
text
stringlengths 20
57.3k
| labels
class label 4
classes |
|---|---|
Title: generate random ports for multiple protocols in gateway
Body: generate random ports for multiple protocols in gateway.
This will entail the following changes:
parser ports default to None
in flow constructor, and gateway config, we generate ports up to the number of protocols
in jina gateway cli, when displaying pod settings, we will be printing None instead of the random port
| 1medium
|
Title: Can not add patch in every axes
Body: <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
I try to draw the Nino3 area in every axes, BUT here it is the Error:"ValueError: Can not reset the axes. You are probably trying to re-use an artist in more than one Axes which is not supported". The nino3 area is only drawn on the first axs. so How can i fix this?
Thanks a lot.

Here is the code for add patch:
```
from matplotlib.path import Path
from matplotlib.patches import PathPatch
codes = [Path.MOVETO] + [Path.LINETO]*3 + [Path.CLOSEPOLY]
vertices = [(210,-5), (210,5), (270,5), (270,-5), (0, 0)]
path = Path(vertices, codes)
pathpatch = PathPatch(path, facecolor='none', edgecolor='k',lw=1.5,label='Nino3',transform = ccrs.PlateCarree(),alpha = 0.6)
axs[0].add_patch(pathpatch)
axs[1].add_patch(pathpatch)
axs[2].add_patch(pathpatch)
```
### Proplot version
0.9.5.post332
| 1medium
|
Title: token streaming to stdout
Body: ### Describe the bug
versions after 0.16 verbose streaming
> hi
```
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": "Hello"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": "!"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " How"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " can"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " I"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " assist"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " you"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " today"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": "?"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {},
"finish_reason": "stop"
}
]
}
```
Hello! How can I assist you today?
### Reproduce
install latest version
### Expected behavior
no streaming jsons
### Screenshots
_No response_
### Open Interpreter version
>=0.1.7
### Python version
3.11.6
### Operating System name and version
Windows 11
### Additional context
_No response_
| 1medium
|
Title: upgrade to gradio 5.0
Body: gradio 5.0 is out, see: https://huggingface.co/blog/gradio-5
| 1medium
|
Title: context_length_exceeded error
Body: I think the message history keeps building up when running the agent over a large loop like:
```
for keyword in keywords:
result = lead_generation_agent.run_sync(user_promt, deps=keyword)
```
because the first iteration runs just fine but after dozen I get this error, why and how can I fix it?
File "/Users/UA/.venv/lib/python3.13/site-packages/openai/_base_client.py", line 1638, in _request
raise self._make_status_error_from_response(err.response) from None
openai.OpenAIError: Error code: 400 - {'error': {'message': "This model's maximum context length is 128000 tokens. However, your messages resulted in 136707 tokens (136367 in the messages, 340 in the functions). Please reduce the length of the messages or functions.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
How `Agent` class works, why does it pass the history messages to the next iteration of the for loop?
| 1medium
|
Title: Gemma3
Body: ### System Info
After installing the latest Transformers and reasoning about Gemma 3 video understanding, this error is reported
pip install -q git+https://github.com/huggingface/[email protected]
# -*- coding: utf-8 -*-
"""Let's load the model."""
import torch
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
ckpt = "google/gemma-3-4b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
ckpt, device_map="auto", torch_dtype=torch.bfloat16,
)
processor = AutoProcessor.from_pretrained(ckpt)
"""Download the video and downsample the frames from the video."""
import cv2
from PIL import Image
import numpy as np
def downsample_video(video_path):
vidcap = cv2.VideoCapture(video_path)
total_frames = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
fps = vidcap.get(cv2.CAP_PROP_FPS)
frames = []
frame_indices = np.linspace(0, total_frames - 1, 10, dtype=int)
for i in frame_indices:
vidcap.set(cv2.CAP_PROP_POS_FRAMES, i)
success, image = vidcap.read()
if success:
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Convert from BGR to RGB
pil_image = Image.fromarray(image)
timestamp = round(i / fps, 2)
frames.append((pil_image, timestamp))
vidcap.release()
return frames
frames = downsample_video("30515642-b6d9-11ef-b24f-fa163ea3a38d_zip.mp4")
frames
"""Here's our system prompt and the instruction. We will add frames and images on top of it."""
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "text", "text": f"What is happening in this video? Summarize the events."}]
}
]
messages[1]["content"][0]
for frame in frames:
image, timestamp = frame
messages[1]["content"].append({"type": "text", "text": f"Frame {timestamp}:"})
image.save(f"image_{timestamp}.png")
messages[1]["content"].append({"type": "image", "url": f"image_{timestamp}.png"})
messages
"""Preprocess our input and infer."""
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device)
processed_chat = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
video_fps=32,
video_load_backend="decord",
)
input_len = inputs["input_ids"].shape[-1]
generation = model.generate(**inputs, max_new_tokens=500, do_sample=True)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
Traceback (most recent call last):
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/Gemma_3_for_Video_Understanding.py", line 89, in <module>
generation = model.generate(**inputs, max_new_tokens=500, do_sample=True)
File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/generation/utils.py", line 2314, in generate
result = self._sample(
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/generation/utils.py", line 3294, in _sample
outputs = model_forward(**model_inputs, return_dict=True)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/utils/deprecation.py", line 172, in wrapped_func
return func(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 1352, in forward
outputs = self.language_model(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/utils/deprecation.py", line 172, in wrapped_func
return func(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 976, in forward
outputs = self.model(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 754, in forward
layer_outputs = decoder_layer(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 443, in forward
hidden_states, self_attn_weights = self.self_attn(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 365, in forward
attn_output, attn_weights = attention_interface(
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/integrations/sdpa_attention.py", line 54, in sdpa_attention_forward
attn_output = torch.nn.functional.scaled_dot_product_attention(
RuntimeError: p.attn_bias_ptr is not correctly aligned
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
test
### Expected behavior
bug
| 2hard
|
Title: The provided `peft_type` 'PROMPT_TUNING' is not compatible with the `PeftMixedModel`.
Body: ### Feature request
PROMPT_TUNING is an useful adapter and it would be great if we can combine it with LORA.
### Motivation
Lots of finetunes on consumer grade hardware leverage lora. It would be great we can mix prompt tuning with lora as plug and play.
### Your contribution
I would like to submit a PR if there is interest.
| 1medium
|
Title: GitHub Action fails when loading arcgis package on subprocess
Body: **Describe the bug**
I am getting a subprocess error when trying to run arcgis 2.1.0
Most likely I am doing something wrong within my set-up, any suggestions? It looks to be locked up on gssapi or krb5
error:
```python
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [21 lines of output]
/bin/sh: 1: krb5-config: not found
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 353, in <module>
main()
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 335, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 118, in get_requires_for_build_wheel
return hook(config_settings)
File "/tmp/pip-build-env-ilhbhnfb/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 355, in get_requires_for_build_wheel
return self._get_build_requires(config_settings, requirements=['wheel'])
File "/tmp/pip-build-env-ilhbhnfb/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 325, in _get_build_requires
self.run_setup()
File "/tmp/pip-build-env-ilhbhnfb/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 341, in run_setup
exec(code, locals())
File "<string>", line 109, in <module>
File "<string>", line 22, in get_output
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/subprocess.py", line 424, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/subprocess.py", line 528, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command 'krb5-config --libs gssapi' returned non-zero exit status 127.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
```
My .yml file:
```
name: run script
on:
workflow_dispatch:
jobs:
run-python-script:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Set environment variables from secrets
env:
AGOL_URL: ${{ secrets.AGOL_URL }}
AGOL_USERNAME: ${{ secrets.AGOL_USERNAME }}
AGOL_PASSWORD: ${{ secrets.AGOL_PASSWORD }}
run: echo Setting environment variables
- name: Run main.py
run: python main.py
```
| 1medium
|
Title: Warnings about wrong grpc options
Body: **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
```python
Client(host="grpcs://someflow-somens-grpc.wolf.jina.ai").post(on='/', inputs=...)
```
```
E0308 16:59:23.961063922 551261 channel_args.cc:374] grpc.max_send_message_length ignored: it must be >= -1
E0308 16:59:23.961081461 551261 channel_args.cc:374] grpc.max_receive_message_length ignored: it must be >= -1
E0308 16:59:23.961096321 551261 channel_args.cc:374] grpc.max_receive_message_length ignored: it must be >= -1
```
**Describe how you solve it**
<!-- copy past your code/pull request link -->
Change these values in utils to >=-1
https://github.com/jina-ai/jina/blob/8b983a49be3289193e3a0ec768f24b22bc690fb3/jina/serve/networking/utils.py#L219-L221
| 1medium
|
Title: Private code to generate test data for geoarrow/deck.gl-layers
Body: There's so much helper code here to create geoarrow-formatted data and validate other attributes, that it would be nice to have a private method to export for test data for the JS lib
| 1medium
|
Title: 请问可否出一个相对简单的使用教程?
Body:
| 0easy
|
Title: Dependencies too strict for numpy and scipy
Body: **Issue**
I have a request regarding the dependencies for `mljar-supervised = "0.10.4"`. In particular, my question is whether it would be possible to allow for older versions of `numpy` and `scipy` (maybe in future releases).
I am currently trying to install `mljar-supervised = "0.10.4"` along with `tensorflow = "^2.2"`. It seems to me that these two dependencies should definitely be compatible in one application. However, this is not possible due to the following reason: `because mljar-supervised (0.10.4) depends on both numpy (>=1.20.0) and scipy (1.6.1), mljar-supervised (0.10.4) is incompatible with tensorflow (>=2.2,<3.0)`
**Full dependency issue**
```shell
Because no versions of tensorflow match >2.2,<2.2.1 || >2.2.1,<2.2.2 || >2.2.2,<2.3.0 || >2.3.0,<2.3.1 || >2.3.1,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0
and tensorflow (2.2.0) depends on scipy (1.4.1), tensorflow (>=2.2,<2.2.1 || >2.2.1,<2.2.2 || >2.2.2,<2.3.0 || >2.3.0,<2.3.1 || >2.3.1,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1).
And because tensorflow (2.2.1) depends on numpy (>=1.16.0,<1.19.0)
and tensorflow (2.2.2) depends on numpy (>=1.16.0,<1.19.0), tensorflow (>=2.2,<2.3.0 || >2.3.0,<2.3.1 || >2.3.1,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1) or numpy (>=1.16.0,<1.19.0).
And because tensorflow (2.3.0) depends on scipy (1.4.1)
and tensorflow (2.3.1) depends on numpy (>=1.16.0,<1.19.0), tensorflow (>=2.2,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1) or numpy (>=1.16.0,<1.19.0).
And because tensorflow (2.3.2) depends on numpy (>=1.16.0,<1.19.0)
and tensorflow (2.4.0) depends on numpy (>=1.19.2,<1.20.0), tensorflow (>=2.2,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1) or numpy (>=1.16.0,<1.19.0 || >=1.19.2,<1.20.0).
And because tensorflow (2.4.1) depends on numpy (>=1.19.2,<1.20.0)
and tensorflow (2.5.0) depends on numpy (>=1.19.2,<1.20.0), tensorflow (>=2.2,<3.0) requires numpy (>=1.16.0,<1.19.0 || >=1.19.2,<1.20.0) or scipy (1.4.1).
And because mljar-supervised (0.10.4) depends on both numpy (>=1.20.0) and scipy (1.6.1), mljar-supervised (0.10.4) is incompatible with tensorflow (>=2.2,<3.0).
So, because property-prediction-challenge depends on both tensorflow (^2.2) and mljar-supervised (0.10.4), version solving failed.
```
**Reproducible example**
- Step 1: Install poetry dependency management package with `pip install poetry==1.1.6`
- Step 2: Create a new folder and put the following into a new file `pyproject.toml`.
```shell
[tool.poetry]
name = "Dependency issues."
version = "0.1.0"
description = "Investigate dependency issues."
authors = ["nobody"]
[tool.poetry.dependencies]
python = "3.8.x"
tensorflow = "^2.2"
mljar-supervised = "0.10.4"
```
- Step 3: cd into the new folder and run `poetry install`
| 1medium
|
Title: Agent support multiple exit conditions
Body: **Is your feature request related to a problem? Please describe.**
I'm testing out the new experimental Agent implementation, which feels great (I'm not sure if I should create these issues here or in the haystack-experimental repository).
In my use case, In addition to the text responses, I also have multiple tool exit conditions, not just one. For example, think of an AI bot that can render different UI elements. Each UI element is a separate tool for the Agent. (same way as [Vercel's AI SDK generative UI](https://sdk.vercel.ai/docs/ai-sdk-ui/generative-user-interfaces) works).
**Describe the solution you'd like**
The agent could take a list of `exit_conditions` rather than only one. It could include `text` but also multiple tools that should end the loop. This way, the Agent could answer text (for example, ask a question from the user) or trigger one of the many UI tools.
Especially after [the latest change](https://github.com/deepset-ai/haystack-experimental/pull/245) on how the Agent is implemented, I see this could be trivial to implement. Change the `exit_condition` to a list of str and check if the tool is in the list (or if the bot decided to answer text and if the `exit_condition` includes `text`).
**Additional context**
- The latest update to Agent impl. https://github.com/deepset-ai/haystack-experimental/pull/245
- Example feature in Vercel SDK https://sdk.vercel.ai/docs/ai-sdk-ui/generative-user-interfaces
| 1medium
|
Title: Allow violinplot areas to be scaled by count
Body: Currently there are 3 methods to scale a violinplot:
> scale : _{“area”, “count”, “width”}, optional_
> The method used to scale the width of each violin. If `area`, each violin will have the same area. If `count`, the **width** of the violins will be scaled by the number of observations in that bin. If `width`, each violin will have the same width.
The count option is only able to scale the **width** by number of observations, but cannot scale the area by the number of observations. This means that if you have 3 violins, where the first two violins have 10 datapoints each and the 3rd violin has all 20 datapoints contained in the first two violins, you cannot make the area of the third violin equal to the sum of the area of the first two violins. Instead, using count will make the third violin double as wide as a 10 point violin, as is explained in the violinplot documentation.
In the following code, you can see that count scales the width, but I would like a version of count that can scale the area.
```python
import matplotlib.pyplot as plt
import seaborn as sns
one = [0.01*i for i in range(10)]
two = [0.3+0.03*i for i in range(10)]
data = [one, two, one+two]
fig = sns.violinplot(data=data, scale="count")
fig.set_xticklabels(['10 datapoints', 'another 10 datapoints\n(area should be equal\nto first violin)', '20 datapoints\n(area should be sum\nof first two violins)'])
plt.title('Violin Plot')
plt.show()
```

Here is the seaborn code:
```python
if np.isnan(peak_density):
span = 1
elif density_norm == "area":
span = data["density"] / max_density[norm_key]
elif density_norm == "count":
count = len(violin["observations"])
span = data["density"] / peak_density * (count / max_count[norm_key])
elif density_norm == "width":
span = data["density"] / peak_density
```
I would like it to be changed to something like:
<pre>
if np.isnan(peak_density):
span = 1
elif density_norm == "area":
span = data["density"] / max_density[norm_key]
</pre>
```diff
+ elif density_norm == "count_area":
+ count = len(violin["observations"])
+ span = data["density"] / max_density[norm_key] * (count / max_count[norm_key])
```
<pre>
elif density_norm == "width":
span = data["density"] / peak_density
elif density_norm == "count" or density_norm == "count_width":
count = len(violin["observations"])
span = data["density"] / peak_density * (count / max_count[norm_key])
</pre>
Also, the old "count" could be changed to "count_width". You could leave in "count" for backwards compatibility.
| 1medium
|
Title: Create a `_process_emscripten.py`
Body: See https://github.com/ipython/ipython/issues/14312#issuecomment-1918742541_
It would be good to have a test that check we don't have regression or prevent importing on emscripten
| 1medium
|
Title: [Bug] v4.4.0版本,前端不能滚动问题
Body: ### Product Version
v4.4.0
### Product Edition
- [X] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [ ] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [X] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### Environment Information

如图,下面明明还有数据,但是滚动条却无法继续滚动了,缩小网页尺寸可以看到下面的内容

### 🐛 Bug Description

如图,下面明明还有数据,但是滚动条却无法继续滚动了,缩小网页尺寸可以看到下面的内容

### Recurrence Steps
将每页显示数量调整到一页显示不全需要滚动的情况下就会复现
### Expected Behavior
_No response_
### Additional Information
_No response_
### Attempted Solutions
_No response_
| 1medium
|
Title: Add support for Earthformer
Body: https://github.com/amazon-science/earth-forecasting-transformer
| 1medium
|
Title: [Bug] Cannot install, spleeter wants llvmlite 0.36.0 while pulling in numba that wants llvmlite 0.37.0
Body: - [X] I didn't find a similar issue already open.
- [ ] I read the documentation (README AND Wiki)
- [X] I have installed FFMpeg
- [X] My problem is related to Spleeter only, not a derivative product (such as Webapplication, or GUI provided by others)
## Description
```
$ python3.7 -m spleeter separate -p spleeter:2stems -o output inneruniverse.mp3
Traceback (most recent call last):
File "/usr/lib64/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib64/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.7/site-packages/spleeter/__main__.py", line 262, in <module>
entrypoint()
File "/usr/local/lib/python3.7/site-packages/spleeter/__main__.py", line 256, in entrypoint
spleeter()
File "/usr/local/lib/python3.7/site-packages/typer/main.py", line 214, in __call__
return get_command(self)(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/typer/main.py", line 497, in wrapper
return callback(**use_params) # type: ignore
File "/usr/local/lib/python3.7/site-packages/spleeter/__main__.py", line 114, in separate
from .separator import Separator
File "/usr/local/lib/python3.7/site-packages/spleeter/separator.py", line 27, in <module>
from librosa.core import istft, stft
File "/usr/local/lib/python3.7/site-packages/librosa/__init__.py", line 211, in <module>
from . import core
File "/usr/local/lib/python3.7/site-packages/librosa/core/__init__.py", line 5, in <module>
from .convert import * # pylint: disable=wildcard-import
File "/usr/local/lib/python3.7/site-packages/librosa/core/convert.py", line 7, in <module>
from . import notation
File "/usr/local/lib/python3.7/site-packages/librosa/core/notation.py", line 8, in <module>
from ..util.exceptions import ParameterError
File "/usr/local/lib/python3.7/site-packages/librosa/util/__init__.py", line 83, in <module>
from .utils import * # pylint: disable=wildcard-import
File "/usr/local/lib/python3.7/site-packages/librosa/util/utils.py", line 10, in <module>
import numba
File "/usr/local/lib64/python3.7/site-packages/numba/__init__.py", line 197, in <module>
_ensure_llvm()
File "/usr/local/lib64/python3.7/site-packages/numba/__init__.py", line 109, in _ensure_llvm
raise ImportError(msg)
ImportError: Numba requires at least version 0.37.0 of llvmlite.
Installed version is 0.36.0.
Please update llvmlite.
```
```
$ sudo python3.7 -m pip install -U llvmlite==0.37.0
Collecting llvmlite==0.37.0
Downloading https://files.pythonhosted.org/packages/55/21/f7df5d35f3f5d0637d64a89f6b0461f2adf78e22916d6372486f8fc2193d/llvmlite-0.37.0.tar.gz (125kB)
97% |███████████████████████████████▏| 122kB 49kB/s eta 0:00 100% |████████████████████████████████| 133kB 49kB/s
Building wheels for collected packages: llvmlite
Building wheel for llvmlite (setup.py) ... error
Complete output from command /usr/bin/python3.7 -u -c "import setuptools, tokenize;__file__='/tmp/pip-install-7r17xd2s/llvmlite/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" bdist_wheel -d /tmp/pip-wheel-m1g2weyd --python-tag cp37:
running bdist_wheel
/usr/bin/python3.7 /tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py
LLVM version... Traceback (most recent call last):
File "/tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py", line 220, in <module>
main()
File "/tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py", line 210, in main
main_posix('linux', '.so')
File "/tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py", line 134, in main_posix
raise RuntimeError(msg) from None
RuntimeError: Could not find a `llvm-config` binary. There are a number of reasons this could occur, please see: https://llvmlite.readthedocs.io/en/latest/admin-guide/install.html#using-pip for help.
error: command '/usr/bin/python3.7' failed with exit status 1
----------------------------------------
Failed building wheel for llvmlite
Running setup.py clean for llvmlite
Failed to build llvmlite
spleeter 2.3.0 has requirement llvmlite<0.37.0,>=0.36.0, but you'll have llvmlite 0.37.0 which is incompatible.
```
## Step to reproduce
<!-- Indicates clearly steps to reproduce the behavior: -->
1. Install using `python3.7 -m pip` on Fedora 35
2. End up with above
## Environment
<!-- Fill the following table -->
| | |
| ----------------- | ------------------------------- |
| OS | Fedora Linux 35 |
| Installation type | pip |
| RAM available | |
| Hardware spec | skylake laptop cpu |
## Additional context
<!-- Add any other context about the problem here, references, cites, etc.. -->
| 1medium
|
Title: set jwt_cookie on signup
Body: First of all, thank you for the lib.
In my case, I need to set the `jwt_cookie` right after the signup. I've already read the docs and the issues too, so I know about the `get_token` decorator but I need a solution to be able to set the cookie.
is there any way to `authenticate` the user in a func, so the necessary tasks get done automatically? (including `jwt_cookie setup`)
if no, is it alright to set up the cookie manually?
| 1medium
|
Title: [tabular] Add target encoding preprocessing option
Body: Add target encoding preprocessing option. Likely best as a toggle for models, such as `"ag.target_encoding": True`.
