
qid
int64 4
8.14M
| question
stringlengths 20
48.3k
| answers
list | date
stringlengths 10
10
| metadata
list | input
stringlengths 12
45k
| output
stringlengths 2
31.8k
|
|---|---|---|---|---|---|---|
167,990 |
<p>I am developing a small web app project (ColdFusion) and I am trying to keep my project split into multiple files during development, but deploy just one file on completion.</p>
<p>I have references to external files, for instance:</p>
<pre><code><script type="text/javascript" src="jquery-1.2.6.pack.js"></script>
<link type="text/css" rel="stylesheet" href="project.css" />
</code></pre>
<p>And when I build my project, I want to have the files included and embedded within the single finished product file.</p>
<pre><code><script type="text/javascript">eval(function(p,a,c,k,e,r) [...]</script>
<style type="text/css">div{font:normal;} [...]</style>
</code></pre>
<p>Anyway, it doesn't look like there is a basic way for Ant to do this. Anyone know?</p>
|
[
{
"answer_id": 169052,
"author": "Peter Boughton",
"author_id": 9360,
"author_profile": "https://Stackoverflow.com/users/9360",
"pm_score": 2,
"selected": false,
"text": "<p>Does this do what you want?</p>\n\n<pre><code><property\n name=\"filename\"\n value=\"jquery-1.2.6.pack.js\"\n/>\n\n<loadfile\n property=\"contents\"\n srcfile=\"${filename}\"\n/>\n\n<replace dir=\".\">\n <include name=\"index.cfm\"/>\n <replacetoken><![CDATA[<script type=\"text/javascript\" src=\"${filename}\"></script>]]></replacetoken>\n <replacevalue><![CDATA[<script type=\"text/javascript\">${contents}</script>]]></replacevalue>\n</replace>\n</code></pre>\n"
},
{
"answer_id": 175269,
"author": "Nathan Strutz",
"author_id": 5918,
"author_profile": "https://Stackoverflow.com/users/5918",
"pm_score": 2,
"selected": true,
"text": "<p>Answering my own question after a few hours of hacking...</p>\n\n<pre><code><script language=\"groovy\" src=\"build.groovy\" />\n</code></pre>\n\n<p>and this groovy script replaces any referenced javascript or css file with the file contents itself.</p>\n\n<pre><code>f = new File(\"${targetDir}/index.cfm\")\nfContent = f.text\nfContent = jsReplace(fContent)\nfContent = cssReplace(fContent)\nf.write(fContent)\n\n// JS Replacement\ndef jsReplace(htmlFileText) {\n println \"Groovy: Replacing Javascript includes\"\n // extract all matched javascript src links\n def jsRegex = /<script [^>]*src=\\\"([^\\\"]+)\\\"><\\/script>/\n def matcher = (htmlFileText =~ jsRegex)\n for (i in matcher) {\n // read external files in\n def includeText = new File(matcher.group(1)).text\n // sanitize the string for being regex replace string (dollar signs like jQuery/Prototype will screw it up)\n includeText = java.util.regex.Matcher.quoteReplacement(includeText)\n // weak compression (might as well)\n includeText = includeText.replaceAll(/\\/\\/.*/, \"\") // remove single-line comments (like this!)\n includeText = includeText.replaceAll(/[\\n\\r\\f\\s]+/, \" \") // replace all whitespace with single space\n // return content with embedded file\n htmlFileText = htmlFileText.replaceFirst('<script [^>]*src=\"'+ matcher.group(1) +'\"[^>]*></script>', '<script type=\"text/javascript\">'+ includeText+'</script>');\n }\n return htmlFileText;\n}\n\n// CSS Replacement\ndef cssReplace(htmlFileText) {\n println \"Groovy: Replacing CSS includes\"\n // extract all matched CSS style href links\n def cssRegex = /<link [^>]*href=\\\"([^\\\"]+)\\\"[^>]*>(<\\/link>)?/\n def matcher = (htmlFileText =~ cssRegex)\n for (i in matcher) {\n // read external files in\n def includeText = new File(matcher.group(1)).text\n // compress CSS\n includeText = includeText.replaceAll(/[\\n\\r\\t\\f\\s]+/, \" \")\n // sanitize the string for being regex replace string (dollar signs like jQuery/Prototype will screw it up)\n includeText = java.util.regex.Matcher.quoteReplacement(includeText)\n // return content with embedded file\n htmlFileText = htmlFileText.replaceFirst('<link [^>]*href=\"'+ matcher.group(1) +'\"[^>]*>(<\\\\/link>)?', '<style type=\\\"text/css\\\">'+ includeText+'</style>');\n }\n return htmlFileText;\n}\n</code></pre>\n\n<p>So I guess that does it for me. It's been working pretty well, and it's extensible. Definitely not the best Groovy ever, but it's one of my first. Also, it required a few classpathed jars for it to compile. I lost track of which, but I believe it is the javax.scripting engine, groovy-engine.jar and groovy-all-1.5.6.jar</p>\n"
},
{
"answer_id": 265841,
"author": "Mnementh",
"author_id": 21005,
"author_profile": "https://Stackoverflow.com/users/21005",
"pm_score": 2,
"selected": false,
"text": "<p>For a solution in pure ant, try the following:</p>\n\n<pre><code><target name=\"replace\">\n <property name=\"js-filename\" value=\"jquery-1.2.6.pack.js\"/>\n <property name=\"css-filename\" value=\"project.css\"/>\n <loadfile property=\"js-file\" srcfile=\"${js-filename}\"/>\n <loadfile property=\"css-file\" srcfile=\"${css-filename}\"/>\n <replace file=\"input.txt\">\n <replacefilter token=\"&lt;script type=&quot;text/javascript&quot; src=&quot;${js-filename}&quot;&gt;&lt;/script&gt;\" value=\"&lt;script type=&quot;text/javascript&quot;&gt;${js-file}&lt;/script&gt;\"/>\n <replacefilter token=\"&lt;link type=&quot;text/css&quot; rel=&quot;stylesheet&quot; href=&quot;${css-filename}&quot; /&gt;\" value=\"&lt;style type=&quot;text/css&quot;&gt;${css-file}&lt;/style&gt;\"/>\n </replace>\n</target>\n</code></pre>\n\n<p>I tested it, and it worked as expected. In the text to replace and the value you insert instead all characters '<', '>' and '\"' should be quoted as &lt;, &gt; and &quot.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/167990",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5918/"
] |
I am developing a small web app project (ColdFusion) and I am trying to keep my project split into multiple files during development, but deploy just one file on completion.
I have references to external files, for instance:
```
<script type="text/javascript" src="jquery-1.2.6.pack.js"></script>
<link type="text/css" rel="stylesheet" href="project.css" />
```
And when I build my project, I want to have the files included and embedded within the single finished product file.
```
<script type="text/javascript">eval(function(p,a,c,k,e,r) [...]</script>
<style type="text/css">div{font:normal;} [...]</style>
```
Anyway, it doesn't look like there is a basic way for Ant to do this. Anyone know?
|
Answering my own question after a few hours of hacking...
```
<script language="groovy" src="build.groovy" />
```
and this groovy script replaces any referenced javascript or css file with the file contents itself.
```
f = new File("${targetDir}/index.cfm")
fContent = f.text
fContent = jsReplace(fContent)
fContent = cssReplace(fContent)
f.write(fContent)
// JS Replacement
def jsReplace(htmlFileText) {
println "Groovy: Replacing Javascript includes"
// extract all matched javascript src links
def jsRegex = /<script [^>]*src=\"([^\"]+)\"><\/script>/
def matcher = (htmlFileText =~ jsRegex)
for (i in matcher) {
// read external files in
def includeText = new File(matcher.group(1)).text
// sanitize the string for being regex replace string (dollar signs like jQuery/Prototype will screw it up)
includeText = java.util.regex.Matcher.quoteReplacement(includeText)
// weak compression (might as well)
includeText = includeText.replaceAll(/\/\/.*/, "") // remove single-line comments (like this!)
includeText = includeText.replaceAll(/[\n\r\f\s]+/, " ") // replace all whitespace with single space
// return content with embedded file
htmlFileText = htmlFileText.replaceFirst('<script [^>]*src="'+ matcher.group(1) +'"[^>]*></script>', '<script type="text/javascript">'+ includeText+'</script>');
}
return htmlFileText;
}
// CSS Replacement
def cssReplace(htmlFileText) {
println "Groovy: Replacing CSS includes"
// extract all matched CSS style href links
def cssRegex = /<link [^>]*href=\"([^\"]+)\"[^>]*>(<\/link>)?/
def matcher = (htmlFileText =~ cssRegex)
for (i in matcher) {
// read external files in
def includeText = new File(matcher.group(1)).text
// compress CSS
includeText = includeText.replaceAll(/[\n\r\t\f\s]+/, " ")
// sanitize the string for being regex replace string (dollar signs like jQuery/Prototype will screw it up)
includeText = java.util.regex.Matcher.quoteReplacement(includeText)
// return content with embedded file
htmlFileText = htmlFileText.replaceFirst('<link [^>]*href="'+ matcher.group(1) +'"[^>]*>(<\\/link>)?', '<style type=\"text/css\">'+ includeText+'</style>');
}
return htmlFileText;
}
```
So I guess that does it for me. It's been working pretty well, and it's extensible. Definitely not the best Groovy ever, but it's one of my first. Also, it required a few classpathed jars for it to compile. I lost track of which, but I believe it is the javax.scripting engine, groovy-engine.jar and groovy-all-1.5.6.jar
|
168,046 |
<p>I'm maintaining a library that contains compiled objects that need to be linked into
a 3rd party executable. sometimes the executable has been compiled for Solaris, sometimes as a 32bit Linux Application, sometimes its a 64bit linux application.
What I'd love to do is pass one "path" to the library, and have the application then automatically pick up the right flavor of the library.
It'd be OK if it only worked on linux, so that I could just define the path in terms of the OS. </p>
<p>this particular case is for a library of PLI/VPI functions I want to link into a verilog simulator.</p>
<p>What I have now is</p>
<pre><code>root/path/${MYPLILIB_VER}/rootname/${MYPLIFLAVOR}/plilib.so
</code></pre>
<p>where flavor is one of</p>
<pre><code>solaris linux linux64
</code></pre>
<p>The flavor depends on the os, and if Linux, if running on a 64bit platform, it also depends on which version 32/64bit of the program I am running.
I'm looking for a better way.. </p>
|
[
{
"answer_id": 168225,
"author": "Marty",
"author_id": 4131,
"author_profile": "https://Stackoverflow.com/users/4131",
"pm_score": 1,
"selected": false,
"text": "<p>Use the system info given from \"uname\" to set the paths automatically?<br>\n'uname -s' gives you the kernel name (eg Linux / SunOS)<br>\n'uname -i' will give you the architecture (eg x86 / x86_64) </p>\n"
},
{
"answer_id": 168289,
"author": "jbdavid",
"author_id": 6314,
"author_profile": "https://Stackoverflow.com/users/6314",
"pm_score": 1,
"selected": false,
"text": "<p>Hm.. its looking like ELF might do what I want.. now for some good \napplication notes..</p>\n\n<p>and on the LAST page of this paper <a href=\"http://people.redhat.com/drepper/dsohowto.pdf\" rel=\"nofollow noreferrer\">on making DSO's</a> is some info\non the $PLATFORM and $LIB expectations.. \nseems like on linux I should be able to use the lib lib64 directory structure\nto hold the two objects.. </p>\n\n<p>off to learn more.</p>\n\n<p><a href=\"http://www.ibm.com/developerworks/library/l-shobj/\" rel=\"nofollow noreferrer\">shared objects for the disoriented</a></p>\n"
},
{
"answer_id": 1005462,
"author": "Steve K",
"author_id": 121394,
"author_profile": "https://Stackoverflow.com/users/121394",
"pm_score": 0,
"selected": false,
"text": "<p>I don't know which simulator you are using but you might try putting the path in the <code>LD_LIBRARY_PATH</code> environment variable. I believe both Cadence and Mentor simulators will look in there. I'm not sure abut VCS. Your simulator's user manual will have details.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168046",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6314/"
] |
I'm maintaining a library that contains compiled objects that need to be linked into
a 3rd party executable. sometimes the executable has been compiled for Solaris, sometimes as a 32bit Linux Application, sometimes its a 64bit linux application.
What I'd love to do is pass one "path" to the library, and have the application then automatically pick up the right flavor of the library.
It'd be OK if it only worked on linux, so that I could just define the path in terms of the OS.
this particular case is for a library of PLI/VPI functions I want to link into a verilog simulator.
What I have now is
```
root/path/${MYPLILIB_VER}/rootname/${MYPLIFLAVOR}/plilib.so
```
where flavor is one of
```
solaris linux linux64
```
The flavor depends on the os, and if Linux, if running on a 64bit platform, it also depends on which version 32/64bit of the program I am running.
I'm looking for a better way..
|
Use the system info given from "uname" to set the paths automatically?
'uname -s' gives you the kernel name (eg Linux / SunOS)
'uname -i' will give you the architecture (eg x86 / x86\_64)
|
168,073 |
<p>I'm currently writing a website that allows people to download Excel and text files. Is there a way to redirect to a different page when they click, so that we run javascript and do analytics (i.e. keep download count)? Currently, nothing prevents the user from simply right-clicking and saving. </p>
<p>Edit: </p>
<p>To be more specific, it would be nice for a single or double click of a file link to redirect to a temporary download page for analytics, then have the file be downloaded.</p>
|
[
{
"answer_id": 168121,
"author": "Joe Skora",
"author_id": 14057,
"author_profile": "https://Stackoverflow.com/users/14057",
"pm_score": 0,
"selected": false,
"text": "<p>I'm not sure what you are asking here, are you trying to figure out how to redirect in the controller or are you trying to override the right-click behavior in the browser?</p>\n\n<p>To redirect in the controller you can do something like this documented <a href=\"http://grails.org/doc/1.0.x/\" rel=\"nofollow noreferrer\">here</a>.</p>\n\n<pre><code>redirect(controller:\"book\",action:\"list\")\n</code></pre>\n\n<p>If you are trying to change button or link behavior that's client side and will require some Javascript most likely.</p>\n\n<p>If you clarify I might be able to help more.</p>\n"
},
{
"answer_id": 171574,
"author": "mbrevoort",
"author_id": 18228,
"author_profile": "https://Stackoverflow.com/users/18228",
"pm_score": 3,
"selected": true,
"text": "<p>I started describing how you might do this in Grails but then remembered most analytics services (Google, Omniture, etc.) will let you track downloaded files by using the onclick event. If you have some custom javascript based tracking you're doing, you can do the same thing. The onclick will get called before the document starts downloading. For example:</p>\n\n<pre><code><a href=\"/path-to-download-file\" onclick=\"record_download('filename')\">myfile.txt</a>\n</code></pre>\n\n<p>More specifically for Google Analytics, here's some javascript to do this automatically:\n<a href=\"http://www.goodwebpractices.com/downloads/gatag.js\" rel=\"nofollow noreferrer\">http://www.goodwebpractices.com/downloads/gatag.js</a></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168073",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6833/"
] |
I'm currently writing a website that allows people to download Excel and text files. Is there a way to redirect to a different page when they click, so that we run javascript and do analytics (i.e. keep download count)? Currently, nothing prevents the user from simply right-clicking and saving.
Edit:
To be more specific, it would be nice for a single or double click of a file link to redirect to a temporary download page for analytics, then have the file be downloaded.
|
I started describing how you might do this in Grails but then remembered most analytics services (Google, Omniture, etc.) will let you track downloaded files by using the onclick event. If you have some custom javascript based tracking you're doing, you can do the same thing. The onclick will get called before the document starts downloading. For example:
```
<a href="/path-to-download-file" onclick="record_download('filename')">myfile.txt</a>
```
More specifically for Google Analytics, here's some javascript to do this automatically:
<http://www.goodwebpractices.com/downloads/gatag.js>
|
168,080 |
<p>I have a some JPA entities that inherit from one another and uses discriminator to determine what class to be created (untested as of yet).</p>
<pre><code>@Entity(name="switches")
@DiscriminatorColumn(name="type")
@DiscriminatorValue(value="500")
public class DmsSwitch extends Switch implements Serializable {}
@MappedSuperclass
public abstract class Switch implements ISwitch {}
@Entity(name="switch_accounts")
public class SwitchAccounts implements Serializable {
@ManyToOne()
@JoinColumn(name="switch_id")
DmsSwitch _switch;
}
</code></pre>
<p>So in the SwitchAccounts class I would like to use the base class Switch because I don't know which object will be created until runtime. How can I achieve this?</p>
|
[
{
"answer_id": 168439,
"author": "Dan Dyer",
"author_id": 5171,
"author_profile": "https://Stackoverflow.com/users/5171",
"pm_score": 0,
"selected": false,
"text": "<p>I don't think that you can with your current object model. The Switch class is not an entity, therefore it can't be used in relationships. The @MappedSuperclass annotation is for convenience rather than for writing polymorphic entities. There is no database table associated with the Switch class.</p>\n\n<p>You'll either have to make Switch an entity, or change things in some other way so that you have a common superclass that <em>is</em> an entity.</p>\n"
},
{
"answer_id": 168444,
"author": "Nicolas",
"author_id": 1730,
"author_profile": "https://Stackoverflow.com/users/1730",
"pm_score": 2,
"selected": true,
"text": "<p>As your switch class is not an entity, it cannot be used in an entity relationship... Unfortunately, you'll have to transform your mappedsuperclass as an entity to involve it in a relationship.</p>\n"
},
{
"answer_id": 168728,
"author": "extraneon",
"author_id": 24582,
"author_profile": "https://Stackoverflow.com/users/24582",
"pm_score": 2,
"selected": false,
"text": "<p>As the previous commentors I agree that the class model should be different. I think something like the following would suffice:</p>\n\n<pre><code>@Entity(name=\"switches\")\n@DiscriminatorColumn(name=\"type\")\n@DiscriminatorValue(value=\"400\")\npublic class Switch implements ISwitch {\n // Implementation details\n}\n\n@Entity(name=\"switches\")\n@DiscriminatorValue(value=\"500\")\npublic class DmsSwitch extends Switch implements Serializable {\n // implementation\n}\n\n@Entity(name=\"switches\")\n@DiscriminatorValue(value=\"600\")\npublic class SomeOtherSwitch extends Switch implements Serializable {\n // implementation\n}\n</code></pre>\n\n<p>You could possibly prevent instantiation of a Switch directly by making the constructor protected. I believe Hibernate accepts that. </p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168080",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22763/"
] |
I have a some JPA entities that inherit from one another and uses discriminator to determine what class to be created (untested as of yet).
```
@Entity(name="switches")
@DiscriminatorColumn(name="type")
@DiscriminatorValue(value="500")
public class DmsSwitch extends Switch implements Serializable {}
@MappedSuperclass
public abstract class Switch implements ISwitch {}
@Entity(name="switch_accounts")
public class SwitchAccounts implements Serializable {
@ManyToOne()
@JoinColumn(name="switch_id")
DmsSwitch _switch;
}
```
So in the SwitchAccounts class I would like to use the base class Switch because I don't know which object will be created until runtime. How can I achieve this?
|
As your switch class is not an entity, it cannot be used in an entity relationship... Unfortunately, you'll have to transform your mappedsuperclass as an entity to involve it in a relationship.
|
168,084 |
<p>Usually pagination queries look like this. Is there a better way instead of making two almost equal methods, one of which executing "select *..." and the other one "count *..."?</p>
<pre><code>public List<Cat> findCats(String name, int offset, int limit) {
Query q = session.createQuery("from Cat where name=:name");
q.setString("name", name);
if (offset > 0) {
q.setFirstResult(offset);
}
if (limit > 0) {
q.setMaxResults(limit);
}
return q.list();
}
public Long countCats(String name) {
Query q = session.createQuery("select count(*) from Cat where name=:name");
q.setString("name", name);
return (Long) q.uniqueResult();
}
</code></pre>
|
[
{
"answer_id": 168353,
"author": "Kyle Dyer",
"author_id": 24011,
"author_profile": "https://Stackoverflow.com/users/24011",
"pm_score": 3,
"selected": false,
"text": "<p>If you don't need to display the total number of pages then I'm not sure you need the count query. Lots of sites including google don't show the total on the paged results. Instead they just say \"next>\".</p>\n"
},
{
"answer_id": 168858,
"author": "anjanb",
"author_id": 11142,
"author_profile": "https://Stackoverflow.com/users/11142",
"pm_score": -1,
"selected": false,
"text": "<p>here's the way pagination is done in hibernate</p>\n\n<pre><code>Query q = sess.createQuery(\"from DomesticCat cat\");\nq.setFirstResult(20);\nq.setMaxResults(10);\nList cats = q.list();\n</code></pre>\n\n<p>you can get more info from hibernate docs at : <a href=\"http://www.hibernate.org/hib_docs/v3/reference/en-US/html_single/#objectstate-querying-executing-pagination\" rel=\"nofollow noreferrer\">http://www.hibernate.org/hib_docs/v3/reference/en-US/html_single/#objectstate-querying-executing-pagination</a>\n10.4.1.5 and 10.4.1.6 section give you more flexbile options.</p>\n\n<p>BR,<BR>\n~A</p>\n"
},
{
"answer_id": 169315,
"author": "mike",
"author_id": 19217,
"author_profile": "https://Stackoverflow.com/users/19217",
"pm_score": 2,
"selected": false,
"text": "<p>There is a way</p>\n\n<pre><code>mysql> SELECT SQL_CALC_FOUND_ROWS * FROM tbl_name\n -> WHERE id > 100 LIMIT 10;\nmysql> SELECT FOUND_ROWS();\n</code></pre>\n\n<p>The second SELECT returns a number indicating how many rows the first SELECT would have returned had it been written without the LIMIT clause.</p>\n\n<p>Reference: <a href=\"http://dev.mysql.com/doc/refman/5.1/en/information-functions.html#function_found-rows\" rel=\"nofollow noreferrer\">FOUND_ROWS()</a></p>\n"
},
{
"answer_id": 182899,
"author": "Josh",
"author_id": 2204759,
"author_profile": "https://Stackoverflow.com/users/2204759",
"pm_score": 2,
"selected": false,
"text": "<p>I know this problem and have faced it before. For starters, the double query mechanism where it does the same SELECT conditions is indeed not optimal. But, it works, and before you go off and do some giant change, just realize it might not be worth it.</p>\n\n<p>But, anyways:</p>\n\n<p>1) If you are dealing with small data on the client side, use a result set implementation that lets you set the cursor to the end of the set, get its row offset, then reset the cursor to before first.</p>\n\n<p>2) Redesign the query so that you get COUNT(*) as an extra column in the normal rows. Yes, it contains the same value for every row, but it only involves 1 extra column that is an integer. This is improper SQL to represent an aggregated value with non aggregated values, but it may work.</p>\n\n<p>3) Redesign the query to use an estimated limit, similar to what was being mentioned. Use rows per page and some upper limit. E.g. just say something like \"Showing 1 to 10 of 500 or more\". When they browse to \"Showing 25o to 260 of X\", its a later query so you can just update the X estimate by making the upper bound relative to page * rows/page.</p>\n"
},
{
"answer_id": 183902,
"author": "Eric R. Rath",
"author_id": 23883,
"author_profile": "https://Stackoverflow.com/users/23883",
"pm_score": 3,
"selected": false,
"text": "<p>Baron Schwartz at MySQLPerformanceBlog.com authored a <a href=\"http://www.mysqlperformanceblog.com/2008/09/24/four-ways-to-optimize-paginated-displays/\" rel=\"noreferrer\">post</a> about this. I wish there was a magic bullet for this problem, but there isn't. Summary of the options he presented:</p>\n\n<ol>\n<li>On the first query, fetch and cache all the results.</li>\n<li>Don't show all results.</li>\n<li>Don't show the total count or the intermediate links to other pages. Show only the \"next\" link.</li>\n<li>Estimate how many results there are.</li>\n</ol>\n"
},
{
"answer_id": 240003,
"author": "tobinharris",
"author_id": 1136215,
"author_profile": "https://Stackoverflow.com/users/1136215",
"pm_score": 2,
"selected": false,
"text": "<p>You can use <a href=\"http://www.hibernate.org/hib_docs/nhibernate/1.2/reference/en/html_single/#performance-multi-query\" rel=\"nofollow noreferrer\">MultiQuery</a> to execute both queries in a single database call, which is much more efficient. You can also generate the count query, so you don't have to write it each time. Here's the general idea ...</p>\n\n<pre><code>var hql = \"from Item where i.Age > :age\"\nvar countHql = \"select count(*) \" + hql;\n\nIMultiQuery multiQuery = _session.CreateMultiQuery()\n .Add(s.CreateQuery(hql)\n .SetInt32(\"age\", 50).SetFirstResult(10))\n .Add(s.CreateQuery(countHql)\n .SetInt32(\"age\", 50));\n\nvar results = multiQuery.List();\nvar items = (IList<Item>) results[0];\nvar count = (long)((IList<Item>) results[1])[0];\n</code></pre>\n\n<p>I imagine it would be easy enough to wrap this up into some easy-to-use method so you can have paginateable, countable queries in a single line of code.</p>\n\n<p>As an <strong>alternative</strong>, if you're willing to test the work-in-progress Linq for NHibernate in <a href=\"https://nhcontrib.svn.sourceforge.net/svnroot/nhcontrib/trunk/src/NHibernate.Linq/src/\" rel=\"nofollow noreferrer\">nhcontrib</a>, you might find you can do something like this:</p>\n\n<pre><code>var itemSpec = (from i in Item where i.Age > age);\nvar count = itemSpec.Count();\nvar list = itemSpec.Skip(10).Take(10).AsList(); \n</code></pre>\n\n<p>Obviously there's no batching going on, so that's not as efficient, but it may still suite your needs?</p>\n\n<p>Hope this helps!</p>\n"
},
{
"answer_id": 767606,
"author": "ruslan",
"author_id": 89935,
"author_profile": "https://Stackoverflow.com/users/89935",
"pm_score": 1,
"selected": false,
"text": "<p>I think the solution depends on database you are using. For example, we are using MS SQL and using next query</p>\n\n<pre><code>select \n COUNT(Table.Column) OVER() as TotalRowsCount,\n Table.Column,\n Table.Column2\nfrom Table ...\n</code></pre>\n\n<p>That part of query can be changed with database specified SQL.</p>\n\n<p>Also we set the query max result we are expecting to see, e.g.</p>\n\n<pre><code>query.setMaxResults(pageNumber * itemsPerPage)\n</code></pre>\n\n<p>And gets the ScrollableResults instance as result of query execution:</p>\n\n<pre><code>ScrollableResults result = null;\ntry {\n result = query.scroll();\n int totalRowsNumber = result.getInteger(0);\n int from = // calculate the index of row to get for the expected page if any\n\n /*\n * Reading data form page and using Transformers.ALIAS_TO_ENTITY_MAP\n * to make life easier.\n */ \n}\nfinally {\n if (result != null) \n result.close()\n}\n</code></pre>\n"
},
{
"answer_id": 836820,
"author": "Pietro Polsinelli",
"author_id": 20478,
"author_profile": "https://Stackoverflow.com/users/20478",
"pm_score": 1,
"selected": false,
"text": "<p>At this Hibernate wiki page:</p>\n\n<p><a href=\"https://www.hibernate.org/314.html\" rel=\"nofollow noreferrer\">https://www.hibernate.org/314.html</a></p>\n\n<p>I present a complete pagination solution; in particular, the total number of elements is computed by scrolling to the end of the resultset, which is supported by now by several JDBC drivers. This avoids the second \"count\" query.</p>\n"
},
{
"answer_id": 7405444,
"author": "randomThought",
"author_id": 178437,
"author_profile": "https://Stackoverflow.com/users/178437",
"pm_score": 0,
"selected": false,
"text": "<p>I found a way to do paging in hibernate without doing a select count (*) over a large dataset size. Look at the solution that I posted for my answer here.</p>\n\n<blockquote>\n <p><a href=\"https://stackoverflow.com/questions/7395681/processing-a-large-number-of-database-entries-with-paging-slows-down-with-time\">processing a large number of database entries with paging slows down with time</a></p>\n</blockquote>\n\n<p>you can perform paging one at a time without knowing how many pages you will need originally</p>\n"
},
{
"answer_id": 17148956,
"author": "kommradHomer",
"author_id": 489364,
"author_profile": "https://Stackoverflow.com/users/489364",
"pm_score": 0,
"selected": false,
"text": "<p><a href=\"http://blog.kennardconsulting.com/2011/03/mysql-performance-leveraging.html\" rel=\"nofollow\">Here is a solution</a> by Dr Richard Kennard (mind the bug fix in the blog comment!), using <a href=\"http://www.oreillynet.com/onjava/blog/2007/05/interceptors_in_hibernate.html\" rel=\"nofollow\">Hibernate Interceptors</a></p>\n\n<p>For summary, you bind your sessionFactory to your interceptor class, so that your interceptor can give you the number of found rows later. </p>\n\n<p>You can find the code on the solution link. And below is an example usage.</p>\n\n<pre><code>SessionFactory sessionFactory = ((org.hibernate.Session) mEntityManager.getDelegate()).getSessionFactory();\nMySQLCalcFoundRowsInterceptor foundRowsInterceptor = new MySQLCalcFoundRowsInterceptor( sessionFactory );\nSession session = sessionFactory.openSession( foundRowsInterceptor );\n\ntry {\n org.hibernate.Query query = session.createQuery( ... ) // Note: JPA-QL, not createNativeQuery!\n query.setFirstResult( ... );\n query.setMaxResults( ... );\n\n List entities = query.list();\n long foundRows = foundRowsInterceptor.getFoundRows();\n\n ...\n\n} finally {\n\n // Disconnect() is good practice, but close() causes problems. Note, however, that\n // disconnect could lead to lazy-loading problems if the returned list of entities has\n // lazy relations\n\n session.disconnect();\n}\n</code></pre>\n"
},
{
"answer_id": 26499062,
"author": "Yinzara",
"author_id": 1304288,
"author_profile": "https://Stackoverflow.com/users/1304288",
"pm_score": 3,
"selected": false,
"text": "<p>My solution will work for the very common use case of Hibernate+Spring+MySQL</p>\n\n<p>Similar to the above answer, I based my solution upon <a href=\"http://blog.kennardconsulting.com/2011/03/mysql-performance-leveraging.html\">Dr Richard Kennar's</a>. However, since Hibernate is often used with Spring, I wanted my solution to work very well with Spring and the standard method for using Hibernate. Therefore my solution uses a combination of thread locals and singleton beans to achieve the result. Technically the interceptor is invoked on every prepared SQL statement for the SessionFactory, but it skips all logic and does not initialize any ThreadLocal(s) unless it is a query specifically set to count the total rows.</p>\n\n<p>Using the below class, your Spring configuration looks like:</p>\n\n<pre><code><bean id=\"foundRowCalculator\" class=\"my.hibernate.classes.MySQLCalcFoundRowsInterceptor\" />\n <!-- p:sessionFactoryBeanName=\"mySessionFactory\"/ -->\n\n<bean id=\"mySessionFactory\"\n class=\"org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean\"\n p:dataSource-ref=\"dataSource\"\n p:packagesToScan=\"my.hibernate.classes\"\n p:entityInterceptor-ref=\"foundRowCalculator\"/>\n</code></pre>\n\n<p>Basically you must declare the interceptor bean and then reference it in the \"entityInterceptor\" property of the SessionFactoryBean. You must only set \"sessionFactoryBeanName\" if there is more than one SessionFactory in your Spring context and the session factory you want to reference is not called \"sessionFactory\". The reason you cannot set a reference is that this would cause an interdependency between the beans that cannot be resolved.</p>\n\n<p>Using a wrapper bean for the result:</p>\n\n<pre><code>package my.hibernate.classes;\n\npublic class PagedResponse<T> {\n public final List<T> items;\n public final int total;\n public PagedResponse(List<T> items, int total) {\n this.items = items;\n this.total = total;\n }\n}\n</code></pre>\n\n<p>Then using an abstract base DAO class you must call \"setCalcFoundRows(true)\" before making the query and \"reset()\" after [in a finally block to ensure it's called]:</p>\n\n<pre><code>package my.hibernate.classes;\n\nimport org.hibernate.Criteria;\nimport org.hibernate.Query;\nimport org.springframework.beans.factory.annotation.Autowired;\n\npublic abstract class BaseDAO {\n\n @Autowired\n private MySQLCalcFoundRowsInterceptor rowCounter;\n\n public <T> PagedResponse<T> getPagedResponse(Criteria crit, int firstResult, int maxResults) {\n rowCounter.setCalcFoundRows(true);\n try {\n @SuppressWarnings(\"unchecked\")\n return new PagedResponse<T>(\n crit.\n setFirstResult(firstResult).\n setMaxResults(maxResults).\n list(),\n rowCounter.getFoundRows());\n } finally {\n rowCounter.reset();\n }\n }\n\n public <T> PagedResponse<T> getPagedResponse(Query query, int firstResult, int maxResults) {\n rowCounter.setCalcFoundRows(true);\n try {\n @SuppressWarnings(\"unchecked\")\n return new PagedResponse<T>(\n query.\n setFirstResult(firstResult).\n setMaxResults(maxResults).\n list(),\n rowCounter.getFoundRows());\n } finally {\n rowCounter.reset();\n }\n }\n}\n</code></pre>\n\n<p>Then a concrete DAO class example for an @Entity named MyEntity with a String property \"prop\":</p>\n\n<pre><code>package my.hibernate.classes;\n\nimport org.hibernate.SessionFactory;\nimport org.hibernate.criterion.Restrictions\nimport org.springframework.beans.factory.annotation.Autowired;\n\npublic class MyEntityDAO extends BaseDAO {\n\n @Autowired\n private SessionFactory sessionFactory;\n\n public PagedResponse<MyEntity> getPagedEntitiesWithPropertyValue(String propVal, int firstResult, int maxResults) {\n return getPagedResponse(\n sessionFactory.\n getCurrentSession().\n createCriteria(MyEntity.class).\n add(Restrictions.eq(\"prop\", propVal)),\n firstResult, \n maxResults);\n }\n}\n</code></pre>\n\n<p>Finally the interceptor class that does all the work:</p>\n\n<pre><code>package my.hibernate.classes;\n\nimport java.io.IOException;\nimport java.sql.Connection;\nimport java.sql.ResultSet;\nimport java.sql.SQLException;\nimport java.sql.Statement;\n\nimport org.hibernate.EmptyInterceptor;\nimport org.hibernate.HibernateException;\nimport org.hibernate.SessionFactory;\nimport org.hibernate.Transaction;\nimport org.hibernate.jdbc.Work;\nimport org.springframework.beans.BeansException;\nimport org.springframework.beans.factory.BeanFactory;\nimport org.springframework.beans.factory.BeanFactoryAware;\n\npublic class MySQLCalcFoundRowsInterceptor extends EmptyInterceptor implements BeanFactoryAware {\n\n\n\n /**\n * \n */\n private static final long serialVersionUID = 2745492452467374139L;\n\n //\n // Private statics\n //\n\n private final static String SELECT_PREFIX = \"select \";\n\n private final static String CALC_FOUND_ROWS_HINT = \"SQL_CALC_FOUND_ROWS \";\n\n private final static String SELECT_FOUND_ROWS = \"select FOUND_ROWS()\";\n\n //\n // Private members\n //\n private SessionFactory sessionFactory;\n\n private BeanFactory beanFactory;\n\n private String sessionFactoryBeanName;\n\n private ThreadLocal<Boolean> mCalcFoundRows = new ThreadLocal<Boolean>();\n\n private ThreadLocal<Integer> mSQLStatementsPrepared = new ThreadLocal<Integer>() {\n @Override\n protected Integer initialValue() {\n return Integer.valueOf(0);\n }\n };\n\n private ThreadLocal<Integer> mFoundRows = new ThreadLocal<Integer>();\n\n\n\n private void init() {\n if (sessionFactory == null) {\n if (sessionFactoryBeanName != null) {\n sessionFactory = beanFactory.getBean(sessionFactoryBeanName, SessionFactory.class);\n } else {\n try {\n sessionFactory = beanFactory.getBean(\"sessionFactory\", SessionFactory.class);\n } catch (RuntimeException exp) {\n\n }\n if (sessionFactory == null) {\n sessionFactory = beanFactory.getBean(SessionFactory.class); \n }\n }\n }\n }\n\n @Override\n public String onPrepareStatement(String sql) {\n if (mCalcFoundRows.get() == null || !mCalcFoundRows.get().booleanValue()) {\n return sql;\n }\n switch (mSQLStatementsPrepared.get()) {\n\n case 0: {\n mSQLStatementsPrepared.set(mSQLStatementsPrepared.get() + 1);\n\n // First time, prefix CALC_FOUND_ROWS_HINT\n\n StringBuilder builder = new StringBuilder(sql);\n int indexOf = builder.indexOf(SELECT_PREFIX);\n\n if (indexOf == -1) {\n throw new HibernateException(\"First SQL statement did not contain '\" + SELECT_PREFIX + \"'\");\n }\n\n builder.insert(indexOf + SELECT_PREFIX.length(), CALC_FOUND_ROWS_HINT);\n return builder.toString();\n }\n\n case 1: {\n mSQLStatementsPrepared.set(mSQLStatementsPrepared.get() + 1);\n\n // Before any secondary selects, capture FOUND_ROWS. If no secondary\n // selects are\n // ever executed, getFoundRows() will capture FOUND_ROWS\n // just-in-time when called\n // directly\n\n captureFoundRows();\n return sql;\n }\n\n default:\n // Pass-through untouched\n return sql;\n }\n }\n\n public void reset() {\n if (mCalcFoundRows.get() != null && mCalcFoundRows.get().booleanValue()) {\n mSQLStatementsPrepared.remove();\n mFoundRows.remove();\n mCalcFoundRows.remove();\n }\n }\n\n @Override\n public void afterTransactionCompletion(Transaction tx) {\n reset();\n }\n\n public void setCalcFoundRows(boolean calc) {\n if (calc) {\n mCalcFoundRows.set(Boolean.TRUE);\n } else {\n reset();\n }\n }\n\n public int getFoundRows() {\n if (mCalcFoundRows.get() == null || !mCalcFoundRows.get().booleanValue()) {\n throw new IllegalStateException(\"Attempted to getFoundRows without first calling 'setCalcFoundRows'\");\n }\n if (mFoundRows.get() == null) {\n captureFoundRows();\n }\n\n return mFoundRows.get();\n }\n\n //\n // Private methods\n //\n\n private void captureFoundRows() {\n init();\n\n // Sanity checks\n\n if (mFoundRows.get() != null) {\n throw new HibernateException(\"'\" + SELECT_FOUND_ROWS + \"' called more than once\");\n }\n\n if (mSQLStatementsPrepared.get() < 1) {\n throw new HibernateException(\"'\" + SELECT_FOUND_ROWS + \"' called before '\" + SELECT_PREFIX + CALC_FOUND_ROWS_HINT + \"'\");\n }\n\n // Fetch the total number of rows\n\n sessionFactory.getCurrentSession().doWork(new Work() {\n @Override\n public void execute(Connection connection) throws SQLException {\n final Statement stmt = connection.createStatement();\n ResultSet rs = null;\n try {\n rs = stmt.executeQuery(SELECT_FOUND_ROWS);\n if (rs.next()) {\n mFoundRows.set(rs.getInt(1));\n } else {\n mFoundRows.set(0);\n }\n } finally {\n if (rs != null) {\n rs.close();\n }\n try {\n stmt.close();\n } catch (RuntimeException exp) {\n\n }\n }\n }\n });\n }\n\n public void setSessionFactoryBeanName(String sessionFactoryBeanName) {\n this.sessionFactoryBeanName = sessionFactoryBeanName;\n }\n\n @Override\n public void setBeanFactory(BeanFactory arg0) throws BeansException {\n this.beanFactory = arg0;\n }\n\n}\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168084",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/20128/"
] |
Usually pagination queries look like this. Is there a better way instead of making two almost equal methods, one of which executing "select \*..." and the other one "count \*..."?
```
public List<Cat> findCats(String name, int offset, int limit) {
Query q = session.createQuery("from Cat where name=:name");
q.setString("name", name);
if (offset > 0) {
q.setFirstResult(offset);
}
if (limit > 0) {
q.setMaxResults(limit);
}
return q.list();
}
public Long countCats(String name) {
Query q = session.createQuery("select count(*) from Cat where name=:name");
q.setString("name", name);
return (Long) q.uniqueResult();
}
```
|
If you don't need to display the total number of pages then I'm not sure you need the count query. Lots of sites including google don't show the total on the paged results. Instead they just say "next>".
|
168,113 |
<p>I have a pretty standard django app, and am wondering how to set the url routing so that I don't have to explicitly map each url to a view. </p>
<p>For example, let's say that I have the following views: <code>Project, Links, Profile, Contact</code>. I'd rather not have my <code>urlpatterns</code> look like this:</p>
<pre><code>(r'^Project/$', 'mysite.app.views.project'),
(r'^Links/$', 'mysite.app.views.links'),
(r'^Profile/$', 'mysite.app.views.profile'),
(r'^Contact/$', 'mysite.app.views.contact'),
</code></pre>
<p>And so on. In <a href="http://www.pylonshq.com" rel="noreferrer">Pylons</a>, it would be as simple as:</p>
<pre><code>map.connect(':controller/:action/:id')
</code></pre>
<p>And it would automatically grab the right controller and function. Is there something similar in Django?</p>
|
[
{
"answer_id": 231624,
"author": "Dave Cluderay",
"author_id": 30933,
"author_profile": "https://Stackoverflow.com/users/30933",
"pm_score": 1,
"selected": false,
"text": "<p>In answer to your first question, hopefully, you'll see something in the sys.transmission_queue system view. See\n<a href=\"http://msdn.microsoft.com/en-us/library/ms190336.aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/ms190336.aspx</a> for documentation on that.</p>\n\n<p>If you Google that, you might find some useful troubleshooting resources too.</p>\n\n<p>Dave</p>\n"
},
{
"answer_id": 661829,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>John,</p>\n\n<p>I've only recently begun looking into the service broker in order to implement asynch messaging between DB instances. I found the following to be quite useful in getting my head around it.</p>\n\n<p><a href=\"http://msdn.microsoft.com/en-us/library/bb839489(SQL.90).aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/bb839489(SQL.90).aspx</a></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168113",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/736/"
] |
I have a pretty standard django app, and am wondering how to set the url routing so that I don't have to explicitly map each url to a view.
For example, let's say that I have the following views: `Project, Links, Profile, Contact`. I'd rather not have my `urlpatterns` look like this:
```
(r'^Project/$', 'mysite.app.views.project'),
(r'^Links/$', 'mysite.app.views.links'),
(r'^Profile/$', 'mysite.app.views.profile'),
(r'^Contact/$', 'mysite.app.views.contact'),
```
And so on. In [Pylons](http://www.pylonshq.com), it would be as simple as:
```
map.connect(':controller/:action/:id')
```
And it would automatically grab the right controller and function. Is there something similar in Django?
|
In answer to your first question, hopefully, you'll see something in the sys.transmission\_queue system view. See
<http://msdn.microsoft.com/en-us/library/ms190336.aspx> for documentation on that.
If you Google that, you might find some useful troubleshooting resources too.
Dave
|
168,119 |
<p>I have a pretty unusual problem (for me). I am writing an application that will allow a user to change their system time forward or back either by explicit date (change my date to 6/3/1955) or by increment using buttons (go forward 1 month).</p>
<p>I'm writing this to help some of my users test some software that requires jumps like this in order to simulate real world usage of a billing system.</p>
<p>Changing the time in Delphi is of course very easy:</p>
<pre><code>SetDateTime(2008,05,21,16,07,21,00);
</code></pre>
<p>But I'm not sure if Delphi (2006) has any built in helpers for date math, which is one of my least favorite things :)</p>
<p>Any suggestions for the best way to handle this? I'd prefer to stay native as the winapi datetime calls suck.</p>
<p>Thanks!</p>
|
[
{
"answer_id": 168134,
"author": "Richard Harrison",
"author_id": 19624,
"author_profile": "https://Stackoverflow.com/users/19624",
"pm_score": 2,
"selected": false,
"text": "<p>The VCL has types (TDate and TDateTime) which are doubles and you can use in arithmetic operations. </p>\n\n<p>Also see EncodeDate and DecodeDate</p>\n"
},
{
"answer_id": 168155,
"author": "gabr",
"author_id": 4997,
"author_profile": "https://Stackoverflow.com/users/4997",
"pm_score": 3,
"selected": false,
"text": "<p>There is plenty of helpers in the <a href=\"http://docwiki.embarcadero.com/CodeExamples/Seattle/en/DateUtils_(Delphi)\" rel=\"nofollow noreferrer\">DateUtils</a> unit.</p>\n"
},
{
"answer_id": 168994,
"author": "Martin Liesén",
"author_id": 20715,
"author_profile": "https://Stackoverflow.com/users/20715",
"pm_score": 0,
"selected": false,
"text": "<p>There is plenty of helpers in the SysUtils unit (and as gabr pointed out, also in DateUtils).</p>\n"
},
{
"answer_id": 172472,
"author": "stukelly",
"author_id": 5891,
"author_profile": "https://Stackoverflow.com/users/5891",
"pm_score": 5,
"selected": true,
"text": "<p>As mentioned by gabr and mliesen, have a look at the <a href=\"http://docwiki.embarcadero.com/VCL/en/DateUtils\" rel=\"noreferrer\">DateUtils</a> and <a href=\"http://docwiki.embarcadero.com/VCL/en/SysUtils\" rel=\"noreferrer\">SysUtils</a> units, useful functions include.</p>\n\n<ul>\n<li><a href=\"http://docwiki.embarcadero.com/VCL/en/DateUtils.IncDay\" rel=\"noreferrer\">IncDay</a> - Add a or subtract a number of days.</li>\n<li><a href=\"http://docwiki.embarcadero.com/VCL/en/SysUtils.IncMonth\" rel=\"noreferrer\">IncMonth</a> - Add a or subtract a number of months.</li>\n<li><a href=\"http://docwiki.embarcadero.com/VCL/en/DateUtils.IncWeek\" rel=\"noreferrer\">IncWeek</a> - Add a or subtract a number of weeks.</li>\n<li><a href=\"http://docwiki.embarcadero.com/VCL/en/DateUtils.IncYear\" rel=\"noreferrer\">IncYear</a> - Add a or subtract a number of years.</li>\n<li><a href=\"http://docwiki.embarcadero.com/VCL/en/SysUtils.EncodeDate\" rel=\"noreferrer\">EncodeDate</a> - Returns a TDateTime value from the Year, Month, and Day params.</li>\n</ul>\n"
},
{
"answer_id": 190434,
"author": "user26293",
"author_id": 26293,
"author_profile": "https://Stackoverflow.com/users/26293",
"pm_score": 3,
"selected": false,
"text": "<p>What do you want to happen if the day of the current month doesn't exist in your future month? Say, January 31 + 1 month? You have the same problem if you increment the year and the starting date is February 29 on a leap year. So there can't be a universal IncMonth or IncYear function that will work consistantly on all dates. </p>\n\n<p>For anyone interested, I heartily recommend <a href=\"http://www.boyet.com/Articles/PublishedArticles/Calculatingthenumberofmon.html\" rel=\"noreferrer\">Julian Bucknall's article</a> on the complexities that are inherent in this type of calculation\non how to calculate the number of months and days between two dates.</p>\n\n<p>The following is the only generic date increment functions possible that do not introduce anomolies into generic date math. But it only accomplishes this by shifting the responsibility back onto the programmer who presumably has the exact requirements of the specific application he/she is programming.</p>\n\n<p><a href=\"http://docs.codegear.com/docs/radstudio/radstudio2007/RS2007_helpupdates/HUpdate3/EN/html/delphivclwin32/DateUtils_IncDay.html\" rel=\"noreferrer\">IncDay</a> - Add a or subtract a number of days.<br>\n<a href=\"http://docs.codegear.com/docs/radstudio/radstudio2007/RS2007_helpupdates/HUpdate3/EN/html/delphivclwin32/DateUtils_IncWeek.html\" rel=\"noreferrer\">IncWeek</a> - Add or subtract a number of weeks.<br></p>\n\n<p>But if you must use the built in functions then at least be sure that they do what you want them to do. Have a look at the DateUtils and SysUtils units. Having the source code to these functions is one of the coolest aspects of Delphi. Having said that, here is the complete list of built in functions:</p>\n\n<p><a href=\"http://docs.codegear.com/docs/radstudio/radstudio2007/RS2007_helpupdates/HUpdate3/EN/html/delphivclwin32/DateUtils_IncDay.html\" rel=\"noreferrer\">IncDay</a> - Add a or subtract a number of days.<br>\n<a href=\"http://docs.codegear.com/docs/radstudio/radstudio2007/RS2007_helpupdates/HUpdate3/EN/html/delphivclwin32/DateUtils_IncWeek.html\" rel=\"noreferrer\">IncWeek</a> - Add or subtract a number of weeks.<br>\n<a href=\"http://docs.codegear.com/docs/radstudio/radstudio2007/RS2007_helpupdates/HUpdate4/EN/html/delphivclwin32/SysUtils_IncMonth.html\" rel=\"noreferrer\">IncMonth</a> - Add a or subtract a number of months.<br>\n<a href=\"http://docs.codegear.com/docs/radstudio/radstudio2007/RS2007_helpupdates/HUpdate3/EN/html/delphivclwin32/DateUtils_IncYear.html\" rel=\"noreferrer\">IncYear</a> - Add a or subtract a number of years.</p>\n\n<p>As for the second part of your question, how to set the system date & time using a TDatetime, the following shamelessly stolen code from another post will do the job:</p>\n\n<pre><code>procedure SetSystemDateTime(aDateTime: TDateTime);\nvar\n lSystemTime: TSystemTime;\n lTimeZone: TTimeZoneInformation;\n begin\n GetTimeZoneInformation(lTimeZone);\n aDateTime := aDateTime + (lTimeZone.Bias / 1440);\n DateTimeToSystemTime(aDateTime, lSystemTime);\n setSystemTime(lSystemTime);\nend;\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168119",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/172/"
] |
I have a pretty unusual problem (for me). I am writing an application that will allow a user to change their system time forward or back either by explicit date (change my date to 6/3/1955) or by increment using buttons (go forward 1 month).
I'm writing this to help some of my users test some software that requires jumps like this in order to simulate real world usage of a billing system.
Changing the time in Delphi is of course very easy:
```
SetDateTime(2008,05,21,16,07,21,00);
```
But I'm not sure if Delphi (2006) has any built in helpers for date math, which is one of my least favorite things :)
Any suggestions for the best way to handle this? I'd prefer to stay native as the winapi datetime calls suck.
Thanks!
|
As mentioned by gabr and mliesen, have a look at the [DateUtils](http://docwiki.embarcadero.com/VCL/en/DateUtils) and [SysUtils](http://docwiki.embarcadero.com/VCL/en/SysUtils) units, useful functions include.
* [IncDay](http://docwiki.embarcadero.com/VCL/en/DateUtils.IncDay) - Add a or subtract a number of days.
* [IncMonth](http://docwiki.embarcadero.com/VCL/en/SysUtils.IncMonth) - Add a or subtract a number of months.
* [IncWeek](http://docwiki.embarcadero.com/VCL/en/DateUtils.IncWeek) - Add a or subtract a number of weeks.
* [IncYear](http://docwiki.embarcadero.com/VCL/en/DateUtils.IncYear) - Add a or subtract a number of years.
* [EncodeDate](http://docwiki.embarcadero.com/VCL/en/SysUtils.EncodeDate) - Returns a TDateTime value from the Year, Month, and Day params.
|
168,150 |
<p>I've been trying to get up to speed on some of the newer features in C# and one of them that I haven't had occasion to use is anonymous types.</p>
<p>I understand the usage as it pertains to LINQ queries and I looked at <a href="https://stackoverflow.com/questions/48668/how-should-anonymous-types-be-used-in-c">this SO post</a> which asked a similar question. Most of the examples I've seen on the net are related to LINQ queries, which is cool. I saw some somewhat contrived examples too but not really anything where I saw a lot of value. </p>
<p>Do you have a novel use for anonymous types where you think it really provides you some utility?</p>
|
[
{
"answer_id": 168159,
"author": "Giovanni Galbo",
"author_id": 4050,
"author_profile": "https://Stackoverflow.com/users/4050",
"pm_score": 2,
"selected": false,
"text": "<p>The biggest use for anonymous types is LINQ, in fact that's why it was created.</p>\n\n<p>I guess one reason for an anonymous type outside of linq is to create a temporary struct-like object, e.g.:</p>\n\n<pre><code>var x = new { a = 1, b = 2 };\n</code></pre>\n\n<p>That may make your life a little easier in some situations.</p>\n"
},
{
"answer_id": 168205,
"author": "yfeldblum",
"author_id": 12349,
"author_profile": "https://Stackoverflow.com/users/12349",
"pm_score": 3,
"selected": false,
"text": "<p>ASP.NET MVC routing uses these objects all over the place.</p>\n"
},
{
"answer_id": 168542,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 2,
"selected": false,
"text": "<p>Occasionally I suspect it may be useful to perform something which is <em>like</em> a LINQ query, but doesn't happen to use LINQ - but you still want a projection of some kind. I don't think I'd use anonymous types in their current form for anything radically different to LINQ projections.</p>\n\n<p>One thing I <em>would</em> like to see is the ability to create \"named\" types with simple declarations, which would generate the properties and constructor in the same way as for anonymous types, as well as overriding Equals/GetHashCode/ToString in the same (useful) way. Those types could then be converted into \"normal\" types when the need to add more behaviour arose.</p>\n\n<p>Again, I don't think I'd use it terribly often - but every so often the ability would be handy, particularly within a few methods of a class. This could perhaps be part of a larger effort to give more support to immutable types in C# 5.</p>\n"
},
{
"answer_id": 172629,
"author": "Bradley Grainger",
"author_id": 23633,
"author_profile": "https://Stackoverflow.com/users/23633",
"pm_score": 4,
"selected": true,
"text": "<p>With a bit of reflection, you can turn an anonymous type into a Dictionary<string, object>; Roy Osherove blogs his technique for this here: <a href=\"http://weblogs.asp.net/rosherove/archive/2008/03/11/turn-anonymous-types-into-idictionary-of-values.aspx\" rel=\"nofollow noreferrer\">http://weblogs.asp.net/rosherove/archive/2008/03/11/turn-anonymous-types-into-idictionary-of-values.aspx</a></p>\n\n<p>Jacob Carpenter uses anonymous types as a way to initialize immutable objects with syntax similar to object initialization: <a href=\"http://jacobcarpenter.wordpress.com/2007/11/19/named-parameters-part-2/\" rel=\"nofollow noreferrer\">http://jacobcarpenter.wordpress.com/2007/11/19/named-parameters-part-2/</a></p>\n\n<p>Anonymous types can be used as a way to give easier-to-read aliases to the properties of objects in a collection being iterated over with a <code>foreach</code> statement. (Though, to be honest, this is really nothing more than the standard use of anonymous types with <a href=\"http://msdn.microsoft.com/en-us/library/bb397919.aspx\" rel=\"nofollow noreferrer\">LINQ to Objects</a>.) For example:</p>\n\n<pre><code>Dictionary<int, string> employees = new Dictionary<int, string>\n{\n { 1, \"Bob\" },\n { 2, \"Alice\" },\n { 3, \"Fred\" },\n};\n\n// standard iteration\nforeach (var pair in employees)\n Console.WriteLine(\"ID: {0}, Name: {1}\", pair.Key, pair.Value);\n\n// alias Key/Value as ID/Name\nforeach (var emp in employees.Select(p => new { ID = p.Key, Name = p.Value }))\n Console.WriteLine(\"ID: {0}, Name: {1}\", emp.ID, emp.Name);\n</code></pre>\n\n<p>While there's not much improvement in this short sample, if the <code>foreach</code> loop were longer, referring to <code>ID</code> and <code>Name</code> might improve readability.</p>\n"
},
{
"answer_id": 172674,
"author": "mmacaulay",
"author_id": 22152,
"author_profile": "https://Stackoverflow.com/users/22152",
"pm_score": 2,
"selected": false,
"text": "<p>To add to what Justice said, ASP.Net MVC is the first place I've seen these used in interesting and useful ways. Here's one example:</p>\n\n<pre><code>\nHtml.ActionLink(\"A Link\", \"Resolve\", new { onclick = \"someJavascriptFn();\" })\n</code></pre>\n\n<p>ASP.Net MVC uses anonymous types like this to add arbitrary attributes to HTML elements. I suppose there's a number of different ways you could accomplish the same thing, but I like the terse style of anonymous types, it gives things more of a dynamic language feel.</p>\n"
},
{
"answer_id": 172710,
"author": "Aaron Powell",
"author_id": 11388,
"author_profile": "https://Stackoverflow.com/users/11388",
"pm_score": 1,
"selected": false,
"text": "<p>I've used them for doing templated emails as they are great if you're using reflection and generics.</p>\n\n<p>Some info can be found here: <a href=\"http://www.aaron-powell.com/blog.aspx?id=1247\" rel=\"nofollow noreferrer\">http://www.aaron-powell.com/blog.aspx?id=1247</a></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168150",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7862/"
] |
I've been trying to get up to speed on some of the newer features in C# and one of them that I haven't had occasion to use is anonymous types.
I understand the usage as it pertains to LINQ queries and I looked at [this SO post](https://stackoverflow.com/questions/48668/how-should-anonymous-types-be-used-in-c) which asked a similar question. Most of the examples I've seen on the net are related to LINQ queries, which is cool. I saw some somewhat contrived examples too but not really anything where I saw a lot of value.
Do you have a novel use for anonymous types where you think it really provides you some utility?
|
With a bit of reflection, you can turn an anonymous type into a Dictionary<string, object>; Roy Osherove blogs his technique for this here: <http://weblogs.asp.net/rosherove/archive/2008/03/11/turn-anonymous-types-into-idictionary-of-values.aspx>
Jacob Carpenter uses anonymous types as a way to initialize immutable objects with syntax similar to object initialization: <http://jacobcarpenter.wordpress.com/2007/11/19/named-parameters-part-2/>
Anonymous types can be used as a way to give easier-to-read aliases to the properties of objects in a collection being iterated over with a `foreach` statement. (Though, to be honest, this is really nothing more than the standard use of anonymous types with [LINQ to Objects](http://msdn.microsoft.com/en-us/library/bb397919.aspx).) For example:
```
Dictionary<int, string> employees = new Dictionary<int, string>
{
{ 1, "Bob" },
{ 2, "Alice" },
{ 3, "Fred" },
};
// standard iteration
foreach (var pair in employees)
Console.WriteLine("ID: {0}, Name: {1}", pair.Key, pair.Value);
// alias Key/Value as ID/Name
foreach (var emp in employees.Select(p => new { ID = p.Key, Name = p.Value }))
Console.WriteLine("ID: {0}, Name: {1}", emp.ID, emp.Name);
```
While there's not much improvement in this short sample, if the `foreach` loop were longer, referring to `ID` and `Name` might improve readability.
|
168,169 |
<p>Has anyone else seen people do this:</p>
<pre><code>private string _name;
public string Name{ get{ return _name; } set{ _name = value;}}</code></pre>
<p>I understand using accessors if you are going to exercise some sort of control over how it gets set or perform some sort of function on it when there is a get. But if you are just going to do this, why not just make the variable public to begin with? Am I missing something?</p>
|
[
{
"answer_id": 168180,
"author": "marc",
"author_id": 12260,
"author_profile": "https://Stackoverflow.com/users/12260",
"pm_score": 0,
"selected": false,
"text": "<p>Preparation. You never know when you'll want to removed the set accessor down the road, perform additional operations in the setter, or change the data source for the get.</p>\n"
},
{
"answer_id": 168189,
"author": "yfeldblum",
"author_id": 12349,
"author_profile": "https://Stackoverflow.com/users/12349",
"pm_score": 0,
"selected": false,
"text": "<p>Publicly accessible members should typically be methods and not fields. It's just good practice, and that practice helps you ensure that the encapsulated state of your objects is always under your control.</p>\n"
},
{
"answer_id": 168203,
"author": "AdamC",
"author_id": 16476,
"author_profile": "https://Stackoverflow.com/users/16476",
"pm_score": 3,
"selected": false,
"text": "<p>The idea is that if you use accessors, the underlying implementation can be changed without changing the API. For example, if you decide that when you set the name, you also need to update a text box, or another variable, none of your client code would have to change. </p>\n"
},
{
"answer_id": 168208,
"author": "Scott Langham",
"author_id": 11898,
"author_profile": "https://Stackoverflow.com/users/11898",
"pm_score": 4,
"selected": false,
"text": "<p>If you define a public interface with a property in assembly A, you could then use this interface in assembly B.</p>\n\n<p>Now, you can change the property's implementation (maybe fetching the value from a database instead of storing it in a field). Then you can recompile assembly A, and replace an older one. Assembly B would carry on fine because the interface wouldn't have changed.</p>\n\n<p>However, if you'd started off initially with a public field, and decided this wasn't suitable and wanted to change the implementation and to do that you needed to convert it to a property, then this would mean you'd have to change assembly A's public interface. Any clients of that interface (including assembly B) would also have to be recompiled and replaced to be able to work with this new interface.</p>\n\n<p>So, you're better off starting with a property initially. This encapsulates the implementation of the property, leaving you free to change it in the future without having to worry what clients (including assembly B) are already out in the world using assembly A. Because, if there are any clients already out in the world making use of assembly A, changing the interface would break all clients. If they're used by another team in your company, or another company, then they are going to be not happy if you break their assemblies by changing the interface of yours!</p>\n"
},
{
"answer_id": 168219,
"author": "Scott Dorman",
"author_id": 1559,
"author_profile": "https://Stackoverflow.com/users/1559",
"pm_score": 2,
"selected": false,
"text": "<p>Good programming practice. This is a very common pattern that fits with OO design methodologies. By exposing a public field you expose the internals of how that data is being stored. Using a public property instead allows you more flexibility to change the way the data is stored internally and not break the public interface. It also allows you more control over what happens when the data is accessed (lazy initialization, null checks, etc.)</p>\n"
},
{
"answer_id": 168221,
"author": "Robert Rossney",
"author_id": 19403,
"author_profile": "https://Stackoverflow.com/users/19403",
"pm_score": 6,
"selected": true,
"text": "<p>If you make the member a public field, then you can't later refactor it into a property without changing the interface to your class. If you expose it as a property from the very beginning, you can make whatever changes to the property accessor functions that you need and the class's interface remains unchanged.</p>\n\n<p>Note that as of C# 3.0, you can implement a property without creating a backing field, e.g.:</p>\n\n<pre><code>public string Name { get; set; }\n</code></pre>\n\n<p>This removes what is pretty much the only justification for not implementing public fields as properties in the first place.</p>\n"
},
{
"answer_id": 168398,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 2,
"selected": false,
"text": "<p>Variables are part of the implementation of a class. Properties more logically represent the interface to it. With C# 3.0, automatically implemented properties make this a breeze to do from the start.</p>\n\n<p>I've written more thoughts on this, including the various ways in which changing from a variable to a property breaks not just binary compatibility but also source compatibility, in <a href=\"http://csharpindepth.com/Articles/Chapter8/PropertiesMatter.aspx\" rel=\"nofollow noreferrer\">an article on the topic</a>.</p>\n"
},
{
"answer_id": 168449,
"author": "Hafthor",
"author_id": 4489,
"author_profile": "https://Stackoverflow.com/users/4489",
"pm_score": 0,
"selected": false,
"text": "<p>For encapsulation, it is not recommended to use public fields.</p>\n\n<p><a href=\"http://my.safaribooksonline.com/9780321578815/ch05lev1sec5?displaygrbooks=0\" rel=\"nofollow noreferrer\">http://my.safaribooksonline.com/9780321578815/ch05lev1sec5?displaygrbooks=0</a></p>\n\n<p>As Chris Anderson said later in this book, it would be ideal would be if the caller were blind to the difference of field vs. property.</p>\n"
},
{
"answer_id": 168525,
"author": "David Robbins",
"author_id": 19799,
"author_profile": "https://Stackoverflow.com/users/19799",
"pm_score": 0,
"selected": false,
"text": "<p>To retain a high degree of extensibility without the pain of re-compiling all your assemblies, you want to use public properties as accessors. By following a \"contract\" or a defined mechanism that describes how your objects will exchange data a set of rules will be put in place. This contract is enforced with an interface and fulfilled by the getters and setters of your class that inherits this interface.</p>\n\n<p>Later on, should you create additional classes from that interface, you have flexibility of adhering to the contract with the use of the properties, but since you are providing the data via the getters and setters, the implementation or process of assembling data can anything you want, as along as it returns the type that the \"contract\" expects. </p>\n"
},
{
"answer_id": 174343,
"author": "Quibblesome",
"author_id": 1143,
"author_profile": "https://Stackoverflow.com/users/1143",
"pm_score": 3,
"selected": false,
"text": "<p>It might be worth noting that DataBinding in .NET also refuses to work off public fields and demands properties. So that might be another reason.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168169",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/19038/"
] |
Has anyone else seen people do this:
```
private string _name;
public string Name{ get{ return _name; } set{ _name = value;}}
```
I understand using accessors if you are going to exercise some sort of control over how it gets set or perform some sort of function on it when there is a get. But if you are just going to do this, why not just make the variable public to begin with? Am I missing something?
|
If you make the member a public field, then you can't later refactor it into a property without changing the interface to your class. If you expose it as a property from the very beginning, you can make whatever changes to the property accessor functions that you need and the class's interface remains unchanged.
Note that as of C# 3.0, you can implement a property without creating a backing field, e.g.:
```
public string Name { get; set; }
```
This removes what is pretty much the only justification for not implementing public fields as properties in the first place.
|
168,171 |
<p>Can someone provide a regular expression for parsing name/value pairs from a string? The pairs are separated by commas, and the value can optionally be enclosed in quotes. For example:</p>
<pre><code>AssemblyName=foo.dll,ClassName="SomeClass",Parameters="Some,Parameters"
</code></pre>
|
[
{
"answer_id": 168196,
"author": "Markus Jarderot",
"author_id": 22364,
"author_profile": "https://Stackoverflow.com/users/22364",
"pm_score": 6,
"selected": true,
"text": "<ul>\n<li><p><strong>No escape:</strong></p>\n\n<pre><code>/([^=,]*)=(\"[^\"]*\"|[^,\"]*)/\n</code></pre></li>\n<li><p><strong>Double quote escape for both key and value:</strong></p>\n\n<pre><code>/((?:\"[^\"]*\"|[^=,])*)=((?:\"[^\"]*\"|[^=,])*)/\n\nkey=value,\"key with \"\" in it\"=\"value with \"\" in it\",key=value\" \"with\" \"spaces\n</code></pre></li>\n<li><p><strong>Backslash string escape:</strong></p>\n\n<pre><code>/([^=,]*)=(\"(?:\\\\.|[^\"\\\\]+)*\"|[^,\"]*)/\n\nkey=value,key=\"value\",key=\"val\\\"ue\"\n</code></pre></li>\n<li><p><strong>Full backslash escape:</strong></p>\n\n<pre><code>/((?:\\\\.|[^=,]+)*)=(\"(?:\\\\.|[^\"\\\\]+)*\"|(?:\\\\.|[^,\"\\\\]+)*)/\n\nkey=value,key=\"value\",key=\"val\\\"ue\",ke\\,y=val\\,ue\n</code></pre></li>\n</ul>\n\n<p><strong>Edit:</strong> Added escaping alternatives.</p>\n\n<p><strong>Edit2:</strong> Added another escaping alternative.</p>\n\n<p>You would have to clean up the keys/values by removing any escape-characters and surrounding quotes.</p>\n"
},
{
"answer_id": 168358,
"author": "Jonathan Leffler",
"author_id": 15168,
"author_profile": "https://Stackoverflow.com/users/15168",
"pm_score": 2,
"selected": false,
"text": "<p>Nice answer from MizardX. Minor niggles - it doesn't allow for spaces around names etc (which may not matter), and it collects the quotes as well as the quoted value (which also may not matter), and it doesn't have an escape mechanism for embedding double quote characters in the quoted value (which, once more, may not matter).</p>\n\n<p>As written, the pattern works with most of the extended regular expression systems. Fixing the niggles would probably require descent into, say, Perl. This version uses doubled quotes to escape -- hence a=\"a\"\"b\" generates a field value 'a\"\"b' (which ain't perfect, but could be fixed afterwards easily enough):</p>\n\n<pre><code>/\\s*([^=,\\s]+)\\s*=\\s*(?:\"((?:[^\"]|\"\")*)\"|([^,\"]*))\\s*,?/\n</code></pre>\n\n<p>Further, you'd have to use $2 or $3 to collect the value, whereas with MizardX's answer, you simply use $2. So, it isn't as easy or nice, but it covers a few edge cases. If the simpler answer is adequate, use it.</p>\n\n<p>Test script:</p>\n\n<pre><code>#!/bin/perl -w\n\nuse strict;\nmy $qr = qr/\\s*([^=,\\s]+)\\s*=\\s*(?:\"((?:[^\"]|\"\")*)\"|([^,\"]*))\\s*,?/;\n\nwhile (<>)\n{\n while (m/$qr/)\n {\n print \"1= $1, 2 = $2, 3 = $3\\n\";\n $_ =~ s/$qr//;\n }\n}\n</code></pre>\n\n<p>This witters about either $2 or $3 being undefined - accurately.</p>\n"
},
{
"answer_id": 209317,
"author": "Brad Gilbert",
"author_id": 1337,
"author_profile": "https://Stackoverflow.com/users/1337",
"pm_score": 0,
"selected": false,
"text": "<p>This is how I would do it if you can use <code>Perl 5.10</code>.</p>\n\n<pre>\nqr/\n (?<key>\n (?:\n [^=,\\\\]\n |\n (?&escape)\n )++ # Prevent null keys\n )\n\n \\s*+\n =\n \\s*+\n\n (?<value>\n (?"ed)\n |\n (?:\n [^=,\\s\\\\]\n |\n (?&escape)\n )++ # Prevent null value ( use quotes for that )\n )\n\n (?(DEFINE)\n (?<escape>\\\\.)\n (?<quoted>\n \"\n (?:\n (?&escaped)\n |\n [^\"\\\\]\n )*+\n \"\n )\n )\n/x\n</pre>\n\n<p>The elements would be accessed through <code>%+</code>.</p>\n\n<p><em><a href=\"http://perldoc.perl.org/perlretut.html\" rel=\"nofollow noreferrer\"><code>perlretut</code></a> was very helpful in creating this answer.</em></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168171",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2773/"
] |
Can someone provide a regular expression for parsing name/value pairs from a string? The pairs are separated by commas, and the value can optionally be enclosed in quotes. For example:
```
AssemblyName=foo.dll,ClassName="SomeClass",Parameters="Some,Parameters"
```
|
* **No escape:**
```
/([^=,]*)=("[^"]*"|[^,"]*)/
```
* **Double quote escape for both key and value:**
```
/((?:"[^"]*"|[^=,])*)=((?:"[^"]*"|[^=,])*)/
key=value,"key with "" in it"="value with "" in it",key=value" "with" "spaces
```
* **Backslash string escape:**
```
/([^=,]*)=("(?:\\.|[^"\\]+)*"|[^,"]*)/
key=value,key="value",key="val\"ue"
```
* **Full backslash escape:**
```
/((?:\\.|[^=,]+)*)=("(?:\\.|[^"\\]+)*"|(?:\\.|[^,"\\]+)*)/
key=value,key="value",key="val\"ue",ke\,y=val\,ue
```
**Edit:** Added escaping alternatives.
**Edit2:** Added another escaping alternative.
You would have to clean up the keys/values by removing any escape-characters and surrounding quotes.
|
168,173 |
<p>I have a webpage that pulls information from a database, converts it to .csv format, and writes the file to the HTTPResponse. </p>
<pre><code>string csv = GetCSV();
Response.Clear();
Response.ContentType = "text/csv";
Response.Write(csv);
</code></pre>
<p>This works fine, and the file is sent to the client with no problems. However, when the file is sent to the client, the name of the current page is used, instead of a more friendly name (like "data.csv").</p>
<p><img src="https://ktrauberman.files.wordpress.com/2008/10/exportcsv.gif" alt="alt text"></p>
<p>My question is, how can I change the name of the file that is written to the output stream without writing the file to disk and redirecting the client to the file's url? </p>
<p><strong>EDIT: Thanks for the responses guys. I got 4 of the same response, so I just chose the first one as the answer.</strong></p>
|
[
{
"answer_id": 168182,
"author": "Joe Skora",
"author_id": 14057,
"author_profile": "https://Stackoverflow.com/users/14057",
"pm_score": 5,
"selected": true,
"text": "<p>I believe this will work for you.</p>\n\n<pre><code>Response.AddHeader(\"content-disposition\", \"attachment; filename=NewFileName.csv\");\n</code></pre>\n"
},
{
"answer_id": 168184,
"author": "James Schek",
"author_id": 17871,
"author_profile": "https://Stackoverflow.com/users/17871",
"pm_score": 2,
"selected": false,
"text": "<p>Add a \"Content-Disposition\" header with the value \"attachment; filename=filename.csv\".</p>\n"
},
{
"answer_id": 168187,
"author": "Matt Lacey",
"author_id": 1755,
"author_profile": "https://Stackoverflow.com/users/1755",
"pm_score": 2,
"selected": false,
"text": "<pre><code>Response.AddHeader(\"content-disposition\", \"attachment; filename=File.doc\")\n</code></pre>\n"
},
{
"answer_id": 168188,
"author": "Mark Biek",
"author_id": 305,
"author_profile": "https://Stackoverflow.com/users/305",
"pm_score": 2,
"selected": false,
"text": "<p>You just need to set the <strong>Content-Disposition</strong> header</p>\n\n<pre><code>Content-Disposition: attachment; filename=data.csv\n</code></pre>\n\n<hr>\n\n<p>This Microsoft Support article has some good information</p>\n\n<p><a href=\"http://support.microsoft.com/kb/260519\" rel=\"nofollow noreferrer\">How To Raise a \"File Download\" Dialog Box for a Known MIME Type</a></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168173",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/21461/"
] |
I have a webpage that pulls information from a database, converts it to .csv format, and writes the file to the HTTPResponse.
```
string csv = GetCSV();
Response.Clear();
Response.ContentType = "text/csv";
Response.Write(csv);
```
This works fine, and the file is sent to the client with no problems. However, when the file is sent to the client, the name of the current page is used, instead of a more friendly name (like "data.csv").
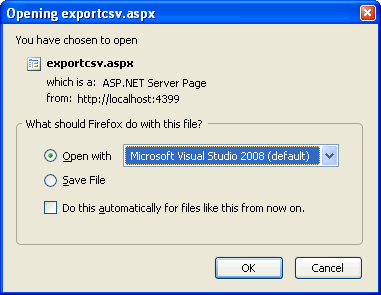
My question is, how can I change the name of the file that is written to the output stream without writing the file to disk and redirecting the client to the file's url?
**EDIT: Thanks for the responses guys. I got 4 of the same response, so I just chose the first one as the answer.**
|
I believe this will work for you.
```
Response.AddHeader("content-disposition", "attachment; filename=NewFileName.csv");
```
|
168,186 |
<p>Trying to update some gems on a Windows machine and I continually get this error output for gems that do not have pre-compiled binaries:</p>
<p>Provided configuration options:</p>
<blockquote>
<pre><code> --with-opt-dir
--without-opt-dir
--with-opt-include
--without-opt-include=${opt-dir}/include
--with-opt-lib
--without-opt-lib=${opt-dir}/lib
--with-make-prog
--srcdir=.
--curdir
--ruby=c:/server/ruby/bin/ruby
</code></pre>
</blockquote>
<p>These are configuration options that are provided to the <em>extconf.rb</em> ruby file during the installation of the gem.</p>
<p>I have installed <em>MinGW</em> so I should have everything I need to install, make and compile these gems.<br>
However, I do not know how to change the configuration for <em>RubyGems</em> so that when <em>extconf.rb</em> is called it includes the appropriate options pointing to the <em>MinGW</em> include directory.</p>
|
[
{
"answer_id": 169967,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>I don't know if this works with the native Windows Ruby, but if you use the Cygwin version and have a full Cygwin installed (compilers etc) then you shouldn't have any problems - we've been able to use a lot of gems that require compiled stuff.</p>\n"
},
{
"answer_id": 170781,
"author": "Charles Roper",
"author_id": 1944,
"author_profile": "https://Stackoverflow.com/users/1944",
"pm_score": 3,
"selected": true,
"text": "<p>There's a <a href=\"http://wiki.github.com/oneclick/rubyinstaller/development-kit\" rel=\"nofollow noreferrer\">DevKit</a> that could well be what you're after.</p>\n"
},
{
"answer_id": 184256,
"author": "jakobengblom2",
"author_id": 23054,
"author_profile": "https://Stackoverflow.com/users/23054",
"pm_score": -1,
"selected": false,
"text": "<p>In general, in my experience, code designed for a unix system can be very hard to make work on MinGW. For a quick port, use CygWin. Or do a full port of the software to Windows host, including using native windows shell and OS API -- which is pretty darn expensive in terms of time, but it pays of if you plan to support Windows long term. </p>\n\n<p>Not familiar with this particular software package, this is just a general observation on trying to port some other dastardly pieces of code to Windows.</p>\n"
},
{
"answer_id": 481034,
"author": "Joe Soul-bringer",
"author_id": 56279,
"author_profile": "https://Stackoverflow.com/users/56279",
"pm_score": 0,
"selected": false,
"text": "<p>I had just the same problem. </p>\n\n<p>The only way I found to get gems that did not have pre-compiled binaries - such as parsetree - to run on windows was to recompile the Ruby source using Mingw as well as copy several libraries and applications from the visual c++ install I already had. What I copied included the zlib library as well as the iconv library and application. </p>\n\n<p>Note: I am using this setup as a test configuration. I would not use such a setup for production (since who knows what happens when you a library from one distribution to another). </p>\n"
},
{
"answer_id": 950164,
"author": "Luis Lavena",
"author_id": 117298,
"author_profile": "https://Stackoverflow.com/users/117298",
"pm_score": 1,
"selected": false,
"text": "<p>Yardboy,</p>\n\n<p>Too bad you didn't mention which gem are you trying to update, you only put there the options output.</p>\n\n<p>Also, some of these gems needs development headers and libraries, not just the compiler (MinGW).</p>\n\n<p>Plus, MinGW is going to work as long the Ruby build you have is created <strong>with</strong> MinGW.</p>\n\n<p>There is some work being done to ease this, but compiler, headers and library requirements are needed on <em>all</em> the platforms, not just Windows.</p>\n\n<p>You can find more info and resources on <a href=\"http://blog.mmediasys.com\" rel=\"nofollow noreferrer\">my blog</a></p>\n\n<p>Cheers.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168186",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/9550/"
] |
Trying to update some gems on a Windows machine and I continually get this error output for gems that do not have pre-compiled binaries:
Provided configuration options:
>
>
> ```
> --with-opt-dir
> --without-opt-dir
> --with-opt-include
> --without-opt-include=${opt-dir}/include
> --with-opt-lib
> --without-opt-lib=${opt-dir}/lib
> --with-make-prog
> --srcdir=.
> --curdir
> --ruby=c:/server/ruby/bin/ruby
>
> ```
>
>
These are configuration options that are provided to the *extconf.rb* ruby file during the installation of the gem.
I have installed *MinGW* so I should have everything I need to install, make and compile these gems.
However, I do not know how to change the configuration for *RubyGems* so that when *extconf.rb* is called it includes the appropriate options pointing to the *MinGW* include directory.
|
There's a [DevKit](http://wiki.github.com/oneclick/rubyinstaller/development-kit) that could well be what you're after.
|
168,214 |
<p>What is the easiest way to encode a PHP string for output to a JavaScript variable?</p>
<p>I have a PHP string which includes quotes and newlines. I need the contents of this string to be put into a JavaScript variable.</p>
<p>Normally, I would just construct my JavaScript in a PHP file, à la:</p>
<pre><code><script>
var myvar = "<?php echo $myVarValue;?>";
</script>
</code></pre>
<p>However, this doesn't work when <code>$myVarValue</code> contains quotes or newlines.</p>
|
[
{
"answer_id": 168245,
"author": "Javier",
"author_id": 11649,
"author_profile": "https://Stackoverflow.com/users/11649",
"pm_score": 5,
"selected": false,
"text": "<p>encode it with JSON</p>\n"
},
{
"answer_id": 168255,
"author": "Adam",
"author_id": 1366,
"author_profile": "https://Stackoverflow.com/users/1366",
"pm_score": -1,
"selected": false,
"text": "<p>If you use a templating engine to construct your HTML then you can fill it with what ever you want!</p>\n\n<p>Check out <a href=\"http://www.phpxtemplate.org\" rel=\"nofollow noreferrer\">XTemplates</a>.\nIt's a nice, open source, lightweight, template engine.</p>\n\n<p>Your HTML/JS there would look like this:</p>\n\n<pre><code><script>\n var myvar = {$MyVarValue};\n</script>\n</code></pre>\n"
},
{
"answer_id": 168265,
"author": "Chris MacDonald",
"author_id": 18146,
"author_profile": "https://Stackoverflow.com/users/18146",
"pm_score": 1,
"selected": false,
"text": "<p>htmlspecialchars</p>\n\n<p>Description</p>\n\n<pre><code>string htmlspecialchars ( string $string [, int $quote_style [, string $charset [, bool $double_encode ]]] )\n</code></pre>\n\n<p>Certain characters have special significance in HTML, and should be represented by HTML entities if they are to preserve their meanings. This function returns a string with some of these conversions made; the translations made are those most useful for everyday web programming. If you require all HTML character entities to be translated, use htmlentities() instead.</p>\n\n<p>This function is useful in preventing user-supplied text from containing HTML markup, such as in a message board or guest book application.</p>\n\n<p>The translations performed are:</p>\n\n<pre><code>* '&' (ampersand) becomes '&amp;'\n* '\"' (double quote) becomes '&quot;' when ENT_NOQUOTES is not set.\n* ''' (single quote) becomes '&#039;' only when ENT_QUOTES is set.\n* '<' (less than) becomes '&lt;'\n* '>' (greater than) becomes '&gt;'\n</code></pre>\n\n<p><a href=\"http://ca.php.net/htmlspecialchars\" rel=\"nofollow noreferrer\">http://ca.php.net/htmlspecialchars</a></p>\n"
},
{
"answer_id": 168272,
"author": "micahwittman",
"author_id": 11181,
"author_profile": "https://Stackoverflow.com/users/11181",
"pm_score": 5,
"selected": false,
"text": "<pre><code>function escapeJavaScriptText($string)\n{\n return str_replace(\"\\n\", '\\n', str_replace('\"', '\\\"', addcslashes(str_replace(\"\\r\", '', (string)$string), \"\\0..\\37'\\\\\")));\n}\n</code></pre>\n"
},
{
"answer_id": 168277,
"author": "Diodeus - James MacFarlane",
"author_id": 12579,
"author_profile": "https://Stackoverflow.com/users/12579",
"pm_score": 2,
"selected": false,
"text": "<p>You can insert it into a hidden DIV, then assign the innerHTML of the DIV to your JavaScript variable. You don't have to worry about escaping anything. Just be sure not to put broken HTML in there.</p>\n"
},
{
"answer_id": 168332,
"author": "Jacob",
"author_id": 8119,
"author_profile": "https://Stackoverflow.com/users/8119",
"pm_score": 2,
"selected": false,
"text": "<p>You could try</p>\n\n<pre><code><script type=\"text/javascript\">\n myvar = unescape('<?=rawurlencode($myvar)?>');\n</script>\n</code></pre>\n"
},
{
"answer_id": 169035,
"author": "bobwienholt",
"author_id": 24257,
"author_profile": "https://Stackoverflow.com/users/24257",
"pm_score": 10,
"selected": true,
"text": "<p>Expanding on someone else's answer:</p>\n\n<pre><code><script>\n var myvar = <?php echo json_encode($myVarValue); ?>;\n</script>\n</code></pre>\n\n<p>Using <a href=\"http://php.net/json_encode\" rel=\"noreferrer\">json_encode()</a> requires:</p>\n\n<ul>\n<li>PHP 5.2.0 or greater</li>\n<li><code>$myVarValue</code> encoded as UTF-8 (or US-ASCII, of course)</li>\n</ul>\n\n<p>Since UTF-8 supports full Unicode, it should be safe to convert on the fly.</p>\n\n<p>Note that because <code>json_encode</code> escapes forward slashes, even a string that contains <code></script></code> will be escaped safely for printing with a script block.</p>\n"
},
{
"answer_id": 442949,
"author": "pr1001",
"author_id": 46768,
"author_profile": "https://Stackoverflow.com/users/46768",
"pm_score": 5,
"selected": false,
"text": "<p>I have had a similar issue and understand that the following is the best solution:</p>\n\n<pre><code><script>\n var myvar = decodeURIComponent(\"<?php echo rawurlencode($myVarValue); ?>\");\n</script>\n</code></pre>\n\n<p>However, the <a href=\"http://www.the-art-of-web.com/javascript/escape/\" rel=\"noreferrer\">link</a> that micahwittman posted suggests that there are some minor encoding differences. PHP's <code>rawurlencode()</code> function is supposed to comply with <a href=\"http://www.faqs.org/rfcs/rfc1738\" rel=\"noreferrer\">RFC 1738</a>, while there appear to have been no such effort with Javascript's <code>decodeURIComponent()</code>.</p>\n"
},
{
"answer_id": 2426927,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>Micah's solution below worked for me as the site I had to customise was not in UTF-8, so I could not use json; I'd vote it up but my rep isn't high enough.</p>\n\n<pre><code>function escapeJavaScriptText($string) \n{ \n return str_replace(\"\\n\", '\\n', str_replace('\"', '\\\"', addcslashes(str_replace(\"\\r\", '', (string)$string), \"\\0..\\37'\\\\\"))); \n} \n</code></pre>\n"
},
{
"answer_id": 3580539,
"author": "ioTus",
"author_id": 432448,
"author_profile": "https://Stackoverflow.com/users/432448",
"pm_score": -1,
"selected": false,
"text": "<p>I'm not sure if this is bad practice or no, but my team and I have been using a mixed html, JS, and php solution. We start with the PHP string we want to pull into a JS variable, lets call it:</p>\n\n<pre><code>$someString\n</code></pre>\n\n<p>Next we use in-page hidden form elements, and have their value set as the string:</p>\n\n<pre><code><form id=\"pagePhpVars\" method=\"post\">\n<input type=\"hidden\" name=\"phpString1\" id=\"phpString1\" value=\"'.$someString.'\" />\n</form>\n</code></pre>\n\n<p>Then its a simple matter of defining a JS var through document.getElementById:</p>\n\n<pre><code><script type=\"text/javascript\" charset=\"UTF-8\">\n var moonUnitAlpha = document.getElementById('phpString1').value;\n</script>\n</code></pre>\n\n<p>Now you can use the JS variable \"moonUnitAlpha\" anywhere you want to grab that PHP string value.\nThis seems to work really well for us. We'll see if it holds up to heavy use.</p>\n"
},
{
"answer_id": 5763433,
"author": "giraff",
"author_id": 75017,
"author_profile": "https://Stackoverflow.com/users/75017",
"pm_score": 4,
"selected": false,
"text": "<p>The paranoid version: <a href=\"http://sixohthree.com/241/escaping\" rel=\"noreferrer\">Escaping every single character</a>.</p>\n\n<pre><code>function javascript_escape($str) {\n $new_str = '';\n\n $str_len = strlen($str);\n for($i = 0; $i < $str_len; $i++) {\n $new_str .= '\\\\x' . sprintf('%02x', ord(substr($str, $i, 1)));\n }\n\n return $new_str;\n}\n</code></pre>\n\n<p><strong>EDIT:</strong> The reason why <code>json_encode()</code> may not be appropriate is that sometimes, you need to prevent <code>\"</code> to be generated, e.g. </p>\n\n<pre><code><div onclick=\"alert(???)\" />\n</code></pre>\n"
},
{
"answer_id": 12971648,
"author": "Craig Francis",
"author_id": 6632,
"author_profile": "https://Stackoverflow.com/users/6632",
"pm_score": 2,
"selected": false,
"text": "<p>Don't run it though <code>addslashes()</code>; if you're in the context of the HTML page, the HTML parser can still see the <code></script></code> tag, even mid-string, and assume it's the end of the JavaScript:</p>\n\n<pre><code><?php\n $value = 'XXX</script><script>alert(document.cookie);</script>';\n?>\n\n<script type=\"text/javascript\">\n var foo = <?= json_encode($value) ?>; // Use this\n var foo = '<?= addslashes($value) ?>'; // Avoid, allows XSS!\n</script>\n</code></pre>\n"
},
{
"answer_id": 13627734,
"author": "Kld",
"author_id": 1551411,
"author_profile": "https://Stackoverflow.com/users/1551411",
"pm_score": 3,
"selected": false,
"text": "<pre><code><script>\nvar myVar = <?php echo json_encode($myVarValue); ?>;\n</script>\n</code></pre>\n\n<p>or</p>\n\n<pre><code><script>\nvar myVar = <?= json_encode($myVarValue) ?>;\n</script>\n</code></pre>\n"
},
{
"answer_id": 21003517,
"author": "Ry-",
"author_id": 707111,
"author_profile": "https://Stackoverflow.com/users/707111",
"pm_score": 2,
"selected": false,
"text": "<ol>\n<li><p>Don’t. Use Ajax, put it in <code>data-*</code> attributes in your HTML, or something else meaningful. Using inline scripts makes your pages bigger, and <a href=\"http://codepad.org/jQopjG0k\" rel=\"nofollow\">could be insecure or still allow users to ruin layout</a>, unless…</p></li>\n<li><p>… you make a safer function:</p>\n\n<pre><code>function inline_json_encode($obj) {\n return str_replace('<!--', '<\\!--', json_encode($obj));\n}\n</code></pre></li>\n</ol>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168214",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13238/"
] |
What is the easiest way to encode a PHP string for output to a JavaScript variable?
I have a PHP string which includes quotes and newlines. I need the contents of this string to be put into a JavaScript variable.
Normally, I would just construct my JavaScript in a PHP file, à la:
```
<script>
var myvar = "<?php echo $myVarValue;?>";
</script>
```
However, this doesn't work when `$myVarValue` contains quotes or newlines.
|
Expanding on someone else's answer:
```
<script>
var myvar = <?php echo json_encode($myVarValue); ?>;
</script>
```
Using [json\_encode()](http://php.net/json_encode) requires:
* PHP 5.2.0 or greater
* `$myVarValue` encoded as UTF-8 (or US-ASCII, of course)
Since UTF-8 supports full Unicode, it should be safe to convert on the fly.
Note that because `json_encode` escapes forward slashes, even a string that contains `</script>` will be escaped safely for printing with a script block.
|
168,236 |
<p>I am trying to set attributes for an IFRAME html control from the code-behind aspx.cs file.</p>
<p>I came across a <a href="https://web.archive.org/web/20210128094503/http://geekswithblogs.net/ranganh/archive/2005/04/25/37635.aspx" rel="nofollow noreferrer">post</a> that says you can use FindControl to find the non-asp controls using:</p>
<p>The aspx file contains:</p>
<pre><code><iframe id="contentPanel1" runat="server" />
</code></pre>
<p>and then the code-behind file contains:</p>
<pre><code>protected void Page_Load(object sender, EventArgs e)
{
HtmlControl contentPanel1 = (HtmlControl)this.FindControl("contentPanel1");
if (contentPanel1 != null)
contentPanel1.Attributes["src"] = "http://www.stackoverflow.com";
}
</code></pre>
<p>Except that it's not finding the control, contentPanel1 is null.</p>
<hr />
<p><strong>Update 1</strong></p>
<p>Looking at the rendered html:</p>
<pre><code><iframe id="ctl00_ContentPlaceHolder1_contentPanel1"></iframe>
</code></pre>
<p>i tried changing the code-behind to:</p>
<pre><code>HtmlControl contentPanel1 = (HtmlControl)this.FindControl("ctl00_ContentPlaceHolder1_contentPanel1");
if (contentPanel1 != null)
contentPanel1.Attributes["src"] = "http://www.clis.com";
</code></pre>
<p>But it didn't help.</p>
<p>i am using a MasterPage.</p>
<hr />
<p><strong>Update 2</strong></p>
<p>Changing the aspx file to:</p>
<pre><code><iframe id="contentPanel1" name="contentPanel1" runat="server" />
</code></pre>
<p>also didn't help</p>
<hr />
<p><strong>Answer</strong></p>
<p>The answer is obvious, and unworthy of even asking the original question. If you have the aspx code:</p>
<pre><code><iframe id="contentPanel1" runat="server" />
</code></pre>
<p>and want to access the iframe from the code-behind file, you just access it:</p>
<pre><code>this.contentPanel1.Attributes["src"] = "http://www.stackoverflow.com";
</code></pre>
|
[
{
"answer_id": 168248,
"author": "Ian Jacobs",
"author_id": 22818,
"author_profile": "https://Stackoverflow.com/users/22818",
"pm_score": 0,
"selected": false,
"text": "<p>Try instantiating contentPanel1 outside the Load event; keep it global to the class.</p>\n"
},
{
"answer_id": 168286,
"author": "Joe Ratzer",
"author_id": 4092,
"author_profile": "https://Stackoverflow.com/users/4092",
"pm_score": 1,
"selected": false,
"text": "<p>Try using</p>\n\n<pre><code>this.Master.FindControl(\"ContentId\").FindControl(\"controlId\")\n</code></pre>\n\n<p>instead.</p>\n"
},
{
"answer_id": 168306,
"author": "RyanFetz",
"author_id": 23776,
"author_profile": "https://Stackoverflow.com/users/23776",
"pm_score": 0,
"selected": false,
"text": "<p>The FindControl method looks in the child controls of the \"control\" the method is executed on. Try looking through the control collection recursively.</p>\n\n<pre><code> protected virtual Control FindControlRecursive(Control root, String id)\n {\n if (root.ID == id) { return root; }\n foreach (Control c in root.Controls)\n {\n Control t = FindControlRecursive(c, id);\n if (t != null)\n {\n return t;\n }\n }\n return null;\n }\n</code></pre>\n"
},
{
"answer_id": 168321,
"author": "AaronSieb",
"author_id": 16911,
"author_profile": "https://Stackoverflow.com/users/16911",
"pm_score": 5,
"selected": true,
"text": "<p>If the iframe is directly on the page where the code is running, you should be able to reference it directly:</p>\n\n<pre><code>\ncontentPanel1.Attribute = value;\n</code></pre>\n\n<p>If not (it's in a child control, or the MasterPage), you'll need a good idea of the hierarchy of the page... Or use the brute-force method of writing a recursive version of FindControl().</p>\n"
},
{
"answer_id": 1206041,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Try this.</p>\n\n<p>ContentPlaceHolder cplHolder = (ContentPlaceHolder)this.CurrentMaster.FindControl(\"contentMain\");</p>\n\n<p>HtmlControl cpanel= (HtmlControl)cplHolder.FindControl(\"contentPanel1\");</p>\n"
},
{
"answer_id": 9170096,
"author": "Mark Ibanez",
"author_id": 1193662,
"author_profile": "https://Stackoverflow.com/users/1193662",
"pm_score": 4,
"selected": false,
"text": "<p>This works for me. </p>\n\n<p><strong>ASPX :</strong> </p>\n\n<pre><code><iframe id=\"ContentIframe\" runat=\"server\"></iframe>\n</code></pre>\n\n<p>I can access the iframe directly via id.</p>\n\n<p><strong>Code Behind :</strong> </p>\n\n<pre><code>ContentIframe.Attributes[\"src\"] = \"stackoverflow.com\";\n</code></pre>\n"
},
{
"answer_id": 11776708,
"author": "Sedecimdies",
"author_id": 1571280,
"author_profile": "https://Stackoverflow.com/users/1571280",
"pm_score": 0,
"selected": false,
"text": "<pre><code><iframe id=\"yourIframe\" clientIDMode=\"static\" runat=\"server\"></iframe>\n</code></pre>\n\n<p>You should them be able to find your iframe using the findcontrol method.</p>\n\n<p>setting <code>clientIDMode</code> to <code>Static</code> prevents you object from being renamed while rendering. </p>\n"
},
{
"answer_id": 16412074,
"author": "andyc",
"author_id": 2357037,
"author_profile": "https://Stackoverflow.com/users/2357037",
"pm_score": 0,
"selected": false,
"text": "<p>None of your suggestions worked for me, here is my solution:</p>\n\n<pre><code>add src=\"<%=_frame1%>\" //to the iframe id=\"frame1\" html control\npublic string _frame1 = \"http://www.google.com\";\n</code></pre>\n"
},
{
"answer_id": 22537937,
"author": "Jorge",
"author_id": 1528483,
"author_profile": "https://Stackoverflow.com/users/1528483",
"pm_score": 1,
"selected": false,
"text": "<p>Where is your iframe embedded?</p>\n\n<p>Having this code</p>\n\n<pre><code><body>\n\n<iframe id=\"iFrame1\" runat=\"server\"></iframe>\n\n<form id=\"form1\" runat=\"server\">\n\n<div>\n <iframe id=\"iFrame2\" runat=\"server\"></iframe>\n</div>\n</form>\n</code></pre>\n\n<p>I can access with <code>iFrame1.Attributes[\"src\"]</code> just to iFrame1 and not to iFrame2.</p>\n\n<p>Alternatively, you can access to any element in your form with:</p>\n\n<pre><code>FindControl(\"iFrame2\") as System.Web.UI.HtmlControls.HtmlGenericControl\n</code></pre>\n"
},
{
"answer_id": 24265916,
"author": "Rajib Chy",
"author_id": 3301985,
"author_profile": "https://Stackoverflow.com/users/3301985",
"pm_score": -1,
"selected": false,
"text": "<p>aspx page</p>\n\n<pre><code><iframe id=\"fblikes\" runat=\"server\"></iframe>\n</code></pre>\n\n<p>Code behind</p>\n\n<p>this.fblikes.Attributes[\"src\"] = \"/productdetails/fblike.ashx\";</p>\n\n<p>Very simple....</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168236",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/12597/"
] |
I am trying to set attributes for an IFRAME html control from the code-behind aspx.cs file.
I came across a [post](https://web.archive.org/web/20210128094503/http://geekswithblogs.net/ranganh/archive/2005/04/25/37635.aspx) that says you can use FindControl to find the non-asp controls using:
The aspx file contains:
```
<iframe id="contentPanel1" runat="server" />
```
and then the code-behind file contains:
```
protected void Page_Load(object sender, EventArgs e)
{
HtmlControl contentPanel1 = (HtmlControl)this.FindControl("contentPanel1");
if (contentPanel1 != null)
contentPanel1.Attributes["src"] = "http://www.stackoverflow.com";
}
```
Except that it's not finding the control, contentPanel1 is null.
