
qid
int64 4
8.14M
| question
stringlengths 20
48.3k
| answers
list | date
stringlengths 10
10
| metadata
list | input
stringlengths 12
45k
| output
stringlengths 2
31.8k
|
|---|---|---|---|---|---|---|
189,830 |
<p>I am encountering error like </p>
<pre><code>test(10)[1].csv file cannot be found at
C:\Documents and Settings\Ron\Local Settings\Temporary Internet Files\Content.IE5\PQ0STUVW
</code></pre>
<p>When trying to do export of CSV file using the following codes.
Anyone have any idea what could be wrong? This issue does not occur in IE7 / Firefox and is only specific to IE6. </p>
<pre><code>response.setContentType("application/vnd.ms-excel");
response.setHeader("Content-Disposition", "attachment;filename=" + fileFullName);
</code></pre>
|
[
{
"answer_id": 204430,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Are there \"special\" characters in your \"fileFullName\"? You cold also try to check the length of your file name, I once had an issue with IE6 when the file name got too long.</p>\n\n<p>Just to be on the safe side: your \"fileFullName\" only contains the name of the file and not the path, right? </p>\n"
},
{
"answer_id": 275558,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>I'm not sure exactly why the filename is getting munged, but the 'not found' in IE usually means that you're also setting no-cache headers, or a cache time of zero seconds. </p>\n\n<p>If I remember correctly, IE can't open the file directly - it has to cache it first, and then open it from the cache. So you have to allow it to be cached.</p>\n\n<p>This means that:\n1. For things to work properly, the file name needs to be unique each time - I usually add the timestamp (to the millisecond) to the filename.</p>\n\n<ol start=\"2\">\n<li>So as to keep your clients' caches from growing unnecessarily, you should probably set the cache time to something short (1 or 2 seconds or so), but definitely not 0;</li>\n</ol>\n"
},
{
"answer_id": 720680,
"author": "paulgreg",
"author_id": 3122,
"author_profile": "https://Stackoverflow.com/users/3122",
"pm_score": 1,
"selected": false,
"text": "<p>I've already got that problem and asked the <a href=\"https://stackoverflow.com/questions/120497/how-to-work-around-the-1-ie-bug-while-saving-an-excel-file-from-a-web-server\">question that as a correct answer</a> (or, shall I say, a good workaround for IE).</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189830",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25368/"
] |
I am encountering error like
```
test(10)[1].csv file cannot be found at
C:\Documents and Settings\Ron\Local Settings\Temporary Internet Files\Content.IE5\PQ0STUVW
```
When trying to do export of CSV file using the following codes.
Anyone have any idea what could be wrong? This issue does not occur in IE7 / Firefox and is only specific to IE6.
```
response.setContentType("application/vnd.ms-excel");
response.setHeader("Content-Disposition", "attachment;filename=" + fileFullName);
```
|
I've already got that problem and asked the [question that as a correct answer](https://stackoverflow.com/questions/120497/how-to-work-around-the-1-ie-bug-while-saving-an-excel-file-from-a-web-server) (or, shall I say, a good workaround for IE).
|
189,855 |
<p>Which would be a neat implemenation of a N-ary tree in C language?</p>
<p>Particulary, I want to implement an n-ary tree, not self-ballancing, with an unbound number of children in each node, in which each node holds an already defined struct, like this for example:</p>
<pre><code>struct task {
char command[MAX_LENGTH];
int required_time;
};
</code></pre>
|
[
{
"answer_id": 189900,
"author": "Matt J",
"author_id": 18528,
"author_profile": "https://Stackoverflow.com/users/18528",
"pm_score": 5,
"selected": true,
"text": "<p>As a first pass, you could simply create a <em>struct</em> (let's call it <em>TreeNode</em>) which holds a <em>task</em>, as well as a set of pointers to <em>TreeNode</em>s. This set could either be an array (if <strong>N</strong> is fixed) or a linked list (if <strong>N</strong> is variable). The linked list would require you to declare an additional <em>struct</em> (let's called it <em>ListNode</em>) with a <em>TreeNode</em> pointer to the actual child (part of the tree), and a pointer to the next <em>ListNode</em> in the list (<strong>null</strong> if at the end of the list).</p>\n\n<p>It might look something like this:</p>\n\n<pre><code>struct task {\n char command[MAX_LENGTH];\n int required_time;\n};\n\nstruct TreeNode;\n\nstruct ListNode {\n struct TreeNode * child;\n struct ListNode * next;\n};\n\nstruct TreeNode {\n struct task myTask;\n struct ListNode myChildList;\n};\n</code></pre>\n"
},
{
"answer_id": 192089,
"author": "Remo.D",
"author_id": 16827,
"author_profile": "https://Stackoverflow.com/users/16827",
"pm_score": 6,
"selected": false,
"text": "<p>Any n-ary tree can be represented as a binary tree where in each node the left pointer points to the first child and the right pointer points to the next brother.</p>\n\n<pre>\n R R\n / | \\ |\n B C D B -- C -- D\n / \\ | | |\n E F G E -- F G\n</pre>\n\n<p>So, your case would be:</p>\n\n<pre><code>struct task {\n char command[MAX_LENGTH];\n int required_time;\n};\n\nstruct node {\n struct task taskinfo;\n struct node *firstchild;\n struct node *nextsibling;\n};\n</code></pre>\n\n<p>This technique has the advantage that many algorithms are simpler to write as they can be expressed on a binary tree rather than on a more complicated data structure.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189855",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26699/"
] |
Which would be a neat implemenation of a N-ary tree in C language?
Particulary, I want to implement an n-ary tree, not self-ballancing, with an unbound number of children in each node, in which each node holds an already defined struct, like this for example:
```
struct task {
char command[MAX_LENGTH];
int required_time;
};
```
|
As a first pass, you could simply create a *struct* (let's call it *TreeNode*) which holds a *task*, as well as a set of pointers to *TreeNode*s. This set could either be an array (if **N** is fixed) or a linked list (if **N** is variable). The linked list would require you to declare an additional *struct* (let's called it *ListNode*) with a *TreeNode* pointer to the actual child (part of the tree), and a pointer to the next *ListNode* in the list (**null** if at the end of the list).
It might look something like this:
```
struct task {
char command[MAX_LENGTH];
int required_time;
};
struct TreeNode;
struct ListNode {
struct TreeNode * child;
struct ListNode * next;
};
struct TreeNode {
struct task myTask;
struct ListNode myChildList;
};
```
|
189,878 |
<p>I'm looking for a regex that will allow me to validate whether or not a string is the reference to a website address, or a specific page in that website. </p>
<p>So it would match:</p>
<pre><code>http://google.com
ftp://google.com
http://google.com/
http://lots.of.subdomains.google.com
</code></pre>
<p>But not:</p>
<pre><code>http://google.com/search.whatever
ftp://google.com/search.whatever
http://lots.of.subdomains.google.com/search.whatever
</code></pre>
<p>Any ideas? I can't quite figure out how to handle allowing the <code>/</code> at the end of the URL.</p>
|
[
{
"answer_id": 189941,
"author": "Paige Ruten",
"author_id": 813,
"author_profile": "https://Stackoverflow.com/users/813",
"pm_score": 4,
"selected": true,
"text": "<p>Try this:</p>\n\n<pre><code>(http|ftp|https)://([a-zA-Z0-9\\-\\.]+)/?\n</code></pre>\n"
},
{
"answer_id": 190053,
"author": "Dov Wasserman",
"author_id": 26010,
"author_profile": "https://Stackoverflow.com/users/26010",
"pm_score": 2,
"selected": false,
"text": "<p>Great answer by Jeremy. Depending on which regex dialect you're using to match, you might want to wrap the whole expression with anchors (to avoid matching URLs like <code>http://example.com/bin/cgi?returnUrl=http://google.com</code>), and maybe generalize the valid protocol and domain name characters:</p>\n\n<pre><code>^\\w+://(\\w+\\.)+\\w+/?$\n</code></pre>\n"
},
{
"answer_id": 190340,
"author": "eyelidlessness",
"author_id": 17964,
"author_profile": "https://Stackoverflow.com/users/17964",
"pm_score": 3,
"selected": false,
"text": "<p>This is a shortened version of my full URI validation pattern, based on the <a href=\"http://www.ietf.org/rfc/rfc2396.txt\" rel=\"noreferrer\">specification</a>. I wrote this because the specification allows many characters never included in any validation pattern I've found on the web. You'll see that the user/pass (and in the second pattern, path and query string) are far more permissive than you'd have thought.</p>\n\n<pre><code>/^(https?|ftp):\\/\\/(?# protocol\n)(([a-z0-9$_\\.\\+!\\*\\'\\(\\),;\\?&=-]|%[0-9a-f]{2})+(?# username\n)(:([a-z0-9$_\\.\\+!\\*\\'\\(\\),;\\?&=-]|%[0-9a-f]{2})+)?(?# password\n)@)?(?# auth requires @\n)((([a-z0-9][a-z0-9-]*[a-z0-9]\\.)*(?# domain segments AND\n)[a-z]{2}[a-z0-9-]*[a-z0-9](?# top level domain OR\n)|(\\d|[1-9]\\d|1\\d{2}|2[0-4][0-9]|25[0-5]\\.){3}(?#\n )(\\d|[1-9]\\d|1\\d{2}|2[0-4][0-9]|25[0-5])(?# IP address\n))(:\\d+)?(?# port\n))\\/?$/i\n</code></pre>\n\n<p>And since I've taken the time to break this out to be somewhat more readable, here is the complete pattern:</p>\n\n<pre><code>/^(https?|ftp):\\/\\/(?# protocol\n)(([a-z0-9$_\\.\\+!\\*\\'\\(\\),;\\?&=-]|%[0-9a-f]{2})+(?# username\n)(:([a-z0-9$_\\.\\+!\\*\\'\\(\\),;\\?&=-]|%[0-9a-f]{2})+)?(?# password\n)@)?(?# auth requires @\n)((([a-z0-9][a-z0-9-]*[a-z0-9]\\.)*(?# domain segments AND\n)[a-z]{2}[a-z0-9-]*[a-z0-9](?# top level domain OR\n)|(\\d|[1-9]\\d|1\\d{2}|2[0-4][0-9]|25[0-5]\\.){3}(?#\n )(\\d|[1-9]\\d|1\\d{2}|2[0-4][0-9]|25[0-5])(?# IP address\n))(:\\d+)?(?# port\n))(((\\/+([a-z0-9$_\\.\\+!\\*\\'\\(\\),;:@&=-]|%[0-9a-f]{2})*)*(?# path\n)(\\?([a-z0-9$_\\.\\+!\\*\\'\\(\\),;:@&=-]|%[0-9a-f]{2})*)(?# query string\n)?)?)?(?# path and query string optional\n)(#([a-z0-9$_\\.\\+!\\*\\'\\(\\),;:@&=-]|%[0-9a-f]{2})*)?(?# fragment\n)$/i\n</code></pre>\n\n<p>Note that some (all?) javascript implementations do not support comments in regular expressions.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189878",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4965/"
] |
I'm looking for a regex that will allow me to validate whether or not a string is the reference to a website address, or a specific page in that website.
So it would match:
```
http://google.com
ftp://google.com
http://google.com/
http://lots.of.subdomains.google.com
```
But not:
```
http://google.com/search.whatever
ftp://google.com/search.whatever
http://lots.of.subdomains.google.com/search.whatever
```
Any ideas? I can't quite figure out how to handle allowing the `/` at the end of the URL.
|
Try this:
```
(http|ftp|https)://([a-zA-Z0-9\-\.]+)/?
```
|
189,887 |
<p>is there an if statement when it comes to mysql query statements?</p>
<p>when i am updating a table record, i want to only update certain columns if they have a value to be updated.</p>
<p>for example, i want an update table function, and there is a table for volunteers and a table for people who just want email updates.</p>
<p>i want to use the same function (there will be a function that only deals w/ the upd queries) and is it possible to do this in theory...</p>
<p>if you are updating volunteer table, only update these columns, if mailing_list, then update these</p>
<p>i know this can by done using an if statement w/ two query statements, based on what table you're updating, but i am wondering is it possible to use only one query statement w/ the conditionals in it to update the appropriate columns in the table.</p>
<p>this may sound like something you would dream about, let me know.</p>
<p>thanks.</p>
|
[
{
"answer_id": 190011,
"author": "Darryl Hein",
"author_id": 5441,
"author_profile": "https://Stackoverflow.com/users/5441",
"pm_score": 3,
"selected": true,
"text": "<p>I think this should work:</p>\n\n<pre><code>UPDATE volunteer, people\nSET volunteer.email = '[email protected]',\n people.email = '[email protected]',\n people.first_name = 'first',\nWHERE people.id = 2 AND volunteer.id = 5;\n</code></pre>\n\n<p>I got this from the <a href=\"http://dev.mysql.com/doc/refman/5.1/en/update.html\" rel=\"nofollow noreferrer\">update syntax</a> on the MySQL website.</p>\n"
},
{
"answer_id": 190141,
"author": "ysth",
"author_id": 17389,
"author_profile": "https://Stackoverflow.com/users/17389",
"pm_score": 0,
"selected": false,
"text": "<p>You <em>could</em> do this in one query, but it's not making sense to me why you would want to.\nMaybe describe the arguments to your desired function and what effect they would have?</p>\n\n<p>You can conditionally update something like this:</p>\n\n<pre><code>update tablereferences\n set foo.bar = if( somebooleanexpression, newbarvalue, foo.bar ),\n baz.quux = if( somebooleanexpression, newbazvalue, baz.quux )\n where ...\n</code></pre>\n\n<p>allowing you to use the same query but control which tables are updated.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189887",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26130/"
] |
is there an if statement when it comes to mysql query statements?
when i am updating a table record, i want to only update certain columns if they have a value to be updated.
for example, i want an update table function, and there is a table for volunteers and a table for people who just want email updates.
i want to use the same function (there will be a function that only deals w/ the upd queries) and is it possible to do this in theory...
if you are updating volunteer table, only update these columns, if mailing\_list, then update these
i know this can by done using an if statement w/ two query statements, based on what table you're updating, but i am wondering is it possible to use only one query statement w/ the conditionals in it to update the appropriate columns in the table.
this may sound like something you would dream about, let me know.
thanks.
|
I think this should work:
```
UPDATE volunteer, people
SET volunteer.email = '[email protected]',
people.email = '[email protected]',
people.first_name = 'first',
WHERE people.id = 2 AND volunteer.id = 5;
```
I got this from the [update syntax](http://dev.mysql.com/doc/refman/5.1/en/update.html) on the MySQL website.
|
189,889 |
<p>I'm having a problem using the java.text.MessageFormat object.</p>
<p>I'm trying to create SQL insert statements. The problem is, when I do something like this:</p>
<pre><code>MessageFormat messageFormat = "insert into {0} values ( '{1}', '{2}', '{3}', {4} )";
Object[] args = { str0, str1, str2, str3, str4 };
String result = messageFormat.format(args);
</code></pre>
<p>I get this for the value of <code>result</code>:</p>
<pre><code>"insert into <str0> values ( {1}, {2}, {3}, <str4> )"
</code></pre>
<p>As you can see, the problem is that any of the target locations that are enclosed by single quotes do not get replaced by arguments. I have tried using double single quotes like this: <code>''{1}''</code> and escaped characters like this: <code>\'{1}\'</code> but it still gives the same result. </p>
<p>edit: I forgot to mention that I also tried <code>'''{1}'''</code>. The result is: <code>"insert into <str0> values ( '{1}', '{2}', '{3}', <str4> )"</code>. It is keeping the original quotes around but still not inserting the values.</p>
<p>How can I resolve this issue? For the record, I am using JDK 6u7.</p>
|
[
{
"answer_id": 189895,
"author": "billjamesdev",
"author_id": 13824,
"author_profile": "https://Stackoverflow.com/users/13824",
"pm_score": 0,
"selected": false,
"text": "<p>First thing that came to mind was to change str1, str2, str3 to have the single quotes around them.</p>\n\n<pre>\nObject[] args = { str0, \"'\" + str1 + \"'\", \"'\" + str2 + \"'\", \"'\" + str3 + \"'\", str4 };\n</pre>\n\n<p>Then, of course, remove the single-quotes from your query string.</p>\n"
},
{
"answer_id": 189896,
"author": "Chris Boran",
"author_id": 25660,
"author_profile": "https://Stackoverflow.com/users/25660",
"pm_score": 4,
"selected": false,
"text": "<blockquote>\n <p>Within a <em>String</em>, a pair of single quotes can be used to quote any arbitrary characters except single quotes. For example, pattern string <code>\"'{0}'\"</code> represents string <code>\"{0}\"</code>, not a <em>FormatElement</em>. A single quote itself must be represented by doubled single quotes <code>''</code> throughout a <code>String</code>. For example, pattern string <code>\"'{''}'\"</code> is interpreted as a sequence of <code>'{</code> (start of quoting and a left curly brace), <code>''</code> (a single quote), and <code>}'</code> (a right curly brace and end of quoting), <strong>not</strong> <code>'{'</code> and <code>'}'</code> (quoted left and right curly braces): representing string <code>\"{'}\"</code>, <strong>not</strong> <code>\"{}\"</code>.</p>\n</blockquote>\n\n<p>From: <a href=\"https://docs.oracle.com/javase/8/docs/api/java/text/MessageFormat.html\" rel=\"noreferrer\">MessageFormat (Java Platform SE 8 )</a></p>\n"
},
{
"answer_id": 189898,
"author": "Brian Duff",
"author_id": 3643,
"author_profile": "https://Stackoverflow.com/users/3643",
"pm_score": 2,
"selected": false,
"text": "<p>Use triple single quote characters:</p>\n\n<pre><code>MessageFormat messageFormat = \"insert into {0} values ( '''{1}''', '''{2}''', '''{3}''', '''{4}''' )\";\n</code></pre>\n"
},
{
"answer_id": 189955,
"author": "serg",
"author_id": 20128,
"author_profile": "https://Stackoverflow.com/users/20128",
"pm_score": 8,
"selected": true,
"text": "<p>I just tried double quotes and it worked fine for me:</p>\n\n<pre><code>MessageFormat messageFormat = new MessageFormat(\"insert into {0} values ( ''{1}'', ''{2}'', ''{3}'', {4} )\");\nObject[] args = {\"000\", \"111\", \"222\",\"333\",\"444\",\"555\"};\nString result = messageFormat.format(args);\n</code></pre>\n\n<p>The result is:</p>\n\n<pre><code>insert into 000 values ( '111', '222', '333', 444 )\n</code></pre>\n\n<p>Is this what you need?</p>\n"
},
{
"answer_id": 190050,
"author": "Aidos",
"author_id": 12040,
"author_profile": "https://Stackoverflow.com/users/12040",
"pm_score": 5,
"selected": false,
"text": "<p>Sorry if this is off the side, but it looks like you're trying to replicate the PreparedStatement that is already in JDBC.</p>\n\n<p>If you are trying to create SQL to run against a database then I suggest that you look at PreparedStatement, it already does what you're trying to do (with a slightly different syntax).</p>\n\n<p>Sorry if this isn't what you are doing, I just thought I would point it out.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189889",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/12983/"
] |
I'm having a problem using the java.text.MessageFormat object.
I'm trying to create SQL insert statements. The problem is, when I do something like this:
```
MessageFormat messageFormat = "insert into {0} values ( '{1}', '{2}', '{3}', {4} )";
Object[] args = { str0, str1, str2, str3, str4 };
String result = messageFormat.format(args);
```
I get this for the value of `result`:
```
"insert into <str0> values ( {1}, {2}, {3}, <str4> )"
```
As you can see, the problem is that any of the target locations that are enclosed by single quotes do not get replaced by arguments. I have tried using double single quotes like this: `''{1}''` and escaped characters like this: `\'{1}\'` but it still gives the same result.
edit: I forgot to mention that I also tried `'''{1}'''`. The result is: `"insert into <str0> values ( '{1}', '{2}', '{3}', <str4> )"`. It is keeping the original quotes around but still not inserting the values.
How can I resolve this issue? For the record, I am using JDK 6u7.
|
I just tried double quotes and it worked fine for me:
```
MessageFormat messageFormat = new MessageFormat("insert into {0} values ( ''{1}'', ''{2}'', ''{3}'', {4} )");
Object[] args = {"000", "111", "222","333","444","555"};
String result = messageFormat.format(args);
```
The result is:
```
insert into 000 values ( '111', '222', '333', 444 )
```
Is this what you need?
|
189,892 |
<p>If I have an array of a fixed size depending on how it is defined and used, I typically use one of two ways to reference it.</p>
<p>Array type 1: Since it is a fixed size based on a define, I just use that define in all my loops referencing it.</p>
<pre><code>#define MAXPLAYERS 4
int playerscores[MAXPLAYERS];
for(i=0;i<MAXPLAYERS;++i)
{
.... do something with each player
}
</code></pre>
<p>Array type 2: Since this array can grow as items are added to it, I use the sizeof to count the number of entries in it. The size would be converted to a constant by the compiler so there shouldn't be any runtime penalty to doing it this way.</p>
<pre><code>typedef struct
{
fields....
}MYSTRUCT_DEF;
MYSTRUCT_DEF mystruct[]={
{entry 1},
{entry 2},
{entry 3...n}
};
for(i=0;i<(sizeof(mystruct)/sizeof(MYSTRUCT_DEF));++i)
{
..... do something with each entry
}
</code></pre>
<p>Is there a more elegant solution to handling processing of arrays without going past the end or stopping too early. Thoughts? Comments?</p>
|
[
{
"answer_id": 189907,
"author": "Alex B",
"author_id": 23643,
"author_profile": "https://Stackoverflow.com/users/23643",
"pm_score": 4,
"selected": true,
"text": "<p>This will work for both of your cases, regardless of array element type:</p>\n\n<pre><code>#define ARRAY_COUNT(x) (sizeof(x)/sizeof((x)[0]))\n\n...\n\nstruct foo arr[100];\n...\n\nfor (i = 0; i < ARRAY_COUNT(arr); ++i) {\n /* do stuff to arr[i] */\n}\n</code></pre>\n"
},
{
"answer_id": 189911,
"author": "Michael Burr",
"author_id": 12711,
"author_profile": "https://Stackoverflow.com/users/12711",
"pm_score": 3,
"selected": false,
"text": "<p>In C++ just use the vector class.</p>\n\n<p>If you can't for some reason then there are macro implementations of what you want.\nSee this answer for a set of macros from winnt.h that work in C and even more safely in C++:</p>\n\n<p><a href=\"https://stackoverflow.com/questions/95500/can-this-macro-be-converted-to-a-function#95714\">Can this macro be converted to a function?</a></p>\n"
},
{
"answer_id": 189922,
"author": "Brian R. Bondy",
"author_id": 3153,
"author_profile": "https://Stackoverflow.com/users/3153",
"pm_score": 3,
"selected": false,
"text": "<p>Use the _countof macro of stdlib.h</p>\n\n<p><a href=\"http://msdn.microsoft.com/en-us/library/ms175773(VS.80).aspx\" rel=\"nofollow noreferrer\">From this MSDN article</a>:</p>\n\n<pre><code>// crt_countof.cpp\n#define _UNICODE\n#include <stdio.h>\n#include <stdlib.h>\n#include <tchar.h>\nint main( void )\n{\n _TCHAR arr[20], *p;\n printf( \"sizeof(arr) = %d bytes\\n\", sizeof(arr) );\n printf( \"_countof(arr) = %d elements\\n\", _countof(arr) );\n // In C++, the following line would generate a compile-time error:\n // printf( \"%d\\n\", _countof(p) ); // error C2784 (because p is a pointer)\n\n _tcscpy_s( arr, _countof(arr), _T(\"a string\") );\n // unlike sizeof, _countof works here for both narrow- and wide-character strings\n}\n</code></pre>\n"
},
{
"answer_id": 189927,
"author": "Paul Nathan",
"author_id": 26227,
"author_profile": "https://Stackoverflow.com/users/26227",
"pm_score": 1,
"selected": false,
"text": "<p>For C, I would suggest realloc to bring in new variables dynamically. If you are doing something statically, I would suggest keeping with the #define. I'm not sure if I'd call that best practice, but, today, that's how I would practice it.</p>\n\n<p>The C++ best practice is to use stl::vector. <a href=\"http://www.cplusplus.com/reference/stl/\" rel=\"nofollow noreferrer\">A reference here</a></p>\n"
},
{
"answer_id": 189928,
"author": "Nick",
"author_id": 26240,
"author_profile": "https://Stackoverflow.com/users/26240",
"pm_score": 1,
"selected": false,
"text": "<p>I almost always use a wrapper class (MFC CArray, stl vector, etc.) unless there's a specific reason not too. There's not much overhead, you get a lot of debug checking, you can dynamically size, getting the size is easy, etc.</p>\n"
},
{
"answer_id": 189996,
"author": "ephemient",
"author_id": 20713,
"author_profile": "https://Stackoverflow.com/users/20713",
"pm_score": 2,
"selected": false,
"text": "<p>It's fairly common to see C code like</p>\n\n<pre><code>struct foo {\n ... /* fields */\n};\nstruct foo array[] = {\n { ... }, /* item 1 */\n { ... }, /* item 2 */\n ...,\n { 0 } /* terminator */\n};\nfor (i = 0; array[i].some_field; i++) {\n ...\n}\n</code></pre>\n\n<p>Often you can find at least one field which is never <code>0</code>/<code>NULL</code> for normal elements, and if not, you can use some other special END value.</p>\n\n<p>In code that I write, anything that involves compiletime-sized arrays is done with a macro like <code>ARRAY_COUNT</code> from Checkers's answer, and runtime-sized arrays always come with a size counter, in a struct with the array.</p>\n\n<pre><code>struct array_of_stuff {\n struct stuff *array;\n int count; /* number of used elements */\n int length; /* number of elements allocated */\n};\n</code></pre>\n\n<p>The <code>length</code> field allows for easy batched resizing.</p>\n"
},
{
"answer_id": 190514,
"author": "paercebal",
"author_id": 14089,
"author_profile": "https://Stackoverflow.com/users/14089",
"pm_score": 1,
"selected": false,
"text": "<h2>For C++, using std::vector</h2>\n<p>There's no real point in using a C-array. The std::vector has (almost) the same performance as a C array, and it will:</p>\n<ul>\n<li>grow as needed</li>\n<li>know its size</li>\n<li>verify you are really accessing the right memory (i.e. it could throw an exception if you go beyond its bounds)</li>\n</ul>\n<p>And this is not even considering the generic algorithm associated with the std::vector.</p>\n<h2>Now, using C</h2>\n<p>You can write it somewhat better at least in two ways. First, replacing a define with a true constant variable:</p>\n<pre><code>// #define MAXPLAYERS 4\nconst unsigned int MAXPLAYERS = 4 ;\n\nint playerscores[MAXPLAYERS];\n\nfor(i=0;i<MAXPLAYERS;++i)\n{\n.... do something with each player\n}\n</code></pre>\n<p>Using a true variable will offer your somewhat more type safety, and won't pollute the global scope. To minimize dependancies, you can even declare the variables in the header, and define them in a source:</p>\n<pre><code>/* header.h */\nextern const unsigned int MAXPLAYERS ;\nextern int playerscores[] ;\n\n/* source.c */\nconst unsigned int MAXPLAYERS = 4\nint playerscores[MAXPLAYERS];\n\n/* another_source.c */\n#include "header.h"\n\nfor(i=0;i<MAXPLAYERS;++i)\n{\n.... do something with each player\n}\n</code></pre>\n<p>This way, you'll be able to change the size of the array in one source, without needing recompilation of all the sources using it. The downside is that MAXPLAYERS is not anymore known at compile time (but, is this really a downside?)</p>\n<p>Note that your second type of array cannot grow dynamically. The sizeof is (at least in C++) evaluated at compile time. For growing arrays, malloc/realloc/free is the way to go in C, and std::vector (or any other generic STL container) is the way to go in C++.</p>\n"
},
{
"answer_id": 190639,
"author": "xtofl",
"author_id": 6610,
"author_profile": "https://Stackoverflow.com/users/6610",
"pm_score": 1,
"selected": false,
"text": "<p>Make sure to also read <a href=\"https://stackoverflow.com/questions/95500/can-this-macro-be-converted-to-a-function\">this question's answers</a> - many solutions to the array size problem that <em>are</em> portable.</p>\n\n<p>I especially like the <code>_countof</code> (cfr. Brian R. Bondy's answer) - Pulitzer for the inventor of that name!</p>\n"
},
{
"answer_id": 191688,
"author": "MSalters",
"author_id": 15416,
"author_profile": "https://Stackoverflow.com/users/15416",
"pm_score": 0,
"selected": false,
"text": "<p>Addition to the answers so far, if you are using T[] arrays in C++:\nUse template argument deduction to deduce the array size. It's much safer:</p>\n\n<p><code>template<int N> void for_all_objects(MYSTRUCT_DEF[N] myobjects)</code></p>\n\n<p>Your <code>sizeof(mystruct)/sizeof(MYSTRUCT_DEF)</code> expression fails quite silently if you change mystruct to a malloc'ed/new'ed <code>MYSTRUCT_DEF*</code>. <code>sizeof(mystruct)</code> then becomes <code>sizeof(MYSTRUCT_DEF*)</code>, which often is smaller than <code>sizeof(MYSTRUCT_DEF)</code>, and you'll have a loopcount of 0. It will seem like the code is simply not executed, which can be quite perplexing. The template declaration above will give you a clear compiler error instead (\"mystruct is not an array\")</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189892",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13676/"
] |
If I have an array of a fixed size depending on how it is defined and used, I typically use one of two ways to reference it.
Array type 1: Since it is a fixed size based on a define, I just use that define in all my loops referencing it.
```
#define MAXPLAYERS 4
int playerscores[MAXPLAYERS];
for(i=0;i<MAXPLAYERS;++i)
{
.... do something with each player
}
```
Array type 2: Since this array can grow as items are added to it, I use the sizeof to count the number of entries in it. The size would be converted to a constant by the compiler so there shouldn't be any runtime penalty to doing it this way.
```
typedef struct
{
fields....
}MYSTRUCT_DEF;
MYSTRUCT_DEF mystruct[]={
{entry 1},
{entry 2},
{entry 3...n}
};
for(i=0;i<(sizeof(mystruct)/sizeof(MYSTRUCT_DEF));++i)
{
..... do something with each entry
}
```
Is there a more elegant solution to handling processing of arrays without going past the end or stopping too early. Thoughts? Comments?
|
This will work for both of your cases, regardless of array element type:
```
#define ARRAY_COUNT(x) (sizeof(x)/sizeof((x)[0]))
...
struct foo arr[100];
...
for (i = 0; i < ARRAY_COUNT(arr); ++i) {
/* do stuff to arr[i] */
}
```
|
189,906 |
<p>I'm trying to upgrade my subversion server (I have it hosted with Dreamhost)</p>
<p>This is what I run:</p>
<ul>
<li>wget <a href="http://subversion.tigris.org/downloads/subversion-1.5.2.tar.bz2" rel="nofollow noreferrer">http://subversion.tigris.org/downloads/subversion-1.5.2.tar.bz2</a></li>
<li>wget <a href="http://subversion.tigris.org/downloads/subversion-deps-1.5.2.tar.bz2" rel="nofollow noreferrer">http://subversion.tigris.org/downloads/subversion-deps-1.5.2.tar.bz2</a></li>
<li>tar -xjf subversion-1.5.2.tar.bz2</li>
<li>tar -xjf subversion-deps-1.5.2.tar.bz2</li>
<li>cd subversion-1.5.2</li>
<li>./configure --prefix=/usr/bin --with-libs=/usr/bin/openssl --with-ssl</li>
</ul>
<p>But I'm unable to continue any further because of this error:</p>
<ul>
<li>checking for C compiler default output file name...</li>
<li><strong>configure: error: C compiler cannot create executables</strong></li>
<li>See `<a href="http://cid-e67e25d636aab24c.skydrive.live.com/self.aspx/Public/config.log" rel="nofollow noreferrer">config.log</a>' for more details.</li>
<li>configure failed for neon</li>
</ul>
<p>Since I'm no expert with Linux, I'm not sure how to proceed.</p>
<p>So the question is: what is the best way to upgrade (given the constraints of being with this hosted provider).</p>
<p><strong>Update:</strong></p>
<p>Contents of <a href="http://cid-e67e25d636aab24c.skydrive.live.com/self.aspx/Public/config.log" rel="nofollow noreferrer">config.log can be seen here</a> (don't know the best way to show files here at SO)</p>
<p><strong>Update:</strong></p>
<p>I seem to have been looking at the wrong config.log file.<br>
I probably should have been looking at <strong><a href="http://cid-e67e25d636aab24c.skydrive.live.com/self.aspx/Public/neon-config.log" rel="nofollow noreferrer">subversion.1.5.2/neon/config.log</a></strong></p>
|
[
{
"answer_id": 189948,
"author": "Aupajo",
"author_id": 10407,
"author_profile": "https://Stackoverflow.com/users/10407",
"pm_score": 3,
"selected": false,
"text": "<p>You'll need to build your own copy under your own account.</p>\n\n<pre><code>mkdir ~/src\ncd ~/src\nwget http://subversion.tigris.org/downloads/subversion-1.5.2.tar.bz2\nwget http://subversion.tigris.org/downloads/subversion-deps-1.5.2.tar.bz2\ntar -xjf subversion-1.5.2.tar.bz2\ntar -xjf subversion-deps-1.5.2.tar.bz2\ncd subversion-1.5.2\n./configure --prefix=/home/$USER --with-ssl\nmake\nmake install\n</code></pre>\n\n<p>You'll also need to alter your path for this to work if you haven't already.</p>\n"
},
{
"answer_id": 194115,
"author": "Dana the Sane",
"author_id": 2567,
"author_profile": "https://Stackoverflow.com/users/2567",
"pm_score": 0,
"selected": false,
"text": "<p>This might be a security measure, if the system is compromised it will theoretically be harder for the malicious user to build more attack code on the system to get more access.</p>\n\n<p>The solution to this is to cross compile the code on a local machine, then transfer it to the server. If you can't install to the system as Aupajo suggests, put the executable in your $HOME/bin directory. Keep in mind though that this probably means that you won't have permission to run the svn server, just the client application.</p>\n\n<p><a href=\"http://people.debian.org/~debacle/cross/\" rel=\"nofollow noreferrer\">Here's a link on using debian to do cross compiling, some google searches should provide more information for you though.</a></p>\n"
},
{
"answer_id": 221637,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>When using </p>\n\n<pre><code>./configure --prefix=/usr/bin --with-libs=/usr/bin/openssl --with-ssl\n</code></pre>\n\n<p>then you can see in neon/config.log that it searches the includes in /usr/bin/openssl/include ... while this is ofcourse only a binary.\nSo, skip this \"--with-libs\" option, and just make sure that the ssl development package is installed using</p>\n\n<pre><code>apt-get install libssl-dev\n</code></pre>\n"
},
{
"answer_id": 330061,
"author": "OJ.",
"author_id": 611,
"author_profile": "https://Stackoverflow.com/users/611",
"pm_score": 3,
"selected": true,
"text": "<p>If you're using openssl with SVN then you need to configure SVN with</p>\n\n<pre><code>./configure .... --with-openssl=/path/to/openssl\n</code></pre>\n\n<p>When I've done this in the past I've had issues building other binaries that use this lib if I don't specify the <code>-fPIC</code> flag. So it's best to run make with that parameter (if you have that issue). You may also have to point make at your build binary as well.. so your make call will look something like this:</p>\n\n<pre><code>make CC=\"gcc -fPIC\" LDFLAGS=\"/path/to/openssl/lib\"\n</code></pre>\n\n<p>Don't forget to build openssl with <code>CC=\"gcc -fPIC\"</code> too!</p>\n\n<p>Good luck!</p>\n"
},
{
"answer_id": 419930,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>I was stuck with this error too:</p>\n\n<pre><code>configure: error: C compiler cannot create executables\n</code></pre>\n\n<p>Turns out in my case I had a clean installation of Debian Etch, without a C compiler. I had installed it (wrongly, I suppose) via <code>apt-get install gcc</code> . A few google searches led me to install g++ instead via </p>\n\n<pre><code>apt-get install g++\n</code></pre>\n\n<p>Afterwards it worked. Not sure if this helps you, but did help me.</p>\n"
},
{
"answer_id": 63847971,
"author": "Nicolas PERNOUD",
"author_id": 14260656,
"author_profile": "https://Stackoverflow.com/users/14260656",
"pm_score": 0,
"selected": false,
"text": "<p>On ubuntu installing pkg-config libtool libssl-dev (<code>sudo apt install -y pkg-config libtool libssl-dev</code>) solved the problem for me...</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189906",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18274/"
] |
I'm trying to upgrade my subversion server (I have it hosted with Dreamhost)
This is what I run:
* wget <http://subversion.tigris.org/downloads/subversion-1.5.2.tar.bz2>
* wget <http://subversion.tigris.org/downloads/subversion-deps-1.5.2.tar.bz2>
* tar -xjf subversion-1.5.2.tar.bz2
* tar -xjf subversion-deps-1.5.2.tar.bz2
* cd subversion-1.5.2
* ./configure --prefix=/usr/bin --with-libs=/usr/bin/openssl --with-ssl
But I'm unable to continue any further because of this error:
* checking for C compiler default output file name...
* **configure: error: C compiler cannot create executables**
* See `[config.log](http://cid-e67e25d636aab24c.skydrive.live.com/self.aspx/Public/config.log)' for more details.
* configure failed for neon
Since I'm no expert with Linux, I'm not sure how to proceed.
So the question is: what is the best way to upgrade (given the constraints of being with this hosted provider).
**Update:**
Contents of [config.log can be seen here](http://cid-e67e25d636aab24c.skydrive.live.com/self.aspx/Public/config.log) (don't know the best way to show files here at SO)
**Update:**
I seem to have been looking at the wrong config.log file.
I probably should have been looking at **[subversion.1.5.2/neon/config.log](http://cid-e67e25d636aab24c.skydrive.live.com/self.aspx/Public/neon-config.log)**
|
If you're using openssl with SVN then you need to configure SVN with
```
./configure .... --with-openssl=/path/to/openssl
```
When I've done this in the past I've had issues building other binaries that use this lib if I don't specify the `-fPIC` flag. So it's best to run make with that parameter (if you have that issue). You may also have to point make at your build binary as well.. so your make call will look something like this:
```
make CC="gcc -fPIC" LDFLAGS="/path/to/openssl/lib"
```
Don't forget to build openssl with `CC="gcc -fPIC"` too!
Good luck!
|
189,921 |
<p>I'm trying to port an old library (that doesn't use namespaces as far as I can tell) to modern compilers. One of my targets can't tell the difference between System::TObject and ::TObject (without a namespace). System::TObject is native to the compiler.</p>
<p>I've tried a using directive, i.e. using ::TObject;</p>
<p>But that doesn't do it.</p>
<p>The obvious solution is to wrap all the original library in a namespace and then calling it by name- that should avoid the ambiguity. But is that the wisest solution? Is there any other solution? Adding a namespace would require changing a bunch of files and I don't know if it would have unwanted repercussions later.</p>
|
[
{
"answer_id": 189957,
"author": "Jim Buck",
"author_id": 2666,
"author_profile": "https://Stackoverflow.com/users/2666",
"pm_score": 0,
"selected": false,
"text": "<p>If you have the source to the library, maybe include a header file at the top of each source where that header file has only:</p>\n\n<pre><code>#define TObject TMadeUpNameObject\n</code></pre>\n"
},
{
"answer_id": 189990,
"author": "John Dibling",
"author_id": 241536,
"author_profile": "https://Stackoverflow.com/users/241536",
"pm_score": 0,
"selected": false,
"text": "<p>Try this:</p>\n\n<pre><code>namespace oldlib\n{\n #inclcude \"oldlib.h\"\n};\n</code></pre>\n"
},
{
"answer_id": 189995,
"author": "Adam Pierce",
"author_id": 5324,
"author_profile": "https://Stackoverflow.com/users/5324",
"pm_score": 1,
"selected": false,
"text": "<p>You could make a wrapper for all the old functions and package them up into a DLL or static library.</p>\n"
},
{
"answer_id": 190100,
"author": "David Segonds",
"author_id": 13673,
"author_profile": "https://Stackoverflow.com/users/13673",
"pm_score": 0,
"selected": false,
"text": "<p>I have used the following in the past while encapsulating a third party header file containing classes colliding with the code:</p>\n\n<pre><code>#ifdef Symbol\n#undef Symbol\n#define Symbol ThirdPartySymbol\n#endif\n#include <third_party_header.h>\n#undef Symbol\n</code></pre>\n\n<p>This way, \"Symbol\" in the header was prefixed by ThirdParty and this was not colliding with my code. </p>\n"
},
{
"answer_id": 190170,
"author": "Nick",
"author_id": 26240,
"author_profile": "https://Stackoverflow.com/users/26240",
"pm_score": 2,
"selected": false,
"text": "<p>You can do as Dib suggested, with a slight modification:</p>\n\n<pre><code>// In a wrapper header, eg: include_oldlib.h...\n\nnamespace oldlib\n{\n #include \"oldlib.h\"\n};\n\n#ifndef DONT_AUTO_INCLUDE_OLD_NAMESPACE\nusing namespace oldlib;\n#endif\n</code></pre>\n\n<p>This allows you to #define the exclusion in only the files where you're getting conflicts, and use all the symbols as global symbols otherwise.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189921",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22885/"
] |
I'm trying to port an old library (that doesn't use namespaces as far as I can tell) to modern compilers. One of my targets can't tell the difference between System::TObject and ::TObject (without a namespace). System::TObject is native to the compiler.
I've tried a using directive, i.e. using ::TObject;
But that doesn't do it.
The obvious solution is to wrap all the original library in a namespace and then calling it by name- that should avoid the ambiguity. But is that the wisest solution? Is there any other solution? Adding a namespace would require changing a bunch of files and I don't know if it would have unwanted repercussions later.
|
You can do as Dib suggested, with a slight modification:
```
// In a wrapper header, eg: include_oldlib.h...
namespace oldlib
{
#include "oldlib.h"
};
#ifndef DONT_AUTO_INCLUDE_OLD_NAMESPACE
using namespace oldlib;
#endif
```
This allows you to #define the exclusion in only the files where you're getting conflicts, and use all the symbols as global symbols otherwise.
|
189,934 |
<p>I'm trying to convert some code that worked great in VB, but I can't figure out what objects to use in .Net. </p>
<pre><code> Dim oXMLHttp As XMLHTTP
oXMLHttp = New XMLHTTP
oXMLHttp.open "POST", "https://www.server.com/path", False
oXMLHttp.setRequestHeader "Content-Type", "application/x-www-form-urlencoded"
oXMLHttp.send requestString
</code></pre>
<p>Basically, I want to send an XML file to a server, then store the response that it returns. Can anyone point me in the right direction on this? </p>
|
[
{
"answer_id": 189966,
"author": "Booji Boy",
"author_id": 1433,
"author_profile": "https://Stackoverflow.com/users/1433",
"pm_score": 2,
"selected": true,
"text": "<p>See the following for a sample which does this: <a href=\"http://www.codeproject.com/KB/dotnet/NET_Interact_j2EE.aspx\" rel=\"nofollow noreferrer\">http://www.codeproject.com/KB/dotnet/NET_Interact_j2EE.aspx</a>\nI have put the sample below. Sorry, I know it's big, but you never know how long links like this will stay valid. \nNOTE: the first version of the question didn't say in C# .NET - it just said \"in .NET\". (perhaps it was tagged C# and I didn't see it) Converting from VB.NET to C# is pretty easy (though unnecessary).\n'This class is representing the same functionality of xmlHTTP object in MSXML.XMLHTTP.</p>\n\n<pre><code>Imports System.Net\nImports System.Web.HttpUtility\n\nPublic Class XMLHTTP\n'Makes an internet connection to specified URL \n Public Overridable Sub open(ByVal bstrMethod As String, _\n ByVal bstrUrl As String, Optional ByVal varAsync As _\n Object = False, Optional ByVal bstrUser _\n As Object = \"\", Optional ByVal bstrPassword As Object = \"\")\n Try\n strUrl = bstrUrl\n strMethod = bstrMethod\n\n 'Checking if proxy configuration \n 'is required...(blnIsProxy value \n 'from config file)\n If blnIsProxy Then\n 'Set the proxy object\n proxyObject = WebProxy.GetDefaultProxy()\n\n 'Finding if proxy exists and if so set \n 'the proxy configuration parameters...\n If Not (IsNothing(proxyObject.Address)) Then\n uriAddress = proxyObject.Address\n If Not (IsNothing(uriAddress)) Then\n _ProxyName = uriAddress.Host\n _ProxyPort = uriAddress.Port\n End If\n UpdateProxy()\n End If\n urlWebRequest.Proxy = proxyObject\n End If\n\n 'Make the webRequest...\n urlWebRequest = System.Net.HttpWebRequest.Create(strUrl)\n urlWebRequest.Method = strMethod\n\n If (strMethod = \"POST\") Then\n setRequestHeader(\"Content-Type\", _\n \"application/x-www-form-urlencoded\")\n End If\n\n 'Add the cookie values of jessionid of weblogic \n 'and PH-Session value of webseal \n 'for retaining the same session\n urlWebRequest.Headers.Add(\"Cookie\", str_g_cookieval)\n\n Catch exp As Exception\n SetErrStatusText(\"Error opening method level url connection\")\n End Try\n End Sub\n 'Sends the request with post parameters...\n Public Overridable Sub Send(Optional ByVal objBody As Object = \"\")\n Try\n Dim rspResult As System.Net.HttpWebResponse\n Dim strmRequestStream As System.IO.Stream\n Dim strmReceiveStream As System.IO.Stream\n Dim encode As System.Text.Encoding\n Dim sr As System.IO.StreamReader\n Dim bytBytes() As Byte\n Dim UrlEncoded As New System.Text.StringBuilder\n Dim reserved() As Char = {ChrW(63), ChrW(61), ChrW(38)}\n urlWebRequest.Expect = Nothing\n If (strMethod = \"POST\") Then\n If objBody <> Nothing Then\n Dim intICounter As Integer = 0\n Dim intJCounter As Integer = 0\n While intICounter < objBody.Length\n intJCounter = _\n objBody.IndexOfAny(reserved, intICounter)\n If intJCounter = -1 Then\nUrlEncoded.Append(System.Web.HttpUtility.UrlEncode(objBody.Substring(intICounter, _\n objBody.Length - intICounter)))\n Exit While\n End If\nUrlEncoded.Append(System.Web.HttpUtility.UrlEncode(objBody.Substring(intICounter, _\n intJCounter - intICounter)))\n UrlEncoded.Append(objBody.Substring(intJCounter, 1))\n intICounter = intJCounter + 1\n End While\n\n bytBytes = _\n System.Text.Encoding.UTF8.GetBytes(UrlEncoded.ToString())\n urlWebRequest.ContentLength = bytBytes.Length\n strmRequestStream = urlWebRequest.GetRequestStream\n strmRequestStream.Write(bytBytes, 0, bytBytes.Length)\n strmRequestStream.Close()\n Else\n urlWebRequest.ContentLength = 0\n End If\n End If\n rspResult = urlWebRequest.GetResponse()\n strmReceiveStream = rspResult.GetResponseStream()\n encode = System.Text.Encoding.GetEncoding(\"utf-8\")\n sr = New System.IO.StreamReader(strmReceiveStream, encode)\n\n Dim read(256) As Char\n Dim count As Integer = sr.Read(read, 0, 256)\n Do While count > 0\n Dim str As String = New String(read, 0, count)\n strResponseText = strResponseText & str\n count = sr.Read(read, 0, 256)\n Loop\n Catch exp As Exception\n SetErrStatusText(\"Error while sending parameters\")\n WritetoLog(exp.ToString)\n End Try\n End Sub\n 'Setting header values...\n Public Overridable Sub setRequestHeader(ByVal bstrHeader _\n As String, ByVal bstrValue As String)\n Select Case bstrHeader\n Case \"Referer\"\n urlWebRequest.Referer = bstrValue\n Case \"User-Agent\"\n urlWebRequest.UserAgent = bstrValue\n Case \"Content-Type\"\n urlWebRequest.ContentType = bstrValue\n Case Else\n urlWebRequest.Headers(bstrHeader) = bstrValue\n End Select\n End Sub\n\n Private Function UpdateProxy()\n Try\n If Not (IsNothing(uriAddress)) Then\n If ((Not IsNothing(_ProxyName)) And _\n (_ProxyName.Length > 0) And (_ProxyPort > 0)) Then\n proxyObject = New WebProxy(_ProxyName, _ProxyPort)\n Dim strByPass() As String = Split(strByPassList, \"|\")\n If strByPass.Length > 0 Then\n proxyObject.BypassList = strByPass\n End If\n proxyObject.BypassProxyOnLocal = True\n If blnNetworkCredentials Then\n If strDomain <> \"\" Then\n proxyObject.Credentials = New _\n NetworkCredential(strUserName, _\n strPwd, strDomain)\n Else\n proxyObject.Credentials = New _\n NetworkCredential(strUserName, _\n strPwd)\n End If\n End If\n End If\n End If\n Catch exp As Exception\n SetErrStatusText(\"Error while updating proxy configurations\")\n WritetoLog(exp.ToString)\n End Try\n End Function\n 'Property for setting the Responsetext\n Public Overridable ReadOnly Property ResponseText() As String\n Get\n ResponseText = strResponseText\n End Get\n End Property\n\n Private urlWebRequest As System.Net.HttpWebRequest\n Private urlWebResponse As System.Net.HttpWebResponse\n Private strResponseText As String\n Private strUrl As String\n Private strMethod As String\n Private proxyObject As WebProxy\n Private intCount As Integer\n Private uriAddress As Uri\n Private _ProxyName As String\n Private _ProxyPort As Integer\nEnd Class\n</code></pre>\n"
},
{
"answer_id": 190650,
"author": "AnthonyWJones",
"author_id": 17516,
"author_profile": "https://Stackoverflow.com/users/17516",
"pm_score": 2,
"selected": false,
"text": "<p>The answer is to use the <code>WebClient</code> class:-</p>\n\n<pre><code>WebClient webClient = new WebClient();\n\nNameValueCollection values = new NameValueCollection();\n\nvalues.add(\"firstname\", \"Slarti\");\nvalues.add(\"lastname\", \"Bart-fast\");\n\nbyte[] response = webClient.UploadValues(\"http://server/path\", values);\n</code></pre>\n\n<p>The UploadValues method builds a POST request with an <code>application/x-www-form-urlencoded</code> content type and correctly encodes the set of values listed in the <code>NameValueCollection</code> passed to it.</p>\n\n<p>The response is a byte array that you can then do something appropriate with.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189934",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/232/"
] |
I'm trying to convert some code that worked great in VB, but I can't figure out what objects to use in .Net.
```
Dim oXMLHttp As XMLHTTP
oXMLHttp = New XMLHTTP
oXMLHttp.open "POST", "https://www.server.com/path", False
oXMLHttp.setRequestHeader "Content-Type", "application/x-www-form-urlencoded"
oXMLHttp.send requestString
```
Basically, I want to send an XML file to a server, then store the response that it returns. Can anyone point me in the right direction on this?
|
See the following for a sample which does this: <http://www.codeproject.com/KB/dotnet/NET_Interact_j2EE.aspx>
I have put the sample below. Sorry, I know it's big, but you never know how long links like this will stay valid.
NOTE: the first version of the question didn't say in C# .NET - it just said "in .NET". (perhaps it was tagged C# and I didn't see it) Converting from VB.NET to C# is pretty easy (though unnecessary).
'This class is representing the same functionality of xmlHTTP object in MSXML.XMLHTTP.
```
Imports System.Net
Imports System.Web.HttpUtility
Public Class XMLHTTP
'Makes an internet connection to specified URL
Public Overridable Sub open(ByVal bstrMethod As String, _
ByVal bstrUrl As String, Optional ByVal varAsync As _
Object = False, Optional ByVal bstrUser _
As Object = "", Optional ByVal bstrPassword As Object = "")
Try
strUrl = bstrUrl
strMethod = bstrMethod
'Checking if proxy configuration
'is required...(blnIsProxy value
'from config file)
If blnIsProxy Then
'Set the proxy object
proxyObject = WebProxy.GetDefaultProxy()
'Finding if proxy exists and if so set
'the proxy configuration parameters...
If Not (IsNothing(proxyObject.Address)) Then
uriAddress = proxyObject.Address
If Not (IsNothing(uriAddress)) Then
_ProxyName = uriAddress.Host
_ProxyPort = uriAddress.Port
End If
UpdateProxy()
End If
urlWebRequest.Proxy = proxyObject
End If
'Make the webRequest...
urlWebRequest = System.Net.HttpWebRequest.Create(strUrl)
urlWebRequest.Method = strMethod
If (strMethod = "POST") Then
setRequestHeader("Content-Type", _
"application/x-www-form-urlencoded")
End If
'Add the cookie values of jessionid of weblogic
'and PH-Session value of webseal
'for retaining the same session
urlWebRequest.Headers.Add("Cookie", str_g_cookieval)
Catch exp As Exception
SetErrStatusText("Error opening method level url connection")
End Try
End Sub
'Sends the request with post parameters...
Public Overridable Sub Send(Optional ByVal objBody As Object = "")
Try
Dim rspResult As System.Net.HttpWebResponse
Dim strmRequestStream As System.IO.Stream
Dim strmReceiveStream As System.IO.Stream
Dim encode As System.Text.Encoding
Dim sr As System.IO.StreamReader
Dim bytBytes() As Byte
Dim UrlEncoded As New System.Text.StringBuilder
Dim reserved() As Char = {ChrW(63), ChrW(61), ChrW(38)}
urlWebRequest.Expect = Nothing
If (strMethod = "POST") Then
If objBody <> Nothing Then
Dim intICounter As Integer = 0
Dim intJCounter As Integer = 0
While intICounter < objBody.Length
intJCounter = _
objBody.IndexOfAny(reserved, intICounter)
If intJCounter = -1 Then
UrlEncoded.Append(System.Web.HttpUtility.UrlEncode(objBody.Substring(intICounter, _
objBody.Length - intICounter)))
Exit While
End If
UrlEncoded.Append(System.Web.HttpUtility.UrlEncode(objBody.Substring(intICounter, _
intJCounter - intICounter)))
UrlEncoded.Append(objBody.Substring(intJCounter, 1))
intICounter = intJCounter + 1
End While
bytBytes = _
System.Text.Encoding.UTF8.GetBytes(UrlEncoded.ToString())
urlWebRequest.ContentLength = bytBytes.Length
strmRequestStream = urlWebRequest.GetRequestStream
strmRequestStream.Write(bytBytes, 0, bytBytes.Length)
strmRequestStream.Close()
Else
urlWebRequest.ContentLength = 0
End If
End If
rspResult = urlWebRequest.GetResponse()
strmReceiveStream = rspResult.GetResponseStream()
encode = System.Text.Encoding.GetEncoding("utf-8")
sr = New System.IO.StreamReader(strmReceiveStream, encode)
Dim read(256) As Char
Dim count As Integer = sr.Read(read, 0, 256)
Do While count > 0
Dim str As String = New String(read, 0, count)
strResponseText = strResponseText & str
count = sr.Read(read, 0, 256)
Loop
Catch exp As Exception
SetErrStatusText("Error while sending parameters")
WritetoLog(exp.ToString)
End Try
End Sub
'Setting header values...
Public Overridable Sub setRequestHeader(ByVal bstrHeader _
As String, ByVal bstrValue As String)
Select Case bstrHeader
Case "Referer"
urlWebRequest.Referer = bstrValue
Case "User-Agent"
urlWebRequest.UserAgent = bstrValue
Case "Content-Type"
urlWebRequest.ContentType = bstrValue
Case Else
urlWebRequest.Headers(bstrHeader) = bstrValue
End Select
End Sub
Private Function UpdateProxy()
Try
If Not (IsNothing(uriAddress)) Then
If ((Not IsNothing(_ProxyName)) And _
(_ProxyName.Length > 0) And (_ProxyPort > 0)) Then
proxyObject = New WebProxy(_ProxyName, _ProxyPort)
Dim strByPass() As String = Split(strByPassList, "|")
If strByPass.Length > 0 Then
proxyObject.BypassList = strByPass
End If
proxyObject.BypassProxyOnLocal = True
If blnNetworkCredentials Then
If strDomain <> "" Then
proxyObject.Credentials = New _
NetworkCredential(strUserName, _
strPwd, strDomain)
Else
proxyObject.Credentials = New _
NetworkCredential(strUserName, _
strPwd)
End If
End If
End If
End If
Catch exp As Exception
SetErrStatusText("Error while updating proxy configurations")
WritetoLog(exp.ToString)
End Try
End Function
'Property for setting the Responsetext
Public Overridable ReadOnly Property ResponseText() As String
Get
ResponseText = strResponseText
End Get
End Property
Private urlWebRequest As System.Net.HttpWebRequest
Private urlWebResponse As System.Net.HttpWebResponse
Private strResponseText As String
Private strUrl As String
Private strMethod As String
Private proxyObject As WebProxy
Private intCount As Integer
Private uriAddress As Uri
Private _ProxyName As String
Private _ProxyPort As Integer
End Class
```
|
189,943 |
<p>Here's what I would like to do:</p>
<p>I'm taking pictures with a webcam at regular intervals. Sort of like a time lapse thing. However, if nothing has really changed, that is, the picture pretty much <em>looks</em> the same, I don't want to store the latest snapshot.</p>
<p>I imagine there's some way of quantifying the difference, and I would have to empirically determine a threshold. </p>
<p>I'm looking for simplicity rather than perfection.
I'm using python.</p>
|
[
{
"answer_id": 189960,
"author": "keparo",
"author_id": 19468,
"author_profile": "https://Stackoverflow.com/users/19468",
"pm_score": 6,
"selected": false,
"text": "<p><strong>A simple solution:</strong></p>\n\n<p>Encode the image as a <strong>jpeg</strong> and look for a substantial change in <strong>filesize</strong>.</p>\n\n<p>I've implemented something similar with video thumbnails, and had a lot of success and scalability.</p>\n"
},
{
"answer_id": 189967,
"author": "Federico A. Ramponi",
"author_id": 18770,
"author_profile": "https://Stackoverflow.com/users/18770",
"pm_score": 0,
"selected": false,
"text": "<p>I think you could simply compute the euclidean distance (i.e. sqrt(sum of squares of differences, pixel by pixel)) between the luminance of the two images, and consider them equal if this falls under some empirical threshold. And you would better do it wrapping a C function.</p>\n"
},
{
"answer_id": 189968,
"author": "shoosh",
"author_id": 9611,
"author_profile": "https://Stackoverflow.com/users/9611",
"pm_score": 1,
"selected": false,
"text": "<p><a href=\"http://www.google.ca/search?hl=en&safe=off&client=firefox-a&rls=org.mozilla:en-US:official&hs=HD8&pwst=1&sa=X&oi=spell&resnum=0&ct=result&cd=1&q=earth+mover%27s+distance+image&spell=1\" rel=\"nofollow noreferrer\">Earth movers distance</a> might be exactly what you need.\nIt might be <em>abit</em> heavy to implement in real time though.</p>\n"
},
{
"answer_id": 189977,
"author": "Tobias",
"author_id": 14027,
"author_profile": "https://Stackoverflow.com/users/14027",
"pm_score": 1,
"selected": false,
"text": "<p>What about calculating the <a href=\"http://en.wikipedia.org/wiki/Manhattan_distance\" rel=\"nofollow noreferrer\">Manhattan Distance</a> of the two images. That gives you n*n values. Then you could do something like an row average to reduce to n values and a function over that to get one single value.</p>\n"
},
{
"answer_id": 190000,
"author": "tzot",
"author_id": 6899,
"author_profile": "https://Stackoverflow.com/users/6899",
"pm_score": 2,
"selected": false,
"text": "<p>Have you seen the <a href=\"https://stackoverflow.com/questions/75891/algorithm-for-finding-similar-images\">Algorithm for finding similar images</a> question? Check it out to see suggestions.</p>\n\n<p>I would suggest a wavelet transformation of your frames (I've written a C extension for that using Haar transformation); then, comparing the indexes of the largest (proportionally) wavelet factors between the two pictures, you should get a numerical similarity approximation.</p>\n"
},
{
"answer_id": 190036,
"author": "Ates Goral",
"author_id": 23501,
"author_profile": "https://Stackoverflow.com/users/23501",
"pm_score": 4,
"selected": false,
"text": "<p>A trivial thing to try:</p>\n\n<p>Resample both images to small thumbnails (e.g. 64 x 64) and compare the thumbnails pixel-by-pixel with a certain threshold. If the original images are almost the same, the resampled thumbnails will be very similar or even exactly the same. This method takes care of noise that can occur especially in low-light scenes. It may even be better if you go grayscale.</p>\n"
},
{
"answer_id": 190061,
"author": "Mr Fooz",
"author_id": 25050,
"author_profile": "https://Stackoverflow.com/users/25050",
"pm_score": 5,
"selected": false,
"text": "<p>Two popular and relatively simple methods are: (a) the Euclidean distance already suggested, or (b) normalized cross-correlation. Normalized cross-correlation tends to be noticeably more robust to lighting changes than simple cross-correlation. Wikipedia gives a formula for the <a href=\"http://en.wikipedia.org/wiki/Cross-correlation#Normalized_cross-correlation\" rel=\"noreferrer\">normalized cross-correlation</a>. More sophisticated methods exist too, but they require quite a bit more work.</p>\n\n<p>Using numpy-like syntax,</p>\n\n<pre>\ndist_euclidean = sqrt(sum((i1 - i2)^2)) / i1.size\n\ndist_manhattan = sum(abs(i1 - i2)) / i1.size\n\ndist_ncc = sum( (i1 - mean(i1)) * (i2 - mean(i2)) ) / (\n (i1.size - 1) * stdev(i1) * stdev(i2) )\n</pre>\n\n<p>assuming that <code>i1</code> and <code>i2</code> are 2D grayscale image arrays. </p>\n"
},
{
"answer_id": 190078,
"author": "Loren Pechtel",
"author_id": 10659,
"author_profile": "https://Stackoverflow.com/users/10659",
"pm_score": 3,
"selected": false,
"text": "<p>Most of the answers given won't deal with lighting levels.</p>\n\n<p>I would first normalize the image to a standard light level before doing the comparison.</p>\n"
},
{
"answer_id": 196882,
"author": "elifiner",
"author_id": 15109,
"author_profile": "https://Stackoverflow.com/users/15109",
"pm_score": 6,
"selected": false,
"text": "<p>You can compare two images using functions from <a href=\"http://www.pythonware.com/products/pil/\" rel=\"noreferrer\">PIL</a>. </p>\n\n<pre><code>import Image\nimport ImageChops\n\nim1 = Image.open(\"splash.png\")\nim2 = Image.open(\"splash2.png\")\n\ndiff = ImageChops.difference(im2, im1)\n</code></pre>\n\n<p>The diff object is an image in which every pixel is the result of the subtraction of the color values of that pixel in the second image from the first image. Using the diff image you can do several things. The simplest one is the <code>diff.getbbox()</code> function. It will tell you the minimal rectangle that contains all the changes between your two images.</p>\n\n<p>You can probably implement approximations of the other stuff mentioned here using functions from PIL as well.</p>\n"
},
{
"answer_id": 3935002,
"author": "sastanin",
"author_id": 25450,
"author_profile": "https://Stackoverflow.com/users/25450",
"pm_score": 9,
"selected": true,
"text": "<h2>General idea</h2>\n\n<p>Option 1: Load both images as arrays (<code>scipy.misc.imread</code>) and calculate an element-wise (pixel-by-pixel) difference. Calculate the norm of the difference.</p>\n\n<p>Option 2: Load both images. Calculate some feature vector for each of them (like a histogram). Calculate distance between feature vectors rather than images.</p>\n\n<p>However, there are some decisions to make first.</p>\n\n<h2>Questions</h2>\n\n<p>You should answer these questions first:</p>\n\n<ul>\n<li><p>Are images of the same shape and dimension?</p>\n\n<p>If not, you may need to resize or crop them. PIL library will help to do it in Python.</p>\n\n<p>If they are taken with the same settings and the same device, they are probably the same.</p></li>\n<li><p>Are images well-aligned?</p>\n\n<p>If not, you may want to run cross-correlation first, to find the best alignment first. SciPy has functions to do it.</p>\n\n<p>If the camera and the scene are still, the images are likely to be well-aligned.</p></li>\n<li><p>Is exposure of the images always the same? (Is lightness/contrast the same?)</p>\n\n<p>If not, you may want <a href=\"http://en.wikipedia.org/wiki/Normalization_(image_processing)\" rel=\"noreferrer\">to normalize</a> images.</p>\n\n<p>But be careful, in some situations this may do more wrong than good. For example, a single bright pixel on a dark background will make the normalized image very different.</p></li>\n<li><p>Is color information important?</p>\n\n<p>If you want to notice color changes, you will have a vector of color values per point, rather than a scalar value as in gray-scale image. You need more attention when writing such code.</p></li>\n<li><p>Are there distinct edges in the image? Are they likely to move?</p>\n\n<p>If yes, you can apply edge detection algorithm first (e.g. calculate gradient with Sobel or Prewitt transform, apply some threshold), then compare edges on the first image to edges on the second.</p></li>\n<li><p>Is there noise in the image?</p>\n\n<p>All sensors pollute the image with some amount of noise. Low-cost sensors have more noise. You may wish to apply some noise reduction before you compare images. Blur is the most simple (but not the best) approach here.</p></li>\n<li><p>What kind of changes do you want to notice?</p>\n\n<p>This may affect the choice of norm to use for the difference between images.</p>\n\n<p>Consider using Manhattan norm (the sum of the absolute values) or zero norm (the number of elements not equal to zero) to measure how much the image has changed. The former will tell you how much the image is off, the latter will tell only how many pixels differ.</p></li>\n</ul>\n\n<h2>Example</h2>\n\n<p>I assume your images are well-aligned, the same size and shape, possibly with different exposure. For simplicity, I convert them to grayscale even if they are color (RGB) images.</p>\n\n<p>You will need these imports:</p>\n\n<pre><code>import sys\n\nfrom scipy.misc import imread\nfrom scipy.linalg import norm\nfrom scipy import sum, average\n</code></pre>\n\n<p>Main function, read two images, convert to grayscale, compare and print results:</p>\n\n<pre><code>def main():\n file1, file2 = sys.argv[1:1+2]\n # read images as 2D arrays (convert to grayscale for simplicity)\n img1 = to_grayscale(imread(file1).astype(float))\n img2 = to_grayscale(imread(file2).astype(float))\n # compare\n n_m, n_0 = compare_images(img1, img2)\n print \"Manhattan norm:\", n_m, \"/ per pixel:\", n_m/img1.size\n print \"Zero norm:\", n_0, \"/ per pixel:\", n_0*1.0/img1.size\n</code></pre>\n\n<p>How to compare. <code>img1</code> and <code>img2</code> are 2D SciPy arrays here:</p>\n\n<pre><code>def compare_images(img1, img2):\n # normalize to compensate for exposure difference, this may be unnecessary\n # consider disabling it\n img1 = normalize(img1)\n img2 = normalize(img2)\n # calculate the difference and its norms\n diff = img1 - img2 # elementwise for scipy arrays\n m_norm = sum(abs(diff)) # Manhattan norm\n z_norm = norm(diff.ravel(), 0) # Zero norm\n return (m_norm, z_norm)\n</code></pre>\n\n<p>If the file is a color image, <code>imread</code> returns a 3D array, average RGB channels (the last array axis) to obtain intensity. No need to do it for grayscale images (e.g. <code>.pgm</code>):</p>\n\n<pre><code>def to_grayscale(arr):\n \"If arr is a color image (3D array), convert it to grayscale (2D array).\"\n if len(arr.shape) == 3:\n return average(arr, -1) # average over the last axis (color channels)\n else:\n return arr\n</code></pre>\n\n<p>Normalization is trivial, you may choose to normalize to [0,1] instead of [0,255]. <code>arr</code> is a SciPy array here, so all operations are element-wise:</p>\n\n<pre><code>def normalize(arr):\n rng = arr.max()-arr.min()\n amin = arr.min()\n return (arr-amin)*255/rng\n</code></pre>\n\n<p>Run the <code>main</code> function:</p>\n\n<pre><code>if __name__ == \"__main__\":\n main()\n</code></pre>\n\n<p>Now you can put this all in a script and run against two images. If we compare image to itself, there is no difference:</p>\n\n<pre><code>$ python compare.py one.jpg one.jpg\nManhattan norm: 0.0 / per pixel: 0.0\nZero norm: 0 / per pixel: 0.0\n</code></pre>\n\n<p>If we blur the image and compare to the original, there is some difference:</p>\n\n<pre><code>$ python compare.py one.jpg one-blurred.jpg \nManhattan norm: 92605183.67 / per pixel: 13.4210411116\nZero norm: 6900000 / per pixel: 1.0\n</code></pre>\n\n<p>P.S. Entire <a href=\"http://gist.github.com/626356\" rel=\"noreferrer\">compare.py</a> script.</p>\n\n<h2>Update: relevant techniques</h2>\n\n<p>As the question is about a video sequence, where frames are likely to be almost the same, and you look for something unusual, I'd like to mention some alternative approaches which may be relevant:</p>\n\n<ul>\n<li>background subtraction and segmentation (to detect foreground objects)</li>\n<li>sparse optical flow (to detect motion)</li>\n<li>comparing histograms or some other statistics instead of images</li>\n</ul>\n\n<p>I strongly recommend taking a look at “Learning OpenCV” book, Chapters 9 (Image parts and segmentation) and 10 (Tracking and motion). The former teaches to use Background subtraction method, the latter gives some info on optical flow methods. All methods are implemented in OpenCV library. If you use Python, I suggest to use OpenCV ≥ 2.3, and its <code>cv2</code> Python module.</p>\n\n<p>The most simple version of the background subtraction:</p>\n\n<ul>\n<li>learn the average value μ and standard deviation σ for every pixel of the background</li>\n<li>compare current pixel values to the range of (μ-2σ,μ+2σ) or (μ-σ,μ+σ)</li>\n</ul>\n\n<p>More advanced versions make take into account time series for every pixel and handle non-static scenes (like moving trees or grass).</p>\n\n<p>The idea of optical flow is to take two or more frames, and assign velocity vector to every pixel (dense optical flow) or to some of them (sparse optical flow). To estimate sparse optical flow, you may use <a href=\"http://en.wikipedia.org/wiki/Lucas%E2%80%93Kanade_method\" rel=\"noreferrer\">Lucas-Kanade method</a> (it is also implemented in OpenCV). Obviously, if there is a lot of flow (high average over max values of the velocity field), then something is moving in the frame, and subsequent images are more different.</p>\n\n<p>Comparing histograms may help to detect sudden changes between consecutive frames. This approach was used in <a href=\"http://www.sciencedirect.com/science/article/pii/S0967066110000808\" rel=\"noreferrer\">Courbon et al, 2010</a>:</p>\n\n<blockquote>\n <p><em>Similarity of consecutive frames.</em> The distance between two consecutive frames is measured. If it is too high, it means that the second frame is corrupted and thus the image is eliminated. The <a href=\"https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence\" rel=\"noreferrer\">Kullback–Leibler distance</a>, or mutual entropy, on the histograms of the two frames:</p>\n \n <p><img src=\"https://i.imgur.com/hdeh8ni.gif\" alt=\"$$ d(p,q) = \\sum_i p(i) \\log (p(i)/q(i)) $$\"></p>\n \n <p>where <em>p</em> and <em>q</em> are the histograms of the frames is used. The threshold is fixed on 0.2.</p>\n</blockquote>\n"
},
{
"answer_id": 3935187,
"author": "Larry Gritz",
"author_id": 3832,
"author_profile": "https://Stackoverflow.com/users/3832",
"pm_score": 3,
"selected": false,
"text": "<p>I am addressing specifically the question of how to compute if they are \"different enough\". I assume you can figure out how to subtract the pixels one by one.</p>\n\n<p>First, I would take a bunch of images with <em>nothing</em> changing, and find out the maximum amount that any pixel changes just because of variations in the capture, noise in the imaging system, JPEG compression artifacts, and moment-to-moment changes in lighting. Perhaps you'll find that 1 or 2 bit differences are to be expected even when nothing moves.</p>\n\n<p>Then for the \"real\" test, you want a criterion like this:</p>\n\n<ul>\n<li>same if up to P pixels differ by no more than E.</li>\n</ul>\n\n<p>So, perhaps, if E = 0.02, P = 1000, that would mean (approximately) that it would be \"different\" if any single pixel changes by more than ~5 units (assuming 8-bit images), or if more than 1000 pixels had any errors at all.</p>\n\n<p>This is intended mainly as a good \"triage\" technique to quickly identify images that are close enough to not need further examination. The images that \"fail\" may then more to a more elaborate/expensive technique that wouldn't have false positives if the camera shook bit, for example, or was more robust to lighting changes.</p>\n\n<p>I run an open source project, <a href=\"http://www.openimageio.org\" rel=\"noreferrer\">OpenImageIO</a>, that contains a utility called \"idiff\" that compares differences with thresholds like this (even more elaborate, actually). Even if you don't want to use this software, you may want to look at the source to see how we did it. It's used commercially quite a bit and this thresholding technique was developed so that we could have a test suite for rendering and image processing software, with \"reference images\" that might have small differences from platform-to-platform or as we made minor tweaks to tha algorithms, so we wanted a \"match within tolerance\" operation.</p>\n"
},
{
"answer_id": 5053648,
"author": "Roman Dial",
"author_id": 624744,
"author_profile": "https://Stackoverflow.com/users/624744",
"pm_score": 1,
"selected": false,
"text": "<p>I have been having a lot of luck with jpg images taken with the same camera on a tripod by\n(1) simplifying greatly (like going from 3000 pixels wide to 100 pixels wide or even fewer)\n(2) flattening each jpg array into a single vector\n(3) pairwise correlating sequential images with a simple correlate algorithm to get correlation coefficient\n(4) squaring correlation coefficient to get r-square (i.e fraction of variability in one image explained by variation in the next)\n(5) generally in my application if r-square < 0.9, I say the two images are different and something happened in between.</p>\n\n<p>This is robust and fast in my implementation (Mathematica 7)</p>\n\n<p>It's worth playing around with the part of the image you are interested in and focussing on that by cropping all images to that little area, otherwise a distant-from-the-camera but important change will be missed. </p>\n\n<p>I don't know how to use Python, but am sure it does correlations, too, no?</p>\n"
},
{
"answer_id": 5100965,
"author": "vishalv2050",
"author_id": 622889,
"author_profile": "https://Stackoverflow.com/users/622889",
"pm_score": 1,
"selected": false,
"text": "<p>you can compute the histogram of both the images and then calculate the <a href=\"http://en.wikipedia.org/wiki/Bhattacharyya_distance#Bhattacharyya_coefficient\" rel=\"nofollow\">Bhattacharyya Coefficient</a>, this is a very fast algorithm and I have used it to detect shot changes in a cricket video (in C using openCV)</p>\n"
},
{
"answer_id": 8886316,
"author": "Ricardo Cabral",
"author_id": 18741,
"author_profile": "https://Stackoverflow.com/users/18741",
"pm_score": 1,
"selected": false,
"text": "<p>Check out how Haar Wavelets are implemented by <a href=\"http://server.imgseek.net/\" rel=\"nofollow\">isk-daemon</a>. You could use it's imgdb C++ code to calculate the difference between images on-the-fly:</p>\n\n<blockquote>\n <p>isk-daemon is an open source database server capable of adding content-based (visual) image searching to any image related website or software.</p>\n \n <p>This technology allows users of any image-related website or software to sketch on a widget which image they want to find and have the website reply to them the most similar images or simply request for more similar photos at each image detail page.</p>\n</blockquote>\n"
},
{
"answer_id": 40711075,
"author": "datenhahn",
"author_id": 4559200,
"author_profile": "https://Stackoverflow.com/users/4559200",
"pm_score": 2,
"selected": false,
"text": "<p>I had the same problem and wrote a simple python module which compares two same-size images using pillow's ImageChops to create a black/white diff image and sums up the histogram values.</p>\n\n<p>You can get either this score directly, or a percentage value compared to a full black vs. white diff.</p>\n\n<p>It also contains a simple is_equal function, with the possibility to supply a fuzzy-threshold under (and including) the image passes as equal.</p>\n\n<p>The approach is not very elaborate, but maybe is of use for other out there struggling with the same issue.</p>\n\n<p><a href=\"https://pypi.python.org/pypi/imgcompare/\" rel=\"nofollow noreferrer\">https://pypi.python.org/pypi/imgcompare/</a></p>\n"
},
{
"answer_id": 44106540,
"author": "admin",
"author_id": 6489637,
"author_profile": "https://Stackoverflow.com/users/6489637",
"pm_score": 2,
"selected": false,
"text": "<pre><code>import os\nfrom PIL import Image\nfrom PIL import ImageFile\nimport imagehash\n \n#just use to the size diferent picture\ndef compare_image(img_file1, img_file2):\n if img_file1 == img_file2:\n return True\n fp1 = open(img_file1, 'rb')\n fp2 = open(img_file2, 'rb')\n\n img1 = Image.open(fp1)\n img2 = Image.open(fp2)\n\n ImageFile.LOAD_TRUNCATED_IMAGES = True\n b = img1 == img2\n\n fp1.close()\n fp2.close()\n\n return b\n\n\n\n\n\n#through picturu hash to compare\ndef get_hash_dict(dir):\n hash_dict = {}\n image_quantity = 0\n for _, _, files in os.walk(dir):\n for i, fileName in enumerate(files):\n with open(dir + fileName, 'rb') as fp:\n hash_dict[dir + fileName] = imagehash.average_hash(Image.open(fp))\n image_quantity += 1\n\n return hash_dict, image_quantity\n\ndef compare_image_with_hash(image_file_name_1, image_file_name_2, max_dif=0):\n """\n max_dif: The maximum hash difference is allowed, the smaller and more accurate, the minimum is 0.\n recommend to use\n """\n ImageFile.LOAD_TRUNCATED_IMAGES = True\n hash_1 = None\n hash_2 = None\n with open(image_file_name_1, 'rb') as fp:\n hash_1 = imagehash.average_hash(Image.open(fp))\n with open(image_file_name_2, 'rb') as fp:\n hash_2 = imagehash.average_hash(Image.open(fp))\n dif = hash_1 - hash_2\n if dif < 0:\n dif = -dif\n if dif <= max_dif:\n return True\n else:\n return False\n\n\ndef compare_image_dir_with_hash(dir_1, dir_2, max_dif=0):\n """\n max_dif: The maximum hash difference is allowed, the smaller and more accurate, the minimum is 0.\n\n """\n ImageFile.LOAD_TRUNCATED_IMAGES = True\n hash_dict_1, image_quantity_1 = get_hash_dict(dir_1)\n hash_dict_2, image_quantity_2 = get_hash_dict(dir_2)\n\n if image_quantity_1 > image_quantity_2:\n tmp = image_quantity_1\n image_quantity_1 = image_quantity_2\n image_quantity_2 = tmp\n\n tmp = hash_dict_1\n hash_dict_1 = hash_dict_2\n hash_dict_2 = tmp\n\n result_dict = {}\n\n for k in hash_dict_1.keys():\n result_dict[k] = None\n\n for dif_i in range(0, max_dif + 1):\n have_none = False\n\n for k_1 in result_dict.keys():\n if result_dict.get(k_1) is None:\n have_none = True\n\n if not have_none:\n return result_dict\n\n for k_1, v_1 in hash_dict_1.items():\n for k_2, v_2 in hash_dict_2.items():\n sub = (v_1 - v_2)\n if sub < 0:\n sub = -sub\n if sub == dif_i and result_dict.get(k_1) is None:\n result_dict[k_1] = k_2\n break\n return result_dict\n\n\ndef main():\n print(compare_image('image1\\\\815.jpg', 'image2\\\\5.jpg'))\n print(compare_image_with_hash('image1\\\\815.jpg', 'image2\\\\5.jpg', 7))\n r = compare_image_dir_with_hash('image1\\\\', 'image2\\\\', 10)\n for k in r.keys():\n print(k, r.get(k))\n\n\nif __name__ == '__main__':\n main()\n</code></pre>\n<ul>\n<li><p>output:</p>\n<p>False<br>\nTrue<br>\nimage2\\5.jpg image1\\815.jpg<br>\nimage2\\6.jpg image1\\819.jpg<br>\nimage2\\7.jpg image1\\900.jpg<br>\nimage2\\8.jpg image1\\998.jpg<br>\nimage2\\9.jpg image1\\1012.jpg<br>\n<br></p>\n</li>\n<li><p>the example pictures:</p>\n<ul>\n<li><p>815.jpg\n<br>\n<a href=\"https://i.stack.imgur.com/xVGI8.jpg\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/xVGI8.jpg\" alt=\"815.jpg\" /></a></p>\n</li>\n<li><p>5.jpg\n<br>\n<a href=\"https://i.stack.imgur.com/py9j1.jpg\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/py9j1.jpg\" alt=\"5.jpg\" /></a></p>\n</li>\n</ul>\n</li>\n</ul>\n"
},
{
"answer_id": 47543363,
"author": "Felix Goldberg",
"author_id": 1813736,
"author_profile": "https://Stackoverflow.com/users/1813736",
"pm_score": 1,
"selected": false,
"text": "<p>A somewhat more principled approach is to use a global descriptor to compare images, such as GIST or CENTRIST. A hash function, as described <a href=\"https://www.pyimagesearch.com/2017/11/27/image-hashing-opencv-python/\" rel=\"nofollow noreferrer\">here</a>, also provides a similar solution.</p>\n"
},
{
"answer_id": 49574931,
"author": "duhaime",
"author_id": 1727392,
"author_profile": "https://Stackoverflow.com/users/1727392",
"pm_score": 3,
"selected": false,
"text": "<p>Another nice, simple way to measure the similarity between two images:</p>\n\n<pre><code>import sys\nfrom skimage.measure import compare_ssim\nfrom skimage.transform import resize\nfrom scipy.ndimage import imread\n\n# get two images - resize both to 1024 x 1024\nimg_a = resize(imread(sys.argv[1]), (2**10, 2**10))\nimg_b = resize(imread(sys.argv[2]), (2**10, 2**10))\n\n# score: {-1:1} measure of the structural similarity between the images\nscore, diff = compare_ssim(img_a, img_b, full=True)\nprint(score)\n</code></pre>\n\n<p>If others are interested in a more powerful way to compare image similarity, I put together a <a href=\"http://douglasduhaime.com/posts/identifying-similar-images-with-tensorflow.html\" rel=\"noreferrer\">tutorial</a> and web <a href=\"https://github.com/YaleDHLab/pix-plot\" rel=\"noreferrer\">app</a> for measuring and visualizing similar images using Tensorflow.</p>\n"
},
{
"answer_id": 50553679,
"author": "nicolashahn",
"author_id": 4394625,
"author_profile": "https://Stackoverflow.com/users/4394625",
"pm_score": 3,
"selected": false,
"text": "<p>I had a similar problem at work, I was rewriting our image transform endpoint and I wanted to check that the new version was producing the same or nearly the same output as the old version. So I wrote this:</p>\n\n<p><a href=\"https://github.com/nicolashahn/diffimg\" rel=\"noreferrer\">https://github.com/nicolashahn/diffimg</a></p>\n\n<p>Which operates on images of the same size, and at a per-pixel level, measures the difference in values at each channel: R, G, B(, A), takes the average difference of those channels, and then averages the difference over all pixels, and returns a ratio.</p>\n\n<p>For example, with a 10x10 image of white pixels, and the same image but one pixel has changed to red, the difference at that pixel is 1/3 or 0.33... (RGB 0,0,0 vs 255,0,0) and at all other pixels is 0. With 100 pixels total, 0.33.../100 = a ~0.33% difference in image.</p>\n\n<p>I believe this would work perfectly for OP's project (I realize this is a very old post now, but posting for future StackOverflowers who also want to compare images in python).</p>\n"
},
{
"answer_id": 50879276,
"author": "zanfranceschi",
"author_id": 3149605,
"author_profile": "https://Stackoverflow.com/users/3149605",
"pm_score": 2,
"selected": false,
"text": "<p>I apologize if this is too late to reply, but since I've been doing something similar I thought I could contribute somehow.</p>\n\n<p>Maybe with OpenCV you could use template matching. Assuming you're using a webcam as you said:</p>\n\n<ol>\n<li>Simplify the images (thresholding maybe?)</li>\n<li>Apply template matching and check the max_val with minMaxLoc</li>\n</ol>\n\n<p>Tip: max_val (or min_val depending on the method used) will give you numbers, large numbers. To get the difference in percentage, use template matching with the same image -- the result will be your 100%.</p>\n\n<p>Pseudo code to exemplify:</p>\n\n<pre><code>previous_screenshot = ...\ncurrent_screenshot = ...\n\n# simplify both images somehow\n\n# get the 100% corresponding value\nres = matchTemplate(previous_screenshot, previous_screenshot, TM_CCOEFF)\n_, hundred_p_val, _, _ = minMaxLoc(res)\n\n# hundred_p_val is now the 100%\n\nres = matchTemplate(previous_screenshot, current_screenshot, TM_CCOEFF)\n_, max_val, _, _ = minMaxLoc(res)\n\ndifference_percentage = max_val / hundred_p_val\n\n# the tolerance is now up to you\n</code></pre>\n\n<p>Hope it helps.</p>\n"
},
{
"answer_id": 56026420,
"author": "cyfex",
"author_id": 3971097,
"author_profile": "https://Stackoverflow.com/users/3971097",
"pm_score": 0,
"selected": false,
"text": "<p>There are many metrics out there for evaluating whether two images look like/how much they look like.</p>\n\n<p>I will not go into any code here, because I think it should be a scientific problem, other than a technical problem.</p>\n\n<p>Generally, the question is related to human's perception on images, so each algorithm has its support on human visual system traits.</p>\n\n<p>Classic approaches are:</p>\n\n<p>Visible differences predictor: an algorithm for the assessment of image fidelity (<a href=\"https://www.spiedigitallibrary.org/conference-proceedings-of-spie/1666/0000/Visible-differences-predictor--an-algorithm-for-the-assessment-of/10.1117/12.135952.short?SSO=1\" rel=\"nofollow noreferrer\">https://www.spiedigitallibrary.org/conference-proceedings-of-spie/1666/0000/Visible-differences-predictor--an-algorithm-for-the-assessment-of/10.1117/12.135952.short?SSO=1</a>)</p>\n\n<p>Image Quality Assessment: From Error Visibility to Structural Similarity (<a href=\"http://www.cns.nyu.edu/pub/lcv/wang03-reprint.pdf\" rel=\"nofollow noreferrer\">http://www.cns.nyu.edu/pub/lcv/wang03-reprint.pdf</a>)</p>\n\n<p>FSIM: A Feature Similarity Index for Image Quality Assessment (<a href=\"https://www4.comp.polyu.edu.hk/~cslzhang/IQA/TIP_IQA_FSIM.pdf\" rel=\"nofollow noreferrer\">https://www4.comp.polyu.edu.hk/~cslzhang/IQA/TIP_IQA_FSIM.pdf</a>)</p>\n\n<p>Among them, SSIM (Image Quality Assessment: From Error Visibility to Structural Similarity ) is the easiest to calculate and its overhead is also small, as reported in another paper \"Image Quality Assessment Based on Gradient Similarity\" (<a href=\"https://www.semanticscholar.org/paper/Image-Quality-Assessment-Based-on-Gradient-Liu-Lin/2b819bef80c02d5d4cb56f27b202535e119df988\" rel=\"nofollow noreferrer\">https://www.semanticscholar.org/paper/Image-Quality-Assessment-Based-on-Gradient-Liu-Lin/2b819bef80c02d5d4cb56f27b202535e119df988</a>).</p>\n\n<p>There are many more other approaches. Take a look at Google Scholar and search for something like \"visual difference\", \"image quality assessment\", etc, if you are interested/really care about the art.</p>\n"
},
{
"answer_id": 57098987,
"author": "Arian Soltani",
"author_id": 5259791,
"author_profile": "https://Stackoverflow.com/users/5259791",
"pm_score": 1,
"selected": false,
"text": "<p>There's a simple and fast solution using numpy by calculating mean squared error:</p>\n\n<pre><code>before = np.array(get_picture())\nwhile True:\n now = np.array(get_picture())\n MSE = np.mean((now - before)**2)\n\n if MSE > threshold:\n break\n\n before = now\n</code></pre>\n"
},
{
"answer_id": 66402594,
"author": "Pedro Vernetti",
"author_id": 4233943,
"author_profile": "https://Stackoverflow.com/users/4233943",
"pm_score": 1,
"selected": false,
"text": "<p>Here is a function I wrote, which takes 2 images (filepaths) as arguments and returns the average difference between the two images' pixels' components. This worked pretty well for me to determine visually "equal" images (when they're not <code>==</code> equal).</p>\n<p><em>(I found 8 to be a good limit to determine if images are essentially the same.)</em></p>\n<p><em>(Images must have the same dimensions if you add no preprocessing to this.)</em></p>\n<pre class=\"lang-py prettyprint-override\"><code>from PIL import Image\n\ndef imagesDifference( imageA, imageB ):\n A = list(Image.open(imageA, r'r').convert(r'RGB').getdata())\n B = list(Image.open(imageB, r'r').convert(r'RGB').getdata())\n if (len(A) != len(B)): return -1\n diff = []\n for i in range(0, len(A)):\n diff += [abs(A[i][0] - B[i][0]), abs(A[i][1] - B[i][1]), abs(A[i][2] - B[i][2])]\n return (sum(diff) / len(diff))\n</code></pre>\n"
},
{
"answer_id": 69118422,
"author": "Saqib Shakeel",
"author_id": 10998432,
"author_profile": "https://Stackoverflow.com/users/10998432",
"pm_score": 0,
"selected": false,
"text": "<p>Use SSIM to measure the Structural Similarity Index Measure between 2 images.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189943",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/20498/"
] |
Here's what I would like to do:
I'm taking pictures with a webcam at regular intervals. Sort of like a time lapse thing. However, if nothing has really changed, that is, the picture pretty much *looks* the same, I don't want to store the latest snapshot.
I imagine there's some way of quantifying the difference, and I would have to empirically determine a threshold.
I'm looking for simplicity rather than perfection.
I'm using python.
|
General idea
------------
Option 1: Load both images as arrays (`scipy.misc.imread`) and calculate an element-wise (pixel-by-pixel) difference. Calculate the norm of the difference.
Option 2: Load both images. Calculate some feature vector for each of them (like a histogram). Calculate distance between feature vectors rather than images.
However, there are some decisions to make first.
Questions
---------
You should answer these questions first:
* Are images of the same shape and dimension?
If not, you may need to resize or crop them. PIL library will help to do it in Python.
If they are taken with the same settings and the same device, they are probably the same.
* Are images well-aligned?
If not, you may want to run cross-correlation first, to find the best alignment first. SciPy has functions to do it.
If the camera and the scene are still, the images are likely to be well-aligned.
* Is exposure of the images always the same? (Is lightness/contrast the same?)
If not, you may want [to normalize](http://en.wikipedia.org/wiki/Normalization_(image_processing)) images.
But be careful, in some situations this may do more wrong than good. For example, a single bright pixel on a dark background will make the normalized image very different.
* Is color information important?
If you want to notice color changes, you will have a vector of color values per point, rather than a scalar value as in gray-scale image. You need more attention when writing such code.
* Are there distinct edges in the image? Are they likely to move?
If yes, you can apply edge detection algorithm first (e.g. calculate gradient with Sobel or Prewitt transform, apply some threshold), then compare edges on the first image to edges on the second.
* Is there noise in the image?
All sensors pollute the image with some amount of noise. Low-cost sensors have more noise. You may wish to apply some noise reduction before you compare images. Blur is the most simple (but not the best) approach here.
* What kind of changes do you want to notice?
This may affect the choice of norm to use for the difference between images.
Consider using Manhattan norm (the sum of the absolute values) or zero norm (the number of elements not equal to zero) to measure how much the image has changed. The former will tell you how much the image is off, the latter will tell only how many pixels differ.
Example
-------
I assume your images are well-aligned, the same size and shape, possibly with different exposure. For simplicity, I convert them to grayscale even if they are color (RGB) images.
You will need these imports:
```
import sys
from scipy.misc import imread
from scipy.linalg import norm
from scipy import sum, average
```
Main function, read two images, convert to grayscale, compare and print results:
```
def main():
file1, file2 = sys.argv[1:1+2]
# read images as 2D arrays (convert to grayscale for simplicity)
img1 = to_grayscale(imread(file1).astype(float))
img2 = to_grayscale(imread(file2).astype(float))
# compare
n_m, n_0 = compare_images(img1, img2)
print "Manhattan norm:", n_m, "/ per pixel:", n_m/img1.size
print "Zero norm:", n_0, "/ per pixel:", n_0*1.0/img1.size
```
How to compare. `img1` and `img2` are 2D SciPy arrays here:
```
def compare_images(img1, img2):
# normalize to compensate for exposure difference, this may be unnecessary
# consider disabling it
img1 = normalize(img1)
img2 = normalize(img2)
# calculate the difference and its norms
diff = img1 - img2 # elementwise for scipy arrays
m_norm = sum(abs(diff)) # Manhattan norm
z_norm = norm(diff.ravel(), 0) # Zero norm
return (m_norm, z_norm)
```
If the file is a color image, `imread` returns a 3D array, average RGB channels (the last array axis) to obtain intensity. No need to do it for grayscale images (e.g. `.pgm`):
```
def to_grayscale(arr):
"If arr is a color image (3D array), convert it to grayscale (2D array)."
if len(arr.shape) == 3:
return average(arr, -1) # average over the last axis (color channels)
else:
return arr
```
Normalization is trivial, you may choose to normalize to [0,1] instead of [0,255]. `arr` is a SciPy array here, so all operations are element-wise:
```
def normalize(arr):
rng = arr.max()-arr.min()
amin = arr.min()
return (arr-amin)*255/rng
```
Run the `main` function:
```
if __name__ == "__main__":
main()
```
Now you can put this all in a script and run against two images. If we compare image to itself, there is no difference:
```
$ python compare.py one.jpg one.jpg
Manhattan norm: 0.0 / per pixel: 0.0
Zero norm: 0 / per pixel: 0.0
```
If we blur the image and compare to the original, there is some difference:
```
$ python compare.py one.jpg one-blurred.jpg
Manhattan norm: 92605183.67 / per pixel: 13.4210411116
Zero norm: 6900000 / per pixel: 1.0
```
P.S. Entire [compare.py](http://gist.github.com/626356) script.
Update: relevant techniques
---------------------------
As the question is about a video sequence, where frames are likely to be almost the same, and you look for something unusual, I'd like to mention some alternative approaches which may be relevant:
* background subtraction and segmentation (to detect foreground objects)
* sparse optical flow (to detect motion)
* comparing histograms or some other statistics instead of images
I strongly recommend taking a look at “Learning OpenCV” book, Chapters 9 (Image parts and segmentation) and 10 (Tracking and motion). The former teaches to use Background subtraction method, the latter gives some info on optical flow methods. All methods are implemented in OpenCV library. If you use Python, I suggest to use OpenCV ≥ 2.3, and its `cv2` Python module.
The most simple version of the background subtraction:
* learn the average value μ and standard deviation σ for every pixel of the background
* compare current pixel values to the range of (μ-2σ,μ+2σ) or (μ-σ,μ+σ)
More advanced versions make take into account time series for every pixel and handle non-static scenes (like moving trees or grass).
The idea of optical flow is to take two or more frames, and assign velocity vector to every pixel (dense optical flow) or to some of them (sparse optical flow). To estimate sparse optical flow, you may use [Lucas-Kanade method](http://en.wikipedia.org/wiki/Lucas%E2%80%93Kanade_method) (it is also implemented in OpenCV). Obviously, if there is a lot of flow (high average over max values of the velocity field), then something is moving in the frame, and subsequent images are more different.
Comparing histograms may help to detect sudden changes between consecutive frames. This approach was used in [Courbon et al, 2010](http://www.sciencedirect.com/science/article/pii/S0967066110000808):
>
> *Similarity of consecutive frames.* The distance between two consecutive frames is measured. If it is too high, it means that the second frame is corrupted and thus the image is eliminated. The [Kullback–Leibler distance](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence), or mutual entropy, on the histograms of the two frames:
>
>
> 
>
>
> where *p* and *q* are the histograms of the frames is used. The threshold is fixed on 0.2.