Examples of target encoding getting performance improvements:
1. Kaggle Playground Series: https://www.kaggle.com/code/theoviel/explaining-and-accelerating-target-encoding
2. Nested K-Fold: https://github.com/rapidsai/deeplearning/blob/main/RecSys2020Tutorial/03_3_TargetEncoding.ipynb
3. category_encoders package: https://contrib.scikit-learn.org/category_encoders/index.html
| 1medium
|
Title: Audio preview in dataset viewer for audio array data without a path/filename
Body: ### Feature request
Huggingface has quite a comprehensive set of guides for [audio datasets](https://huggingface.co/docs/datasets/en/audio_dataset). It seems, however, all these guides assume the audio array data to be decoded/inserted into a HF dataset always originates from individual files. The [Audio-dataclass](https://github.com/huggingface/datasets/blob/3.0.1/src/datasets/features/audio.py#L20) appears designed with this assumption in mind. Looking at its source code it returns a dictionary with the keys `path`, `array` and `sampling_rate`.
However, sometimes users may have different pipelines where they themselves decode the audio array. This feature request has to do with wishing some clarification in guides on whether it is possible, and in such case how users can insert already decoded audio array data into datasets (pandas DataFrame, HF dataset or whatever) that are later saved as parquet, and still get a functioning audio preview in the dataset viewer.
Do I perhaps need to write a tempfile of my audio array slice to wav and capture the bytes object with `io.BytesIO` and pass that to `Audio()`?
### Motivation
I'm working with large audio datasets, and my pipeline reads (decodes) audio from larger files, and slices the relevant portions of audio from that larger file based on metadata I have available.
The pipeline is designed this way to avoid having to store multiple copies of data, and to avoid having to store tens of millions of small files.
I tried [test-uploading parquet files](https://huggingface.co/datasets/Lauler/riksdagen_test) where I store the audio array data of decoded slices of audio in an `audio` column with a dictionary with the keys `path`, `array` and `sampling_rate`. But I don't know the secret sauce of what the Huggingface Hub expects and requires to be able to display audio previews correctly.
### Your contribution
I could contribute a tool agnostic guide of creating HF audio datasets directly as parquet to the HF documentation if there is an interest. Provided you help me figure out the secret sauce of what the dataset viewer expects to display the preview correctly.
| 1medium
|
Title: Add example notebook that adds semantic search to existing system
Body: Use similarity pipeline to add semantic search to Elasticsearch
| 1medium
|
Title: 要是有能支持list为参数的_type就好了
Body: <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
**Why is this needed**:比如在多层卷积网络中设计卷积通道数,希望一次设计多层,而不是单个层的通道数设计,因为这样会产生很多冗余的不想要的没有价值的参数组合。这样一来,就需要一系列的list来表达这些设计方案。

这个batch tuner的办法似乎可以,但是又不支持普通的参数输入了。
**Without this feature, how does current nni work**:
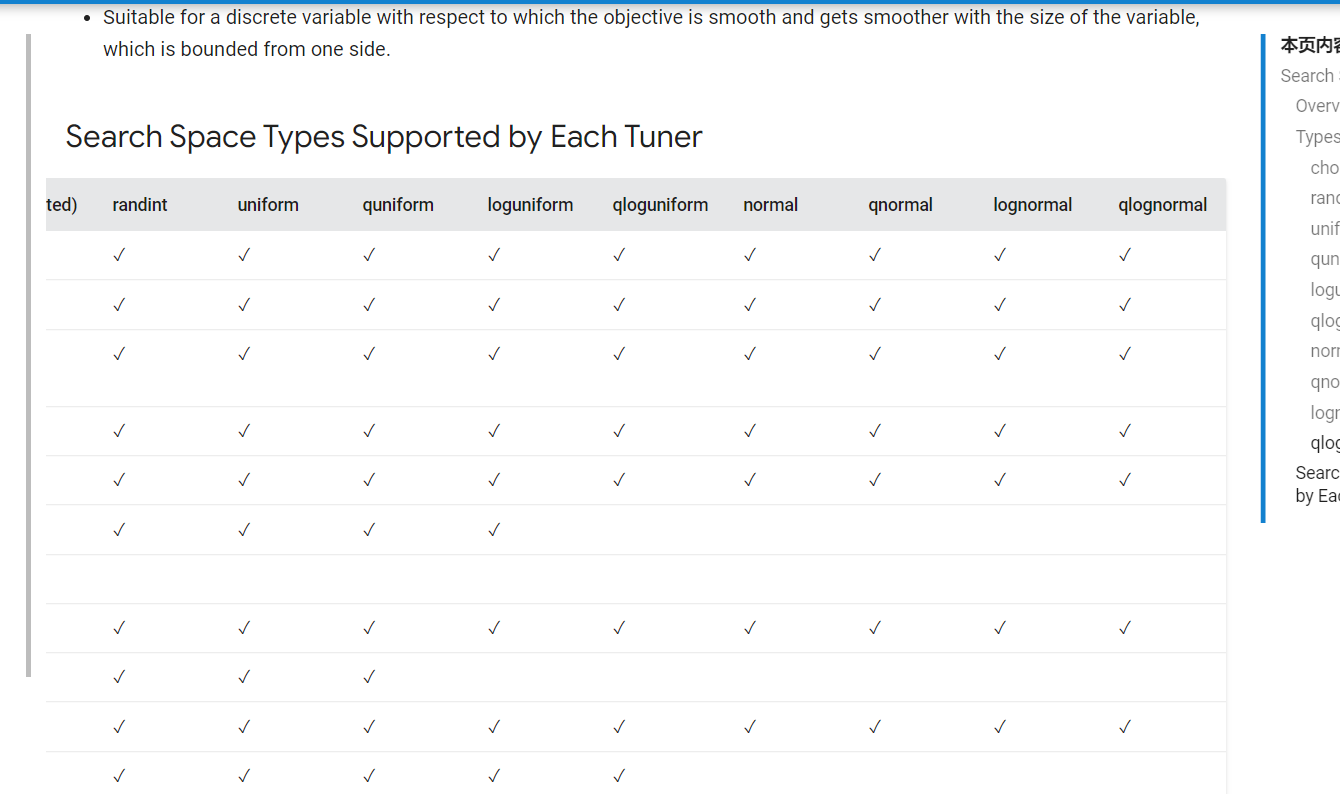
现有的所有seach space的type全都是标量
**Components that may involve changes**:
_type
**Brief description of your proposal if any**:
暂时没有
| 1medium
|
Title: django-storages, boto3, and django-progressbarupload
Body: I'm building a small app that stores whalesong. I've got my forms uploading to an S3 via boto3 and django-storages. I've also installed the development version of django-progressbarupload and am running django 2.0.6
django-progressbarupload gets it's progress data via
```
$.getJSON(upload_progress_url, {'X-Progress-ID': uuid}, function(data, status){
```
upload_progress_url is 'progressbarupload/upload_progress'. but the progress data just returns success / the full file size right away, even though the file is still uploading to S3. I'm not sure how these two components interact but thought perhaps django-storages isn't reporting upload progress in a way that django-progressbarupload expects.
Project Here:
https://github.com/kidconcept/whalejams
Video Here
https://tinytake.s3.amazonaws.com/pulse/elpulpo/attachments/8400940/TinyTake29-07-2018-11-47-06.mp4
| 1medium
|
Title: streamlit DuplicateWidgetID websearch = st.checkbox("Enable websearch")
Body: ### Description
I was trying to modify chain Smart Instruct.
```
agixt-streamlit-1 | File "/app/components/selectors.py", line 73, in prompt_options
agixt-streamlit-1 | websearch = st.checkbox("Enable websearch")
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/metrics_util.py", line 356, in wrapped_func
agixt-streamlit-1 | result = non_optional_func(*args, **kwargs)
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/elements/checkbox.py", line 137, in checkbox
agixt-streamlit-1 | return self._checkbox(
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/elements/checkbox.py", line 181, in _checkbox
agixt-streamlit-1 | checkbox_state = register_widget(
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/widgets.py", line 164, in register_widget
agixt-streamlit-1 | return register_widget_from_metadata(metadata, ctx, widget_func_name, element_type)
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/widgets.py", line 209, in register_widget_from_metadata
agixt-streamlit-1 | raise DuplicateWidgetID(
agixt-streamlit-1 | streamlit.errors.DuplicateWidgetID: There are multiple identical `st.checkbox` widgets with the
agixt-streamlit-1 | same generated key.
agixt-streamlit-1 |
agixt-streamlit-1 | When a widget is created, it's assigned an internal key based on
agixt-streamlit-1 | its structure. Multiple widgets with an identical structure will
agixt-streamlit-1 | result in the same internal key, which causes this error.
agixt-streamlit-1 |
agixt-streamlit-1 | To fix this error, please pass a unique `key` argument to
agixt-streamlit-1 | `st.checkbox`.
agixt-streamlit-1 |
```
### Steps to Reproduce the Bug
1. Chain Management
2. Select Modify chain
3. Select Smart Instruct
4. For 1st step, check "Show Advanced Options" and check "Enable websearch".
5. Press Modify step
6. Scrolling down to 2nd step, and do the same.
### Expected Behavior
to run w/o error
### Operating System
- [X] Linux
- [ ] Microsoft Windows
- [ ] Apple MacOS
- [ ] Android
- [ ] iOS
- [ ] Other
### Python Version
- [ ] Python <= 3.9
- [X] Python 3.10
- [ ] Python 3.11
### Environment Type - Connection
- [X] Local - You run AGiXT in your home network
- [ ] Remote - You access AGiXT through the internet
### Runtime environment
- [X] Using docker compose
- [ ] Using local
- [ ] Custom setup (please describe above!)
### Acknowledgements
- [X] I have searched the existing issues to make sure this bug has not been reported yet.
- [X] I am using the latest version of AGiXT.
- [X] I have provided enough information for the maintainers to reproduce and diagnose the issue.
| 1medium
|
Title: Engine crashes
Body: ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Training
### Bug

### Environment
I have tried the old version and the new version of yolov5 6.2 and 7.0, and the situation is the same. I also found a lot of information and changed the parameters in export.py, but it still doesn't work.
### Minimal Reproducible Example
_No response_
### Additional
_No response_
### Are you willing to submit a PR?
- [X] Yes I'd like to help by submitting a PR!
| 1medium
|
Title: [Feature request] Can SpaceToDepth also add mode attribute?
Body: ### System information
ONNX 1.17
### What is the problem that this feature solves?
Current SpaceToDepth Op https://github.com/onnx/onnx/blob/main/docs/Operators.md#spacetodepth doesn't have attributes to assign the DCR/CRD, and can only supports CRD in computation.
But the DepthToSpace Op https://github.com/onnx/onnx/blob/main/docs/Operators.md#depthtospace has such mode attributes, and is more flexible in supporting models conversion from tensorflow.
### Alternatives considered
_No response_
### Describe the feature
_No response_
### Will this influence the current api (Y/N)?
_No response_
### Feature Area
_No response_
### Are you willing to contribute it (Y/N)
None
### Notes
_No response_
| 1medium
|
Title: Add Hadolint
Body: ## Description
Adding hadolint to pre-commit
## Rationale
Linting Dockerfile. Current lint warnings:
```
Lint Dockerfiles.........................................................Failed
- hook id: hadolint-docker
- exit code: 1
compose/local/django/Dockerfile:10 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/django/Dockerfile:17 DL3045 warning: `COPY` to a relative destination without `WORKDIR` set.
compose/local/django/Dockerfile:38 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/django/Dockerfile:38 DL3009 info: Delete the apt-get lists after installing something
compose/local/django/Dockerfile:49 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/django/Dockerfile:68 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:72 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:77 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:81 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:85 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/docs/Dockerfile:10 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/docs/Dockerfile:35 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/docs/Dockerfile:55 DL3042 warning: Avoid use of cache directory with pip. Use `pip install --no-cache-dir <package>`
compose/local/docs/Dockerfile:60 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:11 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/production/django/Dockerfile:18 DL3045 warning: `COPY` to a relative destination without `WORKDIR` set.
compose/production/django/Dockerfile:42 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/production/django/Dockerfile:62 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:67 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:70 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:75 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:80 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
```
| 1medium
|
Title: GPU not using more than 2
Body: Hi. I am trying to train the model.
Currently, I am training the model with the following configurations :
num_threads = 64
batch_size = 2
load_size = 1024
crop_size = 512
In this setting, it only uses 2 gpus.
If I increase the batch size, the number of GPU usage increases accordingly.
That is, batch size of 4 results to using 4 GPUs, batch size of 8 results to using 8 GPUs and etc.
However, if I increase the batch size more than 2, CUDA out of memory error pops out.
How can I increase the batch size? is decreasing the load_size only option?
Thank you
| 1medium
|
Title: Age Prediction being either 0 or 90+
Body: I am currently working on a school project and I have taken deepface's code and compacted the code to only the stuff I needed to predict Age, Gender and Race.
my current code is working fine for Gender and Race, but my age is either 0 or 90+ most of the time, please advise on what I am doing wrong, thank you for your time! (Source Code is pasted below for demonstration video, click [here](https://1drv.ms/f/s!AkXMBs0vVpo9kIZt6gcGCyZ3OvITXw?e=Sus8eo))
```py
import os
import cv2
import sys
import time
import math
import gdown
import warnings
import tensorflow
import numpy as np
import pandas as pd
from numba import jit
import seaborn as sns
from PIL import Image
import tensorflow as tf
from glob import glob, iglob
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
if tf_version == 1:
from keras.models import Model, Sequential
from keras.layers import (
Convolution2D,
ZeroPadding2D,
MaxPooling2D,
Flatten,
Dropout,
Activation,
)
else:
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.layers import (
Convolution2D,
ZeroPadding2D,
MaxPooling2D,
Flatten,
Dropout,
Activation,
)
class VGGface:
def __init__(self):
self.home = os.getcwd() + "\deepface"
print("Loading VGG Face Model . . .")
self.VGGfaceModel = Sequential()
self.VGGfaceModel.add(ZeroPadding2D((1, 1), input_shape=(224, 224, 3)))
self.VGGfaceModel.add(Convolution2D(64, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(64, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(128, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(128, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(256, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(256, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(256, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(Convolution2D(4096, (7, 7), activation="relu"))
self.VGGfaceModel.add(Dropout(0.5))
self.VGGfaceModel.add(Convolution2D(4096, (1, 1), activation="relu"))
self.VGGfaceModel.add(Dropout(0.5))
self.VGGfaceModel.add(Convolution2D(2622, (1, 1)))
self.VGGfaceModel.add(Flatten())
self.VGGfaceModel.add(Activation("softmax"))
# -----------------------------------
output = self.home + "/.deepface/weights/vgg_face_weights.h5"
if os.path.isfile(output) != True:
print("vgg_face_weights.h5 will be downloaded...")
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/vgg_face_weights.h5", output, quiet=False)
# -----------------------------------
self.VGGfaceModel.load_weights(output)
# -----------------------------------
# TO-DO: why?
self.vgg_face_descriptor = Model(inputs=self.VGGfaceModel.layers[0].input, outputs=self.VGGfaceModel.layers[-2].output)
def AgeDetectionModel(self):
model = self.VGGfaceModel
# --------------------------
classes = 101
base_model_output = Sequential()
base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
base_model_output = Flatten()(base_model_output)
base_model_output = Activation("softmax")(base_model_output)
# --------------------------
age_model = Model(inputs=model.input, outputs=base_model_output)
# --------------------------
# load weights
if os.path.isfile(self.home + "/.deepface/weights/age_model_weights.h5") != True:
print("age_model_weights.h5 will be downloaded...")
output = self.home + "/.deepface/weights/age_model_weights.h5"
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/age_model_weights.h5", output, quiet=False)
age_model.load_weights(self.home + "/.deepface/weights/age_model_weights.h5")
return age_model
def GenderDetectionModel(self):
model = self.VGGfaceModel
# --------------------------
classes = 2
base_model_output = Sequential()
base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
base_model_output = Flatten()(base_model_output)
base_model_output = Activation("softmax")(base_model_output)
# --------------------------
gender_model = Model(inputs=model.input, outputs=base_model_output)
# --------------------------
# load weights
if os.path.isfile(self.home + "/.deepface/weights/gender_model_weights.h5") != True:
print("gender_model_weights.h5 will be downloaded...")
output = self.home + "/.deepface/weights/gender_model_weights.h5"
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/gender_model_weights.h5", output, quiet=False)
gender_model.load_weights(self.home + "/.deepface/weights/gender_model_weights.h5")
return gender_model
def RaceDetectionModel(self):
model = self.VGGfaceModel
# --------------------------
classes = 6
base_model_output = Sequential()
base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
base_model_output = Flatten()(base_model_output)
base_model_output = Activation("softmax")(base_model_output)
# --------------------------
race_model = Model(inputs=model.input, outputs=base_model_output)
# --------------------------
# load weights
if os.path.isfile(self.home + "/.deepface/weights/race_model_single_batch.h5") != True:
print("race_model_single_batch.h5 will be downloaded...")
output = self.home + "/.deepface/weights/race_model_single_batch.h5"
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/race_model_single_batch.h5", output, quiet=False)
race_model.load_weights(self.home + "/.deepface/weights/race_model_single_batch.h5")
return race_model
def results2StringLabel_DeepFace(self, genderArray:np.ndarray, raceArray:np.ndarray, ageArray:np.ndarray):
genderLabels = ("woman", "man")
raceLabels = ("asian", "indian", "black", "white", "middle eastern", "latino hispanic")
# Evaluate Gender Label
for index, boolean in enumerate(genderArray[0]):
if boolean:
gender = genderLabels[index]
# Evaluate Race Label
for index, boolean in enumerate(raceArray[0]):
if boolean:
race = raceLabels[index]
# Turn Age into Integer
output_indexes = np.array(list(range(0, 101)))
apparent_age = np.sum(ageArray * output_indexes)
age = int(apparent_age)
return age, gender, race
def loadModels(self):
print("Loading Age Detection Model")
self.ageDetection = self.AgeDetectionModel()
print("Loading Gender Detection Model")
self.genderDetection = self.GenderDetectionModel()
print("Loading Race Detection Model")
self.raceDetection = self.RaceDetectionModel()
print("Model Loading Complete!")
def predict(self, image:np.ndarray):
image = cv2.resize(image, (224,224))
image = np.reshape(image, (-1,224,224,3))
ageResult = self.ageDetection.predict(image)
genderResult = self.genderDetection.predict(image)
raceResult = self.raceDetection.predict(image)
age, gender, race = self.results2StringLabel_DeepFace(genderArray=genderResult,\
raceArray=raceResult,\
ageArray=ageResult)
return age, gender, race
# OpenCV backend for deepface Face Detection
class OpenCV_FaceDetector:
def __init__(self) -> None:
# Get OpenCV Path.
opencv_home = cv2.__file__
folders = opencv_home.split(os.path.sep)[0:-1]
self.opencv_path = "\\".join(folders)
"""
path = folders[0]
for folder in folders[1:]:
self.opencv_path = path + "/" + folder
- Windows Design only huh
"""
# Initiate the detector dict. and build cascades to save on processing time later (hopefully)
self.detector = {}
self.detector["face_detector"] = self.build_cascade("haarcascade")
self.detector["eye_detector"] = self.build_cascade("haarcascade_eye")
def build_cascade(self, model_name="haarcascade"):
if model_name == "haarcascade":
face_detector_path = self.opencv_path + "\\data\\haarcascade_frontalface_default.xml"
if os.path.isfile(face_detector_path) != True:
raise ValueError(
"Confirm that opencv is installed on your environment! Expected path ",
face_detector_path,
" violated.",
)
detector = cv2.CascadeClassifier(face_detector_path)
elif model_name == "haarcascade_eye":
eye_detector_path = self.opencv_path + "\\data\\haarcascade_eye.xml"
if os.path.isfile(eye_detector_path) != True:
raise ValueError(
"Confirm that opencv is installed on your environment! Expected path ",
eye_detector_path,
" violated.",
)
detector = cv2.CascadeClassifier(eye_detector_path)
else:
raise ValueError(f"unimplemented model_name for build_cascade - {model_name}")
return detector
def detect_face(self, img, align=True):
responses = []
detected_face = None
img_region = [0, 0, img.shape[1], img.shape[0]]
faces = []
try:
# faces = detector["face_detector"].detectMultiScale(img, 1.3, 5)
# note that, by design, opencv's haarcascade scores are >0 but not capped at 1
faces, _, scores = self.detector["face_detector"].detectMultiScale3(
img, 1.1, 10, outputRejectLevels=True
)
except:
pass
if len(faces) > 0:
for (x, y, w, h), confidence in zip(faces, scores):
detected_face = img[int(y) : int(y + h), int(x) : int(x + w)]
if align:
detected_face = self.align_face(self.detector["eye_detector"], detected_face)
img_region = [x, y, w, h]
responses.append((detected_face, img_region, confidence))
return responses
def align_face(self,eye_detector, img):
detected_face_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # eye detector expects gray scale image
# eyes = eye_detector.detectMultiScale(detected_face_gray, 1.3, 5)
eyes = eye_detector.detectMultiScale(detected_face_gray, 1.1, 10)