---
**Update 1**
Looking at the rendered html:
```
<iframe id="ctl00_ContentPlaceHolder1_contentPanel1"></iframe>
```
i tried changing the code-behind to:
```
HtmlControl contentPanel1 = (HtmlControl)this.FindControl("ctl00_ContentPlaceHolder1_contentPanel1");
if (contentPanel1 != null)
contentPanel1.Attributes["src"] = "http://www.clis.com";
```
But it didn't help.
i am using a MasterPage.
---
**Update 2**
Changing the aspx file to:
```
<iframe id="contentPanel1" name="contentPanel1" runat="server" />
```
also didn't help
---
**Answer**
The answer is obvious, and unworthy of even asking the original question. If you have the aspx code:
```
<iframe id="contentPanel1" runat="server" />
```
and want to access the iframe from the code-behind file, you just access it:
```
this.contentPanel1.Attributes["src"] = "http://www.stackoverflow.com";
```
|
If the iframe is directly on the page where the code is running, you should be able to reference it directly:
```
contentPanel1.Attribute = value;
```
If not (it's in a child control, or the MasterPage), you'll need a good idea of the hierarchy of the page... Or use the brute-force method of writing a recursive version of FindControl().
|
168,249 |
<p>Let's say I have a multithreaded C++ program that handles requests in the form of a function call to <code>handleRequest(string key)</code>. Each call to <code>handleRequest</code> occurs in a separate thread, and there are an arbitrarily large number of possible values for <code>key</code>.</p>
<p>I want the following behavior:</p>
<ul>
<li>Simultaneous calls to <code>handleRequest(key)</code> are serialized when they have the same value for <code>key</code>.</li>
<li>Global serialization is minimized.</li>
</ul>
<p>The body of <code>handleRequest</code> might look like this:</p>
<pre><code>void handleRequest(string key) {
KeyLock lock(key);
// Handle the request.
}
</code></pre>
<p><b>Question:</b> How would I implement <code>KeyLock</code> to get the required behavior?</p>
<p>A naive implementation might start off like this:</p>
<pre><code>KeyLock::KeyLock(string key) {
global_lock->Lock();
internal_lock_ = global_key_map[key];
if (internal_lock_ == NULL) {
internal_lock_ = new Lock();
global_key_map[key] = internal_lock_;
}
global_lock->Unlock();
internal_lock_->Lock();
}
KeyLock::~KeyLock() {
internal_lock_->Unlock();
// Remove internal_lock_ from global_key_map iff no other threads are waiting for it.
}
</code></pre>
<p>...but that requires a global lock at the beginning and end of each request, and the creation of a separate <code>Lock</code> object for each request. If contention is high between calls to <code>handleRequest</code>, that might not be a problem, but it could impose a lot of overhead if contention is low.</p>
|
[
{
"answer_id": 168271,
"author": "Michael Burr",
"author_id": 12711,
"author_profile": "https://Stackoverflow.com/users/12711",
"pm_score": 5,
"selected": true,
"text": "<p>You could do something similar to what you have in your question, but instead of a single global_key_map have several (probably in an array or vector) - which one is used is determined by some simple hash function on the string.</p>\n\n<p>That way instead of a single global lock, you spread that out over several independent ones.</p>\n\n<p>This is a pattern that is often used in memory allocators (I don't know if the pattern has a name - it should). When a request comes in, something determines which pool the allocation will come from (usually the size of the request, but other parameters can factor in as well), then only that pool needs to be locked. If an allocation request comes in from another thread that will use a different pool, there's no lock contention.</p>\n"
},
{
"answer_id": 168276,
"author": "Roddy",
"author_id": 1737,
"author_profile": "https://Stackoverflow.com/users/1737",
"pm_score": 2,
"selected": false,
"text": "<p>It will depend on the platform, but the two techniques that I'd try would be:</p>\n\n<ul>\n<li>Use named mutex/synchronization\nobjects, where object name = Key</li>\n<li>Use filesystem-based locking, where you\ntry to create a non-shareable\ntemporary file with the key name. If it exists already (=already\nlocked) this will fail and you'll\nhave to poll to retry</li>\n</ul>\n\n<p>Both techniques will depend on the detail of your OS. Experiment and see which works.\n. </p>\n"
},
{
"answer_id": 168282,
"author": "coppro",
"author_id": 16855,
"author_profile": "https://Stackoverflow.com/users/16855",
"pm_score": 2,
"selected": false,
"text": "<p>Perhaps an <code>std::map<std::string, MutexType></code> would be what you want, where <code>MutexType</code> is the type of the mutex you want. You will probably have to wrap accesses to the map in another mutex in order to ensure that no other thread is inserting at the same time (and remember to perform the check again after the mutex is locked to ensure that another thread didn't add the key while waiting on the mutex!).</p>\n\n<p>The same principle could apply to any other synchronization method, such as a critical section.</p>\n"
},
{
"answer_id": 169106,
"author": "Constantin",
"author_id": 20310,
"author_profile": "https://Stackoverflow.com/users/20310",
"pm_score": 2,
"selected": false,
"text": "<p><strong>Raise granularity and lock entire key-ranges</strong></p>\n\n<p>This is a variation on Mike B's answer, where instead of having several fluid lock maps you have a single fixed array of locks that apply to key-ranges instead of single keys.</p>\n\n<p>Simplified example: create array of 256 locks at startup, then use first byte of key to determine index of lock to be acquired (i.e. all keys starting with 'k' will be guarded by <code>locks[107]</code>).</p>\n\n<p>To sustain optimal throughput you should analyze distribution of keys and contention rate. The benefits of this approach are zero dynamic allocations and simple cleanup; you also avoid two-step locking. The downside is potential contention peaks if key distribution becomes skewed over time.</p>\n"
},
{
"answer_id": 169192,
"author": "eschercycle",
"author_id": 24923,
"author_profile": "https://Stackoverflow.com/users/24923",
"pm_score": 0,
"selected": false,
"text": "<p>After thinking about it, another approach might go something like this: </p>\n\n<ul>\n<li>In <code>handleRequest</code>, create a <code>Callback</code> that does the actual work.</li>\n<li>Create a <code>multimap<string, Callback*> global_key_map</code>, protected by a mutex.</li>\n<li>If a thread sees that <code>key</code> is already being processed, it adds its <code>Callback*</code> to the <code>global_key_map</code> and returns.</li>\n<li>Otherwise, it calls its callback immediately, and then calls the callbacks that have shown up in the meantime for the same key.</li>\n</ul>\n\n<p>Implemented something like this:</p>\n\n<pre><code>LockAndCall(string key, Callback* callback) {\n global_lock.Lock();\n if (global_key_map.contains(key)) {\n iterator iter = global_key_map.insert(key, callback);\n while (true) {\n global_lock.Unlock();\n iter->second->Call();\n global_lock.Lock();\n global_key_map.erase(iter);\n iter = global_key_map.find(key);\n if (iter == global_key_map.end()) {\n global_lock.Unlock();\n return;\n }\n }\n } else {\n global_key_map.insert(key, callback);\n global_lock.Unlock();\n }\n}\n</code></pre>\n\n<p>This has the advantage of freeing up threads that would otherwise be waiting for a key lock, but apart from that it's pretty much the same as the naive solution I posted in the question.</p>\n\n<p>It could be combined with the answers given by Mike B and Constantin, though.</p>\n"
},
{
"answer_id": 412233,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<pre><code> /**\n * StringLock class for string based locking mechanism\n * e.g. usage\n * StringLock strLock;\n * strLock.Lock(\"row1\");\n * strLock.UnLock(\"row1\");\n */\n class StringLock {\n public:\n /**\n * Constructor\n * Initializes the mutexes\n */\n StringLock() {\n pthread_mutex_init(&mtxGlobal, NULL);\n }\n /**\n * Lock Function\n * The thread will return immediately if the string is not locked\n * The thread will wait if the string is locked until it gets a turn\n * @param string the string to lock\n */\n void Lock(string lockString) {\n pthread_mutex_lock(&mtxGlobal);\n TListIds *listId = NULL;\n TWaiter *wtr = new TWaiter;\n wtr->evPtr = NULL;\n wtr->threadId = pthread_self();\n if (lockMap.find(lockString) == lockMap.end()) {\n listId = new TListIds();\n listId->insert(listId->end(), wtr);\n lockMap[lockString] = listId;\n pthread_mutex_unlock(&mtxGlobal);\n } else {\n wtr->evPtr = new Event(false);\n listId = lockMap[lockString];\n listId->insert(listId->end(), wtr);\n pthread_mutex_unlock(&mtxGlobal);\n wtr->evPtr->Wait();\n }\n }\n /**\n * UnLock Function\n * @param string the string to unlock\n */\n void UnLock(string lockString) {\n pthread_mutex_lock(&mtxGlobal);\n TListIds *listID = NULL;\n if (lockMap.find(lockString) != lockMap.end()) {\n lockMap[lockString]->pop_front();\n listID = lockMap[lockString];\n if (!(listID->empty())) {\n TWaiter *wtr = listID->front();\n Event *thdEvent = wtr->evPtr;\n thdEvent->Signal();\n } else {\n lockMap.erase(lockString);\n delete listID;\n }\n }\n pthread_mutex_unlock(&mtxGlobal);\n }\n protected:\n struct TWaiter {\n Event *evPtr;\n long threadId;\n };\n StringLock(StringLock &);\n void operator=(StringLock&);\n typedef list TListIds;\n typedef map TMapLockHolders;\n typedef map TMapLockWaiters;\n private:\n pthread_mutex_t mtxGlobal;\n TMapLockWaiters lockMap;\n };\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168249",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24923/"
] |
Let's say I have a multithreaded C++ program that handles requests in the form of a function call to `handleRequest(string key)`. Each call to `handleRequest` occurs in a separate thread, and there are an arbitrarily large number of possible values for `key`.
I want the following behavior:
* Simultaneous calls to `handleRequest(key)` are serialized when they have the same value for `key`.
* Global serialization is minimized.
The body of `handleRequest` might look like this:
```
void handleRequest(string key) {
KeyLock lock(key);
// Handle the request.
}
```
**Question:** How would I implement `KeyLock` to get the required behavior?
A naive implementation might start off like this:
```
KeyLock::KeyLock(string key) {
global_lock->Lock();
internal_lock_ = global_key_map[key];
if (internal_lock_ == NULL) {
internal_lock_ = new Lock();
global_key_map[key] = internal_lock_;
}
global_lock->Unlock();
internal_lock_->Lock();
}
KeyLock::~KeyLock() {
internal_lock_->Unlock();
// Remove internal_lock_ from global_key_map iff no other threads are waiting for it.
}
```
...but that requires a global lock at the beginning and end of each request, and the creation of a separate `Lock` object for each request. If contention is high between calls to `handleRequest`, that might not be a problem, but it could impose a lot of overhead if contention is low.
|
You could do something similar to what you have in your question, but instead of a single global\_key\_map have several (probably in an array or vector) - which one is used is determined by some simple hash function on the string.
That way instead of a single global lock, you spread that out over several independent ones.
This is a pattern that is often used in memory allocators (I don't know if the pattern has a name - it should). When a request comes in, something determines which pool the allocation will come from (usually the size of the request, but other parameters can factor in as well), then only that pool needs to be locked. If an allocation request comes in from another thread that will use a different pool, there's no lock contention.
|
168,273 |
<p>I've been unable to build <a href="http://www.perforce.com/perforce/loadsupp.html#api" rel="nofollow noreferrer">P4Python</a> for an Intel Mac OS X 10.5.5.</p>
<p>These are my steps:</p>
<ol>
<li>I downloaded p4python.tgz (from
<a href="http://filehost.perforce.com/perforce/r07.3/tools/" rel="nofollow noreferrer">http://filehost.perforce.com/perforce/r07.3/tools/</a>) and expanded
it into "P4Python-2007.3".</li>
<li>I downloaded p4api.tar (from
<a href="http://filehost.perforce.com/perforce/r07.3/bin.macosx104x86/" rel="nofollow noreferrer">http://filehost.perforce.com/perforce/r07.3/bin.macosx104x86/</a>)
and expanded it into "p4api-2007.3.143793".</li>
<li>I placed "p4api-2007.3.143793" into "P4Python-2007.3" and edited
setup.cfg to set "p4_api=./p4api-2007.3.143793".</li>
<li><p>I added the line 'extra_link_args = ["-framework", "Carbon"]' to
setup.py after:</p>
<pre><code>elif unameOut[0] == "Darwin":
unix = "MACOSX"
release = "104"
platform = self.architecture(unameOut[4])
</code></pre></li>
<li><p>I ran <code>python setup.py build</code> and got:</p></li>
</ol>
<p>$ python setup.py build</p>
<pre><code>API Release 2007.3
running build
running build_py
running build_ext
building 'P4API' extension
gcc -fno-strict-aliasing -Wno-long-double -no-cpp-precomp -mno-fused-madd -DNDEBUG -g -O3 -Wall -Wstrict-prototypes -DID_OS="MACOSX104X86" -DID_REL="2007.3" -DID_PATCH="151416" -DID_API="2007.3" -DID_Y="2008" -DID_M="04" -DID_D="09" -I./p4api-2007.3.143793 -I./p4api-2007.3.143793/include/p4 -I/build/toolchain/mac32/python-2.4.3/include/python2.4 -c P4API.cpp -o build/temp.darwin-9.5.0-i386-2.4/P4API.o -DOS_MACOSX -DOS_MACOSX104 -DOS_MACOSXX86 -DOS_MACOSX104X86
cc1plus: warning: command line option "-Wstrict-prototypes" is valid for C/ObjC but not for C++
P4API.cpp: In function âint P4Adapter_init(P4Adapter*, PyObject*, PyObject*)â:
P4API.cpp:105: error: âPy_ssize_tâ was not declared in this scope
P4API.cpp:105: error: expected `;' before âposâ
P4API.cpp:107: error: âposâ was not declared in this scope
P4API.cpp: In function âPyObject* P4Adapter_run(P4Adapter*, PyObject*)â:
P4API.cpp:177: error: âPy_ssize_tâ was not declared in this scope
P4API.cpp:177: error: expected `;' before âiâ
P4API.cpp:177: error: âiâ was not declared in this scope
error: command 'gcc' failed with exit status 1
</code></pre>
<p><code>which gcc</code> returns /usr/bin/gcc and <code>gcc -v</code> returns:</p>
<pre><code>Using built-in specs.
Target: i686-apple-darwin9
Configured with: /var/tmp/gcc/gcc-5465~16/src/configure
--disable-checking -enable-werror --prefix=/usr --mandir=/share/man
--enable-languages=c,objc,c++,obj-c++
--program-transform-name=/^[cg][^.-]*$/s/$/-4.0/
--with-gxx-include-dir=/include/c++/4.0.0 --with-slibdir=/usr/lib
--build=i686-apple-darwin9 --with-arch=apple --with-tune=generic
--host=i686-apple-darwin9 --target=i686-apple-darwin9
Thread model: posix
gcc version 4.0.1 (Apple Inc. build 5465)
</code></pre>
<p><code>python -V</code> returns Python 2.4.3.</p>
|
[
{
"answer_id": 170068,
"author": "Douglas Leeder",
"author_id": 3978,
"author_profile": "https://Stackoverflow.com/users/3978",
"pm_score": 1,
"selected": false,
"text": "<p>From <a href=\"http://bugs.mymediasystem.org/?do=details&task_id=676\" rel=\"nofollow noreferrer\">http://bugs.mymediasystem.org/?do=details&task_id=676</a> suggests that Py_ssize_t was added in python 2.5, so it won't work (without some modifications) with python 2.4.</p>\n\n<p>Either install/compile your own copy of python 2.5/2.6, or work out how to change P4Python, or look for an alternative python-perforce library.</p>\n"
},
{
"answer_id": 175097,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Very outdated, but maybe you can use <a href=\"http://public.perforce.com:8080/@md=d&cd=//guest/miki_tebeka/p4py/&c=5Fm@//guest/miki_tebeka/p4py/main/?ac=83\" rel=\"nofollow noreferrer\">http://public.perforce.com:8080/@md=d&cd=//guest/miki_tebeka/p4py/&c=5Fm@//guest/miki_tebeka/p4py/main/?ac=83</a> for now</p>\n"
},
{
"answer_id": 478587,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": true,
"text": "<p>The newer version 2008.1 will build with Python 2.4.</p>\n\n<p>I had posted the minor changes required to do that on my P4Python page, but they were rolled in to the official version.</p>\n\n<p>Robert</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168273",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4766/"
] |
I've been unable to build [P4Python](http://www.perforce.com/perforce/loadsupp.html#api) for an Intel Mac OS X 10.5.5.
These are my steps:
1. I downloaded p4python.tgz (from
<http://filehost.perforce.com/perforce/r07.3/tools/>) and expanded
it into "P4Python-2007.3".
2. I downloaded p4api.tar (from
<http://filehost.perforce.com/perforce/r07.3/bin.macosx104x86/>)
and expanded it into "p4api-2007.3.143793".
3. I placed "p4api-2007.3.143793" into "P4Python-2007.3" and edited
setup.cfg to set "p4\_api=./p4api-2007.3.143793".
4. I added the line 'extra\_link\_args = ["-framework", "Carbon"]' to
setup.py after:
```
elif unameOut[0] == "Darwin":
unix = "MACOSX"
release = "104"
platform = self.architecture(unameOut[4])
```
5. I ran `python setup.py build` and got:
$ python setup.py build
```
API Release 2007.3
running build
running build_py
running build_ext
building 'P4API' extension
gcc -fno-strict-aliasing -Wno-long-double -no-cpp-precomp -mno-fused-madd -DNDEBUG -g -O3 -Wall -Wstrict-prototypes -DID_OS="MACOSX104X86" -DID_REL="2007.3" -DID_PATCH="151416" -DID_API="2007.3" -DID_Y="2008" -DID_M="04" -DID_D="09" -I./p4api-2007.3.143793 -I./p4api-2007.3.143793/include/p4 -I/build/toolchain/mac32/python-2.4.3/include/python2.4 -c P4API.cpp -o build/temp.darwin-9.5.0-i386-2.4/P4API.o -DOS_MACOSX -DOS_MACOSX104 -DOS_MACOSXX86 -DOS_MACOSX104X86
cc1plus: warning: command line option "-Wstrict-prototypes" is valid for C/ObjC but not for C++
P4API.cpp: In function âint P4Adapter_init(P4Adapter*, PyObject*, PyObject*)â:
P4API.cpp:105: error: âPy_ssize_tâ was not declared in this scope
P4API.cpp:105: error: expected `;' before âposâ
P4API.cpp:107: error: âposâ was not declared in this scope
P4API.cpp: In function âPyObject* P4Adapter_run(P4Adapter*, PyObject*)â:
P4API.cpp:177: error: âPy_ssize_tâ was not declared in this scope
P4API.cpp:177: error: expected `;' before âiâ
P4API.cpp:177: error: âiâ was not declared in this scope
error: command 'gcc' failed with exit status 1
```
`which gcc` returns /usr/bin/gcc and `gcc -v` returns:
```
Using built-in specs.
Target: i686-apple-darwin9
Configured with: /var/tmp/gcc/gcc-5465~16/src/configure
--disable-checking -enable-werror --prefix=/usr --mandir=/share/man
--enable-languages=c,objc,c++,obj-c++
--program-transform-name=/^[cg][^.-]*$/s/$/-4.0/
--with-gxx-include-dir=/include/c++/4.0.0 --with-slibdir=/usr/lib
--build=i686-apple-darwin9 --with-arch=apple --with-tune=generic
--host=i686-apple-darwin9 --target=i686-apple-darwin9
Thread model: posix
gcc version 4.0.1 (Apple Inc. build 5465)
```
`python -V` returns Python 2.4.3.
|
The newer version 2008.1 will build with Python 2.4.
I had posted the minor changes required to do that on my P4Python page, but they were rolled in to the official version.
Robert
|
168,317 |
<p>We have a SmartClient built in C# that stubornly remains open when the PC its running on is being restarted. This halts the restart process unless the user first closes the SmartClient or there is some other manual intervention.</p>
<p>This is causing problems when the infrastructure team remotely installs new software that requires a machine reboot.</p>
<p>Any ideas for getting the SmartClient app to recognize the shutdown/restart event from Windows and gracefully kill itself?</p>
<p><strong>UPDATE:</strong>
This is a highly threaded application with multiple gui threads. yes, multiple gui threads. Its really a consolidation of many project that in and of themselves could be standalone applications - all of which are launched and managed from a single exe that centralizes those management methods and keeps track of those threads. I don't believe using background threads is an option.</p>
|
[
{
"answer_id": 168323,
"author": "Joel Coehoorn",
"author_id": 3043,
"author_profile": "https://Stackoverflow.com/users/3043",
"pm_score": 0,
"selected": false,
"text": "<p>Normally a .Net app would respond correctly- at least, that's the 'out of the box' behavior. If it's not, there could be a number of things going on. My best guess without knowing anything more about your program is that you have a long-running process going in the main UI thread that's preventing the app from responding to window messages.</p>\n"
},
{
"answer_id": 168339,
"author": "Hristo Deshev",
"author_id": 17977,
"author_profile": "https://Stackoverflow.com/users/17977",
"pm_score": 1,
"selected": false,
"text": "<p>Or maybe the .Net app is ignoring close or quit messages on purpose?</p>\n"
},
{
"answer_id": 168345,
"author": "Catalin DICU",
"author_id": 13030,
"author_profile": "https://Stackoverflow.com/users/13030",
"pm_score": 3,
"selected": false,
"text": "<p>It must be a thread that continues to run preventing your application to close. If you are using threading an easy fix would be to set it to background.</p>\n\n<blockquote>\n <p>A thread is either a background thread or a foreground thread. Background threads are identical to foreground threads, except that background threads do not prevent a process from terminating. Once all foreground threads belonging to a process have terminated, the common language runtime ends the process. Any remaining background threads are stopped and do not complete.</p>\n \n <p><a href=\"http://msdn.microsoft.com/en-us/library/system.threading.thread.isbackground.aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/system.threading.thread.isbackground.aspx</a></p>\n</blockquote>\n"
},
{
"answer_id": 168365,
"author": "Vincent McNabb",
"author_id": 16299,
"author_profile": "https://Stackoverflow.com/users/16299",
"pm_score": 4,
"selected": true,
"text": "<p>OK, if you have access to the app, you can handle the SessionEnded event.</p>\n\n<pre><code>...\nMicrosoft.Win32.SystemEvents.SessionEnded +=new\n Microsoft.Win32.SessionEndedEventHandler(shutdownHandler);\n\n...\n\nprivate void shutdownHandler(object sender, Microsoft.Win32.SessionEndedEventArgs e) {\n // Do stuff\n}\n</code></pre>\n"
},
{
"answer_id": 168405,
"author": "Catalin DICU",
"author_id": 13030,
"author_profile": "https://Stackoverflow.com/users/13030",
"pm_score": 1,
"selected": false,
"text": "<p>Background threads was a quick and dirty solution, best solution is to use synchronization objects (<code>ManualResetEvent</code>, <code>Mutex</code> or something else) to stop the other threads;</p>\n\n<p>Or else keep track of all your opened windows and sent <code>WM_CLOSE</code> message when main app closes. </p>\n\n<p>You have to give more information about how do you start those GUI applications. maybe you start one thread for each application and call <code>Application.Run(new Form1());</code> ?</p>\n\n<p>You may also look into creating a <code>AppDomain</code> for each GUI Application</p>\n"
},
{
"answer_id": 168482,
"author": "liggett78",
"author_id": 19762,
"author_profile": "https://Stackoverflow.com/users/19762",
"pm_score": 3,
"selected": false,
"text": "<p>When a user is logging off or Windows is being shut down, <code>WM_QUERYENDSESSION</code> message is sent to all top-level windows. See <a href=\"http://msdn.microsoft.com/en-us/library/aa376890(VS.85).aspx\" rel=\"nofollow noreferrer\">MSDN documentation here.</a></p>\n\n<p>The default behavior of a WinForm application in response to this message is to trigger the <code>FormClosing</code> event with <code>CloseReason == WindowsShutDown</code> or others. The event handler though can choose to be stubborn and refuse to shut the app down, thus keeping the system running.</p>\n\n<p>Check <code>FormClosing</code> handlers of your applications. Maybe there is something in there. I've seen this kind of stuff a couple of times.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168317",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24179/"
] |
We have a SmartClient built in C# that stubornly remains open when the PC its running on is being restarted. This halts the restart process unless the user first closes the SmartClient or there is some other manual intervention.
This is causing problems when the infrastructure team remotely installs new software that requires a machine reboot.
Any ideas for getting the SmartClient app to recognize the shutdown/restart event from Windows and gracefully kill itself?
**UPDATE:**
This is a highly threaded application with multiple gui threads. yes, multiple gui threads. Its really a consolidation of many project that in and of themselves could be standalone applications - all of which are launched and managed from a single exe that centralizes those management methods and keeps track of those threads. I don't believe using background threads is an option.
|
OK, if you have access to the app, you can handle the SessionEnded event.
```
...
Microsoft.Win32.SystemEvents.SessionEnded +=new
Microsoft.Win32.SessionEndedEventHandler(shutdownHandler);
...
private void shutdownHandler(object sender, Microsoft.Win32.SessionEndedEventArgs e) {
// Do stuff
}
```
|
168,349 |
<p>I have a bunch of regression test data. Each test is just a list of messages (associative arrays), mapping message field names to values. There's a lot of repetition within this data.</p>
<p>For example</p>
<pre><code> test1 = [
{ sender => 'client', msg => '123', arg => '900', foo => 'bar', ... },
{ sender => 'server', msg => '456', arg => '800', foo => 'bar', ... },
{ sender => 'client', msg => '789', arg => '900', foo => 'bar', ... },
]
</code></pre>
<p>I would like to represent the field data (as a minimal-depth decision tree?) so that each message can be programatically regenerated using a minimal number of parameters. For example, in the above</p>
<ul>
<li>foo is always 'bar', so I don't need to mention it</li>
<li>sender and client are correlated, so I only need to mention one or the other</li>
<li>and msg is different each time</li>
</ul>
<p>So I would like to be able to regenerate these messages with a program along the lines of</p>
<pre><code>write_msg( 'client', '123' )
write_msg( 'server', '456' )
write_msg( 'client', '789' )
</code></pre>
<p>where the write_msg function would be composed of nested if statements or subfunction calls using the parameters.</p>
<p>Based on my original data, how can I determine the 'most important' set of parameters, i.e. the ones that will let me recreate my data set using the smallest number of arguments?</p>
|
[
{
"answer_id": 170086,
"author": "finnw",
"author_id": 12048,
"author_profile": "https://Stackoverflow.com/users/12048",
"pm_score": 1,
"selected": false,
"text": "<p>This looks very similar to <a href=\"http://en.wikipedia.org/wiki/Database_normalization\" rel=\"nofollow noreferrer\">Database Normalization</a>.</p>\n\n<p>You have a relation (your test data set), and some known functional dependencies ({sender} => arg, {} => foo and possibly {msg} => sender. If the order of tests is important then add {testNr} => msg.) and you want to eliminate redundancies.</p>\n\n<p>Treat your test set as a database table, apply the normalization rules and create equivalent functions (getArgFromSender(sender) etc.) for each join.</p>\n"
},
{
"answer_id": 170990,
"author": "Dickon Reed",
"author_id": 22668,
"author_profile": "https://Stackoverflow.com/users/22668",
"pm_score": 1,
"selected": false,
"text": "<p><strong>If the number of fields and records is small:</strong></p>\n\n<p>Brute force it by looping through every combination of fields, and for each combination detect if there are multiple items in the list which map to the same value.</p>\n\n<p><strong>If you can live with a fairly good choice of fields:</strong></p>\n\n<p>Start off assuming you need all fields. Then, select a field at random and see if it can be eliminated; if it can, cross it off the set of fields. Otherwise, choose another field at random and try again. If you find no fields can be eliminated, then you've found a reasonable set of fields. Had you chosen other fields first, you may find a better solution. You can repeat the whole procedure a few times and pick the best solution if you like. This kind of approach is called <a href=\"http://en.wikipedia.org/wiki/Hill_climbing\" rel=\"nofollow noreferrer\">hill climbing</a>.</p>\n\n<p>(I suspect that this problem is <a href=\"http://en.wikipedia.org/wiki/NP-complete\" rel=\"nofollow noreferrer\">NP complete</a>, i.e. we probably don't know of an efficient and powerful solution so it is not worth losing sleep over trying to dream up a perfect solution.)</p>\n"
},
{
"answer_id": 188272,
"author": "Vebjorn Ljosa",
"author_id": 17498,
"author_profile": "https://Stackoverflow.com/users/17498",
"pm_score": 3,
"selected": true,
"text": "<p>The following papers describe algortithms for discovering functional dependencies:</p>\n\n<blockquote>\n <p>Y. Huhtala, J. Kärkkäinen, P. Porkka,\n and H. Toivonen. TANE: An efficient\n algorithm for discovering functional \n and approximate dependencies. <em>The\n Computer Journal</em>, 42(2):100–111,\n 1999, <a href=\"http://dx.doi.org/10.1093/comjnl/42.2.100\" rel=\"nofollow noreferrer\">doi:10.1093/comjnl/42.2.100</a>.</p>\n \n <p>I. Savnik and P. A. Flach. Bottom-up\n induction of functional dependencies\n from relations. In Proc. <em>AAAI-93 Workshop:\n Knowledge Discovery in Databases</em>,\n pages 174–185, Washington, DC, USA,\n 1993. </p>\n \n <p>C. Wyss, C. Giannella, and E.\n Robertson. FastFDs: A \n Heuristic-Driven, Depth-First\n Algorithm for Mining Functional\n Dependencies from Relation Instances.\n In <i>Proc. Data Warehousing and Knowledge Discovery</i>, pages 101–110, Munich,\n Germany, 2001, <a href=\"http://dx.doi.org/10.1007/3-540-44801-2\" rel=\"nofollow noreferrer\">doi:10.1007/3-540-44801-2</a>.</p>\n \n <p>Hong Yao and Howard J. Hamilton. \"Mining functional dependencies from data.\" <em>Data Mining and Knowledge Discovery</em>, 2008, <a href=\"http://dx.doi.org/10.1007/s10618-007-0083-9\" rel=\"nofollow noreferrer\">doi:10.1007/s10618-007-0083-9</a>.</p>\n</blockquote>\n\n<p>There has also been some work on discovering multivalued dependencies:</p>\n\n<blockquote>\n <p>I. Savnik and P. A. Flach. \"Discovery\n of Mutlivalued Dependencies from\n Relations.\" <i>Intelligent Data Analysis\n Journal</i>, 4(3):195–211, <a href=\"http://iospress.metapress.com/content/18wpfh7nvxqjamnm/\" rel=\"nofollow noreferrer\">IOS Press</a>, 2000.</p>\n</blockquote>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168349",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4540/"
] |
I have a bunch of regression test data. Each test is just a list of messages (associative arrays), mapping message field names to values. There's a lot of repetition within this data.
For example
```
test1 = [
{ sender => 'client', msg => '123', arg => '900', foo => 'bar', ... },
{ sender => 'server', msg => '456', arg => '800', foo => 'bar', ... },
{ sender => 'client', msg => '789', arg => '900', foo => 'bar', ... },
]
```
I would like to represent the field data (as a minimal-depth decision tree?) so that each message can be programatically regenerated using a minimal number of parameters. For example, in the above
* foo is always 'bar', so I don't need to mention it
* sender and client are correlated, so I only need to mention one or the other
* and msg is different each time
So I would like to be able to regenerate these messages with a program along the lines of
```
write_msg( 'client', '123' )
write_msg( 'server', '456' )
write_msg( 'client', '789' )
```
where the write\_msg function would be composed of nested if statements or subfunction calls using the parameters.
Based on my original data, how can I determine the 'most important' set of parameters, i.e. the ones that will let me recreate my data set using the smallest number of arguments?
|
The following papers describe algortithms for discovering functional dependencies:
>
> Y. Huhtala, J. Kärkkäinen, P. Porkka,
> and H. Toivonen. TANE: An efficient
> algorithm for discovering functional
> and approximate dependencies. *The
> Computer Journal*, 42(2):100–111,
> 1999, [doi:10.1093/comjnl/42.2.100](http://dx.doi.org/10.1093/comjnl/42.2.100).
>
>
> I. Savnik and P. A. Flach. Bottom-up
> induction of functional dependencies
> from relations. In Proc. *AAAI-93 Workshop:
> Knowledge Discovery in Databases*,
> pages 174–185, Washington, DC, USA,
> 1993.
>
>
> C. Wyss, C. Giannella, and E.
> Robertson. FastFDs: A
> Heuristic-Driven, Depth-First
> Algorithm for Mining Functional
> Dependencies from Relation Instances.
> In *Proc. Data Warehousing and Knowledge Discovery*, pages 101–110, Munich,
> Germany, 2001, [doi:10.1007/3-540-44801-2](http://dx.doi.org/10.1007/3-540-44801-2).
>
>
> Hong Yao and Howard J. Hamilton. "Mining functional dependencies from data." *Data Mining and Knowledge Discovery*, 2008, [doi:10.1007/s10618-007-0083-9](http://dx.doi.org/10.1007/s10618-007-0083-9).
>
>
>
There has also been some work on discovering multivalued dependencies:
>
> I. Savnik and P. A. Flach. "Discovery
> of Mutlivalued Dependencies from
> Relations." *Intelligent Data Analysis
> Journal*, 4(3):195–211, [IOS Press](http://iospress.metapress.com/content/18wpfh7nvxqjamnm/), 2000.
>
>
>
|
168,402 |
<p>I have run across an XML Schema with the following definition:</p>
<pre><code><xs:simpleType name="ClassRankType">
<xs:restriction base="xs:integer">
<xs:totalDigits value="4"/>
<xs:minInclusive value="1"/>
<xs:maxInclusive value="9999"/>
</xs:restriction>
</xs:simpleType>
</code></pre>
<p>However, it seems to me that <code>totalDigits</code> is redundant. I am somewhat new to XML Schema, and want to make sure I'm not missing something.</p>
<p>What is the actual behavior of <code>totalDigits</code> vs. <code>maxInclusive</code>?</p>
<p>Can <code>totalDigits</code> always be represented with a combination of <code>minInclusive</code> and <code>MaxInclusive</code>? </p>
<p>How does <code>totalDigits</code> affect negative numbers?</p>
|
[
{
"answer_id": 168466,
"author": "ConroyP",
"author_id": 2287,
"author_profile": "https://Stackoverflow.com/users/2287",
"pm_score": 4,
"selected": true,
"text": "<blockquote>\n <p>can totalDigits always be represented with a combination of minInclusive and MaxInclusive?</p>\n</blockquote>\n\n<p>In this case, yes. As you're dealing with an integer, the value must be a whole number, so you have a finite set of values between <code>minInclusive</code> and <code>maxInclusive</code>. If you had decimal values, <code>totalDigits</code> would tell you how many numbers in total that value could have.</p>\n\n<blockquote>\n <p>How does totalDigits affect negative numbers?</p>\n</blockquote>\n\n<p>It is the total number of digits allowed in the number, and is not affected by decimal points, minus signs, etc. From <a href=\"http://www.auxy.com/study/xml_notes/04.Adding_XSD_restrictions/\" rel=\"noreferrer\">auxy.com</a>:</p>\n\n<blockquote>\n <p>The number specified by the value attribute of the <code><xsd:totalDigits></code> facet will restrict the total number of digits that are allowed in the number, on both sides of the decimal point.</p>\n</blockquote>\n"
},
{
"answer_id": 168477,
"author": "Wes P",
"author_id": 13611,
"author_profile": "https://Stackoverflow.com/users/13611",
"pm_score": 2,
"selected": false,
"text": "<p>totalDigits is the total number of digits the number can have, including decimal numbers. So a totalDigits of 4 would allow 4.345 or 65.43 or 932.1 or a 4 digit whole integer as in the example above. Same for negative. Any of those previous examples can all be made negative and still validate as a totalDigits of 4.</p>\n\n<p>max and min inclusive/exclusive limit the range of the numbers. The maxinclusive might seem be a little redundant in your example, but the mininclusive makes certain the number is greater than 0.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168402",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24954/"
] |
I have run across an XML Schema with the following definition:
```
<xs:simpleType name="ClassRankType">
<xs:restriction base="xs:integer">
<xs:totalDigits value="4"/>
<xs:minInclusive value="1"/>
<xs:maxInclusive value="9999"/>
</xs:restriction>
</xs:simpleType>
```
However, it seems to me that `totalDigits` is redundant. I am somewhat new to XML Schema, and want to make sure I'm not missing something.
What is the actual behavior of `totalDigits` vs. `maxInclusive`?
Can `totalDigits` always be represented with a combination of `minInclusive` and `MaxInclusive`?
How does `totalDigits` affect negative numbers?
|
>
> can totalDigits always be represented with a combination of minInclusive and MaxInclusive?
>
>
>
In this case, yes. As you're dealing with an integer, the value must be a whole number, so you have a finite set of values between `minInclusive` and `maxInclusive`. If you had decimal values, `totalDigits` would tell you how many numbers in total that value could have.
>
> How does totalDigits affect negative numbers?
>
>
>
It is the total number of digits allowed in the number, and is not affected by decimal points, minus signs, etc. From [auxy.com](http://www.auxy.com/study/xml_notes/04.Adding_XSD_restrictions/):
>
> The number specified by the value attribute of the `<xsd:totalDigits>` facet will restrict the total number of digits that are allowed in the number, on both sides of the decimal point.
>
>
>
|
168,408 |
<p>It looks like I had a fundamental misunderstanding about C++ :<</p>
<p>I like the polymorphic container solution. Thank you SO, for bringing that to my attention :)</p>
<hr>
<p>So, we have a need to create a relatively generic container type object. It also happens to encapsulate some business related logic. However, we need to store essentially arbitrary data in this container - everything from primitive data types to complex classes.</p>
<p>Thus, one would immediately jump to the idea of a template class and be done with it. However, I have noticed C++ polymorphism and templates do not play well together. Being that there is some complex logic that we are going to have to work, I would rather just stick with either templates OR polymorphism, and not try to fight C++ by making it do both.</p>
<p>Finally, given that I want to do one or the other, I would prefer polymorphism. I find it much easier to represent constraints like "this container contains Comparable types" - a la java.</p>
<p>Bringing me to the topic of question: At the most abstract, I imagine that I could have a "Container" pure virtual interface that has something akin to "push(void* data) and pop(void* data)" (for the record, I am not actually trying to implement a stack).</p>
<p>However, I don't really like void* at the top level, not to mention the signature is going to change every time I want to add a constraint to the type of data a concrete container can work with.</p>
<p>Summarizing: We have relatively complex containers that have various ways to retrieve elements. We want to be able to vary the constraints on the elements that can go into the containers. Elements should work with multiple kinds of containers (so long as they meet the constraints of that particular container).</p>
<p>Edit: I should also mention that the containers themselves need to be polymorphic. That is my primary reason for not wanting to use templated C++.</p>
<p>So - should I drop my love for Java type interfaces and go with templates? Should I use void* and statically cast everything? Or should I go with an empty class definition "Element" that declares nothing and use that as my top level class in the "Element" hierarchy?</p>
<p>One of the reasons why I love stack overflow is that many of the responses provide some interesting insight on other approaches that I hadn't not have even considered. So thank you in advance for your insights and comments.</p>
|
[
{
"answer_id": 168442,
"author": "Lev",
"author_id": 7224,
"author_profile": "https://Stackoverflow.com/users/7224",
"pm_score": 3,
"selected": false,
"text": "<p>Polymorphism and templates do play very well together, if you use them correctly.</p>\n\n<p>Anyway, I understand that you want to store only one type of objects in each container instance. If so, use templates. This will prevent you from storing the wrong object type by mistake. </p>\n\n<p>As for container interfaces: Depending on your design, maybe you'll be able to make them templated, too, and then they'll have methods like <code>void push(T* new_element)</code>. Think of what you'll know about the object when you want to add it to a container (of an unknown type). Where will the object come from in the first place? A function that returns <code>void*</code>? Do you know that it'll be Comparable? At least, if all stored object classes are defined in your code, you can make them all inherit from a common ancestor, say, <code>Storable</code>, and use <code>Storable*</code> instead of <code>void*</code>.</p>\n\n<p>Now if you see that objects will always be added to a container by a method like <code>void push(Storable* new_element)</code>, then really there will be no added value in making the container a template. But then you'll know it should store Storables.</p>\n"
},
{
"answer_id": 168451,
"author": "Dima",
"author_id": 13313,
"author_profile": "https://Stackoverflow.com/users/13313",
"pm_score": 3,
"selected": false,
"text": "<p>The simple thing is to define an abstract base class called <code>Container</code>, and subclass it for each kind of item you may wish to store. Then you can use any standard collection class (<code>std::vector</code>, <code>std::list</code>, etc.) to store pointers to <code>Container</code>. Keep in mind, that since you would be storing pointers, you would have to handle their allocation/deallocation.</p>\n\n<p>However, the fact that you need a single collection to store objects of such wildly different types is an indication that something may be wrong with the design of your application. It may be better to revisit the business logic before you implement this super-generic container.</p>\n"
},
{
"answer_id": 168461,
"author": "Greg Rogers",
"author_id": 5963,
"author_profile": "https://Stackoverflow.com/users/5963",
"pm_score": 4,
"selected": false,
"text": "<p>You can look at using a standard container of <a href=\"http://www.boost.org/doc/libs/1_36_0/doc/html/any.html\" rel=\"noreferrer\">boost::any</a> if you are storing truly arbitrary data into the container.</p>\n\n<p>It sounds more like you would rather have something like a <a href=\"http://www.boost.org/doc/libs/1_36_0/libs/ptr_container/doc/ptr_container.html\" rel=\"noreferrer\">boost::ptr_container</a> where anything that <em>can</em> be stored in the container has to derive from some base type, and the container itself can only give you reference's to the base type.</p>\n"
},
{
"answer_id": 168462,
"author": "Caleb Huitt - cjhuitt",
"author_id": 9876,
"author_profile": "https://Stackoverflow.com/users/9876",
"pm_score": 1,
"selected": false,
"text": "<p>Using polymorphism, you are basically left with a base class for the container, and derived classes for the data types. The base class/derived classes can have as many virtual functions as you need, in both directions.</p>\n\n<p>Of course, this would mean that you would need to wrap the primitive data types in derived classes as well. If you would reconsider the use of templates overall, this is where I would use the templates. Make one derived class from the base which is a template, and use that for the primitive data types (and others where you don't need any more functionality than is provided by the template).</p>\n\n<p>Don't forget that you might make your life easier by typedefs for each of the templated types -- especially if you later need to turn one of them into a class.</p>\n"
},
{
"answer_id": 168463,
"author": "David Nehme",
"author_id": 14167,
"author_profile": "https://Stackoverflow.com/users/14167",
"pm_score": 2,
"selected": false,
"text": "<p>First, of all, templates and polymorphism are orthogonal concepts and they do play well together. Next, why do you want a specific data structure? What about the STL or boost data structures (specifically <a href=\"http://www.boost.org/doc/libs/1_35_0/libs/ptr_container/doc/reference.html\" rel=\"nofollow noreferrer\">pointer containter</a>) doesn't work for you.</p>\n\n<p>Given your question, it sounds like you would be misusing inheritance in your situation. It's possible to create \"<a href=\"http://www.boost.org/doc/libs/1_36_0/libs/static_assert/static_assert.htm\" rel=\"nofollow noreferrer\">constraints</a>\" on what goes in your containers, especially if you are using templates. Those constraints can go beyond what your compiler and linker will give you. It's actually more awkward to that sort of thing with inheritance and errors are more likely left for run time.</p>\n"
},
{
"answer_id": 168509,
"author": "Eclipse",
"author_id": 8701,
"author_profile": "https://Stackoverflow.com/users/8701",
"pm_score": 3,
"selected": true,
"text": "<p>Can you not have a root Container class that contains elements:</p>\n\n<pre><code>template <typename T>\nclass Container\n{\npublic: \n\n // You'll likely want to use shared_ptr<T> instead.\n virtual void push(T *element) = 0;\n virtual T *pop() = 0;\n virtual void InvokeSomeMethodOnAllItems() = 0;\n};\n\ntemplate <typename T>\nclass List : public Container<T>\n{\n iterator begin();\n iterator end();\npublic:\n virtual void push(T *element) {...}\n virtual T* pop() { ... }\n virtual void InvokeSomeMethodOnAllItems() \n {\n for(iterator currItem = begin(); currItem != end(); ++currItem)\n {\n T* item = *currItem;\n item->SomeMethod();\n }\n }\n};\n</code></pre>\n\n<p>These containers can then be passed around polymorphically:</p>\n\n<pre><code>class Item\n{\npublic:\n virtual void SomeMethod() = 0;\n};\n\nclass ConcreteItem\n{\npublic:\n virtual void SomeMethod() \n {\n // Do something\n }\n}; \n\nvoid AddItemToContainer(Container<Item> &container, Item *item)\n{\n container.push(item);\n}\n\n...\n\nList<Item> listInstance;\nAddItemToContainer(listInstance, new ConcreteItem());\nlistInstance.InvokeSomeMethodOnAllItems();\n</code></pre>\n\n<p>This gives you the Container interface in a type-safe generic way.</p>\n\n<p>If you want to add constraints to the type of elements that can be contained, you can do something like this:</p>\n\n<pre><code>class Item\n{\npublic:\n virtual void SomeMethod() = 0;\n typedef int CanBeContainedInList;\n};\n\ntemplate <typename T>\nclass List : public Container<T>\n{\n typedef typename T::CanBeContainedInList ListGuard;\n // ... as before\n};\n</code></pre>\n"
},
{
"answer_id": 168566,
"author": "KeithB",
"author_id": 2298,
"author_profile": "https://Stackoverflow.com/users/2298",
"pm_score": 1,
"selected": false,
"text": "<p>You might also want to check out <a href=\"http://www.boost.org/doc/libs/1_36_0/libs/concept_check/concept_check.htm\" rel=\"nofollow noreferrer\">The Boost Concept Check Library (BCCL)</a> which is designed to provide constraints on the template parameters of templated classes, your containers in this case.</p>\n\n<p>And just to reiterate what others have said, I've never had a problem mixing polymorphism and templates, and I've done some fairly complex stuff with them.</p>\n"
},
{
"answer_id": 168583,
"author": "Reddog",
"author_id": 24965,
"author_profile": "https://Stackoverflow.com/users/24965",
"pm_score": 0,
"selected": false,
"text": "<p>You could not have to give up Java-like interfaces and use templates as well. <a href=\"https://stackoverflow.com/questions/168408/c-alternatives-to-void-pointers-that-isnt-templates#168509\" title=\"Josh's suggestion\">Josh's suggestion</a> of a generic base template Container would certainly allow you do polymorphically pass Containers and their children around, but additionally you could certainly implement interfaces as abstract classes to be the contained items. There's no reason you couldn't create an abstract IComparable class as you suggested, such that you could have a polymorphic function as follows:</p>\n\n<pre><code>class Whatever\n{\n void MyPolymorphicMethod(Container<IComparable*> &listOfComparables);\n}\n</code></pre>\n\n<p>This method can now take any child of Container that contains any class implementing IComparable, so it would be extremely flexible.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168408",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14621/"
] |
It looks like I had a fundamental misunderstanding about C++ :<
I like the polymorphic container solution. Thank you SO, for bringing that to my attention :)
---
So, we have a need to create a relatively generic container type object. It also happens to encapsulate some business related logic. However, we need to store essentially arbitrary data in this container - everything from primitive data types to complex classes.
Thus, one would immediately jump to the idea of a template class and be done with it. However, I have noticed C++ polymorphism and templates do not play well together. Being that there is some complex logic that we are going to have to work, I would rather just stick with either templates OR polymorphism, and not try to fight C++ by making it do both.
Finally, given that I want to do one or the other, I would prefer polymorphism. I find it much easier to represent constraints like "this container contains Comparable types" - a la java.
Bringing me to the topic of question: At the most abstract, I imagine that I could have a "Container" pure virtual interface that has something akin to "push(void\* data) and pop(void\* data)" (for the record, I am not actually trying to implement a stack).
However, I don't really like void\* at the top level, not to mention the signature is going to change every time I want to add a constraint to the type of data a concrete container can work with.
Summarizing: We have relatively complex containers that have various ways to retrieve elements. We want to be able to vary the constraints on the elements that can go into the containers. Elements should work with multiple kinds of containers (so long as they meet the constraints of that particular container).
Edit: I should also mention that the containers themselves need to be polymorphic. That is my primary reason for not wanting to use templated C++.
So - should I drop my love for Java type interfaces and go with templates? Should I use void\* and statically cast everything? Or should I go with an empty class definition "Element" that declares nothing and use that as my top level class in the "Element" hierarchy?
One of the reasons why I love stack overflow is that many of the responses provide some interesting insight on other approaches that I hadn't not have even considered. So thank you in advance for your insights and comments.
|
Can you not have a root Container class that contains elements:
```
template <typename T>
class Container
{
public:
// You'll likely want to use shared_ptr<T> instead.
virtual void push(T *element) = 0;
virtual T *pop() = 0;
virtual void InvokeSomeMethodOnAllItems() = 0;
};
template <typename T>
class List : public Container<T>
{
iterator begin();
iterator end();
public:
virtual void push(T *element) {...}
virtual T* pop() { ... }
virtual void InvokeSomeMethodOnAllItems()
{
for(iterator currItem = begin(); currItem != end(); ++currItem)
{
T* item = *currItem;
item->SomeMethod();
}
}
};
```
These containers can then be passed around polymorphically:
```
class Item
{
public:
virtual void SomeMethod() = 0;
};
class ConcreteItem
{
public:
virtual void SomeMethod()
{
// Do something
}
};
void AddItemToContainer(Container<Item> &container, Item *item)
{
container.push(item);
}
...
List<Item> listInstance;
AddItemToContainer(listInstance, new ConcreteItem());
listInstance.InvokeSomeMethodOnAllItems();
```
This gives you the Container interface in a type-safe generic way.
If you want to add constraints to the type of elements that can be contained, you can do something like this:
```
class Item
{
public:
virtual void SomeMethod() = 0;
typedef int CanBeContainedInList;
};
template <typename T>
class List : public Container<T>
{
typedef typename T::CanBeContainedInList ListGuard;
// ... as before
};
```
|
168,409 |
<p>What is the best way to get a list of all files in a directory, sorted by date [created | modified], using python, on a windows machine?</p>
|
[
{
"answer_id": 168424,
"author": "Jay",
"author_id": 20840,
"author_profile": "https://Stackoverflow.com/users/20840",
"pm_score": 8,
"selected": false,
"text": "<p>I've done this in the past for a Python script to determine the last updated files in a directory: </p>\n\n<pre><code>import glob\nimport os\n\nsearch_dir = \"/mydir/\"\n# remove anything from the list that is not a file (directories, symlinks)\n# thanks to J.F. Sebastion for pointing out that the requirement was a list \n# of files (presumably not including directories) \nfiles = list(filter(os.path.isfile, glob.glob(search_dir + \"*\")))\nfiles.sort(key=lambda x: os.path.getmtime(x))\n</code></pre>\n\n<p>That should do what you're looking for based on file mtime.</p>\n\n<p><strong>EDIT</strong>: Note that you can also use os.listdir() in place of glob.glob() if desired - the reason I used glob in my original code was that I was wanting to use glob to only search for files with a particular set of file extensions, which glob() was better suited to. To use listdir here's what it would look like: </p>\n\n<pre><code>import os\n\nsearch_dir = \"/mydir/\"\nos.chdir(search_dir)\nfiles = filter(os.path.isfile, os.listdir(search_dir))\nfiles = [os.path.join(search_dir, f) for f in files] # add path to each file\nfiles.sort(key=lambda x: os.path.getmtime(x))\n</code></pre>\n"
},
{
"answer_id": 168430,
"author": "stephanea",
"author_id": 8776,
"author_profile": "https://Stackoverflow.com/users/8776",
"pm_score": -1,
"selected": false,
"text": "<p>Maybe you should use shell commands. In Unix/Linux, find piped with sort will probably be able to do what you want. </p>\n"
},
{
"answer_id": 168435,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 4,
"selected": false,
"text": "<p>Here's a one-liner:</p>\n\n<pre><code>import os\nimport time\nfrom pprint import pprint\n\npprint([(x[0], time.ctime(x[1].st_ctime)) for x in sorted([(fn, os.stat(fn)) for fn in os.listdir(\".\")], key = lambda x: x[1].st_ctime)])\n</code></pre>\n\n<p>This calls os.listdir() to get a list of the filenames, then calls os.stat() for each one to get the creation time, then sorts against the creation time.</p>\n\n<p>Note that this method only calls os.stat() once for each file, which will be more efficient than calling it for each comparison in a sort.</p>\n"
},
{
"answer_id": 168580,
"author": "efotinis",
"author_id": 12320,
"author_profile": "https://Stackoverflow.com/users/12320",
"pm_score": 5,
"selected": false,
"text": "<p>Here's my version:</p>\n\n<pre><code>def getfiles(dirpath):\n a = [s for s in os.listdir(dirpath)\n if os.path.isfile(os.path.join(dirpath, s))]\n a.sort(key=lambda s: os.path.getmtime(os.path.join(dirpath, s)))\n return a\n</code></pre>\n\n<p>First, we build a list of the file names. isfile() is used to skip directories; it can be omitted if directories should be included. Then, we sort the list in-place, using the modify date as the key.</p>\n"
},
{
"answer_id": 168658,
"author": "Alex Coventry",
"author_id": 1941213,
"author_profile": "https://Stackoverflow.com/users/1941213",
"pm_score": 3,
"selected": false,
"text": "<pre><code>sorted(filter(os.path.isfile, os.listdir('.')), \n key=lambda p: os.stat(p).st_mtime)\n</code></pre>\n\n<p>You could use <code>os.walk('.').next()[-1]</code> instead of filtering with <code>os.path.isfile</code>, but that leaves dead symlinks in the list, and <code>os.stat</code> will fail on them.</p>\n"
},
{
"answer_id": 539024,
"author": "jfs",
"author_id": 4279,
"author_profile": "https://Stackoverflow.com/users/4279",
"pm_score": 8,
"selected": true,
"text": "<p><em>Update</em>: to sort <code>dirpath</code>'s entries by modification date in Python 3:</p>\n<pre><code>import os\nfrom pathlib import Path\n\npaths = sorted(Path(dirpath).iterdir(), key=os.path.getmtime)\n</code></pre>\n<p><sub>(put <a href=\"https://stackoverflow.com/a/58772122/4279\">@Pygirl's answer</a> here for greater visibility)</sub></p>\n<p>If you already have a list of filenames <code>files</code>, then to sort it inplace by creation time on Windows (make sure that list contains absolute path):</p>\n<pre><code>files.sort(key=os.path.getctime)\n</code></pre>\n<p>The list of files you could get, for example, using <code>glob</code> as shown in <a href=\"https://stackoverflow.com/a/168424/4279\">@Jay's answer</a>.</p>\n<hr />\n<p><sup>old answer</sup>\nHere's a more verbose version of <a href=\"https://stackoverflow.com/questions/168409/how-do-you-get-a-directory-listing-sorted-by-creation-date-in-python/168435#168435\"><code>@Greg Hewgill</code>'s answer</a>. It is the most conforming to the question requirements. It makes a distinction between creation and modification dates (at least on Windows).</p>\n<pre><code>#!/usr/bin/env python\nfrom stat import S_ISREG, ST_CTIME, ST_MODE\nimport os, sys, time\n\n# path to the directory (relative or absolute)\ndirpath = sys.argv[1] if len(sys.argv) == 2 else r'.'\n\n# get all entries in the directory w/ stats\nentries = (os.path.join(dirpath, fn) for fn in os.listdir(dirpath))\nentries = ((os.stat(path), path) for path in entries)\n\n# leave only regular files, insert creation date\nentries = ((stat[ST_CTIME], path)\n for stat, path in entries if S_ISREG(stat[ST_MODE]))\n#NOTE: on Windows `ST_CTIME` is a creation date \n# but on Unix it could be something else\n#NOTE: use `ST_MTIME` to sort by a modification date\n \nfor cdate, path in sorted(entries):\n print time.ctime(cdate), os.path.basename(path)\n</code></pre>\n<p>Example:</p>\n<pre><code>$ python stat_creation_date.py\nThu Feb 11 13:31:07 2009 stat_creation_date.py\n</code></pre>\n"
},
{
"answer_id": 4914674,
"author": "gypaetus",
"author_id": 605436,
"author_profile": "https://Stackoverflow.com/users/605436",
"pm_score": 5,
"selected": false,
"text": "<p>There is an <code>os.path.getmtime</code> function that gives the number of seconds since the epoch\nand should be faster than <code>os.stat</code>.</p>\n\n<pre><code>import os \n\nos.chdir(directory)\nsorted(filter(os.path.isfile, os.listdir('.')), key=os.path.getmtime)\n</code></pre>\n"
},
{
"answer_id": 7801791,
"author": "cumulus13",
"author_id": 1000188,
"author_profile": "https://Stackoverflow.com/users/1000188",
"pm_score": 1,
"selected": false,
"text": "<p>this is a basic step for learn:</p>\n\n<pre><code>import os, stat, sys\nimport time\n\ndirpath = sys.argv[1] if len(sys.argv) == 2 else r'.'\n\nlistdir = os.listdir(dirpath)\n\nfor i in listdir:\n os.chdir(dirpath)\n data_001 = os.path.realpath(i)\n listdir_stat1 = os.stat(data_001)\n listdir_stat2 = ((os.stat(data_001), data_001))\n print time.ctime(listdir_stat1.st_ctime), data_001\n</code></pre>\n"
},
{
"answer_id": 18783474,
"author": "dinos66",
"author_id": 1961612,
"author_profile": "https://Stackoverflow.com/users/1961612",
"pm_score": 4,
"selected": false,
"text": "<p>Here's my answer using glob without filter if you want to read files with a certain extension in date order (Python 3). </p>\n\n<pre><code>dataset_path='/mydir/' \nfiles = glob.glob(dataset_path+\"/morepath/*.extension\") \nfiles.sort(key=os.path.getmtime)\n</code></pre>\n"
},
{
"answer_id": 30381619,
"author": "Nic",
"author_id": 4130524,
"author_profile": "https://Stackoverflow.com/users/4130524",
"pm_score": 4,
"selected": false,
"text": "<p>Without changing directory:</p>\n\n<pre><code>import os \n\npath = '/path/to/files/'\nname_list = os.listdir(path)\nfull_list = [os.path.join(path,i) for i in name_list]\ntime_sorted_list = sorted(full_list, key=os.path.getmtime)\n\nprint time_sorted_list\n\n# if you want just the filenames sorted, simply remove the dir from each\nsorted_filename_list = [ os.path.basename(i) for i in time_sorted_list]\nprint sorted_filename_list\n</code></pre>\n"
},
{
"answer_id": 45643927,
"author": "Paolo Benvenuto",
"author_id": 1242139,
"author_profile": "https://Stackoverflow.com/users/1242139",
"pm_score": 1,
"selected": false,
"text": "<p>Alex Coventry's answer will produce an exception if the file is a symlink to an unexistent file, the following code corrects that answer:</p>\n\n<pre><code>import time\nimport datetime\nsorted(filter(os.path.isfile, os.listdir('.')), \n key=lambda p: os.path.exists(p) and os.stat(p).st_mtime or time.mktime(datetime.now().timetuple())\n</code></pre>\n\n<p>When the file doesn't exist, now() is used, and the symlink will go at the very end of the list.</p>\n"
},
{
"answer_id": 46231690,
"author": "ignorant",
"author_id": 2029648,
"author_profile": "https://Stackoverflow.com/users/2029648",
"pm_score": 4,
"selected": false,
"text": "<p>In python 3.5+</p>\n\n<pre><code>from pathlib import Path\nsorted(Path('.').iterdir(), key=lambda f: f.stat().st_mtime)\n</code></pre>\n"
},
{
"answer_id": 55499815,
"author": "TXN_747",
"author_id": 4220424,
"author_profile": "https://Stackoverflow.com/users/4220424",
"pm_score": 0,
"selected": false,
"text": "<p>Here is a simple couple lines that looks for extention as well as provides a sort option</p>\n\n<pre><code>def get_sorted_files(src_dir, regex_ext='*', sort_reverse=False): \n files_to_evaluate = [os.path.join(src_dir, f) for f in os.listdir(src_dir) if re.search(r'.*\\.({})$'.format(regex_ext), f)]\n files_to_evaluate.sort(key=os.path.getmtime, reverse=sort_reverse)\n return files_to_evaluate\n</code></pre>\n"
},
{
"answer_id": 57831290,
"author": "Arash",
"author_id": 10937550,
"author_profile": "https://Stackoverflow.com/users/10937550",
"pm_score": 3,
"selected": false,
"text": "<pre><code># *** the shortest and best way ***\n# getmtime --> sort by modified time\n# getctime --> sort by created time\n\nimport glob,os\n\nlst_files = glob.glob(\"*.txt\")\nlst_files.sort(key=os.path.getmtime)\nprint(\"\\n\".join(lst_files))\n</code></pre>\n"
},
{
"answer_id": 58031458,
"author": "n1nj4",
"author_id": 2387835,
"author_profile": "https://Stackoverflow.com/users/2387835",
"pm_score": 2,
"selected": false,
"text": "<p>For completeness with <code>os.scandir</code> (2x faster over <code>pathlib</code>):</p>\n\n<pre class=\"lang-py prettyprint-override\"><code>import os\nsorted(os.scandir('/tmp/test'), key=lambda d: d.stat().st_mtime)\n</code></pre>\n"
},
{
"answer_id": 58772122,
"author": "Pygirl",
"author_id": 6660373,
"author_profile": "https://Stackoverflow.com/users/6660373",
"pm_score": 4,
"selected": false,
"text": "<pre><code>from pathlib import Path\nimport os\n\nsorted(Path('./').iterdir(), key=lambda t: t.stat().st_mtime)\n</code></pre>\n\n<p>or</p>\n\n<pre><code>sorted(Path('./').iterdir(), key=os.path.getmtime)\n</code></pre>\n\n<p>or</p>\n\n<pre><code>sorted(os.scandir('./'), key=lambda t: t.stat().st_mtime)\n</code></pre>\n\n<p>where m time is modified time.</p>\n"
},
{
"answer_id": 62169394,
"author": "haqrafiul",
"author_id": 13459502,
"author_profile": "https://Stackoverflow.com/users/13459502",
"pm_score": 2,
"selected": false,
"text": "<p>This was my version: </p>\n\n<pre><code>import os\n\nfolder_path = r'D:\\Movies\\extra\\new\\dramas' # your path\nos.chdir(folder_path) # make the path active\nx = sorted(os.listdir(), key=os.path.getctime) # sorted using creation time\n\nfolder = 0\n\nfor folder in range(len(x)):\n print(x[folder]) # print all the foldername inside the folder_path\n folder = +1\n</code></pre>\n"
},
{
"answer_id": 66012868,
"author": "Mayank",
"author_id": 11728685,
"author_profile": "https://Stackoverflow.com/users/11728685",
"pm_score": -1,
"selected": false,
"text": "<p>Turns out <code>os.listdir</code> sorts by last modified but in reverse so you can do:</p>\n<pre><code>import os\nlast_modified=os.listdir()[::-1]\n</code></pre>\n"
},
{
"answer_id": 71833978,
"author": "Aps",
"author_id": 13079256,
"author_profile": "https://Stackoverflow.com/users/13079256",
"pm_score": 0,
"selected": false,
"text": "<p>Add the file directory/folder in path, if you want to have specific file type add the file extension, and then get file name in chronological order.\nThis works for me.</p>\n<pre><code>import glob, os\nfrom pathlib import Path\npath = os.path.expanduser(file_location+"/"+date_file) \nos.chdir(path) \nsaved_file=glob.glob('*.xlsx')\nsaved_file.sort(key=os.path.getmtime)\n\nprint(saved_file)\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168409",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24953/"
] |
What is the best way to get a list of all files in a directory, sorted by date [created | modified], using python, on a windows machine?
|
*Update*: to sort `dirpath`'s entries by modification date in Python 3:
```
import os
from pathlib import Path
paths = sorted(Path(dirpath).iterdir(), key=os.path.getmtime)
```
(put [@Pygirl's answer](https://stackoverflow.com/a/58772122/4279) here for greater visibility)
If you already have a list of filenames `files`, then to sort it inplace by creation time on Windows (make sure that list contains absolute path):
```
files.sort(key=os.path.getctime)
```
The list of files you could get, for example, using `glob` as shown in [@Jay's answer](https://stackoverflow.com/a/168424/4279).
---
old answer
Here's a more verbose version of [`@Greg Hewgill`'s answer](https://stackoverflow.com/questions/168409/how-do-you-get-a-directory-listing-sorted-by-creation-date-in-python/168435#168435). It is the most conforming to the question requirements. It makes a distinction between creation and modification dates (at least on Windows).
```
#!/usr/bin/env python
from stat import S_ISREG, ST_CTIME, ST_MODE
import os, sys, time
# path to the directory (relative or absolute)
dirpath = sys.argv[1] if len(sys.argv) == 2 else r'.'
# get all entries in the directory w/ stats
entries = (os.path.join(dirpath, fn) for fn in os.listdir(dirpath))
entries = ((os.stat(path), path) for path in entries)
# leave only regular files, insert creation date
entries = ((stat[ST_CTIME], path)
for stat, path in entries if S_ISREG(stat[ST_MODE]))
#NOTE: on Windows `ST_CTIME` is a creation date
# but on Unix it could be something else
#NOTE: use `ST_MTIME` to sort by a modification date
for cdate, path in sorted(entries):
print time.ctime(cdate), os.path.basename(path)
```
Example:
```
$ python stat_creation_date.py
Thu Feb 11 13:31:07 2009 stat_creation_date.py
```
|
168,415 |
<p>For my current project, I need to request XML data over a tcp/ip socket connection. For this, I am using the TcpClient class:</p>
<pre><code>Dim client As New TcpClient()
client.Connect(server, port)
Dim stream As NetworkStream = client.GetStream()
stream.Write(request)
stream.Read(buffer, 0, buffer.length)
// Output buffer and return results...
</code></pre>
<p>Now this works fine and dandy for small responses. However, when I start receiving larger blocks of data, it appears that the data gets pushed over the socket connection in bursts. When this happens, the stream.Read call only reads the first burst, and thus I miss out on the rest of the response. </p>
<p>What's the best way to handle this issue? Initially I tried to just loop until I had a valid XML document, but I found that in between stream.Read calls the underlying stream would sometimes get shut down and I would miss out on the last portion of the data.</p>
|
[
{
"answer_id": 168418,
"author": "Sunny Milenov",
"author_id": 8220,
"author_profile": "https://Stackoverflow.com/users/8220",
"pm_score": 3,
"selected": true,
"text": "<p>You create a loop for reading.</p>\n\n<p>Stream.Read returns int for the bytes it read so far, or 0 if the end of stream is reached.</p>\n\n<p>So, its like:</p>\n\n<pre><code>int bytes_read = 0;\nwhile (bytes_read < buffer.Length)\n bytes_read += stream.Read(buffer, bytes_read, buffer.length - bytes_read);\n</code></pre>\n\n<p>EDIT: now, the question is how you determine the size of the buffer. If your server first sends the size, that's ok, you can use the above snippet. But if you have to read until the server closes the connection, then you have to use try/catch (which is good idea even if you know the size), and use bytes_read to determine what you received.</p>\n\n<pre><code>int bytes_read = 0;\ntry\n{\n int i = 0;\n while ( 0 < (i = stream.Read(buffer, bytes_read, buffer.Length - bytes_read) )\n bytes_read += i;\n}\ncatch (Exception e)\n{\n//recover\n}\nfinally\n{\nif (stream != null)\n stream.Close();\n}\n</code></pre>\n"
},
{
"answer_id": 168443,
"author": "Lou Franco",
"author_id": 3937,
"author_profile": "https://Stackoverflow.com/users/3937",
"pm_score": 2,
"selected": false,
"text": "<p>Read is not guaranteed to fully read the stream. It returns the number of actual bytes read and 0 if there are no more bytes to read. You should keep looping to read all of the data out of the stream.</p>\n"
},
{
"answer_id": 539052,
"author": "Tute",
"author_id": 4386,
"author_profile": "https://Stackoverflow.com/users/4386",
"pm_score": 0,
"selected": false,
"text": "<p>This is a possible way to do that and get in \"response\" the response string. If you need the byte array, just save ms.ToArray().</p>\n\n<pre><code>string response;\n\nTcpClient client = new TcpClient();\nclient.Connect(server, port);\nusing (NetworkStream ns = c.GetStream())\nusing (MemoryStream ms = new MemoryStream())\n{\n ns.Write(request);\n\n byte[] buffer = new byte[512];\n int bytes = 0;\n\n while(ns.DataAvailable)\n {\n bytes = ns.Read(buffer,0, buffer.Length);\n ms.Write(buffer, 0, bytes);\n }\n\n response = Encoding.ASCII.GetString(ms.ToArray());\n}\n</code></pre>\n"
},
{
"answer_id": 819609,
"author": "pomarc",
"author_id": 85738,
"author_profile": "https://Stackoverflow.com/users/85738",
"pm_score": 0,
"selected": false,
"text": "<p>I strongly advice you to try WCF for such tasks. It gives you, after a not so steep learning curve, many benefits over raw socket communications.\nFor the task at hand, I agree with the preceeding answers, you should use a loop and dynamically allocate memory as needed.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168415",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1574/"
] |
For my current project, I need to request XML data over a tcp/ip socket connection. For this, I am using the TcpClient class:
```
Dim client As New TcpClient()
client.Connect(server, port)
Dim stream As NetworkStream = client.GetStream()
stream.Write(request)
stream.Read(buffer, 0, buffer.length)
// Output buffer and return results...
```
Now this works fine and dandy for small responses. However, when I start receiving larger blocks of data, it appears that the data gets pushed over the socket connection in bursts. When this happens, the stream.Read call only reads the first burst, and thus I miss out on the rest of the response.
What's the best way to handle this issue? Initially I tried to just loop until I had a valid XML document, but I found that in between stream.Read calls the underlying stream would sometimes get shut down and I would miss out on the last portion of the data.
|
You create a loop for reading.
Stream.Read returns int for the bytes it read so far, or 0 if the end of stream is reached.
So, its like:
```
int bytes_read = 0;
while (bytes_read < buffer.Length)
bytes_read += stream.Read(buffer, bytes_read, buffer.length - bytes_read);
```
EDIT: now, the question is how you determine the size of the buffer. If your server first sends the size, that's ok, you can use the above snippet. But if you have to read until the server closes the connection, then you have to use try/catch (which is good idea even if you know the size), and use bytes\_read to determine what you received.
```
int bytes_read = 0;
try
{
int i = 0;
while ( 0 < (i = stream.Read(buffer, bytes_read, buffer.Length - bytes_read) )
bytes_read += i;
}
catch (Exception e)
{
//recover
}
finally
{
if (stream != null)
stream.Close();
}
```
|
168,423 |
<p>I have a personal wiki that I take notes on. The wiki's pages are in a subversion working copy directory, "pages", and I set their permissions to 664, owned by www-data:www-data. My username is in the "www-data" group, so I can checkin and mess with the pages manually.</p>
<p>For a while, I had an issue because every time I ran a checkin, the files would be owned by me:www-data instead of www-data:www-data, and I would no longer be able to change the wiki files through my web interface! I solved the issue by flipping the setgid bit on the "pages" directory, but I'm still confused as to why this happened in the first place:</p>
<p>Every time I check something into subversion, it appears as if svn deletes it and recreates it. Why? Does this behavior support some functionality that I'm not aware of? Is there a way to change it?</p>
<p>Thanks!</p>
|
[
{
"answer_id": 178038,
"author": "Isak Savo",
"author_id": 8521,
"author_profile": "https://Stackoverflow.com/users/8521",
"pm_score": 2,
"selected": false,
"text": "<p>I think you are using it wrong. What you could do is still have everything in subversion and have your local working copy separate from the www directory which you develop on.</p>\n\n<p>Then just have the www working-copy auto-updated (or exported if you don't want the .svn directories in the www foldeR) for the www-user by some script (perhaps as a <a href=\"http://svnbook.red-bean.com/en/1.5/svn.ref.reposhooks.post-commit.html\" rel=\"nofollow noreferrer\">post-commit</a> hook) which then setups permissions accordingly.</p>\n\n<p>Work flow would be:</p>\n\n<ol>\n<li>edit files in /home/youruser/yourwiki-working-copy/</li>\n<li>do svn commit\n\n<ul>\n<li>post-commit hook updates the files in /var/www/ (or wherever the wiki is located)</li>\n</ul></li>\n<li>goto 1.</li>\n</ol>\n\n<p>This way, you don't have to worry about permissions and you can even have more than one person work on the web site with all the benefits of version control.</p>\n"
},
{
"answer_id": 178496,
"author": "Kent Fredric",
"author_id": 15614,
"author_profile": "https://Stackoverflow.com/users/15614",
"pm_score": 3,
"selected": true,
"text": "<p>Set the \"sticky\" permissions bit. </p>\n\n<pre><code>find -type d -exec chgrp www-data {} + \nfind -type d -exec chmod g+s {} + \n</code></pre>\n\n<p>this will encourage checkout's file creation phase to inherit the directories permissions instead of switching to the person whom last edited it. </p>\n\n<p><strong>Edit</strong>: dow +s == setgid. Information left here for posterity and other readers. </p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168423",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/16034/"
] |
I have a personal wiki that I take notes on. The wiki's pages are in a subversion working copy directory, "pages", and I set their permissions to 664, owned by www-data:www-data. My username is in the "www-data" group, so I can checkin and mess with the pages manually.
For a while, I had an issue because every time I ran a checkin, the files would be owned by me:www-data instead of www-data:www-data, and I would no longer be able to change the wiki files through my web interface! I solved the issue by flipping the setgid bit on the "pages" directory, but I'm still confused as to why this happened in the first place:
Every time I check something into subversion, it appears as if svn deletes it and recreates it. Why? Does this behavior support some functionality that I'm not aware of? Is there a way to change it?
Thanks!
|
Set the "sticky" permissions bit.
```
find -type d -exec chgrp www-data {} +
find -type d -exec chmod g+s {} +
```
this will encourage checkout's file creation phase to inherit the directories permissions instead of switching to the person whom last edited it.
**Edit**: dow +s == setgid. Information left here for posterity and other readers.
|
168,455 |
<p>How do you post data to an iframe?</p>
|
[
{
"answer_id": 168488,
"author": "Dylan Beattie",
"author_id": 5017,
"author_profile": "https://Stackoverflow.com/users/5017",
"pm_score": 10,
"selected": true,
"text": "<p>Depends what you mean by \"post data\". You can use the HTML <code>target=\"\"</code> attribute on a <code><form /></code> tag, so it could be as simple as:</p>\n\n<pre><code><form action=\"do_stuff.aspx\" method=\"post\" target=\"my_iframe\">\n <input type=\"submit\" value=\"Do Stuff!\">\n</form>\n\n<!-- when the form is submitted, the server response will appear in this iframe -->\n<iframe name=\"my_iframe\" src=\"not_submitted_yet.aspx\"></iframe>\n</code></pre>\n\n<p>If that's not it, or you're after something more complex, please edit your question to include more detail.</p>\n\n<p>There is a known bug with Internet Explorer that only occurs when you're dynamically creating your iframes, etc. using Javascript (there's a <a href=\"https://stackoverflow.com/questions/2181385/ie-issue-submitting-form-to-an-iframe-using-javascript\">work-around here</a>), but if you're using ordinary HTML markup, you're fine. The target attribute and frame names isn't some clever ninja hack; although it was deprecated (and therefore won't validate) in HTML 4 Strict or XHTML 1 Strict, it's been part of HTML since 3.2, it's formally part of HTML5, and it works in just about every browser since Netscape 3.</p>\n\n<p>I have verified this behaviour as working with XHTML 1 Strict, XHTML 1 Transitional, HTML 4 Strict and in \"quirks mode\" with no DOCTYPE specified, and it works in all cases using Internet Explorer 7.0.5730.13. My test case consist of two files, using classic ASP on IIS 6; they're reproduced here in full so you can verify this behaviour for yourself.</p>\n\n<p><strong>default.asp</strong></p>\n\n<pre><code><?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<!DOCTYPE html PUBLIC\n \"-//W3C//DTD XHTML 1.0 Strict//EN\"\n \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd\">\n<html>\n <head>\n <title>Form Iframe Demo</title>\n </head>\n <body>\n <form action=\"do_stuff.asp\" method=\"post\" target=\"my_frame\">\n <input type=\"text\" name=\"someText\" value=\"Some Text\">\n <input type=\"submit\">\n </form>\n <iframe name=\"my_frame\" src=\"do_stuff.asp\">\n </iframe>\n </body>\n</html>\n</code></pre>\n\n<p><strong>do_stuff.asp</strong></p>\n\n<pre><code><%@Language=\"JScript\"%><?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<!DOCTYPE html PUBLIC\n \"-//W3C//DTD XHTML 1.0 Strict//EN\"\n \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd\">\n<html>\n <head>\n <title>Form Iframe Demo</title>\n </head>\n <body>\n <% if (Request.Form.Count) { %>\n You typed: <%=Request.Form(\"someText\").Item%>\n <% } else { %>\n (not submitted)\n <% } %>\n </body>\n</html>\n</code></pre>\n\n<p>I would be very interested to hear of any browser that doesn't run these examples correctly.</p>\n"
},
{
"answer_id": 11131626,
"author": "kapil",
"author_id": 980571,
"author_profile": "https://Stackoverflow.com/users/980571",
"pm_score": 5,
"selected": false,
"text": "<p>An iframe is used to embed another document inside a html page.</p>\n\n<p>If the form is to be submitted to an iframe within the form page, then it can be easily acheived using the target attribute of the tag.</p>\n\n<p>Set the target attribute of the form to the name of the iframe tag.</p>\n\n<pre><code><form action=\"action\" method=\"post\" target=\"output_frame\">\n <!-- input elements here --> \n</form>\n<iframe name=\"output_frame\" src=\"\" id=\"output_frame\" width=\"XX\" height=\"YY\">\n</iframe> \n</code></pre>\n\n<hr>\n\n<p><strong>Advanced iframe target use</strong><br>\nThis property can also be used to produce an ajax like experience, especially in cases like file upload, in which case where it becomes mandatory to submit the form, in order to upload the files</p>\n\n<p>The iframe can be set to a width and height of 0, and the form can be submitted with the target set to the iframe, and a loading dialog opened before submitting the form. So, it mocks a ajax control as the control still remains on the input form jsp, with the loading dialog open.</p>\n\n<p>Exmaple</p>\n\n<pre><code><script>\n$( \"#uploadDialog\" ).dialog({ autoOpen: false, modal: true, closeOnEscape: false, \n open: function(event, ui) { jQuery('.ui-dialog-titlebar-close').hide(); } });\n\nfunction startUpload()\n{ \n $(\"#uploadDialog\").dialog(\"open\");\n}\n\nfunction stopUpload()\n{ \n $(\"#uploadDialog\").dialog(\"close\");\n}\n</script>\n\n<div id=\"uploadDialog\" title=\"Please Wait!!!\">\n <center>\n <img src=\"/imagePath/loading.gif\" width=\"100\" height=\"100\"/>\n <br/>\n Loading Details...\n </center>\n </div>\n\n<FORM ENCTYPE=\"multipart/form-data\" ACTION=\"Action\" METHOD=\"POST\" target=\"upload_target\" onsubmit=\"startUpload()\"> \n<!-- input file elements here--> \n</FORM>\n\n<iframe id=\"upload_target\" name=\"upload_target\" src=\"#\" style=\"width:0;height:0;border:0px solid #fff;\" onload=\"stopUpload()\"> \n </iframe>\n</code></pre>\n"
},
{
"answer_id": 50438495,
"author": "Dr Fred",
"author_id": 468445,
"author_profile": "https://Stackoverflow.com/users/468445",
"pm_score": 2,
"selected": false,
"text": "<p>This function creates a temporary form, then send data using jQuery :</p>\n\n<pre><code>function postToIframe(data,url,target){\n $('body').append('<form action=\"'+url+'\" method=\"post\" target=\"'+target+'\" id=\"postToIframe\"></form>');\n $.each(data,function(n,v){\n $('#postToIframe').append('<input type=\"hidden\" name=\"'+n+'\" value=\"'+v+'\" />');\n });\n $('#postToIframe').submit().remove();\n}\n</code></pre>\n\n<p>target is the 'name' attr of the target iFrame, and data is a JS object :</p>\n\n<pre><code>data={last_name:'Smith',first_name:'John'}\n</code></pre>\n"
},
{
"answer_id": 53092796,
"author": "Dominique Fortin",
"author_id": 1571709,
"author_profile": "https://Stackoverflow.com/users/1571709",
"pm_score": 0,
"selected": false,
"text": "<p>If you want to change inputs in an iframe then submit the form from that iframe, do this</p>\n\n<pre><code>...\nvar el = document.getElementById('targetFrame');\n\nvar doc, frame_win = getIframeWindow(el); // getIframeWindow is defined below\n\nif (frame_win) {\n doc = (window.contentDocument || window.document);\n}\n\nif (doc) {\n doc.forms[0].someInputName.value = someValue;\n ...\n doc.forms[0].submit();\n}\n...\n</code></pre>\n\n<p>Normally, you can only do this if the page in the iframe is from the same origin, but you can start Chrome in a debug mode to disregard the same origin policy and test this on any page.</p>\n\n<pre><code>function getIframeWindow(iframe_object) {\n var doc;\n\n if (iframe_object.contentWindow) {\n return iframe_object.contentWindow;\n }\n\n if (iframe_object.window) {\n return iframe_object.window;\n } \n\n if (!doc && iframe_object.contentDocument) {\n doc = iframe_object.contentDocument;\n } \n\n if (!doc && iframe_object.document) {\n doc = iframe_object.document;\n }\n\n if (doc && doc.defaultView) {\n return doc.defaultView;\n }\n\n if (doc && doc.parentWindow) {\n return doc.parentWindow;\n }\n\n return undefined;\n}\n</code></pre>\n"
},
{
"answer_id": 70588441,
"author": "vinayp",
"author_id": 14117367,
"author_profile": "https://Stackoverflow.com/users/14117367",
"pm_score": 0,
"selected": false,
"text": "<p>You can use this code, will have to add proper params to be passed and also the api url to get the data.</p>\n<pre><code>var allParams = { xyz, abc }\n\n var parentElm = document.getElementBy... // your own element where you want to create the iframe\n\n // create an iframe \n var addIframe = document.createElement('iframe');\n addIframe.setAttribute('name', 'sample-iframe');\n addIframe.style.height = height ? height : "360px";\n addIframe.style.width = width ? width : "360px";\n parentElm.appendChild(addIframe)\n\n // make an post request\n var form, input;\n form = document.createElement("form");\n form.action = 'example.com';\n form.method = "post";\n form.target = "sample-iframe";\n Object.keys(allParams).forEach(function (elm) {\n console.log('elm: ', elm, allParams[elm]);\n input = document.createElement("input");\n input.name = elm;\n input.value = allParams[elm];\n input.type = "hidden";\n form.appendChild(input);\n })\n parentElm.appendChild(form);\n form.submit();\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168455",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24958/"
] |
How do you post data to an iframe?
|
Depends what you mean by "post data". You can use the HTML `target=""` attribute on a `<form />` tag, so it could be as simple as:
```
<form action="do_stuff.aspx" method="post" target="my_iframe">
<input type="submit" value="Do Stuff!">
</form>
<!-- when the form is submitted, the server response will appear in this iframe -->
<iframe name="my_iframe" src="not_submitted_yet.aspx"></iframe>
```
If that's not it, or you're after something more complex, please edit your question to include more detail.
There is a known bug with Internet Explorer that only occurs when you're dynamically creating your iframes, etc. using Javascript (there's a [work-around here](https://stackoverflow.com/questions/2181385/ie-issue-submitting-form-to-an-iframe-using-javascript)), but if you're using ordinary HTML markup, you're fine. The target attribute and frame names isn't some clever ninja hack; although it was deprecated (and therefore won't validate) in HTML 4 Strict or XHTML 1 Strict, it's been part of HTML since 3.2, it's formally part of HTML5, and it works in just about every browser since Netscape 3.
I have verified this behaviour as working with XHTML 1 Strict, XHTML 1 Transitional, HTML 4 Strict and in "quirks mode" with no DOCTYPE specified, and it works in all cases using Internet Explorer 7.0.5730.13. My test case consist of two files, using classic ASP on IIS 6; they're reproduced here in full so you can verify this behaviour for yourself.
