
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4a00cc07fe4eac66d6cd2c3e52059b5e262e3781
| 1,622 |
ipynb
|
Jupyter Notebook
|
dungaaaaa.ipynb
|
new20121439/datacube
|
303cc4303c30c634feba80672bde1207df77a41a
|
[
"Apache-2.0"
] | null | null | null |
dungaaaaa.ipynb
|
new20121439/datacube
|
303cc4303c30c634feba80672bde1207df77a41a
|
[
"Apache-2.0"
] | null | null | null |
dungaaaaa.ipynb
|
new20121439/datacube
|
303cc4303c30c634feba80672bde1207df77a41a
|
[
"Apache-2.0"
] | null | null | null | 30.037037 | 386 | 0.575216 |
[
[
[
"from .apps.data_cube_manager import DatasetType",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4a00cfb1d86d88a179fe03a567e27d33134a5594
| 6,925 |
ipynb
|
Jupyter Notebook
|
phathom/phenotype/notebbooks/Cluster nuclei coordinates.ipynb
|
chunglabmit/phathom
|
304db7a95e898e9b03d6b2640172752d21a7e3ed
|
[
"MIT"
] | 1 |
2018-04-18T11:54:29.000Z
|
2018-04-18T11:54:29.000Z
|
phathom/phenotype/notebbooks/Cluster nuclei coordinates.ipynb
|
chunglabmit/phathom
|
304db7a95e898e9b03d6b2640172752d21a7e3ed
|
[
"MIT"
] | 2 |
2018-04-05T20:53:52.000Z
|
2018-11-01T16:37:39.000Z
|
phathom/phenotype/notebbooks/Cluster nuclei coordinates.ipynb
|
chunglabmit/phathom
|
304db7a95e898e9b03d6b2640172752d21a7e3ed
|
[
"MIT"
] | null | null | null | 21.506211 | 88 | 0.493285 |
[
[
[
"import os\nimport numpy as np\nfrom sklearn.cluster import KMeans\nfrom mayavi import mlab\nfrom phathom.phenotype.mesh import randomly_sample",
"_____no_output_____"
],
[
"working_dir = '/media/jswaney/SSD EVO 860/organoid_phenotyping/20181206_eF9_A34_1'",
"_____no_output_____"
],
[
"centers = np.load(os.path.join(working_dir, 'centers.npy'))\ncenters.shape",
"_____no_output_____"
],
[
"sox2_labels_path = 'sox2_labels.npy'\ntbr1_labels_path = 'tbr1_labels.npy'\n\nsox2_labels = np.load(os.path.join(working_dir, sox2_labels_path))\ntbr1_labels = np.load(os.path.join(working_dir, tbr1_labels_path))",
"_____no_output_____"
],
[
"voxel_size = np.array((2.052, 1.082, 1.082))\n\ncenters_um = centers * voxel_size\ncenters_um.shape",
"_____no_output_____"
]
],
[
[
"# KMeans on nuclei centroids",
"_____no_output_____"
]
],
[
[
"n_clusters = 3\n\nkmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(centers_um)\nlabels = kmeans.labels_\ncentroids = kmeans.cluster_centers_\nlabels",
"_____no_output_____"
],
[
"# Extract indices for each cluster\nindices = [np.where(labels == c)[0] for c in range(n_clusters)]\nlen(indices[0]) ",
"_____no_output_____"
],
[
"n = 10000\n\nsamples = np.asarray([randomly_sample(n, idx)[0] for idx in indices])\nsamples.shape",
"_____no_output_____"
],
[
"# Plot the random samples\nscale_factor = 25\n\nnp.random.seed(1)\nfor c in range(n_clusters):\n idx = samples[c]\n coords = centers_um[idx]\n mlab.points3d(coords[:, 0], \n coords[:, 1], \n coords[:, 2], \n scale_factor=scale_factor, \n color=tuple(np.random.random(3)))\nmlab.show()",
"_____no_output_____"
],
[
"tuple(np.random.random(3))",
"_____no_output_____"
]
],
[
[
"# 3D render of cell types in whole org",
"_____no_output_____"
]
],
[
[
"dn_labels = ~np.logical_or(sox2_labels, tbr1_labels)\ndn_labels.shape",
"_____no_output_____"
],
[
"centers_sox2 = centers_um[np.where(sox2_labels)]\ncenters_tbr1 = centers_um[np.where(tbr1_labels)]\ncenters_dn = centers_um[np.where(dn_labels)]\ncenters_sox2.shape, centers_tbr1.shape, centers_dn.shape",
"_____no_output_____"
],
[
"(samples_sox2,) = randomly_sample(20000, centers_sox2)\n(samples_tbr1,) = randomly_sample(10000, centers_tbr1)\n(samples_dn,) = randomly_sample(20000, centers_dn)",
"_____no_output_____"
],
[
"# Plot the random samples\nscale_factor = 15\n\nmlab.points3d(samples_sox2[:, 0], \n samples_sox2[:, 1], \n samples_sox2[:, 2], \n scale_factor=scale_factor, \n color=(1, 0, 0))\n\nmlab.points3d(samples_tbr1[:, 0], \n samples_tbr1[:, 1], \n samples_tbr1[:, 2], \n scale_factor=scale_factor, \n color=(0, 0.95, 0))\n\nmlab.points3d(samples_dn[:, 0], \n samples_dn[:, 1], \n samples_dn[:, 2], \n scale_factor=scale_factor, \n color=(0, 0, 0.9))\n \nmlab.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a00d1247db2b593987de75a6df63d8652350952
| 5,459 |
ipynb
|
Jupyter Notebook
|
fair_drop/find_minting_data.ipynb
|
forkoooor/honestnft-shenanigans
|
fd33e8502e4d6b60c6efdf2a84e17c8c4a88fbec
|
[
"MIT"
] | 88 |
2021-10-25T23:57:36.000Z
|
2022-03-31T17:01:57.000Z
|
fair_drop/find_minting_data.ipynb
|
forkoooor/honestnft-shenanigans
|
fd33e8502e4d6b60c6efdf2a84e17c8c4a88fbec
|
[
"MIT"
] | 14 |
2021-11-17T18:48:27.000Z
|
2022-03-10T15:57:13.000Z
|
fair_drop/find_minting_data.ipynb
|
forkoooor/honestnft-shenanigans
|
fd33e8502e4d6b60c6efdf2a84e17c8c4a88fbec
|
[
"MIT"
] | 41 |
2021-10-30T16:20:53.000Z
|
2022-03-31T17:02:00.000Z
| 31.194286 | 249 | 0.519692 |
[
[
[
"\"\"\"\nUpdate Parameters Here\n\"\"\"\nCOLLECTION_NAME = \"Quaks\"\nCONTRACT = \"0x07bbdaf30e89ea3ecf6cadc80d6e7c4b0843c729\"\nBEFORE_TIME = \"2021-09-02T00:00:00\" # One day after the last mint (e.g. https://etherscan.io/tx/0x206c846d0d1739faa9835e16ff419d15708a558357a9413619e65dacf095ac7a)\n\n# these should usually stay the same\nMETHOD = \"raritytools\"",
"_____no_output_____"
],
[
"\"\"\"\nCreated on Tue Sep 14 20:17:07 2021\nmint data. Doesn't work when Opensea's API is being shitty\n@author: nbax1, slight modifications by mdigi14\n\"\"\"\n\nimport pandas as pd\n\nfrom utils import config\nfrom utils import constants\nfrom utils import opensea\n\n\n\"\"\"\nHelper Functions\n\"\"\"\n\n\ndef get_mint_events(contract, before_time, rarity_db):\n data = opensea.get_opensea_events(\n contract_address=contract,\n account_address=constants.MINT_ADDRESS,\n event_type=\"transfer\",\n occurred_before=before_time,\n )\n\n df = pd.json_normalize(data)\n\n df = df.loc[df[\"from_account.address\"] == constants.MINT_ADDRESS]\n df_rar = pd.DataFrame(rarity_db)\n\n os_tokens = df[\"asset.token_id\"].astype(int).tolist()\n rar_tokens = df_rar[\"TOKEN_ID\"].astype(int).tolist()\n\n set1 = set(rar_tokens)\n set2 = set(os_tokens)\n\n missing_tokens = list(sorted(set1 - set2))\n if missing_tokens:\n print(\n f\"Missing tokens: {missing_tokens}\\nTrying to fetch event for missing tokens...\"\n )\n\n missing_data = []\n for token in missing_tokens:\n missing_data.extend(\n opensea.get_opensea_events(\n contract_address=contract,\n account_address=constants.MINT_ADDRESS,\n event_type=\"transfer\",\n occurred_before=before_time,\n token_id=token,\n )\n )\n\n df_missing_data = pd.json_normalize(missing_data)\n\n # Merge missing data with rest of data\n df_all = pd.concat([df, df_missing_data])\n\n # make sure token_id is an integer\n df_all[\"asset.token_id\"] = df_all[\"asset.token_id\"].astype(int)\n RARITY_DB[\"TOKEN_ID\"] = RARITY_DB[\"TOKEN_ID\"].astype(int)\n\n # add rarity rank to minting data\n df_all = df_all.merge(RARITY_DB, left_on=\"asset.token_id\", right_on=\"TOKEN_ID\")\n\n # Keep only the columns we want\n df_all = df_all[\n [\n \"transaction.transaction_hash\",\n \"to_account.address\",\n \"asset.token_id\",\n \"asset.owner.address\",\n \"Rank\",\n \"transaction.timestamp\",\n ]\n ]\n\n # Rename columns\n df_all.columns = [\n \"txid\",\n \"to_account\",\n \"TOKEN_ID\",\n \"current_owner\",\n \"rank\",\n \"time\",\n ]\n print(f\"Downloaded {df_all.shape[0]} events\")\n return df_all",
"_____no_output_____"
],
[
"\"\"\"\nGerenerate Dataset\n\"\"\"\nRARITY_CSV = f\"{config.RARITY_FOLDER}/{COLLECTION_NAME}_{METHOD}.csv\"\nRARITY_DB = pd.read_csv(RARITY_CSV)\n\nmint_db = get_mint_events(CONTRACT, BEFORE_TIME, RARITY_DB)\nmint_db = mint_db.sort_values(by=[\"TOKEN_ID\"])\nmint_db.to_csv(f\"{config.MINTING_FOLDER}/{COLLECTION_NAME}_minting.csv\", index=False)",
"Missing tokens: [1453, 1454, 1455, 1456, 1457, 1458, 1459, 1460, 1461, 1465, 1466, 1467, 1468, 1469, 1470, 1471, 1472, 1473, 1474, 1475, 1476, 1477, 1478, 1479, 1480, 1481, 2375, 2376, 2781, 2782, 2783, 2784, 2785, 2786, 2787, 2788, 2789]\nTrying to fetch event for missing tokens...\nDownloaded 6000 events\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a00d9d1b0ef88ee32ce342c5fc32be2f7ce8bc1
| 237,449 |
ipynb
|
Jupyter Notebook
|
notebooks/TMP Mass Notebook.ipynb
|
mclaughlin6464/pearce
|
746f2bf4bf45e904d66996e003043661a01423ba
|
[
"MIT"
] | null | null | null |
notebooks/TMP Mass Notebook.ipynb
|
mclaughlin6464/pearce
|
746f2bf4bf45e904d66996e003043661a01423ba
|
[
"MIT"
] | 16 |
2016-11-04T22:24:32.000Z
|
2018-05-01T22:53:39.000Z
|
notebooks/TMP Mass Notebook.ipynb
|
mclaughlin6464/pearce
|
746f2bf4bf45e904d66996e003043661a01423ba
|
[
"MIT"
] | 3 |
2016-10-04T08:07:52.000Z
|
2019-05-03T23:50:01.000Z
| 134.303733 | 105,339 | 0.81265 |
[
[
[
"from matplotlib import pyplot as plt\n%matplotlib notebook\nfrom matplotlib import animation\nimport numpy as np",
"_____no_output_____"
],
[
"#make a fake galaxy distribution from a MOG\nmean1, std1 = (np.random.rand()*2-1, np.random.rand()*2-1), (np.random.rand()*3+0.5, np.random.rand()*3+0.5)\nmean2, std2 = (np.random.rand()*2+1, np.random.rand()*2+1), (np.random.rand()*3+0.5, np.random.rand()*3+0.5)\nN1, N2 = 500, 500\npoints = np.zeros((N1+N2, 2))\n\npoints[:N1] = np.random.randn(N1, 2)*np.array(std1)+np.array(mean1)\npoints[N1:] = np.random.randn(N2, 2)*np.array(std2)+np.array(mean2)",
"_____no_output_____"
],
[
"plt.scatter(points[:,0], points[:,1])\nplt.scatter(mean1[0], mean1[ 1], color = 'r')\nplt.scatter(mean2[0], mean2[1], color = 'r')",
"_____no_output_____"
],
[
"from itertools import combinations",
"_____no_output_____"
],
[
"random_points = np.random.randn(N1+N2, 2)*5\npairs = list(combinations(range(random_points.shape[0]), 2) )\nn_bins = 10\n\nhist_bins = np.logspace(-1, 1, n_bins+1)\nhbc = (hist_bins[1:]+hist_bins[:-1])/2.0\n\ndists = np.zeros(( len(pairs), ))\n\nfor i, pair in enumerate(pairs):\n p1, p2 = pairs[i][0], pairs[i][1]\n x1, y1 = random_points[p1]\n x2, y2 = random_points[p2]\n dists[i] = np.sqrt((x2-x1)**2+(y2-y1)**2)\n \nrandom_hist, _ = np.histogram(dists, bins=hist_bins)\nrandom_hist[random_hist==0] = 1e-3",
"_____no_output_____"
],
[
"# First set up the figure, the axis, and the plot element we want to animate\nfig = plt.figure(figsize = (8, 5))\nax1 = plt.subplot(1, 2, 1, xlim=(-6, 6), ylim=(-6, 6))\nax2 = plt.subplot(1, 2, 2, xlim=(-1, 1), ylim = (-5, 0))\npairs = list(combinations(range(points.shape[0]), 2) ) \nnp.random.shuffle(pairs)\ndist_counts = np.zeros((len(pairs),))\n\nline1, = ax1.plot([], [], lw=2, color = 'r')\nline2, = ax2.plot([], [], lw = 2, color = 'g', marker = 'o')\n\n# initialization function: plot the background of each frame\ndef init():\n ax1.scatter(points[:,0], points[:,1], color = 'b', alpha = 0.7)\n return line1, line2\n\n# animation function. This is called sequentially\ndef animate(i):\n p1, p2 = pairs[i][0], pairs[i][1]\n x1, y1 = points[p1]\n x2, y2 = points[p2]\n x = np.linspace(x1, x2, 100)\n y = np.linspace(y1, y2, 100)\n line1.set_data(x, y)\n dist_counts[i] = np.sqrt((x2-x1)**2+(y2-y1)**2)\n data_hist = np.histogram(dist_counts[:i], bins = hist_bins)[0].astype(float)\n data_hist = data_hist*(N1+N2)/(i+1) # reweight\n data_hist[data_hist == 0] = data_hist[data_hist==0]+ 1e-3\n #print np.log10(data_hist /random_hist)\n line2.set_data(np.log10(hbc), np.log10(data_hist/random_hist ))\n return line1, line2\n\n# call the animator. blit=True means only re-draw the parts that have changed.\n#for i in xrange(100):\n# animate(i)\nanim = animation.FuncAnimation(fig, animate, init_func=init,\n frames=50000, interval=1, blit=True)#, repeat = False)\n\n# save the animation as an mp4. This requires ffmpeg or mencoder to be\n# installed. The extra_args ensure that the x264 codec is used, so that\n# the video can be embedded in html5. You may need to adjust this for\n# your system: for more information, see\n# http://matplotlib.sourceforge.net/api/animation_api.html\n#anim.save('basic_animation.mp4', fps=30, extra_args=['-vcodec', 'libx264'])\n\n#ax2.xlabel('Log r')\n#ax2.ylabel('Log Xi')\n#ax1.xlabel('x')\n#ax2.ylabel('y')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a00db7f1de9714362306c162068644bb6ad1ab7
| 11,641 |
ipynb
|
Jupyter Notebook
|
2 digit recognizer/recurrent-neural-network-with-pytorch.ipynb
|
MLVPRASAD/KaggleProjects
|
379e062cf58d83ff57a456552bb956df68381fdd
|
[
"MIT"
] | 2 |
2020-01-25T08:31:14.000Z
|
2022-03-23T18:24:03.000Z
|
2 digit recognizer/recurrent-neural-network-with-pytorch.ipynb
|
MLVPRASAD/KaggleProjects
|
379e062cf58d83ff57a456552bb956df68381fdd
|
[
"MIT"
] | null | null | null |
2 digit recognizer/recurrent-neural-network-with-pytorch.ipynb
|
MLVPRASAD/KaggleProjects
|
379e062cf58d83ff57a456552bb956df68381fdd
|
[
"MIT"
] | null | null | null | 11,641 | 11,641 | 0.69616 |
[
[
[
"## INTRODUCTION\n- It’s a Python based scientific computing package targeted at two sets of audiences:\n - A replacement for NumPy to use the power of GPUs\n - Deep learning research platform that provides maximum flexibility and speed\n- pros: \n - Iinteractively debugging PyTorch. Many users who have used both frameworks would argue that makes pytorch significantly easier to debug and visualize.\n - Clean support for dynamic graphs\n - Organizational backing from Facebook\n - Blend of high level and low level APIs\n- cons:\n - Much less mature than alternatives\n - Limited references / resources outside of the official documentation\n- I accept you know neural network basics. If you do not know check my tutorial. Because I will not explain neural network concepts detailed, I only explain how to use pytorch for neural network\n- Neural Network tutorial: https://www.kaggle.com/kanncaa1/deep-learning-tutorial-for-beginners \n- The most important parts of this tutorial from matrices to ANN. If you learn these parts very well, implementing remaining parts like CNN or RNN will be very easy. \n<br>\n<br>**Content:**\n1. Basics of Pytorch, Linear Regression, Logistic Regression, Artificial Neural Network (ANN), Concolutional Neural Network (CNN)\n - https://www.kaggle.com/kanncaa1/pytorch-tutorial-for-deep-learning-lovers/code\n1. [Recurrent Neural Network (RNN)](#1)",
"_____no_output_____"
]
],
[
[
"# This Python 3 environment comes with many helpful analytics libraries installed\n# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python\n# For example, here's several helpful packages to load in \n\nimport numpy as np # linear algebra\nimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\nimport matplotlib.pyplot as plt\n\n# Input data files are available in the \"../input/\" directory.\n# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory\n\nimport os\nprint(os.listdir(\"../input\"))\n\n# Any results you write to the current directory are saved as output.",
"_____no_output_____"
]
],
[
[
"<a id=\"1\"></a> <br>\n### Recurrent Neural Network (RNN)\n- RNN is essentially repeating ANN but information get pass through from previous non-linear activation function output.\n- **Steps of RNN:**\n 1. Import Libraries\n 1. Prepare Dataset\n 1. Create RNN Model\n - hidden layer dimension is 100\n - number of hidden layer is 1 \n 1. Instantiate Model Class\n 1. Instantiate Loss Class\n - Cross entropy loss\n - It also has softmax(logistic function) in it.\n 1. Instantiate Optimizer Class\n - SGD Optimizer\n 1. Traning the Model\n 1. Prediction",
"_____no_output_____"
]
],
[
[
"# Import Libraries\nimport torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nfrom torch.autograd import Variable\nfrom sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"# Prepare Dataset\n# load data\ntrain = pd.read_csv(r\"../input/train.csv\",dtype = np.float32)\n\n# split data into features(pixels) and labels(numbers from 0 to 9)\ntargets_numpy = train.label.values\nfeatures_numpy = train.loc[:,train.columns != \"label\"].values/255 # normalization\n\n# train test split. Size of train data is 80% and size of test data is 20%. \nfeatures_train, features_test, targets_train, targets_test = train_test_split(features_numpy,\n targets_numpy,\n test_size = 0.2,\n random_state = 42) \n\n# create feature and targets tensor for train set. As you remember we need variable to accumulate gradients. Therefore first we create tensor, then we will create variable\nfeaturesTrain = torch.from_numpy(features_train)\ntargetsTrain = torch.from_numpy(targets_train).type(torch.LongTensor) # data type is long\n\n# create feature and targets tensor for test set.\nfeaturesTest = torch.from_numpy(features_test)\ntargetsTest = torch.from_numpy(targets_test).type(torch.LongTensor) # data type is long\n\n# batch_size, epoch and iteration\nbatch_size = 100\nn_iters = 10000\nnum_epochs = n_iters / (len(features_train) / batch_size)\nnum_epochs = int(num_epochs)\n\n# Pytorch train and test sets\ntrain = torch.utils.data.TensorDataset(featuresTrain,targetsTrain)\ntest = torch.utils.data.TensorDataset(featuresTest,targetsTest)\n\n# data loader\ntrain_loader = torch.utils.data.DataLoader(train, batch_size = batch_size, shuffle = False)\ntest_loader = torch.utils.data.DataLoader(test, batch_size = batch_size, shuffle = False)\n\n# visualize one of the images in data set\nplt.imshow(features_numpy[10].reshape(28,28))\nplt.axis(\"off\")\nplt.title(str(targets_numpy[10]))\nplt.savefig('graph.png')\nplt.show()",
"_____no_output_____"
],
[
"# Create RNN Model\nclass RNNModel(nn.Module):\n def __init__(self, input_dim, hidden_dim, layer_dim, output_dim):\n super(RNNModel, self).__init__()\n # Number of hidden dimensions\n self.hidden_dim = hidden_dim\n \n # Number of hidden layers\n self.layer_dim = layer_dim\n \n # RNN\n self.rnn = nn.RNN(input_dim, hidden_dim, layer_dim, batch_first=True, \n nonlinearity='relu')\n \n # Readout layer\n self.fc = nn.Linear(hidden_dim, output_dim)\n \n def forward(self, x):\n # Initialize hidden state with zeros\n h0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim))\n \n # One time step\n out, hn = self.rnn(x, h0)\n out = self.fc(out[:, -1, :]) \n return out\n\n# batch_size, epoch and iteration\nbatch_size = 100\nn_iters = 2500\nnum_epochs = n_iters / (len(features_train) / batch_size)\nnum_epochs = int(num_epochs)\n\n# Pytorch train and test sets\ntrain = torch.utils.data.TensorDataset(featuresTrain,targetsTrain)\ntest = torch.utils.data.TensorDataset(featuresTest,targetsTest)\n\n# data loader\ntrain_loader = torch.utils.data.DataLoader(train, batch_size = batch_size, shuffle = False)\ntest_loader = torch.utils.data.DataLoader(test, batch_size = batch_size, shuffle = False)\n \n# Create RNN\ninput_dim = 28 # input dimension\nhidden_dim = 100 # hidden layer dimension\nlayer_dim = 2 # number of hidden layers\noutput_dim = 10 # output dimension\n\nmodel = RNNModel(input_dim, hidden_dim, layer_dim, output_dim)\n\n# Cross Entropy Loss \nerror = nn.CrossEntropyLoss()\n\n# SGD Optimizer\nlearning_rate = 0.05\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)",
"_____no_output_____"
],
[
"seq_dim = 28 \nloss_list = []\niteration_list = []\naccuracy_list = []\ncount = 0\nfor epoch in range(num_epochs):\n for i, (images, labels) in enumerate(train_loader):\n\n train = Variable(images.view(-1, seq_dim, input_dim))\n labels = Variable(labels )\n \n # Clear gradients\n optimizer.zero_grad()\n \n # Forward propagation\n outputs = model(train)\n \n # Calculate softmax and ross entropy loss\n loss = error(outputs, labels)\n \n # Calculating gradients\n loss.backward()\n \n # Update parameters\n optimizer.step()\n \n count += 1\n \n if count % 250 == 0:\n # Calculate Accuracy \n correct = 0\n total = 0\n # Iterate through test dataset\n for images, labels in test_loader:\n images = Variable(images.view(-1, seq_dim, input_dim))\n \n # Forward propagation\n outputs = model(images)\n \n # Get predictions from the maximum value\n predicted = torch.max(outputs.data, 1)[1]\n \n # Total number of labels\n total += labels.size(0)\n \n correct += (predicted == labels).sum()\n \n accuracy = 100 * correct / float(total)\n \n # store loss and iteration\n loss_list.append(loss.data)\n iteration_list.append(count)\n accuracy_list.append(accuracy)\n if count % 500 == 0:\n # Print Loss\n print('Iteration: {} Loss: {} Accuracy: {} %'.format(count, loss.data[0], accuracy))",
"_____no_output_____"
],
[
"# visualization loss \nplt.plot(iteration_list,loss_list)\nplt.xlabel(\"Number of iteration\")\nplt.ylabel(\"Loss\")\nplt.title(\"RNN: Loss vs Number of iteration\")\nplt.show()\n\n# visualization accuracy \nplt.plot(iteration_list,accuracy_list,color = \"red\")\nplt.xlabel(\"Number of iteration\")\nplt.ylabel(\"Accuracy\")\nplt.title(\"RNN: Accuracy vs Number of iteration\")\nplt.savefig('graph.png')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Conclusion\nIn this tutorial, we learn: \n1. Basics of pytorch\n1. Linear regression with pytorch\n1. Logistic regression with pytorch\n1. Artificial neural network with with pytorch\n1. Convolutional neural network with pytorch\n - https://www.kaggle.com/kanncaa1/pytorch-tutorial-for-deep-learning-lovers/code\n1. Recurrent neural network with pytorch\n\n<br> If you have any question or suggest, I will be happy to hear it ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a00f1d2fbdf427cb58ab5d45279e3d0453d271c
| 96,621 |
ipynb
|
Jupyter Notebook
|
sampling.ipynb
|
amungale/computational_statistics
|
d71898018c2531d10ad4f538f76aff0822b6322c
|
[
"MIT"
] | null | null | null |
sampling.ipynb
|
amungale/computational_statistics
|
d71898018c2531d10ad4f538f76aff0822b6322c
|
[
"MIT"
] | null | null | null |
sampling.ipynb
|
amungale/computational_statistics
|
d71898018c2531d10ad4f538f76aff0822b6322c
|
[
"MIT"
] | null | null | null | 83.799653 | 17,104 | 0.83812 |
[
[
[
"Random Sampling\n=============\n\nCopyright 2016 Allen Downey\n\nLicense: [Creative Commons Attribution 4.0 International](http://creativecommons.org/licenses/by/4.0/)",
"_____no_output_____"
]
],
[
[
"from __future__ import print_function, division\n\nimport numpy\nimport scipy.stats\n\nimport matplotlib.pyplot as pyplot\n\nfrom ipywidgets import interact, interactive, fixed\nimport ipywidgets as widgets\n\n# seed the random number generator so we all get the same results\nnumpy.random.seed(18)\n\n# some nicer colors from http://colorbrewer2.org/\nCOLOR1 = '#7fc97f'\nCOLOR2 = '#beaed4'\nCOLOR3 = '#fdc086'\nCOLOR4 = '#ffff99'\nCOLOR5 = '#386cb0'\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Part One\n========\n\nSuppose we want to estimate the average weight of men and women in the U.S.\n\nAnd we want to quantify the uncertainty of the estimate.\n\nOne approach is to simulate many experiments and see how much the results vary from one experiment to the next.\n\nI'll start with the unrealistic assumption that we know the actual distribution of weights in the population. Then I'll show how to solve the problem without that assumption.\n\nBased on data from the [BRFSS](http://www.cdc.gov/brfss/), I found that the distribution of weight in kg for women in the U.S. is well modeled by a lognormal distribution with the following parameters:",
"_____no_output_____"
]
],
[
[
"weight = scipy.stats.lognorm(0.23, 0, 70.8)\nweight.mean(), weight.std()",
"_____no_output_____"
]
],
[
[
"Here's what that distribution looks like:",
"_____no_output_____"
]
],
[
[
"xs = numpy.linspace(20, 160, 100)\nys = weight.pdf(xs)\npyplot.plot(xs, ys, linewidth=4, color=COLOR1)\npyplot.xlabel('weight (kg)')\npyplot.ylabel('PDF')\nNone",
"_____no_output_____"
]
],
[
[
"`make_sample` draws a random sample from this distribution. The result is a NumPy array.",
"_____no_output_____"
]
],
[
[
"def make_sample(n=100):\n sample = weight.rvs(n)\n return sample",
"_____no_output_____"
]
],
[
[
"Here's an example with `n=100`. The mean and std of the sample are close to the mean and std of the population, but not exact.",
"_____no_output_____"
]
],
[
[
"sample = make_sample(n=100)\nsample.mean(), sample.std()",
"_____no_output_____"
]
],
[
[
"We want to estimate the average weight in the population, so the \"sample statistic\" we'll use is the mean:",
"_____no_output_____"
]
],
[
[
"def sample_stat(sample):\n return sample.mean()",
"_____no_output_____"
]
],
[
[
"One iteration of \"the experiment\" is to collect a sample of 100 women and compute their average weight.\n\nWe can simulate running this experiment many times, and collect a list of sample statistics. The result is a NumPy array.",
"_____no_output_____"
]
],
[
[
"def compute_sample_statistics(n=100, iters=1000):\n stats = [sample_stat(make_sample(n)) for i in range(iters)]\n return numpy.array(stats)",
"_____no_output_____"
]
],
[
[
"The next line runs the simulation 1000 times and puts the results in\n`sample_means`:",
"_____no_output_____"
]
],
[
[
"sample_means = compute_sample_statistics(n=100, iters=1000)",
"_____no_output_____"
]
],
[
[
"Let's look at the distribution of the sample means. This distribution shows how much the results vary from one experiment to the next.\n\nRemember that this distribution is not the same as the distribution of weight in the population. This is the distribution of results across repeated imaginary experiments.",
"_____no_output_____"
]
],
[
[
"pyplot.hist(sample_means, color=COLOR5)\npyplot.xlabel('sample mean (n=100)')\npyplot.ylabel('count')\nNone",
"_____no_output_____"
]
],
[
[
"The mean of the sample means is close to the actual population mean, which is nice, but not actually the important part.",
"_____no_output_____"
]
],
[
[
"sample_means.mean()",
"_____no_output_____"
]
],
[
[
"The standard deviation of the sample means quantifies the variability from one experiment to the next, and reflects the precision of the estimate.\n\nThis quantity is called the \"standard error\".",
"_____no_output_____"
]
],
[
[
"std_err = sample_means.std()\nstd_err",
"_____no_output_____"
]
],
[
[
"We can also use the distribution of sample means to compute a \"90% confidence interval\", which contains 90% of the experimental results:",
"_____no_output_____"
]
],
[
[
"conf_int = numpy.percentile(sample_means, [5, 95])\nconf_int",
"_____no_output_____"
]
],
[
[
"The following function takes an array of sample statistics and prints the SE and CI:",
"_____no_output_____"
]
],
[
[
"def summarize_sampling_distribution(sample_stats):\n print('SE', sample_stats.std())\n print('90% CI', numpy.percentile(sample_stats, [5, 95]))",
"_____no_output_____"
]
],
[
[
"And here's what that looks like:",
"_____no_output_____"
]
],
[
[
"summarize_sampling_distribution(sample_means)",
"SE 1.6355262477\n90% CI [ 69.92149384 75.40866638]\n"
]
],
[
[
"Now we'd like to see what happens as we vary the sample size, `n`. The following function takes `n`, runs 1000 simulated experiments, and summarizes the results.",
"_____no_output_____"
]
],
[
[
"def plot_sample_stats(n, xlim=None):\n sample_stats = compute_sample_statistics(n, iters=1000)\n summarize_sampling_distribution(sample_stats)\n pyplot.hist(sample_stats, color=COLOR2)\n pyplot.xlabel('sample statistic')\n pyplot.xlim(xlim)",
"_____no_output_____"
]
],
[
[
"Here's a test run with `n=100`:",
"_____no_output_____"
]
],
[
[
"plot_sample_stats(100)",
"SE 1.71202891175\n90% CI [ 69.96057332 75.58582662]\n"
]
],
[
[
"Now we can use `interact` to run `plot_sample_stats` with different values of `n`. Note: `xlim` sets the limits of the x-axis so the figure doesn't get rescaled as we vary `n`.",
"_____no_output_____"
]
],
[
[
"def sample_stat(sample):\n return sample.mean()\n\nslider = widgets.IntSlider(min=10, max=1000, value=100)\ninteract(plot_sample_stats, n=slider, xlim=fixed([55, 95]))\nNone",
"SE 5.34419450661\n90% CI [ 64.25964402 81.60659174]\n"
]
],
[
[
"### Other sample statistics\n\nThis framework works with any other quantity we want to estimate. By changing `sample_stat`, you can compute the SE and CI for any sample statistic.\n\n**Exercise 1**: Fill in `sample_stat` below with any of these statistics:\n\n* Standard deviation of the sample.\n* Coefficient of variation, which is the sample standard deviation divided by the sample standard mean.\n* Min or Max\n* Median (which is the 50th percentile)\n* 10th or 90th percentile.\n* Interquartile range (IQR), which is the difference between the 75th and 25th percentiles.\n\nNumPy array methods you might find useful include `std`, `min`, `max`, and `percentile`.\nDepending on the results, you might want to adjust `xlim`.",
"_____no_output_____"
]
],
[
[
"def sample_stat(sample):\n # TODO: replace the following line with another sample statistic\n return sample.std()\n\nslider = widgets.IntSlider(min=10, max=1000, value=100)\ninteract(plot_sample_stats, n=slider, xlim=fixed([0, 100]))\nNone",
"SE 1.42826323302\n90% CI [ 14.51440703 19.17152091]\n"
]
],
[
[
"STOP HERE\n---------\n\nWe will regroup and discuss before going on.",
"_____no_output_____"
],
[
"Part Two\n========\n\nSo far we have shown that if we know the actual distribution of the population, we can compute the sampling distribution for any sample statistic, and from that we can compute SE and CI.\n\nBut in real life we don't know the actual distribution of the population. If we did, we wouldn't need to estimate it!\n\nIn real life, we use the sample to build a model of the population distribution, then use the model to generate the sampling distribution. A simple and popular way to do that is \"resampling,\" which means we use the sample itself as a model of the population distribution and draw samples from it.\n\nBefore we go on, I want to collect some of the code from Part One and organize it as a class. This class represents a framework for computing sampling distributions.",
"_____no_output_____"
]
],
[
[
"class Resampler(object):\n \"\"\"Represents a framework for computing sampling distributions.\"\"\"\n \n def __init__(self, sample, xlim=None):\n \"\"\"Stores the actual sample.\"\"\"\n self.sample = sample\n self.n = len(sample)\n self.xlim = xlim\n \n def resample(self):\n \"\"\"Generates a new sample by choosing from the original\n sample with replacement.\n \"\"\"\n new_sample = numpy.random.choice(self.sample, self.n, replace=True)\n return new_sample\n \n def sample_stat(self, sample):\n \"\"\"Computes a sample statistic using the original sample or a\n simulated sample.\n \"\"\"\n return sample.mean()\n \n def compute_sample_statistics(self, iters=1000):\n \"\"\"Simulates many experiments and collects the resulting sample\n statistics.\n \"\"\"\n stats = [self.sample_stat(self.resample()) for i in range(iters)]\n return numpy.array(stats)\n \n def plot_sample_stats(self):\n \"\"\"Runs simulated experiments and summarizes the results.\n \"\"\"\n sample_stats = self.compute_sample_statistics()\n summarize_sampling_distribution(sample_stats)\n pyplot.hist(sample_stats, color=COLOR2)\n pyplot.xlabel('sample statistic')\n pyplot.xlim(self.xlim)",
"_____no_output_____"
]
],
[
[
"The following function instantiates a `Resampler` and runs it.",
"_____no_output_____"
]
],
[
[
"def plot_resampled_stats(n=100):\n sample = weight.rvs(n)\n resampler = Resampler(sample, xlim=[55, 95])\n resampler.plot_sample_stats()",
"_____no_output_____"
]
],
[
[
"Here's a test run with `n=100`",
"_____no_output_____"
]
],
[
[
"plot_resampled_stats(100)",
"SE 1.72606450921\n90% CI [ 71.35648645 76.82647135]\n"
]
],
[
[
"Now we can use `plot_resampled_stats` in an interaction:",
"_____no_output_____"
]
],
[
[
"slider = widgets.IntSlider(min=10, max=1000, value=100)\ninteract(plot_resampled_stats, n=slider, xlim=fixed([1, 15]))\nNone",
"SE 1.67407589545\n90% CI [ 69.60129748 75.13161693]\n"
]
],
[
[
"**Exercise 2**: write a new class called `StdResampler` that inherits from `Resampler` and overrides `sample_stat` so it computes the standard deviation of the resampled data.",
"_____no_output_____"
]
],
[
[
