover.py", line 87, in visit_test
self._clear_content(item)
~~~~~~~~~~~~~~~~~~~^^^^^^
File "C:\Users\LAMS009\Documents\Debug\.venv\Lib\site-packages\robot\result\keywordremover.py", line 47, in _clear_content
if item.body:
^^^^^^^^^
AttributeError: 'Message' object has no attribute 'body'
```
I have no idea how to reproduce it, hence i will attached my output.xml along.
[output_original_abc.zip](https://github.com/user-attachments/files/18441688/output_original_abc.zip)
| 0easy
|
Title: OAuth module: SQLAlchemy v2 compatibility
Body: As reported at https://github.com/slackapi/bolt-python/issues/822, our StateStore/InstallationStore implementations are not compatible with SQLAlchemy v2.
### Reproducible in:
#### The Slack SDK version
Any versions
#### Python runtime version
Any versions
#### OS info
Any operating systems
#### Steps to reproduce:
Refer to https://github.com/slackapi/bolt-python/issues/822
### Expected result:
The state parameter validation succeeds
### Actual result:
Always fails with an exception
| 0easy
|
Title: phase exponent ignored in approximate comparisons of `cirq.PhasedISwapPowGate`
Body: **Description of the issue**
`PhasedISwapPowGate` doesn't override the `_value_equality_approximate_values_` implementation it inherits from `EigenGate`, which means its phase exponent attribute isn't included in approximate comparisons
the one exception is when its phase exponent is zero, in which case approximate comparison fails even when it shouldn't due to some of the same inconsistencies described for `cirq.PhasedXPowGate` in #6528
**How to reproduce the issue**
```python
gate0 = cirq.PhasedISwapPowGate(phase_exponent=0)
gate1 = cirq.PhasedISwapPowGate(phase_exponent=1e-12)
gate2 = cirq.PhasedISwapPowGate(phase_exponent=2e-12)
gate3 = cirq.PhasedISwapPowGate(phase_exponent=0.345)
assert cirq.approx_eq(gate1, gate2) # ok
assert cirq.approx_eq(gate1, gate0) # fails, even though they are as close as the previous two
assert cirq.approx_eq(gate1, gate3) # passes, but shouldn't
assert cirq.equal_up_to_global_phase(gate1, gate2) # ok
assert cirq.equal_up_to_global_phase(gate1, gate0) # fails, even though they are as close as the previous two
assert cirq.equal_up_to_global_phase(gate1, gate3) # passes, but shouldn't
```
**Cirq version**
```
1.4.0.dev20240209232305
```
| 0easy
|
Title: User Guide generation broken on Windows
Body: env:
platform: Windows 10 Pro
python: 3.7
RF: master branch
problem: when calling the script ug2html.py to generate the RF user guide, encoutered the following encoding issue,

this may due to this function:
`doc.userguide.translations.update`
```python
def update(path: Path, content):
source = path.read_text(encoding='UTF-8').splitlines()
with open(path, 'w') as file:
write(source, file, end_marker='.. START GENERATED CONTENT')
file.write('.. Generated by translations.py used by ug2html.py.\n')
write(content, file)
write(source, file, start_marker='.. END GENERATED CONTENT')
```
when calling the open function, does not specify the encoding, the default encoding will be platform dependent. In my case, the encoding cp1252 will be used, this issue happened when write the content that was Bg language and other languages will also meet this issue if cp1252 not support them.
possible solution:
specify the encoding to be 'utf-8' when open the file.
| 0easy
|
Title: Invalid Request | empty message error
Body: ### Describe the bug
After getting OI setup in my Command Prompt environment, I tried to run it but it said I had no credits for my API key. After setting up billing and trying to rerun the interpreter--os command prompt it automatically says "empty message". It's as if after I run interpreter--os it automatically tries to submit a prompt without my prompting and fails because the prompt is empty, which then tosses me out of the environment.