>
>
>
|
189,947 |
<p>Have a n-tire web application and search often times out after 30 secs. How to detect the root cause of the problem?</p>
|
[
{
"answer_id": 189960,
"author": "keparo",
"author_id": 19468,
"author_profile": "https://Stackoverflow.com/users/19468",
"pm_score": 6,
"selected": false,
"text": "<p><strong>A simple solution:</strong></p>\n\n<p>Encode the image as a <strong>jpeg</strong> and look for a substantial change in <strong>filesize</strong>.</p>\n\n<p>I've implemented something similar with video thumbnails, and had a lot of success and scalability.</p>\n"
},
{
"answer_id": 189967,
"author": "Federico A. Ramponi",
"author_id": 18770,
"author_profile": "https://Stackoverflow.com/users/18770",
"pm_score": 0,
"selected": false,
"text": "<p>I think you could simply compute the euclidean distance (i.e. sqrt(sum of squares of differences, pixel by pixel)) between the luminance of the two images, and consider them equal if this falls under some empirical threshold. And you would better do it wrapping a C function.</p>\n"
},
{
"answer_id": 189968,
"author": "shoosh",
"author_id": 9611,
"author_profile": "https://Stackoverflow.com/users/9611",
"pm_score": 1,
"selected": false,
"text": "<p><a href=\"http://www.google.ca/search?hl=en&safe=off&client=firefox-a&rls=org.mozilla:en-US:official&hs=HD8&pwst=1&sa=X&oi=spell&resnum=0&ct=result&cd=1&q=earth+mover%27s+distance+image&spell=1\" rel=\"nofollow noreferrer\">Earth movers distance</a> might be exactly what you need.\nIt might be <em>abit</em> heavy to implement in real time though.</p>\n"
},
{
"answer_id": 189977,
"author": "Tobias",
"author_id": 14027,
"author_profile": "https://Stackoverflow.com/users/14027",
"pm_score": 1,
"selected": false,
"text": "<p>What about calculating the <a href=\"http://en.wikipedia.org/wiki/Manhattan_distance\" rel=\"nofollow noreferrer\">Manhattan Distance</a> of the two images. That gives you n*n values. Then you could do something like an row average to reduce to n values and a function over that to get one single value.</p>\n"
},
{
"answer_id": 190000,
"author": "tzot",
"author_id": 6899,
"author_profile": "https://Stackoverflow.com/users/6899",
"pm_score": 2,
"selected": false,
"text": "<p>Have you seen the <a href=\"https://stackoverflow.com/questions/75891/algorithm-for-finding-similar-images\">Algorithm for finding similar images</a> question? Check it out to see suggestions.</p>\n\n<p>I would suggest a wavelet transformation of your frames (I've written a C extension for that using Haar transformation); then, comparing the indexes of the largest (proportionally) wavelet factors between the two pictures, you should get a numerical similarity approximation.</p>\n"
},
{
"answer_id": 190036,
"author": "Ates Goral",
"author_id": 23501,
"author_profile": "https://Stackoverflow.com/users/23501",
"pm_score": 4,
"selected": false,
"text": "<p>A trivial thing to try:</p>\n\n<p>Resample both images to small thumbnails (e.g. 64 x 64) and compare the thumbnails pixel-by-pixel with a certain threshold. If the original images are almost the same, the resampled thumbnails will be very similar or even exactly the same. This method takes care of noise that can occur especially in low-light scenes. It may even be better if you go grayscale.</p>\n"
},
{
"answer_id": 190061,
"author": "Mr Fooz",
"author_id": 25050,
"author_profile": "https://Stackoverflow.com/users/25050",
"pm_score": 5,
"selected": false,
"text": "<p>Two popular and relatively simple methods are: (a) the Euclidean distance already suggested, or (b) normalized cross-correlation. Normalized cross-correlation tends to be noticeably more robust to lighting changes than simple cross-correlation. Wikipedia gives a formula for the <a href=\"http://en.wikipedia.org/wiki/Cross-correlation#Normalized_cross-correlation\" rel=\"noreferrer\">normalized cross-correlation</a>. More sophisticated methods exist too, but they require quite a bit more work.</p>\n\n<p>Using numpy-like syntax,</p>\n\n<pre>\ndist_euclidean = sqrt(sum((i1 - i2)^2)) / i1.size\n\ndist_manhattan = sum(abs(i1 - i2)) / i1.size\n\ndist_ncc = sum( (i1 - mean(i1)) * (i2 - mean(i2)) ) / (\n (i1.size - 1) * stdev(i1) * stdev(i2) )\n</pre>\n\n<p>assuming that <code>i1</code> and <code>i2</code> are 2D grayscale image arrays. </p>\n"
},
{
"answer_id": 190078,
"author": "Loren Pechtel",
"author_id": 10659,
"author_profile": "https://Stackoverflow.com/users/10659",
"pm_score": 3,
"selected": false,
"text": "<p>Most of the answers given won't deal with lighting levels.</p>\n\n<p>I would first normalize the image to a standard light level before doing the comparison.</p>\n"
},
{
"answer_id": 196882,
"author": "elifiner",
"author_id": 15109,
"author_profile": "https://Stackoverflow.com/users/15109",
"pm_score": 6,
"selected": false,
"text": "<p>You can compare two images using functions from <a href=\"http://www.pythonware.com/products/pil/\" rel=\"noreferrer\">PIL</a>. </p>\n\n<pre><code>import Image\nimport ImageChops\n\nim1 = Image.open(\"splash.png\")\nim2 = Image.open(\"splash2.png\")\n\ndiff = ImageChops.difference(im2, im1)\n</code></pre>\n\n<p>The diff object is an image in which every pixel is the result of the subtraction of the color values of that pixel in the second image from the first image. Using the diff image you can do several things. The simplest one is the <code>diff.getbbox()</code> function. It will tell you the minimal rectangle that contains all the changes between your two images.</p>\n\n<p>You can probably implement approximations of the other stuff mentioned here using functions from PIL as well.</p>\n"
},
{
"answer_id": 3935002,
"author": "sastanin",
"author_id": 25450,
"author_profile": "https://Stackoverflow.com/users/25450",
"pm_score": 9,
"selected": true,
"text": "<h2>General idea</h2>\n\n<p>Option 1: Load both images as arrays (<code>scipy.misc.imread</code>) and calculate an element-wise (pixel-by-pixel) difference. Calculate the norm of the difference.</p>\n\n<p>Option 2: Load both images. Calculate some feature vector for each of them (like a histogram). Calculate distance between feature vectors rather than images.</p>\n\n<p>However, there are some decisions to make first.</p>\n\n<h2>Questions</h2>\n\n<p>You should answer these questions first:</p>\n\n<ul>\n<li><p>Are images of the same shape and dimension?</p>\n\n<p>If not, you may need to resize or crop them. PIL library will help to do it in Python.</p>\n\n<p>If they are taken with the same settings and the same device, they are probably the same.</p></li>\n<li><p>Are images well-aligned?</p>\n\n<p>If not, you may want to run cross-correlation first, to find the best alignment first. SciPy has functions to do it.</p>\n\n<p>If the camera and the scene are still, the images are likely to be well-aligned.</p></li>\n<li><p>Is exposure of the images always the same? (Is lightness/contrast the same?)</p>\n\n<p>If not, you may want <a href=\"http://en.wikipedia.org/wiki/Normalization_(image_processing)\" rel=\"noreferrer\">to normalize</a> images.</p>\n\n<p>But be careful, in some situations this may do more wrong than good. For example, a single bright pixel on a dark background will make the normalized image very different.</p></li>\n<li><p>Is color information important?</p>\n\n<p>If you want to notice color changes, you will have a vector of color values per point, rather than a scalar value as in gray-scale image. You need more attention when writing such code.</p></li>\n<li><p>Are there distinct edges in the image? Are they likely to move?</p>\n\n<p>If yes, you can apply edge detection algorithm first (e.g. calculate gradient with Sobel or Prewitt transform, apply some threshold), then compare edges on the first image to edges on the second.</p></li>\n<li><p>Is there noise in the image?</p>\n\n<p>All sensors pollute the image with some amount of noise. Low-cost sensors have more noise. You may wish to apply some noise reduction before you compare images. Blur is the most simple (but not the best) approach here.</p></li>\n<li><p>What kind of changes do you want to notice?</p>\n\n<p>This may affect the choice of norm to use for the difference between images.</p>\n\n<p>Consider using Manhattan norm (the sum of the absolute values) or zero norm (the number of elements not equal to zero) to measure how much the image has changed. The former will tell you how much the image is off, the latter will tell only how many pixels differ.</p></li>\n</ul>\n\n<h2>Example</h2>\n\n<p>I assume your images are well-aligned, the same size and shape, possibly with different exposure. For simplicity, I convert them to grayscale even if they are color (RGB) images.</p>\n\n<p>You will need these imports:</p>\n\n<pre><code>import sys\n\nfrom scipy.misc import imread\nfrom scipy.linalg import norm\nfrom scipy import sum, average\n</code></pre>\n\n<p>Main function, read two images, convert to grayscale, compare and print results:</p>\n\n<pre><code>def main():\n file1, file2 = sys.argv[1:1+2]\n # read images as 2D arrays (convert to grayscale for simplicity)\n img1 = to_grayscale(imread(file1).astype(float))\n img2 = to_grayscale(imread(file2).astype(float))\n # compare\n n_m, n_0 = compare_images(img1, img2)\n print \"Manhattan norm:\", n_m, \"/ per pixel:\", n_m/img1.size\n print \"Zero norm:\", n_0, \"/ per pixel:\", n_0*1.0/img1.size\n</code></pre>\n\n<p>How to compare. <code>img1</code> and <code>img2</code> are 2D SciPy arrays here:</p>\n\n<pre><code>def compare_images(img1, img2):\n # normalize to compensate for exposure difference, this may be unnecessary\n # consider disabling it\n img1 = normalize(img1)\n img2 = normalize(img2)\n # calculate the difference and its norms\n diff = img1 - img2 # elementwise for scipy arrays\n m_norm = sum(abs(diff)) # Manhattan norm\n z_norm = norm(diff.ravel(), 0) # Zero norm\n return (m_norm, z_norm)\n</code></pre>\n\n<p>If the file is a color image, <code>imread</code> returns a 3D array, average RGB channels (the last array axis) to obtain intensity. No need to do it for grayscale images (e.g. <code>.pgm</code>):</p>\n\n<pre><code>def to_grayscale(arr):\n \"If arr is a color image (3D array), convert it to grayscale (2D array).\"\n if len(arr.shape) == 3:\n return average(arr, -1) # average over the last axis (color channels)\n else:\n return arr\n</code></pre>\n\n<p>Normalization is trivial, you may choose to normalize to [0,1] instead of [0,255]. <code>arr</code> is a SciPy array here, so all operations are element-wise:</p>\n\n<pre><code>def normalize(arr):\n rng = arr.max()-arr.min()\n amin = arr.min()\n return (arr-amin)*255/rng\n</code></pre>\n\n<p>Run the <code>main</code> function:</p>\n\n<pre><code>if __name__ == \"__main__\":\n main()\n</code></pre>\n\n<p>Now you can put this all in a script and run against two images. If we compare image to itself, there is no difference:</p>\n\n<pre><code>$ python compare.py one.jpg one.jpg\nManhattan norm: 0.0 / per pixel: 0.0\nZero norm: 0 / per pixel: 0.0\n</code></pre>\n\n<p>If we blur the image and compare to the original, there is some difference:</p>\n\n<pre><code>$ python compare.py one.jpg one-blurred.jpg \nManhattan norm: 92605183.67 / per pixel: 13.4210411116\nZero norm: 6900000 / per pixel: 1.0\n</code></pre>\n\n<p>P.S. Entire <a href=\"http://gist.github.com/626356\" rel=\"noreferrer\">compare.py</a> script.</p>\n\n<h2>Update: relevant techniques</h2>\n\n<p>As the question is about a video sequence, where frames are likely to be almost the same, and you look for something unusual, I'd like to mention some alternative approaches which may be relevant:</p>\n\n<ul>\n<li>background subtraction and segmentation (to detect foreground objects)</li>\n<li>sparse optical flow (to detect motion)</li>\n<li>comparing histograms or some other statistics instead of images</li>\n</ul>\n\n<p>I strongly recommend taking a look at “Learning OpenCV” book, Chapters 9 (Image parts and segmentation) and 10 (Tracking and motion). The former teaches to use Background subtraction method, the latter gives some info on optical flow methods. All methods are implemented in OpenCV library. If you use Python, I suggest to use OpenCV ≥ 2.3, and its <code>cv2</code> Python module.</p>\n\n<p>The most simple version of the background subtraction:</p>\n\n<ul>\n<li>learn the average value μ and standard deviation σ for every pixel of the background</li>\n<li>compare current pixel values to the range of (μ-2σ,μ+2σ) or (μ-σ,μ+σ)</li>\n</ul>\n\n<p>More advanced versions make take into account time series for every pixel and handle non-static scenes (like moving trees or grass).</p>\n\n<p>The idea of optical flow is to take two or more frames, and assign velocity vector to every pixel (dense optical flow) or to some of them (sparse optical flow). To estimate sparse optical flow, you may use <a href=\"http://en.wikipedia.org/wiki/Lucas%E2%80%93Kanade_method\" rel=\"noreferrer\">Lucas-Kanade method</a> (it is also implemented in OpenCV). Obviously, if there is a lot of flow (high average over max values of the velocity field), then something is moving in the frame, and subsequent images are more different.</p>\n\n<p>Comparing histograms may help to detect sudden changes between consecutive frames. This approach was used in <a href=\"http://www.sciencedirect.com/science/article/pii/S0967066110000808\" rel=\"noreferrer\">Courbon et al, 2010</a>:</p>\n\n<blockquote>\n <p><em>Similarity of consecutive frames.</em> The distance between two consecutive frames is measured. If it is too high, it means that the second frame is corrupted and thus the image is eliminated. The <a href=\"https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence\" rel=\"noreferrer\">Kullback–Leibler distance</a>, or mutual entropy, on the histograms of the two frames:</p>\n \n <p><img src=\"https://i.imgur.com/hdeh8ni.gif\" alt=\"$$ d(p,q) = \\sum_i p(i) \\log (p(i)/q(i)) $$\"></p>\n \n <p>where <em>p</em> and <em>q</em> are the histograms of the frames is used. The threshold is fixed on 0.2.</p>\n</blockquote>\n"
},
{
"answer_id": 3935187,
"author": "Larry Gritz",
"author_id": 3832,
"author_profile": "https://Stackoverflow.com/users/3832",
"pm_score": 3,
"selected": false,
"text": "<p>I am addressing specifically the question of how to compute if they are \"different enough\". I assume you can figure out how to subtract the pixels one by one.</p>\n\n<p>First, I would take a bunch of images with <em>nothing</em> changing, and find out the maximum amount that any pixel changes just because of variations in the capture, noise in the imaging system, JPEG compression artifacts, and moment-to-moment changes in lighting. Perhaps you'll find that 1 or 2 bit differences are to be expected even when nothing moves.</p>\n\n<p>Then for the \"real\" test, you want a criterion like this:</p>\n\n<ul>\n<li>same if up to P pixels differ by no more than E.</li>\n</ul>\n\n<p>So, perhaps, if E = 0.02, P = 1000, that would mean (approximately) that it would be \"different\" if any single pixel changes by more than ~5 units (assuming 8-bit images), or if more than 1000 pixels had any errors at all.</p>\n\n<p>This is intended mainly as a good \"triage\" technique to quickly identify images that are close enough to not need further examination. The images that \"fail\" may then more to a more elaborate/expensive technique that wouldn't have false positives if the camera shook bit, for example, or was more robust to lighting changes.</p>\n\n<p>I run an open source project, <a href=\"http://www.openimageio.org\" rel=\"noreferrer\">OpenImageIO</a>, that contains a utility called \"idiff\" that compares differences with thresholds like this (even more elaborate, actually). Even if you don't want to use this software, you may want to look at the source to see how we did it. It's used commercially quite a bit and this thresholding technique was developed so that we could have a test suite for rendering and image processing software, with \"reference images\" that might have small differences from platform-to-platform or as we made minor tweaks to tha algorithms, so we wanted a \"match within tolerance\" operation.</p>\n"
},
{
"answer_id": 5053648,
"author": "Roman Dial",
"author_id": 624744,
"author_profile": "https://Stackoverflow.com/users/624744",
"pm_score": 1,
"selected": false,
"text": "<p>I have been having a lot of luck with jpg images taken with the same camera on a tripod by\n(1) simplifying greatly (like going from 3000 pixels wide to 100 pixels wide or even fewer)\n(2) flattening each jpg array into a single vector\n(3) pairwise correlating sequential images with a simple correlate algorithm to get correlation coefficient\n(4) squaring correlation coefficient to get r-square (i.e fraction of variability in one image explained by variation in the next)\n(5) generally in my application if r-square < 0.9, I say the two images are different and something happened in between.</p>\n\n<p>This is robust and fast in my implementation (Mathematica 7)</p>\n\n<p>It's worth playing around with the part of the image you are interested in and focussing on that by cropping all images to that little area, otherwise a distant-from-the-camera but important change will be missed. </p>\n\n<p>I don't know how to use Python, but am sure it does correlations, too, no?</p>\n"
},
{
"answer_id": 5100965,
"author": "vishalv2050",
"author_id": 622889,
"author_profile": "https://Stackoverflow.com/users/622889",
"pm_score": 1,
"selected": false,
"text": "<p>you can compute the histogram of both the images and then calculate the <a href=\"http://en.wikipedia.org/wiki/Bhattacharyya_distance#Bhattacharyya_coefficient\" rel=\"nofollow\">Bhattacharyya Coefficient</a>, this is a very fast algorithm and I have used it to detect shot changes in a cricket video (in C using openCV)</p>\n"
},
{
"answer_id": 8886316,
"author": "Ricardo Cabral",
"author_id": 18741,
"author_profile": "https://Stackoverflow.com/users/18741",
"pm_score": 1,
"selected": false,
"text": "<p>Check out how Haar Wavelets are implemented by <a href=\"http://server.imgseek.net/\" rel=\"nofollow\">isk-daemon</a>. You could use it's imgdb C++ code to calculate the difference between images on-the-fly:</p>\n\n<blockquote>\n <p>isk-daemon is an open source database server capable of adding content-based (visual) image searching to any image related website or software.</p>\n \n <p>This technology allows users of any image-related website or software to sketch on a widget which image they want to find and have the website reply to them the most similar images or simply request for more similar photos at each image detail page.</p>\n</blockquote>\n"
},
{
"answer_id": 40711075,
"author": "datenhahn",
"author_id": 4559200,
"author_profile": "https://Stackoverflow.com/users/4559200",
"pm_score": 2,
"selected": false,
"text": "<p>I had the same problem and wrote a simple python module which compares two same-size images using pillow's ImageChops to create a black/white diff image and sums up the histogram values.</p>\n\n<p>You can get either this score directly, or a percentage value compared to a full black vs. white diff.</p>\n\n<p>It also contains a simple is_equal function, with the possibility to supply a fuzzy-threshold under (and including) the image passes as equal.</p>\n\n<p>The approach is not very elaborate, but maybe is of use for other out there struggling with the same issue.</p>\n\n<p><a href=\"https://pypi.python.org/pypi/imgcompare/\" rel=\"nofollow noreferrer\">https://pypi.python.org/pypi/imgcompare/</a></p>\n"
},
{
"answer_id": 44106540,
"author": "admin",
"author_id": 6489637,
"author_profile": "https://Stackoverflow.com/users/6489637",
"pm_score": 2,
"selected": false,
"text": "<pre><code>import os\nfrom PIL import Image\nfrom PIL import ImageFile\nimport imagehash\n \n#just use to the size diferent picture\ndef compare_image(img_file1, img_file2):\n if img_file1 == img_file2:\n return True\n fp1 = open(img_file1, 'rb')\n fp2 = open(img_file2, 'rb')\n\n img1 = Image.open(fp1)\n img2 = Image.open(fp2)\n\n ImageFile.LOAD_TRUNCATED_IMAGES = True\n b = img1 == img2\n\n fp1.close()\n fp2.close()\n\n return b\n\n\n\n\n\n#through picturu hash to compare\ndef get_hash_dict(dir):\n hash_dict = {}\n image_quantity = 0\n for _, _, files in os.walk(dir):\n for i, fileName in enumerate(files):\n with open(dir + fileName, 'rb') as fp:\n hash_dict[dir + fileName] = imagehash.average_hash(Image.open(fp))\n image_quantity += 1\n\n return hash_dict, image_quantity\n\ndef compare_image_with_hash(image_file_name_1, image_file_name_2, max_dif=0):\n """\n max_dif: The maximum hash difference is allowed, the smaller and more accurate, the minimum is 0.\n recommend to use\n """\n ImageFile.LOAD_TRUNCATED_IMAGES = True\n hash_1 = None\n hash_2 = None\n with open(image_file_name_1, 'rb') as fp:\n hash_1 = imagehash.average_hash(Image.open(fp))\n with open(image_file_name_2, 'rb') as fp:\n hash_2 = imagehash.average_hash(Image.open(fp))\n dif = hash_1 - hash_2\n if dif < 0:\n dif = -dif\n if dif <= max_dif:\n return True\n else:\n return False\n\n\ndef compare_image_dir_with_hash(dir_1, dir_2, max_dif=0):\n """\n max_dif: The maximum hash difference is allowed, the smaller and more accurate, the minimum is 0.\n\n """\n ImageFile.LOAD_TRUNCATED_IMAGES = True\n hash_dict_1, image_quantity_1 = get_hash_dict(dir_1)\n hash_dict_2, image_quantity_2 = get_hash_dict(dir_2)\n\n if image_quantity_1 > image_quantity_2:\n tmp = image_quantity_1\n image_quantity_1 = image_quantity_2\n image_quantity_2 = tmp\n\n tmp = hash_dict_1\n hash_dict_1 = hash_dict_2\n hash_dict_2 = tmp\n\n result_dict = {}\n\n for k in hash_dict_1.keys():\n result_dict[k] = None\n\n for dif_i in range(0, max_dif + 1):\n have_none = False\n\n for k_1 in result_dict.keys():\n if result_dict.get(k_1) is None:\n have_none = True\n\n if not have_none:\n return result_dict\n\n for k_1, v_1 in hash_dict_1.items():\n for k_2, v_2 in hash_dict_2.items():\n sub = (v_1 - v_2)\n if sub < 0:\n sub = -sub\n if sub == dif_i and result_dict.get(k_1) is None:\n result_dict[k_1] = k_2\n break\n return result_dict\n\n\ndef main():\n print(compare_image('image1\\\\815.jpg', 'image2\\\\5.jpg'))\n print(compare_image_with_hash('image1\\\\815.jpg', 'image2\\\\5.jpg', 7))\n r = compare_image_dir_with_hash('image1\\\\', 'image2\\\\', 10)\n for k in r.keys():\n print(k, r.get(k))\n\n\nif __name__ == '__main__':\n main()\n</code></pre>\n<ul>\n<li><p>output:</p>\n<p>False<br>\nTrue<br>\nimage2\\5.jpg image1\\815.jpg<br>\nimage2\\6.jpg image1\\819.jpg<br>\nimage2\\7.jpg image1\\900.jpg<br>\nimage2\\8.jpg image1\\998.jpg<br>\nimage2\\9.jpg image1\\1012.jpg<br>\n<br></p>\n</li>\n<li><p>the example pictures:</p>\n<ul>\n<li><p>815.jpg\n<br>\n<a href=\"https://i.stack.imgur.com/xVGI8.jpg\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/xVGI8.jpg\" alt=\"815.jpg\" /></a></p>\n</li>\n<li><p>5.jpg\n<br>\n<a href=\"https://i.stack.imgur.com/py9j1.jpg\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/py9j1.jpg\" alt=\"5.jpg\" /></a></p>\n</li>\n</ul>\n</li>\n</ul>\n"
},
{
"answer_id": 47543363,
"author": "Felix Goldberg",
"author_id": 1813736,
"author_profile": "https://Stackoverflow.com/users/1813736",
"pm_score": 1,
"selected": false,
"text": "<p>A somewhat more principled approach is to use a global descriptor to compare images, such as GIST or CENTRIST. A hash function, as described <a href=\"https://www.pyimagesearch.com/2017/11/27/image-hashing-opencv-python/\" rel=\"nofollow noreferrer\">here</a>, also provides a similar solution.</p>\n"
},
{
"answer_id": 49574931,
"author": "duhaime",
"author_id": 1727392,
"author_profile": "https://Stackoverflow.com/users/1727392",
"pm_score": 3,
"selected": false,
"text": "<p>Another nice, simple way to measure the similarity between two images:</p>\n\n<pre><code>import sys\nfrom skimage.measure import compare_ssim\nfrom skimage.transform import resize\nfrom scipy.ndimage import imread\n\n# get two images - resize both to 1024 x 1024\nimg_a = resize(imread(sys.argv[1]), (2**10, 2**10))\nimg_b = resize(imread(sys.argv[2]), (2**10, 2**10))\n\n# score: {-1:1} measure of the structural similarity between the images\nscore, diff = compare_ssim(img_a, img_b, full=True)\nprint(score)\n</code></pre>\n\n<p>If others are interested in a more powerful way to compare image similarity, I put together a <a href=\"http://douglasduhaime.com/posts/identifying-similar-images-with-tensorflow.html\" rel=\"noreferrer\">tutorial</a> and web <a href=\"https://github.com/YaleDHLab/pix-plot\" rel=\"noreferrer\">app</a> for measuring and visualizing similar images using Tensorflow.</p>\n"
},
{
"answer_id": 50553679,
"author": "nicolashahn",
"author_id": 4394625,
"author_profile": "https://Stackoverflow.com/users/4394625",
"pm_score": 3,
"selected": false,
"text": "<p>I had a similar problem at work, I was rewriting our image transform endpoint and I wanted to check that the new version was producing the same or nearly the same output as the old version. So I wrote this:</p>\n\n<p><a href=\"https://github.com/nicolashahn/diffimg\" rel=\"noreferrer\">https://github.com/nicolashahn/diffimg</a></p>\n\n<p>Which operates on images of the same size, and at a per-pixel level, measures the difference in values at each channel: R, G, B(, A), takes the average difference of those channels, and then averages the difference over all pixels, and returns a ratio.</p>\n\n<p>For example, with a 10x10 image of white pixels, and the same image but one pixel has changed to red, the difference at that pixel is 1/3 or 0.33... (RGB 0,0,0 vs 255,0,0) and at all other pixels is 0. With 100 pixels total, 0.33.../100 = a ~0.33% difference in image.</p>\n\n<p>I believe this would work perfectly for OP's project (I realize this is a very old post now, but posting for future StackOverflowers who also want to compare images in python).</p>\n"
},
{
"answer_id": 50879276,
"author": "zanfranceschi",
"author_id": 3149605,
"author_profile": "https://Stackoverflow.com/users/3149605",
"pm_score": 2,
"selected": false,
"text": "<p>I apologize if this is too late to reply, but since I've been doing something similar I thought I could contribute somehow.</p>\n\n<p>Maybe with OpenCV you could use template matching. Assuming you're using a webcam as you said:</p>\n\n<ol>\n<li>Simplify the images (thresholding maybe?)</li>\n<li>Apply template matching and check the max_val with minMaxLoc</li>\n</ol>\n\n<p>Tip: max_val (or min_val depending on the method used) will give you numbers, large numbers. To get the difference in percentage, use template matching with the same image -- the result will be your 100%.</p>\n\n<p>Pseudo code to exemplify:</p>\n\n<pre><code>previous_screenshot = ...\ncurrent_screenshot = ...\n\n# simplify both images somehow\n\n# get the 100% corresponding value\nres = matchTemplate(previous_screenshot, previous_screenshot, TM_CCOEFF)\n_, hundred_p_val, _, _ = minMaxLoc(res)\n\n# hundred_p_val is now the 100%\n\nres = matchTemplate(previous_screenshot, current_screenshot, TM_CCOEFF)\n_, max_val, _, _ = minMaxLoc(res)\n\ndifference_percentage = max_val / hundred_p_val\n\n# the tolerance is now up to you\n</code></pre>\n\n<p>Hope it helps.</p>\n"
},
{
"answer_id": 56026420,
"author": "cyfex",
"author_id": 3971097,
"author_profile": "https://Stackoverflow.com/users/3971097",
"pm_score": 0,
"selected": false,
"text": "<p>There are many metrics out there for evaluating whether two images look like/how much they look like.</p>\n\n<p>I will not go into any code here, because I think it should be a scientific problem, other than a technical problem.</p>\n\n<p>Generally, the question is related to human's perception on images, so each algorithm has its support on human visual system traits.</p>\n\n<p>Classic approaches are:</p>\n\n<p>Visible differences predictor: an algorithm for the assessment of image fidelity (<a href=\"https://www.spiedigitallibrary.org/conference-proceedings-of-spie/1666/0000/Visible-differences-predictor--an-algorithm-for-the-assessment-of/10.1117/12.135952.short?SSO=1\" rel=\"nofollow noreferrer\">https://www.spiedigitallibrary.org/conference-proceedings-of-spie/1666/0000/Visible-differences-predictor--an-algorithm-for-the-assessment-of/10.1117/12.135952.short?SSO=1</a>)</p>\n\n<p>Image Quality Assessment: From Error Visibility to Structural Similarity (<a href=\"http://www.cns.nyu.edu/pub/lcv/wang03-reprint.pdf\" rel=\"nofollow noreferrer\">http://www.cns.nyu.edu/pub/lcv/wang03-reprint.pdf</a>)</p>\n\n<p>FSIM: A Feature Similarity Index for Image Quality Assessment (<a href=\"https://www4.comp.polyu.edu.hk/~cslzhang/IQA/TIP_IQA_FSIM.pdf\" rel=\"nofollow noreferrer\">https://www4.comp.polyu.edu.hk/~cslzhang/IQA/TIP_IQA_FSIM.pdf</a>)</p>\n\n<p>Among them, SSIM (Image Quality Assessment: From Error Visibility to Structural Similarity ) is the easiest to calculate and its overhead is also small, as reported in another paper \"Image Quality Assessment Based on Gradient Similarity\" (<a href=\"https://www.semanticscholar.org/paper/Image-Quality-Assessment-Based-on-Gradient-Liu-Lin/2b819bef80c02d5d4cb56f27b202535e119df988\" rel=\"nofollow noreferrer\">https://www.semanticscholar.org/paper/Image-Quality-Assessment-Based-on-Gradient-Liu-Lin/2b819bef80c02d5d4cb56f27b202535e119df988</a>).</p>\n\n<p>There are many more other approaches. Take a look at Google Scholar and search for something like \"visual difference\", \"image quality assessment\", etc, if you are interested/really care about the art.</p>\n"
},
{
"answer_id": 57098987,
"author": "Arian Soltani",
"author_id": 5259791,
"author_profile": "https://Stackoverflow.com/users/5259791",
"pm_score": 1,
"selected": false,
"text": "<p>There's a simple and fast solution using numpy by calculating mean squared error:</p>\n\n<pre><code>before = np.array(get_picture())\nwhile True:\n now = np.array(get_picture())\n MSE = np.mean((now - before)**2)\n\n if MSE > threshold:\n break\n\n before = now\n</code></pre>\n"
},
{
"answer_id": 66402594,
"author": "Pedro Vernetti",
"author_id": 4233943,
"author_profile": "https://Stackoverflow.com/users/4233943",
"pm_score": 1,
"selected": false,
"text": "<p>Here is a function I wrote, which takes 2 images (filepaths) as arguments and returns the average difference between the two images' pixels' components. This worked pretty well for me to determine visually "equal" images (when they're not <code>==</code> equal).</p>\n<p><em>(I found 8 to be a good limit to determine if images are essentially the same.)</em></p>\n<p><em>(Images must have the same dimensions if you add no preprocessing to this.)</em></p>\n<pre class=\"lang-py prettyprint-override\"><code>from PIL import Image\n\ndef imagesDifference( imageA, imageB ):\n A = list(Image.open(imageA, r'r').convert(r'RGB').getdata())\n B = list(Image.open(imageB, r'r').convert(r'RGB').getdata())\n if (len(A) != len(B)): return -1\n diff = []\n for i in range(0, len(A)):\n diff += [abs(A[i][0] - B[i][0]), abs(A[i][1] - B[i][1]), abs(A[i][2] - B[i][2])]\n return (sum(diff) / len(diff))\n</code></pre>\n"
},
{
"answer_id": 69118422,
"author": "Saqib Shakeel",
"author_id": 10998432,
"author_profile": "https://Stackoverflow.com/users/10998432",
"pm_score": 0,
"selected": false,
"text": "<p>Use SSIM to measure the Structural Similarity Index Measure between 2 images.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189947",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26365/"
] |
Have a n-tire web application and search often times out after 30 secs. How to detect the root cause of the problem?
|
General idea
------------
Option 1: Load both images as arrays (`scipy.misc.imread`) and calculate an element-wise (pixel-by-pixel) difference. Calculate the norm of the difference.
Option 2: Load both images. Calculate some feature vector for each of them (like a histogram). Calculate distance between feature vectors rather than images.
However, there are some decisions to make first.
Questions
---------
You should answer these questions first:
* Are images of the same shape and dimension?
If not, you may need to resize or crop them. PIL library will help to do it in Python.
If they are taken with the same settings and the same device, they are probably the same.
* Are images well-aligned?
If not, you may want to run cross-correlation first, to find the best alignment first. SciPy has functions to do it.
If the camera and the scene are still, the images are likely to be well-aligned.
* Is exposure of the images always the same? (Is lightness/contrast the same?)
If not, you may want [to normalize](http://en.wikipedia.org/wiki/Normalization_(image_processing)) images.
But be careful, in some situations this may do more wrong than good. For example, a single bright pixel on a dark background will make the normalized image very different.
* Is color information important?
If you want to notice color changes, you will have a vector of color values per point, rather than a scalar value as in gray-scale image. You need more attention when writing such code.
* Are there distinct edges in the image? Are they likely to move?
If yes, you can apply edge detection algorithm first (e.g. calculate gradient with Sobel or Prewitt transform, apply some threshold), then compare edges on the first image to edges on the second.
* Is there noise in the image?
All sensors pollute the image with some amount of noise. Low-cost sensors have more noise. You may wish to apply some noise reduction before you compare images. Blur is the most simple (but not the best) approach here.
* What kind of changes do you want to notice?
This may affect the choice of norm to use for the difference between images.
Consider using Manhattan norm (the sum of the absolute values) or zero norm (the number of elements not equal to zero) to measure how much the image has changed. The former will tell you how much the image is off, the latter will tell only how many pixels differ.
Example
-------
I assume your images are well-aligned, the same size and shape, possibly with different exposure. For simplicity, I convert them to grayscale even if they are color (RGB) images.
You will need these imports:
```
import sys
from scipy.misc import imread
from scipy.linalg import norm
from scipy import sum, average
```
Main function, read two images, convert to grayscale, compare and print results:
```
def main():
file1, file2 = sys.argv[1:1+2]
# read images as 2D arrays (convert to grayscale for simplicity)
img1 = to_grayscale(imread(file1).astype(float))
img2 = to_grayscale(imread(file2).astype(float))
# compare
n_m, n_0 = compare_images(img1, img2)
print "Manhattan norm:", n_m, "/ per pixel:", n_m/img1.size
print "Zero norm:", n_0, "/ per pixel:", n_0*1.0/img1.size
```
How to compare. `img1` and `img2` are 2D SciPy arrays here:
```
def compare_images(img1, img2):
# normalize to compensate for exposure difference, this may be unnecessary
# consider disabling it
img1 = normalize(img1)
img2 = normalize(img2)
# calculate the difference and its norms
diff = img1 - img2 # elementwise for scipy arrays
m_norm = sum(abs(diff)) # Manhattan norm
z_norm = norm(diff.ravel(), 0) # Zero norm
return (m_norm, z_norm)
```
If the file is a color image, `imread` returns a 3D array, average RGB channels (the last array axis) to obtain intensity. No need to do it for grayscale images (e.g. `.pgm`):
```
def to_grayscale(arr):
"If arr is a color image (3D array), convert it to grayscale (2D array)."
if len(arr.shape) == 3:
return average(arr, -1) # average over the last axis (color channels)
else:
return arr
```
Normalization is trivial, you may choose to normalize to [0,1] instead of [0,255]. `arr` is a SciPy array here, so all operations are element-wise:
```
def normalize(arr):
rng = arr.max()-arr.min()
amin = arr.min()
return (arr-amin)*255/rng
```
Run the `main` function:
```
if __name__ == "__main__":
main()
```
Now you can put this all in a script and run against two images. If we compare image to itself, there is no difference:
```
$ python compare.py one.jpg one.jpg
Manhattan norm: 0.0 / per pixel: 0.0
Zero norm: 0 / per pixel: 0.0
```
If we blur the image and compare to the original, there is some difference:
```
$ python compare.py one.jpg one-blurred.jpg
Manhattan norm: 92605183.67 / per pixel: 13.4210411116
Zero norm: 6900000 / per pixel: 1.0
```
P.S. Entire [compare.py](http://gist.github.com/626356) script.
Update: relevant techniques
---------------------------
As the question is about a video sequence, where frames are likely to be almost the same, and you look for something unusual, I'd like to mention some alternative approaches which may be relevant:
* background subtraction and segmentation (to detect foreground objects)
* sparse optical flow (to detect motion)
* comparing histograms or some other statistics instead of images
I strongly recommend taking a look at “Learning OpenCV” book, Chapters 9 (Image parts and segmentation) and 10 (Tracking and motion). The former teaches to use Background subtraction method, the latter gives some info on optical flow methods. All methods are implemented in OpenCV library. If you use Python, I suggest to use OpenCV ≥ 2.3, and its `cv2` Python module.
The most simple version of the background subtraction:
* learn the average value μ and standard deviation σ for every pixel of the background
* compare current pixel values to the range of (μ-2σ,μ+2σ) or (μ-σ,μ+σ)
More advanced versions make take into account time series for every pixel and handle non-static scenes (like moving trees or grass).
The idea of optical flow is to take two or more frames, and assign velocity vector to every pixel (dense optical flow) or to some of them (sparse optical flow). To estimate sparse optical flow, you may use [Lucas-Kanade method](http://en.wikipedia.org/wiki/Lucas%E2%80%93Kanade_method) (it is also implemented in OpenCV). Obviously, if there is a lot of flow (high average over max values of the velocity field), then something is moving in the frame, and subsequent images are more different.
Comparing histograms may help to detect sudden changes between consecutive frames. This approach was used in [Courbon et al, 2010](http://www.sciencedirect.com/science/article/pii/S0967066110000808):
>
> *Similarity of consecutive frames.* The distance between two consecutive frames is measured. If it is too high, it means that the second frame is corrupted and thus the image is eliminated. The [Kullback–Leibler distance](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence), or mutual entropy, on the histograms of the two frames:
>
>
> 
>
>
> where *p* and *q* are the histograms of the frames is used. The threshold is fixed on 0.2.
>
>
>
|
189,976 |
<p>This is more of a design question. </p>
<p>I am building a tool that displays business objects in various ways (ie Tree Nodes, List View Items, Combo Boxes, Text Fields, etc). Anytime the user changes any of one of them, an event is raised that signals that that business object has been changed or the collection that it belongs to has been changed. Since this business object, or the collection that it might belong to, may be displayed in more than one place, each of those UI elements needs to be updated to reflect this change. Is there an elegant solution to having each type of UI element update correctly in the event of a change?</p>
<p>I have a few ideas of how this can be done, but I'd like to see if anyone has had this problem and was happy with their solution. This is a C# WinForm, but a solution can be in any language.</p>
<p>My current thoughts on the problem and a possible solution:</p>
<p>It gets more complicated when you want to clean up event bindings (ie businessObject.Changed -= ObjectChanged) when your business objects become part of a TreeNodeCollection/ListViewITemCollection/ComboBoxItemCollection and Clear() is called on the collection. </p>
<p>What about a "Service", where each object and its ui element can register itself with, where the business object's events can be listened for in one location, and each UI element would be updated when events are raised? When all UI elements have unregistered themselves, then the subscription to that object's event is removed. </p>
<p>The problem with this solution is that every control will have to be responsible for registering the UI component and the object on every creation - which can get messy.</p>
<p>Your thoughts?</p>
|
[
{
"answer_id": 189991,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>Use a messaging system. Create a delegate like this:</p>\n\n<pre><code>public delegate void ObjectRefresh(BusinessObject obj);\n</code></pre>\n\n<p>Then, in your BusinessObject class:</p>\n\n<pre><code>public event ObjectRefresh;\n</code></pre>\n\n<p>And when a property is changed:</p>\n\n<pre><code>if (ObjectRefresh)\n ObjectRefresh(this);\n</code></pre>\n\n<p>And on all of your uis:</p>\n\n<pre><code>BusinessObject obj = GetBusinessObject();\nobj.ObjectRefresh += this.ObjectRefresh;\n...\nprivate void ObjectRefresh(BusinessObject obj)\n{\n // update UI\n}\n</code></pre>\n\n<p>:)</p>\n"
},
{
"answer_id": 189994,
"author": "boxoft",
"author_id": 23773,
"author_profile": "https://Stackoverflow.com/users/23773",
"pm_score": 2,
"selected": false,
"text": "<p>You may want to try the observer pattern. <a href=\"http://en.wikipedia.org/wiki/Observer_pattern\" rel=\"nofollow noreferrer\">http://en.wikipedia.org/wiki/Observer_pattern</a></p>\n"
},
{
"answer_id": 190001,
"author": "JTew",
"author_id": 25372,
"author_profile": "https://Stackoverflow.com/users/25372",
"pm_score": 0,
"selected": false,
"text": "<p>Have a look at Bindable Linq ... a solution to this problem by Paul Stovell.</p>\n\n<p><a href=\"http://www.codeplex.com/bindablelinq\" rel=\"nofollow noreferrer\">http://www.codeplex.com/bindablelinq</a></p>\n\n<p>If it doesn't provide a solution to your problem it would give you some insite into writing this yourself.</p>\n\n<p>Have a read through his blog as well.</p>\n\n<p><a href=\"http://www.paulstovell.com/blog/\" rel=\"nofollow noreferrer\">http://www.paulstovell.com/blog/</a></p>\n"
},
{
"answer_id": 190047,
"author": "Steven A. Lowe",
"author_id": 9345,
"author_profile": "https://Stackoverflow.com/users/9345",
"pm_score": 0,
"selected": false,
"text": "<p>make sure you really need this, i.e. that it isn't happening already. For example, if your GUI objects are bound to datasets and your business objects merge changes into dataset, the dataset will automatically notify the gui objects that the data has changed; a database gui object will update itself automatically</p>\n\n<p>if not, then the Observer pattern as mentioned above is what you want</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189976",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
This is more of a design question.
I am building a tool that displays business objects in various ways (ie Tree Nodes, List View Items, Combo Boxes, Text Fields, etc). Anytime the user changes any of one of them, an event is raised that signals that that business object has been changed or the collection that it belongs to has been changed. Since this business object, or the collection that it might belong to, may be displayed in more than one place, each of those UI elements needs to be updated to reflect this change. Is there an elegant solution to having each type of UI element update correctly in the event of a change?
I have a few ideas of how this can be done, but I'd like to see if anyone has had this problem and was happy with their solution. This is a C# WinForm, but a solution can be in any language.
My current thoughts on the problem and a possible solution:
It gets more complicated when you want to clean up event bindings (ie businessObject.Changed -= ObjectChanged) when your business objects become part of a TreeNodeCollection/ListViewITemCollection/ComboBoxItemCollection and Clear() is called on the collection.
What about a "Service", where each object and its ui element can register itself with, where the business object's events can be listened for in one location, and each UI element would be updated when events are raised? When all UI elements have unregistered themselves, then the subscription to that object's event is removed.
The problem with this solution is that every control will have to be responsible for registering the UI component and the object on every creation - which can get messy.
Your thoughts?
|
Use a messaging system. Create a delegate like this:
```
public delegate void ObjectRefresh(BusinessObject obj);
```
Then, in your BusinessObject class:
```
public event ObjectRefresh;
```
And when a property is changed:
```
if (ObjectRefresh)
ObjectRefresh(this);
```
And on all of your uis:
```
BusinessObject obj = GetBusinessObject();
obj.ObjectRefresh += this.ObjectRefresh;
...
private void ObjectRefresh(BusinessObject obj)
{
// update UI
}
```
:)
|
189,988 |
<p>An idiom commonly used in OO languages like Python and Ruby is instantiating an object and chaining methods that return a reference to the object itself, such as:</p>
<pre><code>s = User.new.login.get_db_data.get_session_data
</code></pre>
<p>In PHP, it is possible to replicate this behavior like so:</p>
<pre><code>$u = new User();
$s = $u->login()->get_db_data()->get_session_data();
</code></pre>
<p>Attempting the following results in <code>syntax error, unexpected T_OBJECT_OPERATOR</code>:</p>
<pre><code>$s = new User()->login()->get_db_data()->get_session_data();
</code></pre>
<p>It seems like this could be accomplished using static methods, which is probably what I'll end up doing, but I wanted to check the lazyweb: <strong>Is there actually a clean, simple way to instantiate PHP classes "inline" (as shown in the above snippet)</strong> for this purpose?</p>
<p>If I do decide to use static methods, <strong>is it too sorcerous to have a class's static method return an instantiation of the class itself</strong>? (Effectively writing my own constructor-that-isn't-a-constructor?) It feels kind of dirty, but if there aren't too many scary side effects, I might just do it.</p>
<p>I guess I could also pre-instantiate a UserFactory with a get_user() method, but I'm curious about solutions to what I asked above.</p>
|
[
{
"answer_id": 190014,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<pre><code><?php\n\n class User\n {\n function __construct()\n {\n }\n\n function Login()\n {\n return $this;\n }\n\n function GetDbData()\n {\n return $this;\n }\n\n function GetSession()\n {\n return array(\"hello\" => \"world\");\n }\n }\n\n function Create($name)\n {\n return new $name();\n }\n\n $s = Create(\"User\")->Login()->GetDbData()->GetSession();\n\n var_dump($s);\n?>\n</code></pre>\n\n<p>This is a possible solution :) Of course, you should choose a better name for the function...</p>\n\n<p>Or if you don't mind a little overhead:</p>\n\n<pre><code><?php\n\n class User\n {\n function __construct($test)\n {\n echo $test;\n }\n...\n }\n\n function CreateArgs($name)\n {\n $ref = new ReflectionClass($name);\n return $ref->newInstanceArgs(array_slice(func_get_args(), 1));\n }\n\n $s = CreateArgs(\"User\", \"hi\")->Login()->GetDbData()->GetSession();\n\n var_dump($s);\n?>\n</code></pre>\n"
},
{
"answer_id": 190027,
"author": "dcousineau",
"author_id": 20265,
"author_profile": "https://Stackoverflow.com/users/20265",
"pm_score": 2,
"selected": false,
"text": "<p>The only way you can get something similar is with a factory or singleton static method. For example:</p>\n\n<pre><code>class User\n{\n //...\n /**\n *\n * @return User\n */\n public static function instance()\n {\n $args = func_get_args();\n $class = new ReflectionClass(__CLASS__);\n return $class->newInstanceArgs($args);\n }\n //...\n}\n</code></pre>\n\n<p>That uses the PHP5 reflection API to create a new instance (using any args sent to ::instance()) and returns it allowing you to do the chaining:</p>\n\n<pre><code>$s = User::instance()->login()->get_db_data()->get_session_data();\n</code></pre>\n\n<p>By the way that code is flexible enough that the only thing you'll have to change when copying that static method is the PHPDoc comment's @return.</p>\n\n<hr>\n\n<p>If you want to prematurely optimize your code like our friend Nelson you can replace the contents of User::instance() with:</p>\n\n<pre><code>return new self();\n</code></pre>\n"
},
{
"answer_id": 190052,
"author": "Toby Hede",
"author_id": 14971,
"author_profile": "https://Stackoverflow.com/users/14971",
"pm_score": 5,
"selected": true,
"text": "<p>All of these proposed solutions complicate your code in order to bend PHP to accomplish some syntactic nicety. Wanting PHP to be something it's not (like good) is the path to madness.</p>\n\n<p>I would just use:</p>\n\n<pre><code>$u = new User();\n$s = $u->login()->get_db_data()->get_session_data();\n</code></pre>\n\n<p>It is clear, relatively concise and involves no <em>black magic</em> that can introduce errors.</p>\n\n<p>And of course, you could always move to Ruby or Python. It will change your life. </p>\n\n<ul>\n<li>And yeah, I am harsh on PHP. I use it every day. Been using it for years. The reality is that it has <strong>accreted</strong>, rather than been designed and it shows. </li>\n</ul>\n"
},
{
"answer_id": 1429788,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>There's no reason to stick together a hack (to work around the syntax issue) and the object creation code itself. </p>\n\n<p>Since a new-expression cannot be used as the left member of your object operator, but a function call expression can, you only need to wrap your object in a call to a function that returns its own argument:</p>\n\n<pre><code>function hack($obj) { return $obj; }\n\n$mail = hack(new Zend_Mail())\n -> setBodyText('This is the text of the mail.')\n -> setFrom('[email protected]', 'Some Sender')\n -> addTo('[email protected]', 'Some Recipient')\n -> setSubject('TestSubject');\n</code></pre>\n"
},
{
"answer_id": 22400374,
"author": "igaster",
"author_id": 1680535,
"author_profile": "https://Stackoverflow.com/users/1680535",
"pm_score": 3,
"selected": false,
"text": "<p>A simple shortcut to</p>\n\n<pre><code>$Obj = new ClassName();\n$result = $Obj->memberFunction();\n</code></pre>\n\n<p>is </p>\n\n<pre><code>$result = (new ClassName())->memberFunction();\n</code></pre>\n"
},
{
"answer_id": 31662890,
"author": "PHPDave",
"author_id": 3712596,
"author_profile": "https://Stackoverflow.com/users/3712596",
"pm_score": 1,
"selected": false,
"text": "<pre><code><?php \n//PHP 5.4+ class member access on instantiation support.\n$s = (new User())->login()->get_db_data()->get_session_data();\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189988",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/16034/"
] |
An idiom commonly used in OO languages like Python and Ruby is instantiating an object and chaining methods that return a reference to the object itself, such as:
```
s = User.new.login.get_db_data.get_session_data
```
In PHP, it is possible to replicate this behavior like so:
```
$u = new User();
$s = $u->login()->get_db_data()->get_session_data();
```
Attempting the following results in `syntax error, unexpected T_OBJECT_OPERATOR`:
```
$s = new User()->login()->get_db_data()->get_session_data();
```
It seems like this could be accomplished using static methods, which is probably what I'll end up doing, but I wanted to check the lazyweb: **Is there actually a clean, simple way to instantiate PHP classes "inline" (as shown in the above snippet)** for this purpose?
If I do decide to use static methods, **is it too sorcerous to have a class's static method return an instantiation of the class itself**? (Effectively writing my own constructor-that-isn't-a-constructor?) It feels kind of dirty, but if there aren't too many scary side effects, I might just do it.
I guess I could also pre-instantiate a UserFactory with a get\_user() method, but I'm curious about solutions to what I asked above.
|
All of these proposed solutions complicate your code in order to bend PHP to accomplish some syntactic nicety. Wanting PHP to be something it's not (like good) is the path to madness.
I would just use:
```
$u = new User();
$s = $u->login()->get_db_data()->get_session_data();
```
It is clear, relatively concise and involves no *black magic* that can introduce errors.
And of course, you could always move to Ruby or Python. It will change your life.
* And yeah, I am harsh on PHP. I use it every day. Been using it for years. The reality is that it has **accreted**, rather than been designed and it shows.
|
189,993 |
<p>When I use ApacheBench to test https, the error is returned, "ssl handshake failed".</p>
<p>How can I use ApacheBench to test https?</p>
|
[
{
"answer_id": 4149548,
"author": "naugtur",
"author_id": 173077,
"author_profile": "https://Stackoverflow.com/users/173077",
"pm_score": 3,
"selected": false,
"text": "<p>ApacheBench doesn't seem to be capable of ignoring certificate problems (at least some of them) so I wrote this script:</p>\n\n<pre><code>#!/bin/bash\nK=200; \nHTTPSA='https://192.168.1.103:443/' \ndate +%M-%S-%N>wgetres.txt\nfor (( c=1; c<=$K; c++ ))\ndo\n wget --no-check-certificate --secure-protocol=SSLv3 --spider $HTTPSA\ndone\ndate +%M-%S-%N>>wgetres.txt\n</code></pre>\n\n<p>It's not as precise as AB, but gives the idea. Does well in comparison tests.</p>\n"
},
{
"answer_id": 12224732,
"author": "comb",
"author_id": 786984,
"author_profile": "https://Stackoverflow.com/users/786984",
"pm_score": 3,
"selected": false,
"text": "<p><a href=\"https://github.com/httperf/httperf\" rel=\"nofollow noreferrer\">httperf</a> is also single threaded, but as of today (Aug 31, 2012), it correctly handles SSL and even has a some useful additional features surrounding SSL:</p>\n\n<blockquote>\n<pre><code> --ssl Specifies that all communication between httperf and the server\n should utilize the Secure Sockets Layer (SSL) protocol. This\n option is available only if httperf was compiled with SSL supâ€\n port enabled.\n\n --ssl-ciphers=L\n This option is only meaningful if SSL is in use (see --ssl\n option). This option specifies the list L of cipher suites that\n httperf may use in negotiating a secure connection with the\n server. If the list contains more than one cipher suite, the\n ciphers must be separated by a colon. If the server does not\n accept any of the listed cipher suites, the connection estabâ€\n lishment will fail and httperf will exit immediately. If this\n option is not specified when the --ssl option is present then\n httperf will use all of the SSLv3 cipher suites provided by the\n underlying SSL library.\n\n --ssl-no-reuse\n This option is only meaningful if SSL and sessions are in use\n (see --ssl, --wsess, --wsesslog). When an SSL connection is\n established the client receives a session identifier (session\n id) from the server. On subsequent SSL connections, the client\n normally reuses this session id in order to avoid the expense of\n repeating the (slow) SSL handshake to establish a new SSL sesâ€\n sion and obtain another session id (even if the client attempts\n to re-use a session id, the server may force the client to reneâ€\n gotiate a session). By default httperf reuses the session id\n across all connections in a session. If the --ssl-no-reuse\n option is in effect, then httperf will not reuse the session id,\n and the entire SSL handshake will be performed for each new conâ€\n nection in a session.\n</code></pre>\n</blockquote>\n"
},
{
"answer_id": 63011579,
"author": "Ashok Kumar",
"author_id": 7895559,
"author_profile": "https://Stackoverflow.com/users/7895559",
"pm_score": 0,
"selected": false,
"text": "<p>I ran into this problem recently. As a work around I used the loadtest npm package, which has similar options as ab:</p>\n<p><a href=\"https://www.npmjs.com/package/loadtest\" rel=\"nofollow noreferrer\">https://www.npmjs.com/package/loadtest</a></p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/189993",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
When I use ApacheBench to test https, the error is returned, "ssl handshake failed".
How can I use ApacheBench to test https?
|
ApacheBench doesn't seem to be capable of ignoring certificate problems (at least some of them) so I wrote this script:
```
#!/bin/bash
K=200;
HTTPSA='https://192.168.1.103:443/'
date +%M-%S-%N>wgetres.txt
for (( c=1; c<=$K; c++ ))
do
wget --no-check-certificate --secure-protocol=SSLv3 --spider $HTTPSA
done
date +%M-%S-%N>>wgetres.txt
```
It's not as precise as AB, but gives the idea. Does well in comparison tests.
|
190,007 |
<p>When developing Java applications, I often override Object methods (usually equals and hashCode). I would like some way to systematically check that I'm adhering to the contract for Object methods for every one of my classes. For example, I want tests that assert that for equal objects, the hash code is also equal. I'm using the JUnit test framework, so preferably I'd like some JUnit solution where I can automatically generate these tests, or some test case that can somehow visit all of my classes and make sure that the contract is upheld.</p>
<p>I'm using JDK6 and JUnit 4.4.</p>
|
[
{
"answer_id": 190112,
"author": "VonC",
"author_id": 6309,
"author_profile": "https://Stackoverflow.com/users/6309",
"pm_score": 1,
"selected": false,
"text": "<p>Just a some initial thoughts on that question (which may explain why there are still no answer after a full hour!? ;)</p>\n\n<p>There seems to be two parts when it comes to implement a solution to the question:</p>\n\n<p>1/ retrieve every classes of my own. Easy, you give a jar name, the Junit test initialization method would:</p>\n\n<ul>\n<li>check if that jar is in the JUnit execution classpath</li>\n<li>read and load every classes in it</li>\n<li>memorizes only those for which equals() and hash() has been declared and redefined (through Reflection)</li>\n</ul>\n\n<p>2/ test every objects<br>\n... and therein lies the catch: you have to <strong>instantiate</strong> those objects, that is create two instances, and use them for equals() tests.</p>\n\n<p>That means if your constructors are taken arguments, you have to consider,</p>\n\n<ul>\n<li>for primitive types arguments (int, boolean, float, ...) or String, every combinations of limit values (for a String, \"xxx\", \"\", null; fonr int, 0, -x, +x, -Integer.MIN, +Integer.MAX, ... and so on)</li>\n<li>for non-primitive types, build an instance of those to be passed to the constructor of the object to test (meaning you recursively have to consider the constructor parameters of that parameter: primitive types or not)</li>\n</ul>\n\n<p>Finally, not every parameters automatically created for those constructor would make sense in a functional way, meaning some of those values will fail to build the instance because of an Assert: that must be detected.</p>\n\n<p>Yet it seems to be possible (you can make it a <strong><a href=\"https://stackoverflow.com/questions/172184/are-you-elite-coder-enough-to-take-a-code-challenge\">code-challenge</a></strong> if you want), but I want first let other StackOverflow readers respond to this issue, as they may see a far simpler solution that I am.</p>\n\n<hr>\n\n<p>To avoid combinations problem and to keep test <em><strong>relevant</strong></em> testing values close to the actual code itself, I would recommend the definition of an dedicated annotation, with a String representing valid values for constructors. There would be located right above the equals() overridden method of one of your object.</p>\n\n<p>Those annotation values would then be read, and the instances created from those would be combined for testing equals(). That would keep the <a href=\"http://en.wikipedia.org/wiki/Combination\" rel=\"nofollow noreferrer\">number of combinations</a> down enough</p>\n\n<p>Side-node: a generic JUnit test case would of course check that, for each equals() to tests, there is:</p>\n\n<ul>\n<li>some annotations as described above (unless there is only default constructor available)</li>\n<li>a corresponding hash() method also overridden (if not, if would throw an assert exception and fail on that class)</li>\n</ul>\n"
},
{
"answer_id": 190123,
"author": "Julie",
"author_id": 8217,
"author_profile": "https://Stackoverflow.com/users/8217",
"pm_score": 0,
"selected": false,
"text": "<p>I think VonC's on the right track, but I would even settle for something less sophisticated, such as a parameterized test that takes in the .class object (for which the Object methods are being tested), followed by a variable number of constructor args. Then, you'd have to use reflection to find the constructor that matches the types for the passed-in arguments, and call the constructor. This test would assume that the parameters being passed into it would create a valid instance of the object.</p>\n\n<p>The downside to this solution is that you have to \"register\" each class you want to test with this test class, and you have to make sure that valid input is given to the constructor, which would not always be easy. In that light, I'm on the fence as to whether or not this would be more or less work than manually writing all the tests for each class anyway.</p>\n\n<p>Vote up if you think this could work...leave a comment if you want me to flush it out more (if it turns out to be a feasible solution, I may just do this anyway)</p>\n"
},
{
"answer_id": 190293,
"author": "gizmo",
"author_id": 9396,
"author_profile": "https://Stackoverflow.com/users/9396",
"pm_score": 0,
"selected": false,
"text": "<p>This problem doesn't have \"easy\" solution unless you're putting strong constraints on your classes. </p>\n\n<p>For example, if you're using several constructors for a given class, how can you ensure that all your parameters are well taken into account in your equals/hash methods? How about defaults values? These are things that, unfortunately, cannot be automated blindly.</p>\n"
},
{
"answer_id": 190989,
"author": "alex",
"author_id": 26787,
"author_profile": "https://Stackoverflow.com/users/26787",
"pm_score": 2,
"selected": false,
"text": "<pre>\n public static void checkObjectIdentity(Object a1, Object a2, Object b1) {\n assertEquals(a1, a2);\n assertEquals(a2, a1);\n assertNotSame(a1, a2);\n assertEquals(a1.hashCode(), a2.hashCode());\n assertFalse(a1.equals(b1));\n assertFalse(a2.equals(b1));\n assertFalse(b1.equals(a1));\n assertFalse(b1.equals(a2));\n }\n</pre>\n\n<p>Usage:</p>\n\n<pre>\n checkObjectIdentity(new Integer(3), new Integer(3), new Integer(4));\n</pre>\n\n<p>Can't think of anything better. Add new calls to checkObjectIdentity when you find a bug.</p>\n"
},
{
"answer_id": 191722,
"author": "VonC",
"author_id": 6309,
"author_profile": "https://Stackoverflow.com/users/6309",
"pm_score": 0,
"selected": false,
"text": "<p>[community post here, no karma involved ;) ]</p>\n\n<p>Here is another <strong><a href=\"https://stackoverflow.com/questions/172184/are-you-elite-coder-enough-to-take-a-code-challenge\">code-challenge</a></strong> for you:</p>\n\n<p><strong><em>One</em></strong> java class, implementing a JUnit test case, with a main method able to launch JUnit on itself!</p>\n\n<p>This class will also:</p>\n\n<ul>\n<li>override hash() and equals()</li>\n<li>define a few attributes (with primitive types)</li>\n<li>define a default constructor but also some constructors with various combinations of parameters</li>\n<li>define an annotation able to enumerate \"interesting\" values to pass to those constructor</li>\n<li>annotate equals() with those \"interesting\" values</li>\n</ul>\n\n<p>The test method takes a class name parameter (here: it will be itself), check if the class with that name has an equals() overridden method with \"interesting values\" annotations.<br>\nIf it does, it will builds the appropriate instances (of itself) based on the annotations, and test equals()</p>\n\n<p>This is a self-contained test class, which defines a mechanism able to be generalized to any class with an annotated overridden equals() function.</p>\n\n<p>Please Use JDK6 and JUnit4.4</p>\n\n<p>That class should be copied-paste in the appropriate package of an empty java project... and just run ;)</p>\n\n<hr>\n\n<p>To add some more thought, in response to Nicolas (see comments):</p>\n\n<ul>\n<li>yes the data needed for test are within the class candidate to be tested (that is, the one overriding equals and helping any 'automatic tester' to build appropriate instances)</li>\n<li>I do not see that <em>exactly</em> as \"testing logic\", but as useful comments on what is supposed to do the equals (and incidentally as data to be exploited by the aforementioned tester ;) )</li>\n</ul>\n\n<p>Should annotations representing potential testing data never ever be in the class itself ?... Hey that could be a great question to ask :)</p>\n"
},
{
"answer_id": 191937,
"author": "Uri",
"author_id": 23072,
"author_profile": "https://Stackoverflow.com/users/23072",
"pm_score": 0,
"selected": false,
"text": "<p>Maybe I'm misunderstanding the question (and being too CS), but it doesn't sound like the problem you're describing is decidable in the general case.</p>\n\n<p>In other words, the only way a unit test can assure you that an overriding method works the same on all inputs as the overridden method would be to try it on all the inputs; in the case of equals, that would mean all object states.</p>\n\n<p>I am not sure if any current test framework will automatically trim down and abstract the possibilities for you.</p>\n"
},
{
"answer_id": 216508,
"author": "VonC",
"author_id": 6309,
"author_profile": "https://Stackoverflow.com/users/6309",
"pm_score": 0,
"selected": false,
"text": "<p>I have a first rough implementation, for equals testing with Constructor using only primitive parameters here. Just copy-paste it in test.MyClass.java file and run it.</p>\n\n<p>Warning: 1720 lines of code (0 errors in findbugs, 0 in \"modified\" checkstyle, cyclomatic complexity under 10 for all functions).</p>\n\n<p>See all the code at: <a href=\"http://snippets.dzone.com/posts/show/6288\" rel=\"nofollow noreferrer\">Auto-test for equals function in java classes through annotations</a></p>\n"
},
{
"answer_id": 13152063,
"author": "Jeff Bowman",
"author_id": 1426891,
"author_profile": "https://Stackoverflow.com/users/1426891",
"pm_score": 0,
"selected": false,
"text": "<p>New answer for an old question, but in May of 2011 <a href=\"https://code.google.com/p/guava-libraries/\" rel=\"nofollow\">Guava</a> (formerly Google Collections) released a class that removes a lot of the boilerplate, called <a href=\"https://code.google.com/p/guava-libraries/source/browse/guava-testlib/src/com/google/common/testing/EqualsTester.java\" rel=\"nofollow\"><code>EqualsTester</code></a>. You still have to create your own instances but it takes care of comparing each object to itself, to null, to every object in the equality group, to every object in every other equality group, and to a secret instance that should match nothing. It also checks that <code>a.equals(b)</code> implies <code>a.hashCode() == b.hashCode()</code> across all those combinations.</p>\n\n<p>Example from Javadoc:</p>\n\n<pre><code>new EqualsTester()\n .addEqualityGroup(\"hello\", \"h\" + \"ello\")\n .addEqualityGroup(\"world\", \"wor\" + \"ld\")\n .addEqualityGroup(2, 1 + 1)\n .testEquals();\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190007",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8217/"
] |
When developing Java applications, I often override Object methods (usually equals and hashCode). I would like some way to systematically check that I'm adhering to the contract for Object methods for every one of my classes. For example, I want tests that assert that for equal objects, the hash code is also equal. I'm using the JUnit test framework, so preferably I'd like some JUnit solution where I can automatically generate these tests, or some test case that can somehow visit all of my classes and make sure that the contract is upheld.
I'm using JDK6 and JUnit 4.4.
|
```
public static void checkObjectIdentity(Object a1, Object a2, Object b1) {
assertEquals(a1, a2);
assertEquals(a2, a1);
assertNotSame(a1, a2);
assertEquals(a1.hashCode(), a2.hashCode());
assertFalse(a1.equals(b1));
assertFalse(a2.equals(b1));
assertFalse(b1.equals(a1));
assertFalse(b1.equals(a2));
}
```
Usage:
```
checkObjectIdentity(new Integer(3), new Integer(3), new Integer(4));
```
Can't think of anything better. Add new calls to checkObjectIdentity when you find a bug.
|
190,045 |
<p>I have a large int[] array and a much smaller int[] array. I want to fill up the large array with values from the small array, by repeat copying the small array into the large array until it is full (so that large[0] = large[13] = large[26] ... = small[0] etc.). I already have a simple method:</p>
<pre><code>int iSource = 0;
for (int i = 0; i < destArray.Length; i++)
{
if (iSource >= sourceArray.Length)
{
iSource = 0; // reset if at end of source
}
destArray[i] = sourceArray[iSource++];
}
</code></pre>
<p>But I need something more elegant, and hopefully faster.</p>
|
[
{
"answer_id": 190017,
"author": "C. K. Young",
"author_id": 13,
"author_profile": "https://Stackoverflow.com/users/13",
"pm_score": 10,
"selected": true,
"text": "<p>Some threads do background tasks, like sending keepalive packets, or performing periodic garbage collection, or whatever. These are only useful when the main program is running, and it's okay to kill them off once the other, non-daemon, threads have exited.</p>\n\n<p>Without daemon threads, you'd have to keep track of them, and tell them to exit, before your program can completely quit. By setting them as daemon threads, you can let them run and forget about them, and when your program quits, any daemon threads are killed automatically.</p>\n"
},
{
"answer_id": 190033,
"author": "John Fouhy",
"author_id": 15154,
"author_profile": "https://Stackoverflow.com/users/15154",
"pm_score": 5,
"selected": false,
"text": "<p>Let's say you're making some kind of dashboard widget. As part of this, you want it to display the unread message count in your email box. So you make a little thread that will:</p>\n\n<ol>\n<li>Connect to the mail server and ask how many unread messages you have.</li>\n<li>Signal the GUI with the updated count.</li>\n<li>Sleep for a little while.</li>\n</ol>\n\n<p>When your widget starts up, it would create this thread, designate it a daemon, and start it. Because it's a daemon, you don't have to think about it; when your widget exits, the thread will stop automatically.</p>\n"
},
{
"answer_id": 190131,
"author": "Jonathan",
"author_id": 14850,
"author_profile": "https://Stackoverflow.com/users/14850",
"pm_score": 4,
"selected": false,
"text": "<p>A simpler way to think about it, perhaps: when main returns, your process will not exit if there are non-daemon threads still running.</p>\n\n<p>A bit of advice: Clean shutdown is easy to get wrong when threads and synchronization are involved - if you can avoid it, do so. Use daemon threads whenever possible.</p>\n"
},
{
"answer_id": 583996,
"author": "Joe Shaw",
"author_id": 156,
"author_profile": "https://Stackoverflow.com/users/156",
"pm_score": 4,
"selected": false,
"text": "<p>Other posters gave some examples for situations in which you'd use daemon threads. My recommendation, however, is never to use them.</p>\n\n<p>It's not because they're not useful, but because there are some bad side effects you can experience if you use them. Daemon threads can still execute after the Python runtime starts tearing down things in the main thread, causing some pretty bizarre exceptions.</p>\n\n<p>More info here:</p>\n\n<p><a href=\"https://joeshaw.org/python-daemon-threads-considered-harmful/\" rel=\"nofollow noreferrer\">https://joeshaw.org/python-daemon-threads-considered-harmful/</a></p>\n\n<p><a href=\"https://mail.python.org/pipermail/python-list/2005-February/343699.html\" rel=\"nofollow noreferrer\">https://mail.python.org/pipermail/python-list/2005-February/343697.html</a></p>\n\n<p>Strictly speaking you never need them, it just makes implementation easier in some cases.</p>\n"
},
{
"answer_id": 7044487,
"author": "Bass",
"author_id": 892270,
"author_profile": "https://Stackoverflow.com/users/892270",
"pm_score": 4,
"selected": false,
"text": "<p>Quoting Chris: \"... when your program quits, any daemon threads are killed automatically.\". I think that sums it up. You should be careful when you use them as they abruptly terminate when main program executes to completion.</p>\n"
},
{
"answer_id": 39182331,
"author": "Amit",
"author_id": 2156678,
"author_profile": "https://Stackoverflow.com/users/2156678",
"pm_score": 4,
"selected": false,
"text": "<p>Chris already explained what daemon threads are, so let's talk about practical usage. Many thread pool implementations use daemon threads for task workers. Workers are threads which execute tasks from task queue. </p>\n\n<p>Worker needs to keep waiting for tasks in task queue indefinitely as they don't know when new task will appear. Thread which assigns tasks (say main thread) only knows when tasks are over. Main thread waits on task queue to get empty and then exits. If workers are user threads i.e. non-daemon, program won't terminate. It will keep waiting for these indefinitely running workers, even though workers aren't doing anything useful. Mark workers daemon threads, and main thread will take care of killing them as soon as it's done handling tasks. </p>\n"
},
{
"answer_id": 51340417,
"author": "truthadjustr",
"author_id": 2856202,
"author_profile": "https://Stackoverflow.com/users/2856202",
"pm_score": 3,
"selected": false,
"text": "<p>When your second thread is non-Daemon, your application's primary main thread cannot quit because its exit criteria is being tied to the exit also of non-Daemon thread(s). Threads cannot be forcibly killed in python, therefore your app will have to really wait for the non-Daemon thread(s) to exit. If this behavior is not what you want, then set your second thread as daemon so that it won't hold back your application from exiting. </p>\n"
},
{
"answer_id": 68556232,
"author": "Rohit",
"author_id": 6695608,
"author_profile": "https://Stackoverflow.com/users/6695608",
"pm_score": 4,
"selected": false,
"text": "<p>I will also add my few bits here, I think one of the reasons why daemon threads are confusing to most people(atleast they were to me) is because of the Unix context to the word <code>dameon</code>.</p>\n<p>In Unix terminology the word <code>daemon</code> refers to a process which once spawned; keeps running in the background and user can move on to do other stuff with the foreground process.</p>\n<p>In Python threading context, every thread upon creation runs in the background, whether it is <code>daemon</code> or <code>non-daemon</code>, the difference comes from the fact how these threads affect the main thread.</p>\n<p>When you start a <code>non-daemon</code> thread, it starts running in background and you can perform other stuff, however, your main thread will not exit until all such <code>non-daemon</code> threads have completed their execution, so in a way, your program or main thread is blocked.</p>\n<p>With <code>daemon</code> threads they still run in the background but with one key difference that they do not block the main thread.\nAs soon as the main thread completes its execution & the program exits, all the remaining <code>daemon</code> threads will be reaped. This makes them useful for operations which you want to perform in background but want these operations to exit automatically as soon as the main application exits.</p>\n<p>One point to keep note of is that you should be aware of what exactly you are doing in <code>daemon</code> threads, the fact they exit when main thread exits can give you unexpected surprises. One of the ways to gracefully clean up the <code>daemon</code> threads is to use the <a href=\"https://docs.python.org/3/library/threading.html#event-objects\" rel=\"noreferrer\">Threading Events</a> to set the event as an exit handler and check if the event is set inside the thread and then break from the thread function accordingly.</p>\n<p>Another thing that confused about <code>daemon</code> threads is the definition from python documentation.</p>\n<blockquote>\n<p>The significance of this flag is that the entire Python program exits\nwhen only daemon threads are left</p>\n</blockquote>\n<p>In simple words what this means is that if your program has both <code>daemon</code> and <code>non-daemon</code> threads the main program will be blocked and wait until all the <code>non-daemon</code> have exited, as soon as they exit main thread will exit as well. What this statement also implies but is not clear at first glance is that all <code>daemon</code> threads will be exited automatically once the main threads exits.</p>\n"
},
{
"answer_id": 73620481,
"author": "Sairam Parshi",
"author_id": 17749156,
"author_profile": "https://Stackoverflow.com/users/17749156",
"pm_score": 0,
"selected": false,
"text": "<p><strong>Create a Daemon thread when:</strong></p>\n<ul>\n<li>You want a low-priority thread</li>\n<li>Your Thread does background-specific tasks, and more importantly,</li>\n<li>When you want this thread to die as soon as all user threads accomplish their tasks.</li>\n</ul>\n<p><strong>Some Examples of Daemon Thread Services:</strong> Garbage collection in Java, Word count checker in MS Word, Auto-saver in medium, File downloads counter in a parallel file downloads application, etc.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190045",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14606/"
] |
I have a large int[] array and a much smaller int[] array. I want to fill up the large array with values from the small array, by repeat copying the small array into the large array until it is full (so that large[0] = large[13] = large[26] ... = small[0] etc.). I already have a simple method:
```
int iSource = 0;
for (int i = 0; i < destArray.Length; i++)
{
if (iSource >= sourceArray.Length)
{
iSource = 0; // reset if at end of source
}
destArray[i] = sourceArray[iSource++];
}
```
But I need something more elegant, and hopefully faster.
|
Some threads do background tasks, like sending keepalive packets, or performing periodic garbage collection, or whatever. These are only useful when the main program is running, and it's okay to kill them off once the other, non-daemon, threads have exited.
Without daemon threads, you'd have to keep track of them, and tell them to exit, before your program can completely quit. By setting them as daemon threads, you can let them run and forget about them, and when your program quits, any daemon threads are killed automatically.
|
190,049 |
<p>Given a table structure like this:</p>
<pre><code>CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL auto_increment,
`name` varchar(32) NOT NULL,
`username` varchar(16) NOT NULL,
`password` char(32) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `username` (`username`)
);
</code></pre>
<p>Is there any use in using the LIMIT keyword when searching by username, or is the DB smart enough to know that there can only possibly be one result, and therefore stop searching once it's found one?</p>
<pre><code>SELECT * FROM `user` WHERE `username` = 'nick';
-- vs --
SELECT * FROM `user` WHERE `username` = 'nick' LIMIT 1;
</code></pre>
<hr>
<p><em>Update:</em> Thanks for the answers, they've been enlightening. It seems like, even though it's unnecessary, putting <code>LIMIT 1</code> on the query doesn't hurt, and probably increases readability (you don't have to go looking into the DB schema to know that only one is going to be returned). Special shoutout for JR's answer - I didn't even know you could do that with indices.</p>
<p>Also, there's a similar question I've found <a href="https://stackoverflow.com/questions/34488/does-limiting-a-query-to-one-record-improve-performance">here</a>, which might also help.</p>
|
[
{
"answer_id": 190067,
"author": "Mike Thompson",
"author_id": 2754,
"author_profile": "https://Stackoverflow.com/users/2754",
"pm_score": 1,
"selected": false,
"text": "<p>The sql query optimizer should be smart enough to figure this out.</p>\n"
},
{
"answer_id": 190079,
"author": "Darryl Hein",
"author_id": 5441,
"author_profile": "https://Stackoverflow.com/users/5441",
"pm_score": 3,
"selected": true,
"text": "<p>I've always been told and read that you should include the <code>LIMIT</code> everytime you only want 1 result. This just tells the DB that it should stop so matter what. In your case, you're probably right it doesn't make a difference, but I think it's better just to always do than always deciding and leaving it out one time when you need it.</p>\n"
},
{
"answer_id": 190081,
"author": "JR Lawhorne",
"author_id": 22917,
"author_profile": "https://Stackoverflow.com/users/22917",
"pm_score": 2,
"selected": false,
"text": "<p>There is no need to use LIMIT.</p>\n\n<p>However... If you have a HUGE HUGE HUGE cardinality on the table (and you're worried about speed), you might consider not using the special UNIQUE constraint in the DB and manage it from your application. Then, you can specify an INDEX on only the first few characters of your username field. This will drastically reduce the size of your index, being sure the whole thing fits into RAM, and possibly speed up your queries.</p>\n\n<p>So, you might try:</p>\n\n<pre><code>CREATE TABLE `user` (\n `id` int(10) unsigned NOT NULL auto_increment,\n `name` varchar(32) NOT NULL,\n `username` varchar(16) NOT NULL,\n `password` char(32) NOT NULL,\n PRIMARY KEY (`id`),\n KEY `username` (`username`(4))\n);\n</code></pre>\n\n<p>as an alternative if your first attempt turns out to be too slow. This means, of course, you have to check for duplicate user names before inserting, but you'll probably have to do that anyway to tell the user they have to pick another user name.</p>\n\n<p>Depending on what DB server and engine you're using, it may also be faster to specify fixed width fields for all your strings also. Instead of <em>varchar</em>, use <em>char</em>.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190049",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/9021/"
] |
Given a table structure like this:
```
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL auto_increment,
`name` varchar(32) NOT NULL,
`username` varchar(16) NOT NULL,
`password` char(32) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `username` (`username`)
);
```
Is there any use in using the LIMIT keyword when searching by username, or is the DB smart enough to know that there can only possibly be one result, and therefore stop searching once it's found one?
```
SELECT * FROM `user` WHERE `username` = 'nick';
-- vs --
SELECT * FROM `user` WHERE `username` = 'nick' LIMIT 1;
```
---
*Update:* Thanks for the answers, they've been enlightening. It seems like, even though it's unnecessary, putting `LIMIT 1` on the query doesn't hurt, and probably increases readability (you don't have to go looking into the DB schema to know that only one is going to be returned). Special shoutout for JR's answer - I didn't even know you could do that with indices.
Also, there's a similar question I've found [here](https://stackoverflow.com/questions/34488/does-limiting-a-query-to-one-record-improve-performance), which might also help.
|
I've always been told and read that you should include the `LIMIT` everytime you only want 1 result. This just tells the DB that it should stop so matter what. In your case, you're probably right it doesn't make a difference, but I think it's better just to always do than always deciding and leaving it out one time when you need it.
|
190,054 |
<p>I've been refactoring my models and controllers in an effort to remove code duplication, and so far it seems to be all peachy creamy. Currently I've got a bit of code that is common to two of my controllers, like so:</p>
<pre><code>def process_filters
# Filter hash we're going to pass to the model
filter_to_use = {}
# To process filters, we first query the model to find out what filters
# we should be looking for, as the model knows what we can filter.
Iso.available_filters.each do |filter|
# We should have our array with our filter listing.
# Check the purchase order model for a description
filter_name = filter[0][:filter_name]
# Filters are stored in a session variable, this way filters survive
# page reloads, etc. First thing we do, is set the session if new filters
# have been set for the filter.
session_name = session_filter_name( filter_name )
if params[session_name]
if params[session_name] == 'All'
session[session_name] = nil
else
session[session_name] = params[session_name]
filter_to_use[filter_name] = params[session_name]
end
elsif session[session_name]
# If params aren't read, we still need to filter based off the users
# session
filter_to_use[filter_name] = session[session_name]
end
end
# Just using this variable for now until I can refactor the helper code
# so that this is passed in.
@current_filter_values = filter_to_use
filter_to_use[:page] = @current_page
@isos = Iso.find_filtered( filter_to_use )
if @isos.out_of_bounds?
filter_to_use[:page] = session[:previous_page] = @current_page = 1
@isos = Iso.find_filtered( filter_to_use )
end
end
</code></pre>
<p>Now this code is exactly the same as code in another controller, except for the model reference (in this case Iso). Is there someway I can make that model reference dynamic? </p>
<p>Basically I'ld like to replace the Iso references (including the @iso variable) to something based off controller.controller_name or similar.</p>
|
[
{
"answer_id": 190067,
"author": "Mike Thompson",
"author_id": 2754,
"author_profile": "https://Stackoverflow.com/users/2754",
"pm_score": 1,
"selected": false,
"text": "<p>The sql query optimizer should be smart enough to figure this out.</p>\n"
},
{
"answer_id": 190079,
"author": "Darryl Hein",
"author_id": 5441,
"author_profile": "https://Stackoverflow.com/users/5441",
"pm_score": 3,
"selected": true,
"text": "<p>I've always been told and read that you should include the <code>LIMIT</code> everytime you only want 1 result. This just tells the DB that it should stop so matter what. In your case, you're probably right it doesn't make a difference, but I think it's better just to always do than always deciding and leaving it out one time when you need it.</p>\n"
},
{
"answer_id": 190081,
"author": "JR Lawhorne",
"author_id": 22917,
"author_profile": "https://Stackoverflow.com/users/22917",
"pm_score": 2,
"selected": false,
"text": "<p>There is no need to use LIMIT.</p>\n\n<p>However... If you have a HUGE HUGE HUGE cardinality on the table (and you're worried about speed), you might consider not using the special UNIQUE constraint in the DB and manage it from your application. Then, you can specify an INDEX on only the first few characters of your username field. This will drastically reduce the size of your index, being sure the whole thing fits into RAM, and possibly speed up your queries.</p>\n\n<p>So, you might try:</p>\n\n<pre><code>CREATE TABLE `user` (\n `id` int(10) unsigned NOT NULL auto_increment,\n `name` varchar(32) NOT NULL,\n `username` varchar(16) NOT NULL,\n `password` char(32) NOT NULL,\n PRIMARY KEY (`id`),\n KEY `username` (`username`(4))\n);\n</code></pre>\n\n<p>as an alternative if your first attempt turns out to be too slow. This means, of course, you have to check for duplicate user names before inserting, but you'll probably have to do that anyway to tell the user they have to pick another user name.</p>\n\n<p>Depending on what DB server and engine you're using, it may also be faster to specify fixed width fields for all your strings also. Instead of <em>varchar</em>, use <em>char</em>.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190054",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/841/"
] |
I've been refactoring my models and controllers in an effort to remove code duplication, and so far it seems to be all peachy creamy. Currently I've got a bit of code that is common to two of my controllers, like so:
```
def process_filters
# Filter hash we're going to pass to the model
filter_to_use = {}
# To process filters, we first query the model to find out what filters
# we should be looking for, as the model knows what we can filter.
Iso.available_filters.each do |filter|
# We should have our array with our filter listing.
# Check the purchase order model for a description
filter_name = filter[0][:filter_name]
# Filters are stored in a session variable, this way filters survive
# page reloads, etc. First thing we do, is set the session if new filters
# have been set for the filter.
session_name = session_filter_name( filter_name )
if params[session_name]
if params[session_name] == 'All'
session[session_name] = nil
else
session[session_name] = params[session_name]
filter_to_use[filter_name] = params[session_name]
end
elsif session[session_name]
# If params aren't read, we still need to filter based off the users
# session
filter_to_use[filter_name] = session[session_name]
end
end
# Just using this variable for now until I can refactor the helper code
# so that this is passed in.
@current_filter_values = filter_to_use
filter_to_use[:page] = @current_page
@isos = Iso.find_filtered( filter_to_use )
if @isos.out_of_bounds?
filter_to_use[:page] = session[:previous_page] = @current_page = 1
@isos = Iso.find_filtered( filter_to_use )
end
end
```
Now this code is exactly the same as code in another controller, except for the model reference (in this case Iso). Is there someway I can make that model reference dynamic?
Basically I'ld like to replace the Iso references (including the @iso variable) to something based off controller.controller\_name or similar.
|
I've always been told and read that you should include the `LIMIT` everytime you only want 1 result. This just tells the DB that it should stop so matter what. In your case, you're probably right it doesn't make a difference, but I think it's better just to always do than always deciding and leaving it out one time when you need it.
|
190,066 |
<p>Does anyone have some good information on the usage of the .SaveChanges() method?</p>
<p>I am experiencing a variety of issues when attempting to use the .SaveChanges() method on my data context object. I am taking data from an existing data source, creating the appropriate EntityFramework/DataService objects, populating those created objects with data, adding those objects to the context and then saving that data by calling .SaveChanges.</p>
<p>The scenarios I've come up with (and the problems associated with them) are as such ... In each scenario I have a foreach loop that is taking data from rows in a DataTable and generating the objects, attaching them to the context as they go. (note: three objects a "member" and two "addresses" that are attached via a SetLink call) - basically this is a conversion tool to take data from one data store and massage it into a data store that is exposed by Data Services.</p>
<ul>
<li>Call .SaveChanges() without any parameters once at the end of the foreach loop (i.e. outside the loop)
<ul>
<li>OutOfMemory error about 1/3 of the way (30,000 out of 90,000 saves) - not sure how that is happening though as each save item is a seperate SQL call to the database, what is there to run out of memory on?</li>
</ul></li>
<li>Call .SaveChanges() without any parameters once per loop
<ul>
<li>This works, but takes absolutly forever (8 hours for 90,000 saves)</li>
</ul></li>
<li>Call .SaveChanges(SaveChangesOption.Batch) once at the end of the foreach loop
<ul>
<li>Same OutOfMemory error, but without any saves to the database</li>
</ul></li>
<li>Call .SaveChanges(SaveChangesOption.Batch) once per loop
<ul>
<li>404 not found error</li>
</ul></li>
<li>Call .SaveChanges(SaveChangesOption.Batch) once per 10 loops
<ul>
<li>400 Bad Request error (occassionally)</li>
<li>OutOfMemory after a number of itterations</li>
</ul></li>
<li>A number of random attempts to create the context once per loop, or have it as a variable at the start of the loop or have it as a private member variable that is available.
<ul>
<li>Differing results, unable to quantify, none really that good</li>
</ul></li>
</ul>
<p>What is the prefered method of calling .SaveChanges() from a client object when doing a large data load like this? Is there something I'm not getting about how .SaveChanges() works? Can anyone provide more details on how once should be utilizing this function and what (if any) are the limitations to saving data via Data Services? Are there any best practices around the .SaveChanges() method call? Is there any particularly good documentation on the .SaveChanges() method call?</p>
|
[
{
"answer_id": 261984,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>I am using EntityFramework on a small project also so I am very interested in the question also. \nTwo quick questions:\n Have you tried to turn of the caching og the data objects in the datacontext? \n Have you tried to close the datacontext and created a new one during the loop to free up memory?</p>\n\n<p>Regards</p>\n\n<p>Kenneth</p>\n"
},
{
"answer_id": 359658,
"author": "Maghis",
"author_id": 45355,
"author_profile": "https://Stackoverflow.com/users/45355",
"pm_score": 3,
"selected": true,
"text": "<p>I have no big experience in using EntityFramework (just some random experiment), have you tried calling .SaveChanges() every n iterations?</p>\n\n<p>I mean something like this:</p>\n\n<pre><code>int i = 0;\nforeach (var item in collection)\n{\n // do something with your data\n if ((i++ % 10) == 0)\n context.SaveChanges();\n}\ncontext.SaveChanges();\n</code></pre>\n\n<p>I know it's ugly, but it's the first possible solution i came up with.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190066",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25719/"
] |
Does anyone have some good information on the usage of the .SaveChanges() method?
I am experiencing a variety of issues when attempting to use the .SaveChanges() method on my data context object. I am taking data from an existing data source, creating the appropriate EntityFramework/DataService objects, populating those created objects with data, adding those objects to the context and then saving that data by calling .SaveChanges.
The scenarios I've come up with (and the problems associated with them) are as such ... In each scenario I have a foreach loop that is taking data from rows in a DataTable and generating the objects, attaching them to the context as they go. (note: three objects a "member" and two "addresses" that are attached via a SetLink call) - basically this is a conversion tool to take data from one data store and massage it into a data store that is exposed by Data Services.
* Call .SaveChanges() without any parameters once at the end of the foreach loop (i.e. outside the loop)
+ OutOfMemory error about 1/3 of the way (30,000 out of 90,000 saves) - not sure how that is happening though as each save item is a seperate SQL call to the database, what is there to run out of memory on?
* Call .SaveChanges() without any parameters once per loop
+ This works, but takes absolutly forever (8 hours for 90,000 saves)
* Call .SaveChanges(SaveChangesOption.Batch) once at the end of the foreach loop
+ Same OutOfMemory error, but without any saves to the database
* Call .SaveChanges(SaveChangesOption.Batch) once per loop
+ 404 not found error
* Call .SaveChanges(SaveChangesOption.Batch) once per 10 loops
+ 400 Bad Request error (occassionally)
+ OutOfMemory after a number of itterations
* A number of random attempts to create the context once per loop, or have it as a variable at the start of the loop or have it as a private member variable that is available.
+ Differing results, unable to quantify, none really that good
What is the prefered method of calling .SaveChanges() from a client object when doing a large data load like this? Is there something I'm not getting about how .SaveChanges() works? Can anyone provide more details on how once should be utilizing this function and what (if any) are the limitations to saving data via Data Services? Are there any best practices around the .SaveChanges() method call? Is there any particularly good documentation on the .SaveChanges() method call?
|
I have no big experience in using EntityFramework (just some random experiment), have you tried calling .SaveChanges() every n iterations?
I mean something like this:
```
int i = 0;
foreach (var item in collection)
{
// do something with your data
if ((i++ % 10) == 0)
context.SaveChanges();
}
context.SaveChanges();
```
I know it's ugly, but it's the first possible solution i came up with.
|
190,102 |
<p>I want to use data binding with an XML document to populate a simple form that shows details about a list of people. I've got it all set up and working like so right now:</p>
<pre><code><Window x:Class="DataBindingSample.Window1"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Window1">
<Window.Resources>
<XmlDataProvider x:Key="xmlProvider" XPath="People" Source="c:\someuri.xml"/>
</Window.Resources>
<Grid>
<ListBox Name="personList" ItemsSource="{Binding Source={StaticResource xmlProvider}, XPath=Person}">
<ListBox.ItemTemplate>
<DataTemplate>
<TextBlock Text="{Binding XPath=Name}" />
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
<GroupBox Header="GroupBox" Name="groupBox1" DataContext="{Binding ElementName=personList, Path=SelectedItem}">
<Grid>
<TextBox Name="nameText" Text="{Binding XPath=Name}"/>
<ComboBox Name="genderCombo" Text="{Binding XPath=Gender}">
<ComboBoxItem>Male</ComboBoxItem>
<ComboBoxItem>Female</ComboBoxItem>
</ComboBox>
</Grid>
</GroupBox>
</Grid>
</Window>
</code></pre>
<p>(All position/layout elements have been removed for clarity)</p>
<p>Now this works great! If I provide it with some XML that matches the paths provided I get a list of names in the listbox that show both the name and gender in the appropriate fields when clicked. The problem comes when I start to try and use namespaces in my XML source. The XAML then changes to look like this:</p>
<pre><code><Window x:Class="DataBindingSample.Window1"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Window1">
<Window.Resources>
<XmlNamespaceMappingCollection x:Key="namespaceMappings">
<XmlNamespaceMapping Uri="http://www.mynamespace.com" Prefix="mns"/>
</XmlNamespaceMappingCollection>
<XmlDataProvider x:Key="xmlProvider" XmlNamespaceManager="{StaticResource namespaceMappings}" XPath="mns:People" Source="c:\someuriwithnamespaces.xml"/>
</Window.Resources>
<Grid>
<ListBox Name="personList" ItemsSource="{Binding Source={StaticResource xmlProvider}, XPath=mns:Person}">
<ListBox.ItemTemplate>
<DataTemplate>
<TextBlock Text="{Binding XPath=mns:Name}" />
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
<GroupBox Header="GroupBox" Name="groupBox1" DataContext="{Binding ElementName=personList, Path=SelectedItem}">
<Grid>
<TextBox Name="nameText" Text="{Binding XPath=mns:Name}"/>
<ComboBox Name="genderCombo" Text="{Binding XPath=mns:Gender}">
<ComboBoxItem>Male</ComboBoxItem>
<ComboBoxItem>Female</ComboBoxItem>
</ComboBox>
</Grid>
</GroupBox>
</Grid>
</Window>
</code></pre>
<p>With this code (and the appropriately namespaced xml, of course) the Listbox still displays the names properly, but clicking on those names no longer updates the Name and Gender fields! My suspicion is that somehow the xml namespace is reacting adversely to the groupbox's DataContext, but I'm not sure why or how. Does anyone know how to use XML namespaces in this context? </p>
|
[
{
"answer_id": 191467,
"author": "aogan",
"author_id": 4795,
"author_profile": "https://Stackoverflow.com/users/4795",
"pm_score": 2,
"selected": true,
"text": "<p>You could use local names in your XPath queries like this: </p>\n\n<pre><code> <TextBox Name=\"nameText\">\n <TextBox.Text>\n <Binding XPath=\"*[local-name()='Name']\" />\n </TextBox.Text>\n </TextBox>\n</code></pre>\n"
},
{
"answer_id": 206879,
"author": "Toji",
"author_id": 25968,
"author_profile": "https://Stackoverflow.com/users/25968",
"pm_score": 2,
"selected": false,
"text": "<p>I also <a href=\"http://social.msdn.microsoft.com/Forums/en-US/wpf/thread/cb6b22e7-3a48-425b-bbad-2575d2618968/\" rel=\"nofollow noreferrer\">asked this question</a> on the MSDN WPF forms. Marco Zhou answered me with this, which is ultimately the answer I was seeking. I've reproduced it here for the benefit of anyone looking for the same answer:</p>\n\n<blockquote>\n <p>This works:</p>\n \n <p>\n \n \n \n </p>\n\n<pre><code> <XmlDataProvider x:Key=\"dataProvider\"\n XmlNamespaceManager=\"{StaticResource namespaceMappings}\"\n XPath=\"p:players/p:player\">\n <x:XData>\n <p:players xmlns:p=\"http://www.footballism.com/2005/SoccerPlayers\">\n <p:player>\n <p:fullName>Sebastian Batistuta</p:fullName>\n <p:age>26</p:age>\n </p:player>\n <p:player>\n <p:fullName>Andriey Shevchenko</p:fullName>\n <p:age>30</p:age>\n </p:player>\n <p:player>\n <p:fullName>Paviel Nedved</p:fullName>\n <p:age>21</p:age>\n </p:player>\n <p:player>\n <p:fullName>David Beckham</p:fullName>\n <p:age>19</p:age>\n </p:player>\n </p:players>\n </x:XData>\n </XmlDataProvider>\n</Page.Resources>\n<StackPanel>\n <TextBlock\n Text=\"{Binding XPath=p:fullName}\"\n FontWeight=\"Bold\"\n Binding.XmlNamespaceManager=\"{StaticResource namespaceMappings}\"\n DataContext=\"{Binding ElementName=listBox, Path=SelectedItem}\"/>\n <ListBox ItemsSource=\"{Binding Source={StaticResource dataProvider}}\"\n x:Name=\"listBox\"\n DisplayMemberPath=\"p:fullName\">\n </ListBox>\n</StackPanel> </Page>\n</code></pre>\n \n <p>I suppose after looking at the code,\n you should be able to understand why\n it works after specify the\n Binding.XmlNamespaceManager attached\n property for TextBlock.</p>\n \n <p>ListBox is data bound to a data\n provider which has xml namespace\n mapping information, but the binding\n on the TextBlock doesn't have this\n information, that's why it fails.</p>\n \n <p>Actually, when doing master detail\n data binding, it's more appropriate to\n do something like the following:</p>\n \n <p>\n \n \n \n </p>\n\n<pre><code> <XmlDataProvider x:Key=\"dataProvider\"\n XmlNamespaceManager=\"{StaticResource namespaceMappings}\"\n XPath=\"p:players/p:player\">\n <x:XData>\n <p:players xmlns:p=\"http://www.footballism.com/2005/SoccerPlayers\">\n <p:player>\n <p:fullName>Sebastian Batistuta</p:fullName>\n <p:age>26</p:age>\n </p:player>\n <p:player>\n <p:fullName>Andriey Shevchenko</p:fullName>\n <p:age>30</p:age>\n </p:player>\n <p:player>\n <p:fullName>Paviel Nedved</p:fullName>\n <p:age>21</p:age>\n </p:player>\n <p:player>\n <p:fullName>David Beckham</p:fullName>\n <p:age>19</p:age>\n </p:player>\n </p:players>\n </x:XData>\n </XmlDataProvider>\n</Page.Resources>\n<StackPanel DataContext=\"{Binding Source={StaticResource dataProvider}}\">\n <TextBlock\n Text=\"{Binding XPath=p:fullName}\"\n FontWeight=\"Bold\"/>\n <ListBox ItemsSource=\"{Binding}\"\n x:Name=\"listBox\"\n DisplayMemberPath=\"p:fullName\"\n IsSynchronizedWithCurrentItem=\"True\">\n </ListBox>\n</StackPanel> </Page>\n</code></pre>\n \n <p>Hope this clears things up a little\n bit.</p>\n</blockquote>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190102",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25968/"
] |
I want to use data binding with an XML document to populate a simple form that shows details about a list of people. I've got it all set up and working like so right now:
```
<Window x:Class="DataBindingSample.Window1"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Window1">
<Window.Resources>
<XmlDataProvider x:Key="xmlProvider" XPath="People" Source="c:\someuri.xml"/>
</Window.Resources>
<Grid>
<ListBox Name="personList" ItemsSource="{Binding Source={StaticResource xmlProvider}, XPath=Person}">
<ListBox.ItemTemplate>
<DataTemplate>
<TextBlock Text="{Binding XPath=Name}" />
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
<GroupBox Header="GroupBox" Name="groupBox1" DataContext="{Binding ElementName=personList, Path=SelectedItem}">
<Grid>
<TextBox Name="nameText" Text="{Binding XPath=Name}"/>
<ComboBox Name="genderCombo" Text="{Binding XPath=Gender}">
<ComboBoxItem>Male</ComboBoxItem>
<ComboBoxItem>Female</ComboBoxItem>
</ComboBox>
</Grid>
</GroupBox>
</Grid>
</Window>
```
(All position/layout elements have been removed for clarity)
Now this works great! If I provide it with some XML that matches the paths provided I get a list of names in the listbox that show both the name and gender in the appropriate fields when clicked. The problem comes when I start to try and use namespaces in my XML source. The XAML then changes to look like this:
```
<Window x:Class="DataBindingSample.Window1"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Window1">
<Window.Resources>
<XmlNamespaceMappingCollection x:Key="namespaceMappings">
<XmlNamespaceMapping Uri="http://www.mynamespace.com" Prefix="mns"/>
</XmlNamespaceMappingCollection>
<XmlDataProvider x:Key="xmlProvider" XmlNamespaceManager="{StaticResource namespaceMappings}" XPath="mns:People" Source="c:\someuriwithnamespaces.xml"/>
</Window.Resources>
<Grid>
<ListBox Name="personList" ItemsSource="{Binding Source={StaticResource xmlProvider}, XPath=mns:Person}">
<ListBox.ItemTemplate>
<DataTemplate>
<TextBlock Text="{Binding XPath=mns:Name}" />
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
<GroupBox Header="GroupBox" Name="groupBox1" DataContext="{Binding ElementName=personList, Path=SelectedItem}">
<Grid>
<TextBox Name="nameText" Text="{Binding XPath=mns:Name}"/>
<ComboBox Name="genderCombo" Text="{Binding XPath=mns:Gender}">
<ComboBoxItem>Male</ComboBoxItem>
<ComboBoxItem>Female</ComboBoxItem>
</ComboBox>
</Grid>
</GroupBox>
</Grid>
</Window>
```
With this code (and the appropriately namespaced xml, of course) the Listbox still displays the names properly, but clicking on those names no longer updates the Name and Gender fields! My suspicion is that somehow the xml namespace is reacting adversely to the groupbox's DataContext, but I'm not sure why or how. Does anyone know how to use XML namespaces in this context?
|
You could use local names in your XPath queries like this:
```
<TextBox Name="nameText">
<TextBox.Text>
<Binding XPath="*[local-name()='Name']" />
</TextBox.Text>
</TextBox>
```
|
190,108 |
<p>I am having trouble grabbing the values from the form once processed. I need your help.</p>
<pre><code>function updateUser($table, $id) {
if($_POST) {
processUpdate($table, $id);
} else {
updateForm($table, $id);
}
}
function processUpdate($table, $id) {
print $table; //testing
print $id; //testing
$email=addslashes($HTTP_POST_VARS['email']);
$lname=addslashes($HTTP_POST_VARS['lname']);
$fname=addslashes($HTTP_POST_VARS['fname']);
print $lname;
//which table do we update
switch($table) {
case "maillist":
$result = mysql_query("UPDATE $table SET email='$email', lname='$lname', fname='$fname' WHERE id='$id'")
or die(mysql_error());
break;
}
}
</code></pre>
<p>The function updateForm($table, $id); just outputs the form, has email, lname, fname fields. And when you process the form, the action is the same, w/ the table and id being passed thru the URL, so it GET's the id and table that way, and for lname, fname, and email, it should grab it via post.</p>
<p>EDIT: this is what the form tag is for the updateForm function: <code><form method="post" action="?mode=upd&id='.$id.'&table='.$table.'"></code></p>
<p>But for some reason, it does not post the values.</p>
|
[
{
"answer_id": 190120,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": true,
"text": "<p>Is the method attribute of the form set to post?</p>\n\n<pre><code><form method = \"post\" action = \"...\">\n</code></pre>\n\n<p>And are all of the input's name attribute set right?</p>\n\n<p>Have you looked at the html output to make sure that there were no syntax errors? Also, try using</p>\n\n<p><code>$_POST</code></p>\n\n<p>instead of</p>\n\n<p><code>$HTTP_POST_VARS</code></p>\n"
},
{
"answer_id": 190328,
"author": "SchizoDuckie",
"author_id": 18077,
"author_profile": "https://Stackoverflow.com/users/18077",
"pm_score": 0,
"selected": false,
"text": "<p>Please make sure that you use an up-to-date tutorial for one of the latest versions of PHP5. NOT some PHP 3.x tut full of deprecated functions ;-)</p>\n\n<p>That will make your life (and ours) a whole lot easier :P</p>\n\n<p>By the way one more tip that will prevent you from having major SQL injections in this script: \n<strong>ESCAPE EVERY VARIABLE YOU ARE GOING TO PASS!!</strong></p>\n\n<p>You don't escape ID here, which is a nice huge hole to drop your db</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190108",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26130/"
] |
I am having trouble grabbing the values from the form once processed. I need your help.
```
function updateUser($table, $id) {
if($_POST) {
processUpdate($table, $id);
} else {
updateForm($table, $id);
}
}
function processUpdate($table, $id) {
print $table; //testing
print $id; //testing
$email=addslashes($HTTP_POST_VARS['email']);
$lname=addslashes($HTTP_POST_VARS['lname']);
$fname=addslashes($HTTP_POST_VARS['fname']);
print $lname;
//which table do we update
switch($table) {
case "maillist":
$result = mysql_query("UPDATE $table SET email='$email', lname='$lname', fname='$fname' WHERE id='$id'")
or die(mysql_error());
break;
}
}
```
The function updateForm($table, $id); just outputs the form, has email, lname, fname fields. And when you process the form, the action is the same, w/ the table and id being passed thru the URL, so it GET's the id and table that way, and for lname, fname, and email, it should grab it via post.
EDIT: this is what the form tag is for the updateForm function: `<form method="post" action="?mode=upd&id='.$id.'&table='.$table.'">`
But for some reason, it does not post the values.
|
Is the method attribute of the form set to post?
```
<form method = "post" action = "...">
```
And are all of the input's name attribute set right?
Have you looked at the html output to make sure that there were no syntax errors? Also, try using
`$_POST`
instead of
`$HTTP_POST_VARS`
|
190,138 |
<p>I want to create a collection in VB.NET, but I only want it to accept objects of a certain type. For example, I want to create a class called "FooCollection" that acts like a collection in every way, but only accepts objects of type "Foo".</p>
<p>I thought I could do this using generics, using the following syntax:</p>
<pre><code> Public Class FooCollection(Of type As Foo)
Inherits CollectionBase
...
End Class
</code></pre>
<p>But I get an error when I compile it that I "must implement a default accessor", so clearly there's something missing. I don't want to specify the type it accepts when I instantiate - I want the FooCollection itself to specific that it only accepts Foo objects. I've seen it done in C# with a strong-typed list, so maybe all I'm looking for is VB.NET syntax.</p>
<p>Thanks for your help!</p>
<p><strong>EDIT: Thanks for the answer. That would do it, but I wanted to have the classtype named a certain way, I actually accomplished exactly what I was looking for with the following code:</strong></p>
<pre><code>Public Class FooCollection
Inherits List(Of Foo)
End Class
</code></pre>
|
[
{
"answer_id": 190153,
"author": "Andrew Moore",
"author_id": 26210,
"author_profile": "https://Stackoverflow.com/users/26210",
"pm_score": 4,
"selected": true,
"text": "<p>Why don't you just use a <code>List(Of Foo)</code>... It is already in VB.NET under <code>System.Collections.Generic</code>. To use, simply declare as such:</p>\n\n<pre><code>Private myList As New List(Of Foo) 'Creates a Foo List'\nPrivate myIntList As New List(Of Integer) 'Creates an Integer List'\n</code></pre>\n\n<p>See <code><a href=\"http://msdn.microsoft.com/en-us/library/6sh2ey19.aspx\" rel=\"noreferrer\" title=\"MSDN\">MSDN > List(T) Class (System.Collections.Generic)</a></code> for more information.</p>\n"
},
{
"answer_id": 2269794,
"author": "Jeff Cope",
"author_id": 273952,
"author_profile": "https://Stackoverflow.com/users/273952",
"pm_score": 1,
"selected": false,
"text": "<p>You needed to implement a default property for the collection like this:</p>\n\n<pre><code>Default Public Property Item(ByVal Index As Integer) As Foo\nGet\n Return CType(List.Item(Index), Foo)\nEnd Get\nSet(ByVal Value As Foo)\n List.Item(Index) = Value\nEnd Set\n</code></pre>\n\n<p>End Property</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190138",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8114/"
] |
I want to create a collection in VB.NET, but I only want it to accept objects of a certain type. For example, I want to create a class called "FooCollection" that acts like a collection in every way, but only accepts objects of type "Foo".
I thought I could do this using generics, using the following syntax:
```
Public Class FooCollection(Of type As Foo)
Inherits CollectionBase
...
End Class
```
But I get an error when I compile it that I "must implement a default accessor", so clearly there's something missing. I don't want to specify the type it accepts when I instantiate - I want the FooCollection itself to specific that it only accepts Foo objects. I've seen it done in C# with a strong-typed list, so maybe all I'm looking for is VB.NET syntax.
Thanks for your help!