**default.asp**
```
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC
"-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>Form Iframe Demo</title>
</head>
<body>
<form action="do_stuff.asp" method="post" target="my_frame">
<input type="text" name="someText" value="Some Text">
<input type="submit">
</form>
<iframe name="my_frame" src="do_stuff.asp">
</iframe>
</body>
</html>
```
**do\_stuff.asp**
```
<%@Language="JScript"%><?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC
"-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>Form Iframe Demo</title>
</head>
<body>
<% if (Request.Form.Count) { %>
You typed: <%=Request.Form("someText").Item%>
<% } else { %>
(not submitted)
<% } %>
</body>
</html>
```
I would be very interested to hear of any browser that doesn't run these examples correctly.
|
168,464 |
<p>Since <em>length</em> is a JavaScript property, does it matter whether I use</p>
<pre><code>for( var i = 0; i < myArray.length; i++ )
</code></pre>
<p>OR</p>
<pre><code>var myArrayLength = myArray.length;
for( var i = 0; i < myArrayLength ; i++ )
</code></pre>
<p></p>
|
[
{
"answer_id": 168473,
"author": "Grant Wagner",
"author_id": 9254,
"author_profile": "https://Stackoverflow.com/users/9254",
"pm_score": 3,
"selected": false,
"text": "<pre><code>for(var i = 0, iLen = myArray.length; i < iLen; i++)\n</code></pre>\n\n<p>See <a href=\"http://blogs.oracle.com/greimer/resource/loop-test.html\" rel=\"nofollow noreferrer\">http://blogs.oracle.com/greimer/resource/loop-test.html</a> for benchmarks of various Javascript loop constructs.</p>\n"
},
{
"answer_id": 168479,
"author": "AnthonyWJones",
"author_id": 17516,
"author_profile": "https://Stackoverflow.com/users/17516",
"pm_score": 2,
"selected": false,
"text": "<p>If myArray is javascript array then it doesn't matter enough for you to worry about it, its just a property look up on an object but then so is variable usage.</p>\n\n<p>If OTH length is a property exposed by a collection object provided by a browsers DOM (especially IE) then it can be surprisingly expensive. Hence when enumerating such a DOM provided collection I tend to use:-</p>\n\n<pre><code>for (var i = 0, length = col.length; i < length; i++)\n</code></pre>\n\n<p>but for arrays I don't bother with that.</p>\n"
},
{
"answer_id": 168497,
"author": "Jonathan Lonowski",
"author_id": 15031,
"author_profile": "https://Stackoverflow.com/users/15031",
"pm_score": 1,
"selected": false,
"text": "<p>No. It doesn't recalculate on call. It recalculates as required within the Array class.</p>\n\n<p>It'll change when you use <strong>push</strong>, <strong>pop</strong>, <strong>shift</strong>, <strong>unshift</strong>, <strong>concat</strong>, <strong>splice</strong>, etc. Otherwise, it's just a Number -- the same instance every time you call for its value.</p>\n\n<p>But, as long as you don't override it explicitly (<strong>array.length = 0</strong>), it'll be accurate with each call.</p>\n"
},
{
"answer_id": 168514,
"author": "Nickolay",
"author_id": 1026,
"author_profile": "https://Stackoverflow.com/users/1026",
"pm_score": 0,
"selected": false,
"text": "<p>While the second form may be faster:</p>\n\n<pre><code>function p(f) { var d1=new Date(); for(var i=0;i<20;i++) f(); print(new Date()-d1) }\np(function(){for(var i=0;i<1000000; i++) ;})\np(function(){var a = new Array(1000000); for(var i=0;i<a.length; i++) ;})\n> 823\n> 1283\n</code></pre>\n\n<p>..it shouldn't really matter in any non-edge case.</p>\n"
},
{
"answer_id": 169073,
"author": "olliej",
"author_id": 784,
"author_profile": "https://Stackoverflow.com/users/784",
"pm_score": 1,
"selected": false,
"text": "<p>The length property is not computed on each call, but the latter version will be faster as you are caching the property lookup. Even with the most up to date JS implementations (V8, TraceMonkey, SquirrelFish Extreme) which use advanced (eg. SmallTalk era ;) ) property caching the property lookup is still at least one extra conditional branch more than your second version.</p>\n\n<p>Array.length is not constant however as JS Arrays are mutable, so <code>push, pop, array[array.length]=0, etc</code> may all change it.</p>\n\n<p>There are other concepts like the DOM <code>NodeList</code>s that you get from calls like <code>document.getElementsBySelector</code> which are expected to be live in which case the length may be recomputed as you iterate. But then if the length does get recomputed there's a good chance that it will also have actually changed, so manually caching the output may not be valid.</p>\n"
},
{
"answer_id": 169143,
"author": "Pablo Cabrera",
"author_id": 12540,
"author_profile": "https://Stackoverflow.com/users/12540",
"pm_score": 0,
"selected": false,
"text": "<p>According to the <a href=\"https://stackoverflow.com/users/15031/jonathan-lonowski\">ECMAScript specification</a>, it just tells <strong>how</strong> the \"length\" property should be calculated, but it doesn't says <strong>when</strong>.\nI think that it might be implementation dependent.</p>\n\n<p>If I were to implement it, I would do as <a href=\"https://stackoverflow.com/questions/168464/do-javascript-properties-calculate-on-each-call#168497\">Jonathan</a> pointed out, but that in case of the \"length\" property from the Array objects.</p>\n"
},
{
"answer_id": 172610,
"author": "roenving",
"author_id": 23142,
"author_profile": "https://Stackoverflow.com/users/23142",
"pm_score": 0,
"selected": false,
"text": "<p>If you ever has an idea that it could change during the looping then of course it should be checked for every loop ...</p>\n\n<p>-- else it's obviously nuts to ask an object several times, as it would be if you place it in the evaluation-property of the if-statement ...</p>\n\n<pre><code>if(i=0, iMax=object.length; iMax>i; i++)\n</code></pre>\n\n<p>-- only in special cases you should think of doing otherwise !-)</p>\n"
},
{
"answer_id": 172647,
"author": "Jerod Venema",
"author_id": 25330,
"author_profile": "https://Stackoverflow.com/users/25330",
"pm_score": 2,
"selected": false,
"text": "<p>I think the answer to the intent of your question is, yes, the array.length property gets recalculated each iteration through the loop if you modify the array in the loop. For example, the following code:</p>\n\n<pre><code>var arr = [1,2,3];\nfor(var i = 0; i < arr.length; i++){\n console.debug(\"i = \" + i);\n console.debug(\"indexed value = \" + arr[i])\n arr.pop();\n}\n</code></pre>\n\n<p>will output:</p>\n\n<pre><code>i = 0\nindexed value = 1\ni = 1\nindexed value = 2\n</code></pre>\n\n<p>whereas this code:</p>\n\n<pre><code>var arr = [1,2,3];\nvar l = arr.length;\nfor(var i = 0; i < l; i++){\n console.debug(\"i = \" + i);\n console.debug(\"indexed value = \" + arr[i])\n arr.pop();\n}\n</code></pre>\n\n<p>will output:</p>\n\n<pre><code>i = 0\nindexed value = 1\ni = 1\nindexed value = 2\ni = 2\nindexed value = undefined\n</code></pre>\n\n<p>-J</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168464",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
Since *length* is a JavaScript property, does it matter whether I use
```
for( var i = 0; i < myArray.length; i++ )
```
OR
```
var myArrayLength = myArray.length;
for( var i = 0; i < myArrayLength ; i++ )
```
|
```
for(var i = 0, iLen = myArray.length; i < iLen; i++)
```
See <http://blogs.oracle.com/greimer/resource/loop-test.html> for benchmarks of various Javascript loop constructs.
|
168,486 |
<p>For my customer I occasionally do work in their live database in order to fix a problem they have created for themselves, or in order to fix bad data that my product's bugs created. Much like Unix root access, it's just dangerous. What lessons should I learn ahead of time?</p>
<p>What is the #1 thing you do to be careful about operating on live data?</p>
|
[
{
"answer_id": 168494,
"author": "Bob King",
"author_id": 6897,
"author_profile": "https://Stackoverflow.com/users/6897",
"pm_score": 5,
"selected": false,
"text": "<p>Make your changes to a copy, and when you're satisfied, then apply the fix to live.</p>\n"
},
{
"answer_id": 168496,
"author": "Wayne",
"author_id": 8236,
"author_profile": "https://Stackoverflow.com/users/8236",
"pm_score": 4,
"selected": false,
"text": "<p>Always make sure your UPDATEs and DELETEs have the proper WHERE clause.</p>\n"
},
{
"answer_id": 168498,
"author": "Bill the Lizard",
"author_id": 1288,
"author_profile": "https://Stackoverflow.com/users/1288",
"pm_score": 1,
"selected": false,
"text": "<p>Make sure you specify a where clause when deleting records.</p>\n"
},
{
"answer_id": 168503,
"author": "Carlton Jenke",
"author_id": 1215,
"author_profile": "https://Stackoverflow.com/users/1215",
"pm_score": 1,
"selected": false,
"text": "<p>always test any queries beyond select on development data first to ensure it has the correct impact.</p>\n"
},
{
"answer_id": 168507,
"author": "Lou Franco",
"author_id": 3937,
"author_profile": "https://Stackoverflow.com/users/3937",
"pm_score": 2,
"selected": false,
"text": "<p>Backup or dump the database before starting.</p>\n"
},
{
"answer_id": 168508,
"author": "bdukes",
"author_id": 2688,
"author_profile": "https://Stackoverflow.com/users/2688",
"pm_score": 2,
"selected": false,
"text": "<p>To add on to what @<a href=\"https://stackoverflow.com/questions/168486/whats-your-1-way-to-be-careful-with-a-live-database#168496\">Wayne</a> said, write your <code>WHERE</code> before the table name in a <code>DELETE</code> or <code>UPDATE</code> statement.</p>\n"
},
{
"answer_id": 168511,
"author": "warren",
"author_id": 4418,
"author_profile": "https://Stackoverflow.com/users/4418",
"pm_score": 6,
"selected": false,
"text": "<p>Do a backup first: it should be the number 1 law of sysadmining anyways</p>\n\n<p><strong>EDIT</strong>: incorporating what others have said, make sure your UPDATES have appropriate WHERE clauses.</p>\n\n<p>Ideally, changing a live database should never happen (beyond INSERTs and basic maintenance). Changing the live DB's structure is especially fraught with potential bad karma.</p>\n"
},
{
"answer_id": 168513,
"author": "Jay",
"author_id": 20840,
"author_profile": "https://Stackoverflow.com/users/20840",
"pm_score": 2,
"selected": false,
"text": "<p>BACK UP YOUR DATA. Learned that one the hard way working with customer databases on a regular basis.</p>\n"
},
{
"answer_id": 168519,
"author": "Gilles",
"author_id": 10024,
"author_profile": "https://Stackoverflow.com/users/10024",
"pm_score": 2,
"selected": false,
"text": "<p>Maybe consider not using any deletes or drops at all. Or maybe reduce the user permissions so that only a special DB user can delete/drop things.</p>\n"
},
{
"answer_id": 168520,
"author": "cciotti",
"author_id": 16834,
"author_profile": "https://Stackoverflow.com/users/16834",
"pm_score": 2,
"selected": false,
"text": "<p>Always add a using clause.</p>\n"
},
{
"answer_id": 168526,
"author": "Wayne",
"author_id": 8236,
"author_profile": "https://Stackoverflow.com/users/8236",
"pm_score": 2,
"selected": false,
"text": "<p>If you're using Oracle or another database that supports it, verify your changes before doing a COMMIT.</p>\n"
},
{
"answer_id": 168529,
"author": "Paul Tomblin",
"author_id": 3333,
"author_profile": "https://Stackoverflow.com/users/3333",
"pm_score": 7,
"selected": false,
"text": "<pre><code>BEGIN TRANSACTION;\n</code></pre>\n\n<p>That way you can rollback after a mistake.</p>\n"
},
{
"answer_id": 168532,
"author": "easeout",
"author_id": 10906,
"author_profile": "https://Stackoverflow.com/users/10906",
"pm_score": 4,
"selected": false,
"text": "<p>To answer my own question:</p>\n\n<p>When writing an update statement, write it out of order.</p>\n\n<ol>\n<li>Write <code>UPDATE [table-name]</code></li>\n<li>Write <code>WHERE [conditions]</code></li>\n<li>Go back and write <code>SET [columns-and-values]</code></li>\n</ol>\n\n<p>Choosing the rows you want to update before you say what values you want to change is much safer than doing it in the other order. It makes it impossible for <code>update person set email = '[email protected]'</code> to be sitting in your query window, ready to be run by a misplaced keystroke, ready to mess up every row in the table.</p>\n\n<p>Edit: As others have said, write the <code>WHERE</code> clause for your deletes before you write <code>DELETE</code>.</p>\n"
},
{
"answer_id": 168535,
"author": "Patrick Szalapski",
"author_id": 7453,
"author_profile": "https://Stackoverflow.com/users/7453",
"pm_score": 4,
"selected": false,
"text": "<p>NEVER do an update unless you are in a BEGIN TRAN t1--not in a dev database, not in production, not anywhere. NEVER run a COMMIT TRAN t1 outside a comment--always type</p>\n\n<pre><code>--COMMIT TRAN t1\n</code></pre>\n\n<p>and then select the statement in order to run it. (Obviously, this only applies to GUI query clients.) If you do these things, it will become second nature to do them and you won't lose hardly any time.</p>\n\n<p>I actually have a \"update\" macro that types this. I always paste this in to set up my updates. You can make a similar one for deletes and inserts.</p>\n\n<pre><code>begin tran t1\nupdate \nset \nwhere \nrollback tran t1\n--commit tran t1\n</code></pre>\n"
},
{
"answer_id": 168536,
"author": "ConroyP",
"author_id": 2287,
"author_profile": "https://Stackoverflow.com/users/2287",
"pm_score": 0,
"selected": false,
"text": "<p><strong>Make sure your query has a <code>WHERE</code> parameter specified</strong></p>\n\n<p>I was once mid-way through a complex update, got distracted, and finished the query early, forgetting the \"where\" clause. Then I got that sinking feeling, watching a half-second query rumble on for 3.. The several hours afterwards spent cleaning up customer data was quite the lesson!</p>\n\n<p>A result of which is now when I work on the live db, I structure my queries like:</p>\n\n<pre><code>UPDATE my_table WHERE condition = true;\n</code></pre>\n\n<p>then go back and put in the columns etc to update. Takes a bit longer to write, but <em>massively</em> reduces my chance of making the same mistake again!</p>\n"
},
{
"answer_id": 168537,
"author": "Patrick McElhaney",
"author_id": 437,
"author_profile": "https://Stackoverflow.com/users/437",
"pm_score": 5,
"selected": false,
"text": "<p>Often before I do an UPDATE or DELETE, I write the equivalent SELECT. </p>\n"
},
{
"answer_id": 168538,
"author": "dmercer",
"author_id": 8636,
"author_profile": "https://Stackoverflow.com/users/8636",
"pm_score": 3,
"selected": false,
"text": "<ol>\n<li>Check, recheck, and check again any statment that is doing updates. Even if you think you're just doing a simple, single column update, sooner or later you will not have enough coffee and forget a 'where' clause, nuking a whole table.</li>\n</ol>\n\n<p>A couple other things I've found helpful:</p>\n\n<ul>\n<li><p>if using MySQL, enable <a href=\"http://dev.mysql.com/doc/refman/5.0/en/mysql-tips.html#safe-updates\" rel=\"nofollow noreferrer\">Safe updates</a> </p></li>\n<li><p>If you have a DBA, ask them to do it.</p></li>\n</ul>\n\n<p>I 've found these 3 things have kept me from doing any serious harm.</p>\n"
},
{
"answer_id": 168541,
"author": "Derek",
"author_id": 5440,
"author_profile": "https://Stackoverflow.com/users/5440",
"pm_score": 0,
"selected": false,
"text": "<p>Do the exact same update in a Development environment first to make sure it works properly.</p>\n"
},
{
"answer_id": 168546,
"author": "Dylan Beattie",
"author_id": 5017,
"author_profile": "https://Stackoverflow.com/users/5017",
"pm_score": 8,
"selected": true,
"text": "<p>Three things I've learned the hard way over the years...</p>\n\n<p>First, if you're doing updates or deletes on live data, first write a SELECT query with the WHERE clause you'll be using. Make sure it works. Make sure it's correct. Then prepend the UPDATE/DELETE statement to the known working WHERE clause.</p>\n\n<p>You never want to have </p>\n\n<pre><code>DELETE FROM Customers\n</code></pre>\n\n<p>sitting in your query analyzer waiting for you to write the WHERE clause... accidentally hit \"execute\" and you've just killed your Customer table. Oops.</p>\n\n<p>Also, depending on your platform, find out how to take a quick'n'dirty backup of a table. In SQL Server 2005,</p>\n\n<pre><code>SELECT *\nINTO CustomerBackup200810032034\nFROM Customer\n</code></pre>\n\n<p>will copy every row from the entire Customer table into a new table called CustomerBackup200810032034, which you can then delete once you've done your updates and made sure everything's OK. If the worst happens, it's a lot easier to restore missing data from this table than to try and restore last night's backup from disk or tape.</p>\n\n<p>Finally, be wary of cascade deletes getting rid of stuff you didn't intend to delete - check your tables' relationships and key constraints before modifying anything.</p>\n"
},
{
"answer_id": 168554,
"author": "Georgi",
"author_id": 13209,
"author_profile": "https://Stackoverflow.com/users/13209",
"pm_score": 3,
"selected": false,
"text": "<ul>\n<li><strong>Nobody wants backup but everyone cries for recovery</strong></li>\n<li>Create your DB with foreign key references, because you should:</li>\n<li>make it as hard as possible for yourself to update/delete data and destroying the structural integrity / something else with that</li>\n<li>If possible, run on a system where you have to commit the changes before you permanently store them (i.e. deactivate autocommit while repairing the db)</li>\n<li>Try to identify your problem's classes so that you get an understanding how to fix without trouble</li>\n<li>Get a routine in playing backups into a database, always have a second database on a test server at hand so you can just work on that</li>\n<li>Because remember: <strong>If something fails totally, you need to be up and running again as fast as any possible</strong></li>\n</ul>\n\n<p>Well, that's about all I can think of now. Take the bold passages and you see whats #1 for me. ;-)</p>\n"
},
{
"answer_id": 168600,
"author": "Ted Elliott",
"author_id": 16501,
"author_profile": "https://Stackoverflow.com/users/16501",
"pm_score": 0,
"selected": false,
"text": "<p>Turn off AutoCommit in Database IDE if it supports it. I have it turned off in Oracle SQL Developer all the time.</p>\n"
},
{
"answer_id": 168607,
"author": "wcm",
"author_id": 2173,
"author_profile": "https://Stackoverflow.com/users/2173",
"pm_score": 4,
"selected": false,
"text": "<p>As an example, I create SQL like this</p>\n\n<pre><code>--Update P Set\n--Select ID, Name as OldName, \n Name='Jones'\nFrom Person P\nWhere ID = 1000\n</code></pre>\n\n<p>I highlight the text from the end up to the Select and run that SQL. Once I verify that it is pulling the record I want to update, I hit shift-up to hightlight the Update statement and run that. </p>\n\n<p>Note that I used an alias. I never update a table name explicity. I always use an alias.</p>\n\n<p>If I do this in conjunction with transactions and rollback/commits, I am really, really safe.</p>\n"
},
{
"answer_id": 168632,
"author": "Peter",
"author_id": 5189,
"author_profile": "https://Stackoverflow.com/users/5189",
"pm_score": 0,
"selected": false,
"text": "<p>One quick extra I have not seen but that I do often is: backup the table your are updating. I do this by having a database to hold these backups. I can then write:</p>\n\n<pre><code>select *\n into MyBackupDb..PeterTableName2008_09_28BeforeABigUpdate\n</code></pre>\n\n<p>This makes recovery from mistakes much faster down the road (when a full restore is not practical).</p>\n"
},
{
"answer_id": 168734,
"author": "Haoest",
"author_id": 10088,
"author_profile": "https://Stackoverflow.com/users/10088",
"pm_score": 2,
"selected": false,
"text": "<p>Data should always be deployed to live via scripts, which can be rehearsed as many times as it is required to get it right on dev. When there's dependent data for the script to run correctly on dev, stage it appropriately -- you can not get away with this step if you truly want to be careful. </p>\n"
},
{
"answer_id": 168778,
"author": "Michael Easter",
"author_id": 12704,
"author_profile": "https://Stackoverflow.com/users/12704",
"pm_score": 1,
"selected": false,
"text": "<ol>\n<li>if possible, ask to pair with someone</li>\n<li>always count to 3 before pressing Enter (if alone, as this will infuriate your pair partner!)</li>\n</ol>\n"
},
{
"answer_id": 168792,
"author": "Gabriel Isenberg",
"author_id": 1473493,
"author_profile": "https://Stackoverflow.com/users/1473493",
"pm_score": 4,
"selected": false,
"text": "<p>My #1 way to be careful with a live database? Don't touch it. :) </p>\n\n<p>Backups can undo damage that you inflict on the database, but you're still likely to introduce negative side effects during that span of time.</p>\n\n<p>No matter how solid you think the script you're working with is, run it through a test cycle. Even if a \"test cycle\" means running the script against your own instance of the database, make sure you do it. It's much better to introduce defects on your local box than a production environment.</p>\n"
},
{
"answer_id": 168793,
"author": "Herms",
"author_id": 1409,
"author_profile": "https://Stackoverflow.com/users/1409",
"pm_score": 2,
"selected": false,
"text": "<p>My rule (as an app developer): Don't touch it! That's what the trained DBAs are for. Heck, I don't even want permission to touch it. :)</p>\n"
},
{
"answer_id": 168917,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>Check twice, commit once!</p>\n"
},
{
"answer_id": 168968,
"author": "Brian Vander Plaats",
"author_id": 24892,
"author_profile": "https://Stackoverflow.com/users/24892",
"pm_score": 1,
"selected": false,
"text": "<p>If I'm updating a database with a script, I always make sure I put a breakpoint or two at the start of my script, just in case I hit the run/execute by accident. </p>\n"
},
{
"answer_id": 169230,
"author": "Declan Shanaghy",
"author_id": 21297,
"author_profile": "https://Stackoverflow.com/users/21297",
"pm_score": 0,
"selected": false,
"text": "<p>1 - Always create a backup before opening a connection when you know you will need to update or insert records.</p>\n\n<p>2 - When writing an update statement ALWAYS write the WHERE clause first then cursor back to the beginning of the line and write the field update portion.</p>\n\n<p>3 - the where statement for #2 should be checked with a select statement.</p>\n"
},
{
"answer_id": 169271,
"author": "SqlACID",
"author_id": 19797,
"author_profile": "https://Stackoverflow.com/users/19797",
"pm_score": 1,
"selected": false,
"text": "<p>I'll add to recommendations of doing BEGIN TRAN before your UPDATE, just don't forget to actually do the COMMIT; you can do just as much damage if you leave your uncommitted transaction open. Don't get distracted by phones, co-workers, lunch etc when in the middle of updates or you'll find everyone else is locked up until you COMMIT or ROLLBACK.</p>\n"
},
{
"answer_id": 169431,
"author": "Darrel Miller",
"author_id": 6819,
"author_profile": "https://Stackoverflow.com/users/6819",
"pm_score": 0,
"selected": false,
"text": "<p>Go buy <a href=\"http://www.apexsql.com/sql_tools_log.asp\" rel=\"nofollow noreferrer\">Apex SQL Log</a>. If you realize that you really screwed up, or even if it was someone else, you can use the log to reverse the changes.</p>\n"
},
{
"answer_id": 169496,
"author": "Kibbee",
"author_id": 1862,
"author_profile": "https://Stackoverflow.com/users/1862",
"pm_score": 1,
"selected": false,
"text": "<p>I always comment out any destructive queries (insert, update, delete, drop, alter) when writing out adhoc queries in Query Analyzer. That way, the only way to run them, is to highlight them, without selecting the commented part, and press F5.</p>\n\n<p>I also think it's a good idea, as already mentioned, to write your where statement first, with a select, and ensure that you are altering the right data. </p>\n"
},
{
"answer_id": 169956,
"author": "user20282",
"author_id": 20282,
"author_profile": "https://Stackoverflow.com/users/20282",
"pm_score": 1,
"selected": false,
"text": "<ol>\n<li>Always back up before changing.</li>\n<li>Always make mods (eg. ALTER TABLE) via a script.</li>\n<li>Always modify data (eg. DELETE) via a stored procedure.</li>\n</ol>\n"
},
{
"answer_id": 170210,
"author": "MikeJ",
"author_id": 10676,
"author_profile": "https://Stackoverflow.com/users/10676",
"pm_score": 0,
"selected": false,
"text": "<p>dev against a backup - make sure the changes/fixes you want to apply come from a script. fat, clumsy fingers have no place when working with live data. If you can, wait for a maintenance window to apply and roll back if you can. </p>\n\n<p>If you can't wait to apply right after a snapshot,backup, Make sure eveyrone understands how much work might be invovled in rolling forward the changes between the last snapshot and the time whne you applied the \"fix\" should it not work out. </p>\n"
},
{
"answer_id": 170538,
"author": "Richard Nienaber",
"author_id": 9539,
"author_profile": "https://Stackoverflow.com/users/9539",
"pm_score": 1,
"selected": false,
"text": "<p>Create a read only user (or get the DBA to do it) and only use that user to look at the DB. Add the appropriate permissions to schema so that you can view the content of stored procedures/views/triggers/etc. but not have the ability to change them.</p>\n"
},
{
"answer_id": 170560,
"author": "Doron Yaacoby",
"author_id": 3389,
"author_profile": "https://Stackoverflow.com/users/3389",
"pm_score": 2,
"selected": false,
"text": "<p>Different colors per environment: We've setup our PL\\SQL developer (IDE for Oracle) so that when you logon to the production DB all the windows are in bright red. Some have gone as far as assigning a different color for dev and test as well.</p>\n"
},
{
"answer_id": 170561,
"author": "MarkR",
"author_id": 13724,
"author_profile": "https://Stackoverflow.com/users/13724",
"pm_score": 0,
"selected": false,
"text": "<p>Use the same process to QA even a simple SQL data fix as you would a code change of any kind. Ours includes being committed into CVS, Having and having executed a documented test plan, having a code review and having a change control process (where various members of management and the senior operations engineer review and sign off a change).</p>\n\n<p>We do this for all normal SQL data fixes, even simple ones- the only exception being when something is required to fix a major issue with production RIGHT NOW (e.g. blocking all customers from logging in) - in which case we ensure that there are as many pairs of eyes on the job as possible (typically 3-4 people around one workstation, all of whom can veto any action).</p>\n"
},
{
"answer_id": 170644,
"author": "mmacaulay",
"author_id": 22152,
"author_profile": "https://Stackoverflow.com/users/22152",
"pm_score": 0,
"selected": false,
"text": "<p>Besides making a backup of the database before making any destructive changes, another trick I find useful sometimes is if I know the exact number of records I expect to be changed by whatever I'm doing, then add a limit clause:</p>\n\n<p>delete from customers where id = 5 limit 1;</p>\n\n<p>\"id\" might be a unique index and I know there's only row that's going to match my where clause, but the limit is additional layer of prevention against accidentally nuking the wrong data. I've gotten in the habit of typing this part first, in hopes of further prevention against accidental keystrokes. I start out with \"delete limit 1\", then go back and add the other stuff.</p>\n"
},
{
"answer_id": 170895,
"author": "Almond",
"author_id": 1603,
"author_profile": "https://Stackoverflow.com/users/1603",
"pm_score": 0,
"selected": false,
"text": "<p>If your using SQL Server 2005 and above you can create a database snapshot that will allow you to roll back any changes made to the snapshot point in time.</p>\n"
},
{
"answer_id": 175560,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>When updating/deleting only one record mysql lets you put \"LIMIT 1\" at the end so only one record gets damaged even when WHEN clause is wrong.</p>\n"
},
{
"answer_id": 175729,
"author": "HLGEM",
"author_id": 9034,
"author_profile": "https://Stackoverflow.com/users/9034",
"pm_score": 0,
"selected": false,
"text": "<p>I often have to insert,update or delete data on the live production site (As a data analyst that is probably 40% of my job). Most of the time it is through automated DTS or SSIS packages. However, we are also the people who have to fix problem records or update production when a major client driven change occurs (such as a re-organization of the sales force). Sometimes the issues are due to bugs in the code, but usually they are as a result of strange things the client did to their file or things the users managed to mess up to save us time fixing a problem or because they wanted to circumvent the normal process for just this one quick easy change!(Note to users -Please don't try to fix things manually that are normally done thorugh an automated process, you do not know what else the process may be doing!!!!!) So sometimes we don't have the luxury of testing a script on dev first as what is in need of fixing is not on dev. </p>\n\n<p>My rules: Never insert data directly from a file to a production table. Always bring it into a work table so you can view it first. Have checks in place so that if there is bad data in the file, the process will fail before you get to the final step of inserting into production data. Clean up the data first.</p>\n\n<p>If you must delete a large number of records, it can save you if you select those records first into a work table. Then do the delete. That way if things go wrong it is much easier to recover. If you have audit tables, know how to recover data from them quickly. Again if something goes wrong it is much faster to recover from the audit tables than from the tape backup.</p>\n\n<p>I write a delete statement like this:</p>\n\n<p>begin tran</p>\n\n<p>delete a </p>\n\n<p>--select (list important fields to see here)</p>\n\n<p>from table1 a where field1 = 'x'</p>\n\n<p>--rollback tran</p>\n\n<p>--commit tran</p>\n\n<p>Note several things about this. First by using the alias I can't accidentally delete the whole table by only highlighting one line and running the code. By starting the where clause on the same line as the table I am much less likely to miss highlighting it. If I had joins I would make sure each line ends in a place where the code won't work unless it goes to the next line. Again, this ensures you get an error instead of an oopsie. Always run the select first and note the number of records affected (and look at the data to make sure it looks like the right records!) Then do not commit unless the number of records is correct when you run the actual delete. Yeah, it's prettier to start the where on a separate line, it is safer to end each line of a delete so that it will not run unless the whole query is highlighted.</p>\n\n<p>Updates follow simliar rules.</p>\n"
},
{
"answer_id": 240563,
"author": "Bob Probst",
"author_id": 12424,
"author_profile": "https://Stackoverflow.com/users/12424",
"pm_score": 1,
"selected": false,
"text": "<p>The danger of running unintentional Deletes (or inserts, or updates) is always on my mind.</p>\n\n<p>I always add \"where 1=2\" after them until I'm ready to pull the trigger.</p>\n"
},
{
"answer_id": 251330,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>if you are using oracle 10/11g... Flashback</p>\n\n<p><a href=\"http://www.oracle.com/technology/deploy/availability/htdocs/Flashback_Overview.htm\" rel=\"nofollow noreferrer\">http://www.oracle.com/technology/deploy/availability/htdocs/Flashback_Overview.htm</a></p>\n\n<p>It basically maintains a sliding window of undo logs that can be referenced by time or a named marker. It makes dead simple to undo days worth of changes in a couple minutes. without bringing the database down.</p>\n"
},
{
"answer_id": 357230,
"author": "Joseph Ferris",
"author_id": 15906,
"author_profile": "https://Stackoverflow.com/users/15906",
"pm_score": 0,
"selected": false,
"text": "<p>To let the DBAs do the work. Coming from a development background, I don't want/need/should have access to anyone's live database. To me, it is the equivalent of letting a DBA fix coding issue in the DAL, just because it has \"database\" in the title. :-)</p>\n"
},
{
"answer_id": 710618,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>If you are using SQL Server 2005+ Management Studio, you can turn Implicit Transactions ON.</p>\n"
},
{
"answer_id": 766814,
"author": "Nathan Feger",
"author_id": 8563,
"author_profile": "https://Stackoverflow.com/users/8563",
"pm_score": 0,
"selected": false,
"text": "<ol>\n<li><p>I always like to have someone look over my shoulder whenever I connect to a live database.</p></li>\n<li><p>Have a recent copy of the production database stored somewhere. This will often preclude your need to query the production db.</p></li>\n<li><p>If you ever have to do anything to a running db. Document it, and add a fix in as a coded feature available to admins. This way you have one less excuse to point a query tool at your db.</p></li>\n</ol>\n"
},
{
"answer_id": 890697,
"author": "Aaron",
"author_id": 71608,
"author_profile": "https://Stackoverflow.com/users/71608",
"pm_score": 1,
"selected": false,
"text": "<p>I learned this in an interview and thought it was a great idea.</p>\n\n<pre><code>Begin Transaction\n Delete from foo where FooID = 100\nIF @@RowCount <> 1 Begin\n Rollback Transaction\nEnd \n</code></pre>\n"
},
{
"answer_id": 994608,
"author": "tsilb",
"author_id": 11112,
"author_profile": "https://Stackoverflow.com/users/11112",
"pm_score": 0,
"selected": false,
"text": "<p>Whenever I open a connection to PROD, or switch to a PROD data context, the first thing I always do is add this comment before and after my active working code block:</p>\n\n<pre><code>-- PROD -- PROD -- PROD -- PROD -- PROD -- PROD --\n</code></pre>\n\n<p>There have been times when I noticed this while my thumb was on the Alt key and my middle finger was halfway to the 'X' key. Whew!</p>\n"
},
{
"answer_id": 1174212,
"author": "Cesar Reyes",
"author_id": 137740,
"author_profile": "https://Stackoverflow.com/users/137740",
"pm_score": 0,
"selected": false,
"text": "<p>If you are using Microsoft SQL Server Management Studio <strong>2008</strong> you can specify which color to be used in the info window while executing querys (at the bottom of the Sql Query Editor)</p>\n\n<p>On the Connection Promt choose Options > Use Custom Color and select RED for production.</p>\n"
},
{
"answer_id": 1397186,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>Never design any databases with cascading deletes. They're evil. If you do have cascading deletes on FKs, you never know how many rows in other referenced tables will be deleted when you delete a row with a delete statement.</p>\n\n<p>That said, you can't assume anything about what other people do. I always do this:\n1. Copy database to locally installed db (use dumps). Simply tell management you refuse to work if you cannot have a copy of the full DB on you local computer.\n2. Make your script work on your local db, import the dump over and over until the script works perfectly on a cleanly imported dump. Then save the script to a file on disk.\n3. Run script on production server.\n4. Import script into SCM.</p>\n"
},
{
"answer_id": 1971524,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Backups of the data before you start messing with it just like anything else.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168486",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10906/"
] |
For my customer I occasionally do work in their live database in order to fix a problem they have created for themselves, or in order to fix bad data that my product's bugs created. Much like Unix root access, it's just dangerous. What lessons should I learn ahead of time?
What is the #1 thing you do to be careful about operating on live data?
|
Three things I've learned the hard way over the years...
First, if you're doing updates or deletes on live data, first write a SELECT query with the WHERE clause you'll be using. Make sure it works. Make sure it's correct. Then prepend the UPDATE/DELETE statement to the known working WHERE clause.
You never want to have
```
DELETE FROM Customers
```
sitting in your query analyzer waiting for you to write the WHERE clause... accidentally hit "execute" and you've just killed your Customer table. Oops.
Also, depending on your platform, find out how to take a quick'n'dirty backup of a table. In SQL Server 2005,
```
SELECT *
INTO CustomerBackup200810032034
FROM Customer
```
will copy every row from the entire Customer table into a new table called CustomerBackup200810032034, which you can then delete once you've done your updates and made sure everything's OK. If the worst happens, it's a lot easier to restore missing data from this table than to try and restore last night's backup from disk or tape.
Finally, be wary of cascade deletes getting rid of stuff you didn't intend to delete - check your tables' relationships and key constraints before modifying anything.
|
168,487 |
<p>How do I solve the error:</p>
<blockquote>
<p>Unable to read WSDL from URL: <a href="https://workflowtest.site.edu/_vti_bin/Lists.asmx?WSDL" rel="nofollow noreferrer">https://workflowtest.site.edu/_vti_bin/Lists.asmx?WSDL</a>.<br>
Error: 401 Unauthorized.</p>
</blockquote>
<p>I can successfully view the WSDL from the browser using the same user account.
I'm not sure which authentication is being used (Basic or Integrated).</p>
<p>How would I find that out?</p>
<p>The code making the call is:</p>
<pre><code><cfinvoke
username="username"
password="password"
webservice="https://workflowtest.liberty.edu/_vti_bin/Lists.asmx?WSDL"
method="GetList"
listName="{CB02EB71-392E-4906-B512-8EC002F72436}"
>
</code></pre>
<p>The impression I get is that ColdFusion doesn't like being made to authenticate to get the WSDL.</p>
<p>Full stack trace:</p>
<pre><code>coldfusion.xml.rpc.XmlRpcServiceImpl$CantFindWSDLException: Unable to read WSDL from URL: https://workflowtest.liberty.edu/_vti_bin/Lists.asmx?WSDL.
at coldfusion.xml.rpc.XmlRpcServiceImpl.retrieveWSDL(XmlRpcServiceImpl.java:709)
at coldfusion.xml.rpc.XmlRpcServiceImpl.access$000(XmlRpcServiceImpl.java:53)
at coldfusion.xml.rpc.XmlRpcServiceImpl$1.run(XmlRpcServiceImpl.java:239)
at java.security.AccessController.doPrivileged(Native Method)
at coldfusion.xml.rpc.XmlRpcServiceImpl.registerWebService(XmlRpcServiceImpl.java:232)
at coldfusion.xml.rpc.XmlRpcServiceImpl.getWebService(XmlRpcServiceImpl.java:496)
at coldfusion.xml.rpc.XmlRpcServiceImpl.getWebServiceProxy(XmlRpcServiceImpl.java:450)
at coldfusion.tagext.lang.InvokeTag.doEndTag(InvokeTag.java:413)
at coldfusion.runtime.CfJspPage._emptyTcfTag(CfJspPage.java:2662)
at cftonytest2ecfm1787185330.runPage(/var/www/webroot/tonytest.cfm:16)
at coldfusion.runtime.CfJspPage.invoke(CfJspPage.java:196)
at coldfusion.tagext.lang.IncludeTag.doStartTag(IncludeTag.java:370)
at coldfusion.filter.CfincludeFilter.invoke(CfincludeFilter.java:65)
at coldfusion.filter.ApplicationFilter.invoke(ApplicationFilter.java:279)
at coldfusion.filter.RequestMonitorFilter.invoke(RequestMonitorFilter.java:48)
at coldfusion.filter.MonitoringFilter.invoke(MonitoringFilter.java:40)
at coldfusion.filter.PathFilter.invoke(PathFilter.java:86)
at coldfusion.filter.ExceptionFilter.invoke(ExceptionFilter.java:70)
at coldfusion.filter.BrowserDebugFilter.invoke(BrowserDebugFilter.java:74)
at coldfusion.filter.ClientScopePersistenceFilter.invoke(ClientScopePersistenceFilter.java:28)
at coldfusion.filter.BrowserFilter.invoke(BrowserFilter.java:38)
at coldfusion.filter.NoCacheFilter.invoke(NoCacheFilter.java:46)
at coldfusion.filter.GlobalsFilter.invoke(GlobalsFilter.java:38)
at coldfusion.filter.DatasourceFilter.invoke(DatasourceFilter.java:22)
at coldfusion.CfmServlet.service(CfmServlet.java:175)
at coldfusion.bootstrap.BootstrapServlet.service(BootstrapServlet.java:89)
at jrun.servlet.FilterChain.doFilter(FilterChain.java:86)
at coldfusion.monitor.event.MonitoringServletFilter.doFilter(MonitoringServletFilter.java:42)
at coldfusion.bootstrap.BootstrapFilter.doFilter(BootstrapFilter.java:46)
at jrun.servlet.FilterChain.doFilter(FilterChain.java:94)
at jrun.servlet.FilterChain.service(FilterChain.java:101)
at jrun.servlet.ServletInvoker.invoke(ServletInvoker.java:106)
at jrun.servlet.JRunInvokerChain.invokeNext(JRunInvokerChain.java:42)
at jrun.servlet.JRunRequestDispatcher.invoke(JRunRequestDispatcher.java:286)
at jrun.servlet.ServletEngineService.dispatch(ServletEngineService.java:543)
at jrun.servlet.jrpp.JRunProxyService.invokeRunnable(JRunProxyService.java:203)
at jrunx.scheduler.ThreadPool$DownstreamMetrics.invokeRunnable(ThreadPool.java:320)
at jrunx.scheduler.ThreadPool$ThreadThrottle.invokeRunnable(ThreadPool.java:428)
at jrunx.scheduler.ThreadPool$UpstreamMetrics.invokeRunnable(ThreadPool.java:266)
at jrunx.scheduler.WorkerThread.run(WorkerThread.java:66)
</code></pre>
|
[
{
"answer_id": 168806,
"author": "Ryan",
"author_id": 20198,
"author_profile": "https://Stackoverflow.com/users/20198",
"pm_score": 1,
"selected": false,
"text": "<p>I know nothing about ColdFusion but I my first suspect would be a simple permision problem rather than anything CF specific.</p>\n\n<p>Does that CF call use Basic or Integrated authentication? Does IIS match?\nCan you browse to the WSDL using IE/Firefox and the same user account?</p>\n"
},
{
"answer_id": 201053,
"author": "user26888",
"author_id": 26888,
"author_profile": "https://Stackoverflow.com/users/26888",
"pm_score": 3,
"selected": true,
"text": "<p>CFInvoke can only pass basic authentication, not windows integrated authentication. </p>\n\n<p>Sharepoint won't be able to downgrade to basic authentication since sharepoint needs to know who is calling the services to check authentication and authorization of the data being requested.</p>\n\n<p>Your best bet here is to create an asp.net proxy service you can call with CFInvoke which will impersonate the windows authentication you need to call the sharepoint web service.</p>\n\n<p>Another option would be to create a C# com object which makes the authenticated call and passes the information back to CF when you call the C# com object from CF.</p>\n"
},
{
"answer_id": 375077,
"author": "Adrocknaphobia",
"author_id": 41976,
"author_profile": "https://Stackoverflow.com/users/41976",
"pm_score": 1,
"selected": false,
"text": "<p>It it's a permission error like darpy and Ryan suggest, the easiest thing to do is grant the right permission to ColdFusion. On Windows, ColdFusion defaults and runs as the Local System account. You can change that by updating the LogOn properties of the Windows Service for ColdFusion.</p>\n"
},
{
"answer_id": 747711,
"author": "Kevin Busch",
"author_id": 59689,
"author_profile": "https://Stackoverflow.com/users/59689",
"pm_score": 0,
"selected": false,
"text": "<p>I had the same problem.</p>\n\n<p>Open your IIS, and change the LoginType to Basic.\n(in my german Windows it is: \"Verzeichnissicherheit\" -> \"Steuerung des Anonymen Zugriffs und der Authentifizierung\" -> \"Bearbeiten\" -> Set the checkbox for \"Standardauthentifizierung\" )</p>\n\n<p>-Kevin</p>\n"
},
{
"answer_id": 752635,
"author": "Tomalak",
"author_id": 18771,
"author_profile": "https://Stackoverflow.com/users/18771",
"pm_score": 2,
"selected": false,
"text": "<p>This blog post on cfsilence.com might help. <a href=\"http://cfsilence.com/blog/client/index.cfm/2008/3/17/ColdFusionSharepoint-Integration--Part-1--Authenticating\" rel=\"nofollow noreferrer\">ColdFusion/Sharepoint Integration - Part 1 - Authenticating</a></p>\n\n<p>What it boils down to:</p>\n\n<ul>\n<li>ColdFusion uses the Apache Axis web service library</li>\n<li>by default, this library can do nothing but basic HTTP authentication</li>\n<li>you can configure Axis to use an alternative HTTP client library (Jakarta Commons)</li>\n<li>this one can do NTLM authentication, no need to change code or IIS authentication scheme</li>\n<li>after a restart of ColdFusion, you should be good to go</li>\n</ul>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168487",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5849/"
] |
How do I solve the error:
>
> Unable to read WSDL from URL: <https://workflowtest.site.edu/_vti_bin/Lists.asmx?WSDL>.
>
> Error: 401 Unauthorized.
>
>
>
I can successfully view the WSDL from the browser using the same user account.
I'm not sure which authentication is being used (Basic or Integrated).
How would I find that out?
The code making the call is:
```
<cfinvoke
username="username"
password="password"
webservice="https://workflowtest.liberty.edu/_vti_bin/Lists.asmx?WSDL"
method="GetList"
listName="{CB02EB71-392E-4906-B512-8EC002F72436}"
>
```
The impression I get is that ColdFusion doesn't like being made to authenticate to get the WSDL.
Full stack trace:
```
coldfusion.xml.rpc.XmlRpcServiceImpl$CantFindWSDLException: Unable to read WSDL from URL: https://workflowtest.liberty.edu/_vti_bin/Lists.asmx?WSDL.
at coldfusion.xml.rpc.XmlRpcServiceImpl.retrieveWSDL(XmlRpcServiceImpl.java:709)
at coldfusion.xml.rpc.XmlRpcServiceImpl.access$000(XmlRpcServiceImpl.java:53)
at coldfusion.xml.rpc.XmlRpcServiceImpl$1.run(XmlRpcServiceImpl.java:239)
at java.security.AccessController.doPrivileged(Native Method)
at coldfusion.xml.rpc.XmlRpcServiceImpl.registerWebService(XmlRpcServiceImpl.java:232)
at coldfusion.xml.rpc.XmlRpcServiceImpl.getWebService(XmlRpcServiceImpl.java:496)
at coldfusion.xml.rpc.XmlRpcServiceImpl.getWebServiceProxy(XmlRpcServiceImpl.java:450)
at coldfusion.tagext.lang.InvokeTag.doEndTag(InvokeTag.java:413)
at coldfusion.runtime.CfJspPage._emptyTcfTag(CfJspPage.java:2662)
at cftonytest2ecfm1787185330.runPage(/var/www/webroot/tonytest.cfm:16)
at coldfusion.runtime.CfJspPage.invoke(CfJspPage.java:196)
at coldfusion.tagext.lang.IncludeTag.doStartTag(IncludeTag.java:370)
at coldfusion.filter.CfincludeFilter.invoke(CfincludeFilter.java:65)
at coldfusion.filter.ApplicationFilter.invoke(ApplicationFilter.java:279)
at coldfusion.filter.RequestMonitorFilter.invoke(RequestMonitorFilter.java:48)
at coldfusion.filter.MonitoringFilter.invoke(MonitoringFilter.java:40)
at coldfusion.filter.PathFilter.invoke(PathFilter.java:86)
at coldfusion.filter.ExceptionFilter.invoke(ExceptionFilter.java:70)
at coldfusion.filter.BrowserDebugFilter.invoke(BrowserDebugFilter.java:74)
at coldfusion.filter.ClientScopePersistenceFilter.invoke(ClientScopePersistenceFilter.java:28)
at coldfusion.filter.BrowserFilter.invoke(BrowserFilter.java:38)
at coldfusion.filter.NoCacheFilter.invoke(NoCacheFilter.java:46)
at coldfusion.filter.GlobalsFilter.invoke(GlobalsFilter.java:38)
at coldfusion.filter.DatasourceFilter.invoke(DatasourceFilter.java:22)
at coldfusion.CfmServlet.service(CfmServlet.java:175)
at coldfusion.bootstrap.BootstrapServlet.service(BootstrapServlet.java:89)
at jrun.servlet.FilterChain.doFilter(FilterChain.java:86)
at coldfusion.monitor.event.MonitoringServletFilter.doFilter(MonitoringServletFilter.java:42)
at coldfusion.bootstrap.BootstrapFilter.doFilter(BootstrapFilter.java:46)
at jrun.servlet.FilterChain.doFilter(FilterChain.java:94)
at jrun.servlet.FilterChain.service(FilterChain.java:101)
at jrun.servlet.ServletInvoker.invoke(ServletInvoker.java:106)
at jrun.servlet.JRunInvokerChain.invokeNext(JRunInvokerChain.java:42)
at jrun.servlet.JRunRequestDispatcher.invoke(JRunRequestDispatcher.java:286)
at jrun.servlet.ServletEngineService.dispatch(ServletEngineService.java:543)
at jrun.servlet.jrpp.JRunProxyService.invokeRunnable(JRunProxyService.java:203)
at jrunx.scheduler.ThreadPool$DownstreamMetrics.invokeRunnable(ThreadPool.java:320)
at jrunx.scheduler.ThreadPool$ThreadThrottle.invokeRunnable(ThreadPool.java:428)
at jrunx.scheduler.ThreadPool$UpstreamMetrics.invokeRunnable(ThreadPool.java:266)
at jrunx.scheduler.WorkerThread.run(WorkerThread.java:66)
```
|
CFInvoke can only pass basic authentication, not windows integrated authentication.
Sharepoint won't be able to downgrade to basic authentication since sharepoint needs to know who is calling the services to check authentication and authorization of the data being requested.
Your best bet here is to create an asp.net proxy service you can call with CFInvoke which will impersonate the windows authentication you need to call the sharepoint web service.
Another option would be to create a C# com object which makes the authenticated call and passes the information back to CF when you call the C# com object from CF.
|
168,528 |
<p>I know I can get this to technically work but I'd like to implement the cleanest possible solution. Here's the situation:</p>
<p>I have a managed library which wraps an unmanaged C-style library. The C-style library functionality I'm currently wrapping does some processing involving a list of strings. The library's client code can provide a delegate, such that during the list processing, if an "invalid" scenario is encountered, the library can callback to the client via this delegate and allow them to choose the strategy to use (throw an exception, replace the invalid characters, etc.)</p>
<p>What I'd ideally like to have is all of the managed C++ isolated in one function, and then be able to call a separate function which takes only unmanaged parameters so that all of the native C++ and unmanaged code is isolated at that one point. Providing the callback mechanism to this unmanaged code is proving to be the sticking point for me.</p>
<pre><code>
#pragma managed
public delegate string InvalidStringFilter(int lineNumber, string text);
...
public IList<Result> DoListProcessing(IList<string> listToProcess, InvalidStringFilter filter)
{
// Managed code goes here, translate parameters etc.
}
#pragma unmanaged
// This should be the only function that actually touches the C-library directly
std::vector<NativeResult> ProcessList(std::vector<char*> list, ?? callback);
</code></pre>
<p>In this snippet, I want to keep all of the C-library access within ProcessList, but during the processing, it will need to do callbacks, and this callback is provided in the form of the InvalidStringFilter delegate which is passed in from some client of my managed library.</p>
|
[
{
"answer_id": 168598,
"author": "Lou Franco",
"author_id": 3937,
"author_profile": "https://Stackoverflow.com/users/3937",
"pm_score": 2,
"selected": false,
"text": "<p>.NET can auto-convert the delegate to a pointer to function if it is declared right. There are two caveats</p>\n\n<ol>\n<li>The C function must be built STDCALL</li>\n<li>The pointer to function does not count as a reference to the object, so you must arrange for a reference to be kept so that the underlying object is not Garbage collected</li>\n</ol>\n\n<p><a href=\"http://www.codeproject.com/KB/mcpp/FuncPtrDelegate.aspx?display=Print\" rel=\"nofollow noreferrer\">http://www.codeproject.com/KB/mcpp/FuncPtrDelegate.aspx?display=Print</a></p>\n"
},
{
"answer_id": 168604,
"author": "Rob Walker",
"author_id": 3631,
"author_profile": "https://Stackoverflow.com/users/3631",
"pm_score": 2,
"selected": false,
"text": "<p>If I am understanding the problem correctly you need to declare an unmanaged callback function in your C++/CLI assembly that acts as the bridge between your C library and managed delegate.</p>\n\n<pre><code>\n#pragma managed\npublic delegate string InvalidStringFilter(int lineNumber, string text);\n\n...\nstatic InvalidStringFilter sFilter;\n\npublic IList<Result> DoListProcessing(IList<string> listToProcess, InvalidStringFilter filter)\n{\n // Managed code goes here, translate parameters etc.\n SFilter = filter;\n}\n\n#pragma unmanaged\n\nvoid StringCallback(???)\n{\n sFilter(????);\n}\n\n// This should be the only function that actually touches the C-library directly\nstd::vector<NativeResult> ProcessList(std::vector<char*> list, StringCallback);\n</code></pre>\n\n<p>As written this code is clearly not thread-safe. If you need thread safety then some other mechanism would be needed to look up the correct managed delegate in the callback, either a ThreadStatic, or perhaps the callback gets passed a user supplied variable you could use.</p>\n"
},
{
"answer_id": 258472,
"author": "Rasmus Faber",
"author_id": 5542,
"author_profile": "https://Stackoverflow.com/users/5542",
"pm_score": 0,
"selected": false,
"text": "<p>You want to do something like this:</p>\n\n<pre><code>typedef void (__stdcall *w_InvalidStringFilter) (int lineNumber, string message);\n\nGCHandle handle = GCHandle::Alloc(InvalidStringFilter);\nw_InvalidStringFilter callback = \n static_cast<w_InvalidStringFilter>(\n Marshal::GetFunctionPointerForDelegate(InvalidStringFilter).ToPointer()\n );\n\nstd::vector<NativeResult> res = ProcessList(list, callback);\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168528",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24965/"
] |
I know I can get this to technically work but I'd like to implement the cleanest possible solution. Here's the situation:
I have a managed library which wraps an unmanaged C-style library. The C-style library functionality I'm currently wrapping does some processing involving a list of strings. The library's client code can provide a delegate, such that during the list processing, if an "invalid" scenario is encountered, the library can callback to the client via this delegate and allow them to choose the strategy to use (throw an exception, replace the invalid characters, etc.)
What I'd ideally like to have is all of the managed C++ isolated in one function, and then be able to call a separate function which takes only unmanaged parameters so that all of the native C++ and unmanaged code is isolated at that one point. Providing the callback mechanism to this unmanaged code is proving to be the sticking point for me.
```
#pragma managed
public delegate string InvalidStringFilter(int lineNumber, string text);
...
public IList<Result> DoListProcessing(IList<string> listToProcess, InvalidStringFilter filter)
{
// Managed code goes here, translate parameters etc.
}
#pragma unmanaged
// This should be the only function that actually touches the C-library directly
std::vector<NativeResult> ProcessList(std::vector<char*> list, ?? callback);
```
In this snippet, I want to keep all of the C-library access within ProcessList, but during the processing, it will need to do callbacks, and this callback is provided in the form of the InvalidStringFilter delegate which is passed in from some client of my managed library.
|
.NET can auto-convert the delegate to a pointer to function if it is declared right. There are two caveats
1. The C function must be built STDCALL
2. The pointer to function does not count as a reference to the object, so you must arrange for a reference to be kept so that the underlying object is not Garbage collected
<http://www.codeproject.com/KB/mcpp/FuncPtrDelegate.aspx?display=Print>
|
168,531 |
<p>I have a very large file that looks like this (see below). I have two basic choices of regex to use on it (I know there may be others but I'm really trying to compare Greedy and Negated Char Class) methods.</p>
<pre><code>ftp: [^\D]{1,}
ftp: (\d)+
ftp: \d+
</code></pre>
<p><strong><em>Note: what if I took off the parense around the \d?</em></strong></p>
<p>Now + is greedy which forces backtracking but the Negated Char Class require a char-by-char comparison. Which is more efficient? Assume the file is very-very large so minute differences in processor usage will become exaggerated due to the length of the file.</p>
<p>Now that you've answered that, What if my Negated Char Class was very large, say 18 different characters? Would that change your answer?</p>
<p>Thanks.</p>
<blockquote>
<p>ftp: 1117 bytes<br>
ftp: 5696 bytes<br>
ftp: 3207 bytes<br>
ftp: 5696 bytes<br>
ftp: 7200 bytes</p>
</blockquote>
|
[
{
"answer_id": 168551,
"author": "Jay",
"author_id": 20840,
"author_profile": "https://Stackoverflow.com/users/20840",
"pm_score": 0,
"selected": false,
"text": "<p>Not a direct answer to the question, but why not a different approach altogether, since you know the format of the lines already? For example, you could use a regex on the whitespace between the fields, or avoid regex altogether and split() on the whitespace, which is generally going to be faster than any regular expression, depending on the language you're using.</p>\n"
},
{
"answer_id": 168563,
"author": "Markus Jarderot",
"author_id": 22364,
"author_profile": "https://Stackoverflow.com/users/22364",
"pm_score": 2,
"selected": false,
"text": "<p>[^\\D]{1,} and \\d+ is exactly the same. The regex parser will compile [^\\D] and \\d into character classes with the equal content, and + is just short for {1,}.</p>\n\n<p>If you want lazy repetition you can add a ? at the end.</p>\n\n<pre><code>\\d+?\n</code></pre>\n\n<p>The character classes are usually compiled into bitmaps for ASCII-characters. For Unicode (>=256) it is implementation dependent. One way could be to create a list of ranges, and use binary search on it.</p>\n\n<p>For ASCII the lookup time is constant over the size. For Unicode it is logarithmic or linear.</p>\n"
},
{
"answer_id": 168570,
"author": "thelsdj",
"author_id": 163,
"author_profile": "https://Stackoverflow.com/users/163",
"pm_score": 1,
"selected": false,
"text": "<p>My initial tests show that [^\\D{1,} is a bit slower than \\d+, on a 184M file the former takes 9.6 seconds while the latter takes 8.2</p>\n\n<p>Without capturing (the ()'s) both are about 1 second faster, but the difference between the two is about the same.</p>\n\n<p>I also did a more extensive test where the captured value is printed to /dev/null, with a third version splitting on the space, results:</p>\n\n<pre><code>([^\\D]{1,}): ~18s\n(\\d+): ~17s\n(split / /)[1]: ~17s\n</code></pre>\n\n<p>Edit: split version improved and time decreased to be the same or lower than (\\d+)</p>\n\n<p>Fastest version so far (can anyone improve?):</p>\n\n<pre><code>while (<>)\n{\n if ($foo = (split / /)[1])\n {\n print $foo . \"\\n\";\n }\n}\n</code></pre>\n"
},
{
"answer_id": 168571,
"author": "jj33",
"author_id": 430,
"author_profile": "https://Stackoverflow.com/users/430",
"pm_score": 1,
"selected": false,
"text": "<p>This is kind of a trick question as written because <code>(\\d)+</code> takes slightly longer due to the overhead of the capturing parentheses. If you change it to <code>\\d+</code> they take the same amount of time in my Perl / system.</p>\n"
},
{
"answer_id": 168579,
"author": "harpo",
"author_id": 4525,
"author_profile": "https://Stackoverflow.com/users/4525",
"pm_score": 1,
"selected": false,
"text": "<p>Yeah, I agree with MizardX... these two expressions are semantically equivalent. Although the grouping could require additional resources. That's not what you were asking about.</p>\n"
},
{
"answer_id": 168625,
"author": "rslite",
"author_id": 15682,
"author_profile": "https://Stackoverflow.com/users/15682",
"pm_score": 3,
"selected": true,
"text": "<p>Both your expressions have the same greediness. As others have said here, except for the capturing group they will execute in the same way. </p>\n\n<p>Also in this case greediness won't matter much at the execution speed since you don't have anything following \\d*. In this case the expression will simply process all the digits it can find and stop when the space is encountered. No backtracking should occur with these expressions.</p>\n\n<p>To make it more explicit, backtracking should occur if you have an expression like this:</p>\n\n<pre><code>\\d*123\n</code></pre>\n\n<p>In this case the parser will engulf all the digits, then backtrack to match the three following digits.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168531",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/730/"
] |
I have a very large file that looks like this (see below). I have two basic choices of regex to use on it (I know there may be others but I'm really trying to compare Greedy and Negated Char Class) methods.
```
ftp: [^\D]{1,}
ftp: (\d)+
ftp: \d+
```
***Note: what if I took off the parense around the \d?***
Now + is greedy which forces backtracking but the Negated Char Class require a char-by-char comparison. Which is more efficient? Assume the file is very-very large so minute differences in processor usage will become exaggerated due to the length of the file.
Now that you've answered that, What if my Negated Char Class was very large, say 18 different characters? Would that change your answer?
Thanks.
>
> ftp: 1117 bytes
>
> ftp: 5696 bytes
>
> ftp: 3207 bytes
>
> ftp: 5696 bytes
>
> ftp: 7200 bytes
>
>
>
|
Both your expressions have the same greediness. As others have said here, except for the capturing group they will execute in the same way.
Also in this case greediness won't matter much at the execution speed since you don't have anything following \d\*. In this case the expression will simply process all the digits it can find and stop when the space is encountered. No backtracking should occur with these expressions.
To make it more explicit, backtracking should occur if you have an expression like this:
```
\d*123
```
In this case the parser will engulf all the digits, then backtrack to match the three following digits.
|
168,550 |
<p>How can I display a tooltip over a button using <a href="http://en.wikipedia.org/wiki/Windows_Forms" rel="noreferrer">Windows Forms</a>?</p>
|
[
{
"answer_id": 168555,
"author": "Fry",
"author_id": 23553,
"author_profile": "https://Stackoverflow.com/users/23553",
"pm_score": -1,
"selected": false,
"text": "<p>Sure, just handle the mousehover event and tell it to display a tool tip.\nt is a tooltip defined either in the globals or in the constructor using:</p>\n\n<pre><code>ToolTip t = new ToolTip();\n</code></pre>\n\n<p>then the event handler:</p>\n\n<pre><code>private void control_MouseHover(object sender, EventArgs e)\n{\n t.Show(\"Text\", (Control)sender);\n}\n</code></pre>\n"
},
{
"answer_id": 168585,
"author": "DaveK",
"author_id": 4244,
"author_profile": "https://Stackoverflow.com/users/4244",
"pm_score": 6,
"selected": false,
"text": "<p>You can use the ToolTip class:</p>\n\n<p><a href=\"http://msdn.microsoft.com/en-us/library/aa288412(VS.71).aspx\" rel=\"noreferrer\">Creating a ToolTip for a Control </a></p>\n\n<p>Example:</p>\n\n<pre><code>private void Form1_Load(object sender, System.EventArgs e)\n{\n System.Windows.Forms.ToolTip ToolTip1 = new System.Windows.Forms.ToolTip();\n ToolTip1.SetToolTip(this.Button1, \"Hello\");\n}\n</code></pre>\n"
},
{
"answer_id": 168591,
"author": "Timothy Carter",
"author_id": 4660,
"author_profile": "https://Stackoverflow.com/users/4660",
"pm_score": 3,
"selected": false,
"text": "<p>The .NET framework provides a ToolTip class. Add one of those to your form and then on the MouseHover event for each item you would like a tooltip for, do something like the following:</p>\n<pre><code>private void checkBox1_MouseHover(object sender, EventArgs e)\n{\n toolTip1.Show("text", checkBox1);\n}\n</code></pre>\n"
},
{
"answer_id": 168599,
"author": "Dylan Beattie",
"author_id": 5017,
"author_profile": "https://Stackoverflow.com/users/5017",
"pm_score": 8,
"selected": false,
"text": "<p>The ToolTip is a <strong>single</strong> WinForms control that handles displaying tool tips for <strong>multiple</strong> elements on a single form.</p>\n<p>Say your button is called MyButton.</p>\n<ol>\n<li>Add a ToolTip control (under Common\nControls in the Windows Forms\ntoolbox) to your form.</li>\n<li>Give it a\nname - say MyToolTip</li>\n<li>Set the "Tooltip on MyToolTip" property of MyButton (under Misc in\nthe button property grid) to the text that should appear when you hover over it.</li>\n</ol>\n<p>The tooltip will automatically appear when the cursor hovers over the button, but if you need to display it programmatically, call</p>\n<pre><code>MyToolTip.Show("Tooltip text goes here", MyButton);\n</code></pre>\n<p>in your code to show the tooltip, and</p>\n<pre><code>MyToolTip.Hide(MyButton);\n</code></pre>\n<p>to make it disappear again.</p>\n"
},
{
"answer_id": 168622,
"author": "jmatthias",
"author_id": 2768,
"author_profile": "https://Stackoverflow.com/users/2768",
"pm_score": 7,
"selected": false,
"text": "<p>Using the form designer:</p>\n\n<ul>\n<li>Drag the ToolTip control from the Toolbox, onto the form.</li>\n<li>Select the properties of the control you want the tool tip to appear on.</li>\n<li>Find the property 'ToolTip on toolTip1' (the name may not be toolTip1 if you changed it's default name).</li>\n<li>Set the text of the property to the tool tip text you would like to display.</li>\n</ul>\n\n<p>You can set also the tool tip programatically using the following call:</p>\n\n<pre><code>this.toolTip1.SetToolTip(this.targetControl, \"My Tool Tip\");\n</code></pre>\n"
},
{
"answer_id": 31805340,
"author": "nvivekgoyal",
"author_id": 1005063,
"author_profile": "https://Stackoverflow.com/users/1005063",
"pm_score": 3,
"selected": false,
"text": "<p>For default tooltip this can be used -</p>\n\n<pre><code>System.Windows.Forms.ToolTip ToolTip1 = new System.Windows.Forms.ToolTip();\nToolTip1.SetToolTip(this.textBox1, \"Hello world\");\n</code></pre>\n\n<p>A customized tooltip can also be used in case if formatting is required for tooltip message. This can be created by custom formatting the form and use it as tooltip dialog on mouse hover event of the control. Please check following link for more details -</p>\n\n<p><a href=\"http://newapputil.blogspot.in/2015/08/create-custom-tooltip-dialog-from-form.html\" rel=\"noreferrer\">http://newapputil.blogspot.in/2015/08/create-custom-tooltip-dialog-from-form.html</a></p>\n"
},
{
"answer_id": 37788880,
"author": "flodis",
"author_id": 4299943,
"author_profile": "https://Stackoverflow.com/users/4299943",
"pm_score": 3,
"selected": false,
"text": "<p><strong>Lazy and compact storing text in the <em>Tag</em> property</strong></p>\n<p>If you are a bit lazy and do not use the <em>Tag</em> property of the controls for anything else you can use it to store the tooltip text and assign <em>MouseHover</em> event handlers to all such controls in one go like this:</p>\n<pre><code>private System.Windows.Forms.ToolTip ToolTip1;\nprivate void PrepareTooltips()\n{\n ToolTip1 = new System.Windows.Forms.ToolTip();\n foreach(Control ctrl in this.Controls)\n {\n if (ctrl is Button && ctrl.Tag is string)\n {\n ctrl.MouseHover += new EventHandler(delegate(Object o, EventArgs a)\n {\n var btn = (Control)o;\n ToolTip1.SetToolTip(btn, btn.Tag.ToString());\n });\n }\n }\n}\n</code></pre>\n<p>In this case all buttons having a string in the <em>Tag</em> property is assigned a <em>MouseHover</em> event. To keep it compact the <em>MouseHover</em> event is defined inline using a lambda expression. In the event any button hovered will have its <em>Tag</em> text assigned to the Tooltip and shown.</p>\n"
},
{
"answer_id": 49053929,
"author": "akn",
"author_id": 9429951,
"author_profile": "https://Stackoverflow.com/users/9429951",
"pm_score": 2,
"selected": false,
"text": "<pre><code>private void Form1_Load(object sender, System.EventArgs e)\n{\n ToolTip toolTip1 = new ToolTip();\n toolTip1.AutoPopDelay = 5000;\n toolTip1.InitialDelay = 1000;\n toolTip1.ReshowDelay = 500;\n toolTip1.ShowAlways = true;\n toolTip1.SetToolTip(this.button1, \"My button1\");\n toolTip1.SetToolTip(this.checkBox1, \"My checkBox1\");\n}\n</code></pre>\n"
},
{
"answer_id": 62537758,
"author": "The_Black_Smurf",
"author_id": 315493,
"author_profile": "https://Stackoverflow.com/users/315493",
"pm_score": 2,
"selected": false,
"text": "<p>Based on <a href=\"https://stackoverflow.com/a/168585/315493\">DaveK's answer</a>, I created a control extension:</p>\n<pre><code>public static void SetToolTip(this Control control, string txt)\n{\n new ToolTip().SetToolTip(control, txt);\n}\n</code></pre>\n<p>Then you can set the tooltip for any control with a single line:</p>\n<pre><code>this.MyButton.SetToolTip("Hello world");\n</code></pre>\n"
},
{
"answer_id": 73166890,
"author": "Charan Vasant Achari",
"author_id": 19648065,
"author_profile": "https://Stackoverflow.com/users/19648065",
"pm_score": 0,
"selected": false,
"text": "<p>I have done the cool tool tip\nCode is:</p>\n<p>1.Initialize the tooltip object</p>\n<p>2.call the object when or where you want to displays your creativity</p>\n<pre><code>Ex- \nToolTip t=new ToolTip();\nt.setToolTip(textBoxName,"write your message here what tp you want to show up");\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168550",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
How can I display a tooltip over a button using [Windows Forms](http://en.wikipedia.org/wiki/Windows_Forms)?
|
The ToolTip is a **single** WinForms control that handles displaying tool tips for **multiple** elements on a single form.
Say your button is called MyButton.
1. Add a ToolTip control (under Common
Controls in the Windows Forms
toolbox) to your form.
2. Give it a
name - say MyToolTip
3. Set the "Tooltip on MyToolTip" property of MyButton (under Misc in
the button property grid) to the text that should appear when you hover over it.
The tooltip will automatically appear when the cursor hovers over the button, but if you need to display it programmatically, call
```
MyToolTip.Show("Tooltip text goes here", MyButton);
```
in your code to show the tooltip, and
```
MyToolTip.Hide(MyButton);
```
to make it disappear again.
|
168,559 |
<p><a href="http://www.python.org/doc/2.5.2/lib/module-tempfile.html" rel="noreferrer">tempfile.mkstemp()</a> returns:</p>
<blockquote>
<p>a tuple containing an OS-level handle to an open file (as would be returned by os.open()) and the absolute pathname of that file, in that order.</p>
</blockquote>
<p>How do I convert that OS-level handle to a file object?</p>
<p>The <a href="http://www.python.org/doc/2.5.2/lib/os-fd-ops.html" rel="noreferrer">documentation for os.open()</a> states: </p>
<blockquote>
<p>To wrap a file descriptor in a "file
object", use fdopen().</p>
</blockquote>
<p>So I tried:</p>
<pre><code>>>> import tempfile
>>> tup = tempfile.mkstemp()
>>> import os
>>> f = os.fdopen(tup[0])
>>> f.write('foo\n')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
IOError: [Errno 9] Bad file descriptor
</code></pre>
|
[
{
"answer_id": 168584,
"author": "Peter Hoffmann",
"author_id": 720,
"author_profile": "https://Stackoverflow.com/users/720",
"pm_score": 7,
"selected": true,
"text": "<p>You can use </p>\n\n<pre><code>os.write(tup[0], \"foo\\n\")\n</code></pre>\n\n<p>to write to the handle.</p>\n\n<p>If you want to open the handle for writing you need to add the <strong>\"w\"</strong> mode</p>\n\n<pre><code>f = os.fdopen(tup[0], \"w\")\nf.write(\"foo\")\n</code></pre>\n"
},
{
"answer_id": 168640,
"author": "efotinis",
"author_id": 12320,
"author_profile": "https://Stackoverflow.com/users/12320",
"pm_score": 3,
"selected": false,
"text": "<p>You forgot to specify the open mode ('w') in fdopen(). The default is 'r', causing the write() call to fail.</p>\n\n<p>I think mkstemp() creates the file for reading only. Calling fdopen with 'w' probably reopens it for writing (you <em>can</em> reopen the file created by mkstemp).</p>\n"
},
{
"answer_id": 168705,
"author": "Alex Coventry",
"author_id": 1941213,
"author_profile": "https://Stackoverflow.com/users/1941213",
"pm_score": 2,
"selected": false,
"text": "<p>What's your goal, here? Is <code>tempfile.TemporaryFile</code> inappropriate for your purposes?</p>\n"
},
{
"answer_id": 1296063,
"author": "Daryl Spitzer",
"author_id": 4766,
"author_profile": "https://Stackoverflow.com/users/4766",
"pm_score": 4,
"selected": false,
"text": "<p>Here's how to do it using a with statement:</p>\n\n<pre><code>from __future__ import with_statement\nfrom contextlib import closing\nfd, filepath = tempfile.mkstemp()\nwith closing(os.fdopen(fd, 'w')) as tf:\n tf.write('foo\\n')\n</code></pre>\n"
},
{
"answer_id": 2414333,
"author": "hoju",
"author_id": 105066,
"author_profile": "https://Stackoverflow.com/users/105066",
"pm_score": 2,
"selected": false,
"text": "<pre><code>temp = tempfile.NamedTemporaryFile(delete=False)\ntemp.file.write('foo\\n')\ntemp.close()\n</code></pre>\n"
},
{
"answer_id": 16942329,
"author": "MartinD",
"author_id": 1027660,
"author_profile": "https://Stackoverflow.com/users/1027660",
"pm_score": 0,
"selected": false,
"text": "<p>I can't comment on the answers, so I will post my comment here:</p>\n\n<p>To create a temporary file for write access you can use tempfile.mkstemp and specify \"w\" as the last parameter, like:</p>\n\n<pre><code>f = tempfile.mkstemp(\"\", \"\", \"\", \"w\") # first three params are 'suffix, 'prefix', 'dir'...\nos.write(f[0], \"write something\")\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168559",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4766/"
] |
[tempfile.mkstemp()](http://www.python.org/doc/2.5.2/lib/module-tempfile.html) returns:
>
> a tuple containing an OS-level handle to an open file (as would be returned by os.open()) and the absolute pathname of that file, in that order.
>
>
>
How do I convert that OS-level handle to a file object?
The [documentation for os.open()](http://www.python.org/doc/2.5.2/lib/os-fd-ops.html) states:
>
> To wrap a file descriptor in a "file
> object", use fdopen().
>
>
>
So I tried:
```
>>> import tempfile
>>> tup = tempfile.mkstemp()
>>> import os
>>> f = os.fdopen(tup[0])
>>> f.write('foo\n')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
IOError: [Errno 9] Bad file descriptor
```
|
You can use
```
os.write(tup[0], "foo\n")
```
to write to the handle.
If you want to open the handle for writing you need to add the **"w"** mode
```
f = os.fdopen(tup[0], "w")
f.write("foo")
```
|
168,560 |
<p>What is the best way to perform a couple of tasks together and if one task fails then the next tasks should not be completed? I know if it were the database operations then I should have used Transactions but I am talking about different types of operations like the following: </p>
<p>All tasks must pass: </p>
<p>SendEmail
ArchiveReportsInDatabase
CreateAFile</p>
<p>In the above scenario all the tasks must pass or else the whole batch operation must be rollback. </p>
|
[
{
"answer_id": 168567,
"author": "Echostorm",
"author_id": 12862,
"author_profile": "https://Stackoverflow.com/users/12862",
"pm_score": 2,
"selected": false,
"text": "<p>in C#</p>\n\n<p>return SendEmail() && ArchiveResportsInDatabase() && CreateAFile();</p>\n"
},
{
"answer_id": 168576,
"author": "easeout",
"author_id": 10906,
"author_profile": "https://Stackoverflow.com/users/10906",
"pm_score": 0,
"selected": false,
"text": "<p>If your language allows it, this is very tidy:</p>\n\n<ol>\n<li>Put your tasks in an array of code blocks or function pointers.</li>\n<li>Iterate over the array.</li>\n<li>Break if any block returns failure.</li>\n</ol>\n"
},
{
"answer_id": 168605,
"author": "easeout",
"author_id": 10906,
"author_profile": "https://Stackoverflow.com/users/10906",
"pm_score": 1,
"selected": false,
"text": "<p>Another idea:</p>\n\n<pre><code>try {\n task1();\n task2();\n task3();\n ...\n taskN();\n}\ncatch (TaskFailureException e) {\n dealWith(e);\n}\n</code></pre>\n"
},
{
"answer_id": 168608,
"author": "Yuval",
"author_id": 23202,
"author_profile": "https://Stackoverflow.com/users/23202",
"pm_score": 0,
"selected": false,
"text": "<p>You didn't mention what programming language/environment you're using. If it's the .NET Framework, you might want to take a look at <a href=\"http://msdn.microsoft.com/en-us/magazine/cc163556.aspx\" rel=\"nofollow noreferrer\">this article</a>. It describes the Concurrency and Control Runtime from Microsoft's Robotics Studio, which allows you to apply all sorts of rules on a set of (asynchronous) events: for example, you can wait for any number of them to complete, cancel if one event fails, etc. It can run things in multiple threads as well, so you get a very powerful method of doing stuff.</p>\n"
},
{
"answer_id": 168609,
"author": "Andru Luvisi",
"author_id": 5922,
"author_profile": "https://Stackoverflow.com/users/5922",
"pm_score": 0,
"selected": false,
"text": "<p>You don't specify your environment. In Unix shell scripting, the && operator does just this.</p>\n\n<pre><code>SendEmail () {\n # ...\n}\nArchiveReportsInDatabase () {\n # ...\n}\nCreateAFile () {\n # ...\n}\n\nSendEmail && ArchiveReportsInDatabase && CreateAFile\n</code></pre>\n"
},
{
"answer_id": 168615,
"author": "Kristopher Johnson",
"author_id": 1175,
"author_profile": "https://Stackoverflow.com/users/1175",
"pm_score": 1,
"selected": false,
"text": "<p>A couple of suggestions:</p>\n\n<p>In a distributed scenario, some sort of two-phase commit protocol may be needed. Essentially, you send all participants a message saying \"Prepare to do X\". Each participant must then send a response saying \"OK, I guarantee I can do X\" or \"No, can't do it.\" If all participants guarantee they can complete, then send the message telling them to do it. The \"guarantees\" can be as strict as needed.</p>\n\n<p>Another approach is to provide some sort of undo mechanism for each operation, then have logic like this:</p>\n\n<pre><code>try:\n SendEmail()\n try:\n ArchiveReportsInDatabase()\n try:\n CreateAFile()\n except:\n UndoArchiveReportsInDatabase()\n raise\n except:\n UndoSendEmail()\n raise\nexcept:\n // handle failure\n</code></pre>\n\n<p>(You wouldn't want your code to look like that; this is just an illustration of how the logic should flow.)</p>\n"
},
{
"answer_id": 168630,
"author": "Eugene Katz",
"author_id": 1533,
"author_profile": "https://Stackoverflow.com/users/1533",
"pm_score": 0,
"selected": false,
"text": "<p>If you're using a language which uses <a href=\"http://en.wikipedia.org/wiki/Short-circuit_evaluation\" rel=\"nofollow noreferrer\">sort-circuit evaluation</a> (Java and C# do), you can simply do:</p>\n\n<pre><code>return SendEmail() && ArchiveResportsInDatabase() && CreateAFile();\n</code></pre>\n\n<p>This will return true if all the functions return true, and stop as soon as the first one return false.</p>\n"
},
{
"answer_id": 168641,
"author": "Ates Goral",
"author_id": 23501,
"author_profile": "https://Stackoverflow.com/users/23501",
"pm_score": 1,
"selected": true,
"text": "<p>Exceptions are generally good for this sort of thing. Pseudo-Java/JavaScript/C++ code:</p>\n\n<pre><code>try {\n if (!SendEmail()) {\n throw \"Could not send e-mail\";\n }\n\n if (!ArchiveReportsInDatabase()) {\n throw \"Could not archive reports in database\";\n }\n\n if (!CreateAFile()) {\n throw \"Could not create file\";\n }\n\n ...\n\n} catch (Exception) {\n LogError(Exception);\n ...\n}\n</code></pre>\n\n<p>Better still if your methods throw exceptions themselves:</p>\n\n<pre><code>try {\n SendEmail();\n ArchiveReportsInDatabase();\n CreateAFile();\n ...\n\n} catch (Exception) {\n LogError(Exception);\n ...\n}\n</code></pre>\n\n<p>A very nice outcome of this style is that your code doesn't get increasingly indented as you move down the task chain; all your method calls remain at the same indentation level. Too much indentation makes the code harder to read.</p>\n\n<p>Moreover, you have a single point in the code for error handling, logging, rollback etc.</p>\n"
},
{
"answer_id": 168680,
"author": "JC.",
"author_id": 3615,
"author_profile": "https://Stackoverflow.com/users/3615",
"pm_score": 0,
"selected": false,
"text": "<p>To really do it right you should use an asyncronous messaging pattern. I just finished a project where I did this using <a href=\"http://www.nservicebus.com/\" rel=\"nofollow noreferrer\">nServiceBus</a> and MSMQ.</p>\n\n<p>Basically, each step happens by sending a message to a queue. When nServiceBus finds messages waiting in the queue it calls your Handle method corresponding to that message type. This way each individual step is independently failable and retryable. If one step fails the message ends up in an error queue so you can easily retry it later.</p>\n\n<p>These pure-code solutions being suggested aren't as robust since if a step fails you would have no way to retry only that one step in the future and you'd have to implement rollback code which isn't even possible in some cases.</p>\n"
},
{
"answer_id": 168856,
"author": "Mark Brackett",
"author_id": 2199,
"author_profile": "https://Stackoverflow.com/users/2199",
"pm_score": 2,
"selected": false,
"text": "<p>Rollbacks are tough - AFAIK, there's really only 2 ways to go about it. Either a <a href=\"http://en.wikipedia.org/wiki/Two-phase-commit_protocol\" rel=\"nofollow noreferrer\">2 phase commit protocol</a>, or <a href=\"http://en.wikipedia.org/wiki/Compensating_transaction\" rel=\"nofollow noreferrer\">compensating transactions</a>. You really have to find a way to structure your tasks in one of these fashions.</p>\n\n<p>Usually, the better idea is to take advantage of other folks' hard work and use technologies that already have 2PC or compensation built in. That's one reason that RDBMS are so popular.</p>\n\n<p>So, the specifics are task dependent...but the pattern is fairly easy:</p>\n\n<pre><code>class Compensator {\n Action Action { get; set; }\n Action Compensate { get; set; }\n}\n\nQueue<Compensator> actions = new Queue<Compensator>(new Compensator[] { \n new Compensator(SendEmail, UndoSendEmail),\n new Compensator(ArchiveReportsInDatabase, UndoArchiveReportsInDatabase),\n new Compensator(CreateAFile, UndoCreateAFile)\n});\n\nQueue<Compensator> doneActions = new Queue<Compensator>();\nwhile (var c = actions.Dequeue() != null) {\n try {\n c.Action();\n doneActions.Add(c);\n } catch {\n try {\n doneActions.Each(d => d.Compensate());\n } catch (EXception ex) {\n throw new OhCrapException(\"Couldn't rollback\", doneActions, ex);\n }\n throw;\n }\n}\n</code></pre>\n\n<p>Of course, for your specific tasks - you may be in luck. </p>\n\n<ul>\n<li>Obviously, the RDBMS work can already be wrapped in a transaction. </li>\n<li>If you're on Vista or Server 2008, then you get <a href=\"http://en.wikipedia.org/wiki/Transactional_NTFS\" rel=\"nofollow noreferrer\">Transactional NTFS</a> to cover your CreateFile scenario.</li>\n<li>Email is a bit trickier - I don't know of any 2PC or Compensators around it (I'd only be slightly surprised if someone pointed out that Exchange has one, though) so I'd probably use <a href=\"http://en.wikipedia.org/wiki/Microsoft_Message_Queuing\" rel=\"nofollow noreferrer\">MSMQ</a> to write a notification and let a subscriber pick it up and eventually email it. At that point, your transaction really covers just sending the message to the queue, but that's probably good enough.</li>\n</ul>\n\n<p>All of these can participate in a <a href=\"http://msdn.microsoft.com/en-us/library/ms973865.aspx\" rel=\"nofollow noreferrer\">System.Transactions</a> Transaction, so you should be in pretty good shape.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168560",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3797/"
] |
What is the best way to perform a couple of tasks together and if one task fails then the next tasks should not be completed? I know if it were the database operations then I should have used Transactions but I am talking about different types of operations like the following:
All tasks must pass:
SendEmail
ArchiveReportsInDatabase
CreateAFile
In the above scenario all the tasks must pass or else the whole batch operation must be rollback.
|
Exceptions are generally good for this sort of thing. Pseudo-Java/JavaScript/C++ code:
```
try {
if (!SendEmail()) {
throw "Could not send e-mail";
}
if (!ArchiveReportsInDatabase()) {
throw "Could not archive reports in database";
}
if (!CreateAFile()) {
throw "Could not create file";
}
...
} catch (Exception) {
LogError(Exception);
...
}
```
Better still if your methods throw exceptions themselves:
```
try {
SendEmail();
ArchiveReportsInDatabase();
CreateAFile();
...
} catch (Exception) {
LogError(Exception);
...
}
```
A very nice outcome of this style is that your code doesn't get increasingly indented as you move down the task chain; all your method calls remain at the same indentation level. Too much indentation makes the code harder to read.
Moreover, you have a single point in the code for error handling, logging, rollback etc.
|
168,589 |
<p>I can do this:</p>
<pre><code>$ find .
.
./b
./b/foo
./c
./c/foo
</code></pre>
<p>And this:</p>
<pre><code>$ find . -type f -exec cat {} \;
This is in b.
This is in c.
</code></pre>
<p>But not this:</p>
<pre><code>$ find . -type f -exec cat > out.txt {} \;
</code></pre>
<p>Why not?</p>
|
[
{
"answer_id": 168595,
"author": "Commodore Jaeger",
"author_id": 4659,
"author_profile": "https://Stackoverflow.com/users/4659",
"pm_score": 6,
"selected": true,
"text": "<p>find's -exec argument runs the command you specify once for each file it finds. Try:</p>\n\n<pre><code>$ find . -type f -exec cat {} \\; > out.txt\n</code></pre>\n\n<p>or:</p>\n\n<pre><code>$ find . -type f | xargs cat > out.txt\n</code></pre>\n\n<p>xargs converts its standard input into command-line arguments for the command you specify. If you're worried about embedded spaces in filenames, try:</p>\n\n<pre><code>$ find . -type f -print0 | xargs -0 cat > out.txt\n</code></pre>\n"
},
{
"answer_id": 168603,
"author": "Jay",
"author_id": 20840,
"author_profile": "https://Stackoverflow.com/users/20840",
"pm_score": 2,
"selected": false,
"text": "<p>How about just redirecting the output of find into a file, since all you're wanting to do is cat all the files into one large file:</p>\n\n<pre><code>find . -type f -exec cat {} \\; > /tmp/out.txt\n</code></pre>\n"
},
{
"answer_id": 168613,
"author": "JoMo",
"author_id": 4107,
"author_profile": "https://Stackoverflow.com/users/4107",
"pm_score": 2,
"selected": false,
"text": "<p>You could do something like this : </p>\n\n<pre><code>$ cat `find . -type f` > out.txt\n</code></pre>\n"
},
{
"answer_id": 168636,
"author": "Zsolt Botykai",
"author_id": 11621,
"author_profile": "https://Stackoverflow.com/users/11621",
"pm_score": 0,
"selected": false,
"text": "<p>Or just leave out the find which is useless if you use the really great Z shell (<code>zsh</code>), and you can do this:</p>\n\n<pre><code>setopt extendedglob\n</code></pre>\n\n<p>(this should be in your <code>.zshrc</code>)\nThen:</p>\n\n<pre><code>cat **/*(.) > outfile \n</code></pre>\n\n<p>just works :-)</p>\n"
},
{
"answer_id": 168673,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>Hmm... find seems to be recursing as you output out.txt to the current directory</p>\n\n<p>Try something like</p>\n\n<pre><code>find . -type f -exec cat {} \\; > ../out.txt\n</code></pre>\n"
},
{
"answer_id": 168752,
"author": "dlamblin",
"author_id": 459,
"author_profile": "https://Stackoverflow.com/users/459",
"pm_score": 1,
"selected": false,
"text": "<p>Maybe you've inferred from the other responses that the <code>></code> symbol is interpreted by the shell before find gets it as an argument. But to answer your \"why not\" lets look at your command, which is:</p>\n\n<pre><code>$ find . -type f -exec cat > out.txt {} \\;\n</code></pre>\n\n<p>So you're giving <code>find</code> these arguments: <code>\".\" \"-type\" \"f\" \"-exec\" \"cat\"</code> you're giving the redirect these arguments: <code>\"out.txt\" \"{}\"</code> and <code>\";\"</code>. This confuses <code>find</code> by not terminating the <code>-exec</code> arguments with a semi-colon and by not using the file name as an argument (\"{}\"), it possibly confuses the redirection too.</p>\n\n<p>Looking at the other suggestions you should really avoid creating the output in the same directory you're finding in. But they'd work with that in mind. And the <code>-print0 | xargs -0</code> combination is greatly useful. What you wanted to type was probably more like:</p>\n\n<pre><code>$ find . -type f -exec cat \\{} \\; > /tmp/out.txt\n</code></pre>\n\n<p>Now if you really only have one level of sub directories and only normal files, you can do something silly and simple like this:</p>\n\n<pre><code>cat `ls -p|sed 's/\\/$/\\/*/'` > /tmp/out.txt\n</code></pre>\n\n<p>Which gets <code>ls</code> to list all your files and directories appending <code>'/'</code> to the directories, while <code>sed</code> will append a <code>'*'</code> to the directories. The shell will then interpret this list and expand the globs. Assuming that doesn't result in too many files for the shell to handle, these will all be passed as arguments to cat, and the output will be written to out.txt.</p>\n"
},
{
"answer_id": 168785,
"author": "Milan Babuškov",
"author_id": 14690,
"author_profile": "https://Stackoverflow.com/users/14690",
"pm_score": 0,
"selected": false,
"text": "<p>Try this:</p>\n\n<pre><code>(find . -type f -exec cat {} \\;) > out.txt \n</code></pre>\n"
},
{
"answer_id": 168984,
"author": "ljorquera",
"author_id": 9132,
"author_profile": "https://Stackoverflow.com/users/9132",
"pm_score": 0,
"selected": false,
"text": "<p>In bash you could do </p>\n\n<pre><code>cat $(find . -type f) > out.txt\n</code></pre>\n\n<p>with $( ) you can get the output from a command and pass it to another</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168589",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22917/"
] |
I can do this:
```
$ find .
.
./b
./b/foo
./c
./c/foo
```
And this:
```
$ find . -type f -exec cat {} \;
This is in b.
This is in c.
```
But not this:
```
$ find . -type f -exec cat > out.txt {} \;
```
Why not?
|
find's -exec argument runs the command you specify once for each file it finds. Try:
```
$ find . -type f -exec cat {} \; > out.txt
```
or:
```
$ find . -type f | xargs cat > out.txt
```
xargs converts its standard input into command-line arguments for the command you specify. If you're worried about embedded spaces in filenames, try:
```
$ find . -type f -print0 | xargs -0 cat > out.txt
```
|
168,594 |
<p>I am creating some build scripts that interact with Perforce and I would like to mark for delete a few files. What exactly is the P4 syntax using the command line?</p>
|
[
{
"answer_id": 168614,
"author": "JR Lawhorne",
"author_id": 22917,
"author_profile": "https://Stackoverflow.com/users/22917",
"pm_score": 4,
"selected": true,
"text": "<pre><code>p4 delete filename\n</code></pre>\n\n<p>(output of p4 help delete)</p>\n\n<p>delete -- Open an existing file to delete it from the depot</p>\n\n<p>p4 delete [ -c changelist# ] [ -n ] file ...</p>\n\n<pre><code>Opens a file that currently exists in the depot for deletion.\nIf the file is present on the client it is removed. If a pending\nchangelist number is given with the -c flag the opened file is\nassociated with that changelist, otherwise it is associated with\nthe 'default' pending changelist.\n\nFiles that are deleted generally do not appear on the have list.\n\nThe -n flag displays what would be opened for delete without actually\nchanging any files or metadata.\n</code></pre>\n"
},
{
"answer_id": 168617,
"author": "Swati",
"author_id": 12682,
"author_profile": "https://Stackoverflow.com/users/12682",
"pm_score": 2,
"selected": false,
"text": "<p><a href=\"http://www.perforce.com/perforce/doc.062/manuals/boilerplates/quickstart.html\" rel=\"nofollow noreferrer\">http://www.perforce.com/perforce/doc.062/manuals/boilerplates/quickstart.html</a></p>\n\n<p><strong>Deleting files</strong></p>\n\n<p>To delete files from both the Perforce server and your workspace, issue the p4 delete command. For example:</p>\n\n<pre><code>p4 delete demo.txt readme.txt\n</code></pre>\n\n<p>The specified files are removed from your workspace and marked for deletion from the server. If you decide you don't want to delete the files after all, issue the p4 revert command. When you revert files opened for delete, Perforce restores them to your workspace.</p>\n"
},
{
"answer_id": 168627,
"author": "Michael Burr",
"author_id": 12711,
"author_profile": "https://Stackoverflow.com/users/12711",
"pm_score": 3,
"selected": false,
"text": "<p>Teach a man to fish:</p>\n\n<ul>\n<li><code>p4 help</code> - gets you general command\nsyntax </li>\n<li><code>p4 help commands</code> - lists the\ncommands </li>\n<li><code>p4 help <command name></code> - \nprovides detailed help for a specific\ncommand</li>\n</ul>\n"
},
{
"answer_id": 2314692,
"author": "ssc",
"author_id": 217844,
"author_profile": "https://Stackoverflow.com/users/217844",
"pm_score": 0,
"selected": false,
"text": "<p>Admitted - it takes a (small) number of steps to find the (excellent!) Perforce user guide online in the version that matches your installation and get to the chapter with the information you need.</p>\n\n<p>Whenever I find myself in need of anything about the p4 command line client, I rely on the help Perforce have built into it. Accessing it could not be easier:</p>\n\n<ol>\n<li>on the command line, enter <code>p4</code></li>\n</ol>\n\n<p>This gets you to the information Michael Burr has shown in his answer (and some more).\nIf you do not get a help screen right away, something is wrong with our client configuration, e.g. P4PORT is not set properly. You obviously need to fix that first.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168594",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4872/"
] |
I am creating some build scripts that interact with Perforce and I would like to mark for delete a few files. What exactly is the P4 syntax using the command line?
|
```
p4 delete filename
```
(output of p4 help delete)
delete -- Open an existing file to delete it from the depot
p4 delete [ -c changelist# ] [ -n ] file ...
```
Opens a file that currently exists in the depot for deletion.
If the file is present on the client it is removed. If a pending
changelist number is given with the -c flag the opened file is
associated with that changelist, otherwise it is associated with
the 'default' pending changelist.
Files that are deleted generally do not appear on the have list.
The -n flag displays what would be opened for delete without actually
changing any files or metadata.
```
|
168,596 |
<p>When an Event is triggered by a user in IE, it is set to the <code>window.event</code> object. The only way to see what triggered the event is by accessing the <code>window.event</code> object (as far as I know)</p>
<p>This causes a problem in ASP.NET validators if an event is triggered programmatically, like when triggering an event through jQuery. In this case, the <code>window.event</code> object stores the last user-triggered event.</p>
<p>When the <code>onchange</code> event is fired programmatically for a text box that has an ASP.NET validator attached to it, the validation breaks because it is looking at the element that fired last event, which is not the element the validator is for.</p>
<p>Does anyone know a way around this? It seems like a problem that is solvable, but from looking online, most people just find ways to ignore the problem instead of solving it.</p>
<hr>
<p><strong>To explain what I'm doing specifically:</strong><br>
I'm using a jQuery time picker plugin on a text box that also has 2 ASP.NET validators associated with it. When the time is changed, I'm using an update panel to post back to the server to do some things dynamically, so I need the onchange event to fire in order to trigger the postback for that text box.</p>
<p>The jQuery time picker operates by creating a hidden unordered list that is made visible when the text box is clicked. When one of the list items is clicked, the "change" event is fired programmatically for the text box through jQuery's <code>change()</code> method.</p>
<p>Because the trigger for the event was a list item, IE sees the <em>list item</em> as the source of the event, not the text box, like it should.</p>
<p>I'm not too concerned with this ASP.NET validator working as soon as the text box is changed, I just need the "<code>change</code>" event to be processed so my postback event is called for the text box. The problem is that the validator throws an exception in IE which stops any event from being triggered.</p>
<p>Firefox (and I assume other browsers) don't have this issue. Only IE due to the different event model. Has anyone encountered this and seen how to fix it?</p>
<hr>
<p>I've found this problem reported several other places, but they offer no solutions: </p>
<ul>
<li><a href="http://groups.google.com/group/jquery-en/browse_thread/thread/a8902f2774edc05a/d119026f561ca528?lnk=raot" rel="noreferrer">jQuery's forum, with the jQuery UI Datepicker and an ASP.NET Validator</a></li>
<li><a href="http://forums.asp.net/t/1326208.aspx" rel="noreferrer">ASP.NET forums, bug with ValidatorOnChange() function</a></li>
</ul>
|
[
{
"answer_id": 169370,
"author": "Lucas Goodwin",
"author_id": 25025,
"author_profile": "https://Stackoverflow.com/users/25025",
"pm_score": 2,
"selected": false,
"text": "<p>From what you're describing, this problem is likely a result of the unique event bubbling model that IE uses for JS.</p>\n\n<p>My only real answer is to ditch the ASP.NET validators and use a jQuery form validation plugin instead. Then your textbox can just be a regular ASP Webforms control and when the contents change and a postback occures all is good. In addition you keep more client-side concerns seperated from the server code.</p>\n\n<p>I've never had much luck mixing Webform Client controls (like the Form Validation controls) with external JS libraries like jQuery. I've found the better route is just to go with one or the other, but not to mix and match.</p>\n\n<p>Not the answer you're probably looking for.</p>\n\n<p>If you want to go with a jQuery form validation plugin concider this one <a href=\"http://randomactsofcoding.blogspot.com/2008/09/starting-with-jquery-dynamically.html\" rel=\"nofollow noreferrer\">jQuery Form Validation</a></p>\n"
},
{
"answer_id": 171931,
"author": "tvanfosson",
"author_id": 12950,
"author_profile": "https://Stackoverflow.com/users/12950",
"pm_score": 2,
"selected": false,
"text": "<p>Consider setting the hidden field _EVENTTARGET value before initiating the event with javascript. You'll need to set it to the server side id (replace underscore with $ in the client id) for the server to understand it. I do this on button clicks that I simulate so that the server side can determine which OnClick method to fire when the result gets posted back -- Ajax or not, doesn't really matter.</p>\n"
},
{
"answer_id": 327477,
"author": "Mukthar",
"author_id": 36808,
"author_profile": "https://Stackoverflow.com/users/36808",
"pm_score": 0,
"selected": false,
"text": "<p>This is how I solved a simlar issue.\nWrote an onSelect() handler for the datepicker.\n<a href=\"http://docs.jquery.com/UI/Datepicker/datepicker#options\" rel=\"nofollow noreferrer\">link text</a>\nIn that function, called __doPostBack('textboxcontrolid','').\nThis triggered a partial postback for the textbox to the server, which called the validators in turn.</p>\n"
},
{
"answer_id": 371396,
"author": "quark",
"author_id": 46680,
"author_profile": "https://Stackoverflow.com/users/46680",
"pm_score": 3,
"selected": false,
"text": "<p>I had the same problem. Solved by using this function:</p>\n\n<pre><code>jQuery.fn.extend({\n fire: function(evttype){ \n el = this.get(0);\n if (document.createEvent) {\n var evt = document.createEvent('HTMLEvents'); \n evt.initEvent(evttype, false, false); \n el.dispatchEvent(evt); \n } else if (document.createEventObject) { \n el.fireEvent('on' + evttype); \n }\n return this;\n }\n});\n</code></pre>\n\n<p>So my \"onSelect\" event handler to datepicker looks like:</p>\n\n<pre><code>if ($.browser.msie) {\n datepickerOptions = $.extend(datepickerOptions, { \n onSelect: function(){\n $(this).fire(\"change\").blur();\n }\n });\n}\n</code></pre>\n"
},
{
"answer_id": 2905196,
"author": "Ben McIntyre",
"author_id": 208465,
"author_profile": "https://Stackoverflow.com/users/208465",
"pm_score": 2,
"selected": false,
"text": "<p>This is an endemic problem with jQuery datepickers and ASP validation controls.\nAs you are saying, the wrong element cross-triggers an ASP NET javascript validation routine, and then the M$ code throws an error because the triggering element in the routine is undefined.</p>\n\n<p>I solved this one differently from anyone else I have seen - by deciding that M$ should have written their code more robustly, and hence redeclaring some of the M$ validator code to cope with the undefined element. Everything else I have seen is essentially a workaround on the jQuery side, and cuts possible functionality out (eg. using the click event instead of change).</p>\n\n<p>The bit that fails is</p>\n\n<pre><code> for (i = 0; i < vals.length; i++) {\n ValidatorValidate(vals[i], null, event);\n }\n</code></pre>\n\n<p>which throws an error when it tries to get a length for the undefined 'vals'.</p>\n\n<p>I just added</p>\n\n<pre><code>if (vals) {\n for (i = 0; i < vals.length; i++) {\n ValidatorValidate(vals[i], null, event);\n }\n}\n</code></pre>\n\n<p>and she's good to go. Final code, which redeclares the entire offending function, is below. I put it as a script include at the bottom of my master page or page.</p>\n\n<p>Yes, this does break upwards compatibility if M$ decide to change their validator code in the future. But one would hope they'll fix it and then we can get rid of this patch altogether.</p>\n\n<pre><code>// Fix issue with datepicker and ASPNET validators: redeclare MS validator code with fix\n function ValidatorOnChange(event) {\n if (!event) {\n event = window.event;\n }\n Page_InvalidControlToBeFocused = null;\n var targetedControl;\n if ((typeof (event.srcElement) != \"undefined\") && (event.srcElement != null)) {\n targetedControl = event.srcElement;\n }\n else {\n targetedControl = event.target;\n }\n var vals;\n if (typeof (targetedControl.Validators) != \"undefined\") {\n vals = targetedControl.Validators;\n }\n else {\n if (targetedControl.tagName.toLowerCase() == \"label\") {\n targetedControl = document.getElementById(targetedControl.htmlFor);\n vals = targetedControl.Validators;\n }\n }\n var i;\n if (vals) {\n for (i = 0; i < vals.length; i++) {\n ValidatorValidate(vals[i], null, event);\n }\n }\n ValidatorUpdateIsValid();\n}\n</code></pre>\n"
},
{
"answer_id": 8993921,
"author": "thorn0",
"author_id": 76173,
"author_profile": "https://Stackoverflow.com/users/76173",
"pm_score": 2,
"selected": false,
"text": "<p>I solved the issue with a patch:</p>\n\n<pre><code> window.ValidatorHookupEvent = function(control, eventType, body) {\n $(control).bind(eventType.slice(2), new Function(\"event\", body));\n };\n</code></pre>\n\n<p><strong>Update:</strong> I've submitted the issue to MS (<a href=\"https://connect.microsoft.com/VisualStudio/feedback/details/720704/asp-net-web-forms-programmatically-triggering-events-in-ie-leads-to-js-error-in-the-code-related-to-client-side-validators\" rel=\"nofollow\">link</a>).</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168596",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/392/"
] |
When an Event is triggered by a user in IE, it is set to the `window.event` object. The only way to see what triggered the event is by accessing the `window.event` object (as far as I know)
This causes a problem in ASP.NET validators if an event is triggered programmatically, like when triggering an event through jQuery. In this case, the `window.event` object stores the last user-triggered event.
When the `onchange` event is fired programmatically for a text box that has an ASP.NET validator attached to it, the validation breaks because it is looking at the element that fired last event, which is not the element the validator is for.
Does anyone know a way around this? It seems like a problem that is solvable, but from looking online, most people just find ways to ignore the problem instead of solving it.
---
**To explain what I'm doing specifically:**
I'm using a jQuery time picker plugin on a text box that also has 2 ASP.NET validators associated with it. When the time is changed, I'm using an update panel to post back to the server to do some things dynamically, so I need the onchange event to fire in order to trigger the postback for that text box.
The jQuery time picker operates by creating a hidden unordered list that is made visible when the text box is clicked. When one of the list items is clicked, the "change" event is fired programmatically for the text box through jQuery's `change()` method.
Because the trigger for the event was a list item, IE sees the *list item* as the source of the event, not the text box, like it should.
I'm not too concerned with this ASP.NET validator working as soon as the text box is changed, I just need the "`change`" event to be processed so my postback event is called for the text box. The problem is that the validator throws an exception in IE which stops any event from being triggered.
Firefox (and I assume other browsers) don't have this issue. Only IE due to the different event model. Has anyone encountered this and seen how to fix it?
---
I've found this problem reported several other places, but they offer no solutions:
* [jQuery's forum, with the jQuery UI Datepicker and an ASP.NET Validator](http://groups.google.com/group/jquery-en/browse_thread/thread/a8902f2774edc05a/d119026f561ca528?lnk=raot)
* [ASP.NET forums, bug with ValidatorOnChange() function](http://forums.asp.net/t/1326208.aspx)
|
I had the same problem. Solved by using this function:
```
jQuery.fn.extend({
fire: function(evttype){
el = this.get(0);
if (document.createEvent) {
var evt = document.createEvent('HTMLEvents');
evt.initEvent(evttype, false, false);
el.dispatchEvent(evt);
} else if (document.createEventObject) {
el.fireEvent('on' + evttype);
}
return this;
}
});
```
So my "onSelect" event handler to datepicker looks like:
```
if ($.browser.msie) {
datepickerOptions = $.extend(datepickerOptions, {
onSelect: function(){
$(this).fire("change").blur();
}
});
}
```
|
168,621 |
<p>I'm having trouble with my php code not indenting correctly...</p>
<p>I would like my code to look like this</p>
<pre><code>if (foo)
{
print "i am indented";
}
</code></pre>
<p>but it always looks like this:</p>
<pre><code>if (foo)
{
print "i am not indented correctly";
}
</code></pre>
<p>I tired googling for similar things and tried adding the following to my .emacs, but it didn't work at all.</p>
<p>Any thoughts?</p>
<pre><code> (add-hook 'php-mode-hook
(function (lambda ()
;; GNU style
(setq php-indent-level 4
php-continued-statement-offset 4
php-continued-brace-offset 0
php-brace-offset 0
php-brace-imaginary-offset 0
php-label-offset -4))))
</code></pre>
|
[
{
"answer_id": 168696,
"author": "Jonathan Arkell",
"author_id": 11052,
"author_profile": "https://Stackoverflow.com/users/11052",
"pm_score": 1,
"selected": false,
"text": "<p>Customize the variable c-default-style. You either want your \"Other\" mode (or \"php\" if its available) set to \"bsd\" or you can set hte style in all modes to bsd.</p>\n\n<p>From what I understand, PHP mode is built on top of c mode, so it inherits its customizations.</p>\n"
},
{
"answer_id": 171798,
"author": "troelskn",
"author_id": 18180,
"author_profile": "https://Stackoverflow.com/users/18180",
"pm_score": 1,
"selected": false,
"text": "<p>Try with this:</p>\n\n<pre class=\"lang-lisp prettyprint-override\"><code>(defun my-build-tab-stop-list (width)\n (let ((num-tab-stops (/ 80 width))\n (counter 1)\n (ls nil))\n (while (<= counter num-tab-stops)\n (setq ls (cons (* width counter) ls))\n (setq counter (1+ counter)))\n (nreverse ls)))\n\n(add-hook 'c-mode-common-hook\n #'(lambda ()\n ;; You an remove this, if you don't want fixed tab-stop-widths\n (set (make-local-variable 'tab-stop-list)\n (my-build-tab-stop-list tab-width))\n (setq c-basic-offset tab-width)\n (c-set-offset 'defun-block-intro tab-width)\n (c-set-offset 'arglist-intro tab-width)\n (c-set-offset 'arglist-close 0)\n (c-set-offset 'defun-close 0)\n (setq abbrev-mode nil)))\n</code></pre>\n"
},
{
"answer_id": 485553,
"author": "Pavel Chuchuva",
"author_id": 14131,
"author_profile": "https://Stackoverflow.com/users/14131",
"pm_score": 4,
"selected": false,
"text": "<p>Customize c-default-style variable. Add this to your .emacs file:</p>\n\n<pre><code>(setq c-default-style \"bsd\"\n c-basic-offset 4)\n</code></pre>\n\n<p><a href=\"http://en.wikipedia.org/wiki/Indent_style#Allman_style\" rel=\"noreferrer\">Description of bsd style</a>.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168621",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I'm having trouble with my php code not indenting correctly...
I would like my code to look like this
```
if (foo)
{
print "i am indented";
}
```
but it always looks like this:
```
if (foo)
{
print "i am not indented correctly";
}
```
I tired googling for similar things and tried adding the following to my .emacs, but it didn't work at all.
Any thoughts?
```
(add-hook 'php-mode-hook
(function (lambda ()
;; GNU style
(setq php-indent-level 4
php-continued-statement-offset 4
php-continued-brace-offset 0
php-brace-offset 0
php-brace-imaginary-offset 0
php-label-offset -4))))
```
|
Customize c-default-style variable. Add this to your .emacs file:
```
(setq c-default-style "bsd"
c-basic-offset 4)
```
[Description of bsd style](http://en.wikipedia.org/wiki/Indent_style#Allman_style).
|
168,639 |
<p>In Java, suppose I have a String variable S, and I want to search for it inside of another String T, like so:</p>
<pre><code> if (T.matches(S)) ...
</code></pre>
<p>(note: the above line was T.contains() until a few posts pointed out that that method does not use regexes. My bad.)</p>
<p>But now suppose S may have unsavory characters in it. For instance, let S = "[hi". The left square bracket is going to cause the regex to fail. Is there a function I can call to escape S so that this doesn't happen? In this particular case, I would like it to be transformed to "\[hi".</p>
|
[
{
"answer_id": 168642,
"author": "Jay",
"author_id": 20840,
"author_profile": "https://Stackoverflow.com/users/20840",
"pm_score": 2,
"selected": false,
"text": "<p>Any particular reason not to use String.indexOf() instead? That way it will always be interpreted as a regular string rather than a regex.</p>\n"
},
{
"answer_id": 168652,
"author": "Tom Hawtin - tackline",
"author_id": 4725,
"author_profile": "https://Stackoverflow.com/users/4725",
"pm_score": 5,
"selected": true,
"text": "<p>String.contains does not use regex, so there isn't a problem in this case.</p>\n\n<p>Where a regex is required, rather rejecting strings with regex special characters, use java.util.regex.Pattern.quote to escape them.</p>\n"
},
{
"answer_id": 168662,
"author": "Aaron",
"author_id": 19130,
"author_profile": "https://Stackoverflow.com/users/19130",
"pm_score": 0,
"selected": false,
"text": "<p>Regex uses the backslash character '\\' to escape a literal. Given that java also uses the backslash character you would need to use a double bashslash like:</p>\n\n<pre><code> String S = \"\\\\[hi\"\n</code></pre>\n\n<p>That will become the String:</p>\n\n<pre><code> \\[hi\n</code></pre>\n\n<p>which will be passed to the regex. </p>\n\n<p>Or if you only care about a literal String and don't need a regex you could do the following:</p>\n\n<pre><code>if (T.indexOf(\"[hi\") != -1) {\n</code></pre>\n"
},
{
"answer_id": 168690,
"author": "anjanb",
"author_id": 11142,
"author_profile": "https://Stackoverflow.com/users/11142",
"pm_score": 0,
"selected": false,
"text": "<p>T.contains() (according to javadoc : <a href=\"http://java.sun.com/javase/6/docs/api/java/lang/String.html\" rel=\"nofollow noreferrer\">http://java.sun.com/javase/6/docs/api/java/lang/String.html</a>) does not use regexes. contains() delegates to indexOf() only.</p>\n\n<p>So, there are NO regexes used here. Were you thinking of some other String method ?</p>\n"
},
{
"answer_id": 168884,
"author": "Michael Myers",
"author_id": 13531,
"author_profile": "https://Stackoverflow.com/users/13531",
"pm_score": 4,
"selected": false,
"text": "<p>As <a href=\"https://stackoverflow.com/questions/168639/escaping-a-string-from-getting-regex-parsed-in-java#168652\">Tom Hawtin</a> said, you need to quote the pattern. You can do this in two ways (edit: actually three ways, as pointed out by @<a href=\"https://stackoverflow.com/questions/168639/escaping-a-string-from-getting-regex-parsed-in-java#169133\">diastrophism</a>):</p>\n\n<ol>\n<li><p>Surround the string with \"\\Q\" and \"\\E\", like:</p>\n\n<pre><code>if (T.matches(\"\\\\Q\" + S + \"\\\\E\"))\n</code></pre></li>\n<li><p>Use <a href=\"http://java.sun.com/javase/6/docs/api/java/util/regex/Pattern.html\" rel=\"nofollow noreferrer\">Pattern</a> instead. The code would be something like this:</p>\n\n<pre><code>Pattern sPattern = Pattern.compile(S, Pattern.LITERAL);\nif (sPattern.matcher(T).matches()) { /* do something */ }\n</code></pre>\n\n<p>This way, you can cache the compiled Pattern and reuse it. If you are using the same regex more than once, you almost certainly want to do it this way.</p></li>\n</ol>\n\n<p>Note that if you are using regular expressions to test whether a string is inside a larger string, you should put .* at the start and end of the expression. But this will not work if you are quoting the pattern, since it will then be looking for actual dots. So, are you absolutely certain you want to be using regular expressions?</p>\n"
},
{
"answer_id": 169133,
"author": "Diastrophism",
"author_id": 18093,
"author_profile": "https://Stackoverflow.com/users/18093",
"pm_score": 3,
"selected": false,
"text": "<p>Try <a href=\"http://java.sun.com/javase/6/docs/api/java/util/regex/Pattern.html#quote(java.lang.String)\" rel=\"noreferrer\">Pattern.quote(String)</a>. It will fix up anything that has special meaning in the string.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168639",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24973/"
] |
In Java, suppose I have a String variable S, and I want to search for it inside of another String T, like so:
```
if (T.matches(S)) ...