# ----------------------------------------------------------------
# opencv eye detectin module is not strong. it might find more than 2 eyes!
# besides, it returns eyes with different order in each call (issue 435)
# this is an important issue because opencv is the default detector and ssd also uses this
# find the largest 2 eye. Thanks to @thelostpeace
eyes = sorted(eyes, key=lambda v: abs(v[2] * v[3]), reverse=True)
# ----------------------------------------------------------------
if len(eyes) >= 2:
# decide left and right eye
eye_1 = eyes[0]
eye_2 = eyes[1]
if eye_1[0] < eye_2[0]:
left_eye = eye_1
right_eye = eye_2
else:
left_eye = eye_2
right_eye = eye_1
# -----------------------
# find center of eyes
left_eye = (int(left_eye[0] + (left_eye[2] / 2)), int(left_eye[1] + (left_eye[3] / 2)))
right_eye = (int(right_eye[0] + (right_eye[2] / 2)), int(right_eye[1] + (right_eye[3] / 2)))
img = self.alignment_procedure(img, left_eye, right_eye)
return img # return img anyway
def alignment_procedure(self, img, left_eye, right_eye):
# this function aligns given face in img based on left and right eye coordinates
left_eye_x, left_eye_y = left_eye
right_eye_x, right_eye_y = right_eye
# -----------------------
# find rotation direction
if left_eye_y > right_eye_y:
point_3rd = (right_eye_x, left_eye_y)
direction = -1 # rotate same direction to clock
else:
point_3rd = (left_eye_x, right_eye_y)
direction = 1 # rotate inverse direction of clock
# -----------------------
# find length of triangle edges
a = self.findEuclideanDistance(np.array(left_eye), np.array(point_3rd))
b = self.findEuclideanDistance(np.array(right_eye), np.array(point_3rd))
c = self.findEuclideanDistance(np.array(right_eye), np.array(left_eye))
# -----------------------
# apply cosine rule
if b != 0 and c != 0: # this multiplication causes division by zero in cos_a calculation
cos_a = (b * b + c * c - a * a) / (2 * b * c)
angle = np.arccos(cos_a) # angle in radian
angle = (angle * 180) / math.pi # radian to degree
# -----------------------
# rotate base image
if direction == -1:
angle = 90 - angle
img = Image.fromarray(img)
img = np.array(img.rotate(direction * angle))
# -----------------------
return img # return img anyway
def findEuclideanDistance(self, source_representation, test_representation):
if isinstance(source_representation, list):
source_representation = np.array(source_representation)
if isinstance(test_representation, list):
test_representation = np.array(test_representation)
euclidean_distance = source_representation - test_representation
euclidean_distance = np.sum(np.multiply(euclidean_distance, euclidean_distance))
euclidean_distance = np.sqrt(euclidean_distance)
return euclidean_distance
```
The code that is interfacing with my class. Above code is in a file named 'operations.py'
```py
from operations import VGGface, OpenCV_FaceDetector
from glob import glob
import numpy as np
import cv2
VGGface = VGGface()
VGGface.loadModels()
faceDetector = OpenCV_FaceDetector()
"""
testImage = cv2.imread("UTKFace\\InTheWild_part1\\10_0_0_20170103233459275.jpg")
faces = faceDetector.detect_face(img=testImage,align=True)
# [<Detection Index>][<0:Detection Image, 1:Detection Cordinates>]
testImage1 = faces[0][0]
print(testImage)
print(type(testImage))
age, gender, race = VGG.predict(testImage1)
print(age,gender, race)
# Using cv2.imshow() method
# Displaying the image
cv2.imshow("test", testImage)
# waits for user to press any key
# (this is necessary to avoid Python kernel form crashing)
cv2.waitKey(0)
# closing all open windows
cv2.destroyAllWindows()
"""
print(glob("Videos\\DEMO_*_*_NG.mp4"))
for file in glob("Videos\\DEMO_*_*_NG.mp4"):
# Create an object to read
# from File
VideoFile_path = file
video = cv2.VideoCapture(file)
# We need to check if File
# is opened previously or not
if (video.isOpened() == False):
print("Error reading video file")
# We need to set resolutions.
# so, convert them from float to integer.
size = (int(video.get(3)), int(video.get(4)))
print(size)
# Below VideoWriter object will create
# a frame of above defined The output
# is stored in '*.mp4' file.
result = cv2.VideoWriter(f'{file[:-4]}_preds.mp4',\
cv2.VideoWriter_fourcc(*'mp4v'),\
20.0, size)
while(True):
ret, frame = video.read()
if ret == True:
# Process the frame with bounding boxes
processingFrame = faceDetector.detect_face(img=frame,align=True)
# [<Detection Index>][<0:Detection Image, 1:Detection Cordinates>]
for detection in processingFrame:
predictedAge, predictedGender, predictedRace = VGGface.predict(detection[0])
text_size, _ = cv2.getTextSize(f"Age: {predictedAge} | Gender: {predictedGender} | Race: {predictedRace}", cv2.FONT_HERSHEY_SIMPLEX, 1, 2)
rectangle_width = text_size[0] + 10
rectangle_height = text_size[1] + 40
print(detection[1])
# Draw Bounding boxes and display predictions
# x1,y1 = start_point
# y1 + x2,y1 + y2 = end_point
# frame x1 y1 x2 y2 B G R line Thickness
frame = cv2.rectangle(frame, (detection[1][0], detection[1][1]), (detection[1][0] + detection[1][2], detection[1][1] + detection[1][3]), (255, 0, 0), 2)
# Draw Bounding Boxes Around text
frame = cv2.rectangle(frame, (detection[1][0], detection[1][1]),\
(detection[1][0] + rectangle_width, detection[1][1] - rectangle_height), (255, 0, 0), -1)
# Displaying Text
frame = cv2.putText(frame, f"Age: {predictedAge} | Gender: {predictedGender} | Race: {predictedRace}",\
(detection[1][0], detection[1][1] - 20),\
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# Display the frames
# saved in the file
cv2.imshow('Frame', frame)
# Write the frame into the
# file '*.mp4'
result.write(frame)
# Press S on keyboard
# to stop the process
if cv2.waitKey(1) & 0xFF == ord('s'):
break
# Break the loop
else:
break
# When everything done, release
# the video capture and video
# write objects
video.release()
result.release()
# Closes all the frames
cv2.destroyAllWindows()
print(f"The video {VideoFile_path} was successfully saved")
```
Any and all help will be appreciated.
| 1medium
|
Title: `strict = False` does not work when the checkpoint is distributed
Body: ### Bug description
When loading a sharded checkpoint with:
```python
fabric.load(ckpt_path, state, strict = False)
```
the `_distributed_checkpoint_load` function called in the `FSDPStrategy` will raise an error if a checkpoint misses a key from the model in `state`, which should not be the case as `strict = False`.
A fix could be to take advantage of the [DefaultLoadPlanner](https://pytorch.org/docs/stable/distributed.checkpoint.html#torch.distributed.checkpoint.DefaultLoadPlanner) in `torch.distributed.checkpoint.load`, setting the `allow_partial_load` argument to the opposite of `strict`.
### What version are you seeing the problem on?
v2.4
### How to reproduce the bug
_No response_
### Error messages and logs
```
[rank7]: Traceback (most recent call last):
[rank7]: File "my_codebase/train_fabric.py", line 226, in <module>
[rank7]: main(**vars(args))
[rank7]: File "my_codebase/train_fabric.py", line 148, in main
[rank7]: fabric.load(ckpt_path, state, strict = strict_mode)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/lightning/fabric/fabric.py", line 773, in load
[rank7]: remainder = self._strategy.load_checkpoint(path=path, state=unwrapped_state, strict=strict)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/lightning/fabric/strategies/fsdp.py", line 570, in load_checkpoint
[rank7]: _distributed_checkpoint_load(module_state, path)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/lightning/fabric/strategies/fsdp.py", line 886, in _distributed_checkpoint_load
[rank7]: load(module_state, checkpoint_id=path)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 434, in inner_func
[rank7]: return func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 168, in load
[rank7]: _load_state_dict(
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 220, in _load_state_dict
[rank7]: central_plan: LoadPlan = distW.reduce_scatter("plan", local_step, global_step)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 192, in reduce_scatter
[rank7]: raise result
[rank7]: torch.distributed.checkpoint.api.CheckpointException: CheckpointException ranks:dict_keys([0, 1, 2, 3, 4, 5, 6, 7])
[rank7]: Traceback (most recent call last): (RANK 0)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 165, in reduce_scatter
[rank7]: local_data = map_fun()
[rank7]: ^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 209, in local_step
[rank7]: local_plan = planner.create_local_plan()
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 197, in create_local_plan
[rank7]: return create_default_local_load_plan(
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 316, in create_default_local_load_plan
[rank7]: raise RuntimeError(f"Missing key in checkpoint state_dict: {fqn}.")
[rank7]: RuntimeError: Missing key in checkpoint state_dict: model.lm_model.lm_head.weight.
[rank7]: Traceback (most recent call last): (RANK 1)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 165, in reduce_scatter
[rank7]: local_data = map_fun()
[rank7]: ^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 209, in local_step
[rank7]: local_plan = planner.create_local_plan()
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 197, in create_local_plan
[rank7]: return create_default_local_load_plan(
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 316, in create_default_local_load_plan
[rank7]: raise RuntimeError(f"Missing key in checkpoint state_dict: {fqn}.")
[rank7]: RuntimeError: Missing key in checkpoint state_dict: model.lm_model.lm_head.weight.
[rank7]: Traceback (most recent call last): (RANK 2)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 165, in reduce_scatter
[rank7]: local_data = map_fun()
[rank7]: ^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 209, in local_step
[rank7]: local_plan = planner.create_local_plan()
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 197, in create_local_plan
[rank7]: return create_default_local_load_plan(
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 316, in create_default_local_load_plan
[rank7]: raise RuntimeError(f"Missing key in checkpoint state_dict: {fqn}.")
[rank7]: RuntimeError: Missing key in checkpoint state_dict: model.my_key.
```
### Environment
<details>
<summary>Current environment</summary>
```
#- PyTorch Lightning Version (e.g., 2.4.0): 2.4.0
#- PyTorch Version (e.g., 2.4): 2.4.0+rocm6.0
#- Python version (e.g., 3.12): 3.11
</details>
### More info
_No response_
| 1medium
|
Title: Jupyter>>nbviewer slides Fail, notebook view fine
Body: When using the web based iPython Notebook/Jupyter capability, i created a notebook with markdown cells of text and code cells to display the code and plots for matplotlib and bokeh. I then download that as .ipynb open with sublime, copy and paste to git, then access it on nbviewer through my git account. When looking at it here:
http://nbviewer.ipython.org/github/angisgrate/test/blob/master/pyohio3.ipynb
in notebook view, it works fine. the markdown, code, and plot steps are all there.
When switching to slides view, the intent of the creation needed for the presentation, this code blocks occurs first, blocking out the first 10 markdown steps and all the matplotlib steps, rendering this weird code without the plots:
http://nbviewer.ipython.org/format/slides/github/angisgrate/test/blob/master/pyohio3.ipynb
How can i fix this asap?? I've looked through and there was a similar problem in 2014 with slides, but it yielded an actual "Error" that i'm not seeing, just this contorted view
| 1medium
|
Title: question: trendline equation
Body: ### Question
Is it possible to extract trendline equation from chart?
| 1medium
|
Title: MultiselectField is not working (with xlsx format)
Body: **Describe the bug**
In our Django project, we have a model with Multiselectfield, when we import an export from this model, we see that these fields are not loaded.
https://pypi.org/project/django-multiselectfield/
**To Reproduce**
1. Create a model with a MultiSelectField. (for example:
```python
class SampleStudent:
name= models.CharField(max_length=128, null=True, blank=True)
countries = MultiSelectField(
choices=COUNTRY_CODE_CHOICES,
null=True,
blank=True
)
```
2. Generate a few random rows.
3. export as xlsx
4. try to import related file
**Versions (please complete the following information):**
- Django Import Export: 4.2.0
- Python 3.11
- Django 4.2.13
**Expected behavior**
What should happen is that MultiSelectField should be exported correctly and imported correctly.
| 1medium
|
Title: [Bug]
Body: ### Product Version
ssh 秘钥连接windows报错
### Product Edition
- [x] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [x] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### Environment Information
目标机器
ssh server: v9.8.1.0p1-Preview
os version :win10 1809
### 🐛 Bug Description

测试过用其他客户端,用私钥登录没有问题。
如果用ssh密码登录也是没有问题的,只在用秘钥对登录的时候有问题
### Recurrence Steps
ssh 密钥对登录
### Expected Behavior
_No response_
### Additional Information
_No response_
### Attempted Solutions
_No response_
| 1medium
|
Title: training question
Body: Hello! I trained the code 'train_refine.py' without any revise using my own dataset to get the pth file.However,I find the network structure I have got is different from the pretrained model you have provide:pytorch_mobilenetv2.The following image1 is your pretrained model structure and the second one image2 is mine

image1

image2
Could you please tell me why the network structure of mine has another 10 layers than yours? and if I want to change the code to get a model like yours,how should I do ?
2.Another question is that I test the model between yours and mine on CPU,I found that your model's flops is twice smaller than mine,which using the same training code.I don’t know if it’s because my network structure has 10 layers more than yours. Like the first question said.
my English is not good,sorry And I hope you can solve my doubts,Thank you!
| 1medium
|
Title: 【BUG】Video example code is not working...
Body: * face_recognition version: 1.3.0
* Python version: 3.9.16
* Operating System: Rocky Linux 9.2 (Blue Onyx) x86_64
### Description
The example `facerec_from_video_file.py` is not running.
Here's the the terminal output...
```bash
$ /bin/python /home/ander/face_recognition/examples/facerec_from_video_file.py
Traceback (most recent call last):
File "/home/ander/face_recognition/examples/facerec_from_video_file.py", line 50, in <module>
face_encodings = face_recognition.face_encodings(rgb_frame, face_locations)
File "/home/ander/.local/lib/python3.9/site-packages/face_recognition/api.py", line 214, in face_encodings
return [np.array(face_encoder.compute_face_descriptor(face_image, raw_landmark_set, num_jitters)) for raw_landmark_set in raw_landmarks]
File "/home/ander/.local/lib/python3.9/site-packages/face_recognition/api.py", line 214, in <listcomp>
return [np.array(face_encoder.compute_face_descriptor(face_image, raw_landmark_set, num_jitters)) for raw_landmark_set in raw_landmarks]
TypeError: compute_face_descriptor(): incompatible function arguments. The following argument types are supported:
1. (self: _dlib_pybind11.face_recognition_model_v1, img: numpy.ndarray[(rows,cols,3),numpy.uint8], face: _dlib_pybind11.full_object_detection, num_jitters: int = 0, padding: float = 0.25) -> _dlib_pybind11.vector
2. (self: _dlib_pybind11.face_recognition_model_v1, img: numpy.ndarray[(rows,cols,3),numpy.uint8], num_jitters: int = 0) -> _dlib_pybind11.vector
3. (self: _dlib_pybind11.face_recognition_model_v1, img: numpy.ndarray[(rows,cols,3),numpy.uint8], faces: _dlib_pybind11.full_object_detections, num_jitters: int = 0, padding: float = 0.25) -> _dlib_pybind11.vectors
4. (self: _dlib_pybind11.face_recognition_model_v1, batch_img: List[numpy.ndarray[(rows,cols,3),numpy.uint8]], batch_faces: List[_dlib_pybind11.full_object_detections], num_jitters: int = 0, padding: float = 0.25) -> _dlib_pybind11.vectorss
5. (self: _dlib_pybind11.face_recognition_model_v1, batch_img: List[numpy.ndarray[(rows,cols,3),numpy.uint8]], num_jitters: int = 0) -> _dlib_pybind11.vectors
Invoked with: <_dlib_pybind11.face_recognition_model_v1 object at 0x7f8bc98bb2b0>, array([[[ 8, 3, 0],
[12, 7, 4],
[18, 13, 10],
...,
[24, 9, 0],
[24, 9, 0],
[24, 9, 0]],
[[ 8, 3, 0],
[12, 7, 4],
[18, 13, 10],
...,
[24, 9, 0],
[24, 9, 0],
[24, 9, 0]],
[[ 7, 2, 0],
[11, 6, 3],
[16, 11, 8],
...,
[24, 9, 0],
[24, 9, 0],
[24, 9, 0]],
...,
[[ 7, 3, 0],
[ 7, 3, 0],
[ 9, 3, 0],
...,
[17, 1, 0],
[11, 1, 2],
[11, 1, 2]],
[[ 7, 3, 0],
[ 7, 3, 0],
[ 9, 3, 0],
...,
[17, 2, 0],
[11, 1, 0],
[11, 1, 0]],
[[ 7, 3, 0],
[ 7, 3, 0],
[ 9, 3, 0],
...,
[17, 2, 0],
[11, 1, 0],
[11, 1, 0]]], dtype=uint8), <_dlib_pybind11.full_object_detection object at 0x7f8ba3186e70>, 1
```
### What I Did
```bash
git clone https://github.com/ageitgey/face_recognition.git
cd face_recognition/examples
python facerec_from_video_file.py
```
| 1medium
|
Title: WebGL backend
Body: How complicated it would be to implement a WebGL backend? Assuming we have a `gloo.js` that implements gloo in JavaScript, we'd at least need to export an entire window to a structure with the list of programs, GLSL, variables, data, etc.
Alternatively, we could have another gloo implementation which creates such structure instead of displaying something, or it could generate GLIR commands like in VisPy.
For interactivity we can always reimplement it in JavaScript on top of gloo.js.
| 2hard
|
Title: Actual query results and Tortoise results inconsistent with filtering using custom SQL annotations
Body: **Describe the bug**
The following demo model outputs SQL that returns multiple results. However, when actually executing the query, Tortoise for unknown reasons only returns one result.
Here is the model:
```python
class Demo(Model):
active = fields.BooleanField(default=True)
user_id = fields.BigIntField(index=True)
start = fields.DatetimeField(auto_now=True)
end = fields.DatetimeField(default=None, null=True)
@staticmethod
async def get_active():
return Demo.filter(consumed__gt=0.0)\
.filter(active=True)\
.annotate(active_seconds=RawSQL(f'{int(time.time())} - UNIX_TIMESTAMP(`start`)'))\
.filter(active_seconds__lt=90000)\
.sql()
```
Here is the query it outputs:
```sql
SELECT `user_id`,`end`,`id`,`active`,`start`,1675345393 - UNIX_TIMESTAMP(`start`) `active_seconds` FROM `demo` WHERE `active`=true AND 1675345393 - UNIX_TIMESTAMP(`start`)<90000
```
This query returns 4 results,

Running the query through Tortoise again now, it returns nothing, unless I increase active_seconds to 100,000, then it returns 2 results again.
**To Reproduce**
You'll likely need to re-create your own demo tables and run a query with a filter similar to what is demonstrated above.
**Expected behavior**
It is doing something outside of the query and filtering results that it should not be filtering. Any results that are returned by the database backend should be processed. For some reason, that is not happening here. I have no idea what it could be doing between running the query, which works and returns the correct number of results, and processing the results into objects.
| 1medium
|
Title: torch::jit::load error
Body: ### 🐛 Describe the bug
I have done script my model in python, and want load it in c++. It can be confirmed that torch_scatcher and torch_sparse have been successfully compiled.
I can run the following example and get the correct result.
````
#include <torch/script.h>
#include <torch/torch.h>
#include <pytorch_scatter/scatter.h>
#include <pytorch_sparse/sparse.h>
#include <iostream>
int main()
{
torch::Tensor src = torch::tensor({ 0.5, 0.4, 0.1, 0.6 });
torch::Tensor index = torch::tensor({ 0, 0, 1, 1 });
std::cout << src << std::endl;
std::cout << index << std::endl;
std::cout << torch::cuda::cudnn_is_available() << std::endl;
std::cout << torch::cuda::is_available() << std::endl;
std::cout << scatter_sum(src, index, 0, torch::nullopt, torch::nullopt) << std::endl;
torch::Tensor tensor = torch::tensor({ 0, 0, 0, 0, 1, 1, 1});
std::cout << tensor << std::endl;
std::cout << ind2ptr(tensor, 2) << std::endl;
}
````
````
output:
0.5000
0.4000
0.1000
0.6000
[ CPUFloatType{4} ]
0
0
1
1
[ CPULongType{4} ]
1
1
0.9000
0.7000
[ CPUFloatType{2} ]
0
0
0
0
1
1
1
[ CPULongType{7} ]
0
4
7
[ CPULongType{3} ]
````
But when I load my script model, an error will be thrown.
````
torch::jit::script::Module model;
std::string file_name = "D:\\TESTProgram\\Libtorch_1.13_cu116\\TorchTest_1.13+cu116\\Dualgnn_module_0409.pt";
try {
model = torch::jit::load(file_name);
}
catch (std::exception& e)
{
std::cout << e.what() << std::endl;
return -1;
}
````
````
Unknown builtin op: torch_scatter::segment_sum_csr.
Could not find any similar ops to torch_scatter::segment_sum_csr. This op may not exist or may not be currently supported in TorchScript.