**EDIT: Thanks for the answer. That would do it, but I wanted to have the classtype named a certain way, I actually accomplished exactly what I was looking for with the following code:**
```
Public Class FooCollection
Inherits List(Of Foo)
End Class
```
|
Why don't you just use a `List(Of Foo)`... It is already in VB.NET under `System.Collections.Generic`. To use, simply declare as such:
```
Private myList As New List(Of Foo) 'Creates a Foo List'
Private myIntList As New List(Of Integer) 'Creates an Integer List'
```
See `[MSDN > List(T) Class (System.Collections.Generic)](http://msdn.microsoft.com/en-us/library/6sh2ey19.aspx "MSDN")` for more information.
|
190,145 |
<p>I know it's a long shot, but is there some package or means to insert emoticons into a LaTeX document?</p>
|
[
{
"answer_id": 190195,
"author": "freespace",
"author_id": 8297,
"author_profile": "https://Stackoverflow.com/users/8297",
"pm_score": 3,
"selected": false,
"text": "<p>Unicode's \"miscellaneous symbols\" include 3 simple emoticons: <code>0x2639</code>-<code>0x263B</code>. You can possibly use <code>0x2686</code>-<code>0x2689</code> as well.</p>\n\n<p>For more variation you are going to need to use images and include them somehow.</p>\n\n<p>I am curious as to the circumstances which lead to this question :)</p>\n"
},
{
"answer_id": 190321,
"author": "ADEpt",
"author_id": 10105,
"author_profile": "https://Stackoverflow.com/users/10105",
"pm_score": 6,
"selected": true,
"text": "<p>I know at least two partial ways:</p>\n\n<p>First:</p>\n\n<pre><code>$\\ddot\\smile$\n</code></pre>\n\n<p>Second:</p>\n\n<pre><code>\\usepackage{wasysym}\n\\smiley\n\\frownie\n</code></pre>\n\n<p>Or you can use images (as mentioned in other replies).</p>\n"
},
{
"answer_id": 274030,
"author": "DaG",
"author_id": 35664,
"author_profile": "https://Stackoverflow.com/users/35664",
"pm_score": 4,
"selected": false,
"text": "<p>What's against a simple {\\tt :-)}?</p>\n"
},
{
"answer_id": 15903680,
"author": "Vincent Belaïche",
"author_id": 2262010,
"author_profile": "https://Stackoverflow.com/users/2262010",
"pm_score": 1,
"selected": false,
"text": "<p>One solution is to use bclogo package. It contains two smileys (happy & sad), plus many other small \"logos\" like flags and others.</p>\n"
},
{
"answer_id": 33983439,
"author": "Martin Ueding",
"author_id": 653152,
"author_profile": "https://Stackoverflow.com/users/653152",
"pm_score": 2,
"selected": false,
"text": "<p>By now there also is the <code>tikzsymbols</code> package which has nice emoticons.</p>\n"
},
{
"answer_id": 57076064,
"author": "Ryutaroh Matsumoto",
"author_id": 11797631,
"author_profile": "https://Stackoverflow.com/users/11797631",
"pm_score": 4,
"selected": false,
"text": "<p>If you use <code>xelatex</code> or <code>lualatex</code>, then</p>\n<pre><code>\\documentclass{article}\n\\usepackage{fontspec}\n\\setmainfont{Symbola}\n\\begin{document}\n\n \n\\end{document}\n</code></pre>\n<p>should produce black-and-white emoji letters in Symbola font,\nwhich is available from <a href=\"http://users.teilar.gr/%7Eg1951d/\" rel=\"nofollow noreferrer\">http://users.teilar.gr/%7Eg1951d/</a>\nor standard package repositories in some Linux distros (e.g. Ubuntu).\nThe MS Windows emoji font can also be used by <code>\\fontspec{Segoe UI Emoji}[RawFeature={ccmp,dist}]</code>\nin place of <code>\\fontspec{Symbola}</code>.</p>\n<p>Unfortunately the color (emoji) fonts are not supported by the standard\nlualatex or xelatex. <code>harflatex</code> and <code>luahblatex</code> can typeset color emojis using</p>\n<pre><code>\\documentclass{minimal}\n\\usepackage{harfload}\n\\usepackage{fontspec}\n\n\\begin{document}\n\\noindent\n\\fontspec{Noto Color Emoji}[RawFeature={mode=harf}]\n☃⛄\\quad ❤️\n\\end{document}\n</code></pre>\n<p><code>harflatex</code> and <code>luahblatex</code> can be installed from TeXLive Contrib at\n<a href=\"https://contrib.texlive.info/\" rel=\"nofollow noreferrer\">https://contrib.texlive.info/</a> as of July 2019.</p>\n<p>The above is learnt from <a href=\"https://tex.stackexchange.com/questions/497403/how-to-use-noto-color-emoji-with-lualatex/500180\">https://tex.stackexchange.com/questions/497403/how-to-use-noto-color-emoji-with-lualatex/500180</a>\nwith a bit of my own investigation.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190145",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1630/"
] |
I know it's a long shot, but is there some package or means to insert emoticons into a LaTeX document?
|
I know at least two partial ways:
First:
```
$\ddot\smile$
```
Second:
```
\usepackage{wasysym}
\smiley
\frownie
```
Or you can use images (as mentioned in other replies).
|
190,168 |
<p>I am trying to set my DOS environment variable in Ruby, and have it persist after the script exits. For example, if I want a ruby script <code>set_abc_env.rb</code> to set environment variable 'ABC' to 'blah', I expect to run the following:</p>
<pre><code>C:> echo %ABC%
C:> set_abc_env.rb
C:> echo %ABC% blah
</code></pre>
<p>How do I do this?</p>
|
[
{
"answer_id": 190437,
"author": "Alexander Prokofyev",
"author_id": 11256,
"author_profile": "https://Stackoverflow.com/users/11256",
"pm_score": 6,
"selected": true,
"text": "<p>You can access environment variables via Ruby ENV object:</p>\n\n<pre><code>i = ENV['ABC']; # nil\nENV['ABC'] = '123';\ni = ENV['ABC']; # '123'\n</code></pre>\n\n<p>Bad news is, as MSDN <a href=\"http://msdn.microsoft.com/en-us/library/ms682009(VS.85).aspx\" rel=\"noreferrer\">says</a>, a process can never directly change the environment variables of another process that is not a child of that process. So when script exits, you lose all changes it did.</p>\n\n<p>Good news is what Microsoft Windows stores environment variables in the registry and it's possible to <a href=\"http://support.microsoft.com/kb/104011\" rel=\"noreferrer\">propagate</a> environment variables to the system. This is a way to modify user environment variables:</p>\n\n<pre><code>require 'win32/registry.rb'\n\nWin32::Registry::HKEY_CURRENT_USER.open('Environment', Win32::Registry::KEY_WRITE) do |reg|\n reg['ABC'] = '123'\nend\n</code></pre>\n\n<p>The documentation also says you should log off and log back on or broadcast a WM_SETTINGCHANGE message to make changes seen to applications. This is how broadcasting can be done in Ruby:</p>\n\n<pre><code>require 'Win32API' \n\nSendMessageTimeout = Win32API.new('user32', 'SendMessageTimeout', 'LLLPLLP', 'L') \nHWND_BROADCAST = 0xffff\nWM_SETTINGCHANGE = 0x001A\nSMTO_ABORTIFHUNG = 2\nresult = 0\nSendMessageTimeout.call(HWND_BROADCAST, WM_SETTINGCHANGE, 0, 'Environment', SMTO_ABORTIFHUNG, 5000, result) \n</code></pre>\n"
},
{
"answer_id": 5492321,
"author": "konung",
"author_id": 198424,
"author_profile": "https://Stackoverflow.com/users/198424",
"pm_score": 1,
"selected": false,
"text": "<p>For anyone else looking for a solution for this and looking for a more of a hack that doesn't require logging in or out I came up with this solution for a similar problem :</p>\n\n<p><strong>WORKAROUND:</strong></p>\n\n<p>My work around is dependent on combination of ruby and a command line utility called <a href=\"http://barnyard.syr.edu/~vefatica/#SETENV\" rel=\"nofollow\">SETENV.EXE</a> develped by Vincent Fatica. It's more than a decade old at this point but works fine in windows XP ( didn't test under Windows 7 yet). It works better than setx utility available from MS IMHO. At lest for deleting stuff. Make sure setenv is available from command line. Put it in some c:\\tools and put c:\\tools in your PATH.</p>\n\n<p>Here is a short example of a method using it:</p>\n\n<pre><code>def switch_ruby_env\n if RUBY_VERSION.match(\"1.8.7\").nil? \n `setenv -m CUSTOM_PATH \" \"`\n else\n `setenv -m CUSTOM_PATH -delete`\n end\nend \n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190168",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24560/"
] |
I am trying to set my DOS environment variable in Ruby, and have it persist after the script exits. For example, if I want a ruby script `set_abc_env.rb` to set environment variable 'ABC' to 'blah', I expect to run the following:
```
C:> echo %ABC%
C:> set_abc_env.rb
C:> echo %ABC% blah
```
How do I do this?
|
You can access environment variables via Ruby ENV object:
```
i = ENV['ABC']; # nil
ENV['ABC'] = '123';
i = ENV['ABC']; # '123'
```
Bad news is, as MSDN [says](http://msdn.microsoft.com/en-us/library/ms682009(VS.85).aspx), a process can never directly change the environment variables of another process that is not a child of that process. So when script exits, you lose all changes it did.
Good news is what Microsoft Windows stores environment variables in the registry and it's possible to [propagate](http://support.microsoft.com/kb/104011) environment variables to the system. This is a way to modify user environment variables:
```
require 'win32/registry.rb'
Win32::Registry::HKEY_CURRENT_USER.open('Environment', Win32::Registry::KEY_WRITE) do |reg|
reg['ABC'] = '123'
end
```
The documentation also says you should log off and log back on or broadcast a WM\_SETTINGCHANGE message to make changes seen to applications. This is how broadcasting can be done in Ruby:
```
require 'Win32API'
SendMessageTimeout = Win32API.new('user32', 'SendMessageTimeout', 'LLLPLLP', 'L')
HWND_BROADCAST = 0xffff
WM_SETTINGCHANGE = 0x001A
SMTO_ABORTIFHUNG = 2
result = 0
SendMessageTimeout.call(HWND_BROADCAST, WM_SETTINGCHANGE, 0, 'Environment', SMTO_ABORTIFHUNG, 5000, result)
```
|
190,184 |
<p>I often use the <code>execv()</code> function in C++, but if some of the arguments are in C++ strings, it annoys me that I cannot do this:</p>
<pre><code>const char *args[4];
args[0] = "/usr/bin/whatever";
args[1] = filename.c_str();
args[2] = someparameter.c_str();
args[3] = 0;
execv(args[0], args);
</code></pre>
<p>This doesn't compile because <code>execv()</code> takes <code>char *const argv[]</code> which is not compatible with <code>const char *</code>, so I have to copy my <code>std::string</code>s to character arrays using <code>strdup()</code>, which is a pain.</p>
<p>Does anyone know the reason for this?</p>
|
[
{
"answer_id": 190197,
"author": "Jonathan",
"author_id": 14850,
"author_profile": "https://Stackoverflow.com/users/14850",
"pm_score": 2,
"selected": false,
"text": "<p>const is a C++ thing - execv has taken char * arguments since before C++ existed.</p>\n\n<p>You can use const_cast instead of copying, because execv doesn't actually modify its arguments. You might consider writing a wrapper to save yourself the typing.</p>\n\n<p>Actually, a bigger problem with your code is that you declared an array of characters instead of an array of strings.</p>\n\n<p>Try:\nconst char* args[4];</p>\n"
},
{
"answer_id": 190208,
"author": "C. K. Young",
"author_id": 13,
"author_profile": "https://Stackoverflow.com/users/13",
"pm_score": 6,
"selected": true,
"text": "<p>The Open Group Base Specifications explains why this is: for compatibility with existing C code. Neither the pointers nor the string contents themselves are intended to be changed, though. Thus, in this case, you can get away with <code>const_cast</code>-ing the result of <code>c_str()</code>.</p>\n\n<p><a href=\"http://pubs.opengroup.org/onlinepubs/9699919799/functions/exec.html\" rel=\"noreferrer\">Quote:</a></p>\n\n<blockquote>\n <p>The statement about <code>argv[]</code> and <code>envp[]</code> being constants is included to make explicit to future writers of language bindings that these objects are completely constant. Due to a limitation of the ISO C standard, it is not possible to state that idea in standard C. Specifying two levels of <code>const</code>- qualification for the <code>argv[]</code> and <code>envp[]</code> parameters for the exec functions may seem to be the natural choice, given that these functions do not modify either the array of pointers or the characters to which the function points, but this would disallow existing correct code. Instead, only the array of pointers is noted as constant.</p>\n</blockquote>\n\n<p>The table and text after that is even more insightful. However, Stack Overflow doesn't allow tables to be inserted, so the quote above should be enough context for you to search for the right place in the linked document.</p>\n"
},
{
"answer_id": 5433327,
"author": "Tomi",
"author_id": 676834,
"author_profile": "https://Stackoverflow.com/users/676834",
"pm_score": -1,
"selected": false,
"text": "<p>I have usually hacked this with:</p>\n\n<pre><code>#define execve xexecve\n#include <...>\n#include <...>\n#include <...>\n#undef execve\n\n// in case of c++\nextern \"C\" {\n int execve(const char * filename, char ** argvs, char * const * envp);\n}\n</code></pre>\n\n<p>;/</p>\n"
},
{
"answer_id": 29501925,
"author": "cmccabe",
"author_id": 560814,
"author_profile": "https://Stackoverflow.com/users/560814",
"pm_score": 1,
"selected": false,
"text": "<p>This is just a situation where C / C++ style const doesn't work very well. In reality, the kernel is not going to modify the arguments passed to exec(). It's just going to copy them when it creates a new process. But the type system is not expressive enough to really deal with this well.</p>\n\n<p>A lot of people on this page are proposing making exec take \"char**\" or \"const char * const[]\". But neither of those actually works for your original example. \"char**\" means that everything is mutable (certainly not not true for the string constant \"/usr/bin/whatever\"). \"const char *const[]\" means that nothing is mutable. But then you cannot assign any values to the elements of the array, since the array itself is then const.</p>\n\n<p>The best you could do is have a compile-time C constant like this:</p>\n\n<pre><code>const char * const args[] = {\n \"/usr/bin/whatever\",\n filename.c_str(),\n someparameter.c_str(),\n 0};\n</code></pre>\n\n<p>This will actually work with the proposed type signature of \"const char *const[]\". But what if you need a variable number of arguments? Then you can't have a compile-time constant, but you need a mutable array. So you're back to fudging things. That is the real reason why the type signature of exec takes \"const char **\" for arguments.</p>\n\n<p>The issues are the same in C++, by the way. You can't pass a std::vector < std::string > to a function that needs a std::vector < const std::string >. You have to typecast or copy the entire std::vector.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190184",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5324/"
] |
I often use the `execv()` function in C++, but if some of the arguments are in C++ strings, it annoys me that I cannot do this:
```
const char *args[4];
args[0] = "/usr/bin/whatever";
args[1] = filename.c_str();
args[2] = someparameter.c_str();
args[3] = 0;
execv(args[0], args);
```
This doesn't compile because `execv()` takes `char *const argv[]` which is not compatible with `const char *`, so I have to copy my `std::string`s to character arrays using `strdup()`, which is a pain.
Does anyone know the reason for this?
|
The Open Group Base Specifications explains why this is: for compatibility with existing C code. Neither the pointers nor the string contents themselves are intended to be changed, though. Thus, in this case, you can get away with `const_cast`-ing the result of `c_str()`.
[Quote:](http://pubs.opengroup.org/onlinepubs/9699919799/functions/exec.html)
>
> The statement about `argv[]` and `envp[]` being constants is included to make explicit to future writers of language bindings that these objects are completely constant. Due to a limitation of the ISO C standard, it is not possible to state that idea in standard C. Specifying two levels of `const`- qualification for the `argv[]` and `envp[]` parameters for the exec functions may seem to be the natural choice, given that these functions do not modify either the array of pointers or the characters to which the function points, but this would disallow existing correct code. Instead, only the array of pointers is noted as constant.
>
>
>
The table and text after that is even more insightful. However, Stack Overflow doesn't allow tables to be inserted, so the quote above should be enough context for you to search for the right place in the linked document.
|
190,188 |
<p>I have this Document table with some meta data for the document in it and also the document content as a blob.</p>
<p>then I use lucene.Net to query my documents; which in return gives me a list of Guids to my Document table and also two fields containing the highlighted html versions of the document name and extract with the search keywords highlighted. </p>
<p>then I use linq to join this result with my document table fields to get a list to show as the search result. stupid thing is linq tries to load the blob to the document although it's not used in the join. </p>
<p>I'm thinking of two options, neither of them I like:</p>
<ul>
<li>move my blob to a new table and link it 1-1 to the document table. which I don't like because the limitation in linq is forcing me to change my db structure.</li>
<li>add a new dbml with a "LiteDocument" table in it and remove the blob from the document table in dbml; which I don't like because I have two places to maintain if document table has a change.</li>
</ul>
<p>I was wondering if there is a better way to do this? here are the code snippets:</p>
<pre><code> public class LuceneSearchResult
{
public Guid DocumentID { get; set; }
public string FormattedDocumentFileName { get; set; }
public string FormattedDocumentExtract { get; set; }
}
</code></pre>
<p>and </p>
<pre><code> public IList Search(string searchPhrase, Guid? ProductId)
{
searchPhrase = PrepareSearchPhraseWithThesaurus(searchPhrase);
var result = RunLuceneQuery(searchPhrase, ProductId);
var dc = new ChinaHcpDataContext();
var docs =
from r in result
join d in dc.Documents on r.DocumentID equals d.DocumentID
select
new
{
d.DocumentID,
TradeNameEN = d.TradeProduct != null ? d.TradeProduct.TradeNameEN : "",
TradeNameZH = d.TradeProduct != null ? d.TradeProduct.TradeNameZH : "",
d.DocumentFileName,
d.InsertedDateUtc,
d.Size,
DocumentDisplayText = r.FormattedDocumentFileName,
DocumentSelectionReason = r.FormattedDocumentExtract
};
return docs.ToList();
}
</code></pre>
|
[
{
"answer_id": 196015,
"author": "Joel Mueller",
"author_id": 24380,
"author_profile": "https://Stackoverflow.com/users/24380",
"pm_score": 0,
"selected": false,
"text": "<p>Would it help to create a View in your database that excludes the blob, and then generate your dbml from the view? It's not too terribly different from your second option, but keeps the changes mainly in the database itself, without requiring any changes to your existing table structure.</p>\n"
},
{
"answer_id": 268219,
"author": "Frank Schwieterman",
"author_id": 32203,
"author_profile": "https://Stackoverflow.com/users/32203",
"pm_score": 2,
"selected": false,
"text": "<p>You can specify that a field is delay loaded. Its one of the properties available for table fields in the DBML designer.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190188",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24351/"
] |
I have this Document table with some meta data for the document in it and also the document content as a blob.
then I use lucene.Net to query my documents; which in return gives me a list of Guids to my Document table and also two fields containing the highlighted html versions of the document name and extract with the search keywords highlighted.
then I use linq to join this result with my document table fields to get a list to show as the search result. stupid thing is linq tries to load the blob to the document although it's not used in the join.
I'm thinking of two options, neither of them I like:
* move my blob to a new table and link it 1-1 to the document table. which I don't like because the limitation in linq is forcing me to change my db structure.
* add a new dbml with a "LiteDocument" table in it and remove the blob from the document table in dbml; which I don't like because I have two places to maintain if document table has a change.
I was wondering if there is a better way to do this? here are the code snippets:
```
public class LuceneSearchResult
{
public Guid DocumentID { get; set; }
public string FormattedDocumentFileName { get; set; }
public string FormattedDocumentExtract { get; set; }
}
```
and
```
public IList Search(string searchPhrase, Guid? ProductId)
{
searchPhrase = PrepareSearchPhraseWithThesaurus(searchPhrase);
var result = RunLuceneQuery(searchPhrase, ProductId);
var dc = new ChinaHcpDataContext();
var docs =
from r in result
join d in dc.Documents on r.DocumentID equals d.DocumentID
select
new
{
d.DocumentID,
TradeNameEN = d.TradeProduct != null ? d.TradeProduct.TradeNameEN : "",
TradeNameZH = d.TradeProduct != null ? d.TradeProduct.TradeNameZH : "",
d.DocumentFileName,
d.InsertedDateUtc,
d.Size,
DocumentDisplayText = r.FormattedDocumentFileName,
DocumentSelectionReason = r.FormattedDocumentExtract
};
return docs.ToList();
}
```
|
You can specify that a field is delay loaded. Its one of the properties available for table fields in the DBML designer.
|
190,194 |
<p>How do you create a database backup of a mysql database in VB.Net? </p>
|
[
{
"answer_id": 190505,
"author": "Osama Al-Maadeed",
"author_id": 25544,
"author_profile": "https://Stackoverflow.com/users/25544",
"pm_score": 1,
"selected": false,
"text": "<p>you could invoke mysqldump, but you may need to be running your VB.NET on the Mysql server.</p>\n"
},
{
"answer_id": 210358,
"author": "Bob King",
"author_id": 6897,
"author_profile": "https://Stackoverflow.com/users/6897",
"pm_score": 0,
"selected": false,
"text": "<p>You can read each table's data and write it to a new database.</p>\n"
},
{
"answer_id": 248520,
"author": "websch01ar",
"author_id": 32567,
"author_profile": "https://Stackoverflow.com/users/32567",
"pm_score": 0,
"selected": false,
"text": "<p>I would write a stored proc, since MySQL 5 has support for them, that handles all the data \"heavy\" work. Then just create scheduled task that calls the procedure every \"night\". For this latter component, I highly recommend Powershell....its awesome.</p>\n"
},
{
"answer_id": 256271,
"author": "SecretDeveloper",
"author_id": 2720,
"author_profile": "https://Stackoverflow.com/users/2720",
"pm_score": 1,
"selected": false,
"text": "<p>I found the easiest way was to use the mysqldump.exe which is a standalone application. </p>\n\n<pre><code>mysqldump --host=[HOSTNAME] --user=[USER] --password=[PASSWORD] -R [DATABASE NAME] > [PATH TO BACKUP FILE]\n</code></pre>\n\n<p>We had issues with backups not saving db functions but the -R switch sorted it so id recommend using it if you use stored procedures or functions in your DB.</p>\n\n<p>to restore the created file use the mysql command instead.</p>\n\n<pre><code>mysql --host=[HOSTNAME] --user=[USER] --password=[PASSWORD] [DATABASE NAME] < [PATH TO BACKUP FILE]\n</code></pre>\n"
},
{
"answer_id": 14009385,
"author": "mjb",
"author_id": 520848,
"author_profile": "https://Stackoverflow.com/users/520848",
"pm_score": 3,
"selected": false,
"text": "<p>You can use <strong>MySqlBackup.NET</strong>, which is an alternative to mysqldump.</p>\n\n<p>Official Website & Documentation > <a href=\"https://github.com/MySqlBackupNET/MySqlBackup.Net\" rel=\"nofollow noreferrer\">https://github.com/MySqlBackupNET/MySqlBackup.Net</a></p>\n\n<p>Examples:</p>\n\n<p><strong>Backup a MySql Database</strong></p>\n\n<pre><code>Dim conn As MySqlConnection = New MySqlConnection(constr)\nDim cmd As MySqlCommand = New MySqlCommand\ncmd.Connection = conn\nconn.Open\nDim mb As MySqlBackup = New MySqlBackup(cmd)\nmb.ExportToFile(\"C:\\backup.sql\")\nconn.Close\n</code></pre>\n\n<p><strong>Restore a MySql Database</strong></p>\n\n<pre><code>Dim conn As MySqlConnection = New MySqlConnection(constr)\nDim cmd As MySqlCommand = New MySqlCommand\ncmd.Connection = conn\nconn.Open\nDim mb As MySqlBackup = New MySqlBackup(cmd)\nmb.ImportFromFile(\"C:\\backup.sql\")\nconn.Close\n</code></pre>\n\n<p>I am one of the author of this project.</p>\n"
},
{
"answer_id": 14957354,
"author": "Allan Empalmado",
"author_id": 1119553,
"author_profile": "https://Stackoverflow.com/users/1119553",
"pm_score": 0,
"selected": false,
"text": "<p>This is what I use to backup data on mysql. I make a copy of mysqldump.exe and mysql.exe and store it on my LIB_PATH then the following code will backup your data. You can specify your mysqldump.exe directory and assign it to LIB_PATH, provide your login details under the Arguments then specify your output directory, mine is set to BACKUP_DIR and I use the preformatted Now() as my filename. The code is pretty straight forward. Goodluck</p>\n\n<pre><code> Using myProcess As New Process()\n Dim newfiledb As String = BACKUPDIR_PATH & Format(Now(), \"MMM_dd_yyyy@h~mm_tt\").ToString & \"_local.sql\"\n Try\n myProcess.StartInfo.FileName = \"mysqldump.exe\"\n myProcess.StartInfo.WorkingDirectory = LIB_PATH\n myProcess.StartInfo.Arguments = \"--host=localhost --user=username --password=yourpassword yourdatabase -r \" & newfiledb\n myProcess.StartInfo.WindowStyle = ProcessWindowStyle.Hidden\n myProcess.Start()\n myProcess.WaitForExit()\n MsgBox(\"Backup Created ... \" & vbNewLine & newfiledb)\n Catch ex As Exception\n MsgBox(ex.Message, vbCritical + vbOKOnly, ex.Message)\n Finally\n myProcess.Close()\n End Try\n End Using\n</code></pre>\n"
},
{
"answer_id": 29105049,
"author": "GGSoft",
"author_id": 3326849,
"author_profile": "https://Stackoverflow.com/users/3326849",
"pm_score": 2,
"selected": false,
"text": "<p>Use this code.\nIt works for me.</p>\n\n<p>I had such a problem and then found this article </p>\n\n<p>\"<a href=\"http://www.experts-exchange.com/Programming/Languages/.NET/Q_27155602.html\" rel=\"nofollow\">http://www.experts-exchange.com/Programming/Languages/.NET/Q_27155602.html</a>\"</p>\n\n<p>Example was in C#. I manually converted it into vb.net and add converting into 'utf8'.</p>\n\n<pre><code>Imports System.Text\nPublic Class Form1\n Dim OutputStream As System.IO.StreamWriter\n Sub OnDataReceived1(ByVal Sender As Object, ByVal e As System.Diagnostics.DataReceivedEventArgs)\n If e.Data IsNot Nothing Then\n Dim text As String = e.Data\n Dim bytes As Byte() = Encoding.Default.GetBytes(text)\n text = Encoding.UTF8.GetString(bytes)\n OutputStream.WriteLine(text)\n End If\n End Sub\n\n Sub CreateBackup()\n Dim mysqldumpPath As String = \"d:\\mysqldump.exe\"\n Dim host As String = \"localhost\"\n Dim user As String = \"root\"\n Dim pswd As String = \"Yourpwd\"\n Dim dbnm As String = \"BaseName\"\n Dim cmd As String = String.Format(\"-h{0} -u{1} -p{2} {3}\", host, user, pswd, dbnm)\n Dim filePath As String = \"d:\\backup\\fieName.sql\"\n OutputStream = New System.IO.StreamWriter(filePath, False, System.Text.Encoding.UTF8)\n\n Dim startInfo As System.Diagnostics.ProcessStartInfo = New System.Diagnostics.ProcessStartInfo()\n startInfo.FileName = mysqldumpPath\n startInfo.Arguments = cmd\n\n startInfo.RedirectStandardError = True\n startInfo.RedirectStandardInput = False\n startInfo.RedirectStandardOutput = True \n startInfo.UseShellExecute = False\n startInfo.CreateNoWindow = True\n startInfo.ErrorDialog = False\n\n Dim proc As System.Diagnostics.Process = New System.Diagnostics.Process()\n proc.StartInfo = startInfo\n AddHandler proc.OutputDataReceived, AddressOf OnDataReceived1\n proc.Start()\n proc.BeginOutputReadLine()\n proc.WaitForExit()\n\n OutputStream.Flush()\n OutputStream.Close()\n proc.Close()\n End Sub\n\n Private Sub Form1_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load\n\n CreateBackup()\n\n End Sub\n End Class\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190194",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25078/"
] |
How do you create a database backup of a mysql database in VB.Net?
|
You can use **MySqlBackup.NET**, which is an alternative to mysqldump.
Official Website & Documentation > <https://github.com/MySqlBackupNET/MySqlBackup.Net>
Examples:
**Backup a MySql Database**
```
Dim conn As MySqlConnection = New MySqlConnection(constr)
Dim cmd As MySqlCommand = New MySqlCommand
cmd.Connection = conn
conn.Open
Dim mb As MySqlBackup = New MySqlBackup(cmd)
mb.ExportToFile("C:\backup.sql")
conn.Close
```
**Restore a MySql Database**
```
Dim conn As MySqlConnection = New MySqlConnection(constr)
Dim cmd As MySqlCommand = New MySqlCommand
cmd.Connection = conn
conn.Open
Dim mb As MySqlBackup = New MySqlBackup(cmd)
mb.ImportFromFile("C:\backup.sql")
conn.Close
```
I am one of the author of this project.
|
190,198 |
<p>I am trying to generate equivalent MD5 hashes in both JavaScript and .Net. Not having done either, I decided to use against a third party calculation - this <a href="http://www.johnmaguire.us/tools/hashcalc/index.php?strtohash=password&mode=hash" rel="nofollow noreferrer">web site</a> for the word "password". I will add in salts later, but at the moment, I can't get the .net version to match up with the web site's hash:</p>
<pre><code>5f4dcc3b5aa765d61d8327deb882cf99
</code></pre>
<p>I'm guessing it is an encoding problem, but I've tried about 8 different variations of methods for calculating an MD5 hash in .Net, and none of them match what I have obtained in JavaScript (or from the web site). This <a href="http://msdn.microsoft.com/en-us/library/system.security.cryptography.md5.aspx" rel="nofollow noreferrer">MSDN example</a> is one of the methods I have tried, which results in this hash which i have commonly received: </p>
<pre><code>7c6a180b36896a0a8c02787eeafb0e4c
</code></pre>
<p>Edit: Sadly, I've accidentally been providing different source strings to the two different implementations. EBSAK. :-/ Still be interested to hear your answer to the follow-up.</p>
<p>Bonus question: what encoding/format would be best to store hashed values in a database?</p>
|
[
{
"answer_id": 190206,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 0,
"selected": false,
"text": "<p>I get the same value as that web site for the word \"password\":</p>\n\n<pre><code>$ echo -n password | md5\n5f4dcc3b5aa765d61d8327deb882cf99\n</code></pre>\n\n<p>Without seeing the code you are actually using, it's hard to tell what might be going wrong.</p>\n\n<p>As for storing hashes in a database, I store them as a hex string. Although most databases can handle binary blobs, storing them as binary only saves half the space and they're harder to query and manipulate. Chances are the <em>other</em> data you're storing along with the hash is larger anyway.</p>\n"
},
{
"answer_id": 190210,
"author": "Mark Glorie",
"author_id": 952,
"author_profile": "https://Stackoverflow.com/users/952",
"pm_score": 0,
"selected": false,
"text": "<p>This VB.Net version gives the same results as MySQL from my own experience: </p>\n\n<pre><code>Private Function MD5Hash(ByVal str As String) As String\n\n Dim md5 As MD5 = MD5CryptoServiceProvider.Create\n Dim hashed As Byte() = md5.ComputeHash(Encoding.Default.GetBytes(str))\n Dim sb As New StringBuilder\n\n For i As Integer = 0 To hashed.Length - 1\n sb.AppendFormat(\"{0:x2}\", hashed(i))\n Next\n\n Return sb.ToString\n\nEnd Function\n</code></pre>\n"
},
{
"answer_id": 190214,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 0,
"selected": false,
"text": "<p>Do you have any code how you are trying to do this?</p>\n\n<p>(response to second Q)I typically use a string field and store it as BASE64 encoding. Easy enough to work with and make comparisons.</p>\n\n<pre><code>/// <summary>\n/// Gets the Base 64 encoded SHA1 hashed password\n/// </summary>\n/// <returns>A Base 64 encoded string representing the SHA1 Hash of the password</returns>\npublic string ToBase64SHA1String()\n{\n return Convert.ToBase64String(this.GetSHA1HashCode());\n\n}\n</code></pre>\n"
},
{
"answer_id": 190226,
"author": "shoosh",
"author_id": 9611,
"author_profile": "https://Stackoverflow.com/users/9611",
"pm_score": 4,
"selected": true,
"text": "<p>Running the code from the MSDN site you quote:</p>\n\n<pre><code> // Hash an input string and return the hash as\n // a 32 character hexadecimal string.\n static string getMd5Hash(string input)\n {\n // Create a new instance of the MD5CryptoServiceProvider object.\n MD5 md5Hasher = MD5.Create();\n\n // Convert the input string to a byte array and compute the hash.\n byte[] data = md5Hasher.ComputeHash(Encoding.Default.GetBytes(input));\n\n // Create a new Stringbuilder to collect the bytes\n // and create a string.\n StringBuilder sBuilder = new StringBuilder();\n\n // Loop through each byte of the hashed data \n // and format each one as a hexadecimal string.\n for (int i = 0; i < data.Length; i++)\n {\n sBuilder.Append(data[i].ToString(\"x2\"));\n }\n\n // Return the hexadecimal string.\n return sBuilder.ToString();\n }\n\n\n static void Main(string[] args)\n {\n System.Console.WriteLine(getMd5Hash(\"password\"));\n }\n</code></pre>\n\n<p>returns:</p>\n\n<pre><code>5f4dcc3b5aa765d61d8327deb882cf99\n</code></pre>\n"
},
{
"answer_id": 2361021,
"author": "Adam",
"author_id": 272649,
"author_profile": "https://Stackoverflow.com/users/272649",
"pm_score": 0,
"selected": false,
"text": "<p>It should also be noted that MD5 sums can be cracked with rainbow tables (there are free programs on the internet that will accept an MD5 sum as an input and will output a plaintext - which is normally a password)</p>\n\n<p>SHA1 is probably a better choice...</p>\n\n<p><strong>EDIT:</strong> adding salt is a good way to prevent being your hash from being reversed<br>\n<strong>EDIT 2:</strong> if I had bothered to read your post I would've noticed you already mentioned that you plan to add salt</p>\n"
},
{
"answer_id": 7237431,
"author": "sharkswithlasers",
"author_id": 918760,
"author_profile": "https://Stackoverflow.com/users/918760",
"pm_score": 2,
"selected": false,
"text": "<p>This is happening because somehow you are hashing <code>password1</code> instead of <code>password</code>, or perhaps calculating the <code>password</code> incorrectly and it somehow mysteriously equals <code>password1</code>.</p>\n\n<p>You can do a reverse lookup of the md5 hash you provided by googling </p>\n\n<pre><code>7c6a180b36896a0a8c02787eeafb0e4c\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190198",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/525/"
] |
I am trying to generate equivalent MD5 hashes in both JavaScript and .Net. Not having done either, I decided to use against a third party calculation - this [web site](http://www.johnmaguire.us/tools/hashcalc/index.php?strtohash=password&mode=hash) for the word "password". I will add in salts later, but at the moment, I can't get the .net version to match up with the web site's hash:
```
5f4dcc3b5aa765d61d8327deb882cf99
```
I'm guessing it is an encoding problem, but I've tried about 8 different variations of methods for calculating an MD5 hash in .Net, and none of them match what I have obtained in JavaScript (or from the web site). This [MSDN example](http://msdn.microsoft.com/en-us/library/system.security.cryptography.md5.aspx) is one of the methods I have tried, which results in this hash which i have commonly received:
```
7c6a180b36896a0a8c02787eeafb0e4c
```
Edit: Sadly, I've accidentally been providing different source strings to the two different implementations. EBSAK. :-/ Still be interested to hear your answer to the follow-up.
Bonus question: what encoding/format would be best to store hashed values in a database?
|
Running the code from the MSDN site you quote:
```
// Hash an input string and return the hash as
// a 32 character hexadecimal string.
static string getMd5Hash(string input)
{
// Create a new instance of the MD5CryptoServiceProvider object.
MD5 md5Hasher = MD5.Create();
// Convert the input string to a byte array and compute the hash.
byte[] data = md5Hasher.ComputeHash(Encoding.Default.GetBytes(input));
// Create a new Stringbuilder to collect the bytes
// and create a string.
StringBuilder sBuilder = new StringBuilder();
// Loop through each byte of the hashed data
// and format each one as a hexadecimal string.
for (int i = 0; i < data.Length; i++)
{
sBuilder.Append(data[i].ToString("x2"));
}
// Return the hexadecimal string.
return sBuilder.ToString();
}
static void Main(string[] args)
{
System.Console.WriteLine(getMd5Hash("password"));
}
```
returns:
```
5f4dcc3b5aa765d61d8327deb882cf99
```
|
190,224 |
<p>I've made some unit tests (in test class). The tutorial I've read said that I should make a TestSuite for the unittests.</p>
<p>Odd is that when I'm running the unit test directly (selecting the test class - Run as jUnit test) everything is working fine, altough when I'm trying the same thing with the test suite there's always an exception: java.lang.Exception: No runnable methods.</p>
<p>Here is the code of the test suite:</p>
<pre><code>import junit.framework.Test;
import junit.framework.TestSuite;
public class AllTests {
public static Test suite() {
TestSuite suite = new TestSuite("Test suite for com.xxx.yyyy.test");
//$JUnit-BEGIN$
suite.addTestSuite(TestCase.class);
//$JUnit-END$
return suite;
}
}
</code></pre>
<p>Any ideas why this isn't working ?</p>
|
[
{
"answer_id": 190278,
"author": "gizmo",
"author_id": 9396,
"author_profile": "https://Stackoverflow.com/users/9396",
"pm_score": 0,
"selected": false,
"text": "<p>For sure, it won't work since you're not telling the test suite what are your test classes.</p>\n\n<p>But I'm wondering why you're not using the \"classical way\" for building Test suites, which is ant using jUnit's ant tasks.</p>\n"
},
{
"answer_id": 190347,
"author": "bernhardrusch",
"author_id": 3056,
"author_profile": "https://Stackoverflow.com/users/3056",
"pm_score": 4,
"selected": true,
"text": "<p>I'm not experienced in ant - so I'm not using it for testing it right now.</p>\n\n<p>Searching the internet it seems like I'm mixing up the old jUnit 3.8 and jUnit 4.0 behavior.\nTrying now a way to use the \"new behavior\"</p>\n\n<p>edited:<br>\nnow it works:</p>\n\n<p>AllTest changed to: </p>\n\n<pre><code>import org.junit.runner.RunWith;\nimport org.junit.runners.Suite;\nimport org.junit.runners.Suite.SuiteClasses;\n\n\n@RunWith(value=Suite.class)\n@SuiteClasses(value={TestCase.class})\npublic class AllTests {\n\n}\n</code></pre>\n\n<p>TestCase changed to:</p>\n\n<pre><code>import static org.junit.Assert.assertTrue;\nimport org.junit.Test;\n\npublic class TestCase {\n@Test\n public void test1 {\n assertTrue (tmp.getTermin().equals(soll));\n }\n}\n</code></pre>\n"
},
{
"answer_id": 985836,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>Took me a bit too to figure it out, but I think this solves your problem:</p>\n\n<p>You're doing a suite.addTestSuite(TestCase.class), while you should've done a suite.addTest(TestCase.class).</p>\n\n<p>You can also add a testsuite to a testsuite to create a whole hierarchy of testsuites. In that case you'll have to use suite.addTest(). But note that you then use .suite() and not .class: suite.addTest(MyTestSuite.<b>suite()</b>)!</p>\n"
},
{
"answer_id": 49088825,
"author": "AmiNadimi",
"author_id": 4192897,
"author_profile": "https://Stackoverflow.com/users/4192897",
"pm_score": 2,
"selected": false,
"text": "<p>Be careful when using an IDE's code-completion to add the import for <code>@Test</code>. It has to be <code>import org.junit.Test</code> and <strong>not</strong> <code>import org.testng.annotations.Test</code>, for example. If you use the second one by mistake, you'll get the \"no runnable methods\" error.\n(I was using Intellij Idea 2017 which imported <code>org.junit.jupiter.api.Test</code> instead!)</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190224",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3056/"
] |
I've made some unit tests (in test class). The tutorial I've read said that I should make a TestSuite for the unittests.
Odd is that when I'm running the unit test directly (selecting the test class - Run as jUnit test) everything is working fine, altough when I'm trying the same thing with the test suite there's always an exception: java.lang.Exception: No runnable methods.
Here is the code of the test suite:
```
import junit.framework.Test;
import junit.framework.TestSuite;
public class AllTests {
public static Test suite() {
TestSuite suite = new TestSuite("Test suite for com.xxx.yyyy.test");
//$JUnit-BEGIN$
suite.addTestSuite(TestCase.class);
//$JUnit-END$
return suite;
}
}
```
Any ideas why this isn't working ?
|
I'm not experienced in ant - so I'm not using it for testing it right now.
Searching the internet it seems like I'm mixing up the old jUnit 3.8 and jUnit 4.0 behavior.
Trying now a way to use the "new behavior"
edited:
now it works:
AllTest changed to:
```
import org.junit.runner.RunWith;
import org.junit.runners.Suite;
import org.junit.runners.Suite.SuiteClasses;
@RunWith(value=Suite.class)
@SuiteClasses(value={TestCase.class})
public class AllTests {
}
```
TestCase changed to:
```
import static org.junit.Assert.assertTrue;
import org.junit.Test;
public class TestCase {
@Test
public void test1 {
assertTrue (tmp.getTermin().equals(soll));
}
}
```
|
190,227 |
<p>Assume my objects are in perfect working order (i.e. TDD makes me think they work).</p>
<p>I have a list that I create like this (except indented properly):</p>
<pre><code>var result = from v in vendors
from p in v.Products
orderby p.Name
select p;
</code></pre>
<p>This works - I get all products from all vendors.</p>
<p>Now I have a list of conditions, built up at runtime by the user. Let's apply them:</p>
<pre><code>foreach (Attribute a in requiredAttributes)
{
result = result.Where(p => p.Attributes.Contains(a));
}
</code></pre>
<p>This may be primitive, but I thought it'd work. However, after this foreach loop is finished, when you enumerate "result" it will contain all products that has the LAST Attribute of the requiredAttributes collection in it's Attributes property (also a collection).</p>
<p>To me, this smells like "a" is overwritten somewhere with each trip trough the loop, and only the last one applies.</p>
<p>Short of somehow writing an extension method to IEnumerable called ContainsAll(IEnumerable) or something to that effect, how can I achieve what I want, which is basically a logical AND, giving me only those products that has ALL the required attributes?</p>
|
[
{
"answer_id": 190234,
"author": "Omer van Kloeten",
"author_id": 4979,
"author_profile": "https://Stackoverflow.com/users/4979",
"pm_score": 3,
"selected": false,
"text": "<pre><code>var result = from v in vendors\n from p in v.Products\n where requiredAttributes.All(a => p.Attributes.Contains(a))\n orderby p.Name\n select p;\n</code></pre>\n\n<p>HTH.</p>\n"
},
{
"answer_id": 190254,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 5,
"selected": true,
"text": "<p>(Edited for clarity.)</p>\n\n<p>The problem is the foreach loop, and the fact that the \"a\" variable is being captured and then changed each time. Here's a modification which will work, by effectively introducing a \"new\" variable for each iteration of the loop, and capturing that new variable.</p>\n\n<pre><code>foreach (Attribute a in requiredAttributes)\n{\n Attribute copy = a;\n result = result.Where(p => p.Attributes.Contains(copy));\n}\n</code></pre>\n\n<p>Omer's solution is a cleaner one if you can use it, but this may help if your real code is actually more complicated :)</p>\n\n<p>EDIT: There's more about the issue in <a href=\"http://csharpindepth.com/Articles/Chapter5/Closures.aspx\" rel=\"noreferrer\">this closures article</a> - scroll down to \"Comparing capture strategies: complexity vs power\".</p>\n"
},
{
"answer_id": 190260,
"author": "Brian",
"author_id": 19299,
"author_profile": "https://Stackoverflow.com/users/19299",
"pm_score": 3,
"selected": false,
"text": "<p>I haven't coded it up, but change</p>\n\n<pre><code>foreach (Attribute a in requiredAttributes){ \n result = result.Where(p => p.Attributes.Contains(a));\n}\n</code></pre>\n\n<p>to</p>\n\n<pre><code>foreach (Attribute a in requiredAttributes){ \n Attribute b = a;\n result = result.Where(p => p.Attributes.Contains(b));\n}\n</code></pre>\n\n<p>should fix it too, I think.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190227",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2122/"
] |
Assume my objects are in perfect working order (i.e. TDD makes me think they work).
I have a list that I create like this (except indented properly):
```
var result = from v in vendors
from p in v.Products
orderby p.Name
select p;
```
This works - I get all products from all vendors.
Now I have a list of conditions, built up at runtime by the user. Let's apply them:
```
foreach (Attribute a in requiredAttributes)
{
result = result.Where(p => p.Attributes.Contains(a));
}
```
This may be primitive, but I thought it'd work. However, after this foreach loop is finished, when you enumerate "result" it will contain all products that has the LAST Attribute of the requiredAttributes collection in it's Attributes property (also a collection).
To me, this smells like "a" is overwritten somewhere with each trip trough the loop, and only the last one applies.
Short of somehow writing an extension method to IEnumerable called ContainsAll(IEnumerable) or something to that effect, how can I achieve what I want, which is basically a logical AND, giving me only those products that has ALL the required attributes?
|
(Edited for clarity.)
The problem is the foreach loop, and the fact that the "a" variable is being captured and then changed each time. Here's a modification which will work, by effectively introducing a "new" variable for each iteration of the loop, and capturing that new variable.
```
foreach (Attribute a in requiredAttributes)
{
Attribute copy = a;
result = result.Where(p => p.Attributes.Contains(copy));
}
```
Omer's solution is a cleaner one if you can use it, but this may help if your real code is actually more complicated :)
EDIT: There's more about the issue in [this closures article](http://csharpindepth.com/Articles/Chapter5/Closures.aspx) - scroll down to "Comparing capture strategies: complexity vs power".
|
190,229 |
<p><code>itoa()</code> is a really handy function to convert a number to a string. Linux does not seem to have <code>itoa()</code>, is there an equivalent function or do I have to use <code>sprintf(str, "%d", num)</code>?</p>
|
[
{
"answer_id": 190235,
"author": "Matt J",
"author_id": 18528,
"author_profile": "https://Stackoverflow.com/users/18528",
"pm_score": 8,
"selected": true,
"text": "<p>EDIT: Sorry, I should have remembered that this machine is decidedly non-standard, having plugged in various non-standard <code>libc</code> implementations for academic purposes ;-)</p>\n\n<p>As <code>itoa()</code> is indeed non-standard, as mentioned by several helpful commenters, it is best to use <code>sprintf(target_string,\"%d\",source_int)</code> or (better yet, because it's safe from buffer overflows) <code>snprintf(target_string, size_of_target_string_in_bytes, \"%d\", source_int)</code>. I know it's not quite as concise or cool as <code>itoa()</code>, but at least you can Write Once, Run Everywhere (tm) ;-)</p>\n\n<h2>Here's the old (edited) answer</h2>\n\n<p>You are correct in stating that the default <code>gcc libc</code> does not include <code>itoa()</code>, like several other platforms, due to it not technically being a part of the standard. See <a href=\"http://www.cplusplus.com/reference/clibrary/cstdlib/itoa.html\" rel=\"noreferrer\">here</a> for a little more info. Note that you have to </p>\n\n<pre><code>#include <stdlib.h>\n</code></pre>\n\n<p>Of course you already know this, because you wanted to <em>use</em> <code>itoa()</code> on Linux after presumably using it on another platform, but... the code (stolen from the link above) would look like:</p>\n\n<p><strong>Example</strong></p>\n\n<pre><code>/* itoa example */\n#include <stdio.h>\n#include <stdlib.h>\n\nint main ()\n{\n int i;\n char buffer [33];\n printf (\"Enter a number: \");\n scanf (\"%d\",&i);\n itoa (i,buffer,10);\n printf (\"decimal: %s\\n\",buffer);\n itoa (i,buffer,16);\n printf (\"hexadecimal: %s\\n\",buffer);\n itoa (i,buffer,2);\n printf (\"binary: %s\\n\",buffer);\n return 0;\n}\n</code></pre>\n\n<p><strong>Output:</strong></p>\n\n<blockquote>\n<pre><code>Enter a number: 1750\ndecimal: 1750\nhexadecimal: 6d6\nbinary: 11011010110\n</code></pre>\n</blockquote>\n\n<p>Hope this helps!</p>\n"
},
{
"answer_id": 190250,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>As Matt J wrote, there is <code>itoa</code>, but it's not standard. Your code will be more portable if you use <code>snprintf</code>.</p>\n"
},
{
"answer_id": 191957,
"author": "m_pGladiator",
"author_id": 446104,
"author_profile": "https://Stackoverflow.com/users/446104",
"pm_score": 0,
"selected": false,
"text": "<p>I have used _itoa(...) on RedHat 6 and GCC compiler. It works.</p>\n"
},
{
"answer_id": 192700,
"author": "James Antill",
"author_id": 10314,
"author_profile": "https://Stackoverflow.com/users/10314",
"pm_score": 4,
"selected": false,
"text": "<p>If you are calling it a lot, the advice of \"just use snprintf\" can be annoying. So here's what you probably want:</p>\n\n<pre><code>const char *my_itoa_buf(char *buf, size_t len, int num)\n{\n static char loc_buf[sizeof(int) * CHAR_BITS]; /* not thread safe */\n\n if (!buf)\n {\n buf = loc_buf;\n len = sizeof(loc_buf);\n }\n\n if (snprintf(buf, len, \"%d\", num) == -1)\n return \"\"; /* or whatever */\n\n return buf;\n}\n\nconst char *my_itoa(int num)\n{ return my_itoa_buf(NULL, 0, num); }\n</code></pre>\n"
},
{
"answer_id": 12085310,
"author": "Archana Chatterjee",
"author_id": 1618752,
"author_profile": "https://Stackoverflow.com/users/1618752",
"pm_score": -1,
"selected": false,
"text": "<p>You can use this program instead of sprintf.</p>\n\n<pre><code>void itochar(int x, char *buffer, int radix);\n\nint main()\n{\n char buffer[10];\n itochar(725, buffer, 10);\n printf (\"\\n %s \\n\", buffer);\n return 0;\n}\n\nvoid itochar(int x, char *buffer, int radix)\n{\n int i = 0 , n,s;\n n = s;\n while (n > 0)\n {\n s = n%radix;\n n = n/radix;\n buffer[i++] = '0' + s;\n }\n buffer[i] = '\\0';\n strrev(buffer);\n}\n</code></pre>\n"
},
{
"answer_id": 13361077,
"author": "mmdemirbas",
"author_id": 471214,
"author_profile": "https://Stackoverflow.com/users/471214",
"pm_score": 3,
"selected": false,
"text": "<p>Following function allocates just enough memory to keep string representation of the given number and then writes the string representation into this area using standard <code>sprintf</code> method.</p>\n\n<pre><code>char *itoa(long n)\n{\n int len = n==0 ? 1 : floor(log10l(labs(n)))+1;\n if (n<0) len++; // room for negative sign '-'\n\n char *buf = calloc(sizeof(char), len+1); // +1 for null\n snprintf(buf, len+1, \"%ld\", n);\n return buf;\n}\n</code></pre>\n\n<p>Don't forget to <code>free</code> up allocated memory when out of need:</p>\n\n<pre><code>char *num_str = itoa(123456789L);\n// ... \nfree(num_str);\n</code></pre>\n\n<p>N.B. As snprintf copies n-1 bytes, we have to call snprintf(buf, len+1, \"%ld\", n) (not just snprintf(buf, len, \"%ld\", n))</p>\n"
},
{
"answer_id": 13388063,
"author": "Mark Ransom",
"author_id": 5987,
"author_profile": "https://Stackoverflow.com/users/5987",
"pm_score": 3,
"selected": false,
"text": "<p><strong>Edit:</strong> I just found out about <a href=\"http://en.cppreference.com/w/cpp/string/basic_string/to_string\"><code>std::to_string</code></a> which is identical in operation to my own function below. It was introduced in C++11 and is available in recent versions of gcc, at least as early as 4.5 if you enable the c++0x extensions.\n<hr>\nNot only is <code>itoa</code> missing from gcc, it's not the handiest function to use since you need to feed it a buffer. I needed something that could be used in an expression so I came up with this:</p>\n\n<pre><code>std::string itos(int n)\n{\n const int max_size = std::numeric_limits<int>::digits10 + 1 /*sign*/ + 1 /*0-terminator*/;\n char buffer[max_size] = {0};\n sprintf(buffer, \"%d\", n);\n return std::string(buffer);\n}\n</code></pre>\n\n<p>Ordinarily it would be safer to use <code>snprintf</code> instead of <code>sprintf</code> but the buffer is carefully sized to be immune to overrun.</p>\n\n<p>See an example: <a href=\"http://ideone.com/mKmZVE\">http://ideone.com/mKmZVE</a></p>\n"
},
{
"answer_id": 14394283,
"author": "the sudhakar",
"author_id": 1989534,
"author_profile": "https://Stackoverflow.com/users/1989534",
"pm_score": 2,
"selected": false,
"text": "<p>direct copy to buffer : 64 bit integer itoa hex :</p>\n\n<pre><code> char* itoah(long num, char* s, int len)\n {\n long n, m = 16;\n int i = 16+2;\n int shift = 'a'- ('9'+1);\n\n\n if(!s || len < 1)\n return 0;\n\n n = num < 0 ? -1 : 1;\n n = n * num;\n\n len = len > i ? i : len;\n i = len < i ? len : i;\n\n s[i-1] = 0;\n i--;\n\n if(!num)\n {\n if(len < 2)\n return &s[i];\n\n s[i-1]='0';\n return &s[i-1];\n }\n\n while(i && n)\n {\n s[i-1] = n % m + '0';\n\n if (s[i-1] > '9')\n s[i-1] += shift ;\n\n n = n/m;\n i--;\n }\n\n if(num < 0)\n {\n if(i)\n {\n s[i-1] = '-';\n i--;\n }\n }\n\n return &s[i];\n }\n</code></pre>\n\n<p>note: change long to long long for 32 bit machine. long to int in case for 32 bit integer. m is the radix. When decreasing radix, increase number of characters (variable i). When increasing radix, decrease number of characters (better). In case of unsigned data type, i just becomes 16 + 1.</p>\n"
},
{
"answer_id": 16042640,
"author": "Chris Desjardins",
"author_id": 1602642,
"author_profile": "https://Stackoverflow.com/users/1602642",
"pm_score": 2,
"selected": false,
"text": "<p>Here is a much improved version of Archana's solution. It works for any radix 1-16, and numbers <= 0, and it shouldn't clobber memory. </p>\n\n<pre><code>static char _numberSystem[] = \"0123456789ABCDEF\";\nstatic char _twosComp[] = \"FEDCBA9876543210\";\n\nstatic void safestrrev(char *buffer, const int bufferSize, const int strlen)\n{\n int len = strlen;\n if (len > bufferSize)\n {\n len = bufferSize;\n }\n for (int index = 0; index < (len / 2); index++)\n {\n char ch = buffer[index];\n buffer[index] = buffer[len - index - 1];\n buffer[len - index - 1] = ch;\n }\n}\n\nstatic int negateBuffer(char *buffer, const int bufferSize, const int strlen, const int radix)\n{\n int len = strlen;\n if (len > bufferSize)\n {\n len = bufferSize;\n }\n if (radix == 10)\n {\n if (len < (bufferSize - 1))\n {\n buffer[len++] = '-';\n buffer[len] = '\\0';\n }\n }\n else\n {\n int twosCompIndex = 0;\n for (int index = 0; index < len; index++)\n {\n if ((buffer[index] >= '0') && (buffer[index] <= '9'))\n {\n twosCompIndex = buffer[index] - '0';\n }\n else if ((buffer[index] >= 'A') && (buffer[index] <= 'F'))\n {\n twosCompIndex = buffer[index] - 'A' + 10;\n }\n else if ((buffer[index] >= 'a') && (buffer[index] <= 'f'))\n {\n twosCompIndex = buffer[index] - 'a' + 10;\n }\n twosCompIndex += (16 - radix);\n buffer[index] = _twosComp[twosCompIndex];\n }\n if (len < (bufferSize - 1))\n {\n buffer[len++] = _numberSystem[radix - 1];\n buffer[len] = 0;\n }\n }\n return len;\n}\n\nstatic int twosNegation(const int x, const int radix)\n{\n int n = x;\n if (x < 0)\n {\n if (radix == 10)\n {\n n = -x;\n }\n else\n {\n n = ~x;\n }\n }\n return n;\n}\n\nstatic char *safeitoa(const int x, char *buffer, const int bufferSize, const int radix)\n{\n int strlen = 0;\n int n = twosNegation(x, radix);\n int nuberSystemIndex = 0;\n\n if (radix <= 16)\n {\n do\n {\n if (strlen < (bufferSize - 1))\n {\n nuberSystemIndex = (n % radix);\n buffer[strlen++] = _numberSystem[nuberSystemIndex];\n buffer[strlen] = '\\0';\n n = n / radix;\n }\n else\n {\n break;\n }\n } while (n != 0);\n if (x < 0)\n {\n strlen = negateBuffer(buffer, bufferSize, strlen, radix);\n }\n safestrrev(buffer, bufferSize, strlen);\n return buffer;\n }\n return NULL;\n}\n</code></pre>\n"
},
{
"answer_id": 16095691,
"author": "waaagh",
"author_id": 1610731,
"author_profile": "https://Stackoverflow.com/users/1610731",
"pm_score": 2,
"selected": false,
"text": "<p>i tried my own implementation of itoa(), it seem's work in binary, octal, decimal and hex</p>\n\n<pre><code>#define INT_LEN (10)\n#define HEX_LEN (8)\n#define BIN_LEN (32)\n#define OCT_LEN (11)\n\nstatic char * my_itoa ( int value, char * str, int base )\n{\n int i,n =2,tmp;\n char buf[BIN_LEN+1];\n\n\n switch(base)\n {\n case 16:\n for(i = 0;i<HEX_LEN;++i)\n {\n if(value/base>0)\n {\n n++;\n }\n }\n snprintf(str, n, \"%x\" ,value);\n break;\n case 10:\n for(i = 0;i<INT_LEN;++i)\n {\n if(value/base>0)\n {\n n++;\n }\n }\n snprintf(str, n, \"%d\" ,value);\n break;\n case 8:\n for(i = 0;i<OCT_LEN;++i)\n {\n if(value/base>0)\n {\n n++;\n }\n }\n snprintf(str, n, \"%o\" ,value);\n break;\n case 2:\n for(i = 0,tmp = value;i<BIN_LEN;++i)\n {\n if(tmp/base>0)\n {\n n++;\n }\n tmp/=base;\n }\n for(i = 1 ,tmp = value; i<n;++i)\n {\n if(tmp%2 != 0)\n {\n buf[n-i-1] ='1';\n }\n else\n {\n buf[n-i-1] ='0';\n }\n tmp/=base;\n }\n buf[n-1] = '\\0';\n strcpy(str,buf);\n break;\n default:\n return NULL;\n }\n return str;\n}\n</code></pre>\n"
},
{
"answer_id": 21168986,
"author": "Andres Romero",
"author_id": 1126085,
"author_profile": "https://Stackoverflow.com/users/1126085",
"pm_score": 2,
"selected": false,
"text": "<p>If you just want to print them:</p>\n\n<pre><code>void binary(unsigned int n)\n{\n for(int shift=sizeof(int)*8-1;shift>=0;shift--)\n {\n if (n >> shift & 1)\n printf(\"1\");\n else\n printf(\"0\");\n\n }\n printf(\"\\n\");\n} \n</code></pre>\n"
},
{
"answer_id": 29544416,
"author": "haccks",
"author_id": 2455888,
"author_profile": "https://Stackoverflow.com/users/2455888",
"pm_score": 5,
"selected": false,
"text": "<p><a href=\"http://en.wikibooks.org/wiki/C_Programming/C_Reference/stdlib.h/itoa\" rel=\"noreferrer\"><code>itoa</code></a> is not a standard C function. You can implement your own. It appeared in the first edition of <em>Kernighan</em> and <em>Ritchie's</em> <strong>The C Programming Language</strong>, on page 60. The second edition of The C Programming Language (\"K&R2\") contains the following implementation of <code>itoa</code>, on page 64. The book notes several issues with this implementation, including the fact that <strong>it does not correctly handle the most negative number</strong> </p>\n\n<pre><code> /* itoa: convert n to characters in s */\n void itoa(int n, char s[])\n {\n int i, sign;\n\n if ((sign = n) < 0) /* record sign */\n n = -n; /* make n positive */\n i = 0;\n do { /* generate digits in reverse order */\n s[i++] = n % 10 + '0'; /* get next digit */\n } while ((n /= 10) > 0); /* delete it */\n if (sign < 0)\n s[i++] = '-';\n s[i] = '\\0';\n reverse(s);\n} \n</code></pre>\n\n<p>The function <code>reverse</code> used above is implemented two pages earlier:</p>\n\n<pre><code> #include <string.h>\n\n /* reverse: reverse string s in place */\n void reverse(char s[])\n {\n int i, j;\n char c;\n\n for (i = 0, j = strlen(s)-1; i<j; i++, j--) {\n c = s[i];\n s[i] = s[j];\n s[j] = c;\n }\n} \n</code></pre>\n"
},
{
"answer_id": 29544825,
"author": "chux - Reinstate Monica",
"author_id": 2410359,
"author_profile": "https://Stackoverflow.com/users/2410359",
"pm_score": 2,
"selected": false,
"text": "<blockquote>\n <p>Where is the itoa function in Linux?</p>\n</blockquote>\n\n<p>As <code>itoa()</code> is not standard in C, various versions with various function signatures exists.<br>\n<code>char *itoa(int value, char *str, int base);</code> is common in *nix.</p>\n\n<p>Should it be missing from Linux or if code does not want to limit portability, code could make it own.</p>\n\n<p>Below is a version that does not have trouble with <code>INT_MIN</code> and handles problem buffers: <code>NULL</code> or an insufficient buffer returns <code>NULL</code>.</p>\n\n<pre><code>#include <stdlib.h>\n#include <limits.h>\n#include <string.h>\n\n// Buffer sized for a decimal string of a `signed int`, 28/93 > log10(2)\n#define SIGNED_PRINT_SIZE(object) ((sizeof(object) * CHAR_BIT - 1)* 28 / 93 + 3)\n\nchar *itoa_x(int number, char *dest, size_t dest_size) {\n if (dest == NULL) {\n return NULL;\n }\n\n char buf[SIGNED_PRINT_SIZE(number)];\n char *p = &buf[sizeof buf - 1];\n\n // Work with negative absolute value\n int neg_num = number < 0 ? number : -number;\n\n // Form string\n *p = '\\0';\n do {\n *--p = (char) ('0' - neg_num % 10);\n neg_num /= 10;\n } while (neg_num);\n if (number < 0) {\n *--p = '-';\n }\n\n // Copy string\n size_t src_size = (size_t) (&buf[sizeof buf] - p);\n if (src_size > dest_size) {\n // Not enough room\n return NULL;\n }\n return memcpy(dest, p, src_size);\n}\n</code></pre>\n\n<hr>\n\n<p>Below is a C99 or later version that handles any base [2...36]</p>\n\n<pre><code>char *itoa_x(int number, char *dest, size_t dest_size, int base) {\n if (dest == NULL || base < 2 || base > 36) {\n return NULL;\n }\n\n char buf[sizeof number * CHAR_BIT + 2]; // worst case: itoa(INT_MIN,,,2)\n char *p = &buf[sizeof buf - 1];\n\n // Work with negative absolute value to avoid UB of `abs(INT_MIN)`\n int neg_num = number < 0 ? number : -number;\n\n // Form string\n *p = '\\0';\n do {\n *--p = \"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ\"[-(neg_num % base)];\n neg_num /= base;\n } while (neg_num);\n if (number < 0) {\n *--p = '-';\n }\n\n // Copy string\n size_t src_size = (size_t) (&buf[sizeof buf] - p);\n if (src_size > dest_size) {\n // Not enough room\n return NULL;\n }\n return memcpy(dest, p, src_size);\n}\n</code></pre>\n\n<p>For a C89 and onward compliant code, replace inner loop with</p>\n\n<pre><code> div_t qr;\n do {\n qr = div(neg_num, base);\n *--p = \"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ\"[-qr.rem];\n neg_num = qr.quot;\n } while (neg_num);\n</code></pre>\n"
},
{
"answer_id": 36391225,
"author": "Vlatko Šurlan",
"author_id": 2924916,
"author_profile": "https://Stackoverflow.com/users/2924916",
"pm_score": 2,
"selected": false,
"text": "<p>Reading the code of guys who do it for a living will get you a LONG WAY.</p>\n\n<p>Check out how guys from MySQL did it. The source is VERY WELL COMMENTED and will teach you much more than hacked up solutions found all over the place.</p>\n\n<p><a href=\"https://github.com/mysql/mysql-server/blob/5.7/strings/int2str.c\" rel=\"nofollow\">MySQL's implementation of int2str</a></p>\n\n<p>I provide the mentioned implementation here; the link is here for reference and should be used to read the full implementation.</p>\n\n<pre><code>char *\nint2str(long int val, char *dst, int radix, \n int upcase)\n{\n char buffer[65];\n char *p;\n long int new_val;\n char *dig_vec= upcase ? _dig_vec_upper : _dig_vec_lower;\n ulong uval= (ulong) val;\n\n if (radix < 0)\n {\n if (radix < -36 || radix > -2)\n return NullS;\n if (val < 0)\n {\n *dst++ = '-';\n /* Avoid integer overflow in (-val) for LLONG_MIN (BUG#31799). */\n uval = (ulong)0 - uval;\n }\n radix = -radix;\n }\n else if (radix > 36 || radix < 2)\n return NullS;\n\n /*\n The slightly contorted code which follows is due to the fact that\n few machines directly support unsigned long / and %. Certainly\n the VAX C compiler generates a subroutine call. In the interests\n of efficiency (hollow laugh) I let this happen for the first digit\n only; after that \"val\" will be in range so that signed integer\n division will do. Sorry 'bout that. CHECK THE CODE PRODUCED BY\n YOUR C COMPILER. The first % and / should be unsigned, the second\n % and / signed, but C compilers tend to be extraordinarily\n sensitive to minor details of style. This works on a VAX, that's\n all I claim for it.\n */\n p = &buffer[sizeof(buffer)-1];\n *p = '\\0';\n new_val= uval / (ulong) radix;\n *--p = dig_vec[(uchar) (uval- (ulong) new_val*(ulong) radix)];\n val = new_val;\n while (val != 0)\n {\n ldiv_t res;\n res=ldiv(val,radix);\n *--p = dig_vec[res.rem];\n val= res.quot;\n }\n while ((*dst++ = *p++) != 0) ;\n return dst-1;\n}\n</code></pre>\n"
},
{
"answer_id": 46732059,
"author": "rick-rick-rick",
"author_id": 8741673,
"author_profile": "https://Stackoverflow.com/users/8741673",
"pm_score": 3,
"selected": false,
"text": "<blockquote>\n <p>Where is the itoa function in Linux?</p>\n</blockquote>\n\n<p>There is no such function in Linux. I use this code instead.</p>\n\n<pre><code>/*\n=============\nitoa\n\nConvert integer to string\n\nPARAMS:\n- value A 64-bit number to convert\n- str Destination buffer; should be 66 characters long for radix2, 24 - radix8, 22 - radix10, 18 - radix16.\n- radix Radix must be in range -36 .. 36. Negative values used for signed numbers.\n=============\n*/\n\nchar* itoa (unsigned long long value, char str[], int radix)\n{\n char buf [66];\n char* dest = buf + sizeof(buf);\n boolean sign = false;\n\n if (value == 0) {\n memcpy (str, \"0\", 2);\n return str;\n }\n\n if (radix < 0) {\n radix = -radix;\n if ( (long long) value < 0) {\n value = -value;\n sign = true;\n }\n }\n\n *--dest = '\\0';\n\n switch (radix)\n {\n case 16:\n while (value) {\n * --dest = '0' + (value & 0xF);\n if (*dest > '9') *dest += 'A' - '9' - 1;\n value >>= 4;\n }\n break;\n case 10:\n while (value) {\n *--dest = '0' + (value % 10);\n value /= 10;\n }\n break;\n\n case 8:\n while (value) {\n *--dest = '0' + (value & 7);\n value >>= 3;\n }\n break;\n\n case 2:\n while (value) {\n *--dest = '0' + (value & 1);\n value >>= 1;\n }\n break;\n\n default: // The slow version, but universal\n while (value) {\n *--dest = '0' + (value % radix);\n if (*dest > '9') *dest += 'A' - '9' - 1;\n value /= radix;\n }\n break;\n }\n\n if (sign) *--dest = '-';\n\n memcpy (str, dest, buf +sizeof(buf) - dest);\n return str;\n}\n</code></pre>\n"
},
{
"answer_id": 52127877,
"author": "Ciro Santilli OurBigBook.com",
"author_id": 895245,
"author_profile": "https://Stackoverflow.com/users/895245",
"pm_score": 2,
"selected": false,
"text": "<p><strong>glibc internal implementation</strong></p>\n\n<p>glibc 2.28 has an internal implementation:</p>\n\n<ul>\n<li><a href=\"https://sourceware.org/git/?p=glibc.git;a=blob;f=stdio-common/_itoa.c;h=3749ee97e320ceb62cbf76b6c93dd2beb38fe157;hb=3c03baca37fdcb52c3881e653ca392bba7a99c2b\" rel=\"nofollow noreferrer\">stdio-common/_itoa.c</a></li>\n<li><a href=\"https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/generic/_itoa.h;h=3749ee97e320ceb62cbf76b6c93dd2beb38fe157;hb=3c03baca37fdcb52c3881e653ca392bba7a99c2b\" rel=\"nofollow noreferrer\">sysdeps/generic/_itoa.h</a></li>\n</ul>\n\n<p>which is used in several places internally, but I could not find if it can be exposed or how.</p>\n\n<p>At least that should be a robust implementation if you are willing to extract it.</p>\n\n<p>This question asks how to roll your own: <a href=\"https://stackoverflow.com/questions/8257714/how-to-convert-an-int-to-string-in-c\">How to convert an int to string in C?</a></p>\n"
},
{
"answer_id": 55673979,
"author": "Zakhar",
"author_id": 5374102,
"author_profile": "https://Stackoverflow.com/users/5374102",
"pm_score": 1,
"selected": false,
"text": "<p>The replacement with snprintf is NOT complete!</p>\n\n<p>It covers only bases: 2, 8, 10, 16, whereas itoa works for bases between 2 and 36.</p>\n\n<p>Since I was searching a replacement for base 32, I guess I'll have to code my own!</p>\n"
},
{
"answer_id": 57456279,
"author": "Danger Saints",
"author_id": 200513,
"author_profile": "https://Stackoverflow.com/users/200513",
"pm_score": 2,
"selected": false,
"text": "<p>I would prefer this: <a href=\"https://github.com/wsq003/itoa_for_linux\" rel=\"nofollow noreferrer\">https://github.com/wsq003/itoa_for_linux</a></p>\n\n<p>It should be the fastest itoa() ever. We use itoa() instead of sprintf() for performance reason, so a fastest itoa() with limited feature is reasonable and worthwhile.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190229",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5324/"
] |
`itoa()` is a really handy function to convert a number to a string. Linux does not seem to have `itoa()`, is there an equivalent function or do I have to use `sprintf(str, "%d", num)`?
|
EDIT: Sorry, I should have remembered that this machine is decidedly non-standard, having plugged in various non-standard `libc` implementations for academic purposes ;-)
As `itoa()` is indeed non-standard, as mentioned by several helpful commenters, it is best to use `sprintf(target_string,"%d",source_int)` or (better yet, because it's safe from buffer overflows) `snprintf(target_string, size_of_target_string_in_bytes, "%d", source_int)`. I know it's not quite as concise or cool as `itoa()`, but at least you can Write Once, Run Everywhere (tm) ;-)
Here's the old (edited) answer
------------------------------
You are correct in stating that the default `gcc libc` does not include `itoa()`, like several other platforms, due to it not technically being a part of the standard. See [here](http://www.cplusplus.com/reference/clibrary/cstdlib/itoa.html) for a little more info. Note that you have to
```
#include <stdlib.h>
```
Of course you already know this, because you wanted to *use* `itoa()` on Linux after presumably using it on another platform, but... the code (stolen from the link above) would look like:
**Example**
```
/* itoa example */
#include <stdio.h>
#include <stdlib.h>
int main ()
{
int i;
char buffer [33];
printf ("Enter a number: ");
scanf ("%d",&i);
itoa (i,buffer,10);
printf ("decimal: %s\n",buffer);
itoa (i,buffer,16);
printf ("hexadecimal: %s\n",buffer);
itoa (i,buffer,2);
printf ("binary: %s\n",buffer);
return 0;
}
```
**Output:**
>
>
> ```
> Enter a number: 1750
> decimal: 1750
> hexadecimal: 6d6
> binary: 11011010110
>
> ```
>
>
Hope this helps!
|
190,232 |
<pre><code>inline int factorial(int n)
{
if(!n) return 1;
else return n*factorial(n-1);
}
</code></pre>
<p>As I was reading <a href="https://rads.stackoverflow.com/amzn/click/com/0201543303" rel="noreferrer" rel="nofollow noreferrer">this</a>, found that the above code would lead to "infinite compilation" if not handled by compiler correctly.</p>
<p>How does the compiler decide whether to inline a function or not ?</p>
|
[
{
"answer_id": 190245,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 1,
"selected": false,
"text": "<p>The compiler will make a call graph to detect these sorts of things and prevent them. So it would see that the function calls itself and not inline. </p>\n\n<p>But mainly it is controlled by the inline keyword and compiler switches(For example, you can have it auto inline small functions even without the keyword.) Its important to note that Debug compilations should never be inlining as the callstack will not be preserved to mirror the calls you created in code.</p>\n"
},
{
"answer_id": 190256,
"author": "Matt J",
"author_id": 18528,
"author_profile": "https://Stackoverflow.com/users/18528",
"pm_score": 5,
"selected": false,
"text": "<p>Indeed, if your compiler does not act intelligently, it may try inserting copies of your <code>inline</code>d function recursively, creating infinitely-large code. Most modern compilers will recognize this, however. They can either:</p>\n\n<ol>\n<li>Not inline the function at all</li>\n<li>Inline it up to a certain depth, and if it hasn't terminated by then, call the separate instance of your function using the standard function calling convention. This can take care of many common cases in a high-performance manner, while leaving a fallback for the rare case with a large call depth. This also means that you keep both inlined and separate versions of that function's code around.</li>\n</ol>\n\n<p>For case 2, many compilers have <code>#pragma</code>s you can set to specify the maximum depth to which this should be done. In <em>gcc</em>, you can also pass this in from the command-line with <code>--max-inline-insns-recursive</code> (see more info <a href=\"http://gcc.gnu.org/onlinedocs/gcc-4.0.4/gcc/Optimize-Options.html\" rel=\"noreferrer\">here</a>).</p>\n"
},
{
"answer_id": 190262,
"author": "Paul Nathan",
"author_id": 26227,
"author_profile": "https://Stackoverflow.com/users/26227",
"pm_score": 3,
"selected": false,
"text": "<p>The compiler creates a call graph; when a cycle is detected calling itself, the function is no longer inlined after a certain depth(n=1, 10, 100, whatever the compiler is tuned to).</p>\n"
},
{
"answer_id": 190268,
"author": "Derek Park",
"author_id": 872,
"author_profile": "https://Stackoverflow.com/users/872",
"pm_score": 8,
"selected": true,
"text": "<p>First, the <code>inline</code> specification on a function is just a hint. The compiler can (and often does) completely ignore the presence or absence of an <code>inline</code> qualifier. With that said, a compiler <em>can</em> inline a recursive function, much as it can unroll an infinite loop. It simply has to place a limit on the level to which it will \"unroll\" the function.</p>\n\n<p>An optimizing compiler might turn this code:</p>\n\n<pre><code>inline int factorial(int n)\n{\n if (n <= 1)\n {\n return 1;\n }\n else\n {\n return n * factorial(n - 1);\n }\n}\n\nint f(int x)\n{\n return factorial(x);\n}\n</code></pre>\n\n<p>into this code:</p>\n\n<pre><code>int factorial(int n)\n{\n if (n <= 1)\n {\n return 1;\n }\n else\n {\n return n * factorial(n - 1);\n }\n}\n\nint f(int x)\n{\n if (x <= 1)\n {\n return 1;\n }\n else\n {\n int x2 = x - 1;\n if (x2 <= 1)\n {\n return x * 1;\n }\n else\n {\n int x3 = x2 - 1;\n if (x3 <= 1)\n {\n return x * x2 * 1;\n }\n else\n {\n return x * x2 * x3 * factorial(x3 - 1);\n }\n }\n }\n}\n</code></pre>\n\n<p>In this case, we've basically inlined the function 3 times. Some compilers <em>do</em> perform this optimization. I recall MSVC++ having a setting to tune the level of inlining that would be performed on recursive functions (up to 20, I believe).</p>\n"
},
{
"answer_id": 190273,
"author": "Windows programmer",
"author_id": 23705,
"author_profile": "https://Stackoverflow.com/users/23705",
"pm_score": 1,
"selected": false,
"text": "<p>\"How does the compiler decide whether to inline a function or not ?\"</p>\n\n<p>That depends on the compiler, the options that were specified, the version number of the compiler, maybe how much memory is available, etc.</p>\n\n<p>The program's source code still has to obey the rules for inlined functions. Whether or not the function gets inlined, you have to prepare for the possibility that it will be inlined (some unknown number of times).</p>\n\n<p>The Wikipedia statement that recursive macros are typically illegal looks rather poorly informed. C and C++ prevent recursive invocations but a translation unit doesn't become illegal by containing macro code that looks like it would have been recursive. In assemblers, recursive macros are typically legal.</p>\n"
},
{
"answer_id": 190275,
"author": "yungchin",
"author_id": 25756,
"author_profile": "https://Stackoverflow.com/users/25756",
"pm_score": 2,
"selected": false,
"text": "<p>See the answers already given for why this won't typically work.</p>\n\n<p>As a \"footnote\", you could achieve the effect you're looking for (at least for the factorial you're using as an example) using <a href=\"http://en.wikipedia.org/wiki/Template_metaprogramming#Compile-time_class_generation\" rel=\"nofollow noreferrer\">template metaprogramming</a>. Pasting from Wikipedia:</p>\n\n<pre><code>template <int N>\nstruct Factorial \n{\n enum { value = N * Factorial<N - 1>::value };\n};\n\ntemplate <>\nstruct Factorial<0> \n{\n enum { value = 1 };\n};\n</code></pre>\n"
},
{
"answer_id": 190287,
"author": "leppie",
"author_id": 15541,
"author_profile": "https://Stackoverflow.com/users/15541",
"pm_score": 3,
"selected": false,
"text": "<p>AFAIK GCC will do tail call elimination on recursive functions, if possible. Your function however is not tail recursive. </p>\n"
},
{
"answer_id": 210019,
"author": "alex strange",
"author_id": 4478,
"author_profile": "https://Stackoverflow.com/users/4478",
"pm_score": 2,
"selected": false,
"text": "<p>Some recursive functions can be transformed into loops, which effectively infinitely inlines them. I believe gcc can do this, but I don't know about other compilers.</p>\n"
},
{
"answer_id": 211136,
"author": "Roger Nelson",
"author_id": 14964,
"author_profile": "https://Stackoverflow.com/users/14964",
"pm_score": 0,
"selected": false,
"text": "<p>Some compilers (I.e. Borland C++) do not inline code that contains conditional statements (if, case, while etc..) so the recursive function in your example would not be inlined.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190232",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26724/"
] |
```
inline int factorial(int n)
{
if(!n) return 1;
else return n*factorial(n-1);
}
```
As I was reading [this](https://rads.stackoverflow.com/amzn/click/com/0201543303), found that the above code would lead to "infinite compilation" if not handled by compiler correctly.
How does the compiler decide whether to inline a function or not ?
|
First, the `inline` specification on a function is just a hint. The compiler can (and often does) completely ignore the presence or absence of an `inline` qualifier. With that said, a compiler *can* inline a recursive function, much as it can unroll an infinite loop. It simply has to place a limit on the level to which it will "unroll" the function.
An optimizing compiler might turn this code:
```
inline int factorial(int n)
{
if (n <= 1)
{
return 1;
}
else
{
return n * factorial(n - 1);
}
}
int f(int x)
{
return factorial(x);
}
```
into this code:
```
int factorial(int n)
{
if (n <= 1)
{
return 1;
}
else
{
return n * factorial(n - 1);
}
}
int f(int x)
{
if (x <= 1)
{
return 1;
}
else
{
int x2 = x - 1;
if (x2 <= 1)
{
return x * 1;
}
else
{
int x3 = x2 - 1;
if (x3 <= 1)
{
return x * x2 * 1;
}
else
{
return x * x2 * x3 * factorial(x3 - 1);
}
}
}
}
```
In this case, we've basically inlined the function 3 times. Some compilers *do* perform this optimization. I recall MSVC++ having a setting to tune the level of inlining that would be performed on recursive functions (up to 20, I believe).
|
190,236 |
<p>I have found no way of dumping the stack on all threads in .NET. Neither a signal to be send to the process nor programatic access to all the threads. I can only get access to the current thread via Thread.CurrentThread.</p>
<p>Any tricks ?</p>
|
[
{
"answer_id": 190247,
"author": "smaclell",
"author_id": 22914,
"author_profile": "https://Stackoverflow.com/users/22914",
"pm_score": 0,
"selected": false,
"text": "<p>There is a variety of handy classes in the System.Diagnostics that can help you with debugging and gathering various tracking information, i.e. StackTrace.</p>\n\n<p>There is a wonky Process class that can be used to get the number of executing threads but very few details. Use the following Snippet:</p>\n\n<pre><code>Using System.Diagnostics;\n\nvar threads = Process.GetCurrentProcess().Threads;\n</code></pre>\n\n<p>Okay after looking a little bit more it appears the easiest way to capture all the current stacks is through a mini dump and a tool like <a href=\"http://msdn.microsoft.com/en-us/magazine/cc163833.aspx\" rel=\"nofollow noreferrer\">SOS</a> or if you are running vista <a href=\"http://www.nynaeve.net/?p=156.\" rel=\"nofollow noreferrer\">this</a>.</p>\n\n<p>Good luck.</p>\n"
},
{
"answer_id": 190271,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 1,
"selected": false,
"text": "<p>I wrote a dumper for a project i worked on in the past:</p>\n\n<pre><code>void CrashHandler::WriteThreadInfo(StringWriter* sw, ArrayList* threads, String* type)\n{\n sw->WriteLine(type);\n\n IEnumerator* ie = threads->GetEnumerator();\n while(ie->MoveNext())\n {\n botNETThread* bnt = static_cast<botNETThread*>(ie->Current);\n if(!bnt->IsAlive) continue;\n sw->WriteLine(String::Concat(S\"ORIGIN ASSEMBLY: \", bnt->Assembly->FullName));\n sw->WriteLine(String::Concat(S\"THREAD NAME: \", (bnt->Name && bnt->Name->Length)?bnt->Name:S\"Unnamed thread\"));\n\n sw->Write(GetStackTrace(bnt->_thread));\n sw->WriteLine();\n sw->WriteLine();\n }\n}\n\nString* CrashHandler::GetStackTrace(Thread* t)\n{\n\n System::Diagnostics::StackTrace __gc * trace1 = __gc new System::Diagnostics::StackTrace(t, true);\n\n System::String __gc * text1 = System::Environment::NewLine;\n System::Text::StringBuilder __gc * builder1 = __gc new System::Text::StringBuilder(255);\n for (System::Int32 num1 = 0; (num1 < trace1->FrameCount); num1++)\n {\n System::Diagnostics::StackFrame __gc * frame1 = trace1->GetFrame(num1);\n builder1->Append(S\" at \");\n System::Reflection::MethodBase __gc * base1 = frame1->GetMethod();\n System::Type __gc * type1 = base1->DeclaringType;\n if (type1 != 0)\n {\n System::String __gc * text2 = type1->Namespace;\n if (text2 != 0)\n {\n builder1->Append(text2);\n if (builder1 != 0)\n {\n builder1->Append(S\".\");\n }\n }\n builder1->Append(type1->Name);\n builder1->Append(S\".\");\n }\n builder1->Append(base1->Name);\n builder1->Append(S\"(\");\n System::Reflection::ParameterInfo __gc * infoArray1 __gc [] = base1->GetParameters();\n for (System::Int32 num2 = 0; (num2 < infoArray1->Length); num2++)\n {\n System::String __gc * text3 = S\"<UnknownType>\";\n if (infoArray1[num2]->ParameterType != 0)\n {\n text3 = infoArray1[num2]->ParameterType->Name;\n }\n builder1->Append(System::String::Concat(((num2 != 0) ? S\", \" : S\"\"), text3, S\" \", infoArray1[num2]->Name));\n }\n builder1->Append(S\")\");\n if (frame1->GetILOffset() != -1)\n {\n System::String __gc * text4 = 0;\n try\n {\n text4 = frame1->GetFileName();\n }\n catch (System::Security::SecurityException*)\n {\n }\n if (text4 != 0)\n {\n builder1->Append(System::String::Concat(S\" in \", text4, S\":line \", frame1->GetFileLineNumber().ToString()));\n }\n }\n if (num1 != (trace1->FrameCount - 1))\n {\n builder1->Append(text1);\n }\n }\n return builder1->ToString();\n\n\n\n}\n</code></pre>\n\n<p>You can use Process.GetCurrentProcess().Threads to get threads</p>\n\n<p>And I know i spasted Managed C++ but its easy enough to follow. I take an arraylist of threads because for my purpose I had catagorized my threads. And yes i used previously written stack frame code as I was new to MC++ at the time :)</p>\n\n<p>The entire file is <a href=\"http://mattlant.com/CrashHandler.cpp\" rel=\"nofollow noreferrer\">here</a>. This was for a <a href=\"http://www.d2botnet.org\" rel=\"nofollow noreferrer\">Diablo II botting engine</a> I wrote some time ago.</p>\n"
},
{
"answer_id": 615426,
"author": "Squirrel",
"author_id": 11835,
"author_profile": "https://Stackoverflow.com/users/11835",
"pm_score": 3,
"selected": false,
"text": "<p>Just to save anyone else the bother here's the port of the above to c#:</p>\n\n<pre><code> static void WriteThreadInfo(StringBuilder sw, IEnumerable<Thread> threads)\n {\n foreach(Thread thread in threads)\n {\n if(!thread.IsAlive) continue;\n sw.Append(String.Concat(\"THREAD NAME: \", thread.Name));\n\n sw.Append(GetStackTrace(thread));\n sw.AppendLine();\n sw.AppendLine();\n }\n }\n\n static String GetStackTrace(Thread t)\n {\n t.Suspend();\n var trace1 = new StackTrace(t, true);\n t.Resume();\n\n String text1 = System.Environment.NewLine;\n var builder1 = new StringBuilder(255);\n for (Int32 num1 = 0; (num1 < trace1.FrameCount); num1++)\n {\n StackFrame frame1 = trace1.GetFrame(num1);\n builder1.Append(\" at \");\n System.Reflection.MethodBase base1 = frame1.GetMethod();\n Type type1 = base1.DeclaringType;\n if (type1 != null)\n {\n String text2 = type1.Namespace;\n if (text2 != null)\n {\n builder1.Append(text2);\n builder1.Append(\".\"); \n }\n builder1.Append(type1.Name);\n builder1.Append(\".\");\n }\n builder1.Append(base1.Name);\n builder1.Append(\"(\");\n System.Reflection.ParameterInfo [] infoArray1 = base1.GetParameters();\n for (Int32 num2 = 0; (num2 < infoArray1.Length); num2++)\n {\n String text3 = \"<UnknownType>\";\n if (infoArray1[num2].ParameterType != null)\n {\n text3 = infoArray1[num2].ParameterType.Name;\n }\n builder1.Append(String.Concat(((num2 != 0) ? \", \" : \"\"), text3, \" \", infoArray1[num2].Name));\n }\n builder1.Append(\")\");\n if (frame1.GetILOffset() != -1)\n {\n String text4 = null;\n try\n {\n text4 = frame1.GetFileName();\n }\n catch (System.Security.SecurityException)\n {\n }\n if (text4 != null)\n {\n builder1.Append(String.Concat(\" in \", text4, \":line \", frame1.GetFileLineNumber().ToString()));\n }\n }\n if (num1 != (trace1.FrameCount - 1))\n {\n builder1.Append(text1);\n }\n }\n return builder1.ToString();\n }\n</code></pre>\n\n<p>I've not found a way to get a list of all managed threads in C# (only ProcessThreads), so it does look like you need to maintain the list of threads your interested in yourself.</p>\n\n<p>Also I found I couldn't call new Stacktrace(t,true) on a running thread, so have added pause and resumes. <em>Obviously you'll need to consider whether this could cause problems were you to thread dump your production app</em>.</p>\n\n<p>btw, we've put this call on our apps wcf rest interface so it's easy to do.</p>\n"
},
{
"answer_id": 658606,
"author": "Tomer Gabel",
"author_id": 11558,
"author_profile": "https://Stackoverflow.com/users/11558",
"pm_score": 4,
"selected": false,
"text": "<p>If you're trying to get a stack dump while the process is already running (a la jstack), there are two methods as described <a href=\"http://www.tomergabel.com/NETProductionDebugging101.aspx\" rel=\"noreferrer\">here</a>:</p>\n\n<h3>Using Managed Stack Explorer</h3>\n\n<p>There is a little-known but effective tool called the <a href=\"http://www.tomergabel.com/ct.ashx?id=1db72c20-3c25-42ad-93c4-b0551a0fed4e&url=http%3a%2f%2fwww.microsoft.com%2fdownloads%2fdetails.aspx%3fFamilyID%3d80CF81F7-D710-47E3-8B95-5A6555A230C2%26displaylang%3den\" rel=\"noreferrer\">Managed Stack Explorer</a>. Although it features a basic GUI, it can effectively be a .NET equivalent of jstack if you add to the path; then it’s just a question of typing:<pre>mse /s /p <i><pid></i></pre></p>\n\n<h3>Using windbg</h3>\n\n<ol>\n<li>Download and install the appropriate Debugging Tools for Windows version for your architecture (x86/x64/Itanium)</li>\n<li>If you need information about Windows function calls (e.g. you want to trace into kernel calls), download and install the appropriate symbols. This isn't strictly necessary if you just want a thread dump of your own code.</li>\n<li>If you need line numbers or any other detailed information, make sure to place your assemblies' PDB files where the debugger can find them (normally you just put them next to your actual assemblies).</li>\n<li>Start->Programs->Debugging Tools for Windows [x64]->windbg</li>\n<li>Attach the debugger to your running process using the menu</li>\n<li>Load the SOS extension with \".loadby sos mscorwks\" for .NET 2.0 (\".load sos\" for .NET 1.0/1.1)</li>\n<li>Take a thread dump using \"!eestack\"</li>\n<li>Detach using \".detach\"</li>\n</ol>\n\n<p>I just found it necessary to take a production thread dump and this worked for me. Hope it helps :-)</p>\n"
},
{
"answer_id": 18536545,
"author": "P-H",
"author_id": 1863194,
"author_profile": "https://Stackoverflow.com/users/1863194",
"pm_score": 2,
"selected": false,
"text": "<p>The best tool I have seen at this point to generate thread dumps for the .NET CLR is DebugDiag. This tool will generate a very detailed report (using the Crash/Hang analyzer) of the active CLR threads along with recommendations.</p>\n\n<p>I recommend to review the following <a href=\"http://javaeesupportpatterns.blogspot.com/2011/10/net-framework-4-debugdiag-tutorial.html\" rel=\"nofollow\">.NET DebugDiag tutorial</a> as it is showing the analysis process in action following a production problem. The steps are as per below:</p>\n\n<ul>\n<li>Create a dump file of your affected w3wp process</li>\n<li>Start the Debug Diagnostic Tool, select and launch the Crash/Hang analyzers.</li>\n<li>Open and analyze the report analysis overview.</li>\n<li>Finally, review the blocked Thread summary and perform a deeper dive analysis.</li>\n</ul>\n"
},
{
"answer_id": 38526361,
"author": "Søren Boisen",
"author_id": 567000,
"author_profile": "https://Stackoverflow.com/users/567000",
"pm_score": 2,
"selected": false,
"text": "<p>If you need to do this programmatically (maybe you want automatic dumps during your CI process), you can use the info from <a href=\"https://stackoverflow.com/a/35558240/567000\">this answer</a> to a different question.</p>\n\n<p>Basically, attach to your own process using <a href=\"https://github.com/Microsoft/clrmd\" rel=\"nofollow noreferrer\">CLR MD</a>:</p>\n\n<pre><code>using Microsoft.Diagnostics.Runtime;\n\nusing (DataTarget target = DataTarget.AttachToProcess(\n Process.GetCurrentProcess().Id, 5000, AttachFlag.Passive))\n{\n ClrRuntime runtime = target.ClrVersions.First().CreateRuntime();\n foreach (ClrThread thread in runtime.Threads)\n {\n IList<ClrStackFrame> stackFrames = thread.StackTrace;\n PrintStackTrace(stackFrames); \n }\n}\n</code></pre>\n\n<p>Here PrintStackTrace is left as an exercise for the reader.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190236",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I have found no way of dumping the stack on all threads in .NET. Neither a signal to be send to the process nor programatic access to all the threads. I can only get access to the current thread via Thread.CurrentThread.
Any tricks ?
|
If you're trying to get a stack dump while the process is already running (a la jstack), there are two methods as described [here](http://www.tomergabel.com/NETProductionDebugging101.aspx):
### Using Managed Stack Explorer
There is a little-known but effective tool called the [Managed Stack Explorer](http://www.tomergabel.com/ct.ashx?id=1db72c20-3c25-42ad-93c4-b0551a0fed4e&url=http%3a%2f%2fwww.microsoft.com%2fdownloads%2fdetails.aspx%3fFamilyID%3d80CF81F7-D710-47E3-8B95-5A6555A230C2%26displaylang%3den). Although it features a basic GUI, it can effectively be a .NET equivalent of jstack if you add to the path; then it’s just a question of typing:
```
mse /s /p *<pid>*
```
### Using windbg
1. Download and install the appropriate Debugging Tools for Windows version for your architecture (x86/x64/Itanium)
2. If you need information about Windows function calls (e.g. you want to trace into kernel calls), download and install the appropriate symbols. This isn't strictly necessary if you just want a thread dump of your own code.
3. If you need line numbers or any other detailed information, make sure to place your assemblies' PDB files where the debugger can find them (normally you just put them next to your actual assemblies).
4. Start->Programs->Debugging Tools for Windows [x64]->windbg
5. Attach the debugger to your running process using the menu
6. Load the SOS extension with ".loadby sos mscorwks" for .NET 2.0 (".load sos" for .NET 1.0/1.1)
7. Take a thread dump using "!eestack"
8. Detach using ".detach"
I just found it necessary to take a production thread dump and this worked for me. Hope it helps :-)
|
190,243 |
<p>One of our internally written tool is fed a cvs commit trace of the form:</p>
<pre><code>Checking in src/com/package/AFile.java;
/home/cvs/src/com/package/AFile.java,v <-- Afile.java
new revision: 1.1.2.56; previous revision: 1.1.2.55
done
</code></pre>
<p>The tool then acquires the file from cvs by issuing a <code>cvs update -r 1.1.2.56</code> command in a working directory that already have specific branch of code checked-out. </p>
<p>This commands work correctly if there is an existing version of <strong>AFile.java</strong> in working directory. But when we get a trace of a file that has no version in working directory the command is not able to acquire the file.</p>
<p>Is there a way to do it? </p>
|
[
{
"answer_id": 190301,
"author": "Jason Etheridge",
"author_id": 2193,
"author_profile": "https://Stackoverflow.com/users/2193",
"pm_score": 1,
"selected": false,
"text": "<p>One solution would be to change the tool to issue a \"cvs co\" for the file, specifying the revision as is being now with the update. The checkout command would have to be done from the top of your tree, not in the directory containing the file. I've come across similar cases where the update fails to find a new file, requiring a checkout of the file as I've described.</p>\n"
},
{
"answer_id": 190317,
"author": "ADEpt",
"author_id": 10105,
"author_profile": "https://Stackoverflow.com/users/10105",
"pm_score": 6,
"selected": true,
"text": "<p>It is not clear what is your final goal: to bring whole repository into required state (choosen revision of the choosen branch) or to acquire the single file from the repository for further processing. I assume it is the latter.</p>\n\n<p>Then, you need this command:</p>\n\n<pre><code>cvs checkout -r <revision> -p filename.ext > ~/tmp/filename.ext\n</code></pre>\n\n<p>This will dump to stdout specified revision of the specified file (or files), which could be redirected into temporary location and processed. </p>\n\n<p>Or you could use:</p>\n\n<pre><code>cvs export -r <revision> -d ~/tmp module/filename.ext\n</code></pre>\n\n<p>, which would export (part of) repository to specified destination directory.</p>\n"
},
{
"answer_id": 16150687,
"author": "Jess",
"author_id": 1804678,
"author_profile": "https://Stackoverflow.com/users/1804678",
"pm_score": 2,
"selected": false,
"text": "<p><code>cvs --help</code> </p>\n\n<p>tells you that you can use the <code>-H</code> arg to view help on a specific CVS command like so:</p>\n\n<pre><code>$ cvs -H checkout\nUsage:\n cvs checkout [-ANPRcflnps] [-r rev] [-D date] [-d dir]\n [-j rev1] [-j rev2] [-k kopt] modules...\n -A Reset any sticky tags/date/kopts.\n -N Don't shorten module paths if -d specified.\n -P Prune empty directories.\n -R Process directories recursively.\n -c \"cat\" the module database.\n -f Force a head revision match if tag/date not found.\n -l Local directory only, not recursive\n -n Do not run module program (if any).\n -p Check out files to standard output (avoids stickiness).\n -s Like -c, but include module status.\n -r rev Check out revision or tag. (implies -P) (is sticky)\n -D date Check out revisions as of date. (implies -P) (is sticky)\n -d dir Check out into dir instead of module name.\n -k kopt Use RCS kopt -k option on checkout. (is sticky)\n -j rev Merge in changes made between current revision and rev.\n(Specify the --help global option for a list of other help options)\n</code></pre>\n\n<p>... teach a person how to fish ... :)</p>\n"
},
{
"answer_id": 34062839,
"author": "Jeegar Patel",
"author_id": 775964,
"author_profile": "https://Stackoverflow.com/users/775964",
"pm_score": 2,
"selected": false,
"text": "<p>I have tried as below way</p>\n\n<pre><code>cvs checkout -r <revision> -p filename.ext > ~/tmp/filename.ext\n</code></pre>\n\n<p>It was giving error like</p>\n\n<pre><code>cvs checkout: cannot find module `filename.ext` -ignored.\n</code></pre>\n\n<p>So i have done as below way</p>\n\n<pre><code>cvs checkout -r <revision> -p Module_name/path_to_file/filename.ext > ~/tmp/filename.ext\n</code></pre>\n\n<p>Now it worked fine.</p>\n"
},
{
"answer_id": 42814624,
"author": "CpnCrunch",
"author_id": 1192732,
"author_profile": "https://Stackoverflow.com/users/1192732",
"pm_score": 1,
"selected": false,
"text": "<p>This is the only way that works for me, as the checkout command always gives a \"module not found\" error:</p>\n\n<pre><code>cvs diff -r <revision> <file> > /tmp/patch\ncp <file> /tmp\ncd /tmp\npatch -R < patch\n</code></pre>\n\n<p>It seems that cvs dropped the ball on this.</p>\n"
},
{
"answer_id": 71642449,
"author": "Charlie",
"author_id": 4111860,
"author_profile": "https://Stackoverflow.com/users/4111860",
"pm_score": 0,
"selected": false,
"text": "<p>I did this:</p>\n<pre><code>cd <to_your_file_directory>\nmv user.cpp user.cpp.bak\ncvs update -r 1.55 user.cpp\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190243",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18027/"
] |
One of our internally written tool is fed a cvs commit trace of the form:
```
Checking in src/com/package/AFile.java;
/home/cvs/src/com/package/AFile.java,v <-- Afile.java
new revision: 1.1.2.56; previous revision: 1.1.2.55
done
```
The tool then acquires the file from cvs by issuing a `cvs update -r 1.1.2.56` command in a working directory that already have specific branch of code checked-out.
This commands work correctly if there is an existing version of **AFile.java** in working directory. But when we get a trace of a file that has no version in working directory the command is not able to acquire the file.
Is there a way to do it?
|
It is not clear what is your final goal: to bring whole repository into required state (choosen revision of the choosen branch) or to acquire the single file from the repository for further processing. I assume it is the latter.
Then, you need this command:
```
cvs checkout -r <revision> -p filename.ext > ~/tmp/filename.ext
```
This will dump to stdout specified revision of the specified file (or files), which could be redirected into temporary location and processed.
Or you could use:
```
cvs export -r <revision> -d ~/tmp module/filename.ext
```
, which would export (part of) repository to specified destination directory.
|
190,251 |
<p>I have a multi-table query, similar to this (simplified version)</p>
<pre><code>SELECT columns, count(table2.rev_id) As rev_count, sum(table2.rev_rating) As sum_rev_rating
FROM table1
LEFT JOIN table2
ON table1.dom_id = table2.rev_domain_from
WHERE dom_lastreview != 0 AND rev_status = 1
GROUP BY dom_url
ORDER BY sum_rev_rating/rev_count DESC
</code></pre>
<p>The problem is in the <code>ORDER BY</code> clause. This causes a MySQL error to show, which is as follows:</p>
<blockquote>
<p>Reference 'sum_ rev_ rating' not supported (reference to group function)</p>
</blockquote>
|
[
{
"answer_id": 190319,
"author": "Steven A. Lowe",
"author_id": 9345,
"author_profile": "https://Stackoverflow.com/users/9345",
"pm_score": 1,
"selected": false,
"text": "<p>my mysql is rusty; you might try</p>\n\n<pre><code>SELECT columns, count(table2.rev_id) As rev_count, \n sum(table2.rev_rating) As sum_rev_rating,\n sum(table2.rev_rating)/count(table2.rev_id) as rev_ratio\nFROM table1\n LEFT JOIN table2ON table1.dom_id = table2.rev_domain_from \nWHERE dom_lastreview != 0 \nAND rev_status = 1 \nGROUP BY dom_url \nORDER BY rev_Ratio DESC\n</code></pre>\n\n<p>or</p>\n\n<pre><code>SELECT * from (\n SELECT columns, count(table2.rev_id) As rev_count, \n sum(table2.rev_rating) As sum_rev_rating \n FROM table1\n LEFT JOIN table2ON table1.dom_id = table2.rev_domain_from \n WHERE dom_lastreview != 0 \n AND rev_status = 1 \n GROUP BY dom_url \n) X\nORDER BY X.sum_rev_rating/X.rev_count DESC\n</code></pre>\n\n<p>or</p>\n\n<pre><code>SELECT * from (\n SELECT columns, count(table2.rev_id) As rev_count, \n sum(table2.rev_rating) As sum_rev_rating,\n sum(table2.rev_rating)/count(table2.rev_id) as rev_ratio\n FROM table1\n LEFT JOIN table2ON table1.dom_id = table2.rev_domain_from \n WHERE dom_lastreview != 0 \n AND rev_status = 1 \n GROUP BY dom_url \n) X\nORDER BY rev_Ratio DESC\n</code></pre>\n"
},
{
"answer_id": 190327,
"author": "djt",
"author_id": 26677,
"author_profile": "https://Stackoverflow.com/users/26677",
"pm_score": 5,
"selected": true,
"text": "<p>You're not able to do calculations with aliases. One way of doing this would be to simply create another alias and order by that.</p>\n\n<pre><code>SELECT columns, count(table2.rev_id) As rev_count, sum(table2.rev_rating) As sum_rev_rating, sum(table2.rev_rating)/count(table2.rev_id) as avg_rev_rating\nFROM table1\nLEFT JOIN table2\nON table1.dom_id = table2.rev_domain_from \nWHERE dom_lastreview != 0 AND rev_status = 1 \nGROUP BY dom_url \nORDER BY avg_rev_rating DESC\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190251",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I have a multi-table query, similar to this (simplified version)
```
SELECT columns, count(table2.rev_id) As rev_count, sum(table2.rev_rating) As sum_rev_rating
FROM table1
LEFT JOIN table2
ON table1.dom_id = table2.rev_domain_from
WHERE dom_lastreview != 0 AND rev_status = 1
GROUP BY dom_url
ORDER BY sum_rev_rating/rev_count DESC
```
The problem is in the `ORDER BY` clause. This causes a MySQL error to show, which is as follows:
>
> Reference 'sum\_ rev\_ rating' not supported (reference to group function)
>
>
>
|
You're not able to do calculations with aliases. One way of doing this would be to simply create another alias and order by that.