"class StdResampler(Resampler):\n def sample_stat(self, sample):\n \"\"\"Computes a sample statistic using the original sample or a\n simulated sample.\n \"\"\"\n return sample.std()\n",
"_____no_output_____"
]
],
[
[
"Test your code using the cell below:",
"_____no_output_____"
]
],
[
[
"def plot_resampled_stats(n=100):\n sample = weight.rvs(n)\n resampler = StdResampler(sample, xlim=[0, 100])\n resampler.plot_sample_stats()\n \nplot_resampled_stats()",
"SE 1.16097458361\n90% CI [ 13.71301577 17.62512913]\n"
]
],
[
[
"When your `StdResampler` is working, you should be able to interact with it:",
"_____no_output_____"
]
],
[
[
"slider = widgets.IntSlider(min=10, max=1000, value=100)\ninteract(plot_resampled_stats, n=slider)\nNone",
"_____no_output_____"
]
],
[
[
"STOP HERE\n---------\n\nWe will regroup and discuss before going on.",
"_____no_output_____"
],
[
"Part Three\n==========\n\nWe can extend this framework to compute SE and CI for a difference in means.\n\nFor example, men are heavier than women on average. Here's the women's distribution again (from BRFSS data):",
"_____no_output_____"
]
],
[
[
"female_weight = scipy.stats.lognorm(0.23, 0, 70.8)\nfemale_weight.mean(), female_weight.std()",
"_____no_output_____"
]
],
[
[
"And here's the men's distribution:",
"_____no_output_____"
]
],
[
[
"male_weight = scipy.stats.lognorm(0.20, 0, 87.3)\nmale_weight.mean(), male_weight.std()",
"_____no_output_____"
]
],
[
[
"I'll simulate a sample of 100 men and 100 women:",
"_____no_output_____"
]
],
[
[
"female_sample = female_weight.rvs(100)\nmale_sample = male_weight.rvs(100)",
"_____no_output_____"
]
],
[
[
"The difference in means should be about 17 kg, but will vary from one random sample to the next:",
"_____no_output_____"
]
],
[
[
"male_sample.mean() - female_sample.mean()",
"_____no_output_____"
]
],
[
[
"Here's the function that computes Cohen's $d$ again:",
"_____no_output_____"
]
],
[
[
"def CohenEffectSize(group1, group2):\n \"\"\"Compute Cohen's d.\n\n group1: Series or NumPy array\n group2: Series or NumPy array\n\n returns: float\n \"\"\"\n diff = group1.mean() - group2.mean()\n\n n1, n2 = len(group1), len(group2)\n var1 = group1.var()\n var2 = group2.var()\n\n pooled_var = (n1 * var1 + n2 * var2) / (n1 + n2)\n d = diff / numpy.sqrt(pooled_var)\n return d",
"_____no_output_____"
]
],
[
[
"The difference in weight between men and women is about 1 standard deviation:",
"_____no_output_____"
]
],
[
[
"CohenEffectSize(male_sample, female_sample)",
"_____no_output_____"
]
],
[
[
"Now we can write a version of the `Resampler` that computes the sampling distribution of $d$.",
"_____no_output_____"
]
],
[
[
"class CohenResampler(Resampler):\n def __init__(self, group1, group2, xlim=None):\n self.group1 = group1\n self.group2 = group2\n self.xlim = xlim\n \n def resample(self):\n group1 = numpy.random.choice(self.group1, len(self.group1), replace=True)\n group2 = numpy.random.choice(self.group2, len(self.group2), replace=True)\n return group1, group2\n \n def sample_stat(self, groups):\n group1, group2 = groups\n return CohenEffectSize(group1, group2)\n \n # NOTE: The following functions are the same as the ones in Resampler,\n # so I could just inherit them, but I'm including them for readability\n def compute_sample_statistics(self, iters=1000):\n stats = [self.sample_stat(self.resample()) for i in range(iters)]\n return numpy.array(stats)\n \n def plot_sample_stats(self):\n sample_stats = self.compute_sample_statistics()\n summarize_sampling_distribution(sample_stats)\n pyplot.hist(sample_stats, color=COLOR2)\n pyplot.xlabel('sample statistic')\n pyplot.xlim(self.xlim)",
"_____no_output_____"
]
],
[
[
"Now we can instantiate a `CohenResampler` and plot the sampling distribution.",
"_____no_output_____"
]
],
[
[
"resampler = CohenResampler(male_sample, female_sample)\nresampler.plot_sample_stats()",
"SE 0.175914055487\n90% CI [ 0.57405878 1.16434114]\n"
]
],
[
[
"This example demonstrates an advantage of the computational framework over mathematical analysis. Statistics like Cohen's $d$, which is the ratio of other statistics, are relatively difficult to analyze. But with a computational approach, all sample statistics are equally \"easy\".\n\nOne note on vocabulary: what I am calling \"resampling\" here is a specific kind of resampling called \"bootstrapping\". Other techniques that are also considering resampling include permutation tests, which we'll see in the next section, and \"jackknife\" resampling. You can read more at <http://en.wikipedia.org/wiki/Resampling_(statistics)>.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a00f83ac0d3bbe740ae342971bfe3d32c1a44a1
| 7,400 |
ipynb
|
Jupyter Notebook
|
tutorials/5_route_planner/tutorial_route_planner.ipynb
|
ZhuowenZou/CSE203MotionPlanning
|
7af9ecff5b5342f15247db0d6b331cd8108a736d
|
[
"BSD-3-Clause"
] | null | null | null |
tutorials/5_route_planner/tutorial_route_planner.ipynb
|
ZhuowenZou/CSE203MotionPlanning
|
7af9ecff5b5342f15247db0d6b331cd8108a736d
|
[
"BSD-3-Clause"
] | null | null | null |
tutorials/5_route_planner/tutorial_route_planner.ipynb
|
ZhuowenZou/CSE203MotionPlanning
|
7af9ecff5b5342f15247db0d6b331cd8108a736d
|
[
"BSD-3-Clause"
] | null | null | null | 36.81592 | 427 | 0.653784 |
[
[
[
"# Tutorial: CommonRoad Route Planner\n\nThis tutorial demonstrates how the CommonRoad Route Planner package can be used to plan high-level routes for planning problems given in CommonRoad scenarios.",
"_____no_output_____"
],
[
"## 0. Preparation\n* you have gone through the tutorial for **CommonRoad Input-Output**\n* you have installed the [route planner](https://gitlab.lrz.de/tum-cps/commonroad-route-planner) package\n\nLet's start with importing relevant modules and classes.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%load_ext autoreload\n%autoreload 2\n\nimport os\nimport sys\n\n# add the root folder to python path\npath_notebook = os.getcwd()\nsys.path.append(os.path.join(path_notebook, \"../\"))\n\nimport matplotlib.pyplot as plt\nfrom commonroad.common.file_reader import CommonRoadFileReader\nfrom commonroad_route_planner.route_planner import RoutePlanner\nfrom commonroad_route_planner.utility.visualization import visualize_route\nfrom commonroad.visualization.mp_renderer import MPRenderer",
"_____no_output_____"
]
],
[
[
"## 1. Loading CR Scenario and Planning Problem\nIn the next step, we load a CommonRoad scenario and its planning problem(s), for which the routes should be planned. The route planner handles **one planning problem** at a time, thus we need to manually specify the planning problem for which the routes should be planned. In our case, we select the first planning problem in the planning problem set. The meaning of the symbols in a scenario are explained as follows:\n* **Dot**: initial state of the planning problem projected onto the position domain\n* **Blue rectangle**: dynamic obstacle\n* **Yellow rectangle**: goal region projected onto the position domain",
"_____no_output_____"
]
],
[
[
"# load scenario\npath_scenario = os.path.join(path_notebook, \"../../scenarios/tutorial/\")\nid_scenario = 'USA_Peach-2_1_T-1'\n\n# read in scenario and planning problem set\nscenario, planning_problem_set = CommonRoadFileReader(path_scenario + id_scenario + '.xml').open()\n# retrieve the first planning problem in the problem set\nplanning_problem = list(planning_problem_set.planning_problem_dict.values())[0]\n\n# plot the scenario and the planning problem set\nrenderer = MPRenderer(figsize=(12, 12))\n\nscenario.draw(renderer)\nplanning_problem.draw(renderer)\n\nrenderer.render()\nplt.margins(0, 0)",
"_____no_output_____"
]
],
[
[
"## 2. Creating a route planner and planning for routes\n\n### 2.1 Instantiation\nA route planner can be easily constructed by passing the **scenario** and the **planning problem** to `RoutePlanner` object. As for the backend, there are currently three supported options:\n1. NETWORKX: uses built-in functions from the networkx package, tends to change lane later\n2. NETWORKX_REVERSED: uses built-in functions from the networkx package, tends to change lane earlier\n3. PRIORITY_QUEUE: uses A-star search to find routes, lane change maneuver depends on the heuristic cost\n\n### 2.2 Planning all possible routes\nThe route planner plans a route for all possible combinations of start / goal lanelets. E.g. if our initial state is located in two lanes (due to overlapping of lanelets), and the same for our goal state, the route planner will try to plan routes for the four possible combinations.\n\n### 2.3 Retrieving a route\nPlanned routes can be retrieved by using simple indices, or based on some heuristic functions to determine the best route of all. A route consists of a list of lanelet ids that leads from the initial state to the goal state.\n\n### 2.4 Retrieving reference path\nA reference path is automatically generated for each planned routes. The center lines of lanelets of a route is used to construct the reference path. The resulting polyline is then smoothened with Chaikin's corner cutting algorithm.",
"_____no_output_____"
]
],
[
[
"# instantiate a route planner with the scenario and the planning problem\nroute_planner = RoutePlanner(scenario, planning_problem, backend=RoutePlanner.Backend.NETWORKX_REVERSED)\n\n# plan routes, and save the routes in a route candidate holder\ncandidate_holder = route_planner.plan_routes()\n\n# option 1: retrieve all routes\nlist_routes, num_route_candidates = candidate_holder.retrieve_all_routes()\nprint(f\"Number of route candidates: {num_route_candidates}\")\n# here we retrieve the first route in the list, this is equivalent to: route = list_routes[0]\nroute = candidate_holder.retrieve_first_route()\n\n# option 2: retrieve the best route by orientation metric\n# route = candidate_holder.retrieve_best_route_by_orientation()\n\n# print coordinates of the vertices of the reference path\nprint(\"\\nCoordinates [x, y]:\")\nprint(route.reference_path)",
"_____no_output_____"
]
],
[
[
"## 3. Visualizing planning results",
"_____no_output_____"
],
[
"The planned routes can be easily visualized with the `visualize_route` function. The arguements `draw_route_lanelets` and `draw_reference_path` indicates whether the lanelets of the route and the reference path should be drawn, respectively. The lanelets of the route is colored in green.",
"_____no_output_____"
]
],
[
[
"visualize_route(route, draw_route_lanelets=True, draw_reference_path=False, size_x=6)",
"_____no_output_____"
]
],
[
[
"We now plot the generated reference path as well, which is colored in red.",
"_____no_output_____"
]
],
[
[
"visualize_route(route, draw_route_lanelets=True, draw_reference_path=True, size_x=6)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a00f885bf28abccd077a7bf7568e2320b9f8276
| 41,284 |
ipynb
|
Jupyter Notebook
|
exp2.ipynb
|
NIKKI027/Quiz_
|
68790135cd9bdd8419911c2088eb4a218be48b56
|
[
"MIT"
] | 1 |
2021-10-10T17:22:30.000Z
|
2021-10-10T17:22:30.000Z
|
exp2.ipynb
|
NIKKI027/Quiz_
|
68790135cd9bdd8419911c2088eb4a218be48b56
|
[
"MIT"
] | null | null | null |
exp2.ipynb
|
NIKKI027/Quiz_
|
68790135cd9bdd8419911c2088eb4a218be48b56
|
[
"MIT"
] | 1 |
2021-10-10T17:25:45.000Z
|
2021-10-10T17:25:45.000Z
| 48.172695 | 5,365 | 0.361399 |
[
[
[
"<a href=\"https://colab.research.google.com/github/NIKKI027/Quiz_/blob/main/exp2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import datasets, layers, models\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport numpy as np",
"_____no_output_____"
],
[
"(X_train, y_train) , (X_test, y_test) = keras.datasets.mnist.load_data()",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz\n11493376/11490434 [==============================] - 0s 0us/step\n11501568/11490434 [==============================] - 0s 0us/step\n"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"X_test.shape",
"_____no_output_____"
],
[
"y_train",
"_____no_output_____"
],
[
"X_train[0].shape",
"_____no_output_____"
],
[
"plt.matshow(X_train[0])",
"_____no_output_____"
],
[
"y_train[0]",
"_____no_output_____"
],
[
"X_train[0]",
"_____no_output_____"
],
[
"X_train = X_train / 255\nX_test = X_test / 255",
"_____no_output_____"
],
[
"X_train[0]",
"_____no_output_____"
]
],
[
[
"Using ANN for classification",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential([\n keras.layers.Flatten(input_shape=(28, 28)),\n keras.layers.Dense(100, activation='relu'),\n keras.layers.Dense(10, activation='sigmoid')\n])\n\nmodel.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])\n\nmodel.fit(X_train, y_train, epochs=10)",
"Epoch 1/10\n1875/1875 [==============================] - 5s 2ms/step - loss: 0.2788 - accuracy: 0.9200\nEpoch 2/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.1233 - accuracy: 0.9637\nEpoch 3/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0867 - accuracy: 0.9741\nEpoch 4/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0668 - accuracy: 0.9800\nEpoch 5/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0519 - accuracy: 0.9844\nEpoch 6/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0412 - accuracy: 0.9875\nEpoch 7/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0335 - accuracy: 0.9898\nEpoch 8/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0283 - accuracy: 0.9912\nEpoch 9/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0224 - accuracy: 0.9931\nEpoch 10/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.0193 - accuracy: 0.9940\n"
],
[
"model.evaluate(X_test,y_test)",
"313/313 [==============================] - 1s 2ms/step - loss: 0.0815 - accuracy: 0.9782\n"
],
[
"X_train = X_train.reshape(-1,28,28,1)\nX_train.shape",
"_____no_output_____"
],
[
"X_test = X_test.reshape(-1,28,28,1)\nX_test.shape",
"_____no_output_____"
]
],
[
[
"Using CNN for classification",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential([\n \n layers.Conv2D(30, (3,3), activation='relu', input_shape=(28, 28, 1)),\n layers.MaxPooling2D((2,2)),\n \n layers.Flatten(),\n layers.Dense(100, activation='relu'),\n keras.layers.Dense(10, activation='sigmoid')\n])",
"_____no_output_____"
],
[
"model.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])\n\nmodel.fit(X_train, y_train, epochs=5)",
"Epoch 1/5\n1875/1875 [==============================] - 34s 18ms/step - loss: 0.1590 - accuracy: 0.9534\nEpoch 2/5\n1875/1875 [==============================] - 34s 18ms/step - loss: 0.0548 - accuracy: 0.9836\nEpoch 3/5\n1875/1875 [==============================] - 34s 18ms/step - loss: 0.0358 - accuracy: 0.9888\nEpoch 4/5\n1875/1875 [==============================] - 34s 18ms/step - loss: 0.0247 - accuracy: 0.9919\nEpoch 5/5\n1875/1875 [==============================] - 34s 18ms/step - loss: 0.0161 - accuracy: 0.9947\n"
],
[
"y_train[:5]",
"_____no_output_____"
],
[
"model.evaluate(X_test,y_test)",
"313/313 [==============================] - 2s 7ms/step - loss: 0.0416 - accuracy: 0.9881\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a00fc62aeef9ee27bea60f6a61f04e4b1769a1c
| 26,935 |
ipynb
|
Jupyter Notebook
|
notebooks/Rat-GEM2JMS.ipynb
|
gmhhope/JMS
|
5097c1fa11bf112b71330c878455003a1326f528
|
[
"MIT"
] | null | null | null |
notebooks/Rat-GEM2JMS.ipynb
|
gmhhope/JMS
|
5097c1fa11bf112b71330c878455003a1326f528
|
[
"MIT"
] | null | null | null |
notebooks/Rat-GEM2JMS.ipynb
|
gmhhope/JMS
|
5097c1fa11bf112b71330c878455003a1326f528
|
[
"MIT"
] | 1 |
2022-02-16T18:58:27.000Z
|
2022-02-16T18:58:27.000Z
| 27.911917 | 185 | 0.484166 |
[
[
[
"# Porting genome scale metabolic models for metabolomics\n\n**rat-GEM as default rat model, for better compatibility**\nhttps://github.com/SysBioChalmers/rat-GEM\n\n**Use cobra to parse SBML models whereas applicable**\n\nNot all models comply with the formats in cobra. Models from USCD and Thiele labs should comply.\n\n**Base our code on metDataModel**\n\nEach model needs a list of Reactions, list of Pathways, and a list of Compounds.\nIt's important to include with Compounds with all linked identifiers to other DBs (HMDB, PubChem, etc), and with formulae (usually charged form in these models) when available.\nWe can alwasy update the data later. E.g. the neural formulae can be inferred from charged formula or retrieved from public metabolite database (e.g., HMDB) if linked.\nSave in Python pickle and in JSON.\n\n**No compartmentalization**\n- After decompartmentalization,\n - transport reactions can be removed - they are identified by reactants and products being the same.\n - redundant reactions can be merge - same reactions in diff compartments become one.\n\nShuzhao Li, 2021-10-21|\nMinghao Gong, 2022-04-19",
"_____no_output_____"
]
],
[
[
"# !pip install cobra --user --ignore-installed ruamel.yaml\n# !pip install --upgrade metDataModel # https://github.com/shuzhao-li/metDataModel/ \n# !pip install --upgrade numpy pandas",
"_____no_output_____"
],
[
"import cobra # https://cobrapy.readthedocs.io/en/latest/io.html#SBML\nfrom metDataModel.core import Compound, Reaction, Pathway, MetabolicModel\nimport requests\nimport sys\nimport re\n\nsys.path.append(\"/Users/gongm/Documents/projects/mass2chem/\")\nsys.path.append(\"/Users/gongm/Documents/projects/JMS/JMS/JMS\")\nfrom mass2chem.formula import *\nfrom jms.formula import *\nfrom jms.utils.gems import *\nfrom jms.utils.git_download import *",
"_____no_output_____"
],
[
"# download the most updated Rat-GEM.xml\nmodel_name = 'Rat-GEM'\nxml_url = f'https://github.com/SysBioChalmers/{model_name}/blob/main/model/{model_name}.xml'\nlocal_path = output_fdr = f'../testdata/{model_name}/'\n\ntry:\n os.mkdir(local_path)\nexcept:\n None\n\nxml_file_name = f'{model_name}.xml'\ngit_download_from_file(xml_url,local_path,xml_file_name)",
"_____no_output_____"
],
[
"# Read the model via cobra\nxmlFile = os.path.join(local_path,xml_file_name)\nmodel = cobra.io.read_sbml_model(xmlFile)",
"'' is not a valid SBML 'SId'.\nhttps://identifiers.org/taxonomy/ does not conform to 'http(s)://identifiers.org/collection/id' or'http(s)://identifiers.org/COLLECTION:id\n"
],
[
"model",
"_____no_output_____"
],
[
"# metabolite entries, readily convert to list of metabolites\nmodel.metabolites[990] ",
"_____no_output_____"
],
[
"# reaction entries, Readily convert to list of reactions\nmodel.reactions[33]",
"_____no_output_____"
],
[
"# groups are similar to pathways? Readily convert to list of pathway\nmodel.groups[11].__dict__",
"_____no_output_____"
]
],
[
[
"## Port metabolite",
"_____no_output_____"
]
],
[
[
"def port_metabolite(M):\n # convert cobra Metabolite to metDataModel Compound\n Cpd = Compound()\n Cpd.src_id = remove_compartment_by_substr(M.id,1)\n Cpd.id = remove_compartment_by_substr(M.id,1) # temporarily the same with the source id\n Cpd.name = M.name\n Cpd.charge = M.charge\n Cpd.neutral_formula = adjust_charge_in_formula(M.formula,M.charge)\n Cpd.neutral_mono_mass = neutral_formula2mass(Cpd.neutral_formula)\n Cpd.charged_formula = M.formula\n Cpd.db_ids = [[model_name,Cpd.src_id]] # using src_id to also reference Rat-GEM ID in db_ids field\n for k,v in M.annotation.items():\n if k != 'sbo':\n if isinstance(v,list):\n Cpd.db_ids.append([[k,x] for x in v])\n else: \n if \":\" in v:\n Cpd.db_ids.append([k,v.split(\":\")[1]])\n else:\n Cpd.db_ids.append([k,v])\n \n inchi_list = [x[1].split('=')[1] for x in Cpd.db_ids if x[0] == 'inchi']\n if len(inchi_list) ==1:\n Cpd.inchi = inchi_list[0]\n elif len(inchi_list) >1:\n Cpd.inchi = inchi_list\n \n return Cpd",
"_____no_output_____"
],
[
"myCpds = []\nfor i in range(len(model.metabolites)):\n myCpds.append(port_metabolite(model.metabolites[i]))",
"_____no_output_____"
],
[
"len(myCpds)",
"_____no_output_____"
],
[
"# remove duplicated compounds\nmyCpds = remove_duplicate_cpd(myCpds)",
"_____no_output_____"
],
[
"len(myCpds)",
"_____no_output_____"
],
[
"myCpds[100].__dict__",
"_____no_output_____"
],
[
"fetch_MetabAtlas_GEM_identifiers(compound_list = myCpds,\n modelName = model_name,\n local_path = local_path,\n metab_file_name = 'metabolites.tsv',\n overwrite = True)",
"_____no_output_____"
],
[
"myCpds[100].__dict__",
"_____no_output_____"
]
],
[
[
"## Port reactions",
"_____no_output_____"
]
],
[
[
"# port reactions, to include genes and enzymes\ndef port_reaction(R):\n new = Reaction()\n new.id = R.id\n new.reactants = [remove_compartment_by_substr(m.id,1) for m in R.reactants] # decompartmentalization\n new.products = [remove_compartment_by_substr(m.id,1) for m in R.products] # decompartmentalization\n new.genes = [g.id for g in R.genes]\n ecs = R.annotation.get('ec-code', [])\n if isinstance(ecs, list):\n new.enzymes = ecs\n else:\n new.enzymes = [ecs] # this version of Rat-GEM may have it as string\n return new\n\ntest99 = port_reaction(model.reactions[199])\n[test99.id,\n test99.reactants,\n test99.products,\n test99.genes,\n test99.enzymes\n]",
"_____no_output_____"
],
[
"## Reactions to port\nmyRxns = []\nfor R in model.reactions:\n myRxns.append( port_reaction(R) )\n \nprint(len(myRxns))",
"13086\n"
],
[
"# remove duplicated reactions after decompartmentalization\nmyRxns = remove_duplicate_rxn(myRxns)",
"_____no_output_____"
],
[
"len(myRxns)",
"_____no_output_____"
],
[
"myRxns[0].__dict__",
"_____no_output_____"
]
],
[
[
"## Port pathway",
"_____no_output_____"
]
],
[
[
"# pathways, using group as pathway. Other models may use subsystem etc.\n\ndef port_pathway(P, model_name):\n new = Pathway()\n new.id = P.id\n new.source = [f'{model_name} v1.10.0',]\n new.name = P.name\n new.list_of_reactions = [x.id for x in P.members]\n return new\n\np = port_pathway(model.groups[12],model_name)\n\n[p.id, p.name, p.list_of_reactions[:5]]",
"_____no_output_____"
],
[
"## Pathways to port\nmyPathways = []\nfor P in model.groups:\n myPathways.append(port_pathway(P,model_name))\n\nlen(myPathways)",
"_____no_output_____"
],
[
"# retain the valid reactions in list of pathway\nmyPathways = retain_valid_Rxns_in_Pathways(myPathways,myRxns)",
"_____no_output_____"
],
[
"# test if the length of unique reactions matched with the length of decompartmentalized reaction list \ntest_list_Rxns = []\nfor pathway in myPathways:\n for y in pathway.list_of_reactions:\n test_list_Rxns.append(y)\n\nlen(set(test_list_Rxns))",
"_____no_output_____"
]
],
[
[
"## Collected data; now output",
"_____no_output_____"
]
],
[
[
"from datetime import datetime\ntoday = str(datetime.today()).split(\" \")[0]",
"_____no_output_____"
],
[
"today",
"_____no_output_____"
],
[
"note = \"\"\"Rat-GEM compartmentalized, with genes and ECs.\"\"\"\n\n## metabolicModel to export\nMM = MetabolicModel()\nMM.id = f'az_{model_name}_{today}' #\nMM.meta_data = {\n 'species': model_name.split('-')[0],\n 'version': '',\n 'sources': [f'https://github.com/SysBioChalmers/{model_name}, retrieved {today}'], #\n 'status': '',\n 'last_update': today, #\n 'note': note,\n }\nMM.list_of_pathways = [P.serialize() for P in myPathways]\nMM.list_of_reactions = [R.serialize() for R in myRxns]\nMM.list_of_compounds = [C.serialize() for C in myCpds]",
"_____no_output_____"
],
[
"# check output\n[\nMM.list_of_pathways[2],\nMM.list_of_reactions[:2],\nMM.list_of_compounds[100:102],\n]",
"_____no_output_____"
],
[
"import pickle\nimport os\n\n# Write pickle file\nexport_pickle(os.path.join(output_fdr,f'{MM.id}.pickle'), MM)",
"_____no_output_____"
],
[
"# Write json file\nexport_json(os.path.join(output_fdr,f'{MM.id}.json'), MM)",
"_____no_output_____"
],
[
"# Write dataframe \nimport pandas as pd\nexport_table(os.path.join(output_fdr,f'{MM.id}_list_of_compounds.csv'),MM, 'list_of_compounds')\nexport_table(os.path.join(output_fdr,f'{MM.id}_list_of_reactions.csv'),MM, 'list_of_reactions')\nexport_table(os.path.join(output_fdr,f'{MM.id}_list_of_pathways.csv'),MM, 'list_of_pathways')",
"_____no_output_____"
]
],
[
[
"## Summary\n\nThis ports reactions, pathways and compounds. Gene and enzyme information is now included. \n\nThe exported pickle can be re-imported and uploaded to Database easily.\n\nThis notebook, the pickle file and the JSON file go to GitHub repo (https://github.com/shuzhao-li/Azimuth).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a010b19bcd43ddf65d5c312ab1402c8c9323c57
| 6,298 |
ipynb
|
Jupyter Notebook
|
tests/Untitled.ipynb
|
ohcpaull/lattice
|
67e3c002b3a64fa62cd8bce48d09bf85ffe4d137
|
[
"MIT"
] | null | null | null |
tests/Untitled.ipynb
|
ohcpaull/lattice
|
67e3c002b3a64fa62cd8bce48d09bf85ffe4d137
|
[
"MIT"
] | null | null | null |
tests/Untitled.ipynb
|
ohcpaull/lattice
|
67e3c002b3a64fa62cd8bce48d09bf85ffe4d137
|
[
"MIT"
] | null | null | null | 41.434211 | 1,475 | 0.605113 |
[
[
[
"import xrdtools\n\nfpath = r'D:\\VG180301\\VG180301_Rphase_rockingcurve.xrdml'\n\ndata = xrdtools.read_xrdml(fpath)\n",
"File \"D:\\VG180301\\VG180301_Rphase_rockingcurve.xrdml\" does not exist.\n"
],
[
"def ras_file( file ):\n # Read RAS data to object\n rasFile = xu.io.rigaku_ras.RASFile(file)\n \n self.scanaxis = rasFile.scans.scan_axis\n self.stepSize = rasFile.scans.meas_step\n self.measureSpeed= rasFile.scans.meas_speed\n self.dataCount = rasFile.scans.length\n # Read raw motor position and intensity data to large 1D arrays\n\n ax1, data = xu.io.getras_scan(rasFile.filename+'%s', '', self.scanaxis)\n\n npinte = np.array(data['int'])\n \n \n # Read omega data from motor positions at the start of each 2theta-Omega scan\n om = [rasFile.scans[i].init_mopo['Omega'] for i in range(0, len(rasFile.scans))]\n # Convert 2theta-omega data to 1D array\n \n return (np.transpose(omga), np.transpose(tt), np.transpose(intensities))",
"_____no_output_____"
],
[
"import xrayutilities as xu\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom tkinter import filedialog\nimport os\n\n\nroot = tk.Tk()\nroot.withdraw()\nfilepath = filedialog.askopenfilename()\nfilename = os.path.basename(filepath)\n\n#file = r'C:\\Users\\olive\\OneDrive - UNSW\\Experiments 2019\\Xrays\\VG180301\\VG180301_rockingCurve_alignment.ras'\nrasFile = xu.io.rigaku_ras.RASFile(filepath)\nax1, data = xu.io.getras_scan(rasFile.filename+'%s', '', rasFile.scans[0].scan_axis)\n%matplotlib widget\nfig, ax = plt.subplots()\nax.plot(ax1, data['int']*data['att'])\nax.set_xlabel( rasFile.scans[0].scan_axis)\nax.set_ylabel( 'Intensity (a.u.)')\n#ax.set_yscale('log')\n\nparams, sd_params, itlim = xu.math.fit.gauss_fit(ax1, data['int']*data['att'], iparams=[], maxit=300)\n\nax.plot(ax1, xu.math.Gauss1d(ax1, *params))\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a010dd01b86b2cd2deca4f50eaafeacec20672a
| 793,309 |
ipynb
|
Jupyter Notebook
|
project 1 - Analyzing a Loyalty Program/Loyalty Program - analyzing data.ipynb
|
MauCFD/Project_1
|
1790f40e50a69490035630a771243560b17edf2c
|
[
"FTL"
] | null | null | null |
project 1 - Analyzing a Loyalty Program/Loyalty Program - analyzing data.ipynb
|
MauCFD/Project_1
|
1790f40e50a69490035630a771243560b17edf2c
|
[
"FTL"
] | null | null | null |
project 1 - Analyzing a Loyalty Program/Loyalty Program - analyzing data.ipynb
|
MauCFD/Project_1
|
1790f40e50a69490035630a771243560b17edf2c
|
[
"FTL"
] | 1 |
2021-02-10T20:55:40.000Z
|
2021-02-10T20:55:40.000Z
| 137.918811 | 41,287 | 0.819234 |
[
[
[
"#The birth of skynet, always good to start with a joke\nprint(\"hello World!\")",
"hello World!\n"
],
[
"# Dependencies\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport os\nimport scipy.stats as st\nimport numpy as np\nimport requests\nimport time\nimport gmaps\nimport json\nfrom pprint import pprint\nfrom statsmodels.tsa.stattools import adfuller\nfrom statsmodels.tsa.seasonal import seasonal_decompose\nfrom statsmodels.tsa.arima_model import ARIMA\nfrom pandas.plotting import register_matplotlib_converters\n\n# Import API key\nfrom config import api_key\nfrom config import g_key\n\nregister_matplotlib_converters()",
"_____no_output_____"
],
[
"# Study data files\nproject_path = \"Project_df.csv\"\n\n# Read the csv file\nProject_df = pd.read_csv(project_path)\n\n# Display the data table for preview\nProject_df",
"_____no_output_____"
]
],
[
[
"# Part 1 - Statistical Analysis.",
"_____no_output_____"
],
[
"#### We will use statistical analysis to understand our data",
"_____no_output_____"
]
],
[
[
"# Filtering the data by year to run aggregate function.\ngb_year = Project_df.groupby('Year')\n\nProject_18_df = gb_year.get_group(2018)\nProject_19_df = gb_year.get_group(2019)\nProject_20_df = gb_year.get_group(2020)",
"_____no_output_____"
],
[
"# Working with 2018 Data by Category Sales\nstats_summary_2018_df = (Project_18_df.groupby(\"Category\")[\"Total Sales\"].agg([\"min\",\"max\", \"sum\", \"mean\",\"median\",\"var\",\"std\",\"sem\"]).style.format('${0:,.2f}'))\nstats_summary_2018_df",
"_____no_output_____"
],
[
"# Working with 2019 Data by Category Sales\nstats_summary_2019_df = (Project_19_df.groupby(\"Category\")[\"Total Sales\"].agg([\"min\",\"max\", \"sum\",\"mean\",\"median\",\"var\",\"std\",\"sem\"]).style.format('${0:,.2f}'))\nstats_summary_2019_df",
"_____no_output_____"
],
[
"# Working with 2020 Data by Category Sales\nstats_summary_2020_df = (Project_20_df.groupby(\"Category\")[\"Total Sales\"].agg([\"min\",\"max\", \"sum\",\"mean\",\"median\",\"var\",\"std\",\"sem\"]).style.format('${0:,.2f}'))\nstats_summary_2020_df",
"_____no_output_____"
]
],
[
[
"# Part 2 - Analyzing Data by Number of Clients.",
"_____no_output_____"
],
[
"#### We will try to analyze if the Number of Clients has a direct impact on the Total Sales, regardless of their Category ",
"_____no_output_____"
]
],
[
[
"# We will create a Data Frame with the number of different clients we had for each month of the three years\nclients_by_month = Project_df.groupby('Year')\n\nclient_no_18 = pd.DataFrame(clients_by_month.get_group(2018))\nclient_no_18 = client_no_18.groupby('Month').count()[[\"Client ID\"]]\nclient_no_18 = client_no_18.values.tolist()\n\nclient_no_19 = pd.DataFrame(clients_by_month.get_group(2019))\nclient_no_19 = client_no_19.groupby('Month').count()[[\"Client ID\"]]\nclient_no_19 = client_no_19.values.tolist()\n\nclient_no_20 = pd.DataFrame(clients_by_month.get_group(2020))\nclient_no_20 = client_no_20.groupby('Month').count()[[\"Client ID\"]]\nclient_no_20 = client_no_20.values.tolist()\n\nclients_number = client_no_18 + client_no_19 + client_no_20\nmonths = list(range(1, 37))\n\nclients_by_month = pd.DataFrame(clients_number, index = months, columns =['Number of DIfferent Clients']) \nclients_by_month.head()",
"_____no_output_____"
],
[
"# Plotting the Data Frame of Clients by Month on a 3 year term\nclients_by_month.plot(kind=\"bar\", color=\"r\", figsize=(9,3))\n\nplt.title(\"Clients by Month\")\nplt.xlabel(\"Month\")\nplt.ylabel(\"Number of Different Clients\")\nplt.legend(loc=1, prop={'size': 8})\nplt.xticks(rotation = 0)\n\nplt.savefig(\"plots/Count of different clients by month.png\")\nplt.show()",
"_____no_output_____"
],
[
"# Analizing total sales behavior per month\ngrouped_sales_by_month = Project_df.groupby(['Year','Month'])\nsales_df = pd.DataFrame(grouped_sales_by_month['Total Sales'].sum())\nsales_df['Date']= sales_df.index\nsales_df",
"_____no_output_____"
],
[
"# Defining axes\nxticks = sales_df['Total Sales'].tolist()\nx_axis = np.arange(len(sales_df['Total Sales']))\n\n# Plot the line\nplt.plot(x_axis, sales_df['Total Sales'])\nplt.title('Total Sales in Millons per Month')\nplt.xticks(ticks=[0,12,24], labels = ['2018','2019','2020'])\nplt.savefig('plots/Total sales per month.png')\n\nplt.show()",
"_____no_output_____"
],
[
"# We will try to forecast the sales for the next year using an ARIMA model\n\n# First we convert the columns we need into lists\nmonth_list = list(range(1, 37))\nsales_list = sales_df['Total Sales'].tolist()\n\n# With those lists, we will create our Data Frame\narima_df = pd.DataFrame()\narima_df['Month'] = month_list\narima_df['Total Sales'] = sales_list\narima_df = arima_df.set_index('Month')\narima_df.head()",
