
qid
int64 4
8.14M
| question
stringlengths 20
48.3k
| answers
list | date
stringlengths 10
10
| metadata
list | input
stringlengths 12
45k
| output
stringlengths 2
31.8k
|
|---|---|---|---|---|---|---|
176,840 |
<p>It's the first <a href="http://oreilly.com/catalog/opensources/book/larry.html" rel="nofollow noreferrer">great virtue</a> of programmers. All of us have, at one time or another automated a task with a bit of throw-away code. Sometimes it takes a couple seconds tapping out a one-liner, sometimes we spend an exorbitant amount of time automating away a two-second task and then never use it again.</p>
<p>What tiny hack have you found useful enough to <b>reuse</b>? To make go so far as to make an alias for?</p>
<p>Note: before answering, please check to make sure it's not already on <a href="https://stackoverflow.com/questions/68372/what-is-your-single-most-favorite-command-line-trick-using-bash">favourite command-line tricks using BASH</a> or perl/ruby one-liner questions. </p>
|
[
{
"answer_id": 176843,
"author": "Kibbee",
"author_id": 1862,
"author_profile": "https://Stackoverflow.com/users/1862",
"pm_score": 1,
"selected": false,
"text": "<p>Sorry, don't have the exact code handy, but I coded a regular expression for searching source code in VS.Net that allowed me to search anything not in comments. It came in very useful in a particular project I was working on, where people insisted that commenting out code was good practice, in case you wanted to go back and see what the code used to do.</p>\n"
},
{
"answer_id": 176849,
"author": "Taptronic",
"author_id": 14728,
"author_profile": "https://Stackoverflow.com/users/14728",
"pm_score": 0,
"selected": false,
"text": "<p>This goes back to my COBOL days but I had two generic COBOL programs, one batch and one online (mainframe folks will know what these are). They were shells of a program that could take any set of parameters and/or files and be run, batch or executed in an IMS test region. I had them set up so that depending on the parameters I could access files, databases(DB2 or IMS DB) and or just manipulate working storage or whatever. </p>\n\n<p>It was great because I could test that date function without guessing or test why there was truncation or why there was a database ABEND. The programs grew in size as time went on to include all sorts of tests and become a staple of the development group. Everyone knew where the code resided and included them in their unit testing as well. Those programs got so large (most of the code were commented out tests) and it was all contributed by people through the years. They saved so much time and settled so many disagreements!</p>\n"
},
{
"answer_id": 176861,
"author": "J.J.",
"author_id": 21204,
"author_profile": "https://Stackoverflow.com/users/21204",
"pm_score": 0,
"selected": false,
"text": "<p>I coded a Perl script to map dependencies, without going into an endless loop, For a legacy C program I inherited .... that also had a diamond dependency problem.</p>\n\n<p>I wrote small program that e-mailed me when I received e-mails from friends, on an rarely used e-mail account.</p>\n\n<p>I wrote another small program that sent me text messages if my home IP changes.</p>\n\n<p>To name a few.</p>\n"
},
{
"answer_id": 176872,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Years ago I built a suite of applications on a custom web application platform in PERL.\nOne cool feature was to convert SQL query strings into human readable sentences that described what the results were.</p>\n\n<p>The code was relatively short but the end effect was nice.</p>\n"
},
{
"answer_id": 176898,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>I've got a little app that you run and it dumps a GUID into the clipboard. You can run it /noui or not. With UI, its a single button that drops a new GUID every time you click it. Without it drops a new one and then exits. </p>\n\n<p>I mostly use it from within VS. I have it as an external app and mapped to a shortcut. I'm writing an app that relies heavily on xaml and guids, so I always find I need to paste a new guid into xaml...</p>\n"
},
{
"answer_id": 176930,
"author": "Frew Schmidt",
"author_id": 12448,
"author_profile": "https://Stackoverflow.com/users/12448",
"pm_score": 1,
"selected": false,
"text": "<p>I have two ruby scripts that I modify regularly to download all of various webcomics. Extremely handy! <em>Note: They require wget, so probably linux.</em> <em>Note2: read these before you try them, they need a little bit of modification for each site.</em></p>\n\n<p>Date based downloader:</p>\n\n<pre><code>#!/usr/bin/ruby -w\n\nDay = 60 * 60 * 24\n\nFromat = \"hjlsdahjsd/comics/st%Y%m%d.gif\"\n\nt = Time.local(2005, 2, 5)\n\nMWF = [1,3,5]\n\nuntil t == Time.local(2007, 7, 9)\n if MWF.include? t.wday\n `wget #{t.strftime(Fromat)}`\n sleep 3\n end\n\n t += Day\nend\n</code></pre>\n\n<p>Or you can use the number based one:</p>\n\n<pre><code>#!/usr/bin/ruby -w\n\nFromat = \"http://fdsafdsa/comics/%08d.gif\"\n1.upto(986) do |i|\n `wget #{sprintf(Fromat, i)}`\n sleep 1\nend\n</code></pre>\n"
},
{
"answer_id": 176933,
"author": "Frentos",
"author_id": 23978,
"author_profile": "https://Stackoverflow.com/users/23978",
"pm_score": 2,
"selected": false,
"text": "<p>I use this script under assorted linuxes to check whether a directory copy between machines (or to CD/DVD) worked or whether copying (e.g. ext3 utf8 filenames -> fusebl\nk) has mangled special characters in the filenames.</p>\n\n<pre><code>#!/bin/bash\n## dsum Do checksums recursively over a directory.\n## Typical usage: dsum <directory> > outfile\n\nexport LC_ALL=C # Optional - use sort order across different locales\n\nif [ $# != 1 ]; then echo \"Usage: ${0/*\\//} <directory>\" 1>&2; exit; fi\ncd $1 1>&2 || exit\n#findargs=-follow # Uncomment to follow symbolic links\nfind . $findargs -type f | sort | xargs -d'\\n' cksum\n</code></pre>\n"
},
{
"answer_id": 176950,
"author": "Claudiu",
"author_id": 15055,
"author_profile": "https://Stackoverflow.com/users/15055",
"pm_score": 0,
"selected": false,
"text": "<p>Any time I write a clever list comprehension or use of map/reduce in python. There was one like this:</p>\n\n<pre><code>if reduce(lambda x, c: locks[x] and c, locknames, True):\n print \"Sub-threads terminated!\"\n</code></pre>\n\n<p>The reason I remember that is that I came up with it myself, then saw the exact same code on somebody else's website. Now-adays it'd probably be done like:</p>\n\n<pre><code>if all(map(lambda z: locks[z], locknames)):\n print \"ya trik\"\n</code></pre>\n"
},
{
"answer_id": 176995,
"author": "joh6nn",
"author_id": 21837,
"author_profile": "https://Stackoverflow.com/users/21837",
"pm_score": 4,
"selected": false,
"text": "<p>i found this on dotfiles.org just today. it's very simple, but clever. i felt stupid for not having thought of it myself.</p>\n\n<pre><code>###\n### Handy Extract Program\n###\nextract () {\n if [ -f $1 ] ; then\n case $1 in\n *.tar.bz2) tar xvjf $1 ;;\n *.tar.gz) tar xvzf $1 ;;\n *.bz2) bunzip2 $1 ;;\n *.rar) unrar x $1 ;;\n *.gz) gunzip $1 ;;\n *.tar) tar xvf $1 ;;\n *.tbz2) tar xvjf $1 ;;\n *.tgz) tar xvzf $1 ;;\n *.zip) unzip $1 ;;\n *.Z) uncompress $1 ;;\n *.7z) 7z x $1 ;;\n *) echo \"'$1' cannot be extracted via >extract<\" ;;\n esac\n else\n echo \"'$1' is not a valid file\"\n fi\n}\n</code></pre>\n"
},
{
"answer_id": 177116,
"author": "Andy Lester",
"author_id": 8454,
"author_profile": "https://Stackoverflow.com/users/8454",
"pm_score": 3,
"selected": false,
"text": "<p>Here's a filter that puts commas in the middle of any large numbers in standard input.</p>\n\n<pre><code>$ cat ~/bin/comma\n#!/usr/bin/perl -p\n\ns/(\\d{4,})/commify($1)/ge;\n\nsub commify {\n local $_ = shift;\n 1 while s/^([ -+]?\\d+)(\\d{3})/$1,$2/;\n return $_;\n}\n</code></pre>\n\n<p>I usually wind up using it for long output lists of big numbers, and I tire of counting decimal places. Now instead of seeing</p>\n\n<pre><code>-rw-r--r-- 1 alester alester 2244487404 Oct 6 15:38 listdetail.sql\n</code></pre>\n\n<p>I can run that as <code>ls -l | comma</code> and see</p>\n\n<pre><code>-rw-r--r-- 1 alester alester 2,244,487,404 Oct 6 15:38 listdetail.sql\n</code></pre>\n"
},
{
"answer_id": 177179,
"author": "Scott Dillman",
"author_id": 10111,
"author_profile": "https://Stackoverflow.com/users/10111",
"pm_score": 0,
"selected": false,
"text": "<p>I've got 20 or 30 of these things lying around because once I coded up the framework for my standard console app in windows I can pretty much drop in any logic I want, so I got a lot of these little things that solve specific problems. </p>\n\n<p>I guess the ones I'm using a lot right now is a console app that takes stdin and colorizes the output based on xml profiles that match regular expressions to colors. I use it for watching my log files from builds. The other one is a command line launcher so I don't pollute my PATH env var and it would exceed the limit on some systems anyway, namely win2k.</p>\n"
},
{
"answer_id": 201722,
"author": "Magnus Smith",
"author_id": 11461,
"author_profile": "https://Stackoverflow.com/users/11461",
"pm_score": 1,
"selected": false,
"text": "<p>Instead of having to repeatedly open files in SQL Query Analyser and run them, I found the syntax needed to make a batch file, and could then run 100 at once. Oh the sweet sweet joy! I've used this ever since.</p>\n\n<pre><code>isqlw -S servername -d dbname -E -i F:\\blah\\whatever.sql -o F:\\results.txt\n</code></pre>\n"
},
{
"answer_id": 256762,
"author": "Adam Liss",
"author_id": 29157,
"author_profile": "https://Stackoverflow.com/users/29157",
"pm_score": 0,
"selected": false,
"text": "<p>I'm constantly connecting to various linux servers from my own desktop throughout my workday, so I created a few aliases that will launch an <code>xterm</code> on those machines and set the title, background color, and other tweaks:</p>\n\n<pre><code>alias x=\"xterm\" # local\nalias xd=\"ssh -Xf me@development_host xterm -bg aliceblue -ls -sb -bc -geometry 100x30 -title Development\"\nalias xp=\"ssh -Xf me@production_host xterm -bg thistle1 ...\"\n</code></pre>\n"
},
{
"answer_id": 271036,
"author": "Jim Puls",
"author_id": 6010,
"author_profile": "https://Stackoverflow.com/users/6010",
"pm_score": 0,
"selected": false,
"text": "<p>I have a bunch of servers I frequently connect to, as well, but they're all on my local network. This Ruby script prints out the command to create aliases for any machine with ssh open: </p>\n\n<pre><code>#!/usr/bin/env ruby\n\nrequire 'rubygems'\nrequire 'dnssd'\n\nhandle = DNSSD.browse('_ssh._tcp') do |reply|\n print \"alias #{reply.name}='ssh #{reply.name}.#{reply.domain}';\"\nend\n\nsleep 1\nhandle.stop\n</code></pre>\n\n<p>Use it like this in your <code>.bash_profile</code>:</p>\n\n<pre>\neval `ruby ~/.alias_shares`\n</pre>\n"
},
{
"answer_id": 386621,
"author": "Dutch Masters",
"author_id": 42037,
"author_profile": "https://Stackoverflow.com/users/42037",
"pm_score": 2,
"selected": false,
"text": "<p><strong>This script saved my career!</strong></p>\n\n<p>Quite a few years ago, i was working remotely on a client database. I updated a shipment to change its status. But I forgot the where clause. </p>\n\n<p>I'll never forget the feeling in the pit of my stomach when I saw (6834 rows affected). I basically spent the entire night going through event logs and figuring out the proper status on all those shipments. <strong><em>Crap!</em></strong></p>\n\n<p>So I wrote a script (originally in awk) that would start a transaction for any updates, and check the rows affected before committing. This prevented any surprises.</p>\n\n<p>So now I never do updates from command line without going through a script like this. Here it is (now in Python):</p>\n\n<pre><code>import sys\nimport subprocess as sp\npgm = \"isql\"\nif len(sys.argv) == 1:\n print \"Usage: \\nsql sql-string [rows-affected]\"\n sys.exit()\nsql_str = sys.argv[1].upper()\nmax_rows_affected = 3\nif len(sys.argv) > 2:\n max_rows_affected = int(sys.argv[2])\n\nif sql_str.startswith(\"UPDATE\"):\n sql_str = \"BEGIN TRANSACTION\\\\n\" + sql_str\n p1 = sp.Popen([pgm, sql_str],stdout=sp.PIPE,\n shell=True)\n (stdout, stderr) = p1.communicate()\n print stdout\n # example -> (33 rows affected)\n affected = stdout.splitlines()[-1]\n affected = affected.split()[0].lstrip('(')\n num_affected = int(affected)\n if num_affected > max_rows_affected:\n print \"WARNING! \", num_affected,\"rows were affected, rolling back...\"\n sql_str = \"ROLLBACK TRANSACTION\"\n ret_code = sp.call([pgm, sql_str], shell=True)\n else:\n sql_str = \"COMMIT TRANSACTION\"\n ret_code = sp.call([pgm, sql_str], shell=True)\nelse:\n ret_code = sp.call([pgm, sql_str], shell=True)\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176840",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1582786/"
] |
It's the first [great virtue](http://oreilly.com/catalog/opensources/book/larry.html) of programmers. All of us have, at one time or another automated a task with a bit of throw-away code. Sometimes it takes a couple seconds tapping out a one-liner, sometimes we spend an exorbitant amount of time automating away a two-second task and then never use it again.
What tiny hack have you found useful enough to **reuse**? To make go so far as to make an alias for?
Note: before answering, please check to make sure it's not already on [favourite command-line tricks using BASH](https://stackoverflow.com/questions/68372/what-is-your-single-most-favorite-command-line-trick-using-bash) or perl/ruby one-liner questions.
|
i found this on dotfiles.org just today. it's very simple, but clever. i felt stupid for not having thought of it myself.
```
###
### Handy Extract Program
###
extract () {
if [ -f $1 ] ; then
case $1 in
*.tar.bz2) tar xvjf $1 ;;
*.tar.gz) tar xvzf $1 ;;
*.bz2) bunzip2 $1 ;;
*.rar) unrar x $1 ;;
*.gz) gunzip $1 ;;
*.tar) tar xvf $1 ;;
*.tbz2) tar xvjf $1 ;;
*.tgz) tar xvzf $1 ;;
*.zip) unzip $1 ;;
*.Z) uncompress $1 ;;
*.7z) 7z x $1 ;;
*) echo "'$1' cannot be extracted via >extract<" ;;
esac
else
echo "'$1' is not a valid file"
fi
}
```
|
176,850 |
<p>I've used NUnit before, but not in a while, and never on this machine. I unzipped version 2.4.8 under <code>Program Files</code>, and I keep getting this error when trying to load my tests.</p>
<blockquote>
<p>Could not load file or assembly 'nunit.framework, Version=2.4.8.0, Culture=neutral, PublicKeyToken=96d09a1eb7f44a77' or one of its dependencies. The system cannot find the file specified**</p>
</blockquote>
<p>In order to simplify the problem, I've compiled the most basic possible test file.</p>
<pre><code>using NUnit.Framework;
namespace test
{
[TestFixture]
public class Tester
{
[Test]
public void ATest()
{
Assert.IsTrue(false, "At least the test ran!");
}
}
}
</code></pre>
<p>I've added "C:\Program Files\NUnit-2.4.8-net-2.0\bin" to my PATH (and rebooted). Note that if I copy the test assembly into that folder, then</p>
<pre>
C:\Program Files\NUnit-2.4.8-net-2.0\bin>nunit-console test.dll
</pre>
<p>works, but</p>
<pre>
C:\Program Files\NUnit-2.4.8-net-2.0\bin>nunit-console c:\dev\nunit_test\test.dll
</pre>
<p>and</p>
<pre>
C:\dev\nunit_test>nunit_console test.dll
</pre>
<p>fail with the above error.</p>
<p>Presumably I could get around this by copying the NUnit.Framework DLL file into my project's <code>bin</code> folder, but I don't remember having to do this in the past. Moreover, I get the same error in the GUI. Shouldn't the GUI know where the framework is located (that is, in the same folder)?</p>
<p>I'm not using Visual Studio. I use the following line to compile the test project.</p>
<pre>
%windir%\Microsoft.NET\Framework\v2.0.50727\csc.exe /r:"C:\Program Files\NUnit-2.4.8-net-2.0\bin\nunit.framework.dll" /t:library /out:test.dll test.cs
</pre>
<p>I tried both the .msi and the .zip file with the same result.</p>
|
[
{
"answer_id": 176859,
"author": "Scott Pedersen",
"author_id": 16002,
"author_profile": "https://Stackoverflow.com/users/16002",
"pm_score": 4,
"selected": false,
"text": "<p>Make sure you have added a reference to nunit.framework. If you have, then make sure the properties of that reference have the copy local property set to true.</p>\n"
},
{
"answer_id": 176862,
"author": "devio",
"author_id": 21336,
"author_profile": "https://Stackoverflow.com/users/21336",
"pm_score": 4,
"selected": true,
"text": "<p>If you install using NUnit-2.4.8-net-2.0.msi, the NUnit assemblies are added to the <a href=\"http://en.wikipedia.org/wiki/Global_Assembly_Cache\" rel=\"nofollow noreferrer\">GAC</a>.</p>\n\n<p>You can also reinstall manually by running gacutil from the Visual Studio 2005 command prompt.</p>\n"
},
{
"answer_id": 688174,
"author": "Jeffrey Knight",
"author_id": 83418,
"author_profile": "https://Stackoverflow.com/users/83418",
"pm_score": 4,
"selected": false,
"text": "<p>I had the same problem, and I had installed using NUnit-2.4.8-net-2.0.msi. Expanding on <a href=\"https://stackoverflow.com/questions/176850/nunit-assembly-not-found/176862#176862\">the \"add to the GAC\" comment</a>, here's what I did:</p>\n\n<ul>\n<li><p>Open your \"Visual Studio command prompt (generally: make sure gacutil is in your path) and: cd \"C:\\Program Files\\NUnit 2.4.8\\bin\"</p></li>\n<li><p>Unregister your NUnit entries from the GAC. You can do this by finding the NUnit entries registered in the GAC:</p>\n\n<pre><code>gacutil /l | find /i \"nunit\" > temp.bat && notepad temp.bat\n</code></pre></li>\n<li><p>Prepend the nunit.core and nunit.framework lines with \"gacutil /uf\", i.e.:</p>\n\n<pre><code>gacutil /uf nunit.core,Version=2.4.2.0,Culture=neutral,PublicKeyToken=96d09a1eb7f44a77\n\ngacutil /uf nunit.framework,Version=2.4.2.0,Culture=neutral,PublicKeyToken=96d09a1eb7f44a77\n</code></pre></li>\n<li><p>Run your .bat file to remove them:\n<code>temp.bat</code></p></li>\n<li><p>Register the NUnit DLL files you need:</p>\n\n<pre><code>gacutil /i nunit.core.dll\n\ngacutil /i nunit.framework.dll\n</code></pre></li>\n</ul>\n"
},
{
"answer_id": 3524273,
"author": "Curt",
"author_id": 384979,
"author_profile": "https://Stackoverflow.com/users/384979",
"pm_score": 1,
"selected": false,
"text": "<p>I got this error message today when I tried to add a new test assembly to an existing NUnit test project. It seems that my test projects had multiple path references to identical nunit.framework.dll assemblies.</p>\n\n<p>If you have more than one test assembly in your NUnit project, you may want to verify the Path property of the nunit.framework reference in your test projects. Once I made them match, the error message went away.</p>\n"
},
{
"answer_id": 7812614,
"author": "Juancentro",
"author_id": 645080,
"author_profile": "https://Stackoverflow.com/users/645080",
"pm_score": 2,
"selected": false,
"text": "<p>Note that the current NUnit installation (2.5.10) doesn't register itself automatically in the GAC.</p>\n\n<p>If you must use GAC, register it via <code>gacutil /i <nunitframeworkpath></code> where <code>nunitframeworkpath</code> is usually <code>%Program Files%\\NUnit\\net-2.0\\framework\\nunit-framework</code>.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176850",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4525/"
] |
I've used NUnit before, but not in a while, and never on this machine. I unzipped version 2.4.8 under `Program Files`, and I keep getting this error when trying to load my tests.
>
> Could not load file or assembly 'nunit.framework, Version=2.4.8.0, Culture=neutral, PublicKeyToken=96d09a1eb7f44a77' or one of its dependencies. The system cannot find the file specified\*\*
>
>
>
In order to simplify the problem, I've compiled the most basic possible test file.
```
using NUnit.Framework;
namespace test
{
[TestFixture]
public class Tester
{
[Test]
public void ATest()
{
Assert.IsTrue(false, "At least the test ran!");
}
}
}
```
I've added "C:\Program Files\NUnit-2.4.8-net-2.0\bin" to my PATH (and rebooted). Note that if I copy the test assembly into that folder, then
```
C:\Program Files\NUnit-2.4.8-net-2.0\bin>nunit-console test.dll
```
works, but
```
C:\Program Files\NUnit-2.4.8-net-2.0\bin>nunit-console c:\dev\nunit_test\test.dll
```
and
```
C:\dev\nunit_test>nunit_console test.dll
```
fail with the above error.
Presumably I could get around this by copying the NUnit.Framework DLL file into my project's `bin` folder, but I don't remember having to do this in the past. Moreover, I get the same error in the GUI. Shouldn't the GUI know where the framework is located (that is, in the same folder)?
I'm not using Visual Studio. I use the following line to compile the test project.
```
%windir%\Microsoft.NET\Framework\v2.0.50727\csc.exe /r:"C:\Program Files\NUnit-2.4.8-net-2.0\bin\nunit.framework.dll" /t:library /out:test.dll test.cs
```
I tried both the .msi and the .zip file with the same result.
|
If you install using NUnit-2.4.8-net-2.0.msi, the NUnit assemblies are added to the [GAC](http://en.wikipedia.org/wiki/Global_Assembly_Cache).
You can also reinstall manually by running gacutil from the Visual Studio 2005 command prompt.
|
176,851 |
<p>I have taken a copy of a database home with me so I can do some testing. However when I try to run a stored procedure I get Cannot open user default database. Login failed.. </p>
<p>I have checked and checked and checked I can open tables in the databases login to sql management studio and access the default as well as other databases any ideas?</p>
<p>Possibly a corrupt user it was from sql 2000 at work to 2005 at home</p>
|
[
{
"answer_id": 176864,
"author": "Brian Kim",
"author_id": 5704,
"author_profile": "https://Stackoverflow.com/users/5704",
"pm_score": 2,
"selected": false,
"text": "<p><strong>EDIT:</strong> Mine was from 2005 to 2005. Not sure if this will work for your case...</p>\n\n<p>I had a similar problem. For me, when I detach or create a back up and then re-create the database, it will loose connection to users. User I've been using is still there under Login but it would fail to log in.</p>\n\n<p>In my case, I was able to log in by deleting the User under the database -> security -> users, not the user that's in the root sql server users list.</p>\n\n<p>Then go to root users list and reassign database mapping or create user if not exists.</p>\n\n<p>Hope this helps.</p>\n"
},
{
"answer_id": 176868,
"author": "devio",
"author_id": 21336,
"author_profile": "https://Stackoverflow.com/users/21336",
"pm_score": 0,
"selected": false,
"text": "<p>My understanding is that Logins are stored in the server, whereas a User is an assignment of a login to a database (correct me if I'm wrong).</p>\n\n<p>Therefore, you cannot move Logins by detaching/attaching databases, and the solution would be to create a database User connecting a (valid) login to the copied database.</p>\n"
},
{
"answer_id": 176899,
"author": "Eric Tuttleman",
"author_id": 25677,
"author_profile": "https://Stackoverflow.com/users/25677",
"pm_score": 2,
"selected": false,
"text": "<p>This is a shot in the dark, so forgive me if it just wastes your time.</p>\n\n<p>Another poster mentioned that a given user has an id for the system and an id for any given database. This can be proven out by comparing sid's between the master.sys.syslogins and dbname.sys.users for the same login / user name. If you restore a backup from another sql server that has it's own copy of the master databases, the sids won't match.</p>\n\n<p>Sql Server 2005 doesn't allow direct editing of system tables with out a lot of pain. To help out with these mis matches, they added a stored procedure to help you fix them:</p>\n\n<p>USE dbName\nGO</p>\n\n<p>sp_change_users_login @Action='Report'</p>\n\n<p>That will show you what users have a dbName.sys.users entry, but no master.sys.syslogins one - or where the name exists in both, but differ by sids.</p>\n\n<p>If it shows that your user is out of synch, the procedure also has a mode to change the linking:</p>\n\n<p>USE dbName\nGO\nsp_change_users_login 'Update_One', 'userNameInDbUsers', 'UserNameInLogins' </p>\n\n<p>If the sid mis-match isn't your problem, I've also seen really screwy stuff with Sql Server 2005. The gui is especially buggy. To fix a problem like this, I had to actually drop the syslogins entry (via the gui or DROP LOGIN command )</p>\n\n<p>sp_change_users_login: <a href=\"http://msdn.microsoft.com/en-us/library/ms174378(SQL.90).aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/ms174378(SQL.90).aspx</a></p>\n\n<p>Drop Login syntax: <a href=\"http://msdn.microsoft.com/en-us/library/ms188012(SQL.90).aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/ms188012(SQL.90).aspx</a></p>\n"
},
{
"answer_id": 176939,
"author": "flatline",
"author_id": 20846,
"author_profile": "https://Stackoverflow.com/users/20846",
"pm_score": 0,
"selected": false,
"text": "<p>As was mentioned before, the login mapping to that user account probably became disassociated during the move. Or, you moved it without creating the credentials it was expecting, in which case, you'd need to create the login first...</p>\n\n<p>If it was a backup set and you are restoring it, however, there is no way (that I know of) to reassociate the login to the user via the management UI. Instead, you have to use:</p>\n\n<pre><code>exec sp_change_users_login update_one, 'user', 'login'\n</code></pre>\n\n<p>to get it to restore the link.</p>\n"
},
{
"answer_id": 177048,
"author": "Hector Sosa Jr",
"author_id": 12829,
"author_profile": "https://Stackoverflow.com/users/12829",
"pm_score": 2,
"selected": true,
"text": "<p>I moved 8 databases from SQL Server 2000 to SQL Server 2005 and onto a whole different computer. I normally like to know what stored procs are doing so I dug a little bit and found that the actual command is <strong>ALTER USER</strong>.</p>\n\n<p>It's what everybody else has been saying. The users get disassociated when you detach and reattach databases in SQL Server 2005. I find this behavior most annoying, as I didn't see that behavior in SQL Server 2000.</p>\n\n<p>The T-SQL to fix this issue looks like this:</p>\n\n<pre><code>USE AdventureWorks;\nALTER USER Mary5 WITH NAME = Mary51;\nGO\n</code></pre>\n\n<p>This MSDN article talks a bit more about this:</p>\n\n<p><a href=\"http://msdn.microsoft.com/en-us/library/ms176060.aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/ms176060.aspx</a></p>\n"
},
{
"answer_id": 426235,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p><code>ALTER LOGIN</code> works only in SQL 2005 and up. </p>\n\n<p>To change the default database for a user in 2000 use </p>\n\n<pre><code>EXEC master.dbo.sp_defaultdb @loginname = N'BuiltIn\\Administrators', @defdb = N'master'\n</code></pre>\n\n<p>I found this out the hard way when I set the builtin\\administrators account to default to the application db and it went Offline somehow and I could no longer login. Using Management Studio, you can set the option to login to master but you must run the above command before any other operation will work, less you get the default database is unavailable error.</p>\n"
},
{
"answer_id": 618921,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p><a href=\"http://benharrell.wordpress.com/2007/01/15/cannot-open-user-default-database-login-failed-login-failed-for-user-username-microsoft-sql-server-error-4064/\" rel=\"nofollow noreferrer\">http://benharrell.wordpress.com/2007/01/15/cannot-open-user-default-database-login-failed-login-failed-for-user-username-microsoft-sql-server-error-4064/</a></p>\n"
},
{
"answer_id": 5639558,
"author": "Spydermary",
"author_id": 704624,
"author_profile": "https://Stackoverflow.com/users/704624",
"pm_score": 1,
"selected": false,
"text": "<p>I just solved this issue. My default database was AdventureWorks2008, so as an Administrator, I ended up removing my login from the server. Then running the following to recreate my user</p>\n\n<pre><code>CREATE LOGIN [NT\\mylogin] FROM WINDOWS WITH DEFAULT_DATABASE=[Master], DEFAULT_LANGUAGE=[us_english]\nGO\n</code></pre>\n"
},
{
"answer_id": 6911131,
"author": "Filippo Vitale",
"author_id": 81444,
"author_profile": "https://Stackoverflow.com/users/81444",
"pm_score": 2,
"selected": false,
"text": "<p>I had the same issue and I fixed it with:</p>\n\n<pre><code>C:\\> sqlcmd -E -d master\n1> ALTER LOGIN ***** WITH DEFAULT_DATABASE=master\n2> GO\n</code></pre>\n\n<p>Where <code>*****</code> is your username.</p>\n\n<p>(If you are using a domain username: <code>[*****]</code>)</p>\n\n<p><strong>Edit:</strong></p>\n\n<p>Where <code>*****</code> could be:</p>\n\n<ul>\n<li><code>username</code> if the user is local</li>\n<li><code>[username]</code> if the user belongs to the actual domain</li>\n<li><code>[domain\\username]</code> if the user belongs to another domain (not tested)</li>\n</ul>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176851",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/16989/"
] |
I have taken a copy of a database home with me so I can do some testing. However when I try to run a stored procedure I get Cannot open user default database. Login failed..
I have checked and checked and checked I can open tables in the databases login to sql management studio and access the default as well as other databases any ideas?
Possibly a corrupt user it was from sql 2000 at work to 2005 at home
|
I moved 8 databases from SQL Server 2000 to SQL Server 2005 and onto a whole different computer. I normally like to know what stored procs are doing so I dug a little bit and found that the actual command is **ALTER USER**.
It's what everybody else has been saying. The users get disassociated when you detach and reattach databases in SQL Server 2005. I find this behavior most annoying, as I didn't see that behavior in SQL Server 2000.
The T-SQL to fix this issue looks like this:
```
USE AdventureWorks;
ALTER USER Mary5 WITH NAME = Mary51;
GO
```
This MSDN article talks a bit more about this:
<http://msdn.microsoft.com/en-us/library/ms176060.aspx>
|
176,856 |
<p>What's the best way for constructing headers, and footers? Should you call it all from the controller, or include it from the view file? I'm using CodeIgniter, and I'm wanting to know what's the best practice for this. Loading all the included view files from the controller, like this?</p>
<pre><code>class Page extends Controller {
function index()
{
$data['page_title'] = 'Your title';
$this->load->view('header');
$this->load->view('menu');
$this->load->view('content', $data);
$this->load->view('footer');
}
}
</code></pre>
<p>or calling the single view file, and calling the header and footer views from there:</p>
<pre><code>//controller file
class Page extends Controller {
function index()
{
$data['page_title'] = 'Your title';
$this->load->view('content', $data);
}
}
//view file
<?php $this->load->view('header'); ?>
<p>The data from the controller</p>
<?php $this->load->view('footer'); ?>
</code></pre>
<p>I've seen it done both ways, but want to choose now before I go too far down a path.</p>
|
[
{
"answer_id": 176988,
"author": "gradbot",
"author_id": 17919,
"author_profile": "https://Stackoverflow.com/users/17919",
"pm_score": 2,
"selected": false,
"text": "<p>It's bad practice to call views inside of other views. This could be a form of controller view mixing. The view function in CI allows you to pass a third parameter that causes it to return that view's output as a string. You can use this to create a compound view.</p>\n<p>For example:</p>\n<pre><code>class Page extends Controller {\n function index() {\n $data['page_title'] = 'Your title';\n \n $this->load->view('default_layout', array(\n 'header' => $this->load->view('header' , array(), true), \n 'menu' => $this->load->view('menu' , array(), true), \n 'content' => $this->load->view('content', $data , true), \n 'footer' => $this->load->view('footer' , array(), true), \n ));\n }\n}\n</code></pre>\n<p>default_layout.php</p>\n<pre><code><? echo $header, $menu, $content, $footer; ?>\n</code></pre>\n<p>You may want to combine your header and footer to make a template like this.</p>\n<pre><code>class Page extends Controller {\n function index() {\n $data['page_title'] = 'Your title';\n \n $this->load->view('default_template', array(\n 'menu' => $this->load->view('menu' , array(), true), \n 'content' => $this->load->view('content', $data , true), \n ));\n }\n}\n</code></pre>\n<p>default_template.php</p>\n<pre><code><html><head></head><body><span>Some Header HTML</span> // this is your header html\n<? echo $menu, $content; ?>\n<span>some footer HTML</span></body></html> // this is your footer html\n</code></pre>\n"
},
{
"answer_id": 177168,
"author": "Jack B Nimble",
"author_id": 3800,
"author_profile": "https://Stackoverflow.com/users/3800",
"pm_score": 2,
"selected": false,
"text": "<p>I think the first way you are doing it is cleaner. Simply from a point of view of knowledge that is going to be rendered. Rather than having to enter the view file to find the rest.</p>\n"
},
{
"answer_id": 178882,
"author": "meleyal",
"author_id": 4196,
"author_profile": "https://Stackoverflow.com/users/4196",
"pm_score": 4,
"selected": true,
"text": "<p>You could also try it this way -- define a default view template, which then pulls in the content based on a variable ('content' in my example) passed by the controller.</p>\n<p>In your controller:</p>\n<pre><code>$data['content'] = 'your_controller/index';\n\n// more code...\n\n$this->load->vars($data);\n$this->load->view('layouts/default');\n</code></pre>\n<p>Then define a default layout for all pages e.g. views/layouts/default.php</p>\n<pre><code>// doctype, header html etc.\n\n<div id="content">\n <?= $this->load->view($content) ?>\n</div>\n\n// footer html etc.\n</code></pre>\n<p>Then your views can just contain the pure content e.g. views/your_controller/index.php might contain just the variables passed from the controller/data array</p>\n<pre><code><?= $archives_table ?>\n<?= $pagination ?>\n// etc.\n</code></pre>\n<p><a href=\"http://codeigniter.com/wiki/FAQ\" rel=\"nofollow noreferrer\">More details on the CI wiki/FAQ</a> -- (Q. How do I embed views within views? Nested templates?...)</p>\n"
},
{
"answer_id": 476559,
"author": "Jens Roland",
"author_id": 57068,
"author_profile": "https://Stackoverflow.com/users/57068",
"pm_score": 4,
"selected": false,
"text": "<p>Actually, after researching this quite a bit myself, I came to the conclusion that the best practice for including headers and footers in MVC is a third option - namely extending a base controller. That will give you a little more flexibility than the text's suggestion, particularly if you're building a very modular layout (not just header and footer, also sidebar panels, non-static menus, etc.).</p>\n<p>First, define a <code>Base_controller</code> class, in which you create methods that append your page elements (header, footer, etc.) to an output string:</p>\n<pre><code>class Base_controller extends Controller\n{\n var $_output = '';\n\n function _standard_header($data=null)\n {\n if (empty($data))\n $data = ...; // set default data for standard header here\n\n $this->_output .= $this->load->view('header', $data, true);\n }\n\n function _admin_header($data=null)\n {\n if (empty($data))\n $data = ...; // set default data for expanded header here\n\n $this->_output .= $this->load->view('admin_header', $data, true);\n }\n\n function _standard_page($data)\n {\n $this->_standard_header();\n $this->_output .=\n $this->load->view('standard_content', $data, true);\n echo $this->_output; // note: place the echo statement in a\n // separate function for added flexibility\n }\n\n function _page_with_admin_header($data)\n {\n $this->_admin_header($data);\n $this->_output .=\n $this->load->view('standard_content', $data, true);\n echo $this->_output;\n }\n}\n</code></pre>\n<p>Then, in your page controllers, simply extend the base class and call your functions to build the page.</p>\n<pre><code>class Page_controller extends Base_controller\n{\n function index()\n {\n $data = ...; // Set content data here\n $this->_standard_page($data);\n }\n\n function admin()\n {\n $data = ...; // Set content and header data here\n $this->_page_with_admin_header($data);\n }\n}\n</code></pre>\n<p>Using a base controller, you can achieve very clean code in your individual page controllers AND have separate views for elements on the page (allowing code reuse in both views and controllers). All you need to do is define your common page 'sections' (what you might be tempted to call 'fragments') as functions in your base controller.</p>\n<p>And if the base controller should start to grow uncontrollably (which can happen on large sites), you can rearrange some of its less-general functions by placing them in subclasses and letting the corresponding page controllers extend those instead of the original base controller.</p>\n<p>Enjoy!</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176856",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24708/"
] |
What's the best way for constructing headers, and footers? Should you call it all from the controller, or include it from the view file? I'm using CodeIgniter, and I'm wanting to know what's the best practice for this. Loading all the included view files from the controller, like this?
```
class Page extends Controller {
function index()
{
$data['page_title'] = 'Your title';
$this->load->view('header');
$this->load->view('menu');
$this->load->view('content', $data);
$this->load->view('footer');
}
}
```
or calling the single view file, and calling the header and footer views from there:
```
//controller file
class Page extends Controller {
function index()
{
$data['page_title'] = 'Your title';
$this->load->view('content', $data);
}
}
//view file
<?php $this->load->view('header'); ?>
<p>The data from the controller</p>
<?php $this->load->view('footer'); ?>
```
I've seen it done both ways, but want to choose now before I go too far down a path.
|
You could also try it this way -- define a default view template, which then pulls in the content based on a variable ('content' in my example) passed by the controller.
In your controller:
```
$data['content'] = 'your_controller/index';
// more code...
$this->load->vars($data);
$this->load->view('layouts/default');
```
Then define a default layout for all pages e.g. views/layouts/default.php
```
// doctype, header html etc.
<div id="content">
<?= $this->load->view($content) ?>
</div>
// footer html etc.
```
Then your views can just contain the pure content e.g. views/your\_controller/index.php might contain just the variables passed from the controller/data array
```
<?= $archives_table ?>
<?= $pagination ?>
// etc.
```
[More details on the CI wiki/FAQ](http://codeigniter.com/wiki/FAQ) -- (Q. How do I embed views within views? Nested templates?...)
|
176,858 |
<p>In a static view, how can I view an old version of a file?</p>
<p>Given an empty file (called <code>empty</code> in this example) I can subvert <code>diff</code> to show me the old version:</p>
<pre>
% cleartool diff -ser empty File@@/main/28
</pre>
<p>This feels like a pretty ugly hack. Have I missed a more basic command? Is there a neater way to do this?</p>
<p>(I don't want to edit the config spec - that's pretty tedious, and I'm trying to look at a bunch of old versions.)</p>
<p><strong>Clarification</strong>: I want to send the version of the file to stdout, so I can use it with the rest of Unix (grep, sed, and so on.) If you found this question because you're looking for a way to save a version of an element to a file, see <a href="https://stackoverflow.com/questions/176858/in-clearcase-how-can-i-view-old-version-of-a-file-in-a-static-view-from-the-com/4962643#4962643">Brian's answer</a>.</p>
|
[
{
"answer_id": 177273,
"author": "Chris Arguin",
"author_id": 25704,
"author_profile": "https://Stackoverflow.com/users/25704",
"pm_score": 2,
"selected": false,
"text": "<p>[ Rewritten based on the first comment ]</p>\n\n<p>All files in Clearcase, including versions, are available in the virtual directory structure. I don't have a lot of familiarity with static views, but I believe they still go through a virtual fs; they just get updated differently.</p>\n\n<p>In that case, you can just do:</p>\n\n<pre><code> cat File@@/main/28\n</code></pre>\n\n<p>It can get ugly if you also have to find the right version of a directory that contained that file element. We have a PERL script at work that uses this approach to analyze historical changes made to files, and we quickly ran out of command-line space on Windows to actually run the commands!</p>\n"
},
{
"answer_id": 177350,
"author": "VonC",
"author_id": 6309,
"author_profile": "https://Stackoverflow.com/users/6309",
"pm_score": 5,
"selected": true,
"text": "<blockquote>\n<p>I'm trying to look at a bunch of old versions</p>\n</blockquote>\n<p>I am not sure if you are speaking about "a bunch of old versions" of <em>one file</em>, "a bunch of old versions" from <em>several</em> files.</p>\n<p>To visualize several old versions of one file, the simplest mean is to display its version tree (<code>ct lsvtree -graph File</code>), and then select a version, right-click on it and '<code>Send To</code>' an editor which accepts multiple files (like Notepad++). In a few click you will have a view of those old versions.<br />\nNote: you must have CC6.0 or 7.0.1 IFix01 (7.0.0 and 7.0.1 fail to 'sent to' a file with the following error message "<code>Access to unnamed file was denied</code>")</p>\n<p>But to visualize several old versions of different files, I would recommend a dynamic view and editing the config spec of that view (and not the snapshot view you are currently working with), in order to quickly select all those old files (hopefully through a simple select rule like '<code>element * aLabel</code>')</p>\n<hr />\n<p>[From the comments:]</p>\n<blockquote>\n<p>what's the idiomatic way to "cat" an earlier revision of a file?</p>\n</blockquote>\n<p>The idiomatic way is through a <strong>dynamic</strong> view (that you configure with the exact same config spec than your existing snapshot view).</p>\n<p>You can then browse (as in 'change directory to') the various <strong>extended paths</strong> of a file.</p>\n<p>If you want to cat all versions of a branch of a file, you go in:</p>\n<pre><code>cd /view/MyView/vobs/myVobs/myPath/myFile@@/main/[...]/maBranch\ncat 1\ncat 2\n...\ncat x\n</code></pre>\n<p>'<code>1</code>', '<code>2</code>', ... '<code>x</code>' being the version 1, 2, ... x of your file within that branch.</p>\n<hr />\n<p>For a <strong>snapshot view</strong>, the <strong>extended path is not accessible</strong>, so your "hack" is the way to go.</p>\n<p>However, 2 remarks here:</p>\n<ul>\n<li>to quickly display all previous revisions of a snapshot file in a given branch, you can type:</li>\n</ul>\n<p>(one line version for copy-paste, Unix syntax:)</p>\n<pre>\ncleartool find addon.xml -ver 'brtype(aBranch) && !version(.../aBranch/LATEST) && ! version(.../aBranch/0)' -exec 'cleartool diff -ser empty \"$CLEARCASE_XPN\"'\n</pre> \n<p>(multi-line version for readability:)</p>\n<pre>\ncleartool find addon.xml -ver 'brtype(aBranch) && \n !version(.../aBranch/LATEST) && \n ! version(.../aBranch/0)' \n -exec 'cleartool diff -ser empty \"$CLEARCASE_XPN\"'\n</pre> \n<ul>\n<li>you can quickly have an output a little nicer with</li>\n</ul>\n<p>(one line version for copy-paste, Unix syntax:)</p>\n<pre>\ncleartool find addon.xml -ver 'brtype(aBranch) && !version(.../aBranch/LATEST) && ! version(.../aBranch/0)' -exec 'cleartool diff -ser empty \"$CLEARCASE_XPN\"' | ccperl -nle '$a=$_; $b = $a; $b =~ s/^>+\\s(?:file\\s+\\d+:\\s+)?//g;print $b if $a =~/^>/'\n</pre> \n<p>(multi-line version for readability:)</p>\n<pre>\ncleartool find addon.xml -ver 'brtype(aBranch) && \n !version(.../aBranch/LATEST) && \n ! version(.../aBranch/0)' \n -exec 'cleartool diff -ser empty \"$CLEARCASE_XPN\"'\n| ccperl -nle '$a=$_; $b = $a; \n $b =~ s/^>+\\s(?:file\\s+\\d+:\\s+)?//g;\n print $b if $a =~/^>/'\n</pre> \n<p>That way, the output is nicer.</p>\n<hr />\n<p>The <a href=\"http://publib.boulder.ibm.com/infocenter/cchelp/v7r0m1/index.jsp?topic=/com.ibm.rational.clearcase.cc_ref.doc/topics/ct_get.htm\" rel=\"noreferrer\">"<code>cleartool get</code>" command (man page)</a> <a href=\"https://stackoverflow.com/questions/176858/in-clearcase-how-can-i-view-old-version-of-a-file-in-a-static-view-from-the-com/4962643#4962643\">mentioned below</a> by <a href=\"https://stackoverflow.com/users/612108/brian\">Brian</a> don't do stdout:</p>\n<blockquote>\n<p>The get command copies only file elements into a view.</p>\n<p>On a UNIX or Linux system, copy <code>/dev/hello_world/foo.c@@/main/2</code> into the current directory.</p>\n</blockquote>\n<pre><code>cmd-context get –to foo.c.temp /dev/hello_world/foo.c@@/main/2\n</code></pre>\n<blockquote>\n<p>On a Windows system, copy <code>\\dev\\hello_world\\foo.c@@\\main\\2</code> into the <code>C:\\build</code> directory.</p>\n</blockquote>\n<pre><code>cmd-context get –to C:\\build\\foo.c.temp \\dev\\hello_world\\foo.c@@\\main\\2\n</code></pre>\n<p>So maybe than, by piping the result to a <code>cat</code> (or <code>type</code> in windows), you can then do something with the output of said <code>cat</code> (<code>type</code>) command.</p>\n<pre><code>cmd-context get –to C:\\build\\foo.c.temp \\dev\\hello_world\\foo.c@@\\main\\2 | type C:\\build\\foo.c.temp \n</code></pre>\n"
},
{
"answer_id": 1968102,
"author": "Justin",
"author_id": 239410,
"author_profile": "https://Stackoverflow.com/users/239410",
"pm_score": -1,
"selected": false,
"text": "<p>ct shell cat File@@version</p>\n"
},
{
"answer_id": 3868050,
"author": "Bart",
"author_id": 467350,
"author_profile": "https://Stackoverflow.com/users/467350",
"pm_score": 1,
"selected": false,
"text": "<p>If File is a Clearcase element, and <code>cat File</code> works, and the view is set correctly, then try:</p>\n\n<pre><code>cat File@@/main/28\n</code></pre>\n\n<p>(note: without the <code>ct shell</code>-- you shouldn't need this if you're already in the view.)</p>\n\n<p>Try typing:</p>\n\n<pre><code>ct ls -l File\n</code></pre>\n\n<p>If it shows the file with an extended name similar to the above, then you should be able to cat the file using an extended name.</p>\n"
},
{
"answer_id": 4962643,
"author": "Brian",
"author_id": 612108,
"author_profile": "https://Stackoverflow.com/users/612108",
"pm_score": 4,
"selected": false,
"text": "<p>I know this is an old thread...but I couldn't let this thrashing go by unresolved....</p>\n\n<p>Static views have a \"ct get\" command that does exactly what you are looking for.</p>\n\n<pre><code>cleartool get -to ~/foo File@@/main/28\n</code></pre>\n\n<p>will save this version of the file in <code>~/foo</code>.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176858",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/17221/"
] |
In a static view, how can I view an old version of a file?
Given an empty file (called `empty` in this example) I can subvert `diff` to show me the old version:
```
% cleartool diff -ser empty File@@/main/28
```
This feels like a pretty ugly hack. Have I missed a more basic command? Is there a neater way to do this?
(I don't want to edit the config spec - that's pretty tedious, and I'm trying to look at a bunch of old versions.)
**Clarification**: I want to send the version of the file to stdout, so I can use it with the rest of Unix (grep, sed, and so on.) If you found this question because you're looking for a way to save a version of an element to a file, see [Brian's answer](https://stackoverflow.com/questions/176858/in-clearcase-how-can-i-view-old-version-of-a-file-in-a-static-view-from-the-com/4962643#4962643).
|
>
> I'm trying to look at a bunch of old versions
>
>
>
I am not sure if you are speaking about "a bunch of old versions" of *one file*, "a bunch of old versions" from *several* files.
To visualize several old versions of one file, the simplest mean is to display its version tree (`ct lsvtree -graph File`), and then select a version, right-click on it and '`Send To`' an editor which accepts multiple files (like Notepad++). In a few click you will have a view of those old versions.
Note: you must have CC6.0 or 7.0.1 IFix01 (7.0.0 and 7.0.1 fail to 'sent to' a file with the following error message "`Access to unnamed file was denied`")
But to visualize several old versions of different files, I would recommend a dynamic view and editing the config spec of that view (and not the snapshot view you are currently working with), in order to quickly select all those old files (hopefully through a simple select rule like '`element * aLabel`')
---
[From the comments:]
>
> what's the idiomatic way to "cat" an earlier revision of a file?
>
>
>
The idiomatic way is through a **dynamic** view (that you configure with the exact same config spec than your existing snapshot view).
You can then browse (as in 'change directory to') the various **extended paths** of a file.
If you want to cat all versions of a branch of a file, you go in:
```
cd /view/MyView/vobs/myVobs/myPath/myFile@@/main/[...]/maBranch
cat 1
cat 2
...
cat x
```
'`1`', '`2`', ... '`x`' being the version 1, 2, ... x of your file within that branch.
---
For a **snapshot view**, the **extended path is not accessible**, so your "hack" is the way to go.
However, 2 remarks here:
* to quickly display all previous revisions of a snapshot file in a given branch, you can type:
(one line version for copy-paste, Unix syntax:)
```
cleartool find addon.xml -ver 'brtype(aBranch) && !version(.../aBranch/LATEST) && ! version(.../aBranch/0)' -exec 'cleartool diff -ser empty "$CLEARCASE_XPN"'
```
(multi-line version for readability:)
```
cleartool find addon.xml -ver 'brtype(aBranch) &&
!version(.../aBranch/LATEST) &&
! version(.../aBranch/0)'
-exec 'cleartool diff -ser empty "$CLEARCASE_XPN"'
```
* you can quickly have an output a little nicer with
(one line version for copy-paste, Unix syntax:)
```
cleartool find addon.xml -ver 'brtype(aBranch) && !version(.../aBranch/LATEST) && ! version(.../aBranch/0)' -exec 'cleartool diff -ser empty "$CLEARCASE_XPN"' | ccperl -nle '$a=$_; $b = $a; $b =~ s/^>+\s(?:file\s+\d+:\s+)?//g;print $b if $a =~/^>/'
```
(multi-line version for readability:)
```
cleartool find addon.xml -ver 'brtype(aBranch) &&
!version(.../aBranch/LATEST) &&
! version(.../aBranch/0)'
-exec 'cleartool diff -ser empty "$CLEARCASE_XPN"'
| ccperl -nle '$a=$_; $b = $a;
$b =~ s/^>+\s(?:file\s+\d+:\s+)?//g;
print $b if $a =~/^>/'
```
That way, the output is nicer.
---
The ["`cleartool get`" command (man page)](http://publib.boulder.ibm.com/infocenter/cchelp/v7r0m1/index.jsp?topic=/com.ibm.rational.clearcase.cc_ref.doc/topics/ct_get.htm) [mentioned below](https://stackoverflow.com/questions/176858/in-clearcase-how-can-i-view-old-version-of-a-file-in-a-static-view-from-the-com/4962643#4962643) by [Brian](https://stackoverflow.com/users/612108/brian) don't do stdout:
>
> The get command copies only file elements into a view.
>
>
> On a UNIX or Linux system, copy `/dev/hello_world/foo.c@@/main/2` into the current directory.
>
>
>
```
cmd-context get –to foo.c.temp /dev/hello_world/foo.c@@/main/2
```
>
> On a Windows system, copy `\dev\hello_world\foo.c@@\main\2` into the `C:\build` directory.
>
>
>
```
cmd-context get –to C:\build\foo.c.temp \dev\hello_world\foo.c@@\main\2
```
So maybe than, by piping the result to a `cat` (or `type` in windows), you can then do something with the output of said `cat` (`type`) command.
```
cmd-context get –to C:\build\foo.c.temp \dev\hello_world\foo.c@@\main\2 | type C:\build\foo.c.temp
```
|
176,902 |
<p>How do I run a .jar executable java file from outside NetBeans IDE? (Windows Vista). My project has a .jar file created by Netbeans. We'd like to run it. Either: how do we run the file or how do we create a 'proper' executable file in NetBeans 6.1?</p>
|
[
{
"answer_id": 176905,
"author": "Laplie Anderson",
"author_id": 14204,
"author_profile": "https://Stackoverflow.com/users/14204",
"pm_score": 4,
"selected": false,
"text": "<p>Running a jar is as simple as</p>\n\n<pre><code>java -jar filename.jar\n</code></pre>\n"
},
{
"answer_id": 176911,
"author": "Josh Moore",
"author_id": 5004,
"author_profile": "https://Stackoverflow.com/users/5004",
"pm_score": 1,
"selected": false,
"text": "<p>from a command prompt you can run this command: <code>java -jar your_jar.jar</code>.</p>\n"
},
{
"answer_id": 176912,
"author": "Brian Gianforcaro",
"author_id": 3415,
"author_profile": "https://Stackoverflow.com/users/3415",
"pm_score": 2,
"selected": false,
"text": "<p>You can do it from the command prompt if java isn't in your path by finding the full path to your java install, something like:</p>\n\n<pre><code>C:\\java\\java.exe -jar C:\\jar_you_want_to_run.jar\n</code></pre>\n\n<p>or if java is in your path:</p>\n\n<pre><code>java.exe -jar jar_you_want_to_run.jar\n</code></pre>\n\n<p>This will run the jar produced by netbeans. </p>\n"
},
{
"answer_id": 176914,
"author": "anjanb",
"author_id": 11142,
"author_profile": "https://Stackoverflow.com/users/11142",
"pm_score": 2,
"selected": false,
"text": "<p>as Laplie said, java -jar your.jar</p>\n\n<p>EXECUTABLE file : see this thread for answers <a href=\"https://stackoverflow.com/questions/147181/how-can-i-convert-my-java-program-to-an-exe-file\">How can I convert my Java program to an .exe file?</a></p>\n"
},
{
"answer_id": 200209,
"author": "Richard Walton",
"author_id": 15075,
"author_profile": "https://Stackoverflow.com/users/15075",
"pm_score": 0,
"selected": false,
"text": "<p>In the project properties dialog in NetBeans you need to set the Main Class - otherwise the generated .jar will not be executable. Then, as already indicated, either double clicking on the .jar or the command java -jar will start the program.</p>\n"
},
{
"answer_id": 200251,
"author": "Galghamon",
"author_id": 26511,
"author_profile": "https://Stackoverflow.com/users/26511",
"pm_score": 2,
"selected": false,
"text": "<p>First, make sure you set the Main Class in your NetBeans project properties dialog.<br>\nThen, you can either</p>\n\n<ul>\n<li>Double-click the jar file (This should work on any machine with an installed JRE)</li>\n</ul>\n\n<p>or</p>\n\n<ul>\n<li>Make sure that java.exe is in the path (or replace <code>java</code> below with the fullpath and file name of the executable), put the following in a batch file:<br>\n<code>java -jar filename.jar</code><br>\nThen you can double-click the batch file instead of the jar (useful if you have people unaccustomed to using naked jar files)</li>\n</ul>\n\n<p>OR</p>\n\n<ul>\n<li>You can go down the path described here <a href=\"https://stackoverflow.com/questions/147181/how-can-i-convert-my-java-program-to-an-exe-file\">How can I convert my Java program to an .exe file?</a> to build a .exe for windows.</li>\n</ul>\n"
},
{
"answer_id": 3683843,
"author": "Mr. Brahm Deo Sah",
"author_id": 444245,
"author_profile": "https://Stackoverflow.com/users/444245",
"pm_score": 2,
"selected": false,
"text": "<p>One of the best technique to run the jar file or jar jar file </p>\n\n<ol>\n<li>Create the jar file by jar command choose your jar filename\n<code>Java_Jar_File.jar</code></li>\n<li>Run the jar file us the command like <code>java -jar Java_Jar_File.jar</code></li>\n</ol>\n"
},
{
"answer_id": 6599377,
"author": "Raahil",
"author_id": 831942,
"author_profile": "https://Stackoverflow.com/users/831942",
"pm_score": 2,
"selected": false,
"text": "<p>Make a BAT file with </p>\n\n<pre><code>java -jar filepath.jar\n</code></pre>\n"
},
{
"answer_id": 6914351,
"author": "Jithin",
"author_id": 874918,
"author_profile": "https://Stackoverflow.com/users/874918",
"pm_score": 1,
"selected": false,
"text": "<p>To run a java jar file its file association should be properly configured. There is a free tool called <a href=\"http://johann.loefflmann.net/en/software/jarfix/index.html\" rel=\"nofollow\">jarfix</a> to fix all jar file association problems. Run this file to fix all jar issues.</p>\n"
},
{
"answer_id": 10054369,
"author": "Jirik",
"author_id": 1303387,
"author_profile": "https://Stackoverflow.com/users/1303387",
"pm_score": 0,
"selected": false,
"text": "<p>If you have problems with running your jar, make sure you are trying to run your current version to get newest version in Netbeans: <code>GoTo Run Menu</code> --> <code>Clean and build</code></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176902",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
How do I run a .jar executable java file from outside NetBeans IDE? (Windows Vista). My project has a .jar file created by Netbeans. We'd like to run it. Either: how do we run the file or how do we create a 'proper' executable file in NetBeans 6.1?
|
Running a jar is as simple as
```
java -jar filename.jar
```
|
176,913 |
<p>I basically want to run all JUnit <strong><em>unit</em></strong> tests in my IntelliJ IDEA project (excluding JUnit integration tests), using the static suite() method of JUnit. Why use the static suite() method? Because I can then use IntelliJ IDEA's JUnit test runner to run all unit tests in my application (and easily exclude all integration tests by naming convention). The code so far looks like this:</p>
<pre><code>package com.acme;
import junit.framework.Test;
import junit.framework.TestCase;
import junit.framework.TestSuite;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class AllUnitTests extends TestCase {
public static Test suite() {
List classes = getUnitTestClasses();
return createTestSuite(classes);
}
private static List getUnitTestClasses() {
List classes = new ArrayList();
classes.add(CalculatorTest.class);
return classes;
}
private static TestSuite createTestSuite(List allClasses) {
TestSuite suite = new TestSuite("All Unit Tests");
for (Iterator i = allClasses.iterator(); i.hasNext();) {
suite.addTestSuite((Class<? extends TestCase>) i.next());
}
return suite;
}
}
</code></pre>
<p>The method getUnitTestClasses() should be rewritten to add all project classes extending TestCase, except if the class name ends in "IntegrationTest".</p>
<p>I know I can do this easily in Maven for example, but I need to do it in IntelliJ IDEA so I can use the integrated test runner - I like the green bar :)</p>
|
[
{
"answer_id": 178030,
"author": "Roel Spilker",
"author_id": 12634,
"author_profile": "https://Stackoverflow.com/users/12634",
"pm_score": 4,
"selected": true,
"text": "<p>I've written some code to do most of the work. It works only if your files are on the local disk instead of in a JAR. All you need is one class in the package. You could, for this purpose, create a Locator.java class, just to be able to find the package.</p>\n\n<pre><code>public class ClassEnumerator {\n public static void main(String[] args) throws ClassNotFoundException {\n List<Class<?>> list = listClassesInSamePackage(Locator.class, true);\n\n System.out.println(list);\n }\n\n private static List<Class<?>> listClassesInSamePackage(Class<?> locator, boolean includeLocator) \n throws ClassNotFoundException {\n\n File packageFile = getPackageFile(locator);\n\n String ignore = includeLocator ? null : locator.getSimpleName() + \".class\";\n\n return toClassList(locator.getPackage().getName(), listClassNames(packageFile, ignore));\n }\n\n private static File getPackageFile(Class<?> locator) {\n URL url = locator.getClassLoader().getResource(locator.getName().replace(\".\", \"/\") + \".class\");\n if (url == null) {\n throw new RuntimeException(\"Cannot locate \" + Locator.class.getName());\n }\n\n try {\n return new File(url.toURI()).getParentFile();\n }\n catch (URISyntaxException e) {\n throw new RuntimeException(e);\n }\n }\n\n private static String[] listClassNames(File packageFile, final String ignore) {\n return packageFile.list(new FilenameFilter(){\n @Override\n public boolean accept(File dir, String name) {\n if (name.equals(ignore)) {\n return false;\n }\n return name.endsWith(\".class\");\n }\n });\n }\n\n private static List<Class<?>> toClassList(String packageName, String[] classNames)\n throws ClassNotFoundException {\n\n List<Class<?>> result = new ArrayList<Class<?>>(classNames.length);\n for (String className : classNames) {\n // Strip the .class\n String simpleName = className.substring(0, className.length() - 6);\n\n result.add(Class.forName(packageName + \".\" + simpleName));\n }\n return result;\n }\n}\n</code></pre>\n"
},
{
"answer_id": 179707,
"author": "Arne Evertsson",
"author_id": 16686,
"author_profile": "https://Stackoverflow.com/users/16686",
"pm_score": 3,
"selected": false,
"text": "<p>How about putting each major group of junit tests into their own root package. I use this package structure in my project:</p>\n\n<pre><code>test.\n quick.\n com.acme\n slow.\n com.acme\n</code></pre>\n\n<p>Without any coding, you can set up IntelliJ to run all tests, just the quick ones or just the slow ones.</p>\n"
},
{
"answer_id": 2351625,
"author": "timomeinen",
"author_id": 283136,
"author_profile": "https://Stackoverflow.com/users/283136",
"pm_score": 3,
"selected": false,
"text": "<p>What about using JUnit4 and the Suite-Runner?</p>\n\n<p>Example:</p>\n\n<pre><code>@RunWith(Suite.class)\[email protected]({\nUserUnitTest.class,\nAnotherUnitTest.class\n})\npublic class UnitTestSuite {}\n</code></pre>\n\n<p>I made a small Shell-Script to find all Unit-Tests and another one to find my Integration-Tests. Have a look at my blog entry:\n<a href=\"http://blog.timomeinen.de/2010/02/find-all-junit-tests-in-a-project/\" rel=\"noreferrer\">http://blog.timomeinen.de/2010/02/find-all-junit-tests-in-a-project/</a></p>\n\n<p>If you use Spring TestContext you can use the @IfProfile Annotation to declare different tests.</p>\n\n<p>Kind regards,\nTimo Meinen</p>\n"
},
{
"answer_id": 3636771,
"author": "John Ellinwood",
"author_id": 69572,
"author_profile": "https://Stackoverflow.com/users/69572",
"pm_score": 0,
"selected": false,
"text": "<p>Spring has implemented an excellent classpath search function in the PathMatchingResourcePatternResolver. If you use the classpath*: prefix, you can find all the resources, including classes in a given hierarchy, and even filter them if you want. Then you can use the children of AbstractTypeHierarchyTraversingFilter, AnnotationTypeFilter and AssignableTypeFilter to filter those resources either on class level annotations or on interfaces they implement.</p>\n\n<p><a href=\"http://static.springsource.org/spring/docs/2.0.x/api/org/springframework/core/io/support/PathMatchingResourcePatternResolver.html\" rel=\"nofollow noreferrer\">http://static.springsource.org/spring/docs/2.0.x/api/org/springframework/core/io/support/PathMatchingResourcePatternResolver.html</a></p>\n\n<p><a href=\"http://static.springsource.org/spring/docs/2.5.x/api/org/springframework/core/type/filter/AbstractTypeHierarchyTraversingFilter.html\" rel=\"nofollow noreferrer\">http://static.springsource.org/spring/docs/2.5.x/api/org/springframework/core/type/filter/AbstractTypeHierarchyTraversingFilter.html</a></p>\n"
},
{
"answer_id": 37848062,
"author": "Creos",
"author_id": 3903990,
"author_profile": "https://Stackoverflow.com/users/3903990",
"pm_score": 0,
"selected": false,
"text": "<p>Solution: <a href=\"https://github.com/MichaelTamm/junit-toolbox\" rel=\"nofollow\">https://github.com/MichaelTamm/junit-toolbox</a><br>\nUse the following features</p>\n\n<pre><code>@RunWith(WildcardPatternSuite.class)\n@SuiteClasses({\"**/*.class\", \"!**/*IntegrationTest.class\"})\npublic class AllTestsExceptionIntegrationSuit {\n}\n</code></pre>\n\n<p>assuming you following a naming pattern where you integration tests end in ...IntegrationTest and you place the file in the top-most package (so the **/*.class search will have the opportunity to pick up all your tests)</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176913",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13041/"
] |
I basically want to run all JUnit ***unit*** tests in my IntelliJ IDEA project (excluding JUnit integration tests), using the static suite() method of JUnit. Why use the static suite() method? Because I can then use IntelliJ IDEA's JUnit test runner to run all unit tests in my application (and easily exclude all integration tests by naming convention). The code so far looks like this:
```
package com.acme;
import junit.framework.Test;
import junit.framework.TestCase;
import junit.framework.TestSuite;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class AllUnitTests extends TestCase {
public static Test suite() {
List classes = getUnitTestClasses();
return createTestSuite(classes);
}
private static List getUnitTestClasses() {
List classes = new ArrayList();
classes.add(CalculatorTest.class);
return classes;
}
private static TestSuite createTestSuite(List allClasses) {
TestSuite suite = new TestSuite("All Unit Tests");
for (Iterator i = allClasses.iterator(); i.hasNext();) {
suite.addTestSuite((Class<? extends TestCase>) i.next());
}
return suite;
}
}
```
The method getUnitTestClasses() should be rewritten to add all project classes extending TestCase, except if the class name ends in "IntegrationTest".
I know I can do this easily in Maven for example, but I need to do it in IntelliJ IDEA so I can use the integrated test runner - I like the green bar :)
|
I've written some code to do most of the work. It works only if your files are on the local disk instead of in a JAR. All you need is one class in the package. You could, for this purpose, create a Locator.java class, just to be able to find the package.
```
public class ClassEnumerator {
public static void main(String[] args) throws ClassNotFoundException {
List<Class<?>> list = listClassesInSamePackage(Locator.class, true);
System.out.println(list);
}
private static List<Class<?>> listClassesInSamePackage(Class<?> locator, boolean includeLocator)
throws ClassNotFoundException {
File packageFile = getPackageFile(locator);
String ignore = includeLocator ? null : locator.getSimpleName() + ".class";
return toClassList(locator.getPackage().getName(), listClassNames(packageFile, ignore));
}
private static File getPackageFile(Class<?> locator) {
URL url = locator.getClassLoader().getResource(locator.getName().replace(".", "/") + ".class");
if (url == null) {
throw new RuntimeException("Cannot locate " + Locator.class.getName());
}
try {
return new File(url.toURI()).getParentFile();
}
catch (URISyntaxException e) {
throw new RuntimeException(e);
}
}
private static String[] listClassNames(File packageFile, final String ignore) {
return packageFile.list(new FilenameFilter(){
@Override
public boolean accept(File dir, String name) {
if (name.equals(ignore)) {
return false;
}
return name.endsWith(".class");
}
});
}
private static List<Class<?>> toClassList(String packageName, String[] classNames)
throws ClassNotFoundException {
List<Class<?>> result = new ArrayList<Class<?>>(classNames.length);
for (String className : classNames) {
// Strip the .class
String simpleName = className.substring(0, className.length() - 6);
result.add(Class.forName(packageName + "." + simpleName));
}
return result;
}
}
```
|
176,918 |
<p>Given a list <code>["foo", "bar", "baz"]</code> and an item in the list <code>"bar"</code>, how do I get its index <code>1</code>?</p>
|
[
{
"answer_id": 176921,
"author": "Alex Coventry",
"author_id": 1941213,
"author_profile": "https://Stackoverflow.com/users/1941213",
"pm_score": 13,
"selected": true,
"text": "<pre><code>>>> ["foo", "bar", "baz"].index("bar")\n1\n</code></pre>\n<p>Reference: <a href=\"https://docs.python.org/tutorial/datastructures.html#more-on-lists\" rel=\"noreferrer\">Data Structures > More on Lists</a></p>\n<h1>Caveats follow</h1>\n<p>Note that while this is perhaps the cleanest way to answer the question <em>as asked</em>, <code>index</code> is a rather weak component of the <code>list</code> API, and I can't remember the last time I used it in anger. It's been pointed out to me in the comments that because this answer is heavily referenced, it should be made more complete. Some caveats about <code>list.index</code> follow. It is probably worth initially taking a look at the documentation for it:</p>\n<blockquote>\n<pre><code>list.index(x[, start[, end]])\n</code></pre>\n<p>Return zero-based index in the list of the first item whose value is equal to <em>x</em>. Raises a <a href=\"https://docs.python.org/library/exceptions.html#ValueError\" rel=\"noreferrer\"><code>ValueError</code></a> if there is no such item.</p>\n<p>The optional arguments <em>start</em> and <em>end</em> are interpreted as in the <a href=\"https://docs.python.org/tutorial/introduction.html#lists\" rel=\"noreferrer\">slice notation</a> and are used to limit the search to a particular subsequence of the list. The returned index is computed relative to the beginning of the full sequence rather than the start argument.</p>\n</blockquote>\n<h2>Linear time-complexity in list length</h2>\n<p>An <code>index</code> call checks every element of the list in order, until it finds a match. If your list is long, and you don't know roughly where in the list it occurs, this search could become a bottleneck. In that case, you should consider a different data structure. Note that if you know roughly where to find the match, you can give <code>index</code> a hint. For instance, in this snippet, <code>l.index(999_999, 999_990, 1_000_000)</code> is roughly five orders of magnitude faster than straight <code>l.index(999_999)</code>, because the former only has to search 10 entries, while the latter searches a million:</p>\n<pre><code>>>> import timeit\n>>> timeit.timeit('l.index(999_999)', setup='l = list(range(0, 1_000_000))', number=1000)\n9.356267921015387\n>>> timeit.timeit('l.index(999_999, 999_990, 1_000_000)', setup='l = list(range(0, 1_000_000))', number=1000)\n0.0004404920036904514\n \n</code></pre>\n<h2>Only returns the index of the <em>first match</em> to its argument</h2>\n<p>A call to <code>index</code> searches through the list in order until it finds a match, and <em>stops there.</em> If you expect to need indices of more matches, you should use a list comprehension, or generator expression.</p>\n<pre><code>>>> [1, 1].index(1)\n0\n>>> [i for i, e in enumerate([1, 2, 1]) if e == 1]\n[0, 2]\n>>> g = (i for i, e in enumerate([1, 2, 1]) if e == 1)\n>>> next(g)\n0\n>>> next(g)\n2\n</code></pre>\n<p>Most places where I once would have used <code>index</code>, I now use a list comprehension or generator expression because they're more generalizable. So if you're considering reaching for <code>index</code>, take a look at these excellent Python features.</p>\n<h2>Throws if element not present in list</h2>\n<p>A call to <code>index</code> results in a <a href=\"https://docs.python.org/library/exceptions.html#ValueError\" rel=\"noreferrer\"><code>ValueError</code></a> if the item's not present.</p>\n<pre><code>>>> [1, 1].index(2)\nTraceback (most recent call last):\n File "<stdin>", line 1, in <module>\nValueError: 2 is not in list\n</code></pre>\n<p>If the item might not be present in the list, you should either</p>\n<ol>\n<li>Check for it first with <code>item in my_list</code> (clean, readable approach), or</li>\n<li>Wrap the <code>index</code> call in a <code>try/except</code> block which catches <code>ValueError</code> (probably faster, at least when the list to search is long, and the item is usually present.)</li>\n</ol>\n"
},
{
"answer_id": 178399,
"author": "davidavr",
"author_id": 8247,
"author_profile": "https://Stackoverflow.com/users/8247",
"pm_score": 10,
"selected": false,
"text": "<p>One thing that is really helpful in learning Python is to use the interactive help function:</p>\n\n<pre><code>>>> help([\"foo\", \"bar\", \"baz\"])\nHelp on list object:\n\nclass list(object)\n ...\n\n |\n | index(...)\n | L.index(value, [start, [stop]]) -> integer -- return first index of value\n |\n</code></pre>\n\n<p>which will often lead you to the method you are looking for.</p>\n"
},
{
"answer_id": 7241298,
"author": "HongboZhu",
"author_id": 270222,
"author_profile": "https://Stackoverflow.com/users/270222",
"pm_score": 7,
"selected": false,
"text": "<p><code>index()</code> returns the <strong>first</strong> index of value!</p>\n\n<blockquote>\n <p>| index(...)<br>\n | L.index(value, [start, [stop]]) -> integer -- return first index of value</p>\n</blockquote>\n\n<pre><code>def all_indices(value, qlist):\n indices = []\n idx = -1\n while True:\n try:\n idx = qlist.index(value, idx+1)\n indices.append(idx)\n except ValueError:\n break\n return indices\n\nall_indices(\"foo\", [\"foo\",\"bar\",\"baz\",\"foo\"])\n</code></pre>\n"
},
{
"answer_id": 12054409,
"author": "savinson",
"author_id": 1614145,
"author_profile": "https://Stackoverflow.com/users/1614145",
"pm_score": 7,
"selected": false,
"text": "<pre><code>a = [\"foo\",\"bar\",\"baz\",'bar','any','much']\n\nindexes = [index for index in range(len(a)) if a[index] == 'bar']\n</code></pre>\n"
},
{
"answer_id": 16034499,
"author": "tanzil",
"author_id": 2239760,
"author_profile": "https://Stackoverflow.com/users/2239760",
"pm_score": 7,
"selected": false,
"text": "<p>A problem will arise if the element is not in the list. This function handles the issue:</p>\n\n<pre><code># if element is found it returns index of element else returns None\n\ndef find_element_in_list(element, list_element):\n try:\n index_element = list_element.index(element)\n return index_element\n except ValueError:\n return None\n</code></pre>\n"
},
{
"answer_id": 16593099,
"author": "Graham Giller",
"author_id": 2033154,
"author_profile": "https://Stackoverflow.com/users/2033154",
"pm_score": 6,
"selected": false,
"text": "<p>All of the proposed functions here reproduce inherent language behavior but obscure what's going on.</p>\n\n<pre><code>[i for i in range(len(mylist)) if mylist[i]==myterm] # get the indices\n\n[each for each in mylist if each==myterm] # get the items\n\nmylist.index(myterm) if myterm in mylist else None # get the first index and fail quietly\n</code></pre>\n\n<p>Why write a function with exception handling if the language provides the methods to do what you want itself?</p>\n"
},
{
"answer_id": 16807733,
"author": "kiriloff",
"author_id": 1141493,
"author_profile": "https://Stackoverflow.com/users/1141493",
"pm_score": 5,
"selected": false,
"text": "<p>Simply you can go with</p>\n\n<pre><code>a = [['hand', 'head'], ['phone', 'wallet'], ['lost', 'stock']]\nb = ['phone', 'lost']\n\nres = [[x[0] for x in a].index(y) for y in b]\n</code></pre>\n"
},
{
"answer_id": 16822116,
"author": "Mathitis2Software",
"author_id": 1563847,
"author_profile": "https://Stackoverflow.com/users/1563847",
"pm_score": 4,
"selected": false,
"text": "<p>Another option</p>\n\n<pre><code>>>> a = ['red', 'blue', 'green', 'red']\n>>> b = 'red'\n>>> offset = 0;\n>>> indices = list()\n>>> for i in range(a.count(b)):\n... indices.append(a.index(b,offset))\n... offset = indices[-1]+1\n... \n>>> indices\n[0, 3]\n>>> \n</code></pre>\n"
},
{
"answer_id": 17202481,
"author": "TerryA",
"author_id": 1971805,
"author_profile": "https://Stackoverflow.com/users/1971805",
"pm_score": 9,
"selected": false,
"text": "<p>The majority of answers explain how to find <strong>a single index</strong>, but their methods do not return multiple indexes if the item is in the list multiple times. Use <a href=\"https://docs.python.org/library/functions.html#enumerate\" rel=\"noreferrer\"><code>enumerate()</code></a>:</p>\n\n<pre><code>for i, j in enumerate(['foo', 'bar', 'baz']):\n if j == 'bar':\n print(i)\n</code></pre>\n\n<p>The <code>index()</code> function only returns the first occurrence, while <code>enumerate()</code> returns all occurrences.</p>\n\n<p>As a list comprehension:</p>\n\n<pre><code>[i for i, j in enumerate(['foo', 'bar', 'baz']) if j == 'bar']\n</code></pre>\n\n<hr>\n\n<p>Here's also another small solution with <a href=\"http://docs.python.org/library/itertools.html#itertools.count\" rel=\"noreferrer\"><code>itertools.count()</code></a> (which is pretty much the same approach as enumerate):</p>\n\n<pre><code>from itertools import izip as zip, count # izip for maximum efficiency\n[i for i, j in zip(count(), ['foo', 'bar', 'baz']) if j == 'bar']\n</code></pre>\n\n<p>This is more efficient for larger lists than using <code>enumerate()</code>:</p>\n\n<pre><code>$ python -m timeit -s \"from itertools import izip as zip, count\" \"[i for i, j in zip(count(), ['foo', 'bar', 'baz']*500) if j == 'bar']\"\n10000 loops, best of 3: 174 usec per loop\n$ python -m timeit \"[i for i, j in enumerate(['foo', 'bar', 'baz']*500) if j == 'bar']\"\n10000 loops, best of 3: 196 usec per loop\n</code></pre>\n"
},
{
"answer_id": 17300987,
"author": "FMc",
"author_id": 55857,
"author_profile": "https://Stackoverflow.com/users/55857",
"pm_score": 8,
"selected": false,
"text": "<p>To get all indexes:</p>\n<pre><code>indexes = [i for i, x in enumerate(xs) if x == 'foo']\n</code></pre>\n"
},
{
"answer_id": 22708420,
"author": "bvanlew",
"author_id": 584201,
"author_profile": "https://Stackoverflow.com/users/584201",
"pm_score": 4,
"selected": false,
"text": "<p>A variant on the answer from FMc and user7177 will give a dict that can return all indices for any entry:</p>\n\n<pre><code>>>> a = ['foo','bar','baz','bar','any', 'foo', 'much']\n>>> l = dict(zip(set(a), map(lambda y: [i for i,z in enumerate(a) if z is y ], set(a))))\n>>> l['foo']\n[0, 5]\n>>> l ['much']\n[6]\n>>> l\n{'baz': [2], 'foo': [0, 5], 'bar': [1, 3], 'any': [4], 'much': [6]}\n>>> \n</code></pre>\n\n<p>You could also use this as a one liner to get all indices for a single entry. There are no guarantees for efficiency, though I did use set(a) to reduce the number of times the lambda is called.</p>\n"
},
{
"answer_id": 23862698,
"author": "user3670684",
"author_id": 3670684,
"author_profile": "https://Stackoverflow.com/users/3670684",
"pm_score": 6,
"selected": false,
"text": "<p>You have to set a condition to check if the element you're searching is in the list</p>\n\n<pre><code>if 'your_element' in mylist:\n print mylist.index('your_element')\nelse:\n print None\n</code></pre>\n"
},
{
"answer_id": 27712517,
"author": "MrWonderful",
"author_id": 2069807,
"author_profile": "https://Stackoverflow.com/users/2069807",
"pm_score": 4,
"selected": false,
"text": "<h1>And now, for something completely different... </h1>\n\n<p>... like confirming the existence of the item before getting the index. The nice thing about this approach is the function always returns a list of indices -- even if it is an empty list. It works with strings as well.</p>\n\n<pre><code>def indices(l, val):\n \"\"\"Always returns a list containing the indices of val in the_list\"\"\"\n retval = []\n last = 0\n while val in l[last:]:\n i = l[last:].index(val)\n retval.append(last + i)\n last += i + 1 \n return retval\n\nl = ['bar','foo','bar','baz','bar','bar']\nq = 'bar'\nprint indices(l,q)\nprint indices(l,'bat')\nprint indices('abcdaababb','a')\n</code></pre>\n\n<p>When pasted into an interactive python window:</p>\n\n<pre><code>Python 2.7.6 (v2.7.6:3a1db0d2747e, Nov 10 2013, 00:42:54) \n[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> def indices(the_list, val):\n... \"\"\"Always returns a list containing the indices of val in the_list\"\"\"\n... retval = []\n... last = 0\n... while val in the_list[last:]:\n... i = the_list[last:].index(val)\n... retval.append(last + i)\n... last += i + 1 \n... return retval\n... \n>>> l = ['bar','foo','bar','baz','bar','bar']\n>>> q = 'bar'\n>>> print indices(l,q)\n[0, 2, 4, 5]\n>>> print indices(l,'bat')\n[]\n>>> print indices('abcdaababb','a')\n[0, 4, 5, 7]\n>>> \n</code></pre>\n\n<h1>Update</h1>\n\n<p>After another year of heads-down python development, I'm a bit embarrassed by my original answer, so to set the record straight, one can certainly use the above code; however, the <em>much</em> more idiomatic way to get the same behavior would be to use list comprehension, along with the enumerate() function. </p>\n\n<p>Something like this: </p>\n\n<pre><code>def indices(l, val):\n \"\"\"Always returns a list containing the indices of val in the_list\"\"\"\n return [index for index, value in enumerate(l) if value == val]\n\nl = ['bar','foo','bar','baz','bar','bar']\nq = 'bar'\nprint indices(l,q)\nprint indices(l,'bat')\nprint indices('abcdaababb','a')\n</code></pre>\n\n<p>Which, when pasted into an interactive python window yields:</p>\n\n<pre><code>Python 2.7.14 |Anaconda, Inc.| (default, Dec 7 2017, 11:07:58) \n[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] on darwin\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> def indices(l, val):\n... \"\"\"Always returns a list containing the indices of val in the_list\"\"\"\n... return [index for index, value in enumerate(l) if value == val]\n... \n>>> l = ['bar','foo','bar','baz','bar','bar']\n>>> q = 'bar'\n>>> print indices(l,q)\n[0, 2, 4, 5]\n>>> print indices(l,'bat')\n[]\n>>> print indices('abcdaababb','a')\n[0, 4, 5, 7]\n>>> \n</code></pre>\n\n<p>And now, after reviewing this question and all the answers, I realize that this is exactly what <a href=\"https://stackoverflow.com/users/55857/fmc\">FMc</a> suggested in his <a href=\"https://stackoverflow.com/questions/176918/finding-the-index-of-an-item-given-a-list-containing-it-in-python/17300987#17300987\">earlier answer</a>. At the time I originally answered this question, I didn't even <em>see</em> that answer, because I didn't understand it. I hope that my somewhat more verbose example will aid understanding. </p>\n\n<p>If the single line of code above still <em>doesn't</em> make sense to you, I highly recommend you Google 'python list comprehension' and take a few minutes to familiarize yourself. It's just one of the many powerful features that make it a joy to use Python to develop code.</p>\n"
},
{
"answer_id": 30283031,
"author": "dylankb",
"author_id": 3950092,
"author_profile": "https://Stackoverflow.com/users/3950092",
"pm_score": 4,
"selected": false,
"text": "<p>This solution is not as powerful as others, but if you're a beginner and only know about <code>for</code>loops it's still possible to find the first index of an item while avoiding the ValueError:</p>\n\n<pre><code>def find_element(p,t):\n i = 0\n for e in p:\n if e == t:\n return i\n else:\n i +=1\n return -1\n</code></pre>\n"
},
{
"answer_id": 31230699,
"author": "Coder123",
"author_id": 5082430,
"author_profile": "https://Stackoverflow.com/users/5082430",
"pm_score": 3,
"selected": false,
"text": "<pre><code>name =\"bar\"\nlist = [[\"foo\", 1], [\"bar\", 2], [\"baz\", 3]]\nnew_list=[]\nfor item in list:\n new_list.append(item[0])\nprint(new_list)\ntry:\n location= new_list.index(name)\nexcept:\n location=-1\nprint (location)\n</code></pre>\n\n<p>This accounts for if the string is not in the list too, if it isn't in the list then <code>location = -1</code></p>\n"
},
{
"answer_id": 33644671,
"author": "Arnaldo P. Figueira Figueira",
"author_id": 1579731,
"author_profile": "https://Stackoverflow.com/users/1579731",
"pm_score": 5,
"selected": false,
"text": "<p>All indexes with the <a href=\"https://docs.python.org/2/library/functions.html#zip\" rel=\"noreferrer\"><code>zip</code></a> function:</p>\n\n<pre><code>get_indexes = lambda x, xs: [i for (y, i) in zip(xs, range(len(xs))) if x == y]\n\nprint get_indexes(2, [1, 2, 3, 4, 5, 6, 3, 2, 3, 2])\nprint get_indexes('f', 'xsfhhttytffsafweef')\n</code></pre>\n"
},
{
"answer_id": 33765024,
"author": "rbrisuda",
"author_id": 2250569,
"author_profile": "https://Stackoverflow.com/users/2250569",
"pm_score": 6,
"selected": false,
"text": "<p>If you want all indexes, then you can use <a href=\"http://en.wikipedia.org/wiki/NumPy\" rel=\"noreferrer\">NumPy</a>:</p>\n\n<pre><code>import numpy as np\n\narray = [1, 2, 1, 3, 4, 5, 1]\nitem = 1\nnp_array = np.array(array)\nitem_index = np.where(np_array==item)\nprint item_index\n# Out: (array([0, 2, 6], dtype=int64),)\n</code></pre>\n\n<p>It is clear, readable solution.</p>\n"
},
{
"answer_id": 45559614,
"author": "PythonProgrammi",
"author_id": 6464947,
"author_profile": "https://Stackoverflow.com/users/6464947",
"pm_score": 5,
"selected": false,
"text": "<h3>Getting all the occurrences and the position of one or more (identical) items in a list</h3>\n\n<p>With enumerate(alist) you can store the first element (n) that is the index of the list when the element x is equal to what you look for.</p>\n\n<pre><code>>>> alist = ['foo', 'spam', 'egg', 'foo']\n>>> foo_indexes = [n for n,x in enumerate(alist) if x=='foo']\n>>> foo_indexes\n[0, 3]\n>>>\n</code></pre>\n\n<h3>Let's make our function findindex</h3>\n\n<p>This function takes the item and the list as arguments and return the position of the item in the list, like we saw before.</p>\n\n<pre><code>def indexlist(item2find, list_or_string):\n \"Returns all indexes of an item in a list or a string\"\n return [n for n,item in enumerate(list_or_string) if item==item2find]\n\nprint(indexlist(\"1\", \"010101010\"))\n</code></pre>\n\n<hr>\n\n<p><strong>Output</strong></p>\n\n<hr>\n\n<pre><code>[1, 3, 5, 7]\n</code></pre>\n\n<h2>Simple</h2>\n\n<pre><code>for n, i in enumerate([1, 2, 3, 4, 1]):\n if i == 1:\n print(n)\n</code></pre>\n\n<p>Output:</p>\n\n<pre><code>0\n4\n</code></pre>\n"
},
{
"answer_id": 45654421,
"author": "jihed gasmi",
"author_id": 1946787,
"author_profile": "https://Stackoverflow.com/users/1946787",
"pm_score": 2,
"selected": false,
"text": "<p>Since Python lists are zero-based, we can use the zip built-in function as follows:</p>\n\n<pre><code>>>> [i for i,j in zip(range(len(haystack)), haystack) if j == 'needle' ]\n</code></pre>\n\n<p>where \"haystack\" is the list in question and \"needle\" is the item to look for.</p>\n\n<p>(Note: Here we are iterating using i to get the indexes, but if we need rather to focus on the items we can switch to j.)</p>\n"
},
{
"answer_id": 45808300,
"author": "Russia Must Remove Putin",
"author_id": 541136,
"author_profile": "https://Stackoverflow.com/users/541136",
"pm_score": 6,
"selected": false,
"text": "<blockquote>\n<h2>Finding the index of an item given a list containing it in Python</h2>\n<p>For a list <code>["foo", "bar", "baz"]</code> and an item in the list <code>"bar"</code>, what's the cleanest way to get its index (1) in Python?</p>\n</blockquote>\n<p>Well, sure, there's the index method, which returns the index of the first occurrence:</p>\n<pre><code>>>> l = ["foo", "bar", "baz"]\n>>> l.index('bar')\n1\n</code></pre>\n<p>There are a couple of issues with this method:</p>\n<ul>\n<li>if the value isn't in the list, you'll get a <code>ValueError</code></li>\n<li>if more than one of the value is in the list, you only get the index for the first one</li>\n</ul>\n<h3>No values</h3>\n<p>If the value could be missing, you need to catch the <code>ValueError</code>.</p>\n<p>You can do so with a reusable definition like this:</p>\n<pre><code>def index(a_list, value):\n try:\n return a_list.index(value)\n except ValueError:\n return None\n</code></pre>\n<p>And use it like this:</p>\n<pre><code>>>> print(index(l, 'quux'))\nNone\n>>> print(index(l, 'bar'))\n1\n</code></pre>\n<p>And the downside of this is that you will probably have a check for if the returned value <code>is</code> or <code>is not</code> None:</p>\n<pre><code>result = index(a_list, value)\nif result is not None:\n do_something(result)\n</code></pre>\n<h3>More than one value in the list</h3>\n<p>If you could have more occurrences, you'll <strong>not</strong> get complete information with <code>list.index</code>:</p>\n<pre><code>>>> l.append('bar')\n>>> l\n['foo', 'bar', 'baz', 'bar']\n>>> l.index('bar') # nothing at index 3?\n1\n</code></pre>\n<p>You might enumerate into a list comprehension the indexes:</p>\n<pre><code>>>> [index for index, v in enumerate(l) if v == 'bar']\n[1, 3]\n>>> [index for index, v in enumerate(l) if v == 'boink']\n[]\n</code></pre>\n<p>If you have no occurrences, you can check for that with boolean check of the result, or just do nothing if you loop over the results:</p>\n<pre><code>indexes = [index for index, v in enumerate(l) if v == 'boink']\nfor index in indexes:\n do_something(index)\n</code></pre>\n<h3>Better data munging with pandas</h3>\n<p>If you have pandas, you can easily get this information with a Series object:</p>\n<pre><code>>>> import pandas as pd\n>>> series = pd.Series(l)\n>>> series\n0 foo\n1 bar\n2 baz\n3 bar\ndtype: object\n</code></pre>\n<p>A comparison check will return a series of booleans:</p>\n<pre><code>>>> series == 'bar'\n0 False\n1 True\n2 False\n3 True\ndtype: bool\n</code></pre>\n<p>Pass that series of booleans to the series via subscript notation, and you get just the matching members:</p>\n<pre><code>>>> series[series == 'bar']\n1 bar\n3 bar\ndtype: object\n</code></pre>\n<p>If you want just the indexes, the index attribute returns a series of integers:</p>\n<pre><code>>>> series[series == 'bar'].index\nInt64Index([1, 3], dtype='int64')\n</code></pre>\n<p>And if you want them in a list or tuple, just pass them to the constructor:</p>\n<pre><code>>>> list(series[series == 'bar'].index)\n[1, 3]\n</code></pre>\n<p>Yes, you could use a list comprehension with enumerate too, but that's just not as elegant, in my opinion - you're doing tests for equality in Python, instead of letting builtin code written in C handle it:</p>\n<pre><code>>>> [i for i, value in enumerate(l) if value == 'bar']\n[1, 3]\n</code></pre>\n<h2>Is this an <a href=\"https://meta.stackexchange.com/a/66378/239121\">XY problem</a>?</h2>\n<blockquote>\n<p>The XY problem is asking about your attempted solution rather than your actual problem.</p>\n</blockquote>\n<p>Why do you think you need the index given an element in a list?</p>\n<p>If you already know the value, why do you care where it is in a list?</p>\n<p>If the value isn't there, catching the <code>ValueError</code> is rather verbose - and I prefer to avoid that.</p>\n<p>I'm usually iterating over the list anyways, so I'll usually keep a pointer to any interesting information, getting the <a href=\"https://stackoverflow.com/q/522563/541136\">index with enumerate.</a></p>\n<p>If you're munging data, you should probably be using pandas - which has far more elegant tools than the pure Python workarounds I've shown.</p>\n<p>I do not recall needing <code>list.index</code>, myself. However, I have looked through the Python standard library, and I see some excellent uses for it.</p>\n<p>There are many, many uses for it in <code>idlelib</code>, for GUI and text parsing.</p>\n<p>The <code>keyword</code> module uses it to find comment markers in the module to automatically regenerate the list of keywords in it via metaprogramming.</p>\n<p>In Lib/mailbox.py it seems to be using it like an ordered mapping:</p>\n<pre><code>key_list[key_list.index(old)] = new\n</code></pre>\n<p>and</p>\n<pre><code>del key_list[key_list.index(key)]\n</code></pre>\n<p>In Lib/http/cookiejar.py, seems to be used to get the next month:</p>\n<pre><code>mon = MONTHS_LOWER.index(mon.lower())+1\n</code></pre>\n<p>In Lib/tarfile.py similar to distutils to get a slice up to an item:</p>\n<pre><code>members = members[:members.index(tarinfo)]\n</code></pre>\n<p>In Lib/pickletools.py:</p>\n<pre><code>numtopop = before.index(markobject)\n</code></pre>\n<p>What these usages seem to have in common is that they seem to operate on lists of constrained sizes (important because of O(n) lookup time for <code>list.index</code>), and they're mostly used in parsing (and UI in the case of Idle).</p>\n<p>While there are use-cases for it, they are fairly uncommon. If you find yourself looking for this answer, ask yourself if what you're doing is the most direct usage of the tools provided by the language for your use-case.</p>\n"
},
{
"answer_id": 48530557,
"author": "someone",
"author_id": 1434265,
"author_profile": "https://Stackoverflow.com/users/1434265",
"pm_score": 2,
"selected": false,
"text": "<p>For those coming from another language like me, maybe with a simple loop it's easier to understand and use it:</p>\n\n<pre><code>mylist = [\"foo\", \"bar\", \"baz\", \"bar\"]\nnewlist = enumerate(mylist)\nfor index, item in newlist:\n if item == \"bar\":\n print(index, item)\n</code></pre>\n\n<p>I am thankful for <em><a href=\"https://www.codecademy.com/en/forum_questions/5087f2d786a27b02000041a9\" rel=\"nofollow noreferrer\">So what exactly does enumerate do?</a></em>. That helped me to understand.</p>\n"
},
{
"answer_id": 49093542,
"author": "Hamed Baatour",
"author_id": 2602962,
"author_profile": "https://Stackoverflow.com/users/2602962",
"pm_score": 3,
"selected": false,
"text": "<p>Python <code>index()</code> method throws an error if the item was not found. So instead you can make it similar to the <code>indexOf()</code> function of JavaScript which returns <code>-1</code> if the item was not found:</p>\n\n<pre><code>try:\n index = array.index('search_keyword')\nexcept ValueError:\n index = -1\n</code></pre>\n"
},
{
"answer_id": 49159543,
"author": "Ankit Gupta",
"author_id": 7864006,
"author_profile": "https://Stackoverflow.com/users/7864006",
"pm_score": 3,
"selected": false,
"text": "<p>There is a more functional answer to this.</p>\n\n<pre><code>list(filter(lambda x: x[1]==\"bar\",enumerate([\"foo\", \"bar\", \"baz\", \"bar\", \"baz\", \"bar\", \"a\", \"b\", \"c\"])))\n</code></pre>\n\n<p>More generic form:</p>\n\n<pre><code>def get_index_of(lst, element):\n return list(map(lambda x: x[0],\\\n (list(filter(lambda x: x[1]==element, enumerate(lst))))))\n</code></pre>\n"
},
{
"answer_id": 50537324,
"author": "Ketan",
"author_id": 2595035,
"author_profile": "https://Stackoverflow.com/users/2595035",
"pm_score": 4,
"selected": false,
"text": "<p>Finding index of item x in list L:</p>\n\n<pre><code>idx = L.index(x) if (x in L) else -1\n</code></pre>\n"
},
{
"answer_id": 52263806,
"author": "FatihAkici",
"author_id": 6520041,
"author_profile": "https://Stackoverflow.com/users/6520041",
"pm_score": 2,
"selected": false,
"text": "<h1>If performance is of concern:</h1>\n\n<p>It is mentioned in numerous answers that the built-in method of <code>list.index(item)</code> method is an O(n) algorithm. It is fine if you need to perform this once. But if you need to access the indices of elements a number of times, it makes more sense to first create a dictionary (O(n)) of item-index pairs, and then access the index at O(1) every time you need it.</p>\n\n<p>If you are sure that the items in your list are never repeated, you can easily:</p>\n\n<pre><code>myList = [\"foo\", \"bar\", \"baz\"]\n\n# Create the dictionary\nmyDict = dict((e,i) for i,e in enumerate(myList))\n\n# Lookup\nmyDict[\"bar\"] # Returns 1\n# myDict.get(\"blah\") if you don't want an error to be raised if element not found.\n</code></pre>\n\n<p>If you may have duplicate elements, and need to return all of their indices:</p>\n\n<pre><code>from collections import defaultdict as dd\nmyList = [\"foo\", \"bar\", \"bar\", \"baz\", \"foo\"]\n\n# Create the dictionary\nmyDict = dd(list)\nfor i,e in enumerate(myList):\n myDict[e].append(i)\n\n# Lookup\nmyDict[\"foo\"] # Returns [0, 4]\n</code></pre>\n"
},
{
"answer_id": 52502151,
"author": "pylang",
"author_id": 4531270,
"author_profile": "https://Stackoverflow.com/users/4531270",
"pm_score": 2,
"selected": false,
"text": "<p>As indicated by @TerryA, many answers discuss how to find <em>one</em> index.</p>\n\n<p><a href=\"https://github.com/erikrose/more-itertools\" rel=\"nofollow noreferrer\"><code>more_itertools</code></a> is a third-party library with tools to locate <em>multiple</em> indices within an iterable. </p>\n\n<p><strong>Given</strong></p>\n\n<pre><code>import more_itertools as mit\n\n\niterable = [\"foo\", \"bar\", \"baz\", \"ham\", \"foo\", \"bar\", \"baz\"]\n</code></pre>\n\n<p><strong>Code</strong></p>\n\n<p>Find indices of multiple observations:</p>\n\n<pre><code>list(mit.locate(iterable, lambda x: x == \"bar\"))\n# [1, 5]\n</code></pre>\n\n<p>Test multiple items:</p>\n\n<pre><code>list(mit.locate(iterable, lambda x: x in {\"bar\", \"ham\"}))\n# [1, 3, 5]\n</code></pre>\n\n<p>See also more options with <a href=\"https://more-itertools.readthedocs.io/en/stable/api.html#more_itertools.locate\" rel=\"nofollow noreferrer\"><code>more_itertools.locate</code></a>. Install via <a href=\"https://github.com/erikrose/more-itertools\" rel=\"nofollow noreferrer\"><code>> pip install more_itertools</code></a>.</p>\n"
},
{
"answer_id": 53306924,
"author": "Siddharth Satpathy",
"author_id": 10626090,
"author_profile": "https://Stackoverflow.com/users/10626090",
"pm_score": 2,
"selected": false,
"text": "<p>Let’s give the name <code>lst</code> to the list that you have. One can convert the list <code>lst</code> to a <code>numpy array</code>. And, then use <a href=\"https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.where.html\" rel=\"nofollow noreferrer\">numpy.where</a> to get the index of the chosen item in the list. Following is the way in which you will implement it.</p>\n\n<pre><code>import numpy as np\n\nlst = [\"foo\", \"bar\", \"baz\"] #lst: : 'list' data type\nprint np.where( np.array(lst) == 'bar')[0][0]\n\n>>> 1\n</code></pre>\n"
},
{
"answer_id": 55218236,
"author": "sahasrara62",
"author_id": 5086255,
"author_profile": "https://Stackoverflow.com/users/5086255",
"pm_score": 1,
"selected": false,
"text": "<p>using dictionary , where process the list first and then add the index to it </p>\n\n<pre><code>from collections import defaultdict\n\nindex_dict = defaultdict(list) \nword_list = ['foo','bar','baz','bar','any', 'foo', 'much']\n\nfor word_index in range(len(word_list)) :\n index_dict[word_list[word_index]].append(word_index)\n\nword_index_to_find = 'foo' \nprint(index_dict[word_index_to_find])\n\n# output : [0, 5]\n</code></pre>\n"
},
{
"answer_id": 61016685,
"author": "Vlad Bezden",
"author_id": 30038,
"author_profile": "https://Stackoverflow.com/users/30038",
"pm_score": 3,
"selected": false,
"text": "<p>If you are going to find an index once then using \"index\" method is fine. However, if you are going to search your data more than once then I recommend using <a href=\"https://docs.python.org/3/library/bisect.html\" rel=\"noreferrer\">bisect</a> module. Keep in mind that using bisect module data must be sorted. So you sort data once and then you can use bisect.\nUsing <a href=\"https://docs.python.org/3/library/bisect.html\" rel=\"noreferrer\">bisect</a> module on my machine is about 20 times faster than using index method.</p>\n\n<p>Here is an example of code using Python 3.8 and above syntax:</p>\n\n<pre><code>import bisect\nfrom timeit import timeit\n\ndef bisect_search(container, value):\n return (\n index \n if (index := bisect.bisect_left(container, value)) < len(container) \n and container[index] == value else -1\n )\n\ndata = list(range(1000))\n# value to search\nvalue = 666\n\n# times to test\nttt = 1000\n\nt1 = timeit(lambda: data.index(value), number=ttt)\nt2 = timeit(lambda: bisect_search(data, value), number=ttt)\n\nprint(f\"{t1=:.4f}, {t2=:.4f}, diffs {t1/t2=:.2f}\")\n</code></pre>\n\n<p>Output:</p>\n\n<pre><code>t1=0.0400, t2=0.0020, diffs t1/t2=19.60\n</code></pre>\n"
},
{
"answer_id": 62518645,
"author": "Caveman",
"author_id": 9225733,
"author_profile": "https://Stackoverflow.com/users/9225733",
"pm_score": 3,
"selected": false,
"text": "<h3>For one comparable</h3>\n<pre class=\"lang-py prettyprint-override\"><code># Throws ValueError if nothing is found\nsome_list = ['foo', 'bar', 'baz'].index('baz')\n# some_list == 2\n</code></pre>\n<h3>Custom predicate</h3>\n<pre class=\"lang-py prettyprint-override\"><code>some_list = [item1, item2, item3]\n\n# Throws StopIteration if nothing is found\n# *unless* you provide a second parameter to `next`\nindex_of_value_you_like = next(\n i for i, item in enumerate(some_list)\n if item.matches_your_criteria())\n</code></pre>\n<h3>Finding index of all items by predicate</h3>\n<pre class=\"lang-py prettyprint-override\"><code>index_of_staff_members = [\n i for i, user in enumerate(users)\n if user.is_staff()]\n</code></pre>\n"
},
{
"answer_id": 63631183,
"author": "Badri Paudel",
"author_id": 9898251,
"author_profile": "https://Stackoverflow.com/users/9898251",
"pm_score": 4,
"selected": false,
"text": "<p>There is a chance that that value may not be present so to avoid this ValueError, we can check if that actually exists in the list .</p>\n<pre><code>list = ["foo", "bar", "baz"]\n\nitem_to_find = "foo"\n\nif item_to_find in list:\n index = list.index(item_to_find)\n print("Index of the item is " + str(index))\nelse:\n print("That word does not exist") \n</code></pre>\n"
},
{
"answer_id": 67031974,
"author": "Blackjack",
"author_id": 13682949,
"author_profile": "https://Stackoverflow.com/users/13682949",
"pm_score": 3,
"selected": false,
"text": "<p>It just uses the python function <code>array.index()</code> and with a simple Try / Except it returns the position of the record if it is found in the list and return -1 if it is not found in the list (like on JavaScript with the function <code>indexOf()</code>).</p>\n<pre class=\"lang-py prettyprint-override\"><code>fruits = ['apple', 'banana', 'cherry']\n\ntry:\n pos = fruits.index("mango")\nexcept:\n pos = -1\n</code></pre>\n<p>In this case "mango" is not present in the list <code>fruits</code> so the <code>pos</code> variable is -1, if I had searched for "cherry" the <code>pos</code> variable would be 2.</p>\n"
},
{
"answer_id": 67384774,
"author": "illuminato",
"author_id": 2975438,
"author_profile": "https://Stackoverflow.com/users/2975438",
"pm_score": -1,
"selected": false,
"text": "<p>Simple option:</p>\n<pre><code>a = ["foo", "bar", "baz"]\n[i for i in range(len(a)) if a[i].find("bar") != -1]\n</code></pre>\n"
},
{
"answer_id": 69425614,
"author": "MD SHAYON",
"author_id": 8725395,
"author_profile": "https://Stackoverflow.com/users/8725395",
"pm_score": 2,
"selected": false,
"text": "<p>I find this two solution is better and I tried it by myself</p>\n<pre><code>>>> expences = [2200, 2350, 2600, 2130, 2190]\n>>> 2000 in expences\nFalse\n>>> expences.index(2200)\n0\n>>> expences.index(2350)\n1\n>>> index = expences.index(2350)\n>>> expences[index]\n2350\n\n>>> try:\n... print(expences.index(2100))\n... except ValueError as e:\n... print(e)\n... \n2100 is not in list\n>>> \n\n\n</code></pre>\n"
},
{
"answer_id": 70143454,
"author": "Abdul Niyas P M",
"author_id": 6699447,
"author_profile": "https://Stackoverflow.com/users/6699447",
"pm_score": 1,
"selected": false,
"text": "<p>Pythonic way would to use <code>enumerate</code> but you can also use <a href=\"https://docs.python.org/3/library/operator.html#operator.indexOf\" rel=\"nofollow noreferrer\"><code>indexOf</code></a> from <code>operator</code> module. Please note that this will raise <a href=\"https://github.com/python/cpython/blob/3.10/Lib/operator.py#L179\" rel=\"nofollow noreferrer\"><code>ValueError</code> if <code>b</code> not in <code>a</code>.</a></p>\n<pre><code>>>> from operator import indexOf\n>>>\n>>>\n>>> help(indexOf)\nHelp on built-in function indexOf in module _operator:\n\nindexOf(a, b, /)\n Return the first index of b in a.\n\n>>>\n>>>\n>>> indexOf(("foo", "bar", "baz"), "bar") # with tuple\n1\n>>> indexOf(["foo", "bar", "baz"], "bar") # with list\n1\n</code></pre>\n"
},
{
"answer_id": 70523709,
"author": "Franz Kurt",
"author_id": 7327114,
"author_profile": "https://Stackoverflow.com/users/7327114",
"pm_score": 2,
"selected": false,
"text": "<p>Certain structures in python contains a index method that works beautifully to solve this question.</p>\n<pre><code>'oi tchau'.index('oi') # 0\n['oi','tchau'].index('oi') # 0\n('oi','tchau').index('oi') # 0\n</code></pre>\n<p>References:</p>\n<p><a href=\"https://www.programiz.com/python-programming/methods/list/index\" rel=\"nofollow noreferrer\">In lists</a></p>\n<p><a href=\"https://www.programiz.com/python-programming/methods/list/index\" rel=\"nofollow noreferrer\">In tuples</a></p>\n<p><a href=\"https://www.programiz.com/python-programming/methods/list/index\" rel=\"nofollow noreferrer\">In string</a></p>\n"
},
{
"answer_id": 70615103,
"author": "sargupta",
"author_id": 9658895,
"author_profile": "https://Stackoverflow.com/users/9658895",
"pm_score": 2,
"selected": false,
"text": "<pre><code>text = ["foo", "bar", "baz"]\ntarget = "bar"\n\n[index for index, value in enumerate(text) if value == target]\n</code></pre>\n<blockquote>\n<p>For a small list of elements, this would work fine. However, if the\nlist contains a large number of elements, better to <strong>apply binary\nsearch with O(log n) runtime complexity</strong>\n.</p>\n</blockquote>\n"
},
{
"answer_id": 70702309,
"author": "LunaticXXD10",
"author_id": 16067738,
"author_profile": "https://Stackoverflow.com/users/16067738",
"pm_score": 4,
"selected": false,
"text": "<p>My friend, I have made the easiest code to solve your question. While you were receiving gigantic lines of codes, I am here to cater you a two line code which is all due to the help of <code>index()</code> function in python.</p>\n<pre><code>LIST = ['foo' ,'boo', 'shoo']\nprint(LIST.index('boo'))\n</code></pre>\n<p>Output:</p>\n<pre><code>1\n</code></pre>\n<p>I Hope I have given you the best and the simplest answer which might help you greatly.</p>\n"
},
{
"answer_id": 71017253,
"author": "Kofi",
"author_id": 12888115,
"author_profile": "https://Stackoverflow.com/users/12888115",
"pm_score": 3,
"selected": false,
"text": "<p>List comprehension would be the best option to acquire a compact implementation in finding the index of an item in a list.</p>\n<pre><code>a_list = ["a", "b", "a"]\nprint([index for (index , item) in enumerate(a_list) if item == "a"])\n</code></pre>\n"
},
{
"answer_id": 71900535,
"author": "Abiodun Mustapha",
"author_id": 18475123,
"author_profile": "https://Stackoverflow.com/users/18475123",
"pm_score": 5,
"selected": false,
"text": "<pre><code>me = ["foo", "bar", "baz"]\nme.index("bar") \n</code></pre>\n<p>You can apply this for any member of the list to get their index</p>\n"
},
{
"answer_id": 72121787,
"author": "Deepeshkumar",
"author_id": 1780667,
"author_profile": "https://Stackoverflow.com/users/1780667",
"pm_score": 0,
"selected": false,
"text": "<p>One can use zip() function to get the index of the value in the list. The code could be;</p>\n<pre><code>list1 = ["foo","bar","baz"]\nfor index,value in zip(range(0,len(list1)),list1):\n if value == "bar":\n print(index)\n</code></pre>\n"
},
{
"answer_id": 73924789,
"author": "My Car",
"author_id": 16124033,
"author_profile": "https://Stackoverflow.com/users/16124033",
"pm_score": 2,
"selected": false,
"text": "<p>Try the following code:</p>\n<pre><code>["foo", "bar", "baz"].index("bar")\n</code></pre>\n<p>Refer to: <a href=\"https://www.programiz.com/python-programming/methods/list/index\" rel=\"nofollow noreferrer\">https://www.programiz.com/python-programming/methods/list/index</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176918",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25680/"
] |
Given a list `["foo", "bar", "baz"]` and an item in the list `"bar"`, how do I get its index `1`?
|
```
>>> ["foo", "bar", "baz"].index("bar")
1
```
Reference: [Data Structures > More on Lists](https://docs.python.org/tutorial/datastructures.html#more-on-lists)
Caveats follow
==============
Note that while this is perhaps the cleanest way to answer the question *as asked*, `index` is a rather weak component of the `list` API, and I can't remember the last time I used it in anger. It's been pointed out to me in the comments that because this answer is heavily referenced, it should be made more complete. Some caveats about `list.index` follow. It is probably worth initially taking a look at the documentation for it:
>
>
> ```
> list.index(x[, start[, end]])
>
> ```
>
> Return zero-based index in the list of the first item whose value is equal to *x*. Raises a [`ValueError`](https://docs.python.org/library/exceptions.html#ValueError) if there is no such item.