### Reproduce
Run python -m interpreter --os
Then wait
### Expected behavior
I expect interpreter to run correctly and allow me to use the environment (first time user)
### Screenshots

### Open Interpreter version
0.4.3
### Python version
3.11.1
### Operating System name and version
Windows 10 Pro
### Additional context
_No response_
| 0easy
|
Title: Parse files with `.robot.rst` extension automatically
Body: Robot Framework can parse reStructuredText files having `.rst` or `.rest` extension, but to avoid parsing unrelated reST files that support needs to be enabled separately by using the `--extension` option. To make using reST files more convenient, we could automatically parse files with `.robot.rst` extension.
This is easy to implement, because we already support for such multipart extensions with custom parsers (#1283).
| 0easy
|
Title: Library components interaction
Body: **Is your feature request related to a problem? Please describe.**
Difficulty to understand how it works under the lines and how it is structured
**Describe the solution you'd like**
A scheme showing what are the main modules contained in the library and how they interact with each other.
Showing different types of graphs and nodes etc.
| 0easy
|
Title: Dialogs created by `Dialogs` should bind `Enter` key to `OK` button
Body: When creating a popup dialog asking the user for an input, the dialog already nicely auto-focuses into the textbox, allowing immediate keyboard input. However, then pressing the Enter key does nothing. I would have expected it to to be the same as pressing the left "OK" button. It would be very useful to have that so that users don't have to use the mouse to press that button.
Example:
```robot
*** Settings ***
Library Dialogs
*** Test Cases ***
Get Device Number
[Documentation] Grab the device number from the user
[Tags] production
${dev_num_usr}= Get Value From User Input the number of the device (on the label) invalid
```

I'm on Ubuntu Budgie 22.04.
The code for it might be [here](https://github.com/robotframework/robotframework/blob/15e11c63be0e7a4ce8401c7d47346a7dc8c81bf5/src/robot/libraries/dialogs_py.py#L51-L58).
| 0easy
|
Title: Improve error message when pipeline.yaml has empty tasks
Body: ```yaml
# pipeline.yaml
tasks:
# Add tasks here...
```
Error is pretty confusing:
```pytb
Traceback (most recent call last):
File "/Users/Edu/miniconda3/envs/soopervisor/bin/soopervisor", line 33, in <module>
sys.exit(load_entry_point('soopervisor', 'console_scripts', 'soopervisor')())
File "/Users/Edu/miniconda3/envs/soopervisor/lib/python3.8/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/Users/Edu/miniconda3/envs/soopervisor/lib/python3.8/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/Users/Edu/miniconda3/envs/soopervisor/lib/python3.8/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/Edu/miniconda3/envs/soopervisor/lib/python3.8/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/Edu/miniconda3/envs/soopervisor/lib/python3.8/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/Users/Edu/dev/soopervisor/src/soopervisor/cli.py", line 64, in add
Exporter.new('soopervisor.yaml', env_name=env_name, preset=preset).add()
File "/Users/Edu/dev/soopervisor/src/soopervisor/abc.py", line 282, in new
dag, spec = load_dag_and_spec(env_name)
File "/Users/Edu/dev/soopervisor/src/soopervisor/commons/dag.py", line 175, in load_dag_and_spec
spec, _ = commons.find_spec(cmdr=cmdr, name=env_name)
File "/Users/Edu/dev/soopervisor/src/soopervisor/commons/dag.py", line 59, in find_spec
spec, relative_path = DAGSpec._find_relative()
File "/Users/Edu/dev/ploomber/src/ploomber/spec/dagspec.py", line 499, in _find_relative
return cls(relative_path), relative_path
File "/Users/Edu/dev/ploomber/src/ploomber/spec/dagspec.py", line 195, in __init__
self._init(data=data,
File "/Users/Edu/dev/ploomber/src/ploomber/spec/dagspec.py", line 340, in _init
self.data['tasks'] = [
TypeError: 'NoneType' object is not iterable
```
| 0easy
|
Title: Allowing to switch start_method in Parallel executor
Body: I have some Pytorch code which I want to run on GPU (`net.cuda()` and whatnot)
I get the following error:
```
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method
```
I tried to fix this by either calling
```
mp.set_start_method('spawn', force=True)
```
or
```
torch.multiprocessing.set_start_method('spawn')
```
In the first case nothing happens, and in the second I get `RuntimeError: context has already been set`
How to set multiprocessing start method with ploomber?