:
File "code/__torch__/torch_scatter/segment_csr.py", line 35
indptr: Tensor,
out: Optional[Tensor]=None) -> Tensor:
_10 = ops.torch_scatter.segment_sum_csr(src, indptr, out)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return _10
def segment_mean_csr(src: Tensor,
'segment_sum_csr' is being compiled since it was called from 'segment_csr'
Serialized File "code/__torch__/torch_scatter/segment_csr.py", line 5
out: Optional[Tensor]=None,
reduce: str="sum") -> Tensor:
_0 = __torch__.torch_scatter.segment_csr.segment_sum_csr
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
_1 = __torch__.torch_scatter.segment_csr.segment_mean_csr
_2 = __torch__.torch_scatter.segment_csr.segment_min_csr
'segment_csr' is being compiled since it was called from 'segment'
Serialized File "code/__torch__/torch_geometric/utils/segment.py", line 4
ptr: Tensor,
reduce: str="sum") -> Tensor:
_0 = __torch__.torch_scatter.segment_csr.segment_csr
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return _0(src, ptr, None, reduce, )
'segment' is being compiled since it was called from 'MeanAggregation.reduce'
Serialized File "code/__torch__/torch_geometric/nn/aggr/basic.py", line 22
reduce: str="sum") -> Tensor:
_1 = __torch__.torch_geometric.nn.aggr.base.expand_left
_2 = __torch__.torch_geometric.utils.segment.segment
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
_3 = __torch__.torch_geometric.utils.scatter.scatter
_4 = uninitialized(Tensor)
'MeanAggregation.reduce' is being compiled since it was called from 'MeanAggregation.forward'
File "E:\Anaconda\envs\Mesh_Net\lib\site-packages\torch_geometric\nn\aggr\basic.py", line 34
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
dim: int = -2) -> Tensor:
return self.reduce(x, index, ptr, dim_size, dim, reduce='mean')
~~~~~ <--- HERE
Serialized File "code/__torch__/torch_geometric/nn/aggr/basic.py", line 12
dim_size: Optional[int]=None,
dim: int=-2) -> Tensor:
_0 = (self).reduce(x, index, ptr, dim_size, dim, "mean", )
~~~~~~ <--- HERE
return _0
def reduce(self: __torch__.torch_geometric.nn.aggr.basic.MeanAggregation,
````
See same question at https://github.com/pyg-team/pytorch_geometric/issues/1718#issuecomment-1072448621
But it's not clear where the problem lies.
What other work can I do? Or do you have any suggestions to solve this problem?
### Versions
pytorch: 1.13.0
libtorch:1.13.0
cuda: 11.6
pyg: 2.3.1
torch_scatter: 2.1.1
torch_sparse: 0.6.18
| 1medium
|
Title: MixVisionTransformer in combination with PAN fails with "encoder does not support dilated mode"
Body: ```
import segmentation_models_pytorch as smp
smp.PAN(encoder_name="mit_b0")
```
raises the exception:
```
ValueError: MixVisionTransformer encoder does not support dilated mode
```
Since the default PAN uses dilation, this config is uncompatible atm?
If we use a configuration of PAN that does not use dilation the error, of course, does not apper:
```
smp.PAN(encoder_name="mit_b0", encoder_output_stride=32)
```
I did not test yet though if output strides of 32 still deliver comparable results. My guess would be that the default stride of 16 should encode a lot more of information that might be beneficial for better performence.
Is there any way to get it to work with dilation?
| 1medium
|
Title: open_dict_of_datasets function to open any file containing nested groups
Body: ### Is your feature request related to a problem?
In https://github.com/pydata/xarray/issues/9077#issuecomment-2161622347 I suggested the idea of a function which could open any netCDF file with groups as a dictionary mapping group path strings to `xr.Dataset` objects.
The motivation is as follows:
- People want the new `xarray.DataTree` class to support inheriting coordinates from parent groups,
- This can only be done if the coordinates align with the variables in the child group (i.e. using `xr.align`),
- The best time to enforce this alignment is at `DataTree` construction time,
- This requirement is not enforced in the netCDF/Zarr model, so this would mean some files can no longer be opened by `open_datatree` directly, as doing so would raise an alignment error,
- _But_ we still really want users to have some way to open an arbitrary file with xarray and see what's inside (including displaying all the groups #4840).
- A simpler intermediate structure of a dictionary mapping group paths to `xarray.Dataset` objects doesn't enforce alignment, so can represent any file.
- We should add a new opening function to allow any file to be opened as this dict-of-datasets structure.
- Users can then use this to inspect "untidy" data, and make changes to the dict returned before creating an aligned `DataTree` object via `DataTree.from_dict` if they like.
### Describe the solution you'd like
Add a function like this:
```python
def open_dict_of_datasets(
filename_or_obj: str | os.PathLike[Any] | BufferedIOBase | AbstractDataStore,
engine: T_Engine = None,
group: Optional[str] = None,
**kwargs,
) -> dict[str, Dataset]:
"""
Open and decode a file or file-like object, creating a dictionary containing one xarray Dataset for each group in the file.
Useful when you have e.g. a netCDF file containing many groups, some of which are not alignable with their parents and so the file cannot be opened directly with ``open_datatree``.
It is encouraged to use this function to inspect your data, then make the necessary changes to make the structure coercible to a `DataTree` object before calling `DataTree.from_dict()` and proceeding with your analysis.
Parameters
----------
filename_or_obj : str, Path, file-like, or DataStore
Strings and Path objects are interpreted as a path to a netCDF file or Zarr store.
engine : str, optional
Xarray backend engine to use. Valid options include `{"netcdf4", "h5netcdf", "zarr"}`.
group : str, optional
Group to use as the root group to start reading from. Groups above this root group will not be included in the output.
**kwargs : dict
Additional keyword arguments passed to :py:func:`~xarray.open_dataset` for each group.
Returns
-------
dict[str, xarray.Dataset]
See Also
--------
open_datatree()
DataTree.from_dict()
"""
...
```
This would live inside `backends.api.py`, and be exposed publicly as a top-level function along with the rest of `open_datatree`/`DataTree` etc. as part of #9033.
The actual implementation could re-use the code for opening many groups of the same file performantly from #9014. Indeed we could add a `open_dict_of_datasets` method to the `BackendEntryPoint` class, which uses pretty much the same code as the existing `open_datatree` method added in #9014 but just doesn't actually create a `DataTree` object.
### Describe alternatives you've considered
Really the main alternative to this is not to have coordinate inheritance in `DataTree` at all (see [9077](https://github.com/pydata/xarray/issues/9077)), in which case `open_datatree` would be sufficient to open any file.
---
The name of the function is up for debate. I prefer nothing with the word "datatree" in it since this doesn't actually create a `DataTree` object at any point. (In fact we could and perhaps should have implemented this function years ago, even without the new `DataTree` class.) The reason for not calling it "`open_as_dict_of_datasets`" is that we don't use "as" in the existing `open_dataset`/`open_dataarray` etc.
### Additional context
cc @eni-awowale @flamingbear @owenlittlejohns @keewis @shoyer @autydp
| 1medium
|
Title: In certain situations, it is impossible to enter the method under @crawler.router.default_handler, and the execution ends directly.
Body: code :
```py
async def crawling(urls: List, output_path: str, unique_filter:set) -> None:
# initialize crawler configuration
concurrency_settings = ConcurrencySettings(
max_concurrency=50,
max_tasks_per_minute=200,
)
session_pool = SessionPool(max_pool_size=100)
crawler = BeautifulSoupCrawler(
max_request_retries=3,
request_handler_timeout=timedelta(
seconds=30,
),
max_requests_per_crawl=100,
max_crawl_depth=1,
concurrency_settings=concurrency_settings,
session_pool=session_pool,
)
# Define the default request handler, which will be called for every request
@crawler.router.default_handler
async def request_handler(context: BeautifulSoupCrawlingContext) -> None:
url = context.request.url
logger.info(f'Processing {url} ...')
depth = context.request.crawl_depth
logger.info(f'The depth of {url} is:{depth}.')
await context.enqueue_links(
strategy='same-hostname',
include=init_filters(),
transform_request_function=transform_request,
)
await crawler.run(urls)
```
Issue 1: In the above code, debugging revealed that after executing the crawling method, when it reaches await crawler.run(urls), it does not enter the method under @crawler.router.default_handler (sometimes it works, sometimes it doesn't).
Issue 2: If crawling a URL fails due to network issues, attempting to crawl the same URL again also does not enter the @crawler.router.default_handler.
| 2hard
|
Title: About loss in Tensorboard
Body: Hello everyone,
I run the example of Multi-layer perceptron, and visualize the loss in Tensorboard.
Does "Loss" refer to the training loss on each batch? And "Loss/Validation" refers to the loss on validation set? What does "Loss_var_loss" refer to?

| 3misc
|
Title: I can't user user.save() to update the identifies of user
Body: ## Description of the problem, including code/CLI snippet
I use get user and change the identifies of it,but after use user.save(),it not changes.
when i update user's name,it works. but if i update identifies, it not work.
The identifies correct ,i can update it by hand.
## Expected Behavior
after user.save() update indetifies success
## Actual Behavior
not work,don't get any error
## Specifications
- python-gitlab version:3.14.0
- API version you are using (v3/v4):v4
- Gitlab server version (or gitlab.com):15.0.1
| 1medium
|
Title: labelme2coco.py crash when just contines __ignore__ label
Body: ### Provide environment information
(DET2) D:\FPCs>python --version
Python 3.9.13
(DET2) D:\FPCs>pip list labelme
Package Version Editable project location
----------------------- ------------------ --------------------------
labelme 5.0.5
### What OS are you using?
windows11
### Describe the Bug
(DET2) D:\FPCs>python D:/DeepLearning/labelme/examples/instance_segmentation/labelme2coco.py --labels classes.txt 000003 labels
Creating dataset: labels
Generating dataset from: 000003\dog.json
Traceback (most recent call last):
File "D:\DeepLearning\labelme\examples\instance_segmentation\labelme2coco.py", line 209, in <module>
main()
File "D:\DeepLearning\labelme\examples\instance_segmentation\labelme2coco.py", line 184, in main
labels, captions, masks = zip(
ValueError: not enough values to unpack (expected 3, got 0)
### Expected Behavior
Skip the label file
### To Reproduce
1. Just set __ignore__ label of an image
2. Create classes.txt file
3. run labelme2coco.py
| 1medium
|
Title: 请问llama2-7b的显存要求是多少
Body: ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[text-generation-webui](https://github.com/oobabooga/text-generation-webui)等,同时建议到对应的项目中查找解决方案
### 问题类型
模型训练与精调
### 基础模型
LLaMA-2-7B
### 操作系统
Linux
### 详细描述问题
```
# 用了6张a10(24G)进行预训练,block开到512,没有加lm_head,embedding层,开启了zero2 offload依旧报错
```
### 运行日志或截图
```
# torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 130.00 MiB (GPU 0; 22.20 GiB total capacity; 20.60 GiB already allocated; 126.12 MiB free; 20.98 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
0%| | 0/3 [00:00<?, ?it/s
```
| 2hard
|
Title: The error was: Failed to connect to localhost port 8988: Connection refused
Body: Hi! Thanks for using Jupyter Notebook Viewer (nbviewer) and taking the time to report a bug you've encountered. Please use the template below to tell us about the problem.
If you've found a bug in a different Jupyter project (e.g., [Jupyter Notebook](http://github.com/jupyter/notebook), [JupyterLab](http://github.com/jupyterlab/jupyterlab), [JupyterHub](http://github.com/jupyterhub/jupyterhub), etc.), please open an issue using that project's issue tracker instead.
If you need help using or installing Jupyter Notebook Viewer, please use the [jupyter/help](https://github.com/jupyter/help) issue tracker instead.
**Describe the bug**
Should be a working notebook however the error that is stated in the title shows up
**To Reproduce**
Steps to reproduce the behavior:
Copy URL and paste into nbviewer
**Expected behavior**
Should see the notebook
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: Windows 10
- Browser Firefox
- Version Not sure
**Additional context**
Add any other context about the problem here.
| 1medium
|
Title: make typecheck failing
Body: ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
I'm trying to commit a change and the pre-commit hook make typecheck is failing on various bits of v1 code. I reverted my changes and ran the check - same result, so not sure how others are managing to commit!
There are 144 errors, so I'll spare everyone the whole output, but a couple of samples are below. I've checked that I've got the latest versions of all dependencies, such as mypy.
Typecheck................................................................Failed
- hook id: typecheck
- exit code: 3
Pyproject file parse attempt 1 error: {}
Pyproject file parse attempt 2 error: {}
Pyproject file parse attempt 3 error: {}
Pyproject file parse attempt 4 error: {}
Pyproject file parse attempt 5 error: {}
Pyproject file parse attempt 6 error: {}
Config file "/Users/Nick/Code/github/pydantic/pyproject.toml" could not be parsed. Verify that format is correct.
/Users/Nick/Code/github/pydantic/pydantic/mypy.py
/Users/Nick/Code/github/pydantic/pydantic/mypy.py:630:54 - error: Argument of type "SemanticAnalyzerPluginInterface" cannot be assigned to parameter "api" of type "CheckerPluginInterface" in function "error_extra_fields_on_root_model"
"SemanticAnalyzerPluginInterface" is not assignable to "CheckerPluginInterface" (reportArgumentType)
/Users/Nick/Code/github/pydantic/pydantic/_internal/_std_types_schema.py
/Users/Nick/Code/github/pydantic/pydantic/_internal/_std_types_schema.py:111:20 - error: Cannot instantiate abstract class "PathLike"
"PathLike.__fspath__" is not implemented (reportAbstractUsage)
/Users/Nick/Code/github/pydantic/pydantic/_internal/_std_types_schema.py:111:20 - error: Cannot instantiate Protocol class "PathLike" (reportAbstractUsage)
/Users/Nick/Code/github/pydantic/pydantic/_internal/_std_types_schema.py:111:35 - error: Expected 0 positional arguments (reportCallIssue)
/Users/Nick/Code/github/pydantic/pydantic/v1/_hypothesis_plugin.py
/Users/Nick/Code/github/pydantic/pydantic/v1/_hypothesis_plugin.py:33:8 - error: Import "hypothesis.strategies" could not be resolved (reportMissingImports)
...
/Users/Nick/Code/github/pydantic/pydantic/v1/validators.py:81:32 - error: Union requires two or more type arguments (reportInvalidTypeArguments)
### Example Code
_No response_
### Python, Pydantic & OS Version
```Text
pydantic version: 2.10.3
pydantic-core version: 2.27.1
pydantic-core build: profile=release pgo=false
install path: /Users/Nick/Code/github/pydantic/pydantic
python version: 3.12.8 | packaged by Anaconda, Inc. | (main, Dec 11 2024, 10:37:40) [Clang 14.0.6 ]
platform: macOS-15.2-arm64-arm-64bit
related packages: fastapi-0.115.6 mypy-1.13.0 pyright-1.1.391 pydantic-settings-2.7.0 typing_extensions-4.12.2 pydantic-extra-types-2.10.1
commit: a915c7cd
```
| 2hard
|
Title: Extract features of a word given a text
Body: I am interested in getting the features of only one word in a text, but the current implementation gives the features of all the words in the text. I guess this makes the computations much slower, so I would like to simplify the implementation. Is this possible?
Thanks!!!
| 1medium
|
Title: How to use xlnet to guess a word in a sentence
Body: I am wonder how to use the xlnet to guess a word in a sentence.
| 1medium
|
Title: IUserUpdate should have id of UUID
Body: https://github.com/jonra1993/fastapi-alembic-sqlmodel-async/blob/a11c40077ec0bad51508974704d3343d187557a1/fastapi-alembic-sqlmodel-async/app/schemas/user_schema.py : 37
| 1medium
|
Title: Update script to download chromedriver from the newer location (on version 121+)
Body: ## Update script to download chromedriver from the newer location (on version 121+)
The Chromedriver team is starting to switch `chromedriver` storage from `https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/` to `https://storage.googleapis.com/chrome-for-testing-public/`.
This caused issues here: https://github.com/seleniumbase/SeleniumBase/issues/2495, but thankfully the Chromedriver team quickly made a change to at least temporarily use both locations. That was probably a warning shot so that frameworks are made aware to make changes soon.
If downloading `chromedriver` 121 (or newer), SeleniumBase should grab `chromedriver` from the newer location: `https://storage.googleapis.com/chrome-for-testing-public/`.
| 1medium
|
Title: Ability to add custom imports
Body: **Is your feature request related to a problem? Please describe.**
Can't customize my template to add new imports
**Describe the solution you'd like**
New argument `additional_imports` in `generate` function which adds additional imports to final rendered template
**Describe alternatives you've considered**
-
**Additional context**
-
| 1medium
|
Title: The prediction results of the segmentation model are strange
Body: ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
## Background
To obtain contour data of a specific object, I created a segmentation model using the following steps:
1. Generated a mask for the object using `sam2.1_b.pt` and created labels using `result.masks.xyn.pop()`.
```python
normalized_contour = result.masks.xyn.pop()
with open(os.path.join(output_label_path, img_file.replace('.jpg', '.txt')), 'w') as f:
class_id = 0
points_str = " ".join([f"{x:.4f} {y:.4f}" for x, y in normalized_contour])
output_str = f"{class_id} {points_str}"
f.write(output_str)
```
2. Fine-tuned `yolo11n-seg.pt` using the generated labels.
```python
model = YOLO('yolo11n-seg.pt')
model.train(data="dataset.yaml", epochs=1000, patience=50, batch=16, imgsz=1024, device=0)
```
3. Performed predictions using the fine-tuned model (`best.pt`).
```python
result = model(img_path, device=0)[0]
```
## Isuue
The prediction results are shown in the image below.
When examining the boundary between the mask and the bounding box (circled areas), certain parts of the mask protrude in a square-like shape.
## Question
Why is this happening?
Are there any possible solutions to this issue?

### Additional
_No response_
| 1medium
|
Title: Add option to scrub all region tags in Exif information when using "delete face"
Body: **Describe the enhancement you'd like**
I have some pictures that have (wrong) face areas defined from a previous version of digikam - would it be possible to scrub the EXIF info from all face info when using "delete face"? It seems right now only librephoto tags are scrubbed
After using the "delete face" I still have region and name information in the file
**Describe why this will benefit the LibrePhotos**
Deleting face regions that are wrong would improve the data quality and training date for face recognition
**Additional context**
It seems Librephotos is using the "Region Rectangle" to define the face area.
Digikam tags look like this (real example)
Region Applied To Dimensions H : 2304
Region Applied To Dimensions Unit: pixel
Region Applied To Dimensions W : 3456
Region Name : Personname
Region Type : Face, Face
Region Area X : 0.330874, 0.161892
Region Area Y : 0.771701, 0.498047
Region Area W : 0.175637, 0.128762
Region Area H : 0.315972, 0.193142
Region Area Unit : normalized, normalized
Tags List : People/Personname
Adding an option in settings to scrub this when deleting faces would make sense. This should only be applied to face regions, which is the defined in the "Region Type" tag
| 1medium
|
Title: Error while trying to even install numpy
Body: error: subprocess-exited-with-error
× Building wheel for numpy (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [271 lines of output]
Running from numpy source directory. setup.py:67: DeprecationWarning:
`numpy.distutils` is deprecated since NumPy 1.23.0, as a result of the deprecation of `distutils` itself. It will be removed for
Python >= 3.12. For older Python versions it will remain present. It is recommended to use `setuptools < 60.0` for those Python versions.
For more details, see:
https://numpy.org/devdocs/reference/distutils_status_migration.html
import numpy.distutils.command.sdist
Processing numpy/random/_bounded_integers.pxd.in
Processing numpy/random/_bounded_integers.pyx.in
Processing numpy/random/_common.pyx
Processing numpy/random/_generator.pyx
Processing numpy/random/_mt19937.pyx
Processing numpy/random/_pcg64.pyx
Processing numpy/random/_philox.pyx
Processing numpy/random/_sfc64.pyx
Processing numpy/random/bit_generator.pyx
Processing numpy/random/mtrand.pyx
Cythonizing sources
INFO: blas_opt_info:
INFO: blas_armpl_info:
INFO: customize UnixCCompiler
INFO: libraries armpl_lp64_mp not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: blas_mkl_info:
INFO: libraries mkl_rt not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: blis_info:
INFO: libraries blis not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: openblas_info:
INFO: libraries openblas not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: accelerate_info:
INFO: NOT AVAILABLE
INFO:
INFO: atlas_3_10_blas_threads_info:
INFO: Setting PTATLAS=ATLAS
INFO: libraries tatlas not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: atlas_3_10_blas_info:
INFO: libraries satlas not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: atlas_blas_threads_info:
INFO: Setting PTATLAS=ATLAS
INFO: libraries ptf77blas,ptcblas,atlas not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: atlas_blas_info:
INFO: libraries f77blas,cblas,atlas not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/system_info.py:2077: UserWarning:
Optimized (vendor) Blas libraries are not found.
Falls back to netlib Blas library which has worse performance.
A better performance should be easily gained by switching
Blas library.
if self._calc_info(blas):
INFO: blas_info:
INFO: libraries blas not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/system_info.py:2077: UserWarning:
Blas (http://www.netlib.org/blas/) libraries not found.
Directories to search for the libraries can be specified in the
numpy/distutils/site.cfg file (section [blas]) or by setting
the BLAS environment variable.
if self._calc_info(blas):
INFO: blas_src_info:
INFO: NOT AVAILABLE
INFO:
/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/system_info.py:2077: UserWarning:
Blas (http://www.netlib.org/blas/) sources not found.
Directories to search for the sources can be specified in the
numpy/distutils/site.cfg file (section [blas_src]) or by setting
the BLAS_SRC environment variable.
if self._calc_info(blas):
INFO: NOT AVAILABLE
INFO:
non-existing path in 'numpy/distutils': 'site.cfg'
INFO: lapack_opt_info:
INFO: lapack_armpl_info:
INFO: libraries armpl_lp64_mp not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: lapack_mkl_info:
INFO: libraries mkl_rt not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: openblas_lapack_info:
INFO: libraries openblas not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: openblas_clapack_info:
INFO: libraries openblas,lapack not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: flame_info:
INFO: libraries flame not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
INFO: atlas_3_10_threads_info:
INFO: Setting PTATLAS=ATLAS
INFO: libraries tatlas,tatlas not found in /data/data/com.termux/files/usr/lib
INFO: <class 'numpy.distutils.system_info.atlas_3_10_threads_info'>
INFO: NOT AVAILABLE
INFO:
INFO: atlas_3_10_info:
INFO: libraries satlas,satlas not found in /data/data/com.termux/files/usr/lib
INFO: <class 'numpy.distutils.system_info.atlas_3_10_info'>
INFO: NOT AVAILABLE
INFO:
INFO: atlas_threads_info:
INFO: Setting PTATLAS=ATLAS
INFO: libraries ptf77blas,ptcblas,atlas not found in /data/data/com.termux/files/usr/lib
INFO: <class 'numpy.distutils.system_info.atlas_threads_info'>
INFO: NOT AVAILABLE
INFO:
INFO: atlas_info:
INFO: libraries f77blas,cblas,atlas not found in /data/data/com.termux/files/usr/lib
INFO: <class 'numpy.distutils.system_info.atlas_info'>
INFO: NOT AVAILABLE
INFO:
INFO: lapack_info:
INFO: libraries lapack not found in ['/data/data/com.termux/files/usr/lib']
INFO: NOT AVAILABLE
INFO:
/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/system_info.py:1902: UserWarning:
Lapack (http://www.netlib.org/lapack/) libraries not found.