>
>
> The optional arguments *start* and *end* are interpreted as in the [slice notation](https://docs.python.org/tutorial/introduction.html#lists) and are used to limit the search to a particular subsequence of the list. The returned index is computed relative to the beginning of the full sequence rather than the start argument.
>
>
>
Linear time-complexity in list length
-------------------------------------
An `index` call checks every element of the list in order, until it finds a match. If your list is long, and you don't know roughly where in the list it occurs, this search could become a bottleneck. In that case, you should consider a different data structure. Note that if you know roughly where to find the match, you can give `index` a hint. For instance, in this snippet, `l.index(999_999, 999_990, 1_000_000)` is roughly five orders of magnitude faster than straight `l.index(999_999)`, because the former only has to search 10 entries, while the latter searches a million:
```
>>> import timeit
>>> timeit.timeit('l.index(999_999)', setup='l = list(range(0, 1_000_000))', number=1000)
9.356267921015387
>>> timeit.timeit('l.index(999_999, 999_990, 1_000_000)', setup='l = list(range(0, 1_000_000))', number=1000)
0.0004404920036904514
```
Only returns the index of the *first match* to its argument
-----------------------------------------------------------
A call to `index` searches through the list in order until it finds a match, and *stops there.* If you expect to need indices of more matches, you should use a list comprehension, or generator expression.
```
>>> [1, 1].index(1)
0
>>> [i for i, e in enumerate([1, 2, 1]) if e == 1]
[0, 2]
>>> g = (i for i, e in enumerate([1, 2, 1]) if e == 1)
>>> next(g)
0
>>> next(g)
2
```
Most places where I once would have used `index`, I now use a list comprehension or generator expression because they're more generalizable. So if you're considering reaching for `index`, take a look at these excellent Python features.
Throws if element not present in list
-------------------------------------
A call to `index` results in a [`ValueError`](https://docs.python.org/library/exceptions.html#ValueError) if the item's not present.
```
>>> [1, 1].index(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 2 is not in list
```
If the item might not be present in the list, you should either
1. Check for it first with `item in my_list` (clean, readable approach), or
2. Wrap the `index` call in a `try/except` block which catches `ValueError` (probably faster, at least when the list to search is long, and the item is usually present.)
|
176,931 |
<p>How can I get MSBuild to evaluate and print in a <code><Message /></code> task an absolute path given a relative path?</p>
<p><strong>Property Group</strong></p>
<pre><code><Source_Dir>..\..\..\Public\Server\</Source_Dir>
<Program_Dir>c:\Program Files (x86)\Program\</Program_Dir>
</code></pre>
<p><strong>Task</strong></p>
<pre><code><Message Importance="low" Text="Copying '$(Source_Dir.FullPath)' to '$(Program_Dir)'" />
</code></pre>
<p><strong>Output</strong></p>
<blockquote>
<p>Copying '' to 'c:\Program Files (x86)\Program\'</p>
</blockquote>
|
[
{
"answer_id": 177136,
"author": "brock.holum",
"author_id": 15860,
"author_profile": "https://Stackoverflow.com/users/15860",
"pm_score": 3,
"selected": false,
"text": "<p>Wayne is correct that well-known metadata does not apply to properties - only to items. Using properties such as \"MSBuildProjectDirectory\" will work, but I'm not aware of a built in way to resolve the full path.</p>\n\n<p>Another option is to write a simple, custom task that will take a relative path and spit out the fully-resolved path. It would look something like this:</p>\n\n<pre><code>public class ResolveRelativePath : Task\n{\n [Required]\n public string RelativePath { get; set; }\n\n [Output]\n public string FullPath { get; private set; }\n\n public override bool Execute()\n {\n try\n {\n DirectoryInfo dirInfo = new DirectoryInfo(RelativePath);\n FullPath = dirInfo.FullName;\n }\n catch (Exception ex)\n {\n Log.LogErrorFromException(ex);\n }\n return !Log.HasLoggedErrors;\n }\n}\n</code></pre>\n\n<p>And your MSBuild lines would look something like:</p>\n\n<pre><code><PropertyGroup>\n <TaskAssembly>D:\\BuildTasks\\Build.Tasks.dll</TaskAssembly>\n <Source_Dir>..\\..\\..\\Public\\Server\\</Source_Dir>\n <Program_Dir>c:\\Program Files (x86)\\Program\\</Program_Dir>\n</PropertyGroup>\n<UsingTask AssemblyFile=\"$(TaskAssembly)\" TaskName=\"ResolveRelativePath\" />\n\n<Target Name=\"Default\">\n <ResolveRelativePath RelativePath=\"$(Source_Dir)\">\n <Output TaskParameter=\"FullPath\" PropertyName=\"_FullPath\" />\n </ResolveRelativePath>\n <Message Importance=\"low\" Text=\"Copying '$(_FullPath)' to '$(Program_Dir)'\" />\n</Target>\n</code></pre>\n"
},
{
"answer_id": 177151,
"author": "Scott Dorman",
"author_id": 1559,
"author_profile": "https://Stackoverflow.com/users/1559",
"pm_score": 3,
"selected": false,
"text": "<p>You are trying to access an item metadata property through a property, which isn't possible. What you want to do is something like this:</p>\n\n<pre><code><PropertyGroup>\n <Program_Dir>c:\\Program Files (x86)\\Program\\</Program_Dir>\n</PropertyGroup>\n<ItemGroup>\n <Source_Dir Include=\"..\\Desktop\"/>\n</ItemGroup> \n<Target Name=\"BuildAll\">\n <Message Text=\"Copying '%(Source_Dir.FullPath)' to '$(Program_Dir)'\" />\n</Target>\n</code></pre>\n\n<p>Which will generate output as:</p>\n\n<pre><code> Copying 'C:\\Users\\sdorman\\Desktop' to 'c:\\Program Files (x86)\\Program\\'\n</code></pre>\n\n<p>(The script was run from my Documents folder, so ..\\Desktop is the correct relative path to get to my desktop.)</p>\n\n<p>In your case, replace the \"..\\Desktop\" with \"......\\Public\\Server\" in the Source_Dir item and you should be all set.</p>\n"
},
{
"answer_id": 179289,
"author": "Scott Weinstein",
"author_id": 25201,
"author_profile": "https://Stackoverflow.com/users/25201",
"pm_score": 2,
"selected": false,
"text": "<p>If you need to convert Properties to Items you have two options. With msbuild 2, you can use the <strong>CreateItem</strong> task</p>\n\n<pre><code> <Target Name='Build'>\n <CreateItem Include='$(Source_Dir)'>\n <Output ItemName='SRCDIR' TaskParameter='Include' />\n </CreateItem>\n</code></pre>\n\n<p>and with MSBuild 3.5 you can have ItemGroups inside of a Task</p>\n\n<pre><code> <Target Name='Build'>\n <ItemGroup>\n <SRCDIR2 Include='$(Source_Dir)' />\n </ItemGroup>\n <Message Text=\"%(SRCDIR2.FullPath)\" />\n <Message Text=\"%(SRCDIR.FullPath)\" />\n </Target>\n</code></pre>\n"
},
{
"answer_id": 1251198,
"author": "Roman Starkov",
"author_id": 33080,
"author_profile": "https://Stackoverflow.com/users/33080",
"pm_score": 8,
"selected": true,
"text": "<p><strong>In MSBuild 4.0</strong>, the easiest way is the following:</p>\n\n<pre><code>$([System.IO.Path]::GetFullPath('$(MSBuildThisFileDirectory)\\your\\path'))\n</code></pre>\n\n<p>This method works even if the script is <code><Import></code>ed into another script; the path is relative to the file containing the above code.</p>\n\n<p>(consolidated from <a href=\"https://stackoverflow.com/a/4894456/33080\">Aaron's answer</a> as well as the last part of <a href=\"https://stackoverflow.com/a/2421596/33080\">Sayed's answer</a>)</p>\n\n<hr>\n\n<p><strong>In MSBuild 3.5</strong>, you can use the <a href=\"http://msdn.microsoft.com/en-us/library/bb882668.aspx\" rel=\"noreferrer\" title=\"ConvertToAbsolutePath\">ConvertToAbsolutePath</a> task:</p>\n\n<pre><code><Project xmlns=\"http://schemas.microsoft.com/developer/msbuild/2003\"\n DefaultTargets=\"Test\"\n ToolsVersion=\"3.5\">\n <PropertyGroup>\n <Source_Dir>..\\..\\..\\Public\\Server\\</Source_Dir>\n <Program_Dir>c:\\Program Files (x86)\\Program\\</Program_Dir>\n </PropertyGroup>\n\n <Target Name=\"Test\">\n <ConvertToAbsolutePath Paths=\"$(Source_Dir)\">\n <Output TaskParameter=\"AbsolutePaths\" PropertyName=\"Source_Dir_Abs\"/>\n </ConvertToAbsolutePath>\n <Message Text='Copying \"$(Source_Dir_Abs)\" to \"$(Program_Dir)\".' />\n </Target>\n</Project>\n</code></pre>\n\n<p>Relevant output:</p>\n\n<pre><code>Project \"P:\\software\\perforce1\\main\\XxxxxxXxxx\\Xxxxx.proj\" on node 0 (default targets).\n Copying \"P:\\software\\Public\\Server\\\" to \"c:\\Program Files (x86)\\Program\\\".\n</code></pre>\n\n<p>A little long-winded if you ask me, but it works. This will be relative to the \"original\" project file, so if placed inside a file that gets <code><Import></code>ed, this won't be relative to that file.</p>\n\n<hr>\n\n<p><strong>In MSBuild 2.0</strong>, there is an approach which doesn't resolve \"..\". It does however behave just like an absolute path:</p>\n\n<pre><code><PropertyGroup>\n <Source_Dir_Abs>$(MSBuildProjectDirectory)\\$(Source_Dir)</Source_Dir_Abs>\n</PropertyGroup>\n</code></pre>\n\n<p>The <a href=\"http://msdn.microsoft.com/en-us/library/ms164309%28VS.80%29.aspx\" rel=\"noreferrer\">$(MSBuildProjectDirectory)</a> reserved property is always the directory of the script that contains this reference.</p>\n\n<p>This will also be relative to the \"original\" project file, so if placed inside a file that gets <code><Import></code>ed, this won't be relative to that file.</p>\n"
},
{
"answer_id": 4894456,
"author": "Aaron Carlson",
"author_id": 57913,
"author_profile": "https://Stackoverflow.com/users/57913",
"pm_score": 5,
"selected": false,
"text": "<p>MSBuild 4.0 added <a href=\"http://msdn.microsoft.com/en-us/library/dd633440.aspx\" rel=\"noreferrer\">Property Functions</a> which allow you to call into static functions in some of the .net system dlls. A really nice thing about Property Functions is that they will evaluate out side of a target. </p>\n\n<p>To evaluate a full path you can use <a href=\"http://msdn.microsoft.com/en-us/library/system.io.path.getfullpath.aspx\" rel=\"noreferrer\">System.IO.Path.GetFullPath</a> when defining a property like so:</p>\n\n<pre><code><PropertyGroup>\n <Source_Dir>$([System.IO.Path]::GetFullPath('..\\..\\..\\Public\\Server\\'))</Source_Dir>\n</PropertyGroup>\n</code></pre>\n\n<p>The syntax is a little ugly but very powerful.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176931",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3957/"
] |
How can I get MSBuild to evaluate and print in a `<Message />` task an absolute path given a relative path?
**Property Group**
```
<Source_Dir>..\..\..\Public\Server\</Source_Dir>
<Program_Dir>c:\Program Files (x86)\Program\</Program_Dir>
```
**Task**
```
<Message Importance="low" Text="Copying '$(Source_Dir.FullPath)' to '$(Program_Dir)'" />
```
**Output**
>
> Copying '' to 'c:\Program Files (x86)\Program\'
>
>
>
|
**In MSBuild 4.0**, the easiest way is the following:
```
$([System.IO.Path]::GetFullPath('$(MSBuildThisFileDirectory)\your\path'))
```
This method works even if the script is `<Import>`ed into another script; the path is relative to the file containing the above code.
(consolidated from [Aaron's answer](https://stackoverflow.com/a/4894456/33080) as well as the last part of [Sayed's answer](https://stackoverflow.com/a/2421596/33080))
---
**In MSBuild 3.5**, you can use the [ConvertToAbsolutePath](http://msdn.microsoft.com/en-us/library/bb882668.aspx "ConvertToAbsolutePath") task:
```
<Project xmlns="http://schemas.microsoft.com/developer/msbuild/2003"
DefaultTargets="Test"
ToolsVersion="3.5">
<PropertyGroup>
<Source_Dir>..\..\..\Public\Server\</Source_Dir>
<Program_Dir>c:\Program Files (x86)\Program\</Program_Dir>
</PropertyGroup>
<Target Name="Test">
<ConvertToAbsolutePath Paths="$(Source_Dir)">
<Output TaskParameter="AbsolutePaths" PropertyName="Source_Dir_Abs"/>
</ConvertToAbsolutePath>
<Message Text='Copying "$(Source_Dir_Abs)" to "$(Program_Dir)".' />
</Target>
</Project>
```
Relevant output:
```
Project "P:\software\perforce1\main\XxxxxxXxxx\Xxxxx.proj" on node 0 (default targets).
Copying "P:\software\Public\Server\" to "c:\Program Files (x86)\Program\".
```
A little long-winded if you ask me, but it works. This will be relative to the "original" project file, so if placed inside a file that gets `<Import>`ed, this won't be relative to that file.
---
**In MSBuild 2.0**, there is an approach which doesn't resolve "..". It does however behave just like an absolute path:
```
<PropertyGroup>
<Source_Dir_Abs>$(MSBuildProjectDirectory)\$(Source_Dir)</Source_Dir_Abs>
</PropertyGroup>
```
The [$(MSBuildProjectDirectory)](http://msdn.microsoft.com/en-us/library/ms164309%28VS.80%29.aspx) reserved property is always the directory of the script that contains this reference.
This will also be relative to the "original" project file, so if placed inside a file that gets `<Import>`ed, this won't be relative to that file.
|
176,964 |
<p>I want to return top 10 records from each section in one query. Can anyone help with how to do it? Section is one of the columns in the table.</p>
<p>Database is SQL Server 2005. I want to return the top 10 by date entered. Sections are business, local, and feature. For one particular date I want only the top (10) business rows (most recent entry), the top (10) local rows, and the top (10) features.</p>
|
[
{
"answer_id": 176970,
"author": "sblundy",
"author_id": 4893,
"author_profile": "https://Stackoverflow.com/users/4893",
"pm_score": 2,
"selected": false,
"text": "<p>Might the <a href=\"http://www.w3schools.com/sql/sql_union.asp\" rel=\"nofollow noreferrer\">UNION</a> operator work for you? Have one SELECT for each section, then UNION them together. Guess it would only work for a fixed number of sections though.</p>\n"
},
{
"answer_id": 176977,
"author": "Matt Hamilton",
"author_id": 615,
"author_profile": "https://Stackoverflow.com/users/615",
"pm_score": 5,
"selected": false,
"text": "<p>This works on SQL Server 2005 (edited to reflect your clarification):</p>\n\n<pre><code>select *\nfrom Things t\nwhere t.ThingID in (\n select top 10 ThingID\n from Things tt\n where tt.Section = t.Section and tt.ThingDate = @Date\n order by tt.DateEntered desc\n )\n and t.ThingDate = @Date\norder by Section, DateEntered desc\n</code></pre>\n"
},
{
"answer_id": 176979,
"author": "Blorgbeard",
"author_id": 369,
"author_profile": "https://Stackoverflow.com/users/369",
"pm_score": 4,
"selected": false,
"text": "<p>If you know what the sections are, you can do:</p>\n\n<pre><code>select top 10 * from table where section=1\nunion\nselect top 10 * from table where section=2\nunion\nselect top 10 * from table where section=3\n</code></pre>\n"
},
{
"answer_id": 176985,
"author": "Darrel Miller",
"author_id": 6819,
"author_profile": "https://Stackoverflow.com/users/6819",
"pm_score": 8,
"selected": false,
"text": "<p>If you are using SQL 2005 you can do something like this...</p>\n\n<pre><code>SELECT rs.Field1,rs.Field2 \n FROM (\n SELECT Field1,Field2, Rank() \n over (Partition BY Section\n ORDER BY RankCriteria DESC ) AS Rank\n FROM table\n ) rs WHERE Rank <= 10\n</code></pre>\n\n<p>If your RankCriteria has ties then you may return more than 10 rows and Matt's solution may be better for you.</p>\n"
},
{
"answer_id": 177212,
"author": "Bill Karwin",
"author_id": 20860,
"author_profile": "https://Stackoverflow.com/users/20860",
"pm_score": 4,
"selected": false,
"text": "<p>I do it this way:</p>\n\n<pre><code>SELECT a.* FROM articles AS a\n LEFT JOIN articles AS a2 \n ON a.section = a2.section AND a.article_date <= a2.article_date\nGROUP BY a.article_id\nHAVING COUNT(*) <= 10;\n</code></pre>\n\n<hr>\n\n<p><strong>update:</strong> This example of GROUP BY works in MySQL and SQLite only, because those databases are more permissive than standard SQL regarding GROUP BY. Most SQL implementations require that all columns in the select-list that aren't part of an aggregate expression are also in the GROUP BY.</p>\n"
},
{
"answer_id": 4991993,
"author": "Diadistis",
"author_id": 47401,
"author_profile": "https://Stackoverflow.com/users/47401",
"pm_score": 3,
"selected": false,
"text": "<p>I know this thread is a little bit old but I've just bumped into a similar problem (select the newest article from each category) and this is the solution I came up with :</p>\n\n<pre><code>WITH [TopCategoryArticles] AS (\n SELECT \n [ArticleID],\n ROW_NUMBER() OVER (\n PARTITION BY [ArticleCategoryID]\n ORDER BY [ArticleDate] DESC\n ) AS [Order]\n FROM [dbo].[Articles]\n)\nSELECT [Articles].* \nFROM \n [TopCategoryArticles] LEFT JOIN \n [dbo].[Articles] ON\n [TopCategoryArticles].[ArticleID] = [Articles].[ArticleID]\nWHERE [TopCategoryArticles].[Order] = 1\n</code></pre>\n\n<p>This is very similar to Darrel's solution but overcomes the RANK problem that might return more rows than intended.</p>\n"
},
{
"answer_id": 5058731,
"author": "bharathreddy",
"author_id": 625448,
"author_profile": "https://Stackoverflow.com/users/625448",
"pm_score": 3,
"selected": false,
"text": "<p>Q) Finding TOP X records from each group(Oracle)</p>\n\n<pre><code>SQL> select * from emp e \n 2 where e.empno in (select d.empno from emp d \n 3 where d.deptno=e.deptno and rownum<3)\n 4 order by deptno\n 5 ;\n\n EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO\n</code></pre>\n\n<hr>\n\n<pre><code> 7782 CLARK MANAGER 7839 09-JUN-81 2450 10\n 7839 KING PRESIDENT 17-NOV-81 5000 10\n 7369 SMITH CLERK 7902 17-DEC-80 800 20\n 7566 JONES MANAGER 7839 02-APR-81 2975 20\n 7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30\n 7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30\n</code></pre>\n\n<p>6 rows selected.</p>\n\n<hr>\n"
},
{
"answer_id": 11052618,
"author": "lorond",
"author_id": 513392,
"author_profile": "https://Stackoverflow.com/users/513392",
"pm_score": 5,
"selected": false,
"text": "<pre><code>SELECT r.*\nFROM\n(\n SELECT\n r.*,\n ROW_NUMBER() OVER(PARTITION BY r.[SectionID]\n ORDER BY r.[DateEntered] DESC) rn\n FROM [Records] r\n) r\nWHERE r.rn <= 10\nORDER BY r.[DateEntered] DESC\n</code></pre>\n"
},
{
"answer_id": 11187383,
"author": "Phil Rabbitt",
"author_id": 1479651,
"author_profile": "https://Stackoverflow.com/users/1479651",
"pm_score": 7,
"selected": false,
"text": "<p>In T-SQL, I would do:</p>\n\n<pre><code>WITH TOPTEN AS (\n SELECT *, ROW_NUMBER() \n over (\n PARTITION BY [group_by_field] \n order by [prioritise_field]\n ) AS RowNo \n FROM [table_name]\n)\nSELECT * FROM TOPTEN WHERE RowNo <= 10\n</code></pre>\n"
},
{
"answer_id": 14640138,
"author": "Craig Tullis",
"author_id": 618649,
"author_profile": "https://Stackoverflow.com/users/618649",
"pm_score": 3,
"selected": false,
"text": "<p>If you want to produce output grouped by section, displaying only the top <em>n</em> records from each section something like this:</p>\n\n<pre><code>SECTION SUBSECTION\n\ndeer American Elk/Wapiti\ndeer Chinese Water Deer\ndog Cocker Spaniel\ndog German Shephard\nhorse Appaloosa\nhorse Morgan\n</code></pre>\n\n<p>...then the following should work pretty generically with all SQL databases. If you want the top 10, just change the 2 to a 10 toward the end of the query.</p>\n\n<pre><code>select\n x1.section\n , x1.subsection\nfrom example x1\nwhere\n (\n select count(*)\n from example x2\n where x2.section = x1.section\n and x2.subsection <= x1.subsection\n ) <= 2\norder by section, subsection;\n</code></pre>\n\n<p>To set up:</p>\n\n<pre><code>create table example ( id int, section varchar(25), subsection varchar(25) );\n\ninsert into example select 0, 'dog', 'Labrador Retriever';\ninsert into example select 1, 'deer', 'Whitetail';\ninsert into example select 2, 'horse', 'Morgan';\ninsert into example select 3, 'horse', 'Tarpan';\ninsert into example select 4, 'deer', 'Row';\ninsert into example select 5, 'horse', 'Appaloosa';\ninsert into example select 6, 'dog', 'German Shephard';\ninsert into example select 7, 'horse', 'Thoroughbred';\ninsert into example select 8, 'dog', 'Mutt';\ninsert into example select 9, 'horse', 'Welara Pony';\ninsert into example select 10, 'dog', 'Cocker Spaniel';\ninsert into example select 11, 'deer', 'American Elk/Wapiti';\ninsert into example select 12, 'horse', 'Shetland Pony';\ninsert into example select 13, 'deer', 'Chinese Water Deer';\ninsert into example select 14, 'deer', 'Fallow';\n</code></pre>\n"
},
{
"answer_id": 27658678,
"author": "Vadim Loboda",
"author_id": 623190,
"author_profile": "https://Stackoverflow.com/users/623190",
"pm_score": 4,
"selected": false,
"text": "<p>If we use SQL Server >= 2005, then we can solve the task with one <em>select</em> only:</p>\n\n<pre><code>declare @t table (\n Id int ,\n Section int,\n Moment date\n);\n\ninsert into @t values\n( 1 , 1 , '2014-01-01'),\n( 2 , 1 , '2014-01-02'),\n( 3 , 1 , '2014-01-03'),\n( 4 , 1 , '2014-01-04'),\n( 5 , 1 , '2014-01-05'),\n\n( 6 , 2 , '2014-02-06'),\n( 7 , 2 , '2014-02-07'),\n( 8 , 2 , '2014-02-08'),\n( 9 , 2 , '2014-02-09'),\n( 10 , 2 , '2014-02-10'),\n\n( 11 , 3 , '2014-03-11'),\n( 12 , 3 , '2014-03-12'),\n( 13 , 3 , '2014-03-13'),\n( 14 , 3 , '2014-03-14'),\n( 15 , 3 , '2014-03-15');\n\n\n-- TWO earliest records in each Section\n\nselect top 1 with ties\n Id, Section, Moment \nfrom\n @t\norder by \n case \n when row_number() over(partition by Section order by Moment) <= 2 \n then 0 \n else 1 \n end;\n\n\n-- THREE earliest records in each Section\n\nselect top 1 with ties\n Id, Section, Moment \nfrom\n @t\norder by \n case \n when row_number() over(partition by Section order by Moment) <= 3 \n then 0 \n else 1 \n end;\n\n\n-- three LATEST records in each Section\n\nselect top 1 with ties\n Id, Section, Moment \nfrom\n @t\norder by \n case \n when row_number() over(partition by Section order by Moment desc) <= 3 \n then 0 \n else 1 \n end;\n</code></pre>\n"
},
{
"answer_id": 41863032,
"author": "Ali",
"author_id": 2588755,
"author_profile": "https://Stackoverflow.com/users/2588755",
"pm_score": 1,
"selected": false,
"text": "<p>You can try this approach. \nThis query returns 10 most populated cities for each country.</p>\n\n<pre><code> SELECT city, country, population\n FROM\n (SELECT city, country, population, \n @country_rank := IF(@current_country = country, @country_rank + 1, 1) AS country_rank,\n @current_country := country \n FROM cities\n ORDER BY country, population DESC\n ) ranked\n WHERE country_rank <= 10;\n</code></pre>\n"
},
{
"answer_id": 47246291,
"author": "Raghu S",
"author_id": 3437885,
"author_profile": "https://Stackoverflow.com/users/3437885",
"pm_score": 3,
"selected": false,
"text": "<p>Tried the following and it worked with ties too.</p>\n\n<pre><code>SELECT rs.Field1,rs.Field2 \nFROM (\n SELECT Field1,Field2, ROW_NUMBER() \n OVER (Partition BY Section\n ORDER BY RankCriteria DESC ) AS Rank\n FROM table\n ) rs WHERE Rank <= 10\n</code></pre>\n"
},
{
"answer_id": 50326690,
"author": "Lukas Eder",
"author_id": 521799,
"author_profile": "https://Stackoverflow.com/users/521799",
"pm_score": 2,
"selected": false,
"text": "<p>While the question was about SQL Server 2005, most people have moved on and if they do find this question, what could be the preferred answer in other situations is one <a href=\"https://blog.jooq.org/2017/09/22/how-to-write-efficient-top-n-queries-in-sql/\" rel=\"nofollow noreferrer\">using <code>CROSS APPLY</code> as illustrated in this blog post</a>.</p>\n\n<pre class=\"lang-sql prettyprint-override\"><code>SELECT *\nFROM t\nCROSS APPLY (\n SELECT TOP 10 u.*\n FROM u\n WHERE u.t_id = t.t_id\n ORDER BY u.something DESC\n) u\n</code></pre>\n\n<p>This query involves 2 tables. The OP's query only involves 1 table, in case of which a window function based solution might be more efficient.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176964",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14752/"
] |
I want to return top 10 records from each section in one query. Can anyone help with how to do it? Section is one of the columns in the table.
Database is SQL Server 2005. I want to return the top 10 by date entered. Sections are business, local, and feature. For one particular date I want only the top (10) business rows (most recent entry), the top (10) local rows, and the top (10) features.
|
If you are using SQL 2005 you can do something like this...
```
SELECT rs.Field1,rs.Field2
FROM (
SELECT Field1,Field2, Rank()
over (Partition BY Section
ORDER BY RankCriteria DESC ) AS Rank
FROM table
) rs WHERE Rank <= 10
```
If your RankCriteria has ties then you may return more than 10 rows and Matt's solution may be better for you.
|
176,966 |
<p>I've been looking for the answer for how to use BSWAP for lower 32-bit sub-register of 64-bit register. For example, <code>0x0123456789abcdef</code> is inside RAX register, and I want to change it to <code>0x01234567efcdab89</code> with a single instruction (because of performance).</p>
<p>So I tried following inline function:</p>
<pre class="lang-c prettyprint-override"><code>#define BSWAP(T) { \
__asm__ __volatile__ ( \
"bswap %k0" \
: "=q" (T) \
: "q" (T)); \
}
</code></pre>
<p>And the result was <code>0x00000000efcdab89</code>. I don't understand why the compiler acts like this. Does anybody know the efficient solution?</p>
|
[
{
"answer_id": 176981,
"author": "Dan Lenski",
"author_id": 20789,
"author_profile": "https://Stackoverflow.com/users/20789",
"pm_score": -1,
"selected": false,
"text": "<p>Check the assembly output generated by gcc! Use the <code>gcc -s</code> flag to compile the code and generate asm output.</p>\n\n<p>IIRC, x86-64 uses 32-bit integers by default when not explicitly directed to do otherwise, so this may be (part of) the problem.</p>\n"
},
{
"answer_id": 178474,
"author": "Dan Lenski",
"author_id": 20789,
"author_profile": "https://Stackoverflow.com/users/20789",
"pm_score": 4,
"selected": true,
"text": "<p>Ah, yes, I understand the problem now:</p>\n\n<p>the x86-64 processors <em><a href=\"http://www.x86-64.org/documentation/assembly.html\" rel=\"noreferrer\">implicitly zero-extend</a></em> the 32-bit registers to 64-bit when doing 32-bit operations (on %eax, %ebx, etc). This is to maintain compatibility with legacy code that expects 32-bit semantics for these registers, as I understand it.</p>\n\n<p>So I'm afraid that there is <strong>no way</strong> to do <code>ror</code> on just the lower 32 bits of a 64-bit register. You'll have to do use a series of several instructions...</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176966",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25683/"
] |
I've been looking for the answer for how to use BSWAP for lower 32-bit sub-register of 64-bit register. For example, `0x0123456789abcdef` is inside RAX register, and I want to change it to `0x01234567efcdab89` with a single instruction (because of performance).
So I tried following inline function:
```c
#define BSWAP(T) { \
__asm__ __volatile__ ( \
"bswap %k0" \
: "=q" (T) \
: "q" (T)); \
}
```
And the result was `0x00000000efcdab89`. I don't understand why the compiler acts like this. Does anybody know the efficient solution?
|
Ah, yes, I understand the problem now:
the x86-64 processors *[implicitly zero-extend](http://www.x86-64.org/documentation/assembly.html)* the 32-bit registers to 64-bit when doing 32-bit operations (on %eax, %ebx, etc). This is to maintain compatibility with legacy code that expects 32-bit semantics for these registers, as I understand it.
So I'm afraid that there is **no way** to do `ror` on just the lower 32 bits of a 64-bit register. You'll have to do use a series of several instructions...
|
176,983 |
<p>I am trying to learn CodeIgniter to use for a shopping site, but I am not having luck with the official doc. Does anyone know of anything that will help?</p>
|
[
{
"answer_id": 177010,
"author": "csjohnst",
"author_id": 1292,
"author_profile": "https://Stackoverflow.com/users/1292",
"pm_score": 2,
"selected": false,
"text": "<p>We've used Code Igniter on a couple of projects and found the videos on their site to be helpful for an intro:\n<a href=\"http://codeigniter.com/tutorials/\" rel=\"nofollow noreferrer\">http://codeigniter.com/tutorials/</a></p>\n"
},
{
"answer_id": 177055,
"author": "csjohnst",
"author_id": 1292,
"author_profile": "https://Stackoverflow.com/users/1292",
"pm_score": 2,
"selected": false,
"text": "<p>Specifically for you query about CSS this is a good starter reference written by a new user: <a href=\"http://codeignitercamp.blogspot.com/2007/08/codeigniter-tutorial-2.html\" rel=\"nofollow noreferrer\">http://codeignitercamp.blogspot.com/2007/08/codeigniter-tutorial-2.html</a></p>\n"
},
{
"answer_id": 177075,
"author": "Click Online Design",
"author_id": 25695,
"author_profile": "https://Stackoverflow.com/users/25695",
"pm_score": 1,
"selected": false,
"text": "<p>Just found a pretty good series on the basics of it: </p>\n\n<p><a href=\"http://capsizedesigns.com/blog/2008/05/getting-started-with-codeigniter-part-1/\" rel=\"nofollow noreferrer\">http://capsizedesigns.com/blog/2008/05/getting-started-with-codeigniter-part-1/</a>\n<a href=\"http://capsizedesigns.com/blog/2008/05/getting-started-with-codeigniter-part-2/\" rel=\"nofollow noreferrer\">http://capsizedesigns.com/blog/2008/05/getting-started-with-codeigniter-part-2/</a>\n<a href=\"http://capsizedesigns.com/blog/2008/05/getting-started-with-codeigniter-part-3/\" rel=\"nofollow noreferrer\">http://capsizedesigns.com/blog/2008/05/getting-started-with-codeigniter-part-3/</a></p>\n"
},
{
"answer_id": 177117,
"author": "jmccartie",
"author_id": 24708,
"author_profile": "https://Stackoverflow.com/users/24708",
"pm_score": 3,
"selected": true,
"text": "<p>re: CSS.</p>\n\n<p>I've got my CSS a separate folder at the root. (same place as 'index.php') ... /content/css/main.css</p>\n\n<p>Called as:</p>\n\n<pre><code><link href=\"<?=base_url();?>content/css/main.css\" rel=\"stylesheet\" type=\"text/css\" />\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176983",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25695/"
] |
I am trying to learn CodeIgniter to use for a shopping site, but I am not having luck with the official doc. Does anyone know of anything that will help?
|
re: CSS.
I've got my CSS a separate folder at the root. (same place as 'index.php') ... /content/css/main.css
Called as:
```
<link href="<?=base_url();?>content/css/main.css" rel="stylesheet" type="text/css" />
```
|
176,989 |
<p>In the early days of C++ when it was bolted on top of C, you could not use NULL as it was defined as <code>(void*)0</code>. You could not assign NULL to any pointer other than <code>void*</code>, which made it kind of useless. Back in those days, it was accepted that you used <code>0</code> (zero) for null pointers.</p>
<p>To this day, I have continued to use zero as a null pointer but those around me insist on using <code>NULL</code>. I personally do not see any benefit to giving a name (<code>NULL</code>) to an existing value - and since I also like to test pointers as truth values:</p>
<pre><code>if (p && !q)
do_something();
</code></pre>
<p>then using zero makes more sense (as in if you use <code>NULL</code>, you cannot logically use <code>p && !q</code> - you need to explicitly compare against <code>NULL</code>, unless you assume <code>NULL</code> is zero, in which case why use <code>NULL</code>).</p>
<p>Is there any objective reason to prefer zero over NULL (or vice versa), or is all just personal preference?</p>
<p>Edit: I should add (and meant to originally say) that with RAII and exceptions, I rarely use zero/NULL pointers, but sometimes you do need them still.</p>
|
[
{
"answer_id": 177007,
"author": "Martin Cote",
"author_id": 9936,
"author_profile": "https://Stackoverflow.com/users/9936",
"pm_score": 9,
"selected": true,
"text": "<p>Here's Stroustrup's take on this: <a href=\"http://www.stroustrup.com/bs_faq2.html#null\" rel=\"noreferrer\">C++ Style and Technique FAQ</a></p>\n<blockquote>\n<p>In C++, the definition of <code>NULL</code> is 0, so there is only an aesthetic difference. I prefer to avoid macros, so I use 0. Another problem with <code>NULL</code> is that people sometimes mistakenly believe that it is different from 0 and/or not an integer. In pre-standard code, <code>NULL</code> was/is sometimes defined to something unsuitable and therefore had/has to be avoided. That's less common these days.</p>\n<p>If you have to name the null pointer, call it <code>nullptr</code>; that's what it's called in C++11. Then, <code>nullptr</code> will be a keyword.</p>\n</blockquote>\n<p>That said, don't sweat the small stuff.</p>\n"
},
{
"answer_id": 177008,
"author": "Mark Ransom",
"author_id": 5987,
"author_profile": "https://Stackoverflow.com/users/5987",
"pm_score": 3,
"selected": false,
"text": "<p>I think the standard guarantees that NULL == 0, so you can do either. I prefer NULL because it documents your intent.</p>\n"
},
{
"answer_id": 177009,
"author": "mxg",
"author_id": 11157,
"author_profile": "https://Stackoverflow.com/users/11157",
"pm_score": 4,
"selected": false,
"text": "<p>I once worked on a machine where 0 was a valid address and NULL was defined as a special octal value. On that machine (0 != NULL), so code such as</p>\n\n<pre><code>char *p;\n\n...\n\nif (p) { ... }\n</code></pre>\n\n<p>would not work as you expect. You HAD to write </p>\n\n<pre><code>if (p != NULL) { ... }\n</code></pre>\n\n<p>Although I believe most compilers define NULL as 0 these days I still remember the lesson from those years ago: NULL is not necessarily 0.</p>\n"
},
{
"answer_id": 177013,
"author": "Dominik Grabiec",
"author_id": 3719,
"author_profile": "https://Stackoverflow.com/users/3719",
"pm_score": 4,
"selected": false,
"text": "<p>If I recall correctly NULL is defined differently in the headers that I have used. For C it is defined as (void*)0, and for C++ it's defines as just 0. The code looked something like:</p>\n\n<pre><code>#ifndef __cplusplus\n#define NULL (void*)0\n#else\n#define NULL 0\n#endif\n</code></pre>\n\n<p>Personally I still use the NULL value to represent null pointers, it makes it explicit that you're using a pointer rather than some integral type. Yes internally the NULL value is still 0 but it isn't represented as such. </p>\n\n<p>Additionally I don't rely on the automatic conversion of integers to boolean values but explicitly compare them.</p>\n\n<p>For example prefer to use:</p>\n\n<pre><code>if (pointer_value != NULL || integer_value == 0)\n</code></pre>\n\n<p>rather than:</p>\n\n<pre><code>if (pointer_value || !integer_value)\n</code></pre>\n\n<hr>\n\n<p>Suffice to say that this is all remedied in C++11 where one can simply use <code>nullptr</code> instead of <code>NULL</code>, and also <code>nullptr_t</code> that is the type of a <code>nullptr</code>.</p>\n"
},
{
"answer_id": 177014,
"author": "Rob",
"author_id": 18505,
"author_profile": "https://Stackoverflow.com/users/18505",
"pm_score": 2,
"selected": false,
"text": "<p>I'm with Stroustrup on this one :-)\nSince NULL is not part of the language, I prefer to use 0.</p>\n"
},
{
"answer_id": 177016,
"author": "Jimmy",
"author_id": 25071,
"author_profile": "https://Stackoverflow.com/users/25071",
"pm_score": 2,
"selected": false,
"text": "<p>Mostly personal preference, though one could make the argument that NULL makes it quite obvious that the object is a pointer which currently doesn't point to anything, e.g.</p>\n\n<pre><code>void *ptr = &something;\n/* lots o' code */\nptr = NULL; // more obvious that it's a pointer and not being used\n</code></pre>\n\n<p>IIRC, the standard does not require NULL to be 0, so using whatever is defined in <stddef.h> is probably best for your compiler.</p>\n\n<p>Another facet to the argument is whether you should use logical comparisons (implicit cast to bool) or explicity check against NULL, but that comes down to readability as well.</p>\n"
},
{
"answer_id": 177068,
"author": "Gerald",
"author_id": 19404,
"author_profile": "https://Stackoverflow.com/users/19404",
"pm_score": 1,
"selected": false,
"text": "<p>I always use 0. Not for any real thought out reason, just because when I was first learning C++ I read something that recommended using 0 and I've just always done it that way. In theory there could be a confusion issue in readability but in practice I have never once come across such an issue in thousands of man-hours and millions of lines of code. As Stroustrup says, it's really just a personal aesthetic issue until the standard becomes nullptr.</p>\n"
},
{
"answer_id": 177072,
"author": "Michael Burr",
"author_id": 12711,
"author_profile": "https://Stackoverflow.com/users/12711",
"pm_score": 2,
"selected": false,
"text": "<p>I prefer to use NULL as it makes clear that your intent is the value represents a pointer not an arithmetic value. The fact that it's a macro is unfortunate, but since it's so widely ingrained there's little danger (unless someone does something really boneheaded). I do wish it were a keyword from the beginning, but what can you do?</p>\n\n<p>That said, I have no problem with using pointers as truth values in themselves. Just as with NULL, it's an ingrained idiom.</p>\n\n<p>C++09 will add the the nullptr construct which I think is long overdue. </p>\n"
},
{
"answer_id": 177095,
"author": "Ferruccio",
"author_id": 4086,
"author_profile": "https://Stackoverflow.com/users/4086",
"pm_score": 5,
"selected": false,
"text": "<p>I stopped using NULL in favor of 0 long ago (as well as as most other macros). I did this not only because I wanted to avoid macros as much as possible, but also because NULL seems to have become over-used in C and C++ code. It seems to be used whenever a 0 value is needed, not just for pointers.</p>\n\n<p>On new projects, I put this in a project header:</p>\n\n<pre><code>static const int nullptr = 0;\n</code></pre>\n\n<p>Now, when C++0x compliant compilers arrive, all I have to do is remove that line.\nA nice benefit of this is that Visual Studio already recognizes nullptr as a keyword and highlights it appropriately.</p>\n"
},
{
"answer_id": 177105,
"author": "Andy Lester",
"author_id": 8454,
"author_profile": "https://Stackoverflow.com/users/8454",
"pm_score": 6,
"selected": false,
"text": "<p>Use NULL. NULL shows your intent. That it is 0 is an implementation detail that should not matter.</p>\n"
},
{
"answer_id": 177187,
"author": "Andrew Stein",
"author_id": 13029,
"author_profile": "https://Stackoverflow.com/users/13029",
"pm_score": 6,
"selected": false,
"text": "<p>I always use:</p>\n\n<ul>\n<li><code>NULL</code> for pointers</li>\n<li><code>'\\0'</code> for chars</li>\n<li><code>0.0</code> for floats and doubles</li>\n</ul>\n\n<p>where 0 would do fine. It is a matter of signaling intent. That said, I am not anal about it.</p>\n"
},
{
"answer_id": 177716,
"author": "Richard Corden",
"author_id": 11698,
"author_profile": "https://Stackoverflow.com/users/11698",
"pm_score": 7,
"selected": false,
"text": "<p>There are a few arguments (one of which is relatively recent) which I believe contradict Bjarne's position on this.</p>\n<ol>\n<li><p><strong>Documentation of intent</strong></p>\n<p>Using <code>NULL</code> allows for searches on its use and it also highlights that the developer <strong>wanted</strong> to use a <code>NULL</code> pointer, irrespective of whether it is being interpreted by the compiler as <code>NULL</code> or not.</p>\n</li>\n<li><p><strong>Overload of pointer and 'int' is relatively rare</strong></p>\n<p>The example that everybody quotes is:</p>\n<pre><code> void foo(int*);\n void foo (int);\n\n void bar() {\n foo (NULL); // Calls 'foo(int)'\n }\n</code></pre>\n<p>However, at least in my opinion, the problem with the above is not that we're using <code>NULL</code> for the null pointer constant: it's that we have overloads of <code>foo()</code> which take very different kinds of arguments. The parameter must be an <code>int</code> too, as any other type will result in an ambiguous call and so generate a helpful compiler warning.</p>\n</li>\n<li><p><strong>Analysis tools can help TODAY!</strong></p>\n<p>Even in the absence of C++0x, there are tools available today that verify that <code>NULL</code> is being used for pointers, and that <code>0</code> is being used for integral types.</p>\n</li>\n<li><p><strong><a href=\"http://en.wikipedia.org/wiki/C++11\" rel=\"nofollow noreferrer\">C++ 11</a> will have a new <code>std::nullptr_t</code> type.</strong></p>\n<p>This is the newest argument to the table. The problem of <code>0</code> and <code>NULL</code> is being actively addressed for C++0x, and you can guarantee that for every implementation that provides <code>NULL</code>, the very first thing that they will do is:</p>\n<pre><code> #define NULL nullptr\n</code></pre>\n<p>For those who use <code>NULL</code> rather than <code>0</code>, the change will be an improvement in type-safety with little or no effort - if anything it may also catch a few bugs where they've used <code>NULL</code> for <code>0</code>. For anybody using <code>0</code> today... well, hopefully they have a good knowledge of regular expressions...</p>\n</li>\n</ol>\n"
},
{
"answer_id": 700412,
"author": "jon-hanson",
"author_id": 84538,
"author_profile": "https://Stackoverflow.com/users/84538",
"pm_score": 4,
"selected": false,
"text": "<p>I usually use 0. I don't like macros, and there's no guarantee that some third party header you're using doesn't redefine NULL to be something odd.</p>\n\n<p>You could use a nullptr object as proposed by Scott Meyers and others until C++ gets a nullptr keyword:</p>\n\n<pre><code>const // It is a const object...\nclass nullptr_t \n{\npublic:\n template<class T>\n operator T*() const // convertible to any type of null non-member pointer...\n { return 0; }\n\n template<class C, class T>\n operator T C::*() const // or any type of null member pointer...\n { return 0; }\n\nprivate:\n void operator&() const; // Can't take address of nullptr\n\n} nullptr = {};\n</code></pre>\n\n<p>Google \"nullptr\" for more info.</p>\n"
},
{
"answer_id": 700895,
"author": "Ðаn",
"author_id": 8877,
"author_profile": "https://Stackoverflow.com/users/8877",
"pm_score": 2,
"selected": false,
"text": "<p>I try to avoid the whole question by using C++ references where possible. Rather than</p>\n\n<pre><code>void foo(const Bar* pBar) { ... }\n</code></pre>\n\n<p>you might often be able to write</p>\n\n<pre><code>void foo(const Bar& bar) { ... }\n</code></pre>\n\n<p>Of course, this doesn't always work; but null pointers can be overused.</p>\n"
},
{
"answer_id": 1234382,
"author": "Fernando N.",
"author_id": 147336,
"author_profile": "https://Stackoverflow.com/users/147336",
"pm_score": 1,
"selected": false,
"text": "<p>Someone told me once... I am going to redefine NULL to 69. Since then I don't use it :P</p>\n\n<p>It makes your code quite vulnerable.</p>\n\n<p><strong>Edit:</strong></p>\n\n<p>Not everything in the standard is perfect. The macro NULL is an implementation-defined C++ null pointer constant not fully compatible with C NULL macro, what besides the type hiding implicit convert it in a useless and prone to errors tool. </p>\n\n<p>NULL does not behaves as a null pointer but as a O/OL literal. </p>\n\n<p>Tell me next example is not confusing: </p>\n\n<pre><code>void foo(char *); \nvoid foo(int); \nfoo(NULL); // calls int version instead of pointer version! \n</code></pre>\n\n<p>Is because of all that, in the new standard appears std::nullptr_t</p>\n\n<p>If you don't want to wait for the new standard and want to use a nullptr, use at least a decent one like the proposed by Meyers (see jon.h comment).</p>\n"
},
{
"answer_id": 1437224,
"author": "Michael Krelin - hacker",
"author_id": 95382,
"author_profile": "https://Stackoverflow.com/users/95382",
"pm_score": 3,
"selected": false,
"text": "<p>Strange, nobody, including Stroustroup mentioned that. While talking a lot about standards and aesthetics nobody noticed that it is <em>dangerous</em> to use <code>0</code> in <code>NULL</code>'s stead, for instance, in variable argument list on the architecture where <code>sizeof(int) != sizeof(void*)</code>. Like Stroustroup, I prefer <code>0</code> for aesthetic reasons, but one has to be careful not to use it where its type might be ambiguous.</p>\n"
},
{
"answer_id": 4227356,
"author": "abonet",
"author_id": 513751,
"author_profile": "https://Stackoverflow.com/users/513751",
"pm_score": 5,
"selected": false,
"text": "<pre><code> cerr << sizeof(0) << endl;\n cerr << sizeof(NULL) << endl;\n cerr << sizeof(void*) << endl;\n\n ============\n On a 64-bit gcc RHEL platform you get:\n 4\n 8\n 8\n ================\n</code></pre>\n\n<p>The moral of the story. You should use NULL when you're dealing with pointers.</p>\n\n<p>1) It declares your intent (don't make me search through all your code trying to figure out if a variable is a pointer or some numeric type).</p>\n\n<p>2) In certain API calls that expect variable arguments, they'll use a NULL-pointer to indicate the end of the argument list. In this case, using a '0' instead of NULL can cause problems. On a 64-bit platform, the va_arg call wants a 64-bit pointer, yet you'll be passing only a 32-bit integer. Seems to me like you're relying on the other 32-bits to be zeroed out for you? I've seen certain compilers (e.g. Intel's icpc) that aren't so gracious -- and this has resulted in runtime errors.</p>\n"
},
{
"answer_id": 4331500,
"author": "Pizzach",
"author_id": 527477,
"author_profile": "https://Stackoverflow.com/users/527477",
"pm_score": -1,
"selected": false,
"text": "<p>Setting a pointer to 0 is just not that clear. Especially if you come a language other than C++. This includes C as well as Javascript.</p>\n\n<p>I recently delt with some code like so:</p>\n\n<p><code>virtual void DrawTo(BITMAP *buffer) =0;</code></p>\n\n<p>for pure virtual function for the first time. I thought it to be some magic jiberjash for a week. When I realized it was just basically setting the function pointer to a <code>null</code> (as virtual functions are just function pointers in most cases for C++) I kicked myself.</p>\n\n<p><code>virtual void DrawTo(BITMAP *buffer) =null;</code></p>\n\n<p>would have been less confusing than that basterdation without proper spacing to my new eyes. Actually, I am wondering why C++ doesn't employ lowercase <code>null</code> much like it employes lowercase false and true now.</p>\n"
},
{
"answer_id": 5450273,
"author": "Chris",
"author_id": 661190,
"author_profile": "https://Stackoverflow.com/users/661190",
"pm_score": 3,
"selected": false,
"text": "<p>Using either 0 or NULL will have the same effect.</p>\n\n<p>However, that doesn't mean that they are both good programming practices. Given that there is no difference in performance, choosing a low-level-aware option over an agnostic/abstract alternative is a bad programming practice. <strong>Help readers of your code understand your thought process</strong>. </p>\n\n<p>NULL, 0, 0.0, '\\0', 0x00 and whatelse all translate to the same thing, but are different logical entities in your program. They should be used as such. NULL is a pointer, 0 is quantity, 0x0 is a value whose bits are interesting etc. You wouldn't assign '\\0' to a pointer whether it compiles or not.</p>\n\n<p>I know some communities encourage demonstrating in-depth knowledge of an environment by breaking the environment's contracts. Responsible programmers, however, make maintainable code and keep such practices out of their code.</p>\n"
},
{
"answer_id": 17565908,
"author": "Jan P",
"author_id": 2567667,
"author_profile": "https://Stackoverflow.com/users/2567667",
"pm_score": 1,
"selected": false,
"text": "<p>Well I argue for not using 0 or NULL pointers at all whenever possible.</p>\n\n<p>Using them will sooner or later lead to segmentation faults in your code. In my experience this, and pointers in gereral is one of the biggest source of bugs in C++</p>\n\n<p>also, it leads to \"if-not-null\" statements all over your code. Much nicer if you can rely on always a valid state.</p>\n\n<p>There is almost always a better alternative.</p>\n"
},
{
"answer_id": 27041978,
"author": "Gaute Lindkvist",
"author_id": 4247120,
"author_profile": "https://Stackoverflow.com/users/4247120",
"pm_score": 4,
"selected": false,
"text": "<p>I would say history has spoken and those who argued in favour of using 0 (zero) were wrong (including Bjarne Stroustrup). The arguments in favour of 0 were mostly aesthetics and \"personal preference\".</p>\n\n<p>After the creation of C++11, with its new nullptr type, some compilers have started complaining (with default parameters) about passing 0 to functions with pointer arguments, because 0 is not a pointer. </p>\n\n<p>If the code had been written using NULL, a simple search and replace could have been performed through the codebase to make it nullptr instead. If you are stuck with code written using the choice of 0 as a pointer it is far more tedious to update it.</p>\n\n<p>And if you have to write new code right now to the C++03 standard (and can't use nullptr), you really should just use NULL. It'll make it much easier for you to update in the future.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/176989",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/23744/"
] |
In the early days of C++ when it was bolted on top of C, you could not use NULL as it was defined as `(void*)0`. You could not assign NULL to any pointer other than `void*`, which made it kind of useless. Back in those days, it was accepted that you used `0` (zero) for null pointers.
To this day, I have continued to use zero as a null pointer but those around me insist on using `NULL`. I personally do not see any benefit to giving a name (`NULL`) to an existing value - and since I also like to test pointers as truth values:
```
if (p && !q)
do_something();
```
then using zero makes more sense (as in if you use `NULL`, you cannot logically use `p && !q` - you need to explicitly compare against `NULL`, unless you assume `NULL` is zero, in which case why use `NULL`).
Is there any objective reason to prefer zero over NULL (or vice versa), or is all just personal preference?
Edit: I should add (and meant to originally say) that with RAII and exceptions, I rarely use zero/NULL pointers, but sometimes you do need them still.
|
Here's Stroustrup's take on this: [C++ Style and Technique FAQ](http://www.stroustrup.com/bs_faq2.html#null)
>
> In C++, the definition of `NULL` is 0, so there is only an aesthetic difference. I prefer to avoid macros, so I use 0. Another problem with `NULL` is that people sometimes mistakenly believe that it is different from 0 and/or not an integer. In pre-standard code, `NULL` was/is sometimes defined to something unsuitable and therefore had/has to be avoided. That's less common these days.
>
>
> If you have to name the null pointer, call it `nullptr`; that's what it's called in C++11. Then, `nullptr` will be a keyword.
>
>
>
That said, don't sweat the small stuff.
|
177,011 |
<p>OK I have an array of tserversocket and am using the tag property to keep track of its index. When an event is fired off such as _clientconnect i am using Index := (Sender as TServerSocket).Tag; but i get an error that highlights that line and tells me its an invalid typecast. What am I doing wrong if all I want to do is get the tag property field? It works with other objects.</p>
|
[
{
"answer_id": 177270,
"author": "Chris Latta",
"author_id": 20977,
"author_profile": "https://Stackoverflow.com/users/20977",
"pm_score": 2,
"selected": false,
"text": "<p>Are you sure Sender is the TServerSocket? Isn't the event defined like below:</p>\n\n<pre><code>procedure TfrmServer.sskServerClientConnect(Sender: TObject; Socket: TCustomWinSocket);\n</code></pre>\n\n<p>In which case your code probably should be:</p>\n\n<pre><code>Index := (Socket as TServerSocket).Tag;\n</code></pre>\n\n<p>Have a look at <code>Sender.ClassName</code> to see what Sender really is.</p>\n"
},
{
"answer_id": 179830,
"author": "Jody Dawkins",
"author_id": 1234,
"author_profile": "https://Stackoverflow.com/users/1234",
"pm_score": 2,
"selected": false,
"text": "<p>I'm afraid you won't be able to find the TServerSocket tag property using this method. The reason is that Sender is an instance of TServerWinSocket and Socket is an instance of TCustomWinSocket - neither of these can be cast to a TServerSocket. Take a look in ScktComp.pas (in Source\\Vcl). TServerSocket is simply a wrapper for an internal instance of TServerWinSocket. </p>\n\n<p>You could do something like this:</p>\n\n<pre><code>TMyServerWinSocket = class(TServerWinSocket)\nprivate\n FServerSocket : TServerSocket;\npublic\n destructor Destroy; override;\n property Server : TServerSocket read FServerSocket write FServerSocket;\nend;\n\nTMyServerSocket = class(TServerSocket)\npublic\n constructor Create(AOwner : TComponent);\nend;\n</code></pre>\n\n<p>The implementation would look like this:</p>\n\n<pre><code>destructor TMyServerWinSocket.Destroy;\nbegin\n Server := nil;\nend;\n\nconstructor TMyServerSocket.Create(AOwner : TComponent);\nbegin\n FServerSocket := TMyServerWinSocket.Create(INVALID_SOCKET);\n TMyServerWinSocket(FServerSocket).Server := Self;\n InitSocket(FServerSocket);\n FServerSocket.ThreadCacheSize := 10;\nend;\n</code></pre>\n\n<p>Then (whew, almost there) in your event handler you can do this:</p>\n\n<pre><code>procedure TfrmServer.sskServerClientConnect(Sender: TObject; Socket: TCustomWinSocket);\nbegin\n Index := (Sender as TMyServerWinSocket).Server.Tag;\nend;\n</code></pre>\n\n<p>What this means is that instead of creating TServerSocket objects in your array you'll need to create TMyServerSocket instances.</p>\n\n<p>Hope that helps.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177011",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
OK I have an array of tserversocket and am using the tag property to keep track of its index. When an event is fired off such as \_clientconnect i am using Index := (Sender as TServerSocket).Tag; but i get an error that highlights that line and tells me its an invalid typecast. What am I doing wrong if all I want to do is get the tag property field? It works with other objects.
|
Are you sure Sender is the TServerSocket? Isn't the event defined like below:
```
procedure TfrmServer.sskServerClientConnect(Sender: TObject; Socket: TCustomWinSocket);
```
In which case your code probably should be:
```
Index := (Socket as TServerSocket).Tag;
```
Have a look at `Sender.ClassName` to see what Sender really is.
|
177,039 |
<p>First, two examples:</p>
<pre><code>// This works
int foo = 43;
long lFoo = foo;
// This doesn't
object foo = (int)43;
long? nullFoo = foo as long?; // returns null
long lFoo = (long)foo; // throws InvalidCastException
if (foo.GetType() == typeof(int))
Console.WriteLine("But foo is an int..."); // This gets written out
</code></pre>
<p>Now, my guess as to why the second doesn't work is because of boxing. The purpose behind this code is to implement <code>IComparable</code>. I need some way to coerce an object into either a long or a ulong as appropriate, or if it's neither, than to throw an error. I don't want to have to implement checks for each basic numeric type (byte, int, long, ubyte, ...) I'd rather just catch them in the largest numeric type and deal with it that way. Thoughts from all the smart people here? How can I unbox the object, preferably avoiding reflection, but I suppose if that's the only way... Or should I just not implement the non-generics version of <code>IComparable</code>?</p>
<p><strong>Edit:</strong></p>
<p>This seems to work, but seems like a horrible hack around the problem. Is it just me?</p>
<pre><code>long lFoo = long.Parse(foo.ToString());
</code></pre>
|
[
{
"answer_id": 177057,
"author": "tomasr",
"author_id": 10292,
"author_profile": "https://Stackoverflow.com/users/10292",
"pm_score": 2,
"selected": false,
"text": "<p>When you're casting to a value type you're really forcing an unbox IL operation, which requires that the type you're casting to matches <em>exactly</em> the boxed value; there are no conversions, implicit, or explicit that can happen at the same time.</p>\n\n<p>This usually means that you either need to do a switch using the typecode (or an if/else if using types), or, in your case, go with a check for null followed by Convert.ToInt64(), which should deal with it correctly.</p>\n"
},
{
"answer_id": 177081,
"author": "Nat",
"author_id": 13813,
"author_profile": "https://Stackoverflow.com/users/13813",
"pm_score": 0,
"selected": false,
"text": "<p>Its not just you, however tryparse does not raise an exception.</p>\n\n<pre><code>object foo = (int)43;\nlong outVal;\nif(long.TryParse(foo.ToString(),out outVal))\n{\n//take action with correct value of long\n}\nelse\n{\n//maybe passed you another type of object\n}\n</code></pre>\n"
},
{
"answer_id": 177101,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 4,
"selected": true,
"text": "<pre><code>object foo = (int) 43;\nlong lFoo = ((IConvertible) foo).ToInt64(null);\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177039",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15537/"
] |
First, two examples:
```
// This works
int foo = 43;
long lFoo = foo;
// This doesn't
object foo = (int)43;
long? nullFoo = foo as long?; // returns null
long lFoo = (long)foo; // throws InvalidCastException
if (foo.GetType() == typeof(int))
Console.WriteLine("But foo is an int..."); // This gets written out
```
Now, my guess as to why the second doesn't work is because of boxing. The purpose behind this code is to implement `IComparable`. I need some way to coerce an object into either a long or a ulong as appropriate, or if it's neither, than to throw an error. I don't want to have to implement checks for each basic numeric type (byte, int, long, ubyte, ...) I'd rather just catch them in the largest numeric type and deal with it that way. Thoughts from all the smart people here? How can I unbox the object, preferably avoiding reflection, but I suppose if that's the only way... Or should I just not implement the non-generics version of `IComparable`?
**Edit:**
This seems to work, but seems like a horrible hack around the problem. Is it just me?
```
long lFoo = long.Parse(foo.ToString());
```
|
```
object foo = (int) 43;
long lFoo = ((IConvertible) foo).ToInt64(null);
```
|
177,042 |
<p>I am having an issue setting up cURL with IIS 6.0, Windows Server 2003, PHP 5.2.6</p>
<p>I have installed to <code>C:\PHP</code></p>
<pre><code>set PHPRC = C:\PHP\php.ini
</code></pre>
<p>copied <code>ssleay32.dll</code> and <code>libeay32.dll</code> to <code>C:\PHP</code></p>
<p>in php.ini, uncommented the line</p>
<pre><code>extension=php_curl.dll
extension_dir="C:\PHP\ext"
</code></pre>
<p><code>c:\php\ext</code> has the dll <code>php_curl.dll</code></p>
<p><code>C:\PHP</code> is in <code>PATH</code></p>
<p>still getting </p>
<blockquote>
<p>Fatal error: Call to undefined function curl_init()</p>
</blockquote>
|
[
{
"answer_id": 177112,
"author": "Randy",
"author_id": 9361,
"author_profile": "https://Stackoverflow.com/users/9361",
"pm_score": 2,
"selected": false,
"text": "<p>Make sure php_curl.dll is in the directory listed under \"extension_dir\" in php.ini. If it is already, try restarting IIS (Apache always needs a restart from me when making php.ini changes).</p>\n\n<p>EDIT 1:</p>\n\n<p>Try opening up a command prompt to c:\\php and running:</p>\n\n<pre><code>php -c . -i | find /i \"curl\"\n</code></pre>\n\n<p>Does it come back with any output? If so, IIS is using the wrong php.ini file.</p>\n\n<p>EDIT 2:</p>\n\n<p>Is c:\\php in your PATH? You can check with \"echo %PATH%\" from the command prompt.</p>\n"
},
{
"answer_id": 178103,
"author": "Greg",
"author_id": 24181,
"author_profile": "https://Stackoverflow.com/users/24181",
"pm_score": 1,
"selected": false,
"text": "<p>Maybe it's loading c:\\windows\\php.ini?\nI take it you've restarted IIS since you changed the config... :)</p>\n"
},
{
"answer_id": 228761,
"author": "joshjdevl",
"author_id": 20641,
"author_profile": "https://Stackoverflow.com/users/20641",
"pm_score": 2,
"selected": false,
"text": "<p>i ended up doin a reinstall of php, then unistalling php. then i copied and extracted the thread safe php package into c:\\php rather than using the non thread safe package</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177042",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/20641/"
] |
I am having an issue setting up cURL with IIS 6.0, Windows Server 2003, PHP 5.2.6
I have installed to `C:\PHP`
```
set PHPRC = C:\PHP\php.ini
```
copied `ssleay32.dll` and `libeay32.dll` to `C:\PHP`
in php.ini, uncommented the line
```
extension=php_curl.dll
extension_dir="C:\PHP\ext"
```
`c:\php\ext` has the dll `php_curl.dll`
`C:\PHP` is in `PATH`
still getting
>
> Fatal error: Call to undefined function curl\_init()
>
>
>
|
Make sure php\_curl.dll is in the directory listed under "extension\_dir" in php.ini. If it is already, try restarting IIS (Apache always needs a restart from me when making php.ini changes).
EDIT 1:
Try opening up a command prompt to c:\php and running:
```
php -c . -i | find /i "curl"
```
Does it come back with any output? If so, IIS is using the wrong php.ini file.
EDIT 2:
Is c:\php in your PATH? You can check with "echo %PATH%" from the command prompt.
|
177,052 |
<p>I am working on integrating geolocation services into a website and the best source of data I've found so far is MaxMind's GeoIP API with GeoLite City data. Even this data seems to often be questionable though. For example, I am located in downtown Palo Alto, but it locates my IP as being in Portola Valley, which is about 7 miles away. Palo Alto has a population of 60k+, whereas Portola Valley has a population of less than 5k. I would think if you see an IP originating somewhere around there it would make more sense to assume it was coming from the highly populated city, not the tiny one. I've also had it locate Palo Alto IPs completely across the country in Kentucky, etc.</p>
<p>Does anyone know of any better sources of data, or any tools/technologies/efforts to improve the accuracy of geolocation efforts? Commercial solutions are fine.</p>
|
[
{
"answer_id": 177274,
"author": "FryHard",
"author_id": 231,
"author_profile": "https://Stackoverflow.com/users/231",
"pm_score": 0,
"selected": false,
"text": "<p>I am not sure if this will help, but here is a site that has done a pretty good job of IP mapping. Maybe you could ask them for help :) <a href=\"http://www.seomoz.org/ip2loc\" rel=\"nofollow noreferrer\">seomoz.org</a></p>\n"
},
{
"answer_id": 205585,
"author": "stevemegson",
"author_id": 25028,
"author_profile": "https://Stackoverflow.com/users/25028",
"pm_score": 2,
"selected": false,
"text": "<p>Where an IP comes up at the wrong end of the country, you probably won't find a better match elsewhere because it's probably an ISP that uses one group of IPs for customers in a wide area. My favourite example is trains here in the UK where the on-board wifi is identified as being in Sweden because they use a satellite connection to an ISP in Sweden.</p>\n\n<p>A commercial supplier may be able to afford to spend more time tracking down the hard cases, but in many cases there just won't be a good answer to give you. They may, however, give you a confidence factor to tell you when they're guessing. I've heard good things about <a href=\"http://www.quova.com\" rel=\"nofollow noreferrer\">Quova</a>, though I've never used them.</p>\n\n<p>Assuming that you've got the best latitude and longitude that you can get (or can afford), then you're left dealing with cases where they pick the closest city rather than a more likely larger city nearby. Unfortunately I don't have the code to hand, but I had some success using the data from <a href=\"http://www.geonames.org/export/\" rel=\"nofollow noreferrer\">geonames</a> to pick a \"sensible\" city near a point. They list lat/long and population, so you can do something like</p>\n\n<pre><code>ORDER BY ( Distance / LOG( Population ) )\n</code></pre>\n\n<p>You'd need to experiment with that to get something with the right level of bias towards larger cities, but I had it working quite nicely taking the centre of a Google Maps view and displaying a heading like \"Showing results near London...\" that changed as you moved the map.</p>\n"
},
{
"answer_id": 205598,
"author": "Dillie-O",
"author_id": 71,
"author_profile": "https://Stackoverflow.com/users/71",
"pm_score": 0,
"selected": false,
"text": "<p>A couple of sites I saw referenced recently for free GeoIP services are </p>\n\n<p><a href=\"http://www.wipmania.com/en/base/\" rel=\"nofollow noreferrer\">WIPmania</a></p>\n\n<p><a href=\"http://www.hostip.info/\" rel=\"nofollow noreferrer\">hostip.info</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177052",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2168/"
] |
I am working on integrating geolocation services into a website and the best source of data I've found so far is MaxMind's GeoIP API with GeoLite City data. Even this data seems to often be questionable though. For example, I am located in downtown Palo Alto, but it locates my IP as being in Portola Valley, which is about 7 miles away. Palo Alto has a population of 60k+, whereas Portola Valley has a population of less than 5k. I would think if you see an IP originating somewhere around there it would make more sense to assume it was coming from the highly populated city, not the tiny one. I've also had it locate Palo Alto IPs completely across the country in Kentucky, etc.
Does anyone know of any better sources of data, or any tools/technologies/efforts to improve the accuracy of geolocation efforts? Commercial solutions are fine.
|
Where an IP comes up at the wrong end of the country, you probably won't find a better match elsewhere because it's probably an ISP that uses one group of IPs for customers in a wide area. My favourite example is trains here in the UK where the on-board wifi is identified as being in Sweden because they use a satellite connection to an ISP in Sweden.
A commercial supplier may be able to afford to spend more time tracking down the hard cases, but in many cases there just won't be a good answer to give you. They may, however, give you a confidence factor to tell you when they're guessing. I've heard good things about [Quova](http://www.quova.com), though I've never used them.
Assuming that you've got the best latitude and longitude that you can get (or can afford), then you're left dealing with cases where they pick the closest city rather than a more likely larger city nearby. Unfortunately I don't have the code to hand, but I had some success using the data from [geonames](http://www.geonames.org/export/) to pick a "sensible" city near a point. They list lat/long and population, so you can do something like
```
ORDER BY ( Distance / LOG( Population ) )
```
You'd need to experiment with that to get something with the right level of bias towards larger cities, but I had it working quite nicely taking the centre of a Google Maps view and displaying a heading like "Showing results near London..." that changed as you moved the map.
|
177,054 |
<p>There's a common way to store multiple values in one variable, by using a bitmask. For example, if a user has read, write and execute privileges on an item, that can be converted to a single number by saying <code>read = 4 (2^2), write = 2 (2^1), execute = 1 (2^0)</code> and then add them together to get 7.</p>
<p>I use this technique in several web applications, where I'd usually store the variable into a field and give it a type of MEDIUMINT or whatever, depending on the number of different values.</p>
<p>What I'm interested in, is whether or not there is a practical limit to the number of values you can store like this? For example, if the number was over 64, you couldn't use (64 bit) integers any more. If this was the case, what would you use? How would it affect your program logic (ie: could you still use bitwise comparisons)?</p>
<p><em>I know that once you start getting really large sets of values, a different method would be the optimal solution, but I'm interested in the boundaries of <strong>this</strong> method.</em></p>
|
[
{
"answer_id": 177066,
"author": "Tim Williscroft",
"author_id": 2789,
"author_profile": "https://Stackoverflow.com/users/2789",
"pm_score": 2,
"selected": false,
"text": "<p>I've used bit masks in filesystem code where the bit mask is many times bigger than a machine word. think of it like an \"array of booleans\"; </p>\n\n<p>(journalling masks in flash memory if you want to know)</p>\n\n<p>many compilers know how to do this <em>for you</em>. Adda bit of OO code to have types that operate senibly and then your code starts looking like it's intent, not some bit-banging.</p>\n\n<p>My 2 cents.</p>\n"
},
{
"answer_id": 177067,
"author": "warren",
"author_id": 4418,
"author_profile": "https://Stackoverflow.com/users/4418",
"pm_score": 1,
"selected": false,
"text": "<p>With a 64-bit integer, you can store values up to 2^64-1, 64 is only 2^6. So yes, there is a limit, but if you need more than 64-its worth of flags, I'd be very interested to know what they were all doing :)</p>\n\n<p>How many states so you need to potentially think about? If you have 64 potential states, the number of combinations they can exist in is the full size of a 64-bit integer.</p>\n\n<p>If you need to worry about 128 flags, then a pair of bit vectors would suffice (2^64 * 2).</p>\n\n<p><strong>Addition</strong>: in Programming Pearls, there is an extended discussion of using a bit array of length 10^7, implemented in integers (for holding used 800 numbers) - it's very fast, and very appropriate for the task described in that chapter.</p>\n"
},
{
"answer_id": 177084,
"author": "arul",
"author_id": 15409,
"author_profile": "https://Stackoverflow.com/users/15409",
"pm_score": 0,
"selected": false,
"text": "<p>For example .NET uses array of integers as an internal storage for their BitArray class.\nPractically there's no other way around.</p>\n\n<p>That being said, in SQL you will need more than one column (or use the BLOBS) to store all the states.</p>\n"
},
{
"answer_id": 177092,
"author": "Mike Spross",
"author_id": 17862,
"author_profile": "https://Stackoverflow.com/users/17862",
"pm_score": 3,
"selected": true,
"text": "<p>Off the top of my head, I'd write a <code>set_bit</code> and <code>get_bit</code> function that could take an array of bytes and a bit offset in the array, and use some bit-twiddling to set/get the appropriate bit in the array. Something like this (in C, but hopefully you get the idea):</p>\n\n<pre class=\"lang-c prettyprint-override\"><code>// sets the n-th bit in |bytes|. num_bytes is the number of bytes in the array\n// result is 0 on success, non-zero on failure (offset out-of-bounds)\nint set_bit(char* bytes, unsigned long num_bytes, unsigned long offset)\n{\n // make sure offset is valid\n if(offset < 0 || offset > (num_bytes<<3)-1) { return -1; }\n\n //set the right bit\n bytes[offset >> 3] |= (1 << (offset & 0x7));\n\n return 0; //success \n}\n\n//gets the n-th bit in |bytes|. num_bytes is the number of bytes in the array\n// returns (-1) on error, 0 if bit is \"off\", positive number if \"on\"\nint get_bit(char* bytes, unsigned long num_bytes, unsigned long offset)\n{\n // make sure offset is valid\n if(offset < 0 || offset > (num_bytes<<3)-1) { return -1; }\n\n //get the right bit\n return (bytes[offset >> 3] & (1 << (offset & 0x7));\n}\n</code></pre>\n"
},
{
"answer_id": 177096,
"author": "Kent Fredric",
"author_id": 15614,
"author_profile": "https://Stackoverflow.com/users/15614",
"pm_score": 1,
"selected": false,
"text": "<p>Some languages ( I believe perl does, not sure ) permit bitwise arithmetic on strings. Giving you a much greater effective range. ( (strlen * 8bit chars ) combinations )</p>\n\n<p>However, I wouldn't use a single value for superimposition of more than one /type/ of data. The basic r/w/x triplet of 3-bit ints would probably be the upper \"practical\" limit, not for space efficiency reasons, but for practical development reasons. </p>\n\n<p>( Php uses this system to control its error-messages, and I have already found that its a bit over-the-top when you have to define values where php's constants are not resident and you have to generate the integer by hand, and to be honest, if chmod didn't support the 'ugo+rwx' style syntax I'd never want to use it because i can never remember the magic numbers ) </p>\n\n<p>The instant you have to crack open a constants table to debug code you know you've gone too far. </p>\n"
},
{
"answer_id": 177100,
"author": "Mark Ransom",
"author_id": 5987,
"author_profile": "https://Stackoverflow.com/users/5987",
"pm_score": 0,
"selected": false,
"text": "<p>You tagged this question SQL, so I think you need to consult with the documentation for your database to find the size of an integer. Then subtract one bit for the sign, just to be safe.</p>\n\n<p><strong>Edit:</strong> Your comment says you're using MySQL. The documentation for <a href=\"http://dev.mysql.com/doc/refman/5.0/en/numeric-types.html\" rel=\"nofollow noreferrer\">MySQL 5.0 Numeric Types</a> states that the maximum size of a NUMERIC is 64 or 65 digits. That's 212 bits for 64 digits.</p>\n\n<p>Remember that your language of choice has to be able to work with those digits, so you may be limited to a 64-bit integer anyway.</p>\n"
},
{
"answer_id": 18940123,
"author": "Ian Russell",
"author_id": 2803443,
"author_profile": "https://Stackoverflow.com/users/2803443",
"pm_score": 1,
"selected": false,
"text": "<p>Old thread, but it's worth mentioning that there are cases requiring bloated bit masks, e.g., molecular fingerprints, which are often generated as 1024-bit arrays which we have packed in 32 bigint fields (SQL Server not supporting UInt32). Bit wise operations work fine - until your table starts to grow and you realize the sluggishness of separate function calls. The binary data type would work, were it not for T-SQL's ban on bitwise operators having two binary operands.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177054",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/9021/"
] |
There's a common way to store multiple values in one variable, by using a bitmask. For example, if a user has read, write and execute privileges on an item, that can be converted to a single number by saying `read = 4 (2^2), write = 2 (2^1), execute = 1 (2^0)` and then add them together to get 7.
I use this technique in several web applications, where I'd usually store the variable into a field and give it a type of MEDIUMINT or whatever, depending on the number of different values.
What I'm interested in, is whether or not there is a practical limit to the number of values you can store like this? For example, if the number was over 64, you couldn't use (64 bit) integers any more. If this was the case, what would you use? How would it affect your program logic (ie: could you still use bitwise comparisons)?
*I know that once you start getting really large sets of values, a different method would be the optimal solution, but I'm interested in the boundaries of **this** method.*
|
Off the top of my head, I'd write a `set_bit` and `get_bit` function that could take an array of bytes and a bit offset in the array, and use some bit-twiddling to set/get the appropriate bit in the array. Something like this (in C, but hopefully you get the idea):
```c
// sets the n-th bit in |bytes|. num_bytes is the number of bytes in the array
// result is 0 on success, non-zero on failure (offset out-of-bounds)
int set_bit(char* bytes, unsigned long num_bytes, unsigned long offset)
{
// make sure offset is valid
if(offset < 0 || offset > (num_bytes<<3)-1) { return -1; }
//set the right bit
bytes[offset >> 3] |= (1 << (offset & 0x7));
return 0; //success
}
//gets the n-th bit in |bytes|. num_bytes is the number of bytes in the array
// returns (-1) on error, 0 if bit is "off", positive number if "on"
int get_bit(char* bytes, unsigned long num_bytes, unsigned long offset)
{
// make sure offset is valid
if(offset < 0 || offset > (num_bytes<<3)-1) { return -1; }
//get the right bit
return (bytes[offset >> 3] & (1 << (offset & 0x7));
}
```
|
177,080 |
<p>Method signature in Java:</p>
<pre><code>public List<String> getFilesIn(List<File> directories)
</code></pre>
<p>similar one in ruby</p>
<pre><code>def get_files_in(directories)
</code></pre>
<p>In the case of Java, the type system gives me information about what the method expects and delivers. In Ruby's case, I have <strong>no</strong> clue what I'm supposed to pass in, or what I'll expect to receive.</p>
<p>In Java, the object must formally implement the interface. In Ruby, the object being passed in must respond to whatever methods are called in the method defined here. </p>
<p>This seems highly problematic:</p>
<ol>
<li>Even with 100% accurate, up-to-date documentation, the Ruby code has to essentially expose its implementation, breaking encapsulation. "OO purity" aside, this would seem to be a maintenance nightmare.</li>
<li>The Ruby code gives me <strong>no</strong> clue what's being returned; I would have to essentially experiment, or read the code to find out what methods the returned object would respond to.</li>
</ol>
<p>Not looking to debate static typing vs duck typing, but looking to understand how you maintain a production system where you have almost no ability to design by contract.</p>
<h3>Update</h3>
<p>No one has really addressed the exposure of a method's internal implementation via documentation that this approach requires. Since there are no interfaces, if I'm not expecting a particular type, don't I have to itemize every method I might call so that the caller knows what can be passed in? Or is this just an edge case that doesn't really come up?</p>
|
[
{
"answer_id": 177103,
"author": "Camilo Díaz Repka",
"author_id": 861,
"author_profile": "https://Stackoverflow.com/users/861",
"pm_score": 1,
"selected": false,
"text": "<p>It's by no means a maintenance nightmare, just another way of working, that calls for consistence in the API and good documentation. </p>\n\n<p>Your concern seems related to the fact that any dynamic language is a dangerous tool, that cannot enforce API input/output contracts. The fact is, while chosing static may seem safer, the better thing you can do in both worlds is to keep a good set of tests that verify not only the type of the data returned (which is the only thing the Java compiler can verify and enforce), but also it's correctness and inner workings(Black box/white box testing).</p>\n\n<p>As a side note, I don't know about Ruby, but in PHP you can use @phpdoc tags to hint the IDE (Eclipse PDT) about the data types returned by a certain method.</p>\n"
},
{
"answer_id": 177110,
"author": "Kent Fredric",
"author_id": 15614,
"author_profile": "https://Stackoverflow.com/users/15614",
"pm_score": 3,
"selected": false,
"text": "<p>Method Validation via duck-typing:</p>\n\n<pre><code>i = {}\n=> {}\ni.methods.sort\n=> [\"==\", \"===\", \"=~\", \"[]\", \"[]=\", \"__id__\", \"__send__\", \"all?\", \"any?\", \"class\", \"clear\", \"clone\", \"collect\", \"default\", \"default=\", \"default_proc\", \"delete\", \"delete_if\", \"detect\", \"display\", \"dup\", \"each\", \"each_key\", \"each_pair\", \"each_value\", \"each_with_index\", \"empty?\", \"entries\", \"eql?\", \"equal?\", \"extend\", \"fetch\", \"find\", \"find_all\", \"freeze\", \"frozen?\", \"gem\", \"grep\", \"has_key?\", \"has_value?\", \"hash\", \"id\", \"include?\", \"index\", \"indexes\", \"indices\", \"inject\", \"inspect\", \"instance_eval\", \"instance_of?\", \"instance_variable_defined?\", \"instance_variable_get\", \"instance_variable_set\", \"instance_variables\", \"invert\", \"is_a?\", \"key?\", \"keys\", \"kind_of?\", \"length\", \"map\", \"max\", \"member?\", \"merge\", \"merge!\", \"method\", \"methods\", \"min\", \"nil?\", \"object_id\", \"partition\", \"private_methods\", \"protected_methods\", \"public_methods\", \"rehash\", \"reject\", \"reject!\", \"replace\", \"require\", \"respond_to?\", \"select\", \"send\", \"shift\", \"singleton_methods\", \"size\", \"sort\", \"sort_by\", \"store\", \"taint\", \"tainted?\", \"to_a\", \"to_hash\", \"to_s\", \"type\", \"untaint\", \"update\", \"value?\", \"values\", \"values_at\", \"zip\"]\ni.respond_to?('keys')\n=> true\ni.respond_to?('get_files_in') \n=> false\n</code></pre>\n\n<p>Once you've got that reasoning down, method signatures are moot because you can test them in the function dynamically. ( this is partially due to not being able do do signature-match-based-function-dispatch, but this is more flexible because you can define unlimited combinations of signatures ) </p>\n\n<pre><code> def get_files_in(directories)\n fail \"Not a List\" unless directories.instance_of?('List')\n end\n\n def example2( *params ) \n lists = params.map{|x| (x.instance_of?(List))?x:nil }.compact \n fail \"No list\" unless lists.length > 0\n p lists[0] \n end\n\nx = List.new\nget_files_in(x)\nexample2( 'this', 'should', 'still' , 1,2,3,4,5,'work' , x )\n</code></pre>\n\n<p>If you want a more assurable test, you can try <a href=\"http://rspec.info/\" rel=\"nofollow noreferrer\">RSpec</a> for Behaviour driven developement. </p>\n"
},
{
"answer_id": 177115,
"author": "Alan",
"author_id": 17205,
"author_profile": "https://Stackoverflow.com/users/17205",
"pm_score": 3,
"selected": false,
"text": "<p>While I love static typing when I'm writing Java code, there's no reason that you can't insist upon thoughtful preconditions in Ruby code (or any kind of code for that matter). When I really need to insist upon preconditions for method params (in Ruby), I'm happy to write a condition that could throw a runtime exception to warn of programmer errors. I even give myself a semblance of static typing by writing:</p>\n\n<pre><code>def get_files_in(directories)\n unless File.directory? directories\n raise ArgumentError, \"directories should be a file directory, you bozo :)\"\n end\n # rest of my block\nend\n</code></pre>\n\n<p>It doesn't seem to me that the language prevents you from doing design-by-contract. Rather, it seems to me that this is up to the developers.</p>\n\n<p>(BTW, \"bozo\" refers to yours truly :)</p>\n"
},
{
"answer_id": 177127,
"author": "Orion Edwards",
"author_id": 234,
"author_profile": "https://Stackoverflow.com/users/234",
"pm_score": 5,
"selected": false,
"text": "<p>What it comes down to is that <code>get_files_in</code> is a bad name <em>in Ruby</em> - let me explain.</p>\n\n<p>In java/C#/C++, and especially in objective C, the function arguments <em>are part of the name</em>. In ruby they are not.<br>\nThe fancy term for this is <a href=\"http://en.wikipedia.org/wiki/Method_overloading\" rel=\"noreferrer\">Method Overloading</a>, and it's enforced by the compiler.</p>\n\n<p>Thinking of it in those terms, you're just defining a method called <code>get_files_in</code> and you're not actually saying what it should get files in. The arguments are <em>not</em> part of the name so you can't rely on them to identify it.<br>\nShould it get files in a directory? a drive? a network share? This opens up the possibility for it to work in all of the above situations.</p>\n\n<p>If you wanted to limit it to a directory, then to take this information into account, you should call the method <code>get_files_in_directory</code>. Alternatively you could make it a method on the <code>Directory</code> class, which <a href=\"http://www.ruby-doc.org/core/\" rel=\"noreferrer\">Ruby already does for you</a>.</p>\n\n<p>As for the return type, it's implied from <code>get_files</code> that you are returning an array of files. You don't have to worry about it being a <code>List<File></code> or an <code>ArrayList<File</code>>, or so on, because everyone just uses arrays (and if they've written a custom one, they'll write it to inherit from the built in array).</p>\n\n<p>If you only wanted to get one file, you'd call it <code>get_file</code> or <code>get_first_file</code> or so on. If you are doing something more complex such as returning <code>FileWrapper</code> objects rather than just strings, then there is a really good solution:</p>\n\n<pre><code># returns a list of FileWrapper objects\ndef get_files_in_directory( dir )\nend\n</code></pre>\n\n<p>At any rate. You can't enforce contracts in ruby like you can in java, but this is a subset of the wider point, which is that you can't enforce <em>anything</em> in ruby like you can in java. Because of ruby's more expressive syntax, you instead get to more clearly write english-like code which tells other people what your contract is (therein saving you several thousand angle brackets).</p>\n\n<p>I for one believe that this is a net win. You can use your newfound spare time to write some <a href=\"http://rspec.info\" rel=\"noreferrer\">specs and tests</a> and come out with a much better product at the end of the day.</p>\n"
},
{
"answer_id": 177158,
"author": "jop",
"author_id": 11830,
"author_profile": "https://Stackoverflow.com/users/11830",
"pm_score": 2,
"selected": false,
"text": "<p><strong>Short answer:</strong> Automated unit tests and good naming practices.</p>\n\n<p>The proper naming of methods is essential. By giving the name <code>get_files_in(directory)</code> to a method, you are also giving a hint to the users on what the method expects to get and what it will give back in return. For example, I would not expect a <code>Potato</code> object coming out of <code>get_files_in()</code> - it just doesn't make sense. It only makes sense to get a list of filenames or more appropriately, a list of File instances from that method. As for the concrete type of the list, depending on what you wanted to do, the actual type of List returned is not really important. What's important is that you can somehow enumerate the items on that list.</p>\n\n<p>Finally, you make that explicit by writing unit tests against that method - showing examples on how it should work. So that if <code>get_files_in</code> suddenly returns a Potato, the test will raise an error and you'll know that the initial assumptions are now wrong.</p>\n"
},
{
"answer_id": 177710,
"author": "Darren Greaves",
"author_id": 151,
"author_profile": "https://Stackoverflow.com/users/151",
"pm_score": 3,
"selected": false,
"text": "<p>I would argue that although the Java method gives you <em>more</em> information, it doesn't give you <em>enough</em> information to comfortably program against.<br>\nFor example, is that List of Strings just filenames or fully-qualified paths?</p>\n\n<p>Given that, your argument that Ruby doesn't give you enough information also applies to Java.<br>\nYou're still relying on reading documentation, looking at the source code, or calling the method and looking at its output (and decent testing of course).</p>\n"
},
{
"answer_id": 5385237,
"author": "Allyl Isocyanate",
"author_id": 320619,
"author_profile": "https://Stackoverflow.com/users/320619",
"pm_score": 1,
"selected": false,
"text": "<p>I made a half-baked attempt at something like dbc for Ruby a few years ago, may give folks some ideas about how to move forward with a more comprehensive solution:</p>\n\n<p><a href=\"https://github.com/justinwiley/higher-expectations\" rel=\"nofollow\">https://github.com/justinwiley/higher-expectations</a></p>\n"
},
{
"answer_id": 25228749,
"author": "Boris Stitnicky",
"author_id": 1153747,
"author_profile": "https://Stackoverflow.com/users/1153747",
"pm_score": 2,
"selected": false,
"text": "<p>Design by contract is a much subtler principle than just specifying the argument type an return type. Other answers here concentrate much on good naming, which is important. I could go on an on about the many ways in which the name <code>get_files_in</code> is ambiguous. But good naming is just an outward consequence of a deeper principle of having good contracts and designing by them. Names are always a bit ambiguous, and good pragmatic linguistics is a product of good thinking. </p>\n\n<p>You can consider contracts the design principles, and they are frequently hard and boring to state in an abstract form. An untyped language requires that the programmer thinks about contracts for real, that she understands them a deeper level than just as type constraints. If there is a team, the team members must all mean and abide by the same contracts. They must be dedicated thinkers and must spend time together discussing concrete examples in order to establish shared understanding of contracts. </p>\n\n<p>The same requirements apply to the API user: The user must first memorize the documentation, and then she is able to gradually understand the contracts, and start loving the API if the contracts are thoughtfully crafted (or hating it if otherwise).</p>\n\n<p>This is connected to duck typing. A contract must give clue as to what happens regardless of the type of the method inputs. So the contract must be understood in a deeper, more generalized way. This answer itself might seem a bit inconcrete, or even haughty, for which I apologize. I am simply trying to say that the duck is <a href=\"http://css.dzone.com/articles/duck-lie\" rel=\"nofollow noreferrer\">not a lie</a>, the duck means that one thinks about one's problem on a higher level of abstraction. The designers, the programmers, the mathematicians are <a href=\"https://softwareengineering.stackexchange.com/questions/136987/what-does-mathematics-have-to-do-with-programming\">all different names for the same capability</a>, and mathematicians know that there are many levels of aptitude in mathematics, where mathematicians on a next higher level easily solve problems which those on lower levels find too hard to solve. The duck means that your programming has to be good mathematics, and it restricts the successful developers and users to only those, <a href=\"http://blog.codinghorror.com/separating-programming-sheep-from-non-programming-goats/\" rel=\"nofollow noreferrer\">who are able to do so</a>.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177080",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3029/"
] |
Method signature in Java:
```
public List<String> getFilesIn(List<File> directories)
```
similar one in ruby
```
def get_files_in(directories)
```
In the case of Java, the type system gives me information about what the method expects and delivers. In Ruby's case, I have **no** clue what I'm supposed to pass in, or what I'll expect to receive.
In Java, the object must formally implement the interface. In Ruby, the object being passed in must respond to whatever methods are called in the method defined here.
This seems highly problematic:
1. Even with 100% accurate, up-to-date documentation, the Ruby code has to essentially expose its implementation, breaking encapsulation. "OO purity" aside, this would seem to be a maintenance nightmare.
2. The Ruby code gives me **no** clue what's being returned; I would have to essentially experiment, or read the code to find out what methods the returned object would respond to.
Not looking to debate static typing vs duck typing, but looking to understand how you maintain a production system where you have almost no ability to design by contract.
### Update
No one has really addressed the exposure of a method's internal implementation via documentation that this approach requires. Since there are no interfaces, if I'm not expecting a particular type, don't I have to itemize every method I might call so that the caller knows what can be passed in? Or is this just an edge case that doesn't really come up?
|
What it comes down to is that `get_files_in` is a bad name *in Ruby* - let me explain.
In java/C#/C++, and especially in objective C, the function arguments *are part of the name*. In ruby they are not.
The fancy term for this is [Method Overloading](http://en.wikipedia.org/wiki/Method_overloading), and it's enforced by the compiler.
Thinking of it in those terms, you're just defining a method called `get_files_in` and you're not actually saying what it should get files in. The arguments are *not* part of the name so you can't rely on them to identify it.
Should it get files in a directory? a drive? a network share? This opens up the possibility for it to work in all of the above situations.
If you wanted to limit it to a directory, then to take this information into account, you should call the method `get_files_in_directory`. Alternatively you could make it a method on the `Directory` class, which [Ruby already does for you](http://www.ruby-doc.org/core/).
As for the return type, it's implied from `get_files` that you are returning an array of files. You don't have to worry about it being a `List<File>` or an `ArrayList<File`>, or so on, because everyone just uses arrays (and if they've written a custom one, they'll write it to inherit from the built in array).
If you only wanted to get one file, you'd call it `get_file` or `get_first_file` or so on. If you are doing something more complex such as returning `FileWrapper` objects rather than just strings, then there is a really good solution:
```
# returns a list of FileWrapper objects
def get_files_in_directory( dir )
end
```
At any rate. You can't enforce contracts in ruby like you can in java, but this is a subset of the wider point, which is that you can't enforce *anything* in ruby like you can in java. Because of ruby's more expressive syntax, you instead get to more clearly write english-like code which tells other people what your contract is (therein saving you several thousand angle brackets).