```
SELECT columns, count(table2.rev_id) As rev_count, sum(table2.rev_rating) As sum_rev_rating, sum(table2.rev_rating)/count(table2.rev_id) as avg_rev_rating
FROM table1
LEFT JOIN table2
ON table1.dom_id = table2.rev_domain_from
WHERE dom_lastreview != 0 AND rev_status = 1
GROUP BY dom_url
ORDER BY avg_rev_rating DESC
```
|
190,253 |
<p>I am after documentation on using wildcard or regular expressions (not sure on the exact terminology) with a jQuery selector.</p>
<p>I have looked for this myself but have been unable to find information on the syntax and how to use it. Does anyone know where the documentation for the syntax is?</p>
<p>EDIT: The attribute filters allow you to select based on patterns of an attribute value.</p>
|
[
{
"answer_id": 190255,
"author": "Xenph Yan",
"author_id": 264,
"author_profile": "https://Stackoverflow.com/users/264",
"pm_score": 9,
"selected": true,
"text": "<p>James Padolsey created a <a href=\"http://james.padolsey.com/javascript/regex-selector-for-jquery/\" rel=\"noreferrer\">wonderful filter</a> that allows regex to be used for selection.</p>\n<p>Say you have the following <code>div</code>:</p>\n<pre><code><div class="asdf">\n</code></pre>\n<p>Padolsey's <code>:regex</code> filter can select it like so:</p>\n<pre><code>$("div:regex(class, .*sd.*)")\n</code></pre>\n<p>Also, check the <a href=\"http://docs.jquery.com/Selectors\" rel=\"noreferrer\">official documentation on selectors</a>.</p>\n<h2>UPDATE: <code>:</code> syntax Deprecation JQuery 3.0</h2>\n<p>Since <code>jQuery.expr[':']</code> used in Padolsey's implementation is already deprecated and will render a syntax error in the latest version of jQuery, here is his code adapted to jQuery 3+ syntax:</p>\n<pre class=\"lang-js prettyprint-override\"><code>jQuery.expr.pseudos.regex = jQuery.expr.createPseudo(function (expression) {\n return function (elem) {\n var matchParams = expression.split(','),\n validLabels = /^(data|css):/,\n attr = {\n method: matchParams[0].match(validLabels) ?\n matchParams[0].split(':')[0] : 'attr',\n property: matchParams.shift().replace(validLabels, '')\n },\n regexFlags = 'ig',\n regex = new RegExp(matchParams.join('').replace(/^\\s+|\\s+$/g, ''), regexFlags);\n return regex.test(jQuery(elem)[attr.method](attr.property));\n }\n});\n</code></pre>\n"
},
{
"answer_id": 193787,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 10,
"selected": false,
"text": "<p>You can use the <a href=\"http://docs.jquery.com/Traversing/filter#expr\" rel=\"noreferrer\"><code>filter</code></a> function to apply more complicated regex matching.</p>\n\n<p>Here's an example which would just match the first three divs:</p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>$('div')\r\n .filter(function() {\r\n return this.id.match(/abc+d/);\r\n })\r\n .html(\"Matched!\");</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js\"></script>\r\n\r\n<div id=\"abcd\">Not matched</div>\r\n<div id=\"abccd\">Not matched</div>\r\n<div id=\"abcccd\">Not matched</div>\r\n<div id=\"abd\">Not matched</div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 1873261,
"author": "irfan akhtar",
"author_id": 227919,
"author_profile": "https://Stackoverflow.com/users/227919",
"pm_score": 2,
"selected": false,
"text": "<pre><code>$(\"input[name='option[colour]'] :checked \")\n</code></pre>\n"
},
{
"answer_id": 2730504,
"author": "Jānis Elmeris",
"author_id": 99904,
"author_profile": "https://Stackoverflow.com/users/99904",
"pm_score": 3,
"selected": false,
"text": "<p>ids and classes are still attributes, so you can apply a regexp attribute filter to them if you select accordingly. Read more here: \n<a href=\"http://rosshawkins.net/archive/2011/10/14/jquery-wildcard-selectors-some-simple-examples.aspx\" rel=\"noreferrer\">http://rosshawkins.net/archive/2011/10/14/jquery-wildcard-selectors-some-simple-examples.aspx</a></p>\n"
},
{
"answer_id": 9927306,
"author": "Kamil Dąbrowski",
"author_id": 1088058,
"author_profile": "https://Stackoverflow.com/users/1088058",
"pm_score": 5,
"selected": false,
"text": "<pre><code>var test = $('#id').attr('value').match(/[^a-z0-9 ]+/);\n</code></pre>\n\n<p>Here you go!</p>\n"
},
{
"answer_id": 19788198,
"author": "Nicolas Janel",
"author_id": 279326,
"author_profile": "https://Stackoverflow.com/users/279326",
"pm_score": 6,
"selected": false,
"text": "<p>If your use of regular expression is limited to test if an attribut start with a certain string, you can use the <code>^</code> JQuery selector.</p>\n\n<p>For example if your want to only select div with id starting with \"abc\", you can use:</p>\n\n<pre class=\"lang-js prettyprint-override\"><code>$(\"div[id^='abc']\")\n</code></pre>\n\n<p>A lot of very useful selectors to avoid use of regex can be find here: <a href=\"http://api.jquery.com/category/selectors/attribute-selectors/\" rel=\"noreferrer\">http://api.jquery.com/category/selectors/attribute-selectors/</a></p>\n"
},
{
"answer_id": 24740738,
"author": "dnxit",
"author_id": 1106625,
"author_profile": "https://Stackoverflow.com/users/1106625",
"pm_score": 8,
"selected": false,
"text": "<p>These can be helpful.</p>\n\n<p>If you're finding by <strong>Contains</strong> then it'll be like this</p>\n\n<pre><code> $(\"input[id*='DiscountType']\").each(function (i, el) {\n //It'll be an array of elements\n });\n</code></pre>\n\n<p>If you're finding by <strong>Starts With</strong> then it'll be like this</p>\n\n<pre><code> $(\"input[id^='DiscountType']\").each(function (i, el) {\n //It'll be an array of elements\n });\n</code></pre>\n\n<p>If you're finding by <strong>Ends With</strong> then it'll be like this</p>\n\n<pre><code> $(\"input[id$='DiscountType']\").each(function (i, el) {\n //It'll be an array of elements\n });\n</code></pre>\n\n<p>If you want to select elements which <strong>id is not a given string</strong></p>\n\n<pre><code> $(\"input[id!='DiscountType']\").each(function (i, el) {\n //It'll be an array of elements\n });\n</code></pre>\n\n<p>If you want to select elements which <strong>name contains a given word, delimited by spaces</strong></p>\n\n<pre><code> $(\"input[name~='DiscountType']\").each(function (i, el) {\n //It'll be an array of elements\n });\n</code></pre>\n\n<p>If you want to select elements which <strong>id is equal to a given string or starting with that string followed by a hyphen</strong></p>\n\n<pre><code> $(\"input[id|='DiscountType']\").each(function (i, el) {\n //It'll be an array of elements\n });\n</code></pre>\n"
},
{
"answer_id": 32132590,
"author": "brook hong",
"author_id": 1044881,
"author_profile": "https://Stackoverflow.com/users/1044881",
"pm_score": 3,
"selected": false,
"text": "<p>Add a jQuery function,</p>\n\n<pre><code>(function($){\n $.fn.regex = function(pattern, fn, fn_a){\n var fn = fn || $.fn.text;\n return this.filter(function() {\n return pattern.test(fn.apply($(this), fn_a));\n });\n };\n})(jQuery);\n</code></pre>\n\n<p>Then,</p>\n\n<pre><code>$('span').regex(/Sent/)\n</code></pre>\n\n<p>will select all span elements with text matches /Sent/.</p>\n\n<pre><code>$('span').regex(/tooltip.year/, $.fn.attr, ['class'])\n</code></pre>\n\n<p>will select all span elements with their classes match /tooltip.year/.</p>\n"
},
{
"answer_id": 33841205,
"author": "Prakash GPz",
"author_id": 1817755,
"author_profile": "https://Stackoverflow.com/users/1817755",
"pm_score": 1,
"selected": false,
"text": "<p>If you just want to select elements that contain given string then you can use following selector:</p>\n\n<p><code>$(':contains(\"search string\")')</code></p>\n"
},
{
"answer_id": 48848460,
"author": "Vishnu Prasanth G",
"author_id": 6624082,
"author_profile": "https://Stackoverflow.com/users/6624082",
"pm_score": 2,
"selected": false,
"text": "<p>I'm just giving my real time example:</p>\n\n<p>In native javascript I used following snippet to find the elements with ids starts with \"select2-qownerName_select-result\".</p>\n\n<p><code>document.querySelectorAll(\"[id^='select2-qownerName_select-result']\");</code></p>\n\n<p>When we shifted from javascript to jQuery we've replaced above snippet with the following which involves less code changes without disturbing the logic.</p>\n\n<p><code>$(\"[id^='select2-qownerName_select-result']\")</code></p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190253",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5360/"
] |
I am after documentation on using wildcard or regular expressions (not sure on the exact terminology) with a jQuery selector.
I have looked for this myself but have been unable to find information on the syntax and how to use it. Does anyone know where the documentation for the syntax is?
EDIT: The attribute filters allow you to select based on patterns of an attribute value.
|
James Padolsey created a [wonderful filter](http://james.padolsey.com/javascript/regex-selector-for-jquery/) that allows regex to be used for selection.
Say you have the following `div`:
```
<div class="asdf">
```
Padolsey's `:regex` filter can select it like so:
```
$("div:regex(class, .*sd.*)")
```
Also, check the [official documentation on selectors](http://docs.jquery.com/Selectors).
UPDATE: `:` syntax Deprecation JQuery 3.0
-----------------------------------------
Since `jQuery.expr[':']` used in Padolsey's implementation is already deprecated and will render a syntax error in the latest version of jQuery, here is his code adapted to jQuery 3+ syntax:
```js
jQuery.expr.pseudos.regex = jQuery.expr.createPseudo(function (expression) {
return function (elem) {
var matchParams = expression.split(','),
validLabels = /^(data|css):/,
attr = {
method: matchParams[0].match(validLabels) ?
matchParams[0].split(':')[0] : 'attr',
property: matchParams.shift().replace(validLabels, '')
},
regexFlags = 'ig',
regex = new RegExp(matchParams.join('').replace(/^\s+|\s+$/g, ''), regexFlags);
return regex.test(jQuery(elem)[attr.method](attr.property));
}
});
```
|
190,263 |
<p>We are trying to look at optimizing our localization testing. </p>
<p>Our QA group had a suggestion of a special mode to force all strings from the resources to be entirely contained of X. We already API hijack LoadString, and the MFC implementation of it, so doing it should not be a major hurdle. </p>
<p>My question is how would you solve the formatting issues?</p>
<pre><code>Examples -
CString str ;
str . LoadString ( IDS_MYSTRING ) ;
where IDS_MYSTRING is "Hello World", should return "XXXXX XXXXX"
where IDS_MYSTRING is "Hello\nWorld", should return "XXXXX\nXXXXX"
where IDS_MYSTRING is "Hello%dWorld", should return "XXXXX%dXXXXX"
where IDS_MYSTRING is "Hello%.2fWorld", should return "XXXXX%.2fXXXXX"
where IDS_MYSTRING is "Hello%%World", should return "XXXXX%%XXXXX"
</code></pre>
<p>So in summary the string should work if used in a printf or Format statement, it should honor escape characters.</p>
<p>So this is a pure code question, C++/MFC, </p>
<pre><code>CString ConvertStringToXXXX ( const CString& aSource )
{
CString lResult = aSource ;
// Insert your code here
return lResult ;
}
</code></pre>
<p>I know this could be done using tools on the .RC files, but we want to build English, then run like so -</p>
<p>application -L10NTEST</p>
|
[
{
"answer_id": 190316,
"author": "Eugene Yokota",
"author_id": 3827,
"author_profile": "https://Stackoverflow.com/users/3827",
"pm_score": 0,
"selected": false,
"text": "<p>You can apply compiler theory here and generate your scanner and parser using <a href=\"http://dinosaur.compilertools.net/\" rel=\"nofollow noreferrer\">flex/bison</a> (lex/yacc, or whatever tools). You can define \\w+ as word, which can match both \"Hello\" and \"World\" etc..</p>\n"
},
{
"answer_id": 190366,
"author": "RobS",
"author_id": 18471,
"author_profile": "https://Stackoverflow.com/users/18471",
"pm_score": 3,
"selected": true,
"text": "<p>If this approach is to highlight formatted strings (or format sequences) in the application (i.e. all text appearing other than XXXX), you could locate the escape sequence (using regex perhaps) and insert block quotes around the formatted (substituted) values, <br>e.g. Some\\ntext -> Some[\\n]text</p>\n\n<p>You get readability (all strings as XXX might be hard to use the application) and also get to detect non-resource (hardcoded) strings.</p>\n\n<p>Having said that, if you're looking to detect non resource loaded strings (hardcoded strings), instead of substituting Xs, why not just prefix the string? You'll easily be able to tell resource loaded strings from hardcoded strings easily, \n<br>e.g. Some\\ntext -> [EN]Some\\ntext</p>\n\n<p>Hope it helps?</p>\n"
},
{
"answer_id": 190508,
"author": "Osama Al-Maadeed",
"author_id": 25544,
"author_profile": "https://Stackoverflow.com/users/25544",
"pm_score": 0,
"selected": false,
"text": "<p>I think what you need is an XXXX locale, if your software supports locales.</p>\n\n<p>You develop it in English, then switch to the XXXX locale to make sure everything is translatable.</p>\n"
},
{
"answer_id": 190786,
"author": "Serge Wautier",
"author_id": 12379,
"author_profile": "https://Stackoverflow.com/users/12379",
"pm_score": 1,
"selected": false,
"text": "<p>The pseudo-localisation feature of <a href=\"http://www.apptranslator.com\" rel=\"nofollow noreferrer\">appTranslator</a> can help you there: It modifies untranslated strings to use diacritics, text widening or shortening and such. So far, you're not interested. Where it becomes interesting is that it optionally encloses such strings in brackets. The idea was to make it more obvious that a string is pseudo localized. You could use this to detect that the string actually comes from the string table rather than code.</p>\n\n<p>And of course, since the pseudo-localized program must run properly, appTranslator preserves all formatters (including printf-like and FormatMessage-like formatters) and special chars such as % or \\n. Which is what you're looking for.</p>\n\n<p>You wouldn't even have to modify your code: Simply create a 'dummy' translation. By 'dummy', I mean a language into which you don't plan to translate your app. Set the language preference of your app to that language.\nWait, it's even better: The guys at QA can do it entirely on their own. They dont even have to bother you! :-)</p>\n\n<p>Disclaimer: I'm the author of appTranslator.</p>\n\n<p>Edit: answer to your comment:\nGlad to read you already use appTranslator.\nTo avoid problems due to dialogs or strings not in the L10N DLL, you can simply re-build the DLLs (e.g. using a post-link step in your VS project). The process automatically re-scans the source exe and merges new and modified texts in the built resource dlls (doesn't affect the appTranslator project file, as opposed to 'Update Source'). This helps make sure your resource DLLs are always in sync with your exe.</p>\n"
},
{
"answer_id": 207988,
"author": "titanae",
"author_id": 2387,
"author_profile": "https://Stackoverflow.com/users/2387",
"pm_score": 0,
"selected": false,
"text": "<p>My final solution was prefixing the string like so \"*[resource instance name]original string\". It works really well, it shows likely strings that will not fit in say German.</p>\n\n<p>Example:</p>\n\n<p>Original string from appres.dll, \"My Application\"</p>\n\n<p>New string from appres.dll, \"*[appres]My Application\".</p>\n\n<p>Thanks for all the suggestions.</p>\n"
},
{
"answer_id": 382958,
"author": "JasonTrue",
"author_id": 13433,
"author_profile": "https://Stackoverflow.com/users/13433",
"pm_score": 0,
"selected": false,
"text": "<p>I prefer a mechanism that we used when I was at Microsoft for pseudo-localization, which involved putting braces around each localized resource. Resource => [-Resource-], for example. Then you can always tell you have a composed string, and formatting doesn't usually change, barring line breaking rules.</p>\n\n<p>We also usually did some string expansion (add various characters around the original string), and some dictionary- or randomization-based character substition (convert \"o\" to \"ö\").</p>\n\n<p>Some teams also put the literal resource identifier (the name) as the value of the localized resource, which was more useful for localizers than for testers, because they could see where the resource was actually used in the UI.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190263",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2387/"
] |
We are trying to look at optimizing our localization testing.
Our QA group had a suggestion of a special mode to force all strings from the resources to be entirely contained of X. We already API hijack LoadString, and the MFC implementation of it, so doing it should not be a major hurdle.
My question is how would you solve the formatting issues?
```
Examples -
CString str ;
str . LoadString ( IDS_MYSTRING ) ;
where IDS_MYSTRING is "Hello World", should return "XXXXX XXXXX"
where IDS_MYSTRING is "Hello\nWorld", should return "XXXXX\nXXXXX"
where IDS_MYSTRING is "Hello%dWorld", should return "XXXXX%dXXXXX"
where IDS_MYSTRING is "Hello%.2fWorld", should return "XXXXX%.2fXXXXX"
where IDS_MYSTRING is "Hello%%World", should return "XXXXX%%XXXXX"
```
So in summary the string should work if used in a printf or Format statement, it should honor escape characters.
So this is a pure code question, C++/MFC,
```
CString ConvertStringToXXXX ( const CString& aSource )
{
CString lResult = aSource ;
// Insert your code here
return lResult ;
}
```
I know this could be done using tools on the .RC files, but we want to build English, then run like so -
application -L10NTEST
|
If this approach is to highlight formatted strings (or format sequences) in the application (i.e. all text appearing other than XXXX), you could locate the escape sequence (using regex perhaps) and insert block quotes around the formatted (substituted) values,
e.g. Some\ntext -> Some[\n]text
You get readability (all strings as XXX might be hard to use the application) and also get to detect non-resource (hardcoded) strings.
Having said that, if you're looking to detect non resource loaded strings (hardcoded strings), instead of substituting Xs, why not just prefix the string? You'll easily be able to tell resource loaded strings from hardcoded strings easily,
e.g. Some\ntext -> [EN]Some\ntext
Hope it helps?
|
190,270 |
<p>I just got a dedicated server from a hosting company, and for some reason, it didn't have IIS installed.
It did have .Net 2.0, though.</p>
<p>So I installed IIS, but now my ASP.net websites won't work.
I just get a 404, no event log entries, nothing...</p>
<p>I noticed in the redistributable package information that:
"To access the features of ASP.NET, IIS with the latest security updates must be installed prior to installing the .NET Framework"</p>
<p>I also can't uninstall .Net, it just won't let me...</p>
<p>Is there a way to reinstall .Net 2.0, or somehow do whatever it is it does to IIS to make it work?</p>
<p>Thanks!
Daniel</p>
|
[
{
"answer_id": 190276,
"author": "WebDude",
"author_id": 15360,
"author_profile": "https://Stackoverflow.com/users/15360",
"pm_score": 5,
"selected": true,
"text": "<p>run from the command line</p>\n\n<pre><code>aspnet_regiis -i\n</code></pre>\n\n<p>You may have to navigate to the folder it was installed.\nMine and the default is</p>\n\n<pre><code>C:\\WINDOWS\\Microsoft.NET\\Framework\\v2.0.50727\n</code></pre>\n"
},
{
"answer_id": 190825,
"author": "David Robbins",
"author_id": 19799,
"author_profile": "https://Stackoverflow.com/users/19799",
"pm_score": 0,
"selected": false,
"text": "<p>Be sure that you have enabled the extensions for asp and aspx in IIS. They are disabled by default. I'd do this before you go about uninstall more components.</p>\n"
},
{
"answer_id": 1194122,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>same command you can run it from Visual Studio Command Prompt as well, then you don't need to navigate to above path</p>\n"
},
{
"answer_id": 55835286,
"author": "Blaise",
"author_id": 863637,
"author_profile": "https://Stackoverflow.com/users/863637",
"pm_score": 0,
"selected": false,
"text": "<p>It is pretty convenient in Windows 10.</p>\n\n<p>In Control Panel, Windows features, check ASP.NET 3.5, and then just wait for the download and installation.</p>\n\n<p><a href=\"https://i.stack.imgur.com/47xgm.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/47xgm.png\" alt=\"enter image description here\"></a></p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190270",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3314/"
] |
I just got a dedicated server from a hosting company, and for some reason, it didn't have IIS installed.
It did have .Net 2.0, though.
So I installed IIS, but now my ASP.net websites won't work.
I just get a 404, no event log entries, nothing...
I noticed in the redistributable package information that:
"To access the features of ASP.NET, IIS with the latest security updates must be installed prior to installing the .NET Framework"
I also can't uninstall .Net, it just won't let me...
Is there a way to reinstall .Net 2.0, or somehow do whatever it is it does to IIS to make it work?
Thanks!
Daniel
|
run from the command line
```
aspnet_regiis -i
```
You may have to navigate to the folder it was installed.
Mine and the default is
```
C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727
```
|
190,292 |
<p>I'm currently working with PHPUnit to try and develop tests alongside what I'm writing, however, I'm currently working on writing the Session Manager, and am having issues doing so...</p>
<p>The constructor for the Session handling class is</p>
<pre><code>private function __construct()
{
if (!headers_sent())
{
session_start();
self::$session_id = session_id();
}
}
</code></pre>
<p>However, as PHPUnit sends out text before it starts the testing, any testing on this Object returns a failed test, as the HTTP "Headers" have been sent...</p>
|
[
{
"answer_id": 190307,
"author": "pilsetnieks",
"author_id": 6615,
"author_profile": "https://Stackoverflow.com/users/6615",
"pm_score": 0,
"selected": false,
"text": "<p>Can't you use output buffering before starting the test? If you buffer everything that is output, you shouldn't have problems setting any headers as no output would have yet been sent to client at that point.</p>\n\n<p>Even if OB is used somewhere inside your classes, it is stackable and OB shouldn't affect what's going on inside.</p>\n"
},
{
"answer_id": 190436,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>As far as I know Zend Framework uses the same output buffering for their Zend_Session package tests. You can take a look at their test cases to get you started.</p>\n"
},
{
"answer_id": 190498,
"author": "troelskn",
"author_id": 18180,
"author_profile": "https://Stackoverflow.com/users/18180",
"pm_score": 6,
"selected": true,
"text": "<p>Well, your session manager is basically broken by design. To be able to test something, it must be possible to isolate it from side effects. Unfortunately, PHP is designed in such a way, that it encourages liberal use of global state (<code>echo</code>, <code>header</code>, <code>exit</code>, <code>session_start</code> etc. etc.).</p>\n\n<p>The best thing you can do, is to isolate the side-effects in a component, that can be swapped at runtime. That way, your tests can use mocked objects, while the live code uses adapters, that have real side-effects. You'll find that this doesn't play well with singletons, which I presume you're using. So you'll have to use some other mechanism for getting shared objects distributed to your code. You can start with a static registry, but there are even better solutions if you don't mind a bit of learning.</p>\n\n<p>If you can't do that, you always have the option of writing integration-tests. Eg. use the PHPUnit's equivalent of <a href=\"http://www.simpletest.org/en/web_tester_documentation.html\" rel=\"noreferrer\"><code>WebTestCase</code></a>.</p>\n"
},
{
"answer_id": 282582,
"author": "Kornel",
"author_id": 27009,
"author_profile": "https://Stackoverflow.com/users/27009",
"pm_score": 3,
"selected": false,
"text": "<p>I think the \"right\" solution is to create a very simple class (so simple it doesn't need to be tested) that's a wrapper for PHP's session-related functions, and use it instead of calling <code>session_start()</code>, etc. directly.</p>\n\n<p>In the test pass mock object instead of a real stateful, untestable session class.</p>\n\n<pre><code>private function __construct(SessionWrapper $wrapper)\n{\n if (!$wrapper->headers_sent())\n {\n $wrapper->session_start();\n $this->session_id = $wrapper->session_id();\n }\n}\n</code></pre>\n"
},
{
"answer_id": 1701041,
"author": "Dominik",
"author_id": 169773,
"author_profile": "https://Stackoverflow.com/users/169773",
"pm_score": 4,
"selected": false,
"text": "<p>Create a bootstrap file for phpunit, which calls:</p>\n\n<pre><code>session_start();\n</code></pre>\n\n<p>Then start phpunit like this:</p>\n\n<pre><code>phpunit --bootstrap pathToBootstrap.php --anotherSwitch /your/test/path/\n</code></pre>\n\n<p>The bootstrap file gets called before everything else, so the header hasn't been sent and everything should work fine.</p>\n"
},
{
"answer_id": 1845956,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>The creation of the bootstrap file, pointed out 4 posts back seems the cleanest way around this.</p>\n\n<p>Often with PHP we are having to maintain, and try to add some kind of engineering discipline to legacy projects that are abysmally put together. We don't have the time (or the authority) to ditch the whole pile of rubbish and start again, so the first anwer by troelskn isn't always possible as a way forward.\n( If we could go back to the initial design, then we could ditch PHP altogether and use something more modern, such as ruby or python, rather than help perpetuate this COBOL of the web development world. )</p>\n\n<p>If you are trying to write unit tests for modules that use session_start or setcookie throughout them, than starting the session in a boostrap file gets your round these issues.</p>\n"
},
{
"answer_id": 4059399,
"author": "Michael",
"author_id": 492243,
"author_profile": "https://Stackoverflow.com/users/492243",
"pm_score": 4,
"selected": false,
"text": "<p>phpUnit prints output as the tests run thus causing headers_sent() to return true even in your first test.</p>\n\n<p>To overcome this issue for an entire test suite you simply need to use ob_start() in your setup script.</p>\n\n<p>For example, say you have a file named AllTests.php that is the first thing loaded by phpUnit. That script might look like the following:</p>\n\n<pre><code><?php\n\nob_start();\n\nrequire_once 'YourFramework/AllTests.php';\n\nclass AllTests {\n public static function suite() {\n $suite = new PHPUnit_Framework_TestSuite('YourFramework');\n $suite->addTest(YourFramework_AllTests::suite());\n return $suite;\n }\n}\n</code></pre>\n"
},
{
"answer_id": 7822192,
"author": "Flip Vernooij",
"author_id": 1003261,
"author_profile": "https://Stackoverflow.com/users/1003261",
"pm_score": 0,
"selected": false,
"text": "<p>As I'm unittesting my bootstrap right now (yes I know most of you don't do that), I'm running in to the same problem (both header() and session_start()).\nThe solution I found is rather simple, in your unittest bootstrap define a constant and simply check it before sending the header or starting the session:</p>\n\n<pre><code>// phpunit_bootstrap.php\ndefine('UNITTEST_RUNNING', true);\n\n// bootstrap.php (application bootstrap)\ndefined('UNITTEST_RUNNING') || define('UNITTEST_RUNNING', false);\n.....\nif(UNITTEST_RUNNING===false){\n session_start();\n}\n</code></pre>\n\n<p>I agree that this is not perfect by design, but I'm unittesting an existing application, rewriting large parts is not desired. I also using the same logic to test private methods using the __call() and __set() magic methods.</p>\n\n<pre><code>public function __set($name, $value){\n if(UNITTEST_RUNNING===true){\n $name='_' . $name;\n $this->$name=$value;\n }\n throw new Exception('__set() can only be used when unittesting!');\n }\n</code></pre>\n"
},
{
"answer_id": 24778590,
"author": "Juanjo Lainez Reche",
"author_id": 2550230,
"author_profile": "https://Stackoverflow.com/users/2550230",
"pm_score": 4,
"selected": false,
"text": "<p>I had the same issue and I solved it by calling phpunit with --stderr flag just like this:</p>\n\n<pre><code>phpunit --stderr /path/to/your/test\n</code></pre>\n\n<p>Hope it helps someone!</p>\n"
},
{
"answer_id": 33445778,
"author": "user487772",
"author_id": 619978,
"author_profile": "https://Stackoverflow.com/users/619978",
"pm_score": 1,
"selected": false,
"text": "<p>I'm wondering why nobody have listed XDebug option:</p>\n\n<pre><code>/**\n * @runInSeparateProcess\n * @requires extension xdebug\n */\npublic function testGivenHeaderIsIncludedIntoResponse()\n{\n $customHeaderName = 'foo';\n $customHeaderValue = 'bar';\n\n // Here execute the code which is supposed to set headers\n // ...\n\n $expectedHeader = $customHeaderName . ': ' . $customHeaderValue;\n $headers = xdebug_get_headers();\n\n $this->assertContains($expectedHeader, $headers);\n}\n</code></pre>\n"
},
{
"answer_id": 34675243,
"author": "lost in binary",
"author_id": 2515587,
"author_profile": "https://Stackoverflow.com/users/2515587",
"pm_score": 0,
"selected": false,
"text": "<p>It seems that you need to inject the session so that you can test your code. The best option I have used is Aura.Auth for the authentication process and using NullSession and NullSegment for testing. </p>\n\n<p><a href=\"https://github.com/auraphp/Aura.auth#working-without-sessions\" rel=\"nofollow\">Aura testing with null sessions</a></p>\n\n<p>The Aura framework is beautifully written and you can use Aura.Auth on its own without any other Aura framework dependencies.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190292",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/20010/"
] |
I'm currently working with PHPUnit to try and develop tests alongside what I'm writing, however, I'm currently working on writing the Session Manager, and am having issues doing so...
The constructor for the Session handling class is
```
private function __construct()
{
if (!headers_sent())
{
session_start();
self::$session_id = session_id();
}
}
```
However, as PHPUnit sends out text before it starts the testing, any testing on this Object returns a failed test, as the HTTP "Headers" have been sent...
|
Well, your session manager is basically broken by design. To be able to test something, it must be possible to isolate it from side effects. Unfortunately, PHP is designed in such a way, that it encourages liberal use of global state (`echo`, `header`, `exit`, `session_start` etc. etc.).
The best thing you can do, is to isolate the side-effects in a component, that can be swapped at runtime. That way, your tests can use mocked objects, while the live code uses adapters, that have real side-effects. You'll find that this doesn't play well with singletons, which I presume you're using. So you'll have to use some other mechanism for getting shared objects distributed to your code. You can start with a static registry, but there are even better solutions if you don't mind a bit of learning.
If you can't do that, you always have the option of writing integration-tests. Eg. use the PHPUnit's equivalent of [`WebTestCase`](http://www.simpletest.org/en/web_tester_documentation.html).
|
190,295 |
<p>How do I test the concrete methods of an abstract class with PHPUnit?</p>
<p>I'd expect that I'd have to create some sort of object as part of the test. Though, I've no idea the best practice for this or if PHPUnit allows for this.</p>
|
[
{
"answer_id": 284929,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>Eran, your method should work, but it goes against the tendency of writing the test before the actual code.</p>\n\n<p>What I would suggest is to write your tests on the desired functionality of a non-abstract subclass of the abstract class in question, then write both the abstract class and the implementing subclass, and finally run the test.</p>\n\n<p>Your tests should obviously test the defined methods of the abstract class, but always via the subclass.</p>\n"
},
{
"answer_id": 284986,
"author": "hangy",
"author_id": 11963,
"author_profile": "https://Stackoverflow.com/users/11963",
"pm_score": 0,
"selected": false,
"text": "<p>If you do not want to subclass the abstract class just to perform a unit test on the methods which are implemented in the abstract class already, you could try to see whether your framework allows you to <a href=\"http://en.wikipedia.org/wiki/Mock_object\" rel=\"nofollow noreferrer\" title=\"Mock object - Wikipedia, the free encyclopedia\">mock</a> abstract classes.</p>\n"
},
{
"answer_id": 1466684,
"author": "skqr",
"author_id": 177871,
"author_profile": "https://Stackoverflow.com/users/177871",
"pm_score": 1,
"selected": false,
"text": "<p>Nelson's answer is wrong.</p>\n\n<p>Abstract classes don't require all of their methods to be abstract.</p>\n\n<p>The implemented methods are the ones we need to test.</p>\n\n<p>What you can do is create a fake stub class on the unit test file, have it extend the abstract class and implement only what's required with no functionality at all, of course, and test that.</p>\n\n<p>Cheers.</p>\n"
},
{
"answer_id": 2241159,
"author": "Victor Farazdagi",
"author_id": 238300,
"author_profile": "https://Stackoverflow.com/users/238300",
"pm_score": 9,
"selected": true,
"text": "<p>Unit testing of abstract classes doesn't necessary mean testing the interface, as abstract classes can have concrete methods, and this concrete methods can be tested. </p>\n\n<p>It is not so uncommon, when writing some library code, to have certain base class that you expect to extend in your application layer. And if you want to make sure that library code is tested, you need means to UT the concrete methods of abstract classes.</p>\n\n<p>Personally, I use PHPUnit, and it has so called stubs and mock objects to help you testing this kind of things.</p>\n\n<p>Straight from <a href=\"https://phpunit.de/manual/current/en/test-doubles.html#test-doubles.stubs\" rel=\"noreferrer\">PHPUnit manual</a>:</p>\n\n<pre><code>abstract class AbstractClass\n{\n public function concreteMethod()\n {\n return $this->abstractMethod();\n }\n\n public abstract function abstractMethod();\n}\n\nclass AbstractClassTest extends PHPUnit_Framework_TestCase\n{\n public function testConcreteMethod()\n {\n $stub = $this->getMockForAbstractClass('AbstractClass');\n $stub->expects($this->any())\n ->method('abstractMethod')\n ->will($this->returnValue(TRUE));\n\n $this->assertTrue($stub->concreteMethod());\n }\n}\n</code></pre>\n\n<p>Mock object give you several things:</p>\n\n<ul>\n<li>you are not required to have concrete implementation of abstract class, and can get away with stub instead</li>\n<li>you may call concrete methods and assert that they perform correctly</li>\n<li>if concrete method relies to unimplemented (abstract) method, you may stub the return value with will() PHPUnit method </li>\n</ul>\n"
},
{
"answer_id": 4987710,
"author": "takeshin",
"author_id": 234780,
"author_profile": "https://Stackoverflow.com/users/234780",
"pm_score": 5,
"selected": false,
"text": "<p>That's a good question. I've been looking for this too.<br>\nLuckily, PHPUnit already has <a href=\"https://phpunit.readthedocs.io/en/7.1/test-doubles.html#mocking-traits-and-abstract-classes\" rel=\"noreferrer\"><code>getMockForAbstractClass()</code></a> method for this case, e.g.</p>\n\n<pre><code>protected function setUp()\n{\n $stub = $this->getMockForAbstractClass('Some_Abstract_Class');\n $this->_object = $stub;\n}\n</code></pre>\n\n<h3>Important:</h3>\n\n<p>Note that this requires PHPUnit > 3.5.4. There was <a href=\"https://github.com/sebastianbergmann/phpunit-mock-objects/pull/22\" rel=\"noreferrer\">a bug</a> in previous versions.</p>\n\n<p>To upgrade to the newest version:</p>\n\n<pre><code>sudo pear channel-update pear.phpunit.de\nsudo pear upgrade phpunit/PHPUnit\n</code></pre>\n"
},
{
"answer_id": 48889062,
"author": "GordonM",
"author_id": 477127,
"author_profile": "https://Stackoverflow.com/users/477127",
"pm_score": 6,
"selected": false,
"text": "<p>It should be noted that as of PHP 7 support for <a href=\"http://php.net/manual/en/language.oop5.anonymous.php\" rel=\"noreferrer\">anonymous classes</a> has been added. This gives you an additional avenue for setting up a test for an abstract class, one that doesn't depend on PHPUnit-specific functionality. </p>\n\n<pre><code>class AbstractClassTest extends \\PHPUnit_Framework_TestCase\n{\n /**\n * @var AbstractClass\n */\n private $testedClass;\n\n public function setUp()\n {\n $this->testedClass = new class extends AbstractClass {\n\n protected function abstractMethod()\n {\n // Put a barebones implementation here\n }\n };\n }\n\n // Put your tests here\n}\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190295",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/20010/"
] |
How do I test the concrete methods of an abstract class with PHPUnit?
I'd expect that I'd have to create some sort of object as part of the test. Though, I've no idea the best practice for this or if PHPUnit allows for this.
|
Unit testing of abstract classes doesn't necessary mean testing the interface, as abstract classes can have concrete methods, and this concrete methods can be tested.
It is not so uncommon, when writing some library code, to have certain base class that you expect to extend in your application layer. And if you want to make sure that library code is tested, you need means to UT the concrete methods of abstract classes.
Personally, I use PHPUnit, and it has so called stubs and mock objects to help you testing this kind of things.
Straight from [PHPUnit manual](https://phpunit.de/manual/current/en/test-doubles.html#test-doubles.stubs):
```
abstract class AbstractClass
{
public function concreteMethod()
{
return $this->abstractMethod();
}
public abstract function abstractMethod();
}
class AbstractClassTest extends PHPUnit_Framework_TestCase
{
public function testConcreteMethod()
{
$stub = $this->getMockForAbstractClass('AbstractClass');
$stub->expects($this->any())
->method('abstractMethod')
->will($this->returnValue(TRUE));
$this->assertTrue($stub->concreteMethod());
}
}
```
Mock object give you several things:
* you are not required to have concrete implementation of abstract class, and can get away with stub instead
* you may call concrete methods and assert that they perform correctly
* if concrete method relies to unimplemented (abstract) method, you may stub the return value with will() PHPUnit method
|
190,296 |
<p>What are the best practices for modeling inheritance in databases?</p>
<p>What are the trade-offs (e.g. queriability)?</p>
<p>(I'm most interested in SQL Server and .NET, but I also want to understand how other platforms address this issue.)</p>
|
[
{
"answer_id": 190300,
"author": "Per Hornshøj-Schierbeck",
"author_id": 11619,
"author_profile": "https://Stackoverflow.com/users/11619",
"pm_score": 1,
"selected": false,
"text": "<p>You would normalize of your database and that would actually mirror your inheritance.\nIt might have performance degradance, but that's how it is with normalizing. You probably will have to use good common sense to find the balance.</p>\n"
},
{
"answer_id": 190303,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 2,
"selected": false,
"text": "<p>There are two main types of inheritance you can setup in a DB, table per entity and table per Hierarchy.</p>\n\n<p>Table per entity is where you have a base entity table that has shared properties of all child classes. You then have per child class another table each with only properties applicable to that class. They are linked 1:1 by their PK's</p>\n\n<p><img src=\"https://i.stack.imgur.com/wjwxu.jpg\" alt=\"alt text\"></p>\n\n<p>Table per hierarchy is where all classes shared a table, and optional properties are nullable. Their is also a discriminator field which is a number that denotes the type that the record currently holds</p>\n\n<p><img src=\"https://i.stack.imgur.com/cdUe6.jpg\" alt=\"alt text\">\nSessionTypeID is discriminator</p>\n\n<p>Target per hierarchy is faster to query for as you do not need joins(only the discriminator value), whereas target per entity you need to do complex joins in order to detect what type something is as well as retreiuve all its data..</p>\n\n<p>Edit: The images I show here are screen shots of a project I am working on. The Asset image is not complete, hence the emptyness of it, but it was mainly to show how its setup, not what to put inside your tables. That is up to you ;). The session table holds Virtual collaboration session information, and can be of several types of sessions depending on what type of collaboration is involved.</p>\n"
},
{
"answer_id": 190306,
"author": "Brad Wilson",
"author_id": 1554,
"author_profile": "https://Stackoverflow.com/users/1554",
"pm_score": 9,
"selected": true,
"text": "<p>There are several ways to model inheritance in a database. Which you choose depends on your needs. Here are a few options:</p>\n\n<p><strong>Table-Per-Type (TPT)</strong></p>\n\n<p>Each class has its own table. The base class has all the base class elements in it, and each class which derives from it has its own table, with a primary key which is also a foreign key to the base class table; the derived table's class contains only the different elements.</p>\n\n<p>So for example:</p>\n\n<pre><code>class Person {\n public int ID;\n public string FirstName;\n public string LastName;\n}\n\nclass Employee : Person {\n public DateTime StartDate;\n}\n</code></pre>\n\n<p>Would result in tables like:</p>\n\n<pre><code>table Person\n------------\nint id (PK)\nstring firstname\nstring lastname\n\ntable Employee\n--------------\nint id (PK, FK)\ndatetime startdate\n</code></pre>\n\n<p><strong>Table-Per-Hierarchy (TPH)</strong></p>\n\n<p>There is a single table which represents all the inheritance hierarchy, which means several of the columns will probably be sparse. A discriminator column is added which tells the system what type of row this is.</p>\n\n<p>Given the classes above, you end up with this table:</p>\n\n<pre><code>table Person\n------------\nint id (PK)\nint rowtype (0 = \"Person\", 1 = \"Employee\")\nstring firstname\nstring lastname\ndatetime startdate\n</code></pre>\n\n<p>For any rows which are rowtype 0 (Person), the startdate will always be null.</p>\n\n<p><strong>Table-Per-Concrete (TPC)</strong></p>\n\n<p>Each class has its own fully formed table with no references off to any other tables.</p>\n\n<p>Given the classes above, you end up with these tables:</p>\n\n<pre><code>table Person\n------------\nint id (PK)\nstring firstname\nstring lastname\n\ntable Employee\n--------------\nint id (PK)\nstring firstname\nstring lastname\ndatetime startdate\n</code></pre>\n"
},
{
"answer_id": 190309,
"author": "Steven A. Lowe",
"author_id": 9345,
"author_profile": "https://Stackoverflow.com/users/9345",
"pm_score": 1,
"selected": false,
"text": "<p><a href=\"https://stackoverflow.com/questions/5802/inheritance-in-database#86900\">repeat of similar thread answer</a></p>\n\n<p>in O-R mapping, inheritance maps to a parent table where the parent and child tables use the same identifier</p>\n\n<p>for example</p>\n\n<pre><code>create table Object (\n Id int NOT NULL --primary key, auto-increment\n Name varchar(32)\n)\ncreate table SubObject (\n Id int NOT NULL --primary key and also foreign key to Object\n Description varchar(32)\n)\n</code></pre>\n\n<p>SubObject has a foreign-key relationship to Object. when you create a SubObject row, you must first create an Object row and use the Id in both rows</p>\n\n<p>EDIT: if you're looking to model behavior also, you would need a Type table that listed the inheritance relationships between tables, and specified the assembly and class name that implemented each table's behavior</p>\n\n<p>seems like overkill, but that all depends on what you want to use it for!</p>\n"
},
{
"answer_id": 190517,
"author": "Matthew Schinckel",
"author_id": 188,
"author_profile": "https://Stackoverflow.com/users/188",
"pm_score": 1,
"selected": false,
"text": "<p>Using SQL ALchemy (Python ORM), you can do two types of inheritance.</p>\n\n<p>The one I've had experience is using a singe-table, and having a discriminant column. For instances, a Sheep database (no joke!) stored all Sheep in the one table, and Rams and Ewes were handled using a gender column in that table.</p>\n\n<p>Thus, you can query for all Sheep, and get all Sheep. Or you can query by Ram only, and it will only get Rams. You can also do things like have a relation that can only be a Ram (ie, the Sire of a Sheep), and so on.</p>\n"
},
{
"answer_id": 190608,
"author": "Pierre",
"author_id": 24449,
"author_profile": "https://Stackoverflow.com/users/24449",
"pm_score": 1,
"selected": false,
"text": "<p>Note that some database engines already provides inheritance mechanisms natively like <a href=\"http://www.postgres.org\" rel=\"nofollow noreferrer\">Postgres</a>. Look at the <a href=\"http://www.postgresql.org/docs/8.3/interactive/ddl-inherit.html\" rel=\"nofollow noreferrer\">documentation</a>.</p>\n\n<p>For an example, you would query the Person/Employee system described in a response above like this:</p>\n\n<pre>\n /* This shows the first name of all persons or employees */\n SELECT firstname FROM Person ; \n\n /* This shows the start date of all employees only */\n SELECT startdate FROM Employee ;\n</pre>\n\n<p>In that is your database's choice, you don't need to be particularly smart !</p>\n"
},
{
"answer_id": 193222,
"author": "Jeffrey L Whitledge",
"author_id": 10174,
"author_profile": "https://Stackoverflow.com/users/10174",
"pm_score": 7,
"selected": false,
"text": "<p>Proper database design is nothing like proper object design.</p>\n\n<p>If you are planning to use the database for anything other than simply serializing your objects (such as reports, querying, multi-application use, business intelligence, etc.) then I do not recommend any kind of a simple mapping from objects to tables.</p>\n\n<p>Many people think of a row in a database table as an entity (I spent many years thinking in those terms), but a row is not an entity. It is a proposition. A database relation (i.e., table) represents some statement of fact about the world. The presence of the row indicates the fact is true (and conversely, its absence indicates the fact is false).</p>\n\n<p>With this understanding, you can see that a single type in an object-oriented program may be stored across a dozen different relations. And a variety of types (united by inheritance, association, aggregation, or completely unaffiliated) may be partially stored in a single relation.</p>\n\n<p>It is best to ask yourself, what facts do you want to store, what questions are you going to want answers to, what reports do you want to generate.</p>\n\n<p>Once the proper DB design is created, then it is a simple matter to create queries/views that allow you to serialize your objects to those relations.</p>\n\n<p>Example:</p>\n\n<p>In a hotel booking system, you may need to store the fact that Jane Doe has a reservation for a room at the Seaview Inn for April 10-12. Is that an attribute of the customer entity? Is it an attribute of the hotel entity? Is it a reservation entity with properties that include customer and hotel? It could be any or all of those things in an object oriented system. In a database, it is none of those things. It is simply a bare fact.</p>\n\n<p>To see the difference, consider the following two queries. (1) How many hotel reservations does Jane Doe have for next year? (2) How many rooms are booked for April 10 at the Seaview Inn? </p>\n\n<p>In an object-oriented system, query (1) is an attribute of the customer entity, and query (2) is an attribute of the hotel entity. Those are the objects that would expose those properties in their APIs. (Though, obviously the internal mechanisms by which those values are obtained may involve references to other objects.)</p>\n\n<p>In a relational database system, both queries would examine the reservation relation to get their numbers, and conceptually there is no need to bother with any other \"entity\".</p>\n\n<p>Thus, it is by attempting to store facts about the world—rather than attempting to store entities with attributes—that a proper relational database is constructed. And once it is properly designed, then useful queries that were undreamt of during the design phase can be easily constructed, since all the facts needed to fulfill those queries are in their proper places.</p>\n"
},
{
"answer_id": 193234,
"author": "Marcin",
"author_id": 21640,
"author_profile": "https://Stackoverflow.com/users/21640",
"pm_score": 4,
"selected": false,
"text": "<p>Short answer: you don't.</p>\n\n<p>If you need to serialize your objects, use an ORM, or even better something like activerecord or prevaylence.</p>\n\n<p>If you need to store data, store it in a relational manner (being careful about what you are storing, and paying attention to what Jeffrey L Whitledge just said), not one affected by your object design.</p>\n"
},
{
"answer_id": 25452683,
"author": "imang",
"author_id": 3684279,
"author_profile": "https://Stackoverflow.com/users/3684279",
"pm_score": 4,
"selected": false,
"text": "<p>TPT, TPH and TPC patterns are the ways you go, as mentioned by Brad Wilson. But couple of notes:</p>\n\n<ul>\n<li><p>child classes inheriting from a base class can be seen as weak-entities to the base class definition in the database, meaning they are dependent to their base-class and cannot exist without it. I've seen number of times, that unique IDs are stored for each and every child table while also keeping the FK to the parent table. One FK is just enough and its even better to have on-delete cascade enable for the FK-relation between the child and base tables.</p></li>\n<li><p>In TPT, by only seeing the base table records, you're not able to find which child class the record is representing. This is sometimes needed, when you want to load a list of all records (without doing <code> select </code> on each and every child table). One way to handle this, is to have one column representing the type of the child class (similar to the rowType field in the TPH), so mixing the TPT and TPH somehow.</p></li>\n</ul>\n\n<p>Say we want to design a database that holds the following shape class diagram:</p>\n\n<pre><code>public class Shape {\nint id;\nColor color;\nThickness thickness;\n//other fields\n}\n\npublic class Rectangle : Shape {\nPoint topLeft;\nPoint bottomRight;\n}\n\npublic class Circle : Shape {\nPoint center;\nint radius;\n}\n</code></pre>\n\n<p>The database design for the above classes can be like this:</p>\n\n<pre><code>table Shape\n-----------\nint id; (PK)\nint color;\nint thichkness;\nint rowType; (0 = Rectangle, 1 = Circle, 2 = ...)\n\ntable Rectangle\n----------\nint ShapeID; (FK on delete cascade)\nint topLeftX;\nint topLeftY;\nint bottomRightX;\nint bottomRightY;\n\ntable Circle\n----------\nint ShapeID; (FK on delete cascade) \nint centerX;\nint center;\nint radius;\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190296",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/73794/"
] |
What are the best practices for modeling inheritance in databases?
What are the trade-offs (e.g. queriability)?
(I'm most interested in SQL Server and .NET, but I also want to understand how other platforms address this issue.)
|
There are several ways to model inheritance in a database. Which you choose depends on your needs. Here are a few options:
**Table-Per-Type (TPT)**
Each class has its own table. The base class has all the base class elements in it, and each class which derives from it has its own table, with a primary key which is also a foreign key to the base class table; the derived table's class contains only the different elements.
So for example:
```
class Person {
public int ID;
public string FirstName;
public string LastName;
}
class Employee : Person {
public DateTime StartDate;
}
```
Would result in tables like:
```
table Person
------------
int id (PK)
string firstname
string lastname
table Employee
--------------
int id (PK, FK)
datetime startdate
```
**Table-Per-Hierarchy (TPH)**
There is a single table which represents all the inheritance hierarchy, which means several of the columns will probably be sparse. A discriminator column is added which tells the system what type of row this is.
Given the classes above, you end up with this table:
```
table Person
------------
int id (PK)
int rowtype (0 = "Person", 1 = "Employee")
string firstname
string lastname
datetime startdate
```
For any rows which are rowtype 0 (Person), the startdate will always be null.
**Table-Per-Concrete (TPC)**
Each class has its own fully formed table with no references off to any other tables.
Given the classes above, you end up with these tables:
```
table Person
------------
int id (PK)
string firstname
string lastname
table Employee
--------------
int id (PK)
string firstname
string lastname
datetime startdate
```
|
190,335 |
<p>This is my first Latex doc. Using Latex8.sty I'm trying to include a 5 column table. I've commented out everything but the introdution and the table. When I make the pdf it shows the introduction but no table. Any tips? </p>
<pre><code>\begin{tabular}{|ll||l|c|r|rr}
Mass&a1&a2&Fprime1&Fprime2\\
\hline
70g&0.988m/s^2&-2.79m/s^2&467.364N&424.02N\\
80g&1.36m/s&-2.81m/s^2&3.84N&427.12N\\
90g&1.70m/s^2&-2.74m/s^2&471.5N&416.48N\\
100g&1.84m/s^2&-2.76m/s^2&491.12N&419.52N\\
150g&3.11m/s^2&-2.88m/s^2&530.78N&437.76N\\\hline
\end{tabular}
</code></pre>
|
[
{
"answer_id": 190337,
"author": "PW.",
"author_id": 927,
"author_profile": "https://Stackoverflow.com/users/927",
"pm_score": 2,
"selected": true,
"text": "<p>with gnome, you have <a href=\"http://ekiga.org\" rel=\"nofollow noreferrer\">ekiga</a>. You can cross compile it for win32 too. It uses OPAL (Open Phone Abstraction Library) underneath. Maybe the tool itself will suit your needs, otherwise you can adapt it (OSS) or you can only keep low level API</p>\n"
},
{
"answer_id": 190374,
"author": "DanJ",
"author_id": 4697,
"author_profile": "https://Stackoverflow.com/users/4697",
"pm_score": 0,
"selected": false,
"text": "<p>I agree with PW.</p>\n\n<ul>\n<li>OPAL is an excellent choice. </li>\n<li>It supports audio and video devices</li>\n<li>It compiles on windows, linux, and a few others</li>\n</ul>\n\n<p>Also\n- I recommend using the SIP protocol (as opposed to H323)\n- You don't need to use Ekiga. Ekiga is a front-end to OPAL. You can take a look at the OPAL samples, and build up from those.</p>\n"
},
{
"answer_id": 1686936,
"author": "Roman Nikitchenko",
"author_id": 204665,
"author_profile": "https://Stackoverflow.com/users/204665",
"pm_score": 0,
"selected": false,
"text": "<p>I don't recommend usage of H.323 at all to build new applications, especially user oriented. I'd recommend SIP because of much more simple and cleaner signaling / negotiations e.t.c.</p>\n\n<p>From the other point of view I don't recommend to use OPAL if you're building something with more then 5 calls density. This is because of number of architecture solutions placed there (thread management with some race conditions, very complex containers management with lazy copying which actually makes things much more dangerous and so on). This is because of OpenH323 legacy approach (indeed ptlib library which was used for OpenH323).</p>\n\n<p>Maybe something was changed from the days I had headache with OpenH323 and early Opal but I don't think something basic.</p>\n\n<p>What about take a look on <a href=\"http://www.freeswitch.org/\" rel=\"nofollow noreferrer\">FreeSwitch</a> platform? People say it is much more better designed.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190335",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
This is my first Latex doc. Using Latex8.sty I'm trying to include a 5 column table. I've commented out everything but the introdution and the table. When I make the pdf it shows the introduction but no table. Any tips?
```
\begin{tabular}{|ll||l|c|r|rr}
Mass&a1&a2&Fprime1&Fprime2\\
\hline
70g&0.988m/s^2&-2.79m/s^2&467.364N&424.02N\\
80g&1.36m/s&-2.81m/s^2&3.84N&427.12N\\
90g&1.70m/s^2&-2.74m/s^2&471.5N&416.48N\\
100g&1.84m/s^2&-2.76m/s^2&491.12N&419.52N\\
150g&3.11m/s^2&-2.88m/s^2&530.78N&437.76N\\\hline
\end{tabular}
```
|
with gnome, you have [ekiga](http://ekiga.org). You can cross compile it for win32 too. It uses OPAL (Open Phone Abstraction Library) underneath. Maybe the tool itself will suit your needs, otherwise you can adapt it (OSS) or you can only keep low level API
|
190,368 |
<p>In Scala, is it possible to get the string representation of a type at runtime? I am trying to do something along these lines:</p>
<pre><code>def printTheNameOfThisType[T]() = {
println(T.toString)
}
</code></pre>
|
[
{
"answer_id": 190574,
"author": "svrist",
"author_id": 86,
"author_profile": "https://Stackoverflow.com/users/86",
"pm_score": 4,
"selected": true,
"text": "<h1>Note: this answer is out of date!</h1>\n\n<p><em>Please see answer using TypeTag for Scala 2.10 and above</em></p>\n\n<p>May I recommend #Scala on freenode</p>\n\n<pre><code>10:48 <seet_> http://stackoverflow.com/questions/190368/getting-the-string-representation-of-a-type-at-runtime-in-scala <-- isnt this posible?\n10:48 <seet_> possible\n10:48 <lambdabot> Title: Getting the string representation of a type at runtime in Scala - Stack Overflow,\n http://tinyurl.com/53242l\n10:49 <mapreduce> Types aren't objects.\n10:49 <mapreduce> or values\n10:49 <mapreduce> println(classOf[T]) should give you something, but probably not what you want.\n</code></pre>\n\n<p><a href=\"http://www.scala-lang.org/node/109\" rel=\"nofollow noreferrer\">Description of classOf</a></p>\n"
},
{
"answer_id": 195294,
"author": "svrist",
"author_id": 86,
"author_profile": "https://Stackoverflow.com/users/86",
"pm_score": 2,
"selected": false,
"text": "<p>Please note that this isn't really \"the thing:\"</p>\n\n<pre><code>object Test {\n def main (args : Array[String]) {\n println(classOf[List[String]])\n }\n}\n</code></pre>\n\n<p>gives</p>\n\n<pre><code>$ scala Test \nclass scala.List\n</code></pre>\n\n<p>I think you can blame this on erasure</p>\n\n<p>====EDIT====\nI've tried doing it with a method with a generic type parameter:</p>\n\n<pre><code>object TestSv {\n def main(args:Array[String]){\n narf[String]\n }\n def narf[T](){\n println(classOf[T])\n }\n}\n</code></pre>\n\n<p>And the compiler wont accept it. Types arn't classes is the explanation</p>\n"
},
{
"answer_id": 392339,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>There's a new, mostly-undocumented feature called \"manifests\" in Scala; it works like this:</p>\n\n<pre><code>object Foo {\n def apply[T <: AnyRef](t: T)(implicit m: scala.reflect.Manifest[T]) = println(\"t was \" + t.toString + \" of class \" + t.getClass.getName() + \", erased from \" + m.erasure)\n}\n</code></pre>\n\n<p>The AnyRef bound is just there to ensure the value has a .toString method.</p>\n"
},
{
"answer_id": 31191219,
"author": "Julie",
"author_id": 8217,
"author_profile": "https://Stackoverflow.com/users/8217",
"pm_score": 3,
"selected": false,
"text": "<p>In Scala 2.10 and above, use <code>TypeTag</code>, which contains full type information. You'll need to include the <code>scala-reflect</code> library in order to do this:</p>\n\n<pre><code>import scala.reflect.runtime.universe._\ndef printTheNameOfThisType[T: TypeTag]() = {\n println(typeOf[T].toString)\n}\n</code></pre>\n\n<p>You will get results like the following:</p>\n\n<pre><code>scala> printTheNameOfThisType[Int]\nInt\n\nscala> printTheNameOfThisType[String]\nString\n\nscala> printTheNameOfThisType[List[Int]]\nscala.List[Int]\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190368",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10475/"
] |
In Scala, is it possible to get the string representation of a type at runtime? I am trying to do something along these lines:
```
def printTheNameOfThisType[T]() = {
println(T.toString)
}
```
|
Note: this answer is out of date!
=================================
*Please see answer using TypeTag for Scala 2.10 and above*
May I recommend #Scala on freenode
```
10:48 <seet_> http://stackoverflow.com/questions/190368/getting-the-string-representation-of-a-type-at-runtime-in-scala <-- isnt this posible?
10:48 <seet_> possible
10:48 <lambdabot> Title: Getting the string representation of a type at runtime in Scala - Stack Overflow,
http://tinyurl.com/53242l
10:49 <mapreduce> Types aren't objects.
10:49 <mapreduce> or values
10:49 <mapreduce> println(classOf[T]) should give you something, but probably not what you want.
```
[Description of classOf](http://www.scala-lang.org/node/109)
|
190,380 |
<p>I am trying to store more than 1 data item at a single index in my linked-list. All of the examples in my textbook seem to illustrate adding only 1 piece of data per index. I'm assuming it is possible to add more?</p>
<p>For example, using the Collections API to store an integer I would do the following:</p>
<pre><code>LinkedList <Integer>linky = new LinkedList<Integer>();
int num1 = 2, num2 = 22, num3 = 25, num4 = 1337;
linky.add(num1);
</code></pre>
<p>How would I go about adding num2, num3, and num4 to the same first index in the list? Thanks guys. </p>
|
[
{
"answer_id": 190390,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>Use a structure.</p>\n\n<p>For example:</p>\n\n<pre><code>private struct Node\n{\n int Num1;\n int Num2;\n int Num3;\n}\n</code></pre>\n\n<p>...</p>\n\n<pre><code>LinkedList<Node> list = new LnkedList<Node>();\n\nNode n = new Node();\nn.Num1 = 10;\nn.Num2 = 100;\nn.Num3 = 1000;\nlist.Add(n);\n</code></pre>\n\n<p>Note; I assume this is in C#; correct me if I'm wrong and I will fix the code ;)</p>\n\n<p>If you have not gone over OOP yet in your book - then I would recommend giving it a try; it will help you solve problems like this.</p>\n"
},
{
"answer_id": 190392,
"author": "Gregor",
"author_id": 26153,
"author_profile": "https://Stackoverflow.com/users/26153",
"pm_score": 1,
"selected": false,
"text": "<p>Why not something like that:</p>\n\n<pre><code>LinkedList<LinkedList<Integer>> linky = new LinkedList<LinkedList<Integer>>();\n//...\nlinky.add(new LinkedList<Integer>().add( //...\n</code></pre>\n"
},
{
"answer_id": 190393,
"author": "Matt J",
"author_id": 18528,
"author_profile": "https://Stackoverflow.com/users/18528",
"pm_score": 5,
"selected": true,
"text": "<p>There seems to be a little confusion about how linked lists work. Essentially, a linked list is composed of nodes, each of which contains one datum (an object, which itself can contain several member variables, to be precise), and a link to the next node in the list (or a null pointer if there is no such next node). You can also have a doubly-linked list, where each node also has a pointer to the previous node in the list, to speed up certain kinds of access patterns.</p>\n\n<p>To add multiple \"pieces of data\" to a single node sounds like adding several links off of one node, which turns your linked list into an N-ary <em>tree</em>.</p>\n\n<p>To add multiple pieces of data onto the end of the list, in the manner most commonly associated with a linked list, just do:</p>\n\n<pre><code>LinkedList <Integer>linky = new LinkedList<Integer>();\nint num1 = 2, num2 = 22, num3 = 25, num4 = 1337;\nlinky.add(num1);\nlinky.add(num2);\nlinky.add(num3);\nlinky.add(num4);\n</code></pre>\n\n<h2>Alternately, if you want each node of the linked list to have several pieces of data</h2>\n\n<p>These data should be packaged up into an <strong>object</strong> (by defining a <code>class</code> that has them all as member variables). For example:</p>\n\n<pre><code>class GroupOfFourInts\n{\n int myInt1;\n int myInt2;\n int myInt3;\n int myInt4;\n\n public GroupOfFourInts(int a, int b, int c, int d)\n {\n myInt1 = a; myInt2 = b; myInt3 = c; myInt4 = d;\n }\n}\n\nclass someOtherClass\n{\n\n public static void main(String[] args)\n {\n LinkedList<GroupOfFourInts> linky = new LinkedList<GroupOfFourInts>();\n GroupOfFourInts group1 = new GroupOfFourInts(1,2,3,4);\n GroupOfFourInts group2 = new GroupOfFourInts(1337,7331,2345,6789);\n linky.add(group1);\n linky.add(group2);\n }\n}\n</code></pre>\n\n<p>Now, <code>linky</code> will have 2 nodes, each of which will contain 4 <code>int</code>s, <em>myInt1</em>, <em>myInt2</em>, <em>myInt3</em>, and <em>myInt4</em>.</p>\n\n<h2>Note</h2>\n\n<p>None of the above is specific to linked lists. This pattern should be used whenever you want to store a bunch of data together as a unit. You create a class that has member variables for every piece of data you want to be stored together, then create any Java Collections type (ArrayList, LinkedList, TreeList, ...) of that type.</p>\n\n<p>Be sure that you want to use a linked list (as there's no penalty in terms of programming difficulty in choosing an ArrayList or TreeList). This will depend on your data access pattern. Linked lists provide O(1) addition and deletion, but O(n) lookup, whereas ArrayLists provide O(1) lookup, but O(n) arbitrary add and delete. TreeLists provide O(log n) insertion, deletion, and lookup. The tradeoffs between these depend on the amount of data you have and how you're going to be modifying and accessing the data structure.</p>\n\n<p>Of course, none of this matters if you'll only have, say, <100 elements in your list ;-)</p>\n\n<p>Hope this helps!</p>\n"
},
{
"answer_id": 190400,
"author": "GavinCattell",
"author_id": 21644,
"author_profile": "https://Stackoverflow.com/users/21644",
"pm_score": 1,
"selected": false,
"text": "<p>Like Nelson said you need another Object, in Java though you need to use a Class.\nIf you need the 'Node' Class to be used outside the Class you're working in, then you need to make it a Public class, and move it to it's own file.</p>\n\n<pre><code>private Class Node\n{\n //You might want to make these private, and make setters and getters\n public int Num1;\n public int Num2;\n puclic int Num3;\n}\n\nLinkedList<Node> list = new LinkedList<Node>();\n\nNode n = new Node();\nn.Num1 = 10;\nn.Num2 = 100;\nn.Num3 = 1000;\nlist.Add(n);\n</code></pre>\n\n<p>Apologies to Nelson for stealing his code ;)</p>\n"
},
{
"answer_id": 190416,
"author": "paxdiablo",
"author_id": 14860,
"author_profile": "https://Stackoverflow.com/users/14860",
"pm_score": 0,
"selected": false,
"text": "<p>Here's a complete code sample that shows the use of adding a structure to a linked list:</p>\n\n<pre><code>import java.util.LinkedList;\nclass Node {\n int num1;\n int num2;\n int num3;\n int num4;\n public Node(int a, int b, int c, int d) {\n num1 = a; num2 = b; num3 = c; num4 = d;\n }\n}\npublic class dummy {\n public static void main(String[] args) {\n LinkedList <Node>linky = new LinkedList<Node>();\n x myNode = new Node(2, 22, 25, 1337);\n linky.add(myNode);\n }\n}\n</code></pre>\n"
},
{
"answer_id": 190424,
"author": "extraneon",
"author_id": 24582,
"author_profile": "https://Stackoverflow.com/users/24582",
"pm_score": 0,
"selected": false,
"text": "<p>I don't really understand what you are trying to achieve, so I suggest a solution to another reading of the problem (in java).</p>\n\n<pre><code>LinkedList <Integer>linky = new LinkedList<Integer>();\nlinky.add(num1);\n\n// Lots of code possibly adding elements somewhere else in the list\n\nif (linky.size() > 0) { // Always good to be sure; especially if this is in another methode\n int first = linky.get(0);\n linky.set(0, first + num2);// Value of linky.get(0) is num1 + num2 \n}\n\n\n// The same again\n// Lots of code possibly adding elements somewhere else in the list\n\nif (linky.size() > 0) { // Always good to be sure; especially if this is in another methode\n int first = linky.get(0);\n linky.set(0, first + num3); // Value of linky.get(0) is num1 + num2 + num3\n}\n</code></pre>\n\n<p>I personally happen to like Nelson's solution best if the amount of numbers to add is constant (num1 .. num4),\nand if it is not constant I would prefer Gregor's solution (who uses a List in stead of a Node). If you go for the Node method in java I suggest:</p>\n\n<pre><code>// added static, Class to class\nprivate static class Node\n{\n //You might want to make these private, and make setters and getters\n public int Num1;\n public int Num2;\n puclic int Num3;\n}\n\n// Prefer interfaces if possible\nList<Node> list = new LinkedList<Node>();\n\nNode n = new Node();\nn.Num1 = 10;\nn.Num2 = 100;\nn.Num3 = 1000;\nlist.add(n); // Add -> add\n</code></pre>\n\n<p>Lot's of nitpicking, but I think a static class in stead of a none-static private class is preferred if possible (and it normally should be possible).</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190380",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14013/"
] |
I am trying to store more than 1 data item at a single index in my linked-list. All of the examples in my textbook seem to illustrate adding only 1 piece of data per index. I'm assuming it is possible to add more?
For example, using the Collections API to store an integer I would do the following:
```
LinkedList <Integer>linky = new LinkedList<Integer>();
int num1 = 2, num2 = 22, num3 = 25, num4 = 1337;
linky.add(num1);
```
How would I go about adding num2, num3, and num4 to the same first index in the list? Thanks guys.
|
There seems to be a little confusion about how linked lists work. Essentially, a linked list is composed of nodes, each of which contains one datum (an object, which itself can contain several member variables, to be precise), and a link to the next node in the list (or a null pointer if there is no such next node). You can also have a doubly-linked list, where each node also has a pointer to the previous node in the list, to speed up certain kinds of access patterns.
To add multiple "pieces of data" to a single node sounds like adding several links off of one node, which turns your linked list into an N-ary *tree*.
To add multiple pieces of data onto the end of the list, in the manner most commonly associated with a linked list, just do:
```
LinkedList <Integer>linky = new LinkedList<Integer>();
int num1 = 2, num2 = 22, num3 = 25, num4 = 1337;
linky.add(num1);
linky.add(num2);
linky.add(num3);
linky.add(num4);
```
Alternately, if you want each node of the linked list to have several pieces of data
------------------------------------------------------------------------------------
These data should be packaged up into an **object** (by defining a `class` that has them all as member variables). For example:
```
class GroupOfFourInts
{
int myInt1;
int myInt2;
int myInt3;
int myInt4;
public GroupOfFourInts(int a, int b, int c, int d)
{
myInt1 = a; myInt2 = b; myInt3 = c; myInt4 = d;
}
}
class someOtherClass
{
public static void main(String[] args)
{
LinkedList<GroupOfFourInts> linky = new LinkedList<GroupOfFourInts>();
GroupOfFourInts group1 = new GroupOfFourInts(1,2,3,4);
GroupOfFourInts group2 = new GroupOfFourInts(1337,7331,2345,6789);
linky.add(group1);
linky.add(group2);
}
}
```
Now, `linky` will have 2 nodes, each of which will contain 4 `int`s, *myInt1*, *myInt2*, *myInt3*, and *myInt4*.
Note
----
None of the above is specific to linked lists. This pattern should be used whenever you want to store a bunch of data together as a unit. You create a class that has member variables for every piece of data you want to be stored together, then create any Java Collections type (ArrayList, LinkedList, TreeList, ...) of that type.
Be sure that you want to use a linked list (as there's no penalty in terms of programming difficulty in choosing an ArrayList or TreeList). This will depend on your data access pattern. Linked lists provide O(1) addition and deletion, but O(n) lookup, whereas ArrayLists provide O(1) lookup, but O(n) arbitrary add and delete. TreeLists provide O(log n) insertion, deletion, and lookup. The tradeoffs between these depend on the amount of data you have and how you're going to be modifying and accessing the data structure.
Of course, none of this matters if you'll only have, say, <100 elements in your list ;-)
Hope this helps!
|
190,396 |
<p>How do you use the <strong>CSS</strong> <code>content</code> property to add <strong>HTML</strong> entities?</p>
<p>Using something like this just prints <code>&nbsp;</code> to the screen instead of the non-breaking space:</p>
<pre class="lang-css prettyprint-override"><code>.breadcrumbs a:before {
content: '&nbsp;';
}
</code></pre>
|
[
{
"answer_id": 190406,
"author": "John Millikin",
"author_id": 3560,
"author_profile": "https://Stackoverflow.com/users/3560",
"pm_score": 5,
"selected": false,
"text": "<p>Use the hex code for a non-breaking space. Something like this:</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '>\\00a0';\n}\n</code></pre>\n"
},
{
"answer_id": 190412,
"author": "mathieu",
"author_id": 971,
"author_profile": "https://Stackoverflow.com/users/971",
"pm_score": 11,
"selected": true,
"text": "<p>You have to use the escaped unicode :</p>\n<p>Like</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '\\0000a0';\n}\n</code></pre>\n<p>More info on : <a href=\"http://www.evotech.net/blog/2007/04/named-html-entities-in-numeric-order/\" rel=\"noreferrer\">http://www.evotech.net/blog/2007/04/named-html-entities-in-numeric-order/</a></p>\n"
},
{
"answer_id": 1412764,
"author": "dlamblin",
"author_id": 459,
"author_profile": "https://Stackoverflow.com/users/459",
"pm_score": 6,
"selected": false,
"text": "<p><strong>Update</strong>: PointedEars mentions that the correct stand in for <code>&nbsp;</code> in all css situations would be<br>\n<code>'\\a0 '</code> implying that the space is a terminator to the hex string and is absorbed by the escaped sequence. He further pointed out this <a href=\"http://www.w3.org/TR/CSS2/syndata.html#escaped-characters\" rel=\"noreferrer\">authoritative description</a> which sounds like a good solution to the problem I described and fixed below.</p>\n\n<p>What you need to do is use the escaped unicode. Despite what you've been told <code>\\00a0</code> is not a perfect stand-in for <code>&nbsp;</code> within CSS; so try:</p>\n\n<pre><code>content:'>\\a0 '; /* or */\ncontent:'>\\0000a0'; /* because you'll find: */\ncontent:'No\\a0 Break'; /* and */\ncontent:'No\\0000a0Break'; /* becomes No&nbsp;Break as opposed to below */\n</code></pre>\n\n<p>Specifically using <code>\\0000a0</code> as <code>&nbsp;</code>.\nIf you try, as suggested by mathieu and millikin:</p>\n\n<pre><code>content:'No\\00a0Break' /* becomes No&#2571;reak */\n</code></pre>\n\n<p>It takes the B into the hex escaped characters. The same occurs with 0-9a-fA-F.</p>\n"
},
{
"answer_id": 1851564,
"author": "Dare",
"author_id": 225321,
"author_profile": "https://Stackoverflow.com/users/225321",
"pm_score": 4,
"selected": false,
"text": "<p>There is a way to paste an <code>nbsp</code> - open CharMap and copy <strong>character 160</strong>. However, in this case I'd probably space it out with padding, like this:</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before { content: '>'; padding-right: .5em; }\n</code></pre>\n<p>You might need to set the breadcrumbs <code>display:inline-block</code> or something, though.</p>\n"
},
{
"answer_id": 8523731,
"author": "netgoblin",
"author_id": 967024,
"author_profile": "https://Stackoverflow.com/users/967024",
"pm_score": 6,
"selected": false,
"text": "<p>In CSS you need to use a Unicode escape sequence in place of HTML Entities. This is based on the hexadecimal value of a character. </p>\n\n<p>I found that the easiest way to convert symbol to their hexadecimal equivalent is, such as from ▾ (<code>&#9662;</code>) to <code>\\25BE</code> is to use the Microsoft calculator =)</p>\n\n<p>Yes. Enable programmers mode, turn on the decimal system, enter <code>9662</code>, then switch to hex and you'll get <code>25BE</code>. Then just add a backslash <code>\\</code> to the beginning.</p>\n"
},
{
"answer_id": 8595802,
"author": "PointedEars",
"author_id": 855543,
"author_profile": "https://Stackoverflow.com/users/855543",
"pm_score": 8,
"selected": false,
"text": "<p>CSS is not HTML. <code>&nbsp;</code> is a named <a href=\"https://www.w3.org/TR/html52/syntax.html#character-references\" rel=\"nofollow noreferrer\">character reference</a> in HTML; equivalent to the decimal numeric character reference <code>&#160;</code>. 160 is the decimal <em>code point</em> of the <code>NO-BREAK SPACE</code> character in <a href=\"http://unicode.org/\" rel=\"nofollow noreferrer\">Unicode</a> (or <a href=\"http://en.wikipedia.org/wiki/Universal_Character_Set\" rel=\"nofollow noreferrer\">UCS-2</a>; see the <a href=\"https://www.w3.org/TR/1999/REC-html401-19991224/charset.html#h-5.1\" rel=\"nofollow noreferrer\">HTML 4.01 Specification</a>). The hexadecimal representation of that code point is U+00A0 (160 = 10 × 16<sup>1</sup> + 0 × 16<sup>0</sup>). You will find that in the Unicode <a href=\"http://www.unicode.org/charts/\" rel=\"nofollow noreferrer\">Code Charts</a> and <a href=\"http://unicode.org/ucd\" rel=\"nofollow noreferrer\">Character Database</a>.</p>\n<p>In CSS you need to use a Unicode escape sequence for such characters, which is based on the hexadecimal value of the code point of a character. So you need to write</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '\\a0';\n}\n</code></pre>\n<p>This works as long as the escape sequence comes last in a string value. If characters follow, there are two ways to avoid misinterpretation:</p>\n<p>a) (mentioned by others) Use exactly six hexadecimal digits for the escape sequence:</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '\\0000a0foo';\n}\n</code></pre>\n<p>b) Add one white-space (e. g., space) character after the escape sequence:</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '\\a0 foo';\n}\n</code></pre>\n<p>(Since <code>f</code> is a hexadecimal digit, <code>\\a0f</code> would otherwise mean <code>GURMUKHI LETTER EE</code> here, or ਏ if you have a suitable font.)</p>\n<p>The delimiting white-space will be ignored, and this will be displayed <code> foo</code>, where the displayed space here would be a <code>NO-BREAK SPACE</code> character.</p>\n<p>The white-space approach (<code>'\\a0 foo'</code>) has the following advantages over the six-digit approach (<code>'\\0000a0foo'</code>):</p>\n<ul>\n<li>it is <strong>easier to type</strong>, because leading zeroes are not necessary, and digits do not need to be counted;</li>\n<li>it is <strong>easier to read</strong>, because there is white-space between escape sequence and following text, and digits do not need to be counted;</li>\n<li>it <strong>requires less space</strong>, because leading zeroes are not necessary;</li>\n<li>it is <strong>upwards-compatible</strong>, because Unicode supporting code points beyond U+10FFFF in the future would require a modification of the CSS Specification.</li>\n</ul>\n<p>Thus, to display a space after an escaped character, use <em>two</em> spaces in the stylesheet –</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '\\a0 foo';\n}\n</code></pre>\n<p>– or make it explicit:</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '\\a0\\20 foo';\n}\n</code></pre>\n<p>See <a href=\"http://www.w3.org/TR/CSS2/syndata.html#escaped-characters\" rel=\"nofollow noreferrer\">CSS 2.1, section "4.1.3 Characters and case"</a> for details.</p>\n"
},
{
"answer_id": 30105665,
"author": "Ferhat KOÇER",
"author_id": 3129822,
"author_profile": "https://Stackoverflow.com/users/3129822",
"pm_score": 4,
"selected": false,
"text": "<p>For Example :</p>\n<p><a href=\"http://character-code.com/arrows-html-codes.php\" rel=\"noreferrer\">http://character-code.com/arrows-html-codes.php</a></p>\n<p>Example: If you want select your character , I selected "&#8620" "&#x21ac" (We use <strong>HEX</strong> values)</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a:before {\n content: '\\0021ac';\n}\n</code></pre>\n<p>Result: ↬</p>\n<p>Thats it :)</p>\n"
},
{
"answer_id": 39891538,
"author": "Tarandeep Singh",
"author_id": 2754038,
"author_profile": "https://Stackoverflow.com/users/2754038",
"pm_score": 0,
"selected": false,
"text": "<p><strong>Here are two ways:</strong> </p>\n\n<ul>\n<li><p>In HTML:</p>\n\n<p><code><div class=\"ics\">&#9969;</div></code></p></li>\n</ul>\n\n<p>This will result into \n ⛱</p>\n\n<ul>\n<li><p>In Css:</p>\n\n<p><code>.ics::before {content: \"\\9969;\"}</code></p></li>\n</ul>\n\n<p>with HTML code <code><div class=\"ics\"></div></code></p>\n\n<p>This also results in ⛱ </p>\n"
},
{
"answer_id": 47108182,
"author": "brian-welch",
"author_id": 1562842,
"author_profile": "https://Stackoverflow.com/users/1562842",
"pm_score": 1,
"selected": false,
"text": "<p>I know this is an pretty old post, but if spacing is all your after, why not simply:</p>\n<pre class=\"lang-css prettyprint-override\"><code>.breadcrumbs a::before {\n content: '>';\n margin-left: 8px;\n margin-right: 8px;\n}\n</code></pre>\n<p>I have used this method before. It wraps perfectly fine to other lines with ">" by its side in my testing.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190396",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/9021/"
] |
How do you use the **CSS** `content` property to add **HTML** entities?
Using something like this just prints ` ` to the screen instead of the non-breaking space:
```css
.breadcrumbs a:before {
content: ' ';
}
```
|
You have to use the escaped unicode :
Like
```css
.breadcrumbs a:before {
content: '\0000a0';
}
```
More info on : <http://www.evotech.net/blog/2007/04/named-html-entities-in-numeric-order/>
|
190,421 |
<p>Is there a PHP function to find out the name of the caller function in a given function?</p>
|
[
{
"answer_id": 190425,
"author": "Christian C. Salvadó",
"author_id": 5445,
"author_profile": "https://Stackoverflow.com/users/5445",
"pm_score": 4,
"selected": false,
"text": "<p><a href=\"http://www.php.net/debug_backtrace\" rel=\"nofollow noreferrer\"><code>debug_backtrace()</code></a> supplies details of parameters, function/method calls in the current call stack.</p>\n"
},
{
"answer_id": 190426,
"author": "Paul Dixon",
"author_id": 6521,
"author_profile": "https://Stackoverflow.com/users/6521",
"pm_score": 8,
"selected": false,
"text": "<p>See <a href=\"http://php.net/manual/en/function.debug-backtrace.php\" rel=\"noreferrer\">debug_backtrace</a> - this can trace your call stack all the way to the top.</p>\n\n<p>Here's how you'd get your caller:</p>\n\n<pre><code>$trace = debug_backtrace();\n$caller = $trace[1];\n\necho \"Called by {$caller['function']}\";\nif (isset($caller['class']))\n echo \" in {$caller['class']}\";\n</code></pre>\n"
},
{
"answer_id": 190430,
"author": "Richard Turner",
"author_id": 12559,
"author_profile": "https://Stackoverflow.com/users/12559",
"pm_score": 2,
"selected": false,
"text": "<p>You can extract this information from the array returned by <a href=\"http://uk3.php.net/debug_backtrace\" rel=\"nofollow noreferrer\">debug_backtrace</a></p>\n"
},
{
"answer_id": 9934684,
"author": "svassr",
"author_id": 1157322,
"author_profile": "https://Stackoverflow.com/users/1157322",
"pm_score": 4,
"selected": false,
"text": "<p>Xdebug provides some nice functions. </p>\n\n<pre><code><?php\n Class MyClass\n {\n function __construct(){\n $this->callee();\n }\n function callee() {\n echo sprintf(\"callee() called @ %s: %s from %s::%s\",\n xdebug_call_file(),\n xdebug_call_line(),\n xdebug_call_class(),\n xdebug_call_function()\n );\n }\n }\n $rollDebug = new MyClass();\n?>\n</code></pre>\n\n<p>will return trace </p>\n\n<pre><code>callee() called @ /var/www/xd.php: 16 from MyClass::__construct\n</code></pre>\n\n<p>To install Xdebug on ubuntu the best way is</p>\n\n<pre><code>sudo aptitude install php5-xdebug\n</code></pre>\n\n<p>You might need to install php5-dev first</p>\n\n<pre><code>sudo aptitude install php5-dev\n</code></pre>\n\n<p><a href=\"http://xdebug.org/docs/install\" rel=\"noreferrer\">more info</a></p>\n"
},
{
"answer_id": 12463381,
"author": "Paul Gobée",
"author_id": 1872387,
"author_profile": "https://Stackoverflow.com/users/1872387",
"pm_score": 3,
"selected": false,
"text": "<p>Made this and using this myself</p>\n\n<pre><code>/**\n * Gets the caller of the function where this function is called from\n * @param string what to return? (Leave empty to get all, or specify: \"class\", \"function\", \"line\", \"class\", etc.) - options see: http://php.net/manual/en/function.debug-backtrace.php\n */\nfunction getCaller($what = NULL)\n{\n $trace = debug_backtrace();\n $previousCall = $trace[2]; // 0 is this call, 1 is call in previous function, 2 is caller of that function\n\n if(isset($what))\n {\n return $previousCall[$what];\n }\n else\n {\n return $previousCall;\n } \n}\n</code></pre>\n"
},
{
"answer_id": 12813039,
"author": "MANISH ZOPE",
"author_id": 932826,
"author_profile": "https://Stackoverflow.com/users/932826",
"pm_score": 4,
"selected": false,
"text": "<p>This is very late but I would like to share the function that will give name of the function from which current function is called.</p>\n\n<pre><code>public function getCallingFunctionName($completeTrace=false)\n {\n $trace=debug_backtrace();\n if($completeTrace)\n {\n $str = '';\n foreach($trace as $caller)\n {\n $str .= \" -- Called by {$caller['function']}\";\n if (isset($caller['class']))\n $str .= \" From Class {$caller['class']}\";\n }\n }\n else\n {\n $caller=$trace[2];\n $str = \"Called by {$caller['function']}\";\n if (isset($caller['class']))\n $str .= \" From Class {$caller['class']}\";\n }\n return $str;\n }\n</code></pre>\n\n<p>I hope this will be useful.</p>\n"
},
{
"answer_id": 13502124,
"author": "Gershon Herczeg",
"author_id": 1109024,
"author_profile": "https://Stackoverflow.com/users/1109024",
"pm_score": 2,
"selected": false,
"text": "<p>This one worked best for me: <code>var_dump(debug_backtrace());</code></p>\n"
},
{
"answer_id": 16958460,
"author": "vrijdenker",
"author_id": 2459026,
"author_profile": "https://Stackoverflow.com/users/2459026",
"pm_score": 1,
"selected": false,
"text": "<p>Actually I think debug_print_backtrace() does what you need. \n<a href=\"http://php.net/manual/en/function.debug-print-backtrace.php\" rel=\"nofollow\">http://php.net/manual/en/function.debug-print-backtrace.php</a></p>\n"
},
{
"answer_id": 25545623,
"author": "flori",
"author_id": 793476,
"author_profile": "https://Stackoverflow.com/users/793476",
"pm_score": 4,
"selected": false,
"text": "<pre><code>echo debug_backtrace()[1]['function'];\n</code></pre>\n\n<p>Works since <a href=\"http://php.net/manual/en/migration54.new-features.php\" rel=\"noreferrer\">PHP 5.4</a>.</p>\n\n<p>Or optimised (e.g. for non-debug use cases):</p>\n\n<pre><code>echo debug_backtrace( DEBUG_BACKTRACE_IGNORE_ARGS, 2)[1]['function'];\n</code></pre>\n\n<p>The first argument prevents to populate unused function arguments, the second limits the trace to two levels (we need the second).</p>\n"
},
{
"answer_id": 28849906,
"author": "lrd",
"author_id": 3343023,
"author_profile": "https://Stackoverflow.com/users/3343023",
"pm_score": 2,
"selected": false,
"text": "<p>I just wanted to state that flori's way won't work as a function because it will always return the called function name instead of the caller, but I don't have reputation for commenting. I made a very simple function based on flori's answer that works fine for my case:</p>\n\n<pre><code>class basicFunctions{\n\n public function getCallerFunction(){\n return debug_backtrace( DEBUG_BACKTRACE_IGNORE_ARGS, 3)[2]['function'];\n }\n\n}\n</code></pre>\n\n<h2>EXAMPLE:</h2>\n\n<pre><code>function a($authorisedFunctionsList = array(\"b\")){\n $ref = new basicFunctions;\n $caller = $ref->getCallerFunction();\n\n if(in_array($caller,$authorisedFunctionsList)):\n echo \"Welcome!\";\n return true;\n else:\n echo \"Unauthorised caller!\";\n return false; \n endif;\n}\n\nfunction b(){\n $executionContinues = $this->a();\n $executionContinues or exit;\n\n //Do something else..\n}\n</code></pre>\n"
},
{
"answer_id": 35658760,
"author": "kenorb",
"author_id": 55075,
"author_profile": "https://Stackoverflow.com/users/55075",
"pm_score": 0,
"selected": false,
"text": "<p>This should work:</p>\n\n<pre><code>$caller = next(debug_backtrace())['function'];\n</code></pre>\n"
},
{
"answer_id": 62665184,
"author": "Uriahs Victor",
"author_id": 4484799,
"author_profile": "https://Stackoverflow.com/users/4484799",
"pm_score": 0,
"selected": false,
"text": "<p>This will do it nicely:</p>\n<pre><code>\n// Outputs an easy to read call trace\n// Credit: https://www.php.net/manual/en/function.debug-backtrace.php#112238\n// Gist: https://gist.github.com/UVLabs/692e542d3b53e079d36bc53b4ea20a4b\n\nClass MyClass{\n\npublic function generateCallTrace()\n{\n $e = new Exception();\n $trace = explode("\\n", $e->getTraceAsString());\n // reverse array to make steps line up chronologically\n $trace = array_reverse($trace);\n array_shift($trace); // remove {main}\n array_pop($trace); // remove call to this method\n $length = count($trace);\n $result = array();\n \n for ($i = 0; $i < $length; $i++)\n {\n $result[] = ($i + 1) . ')' . substr($trace[$i], strpos($trace[$i], ' ')); // replace '#someNum' with '$i)', set the right ordering\n }\n \n return "\\t" . implode("\\n\\t", $result);\n}\n\n}\n\n// call function where needed to output call trace\n\n/**\nExample output:\n1) /var/www/test/test.php(15): SomeClass->__construct()\n2) /var/www/test/SomeClass.class.php(36): SomeClass->callSomething()\n**/```\n</code></pre>\n"
},
{
"answer_id": 71605491,
"author": "Imran Zahoor",
"author_id": 1843175,
"author_profile": "https://Stackoverflow.com/users/1843175",
"pm_score": 0,
"selected": false,
"text": "<p>I created a generic class, which can be helpful to many people who want to see the caller method's trace in a user-readable way. As in one of my projects we needed such information to be logged.</p>\n<pre><code>use ReflectionClass;\n\nclass DebugUtils\n{\n /**\n * Generates debug traces in user readable form\n *\n * @param integer $steps\n * @param boolean $skipFirstEntry\n * @param boolean $withoutNamespaces\n * @return string\n */\n public static function getReadableBackTracke(\n $steps = 4,\n $skipFirstEntry = true,\n $withoutNamespaces = true\n ) {\n $str = '';\n try {\n $backtrace = debug_backtrace(false, $steps);\n\n // Removing first array entry\n // to make sure getReadableBackTracke() method doesn't gets displayed\n if ($skipFirstEntry)\n array_shift($backtrace);\n\n // Reserved, so it gets displayed in calling order\n $backtrace = array_reverse($backtrace);\n\n foreach ($backtrace as $caller) {\n if ($str) {\n $str .= ' --> ';\n }\n if (isset($caller['class'])) {\n $class = $caller['class'];\n if ($withoutNamespaces) {\n $class = (new ReflectionClass($class))->getShortName();\n }\n $str .= $class . $caller['type'];\n }\n $str .= $caller['function'];\n }\n } catch (\\Throwable $th) {\n return null;\n }\n\n return $str;\n }\n}\n</code></pre>\n<p>Usage: <code>DebugUtils::getReadableBackTracke()</code></p>\n<p>Sample output:</p>\n<pre><code>SomeClass->method1 --> SomeOtherClass->method2 --> TargetClass->targetMethod\n</code></pre>\n<p>Do good and keep helping others, happy coding :)</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190421",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
Is there a PHP function to find out the name of the caller function in a given function?
|
See [debug\_backtrace](http://php.net/manual/en/function.debug-backtrace.php) - this can trace your call stack all the way to the top.
Here's how you'd get your caller:
```
$trace = debug_backtrace();
$caller = $trace[1];
echo "Called by {$caller['function']}";
if (isset($caller['class']))
echo " in {$caller['class']}";
```
|
190,431 |
<p>My motivation for trying out git-svn is the effortless merging and branching. Then I noticed that man git-svn(1) says: </p>
<blockquote>
<p>Running git-merge or git-pull is NOT recommended on a branch you plan
to dcommit from. Subversion does not represent merges in any
reasonable or useful fashion; so users using Subversion cannot see any
merges you've made. Furthermore, if you merge or pull from a git
branch that is a mirror of an SVN branch, dcommit may commit to the
wrong branch.</p>
</blockquote>
<p>Does this mean I cannot create a local branch from svn/trunk (or a branch), hack away, merge back into svn/trunk, then dcommit? I understand that svn users will see the same mess that merges in svn pre 1.5.x have always been, but are there any other drawbacks? That last sentence worries me, too. Do people routinely do these kinds of things?</p>
|
[
{
"answer_id": 190447,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 6,
"selected": false,
"text": "<p>Creating local branches is definitely possible with git-svn. As long as you're just using local branches for yourself, and not trying to use git to merge between upstream svn branches, you should be fine.</p>\n\n<p>I have a \"master\" branch that I use to track the svn server. This is the only branch that I dcommit from. If I'm doing some work, I create a topic branch and work away on it. When I want to commit it, I do the following:</p>\n\n<ol>\n<li>Commit everything to the topic branch</li>\n<li>git svn rebase <em>(resolve any conflicts between your work and svn)</em></li>\n<li>git checkout master</li>\n<li>git svn rebase <em>(this makes the next step a fast-forward merge, see Aaron's comments below)</em></li>\n<li>git merge topic_branch</li>\n<li>resolve any merge conflicts <em>(there shouldn't be any at this point)</em></li>\n<li>git svn dcommit</li>\n</ol>\n\n<p>I also have another situation where I need to maintain some local changes (for debugging) that should never be pushed up to svn. For that, I have the above master branch but also a branch called \"work\" where I normally do work. Topic branches are branched off work. When I want to commit work there, I checkout master and use cherry-pick to pick the commits from the work branch that I want to commit to svn. This is because I want to avoid committing the three local change commits. Then, I dcommit from the master branch and rebase everything.</p>\n\n<p>It is worthwhile running <code>git svn dcommit -n</code> first to make sure that you are about to commit exactly what you intend to commit. Unlike git, rewriting history in svn is hard!</p>\n\n<p>I feel that there must be a better way to merge the change on a topic branch while skipping those local change commits than using cherry-pick, so if anybody has any ideas they would be welcome.</p>\n"
},
{
"answer_id": 1526673,
"author": "luntain",
"author_id": 5978,
"author_profile": "https://Stackoverflow.com/users/5978",
"pm_score": 3,
"selected": false,
"text": "<p>A safe way to merge svn branches in git is to use git merge --squash. This will create a single commit and stop for you to add a message.</p>\n\n<p>Let's say you have a topic svn branch, called svn-branch.</p>\n\n<pre><code>git svn fetch\ngit checkout remotes/trunk -b big-merge\ngit merge --squash svn-branch\n</code></pre>\n\n<p>at this point you have all the changes from the svn-branch squashed into one commit waiting in the index</p>\n\n<pre><code>git commit\n</code></pre>\n"
},
{
"answer_id": 2423689,
"author": "JoeyJ",
"author_id": 291324,
"author_profile": "https://Stackoverflow.com/users/291324",
"pm_score": 3,
"selected": false,
"text": "<p>Rebase the local git branch onto the master git branch then dcommit and that way it looks like you did all those commits in sequence so svn people can see it linearly as they are accustomed to. So assuming you have a local branch called topic you could do</p>\n\n<pre><code>git rebase master topic\n</code></pre>\n\n<p>which will then play your commits over the master branch ready for you to dcommit</p>\n"
},
{
"answer_id": 4238528,
"author": "Sebastien Varrette",
"author_id": 492649,
"author_profile": "https://Stackoverflow.com/users/492649",
"pm_score": 8,
"selected": true,
"text": "<p>Actually, I found an even better way with the <code>--no-ff</code> option on git merge.\nAll this squash technic I used before is no longer required. </p>\n\n<p>My new workflow is now as follows: </p>\n\n<ul>\n<li><p>I have a \"master\" branch that is the only branch that I dcommit from and that clone the SVN repository (<code>-s</code> assume you have a standard SVN layout in the repository <code>trunk/</code>, <code>branches/</code>, and <code>tags/</code>):</p>\n\n<pre><code>git svn clone [-s] <svn-url>\n</code></pre></li>\n<li><p>I work on a local branch \"work\" (<code>-b</code> creates the branch \"work\")</p>\n\n<pre><code>git checkout -b work\n</code></pre></li>\n<li><p>commit locally into the \"work\" branch (<code>-s</code> to sign-off your commit message). In the sequel, I assume you made 3 local commits</p>\n\n<pre><code>...\n(work)$> git commit -s -m \"msg 1\"\n...\n(work)$> git commit -s -m \"msg 2\"\n...\n(work)$> git commit -s -m \"msg 3\"\n</code></pre></li>\n</ul>\n\n<h2>Now you want to commit onto the SVN server</h2>\n\n<ul>\n<li><p>[Eventually] stash the modifications you don't want to see committed on the SVN server (often you commented some code in the main file just because you want to accelerate the compilation and focus on a given feature)</p>\n\n<pre><code>(work)$> git stash\n</code></pre></li>\n<li><p>rebase the master branch with the SVN repository (to update from the SVN server)</p>\n\n<pre><code>(work)$> git checkout master\n(master)$> git svn rebase\n</code></pre></li>\n<li><p>go back to the work branch and rebase with master</p>\n\n<pre><code>(master)$> git checkout work\n(work)$> git rebase master\n</code></pre></li>\n<li><p>Ensure everything is fine using, for instance: </p>\n\n<pre><code>(work)$> git log --graph --oneline --decorate\n</code></pre></li>\n<li><p>Now it's time to merge all three commits from the \"work\" branch into \"master\" using this wonderful <code>--no-ff</code> option</p>\n\n<pre><code>(work)$> git checkout master\n(master)$> git merge --no-ff work\n</code></pre></li>\n<li><p>You can notice the status of the logs: </p>\n\n<pre><code>(master)$> git log --graph --oneline --decorate\n* 56a779b (work, master) Merge branch 'work'\n|\\ \n| * af6f7ae msg 3\n| * 8750643 msg 2\n| * 08464ae msg 1\n|/ \n* 21e20fa (git-svn) last svn commit\n</code></pre></li>\n<li><p>Now you probably want to edit (<code>amend</code>) the last commit for your SVN dudes (otherwise they will only see a single commit with the message \"Merge branch 'work'\"</p>\n\n<pre><code>(master)$> git commit --amend\n</code></pre></li>\n<li><p>Finally commit on the SVN server</p>\n\n<pre><code>(master)$> git svn dcommit\n</code></pre></li>\n<li><p>Go back to work and eventually recover your stashed files:</p>\n\n<pre><code>(master)$> git checkout work\n(work)$> git stash pop\n</code></pre></li>\n</ul>\n"
},
{
"answer_id": 4460460,
"author": "Marius K",
"author_id": 403342,
"author_profile": "https://Stackoverflow.com/users/403342",
"pm_score": 3,
"selected": false,
"text": "<p>Greg Hewgill answer on top is not safe! If any new commits appeared on trunk between the two \"git svn rebase\", the merge will not be fast forward.</p>\n\n<p>It can be ensured by using \"--ff-only\" flag to the git-merge, but I usually do not run \"git svn rebase\" in the branch, only \"git rebase master\" on it (assuming it is only a local branch). Then afterwards a \"git merge thebranch\" is guaranteed to be fast forward.</p>\n"
},
{
"answer_id": 4546438,
"author": "Yaakov Belch",
"author_id": 104746,
"author_profile": "https://Stackoverflow.com/users/104746",
"pm_score": 5,
"selected": false,
"text": "<p><strong>Simple solution: Remove 'work' branch after merging</strong></p>\n\n<p><strong>Short answer:</strong> You can use git however you like (see below for a simple workflow), including merge. Just make sure follow each '<strong>git merge work</strong>' with '<strong>git branch -d work</strong>' to delete the temporary work branch.</p>\n\n<p><strong>Background explanation:</strong> \nThe merge/dcommit problem is that whenever you 'git svn dcommit' a branch, the merge history of that branch is 'flattened': git forgets about all merge operations that went into this branch: Just the file contents is preserved, but the fact that this content (partially) came from a specific other branch is lost. See: <a href=\"https://stackoverflow.com/questions/425766/why-does-git-svn-dcommit-lose-the-history-of-merge-commits-for-local-branches\">Why does git svn dcommit lose the history of merge commits for local branches?</a> </p>\n\n<p>(Note: There is not much that git-svn could do about it: svn simply doesn't understand the much more powerful git merges. So, inside the svn repository this merge information cannot be represented in any way.)</p>\n\n<p>But this is the <em>whole</em> problem. If you delete the 'work' branch after it has been merged into the 'master branch' then your git repository is 100% clean and looks exactly like your svn repository.</p>\n\n<p><strong>My workflow:</strong>\nOf course, I first cloned the remote svn repository into a local git repository (this may take some time):</p>\n\n<pre><code>$> git svn clone <svn-repository-url> <local-directory>\n</code></pre>\n\n<p>All work then happens inside the \"local-directory\". Whenever I need to get updates from the server (like 'svn update'), I do:</p>\n\n<pre><code>$> git checkout master\n$> git svn rebase\n</code></pre>\n\n<p>I do all my development work in a separate branch 'work' that is created like this:</p>\n\n<pre><code>$> git checkout -b work\n</code></pre>\n\n<p>Of course, you can create as many branches for your work as you like and merge and rebase between them as you like (just delete them when you are done with them --- as discussed below). In my normal work, I commit very frequently:</p>\n\n<pre><code>$> git commit -am '-- finished a little piece of work'\n</code></pre>\n\n<p>The next step (git rebase -i) is optional --- it's just cleaning up the history before archiving it on svn: Once I reached a stable mile stone that I want to share with others, I rewrite the history of this 'work' branch and clean up the commit messages (other developers don't need to see all the little steps and mistakes that I made on the way --- just the result). For this, I do </p>\n\n<pre><code>$> git log\n</code></pre>\n\n<p>and copy the sha-1 hash of the last commit that is live in the svn repository (as indicated by a git-svn-id). Then I call </p>\n\n<pre><code>$> git rebase -i 74e4068360e34b2ccf0c5869703af458cde0cdcb\n</code></pre>\n\n<p>Just paste sha-1 hash of our last svn commit instead of mine. You may want to read the documentation with 'git help rebase' for the details. In short: this command first opens an editor presenting your commits ---- just change 'pick' to 'squash' for all those commits that you want to squash with previous commits. Of course, the first line should stay as a 'pick'. In this way, you can condense your many little commits into one or more meaningful units.\nSave and exit the editor. You will get another editor asking you to rewrite the commit log messages.</p>\n\n<p>In short: After I finish 'code hacking', I massage my 'work' branch until it looks how I want to present it to the other programmers (or how I want to see the work in a few weeks time when I browse history).</p>\n\n<p>In order to push the changes to the svn repository, I do:</p>\n\n<pre><code>$> git checkout master\n$> git svn rebase\n</code></pre>\n\n<p>Now we are back at the old 'master' branch updated with all changes that happened in the mean time in the svn repository (your new changes are hidden in the 'work' branch). </p>\n\n<p>If there are changes that may clash with your new 'work' changes, you have to resolve them locally before you may push your new work (see details further below). Then, we can push our changes to svn:</p>\n\n<pre><code>$> git checkout master\n$> git merge work # (1) merge your 'work' into 'master'\n$> git branch -d work # (2) remove the work branch immediately after merging\n$> git svn dcommit # (3) push your changes to the svn repository\n</code></pre>\n\n<p>Note 1: The command 'git branch -d work' is quite safe: It only allows you to delete branches that you don't need anymore (because they are already merged into your current branch). If you execute this command by mistake before merging your work with the 'master' branch, you get an error message. </p>\n\n<p>Note 2: Make sure to delete your branch with 'git branch -d work' <em>between</em> merging and dcommit: If you try to delete the branch after dcommit, you get an error message: When you do 'git svn dcommit', git forgets that your branch has been merged with 'master'. You have to remove it with 'git branch -D work' which doesn't do the safety check.</p>\n\n<p>Now, I immediately create a new 'work' branch to avoid accidentally hacking on the 'master' branch:</p>\n\n<pre><code>$> git checkout -b work\n$> git branch # show my branches:\n master\n* work\n</code></pre>\n\n<p><strong>Integrating your 'work' with changes on svn:</strong>\nHere is what I do when 'git svn rebase' reveals that others changed the svn repository while I was working on my 'work' branch:</p>\n\n<pre><code>$> git checkout master\n$> git svn rebase # 'svn pull' changes\n$> git checkout work # go to my work\n$> git checkout -b integration # make a copy of the branch\n$> git merge master # integrate my changes with theirs\n$> ... check/fix/debug ...\n$> ... rewrite history with rebase -i if needed\n\n$> git checkout master # try again to push my changes\n$> git svn rebase # hopefully no further changes to merge\n$> git merge integration # (1) merge your work with theirs\n$> git branch -d work # (2) remove branches that are merged\n$> git branch -d integration # (2) remove branches that are merged\n$> git svn dcommit # (3) push your changes to the svn repository\n</code></pre>\n\n<p><strong>More powerful solutions exist:</strong>\nThe presented workflow is simplistic: It uses the powers of git only within each round of 'update/hack/dcommit' --- but leaves the long-term project history just as linear as the svn repository. This is ok if you just want to start using git merges in small first steps in a legacy svn project. </p>\n\n<p>When you become more familiar with git merging, feel free to explore other workflows: If you know what you are doing, you <em>can</em> mix git merges with svn merges (<a href=\"https://stackoverflow.com/questions/2945842/using-git-svn-or-similar-just-to-help-out-with-svn-merge\">Using git-svn (or similar) just to help out with svn merge?</a>)</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190431",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5179/"
] |
My motivation for trying out git-svn is the effortless merging and branching. Then I noticed that man git-svn(1) says:
>
> Running git-merge or git-pull is NOT recommended on a branch you plan
> to dcommit from. Subversion does not represent merges in any
> reasonable or useful fashion; so users using Subversion cannot see any
> merges you've made. Furthermore, if you merge or pull from a git
> branch that is a mirror of an SVN branch, dcommit may commit to the
> wrong branch.