"_____no_output_____"
],
[
"# We now will get the rolling mean and the rolling std and plot it with Total Sales\nrolling_mean = arima_df.rolling(window = 3).mean()\nrolling_std = arima_df.rolling(window = 3).std()\nplt.plot(arima_df, color = 'blue', label = 'Original')\nplt.plot(rolling_mean, color = 'red', label = 'Rolling Mean')\nplt.plot(rolling_std, color = 'black', label = 'Rolling Std')\nplt.legend(loc = 'best')\n\nplt.title('Rolling mean and Rolling std')\n\nplt.show()",
"_____no_output_____"
],
[
"# Ploting the log\ndf_log = np.log(arima_df)\nplt.plot(df_log)",
"_____no_output_____"
],
[
"# We will define a function that will helps us know if our time series is stationary\ndef get_stationarity(timeseries):\n \n # rolling statistics\n rolling_mean = timeseries.rolling(window=3).mean()\n rolling_std = timeseries.rolling(window=3).std()\n \n # rolling statistics plot\n original = plt.plot(timeseries, color='blue', label='Original')\n mean = plt.plot(rolling_mean, color='red', label='Rolling Mean')\n std = plt.plot(rolling_std, color='black', label='Rolling Std')\n plt.legend(loc='best')\n plt.title('Rolling Mean and std')\n plt.show(block=False)\n \n # Dickey–Fuller test:\n result = adfuller(timeseries['Total Sales'])\n print('ADF Statistic: {}'.format(result[0]))\n print('p-value: {}'.format(result[1]))\n print('Critical Values:')\n for key, value in result[4].items():\n print('\\t{}: {}'.format(key, value))",
"_____no_output_____"
],
[
"# We will substract the rolling mean now to render it starionaty\nrolling_mean = df_log.rolling(window=3).mean()\ndf_log_minus_mean = df_log - rolling_mean\ndf_log_minus_mean.dropna(inplace=True)\nget_stationarity(df_log_minus_mean)",
"_____no_output_____"
],
[
"# We will now try to substract the point that preceed any given point to look for a better solution\ndf_log_shift = df_log - df_log.shift()\ndf_log_shift.dropna(inplace=True)\nget_stationarity(df_log_shift)",
"_____no_output_____"
],
[
"# We will create an Arima model with an autoregressive model\ndecomposition = seasonal_decompose(df_log, period=1) \nmodel = ARIMA(df_log, order=(2,1,2))\nresults = model.fit(disp=-1)\nplt.plot(df_log_shift)\nplt.plot(results.fittedvalues, color='red')",
"C:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\statsmodels\\tsa\\base\\tsa_model.py:214: ValueWarning: An unsupported index was provided and will be ignored when e.g. forecasting.\n ' ignored when e.g. forecasting.', ValueWarning)\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\statsmodels\\tsa\\base\\tsa_model.py:214: ValueWarning: An unsupported index was provided and will be ignored when e.g. forecasting.\n ' ignored when e.g. forecasting.', ValueWarning)\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\statsmodels\\base\\model.py:548: HessianInversionWarning: Inverting hessian failed, no bse or cov_params available\n 'available', HessianInversionWarning)\n"
],
[
"# We will now compare that model with our original series\npredictions_ARIMA_diff = pd.Series(results.fittedvalues, copy=True)\npredictions_ARIMA_diff_cumsum = predictions_ARIMA_diff.cumsum()\npredictions_ARIMA_log = pd.Series(df_log['Total Sales'].iloc[0], index=df_log.index)\npredictions_ARIMA_log = predictions_ARIMA_log.add(predictions_ARIMA_diff_cumsum, fill_value=0)\npredictions_ARIMA = np.exp(predictions_ARIMA_log)\nplt.plot(arima_df)\nplt.plot(predictions_ARIMA)",
"_____no_output_____"
],
[
"# Now we can predict the Total Sales for the next year\nresults.plot_predict(1,48)\nplt.savefig('plots/ARIMA model for 12 months prediction.png')",
"C:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\statsmodels\\tsa\\base\\tsa_model.py:583: ValueWarning: No supported index is available. Prediction results will be given with an integer index beginning at `start`.\n ValueWarning)\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\statsmodels\\tsa\\base\\tsa_model.py:583: ValueWarning: No supported index is available. Prediction results will be given with an integer index beginning at `start`.\n ValueWarning)\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\statsmodels\\tsa\\base\\tsa_model.py:583: ValueWarning: No supported index is available. Prediction results will be given with an integer index beginning at `start`.\n ValueWarning)\n"
],
[
"# We will compare if Sales and Number of Clients hold a relation\nsales_by_month = Project_df.groupby('Year')\n\ntotal_sales_18 = pd.DataFrame(sales_by_month.get_group(2018))\ntotal_sales_18 = total_sales_18.groupby('Month').sum()[[\"Total Sales\"]]\ntotal_sales_18 = total_sales_18.values.tolist()\n\ntotal_sales_19 = pd.DataFrame(sales_by_month.get_group(2019))\ntotal_sales_19 = total_sales_19.groupby('Month').sum()[[\"Total Sales\"]]\ntotal_sales_19 = total_sales_19.values.tolist()\n\ntotal_sales_20 = pd.DataFrame(sales_by_month.get_group(2020))\ntotal_sales_20 = total_sales_20.groupby('Month').sum()[[\"Total Sales\"]]\ntotal_sales_20 = total_sales_20.values.tolist()\n\ntotal_sales_by_month = total_sales_18 + total_sales_19 + total_sales_20\n\ntotal_sales = pd.DataFrame(total_sales_by_month, index = months, columns =['Total Sales'])\ntotal_sales[\"Number of DIfferent Clients\"] = clients_by_month[\"Number of DIfferent Clients\"]\ntotal_sales = total_sales.set_index(\"Number of DIfferent Clients\")\ntotal_sales.head()",
"_____no_output_____"
],
[
"# Converting 'Year' and 'Month' in to a Complete Date Format (m-d-y)\ndate_df = Project_df[Project_df['Month']!=24]\ndate_df['date'] = pd.to_datetime(date_df[['Year','Month']].assign(DAY=1),format=\"%m-%d-%Y\")\n\n# Create a new dataframe based on the new 'date' and create the columns for the count of 'Client ID' and the sum of 'Total Sales'\npct_change_df = date_df.groupby(['date']).agg({'Client ID':'count',\n 'Total Sales': 'sum'}).reset_index()\npct_change_df['Clients pctChange'] = pct_change_df['Client ID'].pct_change()\npct_change_df['Total Sales pctChange'] = pct_change_df['Total Sales'].pct_change()\n\n# Create combo chart\nfig, ax1 = plt.subplots(figsize = (9,3))\nsns.set_style('whitegrid')\n\n# Create lineplot for the 'Total Sales Percentage Change'\ns = sns.lineplot(data=pct_change_df, x=\"date\", y=\"Total Sales pctChange\",\n linestyle = 'dashed', marker = 'o', color = 'green', label = 'Total Sales')\n\n# Create lineplot for the 'Clients Volume Percentage Change'\nc = sns.lineplot(data=pct_change_df, x=\"date\", y=\"Clients pctChange\",\n linestyle = 'dashed', marker = 'o', color = 'blue', label = 'Clients Volume')\n\n# Set title, label and legend\nplt.title('Percentage Change: Total Sales vs Clients Volume', fontsize = 16)\nplt.xlabel('Date', fontsize = 16)\nplt.ylabel('Percentage Change %', fontsize = 16)\nplt.legend(loc='best')\n\nplt.savefig(\"plots/Percentage Change Total Sales vs Clients Volume.png\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Part 3 - Analyzing Data by Category.",
"_____no_output_____"
],
[
"#### We will try to analyze Sales by Category ",
"_____no_output_____"
]
],
[
[
"# Sum the Total Sales by Category\ncategory_sales_df=(pd.DataFrame(Project_df.groupby('Category')[[\"Total Sales\",\"Points Worth ($)\"]].sum()))\n\n#Calculate expense ratio\n#We define expense ratio as the cost of the Points Worth divided by the Total Sales\n#The objective behind calculating the expense ratio is to compare all categories to see if the percentage of money returned to customer is uniform between categories or if it is different\n#Higher ratios indicate more money returned to customers.\n\ncategory_sales_df[\"ratio_expense\"]=category_sales_df[\"Points Worth ($)\"]/category_sales_df[\"Total Sales\"]*100\ncategory_sales_df",
"_____no_output_____"
],
[
"%matplotlib notebook\n#Grouping sales by percentage to see how much each category contributes\ntotal_sales=category_sales_df[\"Total Sales\"].sum()\nsales_category=category_sales_df[\"Total Sales\"]/total_sales*100\nsales_category\nnames_category= [\"C1\",\"C2\",\"C3\",\"C4\",\"C5\",\"C6\"]\n\n# The colors of each section of the pie chart\ncolors = [\"grey\", \"lightgreen\", \"cornflowerblue\", \"lightskyblue\",\"red\", \"pink\"]\n\n\nexplode = (0.0, 0.0, 0.0, 0.0, 0.0, 0.1)\n\n\nplt.pie(sales_category, explode=explode, labels=names_category, colors=colors,\n autopct=\"%1.1f%%\", shadow=True, startangle=140)\nplt.title(\"Percentage of sales by category\")\n\nplt.savefig(\"plots/Sales percentage by category.png\")\nplt.show()",
"_____no_output_____"
],
[
"# Getting the min Monthly Sales by Category\nmin_sales_by_category = Project_df.drop_duplicates(\"Category\").sort_values(\"Category\", ascending= True)[[\"Category\", \"Min Monthly Sales\"]].set_index('Category')\nmin_sales_by_category",
"_____no_output_____"
],
[
"%matplotlib notebook\n# Comparing Compliance\ncategory_com = Project_df.groupby(['Year','Category'])['Compliance'].mean().reset_index()\n\n# Create line char for each category, to see changes in compliance per year\nsns.set(rc={'axes.facecolor':'white'})\nfig, ax1 = plt.subplots(figsize = (9,3))\ng = sns.lineplot(data=category_com, x=\"Year\", y=\"Compliance\",hue='Category')\nplt.grid(False)\nplt.legend(loc=2, prop={'size': 8})\nplt.xlabel('Year')\nplt.ylabel('Compliance per Category')\ng.set(xticks=[2018, 2019, 2020])\n\nplt.savefig(\"plots/Compliance per Category.png\")\n\nplt.show()",
"_____no_output_____"
],
[
"# Creating Data Frames for ploting Avg Quarterly Sales vs Avg Min Monthly Sales by Category \ngb_category = Project_df.groupby('Category')\n\nProject_c1_df = gb_category.get_group(\"C1\")\nProject_c2_df = gb_category.get_group(\"C2\")\nProject_c3_df = gb_category.get_group(\"C3\")\nProject_c4_df = gb_category.get_group(\"C4\")\nProject_c5_df = gb_category.get_group(\"C5\")\nProject_c6_df = gb_category.get_group(\"C6\")\n\navgsales_vs_avgmin_c1 = Project_c1_df.groupby(['Year', 'Quarter'])\navgsales_vs_avgmin_c1 = avgsales_vs_avgmin_c1['Min Monthly Sales', 'Total Sales'].mean()\navgsales_vs_avgmin_c1 = avgsales_vs_avgmin_c1.reset_index()\navgsales_vs_avgmin_c1 = avgsales_vs_avgmin_c1[['Total Sales', 'Min Monthly Sales']]\navgsales_vs_avgmin_c1[\"Quarter Number\"] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\navgsales_vs_avgmin_c1 = avgsales_vs_avgmin_c1.set_index('Quarter Number')\n\navgsales_vs_avgmin_c2 = Project_c2_df.groupby(['Year', 'Quarter'])\navgsales_vs_avgmin_c2 = avgsales_vs_avgmin_c2['Min Monthly Sales', 'Total Sales'].mean()\navgsales_vs_avgmin_c2 = avgsales_vs_avgmin_c2.reset_index()\navgsales_vs_avgmin_c2 = avgsales_vs_avgmin_c2[['Total Sales', 'Min Monthly Sales']]\navgsales_vs_avgmin_c2[\"Quarter Number\"] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\navgsales_vs_avgmin_c2 = avgsales_vs_avgmin_c2.set_index('Quarter Number')\n\navgsales_vs_avgmin_c3 = Project_c3_df.groupby(['Year', 'Quarter'])\navgsales_vs_avgmin_c3 = avgsales_vs_avgmin_c3['Min Monthly Sales', 'Total Sales'].mean()\navgsales_vs_avgmin_c3 = avgsales_vs_avgmin_c3.reset_index()\navgsales_vs_avgmin_c3 = avgsales_vs_avgmin_c3[['Total Sales', 'Min Monthly Sales']]\navgsales_vs_avgmin_c3[\"Quarter Number\"] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\navgsales_vs_avgmin_c3 = avgsales_vs_avgmin_c3.set_index('Quarter Number')\n\navgsales_vs_avgmin_c4 = Project_c4_df.groupby(['Year', 'Quarter'])\navgsales_vs_avgmin_c4 = avgsales_vs_avgmin_c4['Min Monthly Sales', 'Total Sales'].mean()\navgsales_vs_avgmin_c4 = avgsales_vs_avgmin_c4.reset_index()\navgsales_vs_avgmin_c4 = avgsales_vs_avgmin_c4[['Total Sales', 'Min Monthly Sales']]\navgsales_vs_avgmin_c4[\"Quarter Number\"] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\navgsales_vs_avgmin_c4 = avgsales_vs_avgmin_c4.set_index('Quarter Number')\n\navgsales_vs_avgmin_c5 = Project_c5_df.groupby(['Year', 'Quarter'])\navgsales_vs_avgmin_c5 = avgsales_vs_avgmin_c5['Min Monthly Sales', 'Total Sales'].mean()\navgsales_vs_avgmin_c5 = avgsales_vs_avgmin_c5.reset_index()\navgsales_vs_avgmin_c5 = avgsales_vs_avgmin_c5[['Total Sales', 'Min Monthly Sales']]\navgsales_vs_avgmin_c5[\"Quarter Number\"] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\navgsales_vs_avgmin_c5 = avgsales_vs_avgmin_c5.set_index('Quarter Number')\n\navgsales_vs_avgmin_c6 = Project_c6_df.groupby(['Year', 'Quarter'])\navgsales_vs_avgmin_c6 = avgsales_vs_avgmin_c6['Min Monthly Sales', 'Total Sales'].mean()\navgsales_vs_avgmin_c6 = avgsales_vs_avgmin_c6.reset_index()\navgsales_vs_avgmin_c6 = avgsales_vs_avgmin_c6[['Total Sales', 'Min Monthly Sales']]\navgsales_vs_avgmin_c6[\"Quarter Number\"] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\navgsales_vs_avgmin_c6 = avgsales_vs_avgmin_c6.set_index('Quarter Number')",
"C:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\ipykernel_launcher.py:12: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.\n if sys.path[0] == '':\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\ipykernel_launcher.py:19: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\ipykernel_launcher.py:26: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\ipykernel_launcher.py:33: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\ipykernel_launcher.py:40: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.\nC:\\Users\\HP\\anaconda3\\envs\\pythonData\\lib\\site-packages\\ipykernel_launcher.py:47: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.\n"
],
[
"%matplotlib inline\n\navgsales_vs_avgmin_c1.plot()\nplt.savefig(\"plots/Average Sales vs Average Min Purchase (C1).png\")\navgsales_vs_avgmin_c2.plot()\nplt.savefig(\"plots/Average Sales vs Average Min Purchase (C2).png\")\navgsales_vs_avgmin_c3.plot()\nplt.savefig(\"plots/Average Sales vs Average Min Purchase (C3).png\")\navgsales_vs_avgmin_c4.plot()\nplt.savefig(\"plots/Average Sales vs Average Min Purchase (C4).png\")\navgsales_vs_avgmin_c5.plot()\nplt.savefig(\"plots/Average Sales vs Average Min Purchase (C5).png\")\navgsales_vs_avgmin_c6.plot()\nplt.savefig(\"plots/Average Sales vs Average Min Purchase (C6).png\")",
"_____no_output_____"
],
[
"# Heatmap Points Worth ($)\ncompliance_drop = Project_df.drop(columns =['Min Monthly Sales','Town','State','Distributor','Quarter','Compliance','Total Sales','Total Points','Client ID'])\ncompliance_p = compliance_drop.groupby(['Month','Year']).mean().reset_index()\n\n#Unable to use points and compliance in one map, scales are too different\ncompliance_pi2 = compliance_p.pivot('Month','Year','Points Worth ($)')\ncompliance_pi2",
"_____no_output_____"
],
[
"# Heatmap Compliance per Year\ncompliance_drop2 = Project_df.drop(columns =['Min Monthly Sales','Town','State','Distributor','Quarter','Points Worth ($)','Total Sales','Total Points','Client ID'])\ncompliance_p3 = compliance_drop2.groupby(['Month','Year']).mean().reset_index()\ncompliance_pi4 = compliance_p3.pivot('Month','Year','Compliance')\ncompliance_pi4",
"_____no_output_____"
],
[
"# Plotting the compliance\n#Changed color and lines for a better visualization\ncomp_hm1 = sns.heatmap(compliance_pi4,cmap=\"PuBuGn\", linewidth=.5, linecolor ='m')",
"_____no_output_____"
],
[
"#Chart for expense ratio by category\ntotal_sales=category_sales_df[\"Total Sales\"].sum()\nx_axis=np.arange(0, 6, 1)\ny_axis=category_sales_df[\"ratio_expense\"]\n\nplt.title(\"Expense ratio by category\")\nplt.xlabel(\"Category\")\nplt.ylabel(\"Expense Ratio\")\n\ntick_locations = [value for value in x_axis]\nplt.xticks(tick_locations, [\"C1\",\"C2\",\"C3\",\"C4\",\"C5\",\"C6\"], rotation=\"horizontal\")\n\n\n# Have to plot our chart once again as it doesn't stick after being shown\nplt.plot(x_axis, y_axis)\n\nplt.ylim(0, 5) \nplt.grid(False)\n\nplt.savefig(\"plots/Expense ratio comparison by category.png\")\nplt.show()",
"_____no_output_____"
],
[
"#Points Worth ($)\ncomp_hm = sns.heatmap(compliance_pi2,cmap=\"PuBuGn\", linewidth=.5, linecolor ='m')",
"_____no_output_____"
]
],
[
[
"# Part 3 - Analyzing Data by Location.",
"_____no_output_____"
],
[
"#### We will try to analyze Sales by Client's location.",
"_____no_output_____"
]
],
[
[
"# We will create a States list to use it on our API/json requests\nunique_locations = Project_df.drop_duplicates(\"State\")\nlocations = unique_locations['State'].tolist()\nlocations",
"_____no_output_____"
],
[
"# Building the URL\nurl = \"http://api.openweathermap.org/data/2.5/weather?\"\nappid = api_key\nunits = \"metric\"\nurl = f\"{url}appid={appid}&units={units}&q=\"\n\n# Creating a list for storing information\nlocation_info = []\n\n# For loop\nfor x in locations:\n\n # Generating a unique URL for each location\n location_url = url + x\n\n # API request for each location\n try:\n location_geo = requests.get(location_url).json()\n \n # Retrieving data, Lat and Lng for each city in the list\n location_lat = location_geo[\"coord\"][\"lat\"]\n location_lng = location_geo[\"coord\"][\"lon\"]\n \n # Append the retrieved information into city_info\n location_info.append({\"Location\": x, \n \"Lat\": location_lat, \n \"Lng\": location_lng})\n\n # Exception for a not found value\n except:\n pass",
"_____no_output_____"
],
[
"#Creating a new DF with state and their coordinates\nlocations_df = pd.DataFrame(unique_locations[\"State\"]).reset_index().reset_index()\nlocations_df = locations_df[[\"level_0\", \"State\"]]\n\nlocation_info_df = pd.DataFrame(location_info).reset_index().reset_index()\nlocation_info_df = location_info_df[[\"level_0\", \"Lat\", \"Lng\"]]\n\ngeo_location_df = pd.merge(locations_df, location_info_df, how=\"outer\", on=[\"level_0\"])\ngeo_location_df.head()",
"_____no_output_____"
],
[
"# Merging the coordinates with each state's Total Sales\ntotalsales_state = Project_df.groupby(\"State\").sum()\n\ntotalsales_state = pd.merge(totalsales_state, geo_location_df, how=\"outer\", on=[\"State\"])\ntotalsales_state = totalsales_state[[\"Total Sales\", \"Lat\", \"Lng\"]]\ntotalsales_state[\"Total Sales\"] = totalsales_state[\"Total Sales\"].fillna(0)\ntotalsales_state = totalsales_state.sort_values(\"Total Sales\", ascending= False)\ntotalsales_state.head()",
"_____no_output_____"
],
[
"# Sales heatmap\nsales = totalsales_state[\"Total Sales\"].astype(float)\nmaxsales = sales.max()\nlocation_df = totalsales_state[[\"Lat\", \"Lng\"]]",
"_____no_output_____"
],
[
"figure_layout = {'width': '1000px','height': '600px'}\ngmaps.configure(api_key=g_key)\nfig = gmaps.figure(layout=figure_layout)\nheat_layer = gmaps.heatmap_layer(location_df, weights = sales, dissipating = False, max_intensity = maxsales, point_radius = 1.5)\nfig.add_layer(heat_layer)\nfig",
"_____no_output_____"
]
],
[
[
"### DIVIDE states by economic region:",
"_____no_output_____"
],
[
"### Mexico by region (Banxico's methodology): (https://www.banxico.org.mx/SieInternet/consultarDirectorioInternetAction.do?sector=2&accion=consultarCuadro&idCuadro=CR122&locale=es)\n### Noth zone: Nuevo Leon, Sonora, Tamaulipas, Coahuila, Chihuahua, Baja California\n### Northcentre zone: Aguascalientes, Colima, Durango, Jalisco, michoacan, Nayarit, San Luis Potosi, Sinaloa, Zacatecas, Baja California Sur\n### Central zone: Mexio City, Estado de Mexico, Guanajuato, Hidalgo, Morelos, Puebla, Queretaro, Tlaxcala\n### South zone: Campeche, Chiapas, Guerrero,Oaxaca, Tabasco, Veracruz, Yucatan",
"_____no_output_____"
]
],
[
[
"#NORTH ZONE encompasses the states of:\n#COAHUILA, SONORA, TAMAULIPAS, NUEVO LEON. (NO SALES IN B.C AND CHI and sonora)\n\nNorth_Zone=Project_df[(Project_df.State ==\"Nuevo Leon\")|(Project_df.State ==\"Tamaulipas\")\n |(Project_df.State ==\"Coahuila\")]\n\nNorth_Zone_II=North_Zone[[\"Year\",\"Category\",\"Total Sales\",\"Total Points\",\"Points Worth ($)\"]]\nnorth_zone_category= North_Zone_II.groupby(['Year',\"Category\"]).sum()\nnorth_zone_category[\"ratio_expense\"]=north_zone_category[\"Points Worth ($)\"]/north_zone_category[\"Total Sales\"]*100\nnorth_zone_category.head()",
"_____no_output_____"
],
[
"#NORTH CENTRE ZONE encompasses the states of:\n#AGUASCALIENTES, COLIMA, DURANGO,JALISCO,MICHOACAN,NAYARIT,SAN LUIS POTOSI, ZACATECAS, SINALOA\n\nNorthcentre_Zone=Project_df[(Project_df.State ==\"Aguascalientes\")|(Project_df.State ==\"Colima\")\n |(Project_df.State ==\"Jalisco\") | (Project_df.State == \"Nayarit\")\n |(Project_df.State ==\"Michoacan\")|(Project_df.State ==\"San Luis Potosi\")\n |(Project_df.State ==\"Sinaloa\")|(Project_df.State ==\"Zacatecas\")]\n \nNorthcentre_Zone_II=Northcentre_Zone[[\"Year\",\"Category\",\"Total Sales\",\"Total Points\",\"Points Worth ($)\"]]\nnorthcentre_zone_category= Northcentre_Zone_II.groupby(['Year',\"Category\"]).sum()\nnorthcentre_zone_category[\"ratio_expense\"]=northcentre_zone_category[\"Points Worth ($)\"]/northcentre_zone_category[\"Total Sales\"]*100\nnorthcentre_zone_category.head()",
"_____no_output_____"
],
[
"#CENTRAL ZONE encompasses the states of:\n#CIUDAD DE MEXICO, ESTADO DE MEXICO, GUANAJUATO,HIDALGO,MORELOS, PUEBLA,QUERETARO,TLAXCALA\n\ncentral_Zone=Project_df[(Project_df.State ==\"Ciudad de Mexico\")|(Project_df.State ==\"Estado de Mexico\")\n |(Project_df.State ==\"Guanajuato\") | (Project_df.State == \"Hidalgo\")\n |(Project_df.State ==\"Morelos\")|(Project_df.State ==\"Puebla\")\n |(Project_df.State ==\"Queretaro\")|(Project_df.State ==\"Tlaxcala\")]\n\ncentral_Zone_II=central_Zone[[\"Year\",\"Category\",\"Total Sales\",\"Total Points\",\"Points Worth ($)\"]]\ncentral_zone_category= central_Zone_II.groupby(['Year',\"Category\"]).sum()\ncentral_zone_category[\"ratio_expense\"]=central_zone_category[\"Points Worth ($)\"]/central_zone_category[\"Total Sales\"]*100\ncentral_zone_category .head()",
"_____no_output_____"
],
[
"#SOUTH ZONE encompasses the states of:\n#CHIAPAS,GUERRERO,OAXACA,Q.ROO, TABASCO, VERACRUZ, YUCATAN,CAMPECHE\n\nsouth_Zone=Project_df[(Project_df.State ==\"Chiapas\")|(Project_df.State ==\"Guerrero\")\n |(Project_df.State ==\"Oaxaca\") | (Project_df.State == \"Quintana Roo\")\n |(Project_df.State ==\"Tabasco\")|(Project_df.State ==\"Veracruz\")\n |(Project_df.State ==\"Yucatan\")|(Project_df.State ==\"Campeche\")]\n\nsouth_Zone_II=south_Zone[[\"Year\",\"Category\",\"Total Sales\",\"Total Points\",\"Points Worth ($)\"]]\nsouth_zone_category= south_Zone_II.groupby(['Year',\"Category\"]).sum()\nsouth_zone_category[\"ratio_expense\"]=south_zone_category[\"Points Worth ($)\"]/south_zone_category[\"Total Sales\"]*100\nsouth_zone_category.head()",
"_____no_output_____"
],
[
"#Adding the sales per zone for analysis\nNZ=North_Zone[\"Total Sales\"].sum()\nNCZ= Northcentre_Zone[\"Total Sales\"].sum()\ncZ=central_Zone[\"Total Sales\"].sum()\nsZ=south_Zone[\"Total Sales\"].sum()\ntotal_sales_3_years= NZ+NCZ+cZ+sZ\n#Creating a list of the zones and their sales\nsales_per_zone=[NZ,NCZ,cZ,sZ]\nnames_zones= [\"North Zone\",\"North Centre Zone\",\"Central zone\",\"South Zone\"]\npercentage_sales_zones={\"North Zone\":NZ,\"North Centre Zone\": NCZ,\"Central zone\":cZ,\"South Zone\":sZ}\n\npercentage_sales_zones",
"_____no_output_____"
],
[
"sales_per_zone=[NZ,NCZ,cZ,sZ]\nnames_zones= [\"North Zone\",\"North Centre Zone\",\"Central zone\",\"South Zone\"]\n#Plotting the sales of the zones to identify biggest and smallest zone of sales\n# The colors of each section of the pie chart\ncolors = [\"grey\", \"lightgreen\", \"cornflowerblue\", \"lightskyblue\"]\n\n# Tells matplotlib to seperate the \"Humans\" section from the others\nexplode = (0, 0, 0.1, 0)\n\n\nplt.pie(sales_per_zone, explode=explode, labels=names_zones, colors=colors,\n autopct=\"%1.1f%%\", shadow=True, startangle=140)\n\nplt.title(\"Percentage of sales by zone\")\n\nplt.savefig(\"plots/Percentage of sales by zone.png\")\nplt.show()",
"_____no_output_____"
],
[
"#Grouping the sales per zone per year\nNZ_2018=North_Zone[North_Zone.Year ==2018][\"Total Sales\"].sum()\nNZ_2019=North_Zone[North_Zone.Year ==2019][\"Total Sales\"].sum()\nNZ_2020=North_Zone[North_Zone.Year ==2020][\"Total Sales\"].sum()\n\nNCZ_2018=Northcentre_Zone[Northcentre_Zone.Year ==2018][\"Total Sales\"].sum()\nNCZ_2019=Northcentre_Zone[Northcentre_Zone.Year ==2019][\"Total Sales\"].sum()\nNCZ_2020=Northcentre_Zone[Northcentre_Zone.Year ==2020][\"Total Sales\"].sum()\n\ncZ_2018=central_Zone[central_Zone.Year ==2018][\"Total Sales\"].sum()\ncZ_2019=central_Zone[central_Zone.Year ==2019][\"Total Sales\"].sum()\ncZ_2020=central_Zone[central_Zone.Year ==2020][\"Total Sales\"].sum()\n\nsZ_2018=south_Zone[south_Zone.Year ==2018][\"Total Sales\"].sum()\nsZ_2019=south_Zone[south_Zone.Year ==2019][\"Total Sales\"].sum()\nsZ_2020=south_Zone[south_Zone.Year ==2020][\"Total Sales\"].sum()",
"_____no_output_____"
],
[
"%matplotlib notebook\n#Plotting the zones by sale by year\nsales_byzone = [NZ_2018, NZ_2019, NZ_2020, \n NCZ_2018, NCZ_2019,NCZ_2020,\n cZ_2018,cZ_2019,cZ_2020,\n sZ_2018,sZ_2019,sZ_2020]\n\nx_axis = np.arange(len(sales_byzone))\n\nplt.bar(x_axis, sales_byzone, color=['papayawhip',\"blanchedalmond\",\"moccasin\",\"azure\",\"lightcyan\",\"paleturquoise\",\"whitesmoke\",\"gainsboro\",\"lightgrey\",\"mistyrose\",\"salmon\",\"tomato\"], alpha=0.9, align=\"edge\")\n\n\ntick_locations = [value for value in x_axis]\nplt.xticks(tick_locations, [\"North 18\",\"North 19\",\"North 20\",\n \"NorthCentre 18\",\"NorthCentre 19\",\"NorthCentre 20\",\n \"Central 18\",\"Central 19\",\"Central 20\",\n \"South 18\",\"South 19\",\"South 20\"], rotation=\"vertical\", fontsize= 6)\n \n\nplt.xlim(-0.75, len(x_axis)-0.25)\n#plt.ylim(0, max(sales_byzone)) \n \nplt.title(\"Total Sales by region and year\")\nplt.xlabel(\"Zones\")\nplt.ylabel(\"total sales\")\n\nplt.savefig(\"plots/Total Sales by region and year.png\")\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a01168a09adc56980740cd321dff9659a92f1e9
| 22,772 |
ipynb
|
Jupyter Notebook
|
Spacy/10_Spacy_Finding_Most_Common_Words.ipynb
|
sudevansujit/7_NLP
|
17c275018ee1f4eb41ba5c2e0fba8333cd32dd6d
|
[
"MIT"
] | null | null | null |
Spacy/10_Spacy_Finding_Most_Common_Words.ipynb
|
sudevansujit/7_NLP
|
17c275018ee1f4eb41ba5c2e0fba8333cd32dd6d
|
[
"MIT"
] | null | null | null |
Spacy/10_Spacy_Finding_Most_Common_Words.ipynb
|
sudevansujit/7_NLP
|
17c275018ee1f4eb41ba5c2e0fba8333cd32dd6d
|
[
"MIT"
] | null | null | null | 33.195335 | 1,178 | 0.519146 |
[
[
[
"# Finding_Most_Common_Words",
"_____no_output_____"
]
],
[
[
"import spacy\nfrom collections import Counter\nnlp = spacy.load('en_core_web_sm')",
"_____no_output_____"
],
[
"doc_covid = nlp(open('covid_research.txt').read())\ndoc_covid",
"_____no_output_____"
]
],
[
[
"### Removing Punctuations and Stop Words",
"_____no_output_____"
]
],
[
[
"nouns = [token.text for token in doc_covid if token.is_stop == False and token.pos_ == 'NOUN' and token.is_punct == False]\nnouns",
"_____no_output_____"
],
[
"len(nouns)",
"_____no_output_____"
]
],
[
[
"### Finding Most Common Nouns",
"_____no_output_____"
]
],
[
[
"noun_freq = Counter(nouns)",
"_____no_output_____"
],
[
"common_nouns = noun_freq.most_common(20)\ncommon_nouns",
"_____no_output_____"
]
],
[
[
"### Most Common Verbs",
"_____no_output_____"
]
],
[
[
"# Some stop words can be verbs\n\nverbs = [token.text for token in doc_covid if token.is_stop == False and token.pos_ == 'VERB' and token.is_punct == False]\nverbs\n",
"_____no_output_____"
],
[
"verb_freq = Counter(verbs)",
"_____no_output_____"
],
[
"common_verbs = verb_freq.most_common(20)\nprint(dict(common_verbs))",
"{'said': 6, 'existing': 4, 'tell': 3, 'Given': 3, 'happen': 3, 'hospitalised': 3, 'suggests': 2, 'caused': 2, 'help': 2, 'draw': 2, 'depend': 2, 'associated': 2, 'appears': 2, 'given': 2, 'supporting': 2, 'including': 2, 'needed': 2, 'published': 2, 'dealing': 2, 'learn': 1}\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a011be581a3530fd9e6ec075b9a6f603867c199
| 1,207 |
ipynb
|
Jupyter Notebook
|
reclassify_ui.ipynb
|
i-m-amit/sdg_15.3.1
|
f48f2122d867093e830567449eef78db123c9a11
|
[
"MIT"
] | 2 |
2022-03-26T17:40:25.000Z
|
2022-03-26T17:40:29.000Z
|
reclassify_ui.ipynb
|
i-m-amit/sdg_15.3.1
|
f48f2122d867093e830567449eef78db123c9a11
|
[
"MIT"
] | 3 |
2022-03-22T21:37:46.000Z
|
2022-03-29T07:03:59.000Z
|
reclassify_ui.ipynb
|
sepal-contrib/sdg_15.3.1
|
f48f2122d867093e830567449eef78db123c9a11
|
[
"MIT"
] | null | null | null | 18.859375 | 48 | 0.545982 |
[
[
[
"from component import tile",
"_____no_output_____"
],
[
"reclassify_tile = tile.ReclassifyTile()",
"_____no_output_____"
],
[
"reclassify_tile",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a014506cb6f9da3438c63a88fcd1e42fb6415cd
| 144,867 |
ipynb
|
Jupyter Notebook
|
examples/kepler-36/kepler-36.ipynb
|
astroshrey/ttvnest
|
152ae4766780dc10c594e9fad2f74d952883bc24
|
[
"MIT"
] | 1 |
2020-12-15T10:59:34.000Z
|
2020-12-15T10:59:34.000Z
|
examples/kepler-36/kepler-36.ipynb
|
astroshrey/ttvnest
|
152ae4766780dc10c594e9fad2f74d952883bc24
|
[
"MIT"
] | 1 |
2021-02-11T10:50:12.000Z
|
2021-02-11T10:50:12.000Z
|
examples/kepler-36/kepler-36.ipynb
|
astroshrey/ttvnest
|
152ae4766780dc10c594e9fad2f74d952883bc24
|
[
"MIT"
] | null | null | null | 167.670139 | 14,020 | 0.720295 |
[
[
[
"# TTV Retrieval for Kepler-36 (a well-studied, dynamically-interacting system)\n\nIn this notebook, we will perform a dynamical retrieval for Kepler-36 = KOI-277. With two neighboring planets of drastically different densities (the inner planet is rocky and the outer planet is gaseous; see [Carter et al. 2012](https://ui.adsabs.harvard.edu/abs/2012Sci...337..556C/abstract)), this is one of the more well-studied TTV systems in existence. First, let's import packages and download data from the Rowe et al. (2015) TTV catalog:",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport ttvnest\nimport numpy as np\n\nkoi = 277\nnplanets = 2\ndata, errs, epochs = ttvnest.load_data.get_data(koi, nplanets)",
"Downloading Rowe+15 data from Vizier...\nData retrieved!\n"
]
],
[
[
"Now, let's set up the ttvnest system:",
"_____no_output_____"
]
],
[
[
"kepler36_b = ttvnest.TTVPlanet(data[1], errs[1], epochs[1], mass_prior = ('Uniform', 0, 100.), \n period_prior = ('Normal', 13.84, 0.01)\n )\n\nkepler36_c = ttvnest.TTVPlanet(data[0], errs[0], epochs[0], mass_prior = ('Uniform', 0, 100.), \n period_prior = ('Normal', 16.23, 0.01)\n )\n\nkepler36 = ttvnest.TTVSystem(kepler36_b, kepler36_c)",
"Simulation start/reference time: 53.0\nttvnest timestep: 0.5536\nSimulation length: 1451.0\nSimulation end time: 1504.0\n"
]
],
[
[
"Before retrieval, let's plot the data alone to see what they look like: ",
"_____no_output_____"
]
],
[
[
"ttvnest.plot_utils.plot_ttv_data(kepler36)",
"_____no_output_____"
]
],
[
[
"Clear, anticorrelated signals! Let's retrieve:",
"_____no_output_____"
]
],
[
[
"results = kepler36.retrieve()",