```
(note: the above line was T.contains() until a few posts pointed out that that method does not use regexes. My bad.)
But now suppose S may have unsavory characters in it. For instance, let S = "[hi". The left square bracket is going to cause the regex to fail. Is there a function I can call to escape S so that this doesn't happen? In this particular case, I would like it to be transformed to "\[hi".
|
String.contains does not use regex, so there isn't a problem in this case.
Where a regex is required, rather rejecting strings with regex special characters, use java.util.regex.Pattern.quote to escape them.
|
168,659 |
<p>I found this via google: <a href="http://www.mvps.org/access/api/api0008.htm" rel="nofollow noreferrer">http://www.mvps.org/access/api/api0008.htm</a></p>
<pre class="lang-vb prettyprint-override"><code>'******************** Code Start **************************
' This code was originally written by Dev Ashish.
' It is not to be altered or distributed,
' except as part of an application.
' You are free to use it in any application,
' provided the copyright notice is left unchanged.
'
' Code Courtesy of
' Dev Ashish
'
Private Declare Function apiGetUserName Lib "advapi32.dll" Alias _
"GetUserNameA" (ByVal lpBuffer As String, nSize As Long) As Long
Function fOSUserName() As String
' Returns the network login name
Dim lngLen As Long, lngX As Long
Dim strUserName As String
strUserName = String$(254, 0)
lngLen = 255
lngX = apiGetUserName(strUserName, lngLen)
If ( lngX > 0 ) Then
fOSUserName = Left$(strUserName, lngLen - 1)
Else
fOSUserName = vbNullString
End If
End Function
'******************** Code End **************************
</code></pre>
<p>Is this the best way to do it?</p>
|
[
{
"answer_id": 168666,
"author": "Ken",
"author_id": 20621,
"author_profile": "https://Stackoverflow.com/users/20621",
"pm_score": 4,
"selected": true,
"text": "<p>You could also use Environ$ but the method specified by the question is better. Users/Applications can change the environment variables.</p>\n"
},
{
"answer_id": 168682,
"author": "bugBurger",
"author_id": 13337,
"author_profile": "https://Stackoverflow.com/users/13337",
"pm_score": 1,
"selected": false,
"text": "<p><a href=\"http://www.tek-tips.com/viewthread.cfm?qid=1259771&page=1\" rel=\"nofollow noreferrer\">Alternative way</a> to do that - probably the API you mention is a better way to get username. </p>\n\n<pre><code>For Each strComputer In arrComputers\n Set objWMIService = GetObject(\"winmgmts:\\\\\" & strComputer & \"\\root\\cimv2\")\n Set colItems = objWMIService.ExecQuery(\"Select * from Win32_ComputerSystem\",,48)\n For Each objItem in colItems\n Wscript.Echo \"UserName: \" & objItem.UserName & \" is logged in at computer \" & strComputer\nNext\n</code></pre>\n"
},
{
"answer_id": 168686,
"author": "bobwienholt",
"author_id": 24257,
"author_profile": "https://Stackoverflow.com/users/24257",
"pm_score": 4,
"selected": false,
"text": "<p>You could also do this:</p>\n\n<pre><code>Set WshNetwork = CreateObject(\"WScript.Network\")\nPrint WshNetwork.UserName\n</code></pre>\n\n<p>It also has a UserDomain property and a bunch of other things:</p>\n\n<p><a href=\"http://msdn.microsoft.com/en-us/library/907chf30(VS.85).aspx\" rel=\"noreferrer\">http://msdn.microsoft.com/en-us/library/907chf30(VS.85).aspx</a></p>\n"
},
{
"answer_id": 168986,
"author": "Knox",
"author_id": 4873,
"author_profile": "https://Stackoverflow.com/users/4873",
"pm_score": 2,
"selected": false,
"text": "<p>I generally use an environ from within VBA as in the following. I haven't had the problems that Ken mentions as possibilities.</p>\n\n<pre><code>Function UserNameWindows() As String\n UserNameWindows = VBA.Environ(\"USERNAME\") & \"@\" & VBA.Environ(\"USERDOMAIN\")\nEnd Function\n</code></pre>\n"
},
{
"answer_id": 169891,
"author": "Joe",
"author_id": 13087,
"author_profile": "https://Stackoverflow.com/users/13087",
"pm_score": 1,
"selected": false,
"text": "<p>Lots of alternative methods in other posts, but to answer the question: yes that is the best way to do it. Faster than creating a COM object or WMI if all you want is the username, and available in all versions of Windows from Win95 up.</p>\n"
},
{
"answer_id": 19719939,
"author": "Harsono",
"author_id": 2943641,
"author_profile": "https://Stackoverflow.com/users/2943641",
"pm_score": 0,
"selected": false,
"text": "<p>there are lots of way to get the current logged user name in WMI.\nmy way is to get it through the username from process of 'explorer.exe'\nbecause when user login into window, the access of this file according to the current user.</p>\n\n<p>WMI script would be look like this:</p>\n\n<pre><code>Set objWMIService = GetObject(\"winmgmts:\" & \"{impersonationLevel=impersonate}!\\\\\" & strIP & \"\\root\\cimv2\")\nSet colProcessList = objWMIService.ExecQuery(\"Select * from Win32_Process\")\nFor Each objprocess In colProcessList\n colProperties = objprocess.GetOwner(strNameOfUser, strUserDomain)\n If objprocess.Name = \"explorer.exe\" Then\n UsrName = strNameOfUser\n DmnName = strUserDomain\n End If\nNext\n</code></pre>\n\n<p>for more detailcheck the link on :\n<br><a href=\"http://msdn.microsoft.com/en-us/library/aa394599%28v=vs.85%29.aspx\" rel=\"nofollow\">http://msdn.microsoft.com/en-us/library/aa394599%28v=vs.85%29.aspx</a></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168659",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2462/"
] |
I found this via google: <http://www.mvps.org/access/api/api0008.htm>
```vb
'******************** Code Start **************************
' This code was originally written by Dev Ashish.
' It is not to be altered or distributed,
' except as part of an application.
' You are free to use it in any application,
' provided the copyright notice is left unchanged.
'
' Code Courtesy of
' Dev Ashish
'
Private Declare Function apiGetUserName Lib "advapi32.dll" Alias _
"GetUserNameA" (ByVal lpBuffer As String, nSize As Long) As Long
Function fOSUserName() As String
' Returns the network login name
Dim lngLen As Long, lngX As Long
Dim strUserName As String
strUserName = String$(254, 0)
lngLen = 255
lngX = apiGetUserName(strUserName, lngLen)
If ( lngX > 0 ) Then
fOSUserName = Left$(strUserName, lngLen - 1)
Else
fOSUserName = vbNullString
End If
End Function
'******************** Code End **************************
```
Is this the best way to do it?
|
You could also use Environ$ but the method specified by the question is better. Users/Applications can change the environment variables.
|
168,661 |
<p>I have a table with one column and about ten rows. The first column has rows with text as row headers, "header 1", "header 2". The second column contains fields for the user to type data (<em>textboxes</em> and <em>checkboxes</em>). </p>
<p>I want to have a button at the top labelled "<em>Add New...</em>", and have it create a third column, with the same fields as the first column. If the user clicks it again, it will create another blank column with fields (as in the second column).</p>
<p>Does anyone know of an effective way to manipulate the DOM to achieve this?</p>
<p>I'm experimenting with <code>div</code>'s and <code>TABLES</code> but i'm on my third day of doing this, and it feels harder than it should be.</p>
|
[
{
"answer_id": 168670,
"author": "Tom Ritter",
"author_id": 8435,
"author_profile": "https://Stackoverflow.com/users/8435",
"pm_score": 2,
"selected": false,
"text": "<p>Something along the lines of</p>\n\n<blockquote>\n<pre><code>function(table)\n{\n for(var i=0;i<table.rows.length;i++)\n {\n newcell = table.rows[i].cells[0].cloneNode(true);\n table.rows[i].appendChild(newcell);\n }\n}\n</code></pre>\n</blockquote>\n"
},
{
"answer_id": 168889,
"author": "PhiLho",
"author_id": 15459,
"author_profile": "https://Stackoverflow.com/users/15459",
"pm_score": 2,
"selected": false,
"text": "<p>Amusing exercise. Thanks to AviewAnew's hint, I could do it.</p>\n\n<pre><code>function AddColumn(tableId)\n{\n var table = document.getElementById(tableId);\n if (table == undefined) return;\n var rowNb = table.rows.length;\n // Take care of header\n var bAddNames = (table.tHead.rows[0].cells.length % 2 == 1);\n var newcell = table.rows[0].cells[bAddNames ? 1 : 0].cloneNode(true);\n table.rows[0].appendChild(newcell);\n // Add the remainder of the column\n for(var i = 1; i < rowNb; i++)\n {\n newcell = table.rows[i].cells[0].cloneNode(bAddNames);\n table.rows[i].appendChild(newcell);\n }\n}\n</code></pre>\n\n<p>with following HTML:</p>\n\n<pre><code><input type=\"button\" id=\"BSO\" value=\"Add\" onclick=\"javascript:AddColumn('TSO')\"/>\n<table border=\"1\" id=\"TSO\">\n<thead>\n<tr><th>Fields</th><th>Data</th></tr>\n</thead>\n<tbody>\n<tr><td>Doh</td><td>10</td></tr>\n<tr><td>Toh</td><td>20</td></tr>\n<tr><td>Foo</td><td>30</td></tr>\n<tr><td>Bar</td><td>42</td></tr>\n<tr><td>Ga</td><td>50</td></tr>\n<tr><td>Bu</td><td>666</td></tr>\n<tr><td>Zo</td><td>70</td></tr>\n<tr><td>Meu</td><td>80</td></tr>\n</tbody>\n</table>\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168661",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I have a table with one column and about ten rows. The first column has rows with text as row headers, "header 1", "header 2". The second column contains fields for the user to type data (*textboxes* and *checkboxes*).
I want to have a button at the top labelled "*Add New...*", and have it create a third column, with the same fields as the first column. If the user clicks it again, it will create another blank column with fields (as in the second column).
Does anyone know of an effective way to manipulate the DOM to achieve this?
I'm experimenting with `div`'s and `TABLES` but i'm on my third day of doing this, and it feels harder than it should be.
|
Something along the lines of
>
>
> ```
> function(table)
> {
> for(var i=0;i<table.rows.length;i++)
> {
> newcell = table.rows[i].cells[0].cloneNode(true);
> table.rows[i].appendChild(newcell);
> }
> }
>
> ```
>
>
|
168,664 |
<p>Given a table or a temp table, I'd like to run a procedure that will output a SQL script (i.e. a bunch of INSERT statements) that would populate the table. Is this possible in MS SQL Server 2000?</p>
|
[
{
"answer_id": 168670,
"author": "Tom Ritter",
"author_id": 8435,
"author_profile": "https://Stackoverflow.com/users/8435",
"pm_score": 2,
"selected": false,
"text": "<p>Something along the lines of</p>\n\n<blockquote>\n<pre><code>function(table)\n{\n for(var i=0;i<table.rows.length;i++)\n {\n newcell = table.rows[i].cells[0].cloneNode(true);\n table.rows[i].appendChild(newcell);\n }\n}\n</code></pre>\n</blockquote>\n"
},
{
"answer_id": 168889,
"author": "PhiLho",
"author_id": 15459,
"author_profile": "https://Stackoverflow.com/users/15459",
"pm_score": 2,
"selected": false,
"text": "<p>Amusing exercise. Thanks to AviewAnew's hint, I could do it.</p>\n\n<pre><code>function AddColumn(tableId)\n{\n var table = document.getElementById(tableId);\n if (table == undefined) return;\n var rowNb = table.rows.length;\n // Take care of header\n var bAddNames = (table.tHead.rows[0].cells.length % 2 == 1);\n var newcell = table.rows[0].cells[bAddNames ? 1 : 0].cloneNode(true);\n table.rows[0].appendChild(newcell);\n // Add the remainder of the column\n for(var i = 1; i < rowNb; i++)\n {\n newcell = table.rows[i].cells[0].cloneNode(bAddNames);\n table.rows[i].appendChild(newcell);\n }\n}\n</code></pre>\n\n<p>with following HTML:</p>\n\n<pre><code><input type=\"button\" id=\"BSO\" value=\"Add\" onclick=\"javascript:AddColumn('TSO')\"/>\n<table border=\"1\" id=\"TSO\">\n<thead>\n<tr><th>Fields</th><th>Data</th></tr>\n</thead>\n<tbody>\n<tr><td>Doh</td><td>10</td></tr>\n<tr><td>Toh</td><td>20</td></tr>\n<tr><td>Foo</td><td>30</td></tr>\n<tr><td>Bar</td><td>42</td></tr>\n<tr><td>Ga</td><td>50</td></tr>\n<tr><td>Bu</td><td>666</td></tr>\n<tr><td>Zo</td><td>70</td></tr>\n<tr><td>Meu</td><td>80</td></tr>\n</tbody>\n</table>\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168664",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/17997/"
] |
Given a table or a temp table, I'd like to run a procedure that will output a SQL script (i.e. a bunch of INSERT statements) that would populate the table. Is this possible in MS SQL Server 2000?
|
Something along the lines of
>
>
> ```
> function(table)
> {
> for(var i=0;i<table.rows.length;i++)
> {
> newcell = table.rows[i].cells[0].cloneNode(true);
> table.rows[i].appendChild(newcell);
> }
> }
>
> ```
>
>
|
168,672 |
<p>I have a table on SQL2000 with a numeric column and I need the select to return a 01, 02, 03...</p>
<p>It currently returns 1,2,3,...10,11...</p>
<p>Thanks.</p>
|
[
{
"answer_id": 168689,
"author": "John Millikin",
"author_id": 3560,
"author_profile": "https://Stackoverflow.com/users/3560",
"pm_score": 4,
"selected": true,
"text": "<p>Does this work?</p>\n\n<pre><code>SELECT REPLACE(STR(mycolumn, 2), ' ', '0')\n</code></pre>\n\n<p>From <a href=\"http://foxtricks.blogspot.com/2007/07/zero-padding-numeric-value-in-transact.html\" rel=\"noreferrer\">http://foxtricks.blogspot.com/2007/07/zero-padding-numeric-value-in-transact.html</a></p>\n"
},
{
"answer_id": 168739,
"author": "Patrick Szalapski",
"author_id": 7453,
"author_profile": "https://Stackoverflow.com/users/7453",
"pm_score": 0,
"selected": false,
"text": "<p>John's answer works and is generalizable to any number of digits, but I would be more comfortable with</p>\n\n<pre><code>select case when mycolumn between -9 and 9 then '0' + str(mycolumn) else str(mycolumn) end \n</code></pre>\n"
},
{
"answer_id": 168796,
"author": "Hafthor",
"author_id": 4489,
"author_profile": "https://Stackoverflow.com/users/4489",
"pm_score": 0,
"selected": false,
"text": "<p>where n is a positive integer between 0 and 99:</p>\n\n<pre><code>select right('0'+ltrim(str(n)),2)\n</code></pre>\n\n<p>or</p>\n\n<pre><code>select right(str(100+n),2)\n</code></pre>\n\n<p>but I like John's answer best. Single point of specification for target width, but I posted these because they are also common idioms that might work better in other situations or languages.</p>\n"
},
{
"answer_id": 290893,
"author": "Karl",
"author_id": 36093,
"author_profile": "https://Stackoverflow.com/users/36093",
"pm_score": 1,
"selected": false,
"text": "<p>This sort of question is about the interface to the database. Really the database should return the data and your application can reformat it if it wants the data in a particular format. You shouldn't do this in the database, but out in the presentation layer.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168672",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/212/"
] |
I have a table on SQL2000 with a numeric column and I need the select to return a 01, 02, 03...
It currently returns 1,2,3,...10,11...
Thanks.
|
Does this work?
```
SELECT REPLACE(STR(mycolumn, 2), ' ', '0')
```
From <http://foxtricks.blogspot.com/2007/07/zero-padding-numeric-value-in-transact.html>
|
168,691 |
<p>If I'm deep in a nest of loops I'm wondering which of these is more efficient:</p>
<pre><code>if (!isset($array[$key])) $array[$key] = $val;
</code></pre>
<p>or</p>
<pre><code>$array[$key] = $val;
</code></pre>
<p>The second form is much more desirable as far as readable code goes. In reality the names are longer and the array is multidimensional. So the first form ends up looking pretty gnarly in my program.</p>
<p>But I'm wondering if the second form might be slower. Since the code is in one of the most frequently-executed functions in the program, I'd like to use the faster form.</p>
<p>Generally speaking this code will execute many times with the same value of "$key". So in most cases $array[$key] will already be set, and the isset() will return FALSE.</p>
<p>To clarify for those who fear that I'm treating non-identical code as if it were identical: as far as this part of the program is concerned, $val is a constant. It isn't known until run-time, but it's set earlier in the program and doesn't change here. So both forms produce the same result. And this is the most convenient place to get at $val.</p>
|
[
{
"answer_id": 168698,
"author": "warren",
"author_id": 4418,
"author_profile": "https://Stackoverflow.com/users/4418",
"pm_score": 1,
"selected": false,
"text": "<p>The overhead of a comparison which may or may not be true seems like it should take longer.</p>\n\n<p>What does running the script in both configurations show for performance time?</p>\n"
},
{
"answer_id": 168718,
"author": "Jay",
"author_id": 20840,
"author_profile": "https://Stackoverflow.com/users/20840",
"pm_score": 0,
"selected": false,
"text": "<p>The extra function call to isset() is almost guaranteed to have more overhead than any assignment. I would be extremely surprised if the second form is not faster.</p>\n"
},
{
"answer_id": 168799,
"author": "Milan Babuškov",
"author_id": 14690,
"author_profile": "https://Stackoverflow.com/users/14690",
"pm_score": 2,
"selected": false,
"text": "<p>isset() is very fast with ordinary variables, but you have an array here. The hash-map algorithm for arrays is quick, but it's still takes more time than doing nothing. </p>\n\n<p>Now, first form can be faster if you have more values that are set, than those that are not, simply because it just looks up for hash without fetching or setting the value. So, that could be a point of difference: pick the first form if you have more 'hits' at keys that are set, and pick the second one if you have more 'misses'.</p>\n\n<p>Please note that those two pieces of code are <strong>not</strong> identical. The first form will not set the value for some key when it's already set - it prevents 'overwriting'.</p>\n"
},
{
"answer_id": 168820,
"author": "hangy",
"author_id": 11963,
"author_profile": "https://Stackoverflow.com/users/11963",
"pm_score": 2,
"selected": false,
"text": "<p>Have you measured how often you run into the situation that <code>$array[$key]</code> is set before you try to set it? I think one cannot give a general advice on this, because if there are actually a lot of those cases, the isset check could possibly save some time by avoiding unnessecary sets on the array. However, if this is just rarely the case, the overhead could slow you down …. The best thing would be to do a benchmark on your actual code.</p>\n\n<p>However, be aware that both codes <em>can lead to different results</em>! If $val is not always the same for a <code>$array[$key]</code> combination, the former code would always set the value to the first <code>$val</code> for that <code>$array[$key]</code> where the latter code would always set it to the last value of that combination.</p>\n\n<p>(I guess you are aware of that and <code>$val</code> is always the same for <code>$array[$key]</code>, but some reader stopping by might not.)</p>\n"
},
{
"answer_id": 168824,
"author": "Robert K",
"author_id": 24950,
"author_profile": "https://Stackoverflow.com/users/24950",
"pm_score": 0,
"selected": false,
"text": "<p>Do you need an actual check to see if the key is there? With an assignment to a blank array the <code>isset()</code> will just slow the loop down. And unless you do a second pass with data manipulation I strongly advise against the isset check. This is population, not manipulation.</p>\n"
},
{
"answer_id": 168841,
"author": "Zan Lynx",
"author_id": 13422,
"author_profile": "https://Stackoverflow.com/users/13422",
"pm_score": 3,
"selected": false,
"text": "<p>For an array you actually want: <code>array_key_exists($key, $array)</code> instead of <code>isset($array[$key])</code>.</p>\n"
},
{
"answer_id": 168857,
"author": "Tony L.",
"author_id": 21905,
"author_profile": "https://Stackoverflow.com/users/21905",
"pm_score": 0,
"selected": false,
"text": "<p>i am a newbie to PHP but a combination of both could be with the ternary operator</p>\n\n<pre><code>$array[$key] = !isset($array[$key]) ? $val : $array[$key];\n</code></pre>\n\n<p>that's one way to go with it.</p>\n"
},
{
"answer_id": 175414,
"author": "Bemmu",
"author_id": 8005,
"author_profile": "https://Stackoverflow.com/users/8005",
"pm_score": 0,
"selected": false,
"text": "<p>You can take a look at the PHP source code to see the difference. Didn't check whether this would be different in later versions of PHP, but it would seem in PHP3 the associative array functionality is in <a href=\"http://cvs.php.net/viewvc.cgi/php3/php3_hash.c?view=markup\" rel=\"nofollow noreferrer\">php3/php3_hash.c</a>. </p>\n\n<p>In the function _php3_hash_exists, the following things are done:</p>\n\n<ul>\n<li>key is hashed</li>\n<li>correct bucket found</li>\n<li>bucket walked, until correct item found or not</li>\n</ul>\n\n<p>Function _php3_hash_add_or_update:</p>\n\n<ul>\n<li>hashed</li>\n<li>bucket found</li>\n<li>walked, existing overridden if existed\n\n<ul>\n<li>if didn't exist, new one added</li>\n</ul></li>\n</ul>\n\n<p>Therefore it would seem just setting it is faster, because there is just one function call and this hashing and bucket finding business will only get done once.</p>\n"
},
{
"answer_id": 487447,
"author": "Kris",
"author_id": 18565,
"author_profile": "https://Stackoverflow.com/users/18565",
"pm_score": 1,
"selected": false,
"text": "<p>You should check the array upto but not including the level you are going to set.</p>\n\n<p>If you're going to set</p>\n\n<pre><code>$anArray[ 'level1' ][ 'level2' ][ 'level3' ] = ...\n</code></pre>\n\n<p>You should make sure that the path upto level2 actually exists prior to setting level3.</p>\n\n<pre><code>$anArray[ 'level1' ][ 'level2' ]\n</code></pre>\n\n<p>No puppies will actually be killed if you don't, but they might be annoyed depending on your particular environment. </p>\n\n<p>You don't have to check the index you are actually setting, because setting it automatically means it is declared, but in the interest of good practice you should make sure nothing is magically created.</p>\n\n<p>There is an easy way to do this:</p>\n\n<pre><code><?php\n\nfunction create_array_path( $path, & $inArray )\n{\n if ( ! is_array( $inArray ) )\n {\n throw new Exception( 'The second argument is not an array!' );\n }\n $traversed = array();\n $current = &$inArray;\n\n foreach( $path as $subpath )\n {\n $traversed[] = $subpath;\n if ( ! is_array( $current ) )\n {\n $current = array();\n }\n if ( ! array_key_exists( $subpath, $current ) )\n {\n $current[ $subpath ] = '';\n }\n $current = &$current[ $subpath ];\n }\n}\n\n\n$myArray = array();\n\ncreate_array_path( array( 'level1', 'level2', 'level3' ), $myArray );\n\nprint_r( $myArray );\n\n?>\n</code></pre>\n\n<p>This will output:</p>\n\n<pre><code> Array\n (\n [level1] => Array\n (\n [level2] => Array\n (\n [level3] => \n )\n\n )\n\n )\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168691",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8722/"
] |
If I'm deep in a nest of loops I'm wondering which of these is more efficient:
```
if (!isset($array[$key])) $array[$key] = $val;
```
or
```
$array[$key] = $val;
```
The second form is much more desirable as far as readable code goes. In reality the names are longer and the array is multidimensional. So the first form ends up looking pretty gnarly in my program.
But I'm wondering if the second form might be slower. Since the code is in one of the most frequently-executed functions in the program, I'd like to use the faster form.
Generally speaking this code will execute many times with the same value of "$key". So in most cases $array[$key] will already be set, and the isset() will return FALSE.
To clarify for those who fear that I'm treating non-identical code as if it were identical: as far as this part of the program is concerned, $val is a constant. It isn't known until run-time, but it's set earlier in the program and doesn't change here. So both forms produce the same result. And this is the most convenient place to get at $val.
|
For an array you actually want: `array_key_exists($key, $array)` instead of `isset($array[$key])`.
|
168,727 |
<p>A lot of useful features in Python are somewhat "hidden" inside modules. Named tuples (new in <a href="http://docs.python.org/whatsnew/2.6.html" rel="nofollow noreferrer">Python 2.6</a>), for instance, are found in the <a href="http://docs.python.org/library/collections.html" rel="nofollow noreferrer">collections</a> module. </p>
<p>The <a href="http://docs.python.org/library/" rel="nofollow noreferrer">Library Documentation page</a> will give you all the modules in the language, but newcomers to Python are likely to find themselves saying "Oh, I didn't know I could have done it <em>this way</em> using Python!" unless the important features in the language are pointed out by the experienced developers.</p>
<p>I'm <strong>not</strong> specifically looking for new modules in Python 2.6, but modules that can be found in this latest release.</p>
|
[
{
"answer_id": 168766,
"author": "David Segonds",
"author_id": 13673,
"author_profile": "https://Stackoverflow.com/users/13673",
"pm_score": 3,
"selected": false,
"text": "<p>May be <a href=\"http://www.python.org/dev/peps/pep-0361/\" rel=\"nofollow noreferrer\">PEP 0631</a> and <a href=\"http://docs.python.org/whatsnew/2.6.html\" rel=\"nofollow noreferrer\">What's new in 2.6</a> can provide elements of answer. This last article explains the new features in Python 2.6, released on October 1 2008.</p>\n"
},
{
"answer_id": 168768,
"author": "Eli Courtwright",
"author_id": 1694,
"author_profile": "https://Stackoverflow.com/users/1694",
"pm_score": 4,
"selected": false,
"text": "<p>The most impressive new module is probably the <code>multiprocessing</code> module. First because it lets you execute functions in new processes just as easily and with roughly the same API as you would with the <code>threading</code> module. But more importantly because it introduces a lot of great classes for communicating between processes, such as a <code>Queue</code> class and a <code>Lock</code> class which are each used just like those objects would be in multithreaded code, as well as some other classes for sharing memory between processes.</p>\n\n<p>You can find the documentation at <a href=\"http://docs.python.org/library/multiprocessing.html\" rel=\"nofollow noreferrer\">http://docs.python.org/library/multiprocessing.html</a></p>\n"
},
{
"answer_id": 168795,
"author": "Dan Lenski",
"author_id": 20789,
"author_profile": "https://Stackoverflow.com/users/20789",
"pm_score": 3,
"selected": false,
"text": "<p>The <a href=\"http://docs.python.org/library/json.html\" rel=\"nofollow noreferrer\">new <code>json</code> module</a> is a real boon to web programmers!! (It was known as <a href=\"http://undefined.org/python/#simplejson\" rel=\"nofollow noreferrer\"><code>simplejson</code></a> before being merged into the standard library.)</p>\n\n<p>It's ridiculously easy to use: <code>json.dumps(obj)</code> encodes a built-in-type Python object to a JSON string, while <code>json.loads(string)</code> decodes a JSON string into a Python object.</p>\n\n<p>Really really handy.</p>\n"
},
{
"answer_id": 335299,
"author": "Dutch Masters",
"author_id": 42037,
"author_profile": "https://Stackoverflow.com/users/42037",
"pm_score": 3,
"selected": true,
"text": "<p><strong>Essential Libraries</strong></p>\n\n<p>The main challenge for an experienced programmer coming from another language to Python is figuring out how one language maps to another. Here are a few essential libraries and how they relate to Java equivalents.</p>\n\n<pre><code>os, os.path \n</code></pre>\n\n<p>Has functionality like in java.io.File, java.lang.Process, and others. But cleaner and more sophisticated, with a Unix flavor. Use os.path instead of os for higher-level functionality.</p>\n\n<pre><code>sys \n</code></pre>\n\n<p>Manipulate the sys.path (which is like the classpath), register exit handlers (like in java Runtime object), and access the standard I/O streams, as in java.lang.System. </p>\n\n<pre><code>unittest \n</code></pre>\n\n<p>Very similar (and based on) jUnit, with test fixtures and runnable harnesses.</p>\n\n<pre><code>logging \n</code></pre>\n\n<p>Functionality almost identical to log4j with loglevels and loggers. ( logging is also in the standard java.util.Logging library)</p>\n\n<pre><code>datetime \n</code></pre>\n\n<p>Allows parsing and formatting dates and times, like in java.text.DateFormat, java.util.Date and related.</p>\n\n<pre><code>ConfigParser \n</code></pre>\n\n<p>Allows persistant configuration as in a java Properties file (but also allows nesting). Use this when you don't want the complexity of XML or a database backend.</p>\n\n<pre><code>socket, urllib \n</code></pre>\n\n<p>Similar functionality to what is in java.net, for working with either sockets, or retrieving content via URLs/URIs.</p>\n\n<p>Also, keep in mind that a lot of basic functionality, such as reading files, and working with collections, is in the core python language, whereas in Java it lives in packages. </p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168727",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8669/"
] |
A lot of useful features in Python are somewhat "hidden" inside modules. Named tuples (new in [Python 2.6](http://docs.python.org/whatsnew/2.6.html)), for instance, are found in the [collections](http://docs.python.org/library/collections.html) module.
The [Library Documentation page](http://docs.python.org/library/) will give you all the modules in the language, but newcomers to Python are likely to find themselves saying "Oh, I didn't know I could have done it *this way* using Python!" unless the important features in the language are pointed out by the experienced developers.
I'm **not** specifically looking for new modules in Python 2.6, but modules that can be found in this latest release.
|
**Essential Libraries**
The main challenge for an experienced programmer coming from another language to Python is figuring out how one language maps to another. Here are a few essential libraries and how they relate to Java equivalents.
```
os, os.path
```
Has functionality like in java.io.File, java.lang.Process, and others. But cleaner and more sophisticated, with a Unix flavor. Use os.path instead of os for higher-level functionality.
```
sys
```
Manipulate the sys.path (which is like the classpath), register exit handlers (like in java Runtime object), and access the standard I/O streams, as in java.lang.System.
```
unittest
```
Very similar (and based on) jUnit, with test fixtures and runnable harnesses.
```
logging
```
Functionality almost identical to log4j with loglevels and loggers. ( logging is also in the standard java.util.Logging library)
```
datetime
```
Allows parsing and formatting dates and times, like in java.text.DateFormat, java.util.Date and related.
```
ConfigParser
```
Allows persistant configuration as in a java Properties file (but also allows nesting). Use this when you don't want the complexity of XML or a database backend.
```
socket, urllib
```
Similar functionality to what is in java.net, for working with either sockets, or retrieving content via URLs/URIs.
Also, keep in mind that a lot of basic functionality, such as reading files, and working with collections, is in the core python language, whereas in Java it lives in packages.
|
168,736 |
<p>How do you set a default value for a MySQL Datetime column?</p>
<p>In SQL Server it's <code>getdate()</code>. What is the equivalant for MySQL? I'm using MySQL 5.x if that is a factor.</p>
|
[
{
"answer_id": 168763,
"author": "KernelM",
"author_id": 22328,
"author_profile": "https://Stackoverflow.com/users/22328",
"pm_score": 4,
"selected": false,
"text": "<p>You can use now() to set the value of a datetime column, but keep in mind that you can't use that as a default value.</p>\n"
},
{
"answer_id": 168770,
"author": "Vijesh VP",
"author_id": 22016,
"author_profile": "https://Stackoverflow.com/users/22016",
"pm_score": 3,
"selected": false,
"text": "<p>If you are trying to set default value as NOW(), I don't think MySQL supports that. In MySQL, you cannot use a function or an expression as the default value for any type of column, except for the TIMESTAMP data type column, for which you can specify the CURRENT_TIMESTAMP as the default.</p>\n"
},
{
"answer_id": 168832,
"author": "sebthebert",
"author_id": 24820,
"author_profile": "https://Stackoverflow.com/users/24820",
"pm_score": 11,
"selected": true,
"text": "<p><strong>IMPORTANT EDIT:</strong>\nIt is now possible to achieve this with DATETIME fields since <strong>MySQL 5.6.5</strong>, take a look at the <a href=\"https://stackoverflow.com/a/10603198/24820\">other post</a> below...</p>\n<p>Previous versions can't do that with DATETIME...</p>\n<p>But you can do it with TIMESTAMP:</p>\n<pre><code>mysql> create table test (str varchar(32), ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP);\nQuery OK, 0 rows affected (0.00 sec)\n\nmysql> desc test;\n+-------+-------------+------+-----+-------------------+-------+\n| Field | Type | Null | Key | Default | Extra |\n+-------+-------------+------+-----+-------------------+-------+\n| str | varchar(32) | YES | | NULL | | \n| ts | timestamp | NO | | CURRENT_TIMESTAMP | | \n+-------+-------------+------+-----+-------------------+-------+\n2 rows in set (0.00 sec)\n\nmysql> insert into test (str) values ("demo");\nQuery OK, 1 row affected (0.00 sec)\n\nmysql> select * from test;\n+------+---------------------+\n| str | ts |\n+------+---------------------+\n| demo | 2008-10-03 22:59:52 | \n+------+---------------------+\n1 row in set (0.00 sec)\n\nmysql>\n</code></pre>\n<p><strong>CAVEAT:</strong> <em>IF you define a column with CURRENT_TIMESTAMP ON as default, you will need to ALWAYS specify a value for this column or the value will automatically reset itself to "now()" on update. This means that if you do not want the value to change, your UPDATE statement must contain "[your column name] = [your column name]" (or some other value) or the value will become "now()". Weird, but true. I am using 5.5.56-MariaDB</em></p>\n"
},
{
"answer_id": 631689,
"author": "Kinjal Dixit",
"author_id": 6629,
"author_profile": "https://Stackoverflow.com/users/6629",
"pm_score": 4,
"selected": false,
"text": "<p>this is indeed terrible news.<a href=\"http://bugs.mysql.com/bug.php?id=27645\" rel=\"noreferrer\">here is a long pending bug/feature request for this</a>. that discussion also talks about the limitations of timestamp data type.</p>\n\n<p>I am seriously wondering what is the issue with getting this thing implemented.</p>\n"
},
{
"answer_id": 1483959,
"author": "Stephan Unrau",
"author_id": 179792,
"author_profile": "https://Stackoverflow.com/users/179792",
"pm_score": 7,
"selected": false,
"text": "<p>MySQL (<a href=\"http://dev.mysql.com/doc/refman/5.6/en/timestamp-initialization.html\" rel=\"noreferrer\">before version 5.6.5</a>) does not allow functions to be used for default DateTime values. TIMESTAMP is not suitable due to its odd behavior and is not recommended for use as input data. (See <a href=\"http://dev.mysql.com/doc/refman/5.0/en/data-type-defaults.html\" rel=\"noreferrer\">MySQL Data Type Defaults</a>.)</p>\n\n<p>That said, you can accomplish this <a href=\"http://dev.mysql.com/doc/refman/5.0/en/trigger-syntax.html\" rel=\"noreferrer\">by creating a Trigger</a>.</p>\n\n<p>I have a table with a DateCreated field of type DateTime. I created a trigger on that table \"Before Insert\" and \"<code>SET NEW.DateCreated=NOW()</code>\" and it works great.</p>\n\n<p>I hope this helps somebody.</p>\n"
},
{
"answer_id": 1552804,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 5,
"selected": false,
"text": "<p>I was able to solve this using this alter statement on my table that had two datetime fields.</p>\n\n<pre><code>ALTER TABLE `test_table`\n CHANGE COLUMN `created_dt` `created_dt` TIMESTAMP NOT NULL DEFAULT '0000-00-00 00:00:00',\n CHANGE COLUMN `updated_dt` `updated_dt` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;\n</code></pre>\n\n<p>This works as you would expect the now() function to work. Inserting nulls or ignoring the created_dt and updated_dt fields results in a perfect timestamp value in both fields. Any update to the row changes the updated_dt. If you insert records via the MySQL query browser you needed one more step, a trigger to handle the created_dt with a new timestamp.</p>\n\n<pre><code>CREATE TRIGGER trig_test_table_insert BEFORE INSERT ON `test_table`\n FOR EACH ROW SET NEW.created_dt = NOW();\n</code></pre>\n\n<p>The trigger can be whatever you want I just like the naming convention [trig]_[my_table_name]_[insert]</p>\n"
},
{
"answer_id": 3422808,
"author": "Fabian",
"author_id": 142671,
"author_profile": "https://Stackoverflow.com/users/142671",
"pm_score": 3,
"selected": false,
"text": "<p>For all who use the TIMESTAMP column as a solution i want to second the following limitation from the manual:</p>\n\n<p><a href=\"http://dev.mysql.com/doc/refman/5.0/en/datetime.html\" rel=\"noreferrer\">http://dev.mysql.com/doc/refman/5.0/en/datetime.html</a></p>\n\n<p>\"The TIMESTAMP data type has a range of '1970-01-01 00:00:01' UTC to '<strong>2038-01-19 03:14:07</strong>' UTC. It has varying properties, depending on the MySQL version and the SQL mode the server is running in. These properties are described later in this section. \"</p>\n\n<p>So this will obviously break your software in about 28 years.</p>\n\n<p>I believe the only solution on the database side is to use triggers like mentioned in other answers.</p>\n"
},
{
"answer_id": 3986957,
"author": "Srinivas",
"author_id": 482929,
"author_profile": "https://Stackoverflow.com/users/482929",
"pm_score": -1,
"selected": false,
"text": "<p>You can resolve the default timestamp. First consider which character set you are using for example if u taken utf8 this character set support all languages and if u taken laten1 this character set support only for English. Next setp if you are working under any project you should know client time zone and select you are client zone. This step are mandatory.</p>\n"
},
{
"answer_id": 4979548,
"author": "Donald",
"author_id": 614409,
"author_profile": "https://Stackoverflow.com/users/614409",
"pm_score": 5,
"selected": false,
"text": "<p>You can use triggers to do this type of stuff.</p>\n\n<pre><code>CREATE TABLE `MyTable` (\n`MyTable_ID` int UNSIGNED NOT NULL AUTO_INCREMENT ,\n`MyData` varchar(10) NOT NULL ,\n`CreationDate` datetime NULL ,\n`UpdateDate` datetime NULL ,\nPRIMARY KEY (`MyTable_ID`)\n)\n;\n\nCREATE TRIGGER `MyTable_INSERT` BEFORE INSERT ON `MyTable`\nFOR EACH ROW BEGIN\n -- Set the creation date\n SET new.CreationDate = now();\n\n -- Set the udpate date\n Set new.UpdateDate = now();\nEND;\n\nCREATE TRIGGER `MyTable_UPDATE` BEFORE UPDATE ON `MyTable`\nFOR EACH ROW BEGIN\n -- Set the udpate date\n Set new.UpdateDate = now();\nEND;\n</code></pre>\n"
},
{
"answer_id": 5430103,
"author": "Drawin Kumar",
"author_id": 676350,
"author_profile": "https://Stackoverflow.com/users/676350",
"pm_score": 3,
"selected": false,
"text": "<p>While defining multi-line triggers one has to change the delimiter as semicolon will be taken by MySQL compiler as end of trigger and generate error.\ne.g.</p>\n\n<pre><code>DELIMITER //\nCREATE TRIGGER `MyTable_UPDATE` BEFORE UPDATE ON `MyTable`\nFOR EACH ROW BEGIN\n -- Set the udpate date\n Set new.UpdateDate = now();\nEND//\nDELIMITER ;\n</code></pre>\n"
},
{
"answer_id": 5731720,
"author": "John Larson",
"author_id": 556250,
"author_profile": "https://Stackoverflow.com/users/556250",
"pm_score": 7,
"selected": false,
"text": "<p>For me the trigger approach has worked the best, but I found a snag with the approach. Consider the basic trigger to set a date field to the current time on insert:</p>\n\n<pre><code>CREATE TRIGGER myTable_OnInsert BEFORE INSERT ON `tblMyTable`\n FOR EACH ROW SET NEW.dateAdded = NOW();\n</code></pre>\n\n<p>This is usually great, but say you want to set the field manually via INSERT statement, like so:</p>\n\n<pre><code>INSERT INTO tblMyTable(name, dateAdded) VALUES('Alice', '2010-01-03 04:30:43');\n</code></pre>\n\n<p>What happens is that the trigger immediately overwrites your provided value for the field, and so the only way to set a non-current time is a follow up UPDATE statement--yuck! To override this behavior when a value is provided, try this slightly modified trigger with the IFNULL operator:</p>\n\n<pre><code>CREATE TRIGGER myTable_OnInsert BEFORE INSERT ON `tblMyTable`\n FOR EACH ROW SET NEW.dateAdded = IFNULL(NEW.dateAdded, NOW());\n</code></pre>\n\n<p>This gives the best of both worlds: you can provide a value for your date column and it will take, and otherwise it'll default to the current time. It's still ghetto relative to something clean like DEFAULT GETDATE() in the table definition, but we're getting closer!</p>\n"
},
{
"answer_id": 6444073,
"author": "Augiwan",
"author_id": 770035,
"author_profile": "https://Stackoverflow.com/users/770035",
"pm_score": 5,
"selected": false,
"text": "<p>For all those who lost heart trying to set a default <strong>DATETIME</strong> value in <strong>MySQL</strong>, I know exactly how you feel/felt. So here is is:</p>\n\n<pre><code>ALTER TABLE `table_name` CHANGE `column_name` DATETIME NOT NULL DEFAULT 0\n</code></pre>\n\n<p>Carefully observe that <strong>I haven't added single quotes/double quotes</strong> around the <strong>0</strong></p>\n\n<p>I'm literally jumping after solving this one :D</p>\n"
},
{
"answer_id": 8275966,
"author": "George",
"author_id": 1066382,
"author_profile": "https://Stackoverflow.com/users/1066382",
"pm_score": 3,
"selected": false,
"text": "<p>While you can't do this with <code>DATETIME</code> in the default definition, you can simply incorporate a select statement in your insert statement like this:</p>\n\n<pre><code>INSERT INTO Yourtable (Field1, YourDateField) VALUES('val1', (select now()))\n</code></pre>\n\n<p>Note the lack of quotes around the table.</p>\n\n<p>For MySQL 5.5</p>\n"
},
{
"answer_id": 8860822,
"author": "Samuel",
"author_id": 1149021,
"author_profile": "https://Stackoverflow.com/users/1149021",
"pm_score": 3,
"selected": false,
"text": "<p>Here is how to do it on MySQL 5.1:</p>\n\n<pre><code>ALTER TABLE `table_name` CHANGE `column_name` `column_name` \nTIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP;\n</code></pre>\n\n<p>I have no clue why you have to enter the column name twice.</p>\n"
},
{
"answer_id": 10603198,
"author": "Gustav Bertram",
"author_id": 1005039,
"author_profile": "https://Stackoverflow.com/users/1005039",
"pm_score": 9,
"selected": false,
"text": "<p>In version 5.6.5, it is possible to set a default value on a datetime column, and even make a column that will update when the row is updated. The type definition:</p>\n\n<pre><code>CREATE TABLE foo (\n `creation_time` DATETIME DEFAULT CURRENT_TIMESTAMP,\n `modification_time` DATETIME ON UPDATE CURRENT_TIMESTAMP\n)\n</code></pre>\n\n<p>Reference:\n<a href=\"http://optimize-this.blogspot.com/2012/04/datetime-default-now-finally-available.html\">http://optimize-this.blogspot.com/2012/04/datetime-default-now-finally-available.html</a></p>\n"
},
{
"answer_id": 13411388,
"author": "Dhrumil Shah",
"author_id": 439506,
"author_profile": "https://Stackoverflow.com/users/439506",
"pm_score": 0,
"selected": false,
"text": "<p>If you are trying to set default value as NOW(),MySQL supports that you have to change the type of that column TIMESTAMP instead of DATETIME. TIMESTAMP have current date and time as default..i think it will resolved your problem..</p>\n"
},
{
"answer_id": 13840008,
"author": "Fathah Rehman P",
"author_id": 991065,
"author_profile": "https://Stackoverflow.com/users/991065",
"pm_score": 2,
"selected": false,
"text": "<pre><code>CREATE TABLE `testtable` (\n `id` INT(10) NULL DEFAULT NULL,\n `colname` DATETIME NULL DEFAULT '1999-12-12 12:12:12'\n)\n</code></pre>\n\n<p>In the above query to create 'testtable', i used '1999-12-12 12:12:12' as default value for DATETIME column <code>colname</code></p>\n"
},
{
"answer_id": 15012579,
"author": "Steven Lloyd",
"author_id": 888870,
"author_profile": "https://Stackoverflow.com/users/888870",
"pm_score": 4,
"selected": false,
"text": "<p><a href=\"http://dev.mysql.com/doc/refman/5.6/en/timestamp-initialization.html\" rel=\"noreferrer\">MySQL 5.6 has fixed this problem</a>.</p>\n\n<pre><code>ALTER TABLE mytable CHANGE mydate datetime NOT NULL DEFAULT 'CURRENT_TIMESTAMP'\n</code></pre>\n"
},
{
"answer_id": 19260794,
"author": "Joseph Persico",
"author_id": 1484411,
"author_profile": "https://Stackoverflow.com/users/1484411",
"pm_score": 0,
"selected": false,
"text": "<p>Take for instance If I had a table named 'site' with a created_at and an update_at column that were both DATETIME and need the default value of now, I could execute the following sql to achieve this.</p>\n\n<pre>\nALTER TABLE `site` CHANGE `created_at` `created_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP;\n\nALTER TABLE `site` CHANGE `created_at` `created_at` DATETIME NULL DEFAULT NULL;\n\nALTER TABLE `site` CHANGE `updated_at` `updated_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP;\n\nALTER TABLE `site` CHANGE `updated_at` `updated_at` DATETIME NULL DEFAULT NULL;\n</pre>\n\n<p>The sequence of statements is important because a table can not have two columns of type TIMESTAMP with default values of CUREENT TIMESTAMP</p>\n"
},
{
"answer_id": 28607663,
"author": "Lucas Moyano Angelini",
"author_id": 2372187,
"author_profile": "https://Stackoverflow.com/users/2372187",
"pm_score": 0,
"selected": false,
"text": "<p>This is my trigger example:</p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code>/************ ROLE ************/\r\ndrop table if exists `role`;\r\ncreate table `role` (\r\n `id_role` bigint(20) unsigned not null auto_increment,\r\n `date_created` datetime,\r\n `date_deleted` datetime,\r\n `name` varchar(35) not null,\r\n `description` text,\r\n primary key (`id_role`)\r\n) comment='';\r\n\r\ndrop trigger if exists `role_date_created`;\r\ncreate trigger `role_date_created` before insert\r\n on `role`\r\n for each row \r\n set new.`date_created` = now();</code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 36374254,
"author": "Evhz",
"author_id": 5476782,
"author_profile": "https://Stackoverflow.com/users/5476782",
"pm_score": 4,
"selected": false,
"text": "<p>I'm running MySql Server 5.7.11 and this sentence:</p>\n\n<pre><code>ALTER TABLE table_name CHANGE date_column datetime NOT NULL DEFAULT '0000-00-00 00:00:00'\n</code></pre>\n\n<p>is <strong>not</strong> working. But the following: </p>\n\n<pre><code>ALTER TABLE table_name CHANGE date_column datetime NOT NULL DEFAULT '1000-01-01 00:00:00'\n</code></pre>\n\n<p><strong>just works</strong>. </p>\n\n<p>As a <em>sidenote</em>, it is mentioned in the <a href=\"http://dev.mysql.com/doc/refman/5.7/en/datetime.html\" rel=\"noreferrer\">mysql docs</a>: </p>\n\n<blockquote>\n <p>The DATE type is used for values with a date part but no time part. MySQL retrieves and displays DATE values in 'YYYY-MM-DD' format. The supported range is '1000-01-01' to '9999-12-31'.</p>\n</blockquote>\n\n<p>even if they also say:</p>\n\n<blockquote>\n <p>Invalid DATE, DATETIME, or TIMESTAMP values are converted to the “zero” value of the appropriate type ('0000-00-00' or '0000-00-00 00:00:00').</p>\n</blockquote>\n"
},
{
"answer_id": 39571278,
"author": "Rana Aalamgeer",
"author_id": 3611036,
"author_profile": "https://Stackoverflow.com/users/3611036",
"pm_score": 1,
"selected": false,
"text": "<p>Use the following code </p>\n\n<pre><code>DELIMITER $$\n\n CREATE TRIGGER bu_table1_each BEFORE UPDATE ON table1 FOR EACH ROW\n BEGIN\n SET new.datefield = NOW();\n END $$\n\n DELIMITER ;\n</code></pre>\n"
},
{
"answer_id": 41020080,
"author": "Saveendra Ekanayake",
"author_id": 3103802,
"author_profile": "https://Stackoverflow.com/users/3103802",
"pm_score": 5,
"selected": false,
"text": "<p>If you have already created the table then you can use </p>\n\n<p><strong>To change default value to current date time</strong></p>\n\n<pre><code>ALTER TABLE <TABLE_NAME> \nCHANGE COLUMN <COLUMN_NAME> <COLUMN_NAME> DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP;\n</code></pre>\n\n<p><strong>To change default value to '2015-05-11 13:01:01'</strong></p>\n\n<pre><code>ALTER TABLE <TABLE_NAME> \nCHANGE COLUMN <COLUMN_NAME> <COLUMN_NAME> DATETIME NOT NULL DEFAULT '2015-05-11 13:01:01';\n</code></pre>\n"
},
{
"answer_id": 51533959,
"author": "Deepak N",
"author_id": 8746415,
"author_profile": "https://Stackoverflow.com/users/8746415",
"pm_score": 2,
"selected": false,
"text": "<p>I think it simple in mysql since mysql the inbuilt function called now() which gives current time(time of that insert).</p>\n\n<p>So your query should look like similarly</p>\n\n<pre><code>CREATE TABLE defaultforTime(\n `creation_time` DATETIME DEFAULT CURRENT_TIMESTAMP,\n `modification_time` DATETIME default now()\n);\n</code></pre>\n\n<p>Thank you.</p>\n"
},
{
"answer_id": 60247492,
"author": "Gvs Akhil",
"author_id": 7737777,
"author_profile": "https://Stackoverflow.com/users/7737777",
"pm_score": 3,
"selected": false,
"text": "<p>Working fine with MySQL 8.x </p>\n\n<pre><code>CREATE TABLE `users` (\n `id` int(11) NOT NULL AUTO_INCREMENT,\n `dateCreated` datetime DEFAULT CURRENT_TIMESTAMP,\n `dateUpdated` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,\n PRIMARY KEY (`id`),\n UNIQUE KEY `mobile_UNIQUE` (`mobile`)\n ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;\n</code></pre>\n"
},
{
"answer_id": 64212095,
"author": "Bhargav Variya",
"author_id": 12479629,
"author_profile": "https://Stackoverflow.com/users/12479629",
"pm_score": 2,
"selected": false,
"text": "<p>If you set <code>ON UPDATE CURRENT_TIMESTAMP</code> it will take current time when row data update in table.</p>\n<pre><code> CREATE TABLE bar(\n `create_time` TIMESTAMP CURRENT_TIMESTAMP,\n `update_time` TIMESTAMP ON UPDATE CURRENT_TIMESTAMP\n )\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168736",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3747/"
] |
How do you set a default value for a MySQL Datetime column?
In SQL Server it's `getdate()`. What is the equivalant for MySQL? I'm using MySQL 5.x if that is a factor.
|
**IMPORTANT EDIT:**
It is now possible to achieve this with DATETIME fields since **MySQL 5.6.5**, take a look at the [other post](https://stackoverflow.com/a/10603198/24820) below...
Previous versions can't do that with DATETIME...
But you can do it with TIMESTAMP:
```
mysql> create table test (str varchar(32), ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
Query OK, 0 rows affected (0.00 sec)
mysql> desc test;
+-------+-------------+------+-----+-------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+-------------------+-------+
| str | varchar(32) | YES | | NULL | |
| ts | timestamp | NO | | CURRENT_TIMESTAMP | |
+-------+-------------+------+-----+-------------------+-------+
2 rows in set (0.00 sec)
mysql> insert into test (str) values ("demo");
Query OK, 1 row affected (0.00 sec)
mysql> select * from test;
+------+---------------------+
| str | ts |
+------+---------------------+
| demo | 2008-10-03 22:59:52 |
+------+---------------------+
1 row in set (0.00 sec)
mysql>
```
**CAVEAT:** *IF you define a column with CURRENT\_TIMESTAMP ON as default, you will need to ALWAYS specify a value for this column or the value will automatically reset itself to "now()" on update. This means that if you do not want the value to change, your UPDATE statement must contain "[your column name] = [your column name]" (or some other value) or the value will become "now()". Weird, but true. I am using 5.5.56-MariaDB*
|
168,738 |
<p>I am building the diagram component in JavaScript. It has two layers rendered separately: foreground and background.</p>
<p>To determine the required size of the background:</p>
<ol>
<li>render the foreground </li>
<li>measure the height of the result</li>
<li>render the foreground and the
background together</li>
</ol>
<p>In code it looks like this:</p>
<pre><code>var foreground = renderForegroundIntoString();
parentDiv.innerHTML = foreground;
var height = parentDiv.children[0].clientHeight;
var background = renderBackgroundIntoString(height);
parentDiv.innerHTML = foreground + background;
</code></pre>
<p>Using IE7, this is a piece of cake. However, Firefox2 is not really willing to render the <code>parentDiv.innerHTML</code> right away, therefore I cannot read out the foreground height.</p>
<p>When does Firefox execute the rendering and how can I delay my background generation till foreground rendering is completed, or is there any alternative way to determine the height of my foreground elements?</p>
<p>[Appended after testing Dan's answer (thanx Dan)]</p>
<p>Within the body of the callback method (called back by <code>setTimeout(...))</code> I can see, the rendering of the <code>innerHTML</code> is still not complete. </p>
|
[
{
"answer_id": 168767,
"author": "Dan",
"author_id": 17121,
"author_profile": "https://Stackoverflow.com/users/17121",
"pm_score": 2,
"selected": false,
"text": "<p>You should never, ever rely on something you just inserted into the DOM being rendered by the next line of code. All browsers will group these changes together to some degree, and it can be tricky to work out when and why.</p>\n\n<p>The best way to deal with it is to execute the second part in response to some kind of event. Though it doesn't look like there's a good one you can use in that situation, so failing that, you can trigger the second part with:</p>\n\n<pre><code>setTimeout(renderBackground, 0)\n</code></pre>\n\n<p>That will ensure the current thread is completed before the second part of the code is executed.</p>\n"
},
{
"answer_id": 170540,
"author": "Eric Wendelin",
"author_id": 25066,
"author_profile": "https://Stackoverflow.com/users/25066",
"pm_score": 0,
"selected": false,
"text": "<p>I don't think you want parentDiv.children[0] (children is not a valid property in FF3 anyway), instead you want parentDiv.childNodes[0], but note that this includes text nodes that may have no height. You could try looping waiting for parentDiv's descendants to be rendered like so:</p>\n\n<pre>\nfunction getRenderedHeight(parentDiv) {\nif (parentDiv.childNodes) {\n var i = 0;\n while (parentDiv.childNodes[i].nodeType == 3) { i++; }\n //Now parentDiv.childNodes[i] is your first non-text child\n return parentDiv.childNodes[i].clientHeight;\n //your other code here ...\n} else {\n setTimeout(\"isRendered(\"+parentDiv+\")\",200);\n}\n}\n</pre>\n\n<p>and then invoke by: getRenderedHeight(parentDiv) after setting the innerHTML.</p>\n\n<p>Hope that gives some ideas, anyway.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168738",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24451/"
] |
I am building the diagram component in JavaScript. It has two layers rendered separately: foreground and background.
To determine the required size of the background:
1. render the foreground
2. measure the height of the result
3. render the foreground and the
background together
In code it looks like this:
```
var foreground = renderForegroundIntoString();
parentDiv.innerHTML = foreground;
var height = parentDiv.children[0].clientHeight;
var background = renderBackgroundIntoString(height);
parentDiv.innerHTML = foreground + background;
```
Using IE7, this is a piece of cake. However, Firefox2 is not really willing to render the `parentDiv.innerHTML` right away, therefore I cannot read out the foreground height.
When does Firefox execute the rendering and how can I delay my background generation till foreground rendering is completed, or is there any alternative way to determine the height of my foreground elements?
[Appended after testing Dan's answer (thanx Dan)]
Within the body of the callback method (called back by `setTimeout(...))` I can see, the rendering of the `innerHTML` is still not complete.
|
You should never, ever rely on something you just inserted into the DOM being rendered by the next line of code. All browsers will group these changes together to some degree, and it can be tricky to work out when and why.
The best way to deal with it is to execute the second part in response to some kind of event. Though it doesn't look like there's a good one you can use in that situation, so failing that, you can trigger the second part with:
```
setTimeout(renderBackground, 0)
```
That will ensure the current thread is completed before the second part of the code is executed.
|
168,798 |
<p>I've exposed several web services in our product using Java and WS-Security. One of our customers wants to consume the web service using ColdFusion. Does ColdFusion support WS-Security? Can I get around it by writing a Java client and using that in ColdFusion?</p>
<p>(I don't know much about ColdFusion).</p>
|
[
{
"answer_id": 168981,
"author": "Peter Boughton",
"author_id": 9360,
"author_profile": "https://Stackoverflow.com/users/9360",
"pm_score": 1,
"selected": false,
"text": "<p>I've never done any ws-security, and don't know if ColdFusion can consume it or not, but to answer your secondary question:</p>\n\n<blockquote>\n <blockquote>\n <p>Can I get around it by writing a java client and using that in coldfusion?</p>\n </blockquote>\n</blockquote>\n\n<p>Yes, absolutely. ColdFusion can easily use Java objects and methods.</p>\n"
},
{
"answer_id": 178131,
"author": "Jason",
"author_id": 3242,
"author_profile": "https://Stackoverflow.com/users/3242",
"pm_score": 4,
"selected": true,
"text": "<p>I'm assuming you mean you need to pass the security in as part of the SOAP header. Here's a sample on how to connect to a .Net service. Same approach should apply w/ Java, just the url's would be different.</p>\n\n<pre><code><cfset local.soapHeader = xmlNew()>\n<cfset local.soapHeader.TheSoapHeader = xmlElemNew(local.soapHeader, \"http://someurl.com/\", \"TheSoapHeader\")>\n<cfset local.soapHeader.TheSoapHeader.UserName.XmlText = \"foo\">\n<cfset local.soapHeader.TheSoapHeader.UserName.XmlAttributes[\"xsi:type\"] = \"xsd:string\">\n\n<cfset local.soapHeader.TheSoapHeader = xmlElemNew(local.soapHeader, \"http://webserviceUrl.com/\", \"TheSoapHeader\")>\n<cfset local.soapHeader.TheSoapHeader.Password.XmlText = \"bar\">\n<cfset local.soapHeader.TheSoapHeader.Password.XmlAttributes[\"xsi:type\"] = \"xsd:string\">\n\n<cfset theWebService = createObject(\"webservice\",\"http://webserviceUrl.com/Webservice.asmx?WSDL\")>\n<cfset addSOAPRequestHeader(theWebService, \"ignoredNameSpace\", \"ignoredName\", local.soapHeader, false)>\n\n<cfset aResponse = theWebService.SomeMethod(arg1)>\n</code></pre>\n\n<p>Hope this is what you needed.</p>\n"
},
{
"answer_id": 11567405,
"author": "williambq",
"author_id": 1200607,
"author_profile": "https://Stackoverflow.com/users/1200607",
"pm_score": 2,
"selected": false,
"text": "<p>This is probably more accurate to produce the 'simple' xml soap header. The example above is missing a few lines.</p>\n\n<pre><code>Local['soapHeader'] = xmlNew();\nLocal['soapHeader']['UsernameToken'] = xmlElemNew(local.soapHeader, \"http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-secext-1.0.xsd\", \"UsernameToken\");\nLocal['soapHeader']['UsernameToken']['username'] = xmlElemNew(local.soapHeader, \"http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-secext-1.0.xsd\", \"username\");\nLocal['soapHeader']['UsernameToken']['username'].XmlText = Arguments.szUserName;\nLocal['soapHeader']['UsernameToken']['username'].XmlAttributes[\"xsi:type\"] = \"xsd:string\";\nLocal['soapHeader']['UsernameToken']['password'] = xmlElemNew(local.soapHeader, \"http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-secext-1.0.xsd\", \"password\");\nLocal['soapHeader']['UsernameToken']['password'].XmlText = Arguments.szPassword;\nLocal['soapHeader']['UsernameToken']['password'].XmlAttributes[\"xsi:type\"] = \"xsd:string\";\naddSOAPRequestHeader(ws, \"ignoredNameSpace\", \"ignoredName\", Local.soapHeader, false);\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168798",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1310/"
] |
I've exposed several web services in our product using Java and WS-Security. One of our customers wants to consume the web service using ColdFusion. Does ColdFusion support WS-Security? Can I get around it by writing a Java client and using that in ColdFusion?
(I don't know much about ColdFusion).
|
I'm assuming you mean you need to pass the security in as part of the SOAP header. Here's a sample on how to connect to a .Net service. Same approach should apply w/ Java, just the url's would be different.
```
<cfset local.soapHeader = xmlNew()>
<cfset local.soapHeader.TheSoapHeader = xmlElemNew(local.soapHeader, "http://someurl.com/", "TheSoapHeader")>
<cfset local.soapHeader.TheSoapHeader.UserName.XmlText = "foo">
<cfset local.soapHeader.TheSoapHeader.UserName.XmlAttributes["xsi:type"] = "xsd:string">
<cfset local.soapHeader.TheSoapHeader = xmlElemNew(local.soapHeader, "http://webserviceUrl.com/", "TheSoapHeader")>
<cfset local.soapHeader.TheSoapHeader.Password.XmlText = "bar">
<cfset local.soapHeader.TheSoapHeader.Password.XmlAttributes["xsi:type"] = "xsd:string">
<cfset theWebService = createObject("webservice","http://webserviceUrl.com/Webservice.asmx?WSDL")>
<cfset addSOAPRequestHeader(theWebService, "ignoredNameSpace", "ignoredName", local.soapHeader, false)>
<cfset aResponse = theWebService.SomeMethod(arg1)>
```
Hope this is what you needed.
|
168,838 |
<p>I am trying to visualize some values on a form. They range from 0 to 200 and I would like the ones around 0 be green and turn bright red as they go to 200. </p>
<p>Basically the function should return color based on the value inputted. Any ideas ?</p>
|
[
{
"answer_id": 168846,
"author": "Peter Parker",
"author_id": 23264,
"author_profile": "https://Stackoverflow.com/users/23264",
"pm_score": 3,
"selected": false,
"text": "<pre><code>red = (float)val / 200 * 255;\n\ngreen = (float)(200 - val) / 200 * 255;\n\nblue = 0;\n\nreturn red << 16 + green << 8 + blue;\n</code></pre>\n"
},
{
"answer_id": 168853,
"author": "Tom Ritter",
"author_id": 8435,
"author_profile": "https://Stackoverflow.com/users/8435",
"pm_score": 1,
"selected": false,
"text": "<p>Looking through <a href=\"http://en.wikipedia.org/wiki/Color_space\" rel=\"nofollow noreferrer\">this wikipedia article</a> I personally would pick a path through a color space, and map the values onto that path. </p>\n\n<p>But that's a straight function. I think you might be better suited to a javascript color chooser you can find with a quick color that will give you the Hex, and you can store the Hex.</p>\n"
},
{
"answer_id": 168863,
"author": "Lou Franco",
"author_id": 3937,
"author_profile": "https://Stackoverflow.com/users/3937",
"pm_score": 2,
"selected": false,
"text": "<p>Pick a green that you like (RGB1 = #00FF00, e.g.) and a Red that you like (RGB2 = #FF0000, e.g.) and then calculate the color like this</p>\n\n<pre><code>R = R1 * (200-i)/200 + R2 * i/200\nG = G1 * (200-i)/200 + G2 * i/200\nB = B1 * (200-i)/200 + B2 * i/200\n</code></pre>\n"
},
{
"answer_id": 168874,
"author": "ypnos",
"author_id": 21974,
"author_profile": "https://Stackoverflow.com/users/21974",
"pm_score": 2,
"selected": false,
"text": "<p>For best controllable and accurate effect, you should use the HSV color space. With HSV, you can easily scale Hue, Saturation and/or Brightness seperate from each other. Then, you do the transformation to RGB.</p>\n"
},
{
"answer_id": 168877,
"author": "eaolson",
"author_id": 23669,
"author_profile": "https://Stackoverflow.com/users/23669",
"pm_score": 3,
"selected": false,
"text": "<p>You don't say in what environment you're doing this. If you can work with <a href=\"http://en.wikipedia.org/wiki/HSL_and_HSV\" rel=\"nofollow noreferrer\">HSV colors</a>, this would be pretty easy to do by setting S = 100 and V = 100, and determining H by:</p>\n\n<pre><code>H = 0.4 * value + 120\n</code></pre>\n\n<p><a href=\"http://en.wikipedia.org/wiki/HSL_and_HSV#Conversion_from_HSV_to_RGB\" rel=\"nofollow noreferrer\">Converting from HSV to RGB</a> is also reasonably easy.</p>\n\n<p>[EDIT] Note: in contrast to some other proposed solutions, this will change color green -> yellow -> orange -> red.</p>\n"
},
{
"answer_id": 168974,
"author": "tzot",
"author_id": 6899,
"author_profile": "https://Stackoverflow.com/users/6899",
"pm_score": 5,
"selected": true,
"text": "<p>Basically, the general method for smooth transition between two values is the following function:</p>\n\n<pre><code>function transition(value, maximum, start_point, end_point):\n return start_point + (end_point - start_point)*value/maximum\n</code></pre>\n\n<p>That given, you define a function that does the transition for triplets (RGB, HSV etc).</p>\n\n<pre><code>function transition3(value, maximum, (s1, s2, s3), (e1, e2, e3)):\n r1= transition(value, maximum, s1, e1)\n r2= transition(value, maximum, s2, e2)\n r3= transition(value, maximum, s3, e3)\n return (r1, r2, r3)\n</code></pre>\n\n<p>Assuming you have RGB colours for the <i>s</i> and <i>e</i> triplets, you can use the transition3 function as-is. However, going through the HSV colour space produces more \"natural\" transitions. So, given the conversion functions (stolen shamelessly from the Python colorsys module and converted to pseudocode :):</p>\n\n<pre><code>function rgb_to_hsv(r, g, b):\n maxc= max(r, g, b)\n minc= min(r, g, b)\n v= maxc\n if minc == maxc then return (0, 0, v)\n diff= maxc - minc\n s= diff / maxc\n rc= (maxc - r) / diff\n gc= (maxc - g) / diff\n bc= (maxc - b) / diff\n if r == maxc then\n h= bc - gc\n else if g == maxc then\n h= 2.0 + rc - bc\n else\n h = 4.0 + gc - rc\n h = (h / 6.0) % 1.0 //comment: this calculates only the fractional part of h/6\n return (h, s, v)\n\nfunction hsv_to_rgb(h, s, v):\n if s == 0.0 then return (v, v, v)\n i= int(floor(h*6.0)) //comment: floor() should drop the fractional part\n f= (h*6.0) - i\n p= v*(1.0 - s)\n q= v*(1.0 - s*f)\n t= v*(1.0 - s*(1.0 - f))\n if i mod 6 == 0 then return v, t, p\n if i == 1 then return q, v, p\n if i == 2 then return p, v, t\n if i == 3 then return p, q, v\n if i == 4 then return t, p, v\n if i == 5 then return v, p, q\n //comment: 0 <= i <= 6, so we never come here\n</code></pre>\n\n<p>, you can have code as following:</p>\n\n<pre><code>start_triplet= rgb_to_hsv(0, 255, 0) //comment: green converted to HSV\nend_triplet= rgb_to_hsv(255, 0, 0) //comment: accordingly for red\n\nmaximum= 200\n\n… //comment: value is defined somewhere here\n\nrgb_triplet_to_display= hsv_to_rgb(transition3(value, maximum, start_triplet, end_triplet))\n</code></pre>\n"
},
{
"answer_id": 168980,
"author": "Ates Goral",
"author_id": 23501,
"author_profile": "https://Stackoverflow.com/users/23501",
"pm_score": 1,
"selected": false,
"text": "<p>If you use linear ramps for Red and Green values as Peter Parker suggested, the color for value 100 will basically be <a href=\"http://www.colourlovers.com/patterns/search?hex=7f7f00\" rel=\"nofollow noreferrer\">puke green</a> (127, 127, 0). You ideally want it to be a bright orange or yellow at that midpoint. For that, you can use:</p>\n\n<pre><code>Red = max(value / 100, 1) * 255\nGreen = (1 - max(value / 100, 1)) * 255\nBlue = 0\n</code></pre>\n"
},
{
"answer_id": 9338274,
"author": "Jon Lemmon",
"author_id": 307438,
"author_profile": "https://Stackoverflow.com/users/307438",
"pm_score": 2,
"selected": false,
"text": "<p>extending upon @tzot's code... you can also set up a mid-point in between the start and end points, which can be useful if you want a \"transition color\"!</p>\n\n<pre><code>//comment: s = start_triplet, m = mid_triplet, e = end_triplet\nfunction transition3midpoint = (value, maximum, s, m, e):\n mid = maximum / 2\n if value < mid\n return transition3(value, mid, s, m)\n else\n return transition3(value - mid, mid, m, e)\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168838",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4694/"
] |
I am trying to visualize some values on a form. They range from 0 to 200 and I would like the ones around 0 be green and turn bright red as they go to 200.
Basically the function should return color based on the value inputted. Any ideas ?
|
Basically, the general method for smooth transition between two values is the following function:
```
function transition(value, maximum, start_point, end_point):
return start_point + (end_point - start_point)*value/maximum
```
That given, you define a function that does the transition for triplets (RGB, HSV etc).
```
function transition3(value, maximum, (s1, s2, s3), (e1, e2, e3)):
r1= transition(value, maximum, s1, e1)
r2= transition(value, maximum, s2, e2)
r3= transition(value, maximum, s3, e3)
return (r1, r2, r3)
```
Assuming you have RGB colours for the *s* and *e* triplets, you can use the transition3 function as-is. However, going through the HSV colour space produces more "natural" transitions. So, given the conversion functions (stolen shamelessly from the Python colorsys module and converted to pseudocode :):
```
function rgb_to_hsv(r, g, b):
maxc= max(r, g, b)
minc= min(r, g, b)
v= maxc
if minc == maxc then return (0, 0, v)
diff= maxc - minc
s= diff / maxc
rc= (maxc - r) / diff
gc= (maxc - g) / diff
bc= (maxc - b) / diff
if r == maxc then
h= bc - gc
else if g == maxc then
h= 2.0 + rc - bc
else
h = 4.0 + gc - rc
h = (h / 6.0) % 1.0 //comment: this calculates only the fractional part of h/6
return (h, s, v)
function hsv_to_rgb(h, s, v):
if s == 0.0 then return (v, v, v)
i= int(floor(h*6.0)) //comment: floor() should drop the fractional part
f= (h*6.0) - i
p= v*(1.0 - s)
q= v*(1.0 - s*f)
t= v*(1.0 - s*(1.0 - f))
if i mod 6 == 0 then return v, t, p
if i == 1 then return q, v, p
if i == 2 then return p, v, t
if i == 3 then return p, q, v
if i == 4 then return t, p, v
if i == 5 then return v, p, q
//comment: 0 <= i <= 6, so we never come here
```
, you can have code as following:
```
start_triplet= rgb_to_hsv(0, 255, 0) //comment: green converted to HSV
end_triplet= rgb_to_hsv(255, 0, 0) //comment: accordingly for red
maximum= 200
… //comment: value is defined somewhere here
rgb_triplet_to_display= hsv_to_rgb(transition3(value, maximum, start_triplet, end_triplet))
```
|
168,886 |
<p>I'm looking for a homegrown way to scramble production data for use in development and test. I've built a couple of scripts that make random social security numbers, shift birth dates, scramble emails, etc. But I've come up against a wall trying to scramble customer names. I want to keep real names so we can still use or searches so random letter generation is out. What I have tried so far is building a temp table of all last names in the table then updating the customer table with a random selection from the temp table. Like this:</p>
<pre><code>DECLARE @Names TABLE (Id int IDENTITY(1,1),[Name] varchar(100))
/* Scramble the last names (randomly pick another last name) */
INSERT @Names SELECT LastName FROM Customer ORDER BY NEWID();
WITH [Customer ORDERED BY ROWID] AS
(SELECT ROW_NUMBER() OVER (ORDER BY NEWID()) AS ROWID, LastName FROM Customer)
UPDATE [Customer ORDERED BY ROWID] SET LastName=(SELECT [Name] FROM @Names WHERE ROWID=Id)
</code></pre>
<p>This worked well in test, but completely bogs down dealing with larger amounts of data (>20 minutes for 40K rows)</p>
<p>All of that to ask, how would you scramble customer names while keeping real names and the weight of the production data?</p>
<p><strong>UPDATE:</strong> Never fails, you try to put all the information in the post, and you forget something important. This data will also be used in our sales & demo environments which are publicly available. Some of the answers are what I am attempting to do, to 'switch' the names, but my question is literally, how to code in T-SQL?</p>
|
[
{
"answer_id": 168896,
"author": "warren",
"author_id": 4418,
"author_profile": "https://Stackoverflow.com/users/4418",
"pm_score": 2,
"selected": false,
"text": "<p>A very simple solution would be to ROT13 the text.</p>\n\n<p>A better question may be why you feel the need to scramble the data? If you have an encryption key, you could also consider running the text through DES or AES or similar. Thos would have potential performance issues, however.</p>\n"
},
{
"answer_id": 168898,
"author": "Peter Hoffmann",
"author_id": 720,
"author_profile": "https://Stackoverflow.com/users/720",
"pm_score": 3,
"selected": false,
"text": "<p>I use <a href=\"http://www.generatedata.com/\" rel=\"noreferrer\">generatedata</a>. It is an open source php script which can generate all sorts of dummy data. </p>\n"
},
{
"answer_id": 168902,
"author": "Ryan",
"author_id": 17917,
"author_profile": "https://Stackoverflow.com/users/17917",
"pm_score": 1,
"selected": false,
"text": "<p>Why not just use some sort of <a href=\"http://www.kleimo.com/random/name.cfm\" rel=\"nofollow noreferrer\">Random Name Generator?</a></p>\n"
},
{
"answer_id": 168920,
"author": "Jeff",
"author_id": 23902,
"author_profile": "https://Stackoverflow.com/users/23902",
"pm_score": -1,
"selected": false,
"text": "<p>Frankly, I'm not sure why this is needed. Your dev/test environments should be private, behind your firewall, and not accessible from the web.</p>\n\n<p>Your developers should be trusted, and you have legal recourse against them if they fail to live up to your trust.</p>\n\n<p>I think the real question should be \"Should I scramble the data?\", and the answer is (in my mind) 'no'.</p>\n\n<p>If you're sending it offsite for some reason, or you have to have your environments web-accessible, or if you're paranoid, I would implement a random switch. Rather than build a temp table, run switches between each location and a random row in the table, swapping one piece of data at a time.</p>\n\n<p>The end result will be a table with all the same data, but with it randomly reorganized. It should also be faster than your temp table, I believe.</p>\n\n<p>It should be simple enough to implement the <a href=\"http://en.wikipedia.org/wiki/Fisher-Yates_shuffle\" rel=\"nofollow noreferrer\">Fisher-Yates Shuffle</a> in SQL...or at least in a console app that reads the db and writes to the target.</p>\n\n<p>Edit (2): Off-the cuff answer in T-SQL:</p>\n\n<p>declare @name varchar(50)\nset @name = (SELECT lastName from person where personID = (random id number)\nUpdate person\nset lastname = @name\nWHERE personID = (person id of current row)</p>\n\n<p>Wrap this in a loop, and follow the guidelines of Fisher-Yates for modifying the random value constraints, and you'll be set.</p>\n"
},
{
"answer_id": 168923,
"author": "Milan Babuškov",
"author_id": 14690,
"author_profile": "https://Stackoverflow.com/users/14690",
"pm_score": 2,
"selected": false,
"text": "<p>When doing something like that I usually write a small program that first loads a lot of names and surnames in two arrays, and then just updates the database using random name/surname from arrays. It works really fast even for very big datasets (200.000+ records)</p>\n"
},
{
"answer_id": 807426,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>Use a temporary table instead and the query is very fast. I just ran on 60K rows in 4 seconds. I'll be using this one going forward.</p>\n\n<pre><code>DECLARE TABLE #Names \n(Id int IDENTITY(1,1),[Name] varchar(100))\n</code></pre>\n\n<p>/* Scramble the last names (randomly pick another last name) */</p>\n\n<pre><code>INSERT #Names\n SELECT LastName \n FROM Customer \n ORDER BY NEWID();\nWITH [Customer ORDERED BY ROWID] AS\n(SELECT ROW_NUMBER() OVER (ORDER BY NEWID()) AS ROWID, LastName FROM Customer)\n\nUPDATE [Customer ORDERED BY ROWID] \n\nSET LastName=(SELECT [Name] FROM #Names WHERE ROWID=Id)\n\nDROP TABLE #Names\n</code></pre>\n"
},
{
"answer_id": 7934472,
"author": "Nick Perkins",
"author_id": 138939,
"author_profile": "https://Stackoverflow.com/users/138939",
"pm_score": 0,
"selected": false,
"text": "<p>I am working on this at my company right now -- and it turns out to be a very tricky thing. You want to have names that are realistic, but must not reveal any real personal info.</p>\n\n<p>My approach has been to first create a randomized \"mapping\" of last names to other last names, then use that mapping to change all last names. This is good if you have duplicate name records. Suppose you have 2 \"John Smith\" records that both represent the same real person. If you changed one record to \"John Adams\" and the other to \"John Best\", then your one \"person\" now has 2 different names! With a mapping, all occurrences of \"Smith\" get changed to \"Jones\", and so duplicates ( or even family members ) still end up with the same last name, keeping the data more \"realistic\".</p>\n\n<p>I will also have to scramble the addresses, phone numbers, bank account numbers, etc...and I am not sure how I will approach those. Keeping the data \"realistic\" while scrambling is certainly a deep topic. This must have been done many times by many companies -- who has done this before? What did you learn?</p>\n"
},
{
"answer_id": 38973047,
"author": "AUR",
"author_id": 2322668,
"author_profile": "https://Stackoverflow.com/users/2322668",
"pm_score": 1,
"selected": false,
"text": "<p>The following approach worked for us, lets say we have 2 tables Customers and Products:</p>\n\n<pre><code>CREATE FUNCTION [dbo].[GenerateDummyValues]\n(\n @dataType varchar(100),\n @currentValue varchar(4000)=NULL\n)\nRETURNS varchar(4000)\nAS\nBEGIN\nIF @dataType = 'int'\n BEGIN\n Return '0'\n END\nELSE IF @dataType = 'varchar' OR @dataType = 'nvarchar' OR @dataType = 'char' OR @dataType = 'nchar'\n BEGIN\n Return 'AAAA'\n END\nELSE IF @dataType = 'datetime'\n BEGIN\n Return Convert(varchar(2000),GetDate())\n END\n-- you can add more checks, add complicated logic etc\nReturn 'XXX'\nEND\n</code></pre>\n\n<p>The above function will help in generating different data based on the data type coming in.</p>\n\n<p>Now, for each column of each table which does not have word \"id\" in it, use following query to generate further queries to manipulate the data:</p>\n\n<pre><code>select 'select ''update '' + TABLE_NAME + '' set '' + COLUMN_NAME + '' = '' + '''''''' + dbo.GenerateDummyValues( Data_type,'''') + '''''' where id = '' + Convert(varchar(10),Id) from INFORMATION_SCHEMA.COLUMNS, ' + table_name + ' where RIGHT(LOWER(COLUMN_NAME),2) <> ''id'' and TABLE_NAME = '''+ table_name + '''' + ';' from INFORMATION_SCHEMA.TABLES;\n</code></pre>\n\n<p>When you execute above query it will generate update queries for each table and for each column of that table, for example:</p>\n\n<pre><code>select 'update ' + TABLE_NAME + ' set ' + COLUMN_NAME + ' = ' + '''' + dbo.GenerateDummyValues( Data_type,'') + ''' where id = ' + Convert(varchar(10),Id) from INFORMATION_SCHEMA.COLUMNS, Customers where RIGHT(LOWER(COLUMN_NAME),2) <> 'id' and TABLE_NAME = 'Customers';\nselect 'update ' + TABLE_NAME + ' set ' + COLUMN_NAME + ' = ' + '''' + dbo.GenerateDummyValues( Data_type,'') + ''' where id = ' + Convert(varchar(10),Id) from INFORMATION_SCHEMA.COLUMNS, Products where RIGHT(LOWER(COLUMN_NAME),2) <> 'id' and TABLE_NAME = 'Products';\n</code></pre>\n\n<p>Now, when you execute above queries you will get final update queries, that will update the data of your tables.</p>\n\n<p>You can execute this on any SQL server database, no matter how many tables do you have, it will generate queries for you that can be further executed.</p>\n\n<p>Hope this helps.</p>\n"
},
{
"answer_id": 43948666,
"author": "Josh",
"author_id": 31299,
"author_profile": "https://Stackoverflow.com/users/31299",
"pm_score": 1,
"selected": false,
"text": "<p>Another site to generate shaped fake data sets, with an option for T-SQL output:\n<a href=\"https://mockaroo.com/\" rel=\"nofollow noreferrer\">https://mockaroo.com/</a></p>\n"
},
{
"answer_id": 44853526,
"author": "S3S",
"author_id": 6167855,
"author_profile": "https://Stackoverflow.com/users/6167855",
"pm_score": 1,
"selected": false,
"text": "<p>Here's a way using ROT47 which is reversible, and another which is random. You can add a PK to either to link back to the \"un scrambled\" versions</p>\n\n<pre><code>declare @table table (ID int, PLAIN_TEXT nvarchar(4000))\ninsert into @table\nvalues\n(1,N'Some Dudes name'),\n(2,N'Another Person Name'),\n(3,N'Yet Another Name')\n\n--split your string into a column, and compute the decimal value (N) \nif object_id('tempdb..#staging') is not null drop table #staging\nselect \n substring(a.b, v.number+1, 1) as Val\n ,ascii(substring(a.b, v.number+1, 1)) as N\n --,dense_rank() over (order by b) as RN\n ,a.ID\ninto #staging\nfrom (select PLAIN_TEXT b, ID FROM @table) a\n inner join\n master..spt_values v on v.number < len(a.b)\nwhere v.type = 'P' \n\n--select * from #staging\n\n\n--create a fast tally table of numbers to be used to build the ROT-47 table.\n\n;WITH\n E1(N) AS (select 1 from (values (1),(1),(1),(1),(1),(1),(1),(1),(1),(1))dt(n)),\n E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows\n E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max\n cteTally(N) AS \n (\n SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4\n )\n\n\n\n--Here we put it all together with stuff and FOR XML\nselect \n PLAIN_TEXT\n ,ENCRYPTED_TEXT =\n stuff((\n select\n --s.Val\n --,s.N\n e.ENCRYPTED_TEXT\n from #staging s\n left join(\n select \n N as DECIMAL_VALUE\n ,char(N) as ASCII_VALUE\n ,case \n when 47 + N <= 126 then char(47 + N)\n when 47 + N > 126 then char(N-47)\n end as ENCRYPTED_TEXT\n from cteTally\n where N between 33 and 126) e on e.DECIMAL_VALUE = s.N\n where s.ID = t.ID\n FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 0, '')\nfrom @table t\n\n\n--or if you want really random\nselect \n PLAIN_TEXT\n ,ENCRYPTED_TEXT =\n stuff((\n select\n --s.Val\n --,s.N\n e.ENCRYPTED_TEXT\n from #staging s\n left join(\n select \n N as DECIMAL_VALUE\n ,char(N) as ASCII_VALUE\n ,char((select ROUND(((122 - N -1) * RAND() + N), 0))) as ENCRYPTED_TEXT\n from cteTally\n where (N between 65 and 122) and N not in (91,92,93,94,95,96)) e on e.DECIMAL_VALUE = s.N\n where s.ID = t.ID\n FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 0, '')\nfrom @table t\n</code></pre>\n"
},
{
"answer_id": 50242368,
"author": "elifiner",
"author_id": 15109,
"author_profile": "https://Stackoverflow.com/users/15109",
"pm_score": 1,
"selected": false,
"text": "<p>Encountered the same problem myself and figured out an alternative solution that may work for others.</p>\n\n<p>The idea is to use MD5 on the name and then take the last 3 hex digits of it to map into a table of names. You can do this separately for first name and last name.</p>\n\n<p>3 hex digits represent decimals from 0 to 4095, so we need a list of 4096 first names and 4096 last names.</p>\n\n<p>So <code>conv(substr(md5(first_name), 3),16,10)</code> (in <code>MySQL</code> syntax) would be an index from 0 to 4095 that could be joined with a table that holds 4096 first names. The same concept could be applied to last names.</p>\n\n<p>Using MD5 (as opposed to a random number) guarantees a name in the original data will always be mapped to the same name in the test data.</p>\n\n<p>You can get a list of names here:</p>\n\n<p><a href=\"https://gist.github.com/elifiner/cc90fdd387449158829515782936a9a4\" rel=\"nofollow noreferrer\">https://gist.github.com/elifiner/cc90fdd387449158829515782936a9a4</a></p>\n"
},
{
"answer_id": 54876405,
"author": "mnemotronic",
"author_id": 1368561,
"author_profile": "https://Stackoverflow.com/users/1368561",
"pm_score": 2,
"selected": false,
"text": "<p>I use a method that changes characters in the name to other characters that are in the same \"range\" of usage frequency in English names. Apparently, the distribution of characters in names is different than it is for normal conversational English. For example, \"x\" and \"z\" occur 0.245% of the time, so they get swapped. The the other extreme, \"w\" is used 5.5% of the time, \"s\" 6.86% and \"t\", 15.978%. I change \"s\" to \"w\", \"t\" to \"s\" and \"w\" to \"t\".\nI keep the vowels \"aeio\" in a separate group so that a vowel is only replaced by another vowel. Similarly, \"q\", \"u\" and \"y\" are not replaced at all. My grouping and decisions are totally subjective.</p>\n\n<p>I ended up with 7 different \"groups\" of 2-5 characters , based mostly on frequency. characters within each group are swapped with other chars in that same group.</p>\n\n<p>The net result is names that kinda look like the might be names, but from \"not around here\".</p>\n\n<pre><code>Original name Morphed name\nLoren Nimag\nJuanita Kuogewso\nTennyson Saggywig\nDavid Mijsm\nJulie Kunewa\n</code></pre>\n\n<p>Here's the SQL I use, which includes a \"TitleCase\" function. There are 2 different versions of the \"morphed\" name based on different frequencies of letters I found on the web.</p>\n\n<pre><code>-- from https://stackoverflow.com/a/28712621\n\n-- Convert and return param as Title Case\n\nCREATE FUNCTION [dbo].[fnConvert_TitleCase] (@InputString VARCHAR(4000) )\nRETURNS VARCHAR(4000)AS\nBEGIN\nDECLARE @Index INT\nDECLARE @Char CHAR(1)\nDECLARE @OutputString VARCHAR(255)\n\nSET @OutputString = LOWER(@InputString)\nSET @Index = 2\nSET @OutputString = STUFF(@OutputString, 1, 1,UPPER(SUBSTRING(@InputString,1,1)))\n\nWHILE @Index <= LEN(@InputString)\nBEGIN\n SET @Char = SUBSTRING(@InputString, @Index, 1)\n IF @Char IN (' ', ';', ':', '!', '?', ',', '.', '_', '-', '/', '&','''','(','{','[','@')\n IF @Index + 1 <= LEN(@InputString)\n BEGIN\n IF @Char != '''' OR UPPER(SUBSTRING(@InputString, @Index + 1, 1)) != 'S'\n SET @OutputString = STUFF(@OutputString, @Index + 1, 1,UPPER(SUBSTRING(@InputString, @Index + 1, 1)))\n END\n SET @Index = @Index + 1\n END\n\n RETURN ISNULL(@OutputString,'')\n\nEND\nGo\n\n-- 00.045 x 0.045%\n-- 00.045 z 0.045%\n--\n-- Replace(Replace(Replace(TS_NAME,'x','#'),'z','x'),'#','z')\n--\n-- 00.456 k 0.456%\n-- 00.511 j 0.511%\n-- 00.824 v 0.824%\n-- kjv\n-- Replace(Replace(Replace(Replace(TS_NAME,'k','#'),'j','k'),'v','j'),'#','v')\n--\n-- 01.642 g 1.642%\n-- 02.284 n 2.284%\n-- 02.415 l 2.415%\n-- gnl\n-- Replace(Replace(Replace(Replace(TS_NAME,'g','#'),'n','g'),'l','n'),'#','l')\n--\n-- 02.826 r 2.826%\n-- 03.174 d 3.174%\n-- 03.826 m 3.826%\n-- rdm\n-- Replace(Replace(Replace(Replace(TS_NAME,'r','#'),'d','r'),'m','d'),'#','m')\n--\n-- 04.027 f 4.027%\n-- 04.200 h 4.200%\n-- 04.319 p 4.319%\n-- 04.434 b 4.434%\n-- 05.238 c 5.238%\n-- fhpbc\n-- Replace(Replace(Replace(Replace(Replace(Replace(TS_NAME,'f','#'),'h','f'),'p','h'),'b','p'),'c','b'),'#','c')\n--\n-- 05.497 w 5.497%\n-- 06.686 s 6.686%\n-- 15.978 t 15.978%\n-- wst\n-- Replace(Replace(Replace(Replace(TS_NAME,'w','#'),'s','w'),'t','s'),'#','t')\n--\n--\n-- 02.799 e 2.799%\n-- 07.294 i 7.294%\n-- 07.631 o 7.631%\n-- 11.682 a 11.682%\n-- eioa\n-- Replace(Replace(Replace(Replace(Replace(TS_NAME,'e','#'),'i','ew'),'o','i'),'a','o'),'#','a')\n--\n-- -- dont replace\n-- 00.222 q 0.222%\n-- 00.763 y 0.763%\n-- 01.183 u 1.183%\n\n-- Obfuscate a name\nSelect\n ts_id,\n Cast(ts_name as varchar(42)) as [Original Name]\n\n Cast(dbo.fnConvert_TitleCase(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(TS_NAME,'x','#'),'z','x'),'#','z'),'k','#'),'j','k'),'v','j'),'#','v'),'g','#'),'n','g'),'l','n'),'#','l'),'r','#'),'d','r'),'m','d'),'#','m'),'f','#'),'h','f'),'p','h'),'b','p'),'c','b'),'#','c'),'w','#'),'s','w'),'t','s'),'#','t'),'e','#'),'i','ew'),'o','i'),'a','o'),'#','a')) as VarChar(42)) As [morphed name] ,\n Cast(dbo.fnConvert_TitleCase(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(Replace(TS_NAME,'e','t'),'~','e'),'t','~'),'a','o'),'~','a'),'o','~'),'i','n'),'~','i'),'n','~'),'s','h'),'~','s'),'h','r'),'r','~'),'d','l'),'~','d'),'l','~'),'m','w'),'~','m'),'w','f'),'f','~'),'g','y'),'~','g'),'y','p'),'p','~'),'b','v'),'~','b'),'v','k'),'k','~'),'x','~'),'j','x'),'~','j')) as VarChar(42)) As [morphed name2]\n\nFrom\n ts_users\n;\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168886",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24991/"
] |
I'm looking for a homegrown way to scramble production data for use in development and test. I've built a couple of scripts that make random social security numbers, shift birth dates, scramble emails, etc. But I've come up against a wall trying to scramble customer names. I want to keep real names so we can still use or searches so random letter generation is out. What I have tried so far is building a temp table of all last names in the table then updating the customer table with a random selection from the temp table. Like this:
```
DECLARE @Names TABLE (Id int IDENTITY(1,1),[Name] varchar(100))
/* Scramble the last names (randomly pick another last name) */
INSERT @Names SELECT LastName FROM Customer ORDER BY NEWID();
WITH [Customer ORDERED BY ROWID] AS
(SELECT ROW_NUMBER() OVER (ORDER BY NEWID()) AS ROWID, LastName FROM Customer)
UPDATE [Customer ORDERED BY ROWID] SET LastName=(SELECT [Name] FROM @Names WHERE ROWID=Id)
```
This worked well in test, but completely bogs down dealing with larger amounts of data (>20 minutes for 40K rows)
All of that to ask, how would you scramble customer names while keeping real names and the weight of the production data?
**UPDATE:** Never fails, you try to put all the information in the post, and you forget something important. This data will also be used in our sales & demo environments which are publicly available. Some of the answers are what I am attempting to do, to 'switch' the names, but my question is literally, how to code in T-SQL?
|
I use [generatedata](http://www.generatedata.com/). It is an open source php script which can generate all sorts of dummy data.
|
168,897 |
<p>Is it more performant to have a bidimensional array (<code>type[,]</code>) or an array of arrays (<code>type[][]</code>) in C#?</p>
<p>Particularly for initial allocation and item access</p>
|
[
{
"answer_id": 168969,
"author": "Jeff Kotula",
"author_id": 1382162,
"author_profile": "https://Stackoverflow.com/users/1382162",
"pm_score": 2,
"selected": false,
"text": "<p>I believe that [,] can allocate one contiguous chunk of memory, while [][] is N+1 chunk allocations where N is the size of the first dimension. So I would guess that [,] is faster on initial allocation.</p>\n\n<p>Access is probably about the same, except that [][] would involve one extra dereference. Unless you're in an exceptionally tight loop it's probably a wash. Now, if you're doing something like image processing where you are referencing <em>between</em> rows rather than traversing row by row, locality of reference will play a big factor and [,] will probably edge out [][] depending on your cache size.</p>\n\n<p>As Marc Gravell mentioned, usage is key to evaluating the performance...</p>\n"
},
{
"answer_id": 168970,
"author": "Ihar Bury",
"author_id": 18001,
"author_profile": "https://Stackoverflow.com/users/18001",
"pm_score": -1,
"selected": false,
"text": "<p>type[,] will work faster. Not only because of less offset calculations. Mainly because of less constraint checking, less memory allocation and greater localization in memory. type[][] is not a single object -- it's 1 + N objects that must be allocated and can be away from each other.</p>\n"
},
{
"answer_id": 169958,
"author": "Marc Gravell",
"author_id": 23354,
"author_profile": "https://Stackoverflow.com/users/23354",
"pm_score": 4,
"selected": true,
"text": "<p>Of course, if all else fails... test it! Following gives (in \"Release\", at the console):</p>\n\n<pre><code>Size 1000, Repeat 1000\n int[,] set: 3460\n int[,] get: 4036 (chk=1304808064)\n int[][] set: 2441\n int[][] get: 1283 (chk=1304808064)\n</code></pre>\n\n<p>So a jagged array is quicker, at least in this test. Interesting! However, it is a <em>relatively</em> small factor, so I would still stick with whichever describes my requirement better. Except for some specific (high CPU/processing) scenarios, readability / maintainability should trump a small performance gain. Up to you, though.</p>\n\n<p>Note that this test assumes you access the array much more often than you create it, so I have not included timings for creation, where I would <em>expect</em> rectangular to be slightly quicker unless memory is highly fragmented.</p>\n\n<pre><code>using System;\nusing System.Diagnostics;\nstatic class Program\n{\n static void Main()\n {\n Console.WriteLine(\"First is just for JIT...\");\n Test(10,10);\n Console.WriteLine(\"Real numbers...\");\n Test(1000,1000);\n\n Console.ReadLine();\n }\n\n static void Test(int size, int repeat)\n {\n Console.WriteLine(\"Size {0}, Repeat {1}\", size, repeat);\n int[,] rect = new int[size, size];\n int[][] jagged = new int[size][];\n for (int i = 0; i < size; i++)\n { // don't count this in the metrics...\n jagged[i] = new int[size];\n }\n Stopwatch watch = Stopwatch.StartNew();\n for (int cycle = 0; cycle < repeat; cycle++)\n {\n for (int i = 0; i < size; i++)\n {\n for (int j = 0; j < size; j++)\n {\n rect[i, j] = i * j;\n }\n }\n }\n watch.Stop();\n Console.WriteLine(\"\\tint[,] set: \" + watch.ElapsedMilliseconds);\n\n int sum = 0;\n watch = Stopwatch.StartNew();\n for (int cycle = 0; cycle < repeat; cycle++)\n {\n for (int i = 0; i < size; i++)\n {\n for (int j = 0; j < size; j++)\n {\n sum += rect[i, j];\n }\n }\n }\n watch.Stop();\n Console.WriteLine(\"\\tint[,] get: {0} (chk={1})\", watch.ElapsedMilliseconds, sum);\n\n watch = Stopwatch.StartNew();\n for (int cycle = 0; cycle < repeat; cycle++)\n {\n for (int i = 0; i < size; i++)\n {\n for (int j = 0; j < size; j++)\n {\n jagged[i][j] = i * j;\n }\n }\n }\n watch.Stop();\n Console.WriteLine(\"\\tint[][] set: \" + watch.ElapsedMilliseconds);\n\n sum = 0;\n watch = Stopwatch.StartNew();\n for (int cycle = 0; cycle < repeat; cycle++)\n {\n for (int i = 0; i < size; i++)\n {\n for (int j = 0; j < size; j++)\n {\n sum += jagged[i][j];\n }\n }\n }\n watch.Stop();\n Console.WriteLine(\"\\tint[][] get: {0} (chk={1})\", watch.ElapsedMilliseconds, sum);\n }\n}\n</code></pre>\n"
},
{
"answer_id": 169976,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 2,
"selected": false,
"text": "<p>It really depends. The MSDN Magazine article, <em><a href=\"http://msdn.microsoft.com/en-ca/magazine/cc163995.aspx\" rel=\"nofollow noreferrer\">Harness the Features of C# to Power Your Scientific Computing Projects</a></em>, says this:</p>\n\n<blockquote>\n <p>Although rectangular arrays are generally superior to jagged arrays in terms of structure and performance, there might be some cases where jagged arrays provide an optimal solution. If your application does not require arrays to be sorted, rearranged, partitioned, sparse, or large, then you might find jagged arrays to perform quite well.</p>\n</blockquote>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168897",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1782/"
] |
Is it more performant to have a bidimensional array (`type[,]`) or an array of arrays (`type[][]`) in C#?
Particularly for initial allocation and item access
|
Of course, if all else fails... test it! Following gives (in "Release", at the console):
```
Size 1000, Repeat 1000
int[,] set: 3460
int[,] get: 4036 (chk=1304808064)
int[][] set: 2441
int[][] get: 1283 (chk=1304808064)
```
So a jagged array is quicker, at least in this test. Interesting! However, it is a *relatively* small factor, so I would still stick with whichever describes my requirement better. Except for some specific (high CPU/processing) scenarios, readability / maintainability should trump a small performance gain. Up to you, though.