>
>
>
Does this mean I cannot create a local branch from svn/trunk (or a branch), hack away, merge back into svn/trunk, then dcommit? I understand that svn users will see the same mess that merges in svn pre 1.5.x have always been, but are there any other drawbacks? That last sentence worries me, too. Do people routinely do these kinds of things?
|
Actually, I found an even better way with the `--no-ff` option on git merge.
All this squash technic I used before is no longer required.
My new workflow is now as follows:
* I have a "master" branch that is the only branch that I dcommit from and that clone the SVN repository (`-s` assume you have a standard SVN layout in the repository `trunk/`, `branches/`, and `tags/`):
```
git svn clone [-s] <svn-url>
```
* I work on a local branch "work" (`-b` creates the branch "work")
```
git checkout -b work
```
* commit locally into the "work" branch (`-s` to sign-off your commit message). In the sequel, I assume you made 3 local commits
```
...
(work)$> git commit -s -m "msg 1"
...
(work)$> git commit -s -m "msg 2"
...
(work)$> git commit -s -m "msg 3"
```
Now you want to commit onto the SVN server
------------------------------------------
* [Eventually] stash the modifications you don't want to see committed on the SVN server (often you commented some code in the main file just because you want to accelerate the compilation and focus on a given feature)
```
(work)$> git stash
```
* rebase the master branch with the SVN repository (to update from the SVN server)
```
(work)$> git checkout master
(master)$> git svn rebase
```
* go back to the work branch and rebase with master
```
(master)$> git checkout work
(work)$> git rebase master
```
* Ensure everything is fine using, for instance:
```
(work)$> git log --graph --oneline --decorate
```
* Now it's time to merge all three commits from the "work" branch into "master" using this wonderful `--no-ff` option
```
(work)$> git checkout master
(master)$> git merge --no-ff work
```
* You can notice the status of the logs:
```
(master)$> git log --graph --oneline --decorate
* 56a779b (work, master) Merge branch 'work'
|\
| * af6f7ae msg 3
| * 8750643 msg 2
| * 08464ae msg 1
|/
* 21e20fa (git-svn) last svn commit
```
* Now you probably want to edit (`amend`) the last commit for your SVN dudes (otherwise they will only see a single commit with the message "Merge branch 'work'"
```
(master)$> git commit --amend
```
* Finally commit on the SVN server
```
(master)$> git svn dcommit
```
* Go back to work and eventually recover your stashed files:
```
(master)$> git checkout work
(work)$> git stash pop
```
|
190,450 |
<p>Up until recently, I've been storing multiple values into different hashes with the same keys as follows:</p>
<pre><code>%boss = (
"Allan" => "George",
"Bob" => "George",
"George" => "lisa" );
%status = (
"Allan" => "Contractor",
"Bob" => "Part-time",
"George" => "Full-time" );
</code></pre>
<p>and then I can reference <code>$boss("Bob")</code> and <code>$status("Bob")</code> but this gets unwieldy if there's a lot of properties each key can have and I have to worry about keeping the hashes in sync.</p>
<p>Is there a better way for storing multiple values in a hash? I could store the values as</p>
<pre><code> "Bob" => "George:Part-time"
</code></pre>
<p>and then disassemble the strings with split, but there must be a more elegant way.</p>
|
[
{
"answer_id": 190467,
"author": "Vinko Vrsalovic",
"author_id": 5190,
"author_profile": "https://Stackoverflow.com/users/5190",
"pm_score": 6,
"selected": true,
"text": "<p>This is the standard way, as per <a href=\"http://perldoc.perl.org/perldsc.html\" rel=\"noreferrer\" title=\"Perl Data Structure Cookbook\">perldoc perldsc</a>.</p>\n\n<pre><code>~> more test.pl\n%chums = ( \"Allan\" => {\"Boss\" => \"George\", \"Status\" => \"Contractor\"},\n \"Bob\" => {\"Boss\" => \"Peter\", \"Status\" => \"Part-time\"} );\n\nprint $chums{\"Allan\"}{\"Boss\"}.\"\\n\";\nprint $chums{\"Bob\"}{\"Boss\"}.\"\\n\";\nprint $chums{\"Bob\"}{\"Status\"}.\"\\n\";\n$chums{\"Bob\"}{\"Wife\"} = \"Pam\";\nprint $chums{\"Bob\"}{\"Wife\"}.\"\\n\";\n\n~> perl test.pl\nGeorge\nPeter\nPart-time\nPam\n</code></pre>\n"
},
{
"answer_id": 190472,
"author": "moonshadow",
"author_id": 11834,
"author_profile": "https://Stackoverflow.com/users/11834",
"pm_score": 2,
"selected": false,
"text": "<p>Hashes can contain other hashes or arrays. If you want to refer to your properties by name, store them as a hash per key, otherwise store them as an array per key.</p>\n\n<p>There is a <a href=\"http://perldoc.perl.org/perlref.html\" rel=\"nofollow noreferrer\">reference for the syntax</a>.</p>\n"
},
{
"answer_id": 190479,
"author": "Swaroop C H",
"author_id": 4869,
"author_profile": "https://Stackoverflow.com/users/4869",
"pm_score": 2,
"selected": false,
"text": "<pre><code>my %employees = (\n \"Allan\" => { \"Boss\" => \"George\", \"Status\" => \"Contractor\" },\n);\n\nprint $employees{\"Allan\"}{\"Boss\"}, \"\\n\";\n</code></pre>\n"
},
{
"answer_id": 190497,
"author": "tsee",
"author_id": 13164,
"author_profile": "https://Stackoverflow.com/users/13164",
"pm_score": 5,
"selected": false,
"text": "<p>Hashes of hashes is what you're explicitly asking for. There is a tutorial style piece of documentation part of the Perl documentation which covers this: <a href=\"http://perldoc.perl.org/perldsc.html\" rel=\"noreferrer\">Data Structure Cookbook</a> But maybe you should consider going object-oriented. This is sort of the stereotypical example for object oriented programming tutorials.</p>\n\n<p>How about something like this:</p>\n\n<pre><code>#!/usr/bin/perl\npackage Employee;\nuse Moose;\nhas 'name' => ( is => 'rw', isa => 'Str' );\n\n# should really use a Status class\nhas 'status' => ( is => 'rw', isa => 'Str' );\n\nhas 'superior' => (\n is => 'rw',\n isa => 'Employee',\n default => undef,\n);\n\n###############\npackage main;\nuse strict;\nuse warnings;\n\nmy %employees; # maybe use a class for this, too\n\n$employees{George} = Employee->new(\n name => 'George',\n status => 'Boss',\n);\n\n$employees{Allan} = Employee->new(\n name => 'Allan',\n status => 'Contractor',\n superior => $employees{George},\n);\n\nprint $employees{Allan}->superior->name, \"\\n\";\n</code></pre>\n"
},
{
"answer_id": 20734280,
"author": "user3127931",
"author_id": 3127931,
"author_profile": "https://Stackoverflow.com/users/3127931",
"pm_score": 0,
"selected": false,
"text": "<p>%chums = ( \"Allan\" => {\"Boss\" => \"George\", \"Status\" => \"Contractor\"},\n \"Bob\" => {\"Boss\" => \"Peter\", \"Status\" => \"Part-time\"} );</p>\n\n<p>works great but is there a faster way to enter the data?</p>\n\n<p>I am thinking of something like</p>\n\n<p>%chums = (qw, x)( Allan Boss George Status Contractor Bob Boss Peter Status Part-time)</p>\n\n<p>where x = the number of secondary keys after the primary key, in this case x = 2, \"Boss\" and \"Status\"</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190450",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14860/"
] |
Up until recently, I've been storing multiple values into different hashes with the same keys as follows:
```
%boss = (
"Allan" => "George",
"Bob" => "George",
"George" => "lisa" );
%status = (
"Allan" => "Contractor",
"Bob" => "Part-time",
"George" => "Full-time" );
```
and then I can reference `$boss("Bob")` and `$status("Bob")` but this gets unwieldy if there's a lot of properties each key can have and I have to worry about keeping the hashes in sync.
Is there a better way for storing multiple values in a hash? I could store the values as
```
"Bob" => "George:Part-time"
```
and then disassemble the strings with split, but there must be a more elegant way.
|
This is the standard way, as per [perldoc perldsc](http://perldoc.perl.org/perldsc.html "Perl Data Structure Cookbook").
```
~> more test.pl
%chums = ( "Allan" => {"Boss" => "George", "Status" => "Contractor"},
"Bob" => {"Boss" => "Peter", "Status" => "Part-time"} );
print $chums{"Allan"}{"Boss"}."\n";
print $chums{"Bob"}{"Boss"}."\n";
print $chums{"Bob"}{"Status"}."\n";
$chums{"Bob"}{"Wife"} = "Pam";
print $chums{"Bob"}{"Wife"}."\n";
~> perl test.pl
George
Peter
Part-time
Pam
```
|
190,476 |
<p>I have those maps in my repository. </p>
<pre><code>public IQueryable<AwType> GetAwTypes()
{
return from awt in _db.AwTypes
select new AwType
{
Id = awt.Id,
Header = awt.Header,
Description = awt.Description
};
}
public IQueryable<Aw> GetAws()
{
return from aw in _db.Aws
select new Aw
{
Id = aw.Id,
Bw = (from bw in GetBws()
where bw.Id == aw.Bw
select bw
).SingleOrDefault(),
AwType = (from awt in GetAwTypes()
where awt.Id == awAwType
select awt
).SingleOrDefault(),
AwAttribute = aw.AwAttribute
};
}
</code></pre>
<p>In service I want to get count of Bws grouped by AwType as <code>List<KeyValuePair<AwType, int>></code>.
When I call that linq query :</p>
<pre><code>var awGroups = from aw in _repository.GetAws()
group aw by aw.AwType into newGroup
select newGroup;
List<KeyValuePair<AwType, int>> RetGroups = new List<KeyValuePair<AwType, int>>();
foreach (var group in awGroups)
{
RetGroups.Add(new KeyValuePair<AwType, int>(group.Key, group.Count()));
}
return RetGroups;
</code></pre>
<p>I get an error that is saying I can't group by on an object I have to group by a scalar value like aw.AwType.Id.</p>
<p>Is there a way to get "AwType, int" pairs in one call?</p>
|
[
{
"answer_id": 190487,
"author": "leppie",
"author_id": 15541,
"author_profile": "https://Stackoverflow.com/users/15541",
"pm_score": 0,
"selected": false,
"text": "<p>You can group by an anonymous type, eg new { Foo, Bar }</p>\n"
},
{
"answer_id": 198446,
"author": "Amy B",
"author_id": 8155,
"author_profile": "https://Stackoverflow.com/users/8155",
"pm_score": 2,
"selected": true,
"text": "<p>AwType is a reference type. It would be a bad idea to group on that reference type... Each AwType in that query is a unique reference, so n elements would yield n groups.</p>\n\n<p>Try this:</p>\n\n<pre><code>var awGroups = from aw in _repository.GetAws()\ngroup aw by aw.AwType.ID into newGroup //changed to group on ID\nselect newGroup;\n\nList<KeyValuePair<AwType, int>> RetGroups = new List<KeyValuePair<AwType, int>>();\nforeach (var group in awGroups)\n{\n //changed to get the first element of the group and examine its AwType\n RetGroups.Add(new KeyValuePair<AwType, int>(group.First().AwType, group.Count()));\n}\nreturn RetGroups;\n</code></pre>\n"
},
{
"answer_id": 198523,
"author": "Kibbee",
"author_id": 1862,
"author_profile": "https://Stackoverflow.com/users/1862",
"pm_score": 0,
"selected": false,
"text": "<p>From what I understand of linq, what you would be equivalent to trying to group by every column of a table. This can only be done by listing every single field in a table in the group statement, so in your case, you would need to do the following (I'm not very knowledgable about Linq)</p>\n\n<pre><code>var awGroups = from aw in _repository.GetAws()\ngroup aw by aw.AwType.Id, aw.AwType.Header, aw.AwType.Description into newGroup\nselect newGroup;\n</code></pre>\n\n<p>or maybe you can just group by Id if that's the only column you need.</p>\n\n<pre><code>var awGroups = from aw in _repository.GetAws()\ngroup aw by aw.AwType.Id into newGroup\nselect newGroup;\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190476",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11374/"
] |
I have those maps in my repository.
```
public IQueryable<AwType> GetAwTypes()
{
return from awt in _db.AwTypes
select new AwType
{
Id = awt.Id,
Header = awt.Header,
Description = awt.Description
};
}
public IQueryable<Aw> GetAws()
{
return from aw in _db.Aws
select new Aw
{
Id = aw.Id,
Bw = (from bw in GetBws()
where bw.Id == aw.Bw
select bw
).SingleOrDefault(),
AwType = (from awt in GetAwTypes()
where awt.Id == awAwType
select awt
).SingleOrDefault(),
AwAttribute = aw.AwAttribute
};
}
```
In service I want to get count of Bws grouped by AwType as `List<KeyValuePair<AwType, int>>`.
When I call that linq query :
```
var awGroups = from aw in _repository.GetAws()
group aw by aw.AwType into newGroup
select newGroup;
List<KeyValuePair<AwType, int>> RetGroups = new List<KeyValuePair<AwType, int>>();
foreach (var group in awGroups)
{
RetGroups.Add(new KeyValuePair<AwType, int>(group.Key, group.Count()));
}
return RetGroups;
```
I get an error that is saying I can't group by on an object I have to group by a scalar value like aw.AwType.Id.
Is there a way to get "AwType, int" pairs in one call?
|
AwType is a reference type. It would be a bad idea to group on that reference type... Each AwType in that query is a unique reference, so n elements would yield n groups.
Try this:
```
var awGroups = from aw in _repository.GetAws()
group aw by aw.AwType.ID into newGroup //changed to group on ID
select newGroup;
List<KeyValuePair<AwType, int>> RetGroups = new List<KeyValuePair<AwType, int>>();
foreach (var group in awGroups)
{
//changed to get the first element of the group and examine its AwType
RetGroups.Add(new KeyValuePair<AwType, int>(group.First().AwType, group.Count()));
}
return RetGroups;
```
|
190,480 |
<p>How to to configure apache + mod_lisp + clisp and set up a "Hello World!"? I couldn't find any complete howto on the subject. Thanks.</p>
<p>Edit: Vebjorn's solution works, but then I don't how to code the "hello world!". Can anyone tell me how to proceed? There's something like SWANKing the clisp, then connect to it with SLIME, but then when I launch mod_lisp's demo, the test page is not served and my slime doesn't return?</p>
<p>Thanks again.</p>
|
[
{
"answer_id": 190533,
"author": "ConroyP",
"author_id": 2287,
"author_profile": "https://Stackoverflow.com/users/2287",
"pm_score": 0,
"selected": false,
"text": "<p><a href=\"http://www.newartisans.com/blog_files/common.lisp.with.apache.php\" rel=\"nofollow noreferrer\">This article</a> seems to be a fairly thorough \"how-to\" guide to set up Common Lisp on Apache using mod_lisp2.</p>\n\n<blockquote>\n <p>If all has gone as planned, you should now have a Common Lisp app server running behind Apache</p>\n</blockquote>\n"
},
{
"answer_id": 190538,
"author": "dsm",
"author_id": 7780,
"author_profile": "https://Stackoverflow.com/users/7780",
"pm_score": 1,
"selected": false,
"text": "<p>What backend are you using? If none, I would suggest trying <a href=\"http://www.weitz.de/hunchentoot/#mod_lisp\" rel=\"nofollow noreferrer\">Hunchentoot</a> or, even better, <a href=\"http://trac.common-lisp.net/ucw/wiki/IntroInstallation\" rel=\"nofollow noreferrer\">UCW</a>.</p>\n\n<p>Both of those links will take you to the installation instructions, ending with a Hello World kind of page.</p>\n"
},
{
"answer_id": 190567,
"author": "Vebjorn Ljosa",
"author_id": 17498,
"author_profile": "https://Stackoverflow.com/users/17498",
"pm_score": 3,
"selected": false,
"text": "<ol>\n<li>Download <a href=\"http://www.fractalconcept.com:8000/public/open-source/mod_lisp/mod_lisp.c\" rel=\"noreferrer\">http://www.fractalconcept.com:8000/public/open-source/mod_lisp/mod_lisp.c</a>\n\n<ul>\n<li>Compile and install Apache module with <code>sudo apxs -i -c mod_lisp.c</code></li>\n<li>Add the following to your <code>httpd.conf</code>:\n\n<pre>\nLoadModule lisp_module libexec/httpd/mod_lisp.so\nAddModule mod_lisp.c\nLispServer 127.0.0.1 3000 \"foo\"\n<Location /foo>\nSetHandler lisp-handler\n</Location>\n</pre></li>\n</ul></li>\n<li>Restart apache with <code>sudo apachectl restart</code>\n\n<ul>\n<li>Download example of Lisp-side handling in CLISP: <a href=\"http://www.fractalconcept.com/fcweb/download/modlisp-clisp.lisp\" rel=\"noreferrer\">http://www.fractalconcept.com/fcweb/download/modlisp-clisp.lisp</a></li>\n</ul></li>\n<li><p>Start CLISP and evaluate:</p>\n\n<pre>\n(load \"modlisp-clisp\")\n(modlisp:modlisp-server)\n</pre></li>\n<li><p>Point your browser to <a href=\"http://localhost/foo\" rel=\"noreferrer\">http://localhost/foo</a>. You should see:</p></li>\n</ol>\n\n<blockquote>\n <p>mod_lisp 2.0</p>\n \n <p>This is a constant html string sent by\n mod_lisp 2.0 + CLISP + apache + Linux</p>\n</blockquote>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190480",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26416/"
] |
How to to configure apache + mod\_lisp + clisp and set up a "Hello World!"? I couldn't find any complete howto on the subject. Thanks.
Edit: Vebjorn's solution works, but then I don't how to code the "hello world!". Can anyone tell me how to proceed? There's something like SWANKing the clisp, then connect to it with SLIME, but then when I launch mod\_lisp's demo, the test page is not served and my slime doesn't return?
Thanks again.
|
1. Download <http://www.fractalconcept.com:8000/public/open-source/mod_lisp/mod_lisp.c>
* Compile and install Apache module with `sudo apxs -i -c mod_lisp.c`
* Add the following to your `httpd.conf`:
```
LoadModule lisp_module libexec/httpd/mod_lisp.so
AddModule mod_lisp.c
LispServer 127.0.0.1 3000 "foo"
<Location /foo>
SetHandler lisp-handler
</Location>
```
2. Restart apache with `sudo apachectl restart`
* Download example of Lisp-side handling in CLISP: <http://www.fractalconcept.com/fcweb/download/modlisp-clisp.lisp>
3. Start CLISP and evaluate:
```
(load "modlisp-clisp")
(modlisp:modlisp-server)
```
4. Point your browser to <http://localhost/foo>. You should see:
>
> mod\_lisp 2.0
>
>
> This is a constant html string sent by
> mod\_lisp 2.0 + CLISP + apache + Linux
>
>
>
|
190,493 |
<p>I am trying to figure out how to add a custom control to the iPhone MoviePlayer.
For an example of what I am trying to do see the following image.</p>
<p><img src="https://i.stack.imgur.com/Zt5MG.jpg" alt="alt text"></p>
<p>I am trying to add something like the controls on the right and left of the basic movie controls.</p>
<p>I had done this in the Open SDK by adding a subclass to the playerview, but now in the official SDK and Apple moving to MPMoviePlayerController I am not sure how to do it.</p>
<p>Also with my old 1.x firmware way it required me to capture touch events and hide/show the control myself. I am hoping there is a way that would do this with the standard controls, but if not, that is fine.</p>
<p>Thanks in advance.</p>
|
[
{
"answer_id": 191266,
"author": "Martin Gordon",
"author_id": 2481,
"author_profile": "https://Stackoverflow.com/users/2481",
"pm_score": 3,
"selected": false,
"text": "<p><a href=\"http://developer.apple.com/iphone/library/samplecode/MoviePlayer_iPhone/index.html\" rel=\"noreferrer\">This sample application</a> that Apple provides should help. From the description:</p>\n\n<blockquote>\n <p>Demonstrates how to use the Media\n Player Framework to play a movie\n full-screen. The sample contains code\n to configure the movie background\n color, playback controls and scaling\n mode via the built-in Settings\n application. Also shows how to draw\n custom overlay controls on top of the\n movie during playback.</p>\n</blockquote>\n"
},
{
"answer_id": 194646,
"author": "kdbdallas",
"author_id": 26728,
"author_profile": "https://Stackoverflow.com/users/26728",
"pm_score": 4,
"selected": true,
"text": "<p>I found the BEST way to do this!</p>\n\n<p>You create your movie player like normal and then do the following:</p>\n\n<pre><code>id vvController = [theMovie videoViewController];\n[[vvController _overlayView] addSubview:mainView];\n</code></pre>\n\n<p>Where 'mainView' is your custom overlay. Doing this makes it so your custom overlay will show and hide with the normal overlays as they are now one in the same!</p>\n\n<p><em>Please note that this is still using the standard frameworks, but it is undocumented in the frameworks. So it should be 100% appstore safe, but \"could\" change without notice from Apple in later frameworks.</em></p>\n"
},
{
"answer_id": 1616670,
"author": "sfjava",
"author_id": 158852,
"author_profile": "https://Stackoverflow.com/users/158852",
"pm_score": 3,
"selected": false,
"text": "<p>Folks here have probably also seen in various other blog posts the following approach to \"get the movie-player window\" -- at index = 1. Though this approach (see snippet below) is also possibly a bit \"fragile\", it's likely a bit \"safer\" since it does <em>not</em> make use of any undocumented or non-public methods in MPMoviePlayerController.</p>\n\n<p>Note also that you should wait until you get a MPMoviePlayerContentPreloadDidFinishNotification, so that the movie-player window (idx=1) will indeed exist ;-)</p>\n\n<p>Note I'm also assigning an arbitrary (integer-valued) view \"tag\" to myOverlayView here -- so that I can re-use the view when possible, i.e. check if it's already been added to the parent player window.</p>\n\n<p>anyhoo, here's the relevant code-snippet:</p>\n\n<pre><code>// use slight \"hack\" to get our (parent) movie-player window, should always (?) be the UIWindow at index = 1\n//\nUIWindow *moviePlayerWindow= [[[UIApplication sharedApplication] windows] objectAtIndex:1];\n\nmyOverlayView.center = CGPointMake(\n moviePlayerWindow.bounds.size.width - (myOverlayView.bounds.size.height / 2) - myOverlayView.display_origin.y,\n moviePlayerWindow.center.y\n ); // center our overlay-view\n\nmyOverlayView.hidden = NO; // and show it\n\nif( [moviePlayerWindow viewWithTag: MY_OVERLAY_VIEW_TAG] == nil ) {\n // haven't added our overlay-view as a sub-view to the main MoviePlayer window yet... so do that now\n myOverlayView.tag = MY_OVERLAY_VIEW_TAG;\n [moviePlayerWindow addSubview: myOverlayView];\n}\n[moviePlayerWindow bringSubviewToFront: myOverlayView]; // in any case, bring it to the foreground\n</code></pre>\n"
},
{
"answer_id": 14871445,
"author": "Arnaud",
"author_id": 863394,
"author_profile": "https://Stackoverflow.com/users/863394",
"pm_score": 1,
"selected": false,
"text": "<p>I recommend VideoPlayerKit. Supports streaming, fullscreen, AirPlay. </p>\n\n<p><a href=\"https://github.com/ign/VideoPlayerKit\" rel=\"nofollow\">https://github.com/ign/VideoPlayerKit</a></p>\n"
},
{
"answer_id": 26368857,
"author": "Matt Perejda",
"author_id": 2048923,
"author_profile": "https://Stackoverflow.com/users/2048923",
"pm_score": 1,
"selected": false,
"text": "<p>I have not implemented ALMoviePlayerController but it seems to provide a succinct and sufficient solution to your problem.</p>\n\n<p>From git repo: </p>\n\n<p>\"A drop-in replacement for MPMoviePlayerController that exposes the UI elements and allows for maximum customization\"</p>\n\n<p><a href=\"https://github.com/alobi/ALMoviePlayerController\" rel=\"nofollow\">https://github.com/alobi/ALMoviePlayerController</a></p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190493",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26728/"
] |
I am trying to figure out how to add a custom control to the iPhone MoviePlayer.
For an example of what I am trying to do see the following image.

I am trying to add something like the controls on the right and left of the basic movie controls.
I had done this in the Open SDK by adding a subclass to the playerview, but now in the official SDK and Apple moving to MPMoviePlayerController I am not sure how to do it.
Also with my old 1.x firmware way it required me to capture touch events and hide/show the control myself. I am hoping there is a way that would do this with the standard controls, but if not, that is fine.
Thanks in advance.
|
I found the BEST way to do this!
You create your movie player like normal and then do the following:
```
id vvController = [theMovie videoViewController];
[[vvController _overlayView] addSubview:mainView];
```
Where 'mainView' is your custom overlay. Doing this makes it so your custom overlay will show and hide with the normal overlays as they are now one in the same!
*Please note that this is still using the standard frameworks, but it is undocumented in the frameworks. So it should be 100% appstore safe, but "could" change without notice from Apple in later frameworks.*
|
190,524 |
<p>I have created some extra functionality on my Linq-to-SQL classes to make things easier as I develop my applications. For example I have defined a property that retrieves active contracts from a list of contracts. However if I try to use this property in a lambda expression or in general in a query it either throws an exception that there is no SQL statement matching that property or it generates one query per item (= a lot of roundtrips to the server).</p>
<p>The queries themselves are not overly complex f.ex:</p>
<pre><code>var activeContracts = customer.Contracts.Where(w => w.ContractEndDate == null);
</code></pre>
<p>Whereas I would like it to read as:</p>
<pre><code>var activeContracts = customer.ActiveContracts;
</code></pre>
<p>The main reason for me doing this is because it will minimize logical errors on my part and if I in the future want to change what defines an active contract I don't have to redo a lot of code.</p>
<p>Is there a way to specify on a property what SQL it should genereate. Or is there a way to make sure it is usable in a query like below?</p>
<pre><code>var singleContractCustomers = db.Customers.Where(w => w.ActiveContracts.Count() == 1);
</code></pre>
|
[
{
"answer_id": 190655,
"author": "Marc Gravell",
"author_id": 23354,
"author_profile": "https://Stackoverflow.com/users/23354",
"pm_score": 3,
"selected": true,
"text": "<p>When accessed individually, I suspect that having a query that returns IQueryable would work - however, I expect that when this is part of a larger Expression, the expression interpreter will complain (which seems like what you are describing).</p>\n\n<p>However, I suspect that you might be able to break it down a bit. Try adding (to customer):</p>\n\n<pre><code> public static Expression<Func<Customer, bool>> HasActiveContract\n {\n get { return cust => cust.Contracts.Count() == 1; }\n }\n</code></pre>\n\n<p>Then you should be able to use:</p>\n\n<pre><code> var filtered = db.Customers.Where(Customer.HasActiveContract);\n</code></pre>\n\n<p>Obviously it is hard to run it (from here) to see what TSQL it comes up with, but I'd be surprised if that does roundtrips; I would expect that to do the COUNT() in the TSQL. As a topmost query, you should also be able to wrap this:</p>\n\n<pre><code> public IQueryable<Customer> CustomersWithActiveContract\n {\n get { return Customers.Where(Customer.HasActiveContract); }\n }\n</code></pre>\n\n<p>Does any of that work?</p>\n"
},
{
"answer_id": 190972,
"author": "Kristoffer L",
"author_id": 26746,
"author_profile": "https://Stackoverflow.com/users/26746",
"pm_score": 1,
"selected": false,
"text": "<p>That worked like a charm. The SQL statment generated by <strong>CustomersWithActiveContracts</strong> looked fine to me.</p>\n\n<pre><code>{SELECT [t0].[CustomerID], [t0].[cFirstName], [t0].[cLastName]\nFROM [dbo].[Customers] AS [t0]\nWHERE ((\n SELECT COUNT(*)\n FROM [dbo].[Contracts] AS [t1]\n WHERE (([t1].[ContractEndDate] > @p0) OR ([t1].[ContractEndDate] IS NULL)) AND ([t1].[cId] = [t0].[cId])\n )) > @p1\n}\n</code></pre>\n\n<p>It should also mean that it's possible to build on this query without it generating more trips to the database.</p>\n"
},
{
"answer_id": 13400298,
"author": "luksan",
"author_id": 166131,
"author_profile": "https://Stackoverflow.com/users/166131",
"pm_score": 1,
"selected": false,
"text": "<p>Another option is the use the <a href=\"http://damieng.com/blog/2009/06/24/client-side-properties-and-any-remote-linq-provider\" rel=\"nofollow\">Microsoft.Linq.Translations</a> library. This will allow you to define your property and it's Linq translation as follows:</p>\n\n<pre><code>partial class Customer\n{\n private static readonly CompiledExpression<Employee,IEnumerable<Contract>> activeContractsExpression\n = DefaultTranslationOf<Customer>\n .Property(c => c.ActiveContracts)\n .Is(c => c.Contracts.Where(x => x.ContractEndDate == null));\n\n public IEnumerable<Contract> ActiveContracts\n {\n get \n { \n // This is only called when you access your property outside a query\n return activeContractsExpression.Evaluate(this);\n }\n }\n}\n</code></pre>\n\n<p>Then you can query it like so:</p>\n\n<pre><code>var singleContractCustomers = db.Customers.WithTranslations()\n .Where(w => w.ActiveContracts.Count() == 1);\n</code></pre>\n\n<p>Notice the call to <code>WithTranslations()</code>. This creates a special wrapping <code>IQueryable</code> that will replace all references to your computed property with its translation before the query expression is passed off to Linq to SQL.</p>\n\n<p>Also, if you include the <code>Microsoft.Linq.Translations.Auto</code> namespace instead of <code>System.Linq</code>, then you do not even need to call <code>WithTranslations()</code>!</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190524",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26746/"
] |
I have created some extra functionality on my Linq-to-SQL classes to make things easier as I develop my applications. For example I have defined a property that retrieves active contracts from a list of contracts. However if I try to use this property in a lambda expression or in general in a query it either throws an exception that there is no SQL statement matching that property or it generates one query per item (= a lot of roundtrips to the server).
The queries themselves are not overly complex f.ex:
```
var activeContracts = customer.Contracts.Where(w => w.ContractEndDate == null);
```
Whereas I would like it to read as:
```
var activeContracts = customer.ActiveContracts;
```
The main reason for me doing this is because it will minimize logical errors on my part and if I in the future want to change what defines an active contract I don't have to redo a lot of code.
Is there a way to specify on a property what SQL it should genereate. Or is there a way to make sure it is usable in a query like below?
```
var singleContractCustomers = db.Customers.Where(w => w.ActiveContracts.Count() == 1);
```
|
When accessed individually, I suspect that having a query that returns IQueryable would work - however, I expect that when this is part of a larger Expression, the expression interpreter will complain (which seems like what you are describing).
However, I suspect that you might be able to break it down a bit. Try adding (to customer):
```
public static Expression<Func<Customer, bool>> HasActiveContract
{
get { return cust => cust.Contracts.Count() == 1; }
}
```
Then you should be able to use:
```
var filtered = db.Customers.Where(Customer.HasActiveContract);
```
Obviously it is hard to run it (from here) to see what TSQL it comes up with, but I'd be surprised if that does roundtrips; I would expect that to do the COUNT() in the TSQL. As a topmost query, you should also be able to wrap this:
```
public IQueryable<Customer> CustomersWithActiveContract
{
get { return Customers.Where(Customer.HasActiveContract); }
}
```
Does any of that work?
|
190,525 |
<p>I'm not sure how familiar people are with the hobbit monitoring system - <a href="http://hobbitmon.sourceforge.net/" rel="nofollow noreferrer">http://hobbitmon.sourceforge.net/</a> - but I've got a tricky question.</p>
<p>I've got a custom test, which returns two NCV values. One value normally returns ~300 milliseconds, the other one returns 500 000 euro. Obviously, these two values don't graph very well together. :)</p>
<p>Question is, can hobbit display two graphs for this one test? If so, how do I do it?</p>
<p>Thanks.</p>
|
[
{
"answer_id": 190655,
"author": "Marc Gravell",
"author_id": 23354,
"author_profile": "https://Stackoverflow.com/users/23354",
"pm_score": 3,
"selected": true,
"text": "<p>When accessed individually, I suspect that having a query that returns IQueryable would work - however, I expect that when this is part of a larger Expression, the expression interpreter will complain (which seems like what you are describing).</p>\n\n<p>However, I suspect that you might be able to break it down a bit. Try adding (to customer):</p>\n\n<pre><code> public static Expression<Func<Customer, bool>> HasActiveContract\n {\n get { return cust => cust.Contracts.Count() == 1; }\n }\n</code></pre>\n\n<p>Then you should be able to use:</p>\n\n<pre><code> var filtered = db.Customers.Where(Customer.HasActiveContract);\n</code></pre>\n\n<p>Obviously it is hard to run it (from here) to see what TSQL it comes up with, but I'd be surprised if that does roundtrips; I would expect that to do the COUNT() in the TSQL. As a topmost query, you should also be able to wrap this:</p>\n\n<pre><code> public IQueryable<Customer> CustomersWithActiveContract\n {\n get { return Customers.Where(Customer.HasActiveContract); }\n }\n</code></pre>\n\n<p>Does any of that work?</p>\n"
},
{
"answer_id": 190972,
"author": "Kristoffer L",
"author_id": 26746,
"author_profile": "https://Stackoverflow.com/users/26746",
"pm_score": 1,
"selected": false,
"text": "<p>That worked like a charm. The SQL statment generated by <strong>CustomersWithActiveContracts</strong> looked fine to me.</p>\n\n<pre><code>{SELECT [t0].[CustomerID], [t0].[cFirstName], [t0].[cLastName]\nFROM [dbo].[Customers] AS [t0]\nWHERE ((\n SELECT COUNT(*)\n FROM [dbo].[Contracts] AS [t1]\n WHERE (([t1].[ContractEndDate] > @p0) OR ([t1].[ContractEndDate] IS NULL)) AND ([t1].[cId] = [t0].[cId])\n )) > @p1\n}\n</code></pre>\n\n<p>It should also mean that it's possible to build on this query without it generating more trips to the database.</p>\n"
},
{
"answer_id": 13400298,
"author": "luksan",
"author_id": 166131,
"author_profile": "https://Stackoverflow.com/users/166131",
"pm_score": 1,
"selected": false,
"text": "<p>Another option is the use the <a href=\"http://damieng.com/blog/2009/06/24/client-side-properties-and-any-remote-linq-provider\" rel=\"nofollow\">Microsoft.Linq.Translations</a> library. This will allow you to define your property and it's Linq translation as follows:</p>\n\n<pre><code>partial class Customer\n{\n private static readonly CompiledExpression<Employee,IEnumerable<Contract>> activeContractsExpression\n = DefaultTranslationOf<Customer>\n .Property(c => c.ActiveContracts)\n .Is(c => c.Contracts.Where(x => x.ContractEndDate == null));\n\n public IEnumerable<Contract> ActiveContracts\n {\n get \n { \n // This is only called when you access your property outside a query\n return activeContractsExpression.Evaluate(this);\n }\n }\n}\n</code></pre>\n\n<p>Then you can query it like so:</p>\n\n<pre><code>var singleContractCustomers = db.Customers.WithTranslations()\n .Where(w => w.ActiveContracts.Count() == 1);\n</code></pre>\n\n<p>Notice the call to <code>WithTranslations()</code>. This creates a special wrapping <code>IQueryable</code> that will replace all references to your computed property with its translation before the query expression is passed off to Linq to SQL.</p>\n\n<p>Also, if you include the <code>Microsoft.Linq.Translations.Auto</code> namespace instead of <code>System.Linq</code>, then you do not even need to call <code>WithTranslations()</code>!</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190525",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18673/"
] |
I'm not sure how familiar people are with the hobbit monitoring system - <http://hobbitmon.sourceforge.net/> - but I've got a tricky question.
I've got a custom test, which returns two NCV values. One value normally returns ~300 milliseconds, the other one returns 500 000 euro. Obviously, these two values don't graph very well together. :)
Question is, can hobbit display two graphs for this one test? If so, how do I do it?
Thanks.
|
When accessed individually, I suspect that having a query that returns IQueryable would work - however, I expect that when this is part of a larger Expression, the expression interpreter will complain (which seems like what you are describing).
However, I suspect that you might be able to break it down a bit. Try adding (to customer):
```
public static Expression<Func<Customer, bool>> HasActiveContract
{
get { return cust => cust.Contracts.Count() == 1; }
}
```
Then you should be able to use:
```
var filtered = db.Customers.Where(Customer.HasActiveContract);
```
Obviously it is hard to run it (from here) to see what TSQL it comes up with, but I'd be surprised if that does roundtrips; I would expect that to do the COUNT() in the TSQL. As a topmost query, you should also be able to wrap this:
```
public IQueryable<Customer> CustomersWithActiveContract
{
get { return Customers.Where(Customer.HasActiveContract); }
}
```
Does any of that work?
|
190,542 |
<p>I'm using Java for accessing Alfresco content server via it's web service API for importing some content into it. Content should have some NamedValue properties set to UTF-8(cyrillic) string. I keep getting the Sax parser exception:</p>
<pre><code>org.xml.sax.SAXParseException: An invalid XML character (Unicode: 0x1b) was found in the element content of the document.
</code></pre>
<p>The code looks something like this:</p>
<pre><code>NamedValue[] namedValueProperties = new NamedValue[2];
namedValueProperties[0] = Utils.createNamedValue(Constants.PROP_NAME, name );
namedValueProperties[1] = Utils.createNamedValue("{my.custom.model}myProperty", cyrillicString);
CMLCreate create = new CMLCreate("1", parentReference, null, null, null, documentType, namedValueProperties);
CML cml = new CML();
cml.setCreate(new CMLCreate[]{create});
UpdateResult[] results = null;
try {
results = WebServiceFactory.getRepositoryService().update(cml);
} catch (...)
Here comes the "org.xml.sax.SAXParseException"
}
</code></pre>
<p>Does anyone know how to solve this problem?</p>
|
[
{
"answer_id": 196300,
"author": "Damien B",
"author_id": 3069,
"author_profile": "https://Stackoverflow.com/users/3069",
"pm_score": 0,
"selected": false,
"text": "<p>The easiest way to get around it is I think to escape cyrillicString, for instance with <a href=\"http://commons.apache.org/lang/api-release/org/apache/commons/lang/StringEscapeUtils.html#escapeXml(java.lang.String)\" rel=\"nofollow noreferrer\">escapeXml</a> from Jakarta Commons, or by converting the whole string to XML entities if it's not enough. But in the long run, Alfresco should be fixed, so opening a ticket may be a good choice too.</p>\n"
},
{
"answer_id": 196698,
"author": "Julie",
"author_id": 8217,
"author_profile": "https://Stackoverflow.com/users/8217",
"pm_score": 0,
"selected": false,
"text": "<p>It's a little hard to tell whether or not this is a bug with Alfresco, without seeing the data you're trying to persist. Which version of Alfresco are you using? I found this bug in Alfresco's issue tracking system. Specifically, this is with 2.1 community, and it seems to suggest there are problems with encoding other than UTF-8, so it may or may not be related to your problem. </p>\n\n<p>One thing you could do to debug this problem is to write a little test using Alfresco's embedded Java (server-side) API, attempting to persist the same data, and see if you still get an error (it would probably not be SAXParseException if you do). If you don't get an error, you know that there is probably a bug in Alfresco's web service API (which unfortunately isn't nearly as well supported as their embedded Java or REST APIs), and you may want to add a comment on the bug report I mentioned earlier, or file your own. If you do still get an error with the embedded API, then it could still either be your code or theirs that's the problem. </p>\n\n<p>Hope that was at least a little helpful!</p>\n"
},
{
"answer_id": 197082,
"author": "Aleksandar Marinkovic",
"author_id": 26747,
"author_profile": "https://Stackoverflow.com/users/26747",
"pm_score": 3,
"selected": true,
"text": "<p>The problem was that <code>alfresco-web-service-client.jar</code> library I used was from 2.9B distribution (I am hitting 2.9B community content server), and dependency libs <code>bcprov-jdk15-136.jar</code> and <code>xmlsec-1.4.0.jar</code> were not adequate (remained old from 2.1 verison). I should have used <code>bcprov-jdk15-137.jar</code> and <code>xmlsec-1.4.1.jar</code> which are deployed along with 2.9B distribution. </p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190542",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26747/"
] |
I'm using Java for accessing Alfresco content server via it's web service API for importing some content into it. Content should have some NamedValue properties set to UTF-8(cyrillic) string. I keep getting the Sax parser exception:
```
org.xml.sax.SAXParseException: An invalid XML character (Unicode: 0x1b) was found in the element content of the document.
```
The code looks something like this:
```
NamedValue[] namedValueProperties = new NamedValue[2];
namedValueProperties[0] = Utils.createNamedValue(Constants.PROP_NAME, name );
namedValueProperties[1] = Utils.createNamedValue("{my.custom.model}myProperty", cyrillicString);
CMLCreate create = new CMLCreate("1", parentReference, null, null, null, documentType, namedValueProperties);
CML cml = new CML();
cml.setCreate(new CMLCreate[]{create});
UpdateResult[] results = null;
try {
results = WebServiceFactory.getRepositoryService().update(cml);
} catch (...)
Here comes the "org.xml.sax.SAXParseException"
}
```
Does anyone know how to solve this problem?
|
The problem was that `alfresco-web-service-client.jar` library I used was from 2.9B distribution (I am hitting 2.9B community content server), and dependency libs `bcprov-jdk15-136.jar` and `xmlsec-1.4.0.jar` were not adequate (remained old from 2.1 verison). I should have used `bcprov-jdk15-137.jar` and `xmlsec-1.4.1.jar` which are deployed along with 2.9B distribution.
|
190,553 |
<p>In the following code, both <code>amp_swap()</code> and <code>star_swap()</code> seems to be doing the same thing. So why will someone prefer to use one over the other? Which one is the preferred notation and why? Or is it just a matter of taste?</p>
<pre><code>#include <iostream>
using namespace std;
void amp_swap(int &x, int &y)
{
int temp = x;
x = y;
y = temp;
}
void star_swap(int *x, int *y)
{
int temp = *x;
*x = *y;
*y = temp;
}
int main()
{
int a = 10, b = 20;
cout << "Using amp_swap(): " << endl;
amp_swap(a, b);
cout << "a = " << a << ", b = " << b << endl;
cout << "Using star_swap(): " << endl;
star_swap(&a, &b);
cout << "a = " << a << ", b = " << b << endl;
return 0;
}
</code></pre>
<p>Thanks for your time!</p>
<hr>
<p>See Also</p>
<p><H2><a href="https://stackoverflow.com/questions/57483"><strong>Difference between pointer variable and reference variable in C++</strong></a></H2></p>
|
[
{
"answer_id": 190563,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>They are the exact same thing to the computer. However, one is a reference (&) and the other is a pointer (*)</p>\n\n<p><a href=\"http://www.google.com/search?hl=en&q=pointers+vs+references&btnG=Google+Search&aq=1&oq=pointers+vs\" rel=\"nofollow noreferrer\">http://www.google.com/search?hl=en&q=pointers+vs+references&btnG=Google+Search&aq=1&oq=pointers+vs</a></p>\n\n<p>I believe they both have their uses - as with pointers you can do more low level memory manipulation but the syntax for references is easier.</p>\n\n<p>:)</p>\n"
},
{
"answer_id": 190564,
"author": "John Millikin",
"author_id": 3560,
"author_profile": "https://Stackoverflow.com/users/3560",
"pm_score": 1,
"selected": false,
"text": "<p><code>(int *param)</code> is the older C style, using a direct memory pointer. <code>(int &param)</code> is modern C++ style, using a reference (a type-safe wrapper around raw pointer). If you're using C++, you should probably use a reference.</p>\n"
},
{
"answer_id": 190565,
"author": "Mark Ingram",
"author_id": 986,
"author_profile": "https://Stackoverflow.com/users/986",
"pm_score": 5,
"selected": true,
"text": "<p>One is using a reference, one is using a pointer.</p>\n\n<p>I would use the one with references, because you can't pass a NULL reference (whereas you can pass a NULL pointer).</p>\n\n<p>So if you do:</p>\n\n<pre><code>star_swap(NULL, NULL);\n</code></pre>\n\n<p>Your application will crash. Whereas if you try:</p>\n\n<pre><code>amp_swap(NULL, NULL); // This won't compile\n</code></pre>\n\n<p>Always go with references unless you've got a good reason to use a pointer.</p>\n\n<p>See this link: <a href=\"http://www.google.co.uk/search?q=references+vs+pointers\" rel=\"nofollow noreferrer\">http://www.google.co.uk/search?q=references+vs+pointers</a></p>\n"
},
{
"answer_id": 190568,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 2,
"selected": false,
"text": "<p>References cannot be NULL. So, using the first version would prevent a caller from passing NULL as one of the function arguments.</p>\n\n<p>References cannot be reassigned to point to something else. So, you know that within the function <code>amp_swap()</code>, that <code>x</code> and <code>y</code> always refer to the same thing. In the pointer version, you could (in a more complex function) reassign <code>x</code> and <code>y</code> to point to something else, which could make the logic less clear (yes, you could declare the parameters as <code>int *const x</code> to avoid this reassignment).</p>\n\n<p>The function body for the reference version looks cleaner because it doesn't have as many stars.</p>\n"
},
{
"answer_id": 190579,
"author": "m_pGladiator",
"author_id": 446104,
"author_profile": "https://Stackoverflow.com/users/446104",
"pm_score": 2,
"selected": false,
"text": "<p>This is not a matter of notation.</p>\n\n<p>There are 3 ways to pass parameters to a function:</p>\n\n<ol>\n<li>by value</li>\n<li>by reference</li>\n<li>by pointer</li>\n</ol>\n\n<p>In <code>amp_swap</code> you pass the actual parameters by reference. This is introduced and valid in C++ only.</p>\n\n<p>In <code>star_swap</code> you pass the parameters using pointers. This was the original C-way.</p>\n\n<p>Basically, if you are using C++, it is encouraged to use reference, since it is more readable for variables. If you need pointers, by all means use them.</p>\n\n<p>And remember to use the <code>&</code> sign when declaring the method with references, because otherwise you produce a bug. If you don't declare the reference in <code>amp_swap</code>, the function will not swap anything. Because this way you use method 1 (pass the parameter values only) and in the function will be created two new automatic variables, which live only in the scope of the function. This way the original outer variables will not be touched.</p>\n"
},
{
"answer_id": 190589,
"author": "Henry B",
"author_id": 6414,
"author_profile": "https://Stackoverflow.com/users/6414",
"pm_score": 2,
"selected": false,
"text": "<p>If you look <a href=\"http://www.embedded.com/story/OEG20010311S0024\" rel=\"nofollow noreferrer\">here</a> you can find a description of Pointer vs Reference, the most useful bit of information initially comes form this quotation.</p>\n\n<blockquote>\n <p>C++ doesn't let you declare a \"const reference\" because a reference is inherently > const. In other words, once you bind a reference to refer to an object, you cannot rebind it to refer to a different object. There's no notation for rebinding a reference after you've declared the reference.</p>\n</blockquote>\n\n<p>The following binds ri to refer to i.</p>\n\n<p><code>int &ri = i;</code></p>\n\n<p>Then an assignment such as: </p>\n\n<p><code>ri = j;</code></p>\n\n<p>will not bind ri to j. It will assign the value in j to the object referenced by ri, namely, i.</p>\n\n<p>Hope this is clearer.</p>\n"
},
{
"answer_id": 190607,
"author": "Konrad Rudolph",
"author_id": 1968,
"author_profile": "https://Stackoverflow.com/users/1968",
"pm_score": 2,
"selected": false,
"text": "<p>An argument can also be made for preferring the pointer version over the reference version. In fact, from a documentation point of view it's superior because the caller is made aware of the fact that the input arguments are going to be modified; compare these two calls:</p>\n\n<pre><code>swap(a, b);\nswap(&a, &b); // This cries “will modify arguments” loud and clear.\n</code></pre>\n\n<p>Of course, in the case of the <code>swap</code> function this point is moot; everybody knows its arguments will be modified. There are other cases where this is less obvious. C# has the <code>ref</code> keyword for exactly this reason. In C#, the above would have to look like this:</p>\n\n<pre><code>swap(ref a, ref b);\n</code></pre>\n\n<p>Of course, there are other ways to document this behaviour. Using pointers is one valid technique of doing so.</p>\n"
},
{
"answer_id": 192935,
"author": "paercebal",
"author_id": 14089,
"author_profile": "https://Stackoverflow.com/users/14089",
"pm_score": 1,
"selected": false,
"text": "<ul>\n<li>Like the pointer, the reference enables the modification of the data passed as a parameter</li>\n<li>Like the pointer, the reference enables polymorphism</li>\n<li>Unlike the pointer, the reference is never NULL (you can still achieve this with some hack, but, this is more akin to sabotaging than coding...)</li>\n<li>Unlike the pointer, the reference, when const, enable type promotion (i.e, having a function with a std::string parameter accepting a char *)</li>\n<li>Unlike the pointer, the reference cannot be re-assigned: There is no way to have it modified at some point of the code, whereas a pointer can point to A at one point, B at another, and NULL at another again. And you don't want to have ++ applied to your pointer by error...</li>\n<li>Unlike the pointer, the reference makes the manipulation of the data as easy as it would be with a primitive like \"int\" or \"bool\", without using the * operator all the time</li>\n</ul>\n\n<p>For these reasons, in C++, the reference use is usually a default, and the pointer is the exception.</p>\n\n<p>So, for consistency sake, between the two \"swap\" functions you propose, I would use the amp_swap and remove the star one from the sources (just to be sure no one would use it and add useless pointer code in the sources)...</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190553",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7205/"
] |
In the following code, both `amp_swap()` and `star_swap()` seems to be doing the same thing. So why will someone prefer to use one over the other? Which one is the preferred notation and why? Or is it just a matter of taste?
```
#include <iostream>
using namespace std;
void amp_swap(int &x, int &y)
{
int temp = x;
x = y;
y = temp;
}
void star_swap(int *x, int *y)
{
int temp = *x;
*x = *y;
*y = temp;
}
int main()
{
int a = 10, b = 20;
cout << "Using amp_swap(): " << endl;
amp_swap(a, b);
cout << "a = " << a << ", b = " << b << endl;
cout << "Using star_swap(): " << endl;
star_swap(&a, &b);
cout << "a = " << a << ", b = " << b << endl;
return 0;
}
```
Thanks for your time!
---
See Also
[**Difference between pointer variable and reference variable in C++**](https://stackoverflow.com/questions/57483)
------------------------------------------------------------------------------------------------------------------
|
One is using a reference, one is using a pointer.
I would use the one with references, because you can't pass a NULL reference (whereas you can pass a NULL pointer).
So if you do:
```
star_swap(NULL, NULL);
```
Your application will crash. Whereas if you try:
```
amp_swap(NULL, NULL); // This won't compile
```
Always go with references unless you've got a good reason to use a pointer.
See this link: <http://www.google.co.uk/search?q=references+vs+pointers>
|
190,560 |
<p>I am trying to animate a change in backgroundColor using jQuery on mouseover.</p>
<p>I have checked some example and I seem to have it right, it works with other properties like fontSize, but with backgroundColor I get and "Invalid Property" js error.
The element I am working with is a div.</p>
<pre><code>$(".usercontent").mouseover(function() {
$(this).animate({ backgroundColor: "olive" }, "slow");
});
</code></pre>
<p>Any ideas?</p>
|
[
{
"answer_id": 330133,
"author": "Donny V.",
"author_id": 1231,
"author_profile": "https://Stackoverflow.com/users/1231",
"pm_score": 4,
"selected": false,
"text": "<p>For anyone finding this. Your better off using the jQuery UI version because it works on all browsers. The color plugin has issues with Safari and Chrome. It only works sometimes.</p>\n"
},
{
"answer_id": 590065,
"author": "menardmam",
"author_id": 71830,
"author_profile": "https://Stackoverflow.com/users/71830",
"pm_score": 6,
"selected": false,
"text": "<p>I had the same problem and fixed it by including jQuery UI. Here is the complete script : </p>\n\n<pre class=\"lang-html prettyprint-override\"><code><!-- include Google's AJAX API loader -->\n<script src=\"http://www.google.com/jsapi\"></script>\n<!-- load JQuery and UI from Google (need to use UI to animate colors) -->\n<script type=\"text/javascript\">\ngoogle.load(\"jqueryui\", \"1.5.2\");\n</script>\n\n\n<script type=\"text/javascript\">\n$(document).ready(function() {\n$('#menu ul li.item').hover(\n function() {\n $(this).stop().animate({backgroundColor:'#4E1402'}, 300);\n }, function () {\n $(this).stop().animate({backgroundColor:'#943D20'}, 100);\n });\n});\n</script>\n</code></pre>\n"
},
{
"answer_id": 1184410,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>These days jQuery color plugin supports following named colors:</p>\n\n<pre><code>aqua:[0,255,255],\nazure:[240,255,255],\nbeige:[245,245,220],\nblack:[0,0,0],\nblue:[0,0,255],\nbrown:[165,42,42],\ncyan:[0,255,255],\ndarkblue:[0,0,139],\ndarkcyan:[0,139,139],\ndarkgrey:[169,169,169],\ndarkgreen:[0,100,0],\ndarkkhaki:[189,183,107],\ndarkmagenta:[139,0,139],\ndarkolivegreen:[85,107,47],\ndarkorange:[255,140,0],\ndarkorchid:[153,50,204],\ndarkred:[139,0,0],\ndarksalmon:[233,150,122],\ndarkviolet:[148,0,211],\nfuchsia:[255,0,255],\ngold:[255,215,0],\ngreen:[0,128,0],\nindigo:[75,0,130],\nkhaki:[240,230,140],\nlightblue:[173,216,230],\nlightcyan:[224,255,255],\nlightgreen:[144,238,144],\nlightgrey:[211,211,211],\nlightpink:[255,182,193],\nlightyellow:[255,255,224],\nlime:[0,255,0],\nmagenta:[255,0,255],\nmaroon:[128,0,0],\nnavy:[0,0,128],\nolive:[128,128,0],\norange:[255,165,0],\npink:[255,192,203],\npurple:[128,0,128],\nviolet:[128,0,128],\nred:[255,0,0],\nsilver:[192,192,192],\nwhite:[255,255,255],\nyellow:[255,255,0]\n</code></pre>\n"
},
{
"answer_id": 2302005,
"author": "Andrew",
"author_id": 148346,
"author_profile": "https://Stackoverflow.com/users/148346",
"pm_score": 9,
"selected": true,
"text": "<p>The color plugin is only 4kb so much cheaper than the UI library. Of course you'll want to use a <a href=\"http://github.com/jquery/jquery-color\" rel=\"noreferrer\">decent version</a> of the plugin and not <a href=\"http://plugins.jquery.com/project/color\" rel=\"noreferrer\">some buggy old thing</a> which doesn't handle Safari and crashes when the transitions are too fast. Since a minified version isn't supplied you might like test various compressors and <a href=\"http://compressorrater.thruhere.net/\" rel=\"noreferrer\">make your own</a> min version. YUI gets the best compression in this case needing only 2317 bytes and since it is so small - here it is:</p>\n\n<pre><code>(function (d) {\n d.each([\"backgroundColor\", \"borderBottomColor\", \"borderLeftColor\", \"borderRightColor\", \"borderTopColor\", \"color\", \"outlineColor\"], function (f, e) {\n d.fx.step[e] = function (g) {\n if (!g.colorInit) {\n g.start = c(g.elem, e);\n g.end = b(g.end);\n g.colorInit = true\n }\n g.elem.style[e] = \"rgb(\" + [Math.max(Math.min(parseInt((g.pos * (g.end[0] - g.start[0])) + g.start[0]), 255), 0), Math.max(Math.min(parseInt((g.pos * (g.end[1] - g.start[1])) + g.start[1]), 255), 0), Math.max(Math.min(parseInt((g.pos * (g.end[2] - g.start[2])) + g.start[2]), 255), 0)].join(\",\") + \")\"\n }\n });\n\n function b(f) {\n var e;\n if (f && f.constructor == Array && f.length == 3) {\n return f\n }\n if (e = /rgb\\(\\s*([0-9]{1,3})\\s*,\\s*([0-9]{1,3})\\s*,\\s*([0-9]{1,3})\\s*\\)/.exec(f)) {\n return [parseInt(e[1]), parseInt(e[2]), parseInt(e[3])]\n }\n if (e = /rgb\\(\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*,\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*,\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*\\)/.exec(f)) {\n return [parseFloat(e[1]) * 2.55, parseFloat(e[2]) * 2.55, parseFloat(e[3]) * 2.55]\n }\n if (e = /#([a-fA-F0-9]{2})([a-fA-F0-9]{2})([a-fA-F0-9]{2})/.exec(f)) {\n return [parseInt(e[1], 16), parseInt(e[2], 16), parseInt(e[3], 16)]\n }\n if (e = /#([a-fA-F0-9])([a-fA-F0-9])([a-fA-F0-9])/.exec(f)) {\n return [parseInt(e[1] + e[1], 16), parseInt(e[2] + e[2], 16), parseInt(e[3] + e[3], 16)]\n }\n if (e = /rgba\\(0, 0, 0, 0\\)/.exec(f)) {\n return a.transparent\n }\n return a[d.trim(f).toLowerCase()]\n }\n function c(g, e) {\n var f;\n do {\n f = d.css(g, e);\n if (f != \"\" && f != \"transparent\" || d.nodeName(g, \"body\")) {\n break\n }\n e = \"backgroundColor\"\n } while (g = g.parentNode);\n return b(f)\n }\n var a = {\n aqua: [0, 255, 255],\n azure: [240, 255, 255],\n beige: [245, 245, 220],\n black: [0, 0, 0],\n blue: [0, 0, 255],\n brown: [165, 42, 42],\n cyan: [0, 255, 255],\n darkblue: [0, 0, 139],\n darkcyan: [0, 139, 139],\n darkgrey: [169, 169, 169],\n darkgreen: [0, 100, 0],\n darkkhaki: [189, 183, 107],\n darkmagenta: [139, 0, 139],\n darkolivegreen: [85, 107, 47],\n darkorange: [255, 140, 0],\n darkorchid: [153, 50, 204],\n darkred: [139, 0, 0],\n darksalmon: [233, 150, 122],\n darkviolet: [148, 0, 211],\n fuchsia: [255, 0, 255],\n gold: [255, 215, 0],\n green: [0, 128, 0],\n indigo: [75, 0, 130],\n khaki: [240, 230, 140],\n lightblue: [173, 216, 230],\n lightcyan: [224, 255, 255],\n lightgreen: [144, 238, 144],\n lightgrey: [211, 211, 211],\n lightpink: [255, 182, 193],\n lightyellow: [255, 255, 224],\n lime: [0, 255, 0],\n magenta: [255, 0, 255],\n maroon: [128, 0, 0],\n navy: [0, 0, 128],\n olive: [128, 128, 0],\n orange: [255, 165, 0],\n pink: [255, 192, 203],\n purple: [128, 0, 128],\n violet: [128, 0, 128],\n red: [255, 0, 0],\n silver: [192, 192, 192],\n white: [255, 255, 255],\n yellow: [255, 255, 0],\n transparent: [255, 255, 255]\n }\n})(jQuery);\n</code></pre>\n"
},
{
"answer_id": 3895425,
"author": "Peter Ajtai",
"author_id": 186636,
"author_profile": "https://Stackoverflow.com/users/186636",
"pm_score": 4,
"selected": false,
"text": "<p>You can use 2 divs:</p>\n\n<p>You could put a clone on top of it and fade the original out while fading the clone in.</p>\n\n<p>When the fades are done, restore the original with the new bg.</p>\n\n<pre><code>$(function(){\n var $mytd = $('#mytd'), $elie = $mytd.clone(), os = $mytd.offset();\n\n // Create clone w other bg and position it on original\n $elie.toggleClass(\"class1, class2\").appendTo(\"body\")\n .offset({top: os.top, left: os.left}).hide();\n\n $mytd.mouseover(function() { \n // Fade original\n $mytd.fadeOut(3000, function() {\n $mytd.toggleClass(\"class1, class2\").show();\n $elie.toggleClass(\"class1, class2\").hide(); \n });\n // Show clone at same time\n $elie.fadeIn(3000);\n });\n});\n</code></pre>\n\n<h2><strong><a href=\"http://jsfiddle.net/cq2S8/\" rel=\"noreferrer\">jsFiddle example</a></strong></h2>\n\n<p><br/></p>\n\n<p><strong><a href=\"http://api.jquery.com/toggleClass/\" rel=\"noreferrer\"><code>.toggleClass()</code></a></strong><br>\n<strong><a href=\"http://api.jquery.com/offset/\" rel=\"noreferrer\"><code>.offset()</code></a></strong><br>\n<strong><a href=\"http://api.jquery.com/fadeIn/\" rel=\"noreferrer\"><code>.fadeIn()</code></a></strong><br>\n<strong><a href=\"http://api.jquery.com/fadeOut/\" rel=\"noreferrer\"><code>.fadeOut()</code></a></strong></p>\n"
},
{
"answer_id": 4087898,
"author": "Andy",
"author_id": 104247,
"author_profile": "https://Stackoverflow.com/users/104247",
"pm_score": 3,
"selected": false,
"text": "<p>I like using delay() to get this done, here's an example:</p>\n\n<pre><code>jQuery(element).animate({ backgroundColor: \"#FCFCD8\" },1).delay(1000).animate({ backgroundColor: \"#EFEAEA\" }, 1500);\n</code></pre>\n\n<p>This can be called by a function, with \"element\" being the element class/name/etc. The element will instantly appear with the #FCFCD8 background, hold for a second, then fade into #EFEAEA. </p>\n"
},
{
"answer_id": 4611026,
"author": "Orhaan",
"author_id": 287084,
"author_profile": "https://Stackoverflow.com/users/287084",
"pm_score": 1,
"selected": false,
"text": "<p>ColorBlend plug in does exactly what u want</p>\n\n<p><a href=\"http://plugins.jquery.com/project/colorBlend\" rel=\"nofollow\">http://plugins.jquery.com/project/colorBlend</a></p>\n\n<p>Here is the my highlight code</p>\n\n<pre><code>$(\"#container\").colorBlend([{\n colorList:[\"white\", \"yellow\"], \n param:\"background-color\",\n cycles: 1,\n duration: 500\n}]);\n</code></pre>\n"
},
{
"answer_id": 4836413,
"author": "Emmanuel",
"author_id": 288564,
"author_profile": "https://Stackoverflow.com/users/288564",
"pm_score": 5,
"selected": false,
"text": "<p>Bitstorm has the best jquery color animation plugin I've seen. It's an improvement to the jquery color project. It also supports rgba.</p>\n\n<p><a href=\"http://www.bitstorm.org/jquery/color-animation/\">http://www.bitstorm.org/jquery/color-animation/</a></p>\n"
},
{
"answer_id": 5086660,
"author": "Mary Daisy Sanchez",
"author_id": 560756,
"author_profile": "https://Stackoverflow.com/users/560756",
"pm_score": 0,
"selected": false,
"text": "<p>Try this one:</p>\n\n<pre><code>jQuery(\".usercontent\").hover(function() {\n jQuery(this).animate({backgroundColor:\"pink\"}, \"slow\");\n},function(){\n jQuery(this).animate({backgroundColor:\"white\"}, \"slow\");\n});\n</code></pre>\n\n<p>Revised way with effects:</p>\n\n<pre><code>jQuery(\".usercontent\").hover(function() {\n\n jQuery(this).fadeout(\"slow\",function(){\n jQuery(this).animate({\"color\",\"yellow\"}, \"slow\");\n });\n});\n</code></pre>\n"
},
{
"answer_id": 6993089,
"author": "Faraz Kelhini",
"author_id": 530659,
"author_profile": "https://Stackoverflow.com/users/530659",
"pm_score": 4,
"selected": false,
"text": "<p>You can use jQuery UI to add this functionality. You can grab just what you need, so if you want to animate color, all you have to include is the following code. I got if from latest jQuery UI (currently 1.8.14)</p>\n\n<pre><code>/******************************************************************************/\n/****************************** COLOR ANIMATIONS ******************************/\n/******************************************************************************/\n\n// override the animation for color styles\n$.each(['backgroundColor', 'borderBottomColor', 'borderLeftColor',\n 'borderRightColor', 'borderTopColor', 'borderColor', 'color', 'outlineColor'],\nfunction(i, attr) {\n $.fx.step[attr] = function(fx) {\n if (!fx.colorInit) {\n fx.start = getColor(fx.elem, attr);\n fx.end = getRGB(fx.end);\n fx.colorInit = true;\n }\n\n fx.elem.style[attr] = 'rgb(' +\n Math.max(Math.min(parseInt((fx.pos * (fx.end[0] - fx.start[0])) + fx.start[0], 10), 255), 0) + ',' +\n Math.max(Math.min(parseInt((fx.pos * (fx.end[1] - fx.start[1])) + fx.start[1], 10), 255), 0) + ',' +\n Math.max(Math.min(parseInt((fx.pos * (fx.end[2] - fx.start[2])) + fx.start[2], 10), 255), 0) + ')';\n };\n});\n\n// Color Conversion functions from highlightFade\n// By Blair Mitchelmore\n// http://jquery.offput.ca/highlightFade/\n\n// Parse strings looking for color tuples [255,255,255]\nfunction getRGB(color) {\n var result;\n\n // Check if we're already dealing with an array of colors\n if ( color && color.constructor == Array && color.length == 3 )\n return color;\n\n // Look for rgb(num,num,num)\n if (result = /rgb\\(\\s*([0-9]{1,3})\\s*,\\s*([0-9]{1,3})\\s*,\\s*([0-9]{1,3})\\s*\\)/.exec(color))\n return [parseInt(result[1],10), parseInt(result[2],10), parseInt(result[3],10)];\n\n // Look for rgb(num%,num%,num%)\n if (result = /rgb\\(\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*,\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*,\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*\\)/.exec(color))\n return [parseFloat(result[1])*2.55, parseFloat(result[2])*2.55, parseFloat(result[3])*2.55];\n\n // Look for #a0b1c2\n if (result = /#([a-fA-F0-9]{2})([a-fA-F0-9]{2})([a-fA-F0-9]{2})/.exec(color))\n return [parseInt(result[1],16), parseInt(result[2],16), parseInt(result[3],16)];\n\n // Look for #fff\n if (result = /#([a-fA-F0-9])([a-fA-F0-9])([a-fA-F0-9])/.exec(color))\n return [parseInt(result[1]+result[1],16), parseInt(result[2]+result[2],16), parseInt(result[3]+result[3],16)];\n\n // Look for rgba(0, 0, 0, 0) == transparent in Safari 3\n if (result = /rgba\\(0, 0, 0, 0\\)/.exec(color))\n return colors['transparent'];\n\n // Otherwise, we're most likely dealing with a named color\n return colors[$.trim(color).toLowerCase()];\n}\n\nfunction getColor(elem, attr) {\n var color;\n\n do {\n color = $.curCSS(elem, attr);\n\n // Keep going until we find an element that has color, or we hit the body\n if ( color != '' && color != 'transparent' || $.nodeName(elem, \"body\") )\n break;\n\n attr = \"backgroundColor\";\n } while ( elem = elem.parentNode );\n\n return getRGB(color);\n};\n</code></pre>\n\n<p>It's only 1.43kb after compressing with YUI:</p>\n\n<pre><code>$.each([\"backgroundColor\",\"borderBottomColor\",\"borderLeftColor\",\"borderRightColor\",\"borderTopColor\",\"borderColor\",\"color\",\"outlineColor\"],function(b,a){$.fx.step[a]=function(c){if(!c.colorInit){c.start=getColor(c.elem,a);c.end=getRGB(c.end);c.colorInit=true}c.elem.style[a]=\"rgb(\"+Math.max(Math.min(parseInt((c.pos*(c.end[0]-c.start[0]))+c.start[0],10),255),0)+\",\"+Math.max(Math.min(parseInt((c.pos*(c.end[1]-c.start[1]))+c.start[1],10),255),0)+\",\"+Math.max(Math.min(parseInt((c.pos*(c.end[2]-c.start[2]))+c.start[2],10),255),0)+\")\"}});function getRGB(b){var a;if(b&&b.constructor==Array&&b.length==3){return b}if(a=/rgb\\(\\s*([0-9]{1,3})\\s*,\\s*([0-9]{1,3})\\s*,\\s*([0-9]{1,3})\\s*\\)/.exec(b)){return[parseInt(a[1],10),parseInt(a[2],10),parseInt(a[3],10)]}if(a=/rgb\\(\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*,\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*,\\s*([0-9]+(?:\\.[0-9]+)?)\\%\\s*\\)/.exec(b)){return[parseFloat(a[1])*2.55,parseFloat(a[2])*2.55,parseFloat(a[3])*2.55]}if(a=/#([a-fA-F0-9]{2})([a-fA-F0-9]{2})([a-fA-F0-9]{2})/.exec(b)){return[parseInt(a[1],16),parseInt(a[2],16),parseInt(a[3],16)]}if(a=/#([a-fA-F0-9])([a-fA-F0-9])([a-fA-F0-9])/.exec(b)){return[parseInt(a[1]+a[1],16),parseInt(a[2]+a[2],16),parseInt(a[3]+a[3],16)]}if(a=/rgba\\(0, 0, 0, 0\\)/.exec(b)){return colors.transparent}return colors[$.trim(b).toLowerCase()]}function getColor(c,a){var b;do{b=$.curCSS(c,a);if(b!=\"\"&&b!=\"transparent\"||$.nodeName(c,\"body\")){break}a=\"backgroundColor\"}while(c=c.parentNode);return getRGB(b)};\n</code></pre>\n\n<p>You can also animate colors using CSS3 transitions but it's only supported by modern browsers. </p>\n\n<pre><code>a.test {\n color: red;\n -moz-transition-property: color; /* FF4+ */\n -moz-transition-duration: 1s;\n -webkit-transition-property: color; /* Saf3.2+, Chrome */\n -webkit-transition-duration: 1s;\n -o-transition-property: color; /* Opera 10.5+ */\n -o-transition-duration: 1s;\n -ms-transition-property: color; /* IE10? */\n -ms-transition-duration: 1s;\n transition-property: color; /* Standard */\n transition-duration: 1s;\n }\n\n a.test:hover {\n color: blue;\n }\n</code></pre>\n\n<p>Using shorthand property:</p>\n\n<pre><code>/* shorthand notation for transition properties */\n/* transition: [transition-property] [transition-duration] [transition-timing-function] [transition-delay]; */\n\na.test {\n color: red;\n -moz-transition: color 1s;\n -webkit-transition: color 1s;\n -o-transition: color 1s;\n -ms-transition: color 1s;\n transition: color 1s;\n }\n\na.test {\n color: blue;\n }\n</code></pre>\n\n<p>Unlike regular javascript transitions, CSS3 transitions are hardware accelerated and therefore smoother. You can use Modernizr, to find out if the browser supports CSS3 transitions, if it didn't then you can use jQuery as a fallback:</p>\n\n<pre><code>if ( !cssTransitions() ) {\n $(document).ready(function(){\n $(\".test\").hover(function () {\n $(this).stop().animate({ backgroundColor: \"red\" },500)\n }, function() {\n $(this).stop().animate({ backgroundColor: \"blue\" },500)} \n );\n }); \n}\n</code></pre>\n\n<p>Remember to use stop() to stop the current animation before starting a new one otherwise when you pass over the element too fast, the effect keeps blinking for a while.</p>\n"
},
{
"answer_id": 8587086,
"author": "Anton Rodin",
"author_id": 1107702,
"author_profile": "https://Stackoverflow.com/users/1107702",
"pm_score": 0,
"selected": false,
"text": "<p>Try to use it</p>\n\n<pre><code>-moz-transition: background .2s linear;\n-webkit-transition: background .2s linear;\n-o-transition: background .2s linear;\ntransition: background .2s linear;\n</code></pre>\n"
},
{
"answer_id": 12896867,
"author": "Pebbl",
"author_id": 1490904,
"author_profile": "https://Stackoverflow.com/users/1490904",
"pm_score": 2,
"selected": false,
"text": "<p>I stumbled across this page with the same issue, but the following problems:</p>\n\n<ol>\n<li>I can't include an extra jQuery plugin file with my current set-up.</li>\n<li>I'm not comfortable pasting large blocks of code that I don't have time to read over and validate.</li>\n<li>I don't have access to the css.</li>\n<li>I hardly had any time for implementation (it was only a visual improvement to an admin page)</li>\n</ol>\n\n<p>With the above that pretty much ruled out every answer. Considering my fade of colour was very simple, I used the following quick hack instead:</p>\n\n<pre><code>element\n .css('color','#FF0000')\n;\n$('<div />')\n .css('width',0)\n .animate(\n {'width':100},\n {\n duration: 3000,\n step:function(now){\n var v = (255 - 255/100 * now).toString(16);\n v = (v.length < 2 ? '0' : '') + v.substr(0,2);\n element.css('color','#'+v+'0000');\n }\n }\n )\n;\n</code></pre>\n\n<p>The above creates a temporary div that is never placed in the document flow. I then use jQuery's built-in animation to animate a numeric property of that element - in this case <code>width</code> - which can represent a percentage (0 to 100). Then, using the step function, I transfer this numeric animation to the text colour with a simple hex cacluation.</p>\n\n<p>The same could have been achieved with <code>setInterval</code>, but by using this method you can benefit from jQuery's animation methods - like <code>.stop()</code> - and you can use <code>easing</code> and <code>duration</code>.</p>\n\n<p>Obivously it's only of use for simple colour fades, for more complicated colour conversions you'll need to use one of the above answers - or code your own colour fade math :)</p>\n"
},
{
"answer_id": 13822204,
"author": "Jimbo Jones",
"author_id": 1156525,
"author_profile": "https://Stackoverflow.com/users/1156525",
"pm_score": 3,
"selected": false,
"text": "<p>I used a combination of CSS transitions with JQuery for the desired effect; obviously browsers which don't support CSS transitions will not animate but its a lightweight option which works well for most browsers and for my requirements is acceptable degradation.</p>\n\n<p><strong>Jquery to change the background color:</strong> </p>\n\n<pre><code> $('.mylinkholder a').hover(\n function () {\n $(this).css({ backgroundColor: '#f0f0f0' }); \n },\n function () {\n $(this).css({ backgroundColor: '#fff' });\n }\n );\n</code></pre>\n\n<p><strong>CSS using transition to fade background-color change</strong></p>\n\n<pre><code> .mylinkholder a\n {\n transition: background-color .5s ease-in-out;\n -moz-transition: background-color .5s ease-in-out;\n -webkit-transition: background-color .5s ease-in-out; \n -o-transition: background-color .5s ease-in-out; \n }\n</code></pre>\n"
},
{
"answer_id": 14214879,
"author": "user1029978",
"author_id": 1029978,
"author_profile": "https://Stackoverflow.com/users/1029978",
"pm_score": 1,
"selected": false,
"text": "<p>If you wan't to animate your background using only core jQuery functionality, try this:</p>\n\n<pre><code>jQuery(\".usercontent\").mouseover(function() {\n jQuery(\".usercontent\").animate({backgroundColor:'red'}, 'fast', 'linear', function() {\n jQuery(this).animate({\n backgroundColor: 'white'\n }, 'normal', 'linear', function() {\n jQuery(this).css({'background':'none', backgroundColor : ''});\n });\n });\n</code></pre>\n"
},
{
"answer_id": 15234173,
"author": "volf",
"author_id": 841333,
"author_profile": "https://Stackoverflow.com/users/841333",
"pm_score": 6,
"selected": false,
"text": "<p>Do it with CSS3-Transitions. Support is great (all modern browsers, even IE). With Compass and SASS this is quickly done:</p>\n\n<pre><code>#foo {background:red; @include transition(background 1s)}\n#foo:hover {background:yellow}\n</code></pre>\n\n<p>Pure CSS:</p>\n\n<pre><code>#foo {\nbackground:red;\n-webkit-transition:background 1s;\n-moz-transition:background 1s;\n-o-transition:background 1s;\ntransition:background 1s\n}\n#foo:hover {background:yellow}\n</code></pre>\n\n<p>I've wrote an german article about this topic: <a href=\"http://www.solife.cc/blog/animation-farben-css3-transition.html\">http://www.solife.cc/blog/animation-farben-css3-transition.html</a></p>\n"
},
{
"answer_id": 27926653,
"author": "mag",
"author_id": 2057712,
"author_profile": "https://Stackoverflow.com/users/2057712",
"pm_score": 2,
"selected": false,
"text": "<p>Try this one:</p>\n\n<pre><code>(function($) { \n\n var i = 0; \n\n var someBackground = $(\".someBackground\"); \n var someColors = [ \"yellow\", \"red\", \"blue\", \"pink\" ]; \n\n\n someBackground.css('backgroundColor', someColors[0]); \n\n window.setInterval(function() { \n i = i == someColors.length ? 0 : i; \n someBackground.animate({backgroundColor: someColors[i]}, 3000); \n i++; \n }, 30); \n\n})(jQuery); \n</code></pre>\n\n<p>you can preview example here: <a href=\"http://jquerydemo.com/demo/jquery-animate-background-color.aspx\" rel=\"nofollow\">http://jquerydemo.com/demo/jquery-animate-background-color.aspx</a></p>\n"
},
{
"answer_id": 44585068,
"author": "Darush",
"author_id": 4726718,
"author_profile": "https://Stackoverflow.com/users/4726718",
"pm_score": 3,
"selected": false,
"text": "<p>Simply add the following snippet bellow your jquery script and enjoy:</p>\n\n<pre><code><script src=\"https://cdn.jsdelivr.net/jquery.color-animation/1/mainfile\"></script>\n</code></pre>\n\n<p><a href=\"https://codepen.io/darush/pen/WjqooB/\" rel=\"noreferrer\">See the example</a></p>\n\n<p><a href=\"https://bitstorm.org/jquery/color-animation/\" rel=\"noreferrer\">Reference for more info</a></p>\n"
},
{
"answer_id": 68067629,
"author": "lendoo",
"author_id": 11338800,
"author_profile": "https://Stackoverflow.com/users/11338800",
"pm_score": 1,
"selected": false,
"text": "<p>To change background color with animate effect without jQueryUI:</p>\n<pre><code>selector.css({\n backgroundColor: "#555",\n transition: "background-color 1.8s"\n});\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190560",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6125/"
] |
I am trying to animate a change in backgroundColor using jQuery on mouseover.
I have checked some example and I seem to have it right, it works with other properties like fontSize, but with backgroundColor I get and "Invalid Property" js error.
The element I am working with is a div.
```
$(".usercontent").mouseover(function() {
$(this).animate({ backgroundColor: "olive" }, "slow");
});
```
Any ideas?
|
The color plugin is only 4kb so much cheaper than the UI library. Of course you'll want to use a [decent version](http://github.com/jquery/jquery-color) of the plugin and not [some buggy old thing](http://plugins.jquery.com/project/color) which doesn't handle Safari and crashes when the transitions are too fast. Since a minified version isn't supplied you might like test various compressors and [make your own](http://compressorrater.thruhere.net/) min version. YUI gets the best compression in this case needing only 2317 bytes and since it is so small - here it is:
```
(function (d) {
d.each(["backgroundColor", "borderBottomColor", "borderLeftColor", "borderRightColor", "borderTopColor", "color", "outlineColor"], function (f, e) {
d.fx.step[e] = function (g) {
if (!g.colorInit) {
g.start = c(g.elem, e);
g.end = b(g.end);
g.colorInit = true
}
g.elem.style[e] = "rgb(" + [Math.max(Math.min(parseInt((g.pos * (g.end[0] - g.start[0])) + g.start[0]), 255), 0), Math.max(Math.min(parseInt((g.pos * (g.end[1] - g.start[1])) + g.start[1]), 255), 0), Math.max(Math.min(parseInt((g.pos * (g.end[2] - g.start[2])) + g.start[2]), 255), 0)].join(",") + ")"
}
});
function b(f) {
var e;
if (f && f.constructor == Array && f.length == 3) {
return f
}
if (e = /rgb\(\s*([0-9]{1,3})\s*,\s*([0-9]{1,3})\s*,\s*([0-9]{1,3})\s*\)/.exec(f)) {
return [parseInt(e[1]), parseInt(e[2]), parseInt(e[3])]
}
if (e = /rgb\(\s*([0-9]+(?:\.[0-9]+)?)\%\s*,\s*([0-9]+(?:\.[0-9]+)?)\%\s*,\s*([0-9]+(?:\.[0-9]+)?)\%\s*\)/.exec(f)) {
return [parseFloat(e[1]) * 2.55, parseFloat(e[2]) * 2.55, parseFloat(e[3]) * 2.55]
}
if (e = /#([a-fA-F0-9]{2})([a-fA-F0-9]{2})([a-fA-F0-9]{2})/.exec(f)) {
return [parseInt(e[1], 16), parseInt(e[2], 16), parseInt(e[3], 16)]
}
if (e = /#([a-fA-F0-9])([a-fA-F0-9])([a-fA-F0-9])/.exec(f)) {
return [parseInt(e[1] + e[1], 16), parseInt(e[2] + e[2], 16), parseInt(e[3] + e[3], 16)]
}
if (e = /rgba\(0, 0, 0, 0\)/.exec(f)) {
return a.transparent
}
return a[d.trim(f).toLowerCase()]
}
function c(g, e) {
var f;
do {
f = d.css(g, e);
if (f != "" && f != "transparent" || d.nodeName(g, "body")) {
break
}
e = "backgroundColor"
} while (g = g.parentNode);
return b(f)
}
var a = {
aqua: [0, 255, 255],
azure: [240, 255, 255],
beige: [245, 245, 220],
black: [0, 0, 0],
blue: [0, 0, 255],
brown: [165, 42, 42],
cyan: [0, 255, 255],
darkblue: [0, 0, 139],
darkcyan: [0, 139, 139],
darkgrey: [169, 169, 169],
darkgreen: [0, 100, 0],
darkkhaki: [189, 183, 107],
darkmagenta: [139, 0, 139],
darkolivegreen: [85, 107, 47],
darkorange: [255, 140, 0],
darkorchid: [153, 50, 204],
darkred: [139, 0, 0],
darksalmon: [233, 150, 122],
darkviolet: [148, 0, 211],
fuchsia: [255, 0, 255],
gold: [255, 215, 0],
green: [0, 128, 0],
indigo: [75, 0, 130],
khaki: [240, 230, 140],
lightblue: [173, 216, 230],
lightcyan: [224, 255, 255],
lightgreen: [144, 238, 144],
lightgrey: [211, 211, 211],
lightpink: [255, 182, 193],
lightyellow: [255, 255, 224],
lime: [0, 255, 0],
magenta: [255, 0, 255],
maroon: [128, 0, 0],
navy: [0, 0, 128],
olive: [128, 128, 0],
orange: [255, 165, 0],
pink: [255, 192, 203],
purple: [128, 0, 128],
violet: [128, 0, 128],
red: [255, 0, 0],
silver: [192, 192, 192],
white: [255, 255, 255],
yellow: [255, 255, 0],
transparent: [255, 255, 255]
}
})(jQuery);
```
|
190,590 |
<p>Ruby has a wealth of conditional constructs, including <code>if</code>/<code>unless</code>, <code>while</code>/<code>until</code> etc.</p>
<p>The <code>while</code> block from C:</p>
<pre><code>while (condition) {
...
}
</code></pre>
<p>can be directly translated to Ruby:</p>
<pre><code>while condition
...
end
</code></pre>
<p>However, I can't seem to find a <em>built-in</em> equivalent in Ruby for a C-like <code>do ... while</code> block in which the block contents are executed at least once:</p>
<pre><code>do {
...
} while (condition);
</code></pre>
<p>Any suggestions?</p>
|
[
{
"answer_id": 190591,
"author": "Cristian Diaconescu",
"author_id": 11545,
"author_profile": "https://Stackoverflow.com/users/11545",
"pm_score": 6,
"selected": true,
"text": "<p>...The best I could come up with is the <code>loop</code> construct with a <code>break</code> at the end: </p>\n\n<pre><code>loop do\n ...\n break unless condition\nend\n</code></pre>\n"
},
{
"answer_id": 190626,
"author": "IDBD",
"author_id": 7403,
"author_profile": "https://Stackoverflow.com/users/7403",
"pm_score": -1,
"selected": false,
"text": "<p>You can use</p>\n\n<pre><code>while condition\n ...\nend\n</code></pre>\n"
},
{
"answer_id": 191363,
"author": "Gene T",
"author_id": 413049,
"author_profile": "https://Stackoverflow.com/users/413049",
"pm_score": 4,
"selected": false,
"text": "<p>You can do</p>\n\n<pre><code>i=1\nbegin\n ...\n i+=1 \nend until 10==x\n</code></pre>\n\n<p>(you can also tack on a while clause to the end of begin..end)</p>\n\n<p>see p 128 of Flanagan/Matz Ruby Prog'g Lang book: This is something that may be removed in releases after 1.8</p>\n"
},
{
"answer_id": 1659169,
"author": "haoqi",
"author_id": 131492,
"author_profile": "https://Stackoverflow.com/users/131492",
"pm_score": 3,
"selected": false,
"text": "<pre><code>number=3\nbegin\n puts number\n number-=1\nend while number>0\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190590",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11545/"
] |
Ruby has a wealth of conditional constructs, including `if`/`unless`, `while`/`until` etc.
The `while` block from C:
```
while (condition) {
...
}
```
can be directly translated to Ruby:
```
while condition
...
end
```
However, I can't seem to find a *built-in* equivalent in Ruby for a C-like `do ... while` block in which the block contents are executed at least once:
```
do {
...
} while (condition);
```
Any suggestions?
|
...The best I could come up with is the `loop` construct with a `break` at the end:
```
loop do
...
break unless condition
end
```
|
190,597 |
<p>Say I have class A with</p>
<pre><code>class A {
final String foo() {
// .. computing result, contacting database, whatever ..
return "some computed value";
}
// ... and a bazillion other methods, some of them final.
}
</code></pre>
<p>Now I have class B with</p>
<pre><code>class B {
String methodIWantToTest(A a) {
String output = a.foo();
// ... whatever this method does, e.g.:
output += "_suffix";
return output;
}
}
</code></pre>
<p>How would I go about unit testing this method? The reason <code>foo()</code> is final is because we don't want our classes which extend A to change its functionality. But at the same time to truly unit test the method, I don't want it to reach out and run the actual <code>A.foo()</code> method.</p>
<p>Is there a way to, say, remove the final keyword and add an annotation along the lines of <code>@finalUnlessTest</code>? What would you recommend? Refactoring A to an interface would be very, very difficult, seeing as how it's one of our central classes and is unfortunately <s>pretty</s> extremely coupled.</p>
<p><strong>Edit #1</strong> Sorry, forgot to mention, we're talking Java. We are not using a mocking framework as of yet.</p>
<p><strong>Answer</strong> OK, so: wow. <a href="http://jmockit.org" rel="nofollow noreferrer">JMockit</a> is just incredible and is in my eyes the killer app for testing legacy code. Unbelievably useful especially in my case. Thanks so much! You basically would do something like the following for my psuedo-example:</p>
<pre><code>class AMock {
final String foo() {
return "myTestValue";
}
}
class Test extends TestCase {
A mockedA;
B b;
protected void setUp() {
Mockit.redefineMethods( A.class, AMock.class ); // this "pipes" all mocked methods from A to AMock
mockedA = new A(); // NOT new AMock()!!!
b = new B();
}
public void testB() {
assertEquals("myTestValue",mockedA.foo());
assertEquals("myTestValue_suffix",b.methodIWantToTest(mockedA));
}
}
</code></pre>
<p>Is this frickin' cool or what?</p>
|
[
{
"answer_id": 190611,
"author": "John Millikin",
"author_id": 3560,
"author_profile": "https://Stackoverflow.com/users/3560",
"pm_score": 0,
"selected": false,
"text": "<p>I'd remove the \"final\" and just put in a comment \"Don't override this method!!\". If you can't trust coworkers not to follow simple instructions, it's hopeless anyway.</p>\n"
},
{
"answer_id": 190616,
"author": "Jacek Szymański",
"author_id": 23242,
"author_profile": "https://Stackoverflow.com/users/23242",
"pm_score": 4,
"selected": true,
"text": "<p>You can try the <a href=\"http://jmockit.org\" rel=\"nofollow noreferrer\">JMockit</a> mocking library. </p>\n"
},
{
"answer_id": 197066,
"author": "David Turner",
"author_id": 10171,
"author_profile": "https://Stackoverflow.com/users/10171",
"pm_score": 0,
"selected": false,
"text": "<p>The following code will also allow you to do it. I am not saying that this is good practice, but it is an interesting use (abuse?) of anonymous classes.</p>\n\n<pre><code>public class Jobber {\n\n public final String foo() {\n return fooFactory() ;\n }\n\n String fooFactory() {\n return \"jobber\" ;\n }\n\n\n public static void main(String[] args) {\n\n Jobber jobber = new Jobber() { String fooFactory() { return \"prefix \" + super.fooFactory() ;} } ;\n\n System.out.println(jobber.foo() );\n }\n}\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190597",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6583/"
] |
Say I have class A with
```
class A {
final String foo() {
// .. computing result, contacting database, whatever ..
return "some computed value";
}
// ... and a bazillion other methods, some of them final.
}
```
Now I have class B with
```
class B {
String methodIWantToTest(A a) {
String output = a.foo();
// ... whatever this method does, e.g.:
output += "_suffix";
return output;
}
}
```
How would I go about unit testing this method? The reason `foo()` is final is because we don't want our classes which extend A to change its functionality. But at the same time to truly unit test the method, I don't want it to reach out and run the actual `A.foo()` method.
Is there a way to, say, remove the final keyword and add an annotation along the lines of `@finalUnlessTest`? What would you recommend? Refactoring A to an interface would be very, very difficult, seeing as how it's one of our central classes and is unfortunately ~~pretty~~ extremely coupled.
**Edit #1** Sorry, forgot to mention, we're talking Java. We are not using a mocking framework as of yet.
**Answer** OK, so: wow. [JMockit](http://jmockit.org) is just incredible and is in my eyes the killer app for testing legacy code. Unbelievably useful especially in my case. Thanks so much! You basically would do something like the following for my psuedo-example:
```
class AMock {
final String foo() {
return "myTestValue";
}
}
class Test extends TestCase {
A mockedA;
B b;
protected void setUp() {
Mockit.redefineMethods( A.class, AMock.class ); // this "pipes" all mocked methods from A to AMock
mockedA = new A(); // NOT new AMock()!!!
b = new B();
}
public void testB() {
assertEquals("myTestValue",mockedA.foo());
assertEquals("myTestValue_suffix",b.methodIWantToTest(mockedA));
}
}
```
Is this frickin' cool or what?
|
You can try the [JMockit](http://jmockit.org) mocking library.
|
190,598 |
<p>Delphi 2009 has changed its string type to use 2 bytes to represent a character, which allows support for unicode char sets. Now when you get sizeof(string) you get length(String) * sizeof(char) . Sizeof(char) currently being 2. </p>
<p>What I am interested in is whether anyone knows of a way which on a character by character basis it is possible to find out if it would fit in a single byte, eg find out if a char is ascii or Unicode.</p>
<p>What I'm primarily interested in knowing, is before my string goes to a database (oracle, Documentum) how many bytes the string will use up.</p>
<p>We need to be able to enforce limits before hand and ideally (as we have a large installed base) without having to change the database. If a string field allows 12 bytes, in delphi 2009 a string of length 7 would always show as using 14 bytes even though once it got to the db it would only use 7 if ascii or 14 if double byte, or somewhere in between if a mixture.</p>
|
[
{
"answer_id": 190604,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 4,
"selected": true,
"text": "<p>You could check the value of the character:</p>\n\n<pre><code>if ord(c) < 128 then\n // is an ascii character\n</code></pre>\n"
},
{
"answer_id": 190610,
"author": "Lars Truijens",
"author_id": 1242,
"author_profile": "https://Stackoverflow.com/users/1242",
"pm_score": -1,
"selected": false,
"text": "<p>An ASCII character always fits in one byte. You can't say the same for a unicode character since that depends how it is encoded. You can't see from a single byte if it is an ASCII or unicode character or if it is a character at all for that matter. So what is your question again? And why do you need to know? My guess is you misunderstood unicode or I misunderstood your question.</p>\n"
},
{
"answer_id": 190630,
"author": "Toon Krijthe",
"author_id": 18061,
"author_profile": "https://Stackoverflow.com/users/18061",
"pm_score": 2,
"selected": false,
"text": "<p>If you don't want to use Unicode in Delphi 2009, you can use the AnsiString type. But why should you.</p>\n\n<p>A cumbersome, but valid test could be:</p>\n\n<pre><code>function IsAnsi(const AString: string): Boolean;\nvar\n tempansi : AnsiString;\n temp : string;\nbegin\n tempansi := AnsiString(AString);\n temp := tempansi;\n Result := temp = AString;\nend;\n</code></pre>\n"
},
{
"answer_id": 191586,
"author": "Michael Madsen",
"author_id": 27528,
"author_profile": "https://Stackoverflow.com/users/27528",
"pm_score": 3,
"selected": false,
"text": "<p>First of all, keep in mind that your database lengths may really be in characters, not bytes - you'll have to check the documentation for the datatype. I'm going to assume it really is the latter for the purpose of the question.</p>\n\n<p>The amount of bytes your string will use depends entirely on the character encoding it'll be stored with. If it's UTF-16, the default string type in Delphi, then it will always be 2 bytes per character, excluding surrogates.</p>\n\n<p>The most likely encoding, assuming the database uses a Unicode charset, however, is UTF-8. This is a variable length encoding: characters can require anywhere between 1 and 4 bytes, depending on the character. You can see a chart on Wikipedia of how the ranges are mapped.</p>\n\n<p>However, if you're not changing the database schema at all, then that must mean one of three things:</p>\n\n<ol>\n<li>You currently store everything in a binary way, instead of a textual way (not usually a good choice)</li>\n<li>The database already stores Unicode and counted characters, not bytes (otherwise, you'd have the problem now, more so in the case of accented letters)</li>\n<li>The database stores in a single-byte codepage, such as Windows-1252, preventing you from storing Unicode data at all (making it a non-issue, because characters will be stored the same way as before, although you can't make use of Unicode)</li>\n</ol>\n\n<p>I'm not familiar with Oracle, but if you look at MSSQL, they have two different datatypes: varchar and nvarchar. Varchar counts in bytes, while nvarchar counts in characters, therefore being suitable for Unicode. MySQL, on the other hand, only has varchar, and it always counts in characters (as of 4.1). You should therefore check the Oracle documentation and your database schema to get a decisive answer on whether or not it's a problem at all.</p>\n"
},
{
"answer_id": 222517,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Since with AnsiString 1 char = 1 byte and with Unicode String 1 char = 2 bytes, the simple test to perform is IsAnsiString:= sizeof(aString)=length(aString);</p>\n"
},
{
"answer_id": 272303,
"author": "Bruce McGee",
"author_id": 19183,
"author_profile": "https://Stackoverflow.com/users/19183",
"pm_score": 1,
"selected": false,
"text": "<p>You replied that you really want to find out how many bytes your string will take up.</p>\n\n<p>How about converting to UTF8String? Ansi characters will take up 1 byte. Keep in mind that in UTF-8, Unicode characters may take more than 2 bytes.</p>\n"
},
{
"answer_id": 392158,
"author": "vcldeveloper",
"author_id": 48789,
"author_profile": "https://Stackoverflow.com/users/48789",
"pm_score": 2,
"selected": false,
"text": "<p>You can use <strong>StringElementSize</strong> function to find out if a string is Unicode or ANSI. \nTo check if a character is ANSI, use <strong>TCharacter.IsAnsi</strong> class function in Character.pas unit.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190598",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6244/"
] |
Delphi 2009 has changed its string type to use 2 bytes to represent a character, which allows support for unicode char sets. Now when you get sizeof(string) you get length(String) \* sizeof(char) . Sizeof(char) currently being 2.
What I am interested in is whether anyone knows of a way which on a character by character basis it is possible to find out if it would fit in a single byte, eg find out if a char is ascii or Unicode.
What I'm primarily interested in knowing, is before my string goes to a database (oracle, Documentum) how many bytes the string will use up.
We need to be able to enforce limits before hand and ideally (as we have a large installed base) without having to change the database. If a string field allows 12 bytes, in delphi 2009 a string of length 7 would always show as using 14 bytes even though once it got to the db it would only use 7 if ascii or 14 if double byte, or somewhere in between if a mixture.
|
You could check the value of the character:
```
if ord(c) < 128 then
// is an ascii character
```
|
190,625 |
<p>I have created the following stored procedure..</p>
<pre><code>CREATE PROCEDURE [dbo].[UDSPRBHPRIMBUSTYPESTARTUP]
(
@CODE CHAR(5)
, @DESC VARCHAR(255) OUTPUT
)
AS
DECLARE @SERVERNAME nvarchar(30)
DECLARE @DBASE nvarchar(30)
DECLARE @SQL nvarchar(2000)
SET @SERVERNAME =
Convert(nvarchar,
(SELECT spData FROM dbSpecificData WHERE spLookup = 'CMSSERVER'))
SET @DBASE =
Convert(nvarchar,
(SELECT spData FROM dbSpecificData WHERE spLookup = 'CMSDBNAME'))
SET @SQL =
'SELECT clnt_cat_desc FROM ' + @SERVERNAME +
'.' + @DBASE + '.dbo.hbl_clnt_cat WHERE inactive = ''N''
AND clnt_cat_code = ''' + @CODE + ''''
EXECUTE sp_executeSQL @SQL
RETURN
</code></pre>
<p>This procedure is used in many different databases and many different servers and is written as dynamic SQL to simplify maintenance. The procedure also runs on a different server than the one the procedure points to.</p>
<p>I want to use the output of this procedure as a value in a table...</p>
<pre><code>DECLARE @clid BIGINT
DECLARE @fileid BIGINT
DECLARE @myCode CHAR(5)
DECLARE @myDesc VARCHAR(255)
DECLARE @@tempDesc VARCHAR(255)
SET @clid = 1831400022
SET @fileid = 2072551358
SET @myCode =
(SELECT _clientPrimBusinessType FROM udbhextclient WHERE clid = @clid)
SET @myDesc =
EXEC UDSPRBHPRIMBUSTYPESTARTUP @CODE = @myCode, @DESC = @@tempDesc OUTPUT
----------------------------------------------------------------------------
SELECT
a.clid
, b.fileid
, c.usrfullname AS ClientPartner
, e.usrfullname AS ClientFeeEarner
, @myDesc AS ClientPrimaryBusinessType
FROM
dbclient a
INNER JOIN
dbFile b
ON
a.clid = b.clid
INNER JOIN
dbuser c
ON
a.feeusrid = c.usrid
INNER JOIN
udbhextclient d
ON
a.clid = d.clid
INNER JOIN
dbuser e
ON
d._ClientFeeEarner = e.usrid
WHERE
a.clid = @clid
AND b.fileid = @fileid
</code></pre>
<p>I know this is the incorrect syntax, but you can see what I am trying to achieve this without resorting to temporary tables as this would mean maintenance across 30 different servers with 3 to 5 databases on each.</p>
<p>Smink - Tried your solution and got the following results...</p>
<p><img src="https://farm4.static.flickr.com/3029/2928268613_dd3c454f92.jpg" alt="Running Smink's Solution"></p>
|
[
{
"answer_id": 190648,
"author": "tpower",
"author_id": 18107,
"author_profile": "https://Stackoverflow.com/users/18107",
"pm_score": 0,
"selected": false,
"text": "<p>You can create a function (instead of a procedure) that returns a table.</p>\n\n<pre><code>CREATE FUNCTION [dbo].[my_function]\n(\n @par2 UNIQUEIDENTIFIER, \n @par2 UNIQUEIDENTIFIER,\n @par3 UNIQUEIDENTIFIER\n)\nRETURNS @returntable TABLE \n(\n col1 UNIQUEIDENTIFIER,\n col2 NVARCHAR(50),\n col3 NVARCHAR(50)\n)\nAS\nBEGIN\n...\nEND\n</code></pre>\n"
},
{
"answer_id": 190661,
"author": "Tomalak",
"author_id": 18771,
"author_profile": "https://Stackoverflow.com/users/18771",
"pm_score": 0,
"selected": false,
"text": "<p>If you don't want to touch your PROCEDURE, you can create a FUNCTION that wraps it and use that wrapper function in queries.</p>\n"
},
{
"answer_id": 190665,
"author": "Jorge Ferreira",
"author_id": 6508,
"author_profile": "https://Stackoverflow.com/users/6508",
"pm_score": 4,
"selected": true,
"text": "<p>Change the line:</p>\n\n<pre><code>SET @myDesc = \n EXEC UDSPRBHPRIMBUSTYPESTARTUP @CODE = @myCode, @DESC = @@tempDesc OUTPUT\n</code></pre>\n\n<p>to</p>\n\n<pre><code>EXEC UDSPRBHPRIMBUSTYPESTARTUP @CODE = @myCode, @DESC = @tempDesc OUTPUT\n</code></pre>\n\n<p>And you have missed assigning <code>@DESC</code> in the stored procedure.</p>\n\n<pre><code>SET @SQL = \n 'SELECT @DESC = clnt_cat_desc FROM ' + @SERVERNAME + \n '.' + @DBASE + '.dbo.hbl_clnt_cat WHERE inactive = ''N''\n AND clnt_cat_code = ''' + @CODE + ''''\n\nEXECUTE sp_executeSQL @SQL, N'@DESC varchar(255) output', @DESC output\n</code></pre>\n\n<p>You should then use <code>@tempDesc</code> in the next select:</p>\n\n<pre><code>SELECT\n a.clid\n , b.fileid\n , c.usrfullname AS ClientPartner\n , e.usrfullname AS ClientFeeEarner\n , @tempDesc AS ClientPrimaryBusinessType\n</code></pre>\n\n<p>Also your stored procedure allows for SQL injection around:</p>\n\n<pre><code>SET @SQL = \n 'SELECT clnt_cat_desc \n FROM ' + QUOTENAME(@SERVERNAME) + '.' + QUOTENAME(@DBASE) + '.dbo.hbl_clnt_cat\n WHERE inactive = ''N''\n AND clnt_cat_code = @CODE'\n\nEXECUTE sp_executeSQL @SQL, N'@CODE CHAR(5)', @CODE\n</code></pre>\n\n<p>(Update: Fixed SQL Injection issues.)</p>\n"
},
{
"answer_id": 3969253,
"author": "Miami Web Design",
"author_id": 480562,
"author_profile": "https://Stackoverflow.com/users/480562",
"pm_score": 2,
"selected": false,
"text": "<p>Pheww, I was going crazy on how to do this, I needed to make a result from a stored procedure part of a current query and I was having the hardest time doing this. What I did was wrap Procedure with a function and then return the value and that was it.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190625",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/978/"
] |
I have created the following stored procedure..