I for one believe that this is a net win. You can use your newfound spare time to write some [specs and tests](http://rspec.info) and come out with a much better product at the end of the day.
|
177,118 |
<p>I saw this question on Reddit, and there were no positive solutions presented, and I thought it would be a perfect question to ask here. This was in a thread about interview questions:</p>
<blockquote>
<p>Write a method that takes an int array of size m, and returns (True/False) if the array consists of the numbers n...n+m-1, all numbers in that range and only numbers in that range. The array is not guaranteed to be sorted. (For instance, {2,3,4} would return true. {1,3,1} would return false, {1,2,4} would return false.</p>
<p>The problem I had with this one is that my interviewer kept asking me to optimize (faster O(n), less memory, etc), to the point where he claimed you could do it in one pass of the array using a constant amount of memory. Never figured that one out.</p>
</blockquote>
<p>Along with your solutions please indicate if they assume that the array contains unique items. Also indicate if your solution assumes the sequence starts at 1. (I've modified the question slightly to allow cases where it goes 2, 3, 4...)</p>
<p><strong>edit:</strong> I am now of the opinion that there does not exist a linear in time and constant in space algorithm that handles duplicates. Can anyone verify this?</p>
<p>The duplicate problem boils down to testing to see if the array contains duplicates in O(n) time, O(1) space. If this can be done you can simply test first and if there are no duplicates run the algorithms posted. So can you test for dupes in O(n) time O(1) space?</p>
|
[
{
"answer_id": 177126,
"author": "hazzen",
"author_id": 5066,
"author_profile": "https://Stackoverflow.com/users/5066",
"pm_score": 4,
"selected": false,
"text": "<p>Under the assumption numbers less than one are not allowed and there are no duplicates, there is a simple summation identity for this - the sum of numbers from <code>1</code> to <code>m</code> in increments of <code>1</code> is <code>(m * (m + 1)) / 2</code>. You can then sum the array and use this identity.</p>\n\n<p>You can find out if there is a dupe under the above guarantees, plus the guarantee no number is above m or less than n (which can be checked in <code>O(N)</code>)</p>\n\n<p>The idea in pseudo-code:<br>\n 0) Start at N = 0<br>\n 1) Take the N-th element in the list.<br>\n 2) If it is not in the right place if the list had been sorted, check where it should be.<br>\n 3) If the place where it should be already has the same number, you have a dupe - RETURN TRUE<br>\n 4) Otherwise, swap the numbers (to put the first number in the right place).<br>\n 5) With the number you just swapped with, is it in the right place?<br>\n 6) If no, go back to step two.<br>\n 7) Otherwise, start at step one with N = N + 1. If this would be past the end of the list, you have no dupes.</p>\n\n<p>And, yes, that runs in <code>O(N)</code> although it may look like <code>O(N ^ 2)</code></p>\n\n<h2>Note to everyone (stuff collected from comments)</h2>\n\n<p>This solution works under the assumption you can modify the array, then uses in-place Radix sort (which achieves <code>O(N)</code> speed).</p>\n\n<p>Other mathy-solutions have been put forth, but I'm not sure any of them have been proved. There are a bunch of sums that might be useful, but most of them run into a blowup in the number of bits required to represent the sum, which will violate the constant extra space guarantee. I also don't know if any of them are capable of producing a distinct number for a given set of numbers. I think a sum of squares might work, which has a known formula to compute it (see <a href=\"http://mathworld.wolfram.com/PowerSum.html\" rel=\"noreferrer\">Wolfram's</a>)</p>\n\n<h2>New insight (well, more of musings that don't help solve it but are interesting and I'm going to bed):</h2>\n\n<p>So, it has been mentioned to maybe use sum + sum of squares. No one knew if this worked or not, and I realized that it only becomes an issue when (x + y) = (n + m), such as the fact 2 + 2 = 1 + 3. Squares also have this issue thanks to <a href=\"http://en.wikipedia.org/wiki/Pythagorean_triple\" rel=\"noreferrer\">Pythagorean triples</a> (so 3^2 + 4^2 + 25^2 == 5^2 + 7^2 + 24^2, and the sum of squares doesn't work). If we use <a href=\"http://en.wikipedia.org/wiki/Fermat%27s_Last_Theorem\" rel=\"noreferrer\">Fermat's last theorem</a>, we know this can't happen for n^3. But we also don't know if there is no x + y + z = n for this (unless we do and I don't know it). So no guarantee this, too, doesn't break - and if we continue down this path we quickly run out of bits.</p>\n\n<p>In my glee, however, I forgot to note that you can break the sum of squares, but in doing so you create a normal sum that isn't valid. I don't think you can do both, but, as has been noted, we don't have a proof either way.</p>\n\n<hr>\n\n<p>I must say, finding counterexamples is sometimes a lot easier than proving things! Consider the following sequences, all of which have a sum of 28 and a sum of squares of 140:</p>\n\n<pre><code>[1, 2, 3, 4, 5, 6, 7]\n[1, 1, 4, 5, 5, 6, 6] \n[2, 2, 3, 3, 4, 7, 7]\n</code></pre>\n\n<p>I could not find any such examples of length 6 or less. If you want an example that has the proper min and max values too, try this one of length 8:</p>\n\n<pre><code>[1, 3, 3, 4, 4, 5, 8, 8]\n</code></pre>\n\n<hr>\n\n<h2>Simpler approach (modifying hazzen's idea):</h2>\n\n<p>An integer array of length m contains all the numbers from n to n+m-1 exactly once iff</p>\n\n<ul>\n<li>every array element is between n and n+m-1 </li>\n<li>there are no duplicates</li>\n</ul>\n\n<p>(Reason: there are only m values in the given integer range, so if the array contains m unique values in this range, it must contain every one of them once)</p>\n\n<p>If you are allowed to modify the array, you can check both in one pass through the list with a modified version of hazzen's algorithm idea (there is no need to do any summation):</p>\n\n<ul>\n<li>For all array indexes i from 0 to m-1 do\n\n<ol>\n<li>If array[i] < n or array[i] >= n+m => RETURN FALSE (\"value out of range found\")</li>\n<li>Calculate j = array[i] - n (this is the 0-based position of array[i] in a <em>sorted</em> array with values from n to n+m-1)</li>\n<li>While j is not equal to i\n\n<ol>\n<li>If list[i] is equal to list[j] => RETURN FALSE (\"duplicate found\")</li>\n<li>Swap list[i] with list[j]</li>\n<li>Recalculate j = array[i] - n</li>\n</ol></li>\n</ol></li>\n<li>RETURN TRUE</li>\n</ul>\n\n<p>I'm not sure if the modification of the original array counts against the maximum allowed additional space of O(1), but if it doesn't this should be the solution the original poster wanted.</p>\n"
},
{
"answer_id": 177128,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 0,
"selected": false,
"text": "<pre><code>def test(a, n, m):\n seen = [False] * m\n for x in a:\n if x < n or x >= n+m:\n return False\n if seen[x-n]:\n return False\n seen[x-n] = True\n return False not in seen\n\nprint test([2, 3, 1], 1, 3)\nprint test([1, 3, 1], 1, 3)\nprint test([1, 2, 4], 1, 3)\n</code></pre>\n\n<p>Note that this only makes one pass through the first array, not considering the linear search involved in <code>not in</code>. :)</p>\n\n<p>I also could have used a python <code>set</code>, but I opted for the straightforward solution where the performance characteristics of <code>set</code> need not be considered.</p>\n\n<p>Update: Smashery pointed out that I had misparsed \"constant amount of memory\" and this solution doesn't actually solve the problem.</p>\n"
},
{
"answer_id": 177145,
"author": "Kent Fredric",
"author_id": 15614,
"author_profile": "https://Stackoverflow.com/users/15614",
"pm_score": 0,
"selected": false,
"text": "<p>MY CURRENT BEST OPTION</p>\n\n<pre><code>def uniqueSet( array )\n check_index = 0; \n check_value = 0; \n min = array[0];\n array.each_with_index{ |value,index|\n check_index = check_index ^ ( 1 << index );\n check_value = check_value ^ ( 1 << value );\n min = value if value < min\n } \n check_index = check_index << min;\n return check_index == check_value; \nend\n</code></pre>\n\n<p>O(n) and Space O(1) </p>\n\n<p>I wrote a script to brute force combinations that could fail that and it didn't find any. \nIf you have an array which contravenes this function do tell. :) </p>\n\n<hr>\n\n<p>@J.F. Sebastian</p>\n\n<p>Its not a true hashing algorithm. Technically, its a highly efficient packed boolean array of \"seen\" values.</p>\n\n<pre><code>ci = 0, cv = 0\n[5,4,3]{ \n i = 0 \n v = 5 \n 1 << 0 == 000001\n 1 << 5 == 100000\n 0 ^ 000001 = 000001\n 0 ^ 100000 = 100000\n\n i = 1\n v = 4 \n 1 << 1 == 000010\n 1 << 4 == 010000\n 000001 ^ 000010 = 000011\n 100000 ^ 010000 = 110000 \n\n i = 2\n v = 3 \n 1 << 2 == 000100\n 1 << 3 == 001000\n 000011 ^ 000100 = 000111\n 110000 ^ 001000 = 111000 \n}\nmin = 3 \n000111 << 3 == 111000\n111000 === 111000\n</code></pre>\n\n<p>The point of this being mostly that in order to \"fake\" most the problem cases one uses duplicates to do so. In this system, XOR penalises you for using the same value twice and assumes you instead did it 0 times. </p>\n\n<p>The caveats here being of course:</p>\n\n<ol>\n<li>both input array length and maximum array value is limited by the maximum value for <code>$x</code> in <code>( 1 << $x > 0 )</code></li>\n<li><p>ultimate effectiveness depends on how your underlying system implements the abilities to: </p>\n\n<ol>\n<li>shift 1 bit n places right.</li>\n<li>xor 2 registers. ( where 'registers' may, depending on implementation, span several registers )</li>\n</ol>\n\n<p><strong>edit</strong>\nNoted, above statements seem confusing. Assuming a perfect machine, where an \"integer\" is a register with Infinite precision, which can still perform a ^ b in O(1) time.</p></li>\n</ol>\n\n<p>But failing these assumptions, one has to start asking the algorithmic complexity of simple math. </p>\n\n<ul>\n<li>How complex is 1 == 1 ?, surely that should be O(1) every time right?. </li>\n<li>What about 2^32 == 2^32 . </li>\n<li>O(1)? 2^33 == 2^33? Now you've got a question of register size and the underlying implementation. </li>\n<li>Fortunately XOR and == can be done in parallel, so if one assumes infinite precision and a machine designed to cope with infinite precision, it is safe to assume XOR and == take constant time regardless of their value ( because its infinite width, it will have infinite 0 padding. Obviously this doesn't exist. But also, changing 000000 to 000100 is not increasing memory usage. </li>\n<li>Yet on some machines , ( 1 << 32 ) << 1 <em>will</em> consume more memory, but how much is uncertain. </li>\n</ul>\n"
},
{
"answer_id": 177199,
"author": "CaptSolo",
"author_id": 2025531,
"author_profile": "https://Stackoverflow.com/users/2025531",
"pm_score": 0,
"selected": false,
"text": "<p><strong>note</strong>: this comment is based on the original text of the question (it has been corrected since)</p>\n\n<p>If the question is posed <em>exactly</em> as written above (and it is not just a typo) and for array of size n the function should return (True/False) if the array consists of the numbers 1...n+1, </p>\n\n<p>... then the answer will always be false because the array with all the numbers 1...n+1 will be of size n+1 and not n. hence the question can be answered in O(1). :)</p>\n"
},
{
"answer_id": 177217,
"author": "David Crow",
"author_id": 2783,
"author_profile": "https://Stackoverflow.com/users/2783",
"pm_score": -1,
"selected": false,
"text": "<p>It seems like we could check for duplicates by multiplying all the numbers n...n+m together, and then comparing that value to the expected product of a sequence with no duplicates <strong>m!/(n-1)!</strong> (note that this assumes it is impossible for a sequence to pass both the expected sum test <strong>and</strong> the expected product test).</p>\n\n<p>So adding to <a href=\"https://stackoverflow.com/revisions/viewmarkup/224981\">hazzen's pseudo-code</a>, we have:</p>\n\n<pre><code>is_range(int[] nums, int n, int m) {\n sum_to_m := (m * (m + 1)) / 2\n expected_sum := sum_to_m - (n * (n - 1)) / 2\n real_sum := sum(nums)\n expected_product := m! / (n - 1)!\n real_product := product(nums)\n return ((real_sum == expected_sum) && (expected_product == real_product))\n</code></pre>\n\n<p><br/>\n<strong>EDIT:</strong> Here's my solution in Java using the Sum of Squares to check for duplicates. It also handles any range (including negative numbers) by shifting the sequence to start at 1.</p>\n\n<pre><code>// low must be less than high\npublic boolean isSequence(int[] nums, int low, int high) {\n int shift = 1 - low;\n low += shift;\n high += shift;\n\n int sum = 0;\n int sumSquares = 0;\n for (int i = 0; i < nums.length; i++) {\n int num = nums[i] + shift;\n\n if (num < low)\n return false;\n else if (num > high)\n return false;\n\n sum += num;\n sumSquares += num * num;\n }\n\n int expectedSum = (high * (high + 1)) / 2;\n\n if (sum != expectedSum)\n return false;\n\n int expectedSumSquares = high * (high + 1) * (2 * high + 1) / 6;\n\n if (sumSquares != expectedSumSquares)\n return false;\n\n return true;\n}\n</code></pre>\n"
},
{
"answer_id": 177222,
"author": "CaptSolo",
"author_id": 2025531,
"author_profile": "https://Stackoverflow.com/users/2025531",
"pm_score": -1,
"selected": false,
"text": "<p>If that was a typo and the question is about all numbers being in range 1...n instead, then:</p>\n\n<pre><code>def try_arr(arr):\n n = len(arr)\n return (not any(x<1 or x>n for x in arr)) and sum(arr)==n*(n+1)/2\n\n$ print try_arr([1,2,3])\nTrue\n\n$ print try_arr([1,3,1])\nFalse\n\n$ print try_arr([1,2,4])\nFalse\n</code></pre>\n\n<p>Notes:</p>\n\n<ul>\n<li><p>I am using the definition from the original version that numbers start from 1. Sure code can be modified to account for starting from another number.</p></li>\n<li><p>If the size of the array (n) was known, you could modify this to stream data from e.g., input file, and use almost no memory (1 temp variable inside sum() and 1 variable for the current item taken from the stream)</p></li>\n<li><p>any() is new in python 2.5 (but you have alternative ways to express the same thing in earlier versions of python)</p></li>\n<li><p>it uses O(n) time O(1) space. (update: i wrote it does account for duplicates, but apparently that is not true as demonstrated by a comment to another answer here).</p></li>\n</ul>\n"
},
{
"answer_id": 177245,
"author": "andy",
"author_id": 21482,
"author_profile": "https://Stackoverflow.com/users/21482",
"pm_score": 2,
"selected": false,
"text": "<p>Why do the other solutions use a summation of every value? I think this is risky, because when you add together O(n) items into one number, you're technically using more than O(1) space.</p>\n\n<p>Simpler method:</p>\n\n<p>Step 1, figure out if there are any duplicates. I'm not sure if this is possible in O(1) space. Anyway, return false if there are duplicates.</p>\n\n<p>Step 2, iterate through the list, keep track of the <strong>lowest</strong> and <strong>highest</strong> items.</p>\n\n<p>Step 3, Does (highest - lowest) equal m ? If so, return true.</p>\n"
},
{
"answer_id": 177256,
"author": "Loren Pechtel",
"author_id": 10659,
"author_profile": "https://Stackoverflow.com/users/10659",
"pm_score": -1,
"selected": false,
"text": "<pre><code>Fail := False;\nSum1 := 0;\nSum2 := 0;\nTSum1 := 0;\nTSum2 := 0;\n\nFor i := 1 to m do\n Begin\n TSum1 := TSum1 + i;\n TSum2 := TSum2 + i * i;\n Item := Array[i] - n;\n If (Item < 0) or (Item >= m) then \n Fail := True\n Else \n Begin\n Sum1 := Sum1 + Item;\n Sum2 := Sum2 + Item * Item;\n End;\n End;\nFail := Fail Or (Sum1 <> TSum1) or (Sum2 <> TSum2);\n</code></pre>\n\n<p>Tired and no compiler but I think this gives O(m) runtime and can't be fooled.</p>\n"
},
{
"answer_id": 177264,
"author": "Kevin Day",
"author_id": 10973,
"author_profile": "https://Stackoverflow.com/users/10973",
"pm_score": 1,
"selected": false,
"text": "<p>Awhile back I heard about a very clever sorting algorithm from someone who worked for the phone company. They had to sort a massive number of phone numbers. After going through a bunch of different sort strategies, they finally hit on a very elegant solution: they just created a bit array and treated the offset into the bit array as the phone number. They then swept through their database with a single pass, changing the bit for each number to 1. After that, they swept through the bit array once, spitting out the phone numbers for entries that had the bit set high.</p>\n\n<p>Along those lines, I believe that you can use the data in the array itself as a meta data structure to look for duplicates. Worst case, you could have a separate array, but I'm pretty sure you can use the input array if you don't mind a bit of swapping.</p>\n\n<p>I'm going to leave out the n parameter for time being, b/c that just confuses things - adding in an index offset is pretty easy to do.</p>\n\n<p>Consider:</p>\n\n<pre><code>for i = 0 to m\n if (a[a[i]]==a[i]) return false; // we have a duplicate\n while (a[a[i]] > a[i]) swapArrayIndexes(a[i], i)\n sum = sum + a[i]\nnext\n\nif sum = (n+m-1)*m return true else return false\n</code></pre>\n\n<p>This isn't O(n) - probably closer to O(n Log n) - but it does provide for constant space and may provide a different vector of attack for the problem.</p>\n\n<p>If we want O(n), then using an array of bytes and some bit operations will provide the duplication check with an extra n/32 bytes of memory used (assuming 32 bit ints, of course).</p>\n\n<p>EDIT: The above algorithm could be improved further by adding the sum check to the inside of the loop, and check for:</p>\n\n<pre><code>if sum > (n+m-1)*m return false\n</code></pre>\n\n<p>that way it will fail fast.</p>\n"
},
{
"answer_id": 177268,
"author": "CaptSolo",
"author_id": 2025531,
"author_profile": "https://Stackoverflow.com/users/2025531",
"pm_score": 0,
"selected": false,
"text": "<blockquote>\n <p>Why do the other solutions use a summation of every value? I think this is risky, because when you add together O(n) items into one number, you're technically using more than O(1) space.</p>\n</blockquote>\n\n<p>O(1) indicates constant space which does not change by the number of n. It does not matter if it is 1 or 2 variables as long as it is a constant number. Why are you saying it is more than O(1) space? If you are calculating the sum of n numbers by accumulating it in a temporary variable, you would be using exactly 1 variable anyway.</p>\n\n<p>Commenting in an answer because the system does not allow me to write comments yet.</p>\n\n<p>Update (in reply to comments): in this answer i meant O(1) space wherever \"space\" or \"time\" was omitted. The quoted text is a part of an earlier answer to which this is a reply to. </p>\n"
},
{
"answer_id": 177269,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 0,
"selected": false,
"text": "<p>If you want to know the sum of the numbers <code>[n ... n + m - 1]</code> just use this equation.</p>\n\n<pre><code>var sum = m * (m + 2 * n - 1) / 2;\n</code></pre>\n\n<p>That works for any number, positive or negative, even if n is a decimal.</p>\n"
},
{
"answer_id": 177319,
"author": "user17182",
"author_id": 17182,
"author_profile": "https://Stackoverflow.com/users/17182",
"pm_score": 1,
"selected": false,
"text": "<p>Vote me down if I'm wrong, but I think we can determine if there are duplicates or not using variance. Because we know the mean beforehand (n + (m-1)/2 or something like that) we can just sum up the numbers and square of difference to mean to see if the sum matches the equation (mn + m(m-1)/2) and the variance is (0 + 1 + 4 + ... + (m-1)^2)/m. If the variance doesn't match, it's likely we have a duplicate.</p>\n\n<p><b>EDIT: </b> variance is supposed to be (0 + 1 + 4 + ... + [(m-1)/2]^2)*2/m, because half of the elements are less than the mean and the other half is greater than the mean.<p></p>\n\n<p>If there is a duplicate, a term on the above equation will differ from the correct sequence, even if another duplicate completely cancels out the change in mean. So the function returns true only if both sum and variance matches the desrired values, which we can compute beforehand.</p>\n"
},
{
"answer_id": 177566,
"author": "b3.",
"author_id": 14946,
"author_profile": "https://Stackoverflow.com/users/14946",
"pm_score": -1,
"selected": false,
"text": "<p><em>I don't think I explained myself in my original post well (below the solid line). For an input of [1 2 3 4 5], for example, the algorithm computes the sum:</em></p>\n\n<pre><code>-1 + 2 - 3 + 4 - 5 \n</code></pre>\n\n<p><em>which should be equal to</em></p>\n\n<pre><code>-1^5 * ceil(5/2)\n</code></pre>\n\n<p><em>The pseudo-code below shows how vectors that do not begin at 1 are checked.</em> <strong>The algorithm handles cases where the input vector is not sorted and/or it contains duplicates.</strong></p>\n\n<hr>\n\n<p>The following algorithm solves the problem by calculating the alternating sums of the vector elements:</p>\n\n<pre><code>-1 + 2 - 3 + 4 - 5 + .... + m = (-1)^m * ceil(m/2)\n</code></pre>\n\n<p>where <strong>ceil</strong> rounds up to the closest integer. In other words, odd numbers are subtracted from the running total and even numbers are added to it.</p>\n\n<pre><code>function test(data, m)\n altSum = 0\n n = Inf\n mCheck = -Inf\n for ii = 1:m\n {\n if data(ii) < n\n n = data(ii)\n if data(ii) > mCheck\n mCheck = data(ii)\n altSum = altSum + (-1)^data(ii) * data(ii)\n }\n if ((mCheck-n+1!=m) || (-1)^(n+m-1) * ceil((n+m-1)/2) - ((-1)^(n-1) * ceil((n-1)/2)) != altSum\n return false\n else\n return true\n</code></pre>\n"
},
{
"answer_id": 177605,
"author": "hurst",
"author_id": 10991,
"author_profile": "https://Stackoverflow.com/users/10991",
"pm_score": 0,
"selected": false,
"text": "<p>Given this - </p>\n\n<blockquote>\n <p>Write a method that takes an <strong>int array</strong> of size m ...</p>\n</blockquote>\n\n<p>I suppose it is fair to conclude there is an upper limit for m, equal to the value of the largest <strong>int</strong> (2^32 being typical). <em>In other words, even though m is not specified as an int, the fact that the array can't have duplicates implies there can't be more than the number of values you can form out of 32 bits, which in turn implies m is limited to be an int also.</em></p>\n\n<p>If such a conclusion is acceptable, then I propose to use a fixed space of (2^33 + 2) * 4 bytes = 34,359,738,376 bytes = 34.4GB to handle all possible cases. (Not counting the space required by the input array and its loop).</p>\n\n<p>Of course, for optimization, I would first take m into account, and allocate only the actual amount needed, (2m+2) * 4 bytes.</p>\n\n<p>If this is acceptable for the O(1) space constraint - <em>for the stated problem</em> - then let me proceed to an algorithmic proposal... :)</p>\n\n<p><strong>Assumptions</strong>: array of m ints, positive or negative, none greater than what 4 bytes can hold. Duplicates are handled. First value can be any valid int. Restrict m as above.</p>\n\n<p><em>First</em>, create an int array of length 2m-1, <strong>ary</strong>, and provide three int variables: <strong>left</strong>, <strong>diff</strong>, and <strong>right</strong>. Notice that makes 2m+2...</p>\n\n<p><em>Second</em>, take the first value from the input array and copy it to position m-1 in the new array. Initialize the three variables.</p>\n\n<ul>\n<li>set <strong>ary</strong>[m-1] - nthVal // n=0</li>\n<li>set <strong>left</strong> = <strong>diff</strong> = <strong>right</strong> = <strong>0</strong></li>\n</ul>\n\n<p><em>Third</em>, loop through the remaining values in the input array and do the following for each iteration:</p>\n\n<ul>\n<li>set <strong>diff</strong> = nthVal - <strong>ary</strong>[m-1]</li>\n<li>if (<strong>diff</strong> > m-1 + <strong>right</strong> || <strong>diff</strong> < 1-m + <strong>left</strong>) return false // out of bounds</li>\n<li>if (<strong>ary</strong>[m-1+<strong>diff</strong>] != null) return false // duplicate</li>\n<li>set <strong>ary</strong>[m-1+<strong>diff</strong>] = nthVal</li>\n<li>if (<strong>diff</strong>><strong>left</strong>) <strong>left</strong> = <strong>diff</strong> // constrains left bound further right</li>\n<li>if (<strong>diff</strong><<strong>right</strong>) <strong>right</strong> = <strong>diff</strong> // constrains right bound further left</li>\n</ul>\n\n<p>I decided to put this in code, and it worked.</p>\n\n<p>Here is a working sample using C#:</p>\n\n<pre><code>public class Program\n{\n static bool puzzle(int[] inAry)\n {\n var m = inAry.Count();\n var outAry = new int?[2 * m - 1];\n int diff = 0;\n int left = 0;\n int right = 0;\n outAry[m - 1] = inAry[0];\n for (var i = 1; i < m; i += 1)\n {\n diff = inAry[i] - inAry[0];\n if (diff > m - 1 + right || diff < 1 - m + left) return false;\n if (outAry[m - 1 + diff] != null) return false;\n outAry[m - 1 + diff] = inAry[i];\n if (diff > left) left = diff;\n if (diff < right) right = diff;\n }\n return true;\n }\n\n static void Main(string[] args)\n {\n var inAry = new int[3]{ 2, 3, 4 };\n Console.WriteLine(puzzle(inAry));\n inAry = new int[13] { -3, 5, -1, -2, 9, 8, 2, 3, 0, 6, 4, 7, 1 };\n Console.WriteLine(puzzle(inAry));\n inAry = new int[3] { 21, 31, 41 };\n Console.WriteLine(puzzle(inAry));\n Console.ReadLine();\n }\n\n}\n</code></pre>\n"
},
{
"answer_id": 177659,
"author": "popopome",
"author_id": 1556,
"author_profile": "https://Stackoverflow.com/users/1556",
"pm_score": -1,
"selected": false,
"text": "<p>How about using XOR with even and odd numbers separately.\nThink about bit level not integer value itself.</p>\n\n<pre><code>bool is_same(const int* a, const int* b, int len)\n{\n int even_xor = 0; \n int odd_xor = 0;\n\n for(int i=0;i<len;++i)\n {\n if(a[i] & 0x01) odd_xor ^= a[i];\n else even_xor ^= a[i];\n\n if(b[i] & 0x01) odd_xor ^= b[i];\n else even_xor ^= b[i];\n }\n\n return (even_xor == 0) && (odd_xor == 0);\n}\n</code></pre>\n"
},
{
"answer_id": 177662,
"author": "nickf",
"author_id": 9021,
"author_profile": "https://Stackoverflow.com/users/9021",
"pm_score": 1,
"selected": false,
"text": "<h2>Here's a working solution in O(n)</h2>\n\n<p>This is using the pseudocode suggested by Hazzen plus some of my own ideas. It works for negative numbers as well and doesn't require any sum-of-the-squares stuff.</p>\n\n<pre><code>function testArray($nums, $n, $m) {\n // check the sum. PHP offers this array_sum() method, but it's\n // trivial to write your own. O(n) here.\n if (array_sum($nums) != ($m * ($m + 2 * $n - 1) / 2)) {\n return false; // checksum failed.\n }\n for ($i = 0; $i < $m; ++$i) {\n // check if the number is in the proper range\n if ($nums[$i] < $n || $nums[$i] >= $n + $m) {\n return false; // value out of range.\n }\n\n while (($shouldBe = $nums[$i] - $n) != $i) {\n if ($nums[$shouldBe] == $nums[$i]) {\n return false; // duplicate\n }\n $temp = $nums[$i];\n $nums[$i] = $nums[$shouldBe];\n $nums[$shouldBe] = $temp;\n }\n }\n return true; // huzzah!\n}\n\nvar_dump(testArray(array(1, 2, 3, 4, 5), 1, 5)); // true\nvar_dump(testArray(array(5, 4, 3, 2, 1), 1, 5)); // true\nvar_dump(testArray(array(6, 4, 3, 2, 0), 1, 5)); // false - out of range\nvar_dump(testArray(array(5, 5, 3, 2, 1), 1, 5)); // false - checksum fail\nvar_dump(testArray(array(5, 4, 3, 2, 5), 1, 5)); // false - dupe\nvar_dump(testArray(array(-2, -1, 0, 1, 2), -2, 5)); // true\n</code></pre>\n"
},
{
"answer_id": 177807,
"author": "Skizz",
"author_id": 1898,
"author_profile": "https://Stackoverflow.com/users/1898",
"pm_score": 0,
"selected": false,
"text": "<p>ciphwn has it right. It is all to do with statistics. What the question is asking is, in statistical terms, is whether or not the sequence of numbers form a discrete uniform distribution. A discrete uniform distribution is where all values of a finite set of possible values are equally probable. Fortunately there are some useful formulas to determine if a discrete set is uniform. Firstly, to determine the mean of the set (a..b) is (a+b)/2 and the variance is (n.n-1)/12. Next, determine the variance of the given set:</p>\n\n<pre><code>variance = sum [i=1..n] (f(i)-mean).(f(i)-mean)/n\n</code></pre>\n\n<p>and then compare with the expected variance. This will require two passes over the data, once to determine the mean and again to calculate the variance.</p>\n\n<p>References:</p>\n\n<ul>\n<li><a href=\"http://mathworld.wolfram.com/UniformDistribution.html\" rel=\"nofollow noreferrer\">uniform discrete distribution</a></li>\n<li><a href=\"http://mathworld.wolfram.com/Variance.html\" rel=\"nofollow noreferrer\">variance</a></li>\n</ul>\n"
},
{
"answer_id": 182378,
"author": "Stephen Denne",
"author_id": 11721,
"author_profile": "https://Stackoverflow.com/users/11721",
"pm_score": 3,
"selected": false,
"text": "<p>By working with <code>a[i] % a.length</code> instead of <code>a[i]</code> you reduce the problem to needing to determine that you've got the numbers <code>0</code> to <code>a.length - 1</code>.</p>\n\n<p>We take this observation for granted and try to check if the array contains [0,m).</p>\n\n<p>Find the first node that's not in its correct position, e.g.</p>\n\n<pre><code>0 1 2 3 7 5 6 8 4 ; the original dataset (after the renaming we discussed)\n ^\n `---this is position 4 and the 7 shouldn't be here\n</code></pre>\n\n<p>Swap that number into where it <em>should</em> be. i.e. swap the <code>7</code> with the <code>8</code>:</p>\n\n<pre><code>0 1 2 3 8 5 6 7 4 ; \n | `--------- 7 is in the right place.\n `--------------- this is now the 'current' position\n</code></pre>\n\n<p>Now we repeat this. Looking again at our current position we ask:</p>\n\n<p>\"is this the correct number for here?\"</p>\n\n<ul>\n<li>If not, we swap it into its correct place.</li>\n<li>If it is in the right place, we move right and do this again.</li>\n</ul>\n\n<p>Following this rule again, we get:</p>\n\n<pre><code>0 1 2 3 4 5 6 7 8 ; 4 and 8 were just swapped\n</code></pre>\n\n<p>This will gradually build up the list correctly from left to right, and each number will be moved at most once, and hence this is O(n).</p>\n\n<p>If there are dupes, we'll notice it as soon is there is an attempt to swap a number <code>backwards</code> in the list.</p>\n"
},
{
"answer_id": 185360,
"author": "jfs",
"author_id": 4279,
"author_profile": "https://Stackoverflow.com/users/4279",
"pm_score": 0,
"selected": false,
"text": "<h1>Counter-example for <a href=\"https://stackoverflow.com/questions/177118/algorithm-to-determine-if-array-contains-nnm#177659\">XOR algorithm</a>.</h1>\n\n<p>(can't post it as a comment) </p>\n\n<p>@popopome</p>\n\n<p>For <code>a = {0, 2, 7, 5,}</code> it return <code>true</code> (means that <code>a</code> is a permutation of the range <code>[0, 4)</code> ), but it must return <code>false</code> in this case (<code>a</code> is obviously is not a permutaton of <code>[0, 4)</code> ).</p>\n\n<p>Another counter example: <code>{0, 0, 1, 3, 5, 6, 6}</code> -- all values are in range but there are duplicates.</p>\n\n<p>I could incorrectly implement popopome's idea (or tests), therefore here is the code:</p>\n\n<pre><code>bool isperm_popopome(int m; int a[m], int m, int n)\n{\n /** O(m) in time (single pass), O(1) in space,\n no restrictions on n,\n no overflow,\n a[] may be readonly\n */\n int even_xor = 0;\n int odd_xor = 0;\n\n for (int i = 0; i < m; ++i)\n {\n if (a[i] % 2 == 0) // is even\n even_xor ^= a[i];\n else\n odd_xor ^= a[i];\n\n const int b = i + n;\n if (b % 2 == 0) // is even\n even_xor ^= b;\n else\n odd_xor ^= b;\n }\n\n return (even_xor == 0) && (odd_xor == 0);\n}\n</code></pre>\n"
},
{
"answer_id": 186528,
"author": "Rafał Dowgird",
"author_id": 12166,
"author_profile": "https://Stackoverflow.com/users/12166",
"pm_score": -1,
"selected": false,
"text": "<p>I don't think you need to use sums at all. Just check the minimum and maximum and check for dupes. Checking for dupes is the harder part, since you don't know n in advance, so you cannot sort in one pass. To work around that, relax the condition on the (edit:destination) array. Instead of requiring it to be sorted, go for a cyclical shift of a sorted sequence, so that the array goes [k,k+1,..., n+m-2, n+m-1,n,n+1, ... ,k-2,k-1] for some k.</p>\n\n<p>With the condition above, you can assume that a[0] is already in the right position, then the right position for an element <code>d</code> is <code>(d-a[0]) mod m</code>, assuming zero-based array indexing. For example with [4,?,?,?] you can expect [4,5,6,7] or [4,1,2,3] or [4,5,6,3] or [4,5,2,3]. </p>\n\n<p>Then just scan the array once, putting each element in its calculated position, updating the min and max and checking for clashes. If there are no clashes and max-min=m, then the condition is met, otherwise it is false.</p>\n"
},
{
"answer_id": 188315,
"author": "jfs",
"author_id": 4279,
"author_profile": "https://Stackoverflow.com/users/4279",
"pm_score": 0,
"selected": false,
"text": "<h1>A C version of <a href=\"https://stackoverflow.com/questions/177118/algorithm-to-determine-if-array-contains-nnm#177145\">Kent Fredric's Ruby solution</a></h1>\n\n<p>(to facilitate testing) </p>\n\n<p>Counter-example (for C version): {8, 33, 27, 30, 9, 2, 35, 7, 26, 32, 2, 23, 0, 13, 1, 6, 31, 3, 28, 4, 5, 18, 12, 2, 9, 14, 17, 21, 19, 22, 15, 20, 24, 11, 10, 16, 25}. Here n=0, m=35. This sequence misses <code>34</code> and has two <code>2</code>.</p>\n\n<p>It is an O(m) in time and O(1) in space solution. </p>\n\n<p>Out-of-range values are easily detected in O(n) in time and O(1) in space, therefore tests are concentrated on in-range (means all values are in the valid range <code>[n, n+m)</code>) sequences. Otherwise <em><code>{1, 34}</code> is a counter example</em> (for C version, sizeof(int)==4, standard binary representation of numbers).</p>\n\n<p>The main difference between C and Ruby version: \n <code><<</code> operator will rotate values in C due to a finite sizeof(int), \n but in Ruby numbers will grow to accomodate the result e.g., </p>\n\n<p>Ruby: <code>1 << 100 # -> 1267650600228229401496703205376</code></p>\n\n<p>C: <code>int n = 100; 1 << n // -> 16</code></p>\n\n<p>In Ruby: <code>check_index ^= 1 << i;</code> is equivalent to <code>check_index.setbit(i)</code>. The same effect could be implemented in C++: <code>vector<bool> v(m); v[i] = true;</code> </p>\n\n<pre><code>bool isperm_fredric(int m; int a[m], int m, int n)\n{\n /**\n O(m) in time (single pass), O(1) in space,\n no restriction on n,\n ?overflow?\n a[] may be readonly\n */\n int check_index = 0;\n int check_value = 0;\n\n int min = a[0];\n for (int i = 0; i < m; ++i) {\n\n check_index ^= 1 << i;\n check_value ^= 1 << (a[i] - n); //\n\n if (a[i] < min)\n min = a[i];\n }\n check_index <<= min - n; // min and n may differ e.g., \n // {1, 1}: min=1, but n may be 0.\n return check_index == check_value;\n}\n</code></pre>\n\n<p>Values of the above function were tested against the following code:</p>\n\n<pre><code>bool *seen_isperm_trusted = NULL;\nbool isperm_trusted(int m; int a[m], int m, int n)\n{\n /** O(m) in time, O(m) in space */\n\n for (int i = 0; i < m; ++i) // could be memset(s_i_t, 0, m*sizeof(*s_i_t));\n seen_isperm_trusted[i] = false;\n\n for (int i = 0; i < m; ++i) {\n\n if (a[i] < n or a[i] >= n + m)\n return false; // out of range\n\n if (seen_isperm_trusted[a[i]-n])\n return false; // duplicates\n else\n seen_isperm_trusted[a[i]-n] = true;\n }\n\n return true; // a[] is a permutation of the range: [n, n+m)\n}\n</code></pre>\n\n<p>Input arrays are generated with:</p>\n\n<pre><code>void backtrack(int m; int a[m], int m, int nitems)\n{\n /** generate all permutations with repetition for the range [0, m) */\n if (nitems == m) {\n (void)test_array(a, nitems, 0); // {0, 0}, {0, 1}, {1, 0}, {1, 1}\n }\n else for (int i = 0; i < m; ++i) {\n a[nitems] = i;\n backtrack(a, m, nitems + 1);\n }\n}\n</code></pre>\n"
},
{
"answer_id": 188791,
"author": "jfs",
"author_id": 4279,
"author_profile": "https://Stackoverflow.com/users/4279",
"pm_score": 0,
"selected": false,
"text": "<h1>A C version of <a href=\"https://stackoverflow.com/questions/177118/algorithm-to-determine-if-array-contains-nnm#177566\">b3's pseudo-code</a></h1>\n\n<p>(to avoid misinterpretation of the pseudo-code)</p>\n\n<p>Counter example: <code>{1, 1, 2, 4, 6, 7, 7}</code>.</p>\n\n<pre><code>int pow_minus_one(int power)\n{\n return (power % 2 == 0) ? 1 : -1;\n}\n\nint ceil_half(int n)\n{\n return n / 2 + (n % 2);\n}\n\nbool isperm_b3_3(int m; int a[m], int m, int n)\n{\n /**\n O(m) in time (single pass), O(1) in space,\n doesn't use n\n possible overflow in sum\n a[] may be readonly\n */\n int altsum = 0;\n int mina = INT_MAX;\n int maxa = INT_MIN;\n\n for (int i = 0; i < m; ++i)\n {\n const int v = a[i] - n + 1; // [n, n+m-1] -> [1, m] to deal with n=0\n if (mina > v)\n mina = v;\n if (maxa < v)\n maxa = v;\n\n altsum += pow_minus_one(v) * v;\n }\n return ((maxa-mina == m-1)\n and ((pow_minus_one(mina + m-1) * ceil_half(mina + m-1)\n - pow_minus_one(mina-1) * ceil_half(mina-1)) == altsum));\n}\n</code></pre>\n"
},
{
"answer_id": 189825,
"author": "jfs",
"author_id": 4279,
"author_profile": "https://Stackoverflow.com/users/4279",
"pm_score": 0,
"selected": false,
"text": "<p>In Python:</p>\n\n<pre><code>def ispermutation(iterable, m, n):\n \"\"\"Whether iterable and the range [n, n+m) have the same elements.\n\n pre-condition: there are no duplicates in the iterable\n \"\"\" \n for i, elem in enumerate(iterable):\n if not n <= elem < n+m:\n return False\n\n return i == m-1\n\nprint(ispermutation([1, 42], 2, 1) == False)\nprint(ispermutation(range(10), 10, 0) == True)\nprint(ispermutation((2, 1, 3), 3, 1) == True)\nprint(ispermutation((2, 1, 3), 3, 0) == False)\nprint(ispermutation((2, 1, 3), 4, 1) == False)\nprint(ispermutation((2, 1, 3), 2, 1) == False)\n</code></pre>\n\n<p>It is O(m) in time and O(1) in space. It does <strong>not</strong> take into account duplicates.</p>\n\n<p>Alternate solution:</p>\n\n<pre><code>def ispermutation(iterable, m, n): \n \"\"\"Same as above.\n\n pre-condition: assert(len(list(iterable)) == m)\n \"\"\"\n return all(n <= elem < n+m for elem in iterable)\n</code></pre>\n"
},
{
"answer_id": 189891,
"author": "caskey",
"author_id": 114986,
"author_profile": "https://Stackoverflow.com/users/114986",
"pm_score": 1,
"selected": false,
"text": "<p>Assuming you know only the length of the array and you are allowed to modify the array it can be done in O(1) space and O(n) time.</p>\n\n<p>The process has two straightforward steps.\n1. \"modulo sort\" the array. [5,3,2,4] => [4,5,2,3] (O(2n))\n2. Check that each value's neighbor is one higher than itself (modulo) (O(n))</p>\n\n<p>All told you need at most 3 passes through the array.</p>\n\n<p>The modulo sort is the 'tricky' part, but the objective is simple. Take each value in the array and store it at its own address (modulo length). This requires one pass through the array, looping over each location 'evicting' its value by swapping it to its correct location and moving in the value at its destination. If you ever move in a value which is congruent to the value you just evicted, you have a duplicate and can exit early.\nWorst case, it's O(2n).</p>\n\n<p>The check is a single pass through the array examining each value with it's next highest neighbor. Always O(n).</p>\n\n<p>Combined algorithm is O(n)+O(2n) = O(3n) = O(n)</p>\n\n<p>Pseudocode from my solution:</p>\n\n<pre>\nforeach(values[]) \n while(values[i] not congruent to i)\n to-be-evicted = values[i]\n evict(values[i]) // swap to its 'proper' location\n if(values[i]%length == to-be-evicted%length)\n return false; // a 'duplicate' arrived when we evicted that number\n end while\nend foreach\nforeach(values[])\n if((values[i]+1)%length != values[i+1]%length)\n return false\nend foreach\n</pre>\n\n<p>I've included the java code proof of concept below, it's not pretty, but it passes all the unit tests I made for it. I call these a 'StraightArray' because they correspond to the poker hand of a straight (contiguous sequence ignoring suit).</p>\n\n<pre><code>public class StraightArray { \n static int evict(int[] a, int i) {\n int t = a[i];\n a[i] = a[t%a.length];\n a[t%a.length] = t;\n return t;\n }\n static boolean isStraight(int[] values) {\n for(int i = 0; i < values.length; i++) {\n while(values[i]%values.length != i) {\n int evicted = evict(values, i);\n if(evicted%values.length == values[i]%values.length) {\n return false;\n }\n }\n }\n for(int i = 0; i < values.length-1; i++) {\n int n = (values[i]%values.length)+1;\n int m = values[(i+1)]%values.length;\n if(n != m) {\n return false;\n }\n }\n return true;\n }\n}\n</code></pre>\n"
},
{
"answer_id": 200107,
"author": "Dave",
"author_id": 27731,
"author_profile": "https://Stackoverflow.com/users/27731",
"pm_score": 2,
"selected": false,
"text": "<p>Any one-pass algorithm requires Omega(n) bits of storage.</p>\n\n<p>Suppose to the contrary that there exists a one-pass algorithm that uses o(n) bits. Because it makes only one pass, it must summarize the first n/2 values in o(n) space. Since there are C(n,n/2) = 2^Theta(n) possible sets of n/2 values drawn from S = {1,...,n}, there exist two distinct sets A and B of n/2 values such that the state of memory is the same after both. If A' = S \\ A is the \"correct\" set of values to complement A, then the algorithm cannot possibly answer correctly for the inputs</p>\n\n<p>A A' - yes</p>\n\n<p>B A' - no</p>\n\n<p>since it cannot distinguish the first case from the second.</p>\n\n<p>Q.E.D.</p>\n"
},
{
"answer_id": 307870,
"author": "lalitm",
"author_id": 28555,
"author_profile": "https://Stackoverflow.com/users/28555",
"pm_score": 0,
"selected": false,
"text": "<p>The Answer from \"nickf\" dows not work if the array is unsorted\nvar_dump(testArray(array(5, 3, 1, 2, 4), 1, 5)); //gives \"duplicates\" !!!!</p>\n\n<p>Also your formula to compute sum([n...n+m-1]) looks incorrect....\nthe correct formula is (m(m+1)/2 - n(n-1)/2)</p>\n"
},
{
"answer_id": 311497,
"author": "jfs",
"author_id": 4279,
"author_profile": "https://Stackoverflow.com/users/4279",
"pm_score": -1,
"selected": false,
"text": "<h1>Linear in time, constant in space solution for <code>int m</code></h1>\n\n<p>Constant space is achieved by exploiting a sign bit. It can be done for any mutable <code>int</code> range if <code>m</code> is less than <code>INT_MAX</code> i.e., when the input range <code>[n, n+m)</code> can be shifted to <code>[1, m+1)</code> range if <code>n</code> is not positive. In practice, the precondition is almost always true if input is mutable.</p>\n\n<pre class=\"lang-c prettyprint-override\"><code>/** gcc -std=c99 ... */\n#include <assert.h>\n#include <iso646.h> // and, or\n#include <limits.h> // INT_MIN\n#include <stdbool.h> // bool\n#include <stdlib.h> // abs()\n\nbool inrange(int m; int a[m], int m, int n)\n{\n /** Whether min(a[]) == n and max(a[]) == n+(m-1)\n */\n if (m == 0) return true; // empty range is a valid range\n\n // check out-of-range values\n int max = INT_MIN, min = INT_MAX;\n for (int i = 0; i < m; ++i) {\n if (min > a[i]) min = a[i];\n if (max < a[i]) max = a[i];\n }\n return (min == n and max == n+(m-1));\n}\n\nbool isperm_minus2(int m; int a[m], int m, int n)\n{\n /** O(m) in time, O(1) in space (for 'typeof(m) == typeof(*a) == int')\n\n Whether a[] is a permutation of the range [n, n+m).\n\n feature: It marks visited items using a sign bit.\n */\n if (not inrange(a, m, n))\n return false; // out of range\n\n assert((INT_MIN - (INT_MIN - 1)) == 1); // check n == INT_MIN\n for (int *p = a; p != &a[m]; ++p) {\n *p -= (n - 1); // [n, n+m) -> [1, m+1)\n assert(*p > 0);\n }\n\n // determine: are there duplicates\n bool has_duplicates = false;\n for (int i = 0; i < m; ++i) {\n const int j = abs(a[i]) - 1;\n assert(j >= 0);\n assert(j < m);\n if (a[j] > 0)\n a[j] *= -1; // mark\n else { // already seen\n has_duplicates = true;\n break;\n }\n }\n\n // restore the array\n for (int *p = a; p != &a[m]; ++p) {\n if (*p < 0) \n *p *= -1; // unmark\n // [1, m+1) -> [n, n+m)\n *p += (n - 1); \n }\n\n return not has_duplicates; // no duplicates? (+ inrange)\n}\n</code></pre>\n"
},
{
"answer_id": 499540,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>An array contains N numbers, and you want to determine whether two of the\nnumbers sum to a given number K. For instance, if the input is 8,4, 1,6 and K is 10,\nthe answer is yes (4 and 6). A number may be used twice. Do the following.\na. Give an O(N2) algorithm to solve this problem.\nb. Give an O(N log N) algorithm to solve this problem. (Hint: Sort the items first.\nAfter doing so, you can solve the problem in linear time.)\nc. Code both solutions and compare the running times of your algorithms.\n4.</p>\n"
},
{
"answer_id": 861093,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<h2>Product of m consecutive numbers is divisible by m! [ m factorial ]</h2>\n\n<hr>\n\n<p>so in one pass you can compute the product of the m numbers, also compute m! and see if the product modulo m ! is zero at the end of the pass</p>\n\n<p>I might be missing something but this is what comes to my mind ...</p>\n\n<p><strong>something like this in python</strong></p>\n\n<p>my_list1 = [9,5,8,7,6]</p>\n\n<p>my_list2 = [3,5,4,7]</p>\n\n<p>def consecutive(my_list):</p>\n\n<pre><code>count = 0\nprod = fact = 1\nfor num in my_list:\n prod *= num\n count +=1 \n fact *= count\nif not prod % fact: \n return 1 \nelse: \n return 0 \n</code></pre>\n\n<p>print consecutive(my_list1)</p>\n\n<p>print consecutive(my_list2)</p>\n\n<hr>\n\n<p>HotPotato ~$ python m_consecutive.py </p>\n\n<p>1</p>\n\n<p>0</p>\n"
},
{
"answer_id": 863653,
"author": "Eric Bainville",
"author_id": 80448,
"author_profile": "https://Stackoverflow.com/users/80448",
"pm_score": 0,
"selected": false,
"text": "<p>I propose the following:</p>\n\n<p>Choose a <em>finite</em> set of prime numbers P_1,P_2,...,P_K, and compute the occurrences of the elements in the input sequence (minus the minimum) modulo each P_i. The pattern of a valid sequence is known.</p>\n\n<p>For example for a sequence of 17 elements, modulo 2 we must have the profile: [9 8], modulo 3: [6 6 5], modulo 5: [4 4 3 3 3], etc.</p>\n\n<p>Combining the test using several bases we obtain a more and more precise probabilistic test. Since the entries are bounded by the integer size, there exists a finite base providing an exact test. This is similar to probabilistic pseudo primality tests.</p>\n\n<pre><code>S_i is an int array of size P_i, initially filled with 0, i=1..K\nM is the length of the input sequence\nMn = INT_MAX\nMx = INT_MIN\n\nfor x in the input sequence:\n for i in 1..K: S_i[x % P_i]++ // count occurrences mod Pi\n Mn = min(Mn,x) // update min\n Mx = max(Mx,x) // and max\n\nif Mx-Mn != M-1: return False // Check bounds\n\nfor i in 1..K:\n // Check profile mod P_i\n Q = M / P_i\n R = M % P_i\n Check S_i[(Mn+j) % P_i] is Q+1 for j=0..R-1 and Q for j=R..P_i-1\n if this test fails, return False\n\nreturn True\n</code></pre>\n"
},
{
"answer_id": 867911,
"author": "xtofl",
"author_id": 6610,
"author_profile": "https://Stackoverflow.com/users/6610",
"pm_score": 0,
"selected": false,
"text": "<p>Any contiguous array [ n, n+1, ..., n+m-1 ] can be mapped on to a 'base' interval [ 0, 1, ..., m ] using the modulo operator. For each i in the interval, there is exactly one i%m in the base interval and vice versa.</p>\n\n<p>Any contiguous array also has a 'span' m (maximum - minimum + 1) equal to it's size.</p>\n\n<p>Using these facts, you can create an \"encountered\" boolean array of same size containing all falses initially, and while visiting the input array, put their related \"encountered\" elements to true.</p>\n\n<p>This algorithm is O(n) in space, O(n) in time, and checks for duplicates.</p>\n\n<pre><code>def contiguous( values )\n #initialization\n encountered = Array.new( values.size, false )\n min, max = nil, nil\n visited = 0\n\n values.each do |v|\n\n index = v % encountered.size\n\n if( encountered[ index ] )\n return \"duplicates\"; \n end\n\n encountered[ index ] = true\n min = v if min == nil or v < min\n max = v if max == nil or v > max \n visited += 1\n end\n\n if ( max - min + 1 != values.size ) or visited != values.size\n return \"hole\"\n else\n return \"contiguous\"\n end\n\nend\n\ntests = [ \n[ false, [ 2,4,5,6 ] ], \n[ false, [ 10,11,13,14 ] ] , \n[ true , [ 20,21,22,23 ] ] , \n[ true , [ 19,20,21,22,23 ] ] ,\n[ true , [ 20,21,22,23,24 ] ] ,\n[ false, [ 20,21,22,23,24+5 ] ] ,\n[ false, [ 2,2,3,4,5 ] ]\n]\n\ntests.each do |t|\n result = contiguous( t[1] )\n if( t[0] != ( result == \"contiguous\" ) )\n puts \"Failed Test : \" + t[1].to_s + \" returned \" + result\n end\nend\n</code></pre>\n"
},
{
"answer_id": 1009632,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>I like Greg Hewgill's idea of Radix sorting. To find duplicates, you can sort in O(N) time given the constraints on the values in this array.</p>\n\n<p>For an in-place O(1) space O(N) time that restores the original ordering of the list, you don't have to do an actual swap on that number; you can just mark it with a flag:</p>\n\n<pre><code>//Java: assumes all numbers in arr > 1\nboolean checkArrayConsecutiveRange(int[] arr) {\n\n// find min/max\nint min = arr[0]; int max = arr[0]\nfor (int i=1; i<arr.length; i++) {\n min = (arr[i] < min ? arr[i] : min);\n max = (arr[i] > max ? arr[i] : max);\n}\nif (max-min != arr.length) return false;\n\n// flag and check\nboolean ret = true;\nfor (int i=0; i<arr.length; i++) {\n int targetI = Math.abs(arr[i])-min;\n if (arr[targetI] < 0) {\n ret = false; \n break;\n }\n arr[targetI] = -arr[targetI];\n}\nfor (int i=0; i<arr.length; i++) {\n arr[i] = Math.abs(arr[i]);\n}\n\nreturn ret;\n}\n</code></pre>\n\n<p>Storing the flags inside the given array is kind of cheating, and doesn't play well with parallelization. I'm still trying to think of a way to do it without touching the array in O(N) time and O(log N) space. Checking against the sum and against the sum of least squares (arr[i] - arr.length/2.0)^2 feels like it might work. The one defining characteristic we know about a 0...m array with no duplicates is that it's uniformly distributed; we should just check that.</p>\n\n<p>Now if only I could prove it.</p>\n\n<p>I'd like to note that the solution above involving factorial takes O(N) space to store the factorial itself. N! > 2^N, which takes N bytes to store. </p>\n"
},
{
"answer_id": 2878096,
"author": "erisco",
"author_id": 260584,
"author_profile": "https://Stackoverflow.com/users/260584",
"pm_score": 0,
"selected": false,
"text": "<p>Oops! I got caught up in a duplicate question and did not see the already identical solutions here. And I thought I'd finally done something original! Here is a historical archive of when I was slightly more pleased:</p>\n\n<hr>\n\n<p>Well, I have no certainty if this algorithm satisfies all conditions. In fact, I haven't even validated that it works beyond a couple test cases I have tried. Even if my algorithm does have problems, hopefully my approach sparks some solutions.</p>\n\n<p>This algorithm, to my knowledge, works in constant memory and scans the array three times. Perhaps an added bonus is that it works for the full range of integers, if that wasn't part of the original problem.</p>\n\n<p>I am not much of a pseudo-code person, and I really think the code might simply make more sense than words. Here is an implementation I wrote in PHP. Take heed of the comments.</p>\n\n<pre><code>function is_permutation($ints) {\n\n /* Gather some meta-data. These scans can\n be done simultaneously */\n $lowest = min($ints);\n $length = count($ints);\n\n $max_index = $length - 1;\n\n $sort_run_count = 0;\n\n /* I do not have any proof that running this sort twice\n will always completely sort the array (of course only\n intentionally happening if the array is a permutation) */\n\n while ($sort_run_count < 2) {\n\n for ($i = 0; $i < $length; ++$i) {\n\n $dest_index = $ints[$i] - $lowest;\n\n if ($i == $dest_index) {\n continue;\n }\n\n if ($dest_index > $max_index) {\n return false;\n }\n\n if ($ints[$i] == $ints[$dest_index]) {\n return false;\n }\n\n $temp = $ints[$dest_index];\n $ints[$dest_index] = $ints[$i];\n $ints[$i] = $temp;\n\n }\n\n ++$sort_run_count;\n\n }\n\n return true;\n\n}\n</code></pre>\n"
},
{
"answer_id": 2885916,
"author": "MSN",
"author_id": 6210,
"author_profile": "https://Stackoverflow.com/users/6210",
"pm_score": 0,
"selected": false,
"text": "<p>So there is an algorithm that takes O(n^2) that does not require modifying the input array and takes constant space.</p>\n\n<p>First, assume that you know <code>n</code> and <code>m</code>. This is a linear operation, so it does not add any additional complexity. Next, assume there exists one element equal to <code>n</code> and one element equal to <code>n+m-1</code> and all the rest are in <code>[n, n+m)</code>. Given that, we can reduce the problem to having an array with elements in <code>[0, m)</code>.</p>\n\n<p>Now, since we know that the elements are bounded by the size of the array, we can treat each element as a node with a single link to another element; in other words, the array describes a directed graph. In this directed graph, if there are no duplicate elements, every node belongs to a cycle, that is, a node is reachable from itself in <code>m</code> or less steps. If there is a duplicate element, then there exists one node that is not reachable from itself at all.</p>\n\n<p>So, to detect this, you walk the entire array from start to finish and determine if each element returns to itself in <code><=m</code> steps. If any element is not reachable in <code><=m</code> steps, then you have a duplicate and can return false. Otherwise, when you finish visiting all elements, you can return true:</p>\n\n<pre><code>for (int start_index= 0; start_index<m; ++start_index)\n{\n int steps= 1;\n int current_element_index= arr[start_index];\n while (steps<m+1 && current_element_index!=start_index)\n {\n current_element_index= arr[current_element_index];\n ++steps;\n }\n\n if (steps>m)\n {\n return false;\n }\n}\n\nreturn true;\n</code></pre>\n\n<p>You can optimize this by storing additional information: </p>\n\n<ol>\n<li>Record sum of the length of the cycle from each element, unless the cycle visits an element before that element, call it <code>sum_of_steps</code>.</li>\n<li>For every element, only step <code>m-sum_of_steps</code> nodes out. If you don't return to the starting element and you don't visit an element before the starting element, you have found a loop containing duplicate elements and can return <code>false</code>.</li>\n</ol>\n\n<p>This is still O(n^2), e.g. <code>{1, 2, 3, 0, 5, 6, 7, 4}</code>, but it's a little bit faster.</p>\n"
},
{
"answer_id": 3336509,
"author": "ignoramous",
"author_id": 402375,
"author_profile": "https://Stackoverflow.com/users/402375",
"pm_score": 1,
"selected": false,
"text": "<h2>Hazzen's algorithm implementation in C</h2>\n\n<pre><code>#include<stdio.h>\n\n#define swapxor(a,i,j) a[i]^=a[j];a[j]^=a[i];a[i]^=a[j];\n\nint check_ntom(int a[], int n, int m) {\n int i = 0, j = 0;\n for(i = 0; i < m; i++) {\n if(a[i] < n || a[i] >= n+m) return 0; //invalid entry\n j = a[i] - n;\n while(j != i) {\n if(a[i]==a[j]) return -1; //bucket already occupied. Dupe.\n swapxor(a, i, j); //faster bitwise swap\n j = a[i] - n;\n if(a[i]>=n+m) return 0; //[NEW] invalid entry\n }\n }\n return 200; //OK\n}\n\nint main() {\n int n=5, m=5;\n int a[] = {6, 5, 7, 9, 8};\n int r = check_ntom(a, n, m);\n printf(\"%d\", r);\n return 0;\n}\n</code></pre>\n\n<p><strong>Edit: change made to the code to eliminate illegal memory access.</strong></p>\n"
},
{
"answer_id": 7860115,
"author": "Vibhaj",
"author_id": 941691,
"author_profile": "https://Stackoverflow.com/users/941691",
"pm_score": -1,
"selected": false,
"text": "<p>I suppose the question boils down to ensuring that </p>\n\n<pre><code>(maximum - minimum + 1) == array_size\n</code></pre>\n\n<p>and this can obviously be done in O(N) time and O(1) space as follows :</p>\n\n<pre><code>int check_range(int input[], int N){\n int max = -INFINITY, min = INFINITY, i;\n for(i=0; i<N; i++){\n if(input[i] < min) min=input[i];\n if(input[i] > max) max=input[i];\n }\n return (max - min + 1) == N;\n}\n</code></pre>\n\n<p>Note that this approach takes care of possibility of duplicates. \nPlease report any discrepancy in the solution.</p>\n"
},
{
"answer_id": 8888883,
"author": "yvette",
"author_id": 1153036,
"author_profile": "https://Stackoverflow.com/users/1153036",
"pm_score": 1,
"selected": false,
"text": "<pre><code>boolean determineContinuousArray(int *arr, int len)\n{\n // Suppose the array is like below:\n //int arr[10] = {7,11,14,9,8,100,12,5,13,6};\n //int len = sizeof(arr)/sizeof(int);\n\n int n = arr[0];\n\n int *result = new int[len];\n for(int i=0; i< len; i++)\n result[i] = -1;\n for (int i=0; i < len; i++)\n {\n int cur = arr[i];\n int hold ;\n if ( arr[i] < n){\n n = arr[i];\n }\n while(true){\n if ( cur - n >= len){\n cout << \"array index out of range: meaning this is not a valid array\" << endl;\n return false;\n }\n else if ( result[cur - n] != cur){\n hold = result[cur - n];\n result[cur - n] = cur;\n if (hold == -1) break;\n cur = hold;\n\n }else{\n cout << \"found duplicate number \" << cur << endl;\n return false;\n }\n\n }\n }\n cout << \"this is a valid array\" << endl;\n for(int j=0 ; j< len; j++)\n cout << result[j] << \",\" ;\n cout << endl;\n return true;\n}\n</code></pre>\n"
},
{
"answer_id": 21698030,
"author": "Vikram Bhat",
"author_id": 2661290,
"author_profile": "https://Stackoverflow.com/users/2661290",
"pm_score": 0,
"selected": false,
"text": "<p>Here is a solution in O(N) time and O(1) extra space for finding duplicates :- </p>\n\n<pre><code>public static boolean check_range(int arr[],int n,int m) {\n\n for(int i=0;i<m;i++) {\n arr[i] = arr[i] - n;\n if(arr[i]>=m)\n return(false);\n }\n\n System.out.println(\"In range\");\n\n int j=0;\n while(j<m) {\n System.out.println(j);\n if(arr[j]<m) {\n\n if(arr[arr[j]]<m) {\n\n int t = arr[arr[j]];\n arr[arr[j]] = arr[j] + m;\n arr[j] = t;\n if(j==arr[j]) {\n\n arr[j] = arr[j] + m;\n j++;\n }\n\n }\n\n else return(false);\n\n }\n\n else j++;\n\n }\n</code></pre>\n\n<p><strong>Explanation:-</strong> </p>\n\n<blockquote>\n <ol>\n <li>Bring number to range (0,m-1) by arr[i] = arr[i] - n if out of range return false.</li>\n <li>for each i check if arr[arr[i]] is unoccupied that is it has value less than m</li>\n <li>if so swap(arr[i],arr[arr[i]]) and arr[arr[i]] = arr[arr[i]] + m to signal that it is occupied</li>\n <li>if arr[j] = j and simply add m and increment j</li>\n <li>if arr[arr[j]] >=m means it is occupied hence current value is duplicate hence return false.</li>\n <li>if arr[j] >= m then skip</li>\n </ol>\n</blockquote>\n"
},
{
"answer_id": 68717286,
"author": "maraca",
"author_id": 4785110,
"author_profile": "https://Stackoverflow.com/users/4785110",
"pm_score": 0,
"selected": false,
"text": "<p>There is a simple solution doing it in one pass with O(1) space if the numbers are positive:</p>\n<pre><code>int max = arr[0];\nint min = arr[0];\nfor (int i = 0; i < n; i++) {\n int x = abs(arr[i]);\n int y = x % n;\n if (arr[y] < 0)\n return false;\n arr[y] = -arr[y];\n if (x > max)\n max = x;\n else if (x < min)\n min = x;\n}\nreturn max - min == n - 1;\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177118",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/658/"
] |
I saw this question on Reddit, and there were no positive solutions presented, and I thought it would be a perfect question to ask here. This was in a thread about interview questions:
>
> Write a method that takes an int array of size m, and returns (True/False) if the array consists of the numbers n...n+m-1, all numbers in that range and only numbers in that range. The array is not guaranteed to be sorted. (For instance, {2,3,4} would return true. {1,3,1} would return false, {1,2,4} would return false.
>
>
> The problem I had with this one is that my interviewer kept asking me to optimize (faster O(n), less memory, etc), to the point where he claimed you could do it in one pass of the array using a constant amount of memory. Never figured that one out.
>
>
>
Along with your solutions please indicate if they assume that the array contains unique items. Also indicate if your solution assumes the sequence starts at 1. (I've modified the question slightly to allow cases where it goes 2, 3, 4...)
**edit:** I am now of the opinion that there does not exist a linear in time and constant in space algorithm that handles duplicates. Can anyone verify this?
The duplicate problem boils down to testing to see if the array contains duplicates in O(n) time, O(1) space. If this can be done you can simply test first and if there are no duplicates run the algorithms posted. So can you test for dupes in O(n) time O(1) space?
|
Under the assumption numbers less than one are not allowed and there are no duplicates, there is a simple summation identity for this - the sum of numbers from `1` to `m` in increments of `1` is `(m * (m + 1)) / 2`. You can then sum the array and use this identity.
You can find out if there is a dupe under the above guarantees, plus the guarantee no number is above m or less than n (which can be checked in `O(N)`)
The idea in pseudo-code:
0) Start at N = 0
1) Take the N-th element in the list.
2) If it is not in the right place if the list had been sorted, check where it should be.
3) If the place where it should be already has the same number, you have a dupe - RETURN TRUE
4) Otherwise, swap the numbers (to put the first number in the right place).
5) With the number you just swapped with, is it in the right place?
6) If no, go back to step two.
7) Otherwise, start at step one with N = N + 1. If this would be past the end of the list, you have no dupes.
And, yes, that runs in `O(N)` although it may look like `O(N ^ 2)`
Note to everyone (stuff collected from comments)
------------------------------------------------
This solution works under the assumption you can modify the array, then uses in-place Radix sort (which achieves `O(N)` speed).
Other mathy-solutions have been put forth, but I'm not sure any of them have been proved. There are a bunch of sums that might be useful, but most of them run into a blowup in the number of bits required to represent the sum, which will violate the constant extra space guarantee. I also don't know if any of them are capable of producing a distinct number for a given set of numbers. I think a sum of squares might work, which has a known formula to compute it (see [Wolfram's](http://mathworld.wolfram.com/PowerSum.html))
New insight (well, more of musings that don't help solve it but are interesting and I'm going to bed):
------------------------------------------------------------------------------------------------------
So, it has been mentioned to maybe use sum + sum of squares. No one knew if this worked or not, and I realized that it only becomes an issue when (x + y) = (n + m), such as the fact 2 + 2 = 1 + 3. Squares also have this issue thanks to [Pythagorean triples](http://en.wikipedia.org/wiki/Pythagorean_triple) (so 3^2 + 4^2 + 25^2 == 5^2 + 7^2 + 24^2, and the sum of squares doesn't work). If we use [Fermat's last theorem](http://en.wikipedia.org/wiki/Fermat%27s_Last_Theorem), we know this can't happen for n^3. But we also don't know if there is no x + y + z = n for this (unless we do and I don't know it). So no guarantee this, too, doesn't break - and if we continue down this path we quickly run out of bits.
In my glee, however, I forgot to note that you can break the sum of squares, but in doing so you create a normal sum that isn't valid. I don't think you can do both, but, as has been noted, we don't have a proof either way.
---
I must say, finding counterexamples is sometimes a lot easier than proving things! Consider the following sequences, all of which have a sum of 28 and a sum of squares of 140:
```
[1, 2, 3, 4, 5, 6, 7]
[1, 1, 4, 5, 5, 6, 6]
[2, 2, 3, 3, 4, 7, 7]
```
I could not find any such examples of length 6 or less. If you want an example that has the proper min and max values too, try this one of length 8:
```
[1, 3, 3, 4, 4, 5, 8, 8]
```
---
Simpler approach (modifying hazzen's idea):
-------------------------------------------
An integer array of length m contains all the numbers from n to n+m-1 exactly once iff
* every array element is between n and n+m-1
* there are no duplicates
(Reason: there are only m values in the given integer range, so if the array contains m unique values in this range, it must contain every one of them once)
If you are allowed to modify the array, you can check both in one pass through the list with a modified version of hazzen's algorithm idea (there is no need to do any summation):
* For all array indexes i from 0 to m-1 do
1. If array[i] < n or array[i] >= n+m => RETURN FALSE ("value out of range found")
2. Calculate j = array[i] - n (this is the 0-based position of array[i] in a *sorted* array with values from n to n+m-1)
3. While j is not equal to i
1. If list[i] is equal to list[j] => RETURN FALSE ("duplicate found")
2. Swap list[i] with list[j]
3. Recalculate j = array[i] - n
* RETURN TRUE
I'm not sure if the modification of the original array counts against the maximum allowed additional space of O(1), but if it doesn't this should be the solution the original poster wanted.
|
177,133 |
<p>I am trying to override the DataGridViewTextBoxCell's paint method in a derived class so that I can indent the foreground text by some variable amount of pixels. I would like it if the width of the column adjusts so that its total width is the length of my cells text plus the "buffer" indent. Does anyone know of a way to accomplish this? My lame implementation is listed below:</p>
<pre><code>public class MyTextBoxCell : DataGridViewTextBoxCell{ ....
protected override void Paint(Graphics graphics, Rectangle clipBounds, Rectangle cellBounds, int rowIndex, DataGridViewElementStates cellState, object value, object formattedValue, string errorText, DataGridViewCellStyle cellStyle, DataGridViewAdvancedBorderStyle advancedBorderStyle, DataGridViewPaintParts paintParts) {
clipBounds.Inflate(100, 0);
DataGridViewPaintParts pp = DataGridViewPaintParts.Background | DataGridViewPaintParts.Border | DataGridViewPaintParts.ContentBackground
| DataGridViewPaintParts.ErrorIcon;
base.Paint(graphics, clipBounds, cellBounds, rowIndex, cellState, value, formattedValue, errorText, cellStyle, advancedBorderStyle, pp);
string text = formattedValue as string;
//My lame attempt to indent 20 pixels??
TextRenderer.DrawText(graphics, text, cellStyle.Font, new Point(cellBounds.Location.X + 20, cellBounds.Location.Y), cellStyle.SelectionForeColor ,TextFormatFlags.EndEllipsis);
}
</code></pre>
<p>}</p>
|
[
{
"answer_id": 177184,
"author": "BFree",
"author_id": 15861,
"author_profile": "https://Stackoverflow.com/users/15861",
"pm_score": 2,
"selected": false,
"text": "<p>You can just hook up to the CellFormattingEvent in the datagridview and do your formatting there. Or, if you're inherting from the DataGridView, you can just override the OnCellFormatting method. The code would look something like this:</p>\n\n<pre><code> if (e.ColumnIndex == 1)\n {\n string val = (string)e.Value;\n e.Value = String.Format(\" {0}\", val);\n e.FormattingApplied = true;\n }\n</code></pre>\n\n<p>Just some rough code, but you get the idea.</p>\n"
},
{
"answer_id": 180289,
"author": "sbeskur",
"author_id": 10446,
"author_profile": "https://Stackoverflow.com/users/10446",
"pm_score": 2,
"selected": false,
"text": "<p>Well I think I have it. In case anyone is interested here is the code below:</p>\n\n<pre><code>public class MyTextBoxCell : DataGridViewTextBoxCell{ ....\n private static readonly int INDENTCOEFFICIENT = 5;\n protected override Size GetPreferredSize(Graphics graphics, DataGridViewCellStyle cellStyle, int rowIndex, Size constraintSize) {\n int indent = ((MyRow)OwningRow).Indent * INDENTCOEFFICIENT;\n Size s = base.GetPreferredSize(graphics, cellStyle, rowIndex, constraintSize);\n int textWidth = 2; //arbitrary amount\n if (Value != null) {\n string text = Value as string;\n textWidth = TextRenderer.MeasureText(text, cellStyle.Font).Width;\n }\n\n s.Width += textWidth + indent;\n return s;\n }\n\n private static readonly StringFormat strFmt = new StringFormat(StringFormatFlags.NoWrap);\n\n protected override void Paint(Graphics graphics, Rectangle clipBounds, Rectangle cellBounds, int rowIndex, DataGridViewElementStates cellState, object value, object formattedValue, string errorText, DataGridViewCellStyle cellStyle, DataGridViewAdvancedBorderStyle advancedBorderStyle, DataGridViewPaintParts paintParts) {\n\n DataGridViewPaintParts pp = DataGridViewPaintParts.Background | DataGridViewPaintParts.Border | DataGridViewPaintParts.ContentBackground\n | DataGridViewPaintParts.ErrorIcon;\n\n base.Paint(graphics, clipBounds, cellBounds, rowIndex, cellState, value, formattedValue, errorText, cellStyle, advancedBorderStyle, pp);\n\n string text = formattedValue as string;\n\n int indent = ((MyRow)OwningRow).Indent * INDENTCOEFFICIENT;\n strFmt.Trimming = StringTrimming.EllipsisCharacter;\n Rectangle r = cellBounds;\n r.Offset(indent, 0);\n r.Inflate(-indent, 0);\n graphics.DrawString(text, cellStyle.Font, Brushes.Black, r, strFmt);\n }\n\n}\n</code></pre>\n\n<p>If anyone has a better way I would love to see your solution.</p>\n"
},
{
"answer_id": 180467,
"author": "Vivek",
"author_id": 7418,
"author_profile": "https://Stackoverflow.com/users/7418",
"pm_score": 2,
"selected": true,
"text": "<p>If you are trying to auto-size the columns (depending on size of the cell contents) then you should look at <code>Column.AutoSizeMode</code> property and <code>Column.DefaultCellStyle</code> property.</p>\n\n<pre><code>static const int INDENTCOEFF = 5;\nDataGridViewCellStyle cellStyle = new DataGridViewCellStyle();\n\ncellStyle.Padding = \n new Padding(INDENTCOEFF , 5, INDENTCOEFF , 5); //left,top,right,bottom\nMyColumn.DefaultCellStyle = cellStyle;\nMyColumn.AutoSizeMode = DataGridViewAutoSizeColumnMode.AllCells;\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177133",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10446/"
] |
I am trying to override the DataGridViewTextBoxCell's paint method in a derived class so that I can indent the foreground text by some variable amount of pixels. I would like it if the width of the column adjusts so that its total width is the length of my cells text plus the "buffer" indent. Does anyone know of a way to accomplish this? My lame implementation is listed below:
```
public class MyTextBoxCell : DataGridViewTextBoxCell{ ....
protected override void Paint(Graphics graphics, Rectangle clipBounds, Rectangle cellBounds, int rowIndex, DataGridViewElementStates cellState, object value, object formattedValue, string errorText, DataGridViewCellStyle cellStyle, DataGridViewAdvancedBorderStyle advancedBorderStyle, DataGridViewPaintParts paintParts) {
clipBounds.Inflate(100, 0);
DataGridViewPaintParts pp = DataGridViewPaintParts.Background | DataGridViewPaintParts.Border | DataGridViewPaintParts.ContentBackground
| DataGridViewPaintParts.ErrorIcon;
base.Paint(graphics, clipBounds, cellBounds, rowIndex, cellState, value, formattedValue, errorText, cellStyle, advancedBorderStyle, pp);
string text = formattedValue as string;
//My lame attempt to indent 20 pixels??
TextRenderer.DrawText(graphics, text, cellStyle.Font, new Point(cellBounds.Location.X + 20, cellBounds.Location.Y), cellStyle.SelectionForeColor ,TextFormatFlags.EndEllipsis);
}
```
}
|
If you are trying to auto-size the columns (depending on size of the cell contents) then you should look at `Column.AutoSizeMode` property and `Column.DefaultCellStyle` property.
```
static const int INDENTCOEFF = 5;
DataGridViewCellStyle cellStyle = new DataGridViewCellStyle();
cellStyle.Padding =
new Padding(INDENTCOEFF , 5, INDENTCOEFF , 5); //left,top,right,bottom
MyColumn.DefaultCellStyle = cellStyle;
MyColumn.AutoSizeMode = DataGridViewAutoSizeColumnMode.AllCells;
```
|
177,154 |
<p>I'm trying to create an instance of a class at run time. The classes I'm trying to create all inherit from a base class, ConfigMgrObj, and are named <code>ConfigMgr_xxxxxx</code> e.g. <code>ConfigMgr_Collection</code>. They all take a special object that I'm calling oController and a string as arguments.</p>
<p>This is the line I'm using to do it, where ClassToGet is a string that contains the name of the class e.g. <code>ConfigMgr_Collection</code>.</p>
<pre><code>object oNewObject = System.Activator.CreateInstance(null, "StackOverflowNamespace." + ClassToGet, new object[] { oController, ClassToGet });
</code></pre>
<p>This throws a TypeLoadException exception. What's up with it?</p>
|
[
{
"answer_id": 177159,
"author": "Matt Hamilton",
"author_id": 615,
"author_profile": "https://Stackoverflow.com/users/615",
"pm_score": 4,
"selected": true,
"text": "<p>Are the types you're trying to instantiate actually declared within the same assembly? Passing null as the first parameter is telling Activator that the types live in the current assembly.</p>\n"
},
{
"answer_id": 177164,
"author": "jop",
"author_id": 11830,
"author_profile": "https://Stackoverflow.com/users/11830",
"pm_score": 0,
"selected": false,
"text": "<p>Looks like it did not find the the class named <code>\"StackOverflowNamespace.\"+ClassToGet</code> in the current assembly.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177154",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5133/"
] |
I'm trying to create an instance of a class at run time. The classes I'm trying to create all inherit from a base class, ConfigMgrObj, and are named `ConfigMgr_xxxxxx` e.g. `ConfigMgr_Collection`. They all take a special object that I'm calling oController and a string as arguments.
This is the line I'm using to do it, where ClassToGet is a string that contains the name of the class e.g. `ConfigMgr_Collection`.
```
object oNewObject = System.Activator.CreateInstance(null, "StackOverflowNamespace." + ClassToGet, new object[] { oController, ClassToGet });
```
This throws a TypeLoadException exception. What's up with it?
|
Are the types you're trying to instantiate actually declared within the same assembly? Passing null as the first parameter is telling Activator that the types live in the current assembly.
|
177,161 |
<p>I need to get just the first item (actually, just the first key) off a rather large associative array in JavaScript. Here's how I'm doing it currently (using jQuery):</p>
<pre><code>getKey = function (data) {
var firstKey;
$.each(data, function (key, val) {
firstKey = key;
return false;
});
return firstKey;
};
</code></pre>
<p>Just guessing, but I'd say there's got to be a better (read: more efficient) way of doing this. Any suggestions?</p>
<p>UPDATE: Thanks for the insightful answers and comments! I had forgotten my JavaScript 101, wherein the spec says you're not guaranteed a particular order in an associative array. It's interesting, though, that most browsers do implement it that way. I'd prefer not to sort the array before getting that first key, but it may be unavoidable given my use case.</p>
|
[
{
"answer_id": 177191,
"author": "Jonathan Lonowski",
"author_id": 15031,
"author_profile": "https://Stackoverflow.com/users/15031",
"pm_score": 7,
"selected": true,
"text": "<p>There isn't really a <strong>first</strong> or <strong>last</strong> element in associative arrays (i.e. objects). The only order you can hope to acquire is the order the elements were saved by the parser -- and no guarantees for consistency with that.</p>\n\n<p>But, if you want <strong><em>the first to come up</em></strong>, the classic manner might actually be a bit easier:</p>\n\n<pre><code>function getKey(data) {\n for (var prop in data)\n return prop;\n}\n</code></pre>\n\n<p>Want to avoid inheritance properties?</p>\n\n<pre><code>function getKey(data) {\n for (var prop in data)\n if (data.propertyIsEnumerable(prop))\n return prop;\n}\n</code></pre>\n"
},
{
"answer_id": 13179330,
"author": "dmnc",
"author_id": 904846,
"author_profile": "https://Stackoverflow.com/users/904846",
"pm_score": 2,
"selected": false,
"text": "<p>In addition to Jonathan's solution, we can also extend the default array functionality:</p>\n\n<pre><code>Array.prototype.getKey = function() {\n for (var prop in this)\n if (this.propertyIsEnumerable(prop))\n return prop;\n}\n</code></pre>\n"
},
{
"answer_id": 26617955,
"author": "Erik Anderson",
"author_id": 130614,
"author_profile": "https://Stackoverflow.com/users/130614",
"pm_score": 6,
"selected": false,
"text": "<p>You can avoid having to create a function by referencing the first entry returned from <code>Object.keys()</code>:</p>\n\n<pre><code>var firstKey = Object.keys(data)[0];\n</code></pre>\n\n<p>For the first entry from a sorted key list, simply add a call to the <code>.sort()</code> method:</p>\n\n<pre><code>var firstKey = Object.keys(data).sort()[0];\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177161",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11577/"
] |
I need to get just the first item (actually, just the first key) off a rather large associative array in JavaScript. Here's how I'm doing it currently (using jQuery):
```
getKey = function (data) {
var firstKey;
$.each(data, function (key, val) {
firstKey = key;
return false;
});
return firstKey;
};
```
Just guessing, but I'd say there's got to be a better (read: more efficient) way of doing this. Any suggestions?
UPDATE: Thanks for the insightful answers and comments! I had forgotten my JavaScript 101, wherein the spec says you're not guaranteed a particular order in an associative array. It's interesting, though, that most browsers do implement it that way. I'd prefer not to sort the array before getting that first key, but it may be unavoidable given my use case.
|
There isn't really a **first** or **last** element in associative arrays (i.e. objects). The only order you can hope to acquire is the order the elements were saved by the parser -- and no guarantees for consistency with that.
But, if you want ***the first to come up***, the classic manner might actually be a bit easier:
```
function getKey(data) {
for (var prop in data)
return prop;
}
```
Want to avoid inheritance properties?
```
function getKey(data) {
for (var prop in data)
if (data.propertyIsEnumerable(prop))
return prop;
}
```
|
177,188 |
<p>I'm not talking about a post build event for a project. Rather, I want to run an executable automatically after the entire solution is built. Is there a way to do a post build event for the solution?</p>
|
[
{
"answer_id": 177194,
"author": "shoosh",
"author_id": 9611,
"author_profile": "https://Stackoverflow.com/users/9611",
"pm_score": 2,
"selected": false,
"text": "<p>not directly.<br>\nyou can make a project which has a dependency in all other projects and add a post build step to it. Effectively this will cause it to run after everything else.</p>\n"
},
{
"answer_id": 177243,
"author": "Ryan Lundy",
"author_id": 5486,
"author_profile": "https://Stackoverflow.com/users/5486",
"pm_score": 6,
"selected": true,
"text": "<h2>Visual Studio 2010 and before</h2>\n\n<p>You can do this in the Macro Editor by handling OnBuildDone. The event gives you a couple of handy properties you can check: scope (project/solution/batch) and action (build/rebuild/clean/deploy). To do what you want would be something like this (not tested, mind):</p>\n\n<pre><code>Public Sub AfterBuild(scope As vsBuildScope, action As vsBuildAction) _\n Handles BuildEvents.OnBuildDone\n If scope = vsBuildScope.vsBuildScopeSolution Then\n System.Diagnostics.Process.Start(\"some file I want to run\")\n End If\nEnd Sub\n</code></pre>\n\n<h2>Visual Studio 2012</h2>\n\n<p>The solution above won't work in Visual Studio 2012 because Microsoft has removed macros in that version. However, you can still do essentially the same thing with an add-in. To see how, go here:</p>\n\n<p><a href=\"https://stackoverflow.com/questions/12027485/alternative-to-macros-in-visual-studio-2012/12394986#12394986\">Alternative to Macros in Visual Studio 2012</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177188",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5469/"
] |
I'm not talking about a post build event for a project. Rather, I want to run an executable automatically after the entire solution is built. Is there a way to do a post build event for the solution?
|
Visual Studio 2010 and before
-----------------------------
You can do this in the Macro Editor by handling OnBuildDone. The event gives you a couple of handy properties you can check: scope (project/solution/batch) and action (build/rebuild/clean/deploy). To do what you want would be something like this (not tested, mind):
```
Public Sub AfterBuild(scope As vsBuildScope, action As vsBuildAction) _
Handles BuildEvents.OnBuildDone
If scope = vsBuildScope.vsBuildScopeSolution Then
System.Diagnostics.Process.Start("some file I want to run")
End If
End Sub
```
Visual Studio 2012
------------------
The solution above won't work in Visual Studio 2012 because Microsoft has removed macros in that version. However, you can still do essentially the same thing with an add-in. To see how, go here:
[Alternative to Macros in Visual Studio 2012](https://stackoverflow.com/questions/12027485/alternative-to-macros-in-visual-studio-2012/12394986#12394986)
|
177,240 |
<p>Lets just say you have a table in Oracle:</p>
<pre><code>CREATE TABLE person (
id NUMBER PRIMARY KEY,
given_names VARCHAR2(50),
surname VARCHAR2(50)
);
</code></pre>
<p>with these function-based indices:</p>
<pre><code>CREATE INDEX idx_person_upper_given_names ON person (UPPER(given_names));
CREATE INDEX idx_person_upper_last_name ON person (UPPER(last_name));
</code></pre>
<p>Now, given_names has no NULL values but for argument's sake last_name does. If I do this:</p>
<pre><code>SELECT * FROM person WHERE UPPER(given_names) LIKE 'P%'
</code></pre>
<p>the explain plan tells me its using the index but change it to:</p>
<pre><code>SELECT * FROM person WHERE UPPER(last_name) LIKE 'P%'
</code></pre>
<p>it doesn't. The Oracle docs say that to use the function-based index will only be used when several conditions are met, one of which is ensuring there are no NULL values since they aren't indexed.</p>
<p>I've tried these queries:</p>
<pre><code>SELECT * FROM person WHERE UPPER(last_name) LIKE 'P%' AND UPPER(last_name) IS NOT NULL
</code></pre>
<p>and</p>
<pre><code>SELECT * FROM person WHERE UPPER(last_name) LIKE 'P%' AND last_name IS NOT NULL
</code></pre>
<p>In the latter case I even added an index on last_name but no matter what I try it uses a full table scan. Assuming I can't get rid of the NULL values, how do I get this query to use the index on UPPER(last_name)?</p>
|
[
{
"answer_id": 177304,
"author": "CaptainPicard",
"author_id": 15203,
"author_profile": "https://Stackoverflow.com/users/15203",
"pm_score": 2,
"selected": false,
"text": "<p>In your example you've created the same index twice - this would give an error so I'm assuming that was a mistake in pasting, not the actual code you tried.</p>\n\n<p>I tried it with</p>\n\n<pre><code>CREATE INDEX idx_person_upper_surname ON person (UPPER(surname));\n\nSELECT * FROM person WHERE UPPER(surname) LIKE 'P%';\n</code></pre>\n\n<p>and it produced the expected query plan:</p>\n\n<pre><code>Execution Plan\n----------------------------------------------------------\n 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1 Card=1 Bytes=67)\n 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'PERSON' (TABLE) (Cost=1\n Card=1 Bytes=67)\n\n 2 1 INDEX (RANGE SCAN) OF 'IDX_PERSON_UPPER_SURNAME' (INDEX)\n (Cost=1 Card=1)\n</code></pre>\n\n<p>To answer your question, yes it should work. Try double checking that you do have the second index created correctly.</p>\n\n<p>Also try an explicit hint:</p>\n\n<pre><code>SELECT /*+INDEX(PERSON IDX_PERSON_UPPER_SURNAME)*/ * \nFROM person \nWHERE UPPER(surname) LIKE 'P%';\n</code></pre>\n\n<p>If that works, but only with the hint, then it is likely related to CBO statistics gone wrong, or CBO related init parameters.</p>\n"
},
{
"answer_id": 177318,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Are you sure you want the index to be used? Full table scans are not bad. Depending on the size of the table, it might be more efficient to do a table scan than use an index. It also depends on the density and distribution of the data, which is why statistics are gathered. The cost based optimizer can usually be trusted to make the right choice. Unless you have a specific performance problem, I wouldn't worry too much about it.</p>\n"
},
{
"answer_id": 177765,
"author": "Tony Andrews",
"author_id": 18747,
"author_profile": "https://Stackoverflow.com/users/18747",
"pm_score": 4,
"selected": true,
"text": "<p>The index can be used, though the optimiser may have chosen not to use it for your particular example:</p>\n\n<pre><code>SQL> create table my_objects\n 2 as select object_id, object_name\n 3 from all_objects;\n\nTable created.\n\nSQL> select count(*) from my_objects;\n 2 /\n\n COUNT(*)\n----------\n 83783\n\n\nSQL> alter table my_objects modify object_name null;\n\nTable altered.\n\nSQL> update my_objects\n 2 set object_name=null\n 3 where object_name like 'T%';\n\n1305 rows updated.\n\nSQL> create index my_objects_name on my_objects (lower(object_name));\n\nIndex created.\n\nSQL> set autotrace traceonly\n\nSQL> select * from my_objects\n 2 where lower(object_name) like 'emp%';\n\n29 rows selected.\n\n\nExecution Plan\n----------------------------------------------------------\n\n------------------------------------------------------------------------------------\n| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|\n------------------------------------------------------------------------------------\n| 0 | SELECT STATEMENT | | 17 | 510 | 355 (1)|\n| 1 | TABLE ACCESS BY INDEX ROWID| MY_OBJECTS | 17 | 510 | 355 (1)|\n|* 2 | INDEX RANGE SCAN | MY_OBJECTS_NAME | 671 | | 6 (0)|\n------------------------------------------------------------------------------------\n</code></pre>\n\n<p>The documentation you read was presumably pointing out that, just like any other index, all-null keys are not stored in the index.</p>\n"
},
{
"answer_id": 177957,
"author": "David Aldridge",
"author_id": 6742,
"author_profile": "https://Stackoverflow.com/users/6742",
"pm_score": 0,
"selected": false,
"text": "<p>You can circumvent the problem of null values being unindexed in this or other situations by also indexing based on a literal value:</p>\n\n<pre><code>CREATE INDEX idx_person_upper_surname ON person (UPPER(surname),0);\n</code></pre>\n\n<p>This allows you to use the index for such queries as:</p>\n\n<pre><code>Select *\nFrom person\nWhere UPPER(surname) is null;\n</code></pre>\n\n<p>This query would normally not usa an index, except for bitmap indexes or indexes including a nonnullable real column other than surname.</p>\n"
},
{
"answer_id": 178175,
"author": "Nick Pierpoint",
"author_id": 4003,
"author_profile": "https://Stackoverflow.com/users/4003",
"pm_score": 0,
"selected": false,
"text": "<p>Oracle will still use a function-based indexes with columns that contain null - I think you misinterpreted the documentation.</p>\n\n<p>You need to put a nvl in the function index if you want to check for this though.</p>\n\n<p>Something like...</p>\n\n<pre><code>create index idx_person_upper_surname on person (nvl(upper(surname),'N/A'));\n</code></pre>\n\n<p>You can then query using the index with</p>\n\n<pre><code>select * from person where nvl(upper(surname),'N/A') = 'PIERPOINT'\n</code></pre>\n\n<p>Although, all a bit ugly. Since most people have surnames, perhaps a \"not null\" is appropriate :-).</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177240",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18393/"
] |
Lets just say you have a table in Oracle:
```
CREATE TABLE person (
id NUMBER PRIMARY KEY,
given_names VARCHAR2(50),
surname VARCHAR2(50)
);
```
with these function-based indices:
```
CREATE INDEX idx_person_upper_given_names ON person (UPPER(given_names));
CREATE INDEX idx_person_upper_last_name ON person (UPPER(last_name));
```
Now, given\_names has no NULL values but for argument's sake last\_name does. If I do this:
```
SELECT * FROM person WHERE UPPER(given_names) LIKE 'P%'
```
the explain plan tells me its using the index but change it to:
```
SELECT * FROM person WHERE UPPER(last_name) LIKE 'P%'
```
it doesn't. The Oracle docs say that to use the function-based index will only be used when several conditions are met, one of which is ensuring there are no NULL values since they aren't indexed.
I've tried these queries:
```
SELECT * FROM person WHERE UPPER(last_name) LIKE 'P%' AND UPPER(last_name) IS NOT NULL
```
and
```
SELECT * FROM person WHERE UPPER(last_name) LIKE 'P%' AND last_name IS NOT NULL
```
In the latter case I even added an index on last\_name but no matter what I try it uses a full table scan. Assuming I can't get rid of the NULL values, how do I get this query to use the index on UPPER(last\_name)?
|
The index can be used, though the optimiser may have chosen not to use it for your particular example:
```
SQL> create table my_objects
2 as select object_id, object_name
3 from all_objects;
Table created.
SQL> select count(*) from my_objects;
2 /
COUNT(*)
----------
83783
SQL> alter table my_objects modify object_name null;
Table altered.
SQL> update my_objects
2 set object_name=null
3 where object_name like 'T%';
1305 rows updated.
SQL> create index my_objects_name on my_objects (lower(object_name));
Index created.
SQL> set autotrace traceonly
SQL> select * from my_objects
2 where lower(object_name) like 'emp%';
29 rows selected.
Execution Plan
----------------------------------------------------------
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 17 | 510 | 355 (1)|
| 1 | TABLE ACCESS BY INDEX ROWID| MY_OBJECTS | 17 | 510 | 355 (1)|
|* 2 | INDEX RANGE SCAN | MY_OBJECTS_NAME | 671 | | 6 (0)|
------------------------------------------------------------------------------------
```
The documentation you read was presumably pointing out that, just like any other index, all-null keys are not stored in the index.
|
177,241 |
<p>I know how to load themes dynamically when they are stored locally. Is it possible to store theses themes in the database yet still apply them programmatically as described in referenced MSDN article?</p>
<p>Also - If you do store them in the filesystem, is it possible to change the path of the App_Themes directory to a different location? Like Amazon S3?</p>
<p><a href="http://msdn.microsoft.com/en-us/library/tx35bd89.aspx" rel="nofollow noreferrer">Apply Themes Programattically</a></p>
|
[
{
"answer_id": 177304,
"author": "CaptainPicard",
"author_id": 15203,
"author_profile": "https://Stackoverflow.com/users/15203",
"pm_score": 2,
"selected": false,
"text": "<p>In your example you've created the same index twice - this would give an error so I'm assuming that was a mistake in pasting, not the actual code you tried.</p>\n\n<p>I tried it with</p>\n\n<pre><code>CREATE INDEX idx_person_upper_surname ON person (UPPER(surname));\n\nSELECT * FROM person WHERE UPPER(surname) LIKE 'P%';\n</code></pre>\n\n<p>and it produced the expected query plan:</p>\n\n<pre><code>Execution Plan\n----------------------------------------------------------\n 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1 Card=1 Bytes=67)\n 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'PERSON' (TABLE) (Cost=1\n Card=1 Bytes=67)\n\n 2 1 INDEX (RANGE SCAN) OF 'IDX_PERSON_UPPER_SURNAME' (INDEX)\n (Cost=1 Card=1)\n</code></pre>\n\n<p>To answer your question, yes it should work. Try double checking that you do have the second index created correctly.</p>\n\n<p>Also try an explicit hint:</p>\n\n<pre><code>SELECT /*+INDEX(PERSON IDX_PERSON_UPPER_SURNAME)*/ * \nFROM person \nWHERE UPPER(surname) LIKE 'P%';\n</code></pre>\n\n<p>If that works, but only with the hint, then it is likely related to CBO statistics gone wrong, or CBO related init parameters.</p>\n"
},
{
"answer_id": 177318,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Are you sure you want the index to be used? Full table scans are not bad. Depending on the size of the table, it might be more efficient to do a table scan than use an index. It also depends on the density and distribution of the data, which is why statistics are gathered. The cost based optimizer can usually be trusted to make the right choice. Unless you have a specific performance problem, I wouldn't worry too much about it.</p>\n"
},
{
"answer_id": 177765,
"author": "Tony Andrews",
"author_id": 18747,
"author_profile": "https://Stackoverflow.com/users/18747",
"pm_score": 4,
"selected": true,
"text": "<p>The index can be used, though the optimiser may have chosen not to use it for your particular example:</p>\n\n<pre><code>SQL> create table my_objects\n 2 as select object_id, object_name\n 3 from all_objects;\n\nTable created.\n\nSQL> select count(*) from my_objects;\n 2 /\n\n COUNT(*)\n----------\n 83783\n\n\nSQL> alter table my_objects modify object_name null;\n\nTable altered.\n\nSQL> update my_objects\n 2 set object_name=null\n 3 where object_name like 'T%';\n\n1305 rows updated.\n\nSQL> create index my_objects_name on my_objects (lower(object_name));\n\nIndex created.\n\nSQL> set autotrace traceonly\n\nSQL> select * from my_objects\n 2 where lower(object_name) like 'emp%';\n\n29 rows selected.\n\n\nExecution Plan\n----------------------------------------------------------\n\n------------------------------------------------------------------------------------\n| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|\n------------------------------------------------------------------------------------\n| 0 | SELECT STATEMENT | | 17 | 510 | 355 (1)|\n| 1 | TABLE ACCESS BY INDEX ROWID| MY_OBJECTS | 17 | 510 | 355 (1)|\n|* 2 | INDEX RANGE SCAN | MY_OBJECTS_NAME | 671 | | 6 (0)|\n------------------------------------------------------------------------------------\n</code></pre>\n\n<p>The documentation you read was presumably pointing out that, just like any other index, all-null keys are not stored in the index.</p>\n"
},
{
"answer_id": 177957,
"author": "David Aldridge",
"author_id": 6742,
"author_profile": "https://Stackoverflow.com/users/6742",
"pm_score": 0,
"selected": false,
"text": "<p>You can circumvent the problem of null values being unindexed in this or other situations by also indexing based on a literal value:</p>\n\n<pre><code>CREATE INDEX idx_person_upper_surname ON person (UPPER(surname),0);\n</code></pre>\n\n<p>This allows you to use the index for such queries as:</p>\n\n<pre><code>Select *\nFrom person\nWhere UPPER(surname) is null;\n</code></pre>\n\n<p>This query would normally not usa an index, except for bitmap indexes or indexes including a nonnullable real column other than surname.</p>\n"
},
{
"answer_id": 178175,
"author": "Nick Pierpoint",
"author_id": 4003,
"author_profile": "https://Stackoverflow.com/users/4003",
"pm_score": 0,
"selected": false,
"text": "<p>Oracle will still use a function-based indexes with columns that contain null - I think you misinterpreted the documentation.</p>\n\n<p>You need to put a nvl in the function index if you want to check for this though.</p>\n\n<p>Something like...</p>\n\n<pre><code>create index idx_person_upper_surname on person (nvl(upper(surname),'N/A'));\n</code></pre>\n\n<p>You can then query using the index with</p>\n\n<pre><code>select * from person where nvl(upper(surname),'N/A') = 'PIERPOINT'\n</code></pre>\n\n<p>Although, all a bit ugly. Since most people have surnames, perhaps a \"not null\" is appropriate :-).</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177241",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/12442/"
] |
I know how to load themes dynamically when they are stored locally. Is it possible to store theses themes in the database yet still apply them programmatically as described in referenced MSDN article?
Also - If you do store them in the filesystem, is it possible to change the path of the App\_Themes directory to a different location? Like Amazon S3?
[Apply Themes Programattically](http://msdn.microsoft.com/en-us/library/tx35bd89.aspx)
|
The index can be used, though the optimiser may have chosen not to use it for your particular example:
```
SQL> create table my_objects
2 as select object_id, object_name
3 from all_objects;
Table created.
SQL> select count(*) from my_objects;
2 /
COUNT(*)
----------
83783
SQL> alter table my_objects modify object_name null;
Table altered.
SQL> update my_objects
2 set object_name=null
3 where object_name like 'T%';
1305 rows updated.
SQL> create index my_objects_name on my_objects (lower(object_name));
Index created.
SQL> set autotrace traceonly
SQL> select * from my_objects
2 where lower(object_name) like 'emp%';
29 rows selected.
Execution Plan
----------------------------------------------------------
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 17 | 510 | 355 (1)|
| 1 | TABLE ACCESS BY INDEX ROWID| MY_OBJECTS | 17 | 510 | 355 (1)|
|* 2 | INDEX RANGE SCAN | MY_OBJECTS_NAME | 671 | | 6 (0)|
------------------------------------------------------------------------------------
```
The documentation you read was presumably pointing out that, just like any other index, all-null keys are not stored in the index.
|
177,258 |
<p>Please can someone help me make sense of the Batch madness?</p>
<p>I'm trying to debug an Axapta 3.0 implementation that has about 50 Batch Jobs. Most of the batched classes do not implement the <strong><code>description()</code></strong> method, so when you look at the <em>Batch List</em> form (Basic>>Inquiries>>Batch list) the description field is blank. You can see the <strong>Batch Group</strong> and the <strong>Start Time</strong>, etc. but you can't tell which class is actually being called.</p>
<p>The <em>Batch</em> table contains a hidden field called <em>ClassNum</em> which identifies the <em>ID</em> property of the class. Can anyone tell me how I can find the corresponding class from the ID? Once I've identified the culprits I can add descriptions.</p>
<p>I tried using the standard <em>Find</em> function on the AOT but it doesn't pick them up. </p>
<p>Any suggestions would be most welcome!</p>
<p>Many thanks,
Mike</p>
|
[
{
"answer_id": 177357,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>Jay's answer provides two comprehensive solutions. </p>\n\n<p>I've just discovered that the global class <strong>ClassId2Name</strong> does the same thing, so you can simply have:</p>\n\n<pre><code>display str Classname()\n{\n return ClassId2Name(this.ClassNum); \n}\n</code></pre>\n"
},
{
"answer_id": 179362,
"author": "Jay Hofacker",
"author_id": 535,
"author_profile": "https://Stackoverflow.com/users/535",
"pm_score": 2,
"selected": false,
"text": "<p>There atleast two ways to do this, you can use the <code>DictClass</code> class:</p>\n\n<pre><code>display ClassName className()\n{\n DictClass dictClass = new DictClass(this.ClassNum);\n ;\n if(dictClass!=null)\n return dictClass.name();\n return '';\n}\n</code></pre>\n\n<p>Or using the <code>UtilIdElements</code> table:</p>\n\n<pre><code>display ClassName className()\n{\n UtilIdElements utilIdElements;\n ;\n select utilIdElements where utilIdElements.id==this.ClassNum && utilIdElements.recordType==UtilElementType::Class;\n if(utilIdElements)\n return utilIdElements.name;\n return '';\n}\n</code></pre>\n"
},
{
"answer_id": 66544243,
"author": "Roger Manich",
"author_id": 6548256,
"author_profile": "https://Stackoverflow.com/users/6548256",
"pm_score": 0,
"selected": false,
"text": "<p>Alternative to get ClassName if ClassNum is not available.</p>\n<pre><code>display str Classname()\n{\n return classId2Name(ClassIdGet(this)); \n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177258",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
Please can someone help me make sense of the Batch madness?
I'm trying to debug an Axapta 3.0 implementation that has about 50 Batch Jobs. Most of the batched classes do not implement the **`description()`** method, so when you look at the *Batch List* form (Basic>>Inquiries>>Batch list) the description field is blank. You can see the **Batch Group** and the **Start Time**, etc. but you can't tell which class is actually being called.
The *Batch* table contains a hidden field called *ClassNum* which identifies the *ID* property of the class. Can anyone tell me how I can find the corresponding class from the ID? Once I've identified the culprits I can add descriptions.
I tried using the standard *Find* function on the AOT but it doesn't pick them up.
Any suggestions would be most welcome!
Many thanks,
Mike
|
Jay's answer provides two comprehensive solutions.
I've just discovered that the global class **ClassId2Name** does the same thing, so you can simply have:
```
display str Classname()
{
return ClassId2Name(this.ClassNum);
}
```
|
177,271 |
<p>Can anyone provide some pseudo code for a roulette selection function? How would I implement this:</p>
<p><img src="https://upload.wikimedia.org/math/0/d/2/0d24a82d8e813380f670bf80ae74486b.png" alt="alt text"></p>
<p>I don't really understand how to read this math notation. I never took any probability or statistics.</p>
|
[
{
"answer_id": 177278,
"author": "Jarod Elliott",
"author_id": 1061,
"author_profile": "https://Stackoverflow.com/users/1061",
"pm_score": 6,
"selected": true,
"text": "<p>It's been a few years since i've done this myself, however the following pseudo code was found easily enough on google.</p>\n\n<pre>\nfor all members of population\n sum += fitness of this individual\nend for\n\nfor all members of population\n probability = sum of probabilities + (fitness / sum)\n sum of probabilities += probability\nend for\n\nloop until new population is full\n do this twice\n number = Random between 0 and 1\n for all members of population\n if number > probability but less than next probability \n then you have been selected\n end for\n end\n create offspring\nend loop\n</pre>\n\n<p>The site where this came from can be found <a href=\"http://geneticalgorithms.ai-depot.com/Tutorial/Overview.html\" rel=\"noreferrer\">here</a> if you need further details.</p>\n"
},
{
"answer_id": 391712,
"author": "Wartin",
"author_id": 48778,
"author_profile": "https://Stackoverflow.com/users/48778",
"pm_score": 3,
"selected": false,
"text": "<p>Here is some code in C :</p>\n\n<pre><code>// Find the sum of fitnesses. The function fitness(i) should \n//return the fitness value for member i**\n\nfloat sumFitness = 0.0f;\nfor (int i=0; i < nmembers; i++)\n sumFitness += fitness(i);\n\n// Get a floating point number in the interval 0.0 ... sumFitness**\nfloat randomNumber = (float(rand() % 10000) / 9999.0f) * sumFitness;\n\n// Translate this number to the corresponding member**\nint memberID=0;\nfloat partialSum=0.0f;\n\nwhile (randomNumber > partialSum)\n{\n partialSum += fitness(memberID);\n memberID++;\n} \n\n**// We have just found the member of the population using the roulette algorithm**\n**// It is stored in the \"memberID\" variable**\n**// Repeat this procedure as many times to find random members of the population**\n</code></pre>\n"
},
{
"answer_id": 3995038,
"author": "deceleratedcaviar",
"author_id": 431528,
"author_profile": "https://Stackoverflow.com/users/431528",
"pm_score": 2,
"selected": false,
"text": "<p>From the above answer, I got the following, which was clearer to me than the answer itself.</p>\n\n<p>To give an example:</p>\n\n<p>Random(sum) :: Random(12)\nIterating through the population, we check the following: random < sum</p>\n\n<p>Let us chose 7 as the random number.</p>\n\n<pre><code>Index | Fitness | Sum | 7 < Sum\n0 | 2 | 2 | false\n1 | 3 | 5 | false\n2 | 1 | 6 | false\n3 | 4 | 10 | true\n4 | 2 | 12 | ...\n</code></pre>\n\n<p>Through this example, the most fit (Index 3) has the highest percentage of being chosen (33%); as the random number only has to land within 6->10, and it will be chosen.</p>\n\n<pre><code> for (unsigned int i=0;i<sets.size();i++) {\n sum += sets[i].eval();\n } \n double rand = (((double)rand() / (double)RAND_MAX) * sum);\n sum = 0;\n for (unsigned int i=0;i<sets.size();i++) {\n sum += sets[i].eval();\n if (rand < sum) {\n //breed i\n break;\n }\n }\n</code></pre>\n"
},
{
"answer_id": 5315710,
"author": "noio",
"author_id": 224949,
"author_profile": "https://Stackoverflow.com/users/224949",
"pm_score": 4,
"selected": false,
"text": "<p>The pseudocode posted contained some unclear elements, and it adds the complexity of generating <em>offspring</em> in stead of performing pure selection. Here is a simple python implementation of that pseudocode:</p>\n\n<pre><code>def roulette_select(population, fitnesses, num):\n \"\"\" Roulette selection, implemented according to:\n <http://stackoverflow.com/questions/177271/roulette\n -selection-in-genetic-algorithms/177278#177278>\n \"\"\"\n total_fitness = float(sum(fitnesses))\n rel_fitness = [f/total_fitness for f in fitnesses]\n # Generate probability intervals for each individual\n probs = [sum(rel_fitness[:i+1]) for i in range(len(rel_fitness))]\n # Draw new population\n new_population = []\n for n in xrange(num):\n r = rand()\n for (i, individual) in enumerate(population):\n if r <= probs[i]:\n new_population.append(individual)\n break\n return new_population\n</code></pre>\n"
},
{
"answer_id": 5888841,
"author": "flavour404",
"author_id": 109614,
"author_profile": "https://Stackoverflow.com/users/109614",
"pm_score": -1,
"selected": false,
"text": "<p>I wrote a version in C# and am really looking for confirmation that it is indeed correct:</p>\n\n<p>(roulette_selector is a random number which will be in the range 0.0 to 1.0)</p>\n\n<pre><code>private Individual Select_Roulette(double sum_fitness)\n {\n Individual ret = new Individual();\n bool loop = true;\n\n while (loop)\n {\n //this will give us a double within the range 0.0 to total fitness\n double slice = roulette_selector.NextDouble() * sum_fitness;\n\n double curFitness = 0.0;\n\n foreach (Individual ind in _generation)\n {\n curFitness += ind.Fitness;\n if (curFitness >= slice)\n {\n loop = false;\n ret = ind;\n break;\n }\n }\n }\n return ret;\n\n }\n</code></pre>\n"
},
{
"answer_id": 8463663,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 4,
"selected": false,
"text": "<p>Lots of correct solutions already, but I think this code is clearer.</p>\n\n<pre><code>def select(fs):\n p = random.uniform(0, sum(fs))\n for i, f in enumerate(fs):\n if p <= 0:\n break\n p -= f\n return i\n</code></pre>\n\n<p>In addition, if you accumulate the fs, you can produce a more efficient solution.</p>\n\n<pre><code>cfs = [sum(fs[:i+1]) for i in xrange(len(fs))]\n\ndef select(cfs):\n return bisect.bisect_left(cfs, random.uniform(0, cfs[-1]))\n</code></pre>\n\n<p>This is both faster and it's extremely concise code. STL in C++ has a similar bisection algorithm available if that's the language you're using.</p>\n"
},
{
"answer_id": 10786568,
"author": "Kangwon Lee",
"author_id": 1162135,
"author_profile": "https://Stackoverflow.com/users/1162135",
"pm_score": 1,
"selected": false,
"text": "<p>Prof. Thrun of Stanford AI lab also presented a fast(er?) re-sampling code in python during his CS373 of Udacity. Google search result led to the following link: </p>\n\n<p><a href=\"http://www.udacity-forums.com/cs373/questions/20194/fast-resampling-algorithm\" rel=\"nofollow\">http://www.udacity-forums.com/cs373/questions/20194/fast-resampling-algorithm</a></p>\n\n<p>Hope this helps</p>\n"
},
{
"answer_id": 10949834,
"author": "NickD",
"author_id": 1320066,
"author_profile": "https://Stackoverflow.com/users/1320066",
"pm_score": 1,
"selected": false,
"text": "<p>Here's a compact java implementation I wrote recently for roulette selection, hopefully of use.</p>\n\n<pre><code>public static gene rouletteSelection()\n{\n float totalScore = 0;\n float runningScore = 0;\n for (gene g : genes)\n {\n totalScore += g.score;\n }\n\n float rnd = (float) (Math.random() * totalScore);\n\n for (gene g : genes)\n { \n if ( rnd>=runningScore &&\n rnd<=runningScore+g.score)\n {\n return g;\n }\n runningScore+=g.score;\n }\n\n return null;\n}\n</code></pre>\n"
},
{
"answer_id": 22479118,
"author": "kiaGh",
"author_id": 3419171,
"author_profile": "https://Stackoverflow.com/users/3419171",
"pm_score": 0,
"selected": false,
"text": "<pre><code>Based on my research ,Here is another implementation in C# if there is a need for it:\n\n\n//those with higher fitness get selected wit a large probability \n//return-->individuals with highest fitness\n private int RouletteSelection()\n {\n double randomFitness = m_random.NextDouble() * m_totalFitness;\n int idx = -1;\n int mid;\n int first = 0;\n int last = m_populationSize -1;\n mid = (last - first)/2;\n\n // ArrayList's BinarySearch is for exact values only\n // so do this by hand.\n while (idx == -1 && first <= last)\n {\n if (randomFitness < (double)m_fitnessTable[mid])\n {\n last = mid;\n }\n else if (randomFitness > (double)m_fitnessTable[mid])\n {\n first = mid;\n }\n mid = (first + last)/2;\n // lies between i and i+1\n if ((last - first) == 1)\n idx = last;\n }\n return idx;\n }\n</code></pre>\n"
},
{
"answer_id": 23264253,
"author": "manlio",
"author_id": 3235496,
"author_profile": "https://Stackoverflow.com/users/3235496",
"pm_score": 3,
"selected": false,
"text": "<p>This is called roulette-wheel selection via stochastic acceptance:</p>\n\n<pre><code>/// \\param[in] f_max maximum fitness of the population\n///\n/// \\return index of the selected individual\n///\n/// \\note Assuming positive fitness. Greater is better.\n\nunsigned rw_selection(double f_max)\n{\n for (;;)\n {\n // Select randomly one of the individuals\n unsigned i(random_individual());\n\n // The selection is accepted with probability fitness(i) / f_max\n if (uniform_random_01() < fitness(i) / f_max)\n return i;\n } \n}\n</code></pre>\n\n<p>The average number of attempts needed for a single selection is:</p>\n\n<p>τ = f<sub>max</sub> / avg(f)</p>\n\n<ul>\n<li>f<sub>max</sub> is the maximum fitness of the population</li>\n<li>avg(f) is the average fitness</li>\n</ul>\n\n<p>τ doesn't depend explicitly on the number of individual in the population (N), but the ratio can change with N.</p>\n\n<p>However in many application (where the fitness remains bounded and the average fitness doesn't diminish to 0 for increasing N) τ doesn't increase unboundedly with N and thus <strong>a typical complexity of this algorithm is O(1)</strong> (roulette wheel selection using search algorithms has O(N) or O(log N) complexity).</p>\n\n<p>The probability distribution of this procedure is indeed the same as in the classical roulette-wheel selection.</p>\n\n<p>For further details see:</p>\n\n<ul>\n<li><em>Roulette-wheel selection via stochastic acceptance</em> (Adam Liposki, Dorota Lipowska - 2011)</li>\n</ul>\n"
},
{
"answer_id": 35013768,
"author": "Setu Kumar Basak",
"author_id": 4299527,
"author_profile": "https://Stackoverflow.com/users/4299527",
"pm_score": 1,
"selected": false,
"text": "<p><strong>Roulette Wheel Selection in MatLab:</strong></p>\n\n<pre><code>TotalFitness=sum(Fitness);\n ProbSelection=zeros(PopLength,1);\n CumProb=zeros(PopLength,1);\n\n for i=1:PopLength\n ProbSelection(i)=Fitness(i)/TotalFitness;\n if i==1\n CumProb(i)=ProbSelection(i);\n else\n CumProb(i)=CumProb(i-1)+ProbSelection(i);\n end\n end\n\n SelectInd=rand(PopLength,1);\n\n for i=1:PopLength\n flag=0;\n for j=1:PopLength\n if(CumProb(j)<SelectInd(i) && CumProb(j+1)>=SelectInd(i))\n SelectedPop(i,1:IndLength)=CurrentPop(j+1,1:IndLength);\n flag=1;\n break;\n end\n end\n if(flag==0)\n SelectedPop(i,1:IndLength)=CurrentPop(1,1:IndLength);\n end\n end\n</code></pre>\n"
},
{
"answer_id": 42492888,
"author": "Evgenia Karunus",
"author_id": 3192470,
"author_profile": "https://Stackoverflow.com/users/3192470",
"pm_score": 1,
"selected": false,
"text": "<p>Okay, so there are 2 methods for <strong>roulette wheel selection</strong> implementation: <strong>Usual</strong> and <strong>Stochastic Acceptance</strong> one.</p>\n\n<p><strong>Usual</strong> algorithm: </p>\n\n<pre class=\"lang-rb prettyprint-override\"><code># there will be some amount of repeating organisms here.\nmating_pool = []\n\nall_organisms_in_population.each do |organism|\n organism.fitness.times { mating_pool.push(organism) }\nend\n\n# [very_fit_organism, very_fit_organism, very_fit_organism, not_so_fit_organism]\nreturn mating_pool.sample #=> random, likely fit, parent!\n</code></pre>\n\n<p><strong>Stochastic Acceptance</strong> algorithm:</p>\n\n<pre class=\"lang-rb prettyprint-override\"><code>max_fitness_in_population = all_organisms_in_population.sort_by(:fitness)[0]\nloop do\n random_parent = all_organisms_in_population.sample\n probability = random_parent.fitness/max_fitness_in_population * 100\n # if random_parent's fitness is 90%,\n # it's very likely that rand(100) is smaller than it.\n if rand(100) < probability\n return random_parent #=> random, likely fit, parent!\n else\n next #=> or let's keep on searching for one.\n end\nend\n</code></pre>\n\n<p>You can choose either, they will be returning identical results.</p>\n\n<hr>\n\n<h3>Useful resources:</h3>\n\n<p><a href=\"http://natureofcode.com/book/chapter-9-the-evolution-of-code\" rel=\"nofollow noreferrer\">http://natureofcode.com/book/chapter-9-the-evolution-of-code</a> - a beginner-friendly and clear chapter on genetic algorithms. explains <strong>roulette wheel selection</strong> as a bucket of wooden letters (the more As you put in - the great is the chance of picking an A, <strong>Usual</strong> algorithm). </p>\n\n<p><a href=\"https://en.wikipedia.org/wiki/Fitness_proportionate_selection\" rel=\"nofollow noreferrer\">https://en.wikipedia.org/wiki/Fitness_proportionate_selection</a> - describes <strong>Stochastic Acceptance</strong> algorithm.</p>\n"
},
{
"answer_id": 53402623,
"author": "Pat Niemeyer",
"author_id": 74975,
"author_profile": "https://Stackoverflow.com/users/74975",
"pm_score": 0,
"selected": false,
"text": "<p>This <strong>Swift 4</strong> array extension implements weighted random selection, a.k.a Roulette selection from its elements:</p>\n\n<pre><code>public extension Array where Element == Double {\n\n /// Consider the elements as weight values and return a weighted random selection by index.\n /// a.k.a Roulette wheel selection.\n func weightedRandomIndex() -> Int {\n var selected: Int = 0\n var total: Double = self[0]\n\n for i in 1..<self.count { // start at 1\n total += self[i]\n if( Double.random(in: 0...1) <= (self[i] / total)) { selected = i }\n }\n\n return selected\n }\n}\n</code></pre>\n\n<p>For example given the two element array:</p>\n\n<pre><code>[0.9, 0.1]\n</code></pre>\n\n<p><code>weightedRandomIndex()</code> will return zero 90% of the time and one 10% of the time.</p>\n\n<p>Here is a more complete test:</p>\n\n<pre><code>let weights = [0.1, 0.7, 0.1, 0.1]\nvar results = [Int:Int]()\nlet n = 100000\nfor _ in 0..<n {\n let index = weights.weightedRandomIndex()\n results[index] = results[index, default:0] + 1\n}\nfor (key,val) in results.sorted(by: { a,b in weights[a.key] < weights[b.key] }) {\n print(weights[key], Double(val)/Double(n))\n}\n</code></pre>\n\n<p>output:</p>\n\n<pre><code>0.1 0.09906\n0.1 0.10126\n0.1 0.09876\n0.7 0.70092\n</code></pre>\n\n<p>This answer is basically the same as Andrew Mao's answer here:\n<a href=\"https://stackoverflow.com/a/15582983/74975\">https://stackoverflow.com/a/15582983/74975</a></p>\n"
},
{
"answer_id": 61955345,
"author": "Thieu Nguyen",
"author_id": 5408129,
"author_profile": "https://Stackoverflow.com/users/5408129",
"pm_score": 0,
"selected": false,
"text": "<p>Here is the code in python. This code can also handle the negative value of fitness.</p>\n\n<pre><code>from numpy import min, sum, ptp, array \nfrom numpy.random import uniform \n\nlist_fitness1 = array([-12, -45, 0, 72.1, -32.3])\nlist_fitness2 = array([0.5, 6.32, 988.2, 1.23])\n\ndef get_index_roulette_wheel_selection(list_fitness=None):\n \"\"\" It can handle negative also. Make sure your list fitness is 1D-numpy array\"\"\"\n scaled_fitness = (list_fitness - min(list_fitness)) / ptp(list_fitness)\n minimized_fitness = 1.0 - scaled_fitness\n total_sum = sum(minimized_fitness)\n r = uniform(low=0, high=total_sum)\n for idx, f in enumerate(minimized_fitness):\n r = r + f\n if r > total_sum:\n return idx\n\nget_index_roulette_wheel_selection(list_fitness1)\nget_index_roulette_wheel_selection(list_fitness2)\n</code></pre>\n\n<ol>\n<li>Make sure your fitness list is 1D-numpy array </li>\n<li>Scaled the fitness list to the range [0, 1]</li>\n<li>Transform maximum problem to minimum problem by 1.0 - scaled_fitness_list</li>\n<li>Random a number between 0 and sum(minimizzed_fitness_list)</li>\n<li>Keep adding element in minimized fitness list until we get the value greater than the total sum </li>\n<li>You can see if the fitness is small --> it has bigger value in minimized_fitness --> It has a bigger chance to add and make the value greater than the total sum.</li>\n</ol>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177271",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/577/"
] |
Can anyone provide some pseudo code for a roulette selection function? How would I implement this:
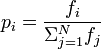
I don't really understand how to read this math notation. I never took any probability or statistics.
|
It's been a few years since i've done this myself, however the following pseudo code was found easily enough on google.