Directories to search for the libraries can be specified in the
numpy/distutils/site.cfg file (section [lapack]) or by setting
the LAPACK environment variable.
return getattr(self, '_calc_info_{}'.format(name))()
INFO: lapack_src_info:
INFO: NOT AVAILABLE
INFO:
/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/system_info.py:1902: UserWarning:
Lapack (http://www.netlib.org/lapack/) sources not found.
Directories to search for the sources can be specified in the
numpy/distutils/site.cfg file (section [lapack_src]) or by setting
the LAPACK_SRC environment variable.
return getattr(self, '_calc_info_{}'.format(name))()
INFO: NOT AVAILABLE
INFO:
INFO: numpy_linalg_lapack_lite:
INFO: FOUND:
INFO: language = c
INFO:
Warning: attempted relative import with no known parent package
/data/data/com.termux/files/usr/lib/python3.11/distutils/dist.py:274: UserWarning: Unknown distribution option: 'define_macros'
warnings.warn(msg)
running bdist_wheel
running build
running config_cc
INFO: unifing config_cc, config, build_clib, build_ext, build commands --compiler options
running config_fc
INFO: unifing config_fc, config, build_clib, build_ext, build commands --fcompiler options
running build_src
INFO: build_src
INFO: building py_modules sources
creating build
creating build/src.linux-aarch64-3.11
creating build/src.linux-aarch64-3.11/numpy
creating build/src.linux-aarch64-3.11/numpy/distutils
INFO: building library "npymath" sources
WARN: Could not locate executable armflang
WARN: Could not locate executable gfortran
WARN: Could not locate executable f95
WARN: Could not locate executable ifort
WARN: Could not locate executable ifc
WARN: Could not locate executable lf95
WARN: Could not locate executable pgfortran
WARN: Could not locate executable nvfortran
WARN: Could not locate executable f90
WARN: Could not locate executable f77
WARN: Could not locate executable fort
WARN: Could not locate executable efort
WARN: Could not locate executable efc
WARN: Could not locate executable g77
WARN: Could not locate executable g95
WARN: Could not locate executable pathf95
WARN: Could not locate executable nagfor
WARN: Could not locate executable frt
WARN: don't know how to compile Fortran code on platform 'posix'
creating build/src.linux-aarch64-3.11/numpy/core
creating build/src.linux-aarch64-3.11/numpy/core/src
creating build/src.linux-aarch64-3.11/numpy/core/src/npymath
INFO: conv_template:> build/src.linux-aarch64-3.11/numpy/core/src/npymath/npy_math_internal.h
INFO: adding 'build/src.linux-aarch64-3.11/numpy/core/src/npymath' to include_dirs.
INFO: conv_template:> build/src.linux-aarch64-3.11/numpy/core/src/npymath/ieee754.c
INFO: conv_template:> build/src.linux-aarch64-3.11/numpy/core/src/npymath/npy_math_complex.c
INFO: None - nothing done with h_files = ['build/src.linux-aarch64-3.11/numpy/core/src/npymath/npy_math_internal.h']
INFO: building library "npyrandom" sources
INFO: building extension "numpy.core._multiarray_tests" sources
creating build/src.linux-aarch64-3.11/numpy/core/src/multiarray
INFO: conv_template:> build/src.linux-aarch64-3.11/numpy/core/src/multiarray/_multiarray_tests.c
INFO: building extension "numpy.core._multiarray_umath" sources
Traceback (most recent call last):
File "/data/data/com.termux/files/usr/lib/python3.11/site-packages/pip/_vendor/pep517/in_process/_in_process.py", line 351, in <module>
main()
File "/data/data/com.termux/files/usr/lib/python3.11/site-packages/pip/_vendor/pep517/in_process/_in_process.py", line 333, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/lib/python3.11/site-packages/pip/_vendor/pep517/in_process/_in_process.py", line 249, in build_wheel
return _build_backend().build_wheel(wheel_directory, config_settings,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/tmp/pip-build-env-goe15s6p/overlay/lib/python3.11/site-packages/setuptools/build_meta.py", line 230, in build_wheel
return self._build_with_temp_dir(['bdist_wheel'], '.whl',
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/tmp/pip-build-env-goe15s6p/overlay/lib/python3.11/site-packages/setuptools/build_meta.py", line 215, in _build_with_temp_dir
self.run_setup()
File "/data/data/com.termux/files/usr/tmp/pip-build-env-goe15s6p/overlay/lib/python3.11/site-packages/setuptools/build_meta.py", line 268, in run_setup
self).run_setup(setup_script=setup_script)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/tmp/pip-build-env-goe15s6p/overlay/lib/python3.11/site-packages/setuptools/build_meta.py", line 158, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 479, in <module>
setup_package()
File "setup.py", line 471, in setup_package
setup(**metadata)
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/core.py", line 169, in setup
return old_setup(**new_attr)
^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/tmp/pip-build-env-goe15s6p/overlay/lib/python3.11/site-packages/setuptools/__init__.py", line 153, in setup
return distutils.core.setup(**attrs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/core.py", line 148, in setup
dist.run_commands()
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/data/data/com.termux/files/usr/tmp/pip-build-env-goe15s6p/overlay/lib/python3.11/site-packages/wheel/bdist_wheel.py", line 299, in run
self.run_command('build')
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/command/build.py", line 62, in run
old_build.run(self)
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/data/data/com.termux/files/usr/lib/python3.11/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/command/build_src.py", line 144, in run
self.build_sources()
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/command/build_src.py", line 161, in build_sources
self.build_extension_sources(ext)
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/command/build_src.py", line 318, in build_extension_sources
sources = self.generate_sources(sources, ext)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/distutils/command/build_src.py", line 378, in generate_sources
source = func(extension, build_dir)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/core/setup.py", line 506, in generate_config_h
check_math_capabilities(config_cmd, ext, moredefs, mathlibs)
File "/data/data/com.termux/files/usr/tmp/pip-install-uc8hi5p2/numpy_0f93abc54da747c3833d8fbd6cec679c/numpy/core/setup.py", line 192, in check_math_capabilities
raise SystemError("One of the required function to build numpy is not"
SystemError: One of the required function to build numpy is not available (the list is ['sin', 'cos', 'tan', 'sinh', 'cosh', 'tanh', 'fabs', 'floor', 'ceil', 'sqrt', 'log10', 'log', 'exp', 'asin', 'acos', 'atan', 'fmod', 'modf', 'frexp', 'ldexp', 'expm1', 'log1p', 'acosh', 'asinh', 'atanh', 'rint', 'trunc', 'exp2', 'copysign', 'nextafter', 'strtoll', 'strtoull', 'cbrt', 'log2', 'pow', 'hypot', 'atan2', 'creal', 'cimag', 'conj']).
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for numpy
Failed to build numpy
ERROR: Could not build wheels for numpy, which is required to install pyproject.toml-based projects
| 2hard
|
Title: msg['ActualNickName']乱码
Body: 昨天还好好的,今天就变成了乱码,找不到原因所在,来求助
| 1medium
|
Title: Cutter tools create leftovers in plotter
Body: It seems some (all?) cutter tools create some leftovers in the plotters that get picked up by subsequent cutting operations
| 1medium
|
Title: Filename is an empty string or file not able to be loaded
Body: I get this error with even the simplest csv input file
```
a,b
1,2
3,4
```
providing full path to the filename, using and specifying different separators... nothing seems to work.
| 1medium
|
Title: Cannot save MQTT input configuration changes
Body: I am using Mycodo 8.9.0. Whenever I add an MQTT input, click the (+) sign and then click "Save" - no changes made at all - I receive the following error :
Error: Modify Input: '<' not supported between instances of 'NoneType' and 'float'
The error happens regardless of which fields I change or attempt to modify (even when no fields are modified as I mentioned above). I'm new to mycodo so please do let me know if I'm doing something wrong. Thanks in advance for your help!
| 1medium
|
Title: Mention NVIDIA non-commercial in top LICENSE section
Body: Could you mention NVIDIA license, which is written in encoders/mix_transformer.py, in the top LICENSE section?
This can cause a problem for commercial use including Kaggle, in which the competition rule often requires commercial use. I misunderstood that segFormer had become completely MIT.
For example, mmcv has a LICENSES page, which lists files with NVIDIA license.
https://github.com/open-mmlab/mmcv/blob/main/LICENSES.md
Thanks for developing and maintaining this great library! I am using a lot for Kaggle.
| 1medium
|
Title: Swagger's preauthorize_apikey feature
Body: Currently there is no "flask_restx" way to use the Swagger ``preauthorize_apikey`` feature. (You can always patch the javascript returned by apidoc using the Api.documentation decorator, but it seems to be the worst way to do it)
We needed this feature, in order to display Swagger documentation allready "populated" with user's apiKey. Our use case :
- a user login with login/password couple in order to fetch an api Token and see swagger doc
- when displaying swagger documentation for this authenticated user, the curl example should contains the Token argument
I wrote two commit implementing this feature in two ways :
- https://github.com/yweber/flask-restx/commit/4c6955eadaa4c93ec8fe6d14d322e1ec01ecc9e3
- a straight-forward template modification using a global Flask.config item referencing a function returning preauth informations
- https://github.com/yweber/flask-restx/commit/85310b3eadbb3d94b18bfecf083fc8cb9c5c6753
- adding a decorator to ``flask_restx.Api`` class in order to register a function returning preauth informations
Both PR will be created soon.
I don't know wich one is the better nor wich one fits best with flask_restx philosophy.
- the global configuration solution is.... global : you register a function once and it will be used for all Api instance. It will be messy if different apiKey swagger's authorization names are used
- the ``Api.apikey_preauthorization`` decorator allows to register a preauth information function per Api : you have to do it for each Api instance with swagger ``preauthorize_apikey`` enabled
- Right now, registered functions do not takes any argument. With the decorator's solution it seems to be trivial to pass the ``flask_restx.Api`` instance as argument. I'm not a flask expert, but it looks like it is useless : the flask application context is accessible globally (with ``Flask.current_app`` or ``Flask.session`` etc.) Is there a use case where this function would like to access the current ``flask_restx.Api`` instance ?
Finally, a mixed solution is possible :
- merging the configuration and the decorator : allowing both with a priority on the function registered with the decorator
Thank's for your time reading this issue (and the associated PRs :) ) !
| 1medium
|
Title: Missing 'url' key raises uncaught KeyError on coveralls.io 503 response
Body: Could not reproduce with `coveralls debug` as coveralls.io had evidently fixed its server-side error by this time. Traceback from original run below:
```
Submitting coverage to coveralls.io...
Coverage submitted!
Failure to submit data. Response [503]: <!DOCTYPE html>
<html>
<head>
<style type="text/css">
html, body, iframe { margin: 0; padding: 0; height: 100%; }
iframe { display: block; width: 100%; border: none; }
</style>
<title>Application Error</title>
</head>
<body>
<iframe src="https://s3.amazonaws.com/assets.coveralls.io/maintenance.html">
<p>Application Error</p>
</iframe>
</body>
</html>
Traceback (most recent call last):
File "/home/rof/.virtualenv/bin/coveralls", line 9, in <module>
load_entry_point('coveralls==0.4.1', 'console_scripts', 'coveralls')()
File "/home/rof/.virtualenv/local/lib/python2.7/site-packages/coveralls/cli.py", line 52, in main
log.info(result['url'])
KeyError: 'url'
```
| 1medium
|
Title: Change folder strucutre from `src` to module name
Body: [//]: # (
. Note: for support questions, please use Stackoverflow or Gitter**.
. This repository's issues are reserved for feature requests and bug reports.
.
. In case of any problems with Allure Jenkins plugin** please use the following repository
. to create an issue: https://github.com/jenkinsci/allure-plugin/issues
.
. Make sure you have a clear name for your issue. The name should start with a capital
. letter and no dot is required in the end of the sentence. An example of good issue names:
.
. - The report is broken in IE11
. - Add an ability to disable default plugins
. - Support emoji in test descriptions
)
#### I'm submitting a ...
- [ ] bug report
- [x] feature request
- [ ] support request => Please do not submit support request here, see note at the top of this template.
#### What is the current behavior?
Folder structure is like this:
```
- allure-pytest\
- src\
- source files (...)
- setup.py
- other files (...)
```
#### If the current behavior is a bug, please provide the steps to reproduce and if possible a minimal demo of the problem
Modules are not available for imports when installing with `pip install --editable .` command.
#### What is the expected behavior?
We could just rename the `src` folder with the module name:
```
- allure-pytest\
- allure_pytest\
- source files (...)
- setup.py
- other files (...)
```
Sure it is redundant (and aesthetically I don't like it myself) but this will easy the development process until the problem with `pip --editable` is solved (see below).
#### What is the motivation / use case for changing the behavior?
The pip editable install does not work with current structure, using `package_dir` option:
https://github.com/pypa/pip/issues/3160
#### Please tell us about your environment:
- Allure version: 2.6.0
- Test framework: [email protected]
- Allure adaptor: [email protected]
#### Other information
[//]: # (
. e.g. detailed explanation, stacktraces, related issues, suggestions
. how to fix, links for us to have more context, eg. Stackoverflow, Gitter etc
)
| 1medium
|
Title: Invalid comparison between dtype=timedelta64[ns] and float64
Body: Traceback (most recent call last):
File "/opt/conda/lib/python3.11/site-packages/pandas/core/arrays/datetimelike.py", line 935, in _cmp_method
other = self._validate_comparison_value(other)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/arrays/datetimelike.py", line 571, in _validate_comparison_value
raise InvalidComparison(other)
pandas.errors.InvalidComparison: 3.4028234663852886e+38
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/conda/lib/python3.11/site-packages/supervised/base_automl.py", line 1195, in _fit
trained = self.train_model(params)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/supervised/base_automl.py", line 401, in train_model
mf.train(results_path, model_subpath)
File "/opt/conda/lib/python3.11/site-packages/supervised/model_framework.py", line 197, in train
].fit_and_transform(
^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/supervised/preprocessing/preprocessing.py", line 298, in fit_and_transform
X_train[numeric_cols] = X_train[numeric_cols].clip(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/frame.py", line 11457, in clip
return super().clip(lower, upper, axis=axis, inplace=inplace, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/generic.py", line 8215, in clip
return self._clip_with_scalar(lower, upper, inplace=inplace)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/generic.py", line 8024, in _clip_with_scalar
subset = self <= upper
^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/ops/common.py", line 81, in new_method
return method(self, other)
^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/arraylike.py", line 52, in __le__
return self._cmp_method(other, operator.le)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/frame.py", line 7445, in _cmp_method
new_data = self._dispatch_frame_op(other, op, axis=axis)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/frame.py", line 7484, in _dispatch_frame_op
bm = self._mgr.apply(array_op, right=right)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/internals/managers.py", line 350, in apply
applied = b.apply(f, **kwargs)
^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/internals/blocks.py", line 329, in apply
result = func(self.values, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/ops/array_ops.py", line 279, in comparison_op
res_values = op(lvalues, rvalues)
^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/ops/common.py", line 81, in new_method
return method(self, other)
^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/arraylike.py", line 52, in __le__
return self._cmp_method(other, operator.le)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/arrays/datetimelike.py", line 937, in _cmp_method
return invalid_comparison(self, other, op)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/pandas/core/ops/invalid.py", line 36, in invalid_comparison
raise TypeError(f"Invalid comparison between dtype={left.dtype} and {typ}")
TypeError: Invalid comparison between dtype=timedelta64[ns] and float64
Please set a GitHub issue with above error message at: https://github.com/mljar/mljar-supervised/issues/new
| 2hard
|
Title: Anyone successfully run a US benchmark yet? There seem to be a bug with US version, instrument variable got evaluated to NAN.
Body: ## 🐛 Bug Description
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1. take any yaml file under examples/benchmark. I'll take workflow_config_lightgbm_Alpha158.yaml for example.
2. Change all fields from china version to US version:
2.1 change (provider_uri: "~/.qlib/qlib_data/cn_data") to (provider_uri: "~/.qlib/qlib_data/us_data")
2.2 change( region: cn) to (region: us)
2.3 change (market: &market csi300) to (market: &market sp500)
2.4 change (benchmark: &benchmark SH000300) to (benchmark: &benchmark ^GSPC)
3. Run
qrun workflow_config_lightgbm_Alpha158.yaml
## Expected Behavior
AttributeError: 'float' object has no attribute 'lower'
Upon closer debugging, the instrument variable was evaluated to Nan.
## Screenshot
<img width="1045" alt="image" src="https://user-images.githubusercontent.com/1435138/215260135-671ad6bc-690e-4651-9314-4ecf138ae5b2.png">
## Environment
**Note**: User could run `cd scripts && python collect_info.py all` under project directory to get system information
and paste them here directly.
Windows
AMD64
Windows-10-10.0.22621-SP0
10.0.22621
Python version: 3.8.15 (default, Nov 24 2022, 14:38:14) [MSC v.1916 64 bit (AMD64)]
Qlib version: 0.9.0.99
numpy==1.23.5
pandas==1.5.2
scipy==1.9.3
requests==2.28.1
sacred==0.8.2
python-socketio==5.7.2
redis==4.4.0
python-redis-lock==4.0.0
schedule==1.1.0
cvxpy==1.2.3
hyperopt==0.1.2
fire==0.5.0
statsmodels==0.13.5
xlrd==2.0.1
plotly==5.11.0
matplotlib==3.6.2
tables==3.8.0
pyyaml==6.0
mlflow==1.30.0
tqdm==4.64.1
loguru==0.6.0
lightgbm==3.3.3
tornado==6.2
joblib==1.2.0
fire==0.5.0
ruamel.yaml==0.17.21
## Additional Notes
| 1medium
|
Title: Add messages support
Body: ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
I would like to display feedback to users after a form submission, not just error messages. This would allow for warnings and success messages.
### Describe the solution you would like.
Django Admin uses this
https://docs.djangoproject.com/en/dev/ref/contrib/messages/#django.contrib.messages.add_message
### Describe alternatives you considered
_No response_
### Additional context
I may be willing to work on this, if there is interest.
| 1medium
|
Title: [Discussion] Desktop Application 🖥
Body: I've been looking into different technologies for making Rust desktop applications because that's personally something I want to get into. I think that [Flutter](https://flutter.dev) is one of the most promising GUI frameworks around right now, and I just yesterday discovered [nativeshell](https://github.com/nativeshell/nativeshell) which is a way to build desktop applications with Rust and Flutter. I was thinking about what might be a good demo application for me to build using nativeview and then I thought of Matchering.
If I get the time, I might try to make a native desktop application for Matching, but I've still got to figure out the best way to embed Matching in a desktop application without requring Python to be installed. I heard that you had experimented with a Rust version of matchering, which would be the easiest way to get matchering embedded, but if that isn't ready yet then that won't be an option.
The other option is to embed the Python interpreter in Rust. This should work, and I've done it before in smaller use-cases, I just have to look into it more.
I wanted to open this issue to start the discussion and ask whether or not the Rust version of matchering is anywhere close to usable or if I should just try to embed the Python interpreter.
| 3misc
|
Title: 请求接入公募基金净值数据接口(fund_nav)
Body: 你好管理员,
新近注册Tushare,承蒙照顾,以博士在读身份获得了千余的初始积分。但还是厚颜地想再请求一下。
我在做一些个人投资,想提取场外公募基金的净值数据,稍微做一些均线分析。说来惭愧,我也是2020年底入市的这批韭菜之一。单就这个接口,需要2000积分,想问问有没可能再补个500积分。或者有没有别的解决办法。
ID: 435618.
| 0easy
|
Title: Problem with save_draw_features
Body: <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- leafmap version: 0.38.5
- Python version: 3.10.13
- Operating System: Ubuntu 22.04
### Description
```
{
"name": "ValueError",
"message": "Assigning CRS to a GeoDataFrame without a geometry column is not supported. Use GeoDataFrame.set_geometry to set the active geometry column.",
"stack": "---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/geopandas/geodataframe.py:517, in GeoDataFrame.crs(self)
516 try:
--> 517 return self.geometry.crs
518 except AttributeError:
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/pandas/core/generic.py:6299, in NDFrame.__getattr__(self, name)
6298 return self[name]
-> 6299 return object.__getattribute__(self, name)
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/geopandas/geodataframe.py:253, in GeoDataFrame._get_geometry(self)
247 msg += (
248 \"\
There are no existing columns with geometry data type. You can \"
249 \"add a geometry column as the active geometry column with \"
250 \"df.set_geometry. \"
251 )
--> 253 raise AttributeError(msg)
254 return self[self._geometry_column_name]
AttributeError: You are calling a geospatial method on the GeoDataFrame, but the active geometry column to use has not been set.
There are no existing columns with geometry data type. You can add a geometry column as the active geometry column with df.set_geometry.