```
CREATE PROCEDURE [dbo].[UDSPRBHPRIMBUSTYPESTARTUP]
(
@CODE CHAR(5)
, @DESC VARCHAR(255) OUTPUT
)
AS
DECLARE @SERVERNAME nvarchar(30)
DECLARE @DBASE nvarchar(30)
DECLARE @SQL nvarchar(2000)
SET @SERVERNAME =
Convert(nvarchar,
(SELECT spData FROM dbSpecificData WHERE spLookup = 'CMSSERVER'))
SET @DBASE =
Convert(nvarchar,
(SELECT spData FROM dbSpecificData WHERE spLookup = 'CMSDBNAME'))
SET @SQL =
'SELECT clnt_cat_desc FROM ' + @SERVERNAME +
'.' + @DBASE + '.dbo.hbl_clnt_cat WHERE inactive = ''N''
AND clnt_cat_code = ''' + @CODE + ''''
EXECUTE sp_executeSQL @SQL
RETURN
```
This procedure is used in many different databases and many different servers and is written as dynamic SQL to simplify maintenance. The procedure also runs on a different server than the one the procedure points to.
I want to use the output of this procedure as a value in a table...
```
DECLARE @clid BIGINT
DECLARE @fileid BIGINT
DECLARE @myCode CHAR(5)
DECLARE @myDesc VARCHAR(255)
DECLARE @@tempDesc VARCHAR(255)
SET @clid = 1831400022
SET @fileid = 2072551358
SET @myCode =
(SELECT _clientPrimBusinessType FROM udbhextclient WHERE clid = @clid)
SET @myDesc =
EXEC UDSPRBHPRIMBUSTYPESTARTUP @CODE = @myCode, @DESC = @@tempDesc OUTPUT
----------------------------------------------------------------------------
SELECT
a.clid
, b.fileid
, c.usrfullname AS ClientPartner
, e.usrfullname AS ClientFeeEarner
, @myDesc AS ClientPrimaryBusinessType
FROM
dbclient a
INNER JOIN
dbFile b
ON
a.clid = b.clid
INNER JOIN
dbuser c
ON
a.feeusrid = c.usrid
INNER JOIN
udbhextclient d
ON
a.clid = d.clid
INNER JOIN
dbuser e
ON
d._ClientFeeEarner = e.usrid
WHERE
a.clid = @clid
AND b.fileid = @fileid
```
I know this is the incorrect syntax, but you can see what I am trying to achieve this without resorting to temporary tables as this would mean maintenance across 30 different servers with 3 to 5 databases on each.
Smink - Tried your solution and got the following results...
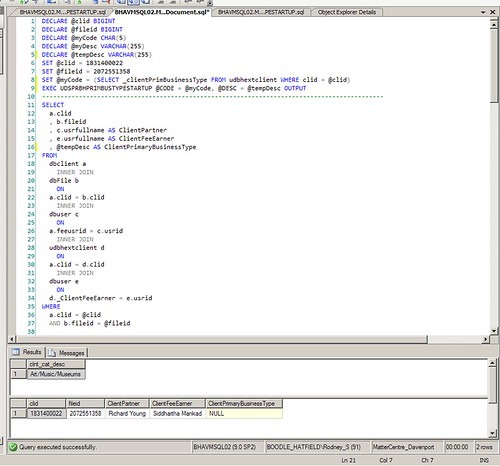
|
Change the line:
```
SET @myDesc =
EXEC UDSPRBHPRIMBUSTYPESTARTUP @CODE = @myCode, @DESC = @@tempDesc OUTPUT
```
to
```
EXEC UDSPRBHPRIMBUSTYPESTARTUP @CODE = @myCode, @DESC = @tempDesc OUTPUT
```
And you have missed assigning `@DESC` in the stored procedure.
```
SET @SQL =
'SELECT @DESC = clnt_cat_desc FROM ' + @SERVERNAME +
'.' + @DBASE + '.dbo.hbl_clnt_cat WHERE inactive = ''N''
AND clnt_cat_code = ''' + @CODE + ''''
EXECUTE sp_executeSQL @SQL, N'@DESC varchar(255) output', @DESC output
```
You should then use `@tempDesc` in the next select:
```
SELECT
a.clid
, b.fileid
, c.usrfullname AS ClientPartner
, e.usrfullname AS ClientFeeEarner
, @tempDesc AS ClientPrimaryBusinessType
```
Also your stored procedure allows for SQL injection around:
```
SET @SQL =
'SELECT clnt_cat_desc
FROM ' + QUOTENAME(@SERVERNAME) + '.' + QUOTENAME(@DBASE) + '.dbo.hbl_clnt_cat
WHERE inactive = ''N''
AND clnt_cat_code = @CODE'
EXECUTE sp_executeSQL @SQL, N'@CODE CHAR(5)', @CODE
```
(Update: Fixed SQL Injection issues.)
|
190,629 |
<p>I am writing a drop-in replacement for a legacy application in Java. One of the requirements is that the ini files that the older application used have to be read as-is into the new Java Application. The format of this ini files is the common windows style, with header sections and key=value pairs, using # as the character for commenting.</p>
<p>I tried using the Properties class from Java, but of course that won't work if there is name clashes between different headers.</p>
<p>So the question is, what would be the easiest way to read in this INI file and access the keys?</p>
|
[
{
"answer_id": 190633,
"author": "Mario Ortegón",
"author_id": 2309,
"author_profile": "https://Stackoverflow.com/users/2309",
"pm_score": 8,
"selected": true,
"text": "<p>The library I've used is <a href=\"http://ini4j.sourceforge.net/\" rel=\"noreferrer\">ini4j</a>. It is lightweight and parses the ini files with ease. Also it uses no esoteric dependencies to 10,000 other jar files, as one of the design goals was to use only the standard Java API</p>\n\n<p>This is an example on how the library is used:</p>\n\n<pre><code>Ini ini = new Ini(new File(filename));\njava.util.prefs.Preferences prefs = new IniPreferences(ini);\nSystem.out.println(\"grumpy/homePage: \" + prefs.node(\"grumpy\").get(\"homePage\", null));\n</code></pre>\n"
},
{
"answer_id": 193299,
"author": "John Meagher",
"author_id": 3535,
"author_profile": "https://Stackoverflow.com/users/3535",
"pm_score": 2,
"selected": false,
"text": "<p>Another option is <a href=\"http://commons.apache.org/configuration/\" rel=\"nofollow noreferrer\">Apache Commons Config</a> also has a class for loading from <a href=\"http://commons.apache.org/configuration/apidocs/org/apache/commons/configuration/INIConfiguration.html\" rel=\"nofollow noreferrer\">INI files</a>. It does have some <a href=\"http://commons.apache.org/configuration/dependencies.html\" rel=\"nofollow noreferrer\">runtime dependencies</a>, but for INI files it should only require Commons collections, lang, and logging. </p>\n\n<p>I've used Commons Config on projects with their properties and XML configurations. It is very easy to use and supports some pretty powerful features. </p>\n"
},
{
"answer_id": 197026,
"author": "Peter",
"author_id": 26483,
"author_profile": "https://Stackoverflow.com/users/26483",
"pm_score": 4,
"selected": false,
"text": "<p>Or with standard Java API you can use <a href=\"http://docs.oracle.com/javase/6/docs/api/java/util/Properties.html\" rel=\"nofollow noreferrer\">java.util.Properties</a>:</p>\n\n<pre><code>Properties props = new Properties();\ntry (FileInputStream in = new FileInputStream(path)) {\n props.load(in);\n}\n</code></pre>\n"
},
{
"answer_id": 486816,
"author": "user50217",
"author_id": 50217,
"author_profile": "https://Stackoverflow.com/users/50217",
"pm_score": 4,
"selected": false,
"text": "<p>Here's a simple, yet powerful example, using the apache class <a href=\"http://commons.apache.org/proper/commons-configuration/javadocs/v1.10/apidocs/index.html?org/apache/commons/configuration/HierarchicalINIConfiguration.html\" rel=\"noreferrer\">HierarchicalINIConfiguration</a>:</p>\n\n<pre><code>HierarchicalINIConfiguration iniConfObj = new HierarchicalINIConfiguration(iniFile); \n\n// Get Section names in ini file \nSet setOfSections = iniConfObj.getSections();\nIterator sectionNames = setOfSections.iterator();\n\nwhile(sectionNames.hasNext()){\n\n String sectionName = sectionNames.next().toString();\n\n SubnodeConfiguration sObj = iniObj.getSection(sectionName);\n Iterator it1 = sObj.getKeys();\n\n while (it1.hasNext()) {\n // Get element\n Object key = it1.next();\n System.out.print(\"Key \" + key.toString() + \" Value \" + \n sObj.getString(key.toString()) + \"\\n\");\n}\n</code></pre>\n\n<p>Commons Configuration has a number of <a href=\"http://commons.apache.org/configuration/dependencies.html\" rel=\"noreferrer\">runtime dependencies</a>. At a minimum, <a href=\"http://commons.apache.org/lang/\" rel=\"noreferrer\">commons-lang</a> and <a href=\"http://commons.apache.org/logging/\" rel=\"noreferrer\">commons-logging</a> are required. Depending on what you're doing with it, you may require additional libraries (see previous link for details).</p>\n"
},
{
"answer_id": 4851893,
"author": "tshepang",
"author_id": 321731,
"author_profile": "https://Stackoverflow.com/users/321731",
"pm_score": 6,
"selected": false,
"text": "<p>As <a href=\"https://stackoverflow.com/a/190633\">mentioned</a>, <a href=\"http://ini4j.sourceforge.net/index.html\" rel=\"noreferrer\">ini4j</a> can be used to achieve this. Let me show one other example.</p>\n\n<p>If we have an INI file like this:</p>\n\n<pre><code>[header]\nkey = value\n</code></pre>\n\n<p>The following should display <code>value</code> to STDOUT:</p>\n\n<pre><code>Ini ini = new Ini(new File(\"/path/to/file\"));\nSystem.out.println(ini.get(\"header\", \"key\"));\n</code></pre>\n\n<p>Check <a href=\"http://ini4j.sourceforge.net/tutorial/\" rel=\"noreferrer\">the tutorials</a> for more examples.</p>\n"
},
{
"answer_id": 14213018,
"author": "Andreas Norman",
"author_id": 819728,
"author_profile": "https://Stackoverflow.com/users/819728",
"pm_score": 2,
"selected": false,
"text": "<p>You could try JINIFile. Is a translation of the TIniFile from Delphi, but for java</p>\n\n<p><a href=\"https://github.com/SubZane/JIniFile\" rel=\"nofollow\">https://github.com/SubZane/JIniFile</a></p>\n"
},
{
"answer_id": 15638381,
"author": "Aerospace",
"author_id": 1770831,
"author_profile": "https://Stackoverflow.com/users/1770831",
"pm_score": 5,
"selected": false,
"text": "<p>As simple as 80 lines:</p>\n\n<pre><code>package windows.prefs;\n\nimport java.io.BufferedReader;\nimport java.io.FileReader;\nimport java.io.IOException;\nimport java.util.HashMap;\nimport java.util.Map;\nimport java.util.regex.Matcher;\nimport java.util.regex.Pattern;\n\npublic class IniFile {\n\n private Pattern _section = Pattern.compile( \"\\\\s*\\\\[([^]]*)\\\\]\\\\s*\" );\n private Pattern _keyValue = Pattern.compile( \"\\\\s*([^=]*)=(.*)\" );\n private Map< String,\n Map< String,\n String >> _entries = new HashMap<>();\n\n public IniFile( String path ) throws IOException {\n load( path );\n }\n\n public void load( String path ) throws IOException {\n try( BufferedReader br = new BufferedReader( new FileReader( path ))) {\n String line;\n String section = null;\n while(( line = br.readLine()) != null ) {\n Matcher m = _section.matcher( line );\n if( m.matches()) {\n section = m.group( 1 ).trim();\n }\n else if( section != null ) {\n m = _keyValue.matcher( line );\n if( m.matches()) {\n String key = m.group( 1 ).trim();\n String value = m.group( 2 ).trim();\n Map< String, String > kv = _entries.get( section );\n if( kv == null ) {\n _entries.put( section, kv = new HashMap<>()); \n }\n kv.put( key, value );\n }\n }\n }\n }\n }\n\n public String getString( String section, String key, String defaultvalue ) {\n Map< String, String > kv = _entries.get( section );\n if( kv == null ) {\n return defaultvalue;\n }\n return kv.get( key );\n }\n\n public int getInt( String section, String key, int defaultvalue ) {\n Map< String, String > kv = _entries.get( section );\n if( kv == null ) {\n return defaultvalue;\n }\n return Integer.parseInt( kv.get( key ));\n }\n\n public float getFloat( String section, String key, float defaultvalue ) {\n Map< String, String > kv = _entries.get( section );\n if( kv == null ) {\n return defaultvalue;\n }\n return Float.parseFloat( kv.get( key ));\n }\n\n public double getDouble( String section, String key, double defaultvalue ) {\n Map< String, String > kv = _entries.get( section );\n if( kv == null ) {\n return defaultvalue;\n }\n return Double.parseDouble( kv.get( key ));\n }\n}\n</code></pre>\n"
},
{
"answer_id": 18897822,
"author": "Mark",
"author_id": 2795935,
"author_profile": "https://Stackoverflow.com/users/2795935",
"pm_score": 2,
"selected": false,
"text": "<p>I personally prefer <a href=\"http://github.com/ivanTrendafilov/Confucius\" rel=\"nofollow noreferrer\">Confucious</a>.</p>\n\n<p>It is nice, as it doesn't require any external dependencies, it's tiny - only 16K, and automatically loads your ini file on initialization. E.g.</p>\n\n<pre><code>Configurable config = Configuration.getInstance(); \nString host = config.getStringValue(\"host\"); \nint port = config.getIntValue(\"port\"); \nnew Connection(host, port);\n</code></pre>\n"
},
{
"answer_id": 41084504,
"author": "hoat4",
"author_id": 2804761,
"author_profile": "https://Stackoverflow.com/users/2804761",
"pm_score": 4,
"selected": false,
"text": "<p>In 18 lines, extending the <code>java.util.Properties</code> to parse into multiple sections:</p>\n\n<pre><code>public static Map<String, Properties> parseINI(Reader reader) throws IOException {\n Map<String, Properties> result = new HashMap();\n new Properties() {\n\n private Properties section;\n\n @Override\n public Object put(Object key, Object value) {\n String header = (((String) key) + \" \" + value).trim();\n if (header.startsWith(\"[\") && header.endsWith(\"]\"))\n return result.put(header.substring(1, header.length() - 1), \n section = new Properties());\n else\n return section.put(key, value);\n }\n\n }.load(reader);\n return result;\n}\n</code></pre>\n"
},
{
"answer_id": 54649170,
"author": "Desmond",
"author_id": 11050483,
"author_profile": "https://Stackoverflow.com/users/11050483",
"pm_score": -1,
"selected": false,
"text": "<p>It is just as simple as this.....</p>\n\n<pre><code>//import java.io.FileInputStream;\n//import java.io.FileInputStream;\n\nProperties prop = new Properties();\n//c:\\\\myapp\\\\config.ini is the location of the ini file\n//ini file should look like host=localhost\nprop.load(new FileInputStream(\"c:\\\\myapp\\\\config.ini\"));\nString host = prop.getProperty(\"host\");\n</code></pre>\n"
},
{
"answer_id": 59332344,
"author": "Bradley Willcott",
"author_id": 12349591,
"author_profile": "https://Stackoverflow.com/users/12349591",
"pm_score": 0,
"selected": false,
"text": "<p><strong>hoat4</strong>'s solution is very elegant and simple. It works for all <em>sane</em> ini files. However, I have seen many that have un-escaped space characters in the <em>key</em>.<br>\nTo solve this, I have downloaded and modified a copy of <code>java.util.Properties</code>. Though this is a little unorthodox, and short-term, the actual mods were but a few lines and quite simple. I will be puting forward a proposal to the JDK community to include the changes.<br><br>\nBy adding an internal class variable:<br></p>\n\n<pre><code>private boolean _spaceCharOn = false;\n</code></pre>\n\n<p>I control the processing related to scanning for the key/value separation point.\nI replaced the space characters search code with a small private method that returns a boolean depending on the state of the above variable.<br></p>\n\n<pre><code>private boolean isSpaceSeparator(char c) {\n if (_spaceCharOn) {\n return (c == ' ' || c == '\\t' || c == '\\f');\n } else {\n return (c == '\\t' || c == '\\f');\n }\n}\n</code></pre>\n\n<p>This method is used in two places within the private method <code>load0(...)</code>.<br>\nThere is also a public method to switch it on, but it would be better to use the original version of <code>Properties</code> if the space separator is not an issue for your application.</p>\n\n<p>If there is interest, I would be willing to post the code to my <code>IniFile.java</code> file. It works with either version of <code>Properties</code>.</p>\n"
},
{
"answer_id": 62985998,
"author": "denka",
"author_id": 4181616,
"author_profile": "https://Stackoverflow.com/users/4181616",
"pm_score": 0,
"selected": false,
"text": "<p>Using answer by @Aerospace, I realized that it is legitimate for INI files to have sections without any key-values. In this case, addition to the top-level map should happen before any key-values are found, ex (minimally updated for Java 8):</p>\n<pre><code> Path location = ...;\n try (BufferedReader br = new BufferedReader(new FileReader(location.toFile()))) {\n String line;\n String section = null;\n while ((line = br.readLine()) != null) {\n Matcher m = this.section.matcher(line);\n if (m.matches()) {\n section = m.group(1).trim();\n entries.computeIfAbsent(section, k -> new HashMap<>());\n } else if (section != null) {\n m = keyValue.matcher(line);\n if (m.matches()) {\n String key = m.group(1).trim();\n String value = m.group(2).trim();\n entries.get(section).put(key, value);\n }\n }\n }\n } catch (IOException ex) {\n System.err.println("Failed to read and parse INI file '" + location + "', " + ex.getMessage());\n ex.printStackTrace(System.err);\n }\n\n</code></pre>\n"
},
{
"answer_id": 68219318,
"author": "Hai Mai",
"author_id": 11327766,
"author_profile": "https://Stackoverflow.com/users/11327766",
"pm_score": 0,
"selected": false,
"text": "<p>You can use <a href=\"http://ini4j.sourceforge.net/index.html\" rel=\"nofollow noreferrer\">ini4j</a> to convert INI to Properties</p>\n<pre class=\"lang-java prettyprint-override\"><code> Properties properties = new Properties();\n Ini ini = new Ini(new File("path/to/file"));\n ini.forEach((header, map) -> {\n map.forEach((subKey, value) -> {\n StringBuilder key = new StringBuilder(header);\n key.append("." + subKey);\n properties.put(key.toString(), value);\n });\n });\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190629",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2309/"
] |
I am writing a drop-in replacement for a legacy application in Java. One of the requirements is that the ini files that the older application used have to be read as-is into the new Java Application. The format of this ini files is the common windows style, with header sections and key=value pairs, using # as the character for commenting.
I tried using the Properties class from Java, but of course that won't work if there is name clashes between different headers.
So the question is, what would be the easiest way to read in this INI file and access the keys?
|
The library I've used is [ini4j](http://ini4j.sourceforge.net/). It is lightweight and parses the ini files with ease. Also it uses no esoteric dependencies to 10,000 other jar files, as one of the design goals was to use only the standard Java API
This is an example on how the library is used:
```
Ini ini = new Ini(new File(filename));
java.util.prefs.Preferences prefs = new IniPreferences(ini);
System.out.println("grumpy/homePage: " + prefs.node("grumpy").get("homePage", null));
```
|
190,642 |
<p>The code below crashes IE6 for some reason. Much as IE is god-awful, i have never seen this before. Does anyone have any ideas?</p>
<pre><code><div id="edit">
<?php
$a = $_POST['category'];
if ($a == "")
{
$a = $_GET['category'];
}
$result = mysql_query("SELECT * FROM media WHERE related_page_id = $a && type= 'copy'");
?>
<table width="460px;">
<tr>
<td>Item</td>
<td>&nbsp;</td>
<td>&nbsp;</td>
<td>&nbsp;</td>
<td>Associated Images</td>
</tr>
<tr>
<td colspan="5">&nbsp;</td>
</tr>
<?php
while($row = mysql_fetch_array($result))
{
echo "<tr style='vertical-align:top'><td>$row[title]</td>";
echo "<td><a href='addimage.php?id=$row[id]&&category=$a'>Add image/file</a>";
echo "<td><a href='change.php?id=$row[id]&&category=$a'>edit</a></td>";
echo "<td><a href='delete.php?id=$row[id]&&category=$a'>delete</a></td>";
echo "<td>";
$id = $row['id'];
$result1 = mysql_query("SELECT * FROM media WHERE assets = $id");
while($row1 = mysql_fetch_array($result1))
{
echo "<a href='$row1[path]'>$row1[title]</a> | <a href='delete.php?id=$row1[id]&&category=$a'>remove?</a><br />";
}
echo "</td></tr>";
}
if($a == 1 || $a == 3 || $a == 5){
}else{
echo "<tr><td colspan='5'>&nbsp;</td></tr>";
echo "<tr><td colspan='5'><a href='change.php?id=0&&category=$a'>New Item</a></td></tr>";
}
?>
</div>
</div>
</div>
</table>
</body>
</html>
</code></pre>
|
[
{
"answer_id": 190657,
"author": "Rimas Kudelis",
"author_id": 25804,
"author_profile": "https://Stackoverflow.com/users/25804",
"pm_score": 0,
"selected": false,
"text": "<p>The generated code doesn't crash IE6 for me. It could probably be one of your stylesheets or javascript though, or maybe it's just my setup (IE6 is used as a standalone browser here).</p>\n\n<p>Also, why do you have those double ampersands? Are you sure you don't want to use <code>&amp;</code> instead?</p>\n"
},
{
"answer_id": 190659,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>here is the generated code:</p>\n\n<pre><code><html xmlns=\"http://www.w3.org/1999/xhtml\" xml:lang=\"en\" lang=\"en\">\n<head>\n <meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\"/>\n\n <script type=\"text/javascript\" src=\"../javascript/tiny_mce/tiny_mce.js\"></script>\n <script type=\"text/javascript\">\n tinyMCE.init({\n mode : \"textareas\",\n theme : \"advanced\"\n });\n </script>\n\n\n <title>Chapman Corp Site - CMS</title>\n <link rel=\"stylesheet\" href=\"../css/admin.css\" type=\"text/css\" media=\"screen\" title=\"Chapman\" charset=\"utf-8\" />\n <!--[if lte IE 6]> \n<link rel=\"stylesheet\" href=\"../css/ie6.css\" type=\"text/css\" media=\"screen\" />\n<script type=\"text/javascript\" src=\"../javascript/unitpngfix.js\"></script>\n<![endif]-->\n\n</head>\n<body>\n<div id=\"page\">\n<div id =\"content\">\n<p><a href=\"index.php\">Home</a></p><div id=\"edit\">\n\n<table width=\"460px;\">\n <tr>\n <td>Item</td>\n <td>&nbsp;</td>\n <td>&nbsp;</td>\n\n <td>&nbsp;</td>\n <td>Associated Images</td>\n </tr>\n <tr>\n <td colspan=\"5\">&nbsp;</td>\n </tr>\n<tr style='vertical-align:top'><td>Home</td><td><a href='addimage.php?id=77&&category=1'>Add image/file</a><td><a href='change.php?id=77&&category=1'>edit</a></td><td><a href='delete.php?id=77&&category=1'>delete</a></td><td><a href='../uploads/footer.jpg'>footer.jpg</a> | <a href='delete.php?id=88&&category=1'>remove?</a><br /></td></tr></div>\n\n</div>\n</div>\n</table>\n</body>\n</html>\n</code></pre>\n"
},
{
"answer_id": 190660,
"author": "xsl",
"author_id": 11387,
"author_profile": "https://Stackoverflow.com/users/11387",
"pm_score": 3,
"selected": false,
"text": "<p>I don't know if it's the reason for the crash, but the <code>td</code> tag in the line</p>\n\n<pre><code>echo \"<td><a href='addimage.php?id=$row[id]&&category=$a'>Add image/file</a>\";\n</code></pre>\n\n<p>is not closed. Also:</p>\n\n<pre><code></div>\n</div>\n</div>\n</table>\n</code></pre>\n\n<p>should be:</p>\n\n<pre><code></table>\n</div>\n</div>\n</div>\n</code></pre>\n\n<p>Furthermore - for security reasons - check if <code>$a</code> is numeric before using it in the query below.</p>\n\n<pre><code>$a = $_POST['category'];\nif ($a == \"\")\n{\n $a = $_GET['category'];\n}\n\n$result = mysql_query(\"SELECT * FROM media WHERE related_page_id = $a && type= 'copy'\");\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190642",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
The code below crashes IE6 for some reason. Much as IE is god-awful, i have never seen this before. Does anyone have any ideas?
```
<div id="edit">
<?php
$a = $_POST['category'];
if ($a == "")
{
$a = $_GET['category'];
}
$result = mysql_query("SELECT * FROM media WHERE related_page_id = $a && type= 'copy'");
?>
<table width="460px;">
<tr>
<td>Item</td>
<td> </td>
<td> </td>
<td> </td>
<td>Associated Images</td>
</tr>
<tr>
<td colspan="5"> </td>
</tr>
<?php
while($row = mysql_fetch_array($result))
{
echo "<tr style='vertical-align:top'><td>$row[title]</td>";
echo "<td><a href='addimage.php?id=$row[id]&&category=$a'>Add image/file</a>";
echo "<td><a href='change.php?id=$row[id]&&category=$a'>edit</a></td>";
echo "<td><a href='delete.php?id=$row[id]&&category=$a'>delete</a></td>";
echo "<td>";
$id = $row['id'];
$result1 = mysql_query("SELECT * FROM media WHERE assets = $id");
while($row1 = mysql_fetch_array($result1))
{
echo "<a href='$row1[path]'>$row1[title]</a> | <a href='delete.php?id=$row1[id]&&category=$a'>remove?</a><br />";
}
echo "</td></tr>";
}
if($a == 1 || $a == 3 || $a == 5){
}else{
echo "<tr><td colspan='5'> </td></tr>";
echo "<tr><td colspan='5'><a href='change.php?id=0&&category=$a'>New Item</a></td></tr>";
}
?>
</div>
</div>
</div>
</table>
</body>
</html>
```
|
I don't know if it's the reason for the crash, but the `td` tag in the line
```
echo "<td><a href='addimage.php?id=$row[id]&&category=$a'>Add image/file</a>";
```
is not closed. Also:
```
</div>
</div>
</div>
</table>
```
should be:
```
</table>
</div>
</div>
</div>
```
Furthermore - for security reasons - check if `$a` is numeric before using it in the query below.
```
$a = $_POST['category'];
if ($a == "")
{
$a = $_GET['category'];
}
$result = mysql_query("SELECT * FROM media WHERE related_page_id = $a && type= 'copy'");
```
|
190,667 |
<p>I'm using a CListCtrl control to display information in my MFC app. At the moment I have LVS_EX_CHECKBOXES set in SetExtendedStyle so all rows in the control have a checkbox next to them. What I would like however is that only some of the rows in the control have checkboxes. Is this possible ? If it is how is this done ?</p>
<p>Thanks</p>
<p>Ian</p>
|
[
{
"answer_id": 190684,
"author": "David L Morris",
"author_id": 3137,
"author_profile": "https://Stackoverflow.com/users/3137",
"pm_score": 0,
"selected": false,
"text": "<p>Yes it is. What you would need to do is to create bitmaps of the check boxes and included those in the call back. One of your bit maps would be blank. </p>\n\n<p>Alternatively, you could do some owner drawing and call the DrawFrameControl function.</p>\n\n<p>You could also add code to test for mouse clicks and respond accordingly. </p>\n"
},
{
"answer_id": 190728,
"author": "Serge Wautier",
"author_id": 12379,
"author_profile": "https://Stackoverflow.com/users/12379",
"pm_score": 4,
"selected": true,
"text": "<p>For each item which shouldn't have a checkbox:</p>\n\n<pre><code>LVITEM lvi;\nlvi.stateMask = LVIS_STATEIMAGEMASK;\nlvi.state = INDEXTOSTATEIMAGEMASK(0);\n::SendMessage(m_hWnd, LVM_SETITEMSTATE, nItem, (LPARAM)&lvi);\n</code></pre>\n\n<p>To 'create' the check box for an item:</p>\n\n<pre><code>SetCheck(Item, true/false);\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190667",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3875/"
] |
I'm using a CListCtrl control to display information in my MFC app. At the moment I have LVS\_EX\_CHECKBOXES set in SetExtendedStyle so all rows in the control have a checkbox next to them. What I would like however is that only some of the rows in the control have checkboxes. Is this possible ? If it is how is this done ?
Thanks
Ian
|
For each item which shouldn't have a checkbox:
```
LVITEM lvi;
lvi.stateMask = LVIS_STATEIMAGEMASK;
lvi.state = INDEXTOSTATEIMAGEMASK(0);
::SendMessage(m_hWnd, LVM_SETITEMSTATE, nItem, (LPARAM)&lvi);
```
To 'create' the check box for an item:
```
SetCheck(Item, true/false);
```
|
190,685 |
<p>I'm trying to write a log file from an ASP.NET application under IIS7, but keep getting the following exception:</p>
<pre><code>UnauthorizedAccessException "Access to the path 'C:\Users\Brady\Exports' is denied."
</code></pre>
<p>I've been advised to use <a href="http://technet.microsoft.com/en-us/sysinternals/bb896645.aspx" rel="nofollow noreferrer">Process Monitor</a> to help resolve this, but it's quite a complex tool, and I really don't have time to spend exploring it. Please can someone assist me and advise how to use PM to determine which user is trying to access the folder etc.</p>
|
[
{
"answer_id": 190763,
"author": "Samuel Kim",
"author_id": 437435,
"author_profile": "https://Stackoverflow.com/users/437435",
"pm_score": 0,
"selected": false,
"text": "<p>Not sure why you would want to use Process Monitor for access problem in file system.</p>\n\n<p>Check that the directory has access permitted for the user which the application is running as at the point of the file IO call. If you are impersonating this would be the Network Service account. If you are impersonating, it would be the impersonating user.</p>\n"
},
{
"answer_id": 190858,
"author": "Treb",
"author_id": 22114,
"author_profile": "https://Stackoverflow.com/users/22114",
"pm_score": 3,
"selected": true,
"text": "<p>When PM starts it displays a filter dialog. Just click 'Reset' to use the standard filtering. This will generate lots of messages, and you are only interested in very few of them. Under <em>Process Name</em>, select a line with the process you want to monitor. Richtclick it and choose <em>include </em>. That limits the reported events to the ones of your app. In the toolbar, the three rightmost icons let you filter the sources: Registry access, file system access and process/thread events. Unselect registry and process/threads, since you only want to monitor file access.\nIn the menu choose <em>Options - Select columns</em>. Under <em>Process Management</em>, check <em>User Name</em>. </p>\n\n<p>Now try to reproduce the error. If you are still getting too many events, you can limit the path (rightclick in the <em>Path</em> column and choose <em>exclude </em>). You can fine tune your filtering by clicking Ctrl-L, the interface should be self explanatory. (Oh, just remember to click <em>Add</em> before clicking <em>OK</em> when you want to create a new filter rule... I almost always fall for that particular trap ;-)</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190685",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8741/"
] |
I'm trying to write a log file from an ASP.NET application under IIS7, but keep getting the following exception:
```
UnauthorizedAccessException "Access to the path 'C:\Users\Brady\Exports' is denied."
```
I've been advised to use [Process Monitor](http://technet.microsoft.com/en-us/sysinternals/bb896645.aspx) to help resolve this, but it's quite a complex tool, and I really don't have time to spend exploring it. Please can someone assist me and advise how to use PM to determine which user is trying to access the folder etc.
|
When PM starts it displays a filter dialog. Just click 'Reset' to use the standard filtering. This will generate lots of messages, and you are only interested in very few of them. Under *Process Name*, select a line with the process you want to monitor. Richtclick it and choose *include* . That limits the reported events to the ones of your app. In the toolbar, the three rightmost icons let you filter the sources: Registry access, file system access and process/thread events. Unselect registry and process/threads, since you only want to monitor file access.
In the menu choose *Options - Select columns*. Under *Process Management*, check *User Name*.
Now try to reproduce the error. If you are still getting too many events, you can limit the path (rightclick in the *Path* column and choose *exclude* ). You can fine tune your filtering by clicking Ctrl-L, the interface should be self explanatory. (Oh, just remember to click *Add* before clicking *OK* when you want to create a new filter rule... I almost always fall for that particular trap ;-)
|
190,691 |
<p>I'm working with dRuby and basicly I'm calling a remote method that returns me an object.</p>
<p>In the clientside I have this code:</p>
<pre><code>handle_error(response) if response.is_a?(Error)
</code></pre>
<p>where response is the DRbObject. (I've developed this code before using dRuby and I'm returning an Error object if something went wrong). The problem is that now </p>
<pre><code>response.is_a?(Error)
</code></pre>
<p>comes back with "false" because the object is actually a DRbObject.
Any idea on how I can check the class of my application object?</p>
<p>Thanks!
Roberto</p>
|
[
{
"answer_id": 195616,
"author": "Federico Builes",
"author_id": 161,
"author_profile": "https://Stackoverflow.com/users/161",
"pm_score": 2,
"selected": false,
"text": "<p>Although I'm not sure how DRb manages the remote objects, I'd expect it to modify #kind_of? to keep the class hierarchy on the remote object, so you could do:</p>\n\n<pre><code>response.kind_of?(Error)\n</code></pre>\n\n<p>If this doesn't work you can always ask it if it responds to an specific method and go from there</p>\n\n<pre><code>response.respond_to?(some_method_on_your_errors)\n</code></pre>\n"
},
{
"answer_id": 195619,
"author": "Richard Turner",
"author_id": 12559,
"author_profile": "https://Stackoverflow.com/users/12559",
"pm_score": 1,
"selected": false,
"text": "<p>Could you not work around the problem by using <a href=\"http://blade.nagaokaut.ac.jp/cgi-bin/scat.rb/ruby/ruby-talk/78502\" rel=\"nofollow noreferrer\">Duck Typing</a>? Instead of checking for whether the object is an Error, check whether the object responds to a call to get the error information. If it does, handle the error according to that information, otherwise handle the (non-error) response.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190691",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22083/"
] |
I'm working with dRuby and basicly I'm calling a remote method that returns me an object.
In the clientside I have this code:
```
handle_error(response) if response.is_a?(Error)
```
where response is the DRbObject. (I've developed this code before using dRuby and I'm returning an Error object if something went wrong). The problem is that now
```
response.is_a?(Error)
```
comes back with "false" because the object is actually a DRbObject.
Any idea on how I can check the class of my application object?
Thanks!
Roberto
|
Although I'm not sure how DRb manages the remote objects, I'd expect it to modify #kind\_of? to keep the class hierarchy on the remote object, so you could do:
```
response.kind_of?(Error)
```
If this doesn't work you can always ask it if it responds to an specific method and go from there
```
response.respond_to?(some_method_on_your_errors)
```
|
190,701 |
<p>I'm writing a small article on humanly readable alternatives to Guids/UIDs, for example those used on TinyURL for the url hashes (which are often printed in magazines, so need to be short).</p>
<p>The simple uid I'm generating is - 6 characters: either a lowercase letter (a-z) or 0-9. </p>
<p>"According to my calculations captain", that's 6 mutually exclusive events, although calculating the probability of a clash gets a little harder than P(A or B) = P(A) + P(B), as obviously it includes numbers and from the code below, you can see it works out whether to use a number or letter using 50/50.</p>
<p>I'm interested in the clash rate and if the code below is a realistic simulation of anticipated clash rate you'd get from generating a hash. On average I get 40-50 clashes per million, however bare in mind the uid wouldn't be generated a million times at once, but probably only around 10-1000 times a minute.</p>
<p>What is the probability of a clash each time, and can anyone suggest a better way of doing it?</p>
<pre><code>static Random _random = new Random();
public static void main()
{
// Size of the key, 6
HashSet<string> set = new HashSet<string>();
int clashes = 0;
for (int n=0;n < 1000000;n++)
{
StringBuilder builder = new StringBuilder();
for (int i =0;i < 7;i++)
{
if (_random.NextDouble() > 0.5)
{
builder.Append((char)_random.Next(97,123));
}
else
{
builder.Append(_random.Next(0,9).ToString());
}
}
if (set.Contains(builder.ToString()))
{
clashes++;
Console.WriteLine("clash: (" +n+ ")" +builder.ToString());
}
set.Add(builder.ToString());
_random.Next();
//Console.Write(builder.ToString());
}
Console.WriteLine("Clashes: " +clashes);
Console.ReadLine();
}
</code></pre>
<p><strong>UPDATE:</strong>
<a href="http://www.yetanotherchris.me/home/2009/3/3/friendly-unique-id-generation-part-1.html" rel="nofollow noreferrer">Here's the resulting article</a> from this question</p>
<p>I really asked two questions here so I was cheating. The answer I was after was rcar's, however Sklivvz's is also the answer to the 2nd part (an alternative). Is it possible to make a custom unique id generator in a database, or would it be client side (which would be 2 possible reads first)?</p>
<p>The general idea I was after was using Ids in databases or other stores that can be used by phone or printed material, not a giant 16 byte guid.</p>
<p><strong>UPDATE 2:</strong> I put the formula for two mutually exclusive events above instead of 2 independent ones (as getting an 'a' the first time doesn't mean you can't get an 'a' the second time). Should've been P(A and B) = P(A) x P(B) </p>
|
[
{
"answer_id": 190715,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 3,
"selected": false,
"text": "<p>Look up the <a href=\"http://en.wikipedia.org/wiki/Birthday_paradox\" rel=\"nofollow noreferrer\">Birthday Paradox</a>, it's the exact problem that you're running into.</p>\n\n<p>The question is: How many people do you need to get together in a room, so that you have a 50% chance of any two people having the same birthdate? The answer may surprise you.</p>\n"
},
{
"answer_id": 190717,
"author": "Omar Kooheji",
"author_id": 20400,
"author_profile": "https://Stackoverflow.com/users/20400",
"pm_score": 0,
"selected": false,
"text": "<p>Why not just use a hashing algorithm? and use a hash of the url?</p>\n\n<p>if you are using random numbers chances are you will get clashes because they are indeterminate.</p>\n\n<p>hashes arent proovably unique but there is a fairly good chance that the hash of a string will be unique.</p>\n\n<p><strong>Correction</strong></p>\n\n<p>Actually wait you want them to be humanly readable... if you put them in hex they are technically humanly readable.</p>\n\n<p>or you could use an algorithm that converted a hash into a humanly readable string. if the humanly readable string is a different representation of the hash it should also be as \"unique\" as the hash, ie base 36 of the original hash.</p>\n"
},
{
"answer_id": 190719,
"author": "Sklivvz",
"author_id": 7028,
"author_profile": "https://Stackoverflow.com/users/7028",
"pm_score": 5,
"selected": false,
"text": "<p>Why do you want to use a random function? I always assumed that tinyurl used a base 62 (0-9A-Za-z) representation of a sequential Id. No clashes and the urls are always as short as possible. </p>\n\n<p>You would have a DB table like</p>\n\n<pre><code>Id URL\n 1 http://google.com\n 2 ...\n... ...\n156 ...\n... ...\n</code></pre>\n\n<p>and the corresponding URLs would be:</p>\n\n<pre><code>http://example.com/1\nhttp://example.com/2\n...\nhttp://example.com/2W\n...\n</code></pre>\n"
},
{
"answer_id": 190739,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 0,
"selected": false,
"text": "<p>I would generate a random value representative of the data that you are going to hash, and then hash that and check clahses rather than trying to simulate with random manually made hashes. This will give you a better indicator. And you will have more randomness because you will have more to randomize (Assuming your data to be hashed is larger :) ).</p>\n"
},
{
"answer_id": 190747,
"author": "Ryan",
"author_id": 93743,
"author_profile": "https://Stackoverflow.com/users/93743",
"pm_score": 0,
"selected": false,
"text": "<p>If you're using 6 characters, a-z and 0-9, thats a total of 36 characters. The number of permutations is thus 36^6 which is 2176782336.. so it should only clash 1/2176782336 times.</p>\n"
},
{
"answer_id": 190752,
"author": "cfeduke",
"author_id": 5645,
"author_profile": "https://Stackoverflow.com/users/5645",
"pm_score": 0,
"selected": false,
"text": "<p>from <a href=\"http://en.wikipedia.org/wiki/Globally_Unique_Identifier\" rel=\"nofollow noreferrer\">wikipedia</a>:</p>\n\n<blockquote>\n <p>When printing fewer characters is desired, GUIDs are sometimes encoded into a base64 or Ascii85 string. Base64-encoded GUID consists of 22 to 24 characters (depending on padding), for instance:</p>\n</blockquote>\n\n<pre><code>7QDBkvCA1+B9K/U0vrQx1A\n7QDBkvCA1+B9K/U0vrQx1A==\n</code></pre>\n\n<blockquote>\n <p>and Ascii85 encoding gives only 20 characters, e. g.:</p>\n</blockquote>\n\n<pre><code>5:$Hj:Pf\\4RLB9%kU\\Lj \n</code></pre>\n\n<p>So if you are concerned with uniqueness, a base64 encoded GUID gets you somewhat closer to what you want, though its not 6 characters.</p>\n\n<p>Its best to work in bytes first, then translate those bytes into hexadecimal for display, rather than working with characters directly.</p>\n"
},
{
"answer_id": 190760,
"author": "Randy",
"author_id": 9361,
"author_profile": "https://Stackoverflow.com/users/9361",
"pm_score": 3,
"selected": true,
"text": "<p>The probability of a collision against one specific ID is:</p>\n\n<pre><code>p = ( 0.5 * ( (0.5*1/10) + (0.5*1/26) ) )^6\n</code></pre>\n\n<p>which is around 1.7×10^-9. </p>\n\n<p>The probability of a collision after generating n IDs is 1-p^n, so you'll have roughly a 0.17% chance of a collision for each new insertion after 1 million IDs have been inserted, around 1.7% after 10 million IDs, and around 16% after 100 million. </p>\n\n<p>1000 IDs/minute works out to about 43 million/month, so as Sklivvz pointed out, using some incrementing ID is probably going to be a better way to go in this case.</p>\n\n<p>EDIT:</p>\n\n<p>To explain the math, he's essentially flipping a coin and then picking a number or letter 6 times. There's a 0.5 probability that the coin flip matches, and then 50% of the time there's a 1/10 chance of matching and a 50% chance of a 1/26 chance of matching. That happens 6 times independently, so you multiply those probabilities together.</p>\n"
},
{
"answer_id": 191152,
"author": "ila",
"author_id": 1178,
"author_profile": "https://Stackoverflow.com/users/1178",
"pm_score": 3,
"selected": false,
"text": "<p>Some time ago I did exactly this, and I followed the way Sklivvz mentioned. The whole logic was developed with a SQL server stored procedure and a couple of UDF (user defined functions). The steps were:</p>\n\n<ul>\n<li>say that you want to shorten this url: <a href=\"https://stackoverflow.com/questions/190701/creating-your-own-tinyurl-style-uid#191152\">Creating your own Tinyurl style uid</a></li>\n<li>Insert the URL in a table</li>\n<li>Obtain the @@identity value of the last insert (a numeric id)</li>\n<li>Transform the id in a corresponding alphanumeric value, based on a \"domain\" of letters and numbers (I actually used this set: \"0123456789abcdefghijklmnopqrstuvwxyz\")</li>\n<li>Return that value back, something like 'cc0'</li>\n</ul>\n\n<p>The conversion was realized thru a couple of very short UDF.</p>\n\n<p>Two conversion called one after the other would return \"sequential\" values like these:</p>\n\n<pre><code>select dbo.FX_CONV (123456) -- returns \"1f5n\"\n\nselect dbo.FX_CONV (123457) -- returns \"1f5o\"\n</code></pre>\n\n<p>If you are interested I can share the UDF's code.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190701",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/21574/"
] |
I'm writing a small article on humanly readable alternatives to Guids/UIDs, for example those used on TinyURL for the url hashes (which are often printed in magazines, so need to be short).
The simple uid I'm generating is - 6 characters: either a lowercase letter (a-z) or 0-9.
"According to my calculations captain", that's 6 mutually exclusive events, although calculating the probability of a clash gets a little harder than P(A or B) = P(A) + P(B), as obviously it includes numbers and from the code below, you can see it works out whether to use a number or letter using 50/50.
I'm interested in the clash rate and if the code below is a realistic simulation of anticipated clash rate you'd get from generating a hash. On average I get 40-50 clashes per million, however bare in mind the uid wouldn't be generated a million times at once, but probably only around 10-1000 times a minute.
What is the probability of a clash each time, and can anyone suggest a better way of doing it?
```
static Random _random = new Random();
public static void main()
{
// Size of the key, 6
HashSet<string> set = new HashSet<string>();
int clashes = 0;
for (int n=0;n < 1000000;n++)
{
StringBuilder builder = new StringBuilder();
for (int i =0;i < 7;i++)
{
if (_random.NextDouble() > 0.5)
{
builder.Append((char)_random.Next(97,123));
}
else
{
builder.Append(_random.Next(0,9).ToString());
}
}
if (set.Contains(builder.ToString()))
{
clashes++;
Console.WriteLine("clash: (" +n+ ")" +builder.ToString());
}
set.Add(builder.ToString());
_random.Next();
//Console.Write(builder.ToString());
}
Console.WriteLine("Clashes: " +clashes);
Console.ReadLine();
}
```
**UPDATE:**
[Here's the resulting article](http://www.yetanotherchris.me/home/2009/3/3/friendly-unique-id-generation-part-1.html) from this question
I really asked two questions here so I was cheating. The answer I was after was rcar's, however Sklivvz's is also the answer to the 2nd part (an alternative). Is it possible to make a custom unique id generator in a database, or would it be client side (which would be 2 possible reads first)?
The general idea I was after was using Ids in databases or other stores that can be used by phone or printed material, not a giant 16 byte guid.
**UPDATE 2:** I put the formula for two mutually exclusive events above instead of 2 independent ones (as getting an 'a' the first time doesn't mean you can't get an 'a' the second time). Should've been P(A and B) = P(A) x P(B)
|
The probability of a collision against one specific ID is:
```
p = ( 0.5 * ( (0.5*1/10) + (0.5*1/26) ) )^6
```
which is around 1.7×10^-9.
The probability of a collision after generating n IDs is 1-p^n, so you'll have roughly a 0.17% chance of a collision for each new insertion after 1 million IDs have been inserted, around 1.7% after 10 million IDs, and around 16% after 100 million.
1000 IDs/minute works out to about 43 million/month, so as Sklivvz pointed out, using some incrementing ID is probably going to be a better way to go in this case.
EDIT:
To explain the math, he's essentially flipping a coin and then picking a number or letter 6 times. There's a 0.5 probability that the coin flip matches, and then 50% of the time there's a 1/10 chance of matching and a 50% chance of a 1/26 chance of matching. That happens 6 times independently, so you multiply those probabilities together.
|
190,702 |
<p>Given this data set:</p>
<pre><code>ID Name City Birthyear
1 Egon Spengler New York 1957
2 Mac Taylor New York 1955
3 Sarah Connor Los Angeles 1959
4 Jean-Luc Picard La Barre 2305
5 Ellen Ripley Nostromo 2092
6 James T. Kirk Riverside 2233
7 Henry Jones Chicago 1899
</code></pre>
<p>I need to find the 3 oldest persons, but only one of every city.</p>
<p>If it would just be the three oldest, it would be...</p>
<ul>
<li>Henry Jones / Chicago</li>
<li>Mac Taylor / New York</li>
<li>Egon Spengler / New York</li>
</ul>
<p>However since both Egon Spengler and Mac Taylor are located in New York, Egon Spengler would drop out and the next one (Sarah Connor / Los Angeles) would come in instead.</p>
<p>Any elegant solutions?</p>
<p><strong>Update:</strong></p>
<p>Currently a variation of PConroy is the best/fastest solution:</p>
<pre><code>SELECT P.*, COUNT(*) AS ct
FROM people P
JOIN (SELECT MIN(Birthyear) AS Birthyear
FROM people
GROUP by City) P2 ON P2.Birthyear = P.Birthyear
GROUP BY P.City
ORDER BY P.Birthyear ASC
LIMIT 10;
</code></pre>
<p>His original query with "IN" is extremly slow with big datasets (aborted after 5 minutes), but moving the subquery to a JOIN will speed it up a lot. It took about 0.15 seconds for approx. 1 mio rows in my test environment. I have an index on "City, Birthyear" and a second one just on "Birthyear".</p>
<p>Note: This is related to...</p>
<ul>
<li><a href="https://stackoverflow.com/questions/150610/selecting-unique-rows-in-a-set-of-two-possibilities">Selecting unique rows in a set of two possibilities</a></li>
<li><a href="https://stackoverflow.com/questions/49404/sql-query-to-get-latest-price">SQL Query to get latest price</a></li>
</ul>
|
[
{
"answer_id": 190735,
"author": "Tomalak",
"author_id": 18771,
"author_profile": "https://Stackoverflow.com/users/18771",
"pm_score": 2,
"selected": false,
"text": "<p>Something like that?</p>\n\n<pre><code>SELECT\n Id, Name, City, Birthyear\nFROM\n TheTable\nWHERE\n Id IN (SELECT TOP 1 Id FROM TheTable i WHERE i.City = TheTable.City ORDER BY Birthyear)\n</code></pre>\n"
},
{
"answer_id": 190761,
"author": "Tamas Czinege",
"author_id": 8954,
"author_profile": "https://Stackoverflow.com/users/8954",
"pm_score": 2,
"selected": false,
"text": "<p>This is probably not the most elegant and quickest solution, but it should work. I am looking forward the see the solutions of real database gurus.</p>\n\n<pre><code>select p.* from people p,\n(select city, max(age) as mage from people group by city) t\nwhere p.city = t.city and p.age = t.mage\norder by p.age desc\n</code></pre>\n"
},
{
"answer_id": 190764,
"author": "ConroyP",
"author_id": 2287,
"author_profile": "https://Stackoverflow.com/users/2287",
"pm_score": 5,
"selected": true,
"text": "<p>Probably not the most elegant of solutions, and the performance of <code>IN</code> may suffer on larger tables.</p>\n\n<p>The nested query gets the minimum <code>Birthyear</code> for each city. Only records who have this <code>Birthyear</code> are matched in the outer query. Ordering by age then limiting to 3 results gets you the 3 oldest people who are also the oldest in their city (Egon Spengler drops out..)</p>\n\n<pre><code>SELECT Name, City, Birthyear, COUNT(*) AS ct\nFROM table\nWHERE Birthyear IN (SELECT MIN(Birthyear)\n FROM table\n GROUP by City)\nGROUP BY City\nORDER BY Birthyear DESC LIMIT 3;\n\n+-----------------+-------------+------+----+\n| name | city | year | ct |\n+-----------------+-------------+------+----+\n| Henry Jones | Chicago | 1899 | 1 |\n| Mac Taylor | New York | 1955 | 1 |\n| Sarah Connor | Los Angeles | 1959 | 1 |\n+-----------------+-------------+------+----+\n</code></pre>\n\n<p><strong>Edit</strong> - added <code>GROUP BY City</code> to outer query, as people with same birth years would return multiple values. Grouping on the outer query ensures that only one result will be returned per city, if more than one person has that minimum <code>Birthyear</code>. The <code>ct</code> column will show if more than one person exists in the city with that <code>Birthyear</code> </p>\n"
},
{
"answer_id": 190884,
"author": "kristof",
"author_id": 3241,
"author_profile": "https://Stackoverflow.com/users/3241",
"pm_score": 1,
"selected": false,
"text": "<p>Not pretty but should work also with multiple people with the same dob:</p>\n\n<p>Test data:</p>\n\n<pre><code>select id, name, city, dob \ninto people\nfrom\n(select 1 id,'Egon Spengler' name, 'New York' city , 1957 dob\nunion all select 2, 'Mac Taylor','New York', 1955\nunion all select 3, 'Sarah Connor','Los Angeles', 1959\nunion all select 4, 'Jean-Luc Picard','La Barre', 2305\nunion all select 5, 'Ellen Ripley','Nostromo', 2092\nunion all select 6, 'James T. Kirk','Riverside', 2233\nunion all select 7, 'Henry Jones','Chicago', 1899\nunion all select 8, 'Blah','New York', 1955) a\n</code></pre>\n\n<p>Query:</p>\n\n<pre><code>select \n * \nfrom \n people p\n left join people p1\n ON \n p.city = p1.city\n and (p.dob > p1.dob and p.id <> p1.id)\n or (p.dob = p1.dob and p.id > p1.id)\nwhere\n p1.id is null\norder by \n p.dob\n</code></pre>\n"
},
{
"answer_id": 3484267,
"author": "gondo",
"author_id": 309268,
"author_profile": "https://Stackoverflow.com/users/309268",
"pm_score": 1,
"selected": false,
"text": "<p>@BlaM</p>\n\n<p><strong>UPDATED</strong>\njust found that its good to use USING instead of ON. it will remove duplicate columns in result.</p>\n\n<pre><code>SELECT P.*, COUNT(*) AS ct\n FROM people P\n JOIN (SELECT City, MIN(Birthyear) AS Birthyear\n FROM people \n GROUP by City) P2 USING(Birthyear, City)\n GROUP BY P.City\n ORDER BY P.Birthyear ASC \n LIMIT 10;\n</code></pre>\n\n<p><strong>ORIGINAL POST</strong></p>\n\n<p>hi, i've tried to use your updated query but i was getting wrong results until i've added extra condition to join (also extra column into join select). transfered to your query, i'am using this:</p>\n\n<pre><code>SELECT P.*, COUNT(*) AS ct\n FROM people P\n JOIN (SELECT City, MIN(Birthyear) AS Birthyear\n FROM people \n GROUP by City) P2 ON P2.Birthyear = P.Birthyear AND P2.City = P.City\n GROUP BY P.City\n ORDER BY P.Birthyear ASC \n LIMIT 10;\n</code></pre>\n\n<p>in theory you should not need last GROUP BY P.City, but i've left it there for now, just in case. will probably remove it later.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190702",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/999/"
] |
Given this data set:
```
ID Name City Birthyear
1 Egon Spengler New York 1957
2 Mac Taylor New York 1955
3 Sarah Connor Los Angeles 1959
4 Jean-Luc Picard La Barre 2305
5 Ellen Ripley Nostromo 2092
6 James T. Kirk Riverside 2233
7 Henry Jones Chicago 1899
```
I need to find the 3 oldest persons, but only one of every city.
If it would just be the three oldest, it would be...
* Henry Jones / Chicago
* Mac Taylor / New York
* Egon Spengler / New York
However since both Egon Spengler and Mac Taylor are located in New York, Egon Spengler would drop out and the next one (Sarah Connor / Los Angeles) would come in instead.
Any elegant solutions?
**Update:**
Currently a variation of PConroy is the best/fastest solution:
```
SELECT P.*, COUNT(*) AS ct
FROM people P
JOIN (SELECT MIN(Birthyear) AS Birthyear
FROM people
GROUP by City) P2 ON P2.Birthyear = P.Birthyear
GROUP BY P.City
ORDER BY P.Birthyear ASC
LIMIT 10;
```
His original query with "IN" is extremly slow with big datasets (aborted after 5 minutes), but moving the subquery to a JOIN will speed it up a lot. It took about 0.15 seconds for approx. 1 mio rows in my test environment. I have an index on "City, Birthyear" and a second one just on "Birthyear".
Note: This is related to...
* [Selecting unique rows in a set of two possibilities](https://stackoverflow.com/questions/150610/selecting-unique-rows-in-a-set-of-two-possibilities)
* [SQL Query to get latest price](https://stackoverflow.com/questions/49404/sql-query-to-get-latest-price)
|
Probably not the most elegant of solutions, and the performance of `IN` may suffer on larger tables.
The nested query gets the minimum `Birthyear` for each city. Only records who have this `Birthyear` are matched in the outer query. Ordering by age then limiting to 3 results gets you the 3 oldest people who are also the oldest in their city (Egon Spengler drops out..)
```
SELECT Name, City, Birthyear, COUNT(*) AS ct
FROM table
WHERE Birthyear IN (SELECT MIN(Birthyear)
FROM table
GROUP by City)
GROUP BY City
ORDER BY Birthyear DESC LIMIT 3;
+-----------------+-------------+------+----+
| name | city | year | ct |
+-----------------+-------------+------+----+
| Henry Jones | Chicago | 1899 | 1 |
| Mac Taylor | New York | 1955 | 1 |
| Sarah Connor | Los Angeles | 1959 | 1 |
+-----------------+-------------+------+----+
```
**Edit** - added `GROUP BY City` to outer query, as people with same birth years would return multiple values. Grouping on the outer query ensures that only one result will be returned per city, if more than one person has that minimum `Birthyear`. The `ct` column will show if more than one person exists in the city with that `Birthyear`
|
190,714 |
<p>I have a Java application that's very String-heavy - it takes a feed of huge numbers of big, different String objects.</p>
<p>Do I need to worry about the String Constant Pool for memory and performance?</p>
<p>Is there any way to see how big the pool is at any point?</p>
|
[
{
"answer_id": 190723,
"author": "C. K. Young",
"author_id": 13,
"author_profile": "https://Stackoverflow.com/users/13",
"pm_score": 1,
"selected": false,
"text": "<p>I think you should profile your application, both with and without interning. You will then see exactly what the effect is.</p>\n\n<p>I don't believe there is a way to see the size of the string constant pool.</p>\n"
},
{
"answer_id": 190754,
"author": "Mario Ortegón",
"author_id": 2309,
"author_profile": "https://Stackoverflow.com/users/2309",
"pm_score": 2,
"selected": false,
"text": "<p>If it is a feed of objects, then they do not go into the String constant pool unless you call intern(), as far as I know. The memory consumption for interned strings is not from the Heap, but from the Perm Gen memory space, so if you intern a lot of strings the application will crash with OutOfMemory, even if there is a lot of Heap left.</p>\n\n<p>So it shouldn't be a concern unless you are interning all of these strings. If it becomes a concern, it would be possible to have your own Map implementation to store these strings, so you don't use the internal mechanism.</p>\n\n<p>I checked the implementation of the intern() method and it is native, so it does not seem to be straightforward to measure the memory consumption, or to see the contents of the pool.</p>\n\n<p>You can use this flag to increase the PermSize if you run out of memory:</p>\n\n<pre><code>-XX:MaxPermSize=64m\n</code></pre>\n"
},
{
"answer_id": 190848,
"author": "mfx",
"author_id": 8015,
"author_profile": "https://Stackoverflow.com/users/8015",
"pm_score": 3,
"selected": true,
"text": "<p>As Mario said, the constant pool is only relevant to intern()ed Strings, and to Strings that are constants in java code (these are implicitly interned).</p>\n\n<p>But there is one more caveat that might apply to your case:\nThe <code>substring()</code> method will share the underlying <code>char[]</code> with the \noriginal String. So the pattern</p>\n\n<pre><code> String large = ... // read 10k string\n String small = large.substring(...) // extrakt a few chars\n large = null; // large String object no longer reachable,\n // but 10k char[] still alive, as long as small lives\n</code></pre>\n\n<p>might cause unexpected memory usage.</p>\n"
},
{
"answer_id": 190887,
"author": "Chii",
"author_id": 17335,
"author_profile": "https://Stackoverflow.com/users/17335",
"pm_score": 0,
"selected": false,
"text": "<p>Not knowing exactly what the program is, I can only suggest you attempt to use the strings as a stream, and store not the string as a whole. Perhaps you need to make more abstractions for your app, and invent an intermediate representation that is more memory efficient?</p>\n"
},
{
"answer_id": 31980852,
"author": "Ankush soni",
"author_id": 4796407,
"author_profile": "https://Stackoverflow.com/users/4796407",
"pm_score": 0,
"selected": false,
"text": "<p>In Java 1.7 substring() - method is not longer using the same char[] instead it is copy the sub string into the new Array i.e.</p>\n\n<pre><code>public String substring(int beginIndex, int endIndex) {\n if (beginIndex < 0) {\n throw new StringIndexOutOfBoundsException(beginIndex);\n }\n if (endIndex > value.length) {\n throw new StringIndexOutOfBoundsException(endIndex);\n }\n int subLen = endIndex - beginIndex;\n if (subLen < 0) {\n throw new StringIndexOutOfBoundsException(subLen);\n }\n return ((beginIndex == 0) && (endIndex == value.length)) ? this\n : new String(value, beginIndex, subLen);\n }\n</code></pre>\n\n<p>which all to the String constructor if beginIndex is not zero or endIndex is not equal to the length of char[] array.</p>\n\n<pre><code>public String(char value[], int offset, int count) {\n if (offset < 0) {\n throw new StringIndexOutOfBoundsException(offset);\n }\n if (count < 0) {\n throw new StringIndexOutOfBoundsException(count);\n }\n // Note: offset or count might be near -1>>>1.\n if (offset > value.length - count) {\n throw new StringIndexOutOfBoundsException(offset + count);\n }\n this.value = Arrays.copyOfRange(value, offset, offset+count);\n }\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190714",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2362/"
] |
I have a Java application that's very String-heavy - it takes a feed of huge numbers of big, different String objects.
Do I need to worry about the String Constant Pool for memory and performance?
Is there any way to see how big the pool is at any point?
|
As Mario said, the constant pool is only relevant to intern()ed Strings, and to Strings that are constants in java code (these are implicitly interned).
But there is one more caveat that might apply to your case:
The `substring()` method will share the underlying `char[]` with the
original String. So the pattern
```
String large = ... // read 10k string
String small = large.substring(...) // extrakt a few chars
large = null; // large String object no longer reachable,
// but 10k char[] still alive, as long as small lives
```
might cause unexpected memory usage.
|
190,738 |
<p>With the following piece of code:</p>
<pre><code>typedef struct
{
char fileName[ 1024];
time_t deleteTime;
} file_item_t;
....
....
setEntry(char *fileName)
{
file_item_t file;
memset( &file, 0x00, sizeof( file_item_t ));
memcpy( file.fileName,
fileName,
sizeof( file.fileName ) - 1 );
...
...
</code></pre>
<p>When the function is called, it runs OK on a SPARC machine but segfaults on an i386 both running Solaris 10.
<code>fileName</code> is a nul-terminated string about 30 chars let's say.
It appears that an attempt to read beyond the range of the <code>fileName</code> using <code>memcpy()</code> triggers a segmentation fault on some systems.</p>
<p>It's legacy code and easily correctable. But what I would like to know is about the underlying characteristics that can result in this failing or not.
Is it related to read violation on the stack? Some boundary crossing?
It is related to memory segmentation and is it just a case of chance (depending on how memory segmentation/paging is done by memory management and OS.) that it can fail or not.</p>
|
[
{
"answer_id": 190744,
"author": "Timbo",
"author_id": 1810,
"author_profile": "https://Stackoverflow.com/users/1810",
"pm_score": 1,
"selected": false,
"text": "<p>Are you sure the string pointed to by <code>fileName</code> is really 1024 bytes in length? It somehow feels to me you should strcpy instead of memcpy.</p>\n\n<p>If fileName is shorter, the memcpy copies the bytes behind the real string data, and will probably cause an access violation reading that memory.</p>\n"
},
{
"answer_id": 190750,
"author": "Nils Pipenbrinck",
"author_id": 15955,
"author_profile": "https://Stackoverflow.com/users/15955",
"pm_score": 3,
"selected": false,
"text": "<p>You already hit the nail on the head:</p>\n\n<p>In your memcpy you're reading past the length of filename. </p>\n\n<p>Also dirty that will often work if the memory behind the filename is readable. In most cases it is, but if you for example pass a string-literal as an argument, and the linker puts the string into the last kilobyte of the data-section you will get a segmentation fault because the CPU tries to read from a memory location that is not mapped into the address space of your process.</p>\n\n<p>The obvious fix is to use strcpy or strncpy.</p>\n"
},
{
"answer_id": 191710,
"author": "ephemient",
"author_id": 20713,
"author_profile": "https://Stackoverflow.com/users/20713",
"pm_score": 1,
"selected": false,
"text": "<p>With the information given, we don't know where the argument <code>char *filename</code> is pointing to -- the stack, the heap, the data section, or other...</p>\n\n<p>If it's on the stack, it may be because the default stack size on SPARC is much larger than on x86, and grows much higher. By the SPARC ABI, a stack frame always has space to back up all 16 registers, plus space for six parameters if the function takes any (even if it takes less). SPARC therefore consumes at least 64 or 92 bytes of stack per function call, whereas x86 can get away with just 8 or 4 bytes per function call.</p>\n\n<p>If it's on the heap or in the data section, then it may just be that the runtime (heap) or compiler (data) happens to place the string near the end of a page on x86, so running off the end results in reading bad memory.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190738",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
With the following piece of code:
```
typedef struct
{
char fileName[ 1024];
time_t deleteTime;
} file_item_t;
....
....
setEntry(char *fileName)
{
file_item_t file;
memset( &file, 0x00, sizeof( file_item_t ));
memcpy( file.fileName,
fileName,
sizeof( file.fileName ) - 1 );
...
...
```
When the function is called, it runs OK on a SPARC machine but segfaults on an i386 both running Solaris 10.
`fileName` is a nul-terminated string about 30 chars let's say.
It appears that an attempt to read beyond the range of the `fileName` using `memcpy()` triggers a segmentation fault on some systems.
It's legacy code and easily correctable. But what I would like to know is about the underlying characteristics that can result in this failing or not.
Is it related to read violation on the stack? Some boundary crossing?
It is related to memory segmentation and is it just a case of chance (depending on how memory segmentation/paging is done by memory management and OS.) that it can fail or not.
|
You already hit the nail on the head:
In your memcpy you're reading past the length of filename.
Also dirty that will often work if the memory behind the filename is readable. In most cases it is, but if you for example pass a string-literal as an argument, and the linker puts the string into the last kilobyte of the data-section you will get a segmentation fault because the CPU tries to read from a memory location that is not mapped into the address space of your process.
The obvious fix is to use strcpy or strncpy.
|
190,740 |
<p>I thought I understood what the default method does to a hash... </p>
<p>Give a default value for a key if it doesn't exist:</p>
<pre><code>irb(main):001:0> a = {}
=> {}
irb(main):002:0> a.default = 4
=> 4
irb(main):003:0> a[8]
=> 4
irb(main):004:0> a[9] += 1
=> 5
irb(main):005:0> a
=> {9=>5}
</code></pre>
<p>All good.</p>
<p>But if I set the default to be a empty list, or empty hash, I don't understand it's behaviour at <strong>all</strong>....</p>
<pre><code>irb(main):001:0> a = {}
=> {}
irb(main):002:0> a.default = []
=> []
irb(main):003:0> a[8] << 9
=> [9] # great!
irb(main):004:0> a
=> {} # ?! would have expected {8=>[9]}
irb(main):005:0> a[8]
=> [9] # awesome!
irb(main):006:0> a[9]
=> [9] # unawesome! shouldn't this be [] ??
</code></pre>
<p>I was hoping/expecting the same behaviour as if I had used the ||= operator...</p>
<pre><code>irb(main):001:0> a = {}
=> {}
irb(main):002:0> a[8] ||= []
=> []
irb(main):003:0> a[8] << 9
=> [9]
irb(main):004:0> a
=> {8=>[9]}
irb(main):005:0> a[9]
=> nil
</code></pre>
<p>Can anyone explain what is going on?</p>
|
[
{
"answer_id": 190801,
"author": "Aaron Hinni",
"author_id": 12086,
"author_profile": "https://Stackoverflow.com/users/12086",
"pm_score": 7,
"selected": true,
"text": "<p><code>Hash.default</code> is used to set the default value <strong>returned</strong> when you query a key that doesn't exist. An entry in the collection is not created for you, just because queried it.</p>\n\n<p>Also, the value you set <code>default</code> to is an instance of an object (an Array in your case), so when this is returned, it can be manipulated.</p>\n\n<pre><code>a = {}\na.default = [] # set default to a new empty Array\na[8] << 9 # a[8] doesn't exist, so the Array instance is returned, and 9 appended to it\na.default # => [9]\na[9] # a[9] doesn't exist, so default is returned\n</code></pre>\n"
},
{
"answer_id": 190832,
"author": "Simon Howard",
"author_id": 24806,
"author_profile": "https://Stackoverflow.com/users/24806",
"pm_score": 3,
"selected": false,
"text": "<pre><code>irb(main):002:0> a.default = []\n=> []\nirb(main):003:0> a[8] << 9\n=> [9] # great!\n</code></pre>\n\n<p>With this statement, you have modified the default; you have not created a new array and added \"9\". At this point, it's identical to if you had done this instead:</p>\n\n<pre><code>irb(main):002:0> a.default = [9]\n=> [9]\n</code></pre>\n\n<p>Hence it's no surprise that you now get this:</p>\n\n<pre><code>irb(main):006:0> a[9]\n=> [9] # unawesome! shouldn't this be [] ??\n</code></pre>\n\n<p>Furthermore, the '<<' added the '9' to the array; it did not add it to the hash, which explains this:</p>\n\n<pre><code>irb(main):004:0> a\n=> {} # ?! would have expected {8=>[9]}\n</code></pre>\n\n<p>Instead of using .default, what you probably want to do in your program is something like this:</p>\n\n<pre><code># Time to add a new entry to the hash table; this might be \n# the first entry for this key..\nmyhash[key] ||= []\nmyhash[key] << value\n</code></pre>\n"
},
{
"answer_id": 192478,
"author": "glenn mcdonald",
"author_id": 7919,
"author_profile": "https://Stackoverflow.com/users/7919",
"pm_score": 6,
"selected": false,
"text": "<p>This is a very useful idiom:</p>\n\n<pre><code>(myhash[key] ||= []) << value\n</code></pre>\n\n<p>It can even be nested:</p>\n\n<pre><code>((myhash[key1] ||= {})[key2] ||= []) << value\n</code></pre>\n\n<p>The other way is to do:</p>\n\n<pre><code>myhash = Hash.new {|hash,key| hash[key] = []}\n</code></pre>\n\n<p>But this has the significant side-effect that <strong>asking</strong> about a key will create it, which renders has_key? fairly useless, so I avoid this method.</p>\n"
},
{
"answer_id": 192622,
"author": "Daniel Beardsley",
"author_id": 13216,
"author_profile": "https://Stackoverflow.com/users/13216",
"pm_score": -1,
"selected": false,
"text": "<p>I'm not sure if this is what you want, but you can do this to always return an empty array when a missing hash key is queried.</p>\n\n<pre><code>h = Hash.new { [] }\nh[:missing]\n => []\n\n#But, you should never modify the empty array because it isn't stored anywhere\n#A new, empty array is returned every time\nh[:missing] << 'entry'\nh[:missing]\n => []\n</code></pre>\n"
},
{
"answer_id": 194297,
"author": "Turp",
"author_id": 24856,
"author_profile": "https://Stackoverflow.com/users/24856",
"pm_score": 5,
"selected": false,
"text": "<p>I think this is the behavior you are looking for. This will automatically initialize any new keys in the Hash to an array:</p>\n\n<pre><code>irb(main):001:0> h = Hash.new{|h, k| h[k] = []}\n=> {}\nirb(main):002:0> h[1] << \"ABC\"\n=> [\"ABC\"]\nirb(main):003:0> h[3]\n=> []\nirb(main):004:0> h\n=> {1=>[\"ABC\"], 3=>[]}\n</code></pre>\n"
},
{
"answer_id": 2582076,
"author": "jrochkind",
"author_id": 307106,
"author_profile": "https://Stackoverflow.com/users/307106",
"pm_score": 3,
"selected": false,
"text": "<p>glenn mcdonald says:</p>\n\n<p>\"The other way is to do:</p>\n\n<p>myhash = Hash.new {|hash,key| hash[key] = []}</p>\n\n<p>But this has the significant side-effect that asking about a key will create it, which renders has_key? fairly useless, so I avoid this method.\"</p>\n\n<p>that does not in fact seem to be true. </p>\n\n<pre><code>irb(main):004:0> a = Hash.new {|hash,key| hash[key] = []}\n=> {}\nirb(main):005:0> a.has_key?(:key)\n=> false\nirb(main):006:0> a[:key]\n=> []\nirb(main):007:0> a.has_key?(:key)\n=> true\n</code></pre>\n\n<p><em>Accessing</em> the key will create it, as I would expect. Merely asking has_key? does not. </p>\n"
},
{
"answer_id": 4251779,
"author": "migbar",
"author_id": 515480,
"author_profile": "https://Stackoverflow.com/users/515480",
"pm_score": 3,
"selected": false,
"text": "<p>If you really wanna have an endlessly deep hash:</p>\n\n<pre><code>endless = Hash.new { |h, k| h[k] = Hash.new(&h.default_proc) }\nendless[\"deep\"][\"in\"][\"here\"] = \"hello\"\n</code></pre>\n\n<p>Of course, as Glenn points out above, if you do this, the has_key? looses its meaning as it will always return true. Thx to jbarnette for this one. </p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190740",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26094/"
] |
I thought I understood what the default method does to a hash...
Give a default value for a key if it doesn't exist:
```
irb(main):001:0> a = {}
=> {}
irb(main):002:0> a.default = 4
=> 4
irb(main):003:0> a[8]
=> 4
irb(main):004:0> a[9] += 1
=> 5
irb(main):005:0> a
=> {9=>5}
```
All good.
But if I set the default to be a empty list, or empty hash, I don't understand it's behaviour at **all**....
```
irb(main):001:0> a = {}
=> {}
irb(main):002:0> a.default = []
=> []
irb(main):003:0> a[8] << 9
=> [9] # great!
irb(main):004:0> a
=> {} # ?! would have expected {8=>[9]}
irb(main):005:0> a[8]
=> [9] # awesome!
irb(main):006:0> a[9]
=> [9] # unawesome! shouldn't this be [] ??
```
I was hoping/expecting the same behaviour as if I had used the ||= operator...
```
irb(main):001:0> a = {}
=> {}
irb(main):002:0> a[8] ||= []
=> []
irb(main):003:0> a[8] << 9
=> [9]
irb(main):004:0> a
=> {8=>[9]}
irb(main):005:0> a[9]
=> nil
```
Can anyone explain what is going on?
|
`Hash.default` is used to set the default value **returned** when you query a key that doesn't exist. An entry in the collection is not created for you, just because queried it.
Also, the value you set `default` to is an instance of an object (an Array in your case), so when this is returned, it can be manipulated.
```
a = {}
a.default = [] # set default to a new empty Array
a[8] << 9 # a[8] doesn't exist, so the Array instance is returned, and 9 appended to it
a.default # => [9]
a[9] # a[9] doesn't exist, so default is returned
```
|
190,748 |
<p>You can, obviously, put a variable declaration in a for loop:</p>
<pre><code>for (int i = 0; ...
</code></pre>
<p>and I've noticed that you can do the same thing in if and switch statements as well:</p>
<pre><code>if ((int i = f()) != 0) ...
switch (int ch = stream.get()) ...
</code></pre>
<p>But when I try to do the same thing in a while loop:</p>
<pre><code>while ((int ch = stream.get()) != -1) ...
</code></pre>
<p>The compiler (VC++ 9.0) does not like it at all.</p>
<p>Is this compliant behavior? Is there a reason for it?</p>
<p><strong>EDIT</strong>: I found I can do this:</p>
<pre><code>while (int ch = stream.get() != -1) ...
</code></pre>
<p>but because of precedence rules, that's interpreted as:</p>
<pre><code>while (int ch = (stream.get() != -1)) ...
</code></pre>
<p>which is not what I want.</p>
|
[
{
"answer_id": 190753,
"author": "RB.",
"author_id": 15393,
"author_profile": "https://Stackoverflow.com/users/15393",
"pm_score": 2,
"selected": false,
"text": "<p>It might be because the contents of the while clause are evaluated each loop, thus it would try and declare \"ch\" multiple times.</p>\n\n<p>The if, switch, and for loop examples you gave will all have \"ch\" being defined only once.</p>\n"
},
{
"answer_id": 190768,
"author": "workmad3",
"author_id": 16035,
"author_profile": "https://Stackoverflow.com/users/16035",
"pm_score": 4,
"selected": false,
"text": "<p>This doesn't appear to be compliant behaviour. Part 6.5.1.2 of the standard states: </p>\n\n<blockquote>\n <p>When the condition of a while statement is a declaration, the scope of the variable that is declared extends\n from its point of declaration (3.3.1) to the end of the while statement. A while statement of the form</p>\n \n <p>while (T t = x) statement</p>\n \n <p>is equivalent to</p>\n</blockquote>\n\n<pre><code>label:\n{ //start of condition scope\n T t = x;\n if (t) {\n statement\n goto label;\n }\n}\n</code></pre>\n\n<p>So in your example, ch should be declared within the scope of the loop and work correctly (with it being recreated through each loop iteration). Reason for the observed behaviour is most likely due to the compiler not scoping the variable correctly and then declaring it multiple times.</p>\n"
},
{
"answer_id": 191550,
"author": "MSalters",
"author_id": 15416,
"author_profile": "https://Stackoverflow.com/users/15416",
"pm_score": 2,
"selected": false,
"text": "<p>You <em>can</em> put a variable declaration in the test expression of a while loop. What you <em>cannot</em> do is put a declaration statement in other expressions. For instance, in the expression a+b+c, you cannot replace b by <code>int i = f()</code>. And the same hold for the expression <code>(a)</code>; you can't insert <code>int i=f()</code> to get an expression <code>(int i=f())</code>.</p>\n\n<p>So, in <code>while (int i = foo())</code>, the outermost brackets are part of the while statement, and not of the text-expression, and everything is legal. In <code>while ((int i = foo()))</code>, the outermost brackets are still part of the while statement. The test-expression would have the form <code>\"(\" expr \")\"</code>, and you end up with a syntax error.</p>\n"
},
{
"answer_id": 191737,
"author": "Mark Ransom",
"author_id": 5987,
"author_profile": "https://Stackoverflow.com/users/5987",
"pm_score": 0,
"selected": false,
"text": "<p><strike>Try</strike> <strong>This doesn't work</strong></p>\n\n<pre><code>while (int ch = stream.get(), ch != -1) ...\n</code></pre>\n\n<p><strike>I've never tried it, but if the comment in your edit is correct, this should work.</strike><br>\nVS 2005 won't even compile it.</p>\n"
},
{
"answer_id": 191876,
"author": "Richard Corden",
"author_id": 11698,
"author_profile": "https://Stackoverflow.com/users/11698",
"pm_score": 5,
"selected": true,
"text": "<p>The grammar for a condition in the '03 standard is defined as follows:</p>\n\n<pre><code>condition:\n expression\n type-specifier-seq declarator = assignment-expression\n</code></pre>\n\n<p>The above will therefore only allow conditions such as:</p>\n\n<pre><code>if ( i && j && k ) {}\nif ( (i = j) ==0 ) {}\nif ( int i = j ) {}\n</code></pre>\n\n<p>The standard allows the condition to declare a variable, however, they have done so by adding a new grammar rule called 'condition' that can be an expression or a declarator with an initializer. The result is that just because you are in the condition of an <code>if</code>, <code>for</code>, <code>while</code>, or <code>switch</code> does not mean that you can declare a variable inside an expression.</p>\n"
},
{
"answer_id": 193051,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 4,
"selected": false,
"text": "<p>The problem is, the standard permits you a <em>declaration</em> inside parenthesis. What you want to do is to get a declaration as part of expression, which is something that standard will not let you do.</p>\n\n<p>while() can have one of two syntaxes: while(<declaration>) or while(<expression>). The declaration uses \"=\", and looks like expression, but it's a different syntactical entity. </p>\n\n<p>When you write</p>\n\n<pre><code>while(int i = 1) {\n}\n</code></pre>\n\n<p>, that's perfectly fine. \"int i=1\" is a declaration. However, what you want is </p>\n\n<pre><code>while ( (int i = 1) + 3) {\n}\n</code></pre>\n\n<p>This is a very different animal. You want an expression inside while(), where one of the terms of the expression is a declaration. Now, declaration is a statement, and as such cannot be part of expression. That's why what you need to be done cannot be done.</p>\n\n<p>(after writing the whole rant, I noticed that 2 other people wrote the same thing. Oh well, the more the merrier.)</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190748",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4086/"
] |
You can, obviously, put a variable declaration in a for loop:
```
for (int i = 0; ...
```
and I've noticed that you can do the same thing in if and switch statements as well:
```
if ((int i = f()) != 0) ...
switch (int ch = stream.get()) ...
```
But when I try to do the same thing in a while loop:
```
while ((int ch = stream.get()) != -1) ...
```
The compiler (VC++ 9.0) does not like it at all.
Is this compliant behavior? Is there a reason for it?
**EDIT**: I found I can do this:
```
while (int ch = stream.get() != -1) ...
```
but because of precedence rules, that's interpreted as:
```
while (int ch = (stream.get() != -1)) ...
```
which is not what I want.
|
The grammar for a condition in the '03 standard is defined as follows:
```
condition:
expression
type-specifier-seq declarator = assignment-expression
```
The above will therefore only allow conditions such as:
```
if ( i && j && k ) {}
if ( (i = j) ==0 ) {}
if ( int i = j ) {}
```
The standard allows the condition to declare a variable, however, they have done so by adding a new grammar rule called 'condition' that can be an expression or a declarator with an initializer. The result is that just because you are in the condition of an `if`, `for`, `while`, or `switch` does not mean that you can declare a variable inside an expression.
|
190,755 |
<p>Any suggestion how I can document my Perl code? What do you use and what tools are available to help me?</p>
<p>Which module do you use to convert pod to html?</p>
|
[
{
"answer_id": 190774,
"author": "GavinCattell",
"author_id": 21644,
"author_profile": "https://Stackoverflow.com/users/21644",
"pm_score": 4,
"selected": false,
"text": "<p><a href=\"http://perldoc.perl.org/perlpod.html\" rel=\"nofollow noreferrer\">Perl pod</a>.</p>\n\n<p>This is how Mozilla documents their Perl.</p>\n"
},
{
"answer_id": 190901,
"author": "Dave Sherohman",
"author_id": 18914,
"author_profile": "https://Stackoverflow.com/users/18914",
"pm_score": 3,
"selected": false,
"text": "<p>Not to be overly flip, but the best way to document Perl code is the same way as you would document code in any other language.</p>\n\n<p>As for specific tools, I use a mix of standard inline comments, pod for larger chunks of documentation where a format similar to <strong>man</strong> is appropriate, and TeX as a final fallback for documents that need to be more freeform. (And, in the spirit of \"same as any other language\", yes, I do use pod for documenting non-Perl code as well.)</p>\n"
},
{
"answer_id": 190903,
"author": "brian d foy",
"author_id": 2766176,
"author_profile": "https://Stackoverflow.com/users/2766176",
"pm_score": 7,
"selected": true,
"text": "<p>Look inside almost any Perl module and you'll see the <a href=\"http://perldoc.perl.org/perlpod.html\" rel=\"noreferrer\">Plain Old Documentation (POD)</a> format. On <a href=\"http://search.cpan.org\" rel=\"noreferrer\">CPAN Search</a>, when looking at a module you have the option of viewing the raw source, so that's one way you can look at the raw pod, but you can also use <a href=\"http://perldoc.perl.org/perldoc.html\" rel=\"noreferrer\">perldoc</a> from the command line. The <code>-m</code> switch shows you the file</p>\n\n<pre><code>perldoc -m Foo::Bar\n</code></pre>\n\n<p>Or, if you want to find the file so you can look at it in your favorite editor, use the <code>-l</code> switch to find it:</p>\n\n<pre><code>perldoc -l Foo::Bar\n</code></pre>\n\n<p>Once you start documenting your program, you put the Pod in the file right with the code, either interwoven with the code so the documentation is next to the relevant parts, or at the beginning, middle, or end as one big chunk.</p>\n\n<p>Pod is easily translated to several other formats, such as LaTeX, Postscript, HTML, and so on with translators that come with Perl (pod2latex, pod2ps, pod2html). I even have a pod translator that goes to InDesign. Writing your own Pod translator is easy with <a href=\"http://search.cpan.org/dist/Pod-Simple\" rel=\"noreferrer\">Pod::Simple</a>, so if you don't find a translator to your favorite final form, just make it yourself.</p>\n\n<p>There are also several tools that you can add to your test suite to check your Pod. The <a href=\"http://search.cpan.org/dist/Test-Pod\" rel=\"noreferrer\">Test::Pod</a> module checks for format errors, the <a href=\"http://search.cpan.org/dist/Test-Pod-Coverage\" rel=\"noreferrer\">Test::Pod::Coverage</a> module checks the you've documented each subroutine, and so on. You also might be interested in my <a href=\"http://www.perlmonks.org/?node_id=408254\" rel=\"noreferrer\">Perl documentation documentation</a>.</p>\n"
},
{
"answer_id": 190930,
"author": "draegtun",
"author_id": 12195,
"author_profile": "https://Stackoverflow.com/users/12195",
"pm_score": 5,
"selected": false,
"text": "<p>I definitely recommend <a href=\"http://en.wikipedia.org/wiki/Plain_Old_Documentation\" rel=\"nofollow noreferrer\">POD</a>.</p>\n\n<p>POD can also be used in-line with code but I prefer to put at bottom of program after __END__ (as recommended by Damian Conway in <a href=\"http://oreilly.com/catalog/9780596001735\" rel=\"nofollow noreferrer\">Perl Best Practices</a>).</p>\n\n<p>Look at <a href=\"http://search.cpan.org/dist/Pod-Server/lib/Pod/Server.pm\" rel=\"nofollow noreferrer\">POD::Server</a> & <a href=\"http://search.cpan.org/dist/Pod-Webserver/lib/Pod/Webserver.pm\" rel=\"nofollow noreferrer\">POD::Webserver</a>, which provides a web front-end to all your PODs.</p>\n"
},
{
"answer_id": 213334,
"author": "JDrago",
"author_id": 29060,
"author_profile": "https://Stackoverflow.com/users/29060",
"pm_score": 3,
"selected": false,
"text": "<blockquote>\n <p>Which module do you use to convert pod\n to html?</p>\n</blockquote>\n\n<p>Check out <a href=\"http://search.cpan.org/dist/Pod-ProjectDocs/\" rel=\"noreferrer\">Pod::ProjectDocs</a> - you get a simple command-line utility that will convert all the POD in your Perl project into a set of HTML pages that look just like what you see on <a href=\"http://search.cpan.org/\" rel=\"noreferrer\">search.cpan.org</a>.</p>\n"
},
{
"answer_id": 222421,
"author": "braveterry",
"author_id": 28991,
"author_profile": "https://Stackoverflow.com/users/28991",
"pm_score": 2,
"selected": false,
"text": "<p>You might also want to check out <a href=\"https://rads.stackoverflow.com/amzn/click/com/0596001738\" rel=\"nofollow noreferrer\" rel=\"nofollow noreferrer\">Perl Best Practices</a> by Damian Conway. I used some of the tips to clean up a small Perl code base I inherited.</p>\n"
},
{
"answer_id": 393124,
"author": "sir_lichtkind",
"author_id": 29269,
"author_profile": "https://Stackoverflow.com/users/29269",
"pm_score": 2,
"selected": false,
"text": "<p>No one mentioned <a href=\"http://search.cpan.org/~dconway/Smart-Comments/lib/Smart/Comments.pm\" rel=\"nofollow noreferrer\">Smart::Comments</a>? It's not always what you want but good if you need more power to comments.</p>\n"
},
{
"answer_id": 8106206,
"author": "sir_lichtkind",
"author_id": 29269,
"author_profile": "https://Stackoverflow.com/users/29269",
"pm_score": 2,
"selected": false,
"text": "<p>seperate user docs and coders docs. maybe put user docs (tuts, faq, reference) in there directory (/doc) and coders in same as the code. unfortunately its expected by conventtion, to have overview in the module itself. this you can as already layed out do it POD after <strong>END</strong>. mane coding docs you can put in comments. additional things like coding style or how to contribute put in seperate .pod files inside the code base (root dir?)</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190755",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10523/"
] |
Any suggestion how I can document my Perl code? What do you use and what tools are available to help me?
Which module do you use to convert pod to html?
|
Look inside almost any Perl module and you'll see the [Plain Old Documentation (POD)](http://perldoc.perl.org/perlpod.html) format. On [CPAN Search](http://search.cpan.org), when looking at a module you have the option of viewing the raw source, so that's one way you can look at the raw pod, but you can also use [perldoc](http://perldoc.perl.org/perldoc.html) from the command line. The `-m` switch shows you the file
```
perldoc -m Foo::Bar
```
Or, if you want to find the file so you can look at it in your favorite editor, use the `-l` switch to find it:
```
perldoc -l Foo::Bar
```
Once you start documenting your program, you put the Pod in the file right with the code, either interwoven with the code so the documentation is next to the relevant parts, or at the beginning, middle, or end as one big chunk.
Pod is easily translated to several other formats, such as LaTeX, Postscript, HTML, and so on with translators that come with Perl (pod2latex, pod2ps, pod2html). I even have a pod translator that goes to InDesign. Writing your own Pod translator is easy with [Pod::Simple](http://search.cpan.org/dist/Pod-Simple), so if you don't find a translator to your favorite final form, just make it yourself.
There are also several tools that you can add to your test suite to check your Pod. The [Test::Pod](http://search.cpan.org/dist/Test-Pod) module checks for format errors, the [Test::Pod::Coverage](http://search.cpan.org/dist/Test-Pod-Coverage) module checks the you've documented each subroutine, and so on. You also might be interested in my [Perl documentation documentation](http://www.perlmonks.org/?node_id=408254).
|
190,776 |
<p>How do you build and use dynamic sql in a MySQL stored procedure?</p>
|
[
{
"answer_id": 190962,
"author": "Jason Stevenson",
"author_id": 13368,
"author_profile": "https://Stackoverflow.com/users/13368",
"pm_score": 7,
"selected": true,
"text": "<p>I don't believe MySQL supports dynamic sql. You can do "prepared" statements which is similar, but different.</p>\n<p>Here is an example:</p>\n<pre><code>mysql> PREPARE stmt FROM \n -> 'select count(*) \n -> from information_schema.schemata \n -> where schema_name = ? or schema_name = ?'\n;\nQuery OK, 0 rows affected (0.00 sec)\nStatement prepared\nmysql> EXECUTE stmt \n -> USING @schema1,@schema2\n+----------+\n| count(*) |\n+----------+\n| 2 |\n+----------+\n1 row in set (0.00 sec)\nmysql> DEALLOCATE PREPARE stmt;\n</code></pre>\n<p>The prepared statements are often used to see an execution plan for a given query. Since they are executed with the <strong>execute</strong> command and the <strong>sql</strong> can be assigned to a variable you can approximate the some of the same behavior as dynamic sql.</p>\n<p>Here is a good <a href=\"http://rpbouman.blogspot.com/2005/11/mysql-5-prepared-statement-syntax-and.html\" rel=\"nofollow noreferrer\">link</a> about this:</p>\n<p>Don't forget to deallocate the <code>stmt</code> using the last line!</p>\n<p>Good Luck!</p>\n"
},
{
"answer_id": 5728155,
"author": "TimoSolo",
"author_id": 253096,
"author_profile": "https://Stackoverflow.com/users/253096",
"pm_score": 7,
"selected": false,
"text": "<p>After 5.0.13, in stored procedures, you can use dynamic SQL:</p>\n\n<pre><code>delimiter // \nCREATE PROCEDURE dynamic(IN tbl CHAR(64), IN col CHAR(64))\nBEGIN\n SET @s = CONCAT('SELECT ',col,' FROM ',tbl );\n PREPARE stmt FROM @s;\n EXECUTE stmt;\n DEALLOCATE PREPARE stmt;\nEND\n//\ndelimiter ;\n</code></pre>\n\n<p>Dynamic SQL does not work in functions or triggers. See <a href=\"http://dev.mysql.com/doc/refman/5.0/en/sql-syntax-prepared-statements.html\" rel=\"noreferrer\">the MySQL documentation</a> for more uses.</p>\n"
},
{
"answer_id": 34313647,
"author": "Elcio",
"author_id": 5686921,
"author_profile": "https://Stackoverflow.com/users/5686921",
"pm_score": 2,
"selected": false,
"text": "<p><strong>You can pass thru outside the dynamic statement using User-Defined Variables</strong></p>\n\n<pre><code>Server version: 5.6.25-log MySQL Community Server (GPL)\n\nmysql> PREPARE stmt FROM 'select \"AAAA\" into @a';\nQuery OK, 0 rows affected (0.01 sec)\nStatement prepared\n\nmysql> EXECUTE stmt;\nQuery OK, 1 row affected (0.01 sec)\n\nDEALLOCATE prepare stmt;\nQuery OK, 0 rows affected (0.01 sec)\n\nmysql> select @a;\n+------+\n| @a |\n+------+\n|AAAA |\n+------+\n1 row in set (0.01 sec)\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190776",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3747/"
] |
How do you build and use dynamic sql in a MySQL stored procedure?
|
I don't believe MySQL supports dynamic sql. You can do "prepared" statements which is similar, but different.
Here is an example:
```
mysql> PREPARE stmt FROM
-> 'select count(*)
-> from information_schema.schemata
-> where schema_name = ? or schema_name = ?'
;
Query OK, 0 rows affected (0.00 sec)
Statement prepared
mysql> EXECUTE stmt
-> USING @schema1,@schema2
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.00 sec)
mysql> DEALLOCATE PREPARE stmt;
```
The prepared statements are often used to see an execution plan for a given query. Since they are executed with the **execute** command and the **sql** can be assigned to a variable you can approximate the some of the same behavior as dynamic sql.
Here is a good [link](http://rpbouman.blogspot.com/2005/11/mysql-5-prepared-statement-syntax-and.html) about this:
Don't forget to deallocate the `stmt` using the last line!
Good Luck!
|
190,809 |
<p>I am trying to use cvs annotate. This is the what I run:</p>
<pre><code>cvs -d /mycvs/cvsroot/ annotate "projects/dg/SomeClass.java"
</code></pre>
<p>However, I get the following error:</p>
<pre><code>cvs annotate: failed to create lock directory for `/mycvs/cvsroot/projects/dg^M' (/mycvs/cvsroot/projects/dg^M/#cvs.lock): No such file or directory
cvs annotate: failed to obtain dir lock in repository `/mycvs/cvsroot/projects/dg^M'
cvs [annotate aborted]: read lock failed - giving up
</code></pre>
<p>What does this mean? How can I overcome this problem? Could it be related to the ^M character I see at the error message?</p>
<p>When I use eclipse to do the annotation it works.
I checked and the directory `/mycvs/cvsroot/projects/dg' exists. The error also occurs when I'm logged in as root, so probably it's not a permissions issue either.</p>
<p>I am using CentOS</p>
|
[
{
"answer_id": 190821,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 1,
"selected": false,
"text": "<p>From your description, I would guess that you've got it right with the stray ^M. What OS are you using? If Windows, are you using cygwin? I see you're using direct filesystem access to the repository. Might you consider setting up a server access mechanism like pserver to see if that helps?</p>\n"
},
{
"answer_id": 630559,
"author": "Nathan Feger",
"author_id": 8563,
"author_profile": "https://Stackoverflow.com/users/8563",
"pm_score": 0,
"selected": false,
"text": "<p>I too am experiencing this problem with cygwin. In fact, I am able to authenticate against a pserver using eclipse cvs tools. However, cygwin... not so much.</p>\n\n<p>Here are a couple of posts that might be related:\n<a href=\"http://www.sat-industry.net/forums/dreambox-development/19893-checkout-failed-create-lock-directory.html\" rel=\"nofollow noreferrer\">http://www.sat-industry.net/forums/dreambox-development/19893-checkout-failed-create-lock-directory.html</a></p>\n\n<p>summary: add an environment variable: CVS_RSH=ssh</p>\n\n<p><a href=\"http://www.mooreds.com/wordpress/archives/000234\" rel=\"nofollow noreferrer\">http://www.mooreds.com/wordpress/archives/000234</a>\nsummary: you may have a config problem with the permissions of the CVS server.</p>\n\n<p>Neither of these worked for me btw. </p>\n"
},
{
"answer_id": 1202813,
"author": "mooreds",
"author_id": 203619,
"author_profile": "https://Stackoverflow.com/users/203619",
"pm_score": 0,
"selected": false,
"text": "<p>You might want to try using the 'local' repository:</p>\n\n<p>cvs -d :local:/mycvs/cvsroot/ annotate \"projects/dg/SomeClass.java\"</p>\n\n<p>and see if that solves the issue.</p>\n\n<p>I use cygwin and cvs regularly, and while I sometimes get this error message: \n\"cvs [checkout aborted]: cannot rename file CVS/Entries.Backup to CVS/Entries: Permission denied\" I just re-run the checkout and it seems fine. I looked into this error and it was related to contention for the filesystem in windows (antivirus stuff, IIRC).</p>\n"
},
{
"answer_id": 1942965,
"author": "Grant Johnson",
"author_id": 12518,
"author_profile": "https://Stackoverflow.com/users/12518",
"pm_score": 0,
"selected": false,
"text": "<p>It appears that you are using CygWin for CVS, but touched your CVS/Root file with a text editor that uses Windows line ends, or did the initial checkout with a CVS client that uses Windows line ends. Although you can mix and match clients to the same repository, it is sometimes bad to mix and match clients (CygWin/WinCVS) with the same working copy.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190809",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/17876/"
] |
I am trying to use cvs annotate. This is the what I run:
```
cvs -d /mycvs/cvsroot/ annotate "projects/dg/SomeClass.java"
```
However, I get the following error:
```
cvs annotate: failed to create lock directory for `/mycvs/cvsroot/projects/dg^M' (/mycvs/cvsroot/projects/dg^M/#cvs.lock): No such file or directory
cvs annotate: failed to obtain dir lock in repository `/mycvs/cvsroot/projects/dg^M'
cvs [annotate aborted]: read lock failed - giving up
```
What does this mean? How can I overcome this problem? Could it be related to the ^M character I see at the error message?
When I use eclipse to do the annotation it works.
I checked and the directory `/mycvs/cvsroot/projects/dg' exists. The error also occurs when I'm logged in as root, so probably it's not a permissions issue either.
I am using CentOS
|
From your description, I would guess that you've got it right with the stray ^M. What OS are you using? If Windows, are you using cygwin? I see you're using direct filesystem access to the repository. Might you consider setting up a server access mechanism like pserver to see if that helps?
|
190,818 |
<p>I want to create an <code>NSOpenPanel</code> that can select any kind of file, so I do this</p>
<pre><code>NSOpenPanel* panel = [NSOpenPanel openPanel];
if([panel runModalForTypes:nil] == NSOKButton) {
// process files here
}
</code></pre>
<p>which lets me select all files <em>except</em> symbolic links.<br>
They're simply not selectable and the obvious <code>setResolvesAliases</code><br>
does nothing.</p>
<p>What gives?</p>
<p><b>Update 1:</b> I did some more testing and found that this strangeness<br>
is present in Leopard (10.5.5) but not in Tiger (10.4.8). </p>
<p><b>Update 2:</b> The code above can select mac aliases (persistent path<br>
data that lives in the resource fork) but not symlinks (files created with ln -s).</p>
|
[
{
"answer_id": 191978,
"author": "Mecki",
"author_id": 15809,
"author_profile": "https://Stackoverflow.com/users/15809",
"pm_score": 1,
"selected": false,
"text": "<p>I cannot reproduce this. I just tried it and it works just fine. If symlink points to a directory, it shows the directory content when I select the symlink and if the symlink points to a file, I can select it as well.</p>\n\n<p>Of course if the symlink points to a directory, you can only select it if choosing directories is allowed</p>\n\n<pre><code>NSOpenPanel * panel = [NSOpenPanel openPanel];\n[panel setCanChooseDirectories:YES];\nif ([panel runModalForTypes:nil] == NSOKButton) {\n NSLog(@\"%@\", [panel filenames]);\n}\n</code></pre>\n"
},
{
"answer_id": 193326,
"author": "Andy",
"author_id": 3857,
"author_profile": "https://Stackoverflow.com/users/3857",
"pm_score": 0,
"selected": false,
"text": "<p>Your code sample worked for me, as well - I'm using 10.5.5 and XCode 3.1, if it matters.</p>\n\n<p>If the alias is to a directory, I couldn't select the alias, since it resolved to the directory that it was pointing to, not the alias itself (the panel seems to resolve aliases by default). I was able to select an alias to a file, though.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190818",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22147/"
] |
I want to create an `NSOpenPanel` that can select any kind of file, so I do this
```
NSOpenPanel* panel = [NSOpenPanel openPanel];
if([panel runModalForTypes:nil] == NSOKButton) {
// process files here
}
```
which lets me select all files *except* symbolic links.