```
for all members of population
sum += fitness of this individual
end for
for all members of population
probability = sum of probabilities + (fitness / sum)
sum of probabilities += probability
end for
loop until new population is full
do this twice
number = Random between 0 and 1
for all members of population
if number > probability but less than next probability
then you have been selected
end for
end
create offspring
end loop
```
The site where this came from can be found [here](http://geneticalgorithms.ai-depot.com/Tutorial/Overview.html) if you need further details.
|
177,277 |
<p>I have a TreeView control in my WinForms .NET application that has multiple levels of childnodes that have childnodes with more childnodes, with no defined depth. When a user selects any parent node (not necessarily at the root level), how can I get a list of all the nodes beneith that parent node?</p>
<p>For example, I started off with this:</p>
<pre><code>Dim nodes As List(Of String)
For Each childNodeLevel1 As TreeNode In parentNode.Nodes
For Each childNodeLevel2 As TreeNode In childNodeLevel1.Nodes
For Each childNodeLevel3 As TreeNode In childNodeLevel2.Nodes
nodes.Add(childNodeLevel3.Text)
Next
Next
Next
</code></pre>
<p>The problem is that this loop depth is defined and I'm only getting nodes burried down three levels. What if next time the user selects a parent node, there are seven levels?</p>
|
[
{
"answer_id": 177282,
"author": "Steven A. Lowe",
"author_id": 9345,
"author_profile": "https://Stackoverflow.com/users/9345",
"pm_score": 4,
"selected": false,
"text": "<p>you need a recursive function to do this [or a loop equivalent, but the recursive version is simpler] - pseudocode:</p>\n\n<pre><code>function outputNodes(Node root)\n writeln(root.Text)\n foreach(Node n in root.ChildNodes)\n outputNodes(n)\n end\nend\n</code></pre>\n"
},
{
"answer_id": 177289,
"author": "jop",
"author_id": 11830,
"author_profile": "https://Stackoverflow.com/users/11830",
"pm_score": 5,
"selected": true,
"text": "<p>Use recursion</p>\n\n<pre><code>Function GetChildren(parentNode as TreeNode) as List(Of String)\n Dim nodes as List(Of String) = New List(Of String)\n GetAllChildren(parentNode, nodes)\n return nodes\nEnd Function\n\nSub GetAllChildren(parentNode as TreeNode, nodes as List(Of String))\n For Each childNode as TreeNode in parentNode.Nodes\n nodes.Add(childNode.Text)\n GetAllChildren(childNode, nodes)\n Next\nEnd Sub\n</code></pre>\n"
},
{
"answer_id": 590437,
"author": "Adrian Regan",
"author_id": 120545,
"author_profile": "https://Stackoverflow.com/users/120545",
"pm_score": 4,
"selected": false,
"text": "<p>Here is a snippet of code that I use to perform this task from my core library.<br>\nIt allows you to list the nodes either depth first or breath first without the use of recursion, which has the overhead of constructing stackframes in the JIT engine. Its very fast.</p>\n\n<p>To use it simply go:</p>\n\n<pre><code>List< TreeNode > nodes = TreeViewUtils.FlattenDepth(tree);\n</code></pre>\n\n<p>Sorry, you have a VB.Net tag; I can't give an example, but I'm sure you'll work it out.</p>\n\n<pre class=\"lang-cs prettyprint-override\"><code>public class TreeViewUtils\n{\n /// <summary>\n /// This static utiltiy method flattens all the nodes in a tree view using\n /// a queue based breath first search rather than the overhead\n /// of recursive method calls.\n /// </summary>\n /// <param name=\"tree\"></param>\n /// <returns></returns>\n public static List<TreeNode> FlattenBreath(TreeView tree) {\n List<TreeNode> nodes = new List<TreeNode>();\n\n Queue<TreeNode> queue = new Queue<TreeNode>();\n\n //\n // Bang all the top nodes into the queue.\n //\n foreach(TreeNode top in tree.Nodes) {\n queue.Enqueue(top);\n }\n\n while(queue.Count > 0) {\n TreeNode node = queue.Dequeue();\n if(node != null) {\n //\n // Add the node to the list of nodes.\n //\n nodes.Add(node);\n\n if(node.Nodes != null && node.Nodes.Count > 0) {\n //\n // Enqueue the child nodes.\n //\n foreach(TreeNode child in node.Nodes) {\n queue.Enqueue(child);\n }\n }\n }\n }\n return nodes;\n }\n\n /// <summary>\n /// This static utiltiy method flattens all the nodes in a tree view using\n /// a stack based depth first search rather than the overhead\n /// of recursive method calls.\n /// </summary>\n /// <param name=\"tree\"></param>\n /// <returns></returns>\n public static List<TreeNode> FlattenDepth(TreeView tree) {\n List<TreeNode> nodes = new List<TreeNode>();\n\n Stack<TreeNode> stack = new Stack<TreeNode>();\n\n //\n // Bang all the top nodes into the queue.\n //\n foreach(TreeNode top in tree.Nodes) {\n stack.Push(top);\n }\n\n while(stack.Count > 0) {\n TreeNode node = stack.Pop();\n if(node != null) {\n\n //\n // Add the node to the list of nodes.\n //\n nodes.Add(node);\n\n if(node.Nodes != null && node.Nodes.Count > 0) {\n //\n // Enqueue the child nodes.\n //\n foreach(TreeNode child in node.Nodes) {\n stack.Push(child);\n }\n }\n }\n }\n return nodes;\n }\n}\n</code></pre>\n"
},
{
"answer_id": 969044,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>I have converted the code to <code>VB.Net</code> with this as a result:</p>\n\n<pre><code>Public Function FlattenBreadth(ByVal tree As TreeView) As List(Of TreeNode)\n Dim nodes As New List(Of TreeNode)\n Dim queue As New Queue(Of TreeNode)\n Dim top As TreeNode\n Dim nod As TreeNode\n For Each top In tree.Nodes\n queue.Enqueue(top)\n Next\n While (queue.Count > 0)\n top = queue.Dequeue\n nodes.Add(top)\n For Each nod In top.Nodes\n queue.Enqueue(nod)\n Next\n End While\n FlattenBreadth = nodes\nEnd Function\n</code></pre>\n"
},
{
"answer_id": 969082,
"author": "Keith",
"author_id": 905,
"author_profile": "https://Stackoverflow.com/users/905",
"pm_score": 4,
"selected": false,
"text": "<p>I have an extension method that I use for this:</p>\n\n<pre><code>public static IEnumerable<TreeNode> DescendantNodes( this TreeNode input ) {\n foreach ( TreeNode node in input.Nodes ) {\n yield return node;\n foreach ( var subnode in node.DescendantNodes() )\n yield return subnode;\n }\n}\n</code></pre>\n\n<p>It's C#, but could be referenced from VB or converted to it.</p>\n"
},
{
"answer_id": 3075412,
"author": "Sunil",
"author_id": 370998,
"author_profile": "https://Stackoverflow.com/users/370998",
"pm_score": 2,
"selected": false,
"text": "<pre><code>nodParent As TreeNode\n'nodParent = your parent Node\ntvwOpt.Nodes.Find(nodParent.Name, True)\n</code></pre>\n\n<p>Thats it</p>\n"
},
{
"answer_id": 32962044,
"author": "Gusstavv Gil",
"author_id": 4304781,
"author_profile": "https://Stackoverflow.com/users/4304781",
"pm_score": 2,
"selected": false,
"text": "<p>Adrian's method it's awesome. Works quite fast and worked better than the recursion approach. I've done a translation to VB. I've learned a lot from it. Hopefully someone still needs it.</p>\n\n<p>To use it simply: </p>\n\n<pre><code>Dim FlattenedNodes As List(Of TreeNode) = clTreeUtil.FlattenDepth(Me.TreeView1) \n</code></pre>\n\n<p>Here is the code, CHEERS! :</p>\n\n<pre><code>Public Class clTreeUtil\n''' <summary>\n''' This static utiltiy method flattens all the nodes in a tree view using\n''' a queue based breath first search rather than the overhead\n''' of recursive method calls.\n''' </summary>\n''' <param name=\"tree\"></param>\n''' <returns></returns>\nPublic Shared Function FlattenBreath(Tree As TreeView) As List(Of TreeNode)\n Dim nodes As List(Of TreeNode) = New List(Of TreeNode)\n Dim queue As Queue(Of TreeNode) = New Queue(Of TreeNode)\n\n ''\n '' Bang all the top nodes into the queue.\n ''\n For Each top As TreeNode In Tree.Nodes\n queue.Enqueue(top)\n Next\n\n While (queue.Count > 0)\n Dim node As TreeNode = queue.Dequeue()\n If node IsNot Nothing Then\n ''\n '' Add the node to the list of nodes.\n ''\n nodes.Add(node)\n\n If node.Nodes IsNot Nothing And node.Nodes.Count > 0 Then\n ''\n '' Enqueue the child nodes.\n ''\n For Each child As TreeNode In node.Nodes\n queue.Enqueue(child)\n Next\n End If\n End If\n End While\n\n Return nodes\nEnd Function\n\n''' <summary>\n''' This static utiltiy method flattens all the nodes in a tree view using\n''' a stack based depth first search rather than the overhead\n''' of recursive method calls.\n''' </summary>\n''' <param name=\"tree\"></param>\n''' <returns></returns>\nPublic Shared Function FlattenDepth(tree As TreeView) As List(Of TreeNode)\n Dim nodes As List(Of TreeNode) = New List(Of TreeNode)\n\n Dim stack As Stack(Of TreeNode) = New Stack(Of TreeNode)\n\n ''\n '' Bang all the top nodes into the queue.\n ''\n For Each top As TreeNode In tree.Nodes\n stack.Push(top)\n Next\n\n While (stack.Count > 0)\n Dim node As TreeNode = stack.Pop()\n\n If node IsNot Nothing Then\n\n ''\n '' Add the node to the list of nodes.\n ''\n nodes.Add(node)\n\n If node.Nodes IsNot Nothing And node.Nodes.Count > 0 Then\n ''\n '' Enqueue the child nodes.\n ''\n For Each child As TreeNode In node.Nodes\n stack.Push(child)\n Next\n End If\n End If\n\n End While\n\n Return nodes\nEnd Function\n\nEnd Class\n</code></pre>\n"
},
{
"answer_id": 32962245,
"author": "Gusstavv Gil",
"author_id": 4304781,
"author_profile": "https://Stackoverflow.com/users/4304781",
"pm_score": 1,
"selected": false,
"text": "<p>If someone still wants to do the recursion approach, using Jop's code, and keeping the TreeNodes (so you can use their .tag, .name, .checked or .text properties) here is my version</p>\n\n<pre><code>Public Shared Function GetChildren(objTree As TreeView) As List(Of TreeNode)\n Dim nodes As List(Of TreeNode) = New List(Of TreeNode)\n For Each parentNode As TreeNode In objTree.Nodes\n nodes.Add(parentNode)\n GetAllChildren(parentNode, nodes)\n Next\n\n Return nodes\nEnd Function\n\nPublic Shared Sub GetAllChildren(parentNode As TreeNode, nodes As List(Of TreeNode))\n For Each childNode As TreeNode In parentNode.Nodes\n nodes.Add(childNode)\n GetAllChildren(childNode, nodes)\n Next\nEnd Sub\n</code></pre>\n"
},
{
"answer_id": 41134563,
"author": "antony thomas",
"author_id": 6628432,
"author_profile": "https://Stackoverflow.com/users/6628432",
"pm_score": 1,
"selected": false,
"text": "<p>Usually get a value at the specified node is interesting to programmers.This can be obtained as follows.Assumes that you have a TextBox control named texbox1 and a TreeView control named treeview1.Following would return the value of text at nodes level 0.</p>\n\n<pre><code>textbox1.Text = treeview1.nodes(0).Text.ToString()\n</code></pre>\n"
},
{
"answer_id": 62589105,
"author": "elle0087",
"author_id": 3061212,
"author_profile": "https://Stackoverflow.com/users/3061212",
"pm_score": 0,
"selected": false,
"text": "<p>in .Net WindowsForm TreeView has <code>Find()</code> method with the optional flag <code>'searchAllChildren'</code>.</p>\n<p>in asp.net instead there isn't.\nto have the same result i use this (similar to Keith answer, but in input i use the TreeView)</p>\n<pre><code>public static IEnumerable<TreeNode> DescendantNodes2(this TreeView input)\n{\n foreach (TreeNode node in input.Nodes)\n {\n yield return node;\n foreach (var subnode in node.DescendantNodes())\n yield return subnode;\n }\n}\nprivate static IEnumerable<TreeNode> DescendantNodes(this TreeNode input)\n{\n foreach (TreeNode node in input.ChildNodes)\n {\n yield return node;\n foreach (var subnode in node.DescendantNodes())\n yield return subnode;\n }\n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177277",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5473/"
] |
I have a TreeView control in my WinForms .NET application that has multiple levels of childnodes that have childnodes with more childnodes, with no defined depth. When a user selects any parent node (not necessarily at the root level), how can I get a list of all the nodes beneith that parent node?
For example, I started off with this:
```
Dim nodes As List(Of String)
For Each childNodeLevel1 As TreeNode In parentNode.Nodes
For Each childNodeLevel2 As TreeNode In childNodeLevel1.Nodes
For Each childNodeLevel3 As TreeNode In childNodeLevel2.Nodes
nodes.Add(childNodeLevel3.Text)
Next
Next
Next
```
The problem is that this loop depth is defined and I'm only getting nodes burried down three levels. What if next time the user selects a parent node, there are seven levels?
|
Use recursion
```
Function GetChildren(parentNode as TreeNode) as List(Of String)
Dim nodes as List(Of String) = New List(Of String)
GetAllChildren(parentNode, nodes)
return nodes
End Function
Sub GetAllChildren(parentNode as TreeNode, nodes as List(Of String))
For Each childNode as TreeNode in parentNode.Nodes
nodes.Add(childNode.Text)
GetAllChildren(childNode, nodes)
Next
End Sub
```
|
177,284 |
<p>I have a table that looks something like this:</p>
<pre>
word big expensive smart fast
dog 9 -10 -20 4
professor 2 4 40 -7
ferrari 7 50 0 48
alaska 10 0 1 0
gnat -3 0 0 0
</pre>
<p>The + and - values are associated with the word, so professor is smart and dog is not smart. Alaska is big, as a proportion of the total value associated with its entries, and the opposite is true of gnat.</p>
<p>Is there a good way to get the absolute value of the number farthest from zero, and some token whether absolute value =/= value? Relatedly, how might I calculate whether the results for a given value are proportionately large with respect to the other values? I would write something to format the output to the effect of: "dog: not smart, probably not expensive; professor smart; ferrari: fast, expensive; alaska: big; gnat: probably small." (The formatting is not a question, just an illustration, I am stuck on the underlying queries.) </p>
<p>Also, the rest of the program is python, so if there is any python solution with normal dbapi modules or a more abstract module, any help appreciated.</p>
|
[
{
"answer_id": 177302,
"author": "Toby Hede",
"author_id": 14971,
"author_profile": "https://Stackoverflow.com/users/14971",
"pm_score": 0,
"selected": false,
"text": "<p>Can you use the built-in database aggregate functions like MAX(column)?</p>\n"
},
{
"answer_id": 177308,
"author": "James Curran",
"author_id": 12725,
"author_profile": "https://Stackoverflow.com/users/12725",
"pm_score": 2,
"selected": false,
"text": "<p>Words listed by absolute value of big:</p>\n\n<pre><code>select word, big from myTable order by abs(big)\n</code></pre>\n\n<p>totals for each category:</p>\n\n<pre><code>select sum(abs(big)) as sumbig, \n sum(abs(expensive)) as sumexpensive, \n sum(abs(smart)) as sumsmart,\n sum(abs(fast)) as sumfast\n from MyTable;\n</code></pre>\n"
},
{
"answer_id": 177311,
"author": "Mark Harrison",
"author_id": 116,
"author_profile": "https://Stackoverflow.com/users/116",
"pm_score": 3,
"selected": true,
"text": "<p>abs value fartherest from zero:</p>\n\n<pre><code>select max(abs(mycol)) from mytbl\n</code></pre>\n\n<p>will be zero if the value is negative:</p>\n\n<pre><code>select n+abs(mycol)\n from zzz\n where abs(mycol)=(select max(abs(mycol)) from mytbl);\n</code></pre>\n"
},
{
"answer_id": 177637,
"author": "unmounted",
"author_id": 11596,
"author_profile": "https://Stackoverflow.com/users/11596",
"pm_score": 0,
"selected": false,
"text": "<p>Asking the question helped clarify the issue; here is a function that gets more at what I am trying to do. Is there a way to represent some of the stuff in ¶2 above, or a more efficient way to do in SQL or python what I am trying to accomplish in <code>show_distinct</code>?</p>\n\n<pre><code>#!/usr/bin/env python\n\nimport sqlite3\n\nconn = sqlite3.connect('so_question.sqlite')\ncur = conn.cursor()\n\ncur.execute('create table soquestion (word, big, expensive, smart, fast)')\ncur.execute(\"insert into soquestion values ('dog', 9, -10, -20, 4)\")\ncur.execute(\"insert into soquestion values ('professor', 2, 4, 40, -7)\")\ncur.execute(\"insert into soquestion values ('ferrari', 7, 50, 0, 48)\")\ncur.execute(\"insert into soquestion values ('alaska', 10, 0, 1, 0)\")\ncur.execute(\"insert into soquestion values ('gnat', -3, 0, 0, 0)\")\n\ncur.execute(\"select * from soquestion\")\nall = cur.fetchall()\n\ndefinition_list = ['word', 'big', 'expensive', 'smart', 'fast']\n\ndef show_distinct(db_tuple, def_list=definition_list):\n minimum = min(db_tuple[1:])\n maximum = max(db_tuple[1:])\n if abs(minimum) > maximum:\n print db_tuple[0], 'is not', def_list[list(db_tuple).index(minimum)]\n elif maximum > abs(minimum):\n print db_tuple[0], 'is', def_list[list(db_tuple).index(maximum)]\n else:\n print 'no distinct value'\n\nfor item in all:\n show_distinct(item)\n</code></pre>\n\n<p>Running this gives:</p>\n\n<pre>\n dog is not smart\n professor is smart\n ferrari is expensive\n alaska is big\n gnat is not big\n >>> \n</pre>\n"
},
{
"answer_id": 177898,
"author": "Thorsten",
"author_id": 25320,
"author_profile": "https://Stackoverflow.com/users/25320",
"pm_score": 1,
"selected": false,
"text": "<p>The problem seems to be that you mainly want to work within one row, and these type of questions are hard to answer in SQL.</p>\n\n<p>I'd try to turn the structure you mentioned into a more \"atomic\" fact table like</p>\n\n<pre><code>word property value\n</code></pre>\n\n<p>either by redesigning the underlying table (if possible and if that makes sense regarding the rest of the application), or by defining a view that does this for you, like</p>\n\n<pre><code>select word, 'big' as property, big as value from soquestion\nUNION ALLL\nselect word, 'expensive', expensive from soquestion\nUNION ALL\n...\n</code></pre>\n\n<p>This allows you to ask for the max value for each word:</p>\n\n<pre><code>select word, max(value), \n (select property from soquestion t2 \n where t1.word = t2.word and t2.value = max(t1.value))\nfrom soquestion t1\ngroup by word\n</code></pre>\n\n<p>Still a little awkward, but most logic will be in SQL, not in your programming language of choice.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177284",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11596/"
] |
I have a table that looks something like this:
```
word big expensive smart fast
dog 9 -10 -20 4
professor 2 4 40 -7
ferrari 7 50 0 48
alaska 10 0 1 0
gnat -3 0 0 0
```
The + and - values are associated with the word, so professor is smart and dog is not smart. Alaska is big, as a proportion of the total value associated with its entries, and the opposite is true of gnat.
Is there a good way to get the absolute value of the number farthest from zero, and some token whether absolute value =/= value? Relatedly, how might I calculate whether the results for a given value are proportionately large with respect to the other values? I would write something to format the output to the effect of: "dog: not smart, probably not expensive; professor smart; ferrari: fast, expensive; alaska: big; gnat: probably small." (The formatting is not a question, just an illustration, I am stuck on the underlying queries.)
Also, the rest of the program is python, so if there is any python solution with normal dbapi modules or a more abstract module, any help appreciated.
|
abs value fartherest from zero:
```
select max(abs(mycol)) from mytbl
```
will be zero if the value is negative:
```
select n+abs(mycol)
from zzz
where abs(mycol)=(select max(abs(mycol)) from mytbl);
```
|
177,287 |
<p>Is it possible to produce an alert similar to JavaScript's alert("message") in python, with an application running as a daemon.</p>
<p>This will be run in Windows, Most likely XP but 2000 and Vista are also very real possibilities.</p>
<p>Update:<br />
This is intended to run in the background and alert the user when certain conditions are met, I figure that the easiest way to alert the user would be to produce a pop-up, as it needs to be handled immediately, and other options such as just logging, or sending an email are not efficient enough.</p>
|
[
{
"answer_id": 177312,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 7,
"selected": true,
"text": "<p>what about this:</p>\n\n<pre><code>import win32api\n\nwin32api.MessageBox(0, 'hello', 'title')\n</code></pre>\n\n<p>Additionally:</p>\n\n<pre><code>win32api.MessageBox(0, 'hello', 'title', 0x00001000) \n</code></pre>\n\n<p>will make the box appear on top of other windows, for urgent messages. See <a href=\"http://msdn.microsoft.com/en-us/library/windows/desktop/ms645505(v=vs.85).aspx\" rel=\"noreferrer\">MessageBox function</a> for other options.</p>\n"
},
{
"answer_id": 177316,
"author": "Mikael Jansson",
"author_id": 18753,
"author_profile": "https://Stackoverflow.com/users/18753",
"pm_score": -1,
"selected": false,
"text": "<p>Start an app as a background process that either has a TCP port bound to localhost, or communicates through a file -- your daemon has the file open, and then you <code>echo \"foo\" > c:\\your\\file</code>. After, say, 1 second of no activity, you display the message and truncate the file.</p>\n"
},
{
"answer_id": 11831178,
"author": "Tabares",
"author_id": 1399262,
"author_profile": "https://Stackoverflow.com/users/1399262",
"pm_score": 2,
"selected": false,
"text": "<p>You can use win32 library in Python, this is classical example of OK or Cancel. </p>\n\n<pre><code>import win32api\nimport win32com.client\nimport pythoncom\n\nresult = win32api.MessageBox(None,\"Do you want to open a file?\", \"title\",1)\n\nif result == 1:\n print 'Ok'\nelif result == 2:\n print 'cancel'\n</code></pre>\n\n<p>The collection:</p>\n\n<pre><code>win32api.MessageBox(0,\"msgbox\", \"title\")\nwin32api.MessageBox(0,\"ok cancel?\", \"title\",1)\nwin32api.MessageBox(0,\"abort retry ignore?\", \"title\",2)\nwin32api.MessageBox(0,\"yes no cancel?\", \"title\",3)\n</code></pre>\n"
},
{
"answer_id": 20461473,
"author": "NoBugs",
"author_id": 778234,
"author_profile": "https://Stackoverflow.com/users/778234",
"pm_score": 2,
"selected": false,
"text": "<p>GTK may be a better option, as it is cross-platform. It'll work great on Ubuntu, and should work just fine on Windows when GTK and Python bindings are installed.</p>\n\n<pre><code>from gi.repository import Gtk\n\ndialog = Gtk.MessageDialog(None, 0, Gtk.MessageType.INFO,\n Gtk.ButtonsType.OK, \"This is an INFO MessageDialog\")\ndialog.format_secondary_text(\n \"And this is the secondary text that explains things.\")\ndialog.run()\nprint \"INFO dialog closed\"\n</code></pre>\n\n<p>You can see other examples <a href=\"http://python-gtk-3-tutorial.readthedocs.org/en/latest/dialogs.html\" rel=\"nofollow\">here</a>. (<a href=\"https://media.readthedocs.org/pdf/python-gtk-3-tutorial/latest/python-gtk-3-tutorial.pdf\" rel=\"nofollow\">pdf</a>)</p>\n\n<p>The arguments passed should be the gtk.window parent (or None), DestroyWithParent, Message type, Message-buttons, title.</p>\n"
},
{
"answer_id": 57871358,
"author": "Matt Binford",
"author_id": 11994601,
"author_profile": "https://Stackoverflow.com/users/11994601",
"pm_score": 4,
"selected": false,
"text": "<p>For those of us looking for a purely Python option that doesn't interface with Windows and is platform independent, I went for the option listed on the following website:</p>\n<p><a href=\"https://pythonspot.com/tk-message-box/\" rel=\"nofollow noreferrer\">https://pythonspot.com/tk-message-box/</a> (archived link: <a href=\"https://archive.ph/JNuvx\" rel=\"nofollow noreferrer\">https://archive.ph/JNuvx</a>)</p>\n<pre><code># Python 3.x code\n# Imports\nimport tkinter\nfrom tkinter import messagebox\n\n# This code is to hide the main tkinter window\nroot = tkinter.Tk()\nroot.withdraw()\n\n# Message Box\nmessagebox.showinfo("Title", "Message")\n</code></pre>\n<p>You can choose to show various types of messagebox options for different scenarios:</p>\n<ul>\n<li>showinfo()</li>\n<li>showwarning()</li>\n<li>showerror ()</li>\n<li>askquestion()</li>\n<li>askokcancel()</li>\n<li>askyesno ()</li>\n<li>askretrycancel ()</li>\n</ul>\n<p><em>edited code per my comment below</em></p>\n"
},
{
"answer_id": 64858863,
"author": "mathcat",
"author_id": 13238936,
"author_profile": "https://Stackoverflow.com/users/13238936",
"pm_score": 2,
"selected": false,
"text": "<p>You can use <a href=\"https://pypi.org/project/PyAutoGUI/\" rel=\"nofollow noreferrer\"><strong>PyAutoGui</strong></a> to make alert boxes\nFirst install pyautogui with pip:</p>\n<pre><code>pip install pyautogui\n</code></pre>\n<p>Then type this in python:</p>\n<pre class=\"lang-py prettyprint-override\"><code>import pyautogui as pag\npag.alert(text="Hello World", title="The Hello World Box")\n</code></pre>\n<p>Here are more message boxes, stolen from Javascript:</p>\n<ul>\n<li><code>confirm()</code><br />\nWith Ok and Cancel Button</li>\n<li><code>prompt()</code><br />\nWith Text Input</li>\n<li><code>password()</code>\nWith Text Input, but typed characters will be appeared as <strong>*</strong></li>\n</ul>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177287",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/115/"
] |
Is it possible to produce an alert similar to JavaScript's alert("message") in python, with an application running as a daemon.
This will be run in Windows, Most likely XP but 2000 and Vista are also very real possibilities.
Update:
This is intended to run in the background and alert the user when certain conditions are met, I figure that the easiest way to alert the user would be to produce a pop-up, as it needs to be handled immediately, and other options such as just logging, or sending an email are not efficient enough.
|
what about this:
```
import win32api
win32api.MessageBox(0, 'hello', 'title')
```
Additionally:
```
win32api.MessageBox(0, 'hello', 'title', 0x00001000)
```
will make the box appear on top of other windows, for urgent messages. See [MessageBox function](http://msdn.microsoft.com/en-us/library/windows/desktop/ms645505(v=vs.85).aspx) for other options.
|
177,323 |
<p>What is the most efficient way to read the last row with SQL Server?</p>
<p>The table is indexed on a unique key -- the "bottom" key values represent the last row.</p>
|
[
{
"answer_id": 177325,
"author": "willurd",
"author_id": 1943957,
"author_profile": "https://Stackoverflow.com/users/1943957",
"pm_score": 4,
"selected": false,
"text": "<p>You'll need some sort of uniquely identifying column in your table, like an auto-filling primary key or a datetime column (preferably the primary key). Then you can do this:</p>\n\n<pre><code>SELECT * FROM table_name ORDER BY unique_column DESC LIMIT 1</code></pre>\n\n<p>The <code>ORDER BY column</code> tells it to rearange the results according to that column's data, and the <code>DESC</code> tells it to reverse the results (thus putting the last one first). After that, the <code>LIMIT 1</code> tells it to only pass back one row.</p>\n"
},
{
"answer_id": 177327,
"author": "Adam Pierce",
"author_id": 5324,
"author_profile": "https://Stackoverflow.com/users/5324",
"pm_score": 5,
"selected": false,
"text": "<pre><code>select whatever,columns,you,want from mytable\n where mykey=(select max(mykey) from mytable);\n</code></pre>\n"
},
{
"answer_id": 177328,
"author": "EggyBach",
"author_id": 15475,
"author_profile": "https://Stackoverflow.com/users/15475",
"pm_score": 9,
"selected": true,
"text": "<p>If you're using MS SQL, you can try:</p>\n\n<pre><code>SELECT TOP 1 * FROM table_Name ORDER BY unique_column DESC \n</code></pre>\n"
},
{
"answer_id": 593540,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>In order to retrieve the last row of a table for MS SQL database 2005, You can use the following query:</p>\n\n<pre><code>select top 1 column_name from table_name order by column_name desc; \n</code></pre>\n\n<p><strong>Note:</strong> To get the first row of the table for MS SQL database 2005, You can use the following query:</p>\n\n<pre><code>select top 1 column_name from table_name; \n</code></pre>\n"
},
{
"answer_id": 5382791,
"author": "maniakk",
"author_id": 670077,
"author_profile": "https://Stackoverflow.com/users/670077",
"pm_score": -1,
"selected": false,
"text": "<p>I am pretty sure that it is:</p>\n\n<pre><code>SELECT last(column_name) FROM table\n</code></pre>\n\n<p>Becaause I use something similar:</p>\n\n<pre><code>SELECT last(id) FROM Status\n</code></pre>\n"
},
{
"answer_id": 6551635,
"author": "manas",
"author_id": 825332,
"author_profile": "https://Stackoverflow.com/users/825332",
"pm_score": 0,
"selected": false,
"text": "<pre><code>SELECT * from Employees where [Employee ID] = ALL (SELECT MAX([Employee ID]) from Employees)\n</code></pre>\n"
},
{
"answer_id": 13135762,
"author": "Muhammad Sajid",
"author_id": 1785061,
"author_profile": "https://Stackoverflow.com/users/1785061",
"pm_score": 0,
"selected": false,
"text": "<p>This is how you get the last record and update a field in Access DB.</p>\n\n<p><strong>UPDATE</strong> <code>compalints</code> <code>SET tkt = addzone &'-'& customer_code &'-'& sn where sn in (select max(sn) from compalints )</code></p>\n"
},
{
"answer_id": 14000778,
"author": "lionelmessi",
"author_id": 1772722,
"author_profile": "https://Stackoverflow.com/users/1772722",
"pm_score": 4,
"selected": false,
"text": "<p>If some of your id are in order, i am assuming there will be some order in your db</p>\n\n<p><code>SELECT * FROM TABLE WHERE ID = (SELECT MAX(ID) FROM TABLE)</code></p>\n"
},
{
"answer_id": 21049665,
"author": "Rogerio Gelonezi",
"author_id": 3096335,
"author_profile": "https://Stackoverflow.com/users/3096335",
"pm_score": 0,
"selected": false,
"text": "<p>If you have a Replicated table, you can have an Identity=1000 in localDatabase and Identity=2000 in the clientDatabase, so if you catch the last ID you may find always the last from client, not the last from the current connected database.\nSo the best method which returns the last connected database is:</p>\n\n<pre><code>SELECT IDENT_CURRENT('tablename')\n</code></pre>\n"
},
{
"answer_id": 24841332,
"author": "Hamza Abuzahra",
"author_id": 3856069,
"author_profile": "https://Stackoverflow.com/users/3856069",
"pm_score": -1,
"selected": false,
"text": "<pre><code>SELECT * FROM TABLE WHERE ID = (SELECT MAX(ID) FROM TABLE)\n</code></pre>\n"
},
{
"answer_id": 25798182,
"author": "Neha Verma",
"author_id": 3746019,
"author_profile": "https://Stackoverflow.com/users/3746019",
"pm_score": 2,
"selected": false,
"text": "<p>I tried using last in sql query in SQl server 2008 but it gives this err:\n\" 'last' is not a recognized built-in function name.\"</p>\n\n<p>So I ended up using :</p>\n\n<pre><code>select max(WorkflowStateStatusId) from WorkflowStateStatus \n</code></pre>\n\n<p>to get the Id of the last row.\nOne could also use </p>\n\n<pre><code>Declare @i int\nset @i=1\nselect WorkflowStateStatusId from Workflow.WorkflowStateStatus\n where WorkflowStateStatusId not in (select top (\n (select count(*) from Workflow.WorkflowStateStatus) - @i ) WorkflowStateStatusId from .WorkflowStateStatus)\n</code></pre>\n"
},
{
"answer_id": 26404801,
"author": "Sylvain Rodrigue",
"author_id": 54783,
"author_profile": "https://Stackoverflow.com/users/54783",
"pm_score": 1,
"selected": false,
"text": "<p>If you don't have any ordered column, you can use the physical id of each lines:</p>\n\n<pre><code>SELECT top 1 sys.fn_PhysLocFormatter(%%physloc%%) AS [File:Page:Slot], \n T.*\nFROM MyTable As T\norder by sys.fn_PhysLocFormatter(%%physloc%%) DESC\n</code></pre>\n"
},
{
"answer_id": 28425923,
"author": "ConsiderItDone",
"author_id": 4548942,
"author_profile": "https://Stackoverflow.com/users/4548942",
"pm_score": 3,
"selected": false,
"text": "<p>I think below query will work for SQL Server with maximum performance without any sortable column</p>\n\n<pre><code>SELECT * FROM table \nWHERE ID not in (SELECT TOP (SELECT COUNT(1)-1 \n FROM table) \n ID \n FROM table)\n</code></pre>\n\n<p>Hope you have understood it... :)</p>\n"
},
{
"answer_id": 29365784,
"author": "Ashish Pathak",
"author_id": 3828166,
"author_profile": "https://Stackoverflow.com/users/3828166",
"pm_score": 1,
"selected": false,
"text": "<p><strong>Try this</strong></p>\n\n<pre><code>SELECT id from comission_fees ORDER BY id DESC LIMIT 1\n</code></pre>\n"
},
{
"answer_id": 29944542,
"author": "Gil Gomes",
"author_id": 2358229,
"author_profile": "https://Stackoverflow.com/users/2358229",
"pm_score": 2,
"selected": false,
"text": "<p>You can use last_value: <code>SELECT LAST_VALUE(column) OVER (PARTITION BY column ORDER BY column)...</code></p>\n\n<p>I test it at one of my databases and it worked as expected.</p>\n\n<p>You can also check de documentation here: <a href=\"https://msdn.microsoft.com/en-us/library/hh231517.aspx\" rel=\"nofollow\">https://msdn.microsoft.com/en-us/library/hh231517.aspx</a></p>\n"
},
{
"answer_id": 51670011,
"author": "Walter Verhoeven",
"author_id": 8000382,
"author_profile": "https://Stackoverflow.com/users/8000382",
"pm_score": 0,
"selected": false,
"text": "<p>Well I'm not getting the \"last value\" in a table, I'm getting the Last value per financial instrument. It's not the same but I guess it is relevant for some that are looking to look up on \"how it is done now\". I also used RowNumber() and CTE's and before that to simply take 1 and order by [column] desc. however we nolonger need to... </p>\n\n<p>I am using SQL server 2017, we are recording all ticks on all exchanges globally, we have ~12 billion ticks a day, we store each Bid, ask, and trade including the volumes and the attributes of a tick (bid, ask, trade) of any of the given exchanges. </p>\n\n<p>We have 253 types of ticks data for any given contract (mostly statistics) in that table, the last traded price is tick type=4 so, when we need to get the \"last\" of Price we use :</p>\n\n<pre><code>select distinct T.contractId,\nLAST_VALUE(t.Price)over(partition by t.ContractId order by created ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)\nfrom [dbo].[Tick] as T\nwhere T.TickType=4\n</code></pre>\n\n<p>You can see the execution plan on my dev system it executes quite efficient, executes in 4 sec while the exchange import ETL is pumping data into the table, there will be some locking slowing me down... that's just how live systems work.\n<a href=\"https://i.stack.imgur.com/HMiJ8.png\" rel=\"nofollow noreferrer\"><img src=\"https://i.stack.imgur.com/HMiJ8.png\" alt=\"execution plan against 85,697,659 rows\"></a></p>\n"
},
{
"answer_id": 56755749,
"author": "Jignesh Bhayani",
"author_id": 7895529,
"author_profile": "https://Stackoverflow.com/users/7895529",
"pm_score": 2,
"selected": false,
"text": "<p><code>OFFSET</code> and <code>FETCH NEXT</code> are a feature of SQL Server 2012 to achieve SQL paging while displaying results. </p>\n\n<p>The <code>OFFSET</code> argument is used to decide the starting row to return rows from a result and <code>FETCH</code> argument is used to return a set of number of rows.</p>\n\n<pre><code>SELECT *\nFROM table_name\nORDER BY unique_column desc\nOFFSET 0 Row\nFETCH NEXT 1 ROW ONLY\n</code></pre>\n"
},
{
"answer_id": 73862651,
"author": "Vintage Coder",
"author_id": 10439286,
"author_profile": "https://Stackoverflow.com/users/10439286",
"pm_score": 0,
"selected": false,
"text": "<p>It is very simple</p>\n<blockquote>\n<p><strong>select top 10 * from TableName order by 1 desc</strong></p>\n</blockquote>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177323",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2536/"
] |
What is the most efficient way to read the last row with SQL Server?
The table is indexed on a unique key -- the "bottom" key values represent the last row.
|
If you're using MS SQL, you can try:
```
SELECT TOP 1 * FROM table_Name ORDER BY unique_column DESC
```
|
177,373 |
<p>I have a generic list...</p>
<p>public List<ApprovalEventDto> ApprovalEvents</p>
<p>The ApprovalEventDto has </p>
<pre><code>public class ApprovalEventDto
{
public string Event { get; set; }
public DateTime EventDate { get; set; }
}
</code></pre>
<p>How do I sort the list by the event date?</p>
|
[
{
"answer_id": 177377,
"author": "SmacL",
"author_id": 22564,
"author_profile": "https://Stackoverflow.com/users/22564",
"pm_score": -1,
"selected": false,
"text": "<p>Merge sorts work very well for lists. See <a href=\"http://en.wikipedia.org/wiki/Merge_sort\" rel=\"nofollow noreferrer\">WikiPedia entry</a> for more details, basically it's a recursive n-Log n sort that doesn't require random access. </p>\n\n<p>For certain data types you can also use <a href=\"http://en.wikipedia.org/wiki/Pigeonhole_sort\" rel=\"nofollow noreferrer\">pigeon holing</a> to get order n at the expense of more memory usage.</p>\n"
},
{
"answer_id": 177380,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 3,
"selected": false,
"text": "<pre><code>using System.Linq;\n\nvoid List<ApprovalEventDto> sort(List<ApprovalEventDto> list)\n { return list.OrderBy(x => x.EventDate).ToList();\n }\n</code></pre>\n"
},
{
"answer_id": 177385,
"author": "PiRX",
"author_id": 25718,
"author_profile": "https://Stackoverflow.com/users/25718",
"pm_score": -1,
"selected": false,
"text": "<p>You can use List.Sort() method with anonymous method or lambda expression. More at \n<a href=\"http://msdn.microsoft.com/en-us/library/3da4abas.aspx\" rel=\"nofollow noreferrer\">MSDN</a></p>\n"
},
{
"answer_id": 177390,
"author": "EggyBach",
"author_id": 15475,
"author_profile": "https://Stackoverflow.com/users/15475",
"pm_score": 5,
"selected": true,
"text": "<p>You can use List.Sort() as follows:</p>\n\n<pre><code>ApprovalEvents.Sort((lhs, rhs) => (lhs.EventDate.CompareTo(rhs.EventDate)));\n</code></pre>\n"
},
{
"answer_id": 177394,
"author": "Afree",
"author_id": 11317,
"author_profile": "https://Stackoverflow.com/users/11317",
"pm_score": 2,
"selected": false,
"text": "<pre><code>ApprovalEvents.Sort((x, y) => { return x.EventDate.CompareTo(y.EventDate); });\n</code></pre>\n"
},
{
"answer_id": 177398,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 1,
"selected": false,
"text": "<p>If you don't need an in-place sort, and you're using .NET 3.5, I'd use OrderBy as suggested by marxidad. If you need the existing list to be sorted, use List.Sort.</p>\n\n<p>List.Sort can take either a Comparison delegate or an IComparer - either will work, it's just a case of working out which will be simpler.</p>\n\n<p>In my <a href=\"http://pobox.com/~skeet/csharp/miscutil\" rel=\"nofollow noreferrer\">MiscUtil</a> project I have a ProjectionComparer which allows you to specify the sort key (just as you do for OrderBy) rather than having to take two parameters and call CompareTo yourself. I personally find that easier to read, but it's up to you, of course. (There are also simple ways of reversing and combining comparisons in MiscUtil. See the unit tests for examples.)</p>\n"
},
{
"answer_id": 2756764,
"author": "al-bex",
"author_id": 204688,
"author_profile": "https://Stackoverflow.com/users/204688",
"pm_score": 0,
"selected": false,
"text": "<p>Like Darksiders solution, but I prefer to keep it non-cryptic:</p>\n\n<pre><code>ApprovalEvents.Sort((a, b) => (a.EventDate.CompareTo(b.EventDate)));\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177373",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6268/"
] |
I have a generic list...
public List<ApprovalEventDto> ApprovalEvents
The ApprovalEventDto has
```
public class ApprovalEventDto
{
public string Event { get; set; }
public DateTime EventDate { get; set; }
}
```
How do I sort the list by the event date?
|
You can use List.Sort() as follows:
```
ApprovalEvents.Sort((lhs, rhs) => (lhs.EventDate.CompareTo(rhs.EventDate)));
```
|
177,389 |
<p>This question will expand on: <a href="https://stackoverflow.com/questions/68774/best-way-to-open-a-socket-in-python">Best way to open a socket in Python</a><br />
When opening a socket how can I test to see if it has been established, and that it did not timeout, or generally fail.
<br /><br />
Edit:
I tried this:</p>
<pre><code>try:
s.connect((address, '80'))
except:
alert('failed' + address, 'down')
</code></pre>
<p>but the alert function is called even when that connection should have worked.</p>
|
[
{
"answer_id": 177411,
"author": "kender",
"author_id": 4172,
"author_profile": "https://Stackoverflow.com/users/4172",
"pm_score": 7,
"selected": true,
"text": "<p>It seems that you catch not the exception you wanna catch out there :)</p>\n\n<p>if the <code>s</code> is a <code>socket.socket()</code> object, then the right way to call <code>.connect</code> would be:</p>\n\n<pre><code>import socket\ns = socket.socket()\naddress = '127.0.0.1'\nport = 80 # port number is a number, not string\ntry:\n s.connect((address, port)) \n # originally, it was \n # except Exception, e: \n # but this syntax is not supported anymore. \nexcept Exception as e: \n print(\"something's wrong with %s:%d. Exception is %s\" % (address, port, e))\nfinally:\n s.close()\n</code></pre>\n\n<p>Always try to see what kind of exception is what you're catching in a try-except loop. </p>\n\n<p>You can check what types of exceptions in a socket module represent what kind of errors (timeout, unable to resolve address, etc) and make separate <code>except</code> statement for each one of them - this way you'll be able to react differently for different kind of problems.</p>\n"
},
{
"answer_id": 177652,
"author": "bortzmeyer",
"author_id": 15625,
"author_profile": "https://Stackoverflow.com/users/15625",
"pm_score": 3,
"selected": false,
"text": "<p>You should really post:</p>\n\n<ol>\n<li>The complete source code of your example</li>\n<li>The <strong>actual</strong> result of it, not a summary</li>\n</ol>\n\n<p>Here is my code, which works:</p>\n\n<pre><code>import socket, sys\n\ndef alert(msg):\n print >>sys.stderr, msg\n sys.exit(1)\n\n(family, socktype, proto, garbage, address) = \\\n socket.getaddrinfo(\"::1\", \"http\")[0] # Use only the first tuple\ns = socket.socket(family, socktype, proto)\n\ntry:\n s.connect(address) \nexcept Exception, e:\n alert(\"Something's wrong with %s. Exception type is %s\" % (address, e))\n</code></pre>\n\n<p>When the server listens, I get nothing (this is normal), when it\ndoesn't, I get the expected message:</p>\n\n<pre><code>Something's wrong with ('::1', 80, 0, 0). Exception type is (111, 'Connection refused')\n</code></pre>\n"
},
{
"answer_id": 20541919,
"author": "ssoto",
"author_id": 423906,
"author_profile": "https://Stackoverflow.com/users/423906",
"pm_score": 4,
"selected": false,
"text": "<p>You can use the function <a href=\"http://docs.python.org/2/library/socket.html#socket.socket.connect_ex\" rel=\"nofollow\">connect_ex</a>. It doesn't throw an exception. Instead of that, returns a C style integer value (referred to as <a href=\"http://linux.die.net/man/3/errno\" rel=\"nofollow\">errno</a> in C):</p>\n\n<pre><code>s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nresult = s.connect_ex((host, port))\ns.close()\nif result:\n print \"problem with socket!\"\nelse:\n print \"everything it's ok!\"\n</code></pre>\n"
},
{
"answer_id": 60972756,
"author": "Patrik Bütler",
"author_id": 13185102,
"author_profile": "https://Stackoverflow.com/users/13185102",
"pm_score": 2,
"selected": false,
"text": "<p>12 years later for anyone having similar problems.</p>\n\n<pre><code>try:\n s.connect((address, '80'))\nexcept:\n alert('failed' + address, 'down')\n</code></pre>\n\n<p>doesn't work because the port '80' is a string. Your port needs to be int.</p>\n\n<pre><code>try:\n s.connect((address, 80))\n</code></pre>\n\n<p>This should work.\nNot sure why even the best answer didnt see this.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177389",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/115/"
] |
This question will expand on: [Best way to open a socket in Python](https://stackoverflow.com/questions/68774/best-way-to-open-a-socket-in-python)
When opening a socket how can I test to see if it has been established, and that it did not timeout, or generally fail.
Edit:
I tried this:
```
try:
s.connect((address, '80'))
except:
alert('failed' + address, 'down')
```
but the alert function is called even when that connection should have worked.
|
It seems that you catch not the exception you wanna catch out there :)
if the `s` is a `socket.socket()` object, then the right way to call `.connect` would be:
```
import socket
s = socket.socket()
address = '127.0.0.1'
port = 80 # port number is a number, not string
try:
s.connect((address, port))
# originally, it was
# except Exception, e:
# but this syntax is not supported anymore.
except Exception as e:
print("something's wrong with %s:%d. Exception is %s" % (address, port, e))
finally:
s.close()
```
Always try to see what kind of exception is what you're catching in a try-except loop.
You can check what types of exceptions in a socket module represent what kind of errors (timeout, unable to resolve address, etc) and make separate `except` statement for each one of them - this way you'll be able to react differently for different kind of problems.
|
177,393 |
<p>In our code we used to have something like this:</p>
<pre><code> *(controller->bigstruct) = ( struct bigstruct ){ 0 };
</code></pre>
<p>This used to work great, and then we upgraded versions of GCC and suddenly started seeing stack overflows. Looking at the assembly, the old GCC code (2.x) was basically doing this:</p>
<pre><code>memset(controller->bigstruct, 0, sizeof(struct bigstruct));
</code></pre>
<p>The new GCC (3.4.x) was doing this</p>
<pre><code> struct bigstruct temp = { 0 };
controller->bigstruct = temp;
</code></pre>
<p>After reviewing the C99 spec, I could see why; C99 basically requires that anonymous structures exist on the stack. It's a good concept, but this structure was 4 Megabytes large, and only ever intended to exist on heap!</p>
<p>We've resorted to making our own 'initialize' function that explicitly sets the members, but that's ugly and a maintenance headache. I don't consider memset a proper solution, because I can't know that a bit-value of 0 is an appropriate zero value for the type ( nit-picking, I know, but there you are; I don't mind that the compiler does it, because it <em>can</em> know )</p>
<p>What is the "correct", or at least best, way to initialize a large structure like this? </p>
<p>To furthur clarify why I think memset isn't a solution: The rules of initialization of members not explicitly initialized are the same as static initialization, and are as follows:
- If it has pointer type, it is initialized to a null pointer;
- If it has arithmetic type, it is initialized to ( positive or unsigned ) zero;
...</p>
<p>'memset' will set the memory to bit-pattern zero, which isn't necessarily the same thing. Imagine a system that doesn't use IEEE floating point numbers. Unusual, but supported by C. The representation of 0.0 doesn't have to mean "all-bits zero", it could be anything convenient to the processor.</p>
|
[
{
"answer_id": 177401,
"author": "SmacL",
"author_id": 22564,
"author_profile": "https://Stackoverflow.com/users/22564",
"pm_score": 3,
"selected": false,
"text": "<p>If you don't want to use memset, you could always declare a static copy of your struct and use memcpy, which will give similar performance. This will add 4 megs to your program but is probably better than setting individual elements.</p>\n\n<p>That said, if GCC was using memset, and it was good enough previously, I would suggest it is good enough now. </p>\n"
},
{
"answer_id": 177402,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 5,
"selected": true,
"text": "<p>memset is the way to go. You do not have many alternatives.</p>\n\n<p>Do something like:</p>\n\n<pre><code>#define InitStruct(var, type) type var; memset(&var, 0, sizeof(type))\n</code></pre>\n\n<p>So that you only have to:</p>\n\n<pre><code>InitStruct(st, BigStruct);\n</code></pre>\n\n<p>And then use st as usual... </p>\n\n<p>I do not get how \"0\" is not a valid \"0\" type for a struct. The only way to \"mass initialize\" a struct is to set all of its memory to a value; otherwise you would have to make extra logic to tell it to use a specific bit pattern per member. The best \"generic\" bit pattern to use is 0.</p>\n\n<p>Besides - this is the same logic that you used when doing</p>\n\n<pre><code>*(controller->bigstruct) = *( struct bigstruct ){ 0 };\n</code></pre>\n\n<p>Therefore I don't get your reluctance to use it :)</p>\n\n<p>The first comment to this post made me do some research before I called him and idiot and I found this:</p>\n\n<p><a href=\"http://www.lysator.liu.se/c/c-faq/c-1.html\" rel=\"noreferrer\">http://www.lysator.liu.se/c/c-faq/c-1.html</a></p>\n\n<p>Very interesting; if I could vote-up a comment I would :)</p>\n\n<p>That being said - your only option if you want to target archaic architectures with non-0 null values is still to do manual initialization to certain members.</p>\n\n<p>Thanks Thomas Padron-McCarthy! I learned something new today :)</p>\n"
},
{
"answer_id": 177425,
"author": "Łukasz Bownik",
"author_id": 24028,
"author_profile": "https://Stackoverflow.com/users/24028",
"pm_score": -1,
"selected": false,
"text": "<p>hmm - first of all making an init function and setting each member explicitly IS THE RIGHT THING - it,s the way constructors in OO languages work.</p>\n\n<p>and second - does anyone know a hardware that implements non IEEE floating point numbers ? - perhaps Commodore 64 or somethig ;-)</p>\n"
},
{
"answer_id": 177460,
"author": "Ilya",
"author_id": 6807,
"author_profile": "https://Stackoverflow.com/users/6807",
"pm_score": 2,
"selected": false,
"text": "<p>Private initialization function is not ugly rather a good OO way to initialize objects (structs). I assume that your structure is not 4MB of pointers, so i would assume that the solution should be like this:</p>\n\n<pre><code>void init_big_struct(struct bigstruct *s) \n{ \n memset(s, 0, sizeof(struct bigstruct)); \n s->some_pointer = NULL; // Multiply this as needed \n}\n</code></pre>\n\n<p>From other hand our code is running on more then 20 embedded operating systems and large number of different hardwares, never meet any problem with just memset of the struct. </p>\n"
},
{
"answer_id": 177931,
"author": "Graeme Perrow",
"author_id": 1821,
"author_profile": "https://Stackoverflow.com/users/1821",
"pm_score": 2,
"selected": false,
"text": "<p>As others have said, memset is the way to go. However, <em>don't</em> use memset on C++ objects, particularly those with virtual methods. The <code>sizeof( foo )</code> will include the table of virtual function pointers, and doing a memset on that will cause serious grief.</p>\n\n<p>If memset doesn't solve the problem by itself, simply do a memset and <em>then</em> initialize any members that should be non-zero (i.e. your non-IEEE floating point values).</p>\n"
},
{
"answer_id": 61413277,
"author": "Antonin GAVREL",
"author_id": 3161139,
"author_profile": "https://Stackoverflow.com/users/3161139",
"pm_score": 0,
"selected": false,
"text": "<p>Many talk about memset without talking about <a href=\"https://linux.die.net/man/3/calloc\" rel=\"nofollow noreferrer\">calloc</a>. I would rather use calloc which was designed for this usecase (please comment if I am wrong):</p>\n\n<blockquote>\n <p>The calloc() function allocates memory for an array of nmemb elements of size bytes each and returns a pointer to the allocated memory. The memory is set to zero. If nmemb or size is 0, then calloc() returns either NULL, or a unique pointer value that can later be successfully passed to free().</p>\n</blockquote>\n\n<p>Example:</p>\n\n<pre class=\"lang-c prettyprint-override\"><code>#include <stdlib.h> // calloc header\n#include <stdio.h> // printf header\n\nvoid *init_heap_array(int elem_nb, int elem_size) {\n void *ptr;\n\n if (!(ptr = calloc(elem_nb, elem_size)))\n return NULL;\n\n return ptr;\n}\n\nvoid set_int_value_at_index(int *ptr, int value, int i) {\n ptr[i] = value;\n}\n\nvoid print_int_array_until(int *ptr, const int until) {\n for (int i = 0; i < until; i++)\n printf(\"%02d \", ptr[i]);\n putchar('\\n');\n}\n\nint main(void) {\n const int array_len = 300000;\n int *n;\n\n if (!(n = init_heap_array(array_len, sizeof(int))))\n return 1; \n\n print_int_array_until(n, 5);\n set_int_value_at_index(n, 42, 1);\n print_int_array_until(n, 5);\n\n return 0;\n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177393",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25704/"
] |
In our code we used to have something like this:
```
*(controller->bigstruct) = ( struct bigstruct ){ 0 };
```
This used to work great, and then we upgraded versions of GCC and suddenly started seeing stack overflows. Looking at the assembly, the old GCC code (2.x) was basically doing this:
```
memset(controller->bigstruct, 0, sizeof(struct bigstruct));
```
The new GCC (3.4.x) was doing this
```
struct bigstruct temp = { 0 };
controller->bigstruct = temp;
```
After reviewing the C99 spec, I could see why; C99 basically requires that anonymous structures exist on the stack. It's a good concept, but this structure was 4 Megabytes large, and only ever intended to exist on heap!
We've resorted to making our own 'initialize' function that explicitly sets the members, but that's ugly and a maintenance headache. I don't consider memset a proper solution, because I can't know that a bit-value of 0 is an appropriate zero value for the type ( nit-picking, I know, but there you are; I don't mind that the compiler does it, because it *can* know )
What is the "correct", or at least best, way to initialize a large structure like this?
To furthur clarify why I think memset isn't a solution: The rules of initialization of members not explicitly initialized are the same as static initialization, and are as follows:
- If it has pointer type, it is initialized to a null pointer;
- If it has arithmetic type, it is initialized to ( positive or unsigned ) zero;
...
'memset' will set the memory to bit-pattern zero, which isn't necessarily the same thing. Imagine a system that doesn't use IEEE floating point numbers. Unusual, but supported by C. The representation of 0.0 doesn't have to mean "all-bits zero", it could be anything convenient to the processor.
|
memset is the way to go. You do not have many alternatives.
Do something like:
```
#define InitStruct(var, type) type var; memset(&var, 0, sizeof(type))
```
So that you only have to:
```
InitStruct(st, BigStruct);
```
And then use st as usual...
I do not get how "0" is not a valid "0" type for a struct. The only way to "mass initialize" a struct is to set all of its memory to a value; otherwise you would have to make extra logic to tell it to use a specific bit pattern per member. The best "generic" bit pattern to use is 0.
Besides - this is the same logic that you used when doing
```
*(controller->bigstruct) = *( struct bigstruct ){ 0 };
```
Therefore I don't get your reluctance to use it :)
The first comment to this post made me do some research before I called him and idiot and I found this:
<http://www.lysator.liu.se/c/c-faq/c-1.html>
Very interesting; if I could vote-up a comment I would :)
That being said - your only option if you want to target archaic architectures with non-0 null values is still to do manual initialization to certain members.
Thanks Thomas Padron-McCarthy! I learned something new today :)
|
177,437 |
<pre><code>const static int foo = 42;
</code></pre>
<p>I saw this in some code here on StackOverflow and I couldn't figure out what it does. Then I saw some confused answers on other forums. My best guess is that it's used in C to hide the constant <code>foo</code> from other modules. Is this correct? If so, why would anyone use it in a C++ context where you can just make it <code>private</code>?</p>
|
[
{
"answer_id": 177443,
"author": "Kevin",
"author_id": 6386,
"author_profile": "https://Stackoverflow.com/users/6386",
"pm_score": 3,
"selected": false,
"text": "<p>It's missing an 'int'. It should be:</p>\n\n<pre><code>const static int foo = 42;\n</code></pre>\n\n<p>In C and C++, it declares an integer constant with local file scope of value 42. </p>\n\n<p>Why 42? If you don't already know (and it's hard to believe you don't), it's a refernce to the <a href=\"http://en.wikipedia.org/wiki/Answer_to_Life,_the_Universe,_and_Everything\" rel=\"noreferrer\"><strong>Answer to Life, the Universe, and Everything</strong></a>.</p>\n"
},
{
"answer_id": 177451,
"author": "Chris Arguin",
"author_id": 25704,
"author_profile": "https://Stackoverflow.com/users/25704",
"pm_score": 8,
"selected": true,
"text": "<p>It has uses in both C and C++.</p>\n\n<p>As you guessed, the <code>static</code> part limits its scope to that <a href=\"https://stackoverflow.com/questions/1106149/what-is-a-translation-unit-in-c\">compilation unit</a>. It also provides for static initialization. <code>const</code> just tells the compiler to not let anybody modify it. This variable is either put in the data or bss segment depending on the architecture, and might be in memory marked read-only.</p>\n\n<p>All that is how C treats these variables (or how C++ treats namespace variables). In C++, a member marked <code>static</code> is shared by all instances of a given class. Whether it's private or not doesn't affect the fact that one variable is shared by multiple instances. Having <code>const</code> on there will warn you if any code would try to modify that.</p>\n\n<p>If it was strictly private, then each instance of the class would get its own version (optimizer notwithstanding).</p>\n"
},
{
"answer_id": 177454,
"author": "Jim Buck",
"author_id": 2666,
"author_profile": "https://Stackoverflow.com/users/2666",
"pm_score": 2,
"selected": false,
"text": "<p>Yes, it hides a variable in a module from other modules. In C++, I use it when I don't want/need to change a .h file that will trigger an unnecessary rebuild of other files. Also, I put the static first:</p>\n\n<pre><code>static const int foo = 42;\n</code></pre>\n\n<p>Also, depending on its use, the compiler won't even allocate storage for it and simply \"inline\" the value where it's used. Without the static, the compiler can't assume it's not being used elsewhere and can't inline.</p>\n"
},
{
"answer_id": 177455,
"author": "Roskoto",
"author_id": 13635,
"author_profile": "https://Stackoverflow.com/users/13635",
"pm_score": 2,
"selected": false,
"text": "<p>This ia s global constant visible/accessible only in the compilation module (.cpp file). BTW using static for this purpose is deprecated. Better use an anonymous namespace and an enum:</p>\n\n<pre><code>namespace\n{\n enum\n {\n foo = 42\n };\n}\n</code></pre>\n"
},
{
"answer_id": 177456,
"author": "yrp",
"author_id": 7228,
"author_profile": "https://Stackoverflow.com/users/7228",
"pm_score": 1,
"selected": false,
"text": "<p>Making it private would still mean it appears in the header. I tend to use \"the weakest\" way that works. See this classic article by Scott Meyers: <a href=\"http://www.ddj.com/cpp/184401197\" rel=\"nofollow noreferrer\">http://www.ddj.com/cpp/184401197</a> (it's about functions, but can be applied here as well).</p>\n"
},
{
"answer_id": 177524,
"author": "oz10",
"author_id": 14069,
"author_profile": "https://Stackoverflow.com/users/14069",
"pm_score": 2,
"selected": false,
"text": "<p>In C++, </p>\n\n<pre><code>static const int foo = 42;\n</code></pre>\n\n<p>is the preferred way to define & use constants. I.e. use this rather than </p>\n\n<pre><code>#define foo 42\n</code></pre>\n\n<p>because it doesn't subvert the type-safety system.</p>\n"
},
{
"answer_id": 177781,
"author": "Richard Corden",
"author_id": 11698,
"author_profile": "https://Stackoverflow.com/users/11698",
"pm_score": 6,
"selected": false,
"text": "<p>That line of code can actually appear in several different contexts and alghough it behaves approximately the same, there are small differences.</p>\n\n<h1>Namespace Scope</h1>\n\n<pre><code>// foo.h\nstatic const int i = 0;\n</code></pre>\n\n<p>'<code>i</code>' will be visible in every translation unit that includes the header. However, unless you actually use the address of the object (for example. '<code>&i</code>'), I'm pretty sure that the compiler will treat '<code>i</code>' simply as a type safe <code>0</code>. Where two more more translation units take the '<code>&i</code>' then the address will be different for each translation unit.</p>\n\n<pre><code>// foo.cc\nstatic const int i = 0;\n</code></pre>\n\n<p>'<code>i</code>' has internal linkage, and so cannot be referred to from outside of this translation unit. However, again unless you use its address it will most likely be treated as a type-safe <code>0</code>.</p>\n\n<p>One thing worth pointing out, is that the following declaration:</p>\n\n<pre><code>const int i1 = 0;\n</code></pre>\n\n<p>is <strong>exactly</strong> the same as <code>static const int i = 0</code>. A variable in a namespace declared with <code>const</code> and not explicitly declared with <code>extern</code> is implicitly static. If you think about this, it was the intention of the C++ committee to allow <code>const</code> variables to be declared in header files without always needing the <code>static</code> keyword to avoid breaking the ODR.</p>\n\n<h1>Class Scope</h1>\n\n<pre><code>class A {\npublic:\n static const int i = 0;\n};\n</code></pre>\n\n<p>In the above example, the standard explicitly specifies that '<code>i</code>' does not need to be defined if its address is not required. In other words if you only use '<code>i</code>' as a type-safe 0 then the compiler will not define it. One difference between the class and namespace versions is that the address of '<code>i</code>' (if used in two ore more translation units) will be the same for the class member. Where the address is used, you must have a definition for it:</p>\n\n<pre><code>// a.h\nclass A {\npublic:\n static const int i = 0;\n};\n\n// a.cc\n#include \"a.h\"\nconst int A::i; // Definition so that we can take the address\n</code></pre>\n"
},
{
"answer_id": 177892,
"author": "Ferruccio",
"author_id": 4086,
"author_profile": "https://Stackoverflow.com/users/4086",
"pm_score": 5,
"selected": false,
"text": "<p>It's a small space optimization.</p>\n\n<p>When you say</p>\n\n<pre><code>const int foo = 42;\n</code></pre>\n\n<p>You're not defining a constant, but creating a read-only variable. The compiler is smart enough to use 42 whenever it sees foo, but it will also allocate space in the initialized data area for it. This is done because, as defined, foo has external linkage. Another compilation unit can say:</p>\n\n<p>extern const int foo;</p>\n\n<p>To get access to its value. That's not a good practice since that compilation unit has no idea what the value of foo is. It just knows it's a const int and has to reload the value from memory whenever it is used.</p>\n\n<p>Now, by declaring that it is static:</p>\n\n<pre><code>static const int foo = 42;\n</code></pre>\n\n<p>The compiler can do its usual optimization, but it can also say \"hey, nobody outside this compilation unit can see foo and I know it's always 42 so there is no need to allocate any space for it.\"</p>\n\n<p>I should also note that in C++, the preferred way to prevent names from escaping the current compilation unit is to use an anonymous namespace:</p>\n\n<pre><code>namespace {\n const int foo = 42; // same as static definition above\n}\n</code></pre>\n"
},
{
"answer_id": 178259,
"author": "Motti",
"author_id": 3848,
"author_profile": "https://Stackoverflow.com/users/3848",
"pm_score": 8,
"selected": false,
"text": "<p>A lot of people gave the basic answer but nobody pointed out that in C++ <code>const</code> defaults to <code>static</code> at <code>namespace</code> level (and some gave wrong information). See the C++98 standard section 3.5.3.</p>\n\n<p>First some background:</p>\n\n<p><em>Translation unit:</em> A source file after the pre-processor (recursively) included all its include files.</p>\n\n<p><em>Static linkage:</em> A symbol is only available within its translation unit.</p>\n\n<p><em>External linkage:</em> A symbol is available from other translation units.</p>\n\n<h3>At <code>namespace</code> level</h3>\n\n<p><em>This includes the global namespace aka global variables</em>. </p>\n\n<pre><code>static const int sci = 0; // sci is explicitly static\nconst int ci = 1; // ci is implicitly static\nextern const int eci = 2; // eci is explicitly extern\nextern int ei = 3; // ei is explicitly extern\nint i = 4; // i is implicitly extern\nstatic int si = 5; // si is explicitly static\n</code></pre>\n\n<h3>At function level</h3>\n\n<p><code>static</code> means the value is maintained between function calls.<br>\nThe semantics of function <code>static</code> variables is similar to global variables in that they reside in the <a href=\"https://stackoverflow.com/questions/93039/where-are-static-variables-stored-in-cc\">program's data-segment</a> (and not the stack or the heap), see <a href=\"https://stackoverflow.com/questions/246564\">this question</a> for more details about <code>static</code> variables' lifetime.</p>\n\n<h3>At <code>class</code> level</h3>\n\n<p><code>static</code> means the value is shared between all instances of the class and <code>const</code> means it doesn't change.</p>\n"
},
{
"answer_id": 181752,
"author": "Black",
"author_id": 25234,
"author_profile": "https://Stackoverflow.com/users/25234",
"pm_score": 2,
"selected": false,
"text": "<p>To all the great answers, I want to add a small detail:</p>\n\n<p>If You write plugins (e.g. DLLs or .so libraries to be loaded by a CAD system), then <em>static</em> is a life saver that avoids name collisions like this one:</p>\n\n<ol>\n<li>The CAD system loads a plugin A, which has a \"const int foo = 42;\" in it.</li>\n<li>The system loads a plugin B, which has \"const int foo = 23;\" in it.</li>\n<li>As a result, plugin B will use the value 42 for foo, because the plugin loader will realize, that there is already a \"foo\" with external linkage.</li>\n</ol>\n\n<p>Even worse: Step 3 may behave differently depending on compiler optimization, plugin load mechanism, etc.</p>\n\n<p>I had this issue once with two helper functions (same name, different behaviour) in two plugins. Declaring them static solved the problem.</p>\n"
},
{
"answer_id": 37169233,
"author": "Alexey Pelekh",
"author_id": 5124187,
"author_profile": "https://Stackoverflow.com/users/5124187",
"pm_score": 3,
"selected": false,
"text": "<p>According to C99/GNU99 specification:</p>\n\n<ul>\n<li><p><code>static</code></p>\n\n<ul>\n<li><p>is storage-class specifier</p></li>\n<li><p>objects of file level scope by default has <strong>external</strong> linkage</p></li>\n<li>objects of file level scope with static specifier has <strong>internal</strong> linkage</li>\n</ul></li>\n<li><p><code>const</code></p>\n\n<ul>\n<li><p>is type-qualifier (is a part of type)</p></li>\n<li><p>keyword applied to immediate left instance - i.e. </p>\n\n<ul>\n<li><p><code>MyObj const * myVar;</code> - unqualified pointer to const qualified object type</p></li>\n<li><p><code>MyObj * const myVar;</code> - const qualified pointer to unqualified object type</p></li>\n</ul></li>\n<li><p>Leftmost usage - applied to the object type, not variable</p>\n\n<ul>\n<li><code>const MyObj * myVar;</code> - unqualified pointer to const qualified object type</li>\n</ul></li>\n</ul></li>\n</ul>\n\n<p><strong>THUS:</strong></p>\n\n<p><code>static NSString * const myVar;</code> - constant pointer to immutable string with internal linkage.</p>\n\n<p>Absence of the <code>static</code> keyword will make variable name global and might lead to name conflicts within the application.</p>\n"
},
{
"answer_id": 53883715,
"author": "Ciro Santilli OurBigBook.com",
"author_id": 895245,
"author_profile": "https://Stackoverflow.com/users/895245",
"pm_score": 3,
"selected": false,
"text": "<p><strong>C++17 <code>inline</code> variables</strong></p>\n\n<p>If you Googled \"C++ const static\", then this is very likely what you really want to use are <a href=\"https://en.cppreference.com/w/cpp/language/inline\" rel=\"noreferrer\">C++17 inline variables</a>.</p>\n\n<p>This awesome C++17 feature allow us to:</p>\n\n<ul>\n<li>conveniently use just a single memory address for each constant</li>\n<li>store it as a <code>constexpr</code>: <a href=\"https://stackoverflow.com/questions/30208685/how-to-declare-constexpr-extern\">How to declare constexpr extern?</a></li>\n<li>do it in a single line from one header</li>\n</ul>\n\n<p>main.cpp</p>\n\n<pre><code>#include <cassert>\n\n#include \"notmain.hpp\"\n\nint main() {\n // Both files see the same memory address.\n assert(&notmain_i == notmain_func());\n assert(notmain_i == 42);\n}\n</code></pre>\n\n<p>notmain.hpp</p>\n\n<pre><code>#ifndef NOTMAIN_HPP\n#define NOTMAIN_HPP\n\ninline constexpr int notmain_i = 42;\n\nconst int* notmain_func();\n\n#endif\n</code></pre>\n\n<p>notmain.cpp</p>\n\n<pre><code>#include \"notmain.hpp\"\n\nconst int* notmain_func() {\n return &notmain_i;\n}\n</code></pre>\n\n<p>Compile and run:</p>\n\n<pre><code>g++ -c -o notmain.o -std=c++17 -Wall -Wextra -pedantic notmain.cpp\ng++ -c -o main.o -std=c++17 -Wall -Wextra -pedantic main.cpp\ng++ -o main -std=c++17 -Wall -Wextra -pedantic main.o notmain.o\n./main\n</code></pre>\n\n<p><a href=\"https://github.com/cirosantilli/cpp-cheat/tree/085c4b22b1b290a6d033a44958d05054e7e303c7/cpp/inline_variable\" rel=\"noreferrer\">GitHub upstream</a>.</p>\n\n<p>See also: <a href=\"https://stackoverflow.com/questions/38043442/how-do-inline-variables-work\">How do inline variables work?</a></p>\n\n<p><strong>C++ standard on inline variables</strong></p>\n\n<p>The C++ standard guarantees that the addresses will be the same. <a href=\"https://github.com/cplusplus/draft/blob/master/papers/n4659.pdf\" rel=\"noreferrer\">C++17 N4659 standard draft</a> \n10.1.6 \"The inline specifier\":</p>\n\n<blockquote>\n <p>6 An inline function or variable with external linkage shall have the same address in all translation units.</p>\n</blockquote>\n\n<p>cppreference <a href=\"https://en.cppreference.com/w/cpp/language/inline\" rel=\"noreferrer\">https://en.cppreference.com/w/cpp/language/inline</a> explains that if <code>static</code> is not given, then it has external linkage.</p>\n\n<p><strong>GCC inline variable implementation</strong></p>\n\n<p>We can observe how it is implemented with:</p>\n\n<pre><code>nm main.o notmain.o\n</code></pre>\n\n<p>which contains:</p>\n\n<pre><code>main.o:\n U _GLOBAL_OFFSET_TABLE_\n U _Z12notmain_funcv\n0000000000000028 r _ZZ4mainE19__PRETTY_FUNCTION__\n U __assert_fail\n0000000000000000 T main\n0000000000000000 u notmain_i\n\nnotmain.o:\n0000000000000000 T _Z12notmain_funcv\n0000000000000000 u notmain_i\n</code></pre>\n\n<p>and <code>man nm</code> says about <code>u</code>:</p>\n\n<blockquote>\n <p>\"u\" The symbol is a unique global symbol. This is a GNU extension to the standard set of ELF symbol bindings. For such a symbol the dynamic linker will make sure that in the entire process\n there is just one symbol with this name and type in use.</p>\n</blockquote>\n\n<p>so we see that there is a dedicated ELF extension for this.</p>\n\n<p><strong>Pre-C++ 17: <code>extern const</code></strong></p>\n\n<p>Before C++ 17, and in C, we can achieve a very similar effect with an <code>extern const</code>, which will lead to a single memory location being used.</p>\n\n<p>The downsides over <code>inline</code> are:</p>\n\n<ul>\n<li>it is not possible to make the variable <code>constexpr</code> with this technique, only <code>inline</code> allows that: <a href=\"https://stackoverflow.com/questions/30208685/how-to-declare-constexpr-extern\">How to declare constexpr extern?</a></li>\n<li>it is less elegant as you have to declare and define the variable separately in the header and cpp file</li>\n</ul>\n\n<p>main.cpp</p>\n\n<pre><code>#include <cassert>\n\n#include \"notmain.hpp\"\n\nint main() {\n // Both files see the same memory address.\n assert(&notmain_i == notmain_func());\n assert(notmain_i == 42);\n}\n</code></pre>\n\n<p>notmain.cpp</p>\n\n<pre><code>#include \"notmain.hpp\"\n\nconst int notmain_i = 42;\n\nconst int* notmain_func() {\n return &notmain_i;\n}\n</code></pre>\n\n<p>notmain.hpp</p>\n\n<pre><code>#ifndef NOTMAIN_HPP\n#define NOTMAIN_HPP\n\nextern const int notmain_i;\n\nconst int* notmain_func();\n\n#endif\n</code></pre>\n\n<p><a href=\"https://github.com/cirosantilli/cpp-cheat/tree/085c4b22b1b290a6d033a44958d05054e7e303c7/cpp/extern_const\" rel=\"noreferrer\">GitHub upstream</a>.</p>\n\n<p><strong>Pre-C++17 header only alternatives</strong></p>\n\n<p>These are not as good as the <code>extern</code> solution, but they work and only take up a single memory location:</p>\n\n<p>A <code>constexpr</code> function, because <a href=\"https://stackoverflow.com/questions/14391272/does-constexpr-imply-inline\"><code>constexpr</code> implies <code>inline</code></a> and <code>inline</code> <a href=\"https://stackoverflow.com/questions/14517546/how-can-a-c-header-file-include-implementation\">allows (forces) the definition to appear on every translation unit</a>:</p>\n\n<pre><code>constexpr int shared_inline_constexpr() { return 42; }\n</code></pre>\n\n<p>and I bet that any decent compiler will inline the call.</p>\n\n<p>You can also use a <code>const</code> or <code>constexpr</code> static variable as in:</p>\n\n<pre><code>#include <iostream>\n\nstruct MyClass {\n static constexpr int i = 42;\n};\n\nint main() {\n std::cout << MyClass::i << std::endl;\n // undefined reference to `MyClass::i'\n //std::cout << &MyClass::i << std::endl;\n}\n</code></pre>\n\n<p>but you can't do things like taking its address, or else it becomes odr-used, see also: <a href=\"https://stackoverflow.com/questions/50109036/defining-constexpr-static-data-members/50111847#50111847\">Defining constexpr static data members</a></p>\n\n<p><strong>C</strong></p>\n\n<p>In C the situation is the same as C++ pre C++ 17, I've uploaded an example at: <a href=\"https://stackoverflow.com/questions/572547/what-does-static-mean-in-c/14339047#14339047\">What does "static" mean in C?</a></p>\n\n<p>The only difference is that in C++, <code>const</code> implies <code>static</code> for globals, but it does not in C: <a href=\"https://stackoverflow.com/questions/3709207/c-semantics-of-static-const-vs-const/54377560#54377560\">C++ semantics of `static const` vs `const`</a></p>\n\n<p><strong>Any way to fully inline it?</strong></p>\n\n<p>TODO: is there any way to fully inline the variable, without using any memory at all?</p>\n\n<p>Much like what the preprocessor does.</p>\n\n<p>This would require somehow:</p>\n\n<ul>\n<li>forbidding or detecting if the address of the variable is taken</li>\n<li>add that information to the ELF object files, and let LTO optimize it up</li>\n</ul>\n\n<p>Related:</p>\n\n<ul>\n<li><a href=\"https://stackoverflow.com/questions/14090583/c11-enum-with-class-members-and-constexpr-link-time-optimization\">C++11 enum with class members and constexpr link-time optimization</a></li>\n</ul>\n\n<p>Tested in Ubuntu 18.10, GCC 8.2.0.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177437",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2079/"
] |
```
const static int foo = 42;
```
I saw this in some code here on StackOverflow and I couldn't figure out what it does. Then I saw some confused answers on other forums. My best guess is that it's used in C to hide the constant `foo` from other modules. Is this correct? If so, why would anyone use it in a C++ context where you can just make it `private`?
|
It has uses in both C and C++.
As you guessed, the `static` part limits its scope to that [compilation unit](https://stackoverflow.com/questions/1106149/what-is-a-translation-unit-in-c). It also provides for static initialization. `const` just tells the compiler to not let anybody modify it. This variable is either put in the data or bss segment depending on the architecture, and might be in memory marked read-only.
All that is how C treats these variables (or how C++ treats namespace variables). In C++, a member marked `static` is shared by all instances of a given class. Whether it's private or not doesn't affect the fact that one variable is shared by multiple instances. Having `const` on there will warn you if any code would try to modify that.
If it was strictly private, then each instance of the class would get its own version (optimizer notwithstanding).
|
177,496 |
<p>I have a simple HTML. I am using the JQuery for AJAX purpose. Now, I want to put my javascript function in a separate javascript file. What is the syntax for this? For example, currently my script section in the HTML is something like this:</p>
<pre><code><script>
<script type="text/javascript" src="scripts/scripts.js"></script>
<script type="text/javascript" src="scripts/jquery.js"></script>
<script type = "text/javascript" language="javascript">
$(document).ready(function() {
$("#SubmitForm").click(Submit());
});
</script>
</code></pre>
<p>But I want to put the function </p>
<pre><code>function() {
$("#SubmitForm").click(Submit());
})
</code></pre>
<p>in the file scripts.js. Can I use assign a name to that function and refer to it? </p>
<p>EDit: I still have a bit of problem here: I changed the code to </p>
<pre><code><script type = "text/javascript" language="javascript">
$(document).ready(function() {
$("#SubmitForm").click(submitMe);
});
</script>
</code></pre>
<p>and in a separate js file, I have the following code:</p>
<pre><code>var submitMe = function(){
alert('clicked23!');
//$('#Testing').html('news');
};
</code></pre>
<p>Here's the body section:</p>
<pre><code><body>
welcome
<form id="SubmitForm" action="/showcontent" method="POST">
<input type="file" name="vsprojFiles" />
<br/>
<input type="submit" id="SubmitButton"/>
</form>
<div id="Testing">
hi
</div>
</body>
</code></pre>
<p>Yet, it is still not working, anything I miss?</p>
|
[
{
"answer_id": 177499,
"author": "Mote",
"author_id": 24789,
"author_profile": "https://Stackoverflow.com/users/24789",
"pm_score": -1,
"selected": false,
"text": "<pre><code>$('head').append('&lt;script type=\"text/javascript\" src=\"scripts/scripts.js\"/&gt;')\n</code></pre>\n"
},
{
"answer_id": 177517,
"author": "NickV",
"author_id": 8322,
"author_profile": "https://Stackoverflow.com/users/8322",
"pm_score": 1,
"selected": false,
"text": "<p>Yes, that's not a problem, simply store the function as a variable, like you would any other.</p>\n\n<pre><code>var myfunc = function(){\n // Do some stuff\n}\n</code></pre>\n\n<p>You can then use the following syntax to run it in your jQuery init function:</p>\n\n<pre><code>$(document).ready(myfunc);\n</code></pre>\n\n<p>There is also a shortcut syntax for code that is run on document ready, which is just to pass a function into jQuery:</p>\n\n<pre><code>$(myfunc);\n</code></pre>\n"
},
{
"answer_id": 177518,
"author": "Luke Bennett",
"author_id": 17602,
"author_profile": "https://Stackoverflow.com/users/17602",
"pm_score": 4,
"selected": true,
"text": "<p>Move the scripts.js <code>script</code> tag down beneath the jQuery <code>script</code> tag and then just move the whole of that inline script block into scripts.js. As jQuery will already have been instantiated by the time scripts.js loads, the Javascript will just execute inline in the same way that it does at the moment.</p>\n\n<p>Also on a separate note, you need to change</p>\n\n<pre><code>$(\"#SubmitForm\").click(Submit());\n</code></pre>\n\n<p>to</p>\n\n<pre><code>$(\"#SubmitForm\").click(Submit);\n</code></pre>\n\n<p>You don't want the parentheses because you are not executing the function at this point, merely telling the click event handler that this is the name of the function that you want to execute when the event fires.</p>\n\n<p>And as another tip, you can replace <code>$(document).ready(</code> with <code>$(</code> ie:</p>\n\n<pre><code> $(function() {\n $(\"#SubmitForm\").click(Submit);\n });\n</code></pre>\n\n<p>Both <code>$</code> and <code>document.ready</code> can be included anywhere on the page (or in external files) and as long as jQuery.js is in scope, they will fire at the same time (once the DOM has loaded) - you don't need to worry about it being the last bit of code to fire. This is why you can move the whole thing to scripts.js rather than needing to assign a name to the function and refer to it from the inline script.</p>\n\n<p>For the record, if you do wish to refer to the function by name, simply define it as a variable:</p>\n\n<pre><code>var func = function() {\n $(\"#SubmitForm\").click(Submit);\n};\n\n$(func);\n</code></pre>\n\n<p>Like I say though, this is possibly somewhat overkill in your situation, you might as well just move the whole thing to scripts.js (unless of course there's more to it than you've mentioned in your question.</p>\n\n<p><strong>Edit (to deal with edit to question)</strong>: Looks like you are dealing with the wrong event handler. You are trying to assign a function to the click event handler for the form, whereas you really want to be assigning it to the handler for the submit button. You should therefore be using the selector '#SubmitButton' ie:</p>\n\n<pre><code>$(\"#SubmitButton\").click(Submit);\n</code></pre>\n"
},
{
"answer_id": 177522,
"author": "Oli",
"author_id": 12870,
"author_profile": "https://Stackoverflow.com/users/12870",
"pm_score": 0,
"selected": false,
"text": "<p>Why not dump</p>\n\n<pre><code>$(document).ready(function() {\n $(\"#SubmitForm\").click(Submit);\n});\n</code></pre>\n\n<p>in the external file? It will work as it currently is because you can stack onDomReady events.</p>\n\n<p>Your html should then be like this (note that first <code><script></code> is bad):</p>\n\n<pre><code><script type=\"text/javascript\" src=\"scripts/scripts.js\"></script>\n<script type=\"text/javascript\" src=\"scripts/jquery.js\"></script>\n<script type=\"text/javascript\" src=\"scripts/scripts.js\"></script>\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177496",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3834/"
] |
I have a simple HTML. I am using the JQuery for AJAX purpose. Now, I want to put my javascript function in a separate javascript file. What is the syntax for this? For example, currently my script section in the HTML is something like this:
```
<script>
<script type="text/javascript" src="scripts/scripts.js"></script>
<script type="text/javascript" src="scripts/jquery.js"></script>
<script type = "text/javascript" language="javascript">
$(document).ready(function() {
$("#SubmitForm").click(Submit());
});
</script>
```
But I want to put the function
```
function() {
$("#SubmitForm").click(Submit());
})
```
in the file scripts.js. Can I use assign a name to that function and refer to it?
EDit: I still have a bit of problem here: I changed the code to
```
<script type = "text/javascript" language="javascript">
$(document).ready(function() {
$("#SubmitForm").click(submitMe);
});
</script>
```
and in a separate js file, I have the following code:
```
var submitMe = function(){
alert('clicked23!');
//$('#Testing').html('news');
};
```
Here's the body section:
```
<body>
welcome
<form id="SubmitForm" action="/showcontent" method="POST">
<input type="file" name="vsprojFiles" />
<br/>
<input type="submit" id="SubmitButton"/>
</form>
<div id="Testing">
hi
</div>
</body>
```
Yet, it is still not working, anything I miss?
|
Move the scripts.js `script` tag down beneath the jQuery `script` tag and then just move the whole of that inline script block into scripts.js. As jQuery will already have been instantiated by the time scripts.js loads, the Javascript will just execute inline in the same way that it does at the moment.
Also on a separate note, you need to change
```
$("#SubmitForm").click(Submit());
```
to
```
$("#SubmitForm").click(Submit);
```
You don't want the parentheses because you are not executing the function at this point, merely telling the click event handler that this is the name of the function that you want to execute when the event fires.
And as another tip, you can replace `$(document).ready(` with `$(` ie:
```
$(function() {
$("#SubmitForm").click(Submit);
});
```
Both `$` and `document.ready` can be included anywhere on the page (or in external files) and as long as jQuery.js is in scope, they will fire at the same time (once the DOM has loaded) - you don't need to worry about it being the last bit of code to fire. This is why you can move the whole thing to scripts.js rather than needing to assign a name to the function and refer to it from the inline script.
For the record, if you do wish to refer to the function by name, simply define it as a variable:
```
var func = function() {
$("#SubmitForm").click(Submit);
};
$(func);
```
Like I say though, this is possibly somewhat overkill in your situation, you might as well just move the whole thing to scripts.js (unless of course there's more to it than you've mentioned in your question.
**Edit (to deal with edit to question)**: Looks like you are dealing with the wrong event handler. You are trying to assign a function to the click event handler for the form, whereas you really want to be assigning it to the handler for the submit button. You should therefore be using the selector '#SubmitButton' ie:
```
$("#SubmitButton").click(Submit);
```
|
177,506 |
<pre class="lang-cpp prettyprint-override"><code>double r = 11.631;
double theta = 21.4;
</code></pre>
<p>In the debugger, these are shown as <code>11.631000000000000</code> and <code>21.399999618530273</code>.</p>
<p>How can I avoid this?</p>
|
[
{
"answer_id": 177512,
"author": "Konrad Rudolph",
"author_id": 1968,
"author_profile": "https://Stackoverflow.com/users/1968",
"pm_score": 7,
"selected": true,
"text": "<p>These <a href=\"http://en.wikipedia.org/wiki/Floating_point_number#Accuracy_problems\" rel=\"noreferrer\">accuracy problems</a> are due to the <a href=\"http://en.wikipedia.org/wiki/Floating_point_number#Internal_representation\" rel=\"noreferrer\">internal representation</a> of floating point numbers and there's not much you can do to avoid it.</p>\n\n<p>By the way, printing these values at run-time often still leads to the correct results, at least using modern C++ compilers. For most operations, this isn't much of an issue.</p>\n"
},
{
"answer_id": 177525,
"author": "Mark Ingram",
"author_id": 986,
"author_profile": "https://Stackoverflow.com/users/986",
"pm_score": 4,
"selected": false,
"text": "\n\n<p>If you have a value like:</p>\n\n<pre class=\"lang-java prettyprint-override\"><code>double theta = 21.4;\n</code></pre>\n\n<p>And you want to do:</p>\n\n<pre class=\"lang-java prettyprint-override\"><code>if (theta == 21.4)\n{\n}\n</code></pre>\n\n<p>You have to be a bit clever, you will need to check if the value of theta is <strong>really</strong> close to 21.4, but not necessarily that value.</p>\n\n<pre class=\"lang-java prettyprint-override\"><code>if (fabs(theta - 21.4) <= 1e-6)\n{\n}\n</code></pre>\n"
},
{
"answer_id": 177527,
"author": "SmacL",
"author_id": 22564,
"author_profile": "https://Stackoverflow.com/users/22564",
"pm_score": 2,
"selected": false,
"text": "<p>One way you can avoid this is to use a library that uses an alternative method of representing decimal numbers, such as <a href=\"http://en.wikipedia.org/wiki/Binary_coded_decimal\" rel=\"nofollow noreferrer\">BCD</a></p>\n"
},
{
"answer_id": 177531,
"author": "Shimi Bandiel",
"author_id": 15100,
"author_profile": "https://Stackoverflow.com/users/15100",
"pm_score": 2,
"selected": false,
"text": "<p>If you are using Java and you need accuracy, use the BigDecimal class for floating point calculations. It is slower but safer.</p>\n"
},
{
"answer_id": 177539,
"author": "Jeff Atwood",
"author_id": 1,
"author_profile": "https://Stackoverflow.com/users/1",
"pm_score": 5,
"selected": false,
"text": "<p>I liked <a href=\"http://www.joelonsoftware.com/items/2007/09/26b.html\" rel=\"noreferrer\">Joel's explanation</a>, which deals with a similar binary floating point precision issue in Excel 2007:</p>\n\n<blockquote>\n <p>See how there's a lot of 0110 0110 0110 there at the end? That's because <strong>0.1</strong> has <em>no exact representation in binary</em>... it's a repeating binary number. It's sort of like how 1/3 has no representation in decimal. 1/3 is 0.33333333 and you have to keep writing 3's forever. If you lose patience, you get something inexact.</p>\n \n <p>So you can imagine how, in decimal, if you tried to do 3*1/3, and you didn't have time to write 3's forever, the result you would get would be 0.99999999, not 1, and people would get angry with you for being wrong.</p>\n</blockquote>\n"
},
{
"answer_id": 177749,
"author": "Peter Wone",
"author_id": 1715673,
"author_profile": "https://Stackoverflow.com/users/1715673",
"pm_score": 3,
"selected": false,
"text": "<p>Use the fixed-point <code>decimal</code> type if you want stability at the limits of precision. There are overheads, and you must explicitly cast if you wish to convert to floating point. If you do convert to floating point you will reintroduce the instabilities that seem to bother you.</p>\n\n<p>Alternately you can get over it and learn to work <em>with</em> the limited precision of floating point arithmetic. For example you can use rounding to make values converge, or you can use epsilon comparisons to describe a tolerance. \"Epsilon\" is a constant you set up that defines a tolerance. For example, you may choose to regard two values as being equal if they are within 0.0001 of each other.</p>\n\n<p>It occurs to me that you could use operator overloading to make epsilon comparisons transparent. That would be very cool.</p>\n\n<hr>\n\n<p>For mantissa-exponent representations EPSILON must be computed to remain within the representable precision. For a number N, Epsilon = N / 10E+14</p>\n\n<p><code>System.Double.Epsilon</code> is the smallest representable positive value for the <code>Double</code> type. It is <em>too</em> small for our purpose. Read <a href=\"https://msdn.microsoft.com/en-us/library/system.double(v=vs.110).aspx#Equality\" rel=\"nofollow noreferrer\">Microsoft's advice on equality testing</a></p>\n"
},
{
"answer_id": 177760,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 3,
"selected": false,
"text": "<p>This is partly platform-specific - and we don't know what platform you're using.</p>\n\n<p>It's also partly a case of knowing what you actually <em>want</em> to see. The debugger is showing you - to some extent, anyway - the precise value stored in your variable. In my <a href=\"http://pobox.com/~skeet/csharp/floatingpoint.html\" rel=\"noreferrer\">article on binary floating point numbers in .NET</a>, there's a <a href=\"http://pobox.com/~skeet/csharp/DoubleConverter.cs\" rel=\"noreferrer\">C# class</a> which lets you see the absolutely <em>exact</em> number stored in a double. The online version isn't working at the moment - I'll try to put one up on another site.</p>\n\n<p>Given that the debugger sees the \"actual\" value, it's got to make a judgement call about what to display - it could show you the value rounded to a few decimal places, or a more precise value. Some debuggers do a better job than others at reading developers' minds, but it's a fundamental problem with binary floating point numbers.</p>\n"
},
{
"answer_id": 177776,
"author": "MikeJ-UK",
"author_id": 25750,
"author_profile": "https://Stackoverflow.com/users/25750",
"pm_score": 2,
"selected": false,
"text": "<p>Seems to me that 21.399999618530273 is the <em>single precision</em> (float) representation of 21.4. Looks like the debugger is casting down from double to float somewhere.</p>\n"
},
{
"answer_id": 177792,
"author": "Larry",
"author_id": 24472,
"author_profile": "https://Stackoverflow.com/users/24472",
"pm_score": 1,
"selected": false,
"text": "<p>If it bothers you, you can customize the way some values are displayed during debug. Use it with care :-)</p>\n<p><a href=\"http://msdn.microsoft.com/en-us/library/ms228992.aspx\" rel=\"nofollow noreferrer\">Enhancing Debugging with the Debugger Display Attributes</a></p>\n"
},
{
"answer_id": 177924,
"author": "akalenuk",
"author_id": 25459,
"author_profile": "https://Stackoverflow.com/users/25459",
"pm_score": 2,
"selected": false,
"text": "<p>You cant avoid this as you're using floating point numbers with fixed quantity of bytes. There's simply no isomorphism possible between real numbers and its limited notation.</p>\n\n<p>But most of the time you can simply ignore it. 21.4==21.4 would still be true because it is still the same numbers with the same error. But 21.4f==21.4 may not be true because the error for float and double are different. </p>\n\n<p>If you need fixed precision, perhaps you should try fixed point numbers. Or even integers. I for example often use int(1000*x) for passing to debug pager.</p>\n"
},
{
"answer_id": 178191,
"author": "Keith",
"author_id": 905,
"author_profile": "https://Stackoverflow.com/users/905",
"pm_score": 2,
"selected": false,
"text": "<p>I've come across this before (<a href=\"http://bizvprog.blogspot.com/2008/05/floating-point-numbers-more-inaccurate.html\" rel=\"nofollow noreferrer\">on my blog</a>) - I think the surprise tends to be that the 'irrational' numbers are different.</p>\n\n<p>By 'irrational' here I'm just referring to the fact that they can't be accurately represented in this format. Real irrational numbers (like π - pi) can't be accurately represented at all.</p>\n\n<p>Most people are familiar with 1/3 not working in decimal: 0.3333333333333...</p>\n\n<p>The odd thing is that 1.1 doesn't work in floats. People expect decimal values to work in floating point numbers because of how they think of them:</p>\n\n<blockquote>\n <p>1.1 is 11 x 10^-1</p>\n</blockquote>\n\n<p>When actually they're in base-2</p>\n\n<blockquote>\n <p>1.1 is 154811237190861 x 2^-47 </p>\n</blockquote>\n\n<p>You can't avoid it, you just have to get used to the fact that some floats are 'irrational', in the same way that 1/3 is.</p>\n"
},
{
"answer_id": 256912,
"author": "Chobicus",
"author_id": 1514822,
"author_profile": "https://Stackoverflow.com/users/1514822",
"pm_score": 2,
"selected": false,
"text": "<p><a href=\"http://spiff.rit.edu/classes/phys317/lectures/dangers.html\" rel=\"nofollow noreferrer\">Dangers of computer arithmetic</a></p>\n"
},
{
"answer_id": 438498,
"author": "grom",
"author_id": 486,
"author_profile": "https://Stackoverflow.com/users/486",
"pm_score": 0,
"selected": false,
"text": "<p>Refer to <a href=\"http://speleotrove.com/decimal/#summary\" rel=\"nofollow noreferrer\">General Decimal Arithmetic</a></p>\n\n<p>Also take note when comparing floats, see <a href=\"https://stackoverflow.com/questions/17333/most-effective-way-for-float-and-double-comparison#17467\">this answer</a> for more information.</p>\n"
},
{
"answer_id": 16840086,
"author": "MaheshVarma",
"author_id": 2416228,
"author_profile": "https://Stackoverflow.com/users/2416228",
"pm_score": 0,
"selected": false,
"text": "<p>According to the javadoc</p>\n\n<p>\"If at least one of the operands to a numerical operator is of type double, then the<br>\n operation is carried out using 64-bit floating-point arithmetic, and the result of the<br>\n numerical operator is a value of type double. If the other operand is not a double, it is<br>\n first widened (§5.1.5) to type double by numeric promotion (§5.6).\"</p>\n\n<p><a href=\"http://docs.oracle.com/javase/specs/jls/se7/html/jls-4.html#jls-4.2.3\" rel=\"nofollow\">Here is the Source</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177506",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22076/"
] |
```cpp
double r = 11.631;
double theta = 21.4;
```
In the debugger, these are shown as `11.631000000000000` and `21.399999618530273`.
How can I avoid this?
|
These [accuracy problems](http://en.wikipedia.org/wiki/Floating_point_number#Accuracy_problems) are due to the [internal representation](http://en.wikipedia.org/wiki/Floating_point_number#Internal_representation) of floating point numbers and there's not much you can do to avoid it.
By the way, printing these values at run-time often still leads to the correct results, at least using modern C++ compilers. For most operations, this isn't much of an issue.
|
177,520 |
<p>I am wondering if there are any alternatives to using the Expand key word when performing an LINQ to ADO.net Data Services query. The expand method does get me the data I am interested in, but it requires me to know all of the sub-objects that I am going to be working with in advance. My absolute preference would be that those sub-objects would be lazy loaded for me when I access them, but this doesn't look to be an option (I could add this lazy loading to the get on that sub-object property, but it gets wiped out when I do an update of the data service reference).</p>
<p>Does anyone have any suggestions/best practices/alternatives for this situation? Thanks.</p>
<p>===== Example Code using Member that has a MailingAddress =====</p>
<p>Works: </p>
<pre><code>var me = (from m in ctx.Member.Expand("MailingAddress")
where m.MemberID == 10000
select m).First();
MessageBox.Show(me.MailingAddress.Street);
</code></pre>
<p>Would Prefer (would really like if this then went and loaded the MailingAddress)</p>
<pre><code>var me = (from m in ctx.Member
where m.MemberID == 10000
select m).First();
MessageBox.Show(me.MailingAddress.Street);
</code></pre>
<p>Or at least (note: something similar to this, with MailingAddressReference, works on the server side if I do so as LINQ to Entities in a Service Operation)</p>
<pre><code>var me = (from m in ctx.Member
where m.MemberID == 10000
select m).First();
if (!(me.MailingAddress.IsLoaded())) me.MailingAddress.Load()
MessageBox.Show(me.MailingAddress.Street);
</code></pre>
|
[
{
"answer_id": 178391,
"author": "Craig Stuntz",
"author_id": 7714,
"author_profile": "https://Stackoverflow.com/users/7714",
"pm_score": 2,
"selected": false,
"text": "<p>With LINQ to Entities you can also use the <a href=\"http://msdn.microsoft.com/en-us/library/bb896272.aspx\" rel=\"nofollow noreferrer\">Include method</a>. You can apply this to me after it's declared but before it's executed, e.g.:</p>\n\n<pre><code>me = me.Include(\"MailingAddress\");\n</code></pre>\n"
},
{
"answer_id": 190016,
"author": "ChrisHDog",
"author_id": 25719,
"author_profile": "https://Stackoverflow.com/users/25719",
"pm_score": 4,
"selected": true,
"text": "<p>Loading sub-objects via ADO.net Data Services seem to have two choices:</p>\n\n<h2>Eager Loading</h2>\n\n<p>Accomplished by .Expand(\"[MemberVariableName]\") on the LINQ to Data Services example</p>\n\n<pre><code>var me = (from m in ctx.Member.Expand(\"MailingAddress\") \n where m.MemberID == 10000 \n select m).First();\nMessageBox.Show(me.MailingAddress.Street);\n</code></pre>\n\n<h2>Lazy Loading</h2>\n\n<p>Accomplished by calling .LoadProperty on the context and passing it the variable and the property that should be lazy loaded.</p>\n\n<pre><code>var me = (from m in ctx.Member \n where m.MemberID == 10000 \n select m).First();\nctx.LoadProperty(myMember, \"MailingAddresses\");\nMessageBox.Show(me.MailingAddress.Street);\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177520",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25719/"
] |
I am wondering if there are any alternatives to using the Expand key word when performing an LINQ to ADO.net Data Services query. The expand method does get me the data I am interested in, but it requires me to know all of the sub-objects that I am going to be working with in advance. My absolute preference would be that those sub-objects would be lazy loaded for me when I access them, but this doesn't look to be an option (I could add this lazy loading to the get on that sub-object property, but it gets wiped out when I do an update of the data service reference).
Does anyone have any suggestions/best practices/alternatives for this situation? Thanks.
===== Example Code using Member that has a MailingAddress =====
Works:
```
var me = (from m in ctx.Member.Expand("MailingAddress")
where m.MemberID == 10000
select m).First();
MessageBox.Show(me.MailingAddress.Street);
```
Would Prefer (would really like if this then went and loaded the MailingAddress)
```
var me = (from m in ctx.Member
where m.MemberID == 10000
select m).First();
MessageBox.Show(me.MailingAddress.Street);
```
Or at least (note: something similar to this, with MailingAddressReference, works on the server side if I do so as LINQ to Entities in a Service Operation)
```
var me = (from m in ctx.Member
where m.MemberID == 10000
select m).First();
if (!(me.MailingAddress.IsLoaded())) me.MailingAddress.Load()
MessageBox.Show(me.MailingAddress.Street);
```
|
Loading sub-objects via ADO.net Data Services seem to have two choices:
Eager Loading
-------------
Accomplished by .Expand("[MemberVariableName]") on the LINQ to Data Services example
```
var me = (from m in ctx.Member.Expand("MailingAddress")
where m.MemberID == 10000
select m).First();
MessageBox.Show(me.MailingAddress.Street);
```
Lazy Loading
------------
Accomplished by calling .LoadProperty on the context and passing it the variable and the property that should be lazy loaded.
```
var me = (from m in ctx.Member
where m.MemberID == 10000
select m).First();
ctx.LoadProperty(myMember, "MailingAddresses");
MessageBox.Show(me.MailingAddress.Street);
```
|
177,536 |
<p>Is there a simple way to prevent browser from downloading and displaying images, best would be via some magic style tag or javasctipe.</p>
<p>The thing is, I'd like to tweak the company's website a bit to be more usable via mobile devices. The company is a gaming one, there's like 5MBs of images on it's main page (and those can't be touched). They alredy display deadly slow on my dsl, and they can be killers to someone who's paying for his GPRS per MB ;)</p>
<p>The code of the page is not mine and shouldn't be touched too (in fact, it should be written from scratch, but it's not in my gesture to do it now) :)</p>
<p>I was thinking about two solutions:</p>
<p>1) If there was some kind of style-tag (or maybe a javascript? the one that would work on mobile browsers tho) that would prevent browser from downloading images and force to display alt-parameter instead I could simply attach this style if I discovered a user-agent to be some known mobile thing.
or 2) I could tweak the webserver a bit to check the User-agent header and if client requests an image (.png, .gif and .jpg) send 404 instead. That has a downside tho - I'd like to allow the user to view images if he actually wants to.</p>
<p>It seems that first solution would be best - what you guys think? And is there a javascript way to do it? </p>
<p>I could try building document DOM, then get all <code><img></code> elements, and replace their <code>src</code> with some placeholder even but will that work on most mobile browsers (Opera Mini I suppose, the Windows Mobile thingy, the basic Symbian browser from Nokia)? And would playing with document DOM be a good solution on a mobile device (I'm not sure about it's memory-and-cpu requirements to be honest).</p>
|
[
{
"answer_id": 177549,
"author": "Gene",
"author_id": 22673,
"author_profile": "https://Stackoverflow.com/users/22673",
"pm_score": 1,
"selected": false,
"text": "<p>I would not rely on javascript or any other client side method with mobile browsers. Most mobile browsers just don't support javascript well enough.</p>\n\n<p>Some server side \"branching\" is probably the way to go. And don't forget to disable the css background images while you're at it.</p>\n"
},
{
"answer_id": 177654,
"author": "Treb",
"author_id": 22114,
"author_profile": "https://Stackoverflow.com/users/22114",
"pm_score": 0,
"selected": false,
"text": "<p>Why not use <a href=\"http://www.howtocreate.co.uk/tutorials/css/mediatypes\" rel=\"nofollow noreferrer\">alternative style sheets</a>? I just don't know how well they are supported by mobile browsers.</p>\n\n<p>You can specify a seperate css for mobile devices:</p>\n\n<pre><code><link rel=\"stylesheet\" media=\"screen,projection,tv\" href=\"main.css\" type=\"text/css\">\n<link rel=\"stylesheet\" media=\"handheld\" href=\"smallscreen.css\" type=\"text/css\">\n</code></pre>\n\n<p>In that css you override the display of <code><img></code> and all background pictures.</p>\n"
},
{
"answer_id": 178182,
"author": "matte",
"author_id": 25768,
"author_profile": "https://Stackoverflow.com/users/25768",
"pm_score": 3,
"selected": true,
"text": "<p>You can use htaccess to redirect image requests made from mobile browser users. I haven't tested this but it should work:</p>\n\n<pre><code>RewriteCond %{HTTP_USER_AGENT} (nokia¦symbian¦iphone¦blackberry) [NC] \nRewriteCond %{REQUEST_URI} !^/images/$\nRewriteRule (.*) /blank.jpg [L]\n</code></pre>\n\n<p>This code redirects all requests made to files in image folder by nokia,symbian,iphone and blackberry to a blank image file.</p>\n"
},
{
"answer_id": 1171841,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>That's like spoofing your user agent. If they really want the full version, just give it to them. Maybe add a suggestion to Blackberry users to complain with the manufacturer about the lack of such an option.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177536",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4172/"
] |
Is there a simple way to prevent browser from downloading and displaying images, best would be via some magic style tag or javasctipe.
The thing is, I'd like to tweak the company's website a bit to be more usable via mobile devices. The company is a gaming one, there's like 5MBs of images on it's main page (and those can't be touched). They alredy display deadly slow on my dsl, and they can be killers to someone who's paying for his GPRS per MB ;)
The code of the page is not mine and shouldn't be touched too (in fact, it should be written from scratch, but it's not in my gesture to do it now) :)
I was thinking about two solutions:
1) If there was some kind of style-tag (or maybe a javascript? the one that would work on mobile browsers tho) that would prevent browser from downloading images and force to display alt-parameter instead I could simply attach this style if I discovered a user-agent to be some known mobile thing.
or 2) I could tweak the webserver a bit to check the User-agent header and if client requests an image (.png, .gif and .jpg) send 404 instead. That has a downside tho - I'd like to allow the user to view images if he actually wants to.
It seems that first solution would be best - what you guys think? And is there a javascript way to do it?
I could try building document DOM, then get all `<img>` elements, and replace their `src` with some placeholder even but will that work on most mobile browsers (Opera Mini I suppose, the Windows Mobile thingy, the basic Symbian browser from Nokia)? And would playing with document DOM be a good solution on a mobile device (I'm not sure about it's memory-and-cpu requirements to be honest).
|
You can use htaccess to redirect image requests made from mobile browser users. I haven't tested this but it should work:
```
RewriteCond %{HTTP_USER_AGENT} (nokia¦symbian¦iphone¦blackberry) [NC]
RewriteCond %{REQUEST_URI} !^/images/$
RewriteRule (.*) /blank.jpg [L]
```
This code redirects all requests made to files in image folder by nokia,symbian,iphone and blackberry to a blank image file.
|
177,538 |
<p>Every time I need to do something <em>N</em> times inside an algorithm using C# I write this code</p>
<pre><code>for (int i = 0; i < N; i++)
{
...
}
</code></pre>
<p>Studying Ruby I have learned about method <em>times()</em> which can be used with the same semantics like this</p>
<pre><code>N.times do
...
end
</code></pre>
<p>Code fragment in C# looks more complex and we should declare useless variable <em>i</em>.</p>
<p>I tried to write extension method which returns <em>IEnumerable</em>, but I am not satisfied with the result because again I have to declare a cycle variable <em>i</em>.</p>
<pre><code>public static class IntExtender
{
public static IEnumerable Times(this int times)
{
for (int i = 0; i < times; i++)
yield return true;
}
}
...
foreach (var i in 5.Times())
{
...
}
</code></pre>
<p>Is it possible using some new C# 3.0 language features to make <em>N</em> times cycle more elegant?</p>
|
[
{
"answer_id": 177551,
"author": "cvk",
"author_id": 25397,
"author_profile": "https://Stackoverflow.com/users/25397",
"pm_score": 4,
"selected": false,
"text": "<p>It is indeed possible with C# 3.0:</p>\n\n<pre><code>public interface ILoopIterator\n{\n void Do(Action action);\n void Do(Action<int> action);\n}\n\nprivate class LoopIterator : ILoopIterator\n{\n private readonly int _start, _end;\n\n public LoopIterator(int count)\n {\n _start = 0;\n _end = count - 1;\n }\n\n public LoopIterator(int start, int end)\n {\n _start = start;\n _end = end;\n } \n\n public void Do(Action action)\n {\n for (int i = _start; i <= _end; i++)\n {\n action();\n }\n }\n\n public void Do(Action<int> action)\n {\n for (int i = _start; i <= _end; i++)\n {\n action(i);\n }\n }\n}\n\npublic static ILoopIterator Times(this int count)\n{\n return new LoopIterator(count);\n}\n</code></pre>\n\n<p>Usage:</p>\n\n<pre><code>int sum = 0;\n5.Times().Do( i => \n sum += i\n);\n</code></pre>\n\n<p>Shamelessly stolen from <a href=\"http://grabbagoft.blogspot.com/2007/10/ruby-style-loops-in-c-30.html\" rel=\"noreferrer\">http://grabbagoft.blogspot.com/2007/10/ruby-style-loops-in-c-30.html</a></p>\n"
},
{
"answer_id": 177554,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>If you are using .NET 3.5 then you can use the extension method Each proposed in this article, and use it to avoid classic loop.</p>\n\n<pre><code>public static class IEnumerableExtensions\n {\n public static void Each<T>(\n this IEnumerable<T> source,\n Action<T> action)\n {\n foreach(T item in source)\n {\n action(item);\n }\n }\n }\n</code></pre>\n\n<blockquote>\n <p>This particular extension method spot\n welds an Each method on anything that\n implements IEnumerable. You know\n this because the first parameter to\n this method defines what this will be\n inside the method body. Action is a\n pre-defined class that basically\n stands in for a function (delegate)\n returning no value. Inside the method,\n is where the elements are extracted\n from the list. What this method\n enables is for me to cleanly apply a\n function in one line of code.</p>\n</blockquote>\n\n<p>(<a href=\"http://www.codeproject.com/KB/linq/linq-to-life.aspx\" rel=\"nofollow noreferrer\">http://www.codeproject.com/KB/linq/linq-to-life.aspx</a>)</p>\n\n<p>Hope this helps.</p>\n"
},
{
"answer_id": 177561,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 7,
"selected": true,
"text": "<p>A slightly briefer version of <a href=\"https://stackoverflow.com/questions/177538/any-chances-to-imitate-times-ruby-method-in-c#177551\">cvk's answer</a>:</p>\n\n<pre><code>public static class Extensions\n{\n public static void Times(this int count, Action action)\n {\n for (int i=0; i < count; i++)\n {\n action();\n }\n }\n\n public static void Times(this int count, Action<int> action)\n {\n for (int i=0; i < count; i++)\n {\n action(i);\n }\n }\n}\n</code></pre>\n\n<p>Use:</p>\n\n<pre><code>5.Times(() => Console.WriteLine(\"Hi\"));\n5.Times(i => Console.WriteLine(\"Index: {0}\", i));\n</code></pre>\n"
},
{
"answer_id": 15975916,
"author": "Anthony Garcia-Labiad",
"author_id": 1380332,
"author_profile": "https://Stackoverflow.com/users/1380332",
"pm_score": 0,
"selected": false,
"text": "<p>I wrote my own extension that add Times to Integer (plus some other stuff). You can get the code here : <a href=\"https://github.com/Razorclaw/Ext.NET\" rel=\"nofollow\">https://github.com/Razorclaw/Ext.NET</a></p>\n\n<p>The code is very similar to Jon Skeet answer:</p>\n\n<pre><code>public static class IntegerExtension\n{\n public static void Times(this int n, Action<int> action)\n {\n if (action == null) throw new ArgumentNullException(\"action\");\n\n for (int i = 0; i < n; ++i)\n {\n action(i);\n }\n }\n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177538",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11256/"
] |
Every time I need to do something *N* times inside an algorithm using C# I write this code
```
for (int i = 0; i < N; i++)
{
...
}
```
Studying Ruby I have learned about method *times()* which can be used with the same semantics like this
```
N.times do
...
end
```
Code fragment in C# looks more complex and we should declare useless variable *i*.
I tried to write extension method which returns *IEnumerable*, but I am not satisfied with the result because again I have to declare a cycle variable *i*.
```
public static class IntExtender
{
public static IEnumerable Times(this int times)
{
for (int i = 0; i < times; i++)
yield return true;
}
}
...
foreach (var i in 5.Times())
{
...