"50195it [11:52, 5.97it/s, batch: 0 | bound: 1 | nc: 25 | ncall: 502670 | eff(%): 9.966 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n/usr/local/lib/python3.7/site-packages/dynesty/sampling.py:216: UserWarning: Random number generation appears to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random number generation appears to be \"\n50552it [13:20, 1.19s/it, batch: 0 | bound: 6 | nc: 874 | ncall: 524994 | eff(%): 9.611 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010]/usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n50563it [13:30, 1.99it/s, batch: 0 | bound: 7 | nc: 25 | ncall: 527326 | eff(%): 9.570 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n51167it [15:24, 6.02it/s, batch: 0 | bound: 14 | nc: 25 | ncall: 553266 | eff(%): 9.231 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n51299it [15:58, 6.32it/s, batch: 0 | bound: 15 | nc: 25 | ncall: 561087 | eff(%): 9.127 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n51546it [16:42, 7.96it/s, batch: 0 | bound: 18 | nc: 25 | ncall: 571130 | eff(%): 9.009 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n51556it [17:20, 1.78it/s, batch: 0 | bound: 19 | nc: 25 | ncall: 580165 | eff(%): 8.871 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n51659it [18:10, 8.00it/s, batch: 0 | bound: 21 | nc: 25 | ncall: 591661 | eff(%): 8.716 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n51893it [18:54, 6.40it/s, batch: 0 | bound: 23 | nc: 25 | ncall: 601643 | eff(%): 8.611 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52012it [19:20, 7.45it/s, batch: 0 | bound: 25 | nc: 25 | ncall: 607683 | eff(%): 8.545 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52093it [19:44, 8.06it/s, batch: 0 | bound: 26 | nc: 25 | ncall: 613193 | eff(%): 8.482 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52187it [20:04, 2.11it/s, batch: 0 | bound: 27 | nc: 307 | ncall: 617557 | eff(%): 8.437 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: inf > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52408it [20:56, 5.12it/s, batch: 0 | bound: 30 | nc: 25 | ncall: 629290 | eff(%): 8.315 | loglstar: -inf < -inf < inf | logz: -inf +/- nan | dlogz: 993352.777 > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52547it [21:39, 8.61it/s, batch: 0 | bound: 32 | nc: 25 | ncall: 639084 | eff(%): 8.209 | loglstar: -inf < -906589.791 < inf | logz: -906649.912 +/- nan | dlogz: 872770.862 > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52586it [21:50, 8.77it/s, batch: 0 | bound: 33 | nc: 25 | ncall: 641751 | eff(%): 8.181 | loglstar: -inf < -884692.188 < inf | logz: -884752.348 +/- nan | dlogz: 850525.597 > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52716it [22:23, 8.46it/s, batch: 0 | bound: 35 | nc: 25 | ncall: 649116 | eff(%): 8.109 | loglstar: -inf < -813302.617 < inf | logz: -813362.907 +/- nan | dlogz: 778957.926 > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n52973it [23:14, 8.47it/s, batch: 0 | bound: 38 | nc: 25 | ncall: 660561 | eff(%): 8.007 | loglstar: -inf < -675617.883 < inf | logz: -675678.430 +/- nan | dlogz: 642622.156 > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n53131it [23:51, 8.41it/s, batch: 0 | bound: 40 | nc: 25 | ncall: 668858 | eff(%): 7.932 | loglstar: -inf < -599700.185 < inf | logz: -599760.889 +/- nan | dlogz: 565354.385 > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n53230it [24:13, 3.56it/s, batch: 0 | bound: 41 | nc: 25 | ncall: 673809 | eff(%): 7.888 | loglstar: -inf < -560058.732 < inf | logz: -560119.537 +/- nan | dlogz: 525750.959 > 0.010] /usr/local/lib/python3.7/site-packages/dynesty/sampling.py:238: UserWarning: Random walk proposals appear to be extremely inefficient. Adjusting the scale-factor accordingly.\n warnings.warn(\"Random walk proposals appear to be \"\n"
]
],
[
[
"Let's check out our results. I'm not going to work out the Carter et al. (2012) posterior distribution on the eccentricity vectors since they use a different basis than I choose here. But it's probably worth converting their mass ratio constraints to what we should expect here. They get a mass ratio sum $q_+ = (M_1 + M_2)/M_\\star= 3.51\\times10^{-5}$. In ttvnest dynamical masses are normalized by $3\\times10^{-6} = M_\\mathrm{Earth}/M_\\mathrm{Sun}$, so this gives $q_+ = 11.7$ in our units. Their planetary mass ratio is $q_p = M_1/M_2 = 0.55$. Taken together, this gives dynamical masses of $M_1/M_\\star = 4.15$ and $M_2/M_\\star = 7.55$.\n\nLet's see if we get there...",
"_____no_output_____"
]
],
[
[
"kepler36.posterior_summary()\nttvnest.plot_utils.plot_results(kepler36, uncertainty_curves = 100, \n sim_length = 365.25*10, outname = 'kepler36')",
"Summary (middle 95 percentile): \n$M_1/M_\\star/3\\times10^{-6}$: $4.030686^{+0.125817}_{-0.136883}$\n$P_1\\ [\\mathrm{days}]$: $13.839197^{+0.000523}_{-0.000518}$\n$\\sqrt{e}_1\\cos(\\omega_1)$: $0.045735^{+0.048222}_{-0.030362}$\n$\\sqrt{e}_1\\sin(\\omega_1)$: $0.189233^{+0.020419}_{-0.010774}$\n$T_{0,1}\\ [\\mathrm{days}]$: $7.959119^{+0.008336}_{-0.008183}$\n$M_2/M_\\star/3\\times10^{-6}$: $7.309738^{+0.184197}_{-0.159146}$\n$P_2\\ [\\mathrm{days}]$: $16.239654^{+0.00036}_{-0.000403}$\n$\\sqrt{e}_2\\cos(\\omega_2)$: $0.036294^{+0.06204}_{-0.054425}$\n$\\sqrt{e}_2\\sin(\\omega_2)$: $0.09211^{+0.031831}_{-0.02035}$\n$T_{0,2}\\ [\\mathrm{days}]$: $2.913044^{+0.001673}_{-0.001708}$\n"
]
],
[
[
"We are a little on the low side, but that's apparently to be expected from other works like Hadden & Lithwick (2017). Let's make the dynesty plots for good measure:",
"_____no_output_____"
]
],
[
[
"ttvnest.plot_utils.dynesty_plots(kepler36, outname = 'kepler36')",
"_____no_output_____"
]
],
[
[
"Wow, what a nice system. Let's save our results for later:",
"_____no_output_____"
]
],
[
[
"ttvnest.io_utils.save_results(kepler36, 'kepler36.p')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a01453cecfdb7f03b734a4ff298dc19e0532f64
| 4,842 |
ipynb
|
Jupyter Notebook
|
Anna/analysis_scripts/group_by_SNR.ipynb
|
howardisaacson/APF-BL-DAP
|
f5dfa1a619a97ebc2d7cb8053fc7e90a3df43ac3
|
[
"MIT"
] | null | null | null |
Anna/analysis_scripts/group_by_SNR.ipynb
|
howardisaacson/APF-BL-DAP
|
f5dfa1a619a97ebc2d7cb8053fc7e90a3df43ac3
|
[
"MIT"
] | 7 |
2021-06-16T17:23:16.000Z
|
2021-12-03T01:06:01.000Z
|
Anna/analysis_scripts/group_by_SNR.ipynb
|
howardisaacson/APF-BL-DAP
|
f5dfa1a619a97ebc2d7cb8053fc7e90a3df43ac3
|
[
"MIT"
] | 1 |
2021-06-09T19:03:03.000Z
|
2021-06-09T19:03:03.000Z
| 33.164384 | 128 | 0.58261 |
[
[
[
"# group_by_SNR.ipynb\n# Many stars that have mulitple APF spectra have some spectra from different nights of observation. \n# Calculates the SNR for each group of spectra from one night of observing (calc_SNR combines all observations of one \n# star and returns an SNR for the star instead), then finds for each star which group of observations together has the \n# highest SNR. Will use only highest SNR group in run of Specmatch-Emp for each star.\n# Last modified 8/12/20 by Anna Zuckerman \n",
"_____no_output_____"
],
[
"import os\nimport pandas as pd\nimport numpy as np\nimport astropy.io.fits\nimport shutil",
"_____no_output_____"
],
[
"def get_SNR(path_name, filenames): # Modified from get_SNR in calc_SNR\n order_data = np.zeros([4608,1])\n for spect_file in filenames:\n hdul = astropy.io.fits.open(path_name + '/' + spect_file) \n order_data = np.add(order_data,(hdul[0].data)[45])\n SNR = np.sqrt(np.median(order_data))\n return SNR",
"_____no_output_____"
],
[
"# for stars with mulitple spectra, get the set of observations with the highest SNR\nbig_path = './APF_spectra/all_apf_spectra' # './APF_spectra/additional_spectra' \nSNR_filename = 'all_apf_highest_SNRs.csv' # 'additional_apf_highest_SNRs.csv' \nnew_dir_path = './APF_spectra/all_apf_spectra_highest_SNR/' #'./APF_spectra/additional_apf_spectra_highest_SNR/' \nSNR_list = []\nnames = []\npathlist = [path for path in sorted(os.listdir(big_path)) if os.path.isdir(big_path + '/' + path)]\nfor star_dir in pathlist:\n names += [star_dir.split('_')[0]]\n spectlist = os.listdir(big_path + '/' + star_dir)\n try: spectlist.remove('.ipynb_checkpoints')\n except: ValueError\n obslist = [filename.split('.')[0] for filename in spectlist]\n unique_obs = list(dict.fromkeys(obslist)) #list of all observations of that star\n highest_SNR = 0\n highest_SNR_obs = ''\n for obs in unique_obs:\n obs_files = [file for file in spectlist if file.split('.')[0] == obs]\n SNR_obs = get_SNR(big_path + '/' + star_dir, obs_files)\n if SNR_obs > highest_SNR:\n highest_SNR = SNR_obs\n highest_SNR_obs = obs\n SNR_list += [highest_SNR]\n new_dir_name = new_dir_path + star_dir\n highest_SNR_obs_files = [file for file in spectlist if file.split('.')[0] == highest_SNR_obs]\n os.mkdir(new_dir_name)\n for file in highest_SNR_obs_files:\n shutil.copyfile(big_path + '/' + star_dir + '/' + file, new_dir_name + '/' + file)\n\ndf = pd.DataFrame(list(zip(names, SNR_list)), columns =['Name (Simbad resolvable)', 'Highest observation set SNR'])\ndf.to_csv('./' + SNR_filename)",
"_____no_output_____"
],
[
"# for stars with only one spectrum, copy that spectrum directly -- not applicable for ./APF_spectra/all_apf_spectra\npathlist_notdir = [path for path in sorted(os.listdir(big_path)) if not(os.path.isdir(big_path + '/' + path))]\nfor file in pathlist_notdir:\n shutil.copyfile(big_path + '/' + file, './APF_spectra/apf_spectra_highest_SNR' + '/' + file)\n",
"_____no_output_____"
],
[
"# check that all stars were processed\nprint(len(os.listdir(big_path)))\nprint(len(os.listdir(new_dir_path)))",
"114\n114\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a014c74af7f1667758ea7a1bda6f62bb61a10d2
| 71,640 |
ipynb
|
Jupyter Notebook
|
notebooks/DenseNet169.ipynb
|
Azariagmt/pulmonary-disorder-detection-using-x-ray-images
|
1db733ed3c0331b340d6a30870625f37d4199139
|
[
"MIT"
] | 4 |
2020-12-24T16:34:00.000Z
|
2021-04-20T08:11:00.000Z
|
notebooks/DenseNet169.ipynb
|
Azariagmt/covid19-detection-using-x-ray-images
|
1db733ed3c0331b340d6a30870625f37d4199139
|
[
"MIT"
] | 15 |
2021-03-31T13:15:40.000Z
|
2021-09-19T08:40:13.000Z
|
notebooks/DenseNet169.ipynb
|
Azariagmt/pulmonary-disorder-detection-using-x-ray-images
|
1db733ed3c0331b340d6a30870625f37d4199139
|
[
"MIT"
] | null | null | null | 111.588785 | 21,569 | 0.826131 |
[
[
[
"## Imports\n",
"_____no_output_____"
]
],
[
[
"%%capture\nimport numpy as np\nimport tensorflow as tf\nfrom matplotlib import pyplot as plt\nimport itertools\nfrom sklearn.utils import shuffle\n%run \"./utils.ipynb\"\n%run \"./Data preprocessing.ipynb\"",
"_____no_output_____"
]
],
[
[
"## Load Numpy Array",
"_____no_output_____"
]
],
[
[
"X.shape",
"_____no_output_____"
],
[
"np.unique(y)",
"_____no_output_____"
]
],
[
[
"### Resize array",
"_____no_output_____"
]
],
[
[
"X, y = shuffle(X, y, random_state=0) ",
"_____no_output_____"
],
[
"X = np.stack((X,)*3, axis=-1)\nprint(X.shape)",
"(17615, 100, 100, 3)\n"
]
],
[
[
"### Train",
"_____no_output_____"
]
],
[
[
"from tensorflow.keras.applications import VGG16,VGG19,NASNetMobile,DenseNet169\nfrom tensorflow.keras.layers import *\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.regularizers import *\nfrom tensorflow.keras.optimizers import Adam",
"_____no_output_____"
],
[
"X = tf.keras.applications.densenet.preprocess_input(\n X, data_format=None\n)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\n# split the data\nX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25, random_state = 101, stratify=y)",
"_____no_output_____"
],
[
"model = Sequential()\n\nconv_base = DenseNet169(input_shape=(100,100,3), include_top=False, pooling='max',weights='imagenet')\n# conv_base.trainable = False\nmodel.add(conv_base)\nmodel.add(Dense(5, activation='softmax'))\n\ntrain_layers = [layer for layer in conv_base.layers[::-1][:2]]\n# print(train_layers)\n# print(len(train_layers), \"train len\")\n\nfor layer in conv_base.layers:\n if layer in train_layers:\n layer.trainable = True\n\nmodel.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=1e-4), metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndensenet169 (Model) (None, 1664) 12642880 \n_________________________________________________________________\ndense (Dense) (None, 5) 8325 \n=================================================================\nTotal params: 12,651,205\nTrainable params: 12,492,805\nNon-trainable params: 158,400\n_________________________________________________________________\n"
],
[
"history = model.fit(X_train, y_train,validation_data=(X_test, y_test), epochs=20, callbacks=cbs,verbose=1)",
"Train on 13211 samples, validate on 4404 samples\nEpoch 1/20\n13211/13211 [==============================] - 147s 11ms/sample - loss: 0.4551 - accuracy: 0.8364 - val_loss: 0.2686 - val_accuracy: 0.9010\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 2/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 0.1366 - accuracy: 0.9503 - val_loss: 0.1570 - val_accuracy: 0.9450\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 3/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 0.0661 - accuracy: 0.9782 - val_loss: 0.1293 - val_accuracy: 0.9612\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 4/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 0.0554 - accuracy: 0.9812 - val_loss: 0.1817 - val_accuracy: 0.9521\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 5/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 0.0227 - accuracy: 0.9926 - val_loss: 0.0965 - val_accuracy: 0.9748\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 6/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 0.0057 - accuracy: 0.9985 - val_loss: 0.0975 - val_accuracy: 0.9762\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 7/20\n13211/13211 [==============================] - 116s 9ms/sample - loss: 0.0023 - accuracy: 0.9995 - val_loss: 0.0914 - val_accuracy: 0.9771\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 8/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 0.0017 - accuracy: 0.9997 - val_loss: 0.0979 - val_accuracy: 0.9775\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 9/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 0.0013 - accuracy: 0.9998 - val_loss: 0.0918 - val_accuracy: 0.9805\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 10/20\n13211/13211 [==============================] - 115s 9ms/sample - loss: 9.0607e-04 - accuracy: 0.9999 - val_loss: 0.0896 - val_accuracy: 0.9807\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 11/20\n 512/13211 [>.............................] - ETA: 1:40 - loss: 9.8692e-04 - accuracy: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\r 544/13211 [>.............................] - ETA: 1:40 - loss: 0.0010 - accuracy: 1.0000 "
],
[
"accuracy_graph(history)",
"_____no_output_____"
],
[
"loss_graph(history)",
"_____no_output_____"
],
[
"predictions = model.predict(X_test).argmax(axis=1)\ncm = confusion_matrix(y_test, predictions)",
"_____no_output_____"
],
[
"plot_confusion_matrix(cm, [\"COVID\" ,\"BACT\", \"VIRAL\", \"TB\", \"NORMAL\"])",
"Confusion matrix, without normalization\n[[892 1 1 5 5]\n [ 2 827 46 0 0]\n [ 0 9 866 0 0]\n [ 7 0 0 866 2]\n [ 7 0 0 0 868]]\n"
],
[
"print(classification_report(y_test, predictions));",
" precision recall f1-score support\n\n 0 0.98 0.99 0.98 904\n 1 0.99 0.95 0.97 875\n 2 0.95 0.99 0.97 875\n 3 0.99 0.99 0.99 875\n 4 0.99 0.99 0.99 875\n\n accuracy 0.98 4404\n macro avg 0.98 0.98 0.98 4404\nweighted avg 0.98 0.98 0.98 4404\n\n"
],
[
"model.save('DenseNet169.h5')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a01559d64f1f2df5b2a154f0acde9b71d6ba15d
| 360,840 |
ipynb
|
Jupyter Notebook
|
Tensorflow_fundamentals_withoutcode.ipynb
|
kishkath/Data_Structures-Hashing-
|
08e9cbf5d87b219b95f96022082970c9e65952fd
|
[
"Apache-2.0"
] | null | null | null |
Tensorflow_fundamentals_withoutcode.ipynb
|
kishkath/Data_Structures-Hashing-
|
08e9cbf5d87b219b95f96022082970c9e65952fd
|
[
"Apache-2.0"
] | null | null | null |
Tensorflow_fundamentals_withoutcode.ipynb
|
kishkath/Data_Structures-Hashing-
|
08e9cbf5d87b219b95f96022082970c9e65952fd
|
[
"Apache-2.0"
] | null | null | null | 188.428198 | 91,014 | 0.880944 |
[
[
[
"<a href=\"https://colab.research.google.com/github/kishkath/Data_Structures-Hashing-/blob/main/Tensorflow_fundamentals_withoutcode.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# **Roadmap of this assignment**\n\n**This assignment is divided into following sections.**\n1. Learning about what is tensorflow, its usecases.\n2. Learning what is tensor, tensor types.\n3. Different tensor formats.\n4. Mathematical operations in tensorflow.\n5. Gradient operations in tensorflow.\n6. Using learning of tensorflow basics to make one simple classifier.",
"_____no_output_____"
],
[
"# **NOTE**\nFollow along the videos, and links given in the assignment. If you have **any doubt** related to assignment, **contact your mentor.**",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"##1. **What is Tensorflow?**\n\nTensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.\n\nvideo - **why tensorflow ?**- https://www.youtube.com/watch?v=yjprpOoH5c8\n\n\n## **Must Read These Tensorflow Use Cases**\n\n1. **How Airbnb uses tensorflow to improve their guests experiences?**\n\nRead this medium article to understand - https://medium.com/airbnb-engineering/categorizing-listing-photos-at-airbnb-f9483f3ab7e3\n\n2. **How paypal uses tensorflow for fraud detection?** \n\nRead this to understand what paypal does - https://medium.com/paypal-tech/machine-learning-model-ci-cd-and-shadow-platform-8c4f44998c78",
"_____no_output_____"
],
[
"##2. **What is a Tensor?**\n\n**A tensor is a container for data—usually numerical data. tensors are also called generalization of matrices to an arbitrary number of dimensions.**\n",
"_____no_output_____"
],
[
"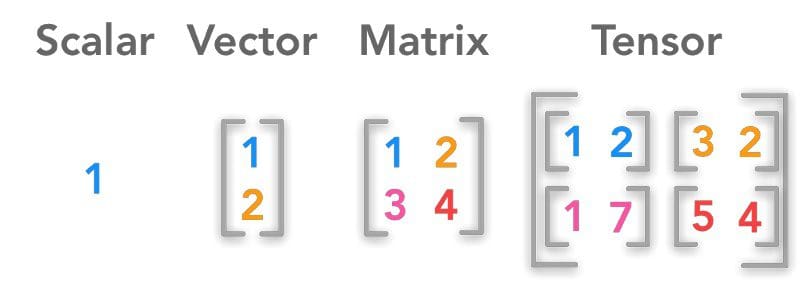",
"_____no_output_____"
],
[
"# **Now we will learn types of tensor with different rank**",
"_____no_output_____"
],
[
"**1.Scalars (rank 0 tensor)** \n- A tensor that contains only one number is called a scalar.\n- a scalar tensor has 0 axes (ndim == 0).",
"_____no_output_____"
],
[
"**Go through this video for numpy array methods used in next cell**",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\n\nYouTubeVideo('a8aDcLk4vRc', width=600, height=400)",
"_____no_output_____"
],
[
"# importing numpy as np\nimport numpy as np\n\n# defining an array using np.array with value passing as 5\n\narray = np.array(5)\n\nzero_rank_tensor = array\n\n# print zero_rank_tensor\n\nprint(\"Tensor with zero rank: {0}\".format(zero_rank_tensor))\n\n# print its dimension using .ndim method\nprint(\"Dimensions: {0}\".format(zero_rank_tensor.ndim))\n\n# print its shape using .shape method\nprint(\"Shape: {0}\".format(zero_rank_tensor.shape))\n",
"Tensor with zero rank: 5\nDimensions: 0\nShape: ()\n"
]
],
[
[
"**The above output of a scalar number shows that and array with a single digit is having zero rank as a tensor.**",
"_____no_output_____"
],
[
"**Observation from previous output**\n- Dimension is 0.\n- Shape gives empty parenthesis bracket.",
"_____no_output_____"
],
[
"**2.Vectors (rank 1 tensor)** \n- An array of numbers is called a vector, or rank-1 tensor, or 1D tensor.\n- A rank-1 tensor is said to have exactly one axis. ",
"_____no_output_____"
]
],
[
[
"# define an array with value 1,2,3 in a list using np.array\n\none_rank_tensor = np.array([1,2,3])\n\n# print one_rank_tensor\nprint(\"Tensor with rank 1:{0}\".format(one_rank_tensor))\n\n# print its dimension using .ndim\nprint(\"Dimensions: {0}\".format(one_rank_tensor.ndim))\n\n\n# print its shape using .shape\nprint(\"Shape: {0}\".format(one_rank_tensor.shape))\n",
"Tensor with rank 1:[1 2 3]\nDimensions: 1\nShape: (3,)\n"
]
],
[
[
"**The above output shows that whenever there is a single square bracket we see around some numbers separated by comma, we get a tensor of rank 1.**",
"_____no_output_____"
],
[
"**Observation**\n- As compared to previous output, this time dimension is 1.\n- Its shape is (3,) showing no of parameters in the array which is 3.",
"_____no_output_____"
],
[
"**3. Matrices (rank 2 tensor)** \n- An array of vectors is a matrix, or rank-2 tensor, or 2D tensor. \n- A matrix has two axes (often referred to as rows and columns).",
"_____no_output_____"
]
],
[
[
"# define a matrix having values [[1, 2, 3, 4, 5],[6, 7, 8, 9, 10],[11, 12, 13, 14, 15]]\n\nrank_2_tensor = np.array([[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]])\n\n# print rank_2_tensor\n\nprint(\"Tensor with rank 2: {0}\".format(rank_2_tensor))\n\n# print its dimension using .ndim\nprint(\"Dimensions: {0}\".format(rank_2_tensor.ndim))\n\n\n# print its shape using .shape\nprint(\"Shape: {0}\".format(rank_2_tensor.shape))\n\n",
"Tensor with rank 2: [[ 1 2 3 4 5]\n [ 6 7 8 9 10]\n [11 12 13 14 15]]\nDimensions: 2\nShape: (3, 5)\n"
]
],
[
[
"**The above output shows that whenever there is a double square bracket we see around some numbers separated by comma, we get a tensor of rank 2.**",
"_____no_output_____"
],
[
"**Observation**\n- This time we got dimension as 2 since it's a matrix.\n- We got shape as (3,5) where 3 is no of rows and 5 points to no of columns.",
"_____no_output_____"
],
[
"**4. Cube (rank 3 tensors)**\n\n- If you pack 2-d matrices in a new array, you obtain a rank-3 tensor (or 3D tensor).\n- By packing rank-3 tensors in an array, you can create a rank-4 tensor, and so on.",
"_____no_output_____"
]
],
[
[
"# define an array of 3 matrices whose matrices are [ [5, 78, 2, 34, 0],[6, 79, 3, 35, 1],[7, 80, 4, 36, 2] ],\n# [ [5, 78, 2, 34, 0],[6, 79, 3, 35, 1],[7, 80, 4, 36, 2] ],[ [5, 78, 2, 34, 0],[6, 79, 3, 35, 1],[7, 80, 4, 36, 2] ] \n\nrank_4_tensor = np.array([[[5,78,2,34,0],[6,79,3,35,1],[7,80,4,36,2]],[[5,78,2,34,0],[6,79,3,35,1],[7,80,4,36,2]],[[5,78,2,34,0],[6,79,3,35,1],[7,80,4,36,2]]])\n\n# print rank_4_tensor\n\nprint(\"Tensor with rank4 :{0}\".format(rank_4_tensor))\n\n# print its dimension using .ndim\n\nprint(\"Dimensions: {0}\".format(rank_4_tensor.ndim))\n\n\n# print its shape using .shape\nprint('Shape: {0}'.format(rank_4_tensor.shape))\n",
"Tensor with rank4 :[[[ 5 78 2 34 0]\n [ 6 79 3 35 1]\n [ 7 80 4 36 2]]\n\n [[ 5 78 2 34 0]\n [ 6 79 3 35 1]\n [ 7 80 4 36 2]]\n\n [[ 5 78 2 34 0]\n [ 6 79 3 35 1]\n [ 7 80 4 36 2]]]\nDimensions: 3\nShape: (3, 3, 5)\n"
]
],
[
[
"**The above output shows that whenever there is a triple square bracket we see around some numbers separated by comma, we get a tensor of rank 3.**",
"_____no_output_____"
],
[
"**Observation**\n- Look at the dimension which outputs 3. Compare it with previous outputs.\n- Look at the shape which has 3 values (3,3,5) where first value 3 is no of matrices, 2nd value 3 is no of rows and third value 5 is no of columns.\n",
"_____no_output_____"
],
[
"##3. **Now we will learn tensors of different formats**",
"_____no_output_____"
],
[
"**Watch this video for basic understanding on tensor operations in tensorflow**",
"_____no_output_____"
]
],
[
[
"YouTubeVideo('HPjBY1H-U4U', width=600, height=400)",
"_____no_output_____"
],
[
"# import tensorflow as tf\nimport tensorflow as tf\n\n\n# create tensor of one's with shape (3,1)\nx = tf.ones((3,1))\nprint(x)",
"tf.Tensor(\n[[1.]\n [1.]\n [1.]], shape=(3, 1), dtype=float32)\n"
],
[
"# create tensor of zeros (3,1)\ny = tf.zeros((3,1))\n\nprint(x+y)\nprint(tf.add(x,y))\n\n# print x + y\n",
"tf.Tensor(\n[[1.]\n [1.]\n [1.]], shape=(3, 1), dtype=float32)\ntf.Tensor(\n[[1.]\n [1.]\n [1.]], shape=(3, 1), dtype=float32)\n"
],
[
"# create tensor of random values using random.uniform with shape (5,1)\n\nx = tf.random.uniform((5,1))\nprint(x)\n\n# print x\n",
"tf.Tensor(\n[[0.06303477]\n [0.32174587]\n [0.34059155]\n [0.34839725]\n [0.4656067 ]], shape=(5, 1), dtype=float32)\n"
],
[
"# create tensor of random values using random.uniform with shape (5,1) with a minval=2., and maxval=4.\n\nx = tf.random.uniform((5,1),minval=2,maxval=4)\nprint(x)\n\n# print x\n",
"tf.Tensor(\n[[3.7869978]\n [2.690718 ]\n [3.601535 ]\n [2.8074622]\n [2.5799694]], shape=(5, 1), dtype=float32)\n"
],
[
"# create tensor of random values using random.normal with a defined mean = 0., and stddev = 1.0\n\nx = tf.random.normal(shape=(5,1),mean=0,stddev=1.0)\nprint(x)\n# print x\n",
"tf.Tensor(\n[[-1.5201534 ]\n [ 0.16458584]\n [-0.36719602]\n [-0.24715239]\n [ 0.148388 ]], shape=(5, 1), dtype=float32)\n"
],
[
"# Do you remember assigning a value in an array ?\n\n# Let's try assigning a value in a tensor (x[0, 0] = 0.)\nx[0, 0] = 0.",
"_____no_output_____"
]
],
[
[
"**We can see, updating the state of tensor above throw error. So we need to use variables in tensor. tf.Variables is the class meant to manage modifiable state in tensorflow.**",
"_____no_output_____"
],
[
"**Watch this video from 45:00 minute to 1:00 hr to understand how tf.variable, tf.assign works.**",
"_____no_output_____"
]
],
[
[
"YouTubeVideo('d9N0IGb5QP0', width=600, height=400)",
"_____no_output_____"
],
[
"# Create a tensor using tf.Variable with initial_value = tf.random.normal having shape (3,1) \n\n\nx = tf.Variable(initial_value=tf.random.normal((3,1)))\nprint(x)\n\n# print x\n",
"<tf.Variable 'Variable:0' shape=(3, 1) dtype=float32, numpy=\narray([[-0.2646851 ],\n [-0.39194712],\n [ 2.158794 ]], dtype=float32)>\n"
],
[
"# assigning value 1. in the tensor variable x using .assign method at position [0,0]\n\nx[0,0].assign(1.)\n# print x\nprint(x)",
"<tf.Variable 'Variable:0' shape=(3, 1) dtype=float32, numpy=\narray([[ 1. ],\n [-0.39194712],\n [ 2.158794 ]], dtype=float32)>\n"
],
[
"# adding one to each value of the tensor variable x using assign_add method\n\nx.assign_add(tf.ones((3,1)))",
"_____no_output_____"
]
],
[
[
"##4. **Now we will learn mathematical operations in tensorflow**",
"_____no_output_____"
],
[
"\n\n**Some tensorflow methods**",
"_____no_output_____"
],
[
"In TensorFlow the differences between constants and variables are that when you declare some constant, its value can't be changed in the future (also the initialization should be with a value, not with operation).\n\nNevertheless, when you declare a Variable, you can change its value in the future with tf.assign() method (and the initialization can be achieved with a value or operation).",
"_____no_output_____"
]
],
[
[
"# All eager tf.Tensor values are immutable (in contrast to tf.Variable)\n\n# define a using tf.constant and pass [40., 30., 50.]\na = tf.constant([40.,30.,50.])\n\n# define b using tf.constant and pass [12., 13., 23.]\nb = tf.constant([12.,13.,23.])\n\nprint(\"a: {0},{1} , b: {2},{3}\".format(a,a.dtype,b,b.dtype))\n\n\n# add a and b using tf.add\n\nprint(\"Addition: \",tf.add(a,b))\n\n",
"a: [40. 30. 50.],<dtype: 'float32'> , b: [12. 13. 23.],<dtype: 'float32'>\nAddition: tf.Tensor([52. 43. 73.], shape=(3,), dtype=float32)\n"
],
[
"# define x using tf.variable and pass initial value as tf.random.uniform(shape=(2,3), minval=3, maxval=5\n\nx = tf.Variable(tf.random.uniform(shape=(2,3),minval=3,maxval=5))\n# define y by squaring x using tf.square\nprint(\"X: {0}\".format(x))\n\ny = tf.pow(x,2)\nprint(\"y: {0}\".format(y))\n# print x and y \n",
"X: <tf.Variable 'Variable:0' shape=(2, 3) dtype=float32, numpy=\narray([[3.1962028, 4.798502 , 3.9701405],\n [4.87659 , 4.0258846, 4.150977 ]], dtype=float32)>\ny: [[10.215712 23.025621 15.762015]\n [23.781128 16.207747 17.230612]]\n"
],
[
"# define z by taking the square root of x using tf.sqrt\nz = tf.sqrt(x)\nprint(\"z: {0}\".format(z))\n\n# print x+z\n\nprint(\"x+z : {0}\".format(tf.add(x,z)))",
"z: [[1.7877927 2.1905484 1.9925212]\n [2.2083 2.0064607 2.0373948]]\nx+z : [[4.9839954 6.9890504 5.9626617]\n [7.08489 6.0323453 6.1883717]]\n"
]
],
[
[
"## **Numpy Compatibility**\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\n# define an array with shape (4,3) using np.ones\nndarray = np.ones((4,3))\n\nprint(\"TensorFlow operations convert numpy arrays to Tensors automatically\")\n# define a variable tensor by multiplying ndarray with value 42 (use tf.multiply)\ntensor = tf.multiply(ndarray,42)\n\n# print variable tensor\nprint(\"tensor: {0}\".format(tensor))\n\n\n\nprint(\"And NumPy operations convert Tensors to numpy arrays automatically\")\n# add one in each value of a tensor using np.add\n\nprint(np.add(tensor,1))\n\nprint(\"The .numpy() method explicitly converts a Tensor to a numpy array\")\n# convert tensor into numpy using tensor.numpy and print it\nprint(tensor.numpy())\n",
"TensorFlow operations convert numpy arrays to Tensors automatically\ntensor: [[42. 42. 42.]\n [42. 42. 42.]\n [42. 42. 42.]\n [42. 42. 42.]]\nAnd NumPy operations convert Tensors to numpy arrays automatically\n[[43. 43. 43.]\n [43. 43. 43.]\n [43. 43. 43.]\n [43. 43. 43.]]\nThe .numpy() method explicitly converts a Tensor to a numpy array\n[[42. 42. 42.]\n [42. 42. 42.]\n [42. 42. 42.]\n [42. 42. 42.]]\n"
]
],
[
[
"##5. **How to do gradient of any differentiable expression?. let's learn how to find it....**\n\nYou must be asking yourself, what is the difference between numpy and tensorflow here. Suppose you want to differentiate some expression, numpy can't help you there. Tensorflow comes in handy then.",
"_____no_output_____"
],
[
"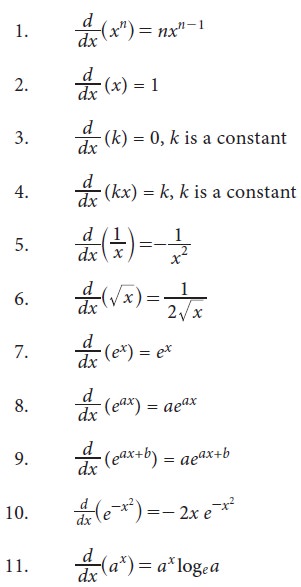",
"_____no_output_____"
],
[
"**Watch this tutorial to understand how gradient works in tensorflow.**",
"_____no_output_____"
]
],
[
[
"YouTubeVideo('ENOycxDU9RY', width=600, height=400)",
"_____no_output_____"
],
[
"# Using GradientTape(Sample example)\n\n# taking some input\n\nsome_input = tf.Variable(initial_value = 5.)\n\n# defining GradientTape as tape\nwith tf.GradientTape() as tape:\n result = tf.square(some_input)\n\n# using gradient tape to find gradient\ngradient = tape.gradient(result, some_input)",
"_____no_output_____"
],
[
"# printing some_input and gradient\nprint(some_input)\nprint(gradient)",
"<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=5.0>\ntf.Tensor(10.0, shape=(), dtype=float32)\n"
],
[
"# another example of gradient\n\n# define variable x using tf.variable and pass value as 3.0\nx = tf.Variable(initial_value=3.0)\n\n# define GradientTape as tape with y = x**2\n\nwith tf.GradientTape() as g: \n \n y = x*x\n \n dy_dx = g.gradient(y,x)\n\n\n# define dy_dx and take derivative using tape.gradient\n\nprint(x)\nprint(y)\nprint(dy_dx)\n# print x, y and dy_dx\n",
"<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=3.0>\ntf.Tensor(9.0, shape=(), dtype=float32)\ntf.Tensor(6.0, shape=(), dtype=float32)\n"
],
[
"# (Add on example)\n# Another example of gradient using equation of \n# falling apple along a vertical exis over time\n\ntime = tf.Variable(3.) \nwith tf.GradientTape() as outer:\n with tf.GradientTape() as inner:\n position = 4.9 * time ** 2\n speed = inner.gradient(position, time)\nacceleration = outer.gradient(speed, time)",
"_____no_output_____"
],
[
"# printing time, position, speed and acceleration\nprint(\"time: \", time)\nprint(\"position: \", position)\nprint(\"speed: \", speed)\nprint(\"acceleration: \", acceleration)",
"time: <tf.Variable 'Variable:0' shape=() dtype=float32, numpy=3.0>\nposition: tf.Tensor(44.100002, shape=(), dtype=float32)\nspeed: tf.Tensor(29.400002, shape=(), dtype=float32)\nacceleration: tf.Tensor(9.8, shape=(), dtype=float32)\n"
],
[
"# Another example using weights and biases\n\n# define w using tf.Variable and pass random values with shape (3,2) using tf.random.normal\nw = tf.Variable(tf.random.normal((3,2)))\n\n# define b using tf.Variable and pass zeros with shape 2 using tf.zeros\nb = tf.Variable(tf.zeros((2,2)))\n\n# define x with values [[1., 2., 3.]]\n\nx = tf.Variable([[1.,2.,3.]])\n\n\n# define GradientTape as tape\nwith tf.GradientTape(persistent=True) as tape:\n # define y under it with values as y = x @ w + b (@ is dot product)\n y = x @ w + b\n \n # define loss using tf.reduce_mean and pass y**2 into it\n dy_w = tape.gradient(y,w)\n dy_x = tape.gradient(y,b)\n \n loss = tf.reduce_mean(y*y)\n\n# print w\nprint(\"w: \", w)\n# print b\nprint(\"b: \", b)\n# print x\nprint(\"x: \", x)\n# print y\nprint(\"y: \", y)\n# print y**2\nprint(\"y**2: \", y**2)\n# print loss\nprint(\"loss: \", loss)\n\nprint(\"*\"*50)\n\n# Now differentiate y w.r.t w and b \n[dy_dw, dy_db] = [dy_w,dy_x]\n\n# Now print dy_dw, dy_db\nprint(dy_dw,dy_db)",