They're simply not selectable and the obvious `setResolvesAliases`
does nothing.
What gives?
**Update 1:** I did some more testing and found that this strangeness
is present in Leopard (10.5.5) but not in Tiger (10.4.8).
**Update 2:** The code above can select mac aliases (persistent path
data that lives in the resource fork) but not symlinks (files created with ln -s).
|
I cannot reproduce this. I just tried it and it works just fine. If symlink points to a directory, it shows the directory content when I select the symlink and if the symlink points to a file, I can select it as well.
Of course if the symlink points to a directory, you can only select it if choosing directories is allowed
```
NSOpenPanel * panel = [NSOpenPanel openPanel];
[panel setCanChooseDirectories:YES];
if ([panel runModalForTypes:nil] == NSOKButton) {
NSLog(@"%@", [panel filenames]);
}
```
|
190,852 |
<p>See code: </p>
<pre><code>var file1 = "50.xsl";
var file2 = "30.doc";
getFileExtension(file1); //returns xsl
getFileExtension(file2); //returns doc
function getFileExtension(filename) {
/*TODO*/
}
</code></pre>
|
[
{
"answer_id": 190864,
"author": "p4bl0",
"author_id": 12043,
"author_profile": "https://Stackoverflow.com/users/12043",
"pm_score": 2,
"selected": false,
"text": "<pre><code>return filename.replace(/\\.([a-zA-Z0-9]+)$/, \"$1\");\n</code></pre>\n\n<p>edit: Strangely (or maybe it's not) the <code>$1</code> in the second argument of the replace method doesn't seem to work... Sorry.</p>\n"
},
{
"answer_id": 190878,
"author": "Tom",
"author_id": 23746,
"author_profile": "https://Stackoverflow.com/users/23746",
"pm_score": 11,
"selected": true,
"text": "<p><strong>Newer Edit:</strong> Lots of things have changed since this question was initially posted - there's a lot of really good information in <a href=\"https://stackoverflow.com/a/1203361/23746\">wallacer's revised answer</a> as well as <a href=\"https://stackoverflow.com/a/12900504/23746\">VisioN's excellent breakdown</a></p>\n\n<hr>\n\n<p><strong>Edit:</strong> Just because this is the accepted answer; <a href=\"https://stackoverflow.com/a/1203361/23746\">wallacer's answer</a> is indeed much better:</p>\n\n<pre><code>return filename.split('.').pop();\n</code></pre>\n\n<hr>\n\n<p>My old answer:</p>\n\n<pre><code>return /[^.]+$/.exec(filename);\n</code></pre>\n\n<p>Should do it.</p>\n\n<p><strong>Edit:</strong> In response to PhiLho's comment, use something like:</p>\n\n<pre><code>return (/[.]/.exec(filename)) ? /[^.]+$/.exec(filename) : undefined;\n</code></pre>\n"
},
{
"answer_id": 190879,
"author": "Randy Sugianto 'Yuku'",
"author_id": 11238,
"author_profile": "https://Stackoverflow.com/users/11238",
"pm_score": 3,
"selected": false,
"text": "<pre><code>var parts = filename.split('.');\nreturn parts[parts.length-1];\n</code></pre>\n"
},
{
"answer_id": 190933,
"author": "PhiLho",
"author_id": 15459,
"author_profile": "https://Stackoverflow.com/users/15459",
"pm_score": 5,
"selected": false,
"text": "<pre><code>function getFileExtension(filename)\n{\n var ext = /^.+\\.([^.]+)$/.exec(filename);\n return ext == null ? \"\" : ext[1];\n}\n</code></pre>\n\n<p>Tested with </p>\n\n<pre><code>\"a.b\" (=> \"b\") \n\"a\" (=> \"\") \n\".hidden\" (=> \"\") \n\"\" (=> \"\") \nnull (=> \"\") \n</code></pre>\n\n<p>Also </p>\n\n<pre><code>\"a.b.c.d\" (=> \"d\")\n\".a.b\" (=> \"b\")\n\"a..b\" (=> \"b\")\n</code></pre>\n"
},
{
"answer_id": 191380,
"author": "Joe Scylla",
"author_id": 25771,
"author_profile": "https://Stackoverflow.com/users/25771",
"pm_score": 3,
"selected": false,
"text": "<pre><code>function file_get_ext(filename)\n {\n return typeof filename != \"undefined\" ? filename.substring(filename.lastIndexOf(\".\")+1, filename.length).toLowerCase() : false;\n }\n</code></pre>\n"
},
{
"answer_id": 191504,
"author": "roenving",
"author_id": 23142,
"author_profile": "https://Stackoverflow.com/users/23142",
"pm_score": 2,
"selected": false,
"text": "<p>I just realized that it's not enough to put a comment on p4bl0's answer, though Tom's answer clearly solves the problem:</p>\n\n<pre><code>return filename.replace(/^.*?\\.([a-zA-Z0-9]+)$/, \"$1\");\n</code></pre>\n"
},
{
"answer_id": 194301,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<pre><code>function extension(fname) {\n var pos = fname.lastIndexOf(\".\");\n var strlen = fname.length;\n if (pos != -1 && strlen != pos + 1) {\n var ext = fname.split(\".\");\n var len = ext.length;\n var extension = ext[len - 1].toLowerCase();\n } else {\n extension = \"No extension found\";\n }\n return extension;\n}\n</code></pre>\n\n<p>//usage</p>\n\n<p>extension('file.jpeg')</p>\n\n<p>always returns the extension lower cas so you can check it on field change\nworks for:</p>\n\n<p>file.JpEg</p>\n\n<p>file (no extension)</p>\n\n<p>file. (noextension)</p>\n"
},
{
"answer_id": 450308,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<pre><code>function func() {\n var val = document.frm.filename.value;\n var arr = val.split(\".\");\n alert(arr[arr.length - 1]);\n var arr1 = val.split(\"\\\\\");\n alert(arr1[arr1.length - 2]);\n if (arr[1] == \"gif\" || arr[1] == \"bmp\" || arr[1] == \"jpeg\") {\n alert(\"this is an image file \");\n } else {\n alert(\"this is not an image file\");\n }\n}\n</code></pre>\n"
},
{
"answer_id": 1203361,
"author": "wallacer",
"author_id": 147458,
"author_profile": "https://Stackoverflow.com/users/147458",
"pm_score": 10,
"selected": false,
"text": "<pre><code>return filename.split('.').pop();\n</code></pre>\n<p><strong>Edit:</strong></p>\n<p>This is another non-regex solution that I think is more efficient:</p>\n<pre><code>return filename.substring(filename.lastIndexOf('.')+1, filename.length) || filename;\n</code></pre>\n<p>There are some corner cases that are better handled by <a href=\"https://stackoverflow.com/a/12900504/1249581\">VisioN's answer</a> below, particularly files with no extension (<code>.htaccess</code> etc included).</p>\n<p>It's very performant, and handles corner cases in an arguably better way by returning <code>""</code> instead of the full string when there's no dot or no string before the dot. It's a very well crafted solution, albeit tough to read. Stick it in your helpers lib and just use it.</p>\n<p><strong>Old Edit:</strong></p>\n<p>A safer implementation if you're going to run into files with no extension, or hidden files with no extension (see VisioN's comment to Tom's answer above) would be something along these lines</p>\n<pre><code>var a = filename.split(".");\nif( a.length === 1 || ( a[0] === "" && a.length === 2 ) ) {\n return "";\n}\nreturn a.pop(); // feel free to tack .toLowerCase() here if you want\n</code></pre>\n<p>If <code>a.length</code> is one, it's a visible file with no extension ie. <em>file</em></p>\n<p>If <code>a[0] === ""</code> and <code>a.length === 2</code> it's a hidden file with no extension ie. <em>.htaccess</em></p>\n<p>This should clear up issues with the slightly more complex cases. In terms of performance, I think this solution is <a href=\"https://stackoverflow.com/a/12900504/1249581\">a little slower than regex</a> in most browsers. However, for most common purposes this code should be perfectly usable.</p>\n"
},
{
"answer_id": 5584260,
"author": "Justin Bull",
"author_id": 229787,
"author_profile": "https://Stackoverflow.com/users/229787",
"pm_score": 2,
"selected": false,
"text": "<p>For most applications, a simple script such as </p>\n\n<pre><code>return /[^.]+$/.exec(filename);\n</code></pre>\n\n<p>would work just fine (as provided by Tom). However this is not fool proof. It does not work if the following file name is provided:</p>\n\n<pre><code>image.jpg?foo=bar\n</code></pre>\n\n<p>It may be a bit overkill but I would suggest using a url parser such as <a href=\"http://phpjs.org/functions/parse_url\" rel=\"nofollow\">this one</a> to avoid failure due to unpredictable filenames.</p>\n\n<p>Using that particular function, you could get the file name like this:</p>\n\n<pre><code>var trueFileName = parse_url('image.jpg?foo=bar').file;\n</code></pre>\n\n<p>This will output \"image.jpg\" without the url vars. Then you are free to grab the file extension.</p>\n"
},
{
"answer_id": 5973162,
"author": "Edward",
"author_id": 749852,
"author_profile": "https://Stackoverflow.com/users/749852",
"pm_score": 2,
"selected": false,
"text": "<p>Try this:</p>\n\n<pre><code>function getFileExtension(filename) {\n var fileinput = document.getElementById(filename);\n if (!fileinput)\n return \"\";\n var filename = fileinput.value;\n if (filename.length == 0)\n return \"\";\n var dot = filename.lastIndexOf(\".\");\n if (dot == -1)\n return \"\";\n var extension = filename.substr(dot, filename.length);\n return extension;\n}\n</code></pre>\n"
},
{
"answer_id": 7908718,
"author": "Dima",
"author_id": 1015402,
"author_profile": "https://Stackoverflow.com/users/1015402",
"pm_score": 5,
"selected": false,
"text": "<pre><code>function getExt(filename)\n{\n var ext = filename.split('.').pop();\n if(ext == filename) return \"\";\n return ext;\n}\n</code></pre>\n"
},
{
"answer_id": 8246456,
"author": "Pono",
"author_id": 591939,
"author_profile": "https://Stackoverflow.com/users/591939",
"pm_score": 4,
"selected": false,
"text": "<pre><code>var extension = fileName.substring(fileName.lastIndexOf('.')+1);\n</code></pre>\n"
},
{
"answer_id": 12900504,
"author": "VisioN",
"author_id": 1249581,
"author_profile": "https://Stackoverflow.com/users/1249581",
"pm_score": 9,
"selected": false,
"text": "<p>The following solution is <strong>fast</strong> and <strong>short</strong> enough to use in bulk operations and save extra bytes:</p>\n<pre><code> return fname.slice((fname.lastIndexOf(".") - 1 >>> 0) + 2);\n</code></pre>\n<p>Here is another one-line non-regexp universal solution:</p>\n<pre><code> return fname.slice((Math.max(0, fname.lastIndexOf(".")) || Infinity) + 1);\n</code></pre>\n<p>Both work correctly with names having no extension (e.g. <em>myfile</em>) or starting with <code>.</code> dot (e.g. <em>.htaccess</em>):</p>\n<pre><code> "" --> ""\n "name" --> ""\n "name.txt" --> "txt"\n ".htpasswd" --> ""\n "name.with.many.dots.myext" --> "myext"\n</code></pre>\n<p>If you care about the speed you may run the <a href=\"http://jsperf.com/extract-file-extension\" rel=\"noreferrer\"><strong>benchmark</strong></a> and check that the provided solutions are the fastest, while the short one is tremendously fast:</p>\n<p><img src=\"https://i.stack.imgur.com/ZL8Bn.png\" alt=\"Speed comparison\" /></p>\n<p><em>How the short one works:</em></p>\n<ol>\n<li><a href=\"https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/lastIndexOf\" rel=\"noreferrer\"><code>String.lastIndexOf</code></a> method returns the last position of the substring (i.e. <code>"."</code>) in the given string (i.e. <code>fname</code>). If the substring is not found method returns <code>-1</code>.</li>\n<li>The "unacceptable" positions of dot in the filename are <code>-1</code> and <code>0</code>, which respectively refer to names with no extension (e.g. <code>"name"</code>) and to names that start with dot (e.g. <code>".htaccess"</code>).</li>\n<li><a href=\"https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Unsigned_right_shift\" rel=\"noreferrer\">Zero-fill right shift operator</a> (<code>>>></code>) if used with zero affects negative numbers transforming <code>-1</code> to <code>4294967295</code> and <code>-2</code> to <code>4294967294</code>, which is useful for remaining the filename unchanged in the edge cases (sort of a trick here).</li>\n<li><a href=\"https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/slice\" rel=\"noreferrer\"><code>String.prototype.slice</code></a> extracts the part of the filename from the position that was calculated as described. If the position number is more than the length of the string method returns <code>""</code>.</li>\n</ol>\n<hr />\n<p>If you want more clear solution which will work in the same way (plus with extra support of full path), check the following extended version. This solution will be <em>slower</em> than previous one-liners but is much easier to understand.</p>\n<pre><code>function getExtension(path) {\n var basename = path.split(/[\\\\/]/).pop(), // extract file name from full path ...\n // (supports `\\\\` and `/` separators)\n pos = basename.lastIndexOf("."); // get last position of `.`\n\n if (basename === "" || pos < 1) // if file name is empty or ...\n return ""; // `.` not found (-1) or comes first (0)\n\n return basename.slice(pos + 1); // extract extension ignoring `.`\n}\n\nconsole.log( getExtension("/path/to/file.ext") );\n// >> "ext"\n</code></pre>\n<p>All three variants should work in any web browser on the client side and can be used in the server side NodeJS code as well.</p>\n"
},
{
"answer_id": 15237857,
"author": "crab",
"author_id": 899829,
"author_profile": "https://Stackoverflow.com/users/899829",
"pm_score": 1,
"selected": false,
"text": "<p>Wallacer's answer is nice, but one more checking is needed.</p>\n\n<p>If file has no extension, it will use filename as extension which is not good.</p>\n\n<p>Try this one:</p>\n\n<pre><code>return ( filename.indexOf('.') > 0 ) ? filename.split('.').pop().toLowerCase() : 'undefined';\n</code></pre>\n"
},
{
"answer_id": 16518830,
"author": "Tamás Pap",
"author_id": 240324,
"author_profile": "https://Stackoverflow.com/users/240324",
"pm_score": 1,
"selected": false,
"text": "<p>Don't forget that some files can have no extension, so:</p>\n\n<pre><code>var parts = filename.split('.');\nreturn (parts.length > 1) ? parts.pop() : '';\n</code></pre>\n"
},
{
"answer_id": 19086634,
"author": "mrbrdo",
"author_id": 364812,
"author_profile": "https://Stackoverflow.com/users/364812",
"pm_score": 3,
"selected": false,
"text": "<p>Fast and works correctly with paths</p>\n\n<pre><code>(filename.match(/[^\\\\\\/]\\.([^.\\\\\\/]+)$/) || [null]).pop()\n</code></pre>\n\n<p>Some edge cases</p>\n\n<pre><code>/path/.htaccess => null\n/dir.with.dot/file => null\n</code></pre>\n\n<p>Solutions using split are slow and solutions with lastIndexOf don't handle edge cases.</p>\n"
},
{
"answer_id": 19185883,
"author": "Hussein Nazzal",
"author_id": 1743214,
"author_profile": "https://Stackoverflow.com/users/1743214",
"pm_score": 3,
"selected": false,
"text": "<p>i just wanted to share this.</p>\n\n<pre><code>fileName.slice(fileName.lastIndexOf('.'))\n</code></pre>\n\n<p>although this has a downfall that files with no extension will return last string.\nbut if you do so this will fix every thing :</p>\n\n<pre><code> function getExtention(fileName){\n var i = fileName.lastIndexOf('.');\n if(i === -1 ) return false;\n return fileName.slice(i)\n }\n</code></pre>\n"
},
{
"answer_id": 20427027,
"author": "Chathuranga",
"author_id": 1386503,
"author_profile": "https://Stackoverflow.com/users/1386503",
"pm_score": 0,
"selected": false,
"text": "<pre><code>var filetypeArray = (file.type).split(\"/\");\nvar filetype = filetypeArray[1];\n</code></pre>\n\n<p>This is a better approach imo. </p>\n"
},
{
"answer_id": 25483772,
"author": "Krisztián Balla",
"author_id": 434742,
"author_profile": "https://Stackoverflow.com/users/434742",
"pm_score": 2,
"selected": false,
"text": "<p>If you are looking for a specific extension and know its length, you can use <strong>substr</strong>:</p>\n\n<pre><code>var file1 = \"50.xsl\";\n\nif (file1.substr(-4) == '.xsl') {\n // do something\n}\n</code></pre>\n\n<p><strong>JavaScript reference:</strong> <a href=\"https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/substr\" rel=\"nofollow\">https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/substr</a></p>\n"
},
{
"answer_id": 31223829,
"author": "DzSoundNirvana",
"author_id": 2510099,
"author_profile": "https://Stackoverflow.com/users/2510099",
"pm_score": 2,
"selected": false,
"text": "<p>I'm many moons late to the party but for simplicity I use something like this</p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>var fileName = \"I.Am.FileName.docx\";\r\nvar nameLen = fileName.length;\r\nvar lastDotPos = fileName.lastIndexOf(\".\");\r\nvar fileNameSub = false;\r\nif(lastDotPos === -1)\r\n{\r\n fileNameSub = false;\r\n}\r\nelse\r\n{\r\n //Remove +1 if you want the \".\" left too\r\n fileNameSub = fileName.substr(lastDotPos + 1, nameLen);\r\n}\r\ndocument.getElementById(\"showInMe\").innerHTML = fileNameSub;</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><div id=\"showInMe\"></div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 31649732,
"author": "Jibesh Patra",
"author_id": 1849454,
"author_profile": "https://Stackoverflow.com/users/1849454",
"pm_score": 1,
"selected": false,
"text": "<p>In node.js, this can be achieved by the following code:</p>\n\n<pre><code>var file1 =\"50.xsl\";\nvar path = require('path');\nconsole.log(path.parse(file1).name);\n</code></pre>\n"
},
{
"answer_id": 35526475,
"author": "Labithiotis",
"author_id": 1872133,
"author_profile": "https://Stackoverflow.com/users/1872133",
"pm_score": 2,
"selected": false,
"text": "<p>A one line solution that will also account for query params and any characters in url.</p>\n\n<pre><code>string.match(/(.*)\\??/i).shift().replace(/\\?.*/, '').split('.').pop()\n\n// Example\n// some.url.com/with.in/&ot.s/files/file.jpg?spec=1&.ext=jpg\n// jpg\n</code></pre>\n"
},
{
"answer_id": 36464585,
"author": "NSD",
"author_id": 3476304,
"author_profile": "https://Stackoverflow.com/users/3476304",
"pm_score": 1,
"selected": false,
"text": "<pre><code>var file = \"hello.txt\";\nvar ext = (function(file, lio) { \n return lio === -1 ? undefined : file.substring(lio+1); \n})(file, file.lastIndexOf(\".\"));\n\n// hello.txt -> txt\n// hello.dolly.txt -> txt\n// hello -> undefined\n// .hello -> hello\n</code></pre>\n"
},
{
"answer_id": 38285146,
"author": "Jack",
"author_id": 1492329,
"author_profile": "https://Stackoverflow.com/users/1492329",
"pm_score": 3,
"selected": false,
"text": "<p><strong>Code</strong></p>\n\n<pre><code>/**\n * Extract file extension from URL.\n * @param {String} url\n * @returns {String} File extension or empty string if no extension is present.\n */\nvar getFileExtension = function (url) {\n \"use strict\";\n if (url === null) {\n return \"\";\n }\n var index = url.lastIndexOf(\"/\");\n if (index !== -1) {\n url = url.substring(index + 1); // Keep path without its segments\n }\n index = url.indexOf(\"?\");\n if (index !== -1) {\n url = url.substring(0, index); // Remove query\n }\n index = url.indexOf(\"#\");\n if (index !== -1) {\n url = url.substring(0, index); // Remove fragment\n }\n index = url.lastIndexOf(\".\");\n return index !== -1\n ? url.substring(index + 1) // Only keep file extension\n : \"\"; // No extension found\n};\n</code></pre>\n\n<p><strong>Test</strong></p>\n\n<p>Notice that in the absence of a query, the fragment might still be present.</p>\n\n<pre><code>\"https://www.example.com:8080/segment1/segment2/page.html?foo=bar#fragment\" --> \"html\"\n\"https://www.example.com:8080/segment1/segment2/page.html#fragment\" --> \"html\"\n\"https://www.example.com:8080/segment1/segment2/.htaccess?foo=bar#fragment\" --> \"htaccess\"\n\"https://www.example.com:8080/segment1/segment2/page?foo=bar#fragment\" --> \"\"\n\"https://www.example.com:8080/segment1/segment2/?foo=bar#fragment\" --> \"\"\n\"\" --> \"\"\nnull --> \"\"\n\"a.b.c.d\" --> \"d\"\n\".a.b\" --> \"b\"\n\".a.b.\" --> \"\"\n\"a...b\" --> \"b\"\n\"...\" --> \"\"\n</code></pre>\n\n<p><strong>JSLint</strong></p>\n\n<p>0 Warnings.</p>\n"
},
{
"answer_id": 45925016,
"author": "Vitim.us",
"author_id": 938822,
"author_profile": "https://Stackoverflow.com/users/938822",
"pm_score": 3,
"selected": false,
"text": "<h1>This simple solution</h1>\n\n<pre><code>function extension(filename) {\n var r = /.+\\.(.+)$/.exec(filename);\n return r ? r[1] : null;\n}\n</code></pre>\n\n<h1>Tests</h1>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>/* tests */\r\ntest('cat.gif', 'gif');\r\ntest('main.c', 'c');\r\ntest('file.with.multiple.dots.zip', 'zip');\r\ntest('.htaccess', null);\r\ntest('noextension.', null);\r\ntest('noextension', null);\r\ntest('', null);\r\n\r\n// test utility function\r\nfunction test(input, expect) {\r\n var result = extension(input);\r\n if (result === expect)\r\n console.log(result, input);\r\n else\r\n console.error(result, input);\r\n}\r\n\r\nfunction extension(filename) {\r\n var r = /.+\\.(.+)$/.exec(filename);\r\n return r ? r[1] : null;\r\n}</code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 47523422,
"author": "James Anderson Jr.",
"author_id": 2690928,
"author_profile": "https://Stackoverflow.com/users/2690928",
"pm_score": 3,
"selected": false,
"text": "<p>I'm sure someone can, and will, minify and/or optimize my code in the future. But, as of <em>right now</em>, I am 200% confident that my code works in every unique situation (e.g. with just the <em>file name only</em>, with <em>relative</em>, <em>root-relative</em>, and <em>absolute</em> URL's, with <em>fragment</em> <code>#</code> tags, with <em>query</em> <code>?</code> strings, and whatever else you may decide to throw at it), flawlessly, and with pin-point precision.</p>\n<p>For proof, visit: <a href=\"https://projects.jamesandersonjr.com/web/js_projects/get_file_extension_test.php\" rel=\"noreferrer\">https://projects.jamesandersonjr.com/web/js_projects/get_file_extension_test.php</a></p>\n<p>Here's the JSFiddle: <a href=\"https://jsfiddle.net/JamesAndersonJr/ffcdd5z3/\" rel=\"noreferrer\">https://jsfiddle.net/JamesAndersonJr/ffcdd5z3/</a></p>\n<p>Not to be overconfident, or blowing my own trumpet, but I haven't seen <em>any</em> block of code for this task (finding the <em>'correct'</em> file extension, amidst a battery of different <code>function</code> input arguments) that works as well as this does.</p>\n<p><strong>Note:</strong> By design, if a file extension doesn't exist for the given input string, it simply returns a blank string <code>""</code>, not an error, nor an error message.</p>\n<blockquote>\n<p><strong>It takes two arguments:</strong></p>\n<ul>\n<li><p><strong><em>String:</em> fileNameOrURL</strong> <em>(self-explanatory)</em></p>\n</li>\n<li><p><strong><em>Boolean:</em> showUnixDotFiles</strong> (Whether or Not to show files that begin with a dot ".")</p>\n</li>\n</ul>\n</blockquote>\n<p><strong>Note (2):</strong> If you like my code, be sure to add it to your js library's, and/or repo's, because I worked hard on perfecting it, and it would be a shame to go to waste. So, without further ado, here it is:</p>\n<pre><code>function getFileExtension(fileNameOrURL, showUnixDotFiles)\n {\n /* First, let's declare some preliminary variables we'll need later on. */\n var fileName;\n var fileExt;\n \n /* Now we'll create a hidden anchor ('a') element (Note: No need to append this element to the document). */\n var hiddenLink = document.createElement('a');\n \n /* Just for fun, we'll add a CSS attribute of [ style.display = "none" ]. Remember: You can never be too sure! */\n hiddenLink.style.display = "none";\n \n /* Set the 'href' attribute of the hidden link we just created, to the 'fileNameOrURL' argument received by this function. */\n hiddenLink.setAttribute('href', fileNameOrURL);\n \n /* Now, let's take advantage of the browser's built-in parser, to remove elements from the original 'fileNameOrURL' argument received by this function, without actually modifying our newly created hidden 'anchor' element.*/ \n fileNameOrURL = fileNameOrURL.replace(hiddenLink.protocol, ""); /* First, let's strip out the protocol, if there is one. */\n fileNameOrURL = fileNameOrURL.replace(hiddenLink.hostname, ""); /* Now, we'll strip out the host-name (i.e. domain-name) if there is one. */\n fileNameOrURL = fileNameOrURL.replace(":" + hiddenLink.port, ""); /* Now finally, we'll strip out the port number, if there is one (Kinda overkill though ;-)). */ \n \n /* Now, we're ready to finish processing the 'fileNameOrURL' variable by removing unnecessary parts, to isolate the file name. */\n \n /* Operations for working with [relative, root-relative, and absolute] URL's ONLY [BEGIN] */ \n \n /* Break the possible URL at the [ '?' ] and take first part, to shave of the entire query string ( everything after the '?'), if it exist. */\n fileNameOrURL = fileNameOrURL.split('?')[0];\n\n /* Sometimes URL's don't have query's, but DO have a fragment [ # ](i.e 'reference anchor'), so we should also do the same for the fragment tag [ # ]. */\n fileNameOrURL = fileNameOrURL.split('#')[0];\n\n /* Now that we have just the URL 'ALONE', Let's remove everything to the last slash in URL, to isolate the file name. */\n fileNameOrURL = fileNameOrURL.substr(1 + fileNameOrURL.lastIndexOf("/"));\n\n /* Operations for working with [relative, root-relative, and absolute] URL's ONLY [END] */ \n\n /* Now, 'fileNameOrURL' should just be 'fileName' */\n fileName = fileNameOrURL;\n \n /* Now, we check if we should show UNIX dot-files, or not. This should be either 'true' or 'false'. */ \n if ( showUnixDotFiles == false )\n {\n /* If not ('false'), we should check if the filename starts with a period (indicating it's a UNIX dot-file). */\n if ( fileName.startsWith(".") )\n {\n /* If so, we return a blank string to the function caller. Our job here, is done! */\n return "";\n };\n };\n \n /* Now, let's get everything after the period in the filename (i.e. the correct 'file extension'). */\n fileExt = fileName.substr(1 + fileName.lastIndexOf("."));\n\n /* Now that we've discovered the correct file extension, let's return it to the function caller. */\n return fileExt;\n };\n</code></pre>\n<p>Enjoy! You're Quite Welcome!:</p>\n"
},
{
"answer_id": 47734420,
"author": "Jakob Sternberg",
"author_id": 1576463,
"author_profile": "https://Stackoverflow.com/users/1576463",
"pm_score": 4,
"selected": false,
"text": "<p>If you are dealing with web urls, you can use:</p>\n\n<pre><code>function getExt(filepath){\n return filepath.split(\"?\")[0].split(\"#\")[0].split('.').pop();\n}\n\ngetExt(\"../js/logic.v2.min.js\") // js\ngetExt(\"http://example.net/site/page.php?id=16548\") // php\ngetExt(\"http://example.net/site/page.html#welcome.to.me\") // html\ngetExt(\"c:\\\\logs\\\\yesterday.log\"); // log\n</code></pre>\n\n<p>Demo: <a href=\"https://jsfiddle.net/squadjot/q5ard4fj/\" rel=\"noreferrer\">https://jsfiddle.net/squadjot/q5ard4fj/</a></p>\n"
},
{
"answer_id": 49506631,
"author": "GauRang Omar",
"author_id": 6653785,
"author_profile": "https://Stackoverflow.com/users/6653785",
"pm_score": 2,
"selected": false,
"text": "<pre><code>fetchFileExtention(fileName) {\n return fileName.slice((fileName.lastIndexOf(\".\") - 1 >>> 0) + 2);\n}\n</code></pre>\n"
},
{
"answer_id": 50826632,
"author": "omarjebari",
"author_id": 2867894,
"author_profile": "https://Stackoverflow.com/users/2867894",
"pm_score": 0,
"selected": false,
"text": "<p>I prefer to use lodash for most things so here's a solution:</p>\n\n<pre><code>function getExtensionFromFilename(filename) {\n let extension = '';\n if (filename > '') {\n let parts = _.split(filename, '.');\n if (parts.length >= 2) {\n extension = _.last(parts);\n }\n return extension;\n}\n</code></pre>\n"
},
{
"answer_id": 52738209,
"author": "sdgfsdh",
"author_id": 1256041,
"author_profile": "https://Stackoverflow.com/users/1256041",
"pm_score": 5,
"selected": false,
"text": "<p>There is a standard library function for this in the <code>path</code> module: </p>\n\n<pre><code>import path from 'path';\n\nconsole.log(path.extname('abc.txt'));\n</code></pre>\n\n<p>Output: </p>\n\n<blockquote>\n <p>.txt</p>\n</blockquote>\n\n<p>So, if you only want the format: </p>\n\n<pre><code>path.extname('abc.txt').slice(1) // 'txt'\n</code></pre>\n\n<p>If there is no extension, then the function will return an empty string: </p>\n\n<pre><code>path.extname('abc') // ''\n</code></pre>\n\n<p>If you are using Node, then <code>path</code> is built-in. If you are targetting the browser, then Webpack will bundle a <code>path</code> implementation for you. If you are targetting the browser without Webpack, then you can include <a href=\"https://www.npmjs.com/package/path-browserify\" rel=\"noreferrer\">path-browserify</a> manually. </p>\n\n<p>There is no reason to do string splitting or regex.</p>\n"
},
{
"answer_id": 53048066,
"author": "boehm_s",
"author_id": 4756304,
"author_profile": "https://Stackoverflow.com/users/4756304",
"pm_score": 3,
"selected": false,
"text": "<p>\"one-liner\" to get filename and extension using <a href=\"https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/Reduce\" rel=\"noreferrer\"><code>reduce</code></a> and <a href=\"https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment\" rel=\"noreferrer\">array destructuring</a> : </p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>var str = \"filename.with_dot.png\";\r\nvar [filename, extension] = str.split('.').reduce((acc, val, i, arr) => (i == arr.length - 1) ? [acc[0].substring(1), val] : [[acc[0], val].join('.')], [])\r\n\r\nconsole.log({filename, extension});</code></pre>\r\n</div>\r\n</div>\r\n</p>\n\n<p>with better indentation :</p>\n\n<pre><code>var str = \"filename.with_dot.png\";\nvar [filename, extension] = str.split('.')\n .reduce((acc, val, i, arr) => (i == arr.length - 1) \n ? [acc[0].substring(1), val] \n : [[acc[0], val].join('.')], [])\n\n\nconsole.log({filename, extension});\n\n// {\n// \"filename\": \"filename.with_dot\",\n// \"extension\": \"png\"\n// }\n</code></pre>\n"
},
{
"answer_id": 53590524,
"author": "山茶树和葡萄树",
"author_id": 5819157,
"author_profile": "https://Stackoverflow.com/users/5819157",
"pm_score": 3,
"selected": false,
"text": "<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>// 获取文件后缀名\r\nfunction getFileExtension(file) {\r\n var regexp = /\\.([0-9a-z]+)(?:[\\?#]|$)/i;\r\n var extension = file.match(regexp);\r\n return extension && extension[1];\r\n}\r\n\r\nconsole.log(getFileExtension(\"https://www.example.com:8080/path/name/foo\"));\r\nconsole.log(getFileExtension(\"https://www.example.com:8080/path/name/foo.BAR\"));\r\nconsole.log(getFileExtension(\"https://www.example.com:8080/path/name/.quz/foo.bar?key=value#fragment\"));\r\nconsole.log(getFileExtension(\"https://www.example.com:8080/path/name/.quz.bar?key=value#fragment\"));</code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 58954791,
"author": "Josh",
"author_id": 7066622,
"author_profile": "https://Stackoverflow.com/users/7066622",
"pm_score": 1,
"selected": false,
"text": "<p>I know this is an old question, but I wrote this function with tests for extracting file extension, and her available with NPM, Yarn, Bit.<br>\nMaybe it will help someone.<br>\n<a href=\"https://bit.dev/joshk/jotils/get-file-extension\" rel=\"nofollow noreferrer\">https://bit.dev/joshk/jotils/get-file-extension</a></p>\n\n<pre><code>function getFileExtension(path: string): string {\n var regexp = /\\.([0-9a-z]+)(?:[\\?#]|$)/i\n var extension = path.match(regexp)\n return extension && extension[1]\n}\n</code></pre>\n\n<p>You can see the tests I wrote <a href=\"https://bit.dev/joshk/jotils/get-file-extension/~code#test.ts\" rel=\"nofollow noreferrer\">here</a>. </p>\n"
},
{
"answer_id": 61666295,
"author": "manoj patel",
"author_id": 11984368,
"author_profile": "https://Stackoverflow.com/users/11984368",
"pm_score": 1,
"selected": false,
"text": "<p>Simple way to get filename even multiple dot in name</p>\n\n<pre><code>var filename = \"my.filehere.txt\";\n\nfile_name = filename.replace('.'+filename.split('.').pop(),'');\n\nconsole.log(\"Filename =>\"+file_name);\n</code></pre>\n\n<p>OutPut : my.filehere</p>\n\n<pre><code>extension = filename.split('.').pop();\nconsole.log(\"Extension =>\"+extension);\n</code></pre>\n\n<p>OutPut : txt</p>\n\n<p><strong>Try this is one line code</strong></p>\n"
},
{
"answer_id": 62803788,
"author": "Mateja Petrovic",
"author_id": 8809024,
"author_profile": "https://Stackoverflow.com/users/8809024",
"pm_score": 3,
"selected": false,
"text": "<p>There's also a simple approach using ES6 destructuring:</p>\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>const path = 'hello.world.txt'\nconst [extension, ...nameParts] = path.split('.').reverse();\nconsole.log('extension:', extension);</code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190852",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2138/"
] |
See code:
```
var file1 = "50.xsl";
var file2 = "30.doc";
getFileExtension(file1); //returns xsl
getFileExtension(file2); //returns doc
function getFileExtension(filename) {
/*TODO*/
}
```
|
**Newer Edit:** Lots of things have changed since this question was initially posted - there's a lot of really good information in [wallacer's revised answer](https://stackoverflow.com/a/1203361/23746) as well as [VisioN's excellent breakdown](https://stackoverflow.com/a/12900504/23746)
---
**Edit:** Just because this is the accepted answer; [wallacer's answer](https://stackoverflow.com/a/1203361/23746) is indeed much better:
```
return filename.split('.').pop();
```
---
My old answer:
```
return /[^.]+$/.exec(filename);
```
Should do it.
**Edit:** In response to PhiLho's comment, use something like:
```
return (/[.]/.exec(filename)) ? /[^.]+$/.exec(filename) : undefined;
```
|
190,867 |
<p>Is it possible to have multiple view of the same display object? (e.g. same-computer multi-player game using split screen)</p>
<p>The sample code that failed to work follows:</p>
<pre><code> var content: Sprite = new Sprite();
var v1: Sprite = new Sprite();
var v2: Sprite = new Sprite();
with(content.graphics) {
lineStyle(2, 0xff0000);
drawCircle(100, 100, 80);
lineStyle(5, 0x009999);
drawRect(50, 80, 200, 30);
}
v1.addChild(content);
v1.x = 0;
v1.y = 0;
v1.scrollRect = new Rectangle(0, 0, 100, 100);
addChild(v1);
v2.addChild(content);
v2.x = 100;
v2.y = 0;
v2.scrollRect = new Rectangle(0, 0, 100, 100);
addChild(v2);
</code></pre>
<p>I thought this would make two viewports (<code>v1</code> and <code>v2</code>) of the same object (<code>content</code>).
But when I checked the docs, DisplayObjectContaner/addChild method, it says,</p>
<p>"If you add a child object that already has a different display object container as a parent, the object is removed from the child list of the other display object container."</p>
<p>Is there a solution for this?</p>
<hr>
<p>Obtained result</p>
<p><img src="https://i.stack.imgur.com/aWKOO.png" alt="Obtained result"></p>
<p>Expected result (simulated)</p>
<p><a href="http://img337.imageshack.us/img337/7914/222mq4.png" rel="nofollow noreferrer">Expected result (simulated) http://img337.imageshack.us/img337/7914/222mq4.png</a></p>
<hr>
<p>Rendering to a bitmap as suggested by Antti is a great idea, but the rendered sprites will not be able to catch mouse events. Is there a way to redirect the mouse clicks on the bitmap to trigger clicks on the original sprites?</p>
|
[
{
"answer_id": 191398,
"author": "Antti",
"author_id": 6037,
"author_profile": "https://Stackoverflow.com/users/6037",
"pm_score": 3,
"selected": true,
"text": "<p>The easiest way to do this is to have a bitmap that's updated with the original display object's contents, something like:</p>\n\n<pre>\nvar bitmap:Bitmap = new Bitmap(new BitmapData(1,1));\naddChild(bitmap);\n\naddEventListener(Event.ENTER_FRAME,enterFrameHandler);\n\nfunction enterFrameHandler(event:Event):void {\n bitmap.bitmapData.dispose();\n bitmap.bitmapData = new BitmapData(displayObject.width, displayObject.height, true, 0x00000000);\n bitmap.bitmapData.draw(displayObject);\n}\n</pre>\n"
},
{
"answer_id": 196583,
"author": "mikechambers",
"author_id": 10232,
"author_profile": "https://Stackoverflow.com/users/10232",
"pm_score": 0,
"selected": false,
"text": "<p>If you put render to a bitmap inside of sprite, then you can capture mouse clicks.</p>\n\n<p>mike</p>\n"
},
{
"answer_id": 197144,
"author": "Iain",
"author_id": 11911,
"author_profile": "https://Stackoverflow.com/users/11911",
"pm_score": 1,
"selected": false,
"text": "<p>One way you could go is to adopt an MVC pattern, where you have a model that controls your game logic etc, and separate view classes that control display. This way it is more manageable to have multiple views of the same scene.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190867",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11238/"
] |
Is it possible to have multiple view of the same display object? (e.g. same-computer multi-player game using split screen)
The sample code that failed to work follows:
```
var content: Sprite = new Sprite();
var v1: Sprite = new Sprite();
var v2: Sprite = new Sprite();
with(content.graphics) {
lineStyle(2, 0xff0000);
drawCircle(100, 100, 80);
lineStyle(5, 0x009999);
drawRect(50, 80, 200, 30);
}
v1.addChild(content);
v1.x = 0;
v1.y = 0;
v1.scrollRect = new Rectangle(0, 0, 100, 100);
addChild(v1);
v2.addChild(content);
v2.x = 100;
v2.y = 0;
v2.scrollRect = new Rectangle(0, 0, 100, 100);
addChild(v2);
```
I thought this would make two viewports (`v1` and `v2`) of the same object (`content`).
But when I checked the docs, DisplayObjectContaner/addChild method, it says,
"If you add a child object that already has a different display object container as a parent, the object is removed from the child list of the other display object container."
Is there a solution for this?
---
Obtained result
Expected result (simulated)
[Expected result (simulated) http://img337.imageshack.us/img337/7914/222mq4.png](http://img337.imageshack.us/img337/7914/222mq4.png)
---
Rendering to a bitmap as suggested by Antti is a great idea, but the rendered sprites will not be able to catch mouse events. Is there a way to redirect the mouse clicks on the bitmap to trigger clicks on the original sprites?
|
The easiest way to do this is to have a bitmap that's updated with the original display object's contents, something like:
```
var bitmap:Bitmap = new Bitmap(new BitmapData(1,1));
addChild(bitmap);
addEventListener(Event.ENTER_FRAME,enterFrameHandler);
function enterFrameHandler(event:Event):void {
bitmap.bitmapData.dispose();
bitmap.bitmapData = new BitmapData(displayObject.width, displayObject.height, true, 0x00000000);
bitmap.bitmapData.draw(displayObject);
}
```
|
190,876 |
<p>I have a few combo-boxes and double spin boxes on my Qt Dialog. Now I need a "ResetToDefault" item on a menu that comes up when you right click on the widget (spin box or combo box).</p>
<p>How do i get it. Is there some way I can have a custom menu that comes up on right click or Is there a way i can add items to the menu that comes on right click.</p>
|
[
{
"answer_id": 190895,
"author": "PierreBdR",
"author_id": 7136,
"author_profile": "https://Stackoverflow.com/users/7136",
"pm_score": 4,
"selected": true,
"text": "<p>First, for Qt4, the simplest way is to create an action to reset the data, and add it the the widget using the <code>addAction</code> method (or use the designer). Then, set the <code>contextMenuPolicy</code> attribute to <code>Qt::ActionsContextMenu</code>. The context menu will appear and the action will be triggered.</p>\n\n<p>Code example:</p>\n\n<pre><code>QAction *reset_act = new QAction(\"Reset to default\");\nmywidget->addAction(reset_act);\nmywidget->setContextMenuPolicy(Qt::ActionsContextMenu);\n// here connect the 'triggered' signal to some slot\n</code></pre>\n\n<p>For Qt3, you might have to intercept the context menu event, and thus inherit the QSpinBox and others. Or maybe you can intercept the context menu event from the main window, detect if it occurred above the widget supposed to have a context menu (using the <code>QWidget::childAt</code> method) and show it there. But you'll have to test.</p>\n"
},
{
"answer_id": 191228,
"author": "David Dibben",
"author_id": 5022,
"author_profile": "https://Stackoverflow.com/users/5022",
"pm_score": 1,
"selected": false,
"text": "<p>For Qt4, you can do this for an editable QComboBox by using your own QLineEdit. Create a derived QLineEdit class which implements the contextMenuEvent</p>\n\n<pre><code>class MyLineEdit : public QLineEdit\n{\n Q_OBJECT\npublic:\n\n MyLineEdit(QWidget* parent = 0) : QLineEdit(parent){}\n\n void contextMenuEvent(QContextMenuEvent *event)\n {\n QPointer<QMenu> menu = createStandardContextMenu();\n //add your actions here\n menu->exec(event->globalPos());\n delete menu;\n }\n\n};\n</code></pre>\n\n<p>Then, use the setLineEdit function of QComboBox to set the line edit</p>\n\n<pre><code>MyLineEdit* edit = new MyLineEdit();\ncomboBox->setLineEdit(edit);\n</code></pre>\n\n<p>The combo box will now use your line edit class. The createStandardContextMenu function creates the normal context menu and you can add any new actions to it that you like in the contextMenuEvent handler before it is shown. </p>\n\n<p>If the QComboBox is not editable then it doesn't have a default context menu so using the Qt::ActionsContextMenu method is much simpler.</p>\n\n<p>QAbstractSpinBox also has a setLineEdit function so you can use a similar technique. Although, for some reason the setLineEdit function is protected on QAbstractSpinBox but public on QLineEdit. </p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190876",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11212/"
] |
I have a few combo-boxes and double spin boxes on my Qt Dialog. Now I need a "ResetToDefault" item on a menu that comes up when you right click on the widget (spin box or combo box).
How do i get it. Is there some way I can have a custom menu that comes up on right click or Is there a way i can add items to the menu that comes on right click.
|
First, for Qt4, the simplest way is to create an action to reset the data, and add it the the widget using the `addAction` method (or use the designer). Then, set the `contextMenuPolicy` attribute to `Qt::ActionsContextMenu`. The context menu will appear and the action will be triggered.
Code example:
```
QAction *reset_act = new QAction("Reset to default");
mywidget->addAction(reset_act);
mywidget->setContextMenuPolicy(Qt::ActionsContextMenu);
// here connect the 'triggered' signal to some slot
```
For Qt3, you might have to intercept the context menu event, and thus inherit the QSpinBox and others. Or maybe you can intercept the context menu event from the main window, detect if it occurred above the widget supposed to have a context menu (using the `QWidget::childAt` method) and show it there. But you'll have to test.
|
190,908 |
<p>When you tap a row in a <code>UITableView</code>, the row is highlighted and selected. Is it possible to disable this so tapping a row does nothing?</p>
|
[
{
"answer_id": 191245,
"author": "Martin Gordon",
"author_id": 2481,
"author_profile": "https://Stackoverflow.com/users/2481",
"pm_score": 11,
"selected": false,
"text": "<p>All you have to do is set the selection style on the <code>UITableViewCell</code> instance using either:</p>\n\n<p>Objective-C:</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>or</p>\n\n<pre><code>[cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n\n<p>Swift 2:</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyle.None\n</code></pre>\n\n<p>Swift 3 and 4.x:</p>\n\n<pre><code>cell.selectionStyle = .none\n</code></pre>\n\n<p>Further, make sure you either don't implement <code>-tableView:didSelectRowAtIndexPath:</code> in your table view delegate or explicitly exclude the cells you want to have no action if you do implement it.</p>\n\n<p><a href=\"https://web.archive.org/web/20100825164330/http://developer.apple.com:80/iphone/library/documentation/uikit/reference/UITableViewCell_Class/Reference/Reference.html#//apple_ref/occ/instp/UITableViewCell/selectionStyle\" rel=\"noreferrer\">More info here</a> and <a href=\"https://web.archive.org/web/20100901120334/http://developer.apple.com:80/iphone/library/documentation/uikit/reference/UITableViewDelegate_Protocol/Reference/Reference.html#//apple_ref/occ/intfm/UITableViewDelegate/tableView:didSelectRowAtIndexPath:\" rel=\"noreferrer\">here</a></p>\n"
},
{
"answer_id": 1062825,
"author": "user41806",
"author_id": 41806,
"author_profile": "https://Stackoverflow.com/users/41806",
"pm_score": 5,
"selected": false,
"text": "<p>From the <code>UITableViewDelegate</code> Protocol you can use the method <code>willSelectRowAtIndexPath</code> \nand <code>return nil</code> if you don't want the row selected.</p>\n\n<p>In the same way the you can use the <code>willDeselectRowAtIndexPath</code> method and <code>return nil</code> if you don't want the row to deselect.</p>\n"
},
{
"answer_id": 1166670,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 10,
"selected": true,
"text": "<p>For me, the following worked fine:</p>\n\n<pre><code>tableView.allowsSelection = false\n</code></pre>\n\n<p>This means <code>didSelectRowAt#</code> simply won't work. That is to say, touching a row of the table, as such, will do absolutely nothing. (And hence, obviously, there will never be a selected-animation.)</p>\n\n<p>(Note that if, on the cells, you have <code>UIButton</code> or any other controls, of course those controls will still work. Any controls you happen to have on the table cell, are totally unrelated to UITableView's ability to allow you to \"select a row\" using <code>didSelectRowAt#</code>.)</p>\n\n<p>Another point to note is that: This doesn't work when the <code>UITableView</code> is in editing mode. To restrict cell selection in editing mode use the code as below:</p>\n\n<pre><code>tableView.allowsSelectionDuringEditing = false \n</code></pre>\n"
},
{
"answer_id": 6154555,
"author": "Denis Kutlubaev",
"author_id": 751641,
"author_profile": "https://Stackoverflow.com/users/751641",
"pm_score": 4,
"selected": false,
"text": "<p>Try to type: </p>\n\n<pre><code>cell.selected = NO;\n</code></pre>\n\n<p>It will deselect your row when needed. </p>\n\n<p>In Swift3 ...</p>\n\n<pre><code>override func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {\n let r = indexPath.row\n print(\"clicked .. \\(r)\")\n tableView.cellForRow(at: indexPath)?.setSelected(false, animated: true)\n}\n</code></pre>\n"
},
{
"answer_id": 6201993,
"author": "JosephH",
"author_id": 292166,
"author_profile": "https://Stackoverflow.com/users/292166",
"pm_score": 7,
"selected": false,
"text": "<p>To sum up what I believe are the correct answers based on my own experience in implementing this:</p>\n\n<p>If you want to disable selection for just some of the cells, use:</p>\n\n<pre><code>cell.userInteractionEnabled = NO;\n</code></pre>\n\n<p>As well as preventing selection, this also stops tableView:didSelectRowAtIndexPath: being called for the cells that have it set. (Credit goes to Tony Million for this answer, thanks!)</p>\n\n<p>If you have buttons in your cells that need to be clicked, you need to instead:</p>\n\n<pre><code>[cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n\n<p>and you also need to ignore any clicks on the cell in <code>- (void)tableView:(UITableView *)tableView didSelectRowAtIndexPath:(NSIndexPath *)indexPath</code>.</p>\n\n<p>If you want to disable selection for the whole table, use:</p>\n\n<pre><code>tableView.allowsSelection = NO;\n</code></pre>\n\n<p>(Credit to Paulo De Barros, thanks!)</p>\n"
},
{
"answer_id": 6305493,
"author": "mbm29414",
"author_id": 394484,
"author_profile": "https://Stackoverflow.com/users/394484",
"pm_score": 9,
"selected": false,
"text": "<p>Because I've read this post recently and it has helped me, I wanted to post another answer to consolidate all of the answers (for posterity).\n<br><br><br></p>\n\n<hr>\n\n<p>So, there are actually 5 different answers depending on your desired logic and/or result:</p>\n\n<p>1.To disable the blue highlighting without changing any other interaction of the cell:</p>\n\n<pre><code>[cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n\n<p>I use this when I have a UIButton - or some other control(s) - hosted in a UITableViewCell and I want the user to be able to interact with the controls but not the cell itself.</p>\n\n<p><sub><strong><em>NOTE</em></strong>: As Tony Million noted above, this does NOT prevent <code>tableView:didSelectRowAtIndexPath:</code>. I get around this by simple \"if\" statements, most often testing for the section and avoiding action for a particular section. </sub></p>\n\n<p>Another way I thought of to test for the tapping of a cell like this is:</p>\n\n<pre><code>- (void)tableView:(UITableView *)tableView didSelectRowAtIndexPath:(NSIndexPath *)indexPath {\n // A case was selected, so push into the CaseDetailViewController\n UITableViewCell *cell = [tableView cellForRowAtIndexPath:indexPath];\n if (cell.selectionStyle != UITableViewCellSelectionStyleNone) {\n // Handle tap code here\n }\n}\n</code></pre>\n\n<p><br><br>\n2.To do this for an entire table, you can apply the above solution to each cell in the table, but you can also do this:</p>\n\n<pre><code>[tableView setAllowsSelection:NO];\n</code></pre>\n\n<p><sub><strong>In my testing, this still allows controls inside the <code>UITableViewCell</code> to be interactive.</strong></sub>\n<br><br><br>\n3.To make a cell \"read-only\", you can simply do this:</p>\n\n<pre><code>[cell setUserInteractionEnabled:NO];\n</code></pre>\n\n<p><br><br>\n4.To make an entire table \"read-only\"</p>\n\n<pre><code>[tableView setUserInteractionEnabled:NO];\n</code></pre>\n\n<p><br><br>\n5.To determine on-the-fly whether to highlight a cell (which according to <a href=\"https://stackoverflow.com/a/13167946/394484\">this answer</a> implicitly includes selection), you can implement the following <code>UITableViewDelegate</code> protocol method:</p>\n\n<pre><code>- (BOOL)tableView:(UITableView *)tableView \n shouldHighlightRowAtIndexPath:(NSIndexPath *)indexPath\n</code></pre>\n"
},
{
"answer_id": 9852081,
"author": "iDhaval",
"author_id": 921510,
"author_profile": "https://Stackoverflow.com/users/921510",
"pm_score": 4,
"selected": false,
"text": "<p>We can write code like</p>\n\n<pre><code> cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>but when we have <strong>custom cell xib</strong> above line <strong>give warning</strong> at that time for</p>\n\n<p><strong>custom cell xib</strong></p>\n\n<p>we need to <strong>set selection style None from the interface builder</strong> </p>\n"
},
{
"answer_id": 11390674,
"author": "v_1",
"author_id": 1642772,
"author_profile": "https://Stackoverflow.com/users/1642772",
"pm_score": 3,
"selected": false,
"text": "<p>try this</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>and</p>\n\n<pre><code>[cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n\n<p>and you can also set selection style using interfacebuilder.</p>\n"
},
{
"answer_id": 13167946,
"author": "cbowns",
"author_id": 774,
"author_profile": "https://Stackoverflow.com/users/774",
"pm_score": 6,
"selected": false,
"text": "<p>As of iOS 6.0, <code>UITableViewDelegate</code> has <code>tableView:shouldHighlightRowAtIndexPath:</code>. (Read about it in the iOS <a href=\"http://developer.apple.com/library/ios/documentation/uikit/reference/UITableViewDelegate_Protocol/Reference/Reference.html#//apple_ref/occ/intfm/UITableViewDelegate/tableView:shouldHighlightRowAtIndexPath:\" rel=\"noreferrer\">Documentation</a>.)</p>\n\n<p>This method lets you mark specific rows as unhighlightable (and implicitly, unselectable) without having to change a cell's selection style, messing with the cell's event handling with <code>userInteractionEnabled = NO</code>, or any other techniques documented here.</p>\n"
},
{
"answer_id": 13363194,
"author": "Chris Fox",
"author_id": 1119654,
"author_profile": "https://Stackoverflow.com/users/1119654",
"pm_score": 5,
"selected": false,
"text": "<p>If you want selection to only flash, not remain in the selected state, you can call, in</p>\n\n<pre><code>didSelectRowAtIndexPath\n</code></pre>\n\n<p>the following</p>\n\n<pre><code>[tableView deselectRowAtIndexPath:indexPath animated:YES];\n</code></pre>\n\n<p>so it will flash the selected state and revert.</p>\n"
},
{
"answer_id": 13910050,
"author": "Aniruddh",
"author_id": 530432,
"author_profile": "https://Stackoverflow.com/users/530432",
"pm_score": 2,
"selected": false,
"text": "<p>The better approach will be:</p>\n\n<pre><code>cell.userInteractionEnabled = NO;\n</code></pre>\n\n<p>This approach will not call <code>didSelectRowAtIndexPath:</code> method.</p>\n"
},
{
"answer_id": 14147268,
"author": "Yarek T",
"author_id": 274503,
"author_profile": "https://Stackoverflow.com/users/274503",
"pm_score": 4,
"selected": false,
"text": "<p>I've been battling with this quite profusely too, having a control in my <code>UITableViewCell</code> prohibited the use of <code>userInteractionEnabled</code> property. I have a 3 cell static table for settings, 2 with dates, 1 with an on/off switch. After playing about in Storyboard/IB i've managed to make the bottom one non-selectable, but when you tap it the selection from one of the top rows disappears. Here is a WIP image of my settings UITableView:</p>\n\n<p><img src=\"https://i.stack.imgur.com/6qV3g.png\" alt=\"Settings UITableView\"></p>\n\n<p>If you tap the 3rd row nothing at all happens, the selection will stay on the second row. The functionality is practically a copy of Apple's Calendar app's add event time selection screen.</p>\n\n<p>The code is surprisingly compatible, all the way down to IOS2 =/:</p>\n\n<pre><code>- (NSIndexPath *)tableView: (UITableView *)tableView willSelectRowAtIndexPath:(NSIndexPath *)indexPath {\n if (indexPath.row == 2) {\n return nil;\n }\n return indexPath;\n}\n</code></pre>\n\n<p>This works in conjunction with setting the selection style to none, so the cell doesn't flicker on touch down events</p>\n"
},
{
"answer_id": 14390807,
"author": "Sharme",
"author_id": 867280,
"author_profile": "https://Stackoverflow.com/users/867280",
"pm_score": 3,
"selected": false,
"text": "<p>To disable the highlighting of the UItableviewcell</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>And should not allow the user to interact with the cell. </p>\n\n<pre><code>cell.userInteractionEnabled = NO;\n</code></pre>\n"
},
{
"answer_id": 16214897,
"author": "ashevin",
"author_id": 867943,
"author_profile": "https://Stackoverflow.com/users/867943",
"pm_score": 2,
"selected": false,
"text": "<p>At least as of iOS 6, you can override methods in your custom cell to prevent the blue highlight. No other interaction is disabled or affected. All three must be overridden.</p>\n\n<pre><code>- (void) setHighlighted:(BOOL)highlighted\n{\n}\n\n- (void) setHighlighted:(BOOL)highlighted animated:(BOOL)animated\n{\n}\n\n- (void) setSelected:(BOOL)selected animated:(BOOL)animated\n{\n}\n</code></pre>\n"
},
{
"answer_id": 16215743,
"author": "vignesh kumar",
"author_id": 1211532,
"author_profile": "https://Stackoverflow.com/users/1211532",
"pm_score": 6,
"selected": false,
"text": "<p>You can also disable selection of row from interface builder itself by choosing <code>NoSelection</code> from the <code>selection</code> option(of UITableView Properties) in inspector pane as shown in the below image</p>\n\n<p><img src=\"https://i.stack.imgur.com/Qw1bX.png\" alt=\"UITableView Inspector\"></p>\n"
},
{
"answer_id": 16479416,
"author": "iEinstein",
"author_id": 1603461,
"author_profile": "https://Stackoverflow.com/users/1603461",
"pm_score": 3,
"selected": false,
"text": "<p>You can use this</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n"
},
{
"answer_id": 18345211,
"author": "Steve Barden",
"author_id": 974035,
"author_profile": "https://Stackoverflow.com/users/974035",
"pm_score": 3,
"selected": false,
"text": "<p>While this is the best and easiest solution to prevent a row from showing the highlight during selection</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>I'd like to also suggest that it's occasionally useful to briefly show that the row has been selected and then turning it off. This alerts the users with a confirmation of what they intended to select:</p>\n\n<pre><code>- (void)tableView:(UITableView *)tableView didSelectRowAtIndexPath:(NSIndexPath *)indexPath {\n [tableView deselectRowAtIndexPath:indexPath animated:NO];\n...\n}\n</code></pre>\n"
},
{
"answer_id": 18429455,
"author": "Harini",
"author_id": 980918,
"author_profile": "https://Stackoverflow.com/users/980918",
"pm_score": 3,
"selected": false,
"text": "<p>The best solution would be <strong>Making The selection Style None</strong> </p>\n\n<pre><code>[cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n\n<p>However, Here we are considering the fact that there are no custom images used for selected state.</p>\n"
},
{
"answer_id": 19246155,
"author": "Mak083",
"author_id": 2724163,
"author_profile": "https://Stackoverflow.com/users/2724163",
"pm_score": 3,
"selected": false,
"text": "<p>You can use ....</p>\n\n<pre><code>[cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n"
},
{
"answer_id": 21104706,
"author": "virindh",
"author_id": 1418074,
"author_profile": "https://Stackoverflow.com/users/1418074",
"pm_score": 3,
"selected": false,
"text": "<p>You Can also set the background color to Clear to achieve the same effect as <code>UITableViewCellSelectionStyleNone</code>, in case you don't want to/ can't use <code>UITableViewCellSelectionStyleNone</code>. </p>\n\n<p>You would use code like the following:</p>\n\n<pre><code>UIView *backgroundColorView = [[UIView alloc] init];\nbackgroundColorView.backgroundColor = [UIColor clearColor];\nbackgroundColorView.layer.masksToBounds = YES;\n[cell setSelectedBackgroundView: backgroundColorView];\n</code></pre>\n\n<p>This may <strong><em>degrade</em></strong> your performance as your adding an <em>extra</em> colored view to <strong>each</strong> cell.</p>\n"
},
{
"answer_id": 22987593,
"author": "iDeveloper",
"author_id": 2417281,
"author_profile": "https://Stackoverflow.com/users/2417281",
"pm_score": 3,
"selected": false,
"text": "<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n"
},
{
"answer_id": 24711398,
"author": "Programming Learner",
"author_id": 2484878,
"author_profile": "https://Stackoverflow.com/users/2484878",
"pm_score": 3,
"selected": false,
"text": "<p><strong>You can use :</strong> </p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>in the cell for row at index path method of your UITableView.</p>\n\n<p><strong>Also you can use :</strong> </p>\n\n<pre><code>[tableView deselectRowAtIndexPath:indexPath animated:NO];\n</code></pre>\n\n<p>in the tableview didselectrowatindexpath method.</p>\n"
},
{
"answer_id": 25059393,
"author": "Rinku Sadhwani",
"author_id": 1037317,
"author_profile": "https://Stackoverflow.com/users/1037317",
"pm_score": 3,
"selected": false,
"text": "<pre><code>UITableViewCell *cell = [self.tableView cellForRowAtIndexPath:indexPath];\n[cell setSelected:NO animated:NO];\n[cell setHighlighted:NO animated:NO];\n</code></pre>\n\n<p>Happy coding !!!</p>\n"
},
{
"answer_id": 27076003,
"author": "Arun Gupta",
"author_id": 1732743,
"author_profile": "https://Stackoverflow.com/users/1732743",
"pm_score": 4,
"selected": false,
"text": "<h2>Objective-C:</h2>\n\n<ol>\n<li><p>Below snippet disable highlighting but it also disable the call to <code>didSelectRowAtIndexPath</code>. So if you are not implementing <code>didSelectRowAtIndexPath</code> then use below method. This should be added when you are creating the table. This will work on buttons and <code>UITextField</code> inside the cell though.</p>\n\n<pre><code>self.tableView.allowsSelection = NO;\n</code></pre></li>\n<li><p>Below snippet disable highlighting and it doesn't disable the call to <code>didSelectRowAtIndexPath</code>. Set the selection style of cell to None in <code>cellForRowAtIndexPath</code> </p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre></li>\n<li><p>Below snippet disable everything on the cell. This will disable the interaction to <code>buttons</code>, <code>textfields</code>:</p>\n\n<pre><code>self.tableView.userInteractionEnabled = false;\n</code></pre></li>\n</ol>\n\n<h2>Swift:</h2>\n\n<p>Below are the <code>Swift</code> equivalent of above <code>Objective-C</code> solutions:</p>\n\n<ol>\n<li><p>Replacement of First Solution</p>\n\n<pre><code>self.tableView.allowsSelection = false\n</code></pre></li>\n<li><p>Replacement of Second Solution</p>\n\n<pre><code>cell?.selectionStyle = UITableViewCellSelectionStyle.None\n</code></pre></li>\n<li><p>Replacement of Third Solution</p>\n\n<pre><code>self.tableView.userInteractionEnabled = false\n</code></pre></li>\n</ol>\n"
},
{
"answer_id": 27246135,
"author": "Aks",
"author_id": 1326339,
"author_profile": "https://Stackoverflow.com/users/1326339",
"pm_score": 5,
"selected": false,
"text": "<p>EDIT: for newer Swift it is changed to:</p>\n<pre><code>cell.selectionStyle = .none\n</code></pre>\n<p>See this for more info:\n<a href=\"https://developer.apple.com/documentation/uikit/uitableviewcell/selectionstyle\" rel=\"nofollow noreferrer\">https://developer.apple.com/documentation/uikit/uitableviewcell/selectionstyle</a></p>\n<p>In case anyone needs answer for <a href=\"https://developer.apple.com/swift/\" rel=\"nofollow noreferrer\">Swift</a>:</p>\n<pre><code>cell.selectionStyle = .None\n</code></pre>\n"
},
{
"answer_id": 27286751,
"author": "Cindy",
"author_id": 3042051,
"author_profile": "https://Stackoverflow.com/users/3042051",
"pm_score": 3,
"selected": false,
"text": "<p>You can also do it from the storyboard. Click the table view cell and in the attributes inspector under Table View Cell, change the drop down next to Selection to None.</p>\n"
},
{
"answer_id": 28602027,
"author": "Zorayr",
"author_id": 577878,
"author_profile": "https://Stackoverflow.com/users/577878",
"pm_score": 3,
"selected": false,
"text": "<p><strong>Swift Solution w/ Custom Cell:</strong></p>\n\n<pre><code>import Foundation\n\nclass CustomTableViewCell: UITableViewCell\n{\n required init(coder aDecoder: NSCoder)\n {\n fatalError(\"init(coder:) has not been implemented\")\n }\n\n override init(style: UITableViewCellStyle, reuseIdentifier: String?)\n {\n super.init(style: style, reuseIdentifier: reuseIdentifier)\n self.selectionStyle = UITableViewCellSelectionStyle.None\n } \n}\n</code></pre>\n"
},
{
"answer_id": 29339444,
"author": "parvind",
"author_id": 452344,
"author_profile": "https://Stackoverflow.com/users/452344",
"pm_score": 5,
"selected": false,
"text": "<p>1- All you have to do is set the <strong>selection style on the <code>UITableViewCell</code></strong> instance using either:</p>\n\n<p><br>\n<strong>Objective-C:</strong></p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>or</p>\n\n<pre><code>[cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n\n<p><br></p>\n\n<p><strong>Swift 2:</strong></p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyle.None\n</code></pre>\n\n<p><br> </p>\n\n<p><strong>Swift 3:</strong></p>\n\n<pre><code>cell.selectionStyle = .none\n</code></pre>\n\n<p><br>\n2 - Don't implement -<strong><code>tableView:didSelectRowAtIndexPath:</code></strong> in your table view <code>delegate</code> or explicitly exclude the cells you want to have no action if you do implement it.</p>\n\n<p>3 - Further,You can also do it from the storyboard. Click the table view cell and in the attributes inspector under Table View Cell, change the drop down next to Selection to None.</p>\n\n<p><br>\n4 - You can disable table cell highlight using below code in (iOS) <strong>Xcode 9 , Swift 4.0</strong></p>\n\n<pre><code>func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {\n\n\n let cell = tableView.dequeueReusableCell(withIdentifier: \"OpenTbCell\") as! OpenTbCell\n cell.selectionStyle = .none\n return cell\n\n\n}\n</code></pre>\n"
},
{
"answer_id": 29343919,
"author": "Ahsan Ebrahim",
"author_id": 1825707,
"author_profile": "https://Stackoverflow.com/users/1825707",
"pm_score": 5,
"selected": false,
"text": "<p>This is what I use ,in <code>cellForRowAtIndexPath</code> write this code.:</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n"
},
{
"answer_id": 30255373,
"author": "Jayprakash Dubey",
"author_id": 1753005,
"author_profile": "https://Stackoverflow.com/users/1753005",
"pm_score": 3,
"selected": false,
"text": "<p>You can use <em>selectionStyle</em> property of UITableViewCell</p>\n\n<pre><code> cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p>Or </p>\n\n<pre><code> [cell setSelectionStyle:UITableViewCellSelectionStyleNone];\n</code></pre>\n\n<p>Also, do not implement below delegate</p>\n\n<pre><code>- (void)tableView:(UITableView *)tableView didSelectRowAtIndexPath:(NSIndexPath *)indexPath { ... }\n</code></pre>\n\n<p>If you have created Xib/Storyboard file then you can change <em>setUserInteractionEnabled</em> \nproperty of tableview to <em>No</em> by unchecking it.\nThis will make your tableview to Read-Only.</p>\n"
},
{
"answer_id": 33214518,
"author": "priyanka gautam",
"author_id": 5358005,
"author_profile": "https://Stackoverflow.com/users/5358005",
"pm_score": 3,
"selected": false,
"text": "<p>I am using this, which works for me.</p>\n\n<pre><code>cell?.selectionStyle = UITableViewCellSelectionStyle.None\n</code></pre>\n"
},
{
"answer_id": 37290839,
"author": "Gaurav Patel",
"author_id": 6021734,
"author_profile": "https://Stackoverflow.com/users/6021734",
"pm_score": 4,
"selected": false,
"text": "<p>You just have to put this code into cellForRowAtIndexPath</p>\n\n<p>To disable the cell's selection property:(While tapping the cell).</p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyle.None\n</code></pre>\n"
},
{
"answer_id": 39868238,
"author": "Mohammad Zaid Pathan",
"author_id": 3411787,
"author_profile": "https://Stackoverflow.com/users/3411787",
"pm_score": 5,
"selected": false,
"text": "<p>In your <code>UITableViewCell</code>'s <strong>XIB</strong> in Attribute Inspector set value of <code>Selection</code> to <code>None</code>.</p>\n\n<p><a href=\"https://i.stack.imgur.com/MHHe5.png\" rel=\"noreferrer\"><img src=\"https://i.stack.imgur.com/MHHe5.png\" alt=\"enter image description here\"></a></p>\n"
},
{
"answer_id": 41525449,
"author": "MANISH PATHAK",
"author_id": 729179,
"author_profile": "https://Stackoverflow.com/users/729179",
"pm_score": 6,
"selected": false,
"text": "<p><strong>FIXED SOLUTION FOR SWIFT 3</strong> </p>\n\n<pre><code>cell.selectionStyle = .none\n</code></pre>\n"
},
{
"answer_id": 49825425,
"author": "Kamani Jasmin",
"author_id": 8210517,
"author_profile": "https://Stackoverflow.com/users/8210517",
"pm_score": 3,
"selected": false,
"text": "<p>Directly disable highlighting of TableViewCell into storyboard</p>\n\n<p><a href=\"https://i.stack.imgur.com/SfVKW.png\" rel=\"noreferrer\"><img src=\"https://i.stack.imgur.com/SfVKW.png\" alt=\"enter image description here\"></a></p>\n"
},
{
"answer_id": 52328730,
"author": "Praful Argiddi",
"author_id": 9528204,
"author_profile": "https://Stackoverflow.com/users/9528204",
"pm_score": 2,
"selected": false,
"text": "<p><strong>You can disable table cell highight using below code in (iOS) Xcode 9 , Swift 4.0</strong></p>\n\n<pre><code> func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {\n\n\n let cell = tableView.dequeueReusableCell(withIdentifier: \"OpenTbCell\") as! OpenTbCell\n cell.selectionStyle = .none\n return cell\n\n\n}\n</code></pre>\n"
},
{
"answer_id": 57196754,
"author": "vrat2801",
"author_id": 6593648,
"author_profile": "https://Stackoverflow.com/users/6593648",
"pm_score": 2,
"selected": false,
"text": "<p><strong><em>Scenario - 1</em></strong></p>\n\n<p>If you don't want selection for some specific cells on the <strong>tableview</strong>, you can set selection style in <strong>cellForRow</strong> function for those cells.</p>\n\n<p><strong>Objective-C</strong></p>\n\n<pre><code>cell.selectionStyle = UITableViewCellSelectionStyleNone;\n</code></pre>\n\n<p><strong>Swift 4.2</strong></p>\n\n<pre><code>cell.selectionStyle = .none\n</code></pre>\n\n<p><strong><em>Scenario - 2</em></strong></p>\n\n<p>For disabling selection on the whole table view :</p>\n\n<p><strong>Objective-C</strong></p>\n\n<pre><code>self.tableView.allowsSelection = false;\n</code></pre>\n\n<p><strong>Swift 4.2</strong></p>\n\n<pre><code>self.tableView.allowsSelection = false\n</code></pre>\n"
},
{
"answer_id": 57266532,
"author": "Muhammad Ahmad",
"author_id": 11468227,
"author_profile": "https://Stackoverflow.com/users/11468227",
"pm_score": 1,
"selected": false,
"text": "<p>Very simple stuff. Before returning the tableview Cell use the style property of the table view cell.</p>\n\n<p>Just write this line of code before returning table view cell<br>\n<code>cell.selectionStyle = .none</code></p>\n"
},
{
"answer_id": 59747207,
"author": "Abdul Karim Khan",
"author_id": 10118612,
"author_profile": "https://Stackoverflow.com/users/10118612",
"pm_score": 4,
"selected": false,
"text": "<p>From <strong>UITableViewDataSource</strong> Protocol, inside method <code>cellForRowAt</code> add:</p>\n<pre><code>let cell = tableView.dequeueReusableCell(withIdentifier: "YOUR_CELL_IDENTIFIER", for: indexPath) \ncell.selectionStyle = .none\nreturn cell\n</code></pre>\n<p>OR</p>\n<p>You can goto Storyboard > Select Cell > Identity Inspector > Selection and select none from dropdown.</p>\n"
},
{
"answer_id": 63336051,
"author": "Rashid Latif",
"author_id": 10383865,
"author_profile": "https://Stackoverflow.com/users/10383865",
"pm_score": 4,
"selected": false,
"text": "<p><strong>Swift 3,4 and 5</strong></p>\n<p><strong>Better practice</strong>, write code in <code>UITableViewCell</code></p>\n<p>For example, you have <code>UITableViewCell</code> with the name <code>MyCell</code>,\nIn <code>awakeFromNib</code> just write <code>self.selectionStyle = .none</code></p>\n<p>Full example:</p>\n<pre><code>class MyCell: UITableViewCell {\n \n override func awakeFromNib() {\n super.awakeFromNib()\n self.selectionStyle = .none\n }\n \n}\n</code></pre>\n"
},
{
"answer_id": 64462157,
"author": "testing",
"author_id": 11841585,
"author_profile": "https://Stackoverflow.com/users/11841585",
"pm_score": 3,
"selected": false,
"text": "<p><strong>Disable selection for all UITableViewCells in the UITableView</strong></p>\n<pre><code>tableView.allowsSelection = false\n</code></pre>\n<p><strong>Disable selection for specific UITableViewCells</strong></p>\n<pre><code>cell.selectionStyle = UITableViewCell.SelectionStyle.none\n</code></pre>\n"
},
{
"answer_id": 67984268,
"author": "André Herculano",
"author_id": 1244883,
"author_profile": "https://Stackoverflow.com/users/1244883",
"pm_score": 2,
"selected": false,
"text": "<p>I've gone through all answers and what worked for my use case was the following:</p>\n<pre class=\"lang-swift prettyprint-override\"><code>tableView.allowSelection = false\n</code></pre>\n<pre class=\"lang-swift prettyprint-override\"><code>public func tableView(_ tableView: UITableView, canFocusRowAt indexPath: IndexPath) -> Bool {\n true\n}\n</code></pre>\n<p>This way the table remains focusable, the user can scroll through its elements but is unable to "press / select" them.</p>\n<p>Simply setting <code>cell.selectionStyle = .none</code> will allow the list element to be selectable (just not leave a gray selection mark behind). And just setting <code>allowSelection = false</code> would cause my table not to be focusable. Users wouldn't be able to scroll through the elements.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190908",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2183/"
] |
When you tap a row in a `UITableView`, the row is highlighted and selected. Is it possible to disable this so tapping a row does nothing?
|
For me, the following worked fine:
```
tableView.allowsSelection = false
```
This means `didSelectRowAt#` simply won't work. That is to say, touching a row of the table, as such, will do absolutely nothing. (And hence, obviously, there will never be a selected-animation.)
(Note that if, on the cells, you have `UIButton` or any other controls, of course those controls will still work. Any controls you happen to have on the table cell, are totally unrelated to UITableView's ability to allow you to "select a row" using `didSelectRowAt#`.)
Another point to note is that: This doesn't work when the `UITableView` is in editing mode. To restrict cell selection in editing mode use the code as below:
```
tableView.allowsSelectionDuringEditing = false
```
|
190,914 |
<p>I have a DataGridView which shows the content of a DataTable.</p>
<p>I want to set the backcolor of a row based on the value of a cell in this row.</p>
<p>Note that the cell in question is in a column which is not displayed in the DataGridView (Visible=False).</p>
|
[
{
"answer_id": 190932,
"author": "Jason Stevenson",
"author_id": 13368,
"author_profile": "https://Stackoverflow.com/users/13368",
"pm_score": 2,
"selected": false,
"text": "<p>If you handle the RowDataBound event you can check the value of the data and modify the attributes of the cell or apply a different style in that event handler.</p>\n\n<pre><code>protected void Page_Load(object sender, EventArgs e)\n{\n GridView g1 = new GridView();\n g1.RowDataBound += new GridViewRowEventHandler(g1_RowDataBound);\n}\n\nvoid g1_RowDataBound(object sender, GridViewRowEventArgs e)\n{\n if(e.Row.RowType == DataControlRowType.DataRow)\n {\n // Check the Value\n if(e.Row.Cells[1].Text = someValue)\n {\n e.Row.Cells[1].CssClass = \"colorCellRed\";\n }\n\n }\n}\n</code></pre>\n\n<p>That should give you what you are looking for. Let me know if you need it in VB rather than C#.</p>\n\n<p>Good Luck!</p>\n"
},
{
"answer_id": 190949,
"author": "Keith Williams",
"author_id": 20376,
"author_profile": "https://Stackoverflow.com/users/20376",
"pm_score": 2,
"selected": false,
"text": "<p>RowDataBound, as already mentioned; you can also check the values of your data objects, as well as the text in the grid itself:</p>\n\n<pre>\nvoid gridView_DataBound(object sender, GridViewEventArgs e)\n{\n if (e.Row.RowType == DataControlRowType.DataRow)\n {\n var myObject = (myObject)e.DataItem;\n if (myObject.IsOverdue())\n {\n e.Row.CssClass = \"overdue\";\n }\n }\n}\n</pre>\n"
},
{
"answer_id": 3246896,
"author": "Mr.Mindor",
"author_id": 391656,
"author_profile": "https://Stackoverflow.com/users/391656",
"pm_score": 1,
"selected": false,
"text": "<p>Another option would be to use the CellFormatting event. \nFirst option shows accessing the bound data item and is useful if you don't have a column set up for the data in question. Second option works if there is a column whether it is visible or not.</p>\n\n<pre><code> private void dataGridView_CellFormatting(object sender, DataGridViewCellFormattingEventArgs e)\n {\n if (((MyDataObject)dataGridView.Rows[e.RowIndex].DataBoundItem).Condition == Value)\n {\n e.CellStyle.BackColor = System.Drawing.Color.Gold;\n\n }\n }\n</code></pre>\n\n<p>// Option two -- can use ColumnIndex instead of ColumnName</p>\n\n<pre><code> private void dataGridView_CellFormatting(object sender, DataGridViewCellFormattingEventArgs e)\n {\n if (dataGridView[\"ColumnName\", e.RowIndex].Value).Condition == TargetValue)\n {\n e.CellStyle.BackColor = System.Drawing.Color.Gold;\n\n }\n }\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190914",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15928/"
] |
I have a DataGridView which shows the content of a DataTable.
I want to set the backcolor of a row based on the value of a cell in this row.
Note that the cell in question is in a column which is not displayed in the DataGridView (Visible=False).
|
If you handle the RowDataBound event you can check the value of the data and modify the attributes of the cell or apply a different style in that event handler.
```
protected void Page_Load(object sender, EventArgs e)
{
GridView g1 = new GridView();
g1.RowDataBound += new GridViewRowEventHandler(g1_RowDataBound);
}
void g1_RowDataBound(object sender, GridViewRowEventArgs e)
{
if(e.Row.RowType == DataControlRowType.DataRow)
{
// Check the Value
if(e.Row.Cells[1].Text = someValue)
{
e.Row.Cells[1].CssClass = "colorCellRed";
}
}
}
```
That should give you what you are looking for. Let me know if you need it in VB rather than C#.
Good Luck!
|
190,915 |
<p>I am writing a UDF for Excel 2007 which I want to pass a table to, and then reference parts of that table in the UDF. So, for instance my table called "Stock" may look something like this:</p>
<blockquote>
<p>Name Cost Items in Stock</p>
<p>Teddy Bear £10 10</p>
<p>Lollipops 20p 1000</p>
</blockquote>
<p>I have a UDF which I want to calculate the total cost of all the items left in stock (the actual example is much more complex which can't really be done without very complex formula)</p>
<p>Ideally the syntax of for the UDF would look something like</p>
<pre><code>TOTALPRICE(Stock)
</code></pre>
<p>Which from what I can work out would mean the UDF would have the signature</p>
<pre><code>Function TOTALPRICE(table As Range) As Variant
</code></pre>
<p>What I am having trouble with is how to reference the columns of the table and iterate through them. Ideally I'd like to be able to do it referencing the column headers (so something like table[Cost]).</p>
|
[
{
"answer_id": 190968,
"author": "Mike Woodhouse",
"author_id": 1060,
"author_profile": "https://Stackoverflow.com/users/1060",
"pm_score": 2,
"selected": true,
"text": "<p>This is very basic (no pun intended) but it will do what you describe. For larger tables it may become slow as under the hood it's going back and forth between the macro function and the worksheet, and that kind of activity adds up.</p>\n\n<p>It assumes that you have one row of headers and one column of names (hence the For loop variables starting from 2).</p>\n\n<p>There are all kinds of things that might be necessary - we can save those for another question or another round on this one.</p>\n\n<p>Note that the function returns a \"Variant\", btw...</p>\n\n<pre><code>Public Function TotalPrice(table As Range) As Variant\n\nDim row As Long, col As Long\nDim total As Double\n\n For row = 2 To table.Rows.Count\n For col = 2 To table.Columns.Count\n TotalPrice = TotalPrice + table.Cells(row, col) * table.Cells(row, col + 1)\n Next\n Next\n\nEnd Function\n</code></pre>\n"
},
{
"answer_id": 192288,
"author": "shahkalpesh",
"author_id": 23574,
"author_profile": "https://Stackoverflow.com/users/23574",
"pm_score": 0,
"selected": false,
"text": "<p>Note: I dont have Excel 2007 and I am trying to write this using MSDN doc on the web.<br>\nLooks like the range will have ListColumns collection</p>\n\n<p>So, the syntax could be table.ListColumns(\"Cost\").<br>\nDoes this work?</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190915",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/214/"
] |
I am writing a UDF for Excel 2007 which I want to pass a table to, and then reference parts of that table in the UDF. So, for instance my table called "Stock" may look something like this:
>
> Name Cost Items in Stock
>
>
> Teddy Bear £10 10
>
>
> Lollipops 20p 1000
>
>
>
I have a UDF which I want to calculate the total cost of all the items left in stock (the actual example is much more complex which can't really be done without very complex formula)
Ideally the syntax of for the UDF would look something like
```
TOTALPRICE(Stock)
```
Which from what I can work out would mean the UDF would have the signature
```
Function TOTALPRICE(table As Range) As Variant
```
What I am having trouble with is how to reference the columns of the table and iterate through them. Ideally I'd like to be able to do it referencing the column headers (so something like table[Cost]).
|
This is very basic (no pun intended) but it will do what you describe. For larger tables it may become slow as under the hood it's going back and forth between the macro function and the worksheet, and that kind of activity adds up.
It assumes that you have one row of headers and one column of names (hence the For loop variables starting from 2).
There are all kinds of things that might be necessary - we can save those for another question or another round on this one.
Note that the function returns a "Variant", btw...
```
Public Function TotalPrice(table As Range) As Variant
Dim row As Long, col As Long
Dim total As Double
For row = 2 To table.Rows.Count
For col = 2 To table.Columns.Count
TotalPrice = TotalPrice + table.Cells(row, col) * table.Cells(row, col + 1)
Next
Next
End Function
```
|
190,936 |
<p>When I type 'from' (in a <a href="http://en.wikipedia.org/wiki/Language_Integrated_Query" rel="nofollow noreferrer">LINQ</a> query) after importing <a href="http://msdn.microsoft.com/en-us/library/system.linq.aspx" rel="nofollow noreferrer">System.Linq namespace</a>, it is understood as a keyword. How does this magic happen?</p>
<p>Is 'from' a extension method on some type?</p>
|
[
{
"answer_id": 190945,
"author": "Nico",
"author_id": 22970,
"author_profile": "https://Stackoverflow.com/users/22970",
"pm_score": -1,
"selected": false,
"text": "<p>\"from\" is a language keyword (just like \"if\" or \"foreach\").</p>\n\n<p>You don't even need to import System.Linq to use \"from\", but you need to use 3.5 framework.</p>\n"
},
{
"answer_id": 190948,
"author": "Marc Gravell",
"author_id": 23354,
"author_profile": "https://Stackoverflow.com/users/23354",
"pm_score": 4,
"selected": true,
"text": "<p>In practice, yes - LINQ keywords map to extension methods. But actually, it is more interesting; it is literally as though the compiler substitutes directly for a few key methods, i.e.</p>\n\n<pre><code>var qry = from cust in db.Customers\n where cust.IsActive\n select cust;\n</code></pre>\n\n<p>becomes:</p>\n\n<pre><code>var qry = db.Customers.Where(cust => cust.IsActive);\n</code></pre>\n\n<p>(if we had a non-trivial select, it would add .Select(...some projection...)</p>\n\n<p>Different LINQ kewords map to different methods - i.e. there is OrderBy, GroupBy, ThenBy, OrderByDescending, etc.</p>\n\n<p>In the case of <code>IEnumerable<T></code>/<code>IQueryable<T></code>, this then resolves these via extension methods (typically courtesy of <code>Enumerable</code>/<code>Queryable</code>)- however, if your queryable objects declared their own Where/OrderBy/etc then these would get used in preference.</p>\n\n<p>Jon Skeet covers this a lot more in the latter parts of <a href=\"http://www.manning.com/skeet/\" rel=\"nofollow noreferrer\">C# in Depth</a>. I've also seen <a href=\"http://msmvps.com/blogs/jon_skeet/archive/2008/02/29/odd-query-expressions.aspx\" rel=\"nofollow noreferrer\">an example of Jon's</a> where he discusses some really bizarre implications of this - such as calling static methods on a type.</p>\n"
},
{
"answer_id": 190955,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 2,
"selected": false,
"text": "<p>Marc Gravell has <a href=\"https://stackoverflow.com/questions/190936/how-is-fromwhereselect-keywords-impemented-under-the-hood-clinq#190948\">answered the question admirably</a>, but I can't resist the temptation to mention the <a href=\"http://msmvps.com/blogs/jon_skeet/archive/2008/02/29/odd-query-expressions.aspx\" rel=\"nofollow noreferrer\">weird things you can do with query expressions</a>. The compiler really doesn't care very much how it finds a \"Select\" member, or \"Where\" etc.</p>\n\n<p>The way that the compiler translates the code into \"C# 3.0 without query expressions\" before doing normal compilation is really beautiful - it's a wonderful way of introducing new functionality into the language but only having an impact in one isolated portion of the specification.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190936",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26788/"
] |
When I type 'from' (in a [LINQ](http://en.wikipedia.org/wiki/Language_Integrated_Query) query) after importing [System.Linq namespace](http://msdn.microsoft.com/en-us/library/system.linq.aspx), it is understood as a keyword. How does this magic happen?
Is 'from' a extension method on some type?
|
In practice, yes - LINQ keywords map to extension methods. But actually, it is more interesting; it is literally as though the compiler substitutes directly for a few key methods, i.e.
```
var qry = from cust in db.Customers
where cust.IsActive
select cust;
```
becomes:
```
var qry = db.Customers.Where(cust => cust.IsActive);
```
(if we had a non-trivial select, it would add .Select(...some projection...)
Different LINQ kewords map to different methods - i.e. there is OrderBy, GroupBy, ThenBy, OrderByDescending, etc.
In the case of `IEnumerable<T>`/`IQueryable<T>`, this then resolves these via extension methods (typically courtesy of `Enumerable`/`Queryable`)- however, if your queryable objects declared their own Where/OrderBy/etc then these would get used in preference.
Jon Skeet covers this a lot more in the latter parts of [C# in Depth](http://www.manning.com/skeet/). I've also seen [an example of Jon's](http://msmvps.com/blogs/jon_skeet/archive/2008/02/29/odd-query-expressions.aspx) where he discusses some really bizarre implications of this - such as calling static methods on a type.
|
190,937 |
<p>I'm looking for a way to create an "it will look cool" effect for a full screen WPF application I'm working on - a "screen glint" effect that animates or moves across the whole screen to give off a shiny display experience. I'm thinking of creating a large rectangle with a highlighted-gradient and transparent background, which could be animated across the screen. Any ideas how this can be done effectively in XAML?</p>
|
[
{
"answer_id": 191146,
"author": "LBugnion",
"author_id": 12233,
"author_profile": "https://Stackoverflow.com/users/12233",
"pm_score": 2,
"selected": false,
"text": "<p>It's easy to place any transparent panel \"on top\" of the main Grid, and to animate an element placed in the panel. To place a panel \"on top\", simply put it at the end of the XAML hierarchy, after any other element. Alternatively, you can use the \"ZIndex\" property.</p>\n\n<p>Laurent</p>\n"
},
{
"answer_id": 191668,
"author": "Artur Carvalho",
"author_id": 1013,
"author_profile": "https://Stackoverflow.com/users/1013",
"pm_score": 0,
"selected": false,
"text": "<p>You can put a transparent panel on top like LBugnion said, but don't forget there are many ways you can do this:</p>\n\n<ol>\n<li>Change the visibility of the panel to Hidden. </li>\n<li>Change the opacity to 0.</li>\n<li>Change the Alpha of the color to 0.</li>\n</ol>\n\n<p>If you only change the Alpha it still is <em>clickable</em> even when you don't see the color.</p>\n\n<p>Off topic but: try to make the effect subtle and maybe have a on/off option. </p>\n"
},
{
"answer_id": 192246,
"author": "Thomas",
"author_id": 9970,
"author_profile": "https://Stackoverflow.com/users/9970",
"pm_score": 0,
"selected": false,
"text": "<p>Attached to <a href=\"http://mattserbinski.com/blog/look-and-feel-progressbar\" rel=\"nofollow noreferrer\">this article</a> on progressbars is sample code that has a Vista style progress bar which has the Vista style glint. It uses a Border and a Brush and a Converter to create animations. I can't say I totally understand everything in there, but it works great. Should be easy to copy to your needs.</p>\n"
},
{
"answer_id": 218326,
"author": "Johan Danforth",
"author_id": 6415,
"author_profile": "https://Stackoverflow.com/users/6415",
"pm_score": 4,
"selected": true,
"text": "<p>I came up with a solution that looks pretty good. Some sample XAML that I chalked up in Blend 2.0 SP1 looks like this:</p>\n\n<pre><code><Window\n xmlns=\"http://schemas.microsoft.com/winfx/2006/xaml/presentation\"\n xmlns:x=\"http://schemas.microsoft.com/winfx/2006/xaml\"\n x:Class=\"ScreenGlintApplication.Window1\"\n x:Name=\"Window\"\n Title=\"Window1\"\n Width=\"500\" Height=\"250\" Background=\"#FF000000\" Foreground=\"#FF3EE229\" >\n\n <Grid x:Name=\"LayoutRoot\">\n <TextBlock TextWrapping=\"Wrap\" FontSize=\"40\" >\n <Run Text=\"This is some sample text to have something to work with. Have a nice day! /Johan\"/>\n </TextBlock>\n <Canvas Panel.ZIndex=\"99\" >\n <Rectangle x:Name=\"ScreenGlintRect\" \n Width=\"{Binding Path=ActualWidth, ElementName=Window, Mode=Default}\" \n Height=\"{Binding Path=ActualHeight, ElementName=Window, Mode=Default}\" \n Opacity=\"0.4\" >\n <Rectangle.Triggers> \n <EventTrigger RoutedEvent=\"Rectangle.Loaded\"> \n <BeginStoryboard> \n <Storyboard> \n <DoubleAnimation Storyboard.TargetName=\"ScreenGlintRect\" \n Storyboard.TargetProperty=\"(Canvas.Left)\"\n From=\"-500\" To=\"1000\" Duration=\"0:0:2\" />\n </Storyboard> \n </BeginStoryboard> \n </EventTrigger> \n </Rectangle.Triggers> \n\n <Rectangle.Fill>\n <LinearGradientBrush StartPoint=\"0,1\" EndPoint=\"1,1\">\n <GradientStop Color=\"Transparent\" Offset=\"0.0\" />\n <GradientStop x:Name=\"GlintColor\" Color=\"LightGreen\" Offset=\"0.50\" />\n <GradientStop Color=\"Transparent\" Offset=\"1\" />\n </LinearGradientBrush>\n </Rectangle.Fill>\n </Rectangle>\n </Canvas>\n </Grid>\n</Window>\n</code></pre>\n\n<p>An option is to do this in code behind, which is pretty neat if you want to have granular control of the animation. For example:</p>\n\n<pre><code> ScreenGlintRect.Width = Width;\n ScreenGlintRect.Height = Height;\n var animation = new DoubleAnimation\n {\n Duration = new Duration(TimeSpan.FromSeconds(2)),\n From = (-Width),\n To = Width * 2\n };\n ScreenGlintRect.BeginAnimation(Canvas.LeftProperty, animation);\n</code></pre>\n\n<p>This is the code I'm using and it looks good enough for me. If you got HW acceleration you could try and add some blur to it. You may have to tweak the code and hide/show the rectangle, but basically this is it.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190937",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6415/"
] |
I'm looking for a way to create an "it will look cool" effect for a full screen WPF application I'm working on - a "screen glint" effect that animates or moves across the whole screen to give off a shiny display experience. I'm thinking of creating a large rectangle with a highlighted-gradient and transparent background, which could be animated across the screen. Any ideas how this can be done effectively in XAML?
|
I came up with a solution that looks pretty good. Some sample XAML that I chalked up in Blend 2.0 SP1 looks like this:
```
<Window
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
x:Class="ScreenGlintApplication.Window1"
x:Name="Window"
Title="Window1"
Width="500" Height="250" Background="#FF000000" Foreground="#FF3EE229" >
<Grid x:Name="LayoutRoot">
<TextBlock TextWrapping="Wrap" FontSize="40" >
<Run Text="This is some sample text to have something to work with. Have a nice day! /Johan"/>
</TextBlock>
<Canvas Panel.ZIndex="99" >
<Rectangle x:Name="ScreenGlintRect"
Width="{Binding Path=ActualWidth, ElementName=Window, Mode=Default}"
Height="{Binding Path=ActualHeight, ElementName=Window, Mode=Default}"
Opacity="0.4" >
<Rectangle.Triggers>
<EventTrigger RoutedEvent="Rectangle.Loaded">
<BeginStoryboard>
<Storyboard>
<DoubleAnimation Storyboard.TargetName="ScreenGlintRect"
Storyboard.TargetProperty="(Canvas.Left)"
From="-500" To="1000" Duration="0:0:2" />
</Storyboard>
</BeginStoryboard>
</EventTrigger>
</Rectangle.Triggers>
<Rectangle.Fill>
<LinearGradientBrush StartPoint="0,1" EndPoint="1,1">
<GradientStop Color="Transparent" Offset="0.0" />
<GradientStop x:Name="GlintColor" Color="LightGreen" Offset="0.50" />
<GradientStop Color="Transparent" Offset="1" />
</LinearGradientBrush>
</Rectangle.Fill>
</Rectangle>
</Canvas>
</Grid>
</Window>
```
An option is to do this in code behind, which is pretty neat if you want to have granular control of the animation. For example:
```
ScreenGlintRect.Width = Width;
ScreenGlintRect.Height = Height;
var animation = new DoubleAnimation
{
Duration = new Duration(TimeSpan.FromSeconds(2)),
From = (-Width),
To = Width * 2
};
ScreenGlintRect.BeginAnimation(Canvas.LeftProperty, animation);
```
This is the code I'm using and it looks good enough for me. If you got HW acceleration you could try and add some blur to it. You may have to tweak the code and hide/show the rectangle, but basically this is it.
|
190,940 |
<p>I've just set up a new build server with the Windows 2008 .NET 3.5 SDK, and for some reason it hasn't installed c:\Program Files\Common Files\Microsoft Shared\TextTemplating so I can't run t4 templates on it. I had a look at the install options in add/remove programs and every single option is checked. </p>
<p>Any ideas why it is missing? Any ideas how to get it back?</p>
|
[
{
"answer_id": 191146,
"author": "LBugnion",
"author_id": 12233,
"author_profile": "https://Stackoverflow.com/users/12233",
"pm_score": 2,
"selected": false,
"text": "<p>It's easy to place any transparent panel \"on top\" of the main Grid, and to animate an element placed in the panel. To place a panel \"on top\", simply put it at the end of the XAML hierarchy, after any other element. Alternatively, you can use the \"ZIndex\" property.</p>\n\n<p>Laurent</p>\n"
},
{
"answer_id": 191668,
"author": "Artur Carvalho",
"author_id": 1013,
"author_profile": "https://Stackoverflow.com/users/1013",
"pm_score": 0,
"selected": false,
"text": "<p>You can put a transparent panel on top like LBugnion said, but don't forget there are many ways you can do this:</p>\n\n<ol>\n<li>Change the visibility of the panel to Hidden. </li>\n<li>Change the opacity to 0.</li>\n<li>Change the Alpha of the color to 0.</li>\n</ol>\n\n<p>If you only change the Alpha it still is <em>clickable</em> even when you don't see the color.</p>\n\n<p>Off topic but: try to make the effect subtle and maybe have a on/off option. </p>\n"
},
{
"answer_id": 192246,
"author": "Thomas",
"author_id": 9970,
"author_profile": "https://Stackoverflow.com/users/9970",
"pm_score": 0,
"selected": false,
"text": "<p>Attached to <a href=\"http://mattserbinski.com/blog/look-and-feel-progressbar\" rel=\"nofollow noreferrer\">this article</a> on progressbars is sample code that has a Vista style progress bar which has the Vista style glint. It uses a Border and a Brush and a Converter to create animations. I can't say I totally understand everything in there, but it works great. Should be easy to copy to your needs.</p>\n"
},
{
"answer_id": 218326,
"author": "Johan Danforth",
"author_id": 6415,
"author_profile": "https://Stackoverflow.com/users/6415",
"pm_score": 4,
"selected": true,
"text": "<p>I came up with a solution that looks pretty good. Some sample XAML that I chalked up in Blend 2.0 SP1 looks like this:</p>\n\n<pre><code><Window\n xmlns=\"http://schemas.microsoft.com/winfx/2006/xaml/presentation\"\n xmlns:x=\"http://schemas.microsoft.com/winfx/2006/xaml\"\n x:Class=\"ScreenGlintApplication.Window1\"\n x:Name=\"Window\"\n Title=\"Window1\"\n Width=\"500\" Height=\"250\" Background=\"#FF000000\" Foreground=\"#FF3EE229\" >\n\n <Grid x:Name=\"LayoutRoot\">\n <TextBlock TextWrapping=\"Wrap\" FontSize=\"40\" >\n <Run Text=\"This is some sample text to have something to work with. Have a nice day! /Johan\"/>\n </TextBlock>\n <Canvas Panel.ZIndex=\"99\" >\n <Rectangle x:Name=\"ScreenGlintRect\" \n Width=\"{Binding Path=ActualWidth, ElementName=Window, Mode=Default}\" \n Height=\"{Binding Path=ActualHeight, ElementName=Window, Mode=Default}\" \n Opacity=\"0.4\" >\n <Rectangle.Triggers> \n <EventTrigger RoutedEvent=\"Rectangle.Loaded\"> \n <BeginStoryboard> \n <Storyboard> \n <DoubleAnimation Storyboard.TargetName=\"ScreenGlintRect\" \n Storyboard.TargetProperty=\"(Canvas.Left)\"\n From=\"-500\" To=\"1000\" Duration=\"0:0:2\" />\n </Storyboard> \n </BeginStoryboard> \n </EventTrigger> \n </Rectangle.Triggers> \n\n <Rectangle.Fill>\n <LinearGradientBrush StartPoint=\"0,1\" EndPoint=\"1,1\">\n <GradientStop Color=\"Transparent\" Offset=\"0.0\" />\n <GradientStop x:Name=\"GlintColor\" Color=\"LightGreen\" Offset=\"0.50\" />\n <GradientStop Color=\"Transparent\" Offset=\"1\" />\n </LinearGradientBrush>\n </Rectangle.Fill>\n </Rectangle>\n </Canvas>\n </Grid>\n</Window>\n</code></pre>\n\n<p>An option is to do this in code behind, which is pretty neat if you want to have granular control of the animation. For example:</p>\n\n<pre><code> ScreenGlintRect.Width = Width;\n ScreenGlintRect.Height = Height;\n var animation = new DoubleAnimation\n {\n Duration = new Duration(TimeSpan.FromSeconds(2)),\n From = (-Width),\n To = Width * 2\n };\n ScreenGlintRect.BeginAnimation(Canvas.LeftProperty, animation);\n</code></pre>\n\n<p>This is the code I'm using and it looks good enough for me. If you got HW acceleration you could try and add some blur to it. You may have to tweak the code and hide/show the rectangle, but basically this is it.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190940",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2086/"
] |
I've just set up a new build server with the Windows 2008 .NET 3.5 SDK, and for some reason it hasn't installed c:\Program Files\Common Files\Microsoft Shared\TextTemplating so I can't run t4 templates on it. I had a look at the install options in add/remove programs and every single option is checked.