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/pandas/core/generic.py:6325, in NDFrame.__setattr__(self, name, value)
6324 try:
-> 6325 existing = getattr(self, name)
6326 if isinstance(existing, Index):
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/pandas/core/generic.py:6299, in NDFrame.__getattr__(self, name)
6298 return self[name]
-> 6299 return object.__getattribute__(self, name)
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/geopandas/geodataframe.py:519, in GeoDataFrame.crs(self)
518 except AttributeError:
--> 519 raise AttributeError(
520 \"The CRS attribute of a GeoDataFrame without an active \"
521 \"geometry column is not defined. Use GeoDataFrame.set_geometry \"
522 \"to set the active geometry column.\"
523 )
AttributeError: The CRS attribute of a GeoDataFrame without an active geometry column is not defined. Use GeoDataFrame.set_geometry to set the active geometry column.
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
File /home/user/GeoSegmentation/notebook/esempio.py:6
3 m = leafmap.Map()
4 m
----> 6 m.save_draw_features(\"data.geojson\")
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/leafmap/leafmap.py:3889, in Map.save_draw_features(self, out_file, indent, crs, **kwargs)
3883 geojson = {
3884 \"type\": \"FeatureCollection\",
3885 \"features\": self.draw_features,
3886 }
3888 gdf = gpd.GeoDataFrame.from_features(geojson)
-> 3889 gdf.crs = \"epsg:4326\"
3890 gdf.to_crs(crs).to_file(out_file, **kwargs)
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/geopandas/geodataframe.py:223, in GeoDataFrame.__setattr__(self, attr, val)
221 object.__setattr__(self, attr, val)
222 else:
--> 223 super().__setattr__(attr, val)
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/pandas/core/generic.py:6341, in NDFrame.__setattr__(self, name, value)
6333 if isinstance(self, ABCDataFrame) and (is_list_like(value)):
6334 warnings.warn(
6335 \"Pandas doesn't allow columns to be \"
6336 \"created via a new attribute name - see \"
(...)
6339 stacklevel=find_stack_level(),
6340 )
-> 6341 object.__setattr__(self, name, value)
File ~/GeoSegmentation/.venv/lib/python3.10/site-packages/geopandas/geodataframe.py:529, in GeoDataFrame.crs(self, value)
527 \"\"\"Sets the value of the crs\"\"\"
528 if self._geometry_column_name is None:
--> 529 raise ValueError(
530 \"Assigning CRS to a GeoDataFrame without a geometry column is not \"
531 \"supported. Use GeoDataFrame.set_geometry to set the active \"
532 \"geometry column.\",
533 )
535 if hasattr(self.geometry.values, \"crs\"):
536 if self.crs is not None:
ValueError: Assigning CRS to a GeoDataFrame without a geometry column is not supported. Use GeoDataFrame.set_geometry to set the active geometry column."
}
```
### What I Did
I use this code:
```
import leafmap
m = leafmap.Map()
m
m.save_draw_features("data.geojson")
```
| 1medium
|
Title: Mermaid Crashes If trying to draw a large pipeline
Body: Thanks in advance for your help :)
**Describe the bug**
I was building a huge pipeline, 30 components and 35 connections, and for debugging proposes I wanted to display the diagram, but both .draw() and .show() methods failed. It still works with small pipelines by the way.
**Error message**
```
Failed to draw the pipeline: https://mermaid.ink/img/ returned status 400
No pipeline diagram will be saved.
Failed to draw the pipeline: could not connect to https://mermaid.ink/img/ (400 Client Error: Bad Request for url: https://mermaid.ink/img/{place holder for 2km long data}
No pipeline diagram will be saved.
Traceback (most recent call last):
File "/Users/carlosfernandezloran/Desktop/babyagi-classic-haystack/.venv/lib/python3.10/site-packages/haystack/core/pipeline/draw.py", line 87, in _to_mermaid_image
resp.raise_for_status()
File "/Users/carlosfernandezloran/Desktop/babyagi-classic-haystack/.venv/lib/python3.10/site-packages/requests/models.py", line 1024, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://mermaid.ink/img/{another placeholder}
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/carlosfernandezloran/Desktop/babyagi-classic-haystack/babyagi.py", line 188, in <module>
pipe.draw(path=Path("pipe"))
File "/Users/carlosfernandezloran/Desktop/babyagi-classic-haystack/.venv/lib/python3.10/site-packages/haystack/core/pipeline/base.py", line 649, in draw
image_data = _to_mermaid_image(self.graph)
File "/Users/carlosfernandezloran/Desktop/babyagi-classic-haystack/.venv/lib/python3.10/site-packages/haystack/core/pipeline/draw.py", line 95, in _to_mermaid_image
raise PipelineDrawingError(
haystack.core.errors.PipelineDrawingError: There was an issue with https://mermaid.ink/, see the stacktrace for details.
```
**Expected behavior**
I expect the .show() and .draw() methods to work for all pipelines, no matter the size.
This might be a Mermaid problem and not strictly haystacks, but we would need to work to implement a local diagram generator as said in #7896
**To Reproduce**
I will not add all the 200 lines of add_component, connect statements, but you can imagine how it goes.
**System:**
- OS: macOS
- GPU/CPU: M1
- Haystack version (commit or version number): 2.3.0
| 1medium
|
Title: [Fabric Lightning] Named barriers
Body: ### Description & Motivation
To prevent ranks losing alignment due to user error -- it would be beneficial to have named barriers with lightning allowing nodes to move forward only if same barrier name is met.
### Pitch
For example:
```
if fabric.global_rank == 0:
fabric.barrier("rank_0")
else:
fabric.barrier("not_rank_0")
```
will fail in this case, and upon timeout each rank will raise an error with the barrier at which it is held up.
This is as opposed to potential user error where due to incorrect logic the various ranks might go different paths, reach some other barrier which in turn enables the whole flow to continue.
An issue that will likely repeat itself is with `fabric.save`. It is not obvious to new users (that don't dig into the documentation) that this should be called in all nodes, as it implements its own internal barrier call.
A typical mistake would be to construct
```
if fabric.global_rank == 0:
fabric.save(...)
fabric.barrier()
do_training_stuff
fabric.barrier()
```
In this case, rank 0 will start to lag behind as it performs an additional barrier call.
If `fabric.save` would implement `fabric.barrier("save")` then the above program would exit printing that there is an alignment issue.
### Alternatives
_No response_
### Additional context
https://github.com/Lightning-AI/pytorch-lightning/issues/19780
cc @borda @awaelchli
| 2hard
|
Title: Payment modul
Body: I have a question about creating a payment module for one of the operators.
The operator I want to integrate requires that POST data to the transaction log after it returns a token for further authorization.
One of these data is OrderId, which can be sent only once to the payment system.
After this authorization and status check is carried out by the token given when the payment is registered.
Should I implement the payment as it is with the "Pay in advance" method?
Where an order is created with the possibility of later payment.
Or is it possible to give the orderID in advance to the operator and go to his site to pay for the order?
I have tracked how it is in the case of paypal payment and there the orderID is created only after returning from paypal with information on the correct payment of the order.
| 1medium
|
Title: Choices Property Does Not Work For JSON List
Body: When defining choices for a list in the JSON data input, validation does not work. This is true if type is `list` or if type is `str` and action is `"append"`.
### **Code**
```python
import flask
from flask_restx import Api, Namespace, Resource
from flask_restx import reqparse
from flask_restx import Api
parser = reqparse.RequestParser()
parser.add_argument(
"argList",
dest="arg_list",
type=list,
location="json",
default=[],
choices=[
"one",
"two",
"three",
],
required=False,
help=f"An argument list",
)
# Our Flask app and API
app = flask.Flask(__name__)
api = Api(
app,
version="1.0.0",
title="Tester",
description="Test parsing arguments",
)
class RouteWithArgs(Resource):
@api.expect(parser)
def put(
self,
):
args = parser.parse_args()
return {"data": "Args look good!"}, 200
# routes
api.add_resource(RouteWithArgs, "/args")
if __name__ == "__main__":
app.run(debug=True)
```
### **Repro Steps** (if applicable)
1. Run Flask application for code above with `python <file-name>.py`
2. Send a request with either allowed or disallowed values
3. Observe that you receive an error message either way
### **Expected Behavior**
I would expect to receive an error message with a disallowed parameter and no error message when providing allowed parameters.
### **Actual Behavior**
An error is returned no matter what is present in the request.
### **Error Messages/Stack Trace**
```>>> response = requests.put("http://localhost:5000/args", headers={"Content-Type": "application/json"}, data=json.dumps({"argList": ["a"]}))
>>> response.json()
{'errors': {'argList': "An argument list The value '['a']' is not a valid choice for 'argList'."}, 'message': 'Input payload validation failed'}
>>> response = requests.put("http://localhost:5000/args", headers={"Content-Type": "application/json"}, data=json.dumps({"argList": ["one"]}))
>>> response.json()
{'errors': {'argList': "An argument list The value '['one']' is not a valid choice for 'argList'."}, 'message': 'Input payload validation failed'}
```
### **Environment**
- Python 3.8.12
- Flask 2.0.1
- Flask-RESX 0.5.1
- Flask Cors 3.0.10
| 1medium
|
Title: vocoder.pt drive link is not working.
Body: Getting 404 error while trying to download the vocoder model for the drive link: https://drive.google.com/uc?ixd=1cf2NO6FtI0jDuy8AV3Xgn6leO6dHjIgu
| 0easy
|
Title: transformer2.2.2 加载参数失败
Body: 直接加载会报错
OSError: Model name '/Users/wonbyron/bert/chinese_roberta_wwm_large_ext_pytorch/' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc, bert-base-german-dbmdz-cased, bert-base-german-dbmdz-uncased). We assumed '/Users/wonbyron/bert/chinese_roberta_wwm_large_ext_pytorch/config.json' was a path or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.
经检查,应该将config文件改成bert.config才行
| 1medium
|
Title: using pytorch training reference script with pytorch-metric-learning
Body: Hi @KevinMusgrave !
I have recently been using the reference scripts pytorch provides to train my models (which is wonderful btw) BUT, I would love to use pytorch-metric-learning with this reference script.
The training script and blog re this is here:
https://github.com/pytorch/vision/tree/main/references/classification
https://pytorch.org/blog/how-to-train-state-of-the-art-models-using-torchvision-latest-primitives/
I am particularly interested in classification:
https://github.com/pytorch/vision/blob/main/references/classification/train.py
However, the issue ofc is that they all use CE loss which requires the logits - but I am not sure how to use say ArcFace Loss with this training reference script. Essentially, I would need the logits to make this work, but atm, all my arcface loss models work with an embedder output and distance metrics.
I was wondering if you could provide some guidance/advise on how to proceed to include metric learning in the reference training script.
Thank you!
| 1medium
|
Title: Feature Request: Expose agent errors in the TRMM console
Body: **Is your feature request related to a problem? Please describe.**
The `agent.log` has some errors that indicate possible problems but you don't know they are problems until you work with that specific agent.
**Describe the solution you'd like**
It would be nice if these system level or agent level errors were exposed in the TRMM console. If the agent can't connect to the server, then of course it can't report the errors. However, the majority of the errors can be reported to the server. Out of the 4 errors below, 3 could be reported to the server. The "MeshAgent.exe: file does not exist" error will be found when you go to remote to the agent and the "Connect" button is greyed out. In this case, repairing the agent did not do anything; Mesh needed to be reinstalled. The other 2 errors indicate possible problems with the agent and it's better to fix the issue before they become major problems, or before you try to troubleshoot a problem and run into the specific scenario which caused the error.
**Describe alternatives you've considered**
One alternative is to use a check on an agent to parse the logs and report the errors. Using a script check has one major problem:
1. TRMM checks do not have a memory. They cannot know the last timestamp that was scanned to know where to pickup in the log to prevent duplicate/missing alerts.
**Additional context**
IMHO this should be implemented as part of the core functionality. The reporting should be done as part of the frontend interface to view "TRMM errors", not agent-specific errors that you would expect for script checks for a human to fix. TRMM errors are generally programming issues (i.e. adding extra error handling) and should be reported/treated as such.
```text
time="2023-01-18T08:30:03-05:00" level=error msg="SyncMeshNodeID() getMeshNodeID() exec: \"C:\\\\Program Files\\\\Mesh Agent\\\\MeshAgent.exe\": file does not exist: "
```
```text
time="2022-11-26T19:02:03-05:00" level=error msg="error creating NewUpdateSession: ole.CoInitializeEx(0, ole.COINIT_MULTITHREADED): Cannot change thread mode after it is set."
```
```text
time="2022-03-25T15:09:49-04:00" level=error msg="x509: certificate has expired or is not yet valid: "
```
```text
time="2022-10-18T01:37:13-04:00" level=error msg="Checkrunner RunChecks exit status 2: Exception 0xc0000005 0x0 0xc000618000 0x7ff81957600f
PC=0x7ff81957600f
runtime.cgocall(0x9f57e0, 0xc000056ac0)
C:/Program Files/Go/src/runtime/cgocall.go:157 +0x4a fp=0xc000373660 sp=0xc000373628 pc=0x993f6a
syscall.SyscallN(0xc0003737b0?, {0xc0003736f8?, 0x74006e00650076?, 0x1acaf300001?})
C:/Program Files/Go/src/runtime/syscall_windows.go:556 +0x109 fp=0xc0003736d8 sp=0xc000373660 pc=0x9f0a49
syscall.Syscall9(0xc00060a500?, 0x0?, 0x3?, 0xc0003737d0?, 0xd921e6?, 0x0?, 0x0?, 0x0?, 0x0?, 0x0,...)
C:/Program Files/Go/src/runtime/syscall_windows.go:506 +0x78 fp=0xc000373750 sp=0xc0003736d8 pc=0x9f0758
github.com/amidaware/rmmagent/agent.FormatMessage(0x3800, 0xe7a662?, 0x80001779, 0x0, 0x2?, 0x10000, 0x0?)
C:/users/public/documents/agent/agent/syscall_windows.go:69 +0xc5 fp=0xc0003737e0 sp=0xc000373750 pc=0xd91fe5
github.com/amidaware/rmmagent/agent.getResourceMessage({0xc0002092e0?, 0x2ac?}, {0xc000209bb0, 0x8}, 0xb858bf7d?, 0x11f2d80?)
C:/users/public/documents/agent/agent/eventlog_windows.go:169 +0x1d8 fp=0xc0003838b8 sp=0xc0003737e0 pc=0xd81d98
github.com/amidaware/rmmagent/agent.(*Agent).GetEventLog(0xc00022e4e0, {0xc0002092e0, 0x6}, 0x1)
C:/users/public/documents/agent/agent/eventlog_windows.go:92 +0x5b0 fp=0xc000383ae8 sp=0xc0003838b8 pc=0xd815b0
github.com/amidaware/rmmagent/agent.(*Agent).EventLogCheck(_, {{{0x0, 0x0}, {0x0, 0x0}, 0x0}, {0x0, 0x0, 0x0}, 0xd0, ...}, ...)
C:/users/public/documents/agent/agent/checks.go:259 +0x77 fp=0xc000383d18 sp=0xc000383ae8 pc=0xd7e3d7
github.com/amidaware/rmmagent/agent.(*Agent).RunChecks.func7(0xc000209370, 0x0?)
C:/users/public/documents/agent/agent/checks.go:152 +0x148 fp=0xc000383fc0 sp=0xc000383d18 pc=0xd7bfe8
github.com/amidaware/rmmagent/agent.(*Agent).RunChecks.func14()
C:/users/public/documents/agent/agent/checks.go:154 +0x2e fp=0xc000383fe0 sp=0xc000383fc0 pc=0xd7be6e
runtime.goexit()
C:/Program Files/Go/src/runtime/asm_amd64.s:1571 +0x1 fp=0xc000383fe8 sp=0xc000383fe0 pc=0x9f3f21
created by github.com/amidaware/rmmagent/agent.(*Agent).RunChecks
C:/users/public/documents/agent/agent/checks.go:149 +0x81b
goroutine 1 [semacquire]:
sync.runtime_Semacquire(0xc00020d160?)
C:/Program Files/Go/src/runtime/sema.go:56 +0x25
sync.(*WaitGroup).Wait(0xe5d920?)
C:/Program Files/Go/src/sync/waitgroup.go:136 +0x52
github.com/amidaware/rmmagent/agent.(*Agent).RunChecks(0xc00022e4e0, 0x0)
C:/users/public/documents/agent/agent/checks.go:156 +0x828
main.main()
C:/users/public/documents/agent/main.go:112 +0xe5b
goroutine 43 [syscall, locked to thread]:
syscall.SyscallN(0x7ff819434ad0?, {0xc000077888?, 0x3?, 0x0?})
C:/Program Files/Go/src/runtime/syscall_windows.go:556 +0x109
syscall.Syscall(0xc000027620?, 0x0?, 0x2030000?, 0x20?, 0x2030000?)
C:/Program Files/Go/src/runtime/syscall_windows.go:494 +0x3b
syscall.WaitForSingleObject(0x1ac215b6216?, 0xffffffff)
C:/Program Files/Go/src/syscall/zsyscall_windows.go:1145 +0x65
os.(*Process).wait(0xc000090330)
C:/Program Files/Go/src/os/exec_windows.go:18 +0x65
os.(*Process).Wait(...)
C:/Program Files/Go/src/os/exec.go:132
os/exec.(*Cmd).Wait(0xc0000c42c0)
C:/Program Files/Go/src/os/exec/exec.go:510 +0x54
os/exec.(*Cmd).Run(0xc000238340?)
C:/Program Files/Go/src/os/exec/exec.go:341 +0x39
github.com/amidaware/rmmagent/agent.(*Agent).RunPythonCode(0xc00022e4e0, {0xe976ff?, 0x0?}, 0xd, {0xc000281c50, 0x0, 0x0?})
C:/users/public/documents/agent/agent/agent.go:483 +0x58d
github.com/amidaware/rmmagent/agent.(*Agent).GetCPULoadAvg(0xc00022e4e0)
C:/users/public/documents/agent/agent/agent.go:328 +0x3e
github.com/amidaware/rmmagent/agent.(*Agent).CPULoadCheck(_, {{{0x0, 0x0}, {0x0, 0x0}, 0x0}, {0x0, 0x0, 0x0}, 0x59, ...}, ...)
C:/users/public/documents/agent/agent/checks.go:231 +0x3b
github.com/amidaware/rmmagent/agent.(*Agent).RunChecks.func2({{{0x0, 0x0}, {0x0, 0x0}, 0x0}, {0x0, 0x0, 0x0}, 0x59, {0xc0002091f0, ...}, ...}, ...)
C:/users/public/documents/agent/agent/checks.go:105 +0xa5
created by github.com/amidaware/rmmagent/agent.(*Agent).RunChecks
C:/users/public/documents/agent/agent/checks.go:103 +0x10fe
goroutine 45 [syscall, locked to thread]:
syscall.SyscallN(0x7ff819434ad0?, {0xc00007b6d8?, 0x3?, 0x0?})
C:/Program Files/Go/src/runtime/syscall_windows.go:556 +0x109
syscall.Syscall(0x0?, 0xc0002c0440?, 0x35?,0xc000096000?, 0x1ac215c8014?)
C:/Program Files/Go/src/runtime/syscall_windows.go:494 +0x3b
syscall.WaitForSingleObject(0x20?, 0xffffffff)
C:/Program Files/Go/src/syscall/zsyscall_windows.go:1145 +0x65
os.(*Process).wait(0xc000496ba0)
C:/Program Files/Go/src/os/exec_windows.go:18 +0x65
os.(*Process).Wait(...)
C:/Program Files/Go/src/os/exec.go:132
os/exec.(*Cmd).Wait(0xc0000c4000)
C:/Program Files/Go/src/os/exec/exec.go:510 +0x54
github.com/amidaware/rmmagent/agent.(*Agent).RunScript(0xc00022e4e0, {0xc000202300?, 0x1ac215b3332?}, {0xc000209204, 0xa}, {0x1248e08, 0x0, 0xc000283c78?}, 0x5a, 0x0)
C:/users/public/documents/agent/agent/agent_windows.go:178 +0xd34
github.com/amidaware/rmmagent/agent.(*Agent).ScriptCheck(_, {{{0xc000209204, 0xa}, {0xc000202300, 0x16a}, 0x0}, {0x0, 0x0, 0x0}, 0xab, ...}, ...)
C:/users/public/documents/agent/agent/checks.go:172 +0xbf
github.com/amidaware/rmmagent/agent.(*Agent).RunChecks.func5({{{0xc000209204, 0xa}, {0xc000202300, 0x16a}, 0x0}, {0x0, 0x0, 0x0}, 0xab, {0xc000209210, ...}, ...}, ...)
C:/users/public/documents/agent/agent/checks.go:126 +0xc8
created by github.com/amidaware/rmmagent/agent.(*Agent).RunChecks
C:/users/public/documents/agent/agent/checks.go:123 +0xdfd
goroutine 20 [syscall, locked to thread]:
syscall.SyscallN(0x0?, {0xc000281c70?, 0x0?, 0x0?})
C:/Program Files/Go/src/runtime/syscall_windows.go:556 +0x109
syscall.Syscall6(0x10?, 0x1ac21dd38e0?, 0x35?, 0xc000281d10?, 0x99c89e?, 0x1ac21dd38e0?, 0x35?, 0x0?)
C:/Program Files/Go/src/runtime/syscall_windows.go:500 +0x50
syscall.ReadFile(0xc000281d35?, {0xc000400000?, 0x200, 0x800000?}, 0x7ffff800000?, 0x2?)