| 0easy
|
Title: Add CLI options explanation
Body: ## Description
To add explanations to each option. To tell the user what the option is for. Exactly how `help` has: `Show this message and exit.`
```bash
scanapi --help
Usage: scanapi [OPTIONS]
Automated Testing and Documentation for your REST API.
Options:
-s, --spec-path PATH
-o, --output-path TEXT
-c, --config-path TEXT
-r, --reporter [console|markdown|html]
-t, --template TEXT
--log-level [DEBUG|INFO|WARNING|ERROR|CRITICAL]
--help Show this message and exit.
```
Options:
- [ ] --spec-path
- [ ] --output-path
- [ ] --config-path
- [ ] --reporter
- [ ] --template
- [ ] --log-level
| 0easy
|
Title: Support `separator=<value>` configuration option with scalar variables in Variables section
Body: In the Variables section, if a scalar variable is created so that it gets more then one value, values are concatenated together so that the final value will be a single sting. By default values are joined with a space, but using a special `SEPARATOR=<value>` marker as the first value makes it possible to change it.
```robotframework
*** Variables ***
${JOINED} These values are joined together with a space.
${MULTILINE} SEPARATOR=\n First line. Second line. Third line.
```
We are going to introduce new `VAR` syntax (#3761) for creating variables inside tests and keywords, and plan to support concatenation of scalar values with it as well. That syntax gets a separate `scope` option for controlling the scope where the variable is set, and also the separator will be set using a [separator` option](https://github.com/robotframework/robotframework/issues/3761#issuecomment-1757525898) instead of using a special marker like above.
For consistency reasons, we should support the `separator` option also in the Variables section. In practice it would mean that the latter example above could be written like this:
```robotframework
*** Variables ***
${MULTILINE} First line. Second line. Third line. separator=\n
```
Having two ways to control the separator isn't optimal, but there being a consistent syntax that can be used regardless how variables are created is in my opinion more important. We may consider deprecating the `SEPARATOR` marker at some point, but there's absolutely no hurry with it.
| 0easy
|
Title: Update Python version in Dockerfile-s
Body: **Description of the issue**
#6167 raises the minimum Python version to 3.9,
but the following Dockerfile-s derive from images with Python 3.7 or 3.8:
- https://github.com/quantumlib/Cirq/blob/74cee7e8e8787ab56160124b3a13834550e31cc1/Dockerfile#L1
- https://github.com/quantumlib/Cirq/blob/74cee7e8e8787ab56160124b3a13834550e31cc1/dev_tools/docs/Dockerfile#L29
- https://github.com/quantumlib/Cirq/blob/74cee7e8e8787ab56160124b3a13834550e31cc1/dev_tools/pr_monitor/Dockerfile#L26
**TODO**
Check if all of these Dockerfile-s are in use then update their Python versions to 3.9.
| 0easy
|
Title: Measure region properties example has an error that misses hover over label for first mask
Body: ### Description:
When you copy the example code at the bottom of this webpage:
https://scikit-image.org/docs/stable/auto_examples/segmentation/plot_regionprops.html
The line:
for index in range(1, labels.max()):
label_i = props[index].label
iterates over the proterites starting at 1 which misses the first index and therefore does not plot the first mask with label "1" becasue the property index was actually 0.
The line should be:
for index in range(0, labels.max()):
label_i = props[index].label
Thank you!
This example is great and very helpful otherwise!
### Way to reproduce:
_No response_
### Version information:
_No response_
| 0easy
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.