Note that this test assumes you access the array much more often than you create it, so I have not included timings for creation, where I would *expect* rectangular to be slightly quicker unless memory is highly fragmented.
```
using System;
using System.Diagnostics;
static class Program
{
static void Main()
{
Console.WriteLine("First is just for JIT...");
Test(10,10);
Console.WriteLine("Real numbers...");
Test(1000,1000);
Console.ReadLine();
}
static void Test(int size, int repeat)
{
Console.WriteLine("Size {0}, Repeat {1}", size, repeat);
int[,] rect = new int[size, size];
int[][] jagged = new int[size][];
for (int i = 0; i < size; i++)
{ // don't count this in the metrics...
jagged[i] = new int[size];
}
Stopwatch watch = Stopwatch.StartNew();
for (int cycle = 0; cycle < repeat; cycle++)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
rect[i, j] = i * j;
}
}
}
watch.Stop();
Console.WriteLine("\tint[,] set: " + watch.ElapsedMilliseconds);
int sum = 0;
watch = Stopwatch.StartNew();
for (int cycle = 0; cycle < repeat; cycle++)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
sum += rect[i, j];
}
}
}
watch.Stop();
Console.WriteLine("\tint[,] get: {0} (chk={1})", watch.ElapsedMilliseconds, sum);
watch = Stopwatch.StartNew();
for (int cycle = 0; cycle < repeat; cycle++)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
jagged[i][j] = i * j;
}
}
}
watch.Stop();
Console.WriteLine("\tint[][] set: " + watch.ElapsedMilliseconds);
sum = 0;
watch = Stopwatch.StartNew();
for (int cycle = 0; cycle < repeat; cycle++)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
sum += jagged[i][j];
}
}
}
watch.Stop();
Console.WriteLine("\tint[][] get: {0} (chk={1})", watch.ElapsedMilliseconds, sum);
}
}
```
|
168,901 |
<pre><code>private IEnumerable<string> Tables
{
get
{
yield return "Foo";
yield return "Bar";
}
}
</code></pre>
<p>Let's say I want iterate on those and write something like processing #n of #m. </p>
<p>Is there a way I can find out the value of m without iterating before my main iteration?</p>
<p>I hope I made myself clear.</p>
|
[
{
"answer_id": 168918,
"author": "JesperE",
"author_id": 13051,
"author_profile": "https://Stackoverflow.com/users/13051",
"pm_score": 3,
"selected": false,
"text": "<p>No, not in general. One point in using enumerables is that the actual set of objects in the enumeration is not known (in advance, or even at all).</p>\n"
},
{
"answer_id": 168922,
"author": "Mendelt",
"author_id": 3320,
"author_profile": "https://Stackoverflow.com/users/3320",
"pm_score": 10,
"selected": true,
"text": "<p><code>IEnumerable</code> doesn't support this. This is by design. <code>IEnumerable</code> uses lazy evaluation to get the elements you ask for just before you need them.</p>\n\n<p>If you want to know the number of items without iterating over them you can use <code>ICollection<T></code>, it has a <code>Count</code> property.</p>\n"
},
{
"answer_id": 168954,
"author": "Joel Coehoorn",
"author_id": 3043,
"author_profile": "https://Stackoverflow.com/users/3043",
"pm_score": 4,
"selected": false,
"text": "<p>A friend of mine has a series of blog posts that provide an illustration for why you can't do this. He creates function that return an IEnumerable where each iteration returns the next prime number, all the way to <code>ulong.MaxValue</code>, and the next item isn't calculated until you ask for it. Quick, pop question: how many items are returned?</p>\n\n<p>Here are the posts, but they're kind of long:</p>\n\n<ol>\n<li><a href=\"http://www.fallingcanbedeadly.com/posts/beyond-loops\" rel=\"noreferrer\">Beyond Loops</a> (provides an initial EnumerableUtility class used in the other posts)</li>\n<li><a href=\"http://www.fallingcanbedeadly.com/posts/applications-of-iterate\" rel=\"noreferrer\">Applications of Iterate</a> (Initial implementation)</li>\n<li><a href=\"http://www.fallingcanbedeadly.com/posts/crazy-extention-methods-tolazylist\" rel=\"noreferrer\">Crazy Extention Methods: ToLazyList</a> (Performance optimizations)</li>\n</ol>\n"
},
{
"answer_id": 169004,
"author": "Chris Ammerman",
"author_id": 2729,
"author_profile": "https://Stackoverflow.com/users/2729",
"pm_score": 4,
"selected": false,
"text": "<p>IEnumerable cannot count without iterating.</p>\n\n<p>Under \"normal\" circumstances, it would be possible for classes implementing IEnumerable or IEnumerable<T>, such as List<T>, to implement the Count method by returning the List<T>.Count property. However, the Count method is not actually a method defined on the IEnumerable<T> or IEnumerable interface. (The only one that is, in fact, is GetEnumerator.) And this means that a class-specific implementation cannot be provided for it.</p>\n\n<p>Rather, Count it is an extension method, defined on the static class Enumerable. This means it can be called on any instance of an IEnumerable<T> derived class, regardless of that class's implementation. But it also means it is implemented in a single place, external to any of those classes. Which of course means that it must be implemented in a way that is completely independent of these class' internals. The only such way to do counting is via iteration.</p>\n"
},
{
"answer_id": 169699,
"author": "Robert Paulson",
"author_id": 14033,
"author_profile": "https://Stackoverflow.com/users/14033",
"pm_score": 7,
"selected": false,
"text": "<p>Just adding extra some info:</p>\n\n<p>The <code>Count()</code> extension doesn't always iterate. Consider Linq to Sql, where the count goes to the database, but instead of bringing back all the rows, it issues the Sql <code>Count()</code> command and returns that result instead. </p>\n\n<p>Additionally, the compiler (or runtime) is smart enough that it will call the objects <code>Count()</code> method if it has one. So it's <em>not</em> as other responders say, being completely ignorant and always iterating in order to count elements.</p>\n\n<p>In many cases where the programmer is just checking <code>if( enumerable.Count != 0 )</code> using the <code>Any()</code> extension method, as in <code>if( enumerable.Any() )</code> is far more efficient with linq's lazy evaluation as it can short-circuit once it can determine there are any elements. It's also more readable</p>\n"
},
{
"answer_id": 169769,
"author": "Jonathan Allen",
"author_id": 5274,
"author_profile": "https://Stackoverflow.com/users/5274",
"pm_score": -1,
"selected": false,
"text": "<p>I would suggest calling ToList. Yes you are doing the enumeration early, but you still have access to your list of items.</p>\n"
},
{
"answer_id": 853401,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 4,
"selected": false,
"text": "<p>Alternatively you can do the following:</p>\n\n<pre><code>Tables.ToList<string>().Count;\n</code></pre>\n"
},
{
"answer_id": 853444,
"author": "JP Alioto",
"author_id": 86473,
"author_profile": "https://Stackoverflow.com/users/86473",
"pm_score": 2,
"selected": false,
"text": "<p>Here is a great discussion about <a href=\"http://blogs.msdn.com/ericwhite/pages/Lazy-Evaluation-_2800_and-in-contrast_2C00_-Eager-Evaluation_2900_.aspx\" rel=\"nofollow noreferrer\">lazy evaluation</a> and <a href=\"http://blogs.msdn.com/ericwhite/pages/deferred-execution.aspx\" rel=\"nofollow noreferrer\">deferred execution</a>. Basically you have to materialize the list to get that value.</p>\n"
},
{
"answer_id": 853478,
"author": "Daniel Earwicker",
"author_id": 27423,
"author_profile": "https://Stackoverflow.com/users/27423",
"pm_score": 8,
"selected": false,
"text": "<p>The <code>System.Linq.Enumerable.Count</code> extension method on <code>IEnumerable<T></code> has the following implementation:</p>\n\n<pre><code>ICollection<T> c = source as ICollection<TSource>;\nif (c != null)\n return c.Count;\n\nint result = 0;\nusing (IEnumerator<T> enumerator = source.GetEnumerator())\n{\n while (enumerator.MoveNext())\n result++;\n}\nreturn result;\n</code></pre>\n\n<p>So it tries to cast to <code>ICollection<T></code>, which has a <code>Count</code> property, and uses that if possible. Otherwise it iterates.</p>\n\n<p>So your best bet is to use the <code>Count()</code> extension method on your <code>IEnumerable<T></code> object, as you will get the best performance possible that way.</p>\n"
},
{
"answer_id": 853524,
"author": "Samuel Jack",
"author_id": 1727,
"author_profile": "https://Stackoverflow.com/users/1727",
"pm_score": 3,
"selected": false,
"text": "<p>Going beyond your immediate question (which has been thoroughly answered in the negative), if you're looking to report progress whilst processing an enumerable, you might want to look at my blog post <a href=\"http://blog.functionalfun.net/2008/07/reporting-progress-during-linq-queries.html\" rel=\"noreferrer\">Reporting Progress During Linq Queries</a>.</p>\n\n<p>It lets you do this:</p>\n\n<pre><code>BackgroundWorker worker = new BackgroundWorker();\nworker.WorkerReportsProgress = true;\nworker.DoWork += (sender, e) =>\n {\n // pretend we have a collection of \n // items to process\n var items = 1.To(1000);\n items\n .WithProgressReporting(progress => worker.ReportProgress(progress))\n .ForEach(item => Thread.Sleep(10)); // simulate some real work\n };\n</code></pre>\n"
},
{
"answer_id": 1267328,
"author": "Roman Golubin",
"author_id": 155223,
"author_profile": "https://Stackoverflow.com/users/155223",
"pm_score": 2,
"selected": false,
"text": "<p>Result of the IEnumerable.Count() function may be wrong. This is a very simple sample to test:</p>\n\n<pre><code>using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Collections;\n\nnamespace Test\n{\n class Program\n {\n static void Main(string[] args)\n {\n var test = new[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17 };\n var result = test.Split(7);\n int cnt = 0;\n\n foreach (IEnumerable<int> chunk in result)\n {\n cnt = chunk.Count();\n Console.WriteLine(cnt);\n }\n cnt = result.Count();\n Console.WriteLine(cnt);\n Console.ReadLine();\n }\n }\n\n static class LinqExt\n {\n public static IEnumerable<IEnumerable<T>> Split<T>(this IEnumerable<T> source, int chunkLength)\n {\n if (chunkLength <= 0)\n throw new ArgumentOutOfRangeException(\"chunkLength\", \"chunkLength must be greater than 0\");\n\n IEnumerable<T> result = null;\n using (IEnumerator<T> enumerator = source.GetEnumerator())\n {\n while (enumerator.MoveNext())\n {\n result = GetChunk(enumerator, chunkLength);\n yield return result;\n }\n }\n }\n\n static IEnumerable<T> GetChunk<T>(IEnumerator<T> source, int chunkLength)\n {\n int x = chunkLength;\n do\n yield return source.Current;\n while (--x > 0 && source.MoveNext());\n }\n }\n}\n</code></pre>\n\n<p>Result must be (7,7,3,3) but actual result is (7,7,3,17)</p>\n"
},
{
"answer_id": 5775421,
"author": "prabug",
"author_id": 723253,
"author_profile": "https://Stackoverflow.com/users/723253",
"pm_score": 2,
"selected": false,
"text": "<p>It depends on which version of .Net and implementation of your IEnumerable object.\nMicrosoft has fixed the IEnumerable.Count method to check for the implementation, and uses the ICollection.Count or ICollection< TSource >.Count, see details here <a href=\"https://connect.microsoft.com/VisualStudio/feedback/details/454130\" rel=\"nofollow\">https://connect.microsoft.com/VisualStudio/feedback/details/454130</a></p>\n\n<p>And below is the MSIL from Ildasm for System.Core, in which the System.Linq resides.</p>\n\n<pre><code>.method public hidebysig static int32 Count<TSource>(class \n\n[mscorlib]System.Collections.Generic.IEnumerable`1<!!TSource> source) cil managed\n{\n .custom instance void System.Runtime.CompilerServices.ExtensionAttribute::.ctor() = ( 01 00 00 00 ) \n // Code size 85 (0x55)\n .maxstack 2\n .locals init (class [mscorlib]System.Collections.Generic.ICollection`1<!!TSource> V_0,\n class [mscorlib]System.Collections.ICollection V_1,\n int32 V_2,\n class [mscorlib]System.Collections.Generic.IEnumerator`1<!!TSource> V_3)\n IL_0000: ldarg.0\n IL_0001: brtrue.s IL_000e\n IL_0003: ldstr \"source\"\n IL_0008: call class [mscorlib]System.Exception System.Linq.Error::ArgumentNull(string)\n IL_000d: throw\n IL_000e: ldarg.0\n IL_000f: isinst class [mscorlib]System.Collections.Generic.ICollection`1<!!TSource>\n IL_0014: stloc.0\n IL_0015: ldloc.0\n IL_0016: brfalse.s IL_001f\n IL_0018: ldloc.0\n IL_0019: callvirt instance int32 class [mscorlib]System.Collections.Generic.ICollection`1<!!TSource>::get_Count()\n IL_001e: ret\n IL_001f: ldarg.0\n IL_0020: isinst [mscorlib]System.Collections.ICollection\n IL_0025: stloc.1\n IL_0026: ldloc.1\n IL_0027: brfalse.s IL_0030\n IL_0029: ldloc.1\n IL_002a: callvirt instance int32 [mscorlib]System.Collections.ICollection::get_Count()\n IL_002f: ret\n IL_0030: ldc.i4.0\n IL_0031: stloc.2\n IL_0032: ldarg.0\n IL_0033: callvirt instance class [mscorlib]System.Collections.Generic.IEnumerator`1<!0> class [mscorlib]System.Collections.Generic.IEnumerable`1<!!TSource>::GetEnumerator()\n IL_0038: stloc.3\n .try\n {\n IL_0039: br.s IL_003f\n IL_003b: ldloc.2\n IL_003c: ldc.i4.1\n IL_003d: add.ovf\n IL_003e: stloc.2\n IL_003f: ldloc.3\n IL_0040: callvirt instance bool [mscorlib]System.Collections.IEnumerator::MoveNext()\n IL_0045: brtrue.s IL_003b\n IL_0047: leave.s IL_0053\n } // end .try\n finally\n {\n IL_0049: ldloc.3\n IL_004a: brfalse.s IL_0052\n IL_004c: ldloc.3\n IL_004d: callvirt instance void [mscorlib]System.IDisposable::Dispose()\n IL_0052: endfinally\n } // end handler\n IL_0053: ldloc.2\n IL_0054: ret\n} // end of method Enumerable::Count\n</code></pre>\n"
},
{
"answer_id": 8908126,
"author": "Oliver Kötter",
"author_id": 1155881,
"author_profile": "https://Stackoverflow.com/users/1155881",
"pm_score": -1,
"selected": false,
"text": "<p>I use <code>IEnum<string>.ToArray<string>().Length</code> and it works fine.</p>\n"
},
{
"answer_id": 9023728,
"author": "prosseek",
"author_id": 260127,
"author_profile": "https://Stackoverflow.com/users/260127",
"pm_score": 3,
"selected": false,
"text": "<p>You can use System.Linq.</p>\n\n<pre><code>using System;\nusing System.Collections.Generic;\nusing System.Linq;\n\npublic class Test\n{\n private IEnumerable<string> Tables\n {\n get {\n yield return \"Foo\";\n yield return \"Bar\";\n }\n }\n\n static void Main()\n {\n var x = new Test();\n Console.WriteLine(x.Tables.Count());\n }\n}\n</code></pre>\n\n<p>You'll get the result '2'.</p>\n"
},
{
"answer_id": 13191375,
"author": "Shahidul Haque",
"author_id": 739240,
"author_profile": "https://Stackoverflow.com/users/739240",
"pm_score": 3,
"selected": false,
"text": "<p>I used such way inside a method to check the passed in <code>IEnumberable</code> content</p>\n\n<pre><code>if( iEnum.Cast<Object>().Count() > 0) \n{\n\n}\n</code></pre>\n\n<p>Inside a method like this:</p>\n\n<pre><code>GetDataTable(IEnumberable iEnum)\n{ \n if (iEnum != null && iEnum.Cast<Object>().Count() > 0) //--- proceed further\n\n}\n</code></pre>\n"
},
{
"answer_id": 17315323,
"author": "Hugo",
"author_id": 1496074,
"author_profile": "https://Stackoverflow.com/users/1496074",
"pm_score": -1,
"selected": false,
"text": "<p>It may not yield the best performance, but you can use LINQ to count the elements in an IEnumerable:</p>\n\n<pre><code>public int GetEnumerableCount(IEnumerable Enumerable)\n{\n return (from object Item in Enumerable\n select Item).Count();\n}\n</code></pre>\n"
},
{
"answer_id": 50210008,
"author": "Me Hungry",
"author_id": 8216382,
"author_profile": "https://Stackoverflow.com/users/8216382",
"pm_score": -1,
"selected": false,
"text": "<p>I use such code, if I have list of strings:</p>\n\n<pre><code>((IList<string>)Table).Count\n</code></pre>\n"
},
{
"answer_id": 59611940,
"author": "Abhas Bhoi",
"author_id": 6832033,
"author_profile": "https://Stackoverflow.com/users/6832033",
"pm_score": 2,
"selected": false,
"text": "<p>The best way I found is count by converting it to a list.</p>\n\n<pre><code>IEnumerable<T> enumList = ReturnFromSomeFunction();\n\nint count = new List<T>(enumList).Count;\n</code></pre>\n"
},
{
"answer_id": 61283708,
"author": "Sowvik Roy",
"author_id": 3706956,
"author_profile": "https://Stackoverflow.com/users/3706956",
"pm_score": 3,
"selected": false,
"text": "<p>I think the easiest way to do this</p>\n\n<pre><code>Enumerable.Count<TSource>(IEnumerable<TSource> source)\n</code></pre>\n\n<p>Reference: <a href=\"https://learn.microsoft.com/en-us/dotnet/api/system.linq.enumerable.count?view=netframework-4.8\" rel=\"noreferrer\">system.linq.enumerable</a></p>\n"
},
{
"answer_id": 69828022,
"author": "Russell McDonnell",
"author_id": 4888238,
"author_profile": "https://Stackoverflow.com/users/4888238",
"pm_score": 2,
"selected": false,
"text": "<p>There is a new method in LINQ for .NET 6\nWatch <a href=\"https://www.youtube.com/watch?v=sIXKpyhxHR8\" rel=\"nofollow noreferrer\">https://www.youtube.com/watch?v=sIXKpyhxHR8</a></p>\n<pre><code>Tables.TryGetNonEnumeratedCount(out var count)\n</code></pre>\n"
},
{
"answer_id": 70754203,
"author": "Andre Mesquita",
"author_id": 2788478,
"author_profile": "https://Stackoverflow.com/users/2788478",
"pm_score": 2,
"selected": false,
"text": "<p>Simplifying all answer.</p>\n<p>IEnumerable has not Count function or property. To get this, you can store <em>count variable</em> (with foreach, for example) or solve using <em>Linq</em> to get count.</p>\n<p><strong>If you have:</strong></p>\n<p>IEnumerable<> products</p>\n<p><strong>Then:</strong></p>\n<p>Declare: "using System.Linq;"</p>\n<p><strong>To Count:</strong></p>\n<p>products.ToList().Count</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168901",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/23893/"
] |
```
private IEnumerable<string> Tables
{
get
{
yield return "Foo";
yield return "Bar";
}
}
```
Let's say I want iterate on those and write something like processing #n of #m.
Is there a way I can find out the value of m without iterating before my main iteration?
I hope I made myself clear.
|
`IEnumerable` doesn't support this. This is by design. `IEnumerable` uses lazy evaluation to get the elements you ask for just before you need them.
If you want to know the number of items without iterating over them you can use `ICollection<T>`, it has a `Count` property.
|
168,912 |
<p>I need to show only one element at a time when a link is clicked on. Right now I'm cheating by hiding everything again and then toggling the element clicked on. This works, unless i want EVERYTHING to disappear again. Short of adding a "Hide All" button/link what can i do? I would like to be able to click on the link again, and hide it's content.</p>
<p>EDIT: Pseudo's code would have worked, but the html here mistakenly led you to believe that all the links were in one div. instead of tracking down where they all were, it is easier to call them by their ID.</p>
<p>Here's what I have so far:</p>
<pre><code>$(document).ready(function(){
//hides everything
$("#infocontent *").hide();
//now we show them by which they click on
$("#linkjoedhit").click(function(event){
$("#infocontent *").hide();
$("#infojoedhit").toggle();
return false;
});
$("#linkgarykhit").click(function(event){
$("#infocontent *").hide();
$("#infogarykhit").toggle();
return false;
});
});
</code></pre>
<p>and the html looks like:</p>
<pre><code><div id="theircrappycode">
<a id="linkjoedhit" href="">Joe D</a><br/>
<a id="linkgarykhit" href="">Gary K</a>
</div>
<div id="infocontent">
<p id="infojoedhit">Information about Joe D Hitting.</p>
<p id="infogarykhit">Information about Gary K Hitting.</p>
</div
</code></pre>
<p>there are about 20 links like this. Because I am not coding the actual html, I have no control over the actual layout, which is horrendous. Suffice to say, this is the only way to organize the links/info.</p>
|
[
{
"answer_id": 169036,
"author": "micahwittman",
"author_id": 11181,
"author_profile": "https://Stackoverflow.com/users/11181",
"pm_score": 3,
"selected": true,
"text": "<pre><code>$(\"#linkgarykhit\").click(function(){\n if($(\"#infogarykhit\").css('display') != 'none'){\n $(\"#infogarykhit\").hide();\n }else{\n $(\"#infocontent *\").hide();\n $(\"#infogarykhit\").show();\n }\n return false;\n});\n</code></pre>\n\n<hr>\n\n<p>We could also <a href=\"http://en.wikipedia.org/wiki/Don%27t_repeat_yourself\" rel=\"nofollow noreferrer\">DRY</a> this up a bit:</p>\n\n<pre><code>function toggleInfoContent(id){\n if($('#' + id).css('display') != 'none'){\n $('#' + id).hide();\n }else{\n $(\"#infocontent *\").hide();\n $('#' + id).show();\n }\n}\n\n$(\"#linkgarykhit\").click(function(){\n toggleInfoContent('infogarykhit');\n return false;\n});\n\n$(\"#linkbobkhit\").click(function(){\n toggleInfoContent('infobobkhit');\n return false;\n});\n</code></pre>\n"
},
{
"answer_id": 169062,
"author": "MrChrister",
"author_id": 24229,
"author_profile": "https://Stackoverflow.com/users/24229",
"pm_score": 0,
"selected": false,
"text": "<p>I just started with <code>jQuery</code>, so I don't know if this is dumb or not.</p>\n\n<pre><code>function DoToggleMagic(strParagraphID) {\n strDisplayed = $(strParagraphID).css(\"display\");\n $(\"#infocontent *\").hide();\n if (strDisplayed == \"none\") \n $(strParagraphID).toggle();\n}\n$(document).ready(function(){\n //hides everything\n $(\"#infocontent *\").hide();\n\n //now we show them by which they click on\n $(\"#linkjoedhit\").click(function(event){\n DoToggleMagic(\"#infojoedhit\");\n return false;\n });\n\n $(\"#linkgarykhit\").click(function(event){\n DoToggleMagic(\"#infogarykhit\");\n return false;\n }); \n});\n</code></pre>\n"
},
{
"answer_id": 169160,
"author": "Pseudo Masochist",
"author_id": 8529,
"author_profile": "https://Stackoverflow.com/users/8529",
"pm_score": 2,
"selected": false,
"text": "<p>If your markup \"naming scheme\" is accurate, you can avoid a lot of repetitious code by using a RegEx for your selector, and judicious use of jQuery's \"not\".</p>\n\n<p>You can attach a click event one time to a jQuery collection that should do what you want so you don't need to add any JavaScript as you add more Jim's or John's, as so:</p>\n\n<pre><code>$(document).ready( function () {\n $(\"#infocontent *\").hide();\n\n $(\"div#theircrappycode > a\").click(function(event){\n var toggleId = \"#\" + this.id.replace(/^link/,\"info\");\n $(\"#infocontent *\").not(toggleId).hide();\n $(toggleId).toggle();\n return false;\n });\n});\n</code></pre>\n"
},
{
"answer_id": 169939,
"author": "Philip Tinney",
"author_id": 14930,
"author_profile": "https://Stackoverflow.com/users/14930",
"pm_score": 1,
"selected": false,
"text": "<p>Here is a slightly different approach there are some similarities to Pseudo Masochist's code.</p>\n\n<pre><code>$(document).ready(function(){\n $(\"#infocontent *\").hide();\n $(\"#theircrappycode > a\").click(statlink.togvis);\n});\nvar statlink = {\n visId: \"\",\n togvis: function(){\n $(\"#\" + statlink.visId).toggle();\n statlink.visId = $(this).attr(\"id\").replace(/link/, \"info\");\n $(\"#\" + statlink.visId).toggle();\n }\n};\n</code></pre>\n\n<p>Hope you find this useful also.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168912",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/50/"
] |
I need to show only one element at a time when a link is clicked on. Right now I'm cheating by hiding everything again and then toggling the element clicked on. This works, unless i want EVERYTHING to disappear again. Short of adding a "Hide All" button/link what can i do? I would like to be able to click on the link again, and hide it's content.
EDIT: Pseudo's code would have worked, but the html here mistakenly led you to believe that all the links were in one div. instead of tracking down where they all were, it is easier to call them by their ID.
Here's what I have so far:
```
$(document).ready(function(){
//hides everything
$("#infocontent *").hide();
//now we show them by which they click on
$("#linkjoedhit").click(function(event){
$("#infocontent *").hide();
$("#infojoedhit").toggle();
return false;
});
$("#linkgarykhit").click(function(event){
$("#infocontent *").hide();
$("#infogarykhit").toggle();
return false;
});
});
```
and the html looks like:
```
<div id="theircrappycode">
<a id="linkjoedhit" href="">Joe D</a><br/>
<a id="linkgarykhit" href="">Gary K</a>
</div>
<div id="infocontent">
<p id="infojoedhit">Information about Joe D Hitting.</p>
<p id="infogarykhit">Information about Gary K Hitting.</p>
</div
```
there are about 20 links like this. Because I am not coding the actual html, I have no control over the actual layout, which is horrendous. Suffice to say, this is the only way to organize the links/info.
|
```
$("#linkgarykhit").click(function(){
if($("#infogarykhit").css('display') != 'none'){
$("#infogarykhit").hide();
}else{
$("#infocontent *").hide();
$("#infogarykhit").show();
}
return false;
});
```
---
We could also [DRY](http://en.wikipedia.org/wiki/Don%27t_repeat_yourself) this up a bit:
```
function toggleInfoContent(id){
if($('#' + id).css('display') != 'none'){
$('#' + id).hide();
}else{
$("#infocontent *").hide();
$('#' + id).show();
}
}
$("#linkgarykhit").click(function(){
toggleInfoContent('infogarykhit');
return false;
});
$("#linkbobkhit").click(function(){
toggleInfoContent('infobobkhit');
return false;
});
```
|
168,924 |
<p>Let's say I've got two strings in JavaScript:</p>
<pre><code>var date1 = '2008-10-03T20:24Z'
var date2 = '2008-10-04T12:24Z'
</code></pre>
<p>How would I come to a result like so:</p>
<pre><code>'4 weeks ago'
</code></pre>
<p>or</p>
<pre><code>'in about 15 minutes'
</code></pre>
<p>(should support past and future).</p>
<p>There are solutions out there for the past diffs, but I've yet to find one with support for future time diffs as well.</p>
<p>These are the solutions I tried:</p>
<p><a href="http://ejohn.org/blog/javascript-pretty-date/#postcomment" rel="nofollow noreferrer">John Resig's Pretty Date</a> and <a href="http://www.zachleat.com/web/2008/03/23/yet-another-pretty-date-javascript/" rel="nofollow noreferrer">Zach Leatherman's modification</a></p>
<p>Bonus points for a jQuery solution.</p>
|
[
{
"answer_id": 169009,
"author": "moonshadow",
"author_id": 11834,
"author_profile": "https://Stackoverflow.com/users/11834",
"pm_score": 4,
"selected": true,
"text": "<p>Looking at the solutions you linked... it is actually as simple as my frivolous comment!</p>\n\n<p>Here's a version of the Zach Leatherman code that prepends \"In \" for future dates for you. As you can see, the changes are very minor.</p>\n\n<pre><code> function humane_date(date_str){\n var time_formats = [\n [60, 'Just Now'],\n [90, '1 Minute'], // 60*1.5\n [3600, 'Minutes', 60], // 60*60, 60\n [5400, '1 Hour'], // 60*60*1.5\n [86400, 'Hours', 3600], // 60*60*24, 60*60\n [129600, '1 Day'], // 60*60*24*1.5\n [604800, 'Days', 86400], // 60*60*24*7, 60*60*24\n [907200, '1 Week'], // 60*60*24*7*1.5\n [2628000, 'Weeks', 604800], // 60*60*24*(365/12), 60*60*24*7\n [3942000, '1 Month'], // 60*60*24*(365/12)*1.5\n [31536000, 'Months', 2628000], // 60*60*24*365, 60*60*24*(365/12)\n [47304000, '1 Year'], // 60*60*24*365*1.5\n [3153600000, 'Years', 31536000], // 60*60*24*365*100, 60*60*24*365\n [4730400000, '1 Century'], // 60*60*24*365*100*1.5\n ];\n\n var time = ('' + date_str).replace(/-/g,\"/\").replace(/[TZ]/g,\" \"),\n dt = new Date,\n seconds = ((dt - new Date(time) + (dt.getTimezoneOffset() * 60000)) / 1000),\n token = ' Ago',\n prepend = '',\n i = 0,\n format;\n\n if (seconds < 0) {\n seconds = Math.abs(seconds);\n token = '';\n prepend = 'In ';\n }\n\n while (format = time_formats[i++]) {\n if (seconds < format[0]) {\n if (format.length == 2) {\n return (i>1?prepend:'') + format[1] + (i > 1 ? token : ''); // Conditional so we don't return Just Now Ago\n } else {\n return prepend + Math.round(seconds / format[2]) + ' ' + format[1] + (i > 1 ? token : '');\n }\n }\n }\n\n // overflow for centuries\n if(seconds > 4730400000)\n return Math.round(seconds / 4730400000) + ' Centuries' + token;\n\n return date_str;\n };\n</code></pre>\n"
},
{
"answer_id": 169883,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 2,
"selected": false,
"text": "<p>Heh - I actually wrote a function to do this exact thing yesterday (and it's not on this computer so I'll just have to try to remember it)</p>\n\n<p>I extended the Date prototype class, but this could quite easily just be put into a regular function.</p>\n\n<pre><code>Date.prototype.toRelativeTime = function(otherTime) {\n // if no parameter is passed, use the current date.\n if (otherTime == undefined) otherTime = new Date();\n\n var diff = Math.abs(this.getTime() - otherTime.getTime()) / 1000;\n\n var MIN = 60, // some \"constants\" just \n HOUR = 3600, // for legibility\n DAY = 86400\n ;\n var out, temp;\n if (diff < MIN) {\n out = \"Less than a minute\";\n\n } else if (diff < 15 * MIN) {\n // less than fifteen minutes, show how many minutes\n temp = Math.round(diff / MIN);\n out = temp + \" minute\" + (temp == 1 ? \"\" : \"s\");\n // eg: 12 minutes\n } else if (diff < HOUR) {\n // less than an hour, round down to the nearest 5 minutes\n out = (Math.floor(diff / (5 * MIN)) * 5) + \" minutes\";\n } else if (diff < DAY) {\n // less than a day, just show hours\n temp = Math.round(diff / HOUR);\n out = temp + \" hour\" + (temp == 1 ? \"\" : \"s\");\n } else if (diff < 30 * DAY) {\n // show how many days ago\n temp = Math.round(diff / DAY);\n out = temp + \" day\" + (temp == 1 ? \"\" : \"s\");\n } else if (diff < 90 * DAY) {\n // more than 30 days, but less than 3 months, show the day and month\n return this.getDate() + \" \" + this.getShortMonth(); // see below\n } else {\n // more than three months difference, better show the year too\n return this.getDate() + \" \" + this.getShortMonth() + \" \" + this.getFullYear();\n }\n return out + (this.getTime() > otherTime.getTime() ? \" from now\" : \" ago\");\n\n};\n\nDate.prototype.getShortMonth = function() {\n return [\"Jan\", \"Feb\", \"Mar\",\n \"Apr\", \"May\", \"Jun\",\n \"Jul\", \"Aug\", \"Sep\",\n \"Oct\", \"Nov\", \"Dec\"][this.getMonth()];\n};\n\n// sample usage:\nvar x = new Date(2008, 9, 4, 17, 0, 0);\nalert(x.toRelativeTime()); // 9 minutes from now\n\nx = new Date(2008, 9, 4, 16, 45, 0, 0);\nalert(x.toRelativeTime()); // 6 minutes ago\n\nx = new Date(2008, 11, 1); // 1 Dec\n\nx = new Date(2009, 11, 1); // 1 Dec 2009\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168924",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22468/"
] |
Let's say I've got two strings in JavaScript:
```
var date1 = '2008-10-03T20:24Z'
var date2 = '2008-10-04T12:24Z'
```
How would I come to a result like so:
```
'4 weeks ago'
```
or
```
'in about 15 minutes'
```
(should support past and future).
There are solutions out there for the past diffs, but I've yet to find one with support for future time diffs as well.
These are the solutions I tried:
[John Resig's Pretty Date](http://ejohn.org/blog/javascript-pretty-date/#postcomment) and [Zach Leatherman's modification](http://www.zachleat.com/web/2008/03/23/yet-another-pretty-date-javascript/)
Bonus points for a jQuery solution.
|
Looking at the solutions you linked... it is actually as simple as my frivolous comment!
Here's a version of the Zach Leatherman code that prepends "In " for future dates for you. As you can see, the changes are very minor.
```
function humane_date(date_str){
var time_formats = [
[60, 'Just Now'],
[90, '1 Minute'], // 60*1.5
[3600, 'Minutes', 60], // 60*60, 60
[5400, '1 Hour'], // 60*60*1.5
[86400, 'Hours', 3600], // 60*60*24, 60*60
[129600, '1 Day'], // 60*60*24*1.5
[604800, 'Days', 86400], // 60*60*24*7, 60*60*24
[907200, '1 Week'], // 60*60*24*7*1.5
[2628000, 'Weeks', 604800], // 60*60*24*(365/12), 60*60*24*7
[3942000, '1 Month'], // 60*60*24*(365/12)*1.5
[31536000, 'Months', 2628000], // 60*60*24*365, 60*60*24*(365/12)
[47304000, '1 Year'], // 60*60*24*365*1.5
[3153600000, 'Years', 31536000], // 60*60*24*365*100, 60*60*24*365
[4730400000, '1 Century'], // 60*60*24*365*100*1.5
];
var time = ('' + date_str).replace(/-/g,"/").replace(/[TZ]/g," "),
dt = new Date,
seconds = ((dt - new Date(time) + (dt.getTimezoneOffset() * 60000)) / 1000),
token = ' Ago',
prepend = '',
i = 0,
format;
if (seconds < 0) {
seconds = Math.abs(seconds);
token = '';
prepend = 'In ';
}
while (format = time_formats[i++]) {
if (seconds < format[0]) {
if (format.length == 2) {
return (i>1?prepend:'') + format[1] + (i > 1 ? token : ''); // Conditional so we don't return Just Now Ago
} else {
return prepend + Math.round(seconds / format[2]) + ' ' + format[1] + (i > 1 ? token : '');
}
}
}
// overflow for centuries
if(seconds > 4730400000)
return Math.round(seconds / 4730400000) + ' Centuries' + token;
return date_str;
};
```
|
168,926 |
<p>Ok, I'm using the term "Progressive Enhancement" kind of loosely here but basically I have a Flash-based website that supports deep linking and loads content dynamically - what I'd like to do is provide alternate content (text) for those either not having Flash and for search engine bots. So, for a user with flash they would navigate to:</p>
<pre><code>http://www.samplesite.com/#specific_page
</code></pre>
<p>and they would see a flash site that would navigate to the "<code>specific_page</code>." Those without flash would see the "<code>specific_page</code>" rendered in text in the alternative content section.</p>
<p>Basically, I would use php/mysql to create a backend to handle all of this since the swf is also using dynamic data. The question is, does something out there that does this already exist?</p>
|
[
{
"answer_id": 169009,
"author": "moonshadow",
"author_id": 11834,
"author_profile": "https://Stackoverflow.com/users/11834",
"pm_score": 4,
"selected": true,
"text": "<p>Looking at the solutions you linked... it is actually as simple as my frivolous comment!</p>\n\n<p>Here's a version of the Zach Leatherman code that prepends \"In \" for future dates for you. As you can see, the changes are very minor.</p>\n\n<pre><code> function humane_date(date_str){\n var time_formats = [\n [60, 'Just Now'],\n [90, '1 Minute'], // 60*1.5\n [3600, 'Minutes', 60], // 60*60, 60\n [5400, '1 Hour'], // 60*60*1.5\n [86400, 'Hours', 3600], // 60*60*24, 60*60\n [129600, '1 Day'], // 60*60*24*1.5\n [604800, 'Days', 86400], // 60*60*24*7, 60*60*24\n [907200, '1 Week'], // 60*60*24*7*1.5\n [2628000, 'Weeks', 604800], // 60*60*24*(365/12), 60*60*24*7\n [3942000, '1 Month'], // 60*60*24*(365/12)*1.5\n [31536000, 'Months', 2628000], // 60*60*24*365, 60*60*24*(365/12)\n [47304000, '1 Year'], // 60*60*24*365*1.5\n [3153600000, 'Years', 31536000], // 60*60*24*365*100, 60*60*24*365\n [4730400000, '1 Century'], // 60*60*24*365*100*1.5\n ];\n\n var time = ('' + date_str).replace(/-/g,\"/\").replace(/[TZ]/g,\" \"),\n dt = new Date,\n seconds = ((dt - new Date(time) + (dt.getTimezoneOffset() * 60000)) / 1000),\n token = ' Ago',\n prepend = '',\n i = 0,\n format;\n\n if (seconds < 0) {\n seconds = Math.abs(seconds);\n token = '';\n prepend = 'In ';\n }\n\n while (format = time_formats[i++]) {\n if (seconds < format[0]) {\n if (format.length == 2) {\n return (i>1?prepend:'') + format[1] + (i > 1 ? token : ''); // Conditional so we don't return Just Now Ago\n } else {\n return prepend + Math.round(seconds / format[2]) + ' ' + format[1] + (i > 1 ? token : '');\n }\n }\n }\n\n // overflow for centuries\n if(seconds > 4730400000)\n return Math.round(seconds / 4730400000) + ' Centuries' + token;\n\n return date_str;\n };\n</code></pre>\n"
},
{
"answer_id": 169883,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 2,
"selected": false,
"text": "<p>Heh - I actually wrote a function to do this exact thing yesterday (and it's not on this computer so I'll just have to try to remember it)</p>\n\n<p>I extended the Date prototype class, but this could quite easily just be put into a regular function.</p>\n\n<pre><code>Date.prototype.toRelativeTime = function(otherTime) {\n // if no parameter is passed, use the current date.\n if (otherTime == undefined) otherTime = new Date();\n\n var diff = Math.abs(this.getTime() - otherTime.getTime()) / 1000;\n\n var MIN = 60, // some \"constants\" just \n HOUR = 3600, // for legibility\n DAY = 86400\n ;\n var out, temp;\n if (diff < MIN) {\n out = \"Less than a minute\";\n\n } else if (diff < 15 * MIN) {\n // less than fifteen minutes, show how many minutes\n temp = Math.round(diff / MIN);\n out = temp + \" minute\" + (temp == 1 ? \"\" : \"s\");\n // eg: 12 minutes\n } else if (diff < HOUR) {\n // less than an hour, round down to the nearest 5 minutes\n out = (Math.floor(diff / (5 * MIN)) * 5) + \" minutes\";\n } else if (diff < DAY) {\n // less than a day, just show hours\n temp = Math.round(diff / HOUR);\n out = temp + \" hour\" + (temp == 1 ? \"\" : \"s\");\n } else if (diff < 30 * DAY) {\n // show how many days ago\n temp = Math.round(diff / DAY);\n out = temp + \" day\" + (temp == 1 ? \"\" : \"s\");\n } else if (diff < 90 * DAY) {\n // more than 30 days, but less than 3 months, show the day and month\n return this.getDate() + \" \" + this.getShortMonth(); // see below\n } else {\n // more than three months difference, better show the year too\n return this.getDate() + \" \" + this.getShortMonth() + \" \" + this.getFullYear();\n }\n return out + (this.getTime() > otherTime.getTime() ? \" from now\" : \" ago\");\n\n};\n\nDate.prototype.getShortMonth = function() {\n return [\"Jan\", \"Feb\", \"Mar\",\n \"Apr\", \"May\", \"Jun\",\n \"Jul\", \"Aug\", \"Sep\",\n \"Oct\", \"Nov\", \"Dec\"][this.getMonth()];\n};\n\n// sample usage:\nvar x = new Date(2008, 9, 4, 17, 0, 0);\nalert(x.toRelativeTime()); // 9 minutes from now\n\nx = new Date(2008, 9, 4, 16, 45, 0, 0);\nalert(x.toRelativeTime()); // 6 minutes ago\n\nx = new Date(2008, 11, 1); // 1 Dec\n\nx = new Date(2009, 11, 1); // 1 Dec 2009\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168926",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3435/"
] |
Ok, I'm using the term "Progressive Enhancement" kind of loosely here but basically I have a Flash-based website that supports deep linking and loads content dynamically - what I'd like to do is provide alternate content (text) for those either not having Flash and for search engine bots. So, for a user with flash they would navigate to:
```
http://www.samplesite.com/#specific_page
```
and they would see a flash site that would navigate to the "`specific_page`." Those without flash would see the "`specific_page`" rendered in text in the alternative content section.
Basically, I would use php/mysql to create a backend to handle all of this since the swf is also using dynamic data. The question is, does something out there that does this already exist?
|
Looking at the solutions you linked... it is actually as simple as my frivolous comment!
Here's a version of the Zach Leatherman code that prepends "In " for future dates for you. As you can see, the changes are very minor.
```
function humane_date(date_str){
var time_formats = [
[60, 'Just Now'],
[90, '1 Minute'], // 60*1.5
[3600, 'Minutes', 60], // 60*60, 60
[5400, '1 Hour'], // 60*60*1.5
[86400, 'Hours', 3600], // 60*60*24, 60*60
[129600, '1 Day'], // 60*60*24*1.5
[604800, 'Days', 86400], // 60*60*24*7, 60*60*24
[907200, '1 Week'], // 60*60*24*7*1.5
[2628000, 'Weeks', 604800], // 60*60*24*(365/12), 60*60*24*7
[3942000, '1 Month'], // 60*60*24*(365/12)*1.5
[31536000, 'Months', 2628000], // 60*60*24*365, 60*60*24*(365/12)
[47304000, '1 Year'], // 60*60*24*365*1.5
[3153600000, 'Years', 31536000], // 60*60*24*365*100, 60*60*24*365
[4730400000, '1 Century'], // 60*60*24*365*100*1.5
];
var time = ('' + date_str).replace(/-/g,"/").replace(/[TZ]/g," "),
dt = new Date,
seconds = ((dt - new Date(time) + (dt.getTimezoneOffset() * 60000)) / 1000),
token = ' Ago',
prepend = '',
i = 0,
format;
if (seconds < 0) {
seconds = Math.abs(seconds);
token = '';
prepend = 'In ';
}
while (format = time_formats[i++]) {
if (seconds < format[0]) {
if (format.length == 2) {
return (i>1?prepend:'') + format[1] + (i > 1 ? token : ''); // Conditional so we don't return Just Now Ago
} else {
return prepend + Math.round(seconds / format[2]) + ' ' + format[1] + (i > 1 ? token : '');
}
}
}
// overflow for centuries
if(seconds > 4730400000)
return Math.round(seconds / 4730400000) + ' Centuries' + token;
return date_str;
};
```
|
168,946 |
<p>Here's my scenario. I created an application which uses Integrated Windows Authentication in order to work. In <code>Application_AuthenticateRequest()</code>, I use <code>HttpContext.Current.User.Identity</code> to get the current <code>WindowsPrincipal</code> of the user of my website.</p>
<p>Now here's the funny part. Some of our users have recently gotten married, and their names change. (i.e. the user's NT Login changes from <code>jsmith</code> to <code>jjones</code>) and when my application authenticates them, IIS passes me their OLD LOGIN . I continue to see <code>jsmith</code> passed to my application until I reboot my SERVER! Logging off the client does not work. Restarting the app pool does not work. Only a full reboot. </p>
<p>Does anyone know what's going on here? Is there some sort of command I can use to flush whatever cache is giving me this problem? Is my server misconfigured?</p>
<p>Note: I definitely do NOT want to restart IIS, my application pools, or the machine. As this is a production box, these are not really viable options.</p>
<hr>
<p>AviD -</p>
<p>Yes, their UPN was changed along with their login name. And Mark/Nick... This is a production enterprise server... It can't just be rebooted or have IIS restarted. </p>
<hr>
<p><strong>Follow up (for posterity):</strong></p>
<p>Grhm's answer was spot-on. This problem pops up in low-volume servers where you don't have a lot of people using your applications, but enough requests are made to keep the users' identity in the cache. The key part of the <a href="http://support.microsoft.com/kb/946358" rel="noreferrer">KB</a> which seems to describe why the cache item is not refreshed after the default of 10 minutes is:</p>
<blockquote>
<p>The cache entries do time out, however chances are that recurring
queries by applications keep the existing cache entry alive for the
maximum lifetime of the cache entry.</p>
</blockquote>
<p>I'm not exactly sure what in our code was causing this (the recurring queries), but the resolution which worked for us was to cut the <code>LsaLookupCacheExpireTime</code> value from the seemingly obscene default of 1 week to just a few hours. This, for us, cut the probability that a user would be impacted in the real world to essentially zero, and yet at the same time doesn't cause an extreme number of SID-Name lookups against our directory servers. An even better solution IMO would be if applications looked up user information by SID instead of mapping user data to textual login name. (Take note, vendors! If you're relying on AD authentication in your application, you'll want to put the SID in your authentication database!)</p>
|
[
{
"answer_id": 168998,
"author": "Nick Messick",
"author_id": 24988,
"author_profile": "https://Stackoverflow.com/users/24988",
"pm_score": 1,
"selected": false,
"text": "<p>Restarting IIS, not the whole machine, should do the trick.</p>\n"
},
{
"answer_id": 171295,
"author": "AviD",
"author_id": 10080,
"author_profile": "https://Stackoverflow.com/users/10080",
"pm_score": 1,
"selected": false,
"text": "<p>When these users' names were changed, did you change only their NT Login names, or their UPN names too? the UPN names are the proper names, and used by Kerberos - which is the default protocol for IWA; however, if you just click to change their name in ActiveDirectory, only the NT Login name changes - even though thats what they would use to login (using the default windows GINA). Under the covers, windows would translate the (new) NT Login name to the (old) Kerberos name. This persists until AD is forced to update the Kerberos name according to the NT Login name...</p>\n"
},
{
"answer_id": 577578,
"author": "AviD",
"author_id": 10080,
"author_profile": "https://Stackoverflow.com/users/10080",
"pm_score": 2,
"selected": false,
"text": "<p>If it's not an issue of changing only the NT Username, then it does seem that the authentication service is caching the old username.<br>\nYou can define this to be disabled, go to the Local Security Settings (in Administrative Tools), and depending on version/edition/configuration the settings that are possible relevant (from memory) are \"Number of previous logons to cache\" and \"Do not allow storage of credentials...\". </p>\n\n<p>Additional factors to take into account: </p>\n\n<ul>\n<li>Domain membership might affect this, as member servers may inherit domain settings</li>\n<li>You may still need to restart the whole server once for this to take affect (but then you won't have to worry about updates in the future). </li>\n<li>Logon performance might be affected. </li>\n</ul>\n\n<p>As such, I recommend you test this first before deploying on production (of course).</p>\n"
},
{
"answer_id": 581346,
"author": "Robert MacLean",
"author_id": 53236,
"author_profile": "https://Stackoverflow.com/users/53236",
"pm_score": 2,
"selected": false,
"text": "<p>The problem as <a href=\"https://stackoverflow.com/users/10080/avid\">AviD</a> identified is the Active Directory cache which you can control via the <a href=\"http://technet.microsoft.com/en-us/library/cc747586.aspx\" rel=\"nofollow noreferrer\">registry</a>. Depending on your solution Avid's group policy options will fail or work depending if you are actually logging the users on or not.</p>\n\n<p>How it is being cached depends on how you are authenticating on IIS. I suspect it could be Kerberos so to do the clearing if it is being caused by Kerberos you may want to try <a href=\"http://technet.microsoft.com/en-us/library/cc738673.aspx\" rel=\"nofollow noreferrer\">klist</a> with the purge option which should purge kerberos tickets, which will force a reauth to AD on the next attempt and update the details.</p>\n\n<p>I would also suggest looking at implementing <a href=\"http://www.aspcode.net/Getting-the-authenticated-username.aspx\" rel=\"nofollow noreferrer\">this</a> which is slightly more complex but far less error prone.</p>\n"
},
{
"answer_id": 596169,
"author": "Sean Hanley",
"author_id": 7290,
"author_profile": "https://Stackoverflow.com/users/7290",
"pm_score": 2,
"selected": false,
"text": "<p>I know we've had cached credentials problems in IIS in the past here, too, and after Googling for days we came across an obscure (to us, at least) command you can use to view and clear cached credentials.</p>\n\n<p>Start -> Run (or WinKey+R) and type <strong>control keymgr.dll</strong></p>\n\n<p>This fixed our problems for client machines. Haven't tried it on servers but it might be worth a shot if its the server caching credentials. Our problem was we were getting old credentials but only on a client machine basis. If the user logged in on a separate client machine, everything was fine, but if they used their own machine at their desk that they normally work on it had the cached old credentials.</p>\n"
},
{
"answer_id": 667297,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Login to the server that runs the IIS using the new login name in question. This will refresh the credential without re-starting IIS or rebooting the server.</p>\n"
},
{
"answer_id": 6214585,
"author": "JonH",
"author_id": 168703,
"author_profile": "https://Stackoverflow.com/users/168703",
"pm_score": 0,
"selected": false,
"text": "<p>Just as an FYI we had the exact same issue. What appeared to work for us is to go into Active Directory and do a \"Refresh\". Immediately after this we had to recycle the application pool on the intranet sites that were having this issue.</p>\n"
},
{
"answer_id": 7685602,
"author": "Grhm",
"author_id": 204690,
"author_profile": "https://Stackoverflow.com/users/204690",
"pm_score": 6,
"selected": true,
"text": "<p>I've had similar issues lately and as stated in Robert MacLean's <a href=\"https://stackoverflow.com/questions/168946/iis-returning-old-user-names-to-my-application/581346#581346\">answer</a>, AviD's group policy changes don't work if you're not logging in as the users.</p>\n\n<p>I found changing the <strong>LSA Lookup Cache</strong> size as described is MS <a href=\"http://support.microsoft.com/kb/946358\" rel=\"nofollow noreferrer\">KB946358</a> worked without rebooting or recycling any apppool or services.</p>\n\n<p>I found this as an answer to this similar question: <a href=\"https://stackoverflow.com/questions/5551489/wrong-authentication-after-changing-users-logon-name\">Wrong authentication after changing user's logon name</a>.</p>\n\n<p>You might want to look into the following system calls such as the following ones:</p>\n\n<pre><code>LookupAccountName()\n\nLookupAccountSid()\n\nLsaOpenPolicy()\n</code></pre>\n\n<p>You could use them to write a C++/CLI (/Managed-C++) app to interrogate the LSA cache.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168946",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24995/"
] |
Here's my scenario. I created an application which uses Integrated Windows Authentication in order to work. In `Application_AuthenticateRequest()`, I use `HttpContext.Current.User.Identity` to get the current `WindowsPrincipal` of the user of my website.
Now here's the funny part. Some of our users have recently gotten married, and their names change. (i.e. the user's NT Login changes from `jsmith` to `jjones`) and when my application authenticates them, IIS passes me their OLD LOGIN . I continue to see `jsmith` passed to my application until I reboot my SERVER! Logging off the client does not work. Restarting the app pool does not work. Only a full reboot.
Does anyone know what's going on here? Is there some sort of command I can use to flush whatever cache is giving me this problem? Is my server misconfigured?
Note: I definitely do NOT want to restart IIS, my application pools, or the machine. As this is a production box, these are not really viable options.
---
AviD -
Yes, their UPN was changed along with their login name. And Mark/Nick... This is a production enterprise server... It can't just be rebooted or have IIS restarted.
---
**Follow up (for posterity):**
Grhm's answer was spot-on. This problem pops up in low-volume servers where you don't have a lot of people using your applications, but enough requests are made to keep the users' identity in the cache. The key part of the [KB](http://support.microsoft.com/kb/946358) which seems to describe why the cache item is not refreshed after the default of 10 minutes is:
>
> The cache entries do time out, however chances are that recurring
> queries by applications keep the existing cache entry alive for the
> maximum lifetime of the cache entry.
>
>
>
I'm not exactly sure what in our code was causing this (the recurring queries), but the resolution which worked for us was to cut the `LsaLookupCacheExpireTime` value from the seemingly obscene default of 1 week to just a few hours. This, for us, cut the probability that a user would be impacted in the real world to essentially zero, and yet at the same time doesn't cause an extreme number of SID-Name lookups against our directory servers. An even better solution IMO would be if applications looked up user information by SID instead of mapping user data to textual login name. (Take note, vendors! If you're relying on AD authentication in your application, you'll want to put the SID in your authentication database!)
|
I've had similar issues lately and as stated in Robert MacLean's [answer](https://stackoverflow.com/questions/168946/iis-returning-old-user-names-to-my-application/581346#581346), AviD's group policy changes don't work if you're not logging in as the users.
I found changing the **LSA Lookup Cache** size as described is MS [KB946358](http://support.microsoft.com/kb/946358) worked without rebooting or recycling any apppool or services.
I found this as an answer to this similar question: [Wrong authentication after changing user's logon name](https://stackoverflow.com/questions/5551489/wrong-authentication-after-changing-users-logon-name).
You might want to look into the following system calls such as the following ones:
```
LookupAccountName()
LookupAccountSid()
LsaOpenPolicy()
```
You could use them to write a C++/CLI (/Managed-C++) app to interrogate the LSA cache.
|
168,951 |
<hr />
<p><strong>
The <a href="http://docs.php.net/manual/en/class.httprequestpool.php" rel="noreferrer">HttpRequestPool</a> class provides a solution. Many thanks to those who pointed this out.</p>
<p>A brief tutorial can be found at: <a href="http://www.phptutorial.info/?HttpRequestPool-construct" rel="noreferrer">http://www.phptutorial.info/?HttpRequestPool-construct</a></strong></p>
<hr />
<p><strong>Problem</strong></p>
<p>I'd like to make concurrent/parallel/simultaneous HTTP requests in PHP. I'd like to avoid consecutive requests as:</p>
<ul>
<li>a set of requests will take too long to complete; the more requests the longer</li>
<li>the timeout of one request midway through a set may cause later requests to not be made (if a script has an execution time limit)</li>
</ul>
<p>I have managed to find details for making <a href="http://www.phpied.com/simultaneuos-http-requests-in-php-with-curl/" rel="noreferrer">simultaneuos [sic] HTTP requests in PHP with cURL</a>, however I'd like to explicitly use PHP's <a href="http://php.net/manual/en/book.http.php" rel="noreferrer">HTTP functions</a> if at all possible.</p>
<p>Specifically, I need to POST data concurrently to a set of URLs. The URLs to which data are posted are beyond my control; they are user-set.</p>
<p>I don't mind if I need to wait for all requests to finish before the responses can be processed. If I set a timeout of 30 seconds on each request and requests are made concurrently, I know I must wait a maximum of 30 seconds (perhaps a little more) for all requests to complete.</p>
<p>I can find no details of how this might be achieved. However, I did recently notice a mention in the PHP manual of PHP5+ being able to handle concurrent HTTP requests - I intended to make a note of it at the time, forgot, and cannot find it again.</p>
<p><strong>Single request example (works fine)</strong></p>
<pre><code><?php
$request_1 = new HttpRequest($url_1, HTTP_METH_POST);
$request_1->setRawPostData($dataSet_1);
$request_1->send();
?>
</code></pre>
<p><strong>Concurrent request example (incomplete, clearly)</strong></p>
<pre><code><?php
$request_1 = new HttpRequest($url_1, HTTP_METH_POST);
$request_1->setRawPostData($dataSet_1);
$request_2 = new HttpRequest($url_2, HTTP_METH_POST);
$request_2->setRawPostData($dataSet_2);
// ...
$request_N = new HttpRequest($url_N, HTTP_METH_POST);
$request_N->setRawPostData($dataSet_N);
// Do something to send() all requests at the same time
?>
</code></pre>
<p>Any thoughts would be most appreciated!</p>
<p><strong>Clarification 1</strong>: I'd like to stick to the PECL HTTP functions as:</p>
<ul>
<li>they offer a nice OOP interface</li>
<li>they're used extensively in the application in question and sticking to what's already in use should be beneficial from a maintenance perspective</li>
<li>I generally have to write fewer lines of code to make an HTTP request using the PECL HTTP functions compared to using cURL - fewer lines of code should also be beneficial from a maintenance perspective</li>
</ul>
<p><strong>Clarification 2</strong>: I realise PHP's HTTP functions aren't built in and perhaps I worded things wrongly there, which I shall correct. I have no concerns about people having to install extra stuff - this is not an application that is to be distributed, it's a web app with a server to itself.</p>
<p><strong>Clarification 3</strong>: I'd be perfectly happy if someone authoritatively states that the PECL HTTP cannot do this.</p>
|
[
{
"answer_id": 169001,
"author": "bobwienholt",
"author_id": 24257,
"author_profile": "https://Stackoverflow.com/users/24257",
"pm_score": -1,
"selected": false,
"text": "<p>You could use pcntl_fork() to create a separate process for each request, then wait for them to end:</p>\n\n<p><a href=\"http://www.php.net/manual/en/function.pcntl-fork.php\" rel=\"nofollow noreferrer\">http://www.php.net/manual/en/function.pcntl-fork.php</a></p>\n\n<p>Is there any reason you don't want to use cURL? The curl_multi_* functions would allow for multiple requests at the same time.</p>\n"
},
{
"answer_id": 169046,
"author": "ceejayoz",
"author_id": 1902010,
"author_profile": "https://Stackoverflow.com/users/1902010",
"pm_score": 0,
"selected": false,
"text": "<p>PHP's HTTP functions <a href=\"http://www.php.net/manual/en/http.install.php\" rel=\"nofollow noreferrer\">aren't built in</a>, either - they're a PECL extension. If your concern is people having to install extra stuff, both solutions will have the same problem - and cURL is more likely to be installed, I'd imagine, as it comes default with every web host I've ever been on.</p>\n"
},
{
"answer_id": 190758,
"author": "Till",
"author_id": 2859,
"author_profile": "https://Stackoverflow.com/users/2859",
"pm_score": 2,
"selected": false,
"text": "<p>Did you try <a href=\"http://www.php.net/manual/en/class.httprequestpool.php\" rel=\"nofollow noreferrer\">HttpRequestPool</a> (it's part of Http)? It looks like it would pool up the request objects and work them. I know I read somewhere that Http would support simultaneous requests and aside from <em>pool</em> I can't find anything either.</p>\n"
},
{
"answer_id": 195806,
"author": "Willem",
"author_id": 15447,
"author_profile": "https://Stackoverflow.com/users/15447",
"pm_score": 2,
"selected": false,
"text": "<p>I once had to solve similar problem: doing multiple requests without cumulating the response times.</p>\n\n<p>The solution ended up being a custom-build function which used non-blocking <a href=\"http://www.php.net/sockets\" rel=\"nofollow noreferrer\">sockets</a>.\nIt works something like this:</p>\n\n<pre><code>$request_list = array(\n # address => http request string\n #\n '127.0.0.1' => \"HTTP/1.1 GET /index.html\\nServer: website.com\\n\\n\",\n '192.169.2.3' => \"HTTP/1.1 POST /form.dat\\nForm-data: ...\",\n );\n\nforeach($request_list as $addr => $http_request) {\n # first, create a socket and fire request to every host\n $socklist[$addr] = socket_create();\n socket_set_nonblock($socklist[$addr]); # Make operation asynchronious\n\n if (! socket_connect($socklist[$addr], $addr, 80))\n trigger_error(\"Cannot connect to remote address\");\n\n # the http header is send to this host\n socket_send($socklist[$addr], $http_request, strlen($http_request), MSG_EOF);\n}\n\n$results = array();\n\nforeach(array_keys($socklist) as $host_ip) {\n # Now loop and read every socket until it is exhausted\n $str = socket_read($socklist[$host_ip], 512, PHP_NORMAL_READ);\n if ($str != \"\") \n # add to previous string\n $result[$host_ip] .= $str;\n else\n # Done reading this socket, close it\n socket_close($socklist[$host_ip]);\n}\n# $results now contains an array with the full response (including http-headers)\n# of every connected host.\n</code></pre>\n\n<p>It's much faster since thunked reponses are fetched in semi-parallel since socket_read doesn't wait for the response but returns if the socket-buffer isn't full yet.</p>\n\n<p>You can wrap this in appropriate OOP interfaces. You <em>will</em> need to create the HTTP-request string yourself, and process the server response of course.</p>\n"
},
{
"answer_id": 196236,
"author": "Edward Z. Yang",
"author_id": 23845,
"author_profile": "https://Stackoverflow.com/users/23845",
"pm_score": 4,
"selected": true,
"text": "<p>I'm pretty sure <a href=\"http://docs.php.net/manual/en/class.httprequestpool.php\" rel=\"noreferrer\">HttpRequestPool</a> is what you're looking for.</p>\n\n<p>To elaborate a little, you can use forking to achieve what you're looking for, but that seems unnecessarily complex and not very useful in a HTML context. While I haven't tested, this code should be it:</p>\n\n<pre>\n// let $requests be an array of requests to send\n$pool = new HttpRequestPool();\nforeach ($requests as $request) {\n $pool->attach($request);\n}\n$pool->send();\nforeach ($pool as $request) {\n // do stuff\n}\n</pre>\n"
},
{
"answer_id": 526426,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>A friend pointed me to CurlObjects ( <a href=\"http://trac.curlobjects.com/trac\" rel=\"nofollow noreferrer\">http://trac.curlobjects.com/trac</a> ) recently, which I found quite useful for using curl_multi.</p>\n\n<p><code>\n$curlbase = new CurlBase;\n$curlbase->defaultOptions[ CURLOPT_TIMEOUT ] = 30;\n$curlbase->add( new HttpPost($url, array('name'=> 'value', 'a' => 'b')));\n$curlbase->add( new HttpPost($url2, array('name'=> 'value', 'a' => 'b')));\n$curlbase->add( new HttpPost($url3, array('name'=> 'value', 'a' => 'b')));\n$curlbase->perform();</p>\n\n<p>foreach($curlbase->requests as $request) {\n...\n}\n</code></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168951",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5343/"
] |
---
**The [HttpRequestPool](http://docs.php.net/manual/en/class.httprequestpool.php) class provides a solution. Many thanks to those who pointed this out.**
A brief tutorial can be found at: <http://www.phptutorial.info/?HttpRequestPool-construct>
---
**Problem**
I'd like to make concurrent/parallel/simultaneous HTTP requests in PHP. I'd like to avoid consecutive requests as:
* a set of requests will take too long to complete; the more requests the longer
* the timeout of one request midway through a set may cause later requests to not be made (if a script has an execution time limit)
I have managed to find details for making [simultaneuos [sic] HTTP requests in PHP with cURL](http://www.phpied.com/simultaneuos-http-requests-in-php-with-curl/), however I'd like to explicitly use PHP's [HTTP functions](http://php.net/manual/en/book.http.php) if at all possible.
Specifically, I need to POST data concurrently to a set of URLs. The URLs to which data are posted are beyond my control; they are user-set.
I don't mind if I need to wait for all requests to finish before the responses can be processed. If I set a timeout of 30 seconds on each request and requests are made concurrently, I know I must wait a maximum of 30 seconds (perhaps a little more) for all requests to complete.
I can find no details of how this might be achieved. However, I did recently notice a mention in the PHP manual of PHP5+ being able to handle concurrent HTTP requests - I intended to make a note of it at the time, forgot, and cannot find it again.
**Single request example (works fine)**
```
<?php
$request_1 = new HttpRequest($url_1, HTTP_METH_POST);
$request_1->setRawPostData($dataSet_1);
$request_1->send();
?>
```
**Concurrent request example (incomplete, clearly)**
```
<?php
$request_1 = new HttpRequest($url_1, HTTP_METH_POST);
$request_1->setRawPostData($dataSet_1);
$request_2 = new HttpRequest($url_2, HTTP_METH_POST);
$request_2->setRawPostData($dataSet_2);
// ...
$request_N = new HttpRequest($url_N, HTTP_METH_POST);
$request_N->setRawPostData($dataSet_N);
// Do something to send() all requests at the same time
?>
```
Any thoughts would be most appreciated!
**Clarification 1**: I'd like to stick to the PECL HTTP functions as:
* they offer a nice OOP interface
* they're used extensively in the application in question and sticking to what's already in use should be beneficial from a maintenance perspective
* I generally have to write fewer lines of code to make an HTTP request using the PECL HTTP functions compared to using cURL - fewer lines of code should also be beneficial from a maintenance perspective
**Clarification 2**: I realise PHP's HTTP functions aren't built in and perhaps I worded things wrongly there, which I shall correct. I have no concerns about people having to install extra stuff - this is not an application that is to be distributed, it's a web app with a server to itself.
**Clarification 3**: I'd be perfectly happy if someone authoritatively states that the PECL HTTP cannot do this.
|
I'm pretty sure [HttpRequestPool](http://docs.php.net/manual/en/class.httprequestpool.php) is what you're looking for.
To elaborate a little, you can use forking to achieve what you're looking for, but that seems unnecessarily complex and not very useful in a HTML context. While I haven't tested, this code should be it:
```
// let $requests be an array of requests to send
$pool = new HttpRequestPool();
foreach ($requests as $request) {
$pool->attach($request);
}
$pool->send();
foreach ($pool as $request) {
// do stuff
}
```
|
168,956 |
<p>I need a (php) regex to match Yahoo's username rules:</p>
<blockquote>
<p>Use 4 to 32 characters and start with a letter. You may use letters, numbers, underscores, and one dot (.).</p>
</blockquote>
|
[
{
"answer_id": 168965,
"author": "Joel Coehoorn",
"author_id": 3043,
"author_profile": "https://Stackoverflow.com/users/3043",
"pm_score": 2,
"selected": false,
"text": "<p>A one dot limit? That's tricky.</p>\n\n<p>I'm no regex expert, but I think this would get it, except for that:</p>\n\n<pre><code>[A-Za-z][A-Za-z0-9_.]{3,31}\n</code></pre>\n\n<p>Maybe you could check for the . requirement separately?</p>\n"
},
{
"answer_id": 168971,
"author": "Randy",
"author_id": 9361,
"author_profile": "https://Stackoverflow.com/users/9361",
"pm_score": 3,
"selected": false,
"text": "<pre><code>/[a-zA-Z][a-zA-Z0-9_]*\\.?[a-zA-Z0-9_]*/\n</code></pre>\n\n<p>And check if strlen($username) >= 4 and <= 32.</p>\n"
},
{
"answer_id": 169138,
"author": "Axeman",
"author_id": 11289,
"author_profile": "https://Stackoverflow.com/users/11289",
"pm_score": 1,
"selected": false,
"text": "<p>Using lookaheads you could do the following: </p>\n\n<pre><code>^(?=[A-Za-z](?:\\w*(?:\\.\\w*)?$))(\\S{4,32})$\n</code></pre>\n\n<p>Because you didn't specify what type of regex you needed I added a lot of Perl 5 compatible stuff. Like <code>(?: ... )</code> for non-capturing parens.</p>\n\n<p><strong>Note:</strong> I added the missing close paren back in. </p>\n"
},
{
"answer_id": 169141,
"author": "Markus Jarderot",
"author_id": 22364,
"author_profile": "https://Stackoverflow.com/users/22364",
"pm_score": 5,
"selected": true,
"text": "<pre><code>/^[A-Za-z](?=[A-Za-z0-9_.]{3,31}$)[a-zA-Z0-9_]*\\.?[a-zA-Z0-9_]*$/\n</code></pre>\n\n<p>Or a little shorter:</p>\n\n<pre><code>/^[a-z](?=[\\w.]{3,31}$)\\w*\\.?\\w*$/i\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168956",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24999/"
] |
I need a (php) regex to match Yahoo's username rules:
>
> Use 4 to 32 characters and start with a letter. You may use letters, numbers, underscores, and one dot (.).
>
>
>
|
```
/^[A-Za-z](?=[A-Za-z0-9_.]{3,31}$)[a-zA-Z0-9_]*\.?[a-zA-Z0-9_]*$/
```
Or a little shorter:
```
/^[a-z](?=[\w.]{3,31}$)\w*\.?\w*$/i
```
|
168,961 |
<p>I'm trying to add the lucene sandbox contribution called <a href="http://lucene.apache.org/java/docs/lucene-sandbox/index.html#Term%20Highlighter" rel="nofollow noreferrer">term-highlighter</a> to my pom.xml.
I'm not really that familiar with Maven, but the code has a <a href="http://svn.apache.org/repos/asf/lucene/java/trunk/contrib/highlighter/pom.xml.template" rel="nofollow noreferrer">pom.xml.template</a> which
seems to imply if I add a dependency that looks like:</p>
<pre><code><dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
</dependency>
</code></pre>
<p>It might work. Can someone help me out in adding a lucene-community project to my pom.xml file?</p>
<p>Thanks for the comments, it turns out that adding the version was all I needed, and I just guessed it should match the lucene-core version I was using.:</p>
<pre><code><dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>2.3.1</version>
</dependency>
</code></pre>
|
[
{
"answer_id": 168990,
"author": "Sam Merrell",
"author_id": 782,
"author_profile": "https://Stackoverflow.com/users/782",
"pm_score": 1,
"selected": false,
"text": "<p>You have it right, but you probably want to add the version as well:</p>\n\n<p><a href=\"http://maven.apache.org/guides/getting-started/maven-in-five-minutes.html\" rel=\"nofollow noreferrer\">From The Maven 5 minute tutorial</a></p>\n\n<pre><code><project xmlns=\"http://maven.apache.org/POM/4.0.0\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n xsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">\n <modelVersion>4.0.0</modelVersion>\n <groupId>com.mycompany.app</groupId>\n <artifactId>my-app</artifactId>\n <packaging>jar</packaging>\n <version>1.0-SNAPSHOT</version>\n <name>Maven Quick Start Archetype</name>\n <url>http://maven.apache.org</url>\n\n <dependencies>\n <dependency>\n <groupId>junit</groupId>\n <artifactId>junit</artifactId>\n <version>3.8.1</version>\n <scope>test</scope>\n </dependency>\n </dependencies>\n\n</project>\n</code></pre>\n"
},
{
"answer_id": 169010,
"author": "Hugo",
"author_id": 972,
"author_profile": "https://Stackoverflow.com/users/972",
"pm_score": 3,
"selected": true,
"text": "<p>You have to add the version number, but you only have to do it once in a project structure. That is, if the version number is defined in a parent pom, you don't have to give the version number again. (But you don't even have to provide the dependency in this case since the dependency will be inherited anyways.)</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168961",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/459/"
] |
I'm trying to add the lucene sandbox contribution called [term-highlighter](http://lucene.apache.org/java/docs/lucene-sandbox/index.html#Term%20Highlighter) to my pom.xml.
I'm not really that familiar with Maven, but the code has a [pom.xml.template](http://svn.apache.org/repos/asf/lucene/java/trunk/contrib/highlighter/pom.xml.template) which
seems to imply if I add a dependency that looks like:
```
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
</dependency>
```
It might work. Can someone help me out in adding a lucene-community project to my pom.xml file?
Thanks for the comments, it turns out that adding the version was all I needed, and I just guessed it should match the lucene-core version I was using.:
```
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>2.3.1</version>
</dependency>
```
|
You have to add the version number, but you only have to do it once in a project structure. That is, if the version number is defined in a parent pom, you don't have to give the version number again. (But you don't even have to provide the dependency in this case since the dependency will be inherited anyways.)
|
168,963 |
<p>I have the following code making a GET request on a URL:</p>
<pre><code>$('#searchButton').click(function() {
$('#inquiry').load('/portal/?f=searchBilling&pid=' + $('#query').val());
});
</code></pre>
<p>But the returned result is not always reflected. For example, I made a change in the response that spit out a stack trace but the stack trace did not appear when I clicked on the search button. I looked at the underlying PHP code that controls the ajax response and it had the correct code and visiting the page directly showed the correct result but the output returned by .load was old.</p>
<p>If I close the browser and reopen it it works once and then starts to return the stale information. Can I control this by jQuery or do I need to have my PHP script output headers to control caching?</p>
|
[
{
"answer_id": 168972,
"author": "Lou Franco",
"author_id": 3937,
"author_profile": "https://Stackoverflow.com/users/3937",
"pm_score": 5,
"selected": false,
"text": "<p>One way is to add a unique number to the end of the url:</p>\n\n<pre><code>$('#inquiry').load('/portal/?f=searchBilling&pid=' + $('#query').val()+'&uid='+uniqueId());\n</code></pre>\n\n<p>Where you write uniqueId() to return something different each time it's called.</p>\n"
},
{
"answer_id": 168973,
"author": "Xian",
"author_id": 4642,
"author_profile": "https://Stackoverflow.com/users/4642",
"pm_score": 2,
"selected": false,
"text": "<p>This is of particular annoyance in IE. Basically you have to send 'no-cache' HTTP headers back with your response from the server.</p>\n"
},
{
"answer_id": 168977,
"author": "John Millikin",
"author_id": 3560,
"author_profile": "https://Stackoverflow.com/users/3560",
"pm_score": 10,
"selected": true,
"text": "<p>You have to use a more complex function like <code>$.ajax()</code> if you want to control caching on a per-request basis. Or, if you just want to turn it off for everything, put this at the top of your script:</p>\n\n<pre><code>$.ajaxSetup ({\n // Disable caching of AJAX responses\n cache: false\n});\n</code></pre>\n"
},
{
"answer_id": 169503,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 2,
"selected": false,
"text": "<p>For PHP, add this line to your script which serves the information you want:</p>\n\n<pre><code>header(\"cache-control: no-cache\");\n</code></pre>\n\n<p>or, add a unique variable to the query string:</p>\n\n<pre><code>\"/portal/?f=searchBilling&x=\" + (new Date()).getTime()\n</code></pre>\n"
},
{
"answer_id": 1713433,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Try this:</p>\n\n<pre><code>$(\"#Search_Result\").load(\"AJAX-Search.aspx?q=\" + $(\"#q\").val() + \"&rnd=\" + String((new Date()).getTime()).replace(/\\D/gi, ''));\n</code></pre>\n\n<p>It works fine when i used it.</p>\n"
},
{
"answer_id": 2158535,
"author": "Marshall",
"author_id": 234138,
"author_profile": "https://Stackoverflow.com/users/234138",
"pm_score": 7,
"selected": false,
"text": "<p>Here is an example of how to control caching on a per-request basis</p>\n\n<pre><code>$.ajax({\n url: \"/YourController\",\n cache: false,\n dataType: \"html\",\n success: function(data) {\n $(\"#content\").html(data);\n }\n});\n</code></pre>\n"
},
{
"answer_id": 3149499,
"author": "Sasha",
"author_id": 380087,
"author_profile": "https://Stackoverflow.com/users/380087",
"pm_score": 3,
"selected": false,
"text": "<pre><code>/**\n * Use this function as jQuery \"load\" to disable request caching in IE\n * Example: $('selector').loadWithoutCache('url', function(){ //success function callback... });\n **/\n$.fn.loadWithoutCache = function (){\n var elem = $(this);\n var func = arguments[1];\n $.ajax({\n url: arguments[0],\n cache: false,\n dataType: \"html\",\n success: function(data, textStatus, XMLHttpRequest) {\n elem.html(data);\n if(func != undefined){\n func(data, textStatus, XMLHttpRequest);\n }\n }\n });\n return elem;\n}\n</code></pre>\n"
},
{
"answer_id": 6616200,
"author": "NGRAUPEN",
"author_id": 219560,
"author_profile": "https://Stackoverflow.com/users/219560",
"pm_score": 3,
"selected": false,
"text": "<p>Sasha is good idea, i use a mix.</p>\n\n<p>I create a function </p>\n\n<pre><code>LoadWithoutCache: function (url, source) {\n $.ajax({\n url: url,\n cache: false,\n dataType: \"html\",\n success: function (data) {\n $(\"#\" + source).html(data);\n return false;\n }\n });\n}\n</code></pre>\n\n<p>And invoke for diferents parts of my page for example on init:</p>\n\n<p>Init: function (actionUrl1, actionUrl2, actionUrl3) {</p>\n\n<p>var ExampleJS= {</p>\n\n<pre><code>Init: function (actionUrl1, actionUrl2, actionUrl3) ExampleJS.LoadWithoutCache(actionUrl1, \"div1\");\n</code></pre>\n\n<p>ExampleJS.LoadWithoutCache(actionUrl2, \"div2\");\nExampleJS.LoadWithoutCache(actionUrl3, \"div3\");\n }\n },</p>\n"
},
{
"answer_id": 7061633,
"author": "techexpert",
"author_id": 559669,
"author_profile": "https://Stackoverflow.com/users/559669",
"pm_score": 0,
"selected": false,
"text": "<p>I noticed that if some servers (like Apache2) are not configured to specifically allow or deny any \"caching\", then the server may by default send a \"cached\" response, even if you set the HTTP headers to \"no-cache\". So make sure that your server is not \"caching\" anything before it sents a response:</p>\n\n<p>In the case of Apache2 you have to</p>\n\n<p>1) edit the \"disk_cache.conf\" file - to disable cache add \"CacheDisable /local_files\" directive</p>\n\n<p>2) load mod_cache modules (On Ubuntu \"sudo a2enmod cache\" and \"sudo a2enmod disk_cache\")</p>\n\n<p>3) restart the Apache2 (Ubuntu \"sudo service apache2 restart\");</p>\n\n<p>This should do the trick disabling cache on the servers side.\nCheers! :)</p>\n"
},
{
"answer_id": 11609008,
"author": "user1545320",
"author_id": 1545320,
"author_profile": "https://Stackoverflow.com/users/1545320",
"pm_score": 2,
"selected": false,
"text": "<p>Do NOT use timestamp to make an unique URL as for every page you visit is cached in DOM by jquery mobile and you soon run into trouble of running out of memory on mobiles.</p>\n\n<pre><code>$jqm(document).bind('pagebeforeload', function(event, data) {\n var url = data.url;\n var savePageInDOM = true;\n\n if (url.toLowerCase().indexOf(\"vacancies\") >= 0) {\n savePageInDOM = false;\n }\n\n $jqm.mobile.cache = savePageInDOM;\n})\n</code></pre>\n\n<p>This code activates before page is loaded, you can use url.indexOf() to determine if the URL is the one you want to cache or not and set the cache parameter accordingly.</p>\n\n<p>Do not use window.location = \"\"; to change URL otherwise you will navigate to the address and pagebeforeload will not fire. In order to get around this problem simply use window.location.hash = \"\";</p>\n"
},
{
"answer_id": 13949898,
"author": "Gomes",
"author_id": 902539,
"author_profile": "https://Stackoverflow.com/users/902539",
"pm_score": 3,
"selected": false,
"text": "<p>Another approach to put the below line only when require to get data from server,Append the below line along with your ajax url.</p>\n\n<p>'?_='+Math.round(Math.random()*10000)</p>\n"
},
{
"answer_id": 23930553,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>This code may help you</p>\n\n<pre><code>var sr = $(\"#Search Result\");\nsr.load(\"AJAX-Search.aspx?q=\" + $(\"#q\")\n.val() + \"&rnd=\" + String((new Date).getTime())\n.replace(/\\D/gi, \"\"));\n</code></pre>\n"
},
{
"answer_id": 24655541,
"author": "NickStees",
"author_id": 1943033,
"author_profile": "https://Stackoverflow.com/users/1943033",
"pm_score": 2,
"selected": false,
"text": "<p>If you want to stick with Jquery's .load() method, add something unique to the URL like a JavaScript timestamp. \"+new Date().getTime()\". Notice I had to add an \"&time=\" so it does not alter your pid variable.</p>\n\n<pre><code>$('#searchButton').click(function() {\n$('#inquiry').load('/portal/?f=searchBilling&pid=' + $('#query').val()+'&time='+new Date().getTime()); \n});\n</code></pre>\n"
},
{
"answer_id": 40810038,
"author": "Adam Gordon Bell",
"author_id": 135202,
"author_profile": "https://Stackoverflow.com/users/135202",
"pm_score": 1,
"selected": false,
"text": "<p>You can replace the jquery load function with a version that has cache set to false. </p>\n\n<pre class=\"lang-js prettyprint-override\"><code>(function($) {\n var _load = jQuery.fn.load;\n $.fn.load = function(url, params, callback) {\n if ( typeof url !== \"string\" && _load ) {\n return _load.apply( this, arguments );\n }\n var selector, type, response,\n self = this,\n off = url.indexOf(\" \");\n\n if (off > -1) {\n selector = stripAndCollapse(url.slice(off));\n url = url.slice(0, off);\n }\n\n // If it's a function\n if (jQuery.isFunction(params)) {\n\n // We assume that it's the callback\n callback = params;\n params = undefined;\n\n // Otherwise, build a param string\n } else if (params && typeof params === \"object\") {\n type = \"POST\";\n }\n\n // If we have elements to modify, make the request\n if (self.length > 0) {\n jQuery.ajax({\n url: url,\n\n // If \"type\" variable is undefined, then \"GET\" method will be used.\n // Make value of this field explicit since\n // user can override it through ajaxSetup method\n type: type || \"GET\",\n dataType: \"html\",\n cache: false,\n data: params\n }).done(function(responseText) {\n\n // Save response for use in complete callback\n response = arguments;\n\n self.html(selector ?\n\n // If a selector was specified, locate the right elements in a dummy div\n // Exclude scripts to avoid IE 'Permission Denied' errors\n jQuery(\"<div>\").append(jQuery.parseHTML(responseText)).find(selector) :\n\n // Otherwise use the full result\n responseText);\n\n // If the request succeeds, this function gets \"data\", \"status\", \"jqXHR\"\n // but they are ignored because response was set above.\n // If it fails, this function gets \"jqXHR\", \"status\", \"error\"\n }).always(callback && function(jqXHR, status) {\n self.each(function() {\n callback.apply(this, response || [jqXHR.responseText, status, jqXHR]);\n });\n });\n }\n\n return this;\n }\n})(jQuery);\n</code></pre>\n\n<p>Place this somewhere global where it will run after jquery loads and you should be all set. Your existing load code will no longer be cached.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168963",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/204/"
] |
I have the following code making a GET request on a URL:
```
$('#searchButton').click(function() {
$('#inquiry').load('/portal/?f=searchBilling&pid=' + $('#query').val());
});
```
But the returned result is not always reflected. For example, I made a change in the response that spit out a stack trace but the stack trace did not appear when I clicked on the search button. I looked at the underlying PHP code that controls the ajax response and it had the correct code and visiting the page directly showed the correct result but the output returned by .load was old.
If I close the browser and reopen it it works once and then starts to return the stale information. Can I control this by jQuery or do I need to have my PHP script output headers to control caching?
|
You have to use a more complex function like `$.ajax()` if you want to control caching on a per-request basis. Or, if you just want to turn it off for everything, put this at the top of your script:
```
$.ajaxSetup ({
// Disable caching of AJAX responses
cache: false
});
```
|
168,992 |
<p>I'm trying to display a series of titles varying from 60 characters to 160 or so and the capitalization varies, some of it all caps, some half caps. When it's mostly lowercase the whole 160 characters of text fits in the width I want, but when it starts getting more caps (they must be wider), it starts over flowing.</p>
<p>Is there a way to use an attractive fixed witdh font (upper and lowercase widths the same too), or dynamically shrink the text to fit, or otherwise recognize how much space the text is going to take on the server side, and cut off the end dynamically? Or do you folks have a better solution?</p>
|
[
{
"answer_id": 168997,
"author": "Zebra North",
"author_id": 17440,
"author_profile": "https://Stackoverflow.com/users/17440",
"pm_score": 1,
"selected": false,
"text": "<p>You could fix the width and hide the overflow, <code>style=\"width: Xpx; overflow: hidden;\"</code></p>\n\n<p>That will limit the width and cut off the end if it's too wide.</p>\n"
},
{
"answer_id": 169000,
"author": "David Heggie",
"author_id": 4309,
"author_profile": "https://Stackoverflow.com/users/4309",
"pm_score": 2,
"selected": false,
"text": "<p>When you say \"cut off the end dynamically\", am I wrong in assuming that a CSS rule like:</p>\n\n<pre><code>h1 {\n width: 400px; /* or whatever width */\n overflow: hidden;\n}\n</code></pre>\n\n<p>would \"cut the end off\" as you want?</p>\n"
},
{
"answer_id": 169013,
"author": "Jeff",
"author_id": 23902,
"author_profile": "https://Stackoverflow.com/users/23902",
"pm_score": 1,
"selected": false,
"text": "<p>MrZebra is right in how to hide the overflow, but if there's an attractive fixed width font you want to use you can set it with CSS font-family, just be sure to give it a fallback for people without the font.</p>\n\n<p>You could also use CSS to enforce the capitalization with 'text-transform', if you wanted (though from your reading, that's not your desire).</p>\n\n<p><a href=\"http://www.w3schools.com/css/pr_font_font-variant.asp\" rel=\"nofollow noreferrer\">font-variant:small-caps</a> might work, too.</p>\n"
},
{
"answer_id": 169054,
"author": "keparo",
"author_id": 19468,
"author_profile": "https://Stackoverflow.com/users/19468",
"pm_score": 4,
"selected": true,
"text": "<p><strong>Control the Overflow</strong></p>\n\n<p>The real trick is just setting a limit on size of the text box, and making sure that there aren't overflow problems. You can use overflow: hidden to take care of this, and display: block the element in order to give it the exact dimensions you need.</p>\n\n<p><strong>Monospace is Optional</strong></p>\n\n<p>Yes, you can use a monospace font.. there are only a few to choose from if you want a cross-browser solution. You can use a variable-width font, too.. the monospace will just help you get consistency with the capitalization problem you described. Using a monospace font will help you to choose a good width that will work for different text lengths. In my example below, I've arbitrarily chosen a width of 250 pixels, and typed strings until they were well past the limit, just for the purposes of illustration.</p>\n\n<p><strong>Line-heights and Margins</strong></p>\n\n<p>You want the line height of the text to match the height of the box.. in this case, I've used 20 pixels. If you need to create line height, you can add a bottom margin.</p>\n\n<p><strong>Side note:</strong> I've used an h3 here, because the text is repeated many times across the page. In general it's a better choice to use a lower level of header for more common text (just a semantic choice). Using an h1 will work the same way.. </p>\n\n<pre><code><html>\n<head>\n<title>h1 stackoverflow question</title>\n<style type=\"text/css\">\n\n* { margin:0; padding:0 }\n\nh3 { \n display: block;\n width: 250px;\n height: 20px;\n margin-bottom: 5px;\n overflow: hidden;\n font-family: Courier, Lucidatypewriter, monospace;\n font: normal 20px/20px Courier;\n border: 1px solid red;\n}\n\n</style>\n</head>\n<body>\n\n<h3>Hello, World</h3>\n<h3>Lorem Ipsum dolor sit Amet</h3>\n<h3>Adipiscing Lorem dolor sit lorem ipsum</h3>\n<h3>&quot;C&quot; is for Cookie, that's good enough for lorem ipsum</h3>\n<h3>Oh, it's a lorem ipsum dolor sit amet. Adipiscing elit.</h3>\n\n</body>\n</html>\n</code></pre>\n"
},
{
"answer_id": 169083,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 0,
"selected": false,
"text": "<p>You could try using javascript to programmatically test to see the width of the font, and if it's too large, take it down a step and try again. Instead of testing the width, see if the height of the element is more than one line (measured in ems, since you'll be changing the font size around).</p>\n\n<pre><code>var fontSize = \"200%\"; // your regular heading font size\nvar h1 = document.getElementById(\"myHeading\");\nwhile (h1.offsetHeight > oneLine) {\n fontSize *= (parseInt(fontSize) - 5) + \"%\";\n h1.style.fontSize = fontSize;\n}\n</code></pre>\n\n<p><em>you'll have to figure out that \"oneLine\" bit for yourself, sorry.</em></p>\n"
},
{
"answer_id": 169104,
"author": "jeff.willis",
"author_id": 9829,
"author_profile": "https://Stackoverflow.com/users/9829",
"pm_score": 2,
"selected": false,
"text": "<p>You could also try an ellipsis solution. Truncate the text at a maximum width and apply an ellipsis. Something like:</p>\n\n<p><strong>My title is way too long for this...</strong></p>\n\n<p>CSS3 has text-overflow: ellipsis you can use, but it's not supported in Firefox.</p>\n\n<p>Hedger Wang has found a <a href=\"http://www.hedgerwow.com/360/dhtml/text_overflow/demo3.php\" rel=\"nofollow noreferrer\">workaround</a> that I have used a couple times. Pretty handy.</p>\n"
},
{
"answer_id": 178221,
"author": "Ian Oxley",
"author_id": 1904,
"author_profile": "https://Stackoverflow.com/users/1904",
"pm_score": 0,
"selected": false,
"text": "<p>Rather than trying to constrain the height of your <h1> I would adjust your CSS to make your site more fluid - afterall, you don't want your site to appear broken if the user increases their text size.</p>\n\n<p>Try setting the h1's height in ems rather than pixels. If you add this to your CSS:</p>\n\n<pre><code>body {\n font:62.5%/140% Courier, Lucidatypewriter, monospace;\n}\n</code></pre>\n\n<p>It will make 1em = 10px, so then you can set your heading's height to:</p>\n\n<pre><code>h1, h3 {\n ....\n height:2em;\n ....\n}\n</code></pre>\n\n<p>Hope this helps.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/168992",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13009/"
] |
I'm trying to display a series of titles varying from 60 characters to 160 or so and the capitalization varies, some of it all caps, some half caps. When it's mostly lowercase the whole 160 characters of text fits in the width I want, but when it starts getting more caps (they must be wider), it starts over flowing.
Is there a way to use an attractive fixed witdh font (upper and lowercase widths the same too), or dynamically shrink the text to fit, or otherwise recognize how much space the text is going to take on the server side, and cut off the end dynamically? Or do you folks have a better solution?
|
**Control the Overflow**
The real trick is just setting a limit on size of the text box, and making sure that there aren't overflow problems. You can use overflow: hidden to take care of this, and display: block the element in order to give it the exact dimensions you need.
**Monospace is Optional**
Yes, you can use a monospace font.. there are only a few to choose from if you want a cross-browser solution. You can use a variable-width font, too.. the monospace will just help you get consistency with the capitalization problem you described. Using a monospace font will help you to choose a good width that will work for different text lengths. In my example below, I've arbitrarily chosen a width of 250 pixels, and typed strings until they were well past the limit, just for the purposes of illustration.
**Line-heights and Margins**
You want the line height of the text to match the height of the box.. in this case, I've used 20 pixels. If you need to create line height, you can add a bottom margin.
**Side note:** I've used an h3 here, because the text is repeated many times across the page. In general it's a better choice to use a lower level of header for more common text (just a semantic choice). Using an h1 will work the same way..
```
<html>
<head>
<title>h1 stackoverflow question</title>
<style type="text/css">
* { margin:0; padding:0 }
h3 {
display: block;
width: 250px;
height: 20px;
margin-bottom: 5px;
overflow: hidden;
font-family: Courier, Lucidatypewriter, monospace;
font: normal 20px/20px Courier;
border: 1px solid red;
}
</style>
</head>
<body>
<h3>Hello, World</h3>
<h3>Lorem Ipsum dolor sit Amet</h3>
<h3>Adipiscing Lorem dolor sit lorem ipsum</h3>
<h3>"C" is for Cookie, that's good enough for lorem ipsum</h3>
<h3>Oh, it's a lorem ipsum dolor sit amet. Adipiscing elit.</h3>
</body>
</html>
```
|
169,008 |
<p>I'm trying to write a regex that will parse out the <strong>directory and filename</strong> of a fully qualified path using matching groups.</p>
<p>so...</p>
<pre><code>/var/log/xyz/10032008.log
</code></pre>
<p>would recognize <code>group 1 to be "/var/log/xyz"</code> and <code>group 2 to be "10032008.log"</code></p>
<p>Seems simple but I can't get the matching groups to work for the life of me.</p>
<p>NOTE: As pointed out by some of the respondents this is probably not a good use of regular expressions. Generally I'd prefer to use the file API of the language I was using. What I'm actually trying to do is a little more complicated than this but would have been much more difficult to explain, so I chose a domain that everyone would be familiar with in order to most succinctly describe the root problem.</p>
|
[
{
"answer_id": 169014,
"author": "tzot",
"author_id": 6899,
"author_profile": "https://Stackoverflow.com/users/6899",
"pm_score": 3,
"selected": false,
"text": "<p>What language? and why use regex for this simple task?</p>\n\n<p>If you <em>must</em>:</p>\n\n<pre><code>^(.*)/([^/]*)$\n</code></pre>\n\n<p>gives you the two parts you wanted. You might need to quote the parentheses:</p>\n\n<pre><code>^\\(.*\\)/\\([^/]*\\)$\n</code></pre>\n\n<p>depending on your preferred language syntax.</p>\n\n<p>But I suggest you just use your language's string search function that finds the last \"/\" character, and split the string on that index.</p>\n"
},
{
"answer_id": 169021,
"author": "Paige Ruten",
"author_id": 813,
"author_profile": "https://Stackoverflow.com/users/813",
"pm_score": 7,
"selected": true,
"text": "<p>Try this:</p>\n<pre><code>^(.+)\\/([^\\/]+)$\n</code></pre>\n<p>EDIT: escaped the forward slash to prevent problems when copy/pasting the Regex</p>\n"
},
{
"answer_id": 169033,
"author": "Lucas Oman",
"author_id": 6726,
"author_profile": "https://Stackoverflow.com/users/6726",
"pm_score": 0,
"selected": false,
"text": "<p>Try this:</p>\n\n<pre><code>/^(\\/([^/]+\\/)*)(.*)$/\n</code></pre>\n\n<p>It will leave the trailing slash on the path, though.</p>\n"
},
{
"answer_id": 169056,
"author": "Travis Illig",
"author_id": 8116,
"author_profile": "https://Stackoverflow.com/users/8116",
"pm_score": 4,
"selected": false,
"text": "<p>Most languages have path parsing functions that will give you this already. If you have the ability, I'd recommend using what comes to you for free out-of-the-box.</p>\n\n<p>Assuming / is the path delimiter...</p>\n\n<pre><code>^(.*/)([^/]*)$\n</code></pre>\n\n<p>The first group will be whatever the directory/path info is, the second will be the filename. For example:</p>\n\n<ul>\n<li><strong>/foo/bar/baz.log</strong>: \"/foo/bar/\" is the path, \"baz.log\" is the file</li>\n<li><strong>foo/bar.log</strong>: \"foo/\" is the path, \"bar.log\" is the file</li>\n<li><strong>/foo/bar</strong>: \"/foo/\" is the path, \"bar\" is the file</li>\n<li><strong>/foo/bar/</strong>: \"/foo/bar/\" is the path and there is no file.</li>\n</ul>\n"
},
{
"answer_id": 8369774,
"author": "Aurélien Ooms",
"author_id": 1079252,
"author_profile": "https://Stackoverflow.com/users/1079252",
"pm_score": 2,
"selected": false,
"text": "<p>What about this?</p>\n\n<pre><code>[/]{0,1}([^/]+[/])*([^/]*)\n</code></pre>\n\n<p>Deterministic :</p>\n\n<pre><code>((/)|())([^/]+/)*([^/]*)\n</code></pre>\n\n<p>Strict :</p>\n\n<pre><code>^[/]{0,1}([^/]+[/])*([^/]*)$\n^((/)|())([^/]+/)*([^/]*)$\n</code></pre>\n"
},
{
"answer_id": 26635619,
"author": "Suganthan Madhavan Pillai",
"author_id": 2534236,
"author_profile": "https://Stackoverflow.com/users/2534236",
"pm_score": 1,
"selected": false,
"text": "<p>A very late answer, but hope this will help</p>\n\n<pre><code>^(.+?)/([\\w]+\\.log)$\n</code></pre>\n\n<p>This uses lazy check for <code>/</code>, and I just modified the accepted answer</p>\n\n<p><a href=\"http://regex101.com/r/gV2xB7/1\" rel=\"nofollow\">http://regex101.com/r/gV2xB7/1</a></p>\n"
},
{
"answer_id": 33021907,
"author": "Chad Nouis",
"author_id": 1078068,
"author_profile": "https://Stackoverflow.com/users/1078068",
"pm_score": 5,
"selected": false,
"text": "<p>In languages that support regular expressions with <a href=\"http://www.regular-expressions.info/brackets.html\">non-capturing groups</a>:</p>\n\n<pre class=\"lang-none prettyprint-override\"><code>((?:[^/]*/)*)(.*)\n</code></pre>\n\n<p>I'll explain the gnarly regex by exploding it...</p>\n\n<pre class=\"lang-none prettyprint-override\"><code>(\n (?:\n [^/]*\n /\n )\n *\n)\n(.*)\n</code></pre>\n\n<p>What the parts mean:</p>\n\n<pre class=\"lang-none prettyprint-override\"><code>( -- capture group 1 starts\n (?: -- non-capturing group starts\n [^/]* -- greedily match as many non-directory separators as possible\n / -- match a single directory-separator character\n ) -- non-capturing group ends\n * -- repeat the non-capturing group zero-or-more times\n) -- capture group 1 ends\n(.*) -- capture all remaining characters in group 2\n</code></pre>\n\n<h2>Example</h2>\n\n<p>To test the regular expression, I used the following Perl script...</p>\n\n<pre class=\"lang-perl prettyprint-override\"><code>#!/usr/bin/perl -w\n\nuse strict;\nuse warnings;\n\nsub test {\n my $str = shift;\n my $testname = shift;\n\n $str =~ m#((?:[^/]*/)*)(.*)#;\n\n print \"$str -- $testname\\n\";\n print \" 1: $1\\n\";\n print \" 2: $2\\n\\n\";\n}\n\ntest('/var/log/xyz/10032008.log', 'absolute path');\ntest('var/log/xyz/10032008.log', 'relative path');\ntest('10032008.log', 'filename-only');\ntest('/10032008.log', 'file directly under root');\n</code></pre>\n\n<p>The output of the script...</p>\n\n<pre class=\"lang-none prettyprint-override\"><code>/var/log/xyz/10032008.log -- absolute path\n 1: /var/log/xyz/\n 2: 10032008.log\n\nvar/log/xyz/10032008.log -- relative path\n 1: var/log/xyz/\n 2: 10032008.log\n\n10032008.log -- filename-only\n 1:\n 2: 10032008.log\n\n/10032008.log -- file directly under root\n 1: /\n 2: 10032008.log\n</code></pre>\n"
},
{
"answer_id": 55600175,
"author": "theBuzzyCoder",
"author_id": 2147023,
"author_profile": "https://Stackoverflow.com/users/2147023",
"pm_score": 2,
"selected": false,
"text": "<h1>Reasoning:</h1>\n\n<p>I did a little research through trial and error method. Found out that all the values that are available in keyboard are eligible to be a file or directory except '/' in *nux machine. </p>\n\n<p>I used touch command to create file for following characters and it created a file.</p>\n\n<blockquote>\n <p><em>(Comma separated values below)</em> <br>\n '!', '@', '#', '$', \"'\", '%', '^', '&', '*', '(', ')', ' ', '\"', '\\', '-', ',', '[', ']', '{', '}', '`', '~', '>', '<', '=', '+', ';', ':', '|'</p>\n</blockquote>\n\n<p>It failed only when I tried creating '/' (because it's root directory) and filename container <code>/</code> because it file separator. </p>\n\n<p>And it changed the modified time of current dir <code>.</code> when I did <code>touch .</code>. However, file.log is possible.</p>\n\n<p>And of course, <code>a-z</code>, <code>A-Z</code>, <code>0-9</code>, <code>-</code> (hypen), <code>_</code> (underscore) should work.</p>\n\n<h1>Outcome</h1>\n\n<p>So, by the above reasoning we know that a file name or directory name can contain anything except <code>/</code> forward slash. So, our regex will be derived by what will not be present in the file name/directory name.</p>\n\n<pre><code>/(?:(?P<dir>(?:[/]?)(?:[^\\/]+/)+)(?P<filename>[^/]+))/\n</code></pre>\n\n<h1>Step by Step regexp creation process</h1>\n\n<h2>Pattern Explanation</h2>\n\n<h3>Step-1: Start with matching <code>root</code> directory</h3>\n\n<p>A directory can start with <code>/</code> when it is absolute path and directory name when it's relative. Hence, look for <code>/</code> with zero or one occurrence.</p>\n\n<pre><code>/(?P<filepath>(?P<root>[/]?)(?P<rest_of_the_path>.+))/\n</code></pre>\n\n<p><a href=\"https://i.stack.imgur.com/1fhbA.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/1fhbA.png\" alt=\"enter image description here\"></a></p>\n\n<h3>Step-2: Try to find the first directory.</h3>\n\n<p>Next, a directory and its child is always separated by <code>/</code>. And a directory name can be anything except <code>/</code>. Let's match /var/ first then.</p>\n\n<pre><code>/(?P<filepath>(?P<first_directory>(?P<root>[/]?)[^\\/]+/)(?P<rest_of_the_path>.+))/\n</code></pre>\n\n<p><a href=\"https://i.stack.imgur.com/5OzQh.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/5OzQh.png\" alt=\"enter image description here\"></a></p>\n\n<h3>Step-3: Get full directory path for the file</h3>\n\n<p>Next, let's match all directories</p>\n\n<pre><code>/(?P<filepath>(?P<dir>(?P<root>[/]?)(?P<single_dir>[^\\/]+/)+)(?P<rest_of_the_path>.+))/\n</code></pre>\n\n<p><a href=\"https://i.stack.imgur.com/IlxjF.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/IlxjF.png\" alt=\"enter image description here\"></a></p>\n\n<p>Here, single_dir is <code>yz/</code> because, first it matched <code>var/</code>, then it found next occurrence of same pattern i.e. <code>log/</code>, then it found the next occurrence of same pattern <code>yz/</code>. So, it showed the last occurrence of pattern.</p>\n\n<h3>Step-4: Match filename and clean up</h3>\n\n<p>Now, we know that we're never going to use the groups like single_dir, filepath, root. Hence let's clean that up.</p>\n\n<p>Let's keep them as groups however don't capture those groups.</p>\n\n<p>And rest_of_the_path is just the filename! So, rename it. And a file will not have <code>/</code> in its name, so it's better to keep <code>[^/]</code></p>\n\n<pre><code>/(?:(?P<dir>(?:[/]?)(?:[^\\/]+/)+)(?P<filename>[^/]+))/\n</code></pre>\n\n<p>This brings us to the final result. Of course, there are several other ways you can do it. I am just mentioning one of the ways here.</p>\n\n<p><a href=\"https://i.stack.imgur.com/Yx3BI.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/Yx3BI.png\" alt=\"enter image description here\"></a></p>\n\n<h1>Regex Rules used above are listed here</h1>\n\n<p><code>^</code> means string starts with <br>\n<code>(?P<dir>pattern)</code> means capture group by group name. We have two groups with group name <code>dir</code> and <code>file</code> <br>\n<code>(?:pattern)</code> means don't consider this group or non-capturing group.<br>\n<code>?</code> means match zero or one.\n<code>+</code> means match one or more\n<code>[^\\/]</code> means matches any char except forward slash (<code>/</code>)</p>\n\n<p><code>[/]?</code> means if it is absolute path then it can start with / otherwise it won't. So, match zero or one occurrence of <code>/</code>.<br></p>\n\n<p><code>[^\\/]+/</code> means one or more characters which aren't forward slash (<code>/</code>) which is followed by a forward slash (<code>/</code>). This will match <code>var/</code> or <code>xyz/</code>. One directory at a time.</p>\n"
},
{
"answer_id": 68665097,
"author": "rpmathur 12",
"author_id": 11573816,
"author_profile": "https://Stackoverflow.com/users/11573816",
"pm_score": 0,
"selected": false,
"text": "<p>Given an example upload folder URL:</p>\n<pre><code>https://drive.google.com/drive/folders/14Q6d-KiwgTKE-qm5EOZvHeX86-Wf9Q5f?usp=sharing\n</code></pre>\n<p>The regular expression pattern is:</p>\n<pre><code>[-\\w]{25,} \n</code></pre>\n<p>This pattern also works in Google Sheets as well as custom functions in Excel:</p>\n<pre><code>=REGEXEXTRACT(N2,"[-\\w]{25,}")\n</code></pre>\n<p>The result is: <code>14Q6d-KiwgTKE-qm5EOZvHeX86-Wf9Q5f</code></p>\n<p><a href=\"https://i.stack.imgur.com/ru4hx.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/ru4hx.png\" alt=\"enter image description here\" /></a></p>\n<p><a href=\"https://i.stack.imgur.com/WAsXk.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/WAsXk.png\" alt=\"enter image description here\" /></a></p>\n<p><a href=\"https://i.stack.imgur.com/WAsXk.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/WAsXk.png\" alt=\"enter image description here\" /></a></p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169008",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1247/"
] |
I'm trying to write a regex that will parse out the **directory and filename** of a fully qualified path using matching groups.
so...