"WARNING:tensorflow:Calling GradientTape.gradient on a persistent tape inside its context is significantly less efficient than calling it outside the context (it causes the gradient ops to be recorded on the tape, leading to increased CPU and memory usage). Only call GradientTape.gradient inside the context if you actually want to trace the gradient in order to compute higher order derivatives.\nWARNING:tensorflow:Calling GradientTape.gradient on a persistent tape inside its context is significantly less efficient than calling it outside the context (it causes the gradient ops to be recorded on the tape, leading to increased CPU and memory usage). Only call GradientTape.gradient inside the context if you actually want to trace the gradient in order to compute higher order derivatives.\nw: <tf.Variable 'Variable:0' shape=(3, 2) dtype=float32, numpy=\narray([[ 0.1507082 , 0.20268817],\n [-0.9358254 , 0.19437873],\n [-0.6978883 , -0.805262 ]], dtype=float32)>\nb: <tf.Variable 'Variable:0' shape=(2, 2) dtype=float32, numpy=\narray([[0., 0.],\n [0., 0.]], dtype=float32)>\nx: <tf.Variable 'Variable:0' shape=(1, 3) dtype=float32, numpy=array([[1., 2., 3.]], dtype=float32)>\ny: tf.Tensor(\n[[-3.8146076 -1.8243405]\n [-3.8146076 -1.8243405]], shape=(2, 2), dtype=float32)\ny**2: tf.Tensor(\n[[14.551231 3.3282182]\n [14.551231 3.3282182]], shape=(2, 2), dtype=float32)\nloss: tf.Tensor(8.939724, shape=(), dtype=float32)\n**************************************************\ntf.Tensor(\n[[2. 2.]\n [4. 4.]\n [6. 6.]], shape=(3, 2), dtype=float32) tf.Tensor(\n[[1. 1.]\n [1. 1.]], shape=(2, 2), dtype=float32)\n"
]
],
[
[
"## **Now we will use our learning till now to build a small linear classifier.**",
"_____no_output_____"
],
[
"##6. **Beginning of End to End Linear Classifier**",
"_____no_output_____"
],
[
"** Before we go for linear classifier, let me show you how to plot some points on scatterplot for visualization **",
"_____no_output_____"
],
[
"**Video reference for multivariate normal in method in numpy**",
"_____no_output_____"
]
],
[
[
"YouTubeVideo('mw-svKkGVaI', width=600, height=400)",
"_____no_output_____"
],
[
"# ( Sample code for visualization )\n# we will use np.random.multivariate_normal to get random points having specific mean and covariance\nimport numpy as np\nimport matplotlib.pyplot as plt\nx, y = np.random.multivariate_normal([1, 0.5], [[10, 5], [5, 10]], 5000).T\nplt.plot(x, y, 'x')\nplt.axis('equal')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## **Change Mean And Covariance To See The Differences in Plots in Next Cell**",
"_____no_output_____"
]
],
[
[
"# we will use np.random.multivariate_normal to get random points having specific mean and covariance\n\nimport matplotlib.pyplot as plt\n\nfig, (ax1, ax2, ax3)= plt.subplots(3, figsize=(12, 8))\n\n# visualize mean, cov \nx, y = np.random.multivariate_normal(mean = [1, 0.5], cov = [[1, 0.5], [0.5, 1]],size = 5000).T\nax1.plot(x, y, 'x')\nplt.axis('equal')\n\n# visualize mean, cov\na, b = np.random.multivariate_normal(mean = [2, 3], cov = [[10, 5], [5, 10]], size = 5000).T\nax2.plot(a, b, 'bo')\nplt.axis('equal')\n\n# visualize mean, cov\nc, d = np.random.multivariate_normal(mean = [1, 5], cov = [[5, 15], [15, 5]], size = 5000).T\nax3.plot(c, d, 'r+')\nplt.axis('equal')",
"/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:18: RuntimeWarning: covariance is not positive-semidefinite.\n"
],
[
"# Now we are defining two scatterplot, one for negative and one for positive\nnum_samples_per_class = 1000\n\n# first negative samples\n# Use np.random.multivariate_normal with mean [0, 3] and cov [[1, 0.5], [0.5, 1]] and size as num_samples_per_class\nnegative_samples = np.random.multivariate_normal(mean=[0,3],cov=[[1,0.5],[0.5,1]],size=num_samples_per_class)\n\n# looking at first 5 negative samples\nnegative_samples[:5]",
"_____no_output_____"
],
[
"# defining positive samples\n# Use np.random.multivariate_normal with mean [0, 3] and cov [[1, 0.5], [0.5, 1]] and size as num_samples_per_class\npositive_samples = np.random.multivariate_normal(mean=[0,3],cov=[[1,0.5],[0.5,1]],size=num_samples_per_class)\n\n# looking at first 5 positive samples\npositive_samples[:5]\n",
"_____no_output_____"
],
[
"# Stacking both positive and negative samples using np.vstack\n\nsamples = np.vstack((positive_samples,negative_samples))\nprint(samples)\n\nprint('\\n\\n\\n')\n\nprint(samples.shape)",
"[[-1.39819615 2.78893211]\n [ 2.05632626 3.664108 ]\n [ 0.11227506 3.05320803]\n ...\n [ 0.61468335 4.65622046]\n [-1.68345449 1.72073902]\n [ 1.62092024 4.9278094 ]]\n\n\n\n\n(2000, 2)\n"
],
[
"# defining labels using np.vstack (stack vector of zeros and ones having num_samples_per_class length) \n\ntargets = np.vstack((np.zeros((num_samples_per_class,2)),np.ones((num_samples_per_class,2))))\ntargets.shape\n",
"_____no_output_____"
],
[
"# plot your samples using plt.scatter\nplt.scatter(positive_samples,negative_samples)",
"_____no_output_____"
],
[
"# define input_dim =2 as we have two input variables and output_dim = 1 as we have one target \n\nimport tensorflow as tf\n\ninput_dim = 2 \noutput_dim = 1 \n\n# define weights using tf.variable , shape of weights will be = (input_dim, output_dim)\n\nweights = tf.Variable((input_dim,output_dim))\n\n# define bias using tf.variable , shape of bias will be = (output_dim,)\n\nbias = tf.Variable((output_dim,))\nbias\n\nprint(\"Bias: {0}\".format(bias))\nprint(\"Weights: {0}\".format(weights))\n\n",
"Bias: <tf.Variable 'Variable:0' shape=(1,) dtype=int32, numpy=array([1], dtype=int32)>\nWeights: <tf.Variable 'Variable:0' shape=(2,) dtype=int32, numpy=array([2, 1], dtype=int32)>\n"
],
[
"# here is our model\n# define a function named simple_model which will take inputs(X) and return (inputs*weights+bias )\ndef simple_model(inputs):\n return (inputs*weights)+bias\n",
"_____no_output_____"
],
[
"# returning avg loss from this loss function\n# define mean_sq_loss function which will take targets and predictions\ndef mean_sq_loss(targets, predictions):\n # define losses variable first by taking square difference of targets and predictions \n losses = tf.pow(tf.subtract(targets-predictions),2)\n\n # return mean of losses using tf.reduce_mean\n tf.reduce_mean(losses)\n ",
"_____no_output_____"
],
[
"# define learning_rate=0.1\n\nlearning_rate = 0.1\n\n# define training function which takes inputs and targets\ndef training(inputs, targets):\n # define GradientTape as tape\n with tf.GradientTape() as tape:\n \n # define predictions by using simple_model function\n predictions = simple_model(inputs)\n \n # define losses using mean_sq_loss function\n loss = mean_sq_loss(targets,predictions)\n \n # take derivative of loss w.r.t. w and b\n dloss_w = tape.gradient(loss,w)\n dloss_wb = tape.gradient(dloss,b)\n\n #assign loss w.r.t.w*learning_rate to weights\n weights = weights + (learning_rate*loss)\n \n #assign loss w.r.t.b*learning_rate to bias\n bias = bias + (learning_rate*loss)\n \n # return losses\n return loss\n ",
"_____no_output_____"
],
[
"# running training for multiple epochs usinf for loop\nfor i in range(30):\n # define loss by calling training function\n loss = training(samples,targets)\n print(\"Epoch: {0}, loss: {1}\".format(i,loss))\n \n # print loss epoch wise\n ",
"_____no_output_____"
]
],
[
[
"## **Hurray.... you finished the assignment.... It's time for the feedback**",
"_____no_output_____"
],
[
"## **FEEDBACK FORM**\n\nPlease help us in improving by filling this form. https://forms.zohopublic.in/cloudyml/form/CloudyMLDeepLearningFeedbackForm/formperma/VCFbldnXAnbcgAIl0lWv2blgHdSldheO4RfktMdgK7s",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a016198cd1946a3a2a32f13b2db12985485b8a9
| 3,760 |
ipynb
|
Jupyter Notebook
|
Assignment_1.ipynb
|
Vineelaswathi/Bigdata_assignment1
|
742bfd40369f77e438dcc1239395e7a662613976
|
[
"BSL-1.0"
] | null | null | null |
Assignment_1.ipynb
|
Vineelaswathi/Bigdata_assignment1
|
742bfd40369f77e438dcc1239395e7a662613976
|
[
"BSL-1.0"
] | null | null | null |
Assignment_1.ipynb
|
Vineelaswathi/Bigdata_assignment1
|
742bfd40369f77e438dcc1239395e7a662613976
|
[
"BSL-1.0"
] | null | null | null | 21.123596 | 137 | 0.506383 |
[
[
[
"import time\nimport pyspark\nimport numpy as np",
"_____no_output_____"
],
[
"file_name = 'household_power_consumption.txt'\nsc = pyspark.SparkContext(appName='sample_code_1')\ntext_file = sc.textFile(file_name)",
"_____no_output_____"
],
[
"take_size = 3\nattr_idx = [2, 3]\nbc_attr_idx = sc.broadcast(attr_idx)\nbc_attr_idx.value",
"_____no_output_____"
],
[
"# show data\ntext_file.take(take_size)",
"_____no_output_____"
],
[
"def get_attrs(row):\n attrs = row.split(';')\n return np.take(attrs, bc_attr_idx.value)\n\ndef trans_type(row):\n try:\n return [np.double(value) for value in row]\n except:\n return [np.nan] * len(row)\n\ntext_file.map(get_attrs).map(trans_type).take(take_size)",
"_____no_output_____"
],
[
"def get_max(row1, row2):\n stacked = np.vstack([row1, row2])\n return np.nanmax(stacked, axis=0)\n\ntext_file.map(get_attrs).map(trans_type).reduce(get_max)",
"_____no_output_____"
],
[
"# dont believe this result \n\nstart = time.time()\nresult = text_file.map(get_attrs).map(trans_type).reduce(get_max)\nprint('result: {}'.format(result))\nprint('time: {}'.format(time.time() - start))",
"result: [11.122 1.39 ]\ntime: 42.419591665267944\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a01645fe5d8eb55aec7d3407356d8246c8f074e
| 46,595 |
ipynb
|
Jupyter Notebook
|
examples/nipype_tutorial.ipynb
|
lighthall-lab/NiPype
|
80d3f05d9aa006fa3055785327892e8a89530a80
|
[
"Apache-2.0"
] | null | null | null |
examples/nipype_tutorial.ipynb
|
lighthall-lab/NiPype
|
80d3f05d9aa006fa3055785327892e8a89530a80
|
[
"Apache-2.0"
] | null | null | null |
examples/nipype_tutorial.ipynb
|
lighthall-lab/NiPype
|
80d3f05d9aa006fa3055785327892e8a89530a80
|
[
"Apache-2.0"
] | null | null | null | 26.610508 | 165 | 0.495268 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a017f43b7f14383b315b271fef8f1fdd3ba8cf1
| 48,814 |
ipynb
|
Jupyter Notebook
|
dataset/Femnist_stats.ipynb
|
NCLPhD/FedScale
|
7a7cc0c384a80b2c7e59541c772ae3a6b1ed3b58
|
[
"Apache-2.0"
] | 1 |
2021-12-15T11:36:59.000Z
|
2021-12-15T11:36:59.000Z
|
dataset/Femnist_stats.ipynb
|
NCLPhD/FedScale
|
7a7cc0c384a80b2c7e59541c772ae3a6b1ed3b58
|
[
"Apache-2.0"
] | null | null | null |
dataset/Femnist_stats.ipynb
|
NCLPhD/FedScale
|
7a7cc0c384a80b2c7e59541c772ae3a6b1ed3b58
|
[
"Apache-2.0"
] | 1 |
2022-03-01T18:22:13.000Z
|
2022-03-01T18:22:13.000Z
| 146.149701 | 14,041 | 0.658356 |
[
[
[
"<a href=\"https://colab.research.google.com/github/AmberLJC/FedScale/blob/master/dataset/Femnist_stats.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# **[Jupyter notebook] Understand the heterogeneous FL data.**",
"_____no_output_____"
],
[
"# Download the Femnist dataset and FedScale\nFollow the sownload instruction in /content/FedScale/dataset/download.sh",
"_____no_output_____"
]
],
[
[
"# Download Fedscale and femnist dataset\n!pwd\n\n!wget -O /content/femnist.tar.gz https://fedscale.eecs.umich.edu/dataset/femnist.tar.gz\n!tar -xf /content/femnist.tar.gz -C /content/\n!rm -f /content/femnist.tar.gz\n!echo -e \"${GREEN}FEMNIST dataset downloaded!${NC}\" ",
"--2022-03-27 18:01:54-- https://fedscale.eecs.umich.edu/dataset/femnist.tar.gz\nResolving fedscale.eecs.umich.edu (fedscale.eecs.umich.edu)... 141.212.113.214\nConnecting to fedscale.eecs.umich.edu (fedscale.eecs.umich.edu)|141.212.113.214|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 342784457 (327M) [application/x-gzip]\nSaving to: ‘/content/femnist.tar.gz’\n\n/content/femnist.ta 100%[===================>] 326.90M 105MB/s in 3.1s \n\n2022-03-27 18:01:57 (105 MB/s) - ‘/content/femnist.tar.gz’ saved [342784457/342784457]\n\n"
],
[
"!git clone https://github.com/AmberLJC/FedScale.git",
"Cloning into 'FedScale'...\nremote: Enumerating objects: 1765, done.\u001b[K\nremote: Counting objects: 100% (728/728), done.\u001b[K\nremote: Compressing objects: 100% (475/475), done.\u001b[K\nremote: Total 1765 (delta 469), reused 440 (delta 244), pack-reused 1037\u001b[K\nReceiving objects: 100% (1765/1765), 63.77 MiB | 22.58 MiB/s, done.\nResolving deltas: 100% (1052/1052), done.\n"
],
[
"from torch.utils.data import DataLoader\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom FedScale.core.utils.femnist import FEMNIST\nfrom FedScale.core.utils.utils_data import get_data_transform\nfrom FedScale.core.utils.divide_data import DataPartitioner\nfrom FedScale.core.argParser import args \n",
"_____no_output_____"
]
],
[
[
"# Data Loader",
"_____no_output_____"
]
],
[
[
"\ntrain_transform, test_transform = get_data_transform('mnist')\ntrain_dataset = FEMNIST('/content/femnist', dataset='train', transform=train_transform)\ntest_dataset = FEMNIST('/content/femnist', dataset='test', transform=test_transform)\n",
"_____no_output_____"
]
],
[
[
"Partition the dataset by the `clientclient_data_mapping` file, which gives the real-world client-level heterogeneoity.",
"_____no_output_____"
]
],
[
[
"\nargs.task = 'cv'\ntraining_sets = DataPartitioner(data=train_dataset, args=args, numOfClass=62)\ntraining_sets.partition_data_helper(num_clients=None, data_map_file='/content/femnist/client_data_mapping/train.csv')\n#testing_sets = DataPartitioner(data=test_dataset, args=args, numOfClass=62, isTest=True)\n#testing_sets.partition_data_helper(num_clients=None, data_map_file='/content/femnist/client_data_mapping/train.csv')\n",
"_____no_output_____"
]
],
[
[
"# Print and plot statistics of the dataset.",
"_____no_output_____"
]
],
[
[
"print(f'Total number of data smaples: {training_sets.getDataLen()}')\nprint(f'Total number of clients: {training_sets.getClientLen()}')\nprint(f'The number of data smaples of each clients: {training_sets.getSize()}')\nprint(f'The number of unique labels of each clients: {training_sets.getClientLabel()}')\n",
"Total number of data smaples: 637877\nTotal number of clients: 2800\nThe number of data smaples of each clients: {'size': [299, 151, 335, 157, 181, 354, 180, 179, 126, 161, 351, 159, 165, 169, 301, 143, 148, 333, 375, 170, 152, 308, 277, 171, 142, 173, 146, 332, 259, 292, 181, 151, 159, 50, 169, 157, 176, 168, 168, 181, 246, 47, 177, 413, 230, 221, 121, 155, 365, 179, 159, 167, 174, 167, 178, 171, 152, 242, 166, 175, 165, 180, 344, 414, 19, 173, 423, 164, 404, 305, 135, 176, 279, 179, 246, 177, 323, 248, 173, 172, 31, 176, 164, 173, 228, 271, 169, 404, 437, 273, 274, 157, 177, 169, 378, 141, 207, 176, 172, 151, 164, 163, 315, 173, 177, 311, 376, 287, 185, 96, 238, 379, 437, 222, 168, 408, 167, 353, 383, 176, 150, 393, 175, 176, 183, 145, 391, 374, 321, 331, 333, 178, 158, 177, 344, 183, 176, 149, 178, 342, 267, 325, 170, 168, 127, 161, 249, 182, 164, 269, 170, 117, 150, 367, 257, 244, 175, 149, 169, 164, 179, 316, 112, 169, 169, 132, 160, 169, 174, 176, 157, 330, 175, 243, 259, 169, 212, 164, 131, 378, 275, 154, 178, 179, 172, 182, 154, 174, 173, 353, 354, 169, 151, 169, 167, 261, 181, 345, 361, 173, 155, 385, 171, 177, 319, 179, 160, 371, 173, 181, 179, 396, 352, 132, 175, 262, 278, 181, 108, 309, 159, 177, 282, 276, 167, 320, 370, 169, 175, 361, 336, 150, 347, 144, 305, 176, 178, 174, 375, 310, 218, 139, 298, 173, 178, 162, 335, 173, 180, 180, 175, 406, 160, 167, 356, 354, 283, 137, 168, 143, 181, 184, 319, 171, 143, 259, 176, 179, 162, 295, 183, 335, 168, 422, 369, 153, 158, 177, 111, 138, 103, 177, 180, 296, 173, 295, 324, 213, 140, 156, 372, 170, 256, 171, 263, 292, 303, 337, 247, 169, 178, 168, 345, 325, 336, 179, 230, 175, 96, 176, 134, 223, 370, 385, 325, 294, 179, 282, 169, 183, 181, 157, 344, 183, 221, 307, 161, 373, 308, 366, 172, 159, 393, 175, 187, 178, 245, 321, 166, 174, 150, 320, 173, 351, 175, 174, 149, 160, 405, 175, 160, 225, 169, 181, 281, 150, 176, 171, 156, 181, 181, 319, 182, 176, 156, 376, 396, 250, 170, 154, 172, 285, 160, 173, 181, 162, 181, 145, 182, 141, 178, 291, 129, 166, 167, 172, 160, 184, 163, 172, 178, 153, 331, 155, 249, 344, 152, 180, 170, 146, 257, 179, 272, 183, 181, 181, 165, 167, 182, 397, 135, 180, 370, 173, 172, 173, 390, 130, 322, 408, 180, 416, 416, 321, 183, 156, 77, 165, 378, 206, 248, 133, 175, 382, 369, 395, 172, 164, 259, 175, 170, 236, 301, 101, 304, 174, 258, 166, 179, 260, 175, 165, 325, 184, 170, 159, 337, 347, 130, 327, 388, 176, 178, 254, 404, 170, 294, 325, 353, 155, 150, 156, 176, 159, 331, 174, 151, 162, 270, 398, 167, 165, 138, 180, 325, 145, 171, 205, 179, 180, 266, 168, 147, 165, 271, 109, 330, 302, 172, 159, 147, 158, 301, 353, 256, 381, 176, 158, 40, 151, 156, 307, 195, 170, 157, 181, 131, 170, 284, 153, 396, 160, 323, 181, 181, 145, 136, 369, 282, 301, 128, 178, 135, 149, 182, 298, 315, 247, 175, 300, 398, 367, 248, 116, 174, 329, 182, 182, 178, 316, 286, 163, 309, 183, 172, 228, 381, 332, 150, 438, 180, 352, 169, 180, 277, 138, 333, 352, 369, 178, 305, 393, 159, 367, 166, 177, 131, 434, 164, 414, 293, 170, 51, 172, 130, 434, 278, 389, 161, 144, 182, 172, 134, 362, 125, 319, 415, 115, 379, 384, 164, 148, 168, 318, 251, 414, 359, 302, 136, 180, 354, 156, 160, 283, 356, 173, 127, 163, 133, 244, 153, 171, 178, 177, 380, 140, 178, 183, 369, 360, 325, 385, 168, 162, 361, 375, 303, 410, 226, 322, 302, 178, 343, 206, 170, 380, 180, 339, 132, 182, 178, 182, 194, 361, 259, 257, 172, 180, 330, 159, 87, 166, 172, 173, 351, 396, 302, 370, 155, 179, 154, 316, 161, 326, 183, 172, 348, 178, 318, 311, 169, 221, 172, 343, 154, 163, 360, 302, 285, 153, 306, 375, 182, 181, 355, 369, 175, 264, 348, 386, 318, 182, 171, 288, 22, 284, 307, 176, 168, 178, 356, 179, 169, 282, 164, 289, 157, 160, 146, 182, 389, 120, 387, 365, 180, 167, 348, 177, 291, 310, 177, 296, 377, 175, 180, 120, 143, 183, 104, 173, 160, 172, 334, 372, 176, 182, 169, 164, 179, 200, 309, 380, 387, 172, 170, 368, 307, 416, 291, 398, 148, 389, 231, 164, 317, 352, 168, 156, 168, 170, 182, 168, 150, 164, 265, 347, 355, 136, 343, 153, 363, 167, 167, 159, 176, 163, 167, 170, 183, 182, 198, 263, 327, 182, 165, 318, 162, 153, 178, 335, 179, 177, 325, 148, 163, 181, 349, 172, 384, 182, 176, 256, 174, 148, 380, 25, 363, 135, 417, 171, 101, 171, 283, 344, 151, 149, 176, 333, 168, 277, 139, 409, 380, 161, 163, 318, 172, 230, 162, 158, 320, 179, 163, 171, 361, 175, 178, 138, 168, 436, 135, 250, 380, 171, 175, 241, 174, 304, 389, 163, 307, 365, 177, 298, 170, 166, 371, 149, 387, 417, 340, 358, 183, 259, 180, 119, 144, 221, 268, 313, 392, 254, 352, 447, 144, 296, 403, 170, 181, 177, 264, 177, 179, 153, 169, 172, 176, 388, 176, 380, 293, 207, 160, 178, 414, 165, 180, 153, 378, 164, 162, 164, 156, 339, 180, 182, 168, 177, 172, 173, 148, 291, 142, 145, 47, 390, 333, 328, 336, 217, 271, 181, 394, 176, 368, 159, 180, 163, 80, 184, 402, 293, 169, 157, 376, 355, 301, 178, 160, 159, 394, 170, 154, 368, 173, 408, 184, 168, 307, 255, 183, 298, 237, 312, 163, 281, 164, 405, 161, 248, 160, 181, 322, 163, 171, 420, 108, 298, 351, 339, 285, 168, 152, 373, 425, 177, 165, 169, 179, 183, 322, 130, 145, 345, 244, 330, 166, 178, 180, 221, 103, 187, 296, 376, 183, 315, 395, 179, 168, 272, 145, 314, 322, 157, 349, 171, 262, 245, 401, 168, 182, 183, 176, 401, 178, 277, 161, 371, 171, 183, 397, 264, 180, 123, 169, 169, 175, 183, 289, 162, 315, 178, 173, 302, 171, 377, 167, 164, 173, 170, 171, 314, 365, 180, 359, 171, 274, 173, 180, 217, 417, 180, 324, 172, 157, 163, 348, 213, 129, 183, 173, 126, 173, 282, 179, 164, 397, 170, 336, 316, 174, 160, 218, 68, 166, 179, 175, 173, 183, 104, 177, 156, 277, 158, 173, 132, 375, 379, 384, 178, 327, 92, 375, 168, 146, 400, 179, 158, 179, 252, 316, 153, 150, 171, 174, 152, 339, 383, 95, 165, 377, 258, 179, 181, 304, 371, 161, 137, 170, 166, 173, 171, 168, 270, 209, 311, 414, 173, 133, 164, 266, 180, 163, 148, 171, 291, 170, 238, 352, 116, 375, 175, 184, 429, 159, 179, 167, 155, 394, 169, 141, 358, 247, 177, 179, 339, 298, 388, 80, 389, 174, 170, 173, 166, 160, 235, 173, 232, 50, 360, 178, 295, 171, 138, 168, 324, 175, 143, 214, 181, 163, 169, 155, 136, 126, 284, 169, 171, 128, 183, 175, 162, 156, 415, 161, 346, 419, 160, 169, 176, 327, 222, 183, 178, 181, 167, 443, 259, 163, 183, 186, 148, 178, 366, 237, 155, 387, 162, 316, 176, 130, 171, 257, 177, 351, 178, 171, 294, 319, 183, 163, 320, 155, 176, 166, 137, 180, 335, 107, 176, 167, 139, 342, 173, 284, 178, 171, 167, 174, 171, 267, 173, 406, 219, 176, 161, 183, 164, 156, 279, 151, 394, 170, 362, 153, 167, 383, 247, 392, 393, 182, 179, 175, 363, 167, 311, 133, 176, 144, 177, 190, 175, 400, 160, 170, 182, 318, 156, 181, 177, 277, 389, 150, 172, 423, 175, 180, 181, 178, 187, 140, 134, 280, 407, 216, 322, 168, 347, 174, 353, 310, 241, 175, 268, 149, 150, 257, 179, 346, 353, 177, 271, 392, 233, 383, 295, 106, 162, 176, 362, 150, 183, 347, 179, 104, 170, 153, 176, 154, 171, 170, 312, 376, 138, 397, 315, 167, 300, 136, 319, 174, 244, 160, 274, 164, 175, 344, 178, 308, 175, 390, 317, 180, 174, 179, 388, 324, 169, 128, 175, 147, 405, 164, 183, 160, 176, 293, 147, 152, 261, 157, 158, 172, 344, 271, 397, 175, 160, 151, 370, 146, 169, 179, 173, 296, 388, 376, 151, 240, 109, 180, 172, 143, 180, 172, 167, 239, 168, 183, 170, 176, 382, 183, 367, 177, 106, 265, 180, 345, 164, 147, 390, 169, 173, 262, 167, 176, 141, 339, 168, 173, 318, 173, 396, 177, 177, 246, 285, 178, 125, 344, 291, 172, 363, 156, 301, 317, 162, 345, 180, 181, 180, 157, 176, 293, 356, 172, 388, 280, 174, 182, 251, 157, 148, 301, 177, 174, 383, 175, 411, 173, 119, 148, 330, 161, 242, 144, 173, 367, 386, 230, 138, 170, 374, 168, 369, 166, 269, 148, 218, 145, 176, 176, 177, 362, 139, 355, 149, 352, 126, 176, 163, 136, 157, 176, 157, 160, 176, 147, 426, 181, 252, 172, 160, 155, 278, 306, 430, 173, 239, 162, 178, 170, 406, 183, 427, 355, 167, 326, 165, 234, 176, 171, 165, 144, 173, 178, 177, 339, 329, 181, 181, 171, 176, 158, 163, 307, 171, 140, 158, 344, 291, 121, 215, 178, 397, 173, 357, 109, 178, 171, 103, 174, 108, 259, 183, 167, 302, 179, 168, 157, 159, 211, 324, 348, 262, 325, 317, 153, 353, 156, 150, 155, 172, 148, 170, 181, 358, 129, 177, 183, 135, 385, 169, 262, 362, 153, 169, 408, 171, 168, 168, 142, 378, 177, 257, 169, 162, 167, 181, 159, 165, 174, 353, 157, 161, 180, 372, 345, 302, 158, 276, 289, 366, 216, 309, 184, 371, 424, 156, 149, 231, 165, 328, 168, 180, 179, 182, 331, 381, 142, 158, 179, 150, 177, 99, 169, 156, 396, 104, 158, 429, 309, 143, 181, 137, 164, 142, 146, 170, 401, 116, 428, 177, 393, 356, 177, 183, 139, 328, 181, 154, 173, 362, 119, 348, 347, 166, 174, 175, 169, 346, 183, 181, 156, 108, 41, 324, 286, 219, 384, 167, 178, 175, 364, 173, 183, 138, 344, 292, 169, 279, 220, 223, 179, 171, 169, 329, 374, 269, 179, 175, 170, 267, 170, 109, 203, 177, 374, 151, 314, 183, 343, 328, 344, 169, 173, 192, 328, 164, 173, 292, 307, 167, 254, 156, 348, 146, 175, 177, 183, 322, 174, 166, 175, 88, 368, 175, 178, 179, 293, 196, 417, 167, 171, 174, 180, 394, 365, 137, 345, 180, 340, 127, 402, 145, 336, 309, 407, 162, 159, 332, 162, 431, 178, 266, 327, 380, 307, 170, 163, 165, 182, 275, 165, 180, 98, 177, 173, 213, 341, 176, 241, 178, 129, 168, 189, 150, 361, 352, 347, 356, 156, 183, 126, 175, 171, 318, 397, 177, 174, 352, 170, 175, 403, 148, 360, 154, 174, 308, 183, 315, 170, 379, 181, 177, 168, 164, 173, 157, 307, 179, 209, 168, 359, 391, 270, 140, 173, 134, 169, 337, 302, 170, 246, 207, 368, 168, 159, 276, 179, 182, 160, 149, 181, 319, 333, 276, 180, 392, 174, 171, 393, 298, 181, 347, 176, 169, 152, 176, 178, 178, 163, 292, 465, 182, 179, 155, 414, 287, 172, 307, 108, 347, 343, 395, 179, 171, 313, 329, 180, 179, 149, 296, 177, 182, 355, 175, 402, 177, 274, 117, 249, 318, 331, 173, 158, 347, 177, 314, 172, 178, 166, 171, 159, 175, 166, 174, 229, 261, 138, 166, 166, 403, 360, 174, 166, 287, 173, 297, 272, 348, 155, 399, 353, 160, 165, 174, 146, 388, 142, 381, 379, 148, 176, 171, 329, 243, 73, 411, 161, 115, 337, 332, 181, 169, 169, 179, 179, 177, 429, 364, 345, 147, 313, 164, 182, 171, 271, 228, 293, 377, 271, 182, 177, 169, 372, 160, 295, 183, 345, 167, 172, 281, 182, 418, 146, 154, 386, 291, 168, 329, 162, 178, 168, 413, 380, 403, 159, 304, 158, 158, 173, 149, 321, 177, 158, 176, 173, 304, 314, 183, 175, 262, 181, 177, 171, 162, 313, 299, 392, 377, 166, 166, 142, 233, 180, 180, 427, 278, 181, 348, 330, 162, 165, 163, 298, 144, 170, 172, 145, 170, 167, 143, 180, 358, 143, 155, 228, 183, 172, 141, 390, 173, 177, 139, 261, 172, 350, 171, 236, 178, 372, 172, 277, 173, 202, 380, 171, 169, 329, 355, 156, 184, 168, 146, 313, 167, 129, 140, 340, 401, 145, 423, 281, 177, 367, 174, 353, 162, 181, 345, 355, 180, 178, 232, 151, 176, 150, 309, 365, 180, 334, 356, 178, 280, 119, 337, 160, 183, 306, 161, 166, 399, 182, 171, 145, 170, 171, 162, 165, 338, 140, 334, 175, 178, 338, 178, 173, 166, 174, 349, 381, 165, 156, 165, 381, 351, 361, 172, 164, 153, 177, 179, 180, 150, 321, 357, 137, 172, 334, 164, 155, 250, 289, 171, 325, 304, 159, 164, 138, 168, 187, 266, 156, 303, 397, 177, 179, 176, 118, 172, 172, 351, 151, 369, 279, 183, 391, 168, 250, 175, 379, 254, 180, 196, 142, 286, 160, 177, 180, 346, 233, 251, 303, 176, 351, 241, 177, 300, 135, 388, 183, 181, 344, 163, 182, 171, 155, 133, 165, 161, 187, 282, 391, 300, 372, 113, 341, 117, 154, 320, 174, 175, 209, 283, 174, 174, 281, 351, 177, 376, 169, 156, 165, 183, 175, 415, 181, 164, 374, 421, 122, 176, 166, 163, 369, 157, 169, 165, 151, 52, 345, 149, 170, 299, 171, 174, 311, 157, 337, 317, 160, 161, 150, 184, 181, 179, 187, 267, 154, 266, 134, 360, 110, 176, 297, 235, 162, 423, 376, 340, 156, 169, 131, 333, 385, 154, 292, 188, 139, 164, 253, 161, 167, 357, 170, 273, 172, 175, 126, 177, 153, 166, 163, 133, 178, 237, 167, 382, 367, 124, 171, 179, 302, 147, 349, 183, 52, 334, 153, 249, 176, 338, 275, 177, 309, 135, 163, 403, 412, 367, 166, 178, 427, 183, 164, 243, 173, 179, 339, 242, 184, 326, 173, 183, 161, 264, 171, 173, 91, 155, 104, 160, 168, 240, 272, 407, 151, 167, 143, 181, 169, 178, 332, 159, 174, 177, 191, 400, 166, 384, 181, 214, 174, 338, 328, 172, 117, 404, 150, 148, 181, 164, 155, 181, 174, 181, 303, 332, 394, 291, 327, 165, 180, 163, 177, 424, 150, 179, 178, 369, 419, 160, 178, 180, 181, 267, 171, 335, 403, 364, 176, 126, 182, 289, 178, 302, 297, 183, 364, 359, 301, 380, 331, 347, 409, 134, 172, 150, 177, 404, 264, 155, 395, 359, 359, 158, 146, 160, 382, 380, 185, 321, 374, 167, 179, 178, 374, 158, 151, 114, 175, 173, 349, 184, 313, 319, 144, 335, 136, 136, 175, 179, 169, 165, 158, 247, 303, 142, 304, 394, 180, 419, 178, 151, 249, 178, 153, 174, 169, 428, 295, 226, 164, 175, 342, 169, 165, 314, 174, 161, 178, 179, 162, 146, 155, 177, 154, 174, 167, 315, 99, 144, 329, 158, 182, 210, 178, 295, 378, 176, 163, 303, 164, 177, 366, 167, 404, 205, 153, 180, 251, 158, 370, 156, 395, 165, 169, 175, 176, 152, 168, 290, 163, 172, 175, 231, 140, 177, 352, 265, 238, 420, 254, 296, 170, 178, 168, 327, 179, 177, 131, 181, 421, 108, 244, 182, 142, 170, 173, 173, 179, 114, 144, 376, 325, 173, 165, 398, 161, 366, 170, 183, 178, 350, 160, 160, 180, 173, 164, 308, 164, 290, 244, 361, 165, 350, 345, 166, 170, 167, 160, 361, 174, 162, 180, 166, 167, 176, 169, 181, 175, 400, 259, 278, 184, 286, 392, 156, 178, 159, 177, 175, 163, 181, 404, 177, 165, 161, 174, 314, 169, 282, 120, 336, 171, 163, 368, 339, 386, 283, 302, 180, 170, 176, 227, 216, 180, 129, 232, 176, 180, 158, 346, 336, 171, 256, 342, 171, 317, 171, 173, 180, 390, 416, 174, 398, 138, 148, 321, 376, 180, 176, 177, 217, 332, 260, 173, 178, 305, 181, 153, 346, 114, 175, 182, 332, 163, 378, 364, 157, 184, 402, 174, 165, 219, 185, 288, 160, 175, 182, 183, 177, 183, 327, 404, 390, 370, 369, 134, 363, 119, 259, 400, 377, 162, 179, 163, 364, 140, 170, 172, 108, 172, 168, 275, 352, 178, 129, 160, 181, 110, 252, 173, 339, 317, 443, 365, 409, 388, 154, 169, 168, 242, 114, 182, 173, 376, 177, 168, 348, 108, 175, 177, 252, 34, 365, 181, 155, 160, 236, 173, 331, 331, 178, 234, 309, 160, 305, 178, 157, 180, 358, 312, 373, 155, 165, 42, 154, 181, 179, 393, 315, 155, 165, 316, 342, 166, 176, 402, 182, 312, 167, 368, 182, 181, 160, 177, 210]}\nThe number of unique labels of each clients: [58, 51, 61, 46, 59, 62, 59, 57, 53, 57, 46, 47, 60, 58, 58, 52, 48, 59, 57, 58, 54, 59, 59, 46, 52, 56, 57, 61, 53, 55, 57, 49, 45, 49, 58, 55, 56, 54, 58, 62, 49, 45, 56, 55, 55, 30, 43, 61, 61, 60, 59, 47, 52, 45, 59, 50, 58, 61, 57, 59, 50, 59, 61, 56, 18, 58, 61, 51, 61, 62, 49, 60, 60, 54, 56, 57, 51, 56, 52, 59, 9, 61, 49, 49, 39, 54, 53, 58, 61, 54, 55, 53, 55, 55, 58, 52, 53, 53, 58, 52, 54, 53, 45, 52, 55, 60, 62, 58, 60, 34, 36, 61, 55, 53, 60, 60, 50, 58, 60, 60, 50, 60, 58, 58, 61, 47, 61, 58, 44, 57, 60, 58, 57, 52, 60, 60, 56, 49, 61, 60, 60, 60, 50, 55, 58, 53, 52, 59, 55, 58, 48, 55, 58, 55, 52, 62, 61, 57, 58, 54, 59, 53, 10, 55, 52, 47, 44, 60, 51, 57, 46, 51, 62, 58, 53, 47, 49, 61, 42, 61, 41, 50, 58, 53, 48, 61, 59, 56, 59, 61, 56, 60, 57, 57, 52, 50, 59, 59, 55, 53, 52, 58, 47, 54, 61, 61, 48, 61, 60, 56, 58, 61, 60, 46, 61, 59, 54, 61, 40, 61, 56, 35, 59, 53, 56, 57, 60, 56, 59, 56, 41, 58, 56, 34, 56, 59, 59, 54, 59, 59, 55, 34, 62, 52, 59, 61, 58, 54, 59, 56, 58, 56, 55, 50, 57, 59, 55, 49, 48, 49, 59, 56, 62, 57, 50, 60, 57, 56, 52, 56, 60, 60, 53, 60, 60, 55, 55, 58, 15, 42, 55, 57, 58, 58, 56, 58, 60, 52, 58, 53, 54, 52, 58, 56, 51, 53, 59, 61, 51, 57, 54, 54, 61, 57, 58, 58, 55, 61, 28, 59, 36, 58, 62, 59, 58, 59, 61, 59, 56, 61, 39, 54, 38, 60, 58, 57, 50, 59, 49, 61, 60, 57, 59, 59, 62, 58, 57, 52, 57, 57, 52, 59, 55, 62, 57, 56, 56, 50, 60, 59, 42, 53, 57, 60, 58, 55, 59, 54, 55, 61, 59, 61, 61, 58, 43, 56, 61, 53, 58, 54, 56, 60, 54, 59, 60, 56, 60, 49, 60, 52, 59, 57, 31, 52, 60, 56, 57, 60, 51, 51, 58, 52, 51, 55, 49, 60, 58, 55, 56, 45, 59, 61, 49, 60, 58, 62, 58, 61, 60, 62, 56, 60, 59, 51, 56, 41, 61, 43, 59, 60, 58, 60, 62, 54, 62, 47, 22, 50, 62, 56, 56, 28, 57, 58, 55, 62, 52, 58, 52, 57, 57, 59, 59, 52, 59, 62, 58, 50, 57, 53, 56, 59, 60, 56, 53, 59, 60, 58, 51, 56, 62, 59, 58, 51, 54, 62, 62, 53, 56, 49, 49, 57, 59, 56, 55, 56, 58, 54, 55, 59, 55, 56, 59, 55, 57, 43, 61, 54, 57, 50, 57, 58, 35, 52, 59, 34, 61, 37, 51, 57, 55, 54, 62, 60, 57, 60, 59, 56, 39, 52, 52, 52, 57, 59, 46, 57, 43, 52, 62, 51, 61, 51, 59, 54, 54, 48, 42, 59, 56, 51, 35, 59, 51, 42, 59, 59, 54, 52, 60, 62, 56, 56, 55, 39, 57, 60, 56, 60, 61, 60, 55, 50, 43, 62, 59, 56, 58, 60, 62, 61, 57, 57, 58, 58, 60, 54, 50, 62, 59, 55, 53, 60, 50, 62, 61, 57, 49, 61, 54, 59, 54, 44, 22, 58, 54, 62, 60, 58, 56, 55, 52, 61, 50, 57, 51, 56, 59, 33, 60, 60, 54, 44, 51, 55, 53, 59, 57, 56, 53, 58, 61, 45, 53, 58, 55, 58, 50, 50, 39, 54, 46, 53, 58, 58, 62, 44, 51, 61, 58, 59, 60, 59, 52, 59, 57, 61, 56, 61, 52, 58, 59, 54, 59, 59, 57, 60, 56, 62, 46, 55, 58, 56, 39, 45, 56, 57, 58, 62, 57, 56, 34, 52, 57, 57, 57, 61, 53, 60, 59, 57, 58, 58, 60, 61, 57, 58, 56, 60, 62, 58, 53, 57, 53, 57, 50, 54, 58, 54, 58, 54, 54, 61, 61, 57, 56, 59, 56, 61, 58, 59, 55, 61, 58, 55, 16, 62, 60, 57, 58, 58, 60, 62, 54, 60, 56, 58, 53, 53, 50, 59, 60, 51, 57, 59, 56, 55, 61, 57, 62, 60, 61, 56, 60, 57, 59, 44, 51, 60, 38, 47, 54, 54, 56, 59, 58, 58, 56, 61, 60, 58, 57, 61, 59, 59, 61, 62, 57, 59, 59, 61, 47, 60, 57, 51, 58, 60, 50, 58, 55, 53, 56, 53, 44, 61, 42, 62, 61, 46, 61, 50, 58, 60, 51, 52, 49, 56, 52, 50, 60, 58, 51, 58, 58, 57, 56, 57, 56, 57, 57, 53, 59, 58, 61, 38, 48, 59, 59, 52, 62, 58, 50, 58, 57, 45, 59, 24, 62, 53, 59, 58, 41, 49, 57, 58, 33, 51, 49, 59, 58, 59, 50, 58, 60, 58, 48, 61, 53, 51, 54, 53, 62, 54, 58, 59, 44, 58, 58, 44, 54, 60, 49, 60, 60, 56, 58, 54, 54, 56, 50, 58, 59, 60, 58, 60, 58, 57, 59, 56, 58, 60, 59, 60, 53, 60, 54, 22, 30, 56, 58, 52, 62, 56, 55, 58, 40, 55, 58, 53, 58, 49, 61, 55, 60, 50, 53, 51, 60, 57, 58, 56, 60, 52, 52, 60, 62, 56, 62, 54, 59, 47, 53, 58, 52, 39, 55, 61, 56, 60, 56, 56, 49, 56, 60, 60, 46, 62, 58, 56, 61, 54, 54, 57, 60, 53, 60, 51, 55, 56, 46, 58, 55, 54, 52, 57, 59, 59, 58, 56, 49, 50, 59, 57, 54, 60, 56, 60, 58, 50, 59, 58, 61, 61, 61, 57, 50, 60, 57, 61, 55, 57, 50, 53, 52, 60, 53, 61, 10, 59, 56, 61, 61, 51, 55, 56, 61, 62, 53, 57, 62, 58, 58, 41, 34, 60, 55, 57, 59, 55, 57, 39, 45, 56, 61, 59, 61, 57, 60, 58, 57, 50, 47, 57, 53, 52, 62, 56, 58, 58, 59, 53, 61, 60, 56, 61, 60, 60, 55, 59, 61, 60, 60, 58, 59, 49, 59, 54, 57, 60, 55, 56, 56, 58, 56, 61, 52, 57, 39, 50, 52, 56, 54, 61, 58, 58, 58, 50, 56, 58, 59, 39, 61, 60, 58, 59, 49, 40, 50, 56, 46, 60, 57, 46, 58, 55, 55, 57, 60, 59, 61, 60, 59, 58, 57, 42, 53, 55, 56, 56, 