C:/Program Files/Go/src/syscall/zsyscall_windows.go:1024 +0x94
syscall.Read(0xc0000b2c80?, {0xc000400000?,0x99a43d?, 0xc000281db0?})
C:/Program Files/Go/src/syscall/syscall_windows.go:380 +0x2e
internal/poll.(*FD).Read(0xc0000b2c80, {0xc000400000, 0x200, 0x200})
C:/Program Files/Go/src/internal/poll/fd_windows.go:427 +0x1b4
os.(*File).read(...)
C:/Program Files/Go/src/os/file_posix.go:31
os.(*File).Read(0xc00008c058, {0xc000400000?, 0x1ac4a7e0028?, 0xc000281ea0?})
C:/Program Files/Go/src/os/file.go:119 +0x5e
bytes.(*Buffer).ReadFrom(0xc000089590, {0xf589a0, 0xc00008c058})
C:/Program Files/Go/src/bytes/buffer.go:204 +0x98
io.copyBuffer({0xf580a0, 0xc000089590}, {0xf589a0, 0xc00008c058}, {0x0, 0x0, 0x0})
C:/Program Files/Go/src/io/io.go:412 +0x14b
io.Copy(...)
C:/Program Files/Go/src/io/io.go:385
os/exec.(*Cmd).writerDescriptor.func1()
C:/Program Files/Go/src/os/exec/exec.go:311 +0x3a
os/exec.(*Cmd).Start.func1(0x0?)
C:/Program Files/Go/src/os/exec/exec.go:444 +0x25
created by os/exec.(*Cmd).Start
C:/Program Files/Go/src/os/exec/exec.go:443 +0x845
goroutine 21 [syscall, locked to thread]:
syscall.SyscallN(0xa2f6c5?, {0xc000285c70?, 0xe75aa2?, 0x8?})
C:/Program Files/Go/src/runtime/syscall_windows.go:556 +0x109
syscall.Syscall6(0xc000027350?, 0xc000220820?, 0xc000089470?, 0xc00009e0a0?, 0xc00009e0b4?, 0xc00009e0b0?, 0xc00008a180?, 0x0?)
C:/Program Files/Go/src/runtime/syscall_windows.go:500 +0x50
syscall.ReadFile(0x0?, {0xc000304200?, 0x200, 0x800000?}, 0x7ffff800000?, 0x2?)
C:/Program Files/Go/src/syscall/zsyscall_windows.go:1024 +0x94
syscall.Read(0xc0000b3180?, {0xc000304200?, 0xebc720?, 0xc000285db0?})
C:/Program Files/Go/src/syscall/syscall_windows.go:380 +0x2e
internal/poll.(*FD).Read(0xc0000b3180, {0xc000304200, 0x200, 0x200})
C:/Program Files/Go/src/internal/poll/fd_windows.go:427 +0x1b4
os.(*File).read(...)
C:/Program Files/Go/src/os/file_posix.go:31
os.(*File).Read(0xc00008c070, {0xc000304200?, 0xc000276300?, 0xc000285ea0?})
C:/Program Files/Go/src/os/file.go:119 +0x5e
bytes.(*Buffer).ReadFrom(0xc0000895c0, {0xf589a0, 0xc00008c070})
C:/Program Files/Go/src/bytes/buffer.go:204 +0x98
io.copyBuffer({0xf580a0, 0xc0000895c0}, {0xf589a0, 0xc00008c070}, {0x0, 0x0, 0x0})
C:/Program Files/Go/src/io/io.go:412 +0x14b
io.Copy(...)
C:/Program Files/Go/src/io/io.go:385
os/exec.(*Cmd).writerDescriptor.func1()
C:/Program Files/Go/src/os/exec/exec.go:311 +0x3a
os/exec.(*Cmd).Start.func1(0xc000276300?)
C:/Program Files/Go/src/os/exec/exec.go:444 +0x25
created by os/exec.(*Cmd).Start
C:/Program Files/Go/src/os/exec/exec.go:443 +0x845
goroutine 22 [select]:
os/exec.(*Cmd).Start.func2()
C:/Program Files/Go/src/os/exec/exec.go:452 +0x75
created by os/exec.(*Cmd).Start
C:/Program Files/Go/src/os/exec/exec.go:451 +0x82a
goroutine 73 [IO wait]:
internal/poll.runtime_pollWait(0x1ac21856558, 0x72)
C:/Program Files/Go/src/runtime/netpoll.go:302 +0x89
internal/poll.(*pollDesc).wait(0xc0001bf505?, 0xc0001bf505?, 0x0)
C:/Program Files/Go/src/internal/poll/fd_poll_runtime.go:83 +0x32
internal/poll.execIO(0xc00011aa18, 0xebc568)
C:/Program Files/Go/src/internal/poll/fd_windows.go:175 +0xe5
internal/poll.(*FD).Read(0xc00011aa00, {0xc0001bf500, 0x13b8, 0x13b8})
C:/Program Files/Go/src/internal/poll/fd_windows.go:441 +0x25f
net.(*netFD).Read(0xc00011aa00, {0xc0001bf500?, 0xc0000704a0?, 0xc0001bf505?})
C:/Program Files/Go/src/net/fd_posix.go:55 +0x29
net.(*conn).Read(0xc00008c048, {0xc0001bf500?, 0xa97ebeacd5d1a31f?, 0x1224?})
C:/Program Files/Go/src/net/net.go:183 +0x45
crypto/tls.(*atLeastReader).Read(0xc000210708, {0xc0001bf500?, 0x0?, 0xc00048d8a0?})
C:/Program Files/Go/src/crypto/tls/conn.go:785 +0x3d
bytes.(*Buffer).ReadFrom(0xc0000b8cf8, {0xf58140, 0xc000210708})
C:/Program Files/Go/src/bytes/buffer.go:204 +0x98
crypto/tls.(*Conn).readFromUntil(0xc0000b8a80, {0x1ac21856828?, 0xc00008c048}, 0x13b8?)
C:/Program Files/Go/src/crypto/tls/conn.go:807 +0xe5
crypto/tls.(*Conn).readRecordOrCCS(0xc0000b8a80, 0x0)
C:/Program Files/Go/src/crypto/tls/conn.go:614 +0x116
crypto/tls.(*Conn).readRecord(...)
C:/Program Files/Go/src/crypto/tls/conn.go:582
crypto/tls.(*Conn).Read(0xc0000b8a80, {0xc0000d3000, 0x1000, 0x21010401?})
C:/Program Files/Go/src/crypto/tls/conn.go:1285 +0x16f
bufio.(*Reader).Read(0xc000065560, {0xc00029e660, 0x9, 0xc00031cc00?})
C:/Program Files/Go/src/bufio/bufio.go:236 +0x1b4
io.ReadAtLeast({0xf58040, 0xc000065560}, {0xc00029e660, 0x9, 0x9}, 0x9)
C:/Program Files/Go/src/io/io.go:331 +0x9a
io.ReadFull(...)
C:/Program Files/Go/src/io/io.go:350
net/http.http2readFrameHeader({0xc00029e660?, 0x9?, 0xc000188ad0?}, {0xf58040?, 0xc000065560?})
C:/Program Files/Go/src/net/http/h2_bundle.go:1566 +0x6e
net/http.(*http2Framer).ReadFrame(0xc00029e620)
C:/Program Files/Go/src/net/http/h2_bundle.go:1830 +0x95
net/http.(*http2clientConnReadLoop).run(0xc00048df98)
C:/Program Files/Go/src/net/http/h2_bundle.go:8820 +0x130
net/http.(*http2ClientConn).readLoop(0xc000188a80)
C:/Program Files/Go/src/net/http/h2_bundle.go:8716 +0x6f
created by net/http.(*http2Transport).newClientConn
C:/Program Files/Go/src/net/http/h2_bundle.go:7444 +0xa65
goroutine 114 [syscall, locked to thread]:
syscall.SyscallN(0x0?, {0xc000283c70?, 0xc000066640?, 0x0?})
C:/Program Files/Go/src/runtime/syscall_windows.go:556 +0x109
syscall.Syscall6(0x10?, 0x1ac21dd15d0?, 0x35?, 0xc000283d10?, 0x99c89e?, 0x1ac21dd15d0?, 0xc000283d35?, 0xd97491?)
C:/Program Files/Go/src/runtime/syscall_windows.go:500 +0x50
syscall.ReadFile(0x135?, {0xc000304000?, 0x200, 0x800000?}, 0x7ffff800000?, 0x2?)
C:/Program Files/Go/src/syscall/zsyscall_windows.go:1024 +0x94
syscall.Read(0xc0000b3680?, {0xc000304000?, 0x0?, 0xc000283db0?})
C:/Program Files/Go/src/syscall/syscall_windows.go:380 +0x2e
internal/poll.(*FD).Read(0xc0000b3680, {0xc000304000, 0x200, 0x200})
C:/Program Files/Go/src/internal/poll/fd_windows.go:427 +0x1b4
os.(*File.read(...)
C:/Program Files/Go/src/os/file_posix.go:31
os.(*File).Read(0xc000006040, {0xc000304000?, 0xd7c5e0?, 0xc000283ea0?})
C:/Program Files/Go/src/os/file.go:119 +0x5e
bytes.(*Buffer).ReadFrom(0xc00026a2d0, {0xf589a0, 0xc000006040})
C:/Program Files/Go/src/bytes/buffer.go:204 +0x98
io.copyBuffer({0xf580a0, 0xc00026a2d0}, {0xf589a0, 0xc000006040}, {0x0, 0x0, 0x0})
C:/Program Files/Go/src/io/io.go:412 +0x14b
io.Copy(...)
C:/Program Files/Go/src/io/io.go:385
os/exec.(*Cmd).writerDescriptor.func1()
C:/Program Files/Go/src/os/exec/exec.go:311 +0x3a
os/exec.(*Cmd).Start.func1(0x0?)
C:/Program Files/Go/src/os/exec/exec.go:444 +0x25
created by os/exec.(*Cmd).Start
C:/Program Files/Go/src/os/exec/exec.go:443 +0x845
goroutine 115 [syscall, locked to thread]:
syscall.SyscallN(0x0?, {0xc000489c70?, 0x1ac215be721?, 0x0?})
C:/Program Files/Go/src/runtime/syscall_windows.go:556 +0x109
syscall.Syscall6(0x10?, 0x1ac21dd38e0?, 0x35?, 0xc000489d10?, 0x99c89e?, 0x1ac21dd38e0?, 0xc000489d35?, 0x99d0e5?)
C:/Program Files/Go/src/runtime/syscall_windows.go:500 +0x50
syscall.ReadFile(0xac21570a35?, {0xc000400200?, 0x200, 0x800000?}, 0x7ffff800000?, 0x2?)
C:/Program Files/Go/src/syscall/zsyscall_windows.go:1024 +0x94
syscall.Read(0xc0000b3b80?, {0xc000400200?, 0xc0000b8e00?, 0xc000489db0?})
C:/Program Files/Go/src/syscall/syscall_windows.go:380 +0x2e
internal/poll.(*FD).Read(0xc0000b3b80, {0xc000400200, 0x200, 0x200})
C:/Program Files/Go/src/internal/poll/fd_windows.go:427 +0x1b4
os.(*File).read(...)
C:/Program Files/Go/src/os/file_posix.go:31
os.(*File).Read(0xc0000060f0, {0xc000400200?, 0x0?, 0xc000489ea0?})
C:/Program Files/Go/src/os/file.go:119 +0x5e
bytes.(*Buffer).ReadFrom(0xc00026a300, {0xf589a0, 0xc0000060f0})
C:/Program Files/Go/src/bytes/buffer.go:204 +0x98
io.copyBuffer({0xf580a0, 0xc00026a300}, {0xf589a0, 0xc0000060f0}, {0x0, 0x0, 0x0})
C:/Program Files/Go/src/io/io.go:412 +0x14b
io.Copy(...)
C:/Program Files/Go/src/io/io.go:385
os/exec.(*Cmd).writerDescriptor.func1()
C:/Program Files/Go/src/os/exec/exec.go:311 +0x3a
os/exec.(*Cmd).Start.func1(0x0?)
C:/Program Files/Go/src/os/exec/exec.go:444 +0x25
created by os/exec.(*Cmd).Start
C:/Program Files/Go/src/os/exec/exec.go:443 +0x845
goroutine 116 [chan receive]:
github.com/amidaware/rmmagent/agent.(*Agent).RunScript.func1(0x0?)
C:/users/public/documents/agent/agent/agent_windows.go:172 +0x39
created by github.com/amidaware/rmmagent/agent.(*Agent).RunScript
C:/users/public/documents/agent/agent/agent_windows.go:170 +0xd27
rax 0x0
rbx 0xc000373884
rcx 0x0
rdi 0x198c9ffb10
rsi 0xc000373882
rbp 0x198c9ff370
rsp 0x198c9ff270
r8 0x0
r9 0x7fde8cc33301
r10 0xff01
r11 0x0
r12 0x1acaf31b884
r13 0x0
r14 0xc000618000
r15 0x0
rip 0x7ff81957600f
rflags 0x10202
cs 0x33
fs 0x53
gs 0x2b
"
```
| 1medium
|
Title: TypeError From ProfileReport in Google Colab
Body: ### Current Behaviour
In Google Colab the `.to_notebook_iframe` method on `ProfileReport` throws an error:
```Python
TypeError: concat() got an unexpected keyword argument 'join_axes'
```
This issue has been spotted in other contexts and there are questions in StackOverflow: https://stackoverflow.com/questions/61362942/concat-got-an-unexpected-keyword-argument-join-axes
### Expected Behaviour
This section not applicable. Reporting bug that throws an error.
### Data Description
You can reproduce the error with this data:
```Python
https://projects.fivethirtyeight.com/polls/data/favorability_polls.csv
```
### Code that reproduces the bug
```Python
import pandas as pd
from pandas_profiling import ProfileReport
df = pd.read_csv('https://projects.fivethirtyeight.com/polls/data/favorability_polls.csv')
profile = ProfileReport(df)
profile.to_notebook_iframe
```
### pandas-profiling version
Version 1.4.1
### Dependencies
```Text
absl-py==1.0.0
alabaster==0.7.12
albumentations==0.1.12
altair==4.2.0
appdirs==1.4.4
argon2-cffi==21.3.0
argon2-cffi-bindings==21.2.0
arviz==0.12.0
astor==0.8.1
astropy==4.3.1
astunparse==1.6.3
atari-py==0.2.9
atomicwrites==1.4.0
attrs==21.4.0
audioread==2.1.9
autograd==1.4
Babel==2.10.1
backcall==0.2.0
beautifulsoup4==4.6.3
bleach==5.0.0
blis==0.4.1
bokeh==2.3.3
Bottleneck==1.3.4
branca==0.5.0
bs4==0.0.1
CacheControl==0.12.11
cached-property==1.5.2
cachetools==4.2.4
catalogue==1.0.0
certifi==2021.10.8
cffi==1.15.0
cftime==1.6.0
chardet==3.0.4
charset-normalizer==2.0.12
click==7.1.2
cloudpickle==1.3.0
cmake==3.22.4
cmdstanpy==0.9.5
colorcet==3.0.0
colorlover==0.3.0
community==1.0.0b1
contextlib2==0.5.5
convertdate==2.4.0
coverage==3.7.1
coveralls==0.5
crcmod==1.7
cufflinks==0.17.3
cvxopt==1.2.7
cvxpy==1.0.31
cycler==0.11.0
cymem==2.0.6
Cython==0.29.28
daft==0.0.4
dask==2.12.0
datascience==0.10.6
debugpy==1.0.0
decorator==4.4.2
defusedxml==0.7.1
descartes==1.1.0
dill==0.3.4
distributed==1.25.3
dlib @ file:///dlib-19.18.0-cp37-cp37m-linux_x86_64.whl
dm-tree==0.1.7
docopt==0.6.2
docutils==0.17.1
dopamine-rl==1.0.5
earthengine-api==0.1.307
easydict==1.9
ecos==2.0.10
editdistance==0.5.3
en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.2.5/en_core_web_sm-2.2.5.tar.gz
entrypoints==0.4
ephem==4.1.3
et-xmlfile==1.1.0
fa2==0.3.5
fastai==1.0.61
fastdtw==0.3.4
fastjsonschema==2.15.3
fastprogress==1.0.2
fastrlock==0.8
fbprophet==0.7.1
feather-format==0.4.1
filelock==3.6.0
firebase-admin==4.4.0
fix-yahoo-finance==0.0.22
Flask==1.1.4
flatbuffers==2.0
folium==0.8.3
future==0.16.0
gast==0.5.3
GDAL==2.2.2
gdown==4.4.0
gensim==3.6.0
geographiclib==1.52
geopy==1.17.0
gin-config==0.5.0
glob2==0.7
google==2.0.3
google-api-core==1.31.5
google-api-python-client==1.12.11
google-auth==1.35.0
google-auth-httplib2==0.0.4
google-auth-oauthlib==0.4.6
google-cloud-bigquery==1.21.0
google-cloud-bigquery-storage==1.1.1
google-cloud-core==1.0.3
google-cloud-datastore==1.8.0
google-cloud-firestore==1.7.0
google-cloud-language==1.2.0
google-cloud-storage==1.18.1
google-cloud-translate==1.5.0
google-colab @ file:///colabtools/dist/google-colab-1.0.0.tar.gz
google-pasta==0.2.0
google-resumable-media==0.4.1
googleapis-common-protos==1.56.0
googledrivedownloader==0.4
graphviz==0.10.1
greenlet==1.1.2
grpcio==1.44.0
gspread==3.4.2
gspread-dataframe==3.0.8
gym==0.17.3
h5py==3.1.0
HeapDict==1.0.1
hijri-converter==2.2.3
holidays==0.10.5.2
holoviews==1.14.8
html5lib==1.0.1
httpimport==0.5.18
httplib2==0.17.4
httplib2shim==0.0.3
humanize==0.5.1
hyperopt==0.1.2
ideep4py==2.0.0.post3
idna==2.10
imageio==2.4.1
imagesize==1.3.0
imbalanced-learn==0.8.1
imblearn==0.0
imgaug==0.2.9
importlib-metadata==4.11.3
importlib-resources==5.7.1
imutils==0.5.4
inflect==2.1.0
iniconfig==1.1.1
intel-openmp==2022.1.0
intervaltree==2.1.0
ipykernel==4.10.1
ipython==5.5.0
ipython-genutils==0.2.0
ipython-sql==0.3.9
ipywidgets==7.7.0
itsdangerous==1.1.0
jax==0.3.8
jaxlib @ https://storage.googleapis.com/jax-releases/cuda11/jaxlib-0.3.7+cuda11.cudnn805-cp37-none-manylinux2014_x86_64.whl
jedi==0.18.1
jieba==0.42.1
Jinja2==2.11.3
joblib==1.1.0
jpeg4py==0.1.4
jsonschema==4.3.3
jupyter==1.0.0
jupyter-client==5.3.5
jupyter-console==5.2.0
jupyter-core==4.10.0
jupyterlab-pygments==0.2.2
jupyterlab-widgets==1.1.0
kaggle==1.5.12
kapre==0.3.7
keras==2.8.0
Keras-Preprocessing==1.1.2
keras-vis==0.4.1
kiwisolver==1.4.2
korean-lunar-calendar==0.2.1
libclang==14.0.1
librosa==0.8.1
lightgbm==2.2.3
llvmlite==0.34.0
lmdb==0.99
LunarCalendar==0.0.9
lxml==4.2.6
Markdown==3.3.6
MarkupSafe==2.0.1
matplotlib==3.2.2
matplotlib-inline==0.1.3
matplotlib-venn==0.11.7
missingno==0.5.1
mistune==0.8.4
mizani==0.6.0
mkl==2019.0
mlxtend==0.14.0
more-itertools==8.12.0
moviepy==0.2.3.5
mpmath==1.2.1
msgpack==1.0.3
multiprocess==0.70.12.2
multitasking==0.0.10
murmurhash==1.0.7
music21==5.5.0
natsort==5.5.0
nbclient==0.6.2
nbconvert==5.6.1
nbformat==5.3.0
nest-asyncio==1.5.5
netCDF4==1.5.8
networkx==2.6.3
nibabel==3.0.2
nltk==3.2.5
notebook==5.3.1
numba==0.51.2
numexpr==2.8.1
numpy==1.21.6
nvidia-ml-py3==7.352.0
oauth2client==4.1.3
oauthlib==3.2.0
okgrade==0.4.3
opencv-contrib-python==4.1.2.30
opencv-python==4.1.2.30
openpyxl==3.0.9
opt-einsum==3.3.0
osqp==0.6.2.post0
packaging==21.3
palettable==3.3.0
pandas==1.3.5
pandas-datareader==0.9.0
pandas-gbq==0.13.3
pandas-profiling==1.4.1
pandocfilters==1.5.0
panel==0.12.1
param==1.12.1
parso==0.8.3
pathlib==1.0.1
patsy==0.5.2
pep517==0.12.0
pexpect==4.8.0
pickleshare==0.7.5
Pillow==7.1.2
pip-tools==6.2.0
plac==1.1.3
plotly==5.5.0
plotnine==0.6.0
pluggy==0.7.1
pooch==1.6.0
portpicker==1.3.9
prefetch-generator==1.0.1
preshed==3.0.6
prettytable==3.2.0
progressbar2==3.38.0
prometheus-client==0.14.1
promise==2.3
prompt-toolkit==1.0.18
protobuf==3.17.3
psutil==5.4.8
psycopg2==2.7.6.1
ptyprocess==0.7.0
py==1.11.0
pyarrow==6.0.1
pyasn1==0.4.8
pyasn1-modules==0.2.8
pycocotools==2.0.4
pycparser==2.21
pyct==0.4.8
pydata-google-auth==1.4.0
pydot==1.3.0
pydot-ng==2.0.0
pydotplus==2.0.2
PyDrive==1.3.1
pyemd==0.5.1
pyerfa==2.0.0.1
pyglet==1.5.0
Pygments==2.6.1
pygobject==3.26.1
pymc3==3.11.4
PyMeeus==0.5.11
pymongo==4.1.1
pymystem3==0.2.0
PyOpenGL==3.1.6
pyparsing==3.0.8
pyrsistent==0.18.1
pysndfile==1.3.8
PySocks==1.7.1
pystan==2.19.1.1
pytest==3.6.4
python-apt==0.0.0
python-chess==0.23.11
python-dateutil==2.8.2
python-louvain==0.16
python-slugify==6.1.2
python-utils==3.1.0
pytz==2022.1
pyviz-comms==2.2.0
PyWavelets==1.3.0
PyYAML==3.13
pyzmq==22.3.0
qdldl==0.1.5.post2
qtconsole==5.3.0
QtPy==2.1.0
regex==2019.12.20
requests==2.23.0
requests-oauthlib==1.3.1
resampy==0.2.2
rpy2==3.4.5
rsa==4.8
scikit-image==0.18.3
scikit-learn==1.0.2
scipy==1.4.1
screen-resolution-extra==0.0.0
scs==3.2.0
seaborn==0.11.2
semver==2.13.0
Send2Trash==1.8.0
setuptools-git==1.2
Shapely==1.8.1.post1
simplegeneric==0.8.1
six==1.15.0
sklearn==0.0
sklearn-pandas==1.8.0
smart-open==6.0.0
snowballstemmer==2.2.0
sortedcontainers==2.4.0
SoundFile==0.10.3.post1
soupsieve==2.3.2.post1
spacy==2.2.4
Sphinx==1.8.6
sphinxcontrib-serializinghtml==1.1.5
sphinxcontrib-websupport==1.2.4
SQLAlchemy==1.4.36
sqlparse==0.4.2
srsly==1.0.5
statsmodels==0.10.2
sympy==1.7.1
tables==3.7.0
tabulate==0.8.9
tblib==1.7.0
tenacity==8.0.1
tensorboard==2.8.0
tensorboard-data-server==0.6.1
tensorboard-plugin-wit==1.8.1
tensorflow @ file:///tensorflow-2.8.0-cp37-cp37m-linux_x86_64.whl
tensorflow-datasets==4.0.1
tensorflow-estimator==2.8.0
tensorflow-gcs-config==2.8.0
tensorflow-hub==0.12.0
tensorflow-io-gcs-filesystem==0.25.0
tensorflow-metadata==1.7.0
tensorflow-probability==0.16.0
termcolor==1.1.0
terminado==0.13.3
testpath==0.6.0
text-unidecode==1.3
textblob==0.15.3
Theano-PyMC==1.1.2
thinc==7.4.0
threadpoolctl==3.1.0
tifffile==2021.11.2
tinycss2==1.1.1
tomli==2.0.1
toolz==0.11.2
torch @ https://download.pytorch.org/whl/cu113/torch-1.11.0%2Bcu113-cp37-cp37m-linux_x86_64.whl
torchaudio @ https://download.pytorch.org/whl/cu113/torchaudio-0.11.0%2Bcu113-cp37-cp37m-linux_x86_64.whl
torchsummary==1.5.1
torchtext==0.12.0
torchvision @ https://download.pytorch.org/whl/cu113/torchvision-0.12.0%2Bcu113-cp37-cp37m-linux_x86_64.whl
tornado==5.1.1
tqdm==4.64.0
traitlets==5.1.1
tweepy==3.10.0
typeguard==2.7.1
typing-extensions==4.2.0
tzlocal==1.5.1
uritemplate==3.0.1
urllib3==1.24.3
vega-datasets==0.9.0
wasabi==0.9.1
wcwidth==0.2.5
webencodings==0.5.1
Werkzeug==1.0.1
widgetsnbextension==3.6.0
wordcloud==1.5.0
wrapt==1.14.0
xarray==0.18.2
xgboost==0.90
xkit==0.0.0
xlrd==1.1.0
xlwt==1.3.0
yellowbrick==1.4
zict==2.2.0
zipp==3.8.0
```
```
### OS
Google Colab
### Checklist
- [X] There is not yet another bug report for this issue in the [issue tracker](https://github.com/ydataai/pandas-profiling/issues)
- [X] The problem is reproducible from this bug report. [This guide](http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports) can help to craft a minimal bug report.