```
/var/log/xyz/10032008.log
```
would recognize `group 1 to be "/var/log/xyz"` and `group 2 to be "10032008.log"`
Seems simple but I can't get the matching groups to work for the life of me.
NOTE: As pointed out by some of the respondents this is probably not a good use of regular expressions. Generally I'd prefer to use the file API of the language I was using. What I'm actually trying to do is a little more complicated than this but would have been much more difficult to explain, so I chose a domain that everyone would be familiar with in order to most succinctly describe the root problem.
|
Try this:
```
^(.+)\/([^\/]+)$
```
EDIT: escaped the forward slash to prevent problems when copy/pasting the Regex
|
169,034 |
<p>Every time I call this method my NSMutableData is leaking and I cannot figure out how to plug it. theData's retain count is upped by one after the decoder is allocated and initialized and I have no idea why. I am stuck with a retain count of 2 at the end of the method and attempting to release it causes an app crash.</p>
<pre><code>- (void)readVenueArchiveFile:(NSString *)inFile key:(NSString *)inKey
{
NSMutableData *theData;
NSKeyedUnarchiver *decoder;
theData = [NSData dataWithContentsOfFile:inFile];
decoder = [[NSKeyedUnarchiver alloc] initForReadingWithData:theData];
venueIOList = [[decoder decodeObjectForKey:inKey] mutableCopy];
[decoder finishDecoding];
[decoder release];
}
</code></pre>
|
[
{
"answer_id": 169247,
"author": "Chris Hanson",
"author_id": 714,
"author_profile": "https://Stackoverflow.com/users/714",
"pm_score": 2,
"selected": false,
"text": "<p>Don't worry about retain counts, worry about balance within a method. What you're doing in this method looks correct, assuming <code>venueIOList</code> is an instance variable.</p>\n\n<p>To expand on my answer a little bit: The unarchiver might be retaining your data during the unarchive operation, and then sending the data <code>-autorelease</code> when it's done instead of <code>-release</code>. Since that's not something <em>you</em> did, it's not something <em>you</em> have to care about.</p>\n"
},
{
"answer_id": 169665,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>The ultimate source for refcount-related memory management enlightenment is still, IMO, <a href=\"http://www.stepwise.com/Articles/Technical/HoldMe.html\" rel=\"nofollow noreferrer\">\"Hold Me, Use Me, Free Me\"</a> from Stepwise.</p>\n"
},
{
"answer_id": 169709,
"author": "mmalc",
"author_id": 23233,
"author_profile": "https://Stackoverflow.com/users/23233",
"pm_score": 3,
"selected": true,
"text": "<p>I would suggest replacing this line:</p>\n\n<pre><code>venueIOList = [[decoder decodeObjectForKey:inKey] mutableCopy];\n</code></pre>\n\n<p>with:</p>\n\n<pre><code>ListClassName *decodedList = [decoder decodeObjectForKey:inKey];\nself.venueIOList = decodedList;\n</code></pre>\n\n<p>This makes the memory management of <code>decodedList</code> clear. It is considered best practice to assign instance variables using an accessor method (except in init methods). In your current implementation, if you ever invoke <code>readVenueArchiveFile:</code> a second time on the same object, you <strong>will</strong> leak (as you will if <code>decodedList</code> already has a value). Moreover, you can put the copy logic in your accessor method and forget about it rather than having to remember mutableCopy every time you assign a new value (assuming there's a good reason to make a mutable copy anyway?).</p>\n"
},
{
"answer_id": 169742,
"author": "titaniumdecoy",
"author_id": 18091,
"author_profile": "https://Stackoverflow.com/users/18091",
"pm_score": 0,
"selected": false,
"text": "<p>Your code is correct; there is no memory leak.</p>\n\n<pre><code>theData = [NSData dataWithContentsOfFile:inFile];</code></pre>\n\n<p>is equivalent to </p>\n\n<pre><code>theData = [[[NSData alloc] initWithContentsOfFile:inFile] autorelease];</code></pre>\n\n<p>At this point theData has a reference count of 1 (if less, it would be deallocated). The reference count will be automatically decremented at some point in the future by the autorelease pool.</p>\n\n<pre><code>decoder = [[NSKeyedUnarchiver alloc] initForReadingWithData:theData];</code></pre>\n\n<p>The decoder object keeps a reference to theData which increments its reference count to 2.</p>\n\n<p>After the method returns, the autorelease pool decrements this value to 1. If you release theData at the end of this method, the reference count will become 0, the object will be deallocated, and your app will crash when you try to use it.</p>\n"
},
{
"answer_id": 174835,
"author": "mmalc",
"author_id": 23233,
"author_profile": "https://Stackoverflow.com/users/23233",
"pm_score": 2,
"selected": false,
"text": "<h2>Reducing peak memory footprint</h2>\n\n<p>In general, it is considered best practice to avoid generating autoreleased objects.</p>\n\n<p>[Most of this paragraph amended from <a href=\"https://stackoverflow.com/questions/106627/memory-management-in-objective-c#146720\">this question</a>.] Since you typically(1) don't have direct control over their lifetime, autoreleased objects can persist for a comparatively long time and unnecessarily increase the memory footprint of your application. Whilst on the desktop this <em>may</em> be of little consequence, on more constrained platforms this can be a significant issue. On all platforms, therefore, and especially on more constrained platforms, where possible you are strongly discouraged from using methods that would lead to autoreleased objects and instead encouraged to use the alloc/init pattern.</p>\n\n<p>I would suggest replacing this:</p>\n\n<pre><code>theData = [NSData dataWithContentsOfFile:inFile];\n</code></pre>\n\n<p>with:</p>\n\n<pre><code>theData = [[NSData alloc] initWithContentsOfFile:inFile];\n</code></pre>\n\n<p>then at the end of the method add:</p>\n\n<pre><code>[theData release];\n</code></pre>\n\n<p>This means that <code>theData</code> will be deallocated before the method exits.\nYou should end up with:</p>\n\n<pre><code>- (void)readVenueArchiveFile:(NSString *)inFile key:(NSString *)inKey\n{\n NSMutableData *theData;\n NSKeyedUnarchiver *decoder;\n\n theData = [[NSData alloc] initWithContentsOfFile:inFile];\n decoder = [[NSKeyedUnarchiver alloc] initForReadingWithData:theData];\n ListClassName *decodedList = [decoder decodeObjectForKey:inKey];\n self.venueIOList = decodedList;\n [decoder finishDecoding];\n [decoder release];\n [theData release];\n</code></pre>\n\n<p>}</p>\n\n<p>This makes the memory management semantics clear, and reclaims memory as quickly as possible.</p>\n\n<p>(1) You can take control by using your own local autorelease pools. For more on this, see <a href=\"http://developer.apple.com/documentation/Cocoa/Conceptual/MemoryMgmt/Concepts/AutoreleasePools.html#//apple_ref/doc/uid/20000047\" rel=\"nofollow noreferrer\">Apple's Memory Management Programming Guide</a>.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169034",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25004/"
] |
Every time I call this method my NSMutableData is leaking and I cannot figure out how to plug it. theData's retain count is upped by one after the decoder is allocated and initialized and I have no idea why. I am stuck with a retain count of 2 at the end of the method and attempting to release it causes an app crash.
```
- (void)readVenueArchiveFile:(NSString *)inFile key:(NSString *)inKey
{
NSMutableData *theData;
NSKeyedUnarchiver *decoder;
theData = [NSData dataWithContentsOfFile:inFile];
decoder = [[NSKeyedUnarchiver alloc] initForReadingWithData:theData];
venueIOList = [[decoder decodeObjectForKey:inKey] mutableCopy];
[decoder finishDecoding];
[decoder release];
}
```
|
I would suggest replacing this line:
```
venueIOList = [[decoder decodeObjectForKey:inKey] mutableCopy];
```
with:
```
ListClassName *decodedList = [decoder decodeObjectForKey:inKey];
self.venueIOList = decodedList;
```
This makes the memory management of `decodedList` clear. It is considered best practice to assign instance variables using an accessor method (except in init methods). In your current implementation, if you ever invoke `readVenueArchiveFile:` a second time on the same object, you **will** leak (as you will if `decodedList` already has a value). Moreover, you can put the copy logic in your accessor method and forget about it rather than having to remember mutableCopy every time you assign a new value (assuming there's a good reason to make a mutable copy anyway?).
|
169,070 |
<p>How do I write a decorator that restores the current working directory to what it was before the decorated function was called? In other words, if I use the decorator on a function that does an <code>os.chdir()</code>, the cwd will not be changed after the function is called.</p>
|
[
{
"answer_id": 169079,
"author": "Daryl Spitzer",
"author_id": 4766,
"author_profile": "https://Stackoverflow.com/users/4766",
"pm_score": 2,
"selected": false,
"text": "<pre><code>def preserve_cwd(function):\n def decorator(*args, **kwargs):\n cwd = os.getcwd()\n result = function(*args, **kwargs)\n os.chdir(cwd)\n return result\n return decorator\n</code></pre>\n\n<p>Here's how it's used:</p>\n\n<pre><code>@preserve_cwd\ndef test():\n print 'was:',os.getcwd()\n os.chdir('/')\n print 'now:',os.getcwd()\n\n>>> print os.getcwd()\n/Users/dspitzer\n>>> test()\nwas: /Users/dspitzer\nnow: /\n>>> print os.getcwd()\n/Users/dspitzer\n</code></pre>\n"
},
{
"answer_id": 169112,
"author": "tzot",
"author_id": 6899,
"author_profile": "https://Stackoverflow.com/users/6899",
"pm_score": 6,
"selected": false,
"text": "<p>The answer for a decorator has been given; it works at the function definition stage as requested.</p>\n\n<p>With Python 2.5+, you also have an option to do that at the function <em>call</em> stage using a context manager:</p>\n\n<pre><code>from __future__ import with_statement # needed for 2.5 ≤ Python < 2.6\nimport contextlib, os\n\[email protected]\ndef remember_cwd():\n curdir= os.getcwd()\n try: yield\n finally: os.chdir(curdir)\n</code></pre>\n\n<p>which can be used if needed at the function call time as:</p>\n\n<pre><code>print \"getcwd before:\", os.getcwd()\nwith remember_cwd():\n walk_around_the_filesystem()\nprint \"getcwd after:\", os.getcwd()\n</code></pre>\n\n<p>It's a nice option to have.</p>\n\n<p>EDIT: I added error handling as suggested by codeape. Since my answer has been voted up, it's fair to offer a complete answer, all other issues aside.</p>\n"
},
{
"answer_id": 170174,
"author": "codeape",
"author_id": 3571,
"author_profile": "https://Stackoverflow.com/users/3571",
"pm_score": 5,
"selected": false,
"text": "<p>The given answers fail to take into account that the wrapped function may raise an exception. In that case, the directory will never be restored. The code below adds exception handling to the previous answers.</p>\n\n<p>as a decorator:</p>\n\n<pre><code>def preserve_cwd(function):\n @functools.wraps(function)\n def decorator(*args, **kwargs):\n cwd = os.getcwd()\n try:\n return function(*args, **kwargs)\n finally:\n os.chdir(cwd)\n return decorator\n</code></pre>\n\n<p>and as a context manager:</p>\n\n<pre><code>@contextlib.contextmanager\ndef remember_cwd():\n curdir = os.getcwd()\n try:\n yield\n finally:\n os.chdir(curdir)\n</code></pre>\n"
},
{
"answer_id": 14019583,
"author": "CharlesB",
"author_id": 11343,
"author_profile": "https://Stackoverflow.com/users/11343",
"pm_score": 6,
"selected": true,
"text": "<p>The <a href=\"https://github.com/jaraco/path.py\" rel=\"noreferrer\">path.py</a> module (which you really should use if dealing with paths in python scripts) has a context manager:</p>\n\n<pre><code>subdir = d / 'subdir' #subdir is a path object, in the path.py module\nwith subdir:\n # here current dir is subdir\n\n#not anymore\n</code></pre>\n\n<p>(credits goes to <a href=\"http://ralsina.me/weblog/posts/BB963.html\" rel=\"noreferrer\">this blog post</a> from Roberto Alsina)</p>\n"
},
{
"answer_id": 72163496,
"author": "Machinexa",
"author_id": 11332999,
"author_profile": "https://Stackoverflow.com/users/11332999",
"pm_score": 3,
"selected": false,
"text": "<p>You dont need to write it for you. With python 3.11, the developers have written it for you. Checkout their code at github.com/python/cpython. Its in module contextlib.</p>\n<pre class=\"lang-py prettyprint-override\"><code>import contextlib\nwith contextlib.chdir('/path/to/cwd/to'):\n pass\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169070",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4766/"
] |
How do I write a decorator that restores the current working directory to what it was before the decorated function was called? In other words, if I use the decorator on a function that does an `os.chdir()`, the cwd will not be changed after the function is called.
|
The [path.py](https://github.com/jaraco/path.py) module (which you really should use if dealing with paths in python scripts) has a context manager:
```
subdir = d / 'subdir' #subdir is a path object, in the path.py module
with subdir:
# here current dir is subdir
#not anymore
```
(credits goes to [this blog post](http://ralsina.me/weblog/posts/BB963.html) from Roberto Alsina)
|
169,080 |
<p>I'd like to be able to toggle easily between two values for "maximum number of parallel project builds" in Visual Studio 2008 (in Tools->Options->Projects and Solutions->Build and Run). (When I'm planning on doing concurrent work I'd like to reduce it from 4 to 3.) I'm not too well versed in writing macros for the IDE. When I try recording a macro, and perform all the actions (open the dialog, change the setting, click OK), the only thing that gets recorded is this:</p>
<pre><code>DTE.ExecuteCommand ("Tools.Options")
</code></pre>
<p>Is my goal unattainable?</p>
|
[
{
"answer_id": 169093,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 3,
"selected": true,
"text": "<p>It appears to be impossible, according to the MSDN page for <em><a href=\"http://msdn.microsoft.com/en-us/library/ms165642.aspx\" rel=\"nofollow noreferrer\">Determining Names of Property Items in Tools Options Pages </a></em></p>\n\n<p>If it <em>was</em> possible, it would have been something like this:</p>\n\n<pre><code>Dim p = DTE.Properties(\"ProjectsAndSolutions\",\"BuildAndRun\")\np.Item(\"MaxNumParallelBuilds\")\n</code></pre>\n"
},
{
"answer_id": 6443508,
"author": "Coder_Dan",
"author_id": 449295,
"author_profile": "https://Stackoverflow.com/users/449295",
"pm_score": 1,
"selected": false,
"text": "<p>This appears to now be possible in VS2010. I'm no VB programmer, but here's what I got to work:</p>\n\n<pre><code>Sub EditConcurrentBuilds()\n Dim p As EnvDTE.Properties = DTE.Properties(\"Environment\", \"ProjectsAndSolution\")\n Dim item As EnvDTE.Property = p.Item(\"ConcurrentBuilds\")\n Dim text As String = InputBox(\"Enter number of concurrent builds\", \"Concurrent Build Option\")\n Dim v As Integer = Val(text)\n\n If (v > 0 And v < 5) Then\n item.Value = text\n End If\nEnd Sub\n</code></pre>\n\n<p>In this case, 4 is the most processors I've got on my machine.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169080",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4790/"
] |
I'd like to be able to toggle easily between two values for "maximum number of parallel project builds" in Visual Studio 2008 (in Tools->Options->Projects and Solutions->Build and Run). (When I'm planning on doing concurrent work I'd like to reduce it from 4 to 3.) I'm not too well versed in writing macros for the IDE. When I try recording a macro, and perform all the actions (open the dialog, change the setting, click OK), the only thing that gets recorded is this:
```
DTE.ExecuteCommand ("Tools.Options")
```
Is my goal unattainable?
|
It appears to be impossible, according to the MSDN page for *[Determining Names of Property Items in Tools Options Pages](http://msdn.microsoft.com/en-us/library/ms165642.aspx)*
If it *was* possible, it would have been something like this:
```
Dim p = DTE.Properties("ProjectsAndSolutions","BuildAndRun")
p.Item("MaxNumParallelBuilds")
```
|
169,116 |
<p>I have a type (System.Type) of an enum and a string containing enumeration value to set.</p>
<p>E.g. given: </p>
<pre><code>enum MyEnum { A, B, C };
</code></pre>
<p>I have typeof(MyEnum) and "B".</p>
<p>How do I create MyEnum object set to MyEnum.B?</p>
|
[
{
"answer_id": 169120,
"author": "Yuval",
"author_id": 23202,
"author_profile": "https://Stackoverflow.com/users/23202",
"pm_score": 4,
"selected": false,
"text": "<pre><code>MyEnum enumValue = (MyEnum)Enum.Parse(typeof(MyEnum), \"B\");\n</code></pre>\n\n<p>You also have a case-insensitive overload.</p>\n"
},
{
"answer_id": 169181,
"author": "Pavel Chuchuva",
"author_id": 14131,
"author_profile": "https://Stackoverflow.com/users/14131",
"pm_score": 2,
"selected": false,
"text": "<p>I assume you don't have access to MyEnum, only to typeof(MyEnum):</p>\n\n<pre><code>void foo(Type t)\n{\n Object o = Enum.Parse(t, \"B\");\n}\n</code></pre>\n"
},
{
"answer_id": 13733479,
"author": "Brad Patton",
"author_id": 27989,
"author_profile": "https://Stackoverflow.com/users/27989",
"pm_score": 1,
"selected": false,
"text": "<p>You can do this with generics. I created a Utility class to wrap this:</p>\n\n<pre><code>public static class Utils {\n public static T ParseEnum<T>(string value) {\n return (T)Enum.Parse(typeof(T), value, true);\n }\n</code></pre>\n\n<p>Then invoked like:</p>\n\n<pre><code>string s = \"B\";\nMyEnum enumValue = Utils.ParseEnum<MyEnum>(s);\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169116",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I have a type (System.Type) of an enum and a string containing enumeration value to set.
E.g. given:
```
enum MyEnum { A, B, C };
```
I have typeof(MyEnum) and "B".
How do I create MyEnum object set to MyEnum.B?
|
```
MyEnum enumValue = (MyEnum)Enum.Parse(typeof(MyEnum), "B");
```
You also have a case-insensitive overload.
|
169,146 |
<p>I'm getting an unexpected T_CONCAT_EQUAL error on a line of the following form:</p>
<pre><code>$arg1 .= "arg2".$arg3."arg4";
</code></pre>
<p>I'm using PHP5. I could simply go an do the following:</p>
<pre><code>$arg1 = $arg1."arg2".$arg3."arg4";
</code></pre>
<p>but I'd like to know whats going wrong in the first place. Any ideas?</p>
<p>Thanks,
sweeney</p>
|
[
{
"answer_id": 169159,
"author": "Paige Ruten",
"author_id": 813,
"author_profile": "https://Stackoverflow.com/users/813",
"pm_score": 4,
"selected": true,
"text": "<p>This would happen when $arg1 is undefined (doesn't have a value, was never set.)</p>\n"
},
{
"answer_id": 169162,
"author": "Peter Bailey",
"author_id": 8815,
"author_profile": "https://Stackoverflow.com/users/8815",
"pm_score": 0,
"selected": false,
"text": "<p>sounds like you forgot a semicolon on the line above this one.</p>\n"
},
{
"answer_id": 169187,
"author": "Brian Sweeney",
"author_id": 2170994,
"author_profile": "https://Stackoverflow.com/users/2170994",
"pm_score": 1,
"selected": false,
"text": "<p>So the most accurate reason is that the above posted line of code:</p>\n\n<pre><code>$arg1 .= \"arg2\".$arg3.\"arg4\";\n</code></pre>\n\n<p>was actually as follows in my source:</p>\n\n<pre><code>arg1 .= \"arg2\".$arg3.\"arg4\";\n</code></pre>\n\n<p>The $ was missing from arg1. I dont know why the interpreter did not catch that first, but whatever. Thanks for the input Jeremy and Bailey - it lead me right to the problem.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169146",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2170994/"
] |
I'm getting an unexpected T\_CONCAT\_EQUAL error on a line of the following form:
```
$arg1 .= "arg2".$arg3."arg4";
```
I'm using PHP5. I could simply go an do the following:
```
$arg1 = $arg1."arg2".$arg3."arg4";
```
but I'd like to know whats going wrong in the first place. Any ideas?
Thanks,
sweeney
|
This would happen when $arg1 is undefined (doesn't have a value, was never set.)
|
169,155 |
<p>I am using SetCursor to set the system cursor to my own image. The code looks something like this:</p>
<pre><code>// member on some class
HCURSOR _cursor;
// at init time
_cursor = LoadCursorFromFile("somefilename.cur");
// in some function
SetCursor(_cursor);
</code></pre>
<p>When I do this the cursor does change, but on the first mouse move message it changes back to the default system arrow cursor. This is the only code in the project that is setting the cursor. What do I need to do to make the cursor stay the way I set it?</p>
|
[
{
"answer_id": 169183,
"author": "Mark Ransom",
"author_id": 5987,
"author_profile": "https://Stackoverflow.com/users/5987",
"pm_score": 3,
"selected": false,
"text": "<p>You need to respond to the Windows message <a href=\"http://msdn.microsoft.com/en-us/library/ms648382(VS.85).aspx\" rel=\"noreferrer\">WM_SETCURSOR</a>.</p>\n"
},
{
"answer_id": 169185,
"author": "LarryF",
"author_id": 18518,
"author_profile": "https://Stackoverflow.com/users/18518",
"pm_score": 2,
"selected": false,
"text": "<p>You need to make your HCURSOR handle not go out of scope. When the mouse moves, windows messages start flying all over the place, and it will wipe out your handle (in the example above).</p>\n\n<p>Make an HCURSOR a private member of the class, and use that handle when you call LoadCursor...() and SetCursor(). When you are done, do not forget to free it, and clean it up, or you will end up with a resource leak.</p>\n"
},
{
"answer_id": 169280,
"author": "Joe Ludwig",
"author_id": 1031,
"author_profile": "https://Stackoverflow.com/users/1031",
"pm_score": 4,
"selected": true,
"text": "<p>It seems that I have two options. The first is the one that Mark Ransom suggested here, which is to respond to the windows <code>WM_SETCURSOR</code> message and call SetCursor at that time based on where the mouse is. Normally windows will only send you <code>WM_SETCURSOR</code> when the cursor is over your window, so you would only set the cursor in your window.</p>\n\n<p>The other option is to set the default cursor for the window handle at the same time as I call <code>SetCursor</code>. This changes the cursor set by the default handler to <code>WM_SETCURSOR</code>. That code would look something like this:</p>\n\n<pre><code>// defined somewhere\nHWND windowHandle;\nHCURSOR cursor;\n\nSetCursor(cursor);\nSetClassLong(windowHandle, GCL_HCURSOR, (DWORD)cursor);\n</code></pre>\n\n<p>If you use the second method you have to call both <code>SetCursor</code> and <code>SetClassLong</code> or your cursor will not update until the next mouse move.</p>\n"
},
{
"answer_id": 1592563,
"author": "Heinz Traub",
"author_id": 192841,
"author_profile": "https://Stackoverflow.com/users/192841",
"pm_score": 1,
"selected": false,
"text": "<p>This behavior is intended to be this way. I think the most simple solution is: When creating your window class (<code>RegisterClass || RegisterClassEx</code>), set the <code>WNDCLASS.hCursor || WNDCLASSEX.hCursor</code> member to <code>NULL</code>.</p>\n"
},
{
"answer_id": 40096492,
"author": "sergiol",
"author_id": 383779,
"author_profile": "https://Stackoverflow.com/users/383779",
"pm_score": 0,
"selected": false,
"text": "<p>As @Heinz Traub said the problem comes from the cursor defined on the <code>RegisterClass</code> or <code>RegisterClassEx</code> call. You probably have code like:</p>\n\n<pre><code>BOOL CMyWnd::RegisterWindowClass()\n{\n WNDCLASS wndcls;\n // HINSTANCE hInst = AfxGetInstanceHandle();\n HINSTANCE hInst = AfxGetResourceHandle();\n\n if (!(::GetClassInfo(hInst, _T(\"MyCtrl\"), &wndcls)))\n {\n // otherwise we need to register a new class\n wndcls.style = CS_DBLCLKS | CS_HREDRAW | CS_VREDRAW;\n wndcls.lpfnWndProc = ::DefWindowProc;\n wndcls.cbClsExtra = wndcls.cbWndExtra = 0;\n wndcls.hInstance = hInst;\n wndcls.hIcon = NULL;\n wndcls.hCursor = AfxGetApp()->LoadStandardCursor(IDC_ARROW);\n wndcls.hbrBackground = (HBRUSH) (COLOR_3DFACE + 1);\n wndcls.lpszMenuName = NULL;\n wndcls.lpszClassName = _T(\"MyCtrl\");\n\n if (!AfxRegisterClass(&wndcls))\n {\n AfxThrowResourceException();\n return FALSE;\n }\n }\n\n return TRUE;\n}\n</code></pre>\n\n<p>where the <code>wndcls.hCursor</code>says what cursor will be used when <code>WM_SETCURSOR</code> message is thrown; it happens every time it occurs a mouse move and not only.</p>\n\n<p>I solved a similar problem this way:</p>\n\n<p>In the class' message map add an entry for the <code>WM_SETCURSOR</code> message:</p>\n\n<pre><code>BEGIN_MESSAGE_MAP(CMyWnd, CWnd)\n //... other messages\n ON_WM_SETCURSOR()\nEND_MESSAGE_MAP()\n</code></pre>\n\n<p>Add the method <code>OnSetCursor</code>, which will override the parent class' implementation:</p>\n\n<pre><code>BOOL CMyWnd::OnSetCursor(CWnd* pWnd, UINT nHitTest, UINT message)\n{\n if (SomeCondition())\n return FALSE;\n\n return __super::OnSetCursor(pWnd, nHitTest, message);\n}\n</code></pre>\n\n<p>Explanation: when <code>SomeCondition()</code> is true, you will not call parent's implementation. May be you want always to have a cursor not superseded with parent class behavior, so you just need an even shorter method:</p>\n\n<pre><code>BOOL CMyWnd::OnSetCursor(CWnd* pWnd, UINT nHitTest, UINT message)\n{\n return FALSE;\n}\n</code></pre>\n\n<p>And the declaration of the method in the header file is:</p>\n\n<pre><code>afx_msg BOOL OnSetCursor(CWnd* pWnd, UINT nHitTest, UINT message);\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169155",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1031/"
] |
I am using SetCursor to set the system cursor to my own image. The code looks something like this:
```
// member on some class
HCURSOR _cursor;
// at init time
_cursor = LoadCursorFromFile("somefilename.cur");
// in some function
SetCursor(_cursor);
```
When I do this the cursor does change, but on the first mouse move message it changes back to the default system arrow cursor. This is the only code in the project that is setting the cursor. What do I need to do to make the cursor stay the way I set it?
|
It seems that I have two options. The first is the one that Mark Ransom suggested here, which is to respond to the windows `WM_SETCURSOR` message and call SetCursor at that time based on where the mouse is. Normally windows will only send you `WM_SETCURSOR` when the cursor is over your window, so you would only set the cursor in your window.
The other option is to set the default cursor for the window handle at the same time as I call `SetCursor`. This changes the cursor set by the default handler to `WM_SETCURSOR`. That code would look something like this:
```
// defined somewhere
HWND windowHandle;
HCURSOR cursor;
SetCursor(cursor);
SetClassLong(windowHandle, GCL_HCURSOR, (DWORD)cursor);
```
If you use the second method you have to call both `SetCursor` and `SetClassLong` or your cursor will not update until the next mouse move.
|
169,170 |
<p>I am looking for a way to do a keep alive check in .NET. The scenario is for both UDP and TCP.</p>
<p>Currently in TCP what I do is that one side connects and when there is no data to send it sends a keep alive every X seconds.</p>
<p>I want the other side to check for data, and if non was received in X seconds, to raise an event or so.</p>
<p>One way i tried to do was do a blocking receive and set the socket's RecieveTimeout to X seconds. But the problem was whenever the Timeout happened, the socket's Receive would throw an SocketExeception and the socket on this side would close, is this the correct behaviour ? why does the socket close/die after the timeout instead of just going on ?</p>
<p>A check if there is data and sleep isn't acceptable (since I might be lagging on receiving data while sleeping).</p>
<p>So what is the best way to go about this, and why is the method i described on the other side failing ?</p>
|
[
{
"answer_id": 169209,
"author": "TToni",
"author_id": 20703,
"author_profile": "https://Stackoverflow.com/users/20703",
"pm_score": 0,
"selected": false,
"text": "<p>Since you cannot use the blocking (synchronous) receive, you will have to settle for the asynchronous handling. Fortunately that's quite easy to do with .NET. Look for the description of BeginReceive() and EndReceive(). Or check out this <a href=\"http://www.codeguru.com/csharp/csharp/cs_network/sockets/article.php/c7695\" rel=\"nofollow noreferrer\">article</a> or <a href=\"http://msdn.microsoft.com/en-us/library/fx6588te.aspx\" rel=\"nofollow noreferrer\">this</a>.</p>\n\n<p>As for the timeout behaviour I found no conclusive description of this. Since it's not documented otherwise you have to assume that it's the intended behaviour.</p>\n"
},
{
"answer_id": 170296,
"author": "qbeuek",
"author_id": 5348,
"author_profile": "https://Stackoverflow.com/users/5348",
"pm_score": 1,
"selected": false,
"text": "<p>According to MSDN, a SocketException thrown when ReceiveTimeout is exceeded in Receive call <strong>will not</strong> close the socket. There is something else going on in your code.</p>\n\n<p>Check the caught SocketException details - maybe it's not a timeout after all. Maybe the other side of the connection shuts down the socket.</p>\n\n<p>Consider enabling network tracing to diagnose the exact source of your problems: look for \"Network Tracing\" on MSDN (can't provide you with a link, since right now MSDN is down).</p>\n"
},
{
"answer_id": 171344,
"author": "Greg Dean",
"author_id": 1200558,
"author_profile": "https://Stackoverflow.com/users/1200558",
"pm_score": 4,
"selected": false,
"text": "<p>If you literally mean \"KeepAlive\", try the following.</p>\n\n<pre><code> public static void SetTcpKeepAlive(Socket socket, uint keepaliveTime, uint keepaliveInterval)\n {\n /* the native structure\n struct tcp_keepalive {\n ULONG onoff;\n ULONG keepalivetime;\n ULONG keepaliveinterval;\n };\n */\n\n // marshal the equivalent of the native structure into a byte array\n uint dummy = 0;\n byte[] inOptionValues = new byte[Marshal.SizeOf(dummy) * 3];\n BitConverter.GetBytes((uint)(keepaliveTime)).CopyTo(inOptionValues, 0);\n BitConverter.GetBytes((uint)keepaliveTime).CopyTo(inOptionValues, Marshal.SizeOf(dummy));\n BitConverter.GetBytes((uint)keepaliveInterval).CopyTo(inOptionValues, Marshal.SizeOf(dummy) * 2);\n\n // write SIO_VALS to Socket IOControl\n socket.IOControl(IOControlCode.KeepAliveValues, inOptionValues, null);\n }\n</code></pre>\n\n<p>Note the time units are in milliseconds.</p>\n"
},
{
"answer_id": 69497010,
"author": "Guillermo Ruffino",
"author_id": 229052,
"author_profile": "https://Stackoverflow.com/users/229052",
"pm_score": 2,
"selected": false,
"text": "<p>In case you have a tcp server which just writes data at irregular intervals and you'd like to have keep alive running in background:</p>\n<pre><code>tcpClient.Client.SetSocketOption(SocketOptionLevel.Tcp, SocketOptionName.TcpKeepAliveInterval, 1);\ntcpClient.Client.SetSocketOption(SocketOptionLevel.Tcp, SocketOptionName.TcpKeepAliveTime, 2);\ntcpClient.Client.SetSocketOption(SocketOptionLevel.Tcp, SocketOptionName.TcpKeepAliveRetryCount, 2);\ntcpClient.Client.SetSocketOption(SocketOptionLevel.Socket, SocketOptionName.KeepAlive, true);\n</code></pre>\n<p>Will cause an async read to throw a timeout exception if the server doesn't (automatically usually) replies to tcp keep alives.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169170",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I am looking for a way to do a keep alive check in .NET. The scenario is for both UDP and TCP.
Currently in TCP what I do is that one side connects and when there is no data to send it sends a keep alive every X seconds.
I want the other side to check for data, and if non was received in X seconds, to raise an event or so.
One way i tried to do was do a blocking receive and set the socket's RecieveTimeout to X seconds. But the problem was whenever the Timeout happened, the socket's Receive would throw an SocketExeception and the socket on this side would close, is this the correct behaviour ? why does the socket close/die after the timeout instead of just going on ?
A check if there is data and sleep isn't acceptable (since I might be lagging on receiving data while sleeping).
So what is the best way to go about this, and why is the method i described on the other side failing ?
|
If you literally mean "KeepAlive", try the following.
```
public static void SetTcpKeepAlive(Socket socket, uint keepaliveTime, uint keepaliveInterval)
{
/* the native structure
struct tcp_keepalive {
ULONG onoff;
ULONG keepalivetime;
ULONG keepaliveinterval;
};
*/
// marshal the equivalent of the native structure into a byte array
uint dummy = 0;
byte[] inOptionValues = new byte[Marshal.SizeOf(dummy) * 3];
BitConverter.GetBytes((uint)(keepaliveTime)).CopyTo(inOptionValues, 0);
BitConverter.GetBytes((uint)keepaliveTime).CopyTo(inOptionValues, Marshal.SizeOf(dummy));
BitConverter.GetBytes((uint)keepaliveInterval).CopyTo(inOptionValues, Marshal.SizeOf(dummy) * 2);
// write SIO_VALS to Socket IOControl
socket.IOControl(IOControlCode.KeepAliveValues, inOptionValues, null);
}
```
Note the time units are in milliseconds.
|
169,186 |
<p>I am having a very hard time finding a standard pattern / best practice that deals with rendering child controls inside a composite based on a property value.</p>
<p>Here is a basic scenario. I have a Composite Control that has two child controls, a textbox and a dropdown. Lets say there is a property that toggles which child to render.</p>
<p>so:</p>
<pre><code>myComposite.ShowDropdown = true;
</code></pre>
<p>If true, it shows a dropdown, otherwise it shows the textbox.</p>
<p>The property value should be saved across postbacks, and the the correct control should be displayed based on the postback value. </p>
<p>Any good examples out there?</p>
|
[
{
"answer_id": 169205,
"author": "ckramer",
"author_id": 20504,
"author_profile": "https://Stackoverflow.com/users/20504",
"pm_score": 0,
"selected": false,
"text": "<p>I would think something like:</p>\n\n<pre><code>public bool ShowDropDown\n{\n get{ return (bool)ViewState[\"ShowDropDown\"]; }\n set{ ViewState[\"ShowDropDown\"]; }\n}\n\n\nprivate void Page_Load(object sender, EventArgs e)\n{\n DropDaownControl.Visible = ShowDropDown;\n TextBoxControl.Visible = !ShowDropDown;\n} \n/* some more code */\n</code></pre>\n"
},
{
"answer_id": 169353,
"author": "Pavel Chuchuva",
"author_id": 14131,
"author_profile": "https://Stackoverflow.com/users/14131",
"pm_score": 3,
"selected": true,
"text": "<p>You use ViewState to store property value so that it persists between postbacks but you have to do it <a href=\"http://weblogs.asp.net/infinitiesloop/archive/2006/08/03/truly-understanding-viewstate.aspx\" rel=\"nofollow noreferrer\" title=\"TRULY Understanding ViewState\">correctly</a>.</p>\n\n<pre><code>public virtual bool ShowDropdown\n{\n get\n {\n object o = ViewState[\"ShowDropdown\"];\n if (o != null)\n return (bool)o;\n return false; // Default value\n }\n set\n {\n bool oldValue = ShowDropdown;\n if (value != oldValue)\n {\n ViewState[\"ShowDropdown\"] = value;\n }\n }\n}\n</code></pre>\n\n<p>Probably somewhere in your Render method you show or hide DropDown control based on the property value:</p>\n\n<pre><code>dropDown.Visible = ShowDropDown;\ntextBox.Visible = !ShowDropDown;\n</code></pre>\n\n<p>See also <a href=\"http://msdn.microsoft.com/en-us/library/3257x3ea(VS.80).aspx\" rel=\"nofollow noreferrer\">Composite Web Control Example</a>.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169186",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25020/"
] |
I am having a very hard time finding a standard pattern / best practice that deals with rendering child controls inside a composite based on a property value.
Here is a basic scenario. I have a Composite Control that has two child controls, a textbox and a dropdown. Lets say there is a property that toggles which child to render.
so:
```
myComposite.ShowDropdown = true;
```
If true, it shows a dropdown, otherwise it shows the textbox.
The property value should be saved across postbacks, and the the correct control should be displayed based on the postback value.
Any good examples out there?
|
You use ViewState to store property value so that it persists between postbacks but you have to do it [correctly](http://weblogs.asp.net/infinitiesloop/archive/2006/08/03/truly-understanding-viewstate.aspx "TRULY Understanding ViewState").
```
public virtual bool ShowDropdown
{
get
{
object o = ViewState["ShowDropdown"];
if (o != null)
return (bool)o;
return false; // Default value
}
set
{
bool oldValue = ShowDropdown;
if (value != oldValue)
{
ViewState["ShowDropdown"] = value;
}
}
}
```
Probably somewhere in your Render method you show or hide DropDown control based on the property value:
```
dropDown.Visible = ShowDropDown;
textBox.Visible = !ShowDropDown;
```
See also [Composite Web Control Example](http://msdn.microsoft.com/en-us/library/3257x3ea(VS.80).aspx).
|
169,193 |
<p>There is a way to keep the scroll on bottom for a multi line textbox?</p>
<p>Something like in the vb6 </p>
<pre><code>txtfoo.selstart=len(txtfoo.text)
</code></pre>
<p>I'm trying with txtfoo.selectionstart=txtfoo.text.length without success.</p>
<p>Regards.</p>
|
[
{
"answer_id": 169210,
"author": "MazarD",
"author_id": 22672,
"author_profile": "https://Stackoverflow.com/users/22672",
"pm_score": 4,
"selected": true,
"text": "<p>Ok, I found that the solution was to use </p>\n\n<pre><code>txtfoo.AppendText \n</code></pre>\n\n<p>instead of </p>\n\n<pre><code> txtfoo.text+=\"something\"\n</code></pre>\n"
},
{
"answer_id": 169219,
"author": "Matthew Scharley",
"author_id": 15537,
"author_profile": "https://Stackoverflow.com/users/15537",
"pm_score": 2,
"selected": false,
"text": "<p>The other solution is to use:</p>\n\n<pre><code>txtfoo.Text += \"something\";\ntxtfoo.SelectionStart = txtfoo.Text.Length;\ntxtfoo.ScrollToCaret();\n</code></pre>\n"
},
{
"answer_id": 169264,
"author": "RodgerB",
"author_id": 20900,
"author_profile": "https://Stackoverflow.com/users/20900",
"pm_score": 0,
"selected": false,
"text": "<p>Interesting question. I'm guessing that you are trying to select the text via form load? I can't get it working on form load, but I can on form click. Wierd. :)</p>\n\n<pre><code>Public Class Form1\n\n Private Sub Form1_Click(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Click\n ScrollTextbox()\n End Sub\n\n Private Sub Form1_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load\n ScrollTextbox()\n End Sub\n\n Private Sub ScrollTextbox()\n TextBox1.SelectionStart = TextBox1.TextLength\n TextBox1.ScrollToCaret()\n End Sub\n\nEnd Class\n</code></pre>\n\n<p>If it is completely necessary, you could use a timer.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169193",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22672/"
] |
There is a way to keep the scroll on bottom for a multi line textbox?
Something like in the vb6
```
txtfoo.selstart=len(txtfoo.text)
```
I'm trying with txtfoo.selectionstart=txtfoo.text.length without success.
Regards.
|
Ok, I found that the solution was to use
```
txtfoo.AppendText
```
instead of
```
txtfoo.text+="something"
```
|
169,201 |
<p>In ActionScript 3.0, is there an automatic way to calculate the number of days, hours, minutes and seconds between two specified dates?</p>
<p>Basicly, what I need is the ActionScript equivalent of the .NET Timespan class.</p>
<p>Any idea?</p>
|
[
{
"answer_id": 169218,
"author": "Russell Myers",
"author_id": 18194,
"author_profile": "https://Stackoverflow.com/users/18194",
"pm_score": 4,
"selected": false,
"text": "<p>You can covert the two date times into milliseconds since the epoch, perform your math and then use the resultant milliseconds to calculate these higher timespan numbers.</p>\n\n<pre><code>var someDate:Date = new Date(...);\nvar anotherDate:Date = new Date(...);\nvar millisecondDifference:int = anotherDate.valueOf() - someDate.valueOf();\nvar seconds:int = millisecondDifference / 1000;\n....\n</code></pre>\n\n<p>The <a href=\"http://livedocs.adobe.com/flex/201/langref/Date.html\" rel=\"noreferrer\">LiveDocs</a> are useful for this type of thing too. Sorry if the ActionScript is a bit off, but it has been a while.</p>\n\n<p>I'd also recommend creating a set of static class methods that can perform these operations if you're doing a lot of this type of math. Sadly, this basic functionality doesn't really exist in the standard APIs.</p>\n"
},
{
"answer_id": 169229,
"author": "David Arno",
"author_id": 7122,
"author_profile": "https://Stackoverflow.com/users/7122",
"pm_score": 1,
"selected": false,
"text": "<p>There is no automatic way of doing this. The best you can achieve with the supplied classes is to fetch date1.time and date2.time, to give the number of milliseconds since 1st Jan 1970 for two numbers. You can then work out the number of milliseconds between them. With some basic maths, you can then derive the seconds, hours, days etc.</p>\n"
},
{
"answer_id": 454839,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>For the sake of accuracy the above post by Russell is correct until you get to 25 days difference, then the number becomes too large for the int variable. \nTherefore declare the millisecondDifference:Number;</p>\n\n<p>There may be some difference between the documented getTime() and valueOf(), but in effect I can't see it</p>\n"
},
{
"answer_id": 457213,
"author": "Richard Szalay",
"author_id": 3603,
"author_profile": "https://Stackoverflow.com/users/3603",
"pm_score": 5,
"selected": false,
"text": "<p>I created an ActionScript TimeSpan class with a similar API to System.TimeSpan to fill that void, but there are differences due to the lack of operator overloading. You can use it like so:</p>\n\n<pre><code>TimeSpan.fromDates(later, earlier).totalDays;\n</code></pre>\n\n<p>Below is the code for the class (sorry for the big post - I won't include the Unit Tests ;)</p>\n\n<pre><code>/**\n * Represents an interval of time \n */ \npublic class TimeSpan\n{\n private var _totalMilliseconds : Number;\n\n public function TimeSpan(milliseconds : Number)\n {\n _totalMilliseconds = Math.floor(milliseconds);\n }\n\n /**\n * Gets the number of whole days\n * \n * @example In a TimeSpan created from TimeSpan.fromHours(25), \n * totalHours will be 1.04, but hours will be 1 \n * @return A number representing the number of whole days in the TimeSpan\n */\n public function get days() : int\n {\n return int(_totalMilliseconds / MILLISECONDS_IN_DAY);\n }\n\n /**\n * Gets the number of whole hours (excluding entire days)\n * \n * @example In a TimeSpan created from TimeSpan.fromMinutes(1500), \n * totalHours will be 25, but hours will be 1 \n * @return A number representing the number of whole hours in the TimeSpan\n */\n public function get hours() : int\n {\n return int(_totalMilliseconds / MILLISECONDS_IN_HOUR) % 24;\n }\n\n /**\n * Gets the number of whole minutes (excluding entire hours)\n * \n * @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500), \n * totalSeconds will be 65.5, but seconds will be 5 \n * @return A number representing the number of whole minutes in the TimeSpan\n */\n public function get minutes() : int\n {\n return int(_totalMilliseconds / MILLISECONDS_IN_MINUTE) % 60; \n }\n\n /**\n * Gets the number of whole seconds (excluding entire minutes)\n * \n * @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500), \n * totalSeconds will be 65.5, but seconds will be 5 \n * @return A number representing the number of whole seconds in the TimeSpan\n */\n public function get seconds() : int\n {\n return int(_totalMilliseconds / MILLISECONDS_IN_SECOND) % 60;\n }\n\n /**\n * Gets the number of whole milliseconds (excluding entire seconds)\n * \n * @example In a TimeSpan created from TimeSpan.fromMilliseconds(2123), \n * totalMilliseconds will be 2001, but milliseconds will be 123 \n * @return A number representing the number of whole milliseconds in the TimeSpan\n */\n public function get milliseconds() : int\n {\n return int(_totalMilliseconds) % 1000;\n }\n\n /**\n * Gets the total number of days.\n * \n * @example In a TimeSpan created from TimeSpan.fromHours(25), \n * totalHours will be 1.04, but hours will be 1 \n * @return A number representing the total number of days in the TimeSpan\n */\n public function get totalDays() : Number\n {\n return _totalMilliseconds / MILLISECONDS_IN_DAY;\n }\n\n /**\n * Gets the total number of hours.\n * \n * @example In a TimeSpan created from TimeSpan.fromMinutes(1500), \n * totalHours will be 25, but hours will be 1 \n * @return A number representing the total number of hours in the TimeSpan\n */\n public function get totalHours() : Number\n {\n return _totalMilliseconds / MILLISECONDS_IN_HOUR;\n }\n\n /**\n * Gets the total number of minutes.\n * \n * @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500), \n * totalSeconds will be 65.5, but seconds will be 5 \n * @return A number representing the total number of minutes in the TimeSpan\n */\n public function get totalMinutes() : Number\n {\n return _totalMilliseconds / MILLISECONDS_IN_MINUTE;\n }\n\n /**\n * Gets the total number of seconds.\n * \n * @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500), \n * totalSeconds will be 65.5, but seconds will be 5 \n * @return A number representing the total number of seconds in the TimeSpan\n */\n public function get totalSeconds() : Number\n {\n return _totalMilliseconds / MILLISECONDS_IN_SECOND;\n }\n\n /**\n * Gets the total number of milliseconds.\n * \n * @example In a TimeSpan created from TimeSpan.fromMilliseconds(2123), \n * totalMilliseconds will be 2001, but milliseconds will be 123 \n * @return A number representing the total number of milliseconds in the TimeSpan\n */\n public function get totalMilliseconds() : Number\n {\n return _totalMilliseconds;\n }\n\n /**\n * Adds the timespan represented by this instance to the date provided and returns a new date object.\n * @param date The date to add the timespan to\n * @return A new Date with the offseted time\n */ \n public function add(date : Date) : Date\n {\n var ret : Date = new Date(date.time);\n ret.milliseconds += totalMilliseconds;\n\n return ret;\n }\n\n /**\n * Creates a TimeSpan from the different between two dates\n * \n * Note that start can be after end, but it will result in negative values. \n * \n * @param start The start date of the timespan\n * @param end The end date of the timespan\n * @return A TimeSpan that represents the difference between the dates\n * \n */ \n public static function fromDates(start : Date, end : Date) : TimeSpan\n {\n return new TimeSpan(end.time - start.time);\n }\n\n /**\n * Creates a TimeSpan from the specified number of milliseconds\n * @param milliseconds The number of milliseconds in the timespan\n * @return A TimeSpan that represents the specified value\n */ \n public static function fromMilliseconds(milliseconds : Number) : TimeSpan\n {\n return new TimeSpan(milliseconds);\n }\n\n /**\n * Creates a TimeSpan from the specified number of seconds\n * @param seconds The number of seconds in the timespan\n * @return A TimeSpan that represents the specified value\n */ \n public static function fromSeconds(seconds : Number) : TimeSpan\n {\n return new TimeSpan(seconds * MILLISECONDS_IN_SECOND);\n }\n\n /**\n * Creates a TimeSpan from the specified number of minutes\n * @param minutes The number of minutes in the timespan\n * @return A TimeSpan that represents the specified value\n */ \n public static function fromMinutes(minutes : Number) : TimeSpan\n {\n return new TimeSpan(minutes * MILLISECONDS_IN_MINUTE);\n }\n\n /**\n * Creates a TimeSpan from the specified number of hours\n * @param hours The number of hours in the timespan\n * @return A TimeSpan that represents the specified value\n */ \n public static function fromHours(hours : Number) : TimeSpan\n {\n return new TimeSpan(hours * MILLISECONDS_IN_HOUR);\n }\n\n /**\n * Creates a TimeSpan from the specified number of days\n * @param days The number of days in the timespan\n * @return A TimeSpan that represents the specified value\n */ \n public static function fromDays(days : Number) : TimeSpan\n {\n return new TimeSpan(days * MILLISECONDS_IN_DAY);\n }\n\n /**\n * The number of milliseconds in one day\n */ \n public static const MILLISECONDS_IN_DAY : Number = 86400000;\n\n /**\n * The number of milliseconds in one hour\n */ \n public static const MILLISECONDS_IN_HOUR : Number = 3600000;\n\n /**\n * The number of milliseconds in one minute\n */ \n public static const MILLISECONDS_IN_MINUTE : Number = 60000;\n\n /**\n * The number of milliseconds in one second\n */ \n public static const MILLISECONDS_IN_SECOND : Number = 1000;\n}\n</code></pre>\n"
},
{
"answer_id": 738590,
"author": "James Hay",
"author_id": 47339,
"author_profile": "https://Stackoverflow.com/users/47339",
"pm_score": 0,
"selected": false,
"text": "<p>ArgumentValidation is another class of Mr Szalays that does some checks to make sure each method has the right values to perform it's tasks without throwing unrecognisable errors. They are non-essential to get the TimeSpan class working so you could just comment them out and the class will work correctly.</p>\n\n<p>Rich may post the Argument validation class on here as well as it's very handy but i'll leave that down to him ;P</p>\n"
},
{
"answer_id": 6990505,
"author": "kam",
"author_id": 885083,
"author_profile": "https://Stackoverflow.com/users/885083",
"pm_score": 2,
"selected": false,
"text": "<p>for some a single function like this my be preferable...\n[condensed from Richard Szalay's code] </p>\n\n<pre><code>public function timeDifference(startTime:Date, endTime:Date) : String\n{\nif (startTime == null) { return \"startTime empty.\"; }\nif (endTime == null) { return \"endTime empty.\"; }\nvar aTms = Math.floor(endTime.valueOf() - startTime.valueOf());\nreturn \"Time taken: \" \n + String( int(aTms/(24*60*+60*1000)) ) + \" days, \"\n + String( int(aTms/( 60*60*1000)) %24 ) + \" hours, \"\n + String( int(aTms/( 60*1000)) %60 ) + \" minutes, \"\n + String( int(aTms/( 1*1000)) %60 ) + \" seconds.\";\n}\n</code></pre>\n"
},
{
"answer_id": 10957282,
"author": "kumling",
"author_id": 1256559,
"author_profile": "https://Stackoverflow.com/users/1256559",
"pm_score": 1,
"selected": false,
"text": "<pre><code>var timeDiff:Number = endDate - startDate;\nvar days:Number = timeDiff / (24*60*60*1000);\nvar rem:Number = int(timeDiff % (24*60*60*1000));\nvar hours:Number = int(rem / (60*60*1000));\nrem = int(rem % (60*60*1000));\nvar minutes:Number = int(rem / (60*1000));\nrem = int(rem % (60*1000));\nvar seconds:Number = int(rem / 1000);\n\ntrace(days + \" << >> \" +hours+ \" << >> \" +minutes+ \" << >> \" +seconds);\n</code></pre>\n\n<p>or</p>\n\n<pre><code>var time:Number = targetDate - currentDate;\nvar secs:Number = time/1000;\nvar mins:Number = secs/60; \nvar hrs:Number = mins/60;\nvar days:Number = int(hrs/24);\n\nsecs = int(secs % 60);\nmins = int(mins % 60);\nhrs = int(hrs % 24);\n\ntrace(secs + \" << >> \" + mins + \" << >> \" + hrs + \" << >> \" + days);\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169201",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1965/"
] |
In ActionScript 3.0, is there an automatic way to calculate the number of days, hours, minutes and seconds between two specified dates?
Basicly, what I need is the ActionScript equivalent of the .NET Timespan class.
Any idea?
|
I created an ActionScript TimeSpan class with a similar API to System.TimeSpan to fill that void, but there are differences due to the lack of operator overloading. You can use it like so:
```
TimeSpan.fromDates(later, earlier).totalDays;
```
Below is the code for the class (sorry for the big post - I won't include the Unit Tests ;)
```
/**
* Represents an interval of time
*/
public class TimeSpan
{
private var _totalMilliseconds : Number;
public function TimeSpan(milliseconds : Number)
{
_totalMilliseconds = Math.floor(milliseconds);
}
/**
* Gets the number of whole days
*
* @example In a TimeSpan created from TimeSpan.fromHours(25),
* totalHours will be 1.04, but hours will be 1
* @return A number representing the number of whole days in the TimeSpan
*/
public function get days() : int
{
return int(_totalMilliseconds / MILLISECONDS_IN_DAY);
}
/**
* Gets the number of whole hours (excluding entire days)
*
* @example In a TimeSpan created from TimeSpan.fromMinutes(1500),
* totalHours will be 25, but hours will be 1
* @return A number representing the number of whole hours in the TimeSpan
*/
public function get hours() : int
{
return int(_totalMilliseconds / MILLISECONDS_IN_HOUR) % 24;
}
/**
* Gets the number of whole minutes (excluding entire hours)
*
* @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500),
* totalSeconds will be 65.5, but seconds will be 5
* @return A number representing the number of whole minutes in the TimeSpan
*/
public function get minutes() : int
{
return int(_totalMilliseconds / MILLISECONDS_IN_MINUTE) % 60;
}
/**
* Gets the number of whole seconds (excluding entire minutes)
*
* @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500),
* totalSeconds will be 65.5, but seconds will be 5
* @return A number representing the number of whole seconds in the TimeSpan
*/
public function get seconds() : int
{
return int(_totalMilliseconds / MILLISECONDS_IN_SECOND) % 60;
}
/**
* Gets the number of whole milliseconds (excluding entire seconds)
*
* @example In a TimeSpan created from TimeSpan.fromMilliseconds(2123),
* totalMilliseconds will be 2001, but milliseconds will be 123
* @return A number representing the number of whole milliseconds in the TimeSpan
*/
public function get milliseconds() : int
{
return int(_totalMilliseconds) % 1000;
}
/**
* Gets the total number of days.
*
* @example In a TimeSpan created from TimeSpan.fromHours(25),
* totalHours will be 1.04, but hours will be 1
* @return A number representing the total number of days in the TimeSpan
*/
public function get totalDays() : Number
{
return _totalMilliseconds / MILLISECONDS_IN_DAY;
}
/**
* Gets the total number of hours.
*
* @example In a TimeSpan created from TimeSpan.fromMinutes(1500),
* totalHours will be 25, but hours will be 1
* @return A number representing the total number of hours in the TimeSpan
*/
public function get totalHours() : Number
{
return _totalMilliseconds / MILLISECONDS_IN_HOUR;
}
/**
* Gets the total number of minutes.
*
* @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500),
* totalSeconds will be 65.5, but seconds will be 5
* @return A number representing the total number of minutes in the TimeSpan
*/
public function get totalMinutes() : Number
{
return _totalMilliseconds / MILLISECONDS_IN_MINUTE;
}
/**
* Gets the total number of seconds.
*
* @example In a TimeSpan created from TimeSpan.fromMilliseconds(65500),
* totalSeconds will be 65.5, but seconds will be 5
* @return A number representing the total number of seconds in the TimeSpan
*/
public function get totalSeconds() : Number
{
return _totalMilliseconds / MILLISECONDS_IN_SECOND;
}
/**
* Gets the total number of milliseconds.
*
* @example In a TimeSpan created from TimeSpan.fromMilliseconds(2123),
* totalMilliseconds will be 2001, but milliseconds will be 123
* @return A number representing the total number of milliseconds in the TimeSpan
*/
public function get totalMilliseconds() : Number
{
return _totalMilliseconds;
}
/**
* Adds the timespan represented by this instance to the date provided and returns a new date object.
* @param date The date to add the timespan to
* @return A new Date with the offseted time
*/
public function add(date : Date) : Date
{
var ret : Date = new Date(date.time);
ret.milliseconds += totalMilliseconds;
return ret;
}
/**
* Creates a TimeSpan from the different between two dates
*
* Note that start can be after end, but it will result in negative values.
*
* @param start The start date of the timespan
* @param end The end date of the timespan
* @return A TimeSpan that represents the difference between the dates
*
*/
public static function fromDates(start : Date, end : Date) : TimeSpan
{
return new TimeSpan(end.time - start.time);
}
/**
* Creates a TimeSpan from the specified number of milliseconds
* @param milliseconds The number of milliseconds in the timespan
* @return A TimeSpan that represents the specified value
*/
public static function fromMilliseconds(milliseconds : Number) : TimeSpan
{
return new TimeSpan(milliseconds);
}
/**
* Creates a TimeSpan from the specified number of seconds
* @param seconds The number of seconds in the timespan
* @return A TimeSpan that represents the specified value
*/
public static function fromSeconds(seconds : Number) : TimeSpan
{
return new TimeSpan(seconds * MILLISECONDS_IN_SECOND);
}
/**
* Creates a TimeSpan from the specified number of minutes
* @param minutes The number of minutes in the timespan
* @return A TimeSpan that represents the specified value
*/
public static function fromMinutes(minutes : Number) : TimeSpan
{
return new TimeSpan(minutes * MILLISECONDS_IN_MINUTE);
}
/**
* Creates a TimeSpan from the specified number of hours
* @param hours The number of hours in the timespan
* @return A TimeSpan that represents the specified value
*/
public static function fromHours(hours : Number) : TimeSpan
{
return new TimeSpan(hours * MILLISECONDS_IN_HOUR);
}
/**
* Creates a TimeSpan from the specified number of days
* @param days The number of days in the timespan
* @return A TimeSpan that represents the specified value
*/
public static function fromDays(days : Number) : TimeSpan
{
return new TimeSpan(days * MILLISECONDS_IN_DAY);
}
/**
* The number of milliseconds in one day
*/
public static const MILLISECONDS_IN_DAY : Number = 86400000;
/**
* The number of milliseconds in one hour
*/
public static const MILLISECONDS_IN_HOUR : Number = 3600000;
/**
* The number of milliseconds in one minute
*/
public static const MILLISECONDS_IN_MINUTE : Number = 60000;
/**
* The number of milliseconds in one second
*/
public static const MILLISECONDS_IN_SECOND : Number = 1000;
}
```
|
169,216 |
<p>As kind of a follow up to <a href="https://stackoverflow.com/questions/111605/what-kind-of-prefix-do-you-use-for-member-variables">this question about prefixes</a>, I agree with most people on the thread that prefixes are bad. But what about if you are using getters and setters? Then you need to differeniate the publicly accessible getter name from the privately stored variable. I normally just use an underscore, but is there a better way?</p>
|
[
{
"answer_id": 169238,
"author": "Garry Shutler",
"author_id": 6369,
"author_profile": "https://Stackoverflow.com/users/6369",
"pm_score": 1,
"selected": false,
"text": "<p>In a case sensitive language I just use:</p>\n\n<pre><code>private int myValue;\n\npublic int MyValue\n{\n get { return myValue; }\n}\n</code></pre>\n\n<p>Otherwise I would use an underscore</p>\n\n<pre><code>Private _myValue As Integer\n\nPublic ReadOnly Property MyValue As Integer\n Get\n Return _myValue\n End Get\nEnd Property\n</code></pre>\n"
},
{
"answer_id": 169243,
"author": "Matthew Scharley",
"author_id": 15537,
"author_profile": "https://Stackoverflow.com/users/15537",
"pm_score": 1,
"selected": false,
"text": "<p>There are almost as many different ways of doing this as there are programmers doing this, but some of the more popular ways include (for a property <code>Foo</code>):</p>\n\n<ul>\n<li>mFoo</li>\n<li>m_foo</li>\n<li>_foo</li>\n<li>foo</li>\n</ul>\n"
},
{
"answer_id": 169245,
"author": "André",
"author_id": 9683,
"author_profile": "https://Stackoverflow.com/users/9683",
"pm_score": 2,
"selected": false,
"text": "<p>In java there is this.foo in python there is self.foo and other languages have similar things, so I don't see a need for naming something in a special way, when I can already use a language construct. In the same context good IDEs and editors understand member variables and give them a special highlight, so you can really see it w/o using special names.</p>\n"
},
{
"answer_id": 169246,
"author": "David Arno",
"author_id": 7122,
"author_profile": "https://Stackoverflow.com/users/7122",
"pm_score": 4,
"selected": true,
"text": "<p>This is a completely subjective question. There is no \"better\" way.</p>\n\n<p>One way is:</p>\n\n<pre><code>private int _x;\npublic get x():int { return _x; }\npublic set x(int val):void { _x = val; }\n</code></pre>\n\n<p>Another is:</p>\n\n<pre><code>private int x;\npublic get X():int { return x; }\npublic set X(int val):void { x = val; }\n</code></pre>\n\n<p>Neither is the right answer. Each has style advantages and disadvantages. Pick the one you like best and apply it consistently.</p>\n"
},
{
"answer_id": 169282,
"author": "Craig Walker",
"author_id": 3488,
"author_profile": "https://Stackoverflow.com/users/3488",
"pm_score": 3,
"selected": false,
"text": "<p>I like prefixing fields with an underscore, as others have mentioned. </p>\n\n<pre><code>private int _x;\n</code></pre>\n\n<p>I think this goes beyond straight personal preference though (as David Arno said in this thread). I think there's some real objective reasons for doing this:</p>\n\n<ol>\n<li>It means you avoid having to write \"this.x = x\" for assignments (especially in setters and constructors).</li>\n<li>It distinguishes your fields from your local variables/arguments. It's important to do this: fields are trickier to handle than locals, as their scope is wider / lifetime is longer. Adding in the extra character is a bit of a mental warning sign for coders.</li>\n<li>In some IDEs, the underscore will cause the auto-complete to sort the fields to the top of the suggestion list. This makes it easier to see all the fields for the class in one block. This in turn can be helpful; on big classes, you may not be able to see the fields (usually defined at the top of the class) on the same screen as the code you're working on. Sorting them to the top gives a handy reference.</li>\n</ol>\n\n<p>(These conventions are for Java, but similar ones exist for other languages)</p>\n\n<p>These things seems small but their prevalence definitely makes my life easier when I'm coding.</p>\n"
},
{
"answer_id": 169472,
"author": "Gary Kephart",
"author_id": 17967,
"author_profile": "https://Stackoverflow.com/users/17967",
"pm_score": 1,
"selected": false,
"text": "<p>I <em>like</em> writing \"this.x = x\". It's very clear to me. Plus, when using Eclipse, you can have it automatically generate your getters/setters this way.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169216",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11911/"
] |
As kind of a follow up to [this question about prefixes](https://stackoverflow.com/questions/111605/what-kind-of-prefix-do-you-use-for-member-variables), I agree with most people on the thread that prefixes are bad. But what about if you are using getters and setters? Then you need to differeniate the publicly accessible getter name from the privately stored variable. I normally just use an underscore, but is there a better way?
|
This is a completely subjective question. There is no "better" way.
One way is:
```
private int _x;
public get x():int { return _x; }
public set x(int val):void { _x = val; }
```
Another is:
```
private int x;
public get X():int { return x; }
public set X(int val):void { x = val; }
```
Neither is the right answer. Each has style advantages and disadvantages. Pick the one you like best and apply it consistently.
|
169,217 |
<p>In SQL Server you can use the <code>IsNull()</code> function to check if a value is null, and if it is, return another value. Now I am wondering if there is anything similar in C#.</p>
<p>For example, I want to do something like:</p>
<pre><code>myNewValue = IsNull(myValue, new MyValue());
</code></pre>
<p>instead of:</p>
<pre><code>if (myValue == null)
myValue = new MyValue();
myNewValue = myValue;
</code></pre>
<p>Thanks.</p>
|
[
{
"answer_id": 169226,
"author": "Kent Boogaart",
"author_id": 5380,
"author_profile": "https://Stackoverflow.com/users/5380",
"pm_score": 9,
"selected": true,
"text": "<p>It's called the null coalescing (<code>??</code>) operator:</p>\n\n<pre><code>myNewValue = myValue ?? new MyValue();\n</code></pre>\n"
},
{
"answer_id": 169415,
"author": "Robert Rossney",
"author_id": 19403,
"author_profile": "https://Stackoverflow.com/users/19403",
"pm_score": 4,
"selected": false,
"text": "<p>Sadly, there's no equivalent to the null coalescing operator that works with DBNull; for that, you need to use the ternary operator:</p>\n\n<pre><code>newValue = (oldValue is DBNull) ? null : oldValue;\n</code></pre>\n"
},
{
"answer_id": 169757,
"author": "Jonathan Allen",
"author_id": 5274,
"author_profile": "https://Stackoverflow.com/users/5274",
"pm_score": 1,
"selected": false,
"text": "<p>For working with DB Nulls, I created a bunch for my VB applications. I call them Cxxx2 as they are similar to VB's built-in Cxxx functions.</p>\n\n<p>You can see them in my CLR Extensions project</p>\n\n<p><a href=\"http://www.codeplex.com/ClrExtensions/SourceControl/FileView.aspx?itemId=363867&changeSetId=17967\" rel=\"nofollow noreferrer\">http://www.codeplex.com/ClrExtensions/SourceControl/FileView.aspx?itemId=363867&changeSetId=17967</a></p>\n"
},
{
"answer_id": 169782,
"author": "FlySwat",
"author_id": 1965,
"author_profile": "https://Stackoverflow.com/users/1965",
"pm_score": -1,
"selected": false,
"text": "<p>This is meant half as a joke, since the question is kinda silly.</p>\n\n<pre><code>public static bool IsNull (this System.Object o)\n{\n return (o == null);\n}\n</code></pre>\n\n<p>This is an extension method, however it extends System.Object, so every object you use now has an IsNull() method.</p>\n\n<p>Then you can save tons of code by doing:</p>\n\n<pre><code>if (foo.IsNull())\n</code></pre>\n\n<p>instead of the super lame:</p>\n\n<pre><code>if (foo == null)\n</code></pre>\n"
},
{
"answer_id": 8118670,
"author": "serializer",
"author_id": 256268,
"author_profile": "https://Stackoverflow.com/users/256268",
"pm_score": 2,
"selected": false,
"text": "<p>Use the Equals method:</p>\n\n<pre><code>object value2 = null;\nConsole.WriteLine(object.Equals(value2,null));\n</code></pre>\n"
},
{
"answer_id": 31188861,
"author": "Rudy",
"author_id": 5074534,
"author_profile": "https://Stackoverflow.com/users/5074534",
"pm_score": 3,
"selected": false,
"text": "<pre><code>public static T isNull<T>(this T v1, T defaultValue)\n{\n return v1 == null ? defaultValue : v1;\n}\n\nmyValue.isNull(new MyValue())\n</code></pre>\n"
},
{
"answer_id": 50535628,
"author": "Mansoor Bozorgmehr",
"author_id": 4145647,
"author_profile": "https://Stackoverflow.com/users/4145647",
"pm_score": 0,
"selected": false,
"text": "<p>You Write Two Function</p>\n\n<pre><code> //When Expression is Number\n public static double? isNull(double? Expression, double? Value)\n {\n if (Expression ==null)\n {\n return Value;\n }\n else\n {\n return Expression;\n }\n }\n\n\n //When Expression is string (Can not send Null value in string Expression\n public static string isEmpty(string Expression, string Value)\n {\n if (Expression == \"\")\n {\n return Value;\n }\n else\n {\n return Expression;\n }\n }\n</code></pre>\n\n<p>They Work Very Well</p>\n"
},
{
"answer_id": 53874663,
"author": "Denis M. Kitchen",
"author_id": 120638,
"author_profile": "https://Stackoverflow.com/users/120638",
"pm_score": 0,
"selected": false,
"text": "<p>I've been using the following extension method on my DataRow types:</p>\n\n<pre><code> public static string ColumnIsNull(this System.Data.DataRow row, string colName, string defaultValue = \"\")\n {\n string val = defaultValue;\n if (row.Table.Columns.Contains(colName))\n {\n if (row[colName] != DBNull.Value)\n {\n val = row[colName]?.ToString();\n }\n }\n return val;\n }\n</code></pre>\n\n<p>usage:</p>\n\n<pre><code>MyControl.Text = MyDataTable.Rows[0].ColumnIsNull(\"MyColumn\");\nMyOtherControl.Text = MyDataTable.Rows[0].ColumnIsNull(\"AnotherCol\", \"Doh! I'm null\");\n</code></pre>\n\n<p>I'm checking for the existence of the column first because if none of query results has a non-null value for that column, the DataTable object won't even provide that column.</p>\n"
},
{
"answer_id": 54180643,
"author": "sushil suthar",
"author_id": 4195533,
"author_profile": "https://Stackoverflow.com/users/4195533",
"pm_score": 0,
"selected": false,
"text": "<p>Use below methods.</p>\n\n<pre><code> /// <summary>\n /// Returns replacement value if expression is null\n /// </summary>\n /// <param name=\"expression\"></param>\n /// <param name=\"replacement\"></param>\n /// <returns></returns>\n public static long? IsNull(long? expression, long? replacement)\n {\n if (expression.HasValue)\n return expression;\n else\n return replacement;\n }\n\n /// <summary>\n /// Returns replacement value if expression is null\n /// </summary>\n /// <param name=\"expression\"></param>\n /// <param name=\"replacement\"></param>\n /// <returns></returns>\n public static string IsNull(string expression, string replacement)\n {\n if (string.IsNullOrWhiteSpace(expression))\n return replacement;\n else\n return expression;\n }\n</code></pre>\n"
},
{
"answer_id": 58693434,
"author": "Mansoor Bozorgmehr",
"author_id": 4145647,
"author_profile": "https://Stackoverflow.com/users/4145647",
"pm_score": 0,
"selected": false,
"text": "<pre><code> public static T IsNull<T>(this T DefaultValue, T InsteadValue)\n {\n\n object obj=\"kk\";\n\n if((object) DefaultValue == DBNull.Value)\n {\n obj = null;\n }\n\n if (obj==null || DefaultValue==null || DefaultValue.ToString()==\"\")\n {\n return InsteadValue;\n }\n else\n {\n return DefaultValue;\n }\n\n }\n\n//This method can work with DBNull and null value. This method is question's answer\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169217",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11989/"
] |
In SQL Server you can use the `IsNull()` function to check if a value is null, and if it is, return another value. Now I am wondering if there is anything similar in C#.
For example, I want to do something like:
```
myNewValue = IsNull(myValue, new MyValue());
```
instead of:
```
if (myValue == null)
myValue = new MyValue();
myNewValue = myValue;
```
Thanks.
|
It's called the null coalescing (`??`) operator:
```
myNewValue = myValue ?? new MyValue();
```
|
169,220 |
<p>I'm used to writing classes like this:</p>
<pre><code>public class foo {
private string mBar = "bar";
public string Bar {
get { return mBar; }
set { mBar = value; }
}
//... other methods, no constructor ...
}
</code></pre>
<p>Converting Bar to an auto-property seems convenient and concise, but how can I retain the initialization without adding a constructor and putting the initialization in there?</p>
<pre><code>public class foo2theRevengeOfFoo {
//private string mBar = "bar";
public string Bar { get; set; }
//... other methods, no constructor ...
//behavior has changed.
}
</code></pre>
<p>You could see that adding a constructor isn't inline with the effort savings I'm supposed to be getting from auto-properties.</p>
<p>Something like this would make more sense to me:</p>
<pre><code>public string Bar { get; set; } = "bar";
</code></pre>
|
[
{
"answer_id": 169232,
"author": "Matthew Scharley",
"author_id": 15537,
"author_profile": "https://Stackoverflow.com/users/15537",
"pm_score": 2,
"selected": false,
"text": "<p>In the default constructor (and any non-default ones if you have any too of course):</p>\n\n<pre><code>public foo() {\n Bar = \"bar\";\n}\n</code></pre>\n\n<p>This is no less performant that your original code I believe, since this is what happens behind the scenes anyway.</p>\n"
},
{
"answer_id": 169237,
"author": "Aaron Powell",
"author_id": 11388,
"author_profile": "https://Stackoverflow.com/users/11388",
"pm_score": 5,
"selected": false,
"text": "<p>You can do it via the constructor of your class:</p>\n\n<pre><code>public class foo {\n public foo(){\n Bar = \"bar\";\n }\n public string Bar {get;set;}\n}\n</code></pre>\n\n<p>If you've got another constructor (ie, one that takes paramters) or a bunch of constructors you can always have this (called constructor chaining):</p>\n\n<pre><code>public class foo {\n private foo(){\n Bar = \"bar\";\n Baz = \"baz\";\n }\n public foo(int something) : this(){\n //do specialized initialization here\n Baz = string.Format(\"{0}Baz\", something);\n }\n public string Bar {get; set;}\n public string Baz {get; set;}\n}\n</code></pre>\n\n<p>If you always chain a call to the default constructor you can have all default property initialization set there. When chaining, the chained constructor will be called before the calling constructor so that your more specialized constructors will be able to set different defaults as applicable.</p>\n"
},
{
"answer_id": 169872,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 9,
"selected": true,
"text": "<p>Update - the answer below was written before C# 6 came along. In C# 6 you can write:</p>\n<pre><code>public class Foo\n{\n public string Bar { get; set; } = "bar";\n}\n</code></pre>\n<p>You can <em>also</em> write read-only automatically-implemented properties, which are only writable in the constructor (but can also be given a default initial value):</p>\n<pre><code>public class Foo\n{\n public string Bar { get; }\n\n public Foo(string bar)\n {\n Bar = bar;\n }\n}\n</code></pre>\n<hr />\n<p>It's unfortunate that there's no way of doing this right now. You have to set the value in the constructor. (Using constructor chaining can help to avoid duplication.)</p>\n<p>Automatically implemented properties are handy right now, but could certainly be nicer. I don't find myself wanting this sort of initialization as often as a read-only automatically implemented property which could only be set in the constructor and would be backed by a read-only field.</p>\n<p>This hasn't happened up until and including C# 5, but is being planned for C# 6 - both in terms of allowing initialization at the point of declaration, <em>and</em> allowing for read-only automatically implemented properties to be initialized in a constructor body.</p>\n"
},
{
"answer_id": 25576131,
"author": "romanoza",
"author_id": 3901618,
"author_profile": "https://Stackoverflow.com/users/3901618",
"pm_score": 5,
"selected": false,
"text": "<p>This will be possible in C# 6.0:</p>\n\n<pre><code>public int Y { get; } = 2;\n</code></pre>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169220",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/459/"
] |
I'm used to writing classes like this:
```
public class foo {
private string mBar = "bar";
public string Bar {
get { return mBar; }
set { mBar = value; }
}
//... other methods, no constructor ...
}
```
Converting Bar to an auto-property seems convenient and concise, but how can I retain the initialization without adding a constructor and putting the initialization in there?
```
public class foo2theRevengeOfFoo {
//private string mBar = "bar";
public string Bar { get; set; }
//... other methods, no constructor ...
//behavior has changed.
}
```
You could see that adding a constructor isn't inline with the effort savings I'm supposed to be getting from auto-properties.
Something like this would make more sense to me:
```
public string Bar { get; set; } = "bar";
```
|
Update - the answer below was written before C# 6 came along. In C# 6 you can write:
```
public class Foo
{
public string Bar { get; set; } = "bar";
}
```
You can *also* write read-only automatically-implemented properties, which are only writable in the constructor (but can also be given a default initial value):
```
public class Foo
{
public string Bar { get; }
public Foo(string bar)
{
Bar = bar;
}
}
```
---
It's unfortunate that there's no way of doing this right now. You have to set the value in the constructor. (Using constructor chaining can help to avoid duplication.)
Automatically implemented properties are handy right now, but could certainly be nicer. I don't find myself wanting this sort of initialization as often as a read-only automatically implemented property which could only be set in the constructor and would be backed by a read-only field.
This hasn't happened up until and including C# 5, but is being planned for C# 6 - both in terms of allowing initialization at the point of declaration, *and* allowing for read-only automatically implemented properties to be initialized in a constructor body.
|
169,233 |
<p><a href="http://thedailywtf.com/Articles/The-Hot-Room.aspx" rel="noreferrer">http://thedailywtf.com/Articles/The-Hot-Room.aspx</a></p>
<p>You see how at the bottom there're links to the next and previous articles ("Unprepared For Divide_By_Zero" and "A Completely Different Game")? How do I do that, but selecting the next and previous non-private articles? This works for selecting the next article:</p>
<pre><code>SELECT * FROM articles WHERE id > ? AND private IS NULL
</code></pre>
<p>But I cannot find a way to select the previous article.</p>
<p>What is the proper/efficient way to do this, preferably in one query?</p>
|
[
{
"answer_id": 169270,
"author": "Paige Ruten",
"author_id": 813,
"author_profile": "https://Stackoverflow.com/users/813",
"pm_score": 3,
"selected": false,
"text": "<p>Here's how I would do it:</p>\n\n<pre><code>-- next\nSELECT * FROM articles WHERE id > ? AND private IS NULL ORDER BY id ASC LIMIT 1\n\n-- previous\nSELECT * FROM articles WHERE id < ? AND private IS NULL ORDER BY id DESC LIMIT 1\n</code></pre>\n\n<p>I'm not sure how to do it in one query. The only thing I can think of is possibly getting both the article you're displaying and the next article in one query, but that might be too confusing.</p>\n"
},
{
"answer_id": 169299,
"author": "mike",
"author_id": 19217,
"author_profile": "https://Stackoverflow.com/users/19217",
"pm_score": 4,
"selected": true,
"text": "<p>Or extending Jeremy's answer...<br />\nIn one query</p>\n\n<pre><code>(SELECT * FROM articles WHERE id > ? \n AND private IS NULL \n ORDER BY id ASC LIMIT 1) \nUNION \n(SELECT * FROM articles WHERE id < ? \n AND private IS NULL \n ORDER BY id DESC LIMIT 1)\n</code></pre>\n"
},
{
"answer_id": 169301,
"author": "Max Stewart",
"author_id": 18338,
"author_profile": "https://Stackoverflow.com/users/18338",
"pm_score": 2,
"selected": false,
"text": "<p>How about a nested select?</p>\n\n<pre><code>SELECT * FROM articles WHERE id IN (\n SELECT id FROM articles WHERE id > ? AND private IS NULL ORDER BY id ASC LIMIT 1)\n)\nOR id IN (\n SELECT id FROM articles WHERE id < ? AND private IS NULL ORDER BY id DESC LIMIT 1\n);\n</code></pre>\n"
},
{
"answer_id": 1970457,
"author": "mst",
"author_id": 239520,
"author_profile": "https://Stackoverflow.com/users/239520",
"pm_score": 2,
"selected": false,
"text": "<p>You can get away with subselects etc in your particular case, but if you need anything more complicated (for example: given an initial balance and a list of payments and chargebacks, calculate account balance at every point of time) you probably would want to write a stored procedure that uses SQL REPEAT/WHILE/LOOP clauses and allows use of variables and so on.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169233",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/23107/"
] |
<http://thedailywtf.com/Articles/The-Hot-Room.aspx>
You see how at the bottom there're links to the next and previous articles ("Unprepared For Divide\_By\_Zero" and "A Completely Different Game")? How do I do that, but selecting the next and previous non-private articles? This works for selecting the next article:
```
SELECT * FROM articles WHERE id > ? AND private IS NULL
```
But I cannot find a way to select the previous article.
What is the proper/efficient way to do this, preferably in one query?
|
Or extending Jeremy's answer...
In one query
```
(SELECT * FROM articles WHERE id > ?
AND private IS NULL
ORDER BY id ASC LIMIT 1)
UNION
(SELECT * FROM articles WHERE id < ?
AND private IS NULL
ORDER BY id DESC LIMIT 1)
```
|
169,240 |
<p>I have two databases with the same structure. The tables have an integer as a primary key as used in Rails.</p>
<p>If I have a patients table, I will have one patient using primary key 123 in one database and another patient using the same primary key in the other database.</p>
<p>What would you suggest for merging the data from both databases?</p>
|
[
{
"answer_id": 169606,
"author": "user6325",
"author_id": 6325,
"author_profile": "https://Stackoverflow.com/users/6325",
"pm_score": 3,
"selected": false,
"text": "<p>Set both your databases up with entries in config/database.yml, then generate a new migration.</p>\n\n<p>Use ActiveRecord::Base.establish_connection to switch between the two databases in the migration like this:</p>\n\n<pre><code>def self.up\n ActiveRecord::Base.establish_connection :development\n patients = Patient.find(:all)\n ActiveRecord::Base.establish_connection :production\n patients.each { |patient| Patient.create patient.attributes.except(\"id\") }\nend\n</code></pre>\n\n<p>YMMV depending on the number of records and the associations between models.</p>\n"
},
{
"answer_id": 169793,
"author": "user6325",
"author_id": 6325,
"author_profile": "https://Stackoverflow.com/users/6325",
"pm_score": 0,
"selected": false,
"text": "<p>BTW it probably makes more sense for this to be a rake or capistrano task rather than a migration.</p>\n"
},
{
"answer_id": 169865,
"author": "Daniel Beardsley",
"author_id": 13216,
"author_profile": "https://Stackoverflow.com/users/13216",
"pm_score": 3,
"selected": false,
"text": "<p>If your databases are exactly the same (the data doesn't require custom processing) and there aren't too many records, you could do this (which allows for foreign keys):</p>\n\n<p><strong>Untested...</strong> But you get the idea</p>\n\n<pre><code>#All models and their foreign keys\ntales = {Patients => [:doctor_id, :hospital_id],\n Doctors => [:hospital_id],\n Hospitals}\n\nActiveRecord::Base.establish_connection :development\n\nmax_id = tables.map do |model| \n model.maximum(:id)\nend.max + 1000\n\n\ntables.each do |model, fks| \n ActiveRecord::Base.establish_connection :development\n records = model.find(:all)\n\n ActiveRecord::Base.establish_connection :production\n records.each do |record|\n #update the foreign keys\n fks.each do |attr|\n record[attr] += max_id if not record[attr].nil?\n end\n record.id += max_id\n\n model.create record.attributes\n end\nend\n</code></pre>\n\n<p>If you have a LOT of records you might have to portion this out somehow... do it in groups of 10k or something.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169240",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14755/"
] |
I have two databases with the same structure. The tables have an integer as a primary key as used in Rails.
If I have a patients table, I will have one patient using primary key 123 in one database and another patient using the same primary key in the other database.
What would you suggest for merging the data from both databases?
|
Set both your databases up with entries in config/database.yml, then generate a new migration.
Use ActiveRecord::Base.establish\_connection to switch between the two databases in the migration like this:
```
def self.up
ActiveRecord::Base.establish_connection :development
patients = Patient.find(:all)
ActiveRecord::Base.establish_connection :production
patients.each { |patient| Patient.create patient.attributes.except("id") }
end
```
YMMV depending on the number of records and the associations between models.
|
169,274 |
<p>I'm making a simple scheduler with C# in .Net. All it does is execute a simple select statement on a table in a SQL Server DB once per minute (this does not need to scale or anything... the db does not have a high load). Here is my proposed implementation:</p>
<pre><code>static void Main(string[] args)
{
while (true)
{
System.Threading.Thread.Sleep(timeout); // timeout is, say, 60000
CheckTable();
}
}
</code></pre>
<p>Is this ok? What is a better way?</p>
<p>p.s. Someone suggested using the Windows Forms Timer class... however that seems like overkill.</p>
<p>Cheers!</p>
|
[
{
"answer_id": 169305,
"author": "Doug Trojan",
"author_id": 6982,
"author_profile": "https://Stackoverflow.com/users/6982",
"pm_score": 3,
"selected": true,
"text": "<p>While it is technically legal you are probably better of using a timer. They are not much more code to set up and you can let the runtime take care of spawning new threads. If you ever needed to use this again in another program it would also create a performance bottleneck where a timer would not.</p>\n\n<p>The timer will add more code though since you need to use a timer trigger event.</p>\n"
},
{
"answer_id": 169754,
"author": "Jonathan Allen",
"author_id": 5274,
"author_profile": "https://Stackoverflow.com/users/5274",
"pm_score": 1,
"selected": false,
"text": "<p>Close.</p>\n\n<ol>\n<li>This will run every (1 minute + time to call proc). Maybe that's OK, maybe it isn't. If it isn't OK you need to subtract the amount of time it took to ran.</li>\n<li>You should have a try-catch block around it. You don't want it to die entirely just because of a temporary database or network issue.</li>\n</ol>\n"
},
{
"answer_id": 573611,
"author": "Andy White",
"author_id": 60096,
"author_profile": "https://Stackoverflow.com/users/60096",
"pm_score": 1,
"selected": false,
"text": "<p><a href=\"http://quartznet.sourceforge.net/\" rel=\"nofollow noreferrer\">Quartz.net</a> is a good solution for timing needs. It's pretty easy to setup (good tutorial on the site), and gives you a lot more flexibility than Timers. The CronTrigger is really powerful, and easy to configure.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169274",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22471/"
] |
I'm making a simple scheduler with C# in .Net. All it does is execute a simple select statement on a table in a SQL Server DB once per minute (this does not need to scale or anything... the db does not have a high load). Here is my proposed implementation:
```
static void Main(string[] args)
{
while (true)
{
System.Threading.Thread.Sleep(timeout); // timeout is, say, 60000
CheckTable();
}
}
```
Is this ok? What is a better way?
p.s. Someone suggested using the Windows Forms Timer class... however that seems like overkill.
Cheers!
|
While it is technically legal you are probably better of using a timer. They are not much more code to set up and you can let the runtime take care of spawning new threads. If you ever needed to use this again in another program it would also create a performance bottleneck where a timer would not.
The timer will add more code though since you need to use a timer trigger event.
|
169,277 |
<p>Is there a Generics Friendly way of using Collection.EMPTY_LIST in my Java Program.</p>
<p>I know I could just declare one myself, but I'm just curious to know if there's a way in the JDK to do this.</p>
<p>Something like <code>users = Collections<User>.EMPTY_LIST;</code></p>
|
[
{
"answer_id": 169286,
"author": "Ryan Delucchi",
"author_id": 9931,
"author_profile": "https://Stackoverflow.com/users/9931",
"pm_score": 6,
"selected": true,
"text": "<p>By doing the following:</p>\n\n<pre><code>List<User> users = Collections.emptyList();\n</code></pre>\n\n<p>The type of the returned list from <code>Collections.emptyList();</code> will be <em>inferred</em> as a <code>String</code> due to the left-hand-side of the assignment. However, if you prefer to not have this inference, you can define it explicitly by doing the following:</p>\n\n<pre><code>List<User> users = Collections.<User>emptyList(); \n</code></pre>\n\n<p>In this particular instance, this may appear as redundant to most people (in fact, I've seen very little code out in the wild that makes use of explicit type arguments), however for a method with the signature: <code>void doStuff(List<String> users)</code> it would be perfectly clean for one to invoke <code>doStuff()</code> with an explicit type argument as follows:</p>\n\n<pre><code>doStuff(Collections.<String>emptyList());\n</code></pre>\n"
},
{
"answer_id": 169290,
"author": "Steve Kuo",
"author_id": 24396,
"author_profile": "https://Stackoverflow.com/users/24396",
"pm_score": 1,
"selected": false,
"text": "<pre><code>List<User> users = Collections.emptyList();\n</code></pre>\n"
},
{
"answer_id": 210588,
"author": "Adam Crume",
"author_id": 25498,
"author_profile": "https://Stackoverflow.com/users/25498",
"pm_score": 1,
"selected": false,
"text": "<p>After creating the empty list, I would recommend storing it as a constant rather than creating a new one each time.</p>\n\n<p>Also, there are performance benefits to using <code>Collections.emptyList()</code> versus <code>new ArrayList(0)</code>, although the difference is probably small. The list returned by emptyList() is optimized to be an immutable empty list. For example, the size() method simply returns 0, rather than a field lookup or whatever ArrayList does.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169277",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2443/"
] |
Is there a Generics Friendly way of using Collection.EMPTY\_LIST in my Java Program.
I know I could just declare one myself, but I'm just curious to know if there's a way in the JDK to do this.
Something like `users = Collections<User>.EMPTY_LIST;`
|
By doing the following:
```
List<User> users = Collections.emptyList();
```
The type of the returned list from `Collections.emptyList();` will be *inferred* as a `String` due to the left-hand-side of the assignment. However, if you prefer to not have this inference, you can define it explicitly by doing the following:
```
List<User> users = Collections.<User>emptyList();
```
In this particular instance, this may appear as redundant to most people (in fact, I've seen very little code out in the wild that makes use of explicit type arguments), however for a method with the signature: `void doStuff(List<String> users)` it would be perfectly clean for one to invoke `doStuff()` with an explicit type argument as follows:
```
doStuff(Collections.<String>emptyList());
```
|
169,278 |
<p>How do I get modrewrite to ENTIRELY ignore the /vip/ directory so that all requests pass directly to the folder?</p>
<pre><code><IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^vip/.$ - [PT]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
</code></pre>
<p>See also <a href="https://stackoverflow.com/questions/163302/how-do-i-ignore-a-directory-in-modrewrite">How do I ignore a directory in mod_rewrite?</a> -- reposting because I wasn't sufficiently clear about the problem first time around. </p>
|
[
{
"answer_id": 169347,
"author": "ceejayoz",
"author_id": 1902010,
"author_profile": "https://Stackoverflow.com/users/1902010",
"pm_score": 1,
"selected": false,
"text": "<p>Replace:</p>\n\n<pre><code>RewriteRule ^vip/.$ - [PT]\n</code></pre>\n\n<p>with:</p>\n\n<pre><code>RewriteRule ^vip/.*$ - [PT,L]\n</code></pre>\n"
},
{
"answer_id": 11918202,
"author": "aron.duby",
"author_id": 518064,
"author_profile": "https://Stackoverflow.com/users/518064",
"pm_score": 0,
"selected": false,
"text": "<p>The easy way I do it when needed is add a new .htaccess file to that folder and in it put</p>\n\n<pre><code>RewriteEngine Off\n</code></pre>\n\n<p>edited to fix typo</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169278",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24557/"
] |
How do I get modrewrite to ENTIRELY ignore the /vip/ directory so that all requests pass directly to the folder?