58, 29, 56, 39, 57, 51, 58, 55, 59, 57, 57, 58, 56, 36, 62, 54, 54, 60, 53, 45, 53, 54, 60, 34, 50, 58, 50, 51, 58, 61, 23, 58, 59, 59, 56, 57, 48, 62, 46, 45, 59, 54, 58, 60, 58, 58, 51, 59, 59, 50, 42, 52, 55, 55, 55, 57, 56, 58, 57, 61, 62, 10, 60, 59, 38, 61, 51, 60, 48, 56, 61, 56, 57, 56, 57, 57, 54, 57, 54, 54, 27, 61, 53, 61, 55, 55, 60, 59, 60, 59, 48, 57, 59, 62, 54, 32, 60, 60, 53, 42, 47, 58, 50, 60, 52, 50, 39, 51, 57, 55, 53, 61, 60, 52, 49, 61, 49, 60, 59, 49, 56, 57, 58, 58, 61, 54, 58, 59, 61, 59, 54, 60, 49, 50, 57, 62, 61, 52, 57, 35, 54, 59, 55, 58, 54, 55, 60, 61, 54, 59, 54, 60, 49, 59, 58, 56, 59, 44, 56, 56, 51, 61, 40, 46, 59, 59, 56, 54, 53, 51, 59, 58, 56, 59, 56, 57, 60, 60, 61, 53, 48, 58, 51, 60, 48, 58, 51, 59, 60, 58, 57, 61, 48, 57, 57, 61, 57, 60, 55, 58, 29, 52, 50, 51, 58, 52, 61, 60, 57, 35, 58, 51, 59, 62, 32, 56, 60, 58, 57, 60, 61, 60, 46, 40, 60, 61, 56, 59, 54, 56, 52, 60, 54, 57, 55, 58, 50, 35, 55, 60, 54, 58, 59, 60, 62, 60, 58, 61, 55, 53, 57, 59, 46, 54, 58, 58, 10, 50, 48, 54, 60, 51, 52, 59, 57, 52, 56, 53, 55, 62, 52, 59, 55, 59, 61, 48, 54, 57, 57, 58, 59, 54, 62, 52, 60, 57, 59, 56, 60, 61, 47, 59, 39, 59, 55, 58, 51, 56, 61, 50, 29, 55, 50, 55, 56, 58, 62, 61, 52, 55, 43, 61, 60, 57, 56, 59, 60, 61, 60, 51, 56, 51, 59, 58, 30, 58, 54, 57, 49, 59, 61, 57, 57, 60, 61, 60, 55, 38, 56, 56, 52, 58, 40, 61, 57, 55, 60, 55, 59, 27, 57, 47, 55, 62, 47, 60, 57, 52, 59, 53, 56, 47, 60, 49, 60, 58, 49, 61, 57, 55, 54, 60, 62, 56, 49, 58, 59, 55, 60, 57, 55, 55, 59, 58, 60, 49, 58, 54, 53, 62, 56, 62, 59, 38, 61, 61, 47, 59, 53, 58, 61, 51, 50, 56, 58, 58, 55, 50, 48, 58, 51, 58, 54, 56, 57, 57, 56, 54, 59, 47, 57, 50, 60, 50, 41, 44, 55, 54, 55, 56, 58, 59, 59, 57, 61, 52, 58, 53, 58, 61, 49, 55, 54, 57, 51, 60, 61, 61, 39, 53, 61, 42, 53, 55, 58, 57, 51, 54, 62, 54, 59, 61, 58, 59, 51, 52, 56, 53, 57, 54, 53, 54, 53, 59, 53, 55, 56, 57, 52, 59, 44, 60, 59, 31, 54, 10, 57, 57, 44, 58, 58, 57, 50, 46, 55, 60, 59, 54, 49, 60, 56, 55, 55, 59, 57, 60, 49, 52, 60, 61, 33, 56, 56, 47, 60, 59, 61, 57, 54, 48, 55, 57, 57, 59, 45, 61, 58, 59, 56, 58, 55, 62, 53, 54, 55, 58, 55, 54, 59, 58, 57, 50, 57, 57, 51, 42, 52, 60, 58, 61, 59, 54, 54, 50, 58, 56, 56, 55, 57, 60, 58, 50, 49, 39, 54, 57, 57, 32, 57, 60, 62, 34, 52, 62, 58, 56, 62, 31, 53, 44, 48, 56, 56, 38, 60, 52, 62, 56, 57, 57, 38, 53, 56, 57, 57, 61, 59, 56, 58, 53, 50, 52, 55, 62, 61, 61, 52, 39, 40, 60, 60, 57, 62, 55, 59, 53, 61, 56, 58, 48, 58, 62, 58, 54, 54, 55, 52, 60, 55, 53, 59, 59, 56, 57, 57, 56, 57, 46, 41, 61, 60, 58, 58, 59, 54, 58, 53, 59, 52, 53, 60, 41, 60, 58, 60, 54, 38, 54, 59, 51, 56, 58, 48, 61, 59, 55, 58, 37, 59, 58, 58, 59, 52, 56, 59, 50, 60, 50, 59, 62, 62, 42, 60, 59, 58, 49, 62, 61, 62, 61, 60, 54, 49, 46, 52, 59, 58, 56, 57, 54, 46, 56, 44, 53, 54, 41, 58, 53, 53, 54, 53, 48, 60, 55, 58, 62, 42, 47, 53, 56, 61, 60, 58, 59, 50, 58, 49, 57, 51, 59, 59, 61, 50, 56, 52, 57, 58, 43, 61, 54, 56, 56, 61, 59, 52, 61, 60, 54, 56, 60, 60, 43, 58, 56, 55, 53, 57, 57, 46, 51, 56, 41, 53, 62, 60, 57, 53, 58, 58, 60, 53, 58, 59, 59, 53, 42, 59, 58, 51, 60, 53, 61, 55, 55, 61, 62, 58, 60, 56, 58, 31, 56, 46, 55, 55, 51, 57, 58, 61, 52, 59, 56, 58, 40, 47, 58, 57, 61, 61, 59, 59, 60, 59, 61, 60, 58, 54, 54, 62, 58, 60, 58, 58, 44, 47, 57, 61, 49, 57, 57, 55, 59, 56, 58, 54, 60, 50, 58, 56, 59, 61, 58, 55, 53, 55, 56, 51, 48, 53, 56, 60, 58, 57, 61, 44, 57, 55, 51, 48, 56, 57, 47, 56, 58, 59, 52, 59, 56, 55, 53, 31, 58, 46, 28, 58, 56, 59, 57, 53, 57, 59, 54, 60, 62, 61, 37, 60, 61, 57, 53, 55, 52, 61, 62, 58, 58, 55, 55, 62, 54, 55, 61, 57, 54, 56, 56, 59, 60, 45, 56, 61, 57, 56, 58, 58, 58, 52, 53, 56, 62, 50, 55, 51, 51, 55, 52, 59, 58, 58, 57, 49, 61, 59, 59, 51, 60, 59, 50, 58, 57, 57, 60, 59, 59, 57, 56, 48, 58, 55, 56, 61, 62, 62, 60, 56, 52, 55, 50, 57, 46, 53, 54, 46, 50, 59, 57, 58, 59, 49, 53, 58, 56, 51, 51, 56, 59, 55, 47, 60, 43, 61, 52, 55, 54, 62, 59, 59, 59, 53, 61, 58, 57, 62, 58, 48, 58, 58, 44, 61, 51, 52, 31, 62, 56, 56, 62, 58, 60, 62, 57, 59, 58, 61, 59, 44, 58, 55, 53, 50, 56, 52, 62, 61, 61, 61, 60, 55, 60, 45, 61, 57, 60, 53, 46, 45, 62, 57, 54, 52, 56, 57, 52, 54, 57, 53, 60, 59, 55, 61, 55, 54, 48, 58, 55, 62, 57, 49, 49, 58, 55, 59, 49, 59, 44, 51, 57, 49, 57, 55, 61, 38, 56, 51, 57, 46, 56, 58, 51, 59, 54, 55, 54, 51, 48, 58, 61, 55, 60, 50, 57, 58, 55, 59, 55, 50, 59, 60, 61, 57, 62, 62, 54, 60, 58, 55, 57, 54, 49, 33, 59, 58, 61, 59, 62, 50, 60, 60, 59, 56, 58, 58, 61, 41, 60, 60, 56, 62, 51, 59, 56, 52, 49, 57, 59, 57, 61, 59, 58, 59, 10, 60, 42, 42, 56, 52, 58, 58, 58, 57, 52, 61, 62, 57, 57, 39, 54, 47, 60, 58, 61, 60, 59, 60, 59, 50, 59, 53, 44, 61, 49, 59, 55, 55, 51, 61, 49, 58, 54, 52, 59, 39, 56, 53, 57, 46, 53, 56, 55, 57, 59, 55, 60, 36, 61, 41, 59, 44, 55, 55, 58, 55, 61, 62, 59, 50, 57, 48, 56, 60, 44, 55, 54, 55, 52, 60, 55, 58, 59, 54, 52, 54, 59, 43, 60, 57, 47, 50, 46, 56, 59, 53, 48, 59, 52, 50, 60, 53, 43, 56, 61, 51, 57, 53, 56, 60, 54, 54, 60, 59, 48, 55, 55, 49, 60, 52, 54, 57, 60, 55, 52, 60, 57, 57, 53, 56, 55, 49, 62, 52, 59, 49, 55, 32, 56, 51, 57, 55, 59, 57, 60, 51, 58, 52, 57, 56, 60, 57, 47, 60, 60, 55, 62, 48, 60, 61, 61, 56, 40, 61, 56, 10, 60, 58, 58, 59, 50, 57, 57, 58, 58, 56, 58, 61, 62, 62, 57, 57, 46, 56, 58, 52, 61, 59, 56, 59, 49, 56, 59, 59, 53, 57, 58, 57, 62, 58, 52, 56, 58, 51, 59, 52, 59, 58, 58, 58, 60, 61, 54, 59, 41, 58, 59, 60, 61, 51, 56, 53, 61, 59, 54, 50, 41, 59, 56, 58, 58, 60, 57, 58, 60, 58, 55, 55, 10, 55, 53, 60, 59, 52, 61, 43, 60, 58, 49, 56, 56, 55, 55, 59, 59, 59, 39, 58, 61, 56, 59, 59, 57, 58, 58, 50, 59, 60, 62, 53, 57, 52, 56, 62, 54, 56, 61, 59, 61, 57, 50, 47, 57, 58, 57, 48, 58, 60, 56, 35, 51, 60, 59, 58, 61, 56, 60, 61, 62, 50, 62, 59, 58, 61, 56, 57, 55, 57, 59, 56, 48, 57, 53, 62, 60, 60, 56, 58, 47, 57, 61, 50, 60, 57, 48, 53, 59, 57, 53, 60, 60, 48, 58, 49, 59, 59, 57, 60, 56, 50, 47, 61, 48, 59, 60, 45, 59, 58, 58, 55, 24, 49, 61, 58, 56, 59, 61, 54, 60, 53, 48, 57, 59, 49, 59, 58, 52, 43, 60, 52, 57, 53, 60, 60, 62, 55, 49, 56, 52, 48, 60, 58, 54, 61, 52, 42, 57, 55, 58, 58, 58, 61, 59, 59, 60, 61, 58, 52, 61, 57, 60, 61, 58, 56, 57, 56, 49, 53, 61, 52, 59, 39, 60, 59, 48, 58, 60, 62, 53, 59, 60, 58, 56, 53, 51, 60, 36, 54, 57, 54, 49, 55, 59, 51, 57, 55, 57, 59, 55, 52, 58, 60, 61, 56, 62, 54, 58, 61, 59, 62, 58, 55, 56, 54, 55, 61, 51, 59, 59, 32, 60, 49, 57, 58, 62, 56, 61, 59, 50, 56, 56, 56, 55, 48, 49, 60, 57, 57, 56, 53, 60, 59, 61, 56, 59, 58, 45, 54, 62, 56, 58, 60, 58, 55, 54, 53, 59, 47, 57, 59, 19, 56, 56, 56, 59, 58, 15, 55, 54, 26, 52, 61, 59, 54, 60, 61, 62, 57, 52, 60, 60, 57, 46, 59, 55, 55, 48, 51, 59, 48, 59, 53, 58, 24, 56, 60, 47, 56, 55, 59, 52, 57, 57, 60, 57, 53, 57, 57, 50, 60, 57, 50, 61, 59, 50, 41, 55, 62, 53, 58, 61, 56, 54, 56, 58, 50, 57, 60, 59, 56, 59, 59, 60, 52, 48, 55, 53]\n"
],
[
"fig, axs = plt.subplots(1, 2, sharey=True, tight_layout=True)\nsize_dist = training_sets.getSize()['size']\n \nn_bins = 20\naxs[0].hist(size_dist, bins=n_bins) \naxs[0].set_title('Client data size distribution')\n\nlabel_dist = training_sets.getClientLabel()\naxs[1].hist(label_dist, bins=n_bins) \naxs[1].set_title('Client label distribution')\n",
"_____no_output_____"
]
],
[
[
"# Visiualize the clients' data.\n",
"_____no_output_____"
]
],
[
[
"rank=1\nisTest = False\ndropLast = True\npartition = training_sets.use(rank - 1, isTest)\nnum_loaders = min(int(len(partition)/ args.batch_size/2), args.num_loaders)\ndataloader = DataLoader(partition, batch_size=16, shuffle=True, pin_memory=True, timeout=60, num_workers=num_loaders, drop_last=dropLast)",
"_____no_output_____"
],
[
"for data in iter(dataloader):\n plt.imshow(np.transpose(data[0][0].numpy(), (1, 2, 0)))\n break\n",
"WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a0189cb451e365891f6588b79d12960d9db4ef3
| 14,818 |
ipynb
|
Jupyter Notebook
|
notebooks/testAcc_summary.ipynb
|
cpeng-pz/learn2branch
|
bf51d4e69c621703c2f57d6f2628fbc124f84953
|
[
"MIT"
] | 2 |
2020-10-07T12:55:36.000Z
|
2021-04-13T02:44:04.000Z
|
notebooks/testAcc_summary.ipynb
|
cpeng-pz/learn2branch
|
bf51d4e69c621703c2f57d6f2628fbc124f84953
|
[
"MIT"
] | null | null | null |
notebooks/testAcc_summary.ipynb
|
cpeng-pz/learn2branch
|
bf51d4e69c621703c2f57d6f2628fbc124f84953
|
[
"MIT"
] | 4 |
2021-01-11T09:40:36.000Z
|
2021-12-13T15:14:14.000Z
| 32.353712 | 177 | 0.376906 |
[
[
[
"import os\nos.chdir(\"../\")",
"_____no_output_____"
],
[
"import pandas as pd\nimport glob\nfrom scipy.stats import ttest_ind",
"_____no_output_____"
],
[
"resultDir = 'results'",
"_____no_output_____"
],
[
"problem = 'cauctions' # choices=['setcover', 'cauctions', 'facilities', 'indset']\nsampling_Strategies = ['uniform5', 'depthK', 'depthK2']\nsampling_seeds = [0, 0]\nmetric_columns = ['acc@1','acc@3','acc@5','acc@10']",
"_____no_output_____"
],
[
"df = pd.read_csv(f'{resultDir}/cauctions_uniform5_on_uniform5_ss0_test_20210810-152921.csv')",
"_____no_output_____"
],
[
"sample_dist = [sampling_Strategy + 'dist' for sampling_Strategy in sampling_Strategies]\nacc_levels = metric_columns\noutput_idx = pd.MultiIndex.from_product((sample_dist, acc_levels), names=['Sample distribution', 'Accuracy level'])\nout_df = pd.DataFrame(index=output_idx, columns=sampling_Strategies)\nout_df",
"_____no_output_____"
],
[
"mean1 = df[metric_columns].mean()\nstd1 = df[metric_columns].std()\n[\"%5.4f ± %5.4f\" % (m*100, s*100) for (m, s) in zip(mean1, std1)]",
"_____no_output_____"
],
[
"out_df.loc[('uniform5dist',),'uniform5'] = [\"%5.4f ± %5.4f\" % (m*100, s*100) for (m, s) in zip(mean1, std1)]",
"/opt/anaconda3/envs/learn2branch/lib/python3.8/site-packages/IPython/core/async_helpers.py:68: PerformanceWarning: indexing past lexsort depth may impact performance.\n coro.send(None)\n"
],
[
"for sampling_strategy in sampling_Strategies:\n for test_distribution in sampling_Strategies:\n df_str = f'{resultDir}/{problem}_{sampling_strategy}_on_{test_distribution}_ss{ss1}_*'\n df_str = glob.glob(df_str)[-1]\n df = pd.read_csv(df_str)\n mean1 = df[metric_columns].mean()\n std1 = df[metric_columns].std()\n out_df.loc[(f'{test_distribution}dist',),sampling_strategy] = [\"%5.4f ± %5.4f\" % (m*100, s*100) for (m, s) in zip(mean1, std1)]",
"/opt/anaconda3/envs/learn2branch/lib/python3.8/site-packages/IPython/core/async_helpers.py:68: PerformanceWarning: indexing past lexsort depth may impact performance.\n coro.send(None)\n"
],
[
"out_df",
"_____no_output_____"
],
[
"out_df.to_excel('cauctions_testAcc.xlsx')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a018e5be57f61142d1142fe8d3a3de355699273
| 116,811 |
ipynb
|
Jupyter Notebook
|
src/EDA/test_augmentation.ipynb
|
kshannon/lung-nodule-localization
|
8b42844fcd4abf30bd15bbc1f220cc5d12c77382
|
[
"MIT"
] | 3 |
2017-08-07T09:54:30.000Z
|
2017-11-23T23:00:02.000Z
|
src/EDA/test_augmentation.ipynb
|
kshannon/lung-nodule-localization
|
8b42844fcd4abf30bd15bbc1f220cc5d12c77382
|
[
"MIT"
] | 1 |
2018-09-10T13:28:17.000Z
|
2019-11-16T06:57:08.000Z
|
src/EDA/test_augmentation.ipynb
|
kshannon/ucsd-dse-capstone
|
8b42844fcd4abf30bd15bbc1f220cc5d12c77382
|
[
"MIT"
] | 3 |
2018-04-21T19:02:00.000Z
|
2018-04-27T23:30:00.000Z
| 486.7125 | 37,480 | 0.937566 |
[
[
[
"import h5py\nimport numpy as np \n",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"shape = img.shape\nnp.random.choice(len(shape)-2,len(shape)-2,replace=False)",
"_____no_output_____"
],
[
"-\n",
"_____no_output_____"
],
[
"path_to_hdf5 = \"/nfs/site/home/ganthony/64x64x3-patch.hdf5\"\nhdf5_file = h5py.File(path_to_hdf5, 'r') \n \n ",
"_____no_output_____"
],
[
"imgs = hdf5_file[\"input\"][0,:].reshape(1,3,64,64,1).swapaxes(1,3)",
"_____no_output_____"
],
[
"imgs.shape",
"_____no_output_____"
],
[
"img = imgs[0,:,:,:,:]\nimg_rot = img_rotate(img)\n\nplt.subplot(1,2,1)\nplt.imshow(img[:,:,0,0], cmap=\"bone\")\nplt.subplot(1,2,2)\nplt.imshow(img_rot[:,:,0,0], cmap=\"bone\")",
"_____no_output_____"
],
[
"img = imgs[0,:,:,:,:]\nimg_flipped = img_flip(img)\n\nplt.subplot(1,2,1)\nplt.imshow(img[:,:,0,0], cmap=\"bone\")\nplt.subplot(1,2,2)\nplt.imshow(img_flipped[:,:,0,0], cmap=\"bone\")",
"_____no_output_____"
],
[
"img = imgs[0,:,:,:,:]\nimg_flippedr = img_rotate(img_flip(img))\n\nplt.subplot(1,2,1)\nplt.imshow(img[:,:,0,0], cmap=\"bone\")\nplt.subplot(1,2,2)\nplt.imshow(img_flippedr[:,:,0,0], cmap=\"bone\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a01931fd56d791905207684bf990337a17c0511
| 51,677 |
ipynb
|
Jupyter Notebook
|
00-rouze-orig-notebooks/ProjectedReferenceET_main_Future+Historical_v2.ipynb
|
tonybutzer/eto-draft
|
2f2b17a2f370225af4d83cf54f3cd0c1e33b49f4
|
[
"MIT"
] | null | null | null |
00-rouze-orig-notebooks/ProjectedReferenceET_main_Future+Historical_v2.ipynb
|
tonybutzer/eto-draft
|
2f2b17a2f370225af4d83cf54f3cd0c1e33b49f4
|
[
"MIT"
] | null | null | null |
00-rouze-orig-notebooks/ProjectedReferenceET_main_Future+Historical_v2.ipynb
|
tonybutzer/eto-draft
|
2f2b17a2f370225af4d83cf54f3cd0c1e33b49f4
|
[
"MIT"
] | 1 |
2021-01-22T20:26:05.000Z
|
2021-01-22T20:26:05.000Z
| 64.435162 | 18,516 | 0.713219 |
[
[
[
"# Code ported from laptop onto 10.12.68.72 starting on 8/24/2020 (Gregory Rouze)\n\n# To-do: \n# 1) need to separate user functions and main code - I have done this successfully in the offline version, but I'm having a\n# little more trouble in the cloud version\n# 2) Add comments on putpose of individual user functions\n# 3) Run a long term experiment this weekend to see if I run into VPN problems (processing will take a while)\n\n# v2 differs from v1 in that excess code that I used to prototype this in the cloud (from my local laptop)\n# was removed.\n",
"_____no_output_____"
],
[
"'''Import relevant packages, functions, and user functions used in this reference ET derivation'''\n\nimport boto3\nfrom contextlib import contextmanager \nimport earthpy.spatial as es\nimport fsspec\nfrom math import e\nimport rasterio as rio\nimport xarray as xr\nfrom osgeo.gdalnumeric import *\nfrom osgeo.gdalconst import *\nimport os\nfrom osgeo import gdal, osr, gdal_array, gdalconst\nimport pandas as pd\nimport re\nimport numpy as np\nimport sys\nimport ogr\nfrom rasterio import Affine, MemoryFile\nfrom rasterio.enums import Resampling\nimport rioxarray\nfrom shapely.geometry import Point, Polygon\nimport geopandas as gpd\nfrom shapely.geometry import box\nfrom fiona.crs import from_epsg\nfrom matplotlib import pyplot as plt\nfrom rasterio.plot import plotting_extent\nimport earthpy.plot as ep\nimport math\nfrom itertools import chain\nfrom ipynb.fs.full.ProjectedReferenceET_Classes_Functions import ET0_PM, aggregate_raster_inmem, resample_raster_write, \\\nreproject_raster, grepfxn, rastermath, lapply_brick, write_geotiff, atmospheric_pressure, relative_fromspecific, unique, s3_push_delete_local\nfrom ipynb.fs.full.ProjectedReferenceET_Classes_Functions import *\nimport boto3\n\n'''Set home path if not done so already'''\n\nos.getcwd()\nos.chdir('/home/jupyter-rouze')",
"_____no_output_____"
],
[
"'''Read configuration file and parse out the inputs line by line'''\n\n# Note that the difference between historical and future outputs in cloud are based on these 2 configuration files.\nconfigurationfile = 'configurationfile_referenceET_test_future.ini'\n# configurationfile = 'configurationfile_referenceET_test_historical.ini'\n\n# Note: if you want run rcp 8.5, then all you have to do is change the rcp_source parameter from within config file\n# It only affects grepfxn(rcp_source,all_files) below\n\nwith open(configurationfile) as f:\n data = {}\n for line in f:\n key, value = line.strip().split(' = ')\n data[key] = value\n \nprint(data)\n\nmodel_files = data['model_files']\ndata_source = data['data_source']\noutput_folder = data['output_folder']\nelevfile = data['elevfile']\ntiffolder = data['tiffolder']\nET0_method = data['ET0_method']\nET0_winddat = data['ET0_winddat']\nET0_crop = data['ET0_crop']\nto_clip = data['to_clip']\nmodel = data['model']\nnorthmost = float(data['northmost'])\nsouthmost = float(data['southmost'])\nwestmost = float(data['westmost'])\neastmost = float(data['eastmost'])\npad_factor = float(data['pad_factor'])\nrcp_source = data['rcp_source']\nMACA_start_bucket = data['MACA_start_bucket']\n\n'''This is needed to retrieve the netCDF files from the dev-et-data AWS bucket'''\n# os.chdir(model_files)\nfs = fsspec.filesystem(model_files, anon=False, requester_pays=True)\n\nall_files = fs.find(MACA_start_bucket)\n\n# This prints all of the files in dev-et-data/in/DelawareRiverBasin/ or MACA_start_bucket...a big set of outputs, so skipped\n# print(all_files)",
"{'model_files': 's3', 'data_source': 'METDATA', 'output_folder': 'in', 'elevfile': 'in/Elevation/cgiar_srtmmerge.tif', 'tiffolder': 'C:/Users/GRouze/Desktop/ReferenceET_Python/Future-MACA/Individual/geotiffs', 'ET0_method': 'PM', 'ET0_winddat': 'yes', 'ET0_crop': 'short', 'to_clip': 'True', 'model': 'MIROC5', 'northmost': '42.54', 'southmost': '38.6', 'westmost': '-76.3', 'eastmost': '-74.23', 'pad_factor': '0.50', 'rcp_source': 'rcp45', 'bucket_filepath_root': 'dev-et-data/out/DelawareRiverBasin/', 'bucket_filepath_branch': 'Run08262020_Firstattemptcloudpush', 'MACA_start_bucket': 'dev-et-data/in/DelawareRiverBasin/'}\n"
],
[
"# THE CODE BELOW IS PARSED FROM THE CONDIITION WHEN DEALING WITH METDATA",
"_____no_output_____"
],
[
"# Split models apart that are to be used for ensemble averaging\nmodels_parsed = [x.strip() for x in model.split(',')]\n\n# Whittle down the number of files if the folder contains both rcp 4.5 and rcp 8.5 files\n# Right now, the code can only handle one model of METDATA output (8/21/2020)\nrcp_all_files = [grepfxn(rcp_source,all_files)][0]\n\n# Iterate the files by each each specified model\nmodels_list=[]\nfor i in range(len(models_parsed)):\n model_files_loop = [grepfxn(models_parsed[i],rcp_all_files)][0]\n models_list.append(model_files_loop)\n \n# Flatten series of lists into one list\nrcp_all_files = list(chain(*models_list))\n\n# prints all netCDF files from 1950-2100 from MACA (radiation, precipitation, wind etc.)\nprint(rcp_all_files)\n",
"['dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2011_2015_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2016_2020_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2021_2025_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2026_2030_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2031_2035_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2036_2040_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2041_2045_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2046_2050_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2051_2055_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2056_2060_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2061_2065_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2066_2070_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2071_2075_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2076_2080_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2081_2085_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2086_2090_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2091_2095_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2096_2099_CONUS_daily.nc']\n"
],
[
"# Find and compile the year blocks into a list\ndfis=[]\nfor out in rcp_all_files:\n a=out.split('_')\n dfi = a[5]+'_'+a[6]\n dfis.append(dfi)\n\n# print(dfis)\n \n# Distill the above list into unique year blocks, as there will be duplicates from multiple climate inputs\nyear_all=unique(dfis);print(year_all)\n\n# For prototyping only\nyear_block=0\n# print(year_all)\n# Print the first entry in the year list\nprint(year_all[year_block])",
"['2006_2010', '2011_2015', '2016_2020', '2021_2025', '2026_2030', '2031_2035', '2036_2040', '2041_2045', '2046_2050', '2051_2055', '2056_2060', '2061_2065', '2066_2070', '2071_2075', '2076_2080', '2081_2085', '2086_2090', '2091_2095', '2096_2099']\n2006_2010\n"
],
[
"# Take out the components of the for loop below for showcasing to other members of the ET group \n\n# loop by each block associated with the MACA netCDF file naming structure\nfor year_block in range(0,len(year_all)):\n\n year_block_files = grepfxn(year_all[year_block],rcp_all_files)\n \n print(year_block_files)\n\n bounds=[southmost,northmost,westmost,eastmost]\n\n rcp_pr = lapply_brick(grepfxn(\"pr\",year_block_files), 'precipitation', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n # downwelling shortwave radiation\n rcp_rsds = lapply_brick(grepfxn(\"rsds\",year_block_files), 'surface_downwelling_shortwave_flux_in_air', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n # maximum air temperature\n rcp_tasmax = lapply_brick(grepfxn(\"tasmax\",year_block_files), 'air_temperature', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n # minimum air temperature\n rcp_tasmin = lapply_brick(grepfxn(\"tasmin\",year_block_files), 'air_temperature', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n # Now repeat above for the rcp 8.5 model outputs below\n\n if(data_source == 'METDATA'):\n\n rcp_uas = lapply_brick(grepfxn(\"uas\",year_block_files), 'eastward_wind', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n rcp_vas = lapply_brick(grepfxn(\"vas\",year_block_files), 'northward_wind', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n rcp_rhsmax = lapply_brick(grepfxn(\"rhsmax\",year_block_files), 'relative_humidity', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n rcp_rhsmin = lapply_brick(grepfxn(\"rhsmin\",year_block_files), 'relative_humidity', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n # The section below is meant to convert netCDF files into geoTIFFs\n \n src = rio.open(elevfile)\n # elevation_full_aggregate = aggregate_raster_inmem(src,scale=0.5)\n aggoutput_name='elevation_aggregated.tif'\n \n resample_raster_write(src, name= aggoutput_name,scale=0.5)\n \n dst_filename='elevation_aggregated_resampled.tif'\n match_filename=rcp_pr[0][0].name\n reproject_raster(aggoutput_name, match_filename,dst_filename)\n \n elevation_array=rio.open(dst_filename).read(1)\n\n # from datetime import datetime - will need to update to make start/end adaptive (7/28/2020)\n# start_year=year_all[year_block][0:4]\n# end_year=year_all[year_block][5:9]\n start_year=year_all[year_block][0:4]\n end_year=year_all[year_block][5:9]\n\n start=start_year+'-01-01'\n end=end_year+'-12-31'\n datetimes = pd.date_range(start=start,end=end)\n# i=10\n \n for i in range(0,rcp_pr[0][0].count):\n\n doy_loop = pd.Period(datetimes[i],freq='D').dayofyear\n year_loop = pd.Period(datetimes[i],freq='D').year\n\n # step 1: extract ith band from the raster stack\n # step 2: stack those ith bands together\n # step 3: do raster mean math from step 2\n pr_stack=[]\n\n # Purpose: create stacks of variables individually - this is like brick in R\n pr_ensemble = []\n rsds_ensemble = []\n tasmax_ensemble = []\n tasmin_ensemble = []\n\n j = 0\n\n # should be 1 array for each variable (mean of x ensembles for a given doy)\n # rcp_pr[0][0].read(1, masked=False).shape\n rcp_pr_doy = rastermath(rcp_pr[0], i)\n rcp_rsds_doy = rastermath(rcp_rsds[0], i)\n rcp_tasmax_doy = rastermath(rcp_tasmax[0], i)\n rcp_tasmin_doy = rastermath(rcp_tasmin[0], i)\n\n dims = np.shape(rcp_pr_doy[0])\n rows = dims[0]\n cols = dims[1]\n constant_1_dat = np.full((rows,cols), 17.27)\n constant_2_dat = np.full((rows,cols), 0.6108)\n constant_3_dat = np.full((rows,cols), 273.15)\n constant_4_dat = np.full((rows,cols), 237.3)\n\n rcp_vs_tmax_array = constant_2_dat * np.exp(constant_1_dat * (rcp_tasmax_doy[0]-constant_3_dat) / ( (rcp_tasmax_doy[0]-constant_3_dat) + constant_4_dat)) # Equation S2.5\n rcp_vs_tmin_array = constant_2_dat * np.exp(constant_1_dat * (rcp_tasmin_doy[0]-constant_3_dat) / ( (rcp_tasmin_doy[0]-constant_3_dat) + constant_4_dat)) # Equation S2.5\n rcp_saturatedvapor_doy = (rcp_vs_tmax_array + rcp_vs_tmin_array)/2 \n\n if(data_source == 'METDATA'): # line 180 from R script\n\n # All of these are arrays by the way\n rcp_rhsmax_doy = rastermath(rcp_rhsmax[0], i)\n rcp_rhsmin_doy = rastermath(rcp_rhsmin[0], i)\n rcp_uas_doy = rastermath(rcp_uas[0], i)\n rcp_vas_doy = rastermath(rcp_vas[0], i)\n\n # was below are just arrays, not metadata profiles\n rcp_was_doy_10m = np.sqrt(rcp_uas_doy[0]**2 + rcp_vas_doy[0]**2 )\n\n rcp_actualvapor_doy = (rcp_vs_tmin_array * rcp_rhsmax_doy[0]/100 + rcp_vs_tmax_array * rcp_rhsmin_doy[0]/100)/2\n\n da = xr.open_rasterio(rcp_pr[1])\n da_r = rio.open(rcp_pr[1])\n ny, nx = len(da['y']), len(da['x'])\n longitude_array, latitude_array = np.meshgrid(da['x'], da['y'])\n\n latitude_array_rad = latitude_array * (math.pi/180)\n\n # Wind speed at 2 meters\n z = np.full((rows,cols), 10)\n array_487 = np.full((rows,cols), 4.87)\n array_678 = np.full((rows,cols), 67.8)\n array_542 = np.full((rows,cols), 5.42)\n\n if (data_source == 'METDATA'):\n rcp_was_doy_2m = rcp_was_doy_10m * array_487 / np.log(array_678*z - array_542) # Equation S5.20 for PET formulations other than Penman\n else:\n rcp_was_doy_2m = rcp_was_doy_10m[0] * array_487 / np.log(array_678*z - array_542) # Equation S5.20 for PET formulations other than Penman\n\n doy_array = np.full((rows,cols), i+1)\n\n rcp_pr_doy[1]['count']=1\n rcp_tasmin_doy[1]['count']=1\n rcp_tasmax_doy[1]['count']=1\n\n # To-do: go ahead and developed ET0 directly as opposed to the R implementation(7/29)\n\n ET0_inputarrays_rcp = [rcp_pr_doy[0], rcp_rsds_doy[0], rcp_tasmin_doy[0],\n rcp_tasmax_doy[0],rcp_was_doy_2m,rcp_saturatedvapor_doy,\n rcp_actualvapor_doy,elevation_array,latitude_array_rad,doy_array]\n\n # NameError: name 'ET0_method' is not defined\n if ET0_method == \"yes\":\n if ET0_crop != \"short\" and ET0_crop != \"tall\":\n stop(\"Please enter 'short' or 'tall' for the desired reference crop type\")\n else:\n alpha = 0.23 # albedo for both short and tall crop\n if (ET0_crop == \"short\"):\n z0 = 0.02 # roughness height for short grass\n else:\n z0 = 0.1 # roughness height for tall grass\n else:\n z0 = 0.02 # roughness height for short grass\n alpha = 0.25 # semi-desert short grass - will not be used for calculation - just informative\n\n constants=[alpha, z0]\n\n ET0_rcp = ET0_PM(ET0_inputarrays_rcp,ET0_method,ET0_winddat,ET0_crop,constants)\n ET0_rcp.incoming_shortwave()\n ET0_rcp.outgoing_shortwave()\n ET0_rcp.outgoing_longwave()\n ET0_rcp.net_radiation()\n ET0_rcp_array_from_class = ET0_rcp.ET0_calcs()\n ET0_rcp_array_final = ET0_rcp_array_from_class.astype('float32')\n\n rcp_pr_doy[1]['count']=1\n\n os.chdir('/home/jupyter-rouze')\n gTIFF_filename = write_geotiff(data=ET0_rcp_array_final,meta=rcp_pr_doy[1],var_name='reference_evapotranspiration',\n doy=doy_loop,year=year_loop,folder=output_folder)\n\n local_file = output_folder+'/' + 'reference_evapotranspiration' + '/' + gTIFF_filename \n bucket = 'dev-et-data'\n\n bucket_filepath = 'in/DelawareRiverBasin/ETo/'+ str(year_loop) + '/' + gTIFF_filename \n\n os.chdir('/home/jupyter-rouze')\n s3_push_delete_local(local_file, bucket, bucket_filepath)\n",
"_____no_output_____"
],
[
"##################### Break down for loop by components for showcasing",
"_____no_output_____"
],
[
"# range(0,len(year_all))\nyear_block_files = grepfxn(year_all[0],rcp_all_files)\nprint(year_block_files)\n\nbounds=[southmost,northmost,westmost,eastmost]\n\n'''For a given input netCDF file, lapplybrick() creates a rasterio object that is clipped specifically for Delaware'''\n\nrcp_pr = lapply_brick(grepfxn(\"pr\",year_block_files), 'precipitation', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n# downwelling shortwave radiation\nrcp_rsds = lapply_brick(grepfxn(\"rsds\",year_block_files), 'surface_downwelling_shortwave_flux_in_air', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n# maximum air temperature\nrcp_tasmax = lapply_brick(grepfxn(\"tasmax\",year_block_files), 'air_temperature', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n# minimum air temperature\nrcp_tasmin = lapply_brick(grepfxn(\"tasmin\",year_block_files), 'air_temperature', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n# Now repeat above for the rcp 8.5 model outputs below\n\nif(data_source == 'METDATA'):\n\n rcp_uas = lapply_brick(grepfxn(\"uas\",year_block_files), 'eastward_wind', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n rcp_vas = lapply_brick(grepfxn(\"vas\",year_block_files), 'northward_wind', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n rcp_rhsmax = lapply_brick(grepfxn(\"rhsmax\",year_block_files), 'relative_humidity', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n rcp_rhsmin = lapply_brick(grepfxn(\"rhsmin\",year_block_files), 'relative_humidity', model_files,tiffolder,data_source,to_clip=to_clip,bounds=bounds,pad_factor=pad_factor)\n\n # The section below is meant to convert netCDF files into geoTIFFs\n\nprint(rcp_pr)",
"['dev-et-data/in/DelawareRiverBasin/PPT/Climatology/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RAD/Climatology/macav2metdata_rsds_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMAX/Climatology/macav2metdata_rhsmax_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/RH/RHSMIN/Climatology/macav2metdata_rhsmin_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmax/macav2metdata_tasmax_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/Temp/Climatology/Tmin/macav2metdata_tasmin_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/UAS/Climatology/macav2metdata_uas_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc', 'dev-et-data/in/DelawareRiverBasin/WIND/VAS/Climatology/macav2metdata_vas_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.nc']\n([<open DatasetReader name='in/temp/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.tif' mode='r'>], 'in/temp/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.tif')\n"
],
[
"'''Read and resample elevation to match raster characteristics from all other MACA inputs needed for reference ET'''\n\nsrc = rio.open(elevfile)\n# elevation_full_aggregate = aggregate_raster_inmem(src,scale=0.5)\naggoutput_name='elevation_aggregated.tif'\n\nresample_raster_write(src, name= aggoutput_name,scale=0.5)\n\ndst_filename='elevation_aggregated_resampled.tif'\nmatch_filename=rcp_pr[0][0].name\nreproject_raster(aggoutput_name, match_filename,dst_filename)\n\nelevation_array=rio.open(dst_filename).read(1)\n\n# from datetime import datetime - will need to update to make start/end adaptive (7/28/2020)\nstart_year=year_all[year_block][0:4]\nend_year=year_all[year_block][5:9]\n\nstart=start_year+'-01-01'\nend=end_year+'-12-31'\ndatetimes = pd.date_range(start=start,end=end)\n# i=10\n\nprint(start)\nprint(end)",
"2006-01-01\n2010-12-31\n"
],
[
"# for i in range(0,rcp_pr[0][0].count):\n \ndoy_loop = pd.Period(datetimes[0],freq='D').dayofyear\nyear_loop = pd.Period(datetimes[0],freq='D').year\n\nprint(doy_loop)\nprint(year_loop)\n\n# step 1: extract ith band from the raster stack\n# step 2: stack those ith bands together\n# step 3: do raster mean math from step 2\npr_stack=[]\n\n# Purpose: create stacks of variables individually - this is like brick in R\npr_ensemble = []\nrsds_ensemble = []\ntasmax_ensemble = []\ntasmin_ensemble = []\n",
"1\n2006\n"
],
[
"# Here we are using index = 0 or January 1 of the first year in the given netCDF file (e.g. 2021, 2026 2031, 2036 etc.)\n\n# should be 1 array for each variable (mean of x ensembles for a given doy)\n# rcp_pr[0][0].read(1, masked=False).shape\n\nprint(rcp_pr)\nprint(rcp_pr[0]) # rasterio opened geoTIFF of precipitation \nprint(rcp_pr[0][0])\n'''rastermath() averages across all models...however, since we are only dealing with one model for now (i.e. MIROC5),\nthe rastermath() APPEARS to be redundant. However, future iterations of this code, such as rastermath(), are expecting\nan ensemble average of inputs, which are better for to gauge model uncertainty.'''\nrcp_pr_doy = rastermath(rcp_pr[0], i)\n\n# print(rcp_pr_doy)\n# print(rcp_pr_doy[0]) # array\n# print(rcp_pr_doy[1]) # geoTIFF metadata",