}
```
Is it possible using some new C# 3.0 language features to make *N* times cycle more elegant?
|
A slightly briefer version of [cvk's answer](https://stackoverflow.com/questions/177538/any-chances-to-imitate-times-ruby-method-in-c#177551):
```
public static class Extensions
{
public static void Times(this int count, Action action)
{
for (int i=0; i < count; i++)
{
action();
}
}
public static void Times(this int count, Action<int> action)
{
for (int i=0; i < count; i++)
{
action(i);
}
}
}
```
Use:
```
5.Times(() => Console.WriteLine("Hi"));
5.Times(i => Console.WriteLine("Index: {0}", i));
```
|
177,560 |
<p>I have an app written in C# that lies on a network share. When I run it from a local drive, everything works fine. When I start it from the remote share, calls like</p>
<pre><code>try
{
System.Reflection.Assembly.GetExecutingAssembly();
System.IO.Directory.GetCurrentDirectory();
}
</code></pre>
<p>throw a SecurityException 'Request failed'.</p>
<p>What causes this, what is the difference between an app that is started locally and one that is started from a remote location?</p>
|
[
{
"answer_id": 177580,
"author": "Marc Gravell",
"author_id": 23354,
"author_profile": "https://Stackoverflow.com/users/23354",
"pm_score": 4,
"selected": true,
"text": "<p>This is due to <a href=\"http://msdn.microsoft.com/en-us/library/930b76w0.aspx\" rel=\"nofollow noreferrer\">CAS</a>; code started from the local machine has much more trust than code in the intranet, which in turn has more trust that code from the internet.</p>\n\n<p>IIRC, with the latest SP (3.5SP1?) if you have <em>mapped</em> the share (i.e. as F:) it is trusted; otherwise you will need to either:</p>\n\n<p>a: apply a <a href=\"http://msdn.microsoft.com/en-us/library/cb6t8dtz(VS.80).aspx\" rel=\"nofollow noreferrer\">caspol</a> change to all clients (yeuck)</p>\n\n<p>b: use <a href=\"http://msdn.microsoft.com/en-us/library/t71a733d(VS.80).aspx\" rel=\"nofollow noreferrer\">ClickOnce</a> to deploy the app, and run the .application instead (yay!)</p>\n\n<p>The point is that ClickOnce allows you to sign the app and state your security policy (even if you demand full trust).</p>\n"
},
{
"answer_id": 177622,
"author": "Larry",
"author_id": 24472,
"author_profile": "https://Stackoverflow.com/users/24472",
"pm_score": 2,
"selected": false,
"text": "<p>Because your application is starting on a shared drive, different execution security policies applies.</p>\n\n<p>This implies to learn how .NET Code Access Security is working.</p>\n\n<p><a href=\"http://msdn.microsoft.com/en-us/library/aa302422.aspx\" rel=\"nofollow noreferrer\">http://msdn.microsoft.com/en-us/library/aa302422.aspx</a></p>\n\n<p>A quick and dirty solution consists to go to .NET Framework Configuration, unfold RunTime Security Policy, unfold Machine, then Code Groups, then LocalIntranet Zone, do right click on it, choose Properties, then change Permission Set to FullTrust.</p>\n\n<p>This will allow applications in the intranet zone (including application which runs from the shared network) to run as full trusted.</p>\n\n<p><strong>This is definitely not the recommended way to do</strong>. The best would be to learn how .NET Code Access Security is working and to apply a specific security policy depending on your application needs.</p>\n\n<p>For example, you can give a strong name with your application by signing it, define a new code group with the public key and apply full trusted permission on that code group. Then you may sign all \"approved\" application with this same public key, so the same Code Access Security policy applies.</p>\n"
},
{
"answer_id": 180348,
"author": "Jon Adams",
"author_id": 2291,
"author_profile": "https://Stackoverflow.com/users/2291",
"pm_score": 1,
"selected": false,
"text": "<p>They changed this to some degree in .Net Framework 3.5 SP1. See <a href=\"http://www.infoq.com/news/2008/08/.NET-3.5-SP1-Runs-Managed-Code\" rel=\"nofollow noreferrer\">.NET 3.5 SP1 Runs Managed Applications From Network Shares</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177560",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22114/"
] |
I have an app written in C# that lies on a network share. When I run it from a local drive, everything works fine. When I start it from the remote share, calls like
```
try
{
System.Reflection.Assembly.GetExecutingAssembly();
System.IO.Directory.GetCurrentDirectory();
}
```
throw a SecurityException 'Request failed'.
What causes this, what is the difference between an app that is started locally and one that is started from a remote location?
|
This is due to [CAS](http://msdn.microsoft.com/en-us/library/930b76w0.aspx); code started from the local machine has much more trust than code in the intranet, which in turn has more trust that code from the internet.
IIRC, with the latest SP (3.5SP1?) if you have *mapped* the share (i.e. as F:) it is trusted; otherwise you will need to either:
a: apply a [caspol](http://msdn.microsoft.com/en-us/library/cb6t8dtz(VS.80).aspx) change to all clients (yeuck)
b: use [ClickOnce](http://msdn.microsoft.com/en-us/library/t71a733d(VS.80).aspx) to deploy the app, and run the .application instead (yay!)
The point is that ClickOnce allows you to sign the app and state your security policy (even if you demand full trust).
|
177,569 |
<p>I have Eclipse 3.3.2 with PDT doing PHP development.
All projects that I create, even SVN projects have code completion.
Now I just opened another SVN project and it has no code completion or PHP templates (CTRL-space does nothing in that project).
However, I can open the other projects and code completion all work in them.</p>
<p>Why would code completion and templates be "off" in just one project and how can I turn it back on?</p>
|
[
{
"answer_id": 177601,
"author": "Guido",
"author_id": 12388,
"author_profile": "https://Stackoverflow.com/users/12388",
"pm_score": 6,
"selected": true,
"text": "<p>Maybe Eclipse doesn't understand the project has a \"PHP nature\".\nTry comparing the .project file on both projects to look for differences. It should contain something like:</p>\n\n<pre><code> <natures>\n <nature>org.eclipse.php.core.PHPNature</nature>\n </natures>\n</code></pre>\n\n<p>The .project file will be in your workspace under the project directories.</p>\n"
},
{
"answer_id": 177671,
"author": "Sietse",
"author_id": 6400,
"author_profile": "https://Stackoverflow.com/users/6400",
"pm_score": 1,
"selected": false,
"text": "<p>Be sure the file opens with the \"PHP editor\". Right-click the file, and select <em>open with</em> to select the right editor. </p>\n\n<p>If it turns out you've been using the wrong editor, you can change the association under <em>Preferences » General » Content Types</em></p>\n"
},
{
"answer_id": 177990,
"author": "Joe Scylla",
"author_id": 25771,
"author_profile": "https://Stackoverflow.com/users/25771",
"pm_score": 2,
"selected": false,
"text": "<p>I have the same issue sometimes. For me it works to rebuild the PHP project with \"Project\" -> \"Clean\".</p>\n"
},
{
"answer_id": 178097,
"author": "powtac",
"author_id": 22470,
"author_profile": "https://Stackoverflow.com/users/22470",
"pm_score": -1,
"selected": false,
"text": "<p>One solution could be to include a dummy php file wich requires all your PHP classes. So that the PHP parser recognizes these classes too.\nExample dummy file:</p>\n\n<pre><code>if(false) {\n require_once 'class/one.php';\n require_once 'class/two.php';\n require_once 'class/three.php';\n}\n</code></pre>\n"
},
{
"answer_id": 178746,
"author": "Brendon-Van-Heyzen",
"author_id": 1425,
"author_profile": "https://Stackoverflow.com/users/1425",
"pm_score": 0,
"selected": false,
"text": "<p>I've noticed sometimes when you checkout a project from svn in eclipse (subversive or subsclipe \"checkout a project as\") and even though you check it out as a php project it will either delete the .project file or it would be a generic project. I've found to just go in that directory and delete the .project .settings/ and .cach/</p>\n\n<p>Then create a new php project and point the directory where you checked out the files. And you should have code completion and svn should be link to your repo.</p>\n"
},
{
"answer_id": 209202,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>Thank you!\nI spent all day long to figure out why I did not have code completion...</p>\n\n<p>The problem is that if you create a SVN project the .project is a basic file without codecompletion reference. You have to create a basic PHP project and compare the two files and replacing the missing part in the SVN project one.</p>\n\n<p>Now I have code completion for every file in the project, even for Zend Framework library</p>\n"
},
{
"answer_id": 326782,
"author": "Vanja",
"author_id": 11874,
"author_profile": "https://Stackoverflow.com/users/11874",
"pm_score": 0,
"selected": false,
"text": "<p>I had a problem that build path was empty, so no code completion for any of the files i tried to edit. Make sure you setup properly your build path, especially if you're linking the source from some other location than the workspace.</p>\n\n<p>Like the apache htdocs folder for example.</p>\n"
},
{
"answer_id": 636020,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>Right click in the edit screen, goto Java -> Editor -> Content Assist -> Advanced ...select proposals accordingly</p>\n"
},
{
"answer_id": 897349,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 3,
"selected": false,
"text": "<p>Look out for the file .buildpath in your project... put this line between the tag:</p>\n\n<p><code><buildpathentry kind=\"con\" path=\"org.eclipse.php.core.LANGUAGE\"/></code></p>\n\n<p>Save it and restart eclipse. Now everything should be OK... This worked for me. :)</p>\n"
},
{
"answer_id": 1889858,
"author": "Andre",
"author_id": 229843,
"author_profile": "https://Stackoverflow.com/users/229843",
"pm_score": 0,
"selected": false,
"text": "<p>I have solved this by enabling the Full C/C++ indexer (Windows-> properties -> C/C++ -> Indexer), and also hit the radio button \"Use active button configuration\". After that Clean, and Build all.</p>\n\n<p>That worked on Eclipse CDT 3.4</p>\n"
},
{
"answer_id": 2100178,
"author": "lagopixel",
"author_id": 254732,
"author_profile": "https://Stackoverflow.com/users/254732",
"pm_score": 3,
"selected": false,
"text": "<p>It is just one line to add in the .project file and then restarting eclipse to get codecompletion:\nWhere it says </p>\n\n<pre><code>---\n <natures>\n </natures>\n---\n</code></pre>\n\n<p>after the change has to be </p>\n\n<pre><code>---\n <natures>\n <nature>org.eclipse.php.core.PHPNature</nature>\n </natures>\n---\n</code></pre>\n\n<p>That should do.</p>\n"
},
{
"answer_id": 2374257,
"author": "Camilo",
"author_id": 285656,
"author_profile": "https://Stackoverflow.com/users/285656",
"pm_score": 0,
"selected": false,
"text": "<p>If you came here looking for code completion in php eclipse not working, make sure your project is being supported as a php project. Right click on the project and then go to configure -> Add php support. If you have the right settings for code assist it should work instantaneously. Sometimes newbies as me tweak around with the projects or start projects as clean and not as php so eclipse doesn't know how to treat the project. </p>\n"
},
{
"answer_id": 3493507,
"author": "John",
"author_id": 147234,
"author_profile": "https://Stackoverflow.com/users/147234",
"pm_score": 1,
"selected": false,
"text": "<p>ATTENTION</p>\n\n<p>Besides the already mentioned solutions to get the whole autocomplete help to work, there is another quirk: it might not be enabled.</p>\n\n<p>Go to Window > Properties and then to PHP > Editor > Code Assist (JAVA has a similar option) and set \"Enable auto activation\", preferably with a delay that you see comfortable (0ms). If you are bothered by the program suddenly deciding to do things for you without prompt (and doing it wrong), deselect \"Insert single proposals automatically\" and you should be fine.</p>\n"
},
{
"answer_id": 4118815,
"author": "Ersin DOĞAN",
"author_id": 499976,
"author_profile": "https://Stackoverflow.com/users/499976",
"pm_score": 2,
"selected": false,
"text": "<p>If you have this problem, follow these steps :</p>\n\n<ul>\n<li>Select \"PHP Include Path\" in your project tree </li>\n<li>Right click on it then click \"Build Path>Configure Build Path\"</li>\n<li>On the opening window,add folder that you want to build, so it can do code assist.</li>\n</ul>\n\n<p>Thats all :) I hope it resolves your problem, I solved my one :)</p>\n"
},
{
"answer_id": 5076973,
"author": "strikernl",
"author_id": 628133,
"author_profile": "https://Stackoverflow.com/users/628133",
"pm_score": 0,
"selected": false,
"text": "<p>I had to right click the project in the PHP Explorer, go to \"PHP Build Path\". This was empty. I clicked \"Add Folder\", selected the checkbox next to the root folder of my project and clicked \"OK\", then \"OK\" again.</p>\n\n<p>After that code completion seemed to work. Should just work out of the box if you ask me, but whatever.</p>\n"
},
{
"answer_id": 5350018,
"author": "umpirsky",
"author_id": 177056,
"author_profile": "https://Stackoverflow.com/users/177056",
"pm_score": 2,
"selected": false,
"text": "<p>@Guido PHPNature does not fix this. </p>\n\n<p>@Edward Tanguay Yes, that's because when you create new PHP project, eclipse adds .buildpath file with</p>\n\n<pre><code><?xml version=\"1.0\" encoding=\"UTF-8\"?><buildpath>\n<buildpathentry kind=\"src\" path=\"\"/>\n<buildpathentry kind=\"con\" path=\"org.eclipse.php.core.LANGUAGE\"/></buildpath>\n</code></pre>\n\n<p>when you import existing project you eclipse does not generates .buildpath file, but you can add it by hand or create new PHP project with existin source (you can choose in wizard).</p>\n"
},
{
"answer_id": 5803618,
"author": "Mona",
"author_id": 727114,
"author_profile": "https://Stackoverflow.com/users/727114",
"pm_score": 0,
"selected": false,
"text": "<p>Check the lib of your project. It may be that you have include two such jar files in which same class is available or say one class in code can be refrenced in two jar files. In such case also eclipse stops assisting code as it is totally confused.</p>\n\n<p>Better way to check this is go to the file where assist is not working and comment all imports there, than add imports one by one and check at each import if code-assist is working or not.You can easily find the class with duplicate refrences.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177569",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4639/"
] |
I have Eclipse 3.3.2 with PDT doing PHP development.
All projects that I create, even SVN projects have code completion.
Now I just opened another SVN project and it has no code completion or PHP templates (CTRL-space does nothing in that project).
However, I can open the other projects and code completion all work in them.
Why would code completion and templates be "off" in just one project and how can I turn it back on?
|
Maybe Eclipse doesn't understand the project has a "PHP nature".
Try comparing the .project file on both projects to look for differences. It should contain something like:
```
<natures>
<nature>org.eclipse.php.core.PHPNature</nature>
</natures>
```
The .project file will be in your workspace under the project directories.
|
177,606 |
<p>I am running windows XP with ruby 1.8.6 patchlevel 111. I am using HTTP to connect to a remote server and it has been running fine. All of a sudden it started to through the exception listed below (I did not change any code since the last time I ran it successfully). Does anybody know what is going on?</p>
<pre>
c:/ruby/lib/ruby/1.8/timeout.rb:54:in `rbuf_fill': execution expired (Timeout::E
rror)
from c:/ruby/lib/ruby/1.8/timeout.rb:56:in `timeout'
from c:/ruby/lib/ruby/1.8/timeout.rb:76:in `timeout'
from c:/ruby/lib/ruby/1.8/net/protocol.rb:132:in `rbuf_fill'
from c:/ruby/lib/ruby/1.8/net/protocol.rb:116:in `readuntil'
from c:/ruby/lib/ruby/1.8/net/protocol.rb:126:in `readline'
from c:/ruby/lib/ruby/1.8/net/http.rb:2029:in `read_status_line'
from c:/ruby/lib/ruby/1.8/net/http.rb:2018:in `read_new'
from c:/ruby/lib/ruby/1.8/net/http.rb:1059:in `request'
... 19 levels...
from c:/ruby/lib/ruby/1.8/test/unit/autorunner.rb:216:in `run'
from c:/ruby/lib/ruby/1.8/test/unit/autorunner.rb:12:in `run'
from c:/ruby/lib/ruby/1.8/test/unit.rb:278
from c:/ruby/lib/ruby/gems/1.8/gems/rake-0.8.3/lib/rake/rake_test_loader
.rb:5
rake aborted!
Command failed with status (3): [c:/ruby/bin/ruby -Ilib;test "c:/ruby/lib/r...]
</pre>
|
[
{
"answer_id": 177656,
"author": "Vinko Vrsalovic",
"author_id": 5190,
"author_profile": "https://Stackoverflow.com/users/5190",
"pm_score": 1,
"selected": false,
"text": "<p>Maybe the remote host is down? Or a new firewall has been put between your machine and the remote host?</p>\n\n<p>\"Timeout::Error\" usually points to that direction.</p>\n"
},
{
"answer_id": 179491,
"author": "Gene T",
"author_id": 413049,
"author_profile": "https://Stackoverflow.com/users/413049",
"pm_score": 0,
"selected": false,
"text": "<p>besides the obvious (firewall, you got blacklisted for bad user-agent or ignoring robots.txt), you can try curl</p>\n\n<p><a href=\"http://curl.haxx.se/libcurl/ruby/\" rel=\"nofollow noreferrer\">http://curl.haxx.se/libcurl/ruby/</a></p>\n\n<p>OR increase net/http timeout to say, 30+ seconds</p>\n\n<p><a href=\"http://groups.google.com/group/rubyonrails-talk/msg/cc89e8ae6703d6fb\" rel=\"nofollow noreferrer\">http://groups.google.com/group/rubyonrails-talk/msg/cc89e8ae6703d6fb</a></p>\n"
},
{
"answer_id": 5054097,
"author": "Brian Armstrong",
"author_id": 76486,
"author_profile": "https://Stackoverflow.com/users/76486",
"pm_score": 0,
"selected": false,
"text": "<p>It could be related to this known Ruby bug where Timeout::Error does not subclass Exception. (fixed in 1.9.2 I believe)</p>\n\n<p><a href=\"http://lindsaar.net/2007/12/9/rbuf_filltimeout-error\" rel=\"nofollow\">http://lindsaar.net/2007/12/9/rbuf_filltimeout-error</a></p>\n\n<p>It can be fixed by rescuing from Timeout::Error like <code>rescue Timeout::Error => e</code></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177606",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5004/"
] |
I am running windows XP with ruby 1.8.6 patchlevel 111. I am using HTTP to connect to a remote server and it has been running fine. All of a sudden it started to through the exception listed below (I did not change any code since the last time I ran it successfully). Does anybody know what is going on?
```
c:/ruby/lib/ruby/1.8/timeout.rb:54:in `rbuf_fill': execution expired (Timeout::E
rror)
from c:/ruby/lib/ruby/1.8/timeout.rb:56:in `timeout'
from c:/ruby/lib/ruby/1.8/timeout.rb:76:in `timeout'
from c:/ruby/lib/ruby/1.8/net/protocol.rb:132:in `rbuf_fill'
from c:/ruby/lib/ruby/1.8/net/protocol.rb:116:in `readuntil'
from c:/ruby/lib/ruby/1.8/net/protocol.rb:126:in `readline'
from c:/ruby/lib/ruby/1.8/net/http.rb:2029:in `read_status_line'
from c:/ruby/lib/ruby/1.8/net/http.rb:2018:in `read_new'
from c:/ruby/lib/ruby/1.8/net/http.rb:1059:in `request'
... 19 levels...
from c:/ruby/lib/ruby/1.8/test/unit/autorunner.rb:216:in `run'
from c:/ruby/lib/ruby/1.8/test/unit/autorunner.rb:12:in `run'
from c:/ruby/lib/ruby/1.8/test/unit.rb:278
from c:/ruby/lib/ruby/gems/1.8/gems/rake-0.8.3/lib/rake/rake_test_loader
.rb:5
rake aborted!
Command failed with status (3): [c:/ruby/bin/ruby -Ilib;test "c:/ruby/lib/r...]
```
|
Maybe the remote host is down? Or a new firewall has been put between your machine and the remote host?
"Timeout::Error" usually points to that direction.
|
177,611 |
<p>I am creating an Eclipse RCP application.</p>
<p>I am following Joel's advice in the following article "Daily Builds are your friend":</p>
<p><a href="http://www.joelonsoftware.com/articles/fog0000000023.html" rel="nofollow noreferrer">http://www.joelonsoftware.com/articles/fog0000000023.html</a></p>
<p>So, I've written a nice build script that creates an Eclipse RCP product and that runs unit tests on the code. All results are then distributed to the developer's list (after some grumbling). Now my next step, I want it to create the setup package that I normally create manually using the inno setup compiler.</p>
<p>The question is, how would I get around creating this package automatically? I guess I can generate the inno setup file automatically from ant, and then invoke the compiler from the command line, but I don't know if this is possible.</p>
<p>Any tips for this task? Maybe any other setup application that can be used from ant?</p>
|
[
{
"answer_id": 178237,
"author": "Tom",
"author_id": 20979,
"author_profile": "https://Stackoverflow.com/users/20979",
"pm_score": 4,
"selected": true,
"text": "<p>sure its easy, Inno project is a plain text file so you can even edit setupper script easily by ant, however I would recommend creating a separate small include file by your script. You can have store there \"variables\" such as version+build number that you show in begin of setup.</p>\n\n<p>put this line to your setupper:</p>\n\n<pre><code>#include \"settings.txt\"\n</code></pre>\n\n<p>and make settings.txt have something like this</p>\n\n<pre><code>#define myver=xxx.xxx\n#define tags\n</code></pre>\n\n<p>now you don't need to touch the actual setupper code from build script.</p>\n\n<p>below is a snippet from my build script to compile the setupper.\nyou need to execute batch file from ant like this:</p>\n\n<pre><code><exec dir=\".\" executable=\"cmd\" os=\"Windows NT\">\n <arg line=\"/c build.bat\"/>\n</exec>\n</code></pre>\n\n<p>sample batch build.bat:</p>\n\n<pre><code>set isxpath=\"c:\\program files\\inno setup 5\"\nset isx=%isxpath%\\iscc.exe\nset iwz=myproj.iss\nif not exist %isx% set errormsg=%isx% not found && goto errorhandler\n%isx% \"%iwz%\" /O\"%buildpath%\" /F\"MySetupper.exe\" >>%logfile%\ngoto :eof\n</code></pre>\n"
},
{
"answer_id": 290148,
"author": "Oliver Giesen",
"author_id": 9784,
"author_profile": "https://Stackoverflow.com/users/9784",
"pm_score": 3,
"selected": false,
"text": "<p>Another nice trick when automating installer building is to use the <code>GetFileVersion</code> preprocessor (ISPP) macro. That way you won't have to duplicate your (binary) files' version numbers in hardcoded form (like in Tom's <code>settings.txt</code>) - the installer compiler will simply read it from the files' version resources that way. E.g.:</p>\n\n<pre><code>#define AppName \"My App\"\n#define SrcApp \"MyApp.exe\"\n#define FileVerStr GetFileVersion(SrcApp)\n#define StripBuild(str VerStr) Copy(VerStr, 1, RPos(\".\", VerStr)-1)\n#define AppVerStr StripBuild(FileVerStr)\n\n[Setup]\nAppName={#AppName}\nAppVersion={#AppVerStr}\nAppVerName={#AppName} {#AppVerStr}\nUninstallDisplayName={#AppName} {#AppVerStr}\nVersionInfoVersion={#FileVerStr}\nVersionInfoTextVersion={#AppVerStr}\nOutputBaseFilename=MyApp-{#FileVerStr}-setup\n</code></pre>\n\n<p>Furthermore, you can forward symbols to the compiler via the <code>/d</code> commandline switch, e.g.:</p>\n\n<pre><code>iscc.exe /dSpecialEdition ...\n</code></pre>\n\n<p>and then later use these in <code>ifdef</code>s to create different types of installer (stupid example follows):</p>\n\n<pre><code>[Registry]\n#ifdef SpecialEdition\nRoot: HKLM; Subkey: Software\\MyCompany\\MyApp; ValueName: SpecialEdition; ValueType: dword; ValueData: 1 ...\n#endif\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177611",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2309/"
] |
I am creating an Eclipse RCP application.
I am following Joel's advice in the following article "Daily Builds are your friend":
<http://www.joelonsoftware.com/articles/fog0000000023.html>
So, I've written a nice build script that creates an Eclipse RCP product and that runs unit tests on the code. All results are then distributed to the developer's list (after some grumbling). Now my next step, I want it to create the setup package that I normally create manually using the inno setup compiler.
The question is, how would I get around creating this package automatically? I guess I can generate the inno setup file automatically from ant, and then invoke the compiler from the command line, but I don't know if this is possible.
Any tips for this task? Maybe any other setup application that can be used from ant?
|
sure its easy, Inno project is a plain text file so you can even edit setupper script easily by ant, however I would recommend creating a separate small include file by your script. You can have store there "variables" such as version+build number that you show in begin of setup.
put this line to your setupper:
```
#include "settings.txt"
```
and make settings.txt have something like this
```
#define myver=xxx.xxx
#define tags
```
now you don't need to touch the actual setupper code from build script.
below is a snippet from my build script to compile the setupper.
you need to execute batch file from ant like this:
```
<exec dir="." executable="cmd" os="Windows NT">
<arg line="/c build.bat"/>
</exec>
```
sample batch build.bat:
```
set isxpath="c:\program files\inno setup 5"
set isx=%isxpath%\iscc.exe
set iwz=myproj.iss
if not exist %isx% set errormsg=%isx% not found && goto errorhandler
%isx% "%iwz%" /O"%buildpath%" /F"MySetupper.exe" >>%logfile%
goto :eof
```
|
177,613 |
<p>My <code>Account</code> model has the following two associations:</p>
<pre><code>has_many :expenses,
:order => 'expenses.dated_on DESC',
:dependent => :destroy
has_many :recent_expenses,
:class_name => 'Expense',
:conditions => "expenses.dated_on <= '#{Date.today}'",
:order => 'dated_on DESC',
:limit => 5
</code></pre>
<p>In one of my views I'm rendering recent expenses like so:</p>
<pre><code><% @account.recent_expenses.each do |expense| %>
...
<% end %>
</code></pre>
<p>On my development machine, on the staging server (which runs in production mode) and also on the production console, <code>@account.recent_expenses</code> returns the correct list. However, on our live production server, the most recent expenses are not returned. </p>
<p>If I replace <code>@account.recent_expenses</code> with <code>@account.expenses</code> in the view, the most recent expenses <em>are</em> displayed, so my guess is that the <code>#{Date.today}</code> part of the conditions clause is somehow being cached the first time it is executed. If I restart the production Mongrel cluster, all the latest expenses are returned correctly.</p>
<p>Can anyone think why this would occur and how might I change the <code>:recent_expenses</code> query to prevent this from happening?</p>
<p>I'm using Rails 2.1.0.</p>
|
[
{
"answer_id": 177794,
"author": "Andrew",
"author_id": 17408,
"author_profile": "https://Stackoverflow.com/users/17408",
"pm_score": 4,
"selected": true,
"text": "<p>Rails is building the query when loaded and then will re-use that query every time you call @account.recent_expenses which is exactly what you're experiencing.</p>\n\n<p>If you're using Rails 2.1 you can use named_scope to achieve what you're looking for.</p>\n\n<p>in your <strong>Expense</strong> model, put the following:</p>\n\n<pre><code>named_scope :recent, lambda { {:conditions => [\"expenses.dated_on <= ?\", Date.today], :order => 'dated_on DESC', :limit => 5 } }\n</code></pre>\n\n<p>The lambda is used to ensure rails rebuilds the query each time.</p>\n\n<p>from your <strong>Account</strong> remove:</p>\n\n<pre><code>has_many :recent_expenses ...\n</code></pre>\n\n<p>and then call:</p>\n\n<pre><code><% @account.expenses.recent.each do |expense| %>\n...\n<% end %>\n</code></pre>\n"
},
{
"answer_id": 177806,
"author": "Ben Scofield",
"author_id": 6478,
"author_profile": "https://Stackoverflow.com/users/6478",
"pm_score": 2,
"selected": false,
"text": "<p>Like Andrew said, association macros are read at application startup, so any dynamic bits (like Date.today) are parsed at that point. His solution works if you're on Rails 2.1 or later; for earlier versions, you can use the <a href=\"http://www.railslodge.com/ruby_gems/11-has_finder\" rel=\"nofollow noreferrer\">has_finder gem</a>, or just create the following method on the Expense model:</p>\n\n<pre><code>def self.recent\n find(:all, :conditions => ['dated_on <= ?', Date.today], :limit => 5, :order => 'dated_on DESC')\nend\n</code></pre>\n\n<p>Class methods like this are exposed to associations, and are properly scoped - the difference between them and named_scopes is that you can't chain them.</p>\n"
},
{
"answer_id": 4693009,
"author": "johnmcaliley",
"author_id": 378044,
"author_profile": "https://Stackoverflow.com/users/378044",
"pm_score": 1,
"selected": false,
"text": "<p>Here is what it would look like in Rails 3:</p>\n\n<pre><code>scope :recent, lambda { where(\"expenses.dated_on <= ?\", Date.today).order('dated_on DESC').limit(5) }\n</code></pre>\n\n<p><em><strong>WARNING:</em></strong> Watch out for chained scopes that are not wrapped in lambda. You may think that part of the chain is evaluated at runtime, but it may be evaluated at app server startup. Make sure you lambda wrap any scope that will use these other scopes. Explanation here:\n<a href=\"http://www.slashdotdash.net/2010/09/25/rails-3-scopes-with-chaining/\" rel=\"nofollow\">http://www.slashdotdash.net/2010/09/25/rails-3-scopes-with-chaining/</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177613",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1174/"
] |
My `Account` model has the following two associations:
```
has_many :expenses,
:order => 'expenses.dated_on DESC',
:dependent => :destroy
has_many :recent_expenses,
:class_name => 'Expense',
:conditions => "expenses.dated_on <= '#{Date.today}'",
:order => 'dated_on DESC',
:limit => 5
```
In one of my views I'm rendering recent expenses like so:
```
<% @account.recent_expenses.each do |expense| %>
...
<% end %>
```
On my development machine, on the staging server (which runs in production mode) and also on the production console, `@account.recent_expenses` returns the correct list. However, on our live production server, the most recent expenses are not returned.
If I replace `@account.recent_expenses` with `@account.expenses` in the view, the most recent expenses *are* displayed, so my guess is that the `#{Date.today}` part of the conditions clause is somehow being cached the first time it is executed. If I restart the production Mongrel cluster, all the latest expenses are returned correctly.
Can anyone think why this would occur and how might I change the `:recent_expenses` query to prevent this from happening?
I'm using Rails 2.1.0.
|
Rails is building the query when loaded and then will re-use that query every time you call @account.recent\_expenses which is exactly what you're experiencing.
If you're using Rails 2.1 you can use named\_scope to achieve what you're looking for.
in your **Expense** model, put the following:
```
named_scope :recent, lambda { {:conditions => ["expenses.dated_on <= ?", Date.today], :order => 'dated_on DESC', :limit => 5 } }
```
The lambda is used to ensure rails rebuilds the query each time.
from your **Account** remove:
```
has_many :recent_expenses ...
```
and then call:
```
<% @account.expenses.recent.each do |expense| %>
...
<% end %>
```
|
177,638 |
<p>I had a little discussion with a friend about the usage of collections in return/input values of a method. He told me that we have to use
- the most derived type for return values.
- the least derived type for input parameters.</p>
<p>So, it means that, for example, a method has to get a ReadOnlyCollection as parameter, and as return a List.</p>
<p>Moreover, he said that we must not use List or Dictionary in publics API, and that we have to use, instead Collection, ReadOnlyCollection, ... So, in the case where a method is public, its parameters and its return values must be Collection, ReadOnlyCollection, ...</p>
<p>Is it right ?</p>
|
[
{
"answer_id": 177647,
"author": "Joe",
"author_id": 13087,
"author_profile": "https://Stackoverflow.com/users/13087",
"pm_score": 4,
"selected": true,
"text": "<p>Regarding input parameters, it's generally more flexible to use the least specific type. For example, if all your method is going to do is enumerate the items in a collection passed as an argument, it's more flexible to accept IEnumerable<T>.</p>\n\n<p>For example, consider a method \"ProcessCustomers\" that accepts a parameter that is a collection of customers:</p>\n\n<pre><code>public void ProcessCustomers(IEnumerable<Customer> customers)\n{\n ... implementation ...\n}\n</code></pre>\n\n<p>If you declare the parameter as IEnumerable<Customer>, your callers can easily pass in a subset of a collection, using code like the following (pre-NET 3.5: with .NET 3.5 you could use lambda expressions):</p>\n\n<pre><code>private IEnumerable<Customer> GetCustomersByCountryCode(IEnumerable<Customer> customers, int countryCode)\n{\n foreach(Customer c in customers)\n {\n if (c.CountryCode == countryCode) yield return c;\n }\n}\n\n... \nProcessCustomers(GetCustomersByCountryCode(myCustomers, myCountryCode);\n...\n</code></pre>\n\n<p>In general MS guidelines recommend not exposing List<T>. For a discussion of why this is so, see <a href=\"http://blogs.msdn.com/fxcop/archive/2006/04/27/faq-why-does-donotexposegenericlists-recommend-that-i-expose-collection-lt-t-gt-instead-of-list-lt-t-gt-david-kean.aspx\" rel=\"nofollow noreferrer\">this blog entry</a> from the Code Analysis (FxCop) team.</p>\n"
},
{
"answer_id": 177655,
"author": "Inisheer",
"author_id": 2982,
"author_profile": "https://Stackoverflow.com/users/2982",
"pm_score": 0,
"selected": false,
"text": "<p>I tend to agree with not returning or using List or Dictionary as parameters in API's because it really limits the developer targeting the API. Instead returning or passing IEnumerable<> works really well.</p>\n\n<p>Of coarse, all of this depends on the application. Just my opinion.</p>\n"
},
{
"answer_id": 179893,
"author": "Hallgrim",
"author_id": 15454,
"author_profile": "https://Stackoverflow.com/users/15454",
"pm_score": 0,
"selected": false,
"text": "<p>Maybe your friend read:\n<a href=\"https://rads.stackoverflow.com/amzn/click/com/0321246756\" rel=\"nofollow noreferrer\" rel=\"nofollow noreferrer\">Framework Design Guidelines: Conventions, Idioms, and Patterns for Reusable .NET Libraries</a></p>\n\n<p>It is a great book, and it covers questions like this in detail.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177638",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/12703/"
] |
I had a little discussion with a friend about the usage of collections in return/input values of a method. He told me that we have to use
- the most derived type for return values.
- the least derived type for input parameters.
So, it means that, for example, a method has to get a ReadOnlyCollection as parameter, and as return a List.
Moreover, he said that we must not use List or Dictionary in publics API, and that we have to use, instead Collection, ReadOnlyCollection, ... So, in the case where a method is public, its parameters and its return values must be Collection, ReadOnlyCollection, ...
Is it right ?
|
Regarding input parameters, it's generally more flexible to use the least specific type. For example, if all your method is going to do is enumerate the items in a collection passed as an argument, it's more flexible to accept IEnumerable<T>.
For example, consider a method "ProcessCustomers" that accepts a parameter that is a collection of customers:
```
public void ProcessCustomers(IEnumerable<Customer> customers)
{
... implementation ...
}
```
If you declare the parameter as IEnumerable<Customer>, your callers can easily pass in a subset of a collection, using code like the following (pre-NET 3.5: with .NET 3.5 you could use lambda expressions):
```
private IEnumerable<Customer> GetCustomersByCountryCode(IEnumerable<Customer> customers, int countryCode)
{
foreach(Customer c in customers)
{
if (c.CountryCode == countryCode) yield return c;
}
}
...
ProcessCustomers(GetCustomersByCountryCode(myCustomers, myCountryCode);
...
```
In general MS guidelines recommend not exposing List<T>. For a discussion of why this is so, see [this blog entry](http://blogs.msdn.com/fxcop/archive/2006/04/27/faq-why-does-donotexposegenericlists-recommend-that-i-expose-collection-lt-t-gt-instead-of-list-lt-t-gt-david-kean.aspx) from the Code Analysis (FxCop) team.
|
177,640 |
<p>How can I programmatically lock/unlock, or otherwise prevent/enable editing, a source file on Linux using C++.</p>
<p>I want to be able to lock source file so that if I open it in an editor it will not allow me to save back to the same source file.</p>
<p>I am thinking of maybe changing the permissions to read-only (and change it back to read-write later): how do I do that from C++?</p>
|
[
{
"answer_id": 177646,
"author": "David Dibben",
"author_id": 5022,
"author_profile": "https://Stackoverflow.com/users/5022",
"pm_score": 4,
"selected": true,
"text": "<p>Try man fchmod:</p>\n\n<pre>\nNAME\n chmod, fchmod - change permissions of a file\n\nSYNOPSIS\n #include <sys/types.h>\n #include <sys/stat.h>\n\n int chmod(const char *path, mode_t mode);\n int fchmod(int fildes, mode_t mode);\n</pre>\n"
},
{
"answer_id": 177839,
"author": "S.Lott",
"author_id": 10661,
"author_profile": "https://Stackoverflow.com/users/10661",
"pm_score": 1,
"selected": false,
"text": "<p>Why aren't you using a source code management tool like CVS or Subversion? CVS does nice locking (so does Subversion). More importantly, you have the history of changes. Better still (with CVS anyway) you have to make the step of doing a \"checkout\" to make the file writeable. </p>\n"
},
{
"answer_id": 177948,
"author": "anders.norgaard",
"author_id": 8805,
"author_profile": "https://Stackoverflow.com/users/8805",
"pm_score": 1,
"selected": false,
"text": "<p>Yes, it is a bit hard to tell what you are looking for</p>\n\n<ul>\n<li><p>Security against other users editing you files -> use \"chmod, fchmod\"</p></li>\n<li><p>Security against you yourself accidentally messing with your source files -> you should really change your thinking and use a source control tool. Like <a href=\"http://subversion.tigris.org\" rel=\"nofollow noreferrer\">Subversion (SVN)</a> or even better <a href=\"http://www.selenic.com/mercurial/\" rel=\"nofollow noreferrer\">Mercurial</a>.</p></li>\n</ul>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177640",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15161/"
] |
How can I programmatically lock/unlock, or otherwise prevent/enable editing, a source file on Linux using C++.
I want to be able to lock source file so that if I open it in an editor it will not allow me to save back to the same source file.
I am thinking of maybe changing the permissions to read-only (and change it back to read-write later): how do I do that from C++?
|
Try man fchmod:
```
NAME
chmod, fchmod - change permissions of a file
SYNOPSIS
#include <sys/types.h>
#include <sys/stat.h>
int chmod(const char *path, mode_t mode);
int fchmod(int fildes, mode_t mode);
```
|
177,673 |
<p>I have a strongly-typed MVC View Control which is responsible for the UI where users can create and edit Client items. I'd like them to be able to define the <code>ClientId</code> on creation, but not edit, and this to be reflected in the UI.</p>
<p>To this end, I have the following line:</p>
<pre><code><%= Html.TextBox("Client.ClientId", ViewData.Model.ClientId, new
{ @readonly =
(ViewData.Model.ClientId != null && ViewData.Model.ClientId.Length > 0
? "readonly" : "false")
} )
%>
</code></pre>
<p>It seems that no matter what value I give the readonly attribute (even "false" and ""), Firefox and IE7 make the input read-only, which is annoyingly counter-intuitive. Is there a nice, ternary-operator-based way to drop the attribute completely if it is not required?</p>
|
[
{
"answer_id": 178024,
"author": "Panos",
"author_id": 8049,
"author_profile": "https://Stackoverflow.com/users/8049",
"pm_score": 6,
"selected": true,
"text": "<p>Tough problem... However, if you want to define only the <code>readonly</code> attribute, you can do it like this:</p>\n\n<pre><code><%= Html.TextBox(\"Client.ClientId\", ViewData.Model.ClientId, \n ViewData.Model.ClientId != null && ViewData.Model.ClientId.Length > 0 \n ? new { @readonly = \"readonly\" } \n : null) \n%>\n</code></pre>\n\n<p>If you want to define more attributes then you must define two anonymous types and have multiple copies of the attributes. For example, something like this (which I don't like anyway):</p>\n\n<pre><code>ClientId.Length > 0 \n ? (object)new { @readonly = \"readonly\", @class = \"myCSS\" } \n : (object)new { @class = \"myCSS\" }\n</code></pre>\n"
},
{
"answer_id": 178047,
"author": "leppie",
"author_id": 15541,
"author_profile": "https://Stackoverflow.com/users/15541",
"pm_score": 2,
"selected": false,
"text": "<p>And alternative is just to emit it as plain old HTML. Yes, the editor will make you think you are wrong, but that seems to happen quite frequently with VS2008SP1. This example is specifically for checkboxes which seems to be completely wasted in CTP5, but it gives you an idea how to emit conditional attributes.</p>\n\n<pre><code><input type=\"checkbox\" name=\"roles\" value='<%# Eval(\"Name\") %>' \n <%# ((bool) Eval(\"InRole\")) ? \"checked\" : \"\" %> \n <%# ViewData.Model.IsInRole(\"Admin\") ? \"\" : \"disabled\" %> />\n</code></pre>\n"
},
{
"answer_id": 340179,
"author": "Olaj",
"author_id": 40609,
"author_profile": "https://Stackoverflow.com/users/40609",
"pm_score": 1,
"selected": false,
"text": "<p>I think it should be </p>\n\n<pre><code><%= ((bool) Eval(\"InRole\")) ? \"checked\" : \"\" %> \n</code></pre>\n\n<p>instead of this in leppies answer. </p>\n\n<pre><code><%# ((bool) Eval(\"InRole\")) ? \"checked\" : \"\" %> \n</code></pre>\n\n<p>At least it did not work for me with # but it worked with =. Did i do anything wrong? Thanks for the tip anyway :)</p>\n"
},
{
"answer_id": 3443491,
"author": "silversumo",
"author_id": 415474,
"author_profile": "https://Stackoverflow.com/users/415474",
"pm_score": 0,
"selected": false,
"text": "\n $(function() {\n $(\"[readonly='false']\").removeAttr(\"readonly\");\n });\n\n"
},
{
"answer_id": 13817483,
"author": "Aviko",
"author_id": 1544054,
"author_profile": "https://Stackoverflow.com/users/1544054",
"pm_score": 5,
"selected": false,
"text": "<p>If you want to define several attributes, and conditional readonly <strong>without duplicate the other attributes</strong>, \nyou can use Dictionary instead of anonymous types for the attributes.</p>\n\n<p>e.g.</p>\n\n<pre><code>Dictionary<string, object> htmlAttributes = new Dictionary<string, object>();\nhtmlAttributes.Add(\"class\", \"myCSS\");\nhtmlAttributes.Add(\"data-attr1\", \"val1\");\nhtmlAttributes.Add(\"data-attr2\", \"val2\");\nif (Model.LoggedInData.IsAdmin == false)\n{\n htmlAttributes.Add(\"readonly\", \"readonly\");\n}\n\n\n@:User: @Html.TextBoxFor(\n m => m.User,\n htmlAttributes) \n</code></pre>\n"
},
{
"answer_id": 24056129,
"author": "cronixis",
"author_id": 3203334,
"author_profile": "https://Stackoverflow.com/users/3203334",
"pm_score": -1,
"selected": false,
"text": "<p>I tried most of the suggestions above and now I have arrived at the simplest with a single line. Combine 2 anonymous html attributes object by declaring wither one of it as \"object\" type.</p>\n\n<pre><code>@Html.TextBoxFor(m => m.Email, !isEdit ? new { id = \"email_box\" } : new { id = \"email_box\", @readonly = isEdit ? \"readonly\" : \"false\" } as object)\n</code></pre>\n"
},
{
"answer_id": 33865092,
"author": "pranavn",
"author_id": 2882025,
"author_profile": "https://Stackoverflow.com/users/2882025",
"pm_score": 3,
"selected": false,
"text": "<p>Tip: Its the mere presence of readonly/disabled attribute that makes the element readonly or disabled in the browser.</p>\n\n<pre><code>@Html.TextBoxFor(x => x.Name, isReadonly ?(object) new { @readonly = true } : new { /*Some other attributes*/ })\n</code></pre>\n"
},
{
"answer_id": 43881425,
"author": "cristian gonzalez",
"author_id": 6946357,
"author_profile": "https://Stackoverflow.com/users/6946357",
"pm_score": 1,
"selected": false,
"text": "<p>i use this : </p>\n\n<pre><code> @Html.TextAreaFor(model => model.ComentarioGestor, comentarioGestor? new { @class = \"form-control\" } : new { @class = \"form-control\", @readonly = \"readonly\" } as object)\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177673",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/192/"
] |
I have a strongly-typed MVC View Control which is responsible for the UI where users can create and edit Client items. I'd like them to be able to define the `ClientId` on creation, but not edit, and this to be reflected in the UI.
To this end, I have the following line:
```
<%= Html.TextBox("Client.ClientId", ViewData.Model.ClientId, new
{ @readonly =
(ViewData.Model.ClientId != null && ViewData.Model.ClientId.Length > 0
? "readonly" : "false")
} )
%>
```
It seems that no matter what value I give the readonly attribute (even "false" and ""), Firefox and IE7 make the input read-only, which is annoyingly counter-intuitive. Is there a nice, ternary-operator-based way to drop the attribute completely if it is not required?
|
Tough problem... However, if you want to define only the `readonly` attribute, you can do it like this:
```
<%= Html.TextBox("Client.ClientId", ViewData.Model.ClientId,
ViewData.Model.ClientId != null && ViewData.Model.ClientId.Length > 0
? new { @readonly = "readonly" }
: null)
%>
```
If you want to define more attributes then you must define two anonymous types and have multiple copies of the attributes. For example, something like this (which I don't like anyway):
```
ClientId.Length > 0
? (object)new { @readonly = "readonly", @class = "myCSS" }
: (object)new { @class = "myCSS" }
```
|
177,677 |
<p>I am trying to uncompress some data created in VB6 using the zlib API.</p>
<p>I have read this is possible with the qUncompress function:
<a href="http://doc.trolltech.com/4.4/qbytearray.html#qUncompress" rel="nofollow noreferrer">http://doc.trolltech.com/4.4/qbytearray.html#qUncompress</a></p>
<p>I have read the data in from QDataStream via readRawBytes into a char
array, which I then converted to a QByteArray for decompression. I
have the compressed length and the expected decompressed length but am not getting
anything back from qUncompress.</p>
<p>However I need to prepend the expected decompressed length in big endian format. Has anybody done this and have an example?</p>
|
[
{
"answer_id": 177793,
"author": "Mike G.",
"author_id": 18901,
"author_profile": "https://Stackoverflow.com/users/18901",
"pm_score": 3,
"selected": true,
"text": "<p>I haven't used VB6 in <em>ages</em>, so I hope this is approximately correct. I <em>think</em> that vb6 used () for array indexing. If I got anything wrong, please let me know.</p>\n\n<p>Looking at the qUncompress docs, you should have put your data in your QByteArray starting at byte 5 (I'm going to assume that you left the array index base set to 1 for this example).</p>\n\n<p>Let's say the array is named qArr, and the expected uncompressed size is Size.\nIn a \"big-endian\" representation, the first byte is at the first address.</p>\n\n<pre><code>qArr(1) = int(Size/(256*256*256))\nqArr(2) = 255 And int(Size/256*256)\nqArr(3) = 255 And int(Size/256)\nqArr(4) = 255 And int(Size)\n</code></pre>\n\n<p>Does that make sense? </p>\n\n<p>If you needed little endian, you could just reverse the order of the indexes (qArr(4) - qArr(1)) and leave the calculations the same.</p>\n"
},
{
"answer_id": 177831,
"author": "Dan Cristoloveanu",
"author_id": 24873,
"author_profile": "https://Stackoverflow.com/users/24873",
"pm_score": 0,
"selected": false,
"text": "<p>It looks like you want a C chunk of code that uncompresses some zlib compressed data.\nIn that case is it possible for you to actually use zlib and just feed the zlib data to it. The zlib homepage: <a href=\"http://www.zlib.net/\" rel=\"nofollow noreferrer\">http://www.zlib.net/</a>.</p>\n\n<p>If I got it wrong, could you be specific what is the language that should be used for uncompressing the data and why zlib would not be a choice?</p>\n"
},
{
"answer_id": 177876,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<pre><code>//int length;\nbyte[] bigEndianBytes = BitConverter.GetBytes(IPAddress.HostToNetworkOrder(length))\n</code></pre>\n\n<p>Conversely:</p>\n\n<pre><code>//byte[] bigEndianBytes;\nint length = IPAddress.NetworkToHostOrder(BitConverter.ToInt32(bigEndianBytes))\n</code></pre>\n"
},
{
"answer_id": 178285,
"author": "RS Conley",
"author_id": 7890,
"author_profile": "https://Stackoverflow.com/users/7890",
"pm_score": 1,
"selected": false,
"text": "<p>This is how I can convert arbitary data from one format to another.</p>\n\n<pre><code>Private Type LongByte\n H1 As Byte\n H2 As Byte\n L1 As Byte\n L2 As Byte\nEnd Type\n\nPrivate Type LongType\n L As Long\nEnd Type\n\nFunction SwapEndian(ByVal LongData as Long) as Long\n Dim TempL As LongType\n Dim TempLB As LongByte\n Dim TempVar As Long\n\n TempL.L = LongData\n LSet TempLB = TempL\n'Swap is a subroutine I wrote to swap two variables\n Swap TempLB.H1, TempLB.L2\n Swap TempLB.H2, TempLB.L1\n LSet TempL = TempLB\n TempVar = TempL.L\n\n SwapEndian = TempVar\nEnd Function\n</code></pre>\n\n<p>If you are dealing with FileIO then you can use the Byte fields of TempLB</p>\n\n<p>The trick is using LSET an obscure command of VB6</p>\n\n<p>If you are using .NET then doing the process is much easier. Here the trick is using a MemoryStream to retrieve and set the individual bytes. Now you could do math for int16/int32/int64. But if you are dealing with with floating point data, using LSET or the MemoryStream is much clearer and easier to debug. </p>\n\n<p>If you are using Framework version 1.1 or beyond then you have the BitConvertor Class which uses arrays of bytes.</p>\n\n<pre><code>Private Structure Int32Byte\n Public H1 As Byte\n Public H2 As Byte\n Public L1 As Byte\n Public L2 As Byte\n Public Function Convert() As Integer\n Dim M As New MemoryStream()\n Dim bR As IO.BinaryReader\n Dim bW As New IO.BinaryWriter(M)\n Swap(H1, L2)\n Swap(H2, L1)\n bW.Write(H1)\n bW.Write(H2)\n bW.Write(L1)\n bW.Write(L2)\n M.Seek(0, SeekOrigin.Begin)\n bR = New IO.BinaryReader(M)\n Convert = bR.ReadInt32()\n End Function\nEnd Structure\n</code></pre>\n"
},
{
"answer_id": 178319,
"author": "David Dibben",
"author_id": 5022,
"author_profile": "https://Stackoverflow.com/users/5022",
"pm_score": 0,
"selected": false,
"text": "<p>It wasn't clear to me from your question whether you want to prepend the length in VB so that it is suitable for direct use by qUncompress or whether you wanted to use the VB produced data as it is now and prepend the length in C++ before calling qUncompress.</p>\n\n<p>Mike G has <a href=\"https://stackoverflow.com/questions/177677/how-to-convert-a-number-to-a-bytearray-in-bit-endian-order#177793\">posted</a> a VB solution. If you want to do it in C++ then you have two choices, either add the length at the start of the QByteArray or call zlib's uncompress directly. In both cases the Qt source for qCompress and qUncompress (corelib/tools/qbytearray.cpp) are a good reference.</p>\n\n<p>This is how qCompress adds the length (nbytes) to bazip, the compressed data:</p>\n\n<pre><code>bazip[0] = (nbytes & 0xff000000) >> 24;\nbazip[1] = (nbytes & 0x00ff0000) >> 16;\nbazip[2] = (nbytes & 0x0000ff00) >> 8;\nbazip[3] = (nbytes & 0x000000ff);\n</code></pre>\n\n<p>where bazip is the result QByteArray</p>\n\n<p>Alternatively if you want to call uncompress directly, instead of using the qUncompress wrapper the call it uses is </p>\n\n<pre><code>baunzip.resize(len);\nres = ::uncompress((uchar*)baunzip.data(), &len,\n (uchar*)data+4, nbytes-4);\n</code></pre>\n\n<p>where baunzip is a QByteArray. In your case you would drop the +4 and -4 since your data does not have the length prepended to it. </p>\n"
},
{
"answer_id": 178995,
"author": "Phil Hannent",
"author_id": 24459,
"author_profile": "https://Stackoverflow.com/users/24459",
"pm_score": 0,
"selected": false,
"text": "<p>Thank you for all your help, it was useful.</p>\n\n<p>The I got the code working with:</p>\n\n<pre><code> char slideStr[currentCompressedLen];\n int slideByteRead = in.readRawData(slideStr, currentCompressedLen);\n QByteArray aInCompBytes = QByteArray(slideStr, slideByteRead);\n aInCompBytesPlusLen = aInCompBytes;\n aInCompBytesPlusLen.prepend(QByteArray::number(currentUnCompressedLen));\n aInUnCompBytes.resize(currentUnCompressedLen);\n aInUnCompBytes = qUncompress(aInCompBytesPlusLen);\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177677",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24459/"
] |
I am trying to uncompress some data created in VB6 using the zlib API.
I have read this is possible with the qUncompress function:
<http://doc.trolltech.com/4.4/qbytearray.html#qUncompress>
I have read the data in from QDataStream via readRawBytes into a char
array, which I then converted to a QByteArray for decompression. I
have the compressed length and the expected decompressed length but am not getting
anything back from qUncompress.
However I need to prepend the expected decompressed length in big endian format. Has anybody done this and have an example?
|
I haven't used VB6 in *ages*, so I hope this is approximately correct. I *think* that vb6 used () for array indexing. If I got anything wrong, please let me know.
Looking at the qUncompress docs, you should have put your data in your QByteArray starting at byte 5 (I'm going to assume that you left the array index base set to 1 for this example).
Let's say the array is named qArr, and the expected uncompressed size is Size.
In a "big-endian" representation, the first byte is at the first address.
```
qArr(1) = int(Size/(256*256*256))
qArr(2) = 255 And int(Size/256*256)
qArr(3) = 255 And int(Size/256)
qArr(4) = 255 And int(Size)
```
Does that make sense?
If you needed little endian, you could just reverse the order of the indexes (qArr(4) - qArr(1)) and leave the calculations the same.
|
177,708 |
<p>I can't retrieve cookie maxage it always returns -1</p>
<p>Creating cookie:</p>
<pre><code>Cookie securityCookie = new Cookie("sec", "somevalue");
securityCookie.setMaxAge(EXPIRATION_TIME);
</code></pre>
<p>Retrieve cookie:</p>
<pre><code>Cookie[] cookies = request.getCookies();
if (cookies != null) {
for(int i=0; i<cookies.length; i++) {
Cookie cookie = cookies[i];
if ("sec".equals(cookie.getName())){
int age = cookie.getMaxAge();
}
}
}
</code></pre>
<p>i am always getting age = -1</p>
<p>also when i check in firefox cookie expiration i see strange date.</p>
<p>Thx</p>
|
[
{
"answer_id": 177790,
"author": "Lazarin",
"author_id": 24124,
"author_profile": "https://Stackoverflow.com/users/24124",
"pm_score": 1,
"selected": false,
"text": "<p>The API says that -1 means until browser is running: </p>\n\n<blockquote>\n <p>Returns the maximum age of the cookie, specified in seconds, By default, -1 indicating the cookie will persist until browser shutdown</p>\n</blockquote>\n\n<p>What is the value of EXPIRATION_TIME constant?</p>\n"
},
{
"answer_id": 177949,
"author": "Arne Burmeister",
"author_id": 12890,
"author_profile": "https://Stackoverflow.com/users/12890",
"pm_score": 0,
"selected": false,
"text": "<p>The value may be modified by the browser.</p>\n\n<p>You create a cookie and want to set a max age. The cookie is sent to the browser. The browser may reject the cookie or ignore a max age too long for its policy. This modified cookie is sent back to your application.</p>\n\n<p>Check your browser settings.</p>\n"
},
{
"answer_id": 178880,
"author": "anjanb",
"author_id": 11142,
"author_profile": "https://Stackoverflow.com/users/11142",
"pm_score": 0,
"selected": false,
"text": "<p>Just for grins, can you retrieve the value of the cookie from the browser using javascript ?</p>\n\n<p>Also, can you put a filter before your servlet/jsp so that you can check the value of the cookie after the servlet/jsp sets it ?</p>\n"
},
{
"answer_id": 187047,
"author": "Bruno De Fraine",
"author_id": 6918,
"author_profile": "https://Stackoverflow.com/users/6918",
"pm_score": 4,
"selected": false,
"text": "<p>When a browser sends a cookie back to the origin server, it doesn't include any age. So it is logical that your \"retrieve\" code above does not receive a max age: it is not included in the request.</p>\n\n<p>When the cookie is received from the server, the browser uses the max age parameter to determine how long the cookie should be kept; the age is never communicated back to the server, an expired cookie is simply discarded. When processing a request, if you want to renew the age of the cookie, reinclude the cookie in the response.</p>\n\n<p>Also see the section \"Sending Cookies to the Origin Server\" in the <a href=\"http://www.w3.org/Protocols/rfc2109/rfc2109\" rel=\"noreferrer\">RFC</a>.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177708",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/23968/"
] |
I can't retrieve cookie maxage it always returns -1
Creating cookie:
```
Cookie securityCookie = new Cookie("sec", "somevalue");
securityCookie.setMaxAge(EXPIRATION_TIME);
```
Retrieve cookie:
```
Cookie[] cookies = request.getCookies();
if (cookies != null) {
for(int i=0; i<cookies.length; i++) {
Cookie cookie = cookies[i];
if ("sec".equals(cookie.getName())){
int age = cookie.getMaxAge();
}
}
}
```
i am always getting age = -1
also when i check in firefox cookie expiration i see strange date.
Thx
|
When a browser sends a cookie back to the origin server, it doesn't include any age. So it is logical that your "retrieve" code above does not receive a max age: it is not included in the request.
When the cookie is received from the server, the browser uses the max age parameter to determine how long the cookie should be kept; the age is never communicated back to the server, an expired cookie is simply discarded. When processing a request, if you want to renew the age of the cookie, reinclude the cookie in the response.
Also see the section "Sending Cookies to the Origin Server" in the [RFC](http://www.w3.org/Protocols/rfc2109/rfc2109).
|
177,717 |
<p>Please share you experiences regarding how you localized your WPF applications to support multiple languages and any resources that helped you in it?</p>
<p>Thanks for your feedbacks.</p>
|
[
{
"answer_id": 181456,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Sorry if it is vague (above question),basically it about how you implemented it in your application and what you felt was the best way.It is basically to understand scenarios.</p>\n"
},
{
"answer_id": 640277,
"author": "Robert Macnee",
"author_id": 19273,
"author_profile": "https://Stackoverflow.com/users/19273",
"pm_score": 2,
"selected": false,
"text": "<p>For our WPF application, all of our strings are localized as resources in a <code>ResourceDictionary</code> that we put in a .xaml file named after the language (like en-US.xaml, ja-JP.xaml, etc).</p>\n\n<p>For example, somewhere in the application a button might look like this:</p>\n\n<pre><code><Button Content=\"{StaticResource Strings.FooDialog.BarButtonText}\"/>\n</code></pre>\n\n<p>Each <code>ResourceDictionary</code> for the different languages would contain a version of it:</p>\n\n<pre><code><sys:String x:Key=\"Strings.FooDialog.BarButtonText\">Bar!</sys:String>\n</code></pre>\n\n<p>The <code>ResourceDictionary</code> is dynamically connected to the <code>Application.Resources</code> at runtime like this:</p>\n\n<pre><code>private static void LoadLocalizedStrings(CultureInfo uiCulture)\n{\n ResourceDictionary stringsResourceDictionary = new ResourceDictionary();\n stringsResourceDictionary.Source = new Uri(@\"pack://application:,,,/Resources/Strings/\" + uiCulture.Name + \".xaml\");\n Application.Current.Resources.MergedDictionaries.Add(stringsResourceDictionary);\n}\n</code></pre>\n"
},
{
"answer_id": 5626006,
"author": "cjbarth",
"author_id": 271351,
"author_profile": "https://Stackoverflow.com/users/271351",
"pm_score": 0,
"selected": false,
"text": "<p>I just localized my WPF application successfully using ResourceDictionary. The method I used allows for dynamic changing of languages, easy translation, design-time support, and even allows for partial translations. I based my work on <a href=\"http://www.geektieguy.com/2006/12/12/localizing-an-xbap-application-without-using-locbaml/\" rel=\"nofollow noreferrer\">http://www.geektieguy.com/2006/12/12/localizing-an-xbap-application-without-using-locbaml/</a></p>\n\n<p>You can see my efforts in part at: <a href=\"https://stackoverflow.com/questions/5623008/resourcedictionary-source-binding-to-module-for-localization\">ResourceDictionary Source Binding to Module (for Localization)</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177717",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
Please share you experiences regarding how you localized your WPF applications to support multiple languages and any resources that helped you in it?
Thanks for your feedbacks.
|
For our WPF application, all of our strings are localized as resources in a `ResourceDictionary` that we put in a .xaml file named after the language (like en-US.xaml, ja-JP.xaml, etc).
For example, somewhere in the application a button might look like this:
```
<Button Content="{StaticResource Strings.FooDialog.BarButtonText}"/>
```
Each `ResourceDictionary` for the different languages would contain a version of it:
```
<sys:String x:Key="Strings.FooDialog.BarButtonText">Bar!</sys:String>
```
The `ResourceDictionary` is dynamically connected to the `Application.Resources` at runtime like this:
```
private static void LoadLocalizedStrings(CultureInfo uiCulture)
{
ResourceDictionary stringsResourceDictionary = new ResourceDictionary();
stringsResourceDictionary.Source = new Uri(@"pack://application:,,,/Resources/Strings/" + uiCulture.Name + ".xaml");
Application.Current.Resources.MergedDictionaries.Add(stringsResourceDictionary);
}
```
|
177,719 |
<p>I'm trying to get a case-insensitive search with two strings in JavaScript working.</p>
<p>Normally it would be like this:</p>
<pre><code>var string="Stackoverflow is the BEST";
var result= string.search(/best/i);
alert(result);
</code></pre>
<p>The <code>/i</code> flag would be for case-insensitive.</p>
<p>But I need to search for a second string; without the flag it works perfect:</p>
<pre><code>var string="Stackoverflow is the BEST";
var searchstring="best";
var result= string.search(searchstring);
alert(result);
</code></pre>
<p>If I add the <code>/i</code> flag to the above example it would search for searchstring and not for what is in the variable "searchstring" (next example not working):</p>
<pre><code>var string="Stackoverflow is the BEST";
var searchstring="best";
var result= string.search(/searchstring/i);
alert(result);
</code></pre>
<p>How can I achieve this?</p>
|
[
{
"answer_id": 177724,
"author": "Dan",
"author_id": 17121,
"author_profile": "https://Stackoverflow.com/users/17121",
"pm_score": 10,
"selected": true,
"text": "<p>Yeah, use <code>.match</code>, rather than <code>.search</code>. The result from the <code>.match</code> call will return the actual string that was matched itself, but it can still be used as a boolean value.</p>\n\n<pre><code>var string = \"Stackoverflow is the BEST\";\nvar result = string.match(/best/i);\n// result == 'BEST';\n\nif (result){\n alert('Matched');\n}\n</code></pre>\n\n<p>Using a regular expression like that is probably the tidiest and most obvious way to do that in JavaScript, but bear in mind it <em>is</em> a regular expression, and thus can contain regex metacharacters. If you want to take the string from elsewhere (eg, user input), or if you want to avoid having to escape a lot of metacharacters, then you're probably best using <code>indexOf</code> like this:</p>\n\n<pre><code>matchString = 'best';\n// If the match string is coming from user input you could do\n// matchString = userInput.toLowerCase() here.\n\nif (string.toLowerCase().indexOf(matchString) != -1){\n alert('Matched');\n}\n</code></pre>\n"
},
{
"answer_id": 177775,
"author": "Sergey Ilinsky",
"author_id": 23815,
"author_profile": "https://Stackoverflow.com/users/23815",
"pm_score": 8,
"selected": false,
"text": "<p>Replace</p>\n\n<pre><code>var result= string.search(/searchstring/i);\n</code></pre>\n\n<p>with</p>\n\n<pre><code>var result= string.search(new RegExp(searchstring, \"i\"));\n</code></pre>\n"
},
{
"answer_id": 178383,
"author": "Odilon Redo",
"author_id": 21166,
"author_profile": "https://Stackoverflow.com/users/21166",
"pm_score": 5,
"selected": false,
"text": "<p>If you're just searching for a string rather than a more complicated regular expression, you can use <code>indexOf()</code> - but remember to lowercase both strings first because <code>indexOf()</code> is case sensitive:</p>\n\n<pre><code>var string=\"Stackoverflow is the BEST\"; \nvar searchstring=\"best\";\n\n// lowercase both strings\nvar lcString=string.toLowerCase();\nvar lcSearchString=searchstring.toLowerCase();\n\nvar result = lcString.indexOf(lcSearchString)>=0;\nalert(result);\n</code></pre>\n\n<p>Or in a single line:</p>\n\n<pre><code>var result = string.toLowerCase().indexOf(searchstring.toLowerCase())>=0;\n</code></pre>\n"
},
{
"answer_id": 3560120,
"author": "dsomnus",
"author_id": 373345,
"author_profile": "https://Stackoverflow.com/users/373345",
"pm_score": 2,
"selected": false,
"text": "<p>If you are concerned about the \"unterminated character class\" case, removing all non-alphanumeric chars would be helpful:</p>\n\n<pre>searchstring = searchstring.replace(/[^a-zA-Z 0-9]+/g,'');</pre>\n"
},
{
"answer_id": 27272159,
"author": "Ago",
"author_id": 2448897,
"author_profile": "https://Stackoverflow.com/users/2448897",
"pm_score": -1,
"selected": false,
"text": "<p>I noticed that if the user enters a string of text but leaves the input without selecting any of the autocomplete options no value is set in the hidden input, even if the string coincides with one in the array.\nSo, with help of the other answers I made this:</p>\n\n<pre><code>var $local_source = [{\n value: 1,\n label: \"c++\"\n }, {\n value: 2,\n label: \"java\"\n }, {\n value: 3,\n label: \"php\"\n }, {\n value: 4,\n label: \"coldfusion\"\n }, {\n value: 5,\n label: \"javascript\"\n }, {\n value: 6,\n label: \"asp\"\n }, {\n value: 7,\n label: \"ruby\"\n }];\n $('#search-fld').autocomplete({\n source: $local_source,\n select: function (event, ui) {\n $(\"#search-fld\").val(ui.item.label); // display the selected text\n $(\"#search-fldID\").val(ui.item.value); // save selected id to hidden input\n return false;\n },\n change: function( event, ui ) {\n\n var isInArray = false;\n\n $local_source.forEach(function(element, index){\n\n if ($(\"#search-fld\").val().toUpperCase() == element.label.toUpperCase()) {\n isInArray = true;\n $(\"#search-fld\").val(element.label); // display the selected text\n $(\"#search-fldID\").val(element.value); // save selected id to hidden input\n console.log('inarray: '+isInArray+' label: '+element.label+' value: '+element.value);\n };\n\n });\n\n if(!isInArray){\n\n $(\"#search-fld\").val(''); // display the selected text\n $( \"#search-fldID\" ).val( ui.item? ui.item.value : 0 );\n\n }\n } \n</code></pre>\n"
},
{
"answer_id": 31001303,
"author": "Sohail Arif",
"author_id": 4677755,
"author_profile": "https://Stackoverflow.com/users/4677755",
"pm_score": 1,
"selected": false,
"text": "<p>There are two ways for case insensitive comparison:</p>\n<ol>\n<li><p>Convert strings to upper case and then compare them using the strict operator (<code>===</code>).</p>\n</li>\n<li><p>Pattern matching using string methods:</p>\n<p>Use the "search" string method for case insensitive search.</p>\n</li>\n</ol>\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><!doctype html>\n<html>\n\n<head>\n <script>\n // 1st way\n\n var a = \"apple\";\n var b = \"APPLE\";\n if (a.toUpperCase() === b.toUpperCase()) {\n alert(\"equal\");\n }\n\n //2nd way\n\n var a = \" Null and void\";\n document.write(a.search(/null/i));\n </script>\n</head>\n\n</html></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 38151393,
"author": "Chris Chute",
"author_id": 3095845,
"author_profile": "https://Stackoverflow.com/users/3095845",
"pm_score": 5,
"selected": false,
"text": "<p>Suppose we want to find the string variable <code>needle</code> in the string variable <code>haystack</code>. There are three gotchas:</p>\n\n<ol>\n<li>Internationalized applications should avoid <code>string.toUpperCase</code> and <code>string.toLowerCase</code>. Use a regular expression which ignores case instead. For example, <code>var needleRegExp = new RegExp(needle, \"i\");</code> followed by <code>needleRegExp.test(haystack)</code>.</li>\n<li>In general, you might not know the value of <code>needle</code>. Be careful that <code>needle</code> does not contain any regular expression <a href=\"https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions?redirectlocale=en-US&redirectslug=JavaScript%2FGuide%2FRegular_Expressions\">special characters</a>. Escape these using <code>needle.replace(/[-[\\]{}()*+?.,\\\\^$|#\\s]/g, \"\\\\$&\");</code>.</li>\n<li>In other cases, if you want to precisely match <code>needle</code> and <code>haystack</code>, just ignoring case, make sure to add <code>\"^\"</code> at the start and <code>\"$\"</code> at the end of your regular expression constructor.</li>\n</ol>\n\n<p>Taking points (1) and (2) into consideration, an example would be: </p>\n\n<pre><code>var haystack = \"A. BAIL. Of. Hay.\";\nvar needle = \"bail.\";\nvar needleRegExp = new RegExp(needle.replace(/[-[\\]{}()*+?.,\\\\^$|#\\s]/g, \"\\\\$&\"), \"i\");\nvar result = needleRegExp.test(haystack);\nalert(result);\n</code></pre>\n"
},
{
"answer_id": 38318366,
"author": "Kind Contributor",
"author_id": 887092,
"author_profile": "https://Stackoverflow.com/users/887092",
"pm_score": 2,
"selected": false,
"text": "<p>I like @CHR15TO's answer, unlike other answers I've seen on other similar questions, that answer actually shows how to properly escape a user provided search string (rather than saying it would be necessary without showing how).</p>\n\n<p>However, it's still quite clunky, and possibly relatively slower. So why not have a specific solution to what is likely a common requirement for coders? (And why not include it in the ES6 API BTW?)</p>\n\n<p>My answer [<a href=\"https://stackoverflow.com/a/38290557/887092]\">https://stackoverflow.com/a/38290557/887092]</a> on a similar question enables the following:</p>\n\n<pre><code>var haystack = 'A. BAIL. Of. Hay.';\nvar needle = 'bail.';\nvar index = haystack.naturalIndexOf(needle);\n</code></pre>\n"
},
{
"answer_id": 50080484,
"author": "Andrew",
"author_id": 2079831,
"author_profile": "https://Stackoverflow.com/users/2079831",
"pm_score": 3,
"selected": false,
"text": "<p>ES6+:</p>\n\n<pre><code>let string=\"Stackoverflow is the BEST\";\nlet searchstring=\"best\";\n\n\nlet found = string.toLowerCase()\n .includes(searchstring.toLowerCase());\n</code></pre>\n\n<p><code>includes()</code> returns <code>true</code> if <code>searchString</code> appears at one or more positions or <code>false</code> otherwise.</p>\n"
},
{
"answer_id": 51799980,
"author": "Steven Spungin",
"author_id": 5093961,
"author_profile": "https://Stackoverflow.com/users/5093961",
"pm_score": 1,
"selected": false,
"text": "<p>I do this <strong>often</strong> and use a simple 5 line prototype that accepts varargs. It is <strong>fast</strong> and works <strong>everywhere</strong>.</p>\n\n<pre><code>myString.containsIgnoreCase('red','orange','yellow')\n</code></pre>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>/**\r\n * @param {...string} var_strings Strings to search for\r\n * @return {boolean} true if ANY of the arguments is contained in the string\r\n */\r\nString.prototype.containsIgnoreCase = function(var_strings) {\r\n const thisLowerCase = this.toLowerCase()\r\n for (let i = 0; i < arguments.length; i++) {\r\n let needle = arguments[i]\r\n if (thisLowerCase.indexOf(needle.toLowerCase()) >= 0) {\r\n return true\r\n }\r\n }\r\n return false\r\n}\r\n\r\n/**\r\n * @param {...string} var_strings Strings to search for\r\n * @return {boolean} true if ALL of the arguments are contained in the string\r\n */\r\nString.prototype.containsAllIgnoreCase = function(var_strings) {\r\n const thisLowerCase = this.toLowerCase()\r\n for (let i = 0; i < arguments.length; i++) {\r\n let needle = arguments[i]\r\n if (thisLowerCase.indexOf(needle.toLowerCase()) === -1) {\r\n return false\r\n }\r\n }\r\n return true\r\n}\r\n\r\n// Unit test\r\n\r\nlet content = `\r\nFIRST SECOND\r\n\"At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.\"\r\n\"At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.\"\r\n\"At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.\"\r\n\"At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.\"\r\n\"At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.\"\r\n\"At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.\"\r\nFOO BAR\r\n`\r\n\r\nlet data = [\r\n 'foo',\r\n 'Foo',\r\n 'foobar',\r\n 'barfoo',\r\n 'first',\r\n 'second'\r\n]\r\n\r\nlet result\r\ndata.forEach(item => {\r\n console.log('Searching for', item)\r\n result = content.containsIgnoreCase(item)\r\n console.log(result ? 'Found' : 'Not Found')\r\n})\r\n\r\nconsole.log('Searching for', 'x, y, foo')\r\nresult = content.containsIgnoreCase('x', 'y', 'foo');\r\nconsole.log(result ? 'Found' : 'Not Found')\r\n\r\nconsole.log('Searching for all', 'foo, bar, foobar')\r\nresult = content.containsAllIgnoreCase('foo', 'bar', 'foobar');\r\nconsole.log(result ? 'Found' : 'Not Found')\r\n\r\nconsole.log('Searching for all', 'foo, bar')\r\nresult = content.containsAllIgnoreCase('foo', 'bar');\r\nconsole.log(result ? 'Found' : 'Not Found')</code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 54416115,
"author": "Robbert",
"author_id": 10414516,
"author_profile": "https://Stackoverflow.com/users/10414516",
"pm_score": 0,
"selected": false,
"text": "<p>You can make everything lowercase:</p>\n\n<pre><code>var string=\"Stackoverflow is the BEST\";\nvar searchstring=\"best\";\nvar result= (string.toLowerCase()).search((searchstring.toLowerCase()));\nalert(result);\n</code></pre>\n"
},
{
"answer_id": 67195629,
"author": "Yogaraj K L",
"author_id": 12056822,
"author_profile": "https://Stackoverflow.com/users/12056822",
"pm_score": 0,
"selected": false,
"text": "<p>I was trying for incase-sensitive string search and I tried</p>\n<pre><code> var result = string.toLowerCase().match(searchstring) \n</code></pre>\n<p>and also</p>\n<pre><code>var result= string.search(new RegExp(searchstring, "i"));\n</code></pre>\n<p>But I did some little modifications and that worked for me</p>\n<pre><code>var result = string.match(new RegExp(searchstring, "i"));\n</code></pre>\n<p>This is will either lowercase, uppercase or combination also</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177719",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25741/"
] |
I'm trying to get a case-insensitive search with two strings in JavaScript working.
Normally it would be like this:
```
var string="Stackoverflow is the BEST";
var result= string.search(/best/i);
alert(result);
```
The `/i` flag would be for case-insensitive.
But I need to search for a second string; without the flag it works perfect:
```
var string="Stackoverflow is the BEST";
var searchstring="best";
var result= string.search(searchstring);
alert(result);
```
If I add the `/i` flag to the above example it would search for searchstring and not for what is in the variable "searchstring" (next example not working):
```
var string="Stackoverflow is the BEST";
var searchstring="best";
var result= string.search(/searchstring/i);
alert(result);
```
How can I achieve this?
|
Yeah, use `.match`, rather than `.search`. The result from the `.match` call will return the actual string that was matched itself, but it can still be used as a boolean value.
```
var string = "Stackoverflow is the BEST";
var result = string.match(/best/i);
// result == 'BEST';
if (result){
alert('Matched');
}
```
Using a regular expression like that is probably the tidiest and most obvious way to do that in JavaScript, but bear in mind it *is* a regular expression, and thus can contain regex metacharacters. If you want to take the string from elsewhere (eg, user input), or if you want to avoid having to escape a lot of metacharacters, then you're probably best using `indexOf` like this:
```
matchString = 'best';
// If the match string is coming from user input you could do
// matchString = userInput.toLowerCase() here.
if (string.toLowerCase().indexOf(matchString) != -1){
alert('Matched');
}
```
|
177,722 |
<p>Perl has several built-in functions for accessing /etc/passwd on Unix systems (and elsewhere when supported) for user and group information. For instance,</p>
<pre><code>my $name = getpwuid($uid);
</code></pre>
<p>will return the user name given the user ID, or undef if there is no such user.</p>
<p>If a Perl script needs to be portable and run on Unices and Windows, how should one access user and group information? ActivePerl seems to support User::grent and User::pwent modules, which provide by-field access to /etc/passwd -- even in Windows. Curiously they do not support the built-in functions getpw* and getgr*. What other alternatives are there?</p>
|
[
{
"answer_id": 177865,
"author": "David Webb",
"author_id": 3171,
"author_profile": "https://Stackoverflow.com/users/3171",
"pm_score": 3,
"selected": false,
"text": "<p>You could use the <a href=\"http://aspn.activestate.com/ASPN/CodeDoc/libwin32/NetAdmin/NetAdmin.html\" rel=\"nofollow noreferrer\"><code>Win32::NetAdmin</code> module</a>.</p>\n\n<p><code>UserGetAttributes</code> and <code>GroupIsMember</code> look like they do what you need.</p>\n"
},
{
"answer_id": 1315466,
"author": "MkV",
"author_id": 46235,
"author_profile": "https://Stackoverflow.com/users/46235",
"pm_score": 0,
"selected": false,
"text": "<p>Oddly enough, Interix's build of Perl that ships with Microsoft's Services for Unix does support getpw* and friends.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177722",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
Perl has several built-in functions for accessing /etc/passwd on Unix systems (and elsewhere when supported) for user and group information. For instance,
```
my $name = getpwuid($uid);
```
will return the user name given the user ID, or undef if there is no such user.
If a Perl script needs to be portable and run on Unices and Windows, how should one access user and group information? ActivePerl seems to support User::grent and User::pwent modules, which provide by-field access to /etc/passwd -- even in Windows. Curiously they do not support the built-in functions getpw\* and getgr\*. What other alternatives are there?
|
You could use the [`Win32::NetAdmin` module](http://aspn.activestate.com/ASPN/CodeDoc/libwin32/NetAdmin/NetAdmin.html).
`UserGetAttributes` and `GroupIsMember` look like they do what you need.
|
177,723 |
<p>I'm currently working on a project that depends on me providing a path to a file (eg. <code>C:\Path.pth</code>). Now, I had everything working yesterday by calling my <code>std::string</code> with:</p>
<pre><code>std::string path(`"C:\\Path.pth`");
</code></pre>
<p>But now it doesn't work. It throws a <code>bad_alloc</code>. Seems like the '<code>\</code>' character is the problem. I even tried using <code>\x5C</code> as the ascii-value of it instead, but same result.</p>
<p>Now, my question is, is it possible that I have screwed up some <code>#define</code>, some compiler-option or something else "non-code" that could've caused this? I'm using VS 2005.</p>
<p>Any help would be much appreciated</p>
<hr>
<p>PierreBdR</p>
<p>.. That sounds very likely. Or at least, it have to :P</p>
<p>Since no one have mentioned some kind of /SetStringCharSize:2bit-compiler option, I think it's safe to assume that my code has to mess something up, somewhere, and that it's not just a silly compiler-option (or similar) that's wrong..</p>
|
[
{
"answer_id": 177730,
"author": "Danny Whitt",
"author_id": 375,
"author_profile": "https://Stackoverflow.com/users/375",
"pm_score": 0,
"selected": false,
"text": "<p>Define the string as: \"C:\\\\Path.pth\"</p>\n"
},
{
"answer_id": 177731,
"author": "user22044",
"author_id": 22044,
"author_profile": "https://Stackoverflow.com/users/22044",
"pm_score": 0,
"selected": false,
"text": "<p>No, you didn't have it \"working\" yesterday either. '\\' needs to be escaped like so:</p>\n\n<pre><code>std::string path(\"c:\\\\path.pth\");\n</code></pre>\n\n<p>You probably did a forward slash yesterday, which can work in this situation as well.</p>\n\n<pre><code>std::string path(\"c:/path.pth\");\n</code></pre>\n"
},
{
"answer_id": 177841,
"author": "Roddy",
"author_id": 1737,
"author_profile": "https://Stackoverflow.com/users/1737",
"pm_score": -1,
"selected": false,
"text": "<p>Assuming your double-backslash is correct, I'd guess you're running on Vista?</p>\n\n<p>Vista won't let your write into the root directory of the C drive by default. Try one of the following:</p>\n\n<ul>\n<li>Turn off UAC, or</li>\n<li>Run your application as \"Administrator\", or</li>\n<li>Write into a subdirectory.</li>\n</ul>\n"
},
{
"answer_id": 177857,
"author": "PierreBdR",
"author_id": 7136,
"author_profile": "https://Stackoverflow.com/users/7136",
"pm_score": 3,
"selected": false,
"text": "<p>As your error suggest, the problem is due to <strong>memory allocation</strong> (i.e. the bad_alloc exception).</p>\n\n<p>So either you have no more memory (unlikely) or you have a buffer overrun somewhere before (quite likely in my opinion) or some other memory issues like double free.</p>\n\n<p>In short, you do something that messes up the memory management layout (i.e. all these information in between allocated blocks). Check on what happens <strong>before</strong> this call.</p>\n"
},
{
"answer_id": 178180,
"author": "Meeh",
"author_id": 25745,
"author_profile": "https://Stackoverflow.com/users/25745",
"pm_score": 2,
"selected": false,
"text": "<p>The bug has been found and fixed. </p>\n\n<p>Seems like TinyXML was has a bug when used with the <code>TIXML_USE_STL</code> definition. So for some reason the constructor to the <code>TiDocument</code> corrupted my memory-layout so badly that the next <code>std::string</code> I defined has to throw a <code>bad_alloc</code> exception - and luckily for me, exactly on the 4th char of the string, which in my situation was '\\', resulting in a rather subtle error.</p>\n"
},
{
"answer_id": 178609,
"author": "Jon",
"author_id": 25111,
"author_profile": "https://Stackoverflow.com/users/25111",
"pm_score": 1,
"selected": false,
"text": "<p>Don't forget, you should use forward slashes in paths, even on windows:</p>\n\n<blockquote>\n <p>[15.16] Why can't I open a file in a different directory such as \"..\\test.dat\"?</p>\n \n <p>Because \"\\t\" is a tab character.</p>\n \n <p>You should use forward slashes in your filenames, even on operating systems that use backslashes (DOS, Windows, OS/2, etc.). For example:</p>\n</blockquote>\n\n<pre><code>#include <iostream>\n#include <fstream>\n\nint main()\n{\n #if 1\n std::ifstream file(\"../test.dat\"); // RIGHT!\n #else\n std::ifstream file(\"..\\test.dat\"); // WRONG!\n #endif\n\n ...\n} \n</code></pre>\n\n<blockquote>\n <p>Remember, the backslash (\"\\\") is used in string literals to create special characters: \"\\n\" is a newline, \"\\b\" is a backspace, and \"\\t\" is a tab, \"\\a\" is an \"alert\", \"\\v\" is a vertical-tab, etc. Therefore the file name \"\\version\\next\\alpha\\beta\\test.dat\" is interpreted as a bunch of very funny characters. To be safe, use \"/version/next/alpha/beta/test.dat\" instead, even on systems that use a \"\\\" as the directory separator. This is because the library routines on these operating systems handle \"/\" and \"\\\" interchangeably.</p>\n \n <p>Of course you could use \"\\\\version\\\\next\\\\alpha\\\\beta\\\\test.dat\", but that might hurt you (there's a non-zero chance you'll forget one of the \"\\\"s, a rather subtle bug since most people don't notice it) and it can't help you (there's no benefit for using \"\\\" over \"/\"). Besides \"/\" is more portable since it works on all flavors of Unix, Plan 9, Inferno, all Windows, OS/2, etc., but \"\\\" works only on a subset of that list. So \"\\\" costs you something and gains you nothing: use \"/\" instead. </p>\n</blockquote>\n\n<p>(From <a href=\"http://www.parashift.com/c++-faq-lite/input-output.html#faq-15.16\" rel=\"nofollow noreferrer\" title=\"C++ FAQ Lite\">C++ FAQ Lite</a>)</p>\n"
},
{
"answer_id": 58378916,
"author": "Den-Jason",
"author_id": 1607937,
"author_profile": "https://Stackoverflow.com/users/1607937",
"pm_score": 0,
"selected": false,
"text": "<p>This could simply be due to a clean build being required; it was certainly the case when I experienced this.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177723",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25745/"
] |
I'm currently working on a project that depends on me providing a path to a file (eg. `C:\Path.pth`). Now, I had everything working yesterday by calling my `std::string` with:
```
std::string path(`"C:\\Path.pth`");
```
But now it doesn't work. It throws a `bad_alloc`. Seems like the '`\`' character is the problem. I even tried using `\x5C` as the ascii-value of it instead, but same result.
Now, my question is, is it possible that I have screwed up some `#define`, some compiler-option or something else "non-code" that could've caused this? I'm using VS 2005.
Any help would be much appreciated
---
PierreBdR
.. That sounds very likely. Or at least, it have to :P
Since no one have mentioned some kind of /SetStringCharSize:2bit-compiler option, I think it's safe to assume that my code has to mess something up, somewhere, and that it's not just a silly compiler-option (or similar) that's wrong..
|
As your error suggest, the problem is due to **memory allocation** (i.e. the bad\_alloc exception).
So either you have no more memory (unlikely) or you have a buffer overrun somewhere before (quite likely in my opinion) or some other memory issues like double free.
In short, you do something that messes up the memory management layout (i.e. all these information in between allocated blocks). Check on what happens **before** this call.
|
177,727 |
<p>When I add &nbsp; or &eacute; to a text value of a listitem, it display the code of the HTML entity instead of the result (a space or é).</p>
<p>I can add "physical" non-breaking spaces or special chars, but I would like to avoid that if possible. Sometimes the data stored in database is encoded, and I don't want to always process data before displaying it.</p>
<p>Any solution ?</p>
<p>Thanks</p>
<p>Edit note : previous description noted it was about a dropdownlist simulating a treeview, but it was merely an example ; I can't and don't want to replace the dropdownlist by anything else.</p>
|
[
{
"answer_id": 177737,
"author": "Quentin",
"author_id": 19068,
"author_profile": "https://Stackoverflow.com/users/19068",
"pm_score": 0,
"selected": false,
"text": "<p>Standard drop down lists are very poor at representing treeviews . </p>\n\n<p>They can handle going one level deep if the top level is not selectable (see the <a href=\"http://www.w3.org/TR/html4/interact/forms.html#edef-OPTGROUP\" rel=\"nofollow noreferrer\">optgroup</a> element[1]), but beyond that I suggest taking a regular list (ordered or unordered) with as much nesting as you need (remember sublists go inside list items in their parent list) and including a checkbox or radio button with each selectable list item.</p>\n\n<p>Some JavaScript could then be added to manipulate classes to create a drop down effect if desired.</p>\n\n<p>[1] Optgroup should be able to go deeper but, IIRC, browser support is sucky.</p>\n"
},
{
"answer_id": 177741,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 1,
"selected": false,
"text": "<p>You can use the <a href=\"http://www.w3schools.com/tags/tag_optgroup.asp\" rel=\"nofollow noreferrer\" title=\"W3Schools OPTGROUP tag\"><code><optgroup></code></a> tag for hierarchical (i.e., tree-like) drop-down menus.</p>\n\n<pre><code><select>\n <optgroup label=\"Parent 1\">\n <option>Child 1.1</option>\n <option>Child 1.2</option>\n </optgroup>\n <optgroup label=\"Parent 2\">\n <option>Child 2.1</option>\n <option>Child 2.2</option>\n </optgroup>\n</select> \n</code></pre>\n"
},
{
"answer_id": 177743,
"author": "Mote",
"author_id": 24789,
"author_profile": "https://Stackoverflow.com/users/24789",
"pm_score": 0,
"selected": false,
"text": "<p>Try with ul(ol) and play with the css. You can use jquery to change style if some requirements are met (li has value attribute)</p>\n"
},
{
"answer_id": 177846,
"author": "martin",
"author_id": 8421,
"author_profile": "https://Stackoverflow.com/users/8421",
"pm_score": 4,
"selected": true,
"text": "<p>ListItems are automatically HtmlEncoded.</p>\n\n<p>You can HtmlDecode the list items before hand, so when they are HtmlEncoded you get the proper characters:</p>\n\n<pre><code>DropDownList1.DataSource = new List<string> { Server.HtmlDecode(\"A&hellip;\"), Server.HtmlDecode(\"B&nbsp;C\") };\nDropDownList1.DataBind();\n</code></pre>\n"
},
{
"answer_id": 42601605,
"author": "ChrisW",
"author_id": 49942,
"author_profile": "https://Stackoverflow.com/users/49942",
"pm_score": 0,
"selected": false,
"text": "<p>The problem described in the question isn't what I see using a current version of ASP.NET -- when I try it, both the following <code>&ndash;</code> are rendered correctly:</p>\n\n<pre><code> <asp:RadioButtonList ID=\"Visibility\" runat=\"server\">\n <asp:ListItem Value=\"public\" Text=\"Public &ndash; All users\"></asp:ListItem>\n <asp:ListItem Value=\"private\">Private &ndash; Only you</asp:ListItem>\n </asp:RadioButtonList>\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177727",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6776/"
] |
When I add or é to a text value of a listitem, it display the code of the HTML entity instead of the result (a space or é).
I can add "physical" non-breaking spaces or special chars, but I would like to avoid that if possible. Sometimes the data stored in database is encoded, and I don't want to always process data before displaying it.
Any solution ?
Thanks
Edit note : previous description noted it was about a dropdownlist simulating a treeview, but it was merely an example ; I can't and don't want to replace the dropdownlist by anything else.
|
ListItems are automatically HtmlEncoded.
You can HtmlDecode the list items before hand, so when they are HtmlEncoded you get the proper characters:
```
DropDownList1.DataSource = new List<string> { Server.HtmlDecode("A…"), Server.HtmlDecode("B C") };
DropDownList1.DataBind();
```
|
177,747 |
<p>We have a "master database structure", and need a routine to keep the database structure on client sites up-to-date.</p>
<p>A number of suggestions have been given <a href="https://stackoverflow.com/questions/115389/update-sql-sever-database-schema-with-software-update" title="here">to a related question</a>, but I am looking for a more specific solution, along these lines:</p>
<ol>
<li>I would like to generate a text file (XML or other readable format) which describes the entire database structure (this could go into version control). This routine will run in-house, to provide a database schema file to be distributed with the next version of our product.</li>
<li>Then I need a way to update the database structure on the client site so that it corresponds to the master database structure. (In other words, I don't want to have to keep track of numerous change scripts for different versions of the database structure, but a more general routine which can get the client database structure updated to the current master database structure.)</li>
</ol>
<p>So the main feature I'm looking for could be described as "database structure to text" and "text to database structure".</p>
|
[
{
"answer_id": 177737,
"author": "Quentin",
"author_id": 19068,
"author_profile": "https://Stackoverflow.com/users/19068",
"pm_score": 0,
"selected": false,
"text": "<p>Standard drop down lists are very poor at representing treeviews . </p>\n\n<p>They can handle going one level deep if the top level is not selectable (see the <a href=\"http://www.w3.org/TR/html4/interact/forms.html#edef-OPTGROUP\" rel=\"nofollow noreferrer\">optgroup</a> element[1]), but beyond that I suggest taking a regular list (ordered or unordered) with as much nesting as you need (remember sublists go inside list items in their parent list) and including a checkbox or radio button with each selectable list item.</p>\n\n<p>Some JavaScript could then be added to manipulate classes to create a drop down effect if desired.</p>\n\n<p>[1] Optgroup should be able to go deeper but, IIRC, browser support is sucky.</p>\n"
},
{
"answer_id": 177741,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 1,
"selected": false,
"text": "<p>You can use the <a href=\"http://www.w3schools.com/tags/tag_optgroup.asp\" rel=\"nofollow noreferrer\" title=\"W3Schools OPTGROUP tag\"><code><optgroup></code></a> tag for hierarchical (i.e., tree-like) drop-down menus.</p>\n\n<pre><code><select>\n <optgroup label=\"Parent 1\">\n <option>Child 1.1</option>\n <option>Child 1.2</option>\n </optgroup>\n <optgroup label=\"Parent 2\">\n <option>Child 2.1</option>\n <option>Child 2.2</option>\n </optgroup>\n</select> \n</code></pre>\n"
},
{
"answer_id": 177743,
"author": "Mote",
"author_id": 24789,
"author_profile": "https://Stackoverflow.com/users/24789",
"pm_score": 0,
"selected": false,
"text": "<p>Try with ul(ol) and play with the css. You can use jquery to change style if some requirements are met (li has value attribute)</p>\n"
},
{
"answer_id": 177846,
"author": "martin",
"author_id": 8421,
"author_profile": "https://Stackoverflow.com/users/8421",
"pm_score": 4,
"selected": true,
"text": "<p>ListItems are automatically HtmlEncoded.</p>\n\n<p>You can HtmlDecode the list items before hand, so when they are HtmlEncoded you get the proper characters:</p>\n\n<pre><code>DropDownList1.DataSource = new List<string> { Server.HtmlDecode(\"A&hellip;\"), Server.HtmlDecode(\"B&nbsp;C\") };\nDropDownList1.DataBind();\n</code></pre>\n"
},
{
"answer_id": 42601605,
"author": "ChrisW",
"author_id": 49942,
"author_profile": "https://Stackoverflow.com/users/49942",
"pm_score": 0,
"selected": false,
"text": "<p>The problem described in the question isn't what I see using a current version of ASP.NET -- when I try it, both the following <code>&ndash;</code> are rendered correctly:</p>\n\n<pre><code> <asp:RadioButtonList ID=\"Visibility\" runat=\"server\">\n <asp:ListItem Value=\"public\" Text=\"Public &ndash; All users\"></asp:ListItem>\n <asp:ListItem Value=\"private\">Private &ndash; Only you</asp:ListItem>\n </asp:RadioButtonList>\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177747",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18651/"
] |
We have a "master database structure", and need a routine to keep the database structure on client sites up-to-date.
A number of suggestions have been given [to a related question](https://stackoverflow.com/questions/115389/update-sql-sever-database-schema-with-software-update "here"), but I am looking for a more specific solution, along these lines:
1. I would like to generate a text file (XML or other readable format) which describes the entire database structure (this could go into version control). This routine will run in-house, to provide a database schema file to be distributed with the next version of our product.
2. Then I need a way to update the database structure on the client site so that it corresponds to the master database structure. (In other words, I don't want to have to keep track of numerous change scripts for different versions of the database structure, but a more general routine which can get the client database structure updated to the current master database structure.)
So the main feature I'm looking for could be described as "database structure to text" and "text to database structure".
|
ListItems are automatically HtmlEncoded.
You can HtmlDecode the list items before hand, so when they are HtmlEncoded you get the proper characters:
```
DropDownList1.DataSource = new List<string> { Server.HtmlDecode("A…"), Server.HtmlDecode("B C") };
DropDownList1.DataBind();
```
|
177,750 |
<p>I am trying to get some XML data with LINQ, but running into a problem.</p>
<p>I am using a schema, which is set in the attribute xmlns ...</p>
<pre><code><CarsForSale xmlns="http://schemas.sharplogic.net/CarSales.xsd">
<CarForSale>
</code></pre>
<p>There are many CarForSale elements.</p>
<p>When the schema is set and I do this...</p>
<pre><code>XElement doc = XElement.Load(HttpContext.Current.Server.MapPath("App_Data/XML/CarsForSale.xml"));
var cars2 = from d in doc.Descendants("CarForSale")
select d;
</code></pre>
<p>Then I get in the results i get Enumeration yielded no results </p>
<p>Strip the xmlns out of the XML file and the data comes back as expected??</p>
<p>Any ideas?</p>
<p>Thx</p>
|
[
{
"answer_id": 177754,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 4,
"selected": true,
"text": "<p>You need to prepend the namespace:</p>\n\n<pre><code>var ns = \"http://schemas.sharplogic.net/CarSales.xsd\";\nvar cars2 = from d in doc.Descendants(ns + \"CarForSale\") \n select d;\n</code></pre>\n\n<p>otherwise search by local name:</p>\n\n<pre><code>var cars2 = from d in doc.Descendants()\n where d.Name.LocalName == \"CarForSale\" \n select d;\n</code></pre>\n"
},
{
"answer_id": 1276991,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>To avoid hard coding the namespace you can use this:</p>\n\n<pre><code>XNamespace ns = doc.Root.Name.Namespace;\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177750",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6125/"
] |
I am trying to get some XML data with LINQ, but running into a problem.
I am using a schema, which is set in the attribute xmlns ...
```
<CarsForSale xmlns="http://schemas.sharplogic.net/CarSales.xsd">
<CarForSale>
```
There are many CarForSale elements.
When the schema is set and I do this...
```
XElement doc = XElement.Load(HttpContext.Current.Server.MapPath("App_Data/XML/CarsForSale.xml"));
var cars2 = from d in doc.Descendants("CarForSale")
select d;
```
Then I get in the results i get Enumeration yielded no results
Strip the xmlns out of the XML file and the data comes back as expected??
Any ideas?
Thx
|
You need to prepend the namespace:
```
var ns = "http://schemas.sharplogic.net/CarSales.xsd";
var cars2 = from d in doc.Descendants(ns + "CarForSale")
select d;
```
otherwise search by local name:
```
var cars2 = from d in doc.Descendants()
where d.Name.LocalName == "CarForSale"
select d;
```
|
177,752 |
<p>I'm migrating a TSQL stored procedure to PL/SQL and have encountered a problem - the lack of a CONTINUE keyword in Oracle 10g.</p>
<p>I've read that Oracle 11g has this as a new feature, but upgrading is not an option unfortunately.</p>
<p>Is there any alternative to CONTINUE in 10g? I don't believe it's practical to restructure the logic of the SP as a work-around, because I have an outer loop, an IF, then a nested IF, then the CONTINUE at the end of a statement block within that IF.</p>
<p>Any help would be greatly appreciated, cheers.</p>
|
[
{
"answer_id": 177768,
"author": "cagcowboy",
"author_id": 19629,
"author_profile": "https://Stackoverflow.com/users/19629",
"pm_score": 2,
"selected": false,
"text": "<p>Can you refactor the IFs into a function, returning at the appropriate point (early if necessary). Then the control flow will pick up in the loop at the right place.</p>\n\n<p>Does that make sense?</p>\n"
},
{
"answer_id": 177785,
"author": "jop",
"author_id": 11830,
"author_profile": "https://Stackoverflow.com/users/11830",
"pm_score": 7,
"selected": true,
"text": "<p>You can simulate a continue using <a href=\"http://download.oracle.com/docs/cd/B19306_01/appdev.102/b14261/controlstructures.htm#BCGFGDAA\" rel=\"noreferrer\">goto and labels</a>.</p>\n\n<pre><code>DECLARE\n done BOOLEAN;\nBEGIN\n FOR i IN 1..50 LOOP\n IF done THEN\n GOTO end_loop;\n END IF;\n <<end_loop>> -- not allowed unless an executable statement follows\n NULL; -- add NULL statement to avoid error\n END LOOP; -- raises an error without the previous NULL\nEND;\n</code></pre>\n"
},
{
"answer_id": 177869,
"author": "Thorsten",
"author_id": 25320,
"author_profile": "https://Stackoverflow.com/users/25320",
"pm_score": 1,
"selected": false,
"text": "<p>In Oracle there is a similar statement called EXIT that either exits a loop or a function/procedure (if there is no loop to exit from). You can add a WHEN to check for some condition.</p>\n\n<p>You could rewrite the above example as follows:</p>\n\n<pre><code>DECLARE\n done BOOLEAN;\nBEGIN\n FOR i IN 1..50 LOOP\n EXIT WHEN done;\n END LOOP;\nEND;\n</code></pre>\n\n<p>This may not be enough if you want to exit from deep down some nested loops and logic, but is a lot clearer than a couple of GOTOs and NULLs.</p>\n"
},
{
"answer_id": 242590,
"author": "Dilshod Tadjibaev",
"author_id": 29122,
"author_profile": "https://Stackoverflow.com/users/29122",
"pm_score": 3,
"selected": false,
"text": "<p>It's not available in 10g, however it's a <a href=\"http://www.oracle-base.com/articles/11g/PlsqlNewFeaturesAndEnhancements_11gR1.php#continue_statement\" rel=\"noreferrer\">new feature</a> in 11G </p>\n"
},
{
"answer_id": 637453,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 4,
"selected": false,
"text": "<p>Though it's a bit complex and just a fake, you can use exception this way :</p>\n\n<pre><code>DECLARE\n i NUMBER :=0;\n my_ex exception;\nBEGIN\n FOR i IN 1..10\n LOOP\n BEGIN\n IF i = 5 THEN\n raise my_ex;\n END IF;\n DBMS_OUTPUT.PUT_LINE (i);\n EXCEPTION WHEN my_ex THEN\n NULL;\n END;\n END LOOP;\n\nEND;\n</code></pre>\n"
},
{
"answer_id": 1380326,
"author": "David Oneill",
"author_id": 168646,
"author_profile": "https://Stackoverflow.com/users/168646",
"pm_score": 2,
"selected": false,
"text": "<p>Not exactly elegant, but simple:</p>\n\n<pre><code>DECLARE\n done BOOLEAN;\nBEGIN\n FOR i IN 1..50 LOOP\n IF done THEN\n NULL;\n ELSE\n <do loop stuff>;\n END IF;\n END LOOP; \nEND;\n</code></pre>\n"
},
{
"answer_id": 7149583,
"author": "Sylvain Rodrigue",
"author_id": 54783,
"author_profile": "https://Stackoverflow.com/users/54783",
"pm_score": 3,
"selected": false,
"text": "<p>In fact, PL SQL does have something to replace CONTINUE. All you have to do is to add a label (a name) to the loop : </p>\n\n<pre><code>declare\n i integer;\nbegin\n i := 0;\n\n <<My_Small_Loop>>loop\n\n i := i + 1;\n if i <= 3 then goto My_Small_Loop; end if; -- => means continue\n\n exit;\n\n end loop;\nend;\n</code></pre>\n"
},
{
"answer_id": 17588534,
"author": "eric.itzhak",
"author_id": 1026199,
"author_profile": "https://Stackoverflow.com/users/1026199",
"pm_score": 3,
"selected": false,
"text": "<p>For future searches, in oracle 11g they added a <code>continue</code> statement, which can be used like this :</p>\n\n<pre><code> SQL> BEGIN\n 2 FOR i IN 1 .. 5 LOOP\n 3 IF i IN (2,4) THEN\n 4 CONTINUE;\n 5 END IF;\n 6 DBMS_OUTPUT.PUT_LINE('Reached on line ' || TO_CHAR(i));\n 7 END LOOP;\n 8 END;\n 9 /\nReached on line 1\nReached on line 3\nReached on line 5\n\nPL/SQL procedure successfully completed.\n</code></pre>\n"
},
{
"answer_id": 58116974,
"author": "hvb",
"author_id": 2814025,
"author_profile": "https://Stackoverflow.com/users/2814025",
"pm_score": 1,
"selected": false,
"text": "<p>This isn't exactly an answer to the question, but nevertheless worth noting:</p>\n\n<p>The <code>continue</code> statement in PL/SQL and all other programming languages which use it the same way, can easily be misunderstood.</p>\n\n<p>It would have been much wiser, clearer and more concise if the programming language developers had called the keyword <code>skip</code> instead.</p>\n\n<p>For me, with a background of C, C++, Python, ... it has always been clear what `continue' means.</p>\n\n<p>But without that historical background, you might end intepreting this code</p>\n\n<pre><code>for i in .. tab_xy.count loop\n CONTINUE WHEN some_condition(tab_xy(i));\n do_process(tab_xy(i));\nend loop;\n</code></pre>\n\n<p>like this:</p>\n\n<p>Loop through the records of the table tab_xy.</p>\n\n<p><em>Continue if the record fulfills some_condition, otherwise ignore this record.</em></p>\n\n<p>Do_process the record.</p>\n\n<p><strong>This interpretation is completely wrong</strong>, but if you imagine the PL/SQL code as a kind of cooking receipt and read it aloud, this can happen.</p>\n\n<p>In fact it happened to a very experienced development co-worker just yesterday.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177752",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5827/"
] |
I'm migrating a TSQL stored procedure to PL/SQL and have encountered a problem - the lack of a CONTINUE keyword in Oracle 10g.
I've read that Oracle 11g has this as a new feature, but upgrading is not an option unfortunately.
Is there any alternative to CONTINUE in 10g? I don't believe it's practical to restructure the logic of the SP as a work-around, because I have an outer loop, an IF, then a nested IF, then the CONTINUE at the end of a statement block within that IF.
Any help would be greatly appreciated, cheers.
|
You can simulate a continue using [goto and labels](http://download.oracle.com/docs/cd/B19306_01/appdev.102/b14261/controlstructures.htm#BCGFGDAA).
```
DECLARE
done BOOLEAN;
BEGIN
FOR i IN 1..50 LOOP
IF done THEN
GOTO end_loop;
END IF;
<<end_loop>> -- not allowed unless an executable statement follows
NULL; -- add NULL statement to avoid error
END LOOP; -- raises an error without the previous NULL
END;
```
|
177,762 |
<p>Trying to perform a single boolean NOT operation, it appears that under MS SQL Server 2005, the following block does not work</p>
<pre><code>DECLARE @MyBoolean bit;
SET @MyBoolean = 0;
SET @MyBoolean = NOT @MyBoolean;
SELECT @MyBoolean;
</code></pre>
<p>Instead, I am getting more successful with</p>
<pre><code>DECLARE @MyBoolean bit;
SET @MyBoolean = 0;
SET @MyBoolean = 1 - @MyBoolean;
SELECT @MyBoolean;
</code></pre>
<p>Yet, this looks a bit a twisted way to express something as simple as a negation.</p>
<p>Am I missing something?</p>
|
[
{
"answer_id": 177770,
"author": "Galwegian",
"author_id": 3201,
"author_profile": "https://Stackoverflow.com/users/3201",
"pm_score": 5,
"selected": false,
"text": "<p>Your solution is a good one... you can also use this syntax to toggle a bit in SQL...</p>\n\n<pre><code>DECLARE @MyBoolean bit;\nSET @MyBoolean = 0;\nSET @MyBoolean = @MyBoolean ^ 1; \nSELECT @MyBoolean;\n</code></pre>\n"
},
{
"answer_id": 177780,
"author": "aku",
"author_id": 1196,
"author_profile": "https://Stackoverflow.com/users/1196",
"pm_score": 3,
"selected": false,
"text": "<p>BIT is a numeric data type, not boolean. That's why you can't apply boolean operators to it.<br>\nSQL Server doesn't have BOOLEAN data type (not sure about SQL SERVER 2008) so you have to stick with something like @Matt Hamilton's solution.</p>\n"
},
{
"answer_id": 177782,
"author": "Matt Hamilton",
"author_id": 615,
"author_profile": "https://Stackoverflow.com/users/615",
"pm_score": 5,
"selected": false,
"text": "<p>Subtracting the value from 1 looks like it'll do the trick, but in terms of expressing intent I think I'd prefer to go with:</p>\n\n<pre><code>SET @MyBoolean = CASE @MyBoolean WHEN 0 THEN 1 ELSE 0 END\n</code></pre>\n\n<p>It's more verbose but I think it's a little easier to understand.</p>\n"
},
{
"answer_id": 177893,
"author": "Jonas Lincoln",
"author_id": 17436,
"author_profile": "https://Stackoverflow.com/users/17436",
"pm_score": 8,
"selected": true,
"text": "<p>Use the ~ operator:</p>\n\n<pre><code>DECLARE @MyBoolean bit\nSET @MyBoolean = 0\nSET @MyBoolean = ~@MyBoolean\nSELECT @MyBoolean\n</code></pre>\n"
},
{
"answer_id": 177930,
"author": "Keith",
"author_id": 905,
"author_profile": "https://Stackoverflow.com/users/905",
"pm_score": 3,
"selected": false,
"text": "<p>In SQL 2005 there isn't a real boolean value, the bit value is something else really.</p>\n\n<p>A bit can have three states, 1, 0 and null (because it's data). SQL doesn't automatically convert these to true or false (although, confusingly SQL enterprise manager will)</p>\n\n<p>The best way to think of bit fields in logic is as an integer that's 1 or 0.</p>\n\n<p>If you use logic directly on a bit field it will behave like any other value variable - i.e. the logic will be true if it has a value (any value) and false otherwise.</p>\n"
},
{
"answer_id": 3558825,
"author": "Stephen B Craver",
"author_id": 429810,
"author_profile": "https://Stackoverflow.com/users/429810",
"pm_score": 2,
"selected": false,
"text": "<p>Use <code>ABS</code> to get the absolute value (-1 becomes 1)...</p>\n\n<pre><code>DECLARE @Trend AS BIT\nSET @Trend = 0\nSELECT @Trend, ABS(@Trend-1)\n</code></pre>\n"
},
{
"answer_id": 10299953,
"author": "FistOfFury",
"author_id": 606725,
"author_profile": "https://Stackoverflow.com/users/606725",
"pm_score": 4,
"selected": false,
"text": "<p>To assign an inverted bit, you'll need to use the bitwise NOT operator. When using the bitwise NOT operator, '~', you have to make sure your column or variable is declared as a bit. </p>\n\n<p>This won't give you zero:</p>\n\n<pre><code>Select ~1 \n</code></pre>\n\n<p>This will:</p>\n\n<pre><code>select ~convert(bit, 1)\n</code></pre>\n\n<p>So will this:</p>\n\n<pre><code>declare @t bit\nset @t=1\nselect ~@t\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177762",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/18858/"
] |
Trying to perform a single boolean NOT operation, it appears that under MS SQL Server 2005, the following block does not work
```
DECLARE @MyBoolean bit;
SET @MyBoolean = 0;
SET @MyBoolean = NOT @MyBoolean;
SELECT @MyBoolean;
```
Instead, I am getting more successful with
```
DECLARE @MyBoolean bit;
SET @MyBoolean = 0;
SET @MyBoolean = 1 - @MyBoolean;
SELECT @MyBoolean;
```
Yet, this looks a bit a twisted way to express something as simple as a negation.