```
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^vip/.$ - [PT]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
```
See also [How do I ignore a directory in mod\_rewrite?](https://stackoverflow.com/questions/163302/how-do-i-ignore-a-directory-in-modrewrite) -- reposting because I wasn't sufficiently clear about the problem first time around.
|
Replace:
```
RewriteRule ^vip/.$ - [PT]
```
with:
```
RewriteRule ^vip/.*$ - [PT,L]
```
|
169,287 |
<p>Does anyone have a good resource on dlls and how they are used / generated in Visual Studio? A few questions I'm rather hazy on specifically are:</p>
<ul>
<li>How refresh files work</li>
<li>How dll version numbers are generated</li>
<li>The difference between adding a reference by project vs browsing for the specific dll</li>
</ul>
<p>Any other tips are welcome as well.</p>
|
[
{
"answer_id": 169314,
"author": "Rob Walker",
"author_id": 3631,
"author_profile": "https://Stackoverflow.com/users/3631",
"pm_score": 3,
"selected": false,
"text": "<p>See the question on <a href=\"https://stackoverflow.com/questions/124549/dll-information\">DLL information</a> for some background.</p>\n\n<p>Version numbers for unmanaged DLLs are stored in the DLL's rc file, same as for an exe. For managed DLLs I believe it uses AssemblyFileInfo attribute, usually in AssemblyInfo.cs for a Visual Studio generated project:</p>\n\n<pre><code>[assembly: AssemblyFileVersion(\"1.0.0.0\")]\n</code></pre>\n\n<p>If you add the reference by project then VS will be able to copy the correct flavour (debug/release) of the referenced assembly to your output directory. It can also use this information to implicitly add a dependency between the projects so it builds then in the right order.</p>\n"
},
{
"answer_id": 169668,
"author": "Kev",
"author_id": 419,
"author_profile": "https://Stackoverflow.com/users/419",
"pm_score": 3,
"selected": false,
"text": "<p><em>.NET DLL's</em></p>\n\n<p>The general term for a .NET DLL is an assembly. They are a single atomic unit of deployment and consist of one or more CLR 'modules' (for most developers usually just one unless they are combining compiler output from two or more languages for example). Assemblies contain both CIL code and CLR metadata such as the assembly manifest. </p>\n\n<p><strong>.refresh Files</strong></p>\n\n<p>.refresh files are simply text files that tell VS where to check for new builds of referenced dll's. They are used in file based web projects where there isn't a project file to store this info.</p>\n\n<p><strong>Version Numbers</strong></p>\n\n<p>.NET Assembly version numbers are generated by an assembly scoped attribute AssemblyVersion which is usually found in a source file named 'AssemblyInfo.cs' (found under a project folder named 'Properties' from VS2005 onwards). Version numbers are comprised of major.minor.build.revision, for example -</p>\n\n<p>[assembly: AssemblyVersion(\"1.0.0.0\")]</p>\n\n<p>AssemblyVersion is used as part of an assembly's identity (i.e. in its strong name) and plays an important role in the binding process and during version policy decisions.</p>\n\n<p>For example if I had two assemblies of the same name in the GAC then the AssemblyVersion attribute would differentiate them for the purposes of loading a specific version of the assembly.</p>\n\n<p>AssemblyVersion number can be fixed and incremented manually or you can allow the compiler to generate the build and revision numbers for you by specifying:</p>\n\n<p>[assembly: AssemblyVersion(\"1.0.<code>*</code>\")] - generates build and revision number<br>\n[assembly: AssemblyVersion(\"1.0.0.<code>*</code>\")] - generates revision number</p>\n\n<p>If the AssemblyVersion attribute is not present then the version number default to '0.0.0.0'.</p>\n\n<p>The value of the AssemblyVersion attribute becomes part of an assembly's manifest, the AssemblyFileVersion attribute value does not.</p>\n\n<p>The AssemblyFileVersion attribute is used to embed a Win32 file version into the DLL. If this is not present then AssemblyVersion is used. It has no bearing on how the .NET assembly loader/resolver chooses which version of an assembly to load. </p>\n\n<p><strong>Project References vs Browsing For DLL</strong></p>\n\n<p>If you're adding a project reference it means that the referenced project will be part of your solution. This makes debugging simpler by being able to step directly into your referenced project's code. If you only add a dll reference then you don't have the benefits of the project being part of the solution and being able to step into the code within the solution.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169287",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1574/"
] |
Does anyone have a good resource on dlls and how they are used / generated in Visual Studio? A few questions I'm rather hazy on specifically are:
* How refresh files work
* How dll version numbers are generated
* The difference between adding a reference by project vs browsing for the specific dll
Any other tips are welcome as well.
|
See the question on [DLL information](https://stackoverflow.com/questions/124549/dll-information) for some background.
Version numbers for unmanaged DLLs are stored in the DLL's rc file, same as for an exe. For managed DLLs I believe it uses AssemblyFileInfo attribute, usually in AssemblyInfo.cs for a Visual Studio generated project:
```
[assembly: AssemblyFileVersion("1.0.0.0")]
```
If you add the reference by project then VS will be able to copy the correct flavour (debug/release) of the referenced assembly to your output directory. It can also use this information to implicitly add a dependency between the projects so it builds then in the right order.
|
169,303 |
<p>I want to be able to run unstrusted ruby code. I want to be able to pass variables to said untrusted code that it may use. I also want said code to return a result to me. Here is a conceptual example of what I am thinking</p>
<pre><code>input = "sweet"
output = nil
Thread.start {
$SAFE = 4
#... untrusted code goes here, it uses the input variable(s)
#to calculate some result that it places in the output variable
}
#parse the output variable as a string.
</code></pre>
<p>Just to clarify, I am basically using the untrusted code as a function. I want to
provide its some inputs, and then allow it to write to the output. That is all I really want, I don't care how it is done, I just want the ability to use untrusted Ruby code as a sort of function. The solution does not have to look anything like the code I wrote above, I am just using it to illustrate what I want.</p>
<p>Now, I can currently think of 3 ways to do this:</p>
<ol>
<li>Use the $SAFE level construct above.</li>
<li>whytheluckystiff has a Sandbox plugin for ruby</li>
<li>I could run each function in its own virtual machine, using some sort of os virtualization software like vmware or Xen or something.</li>
</ol>
<p>I am wondering if anyone has any recommendations for running untrusted ruby code in a functional way? What option would you recomend? How would you go about it? Thanks.</p>
|
[
{
"answer_id": 169878,
"author": "James Baker",
"author_id": 9365,
"author_profile": "https://Stackoverflow.com/users/9365",
"pm_score": 5,
"selected": true,
"text": "<p>$SAFE is not enough; you need to be at least at the level of Why's freaky sandbox. However, I don't know if that sandbox code is actively maintained or if he/they ever solved the holes such as infinite loops, etc.</p>\n\n<p>Unsafe generally means hostile. If you can relax from hostile to, say, 'naive', and depending upon the requirements of your app, you might get away with sandboxing in Ruby. It's not really a first-class scenario in the language design.</p>\n\n<p>Even with that, though, you probably don't need to go to the machine level of separation. I'd feel pretty safe using a sandbox in a separately spawned process, with your app functioning as a process manager to kill off any that manage to hang/flame. Now, that is a few orders of magnitude more work than your simple block above.</p>\n\n<p>But remember and keep repeating, \"SAFE can't deal with hostile\".</p>\n"
},
{
"answer_id": 9795155,
"author": "Charles Oliver Nutter",
"author_id": 152946,
"author_profile": "https://Stackoverflow.com/users/152946",
"pm_score": 2,
"selected": false,
"text": "<p>I'd strongly recommend just using JRuby.</p>\n\n<p>The JVM has had a very strong security model built in from the beginning, and JRuby piggy-backs off that. You can restrict access to files, restrict loading of code, and much more. It's <em>far</em> better than anything that exists in native Ruby impls, and there are a number of sites that run sandboxed, user-accessible sites atop JRuby for exactly this purpose.</p>\n"
},
{
"answer_id": 26594052,
"author": "fearless_fool",
"author_id": 558639,
"author_profile": "https://Stackoverflow.com/users/558639",
"pm_score": 2,
"selected": false,
"text": "<p><code>$SAFE</code> doesn't protect you from everything a malicious hacker could do. </p>\n\n<p>Having gone down this path (see <a href=\"https://stackoverflow.com/questions/6074915/ruby-creating-a-sandboxed-eval\">Ruby: creating a sandboxed eval?</a>), I followed commenters' sage advice and embedded an application-specific interpreter that gave me complete control over what could and couldn't be done (see <a href=\"https://stackoverflow.com/questions/6100616/ruby-looking-for-ruby-embeddable-interpreter-or-scripting-language\">Ruby: looking for ruby-embeddable interpreter or scripting language</a>). </p>\n\n<p>It turned out to be incredibly easy using stickup (like less than an hour from downloading the gem to a customized interpreter) -- see <a href=\"https://github.com/jcoglan/stickup\" rel=\"nofollow noreferrer\">https://github.com/jcoglan/stickup</a> </p>\n"
},
{
"answer_id": 26684792,
"author": "AmitA",
"author_id": 455826,
"author_profile": "https://Stackoverflow.com/users/455826",
"pm_score": 2,
"selected": false,
"text": "<p>I created a gem called 'trusted-sandbox' that runs Ruby code within a fully controlled Docker container. You can disable network, set disk quotas, limit execution time, balance CPU with other running containers, set memory limits, etc. And the overhead is quite low.</p>\n\n<p>You can read more about it here:\n<a href=\"https://github.com/vaharoni/trusted-sandbox\" rel=\"nofollow\">https://github.com/vaharoni/trusted-sandbox</a></p>\n\n<p>Let me know what you think!</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169303",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/21317/"
] |
I want to be able to run unstrusted ruby code. I want to be able to pass variables to said untrusted code that it may use. I also want said code to return a result to me. Here is a conceptual example of what I am thinking
```
input = "sweet"
output = nil
Thread.start {
$SAFE = 4
#... untrusted code goes here, it uses the input variable(s)
#to calculate some result that it places in the output variable
}
#parse the output variable as a string.
```
Just to clarify, I am basically using the untrusted code as a function. I want to
provide its some inputs, and then allow it to write to the output. That is all I really want, I don't care how it is done, I just want the ability to use untrusted Ruby code as a sort of function. The solution does not have to look anything like the code I wrote above, I am just using it to illustrate what I want.
Now, I can currently think of 3 ways to do this:
1. Use the $SAFE level construct above.
2. whytheluckystiff has a Sandbox plugin for ruby
3. I could run each function in its own virtual machine, using some sort of os virtualization software like vmware or Xen or something.
I am wondering if anyone has any recommendations for running untrusted ruby code in a functional way? What option would you recomend? How would you go about it? Thanks.
|
$SAFE is not enough; you need to be at least at the level of Why's freaky sandbox. However, I don't know if that sandbox code is actively maintained or if he/they ever solved the holes such as infinite loops, etc.
Unsafe generally means hostile. If you can relax from hostile to, say, 'naive', and depending upon the requirements of your app, you might get away with sandboxing in Ruby. It's not really a first-class scenario in the language design.
Even with that, though, you probably don't need to go to the machine level of separation. I'd feel pretty safe using a sandbox in a separately spawned process, with your app functioning as a process manager to kill off any that manage to hang/flame. Now, that is a few orders of magnitude more work than your simple block above.
But remember and keep repeating, "SAFE can't deal with hostile".
|
169,342 |
<p>I have a solution that contains two projects. One project is an ASP.NET Web Application Project, and one is a class library. The web application has a project reference to the class library. Neither of these is strongly-named.</p>
<p>In the class library, which I'll call "Framework," I have an endpoint behavior (an IEndpointBehavior implementation) and a configuration element (a class derived from BehaviorExtensionsElement). The configuration element is so I can attach the endpoint behavior to a service via configuration.</p>
<p>In the web application, I have an AJAX-enabled WCF service. In web.config, I have the AJAX service configured to use my custom behavior. The system.serviceModel section of the configuration is pretty standard and looks like this:</p>
<pre><code><system.serviceModel>
<behaviors>
<endpointBehaviors>
<behavior name="MyEndpointBehavior">
<enableWebScript />
<customEndpointBehavior />
</behavior>
</endpointBehaviors>
</behaviors>
<serviceHostingEnvironment aspNetCompatibilityEnabled="true" />
<services>
<service name="WebSite.AjaxService">
<endpoint
address=""
behaviorConfiguration="MyEndpointBehavior"
binding="webHttpBinding"
contract="WebSite.AjaxService" />
</service>
</services>
<extensions>
<behaviorExtensions>
<add
name="customEndpointBehavior"
type="Framework.MyBehaviorExtensionsElement, Framework, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null"/>
</behaviorExtensions>
</extensions>
</system.serviceModel>
</code></pre>
<p>At runtime, this works perfectly. The AJAX enabled WCF service correctly uses my custom configured endpoint behavior.</p>
<p>The problem is when I try to add a new AJAX WCF service. If I do Add -> New Item... and select "AJAX-enabled WCF Service," I can watch it add the .svc file and codebehind, but when it gets to updating the web.config file, I get this error:</p>
<blockquote>
<p>The configuration file is not a valid configuration file for WCF Service Library.</p>
<p>The type 'Framework.MyBehaviorExtensionsElement, Framework, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null' registered for extension 'customEndpointBehavior' could not be loaded.</p>
</blockquote>
<p>Obviously the configuration is entirely valid since it works perfectly at runtime. If I remove the element from my behavior configuration temporarily and then add the AJAX-enabled WCF Service, everything goes without a hitch.</p>
<p>Unfortunately, in a larger project where we will have multiple services with various configurations, removing all of the custom behaviors temporarily is going to be error prone. While I realize I could go without using the wizard and do everything manually, not everyone can, and it'd be nice to be able to just use the product as it was meant to be used - wizards and all.</p>
<p><strong>Why isn't my custom WCF behavior extension element type being found?</strong></p>
<p>Updates/clarifications:</p>
<ul>
<li>It does work at runtime, just not design time.</li>
<li>The Framework assembly is in the web project's bin folder when I attempt to add the service.</li>
<li>While I could add services manually ("without configuration"), I need the out-of-the-box item template to work - that's the whole goal of the question.</li>
<li>This issue is being seen in Visual Studio 2008. <strong>In VS 2010 this appears to be resolved.</strong></li>
</ul>
<p><a href="https://connect.microsoft.com/wcf/feedback/ViewFeedback.aspx?FeedbackID=386511" rel="noreferrer">I filed this issue on Microsoft Connect</a> and it turns out you either have to put your custom configuration element in the GAC or put it in the IDE folder. They won't be fixing it, at least for now. I've posted the workaround they provided as the "answer" to this question.</p>
|
[
{
"answer_id": 170981,
"author": "James Bender",
"author_id": 22848,
"author_profile": "https://Stackoverflow.com/users/22848",
"pm_score": 2,
"selected": false,
"text": "<p>Do you have a copy of Framework.dll with your custom behavior in the bin directory of your web project? If not that is probably the problem. Visual Studio is looking for the implementation of the behavior. Since it's listed in your config it doesn't think to look in the other projects; it expects to find the assembly in the bin.</p>\n\n<p>Depending on how your project is setup, it may be able to run in debug without this assembly being put in the bin, although VS usually builds it and puts it there. But again, it depends on how things are setup. </p>\n\n<p>Anyway, might just want to double check at that the assembly is available at design time.</p>\n"
},
{
"answer_id": 180262,
"author": "Joe",
"author_id": 13087,
"author_profile": "https://Stackoverflow.com/users/13087",
"pm_score": 1,
"selected": false,
"text": "<p>Putting the assembly in the GAC would probably help, but I appreciate this isn't the answer you're looking for. Not sure where else VS will look for assemblies apart from the GAC and the directory containing devenv.exe.</p>\n"
},
{
"answer_id": 219347,
"author": "Derek Atlansky",
"author_id": 29713,
"author_profile": "https://Stackoverflow.com/users/29713",
"pm_score": 2,
"selected": false,
"text": "<p>I tried this with a new project just to make sure it wasn't your specific project/config and had the exact same issue.</p>\n\n<p>Using fusion logs, it appears that the system looks for the behavior extensions ONLY in the IDE directory (C:\\Program Files\\Microsoft Visual Studio 9.0\\Common7\\IDE). Copying the assembly to this directory in a post-build step works, but is ugly.</p>\n"
},
{
"answer_id": 443459,
"author": "Travis Illig",
"author_id": 8116,
"author_profile": "https://Stackoverflow.com/users/8116",
"pm_score": 6,
"selected": true,
"text": "<p>Per <a href=\"http://connect.microsoft.com/wcf/feedback/Workaround.aspx?FeedbackID=386511\" rel=\"noreferrer\">the workaround</a> that Microsoft posted on <a href=\"http://connect.microsoft.com/wcf/feedback/ViewFeedback.aspx?FeedbackID=386511\" rel=\"noreferrer\">the Connect issue</a> I filed for this, it's a known issue and there won't be any solution for it, at least in the current release:</p>\n\n<blockquote>\n <p>The reason for failing to add a new\n service item: When adding a new item\n and updating the configuration file,\n the system will try to load\n configuration file, so it will try to\n search and load the assembly of the\n cusom extension in this config file.\n Only in the cases that the assembly is\n GACed or is located in the same path\n as vs exe (Program Files\\Microsoft\n Visual Studio 9.0\\Common7\\IDE), the\n system can find it. Otherwise, the\n error dialog will pop up and \"add a\n new item\" will fail. </p>\n \n <p>I understand your pain points.\n Unfortunately we cannot take this\n change in current release. We will\n investigate it in later releases and\n try to provide a better solution\n then,such as providing a browse dialog\n to enable customers to specify the\n path, or better error message to\n indicate some work around solution,\n etc...</p>\n \n <p>Can you try the work around in current\n stage: GAC your custom extension\n assembly or copy it to \"Program\n Files\\Microsoft Visual Studio\n 9.0\\Common7\\IDE\"?</p>\n \n <p>We will provide the readme to help\n other customers who may run into the\n same issue.</p>\n</blockquote>\n\n<p>Unfortunately, it appears I'm out of luck on this one.</p>\n"
},
{
"answer_id": 3332155,
"author": "cdmdotnet",
"author_id": 178840,
"author_profile": "https://Stackoverflow.com/users/178840",
"pm_score": 3,
"selected": false,
"text": "<p>As an FYI to anyone who stumbles across this these days a possible solution is to FULLY qualify your assembly in your app.config/web.config.\nEG\nif you had</p>\n\n<pre><code><system.serviceModel>\n <extensions>\n <behaviorExtensions>\n <add name=\"clientCredential\" type=\"Client.ClientCredentialElement, Client\" />\n </behaviorExtensions>\n </extensions>\n</code></pre>\n\n<p>try - replacing the values as necassary</p>\n\n<pre><code><system.serviceModel>\n <extensions>\n <behaviorExtensions>\n <add name=\"clientCredential\" type=\"Client.ClientCredentialElement, Client, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null\" />\n </behaviorExtensions>\n </extensions>\n</code></pre>\n\n<p>this particular solution worked for me.</p>\n"
},
{
"answer_id": 10738636,
"author": "NoWar",
"author_id": 196919,
"author_profile": "https://Stackoverflow.com/users/196919",
"pm_score": 3,
"selected": false,
"text": "<p>I just used </p>\n\n<pre><code>[assembly: AssemblyVersion(\"1.0.*\")]\n//[assembly: AssemblyVersion(\"1.0.0.0\")]\n//[assembly: AssemblyFileVersion(\"1.0.0.0\")] \n</code></pre>\n\n<p>So I have new assembly build number every time.</p>\n\n<p>But we have </p>\n\n<pre><code> <add name=\"clientCredential\" type=\"Client.ClientCredentialElement, Client, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null\" />\n</code></pre>\n\n<p>where <strong>Version=1.0.0.0</strong> THIS IS WRONG!!!</p>\n\n<p>So you have 2 options</p>\n\n<ol>\n<li><p>Back to </p>\n\n<pre><code>//[assembly: AssemblyVersion(\"1.0.*\")] \n[assembly: AssemblyVersion(\"1.0.0.0\")] Keep it manually.\n[assembly: AssemblyFileVersion(\"1.0.0.0\")] \n</code></pre></li>\n<li><p>Every build manually replace <strong>Version=1.0.0.0</strong> with a correct number.</p></li>\n</ol>\n"
},
{
"answer_id": 14080043,
"author": "abatishchev",
"author_id": 41956,
"author_profile": "https://Stackoverflow.com/users/41956",
"pm_score": 2,
"selected": false,
"text": "<p>Here's the list of steps worked for me:</p>\n\n<ul>\n<li>Install dll into GAC, i.e. gacutil /i Bla.dll</li>\n<li>Get FQN of dll, i.e. gacutil /l Bla</li>\n<li>Copy resulting FQN into Web.config</li>\n<li>Add new service in VS</li>\n<li>Uninstall dll from GAC, i.e. gacutil /u Bla</li>\n</ul>\n\n<p>All together <strong>only</strong>.</p>\n"
},
{
"answer_id": 18155949,
"author": "Ryan",
"author_id": 246736,
"author_profile": "https://Stackoverflow.com/users/246736",
"pm_score": 0,
"selected": false,
"text": "<p>I solved this by commenting out the relevant sections in the web.config including the element that used the custom extension, the element and the element.</p>\n\n<p>After that I was able to add a WCF service to the project, add the lines back into the web.config and publish the project.</p>\n"
},
{
"answer_id": 21123126,
"author": "MSallal",
"author_id": 2515700,
"author_profile": "https://Stackoverflow.com/users/2515700",
"pm_score": 0,
"selected": false,
"text": "<p>if you are using framework 3.5 the <strong>Culture=neutral</strong> in small not Culture=Neutral in CAPITAL</p>\n"
},
{
"answer_id": 26040244,
"author": "jrmack",
"author_id": 1084207,
"author_profile": "https://Stackoverflow.com/users/1084207",
"pm_score": 0,
"selected": false,
"text": "<p>I had the extension class within the same project (dll) as my service class and could not get it to work. Once I moved it to another project and referenced it from the service project it worked. Just in case anyone else runs into this issue.</p>\n"
},
{
"answer_id": 66503610,
"author": "Christiaan Hattingh",
"author_id": 11590429,
"author_profile": "https://Stackoverflow.com/users/11590429",
"pm_score": 0,
"selected": false,
"text": "<p>I had the extension class defined in my class that implements my interface, which resulted in a "could not load" error, where WCF was unable to load my extension class.</p>\n<p>Moving the extension class definition out of the interface implementation (but still in the same project/dll) sorted out my issue.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169342",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8116/"
] |
I have a solution that contains two projects. One project is an ASP.NET Web Application Project, and one is a class library. The web application has a project reference to the class library. Neither of these is strongly-named.
In the class library, which I'll call "Framework," I have an endpoint behavior (an IEndpointBehavior implementation) and a configuration element (a class derived from BehaviorExtensionsElement). The configuration element is so I can attach the endpoint behavior to a service via configuration.
In the web application, I have an AJAX-enabled WCF service. In web.config, I have the AJAX service configured to use my custom behavior. The system.serviceModel section of the configuration is pretty standard and looks like this:
```
<system.serviceModel>
<behaviors>
<endpointBehaviors>
<behavior name="MyEndpointBehavior">
<enableWebScript />
<customEndpointBehavior />
</behavior>
</endpointBehaviors>
</behaviors>
<serviceHostingEnvironment aspNetCompatibilityEnabled="true" />
<services>
<service name="WebSite.AjaxService">
<endpoint
address=""
behaviorConfiguration="MyEndpointBehavior"
binding="webHttpBinding"
contract="WebSite.AjaxService" />
</service>
</services>
<extensions>
<behaviorExtensions>
<add
name="customEndpointBehavior"
type="Framework.MyBehaviorExtensionsElement, Framework, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null"/>
</behaviorExtensions>
</extensions>
</system.serviceModel>
```
At runtime, this works perfectly. The AJAX enabled WCF service correctly uses my custom configured endpoint behavior.
The problem is when I try to add a new AJAX WCF service. If I do Add -> New Item... and select "AJAX-enabled WCF Service," I can watch it add the .svc file and codebehind, but when it gets to updating the web.config file, I get this error:
>
> The configuration file is not a valid configuration file for WCF Service Library.
>
>
> The type 'Framework.MyBehaviorExtensionsElement, Framework, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null' registered for extension 'customEndpointBehavior' could not be loaded.
>
>
>
Obviously the configuration is entirely valid since it works perfectly at runtime. If I remove the element from my behavior configuration temporarily and then add the AJAX-enabled WCF Service, everything goes without a hitch.
Unfortunately, in a larger project where we will have multiple services with various configurations, removing all of the custom behaviors temporarily is going to be error prone. While I realize I could go without using the wizard and do everything manually, not everyone can, and it'd be nice to be able to just use the product as it was meant to be used - wizards and all.
**Why isn't my custom WCF behavior extension element type being found?**
Updates/clarifications:
* It does work at runtime, just not design time.
* The Framework assembly is in the web project's bin folder when I attempt to add the service.
* While I could add services manually ("without configuration"), I need the out-of-the-box item template to work - that's the whole goal of the question.
* This issue is being seen in Visual Studio 2008. **In VS 2010 this appears to be resolved.**
[I filed this issue on Microsoft Connect](https://connect.microsoft.com/wcf/feedback/ViewFeedback.aspx?FeedbackID=386511) and it turns out you either have to put your custom configuration element in the GAC or put it in the IDE folder. They won't be fixing it, at least for now. I've posted the workaround they provided as the "answer" to this question.
|
Per [the workaround](http://connect.microsoft.com/wcf/feedback/Workaround.aspx?FeedbackID=386511) that Microsoft posted on [the Connect issue](http://connect.microsoft.com/wcf/feedback/ViewFeedback.aspx?FeedbackID=386511) I filed for this, it's a known issue and there won't be any solution for it, at least in the current release:
>
> The reason for failing to add a new
> service item: When adding a new item
> and updating the configuration file,
> the system will try to load
> configuration file, so it will try to
> search and load the assembly of the
> cusom extension in this config file.
> Only in the cases that the assembly is
> GACed or is located in the same path
> as vs exe (Program Files\Microsoft
> Visual Studio 9.0\Common7\IDE), the
> system can find it. Otherwise, the
> error dialog will pop up and "add a
> new item" will fail.
>
>
> I understand your pain points.
> Unfortunately we cannot take this
> change in current release. We will
> investigate it in later releases and
> try to provide a better solution
> then,such as providing a browse dialog
> to enable customers to specify the
> path, or better error message to
> indicate some work around solution,
> etc...
>
>
> Can you try the work around in current
> stage: GAC your custom extension
> assembly or copy it to "Program
> Files\Microsoft Visual Studio
> 9.0\Common7\IDE"?
>
>
> We will provide the readme to help
> other customers who may run into the
> same issue.
>
>
>
Unfortunately, it appears I'm out of luck on this one.
|
169,362 |
<p>I would like to compress a folder and all its sub-folders/files, and email the zip file as an attachment. What would be the best way to achieve this with Python? </p>
|
[
{
"answer_id": 169395,
"author": "S.Lott",
"author_id": 10661,
"author_profile": "https://Stackoverflow.com/users/10661",
"pm_score": 1,
"selected": false,
"text": "<p>Look at <a href=\"http://www.python.org/doc/2.5.2/lib/module-zipfile.html\" rel=\"nofollow noreferrer\">zipfile</a> for compressing a folder and it's subfolders.</p>\n\n<p>Look at <a href=\"http://www.python.org/doc/2.5.2/lib/module-smtplib.html\" rel=\"nofollow noreferrer\">smtplib</a> for an email client.</p>\n"
},
{
"answer_id": 169403,
"author": "Pesto D",
"author_id": 21746,
"author_profile": "https://Stackoverflow.com/users/21746",
"pm_score": 0,
"selected": false,
"text": "<p>You can use <a href=\"http://www.python.org/doc/2.5.2/lib/module-zipfile.html\" rel=\"nofollow noreferrer\">zipfile</a> that ships with python, and <a href=\"http://snippets.dzone.com/posts/show/2038\" rel=\"nofollow noreferrer\">here</a> you can find an example of sending an email with attachments with the standard smtplib</p>\n"
},
{
"answer_id": 169406,
"author": "nosklo",
"author_id": 17160,
"author_profile": "https://Stackoverflow.com/users/17160",
"pm_score": 5,
"selected": true,
"text": "<p>You can use the <a href=\"http://docs.python.org/dev/library/zipfile.html\" rel=\"nofollow noreferrer\">zipfile</a> module to compress the file using the zip standard, the <a href=\"http://docs.python.org/dev/library/email.html\" rel=\"nofollow noreferrer\">email</a> module to create the email with the attachment, and the <a href=\"http://docs.python.org/dev/library/smtplib.html\" rel=\"nofollow noreferrer\">smtplib</a> module to send it - all using only the standard library.</p>\n\n<h1>Python - Batteries Included</h1>\n\n<p>If you don't feel like programming and would rather ask a question on stackoverflow.org instead, or (as suggested in the comments) left off the <code>homework</code> tag, well, here it is:</p>\n\n<pre><code>import smtplib\nimport zipfile\nimport tempfile\nfrom email import encoders\nfrom email.message import Message\nfrom email.mime.base import MIMEBase\nfrom email.mime.multipart import MIMEMultipart \n\ndef send_file_zipped(the_file, recipients, sender='[email protected]'):\n zf = tempfile.TemporaryFile(prefix='mail', suffix='.zip')\n zip = zipfile.ZipFile(zf, 'w')\n zip.write(the_file)\n zip.close()\n zf.seek(0)\n\n # Create the message\n themsg = MIMEMultipart()\n themsg['Subject'] = 'File %s' % the_file\n themsg['To'] = ', '.join(recipients)\n themsg['From'] = sender\n themsg.preamble = 'I am not using a MIME-aware mail reader.\\n'\n msg = MIMEBase('application', 'zip')\n msg.set_payload(zf.read())\n encoders.encode_base64(msg)\n msg.add_header('Content-Disposition', 'attachment', \n filename=the_file + '.zip')\n themsg.attach(msg)\n themsg = themsg.as_string()\n\n # send the message\n smtp = smtplib.SMTP()\n smtp.connect()\n smtp.sendmail(sender, recipients, themsg)\n smtp.close()\n\n \"\"\"\n # alternative to the above 4 lines if you're using gmail\n server = smtplib.SMTP_SSL('smtp.gmail.com', 465)\n server.login(\"username\", \"password\")\n server.sendmail(sender,recipients,themsg)\n server.quit()\n \"\"\"\n</code></pre>\n\n<p>With this function, you can just do:</p>\n\n<pre><code>send_file_zipped('result.txt', ['[email protected]'])\n</code></pre>\n\n<p>You're welcome.</p>\n"
}
] |
2008/10/03
|
[
"https://Stackoverflow.com/questions/169362",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I would like to compress a folder and all its sub-folders/files, and email the zip file as an attachment. What would be the best way to achieve this with Python?
|
You can use the [zipfile](http://docs.python.org/dev/library/zipfile.html) module to compress the file using the zip standard, the [email](http://docs.python.org/dev/library/email.html) module to create the email with the attachment, and the [smtplib](http://docs.python.org/dev/library/smtplib.html) module to send it - all using only the standard library.
Python - Batteries Included
===========================
If you don't feel like programming and would rather ask a question on stackoverflow.org instead, or (as suggested in the comments) left off the `homework` tag, well, here it is:
```
import smtplib
import zipfile
import tempfile
from email import encoders
from email.message import Message
from email.mime.base import MIMEBase
from email.mime.multipart import MIMEMultipart
def send_file_zipped(the_file, recipients, sender='[email protected]'):
zf = tempfile.TemporaryFile(prefix='mail', suffix='.zip')
zip = zipfile.ZipFile(zf, 'w')
zip.write(the_file)
zip.close()
zf.seek(0)
# Create the message
themsg = MIMEMultipart()
themsg['Subject'] = 'File %s' % the_file
themsg['To'] = ', '.join(recipients)
themsg['From'] = sender
themsg.preamble = 'I am not using a MIME-aware mail reader.\n'
msg = MIMEBase('application', 'zip')
msg.set_payload(zf.read())
encoders.encode_base64(msg)
msg.add_header('Content-Disposition', 'attachment',
filename=the_file + '.zip')
themsg.attach(msg)
themsg = themsg.as_string()
# send the message
smtp = smtplib.SMTP()
smtp.connect()
smtp.sendmail(sender, recipients, themsg)
smtp.close()
"""
# alternative to the above 4 lines if you're using gmail
server = smtplib.SMTP_SSL('smtp.gmail.com', 465)
server.login("username", "password")
server.sendmail(sender,recipients,themsg)
server.quit()
"""
```
With this function, you can just do:
```
send_file_zipped('result.txt', ['[email protected]'])
```
You're welcome.
|
169,377 |
<p>As a hobby I'm interesting in programming an Ethernet-connected LED sign to scroll messages across a screen. But I'm having trouble making a UDP sender in <a href="http://en.wikipedia.org/wiki/Visual_Basic_.NET" rel="nofollow noreferrer">VB.NET</a> (I am using 2008 currently).</p>
<p>Now the sign is nice enough to have <a href="http://support.favotech.com/protocol.specs.2.4.jetfile.pdf" rel="nofollow noreferrer">a specifications sheet on programming for it</a>.</p>
<p>But an example of a line to send to it (page 3):</p>
<pre><code><0x01>Z30<0x02>AA<0x06><0x1B>0b<0x1C>1<0x1A>1This message will show up on the screen<0x04>
</code></pre>
<p>With codes such as <0x01> representing the hex character.</p>
<p>Now, to send this to the sign I need to use <a href="http://en.wikipedia.org/wiki/User_Datagram_Protocol" rel="nofollow noreferrer">UDP</a>. However, the examples I have all encode the message as <a href="http://en.wikipedia.org/wiki/ASCII" rel="nofollow noreferrer">ASCII</a> before sending, like this one (from <em><a href="http://www.java2s.com/Code/VB/Network-Remote/UDPClientsendspacketstoandreceivespacketsfromaserver.htm" rel="nofollow noreferrer">UDP: Client sends packets to, and receives packets from, a server</a></em>):</p>
<pre><code>Imports System.Threading
Imports System.Net.Sockets
Imports System.IO
Imports System.Net
Public Class MainClass
Shared Dim client As UdpClient
Shared Dim receivePoint As IPEndPoint
Public Shared Sub Main()
receivePoint = New IPEndPoint(New IPAddress(0), 0)
client = New UdpClient(8888)
Dim thread As Thread = New Thread(New ThreadStart(AddressOf WaitForPackets))
thread.Start()
Dim packet As String = "client"
Console.WriteLine("Sending packet containing: ")
'
' Note the following line below, would appear to be my problem.
'
Dim data As Byte() = System.Text.Encoding.ASCII.GetBytes(packet)
client.Send(data, data.Length, "localhost", 5000)
Console.WriteLine("Packet sent")
End Sub
Shared Public Sub WaitForPackets()
While True
Dim data As Byte() = client.Receive(receivePoint)
Console.WriteLine("Packet received:" & _
vbCrLf & "Length: " & data.Length & vbCrLf & _
System.Text.Encoding.ASCII.GetString(data))
End While
End Sub ' WaitForPackets
End Class
</code></pre>
<p>To output a hexcode in VB.NET, I think the syntax may possibly be &H1A - to send what the specifications would define as <0x1A>.</p>
<p>Could I modify that code, to correctly send a correctly formated packet to this sign?</p>
<p>The answers from Grant (after sending a packet with hex in it), Hamish Smith (using a function to get hex values), and Hafthor (hardcoded chr() message into example) when attempted all did not work. So I'll research to see what else could go wrong. In theory, if this string is sent successfully, I should have a message containing "OK" back, which will help to know when it works.</p>
<p>I have tried and am now able to monitor the packets going through. A working packet example is this (in raw hex): <a href="http://www.brettjamesonline.com/misc/forums/other/working.raw" rel="nofollow noreferrer">http://www.brettjamesonline.com/misc/forums/other/working.raw</a> vs my version: <a href="http://www.brettjamesonline.com/misc/forums/other/failed.raw" rel="nofollow noreferrer">http://www.brettjamesonline.com/misc/forums/other/failed.raw</a>. The difference is my hex codes are still not encoded correctly, seen in this side-by-side image: <a href="http://www.brettjamesonline.com/misc/forums/other/snapshotcoding.png" rel="nofollow noreferrer">http://www.brettjamesonline.com/misc/forums/other/snapshotcoding.png</a>.</p>
<p>I have used this code to generate the packet and send it:</p>
<pre><code>container = &H1 & "Z" & &H30 & &H2 & "temp.nrg" & &H1C & "1Something" & &H4
' This did not appear to work neither
'container = Chr(&H1) & "Z" & Chr(&H30) & Chr(&H2) & Chr(&H1C) & "1Something" & Chr(&H4)
'<0x01>Z00<0x02>FILENAME<0x1C>1Test to display<0x04> <- the "official" spec to send
Dim sendBytes As [Byte]() = Encoding.ASCII.GetBytes(container)
</code></pre>
<p>(Full snippet: <a href="http://pastebin.com/f44417743" rel="nofollow noreferrer">http://pastebin.com/f44417743</a>.)</p>
|
[
{
"answer_id": 169422,
"author": "Grant",
"author_id": 30,
"author_profile": "https://Stackoverflow.com/users/30",
"pm_score": 0,
"selected": false,
"text": "<p>This might help. At my company we have to communicate with our hardware using sort of a combination of ascii and hex. </p>\n\n<p>I use this function to hexify ip addresses before sending them to the hardware</p>\n\n<pre><code>Public Function HexFromIP(ByVal sIP As String)\n Dim aIP As String()\n Dim sHexCode As String = \"\"\n aIP = sIP.Split(\".\")\n\n For Each IPOct As String In aIP\n sHexCode += Hex(Val(IPOct)).PadLeft(2, \"0\")\n Next\n\n Return sHexCode\nEnd Function\n</code></pre>\n\n<p>And occationally I use <code>hexSomething = Hex(Val(number)).PadLeft(2,\"0\")</code> as well. </p>\n\n<p>I can give you the source for the whole program too, though it's designed to talk to different hardware.</p>\n\n<p>EDIT:</p>\n\n<p>Are you trying to send packets in hex, or get packets in hex?</p>\n"
},
{
"answer_id": 169437,
"author": "Hafthor",
"author_id": 4489,
"author_profile": "https://Stackoverflow.com/users/4489",
"pm_score": 2,
"selected": false,
"text": "<p>You could put together a quickie decoder like this one:</p>\n\n<pre><code>Function HexCodeToHexChar(ByVal m as System.Text.RegularExpressions.Match) As String\n Return Chr(Integer.Parse(m.Value.Substring(\"<0x\".Length, 2), _\n Globalization.NumberStyles.HexNumber))\nEnd Function\n</code></pre>\n\n<p>then use this to transform:</p>\n\n<pre><code>Dim r As New System.Text.RegularExpressions.Regex(\"<0x[0-9a-fA-F]{2}>\")\nDim s As String = r.Replace(\"abc<0x44>efg\", AddressOf HexCodeToHexChar)\n' s should now be \"abcDefg\"\n</code></pre>\n\n<p>you could also make an encoder function that undoes this decoding (although a little more complicated)</p>\n\n<pre><code>Function HexCharToHexCode(ByVal m As Match) As String\n If m.Value.StartsWith(\"<0x\") And m.Value.EndsWith(\">\") And m.Value.Length = \"<0x??>\".Length Then\n Return \"<0<0x78>\" + m.Value.Substring(\"<0x\".Length)\n ElseIf Asc(m.Value) >= 0 And Asc(m.Value) <= &HFF Then\n Return \"<0x\" + Right(\"0\" + Hex(Asc(m.Value)), 2) + \">\"\n Else\n Throw New ArgumentException(\"Non-SBCS ANSI characters not supported\")\n End If\nEnd Function\n</code></pre>\n\n<p>and use this to transform:</p>\n\n<pre><code>Dim r As New Regex(\"[^ -~]|<0x[0-9a-fA-F]{2}>\")\nDim s As String = r.Replace(\"abc\"+chr(4)+\"efg\", AddressOf HexCharToHexCode)\n' s should now be \"abc<0x04>efg\"\n</code></pre>\n\n<p>or you could just build the string with the special characters in it to begin with like this:</p>\n\n<pre><code>Dim packet As String = Chr(&H01) + \"Z30\" + Chr(&H02) + \"AA\" + Chr(&H06) + _\n Chr(&H1B) + \"0b\" + Chr(&H1C) + \"1\" + Chr(&H1A) + _\n \"1This message will show up on the screen\" + Chr(&H04)\n</code></pre>\n\n<p>for sending a UDP packet, the following should suffice:</p>\n\n<pre><code>Dim i As New IPEndPoint(IPAddress.Parse(\"192.168.0.5\"), 3001) ''//Target IP:port\nDim u As New UdpClient()\nDim b As Byte() = Encoding.UTF8.GetBytes(s) ''//Where s is the decoded string\nu.Send(b, b.Length, i)\n</code></pre>\n"
},
{
"answer_id": 169449,
"author": "Hamish Smith",
"author_id": 15572,
"author_profile": "https://Stackoverflow.com/users/15572",
"pm_score": 0,
"selected": false,
"text": "<p>The UDP client sends an array of bytes.<br>\nYou could use a memory stream and write bytes to an array. </p>\n\n<pre><code>Public Class MainClass\n Shared client As UdpClient\n Shared receivePoint As IPEndPoint\n\n\n Public Shared Sub Main()\n receivePoint = New IPEndPoint(New IPAddress(0), 0)\n client = New UdpClient(8888)\n Dim thread As Thread = New Thread(New ThreadStart(AddressOf WaitForPackets))\n thread.Start()\n\n\n Dim packet As Packet = New Packet(\"client\")\n Console.WriteLine(\"Sending packet containing: \")\n Dim data As Byte() = packet.Data\n\n client.Send(data, data.Length, \"localhost\", 5000)\n Console.WriteLine(\"Packet sent\")\n\n End Sub\n\n Public Shared Sub WaitForPackets()\n While True\n Dim data As Byte() = client.Receive(receivePoint)\n Console.WriteLine(\"Packet received:\" & _\n vbCrLf & \"Length: \" & data.Length & vbCrLf & _\n System.Text.Encoding.ASCII.GetString(data))\n\n End While\n\n End Sub ' WaitForPackets \n\nEnd Class \n\nPublic Class Packet \n Private _message As String \n\n Public Sub New(ByVal message As String)\n _message = message\n End Sub\n\n Public Function Data() As Byte()\n\n Dim ret(13 + _message.Length) As Byte\n\n Dim ms As New MemoryStream(ret, True)\n\n ms.WriteByte(&H1)\n\n '<0x01>Z30<0x02>AA<0x06><0x1B>0b<0x1C>1<0x1A>1This message will show up on the screen<0x04> \n ms.Write(System.Text.Encoding.ASCII.GetBytes(\"Z30\"), 0, 3)\n\n ms.WriteByte(&H2)\n\n ms.Write(System.Text.Encoding.ASCII.GetBytes(\"AA\"), 0, 2)\n\n ms.WriteByte(&H6)\n\n ms.Write(System.Text.Encoding.ASCII.GetBytes(\"0b\"), 0, 2)\n\n ms.WriteByte(&H1C)\n\n ms.Write(System.Text.Encoding.ASCII.GetBytes(\"1\"), 0, 1)\n\n ms.WriteByte(&H1A)\n\n ms.Write(System.Text.Encoding.ASCII.GetBytes(_message), 0, _message.Length)\n\n ms.WriteByte(&H4)\n\n ms.Close()\n\n Data = ret\n End Function\nEnd Class\n</code></pre>\n"
},
{
"answer_id": 814423,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>They posted libraries for a bunch of languages including Visual Basic (in the separate file). I tested the demos out with one of their signs and they work!</p>\n\n<p><a href=\"http://support.favotech.com\" rel=\"nofollow noreferrer\">http://support.favotech.com</a></p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169377",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25031/"
] |
As a hobby I'm interesting in programming an Ethernet-connected LED sign to scroll messages across a screen. But I'm having trouble making a UDP sender in [VB.NET](http://en.wikipedia.org/wiki/Visual_Basic_.NET) (I am using 2008 currently).
Now the sign is nice enough to have [a specifications sheet on programming for it](http://support.favotech.com/protocol.specs.2.4.jetfile.pdf).
But an example of a line to send to it (page 3):
```
<0x01>Z30<0x02>AA<0x06><0x1B>0b<0x1C>1<0x1A>1This message will show up on the screen<0x04>
```
With codes such as <0x01> representing the hex character.
Now, to send this to the sign I need to use [UDP](http://en.wikipedia.org/wiki/User_Datagram_Protocol). However, the examples I have all encode the message as [ASCII](http://en.wikipedia.org/wiki/ASCII) before sending, like this one (from *[UDP: Client sends packets to, and receives packets from, a server](http://www.java2s.com/Code/VB/Network-Remote/UDPClientsendspacketstoandreceivespacketsfromaserver.htm)*):
```
Imports System.Threading
Imports System.Net.Sockets
Imports System.IO
Imports System.Net
Public Class MainClass
Shared Dim client As UdpClient
Shared Dim receivePoint As IPEndPoint
Public Shared Sub Main()
receivePoint = New IPEndPoint(New IPAddress(0), 0)
client = New UdpClient(8888)
Dim thread As Thread = New Thread(New ThreadStart(AddressOf WaitForPackets))
thread.Start()
Dim packet As String = "client"
Console.WriteLine("Sending packet containing: ")
'
' Note the following line below, would appear to be my problem.
'
Dim data As Byte() = System.Text.Encoding.ASCII.GetBytes(packet)
client.Send(data, data.Length, "localhost", 5000)
Console.WriteLine("Packet sent")
End Sub
Shared Public Sub WaitForPackets()
While True
Dim data As Byte() = client.Receive(receivePoint)
Console.WriteLine("Packet received:" & _
vbCrLf & "Length: " & data.Length & vbCrLf & _
System.Text.Encoding.ASCII.GetString(data))
End While
End Sub ' WaitForPackets
End Class
```
To output a hexcode in VB.NET, I think the syntax may possibly be &H1A - to send what the specifications would define as <0x1A>.
Could I modify that code, to correctly send a correctly formated packet to this sign?
The answers from Grant (after sending a packet with hex in it), Hamish Smith (using a function to get hex values), and Hafthor (hardcoded chr() message into example) when attempted all did not work. So I'll research to see what else could go wrong. In theory, if this string is sent successfully, I should have a message containing "OK" back, which will help to know when it works.
I have tried and am now able to monitor the packets going through. A working packet example is this (in raw hex): <http://www.brettjamesonline.com/misc/forums/other/working.raw> vs my version: <http://www.brettjamesonline.com/misc/forums/other/failed.raw>. The difference is my hex codes are still not encoded correctly, seen in this side-by-side image: <http://www.brettjamesonline.com/misc/forums/other/snapshotcoding.png>.
I have used this code to generate the packet and send it:
```
container = &H1 & "Z" & &H30 & &H2 & "temp.nrg" & &H1C & "1Something" & &H4
' This did not appear to work neither
'container = Chr(&H1) & "Z" & Chr(&H30) & Chr(&H2) & Chr(&H1C) & "1Something" & Chr(&H4)
'<0x01>Z00<0x02>FILENAME<0x1C>1Test to display<0x04> <- the "official" spec to send
Dim sendBytes As [Byte]() = Encoding.ASCII.GetBytes(container)
```
(Full snippet: <http://pastebin.com/f44417743>.)
|
You could put together a quickie decoder like this one:
```
Function HexCodeToHexChar(ByVal m as System.Text.RegularExpressions.Match) As String
Return Chr(Integer.Parse(m.Value.Substring("<0x".Length, 2), _
Globalization.NumberStyles.HexNumber))
End Function
```
then use this to transform:
```
Dim r As New System.Text.RegularExpressions.Regex("<0x[0-9a-fA-F]{2}>")
Dim s As String = r.Replace("abc<0x44>efg", AddressOf HexCodeToHexChar)
' s should now be "abcDefg"
```
you could also make an encoder function that undoes this decoding (although a little more complicated)
```
Function HexCharToHexCode(ByVal m As Match) As String
If m.Value.StartsWith("<0x") And m.Value.EndsWith(">") And m.Value.Length = "<0x??>".Length Then
Return "<0<0x78>" + m.Value.Substring("<0x".Length)
ElseIf Asc(m.Value) >= 0 And Asc(m.Value) <= &HFF Then
Return "<0x" + Right("0" + Hex(Asc(m.Value)), 2) + ">"
Else
Throw New ArgumentException("Non-SBCS ANSI characters not supported")
End If
End Function
```
and use this to transform:
```
Dim r As New Regex("[^ -~]|<0x[0-9a-fA-F]{2}>")
Dim s As String = r.Replace("abc"+chr(4)+"efg", AddressOf HexCharToHexCode)
' s should now be "abc<0x04>efg"
```
or you could just build the string with the special characters in it to begin with like this:
```
Dim packet As String = Chr(&H01) + "Z30" + Chr(&H02) + "AA" + Chr(&H06) + _
Chr(&H1B) + "0b" + Chr(&H1C) + "1" + Chr(&H1A) + _
"1This message will show up on the screen" + Chr(&H04)
```
for sending a UDP packet, the following should suffice:
```
Dim i As New IPEndPoint(IPAddress.Parse("192.168.0.5"), 3001) ''//Target IP:port
Dim u As New UdpClient()
Dim b As Byte() = Encoding.UTF8.GetBytes(s) ''//Where s is the decoded string
u.Send(b, b.Length, i)
```
|
169,398 |
<p>I need to set up an instance of SQL Server 2005 with SQL_Latin1_General_CP850_Bin as the server collation (the vendor did not take into accounting looking at DB collation for a bunch of things so stored procedures and temp tables default to the server level and the default collation will not work). During the install for SQL Server it did not give that as an option so I left it at default and finished installing it.</p>
<p>According to <a href="http://msdn.microsoft.com/en-us/library/ms179254.aspx" rel="nofollow noreferrer">MSDN</a> and <a href="http://technet.microsoft.com/en-us/library/ms179254.aspx" rel="nofollow noreferrer">Technet</a> I should need to just run the following command:</p>
<pre><code>setup.exe /q /ACTION=RebuildDatabase /INSTANCENAME=MSSQLSERVER /SAPWD="sa-pwd" /SQLSYSADMINACCOUNTS="BUILTIN\ADMINISTRATORS" /SqlCollation=SQL_Latin1_General_CP1_CI_AI
</code></pre>
<p>However, whenever I run the above command with my parameters I get the pop-up of the SQL Server installation wizard, accept the agreement, and then it gives me output stating how to use the command.</p>
<p>Any idea what I can do?</p>
|
[
{
"answer_id": 169413,
"author": "GilM",
"author_id": 10192,
"author_profile": "https://Stackoverflow.com/users/10192",
"pm_score": 3,
"selected": true,
"text": "<p>I think you're looking at instructions for SQL Server 2008.</p>\n\n<p>See the article <a href=\"http://msdn.microsoft.com/en-us/library/ms179254(SQL.90).aspx\" rel=\"nofollow noreferrer\">here</a> for instructions for 2005.</p>\n"
},
{
"answer_id": 169532,
"author": "SqlACID",
"author_id": 19797,
"author_profile": "https://Stackoverflow.com/users/19797",
"pm_score": 1,
"selected": false,
"text": "<p>If possible, I would uninstall and reinstall rather than trying to change it. Changing it without re-installing is not a simple process. To change from the default during install, just uncheck the \"Hide advanced configuration options\" check box on the Registration Information screen; doing that will give you a Collation Settings option about 4 screens later in the install.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169398",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/204/"
] |
I need to set up an instance of SQL Server 2005 with SQL\_Latin1\_General\_CP850\_Bin as the server collation (the vendor did not take into accounting looking at DB collation for a bunch of things so stored procedures and temp tables default to the server level and the default collation will not work). During the install for SQL Server it did not give that as an option so I left it at default and finished installing it.
According to [MSDN](http://msdn.microsoft.com/en-us/library/ms179254.aspx) and [Technet](http://technet.microsoft.com/en-us/library/ms179254.aspx) I should need to just run the following command:
```
setup.exe /q /ACTION=RebuildDatabase /INSTANCENAME=MSSQLSERVER /SAPWD="sa-pwd" /SQLSYSADMINACCOUNTS="BUILTIN\ADMINISTRATORS" /SqlCollation=SQL_Latin1_General_CP1_CI_AI
```
However, whenever I run the above command with my parameters I get the pop-up of the SQL Server installation wizard, accept the agreement, and then it gives me output stating how to use the command.
Any idea what I can do?
|
I think you're looking at instructions for SQL Server 2008.
See the article [here](http://msdn.microsoft.com/en-us/library/ms179254(SQL.90).aspx) for instructions for 2005.
|
169,404 |
<p>In a <a href="https://stackoverflow.com/questions/168408/c-alternatives-to-void-pointers-that-isnt-templates">related question</a> I asked about creating a generic container. Using polymorphic templates seems like the right way to go.</p>
<p>However, I can't for the life of me figure out how a destructor should be written. I want the owner of the memory allocated to be the containers even if the example constructor takes in an array of <code>T</code> (along with its dimensions), allocated at some other point.</p>
<p>I would like to be able to do something like</p>
<pre><code>MyContainer<float> blah();
...
delete blah;
</code></pre>
<p>and</p>
<pre><code>MyContainer<ComplexObjectType*> complexBlah();
...
delete complexBlah;`
</code></pre>
<p>Can I do something like this? Can I do it without smart pointers?</p>
<p>Again, thanks for your input.</p>
|
[
{
"answer_id": 169429,
"author": "Scott Langham",
"author_id": 11898,
"author_profile": "https://Stackoverflow.com/users/11898",
"pm_score": 0,
"selected": false,
"text": "<p>It can be done, but this is pretty advanced stuff.\nYou'll need to use something like the boost MPL library (<a href=\"http://www.boost.org/doc/libs/1_36_0/libs/mpl/doc/index.html\" rel=\"nofollow noreferrer\">http://www.boost.org/doc/libs/1_36_0/libs/mpl/doc/index.html</a>) so that you can get MyContainer's destructor to select the right kind of destructing it will need to do on individual items on the container. And you can use the boost TypeTraits library to decide what kind of deleting is required (<a href=\"http://www.boost.org/doc/libs/1_36_0/libs/type_traits/doc/html/index.html\" rel=\"nofollow noreferrer\">http://www.boost.org/doc/libs/1_36_0/libs/type_traits/doc/html/index.html</a>). I'm sure it will have a trait that will let you decide if your contained type is a pointer or not, and thus decide how it needs to be destructed. You may need to implement traits yourself for any other types you want to use in MyContainer that have any other specific deletion requirements. Good luck with it! If you solve it, show us how you did it.</p>\n"
},
{
"answer_id": 169439,
"author": "Scott Langham",
"author_id": 11898,
"author_profile": "https://Stackoverflow.com/users/11898",
"pm_score": 3,
"selected": true,
"text": "<p>I'd recommend if you want to store pointers to complex types, that you use your container as: <code>MyContainer<shared_ptr<SomeComplexType> ></code>, and for primitive types just use <code>MyContainer<float></code>.</p>\n\n<p>The <code>shared_ptr</code> should take care of deleting the complex type appropriately when it is destructed. And nothing fancy will happen when the primitive type is destructed.</p>\n\n<hr>\n\n<p>You don't need much of a destructor if you use your container this way. How do you hold your items in the container? Do you use an STL container, or an array on the heap? An STL container would take care of deleting itself. If you delete the array, this would cause the destructor for each element to be executed, and if each element is a <code>shared_ptr</code>, the <code>shared_ptr</code> destructor will delete the pointer it itself is holding.</p>\n"
},
{
"answer_id": 169688,
"author": "Harald Scheirich",
"author_id": 22080,
"author_profile": "https://Stackoverflow.com/users/22080",
"pm_score": 0,
"selected": false,
"text": "<p>If you don't want to go with smart pointers you can try partial template specialisation, it let's you write a template that is only used when you instatiate a container with a pointer type.</p>\n"
},
{
"answer_id": 169986,
"author": "yrp",
"author_id": 7228,
"author_profile": "https://Stackoverflow.com/users/7228",
"pm_score": 1,
"selected": false,
"text": "<p>You most probably <em>do</em> want to use smart pointers here, it really simplifies the problem. However, just as an excercise, it's quite easy to determine if given type is pointer. Rough implementation (could be more elegant, but I dont want to introduce int2type):</p>\n\n<pre><code>typedef char YesType;\ntypedef char NoType[2];\n\ntemplate<typename T>\nstruct IsPointer\n{\ntypedef NoType Result;\n};\ntemplate<typename T>\nstruct IsPointer<T*>\n{\ntypedef YesType Result;\n};\n\ntemplate<typename T>\nstruct MyContainer\n{\n~MyContainer()\n{\n IsPointer<T>::Result r;\n Clear(&r);\n delete[] data;\n}\nvoid Clear(YesType*)\n{\n for (int i = 0; i < numElements; ++i)\n delete data[i];\n}\nvoid Clear(NoType*) {}\n\nT* data;\nint numElements;\n</code></pre>\n\n<p>};</p>\n"
},
{
"answer_id": 192322,
"author": "Greg Rogers",
"author_id": 5963,
"author_profile": "https://Stackoverflow.com/users/5963",
"pm_score": 0,
"selected": false,
"text": "<p>delete is used to deallocate memory previously allocated with <code>new</code>. You do not need to use delete here, when blah and complexBlah go out of scope they will automatically be destroyed.</p>\n\n<p>While <a href=\"https://stackoverflow.com/questions/169404/c-template-destructors-for-both-primitive-and-complex-data-types#169986\">yrp's answer</a> shows you one way of using template specialization to delete the objects contained if they are pointers, and not if they aren't, this seems like a fragile solution. If you want behavior like this you are better off using <a href=\"http://www.boost.org/doc/libs/release/libs/ptr_container/\" rel=\"nofollow noreferrer\">Boost Pointer Container</a> libraries, which provide this exact behavior. The reason that the standard library doesn't is because the containers themselves don't know if they control the contained pointer or not - you need to wrap the pointer in a type that does know - ie a smart pointer.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169404",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14621/"
] |
In a [related question](https://stackoverflow.com/questions/168408/c-alternatives-to-void-pointers-that-isnt-templates) I asked about creating a generic container. Using polymorphic templates seems like the right way to go.
However, I can't for the life of me figure out how a destructor should be written. I want the owner of the memory allocated to be the containers even if the example constructor takes in an array of `T` (along with its dimensions), allocated at some other point.
I would like to be able to do something like
```
MyContainer<float> blah();
...
delete blah;
```
and
```
MyContainer<ComplexObjectType*> complexBlah();
...
delete complexBlah;`
```
Can I do something like this? Can I do it without smart pointers?
Again, thanks for your input.
|
I'd recommend if you want to store pointers to complex types, that you use your container as: `MyContainer<shared_ptr<SomeComplexType> >`, and for primitive types just use `MyContainer<float>`.
The `shared_ptr` should take care of deleting the complex type appropriately when it is destructed. And nothing fancy will happen when the primitive type is destructed.
---
You don't need much of a destructor if you use your container this way. How do you hold your items in the container? Do you use an STL container, or an array on the heap? An STL container would take care of deleting itself. If you delete the array, this would cause the destructor for each element to be executed, and if each element is a `shared_ptr`, the `shared_ptr` destructor will delete the pointer it itself is holding.
|
169,419 |
<p>I like having my warning level set at W4 but all new projects start at W3. Is there some way to change the default value for warning levels for new projects?</p>
|
[
{
"answer_id": 169434,
"author": "albertein",
"author_id": 23020,
"author_profile": "https://Stackoverflow.com/users/23020",
"pm_score": 2,
"selected": false,
"text": "<p>I don't know how to do it at the IDE but you cand always edit the new project templates at:</p>\n\n<pre><code>%PROGRAM_FILES%\\Microsoft Visual Studio 9.0\\Common7\\IDE\\ProjectTemplates\\\n</code></pre>\n\n<p>If you're using the express version there could be a minor variation in the path:</p>\n\n<pre><code>%PROGRAM_FILES%\\Microsoft Visual Studio 9.0\\Common7\\IDE\\{Version}\\ProjectTemplates\\\n</code></pre>\n\n<p>Where {Version} is the express flavor you are using, VCSExpress, VBExpress, etc.</p>\n\n<p>The templates are zip files, just edit the project changing:</p>\n\n<pre><code><WarningLevel>3</WarningLevel>\n</code></pre>\n\n<p>to</p>\n\n<pre><code><WarningLevel>4</WarningLevel>\n</code></pre>\n"
},
{
"answer_id": 169489,
"author": "Brian Paden",
"author_id": 3176,
"author_profile": "https://Stackoverflow.com/users/3176",
"pm_score": 0,
"selected": false,
"text": "<p>I couldn't find any project templates or anything on my machine so I just searched in all the files for WarningLevel. I found common.js at</p>\n\n<pre><code>%\\Microsoft Visual Studio 9.0\\VC\\VCWizards\\1033\n</code></pre>\n\n<p>Searching in the file showed WarningLevel appeared in three places, lines 672, 699 and 3354. I simply changed the three lines reading</p>\n\n<pre><code>CLTool.WarningLevel = WarningLevel_3;\n</code></pre>\n\n<p>to</p>\n\n<pre><code>CLTool.WarningLevel = WarningLevel_4;\n</code></pre>\n\n<p>When I made a new project it was set at /w4. So this worked for me, won't guarantee it won't hose your machine.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169419",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3176/"
] |
I like having my warning level set at W4 but all new projects start at W3. Is there some way to change the default value for warning levels for new projects?
|
I don't know how to do it at the IDE but you cand always edit the new project templates at:
```
%PROGRAM_FILES%\Microsoft Visual Studio 9.0\Common7\IDE\ProjectTemplates\
```
If you're using the express version there could be a minor variation in the path:
```
%PROGRAM_FILES%\Microsoft Visual Studio 9.0\Common7\IDE\{Version}\ProjectTemplates\
```
Where {Version} is the express flavor you are using, VCSExpress, VBExpress, etc.
The templates are zip files, just edit the project changing:
```
<WarningLevel>3</WarningLevel>
```
to
```
<WarningLevel>4</WarningLevel>
```
|
169,420 |
<p>I've been looking for a generic way to deal with bidirectional associations and a way to handle the inverse updates in manual written Java code.</p>
<p>For those who don't know what I'm talking about, here is an example. Below it are my current results of (unsatisfying) solutions.</p>
<pre><code>public class A {
public B getB();
public void setB(B b);
}
public class B {
public List<A> getAs();
}
</code></pre>
<p>Now, when updating any end of the association, in order to maintain consistency, the other end must be updated as well. Either manually each time </p>
<pre><code>a.setB(b);
b.getA().add(a);
</code></pre>
<p>or by putting matching code in the setter / getter and use a custom List implementation.</p>
<p>I've found an outdated, unmaintained project whose dependencies are no longer available (<a href="https://e-nspire-gemini.dev.java.net/" rel="nofollow noreferrer">https://e-nspire-gemini.dev.java.net/</a>). It deals with the problem by using annotations that are used to inject the necessary code automatically.</p>
<p>Does anyone know of another framework that deals with this in a generic, unobtrusive way ala gemini?</p>
<p>ciao,
Elmar</p>
|
[
{
"answer_id": 169447,
"author": "anjanb",
"author_id": 11142,
"author_profile": "https://Stackoverflow.com/users/11142",
"pm_score": 4,
"selected": true,
"text": "<p>google collections (from google's internal code) -- <a href=\"http://code.google.com/p/google-collections/\" rel=\"nofollow noreferrer\">http://code.google.com/p/google-collections/</a> is Java Generics compatible(not only compatible, uses generics very well)</p>\n\n<p>Class BiMap -- <a href=\"http://google-collections.googlecode.com/svn/trunk/javadoc/index.html?http://google-collections.googlecode.com/svn/trunk/javadoc/com/google/common/collect/package-summary.html\" rel=\"nofollow noreferrer\">http://google-collections.googlecode.com/svn/trunk/javadoc/index.html?http://google-collections.googlecode.com/svn/trunk/javadoc/com/google/common/collect/package-summary.html</a>\nallows for Bidirectional associations.</p>\n\n<p>Some of these classes are expected to make their way into JDK 7.</p>\n"
},
{
"answer_id": 169758,
"author": "Kevin Day",
"author_id": 10973,
"author_profile": "https://Stackoverflow.com/users/10973",
"pm_score": 0,
"selected": false,
"text": "<p>Unless you abstract out the setters, you are going to have to provide some sort of event notification mechanism. If your objects are JavaBeans, then you are looking at using PropertyChangeSupport and firing property change events.</p>\n\n<p>If you do that (or have some other mechanism for detecting changes), then Glazed Lists provides an <a href=\"http://publicobject.com/glazedlists/glazedlists-1.5.0/api/ca/odell/glazedlists/ObservableElementList.html\" rel=\"nofollow noreferrer\">ObservableElementList</a> that could easily be used to handle the association synchronization from the list end (i.e. adding A to List< A> automatically calls a.setB(b)). The other direction is easily handled using property change monitoring (or equivalent).</p>\n\n<p>I realize that this isn't a generic solution, but it seems like it would be an easy foundation for one.</p>\n\n<p>Note that something like this would <em>require</em> a special list implementation in the B class - no way short of AOP type solutions that you could handle it in the general case (i.e. using ArrayList or something like that).</p>\n\n<p>I should also point out that what you are trying to achieve is something of the holy grail of data binding. There are some decent implementations for binding at the field level (stuff like getters and setters) (see JGoodies binding and JSR 295 for examples). There is also one really good implementation for list type binding (Glazed Lists, referred to above). We use both techniques in concert with each other in almost all of our applications, but have never tried to go quite as abstract as what you are asking about.</p>\n\n<p>If I were designing this, I would look at something like this:</p>\n\n<pre><code>AssociationBuilder.createAssociation(A a, Connector< A> ca, B b, Connector< B> cb, Synchronizer< A,B> sync)\n</code></pre>\n\n<p>Connector is an interface that allows for a single interface for various change notification types. Synchronizer is an interface that is called to make sure both objects are in sync whenever one of them is changed.</p>\n\n<pre><code>sync(ChangeInfo info, A a, B b) // make sure that b reflects current state of a and vice-versa. \n</code></pre>\n\n<p>ChangeInfo provides data on which member changed, and what the changes actually were. We are. If you are trying to really keep this generic, then you pretty much have to punt the implementation of this up to the framework user.</p>\n\n<p>With the above in place, it would be possible to have a number of pre-defined Connectors and Synchronizers that meet different binding criteria.</p>\n\n<p>Interestingly, the above method signature is pretty similar to the JSR 295 createAutoBinding() method call. Property objects are the equivalent of Connector. JSR 295 doesn't have the Synchronizer (instead, they have a binding strategy specified as an ENUM - plus JSR 295 works only with property->property binding, trying to bind a field value of one object to that object's list membership in another object is not even on the table for them).</p>\n"
},
{
"answer_id": 170371,
"author": "Tom Hawtin - tackline",
"author_id": 4725,
"author_profile": "https://Stackoverflow.com/users/4725",
"pm_score": 0,
"selected": false,
"text": "<p>To make sense, these calsses will be peers. I suggest a package-private mechanism (in the absense of friend) to keep consistency.</p>\n\n<pre><code>public final class A {\n private B b;\n public B getB() {\n return b;\n }\n public void setB(final B b) {\n if (b == this.b) {\n // Important!!\n return;\n }\n // Be a member of both Bs (hence check in getAs).\n if (b != null) {\n b.addA(this);\n }\n // Atomic commit to change.\n this.b = b;\n // Remove from old B.\n if (this.b != null) {\n this.b.removeA(this);\n }\n }\n}\n\npublic final class B {\n private final List<A> as;\n /* pp */ void addA(A a) {\n if (a == null) {\n throw new NullPointerException();\n }\n // LinkedHashSet may be better under more demanding usage patterns.\n if (!as.contains(a)) {\n as.add(a);\n }\n }\n /* pp */ void removeA(A a) {\n if (a == null) {\n throw new NullPointerException();\n }\n as.removeA(a);\n }\n public List<A> getAs() {\n // Copy only those that really are associated with us.\n List<A> copy = new ArrayList<A>(as.size());\n for (A a : as) {\n if (a.getB() == this) {\n copy.add(a);\n }\n }\n return Collection.unmodifiableList(copy);\n }\n}\n</code></pre>\n\n<p>(Disclaime: Not tested or even compiled.)</p>\n\n<p>Mostly exception safe (may leak in exception case). Thread safety, many-many, performance, libraryisation, etc., is left as an exercise to the interested reader.</p>\n"
},
{
"answer_id": 172638,
"author": "Elmar Weber",
"author_id": 19935,
"author_profile": "https://Stackoverflow.com/users/19935",
"pm_score": 0,
"selected": false,
"text": "<p>Thanks for all suggestions. But none came close to what I was looking for, I probably formulated the question in a wrong way.</p>\n\n<p>I was looking for a replacement for gemini, so for a way to handle this in an unobtrusive manner, without polluting the code with endless checks and special List implementations. This calls of course for an AOP based approach, as suggested by Kevin.</p>\n\n<p>When i looked around a little more I found a package of gemini on cnet that contain all sources and dependencies with sources. The missing sources for the dependencies was the only concern that stopped me from using it. Since now all sources are available bugs can be fixed. \nIn case anyone looks for this: <a href=\"http://www.download.com/Gemini/3000-2413_4-10440077.html\" rel=\"nofollow noreferrer\">http://www.download.com/Gemini/3000-2413_4-10440077.html</a></p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169420",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/19935/"
] |
I've been looking for a generic way to deal with bidirectional associations and a way to handle the inverse updates in manual written Java code.
For those who don't know what I'm talking about, here is an example. Below it are my current results of (unsatisfying) solutions.
```
public class A {
public B getB();
public void setB(B b);
}
public class B {
public List<A> getAs();
}
```
Now, when updating any end of the association, in order to maintain consistency, the other end must be updated as well. Either manually each time
```
a.setB(b);
b.getA().add(a);
```
or by putting matching code in the setter / getter and use a custom List implementation.
I've found an outdated, unmaintained project whose dependencies are no longer available (<https://e-nspire-gemini.dev.java.net/>). It deals with the problem by using annotations that are used to inject the necessary code automatically.
Does anyone know of another framework that deals with this in a generic, unobtrusive way ala gemini?
ciao,
Elmar
|
google collections (from google's internal code) -- <http://code.google.com/p/google-collections/> is Java Generics compatible(not only compatible, uses generics very well)
Class BiMap -- <http://google-collections.googlecode.com/svn/trunk/javadoc/index.html?http://google-collections.googlecode.com/svn/trunk/javadoc/com/google/common/collect/package-summary.html>
allows for Bidirectional associations.
Some of these classes are expected to make their way into JDK 7.
|
169,428 |
<p>this code always returns 0 in PHP 5.2.5 for microseconds:</p>
<pre><code><?php
$dt = new DateTime();
echo $dt->format("Y-m-d\TH:i:s.u") . "\n";
?>
</code></pre>
<p>Output:</p>
<pre><code>[root@www1 ~]$ php date_test.php
2008-10-03T20:31:26.000000
[root@www1 ~]$ php date_test.php
2008-10-03T20:31:27.000000
[root@www1 ~]$ php date_test.php
2008-10-03T20:31:27.000000
[root@www1 ~]$ php date_test.php
2008-10-03T20:31:28.000000
</code></pre>
<p>Any ideas?</p>
|
[
{
"answer_id": 169458,
"author": "eydelber",
"author_id": 25039,
"author_profile": "https://Stackoverflow.com/users/25039",
"pm_score": 6,
"selected": true,
"text": "<p>This seems to work, although it seems illogical that <a href=\"http://us.php.net/date\" rel=\"noreferrer\">http://us.php.net/date</a> documents the microsecond specifier yet doesn't really support it:</p>\n\n<pre><code>function getTimestamp()\n{\n return date(\"Y-m-d\\TH:i:s\") . substr((string)microtime(), 1, 8);\n}\n</code></pre>\n"
},
{
"answer_id": 169499,
"author": "jmccartie",
"author_id": 24708,
"author_profile": "https://Stackoverflow.com/users/24708",
"pm_score": 4,
"selected": false,
"text": "<p>This function pulled from <a href=\"http://us3.php.net/date\" rel=\"noreferrer\">http://us3.php.net/date</a></p>\n\n<pre><code>function udate($format, $utimestamp = null)\n{\n if (is_null($utimestamp))\n $utimestamp = microtime(true);\n\n $timestamp = floor($utimestamp);\n $milliseconds = round(($utimestamp - $timestamp) * 1000000);\n\n return date(preg_replace('`(?<!\\\\\\\\)u`', $milliseconds, $format), $timestamp);\n}\n\necho udate('H:i:s.u'); // 19:40:56.78128\n</code></pre>\n\n<p>Very screwy you have to implement this function to get \"u\" to work... :\\</p>\n"
},
{
"answer_id": 169798,
"author": "scronide",
"author_id": 22844,
"author_profile": "https://Stackoverflow.com/users/22844",
"pm_score": 1,
"selected": false,
"text": "<p><a href=\"http://www.php.net/manual/en/function.date-create.php\" rel=\"nofollow noreferrer\">date_create</a></p>\n\n<blockquote>\n <p>time: String in a format accepted by strtotime(), defaults to \"now\".</p>\n</blockquote>\n\n<p><a href=\"http://www.php.net/manual/en/function.strtotime.php\" rel=\"nofollow noreferrer\">strtotime</a></p>\n\n<blockquote>\n <p>time: The string to parse, according to the GNU » Date Input Formats syntax. Before PHP 5.0.0, microseconds weren't allowed in the time, since PHP 5.0.0 they are allowed but ignored.</p>\n</blockquote>\n"
},
{
"answer_id": 366948,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>String in a format accepted by strtotime()\nIt work!</p>\n"
},
{
"answer_id": 4203058,
"author": "Davis Devasia",
"author_id": 510585,
"author_profile": "https://Stackoverflow.com/users/510585",
"pm_score": -1,
"selected": false,
"text": "<p>date('u') is supported only from PHP 5.2. Your PHP may be older!</p>\n"
},
{
"answer_id": 4329809,
"author": "enobrev",
"author_id": 14651,
"author_profile": "https://Stackoverflow.com/users/14651",
"pm_score": 1,
"selected": false,
"text": "<p>Working from <a href=\"https://stackoverflow.com/users/145709/lucky\">Lucky</a>'s <a href=\"https://stackoverflow.com/questions/169428/php-datetime-microseconds-always-returns-0/169458#169458\">comment</a> and this <a href=\"http://bugs.php.net/bug.php?id=49779\" rel=\"nofollow noreferrer\">feature request in the PHP bug database</a>, I use something like this:</p>\n\n<pre><code>class ExtendedDateTime extends DateTime {\n /**\n * Returns new DateTime object. Adds microtime for \"now\" dates\n * @param string $sTime\n * @param DateTimeZone $oTimeZone \n */\n public function __construct($sTime = 'now', DateTimeZone $oTimeZone = NULL) {\n // check that constructor is called as current date/time\n if (strtotime($sTime) == time()) {\n $aMicrotime = explode(' ', microtime());\n $sTime = date('Y-m-d H:i:s.' . $aMicrotime[0] * 1000000, $aMicrotime[1]);\n }\n\n // DateTime throws an Exception with a null TimeZone\n if ($oTimeZone instanceof DateTimeZone) {\n parent::__construct($sTime, $oTimeZone);\n } else {\n parent::__construct($sTime);\n }\n }\n}\n\n$oDate = new ExtendedDateTime();\necho $oDate->format('Y-m-d G:i:s.u');\n</code></pre>\n\n<p>Output:</p>\n\n<pre><code>2010-12-01 18:12:10.146625\n</code></pre>\n"
},
{
"answer_id": 4414060,
"author": "dbwebtek",
"author_id": 538362,
"author_profile": "https://Stackoverflow.com/users/538362",
"pm_score": 4,
"selected": false,
"text": "<p>Try this and it shows micro seconds:</p>\n\n<pre><code>$t = microtime(true);\n$micro = sprintf(\"%06d\",($t - floor($t)) * 1000000);\n$d = new DateTime( date('Y-m-d H:i:s.'.$micro,$t) );\n\nprint $d->format(\"Y-m-d H:i:s.u\");\n</code></pre>\n"
},
{
"answer_id": 6604836,
"author": "tr0y",
"author_id": 832634,
"author_profile": "https://Stackoverflow.com/users/832634",
"pm_score": 4,
"selected": false,
"text": "<p>You can specify that your input contains microseconds when constructing a <code>DateTime</code> object, and use <code>microtime(true)</code> directly as the input.</p>\n\n<p>Unfortunately, this will fail if you hit an exact second, because there will be no <code>.</code> in the microtime output; so use <code>sprintf</code> to force it to contain a <code>.0</code> in that case:</p>\n\n<pre><code>date_create_from_format(\n 'U.u', sprintf('%.f', microtime(true))\n)->format('Y-m-d\\TH:i:s.uO');\n</code></pre>\n\n<p>Or equivalently (more OO-style)</p>\n\n<pre><code>DateTime::createFromFormat(\n 'U.u', sprintf('%.f', microtime(true))\n)->format('Y-m-d\\TH:i:s.uO');\n</code></pre>\n"
},
{
"answer_id": 10880637,
"author": "f.ardelian",
"author_id": 492130,
"author_profile": "https://Stackoverflow.com/users/492130",
"pm_score": -1,
"selected": false,
"text": "<p>This method is safer than the accepted answer:</p>\n\n<pre><code>date('Y-m-d H:i:s.') . str_pad(substr((float)microtime(), 2), 6, '0', STR_PAD_LEFT)\n</code></pre>\n\n<p>Output:</p>\n\n<pre><code>2012-06-01 12:00:13.036613\n</code></pre>\n\n<p><strong>Update: Not recommended</strong> (see comments)</p>\n"
},
{
"answer_id": 16468901,
"author": "crashmaxed",
"author_id": 2367551,
"author_profile": "https://Stackoverflow.com/users/2367551",
"pm_score": 0,
"selected": false,
"text": "<p>Inside of an application I am writing I have the need to set/display microtime on DateTime objects. It seems the only way to get the DateTime object to recognize microseconds is to initialize it with the time in format of \"YYYY-MM-DD HH:MM:SS.uuuuuu\". The space in between the date and time portions can also be a \"T\" as is usual in ISO8601 format.</p>\n\n<p>The following function returns a DateTime object initialized to the local timezone (code can be modified as needed of course to suit individual needs):</p>\n\n<pre><code>// Return DateTime object including microtime for \"now\"\nfunction dto_now()\n{\n list($usec, $sec) = explode(' ', microtime());\n $usec = substr($usec, 2, 6);\n $datetime_now = date('Y-m-d H:i:s\\.', $sec).$usec;\n return new DateTime($datetime_now, new DateTimeZone(date_default_timezone_get()));\n}\n</code></pre>\n"
},
{
"answer_id": 16922855,
"author": "KyleFarris",
"author_id": 83304,
"author_profile": "https://Stackoverflow.com/users/83304",
"pm_score": 2,
"selected": false,
"text": "<p>This has worked for me and is a simple three-liner:</p>\n\n<pre><code>function udate($format='Y-m-d H:i:s.', $microtime=NULL) {\n if(NULL === $microtime) $microtime = microtime();\n list($microseconds,$unix_time) = explode(' ', $microtime);\n return date($format,$unix_time) . array_pop(explode('.',$microseconds));\n}\n</code></pre>\n\n<p>This, by default (no params supplied) will return a string in this format for the current microsecond it was called:</p>\n\n<blockquote>\n <p>YYYY-MM-DD HH:MM:SS.UUUUUUUU</p>\n</blockquote>\n\n<p>An even simpler/faster one (albeit, with only half the precision) would be as follows:</p>\n\n<pre><code>function udate($format='Y-m-d H:i:s.', $microtime=NULL) {\n if(NULL === $microtime) $microtime = microtime(true);\n list($unix_time,$microseconds) = explode('.', $microtime);\n return date($format,$unix_time) . $microseconds;\n}\n</code></pre>\n\n<p>This one would print out in the following format:</p>\n\n<blockquote>\n <p>YYYY-MM-DD HH:MM:SS.UUUU</p>\n</blockquote>\n"
},
{
"answer_id": 17695036,
"author": "Nadeem",
"author_id": 2389988,
"author_profile": "https://Stackoverflow.com/users/2389988",
"pm_score": 1,
"selected": false,
"text": "<p>How about this?</p>\n\n<pre><code>$micro_date = microtime();\n$date_array = explode(\" \",$micro_date);\n$date = date(\"Y-m-d H:i:s\",$date_array[1]);\necho \"Date: $date:\" . $date_array[0].\"<br>\";\n</code></pre>\n\n<p><strong>Sample Output</strong></p>\n\n<blockquote>\n <blockquote>\n <p>2013-07-17 08:23:37:0.88862400</p>\n </blockquote>\n</blockquote>\n"
},
{
"answer_id": 18502608,
"author": "Manu Manjunath",
"author_id": 495598,
"author_profile": "https://Stackoverflow.com/users/495598",
"pm_score": 0,
"selected": false,
"text": "<p>PHP documentation clearly says \"<em>Note that date() will always generate 000000 since it takes an integer parameter...</em>\". If you want a quick replacement for <code>date()</code> function use below function:</p>\n\n\n\n<pre><code>function date_with_micro($format, $timestamp = null) {\n if (is_null($timestamp) || $timestamp === false) {\n $timestamp = microtime(true);\n }\n $timestamp_int = (int) floor($timestamp);\n $microseconds = (int) round(($timestamp - floor($timestamp)) * 1000000.0, 0);\n $format_with_micro = str_replace(\"u\", $microseconds, $format);\n return date($format_with_micro, $timestamp_int);\n}\n</code></pre>\n\n<p>(available as gist here: <a href=\"https://gist.github.com/m-manu/6248802\" rel=\"nofollow\">date_with_micro.php</a>)</p>\n"
},
{
"answer_id": 28515980,
"author": "mgutt",
"author_id": 318765,
"author_profile": "https://Stackoverflow.com/users/318765",
"pm_score": 1,
"selected": false,
"text": "<p>This should be the most flexible and precise:</p>\n\n<pre><code>function udate($format, $timestamp=null) {\n if (!isset($timestamp)) $timestamp = microtime();\n // microtime(true)\n if (count($t = explode(\" \", $timestamp)) == 1) {\n list($timestamp, $usec) = explode(\".\", $timestamp);\n $usec = \".\" . $usec;\n }\n // microtime (much more precise)\n else {\n $usec = $t[0];\n $timestamp = $t[1];\n }\n // 7 decimal places for \"u\" is maximum\n $date = new DateTime(date('Y-m-d H:i:s' . substr(sprintf('%.7f', $usec), 1), $timestamp));\n return $date->format($format);\n}\necho udate(\"Y-m-d\\TH:i:s.u\") . \"\\n\";\necho udate(\"Y-m-d\\TH:i:s.u\", microtime(true)) . \"\\n\";\necho udate(\"Y-m-d\\TH:i:s.u\", microtime()) . \"\\n\";\n/* returns:\n2015-02-14T14:10:30.472647\n2015-02-14T14:10:30.472700\n2015-02-14T14:10:30.472749\n*/\n</code></pre>\n"
},
{
"answer_id": 28937386,
"author": "Ryan",
"author_id": 563394,
"author_profile": "https://Stackoverflow.com/users/563394",
"pm_score": 3,
"selected": false,
"text": "<pre><code>\\DateTime::createFromFormat('U.u', microtime(true));\n</code></pre>\n\n<p>Will give you (at least on most systems):</p>\n\n<pre><code>object(DateTime)(\n 'date' => '2015-03-09 17:27:39.456200',\n 'timezone_type' => 3,\n 'timezone' => 'Australia/Darwin'\n)\n</code></pre>\n\n<p>But there is a loss of precision because of PHP float rounding. It's not truly microseconds.</p>\n\n<p><strong>Update</strong></p>\n\n<p>This is probably the best compromise of the <code>createFromFormat()</code> options, and provides full precision.</p>\n\n<pre><code>\\DateTime::createFromFormat('0.u00 U', microtime());\n</code></pre>\n\n<p><strong>gettimeofday()</strong></p>\n\n<p>More explicit, and maybe more robust. Solves the bug found by Xavi.</p>\n\n<pre><code>$time = gettimeofday(); \n\\DateTime::createFromFormat('U.u', sprintf('%d.%06d', $time['sec'], $time['usec']));\n</code></pre>\n"
},
{
"answer_id": 30109661,
"author": "JScarry",
"author_id": 791470,
"author_profile": "https://Stackoverflow.com/users/791470",
"pm_score": 0,
"selected": false,
"text": "<p>Building on Lucky’s comment, I wrote a simple way to store messages on the server. In the past I’ve used hashes and increments to get unique file names, but the date with micro-seconds works well for this application.</p>\n\n<pre><code>// Create a unique message ID using the time and microseconds\n list($usec, $sec) = explode(\" \", microtime());\n $messageID = date(\"Y-m-d H:i:s \", $sec) . substr($usec, 2, 8);\n $fname = \"./Messages/$messageID\";\n\n $fp = fopen($fname, 'w');\n</code></pre>\n\n<p>This is the name of the output file:</p>\n\n<pre><code>2015-05-07 12:03:17 65468400\n</code></pre>\n"
},
{
"answer_id": 32552994,
"author": "Gras Double",
"author_id": 289317,
"author_profile": "https://Stackoverflow.com/users/289317",
"pm_score": 0,
"selected": false,
"text": "<p>Some answers make use of several timestamps, which is conceptually wrong, and overlapping issues may occur: seconds from <code>21:15:05.999</code> combined by microseconds from <code>21:15:06.000</code> give <code>21:15:05.000</code>.</p>\n\n<p>Apparently the simplest is to use <a href=\"http://php.net/manual/en/datetime.createfromformat.php\" rel=\"nofollow noreferrer\"><code>DateTime::createFromFormat()</code></a> with <code>U.u</code>, but <a href=\"https://stackoverflow.com/questions/169428/php-datetime-microseconds-always-returns-0#comment-12220584\">as stated in a comment</a>, it fails if there are no microseconds.</p>\n\n<p>So, I'm suggesting this code:</p>\n\n<pre><code>function udate($format, $time = null) {\n\n if (!$time) {\n $time = microtime(true);\n }\n\n // Avoid missing dot on full seconds: (string)42 and (string)42.000000 give '42'\n $time = number_format($time, 6, '.', '');\n\n return DateTime::createFromFormat('U.u', $time)->format($format);\n}\n</code></pre>\n"
},
{
"answer_id": 38334226,
"author": "hozza",
"author_id": 614616,
"author_profile": "https://Stackoverflow.com/users/614616",
"pm_score": 3,
"selected": false,
"text": "<p>Right, I'd like to clear this up once and for all. </p>\n\n<p>An explanation of how to display the <a href=\"https://en.wikipedia.org/wiki/ISO_8601\" rel=\"nofollow noreferrer\">ISO 8601</a> format date & time in PHP with <strong>milli</strong>seconds and <strong>micro</strong>seconds...</p>\n\n<p><em><strong>milli</strong>seconds or 'ms' have 4 digits after the decimal point e.g. 0.1234. <strong>micro</strong>seconds or 'µs' have 7 digits after decimal. Seconds fractions/names explanation <a href=\"http://www.sengpielaudio.com/calculator-millisecond.htm\" rel=\"nofollow noreferrer\">here</a></em></p>\n\n<p>PHP's <code>date()</code> function does not behave entirely as expected with milliseconds or microseconds as it will only except an integer, as explained in the <a href=\"http://php.net/manual/en/function.date.php\" rel=\"nofollow noreferrer\">php date docs</a> under format character 'u'.</p>\n\n<p>Based on Lucky's comment idea (<a href=\"https://stackoverflow.com/questions/169428/php-datetime-microseconds-always-returns-0#comment1068246_169458\">here</a>), but with corrected PHP syntax and properly handling seconds formatting <em>(Lucky's code added an incorrect extra '0' after the seconds)</em></p>\n\n<p>These also eliminate race conditions and correctly formats the seconds.</p>\n\n<h2>PHP Date with <strong>milli</strong>seconds</h2>\n\n<p>Working Equivalent of <code>date('Y-m-d H:i:s').\".$milliseconds\";</code> </p>\n\n<pre><code>list($sec, $usec) = explode('.', microtime(true));\necho date('Y-m-d H:i:s.', $sec) . $usec;\n</code></pre>\n\n<p>Output = <code>2016-07-12 16:27:08.5675</code></p>\n\n<h2>PHP Date with <strong>micro</strong>seconds</h2>\n\n<p>Working Equivalent of <code>date('Y-m-d H:i:s').\".$microseconds\";</code> or <code>date('Y-m-d H:i:s.u')</code> if the date function behaved as expected with microseconds/<code>microtime()</code>/'u'</p>\n\n<pre><code>list($usec, $sec) = explode(' ', microtime());\necho date('Y-m-d H:i:s', $sec) . substr($usec, 1);\n</code></pre>\n\n<p>Output = <code>2016-07-12 16:27:08.56752900</code></p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169428",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25039/"
] |
this code always returns 0 in PHP 5.2.5 for microseconds:
```
<?php
$dt = new DateTime();
echo $dt->format("Y-m-d\TH:i:s.u") . "\n";
?>
```
Output:
```
[root@www1 ~]$ php date_test.php
2008-10-03T20:31:26.000000
[root@www1 ~]$ php date_test.php
2008-10-03T20:31:27.000000
[root@www1 ~]$ php date_test.php
2008-10-03T20:31:27.000000
[root@www1 ~]$ php date_test.php
2008-10-03T20:31:28.000000
```
Any ideas?
|
This seems to work, although it seems illogical that <http://us.php.net/date> documents the microsecond specifier yet doesn't really support it:
```
function getTimestamp()
{
return date("Y-m-d\TH:i:s") . substr((string)microtime(), 1, 8);
}
```
|
169,450 |
<p><em>Information-Expert</em>, <em>Tell-Don't-Ask</em>, and <em>SRP</em> are often mentioned together as best practices. But I think they are at odds. Here is what I'm talking about.</p>
<p>Code that favors SRP but violates Tell-Don't-Ask & Info-Expert:</p>
<pre><code>Customer bob = ...;
// TransferObjectFactory has to use Customer's accessors to do its work,
// violates Tell Don't Ask
CustomerDTO dto = TransferObjectFactory.createFrom(bob);
</code></pre>
<p>Code that favors Tell-Don't-Ask & Info-Expert but violates SRP:</p>
<pre><code>Customer bob = ...;
// Now Customer is doing more than just representing the domain concept of Customer,
// violates SRP
CustomerDTO dto = bob.toDTO();
</code></pre>
<p>Please fill me in on how these practices can co-exist peacefully.</p>
<p>Definitions of the terms,</p>
<ul>
<li><p>Information Expert: objects that have the data needed for an operation should host the operation.</p></li>
<li><p>Tell Don't Ask: don't ask objects for data in order to do work; tell the objects to do the work.</p></li>
<li><p>Single Responsibility Principle: each object should have a narrowly defined responsibility.</p></li>
</ul>
|
[
{
"answer_id": 169493,
"author": "Hamish Smith",
"author_id": 15572,
"author_profile": "https://Stackoverflow.com/users/15572",
"pm_score": 3,
"selected": false,
"text": "<p>I don't think that they are so much at odds as they are emphasizing different things that will cause you pain. One is about structuring code to make it clear where particular responsibilities are and reducing coupling, the other is about reducing the reasons to modify a class.</p>\n\n<p>We all have to make decisions each and every day about how to structure code and what dependencies we are willing to introduce into designs. </p>\n\n<p>We have built up a lot of useful guidelines, maxims and patterns that can help us to make the decisions. </p>\n\n<p>Each of these is useful to detect different kinds of problems that could be present in our designs. For any specific problem that you may be looking at there will be a sweet spot somewhere. </p>\n\n<p>The different guidelines do contradict each other. Just applying every piece of guidance you have heard or read will not make your design better. </p>\n\n<p>For the specific problem you are looking at today you need to decide what the most important factors that are likely to cause you pain are. </p>\n"
},
{
"answer_id": 170023,
"author": "Phil Bennett",
"author_id": 2995,
"author_profile": "https://Stackoverflow.com/users/2995",
"pm_score": 2,
"selected": false,
"text": "<p>Those classes are not at odds. The DTO is simply serving as a conduit of data from storage that is intended to be used as a dumb container. It certainly doesn't violate the SRP. </p>\n\n<p>On the other hand the .toDTO method is questionable -- why should Customer have this responsibility? For \"purity's\" sake I would have another class who's job it was to create DTOs from business objects like Customer. </p>\n\n<p>Don't forget these principles are principles, and when you can et away with simpler solutions until changing requirements force the issue, then do so. Needless complexity is definitely something to avoid.</p>\n\n<p>I highly recommend, BTW, Robert C. Martin's Agile Patterns, Practices and principles for much more in depth treatments of this subject.</p>\n"
},
{
"answer_id": 2955454,
"author": "Seva Parfenov",
"author_id": 179697,
"author_profile": "https://Stackoverflow.com/users/179697",
"pm_score": 3,
"selected": false,
"text": "<p>You can talk about \"Tell Don't Ask\" when you ask for object's state in order to tell object to do something.</p>\n\n<p>In your first example TransferObjectFactory.createFrom just a converter. It doesn't tell Customer object to do something after inspecting it's state.</p>\n\n<p>I think first example is correct.</p>\n"
},
{
"answer_id": 12099089,
"author": "Ed Hastings",
"author_id": 714248,
"author_profile": "https://Stackoverflow.com/users/714248",
"pm_score": 0,
"selected": false,
"text": "<p>I don't 100% agree w/ your two examples as being representative, but from a general perspective you seem to be reasoning from the assumption of two objects and only two objects.</p>\n\n<p>If you separate the problem out further and create one (or more) specialized objects to take on the individual responsibilities you have, and then have the controlling object pass instances of the other objects it is using to the specialized objects you have carved off, you should be able to observe a happy compromise between SRP (each responsibility has handled by a specialized object), and Tell Don't Ask (the controlling object is telling the specialized objects it is composing together to do whatever it is that they do, to each other). </p>\n\n<p>It's a composition solution that relies on a controller of some sort to coordinate and delegate between other objects without getting mired in their internal details.</p>\n"
},
{
"answer_id": 13421639,
"author": "Michael Parker",
"author_id": 1554346,
"author_profile": "https://Stackoverflow.com/users/1554346",
"pm_score": 1,
"selected": false,
"text": "<p>DTOs with a sister class (like you have) violate all three principles you stated, and encapsulation, which is why you're having problems here. </p>\n\n<p>What are you using this CustomerDTO for, and why can't you simply use Customer, and have the DTOs data inside the customer? If you're not careful, the CustomerDTO will need a Customer, and a Customer will need a CustomerDTO.</p>\n\n<p>TellDontAsk says that if you are basing a decision on the state of one object (e.g. a customer), then that decision should be performed inside the customer class itself. </p>\n\n<p>An example is if you want to remind the Customer to pay any outstanding bills, so you call</p>\n\n<pre><code> List<Bill> bills = Customer.GetOutstandingBills();\n PaymentReminder.RemindCustomer(customer, bills);\n</code></pre>\n\n<p>this is a violation. Instead you want to do </p>\n\n<pre><code>Customer.RemindAboutOutstandingBills() \n</code></pre>\n\n<p>(and of course you will need to pass in the PaymentReminder as a dependency upon construction of the customer).</p>\n\n<p>Information Expert says the same thing pretty much.</p>\n\n<p>Single Responsibility Principle can be easily misunderstood - it says that the customer class should have one responsibility, but also that the responsibility of grouping data, methods, and other classes aligned with the 'Customer' concept should be encapsulated by only one class. What constitutes a single responsibility is extremely hard to define exactly and I would recommend more reading on the matter.</p>\n"
},
{
"answer_id": 43689140,
"author": "Matthew Flynn",
"author_id": 243314,
"author_profile": "https://Stackoverflow.com/users/243314",
"pm_score": 1,
"selected": false,
"text": "<p>Craig Larman discussed this when he introduced GRASP in Applying UML and Patterns to Object-Oriented Analysis and Design and Iterative Development (2004):</p>\n<blockquote>\n<p>In some situations, a solution suggested by Expert is undesirable, usually because of problems in coupling and cohesion (these principles are discussed later in this chapter).</p>\n<p>For example, who should be responsible for saving a Sale in a database? Certainly, much of the information to be saved is in the Sale object, and thus Expert could argue that the responsibility lies in the Sale class. And, by logical extension of this decision, each class would have its own services to save itself in a database. But acting on that reasoning leads to problems in cohesion, coupling, and duplication. For example, the Sale class must now contain logic related to database handling, such as that related to SQL and JDBC (Java Database Connectivity). The class no longer focuses on just the pure application logic of “being a sale.” Now other kinds of responsibilities lower its cohesion. The class must be coupled to the technical database services of another subsystem, such as JDBC services, rather than just being coupled to other objects in the domain layer of software objects, so its coupling increases. And it is likely that similar database logic would be duplicated in many persistent classes.</p>\n<p>All these problems indicate violation of a basic architectural principle: design for a separation of major system concerns. Keep application logic in one place (such as the domain software objects), keep database logic in another place (such as a separate persistence services subsystem), and so forth, rather than intermingling different system concerns in the same component.[11]</p>\n<p>Supporting a separation of major concerns improves coupling and cohesion in a design. Thus, even though by Expert we could find some justification for putting the responsibility for database services in the Sale class, for other reasons (usually cohesion and coupling), we'd end up with a poor design.</p>\n</blockquote>\n<p>Thus the SRP generally trumps Information Expert.</p>\n<p>However, the Dependency Inversion Principle can combine well with Expert. The argument here would be that Customer should not have a dependency of CustomerDTO (general to detail), but the other way around. This would mean that CustomerDTO is the Expert and should know how to build itself given a Customer:</p>\n<pre><code>CustomerDTO dto = new CustomerDTO(bob);\n</code></pre>\n<p>If you're allergic to new, you could go static:</p>\n<pre><code>CustomerDTO dto = CustomerDTO.buildFor(bob);\n</code></pre>\n<p>Or, if you hate both, we come back around to an AbstractFactory:</p>\n<pre><code>public abstract class DTOFactory<D, E> {\n public abstract D createDTO(E entity);\n}\n\n\npublic class CustomerDTOFactory extends DTOFactory<CustomerDTO, Customer> {\n @Override\n public CustomerDTO createDTO(Customer entity) {\n return new CustomerDTO(entity);\n }\n}\n</code></pre>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169450",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10759/"
] |
*Information-Expert*, *Tell-Don't-Ask*, and *SRP* are often mentioned together as best practices. But I think they are at odds. Here is what I'm talking about.
Code that favors SRP but violates Tell-Don't-Ask & Info-Expert:
```
Customer bob = ...;
// TransferObjectFactory has to use Customer's accessors to do its work,
// violates Tell Don't Ask
CustomerDTO dto = TransferObjectFactory.createFrom(bob);
```
Code that favors Tell-Don't-Ask & Info-Expert but violates SRP:
```
Customer bob = ...;
// Now Customer is doing more than just representing the domain concept of Customer,
// violates SRP
CustomerDTO dto = bob.toDTO();
```
Please fill me in on how these practices can co-exist peacefully.
Definitions of the terms,
* Information Expert: objects that have the data needed for an operation should host the operation.
* Tell Don't Ask: don't ask objects for data in order to do work; tell the objects to do the work.
* Single Responsibility Principle: each object should have a narrowly defined responsibility.
|
I don't think that they are so much at odds as they are emphasizing different things that will cause you pain. One is about structuring code to make it clear where particular responsibilities are and reducing coupling, the other is about reducing the reasons to modify a class.
We all have to make decisions each and every day about how to structure code and what dependencies we are willing to introduce into designs.
We have built up a lot of useful guidelines, maxims and patterns that can help us to make the decisions.
Each of these is useful to detect different kinds of problems that could be present in our designs. For any specific problem that you may be looking at there will be a sweet spot somewhere.
The different guidelines do contradict each other. Just applying every piece of guidance you have heard or read will not make your design better.