"([<open DatasetReader name='in/temp/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.tif' mode='r'>], 'in/temp/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.tif')\n[<open DatasetReader name='in/temp/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.tif' mode='r'>]\n<open DatasetReader name='in/temp/macav2metdata_pr_MIROC5_r1i1p1_rcp45_2006_2010_CONUS_daily.tif' mode='r'>\n"
],
[
"'''Repeat rastermath() for all other inputs needed for reference ET'''\n\nrcp_rsds_doy = rastermath(rcp_rsds[0], i)\nrcp_tasmax_doy = rastermath(rcp_tasmax[0], i)\nrcp_tasmin_doy = rastermath(rcp_tasmin[0], i)\n\ndims = np.shape(rcp_pr_doy[0])\nrows = dims[0]\ncols = dims[1]\n\n'''Derive saturated vapor pressure for Penman-Monteith Approximation'''\n\nconstant_1_dat = np.full((rows,cols), 17.27)\nconstant_2_dat = np.full((rows,cols), 0.6108)\nconstant_3_dat = np.full((rows,cols), 273.15)\nconstant_4_dat = np.full((rows,cols), 237.3)\n\nrcp_vs_tmax_array = constant_2_dat * np.exp(constant_1_dat * (rcp_tasmax_doy[0]-constant_3_dat) / ( (rcp_tasmax_doy[0]-constant_3_dat) + constant_4_dat)) # Equation S2.5\nrcp_vs_tmin_array = constant_2_dat * np.exp(constant_1_dat * (rcp_tasmin_doy[0]-constant_3_dat) / ( (rcp_tasmin_doy[0]-constant_3_dat) + constant_4_dat)) # Equation S2.5\nrcp_saturatedvapor_doy = (rcp_vs_tmax_array + rcp_vs_tmin_array)/2 # s2.6\n",
"_____no_output_____"
],
[
"if(data_source == 'METDATA'): # line 180 from R script\n\n # All of these are arrays by the way\n rcp_rhsmax_doy = rastermath(rcp_rhsmax[0], i)\n rcp_rhsmin_doy = rastermath(rcp_rhsmin[0], i)\n rcp_uas_doy = rastermath(rcp_uas[0], i)\n rcp_vas_doy = rastermath(rcp_vas[0], i)\n\n # was below are just arrays, not metadata profiles\n rcp_was_doy_10m = np.sqrt(rcp_uas_doy[0]**2 + rcp_vas_doy[0]**2 )\n\n # inputs: min/max saturated vapor pressure from air temp., min/max relative humidity (assuming relative humidity is present)\n rcp_actualvapor_doy = (rcp_vs_tmin_array * rcp_rhsmax_doy[0]/100 + rcp_vs_tmax_array * rcp_rhsmin_doy[0]/100)/2 # s2.7\n",
"_____no_output_____"
],
[
"da = xr.open_rasterio(rcp_pr[1])\nda_r = rio.open(rcp_pr[1])\nny, nx = len(da['y']), len(da['x'])\nlongitude_array, latitude_array = np.meshgrid(da['x'], da['y'])\n\n# Latitude (needed for Extraterrestrial radiation or Ra), in radians\nlatitude_array_rad = latitude_array * (math.pi/180)\n\n# Convert from wind speed at 10 meters to wind speed at 2 meters\nz = np.full((rows,cols), 10)\narray_487 = np.full((rows,cols), 4.87)\narray_678 = np.full((rows,cols), 67.8)\narray_542 = np.full((rows,cols), 5.42)\n\nif (data_source == 'METDATA'):\n rcp_was_doy_2m = rcp_was_doy_10m * array_487 / np.log(array_678*z - array_542) # Equation S5.20 for PET formulations other than Penman\nelse:\n rcp_was_doy_2m = rcp_was_doy_10m[0] * array_487 / np.log(array_678*z - array_542) # Equation S5.20 for PET formulations other than Penman\n\ndoy_array = np.full((rows,cols), i+1)\n\nrcp_pr_doy[1]['count']=1\nrcp_tasmin_doy[1]['count']=1\nrcp_tasmax_doy[1]['count']=1\n\n# To-do: go ahead and developed ET0 directly as opposed to the R implementation(7/29)",
"_____no_output_____"
],
[
"# To-do: go ahead and developed ET0 directly as opposed to the R implementation(7/29)\n\n# Combine all of the inputs into an list of arrays\n\nET0_inputarrays_rcp = [rcp_pr_doy[0], rcp_rsds_doy[0], rcp_tasmin_doy[0],\n rcp_tasmax_doy[0],rcp_was_doy_2m,rcp_saturatedvapor_doy,\n rcp_actualvapor_doy,elevation_array,latitude_array_rad,doy_array]\n\n# NameError: name 'ET0_method' is not defined\nif ET0_method == \"yes\":\n if ET0_crop != \"short\" and ET0_crop != \"tall\":\n stop(\"Please enter 'short' or 'tall' for the desired reference crop type\")\n else:\n alpha = 0.23 # albedo for both short and tall crop\n if (ET0_crop == \"short\"):\n z0 = 0.02 # roughness height for short grass\n else:\n z0 = 0.1 # roughness height for tall grass\nelse:\n z0 = 0.02 # roughness height for short grass\n alpha = 0.25 # semi-desert short grass - will not be used for calculation - just informative\n\nconstants=[alpha, z0]\n\n'''Initialize the ET0 class from the imported Jupyter notebook external to this one (see top for imports)'''\nET0_rcp = ET0_PM(ET0_inputarrays_rcp,ET0_method,ET0_winddat,ET0_crop,constants)\nET0_rcp.incoming_shortwave()\nET0_rcp.outgoing_shortwave()\nET0_rcp.outgoing_longwave()\nET0_rcp.net_radiation()\nET0_rcp_array_from_class = ET0_rcp.ET0_calcs()\nET0_rcp_array_final = ET0_rcp_array_from_class.astype('float32')",
"_____no_output_____"
],
[
"print(ET0_rcp_array_final)\n\nresult = ET0_rcp_array_final.ravel() \ncleanedList = [x for x in result if str(x) != 'nan']\n\nfrom scipy import stats\nstats.describe(cleanedList)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nplt.imshow(ET0_rcp_array_final)\nplt.show()\nplt.title(\"Histogram with 'auto' bins\")\nplt.hist(ET0_rcp_array_final)\nplt.show()",
"_____no_output_____"
],
[
"rcp_pr_doy[1]['count']=1\n\nos.chdir('/home/jupyter-rouze')\ngTIFF_filename = write_geotiff(data=ET0_rcp_array_final,meta=rcp_pr_doy[1],var_name='reference_evapotranspiration',\n doy=doy_loop,year=year_loop,folder=output_folder)\n\nlocal_file = output_folder+'/' + 'reference_evapotranspiration' + '/' + gTIFF_filename \nbucket = 'dev-et-data'\n\nbucket_filepath = 'in/DelawareRiverBasin/ETo/'+ str(year_loop) + '/' + gTIFF_filename \n\nos.chdir('/home/jupyter-rouze')",
"_____no_output_____"
],
[
"reread = rio.open(local_file)\nreread.meta\nprint(round(reread.meta['transform'][0],4),round(reread.meta['transform'][4],4))",
"_____no_output_____"
],
[
"'''Push newly created geoTIFF into specified bucket and its filepath'''\n\ns3_push_delete_local(local_file, bucket, bucket_filepath)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a01b7566d6f1f4b5e34f930892cc5182ca4a5ce
| 417,207 |
ipynb
|
Jupyter Notebook
|
Policy_Section/ABM_Paper_Policy_Section.ipynb
|
pdehaye/COVID19-Demography
|
33ccaeedf713d57de1f6acb2423bf3b1f2173ba7
|
[
"MIT"
] | 13 |
2020-03-31T09:35:27.000Z
|
2020-07-28T05:49:04.000Z
|
Policy_Section/ABM_Paper_Policy_Section.ipynb
|
pdehaye/COVID19-Demography
|
33ccaeedf713d57de1f6acb2423bf3b1f2173ba7
|
[
"MIT"
] | 4 |
2020-04-01T10:55:23.000Z
|
2021-11-24T11:19:38.000Z
|
Policy_Section/ABM_Paper_Policy_Section.ipynb
|
pdehaye/COVID19-Demography
|
33ccaeedf713d57de1f6acb2423bf3b1f2173ba7
|
[
"MIT"
] | 6 |
2020-03-31T14:29:15.000Z
|
2021-06-17T07:33:41.000Z
| 207.256334 | 44,172 | 0.861647 |
[
[
[
"## Code for policy section",
"_____no_output_____"
]
],
[
[
"# Load libraries\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib as mlp\n\n# Ensure type 1 fonts are used\nmlp.rcParams['ps.useafm'] = True\nmlp.rcParams['pdf.use14corefonts'] = True\nmlp.rcParams['text.usetex'] = True\n\nimport seaborn as sns\nimport pandas as pd\nimport pickle\nimport itertools as it",
"_____no_output_____"
]
],
[
[
"## Solve for the final size of the outbreak in Lombardy, Italy",
"_____no_output_____"
]
],
[
[
"# Estimate based on the value of the basic reproduction number as provided by best fit \n# For formula, see here: https://web.stanford.edu/~jhj1/teachingdocs/Jones-on-R0.pdf\nfrom sympy import Symbol, solve, log\n\nx = Symbol('x')\nr0 = 3.16\ns_inf = solve(log(x)-r0_max*(x-1),x)[0]\n\nprint(\"% of the population that is still susceptible by the end of the outbreak in Lombardy, Italy: {0:10.4f}\".format(s_inf*100))\nprint(\"% of the population that has ever been infected by the end of the outbreak in Lombardy, Italy: {0:10.4f}\".format(100-s_inf*100))",
"% of the population that is still susceptible by the end of the outbreak in Lombardy, Italy: 4.9629\n% of the population that has ever been infected by the end of the outbreak in Lombardy, Italy: 95.0371\n"
],
[
"# Set of colors\n# For age group policies\ncolor_list_shahin = ['orange','green','blue','purple','black']\n# For additional baseline policies (50% or 100% of the population being asked to shelter-in-place)\ncolor_list_add = ['dodgerblue','hotpink']",
"_____no_output_____"
],
[
"# Number of distinct ages in the UN age distribution\n# Currently ages 0-100, with each age counted separately\nn_ages = 101\n\n# Shelter-in-place probabilities per age group, equivalent to 1 million of the considered generation in each case\nage_ranges = [(0,14), (15,29), (30,49), (50,69), (70,100)]\nisolation_rates_by_age = [0.803689, 0.713332, 0.380842, 0.358301, 0.516221]\n\n# Learn about the structure of the folder containing the simulation results\nall_possible_combos = []\n\nfor a, iso_rate in zip(age_ranges, isolation_rates_by_age):\n combo = np.zeros(n_ages)\n combo[a[0]:a[1]+1] = iso_rate\n all_possible_combos.append(combo)\n \n# Two possibilities for mean time to isolation: either 4.6 days (default value) or a large number to mimic no isolation in place\nmean_time_to_isolations = [4.6, 10000]\nall_possible_combos = list(it.product(mean_time_to_isolations, all_possible_combos))\nNUM_COMBOS = len(all_possible_combos)\nprint(\"NUM COMBOS:\",NUM_COMBOS)",
"NUM COMBOS: 10\n"
],
[
"mtti_val_even = all_possible_combos[0][0]\ncombo_frac_stay_home_even = all_possible_combos[0][1]\nmtti_val_odd = all_possible_combos[1][0]\ncombo_frac_stay_home_odd = all_possible_combos[1][1]\n\nprint(\"Value of mean time to isolation - even index: \", mtti_val_even)\nprint(\"Combo fraction stay home - even index\", combo_frac_stay_home_even)\n\nprint(\"Value of mean time to isolation - odd index: \", mtti_val_odd)\nprint(\"Combo fraction stay home - odd index: \", combo_frac_stay_home_odd)",
"Value of mean time to isolation - even index: 4.6\nCombo fraction stay home - even index [0.803689 0.803689 0.803689 0.803689 0.803689 0.803689 0.803689 0.803689\n 0.803689 0.803689 0.803689 0.803689 0.803689 0.803689 0.803689 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. ]\nValue of mean time to isolation - odd index: 4.6\nCombo fraction stay home - odd index: [0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.713332\n 0.713332 0.713332 0.713332 0.713332 0.713332 0.713332 0.713332 0.713332\n 0.713332 0.713332 0.713332 0.713332 0.713332 0.713332 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. ]\n"
],
[
"# Learn about the structure of the folder containing the simulation results\nall_possible_combos = []\n\nfor a in age_ranges:\n # Either 50% or 100% of the population in each age group is asked to shelter-in-place\n for val in [0.5, 1.0]:\n combo = np.zeros(n_ages)\n combo[a[0]:a[1]+1]=val\n all_possible_combos.append(combo)\n\n# Two possibilities for mean time to isolation: either 4.6 days (default value) or a large number to mimic no isolation in place\nmean_time_to_isolations = [4.6, 10000]\nall_possible_combos = list(it.product(mean_time_to_isolations, all_possible_combos))\nNUM_COMBOS = len(all_possible_combos)\nprint(\"NUM COMBOS:\",NUM_COMBOS)",
"NUM COMBOS: 20\n"
],
[
"mtti_val_even = all_possible_combos[0][0]\ncombo_frac_stay_home_even = all_possible_combos[0][1]\n\nmtti_val_odd = all_possible_combos[1][0]\ncombo_frac_stay_home_odd = all_possible_combos[1][1]\n\nprint(\"Value of mean time to isolation - even index: \", mtti_val_even)\nprint(\"Combo fraction stay home - even index: \", combo_frac_stay_home_even)\n\nprint(\"Value of mean time to isolation - odd index: \", mtti_val_even)\nprint(\"Combo fraction stay home - odd index: \", combo_frac_stay_home_even)",
"Value of mean time to isolation - even index: 4.6\nCombo fraction stay home - even index: [0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]\nValue of mean time to isolation - odd index: 4.6\nCombo fraction stay home - odd index: [0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]\n"
],
[
"# Set font sizes for plots\nlegend_fontsize = 13\ntitle_fontsize = 15\nxlab_fontsize = 23\nylab_fontsize = 23\nxtick_fontsize = 17\nytick_fontsize = 17",
"_____no_output_____"
]
],
[
[
"## Functions to be used to plot four subgraphs in Figure 8",
"_____no_output_____"
],
[
"### Function to be used to plot the projected percentage of infected people in the population over time, in the absence of physical distancing\n### Figures 8(a) and 8(b)",
"_____no_output_____"
]
],
[
[
"def perc_infected_age_group_node_removal(pop_size, group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder1, folder2, filename1, filename2, option, specific_title):\n if option == 2:\n nb = 0\n \n # baseline\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Mild = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n\n print(\"Baseline 0: No intervention\")\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n \n plt.plot(Infected_Trials,color='gray',linestyle='-.')\n \n for j in range(combo_start,combo_end,2):\n nb +=1\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n if i < 50:\n folder = folder1\n filename = filename1\n else: \n folder = folder2\n filename = filename2\n Mild = pd.read_csv( folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D \n\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n\n print(\"Age group: \", group_vec_age[nb-1])\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n \n plt.plot(Infected_Trials,color=color_list_shahin[nb-1]) \n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4): \n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims): \n Mild = pd.read_csv( base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Baseline: \", j-1)\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n \n plt.plot(Infected_Trials,color=color_list_add[j-2],linestyle='-.') \n \n plt.axvline(t_lockdown_vec[0], 0,color='red',linestyle='--')\n plt.legend(['Absence of\\n intervention']+['Ages ' + str(group_vec_age[i]) for i in range(len(group_vec_age))]+['All ages\\n50\\% confined','All ages\\n100\\% confined'], fontsize = 13)\n plt.ylim(0,100)\n plt.title(specific_title,fontsize=15)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.ylabel('Percentage of infected', fontsize=23)\n plt.xlabel('Days since patient zero', fontsize=23)\n \n return(plt)\n \n elif option == 1:\n nb = 0\n \n # baseline\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n Infected_Trials=np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Mild = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D \n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n\n print(\"Baseline 0: No intervention\")\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]]) \n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n \n plt.plot(Infected_Trials,color='gray',linestyle='-.')\n \n for j in range(combo_start+1,combo_end,2):\n nb +=1\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n if i < 50:\n folder = folder1\n filename = filename1\n else: \n folder = folder2\n filename = filename2\n Mild = pd.read_csv( folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n\n print(\"Age group: \", group_vec_age[nb-1])\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n \n plt.plot(Infected_Trials,color=color_list_shahin[nb-1])\n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4): \n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Mild = pd.read_csv( base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n \n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Baseline: \", j-1)\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color=color_list_add[j-2],linestyle='-.')\n\n plt.axvline(t_lockdown_vec[0], 0,color='red',linestyle='--')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(len(group_vec_age))]+['All ages\\n50\\% confined','All ages\\n100\\% confined'], fontsize = 13)\n plt.ylim(0,100)\n plt.title(specific_title,fontsize=15)\n plt.ylabel('Percentage of infected', fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero', fontsize=23)\n \n return(plt)\n \n else: \n nb = 0\n \n # baseline\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n Infected_Trials=np.zeros((100,sim_end+1))\n for i in range(100):\n Mild = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Documented = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_documented.csv',delimiter='\t',header=None)\n Severe = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Baseline 0: No intervention\")\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color='gray',linestyle='-.')\n \n for j in range(combo_start,combo_end):\n nb +=1\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n if i < 50:\n folder = folder1\n filename = filename1\n else: \n folder = folder2\n filename = filename2\n Mild = pd.read_csv( folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size\n\n print(\"Age group: \", group_vec_age[nb-1])\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color=color_list_shahin[nb-1])\n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4):\n \n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Mild = pd.read_csv( base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Baseline: \", j-1)\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color=color_list_add[j-2],linestyle='-.')\n\n plt.axvline(t_lockdown_vec[0], 0,color='red',linestyle='--')\n plt.ylim(0,100)\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(5)]+['All ages\\n50\\% confined','All ages\\n100\\% confined'], fontsize = 13)\n plt.title(specific_title, fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.ylabel('Percentage of infected', fontsize=23)\n plt.xlabel('Days since patient zero', fontsize=23)\n \n return(plt)",
"_____no_output_____"
]
],
[
[
"### Function to be used to plot the projected number of deaths over time, in the absence of physical distancing\n### Figures 8(c) and 8(d)",
"_____no_output_____"
]
],
[
[
"def death_age_group_node_removal(group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, \n folder1, folder2, filename1, filename2, option, specific_title):\n if option == 2:\n nb = 0\n \n # Baseline - No intervention\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n D=np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv', delimiter='\t',header=None)\n D[i,:]=Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline 0: No intervention\") \n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]])\n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n \n D = D/1000. \n plt.plot(D,color='gray',linestyle='-.')\n \n for j in range(combo_start,combo_end,2):\n nb +=1\n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n if i < 50:\n folder = folder1\n filename = filename1\n else: \n folder = folder2\n filename = filename2\n Deaths = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_deaths.csv', delimiter='\t',header=None)\n D[i,:] = Deaths\n D = D.mean(axis=0)\n \n print(\"Age group: \", group_vec_age[nb-1])\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]]) \n print(\"# of deaths today : \", D[today]) \n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n \n D = D/1000.\n plt.plot(D,color=color_list_shahin[nb-1])\n \n # Additional baselines - 50% and 100% of population stays home\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4): \n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv', delimiter='\t',header=None)\n D[i,:]=Deaths\n \n D = D.mean(axis=0)\n print(\"Baseline: \", j-1) \n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]]) \n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end]) \n \n D = D/1000. \n plt.plot(D,color=color_list_add[j-2], linestyle='-.')\n\n plt.axvline(t_lockdown_vec[0], 0, color='red', linestyle='--')\n plt.legend(['Absence of\\n intervention']+['Ages ' + str(group_vec_age[i]) for i in range(len(group_vec_age))]+['All ages\\n50\\% confined','All ages\\n100\\% confined'], fontsize=legend_fontsize)\n plt.ylim(0,400)\n plt.title(specific_title, fontsize=title_fontsize)\n plt.xlabel('Days since patient zero', fontsize=xlab_fontsize)\n plt.ylabel('Total deaths (thousands)', fontsize=ylab_fontsize)\n plt.xticks(fontsize=xtick_fontsize)\n plt.yticks(fontsize=ytick_fontsize)\n \n return(plt)\n \n elif option == 1:\n nb = 0\n \n # Baseline - No intervention\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv', delimiter='\t', header=None)\n D[i,:]=Deaths \n D = D.mean(axis=0)\n \n print(\"Baseline 0: No intervention\")\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]])\n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n D = D/1000. \n plt.plot(D,color='gray',linestyle='-.')\n \n # Average simulations per age group over n_sims random seeds\n for j in range(combo_start+1,combo_end,2):\n nb +=1\n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n if i < 50:\n folder = folder1\n filename = filename1\n else: \n folder = folder2\n filename = filename2\n Deaths = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_deaths.csv', delimiter='\t',header=None)\n D[i,:] = Deaths\n\n D = D.mean(axis=0)\n print(\"Age group: \", group_vec_age[nb-1])\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]])\n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulatuon: \", D[today])\n \n D = D/1000.\n plt.plot(D,color=color_list_shahin[nb-1])\n \n # Additional baselines - 50% and 100% of population stays home\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4):\n \n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:]=Deaths\n \n D = D.mean(axis=0)\n print(\"Baseline: \", j-1)\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]])\n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n \n D = D/1000. \n plt.plot(D,color=color_list_add[j-2],linestyle='-.')\n\n plt.axvline(t_lockdown_vec[0], 0,color='red',linestyle='--')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(5)]+['All ages\\n50\\% confined','All ages\\n100\\% confined'], fontsize = 13)\n plt.ylim(0,400)\n plt.title(specific_title,fontsize=15)\n plt.ylabel('Total deaths (thousands)', fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero', fontsize=23)\n \n return(plt)\n \n else: \n nb = 0\n \n # baseline\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n D=np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:]=Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline 0: No intervention\")\n print(\"# of deaths on lockdown day: \", Infected_Trials[t_lockdown_vec[0]]) \n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", Infected_Trials[sim_end])\n\n D = D/1000.\n plt.plot(D,color='gray',linestyle='-.')\n \n for j in range(combo_start,combo_end):\n nb = nb+1\n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n if i < 50:\n folder = folder1\n filename = filename1\n else: \n folder = folder2\n filename = filename2\n Deaths = pd.read_csv(folder + filename + str(j) + '_N' + str(i%50) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:] = Deaths\n\n D = D.mean(axis=0)\n print(\"Age group: \", group_vec_age[nb-1])\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]]) \n print(\"# of deaths today: \", D[today]) \n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n\n D = D/1000.\n plt.plot(D,color=color_list_shahin[nb-1])\n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4):\n \n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:]=Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline: \", j-1)\n print(\"% infected on lockdown day: \", D[t_lockdown_vec[0]]) \n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n \n D = D/1000.\n plt.plot(D,color=color_list_add[j-2],linestyle='-.')\n\n plt.axvline(t_lockdown_vec[0], 0,color='red',linestyle='--')\n plt.ylim(0,400)\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(5)]+['All ages\\n50\\% confined','All ages\\n100\\% confined'], fontsize = 13)\n plt.title(specific_title, fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.ylabel('Total deaths (thousands)', fontsize=23)\n plt.xlabel('Days since patient zero', fontsize=23)\n \n return(plt)",
"_____no_output_____"
]
],
[
[
"## Functions to be used to plot four subgraphs in Figure 9",
"_____no_output_____"
],
[
"### Function to be used to plot the projected percentage of infected people in the population over time, when physical distancing is in place\n### Figures 9(a) and 9(b)",
"_____no_output_____"
]
],
[
[
"def perc_infected_age_group_node_removal_lockdown(pop_size, group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder, filename, option, specific_title):\n if option == 2:\n nb = 0\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n \n # Baseline - \"No intervention\" scenario\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n for i in range(n_sims):\n Mild = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_mild.csv', delimiter='\t', header=None)\n Severe = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_severe.csv', delimiter='\t', header=None)\n Critical = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_critical.csv', delimiter='\t',header=None)\n R = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_recovered.csv', delimiter='\t', header=None)\n D = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv', delimiter='\t', header=None) \n Infected_Trials[i,:] = Mild+Severe+Critical+R+D \n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Baseline 0: No intervention\")\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color='gray',linestyle='-.')\n \n for j in range(combo_start,combo_end,2):\n nb +=1\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims): \n Mild = pd.read_csv( folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv', delimiter='\t',header=None)\n Severe = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv', delimiter='\t',header=None)\n Critical = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv', delimiter='\t',header=None)\n R = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv', delimiter='\t',header=None)\n D = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv', delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D \n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Age group: \", group_vec_age[nb-1])\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color=color_list_shahin[nb-1]) \n \n # new baseline - 50% or 100% of the population of an age group is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4):\n \n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Mild = pd.read_csv( base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials/pop_size*100.\n Infected_Trials = Infected_Trials.mean(axis=0)\n \n print(\"Baseline: \", j-1)\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color=color_list_add[j-2],linestyle='-.')\n\n plt.axvline(t_lockdown_vec[0], 0,linestyle='--',color='red')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(len(group_vec_age))]+['All ages\\n50\\% confined','All ages\\n100\\% confined'],fontsize=13)\n plt.ylim(0,100)\n plt.title(specific_title)\n plt.ylabel('Percentage of infected',fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero',fontsize=23)\n \n return(plt)\n \n elif option == 1:\n nb = 0\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n \n # baseline\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n for i in range(n_sims):\n Mild = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D \n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Baseline 0: No intervention\")\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n \n plt.plot(Infected_Trials,color='gray',linestyle='-.')\n \n for j in range(combo_start+1,combo_end,2):\n nb = nb+1\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Mild = pd.read_csv( folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Age group: \", group_vec_age[nb-1])\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color=color_list_shahin[nb-1]) \n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4):\n \n Infected_Trials = np.zeros((n_sims,sim_end+1))\n \n for i in range(n_sims):\n Mild = pd.read_csv( base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n \n print(\"Baseline: \", j-1)\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n\n plt.plot(Infected_Trials,color=color_list_add[j-2],linestyle='-.')\n\n plt.axvline(t_lockdown_vec[0], 0,linestyle='--',color='red')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(5)]+['All ages\\n50\\% confined','All ages\\n100\\% confined'],fontsize=13)\n plt.ylim(0,100)\n plt.title(specific_title)\n plt.ylabel('Percentage of infected',fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero',fontsize=23)\n \n return(plt)\n \n else: \n nb = 0\n Infected_Trials = np.zeros((n_sims,sim+end+1))\n \n # baseline\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n for i in range(n_sims):\n Mild = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Documented = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_documented.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100. \n\n print(\"Baseline 0: No intervention\")\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n\n plt.plot(Infected_Trials,color='gray',linestyle='-.')\n \n for j in range(combo_start,combo_end):\n nb +=1\n Infected_Trials = np.zeros((n_sims,sim_end+1))\n \n for i in range(n_sims):\n Mild = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D \n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100. \n \n print(\"Age group: \", group_vec_age[j-1])\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]]) \n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials, color=color_list_shahin[nb-1]) \n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4):\n \n Infected_Trials = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Mild = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_mild.csv',delimiter='\t',header=None)\n Severe = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_severe.csv',delimiter='\t',header=None)\n Critical = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_critical.csv',delimiter='\t',header=None)\n R = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_recovered.csv',delimiter='\t',header=None)\n D = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n Infected_Trials[i,:] = Mild+Severe+Critical+R+D\n Infected_Trials = Infected_Trials.mean(axis=0)\n Infected_Trials = Infected_Trials/pop_size*100.\n\n print(\"Baseline \",j-1)\n print(\"% infected on lockdown day: \", Infected_Trials[t_lockdown_vec[0]])\n print(\"% infected today: \", Infected_Trials[today])\n print(\"% infected at the end of the simulation: \", Infected_Trials[sim_end])\n plt.plot(Infected_Trials,color=color_list_add[j-2],linestyle='-.')\n \n plt.axvline(t_lockdown_vec[0], 0,linestyle='--',color='red')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(len(group_vec_age))]+['All ages\\n50\\% confined','All ages\\n100\\% confined'],fontsize=13)\n plt.ylim(0,100)\n plt.title(specific_title)\n plt.ylabel('Percentage of infected',fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero',fontsize=23)\n \n return(plt)",
"_____no_output_____"
]
],
[
[
"### Function to be used to plot the projected number of deaths over time, when physical distancing is in place\n### Figures 9(c) and 9(d)",
"_____no_output_____"
]
],
[
[