Am I missing something?
|
Use the ~ operator:
```
DECLARE @MyBoolean bit
SET @MyBoolean = 0
SET @MyBoolean = ~@MyBoolean
SELECT @MyBoolean
```
|
177,835 |
<p>One of our unit tests is to populate properties within our business objects with random data.</p>
<p>These properties are of different intrinsic types and therefore we would like to use the power of generics to return data of the type you pass in. Something along the lines of:</p>
<pre><code>public static T GetData<T>()
</code></pre>
<p>How would you go about approaching this? Would a low level interface work? (IConvertible)</p>
|
[
{
"answer_id": 177847,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 4,
"selected": false,
"text": "<p>You could keep the \"easy to use\" GetData interface you've got there, but internally have a Dictionary<Type, object> where each value is a Func<T> for the relevant type. GetData would then have an implementation such as:</p>\n\n<pre><code>public static T GetData<T>()\n{\n object factory;\n if (!factories.TryGet(typeof(T), out factory))\n {\n throw new ArgumentException(\"No factory for type \" + typeof(T).Name);\n }\n Func<T> factoryFunc = (Func<T>) factory;\n return factoryFunc();\n}\n</code></pre>\n\n<p>You'd then set up the factory dictionary in a static initializer, with one delegate for each type of random data you wanted to create. In some cases you could use a simple lambda expression (e.g. for integers) and in some cases the delegate could point to a method doing more work (e.g. for strings).</p>\n\n<p>You may wish to use my <a href=\"http://pobox.com/~skeet/csharp/miscutil/usage/staticrandom.html\" rel=\"nofollow noreferrer\">StaticRandom</a> class for threads-safe RNG, by the way.</p>\n"
},
{
"answer_id": 177851,
"author": "Sklivvz",
"author_id": 7028,
"author_profile": "https://Stackoverflow.com/users/7028",
"pm_score": 2,
"selected": true,
"text": "<p>It depends on what data you want to randomize, because the <em>way</em> or the <em>algorithm</em> you want to use is totally different depending on the type.</p>\n\n<p>For example:</p>\n\n<pre><code>// Random int\nRandom r = new Random();\nreturn r.Next();\n\n// Random Guid\nreturn Guid.NewGuid();\n\n...\n</code></pre>\n\n<p>So this obviously makes the use of generics a nice semplification on the user's end, but it adds no value to the way you write the class. You could use a switch clause or a dictionary (like Jon Skeet suggests):</p>\n\n<pre><code>switch(typeof(T))\n{\n case System.Int32:\n Random r = new Random();\n return (T)r.Next();\n case System.Guid:\n return (T)Guid.NewGuid();\n ...\n</code></pre>\n\n<p>Then you would use the class as you expect:</p>\n\n<pre><code>RandomGenerator.GetData<Guid>();\n...\n</code></pre>\n"
},
{
"answer_id": 177988,
"author": "Grzenio",
"author_id": 5363,
"author_profile": "https://Stackoverflow.com/users/5363",
"pm_score": 2,
"selected": false,
"text": "<p>In general I would avoid writing random unit tests, because this is just not the purpose of unit tests. While writing unit tests you really want to generate the data manually to make sure that all the paths in your class/program are covered, and usually you hardcode this data in the test, to make it possible to rerun the test.</p>\n\n<p>So I guess you are really writing smoke tests, to see how your software behaves for big data sets. Here I think you should implement a specific generator for each of your business object types, as someone else already suggested - to make sure that the data is reasonably similar to what you expect in production (e.g. if IDs are sequential, then generate them sequential and not random).</p>\n"
},
{
"answer_id": 5960560,
"author": "Oliver",
"author_id": 1838048,
"author_profile": "https://Stackoverflow.com/users/1838048",
"pm_score": 0,
"selected": false,
"text": "<p>I would use <a href=\"http://autopoco.codeplex.com/\" rel=\"nofollow\">AutoPoco</a> to generate the needed data for testing.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177835",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/17540/"
] |
One of our unit tests is to populate properties within our business objects with random data.
These properties are of different intrinsic types and therefore we would like to use the power of generics to return data of the type you pass in. Something along the lines of:
```
public static T GetData<T>()
```
How would you go about approaching this? Would a low level interface work? (IConvertible)
|
It depends on what data you want to randomize, because the *way* or the *algorithm* you want to use is totally different depending on the type.
For example:
```
// Random int
Random r = new Random();
return r.Next();
// Random Guid
return Guid.NewGuid();
...
```
So this obviously makes the use of generics a nice semplification on the user's end, but it adds no value to the way you write the class. You could use a switch clause or a dictionary (like Jon Skeet suggests):
```
switch(typeof(T))
{
case System.Int32:
Random r = new Random();
return (T)r.Next();
case System.Guid:
return (T)Guid.NewGuid();
...
```
Then you would use the class as you expect:
```
RandomGenerator.GetData<Guid>();
...
```
|
177,836 |
<p>In the 'DBUtility' project of Petshop 4.0,the abstract class SqlHelper has a method 'GetCachedParameters':</p>
<pre><code> public static SqlParameter[] GetCachedParameters(string cacheKey) {
SqlParameter[] cachedParms = (SqlParameter[])parmCache[cacheKey];
if (cachedParms == null)
return null;
SqlParameter[] clonedParms = new SqlParameter[cachedParms.Length];
for (int i = 0, j = cachedParms.Length; i < j; i++)
clonedParms[i] = (SqlParameter)((ICloneable)cachedParms[i]).Clone();
return clonedParms;
}
</code></pre>
<p>why not return the 'cachedParms' directly ?</p>
|
[
{
"answer_id": 177840,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 4,
"selected": true,
"text": "<p>If cachedParms were returned directly, the caller could then change the elements of the array. The contents of the cache would then be effectively corrupted - the next caller to fetch the parameters from the cache with the same cache key would get unexpected results.</p>\n\n<p>EDIT: Cloning the array itself prevents the elements being replaced with different parameters. Cloning the elements as well prevents the parameter <em>objects</em> being mutated. Basically it's all defensive coding.</p>\n"
},
{
"answer_id": 177862,
"author": "Henry B",
"author_id": 6414,
"author_profile": "https://Stackoverflow.com/users/6414",
"pm_score": 0,
"selected": false,
"text": "<p>To add to what Jon Skeet said, if the return'd Cache'd values are used internally for then you don't want the user to be using values which could change without them being aware.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177836",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/20910/"
] |
In the 'DBUtility' project of Petshop 4.0,the abstract class SqlHelper has a method 'GetCachedParameters':
```
public static SqlParameter[] GetCachedParameters(string cacheKey) {
SqlParameter[] cachedParms = (SqlParameter[])parmCache[cacheKey];
if (cachedParms == null)
return null;
SqlParameter[] clonedParms = new SqlParameter[cachedParms.Length];
for (int i = 0, j = cachedParms.Length; i < j; i++)
clonedParms[i] = (SqlParameter)((ICloneable)cachedParms[i]).Clone();
return clonedParms;
}
```
why not return the 'cachedParms' directly ?
|
If cachedParms were returned directly, the caller could then change the elements of the array. The contents of the cache would then be effectively corrupted - the next caller to fetch the parameters from the cache with the same cache key would get unexpected results.
EDIT: Cloning the array itself prevents the elements being replaced with different parameters. Cloning the elements as well prevents the parameter *objects* being mutated. Basically it's all defensive coding.
|
177,863 |
<p>I am using the next class (simplified for the sake of understandability) to download images in a struts web application.
It is working fine in every browser but firefox, which cuts names containing spaces. That it is to say: <strong>file with spaces.pdf</strong> gets downloaded in firefox as: <strong>file</strong> while in chrome, IE7 IE6 is downloaded as <strong>file with spaces.pdf</strong>.</p>
<pre><code>public class Download extends Action {
private static final int BUFFER_SIZE = 4096;
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response) throws Exception {
String filename = "file with spaces.pdf";
File file = ... // variable containing the file;
response.setStatus(HttpServletResponse.SC_OK);
response.setContentType(getMimeType(request, file));
response.setHeader("Content-Type", getMimeType(request, file));
response.setHeader("Content-Disposition","attachment; filename="+ filename);
InputStream is = new FileInputStream(file);
sendFile(is, response);
return null;
}
protected String getMimeType(HttpServletRequest request, File file) {
ServletContext application = super.servlet.getServletContext();
return application.getMimeType(file.getName());
}
protected void sendFile(InputStream is, HttpServletResponse response) throws IOException {
BufferedInputStream in = null;
try {
int count;
byte[] buffer = new byte[BUFFER_SIZE];
in = new BufferedInputStream(is);
ServletOutputStream out = response.getOutputStream();
while(-1 != (count = in.read(buffer)))
out.write(buffer, 0, count);
out.flush();
} catch (IOException ioe) {
System.err.println("IOException in Download::sendFile");
ioe.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException ioe) { ioe.printStackTrace(); }
}
}
}
}
</code></pre>
<p>Does anyone know about what is going on here? Note i am using firefox 3.0.3 under Windows Vista. </p>
|
[
{
"answer_id": 177871,
"author": "Henry B",
"author_id": 6414,
"author_profile": "https://Stackoverflow.com/users/6414",
"pm_score": 0,
"selected": false,
"text": "<p>This is a security feature of firefox 3 I believe.</p>\n\n<p>Here we go</p>\n\n<p><a href=\"http://support.mozilla.com/tiki-view_forum_thread.php?locale=no&forumId=1&comments_parentId=91513\" rel=\"nofollow noreferrer\">http://support.mozilla.com/tiki-view_forum_thread.php?locale=no&forumId=1&comments_parentId=91513</a></p>\n\n<p>It's different but it might help :)</p>\n\n<p>Enjoy</p>\n"
},
{
"answer_id": 177872,
"author": "JeeBee",
"author_id": 17832,
"author_profile": "https://Stackoverflow.com/users/17832",
"pm_score": 1,
"selected": false,
"text": "<p>URLEncode the filename?</p>\n\n<p>Or at least substitute %20 for the space character.</p>\n\n<p>(I don't know if this will work, but give it a try)</p>\n\n<p>have you tried just putting quotes around the filename as well?</p>\n"
},
{
"answer_id": 177880,
"author": "Stephen Denne",
"author_id": 11721,
"author_profile": "https://Stackoverflow.com/users/11721",
"pm_score": 6,
"selected": true,
"text": "<p>The filename should be a <strong>quoted</strong> string. (According to <a href=\"http://www.w3.org/Protocols/rfc2616/rfc2616-sec19.html#sec19.5.1\" rel=\"noreferrer\">Section 19.5.1 of RFC 2616</a>)</p>\n\n<pre><code>response.setHeader(\"Content-Disposition\",\"attachment; filename=\\\"\" + filename + \"\\\"\");\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177863",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2138/"
] |
I am using the next class (simplified for the sake of understandability) to download images in a struts web application.
It is working fine in every browser but firefox, which cuts names containing spaces. That it is to say: **file with spaces.pdf** gets downloaded in firefox as: **file** while in chrome, IE7 IE6 is downloaded as **file with spaces.pdf**.
```
public class Download extends Action {
private static final int BUFFER_SIZE = 4096;
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response) throws Exception {
String filename = "file with spaces.pdf";
File file = ... // variable containing the file;
response.setStatus(HttpServletResponse.SC_OK);
response.setContentType(getMimeType(request, file));
response.setHeader("Content-Type", getMimeType(request, file));
response.setHeader("Content-Disposition","attachment; filename="+ filename);
InputStream is = new FileInputStream(file);
sendFile(is, response);
return null;
}
protected String getMimeType(HttpServletRequest request, File file) {
ServletContext application = super.servlet.getServletContext();
return application.getMimeType(file.getName());
}
protected void sendFile(InputStream is, HttpServletResponse response) throws IOException {
BufferedInputStream in = null;
try {
int count;
byte[] buffer = new byte[BUFFER_SIZE];
in = new BufferedInputStream(is);
ServletOutputStream out = response.getOutputStream();
while(-1 != (count = in.read(buffer)))
out.write(buffer, 0, count);
out.flush();
} catch (IOException ioe) {
System.err.println("IOException in Download::sendFile");
ioe.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException ioe) { ioe.printStackTrace(); }
}
}
}
}
```
Does anyone know about what is going on here? Note i am using firefox 3.0.3 under Windows Vista.
|
The filename should be a **quoted** string. (According to [Section 19.5.1 of RFC 2616](http://www.w3.org/Protocols/rfc2616/rfc2616-sec19.html#sec19.5.1))
```
response.setHeader("Content-Disposition","attachment; filename=\"" + filename + "\"");
```
|
177,867 |
<p>I need to copy data values from one element to another, but jQuery's clone() method doesn't clone the data. And I can't iterate over the data either:</p>
<pre><code>element.data().each
</code></pre>
<p>because <code>data()</code> is a function and not a jQuery object. It seems I have to keep a separate list of attribute names and reference those but that seems too hacky. So how can I do either of these:</p>
<p>a) Iterate over data items<br>
OR<br>
b) <code>clone()</code> an element with its data.</p>
|
[
{
"answer_id": 7805272,
"author": "simon",
"author_id": 76777,
"author_profile": "https://Stackoverflow.com/users/76777",
"pm_score": 1,
"selected": false,
"text": "<p>To give another alternative, i.e. instead of cloning the whole object you can copy the data object to a new array containing name/value pairs followingly:</p>\n\n<pre><code>\nfunction getOriginalElementData(domElementJQueryObject){\n var originalElementData = new Array();\n $.each(domElementJQueryObject.data(),function(name,value) {\n originalElementData.push({\"name\":name,\"value\":value});\n });\n\n return originalElementData;\n}\n</code></pre>\n\n<p>To restore the data to another object:</p>\n\n<pre><code>\nfunction restoreOriginalElementData(domElementJQueryObject,originalElementData){\n for(var i=0;i<originalElementData.length;i++){\n domElementJQueryObject.data(originalElementData[i].name,originalElementData[i].value);\n }\n}\n</code></pre>\n\n<p>The part to iterate through the data items is copied from this answer: <a href=\"https://stackoverflow.com/questions/772608/jquery-loop-through-data-object#2952962\">jQuery loop through data() object</a></p>\n"
},
{
"answer_id": 17020885,
"author": "DUzun",
"author_id": 1242333,
"author_profile": "https://Stackoverflow.com/users/1242333",
"pm_score": 2,
"selected": false,
"text": "<p>Answer to: </p>\n\n<blockquote>\n <p>a) Iterate over data items</p>\n</blockquote>\n\n<pre><code>$.each(element.data(), function (name, value) {\n // ... do something\n})\n</code></pre>\n\n<p>If element is a DOM element, use this:</p>\n\n<pre><code>$.each($.data(element), function (name, value) {\n // ... do something\n})\n</code></pre>\n"
},
{
"answer_id": 20074111,
"author": "Nexii Malthus",
"author_id": 938335,
"author_profile": "https://Stackoverflow.com/users/938335",
"pm_score": 5,
"selected": false,
"text": "<p>To really only copy the data-*, this is quite straightforward:</p>\n\n<pre><code>$(destination).data( $(source).data() );\n</code></pre>\n\n<p>This is because using .data() no arguments will return a key-value object of all pieces of data and vice versa you can also update multiple pieces data at once using a key-value object.</p>\n\n<hr>\n\n<p><strong>UPDATE <sup>25th May 2017</sup></strong></p>\n\n<p>A clever alternative in JavaScript without jQuery appears to be:</p>\n\n<pre><code>Object.assign(destination.dataset, source.dataset);\n</code></pre>\n"
},
{
"answer_id": 26328722,
"author": "JasCav",
"author_id": 132528,
"author_profile": "https://Stackoverflow.com/users/132528",
"pm_score": 1,
"selected": false,
"text": "<p>Something that wasn't originally answered as a part of this question was whether or not you wanted the data attributes to be part of the DOM. Using many of the answers provided will make it accessible to jQuery's data() API, but, won't be visible in the DOM (to make things like debugging easier, for example).</p>\n\n<p>A way to do this is:</p>\n\n<pre><code>$.each(original.data(), function (name, value) {\n new.attr('data-' + name, JSON.stringify(value));\n});\n</code></pre>\n\n<p>Note that the stringify is not explicitly required. I have some JSON embedded into my original data tags and, if I don't do this, I get '[Object object]' as the string instead of the actual JSON.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177867",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1896/"
] |
I need to copy data values from one element to another, but jQuery's clone() method doesn't clone the data. And I can't iterate over the data either:
```
element.data().each
```
because `data()` is a function and not a jQuery object. It seems I have to keep a separate list of attribute names and reference those but that seems too hacky. So how can I do either of these:
a) Iterate over data items
OR
b) `clone()` an element with its data.
|
To really only copy the data-\*, this is quite straightforward:
```
$(destination).data( $(source).data() );
```
This is because using .data() no arguments will return a key-value object of all pieces of data and vice versa you can also update multiple pieces data at once using a key-value object.
---
**UPDATE 25th May 2017**
A clever alternative in JavaScript without jQuery appears to be:
```
Object.assign(destination.dataset, source.dataset);
```
|
177,883 |
<p>is it possible to include a servlet in a jsp page? if so how?</p>
|
[
{
"answer_id": 7805272,
"author": "simon",
"author_id": 76777,
"author_profile": "https://Stackoverflow.com/users/76777",
"pm_score": 1,
"selected": false,
"text": "<p>To give another alternative, i.e. instead of cloning the whole object you can copy the data object to a new array containing name/value pairs followingly:</p>\n\n<pre><code>\nfunction getOriginalElementData(domElementJQueryObject){\n var originalElementData = new Array();\n $.each(domElementJQueryObject.data(),function(name,value) {\n originalElementData.push({\"name\":name,\"value\":value});\n });\n\n return originalElementData;\n}\n</code></pre>\n\n<p>To restore the data to another object:</p>\n\n<pre><code>\nfunction restoreOriginalElementData(domElementJQueryObject,originalElementData){\n for(var i=0;i<originalElementData.length;i++){\n domElementJQueryObject.data(originalElementData[i].name,originalElementData[i].value);\n }\n}\n</code></pre>\n\n<p>The part to iterate through the data items is copied from this answer: <a href=\"https://stackoverflow.com/questions/772608/jquery-loop-through-data-object#2952962\">jQuery loop through data() object</a></p>\n"
},
{
"answer_id": 17020885,
"author": "DUzun",
"author_id": 1242333,
"author_profile": "https://Stackoverflow.com/users/1242333",
"pm_score": 2,
"selected": false,
"text": "<p>Answer to: </p>\n\n<blockquote>\n <p>a) Iterate over data items</p>\n</blockquote>\n\n<pre><code>$.each(element.data(), function (name, value) {\n // ... do something\n})\n</code></pre>\n\n<p>If element is a DOM element, use this:</p>\n\n<pre><code>$.each($.data(element), function (name, value) {\n // ... do something\n})\n</code></pre>\n"
},
{
"answer_id": 20074111,
"author": "Nexii Malthus",
"author_id": 938335,
"author_profile": "https://Stackoverflow.com/users/938335",
"pm_score": 5,
"selected": false,
"text": "<p>To really only copy the data-*, this is quite straightforward:</p>\n\n<pre><code>$(destination).data( $(source).data() );\n</code></pre>\n\n<p>This is because using .data() no arguments will return a key-value object of all pieces of data and vice versa you can also update multiple pieces data at once using a key-value object.</p>\n\n<hr>\n\n<p><strong>UPDATE <sup>25th May 2017</sup></strong></p>\n\n<p>A clever alternative in JavaScript without jQuery appears to be:</p>\n\n<pre><code>Object.assign(destination.dataset, source.dataset);\n</code></pre>\n"
},
{
"answer_id": 26328722,
"author": "JasCav",
"author_id": 132528,
"author_profile": "https://Stackoverflow.com/users/132528",
"pm_score": 1,
"selected": false,
"text": "<p>Something that wasn't originally answered as a part of this question was whether or not you wanted the data attributes to be part of the DOM. Using many of the answers provided will make it accessible to jQuery's data() API, but, won't be visible in the DOM (to make things like debugging easier, for example).</p>\n\n<p>A way to do this is:</p>\n\n<pre><code>$.each(original.data(), function (name, value) {\n new.attr('data-' + name, JSON.stringify(value));\n});\n</code></pre>\n\n<p>Note that the stringify is not explicitly required. I have some JSON embedded into my original data tags and, if I don't do this, I get '[Object object]' as the string instead of the actual JSON.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177883",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24481/"
] |
is it possible to include a servlet in a jsp page? if so how?
|
To really only copy the data-\*, this is quite straightforward:
```
$(destination).data( $(source).data() );
```
This is because using .data() no arguments will return a key-value object of all pieces of data and vice versa you can also update multiple pieces data at once using a key-value object.
---
**UPDATE 25th May 2017**
A clever alternative in JavaScript without jQuery appears to be:
```
Object.assign(destination.dataset, source.dataset);
```
|
177,885 |
<p>I'm looking for a way to obtain offsets of data members of a C++ class which is of non-POD nature.</p>
<p>Here's why: </p>
<p>I'd like to store data in <a href="http://www.hdfgroup.org/HDF5/whatishdf5.html" rel="noreferrer">HDF5</a> format, which seems most suited for my kind of material (numerical simulation output), but it is perhaps a rather C-oriented library. I want to use it through the C++ interface, which would require me to declare storage types like so (following documentation from <a href="http://www.hdfgroup.org/HDF5/doc1.6/cpplus_RM/classH5_1_1CompType.html#a16" rel="noreferrer">here</a> and <a href="http://www.hdfgroup.org/HDF5/doc1.6/UG/11_Datatypes.html" rel="noreferrer">here</a> (section 4.3.2.1.1)): </p>
<pre><code>class example {
public:
double member_a;
int member_b;
} //class example
H5::CompType func_that_creates_example_CompType() {
H5::CompType ct;
ct.insertMember("a", HOFFSET(example, member_a), H5::PredType::NATIVE_DOUBLE);
ct.insertMember("b", HOFFSET(example, member_b), H5::PredType::NATIVE_INT);
return ct;
} //func_that_creates_example_CompType
</code></pre>
<p>where HOFFSET is a HDF-specific macro that uses offsetof.</p>
<p>The problem is of course, that as soon as the example-class becomes it little bit more featureful, it is no longer of POD-type, and so using offsetof will give undefined results.</p>
<p>The only workaround I can think of is to first export the data I want to store to a simpler struct, then pass that to HDF. That does however involve data copying, which is exactly what HDF is trying to avoid (and why they have this CompType which enables the library to reach into your objects to save their data to file).</p>
<p>So I was hoping you'd have better ideas. Ideally I'd be looking for a portable workaround for this problem, but if short of that you could give me an idea that works on x86 and x86_64 with GCC I'd already be immensely grateful.</p>
<p>----- appended later: -----</p>
<p>Greg Hewgill suggested below to store the data in a simple struct, then build the actual class by inheriting from that. For HDF specifically, I think that may not practically work. A more elaborate usage scenario than above:</p>
<pre><code>class base_pod {
public:
double member_a;
int member_b;
}; //class base_pod
class derived_non_pod : private base_pod {
public:
//the following method is only virtual to illustrate the problem
virtual double get_member_a() {return member_a; }
}; //class derived_non_pod
class that_uses_derived_non_pod {
public:
void whatever();
private:
derived_non_pod member_c;
}; //class that_uses_derived_non_pod
</code></pre>
<p>Now, when we're storing instances of the class that_uses_derived_non_pod, we cannot describe its memory layout as if it had a base_pod as member_c. This would get the offsets wrong because derived_non_pod adds funky stuff (like a virtual function table, I guess?).</p>
|
[
{
"answer_id": 177887,
"author": "Greg Hewgill",
"author_id": 893,
"author_profile": "https://Stackoverflow.com/users/893",
"pm_score": 2,
"selected": false,
"text": "<p>You could declare the POD types in a base class, then extend that class (perhaps with <code>private</code> inheritance) to add your additional functionality.</p>\n\n<p>Update to your update: Because an instance of <code>derived_non_pod</code> can also be treated as a <code>base_pod</code>, therefore the offsets to data members must be the same. With regard to implementation, your compiler will allocate the vtable pointer <em>after</em> the fields of the <code>base_pod</code> when laying out the <code>derived_non_pod</code> structure.</p>\n\n<p>It occurs to me that if you use private inheritance, the compiler <em>may</em> be able to choose to reorder the data fields. It's unlikely to do so, however, and making the inheritance protected or public would avoid this possible trap.</p>\n"
},
{
"answer_id": 177963,
"author": "Fionn",
"author_id": 21566,
"author_profile": "https://Stackoverflow.com/users/21566",
"pm_score": 0,
"selected": false,
"text": "<p>The problem is as soon as your struct/class is not extern \"C\", C++ compilers are free to rearrange and optimize the layout of your struct/class, so you might end up with an reordered struct depending on your compiler.</p>\n\n<p>There are preprocessor (e.g. #pragma pack) flags for C like behaviour, but they are not portable in most cases.</p>\n"
},
{
"answer_id": 177986,
"author": "Steve Jessop",
"author_id": 13005,
"author_profile": "https://Stackoverflow.com/users/13005",
"pm_score": 3,
"selected": false,
"text": "<p>Greg Hewgill's solution is probably preferable to this (maybe with composition rather than inheritance).</p>\n\n<p>However, I think that with GCC on x86 and x86_64, offsetof will actually work even for members of non-POD types, as long as it \"makes sense\". So for example it won't work for members inherited from virtual base classes, because in GCC that's implemented with an extra indirection. But as long as you stick to plain public single inheritance, GCC just so happens to lay out your objects in a way which means every member is accessible at an offset from the object pointer, so the offsetof implementation will give the right answer.</p>\n\n<p>Trouble with this of course is that you have to ignore the warnings, which means if you do something that doesn't work, you'll dereference a close-to-null pointer. On the plus side, the cause of the problem will probably be obvious at runtime. On the minus side, eeew.</p>\n\n<p>[Edit: I've just tested this on gcc 3.4.4, and actually the warning is upgraded to an error when getting the offset of a member inherited from a virtual base class. Which is nice. I'd still be slightly worried that a future version of gcc (4, even, which I don't have to hand) will be more strict, and that if you take this approach your code may in future stop compiling.]</p>\n"
},
{
"answer_id": 177994,
"author": "Roel",
"author_id": 11449,
"author_profile": "https://Stackoverflow.com/users/11449",
"pm_score": 2,
"selected": false,
"text": "<p>Depending on how portable you want to be, you can use offsetof() even on non-POD types. It's not strictly conformant but in the way offsetof() is implemented on gcc and MSVC, it'll work with non-POD types in the current version and the recent past.</p>\n"
},
{
"answer_id": 179540,
"author": "Michael Burr",
"author_id": 12711,
"author_profile": "https://Stackoverflow.com/users/12711",
"pm_score": 0,
"selected": false,
"text": "<p>Would using a pointer to member work instead of offsetof()? I know that you'd probably have to do all sorts of casting to be able to actually use the pointer since I'm guessing that InsertMember is acting on the type specified in the last parameter at runtime.</p>\n\n<p>But with your current solution you're already going around the type system so I'm not sure that your losing anything there. Except that the syntax for pointers to member is hideous.</p>\n"
},
{
"answer_id": 1234781,
"author": "Richard Corden",
"author_id": 11698,
"author_profile": "https://Stackoverflow.com/users/11698",
"pm_score": 1,
"selected": false,
"text": "<p>I'm pretty sure that Roel's <a href=\"https://stackoverflow.com/questions/177885/looking-for-something-similar-to-offsetof-for-non-pod-types/177994#177994\">answer</a> along with consideration for onebyone's <a href=\"https://stackoverflow.com/questions/177885/looking-for-something-similar-to-offsetof-for-non-pod-types/177986#177986\">answer</a> covers most of what you ask.</p>\n\n<pre><code>struct A\n{\n int i;\n};\n\nclass B: public A\n{\npublic:\n virtual void foo ()\n {\n }\n};\n\nint main ()\n{\n std::cout << offsetof (B, A::i) << std::endl;\n}\n</code></pre>\n\n<p>With g++, the above outputs 4, which is what you'd expect if B has a vtable before the base class member 'i'.</p>\n\n<p>It should be possible though to calculate the offset manually, even for the case where there are virtual bases:</p>\n\n<pre><code>struct A1 {\n int i;\n};\n\nstruct A2 {\n int j;\n};\n\nstruct A3 : public virtual A2 {\n};\n\nclass B: public A1, public A3 {\npublic:\n virtual void foo () {\n }\n};\n\ntemplate <typename MostDerived, typename C, typename M>\nptrdiff_t calcOffset (M C::* member)\n{\n MostDerived d;\n return reinterpret_cast<char*> (&(d.*member)) - reinterpret_cast<char*> (&d);\n}\n\nint main ()\n{\n B b;\n std::cout << calcOffset<B> (&A2::j) << \", \" \n << calcOffset<B> (&A1::i) << std::endl;\n}\n</code></pre>\n\n<p>With g++, this program outputs 4 and 8. Again this is consistent with the vtable as the first member of B followed by the virtual base A2 and its member 'j'. Finally the non virtual base A1 and its member 'i'. </p>\n\n<p>The key point is that you always calculate the offsets based on the most derived object, ie. B. If the members are private then you may need to add a \"getMyOffset\" call for each member. This call will perform the calculation where the name is accessible.</p>\n\n<p>You might find the following useful too. I think it's nice to associate all of this with the object that you're building the HDF type for:</p>\n\n<pre><code>struct H5MemberDef\n{\n const char * member_name;\n ptrdiff_t offset;\n H5PredType h5_type;\n};\n\n\nclass B // ....\n{\npublic:\n\n // ...\n\n static H5memberDef memberDef[];\n};\n\nH5MemberDef B::memberDef[] = {\n { \"i\", calcOffset<B> (&A1::i), H5::PredType::NATIVE_INT }\n , { \"j\", calcOffset<B> (&A2::j), H5::PredType::NATIVE_INT }\n , { 0, 0, H5::PredType::NATIVE_INT }\n};\n</code></pre>\n\n<p>And then you can build the H5type via a loop:</p>\n\n<pre><code>H5::CompType func_that_creates_example_CompType(H5MemberDef * pDef) {\n H5::CompType ct;\n while (*pDef->member_name != 0)\n {\n ct.insertMember(pDef->member_name, pDef->offset, pDef->h5_type);\n ++pDef;\n }\n return ct;\n}\n</code></pre>\n\n<p>Now if you add a member to B or one of its bases, then a simple addition to this table will result in the correct HDF type being generated.</p>\n"
},
{
"answer_id": 16270322,
"author": "Greg Slepak",
"author_id": 1781435,
"author_profile": "https://Stackoverflow.com/users/1781435",
"pm_score": -1,
"selected": false,
"text": "<p>This works fine for me, and I can't see why it wouldn't:</p>\n\n<pre><code>#define myOffset(Class,Member) ({Class o; (size_t)&(o.Member) - (size_t)&o;})\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177885",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25756/"
] |
I'm looking for a way to obtain offsets of data members of a C++ class which is of non-POD nature.
Here's why:
I'd like to store data in [HDF5](http://www.hdfgroup.org/HDF5/whatishdf5.html) format, which seems most suited for my kind of material (numerical simulation output), but it is perhaps a rather C-oriented library. I want to use it through the C++ interface, which would require me to declare storage types like so (following documentation from [here](http://www.hdfgroup.org/HDF5/doc1.6/cpplus_RM/classH5_1_1CompType.html#a16) and [here](http://www.hdfgroup.org/HDF5/doc1.6/UG/11_Datatypes.html) (section 4.3.2.1.1)):
```
class example {
public:
double member_a;
int member_b;
} //class example
H5::CompType func_that_creates_example_CompType() {
H5::CompType ct;
ct.insertMember("a", HOFFSET(example, member_a), H5::PredType::NATIVE_DOUBLE);
ct.insertMember("b", HOFFSET(example, member_b), H5::PredType::NATIVE_INT);
return ct;
} //func_that_creates_example_CompType
```
where HOFFSET is a HDF-specific macro that uses offsetof.
The problem is of course, that as soon as the example-class becomes it little bit more featureful, it is no longer of POD-type, and so using offsetof will give undefined results.
The only workaround I can think of is to first export the data I want to store to a simpler struct, then pass that to HDF. That does however involve data copying, which is exactly what HDF is trying to avoid (and why they have this CompType which enables the library to reach into your objects to save their data to file).
So I was hoping you'd have better ideas. Ideally I'd be looking for a portable workaround for this problem, but if short of that you could give me an idea that works on x86 and x86\_64 with GCC I'd already be immensely grateful.
----- appended later: -----
Greg Hewgill suggested below to store the data in a simple struct, then build the actual class by inheriting from that. For HDF specifically, I think that may not practically work. A more elaborate usage scenario than above:
```
class base_pod {
public:
double member_a;
int member_b;
}; //class base_pod
class derived_non_pod : private base_pod {
public:
//the following method is only virtual to illustrate the problem
virtual double get_member_a() {return member_a; }
}; //class derived_non_pod
class that_uses_derived_non_pod {
public:
void whatever();
private:
derived_non_pod member_c;
}; //class that_uses_derived_non_pod
```
Now, when we're storing instances of the class that\_uses\_derived\_non\_pod, we cannot describe its memory layout as if it had a base\_pod as member\_c. This would get the offsets wrong because derived\_non\_pod adds funky stuff (like a virtual function table, I guess?).
|
Greg Hewgill's solution is probably preferable to this (maybe with composition rather than inheritance).
However, I think that with GCC on x86 and x86\_64, offsetof will actually work even for members of non-POD types, as long as it "makes sense". So for example it won't work for members inherited from virtual base classes, because in GCC that's implemented with an extra indirection. But as long as you stick to plain public single inheritance, GCC just so happens to lay out your objects in a way which means every member is accessible at an offset from the object pointer, so the offsetof implementation will give the right answer.
Trouble with this of course is that you have to ignore the warnings, which means if you do something that doesn't work, you'll dereference a close-to-null pointer. On the plus side, the cause of the problem will probably be obvious at runtime. On the minus side, eeew.
[Edit: I've just tested this on gcc 3.4.4, and actually the warning is upgraded to an error when getting the offset of a member inherited from a virtual base class. Which is nice. I'd still be slightly worried that a future version of gcc (4, even, which I don't have to hand) will be more strict, and that if you take this approach your code may in future stop compiling.]
|
177,910 |
<p>I've produced a python egg using setuptools and would like to access it's metadata at runtime. I currently got working this:</p>
<pre><code>import pkg_resources
dist = pkg_resources.get_distribution("my_project")
print(dist.version)
</code></pre>
<p>but this would probably work incorrectly if I had multiple versions of the same egg installed. And if I have both installed egg and development version, then running this code from development version would pick up version of the installed egg. </p>
<p>So, how do I get metadata for <em>my</em> egg not some random matching egg installed on my system? </p>
|
[
{
"answer_id": 177939,
"author": "Adam Bellaire",
"author_id": 21632,
"author_profile": "https://Stackoverflow.com/users/21632",
"pm_score": 3,
"selected": true,
"text": "<p>I am somewhat new to Python as well, but from what I understand: </p>\n\n<p>Although you can install multiple versions of the \"same\" egg (having the same name), only one of them will be available to any particular piece of code at runtime (based on your discovery method). So if your egg is the one calling this code, it must have already been selected as <em>the</em> version of <code>my_project</code> for this code, and your access will be to your own version.</p>\n"
},
{
"answer_id": 177966,
"author": "Horst Gutmann",
"author_id": 22312,
"author_profile": "https://Stackoverflow.com/users/22312",
"pm_score": 0,
"selected": false,
"text": "<p>Exactly. So you should only be able to get the information for the currently available egg (singular) of a library. If you have multiple eggs of the same library in your site-packages folder, check the easy-install.pth in the same folder to see which egg is really used :-)</p>\n\n<p>On a site note: This is exactly the point of systems like zc.buildout which lets you define the exact version of a library that will be made available to you for example while developing an application or serving a web application. So you can for example use version 1.0 for one project and 1.2 for another. </p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177910",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5821/"
] |
I've produced a python egg using setuptools and would like to access it's metadata at runtime. I currently got working this:
```
import pkg_resources
dist = pkg_resources.get_distribution("my_project")
print(dist.version)
```
but this would probably work incorrectly if I had multiple versions of the same egg installed. And if I have both installed egg and development version, then running this code from development version would pick up version of the installed egg.
So, how do I get metadata for *my* egg not some random matching egg installed on my system?
|
I am somewhat new to Python as well, but from what I understand:
Although you can install multiple versions of the "same" egg (having the same name), only one of them will be available to any particular piece of code at runtime (based on your discovery method). So if your egg is the one calling this code, it must have already been selected as *the* version of `my_project` for this code, and your access will be to your own version.
|
177,911 |
<p>I've got a WPF browser-like application with a few pages. When I switch between pages, I'd like to set the keyboard focus.</p>
<p>When a page is loaded the first time, this works by calling <code>Control.Focus()</code> in the constructor.</p>
<p>But when I switch between pages this does not work anymore - the focus is just on the first field, and ignores my attempts to change it to anything else :(</p>
<p>The pages have the attribute <code>KeepAlive=true</code> - it would be OK if that would keep the focus alive, too, but just setting the focus to the first field is annoying.</p>
<p>I tried to set the focus in the loaded event, but it did not work, too. It seems the default focus is set after reloading the page.</p>
<p>Is there any way to set the focus on entering a page the second time? <strong>When, how and where should I set the focus when switching between WPF pages in a browserlike application</strong>?</p>
|
[
{
"answer_id": 177995,
"author": "Matt Hamilton",
"author_id": 615,
"author_profile": "https://Stackoverflow.com/users/615",
"pm_score": 1,
"selected": false,
"text": "<p>Have you tried setting the focus in the Loaded event handler rather than the constructor? Pages aren't re-constructed when you navigate back to them, but they are reloaded if I recall correctly.</p>\n"
},
{
"answer_id": 221884,
"author": "Sam",
"author_id": 7021,
"author_profile": "https://Stackoverflow.com/users/7021",
"pm_score": 1,
"selected": true,
"text": "<p>Since I found no solution to this problem, I used a simple workaround:</p>\n\n<p>I fire up a secondary thread, which changes the focus after the page has loaded.</p>\n\n<p>Luckily this is done very easily using BeginInvoke:</p>\n\n<pre><code>myControl.Dispatcher.BeginInvoke(System.Windows.Threading.DispatcherPriority.Background, \n(System.Threading.SendOrPostCallback)delegate(object state) \n{ \n myControl.Focus(); \n});\n</code></pre>\n\n<p>This worked way better than I ever expected it to, so probably this workaround will stay in use for a long time.</p>\n"
},
{
"answer_id": 570343,
"author": "Sven Hecht",
"author_id": 1168,
"author_profile": "https://Stackoverflow.com/users/1168",
"pm_score": 2,
"selected": false,
"text": "<p>Try Adding FocusManager.FocusedElement=\"{Binding ElementName=[...]}\"``\nto the first Element in your Page and set [...] to the name of the element which should get the focus.</p>\n"
},
{
"answer_id": 4785145,
"author": "OrPaz",
"author_id": 388894,
"author_profile": "https://Stackoverflow.com/users/388894",
"pm_score": 2,
"selected": false,
"text": "<p>After having a 'WPF Initial Focus Nightmare' and based on some answers on stack, the following proved for me to be the best solution. </p>\n\n<p>First, add your App.xaml OnStartup() the followings:</p>\n\n<pre><code>EventManager.RegisterClassHandler(typeof(Window), Window.LoadedEvent,\n new RoutedEventHandler(WindowLoaded));\n</code></pre>\n\n<p>Then add the 'WindowLoaded' event also in App.xaml : </p>\n\n<pre><code>void WindowLoaded(object sender, RoutedEventArgs e)\n {\n var window = e.Source as Window;\n System.Threading.Thread.Sleep(100);\n window.Dispatcher.Invoke(\n new Action(() =>\n {\n window.MoveFocus(new TraversalRequest(FocusNavigationDirection.First));\n\n }));\n }\n</code></pre>\n\n<p>The threading issue must be use as WPF initial focus mostly fails due to some framework race conditions.</p>\n\n<p>I found the following solution best as it is used globally for the whole app.</p>\n\n<p>Hope it helps...</p>\n\n<p>Oran</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177911",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7021/"
] |
I've got a WPF browser-like application with a few pages. When I switch between pages, I'd like to set the keyboard focus.
When a page is loaded the first time, this works by calling `Control.Focus()` in the constructor.
But when I switch between pages this does not work anymore - the focus is just on the first field, and ignores my attempts to change it to anything else :(
The pages have the attribute `KeepAlive=true` - it would be OK if that would keep the focus alive, too, but just setting the focus to the first field is annoying.
I tried to set the focus in the loaded event, but it did not work, too. It seems the default focus is set after reloading the page.
Is there any way to set the focus on entering a page the second time? **When, how and where should I set the focus when switching between WPF pages in a browserlike application**?
|
Since I found no solution to this problem, I used a simple workaround:
I fire up a secondary thread, which changes the focus after the page has loaded.
Luckily this is done very easily using BeginInvoke:
```
myControl.Dispatcher.BeginInvoke(System.Windows.Threading.DispatcherPriority.Background,
(System.Threading.SendOrPostCallback)delegate(object state)
{
myControl.Focus();
});
```
This worked way better than I ever expected it to, so probably this workaround will stay in use for a long time.
|
177,927 |
<p>In JPA the Entities are nice annotated Plain Old Java Objects. But I have not found a good way to interact with them and the database.</p>
<p>In my current app, my basic design is always to have a sequence based id as primary key so I usually have to look up entities by other properties than PK.</p>
<p>And for each Entity I have a stateless EJB of </p>
<pre><code>@Stateless
public class MyEntApiBean implements MyEntApi {
@PersistenceContext(unitName = "xxx") @Inject EntityManager entityManager;
</code></pre>
<p>with query methods that all are some variation </p>
<pre><code>/**
* @return A List of all MyEnts that have some property
* @param someProp some property
*/
public List<MyEnt> getAllMyEntsFromProp(final String someProp) {
try {
final Query query = entityManager.createQuery("select me from MyEnt me where me.someProp = :someProp");
query.setParameter("someProp", someProp);
return query.getResultList();
} catch(final NoResultException nre) {
log.warn("No MyEnts found");
}
return new ArrayList<MyEnt>();
}
</code></pre>
<p>So:</p>
<ol>
<li><p>I really hate having these methods in an EJB because they seem to belong with the entities themselves, and the EJB local interfaces annoy the crap out of me.</p></li>
<li><p>I hate the duplication that I have in each method with "try, createQuery, getResultList,catch, log, return" (mostly a consequence of no closures or "with statement" or somesuch in Java).</p></li>
</ol>
<p>Does anyone have a suggestion for a better way to interact with the Entities and Database that addresses one or both of my issues?</p>
<p>I am currently thinking of doing some base methods with generics and reflection to get some generic query methods to reduce the duplication (issue 2) (I will put a prototype up for review later).</p>
<p>Thanks,
Anders</p>
|
[
{
"answer_id": 177932,
"author": "Sietse",
"author_id": 6400,
"author_profile": "https://Stackoverflow.com/users/6400",
"pm_score": 3,
"selected": true,
"text": "<p>Try Seam. The <a href=\"http://docs.jboss.com/seam/2.1.0.BETA1/reference/en-US/html_single/#d0e7527\" rel=\"nofollow noreferrer\">Query Objects</a> do most of the work for you, and they're easily extendable. Or, you could always implement a similar pattern.</p>\n\n<p>In general, Seam does a lot of useful stuff to bridge the gap between JPA and you view and business layers. You don't have to use JSF for Seam to be useful.</p>\n"
},
{
"answer_id": 178088,
"author": "Shimi Bandiel",
"author_id": 15100,
"author_profile": "https://Stackoverflow.com/users/15100",
"pm_score": 1,
"selected": false,
"text": "<p>If you do a lot of textual searches, maybe you should also consider some indexing framework like <a href=\"http://www.compass-project.org/\" rel=\"nofollow noreferrer\">Compass</a>. <br/> I don't know if it suits your application, but if so it can both improve code design and performance.</p>\n"
},
{
"answer_id": 178218,
"author": "anders.norgaard",
"author_id": 8805,
"author_profile": "https://Stackoverflow.com/users/8805",
"pm_score": 1,
"selected": false,
"text": "<p>I am actually using Seam. And the Query object suggestion lead me on to find Hibernates <a href=\"http://www.hibernate.org/hib_docs/v3/reference/en/html/querycriteria.html\" rel=\"nofollow noreferrer\">Criteria queries</a> (Query By Example) <a href=\"http://www.javalobby.org/articles/hibernatequery102/\" rel=\"nofollow noreferrer\">functionality</a>. That seems very close to what I was looking for.</p>\n\n<p>Maybe in a base class, and with a <a href=\"http://www.jboss.com/index.html?module=bb&op=viewtopic&p=4007946#4007946\" rel=\"nofollow noreferrer\">dash of generics</a>....?</p>\n"
},
{
"answer_id": 178744,
"author": "cletus",
"author_id": 18393,
"author_profile": "https://Stackoverflow.com/users/18393",
"pm_score": 2,
"selected": false,
"text": "<p>You're being unnecessarily verbose. For one thing, getResultList() doesn't throw an exception when no rows are returned (at least not in Eclipse or Toplink--I can't imagine another provider being any different). getSingleResult() does, getResultList() doesn't. Also, you can use the builder pattern so:</p>\n\n<pre><code>@SuppressWarnings(\"unchecked\")\npublic List<MyEnt> getAllMyEntsFromProp(final String someProp) {\n return entityManager.createQuery(\"select me from MyEnt me where me.someProp = :someProp\")\n .setParameter(\"someProp\", someProp);\n .getResultList();\n}\n</code></pre>\n\n<p>should be sufficient to return a List of results if there are any or an empty List if there are none. Two things to note:</p>\n\n<ol>\n<li><p>@SuppressWarnings(\"unchecked\") is unnecessary but it gets rid of an otherwise unavoidable warning when casting the non-generic List result from getResultList() to a generic List; and</p></li>\n<li><p>It's probably worth replacing the createQuery() call with a @NamedQuery on MyEnt (typically). For one thing, this will enable deploy-time validation and other useful things.</p></li>\n</ol>\n\n<p>Its reasonably concise and complete.</p>\n"
},
{
"answer_id": 1587422,
"author": "Aljoscha Rittner",
"author_id": 192278,
"author_profile": "https://Stackoverflow.com/users/192278",
"pm_score": 1,
"selected": false,
"text": "<p>Moin!</p>\n\n<p>Here is my version for single results (I use it in my desktop JPA applications with TopLink essentials):</p>\n\n<pre><code>public class JPA {\n @SuppressWarnings (\"unchecked\")\n public static <T> T querySingle(\n EntityManager em, \n Class<T> clazz, \n String namedQuery, \n Pair... params) \n {\n Query q = em.createNamedQuery(namedQuery);\n for (Pair pair : params) {\n q.setParameter(pair.key, pair.value); \n }\n List<T> result = q.getResultList();\n if ( result.size() == 0 ) {\n return null;\n }\n if ( result.size() == 1 ) {\n return result.get(0);\n }\n throw new \n IllegalStateException(\n \"To many result rows for query: \" \n + namedQuery \n + \" where \" \n + Arrays.toString(params));\n }\n\n public static class Pair {\n String key;\n Object value;\n\n public static Pair param (String key, Object value) {\n return new Pair (key, value);\n }\n\n public Pair (String key, Object value) {\n this.key = key;\n this.value = value;\n }\n\n @Override\n public String toString() {\n return key + \"=\" + value;\n }\n }\n}\n</code></pre>\n\n<p>And the usage:</p>\n\n<pre><code>import static org.sepix.JPA.*;\n...\n\nString id = ...\nCustomer customer = querySingle (em, Customer.class, \n \"Customer.findByID\", Pair.param (\"id\", id));\n</code></pre>\n\n<p>or:</p>\n\n<pre><code>String inquiryID = ...\nBoolean current = Boolean.TRUE;\nInquiry inq = querySingle (em, Inquiry.class, \n \"Inquiry.findCurrent\", \n Pair.param (\"inquiry\", inquiryID),\n Pair.param (\"current\", current));\n</code></pre>\n\n<p>best regards,\n josh.</p>\n"
},
{
"answer_id": 2202949,
"author": "Rafal Rusin",
"author_id": 252891,
"author_profile": "https://Stackoverflow.com/users/252891",
"pm_score": 0,
"selected": false,
"text": "<p>I prefer using Spring's JpaDaoSupport, which helps to deal with JPA. A good example is here <a href=\"http://github.com/rafalrusin/jpaqb/blob/master/src/test/java/jpaqb/CarDao.java\" rel=\"nofollow noreferrer\">http://github.com/rafalrusin/jpaqb/blob/master/src/test/java/jpaqb/CarDao.java</a>.</p>\n\n<p>A good separation of logic is to have a DAO class (Data Access Object) and DTO (Data Transfer Object). DAO typically contains all required queries and DTOs are entities with fields.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177927",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8805/"
] |
In JPA the Entities are nice annotated Plain Old Java Objects. But I have not found a good way to interact with them and the database.
In my current app, my basic design is always to have a sequence based id as primary key so I usually have to look up entities by other properties than PK.
And for each Entity I have a stateless EJB of
```
@Stateless
public class MyEntApiBean implements MyEntApi {
@PersistenceContext(unitName = "xxx") @Inject EntityManager entityManager;
```
with query methods that all are some variation
```
/**
* @return A List of all MyEnts that have some property
* @param someProp some property
*/
public List<MyEnt> getAllMyEntsFromProp(final String someProp) {
try {
final Query query = entityManager.createQuery("select me from MyEnt me where me.someProp = :someProp");
query.setParameter("someProp", someProp);
return query.getResultList();
} catch(final NoResultException nre) {
log.warn("No MyEnts found");
}
return new ArrayList<MyEnt>();
}
```
So:
1. I really hate having these methods in an EJB because they seem to belong with the entities themselves, and the EJB local interfaces annoy the crap out of me.
2. I hate the duplication that I have in each method with "try, createQuery, getResultList,catch, log, return" (mostly a consequence of no closures or "with statement" or somesuch in Java).
Does anyone have a suggestion for a better way to interact with the Entities and Database that addresses one or both of my issues?
I am currently thinking of doing some base methods with generics and reflection to get some generic query methods to reduce the duplication (issue 2) (I will put a prototype up for review later).
Thanks,
Anders
|
Try Seam. The [Query Objects](http://docs.jboss.com/seam/2.1.0.BETA1/reference/en-US/html_single/#d0e7527) do most of the work for you, and they're easily extendable. Or, you could always implement a similar pattern.
In general, Seam does a lot of useful stuff to bridge the gap between JPA and you view and business layers. You don't have to use JSF for Seam to be useful.
|
177,945 |
<p>I would like to create XML Schema for this chunk of xml, I would like to restrict the values of "name" attribute, so that in output document on and only one instance of day is allowed for each week day:</p>
<pre><code><a>
<day name="monday" />
<day name="tuesday" />
<day name="wednesday" />
</a>
</code></pre>
<p>I have tried to use this:</p>
<pre><code> <xs:complexType name="a">
<xs:sequence>
<xs:element name="day" minOccurs="1" maxOccurs="1">
<xs:complexType>
<xs:attribute name="name" use="required">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="monday" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
<xs:element name="day" minOccurs="1" maxOccurs="1">
<xs:complexType>
<xs:attribute name="name" use="required">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="tuesday" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</code></pre>
<p>but XML Schema validator in eclipse says error "Multiple elements with name 'day', with different types, appear in the model group.".</p>
<p>Is there any other way?</p>
|
[
{
"answer_id": 177954,
"author": "Micah",
"author_id": 17744,
"author_profile": "https://Stackoverflow.com/users/17744",
"pm_score": 0,
"selected": false,
"text": "<p>Try this:</p>\n\n<pre><code><xs:schema attributeFormDefault=\"unqualified\" elementFormDefault=\"qualified\" xmlns:xs=\"http://www.w3.org/2001/XMLSchema\">\n<xs:element name=\"a\">\n <xs:complexType>\n <xs:sequence>\n <xs:element maxOccurs=\"unbounded\" name=\"day\">\n <xs:complexType>\n <xs:attribute name=\"atrib\" type=\"xs:string\" use=\"required\" />\n </xs:complexType>\n </xs:element>\n </xs:sequence>\n </xs:complexType>\n</xs:element>\n</code></pre>\n\n<p></p>\n\n<p>I think the maxOccurs=\"unbounded\" is what you need.</p>\n"
},
{
"answer_id": 178153,
"author": "Cyphus",
"author_id": 1150,
"author_profile": "https://Stackoverflow.com/users/1150",
"pm_score": 1,
"selected": false,
"text": "<p>Have you considered something like this? (i.e. day is a type, and the elements are named after the days of the week)</p>\n\n<pre><code><xs:schema attributeFormDefault=\"unqualified\" elementFormDefault=\"qualified\" xmlns:xs=\"http://www.w3.org/2001/XMLSchema\">\n <xs:complexType name=\"day\" />\n <xs:element name=\"a\">\n <xs:complexType>\n <xs:sequence>\n <xs:element name=\"monday\" maxOccurs=\"1\" minOccurs=\"0\" type=\"day\" />\n <xs:element name=\"tuesday\" maxOccurs=\"1\" minOccurs=\"0\" type=\"day\" />\n <xs:element name=\"wednesday\" maxOccurs=\"1\" minOccurs=\"0\" type=\"day\" />\n </xs:sequence>\n </xs:complexType>\n </xs:element>\n</xs:schema>\n</code></pre>\n"
},
{
"answer_id": 334323,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 5,
"selected": true,
"text": "<p>You need something like this:</p>\n\n<pre><code><?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<xs:schema xmlns:xs=\"http://www.w3.org/2001/XMLSchema\" elementFormDefault=\"qualified\">\n <xs:element name=\"a\">\n <xs:complexType>\n <xs:sequence>\n <xs:element maxOccurs=\"unbounded\" ref=\"day\"/>\n </xs:sequence>\n </xs:complexType>\n </xs:element>\n <xs:element name=\"day\">\n <xs:complexType>\n <xs:attribute name=\"name\" use=\"required\">\n <xs:simpleType>\n <xs:restriction base=\"xs:string\">\n <xs:enumeration value=\"monday\"/>\n <xs:enumeration value=\"tuesday\"/>\n <xs:enumeration value=\"wednesday\"/>\n </xs:restriction>\n </xs:simpleType>\n </xs:attribute>\n </xs:complexType>\n </xs:element>\n</xs:schema>\n</code></pre>\n"
},
{
"answer_id": 870700,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Use choice instead of sequence </p>\n\n<p>By that way u can have only day element one's in a element</p>\n\n<p>And for name attribute use ref attribute and reference it with enumeration</p>\n"
},
{
"answer_id": 2778201,
"author": "Cheeso",
"author_id": 48082,
"author_profile": "https://Stackoverflow.com/users/48082",
"pm_score": 3,
"selected": false,
"text": "<p>In order to satisfy the at-most-once constraint described in the original question, you need to use a <a href=\"http://msdn.microsoft.com/en-us/library/ms256146.aspx\" rel=\"noreferrer\">xs:unique</a> element in your schema.</p>\n\n<pre><code><xs:schema xmlns:xs=\"http://www.w3.org/2001/XMLSchema\"\n elementFormDefault=\"qualified\">\n\n <xs:element name=\"a\">\n <xs:complexType>\n <xs:sequence>\n <xs:element name=\"day\" maxOccurs=\"7\" minOccurs=\"1\">\n <xs:complexType>\n <xs:attribute name=\"name\" use=\"required\">\n <xs:simpleType>\n <xs:restriction base=\"xs:string\">\n <xs:pattern value=\"(mon|tues|wednes|thurs|fri|satur|sun)day\"/>\n </xs:restriction>\n </xs:simpleType>\n </xs:attribute>\n </xs:complexType>\n <xs:unique name=\"eachDayAtMostOnce\">\n <xs:selector xpath=\"day\"/>\n <xs:field xpath=\"@name\"/>\n </xs:unique>\n </xs:element>\n </xs:sequence>\n </xs:complexType>\n </xs:element>\n\n</xs:schema>\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177945",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10560/"
] |
I would like to create XML Schema for this chunk of xml, I would like to restrict the values of "name" attribute, so that in output document on and only one instance of day is allowed for each week day:
```
<a>
<day name="monday" />
<day name="tuesday" />
<day name="wednesday" />
</a>
```
I have tried to use this:
```
<xs:complexType name="a">
<xs:sequence>
<xs:element name="day" minOccurs="1" maxOccurs="1">
<xs:complexType>
<xs:attribute name="name" use="required">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="monday" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
<xs:element name="day" minOccurs="1" maxOccurs="1">
<xs:complexType>
<xs:attribute name="name" use="required">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="tuesday" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
```
but XML Schema validator in eclipse says error "Multiple elements with name 'day', with different types, appear in the model group.".
Is there any other way?
|
You need something like this:
```
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified">
<xs:element name="a">
<xs:complexType>
<xs:sequence>
<xs:element maxOccurs="unbounded" ref="day"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="day">
<xs:complexType>
<xs:attribute name="name" use="required">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="monday"/>
<xs:enumeration value="tuesday"/>
<xs:enumeration value="wednesday"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:schema>
```
|
177,956 |
<p>What is the best way to convert an int or null to boolean value in an SQL query, such that:</p>
<ul>
<li>Any non-null value is <strong>TRUE</strong> in the results</li>
<li>Any null value is <strong>FALSE</strong> in the results</li>
</ul>
|
[
{
"answer_id": 177967,
"author": "Torbjörn Gyllebring",
"author_id": 21182,
"author_profile": "https://Stackoverflow.com/users/21182",
"pm_score": 2,
"selected": false,
"text": "<pre><code>isnull(column - column + 1, 0) != 0\n</code></pre>\n"
},
{
"answer_id": 177978,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 3,
"selected": false,
"text": "<pre><code>SELECT \n CASE\n WHEN thevalue IS NULL THEN 0\n ELSE 1\n END AS newVal\nFROM .... (rest of select)\n</code></pre>\n\n<p>I think it goes something like this</p>\n\n<p>Actually, the ISNULL, may need to be WHEN thevalue IS NULL THEN 0</p>\n"
},
{
"answer_id": 177984,
"author": "cvk",
"author_id": 25397,
"author_profile": "https://Stackoverflow.com/users/25397",
"pm_score": 5,
"selected": false,
"text": "<p>No need to use case... when:</p>\n\n<pre><code>select (column_name is not null) as result from table_name;\n</code></pre>\n\n<p>Returns 1 for all fields not NULL and 0 for all fields that are NULL, which is as close as you can get to booleans in SQL. </p>\n"
},
{
"answer_id": 177987,
"author": "Tomalak",
"author_id": 18771,
"author_profile": "https://Stackoverflow.com/users/18771",
"pm_score": 7,
"selected": true,
"text": "<p>To my knowledge (correct me if I'm wrong), there is no concept of literal boolean values in SQL. You can have expressions evaluating to boolean values, but you cannot output them.</p>\n\n<p>This said, you can use CASE WHEN to produce a value you can use in a comparison:</p>\n\n<pre><code>SELECT \n CASE WHEN ValueColumn IS NULL THEN 'FALSE' ELSE 'TRUE' END BooleanOutput \nFROM \n table \n</code></pre>\n"
},
{
"answer_id": 178112,
"author": "Patrick Parent",
"author_id": 23141,
"author_profile": "https://Stackoverflow.com/users/23141",
"pm_score": 2,
"selected": false,
"text": "<p>You may want to do a Convert(BIT, Value) of your result. Because something SQL will return an error that the value is not a boolean.</p>\n"
},
{
"answer_id": 178405,
"author": "kristof",
"author_id": 3241,
"author_profile": "https://Stackoverflow.com/users/3241",
"pm_score": 2,
"selected": false,
"text": "<p>Assuming you want 0,1 value as a return, and that we are talking about integer I would use the logic specified by <a href=\"https://stackoverflow.com/questions/177956/what-is-the-best-way-to-convert-an-int-or-null-to-boolean-value-in-an-sql-query#177967\">Torbjörn</a> and wrap it in the function</p>\n\n<pre><code>create function dbo.isNotNull(@a int)\nreturns bit\nas\nbegin\nreturn isnull(@a-@a+1,0)\nend\n</code></pre>\n\n<p>so then you can use it whenever you need by simply calling </p>\n\n<pre><code>select dbo.isNotNull(myIntColumn) from myTable\n</code></pre>\n\n<p>The answer provided by <a href=\"https://stackoverflow.com/questions/177956/what-is-the-best-way-to-convert-an-int-or-null-to-boolean-value-in-an-sql-query#177987\">Tomalak</a> is more universal though as it would work with any data type</p>\n"
},
{
"answer_id": 256589,
"author": "WW.",
"author_id": 14663,
"author_profile": "https://Stackoverflow.com/users/14663",
"pm_score": 1,
"selected": false,
"text": "<p>In Oracle, assuming you use 0 for false and 1 for true:-</p>\n\n<pre><code>SELECT DECODE( col, NULL, 0, 1) FROM ...\n</code></pre>\n\n<p>You can also write this using the CASE syntax, but the above is idiomatic in Oracle. DECODE is a bit like a switch/case; if col is NULL then 0 is returned, else 1.</p>\n"
},
{
"answer_id": 30342364,
"author": "PL_kolek",
"author_id": 2926014,
"author_profile": "https://Stackoverflow.com/users/2926014",
"pm_score": 0,
"selected": false,
"text": "<p>The shortest one I know for Oracle:</p>\n\n<pre><code>SELECT NVL2(nullableColumn, 1, 0) FROM someTable\n</code></pre>\n\n<p><code>NVL2(value, ifNotNull, ifNull)</code> returns <code>ifNotNull</code> if the <code>value</code> is not null, and <code>ifNull</code> otherwise.</p>\n"
},
{
"answer_id": 36559035,
"author": "David Castro",
"author_id": 3199531,
"author_profile": "https://Stackoverflow.com/users/3199531",
"pm_score": 1,
"selected": false,
"text": "<p>Usually when use 1, it means is true and else in other case. </p>\n\n<p>So:</p>\n\n<pre><code>SELECT IsDefault = CASE WHEN IsDefault = 1 THEN 'true' ELSE 'false' END\nFROM table\n</code></pre>\n"
},
{
"answer_id": 59251866,
"author": "Daniel Hudsky",
"author_id": 7952824,
"author_profile": "https://Stackoverflow.com/users/7952824",
"pm_score": -1,
"selected": false,
"text": "<p>The syntax works, but I had to figure out how to place it in my query. \nIf OK, I'd like to share an example on how to fit into an extended query: </p>\n\n<pre><code>select count(*) as count, inventory,\nCASE WHEN inventory = 0 THEN 'empty' ELSE 'not empty' END as InventoryStatus\nfrom mytable group by count, inventory\n</code></pre>\n"
},
{
"answer_id": 72212871,
"author": "Go Man",
"author_id": 1661562,
"author_profile": "https://Stackoverflow.com/users/1661562",
"pm_score": 1,
"selected": false,
"text": "<p>We can check if is null return "False" else return "True"</p>\n<pre><code>SELECT IIF(ISNULL(ColumnName<Nullable>, 'true')='false', 'true', 'false') ;\n\n\nSELECT IIF(ISNULL(Email, 'true')='false', 'true', 'false') from Employee ;\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177956",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15985/"
] |
What is the best way to convert an int or null to boolean value in an SQL query, such that:
* Any non-null value is **TRUE** in the results
* Any null value is **FALSE** in the results
|
To my knowledge (correct me if I'm wrong), there is no concept of literal boolean values in SQL. You can have expressions evaluating to boolean values, but you cannot output them.
This said, you can use CASE WHEN to produce a value you can use in a comparison:
```
SELECT
CASE WHEN ValueColumn IS NULL THEN 'FALSE' ELSE 'TRUE' END BooleanOutput
FROM
table
```
|
177,960 |
<p>Have someone ever done this before???</p>
<p>I am trying to use MinGW to compile a program using the MySQL libraries. I keep getting the message that the function 'rint' is redefined. Ok it's true that the function is in both files config-win.h, from MySQL and math.h from the standard library, but both of them are suppose to be libraries with no problems.</p>
<p>After breaking my head a while i tried even this, that wont compile: </p>
<pre><code>#include <iostream>
#include <my_global.h>
#include <mysql.h>
using namespace std;
int main() {
cout << "Hello World!!!" << endl; // prints Hello World!!!
return 0;
}
</code></pre>
<p>And this is the command as well as the output i issue for compiling</p>
<p><strong>i586-mingw32msvc-cc -I/usr/include/mysql probando.cpp -w</strong></p>
<pre><code>In file included from /usr/include/mysql/my_global.h:73,
from probando.cpp:10:
/usr/include/mysql/config-win.h: In function ‘double rint(double)’:
/usr/include/mysql/config-win.h:229: error: redefinition of ‘double rint(double)’
/usr/lib/gcc/i586-mingw32msvc/4.2.1-sjlj/../../../../i586-mingw32msvc/include/math.h:635: error: ‘double rint(double)’ previously defined here
</code></pre>
<p>I have tested it both in WindowsXP with MinGW, with the MySQL libraries properly transformed in .a libraries and in Linux (the output is from Linux, pretty much the same than in Windows) with MinGW32.</p>
<p>People... I am running out of options... Any clues?? Has someone worked before with MySQL and MinGW?? May it work with Cygwin?? </p>
<p>Thanks in advance if you take the time to answer.</p>
|
[
{
"answer_id": 178031,
"author": "Onorio Catenacci",
"author_id": 2820,
"author_profile": "https://Stackoverflow.com/users/2820",
"pm_score": 0,
"selected": false,
"text": "<p>I don't know the stack in question but my guess would be that somehow math.h is getting double included. Take a look at the math.h file. There should be an <a href=\"http://en.wikipedia.org/wiki/Include_guard\" rel=\"nofollow noreferrer\">include guard</a> somewhere close to the top. Follow the link if you're not familiar with the concept of an include guard. In both places you should include math.h using the include guards. </p>\n\n<p>You might also look for #defines that are specific to Linux; the file may not be included twice on Linux due to a #define somewhere. </p>\n\n<p>As I said, this is just a guess. </p>\n"
},
{
"answer_id": 178193,
"author": "mdec",
"author_id": 15534,
"author_profile": "https://Stackoverflow.com/users/15534",
"pm_score": 1,
"selected": false,
"text": "<p>Also a guess, but it appears as if math.h AND config-win.h have a function called rint, make sure that there aren't two functions with the same names. </p>\n\n<p>BTW, because I am not entirely sure, I'm making this community editable, feel free to edit this post if I am incorrect.</p>\n"
},
{
"answer_id": 188054,
"author": "Pablo Herrero",
"author_id": 366094,
"author_profile": "https://Stackoverflow.com/users/366094",
"pm_score": 0,
"selected": false,
"text": "<p>Ok I solved it.</p>\n\n<p>The stupid of mine was including the wrong file. To do it in mingw you have to #include <windows.h> and not <config-win.h></p>\n\n<p>Thanks anyway!!!</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177960",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/366094/"
] |
Have someone ever done this before???
I am trying to use MinGW to compile a program using the MySQL libraries. I keep getting the message that the function 'rint' is redefined. Ok it's true that the function is in both files config-win.h, from MySQL and math.h from the standard library, but both of them are suppose to be libraries with no problems.
After breaking my head a while i tried even this, that wont compile:
```
#include <iostream>
#include <my_global.h>
#include <mysql.h>
using namespace std;
int main() {
cout << "Hello World!!!" << endl; // prints Hello World!!!
return 0;
}
```
And this is the command as well as the output i issue for compiling
**i586-mingw32msvc-cc -I/usr/include/mysql probando.cpp -w**
```
In file included from /usr/include/mysql/my_global.h:73,
from probando.cpp:10:
/usr/include/mysql/config-win.h: In function ‘double rint(double)’:
/usr/include/mysql/config-win.h:229: error: redefinition of ‘double rint(double)’
/usr/lib/gcc/i586-mingw32msvc/4.2.1-sjlj/../../../../i586-mingw32msvc/include/math.h:635: error: ‘double rint(double)’ previously defined here
```
I have tested it both in WindowsXP with MinGW, with the MySQL libraries properly transformed in .a libraries and in Linux (the output is from Linux, pretty much the same than in Windows) with MinGW32.
People... I am running out of options... Any clues?? Has someone worked before with MySQL and MinGW?? May it work with Cygwin??
Thanks in advance if you take the time to answer.
|
Also a guess, but it appears as if math.h AND config-win.h have a function called rint, make sure that there aren't two functions with the same names.
BTW, because I am not entirely sure, I'm making this community editable, feel free to edit this post if I am incorrect.
|
177,974 |
<p>How can I test sending email from my application without flooding my inbox? </p>
<p>Is there a way to tell IIS/ASP.NET how to deliver email to a local folder for inspection?</p>
|
[
{
"answer_id": 178072,
"author": "GEOCHET",
"author_id": 5640,
"author_profile": "https://Stackoverflow.com/users/5640",
"pm_score": 6,
"selected": true,
"text": "<p>Yes there is a way.</p>\n\n<blockquote>\n <p>You can alter web.config like this so\n that when you send email it will\n instead be created as an .EML file in\n c:\\LocalDir.</p>\n</blockquote>\n\n<pre><code> <configuration> \n <system.net> \n <mailSettings> \n <smtp deliveryMethod=\"SpecifiedPickupDirectory\"> \n <specifiedPickupDirectory pickupDirectoryLocation=\"c:\\LocalDir\"/> \n </smtp> \n </mailSettings> \n </system.net>\n </configuration>\n</code></pre>\n\n<p>You can also create an instance of the <a href=\"http://msdn.microsoft.com/en-us/library/system.net.mail.smtpclient.aspx\" rel=\"noreferrer\"><code>SmtpClient</code></a> class with these same settings, if you don't want to/can't change the web.config. In C# that looks something like this:</p>\n\n<pre><code>var smtpClient = new SmtpClient();\nsmtpClient.DeliveryMethod = SmtpDeliveryMethod.SpecifiedPickupDirectory;\nvar emailPickupDirectory = HostingEnvironment.MapPath(\"~/EmailPickup\");\nif (!Directory.Exists(emailPickupDirectory)) { \n Directory.CreateDirectory(emailPickupDirectory)\n}\nsmtpClient.PickupDirectoryLocation = emailPickupDirectory;\n</code></pre>\n"
},
{
"answer_id": 178410,
"author": "ballpointpeon",
"author_id": 8269,
"author_profile": "https://Stackoverflow.com/users/8269",
"pm_score": 1,
"selected": false,
"text": "<p>Configure rules in your email client to move the messages based on the subject/sender's email address?</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/177974",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10676/"
] |
How can I test sending email from my application without flooding my inbox?
Is there a way to tell IIS/ASP.NET how to deliver email to a local folder for inspection?
|
Yes there is a way.
>
> You can alter web.config like this so
> that when you send email it will
> instead be created as an .EML file in
> c:\LocalDir.
>
>
>
```
<configuration>
<system.net>
<mailSettings>
<smtp deliveryMethod="SpecifiedPickupDirectory">
<specifiedPickupDirectory pickupDirectoryLocation="c:\LocalDir"/>
</smtp>
</mailSettings>
</system.net>
</configuration>
```
You can also create an instance of the [`SmtpClient`](http://msdn.microsoft.com/en-us/library/system.net.mail.smtpclient.aspx) class with these same settings, if you don't want to/can't change the web.config. In C# that looks something like this:
```
var smtpClient = new SmtpClient();
smtpClient.DeliveryMethod = SmtpDeliveryMethod.SpecifiedPickupDirectory;
var emailPickupDirectory = HostingEnvironment.MapPath("~/EmailPickup");
if (!Directory.Exists(emailPickupDirectory)) {
Directory.CreateDirectory(emailPickupDirectory)
}
smtpClient.PickupDirectoryLocation = emailPickupDirectory;
```
|
178,016 |
<p>I'm trying to select a specific HTML element in a document, for firefox i just use:</p>
<pre><code>xpathobj = document.evaluate(xpath, document, null,
XPathResult.FIRST_ORDERED_NODE_TYPE, null);
</code></pre>
<p>which works fine. However when I try the IE equivilent:</p>
<pre><code>xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async=false;
xmlDoc.load(document);
xmlDoc.setProperty("SelectionLanguage", "XPath");
xpathobj = xmlDoc.selectNodes(xpath);
</code></pre>
<p>I get no object returned. So my question is there an easy way to use XPath to get to the element I want in IE?
The XPath I'm using looks like </p>
<pre><code>/HTML/BODY/DIV[9]/DIV[2]
</code></pre>
|
[
{
"answer_id": 178021,
"author": "cllpse",
"author_id": 20946,
"author_profile": "https://Stackoverflow.com/users/20946",
"pm_score": 0,
"selected": false,
"text": "<p>Are you sure X-Path is implemented in your version of Internet Explorer? As in: what version are you using?</p>\n"
},
{
"answer_id": 178032,
"author": "Sergey Ilinsky",
"author_id": 23815,
"author_profile": "https://Stackoverflow.com/users/23815",
"pm_score": 2,
"selected": false,
"text": "<p>Take a look at <a href=\"http://dev.abiss.gr/sarissa/\" rel=\"nofollow noreferrer\">http://dev.abiss.gr/sarissa/</a> project. They have migrated most of XML-related APIs to IE.\nOtherwise it is indeed also easy to implement. The problems you would need to solve would be: serialization of HTML into valid XML, syncing result of XMLDOM XPath query with original HTMLDOM. To my knowledge they've done it in their library, however, its performance could have been better.</p>\n"
},
{
"answer_id": 178125,
"author": "Neall",
"author_id": 619,
"author_profile": "https://Stackoverflow.com/users/619",
"pm_score": 0,
"selected": false,
"text": "<p>jQuery implements <a href=\"http://docs.jquery.com/Release:jQuery_1.2#XPath_Compatibility_Plugin\" rel=\"nofollow noreferrer\">a cross-browser-compatible subset of xPath selectors with a plug-in</a>. Your example \"/HTML/BODY/DIV[9]/DIV[2]\" should work in it.</p>\n\n<p>(edit - corrected thanks to Sergey Ilinsky)</p>\n"
},
{
"answer_id": 181704,
"author": "Tim C",
"author_id": 7585,
"author_profile": "https://Stackoverflow.com/users/7585",
"pm_score": 0,
"selected": false,
"text": "<p>Instead of doing</p>\n\n<pre><code>xmlDoc.load(document); \n</code></pre>\n\n<p>try</p>\n\n<pre><code>xmlDoc.loadXML(document.body.outerHTML)\n</code></pre>\n\n<p>This would only really work if your your HTML document is formatted to XHTML standards. Also, the BODY tag would be the root node, so you would have to change your XPATH to \"/BODY/DIV[9]/DIV[2]\"</p>\n"
},
{
"answer_id": 181881,
"author": "Magnus Smith",
"author_id": 11461,
"author_profile": "https://Stackoverflow.com/users/11461",
"pm_score": 0,
"selected": false,
"text": "<p>I'd be a bit worried about using xml like this, as you cannot be sure what version (if any) of the XML DLL a person has. There are still companies using IE5.0 out there in droves, and 5.5 had a particularly ropey XML implementation.</p>\n"
},
{
"answer_id": 182471,
"author": "user11198",
"author_id": 11198,
"author_profile": "https://Stackoverflow.com/users/11198",
"pm_score": 1,
"selected": false,
"text": "<p>Hi well in the end i came up with my own dodgy solution, any sugestions on improving it would be greatly apreciated. It makes use of some prototype functionality:</p>\n\n<p>Works in IE5+ with xpath of the form \"/HTML/BODY/DIV[9]/DIV[2]\"</p>\n\n<p>function getXPathElement (xpath , element) {</p>\n\n<pre><code>//Specific to project, here i know that the body element will always have the id \"top\"\n//but otherwise the element that is passed in should be first element in the xpath \n//statement eg. /HTML/BODY/DIV the element passed in should be HTML\nif(!element){\n element = $(\"top\");\n var xpathArrayIndex = 3;\n} else {\n var xpathArrayIndex = 1;\n}\n//split the xpath statement up\nvar xpathArray = xpath.split(\"/\");\n\nvar carryOn = true; \nwhile(carryOn){\n decendents = element.childElements();\n //check to see if we are at the end of the xpath statement\n if(xpathArrayIndex == xpathArray.length){\n return element;\n }\n //if there is only one decendent make it the next element\n if(decendents.size() == 1) {\n element = decendents.first();\n } else {\n //otherwise search the decendents for the next element\n element = getXPathElementByIndex(decendents, xpathArray[xpathArrayIndex]);\n }\n xpathArrayIndex++;\n}\n</code></pre>\n\n<p>}</p>\n\n<p>function getXPathElementByIndex(decendents, xpathSegment){</p>\n\n<pre><code>var decendentsArray = decendents.toArray();\n//seperate the index from the element name\nvar temp = xpathSegment.split(\"[\");\nvar elementName = temp[0];\n//get the index as a number eg. \"9]\" to 9\nvar elementIndex = +temp[1].replace(\"]\", \"\");\n//the number of matching elements\nvar count = 0;\n\n//keeps track of the number of iterations\nvar i = 0;\nwhile(count != elementIndex) {\n //if the decendent's name matches the xpath element name increment the count\n if(decendentsArray[i].nodeName == elementName){\n count++;\n }\n i++;\n}\nvar element = decendentsArray[i - 1];\nreturn element;\n</code></pre>\n\n<p>}</p>\n\n<p>Thanks to everyone for thier help, either way i learnt a fair bit about various javascript frameworks. </p>\n"
},
{
"answer_id": 811009,
"author": "Richard",
"author_id": 67392,
"author_profile": "https://Stackoverflow.com/users/67392",
"pm_score": 0,
"selected": false,
"text": "<p>Another JavaScript implementation of <a href=\"http://www.w3.org/TR/2004/NOTE-DOM-Level-3-XPath-20040226/\" rel=\"nofollow noreferrer\">W3C Dom Level 3 XPath</a> can be found <a href=\"http://js-xpath.sourceforge.net/\" rel=\"nofollow noreferrer\">on Source Forge</a>. But does not appear to be active.</p>\n"
},
{
"answer_id": 2183658,
"author": "Koder",
"author_id": 264280,
"author_profile": "https://Stackoverflow.com/users/264280",
"pm_score": 2,
"selected": false,
"text": "<p>The problem may be that in IE5+ [1] is in fact [2] in FF. Microsoft solely decided that the numbering should start at [0] and not [1] as specified by w3c.</p>\n"
},
{
"answer_id": 3286586,
"author": "hyperion",
"author_id": 396392,
"author_profile": "https://Stackoverflow.com/users/396392",
"pm_score": 0,
"selected": false,
"text": "<p>I can not find a simple and common solution, you can write custom function to implement a little of xpath but it is hard to get complete in internet explorer 6 or lower version....</p>\n"
},
{
"answer_id": 3286890,
"author": "hyperion",
"author_id": 396392,
"author_profile": "https://Stackoverflow.com/users/396392",
"pm_score": 1,
"selected": false,
"text": "<p>There are some bugs in oly1234's code I try to fix it as follows:</p>\n\n<pre><code>function getXPathElement(xpath, element){\nif(!element){\n element = document;\n}\nvar xpathArray = xpath.split(\"/\");\n\nelement = findXPathRoot(xpathArray[0],xpathArray[1],element);\n\nfor(var i=1; i<xpathArray.length; i++){\n if(xpathArray[i].toLowerCase()==\"html\"){\n continue;\n }\n if(!element){\n return element;\n }\n element = getXPathElementByIndex(element.childNodes,xpathArray[i]); \n}\nreturn element;\n}\n\n\nfunction findXPathRoot(rootPath,htmlPath,element){\nif(rootPath == \"\"&&htmlPath.toLowerCase() == \"html\"){\n return element.documentElement;\n}\nreturn document.getElementsByTagName(rootPath)[0];\n}\nfunction getXPathElementByIndex(decendents, xpathSegment){\n//seperate the index from the element name\nvar temp = xpathSegment.split(\"[\");\nvar elementName = temp[0];\n//get the index as a number eg. \"9]\" to 9\nif(temp[1]){\n var elementIndex = temp[1].replace(\"]\", \"\");\n}else{\n var elementIndex = 1;\n}\n//the number of matching elements\nvar count = 0;\nfor(var i=0;i < decendents.length; i++){\n if (decendents[i].nodeName.toLowerCase() == elementName.toLowerCase()) {\n count++;\n if(count==elementIndex){\n return decendents[i];\n }\n }\n}\nreturn null;\n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178016",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11198/"
] |
I'm trying to select a specific HTML element in a document, for firefox i just use:
```
xpathobj = document.evaluate(xpath, document, null,
XPathResult.FIRST_ORDERED_NODE_TYPE, null);
```
which works fine. However when I try the IE equivilent:
```
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async=false;
xmlDoc.load(document);
xmlDoc.setProperty("SelectionLanguage", "XPath");
xpathobj = xmlDoc.selectNodes(xpath);
```
I get no object returned. So my question is there an easy way to use XPath to get to the element I want in IE?
The XPath I'm using looks like
```
/HTML/BODY/DIV[9]/DIV[2]
```
|
Take a look at <http://dev.abiss.gr/sarissa/> project. They have migrated most of XML-related APIs to IE.
Otherwise it is indeed also easy to implement. The problems you would need to solve would be: serialization of HTML into valid XML, syncing result of XMLDOM XPath query with original HTMLDOM. To my knowledge they've done it in their library, however, its performance could have been better.
|
178,026 |
<p>We noticed that lots of bugs in our software developed in C# (or Java) cause a NullReferenceException.</p>
<p>Is there a reason why "null" has even been included in the language?</p>
<p>After all, if there were no "null", I would have no bug, right?</p>
<p>In other words, what feature in the language couldn't work without null?</p>
|
[
{
"answer_id": 178046,
"author": "peacedog",
"author_id": 1734,
"author_profile": "https://Stackoverflow.com/users/1734",
"pm_score": 1,
"selected": false,
"text": "<p>I can't speak to your specific issue, but it sounds like the problem isn't the existence of null. Null exists in databases, you need some way to account for that in the application level. I don't think that's the only reason it exists in .net, mind you. But I figure it's one of the reasons.</p>\n"
},
{
"answer_id": 178050,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 4,
"selected": false,
"text": "<p>Null is an extremely powerful feature. What do you do if you have an absence of a value? It's NULL!</p>\n\n<p>One school of thought is to never return null, another is to always. For example, some say you should return a valid but empty object.</p>\n\n<p>I prefer null as to me it's a truer indication of what it actually is. If I can't retrieve an entity from my persistence layer, I want null. I don't want some empty value. But that's me. </p>\n\n<p>It is especially handy with primitives. For example, if I have true or false, but it's used on a security form, where a permission can be Allow, Deny, or not set. Well, I want that not set to be null. So I can use bool?</p>\n\n<p>There are a lot more I could go on about, but I will leave it there.</p>\n"
},
{
"answer_id": 178052,
"author": "David Arno",
"author_id": 7122,
"author_profile": "https://Stackoverflow.com/users/7122",
"pm_score": -1,
"selected": false,
"text": "<p>Null is an essential requirement of any OO language. Any object variable that hasn't been assigned an object reference has to be null. </p>\n"
},
{
"answer_id": 178053,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 5,
"selected": false,
"text": "<p>Nullity is a natural consequence of reference types. If you have a reference, it has to refer to some object - or be null. If you were to prohibit nullity, you would always have to make sure that every variable was initialized with some non-null expression - and even then you'd have issues if variables were read during the initialization phase.</p>\n\n<p>How would you propose removing the concept of nullity?</p>\n"
},
{
"answer_id": 178055,
"author": "willem",
"author_id": 22702,
"author_profile": "https://Stackoverflow.com/users/22702",
"pm_score": 2,
"selected": false,
"text": "<p>\"Null\" is included in the language because we have value types and reference types. It's probably a side effect, but a good one I think. It gives us a lot of power over how we manage memory effectively.</p>\n\n<p>Why we have null? ...</p>\n\n<p>Value types are stored on the \"stack\", their value sits directly in that piece of memory (i.e. int x = 5 means that that the memory location for that variable contains \"5\"). </p>\n\n<p>Reference types on the other hand have a \"pointer\" on the stack pointing to the <strong>actual</strong> value on the heap (i.e. string x = \"ello\" means that the memory block on the stack only contains an address pointing to the actual value on the heap).</p>\n\n<p>A null value simply means that our value on the stack does not point to any actual value on the heap - it's an empty pointer.</p>\n\n<p>Hope I explained that well enough.</p>\n"
},
{
"answer_id": 178062,
"author": "Mendelt",
"author_id": 3320,
"author_profile": "https://Stackoverflow.com/users/3320",
"pm_score": 4,
"selected": false,
"text": "<p>Removing null wouldn't solve much. You would need to have a default reference for most variables that is set on init. Instead of null-reference exceptions you would get unexpected behaviour because the variable is pointing to the wrong objects. At least null-references fail fast instead of causing unexpected behaviour.</p>\n\n<p>You can look at the null-object pattern for a way to solve part of this problem</p>\n"
},
{
"answer_id": 178090,
"author": "Julien Hoarau",
"author_id": 12248,
"author_profile": "https://Stackoverflow.com/users/12248",
"pm_score": 8,
"selected": true,
"text": "<p>Anders Hejlsberg, "C# father", just spoke about that point in <a href=\"https://www2.computerworld.com.au/article/261958/a-z_programming_languages_c_/?pp=3\" rel=\"nofollow noreferrer\">his Computerworld interview</a>:</p>\n<blockquote>\n<p>For example, in the type system we do not have separation between value and reference types and nullability of types. This may sound a little wonky or a little technical, but in C# reference types can be null, such as strings, but value types cannot be null. It sure would be nice to have had non-nullable reference types, so you could declare that ‘this string can never be null, and I want you compiler to check that I can never hit a null pointer here’.</p>\n<p>50% of the bugs that people run into today, coding with C# in our platform, and the same is true of Java for that matter, are probably null reference exceptions. If we had had a stronger type system that would allow you to say that ‘this parameter may never be null, and you compiler please check that at every call, by doing static analysis of the code’. Then we could have stamped out classes of bugs.</p>\n</blockquote>\n<p>Cyrus Najmabadi, a former software design engineer on the C# team (now working at Google) discuss on that subject on his blog: (<a href=\"http://blogs.msdn.com/cyrusn/archive/2005/04/25/411617.aspx\" rel=\"nofollow noreferrer\">1st</a>, <a href=\"http://blogs.msdn.com/cyrusn/archive/2005/04/25/411630.aspx\" rel=\"nofollow noreferrer\">2nd</a>, <a href=\"http://blogs.msdn.com/cyrusn/archive/2005/04/26/412040.aspx\" rel=\"nofollow noreferrer\">3rd</a>, <a href=\"http://blogs.msdn.com/cyrusn/archive/2005/04/27/412444.aspx\" rel=\"nofollow noreferrer\">4th</a>).\nIt seems that the biggest hindrance to the adoption of non-nullable types is that notation would disturb programmers’ habits and code base. Something like 70% of references of C# programs are likely to end-up as non-nullable ones.</p>\n<p>If you really want to have non-nullable reference type in C# you should try to use <a href=\"http://research.microsoft.com/specsharp/\" rel=\"nofollow noreferrer\">Spec#</a>\nwhich is a C# extension that allow the use of "!" as a non-nullable sign.</p>\n<pre><code>static string AcceptNotNullObject(object! s)\n{\n return s.ToString();\n}\n</code></pre>\n"
},
{
"answer_id": 178092,
"author": "Mark Cidade",
"author_id": 1659,
"author_profile": "https://Stackoverflow.com/users/1659",
"pm_score": 4,
"selected": false,
"text": "<p><a href=\"http://en.wikipedia.org/wiki/Null_(computer_programming)\" rel=\"noreferrer\" title=\"Wikipedia\">Null</a> in C# is mostly a carry-over from C++, which had pointers that didn't point to anything in memory (or rather, adress <code>0x00</code>). In <a href=\"http://www.computerworld.com.au/index.php/id;1149786074;pp;3\" rel=\"noreferrer\" title=\"Compuworld: The A-Z of Programming Languages: C#\">this interview</a>, Anders Hejlsberg says that he would've like to have added non-nullable reference types in C#. </p>\n\n<p>Null also has a legitimate place in a type system, however, as something akin to the <a href=\"http://en.wikipedia.org/wiki/Bottom_type\" rel=\"noreferrer\">bottom type</a> (where <code>object</code> is the <strong>top</strong> type). In lisp, the bottom type is <code>NIL</code> and in Scala it is <code>Nothing</code>. </p>\n\n<p>It would've been possible to design C# without any nulls but then you'd have to come up with an acceptable solution for the usages that people usually have for <code>null</code>, such as <code>unitialized-value</code>, <code>not-found</code>, <code>default-value</code>, <code>undefined-value</code>, and <code>None<T></code>. There would've probably been less adoption amongst C++ and Java programmers if they did succeed in that anyhow. At least until they saw that C# programs never had any null pointer exceptions.</p>\n"
},
{
"answer_id": 178107,
"author": "Mecki",
"author_id": 15809,
"author_profile": "https://Stackoverflow.com/users/15809",
"pm_score": 0,
"selected": false,
"text": "<p>If you create an object with an instance variable being a reference to some object, what value would you suggest has this variable before you assigned any object reference to it?</p>\n"
},
{
"answer_id": 178186,
"author": "Kimoz",
"author_id": 7753,
"author_profile": "https://Stackoverflow.com/users/7753",
"pm_score": 2,
"selected": false,
"text": "<p>There are situations in which <em>null</em> is a nice way to signify that a reference has not been initialized. This is important in some scenarios.</p>\n\n<p>For instance:</p>\n\n<pre><code>MyResource resource;\ntry\n{\n resource = new MyResource();\n //\n // Do some work\n //\n}\nfinally\n{\n if (resource != null)\n resource.Close();\n}\n</code></pre>\n\n<p>This is in most cases accomplished by the use of a <em>using</em> statement. But the pattern is still widely used.</p>\n\n<p>With regards to your NullReferenceException, the cause of such errors are often easy to reduce by implementing a coding standard where all parameters a checked for validity. Depending on the nature of the project I find that in most cases it's enough to check parameters on exposed members. If the parameters are not within the expected range an <em>ArgumentException</em> of some kind is thrown, or a error result is returned, depending on the error handling pattern in use.</p>\n\n<p>The parameter checking does not in itself remove bugs, but any bugs that occur are easier to locate and correct during the testing phase.</p>\n\n<p>As a note, <a href=\"http://en.wikipedia.org/wiki/Anders_Hejlsberg\" rel=\"nofollow noreferrer\">Anders Hejlsberg</a> has mentioned the lack of non-null enforcement as one of the biggest mistakes in the C# 1.0 specification and that including it now is \"difficult\".</p>\n\n<p>If you still think that a statically enforced non-null reference value is of great importance you could check out the <a href=\"http://research.microsoft.com/SpecSharp/\" rel=\"nofollow noreferrer\">spec#</a> language. It is an extension of C# where non-null references are part of the language. This ensures that a reference marked as non-null can never be assigned a null reference.</p>\n"
},
{
"answer_id": 178202,
"author": "bltxd",
"author_id": 11892,
"author_profile": "https://Stackoverflow.com/users/11892",
"pm_score": 2,
"selected": false,
"text": "<p>Null as it is available in C#/C++/Java/Ruby is best seen as an oddity of some obscure past (Algol) that somehow survived to this day.</p>\n\n<p>You use it in two ways:</p>\n\n<ul>\n<li>To declare references without initializing them (bad).</li>\n<li>To denote optionality (OK).</li>\n</ul>\n\n<p>As you guessed, 1) is what causes us endless trouble in common imperative languages and should have been banned long ago, 2) is the true essential feature.</p>\n\n<p>There are languages out there that avoid 1) without preventing 2).</p>\n\n<p>For example <a href=\"http://caml.inria.fr/resources/doc/index.en.html\" rel=\"nofollow noreferrer\">OCaml</a> is such a language.</p>\n\n<p>A simple function returning an ever incrementing integer starting from 1:</p>\n\n<pre><code>let counter = ref 0;;\nlet next_counter_value () = (counter := !counter + 1; !counter);;\n</code></pre>\n\n<p>And regarding optionality:</p>\n\n<pre><code>type distributed_computation_result = NotYetAvailable | Result of float;;\nlet print_result r = match r with\n | Result(f) -> Printf.printf \"result is %f\\n\" f\n | NotYetAvailable -> Printf.printf \"result not yet available\\n\";;\n</code></pre>\n"
},
{
"answer_id": 178214,
"author": "Glitch",
"author_id": 324306,
"author_profile": "https://Stackoverflow.com/users/324306",
"pm_score": 2,
"selected": false,
"text": "<p>If you're getting a 'NullReferenceException', perhaps you keep referring to objects which no longer exist. This is not an issue with 'null', it's an issue with your code pointing to non-existent addresses.</p>\n"
},
{
"answer_id": 178258,
"author": "CodeRedick",
"author_id": 17145,
"author_profile": "https://Stackoverflow.com/users/17145",
"pm_score": 1,
"selected": false,
"text": "<p>I'm surprised no one has talked about databases for their answer. Databases have nullable fields, and any language which will be receiving data from a DB needs to handle that. That means having a null value.</p>\n\n<p>In fact, this is so important that for basic types like int you can make them nullable!</p>\n\n<p>Also consider return values from functions, what if you wanted to have a function divide a couple numbers and the denominator could be 0? The only \"correct\" answer in such a case would be null. (I know, in such a simple example an exception would likely be a better option... but there can be situations where all values are correct but valid data can produce an invalid or uncalculable answer. Not sure an exception should be used in such cases...)</p>\n"
},
{
"answer_id": 178309,
"author": "Walter Mitty",
"author_id": 19937,
"author_profile": "https://Stackoverflow.com/users/19937",
"pm_score": 2,
"selected": false,
"text": "<p>One response mentioned that there are nulls in databases. That's true, but they are very different from nulls in C#.</p>\n\n<p>In C#, nulls are markers for a reference that doesn't refer to anything.</p>\n\n<p>In databases, nulls are markers for value cells that don't contain a value. By value cells, I generally mean the intersection of a row and a column in a table, but the concept of value cells could be extended beyond tables.</p>\n\n<p>The difference between the two seems trivial, at first clance. But it's not. </p>\n"
},
{
"answer_id": 178337,
"author": "pro3carp3",
"author_id": 7899,
"author_profile": "https://Stackoverflow.com/users/7899",
"pm_score": 4,
"selected": false,
"text": "<blockquote>\n <p><strong>After all, if there were no \"null\", I would have no bug, right?</strong></p>\n</blockquote>\n\n<p>The answer is <strong>NO</strong>. The problem is not that C# allows null, the problem is that you have bugs which happen to manifest themselves with the NullReferenceException. As has been stated already, nulls have a purpose in the language to indicate either an \"empty\" reference type, or a non-value (empty/nothing/unknown).</p>\n"
},
{
"answer_id": 178392,
"author": "Newtopian",
"author_id": 25812,
"author_profile": "https://Stackoverflow.com/users/25812",
"pm_score": 3,
"selected": false,
"text": "<p>Null do not cause NullPointerExceptions...</p>\n\n<p>Programers cause NullPointerExceptions.</p>\n\n<p>Without nulls we are back to using an actual arbitrary value to determine that the return value of a function or method was invalid. You still have to check for the returned -1 (or whatever), removing nulls will not magically solve lazyness, but mearly obfuscate it.</p>\n"
},
{
"answer_id": 178471,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>I propose:</p>\n\n<ol>\n<li>Ban Null</li>\n<li>Extend Booleans: True, False and FileNotFound</li>\n</ol>\n"
},
{
"answer_id": 178500,
"author": "Amy B",
"author_id": 8155,
"author_profile": "https://Stackoverflow.com/users/8155",
"pm_score": 0,
"selected": false,
"text": "<p>Commonly - NullReferenceException means that some method didn't like what it was handed and returned a null reference, which was later used without checking the reference before use.</p>\n\n<p>That method could have thown some more detailed exception instead of returning null, which complies with the <em>fail fast</em> mode of thinking.</p>\n\n<p>Or the method might be returning null as a convenience to you, so that you can write <em>if</em> instead of <em>try</em> and avoid the \"overhead\" of an exception.</p>\n"
},
{
"answer_id": 178545,
"author": "Santiago Palladino",
"author_id": 12791,
"author_profile": "https://Stackoverflow.com/users/12791",
"pm_score": 1,
"selected": false,
"text": "<p>Besides ALL of the reasons already mentioned, NULL is needed when you need a placeholder for a not-yet created object. For example. if you have a circular reference between a pair of objects, then you need null since you cannot instantiate both simultaneously.</p>\n\n<pre><code>class A {\n B fieldb;\n}\n\nclass B {\n A fielda;\n}\n\nA a = new A() // a.fieldb is null\nB b = new B() { fielda = a } // b.fielda isnt\na.fieldb = b // now it isnt null anymore\n</code></pre>\n\n<p>Edit: You may be able to pull out a language that works without nulls, but it will definitely not be an object oriented language. For example, prolog doesn't have null values.</p>\n"
},
{
"answer_id": 178714,
"author": "tafa",
"author_id": 22186,
"author_profile": "https://Stackoverflow.com/users/22186",
"pm_score": 3,
"selected": false,
"text": "<p>The question may be interpreted as \"Is it better to have a default value for each referance type (like String.Empty) or null?\".\nIn this prespective I would prefer to have nulls, because;</p>\n\n<ul>\n<li>I would not like to write a default\nconstructor for each class I write.</li>\n<li>I would not like some unneccessary\nmemory to be allocated for such\ndefault values.</li>\n<li>Checking whether a\nreferance is null is rather cheaper\nthan value comparisons.</li>\n<li>It is highly\npossible to have more bugs that are\nharder to detect, instead of\nNullReferanceExceptions. It is a\ngood thing to have such an exception\nwhich clearly indicates that I am\ndoing (assuming) something wrong.</li>\n</ul>\n"
},
{
"answer_id": 488596,
"author": "Craig Stuntz",
"author_id": 7714,
"author_profile": "https://Stackoverflow.com/users/7714",
"pm_score": 4,
"selected": false,
"text": "<p>Like many things in object-oriented programming, it all goes back to ALGOL. <a href=\"http://lambda-the-ultimate.org/node/3186\" rel=\"noreferrer\" title=\"Tony Hoare / Historically Bad Ideas: 'Null References: The Billion Dollar Mistake'\">Tony Hoare just called it his \"billion-dollar mistake.\"</a> If anything, that's an understatement.</p>\n\n<p>Here is <a href=\"http://www.ccs.neu.edu/scheme/pubs/dissertation-cobbe.pdf\" rel=\"noreferrer\">a really interesting thesis</a> on how to make nullability not the default in Java. The parallels to C# are obvious.</p>\n"
},
{
"answer_id": 4130293,
"author": "blizpasta",
"author_id": 20646,
"author_profile": "https://Stackoverflow.com/users/20646",
"pm_score": 0,
"selected": false,
"text": "<ul>\n<li>Explicit nulling, though that is seldom necessary. Perhaps one can view it as a form of defensive programming.</li>\n<li>Use it (or nullable(T) structure for non-nullables) as a flag to indicate a missing field when mapping fields from one data source (byte stream, database table) to an object. It can get very unwieldy to make a boolean flag for every possible nullable field, and it may be impossible to use sentinel values like -1 or 0 when all values in the range that field is valid. This is especially handy when there are many many fields.</li>\n</ul>\n\n<p>Whether these are cases of use or abuse is subjective, but I use them sometimes.</p>\n"
},
{
"answer_id": 8393668,
"author": "supercat",
"author_id": 363751,
"author_profile": "https://Stackoverflow.com/users/363751",
"pm_score": 0,
"selected": false,
"text": "<p>If a framework allows the creation of an array of some type without specifying what should be done with the new items, that type must have some default value. For types which implement mutable reference semantics (*) there is in the general case no sensible default value. I consider it a weakness of the .NET framework that there is no way to specify that a non-virtual function call should suppress any null check. This would allow immutable types like String to behave as value types, by returning sensible values for properties like Length.</p>\n\n<p>(*) Note that in VB.NET and C#, mutable reference semantics may be implemented by either class or struct types; a struct type would implement mutable reference semantics by acting as a proxy for a wrapped instance of a class object to which it holds an immutable reference.</p>\n\n<p>It would also be helpful if one could specify that a class should have non-nullable mutable value-type semantics (implying that--at minimum--instantiating a field of that type would create a new object instance using a default constructor, and that copying a field of that type would create a new instance by copying the old one (recursively handling any nested value-type classes).</p>\n\n<p>It's unclear, however, exactly how much support should be built into the framework for this. Having the framework itself recognize the distinctions between mutable value types, mutable reference types, and immutable types, would allow classes which themselves hold references to a mixture of mutable and immutable types from outside classes to efficiently avoid making unnecessary copies of deeply-immutable objects.</p>\n"
},
{
"answer_id": 15012087,
"author": "Eldritch Conundrum",
"author_id": 278044,
"author_profile": "https://Stackoverflow.com/users/278044",
"pm_score": 0,
"selected": false,
"text": "<p>Sorry for answering four years late, I am amazed that none of the answers so far have answered the original question this way:</p>\n\n<p>Languages like <strong>C# and Java</strong>, like C and other languages before them, <strong>have <code>null</code></strong> so that the programmer can <strong>write fast, optimized code</strong> by using pointers in an efficient way.</p>\n\n<hr>\n\n<ul>\n<li>Low-level view</li>\n</ul>\n\n<p>A little history first. The reason why <code>null</code> was invented is for efficiency. When doing low-level programming in assembly, there is no abstraction, you have values in registers and you want to make the most of them. Defining zero to be a <strong>not a valid pointer</strong> value is an excellent strategy to represent <strong>either an object or nothing</strong>.</p>\n\n<p>Why waste most of the possible values of a perfectly good word of memory, when you can have a zero-memory-overhead, really fast implementation of the <strong>optional value</strong> pattern? This is why <code>null</code> is so useful.</p>\n\n<ul>\n<li>High-level view.</li>\n</ul>\n\n<p>Semantically, <code>null</code> is in no way necessary to programming languages. For example, in classic functional languages like Haskell or in the ML family, there is no null, but rather types named Maybe or Option. They represent the more high-level concept of <strong>optional value</strong> without being concerned in any way by what the generated assembly code will look like (that will be the compiler's job).</p>\n\n<p>And this is very useful too, because it enables the compiler to <strong>catch more bugs</strong>, and that means less NullReferenceExceptions.</p>\n\n<ul>\n<li>Bringing them together</li>\n</ul>\n\n<p>In contrast to these very high-level programming languages, C# and Java allow a possible value of null for <strong>every reference type</strong> (which is another name for <em>type that will end up being implemented using pointers</em>).</p>\n\n<p>This may seem like a bad thing, but what's good about it is that the programmer can use the knowledge of how it works under the hood, to create more efficient code (even though the language has garbage collection).</p>\n\n<p>This is the reason why <code>null</code> still exists in languages nowadays: a trade-off between the need of a general concept of optional value and the ever-present need for efficiency.</p>\n"
},
{
"answer_id": 22798029,
"author": "Kaz",
"author_id": 1250772,
"author_profile": "https://Stackoverflow.com/users/1250772",
"pm_score": 0,
"selected": false,
"text": "<p>The feature that couldn't work without null is being able to represent \"the absence of an object\".</p>\n\n<p>The absence of an object is an important concept. In object-oriented programming, we need it in order to represent an association between objects that is optional: object A can be attached to an object B, or A might not have an object B. Without null we could still emulate this: for instance we could use a list of objects to associate B with A. That list could contain one element (one B), or be empty. This is somewhat inconvenient and doesn't really solve anything. Code which assumes that there is a B, such as <code>aobj.blist.first().method()</code> is going to blow up in a similar way to a null reference exception: (if <code>blist</code> is empty, what is the behavior of <code>blist.first()</code>?)</p>\n\n<p>Speaking of lists, null lets you terminate a linked list. A <code>ListNode</code> can contain a reference to another <code>ListNode</code> which can be null. The same can be said about other dynamic set structures such as trees. Null lets you have an ordinary binary tree whose leaf nodes are marked by having child references that are null.</p>\n\n<p>Lists and trees can be built without null, but they have to be circular, or else infinite/lazy. That would probably be regarded as an unacceptable constraint by most programmers, who would prefer to have choices in designing data structures.</p>\n\n<p>The pains associated with null references, like null references arising accidentally due to bugs and causing exceptions, are partially a consequence of the static type system, which introduces a null value into every type: there is a null String, null Integer, null Widget, ...</p>\n\n<p>In a dynamically typed language, there can be a single null object, which has its own type. The upshot of this is that you have all the representational advantages of null, plus greater safety. For instance if you write a method which accepts a String parameter, then you're guaranteed that the parameter will be a string object, and not null. There is no null reference in the String class: something that is known to be a String cannot be the object null. References do not have type in a dynamic language. A storage location such as a class member or function parameter contains a value which can be a reference to an object. That object has type, not the reference.</p>\n\n<p>So these languages provide a clean, more or less matematically pure model of \"null\", and then the static ones turn it into somewhat of a Frankenstein's monster.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178026",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25781/"
] |
We noticed that lots of bugs in our software developed in C# (or Java) cause a NullReferenceException.
Is there a reason why "null" has even been included in the language?
After all, if there were no "null", I would have no bug, right?
In other words, what feature in the language couldn't work without null?
|
Anders Hejlsberg, "C# father", just spoke about that point in [his Computerworld interview](https://www2.computerworld.com.au/article/261958/a-z_programming_languages_c_/?pp=3):
>
> For example, in the type system we do not have separation between value and reference types and nullability of types. This may sound a little wonky or a little technical, but in C# reference types can be null, such as strings, but value types cannot be null. It sure would be nice to have had non-nullable reference types, so you could declare that ‘this string can never be null, and I want you compiler to check that I can never hit a null pointer here’.
>
>
> 50% of the bugs that people run into today, coding with C# in our platform, and the same is true of Java for that matter, are probably null reference exceptions. If we had had a stronger type system that would allow you to say that ‘this parameter may never be null, and you compiler please check that at every call, by doing static analysis of the code’. Then we could have stamped out classes of bugs.
>
>
>
Cyrus Najmabadi, a former software design engineer on the C# team (now working at Google) discuss on that subject on his blog: ([1st](http://blogs.msdn.com/cyrusn/archive/2005/04/25/411617.aspx), [2nd](http://blogs.msdn.com/cyrusn/archive/2005/04/25/411630.aspx), [3rd](http://blogs.msdn.com/cyrusn/archive/2005/04/26/412040.aspx), [4th](http://blogs.msdn.com/cyrusn/archive/2005/04/27/412444.aspx)).
It seems that the biggest hindrance to the adoption of non-nullable types is that notation would disturb programmers’ habits and code base. Something like 70% of references of C# programs are likely to end-up as non-nullable ones.
If you really want to have non-nullable reference type in C# you should try to use [Spec#](http://research.microsoft.com/specsharp/)
which is a C# extension that allow the use of "!" as a non-nullable sign.