For the specific problem you are looking at today you need to decide what the most important factors that are likely to cause you pain are.
|
169,459 |
<p>I have an ISAm table in mySql that was created similar to this:</p>
<pre><code>create table mytable (
id int not null auto_increment primary key,
name varchar(64) not null );
create unique index nameIndex on mytable (name);
</code></pre>
<p>I have multiple processes inserting rows into this table. If two processes try to insert the same "name", I want to make sure that one of them either gets an error or finds the row with the matching "name".</p>
<p>Should I lock the table and in the lock make sure that the name doesn't exist, or should I rely on the server giving an error to one of the processes that try to insert a value that already exists in the unique indexed field?</p>
<p>I'm a bit hesitant to use a lock because I don't want to get into a deadlock situation.</p>
|
[
{
"answer_id": 169462,
"author": "Martin",
"author_id": 2581,
"author_profile": "https://Stackoverflow.com/users/2581",
"pm_score": 3,
"selected": true,
"text": "<p>Do not bother locking, your index will prevent duplicates. You should handle the error code from your application.</p>\n\n<p>MySQL should return an error code of 1062 (or SQLSTATE 23000) when your unique key constraint is violated.</p>\n"
},
{
"answer_id": 169481,
"author": "micahwittman",
"author_id": 11181,
"author_profile": "https://Stackoverflow.com/users/11181",
"pm_score": 0,
"selected": false,
"text": "<p>By the way you described the fear of encountering a DEADLOCK, the causation may not be clearly understood (unless there is more to your querying than described in the question).</p>\n\n<p>A good <a href=\"http://www.codinghorror.com/blog/archives/001166.html\" rel=\"nofollow noreferrer\">summary someone else wrote</a>:</p>\n\n<blockquote>\n <ol>\n <li>Query 1 begins by locking resource A</li>\n <li>Query 2 begins by locking resource B</li>\n <li>Query 1, in order to continue, needs a lock on resource B, but Query 2 is locking that resource, so Query 1 starts waiting for it to release</li>\n <li>In the meantime, Query 2 tries to finish, but it needs a lock on resource A in order to finish, but it can't get that because Query 1 has the lock on that.</li>\n </ol>\n</blockquote>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169459",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3740/"
] |
I have an ISAm table in mySql that was created similar to this:
```
create table mytable (
id int not null auto_increment primary key,
name varchar(64) not null );
create unique index nameIndex on mytable (name);
```
I have multiple processes inserting rows into this table. If two processes try to insert the same "name", I want to make sure that one of them either gets an error or finds the row with the matching "name".
Should I lock the table and in the lock make sure that the name doesn't exist, or should I rely on the server giving an error to one of the processes that try to insert a value that already exists in the unique indexed field?
I'm a bit hesitant to use a lock because I don't want to get into a deadlock situation.
|
Do not bother locking, your index will prevent duplicates. You should handle the error code from your application.
MySQL should return an error code of 1062 (or SQLSTATE 23000) when your unique key constraint is violated.
|
169,477 |
<p>I'm trying to implement a server control that frobs a couple of files inside the web directory of an ASP.NET site. I'm using VS Web Dev Express 2008 as my IDE. When I call <code>HttpContext.Current.Request.ApplicationPath</code> to get a path to the web root so I can find those files, it returns C:. What the heck?</p>
<p>Absolute paths work just fine, but I'd like to be able to feed the server control a relative directory and just let it do it's thing. What have I done wrong?</p>
<pre><code>public String Target
{
get { return _target; }
set
{
if (value.StartsWith("~"))
{
// WTF? Gives me C:\? Why?
_target = HttpContext.Current.Request.ApplicationPath +
value.Substring(1);
}
else
{
_target = value;
}
}
}
private String _target;
protected override void Render(HtmlTextWriter writer)
{
HtmlControl wrapper = new HtmlGenericControl("div");
int fileCount = 0;
try
{
DirectoryInfo dir = new DirectoryInfo(_target);
foreach (FileInfo f in dir.GetFiles())
{
fileCount++;
a = new HtmlAnchor();
a.Attributes.Add("href", f.FullName);
a.InnerHtml = f.Name;
wrapper.Controls.Add(a);
}
}
catch (IOException e)
{
throw e;
}
Controls.Add(wrapper);
base.Render(writer);
}
</code></pre>
|
[
{
"answer_id": 169490,
"author": "Kibbee",
"author_id": 1862,
"author_profile": "https://Stackoverflow.com/users/1862",
"pm_score": 2,
"selected": false,
"text": "<p>This might be because it's using the development web server, which can just serve files from any directory on your hard drive. It doesn't have any specific root. Can you run your project under IIS (assuming your version of windows supports it), and see if you get the same results? </p>\n\n<p>To get rid of the problem completely you could just hard code the path you want to look at in your web.config and go around any problems with what Request.ApplicationPath is returning.</p>\n\n<p>[EDIT]</p>\n\n<p>Just found out you can use</p>\n\n<pre><code>HTTPContext.Current.Request.ServerVariables(\"APPL_PHYSICAL_PATH\")\n</code></pre>\n\n<p>to return the path of your application, on the hard disk. I'm pretty sure that's what you are looking for. If that's not right, check out all the other <a href=\"http://neural.cs.nthu.edu.tw/jang/sandbox/asp/examples/request5.asp\" rel=\"nofollow noreferrer\">ServerVariables</a> to see if you can get what you are looking for.</p>\n"
},
{
"answer_id": 169510,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 2,
"selected": false,
"text": "<p>How about this:</p>\n\n<pre><code>Server.MapPath(ResolveUrl(\"~/filename\"))\n</code></pre>\n\n<p>There's also information on a page TLAnews.com titled, <a href=\"http://www.tla.ch/TLA/NEWS/2006vb/07-06-01-VB-url-path.htm\" rel=\"nofollow noreferrer\"><em>Understanding Paths in ASP.NET</em></a>.</p>\n"
},
{
"answer_id": 169576,
"author": "Timothy Lee Russell",
"author_id": 12919,
"author_profile": "https://Stackoverflow.com/users/12919",
"pm_score": -1,
"selected": false,
"text": "<p>The <a href=\"http://peterblum.com/ADME/Home.aspx\" rel=\"nofollow noreferrer\">ADME Developer's Kit</a> may be what you need if you are trying to get the directory at design time.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169477",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/16398/"
] |
I'm trying to implement a server control that frobs a couple of files inside the web directory of an ASP.NET site. I'm using VS Web Dev Express 2008 as my IDE. When I call `HttpContext.Current.Request.ApplicationPath` to get a path to the web root so I can find those files, it returns C:. What the heck?
Absolute paths work just fine, but I'd like to be able to feed the server control a relative directory and just let it do it's thing. What have I done wrong?
```
public String Target
{
get { return _target; }
set
{
if (value.StartsWith("~"))
{
// WTF? Gives me C:\? Why?
_target = HttpContext.Current.Request.ApplicationPath +
value.Substring(1);
}
else
{
_target = value;
}
}
}
private String _target;
protected override void Render(HtmlTextWriter writer)
{
HtmlControl wrapper = new HtmlGenericControl("div");
int fileCount = 0;
try
{
DirectoryInfo dir = new DirectoryInfo(_target);
foreach (FileInfo f in dir.GetFiles())
{
fileCount++;
a = new HtmlAnchor();
a.Attributes.Add("href", f.FullName);
a.InnerHtml = f.Name;
wrapper.Controls.Add(a);
}
}
catch (IOException e)
{
throw e;
}
Controls.Add(wrapper);
base.Render(writer);
}
```
|
This might be because it's using the development web server, which can just serve files from any directory on your hard drive. It doesn't have any specific root. Can you run your project under IIS (assuming your version of windows supports it), and see if you get the same results?
To get rid of the problem completely you could just hard code the path you want to look at in your web.config and go around any problems with what Request.ApplicationPath is returning.
[EDIT]
Just found out you can use
```
HTTPContext.Current.Request.ServerVariables("APPL_PHYSICAL_PATH")
```
to return the path of your application, on the hard disk. I'm pretty sure that's what you are looking for. If that's not right, check out all the other [ServerVariables](http://neural.cs.nthu.edu.tw/jang/sandbox/asp/examples/request5.asp) to see if you can get what you are looking for.
|
169,506 |
<p>I have a form with many input fields.</p>
<p>When I catch the submit form event with jQuery, is it possible to get all the input fields of that form in an associative array?</p>
|
[
{
"answer_id": 169553,
"author": "Oli",
"author_id": 12870,
"author_profile": "https://Stackoverflow.com/users/12870",
"pm_score": 3,
"selected": false,
"text": "<p>Associative? Not without some work, but you can use generic selectors:</p>\n\n<pre><code>var items = new Array();\n\n$('#form_id:input').each(function (el) {\n items[el.name] = el;\n});\n</code></pre>\n"
},
{
"answer_id": 169554,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 10,
"selected": true,
"text": "<pre><code>$('#myForm').submit(function() {\n // get all the inputs into an array.\n var $inputs = $('#myForm :input');\n\n // not sure if you wanted this, but I thought I'd add it.\n // get an associative array of just the values.\n var values = {};\n $inputs.each(function() {\n values[this.name] = $(this).val();\n });\n\n});\n</code></pre>\n\n<hr>\n\n<p>Thanks to the tip from Simon_Weaver, here is another way you could do it, using <a href=\"http://api.jquery.com/serializeArray/\" rel=\"noreferrer\"><code>serializeArray</code></a>:</p>\n\n<pre><code>var values = {};\n$.each($('#myForm').serializeArray(), function(i, field) {\n values[field.name] = field.value;\n});\n</code></pre>\n\n<p>Note that this snippet will fail on <code><select multiple></code> elements.</p>\n\n<p>It appears that the <a href=\"http://diveintohtml5.ep.io/forms.html\" rel=\"noreferrer\">new HTML 5 form inputs</a> don't work with <code>serializeArray</code> in jQuery version 1.3. This works in version 1.4+</p>\n"
},
{
"answer_id": 169961,
"author": "Quentin",
"author_id": 19068,
"author_profile": "https://Stackoverflow.com/users/19068",
"pm_score": 4,
"selected": false,
"text": "<pre><code>$('#myForm').bind('submit', function () {\n var elements = this.elements;\n});</code></pre>\n\n<p>The elements variable will contain all the inputs, selects, textareas and fieldsets within the form.</p>\n"
},
{
"answer_id": 1443005,
"author": "Lance Rushing",
"author_id": 150463,
"author_profile": "https://Stackoverflow.com/users/150463",
"pm_score": 8,
"selected": false,
"text": "<p>Late to the party on this question, but this is even easier:</p>\n\n<pre><code>$('#myForm').submit(function() {\n // Get all the forms elements and their values in one step\n var values = $(this).serialize();\n\n});\n</code></pre>\n"
},
{
"answer_id": 2315772,
"author": "Simon_Weaver",
"author_id": 16940,
"author_profile": "https://Stackoverflow.com/users/16940",
"pm_score": 5,
"selected": false,
"text": "<p>The <a href=\"http://docs.jquery.com/Plugins:Forms\" rel=\"noreferrer\">jquery.form</a> plugin may help with what others are looking for that end up on this question. I'm not sure if it directly does what you want or not. </p>\n\n<p>There is also the <a href=\"http://api.jquery.com/serializeArray/\" rel=\"noreferrer\">serializeArray</a> function.</p>\n"
},
{
"answer_id": 3863951,
"author": "slarti42uk",
"author_id": 429740,
"author_profile": "https://Stackoverflow.com/users/429740",
"pm_score": 0,
"selected": false,
"text": "<p>When I needed to do an ajax call with all the form fields, I had problems with the <strong>:input</strong> selector returning all checkboxes whether or not they were checked. I added a new selector to just get the submit-able form elements:</p>\n\n<pre><code>$.extend($.expr[':'],{\n submitable: function(a){\n if($(a).is(':checkbox:not(:checked)'))\n {\n return false;\n }\n else if($(a).is(':input'))\n {\n return true;\n }\n else\n {\n return false;\n }\n }\n});\n</code></pre>\n\n<p>usage:</p>\n\n<pre><code>$('#form_id :submitable');\n</code></pre>\n\n<p>I've not tested it with multiple select boxes yet though but It works for getting all the form fields in the way a standard submit would.</p>\n\n<p>I used this when customising the product options on an OpenCart site to include checkboxes and text fields as well as the standard select box type.</p>\n"
},
{
"answer_id": 4892057,
"author": "Man Called Haney",
"author_id": 139062,
"author_profile": "https://Stackoverflow.com/users/139062",
"pm_score": 2,
"selected": false,
"text": "<p>Don't forget the checkboxes and radio buttons -</p>\n\n<pre><code>var inputs = $(\"#myForm :input\");\nvar obj = $.map(inputs, function(n, i) {\n var o = {};\n if (n.type == \"radio\" || n.type == \"checkbox\")\n o[n.id] = $(n).attr(\"checked\");\n else\n o[n.id] = $(n).val();\n return o;\n});\nreturn obj\n</code></pre>\n"
},
{
"answer_id": 7305864,
"author": "suizo",
"author_id": 836948,
"author_profile": "https://Stackoverflow.com/users/836948",
"pm_score": 2,
"selected": false,
"text": "<p>I had the same problem and solved it in a different way.</p>\n\n<pre><code>var arr = new Array();\n$(':input').each(function() {\n arr.push($(this).val());\n});\narr;\n</code></pre>\n\n<p>It returns the value of all input fields. You could change the <code>$(':input')</code> to be more specific.</p>\n"
},
{
"answer_id": 7650082,
"author": "Itako",
"author_id": 500921,
"author_profile": "https://Stackoverflow.com/users/500921",
"pm_score": 2,
"selected": false,
"text": "<p>Same solution as given by <strong>nickf</strong>, but with array input names taken into account\neg </p>\n\n<p><code><input type=\"text\" name=\"array[]\" /></code></p>\n\n<pre><code>values = {};\n$(\"#something :input\").each(function() {\n if (this.name.search(/\\[\\]/) > 0) //search for [] in name\n {\n if (typeof values[this.name] != \"undefined\") {\n values[this.name] = values[this.name].concat([$(this).val()])\n } else {\n values[this.name] = [$(this).val()];\n }\n } else {\n values[this.name] = $(this).val();\n }\n});\n</code></pre>\n"
},
{
"answer_id": 8433722,
"author": "Chris",
"author_id": 1088085,
"author_profile": "https://Stackoverflow.com/users/1088085",
"pm_score": 3,
"selected": false,
"text": "<p>Had a similar issue with a slight twist and I thought I'd throw this out. I have a callback function that gets the form so I had a form object already and couldn't easy variants on <code>$('form:input')</code>. Instead I came up with:</p>\n\n<pre><code> var dataValues = {};\n form.find('input').each(\n function(unusedIndex, child) {\n dataValues[child.name] = child.value;\n });\n</code></pre>\n\n<p>Its similar but not identical situation, but I found this thread very useful and thought I'd tuck this on the end and hope someone else found it useful.</p>\n"
},
{
"answer_id": 9891143,
"author": "Sarah Vessels",
"author_id": 38743,
"author_profile": "https://Stackoverflow.com/users/38743",
"pm_score": 3,
"selected": false,
"text": "<p>jQuery's <code>serializeArray</code> does not include disabled fields, so if you need those too, try:</p>\n\n<pre><code>var data = {};\n$('form.my-form').find('input, textarea, select').each(function(i, field) {\n data[field.name] = field.value;\n});\n</code></pre>\n"
},
{
"answer_id": 10164559,
"author": "Billy",
"author_id": 1088500,
"author_profile": "https://Stackoverflow.com/users/1088500",
"pm_score": 0,
"selected": false,
"text": "<p>serialize() is the best method. @ Christopher Parker say that Nickf's anwser accomplishes more, however it does not take into account that the form may contain textarea and select menus. It is far better to use serialize() and then manipulate that as you need to. Data from serialize() can be used in either an Ajax post or get, so there is no issue there.</p>\n"
},
{
"answer_id": 10264676,
"author": "Malachi",
"author_id": 287545,
"author_profile": "https://Stackoverflow.com/users/287545",
"pm_score": 4,
"selected": false,
"text": "<p>Sometimes I find getting one at a time is more useful. For that, there's this:</p>\n\n<pre><code>var input_name = \"firstname\";\nvar input = $(\"#form_id :input[name='\"+input_name+\"']\"); \n</code></pre>\n"
},
{
"answer_id": 11098341,
"author": "Jason Norwood-Young",
"author_id": 493510,
"author_profile": "https://Stackoverflow.com/users/493510",
"pm_score": 1,
"selected": false,
"text": "<p>If you need to get multiple values from inputs and you're using []'s to define the inputs with multiple values, you can use the following:</p>\n\n<pre><code>$('#contentform').find('input, textarea, select').each(function(x, field) {\n if (field.name) {\n if (field.name.indexOf('[]')>0) {\n if (!$.isArray(data[field.name])) {\n data[field.name]=new Array();\n }\n data[field.name].push(field.value);\n } else {\n data[field.name]=field.value;\n }\n } \n});\n</code></pre>\n"
},
{
"answer_id": 20450781,
"author": "Julian",
"author_id": 3013580,
"author_profile": "https://Stackoverflow.com/users/3013580",
"pm_score": 0,
"selected": false,
"text": "<p>Hope this helps somebody. :)</p>\n\n<pre><code>// This html:\n// <form id=\"someCoolForm\">\n// <input type=\"text\" class=\"form-control\" name=\"username\" value=\"....\" />\n// \n// <input type=\"text\" class=\"form-control\" name=\"profile.first_name\" value=\"....\" />\n// <input type=\"text\" class=\"form-control\" name=\"profile.last_name\" value=\"....\" />\n// \n// <input type=\"text\" class=\"form-control\" name=\"emails[]\" value=\"...\" />\n// <input type=\"text\" class=\"form-control\" name=\"emails[]\" value=\"..\" />\n// <input type=\"text\" class=\"form-control\" name=\"emails[]\" value=\".\" />\n// </form>\n// \n// With this js:\n// \n// var form1 = parseForm($('#someCoolForm'));\n// console.log(form1);\n// \n// Will output something like:\n// {\n// username: \"test2\"\n// emails:\n// 0: \"[email protected]\"\n// 1: \"[email protected]\"\n// profile: Object\n// first_name: \"...\"\n// last_name: \"...\"\n// }\n// \n// So, function below:\n\nvar parseForm = function (form) {\n\n var formdata = form.serializeArray();\n\n var data = {};\n\n _.each(formdata, function (element) {\n\n var value = _.values(element);\n\n // Parsing field arrays.\n if (value[0].indexOf('[]') > 0) {\n var key = value[0].replace('[]', '');\n\n if (!data[key])\n data[key] = [];\n\n data[value[0].replace('[]', '')].push(value[1]);\n } else\n\n // Parsing nested objects.\n if (value[0].indexOf('.') > 0) {\n\n var parent = value[0].substring(0, value[0].indexOf(\".\"));\n var child = value[0].substring(value[0].lastIndexOf(\".\") + 1);\n\n if (!data[parent])\n data[parent] = {};\n\n data[parent][child] = value[1];\n } else {\n data[value[0]] = value[1];\n }\n });\n\n return data;\n};\n</code></pre>\n"
},
{
"answer_id": 26843102,
"author": "Chris Wheeler",
"author_id": 2747260,
"author_profile": "https://Stackoverflow.com/users/2747260",
"pm_score": 3,
"selected": false,
"text": "<p><a href=\"http://api.jquery.com/serializearray/\" rel=\"noreferrer\">http://api.jquery.com/serializearray/</a></p>\n\n<pre><code>$('#form').on('submit', function() {\n var data = $(this).serializeArray();\n});\n</code></pre>\n\n<p>This can also be done without jQuery using the XMLHttpRequest Level 2 FormData object</p>\n\n<p><a href=\"http://www.w3.org/TR/2010/WD-XMLHttpRequest2-20100907/#the-formdata-interface\" rel=\"noreferrer\">http://www.w3.org/TR/2010/WD-XMLHttpRequest2-20100907/#the-formdata-interface</a></p>\n\n<pre><code>var data = new FormData([form])\n</code></pre>\n"
},
{
"answer_id": 27176157,
"author": "Ole Aldric",
"author_id": 4301060,
"author_profile": "https://Stackoverflow.com/users/4301060",
"pm_score": 4,
"selected": false,
"text": "<p>Here is another solution, this way you can fetch all data about the form and use it in a serverside call or something.</p>\n\n<pre><code>$('.form').on('submit', function( e )){ \n var form = $( this ), // this will resolve to the form submitted\n action = form.attr( 'action' ),\n type = form.attr( 'method' ),\n data = {};\n\n // Make sure you use the 'name' field on the inputs you want to grab. \n form.find( '[name]' ).each( function( i , v ){\n var input = $( this ), // resolves to current input element.\n name = input.attr( 'name' ),\n value = input.val();\n data[name] = value;\n });\n\n // Code which makes use of 'data'.\n\n e.preventDefault();\n}\n</code></pre>\n\n<p>You can then use this with ajax calls:</p>\n\n<pre><code>function sendRequest(action, type, data) {\n $.ajax({\n url: action,\n type: type,\n data: data\n })\n .done(function( returnedHtml ) {\n $( \"#responseDiv\" ).append( returnedHtml );\n })\n .fail(function() {\n $( \"#responseDiv\" ).append( \"This failed\" );\n });\n}\n</code></pre>\n\n<p>Hope this is of any use for any of you :)</p>\n"
},
{
"answer_id": 36668583,
"author": "Marcelo Rocha",
"author_id": 5905467,
"author_profile": "https://Stackoverflow.com/users/5905467",
"pm_score": 0,
"selected": false,
"text": "<p>All answers are good, but if there's a field that you like to ignore in that function? Easy, give the field a property, for example ignore_this:</p>\n\n<pre><code><input type=\"text\" name=\"some_name\" ignore_this>\n</code></pre>\n\n<p>And in your Serialize Function:</p>\n\n<pre><code>if(!$(name).prop('ignorar')){\n do_your_thing;\n}\n</code></pre>\n\n<p>That's the way you ignore some fields.</p>\n"
},
{
"answer_id": 41141152,
"author": "Roman Grinev",
"author_id": 2834876,
"author_profile": "https://Stackoverflow.com/users/2834876",
"pm_score": 1,
"selected": false,
"text": "<p>I am using this code without each loop:</p>\n\n<pre><code>$('.subscribe-form').submit(function(e){\n var arr=$(this).serializeArray();\n var values={};\n for(i in arr){values[arr[i]['name']]=arr[i]['value']}\n console.log(values);\n return false;\n});\n</code></pre>\n"
},
{
"answer_id": 43871489,
"author": "Ryanman",
"author_id": 1214741,
"author_profile": "https://Stackoverflow.com/users/1214741",
"pm_score": 2,
"selected": false,
"text": "<p>Seems strange that nobody has upvoted or proposed a concise solution to getting list data. Hardly any forms are going to be single-dimension objects. </p>\n\n<p>The downside of this solution is, of course, that your singleton objects are going to have to be accessed at the [0] index. But IMO that's way better than using one of the dozen-line mapping solutions.</p>\n\n<pre><code>var formData = $('#formId').serializeArray().reduce(function (obj, item) {\n if (obj[item.name] == null) {\n obj[item.name] = [];\n } \n obj[item.name].push(item.value);\n return obj;\n}, {});\n</code></pre>\n"
},
{
"answer_id": 44493957,
"author": "sparsh turkane",
"author_id": 7113702,
"author_profile": "https://Stackoverflow.com/users/7113702",
"pm_score": 3,
"selected": false,
"text": "<p><strong>This piece of code will work</strong>\ninstead of name, email enter your form fields name</p>\n\n<pre><code>$(document).ready(function(){\n $(\"#form_id\").submit(function(event){\n event.preventDefault();\n var name = $(\"input[name='name']\",this).val();\n var email = $(\"input[name='email']\",this).val();\n });\n});\n</code></pre>\n"
},
{
"answer_id": 45824035,
"author": "T.Liu",
"author_id": 3574916,
"author_profile": "https://Stackoverflow.com/users/3574916",
"pm_score": 1,
"selected": false,
"text": "<p>Inspired by answers of <a href=\"https://stackoverflow.com/a/1443005/3574916\">Lance Rushing</a> and <a href=\"https://stackoverflow.com/a/2315772/3574916\">Simon_Weaver</a>, this is my favourite solution.</p>\n\n<pre><code>$('#myForm').submit( function( event ) {\n var values = $(this).serializeArray();\n // In my case, I need to fetch these data before custom actions\n event.preventDefault();\n});\n</code></pre>\n\n<p>The output is an array of objects, e.g.</p>\n\n<pre><code>[{name: \"start-time\", value: \"11:01\"}, {name: \"end-time\", value: \"11:11\"}]\n</code></pre>\n\n<p>With the code below,</p>\n\n<pre><code>var inputs = {};\n$.each(values, function(k, v){\n inputs[v.name]= v.value;\n});\n</code></pre>\n\n<p>its final output would be</p>\n\n<pre><code>{\"start-time\":\"11:01\", \"end-time\":\"11:01\"}\n</code></pre>\n"
},
{
"answer_id": 57202528,
"author": "dipenparmar12",
"author_id": 8592918,
"author_profile": "https://Stackoverflow.com/users/8592918",
"pm_score": 2,
"selected": false,
"text": "<p>I hope this is helpful, as well as easiest one.</p>\n\n<pre><code> $(\"#form\").submit(function (e) { \n e.preventDefault();\n input_values = $(this).serializeArray();\n });\n</code></pre>\n"
},
{
"answer_id": 60259912,
"author": "Teodor Rautu",
"author_id": 12911767,
"author_profile": "https://Stackoverflow.com/users/12911767",
"pm_score": 0,
"selected": false,
"text": "<p>Try the following code:</p>\n\n<pre><code>jQuery(\"#form\").serializeArray().filter(obje => \nobje.value!='').map(aobj=>aobj.name+\"=\"+aobj.value).join(\"&\")\n</code></pre>\n"
},
{
"answer_id": 60342733,
"author": "tzazo",
"author_id": 12718345,
"author_profile": "https://Stackoverflow.com/users/12718345",
"pm_score": 1,
"selected": false,
"text": "<p>For multiple select elements (<code><select multiple=\"multiple\"></code>), I modified the solution from @Jason Norwood-Young to get it working.</p>\n\n<p>The answer (as posted) only takes the value from the first element that was selected, not <strong>all of them</strong>. It also didn't initialize or return <code>data</code>, the former throwing a JavaScript error.</p>\n\n<p>Here is the new version:</p>\n\n<pre><code>function _get_values(form) {\n let data = {};\n $(form).find('input, textarea, select').each(function(x, field) {\n if (field.name) {\n if (field.name.indexOf('[]') > 0) {\n if (!$.isArray(data[field.name])) {\n data[field.name] = new Array();\n }\n for (let i = 0; i < field.selectedOptions.length; i++) {\n data[field.name].push(field.selectedOptions[i].value);\n }\n\n } else {\n data[field.name] = field.value;\n }\n }\n\n });\n return data\n}\n</code></pre>\n\n<p>Usage:</p>\n\n<pre><code>_get_values($('#form'))\n</code></pre>\n\n<p>Note: You just need to ensure that the <code>name</code> of your select has <code>[]</code> appended to the end of it, for example:</p>\n\n<pre><code><select name=\"favorite_colors[]\" multiple=\"multiple\">\n <option value=\"red\">Red</option>\n <option value=\"green\">Green</option>\n <option value=\"blue\">Blue</option>\n</select>\n</code></pre>\n"
},
{
"answer_id": 61876539,
"author": "Raushan",
"author_id": 12119519,
"author_profile": "https://Stackoverflow.com/users/12119519",
"pm_score": 2,
"selected": false,
"text": "<pre><code>$(\"#form-id\").submit(function (e) { \n e.preventDefault();\n inputs={};\n input_serialized = $(this).serializeArray();\n input_serialized.forEach(field => {\n inputs[field.name] = field.value;\n })\n console.log(inputs)\n});\n</code></pre>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169506",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7883/"
] |
I have a form with many input fields.
When I catch the submit form event with jQuery, is it possible to get all the input fields of that form in an associative array?
|
```
$('#myForm').submit(function() {
// get all the inputs into an array.
var $inputs = $('#myForm :input');
// not sure if you wanted this, but I thought I'd add it.
// get an associative array of just the values.
var values = {};
$inputs.each(function() {
values[this.name] = $(this).val();
});
});
```
---
Thanks to the tip from Simon\_Weaver, here is another way you could do it, using [`serializeArray`](http://api.jquery.com/serializeArray/):
```
var values = {};
$.each($('#myForm').serializeArray(), function(i, field) {
values[field.name] = field.value;
});
```
Note that this snippet will fail on `<select multiple>` elements.
It appears that the [new HTML 5 form inputs](http://diveintohtml5.ep.io/forms.html) don't work with `serializeArray` in jQuery version 1.3. This works in version 1.4+
|
169,511 |
<p>How do I iterate over a range of numbers in Bash when the range is given by a variable?</p>
<p>I know I can do this (called "sequence expression" in the Bash <a href="http://www.gnu.org/software/bash/manual/bashref.html#Brace-Expansion" rel="noreferrer">documentation</a>):</p>
<pre><code> for i in {1..5}; do echo $i; done
</code></pre>
<p>Which gives:</p>
<blockquote>
<p>1 <br/>
2 <br/>
3 <br/>
4 <br/>
5</p>
</blockquote>
<p>Yet, how can I replace either of the range endpoints with a variable? This doesn't work:</p>
<pre><code>END=5
for i in {1..$END}; do echo $i; done
</code></pre>
<p>Which prints:</p>
<blockquote>
<p>{1..5}</p>
</blockquote>
|
[
{
"answer_id": 169515,
"author": "Peter Hoffmann",
"author_id": 720,
"author_profile": "https://Stackoverflow.com/users/720",
"pm_score": 5,
"selected": false,
"text": "<p>You can use</p>\n\n<pre><code>for i in $(seq $END); do echo $i; done\n</code></pre>\n"
},
{
"answer_id": 169517,
"author": "Jiaaro",
"author_id": 2908,
"author_profile": "https://Stackoverflow.com/users/2908",
"pm_score": 12,
"selected": true,
"text": "<pre><code>for i in $(seq 1 $END); do echo $i; done</code></pre>\n\n<p>edit: I prefer <code>seq</code> over the other methods because I can actually remember it ;)</p>\n"
},
{
"answer_id": 169518,
"author": "paxdiablo",
"author_id": 14860,
"author_profile": "https://Stackoverflow.com/users/14860",
"pm_score": 4,
"selected": false,
"text": "<p>This works fine in <code>bash</code>:</p>\n\n<pre><code>END=5\ni=1 ; while [[ $i -le $END ]] ; do\n echo $i\n ((i = i + 1))\ndone\n</code></pre>\n"
},
{
"answer_id": 169602,
"author": "tzot",
"author_id": 6899,
"author_profile": "https://Stackoverflow.com/users/6899",
"pm_score": 8,
"selected": false,
"text": "<h3>discussion</h3>\n\n<p>Using <code>seq</code> is fine, as Jiaaro suggested. Pax Diablo suggested a Bash loop to avoid calling a subprocess, with the additional advantage of being more memory friendly if $END is too large. Zathrus spotted a typical bug in the loop implementation, and also hinted that since <code>i</code> is a text variable, continuous conversions to-and-fro numbers are performed with an associated slow-down.</p>\n\n<h3>integer arithmetic</h3>\n\n<p>This is an improved version of the Bash loop:</p>\n\n<pre><code>typeset -i i END\nlet END=5 i=1\nwhile ((i<=END)); do\n echo $i\n …\n let i++\ndone\n</code></pre>\n\n<p>If the only thing that we want is the <code>echo</code>, then we could write <code>echo $((i++))</code>.</p>\n\n<p><a href=\"https://stackoverflow.com/questions/169511/how-do-i-iterate-over-a-range-of-numbers-in-bash#171041\">ephemient</a> taught me something: Bash allows <code>for ((expr;expr;expr))</code> constructs. Since I've never read the whole man page for Bash (like I've done with the Korn shell (<code>ksh</code>) man page, and that was a long time ago), I missed that.</p>\n\n<p>So,</p>\n\n<pre><code>typeset -i i END # Let's be explicit\nfor ((i=1;i<=END;++i)); do echo $i; done\n</code></pre>\n\n<p>seems to be the most memory-efficient way (it won't be necessary to allocate memory to consume <code>seq</code>'s output, which could be a problem if END is very large), although probably not the “fastest”.</p>\n\n<h3>the initial question</h3>\n\n<p>eschercycle noted that the {<em>a</em>..<em>b</em>} Bash notation works only with literals; true, accordingly to the Bash manual. One can overcome this obstacle with a single (internal) <code>fork()</code> without an <code>exec()</code> (as is the case with calling <code>seq</code>, which being another image requires a fork+exec):</p>\n\n<pre><code>for i in $(eval echo \"{1..$END}\"); do\n</code></pre>\n\n<p>Both <code>eval</code> and <code>echo</code> are Bash builtins, but a <code>fork()</code> is required for the command substitution (the <code>$(…)</code> construct).</p>\n"
},
{
"answer_id": 171041,
"author": "ephemient",
"author_id": 20713,
"author_profile": "https://Stackoverflow.com/users/20713",
"pm_score": 9,
"selected": false,
"text": "<p>The <code>seq</code> method is the simplest, but Bash has built-in arithmetic evaluation.</p>\n<pre><code>END=5\nfor ((i=1;i<=END;i++)); do\n echo $i\ndone\n# ==> outputs 1 2 3 4 5 on separate lines\n</code></pre>\n<p>The <code>for ((expr1;expr2;expr3));</code> construct works just like <code>for (expr1;expr2;expr3)</code> in C and similar languages, and like other <code>((expr))</code> cases, Bash treats them as arithmetic.</p>\n"
},
{
"answer_id": 5303675,
"author": "bobbogo",
"author_id": 470195,
"author_profile": "https://Stackoverflow.com/users/470195",
"pm_score": 5,
"selected": false,
"text": "<p>Another layer of indirection:</p>\n\n<pre><code>for i in $(eval echo {1..$END}); do\n ∶\n</code></pre>\n"
},
{
"answer_id": 5319280,
"author": "jefeveizen",
"author_id": 659754,
"author_profile": "https://Stackoverflow.com/users/659754",
"pm_score": 4,
"selected": false,
"text": "<p>If you're on BSD / OS X you can use jot instead of seq:</p>\n\n<pre><code>for i in $(jot $END); do echo $i; done\n</code></pre>\n"
},
{
"answer_id": 5723526,
"author": "DigitalRoss",
"author_id": 140740,
"author_profile": "https://Stackoverflow.com/users/140740",
"pm_score": 7,
"selected": false,
"text": "<p>Here is why the original expression didn't work.</p>\n\n<p>From <em>man bash</em>:</p>\n\n<blockquote>\n <p>Brace expansion is performed before\n any other expansions, and any\n characters special to other \n expansions are preserved in the\n result. It is strictly textual. Bash\n does not apply any syntactic\n interpretation to the context of\n the expansion or the text between the\n braces.</p>\n</blockquote>\n\n<p>So, <em>brace expansion</em> is something done early as a purely textual macro operation, before <em>parameter expansion.</em></p>\n\n<p>Shells are highly optimized hybrids between macro processors and more formal programming languages. In order to optimize the typical use cases, the language is made rather more complex and some limitations are accepted.</p>\n\n<blockquote>\n <p>Recommendation</p>\n</blockquote>\n\n<p>I would suggest sticking with Posix<sup>1</sup> features. This means using <code>for i in <list>; do</code>, if the list is already known, otherwise, use <code>while</code> or <code>seq</code>, as in:</p>\n\n<pre><code>#!/bin/sh\n\nlimit=4\n\ni=1; while [ $i -le $limit ]; do\n echo $i\n i=$(($i + 1))\ndone\n# Or -----------------------\nfor i in $(seq 1 $limit); do\n echo $i\ndone\n</code></pre>\n\n<p><hr>\n<sup>1. Bash is a great shell and I use it interactively, but I don't put bash-isms into my scripts. Scripts might need a faster shell, a more secure one, a more embedded-style one. They might need to run on whatever is installed as /bin/sh, and then there are all the usual pro-standards arguments. Remember <em>shellshock,</em> aka <em>bashdoor?</em> </sup></p>\n"
},
{
"answer_id": 7085147,
"author": "SuperBob",
"author_id": 897533,
"author_profile": "https://Stackoverflow.com/users/897533",
"pm_score": 3,
"selected": false,
"text": "<p>These are all nice but seq is supposedly deprecated and most only work with numeric ranges.</p>\n\n<p>If you enclose your for loop in double quotes, the start and end variables will be dereferenced when you echo the string, and you can ship the string right back to BASH for execution. <code>$i</code> needs to be escaped with \\'s so it is NOT evaluated before being sent to the subshell.</p>\n\n<pre><code>RANGE_START=a\nRANGE_END=z\necho -e \"for i in {$RANGE_START..$RANGE_END}; do echo \\\\${i}; done\" | bash\n</code></pre>\n\n<p>This output can also be assigned to a variable:</p>\n\n<pre><code>VAR=`echo -e \"for i in {$RANGE_START..$RANGE_END}; do echo \\\\${i}; done\" | bash`\n</code></pre>\n\n<p>The only \"overhead\" this should generate should be the second instance of bash so it should be suitable for intensive operations.</p>\n"
},
{
"answer_id": 18894729,
"author": "Adrian Frühwirth",
"author_id": 612462,
"author_profile": "https://Stackoverflow.com/users/612462",
"pm_score": 3,
"selected": false,
"text": "<p>I know this question is about <code>bash</code>, but - just for the record - <code>ksh93</code> is smarter and implements it as expected:</p>\n\n<pre><code>$ ksh -c 'i=5; for x in {1..$i}; do echo \"$x\"; done'\n1\n2\n3\n4\n5\n$ ksh -c 'echo $KSH_VERSION'\nVersion JM 93u+ 2012-02-29\n\n$ bash -c 'i=5; for x in {1..$i}; do echo \"$x\"; done'\n{1..5}\n</code></pre>\n"
},
{
"answer_id": 22339375,
"author": "BashTheKeyboard",
"author_id": 3408346,
"author_profile": "https://Stackoverflow.com/users/3408346",
"pm_score": 3,
"selected": false,
"text": "<p>Replace <code>{}</code> with <code>(( ))</code>:</p>\n\n<pre><code>tmpstart=0;\ntmpend=4;\n\nfor (( i=$tmpstart; i<=$tmpend; i++ )) ; do \necho $i ;\ndone\n</code></pre>\n\n<p>Yields:</p>\n\n<pre><code>0\n1\n2\n3\n4\n</code></pre>\n"
},
{
"answer_id": 31365662,
"author": "Ciro Santilli OurBigBook.com",
"author_id": 895245,
"author_profile": "https://Stackoverflow.com/users/895245",
"pm_score": 7,
"selected": false,
"text": "<p><strong>The POSIX way</strong></p>\n\n<p>If you care about portability, use the <a href=\"http://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html#tag_18_06_04_01\" rel=\"noreferrer\">example from the POSIX standard</a>:</p>\n\n<pre><code>i=2\nend=5\nwhile [ $i -le $end ]; do\n echo $i\n i=$(($i+1))\ndone\n</code></pre>\n\n<p>Output:</p>\n\n<pre><code>2\n3\n4\n5\n</code></pre>\n\n<p>Things which are <em>not</em> POSIX:</p>\n\n<ul>\n<li><code>(( ))</code> without dollar, although it is a common extension <a href=\"http://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html#tag_18_09_04\" rel=\"noreferrer\">as mentioned by POSIX itself</a>.</li>\n<li><code>[[</code>. <code>[</code> is enough here. See also: <a href=\"https://stackoverflow.com/questions/13542832/bash-if-difference-between-square-brackets-and-double-square-brackets\">What is the difference between single and double square brackets in Bash?</a></li>\n<li><code>for ((;;))</code></li>\n<li><code>seq</code> (GNU Coreutils)</li>\n<li><code>{start..end}</code>, and that cannot work with variables as mentioned <a href=\"https://stackoverflow.com/a/5723526/895245\">by the Bash manual</a>.</li>\n<li><code>let i=i+1</code>: <a href=\"http://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html#tag_18_06_04\" rel=\"noreferrer\">POSIX 7 2. Shell Command Language</a> does not contain the word <code>let</code>, and it fails on <code>bash --posix</code> 4.3.42</li>\n<li><p>the dollar at <code>i=$i+1</code> might be required, but I'm not sure. <a href=\"http://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html#tag_18_06_04\" rel=\"noreferrer\">POSIX 7 2.6.4 Arithmetic Expansion</a> says:</p>\n\n<blockquote>\n <p>If the shell variable x contains a value that forms a valid integer constant, optionally including a leading plus or minus sign, then the arithmetic expansions \"$((x))\" and \"$(($x))\" shall return the same value.</p>\n</blockquote>\n\n<p>but reading it literally that does not imply that <code>$((x+1))</code> expands since <code>x+1</code> is not a variable.</p></li>\n</ul>\n"
},
{
"answer_id": 31367827,
"author": "Jahid",
"author_id": 3744681,
"author_profile": "https://Stackoverflow.com/users/3744681",
"pm_score": 3,
"selected": false,
"text": "<p>This is another way:</p>\n\n<pre><code>end=5\nfor i in $(bash -c \"echo {1..${end}}\"); do echo $i; done\n</code></pre>\n"
},
{
"answer_id": 43054927,
"author": "Alex Spangher",
"author_id": 2056246,
"author_profile": "https://Stackoverflow.com/users/2056246",
"pm_score": 3,
"selected": false,
"text": "<p>If you're doing shell commands and you (like I) have a fetish for pipelining, this one is good:</p>\n\n<p><code>seq 1 $END | xargs -I {} echo {}</code></p>\n"
},
{
"answer_id": 44348183,
"author": "hossbear",
"author_id": 4413742,
"author_profile": "https://Stackoverflow.com/users/4413742",
"pm_score": 5,
"selected": false,
"text": "<p>If you need it prefix than you might like this</p>\n\n<pre><code> for ((i=7;i<=12;i++)); do echo `printf \"%2.0d\\n\" $i |sed \"s/ /0/\"`;done\n</code></pre>\n\n<p>that will yield</p>\n\n<pre><code>07\n08\n09\n10\n11\n12\n</code></pre>\n"
},
{
"answer_id": 45352296,
"author": "Zac B",
"author_id": 249199,
"author_profile": "https://Stackoverflow.com/users/249199",
"pm_score": 3,
"selected": false,
"text": "<p>If you want to stay as close as possible to the brace-expression syntax, try out the <a href=\"https://github.com/zbentley/bash-tricks/tree/master/range\" rel=\"noreferrer\"><code>range</code> function from bash-tricks' <code>range.bash</code></a>.</p>\n\n<p>For example, all of the following will do the exact same thing as <code>echo {1..10}</code>:</p>\n\n<pre><code>source range.bash\none=1\nten=10\n\nrange {$one..$ten}\nrange $one $ten\nrange {1..$ten}\nrange {1..10}\n</code></pre>\n\n<p>It tries to support the native bash syntax with as few \"gotchas\" as possible: not only are variables supported, but the often-undesirable behavior of invalid ranges being supplied as strings (e.g. <code>for i in {1..a}; do echo $i; done</code>) is prevented as well.</p>\n\n<p>The other answers will work in most cases, but they all have at least one of the following drawbacks:</p>\n\n<ul>\n<li>Many of them use <a href=\"http://tldp.org/LDP/abs/html/subshells.html\" rel=\"noreferrer\">subshells</a>, which can <a href=\"http://rus.har.mn/blog/2010-07-05/subshells/\" rel=\"noreferrer\">harm performance</a> and <a href=\"https://superuser.com/questions/559709/how-to-change-the-maximum-number-of-fork-process-by-user-in-linux\">may not be possible</a> on some systems.</li>\n<li>Many of them rely on external programs. Even <code>seq</code> is a binary which must be installed to be used, must be loaded by bash, and must contain the program you expect, for it to work in this case. Ubiquitous or not, that's a lot more to rely on than just the Bash language itself.</li>\n<li>Solutions that do use only native Bash functionality, like @ephemient's, will not work on alphabetic ranges, like <code>{a..z}</code>; brace expansion will. The question was about ranges of <em>numbers</em>, though, so this is a quibble.</li>\n<li>Most of them aren't visually similar to the <code>{1..10}</code> brace-expanded range syntax, so programs that use both may be a tiny bit harder to read.</li>\n<li>@bobbogo's answer uses some of the familiar syntax, but does something unexpected if the <code>$END</code> variable is not a valid range \"bookend\" for the other side of the range. If <code>END=a</code>, for example, an error will not occur and the verbatim value <code>{1..a}</code> will be echoed. This is the default behavior of Bash, as well--it is just often unexpected.</li>\n</ul>\n\n<p>Disclaimer: I am the author of the linked code.</p>\n"
},
{
"answer_id": 49765602,
"author": "Ethan Post",
"author_id": 4527,
"author_profile": "https://Stackoverflow.com/users/4527",
"pm_score": 0,
"selected": false,
"text": "<p>This works in Bash and Korn, also can go from higher to lower numbers. Probably not fastest or prettiest but works well enough. Handles negatives too.</p>\n\n<pre><code>function num_range {\n # Return a range of whole numbers from beginning value to ending value.\n # >>> num_range start end\n # start: Whole number to start with.\n # end: Whole number to end with.\n typeset s e v\n s=${1}\n e=${2}\n if (( ${e} >= ${s} )); then\n v=${s}\n while (( ${v} <= ${e} )); do\n echo ${v}\n ((v=v+1))\n done\n elif (( ${e} < ${s} )); then\n v=${s}\n while (( ${v} >= ${e} )); do\n echo ${v}\n ((v=v-1))\n done\n fi\n}\n\nfunction test_num_range {\n num_range 1 3 | egrep \"1|2|3\" | assert_lc 3\n num_range 1 3 | head -1 | assert_eq 1\n num_range -1 1 | head -1 | assert_eq \"-1\"\n num_range 3 1 | egrep \"1|2|3\" | assert_lc 3\n num_range 3 1 | head -1 | assert_eq 3\n num_range 1 -1 | tail -1 | assert_eq \"-1\"\n}\n</code></pre>\n"
},
{
"answer_id": 54770805,
"author": "Bruno Bronosky",
"author_id": 117471,
"author_profile": "https://Stackoverflow.com/users/117471",
"pm_score": 5,
"selected": false,
"text": "<p>I've combined a few of the ideas here and measured performance.</p>\n\n<h1>TL;DR Takeaways:</h1>\n\n<ol>\n<li><code>seq</code> and <code>{..}</code> are really fast</li>\n<li><code>for</code> and <code>while</code> loops are slow</li>\n<li><code>$( )</code> is slow</li>\n<li><code>for (( ; ; ))</code> loops are slower</li>\n<li><code>$(( ))</code> is even slower</li>\n<li>Worrying about <em>N</em> numbers in memory (seq or {..}) is silly (at least up to 1 million.)</li>\n</ol>\n\n<p><em>These are not <strong>conclusions</strong>. You would have to look at the C code behind each of these to draw conclusions. This is more about how we tend to use each of these mechanisms for looping over code. Most single operations are close enough to being the same speed that it's not going to matter in most cases. But a mechanism like <code>for (( i=1; i<=1000000; i++ ))</code> is many operations as you can visually see. It is also many more operations <strong>per loop</strong> than you get from <code>for i in $(seq 1 1000000)</code>. And that may not be obvious to you, which is why doing tests like this is valuable.</em></p>\n\n<h1>Demos</h1>\n\n<pre><code># show that seq is fast\n$ time (seq 1 1000000 | wc)\n 1000000 1000000 6888894\n\nreal 0m0.227s\nuser 0m0.239s\nsys 0m0.008s\n\n# show that {..} is fast\n$ time (echo {1..1000000} | wc)\n 1 1000000 6888896\n\nreal 0m1.778s\nuser 0m1.735s\nsys 0m0.072s\n\n# Show that for loops (even with a : noop) are slow\n$ time (for i in {1..1000000} ; do :; done | wc)\n 0 0 0\n\nreal 0m3.642s\nuser 0m3.582s\nsys 0m0.057s\n\n# show that echo is slow\n$ time (for i in {1..1000000} ; do echo $i; done | wc)\n 1000000 1000000 6888896\n\nreal 0m7.480s\nuser 0m6.803s\nsys 0m2.580s\n\n$ time (for i in $(seq 1 1000000) ; do echo $i; done | wc)\n 1000000 1000000 6888894\n\nreal 0m7.029s\nuser 0m6.335s\nsys 0m2.666s\n\n# show that C-style for loops are slower\n$ time (for (( i=1; i<=1000000; i++ )) ; do echo $i; done | wc)\n 1000000 1000000 6888896\n\nreal 0m12.391s\nuser 0m11.069s\nsys 0m3.437s\n\n# show that arithmetic expansion is even slower\n$ time (i=1; e=1000000; while [ $i -le $e ]; do echo $i; i=$(($i+1)); done | wc)\n 1000000 1000000 6888896\n\nreal 0m19.696s\nuser 0m18.017s\nsys 0m3.806s\n\n$ time (i=1; e=1000000; while [ $i -le $e ]; do echo $i; ((i=i+1)); done | wc)\n 1000000 1000000 6888896\n\nreal 0m18.629s\nuser 0m16.843s\nsys 0m3.936s\n\n$ time (i=1; e=1000000; while [ $i -le $e ]; do echo $((i++)); done | wc)\n 1000000 1000000 6888896\n\nreal 0m17.012s\nuser 0m15.319s\nsys 0m3.906s\n\n# even a noop is slow\n$ time (i=1; e=1000000; while [ $((i++)) -le $e ]; do :; done | wc)\n 0 0 0\n\nreal 0m12.679s\nuser 0m11.658s\nsys 0m1.004s\n</code></pre>\n"
},
{
"answer_id": 56329737,
"author": "theBuzzyCoder",
"author_id": 2147023,
"author_profile": "https://Stackoverflow.com/users/2147023",
"pm_score": 4,
"selected": false,
"text": "<p>There are many ways to do this, however the ones I prefer is given below</p>\n\n<h1>Using <code>seq</code></h1>\n\n<blockquote>\n <p>Synopsis from <code>man seq</code></p>\n</blockquote>\n\n<pre><code>$ seq [-w] [-f format] [-s string] [-t string] [first [incr]] last\n</code></pre>\n\n<blockquote>\n <p>Syntax</p>\n</blockquote>\n\n<p>Full command<br>\n<code>seq first incr last</code></p>\n\n<ul>\n<li>first is starting number in the sequence [is optional, by default:1]</li>\n<li>incr is increment [is optional, by default:1]</li>\n<li>last is the last number in the sequence</li>\n</ul>\n\n<p>Example:</p>\n\n<pre><code>$ seq 1 2 10\n1 3 5 7 9\n</code></pre>\n\n<p>Only with first and last:</p>\n\n<pre><code>$ seq 1 5\n1 2 3 4 5\n</code></pre>\n\n<p>Only with last:</p>\n\n<pre><code>$ seq 5\n1 2 3 4 5\n</code></pre>\n\n<h1>Using <code>{first..last..incr}</code></h1>\n\n<p>Here first and last are mandatory and incr is optional</p>\n\n<p>Using just first and last</p>\n\n<pre><code>$ echo {1..5}\n1 2 3 4 5\n</code></pre>\n\n<p>Using incr</p>\n\n<pre><code>$ echo {1..10..2}\n1 3 5 7 9\n</code></pre>\n\n<p>You can use this even for characters like below</p>\n\n<pre><code>$ echo {a..z}\na b c d e f g h i j k l m n o p q r s t u v w x y z\n</code></pre>\n"
},
{
"answer_id": 56653812,
"author": "Zimba",
"author_id": 5958708,
"author_profile": "https://Stackoverflow.com/users/5958708",
"pm_score": 2,
"selected": false,
"text": "<p>if you don't wanna use '<code>seq</code>' or '<code>eval</code>' or <code>jot</code> or arithmetic expansion format eg. <code>for ((i=1;i<=END;i++))</code>, or other loops eg. <code>while</code>, and you don't wanna '<code>printf</code>' and happy to '<code>echo</code>' only, then this simple workaround might fit your budget:</p>\n<p><code>a=1; b=5; d='for i in {'$a'..'$b'}; do echo -n "$i"; done;' echo "$d" | bash</code></p>\n<p>PS: My bash doesn't have '<code>seq</code>' command anyway.</p>\n<p><em>Tested on Mac OSX 10.6.8, Bash 3.2.48</em></p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169511",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24923/"
] |
How do I iterate over a range of numbers in Bash when the range is given by a variable?
I know I can do this (called "sequence expression" in the Bash [documentation](http://www.gnu.org/software/bash/manual/bashref.html#Brace-Expansion)):
```
for i in {1..5}; do echo $i; done
```
Which gives:
>
> 1
>
> 2
>
> 3
>
> 4
>
> 5
>
>
>
Yet, how can I replace either of the range endpoints with a variable? This doesn't work:
```
END=5
for i in {1..$END}; do echo $i; done
```
Which prints:
>
> {1..5}
>
>
>
|
```
for i in $(seq 1 $END); do echo $i; done
```
edit: I prefer `seq` over the other methods because I can actually remember it ;)
|
169,520 |
<blockquote>
<p><strong>Possible Duplicate:</strong><br>
<a href="https://stackoverflow.com/questions/795746/warning-mysql-fetch-array-supplied-argument-is-not-a-valid-mysql-result">Warning: mysql_fetch_array(): supplied argument is not a valid MySQL result</a> </p>
</blockquote>
<p>When I run my php page, I get this error and do not know what's wrong, can anyone help? If anyone needs more infomation, I'll post the whole code.</p>
<pre>Warning: mysql_fetch_assoc(): supplied argument is not a valid MySQL result resource in
H:\Program Files\EasyPHP 2.0b1\www\test\info.php on line 16</pre>
<pre><code><?PHP
$user_name = "root";
$password = "";
$database = "addressbook";
$server = "127.0.0.1";
$db_handle = mysql_connect($server, $user_name, $password);
$db_found = mysql_select_db($database, $db_handle);
if ($db_found) {
$SQL = "SELECT * FROM tb_address_book";
$result = mysql_query($SQL);
while ($db_field = mysql_fetch_assoc($result)) {
print $db_field['ID'] . "<BR>";
print $db_field['First_Name'] . "<BR>";
print $db_field['Surname'] . "<BR>";
print $db_field['Address'] . "<BR>";
}
mysql_close($db_handle);
}
else {
print "Database NOT Found ";
mysql_close($db_handle);
}
?>
</code></pre>
|
[
{
"answer_id": 169527,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<pre><code><?PHP\n\n $user_name = \"root\";\n $password = \"\";\n $database = \"addressbook\";\n $server = \"127.0.0.1\";\n\n$db_handle = mysql_connect($server, $user_name, $password);\n$db_found = mysql_select_db($database, $db_handle);\n\nif ($db_found) {\n\n $SQL = \"SELECT * FROM tb_address_book\";\n $result = mysql_query($SQL);\n\n while ($db_field = mysql_fetch_assoc($result)) {\n print $db_field['ID'] . \"<BR>\";\n print $db_field['First_Name'] . \"<BR>\";\n print $db_field['Surname'] . \"<BR>\";\n print $db_field['Address'] . \"<BR>\";\n } \n\n mysql_close($db_handle);\n\n}\nelse {\n print \"Database NOT Found \";\n mysql_close($db_handle);\n}\n\n?>\n</code></pre>\n"
},
{
"answer_id": 169528,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 4,
"selected": false,
"text": "<p>It generally means that you've got an error in your SQL.</p>\n\n<pre><code>$sql = \"SELECT * FROM myTable\"; // table name only do not add tb\n$result = mysql_query($sql);\nvar_dump($result); // bool(false)\n</code></pre>\n\n<p>Obviously, <code>false</code> is not a MySQL resource, hence you get that error.</p>\n\n<p><strong>EDIT with the code pasted now</strong>:</p>\n\n<p>On the line before your <code>while</code> loop, add this:</p>\n\n<pre><code>if (!$result) {\n echo \"Error. \" . mysql_error();\n} else {\n while ( ... ) {\n ...\n }\n}\n</code></pre>\n\n<p>Make sure that the <code>tb_address_book</code> table actually exists and that you've connected to the DB properly.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169520",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
>
> **Possible Duplicate:**
>
> [Warning: mysql\_fetch\_array(): supplied argument is not a valid MySQL result](https://stackoverflow.com/questions/795746/warning-mysql-fetch-array-supplied-argument-is-not-a-valid-mysql-result)
>
>
>
When I run my php page, I get this error and do not know what's wrong, can anyone help? If anyone needs more infomation, I'll post the whole code.
```
Warning: mysql_fetch_assoc(): supplied argument is not a valid MySQL result resource in
H:\Program Files\EasyPHP 2.0b1\www\test\info.php on line 16
```
```
<?PHP
$user_name = "root";
$password = "";
$database = "addressbook";
$server = "127.0.0.1";
$db_handle = mysql_connect($server, $user_name, $password);
$db_found = mysql_select_db($database, $db_handle);
if ($db_found) {
$SQL = "SELECT * FROM tb_address_book";
$result = mysql_query($SQL);
while ($db_field = mysql_fetch_assoc($result)) {
print $db_field['ID'] . "<BR>";
print $db_field['First_Name'] . "<BR>";
print $db_field['Surname'] . "<BR>";
print $db_field['Address'] . "<BR>";
}
mysql_close($db_handle);
}
else {
print "Database NOT Found ";
mysql_close($db_handle);
}
?>
```
|
It generally means that you've got an error in your SQL.
```
$sql = "SELECT * FROM myTable"; // table name only do not add tb
$result = mysql_query($sql);
var_dump($result); // bool(false)
```
Obviously, `false` is not a MySQL resource, hence you get that error.
**EDIT with the code pasted now**:
On the line before your `while` loop, add this:
```
if (!$result) {
echo "Error. " . mysql_error();
} else {
while ( ... ) {
...
}
}
```
Make sure that the `tb_address_book` table actually exists and that you've connected to the DB properly.
|
169,529 |
<p>So I have a ListView with an upper limit of about 1000 items. I need to be able to filter these items using a textbox's TextChanged event. I have some code that works well for a smaller number of items (~400), but when I need to re-display a full list of all 1000 items, it takes about 4 seconds.</p>
<p>I am not creating new ListViewItems every time. Instead, I keep a list of the full item collection and then add from that. It seems that the .Add method is taking a long time regardless. Here is a little sample:</p>
<pre><code>this.BeginUpdate();
foreach (ListViewItem item in m_cachedItems)
{
MyListView.Add(item);
}
this.EndUpdate;
</code></pre>
<p>I have tried only adding the missing items (i.e., the difference between the items currently being displayed and the total list of items), but this doesn't work either. There can be a situation in which there is only one item currently displayed, the user clears the textbox, and I need to display the entire list.</p>
<p>I am not very experienced in eeking performance out of .NET controls with a large sample like this, so I don't really know a better way to do it. Is there any way around using the .Add() method, or if not, just e better general solution?</p>
|
[
{
"answer_id": 169533,
"author": "Jeff Yates",
"author_id": 23234,
"author_profile": "https://Stackoverflow.com/users/23234",
"pm_score": 3,
"selected": true,
"text": "<p>There are two things to address this:</p>\n\n<ol>\n<li>Turn off sorting while manipulating the list contents.</li>\n<li>Hide the list so it doesn't try to paint.</li>\n</ol>\n\n<p>The 1st point is the biggest performance gain in list manipulation out of these two. To achieve this, just set the ListViewItemSorter to null for the duration of the modification and set it back at the end.</p>\n\n<p>For the 2nd option, I often draw the list to a bitmap and then show that bitmap in a PictureBox so the user doesn't see the list disappear, then just reshow the list when I'm done.</p>\n"
},
{
"answer_id": 169535,
"author": "Frank Krueger",
"author_id": 338,
"author_profile": "https://Stackoverflow.com/users/338",
"pm_score": 2,
"selected": false,
"text": "<p>There is a better way, you can use the <a href=\"http://msdn.microsoft.com/en-us/library/system.windows.forms.listview.virtualmode.aspx\" rel=\"nofollow noreferrer\">VirtualMode</a> of the list view.</p>\n\n<p>That documentation should get you started. The idea is to provide information to the ListView only as it's needed. Such information is retrieved using events. All you have to do is implement those events and tell the list view how many items it contains.</p>\n"
},
{
"answer_id": 169556,
"author": "Phil Wright",
"author_id": 6276,
"author_profile": "https://Stackoverflow.com/users/6276",
"pm_score": 0,
"selected": false,
"text": "<p>Also note that you can hide items and so make them invisible without removing them. So add all your items the first time around and then later on you just hide the ones no longer needed and show the ones that are.</p>\n"
},
{
"answer_id": 169611,
"author": "sieben",
"author_id": 1147,
"author_profile": "https://Stackoverflow.com/users/1147",
"pm_score": 2,
"selected": false,
"text": "<p>AddRange is much faster than add</p>\n\n<pre><code>MyListView.AddRange(items)\n</code></pre>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169529",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1053/"
] |
So I have a ListView with an upper limit of about 1000 items. I need to be able to filter these items using a textbox's TextChanged event. I have some code that works well for a smaller number of items (~400), but when I need to re-display a full list of all 1000 items, it takes about 4 seconds.
I am not creating new ListViewItems every time. Instead, I keep a list of the full item collection and then add from that. It seems that the .Add method is taking a long time regardless. Here is a little sample:
```
this.BeginUpdate();
foreach (ListViewItem item in m_cachedItems)
{
MyListView.Add(item);
}
this.EndUpdate;
```
I have tried only adding the missing items (i.e., the difference between the items currently being displayed and the total list of items), but this doesn't work either. There can be a situation in which there is only one item currently displayed, the user clears the textbox, and I need to display the entire list.
I am not very experienced in eeking performance out of .NET controls with a large sample like this, so I don't really know a better way to do it. Is there any way around using the .Add() method, or if not, just e better general solution?
|
There are two things to address this:
1. Turn off sorting while manipulating the list contents.
2. Hide the list so it doesn't try to paint.
The 1st point is the biggest performance gain in list manipulation out of these two. To achieve this, just set the ListViewItemSorter to null for the duration of the modification and set it back at the end.
For the 2nd option, I often draw the list to a bitmap and then show that bitmap in a PictureBox so the user doesn't see the list disappear, then just reshow the list when I'm done.
|
169,555 |
<p>Greetings,</p>
<p>I need to include a property in my class which is a collection of System.IO.FileInfo objects. I am not really sure how to do this and how I would add and removed objects from an instance of the the class (I would assume like any other collection). </p>
<p>Please let me know if I need to add more information.</p>
<p>Thank you</p>
<p>Update: Am I approaching this the wrong way? I have read comments that adding to a collection which is a property is bad practice. If this is true what is good practice? I have a bunch of objects I need to store in a collection. The collection will be added to and removed from before a final action will be taken on it. Is this a correct approach or am I missing something?</p>
|
[
{
"answer_id": 169568,
"author": "Frank Krueger",
"author_id": 338,
"author_profile": "https://Stackoverflow.com/users/338",
"pm_score": 1,
"selected": false,
"text": "<p><code>File</code> is a static class. So let's assume you meant <code>FileInfo</code>.</p>\n\n<p>There are lots of ways, you can:</p>\n\n<ul>\n<li>Expose a private field</li>\n<li>Use Iterators</li>\n<li>Expose a private field through a ReadOnlyCollection<></li>\n</ul>\n\n<p>For example,</p>\n\n<pre><code>class Foo {\n public IEnumerable<FileInfo> LotsOfFile {\n get {\n for (int i=0; i < 100; i++) {\n yield return new FileInfo(\"C:\\\\\" + i + \".txt\");\n }\n }\n }\n private List<FileInfo> files = new List<FileInfo>();\n public List<FileInfo> MoreFiles {\n get {\n return files;\n }\n }\n public ReadOnlyCollection<FileInfo> MoreFilesReadOnly {\n get {\n return files.AsReadOnly();\n }\n }\n\n}\n</code></pre>\n\n<p>With this code, you can easily add to the property <code>MoreFiles</code>:</p>\n\n<pre><code>Foo f = new Foo();\nf.MoreFiles.Add(new FileInfo(\"foo.txt\"));\nf.MoreFiles.Add(new FileInfo(\"BAR.txt\"));\nf.MoreFiles.Add(new FileInfo(\"baz.txt\"));\nConsole.WriteLine(f.MoreFiles.Count);\n</code></pre>\n"
},
{
"answer_id": 169572,
"author": "Kibbee",
"author_id": 1862,
"author_profile": "https://Stackoverflow.com/users/1862",
"pm_score": 0,
"selected": false,
"text": "<p>One simple way to do this is to create a property as such (sorry for the VB.Net)</p>\n\n<pre><code>Public ReadOnly Property Files As Generic.List(Of IO.File)\n GET\n Return _Files\n END GET\nEND Property\n</code></pre>\n\n<p>Where _Files is a private class variable of type Generic.List(Of IO.File), which holds the list of files. That will allow files to be added and removed by calling the functions of the List data type. Some people will probably say this is bad practice, and that you should never expose the collection itself, and instead recode all the necessary functions as separate parameters, which would basically just call the appropriate functions from your private collection. </p>\n"
},
{
"answer_id": 169608,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 1,
"selected": false,
"text": "<pre><code>using System.Collections.ObjectModel;\n\npublic class Foo\n { private Collection<FileInfo> files = new Collection<FileInfo>();\n public Collection<FileInfo> Files { get { return files;} }\n }\n\n//...\nFoo f = new Foo();\nf.Files.Add(file);\n</code></pre>\n"
},
{
"answer_id": 169619,
"author": "hurst",
"author_id": 10991,
"author_profile": "https://Stackoverflow.com/users/10991",
"pm_score": 0,
"selected": false,
"text": "<p>I just make it either a list or dictionary. I'll show both.</p>\n\n<pre><code>class Example\n{\n public List<FileInfo> FileList { get; set; }\n public Dictionary<string, FileInfo> Files { get; set; }\n\n public Example()\n {\n FileList = new List<FileInfo>();\n Files = new Dictionary<string, FileInfo>();\n }\n\n}\n</code></pre>\n\n<p>You would now use the property as if it were the actual List or Dictionary object.</p>\n\n<pre><code>var obj = new Example();\nobj.FileList.Add(new FileInfo(\"file.txt\")); // List<>\nobj.Files.Add(\"file.txt\", new FileInfo(\"file.txt\")); // Dictionary<>\n// also\nobj.Files[\"file2.txt\"] = new FileInfo(\"file2.txt\"); // Dictionary<>\n\n// fetch \nvar myListedFile = obj.FileList[0]; // List<>\nvar myFile = obj.Files[\"file.txt\"]; // Dictionary<>\n</code></pre>\n\n<p>I prefer the dictionary approach.</p>\n\n<p>Note that since the property is public set, you could replace the entire list or dictionary as well. </p>\n\n<pre><code>obj.Files = new Dictionary<string, FileInfo>();\n// or\nvar otherFiles = new Dictionary<string, FileInfo>();\notherFiles[\"otherfile.txt\"] = new FileInfo(\"otherfile.txt\");\nobj.Files = otherFiles;\n</code></pre>\n\n<p>If you made the property private set, then you could still call Add(), but not reassign the list or dictionary itself.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169555",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5836/"
] |
Greetings,
I need to include a property in my class which is a collection of System.IO.FileInfo objects. I am not really sure how to do this and how I would add and removed objects from an instance of the the class (I would assume like any other collection).
Please let me know if I need to add more information.
Thank you
Update: Am I approaching this the wrong way? I have read comments that adding to a collection which is a property is bad practice. If this is true what is good practice? I have a bunch of objects I need to store in a collection. The collection will be added to and removed from before a final action will be taken on it. Is this a correct approach or am I missing something?
|
`File` is a static class. So let's assume you meant `FileInfo`.
There are lots of ways, you can:
* Expose a private field
* Use Iterators
* Expose a private field through a ReadOnlyCollection<>
For example,
```
class Foo {
public IEnumerable<FileInfo> LotsOfFile {
get {
for (int i=0; i < 100; i++) {
yield return new FileInfo("C:\\" + i + ".txt");
}
}
}
private List<FileInfo> files = new List<FileInfo>();
public List<FileInfo> MoreFiles {
get {
return files;
}
}
public ReadOnlyCollection<FileInfo> MoreFilesReadOnly {
get {
return files.AsReadOnly();
}
}
}
```
With this code, you can easily add to the property `MoreFiles`:
```
Foo f = new Foo();
f.MoreFiles.Add(new FileInfo("foo.txt"));
f.MoreFiles.Add(new FileInfo("BAR.txt"));
f.MoreFiles.Add(new FileInfo("baz.txt"));
Console.WriteLine(f.MoreFiles.Count);
```
|
169,562 |
<p>Ok, my actual problem was this: I was implementing an <code>IList<T></code>. When I got to <code>CopyTo(Array array, int index)</code>, this was my solution:</p>
<pre><code>void ICollection.CopyTo(Array array, int index)
{
// Bounds checking, etc here.
if (!(array.GetValue(0) is T))
throw new ArgumentException("Cannot cast to this type of Array.");
// Handle copying here.
}
</code></pre>
<p>This worked in my original code, and still works. But it has a small flaw, which wasn't exposed till I started building tests for it, specifically this one:</p>
<pre><code>public void CopyToObjectArray()
{
ICollection coll = (ICollection)_list;
string[] testArray = new string[6];
coll.CopyTo(testArray, 2);
}
</code></pre>
<p>Now, this test should pass. It throws the <code>ArgumentException</code> about not being able to cast. Why? <code>array[0] == null</code>. The <code>is</code> keyword always returns false when checking a variable that is set to <code>null</code>. Now, this is handy for all sorts of reasons, including avoiding null dereferences, etc. What I finally came up with for my type checking was this:</p>
<pre><code>try
{
T test = (T)array.GetValue(0);
}
catch (InvalidCastException ex)
{
throw new ArgumentException("Cannot cast to this type of Array.", ex);
}
</code></pre>
<p>This isn't exactly elegant, but it works... Is there a better way though?</p>
|
[
{
"answer_id": 169579,
"author": "justin.m.chase",
"author_id": 12958,
"author_profile": "https://Stackoverflow.com/users/12958",
"pm_score": 2,
"selected": false,
"text": "<p>There is a method on Type specifically for this, try:</p>\n\n<pre><code>if(!typeof(T).IsAssignableFrom(array.GetElementType()))\n</code></pre>\n"
},
{
"answer_id": 169595,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 1,
"selected": false,
"text": "<p><code>List<T></code> uses this:</p>\n\n<pre><code>try\n{\n Array.Copy(this._items, 0, array, index, this.Count);\n}\ncatch (ArrayTypeMismatchException)\n{\n //throw exception...\n}\n</code></pre>\n"
},
{
"answer_id": 169613,
"author": "Alex Lyman",
"author_id": 5897,
"author_profile": "https://Stackoverflow.com/users/5897",
"pm_score": 3,
"selected": true,
"text": "<p>The only way to be sure is with reflection, but 90% of the time you can avoid the cost of that by using <code>array is T[]</code>. Most people are going to pass a properly typed array in, so that will do. But, you should always provide the code to do the reflection check as well, just in case. Here's what my general boiler-plate looks like (note: I wrote this here, from memory, so this might not compile, but it should give the basic idea):</p>\n\n<pre><code>class MyCollection : ICollection<T> {\n void ICollection<T>.CopyTo(T[] array, int index) {\n // Bounds checking, etc here.\n CopyToImpl(array, index);\n }\n void ICollection.CopyTo(Array array, int index) {\n // Bounds checking, etc here.\n if (array is T[]) { // quick, avoids reflection, but only works if array is typed as exactly T[]\n CopyToImpl((T[])localArray, index);\n } else {\n Type elementType = array.GetType().GetElementType();\n if (!elementType.IsAssignableFrom(typeof(T)) && !typeof(T).IsAssignableFrom(elementType)) {\n throw new Exception();\n }\n CopyToImpl((object[])array, index);\n }\n }\n private void CopyToImpl(object[] array, int index) {\n // array will always have a valid type by this point, and the bounds will be checked\n // Handle the copying here\n }\n}\n</code></pre>\n\n<p><strong>EDIT</strong>: Ok, forgot to point something out. A couple answers naively used what, in this code, reads as <code>element.IsAssignableFrom(typeof(T))</code> only. You <em>should</em> also allow <code>typeof(T).IsAssignableFrom(elementType)</code>, as the BCL does, in case a developer knows that all of the values in this specific <code>ICollection</code> are actually of a type <code>S</code> derived from <code>T</code>, and passes an array of type <code>S[]</code></p>\n"
},
{
"answer_id": 546208,
"author": "justin.m.chase",
"author_id": 12958,
"author_profile": "https://Stackoverflow.com/users/12958",
"pm_score": 0,
"selected": false,
"text": "<p>Here is a little test of try / catch vs. reflection:</p>\n\n<pre><code>object[] obj = new object[] { };\nDateTime start = DateTime.Now;\n\nfor (int x = 0; x < 1000; x++)\n{\n try\n {\n throw new Exception();\n }\n catch (Exception ex) { }\n}\nDateTime end = DateTime.Now;\nConsole.WriteLine(\"Try/Catch: \" + (end - start).TotalSeconds.ToString());\n\nstart = DateTime.Now;\n\nfor (int x = 0; x < 1000; x++)\n{\n bool assignable = typeof(int).IsAssignableFrom(obj.GetType().GetElementType());\n}\nend = DateTime.Now;\nConsole.WriteLine(\"IsAssignableFrom: \" + (end - start).TotalSeconds.ToString());\n</code></pre>\n\n<p>The resulting output in Release mode is:</p>\n\n<pre><code>Try/Catch: 1.7501001\nIsAssignableFrom: 0\n</code></pre>\n\n<p>In debug mode:</p>\n\n<pre><code>Try/Catch: 1.8171039\nIsAssignableFrom: 0.0010001\n</code></pre>\n\n<p>Conclusion, just do the reflection check. It's worth it.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169562",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15537/"
] |
Ok, my actual problem was this: I was implementing an `IList<T>`. When I got to `CopyTo(Array array, int index)`, this was my solution:
```
void ICollection.CopyTo(Array array, int index)
{
// Bounds checking, etc here.
if (!(array.GetValue(0) is T))
throw new ArgumentException("Cannot cast to this type of Array.");
// Handle copying here.
}
```
This worked in my original code, and still works. But it has a small flaw, which wasn't exposed till I started building tests for it, specifically this one:
```
public void CopyToObjectArray()
{
ICollection coll = (ICollection)_list;
string[] testArray = new string[6];
coll.CopyTo(testArray, 2);
}
```
Now, this test should pass. It throws the `ArgumentException` about not being able to cast. Why? `array[0] == null`. The `is` keyword always returns false when checking a variable that is set to `null`. Now, this is handy for all sorts of reasons, including avoiding null dereferences, etc. What I finally came up with for my type checking was this:
```
try
{
T test = (T)array.GetValue(0);
}
catch (InvalidCastException ex)
{
throw new ArgumentException("Cannot cast to this type of Array.", ex);
}
```
This isn't exactly elegant, but it works... Is there a better way though?
|
The only way to be sure is with reflection, but 90% of the time you can avoid the cost of that by using `array is T[]`. Most people are going to pass a properly typed array in, so that will do. But, you should always provide the code to do the reflection check as well, just in case. Here's what my general boiler-plate looks like (note: I wrote this here, from memory, so this might not compile, but it should give the basic idea):
```
class MyCollection : ICollection<T> {
void ICollection<T>.CopyTo(T[] array, int index) {
// Bounds checking, etc here.
CopyToImpl(array, index);
}
void ICollection.CopyTo(Array array, int index) {
// Bounds checking, etc here.
if (array is T[]) { // quick, avoids reflection, but only works if array is typed as exactly T[]
CopyToImpl((T[])localArray, index);
} else {
Type elementType = array.GetType().GetElementType();
if (!elementType.IsAssignableFrom(typeof(T)) && !typeof(T).IsAssignableFrom(elementType)) {
throw new Exception();
}
CopyToImpl((object[])array, index);
}
}
private void CopyToImpl(object[] array, int index) {
// array will always have a valid type by this point, and the bounds will be checked
// Handle the copying here
}
}
```
**EDIT**: Ok, forgot to point something out. A couple answers naively used what, in this code, reads as `element.IsAssignableFrom(typeof(T))` only. You *should* also allow `typeof(T).IsAssignableFrom(elementType)`, as the BCL does, in case a developer knows that all of the values in this specific `ICollection` are actually of a type `S` derived from `T`, and passes an array of type `S[]`
|
169,573 |
<p>I am searching for an open source Java library to generate thumbnails for a given URL. I need to bundle this capability, rather than call out to external services, such as <a href="http://aws.amazon.com/ast/" rel="nofollow noreferrer">Amazon</a> or <a href="http://www.websnapr.com/" rel="nofollow noreferrer">websnapr</a>.</p>
<p><a href="http://www.webrenderer.com/" rel="nofollow noreferrer">http://www.webrenderer.com/</a> was mentioned in this post: <a href="https://stackoverflow.com/questions/119116/server-generated-web-screenshots#119264">Server generated web screenshots</a>, but it is a commercial solution.</p>
<p>I'm hoping for a Java based solution, but may need to look into executing an external process such as <a href="http://khtml2png.sourceforge.net/index.php?page=faq" rel="nofollow noreferrer">khtml2png</a>, or integrating something like <a href="http://user.it.uu.se/~jan/html2ps.html" rel="nofollow noreferrer">html2ps</a>.</p>
<p>Any suggestions?</p>
|
[
{
"answer_id": 169578,
"author": "Frank Krueger",
"author_id": 338,
"author_profile": "https://Stackoverflow.com/users/338",
"pm_score": 2,
"selected": false,
"text": "<p>You're essentially asking for a complete rendering engine accessible by Java. Personally, I would save myself the hassle and call out to a child process.</p>\n\n<p>Otherwise, I ran into this pure Java browser: <a href=\"http://lobobrowser.org/java-browser.jsp\" rel=\"nofollow noreferrer\">Lobo</a></p>\n"
},
{
"answer_id": 169605,
"author": "anjanb",
"author_id": 11142,
"author_profile": "https://Stackoverflow.com/users/11142",
"pm_score": 0,
"selected": false,
"text": "<p>wasn't there a QA/test website/service which would let you specify a web page that you wanted to be rendered in a certain browser(IE, FIREFOX, SAFARI version x,y,z) and they would mail the snapshot back to you. '</p>\n\n<p>I can't remember the service -- maybe other developers who frequent ajaxian might remember it ?</p>\n"
},
{
"answer_id": 170392,
"author": "McDowell",
"author_id": 304,
"author_profile": "https://Stackoverflow.com/users/304",
"pm_score": 4,
"selected": true,
"text": "<p>The first thing that comes to mind is using AWT to capture a screen grab (see code below). You could look at capturing the <a href=\"http://java.sun.com/javase/6/docs/api/javax/swing/JEditorPane.html\" rel=\"noreferrer\">JEditorPane</a>, the <a href=\"https://jdic.dev.java.net/\" rel=\"noreferrer\">JDIC</a> <a href=\"https://jdic.dev.java.net/nonav/documentation/javadoc/jdic/org/jdesktop/jdic/browser/package-summary.html\" rel=\"noreferrer\">WebBrowser</a> control or the <a href=\"http://www.eclipse.org/swt/\" rel=\"noreferrer\">SWT</a> <a href=\"http://help.eclipse.org/stable/nftopic/org.eclipse.platform.doc.isv/reference/api/org/eclipse/swt/browser/package-summary.html\" rel=\"noreferrer\">Browser</a> (via the <a href=\"http://help.eclipse.org/stable/nftopic/org.eclipse.platform.doc.isv/reference/api/org/eclipse/swt/awt/package-summary.html\" rel=\"noreferrer\">AWT embedding support</a>). The latter two embed native browsers (IE, Firefox), so introduce dependencies; the JEditorPane HTML support stopped at HTML 3.2. It may be that none of these will work on a headless system.</p>\n\n<pre><code>import java.awt.Component;\nimport java.awt.Graphics2D;\nimport java.awt.image.BufferedImage;\nimport java.io.File;\nimport java.io.IOException;\n\nimport javax.imageio.ImageIO;\nimport javax.swing.JLabel;\n\npublic class Capture {\n\n private static final int WIDTH = 128;\n private static final int HEIGHT = 128;\n\n private BufferedImage image = new BufferedImage(WIDTH, HEIGHT,\n BufferedImage.TYPE_INT_RGB);\n\n public void capture(Component component) {\n component.setSize(image.getWidth(), image.getHeight());\n\n Graphics2D g = image.createGraphics();\n try {\n component.paint(g);\n } finally {\n g.dispose();\n }\n }\n\n private BufferedImage getScaledImage(int width, int height) {\n BufferedImage buffer = new BufferedImage(width, height,\n BufferedImage.TYPE_INT_RGB);\n Graphics2D g = buffer.createGraphics();\n try {\n g.drawImage(image, 0, 0, width, height, null);\n } finally {\n g.dispose();\n }\n return buffer;\n }\n\n public void save(File png, int width, int height) throws IOException {\n ImageIO.write(getScaledImage(width, height), \"png\", png);\n }\n\n public static void main(String[] args) throws IOException {\n JLabel label = new JLabel();\n label.setText(\"Hello, World!\");\n label.setOpaque(true);\n\n Capture cap = new Capture();\n cap.capture(label);\n cap.save(new File(\"foo.png\"), 64, 64);\n }\n\n}\n</code></pre>\n"
},
{
"answer_id": 173489,
"author": "Sietse",
"author_id": 6400,
"author_profile": "https://Stackoverflow.com/users/6400",
"pm_score": 0,
"selected": false,
"text": "<p>Try calling <a href=\"http://www.imagemagick.org/script/index.php\" rel=\"nofollow noreferrer\">ImageMagick</a>. I know it's not a Java solution, but you can call it from Java, and there's even a <a href=\"http://sourceforge.net/projects/jmagick/\" rel=\"nofollow noreferrer\">Java front-end</a>, although I've had less success with that.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169573",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14419/"
] |
I am searching for an open source Java library to generate thumbnails for a given URL. I need to bundle this capability, rather than call out to external services, such as [Amazon](http://aws.amazon.com/ast/) or [websnapr](http://www.websnapr.com/).
<http://www.webrenderer.com/> was mentioned in this post: [Server generated web screenshots](https://stackoverflow.com/questions/119116/server-generated-web-screenshots#119264), but it is a commercial solution.
I'm hoping for a Java based solution, but may need to look into executing an external process such as [khtml2png](http://khtml2png.sourceforge.net/index.php?page=faq), or integrating something like [html2ps](http://user.it.uu.se/~jan/html2ps.html).
Any suggestions?
|
The first thing that comes to mind is using AWT to capture a screen grab (see code below). You could look at capturing the [JEditorPane](http://java.sun.com/javase/6/docs/api/javax/swing/JEditorPane.html), the [JDIC](https://jdic.dev.java.net/) [WebBrowser](https://jdic.dev.java.net/nonav/documentation/javadoc/jdic/org/jdesktop/jdic/browser/package-summary.html) control or the [SWT](http://www.eclipse.org/swt/) [Browser](http://help.eclipse.org/stable/nftopic/org.eclipse.platform.doc.isv/reference/api/org/eclipse/swt/browser/package-summary.html) (via the [AWT embedding support](http://help.eclipse.org/stable/nftopic/org.eclipse.platform.doc.isv/reference/api/org/eclipse/swt/awt/package-summary.html)). The latter two embed native browsers (IE, Firefox), so introduce dependencies; the JEditorPane HTML support stopped at HTML 3.2. It may be that none of these will work on a headless system.
```
import java.awt.Component;
import java.awt.Graphics2D;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
import javax.swing.JLabel;
public class Capture {
private static final int WIDTH = 128;
private static final int HEIGHT = 128;
private BufferedImage image = new BufferedImage(WIDTH, HEIGHT,
BufferedImage.TYPE_INT_RGB);
public void capture(Component component) {
component.setSize(image.getWidth(), image.getHeight());
Graphics2D g = image.createGraphics();
try {
component.paint(g);
} finally {
g.dispose();
}
}
private BufferedImage getScaledImage(int width, int height) {
BufferedImage buffer = new BufferedImage(width, height,
BufferedImage.TYPE_INT_RGB);
Graphics2D g = buffer.createGraphics();
try {
g.drawImage(image, 0, 0, width, height, null);
} finally {
g.dispose();
}
return buffer;
}
public void save(File png, int width, int height) throws IOException {
ImageIO.write(getScaledImage(width, height), "png", png);
}
public static void main(String[] args) throws IOException {
JLabel label = new JLabel();
label.setText("Hello, World!");
label.setOpaque(true);
Capture cap = new Capture();
cap.capture(label);
cap.save(new File("foo.png"), 64, 64);
}
}
```
|
169,590 |
<p>I need to fire an event when the mouse is above a PictureBox with the mouse button already clicked and held down.</p>
<p>Problems: </p>
<p>The MouseDown and MouseEnter event handlers do not work together very well.</p>
<p>For instance once a mouse button is clicked and held down, C# will fire the MouseDown event handler, but when the cursor moves over the PictureBox the MouseEnter event does not fire, until the mouse button is realeased.</p>
|
[
{
"answer_id": 169593,
"author": "Jack B Nimble",
"author_id": 3800,
"author_profile": "https://Stackoverflow.com/users/3800",
"pm_score": -1,
"selected": false,
"text": "<p>set a flag or a state on mouse down. release it on mouse up.\nWhen on mouse over fires for the picture box check your state.\nNow you can detect when a person is dragging something.</p>\n"
},
{
"answer_id": 169604,
"author": "Jeff Yates",
"author_id": 23234,
"author_profile": "https://Stackoverflow.com/users/23234",
"pm_score": 4,
"selected": false,
"text": "<p><strong>Mouse events</strong></p>\n\n<p>Use the MouseDown event to just detect a down press of a mouse button and set this.Capture to true so that you then get other mouse events, even when the mouse leaves the control (i.e. you won't get a MouseLeave event because you captured the mouse). Release capture by setting this.Capture to false when MouseUp occurs.</p>\n\n<p><strong>Just checking the state of the mouse</strong></p>\n\n<p>This may not be relevant, but you can check <code>System.Windows.Control.MousePosition</code> and see if it is in the <code>PictureBox.ClientRectangle</code>, then check the <code>Control.MouseButtons</code> static property for which buttons might be down at any time.</p>\n\n<p>As in:</p>\n\n<pre><code>if (pictureBox.ClientRectangle.Contains(pictureBox.PointToClient(Control.MousePosition)))\n{\n if ((Control.MouseButtons & MouseButtons.Left) != 0)\n {\n // Left button is down.\n }\n}\n</code></pre>\n"
},
{
"answer_id": 169666,
"author": "Phil Wright",
"author_id": 6276,
"author_profile": "https://Stackoverflow.com/users/6276",
"pm_score": 5,
"selected": true,
"text": "<p>When the mouse is pressed down most controls will then <em>Control.Capture</em> the mouse input. This means that all <em>MouseMove</em> events are sent to the original control that captured rather than the control the mouse happens to be over. This continues until the mouse loses capture which typically happens on the mouse up. </p>\n\n<p>If you really need to know when the mouse is over your control even when another control has captured mouse input then you only really have one way. You need to snoop the windows messages destined for other controls inside your application. To do that you need add a message filter ...</p>\n\n<pre><code>Application.AddMessageFilter(myFilterClassInstance);\n</code></pre>\n\n<p>Then you need to implement the IMessageFilter on a suitable class...</p>\n\n<pre><code>public class MyFilterClass : IMessageFilter\n{\n public bool PreFilterMessage(ref Message m)\n {\n if (m.Msg == WM_MOUSEMOVE)\n // Check if mouse is over my picture box!\n\n return false;\n }\n}\n</code></pre>\n\n<p>Then you watch for mouse move events and check if they are over your picture box and do whatever it is you want to do.</p>\n"
},
{
"answer_id": 169772,
"author": "MusiGenesis",
"author_id": 14606,
"author_profile": "https://Stackoverflow.com/users/14606",
"pm_score": 2,
"selected": false,
"text": "<p>If you're trying to implement a drag-and-drop operation of some sort, <strong>the Drag... events</strong> (DragEnter, DragDrop etc.) on the receiving picture box are what you want to use. Basically, you start the drag operation using the DoDragDrop method of the source control, and then any control that you drag over will have its Drag... events raised.</p>\n\n<p>Search \"DoDragDrop\" on MSDN to see how to implement this.</p>\n"
},
{
"answer_id": 4305905,
"author": "Ian Campbell",
"author_id": 524134,
"author_profile": "https://Stackoverflow.com/users/524134",
"pm_score": 3,
"selected": false,
"text": "<p>Set up a MouseMove event within the PictureBox control:</p>\n\n<pre><code>this.myPictureBox.MouseMove += new System.Windows.Forms.MouseEventHandler(this.myPictureBox_MouseMove);\n</code></pre>\n\n<p>Then, within your MouseMove event handler, check to see if the left mouse button (or whatever) is pressed:</p>\n\n<pre><code>private void myPictureBox_MouseMove(object sender, MouseEventArgs e)\n{ \n if (e.Button == MouseButtons.Left)\n // Do what you want to do\n}\n</code></pre>\n"
},
{
"answer_id": 6060735,
"author": "Bruno Ratnieks",
"author_id": 761309,
"author_profile": "https://Stackoverflow.com/users/761309",
"pm_score": 0,
"selected": false,
"text": "<p>The best way to move a Form based on mouse position and control relative position is similar to what Ian Campbell posted.</p>\n\n<pre><code> private void imgMoveWindow_MouseMove(object sender, MouseEventArgs e)\n {\n if (e.Button == MouseButtons.Left)\n {\n Form1.ActiveForm.Left = Control.MousePosition.X - imgMoveWindow.Left - (imgMoveWindow.Size.Width/2);\n Form1.ActiveForm.Top = Control.MousePosition.Y - imgMoveWindow.Top - (imgMoveWindow.Size.Height/2); \n }\n\n }\n</code></pre>\n\n<p>Where imgMoveWindow is a PictureBox Control.</p>\n\n<p>Bruno Ratnieks</p>\n\n<p>Sniffer Networks</p>\n"
},
{
"answer_id": 65057624,
"author": "Jamisco",
"author_id": 7082154,
"author_profile": "https://Stackoverflow.com/users/7082154",
"pm_score": 1,
"selected": false,
"text": "<p>You can use the Preview Events</p>\n<p>For example say I want to detect a mousedown event on my button. The MouseDown event is not going to work because as one of the answers here, the mouse capture is sent to the main control, however what you can do is use the mouse preview event.</p>\n<p>Here is a code example</p>\n<p>I want to check when the Left Mouse Button is pressed on my Button, hence I use the PreviewMouseLeftButtonDown</p>\n<pre><code> private void MyButton_PreviewMouseLeftButtonDown(object sender, MouseButtonEventArgs e)\n {\n // code here\n }\n</code></pre>\n<p>WPF has preview events for alot of other events, you can read about them here</p>\n<p><a href=\"https://learn.microsoft.com/en-us/dotnet/desktop/wpf/advanced/preview-events?view=netframeworkdesktop-4.8\" rel=\"nofollow noreferrer\">Preview Events </a> - It particular talks about Buttons and how the mouse events interacts with it, So I highly recommend you read it</p>\n"
},
{
"answer_id": 69196222,
"author": "Stefanos Zilellis",
"author_id": 7986995,
"author_profile": "https://Stackoverflow.com/users/7986995",
"pm_score": 0,
"selected": false,
"text": "<p>You should try MouseMove of the picture box instead of MouseEnter, MouseMove will normally fire regardless mouse button state.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169590",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/609/"
] |
I need to fire an event when the mouse is above a PictureBox with the mouse button already clicked and held down.
Problems:
The MouseDown and MouseEnter event handlers do not work together very well.
For instance once a mouse button is clicked and held down, C# will fire the MouseDown event handler, but when the cursor moves over the PictureBox the MouseEnter event does not fire, until the mouse button is realeased.
|
When the mouse is pressed down most controls will then *Control.Capture* the mouse input. This means that all *MouseMove* events are sent to the original control that captured rather than the control the mouse happens to be over. This continues until the mouse loses capture which typically happens on the mouse up.
If you really need to know when the mouse is over your control even when another control has captured mouse input then you only really have one way. You need to snoop the windows messages destined for other controls inside your application. To do that you need add a message filter ...
```
Application.AddMessageFilter(myFilterClassInstance);
```
Then you need to implement the IMessageFilter on a suitable class...
```
public class MyFilterClass : IMessageFilter
{
public bool PreFilterMessage(ref Message m)
{
if (m.Msg == WM_MOUSEMOVE)
// Check if mouse is over my picture box!
return false;
}
}
```
Then you watch for mouse move events and check if they are over your picture box and do whatever it is you want to do.
|
169,596 |
<p><strong>EDIT:</strong> <em>I'm still waiting for more answers. Thanks!</em></p>
<p>In SQL 2000 days, I used to use temp table method where you create a temp table with new identity column and primary key then select where identity column between A and B.</p>
<p>When <strong>SQL 2005</strong> came along I found out about <code>Row_Number()</code> and I've been using it ever since...</p>
<p>But now, I found a serious performance issue with <code>Row_Number()</code>.
It performs very well when you are working with not-so-gigantic result sets and sorting over an identity column. However, <strong>it performs very poorly</strong> when you are working with <strong>large result sets</strong> like over 10,000 records and <strong>sorting it over non-identity column</strong>. <code>Row_Number()</code> performs poorly even if you sort by an identity column if the result set is over 250,000 records. For me, it came to a point where it throws an error, "<strong>command timeout!</strong>"</p>
<p><strong>What do you use to do paginate a large result set on SQL 2005?</strong>
Is temp table method still better in this case? I'm not sure if this method <a href="https://web.archive.org/web/20211020131201/https://www.4guysfromrolla.com/webtech/042606-1.shtml" rel="noreferrer">using temp table with SET ROWCOUNT</a> will perform better... But some say there is an issue of giving wrong row number if you have multi-column primary key.</p>
<p>In my case, I need to be able to sort the result set by a date type column... for my production web app.</p>
<p>Let me know what you use for <strong>high-performing pagination in SQL 2005</strong>. And I'd also like to know a smart way of creating indexes. <strong>I'm suspecting choosing right primary keys and/or indexes (clustered/non-clustered) will play a big role here.</strong></p>
<p>Thanks in advance.</p>
<p>P.S. <strong>Does anyone know what stackoverflow uses?</strong></p>
<p><strong>EDIT:</strong> Mine looks something like...</p>
<pre><code>SELECT postID, postTitle, postDate
FROM
(SELECT postID, postTitle, postDate,
ROW_NUMBER() OVER(ORDER BY postDate DESC, postID DESC) as RowNum
FROM MyTable
) as DerivedMyTable
WHERE RowNum BETWEEN @startRowIndex AND (@startRowIndex + @maximumRows) - 1
</code></pre>
<p>postID: Int, Identity (auto-increment), Primary key</p>
<p>postDate: DateTime</p>
<p><strong>EDIT:</strong> Is everyone using Row_Number()?</p>
|
[
{
"answer_id": 169655,
"author": "Mitch Wheat",
"author_id": 16076,
"author_profile": "https://Stackoverflow.com/users/16076",
"pm_score": 3,
"selected": false,
"text": "<p>The row_number() technique should be quick. I have seen good results for 100,000 rows.</p>\n\n<p>Are you using row_number() similiar to the following:</p>\n\n<pre><code>SELECT column_list\nFROM\n (SELECT column_list\n ROW_NUMBER() OVER(ORDER BY OrderByColumnName) as RowNum\n FROM MyTable m\n ) as DerivedTableName\nWHERE RowNum BETWEEN @startRowIndex AND (@startRowIndex + @maximumRows) - 1\n</code></pre>\n\n<p>...and do you have a covering index for the column_list and/or an index on the 'OrderByColumnName' column?</p>\n"
},
{
"answer_id": 219839,
"author": "liggett78",
"author_id": 19762,
"author_profile": "https://Stackoverflow.com/users/19762",
"pm_score": 2,
"selected": true,
"text": "<p>Well, for your sample query ROW_COUNT should be pretty fast with thousands of rows, provided you have an index on your PostDate field. If you don't, the server needs to perform a complete clustered index scan on your PK, practically load every page, fetch your PostDate field, sort by it, determine the rows to extract for the result set and again fetch those rows. It's kind of creating a temp index over and over again (you might see an table/index spool in the plain).</p>\n\n<p>No wonder you get timeouts.</p>\n\n<p>My suggestion: set an index on PostDate DESC, this is what ROW_NUMBER will go over - (ORDER BY PostDate DESC, ...)</p>\n\n<p>As for the article you are referring to - I've done pretty much paging and stuff with SQL Server 2000 in the past without ROW_COUNT and the approach used in the article is the most efficient one. It does not work in all circumstances (you need unique or almost unique values). An overview of some other methods is <a href=\"http://www.codeproject.com/KB/aspnet/PagingLarge.aspx\" rel=\"nofollow noreferrer\">here</a>.</p>\n\n<p>.</p>\n"
}
] |
2008/10/04
|
[
"https://Stackoverflow.com/questions/169596",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5704/"
] |
**EDIT:** *I'm still waiting for more answers. Thanks!*
In SQL 2000 days, I used to use temp table method where you create a temp table with new identity column and primary key then select where identity column between A and B.
When **SQL 2005** came along I found out about `Row_Number()` and I've been using it ever since...
But now, I found a serious performance issue with `Row_Number()`.
It performs very well when you are working with not-so-gigantic result sets and sorting over an identity column. However, **it performs very poorly** when you are working with **large result sets** like over 10,000 records and **sorting it over non-identity column**. `Row_Number()` performs poorly even if you sort by an identity column if the result set is over 250,000 records. For me, it came to a point where it throws an error, "**command timeout!**"
**What do you use to do paginate a large result set on SQL 2005?**
Is temp table method still better in this case? I'm not sure if this method [using temp table with SET ROWCOUNT](https://web.archive.org/web/20211020131201/https://www.4guysfromrolla.com/webtech/042606-1.shtml) will perform better... But some say there is an issue of giving wrong row number if you have multi-column primary key.
In my case, I need to be able to sort the result set by a date type column... for my production web app.
Let me know what you use for **high-performing pagination in SQL 2005**. And I'd also like to know a smart way of creating indexes. **I'm suspecting choosing right primary keys and/or indexes (clustered/non-clustered) will play a big role here.**
Thanks in advance.
P.S. **Does anyone know what stackoverflow uses?**
**EDIT:** Mine looks something like...
```
SELECT postID, postTitle, postDate
FROM
(SELECT postID, postTitle, postDate,
ROW_NUMBER() OVER(ORDER BY postDate DESC, postID DESC) as RowNum
FROM MyTable
) as DerivedMyTable
WHERE RowNum BETWEEN @startRowIndex AND (@startRowIndex + @maximumRows) - 1
```
postID: Int, Identity (auto-increment), Primary key
postDate: DateTime
**EDIT:** Is everyone using Row\_Number()?
|
Well, for your sample query ROW\_COUNT should be pretty fast with thousands of rows, provided you have an index on your PostDate field. If you don't, the server needs to perform a complete clustered index scan on your PK, practically load every page, fetch your PostDate field, sort by it, determine the rows to extract for the result set and again fetch those rows. It's kind of creating a temp index over and over again (you might see an table/index spool in the plain).
No wonder you get timeouts.
My suggestion: set an index on PostDate DESC, this is what ROW\_NUMBER will go over - (ORDER BY PostDate DESC, ...)
As for the article you are referring to - I've done pretty much paging and stuff with SQL Server 2000 in the past without ROW\_COUNT and the approach used in the article is the most efficient one. It does not work in all circumstances (you need unique or almost unique values). An overview of some other methods is [here](http://www.codeproject.com/KB/aspnet/PagingLarge.aspx).
.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.