Any ideas why it is missing? Any ideas how to get it back?
|
I came up with a solution that looks pretty good. Some sample XAML that I chalked up in Blend 2.0 SP1 looks like this:
```
<Window
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
x:Class="ScreenGlintApplication.Window1"
x:Name="Window"
Title="Window1"
Width="500" Height="250" Background="#FF000000" Foreground="#FF3EE229" >
<Grid x:Name="LayoutRoot">
<TextBlock TextWrapping="Wrap" FontSize="40" >
<Run Text="This is some sample text to have something to work with. Have a nice day! /Johan"/>
</TextBlock>
<Canvas Panel.ZIndex="99" >
<Rectangle x:Name="ScreenGlintRect"
Width="{Binding Path=ActualWidth, ElementName=Window, Mode=Default}"
Height="{Binding Path=ActualHeight, ElementName=Window, Mode=Default}"
Opacity="0.4" >
<Rectangle.Triggers>
<EventTrigger RoutedEvent="Rectangle.Loaded">
<BeginStoryboard>
<Storyboard>
<DoubleAnimation Storyboard.TargetName="ScreenGlintRect"
Storyboard.TargetProperty="(Canvas.Left)"
From="-500" To="1000" Duration="0:0:2" />
</Storyboard>
</BeginStoryboard>
</EventTrigger>
</Rectangle.Triggers>
<Rectangle.Fill>
<LinearGradientBrush StartPoint="0,1" EndPoint="1,1">
<GradientStop Color="Transparent" Offset="0.0" />
<GradientStop x:Name="GlintColor" Color="LightGreen" Offset="0.50" />
<GradientStop Color="Transparent" Offset="1" />
</LinearGradientBrush>
</Rectangle.Fill>
</Rectangle>
</Canvas>
</Grid>
</Window>
```
An option is to do this in code behind, which is pretty neat if you want to have granular control of the animation. For example:
```
ScreenGlintRect.Width = Width;
ScreenGlintRect.Height = Height;
var animation = new DoubleAnimation
{
Duration = new Duration(TimeSpan.FromSeconds(2)),
From = (-Width),
To = Width * 2
};
ScreenGlintRect.BeginAnimation(Canvas.LeftProperty, animation);
```
This is the code I'm using and it looks good enough for me. If you got HW acceleration you could try and add some blur to it. You may have to tweak the code and hide/show the rectangle, but basically this is it.
|
190,956 |
<p>Just wanted to get an idea for ways (web) developers get round the short fall of (most) WYSIWYG editors, whereby the users that are editing the text aren't always HTML literate enough to produce good/great results.</p>
<p>In the past we have resigned ourselves to either locking down the editor or simply not supplying one.</p>
<p>What are other peoples experiences?</p>
|
[
{
"answer_id": 191146,
"author": "LBugnion",
"author_id": 12233,
"author_profile": "https://Stackoverflow.com/users/12233",
"pm_score": 2,
"selected": false,
"text": "<p>It's easy to place any transparent panel \"on top\" of the main Grid, and to animate an element placed in the panel. To place a panel \"on top\", simply put it at the end of the XAML hierarchy, after any other element. Alternatively, you can use the \"ZIndex\" property.</p>\n\n<p>Laurent</p>\n"
},
{
"answer_id": 191668,
"author": "Artur Carvalho",
"author_id": 1013,
"author_profile": "https://Stackoverflow.com/users/1013",
"pm_score": 0,
"selected": false,
"text": "<p>You can put a transparent panel on top like LBugnion said, but don't forget there are many ways you can do this:</p>\n\n<ol>\n<li>Change the visibility of the panel to Hidden. </li>\n<li>Change the opacity to 0.</li>\n<li>Change the Alpha of the color to 0.</li>\n</ol>\n\n<p>If you only change the Alpha it still is <em>clickable</em> even when you don't see the color.</p>\n\n<p>Off topic but: try to make the effect subtle and maybe have a on/off option. </p>\n"
},
{
"answer_id": 192246,
"author": "Thomas",
"author_id": 9970,
"author_profile": "https://Stackoverflow.com/users/9970",
"pm_score": 0,
"selected": false,
"text": "<p>Attached to <a href=\"http://mattserbinski.com/blog/look-and-feel-progressbar\" rel=\"nofollow noreferrer\">this article</a> on progressbars is sample code that has a Vista style progress bar which has the Vista style glint. It uses a Border and a Brush and a Converter to create animations. I can't say I totally understand everything in there, but it works great. Should be easy to copy to your needs.</p>\n"
},
{
"answer_id": 218326,
"author": "Johan Danforth",
"author_id": 6415,
"author_profile": "https://Stackoverflow.com/users/6415",
"pm_score": 4,
"selected": true,
"text": "<p>I came up with a solution that looks pretty good. Some sample XAML that I chalked up in Blend 2.0 SP1 looks like this:</p>\n\n<pre><code><Window\n xmlns=\"http://schemas.microsoft.com/winfx/2006/xaml/presentation\"\n xmlns:x=\"http://schemas.microsoft.com/winfx/2006/xaml\"\n x:Class=\"ScreenGlintApplication.Window1\"\n x:Name=\"Window\"\n Title=\"Window1\"\n Width=\"500\" Height=\"250\" Background=\"#FF000000\" Foreground=\"#FF3EE229\" >\n\n <Grid x:Name=\"LayoutRoot\">\n <TextBlock TextWrapping=\"Wrap\" FontSize=\"40\" >\n <Run Text=\"This is some sample text to have something to work with. Have a nice day! /Johan\"/>\n </TextBlock>\n <Canvas Panel.ZIndex=\"99\" >\n <Rectangle x:Name=\"ScreenGlintRect\" \n Width=\"{Binding Path=ActualWidth, ElementName=Window, Mode=Default}\" \n Height=\"{Binding Path=ActualHeight, ElementName=Window, Mode=Default}\" \n Opacity=\"0.4\" >\n <Rectangle.Triggers> \n <EventTrigger RoutedEvent=\"Rectangle.Loaded\"> \n <BeginStoryboard> \n <Storyboard> \n <DoubleAnimation Storyboard.TargetName=\"ScreenGlintRect\" \n Storyboard.TargetProperty=\"(Canvas.Left)\"\n From=\"-500\" To=\"1000\" Duration=\"0:0:2\" />\n </Storyboard> \n </BeginStoryboard> \n </EventTrigger> \n </Rectangle.Triggers> \n\n <Rectangle.Fill>\n <LinearGradientBrush StartPoint=\"0,1\" EndPoint=\"1,1\">\n <GradientStop Color=\"Transparent\" Offset=\"0.0\" />\n <GradientStop x:Name=\"GlintColor\" Color=\"LightGreen\" Offset=\"0.50\" />\n <GradientStop Color=\"Transparent\" Offset=\"1\" />\n </LinearGradientBrush>\n </Rectangle.Fill>\n </Rectangle>\n </Canvas>\n </Grid>\n</Window>\n</code></pre>\n\n<p>An option is to do this in code behind, which is pretty neat if you want to have granular control of the animation. For example:</p>\n\n<pre><code> ScreenGlintRect.Width = Width;\n ScreenGlintRect.Height = Height;\n var animation = new DoubleAnimation\n {\n Duration = new Duration(TimeSpan.FromSeconds(2)),\n From = (-Width),\n To = Width * 2\n };\n ScreenGlintRect.BeginAnimation(Canvas.LeftProperty, animation);\n</code></pre>\n\n<p>This is the code I'm using and it looks good enough for me. If you got HW acceleration you could try and add some blur to it. You may have to tweak the code and hide/show the rectangle, but basically this is it.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190956",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/17540/"
] |
Just wanted to get an idea for ways (web) developers get round the short fall of (most) WYSIWYG editors, whereby the users that are editing the text aren't always HTML literate enough to produce good/great results.
In the past we have resigned ourselves to either locking down the editor or simply not supplying one.
What are other peoples experiences?
|
I came up with a solution that looks pretty good. Some sample XAML that I chalked up in Blend 2.0 SP1 looks like this:
```
<Window
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
x:Class="ScreenGlintApplication.Window1"
x:Name="Window"
Title="Window1"
Width="500" Height="250" Background="#FF000000" Foreground="#FF3EE229" >
<Grid x:Name="LayoutRoot">
<TextBlock TextWrapping="Wrap" FontSize="40" >
<Run Text="This is some sample text to have something to work with. Have a nice day! /Johan"/>
</TextBlock>
<Canvas Panel.ZIndex="99" >
<Rectangle x:Name="ScreenGlintRect"
Width="{Binding Path=ActualWidth, ElementName=Window, Mode=Default}"
Height="{Binding Path=ActualHeight, ElementName=Window, Mode=Default}"
Opacity="0.4" >
<Rectangle.Triggers>
<EventTrigger RoutedEvent="Rectangle.Loaded">
<BeginStoryboard>
<Storyboard>
<DoubleAnimation Storyboard.TargetName="ScreenGlintRect"
Storyboard.TargetProperty="(Canvas.Left)"
From="-500" To="1000" Duration="0:0:2" />
</Storyboard>
</BeginStoryboard>
</EventTrigger>
</Rectangle.Triggers>
<Rectangle.Fill>
<LinearGradientBrush StartPoint="0,1" EndPoint="1,1">
<GradientStop Color="Transparent" Offset="0.0" />
<GradientStop x:Name="GlintColor" Color="LightGreen" Offset="0.50" />
<GradientStop Color="Transparent" Offset="1" />
</LinearGradientBrush>
</Rectangle.Fill>
</Rectangle>
</Canvas>
</Grid>
</Window>
```
An option is to do this in code behind, which is pretty neat if you want to have granular control of the animation. For example:
```
ScreenGlintRect.Width = Width;
ScreenGlintRect.Height = Height;
var animation = new DoubleAnimation
{
Duration = new Duration(TimeSpan.FromSeconds(2)),
From = (-Width),
To = Width * 2
};
ScreenGlintRect.BeginAnimation(Canvas.LeftProperty, animation);
```
This is the code I'm using and it looks good enough for me. If you got HW acceleration you could try and add some blur to it. You may have to tweak the code and hide/show the rectangle, but basically this is it.
|
190,988 |
<p>I have to use the <strong>XMLHttp object in classic ASP</strong> in order to send some data to another server via HTTP from server to server:</p>
<pre><code>sURL = SOME_URL
Set oXHttp = Server.CreateObject("Msxml2.XMLHTTP")
oXHttp.open "POST", sURL, false
oXHttp.setRequestHeader "Content-Type", "application/x-www-form-urlencoded;charset:ISO-8859-1;"
sPost = SOME_FORM_DATA
oXHttp.send(sPost)
</code></pre>
<p>I've been told (by the maintainer of the consuming server) that, depending on whether I use this code from Windows Server 2000 (IIS 5) or Windows Server 2003 (IIS 6), he gets <strong>Latin-1</strong> (Windows 2000 Server) or <strong>UTF-8</strong> (Windows Server 2003) encoded data.</p>
<p>I didn't find any property or method to set the character set of data I have to send. Does it depend on some Windows configuration or scripting (asp) settings?</p>
|
[
{
"answer_id": 191042,
"author": "Adam Byram",
"author_id": 25886,
"author_profile": "https://Stackoverflow.com/users/25886",
"pm_score": 6,
"selected": true,
"text": "<p>There is a keychain you can use - for code, the best bet is to check out the GenericKeychain sample application from Apple:</p>\n\n<p><a href=\"https://developer.apple.com/library/ios/DOCUMENTATION/Security/Conceptual/keychainServConcepts/iPhoneTasks/iPhoneTasks.html\" rel=\"nofollow noreferrer\">GenericKeychain sample</a></p>\n"
},
{
"answer_id": 194330,
"author": "whoisjake",
"author_id": 2609,
"author_profile": "https://Stackoverflow.com/users/2609",
"pm_score": 3,
"selected": false,
"text": "<p>Also remember that when generating an AppID, if you want more than one application to access the same Keychain information, you have to generate a wild card AppID (#####.com.prefix.*)...</p>\n"
},
{
"answer_id": 203657,
"author": "Ben Gottlieb",
"author_id": 6694,
"author_profile": "https://Stackoverflow.com/users/6694",
"pm_score": 6,
"selected": false,
"text": "<p>One other thing to note: the keychain APIs don't work in the simulator when using older versions (2.x, 3.x) of the iPhone SDK. This could save you a lot of frustration when testing!</p>\n"
},
{
"answer_id": 1020022,
"author": "bbrown",
"author_id": 20595,
"author_profile": "https://Stackoverflow.com/users/20595",
"pm_score": 3,
"selected": false,
"text": "<p>I really like <a href=\"http://github.com/ldandersen/scifihifi-iphone/tree/master\" rel=\"noreferrer\">Buzz Anderson's Keychain abstraction layer</a> and I eagerly await <a href=\"http://mooseyard.com/projects/MYCrypto/\" rel=\"noreferrer\">Jens Alfke's MYCrypto</a> to reach a usable state. The latter does a competent job of allowing use on Mac OS X and the iPhone using the same code, though its features only mimic a small subset of the Keychain's.</p>\n"
},
{
"answer_id": 3496725,
"author": "joobik",
"author_id": 422102,
"author_profile": "https://Stackoverflow.com/users/422102",
"pm_score": 2,
"selected": false,
"text": "<p>With the latest version 1.2 of the GenericKeychain sample Apple provides a keychain wrapper that also runs on the iPhone Simulator. Check out at this article for details: <a href=\"http://dev-metal.blogspot.com/2010/08/howto-use-keychain-in-iphone-sdk-to.html\" rel=\"nofollow noreferrer\">http://dev-metal.blogspot.com/2010/08/howto-use-keychain-in-iphone-sdk-to.html</a></p>\n"
},
{
"answer_id": 7314271,
"author": "AlBeebe",
"author_id": 172361,
"author_profile": "https://Stackoverflow.com/users/172361",
"pm_score": 3,
"selected": false,
"text": "<p>Here is what i use to store Key/Value pairs in the keychain. Make sure to add Security.framework to your project</p>\n\n<pre><code>#import <Security/Security.h>\n\n// -------------------------------------------------------------------------\n-(NSString *)getSecureValueForKey:(NSString *)key {\n /*\n\n Return a value from the keychain\n\n */\n\n // Retrieve a value from the keychain\n NSDictionary *result;\n NSArray *keys = [[[NSArray alloc] initWithObjects: (NSString *) kSecClass, kSecAttrAccount, kSecReturnAttributes, nil] autorelease];\n NSArray *objects = [[[NSArray alloc] initWithObjects: (NSString *) kSecClassGenericPassword, key, kCFBooleanTrue, nil] autorelease];\n NSDictionary *query = [[NSDictionary alloc] initWithObjects: objects forKeys: keys];\n\n // Check if the value was found\n OSStatus status = SecItemCopyMatching((CFDictionaryRef) query, (CFTypeRef *) &result);\n [query release];\n if (status != noErr) {\n // Value not found\n return nil;\n } else {\n // Value was found so return it\n NSString *value = (NSString *) [result objectForKey: (NSString *) kSecAttrGeneric];\n return value;\n }\n}\n\n\n\n\n// -------------------------------------------------------------------------\n-(bool)storeSecureValue:(NSString *)value forKey:(NSString *)key {\n /*\n\n Store a value in the keychain\n\n */\n\n // Get the existing value for the key\n NSString *existingValue = [self getSecureValueForKey:key];\n\n // Check if a value already exists for this key\n OSStatus status;\n if (existingValue) {\n // Value already exists, so update it\n NSArray *keys = [[[NSArray alloc] initWithObjects: (NSString *) kSecClass, kSecAttrAccount, nil] autorelease];\n NSArray *objects = [[[NSArray alloc] initWithObjects: (NSString *) kSecClassGenericPassword, key, nil] autorelease];\n NSDictionary *query = [[[NSDictionary alloc] initWithObjects: objects forKeys: keys] autorelease];\n status = SecItemUpdate((CFDictionaryRef) query, (CFDictionaryRef) [NSDictionary dictionaryWithObject:value forKey: (NSString *) kSecAttrGeneric]);\n } else {\n // Value does not exist, so add it\n NSArray *keys = [[[NSArray alloc] initWithObjects: (NSString *) kSecClass, kSecAttrAccount, kSecAttrGeneric, nil] autorelease];\n NSArray *objects = [[[NSArray alloc] initWithObjects: (NSString *) kSecClassGenericPassword, key, value, nil] autorelease];\n NSDictionary *query = [[[NSDictionary alloc] initWithObjects: objects forKeys: keys] autorelease];\n status = SecItemAdd((CFDictionaryRef) query, NULL);\n }\n\n // Check if the value was stored\n if (status != noErr) {\n // Value was not stored\n return false;\n } else {\n // Value was stored\n return true;\n }\n}\n</code></pre>\n\n<p>It is worth noting that these key/values will not get deleted if the user deletes your app. If a user deletes your app, then reinstalls it, the key/values will still be accessible.</p>\n"
},
{
"answer_id": 18741808,
"author": "Bhavin Kansagara",
"author_id": 918300,
"author_profile": "https://Stackoverflow.com/users/918300",
"pm_score": 0,
"selected": false,
"text": "<p>Here is one more good wrapper class from Mr.Granoff\n<a href=\"https://github.com/granoff/Lockbox\" rel=\"nofollow\">https://github.com/granoff/Lockbox</a>\nThanks</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/190988",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6461/"
] |
I have to use the **XMLHttp object in classic ASP** in order to send some data to another server via HTTP from server to server:
```
sURL = SOME_URL
Set oXHttp = Server.CreateObject("Msxml2.XMLHTTP")
oXHttp.open "POST", sURL, false
oXHttp.setRequestHeader "Content-Type", "application/x-www-form-urlencoded;charset:ISO-8859-1;"
sPost = SOME_FORM_DATA
oXHttp.send(sPost)
```
I've been told (by the maintainer of the consuming server) that, depending on whether I use this code from Windows Server 2000 (IIS 5) or Windows Server 2003 (IIS 6), he gets **Latin-1** (Windows 2000 Server) or **UTF-8** (Windows Server 2003) encoded data.
I didn't find any property or method to set the character set of data I have to send. Does it depend on some Windows configuration or scripting (asp) settings?
|
There is a keychain you can use - for code, the best bet is to check out the GenericKeychain sample application from Apple:
[GenericKeychain sample](https://developer.apple.com/library/ios/DOCUMENTATION/Security/Conceptual/keychainServConcepts/iPhoneTasks/iPhoneTasks.html)
|
191,010 |
<pre><code>dir(re.compile(pattern))
</code></pre>
<p>does not return pattern as one of the lists's elements. Namely it returns:</p>
<pre><code>['__copy__', '__deepcopy__', 'findall', 'finditer', 'match', 'scanner', 'search', 'split', 'sub', 'subn']
</code></pre>
<p>According to the manual, it is supposed to contain </p>
<blockquote>
<p>the object's attributes' names, the
names of its class's attributes, and
recursively of the attributes of its
class's base classes.</p>
</blockquote>
<p>It says also that</p>
<blockquote>
<p>The list is not necessarily complete.</p>
</blockquote>
<p>Is there a way to get the <strong>complete</strong> list? I always assumed that dir returns a complete list but apparently it does not...</p>
<p>Also: is there a way to list only attributes? Or only methods?</p>
<p><em>Edit: this is actually a bug in python -> supposedly it is fixed in the 3.0 branch (and perhaps also in 2.6)</em></p>
|
[
{
"answer_id": 191029,
"author": "PierreBdR",
"author_id": 7136,
"author_profile": "https://Stackoverflow.com/users/7136",
"pm_score": 8,
"selected": true,
"text": "<p>For the <strong>complete</strong> list of attributes, the short answer is: no. The problem is that the attributes are actually defined as the arguments accepted by the <code>getattr</code> built-in function. As the user can reimplement <code>__getattr__</code>, suddenly allowing any kind of attribute, there is no possible generic way to generate that list. The <code>dir</code> function returns the keys in the <code>__dict__</code> attribute, i.e. all the attributes accessible if the <code>__getattr__</code> method is not reimplemented.</p>\n\n<p>For the second question, it does not really make sense. Actually, methods are callable attributes, nothing more. You could though filter callable attributes, and, using the <code>inspect</code> module determine the class methods, methods or functions.</p>\n"
},
{
"answer_id": 191679,
"author": "Moe",
"author_id": 3051,
"author_profile": "https://Stackoverflow.com/users/3051",
"pm_score": 6,
"selected": false,
"text": "<p>That is why the new <code>__dir__()</code> method has been added in python 2.6</p>\n\n<p>see:</p>\n\n<ul>\n<li><a href=\"http://docs.python.org/whatsnew/2.6.html#other-language-changes\" rel=\"noreferrer\">http://docs.python.org/whatsnew/2.6.html#other-language-changes</a> (scroll down a little bit)</li>\n<li><a href=\"http://bugs.python.org/issue1591665\" rel=\"noreferrer\">http://bugs.python.org/issue1591665</a></li>\n</ul>\n"
},
{
"answer_id": 10313703,
"author": "ジョージ",
"author_id": 558008,
"author_profile": "https://Stackoverflow.com/users/558008",
"pm_score": 5,
"selected": false,
"text": "<p>Here is a practical addition to the answers of PierreBdR and Moe: </p>\n\n<ul>\n<li>For Python >= 2.6 and <em>new-style classes</em>, <code>dir()</code> seems to be enough.</li>\n<li><p>For <em>old-style classes</em>, we can at least do what a <a href=\"http://docs.python.org/library/rlcompleter.html\" rel=\"nofollow noreferrer\">standard module</a> does to support tab completion: in addition to <code>dir()</code>, look for <code>__class__</code>, and then to go for its <code>__bases__</code>:</p>\n\n<pre class=\"lang-py prettyprint-override\"><code># code borrowed from the rlcompleter module\n# tested under Python 2.6 ( sys.version = '2.6.5 (r265:79063, Apr 16 2010, 13:09:56) \\n[GCC 4.4.3]' )\n\n# or: from rlcompleter import get_class_members\ndef get_class_members(klass):\n ret = dir(klass)\n if hasattr(klass,'__bases__'):\n for base in klass.__bases__:\n ret = ret + get_class_members(base)\n return ret\n\n\ndef uniq( seq ): \n \"\"\" the 'set()' way ( use dict when there's no set ) \"\"\"\n return list(set(seq))\n\n\ndef get_object_attrs( obj ):\n # code borrowed from the rlcompleter module ( see the code for Completer::attr_matches() )\n ret = dir( obj )\n ## if \"__builtins__\" in ret:\n ## ret.remove(\"__builtins__\")\n\n if hasattr( obj, '__class__'):\n ret.append('__class__')\n ret.extend( get_class_members(obj.__class__) )\n\n ret = uniq( ret )\n\n return ret\n</code></pre></li>\n</ul>\n\n<p>(Test code and output are deleted for brevity, but basically for new-style objects we seem to have the same results for <code>get_object_attrs()</code> as for <code>dir()</code>, and for old-style classes the main addition to the <code>dir()</code> output seem to be the <code>__class__</code> attribute.)</p>\n"
},
{
"answer_id": 39286285,
"author": "mluc",
"author_id": 842903,
"author_profile": "https://Stackoverflow.com/users/842903",
"pm_score": 3,
"selected": false,
"text": "<p>This is how I do it, useful for simple custom objects to which you keep adding attributes:</p>\n\n<p>Given an object created with <code>obj = type(\"Obj\",(object,),{})</code>, or by simply: </p>\n\n<pre><code>class Obj: pass\nobj = Obj()\n</code></pre>\n\n<p>Add some attributes:</p>\n\n<pre><code>obj.name = 'gary'\nobj.age = 32\n</code></pre>\n\n<p>then, to obtain a dictionary with only the custom attributes:</p>\n\n<pre><code>{key: value for key, value in obj.__dict__.items() if not key.startswith(\"__\")}\n\n# {'name': 'gary', 'age': 32}\n</code></pre>\n"
},
{
"answer_id": 52846957,
"author": "Chiron",
"author_id": 3829943,
"author_profile": "https://Stackoverflow.com/users/3829943",
"pm_score": 4,
"selected": false,
"text": "<p>Only to supplement:</p>\n\n<ol>\n<li><code>dir()</code> is the <strong>most</strong> powerful/fundamental tool. (<strong>Most recommended</strong>)</li>\n<li><p>Solutions other than <code>dir()</code> merely provide <strong>their way</strong> of dealing <strong>the output of <code>dir()</code></strong>.</p>\n\n<p>Listing 2nd level attributes or not, it is important to do the sifting by yourself, because sometimes you may want to sift out internal vars with leading underscores <code>__</code>, but sometimes you may well need the <code>__doc__</code> doc-string.</p></li>\n<li><code>__dir__()</code> and <code>dir()</code> returns identical content.</li>\n<li><code>__dict__</code> and <code>dir()</code> are different. <code>__dict__</code> returns incomplete content.</li>\n<li><p><strong>IMPORTANT</strong>: <code>__dir__()</code> can be sometimes overwritten with a function, value or type, by the author for whatever purpose.</p>\n\n<p>Here is an example:</p>\n\n<pre><code>\\\\...\\\\torchfun.py in traverse(self, mod, search_attributes)\n445 if prefix in traversed_mod_names:\n446 continue\n447 names = dir(m)\n448 for name in names:\n449 obj = getattr(m,name)\n</code></pre>\n\n<p><strong>TypeError: descriptor <code>__dir__</code> of <code>'object'</code> object needs an argument</strong></p>\n\n<p>The author of PyTorch modified the <code>__dir__()</code> method to something that requires an argument. This modification makes <code>dir()</code> fail.</p></li>\n<li><p>If you want a <strong>reliable</strong> scheme to traverse all attributes of an object, do remember that every pythonic standard <strong>can be overridden and may not hold</strong>, and every convention may be unreliable.</p></li>\n</ol>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191010",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/985/"
] |
```
dir(re.compile(pattern))
```
does not return pattern as one of the lists's elements. Namely it returns:
```
['__copy__', '__deepcopy__', 'findall', 'finditer', 'match', 'scanner', 'search', 'split', 'sub', 'subn']
```
According to the manual, it is supposed to contain
>
> the object's attributes' names, the
> names of its class's attributes, and
> recursively of the attributes of its
> class's base classes.
>
>
>
It says also that
>
> The list is not necessarily complete.
>
>
>
Is there a way to get the **complete** list? I always assumed that dir returns a complete list but apparently it does not...
Also: is there a way to list only attributes? Or only methods?
*Edit: this is actually a bug in python -> supposedly it is fixed in the 3.0 branch (and perhaps also in 2.6)*
|
For the **complete** list of attributes, the short answer is: no. The problem is that the attributes are actually defined as the arguments accepted by the `getattr` built-in function. As the user can reimplement `__getattr__`, suddenly allowing any kind of attribute, there is no possible generic way to generate that list. The `dir` function returns the keys in the `__dict__` attribute, i.e. all the attributes accessible if the `__getattr__` method is not reimplemented.
For the second question, it does not really make sense. Actually, methods are callable attributes, nothing more. You could though filter callable attributes, and, using the `inspect` module determine the class methods, methods or functions.
|
191,013 |
<p>Is it possible to have an anonymous type implement an interface?</p>
<p>I've got a piece of code that I would like to work, but don't know how to do this.</p>
<p>I've had a couple of answers that either say no, or create a class that implements the interface construct new instances of that. This isn't really ideal, but I'm wondering if there is a mechanism to create a thin dynamic class on top of an interface which would make this simple.</p>
<pre><code>public interface DummyInterface
{
string A { get; }
string B { get; }
}
public class DummySource
{
public string A { get; set; }
public string C { get; set; }
public string D { get; set; }
}
public class Test
{
public void WillThisWork()
{
var source = new DummySource[0];
var values = from value in source
select new
{
A = value.A,
B = value.C + "_" + value.D
};
DoSomethingWithDummyInterface(values);
}
public void DoSomethingWithDummyInterface(IEnumerable<DummyInterface> values)
{
foreach (var value in values)
{
Console.WriteLine("A = '{0}', B = '{1}'", value.A, value.B);
}
}
}
</code></pre>
<p>I've found an article <a href="http://channel8.msdn.com/Posts/Adding-some-dynamic-to-C-interface-wrapping/" rel="noreferrer">Dynamic interface wrapping</a> that describes one approach. Is this the best way of doing this?</p>
|
[
{
"answer_id": 191028,
"author": "Marc Gravell",
"author_id": 23354,
"author_profile": "https://Stackoverflow.com/users/23354",
"pm_score": 4,
"selected": false,
"text": "<p>No; an anonymous type can't be made to do anything except have a few properties. You will need to create your own type. I didn't read the linked article in depth, but it looks like it uses Reflection.Emit to create new types on the fly; but if you limit discussion to things <em>within C# itself</em> you can't do what you want.</p>\n"
},
{
"answer_id": 191040,
"author": "HasaniH",
"author_id": 7141,
"author_profile": "https://Stackoverflow.com/users/7141",
"pm_score": 10,
"selected": true,
"text": "<p>No, anonymous types cannot implement an interface. From the <a href=\"http://msdn.microsoft.com/en-us/library/bb397696.aspx\" rel=\"noreferrer\">C# programming guide</a>:</p>\n\n<blockquote>\n <p>Anonymous types are class types that consist of one or more public read-only properties. No other kinds of class members such as methods or events are allowed. An anonymous type cannot be cast to any interface or type except for object.</p>\n</blockquote>\n"
},
{
"answer_id": 191124,
"author": "ICR",
"author_id": 214,
"author_profile": "https://Stackoverflow.com/users/214",
"pm_score": 4,
"selected": false,
"text": "<p>The best solution is just not to use anonymous classes.</p>\n\n<pre><code>public class Test\n{\n class DummyInterfaceImplementor : IDummyInterface\n {\n public string A { get; set; }\n public string B { get; set; }\n }\n\n public void WillThisWork()\n {\n var source = new DummySource[0];\n var values = from value in source\n select new DummyInterfaceImplementor()\n {\n A = value.A,\n B = value.C + \"_\" + value.D\n };\n\n DoSomethingWithDummyInterface(values.Cast<IDummyInterface>());\n\n }\n\n public void DoSomethingWithDummyInterface(IEnumerable<IDummyInterface> values)\n {\n foreach (var value in values)\n {\n Console.WriteLine(\"A = '{0}', B = '{1}'\", value.A, value.B);\n }\n }\n}\n</code></pre>\n\n<p>Note that you need to cast the result of the query to the type of the interface. There might be a better way to do it, but I couldn't find it.</p>\n"
},
{
"answer_id": 258032,
"author": "Arne Claassen",
"author_id": 32577,
"author_profile": "https://Stackoverflow.com/users/32577",
"pm_score": 6,
"selected": false,
"text": "<p>Casting anonymous types to interfaces has been something I've wanted for a while but unfortunately the current implementation forces you to have an implementation of that interface.</p>\n\n<p>The best solution around it is having some type of dynamic proxy that creates the implementation for you. Using the excellent <a href=\"http://www.codeproject.com/KB/cs/LinFuPart1.aspx\" rel=\"noreferrer\">LinFu project</a> you can replace</p>\n\n<pre><code>select new\n{\n A = value.A,\n B = value.C + \"_\" + value.D\n};\n</code></pre>\n\n<p>with</p>\n\n<pre><code> select new DynamicObject(new\n {\n A = value.A,\n B = value.C + \"_\" + value.D\n }).CreateDuck<DummyInterface>();\n</code></pre>\n"
},
{
"answer_id": 3734761,
"author": "Mia Clarke",
"author_id": 83075,
"author_profile": "https://Stackoverflow.com/users/83075",
"pm_score": 7,
"selected": false,
"text": "<p>While the answers in the thread are all true enough, I cannot resist the urge to tell you that it in fact <strong>is possible</strong> to have an anonymous class implement an interface, even though it takes a bit of creative cheating to get there.</p>\n<p>Back in 2008 I was writing a custom LINQ provider for my then employer, and at one point I needed to be able to tell "my" anonymous classes from other anonymous ones, which meant having them implement an interface that I could use to type check them. The way we solved it was by using aspects (we used <a href=\"https://www.postsharp.net/\" rel=\"nofollow noreferrer\">PostSharp</a>), to add the interface implementation directly in the IL. So, in fact, <strong>letting anonymous classes implement interfaces is doable</strong>, you just need to bend the rules slightly to get there.</p>\n"
},
{
"answer_id": 24823427,
"author": "Russell Horwood",
"author_id": 972880,
"author_profile": "https://Stackoverflow.com/users/972880",
"pm_score": 3,
"selected": false,
"text": "<p>The answer to the question specifically asked is no. But have you been looking at mocking frameworks? I use MOQ but there's millions of them out there and they allow you to implement/stub (partially or fully) interfaces in-line. Eg.</p>\n\n<pre><code>public void ThisWillWork()\n{\n var source = new DummySource[0];\n var mock = new Mock<DummyInterface>();\n\n mock.SetupProperty(m => m.A, source.Select(s => s.A));\n mock.SetupProperty(m => m.B, source.Select(s => s.C + \"_\" + s.D));\n\n DoSomethingWithDummyInterface(mock.Object);\n}\n</code></pre>\n"
},
{
"answer_id": 26825196,
"author": "Jason Bowers",
"author_id": 1864507,
"author_profile": "https://Stackoverflow.com/users/1864507",
"pm_score": 4,
"selected": false,
"text": "<p>Anonymous types can implement interfaces via a dynamic proxy.</p>\n\n<p>I wrote an extension method on <a href=\"https://github.com/jcbowers/DuckTyping\">GitHub</a> and a blog post <a href=\"http://wblo.gs/feE\">http://wblo.gs/feE</a> to support this scenario. </p>\n\n<p>The method can be used like this:</p>\n\n<pre><code>class Program\n{\n static void Main(string[] args)\n {\n var developer = new { Name = \"Jason Bowers\" };\n\n PrintDeveloperName(developer.DuckCast<IDeveloper>());\n\n Console.ReadKey();\n }\n\n private static void PrintDeveloperName(IDeveloper developer)\n {\n Console.WriteLine(developer.Name);\n }\n}\n\npublic interface IDeveloper\n{\n string Name { get; }\n}\n</code></pre>\n"
},
{
"answer_id": 55621734,
"author": "Gordon Bean",
"author_id": 2288986,
"author_profile": "https://Stackoverflow.com/users/2288986",
"pm_score": 2,
"selected": false,
"text": "<p>Another option is to create a single, concrete implementing class that takes lambdas in the constructor.</p>\n\n<pre><code>public interface DummyInterface\n{\n string A { get; }\n string B { get; }\n}\n\n// \"Generic\" implementing class\npublic class Dummy : DummyInterface\n{\n private readonly Func<string> _getA;\n private readonly Func<string> _getB;\n\n public Dummy(Func<string> getA, Func<string> getB)\n {\n _getA = getA;\n _getB = getB;\n }\n\n public string A => _getA();\n\n public string B => _getB();\n}\n\npublic class DummySource\n{\n public string A { get; set; }\n public string C { get; set; }\n public string D { get; set; }\n}\n\npublic class Test\n{\n public void WillThisWork()\n {\n var source = new DummySource[0];\n var values = from value in source\n select new Dummy // Syntax changes slightly\n (\n getA: () => value.A,\n getB: () => value.C + \"_\" + value.D\n );\n\n DoSomethingWithDummyInterface(values);\n\n }\n\n public void DoSomethingWithDummyInterface(IEnumerable<DummyInterface> values)\n {\n foreach (var value in values)\n {\n Console.WriteLine(\"A = '{0}', B = '{1}'\", value.A, value.B);\n }\n }\n}\n</code></pre>\n\n<p>If all you are ever going to do is convert <code>DummySource</code> to <code>DummyInterface</code>, then it would be simpler to just have one class that takes a <code>DummySource</code> in the constructor and implements the interface.</p>\n\n<p>But, if you need to convert many types to <code>DummyInterface</code>, this is much less boiler plate.</p>\n"
},
{
"answer_id": 63860837,
"author": "Fidel",
"author_id": 171846,
"author_profile": "https://Stackoverflow.com/users/171846",
"pm_score": 0,
"selected": false,
"text": "<p>Using Roslyn, you can dynamically create a class which inherits from an interface (or abstract class).</p>\n<p>I use the following to create concrete classes from abstract classes.</p>\n<p>In this example, AAnimal is an abstract class.</p>\n<pre><code>var personClass = typeof(AAnimal).CreateSubclass("Person");\n</code></pre>\n<p>Then you can instantiate some objects:</p>\n<pre><code>var person1 = Activator.CreateInstance(personClass);\nvar person2 = Activator.CreateInstance(personClass);\n</code></pre>\n<p>Without a doubt this won't work for every case, but it should be enough to get you started:</p>\n<pre><code>using Microsoft.CodeAnalysis;\nusing Microsoft.CodeAnalysis.CSharp;\nusing System;\nusing System.Collections.Generic;\nusing System.IO;\nusing System.Linq;\nusing System.Reflection;\n\nnamespace Publisher\n{\n public static class Extensions\n {\n public static Type CreateSubclass(this Type baseType, string newClassName, string newNamespace = "Magic")\n {\n //todo: handle ref, out etc.\n var concreteMethods = baseType\n .GetMethods()\n .Where(method => method.IsAbstract)\n .Select(method =>\n {\n var parameters = method\n .GetParameters()\n .Select(param => $"{param.ParameterType.FullName} {param.Name}")\n .ToString(", ");\n\n var returnTypeStr = method.ReturnParameter.ParameterType.Name;\n if (returnTypeStr.Equals("Void")) returnTypeStr = "void";\n\n var methodString = @$"\n public override {returnTypeStr} {method.Name}({parameters})\n {{\n Console.WriteLine(""{newNamespace}.{newClassName}.{method.Name}() was called"");\n }}";\n\n return methodString.Trim();\n })\n .ToList();\n\n var concreteMethodsString = concreteMethods\n .ToString(Environment.NewLine + Environment.NewLine);\n\n var classCode = @$"\n using System;\n\n namespace {newNamespace}\n {{\n public class {newClassName}: {baseType.FullName}\n {{\n public {newClassName}()\n {{\n }}\n\n {concreteMethodsString}\n }}\n }}\n ".Trim();\n\n classCode = FormatUsingRoslyn(classCode);\n\n\n /*\n var assemblies = new[]\n {\n MetadataReference.CreateFromFile(typeof(object).Assembly.Location),\n MetadataReference.CreateFromFile(baseType.Assembly.Location),\n };\n */\n\n var assemblies = AppDomain\n .CurrentDomain\n .GetAssemblies()\n .Where(a => !string.IsNullOrEmpty(a.Location))\n .Select(a => MetadataReference.CreateFromFile(a.Location))\n .ToArray();\n\n var syntaxTree = CSharpSyntaxTree.ParseText(classCode);\n\n var compilation = CSharpCompilation\n .Create(newNamespace)\n .AddSyntaxTrees(syntaxTree)\n .AddReferences(assemblies)\n .WithOptions(new CSharpCompilationOptions(OutputKind.DynamicallyLinkedLibrary));\n\n using (var ms = new MemoryStream())\n {\n var result = compilation.Emit(ms);\n //compilation.Emit($"C:\\\\Temp\\\\{newNamespace}.dll");\n\n if (result.Success)\n {\n ms.Seek(0, SeekOrigin.Begin);\n Assembly assembly = Assembly.Load(ms.ToArray());\n\n var newTypeFullName = $"{newNamespace}.{newClassName}";\n\n var type = assembly.GetType(newTypeFullName);\n return type;\n }\n else\n {\n IEnumerable<Diagnostic> failures = result.Diagnostics.Where(diagnostic =>\n diagnostic.IsWarningAsError ||\n diagnostic.Severity == DiagnosticSeverity.Error);\n\n foreach (Diagnostic diagnostic in failures)\n {\n Console.Error.WriteLine("{0}: {1}", diagnostic.Id, diagnostic.GetMessage());\n }\n\n return null;\n }\n }\n }\n\n public static string ToString(this IEnumerable<string> list, string separator)\n {\n string result = string.Join(separator, list);\n return result;\n }\n\n public static string FormatUsingRoslyn(string csCode)\n {\n var tree = CSharpSyntaxTree.ParseText(csCode);\n var root = tree.GetRoot().NormalizeWhitespace();\n var result = root.ToFullString();\n return result;\n }\n }\n}\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191013",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5932/"
] |
Is it possible to have an anonymous type implement an interface?
I've got a piece of code that I would like to work, but don't know how to do this.
I've had a couple of answers that either say no, or create a class that implements the interface construct new instances of that. This isn't really ideal, but I'm wondering if there is a mechanism to create a thin dynamic class on top of an interface which would make this simple.
```
public interface DummyInterface
{
string A { get; }
string B { get; }
}
public class DummySource
{
public string A { get; set; }
public string C { get; set; }
public string D { get; set; }
}
public class Test
{
public void WillThisWork()
{
var source = new DummySource[0];
var values = from value in source
select new
{
A = value.A,
B = value.C + "_" + value.D
};
DoSomethingWithDummyInterface(values);
}
public void DoSomethingWithDummyInterface(IEnumerable<DummyInterface> values)
{
foreach (var value in values)
{
Console.WriteLine("A = '{0}', B = '{1}'", value.A, value.B);
}
}
}
```
I've found an article [Dynamic interface wrapping](http://channel8.msdn.com/Posts/Adding-some-dynamic-to-C-interface-wrapping/) that describes one approach. Is this the best way of doing this?
|
No, anonymous types cannot implement an interface. From the [C# programming guide](http://msdn.microsoft.com/en-us/library/bb397696.aspx):
>
> Anonymous types are class types that consist of one or more public read-only properties. No other kinds of class members such as methods or events are allowed. An anonymous type cannot be cast to any interface or type except for object.
>
>
>
|
191,082 |
<p>Ok sorry this might seem like a dumb question but I cannot figure this thing out :</p>
<p>I am trying to parse a string and simply want to check whether it only contains the following characters : '0123456789dD+ '</p>
<p>I have tried many things but just can't get to figure out the right regex to use!</p>
<pre><code>
Regex oReg = new Regex(@"[\d dD+]+");
oReg.IsMatch("e4");
</code></pre>
<p>will return true even though e is not allowed...
I've tried many strings, including Regex("[1234567890 dD+]+")...</p>
<p>It always works on <a href="http://regexpal.com/" rel="nofollow noreferrer">Regex Pal</a> but not in C#...</p>
<p>Please advise and again i apologize this seems like a very silly question</p>
|
[
{
"answer_id": 191104,
"author": "Manu",
"author_id": 2133,
"author_profile": "https://Stackoverflow.com/users/2133",
"pm_score": 4,
"selected": true,
"text": "<p>Try this: </p>\n\n<pre><code>@\"^[0-9dD+ ]+$\"\n</code></pre>\n\n<p>The <code>^</code> and <code>$</code> at the beginning and end signify the beginning and end of the input string respectively. Thus between the beginning and then end only the stated characters are allowed. In your example, the regex matches if the string contains one of the characters even if it contains other characters as well.</p>\n\n<p>@comments: Thanks, I fixed the missing <code>+</code> and space.</p>\n"
},
{
"answer_id": 191110,
"author": "Coincoin",
"author_id": 42,
"author_profile": "https://Stackoverflow.com/users/42",
"pm_score": 2,
"selected": false,
"text": "<p>Oops, you forgot the boundaries, try:</p>\n\n<pre><code>Regex oReg = new Regex(@\"^[0-9dD +]+$\");\noReg.IsMatch(\"e4\");\n</code></pre>\n\n<p>^ matches the begining of the text stream, $ matches the end.</p>\n"
},
{
"answer_id": 191111,
"author": "Ian Jacobs",
"author_id": 22818,
"author_profile": "https://Stackoverflow.com/users/22818",
"pm_score": 0,
"selected": false,
"text": "<p>I believe it's returning True because it's finding the 4. Nothing in the regex excludes the letter e from the results.</p>\n"
},
{
"answer_id": 191117,
"author": "Marc Gravell",
"author_id": 23354,
"author_profile": "https://Stackoverflow.com/users/23354",
"pm_score": 1,
"selected": false,
"text": "<p>It is matching the 4; you need ^ and $ to terminate the regex if you want a full match for the entire string - i.e.</p>\n\n<pre><code> Regex re = new Regex(@\"^[\\d dD+]+$\");\n Console.WriteLine(re.IsMatch(\"e4\"));\n Console.WriteLine(re.IsMatch(\"4\"));\n</code></pre>\n"
},
{
"answer_id": 191127,
"author": "Joel Coehoorn",
"author_id": 3043,
"author_profile": "https://Stackoverflow.com/users/3043",
"pm_score": -1,
"selected": false,
"text": "<p>Another option is to invert everything, so it matches on characters you don't want to allow:</p>\n\n<pre><code>Regex oReg = new Regex(@\"[^0-9dD+]\");\n!oReg.IsMatch(\"e4\");\n</code></pre>\n"
},
{
"answer_id": 191132,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>This is because regular expressions can also match parts of the input, in this case it just matches the \"4\" of \"e4\". If you want to match a whole line, you have to surround the regex with \"^\" (matches line start) and \"$\" (matches line end).</p>\n\n<p>So to make your example work, you have to write is as follows:</p>\n\n<pre><code>Regex oReg = new Regex(@\"^[\\d dD+]+$\");\noReg.IsMatch(\"e4\");\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191082",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25152/"
] |
Ok sorry this might seem like a dumb question but I cannot figure this thing out :
I am trying to parse a string and simply want to check whether it only contains the following characters : '0123456789dD+ '
I have tried many things but just can't get to figure out the right regex to use!
```
Regex oReg = new Regex(@"[\d dD+]+");
oReg.IsMatch("e4");
```
will return true even though e is not allowed...
I've tried many strings, including Regex("[1234567890 dD+]+")...
It always works on [Regex Pal](http://regexpal.com/) but not in C#...
Please advise and again i apologize this seems like a very silly question
|
Try this:
```
@"^[0-9dD+ ]+$"
```
The `^` and `$` at the beginning and end signify the beginning and end of the input string respectively. Thus between the beginning and then end only the stated characters are allowed. In your example, the regex matches if the string contains one of the characters even if it contains other characters as well.
@comments: Thanks, I fixed the missing `+` and space.
|
191,159 |
<p>You'd like to call a stored proc on MS SQL that has a parameter type of TIMESTAMP within T-SQL, not ADO.NET using a VARCHAR value (e.g. '0x0000000002C490C8').</p>
<p>What do you do?</p>
<p>UPDATE:
This is where you have a "Timestamp" value coming at you but exists only as VARCHAR. (Think OUTPUT variable on another stored proc, but it's fixed already as VARCHAR, it just has the value of a TIMESTAMP). So, unless you decide to build Dynamic SQL, how can you programmatically change a value stored in VARCHAR into a valid TIMESTAMP?</p>
|
[
{
"answer_id": 191169,
"author": "John Rudy",
"author_id": 14048,
"author_profile": "https://Stackoverflow.com/users/14048",
"pm_score": 2,
"selected": false,
"text": "<p>A TIMESTAMP is semantically equivalent to VARBINARY(8) (nullable) or BINARY(8) (non-nullable). So you should be able to call the procedure with the parameter unquoted, as follows:</p>\n\n<pre><code>EXEC usp_MyProc @myParam=0x0000000002C490C8\n</code></pre>\n\n<p>See also <a href=\"http://msdn.microsoft.com/en-us/library/aa260631(SQL.80).aspx\" rel=\"nofollow noreferrer\">SQL Books Online</a></p>\n\n<p>EDIT for updated question ... </p>\n\n<p>I just tried a few experiments. Frankly, I'm curious as to how you got this represented as a varchar in the first place, since when I do something like:</p>\n\n<pre><code>select top 10 convert(varchar, ts) from foo\n</code></pre>\n\n<p>Where ts is a timestamp, I get 10 blank rows. (If I don't convert, I see my timestamps.)</p>\n\n<p>However, I tried working at it from the proper direction ... I did this:</p>\n\n<pre><code>select convert(timestamp, '0x0000000000170B2E')\n</code></pre>\n\n<p>And the conversion resulted in <code>0x3078303030303030</code>. So that won't play either. Nor will converting to binary. </p>\n\n<p>I hate to say it, but you might be stuck in a dynamic SQL world. I'd <strong>really</strong> like to be wrong, though.</p>\n"
},
{
"answer_id": 220226,
"author": "6eorge Jetson",
"author_id": 23422,
"author_profile": "https://Stackoverflow.com/users/23422",
"pm_score": 1,
"selected": true,
"text": "<p>A timestamp datatype is managed by SQL Server. I've never seen it used anywhere other than as a table column type. In that capacity, the column of type timestamp will give you a rigorous ordinal of the last insert/update on the row in relation to all other updates in the database. To see the most recent ordinal across the entire database, you can retrieve the value of @@DBTS or rowversion().</p>\n\n<p>Per <a href=\"http://msdn.microsoft.com/en-us/library/ms182776(SQL.90).aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/ms182776(SQL.90).aspx</a></p>\n\n<blockquote>timestamp (Transact-SQL)\n<br/>\n<br/>is a data type that exposes automatically generated, unique binary numbers within a database. timestamp is generally used as a mechanism for version-stamping table rows. The storage size is 8 bytes. The timestamp data type is just an incrementing number and does not preserve a date or a time. To record a date or time, use a datetime data type.</blockquote>\n\n<p>Hence, the volatile value of a timestamp column cannot be set and is subject to change upon any modifaction to the row. You can, however, freeze the timestamp value to a varbinary(8) value.</p>\n\n<p>For example, say you had a source table and a target table.</p>\n\n<pre><code>CREATE TABLE tblSource (\nId int not null\ncolData int not null\ncolTimestamp timestamp null)\n\nCREATE TABLE tblTarget (\nId int not null\ncolData int not null\ncolTimestampVarBinary varbinary(8) null)\n</code></pre>\n\n<p>Then, in an extraction process, you might want to capture everything that has been updated since the last time you ran the extraction process.</p>\n\n<pre><code>DECLARE @maxFrozenTargetTimestamp varchar(8)\nSELECT @maxFrozenTargetTimestamp = max(colStamp) FROM tblTarget\n\nINSERT tblTarget(Id, colData, colTimestampVarBinary)\nSELECT \nId\n,colData\ncolTimestampVarBinary = convert(varbinary(8) colTimestamp)\nFROM \ntblSource \nWHERE\ntblSource.colTimestamp > @maxFrozenTargetTimestamp\n</code></pre>\n\n<p>If you are having issues, my first guess would be that crux of your problem\nis in the conversion of a varchar to a varbinary(8), and not to a timestamp type.</p>\n\n<p>For more info (perhaps too much) , see the comment (fourth one down) I left to the blog post <a href=\"http://vadivel.blogspot.com/2004/10/about-timestamp-datatype-of-sql-server.html?showComment=1213612020000\" rel=\"nofollow noreferrer\">http://vadivel.blogspot.com/2004/10/about-timestamp-datatype-of-sql-server.html?showComment=1213612020000</a></p>\n"
},
{
"answer_id": 8316842,
"author": "Sanchitos",
"author_id": 317832,
"author_profile": "https://Stackoverflow.com/users/317832",
"pm_score": 3,
"selected": false,
"text": "<p>Since timestamp is compatible with varbinary the solution will be this in SQL Server 2008:</p>\n\n<pre><code>declare @hexstring varchar(max);\nset @hexstring = '0xabcedf012439';\nselect CONVERT(varbinary(max), @hexstring, 1);\n\nset @hexstring = 'abcedf012439';\nselect CONVERT(varbinary(max), @hexstring, 2);\n</code></pre>\n\n<p>Reference. <a href=\"http://blogs.msdn.com/b/sqltips/archive/2008/07/02/converting-from-hex-string-to-varbinary-and-vice-versa.aspx\" rel=\"noreferrer\">MSN Blogs</a></p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191159",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/307/"
] |
You'd like to call a stored proc on MS SQL that has a parameter type of TIMESTAMP within T-SQL, not ADO.NET using a VARCHAR value (e.g. '0x0000000002C490C8').
What do you do?
UPDATE:
This is where you have a "Timestamp" value coming at you but exists only as VARCHAR. (Think OUTPUT variable on another stored proc, but it's fixed already as VARCHAR, it just has the value of a TIMESTAMP). So, unless you decide to build Dynamic SQL, how can you programmatically change a value stored in VARCHAR into a valid TIMESTAMP?
|
A timestamp datatype is managed by SQL Server. I've never seen it used anywhere other than as a table column type. In that capacity, the column of type timestamp will give you a rigorous ordinal of the last insert/update on the row in relation to all other updates in the database. To see the most recent ordinal across the entire database, you can retrieve the value of @@DBTS or rowversion().
Per <http://msdn.microsoft.com/en-us/library/ms182776(SQL.90).aspx>
> timestamp (Transact-SQL)
>
>
>
> is a data type that exposes automatically generated, unique binary numbers within a database. timestamp is generally used as a mechanism for version-stamping table rows. The storage size is 8 bytes. The timestamp data type is just an incrementing number and does not preserve a date or a time. To record a date or time, use a datetime data type.
Hence, the volatile value of a timestamp column cannot be set and is subject to change upon any modifaction to the row. You can, however, freeze the timestamp value to a varbinary(8) value.
For example, say you had a source table and a target table.
```
CREATE TABLE tblSource (
Id int not null
colData int not null
colTimestamp timestamp null)
CREATE TABLE tblTarget (
Id int not null
colData int not null
colTimestampVarBinary varbinary(8) null)
```
Then, in an extraction process, you might want to capture everything that has been updated since the last time you ran the extraction process.
```
DECLARE @maxFrozenTargetTimestamp varchar(8)
SELECT @maxFrozenTargetTimestamp = max(colStamp) FROM tblTarget
INSERT tblTarget(Id, colData, colTimestampVarBinary)
SELECT
Id
,colData
colTimestampVarBinary = convert(varbinary(8) colTimestamp)
FROM
tblSource
WHERE
tblSource.colTimestamp > @maxFrozenTargetTimestamp
```
If you are having issues, my first guess would be that crux of your problem
is in the conversion of a varchar to a varbinary(8), and not to a timestamp type.
For more info (perhaps too much) , see the comment (fourth one down) I left to the blog post <http://vadivel.blogspot.com/2004/10/about-timestamp-datatype-of-sql-server.html?showComment=1213612020000>
|
191,160 |
<p>I am creating a new build process for a DotNet project which is to be held in Subversion.</p>
<p>For each dll/exe that I compile (via Nant) I would like to include 2 additional attibutes in the dlls that are built.</p>
<p>I already understand the workings of the 'asminfo' nant task. But I need help retrieving the information which I hope to embed in my binaries.</p>
<p>The build will always happen from a full working copy (checked out by the build process itself.) and will therefore always have an .svn directory available.</p>
<p>The attributes I want to add are RepositoryVersion and RepositoryPath. (I understand that these are not the names this information goes by in svn)</p>
<p>In order to do this I will need to extract the RepositoryVersion and RepositoryPath represented by the working copy folder that the BuildFile sits within.</p>
<p><strong>How do I extract this information from any given .svn folder into the 2 nant variables?</strong> </p>
|
[
{
"answer_id": 191186,
"author": "Henry B",
"author_id": 6414,
"author_profile": "https://Stackoverflow.com/users/6414",
"pm_score": -1,
"selected": false,
"text": "<p>The entries in the .svn directory are not really meant to be accessed directly. I don't know much about what you're doing but I'd suggest you use the mechanism you use to checkout the project to find the HEAD version and path. (I'd actually assume that becuase you are checking out the project you already know the path but maybe that is not so).</p>\n\n<p>Sorry I can't give more information than this.</p>\n"
},
{
"answer_id": 191199,
"author": "EggyBach",
"author_id": 15475,
"author_profile": "https://Stackoverflow.com/users/15475",
"pm_score": 3,
"selected": true,
"text": "<p>Firstly, you can use \"svn info --xml >out.xml\" to get the svn information to a text file. You can then use a Nant xml-peek to get a value out of the file into a variable.</p>\n\n<pre><code><xmlpeek file=\"out.xml\" xpath=\"/info/entry/url\" property=\"svn.url\" />\n</code></pre>\n"
},
{
"answer_id": 191238,
"author": "user24881",
"author_id": 24881,
"author_profile": "https://Stackoverflow.com/users/24881",
"pm_score": 0,
"selected": false,
"text": "<p>I'd recommend you embed <a href=\"http://svnbook.red-bean.com/en/1.4/svn.advanced.props.special.keywords.html\" rel=\"nofollow noreferrer\">svn keywords</a> into your build file as properties. Eg:<br>\n<code><property name="RepositoryPath" value="$HeadURL$" /></code><br>\n<code><property name="RepositoryVersion" value="$Revision$" /></code><br></p>\n"
},
{
"answer_id": 219222,
"author": "Tim Scott",
"author_id": 29493,
"author_profile": "https://Stackoverflow.com/users/29493",
"pm_score": 2,
"selected": false,
"text": "<p>This is how I do it for revision number:</p>\n\n<pre><code><exec\n program=\"svn\"\n commandline='log \"${solution.dir}\" --xml --limit 1'\n output=\"${solution.dir}\\_revision.xml\"\n failonerror=\"false\"/>\n<xmlpeek\n file=\"${solution.dir}\\_revision.xml\"\n xpath=\"/log/logentry/@revision\"\n property=\"version.revision\"\n failonerror=\"false\"/>\n<delete file=\"${solution.dir}\\_revision.xml\" failonerror=\"false\"/>\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191160",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11356/"
] |
I am creating a new build process for a DotNet project which is to be held in Subversion.
For each dll/exe that I compile (via Nant) I would like to include 2 additional attibutes in the dlls that are built.
I already understand the workings of the 'asminfo' nant task. But I need help retrieving the information which I hope to embed in my binaries.
The build will always happen from a full working copy (checked out by the build process itself.) and will therefore always have an .svn directory available.
The attributes I want to add are RepositoryVersion and RepositoryPath. (I understand that these are not the names this information goes by in svn)
In order to do this I will need to extract the RepositoryVersion and RepositoryPath represented by the working copy folder that the BuildFile sits within.
**How do I extract this information from any given .svn folder into the 2 nant variables?**
|
Firstly, you can use "svn info --xml >out.xml" to get the svn information to a text file. You can then use a Nant xml-peek to get a value out of the file into a variable.
```
<xmlpeek file="out.xml" xpath="/info/entry/url" property="svn.url" />
```
|
191,179 |
<p>How can I find the font that the user has set in their Windows Display Properties using C# in .NET?</p>
<p>I want to display a form using the fonts that the user has selected. The fonts I want are those selected in the Windows Display Properties form for 3D-objects, menus and window title bars. But I cannot find a way to access them. There is a <code>System.Windows.Forms.Control.DefaultFont</code> property but that is returning the Windows default font (which is, I think, MS Sans Serif on XP).</p>
|
[
{
"answer_id": 191186,
"author": "Henry B",
"author_id": 6414,
"author_profile": "https://Stackoverflow.com/users/6414",
"pm_score": -1,
"selected": false,
"text": "<p>The entries in the .svn directory are not really meant to be accessed directly. I don't know much about what you're doing but I'd suggest you use the mechanism you use to checkout the project to find the HEAD version and path. (I'd actually assume that becuase you are checking out the project you already know the path but maybe that is not so).</p>\n\n<p>Sorry I can't give more information than this.</p>\n"
},
{
"answer_id": 191199,
"author": "EggyBach",
"author_id": 15475,
"author_profile": "https://Stackoverflow.com/users/15475",
"pm_score": 3,
"selected": true,
"text": "<p>Firstly, you can use \"svn info --xml >out.xml\" to get the svn information to a text file. You can then use a Nant xml-peek to get a value out of the file into a variable.</p>\n\n<pre><code><xmlpeek file=\"out.xml\" xpath=\"/info/entry/url\" property=\"svn.url\" />\n</code></pre>\n"
},
{
"answer_id": 191238,
"author": "user24881",
"author_id": 24881,
"author_profile": "https://Stackoverflow.com/users/24881",
"pm_score": 0,
"selected": false,
"text": "<p>I'd recommend you embed <a href=\"http://svnbook.red-bean.com/en/1.4/svn.advanced.props.special.keywords.html\" rel=\"nofollow noreferrer\">svn keywords</a> into your build file as properties. Eg:<br>\n<code><property name="RepositoryPath" value="$HeadURL$" /></code><br>\n<code><property name="RepositoryVersion" value="$Revision$" /></code><br></p>\n"
},
{
"answer_id": 219222,
"author": "Tim Scott",
"author_id": 29493,
"author_profile": "https://Stackoverflow.com/users/29493",
"pm_score": 2,
"selected": false,
"text": "<p>This is how I do it for revision number:</p>\n\n<pre><code><exec\n program=\"svn\"\n commandline='log \"${solution.dir}\" --xml --limit 1'\n output=\"${solution.dir}\\_revision.xml\"\n failonerror=\"false\"/>\n<xmlpeek\n file=\"${solution.dir}\\_revision.xml\"\n xpath=\"/log/logentry/@revision\"\n property=\"version.revision\"\n failonerror=\"false\"/>\n<delete file=\"${solution.dir}\\_revision.xml\" failonerror=\"false\"/>\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191179",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26808/"
] |
How can I find the font that the user has set in their Windows Display Properties using C# in .NET?
I want to display a form using the fonts that the user has selected. The fonts I want are those selected in the Windows Display Properties form for 3D-objects, menus and window title bars. But I cannot find a way to access them. There is a `System.Windows.Forms.Control.DefaultFont` property but that is returning the Windows default font (which is, I think, MS Sans Serif on XP).
|
Firstly, you can use "svn info --xml >out.xml" to get the svn information to a text file. You can then use a Nant xml-peek to get a value out of the file into a variable.
```
<xmlpeek file="out.xml" xpath="/info/entry/url" property="svn.url" />
```
|
191,201 |
<p>I do all my coding in vim and am quite happy with it (so, please, no "use a different editor" responses), but have an ongoing annoyance in that the smartindent feature wants to not indent comments beginning with # at all. e.g., I want</p>
<pre><code> # Do something
$x = $x + 1;
if ($y) {
# Do something else
$y = $y + $z;
}
</code></pre>
<p>instead of vim's preferred</p>
<pre><code># Do something
$x = $x + 1;
if ($y) {
# Do something else
$y = $y + $z;
}
</code></pre>
<p>The only ways I have been able to prevent comments from being sent to the start of the line are to either insert and delete a character on the line before hitting # (a nuisance to have to remember to do every time) or turn off smartindent entirely (losing automatic indentation increase/decrease as I open/close braces).</p>
<p>How can I set vim to maintain my indentation for comments instead of sending them to the start of the line?</p>
|
[
{
"answer_id": 191229,
"author": "Paul Tomblin",
"author_id": 3333,
"author_profile": "https://Stackoverflow.com/users/3333",
"pm_score": 3,
"selected": false,
"text": "<p>I think \"smartindent\" is designed for C, so it thinks \"#\" is the start of a pre-processor directive instead of a comment. I don't know a solution for it, except if you type a space, then a backspace, then the \"#\" it won't do that.</p>\n"
},
{
"answer_id": 191230,
"author": "Ben Hoffstein",
"author_id": 4482,
"author_profile": "https://Stackoverflow.com/users/4482",
"pm_score": 3,
"selected": false,
"text": "<p>This problem can be solved by putting the following in your _vimrc file.</p>\n\n<pre><code>set cindent\nset cinkeys=0{,0},!^F,o,O,e \" default is: 0{,0},0),:,0#,!^F,o,O,e\n</code></pre>\n\n<p><a href=\"http://thenobot.org/stories/?i=117\" rel=\"noreferrer\">More info</a>...</p>\n"
},
{
"answer_id": 191267,
"author": "Richard Waite",
"author_id": 1200605,
"author_profile": "https://Stackoverflow.com/users/1200605",
"pm_score": 7,
"selected": true,
"text": "<p>It looks like you're coding in Perl. Ensure that the following are set in your .vimrc:</p>\n\n<pre><code>filetype plugin indent on\nsyntax enable\n</code></pre>\n\n<p>These will tell Vim to set the filetype when opening a buffer and configure the indentation and syntax highlighting. No need to explicitly set smartindent since Vim's included Perl syntax file will set it (and any other Perl-specific customizations) automatically.</p>\n\n<hr>\n\n<p><em>Note: having either <code>set smartindent</code> and/or <code>set autoindent</code> in <code>~/.vimrc</code> may prevent the solution from working. If you're having problems, look for them.</em></p>\n"
},
{
"answer_id": 2323718,
"author": "Russell Silva",
"author_id": 280043,
"author_profile": "https://Stackoverflow.com/users/280043",
"pm_score": 4,
"selected": false,
"text": "<p>If you are using the \"smartindent\" indenting option, a fix for your problem is explained in the \":help smartindent\" VIM documentation:</p>\n\n<blockquote>\n<pre><code> When typing '#' as the first character in a new line, the indent for\n that line is removed, the '#' is put in the first column. The indent\n is restored for the next line. If you don't want this, use this\n mapping: \":inoremap # X^H#\", where ^H is entered with CTRL-V CTRL-H.\n When using the \">>\" command, lines starting with '#' are not shifted\n right.\n</code></pre>\n</blockquote>\n\n<p>I use \"smartindent\" and can confirm that the fix described works for me. It tricks VIM by replacing the keystroke for \"#\" with typing \"X\", then hitting backspace, then typing \"#\" again. You can try this yourself manually and see that it does not trigger the auto-outdenting.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191201",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18914/"
] |
I do all my coding in vim and am quite happy with it (so, please, no "use a different editor" responses), but have an ongoing annoyance in that the smartindent feature wants to not indent comments beginning with # at all. e.g., I want
```
# Do something
$x = $x + 1;
if ($y) {
# Do something else
$y = $y + $z;
}
```
instead of vim's preferred
```
# Do something
$x = $x + 1;
if ($y) {
# Do something else
$y = $y + $z;
}
```
The only ways I have been able to prevent comments from being sent to the start of the line are to either insert and delete a character on the line before hitting # (a nuisance to have to remember to do every time) or turn off smartindent entirely (losing automatic indentation increase/decrease as I open/close braces).
How can I set vim to maintain my indentation for comments instead of sending them to the start of the line?
|
It looks like you're coding in Perl. Ensure that the following are set in your .vimrc:
```
filetype plugin indent on
syntax enable
```
These will tell Vim to set the filetype when opening a buffer and configure the indentation and syntax highlighting. No need to explicitly set smartindent since Vim's included Perl syntax file will set it (and any other Perl-specific customizations) automatically.
---
*Note: having either `set smartindent` and/or `set autoindent` in `~/.vimrc` may prevent the solution from working. If you're having problems, look for them.*
|
191,206 |
<p>I need to programmatically get a list of running applications as shown in the "Applications" tab inside the Windows Task Manager using PowerShell or VBScript.</p>
<p>All I could find so far is how to list processes using VBScript and WMI.</p>
|
[
{
"answer_id": 191343,
"author": "stahler",
"author_id": 26811,
"author_profile": "https://Stackoverflow.com/users/26811",
"pm_score": 4,
"selected": true,
"text": "<p>This should do the trick:</p>\n\n<pre><code>Set Word = CreateObject(\"Word.Application\")\nSet Tasks = Word.Tasks\nFor Each Task in Tasks\n If Task.Visible Then Wscript.Echo Task.Name\nNext\nWord.Quit\n</code></pre>\n\n<p><a href=\"http://msdn.microsoft.com/en-us/library/bb212832.aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/bb212832.aspx</a></p>\n"
},
{
"answer_id": 191548,
"author": "Steven Murawski",
"author_id": 1233,
"author_profile": "https://Stackoverflow.com/users/1233",
"pm_score": 5,
"selected": false,
"text": "<p>This gets you close in PowerShell:</p>\n\n<pre><code>get-process | where-object {$_.mainwindowhandle -ne 0} | select-object name, mainwindowtitle\n</code></pre>\n\n<p>Or the shorter version:</p>\n\n<pre><code>gps | ? {$_.mainwindowhandle -ne 0} | select name, mainwindowtitle\n</code></pre>\n"
},
{
"answer_id": 194587,
"author": "aleksandar",
"author_id": 8766,
"author_profile": "https://Stackoverflow.com/users/8766",
"pm_score": 1,
"selected": false,
"text": "<p>stahler's answer converted to PowerShell:</p>\n\n<p>$word = new-object -com 'word.application'</p>\n\n<p>$word.tasks | ? {$_.visible} | select name</p>\n\n<p>$word.quit()</p>\n"
},
{
"answer_id": 199204,
"author": "EdgeVB",
"author_id": 24863,
"author_profile": "https://Stackoverflow.com/users/24863",
"pm_score": 3,
"selected": false,
"text": "<p>@Steven Murawski: I noticed that if I used mainwindowhandle I'd get some process that were running, of course, but not in the \"Applications\" tab. Like explorer and UltraMon, etc. You could condition off of mainwindowtitle instead, since those process I encountered didn't have window titles -- like so</p>\n\n<pre><code>gps | ? {$_.mainwindowtitle.length -ne 0} | select name, mainwindowtitle\n</code></pre>\n"
},
{
"answer_id": 13499640,
"author": "Jack",
"author_id": 1784078,
"author_profile": "https://Stackoverflow.com/users/1784078",
"pm_score": 3,
"selected": false,
"text": "<p>from command line you are looking for:</p>\n\n<p><code>tasklist /v</code> the <code>/v</code> means verbose and will include list of \"application running off each process</p>\n\n<p><code>tasklist /v /fi \"imagenaem eq POWERPNT.EXE\"</code>\nfor example can be used to filter just application running under POWERPNT.EXE process.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191206",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/26810/"
] |
I need to programmatically get a list of running applications as shown in the "Applications" tab inside the Windows Task Manager using PowerShell or VBScript.
All I could find so far is how to list processes using VBScript and WMI.
|
This should do the trick:
```
Set Word = CreateObject("Word.Application")
Set Tasks = Word.Tasks
For Each Task in Tasks
If Task.Visible Then Wscript.Echo Task.Name
Next
Word.Quit
```
<http://msdn.microsoft.com/en-us/library/bb212832.aspx>
|
191,250 |
<p>I have the following code fragment that starts a <a href="http://en.wikipedia.org/wiki/Google_Earth" rel="nofollow noreferrer">Google Earth</a> process using a hardcoded path:</p>
<pre><code>var process =
new Process
{
StartInfo =
{
//TODO: Get location of google earth executable from registry
FileName = @"C:\Program Files\Google\Google Earth\googleearth.exe",
Arguments = "\"" + kmlPath + "\""
}
};
process.Start();
</code></pre>
<p>I want to programmatically fetch the installation location of <em>googleearth.exe</em> from somewhere (most likely the registry).</p>
|
[
{
"answer_id": 191281,
"author": "Iain",
"author_id": 5993,
"author_profile": "https://Stackoverflow.com/users/5993",
"pm_score": 2,
"selected": false,
"text": "<p>From the example given you can gauge that I'm actually trying to pass a KML file to Google Earth. Because of this, the simplest way of resolving this problem is relying on the file association of KML with Google Earth and using the following as a replacement for the entire example:</p>\n\n<pre><code>Process.Start(kmlPath);\n</code></pre>\n\n<p>This was found by reviewing the answers to <a href=\"https://stackoverflow.com/questions/181719/how-to-start-a-process-from-c-winforms\">this</a> question.</p>\n"
},
{
"answer_id": 194238,
"author": "ICR",
"author_id": 214,
"author_profile": "https://Stackoverflow.com/users/214",
"pm_score": 3,
"selected": true,
"text": "<p>Obviously if you're opening a specific file associated with the program then launching it via the file is preferable (for instance, the user might have a program associated with the file type they prefer to use).</p>\n\n<p>Here is a method I've used in the past to launch an application associated with a particular file type, but without actually opening a file. There may be a better way to do it.</p>\n\n<pre><code>static Regex pathArgumentsRegex = new Regex(@\"(%\\d+)|(\"\"%\\d+\"\")\", RegexOptions.ExplicitCapture);\nstatic string GetPathAssociatedWithFileExtension(string extension)\n{\n RegistryKey extensionKey = Registry.ClassesRoot.OpenSubKey(extension);\n if (extensionKey != null)\n {\n object applicationName = extensionKey.GetValue(string.Empty);\n if (applicationName != null)\n {\n RegistryKey commandKey = Registry.ClassesRoot.OpenSubKey(applicationName.ToString() + @\"\\shell\\open\\command\");\n if (commandKey != null)\n {\n object command = commandKey.GetValue(string.Empty);\n if (command != null)\n {\n return pathArgumentsRegex.Replace(command.ToString(), \"\");\n }\n }\n }\n }\n return null;\n}\n</code></pre>\n\n<p>Sometimes though there are cases when you want to launch a specific program without opening a file. Usually (hopefully) the program has a registry entry with the install location. Here is an example of how to launch Google Earth in such a manner.</p>\n\n<pre><code>private static string GetGoogleEarthExePath()\n{\n RegistryKey googleEarthRK = Registry.CurrentUser.OpenSubKey(@\"Software\\Google\\Google Earth Plus\\\");\n if (googleEarthRK != null)\n {\n object rootDir = googleEarthRK.GetValue(\"InstallLocation\");\n if (rootDir != null)\n {\n return Path.Combine(rootDir.ToString(), \"googleearth.exe\");\n }\n }\n\n return null;\n}\n</code></pre>\n"
},
{
"answer_id": 814009,
"author": "Hawkeye Parker",
"author_id": 99717,
"author_profile": "https://Stackoverflow.com/users/99717",
"pm_score": 1,
"selected": false,
"text": "<p>Here's a C++ version I just had to write. Taken directly from ICR's C# version.</p>\n\n<pre><code>void PrintString(CString string)\n{\n std::wcout << static_cast<LPCTSTR>(string) << endl;\n}\n\nCString GetClassesRootKeyValue(const wchar_t * keyName)\n{\n HKEY hkey;\n TCHAR keyNameCopy[256] = {0};\n _tcscpy_s(keyNameCopy, 256, keyName);\n BOOL bResult = SUCCEEDED(::RegOpenKey(HKEY_CLASSES_ROOT, keyNameCopy, &hkey));\n CString hkeyValue = CString(\"\");\n if (bResult) {\n TCHAR temporaryValueBuffer[256];\n DWORD bufferSize = sizeof (temporaryValueBuffer);\n DWORD type;\n bResult = SUCCEEDED(RegQueryValueEx(hkey, _T(\"\"), NULL, &type, (BYTE*)temporaryValueBuffer, &bufferSize)) && (bufferSize > 1);\n if (bResult) {\n hkeyValue = CString(temporaryValueBuffer);\n }\n RegCloseKey(hkey);\n return hkeyValue;\n }\n return hkeyValue;\n}\n\n\nint _tmain(int argc, TCHAR* argv[], TCHAR* envp[])\n{\n int nRetCode = 0;\n\n // initialize MFC and print and error on failure\n if (!AfxWinInit(::GetModuleHandle(NULL), NULL, ::GetCommandLine(), 0))\n {\n // TODO: change error code to suit your needs\n _tprintf(_T(\"Fatal Error: MFC initialization failed\\n\"));\n nRetCode = 1;\n }\n else\n {\n\n CString dwgAppName = GetClassesRootKeyValue(_T(\".dwg\"));\n PrintString(dwgAppName);\n\n dwgAppName.Append(_T(\"\\\\shell\\\\open\\\\command\"));\n PrintString(dwgAppName);\n\n CString trueViewOpenCommand = GetClassesRootKeyValue(static_cast<LPCTSTR>(dwgAppName));\n PrintString(trueViewOpenCommand);\n\n // Shell open command usually ends with a \"%1\" for commandline params. We don't want that,\n // so strip it off.\n int firstParameterIndex = trueViewOpenCommand.Find(_T(\"%\"));\n PrintString(trueViewOpenCommand.Left(firstParameterIndex).TrimRight('\"').TrimRight(' '));\n\n\n cout << \"\\n\\nPress <enter> to exit...\";\n getchar();\n }\n}\n</code></pre>\n"
},
{
"answer_id": 1309191,
"author": "snicker",
"author_id": 160359,
"author_profile": "https://Stackoverflow.com/users/160359",
"pm_score": 2,
"selected": false,
"text": "<p>This would also work: (C# code)</p>\n\n<pre><code> Type type = Type.GetTypeFromProgID(\"WindowsInstaller.Installer\");\n Installer msi = (Installer)Activator.CreateInstance(type);\n foreach (string productcode in msi.Products)\n {\n string productname = msi.get_ProductInfo(productcode, \"InstalledProductName\");\n if (productname.Contains(\"Google Earth\"))\n {\n string installdir = msi.get_ProductInfo(productcode, \"InstallLocation\");\n Console.WriteLine(\"{0}: {1} @({2})\", productcode, productname, installdir);\n }\n }\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191250",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5993/"
] |
I have the following code fragment that starts a [Google Earth](http://en.wikipedia.org/wiki/Google_Earth) process using a hardcoded path:
```
var process =
new Process
{
StartInfo =
{
//TODO: Get location of google earth executable from registry
FileName = @"C:\Program Files\Google\Google Earth\googleearth.exe",
Arguments = "\"" + kmlPath + "\""
}
};
process.Start();
```
I want to programmatically fetch the installation location of *googleearth.exe* from somewhere (most likely the registry).
|
Obviously if you're opening a specific file associated with the program then launching it via the file is preferable (for instance, the user might have a program associated with the file type they prefer to use).
Here is a method I've used in the past to launch an application associated with a particular file type, but without actually opening a file. There may be a better way to do it.
```
static Regex pathArgumentsRegex = new Regex(@"(%\d+)|(""%\d+"")", RegexOptions.ExplicitCapture);
static string GetPathAssociatedWithFileExtension(string extension)
{
RegistryKey extensionKey = Registry.ClassesRoot.OpenSubKey(extension);
if (extensionKey != null)
{
object applicationName = extensionKey.GetValue(string.Empty);
if (applicationName != null)
{
RegistryKey commandKey = Registry.ClassesRoot.OpenSubKey(applicationName.ToString() + @"\shell\open\command");
if (commandKey != null)
{
object command = commandKey.GetValue(string.Empty);
if (command != null)
{
return pathArgumentsRegex.Replace(command.ToString(), "");
}
}
}
}
return null;
}
```
Sometimes though there are cases when you want to launch a specific program without opening a file. Usually (hopefully) the program has a registry entry with the install location. Here is an example of how to launch Google Earth in such a manner.
```
private static string GetGoogleEarthExePath()
{
RegistryKey googleEarthRK = Registry.CurrentUser.OpenSubKey(@"Software\Google\Google Earth Plus\");
if (googleEarthRK != null)
{
object rootDir = googleEarthRK.GetValue("InstallLocation");
if (rootDir != null)
{
return Path.Combine(rootDir.ToString(), "googleearth.exe");
}
}
return null;
}
```
|
191,260 |
<p>We've recently completed phase 1 of a ASP.Net website in English and French. We went with using resource files to store language specific strings, but because the site used ASP.Net AJAX and javascript heavily we rigged up a solution to pass the right files through the ASP.Net pipeline where we could catch "tokens" and replace them with the appropriate text pulled from the resource files. </p>
<p>This is the second project I've been involved in that had these kinds of challenges, the first one stored the text strings in a database, and instead of ASP.Net AJAX, it used the AJAX tools that come with the Prototype library and put all Javascript into aspx files so that the tokens could be replaced on the way out.</p>
<p>What I'm wondering is, has anyone else encountered a similar scenario? What approach did you take? What lessons were learned? How did you deal with things like internationalized date formats?</p>
|
[
{
"answer_id": 191754,
"author": "Joe Scylla",
"author_id": 25771,
"author_profile": "https://Stackoverflow.com/users/25771",
"pm_score": 2,
"selected": true,
"text": "<p>In my main project (a RAD framework using PHP with gettext for translations) we're doing already alot of prepare operations on javascript files like merging and minifying them. Within this preperations we parse for gettext-markers and replace them with the language specific text.</p>\n\n<p>The result get save as javascript file and normal included into the html.</p>\n\n<pre><code><script scr=\"var/scripts/en_GB-76909c49e9222ec2bb2f45e0a3c8baef80deb665.js\"></script>\n</code></pre>\n\n<p>The filename contains Locale and a hash value for caching.</p>\n\n<p>Date and money values get always converted from system format to Locale format on output and visa versa for input.</p>\n"
},
{
"answer_id": 1156538,
"author": "Walter Rumsby",
"author_id": 1654,
"author_profile": "https://Stackoverflow.com/users/1654",
"pm_score": 0,
"selected": false,
"text": "<p>To deal with il8n in our applications we dynamically create a JavaScript file (based on the locale we are interested in), that contains keys and translations, e.g.</p>\n\n<pre><code>LOCALISATIONS = {\n 'util.date.day.long': ['Sunday', 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday'],\n 'util.date.day.short': ['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat'],\n ...\n};\n</code></pre>\n\n<p>and other JavaScript code will use this object to get translated text.</p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191260",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22152/"
] |
We've recently completed phase 1 of a ASP.Net website in English and French. We went with using resource files to store language specific strings, but because the site used ASP.Net AJAX and javascript heavily we rigged up a solution to pass the right files through the ASP.Net pipeline where we could catch "tokens" and replace them with the appropriate text pulled from the resource files.
This is the second project I've been involved in that had these kinds of challenges, the first one stored the text strings in a database, and instead of ASP.Net AJAX, it used the AJAX tools that come with the Prototype library and put all Javascript into aspx files so that the tokens could be replaced on the way out.
What I'm wondering is, has anyone else encountered a similar scenario? What approach did you take? What lessons were learned? How did you deal with things like internationalized date formats?
|
In my main project (a RAD framework using PHP with gettext for translations) we're doing already alot of prepare operations on javascript files like merging and minifying them. Within this preperations we parse for gettext-markers and replace them with the language specific text.
The result get save as javascript file and normal included into the html.
```
<script scr="var/scripts/en_GB-76909c49e9222ec2bb2f45e0a3c8baef80deb665.js"></script>
```
The filename contains Locale and a hash value for caching.
Date and money values get always converted from system format to Locale format on output and visa versa for input.
|
191,291 |
<p>How would you manually trigger additional team builds from a team build? For example, when we were in CC.Net other builds would trigger if certain builds were successful. The second build could either be projects that use this component or additional, long running test libraries for the same component. </p>
|
[
{
"answer_id": 191898,
"author": "Martin Woodward",
"author_id": 6438,
"author_profile": "https://Stackoverflow.com/users/6438",
"pm_score": 3,
"selected": true,
"text": "<p>One way you could do it is you could an an AfterEndToEndIteration target to your TFSBuild.proj file that would runs the TfsBuild.exe command line to start you other builds. I'm thinking something like this (though I haven't tested it)</p>\n\n<pre><code> <Target Name=\"AfterEndToEndIteration\">\n\n <GetBuildProperties TeamFoundationServerUrl=\"$(TeamFoundationServerUrl)\"\n BuildUri=\"$(BuildUri)\"\n Condition=\" '$(IsDesktopBuild)' != 'true' \">\n <Output TaskParameter=\"Status\" PropertyName=\"Status\" />\n </GetBuildProperties>\n\n <Exec Condition=\" '$(Status)'=='Succeeded' \"\n Command=\"TfsBuild.exe start /server:$(TeamFoundationServerUrl) /buildDefinition:&quot;Your Build Definition To Run&quot;\" />\n\n </Target>\n</code></pre>\n"
},
{
"answer_id": 290865,
"author": "joshua.ewer",
"author_id": 28664,
"author_profile": "https://Stackoverflow.com/users/28664",
"pm_score": 2,
"selected": false,
"text": "<p>I've done the same thing Martin suggested on a number of occasions (his blog is beyond helpful, BTW). However, I ended up needing to trigger cascading builds like this (based on some other complicated rules) enough that I created a custom task to do it. Keep your build scripts nice and lean and gives you some more flexibility and encapsulation possibilities.</p>\n\n<pre><code> public override bool Execute()\n { \n IBuildDefinition[] buildDefinitions = BuildServer.QueryBuildDefinitions(ProjectName);\n\n foreach (IBuildDefinition build in buildDefinitions)\n {\n if(build.Enabled) //I did a bunch of custom rules here\n {\n Log.LogMessage(String.Concat(\"Queuing build: \", build.Name));\n BuildServer.QueueBuild(build);\n }\n }\n\n return true;\n }\n</code></pre>\n\n<p>There's some more good stuff on Aaron Hallberg's blog too: </p>\n\n<p><a href=\"http://blogs.msdn.com/aaronhallberg/archive/2007/04/24/team-build-object-model-queueing-a-build.aspx\" rel=\"nofollow noreferrer\">http://blogs.msdn.com/aaronhallberg/archive/2007/04/24/team-build-object-model-queueing-a-build.aspx</a></p>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191291",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18264/"
] |
How would you manually trigger additional team builds from a team build? For example, when we were in CC.Net other builds would trigger if certain builds were successful. The second build could either be projects that use this component or additional, long running test libraries for the same component.
|
One way you could do it is you could an an AfterEndToEndIteration target to your TFSBuild.proj file that would runs the TfsBuild.exe command line to start you other builds. I'm thinking something like this (though I haven't tested it)
```
<Target Name="AfterEndToEndIteration">
<GetBuildProperties TeamFoundationServerUrl="$(TeamFoundationServerUrl)"
BuildUri="$(BuildUri)"
Condition=" '$(IsDesktopBuild)' != 'true' ">
<Output TaskParameter="Status" PropertyName="Status" />
</GetBuildProperties>
<Exec Condition=" '$(Status)'=='Succeeded' "
Command="TfsBuild.exe start /server:$(TeamFoundationServerUrl) /buildDefinition:"Your Build Definition To Run"" />
</Target>
```
|
191,329 |
<p>I am working through a book which gives examples of Ranges being converted to equivalent arrays using their "to_a" methods</p>
<p>When i run the code in irb I get the following warning</p>
<pre><code> warning: default `to_a' will be obsolete
</code></pre>
<p>What is the the correct alternative to using to_a?</p>
<p>are there alternate ways to populate an array with a Range?</p>
|
[
{
"answer_id": 191357,
"author": "Daniel Lucraft",
"author_id": 11951,
"author_profile": "https://Stackoverflow.com/users/11951",
"pm_score": 6,
"selected": false,
"text": "<p>This works for me in irb:</p>\n\n<pre><code>irb> (1..4).to_a\n=> [1, 2, 3, 4]\n</code></pre>\n\n<p>I notice that:</p>\n\n<pre><code>irb> 1..4.to_a\n(irb):1: warning: default `to_a' will be obsolete\nArgumentError: bad value for range\n from (irb):1\n</code></pre>\n\n<p>So perhaps you are missing the parentheses? </p>\n\n<p>(I am running Ruby 1.8.6 patchlevel 114)</p>\n"
},
{
"answer_id": 191373,
"author": "Richard Turner",
"author_id": 12559,
"author_profile": "https://Stackoverflow.com/users/12559",
"pm_score": 5,
"selected": false,
"text": "<p>Sounds like you're doing this:</p>\n\n<pre><code>0..10.to_a\n</code></pre>\n\n<p>The warning is from Fixnum#to_a, not from Range#to_a. Try this instead:</p>\n\n<pre><code>(0..10).to_a\n</code></pre>\n"
},
{
"answer_id": 6587096,
"author": "Zamith",
"author_id": 830229,
"author_profile": "https://Stackoverflow.com/users/830229",
"pm_score": 10,
"selected": true,
"text": "<p>You can create an array with a range using splat,</p>\n\n<pre><code>>> a=*(1..10)\n=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n</code></pre>\n\n<p>using <code>Kernel</code> <code>Array</code> method,</p>\n\n<pre><code>Array (1..10)\n=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n</code></pre>\n\n<p>or using to_a</p>\n\n<pre><code>(1..10).to_a\n=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n</code></pre>\n"
},
{
"answer_id": 16038564,
"author": "Nickolay Kondratenko",
"author_id": 1812321,
"author_profile": "https://Stackoverflow.com/users/1812321",
"pm_score": 3,
"selected": false,
"text": "<p>I just tried to use ranges from bigger to smaller amount and got the result I didn't expect:</p>\n\n<pre><code>irb(main):007:0> Array(1..5)\n=> [1, 2, 3, 4, 5]\nirb(main):008:0> Array(5..1)\n=> []\n</code></pre>\n\n<p>That's because of ranges implementations.<br />\nSo I had to use the following option:</p>\n\n<pre><code>(1..5).to_a.reverse\n</code></pre>\n"
},
{
"answer_id": 17057666,
"author": "Boris Stitnicky",
"author_id": 1153747,
"author_profile": "https://Stackoverflow.com/users/1153747",
"pm_score": 3,
"selected": false,
"text": "<p>Check this:</p>\n\n<pre><code>a = [*(1..10), :top, *10.downto( 1 )]\n</code></pre>\n"
},
{
"answer_id": 49009672,
"author": "Jesús Andrés Valencia Montoya",
"author_id": 3582073,
"author_profile": "https://Stackoverflow.com/users/3582073",
"pm_score": 3,
"selected": false,
"text": "<p>This is another way:</p>\n\n<pre><code>irb> [*1..10]\n\n=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191329",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24773/"
] |
I am working through a book which gives examples of Ranges being converted to equivalent arrays using their "to\_a" methods
When i run the code in irb I get the following warning
```
warning: default `to_a' will be obsolete
```
What is the the correct alternative to using to\_a?
are there alternate ways to populate an array with a Range?
|
You can create an array with a range using splat,
```
>> a=*(1..10)
=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
```
using `Kernel` `Array` method,
```
Array (1..10)
=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
```
or using to\_a
```
(1..10).to_a
=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
```
|
191,339 |
<p>I have a <code>DataGridView</code> bound to a <code>DataView</code>. The grid can be sorted by the user on any column.</p>
<p>I add a row to the grid by calling NewRow on the <code>DataView</code>'s underlying <code>DataTable</code>, then adding it to the <code>DataTable</code>'s Rows collection. How can I select the newly-added row in the grid?</p>
<p>I tried doing it by creating a <code>BindingManagerBase</code> object bound to the <code>BindingContext</code> of the <code>DataView</code>, then setting <code>BindingManagerBase.Position = BindingManagerBase.Count</code>. This works if the grid is not sorted, since the new row gets added to the bottom of the grid. However, if the sort order is such that the row is not added to the bottom, this does not work.</p>
<p>How can I reliably set the selected row of the grid to the new row?</p>
|
[
{
"answer_id": 209841,
"author": "Brendan Kendrick",
"author_id": 13473,
"author_profile": "https://Stackoverflow.com/users/13473",
"pm_score": 0,
"selected": false,
"text": "<p>Assuming you have some sort of unique identifier in your data source you could iterate over your collection of rows and compare, as such:</p>\n\n<pre><code>Dim myRecentItemID As Integer = 3\n\nFor Each row As GridViewRow In gvIndividuals.Rows\n Dim drv As DataRowView = DirectCast(row.DataItem, DataRowView)\n If CInt(drv(\"ItemID\")) = myRecentItemID Then\n gvIndividuals.EditIndex = row.RowIndex\n End If\nNext\n</code></pre>\n\n<p>Hope this helps!</p>\n"
},
{
"answer_id": 478650,
"author": "stefano",
"author_id": 58898,
"author_profile": "https://Stackoverflow.com/users/58898",
"pm_score": 2,
"selected": false,
"text": "<p>As soon as you update the bound DataTable, a \"RowsAdded\" event is fired by the DataGridView control, with the DataGridViewRowsAddedEventArgs.RowIndex property containing the index of the added row.</p>\n\n<pre><code>//local member\nprivate int addedRowIndex;\n\nprivate void AddMyRow()\n{\n //add the DataRow \n MyDataSet.MyDataTable.Rows.Add(...);\n\n //RowsAdded event is fired here....\n\n //select the row\n MyDataGrid.Rows[addedRowIndex].Selected = true;\n}\n\nprivate void MyDataGrid_RowsAdded(object sender, DataGridViewRowsAddedEventArgs e)\n{\n addedRowIndex = e.RowIndex;\n}\n</code></pre>\n\n<p>Not the most elegant solution, perhaps, but it works for me</p>\n"
},
{
"answer_id": 1664824,
"author": "Ruben Trancoso",
"author_id": 137149,
"author_profile": "https://Stackoverflow.com/users/137149",
"pm_score": 1,
"selected": false,
"text": "<p>Dont know id its the best solution but for instance looks better than iterate.</p>\n\n<pre><code> DataRowView drv = (DataRowView)source.AddNew();\n grupoTableAdapter.Update(drv.Row);\n grupoBindingSource.Position = grupoBindingSource.Find(\"ID\", drv.Row.ItemArray[0]);\n</code></pre>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191339",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3012/"
] |
I have a `DataGridView` bound to a `DataView`. The grid can be sorted by the user on any column.
I add a row to the grid by calling NewRow on the `DataView`'s underlying `DataTable`, then adding it to the `DataTable`'s Rows collection. How can I select the newly-added row in the grid?
I tried doing it by creating a `BindingManagerBase` object bound to the `BindingContext` of the `DataView`, then setting `BindingManagerBase.Position = BindingManagerBase.Count`. This works if the grid is not sorted, since the new row gets added to the bottom of the grid. However, if the sort order is such that the row is not added to the bottom, this does not work.
How can I reliably set the selected row of the grid to the new row?
|
As soon as you update the bound DataTable, a "RowsAdded" event is fired by the DataGridView control, with the DataGridViewRowsAddedEventArgs.RowIndex property containing the index of the added row.
```
//local member
private int addedRowIndex;
private void AddMyRow()
{
//add the DataRow
MyDataSet.MyDataTable.Rows.Add(...);
//RowsAdded event is fired here....
//select the row
MyDataGrid.Rows[addedRowIndex].Selected = true;
}
private void MyDataGrid_RowsAdded(object sender, DataGridViewRowsAddedEventArgs e)
{
addedRowIndex = e.RowIndex;
}
```
Not the most elegant solution, perhaps, but it works for me
|
191,342 |
<p>Is there a succinct way to retrieve a random record from a sql server table? </p>
<p>I would like to randomize my unit test data, so am looking for a simple way to select a random id from a table. In English, the select would be "Select one id from the table where the id is a random number between the lowest id in the table and the highest id in the table." </p>
<p>I can't figure out a way to do it without have to run the query, test for a null value, then re-run if null.</p>
<p>Ideas?</p>
|
[
{
"answer_id": 191348,
"author": "Sklivvz",
"author_id": 7028,
"author_profile": "https://Stackoverflow.com/users/7028",
"pm_score": 8,
"selected": true,
"text": "<blockquote>\n <p>Is there a succinct way to retrieve a random record from a sql server table?</p>\n</blockquote>\n\n<p>Yes</p>\n\n<pre><code>SELECT TOP 1 * FROM table ORDER BY NEWID()\n</code></pre>\n\n<h2>Explanation</h2>\n\n<p>A <code>NEWID()</code> is generated for each row and the table is then sorted by it. The first record is returned (i.e. the record with the \"lowest\" GUID).</p>\n\n<h3>Notes</h3>\n\n<ol>\n<li><p>GUIDs are generated as pseudo-random numbers since version four:</p>\n\n<blockquote>\n <p>The version 4 UUID is meant for generating UUIDs from truly-random or\n pseudo-random numbers.</p>\n \n <p>The algorithm is as follows:</p>\n \n <ul>\n <li>Set the two most significant bits (bits 6 and 7) of the\n clock_seq_hi_and_reserved to zero and one, respectively.</li>\n <li>Set the four most significant bits (bits 12 through 15) of the\n time_hi_and_version field to the 4-bit version number from\n Section 4.1.3.</li>\n <li>Set all the other bits to randomly (or pseudo-randomly) chosen\n values.</li>\n </ul>\n</blockquote>\n\n<p>—<a href=\"http://www.ietf.org/rfc/rfc4122.txt\" rel=\"noreferrer\">A Universally Unique IDentifier (UUID) URN Namespace - RFC 4122</a></p></li>\n<li><p>The alternative <code>SELECT TOP 1 * FROM table ORDER BY RAND()</code> will not work as one would think. <code>RAND()</code> returns one single value per query, thus all rows will share the same value.</p></li>\n<li><p>While GUID values are pseudo-random, you will need a better PRNG for the more demanding applications.</p></li>\n<li><p>Typical performance is less than 10 seconds for around 1,000,000 rows — of course depending on the system. Note that it's impossible to hit an index, thus performance will be relatively limited.</p></li>\n</ol>\n"
},
{
"answer_id": 191498,
"author": "Sklivvz",
"author_id": 7028,
"author_profile": "https://Stackoverflow.com/users/7028",
"pm_score": 3,
"selected": false,
"text": "<p>Also try your method to get a random Id between MIN(Id) and MAX(Id) and then</p>\n\n<pre><code>SELECT TOP 1 * FROM table WHERE Id >= @yourrandomid\n</code></pre>\n\n<p>It will always get you one row.</p>\n"
},
{
"answer_id": 12129340,
"author": "Martin Smith",
"author_id": 73226,
"author_profile": "https://Stackoverflow.com/users/73226",
"pm_score": 5,
"selected": false,
"text": "<p>On larger tables you can also use <code>TABLESAMPLE</code> for this to avoid scanning the whole table. </p>\n\n<pre><code>SELECT TOP 1 *\nFROM YourTable\nTABLESAMPLE (1000 ROWS)\nORDER BY NEWID()\n</code></pre>\n\n<p>The <code>ORDER BY NEWID</code> is still required to avoid just returning rows that appear first on the data page.</p>\n\n<p>The number to use needs to be chosen carefully for the size and definition of table and you might consider retry logic if no row is returned. The maths behind this and why the technique is not suited to small tables is <a href=\"http://toponewithties.blogspot.co.uk/2005/08/sampling-using-tablesample.html\" rel=\"noreferrer\">discussed here</a></p>\n"
},
{
"answer_id": 18857785,
"author": "user2788934",
"author_id": 2788934,
"author_profile": "https://Stackoverflow.com/users/2788934",
"pm_score": 0,
"selected": false,
"text": "<p>I was looking to improve on the methods I had tried and came across this post. I realize it's old but this method is not listed. I am creating and applying test data; this shows the method for \"address\" in a SP called with @st (two char state)</p>\n\n<pre><code>Create Table ##TmpAddress (id Int Identity(1,1), street VarChar(50), city VarChar(50), st VarChar(2), zip VarChar(5))\nInsert Into ##TmpAddress(street, city, st, zip)\nSelect street, city, st, zip \nFrom tbl_Address (NOLOCK)\nWhere st = @st\n\n\n-- unseeded RAND() will return the same number when called in rapid succession so\n-- here, I seed it with a guaranteed different number each time. @@ROWCOUNT is the count from the most recent table operation.\n\nSet @csr = Ceiling(RAND(convert(varbinary, newid())) * @@ROWCOUNT)\n\nSelect street, city, st, Right(('00000' + ltrim(zip)),5) As zip\nFrom ##tmpAddress (NOLOCK)\nWhere id = @csr\n</code></pre>\n"
},
{
"answer_id": 20606423,
"author": "hmfarimani",
"author_id": 3106590,
"author_profile": "https://Stackoverflow.com/users/3106590",
"pm_score": 3,
"selected": false,
"text": "<p>If you want to select large data the best way that I know is:</p>\n\n<pre><code>SELECT * FROM Table1\nWHERE (ABS(CAST(\n (BINARY_CHECKSUM\n (keycol1, NEWID())) as int))\n % 100) < 10\n</code></pre>\n\n<p>Source: <a href=\"http://msdn.microsoft.com/en-us/library/cc441928.aspx\" rel=\"noreferrer\">MSDN </a></p>\n"
},
{
"answer_id": 58487944,
"author": "XpiritO",
"author_id": 76219,
"author_profile": "https://Stackoverflow.com/users/76219",
"pm_score": 0,
"selected": false,
"text": "<blockquote>\n <p><em>If you really want a random sample of individual rows, modify your query to filter out rows randomly, instead of using TABLESAMPLE. For example, the following query uses the NEWID function to return approximately one percent of the rows of the Sales.SalesOrderDetail table:</em></p>\n</blockquote>\n\n<pre><code>SELECT * FROM Sales.SalesOrderDetail\nWHERE 0.01 >= CAST(CHECKSUM(NEWID(), SalesOrderID) & 0x7fffffff AS float)\n/ CAST (0x7fffffff AS int)\n</code></pre>\n\n<blockquote>\n <p><em>The SalesOrderID column is included in the CHECKSUM expression so that\n NEWID() evaluates once per row to achieve sampling on a per-row basis.\n The expression CAST(CHECKSUM(NEWID(), SalesOrderID) & 0x7fffffff AS\n float / CAST (0x7fffffff AS int) evaluates to a random float value\n between 0 and 1.\"</em></p>\n \n <p>Source: <a href=\"http://technet.microsoft.com/en-us/library/ms189108(v=sql.105).aspx\" rel=\"nofollow noreferrer\">http://technet.microsoft.com/en-us/library/ms189108(v=sql.105).aspx</a></p>\n</blockquote>\n\n<p>This is further explained below:</p>\n\n<blockquote>\n <p>How does this work? Let's split out the WHERE clause and explain it.</p>\n \n <p>The CHECKSUM function is calculating a checksum over the items in the\n list. It is arguable over whether SalesOrderID is even required, since\n NEWID() is a function that returns a new random GUID, so multiplying a\n random figure by a constant should result in a random in any case.\n Indeed, excluding SalesOrderID seems to make no difference. If you are\n a keen statistician and can justify the inclusion of this, please use\n the comments section below and let me know why I'm wrong!</p>\n \n <p>The CHECKSUM function returns a VARBINARY. Performing a bitwise AND\n operation with 0x7fffffff, which is the equivalent of (111111111...)\n in binary, yields a decimal value that is effectively a representation\n of a random string of 0s and 1s. Dividing by the co-efficient\n 0x7fffffff effectively normalizes this decimal figure to a figure\n between 0 and 1. Then to decide whether each row merits inclusion in\n the final result set, a threshold of 1/x is used (in this case, 0.01)\n where x is the percentage of the data to retrieve as a sample.</p>\n \n <p>Source: <a href=\"https://www.mssqltips.com/sqlservertip/3157/different-ways-to-get-random-data-for-sql-server-data-sampling\" rel=\"nofollow noreferrer\">https://www.mssqltips.com/sqlservertip/3157/different-ways-to-get-random-data-for-sql-server-data-sampling</a></p>\n</blockquote>\n"
}
] |
2008/10/10
|
[
"https://Stackoverflow.com/questions/191342",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10693/"
] |
Is there a succinct way to retrieve a random record from a sql server table?
I would like to randomize my unit test data, so am looking for a simple way to select a random id from a table. In English, the select would be "Select one id from the table where the id is a random number between the lowest id in the table and the highest id in the table."
I can't figure out a way to do it without have to run the query, test for a null value, then re-run if null.
Ideas?
|
>
> Is there a succinct way to retrieve a random record from a sql server table?
>
>
>
Yes
```
SELECT TOP 1 * FROM table ORDER BY NEWID()
```
Explanation
-----------
A `NEWID()` is generated for each row and the table is then sorted by it. The first record is returned (i.e. the record with the "lowest" GUID).
### Notes
1. GUIDs are generated as pseudo-random numbers since version four:
>
> The version 4 UUID is meant for generating UUIDs from truly-random or
> pseudo-random numbers.
>
>
> The algorithm is as follows:
>
>
>
> * Set the two most significant bits (bits 6 and 7) of the
> clock\_seq\_hi\_and\_reserved to zero and one, respectively.
> * Set the four most significant bits (bits 12 through 15) of the
> time\_hi\_and\_version field to the 4-bit version number from
> Section 4.1.3.
> * Set all the other bits to randomly (or pseudo-randomly) chosen
> values.
>
—[A Universally Unique IDentifier (UUID) URN Namespace - RFC 4122](http://www.ietf.org/rfc/rfc4122.txt)
2. The alternative `SELECT TOP 1 * FROM table ORDER BY RAND()` will not work as one would think. `RAND()` returns one single value per query, thus all rows will share the same value.
3. While GUID values are pseudo-random, you will need a better PRNG for the more demanding applications.
4. Typical performance is less than 10 seconds for around 1,000,000 rows — of course depending on the system. Note that it's impossible to hit an index, thus performance will be relatively limited.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.