```
static string AcceptNotNullObject(object! s)
{
return s.ToString();
}
```
|
178,114 |
<p>Is there any easier solution in porting a windows manual-reset event to pthread,
than a pthread conditional-variable + pthread mutex + a flag if event is set or unset?</p>
|
[
{
"answer_id": 178962,
"author": "ephemient",
"author_id": 20713,
"author_profile": "https://Stackoverflow.com/users/20713",
"pm_score": 4,
"selected": false,
"text": "<p>Pthreads are low level constructs. No, there isn't a simpler mechanism; <code>pthread_cond__*</code> is conceptually similar to an auto-reset event. Be careful, <code>pthread_cond_wait</code> may have spurious wakeups, so it should never be used without some sort of external flag regardless of the situation.</p>\n\n<p>Building your own wouldn't be too hard, though.</p>\n\n<pre class=\"lang-c prettyprint-override\"><code>#include <pthread.h>\n#include <stdbool.h>\n\nstruct mrevent {\n pthread_mutex_t mutex;\n pthread_cond_t cond;\n bool triggered;\n};\n\nvoid mrevent_init(struct mrevent *ev) {\n pthread_mutex_init(&ev->mutex, 0);\n pthread_cond_init(&ev->cond, 0);\n ev->triggered = false;\n}\n\nvoid mrevent_trigger(struct mrevent *ev) {\n pthread_mutex_lock(&ev->mutex);\n ev->triggered = true;\n pthread_cond_signal(&ev->cond);\n pthread_mutex_unlock(&ev->mutex);\n}\n\nvoid mrevent_reset(struct mrevent *ev) {\n pthread_mutex_lock(&ev->mutex);\n ev->triggered = false;\n pthread_mutex_unlock(&ev->mutex);\n}\n\nvoid mrevent_wait(struct mrevent *ev) {\n pthread_mutex_lock(&ev->mutex);\n while (!ev->triggered)\n pthread_cond_wait(&ev->cond, &ev->mutex);\n pthread_mutex_unlock(&ev->mutex);\n}\n</code></pre>\n\n<p>This may not fit your usage, as you will often have a different lock that you'd want to use in place of <code>ev->mutex</code>, but this is the gist of how it's typically used.</p>\n"
},
{
"answer_id": 1524074,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<p>I think Windows Events are more akin to a semaphore. I.e. for auto-reset, you'd use a binary semaphore and the sem_timedwait() function.</p>\n"
},
{
"answer_id": 9490158,
"author": "Vincent",
"author_id": 137511,
"author_profile": "https://Stackoverflow.com/users/137511",
"pm_score": 2,
"selected": false,
"text": "<p>No there isn't any easier solution but the following code will do the trick:</p>\n\n<pre><code>void LinuxEvent::wait()\n{\n pthread_mutex_lock(&mutex);\n\n int signalValue = signalCounter;\n\n while (!signaled && signalValue == signalCounter)\n {\n pthread_cond_wait(&condition, &mutex);\n }\n\n pthread_mutex_unlock(&mutex);\n}\n\nvoid LinuxEvent::signal()\n{\n pthread_mutex_lock(&mutex);\n\n signaled = true;\n signalCounter++;\n pthread_cond_broadcast(&condition);\n\n pthread_mutex_unlock(&mutex);\n}\n\nvoid LinuxEvent::reset()\n{\n pthread_mutex_lock(&mutex);\n signaled = false;\n pthread_mutex_unlock(&mutex);\n}\n</code></pre>\n\n<p>When calling signal(), the event goes in signaled state and all waiting thread will run. Then the event will stay in signaled state and all the thread calling wait() won't wait. A call to reset() will put the event back to non-signaled state.</p>\n\n<p>The signalCounter is there in case you do a quick signal/reset to wake up waiting threads.</p>\n"
},
{
"answer_id": 10116327,
"author": "lucho",
"author_id": 1327947,
"author_profile": "https://Stackoverflow.com/users/1327947",
"pm_score": 3,
"selected": false,
"text": "<p>You can easy implement manual-reset events with pipes:</p>\n\n<p>event is in triggered state -> there is something to read from the pipe</p>\n\n<p>SetEvent -> write()</p>\n\n<p>ResetEvent -> read()</p>\n\n<p>WaitForMultipleObjects -> poll() (or select()) for reading</p>\n\n<p>the \"SetEvent\" operation should write something (e.g. 1 byte of any value) just to put the pipe in non-empty state, so subsequent \"Wait\" operation, that is, poll() for data available for read will not block.</p>\n\n<p>The \"ResetEvent\" operation will read up the data written to make sure pipe is empty again.\nThe read-end of the pipe should be made non-blocking so that trying to reset (read from) already reset event (empty pipe) wont block - fcntl(pipe_out, F_SETFL, O_NONBLOCK)\nSince there may be more than 1 SetEvents before the ResetEvent, you should code it so that it reads as many bytes as there are in the pipe:</p>\n\n<pre><code>char buf[256]; // 256 is arbitrary\nwhile( read(pipe_out, buf, sizeof(buf)) == sizeof(buf));\n</code></pre>\n\n<p>Note that waiting for the event does not read from the pipe and hence the \"event\" will remain in triggered state until the reset operation.</p>\n"
},
{
"answer_id": 11260894,
"author": "Angel Genchev",
"author_id": 1491030,
"author_profile": "https://Stackoverflow.com/users/1491030",
"pm_score": 3,
"selected": false,
"text": "<p>I prefer the pipe approach, because often one doesn't need just an event to wait for, but multiple objects e.g. <code>WaitForMultipleObjects(...)</code>. And with using pipes one could easily replace the windows <code>WaitForMultipleObjects</code> call with <code>poll(...)</code>, <code>select</code>, <code>pselect</code>, and <code>epoll</code>. </p>\n\n<p>There was a light-weight method for process synchronization called <code>Futex</code> (Fast Userspace Locking system call). There was a function <code>futex_fd</code> to get one or more file descriptors for futexes. This file descriptor, together with possibly many others representing real files, devices, sockets or the like could get passed to <code>select</code>, <code>poll</code>, or <code>epoll</code>. Unfortunately it was <em>removed</em> from the kernel. So the pipes tricks remain the only facility to do this:</p>\n\n<pre><code>int pipefd[2];\nchar buf[256]; // 256 is arbitrary\nint r = pipe2(pipefd, O_NONBLOCK);\n\nvoid setEvent()\n{\n write(pipefd[1], &buf, 1); \n}\n\nvoid resetEvent() { while( read(pipefd[0], &buf, sizeof(buf)) > 0 ) {;} }\n\nvoid waitForEvent(int timeoutMS)\n{ \n struct pollfd fds[1];\n fds[0].fd = pipefd[0];\n fds[0].events = POLLRDNORM;\n poll(fds, 1, timeoutMS);\n}\n\n// finalize:\nclose(pipefd[0]);\nclose(pipefd[1]);\n</code></pre>\n"
},
{
"answer_id": 14460865,
"author": "Mahmoud Al-Qudsi",
"author_id": 17027,
"author_profile": "https://Stackoverflow.com/users/17027",
"pm_score": 2,
"selected": false,
"text": "<p>We were looking for a similar solution to port some heavily-multithreaded C++ code from Windows to Linux, and ended up writing an open source, MIT-licensed <a href=\"https://github.com/NeoSmart/PEvents\" rel=\"nofollow\">Win32 Events for Linux library</a>. It should be the solution you are looking for, and has been heavily vetted for performance and resource consumption.</p>\n\n<p>It implements manual and auto-reset events, and both the <code>WaitForSingleObject</code> and <code>WaitForMultipleObject</code> functionalities.</p>\n"
},
{
"answer_id": 31360505,
"author": "Mahmoud Al-Qudsi",
"author_id": 17027,
"author_profile": "https://Stackoverflow.com/users/17027",
"pm_score": 0,
"selected": false,
"text": "<p>We (full disclosure: I work at NeoSmart Technologies) wrote an open source (MIT licensed) library called <a href=\"https://github.com/NeoSmart/PEvents\" rel=\"nofollow\">pevents</a> which <a href=\"http://neosmart.net/blog/2011/waitformultipleobjects-and-win32-events-for-linux-and-read-write-locks-for-windows/\" rel=\"nofollow\">implements WIN32 manual and auto-reset events</a> on POSIX, and includes both WaitForSingleObject and WaitForMultipleObjects clones. It's seen some adoption since then (it's used in Steam on Linux/Mac) and works fairly well.</p>\n\n<p>Although I'd personally advise you to use POSIX multithreading and signaling paradigms when coding on POSIX machines, pevents gives you another choice if you need it.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178114",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
Is there any easier solution in porting a windows manual-reset event to pthread,
than a pthread conditional-variable + pthread mutex + a flag if event is set or unset?
|
Pthreads are low level constructs. No, there isn't a simpler mechanism; `pthread_cond__*` is conceptually similar to an auto-reset event. Be careful, `pthread_cond_wait` may have spurious wakeups, so it should never be used without some sort of external flag regardless of the situation.
Building your own wouldn't be too hard, though.
```c
#include <pthread.h>
#include <stdbool.h>
struct mrevent {
pthread_mutex_t mutex;
pthread_cond_t cond;
bool triggered;
};
void mrevent_init(struct mrevent *ev) {
pthread_mutex_init(&ev->mutex, 0);
pthread_cond_init(&ev->cond, 0);
ev->triggered = false;
}
void mrevent_trigger(struct mrevent *ev) {
pthread_mutex_lock(&ev->mutex);
ev->triggered = true;
pthread_cond_signal(&ev->cond);
pthread_mutex_unlock(&ev->mutex);
}
void mrevent_reset(struct mrevent *ev) {
pthread_mutex_lock(&ev->mutex);
ev->triggered = false;
pthread_mutex_unlock(&ev->mutex);
}
void mrevent_wait(struct mrevent *ev) {
pthread_mutex_lock(&ev->mutex);
while (!ev->triggered)
pthread_cond_wait(&ev->cond, &ev->mutex);
pthread_mutex_unlock(&ev->mutex);
}
```
This may not fit your usage, as you will often have a different lock that you'd want to use in place of `ev->mutex`, but this is the gist of how it's typically used.
|
178,135 |
<p>I have a UserControl (Composite control) that can be shown as the following pseudo XAML code:</p>
<pre><code><UserControl>
<DockPanel>
<TextBox />
<Button />
</DockPanel>
</UserControl>
</code></pre>
<p>I use this custom control in a bunch of places and style some of them with a WPF Style. This style sets the Background property of the UserControl to a color. But this background color is drawn on UserControl's background surface, but I want it to be drawn only on TextBox control's background. This is what I get (Color=Red):</p>
<p><a href="http://img261.imageshack.us/img261/8600/62858047wi3.png" rel="nofollow noreferrer">alt text http://img261.imageshack.us/img261/8600/62858047wi3.png</a></p>
<p>If I bind the Background property of the UserControl to my TextBox control's background property, I get the following one:</p>
<p><a href="http://img111.imageshack.us/img111/1637/30765795kw5.png" rel="nofollow noreferrer">alt text http://img111.imageshack.us/img111/1637/30765795kw5.png</a></p>
<p>Now it also paints the background of the inner TextBox control but the Background color of the UserControl still exists. Are there any ways to remove that painting of UserControl's background?</p>
|
[
{
"answer_id": 178427,
"author": "Kent Boogaart",
"author_id": 5380,
"author_profile": "https://Stackoverflow.com/users/5380",
"pm_score": 3,
"selected": false,
"text": "<p>There are a number of ways to do this, but I would suggest exposing your own property on your user control and binding to that inside your user control. For example:</p>\n\n<pre><code><UserControl x:Name=\"_root\" ...>\n ...\n <Button Background=\"{Binding ButtonBackground, ElementName=_root}\"/>\n</UserControl>\n</code></pre>\n\n<p>Another way would just be to explicitly set the background color of the <code>TextBox</code> to something.</p>\n"
},
{
"answer_id": 178655,
"author": "cplotts",
"author_id": 22294,
"author_profile": "https://Stackoverflow.com/users/22294",
"pm_score": 1,
"selected": false,
"text": "<p>I agree with Kent. There are a number of ways that you can solve this problem.</p>\n\n<p>But what about just using a Style in the UserControl to set the Background of the TextBox? Is there any special reason that the following wouldn't work for you?</p>\n\n<pre><code><UserControl\n x:Class=\"StackOverflowQuestion.UserControl1\"\n xmlns=\"http://schemas.microsoft.com/winfx/2006/xaml/presentation\"\n xmlns:x=\"http://schemas.microsoft.com/winfx/2006/xaml\"\n Height=\"300\"\n Width=\"300\"\n>\n <UserControl.Resources>\n <Style x:Key=\"textBoxStyle\" TargetType=\"{x:Type TextBox}\">\n <Setter Property=\"Background\" Value=\"Red\"/>\n </Style>\n </UserControl.Resources>\n <DockPanel>\n <TextBox Text=\"Test\" Style=\"{StaticResource textBoxStyle}\"/>\n <Button/>\n </DockPanel>\n</UserControl>\n</code></pre>\n\n<p>If you truly want to utilize a property set on the user control and have it affect the internals of the user control, I would follow Kent's suggestion with one modification. I would Bind the Background of the TextBox instead so that whatever Background Brush the user set on the user control would flow (property value inheritance) to the Button. Or, in other words, the Background of the TextBox is really what you are trying to make different.</p>\n\n<pre><code><UserControl x:Name=\"_root\" ...>\n <TextBox Background=\"{Binding TextBoxBackground, ElementName=_root}\"/>\n <Button/>\n</UserControl>\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178135",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/39/"
] |
I have a UserControl (Composite control) that can be shown as the following pseudo XAML code:
```
<UserControl>
<DockPanel>
<TextBox />
<Button />
</DockPanel>
</UserControl>
```
I use this custom control in a bunch of places and style some of them with a WPF Style. This style sets the Background property of the UserControl to a color. But this background color is drawn on UserControl's background surface, but I want it to be drawn only on TextBox control's background. This is what I get (Color=Red):
[alt text http://img261.imageshack.us/img261/8600/62858047wi3.png](http://img261.imageshack.us/img261/8600/62858047wi3.png)
If I bind the Background property of the UserControl to my TextBox control's background property, I get the following one:
[alt text http://img111.imageshack.us/img111/1637/30765795kw5.png](http://img111.imageshack.us/img111/1637/30765795kw5.png)
Now it also paints the background of the inner TextBox control but the Background color of the UserControl still exists. Are there any ways to remove that painting of UserControl's background?
|
There are a number of ways to do this, but I would suggest exposing your own property on your user control and binding to that inside your user control. For example:
```
<UserControl x:Name="_root" ...>
...
<Button Background="{Binding ButtonBackground, ElementName=_root}"/>
</UserControl>
```
Another way would just be to explicitly set the background color of the `TextBox` to something.
|
178,138 |
<p>I fear this is probably a bit of a dummy question, but it has me pretty stumped.</p>
<p>I'm looking for the simplest way possible to pass a method of an object into a procedure, so that the procedure can call the object's method (e.g. after a timeout, or maybe in a different thread). So basically I want to:</p>
<ul>
<li>Capture a reference to an object's method.</li>
<li>Pass that reference to a procedure.</li>
<li>Using that reference, call the object's method from the procedure.</li>
</ul>
<p>I figure I could achieve the same effect using interfaces, but I thought there was another way, since this "procedure of object" type declaration exists.</p>
<p>The following <em>doesn't</em> work, but might it help explain where I'm confused...?</p>
<pre><code>interface
TCallbackMethod = procedure of object;
TCallbackObject = class
procedure CallbackMethodImpl;
procedure SetupCallback;
end;
implementation
procedure CallbackTheCallback(const callbackMethod: TCallbackMethod);
begin
callbackMethod();
end;
procedure TCallbackObject.CallbackMethodImpl;
begin
// Do whatever.
end;
procedure TCallbackObject.SetupCallback;
begin
// following line doesn't compile - it fails with "E2036 Variable required"
CallbackTheCallback(@self.CallbackMethodImpl);
end;
</code></pre>
<p>(Once the question is answered I'll remove the above code unless it aids the explanation somehow.)</p>
|
[
{
"answer_id": 178174,
"author": "Roman Ganz",
"author_id": 17981,
"author_profile": "https://Stackoverflow.com/users/17981",
"pm_score": 5,
"selected": true,
"text": "<p>Just remove the Pointer stuff. Delphi will do it for you:</p>\n\n<pre><code>procedure TCallbackObject.SetupCallback;\nbegin\n CallbackTheCallback(CallbackMethodImpl);\nend;\n</code></pre>\n"
},
{
"answer_id": 179731,
"author": "Jody Dawkins",
"author_id": 1234,
"author_profile": "https://Stackoverflow.com/users/1234",
"pm_score": 2,
"selected": false,
"text": "<p>The reason you don't need the pointer syntax is that you've declared the method type as a procedure of object. The compiler will figure out from the \"of object\" statement how to handle passing the method off the callback proc.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178138",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11961/"
] |
I fear this is probably a bit of a dummy question, but it has me pretty stumped.
I'm looking for the simplest way possible to pass a method of an object into a procedure, so that the procedure can call the object's method (e.g. after a timeout, or maybe in a different thread). So basically I want to:
* Capture a reference to an object's method.
* Pass that reference to a procedure.
* Using that reference, call the object's method from the procedure.
I figure I could achieve the same effect using interfaces, but I thought there was another way, since this "procedure of object" type declaration exists.
The following *doesn't* work, but might it help explain where I'm confused...?
```
interface
TCallbackMethod = procedure of object;
TCallbackObject = class
procedure CallbackMethodImpl;
procedure SetupCallback;
end;
implementation
procedure CallbackTheCallback(const callbackMethod: TCallbackMethod);
begin
callbackMethod();
end;
procedure TCallbackObject.CallbackMethodImpl;
begin
// Do whatever.
end;
procedure TCallbackObject.SetupCallback;
begin
// following line doesn't compile - it fails with "E2036 Variable required"
CallbackTheCallback(@self.CallbackMethodImpl);
end;
```
(Once the question is answered I'll remove the above code unless it aids the explanation somehow.)
|
Just remove the Pointer stuff. Delphi will do it for you:
```
procedure TCallbackObject.SetupCallback;
begin
CallbackTheCallback(CallbackMethodImpl);
end;
```
|
178,144 |
<p>Originally I thought to ask if there would be an easy way to provide an automatically managed last update field with MS Access.</p>
<p>After some googling I found following approach:</p>
<pre><code>Private Sub Form_Dirty(Cancel As Integer)
Me.Last_Update = Date()
End Sub
</code></pre>
<p>Which seems to do the job. I thought I'd share it with others too (and if somebody has some good points that should be considered, feel free to share them)</p>
|
[
{
"answer_id": 178170,
"author": "tom.dietrich",
"author_id": 15769,
"author_profile": "https://Stackoverflow.com/users/15769",
"pm_score": 2,
"selected": false,
"text": "<p>That might be your best choice on an access database with an access back end- but if you've got a MS-SQL back end, put an update trigger on the table so that you can catch edits regardless of where they come from.</p>\n\n<pre><code>CREATE TRIGGER [Table_stampUpdates] ON [dbo].[Table]\n FOR Update \nAS \nBEGIN \nUPDATE Table\nSET \nmodified_by = right(system_user, len(system_user) - charindex('\\', system_user)), modified_on = getdate() \nFROM Table inner join inserted on Table.PrimaryKey = Inserted.PrimaryKey\n END\n</code></pre>\n"
},
{
"answer_id": 178834,
"author": "onedaywhen",
"author_id": 15354,
"author_profile": "https://Stackoverflow.com/users/15354",
"pm_score": 2,
"selected": false,
"text": "<p>Additionally, add a column Validation Rule (or <code>CHECK</code> constraint) to ensure the 'timestamp' column is updated when the table is being updated other than via your form. The SQL DLL (ANSI-92 Query Mode syntax) would look something like this:</p>\n\n<pre><code>CREATE TABLE MyTable \n(\n key_col INTEGER NOT NULL UNIQUE, \n data_col INTEGER NOT NULL\n)\n;\nALTER TABLE MyTable ADD\n my_timestamp_col DATETIME \n DEFAULT NOW() \n NOT NULL\n;\nALTER TABLE MyTable ADD\n CONSTRAINT my_timestamp_col__must_be_current_timestamp\n CHECK (my_timestamp_col = NOW())\n;\n</code></pre>\n\n<p>Another approach when using Jet 4.0 (pre-Access 2007 i.e. before user level security was removed from the engine) is to create a 'helper' Jet SQL <code>PROCEDURE</code> (Access term: stored Query object defined using an SQL 'Action' statement, as distinct from a SQL <code>SELECT</code> query) that automatically updates the 'timestamp' column then remove 'update' privileges from the table and grant them instead on the <code>PROC</code> e.g. SQL DDL/DCL something like:</p>\n\n<pre><code>CREATE PROCEDURE MyProc \n(\n arg_key INTEGER, \n arg_new_data INTEGER\n)\nAS \nUPDATE MyTable\n SET data_col = arg_new_data, \n my_timestamp_col = NOW()\n WHERE key_col = arg_key\n;\nREVOKE UPDATE ON MyTable FROM PUBLIC\n;\nGRANT UPDATE ON MyProc TO PUBLIC\n;\n</code></pre>\n\n<p>The advantage here is all updates must go via the <code>PROC</code> and therefore is under the developer's control; the disadvantage is Access/Jet SQL is that your form will also have to use the <code>PROC</code>, which means a paradigm shift away from the standard 'data bound forms' approach for which Access is famous.</p>\n"
},
{
"answer_id": 179753,
"author": "BIBD",
"author_id": 685,
"author_profile": "https://Stackoverflow.com/users/685",
"pm_score": 3,
"selected": true,
"text": "<p>You could also put that same code into a BeforeUpdate.</p>\n\n<p>The difference being that the OnDirty will tag the record when you first started to edit the record; while the BeforeUpdate will tag the record just before it gets committed to the database. </p>\n\n<p>The latter may be preferable if you have a user who starts editing a record, goes to a meeting and then finishes editing it an hour later.</p>\n"
},
{
"answer_id": 74277151,
"author": "timbald",
"author_id": 20388639,
"author_profile": "https://Stackoverflow.com/users/20388639",
"pm_score": 0,
"selected": false,
"text": "<p>For anyone reading this in the days of ACE 16.0 (MS Access 2016/365) the answer above from onedaywhen, to use a CONSTRAINT clause, no longer seems to work, sadly. It would seem that ACE 16.0 fails on the constraint check with the NOW() keyword in it, when saving an edited record, and so doesn't update the date field to NOW(), but instead says the validation check failed - probably because the current value in the date field doesn't equal NOW(), and thus prevents you from doing any edit on any record, until you DROP the CONSTRAINT. (Blasted BASIC's dual use of the = operator for both becomes and equality check).</p>\n<p>PS: You CAN add record level CHECK CONSTRAINTS via an ALTER TABLE command in ACE 16.0, but they must be added via ADO code in VBA, and cannot be added from the SQL editor in MS Access. i.e.</p>\n<pre><code>CurrentProject.Connection.Execute "ALTER TABLE TableName ADD CONSTRAINT NameOfConstraint CHECK (ExpressionToCheck);"\n</code></pre>\n<p>The following web page is a good resource for learning about this.\n<a href=\"https://codekabinett.com/rdumps.php?Lang=2&targetDoc=access-table-validation-rule\" rel=\"nofollow noreferrer\">CodeKabinett: Table Level Validation Rules in MS Access</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178144",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/28482/"
] |
Originally I thought to ask if there would be an easy way to provide an automatically managed last update field with MS Access.
After some googling I found following approach:
```
Private Sub Form_Dirty(Cancel As Integer)
Me.Last_Update = Date()
End Sub
```
Which seems to do the job. I thought I'd share it with others too (and if somebody has some good points that should be considered, feel free to share them)
|
You could also put that same code into a BeforeUpdate.
The difference being that the OnDirty will tag the record when you first started to edit the record; while the BeforeUpdate will tag the record just before it gets committed to the database.
The latter may be preferable if you have a user who starts editing a record, goes to a meeting and then finishes editing it an hour later.
|
178,147 |
<p>I have an application in C# (2.0 running on XP embedded) that is communicating with a 'watchdog' that is implemented as a Windows Service. When the device boots, this service typically takes some time to start. I'd like to check, from my code, if the service is running. How can I accomplish this?</p>
|
[
{
"answer_id": 178162,
"author": "Carl",
"author_id": 951280,
"author_profile": "https://Stackoverflow.com/users/951280",
"pm_score": 10,
"selected": true,
"text": "<p>I guess something like this would work:</p>\n\n<p>Add <code>System.ServiceProcess</code> to your project references (It's on the .NET tab).</p>\n\n<pre><code>using System.ServiceProcess;\n\nServiceController sc = new ServiceController(SERVICENAME);\n\nswitch (sc.Status)\n{\n case ServiceControllerStatus.Running:\n return \"Running\";\n case ServiceControllerStatus.Stopped:\n return \"Stopped\";\n case ServiceControllerStatus.Paused:\n return \"Paused\";\n case ServiceControllerStatus.StopPending:\n return \"Stopping\";\n case ServiceControllerStatus.StartPending:\n return \"Starting\";\n default:\n return \"Status Changing\";\n}\n</code></pre>\n\n<p>Edit: There is also a method <code>sc.WaitforStatus()</code> that takes a desired status and a timeout, never used it but it may suit your needs.</p>\n\n<p>Edit: Once you get the status, to get the status again you will need to call <code>sc.Refresh()</code> first.</p>\n\n<p>Reference: <a href=\"http://msdn.microsoft.com/en-us/library/system.serviceprocess.servicecontroller(VS.80).aspx\" rel=\"noreferrer\">ServiceController</a> object in .NET.</p>\n"
},
{
"answer_id": 24381150,
"author": "rhatwar007",
"author_id": 3248226,
"author_profile": "https://Stackoverflow.com/users/3248226",
"pm_score": 4,
"selected": false,
"text": "<p>Here you get all available services and their status in your local machine. </p>\n\n<pre><code>ServiceController[] services = ServiceController.GetServices();\nforeach(ServiceController service in services)\n{\n Console.WriteLine(service.ServiceName+\"==\"+ service.Status);\n}\n</code></pre>\n\n<p>You can Compare your service with service.name property inside loop and you get status of your service.\nFor details go with the <a href=\"http://msdn.microsoft.com/en-us/library/system.serviceprocess.servicecontroller.aspx\" rel=\"noreferrer\">http://msdn.microsoft.com/en-us/library/system.serviceprocess.servicecontroller.aspx</a>\nalso <a href=\"http://msdn.microsoft.com/en-us/library/microsoft.windows.design.servicemanager(v=vs.90).aspx\" rel=\"noreferrer\">http://msdn.microsoft.com/en-us/library/microsoft.windows.design.servicemanager(v=vs.90).aspx</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178147",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6399/"
] |
I have an application in C# (2.0 running on XP embedded) that is communicating with a 'watchdog' that is implemented as a Windows Service. When the device boots, this service typically takes some time to start. I'd like to check, from my code, if the service is running. How can I accomplish this?
|
I guess something like this would work:
Add `System.ServiceProcess` to your project references (It's on the .NET tab).
```
using System.ServiceProcess;
ServiceController sc = new ServiceController(SERVICENAME);
switch (sc.Status)
{
case ServiceControllerStatus.Running:
return "Running";
case ServiceControllerStatus.Stopped:
return "Stopped";
case ServiceControllerStatus.Paused:
return "Paused";
case ServiceControllerStatus.StopPending:
return "Stopping";
case ServiceControllerStatus.StartPending:
return "Starting";
default:
return "Status Changing";
}
```
Edit: There is also a method `sc.WaitforStatus()` that takes a desired status and a timeout, never used it but it may suit your needs.
Edit: Once you get the status, to get the status again you will need to call `sc.Refresh()` first.
Reference: [ServiceController](http://msdn.microsoft.com/en-us/library/system.serviceprocess.servicecontroller(VS.80).aspx) object in .NET.
|
178,187 |
<p>I am designing a class for log entries of my mail server. I have parsed the log entries and created the class hierarchy. Now I need to save the in memory representation to the disk. I need to save it to multiple destinations like mysql and disk files. I am at a loss to find out the proper way to design the persistence mechanism. The challenges are:</p>
<ol>
<li><p>How to pass persistence
initialization information like
filename, db connection parameters
passed to them. The options I can
think of are all ugly for eg:</p>
<p>1.1 Constructor: it becomes ugly as I
add more persistence.</p>
<p>1.2 Method: Object.mysql_params(" "),
again butt ugly</p></li>
<li><p>"Correct" method name to call each
persistance mechanism: eg:
Object.save_mysql, Object.save_file,
or Object.save (mysql) and
Object.save(file)</p></li>
</ol>
<p>I am sure there is some pattern to solve this particular problem. I am using ruby as my language, with out any rails, ie pure ruby code. Any clue is much welcome.</p>
<p>raj</p>
|
[
{
"answer_id": 178504,
"author": "Jon Wood",
"author_id": 25258,
"author_profile": "https://Stackoverflow.com/users/25258",
"pm_score": 3,
"selected": true,
"text": "<p>Personally I'd break things out a bit - the object representing a log entry really shouldn't be worrying about how it should save it, so I'd probably create a MySQLObjectStore, and FileObjectStore, which you can configure separately, and gets passed the object to save. You could give your Object class a class variable which contains the store type, to be called on save.</p>\n\n<pre><code>class Object\n cattr_accessor :store\n\n def save\n @@store.save(self)\n end\nend\n\nclass MySQLObjectStore\n def initialize(connection_string)\n # Connect to DB etc...\n end\n\n def save(obj)\n # Write to database\n end\nend\n\nstore = MySQLObjectStore.new(\"user:password@localhost/database\")\nObject.store = store\n\nobj = Object.new(foo)\nobj.save\n</code></pre>\n"
},
{
"answer_id": 178547,
"author": "Turp",
"author_id": 24856,
"author_profile": "https://Stackoverflow.com/users/24856",
"pm_score": 1,
"selected": false,
"text": "<p>Unless I completely misunstood your question, I would recommend using the Strategy pattern. Instead of having this one class try to write to all of those different sources, delegate that responsibility to another class. Have a bunch of LogWriter classes, each one with the responsibility of persiting the object to a particular data store. So you might have a MySqlLogWriter, FileLogWriter, etc.</p>\n\n<p>Each one of these objects can be instantiated on their own and then the persitence object can be passed to it:</p>\n\n<pre><code>lw = FileLogWriter.new \"log_file.txt\"\nlw.Write(log)\n</code></pre>\n"
},
{
"answer_id": 178567,
"author": "Lucas Oman",
"author_id": 6726,
"author_profile": "https://Stackoverflow.com/users/6726",
"pm_score": 1,
"selected": false,
"text": "<p>You really should separate your concerns here. The message and the way the message is saved are two separate things. In fact, in many cases, it would also be more efficient not to open a new mysql connection or new file pointer for every message.</p>\n\n<p>I would create a Saver class, extended by FileSaver and MysqlSaver, each of which have a save method, which is passed your message. The saver is responsible for pulling out the parts of the message that apply and saving them to the medium it's responsible for.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178187",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25453/"
] |
I am designing a class for log entries of my mail server. I have parsed the log entries and created the class hierarchy. Now I need to save the in memory representation to the disk. I need to save it to multiple destinations like mysql and disk files. I am at a loss to find out the proper way to design the persistence mechanism. The challenges are:
1. How to pass persistence
initialization information like
filename, db connection parameters
passed to them. The options I can
think of are all ugly for eg:
1.1 Constructor: it becomes ugly as I
add more persistence.
1.2 Method: Object.mysql\_params(" "),
again butt ugly
2. "Correct" method name to call each
persistance mechanism: eg:
Object.save\_mysql, Object.save\_file,
or Object.save (mysql) and
Object.save(file)
I am sure there is some pattern to solve this particular problem. I am using ruby as my language, with out any rails, ie pure ruby code. Any clue is much welcome.
raj
|
Personally I'd break things out a bit - the object representing a log entry really shouldn't be worrying about how it should save it, so I'd probably create a MySQLObjectStore, and FileObjectStore, which you can configure separately, and gets passed the object to save. You could give your Object class a class variable which contains the store type, to be called on save.
```
class Object
cattr_accessor :store
def save
@@store.save(self)
end
end
class MySQLObjectStore
def initialize(connection_string)
# Connect to DB etc...
end
def save(obj)
# Write to database
end
end
store = MySQLObjectStore.new("user:password@localhost/database")
Object.store = store
obj = Object.new(foo)
obj.save
```
|
178,188 |
<p>So, bitfields. Specifically, large bitfields. I understand how to manipulate individual values in a bitfield, but how would I go about doing this on a large set, such as say:</p>
<pre><code>uint[] bitfield = new uint[4] { 0x0080000, 0x00FA3020, 0x00C8000, 0x0FF00D0 };
</code></pre>
<p>The specific problem I'm having is doing left and right shifts that carry through across the whole array. So for instance, if I did a <code>>> 4</code> on the above array, I'd end up with:</p>
<pre><code>uint[4] { 0x0008000, 0x000FA302, 0x000C800, 0x00FF00D };
</code></pre>
<p>Now, an (overly) simplistic algorithm here might look something like (this is me writting code on the fly):</p>
<pre><code>int shift = 4;
for (int i = 0; i <= shift; i++) {
for (int j = bitfield.GetUpperBound(0); j > 0; j--) {
bitfield[j] = bitfield[j] >> 1;
bitfield[j] = bitfield[j] + ((bitfield[j-1] & 1) << (sizeof(uint)*8));
}
bitfield[0] = bitfield[0] >> 1;
}
</code></pre>
<p>Is there anything built in that might ease working with this sort of data? </p>
|
[
{
"answer_id": 178197,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 3,
"selected": true,
"text": "<p>What makes you think that BitArray uses bools internally? It uses Boolean values to represent the bits in terms of the API, but under the hood I believe it uses an int[].</p>\n"
},
{
"answer_id": 178623,
"author": "Christoffer Lette",
"author_id": 11808,
"author_profile": "https://Stackoverflow.com/users/11808",
"pm_score": 0,
"selected": false,
"text": "<p>Using extension methods, you could do this:</p>\n\n<pre><code>public static class BitArrayExtensions\n{\n public static void DownShift(this BitArray bitArray, int places)\n {\n for (var i = 0; i < bitArray.Length; i++)\n {\n bitArray[i] = i + places < bitArray.Length && bitArray[i + places];\n }\n }\n\n public static void UpShift(this BitArray bitArray, int places)\n {\n for (var i = bitArray.Length - 1; i >= 0; i--)\n {\n bitArray[i] = i - places >= 0 && bitArray[i - places];\n }\n }\n}\n</code></pre>\n\n<p>Unfortunately, I couldn't come up with a way to overload the shift operators. (Mainly because <code>BitArray</code> is sealed.)</p>\n\n<p>If you intend to manipulate <code>int</code>s or <code>uint</code>s, you could create extension methods for inserting bits into / extracting bits from the <code>BitArray</code>. (<code>BitArray</code> has a constructor that takes an array of <code>int</code>s, but that only takes you that far.)</p>\n"
},
{
"answer_id": 178672,
"author": "Juan Pablo Califano",
"author_id": 24170,
"author_profile": "https://Stackoverflow.com/users/24170",
"pm_score": 0,
"selected": false,
"text": "<p>This doesn't cover specifically shifting, but could be useful for working with large sets. It's in C, but I think it could be easily adapted to C#</p>\n\n<p><a href=\"https://stackoverflow.com/questions/177054/is-there-a-practical-limit-to-the-size-of-bit-masks#177092\">Is there a practical limit to the size of bit masks?</a></p>\n"
},
{
"answer_id": 179067,
"author": "Juan Pablo Califano",
"author_id": 24170,
"author_profile": "https://Stackoverflow.com/users/24170",
"pm_score": 1,
"selected": false,
"text": "<p>I'm not sure if it's the best way to do it, but this could work (constraining shifts to be in the range 0-31.</p>\n\n<pre><code> public static void ShiftLeft(uint[] bitfield, int shift) {\n\n if(shift < 0 || shift > 31) {\n // handle error here\n return;\n }\n\n int len = bitfield.Length;\n int i = len - 1;\n uint prev = 0;\n\n while(i >= 0) {\n uint tmp = bitfield[i];\n bitfield[i] = bitfield[i] << shift;\n if(i < len - 1) {\n bitfield[i] |= (uint)(prev & (1 >> shift) - 1 ) >> (32 - shift);\n }\n prev = tmp;\n\n i--;\n }\n\n }\n\n public static void ShiftRight(uint[] bitfield, int shift) {\n\n if(shift < 0 || shift > 31) {\n // handle error here\n return;\n }\n int len = bitfield.Length;\n int i = 0;\n uint prev = 0;\n\n while(i < len) {\n uint tmp = bitfield[i];\n bitfield[i] = bitfield[i] >> shift;\n if(i > 0) {\n bitfield[i] |= (uint)(prev & (1 << shift) - 1 ) << (32 - shift);\n }\n prev = tmp;\n\n i++;\n }\n\n }\n</code></pre>\n\n<p>PD: With this change, you should be able to handle shifts greater than 31 bits. Could be refactored to make it look a little less ugly, but in my tests, it works and it doesn't seem too bad performance-wise (unless, there's actually something built in to handle large bitsets, which could be the case).</p>\n\n<pre><code> public static void ShiftLeft(uint[] bitfield, int shift) {\n\n if(shift < 0) {\n // error\n return;\n } \n\n int intsShift = shift >> 5;\n\n if(intsShift > 0) {\n if(intsShift > bitfield.Length) {\n // error\n return;\n }\n\n for(int j=0;j < bitfield.Length;j++) {\n if(j > intsShift + 1) { \n bitfield[j] = 0;\n } else {\n bitfield[j] = bitfield[j+intsShift];\n }\n }\n\n BitSetUtils.ShiftLeft(bitfield,shift - intsShift * 32);\n return;\n }\n\n int len = bitfield.Length;\n int i = len - 1;\n uint prev = 0;\n\n while(i >= 0) {\n uint tmp = bitfield[i];\n bitfield[i] = bitfield[i] << shift;\n if(i < len - 1) {\n bitfield[i] |= (uint)(prev & (1 >> shift) - 1 ) >> (32 - shift);\n }\n prev = tmp;\n\n i--;\n }\n\n }\n\n public static void ShiftRight(uint[] bitfield, int shift) {\n\n if(shift < 0) {\n // error\n return;\n } \n\n int intsShift = shift >> 5;\n\n if(intsShift > 0) {\n if(intsShift > bitfield.Length) {\n // error\n return;\n }\n\n for(int j=bitfield.Length-1;j >= 0;j--) {\n if(j >= intsShift) { \n bitfield[j] = bitfield[j-intsShift];\n } else {\n bitfield[j] = 0;\n }\n }\n\n BitSetUtils.ShiftRight(bitfield,shift - intsShift * 32);\n return;\n }\n\n\n int len = bitfield.Length;\n int i = 0;\n uint prev = 0;\n\n while(i < len) {\n uint tmp = bitfield[i];\n bitfield[i] = bitfield[i] >> shift;\n if(i > 0) {\n bitfield[i] |= (uint)(prev & (1 << shift) - 1 ) << (32 - shift);\n }\n prev = tmp;\n\n i++;\n }\n\n }\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178188",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15537/"
] |
So, bitfields. Specifically, large bitfields. I understand how to manipulate individual values in a bitfield, but how would I go about doing this on a large set, such as say:
```
uint[] bitfield = new uint[4] { 0x0080000, 0x00FA3020, 0x00C8000, 0x0FF00D0 };
```
The specific problem I'm having is doing left and right shifts that carry through across the whole array. So for instance, if I did a `>> 4` on the above array, I'd end up with:
```
uint[4] { 0x0008000, 0x000FA302, 0x000C800, 0x00FF00D };
```
Now, an (overly) simplistic algorithm here might look something like (this is me writting code on the fly):
```
int shift = 4;
for (int i = 0; i <= shift; i++) {
for (int j = bitfield.GetUpperBound(0); j > 0; j--) {
bitfield[j] = bitfield[j] >> 1;
bitfield[j] = bitfield[j] + ((bitfield[j-1] & 1) << (sizeof(uint)*8));
}
bitfield[0] = bitfield[0] >> 1;
}
```
Is there anything built in that might ease working with this sort of data?
|
What makes you think that BitArray uses bools internally? It uses Boolean values to represent the bits in terms of the API, but under the hood I believe it uses an int[].
|
178,194 |
<p>I am developing an application using MVC Preview 5. I have used typed views.</p>
<p>After setting debug="false", I have found that I am receiving errors of the form:</p>
<blockquote>
<p>"The model item passed into the
dictionary is of type
'blah.Models.UserAdmin.IndexData' but
this dictionary requires a model item
of type
'blah.Models.OrganisationAdmin.IndexData'".</p>
</blockquote>
<p>I do not get these errors when debug is on.</p>
<p>It looks like that the MVC framework is caching views by view name. If I have two actions that use views with the same name (albeit in different namespaces), I find that only the action that is executed first is successful, the second always results in this error.</p>
<p>For example, I have a UserAdminController and an OrganisationAdminController. </p>
<ul>
<li><p>Both have an ‘Index’ action. </p></li>
<li><p>Both use a view called ‘Index.aspx’ (each contained in the controller’s view folder; Views/UserAdmin/Index.aspx and Views/OrganisationAdmin.Index.aspx).</p></li>
<li><p>Both views are typed and make use of models called IndexData (blah.Models.UserAdmin.IndexData and blah.Models.OrganisationAdmin.IndexData)</p></li>
</ul>
<p>If I visit OrganisationAdmin/Index first, I find that any subsequent attempt to view UserAdmin/Index results in the error message shown above.</p>
<p>Conversely, if I visit UserAdmin/Index first (after restarting the application), I find that navigating to OrganisationAdmin/Index causes an equivalent error (with the types the other way around).</p>
<p>I renamed one of my views “UserAdminIndex.aspx” and this seemed to fix the problem. However, this doesn’t feel like it should be an issue. Surely the MVC framework support similarly named views? I am missing something?</p>
<p>Any help gratefully received.</p>
<p>Sandy</p>
<p>Please note, I have seen the question "In ASP.NET MVC I encounter an incorrect type error when rendering a user control with the correct typed object". I am facing a similar problem, but I am not using RenderUserControl().</p>
<p>The stack trace:</p>
<pre><code>InvalidOperationException: The model item passed into the dictionary is of type 'blah.Models.RoleAdmin.IndexData' but this dictionary requires a model item of type 'blah.Models.UserAdmin.IndexData'.]
System.Web.Mvc.ViewDataDictionary`1.SetModel(Object value) +231
System.Web.Mvc.ViewDataDictionary..ctor(ViewDataDictionary viewDataDictionary) +99
System.Web.Mvc.ViewPage`1.SetViewData(ViewDataDictionary viewData) +60
System.Web.Mvc.WebFormView.RenderViewPage(ViewContext context, ViewPage page) +64
System.Web.Mvc.WebFormView.Render(ViewContext viewContext, TextWriter writer) +85
System.Web.Mvc.ViewResult.ExecuteResult(ControllerContext context) +206
System.Web.Mvc.ControllerActionInvoker.InvokeActionResult(ActionResult actionResult) +19
System.Web.Mvc.<>c__DisplayClass12.<InvokeActionResultWithFilters>b__f() +18
System.Web.Mvc.ControllerActionInvoker.InvokeActionResultFilter(IResultFilter filter, ResultExecutingContext preContext, Func`1 continuation) +257
System.Web.Mvc.<>c__DisplayClass14.<InvokeActionResultWithFilters>b__11() +20
System.Web.Mvc.ControllerActionInvoker.InvokeActionResultFilter(IResultFilter filter, ResultExecutingContext preContext, Func`1 continuation) +257
System.Web.Mvc.<>c__DisplayClass14.<InvokeActionResultWithFilters>b__11() +20
System.Web.Mvc.ControllerActionInvoker.InvokeActionResultWithFilters(ActionResult actionResult, IList`1 filters) +188
System.Web.Mvc.ControllerActionInvoker.InvokeAction(ControllerContext controllerContext, String actionName) +386
System.Web.Mvc.Controller.ExecuteCore() +112
System.Web.Mvc.ControllerBase.Execute(RequestContext requestContext) +23
System.Web.Mvc.ControllerBase.System.Web.Mvc.IController.Execute(RequestContext requestContext) +7
System.Web.Mvc.MvcHandler.ProcessRequest(HttpContextBase httpContext) +107
System.Web.Mvc.MvcHandler.ProcessRequest(HttpContext httpContext) +39
System.Web.Mvc.MvcHandler.System.Web.IHttpHandler.ProcessRequest(HttpContext httpContext) +7
System.Web.CallHandlerExecutionStep.System.Web.HttpApplication.IExecutionStep.Execute() +181
System.Web.HttpApplication.ExecuteStep(IExecutionStep step, Boolean& completedSynchronously) +75
</code></pre>
|
[
{
"answer_id": 178417,
"author": "leppie",
"author_id": 15541,
"author_profile": "https://Stackoverflow.com/users/15541",
"pm_score": 2,
"selected": true,
"text": "<p>Yes, the bug has been reported. Best leave debug on for now, or modify the offending code (sorry cant recall where).</p>\n"
},
{
"answer_id": 1334021,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>I Think your usercontrol and view have same name.</p>\n"
},
{
"answer_id": 24733778,
"author": "bendecko",
"author_id": 1521562,
"author_profile": "https://Stackoverflow.com/users/1521562",
"pm_score": 2,
"selected": false,
"text": "<p>This error was driving me nuts. The Model was being specified at the top of my view. Yet the damn thing was requesting a different model.</p>\n\n<p>Turns out there was an orphan ModelType reference in what had become a Layout page. It was being referenced in my view as Layout = \"~/Views/_layout.vbhtml\"</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178194",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/24289/"
] |
I am developing an application using MVC Preview 5. I have used typed views.
After setting debug="false", I have found that I am receiving errors of the form:
>
> "The model item passed into the
> dictionary is of type
> 'blah.Models.UserAdmin.IndexData' but
> this dictionary requires a model item
> of type
> 'blah.Models.OrganisationAdmin.IndexData'".
>
>
>
I do not get these errors when debug is on.
It looks like that the MVC framework is caching views by view name. If I have two actions that use views with the same name (albeit in different namespaces), I find that only the action that is executed first is successful, the second always results in this error.
For example, I have a UserAdminController and an OrganisationAdminController.
* Both have an ‘Index’ action.
* Both use a view called ‘Index.aspx’ (each contained in the controller’s view folder; Views/UserAdmin/Index.aspx and Views/OrganisationAdmin.Index.aspx).
* Both views are typed and make use of models called IndexData (blah.Models.UserAdmin.IndexData and blah.Models.OrganisationAdmin.IndexData)
If I visit OrganisationAdmin/Index first, I find that any subsequent attempt to view UserAdmin/Index results in the error message shown above.
Conversely, if I visit UserAdmin/Index first (after restarting the application), I find that navigating to OrganisationAdmin/Index causes an equivalent error (with the types the other way around).
I renamed one of my views “UserAdminIndex.aspx” and this seemed to fix the problem. However, this doesn’t feel like it should be an issue. Surely the MVC framework support similarly named views? I am missing something?
Any help gratefully received.
Sandy
Please note, I have seen the question "In ASP.NET MVC I encounter an incorrect type error when rendering a user control with the correct typed object". I am facing a similar problem, but I am not using RenderUserControl().
The stack trace:
```
InvalidOperationException: The model item passed into the dictionary is of type 'blah.Models.RoleAdmin.IndexData' but this dictionary requires a model item of type 'blah.Models.UserAdmin.IndexData'.]
System.Web.Mvc.ViewDataDictionary`1.SetModel(Object value) +231
System.Web.Mvc.ViewDataDictionary..ctor(ViewDataDictionary viewDataDictionary) +99
System.Web.Mvc.ViewPage`1.SetViewData(ViewDataDictionary viewData) +60
System.Web.Mvc.WebFormView.RenderViewPage(ViewContext context, ViewPage page) +64
System.Web.Mvc.WebFormView.Render(ViewContext viewContext, TextWriter writer) +85
System.Web.Mvc.ViewResult.ExecuteResult(ControllerContext context) +206
System.Web.Mvc.ControllerActionInvoker.InvokeActionResult(ActionResult actionResult) +19
System.Web.Mvc.<>c__DisplayClass12.<InvokeActionResultWithFilters>b__f() +18
System.Web.Mvc.ControllerActionInvoker.InvokeActionResultFilter(IResultFilter filter, ResultExecutingContext preContext, Func`1 continuation) +257
System.Web.Mvc.<>c__DisplayClass14.<InvokeActionResultWithFilters>b__11() +20
System.Web.Mvc.ControllerActionInvoker.InvokeActionResultFilter(IResultFilter filter, ResultExecutingContext preContext, Func`1 continuation) +257
System.Web.Mvc.<>c__DisplayClass14.<InvokeActionResultWithFilters>b__11() +20
System.Web.Mvc.ControllerActionInvoker.InvokeActionResultWithFilters(ActionResult actionResult, IList`1 filters) +188
System.Web.Mvc.ControllerActionInvoker.InvokeAction(ControllerContext controllerContext, String actionName) +386
System.Web.Mvc.Controller.ExecuteCore() +112
System.Web.Mvc.ControllerBase.Execute(RequestContext requestContext) +23
System.Web.Mvc.ControllerBase.System.Web.Mvc.IController.Execute(RequestContext requestContext) +7
System.Web.Mvc.MvcHandler.ProcessRequest(HttpContextBase httpContext) +107
System.Web.Mvc.MvcHandler.ProcessRequest(HttpContext httpContext) +39
System.Web.Mvc.MvcHandler.System.Web.IHttpHandler.ProcessRequest(HttpContext httpContext) +7
System.Web.CallHandlerExecutionStep.System.Web.HttpApplication.IExecutionStep.Execute() +181
System.Web.HttpApplication.ExecuteStep(IExecutionStep step, Boolean& completedSynchronously) +75
```
|
Yes, the bug has been reported. Best leave debug on for now, or modify the offending code (sorry cant recall where).
|
178,199 |
<p>In PHP I can name my array indices so that I may have something like:</p>
<pre><code>$shows = Array(0 => Array('id' => 1, 'name' => 'Sesame Street'),
1 => Array('id' => 2, 'name' => 'Dora The Explorer'));
</code></pre>
<p>Is this possible in Python?</p>
|
[
{
"answer_id": 178211,
"author": "Lou Franco",
"author_id": 3937,
"author_profile": "https://Stackoverflow.com/users/3937",
"pm_score": 3,
"selected": false,
"text": "<p>Yes,</p>\n\n<pre><code>a = {\"id\": 1, \"name\":\"Sesame Street\"}\n</code></pre>\n"
},
{
"answer_id": 178213,
"author": "Michael Twomey",
"author_id": 995,
"author_profile": "https://Stackoverflow.com/users/995",
"pm_score": 7,
"selected": true,
"text": "<p>This sounds like the PHP array using named indices is very similar to a python dict:</p>\n\n<pre><code>shows = [\n {\"id\": 1, \"name\": \"Sesaeme Street\"},\n {\"id\": 2, \"name\": \"Dora The Explorer\"},\n]\n</code></pre>\n\n<p>See <a href=\"http://docs.python.org/tutorial/datastructures.html#dictionaries\" rel=\"noreferrer\">http://docs.python.org/tutorial/datastructures.html#dictionaries</a> for more on this.</p>\n"
},
{
"answer_id": 178224,
"author": "Deestan",
"author_id": 6848,
"author_profile": "https://Stackoverflow.com/users/6848",
"pm_score": 5,
"selected": false,
"text": "<p>PHP arrays are actually maps, which is equivalent to dicts in Python.</p>\n<p>Thus, this is the Python equivalent:</p>\n<p><code>showlist = [{'id':1, 'name':'Sesaeme Street'}, {'id':2, 'name':'Dora the Explorer'}]</code></p>\n<p>Sorting example:</p>\n<pre><code>from operator import attrgetter\n\nshowlist.sort(key=attrgetter('id'))\n</code></pre>\n<p>BUT! With the example you provided, a simpler datastructure would be better:</p>\n<pre><code>shows = {1: 'Sesame Street', 2:'Dora the Explorer'}\n</code></pre>\n"
},
{
"answer_id": 178668,
"author": "Dan Lenski",
"author_id": 20789,
"author_profile": "https://Stackoverflow.com/users/20789",
"pm_score": 4,
"selected": false,
"text": "<p>@Unkwntech,</p>\n\n<p>What you want is available in the just-released Python 2.6 in the form of <a href=\"http://docs.python.org/whatsnew/2.6.html#new-improved-and-deprecated-modules\" rel=\"noreferrer\">named tuples</a>. They allow you to do this:</p>\n\n<pre><code>import collections\nperson = collections.namedtuple('Person', 'id name age')\n\nme = person(id=1, age=1e15, name='Dan')\nyou = person(2, 'Somebody', 31.4159)\n\nassert me.age == me[2] # can access fields by either name or position\n</code></pre>\n"
},
{
"answer_id": 179169,
"author": "Amandasaurus",
"author_id": 161922,
"author_profile": "https://Stackoverflow.com/users/161922",
"pm_score": 0,
"selected": false,
"text": "<p>Python has lists and dicts as 2 separate data structures. PHP mixes both into one. You should use dicts in this case. </p>\n"
},
{
"answer_id": 199271,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": -1,
"selected": false,
"text": "<p>I did it like this:</p>\n\n<pre><code>def MyStruct(item1=0, item2=0, item3=0):\n \"\"\"Return a new Position tuple.\"\"\"\n class MyStruct(tuple):\n @property\n def item1(self):\n return self[0]\n @property\n def item2(self):\n return self[1]\n @property\n def item3(self):\n return self[2]\n try:\n # case where first argument a 3-tuple \n return MyStruct(item1)\n except:\n return MyStruct((item1, item2, item3))\n</code></pre>\n\n<p>I did it also a bit more complicate with list instead of tuple, but I had override the setter as well as the getter.</p>\n\n<p>Anyways this allows:</p>\n\n<pre><code> a = MyStruct(1,2,3)\n print a[0]==a.item1\n</code></pre>\n"
},
{
"answer_id": 39307547,
"author": "Sreekanth",
"author_id": 6338857,
"author_profile": "https://Stackoverflow.com/users/6338857",
"pm_score": 2,
"selected": false,
"text": "<p>The <code>pandas</code> library has a really neat solution: <code>Series</code>. </p>\n\n<pre><code>book = pandas.Series( ['Introduction to python', 'Someone', 359, 10],\n index=['Title', 'Author', 'Number of pages', 'Price'])\nprint book['Author']\n</code></pre>\n\n<p>For more information check it's documentation: <a href=\"http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.html\" rel=\"nofollow\">http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.html</a>.</p>\n"
},
{
"answer_id": 62209288,
"author": "Joshna",
"author_id": 12157462,
"author_profile": "https://Stackoverflow.com/users/12157462",
"pm_score": 2,
"selected": false,
"text": "<p>I think what you are asking is about python dictionaries.There you can named your indices as you wish .\nFor ex:</p>\n\n<pre><code>dictionary = {\"name\": \"python\", \"age\": 12}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178199",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/115/"
] |
In PHP I can name my array indices so that I may have something like:
```
$shows = Array(0 => Array('id' => 1, 'name' => 'Sesame Street'),
1 => Array('id' => 2, 'name' => 'Dora The Explorer'));
```
Is this possible in Python?
|
This sounds like the PHP array using named indices is very similar to a python dict:
```
shows = [
{"id": 1, "name": "Sesaeme Street"},
{"id": 2, "name": "Dora The Explorer"},
]
```
See <http://docs.python.org/tutorial/datastructures.html#dictionaries> for more on this.
|
178,200 |
<p>I have the following JSP code, that protects my web page and displays it only to know IP's</p>
<pre><code>String ip_h = request.getRemoteAddr();
String host_h = request.getRemoteHost();
String iplist[] = new String[1];
iplist[0] = "127.0.0.1";
iplist[1] = "10.217.106.248";
int count = iplist.length;
boolean flag = false;
int zz = 0;
//return;
System.out.println(host_h);
while ( (flag==false) && ( zz < count) )
{
if (ip_h.equals(iplist[zz]) || host_h.equals(iplist[zz]) )
{
flag = true;
}
zz++;
}
</code></pre>
<p>However, I would to rather check for subnet ranges, i.e. all users belonging to 10.217.0.0/16 are allowed.</p>
<p>How do I do this?</p>
|
[
{
"answer_id": 178266,
"author": "Will Wagner",
"author_id": 25468,
"author_profile": "https://Stackoverflow.com/users/25468",
"pm_score": 2,
"selected": false,
"text": "<p>IP addresses (at least, IPv4 addresses) are really intended to be represented as 32-bit integers. If you convert the IP address to an integer first, checking subnet ranges becomes a relatively simple matter of checking (in your example) whether the first 16 bits match the first 16 bits of the range. </p>\n"
},
{
"answer_id": 178270,
"author": "SWD",
"author_id": 3034,
"author_profile": "https://Stackoverflow.com/users/3034",
"pm_score": 2,
"selected": false,
"text": "<p>wouldn't you rather use the application server to lock down the ip range? In apache you can create an alias for a directory, put your code in the directory, then in the alias directive only allow certain ip or ranges:</p>\n\n<p>Alias /mydir \"/usr/local/mydir\"</p>\n\n<p>\n order deny,allow\n deny from all\n Allow from 10.217.106.248\n Allow from 127.0.0.1\n allow from 10.217.106 #this is a range\n</p>\n\n<p>this way you don't have to code this sort of \"magic number\"</p>\n\n<p>I am sure you can do this type of thing in other web servers</p>\n"
},
{
"answer_id": 178293,
"author": "Bruno De Fraine",
"author_id": 6918,
"author_profile": "https://Stackoverflow.com/users/6918",
"pm_score": 0,
"selected": false,
"text": "<p>Try the <code>Subnet</code> class from this <a href=\"http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=4262187\" rel=\"nofollow noreferrer\">bug report</a>.</p>\n"
},
{
"answer_id": 178339,
"author": "Lazarin",
"author_id": 24124,
"author_profile": "https://Stackoverflow.com/users/24124",
"pm_score": 0,
"selected": false,
"text": "<p>You can use following piece of code, of course it assumes the input data are correct so it needs some beautifying (just in case)</p>\n\n<pre><code>public class IPUtil\n{\n\n private static int[] split(String ip)\n {\n int[] result = new int[4];\n StringTokenizer st = new StringTokenizer(ip, \".\");\n for (int i = 0; i < 4; i++)\n {\n result[i] = Integer.parseInt(st.nextToken());\n }\n return result;\n }\n\n public static boolean matches(String visitorIpString, String ipString, String maskString)\n {\n int[] vip = split(visitorIpString);\n int[] ip = split(ipString);\n int[] mask = split(maskString);\n\n for (int i = 0; i < 4; i++)\n {\n if ((vip[i] & mask[i]) != ip[i])\n {\n return false;\n }\n }\n return true;\n }\n\n public static void main(String[] args)\n {\n\n String ip = \"192.168.12.0\";\n String mask = \"255.255.255.0\";\n String visitorIP = \"192.168.12.55\";\n\n System.out.println(matches(visitorIP, ip, mask));\n }\n}\n</code></pre>\n"
},
{
"answer_id": 178627,
"author": "skaffman",
"author_id": 21234,
"author_profile": "https://Stackoverflow.com/users/21234",
"pm_score": 2,
"selected": false,
"text": "<p>Feel free to use this IpRangeFilter class. See class comment for explanation.</p>\n\n<pre><code>import java.net.InetAddress;\nimport java.net.UnknownHostException;\nimport java.util.regex.Matcher;\nimport java.util.regex.Pattern;\n\nimport org.apache.commons.collections15.Predicate;\nimport org.apache.commons.lang.builder.EqualsBuilder;\nimport org.apache.commons.lang.builder.HashCodeBuilder;\n\n/**\n * I am a filter used to determine if a given IP Address is covered by the IP range specified in \n * the constructor. I accept IP ranges in the form of full single IP addresses, e.g. 10.1.0.23\n * or network/netmask pairs in CIDR format e.g. 10.1.0.0/16\n */\npublic class IpRangeFilter implements Predicate<InetAddress> {\n\n private final long network;\n private final long netmask;\n\n private final String ipRange;\n\n private static final Pattern PATTERN = Pattern.compile(\"((?:\\\\d|\\\\.)+)(?:/(\\\\d{1,2}))?\");\n\n public IpRangeFilter(String ipRange) throws UnknownHostException {\n Matcher matcher = PATTERN.matcher(ipRange);\n if (matcher.matches()) {\n String networkPart = matcher.group(1);\n String cidrPart = matcher.group(2);\n\n long netmask = 0;\n int cidr = cidrPart == null ? 32 : Integer.parseInt(cidrPart);\n for (int pos = 0; pos < 32; ++pos) {\n if (pos >= 32-cidr) {\n netmask |= (1L << pos);\n }\n }\n\n this.network = netmask & toMask(InetAddress.getByName(networkPart));\n this.netmask = netmask;\n this.ipRange = ipRange;\n\n } else {\n throw new IllegalArgumentException(\"Not a valid IP range: \" + ipRange);\n }\n }\n\n public String getIpRange() {\n return ipRange;\n }\n\n public boolean evaluate(InetAddress address) {\n return isInRange(address);\n }\n\n public boolean isInRange(InetAddress address) {\n return network == (toMask(address) & netmask);\n }\n\n /**\n * Convert the bytes in the InetAddress into a bit mask stored as a long.\n * We could use int's here, but java represents those in as signed numbers, which can be a pain \n * when debugging.\n * @see http://www.captain.at/howto-java-convert-binary-data.php\n */\n static long toMask(InetAddress address) {\n byte[] data = address.getAddress();\n long accum = 0;\n int idx = 3;\n for ( int shiftBy = 0; shiftBy < 32; shiftBy += 8 ) {\n accum |= ( (long)( data[idx] & 0xff ) ) << shiftBy;\n idx--;\n }\n return accum;\n }\n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178200",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] |
I have the following JSP code, that protects my web page and displays it only to know IP's
```
String ip_h = request.getRemoteAddr();
String host_h = request.getRemoteHost();
String iplist[] = new String[1];
iplist[0] = "127.0.0.1";
iplist[1] = "10.217.106.248";
int count = iplist.length;
boolean flag = false;
int zz = 0;
//return;
System.out.println(host_h);
while ( (flag==false) && ( zz < count) )
{
if (ip_h.equals(iplist[zz]) || host_h.equals(iplist[zz]) )
{
flag = true;
}
zz++;
}
```
However, I would to rather check for subnet ranges, i.e. all users belonging to 10.217.0.0/16 are allowed.
How do I do this?
|
IP addresses (at least, IPv4 addresses) are really intended to be represented as 32-bit integers. If you convert the IP address to an integer first, checking subnet ranges becomes a relatively simple matter of checking (in your example) whether the first 16 bits match the first 16 bits of the range.
|
178,210 |
<p>We are building a multi-tenant website in ASP.NET, and we must let each customer configure their own security model. They must be able to define their own roles, and put users in those roles. What is the best way to do this?</p>
<p>There are tons of simple examples of page_load events that have code like:</p>
<pre><code> if (!user.InGroup("Admin")
Response.Redirect("/NoAccess.aspx");
</code></pre>
<p>But that hard codes the groups and permissions in the code. How can I make it user configurable?</p>
|
[
{
"answer_id": 178238,
"author": "ullmark",
"author_id": 23044,
"author_profile": "https://Stackoverflow.com/users/23044",
"pm_score": 0,
"selected": false,
"text": "<p>I would create a configuration system for the website that is easily managed in config-files. Where you could get typed members and use like this.</p>\n\n<pre><code>foreach(var group in ThisPageConfiguration.AcceptedRoleNames)\nif (user.IsInRole(group))\n...\n</code></pre>\n\n<p>Each customer could then configure their site in their configuration files... And every other type of things you'd want to configure.</p>\n"
},
{
"answer_id": 178295,
"author": "Turnkey",
"author_id": 13144,
"author_profile": "https://Stackoverflow.com/users/13144",
"pm_score": 3,
"selected": true,
"text": "<p>Perhaps put the configurable roles in a DB table, where you store the roles and tenant, and then the PagePermissions in another table, for example:</p>\n\n<pre><code>Table \"Role\"\nRoleId, TenantId, Role\n\nTable \"PagePermissions\"\nPageId, RoleId\n\nTable \"UserRoles\"\nUserId, RoleId\n</code></pre>\n\n<p>Then in the page load check whether the User is in a RoleId that has permissions for that page, for example:</p>\n\n<pre><code>Select PageId FROM \nUserRoles UR INNER JOIN PagePermissions PP\nON UR.RoleId = PP.RoleID\nWHERE UR.Userid = @UserId AND PP.PageID = @PageId\n</code></pre>\n\n<p>If there are no rows returned then deny the user.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178210",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/681/"
] |
We are building a multi-tenant website in ASP.NET, and we must let each customer configure their own security model. They must be able to define their own roles, and put users in those roles. What is the best way to do this?
There are tons of simple examples of page\_load events that have code like:
```
if (!user.InGroup("Admin")
Response.Redirect("/NoAccess.aspx");
```
But that hard codes the groups and permissions in the code. How can I make it user configurable?
|
Perhaps put the configurable roles in a DB table, where you store the roles and tenant, and then the PagePermissions in another table, for example:
```
Table "Role"
RoleId, TenantId, Role
Table "PagePermissions"
PageId, RoleId
Table "UserRoles"
UserId, RoleId
```
Then in the page load check whether the User is in a RoleId that has permissions for that page, for example:
```
Select PageId FROM
UserRoles UR INNER JOIN PagePermissions PP
ON UR.RoleId = PP.RoleID
WHERE UR.Userid = @UserId AND PP.PageID = @PageId
```
If there are no rows returned then deny the user.
|
178,216 |
<p>In Informix, how can I cast a <code>char(8)</code> type into a <code>money</code> type, so that I can compare it to another <code>money</code> type?</p>
<p>Using "<code>tblAid.amt::money as aid_amt</code>" did not work.
Using "<code>(tblAid.amt * 1) AS aid_amt</code>" did not work.</p>
|
[
{
"answer_id": 185890,
"author": "SKapsal",
"author_id": 24721,
"author_profile": "https://Stackoverflow.com/users/24721",
"pm_score": 4,
"selected": true,
"text": "<p>try this --> </p>\n\n<pre><code>select (disb_amt::NUMERIC) disb_amt from tmp_kygrants;\n</code></pre>\n\n<p>You may be able to compare the amounts as numeric.</p>\n"
},
{
"answer_id": 185929,
"author": "KristoferA",
"author_id": 11241,
"author_profile": "https://Stackoverflow.com/users/11241",
"pm_score": 1,
"selected": false,
"text": "<p>'tis been a while since I played around with informix and I don't have a running instance handy at the moment. However, there are two things that can cause a problem here:</p>\n\n<p>1) since it is a char(8) it can contain values that can not be casted to numeric without a bit of 'cleanup'. E.g. \"abc\". Or \"1,234,567.00\".<br>\n2) Trailing spaces. (char as opposed to varchar).</p>\n\n<p>What informix error do you get on your explicit cast (::money)?</p>\n"
},
{
"answer_id": 188635,
"author": "Jonathan Leffler",
"author_id": 15168,
"author_profile": "https://Stackoverflow.com/users/15168",
"pm_score": 3,
"selected": false,
"text": "<p>First question - why on earth are you not storing a numeric value in a numeric column? This would make the rest of your question moot. It would also mean that your system will perform better. When you need to store data values, use the obvious type; do not use a string type unless the data is a string.</p>\n\n<p>As already noted, you can use the non-standard Informix cast notation:</p>\n\n<pre><code>SELECT some_column::MONEY FROM WhereEver;\n</code></pre>\n\n<p>You can also be more careful about the cast type - using MONEY(8,2) for example. You can also use the standard notation:</p>\n\n<pre><code>SELECT CAST(some_column AS MONEY(8,2)) FROM WhereEver;\n</code></pre>\n\n<p>This assumes you are using IDS 9.x or later -- older products do not support casts at all. However, in general, Informix is pretty good about doing conversions automatically (for example, converting numbers to strings). However, strings are compared lexicographically and not numerically, so a CAST is probably wiser in this context -- but avoiding the need for a cast by using the correct type in the first place is wiser still.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178216",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13832/"
] |
In Informix, how can I cast a `char(8)` type into a `money` type, so that I can compare it to another `money` type?
Using "`tblAid.amt::money as aid_amt`" did not work.
Using "`(tblAid.amt * 1) AS aid_amt`" did not work.
|
try this -->
```
select (disb_amt::NUMERIC) disb_amt from tmp_kygrants;
```
You may be able to compare the amounts as numeric.
|
178,247 |
<p>I have minified my javascript and my css.</p>
<p>Now, Which is better?</p>
<pre><code><script type="text/javascript">
<?
$r = file_get_contents('min.js');
if($r) echo $r;
?>
</script>
</code></pre>
<p>OR</p>
<pre><code><script type="text/javascript" src="min.js"></script>
</code></pre>
<p>Same question for CSS.</p>
<p>If the answer is 'sometimes because browsers fetch files simultaneously?' Which browsers, and what are examples of the times in either scenario.</p>
|
[
{
"answer_id": 178269,
"author": "Jonny Buchanan",
"author_id": 6760,
"author_profile": "https://Stackoverflow.com/users/6760",
"pm_score": 6,
"selected": true,
"text": "<pre><code><script type=\"text/javascript\" src=\"min.js\"></script>\n</code></pre>\n\n<p>...is better, as the user's browser can cache the file.</p>\n\n<p>Adding a parameter to the <code>src</code> such as the file's last modified timestamp is even better, as the user's browser will cache the file but will always retrieve the most up to date version when the file is modified.</p>\n\n<pre><code><script type=\"text/javascript\" src=\"min.js?version=20081007134916\"></script>\n</code></pre>\n"
},
{
"answer_id": 178313,
"author": "Joe Scylla",
"author_id": 25771,
"author_profile": "https://Stackoverflow.com/users/25771",
"pm_score": 3,
"selected": false,
"text": "<p>It's better the most times to include javascript and css files because that way the browser is able to cache the javascript/css file. That way the file is only loaded once by the browser even if you include the file in several other pages. </p>\n\n<p>But this is only true if you set an appropriate expires and/or cache-control header for javascript and css files via php or Apache mod_expires. </p>\n\n<p>Based on the recommondation by the Yahoo Exceptional Performance there is only one exception:</p>\n\n<blockquote>\n <p>The only exception where inlining is preferable is with home pages, such as Yahoo!'s front page and My Yahoo!. Home pages that have few (perhaps only one) page view per session may find that inlining JavaScript and CSS results in faster end-user response times.</p>\n</blockquote>\n\n<p>I higly suggest you try out the Addon \"YSlow for Firebug\". It answers alot of questions about caching and browser/client -performance.</p>\n\n<p>See also:</p>\n\n<p><a href=\"http://httpd.apache.org/docs/1.3/mod/mod_expires.html\" rel=\"nofollow noreferrer\">Apache mod_expires</a></p>\n\n<p><a href=\"http://developer.yahoo.com/performance/rules.html\" rel=\"nofollow noreferrer\">Best Practices for Speeding Up Your Web Site</a></p>\n\n<p><a href=\"http://developer.yahoo.com/yslow/\" rel=\"nofollow noreferrer\">YSlow</a></p>\n"
},
{
"answer_id": 180959,
"author": "Alex Weinstein",
"author_id": 16668,
"author_profile": "https://Stackoverflow.com/users/16668",
"pm_score": 0,
"selected": false,
"text": "<p>Remember that the browser can download AT MOST two files in parallel from the same domain (that's the default on the modern browsers - i'm certain about IE6 and IE7, not sure about others). This means that if your page references 20 tiny javascript files, many will get downloaded sequentially. </p>\n\n<p>To add to what was already said: remember that if you combine/minify your javascript files, it's better to merge them all into one - the compression will work better. Additionally, even if you don't minify your files, remember to turn on GZIP in your web server config; then, if you combine all your JS files into one and include that file as , the GZIP compression will work best (because compressing two JS files together produces better results than compressing each separately). </p>\n\n<p>If you're looking for a good JS minification utility, try JS Packer (<a href=\"http://dean.edwards.name/packer/\" rel=\"nofollow noreferrer\">http://dean.edwards.name/packer/</a>)</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178247",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/144/"
] |
I have minified my javascript and my css.
Now, Which is better?
```
<script type="text/javascript">
<?
$r = file_get_contents('min.js');
if($r) echo $r;
?>
</script>
```
OR
```
<script type="text/javascript" src="min.js"></script>
```
Same question for CSS.
If the answer is 'sometimes because browsers fetch files simultaneously?' Which browsers, and what are examples of the times in either scenario.
|
```
<script type="text/javascript" src="min.js"></script>
```
...is better, as the user's browser can cache the file.
Adding a parameter to the `src` such as the file's last modified timestamp is even better, as the user's browser will cache the file but will always retrieve the most up to date version when the file is modified.
```
<script type="text/javascript" src="min.js?version=20081007134916"></script>
```
|
178,255 |
<p>I'm talking about c# <del>3.5</del> 3.0.
I know how to do it when cache or ServiceProvider can have only one instance for the whole application. In this case ServiceProvider can look like this</p>
<pre><code>public static class Service<T>
{
public static T Value {get; set;}
}
</code></pre>
<p>and can be used for different types like this:</p>
<pre><code>Service<IDbConnection>.Value = new SqlConnection("...");
Service<IDesigner>.Value = ...;
//...
IDbCommand cmd = Service<IDbConnection>.Value.CreateCommand();
</code></pre>
<p>Static cache is also easy:</p>
<pre><code>public static class Cache<T>
{
private static Dictionary<int, T> cache = new Dictionary<int, T>();
public static void Add(int key, T value)
{
cache.Add(key, value);
}
public static T Find(int key)
{
return cache[key];
}
}
</code></pre>
<p>and can be used like this:</p>
<pre><code>Cache<string>.Add(1, "test");
Cache<DateTime>.Add(2, DateTime.Now);
//...
string found = Cache<string>.Find(1);
</code></pre>
<p><br>
<strong>My question is</strong>: how can I create similiar cache or service provider when I want to have 2 or more different instances of each. Here is example code, how I want to use service provider:</p>
<pre><code>ServiceProvider provider = new ServiceProvider();
provider.Add<IDbConnection>(new SqlConnection("..."));
provider.Add<IDesigner>(...);
//...
ServiceProvider provider1 = new ServiceProvider();
provider1.Add<IDbConnection>(new SqlConnection("..."));
//...
//...
IDbCommand cmd1 = provider.GetService<IDbConnection>().CreateCommand();
IDbCommand cmd2 = provider1.GetService<IDbConnection>().CreateCommand();
</code></pre>
<p>The only implementation that I have in my head is using <strong>casting which I want to avoid</strong>.</p>
<pre><code>public class ServiceProvider
{
private Dictionary<Type, object> services = new Dictionary<Type, object>();
public void Add<T>(T value)
{
services.Add(typeof(T), value);
}
public T GetService<T>()
{
return (T) services[typeof (T)];
}
}
</code></pre>
|
[
{
"answer_id": 178310,
"author": "Jon Skeet",
"author_id": 22656,
"author_profile": "https://Stackoverflow.com/users/22656",
"pm_score": 2,
"selected": false,
"text": "<p>Why are you particularly desperate to avoid casting? Yes, it feels \"unsafe\" - but you can basically guarantee that it's not going to be an issue in ServiceProvider, and the clients aren't doing any casting.</p>\n\n<p>This is a reasonably common problem, but I don't believe there's any nice solution to it within .NET generics - it's a type relationship which can't be expressed, basically.</p>\n\n<p>EDIT: I've now <a href=\"http://msmvps.com/blogs/jon_skeet/archive/2008/10/08/mapping-from-a-type-to-an-instance-of-that-type.aspx\" rel=\"nofollow noreferrer\">blogged</a> about this and encapsulated the behaviour in a type. Feel free to take that code if it keeps things cleaner for you.</p>\n"
},
{
"answer_id": 186847,
"author": "James Hart",
"author_id": 5755,
"author_profile": "https://Stackoverflow.com/users/5755",
"pm_score": 1,
"selected": false,
"text": "<p>As I posted to <a href=\"http://msmvps.com/blogs/jon_skeet/archive/2008/10/08/mapping-from-a-type-to-an-instance-of-that-type.aspx\" rel=\"nofollow noreferrer\">Jon Skeet's blog,</a> the following approach might help you avoid casts, if that's a worry (though perhaps this introduces some other more serious issues than casting :)).</p>\n\n<p>If you have a weak dictionary implementation (one that uses weak-reference keys and cleans out otherwise unreferenced keys and their associated values), you could try something like this:</p>\n\n<pre><code> public class TypeDictionary \n { \n private class InnerTypeDictionary<T>\n {\n static WeakDictionary<TypeDictionary, T> _innerDictionary = new WeakDictionary<TypeDictionary, T>();\n public static void Add(TypeDictionary dic, T value)\n {\n _innerDictionary.Add(dic, value);\n }\n\n public static T GetValue(TypeDictionary dic)\n {\n return _innerDictionary[dic];\n }\n }\n\n public void Add<T>(T value)\n {\n InnerTypeDictionary<T>.Add(this, value);\n }\n\n public T GetValue<T>()\n {\n return InnerTypeDictionary<T>.GetValue(this);\n }\n }\n</code></pre>\n\n<p>It has the benefit of making all the type lookups into static generic type lookups, without direct recourse to <code>System.Type</code> objects, so I guess that might give you a performance kick. I would be interested to know if it does suit your caching scenario.</p>\n"
},
{
"answer_id": 189329,
"author": "SeeR",
"author_id": 22569,
"author_profile": "https://Stackoverflow.com/users/22569",
"pm_score": 0,
"selected": false,
"text": "<p><del>I think I found the solution. Here you have my implementation of ServiceProvider\nYou can find the description of it on <a href=\"http://seermindflow.blogspot.com/2008/10/is-it-possible-to-write-c-application.html\" rel=\"nofollow noreferrer\">my blog</a>.</p>\n\n<pre><code>public class ServiceContainer : IDisposable\n{\n readonly IList<IService> services = new List<IService>();\n\n public void Add<T>(T service)\n {\n Add<T,T>(service);\n }\n\n public void Add<Key, T>(T service) where T : Key\n {\n services.Add(new Service<Key>(this, service));\n }\n\n public void Dispose()\n {\n foreach(var service in services)\n service.Remove(this);\n }\n\n ~ServiceContainer()\n {\n Dispose();\n }\n\n public T Get<T>()\n {\n return Service<T>.Get(this);\n }\n}\n\npublic interface IService\n{\n void Remove(object parent);\n}\n\npublic class Service<T> : IService\n{\n static readonly Dictionary<object, T> services = new Dictionary<object, T>();\n\n public Service(object parent, T service)\n {\n services.Add(parent, service);\n }\n\n public void Remove(object parent)\n {\n services.Remove(parent);\n }\n\n public static T Get(object parent)\n {\n return services[parent];\n }\n}\n</code></pre>\n\n<p>Yes it uses static field, but all references are removed in finalizer so the only drawback is that ServiceProvider stays one GC generation longer than usually.</del></p>\n\n<p><strong>EDIT</strong>: OK, after few tries I must admit that Jon Skeet was right, currently there is no simple solution to this problem. My solution written above can work only if I fulfill 2 constraints:</p>\n\n<ol>\n<li>I use <code>Dictionary<WeakReference, T> services</code> instead of <code>Dictionary<object, T> services</code></li>\n<li>No service will have reference to ServiceProvider.</li>\n</ol>\n\n<p>Otherwise you will have memory leaks :-(</p>\n\n<p>Simple solution that Microsoft could provide is to create native WeakReference< T > which will solve constraint No 2. and we can write services like this:</p>\n\n<pre><code>Dictionary<WeakReference, WeakReference<T>> services\n</code></pre>\n"
},
{
"answer_id": 223299,
"author": "jezell",
"author_id": 27453,
"author_profile": "https://Stackoverflow.com/users/27453",
"pm_score": 0,
"selected": false,
"text": "<p>There is no good way to do this without casting. Don't get hung up on the casting cost. Focus on things that actually impact performance...for example, hashing isn't free to begin with. You shouldn't be calling back into your service provider every time you want to use a service. Get the reference a single time and you don't have to worry about the mounting costs of retrieval:</p>\n\n<pre><code>var service = provider.GetService<MyService>();\nservice.DoSomething();\nservice.DoSomethingElse();\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178255",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/22569/"
] |
I'm talking about c# ~~3.5~~ 3.0.
I know how to do it when cache or ServiceProvider can have only one instance for the whole application. In this case ServiceProvider can look like this
```
public static class Service<T>
{
public static T Value {get; set;}
}
```
and can be used for different types like this:
```
Service<IDbConnection>.Value = new SqlConnection("...");
Service<IDesigner>.Value = ...;
//...
IDbCommand cmd = Service<IDbConnection>.Value.CreateCommand();
```
Static cache is also easy:
```
public static class Cache<T>
{
private static Dictionary<int, T> cache = new Dictionary<int, T>();
public static void Add(int key, T value)
{
cache.Add(key, value);
}
public static T Find(int key)
{
return cache[key];
}
}
```
and can be used like this:
```
Cache<string>.Add(1, "test");
Cache<DateTime>.Add(2, DateTime.Now);
//...
string found = Cache<string>.Find(1);
```
**My question is**: how can I create similiar cache or service provider when I want to have 2 or more different instances of each. Here is example code, how I want to use service provider:
```
ServiceProvider provider = new ServiceProvider();
provider.Add<IDbConnection>(new SqlConnection("..."));
provider.Add<IDesigner>(...);
//...
ServiceProvider provider1 = new ServiceProvider();
provider1.Add<IDbConnection>(new SqlConnection("..."));
//...
//...
IDbCommand cmd1 = provider.GetService<IDbConnection>().CreateCommand();
IDbCommand cmd2 = provider1.GetService<IDbConnection>().CreateCommand();
```
The only implementation that I have in my head is using **casting which I want to avoid**.
```
public class ServiceProvider
{
private Dictionary<Type, object> services = new Dictionary<Type, object>();
public void Add<T>(T value)
{
services.Add(typeof(T), value);
}
public T GetService<T>()
{
return (T) services[typeof (T)];
}
}
```
|
Why are you particularly desperate to avoid casting? Yes, it feels "unsafe" - but you can basically guarantee that it's not going to be an issue in ServiceProvider, and the clients aren't doing any casting.
This is a reasonably common problem, but I don't believe there's any nice solution to it within .NET generics - it's a type relationship which can't be expressed, basically.
EDIT: I've now [blogged](http://msmvps.com/blogs/jon_skeet/archive/2008/10/08/mapping-from-a-type-to-an-instance-of-that-type.aspx) about this and encapsulated the behaviour in a type. Feel free to take that code if it keeps things cleaner for you.
|
178,257 |
<p>Huge files take forever to load and work with in vim, due to syntax-highlighting.</p>
<p>I'm looking for a way to limit size of highlighted files, such that files larger than (say) 10MB will be colorless.</p>
|
[
{
"answer_id": 178267,
"author": "tomasr",
"author_id": 10292,
"author_profile": "https://Stackoverflow.com/users/10292",
"pm_score": 3,
"selected": false,
"text": "<p>I haven't tried it myself, but the <a href=\"http://www.vim.org/scripts/script.php?script_id=1506\" rel=\"noreferrer\">LargeFile</a> plugin seems to be exactly to address the kind of stuff you're looking for.</p>\n"
},
{
"answer_id": 178315,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>vim -c 'syntax off' filename.ext</p>\n"
},
{
"answer_id": 178372,
"author": "HS.",
"author_id": 1398,
"author_profile": "https://Stackoverflow.com/users/1398",
"pm_score": 2,
"selected": false,
"text": "<p>vim -u NONE <filename></p>\n\n<p>This will skip all initializations from configuration files.</p>\n\n<p>Use uppercase U when running gvim.</p>\n\n<p>\"-i NONE\" does only exclude viminfo from being loaded. If you defined syntax hilighting in there, that would help too.</p>\n"
},
{
"answer_id": 179103,
"author": "Zathrus",
"author_id": 16220,
"author_profile": "https://Stackoverflow.com/users/16220",
"pm_score": 4,
"selected": false,
"text": "<p>Add to your .vimrc:</p>\n\n<pre>autocmd BufReadPre * if getfsize(expand(\"%\")) > 10000000 | syntax off | endif</pre>\n\n<p>Note that this disables syntax highlighting in ALL buffers; syntax is a global vim thing and cannot be restricted to a single buffer.</p>\n"
},
{
"answer_id": 559052,
"author": "Paul Oyster",
"author_id": 38193,
"author_profile": "https://Stackoverflow.com/users/38193",
"pm_score": 6,
"selected": true,
"text": "<p>Adding the following line to _vimrc does the trick, with a bonus: it handles gzipped files, too (which is a common case with huge files):</p>\n\n<pre><code>autocmd BufWinEnter * if line2byte(line(\"$\") + 1) > 1000000 | syntax clear | endif\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178257",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6984/"
] |
Huge files take forever to load and work with in vim, due to syntax-highlighting.
I'm looking for a way to limit size of highlighted files, such that files larger than (say) 10MB will be colorless.
|
Adding the following line to \_vimrc does the trick, with a bonus: it handles gzipped files, too (which is a common case with huge files):
```
autocmd BufWinEnter * if line2byte(line("$") + 1) > 1000000 | syntax clear | endif
```
|
178,263 |
<p>I am testing a web app that writes cookies to subdomain.thisdomain.com and several subfolders within that. I'm looking for JavaScript that I can put into a bookmarklet that will delete all cookies under that subdomain, regardless of the folder in which they exist.</p>
<p>Any ideas?</p>
|
[
{
"answer_id": 178294,
"author": "Sergey Ilinsky",
"author_id": 23815,
"author_profile": "https://Stackoverflow.com/users/23815",
"pm_score": 2,
"selected": false,
"text": "<p>I would recommend <a href=\"https://addons.mozilla.org/en-US/firefox/addon/6683\" rel=\"nofollow noreferrer\">Firecookie</a> extension to Firebug.</p>\n"
},
{
"answer_id": 179535,
"author": "Robert J. Walker",
"author_id": 4287,
"author_profile": "https://Stackoverflow.com/users/4287",
"pm_score": 6,
"selected": true,
"text": "<p>Derived from <a href=\"https://stackoverflow.com/questions/179355/clearing-all-cookies-with-javascript#179514\">my answer here</a>:</p>\n\n<pre><code>javascript:new function(){var c=document.cookie.split(\";\");for(var i=0;i<c.length;i++){var e=c[i].indexOf(\"=\");var n=e>-1?c[i].substr(0,e):c[i];document.cookie=n+\"=;expires=Thu, 01 Jan 1970 00:00:00 GMT\";}}(); return void(0);\n</code></pre>\n\n<p>Due to browser security issues, this will only work when executed while on a page that has access to all the cookies you want to delete.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178263",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/335036/"
] |
I am testing a web app that writes cookies to subdomain.thisdomain.com and several subfolders within that. I'm looking for JavaScript that I can put into a bookmarklet that will delete all cookies under that subdomain, regardless of the folder in which they exist.
Any ideas?
|
Derived from [my answer here](https://stackoverflow.com/questions/179355/clearing-all-cookies-with-javascript#179514):
```
javascript:new function(){var c=document.cookie.split(";");for(var i=0;i<c.length;i++){var e=c[i].indexOf("=");var n=e>-1?c[i].substr(0,e):c[i];document.cookie=n+"=;expires=Thu, 01 Jan 1970 00:00:00 GMT";}}(); return void(0);
```
Due to browser security issues, this will only work when executed while on a page that has access to all the cookies you want to delete.
|
178,265 |
<p>Today at work we came across the following code (some of you might recognize it):</p>
<pre><code>#define GET_VAL( val, type ) \
{ \
ASSERT( ( pIP + sizeof(type) ) <= pMethodEnd ); \
val = ( *((type *&)(pIP))++ ); \
}
</code></pre>
<p>Basically we have a byte array and a pointer. The macro returns a reference to a variable of type and advance the pointer to the end of that variable.</p>
<p>It reminded me of the several times that I needed to "think like a parser" in order to understand C++ code.</p>
<p>Do you know of other code examples that caused you to stop and read it several times till you managed to grasp what it was suppose to do?</p>
|
[
{
"answer_id": 178308,
"author": "Simon",
"author_id": 24039,
"author_profile": "https://Stackoverflow.com/users/24039",
"pm_score": 2,
"selected": false,
"text": "<p>C, but present in C++, I find the comma operator really obfuscates code, take this...</p>\n\n<pre><code>ihi = y[0]>y[1] ? (inhi=1,0) : (inhi=0,1);\n</code></pre>\n\n<p>Terse and quite elegant, but very easy to miss or misunderstand.</p>\n"
},
{
"answer_id": 178356,
"author": "wcm",
"author_id": 2173,
"author_profile": "https://Stackoverflow.com/users/2173",
"pm_score": 4,
"selected": false,
"text": "<p>I know it's C and not C++ but there is always the the <a href=\"http://www.ioccc.org/\" rel=\"noreferrer\">International Obfuscated C Code Contest</a>. I have seen some code there that would make your head spin.</p>\n"
},
{
"answer_id": 178361,
"author": "Ma99uS",
"author_id": 20390,
"author_profile": "https://Stackoverflow.com/users/20390",
"pm_score": 3,
"selected": false,
"text": "<p>This is well known but still impressive way to swap two integers without creating temp variable:</p>\n\n<pre><code>// a^=b^=a^=b; // int a and int b will be swapped\n// Technically undefined behavior as variable may only \n// be assined once within the same statement.\n// \n// But this can be written correctly like this.\n// Which still looks cool and unreadable ;-)\n\na^=b;\nb^=a;\na^=b;\n</code></pre>\n"
},
{
"answer_id": 178367,
"author": "Shimi Bandiel",
"author_id": 15100,
"author_profile": "https://Stackoverflow.com/users/15100",
"pm_score": -1,
"selected": false,
"text": "<p>Binary shift confuses me all the time. An example from the <code>java.util.concurrent.ConcurrentHashMap</code> package:</p>\n\n<pre><code>return ((h << 7) - h + (h >>> 9) + (h >>> 17))\n</code></pre>\n"
},
{
"answer_id": 178446,
"author": "Martin Beckett",
"author_id": 10897,
"author_profile": "https://Stackoverflow.com/users/10897",
"pm_score": 5,
"selected": false,
"text": "<p>This was on reddit recently <a href=\"http://www.eelis.net/C++/analogliterals.xhtml\" rel=\"noreferrer\">http://www.eelis.net/C++/analogliterals.xhtml</a></p>\n\n<pre><code> assert((o-----o\n | !\n ! !\n ! !\n ! !\n o-----o ).area == ( o---------o\n | !\n ! !\n o---------o ).area );\n</code></pre>\n"
},
{
"answer_id": 178501,
"author": "mbeckish",
"author_id": 21727,
"author_profile": "https://Stackoverflow.com/users/21727",
"pm_score": 3,
"selected": false,
"text": "<pre><code>unsigned int reverse(register unsigned int x)\n{\n x = (((x & 0xaaaaaaaa) >> 1) | ((x & 0x55555555) << 1));\n x = (((x & 0xcccccccc) >> 2) | ((x & 0x33333333) << 2));\n x = (((x & 0xf0f0f0f0) >> 4) | ((x & 0x0f0f0f0f) << 4));\n x = (((x & 0xff00ff00) >> 8) | ((x & 0x00ff00ff) << 8));\n return((x >> 16) | (x << 16));\n}\n</code></pre>\n\n<p>Reverses the order of the bits in an int.</p>\n"
},
{
"answer_id": 178574,
"author": "Kasprzol",
"author_id": 5957,
"author_profile": "https://Stackoverflow.com/users/5957",
"pm_score": -1,
"selected": false,
"text": "<p>I vote for some black-magic-hackerish template metaprogramming (unfortunately don't have any on hand to post it).</p>\n"
},
{
"answer_id": 178591,
"author": "Matt Rogish",
"author_id": 2590,
"author_profile": "https://Stackoverflow.com/users/2590",
"pm_score": 4,
"selected": false,
"text": "<p>Duff's Device (<a href=\"http://en.wikipedia.org/wiki/Duff%27s_device\" rel=\"nofollow noreferrer\">http://en.wikipedia.org/wiki/Duff%27s_device</a>) give me nightmares:</p>\n\n<pre><code>strcpy(to, from, count)\nchar *to, *from;\nint count;\n{\n int n = (count + 7) / 8;\n switch (count % 8) {\n case 0: do { *to = *from++;\n case 7: *to = *from++;\n case 6: *to = *from++;\n case 5: *to = *from++;\n case 4: *to = *from++;\n case 3: *to = *from++;\n case 2: *to = *from++;\n case 1: *to = *from++;\n } while (--n > 0);\n }\n}\n</code></pre>\n"
},
{
"answer_id": 179208,
"author": "coppro",
"author_id": 16855,
"author_profile": "https://Stackoverflow.com/users/16855",
"pm_score": 3,
"selected": false,
"text": "<p>Most Boost stuff - the template metaprogramming is bad enough, but when you factor in the workarounds necessary to get it to work on some compilers (*coughborlandcough*), it gets pretty ridiculous. Just try to understand Boost.Bind. Just try.</p>\n"
},
{
"answer_id": 179225,
"author": "Ates Goral",
"author_id": 23501,
"author_profile": "https://Stackoverflow.com/users/23501",
"pm_score": 7,
"selected": true,
"text": "<p>The inverse square root implementation in Quake 3:</p>\n\n<pre><code>float InvSqrt (float x){\n float xhalf = 0.5f*x;\n int i = *(int*)&x;\n i = 0x5f3759df - (i>>1);\n x = *(float*)&i;\n x = x*(1.5f - xhalf*x*x);\n return x;\n}\n</code></pre>\n\n<p><strong>Update:</strong>\n<a href=\"http://www.lomont.org/Math/Papers/2003/InvSqrt.pdf\" rel=\"noreferrer\">How this works</a> (thanks ryan_s)</p>\n"
},
{
"answer_id": 2501021,
"author": "Skizz",
"author_id": 1898,
"author_profile": "https://Stackoverflow.com/users/1898",
"pm_score": 2,
"selected": false,
"text": "<p>Anything prefixed with:</p>\n\n<p><a href=\"http://cm.bell-labs.com/cm/cs/who/dmr/odd.html\" rel=\"nofollow noreferrer\">/* You are not expected to understand this */</a></p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178265",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11361/"
] |
Today at work we came across the following code (some of you might recognize it):
```
#define GET_VAL( val, type ) \
{ \
ASSERT( ( pIP + sizeof(type) ) <= pMethodEnd ); \
val = ( *((type *&)(pIP))++ ); \
}
```
Basically we have a byte array and a pointer. The macro returns a reference to a variable of type and advance the pointer to the end of that variable.
It reminded me of the several times that I needed to "think like a parser" in order to understand C++ code.