- [X] The issue has not been resolved by the entries listed under [Frequent Issues](https://pandas-profiling.ydata.ai/docs/master/rtd/pages/support.html#frequent-issues).
| 1medium
|
Title: Outdated documentation
Body: Most of the examples provided in your documentation do not seem to be functioning correctly. Even on your website’s first page, under the “Quick Start” section (https://haystack.deepset.ai/overview/quick-start), there appears to be an error regarding the “PredefinedPipeline.” The line “from haystack import Pipeline, PredefinedPipeline” results in an error indicating that “PredefinedPipeline” cannot be found. Where can I find the correct and up-to-date documentation?
| 1medium
|
Title: [BUG]image classification doesn't work
Body: Ubuntu 20.04
autogluon 1.0.0
My original train_df had column labels 'img' and 'lbl'. This code failed:
```
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor(label='lbl', problem_type='multiclass', presets='medium_quality', path='models/mq')
predictor.fit(train_data=train_df, presets='medium_quality', column_types={'img':'image_path'})
```
That code resulted in the first 3 checkpoints getting saved and no improvement thereafter, no matter which backbone or preset I used. At inference time, predict_proba assigned equal probs to all classes for each row. Note that I had to specify column type else the text predictor would get used since the img column is detected as text instead of filepaths.
Tested that the Quick Start shopee example does work. Initially I thought changing the column names helped but turns out that was just reverting to a text predictor because I hadn't specified the column type.
| 1medium
|
Title: [BUG] Investigate Azure issue
Body: ### What would you like to share or ask?
From a user feedback:
We’re having some odd issues with Taipy App deployment. The Taipy App uses the Taipy framework and has an external connection (i.e., Azure Cosmos).
1. Create WebApp and Deploy Taipy App using Azure CLI
a. Create WebApp resource and Deploy Taipy App ‘taipyapp2-DEV’ using the command ‘az webapp up’.
b. Results: OK. The deployment succeeds and the webapp runs without error.
2. Deploying a Taipy App using Azure CLI to a pre-created WebApp resource.
a. Deploy to ‘taipyapp-DEV’. (Note this is the WebApp I asked you to create yesterday. I assume the WebApp was created via Azure Portal)
b. The Azure CLI command ‘az web app up’ (the same as 1) is used to deploy, and we specify the name of the WebApp to deploy to.
c. Results: Fails during deployment because resource not found. Error states that the WebApp resource cannot be found using Azure CLI ‘az webapp up’ command. It is odd because I can list WebApp via the ‘az webapp list’ command.
3. Deploying a Taipy App using Azure CLI to a pre-created WebApp
a. Deploy to ‘webapp-DEV’. Note this was created a long time ago. I assume the WebApp was created via Azure Portal
b. Azure CLI command ‘az webapp up’ (same as 1) is used to deploy and we specify the name of the WebApp to deploy to.
c. Results: Fails during deployment with a build failure.
4. Deploying a Taipy App using DevOps pipeline to a pre-created WebApp
a. Deploy to ‘webapp-DEV’. Note this was created a long time ago and the deployment uses the build and release pipelines that you set up for us.
b. Results: Build / Deploy succeeds but App throw ‘Monkey Patch Error’ (the one I showed you before). This is an odd error because the Deployment using 1 above uses the exact same code, requirements.txt file, etc. so the only difference is the deployment method and the way the WebApp was created. Likely we need to look at the build and deploy script too.
So, we think it’s a combination of two issues:
- There is something different about the App created via ‘az webapp up’ command and the one’s created separately. On the surface, I didn’t see any major differences.
- There is some adjustment needed for the build and/or deploy script to match what ‘az webapp up’ is doing.
### Code of Conduct
- [X] I have checked the [existing issues](https://github.com/Avaiga/taipy/issues?q=is%3Aissue+).
- [ ] I am willing to work on this issue (optional)
| 2hard
|
Title: Use correct library versions in requirements.txt
Body: Datastream.io is not working because some of the library dependencies are not set to the correct version (tornado and elasticsearch in my case).
Here is the pip freeze (python3.5) of the fully working datastream.io:
`bokeh==1.3.0
dateparser==0.7.1
-e git+https://github.com/MentatInnovations/datastream.io@a243b89ec3c4e06473b5004c498c472ffd37ead2#egg=dsio
elasticsearch==5.5.3
Jinja2==2.10.1
joblib==0.13.2
kibana-dashboard-api==0.1.2
MarkupSafe==1.1.1
numpy==1.17.0
packaging==19.0
pandas==0.24.2
Pillow==6.1.0
pyparsing==2.4.1.1
python-dateutil==2.8.0
pytz==2019.1
PyYAML==5.1.1
regex==2019.6.8
scikit-learn==0.21.2
scipy==1.3.0
six==1.12.0
tornado==4.5.3
tzlocal==2.0.0
urllib3==1.25.3
`
| 1medium
|
Title: Internet not detect
Body: ## Mycodo Issue Report:
- Specific Mycodo Version: 7.4.2
#### Problem Description
Please list: Internet is not detected even if internet is accessible.

Eth0 connection is straight to a laptop to interface with Mycodo.
Wlan0 connection is the one with access to the internet.
### Errors


### Additional Notes
Routing table has Wlan0 as the main gateway.

| 1medium
|
Title: How to create a tensor variable on the chief worker?
Body: I need a scalar variable to count something. In parameter server mode, I created it on the first ps node and all the workers can run `add_op` to update it. It works fine.
```
with tf.device('/job:ps/task:0/cpu:0'):
var_for_count = tf.get_variable('count_variable', (), tf.int32, initializer=tf.zeros_initializer)
add_op = var_for_count.assign_add(1, use_locking=True)
```
In horovod mode, there exists just the worker nodes. So, I created the scalar variable on the chief worker only and expected all the workers can also use `add_op` to update it like this.
```
with tf.device('/job:worker/task:0/cpu:0'):
var_for_count = tf.get_variable('count_variable', (), tf.int32, initializer=tf.zeros_initializer)
add_op = var_for_count.assign_add(1, use_locking=True)
```
However, it caused an error.
```
tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign a device for operation count_variable: node count_variable was explicitly assigned to /job:worker/task:0/device:CPU:0 but available devices are [ /job:localhost/replica:0/task:0/device:CPU:0, /job:localhost/replica:0/task:0/device:GPU:0]
```
| 1medium
|
Title: How to run bot with mutliple users ?
Body: Hello,
I install "Bot" and "Web UI" both and then they work pretty good now. Because I saw the top right corner of the design of [my web page](http://imgur.com/UhKua95) showing "Bots", I wonder if we can run more bots and display on the same page?
| 1medium
|
Title: sgl-kernel for aarch64
Body: Hello,
Thank you very much for your great work on SGLang!
I was wondering if it would be possible to release wheels for `sgl-kernel` for aarch64 (the one on pypi right now only supports x86_64). Alternatively, it would be very helpful if you could provide instructions on how to build `sgl-kernel` from source as well!
| 1medium
|
Title: Wrong Type for FileField based fields in POST type bodies
Body: **Describe the bug**
If I have a model with a models.FileField field, the type of this field is 'url' since the GET Request would include a url to the image, which is right. But when doing post requests, you don't have to provide an url but an file.
**To Reproduce**
It would be most helpful to provide a small snippet to see how the bug was provoked.
```python
class Bar(models.Model):
Image = models.FileField(upload_to="events/", null=True, blank=True)
... Boilerplate with serializers.HyperlinkedModelSerializer Router
```
The generated schema then contains
```yml
post:
operationId: bars_create
tags:
- bars
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/Bar'
```
and
`#/components/schemas/Bar` says:
```yml
Bar:
type: object
properties:
image:
type: string
format: uri
nullable: true
```
**Expected behavior**
If i understand https://swagger.io/docs/specification/describing-request-body/file-upload/ correctly it should be `format: binary`
| 1medium
|
Title: download language model
Body: ### Is your feature request related to a problem? Please describe.
i need to download language model when use local. but disk space available
How to change the download path ?
Download to `C:\Users\z\AppData\Local\Open Interpreter\Open Interpreter\models`?
[?] (Y/n): y
You do not have enough disk space available to download this model.
Open Interpreter will require approval before running code.
### Describe the solution you'd like
How to change the download path ?
### Describe alternatives you've considered
_No response_
### Additional context
_No response_
| 1medium
|
Title: Validation of User Input for Port and URL (Lines 138, 139)
Body: https://github.com/jofpin/trape/blob/6baae245691997742a51979767254d7da580eadd/core/trape.py#L138C4-L138C37
**Potential Issue:** User inputs for the `port` and `URL` fields are currently not validated, which could lead to errors or potential security risks.
**Suggestion:** Add validation checks for port ranges and URL format. This ensures input safety and reduces the likelihood of invalid configurations.
**Code Suggestion:**
```
try:
port = int(options.port)
if port < 1 or port > 65535:
raise ValueError("Port out of range")
except ValueError as e:
print(f"Invalid port: {e}")
sys.exit(1)
if not options.url.startswith(('http://', 'https://')):
print("Invalid URL format. URL must start with 'http://' or 'https://'")
sys.exit(1)
```
**Explanation:** This input validation strengthens security and ensures the application receives expected input formats.
| 1medium
|
Title: Building online APIs from pipelines with scripts/notebooks
Body: we only support exporting online APIs from pipelines with Python functions
| 1medium
|
Title: What is the origin of time for predict function?
Body: Based on the docs:
> If samples are ordered according to their predicted risk score (in ascending order), one obtains the sequence of events, as predicted by the model. This is the return value of the predict() method of all survival models in scikit-survival.
In my use case I need to predict the order in which individuals will die (in absolute/global time frame) given that they survived till the end (last day) of study.
I interpret predicted risk scores (using `predict()` function) as relative time to events.
However, it's not clear to me what is the origin of time for them?
Is it the time of birth for each individual (which would require adjusting risk scores in my use case), or is it the end of study time?
| 1medium
|
Title: Fritzboxtool: wlan with Fritzbox 5690pro
Body: ### The problem
Some actions doesnt work correctly:
Swiching wifi 5 ghz on or off applies to 6 ghz band
Action for the 5ghz band are missing. This box supports 5, 6 and 2.4 ghz but you can only swich 2 bands.
Furher feature request: I would like to limit the wifi to 50% in the night but there is no action for.
### What version of Home Assistant Core has the issue?
2025.3.3
### What was the last working version of Home Assistant Core?
_No response_
### What type of installation are you running?
Home Assistant OS
### Integration causing the issue
Fritzboxtools
### Link to integration documentation on our website
_No response_
### Diagnostics information
_No response_
### Example YAML snippet
```yaml
alias: Nachtschaltung Fritzbox
description: ""
triggers:
- trigger: time
at: "23:00:00"
- type: turned_off
device_id: 0f95a9f999b2383f933599333e279e5a
entity_id: 25f533c2cc809888e9e3964d51b79b6d
domain: remote
trigger: device
conditions:
- condition: time
after: "23:00:00"
before: "04:59:00"
- condition: device
type: is_off
device_id: 0f95a9f999b2383f933599333e279e5a
entity_id: 25f533c2cc809888e9e3964d51b79b6d
domain: remote
actions:
- type: turn_off
device_id: 1963e78c4301cb8c1160fdb4fc1c8558
entity_id: a41d918ab06b7cb7e3584c8e824cf01a
domain: switch
- type: turn_off
device_id: 1963e78c4301cb8c1160fdb4fc1c8558
entity_id: dba2c72a9586466a2a53617a2a0157f8
domain: switch
- wait_for_trigger:
- trigger: time
at: "05:00:00"
continue_on_timeout: false
- type: turn_on
device_id: 1963e78c4301cb8c1160fdb4fc1c8558
entity_id: a41d918ab06b7cb7e3584c8e824cf01a
domain: switch
- type: turn_on
device_id: 1963e78c4301cb8c1160fdb4fc1c8558
entity_id: dba2c72a9586466a2a53617a2a0157f8
domain: switch
mode: single
```
### Anything in the logs that might be useful for us?
```txt
```
### Additional information
_No response_
| 1medium
|
Title: Exception raised in arguments coercer doesn't returns expected error
Body: * **Tartiflette version:** 0.8.3
* **Python version:** 3.7.1
* **Executed in docker:** No
* **Is a regression from a previous versions?** No
SDL example:
```graphql
directive @validateLimit(
limit: Int!
) on ARGUMENT_DEFINITION | INPUT_FIELD_DEFINITION
type Query {
aList(
nbItems: Int! @validateLimit(limit: 2)
): [String!]
}
```
Python:
```python
class LimitReachedException(Exception):
def coerce_value(self, *_args, path=None, locations=None, **_kwargs):
computed_locations = []
try:
for location in locations:
computed_locations.append(location.collect_value())
except AttributeError:
pass
except TypeError:
pass
return {
"message": "Limit reached",
"path": path,
"locations": computed_locations,
"type": "bad_request",
}
@Directive("validateLimit", schema_name="test_issue209")
class ValidateLimitDirective(CommonDirective):
@staticmethod
async def on_argument_execution(
directive_args, next_directive, argument_definition, args, ctx, info
):
value = await next_directive(argument_definition, args, ctx, info)
if value > directive_args["limit"]:
raise LimitReachedException("Limit has been reached")
return value
@Resolver("Query.aList", schema_name="test_issue209")
async def resolver_query_a_list(parent, args, ctx, info):
nb_items = args["nbItems"]
return [f"{nb_items}.{index}" for index in range(nb_items)]
```
Query:
```graphql
query {
aList(nbItems: 3)
} == {
"data": {
"aList": null
},
"errors": [
{
"message": "Limit has been reached",
"path": [
"aList"
],
"locations": [
{
"line": 3,
"column": 15
}
]
}
]
}
```
Expected:
```json
{
"data": {
"aList": null
},
"errors": [
{
"message": "Limit reached",
"path": [
"aList"
],
"locations": [
{
"line": 3,
"column": 15
}
],
"type": "bad_request"
}
]
}
```
| 1medium
|
Title: Dark mode / custom CSS for Sanic's own output
Body: ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Is your feature request related to a problem? Please describe.
Sanic currently creates error pages and assuming that PR #2662 is merged will be producing file listings with bright white background.
The Internet is moving to dark mode, with more or less all sites implementing dark background via `@media (prefers-color-scheme: dark)` if not as the only option. The bright white hurts eyes on modern screens that often output 200 nits of bright light for it, and many are used to working in all-dark-background environments, coders too often in all-dark rooms.
### Describe the solution you'd like
Sanic generates its output from Python source code where the CSS is included as a string. Adding the media selector for automatic dark mode would be simple, or if minimalism is preferred, Sanic could even only implement a dark mode (but it is more polite to implement both so that users' browsers choose the one matching their desktop preference).
However, there is legitimate use for applications and enterprises using Sanic wanting to customize the pages further such that even the errors at least to a degree agree with their general visual style. This would be far harder to implement. Fetching the CSS as an extra file on an error page would be a bad idea, so basically Sanic would instead need to load those strings from some external source (e.g. during server startup).
I am opening this issue for discussion on the matter, that would work as a basis for a PR to come.
### Additional context
_No response_
| 1medium
|
Title: Bug: order of types in openapi spec is not consistent in json rendering
Body: ### Description
We are seeing the order of types change in openapi generation, which makes comparing golden versions of the openapi spec problematic. I think the specific problem we are seeing comes from https://github.com/litestar-org/litestar/blob/ffaf5616b19f6f0f4128209c8b49dbcb41568aa2/litestar/_openapi/schema_generation/schema.py#L160 where we use the `set` operation to uniquify the list of types. The order doesn't matter to the correctness of the openapi spec, so perhaps the responsibility for ensuring a determistic spec file could also come from the serializer, but either way it would be helpful if we could always render the same openapi spec the same way.
### URL to code causing the issue
_No response_
### MCVE
```python
# Your MCVE code here
```
### Steps to reproduce
```bash
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
```
### Screenshots
_No response_
### Logs
_No response_
### Litestar Version
2.9.1
### Platform
- [ ] Linux
- [ ] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
| 1medium
|
Title: Update project docs to point to Github discussions instead of Spectrum
Body: Starting August 2021 Spectrum will become read-only and its sprit lives on as GitHub Discussions.
Readme, issue template and website should be updated to direct users to discussions page, and announcement should be made on spectrum about this.
| 1medium
|
Title: Center word with negative polarity
Body: Hello,
Why does the word have negative polarity. ?
| 1medium
|
Title: Server default not matching for `func.now()` with SQLite
Body: My model has
```python
created = Column(DateTime, server_default=func.now())
```
And every time I invoke `autogenerate` with `compare_server_default=True` on sqlite, it generates the same migrations that do nothing:
```python
def upgrade():
# ### commands auto generated by Alembic - please adjust! ###
with op.batch_alter_table('visitors', schema=None) as batch_op:
batch_op.alter_column('created',
existing_type=sa.DATETIME(),
server_default=sa.text('(CURRENT_TIMESTAMP)'),
existing_nullable=True)
# ### end Alembic commands ###
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
with op.batch_alter_table('visitors', schema=None) as batch_op:
batch_op.alter_column('created',
existing_type=sa.DATETIME(),
server_default=sa.text('(CURRENT_TIMESTAMP)'),
existing_nullable=True)
# ### end Alembic commands ###
```
| 1medium
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.