Do you know of other code examples that caused you to stop and read it several times till you managed to grasp what it was suppose to do?
|
The inverse square root implementation in Quake 3:
```
float InvSqrt (float x){
float xhalf = 0.5f*x;
int i = *(int*)&x;
i = 0x5f3759df - (i>>1);
x = *(float*)&i;
x = x*(1.5f - xhalf*x*x);
return x;
}
```
**Update:**
[How this works](http://www.lomont.org/Math/Papers/2003/InvSqrt.pdf) (thanks ryan\_s)
|
178,325 |
<p>How do I toggle the visibility of an element using <code>.hide()</code>, <code>.show()</code>, or <code>.toggle()</code>?</p>
<p>How do I test if an element is <code>visible</code> or <code>hidden</code>?</p>
|
[
{
"answer_id": 178344,
"author": "Mote",
"author_id": 24789,
"author_profile": "https://Stackoverflow.com/users/24789",
"pm_score": 10,
"selected": false,
"text": "<pre><code>if ( $(element).css('display') == 'none' || $(element).css(\"visibility\") == \"hidden\"){\n // 'element' is hidden\n}\n</code></pre>\n\n<p>The above method does not consider the visibility of the parent. To consider the parent as well, you should use <code>.is(\":hidden\")</code> or <code>.is(\":visible\")</code>.</p>\n\n<p>For example,</p>\n\n<pre><code><div id=\"div1\" style=\"display:none\">\n <div id=\"div2\" style=\"display:block\">Div2</div>\n</div>\n</code></pre>\n\n<blockquote>\n <p>The above method will consider <code>div2</code> visible while <code>:visible</code> not. But the above might be useful in many cases, especially when you need to find if there is any error divs visible in the hidden parent because in such conditions <code>:visible</code> will not work.</p>\n</blockquote>\n"
},
{
"answer_id": 178386,
"author": "twernt",
"author_id": 18846,
"author_profile": "https://Stackoverflow.com/users/18846",
"pm_score": 11,
"selected": false,
"text": "<p>You can use the <a href=\"http://docs.jquery.com/Selectors/hidden\" rel=\"noreferrer\"><code>hidden</code></a> selector:</p>\n\n<pre><code>// Matches all elements that are hidden\n$('element:hidden')\n</code></pre>\n\n<p>And the <a href=\"http://docs.jquery.com/Selectors/visible\" rel=\"noreferrer\"><code>visible</code></a> selector:</p>\n\n<pre><code>// Matches all elements that are visible\n$('element:visible')\n</code></pre>\n"
},
{
"answer_id": 178450,
"author": "Tsvetomir Tsonev",
"author_id": 25449,
"author_profile": "https://Stackoverflow.com/users/25449",
"pm_score": 14,
"selected": true,
"text": "<p>Since the question refers to a single element, this code might be more suitable:</p>\n<pre><code>// Checks CSS content for display:[none|block], ignores visibility:[true|false]\n$(element).is(":visible");\n\n// The same works with hidden\n$(element).is(":hidden");\n</code></pre>\n<p>It is the same as <a href=\"https://stackoverflow.com/questions/178325/how-do-you-test-if-something-is-hidden-in-jquery/178386#178386\">twernt's suggestion</a>, but applied to a single element; and it <a href=\"https://stackoverflow.com/questions/178325/how-do-i-check-if-an-element-is-hidden-in-jquery/4685330#4685330\">matches the algorithm recommended in the jQuery FAQ</a>.</p>\n<p>We use jQuery's <a href=\"https://api.jquery.com/is/\" rel=\"noreferrer\">is()</a> to check the selected element with another element, selector or any jQuery object. This method traverses along the DOM elements to find a match, which satisfies the passed parameter. It will return true if there is a match, otherwise return false.</p>\n"
},
{
"answer_id": 1181809,
"author": "Simon_Weaver",
"author_id": 16940,
"author_profile": "https://Stackoverflow.com/users/16940",
"pm_score": 8,
"selected": false,
"text": "<p>Often when checking if something is visible or not, you are going to go right ahead immediately and do something else with it. jQuery chaining makes this easy.</p>\n\n<p>So if you have a selector and you want to perform some action on it only if is visible or hidden, you can use <code>filter(\":visible\")</code> or <code>filter(\":hidden\")</code> followed by chaining it with the action you want to take.</p>\n\n<p>So instead of an <code>if</code> statement, like this:</p>\n\n<pre><code>if ($('#btnUpdate').is(\":visible\"))\n{\n $('#btnUpdate').animate({ width: \"toggle\" }); // Hide button\n}\n</code></pre>\n\n<p>Or more efficient, but even uglier:</p>\n\n<pre><code>var button = $('#btnUpdate');\nif (button.is(\":visible\"))\n{\n button.animate({ width: \"toggle\" }); // Hide button\n}\n</code></pre>\n\n<p>You can do it all in one line:</p>\n\n<pre><code>$('#btnUpdate').filter(\":visible\").animate({ width: \"toggle\" });\n</code></pre>\n"
},
{
"answer_id": 4685330,
"author": "user574889",
"author_id": 574889,
"author_profile": "https://Stackoverflow.com/users/574889",
"pm_score": 9,
"selected": false,
"text": "<p>From <em><a href=\"http://learn.jquery.com/using-jquery-core/faq/how-do-i-determine-the-state-of-a-toggled-element/\" rel=\"noreferrer\">How do I determine the state of a toggled element?</a></em></p>\n\n<hr>\n\n<p>You can determine whether an element is collapsed or not by using the <code>:visible</code> and <code>:hidden</code> selectors.</p>\n\n<pre><code>var isVisible = $('#myDiv').is(':visible');\nvar isHidden = $('#myDiv').is(':hidden');\n</code></pre>\n\n<p>If you're simply acting on an element based on its visibility, you can just include <code>:visible</code> or <code>:hidden</code> in the selector expression. For example:</p>\n\n<pre><code> $('#myDiv:visible').animate({left: '+=200px'}, 'slow');\n</code></pre>\n"
},
{
"answer_id": 5423934,
"author": "aaronLile",
"author_id": 570371,
"author_profile": "https://Stackoverflow.com/users/570371",
"pm_score": 9,
"selected": false,
"text": "<p>None of these answers address what I understand to be the question, which is what I was searching for, <em>\"How do I handle items that have <code>visibility: hidden</code>?\"</em>. Neither <code>:visible</code> nor <code>:hidden</code> will handle this, as they are both looking for display per the documentation. As far as I could determine, there is no selector to handle CSS visibility. Here is how I resolved it (standard jQuery selectors, there may be a more condensed syntax):</p>\n\n<pre><code>$(\".item\").each(function() {\n if ($(this).css(\"visibility\") == \"hidden\") {\n // handle non visible state\n } else {\n // handle visible state\n }\n});\n</code></pre>\n"
},
{
"answer_id": 6602427,
"author": "Abiy",
"author_id": 832338,
"author_profile": "https://Stackoverflow.com/users/832338",
"pm_score": 8,
"selected": false,
"text": "<p>This works for me, and I am using <code>show()</code> and <code>hide()</code> to make my div hidden/visible:</p>\n\n<pre><code>if( $(this).css('display') == 'none' ){\n /* your code goes here */\n} else {\n /* alternate logic */\n}\n</code></pre>\n"
},
{
"answer_id": 8266879,
"author": "Pedro Rainho",
"author_id": 1020760,
"author_profile": "https://Stackoverflow.com/users/1020760",
"pm_score": 8,
"selected": false,
"text": "<p>The <code>:visible</code> selector according to <a href=\"https://api.jquery.com/hidden-selector/\" rel=\"noreferrer\">the jQuery documentation</a>:</p>\n\n<blockquote>\n <ul>\n <li>They have a CSS <code>display</code> value of <code>none</code>.</li>\n <li>They are form elements with <code>type=\"hidden\"</code>.</li>\n <li>Their width and height are explicitly set to 0.</li>\n <li>An ancestor element is hidden, so the element is not shown on the page.</li>\n </ul>\n \n <p>Elements with <code>visibility: hidden</code> or <code>opacity: 0</code> are considered to be visible, since they still consume space in the layout.</p>\n</blockquote>\n\n<p>This is useful in some cases and useless in others, because if you want to check if the element is visible (<code>display != none</code>), ignoring the parents visibility, you will find that doing <code>.css(\"display\") == 'none'</code> is not only faster, but will also return the visibility check correctly.</p>\n\n<p>If you want to check visibility instead of display, you should use: <code>.css(\"visibility\") == \"hidden\"</code>.</p>\n\n<p>Also take into consideration <a href=\"https://api.jquery.com/visible-selector/\" rel=\"noreferrer\">the additional jQuery notes</a>:</p>\n\n<blockquote>\n <p>Because <code>:visible</code> is a jQuery extension and not part of the CSS specification, queries using <code>:visible</code> cannot take advantage of the performance boost provided by the native DOM <code>querySelectorAll()</code> method. To achieve the best performance when using <code>:visible</code> to select elements, first select the elements using a pure CSS selector, then use <code>.filter(\":visible\")</code>.</p>\n</blockquote>\n\n<p>Also, if you are concerned about performance, you should check <em><a href=\"http://www.learningjquery.com/2010/05/now-you-see-me-showhide-performance\" rel=\"noreferrer\">Now you see me… show/hide performance</a></em> (2010-05-04). And use other methods to show and hide elements.</p>\n"
},
{
"answer_id": 9131633,
"author": "David Levin",
"author_id": 571203,
"author_profile": "https://Stackoverflow.com/users/571203",
"pm_score": 7,
"selected": false,
"text": "<p>I would use CSS class <code>.hide { display: none!important; }</code>. </p>\n\n<p>For hiding/showing, I call <code>.addClass(\"hide\")/.removeClass(\"hide\")</code>. For checking visibility, I use <code>.hasClass(\"hide\")</code>.</p>\n\n<p>It's a simple and clear way to check/hide/show elements, if you don't plan to use <code>.toggle()</code> or <code>.animate()</code> methods.</p>\n"
},
{
"answer_id": 10264006,
"author": "Lucas",
"author_id": 1136709,
"author_profile": "https://Stackoverflow.com/users/1136709",
"pm_score": 7,
"selected": false,
"text": "<p>Another answer you should put into consideration is if you are hiding an element, you should use <a href=\"http://en.wikipedia.org/wiki/JQuery\" rel=\"noreferrer\">jQuery</a>, but instead of actually hiding it, you remove the whole element, but you copy its <a href=\"http://en.wikipedia.org/wiki/HTML\" rel=\"noreferrer\">HTML</a> content and the tag itself into a jQuery variable, and then all you need to do is test if there is such a tag on the screen, using the normal <code>if (!$('#thetagname').length)</code>.</p>\n"
},
{
"answer_id": 10305968,
"author": "webvitaly",
"author_id": 713523,
"author_profile": "https://Stackoverflow.com/users/713523",
"pm_score": 8,
"selected": false,
"text": "<p>How <strong><a href=\"http://web-profile.net/jquery/dev/jquery-element-visible-hidden/\" rel=\"noreferrer\">element visibility and jQuery works</a></strong>;</p>\n\n<p>An element could be hidden with <code>display:none</code>, <code>visibility:hidden</code> or <code>opacity:0</code>. The difference between those methods:</p>\n\n<ul>\n<li><code>display:none</code> hides the element, and it does not take up any space;</li>\n<li><code>visibility:hidden</code> hides the element, but it still takes up space in the layout;</li>\n<li><p><code>opacity:0</code> hides the element as \"visibility:hidden\", and it still takes up space in the layout; the only difference is that opacity lets one to make an element partly transparent; </p>\n\n<pre><code>if ($('.target').is(':hidden')) {\n $('.target').show();\n} else {\n $('.target').hide();\n}\nif ($('.target').is(':visible')) {\n $('.target').hide();\n} else {\n $('.target').show();\n}\n\nif ($('.target-visibility').css('visibility') == 'hidden') {\n $('.target-visibility').css({\n visibility: \"visible\",\n display: \"\"\n });\n} else {\n $('.target-visibility').css({\n visibility: \"hidden\",\n display: \"\"\n });\n}\n\nif ($('.target-visibility').css('opacity') == \"0\") {\n $('.target-visibility').css({\n opacity: \"1\",\n display: \"\"\n });\n} else {\n $('.target-visibility').css({\n opacity: \"0\",\n display: \"\"\n });\n}\n</code></pre>\n\n<p><strong>Useful jQuery toggle methods:</strong> </p>\n\n<pre><code>$('.click').click(function() {\n $('.target').toggle();\n});\n\n$('.click').click(function() {\n $('.target').slideToggle();\n});\n\n$('.click').click(function() {\n $('.target').fadeToggle();\n});\n</code></pre></li>\n</ul>\n"
},
{
"answer_id": 10720438,
"author": "ScoRpion",
"author_id": 995113,
"author_profile": "https://Stackoverflow.com/users/995113",
"pm_score": 7,
"selected": false,
"text": "<p>One can simply use the <code>hidden</code> or <code>visible</code> attribute, like:</p>\n\n<pre><code>$('element:hidden')\n$('element:visible')\n</code></pre>\n\n<p>Or you can simplify the same with <em>is</em> as follows.</p>\n\n<pre><code>$(element).is(\":visible\")\n</code></pre>\n"
},
{
"answer_id": 11015754,
"author": "Vaishu",
"author_id": 1041118,
"author_profile": "https://Stackoverflow.com/users/1041118",
"pm_score": 7,
"selected": false,
"text": "<p><code>ebdiv</code> should be set to <code>style=\"display:none;\"</code>. It works for both show and hide:</p>\n\n<pre><code>$(document).ready(function(){\n $(\"#eb\").click(function(){\n $(\"#ebdiv\").toggle();\n }); \n});\n</code></pre>\n"
},
{
"answer_id": 11511035,
"author": "Matt Brock",
"author_id": 313969,
"author_profile": "https://Stackoverflow.com/users/313969",
"pm_score": 7,
"selected": false,
"text": "<p>You can also do this using plain JavaScript:</p>\n\n<pre><code>function isRendered(domObj) {\n if ((domObj.nodeType != 1) || (domObj == document.body)) {\n return true;\n }\n if (domObj.currentStyle && domObj.currentStyle[\"display\"] != \"none\" && domObj.currentStyle[\"visibility\"] != \"hidden\") {\n return isRendered(domObj.parentNode);\n } else if (window.getComputedStyle) {\n var cs = document.defaultView.getComputedStyle(domObj, null);\n if (cs.getPropertyValue(\"display\") != \"none\" && cs.getPropertyValue(\"visibility\") != \"hidden\") {\n return isRendered(domObj.parentNode);\n }\n }\n return false;\n}\n</code></pre>\n\n<p>Notes:</p>\n\n<ol>\n<li><p>Works everywhere</p></li>\n<li><p>Works for nested elements</p></li>\n<li><p>Works for CSS and inline styles</p></li>\n<li><p>Doesn't require a framework</p></li>\n</ol>\n"
},
{
"answer_id": 11579654,
"author": "Maneesh Kumar",
"author_id": 1187233,
"author_profile": "https://Stackoverflow.com/users/1187233",
"pm_score": 7,
"selected": false,
"text": "<pre><code>expect($("#message_div").css("display")).toBe("none");\n</code></pre>\n"
},
{
"answer_id": 14515952,
"author": "Code Spy",
"author_id": 1045296,
"author_profile": "https://Stackoverflow.com/users/1045296",
"pm_score": 7,
"selected": false,
"text": "<p><strong><a href=\"https://freakyjolly.com/demo/check-if-visible-or-hidden-jquery.html\" rel=\"noreferrer\">Demo Link</a></strong></p>\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>$('#clickme').click(function() {\n $('#book').toggle('slow', function() {\n // Animation complete.\n alert($('#book').is(\":visible\")); //<--- TRUE if Visible False if Hidden\n });\n});</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script>\n<div id=\"clickme\">\n Click here\n</div>\n<img id=\"book\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/87/Google_Chrome_icon_%282011%29.png\" alt=\"\" width=\"300\"/></code></pre>\r\n</div>\r\n</div>\r\n</p>\n<p><strong>Source (from my blog):</strong></p>\n<p><a href=\"http://bloggerplugnplay.blogspot.in/2013/01/how-to-see-if-element-is-hidden-or.html\" rel=\"noreferrer\">Blogger Plug n Play - jQuery Tools and Widgets: How to See if Element is hidden or Visible Using jQuery</a></p>\n"
},
{
"answer_id": 16919498,
"author": "Matthias Wegtun",
"author_id": 1559329,
"author_profile": "https://Stackoverflow.com/users/1559329",
"pm_score": 6,
"selected": false,
"text": "<p>To check if it is not visible I use <code>!</code>:</p>\n\n<pre><code>if ( !$('#book').is(':visible')) {\n alert('#book is not visible')\n}\n</code></pre>\n\n<p>Or the following is also the sam, saving the jQuery selector in a variable to have better performance when you need it multiple times:</p>\n\n<pre><code>var $book = $('#book')\n\nif(!$book.is(':visible')) {\n alert('#book is not visible')\n}\n</code></pre>\n"
},
{
"answer_id": 17734054,
"author": "Ross Brasseaux",
"author_id": 1751792,
"author_profile": "https://Stackoverflow.com/users/1751792",
"pm_score": 6,
"selected": false,
"text": "<h2>Use class toggling, not style editing . . .</h2>\n<p>Using classes designated for "hiding" elements is easy and also one of the most efficient methods. Toggling a class 'hidden' with a <code>Display</code> style of 'none' will perform faster than editing that style directly. I explained some of this pretty thoroughly in Stack Overflow question <em><a href=\"https://stackoverflow.com/questions/17725361/turning-two-elements-visible-hidden-in-same-div/17726550#answer-17726550\">Turning two elements visible/hidden in the same div</a></em>.</p>\n<hr />\n<h2>JavaScript Best Practices and Optimization</h2>\n<p>Here is a truly enlightening video of a Google Tech Talk by Google front-end engineer Nicholas Zakas:</p>\n<ul>\n<li><strong><a href=\"http://www.youtube.com/watch?v=mHtdZgou0qU\" rel=\"noreferrer\">Speed Up Your Javascript</a></strong> (YouTube)</li>\n</ul>\n"
},
{
"answer_id": 19628550,
"author": "Irfan DANISH",
"author_id": 1058406,
"author_profile": "https://Stackoverflow.com/users/1058406",
"pm_score": 6,
"selected": false,
"text": "<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>$(document).ready(function() {\n if ($(\"#checkme:hidden\").length) {\n console.log('Hidden');\n }\n});</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script>\n<div id=\"checkme\" class=\"product\" style=\"display:none\">\n <span class=\"itemlist\"><!-- Shows Results for Fish --></span> Category:Fish\n <br>Product: Salmon Atlantic\n <br>Specie: Salmo salar\n <br>Form: Steaks\n</div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 19801208,
"author": "cssimsek",
"author_id": 2668568,
"author_profile": "https://Stackoverflow.com/users/2668568",
"pm_score": 5,
"selected": false,
"text": "<p>Also here's a ternary conditional expression to check the state of the element and then to toggle it:</p>\n\n<pre><code>$('someElement').on('click', function(){ $('elementToToggle').is(':visible') ? $('elementToToggle').hide('slow') : $('elementToToggle').show('slow'); });\n</code></pre>\n"
},
{
"answer_id": 19999134,
"author": "Gaurav",
"author_id": 2357391,
"author_profile": "https://Stackoverflow.com/users/2357391",
"pm_score": 5,
"selected": false,
"text": "<pre><code>if($('#postcode_div').is(':visible')) {\n if($('#postcode_text').val()=='') {\n $('#spanPost').text('\\u00a0');\n } else {\n $('#spanPost').text($('#postcode_text').val());\n}\n</code></pre>\n"
},
{
"answer_id": 21473745,
"author": "Premshankar Tiwari",
"author_id": 1938122,
"author_profile": "https://Stackoverflow.com/users/1938122",
"pm_score": 6,
"selected": false,
"text": "<p>You need to check both... Display as well as visibility:</p>\n\n<pre><code>if ($(this).css(\"display\") == \"none\" || $(this).css(\"visibility\") == \"hidden\") {\n // The element is not visible\n} else {\n // The element is visible\n}\n</code></pre>\n\n<p>If we check for <code>$(this).is(\":visible\")</code>, jQuery checks for both the things automatically.</p>\n"
},
{
"answer_id": 22506181,
"author": "Andron",
"author_id": 284602,
"author_profile": "https://Stackoverflow.com/users/284602",
"pm_score": 5,
"selected": false,
"text": "<p>Because <code>Elements with visibility: hidden or opacity: 0 are considered visible, since they still consume space in the layout</code> (as described for <a href=\"https://api.jquery.com/visible-selector/\">jQuery :visible Selector</a>) - we can check if element is <em>really</em> visible in this way:</p>\n\n<pre><code>function isElementReallyHidden (el) {\n return $(el).is(\":hidden\") || $(el).css(\"visibility\") == \"hidden\" || $(el).css('opacity') == 0;\n}\n\nvar booElementReallyShowed = !isElementReallyHidden(someEl);\n$(someEl).parents().each(function () {\n if (isElementReallyHidden(this)) {\n booElementReallyShowed = false;\n }\n});\n</code></pre>\n"
},
{
"answer_id": 22969337,
"author": "Aleko",
"author_id": 2274995,
"author_profile": "https://Stackoverflow.com/users/2274995",
"pm_score": 6,
"selected": false,
"text": "<p>After all, none of examples suits me, so I wrote my own.</p>\n\n<p><strong>Tests</strong> (no support of Internet Explorer <code>filter:alpha</code>):</p>\n\n<p>a) Check if the document is not hidden</p>\n\n<p>b) Check if an element has zero width / height / opacity or <code>display:none</code> / <code>visibility:hidden</code> in inline styles</p>\n\n<p>c) Check if the center (also because it is faster than testing every pixel / corner) of element is not hidden by other element (and all ancestors, example: <code>overflow:hidden</code> / scroll / one element over another) or screen edges</p>\n\n<p>d) Check if an element has zero width / height / opacity or <code>display:none</code> / visibility:hidden in computed styles (among all ancestors)</p>\n\n<p><strong>Tested on</strong></p>\n\n<p>Android 4.4 (Native browser/Chrome/Firefox), Firefox (Windows/Mac), Chrome (Windows/Mac), Opera (Windows <a href=\"http://en.wikipedia.org/wiki/Presto_%28layout_engine%29\" rel=\"noreferrer\">Presto</a>/Mac WebKit), Internet Explorer (Internet Explorer 5-11 document modes + Internet Explorer 8 on a virtual machine), and Safari (Windows/Mac/iOS).</p>\n\n<pre><code>var is_visible = (function () {\n var x = window.pageXOffset ? window.pageXOffset + window.innerWidth - 1 : 0,\n y = window.pageYOffset ? window.pageYOffset + window.innerHeight - 1 : 0,\n relative = !!((!x && !y) || !document.elementFromPoint(x, y));\n function inside(child, parent) {\n while(child){\n if (child === parent) return true;\n child = child.parentNode;\n }\n return false;\n };\n return function (elem) {\n if (\n document.hidden ||\n elem.offsetWidth==0 ||\n elem.offsetHeight==0 ||\n elem.style.visibility=='hidden' ||\n elem.style.display=='none' ||\n elem.style.opacity===0\n ) return false;\n var rect = elem.getBoundingClientRect();\n if (relative) {\n if (!inside(document.elementFromPoint(rect.left + elem.offsetWidth/2, rect.top + elem.offsetHeight/2),elem)) return false;\n } else if (\n !inside(document.elementFromPoint(rect.left + elem.offsetWidth/2 + window.pageXOffset, rect.top + elem.offsetHeight/2 + window.pageYOffset), elem) ||\n (\n rect.top + elem.offsetHeight/2 < 0 ||\n rect.left + elem.offsetWidth/2 < 0 ||\n rect.bottom - elem.offsetHeight/2 > (window.innerHeight || document.documentElement.clientHeight) ||\n rect.right - elem.offsetWidth/2 > (window.innerWidth || document.documentElement.clientWidth)\n )\n ) return false;\n if (window.getComputedStyle || elem.currentStyle) {\n var el = elem,\n comp = null;\n while (el) {\n if (el === document) {break;} else if(!el.parentNode) return false;\n comp = window.getComputedStyle ? window.getComputedStyle(el, null) : el.currentStyle;\n if (comp && (comp.visibility=='hidden' || comp.display == 'none' || (typeof comp.opacity !=='undefined' && comp.opacity != 1))) return false;\n el = el.parentNode;\n }\n }\n return true;\n }\n})();\n</code></pre>\n\n<p>How to use:</p>\n\n<pre><code>is_visible(elem) // boolean\n</code></pre>\n"
},
{
"answer_id": 23027643,
"author": "Kareem",
"author_id": 2151420,
"author_profile": "https://Stackoverflow.com/users/2151420",
"pm_score": 5,
"selected": false,
"text": "<pre><code>.is(\":not(':hidden')\") /*if shown*/\n</code></pre>\n"
},
{
"answer_id": 23492646,
"author": "conceptdeluxe",
"author_id": 1510754,
"author_profile": "https://Stackoverflow.com/users/1510754",
"pm_score": 7,
"selected": false,
"text": "<p>When testing an element against <code>:hidden</code> selector in jQuery it should be considered that <strong>an absolute positioned element may be recognized as hidden although their child elements are visible</strong>.</p>\n\n<p>This seems somewhat counter-intuitive in the first place – though having a closer look at the jQuery documentation gives the relevant information:</p>\n\n<blockquote>\n <p>Elements can be considered hidden for several reasons: [...] Their width and height are explicitly set to 0. [...]</p>\n</blockquote>\n\n<p>So this actually makes sense in regards to the box-model and the computed style for the element. Even if width and height are not set <em>explicitly</em> to 0 they may be set <em>implicitly</em>.</p>\n\n<p>Have a look at the following example:</p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>console.log($('.foo').is(':hidden')); // true\r\nconsole.log($('.bar').is(':hidden')); // false</code></pre>\r\n<pre class=\"snippet-code-css lang-css prettyprint-override\"><code>.foo {\r\n position: absolute;\r\n left: 10px;\r\n top: 10px;\r\n background: #ff0000;\r\n}\r\n\r\n.bar {\r\n position: absolute;\r\n left: 10px;\r\n top: 10px;\r\n width: 20px;\r\n height: 20px;\r\n background: #0000ff;\r\n}</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script>\r\n<div class=\"foo\">\r\n <div class=\"bar\"></div>\r\n</div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n\n<hr>\n\n<p><strong>Update for jQuery 3.x:</strong></p>\n\n<p>With jQuery 3 the described behavior will change! Elements will be considered visible if they have any layout boxes, including those of zero width and/or height.</p>\n\n<p>JSFiddle with jQuery 3.0.0-alpha1:</p>\n\n<p><a href=\"http://jsfiddle.net/pM2q3/7/\" rel=\"noreferrer\">http://jsfiddle.net/pM2q3/7/</a></p>\n\n<p>The same JavaScript code will then have this output:</p>\n\n<pre><code>console.log($('.foo').is(':hidden')); // false\nconsole.log($('.bar').is(':hidden')); // false\n</code></pre>\n"
},
{
"answer_id": 25236348,
"author": "pixellabme",
"author_id": 3873204,
"author_profile": "https://Stackoverflow.com/users/3873204",
"pm_score": 5,
"selected": false,
"text": "<p>Simply check visibility by checking for a boolean value, like:</p>\n\n<pre><code>if (this.hidden === false) {\n // Your code\n}\n</code></pre>\n\n<p>I used this code for each function. Otherwise you can use <code>is(':visible')</code> for checking the visibility of an element.</p>\n"
},
{
"answer_id": 25466293,
"author": "RN Kushwaha",
"author_id": 2995263,
"author_profile": "https://Stackoverflow.com/users/2995263",
"pm_score": 5,
"selected": false,
"text": "<p>But what if the element's CSS is like the following?</p>\n\n<pre><code>.element{\n position: absolute;left:-9999; \n}\n</code></pre>\n\n<p>So <a href=\"https://stackoverflow.com/questions/8897289\">this answer to Stack Overflow question <em>How to check if an element is off-screen</em></a> should also be considered.</p>\n"
},
{
"answer_id": 25575642,
"author": "V31",
"author_id": 2081982,
"author_profile": "https://Stackoverflow.com/users/2081982",
"pm_score": 5,
"selected": false,
"text": "<p>A function can be created in order to check for visibility/display attributes in order to gauge whether the element is shown in the UI or not. </p>\n\n<pre><code>function checkUIElementVisible(element) {\n return ((element.css('display') !== 'none') && (element.css('visibility') !== 'hidden'));\n}\n</code></pre>\n\n<p><a href=\"http://jsfiddle.net/w8bytkqc/\" rel=\"noreferrer\">Working Fiddle</a></p>\n"
},
{
"answer_id": 29491573,
"author": "Mathias Stavrou",
"author_id": 2808740,
"author_profile": "https://Stackoverflow.com/users/2808740",
"pm_score": 6,
"selected": false,
"text": "<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"false\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>$(document).ready(function() {\n var visible = $('#tElement').is(':visible');\n\n if(visible) {\n alert(\"visible\");\n // Code\n }\n else\n {\n alert(\"hidden\");\n }\n});</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://code.jquery.com/jquery-1.10.2.js\"></script>\n\n<input type=\"text\" id=\"tElement\" style=\"display:block;\">Firstname</input></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 29890170,
"author": "Roman Losev",
"author_id": 1602375,
"author_profile": "https://Stackoverflow.com/users/1602375",
"pm_score": 6,
"selected": false,
"text": "<p>Example of using the <strong>visible</strong> check for adblocker is activated:</p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>$(document).ready(function(){\r\n if(!$(\"#ablockercheck\").is(\":visible\"))\r\n $(\"#ablockermsg\").text(\"Please disable adblocker.\").show();\r\n});</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script>\r\n<div class=\"ad-placement\" id=\"ablockercheck\"></div>\r\n<div id=\"ablockermsg\" style=\"display: none\"></div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n\n<p>\"ablockercheck\" is a ID which adblocker blocks. So checking it if it is visible you are able to detect if adblocker is turned On.</p>\n"
},
{
"answer_id": 32068044,
"author": "Prabhagaran",
"author_id": 4796478,
"author_profile": "https://Stackoverflow.com/users/4796478",
"pm_score": 5,
"selected": false,
"text": "<pre><code>if($('#id_element').is(\":visible\")){\n alert('shown');\n}else{\n alert('hidden');\n}\n</code></pre>\n"
},
{
"answer_id": 32182004,
"author": "Sangeet Shah",
"author_id": 3539870,
"author_profile": "https://Stackoverflow.com/users/3539870",
"pm_score": 4,
"selected": false,
"text": "<p>This is some option to check that tag is visible or not</p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code> // using a pure CSS selector \r\n if ($('p:visible')) { \r\n alert('Paragraphs are visible (checked using a CSS selector) !'); \r\n }; \r\n \r\n // using jQuery's is() method \r\n if ($('p').is(':visible')) { \r\n alert('Paragraphs are visible (checked using is() method)!'); \r\n }; \r\n \r\n // using jQuery's filter() method \r\n if ($('p').filter(':visible')) { \r\n alert('Paragraphs are visible (checked using filter() method)!'); \r\n }; \r\n \r\n // you can use :hidden instead of :visible to reverse the logic and check if an element is hidden \r\n // if ($('p:hidden')) { \r\n // do something \r\n // }; </code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 36179368,
"author": "cbertelegni",
"author_id": 2800900,
"author_profile": "https://Stackoverflow.com/users/2800900",
"pm_score": 2,
"selected": false,
"text": "<pre><code>if($(\"h1\").is(\":hidden\")){\n // your code..\n}\n</code></pre>\n"
},
{
"answer_id": 36397659,
"author": "Disapamok",
"author_id": 3994304,
"author_profile": "https://Stackoverflow.com/users/3994304",
"pm_score": 4,
"selected": false,
"text": "<p>You can just add a class when it is visible. Add a class, <code>show</code>. Then check for it have a class:</p>\n\n<pre><code>$('#elementId').hasClass('show');\n</code></pre>\n\n<p>It returns true if you have the <code>show</code> class.</p>\n\n<p>Add CSS like this:</p>\n\n<pre><code>.show{ display: block; }\n</code></pre>\n"
},
{
"answer_id": 36561933,
"author": "Oriol",
"author_id": 2817112,
"author_profile": "https://Stackoverflow.com/users/2817112",
"pm_score": 4,
"selected": false,
"text": "<p>This is how <a href=\"https://github.com/jquery/jquery/blob/055cb7534e2dcf7ee8ad145be83cb2d74b5331c7/src/css/hiddenVisibleSelectors.js\">jQuery</a> internally solves this problem:</p>\n\n<pre><code>jQuery.expr.pseudos.visible = function( elem ) {\n return !!( elem.offsetWidth || elem.offsetHeight || elem.getClientRects().length );\n};\n</code></pre>\n\n<p>If you don't use jQuery, you can just leverage this code and turn it into your own function:</p>\n\n<pre><code>function isVisible(elem) {\n return !!( elem.offsetWidth || elem.offsetHeight || elem.getClientRects().length );\n};\n</code></pre>\n\n<p>Which <code>isVisible</code> will return <code>true</code> as long as the element is visible.</p>\n"
},
{
"answer_id": 36982533,
"author": "Abrar Jahin",
"author_id": 2193439,
"author_profile": "https://Stackoverflow.com/users/2193439",
"pm_score": 4,
"selected": false,
"text": "<p>You can use this:</p>\n\n<pre><code>$(element).is(':visible');\n</code></pre>\n\n<h2>Example code</h2>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"false\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>$(document).ready(function()\r\n{\r\n $(\"#toggle\").click(function()\r\n {\r\n $(\"#content\").toggle();\r\n });\r\n\r\n $(\"#visiblity\").click(function()\r\n {\r\n if( $('#content').is(':visible') )\r\n {\r\n alert(\"visible\"); // Put your code for visibility\r\n }\r\n else\r\n {\r\n alert(\"hidden\");\r\n }\r\n });\r\n});</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://ajax.googleapis.com/ajax/libs/jquery/1.12.2/jquery.min.js\"></script>\r\n\r\n<p id=\"content\">This is a Content</p>\r\n\r\n<button id=\"toggle\">Toggle Content Visibility</button>\r\n<button id=\"visibility\">Check Visibility</button></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 37561155,
"author": "lmcDevloper",
"author_id": 3303585,
"author_profile": "https://Stackoverflow.com/users/3303585",
"pm_score": 4,
"selected": false,
"text": "<p>I searched for this, and none of the answers are correct for my case, so I've created a function that will return false if one's eyes can't see the element</p>\n\n<pre><code>jQuery.fn.extend({\n isvisible: function() {\n //\n // This function call this: $(\"div\").isvisible()\n // Return true if the element is visible\n // Return false if the element is not visible for our eyes\n //\n if ( $(this).css('display') == 'none' ){\n console.log(\"this = \" + \"display:none\");\n return false;\n }\n else if( $(this).css('visibility') == 'hidden' ){\n console.log(\"this = \" + \"visibility:hidden\"); \n return false;\n }\n else if( $(this).css('opacity') == '0' ){\n console.log(\"this = \" + \"opacity:0\");\n return false;\n } \n else{\n console.log(\"this = \" + \"Is Visible\");\n return true;\n }\n } \n});\n</code></pre>\n"
},
{
"answer_id": 40438235,
"author": "No one",
"author_id": 4730999,
"author_profile": "https://Stackoverflow.com/users/4730999",
"pm_score": 4,
"selected": false,
"text": "<p>As <code>hide()</code>, <code>show()</code> and <code>toggle()</code> attaches inline css (display:none or display:block) to element.\nSimilarly, we can easily use the ternary operator to check whether the element is hidden or visible by checking display CSS.</p>\n<p><strong>UPDATE:</strong></p>\n<ul>\n<li>You also need to check if element CSS set to visibility: "visible" or visibility: "hidden"</li>\n<li>The element will be also visible if display property set to inline-block, block, flex.</li>\n</ul>\n<p>So we can check for the property of an element that makes it invisible. So they are <code>display: none</code> and <code>visibility: "hidden";</code></p>\n<p>We can create an object for checking property responsible for hiding element:</p>\n<pre><code>var hiddenCssProps = {\ndisplay: "none",\nvisibility: "hidden"\n}\n</code></pre>\n<p>We can check by looping through each key value in object matching if element property for key matches with hidden property value.</p>\n<pre><code>var isHidden = false;\nfor(key in hiddenCssProps) {\n if($('#element').css(key) == hiddenCssProps[key]) {\n isHidden = true;\n }\n}\n</code></pre>\n<p>If you want to check property like element height: 0 or width: 0 or more, you can extend this object and add more property to it and can check.</p>\n"
},
{
"answer_id": 40904208,
"author": "Wolfack",
"author_id": 4482269,
"author_profile": "https://Stackoverflow.com/users/4482269",
"pm_score": 4,
"selected": false,
"text": "<pre><code>$( "div:visible" ).click(function() {\n $( this ).css( "background", "yellow" );\n});\n$( "button" ).click(function() {\n $( "div:hidden" ).show( "fast" );\n});\n</code></pre>\n<p>API Documentation: <a href=\"https://api.jquery.com/visible-selector/\" rel=\"nofollow noreferrer\"><strong>visible Selector</strong></a></p>\n"
},
{
"answer_id": 40991133,
"author": "Sky Yip",
"author_id": 4992983,
"author_profile": "https://Stackoverflow.com/users/4992983",
"pm_score": 4,
"selected": false,
"text": "<p>I just want to clarify that, in jQuery,</p>\n\n<blockquote>\n <p>Elements can be considered hidden for several reasons:</p>\n \n <ul>\n <li>They have a CSS display value of none.</li>\n <li>They are form elements with type=\"hidden\".</li>\n <li>Their width and height are explicitly set to 0.</li>\n <li>An ancestor element is hidden, so the element is not shown on the page.</li>\n </ul>\n \n <p>Elements with visibility: hidden or opacity: 0 are considered to be visible, since they still consume space in the layout. During animations that hide an element, the element is considered to be visible until the end of the animation.</p>\n \n <p>Source: <a href=\"https://api.jquery.com/hidden-selector/\" rel=\"noreferrer\">:hidden Selector | jQuery API Documentation</a></p>\n</blockquote>\n\n<pre><code>if($('.element').is(':hidden')) {\n // Do something\n}\n</code></pre>\n"
},
{
"answer_id": 41117640,
"author": "Arun Karnawat",
"author_id": 3114253,
"author_profile": "https://Stackoverflow.com/users/3114253",
"pm_score": 4,
"selected": false,
"text": "<p>There are quite a few ways to check if an element is visible or hidden in jQuery.</p>\n\n<p><em>Demo HTML for example reference</em></p>\n\n<pre><code><div id=\"content\">Content</div>\n<div id=\"content2\" style=\"display:none\">Content2</div>\n</code></pre>\n\n<p><strong>Use Visibility Filter Selector <code>$('element:hidden')</code> or <code>$('element:visible')</code></strong></p>\n\n<ul>\n<li><p><code>$('element:hidden')</code>: Selects all elements that are hidden.</p>\n\n<pre><code>Example:\n $('#content2:hidden').show();\n</code></pre></li>\n<li><p><code>$('element:visible')</code>: Selects all elements that are visible.</p>\n\n<pre><code>Example:\n $('#content:visible').css('color', '#EEE');\n</code></pre></li>\n</ul>\n\n<blockquote>\n <p>Read more at <a href=\"http://api.jquery.com/category/selectors/visibility-filter-selectors/\" rel=\"noreferrer\">http://api.jquery.com/category/selectors/visibility-filter-selectors/</a></p>\n</blockquote>\n\n<p><strong>Use <code>is()</code> Filtering</strong></p>\n\n<pre><code> Example:\n $('#content').is(\":visible\").css('color', '#EEE');\n\n Or checking condition\n if ($('#content').is(\":visible\")) {\n // Perform action\n }\n</code></pre>\n\n<blockquote>\n <p>Read more at <a href=\"http://api.jquery.com/is/\" rel=\"noreferrer\">http://api.jquery.com/is/</a></p>\n</blockquote>\n"
},
{
"answer_id": 42896214,
"author": "Abdul Aziz Al Basyir",
"author_id": 8314878,
"author_profile": "https://Stackoverflow.com/users/8314878",
"pm_score": 3,
"selected": false,
"text": "<p>There are too many methods to check for hidden elements. This is the best choice (I just recommended you):</p>\n\n<blockquote>\n <p>Using jQuery, make an element, \"display:none\", in CSS for hidden.</p>\n</blockquote>\n\n<p>The point is:</p>\n\n<pre><code>$('element:visible')\n</code></pre>\n\n<p>And an example for use:</p>\n\n<pre><code>$('element:visible').show();\n</code></pre>\n"
},
{
"answer_id": 43014382,
"author": "Peter Wone",
"author_id": 1715673,
"author_profile": "https://Stackoverflow.com/users/1715673",
"pm_score": 3,
"selected": false,
"text": "<p>To be fair the question pre-dates <em>this</em> answer.</p>\n\n<p>I add it not to criticise the OP, but to help anyone still asking this question.</p>\n\n<p>The correct way to determine whether something is visible is to consult your view-model;</p>\n\n<p>If you don't know what that means then you are about to embark on a journey of discovery that will make your work a great deal less difficult.</p>\n\n<p>Here's an overview of the <a href=\"https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel\" rel=\"nofollow noreferrer\">model-view-view-model</a> architecture (MVVM).</p>\n\n<p><a href=\"http://knockoutjs.com\" rel=\"nofollow noreferrer\">KnockoutJS</a> is a binding library that will let you try this stuff out without learning an entire framework.</p>\n\n<p>And here's some JavaScript code and a DIV that may or may not be visible.</p>\n\n<pre><code><html>\n<body>\n<script src=\"https://cdnjs.cloudflare.com/ajax/libs/knockout/3.4.1/knockout-min.js\"></script>\n<script>\n var vm = {\n IsDivVisible: ko.observable(true);\n }\n vm.toggle = function(data, event) {\n // Get current visibility state for the div\n var x = IsDivVisible();\n // Set it to the opposite\n IsDivVisible(!x);\n }\n ko.applyBinding(vm);\n</script>\n<div data-bind=\"visible: IsDivVisible\">Peekaboo!</div>\n<button data-bind=\"click: toggle\">Toggle the div's visibility</button>\n</body>\n</html>\n</code></pre>\n\n<p>Notice that the toggle function does not consult the DOM to determine the visibility of the div; it consults the view-model.</p>\n"
},
{
"answer_id": 43694490,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<pre><code>$('someElement').on('click', function(){ $('elementToToggle').is(':visible')\n</code></pre>\n"
},
{
"answer_id": 43817534,
"author": "Alireza",
"author_id": 5423108,
"author_profile": "https://Stackoverflow.com/users/5423108",
"pm_score": 4,
"selected": false,
"text": "<p>Just simply check if that element is <strong>visible</strong> and it will return a <strong>boolean</strong>. jQuery hides the elements by adding <em>display none</em> to the element, so if you want to use pure JavaScript, you can still do that, for example:</p>\n\n<pre><code>if (document.getElementById(\"element\").style.display === 'block') {\n // Your element is visible; do whatever you'd like\n}\n</code></pre>\n\n<p>Also, you can use jQuery as it seems the rest of your code is using that and you have smaller block of code. Something like the below in jQuery does the same trick for you:</p>\n\n<pre><code>if ($(element).is(\":visible\")) {\n // Your element is visible, do whatever you'd like\n};\n</code></pre>\n\n<p>Also using the <code>css</code> method in jQuery can result in the same thing:</p>\n\n<pre><code>if ($(element).css('display') === 'block') {\n // Your element is visible, do whatever you'd like\n}\n</code></pre>\n\n<p>Also in case of checking for visibility and display, you can do the below:</p>\n\n<pre><code>if ($(this).css(\"display\") === \"block\" || $(this).css(\"visibility\") === \"visible\") {\n // Your element is visible, do whatever you'd like\n}\n</code></pre>\n"
},
{
"answer_id": 45574894,
"author": "Antoine Auffray",
"author_id": 4547217,
"author_profile": "https://Stackoverflow.com/users/4547217",
"pm_score": 3,
"selected": false,
"text": "<p>Simply check for the <code>display</code> attribute (or <code>visibility</code> depending on what kind of invisibility you prefer). Example:</p>\n\n<pre><code>if ($('#invisible').css('display') == 'none') {\n // This means the HTML element with ID 'invisible' has its 'display' attribute set to 'none'\n}\n</code></pre>\n"
},
{
"answer_id": 46422283,
"author": "Disapamok",
"author_id": 3994304,
"author_profile": "https://Stackoverflow.com/users/3994304",
"pm_score": 2,
"selected": false,
"text": "<p>You can use a CSS class when it visible or hidden by toggling the class:</p>\n\n<pre><code>.show{ display :block; }\n</code></pre>\n\n<p>Set your jQuery <code>toggleClass()</code> or <code>addClass()</code> or <code>removeClass();</code>.</p>\n\n<p>As an example,</p>\n\n<p><code>jQuery('#myID').toggleClass('show')</code></p>\n\n<p>The above code will add <code>show</code> css class when the element don't have <code>show</code> and will remove when it has <code>show</code> class.</p>\n\n<p>And when you are checking if it visible or not, You can follow this jQuery code,</p>\n\n<p><code>jQuery('#myID').hasClass('show');</code></p>\n\n<p>Above code will return a boolean (true) when <code>#myID</code> element has our class (<code>show</code>) and false when it don't have the (<code>show</code>) class.</p>\n"
},
{
"answer_id": 47946881,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 2,
"selected": false,
"text": "<pre><code>isHidden = function(element){\n return (element.style.display === "none");\n};\n\nif(isHidden($("element")) == true){\n // Something\n}\n</code></pre>\n"
},
{
"answer_id": 51584576,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>Instead of writing an <code>event</code> for every single <code>element</code>, do this:</p>\n\n<pre><code>$('div').each(function(){\n if($(this).css('display') === 'none'){\n $(this).css({'display':'block'});\n }\n});\n</code></pre>\n\n<p>Also you can use it on the inputs:</p>\n\n<pre><code>$('input').each(function(){\n if($(this).attr('type') === 'hidden'){\n $(this).attr('type', 'text');\n }\n});\n</code></pre>\n"
},
{
"answer_id": 51851876,
"author": "Profesor08",
"author_id": 3654943,
"author_profile": "https://Stackoverflow.com/users/3654943",
"pm_score": 3,
"selected": false,
"text": "<p>If you want to check if an element is visible on the page, depending on the visibility of its parent, you can check if <code>width</code> and <code>height</code> of the element are both equal to <code>0</code>.</p>\n\n<p>jQuery</p>\n\n<p><code>$element.width() === 0 && $element.height() === 0</code></p>\n\n<p>Vanilla</p>\n\n<p><code>element.clientWidth === 0 && element.clientHeight === 0</code></p>\n\n<p>Or</p>\n\n<p><code>element.offsetWidth === 0 && element.offsetHeight === 0</code></p>\n"
},
{
"answer_id": 52291985,
"author": "Muhammad",
"author_id": 1966247,
"author_profile": "https://Stackoverflow.com/users/1966247",
"pm_score": 3,
"selected": false,
"text": "<p>A jQuery solution, but it is still a bit better for those who want to change the button text as well:</p>\n\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>$(function(){\r\n $(\"#showHide\").click(function(){\r\n var btn = $(this);\r\n $(\"#content\").toggle(function () {\r\n btn.text($(this).css(\"display\") === 'none' ? \"Show\" : \"Hide\");\r\n });\r\n });\r\n });</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script>\r\n\r\n<button id=\"showHide\">Hide</button>\r\n<div id=\"content\">\r\n <h2>Some content</h2>\r\n <p>\r\n What is Lorem Ipsum? Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.\r\n </p>\r\n</div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 52743191,
"author": "L Y E S - C H I O U K H",
"author_id": 9317830,
"author_profile": "https://Stackoverflow.com/users/9317830",
"pm_score": 4,
"selected": false,
"text": "<h1>1 • jQuery solution</h1>\n\n<h3>Methods to determine if an element is visible in jQuery</h3>\n\n<pre><code><script>\nif ($(\"#myelement\").is(\":visible\")){alert (\"#myelement is visible\");}\nif ($(\"#myelement\").is(\":hidden\")){alert (\"#myelement is hidden\"); }\n</script>\n</code></pre>\n\n<h3>Loop on all <em>visible</em> div children of the element of id 'myelement':</h3>\n\n<pre><code>$(\"#myelement div:visible\").each( function() {\n //Do something\n});\n</code></pre>\n\n<h3>Peeked at source of jQuery</h3>\n\n<p>This is how jQuery implements this feature:</p>\n\n<pre><code>jQuery.expr.filters.visible = function( elem ) {\n return !!( elem.offsetWidth || elem.offsetHeight || elem.getClientRects().length );\n};\n</code></pre>\n\n<h1>2 • <a href=\"https://stackoverflow.com/questions/8897289/how-to-check-if-an-element-is-off-screen\">How to check if an element is off-screen - CSS</a></h1>\n\n<p>Using Element.getBoundingClientRect() you can easily detect whether or not your element is within the boundaries of your viewport (i.e. onscreen or offscreen):</p>\n\n<pre><code>jQuery.expr.filters.offscreen = function(el) {\n var rect = el.getBoundingClientRect();\n return (\n (rect.x + rect.width) < 0 \n || (rect.y + rect.height) < 0\n || (rect.x > window.innerWidth || rect.y > window.innerHeight)\n );\n};\n</code></pre>\n\n<p>You could then use that in several ways:</p>\n\n<pre><code>// Returns all elements that are offscreen\n$(':offscreen');\n\n// Boolean returned if element is offscreen\n$('div').is(':offscreen');\n</code></pre>\n\n<p>If you use Angular, check: <em><a href=\"http://www.talkingdotnet.com/dont-use-hidden-attribute-angularjs-2/\" rel=\"noreferrer\">Don’t use hidden attribute with Angular</a></em></p>\n"
},
{
"answer_id": 56556127,
"author": "Kamil Kiełczewski",
"author_id": 860099,
"author_profile": "https://Stackoverflow.com/users/860099",
"pm_score": 2,
"selected": false,
"text": "<pre><code>content.style.display != 'none'\n</code></pre>\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>function toggle() {\n $(content).toggle();\n let visible= content.style.display != 'none'\n console.log('visible:', visible);\n}</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js\"></script>\n\n<button onclick=\"toggle()\">Show/hide</button>\n<div id=\"content\">ABC</div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 57092600,
"author": "Aravinda Meewalaarachchi",
"author_id": 3590237,
"author_profile": "https://Stackoverflow.com/users/3590237",
"pm_score": 2,
"selected": false,
"text": "<p>You can use jQuery's <code>is()</code> function to check the selected element visible or hidden. This method traverses along the DOM elements to find a match, which satisfies the passed parameter. It will return true if there is a match otherwise returns false.</p>\n\n<pre><code><script>\n ($(\"#myelement\").is(\":visible\"))? alert(\"#myelement is visible\") : alert(\"#myelement is hidden\");\n</script>\n</code></pre>\n"
},
{
"answer_id": 59261903,
"author": "Ankush Kumar",
"author_id": 12489279,
"author_profile": "https://Stackoverflow.com/users/12489279",
"pm_score": 1,
"selected": false,
"text": "<p>The below code checks if an element is hidden in jQuery or visible</p>\n\n<pre><code>// You can also do this...\n\n $(\"button\").click(function(){\n // show hide paragraph on button click\n $(\"p\").toggle(\"slow\", function(){\n // check paragraph once toggle effect is completed\n if($(\"p\").is(\":visible\")){\n alert(\"The paragraph is visible.\");\n } else{\n alert(\"The paragraph is hidden.\");\n }\n });\n });\n</code></pre>\n"
},
{
"answer_id": 60242555,
"author": "Brane",
"author_id": 3850805,
"author_profile": "https://Stackoverflow.com/users/3850805",
"pm_score": 3,
"selected": false,
"text": "<h3>Extended function for checking if element is visible, display none, or even the opacity level</h3>\n<p>It returns <code>false</code> if the element is not visible.</p>\n<pre><code>function checkVisible(e) {\n if (!(e instanceof Element)) throw Error('not an Element');\n const elementStyle = getComputedStyle(e);\n if (elementStyle.display === 'none' || elementStyle.visibility !== 'visible' || elementStyle.opacity < 0.1) return false;\n if (e.offsetWidth + e.offsetHeight + e.getBoundingClientRect().height +\n e.getBoundingClientRect().width === 0) {\n return false;\n }\n const elemCenter = {\n x: e.getBoundingClientRect().left + e.offsetWidth / 2,\n y: e.getBoundingClientRect().top + e.offsetHeight / 2\n };\n if (elemCenter.x < 0 || elemCenter.y < 0) return false;\n if (elemCenter.x > (document.documentElement.clientWidth || window.innerWidth)) return false;\n if (elemCenter.y > (document.documentElement.clientHeight || window.innerHeight)) return false;\n let pointContainer = document.elementFromPoint(elemCenter.x, elemCenter.y);\n do {\n if (pointContainer === e) return true;\n } while (pointContainer = pointContainer.parentNode);\n return false;\n}\n</code></pre>\n"
},
{
"answer_id": 63700797,
"author": "Mojtaba Nava",
"author_id": 10116812,
"author_profile": "https://Stackoverflow.com/users/10116812",
"pm_score": 1,
"selected": false,
"text": "<pre><code> hideShow(){\n $("#accordionZiarat").hide();\n // Checks CSS content for display:[none|block], ignores visibility:[true|false]\n if ($("#accordionZiarat").is(":visible")) {\n $("#accordionZiarat").hide();\n }\n\n \n else if ($("#accordionZiarat").is(":hidden")) {\n $("#accordionZiarat").show();\n }\n\n else{\n\n }\n</code></pre>\n"
},
{
"answer_id": 64021369,
"author": "Hasee Amarathunga",
"author_id": 7484853,
"author_profile": "https://Stackoverflow.com/users/7484853",
"pm_score": 3,
"selected": false,
"text": "<p>Using hidden selection you can match all hidden elements</p>\n<pre><code>$('element:hidden')\n</code></pre>\n<p>Using Visible selection you can match all visible elements</p>\n<pre><code>$('element:visible')\n</code></pre>\n"
},
{
"answer_id": 65844339,
"author": "centralhubb.com",
"author_id": 1001342,
"author_profile": "https://Stackoverflow.com/users/1001342",
"pm_score": 0,
"selected": false,
"text": "<pre><code>if($(element).is(":visible")) {\n console.log('element is visible');\n} else {\n console.log('element is not visible');\n}\n</code></pre>\n"
},
{
"answer_id": 70433410,
"author": "Vicky P",
"author_id": 14186457,
"author_profile": "https://Stackoverflow.com/users/14186457",
"pm_score": 3,
"selected": false,
"text": "<p>There are two ways to check visibility of element.</p>\n<p><strong>Solution #1</strong></p>\n<pre><code>if($('.selector').is(':visible')){\n // element is visible\n}else{\n // element is hidden\n}\n</code></pre>\n<p><strong>Solution #2</strong></p>\n<pre><code>if($('.selector:visible')){\n // element is visible\n}else{\n // element is hidden\n}\n</code></pre>\n"
},
{
"answer_id": 70470760,
"author": "udorb b",
"author_id": 4493560,
"author_profile": "https://Stackoverflow.com/users/4493560",
"pm_score": -1,
"selected": false,
"text": "<p>if you hide with class - d-none</p>\n<pre><code>if (!$('#ele').hasClass('d-none')) {\n $('#ele').addClass('d-none'); //hide \n\n }\n\n\n \n</code></pre>\n"
},
{
"answer_id": 70595690,
"author": "Enrico König",
"author_id": 16711980,
"author_profile": "https://Stackoverflow.com/users/16711980",
"pm_score": 2,
"selected": false,
"text": "<p>The easiest answer to this question is this:</p>\n<pre><code>function checkUIElementVisible(element) {\n return ((element.css('display') !== 'none') && (element.css('visibility') !== 'hidden'));\n}\n</code></pre>\n"
},
{
"answer_id": 72112111,
"author": "Sahil Thummar",
"author_id": 14229690,
"author_profile": "https://Stackoverflow.com/users/14229690",
"pm_score": 3,
"selected": false,
"text": "<p>Use any of visible Selector or hidden Selector to check visiblity:</p>\n<ol>\n<li>Use <a href=\"https://api.jquery.com/visible-selector/\" rel=\"noreferrer\">:visible Selector - jQuery( ":visible" )</a></li>\n<li><a href=\"https://api.jquery.com/hidden-selector/\" rel=\"noreferrer\">Use :hidden Selector - jQuery( ":hidden" )</a></li>\n</ol>\n<p>use <a href=\"https://api.jquery.com/toggle/\" rel=\"noreferrer\">.toggle()</a> - Display and hide element</p>\n<p><div class=\"snippet\" data-lang=\"js\" data-hide=\"false\" data-console=\"true\" data-babel=\"false\">\r\n<div class=\"snippet-code\">\r\n<pre class=\"snippet-code-js lang-js prettyprint-override\"><code>function checkVisibility() {\n // check if element is hidden or not and return true false\n console.log($('#element').is(':hidden'));\n\n // check if element is visible or not and return true false\n console.log($('#element').is(':visible'));\n\n if ( $('#element').css('display') == 'none' || $('#element').css(\"visibility\") == \"hidden\"){\n console.log('element is hidden');\n } else {\n console.log('element is visibile');\n }\n}\n\ncheckVisibility()\n$('#toggle').click(function() {\n $('#element').toggle()\n checkVisibility()\n})</code></pre>\r\n<pre class=\"snippet-code-html lang-html prettyprint-override\"><code><script src=\"https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js\"></script>\n<button id='toggle'>Toggle</button>\n<div style='display:none' id='element'>\n <h1>Hello</h1>\n <p>it's visible</p>\n</div></code></pre>\r\n</div>\r\n</div>\r\n</p>\n"
},
{
"answer_id": 72772615,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 1,
"selected": false,
"text": "<p>You can try this</p>\n<pre><code>$(document).ready(function() {\n var view = $(this).is(':visible');\n\n if(view) {\n alert("view");\n // Code\n }\n else\n {\n alert("hidden");\n }\n});\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178325",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/21709/"
] |
How do I toggle the visibility of an element using `.hide()`, `.show()`, or `.toggle()`?
How do I test if an element is `visible` or `hidden`?
|
Since the question refers to a single element, this code might be more suitable:
```
// Checks CSS content for display:[none|block], ignores visibility:[true|false]
$(element).is(":visible");
// The same works with hidden
$(element).is(":hidden");
```
It is the same as [twernt's suggestion](https://stackoverflow.com/questions/178325/how-do-you-test-if-something-is-hidden-in-jquery/178386#178386), but applied to a single element; and it [matches the algorithm recommended in the jQuery FAQ](https://stackoverflow.com/questions/178325/how-do-i-check-if-an-element-is-hidden-in-jquery/4685330#4685330).
We use jQuery's [is()](https://api.jquery.com/is/) to check the selected element with another element, selector or any jQuery object. This method traverses along the DOM elements to find a match, which satisfies the passed parameter. It will return true if there is a match, otherwise return false.
|
178,328 |
<p>In PHP, function parameters can be passed by reference by prepending an ampersand to the parameter in the function declaration, like so:</p>
<pre><code>function foo(&$bar)
{
// ...
}
</code></pre>
<p>Now, I am aware that this is <i>not</i> designed to improve performance, but to allow functions to change variables that are normally out of their scope.</p>
<p>Instead, PHP seems to use Copy On Write to avoid copying objects (and maybe also arrays) until they are changed. So, for functions that do not change their parameters, the effect should be the same as if you had passed them by reference.</p>
<p>However, I was wondering if the Copy On Write logic maybe is shortcircuited on pass-by-reference and whether that has any performance impact.</p>
<p><i>ETA: To be sure, I assume that it's not faster, and I am well aware that this is not what references are for. So I think my own guesses are quite good, I'm just looking for an answer from someone who really knows what's definitely happening under the hood. In five years of PHP development, I've always found it hard to get quality information on PHP internals short from reading the source.</i></p>
|
[
{
"answer_id": 178340,
"author": "Greg",
"author_id": 24181,
"author_profile": "https://Stackoverflow.com/users/24181",
"pm_score": 2,
"selected": false,
"text": "<p>I'm pretty sure that no, it's not faster.\nAdditionally, it says specifically in the manual not to try using references to increase performance.</p>\n\n<p>Edit: Can't find where it says that, but it's there!</p>\n"
},
{
"answer_id": 178375,
"author": "Paul Dixon",
"author_id": 6521,
"author_profile": "https://Stackoverflow.com/users/6521",
"pm_score": 6,
"selected": true,
"text": "<p>The Zend Engine uses copy-on-write, and when you use a reference yourself, it incurs a little extra overhead. Can only find <a href=\"http://web.archive.org/web/20130406174901/http://www.thedeveloperday.com/php-lazy-copy/\" rel=\"noreferrer\">this mention</a> at time of writing though, and comments in <a href=\"http://www.php.net/references\" rel=\"noreferrer\">the manual</a> contain other links.</p>\n\n<p>(EDIT) The manual page on <a href=\"http://www.php.net/manual/en/language.oop5.references.php\" rel=\"noreferrer\">Objects and references</a> contains a little more info on how object variables differ from references.</p>\n"
},
{
"answer_id": 178390,
"author": "Michał Niedźwiedzki",
"author_id": 2169,
"author_profile": "https://Stackoverflow.com/users/2169",
"pm_score": -1,
"selected": false,
"text": "<p>There is no need for adding & operator when passing objects. In PHP 5+ objects are passed by reference anyway.</p>\n"
},
{
"answer_id": 3845530,
"author": "ikary",
"author_id": 464550,
"author_profile": "https://Stackoverflow.com/users/464550",
"pm_score": 7,
"selected": false,
"text": "<p>In a test with 100 000 iterations of calling a function with a string of 20 kB, the results are:</p>\n\n<h3>Function that just reads / uses the parameter</h3>\n\n<pre><code>pass by value: 0.12065005 seconds\npass by reference: 1.52171397 seconds\n</code></pre>\n\n<h3>Function to write / change the parameter</h3>\n\n<pre><code>pass by value: 1.52223396 seconds\npass by reference: 1.52388787 seconds\n</code></pre>\n\n<hr>\n\n<h2>Conclusions</h2>\n\n<ol>\n<li><p>Pass the parameter by value is always faster</p></li>\n<li><p>If the function change the value of the variable passed, for practical purposes is the same as pass by reference than by value</p></li>\n</ol>\n"
},
{
"answer_id": 6577819,
"author": "Petah",
"author_id": 268074,
"author_profile": "https://Stackoverflow.com/users/268074",
"pm_score": 5,
"selected": false,
"text": "<p>I ran some test on this because I was unsure of the answers given.</p>\n\n<p>My results show that passing large arrays or strings by reference IS significantly faster.</p>\n\n<p>Here are my results:\n<img src=\"https://i.stack.imgur.com/HIhrA.png\" alt=\"Benchmark\"></p>\n\n<p>The Y axis (Runs) is how many times a function could be called in 1 second * 10</p>\n\n<p>The test was repeated 8 times for each function/variable</p>\n\n<p>And here is the variables I used:</p>\n\n<pre><code>$large_array = array_fill(PHP_INT_MAX / 2, 1000, 'a');\n$small_array = array('this', 'is', 'a', 'small', 'array');\n$large_object = (object)$large_array;\n$large_string = str_repeat('a', 100000);\n$small_string = 'this is a small string';\n$value = PHP_INT_MAX / 2;\n</code></pre>\n\n<p>These are the functions:</p>\n\n<pre><code>function pass_by_ref(&$var) {\n}\n\nfunction pass_by_val($var) {\n}\n</code></pre>\n"
},
{
"answer_id": 7620713,
"author": "Vladimir Fesko",
"author_id": 974507,
"author_profile": "https://Stackoverflow.com/users/974507",
"pm_score": 3,
"selected": false,
"text": "<p>I have experimented with values and references of 10k bytes string passing it to two identical function. One takes argument by value and the second one by reference. They were common functions - take argument, do simple processing and return a value. I did 100 000 calls of both and figured out that references are not designed to increase performance - profit of reference was near 4-5% and it grows only when string becomes large enough (100k and longer, that gave 6-7% improvement). So, my conclusion is <strong>do not use references to increase perfomance, this stuff is not for that.</strong></p>\n\n<p>I used PHP Version 5.3.1</p>\n"
},
{
"answer_id": 24975733,
"author": "Melsi",
"author_id": 642173,
"author_profile": "https://Stackoverflow.com/users/642173",
"pm_score": 1,
"selected": false,
"text": "<p>There is nothing better than a testing piece of code</p>\n\n<pre><code><?PHP\n$r = array();\n\nfor($i=0; $i<500;$i++){\n$r[]=5;\n}\n\nfunction a($r){\n$r[0]=1;\n}\nfunction b(&$r){\n$r[0]=1;\n}\n\n$start = microtime(true);\nfor($i=0;$i<9999;$i++){\n //a($r);\n b($r);\n}\n$end = microtime(true);\n\necho $end-$start;\n?>\n</code></pre>\n\n<p>Final result! The bigger the array (or the greater the count of calls) the bigger the difference. So in this case, calling by reference is faster because the value is changed inside the function. </p>\n\n<p>Otherwise there is no real difference between \"by reference\" and \"by value\", the compiler is smart enough not to create a new copy each time if there is no need. </p>\n"
},
{
"answer_id": 48861538,
"author": "Bob Ray",
"author_id": 1716090,
"author_profile": "https://Stackoverflow.com/users/1716090",
"pm_score": 2,
"selected": false,
"text": "<p>I tried to benchmark this with a real-world example based on a project I was working on. As always, the differences are trivial, but the results were somewhat unexpected. For most of the benchmarks I've seen, the called function doesn't actually change the value passed in. I performed a simple str_replace() on it.</p>\n\n<pre><code>**Pass by Value Test Code:**\n\n$originalString=''; // 1000 pseudo-random digits\n\nfunction replace($string) {\n return str_replace('1', 'x',$string);\n}\n$output = '';\n/* set start time */\n$mtime = microtime();\n$mtime = explode(\" \", $mtime);\n$mtime = $mtime[1] + $mtime[0];\n$tstart = $mtime;\nset_time_limit(0);\n\nfor ($i = 0; $i < 10; $i++ ) {\n for ($j = 0; $j < 1000000; $j++) {\n $string = $originalString;\n $string = replace($string);\n }\n}\n\n/* report how long it took */\n$mtime = microtime();\n$mtime = explode(\" \", $mtime);\n$mtime = $mtime[1] + $mtime[0];\n$tend = $mtime;\n$totalTime = ($tend - $tstart);\n$totalTime = sprintf(\"%2.4f s\", $totalTime);\n$output .= \"\\n\" . 'Total Time' .\n ': ' . $totalTime;\n$output .= \"\\n\" . $string;\necho $output;\n</code></pre>\n\n<p><strong>Pass by Reference Test Code</strong></p>\n\n<p>The same except for</p>\n\n<pre><code>function replace(&$string) {\n $string = str_replace('1', 'x',$string);\n}\n/* ... */\nreplace($string);\n</code></pre>\n\n<p><strong>Results in seconds (10 million iterations):</strong></p>\n\n<pre><code>PHP 5\n Value: 14.1007\n Reference: 11.5564\n\nPHP 7\n Value: 3.0799\n Reference: 2.9489\n</code></pre>\n\n<p>The difference is a fraction of a millisecond per function call, but for this use case, passing by reference is faster in both PHP 5 and PHP 7.</p>\n\n<p>(Note: the PHP 7 tests were performed on a faster machine -- PHP 7 is faster, but probably not that much faster.)</p>\n"
},
{
"answer_id": 54869594,
"author": "orfruit",
"author_id": 1734108,
"author_profile": "https://Stackoverflow.com/users/1734108",
"pm_score": -1,
"selected": false,
"text": "<p>Is simple, there is no need to test anything.\nDepends on use-case.</p>\n\n<p>Pass by value will ALWAYS BE FASTER BY VALUE than reference for small amount of arguments. This depends by how many variables that architecture allows to be passed through registers (ABI).</p>\n\n<p>For example x64 will allow you 4 values 64 bit each to be passed through registers.\n<a href=\"https://en.wikipedia.org/wiki/X86_calling_conventions\" rel=\"nofollow noreferrer\">https://en.wikipedia.org/wiki/X86_calling_conventions</a></p>\n\n<p>This is because you don't have to de-referentiate the pointers, just use value directly.</p>\n\n<p>If your data that needs to be passed is bigger than ABI, rest of values will go to stack.\nIn this case, a array or a object (which in instance is a class, or a structure + headers) will ALWAYS BE FASTER BY REFERENCE. </p>\n\n<p>This is because a reference is just a pointer to your data (not data itself), fixed size, say 32 or 64 bit depending on machine. That pointer will fit in one CPU register.</p>\n\n<p>PHP is written in C/C++ so I'd expect to behave the same.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178328",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2077/"
] |
In PHP, function parameters can be passed by reference by prepending an ampersand to the parameter in the function declaration, like so:
```
function foo(&$bar)
{
// ...
}
```
Now, I am aware that this is *not* designed to improve performance, but to allow functions to change variables that are normally out of their scope.
Instead, PHP seems to use Copy On Write to avoid copying objects (and maybe also arrays) until they are changed. So, for functions that do not change their parameters, the effect should be the same as if you had passed them by reference.
However, I was wondering if the Copy On Write logic maybe is shortcircuited on pass-by-reference and whether that has any performance impact.
*ETA: To be sure, I assume that it's not faster, and I am well aware that this is not what references are for. So I think my own guesses are quite good, I'm just looking for an answer from someone who really knows what's definitely happening under the hood. In five years of PHP development, I've always found it hard to get quality information on PHP internals short from reading the source.*
|
The Zend Engine uses copy-on-write, and when you use a reference yourself, it incurs a little extra overhead. Can only find [this mention](http://web.archive.org/web/20130406174901/http://www.thedeveloperday.com/php-lazy-copy/) at time of writing though, and comments in [the manual](http://www.php.net/references) contain other links.
(EDIT) The manual page on [Objects and references](http://www.php.net/manual/en/language.oop5.references.php) contains a little more info on how object variables differ from references.
|
178,333 |
<p>Since multiple inheritance is bad (it makes the source more complicated) C# does not provide such a pattern directly. But sometimes it would be helpful to have this ability.</p>
<p>For instance I'm able to implement the missing multiple inheritance pattern using interfaces and three classes like that:</p>
<pre><code>public interface IFirst { void FirstMethod(); }
public interface ISecond { void SecondMethod(); }
public class First:IFirst
{
public void FirstMethod() { Console.WriteLine("First"); }
}
public class Second:ISecond
{
public void SecondMethod() { Console.WriteLine("Second"); }
}
public class FirstAndSecond: IFirst, ISecond
{
First first = new First();
Second second = new Second();
public void FirstMethod() { first.FirstMethod(); }
public void SecondMethod() { second.SecondMethod(); }
}
</code></pre>
<p>Every time I add a method to one of the interfaces I need to change the class <em>FirstAndSecond</em> as well.</p>
<p>Is there a way to inject multiple existing classes into one new class like it is possible in C++?</p>
<p>Maybe there is a solution using some kind of code generation?</p>
<p>Or it may look like this (imaginary c# syntax):</p>
<pre><code>public class FirstAndSecond: IFirst from First, ISecond from Second
{ }
</code></pre>
<p>So that there won't be a need to update the class FirstAndSecond when I modify one of the interfaces.</p>
<hr />
<h3>EDIT</h3>
<p>Maybe it would be better to consider a practical example:</p>
<p>You have an existing class (e.g. a text based TCP client based on ITextTcpClient) which you do already use at different locations inside your project. Now you feel the need to create a component of your class to be easy accessible for windows forms developers.</p>
<p>As far as I know you currently have two ways to do this:</p>
<ol>
<li><p>Write a new class that is inherited from components and implements the interface of the TextTcpClient class using an instance of the class itself as shown with FirstAndSecond.</p>
</li>
<li><p>Write a new class that inherits from TextTcpClient and somehow implements IComponent (haven't actually tried this yet).</p>
</li>
</ol>
<p>In both cases you need to do work per method and not per class. Since you know that we will need all the methods of TextTcpClient and Component it would be the easiest solution to just combine those two into one class.</p>
<p>To avoid conflicts this may be done by code generation where the result could be altered afterwards but typing this by hand is a pure pain in the ass.</p>
|
[
{
"answer_id": 178346,
"author": "Joel Coehoorn",
"author_id": 3043,
"author_profile": "https://Stackoverflow.com/users/3043",
"pm_score": 3,
"selected": false,
"text": "<p>You could have one abstract base class that implements both IFirst and ISecond, and then inherit from just that base.</p>\n"
},
{
"answer_id": 178368,
"author": "Chris Wenham",
"author_id": 5548,
"author_profile": "https://Stackoverflow.com/users/5548",
"pm_score": 8,
"selected": false,
"text": "<p>Consider just using <em><a href=\"http://en.wikipedia.org/wiki/Object_composition\" rel=\"noreferrer\">composition</a></em> instead of trying to simulate Multiple Inheritance. You can use Interfaces to define what classes make up the composition, eg: <code>ISteerable</code> implies a property of type <code>SteeringWheel</code>, <code>IBrakable</code> implies a property of type <code>BrakePedal</code>, etc.</p>\n\n<p>Once you've done that, you could use the <a href=\"http://msdn.microsoft.com/en-us/library/bb383977.aspx\" rel=\"noreferrer\">Extension Methods</a> feature added to C# 3.0 to further simplify calling methods on those implied properties, eg:</p>\n\n<pre><code>public interface ISteerable { SteeringWheel wheel { get; set; } }\n\npublic interface IBrakable { BrakePedal brake { get; set; } }\n\npublic class Vehicle : ISteerable, IBrakable\n{\n public SteeringWheel wheel { get; set; }\n\n public BrakePedal brake { get; set; }\n\n public Vehicle() { wheel = new SteeringWheel(); brake = new BrakePedal(); }\n}\n\npublic static class SteeringExtensions\n{\n public static void SteerLeft(this ISteerable vehicle)\n {\n vehicle.wheel.SteerLeft();\n }\n}\n\npublic static class BrakeExtensions\n{\n public static void Stop(this IBrakable vehicle)\n {\n vehicle.brake.ApplyUntilStop();\n }\n}\n\n\npublic class Main\n{\n Vehicle myCar = new Vehicle();\n\n public void main()\n {\n myCar.SteerLeft();\n myCar.Stop();\n }\n}\n</code></pre>\n"
},
{
"answer_id": 178413,
"author": "Amy B",
"author_id": 8155,
"author_profile": "https://Stackoverflow.com/users/8155",
"pm_score": 1,
"selected": false,
"text": "<p>If you can live with the restriction that the methods of IFirst and ISecond must only interact with the contract of IFirst and ISecond (like in your example)... you can do what you ask with extension methods. In practice, this is rarely the case.</p>\n\n<pre><code>public interface IFirst {}\npublic interface ISecond {}\n\npublic class FirstAndSecond : IFirst, ISecond\n{\n}\n\npublic static MultipleInheritenceExtensions\n{\n public static void First(this IFirst theFirst)\n {\n Console.WriteLine(\"First\");\n }\n\n public static void Second(this ISecond theSecond)\n {\n Console.WriteLine(\"Second\");\n }\n}\n</code></pre>\n\n<p>///</p>\n\n<pre><code>public void Test()\n{\n FirstAndSecond fas = new FirstAndSecond();\n fas.First();\n fas.Second();\n}\n</code></pre>\n\n<p>So the basic idea is that you define the required implementation in the interfaces... this required stuff should support the flexible implementation in the extension methods. Anytime you need to \"add methods to the interface\" instead you add an extension method.</p>\n"
},
{
"answer_id": 178452,
"author": "tloach",
"author_id": 14092,
"author_profile": "https://Stackoverflow.com/users/14092",
"pm_score": 0,
"selected": false,
"text": "<p>Multiple inheritance is one of those things that generally causes more problems than it solves. In C++ it fits the pattern of giving you enough rope to hang yourself, but Java and C# have chosen to go the safer route of not giving you the option. The biggest problem is what to do if you inherit multiple classes that have a method with the same signature that the inheritee doesn't implement. Which class's method should it choose? Or should that not compile? There is generally another way to implement most things that doesn't rely on multiple inheritance.</p>\n"
},
{
"answer_id": 1695631,
"author": "IanNorton",
"author_id": 148415,
"author_profile": "https://Stackoverflow.com/users/148415",
"pm_score": 8,
"selected": true,
"text": "<blockquote>\n <p>Since multiple inheritance is bad (it makes the source more complicated) C# does not provide such a pattern directly. But sometimes it would be helpful to have this ability.</p>\n</blockquote>\n\n<p>C# and the .net CLR have not implemented MI because they have not concluded how it would inter-operate between C#, VB.net and the other languages yet, not because \"it would make source more complex\"</p>\n\n<p>MI is a useful concept, the un-answered questions are ones like:- \"What do you do when you have multiple common base classes in the different superclasses?</p>\n\n<p>Perl is the only language I've ever worked with where MI works and works well. .Net may well introduce it one day but not yet, the CLR does already support MI but as I've said, there are no language constructs for it beyond that yet.</p>\n\n<p>Until then you are stuck with Proxy objects and multiple Interfaces instead :(</p>\n"
},
{
"answer_id": 6002552,
"author": "Jordão",
"author_id": 31158,
"author_profile": "https://Stackoverflow.com/users/31158",
"pm_score": 4,
"selected": false,
"text": "<p>I created a <a href=\"https://github.com/jordao76/nroles\" rel=\"noreferrer\">C# post-compiler</a> that enables this kind of thing:</p>\n\n<pre><code>using NRoles;\n\npublic interface IFirst { void FirstMethod(); }\npublic interface ISecond { void SecondMethod(); }\n\npublic class RFirst : IFirst, Role {\n public void FirstMethod() { Console.WriteLine(\"First\"); }\n}\n\npublic class RSecond : ISecond, Role {\n public void SecondMethod() { Console.WriteLine(\"Second\"); }\n}\n\npublic class FirstAndSecond : Does<RFirst>, Does<RSecond> { }\n</code></pre>\n\n<p>You can run the post-compiler as a Visual Studio post-build-event:</p>\n\n<blockquote>\n <p>C:\\some_path\\nroles-v0.1.0-bin\\nutate.exe \"$(TargetPath)\"</p>\n</blockquote>\n\n<p>In the same assembly you use it like this:</p>\n\n<pre><code>var fas = new FirstAndSecond();\nfas.As<RFirst>().FirstMethod();\nfas.As<RSecond>().SecondMethod();\n</code></pre>\n\n<p>In another assembly you use it like this:</p>\n\n<pre><code>var fas = new FirstAndSecond();\nfas.FirstMethod();\nfas.SecondMethod();\n</code></pre>\n"
},
{
"answer_id": 7177360,
"author": "supercat",
"author_id": 363751,
"author_profile": "https://Stackoverflow.com/users/363751",
"pm_score": 0,
"selected": false,
"text": "<p>If X inherits from Y, that has two somewhat orthogonal effects:</p>\n\n<ol>\n<li>Y will provide default functionality for X, so the code for X only has to include stuff which is different from Y.\n<li>Almost anyplace a Y would be expected, an X may be used instead.\n</ol>\n\n<p>Although inheritance provides for both features, it is not hard to imagine circumstances where either could be of use without the other. No .net language I know of has a direct way of implementing the first without the second, though one could obtain such functionality by defining a base class which is never used directly, and having one or more classes that inherit directly from it without adding anything new (such classes could share all their code, but would not be substitutable for each other). Any CLR-compliant language, however, will allow the use of interfaces which provide the second feature of interfaces (substitutability) without the first (member reuse).</p>\n"
},
{
"answer_id": 9906675,
"author": "ariel",
"author_id": 1254236,
"author_profile": "https://Stackoverflow.com/users/1254236",
"pm_score": 0,
"selected": false,
"text": "<p>i know i know\neven though its not allowed and so on, sometime u actualy need it so for the those:</p>\n\n<pre><code>class a {}\nclass b : a {}\nclass c : b {}\n</code></pre>\n\n<p>like in my case i wanted to do this\n class b : Form (yep the windows.forms)\n class c : b {}</p>\n\n<p>cause half of the function were identical and with interface u must rewrite them all</p>\n"
},
{
"answer_id": 21145535,
"author": "Yogi",
"author_id": 1171842,
"author_profile": "https://Stackoverflow.com/users/1171842",
"pm_score": 1,
"selected": false,
"text": "<p>Yes using Interface is a hassle because anytime we add a method in the class we have to add the signature in the interface. Also, what if we already have a class with a bunch of methods but no Interface for it? we have to manually create Interface for all the classes that we want to inherit from. And the worst thing is, we have to implement all methods in the Interfaces in the child class if the child class is to inherit from the multiple interface.</p>\n\n<p>By following Facade design pattern we can simulate inheriting from multiple classes using <strong>accessors</strong>. Declare the classes as properties with {get;set;} inside the class that need to inherit and all public properties and methods are from that class, and in the constructor of the child class instantiate the parent classes.</p>\n\n<p>For example:</p>\n\n<pre><code> namespace OOP\n {\n class Program\n {\n static void Main(string[] args)\n {\n Child somechild = new Child();\n somechild.DoHomeWork();\n somechild.CheckingAround();\n Console.ReadLine();\n }\n }\n\n public class Father \n {\n public Father() { }\n public void Work()\n {\n Console.WriteLine(\"working...\");\n }\n public void Moonlight()\n {\n Console.WriteLine(\"moonlighting...\");\n }\n }\n\n\n public class Mother \n {\n public Mother() { }\n public void Cook()\n {\n Console.WriteLine(\"cooking...\");\n }\n public void Clean()\n {\n Console.WriteLine(\"cleaning...\");\n }\n }\n\n\n public class Child \n {\n public Father MyFather { get; set; }\n public Mother MyMother { get; set; }\n\n public Child()\n {\n MyFather = new Father();\n MyMother = new Mother();\n }\n\n public void GoToSchool()\n {\n Console.WriteLine(\"go to school...\");\n }\n public void DoHomeWork()\n {\n Console.WriteLine(\"doing homework...\");\n }\n public void CheckingAround()\n {\n MyFather.Work();\n MyMother.Cook();\n }\n }\n\n\n }\n</code></pre>\n\n<p>with this structure class Child will have access to all methods and properties of Class Father and Mother, simulating multiple inheritance, inheriting an instance of the parent classes. Not quite the same but it is practical.</p>\n"
},
{
"answer_id": 33081879,
"author": "grek40",
"author_id": 5265292,
"author_profile": "https://Stackoverflow.com/users/5265292",
"pm_score": 0,
"selected": false,
"text": "<p>Since the question of multiple inheritance (MI) pops up from time to time, I'd like to add an approach which addresses some problems with the composition pattern.</p>\n\n<p>I build upon the <code>IFirst</code>, <code>ISecond</code>,<code>First</code>, <code>Second</code>, <code>FirstAndSecond</code> approach, as it was presented in the question. I reduce sample code to <code>IFirst</code>, since the pattern stays the same regardless of the number of interfaces / MI base classes.</p>\n\n<p>Lets assume, that with MI <code>First</code> and <code>Second</code> would both derive from the same base class <code>BaseClass</code>, using only public interface elements from <code>BaseClass</code></p>\n\n<p>This can be expressed, by adding a container reference to <code>BaseClass</code> in the <code>First</code> and <code>Second</code> implementation:</p>\n\n<pre><code>class First : IFirst {\n private BaseClass ContainerInstance;\n First(BaseClass container) { ContainerInstance = container; }\n public void FirstMethod() { Console.WriteLine(\"First\"); ContainerInstance.DoStuff(); } \n}\n...\n</code></pre>\n\n<p>Things become more complicated, when protected interface elements from <code>BaseClass</code> are referenced or when <code>First</code> and <code>Second</code> would be abstract classes in MI, requiring their subclasses to implement some abstract parts.</p>\n\n<pre><code>class BaseClass {\n protected void DoStuff();\n}\n\nabstract class First : IFirst {\n public void FirstMethod() { DoStuff(); DoSubClassStuff(); }\n protected abstract void DoStuff(); // base class reference in MI\n protected abstract void DoSubClassStuff(); // sub class responsibility\n}\n</code></pre>\n\n<p>C# allows nested classes to access protected/private elements of their containing classes, so this can be used to link the abstract bits from the <code>First</code> implementation.</p>\n\n<pre><code>class FirstAndSecond : BaseClass, IFirst, ISecond {\n // link interface\n private class PartFirst : First {\n private FirstAndSecond ContainerInstance;\n public PartFirst(FirstAndSecond container) {\n ContainerInstance = container;\n }\n // forwarded references to emulate access as it would be with MI\n protected override void DoStuff() { ContainerInstance.DoStuff(); }\n protected override void DoSubClassStuff() { ContainerInstance.DoSubClassStuff(); }\n }\n private IFirst partFirstInstance; // composition object\n public FirstMethod() { partFirstInstance.FirstMethod(); } // forwarded implementation\n public FirstAndSecond() {\n partFirstInstance = new PartFirst(this); // composition in constructor\n }\n // same stuff for Second\n //...\n // implementation of DoSubClassStuff\n private void DoSubClassStuff() { Console.WriteLine(\"Private method accessed\"); }\n}\n</code></pre>\n\n<p>There is quite some boilerplate involved, but if the actual implementation of FirstMethod and SecondMethod are sufficiently complex and the amount of accessed private/protected methods is moderate, then this pattern may help to overcome lacking multiple inheritance.</p>\n"
},
{
"answer_id": 42341929,
"author": "William Jockusch",
"author_id": 246568,
"author_profile": "https://Stackoverflow.com/users/246568",
"pm_score": 2,
"selected": false,
"text": "<p>This is along the lines of Lawrence Wenham's answer, but depending on your use case, it may or may not be an improvement -- you don't need the setters.</p>\n\n<pre><code>public interface IPerson {\n int GetAge();\n string GetName();\n}\n\npublic interface IGetPerson {\n IPerson GetPerson();\n}\n\npublic static class IGetPersonAdditions {\n public static int GetAgeViaPerson(this IGetPerson getPerson) { // I prefer to have the \"ViaPerson\" in the name in case the object has another Age property.\n IPerson person = getPerson.GetPersion();\n return person.GetAge();\n }\n public static string GetNameViaPerson(this IGetPerson getPerson) {\n return getPerson.GetPerson().GetName();\n }\n}\n\npublic class Person: IPerson, IGetPerson {\n private int Age {get;set;}\n private string Name {get;set;}\n public IPerson GetPerson() {\n return this;\n }\n public int GetAge() { return Age; }\n public string GetName() { return Name; }\n}\n</code></pre>\n\n<p>Now any object that knows how to get a person can implement IGetPerson, and it will automatically have the GetAgeViaPerson() and GetNameViaPerson() methods. From this point, basically all Person code goes into IGetPerson, not into IPerson, other than new ivars, which have to go into both. And in using such code, you don't have to be concerned about whether or not your IGetPerson object is itself actually an IPerson.</p>\n"
},
{
"answer_id": 47823656,
"author": "hydrix",
"author_id": 5412017,
"author_profile": "https://Stackoverflow.com/users/5412017",
"pm_score": 2,
"selected": false,
"text": "<p>In my own implementation I found that using classes/interfaces for MI, although \"good form\", tended to be a massive over complication since you need to set up all that multiple inheritance for only a few necessary function calls, and in my case, needed to be done literally dozens of times redundantly.</p>\n\n<p>Instead it was easier to simply make static \"functions that call functions that call functions\" in different modular varieties as a sort of OOP replacement. The solution I was working on was the \"spell system\" for a RPG where effects need to <strong>heavily</strong> mix-and-match function calling to give an extreme variety of spells without re-writing code, much like the example seems to indicate. </p>\n\n<p>Most of the functions can now be static because I don't necessarily need an instance for spell logic, whereas class inheritance can't even use virtual or abstract keywords while static. Interfaces can't use them at all.</p>\n\n<p>Coding seems way faster and cleaner this way IMO. If you're just doing functions, and don't need inherited <strong>properties</strong>, use functions.</p>\n"
},
{
"answer_id": 53288366,
"author": "Ludmil Tinkov",
"author_id": 519553,
"author_profile": "https://Stackoverflow.com/users/519553",
"pm_score": 2,
"selected": false,
"text": "<p>With C# 8 now you practically have multiple inheritance via default implementation of interface members:</p>\n\n<pre><code>interface ILogger\n{\n void Log(LogLevel level, string message);\n void Log(Exception ex) => Log(LogLevel.Error, ex.ToString()); // New overload\n}\n\nclass ConsoleLogger : ILogger\n{\n public void Log(LogLevel level, string message) { ... }\n // Log(Exception) gets default implementation\n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178333",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/25782/"
] |
Since multiple inheritance is bad (it makes the source more complicated) C# does not provide such a pattern directly. But sometimes it would be helpful to have this ability.
For instance I'm able to implement the missing multiple inheritance pattern using interfaces and three classes like that:
```
public interface IFirst { void FirstMethod(); }
public interface ISecond { void SecondMethod(); }
public class First:IFirst
{
public void FirstMethod() { Console.WriteLine("First"); }
}
public class Second:ISecond
{
public void SecondMethod() { Console.WriteLine("Second"); }
}
public class FirstAndSecond: IFirst, ISecond
{
First first = new First();
Second second = new Second();
public void FirstMethod() { first.FirstMethod(); }
public void SecondMethod() { second.SecondMethod(); }
}
```
Every time I add a method to one of the interfaces I need to change the class *FirstAndSecond* as well.
Is there a way to inject multiple existing classes into one new class like it is possible in C++?
Maybe there is a solution using some kind of code generation?
Or it may look like this (imaginary c# syntax):
```
public class FirstAndSecond: IFirst from First, ISecond from Second
{ }
```
So that there won't be a need to update the class FirstAndSecond when I modify one of the interfaces.
---
### EDIT
Maybe it would be better to consider a practical example:
You have an existing class (e.g. a text based TCP client based on ITextTcpClient) which you do already use at different locations inside your project. Now you feel the need to create a component of your class to be easy accessible for windows forms developers.
As far as I know you currently have two ways to do this:
1. Write a new class that is inherited from components and implements the interface of the TextTcpClient class using an instance of the class itself as shown with FirstAndSecond.
2. Write a new class that inherits from TextTcpClient and somehow implements IComponent (haven't actually tried this yet).
In both cases you need to do work per method and not per class. Since you know that we will need all the methods of TextTcpClient and Component it would be the easiest solution to just combine those two into one class.
To avoid conflicts this may be done by code generation where the result could be altered afterwards but typing this by hand is a pure pain in the ass.
|
>
> Since multiple inheritance is bad (it makes the source more complicated) C# does not provide such a pattern directly. But sometimes it would be helpful to have this ability.
>
>
>
C# and the .net CLR have not implemented MI because they have not concluded how it would inter-operate between C#, VB.net and the other languages yet, not because "it would make source more complex"
MI is a useful concept, the un-answered questions are ones like:- "What do you do when you have multiple common base classes in the different superclasses?
Perl is the only language I've ever worked with where MI works and works well. .Net may well introduce it one day but not yet, the CLR does already support MI but as I've said, there are no language constructs for it beyond that yet.
Until then you are stuck with Proxy objects and multiple Interfaces instead :(
|
178,398 |
<p>Generally, MVC frameeworks have a structure that looks something like:</p>
<pre><code>/models
/views
/controllers
/utils
</code></pre>
<p>However, in a web application suite, I've decided that clumping all models, views, and controllers together probably wouldn't be the best for clarity, unless I treated the system as one application instead of an application suite. However, some things tie every "application" together, like the notion of users and user roles.</p>
<p>So I have three possible solutions:</p>
<p>(1) Do what I don't really want to do, and keep every model, view, and controller together, regardless of which app it belongs to. This is treating the suite as a single application, since they are tied together by several common threads, including users.</p>
<p>(2) Group the code by application.</p>
<pre><code>/app1
/models
/views
/controllers
/utils
/app2
/models
/views
/controllers
/utils
</code></pre>
<p>(3) Group the code by type, letting utility code be shared among all of the applications.</p>
<pre><code>/models
/app1
/app2
/views
/app1
/app2
/controllers
/app1
/app2
/utils
</code></pre>
<p>Is there an option I missed? What would be the most logical scheme for future developers? I personally prefer 2 and 3, but perhaps most people would expect 1.</p>
|
[
{
"answer_id": 178411,
"author": "Adam Bellaire",
"author_id": 21632,
"author_profile": "https://Stackoverflow.com/users/21632",
"pm_score": 1,
"selected": false,
"text": "<p>If your apps share data, it could make sense (to me) to group the models together. </p>\n\n<p>However, for the views and controllers it probably makes more sense to keep them separate, since I'm assuming they have separate business logic and presentations.</p>\n\n<p>Further, if your apps are kept separately in version control (you are using version control, right? :), that makes the first or third option difficult to implement.</p>\n\n<p>So all things considered, I'd probably separate the apps at the top level, as in your second example.</p>\n"
},
{
"answer_id": 178423,
"author": "Bill the Lizard",
"author_id": 1288,
"author_profile": "https://Stackoverflow.com/users/1288",
"pm_score": 1,
"selected": false,
"text": "<p>I usually group code by feature, so in your case grouping by application would make the most sense to me. The reason is that if I want to work on a particular feature, I shouldn't have to search through three separate folders looking for the components I need. If you group by the high level feature you know everything you need is together.</p>\n"
},
{
"answer_id": 178431,
"author": "Rodger Cooley",
"author_id": 5667,
"author_profile": "https://Stackoverflow.com/users/5667",
"pm_score": 4,
"selected": true,
"text": "<p>It seems like 2) would be your best option, assuming you want some separation of applications. You could also have a \"/common\" folder at the \"/app#\" level for shared resources across all applications... like a shared utility class or whatever.</p>\n"
},
{
"answer_id": 178436,
"author": "Szymon Rozga",
"author_id": 7583,
"author_profile": "https://Stackoverflow.com/users/7583",
"pm_score": 3,
"selected": false,
"text": "<p>2 is a good start. You should consider having a common folder in which you can store any common models, views and utils used by all apps in the application suite.</p>\n\n<pre><code>/app1\n /models\n /views\n /controllers\n /utils\n/app2\n /models\n /views\n /controllers\n /utils\n/common\n /models\n /views\n /utils\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178398",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/572/"
] |
Generally, MVC frameeworks have a structure that looks something like:
```
/models
/views
/controllers
/utils
```
However, in a web application suite, I've decided that clumping all models, views, and controllers together probably wouldn't be the best for clarity, unless I treated the system as one application instead of an application suite. However, some things tie every "application" together, like the notion of users and user roles.
So I have three possible solutions:
(1) Do what I don't really want to do, and keep every model, view, and controller together, regardless of which app it belongs to. This is treating the suite as a single application, since they are tied together by several common threads, including users.
(2) Group the code by application.
```
/app1
/models
/views
/controllers
/utils
/app2
/models
/views
/controllers
/utils
```
(3) Group the code by type, letting utility code be shared among all of the applications.
```
/models
/app1
/app2
/views
/app1
/app2
/controllers
/app1
/app2
/utils
```
Is there an option I missed? What would be the most logical scheme for future developers? I personally prefer 2 and 3, but perhaps most people would expect 1.
|
It seems like 2) would be your best option, assuming you want some separation of applications. You could also have a "/common" folder at the "/app#" level for shared resources across all applications... like a shared utility class or whatever.
|
178,407 |
<p>Say I have the following:</p>
<pre><code><ul>
<li>First item</li>
<li>Second item</li>
<li>Third item</li>
</ul>
</code></pre>
<p>How would I select all the child elements after the first one using jQuery? So I can achieve something like:</p>
<pre><code><ul>
<li>First item</li>
<li class="something">Second item</li>
<li class="something">Third item</li>
</ul>
</code></pre>
|
[
{
"answer_id": 178422,
"author": "Jonny Buchanan",
"author_id": 6760,
"author_profile": "https://Stackoverflow.com/users/6760",
"pm_score": 4,
"selected": false,
"text": "<p><a href=\"http://docs.jquery.com/Traversing/slice\" rel=\"noreferrer\">http://docs.jquery.com/Traversing/slice</a></p>\n\n<pre><code>$(\"li\").slice(1).addClass(\"something\");\n</code></pre>\n"
},
{
"answer_id": 178425,
"author": "twernt",
"author_id": 18846,
"author_profile": "https://Stackoverflow.com/users/18846",
"pm_score": 8,
"selected": true,
"text": "<p>You should be able to use the \"not\" and \"first child\" selectors.</p>\n\n<pre><code>$(\"li:not(:first-child)\").addClass(\"something\");\n</code></pre>\n\n<p><a href=\"http://docs.jquery.com/Selectors/not\" rel=\"noreferrer\">http://docs.jquery.com/Selectors/not</a></p>\n\n<p><a href=\"http://docs.jquery.com/Selectors/firstChild\" rel=\"noreferrer\">http://docs.jquery.com/Selectors/firstChild</a></p>\n"
},
{
"answer_id": 178435,
"author": "Chris Canal",
"author_id": 5802,
"author_profile": "https://Stackoverflow.com/users/5802",
"pm_score": 1,
"selected": false,
"text": "<p>This is what I have working so far</p>\n\n<pre><code>$('.certificateList input:checkbox:gt(0)')\n</code></pre>\n"
},
{
"answer_id": 178445,
"author": "Pat",
"author_id": 238,
"author_profile": "https://Stackoverflow.com/users/238",
"pm_score": 2,
"selected": false,
"text": "<p>This should work </p>\n\n<pre><code>$('ul :not(:first-child)').addClass('something');\n</code></pre>\n"
},
{
"answer_id": 178498,
"author": "Sergey Ilinsky",
"author_id": 23815,
"author_profile": "https://Stackoverflow.com/users/23815",
"pm_score": 3,
"selected": false,
"text": "<p>A more elegant query (select all li elements that are preceded by a li element): </p>\n\n<p><code>\n$('ul li+li')\n</code></p>\n"
},
{
"answer_id": 178723,
"author": "ignu",
"author_id": 24616,
"author_profile": "https://Stackoverflow.com/users/24616",
"pm_score": 2,
"selected": false,
"text": "<p>i'd use</p>\n\n<pre><code>$(\"li:gt(0)\").addClass(\"something\");\n</code></pre>\n"
},
{
"answer_id": 187027,
"author": "twernt",
"author_id": 18846,
"author_profile": "https://Stackoverflow.com/users/18846",
"pm_score": 5,
"selected": false,
"text": "<p>Based on my totally unscientific analysis of the four methods here, it looks like there's not a lot of speed difference among them. I ran each on a page containing a series of unordered lists of varying length and timed them using the Firebug profiler.</p>\n\n<pre><code>$(\"li\").slice(1).addClass(\"something\");\n</code></pre>\n\n<p>Average Time: 5.322ms</p>\n\n<pre><code>$(\"li:gt(0)\").addClass(\"something\");\n</code></pre>\n\n<p>Average Time: 5.590ms</p>\n\n<pre><code>$(\"li:not(:first-child)\").addClass(\"something\");\n</code></pre>\n\n<p>Average Time: 6.084ms</p>\n\n<pre><code>$(\"ul li+li\").addClass(\"something\");\n</code></pre>\n\n<p>Average Time: 7.831ms</p>\n"
},
{
"answer_id": 50445137,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 0,
"selected": false,
"text": "<p>Use jQuery .not() method</p>\n\n<pre><code>$('li').not(':first').addClass('something');\n</code></pre>\n\n<p>OR</p>\n\n<pre><code>var firstElement = $('li').first();\n$('li').not(firstElement).addClass('something');\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178407",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5802/"
] |
Say I have the following:
```
<ul>
<li>First item</li>
<li>Second item</li>
<li>Third item</li>
</ul>
```
How would I select all the child elements after the first one using jQuery? So I can achieve something like:
```
<ul>
<li>First item</li>
<li class="something">Second item</li>
<li class="something">Third item</li>
</ul>
```
|
You should be able to use the "not" and "first child" selectors.
```
$("li:not(:first-child)").addClass("something");
```
<http://docs.jquery.com/Selectors/not>
<http://docs.jquery.com/Selectors/firstChild>
|
178,444 |
<p>I need to get existing web pages into an existing ASP.NET web site project in Visual Studio 2008. I simply tried to drag and drop the whole file folder content into the Visual Studio Solution Explorer or even to copy them into the web site folder.</p>
<p>Both ways, Visual Studio seems unable to map the .designer.cs files to the corresponding .aspx (or .master) file, even after restarting the whole IDE. The Solution Explorer entry looks in a way like this:</p>
<pre><code>- Main.aspx
Main.aspx.cs
Main.aspx.designer.cs
</code></pre>
<p>Can I make Visual Studio file the designer-file below the aspx-file in any way? I strongly hope there is a simpler way than manually creating each file and copying and pasting the contents into each file by hand.</p>
|
[
{
"answer_id": 178514,
"author": "YonahW",
"author_id": 3821,
"author_profile": "https://Stackoverflow.com/users/3821",
"pm_score": 0,
"selected": false,
"text": "<p>try copying the files through the filesystem and then right clicking on the project and selecting to add an existing item at which point you can choose all at once and this usually puts them in the proper places.</p>\n"
},
{
"answer_id": 178570,
"author": "Matthias Meid",
"author_id": 17713,
"author_profile": "https://Stackoverflow.com/users/17713",
"pm_score": 1,
"selected": false,
"text": "<p>Kind of partially self-answering my question:</p>\n\n<p>In a <strong>web project</strong> - in contrast to a <strong>web site</strong> - it works perfectly through drag and drop onto the solution explorer, as I did for the web site before. To make the decision which type of \"web site unit\" to use there is another thread here on stackoverflow: <a href=\"https://stackoverflow.com/questions/10798/aspnet-web-site-or-web-project\">ASP.NET Web Site or Web Project</a>.</p>\n\n<p>In a web site I can't even use YonahW's solution, because I can't just put files into the proper web site directory without causing them to be added to the web site automatically. Thanks to you anyway, YonahW. :-)</p>\n"
},
{
"answer_id": 181546,
"author": "mattlant",
"author_id": 14642,
"author_profile": "https://Stackoverflow.com/users/14642",
"pm_score": 3,
"selected": true,
"text": "<p>It sounds like you are trying to bring web application files into a web site. <em>IIf that is the case</em>, The designer files are not even needed. Just dont include them. They are generated and compiled in at runtime when the website runs.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178444",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/17713/"
] |
I need to get existing web pages into an existing ASP.NET web site project in Visual Studio 2008. I simply tried to drag and drop the whole file folder content into the Visual Studio Solution Explorer or even to copy them into the web site folder.
Both ways, Visual Studio seems unable to map the .designer.cs files to the corresponding .aspx (or .master) file, even after restarting the whole IDE. The Solution Explorer entry looks in a way like this:
```
- Main.aspx
Main.aspx.cs
Main.aspx.designer.cs
```
Can I make Visual Studio file the designer-file below the aspx-file in any way? I strongly hope there is a simpler way than manually creating each file and copying and pasting the contents into each file by hand.
|
It sounds like you are trying to bring web application files into a web site. *IIf that is the case*, The designer files are not even needed. Just dont include them. They are generated and compiled in at runtime when the website runs.
|
178,456 |
<p>Is it better to do this:</p>
<pre><code>try
{
...
}
catch (Exception ex)
{
...
throw;
}
</code></pre>
<p>Or this:</p>
<pre><code>try
{
...
}
catch (Exception ex)
{
...
throw ex;
}
</code></pre>
<p>Do they do the same thing? Is one better than the other?</p>
|
[
{
"answer_id": 178464,
"author": "Torbjörn Gyllebring",
"author_id": 21182,
"author_profile": "https://Stackoverflow.com/users/21182",
"pm_score": 11,
"selected": true,
"text": "<p>You should always use the following syntax to rethrow an exception. Else you'll stomp the stack trace:</p>\n<pre><code>throw;\n</code></pre>\n<p>If you print the trace resulting from <code>throw ex</code>, you'll see that it ends on that statement and not at the real source of the exception.</p>\n<p>Basically, it should be deemed a criminal offense to use <code>throw ex</code>.</p>\n<hr />\n<p>If there is a need to rethrow an exception that comes from somewhere else (AggregateException, TargetInvocationException) or perhaps another thread, you also shouldn't rethrow it directly. Rather there is the <a href=\"https://learn.microsoft.com/en-us/dotnet/api/system.runtime.exceptionservices.exceptiondispatchinfo\" rel=\"noreferrer\">ExceptionDispatchInfo</a> that preserves all the necessary information.</p>\n<pre><code>try\n{\n methodInfo.Invoke(...);\n}\ncatch (System.Reflection.TargetInvocationException e)\n{\n System.Runtime.ExceptionServices.ExceptionDispatchInfo.Capture(e.InnerException).Throw();\n throw; // just to inform the compiler that the flow never leaves the block\n}\n</code></pre>\n"
},
{
"answer_id": 178467,
"author": "Quibblesome",
"author_id": 1143,
"author_profile": "https://Stackoverflow.com/users/1143",
"pm_score": 5,
"selected": false,
"text": "<p>The first preserves the original stack trace of the exception, the second replaces it with the current location.</p>\n<p>Therefore the first is <em>by far</em> the better.</p>\n"
},
{
"answer_id": 178468,
"author": "Mendelt",
"author_id": 3320,
"author_profile": "https://Stackoverflow.com/users/3320",
"pm_score": 3,
"selected": false,
"text": "<p>The first is better. If you try to debug the second and look at the call stack you won't see where the original exception came from. There are tricks to keep the call-stack intact (try search, it's been answered before) if you really need to rethrow.</p>\n"
},
{
"answer_id": 178486,
"author": "RB.",
"author_id": 15393,
"author_profile": "https://Stackoverflow.com/users/15393",
"pm_score": 7,
"selected": false,
"text": "<p>My preferences is to use</p>\n<pre><code>try\n{\n}\ncatch (Exception ex)\n{\n ...\n throw new Exception ("Add more context here", ex)\n}\n</code></pre>\n<p>This preserves the original error, but it allows you to add more context, such as an object ID, a connection string, and stuff like that. Often my exception reporting tool will have five chained exceptions to report, each reporting more detail.</p>\n"
},
{
"answer_id": 178489,
"author": "Community",
"author_id": -1,
"author_profile": "https://Stackoverflow.com/users/-1",
"pm_score": 6,
"selected": false,
"text": "<p>If you throw an exception with<strong>out</strong> a variable (the first example) the stack trace will include the original method that threw the exception.</p>\n<p>In the second example, the stack trace will be changed to reflect the current method.</p>\n<p>Example:</p>\n<pre><code>static string ReadAFile(string fileName) {\n string result = string.Empty;\n try {\n result = File.ReadAllLines(fileName);\n } catch(Exception ex) {\n throw; // This will show ReadAllLines in the stack trace\n throw ex; // This will show ReadAFile in the stack trace\n }\n</code></pre>\n"
},
{
"answer_id": 411750,
"author": "Perry Tribolet",
"author_id": 5668,
"author_profile": "https://Stackoverflow.com/users/5668",
"pm_score": 2,
"selected": false,
"text": "<p>It depends. In a debug build, I want to see the original stack trace with as little effort as possible. In that case, "throw;" fits the bill.</p>\n<p>In a release build, however, (a) I want to log the error with the original stack trace included, and once that's done, (b) refashion the error handling to make more sense to the user. Here "Throw Exception" makes sense. It's true that rethrowing the error discards the original stack trace, but a non-developer gets nothing out of seeing stack trace information, so it's okay to rethrow the error.</p>\n<pre><code> void TrySuspectMethod()\n {\n try\n {\n SuspectMethod();\n }\n#if DEBUG\n catch\n {\n //Don't log error, let developer see\n //original stack trace easily\n throw;\n#else\n catch (Exception ex)\n {\n //Log error for developers and then\n //throw a error with a user-oriented message\n throw new Exception(String.Format\n ("Dear user, sorry but: {0}", ex.Message));\n#endif\n }\n }\n</code></pre>\n<p>The way the question is worded, pitting "Throw:" vs. "Throw ex;" makes it a bit of a red herring. The real choice is between "Throw;" and "Throw Exception," where "Throw ex;" is an unlikely special case of "Throw Exception."</p>\n"
},
{
"answer_id": 3179858,
"author": "Vinod T. Patil",
"author_id": 200752,
"author_profile": "https://Stackoverflow.com/users/200752",
"pm_score": 3,
"selected": false,
"text": "<p>You should always use "throw;" to rethrow the exceptions in .NET,</p>\n<p>Refer to the blog post <em><a href=\"http://weblogs.asp.net/bhouse/archive/2004/11/30/272297.aspx\" rel=\"nofollow noreferrer\">Throw vs. Throw ex</a></em>.</p>\n<p>Basically, MSIL (CIL) has two instructions - "throw" and "rethrow" and C#'s "throw ex;" gets compiled into MSIL's "throw" and C#'s "throw;" - into MSIL "rethrow"! Basically I can see the reason why "throw ex" overrides the stack trace.</p>\n"
},
{
"answer_id": 4631411,
"author": "James",
"author_id": 56753,
"author_profile": "https://Stackoverflow.com/users/56753",
"pm_score": 2,
"selected": false,
"text": "<p>I found that if the exception is thrown in the same method that it is caught, the stack trace is not preserved, for what it's worth. </p>\n\n<pre><code>void testExceptionHandling()\n{\n try\n {\n throw new ArithmeticException(\"illegal expression\");\n }\n catch (Exception ex)\n {\n throw;\n }\n finally\n {\n System.Diagnostics.Debug.WriteLine(\"finally called.\");\n }\n}\n</code></pre>\n"
},
{
"answer_id": 11933410,
"author": "Jon Hanna",
"author_id": 400547,
"author_profile": "https://Stackoverflow.com/users/400547",
"pm_score": 4,
"selected": false,
"text": "<p>I'll agree that most of the time you either want to do a plain <code>throw</code>, to preserve as much information as possible about what went wrong, or you want to throw a new exception that may contain that as an inner-exception, or not, depending on how likely you are to want to know about the inner events that caused it.</p>\n<p>There is an exception though. There are several cases where a method will call into another method and a condition that causes an exception in the inner call should be considered the same exception on the outer call.</p>\n<p>One example is a specialised collection implemented by using another collection. Let's say it's a <code>DistinctList<T></code> that wraps a <code>List<T></code>, but refuses duplicate items.</p>\n<p>If someone called <code>ICollection<T>.CopyTo</code> on your collection class, it might just be a straight call to <code>CopyTo</code> on the inner collection (if say, all the custom logic only applied to adding to the collection, or setting it up). Now, the conditions in which that call would throw are exactly the same conditions in which your collection should throw to match the documentation of <code>ICollection<T>.CopyTo</code>.</p>\n<p>Now, you could just not catch the exception at all, and let it pass through. Here though, the user gets an exception from <code>List<T></code> when they were calling something on a <code>DistinctList<T></code>. It is not the end of the world, but you may want to hide those implementation details.</p>\n<p>Or you could do your own checking:</p>\n<pre><code>public CopyTo(T[] array, int arrayIndex)\n{\n if(array == null)\n throw new ArgumentNullException("array");\n if(arrayIndex < 0)\n throw new ArgumentOutOfRangeException("arrayIndex", "Array Index must be zero or greater.");\n if(Count > array.Length + arrayIndex)\n throw new ArgumentException("Not enough room in array to copy elements starting at index given.");\n _innerList.CopyTo(array, arrayIndex);\n}\n</code></pre>\n<p>That's not the worse code because it's boilerplate and we can probably just copy it from some other implementation of <code>CopyTo</code> where it wasn't a simple pass-through and we had to implement it ourselves. Still, it's needlessly repeating the <em>exact same</em> checks that are going to be done in <code>_innerList.CopyTo(array, arrayIndex)</code>, so the only thing it has added to our code is 6 lines where there could be a bug.</p>\n<p>We could check and wrap:</p>\n<pre><code>public CopyTo(T[] array, int arrayIndex)\n{\n try\n {\n _innerList.CopyTo(array, arrayIndex);\n }\n catch(ArgumentNullException ane)\n {\n throw new ArgumentNullException("array", ane);\n }\n catch(ArgumentOutOfRangeException aore)\n {\n throw new ArgumentOutOfRangeException("Array Index must be zero or greater.", aore);\n }\n catch(ArgumentException ae)\n {\n throw new ArgumentException("Not enough room in array to copy elements starting at index given.", ae);\n }\n}\n</code></pre>\n<p>In terms of new code added that could potentially be buggy, this is even worse. And we don't gain a thing from the inner exceptions. If we pass a null array to this method and receive an <code>ArgumentNullException</code>, we're not going to learn anything by examining the inner exception and learning that a call to <code>_innerList.CopyTo</code> was passed a null array and threw an <code>ArgumentNullException</code>.</p>\n<p>Here, we can do everything we want with:</p>\n<pre><code>public CopyTo(T[] array, int arrayIndex)\n{\n try\n {\n _innerList.CopyTo(array, arrayIndex);\n }\n catch(ArgumentException ae)\n {\n throw ae;\n }\n}\n</code></pre>\n<p>Every one of the exceptions that we expect to have to throw if the user calls it with incorrect arguments, will correctly be thrown by that rethrow. If there's a bug in the logic used here, it's in one of two lines - either we were wrong in deciding this was a case where this approach works, or we were wrong in having <code>ArgumentException</code> as the exception type looked for. It's the only two bugs that the catch block can possibly have.</p>\n<p>Now. I still agree that most of the time you either want a plain <code>throw;</code> or you want to construct your own exception to more directly match the problem from the perspective of the method in question. There are cases like the above where rethrowing like this makes more sense, and there are plenty of other cases. E.g., to take a very different example, if an ATOM file reader implemented with a <code>FileStream</code> and an <code>XmlTextReader</code> receives a file error or invalid XML, then it will perhaps want to throw exactly the same exception it received from those classes, but it should look to the caller that it is <code>AtomFileReader</code> that is throwing a <code>FileNotFoundException</code> or <code>XmlException</code>, so they might be candidates for similarly rethrowing.</p>\n<p>We can also combine the two:</p>\n<pre><code>public CopyTo(T[] array, int arrayIndex)\n{\n try\n {\n _innerList.CopyTo(array, arrayIndex);\n }\n catch(ArgumentException ae)\n {\n throw ae;\n }\n catch(Exception ex)\n {\n //we weren't expecting this, there must be a bug in our code that put\n //us into an invalid state, and subsequently let this exception happen.\n LogException(ex);\n throw;\n }\n}\n</code></pre>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178456",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13913/"
] |
Is it better to do this:
```
try
{
...
}
catch (Exception ex)
{
...
throw;
}
```
Or this:
```
try
{
...
}
catch (Exception ex)
{
...
throw ex;
}
```
Do they do the same thing? Is one better than the other?
|
You should always use the following syntax to rethrow an exception. Else you'll stomp the stack trace:
```
throw;
```
If you print the trace resulting from `throw ex`, you'll see that it ends on that statement and not at the real source of the exception.
Basically, it should be deemed a criminal offense to use `throw ex`.
---
If there is a need to rethrow an exception that comes from somewhere else (AggregateException, TargetInvocationException) or perhaps another thread, you also shouldn't rethrow it directly. Rather there is the [ExceptionDispatchInfo](https://learn.microsoft.com/en-us/dotnet/api/system.runtime.exceptionservices.exceptiondispatchinfo) that preserves all the necessary information.
```
try
{
methodInfo.Invoke(...);
}
catch (System.Reflection.TargetInvocationException e)
{
System.Runtime.ExceptionServices.ExceptionDispatchInfo.Capture(e.InnerException).Throw();
throw; // just to inform the compiler that the flow never leaves the block
}
```
|
178,458 |
<p>I am in a project where we are starting refactoring some massive code base. One problem that immediately sprang up is that each file imports a lot of other files. How do I in an elegant way mock this in my unit test without having to alter the actual code so I can start to write unit-tests?</p>
<p>As an example: The file with the functions I want to test, imports ten other files which is part of our software and not python core libs.</p>
<p>I want to be able to run the unit tests as separately as possible and for now I am only going to test functions that does not depend on things from the files that are being imported.</p>
<p>Thanks for all the answers. </p>
<p>I didn't really know what I wanted to do from the start but now I think I know. </p>
<p>Problem was that some imports was only possible when the whole application was running because of some third-party auto-magic. So I had to make some stubs for these modules in a directory which I pointed out with sys.path</p>
<p>Now I can import the file which contains the functions I want to write tests for in my unit-test file without complaints about missing modules.</p>
|
[
{
"answer_id": 178582,
"author": "S.Lott",
"author_id": 10661,
"author_profile": "https://Stackoverflow.com/users/10661",
"pm_score": 1,
"selected": false,
"text": "<p>"imports a lot of other files"? Imports a lot of other files that are part of your customized code base? Or imports a lot of other files that are part of the Python distribution? Or imports a lot of other open source project files?</p>\n<p>If your imports don't work, you have a "simple" <code>PYTHONPATH</code> problem. Get all of your various project directories onto a <code>PYTHONPATH</code> that you can use for testing. We have a rather complex path, in Windows we manage it like this</p>\n<pre><code>@set Part1=c:\\blah\\blah\\blah\n@set Part2=c:\\some\\other\\path\n@set that=g:\\shared\\stuff\nset PYTHONPATH=%part1%;%part2%;%that%\n</code></pre>\n<p>We keep each piece of the path separate so that we (a) know where things come from and (b) can manage change when we move things around.</p>\n<p>Since the <code>PYTHONPATH</code> is searched in order, we can control what gets used by adjusting the order on the path.</p>\n<p>Once you have "everything", it becomes a question of trust.</p>\n<p>Either</p>\n<ul>\n<li>you trust something (i.e., the Python code base) and just import it.</li>\n</ul>\n<p>Or</p>\n<ul>\n<li><p>You don't trust something (i.e., your own code) and you</p>\n<ol>\n<li>test it separately and</li>\n<li>mock it for stand-alone testing.</li>\n</ol>\n</li>\n</ul>\n<p>Would you test the Python libraries? If so, you've got a lot of work. If not, then, you should perhaps only mock out the things you're actually going to test.</p>\n"
},
{
"answer_id": 178603,
"author": "Alex Coventry",
"author_id": 1941213,
"author_profile": "https://Stackoverflow.com/users/1941213",
"pm_score": 1,
"selected": false,
"text": "<p>If you really want to muck around with the python import mechanism, take a look at the <a href=\"http://pydoc.org/2.4.1/ihooks.html\" rel=\"nofollow noreferrer\"><code>ihooks</code></a> module. It provides tools for changing the behavior of the <code>__import__</code> built-in. But it's not clear from your question why you need to do this.</p>\n"
},
{
"answer_id": 178829,
"author": "DzinX",
"author_id": 18745,
"author_profile": "https://Stackoverflow.com/users/18745",
"pm_score": 0,
"selected": false,
"text": "<p>No difficult manipulation is necessary if you want a quick-and-dirty fix before your unit-tests.</p>\n\n<p>If the unit tests are in the same file as the code you wish to test, simply delete unwanted module from the <code>globals()</code> dictionary.</p>\n\n<p>Here is a rather lengthy example: suppose you have a module <code>impp.py</code> with contents:</p>\n\n<pre><code>value = 5\n</code></pre>\n\n<p>Now, in your test file you can write:</p>\n\n<pre><code>>>> import impp\n>>> print globals().keys()\n>>> def printVal():\n>>> print impp.value\n['printVal', '__builtins__', '__file__', 'impp', '__name__', '__doc__']\n</code></pre>\n\n<p>Note that <code>impp</code> is among the globals, because it was imported. Calling the function <code>printVal</code> that uses <code>impp</code> module still works:</p>\n\n<pre><code>>>> printVal()\n5\n</code></pre>\n\n<p>But now, if you remove <code>impp</code> key from <code>globals()</code>...</p>\n\n<pre><code>>>> del globals()['impp']\n>>> print globals().keys()\n['printVal', '__builtins__', '__file__', '__name__', '__doc__']\n</code></pre>\n\n<p>...and try to call <code>printVal()</code>, you'll get:</p>\n\n<pre><code>>>> printVal()\nTraceback (most recent call last):\n File \"test_imp.py\", line 13, in <module>\n printVal()\n File \"test_imp.py\", line 5, in printVal\n print impp.value\nNameError: global name 'impp' is not defined\n</code></pre>\n\n<p>...which is probably exactly what you're trying to achieve.</p>\n\n<p>To use it in your unit-tests, you can delete the globals just before running the test suite, e.g. in <code>__main__</code>:</p>\n\n<pre><code>if __name__ == '__main__':\n del globals()['impp']\n unittest.main()\n</code></pre>\n"
},
{
"answer_id": 179057,
"author": "Alex Coventry",
"author_id": 1941213,
"author_profile": "https://Stackoverflow.com/users/1941213",
"pm_score": 0,
"selected": false,
"text": "<p>In your comment <a href=\"https://stackoverflow.com/questions/178458/python-unit-testing-and-mocking-imports#178829\">above</a>, you say you want to convince python that certain modules have already been imported. This still seems like a strange goal, but if that's really what you want to do, in principle you can sneak around behind the import mechanism's back, and change <code>sys.modules</code>. Not sure how this'd work for package imports, but should be fine for absolute imports.</p>\n"
},
{
"answer_id": 179531,
"author": "DzinX",
"author_id": 18745,
"author_profile": "https://Stackoverflow.com/users/18745",
"pm_score": 4,
"selected": true,
"text": "<p>If you want to import a module while at the same time ensuring that it doesn't import anything, you can replace the <code>__import__</code> builtin function.</p>\n\n<p>For example, use this class:</p>\n\n<pre><code>class ImportWrapper(object):\n def __init__(self, real_import):\n self.real_import = real_import\n\n def wrapper(self, wantedModules):\n def inner(moduleName, *args, **kwargs):\n if moduleName in wantedModules:\n print \"IMPORTING MODULE\", moduleName\n self.real_import(*args, **kwargs)\n else:\n print \"NOT IMPORTING MODULE\", moduleName\n return inner\n\n def mock_import(self, moduleName, wantedModules):\n __builtins__.__import__ = self.wrapper(wantedModules)\n try:\n __import__(moduleName, globals(), locals(), [], -1)\n finally:\n __builtins__.__import__ = self.real_import\n</code></pre>\n\n<p>And in your test code, instead of writing <code>import myModule</code>, write:</p>\n\n<pre><code>wrapper = ImportWrapper(__import__)\nwrapper.mock_import('myModule', [])\n</code></pre>\n\n<p>The second argument to <code>mock_import</code> is a list of module names you <em>do</em> want to import in inner module.</p>\n\n<p>This example can be modified further to e.g. import other module than desired instead of just not importing it, or even mocking the module object with some custom object of your own.</p>\n"
}
] |
2008/10/07
|
[
"https://Stackoverflow.com/questions/178458",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/12126/"
] |
I am in a project where we are starting refactoring some massive code base. One problem that immediately sprang up is that each file imports a lot of other files. How do I in an elegant way mock this in my unit test without having to alter the actual code so I can start to write unit-tests?
As an example: The file with the functions I want to test, imports ten other files which is part of our software and not python core libs.
I want to be able to run the unit tests as separately as possible and for now I am only going to test functions that does not depend on things from the files that are being imported.
Thanks for all the answers.
I didn't really know what I wanted to do from the start but now I think I know.
Problem was that some imports was only possible when the whole application was running because of some third-party auto-magic. So I had to make some stubs for these modules in a directory which I pointed out with sys.path
Now I can import the file which contains the functions I want to write tests for in my unit-test file without complaints about missing modules.
|
If you want to import a module while at the same time ensuring that it doesn't import anything, you can replace the `__import__` builtin function.
For example, use this class:
```
class ImportWrapper(object):
def __init__(self, real_import):
self.real_import = real_import
def wrapper(self, wantedModules):
def inner(moduleName, *args, **kwargs):
if moduleName in wantedModules:
print "IMPORTING MODULE", moduleName
self.real_import(*args, **kwargs)
else:
print "NOT IMPORTING MODULE", moduleName
return inner
def mock_import(self, moduleName, wantedModules):
__builtins__.__import__ = self.wrapper(wantedModules)
try:
__import__(moduleName, globals(), locals(), [], -1)
finally:
__builtins__.__import__ = self.real_import
```
And in your test code, instead of writing `import myModule`, write:
```
wrapper = ImportWrapper(__import__)
wrapper.mock_import('myModule', [])
```
The second argument to `mock_import` is a list of module names you *do* want to import in inner module.
This example can be modified further to e.g. import other module than desired instead of just not importing it, or even mocking the module object with some custom object of your own.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.