"def death_age_group_node_removal_lockdown(group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder, filename, option, specific_title):\n if option == 2:\n nb = 0\n D=np.zeros((n_sims,sim_end+1))\n \n # baseline\n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n for i in range(n_sims):\n Deaths = pd.read_csv(base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:]=Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline 0: No intervention\")\n print(\"# of deaths on lockdown day\", D[t_lockdown_vec[0]])\n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n \n D = D/1000. \n plt.plot(D,color='gray',linestyle='-.') \n\n # not baseline\n for j in range(combo_start,combo_end,2):\n nb +=1\n D = np.zeros((n_sims,sim_end+1))\n \n for i in range(n_sims):\n Deaths = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:]=Deaths\n\n D = D.mean(axis=0)\n print(\"Age group: \", group_vec_age[nb-1])\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]]) \n print(\"# of deaths today \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n D = D/1000.\n \n plt.plot(D,color=color_list_shahin[nb-1]) \n \n # new baseline - 50% or 100% of the population of an age group is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4):\n \n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:] = Deaths \n D = D.mean(axis=0)\n \n print(\"Baseline: \",j-1)\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]])\n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n\n D = D/1000. \n plt.plot(D,color=color_list_add[j-2],linestyle='-.')\n \n\n plt.axvline(t_lockdown_vec[0], 0, linestyle='--',color='red')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(5)]+['All ages\\n50\\% confined','All ages\\n100\\% confined'],fontsize=13)\n plt.ylim(0,400)\n plt.title(specific_title)\n plt.ylabel('Total deaths (thousands)',fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero',fontsize=23)\n \n return(plt)\n \n elif option == 1:\n nb = 0\n \n # Baseline\n D=np.zeros((n_sims,sim_end+1)) \n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n for i in range(n_sims):\n Deaths = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:] = Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline: No intervention\")\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]]) \n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n \n D = D/1000.\n plt.plot(D,color='gray',linestyle='-.')\n \n # Per age group\n for j in range(combo_start+1,combo_end,2):\n nb = nb +1\n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:] = Deaths\n D = D.mean(axis=0)\n \n print(\"Age group: \", group_vec_age[nb-1])\n print(\"# of deaths on lockdown day: \", D[t_lockdown_vec[0]]) \n print(\"# of deaths today: \", D[today])\n print(\"# of deaths at the end of the simulation: \", D[sim_end])\n \n D = D/1000.\n plt.plot(D,color=color_list_shahin[nb-1]) \n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4): \n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:] = Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline: \", j-1)\n print(\"# of deaths on lockdown day: \" + str(D[t_lockdown_vec[0]]))\n print(\"# of deaths today: \" + str(D[today]))\n print(\"# of deaths at the end of the simulation: \" + str(D[sim_end]))\n \n D = D/1000. \n plt.plot(D,color=color_list_add[j-2],linestyle='-.')\n \n plt.axvline(t_lockdown_vec[0], 0,linestyle='--',color='red')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(5)]+['All ages\\n50\\% confined','All ages\\n100\\% confined'],fontsize=13)\n plt.ylim(0,400)\n plt.title(specific_title)\n plt.ylabel('Total deaths (thousands)',fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero',fontsize=23)\n \n return(plt)\n \n else: \n nb = 0\n \n # baseline\n D = np.zeros((n_sims,sim_end+1)) \n base_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline_0_paramsweep_n10000000.0_i0_N'\n base_folder = 'nolockdown_noage/'\n for i in range(n_sims):\n Deaths = pd.read_csv( base_folder + base_filename + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:] = Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline: No intervention\")\n print(\"# of deaths on lockdown day: \" + str(D[t_lockdown_vec[0]]))\n print(\"# of deaths today: \" + str(D[today]))\n print(\"# of deaths at the end of the simulation: \" + str(D[sim_end]))\n \n D = D/1000. \n plt.plot(D,color='gray',linestyle='-.')\n \n # Per age group\n for j in range(combo_start,combo_end):\n nb +=1\n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(folder + filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:]=Deaths\n D = D.mean(axis=0)\n \n print(\"Age group: \", group_vec_age[nb-1])\n print(\"# of deaths on lockdown day: \" + str(D[t_lockdown_vec[0]]))\n print(\"# of deaths today: \" + str(D[today]))\n print(\"# of deaths at the end of the simulation: \" + str(D[sim_end]))\n \n D = D/1000. \n plt.plot(D,color=color_list_shahin[nb-1])\n \n \n # new baseline - 50% population is isolated\n base2_filename = 'lombardy_distributed_agepolicy_nolockdown_baseline2_0_paramsweep_n10000000.0_i'\n base2_folder = 'nolockdown_fullisolation/'\n \n for j in range(2,4): \n D = np.zeros((n_sims,sim_end+1))\n for i in range(n_sims):\n Deaths = pd.read_csv(base2_folder + base2_filename + str(j) + '_N' + str(i) + '_p0.029_m4_s22_deaths.csv',delimiter='\t',header=None)\n D[i,:] = Deaths\n D = D.mean(axis=0)\n \n print(\"Baseline: \",j-1)\n print(\"# of deaths on lockdown day:\" + str(t_lockdown_vec[0]))\n print(\"# of deaths today: \" + str(D[today]))\n print(\"# of deaths at the end of the simulation: \"+ str(D[sim_end]))\n \n D = D/1000. \n plt.plot(D,color=color_list_add[j-2],linestyle='-.')\n \n plt.axvline(t_lockdown_vec[0], 0,linestyle='--',color='red')\n plt.legend(['Absence of\\nintervention']+['Ages ' + str(group_vec_age[i]) for i in range(len(group_vec_age))]+['All ages\\n50\\% confined','All ages\\n100\\% confined'],fontsize=13)\n plt.ylim(0,400)\n plt.title(specific_title)\n plt.ylabel('Total deaths (thousands)',fontsize=23)\n plt.xticks(fontsize=17)\n plt.yticks(fontsize=17)\n plt.xlabel('Days since patient zero',fontsize=23)\n \n return(plt)",
"_____no_output_____"
]
],
[
[
"## Figure 8(a)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 50% of age category removed\nt_lockdown_vec = [46]\nsim_end = 119\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename1 = 'lombardy_distributed_agepolicy_0_paramsweep_n10000000.0_i'\nfilename2 = 'lombardy_distributed_agepolicy_1_paramsweep_n10000000.0_i'\n\nfolder1 = 'perc_policy_results/run1/'\nfolder2 = 'perc_policy_results/run2/'\noption = 2\nspecific_title = ''\n\nperc_infected_age_group_node_removal(pop_size, group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder1, folder2, filename1, filename2, option, specific_title)",
"Baseline 0: No intervention\n% infected on lockdown day: 1.6968067999999998\n% infected today: 58.381816799999996\n% infected at the end of the simulation: 86.2451102\nAge group: 0-14\n% infected on lockdown day: 1.7882925\n% infected today: 50.8961387\n% infected at the end of the simulation: 81.6420122\nAge group: 15-29\n% infected on lockdown day: 1.7490510000000001\n% infected today: 46.554536\n% infected at the end of the simulation: 79.7420986\nAge group: 30-49\n% infected on lockdown day: 1.7284659\n% infected today: 42.5827597\n% infected at the end of the simulation: 75.8146507\nAge group: 50-69\n% infected on lockdown day: 1.7601601000000002\n% infected today: 49.7889006\n% infected at the end of the simulation: 75.743964\nAge group: 70+\n% infected on lockdown day: 1.7489270000000001\n% infected today: 54.84444820000001\n% infected at the end of the simulation: 80.69495909999999\nBaseline: 1\n% infected on lockdown day: 1.7408981000000001\n% infected today: 15.413509\n% infected at the end of the simulation: 37.0030619\nBaseline: 2\n% infected on lockdown day: 1.641345\n% infected today: 5.959696800000001\n% infected at the end of the simulation: 6.040409\n"
]
],
[
[
"## Figure 8(c)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 50% of age category removed\nt_lockdown_vec = [46]\nsim_end = 119\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename1 = 'lombardy_distributed_agepolicy_0_paramsweep_n10000000.0_i'\nfilename2 = 'lombardy_distributed_agepolicy_1_paramsweep_n10000000.0_i'\n\nfolder1 = 'perc_policy_results/run1/'\nfolder2 = 'perc_policy_results/run2/'\noption = 2\n#specific_title = 'Mean Time to Isolation = 4.6 days for all' + '\\n50% stay home, per age group'\nspecific_title = ''\n\ndeath_age_group_node_removal( group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder1, folder2, filename1, filename2, option, specific_title)",
"Baseline 0: No intervention\n# of deaths on lockdown day: 177.07\n# of deaths today: 23282.59\n# of deaths at the end of the simulation: 391323.13\nAge group: 0-14\n# of deaths on lockdown day: 184.67\n# of deaths today : 21852.42\n# of deaths at the end of the simulation: 375371.79\nAge group: 15-29\n# of deaths on lockdown day: 179.88\n# of deaths today : 20687.88\n# of deaths at the end of the simulation: 368805.88\nAge group: 30-49\n# of deaths on lockdown day: 177.35\n# of deaths today : 19241.45\n# of deaths at the end of the simulation: 352554.09\nAge group: 50-69\n# of deaths on lockdown day: 181.65\n# of deaths today : 19407.39\n# of deaths at the end of the simulation: 309389.45\nAge group: 70+\n# of deaths on lockdown day: 182.27\n# of deaths today : 19301.26\n# of deaths at the end of the simulation: 282918.96\nBaseline: 1\n# of deaths on lockdown day: 181.54\n# of deaths today: 10615.51\n# of deaths at the end of the simulation: 109251.04\nBaseline: 2\n# of deaths on lockdown day: 168.14\n# of deaths today: 7554.48\n# of deaths at the end of the simulation: 16976.74\n"
]
],
[
[
"## Figure 8(b)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 100% of age category removed\nt_lockdown_vec = [46]\nn_sims = 100\nsim_end = 119\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename1 = 'lombardy_distributed_agepolicy_0_paramsweep_n10000000.0_i'\nfilename2 = 'lombardy_distributed_agepolicy_1_paramsweep_n10000000.0_i'\n\nfolder1 = 'perc_policy_results/run1/'\nfolder2 = 'perc_policy_results/run2/'\noption = 1\nspecific_title = ''\n\nperc_infected_age_group_node_removal(pop_size, group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder1, folder2, filename1, filename2, option, specific_title)",
"Baseline 0: No intervention\n% infected on lockdown day: 1.6968067999999998\n% infected today: 58.381816799999996\n% infected at the end of the simulation: 86.2451102\nAge group: 0-14\n% infected on lockdown day: 1.6197347\n% infected today: 43.4403242\n% infected at the end of the simulation: 77.1060876\nAge group: 15-29\n% infected on lockdown day: 1.7788489\n% infected today: 37.4307764\n% infected at the end of the simulation: 72.7434731\nAge group: 30-49\n% infected on lockdown day: 1.8419314999999998\n% infected today: 31.8929594\n% infected at the end of the simulation: 64.1060383\nAge group: 50-69\n% infected on lockdown day: 1.6201382\n% infected today: 41.5542953\n% infected at the end of the simulation: 66.154406\nAge group: 70+\n% infected on lockdown day: 1.8060544\n% infected today: 53.3265709\n% infected at the end of the simulation: 75.58195049999999\nBaseline: 1\n% infected on lockdown day: 1.7408981000000001\n% infected today: 15.413509\n% infected at the end of the simulation: 37.0030619\nBaseline: 2\n% infected on lockdown day: 1.641345\n% infected today: 5.959696800000001\n% infected at the end of the simulation: 6.040409\n"
]
],
[
[
"## Figure 8(d)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 100% of age category removed\nt_lockdown_vec = [46]\nn_sims = 100\nsim_end = 119\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename1 = 'lombardy_distributed_agepolicy_0_paramsweep_n10000000.0_i'\nfilename2 = 'lombardy_distributed_agepolicy_1_paramsweep_n10000000.0_i'\n\nfolder1 = 'perc_policy_results/run1/'\nfolder2 = 'perc_policy_results/run2/'\noption = 1\nspecific_title = ''\n\ndeath_age_group_node_removal(group_vec_age,t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder1, folder2, filename1, filename2, option, specific_title)",
"Baseline 0: No intervention\n# of deaths on lockdown day: 177.07\n# of deaths today: 23282.59\n# of deaths at the end of the simulation: 391323.13\nAge group: 0-14\n# of deaths on lockdown day: 167.21\n# of deaths today: 18737.73\n# of deaths at the end of the simulatuon: 18737.73\nAge group: 15-29\n# of deaths on lockdown day: 183.14\n# of deaths today: 18807.37\n# of deaths at the end of the simulatuon: 18807.37\nAge group: 30-49\n# of deaths on lockdown day: 190.95\n# of deaths today: 17133.46\n# of deaths at the end of the simulatuon: 17133.46\nAge group: 50-69\n# of deaths on lockdown day: 167.28\n# of deaths today: 15079.61\n# of deaths at the end of the simulatuon: 15079.61\nAge group: 70+\n# of deaths on lockdown day: 186.72\n# of deaths today: 16142.77\n# of deaths at the end of the simulatuon: 16142.77\nBaseline: 1\n# of deaths on lockdown day: 181.54\n# of deaths today: 10615.51\n# of deaths at the end of the simulation: 109251.04\nBaseline: 2\n# of deaths on lockdown day: 168.14\n# of deaths today: 7554.48\n# of deaths at the end of the simulation: 16976.74\n"
]
],
[
[
"## Figure 9(a)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 50% of age category removed\nt_lockdown_vec = [46]\nn_sims = 100\nsim_end = 119\n# As of March 29 of 2020\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename = 'lombardy_distributed_agepolicy_yeslockdown_0_paramsweep_n10000000.0_i'\nfolder = 'lockdown_perc_policy_results/'\noption = 2\nspecific_title = ''\n\nperc_infected_age_group_node_removal_lockdown(pop_size, group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder, filename, option, specific_title)",
"Baseline 0: No intervention\n% infected on lockdown day: 1.6968067999999998\n% infected today: 58.381816799999996\n% infected at the end of the simulation: 86.2451102\nAge group: 0-14\n% infected on lockdown day: 1.7398521\n% infected today: 21.181542799999995\n% infected at the end of the simulation: 56.395530900000004\nAge group: 15-29\n% infected on lockdown day: 1.6304800000000002\n% infected today: 18.7859209\n% infected at the end of the simulation: 51.544933199999996\nAge group: 30-49\n% infected on lockdown day: 1.775183\n% infected today: 18.767615900000003\n% infected at the end of the simulation: 49.557410000000004\nAge group: 50-69\n% infected on lockdown day: 1.8384998\n% infected today: 22.3788462\n% infected at the end of the simulation: 54.214534400000005\nAge group: 70+\n% infected on lockdown day: 1.5933061\n% infected today: 23.2123129\n% infected at the end of the simulation: 60.421565\nBaseline: 1\n% infected on lockdown day: 1.7408981\n% infected today: 15.413509000000008\n% infected at the end of the simulation: 37.0030619\nBaseline: 2\n% infected on lockdown day: 1.641345\n% infected today: 5.959696799999998\n% infected at the end of the simulation: 6.0404089999999995\n"
]
],
[
[
"## Figure 9(c)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 50% of age category removed\nt_lockdown_vec = [46]\nn_sims = 100\nsim_end = 119\n# As of March 29 of 2020\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename = 'lombardy_distributed_agepolicy_yeslockdown_0_paramsweep_n10000000.0_i'\nfolder = 'lockdown_perc_policy_results/'\noption = 2\nspecific_title = ''\n\ndeath_age_group_node_removal_lockdown(group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder, filename, option, specific_title)",
"Baseline 0: No intervention\n# of deaths on lockdown day 177.07\n# of deaths today: 23282.59\n# of deaths at the end of the simulation: 391323.13\nAge group: 0-14\n# deaths today 12671.25\n# of deaths on lockdown day: 180.43\n# of deaths at the end of the simulation: 181812.24\nAge group: 15-29\n# deaths today 11715.06\n# of deaths on lockdown day: 169.34\n# of deaths at the end of the simulation: 163234.5\nAge group: 30-49\n# deaths today 12294.35\n# of deaths on lockdown day: 182.47\n# of deaths at the end of the simulation: 160662.4\nAge group: 50-69\n# deaths today 12550.96\n# of deaths on lockdown day: 193.65\n# of deaths at the end of the simulation: 157192.73\nAge group: 70+\n# deaths today 11097.61\n# of deaths on lockdown day: 164.16\n# of deaths at the end of the simulation: 159588.9\nBaseline: 1\n# of deaths on lockdown day: 181.54\n# of deaths today: 10615.51\n# of deaths at the end of the simulation: 109251.04\nBaseline: 2\n# of deaths on lockdown day: 168.14\n# of deaths today: 7554.48\n# of deaths at the end of the simulation: 16976.74\n"
]
],
[
[
"## Figure 9(b)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 100% of age category removed\nt_lockdown_vec = [46]\nn_sims = 100\nsim_end = 119\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename = 'lombardy_distributed_agepolicy_yeslockdown_0_paramsweep_n10000000.0_i'\n\nfolder = 'lockdown_perc_policy_results/'\noption = 1\n# Lombardy - Time of Lockdown = 46 days\\n, \\nInfected = Mild+Severe+Critical+R+D\n#specific_title = 'Mean Time to Isolation = 4.6 days for all' + '\\n100% stay home, per age group' + '\\n+ Social distance increased by a factor of 2'\nspecific_title = ''\n\nperc_infected_age_group_node_removal_lockdown(pop_size, group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder, filename, option, specific_title)",
"Baseline 0: No intervention\n% infected on lockdown day: 1.6968067999999998\n% infected today: 58.381816799999996\n% infected at the end of the simulation: 86.2451102\nAge group: 0-14\n% infected on lockdown day: 1.8065115\n% infected today: 19.1857356\n% infected at the end of the simulation: 50.178790299999996\nAge group: 15-29\n% infected on lockdown day: 1.6362903000000002\n% infected today: 15.721416499999998\n% infected at the end of the simulation: 41.6285776\nAge group: 30-49\n% infected on lockdown day: 1.8073751999999998\n% infected today: 14.9254086\n% infected at the end of the simulation: 36.5143793\nAge group: 50-69\n% infected on lockdown day: 1.7346146999999998\n% infected today: 18.5354506\n% infected at the end of the simulation: 45.582420199999994\nAge group: 70+\n% infected on lockdown day: 1.8074373000000001\n% infected today: 23.982780499999997\n% infected at the end of the simulation: 57.7097835\nBaseline: 1\n% infected on lockdown day: 1.7408981000000001\n% infected today: 15.413509\n% infected at the end of the simulation: 37.0030619\nBaseline: 2\n% infected on lockdown day: 1.641345\n% infected today: 5.959696800000001\n% infected at the end of the simulation: 6.040409\n"
]
],
[
[
"## Figure 9(d)",
"_____no_output_____"
]
],
[
[
"# Mean time to isolation 4.6 and 100% of age category removed\nt_lockdown_vec = [46]\nn_sims = 100\nsim_end = 119\ntoday = 67\ngroup_vec_age = ['0-14','15-29','30-49','50-69','70+']\n\ncombo_start = 0\ncombo_end = 10\npop_size = 10000000\n\nfilename = 'lombardy_distributed_agepolicy_yeslockdown_0_paramsweep_n10000000.0_i'\n\nfolder = 'lockdown_perc_policy_results/'\noption = 1\nspecific_title = ''\n\ndeath_age_group_node_removal_lockdown(group_vec_age, t_lockdown_vec, n_sims, sim_end, today, combo_start, combo_end, folder, filename, option, specific_title)",
"Baseline: No intervention\n# of deaths on lockdown day: 177.07\n# deaths today: 23282.59\n# of deaths at the end of the simulation: 391323.13\nAge group: 0-14\n# of deaths on lockdown day: 187.1\n# deaths today: 12563.18\n# of deaths at the end of the simulation: 161180.6\nAge group: 15-29\n# of deaths on lockdown day: 172.06\n# deaths today: 11148.6\n# of deaths at the end of the simulation: 130288.96\nAge group: 30-49\n# of deaths on lockdown day: 189.17\n# deaths today: 11526.93\n# of deaths at the end of the simulation: 121694.56\nAge group: 50-69\n# of deaths on lockdown day: 178.43\n# deaths today: 10765.52\n# of deaths at the end of the simulation: 113655.13\nAge group: 70+\n# of deaths on lockdown day: 186.92\n# deaths today: 11206.8\n# of deaths at the end of the simulation: 121200.1\nBaseline: 1\n# of deaths on lockdown day: 181.54\n# of deaths today: 10615.51\n# of deaths at the end of the simulation: 109251.04\nBaseline: 2\n# of deaths on lockdown day: 168.14\n# of deaths today: 7554.48\n# of deaths at the end of the simulation: 16976.74\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a01bfcd11945c2366b5ef1d537ec57a5dbb32b3
| 11,580 |
ipynb
|
Jupyter Notebook
|
pc4kidneyapp.ipynb
|
rheiland/pc4kidneyapp
|
658ba134cd4adfb8d9b0f8c709a6078f600e621c
|
[
"BSD-3-Clause"
] | null | null | null |
pc4kidneyapp.ipynb
|
rheiland/pc4kidneyapp
|
658ba134cd4adfb8d9b0f8c709a6078f600e621c
|
[
"BSD-3-Clause"
] | null | null | null |
pc4kidneyapp.ipynb
|
rheiland/pc4kidneyapp
|
658ba134cd4adfb8d9b0f8c709a6078f600e621c
|
[
"BSD-3-Clause"
] | null | null | null | 31.900826 | 140 | 0.407772 |
[
[
[
"style = \"\"\"\n <style>\n .jupyter-widgets-output-area .output_scroll {\n height: unset !important;\n border-radius: unset !important;\n -webkit-box-shadow: unset !important;\n box-shadow: unset !important;\n }\n .jupyter-widgets-output-area {\n height: auto !important;\n }\n </style>\n \"\"\"",
"_____no_output_____"
],
[
"from IPython.core.display import display, HTML\ndisplay(HTML(\"<style>.container { width:100% !important; }</style>\"))\ndisplay(HTML(style))\n%matplotlib inline",
"_____no_output_____"
],
[
"import sys, os\nsys.path.insert(0, os.path.abspath('bin'))\nimport pc4kidneyapp",
"_____no_output_____"
],
[
"pc4kidneyapp.gui",
"_____no_output_____"
],
[
"#from debug import debug_view\n#debug_view",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a01ce3f3ece8c180da8aed2b4ccd18265b3f5c0
| 11,871 |
ipynb
|
Jupyter Notebook
|
examples/sampling-open-problem.ipynb
|
s3664421/hedgehog
|
b77ef40767917a71dcb58287b03d4a0873badeeb
|
[
"MIT"
] | 121 |
2020-05-14T14:46:35.000Z
|
2022-03-21T22:34:12.000Z
|
examples/sampling-open-problem.ipynb
|
s3664421/hedgehog
|
b77ef40767917a71dcb58287b03d4a0873badeeb
|
[
"MIT"
] | 14 |
2020-05-14T20:13:31.000Z
|
2022-01-03T09:04:28.000Z
|
examples/sampling-open-problem.ipynb
|
s3664421/hedgehog
|
b77ef40767917a71dcb58287b03d4a0873badeeb
|
[
"MIT"
] | 24 |
2020-05-15T01:37:20.000Z
|
2022-03-21T22:34:14.000Z
| 34.112069 | 420 | 0.482015 |
[
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"# Sampling from a Bayesian network: an open problem",
"_____no_output_____"
],
[
"A Bayesian network encodes a probability distribution. It is often desirable to be able to sample from a Bayesian network. The most common way to do this is via forward sampling (also called prior sampling). It's a really dumb algorithm that is trivial to implement. You just loop over the nodes in breadth-first order and sample a value each node, conditioning on the parents (which have already been sampled).\n\nThe problem with forward sampling is that impossible situations can arise for some networks. Basically, forward sampling doesn't ensure that the produced samples are *valid*. The easiest way to grok this is via some examples. ",
"_____no_output_____"
],
[
"## Example 1 ",
"_____no_output_____"
]
],
[
[
"import hedgehog as hh\nimport pandas as pd\n\ndef example_1():\n\n X = pd.DataFrame(\n [\n [True, True, True],\n [False, False, False]\n ],\n columns=['A', 'B', 'C']\n )\n\n bn = hh.BayesNet(\n (['A', 'B'], 'C')\n )\n bn.fit(X)\n\n return bn\n\nbn = example_1()\nbn",
"_____no_output_____"
],
[
"bn.full_joint_dist()",
"_____no_output_____"
]
],
[
[
"The problem with forward sampling is this case is that if we sample from A and then B independently, then we can end up by sampling pairs (A, B) that don't exist. This will raise an error when we condition P(C) on its parents.\n\nIn `hedhehog`, this will raise a `KeyError` when `sample` is called because the distribution that corresponds to `(A=False, B=True)` doesn't exist.",
"_____no_output_____"
]
],
[
[
"while True:\n try:\n bn.sample()\n except KeyError:\n print('Yep, told you.')\n break",
"Yep, told you.\n"
]
],
[
[
"## Example 2",
"_____no_output_____"
]
],
[
[
"import hedgehog as hh\nimport pandas as pd\n\ndef example_2():\n\n X = pd.DataFrame(\n [\n [1, 1, 1, 1],\n [2, 1, 2, 1]\n ],\n columns=['A', 'B', 'C', 'D']\n )\n\n bn = hh.BayesNet(\n ('A', 'B'),\n ('B', 'C'),\n (['A', 'C'], 'D')\n )\n bn.fit(X)\n\n return bn\n\nbn = example_2()\nbn",
"_____no_output_____"
]
],
[
[
"In this case, a problem will occur if we sample `(A, 1)`, then `(B, 1)`, then `(C, 2)`. Indeed, `(A, 1)` and `(C, 1)` have never been seen so there's now way of sampling `D`.",
"_____no_output_____"
]
],
[
[
"while True:\n try:\n bn.sample()\n except KeyError:\n print('Yep, told you.')\n break",
"Yep, told you.\n"
]
],
[
[
"One way to circumvent these issues would be to sample from the full joint distribution. But this is too costly. Another way is to add a prior distribution by supposing that every combination occurred once, but that's not elegant.\n\nIdeally we would like to have some way of doing forward sampling that only produces valid data. This is still an open question for me.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a01d3b1d044e2beb268bd853a4a2bef35acfb68
| 4,676 |
ipynb
|
Jupyter Notebook
|
ml_headline_server_code/train.ipynb
|
Juyoung4/MUD
|
faf2c81eb806fc2ffa03231c7d3d7f09042809bb
|
[
"MIT"
] | 4 |
2019-09-21T14:29:01.000Z
|
2020-10-11T17:21:47.000Z
|
ml_headline_server_code/train.ipynb
|
kimzn12/MUD
|
faf2c81eb806fc2ffa03231c7d3d7f09042809bb
|
[
"MIT"
] | null | null | null |
ml_headline_server_code/train.ipynb
|
kimzn12/MUD
|
faf2c81eb806fc2ffa03231c7d3d7f09042809bb
|
[
"MIT"
] | 4 |
2019-09-20T10:13:52.000Z
|
2020-11-18T08:01:07.000Z
| 38.01626 | 160 | 0.561805 |
[
[
[
"import time\nstart = time.perf_counter()\nimport tensorflow as tf\nimport pickle\nimport import_ipynb\nimport os\nfrom model import Model\nfrom utils import build_dict, build_dataset, batch_iter",
"_____no_output_____"
],
[
"embedding_size=300\nnum_hidden = 300\nnum_layers = 3\nlearning_rate = 0.001\nbeam_width = 10\nkeep_prob = 0.8\nglove = True\nbatch_size=256\nnum_epochs=10\n\nif not os.path.exists(\"saved_model\"):\n os.mkdir(\"saved_model\")\nelse:\n old_model_checkpoint_path = open('saved_model/checkpoint', 'r')\n old_model_checkpoint_path = \"\".join([\"saved_model/\",old_model_checkpoint_path.read().splitlines()[0].split('\"')[1]])\n\n\nprint(\"Building dictionary...\")\nword_dict, reversed_dict, article_max_len, summary_max_len = build_dict(\"train\", toy=True)\nprint(\"Loading training dataset...\")\ntrain_x, train_y = build_dataset(\"train\", word_dict, article_max_len, summary_max_len, toy=True)",
"_____no_output_____"
],
[
"with tf.Session() as sess:\n model = Model(reversed_dict, article_max_len, summary_max_len, embedding_size, num_hidden, num_layers, learning_rate, beam_width, keep_prob, glove)\n sess.run(tf.global_variables_initializer())\n saver = tf.train.Saver(tf.global_variables())\n if 'old_model_checkpoint_path' in globals():\n print(\"Continuing from previous trained model:\" , old_model_checkpoint_path , \"...\")\n saver.restore(sess, old_model_checkpoint_path )\n\n batches = batch_iter(train_x, train_y, batch_size, num_epochs)\n num_batches_per_epoch = (len(train_x) - 1) // batch_size + 1\n\n print(\"\\nIteration starts.\")\n print(\"Number of batches per epoch :\", num_batches_per_epoch)\n for batch_x, batch_y in batches:\n batch_x_len = list(map(lambda x: len([y for y in x if y != 0]), batch_x))\n batch_decoder_input = list(map(lambda x: [word_dict[\"<s>\"]] + list(x), batch_y))\n batch_decoder_len = list(map(lambda x: len([y for y in x if y != 0]), batch_decoder_input))\n batch_decoder_output = list(map(lambda x: list(x) + [word_dict[\"</s>\"]], batch_y))\n\n batch_decoder_input = list(\n map(lambda d: d + (summary_max_len - len(d)) * [word_dict[\"<padding>\"]], batch_decoder_input))\n batch_decoder_output = list(\n map(lambda d: d + (summary_max_len - len(d)) * [word_dict[\"<padding>\"]], batch_decoder_output))\n\n train_feed_dict = {\n model.batch_size: len(batch_x),\n model.X: batch_x,\n model.X_len: batch_x_len,\n model.decoder_input: batch_decoder_input,\n model.decoder_len: batch_decoder_len,\n model.decoder_target: batch_decoder_output\n }\n\n _, step, loss = sess.run([model.update, model.global_step, model.loss], feed_dict=train_feed_dict)\n\n if step % 1000 == 0:\n print(\"step {0}: loss = {1}\".format(step, loss))\n\n if step % num_batches_per_epoch == 0:\n hours, rem = divmod(time.perf_counter() - start, 3600)\n minutes, seconds = divmod(rem, 60)\n saver.save(sess, \"./saved_model/model.ckpt\", global_step=step)\n print(\" Epoch {0}: Model is saved.\".format(step // num_batches_per_epoch),\n \"Elapsed: {:0>2}:{:0>2}:{:05.2f}\".format(int(hours),int(minutes),seconds) , \"\\n\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a01d73f1f1c5886527a90555fc2d4ee36befdf2
| 278,769 |
ipynb
|
Jupyter Notebook
|
time-series-analysis/ch2.ipynb
|
ToshikiShimizu/statistics
|
cc93f01dad608ee8a488222d43db0cc1e13aff8d
|
[
"Apache-2.0"
] | null | null | null |
time-series-analysis/ch2.ipynb
|
ToshikiShimizu/statistics
|
cc93f01dad608ee8a488222d43db0cc1e13aff8d
|
[
"Apache-2.0"
] | null | null | null |
time-series-analysis/ch2.ipynb
|
ToshikiShimizu/statistics
|
cc93f01dad608ee8a488222d43db0cc1e13aff8d
|
[
"Apache-2.0"
] | null | null | null | 415.453055 | 48,512 | 0.941963 |
[
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"df_ice = pd.read_csv('input/icecream.csv', skiprows=2,header=None)\ndf_ice.columns = ['year', 'month', 'expenditure_yen']",
"_____no_output_____"
],
[
"y = pd.Series(df_ice.expenditure_yen.values, index=pd.date_range('2003-1', periods=len(df_ice), freq='M'))\ny.plot()",
"_____no_output_____"
],
[
"from statsmodels.tsa import stattools\n\nctt = stattools.adfuller(y[:100], regression='ctt')\nct = stattools.adfuller(y[:100], regression='ct')\nc = stattools.adfuller(y[:100], regression='c')\nnc = stattools.adfuller(y[:100], regression='nc')\nprint(ctt)\nprint(ct)\nprint(c)\nprint(nc)",
"(-3.3089558508822066, 0.1692244861968651, 11, 88, {'1%': -4.507929662788786, '5%': -3.9012866601709244, '10%': -3.595623127758734}, 993.4892589484145)\n(-1.714560199971079, 0.7444294601457553, 11, 88, {'1%': -4.065513968057382, '5%': -3.4616143302732905, '10%': -3.156971502864388}, 1002.5847722693204)\n(-0.6539247687694223, 0.8583259363632658, 11, 88, {'1%': -3.506944401824286, '5%': -2.894989819214876, '10%': -2.584614550619835}, 1003.5884336394024)\n(1.6310949179759076, 0.9751761218376866, 11, 88, {'1%': -2.5916151807851238, '5%': -1.944440985689801, '10%': -1.614115063626972}, 1002.1878264328066)\n"
],
[
"y_diff = y.diff()[:100].dropna()\ny_diff.plot()",
"_____no_output_____"
],
[
"ctt = stattools.adfuller(y_diff, regression='ctt')\nct = stattools.adfuller(y_diff, regression='ct')\nc = stattools.adfuller(y_diff, regression='c')\nnc = stattools.adfuller(y_diff, regression='nc')\nprint(ctt)\nprint(ct)\nprint(c)\nprint(nc)",
"(-20.49413879057406, 0.0, 10, 88, {'1%': -4.507929662788786, '5%': -3.9012866601709244, '10%': -3.595623127758734}, 994.1683226214956)\n(-20.51282538674093, 0.0, 10, 88, {'1%': -4.065513968057382, '5%': -3.4616143302732905, '10%': -3.156971502864388}, 992.6851493902557)\n(-20.635999245555652, 0.0, 10, 88, {'1%': -3.506944401824286, '5%': -2.894989819214876, '10%': -2.584614550619835}, 990.9785010415186)\n(-20.337724459102365, 0.0, 10, 88, {'1%': -2.5916151807851238, '5%': -1.944440985689801, '10%': -1.614115063626972}, 991.6754513068397)\n"
],
[
"from statsmodels.tsa import ar_model\nmodel = ar_model.AR(y_diff)",
"/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/statsmodels/tsa/ar_model.py:791: FutureWarning: \nstatsmodels.tsa.AR has been deprecated in favor of statsmodels.tsa.AutoReg and\nstatsmodels.tsa.SARIMAX.\n\nAutoReg adds the ability to specify exogenous variables, include time trends,\nand add seasonal dummies. The AutoReg API differs from AR since the model is\ntreated as immutable, and so the entire specification including the lag\nlength must be specified when creating the model. This change is too\nsubstantial to incorporate into the existing AR api. The function\nar_select_order performs lag length selection for AutoReg models.\n\nAutoReg only estimates parameters using conditional MLE (OLS). Use SARIMAX to\nestimate ARX and related models using full MLE via the Kalman Filter.\n\nTo silence this warning and continue using AR until it is removed, use:\n\nimport warnings\nwarnings.filterwarnings('ignore', 'statsmodels.tsa.ar_model.AR', FutureWarning)\n\n warnings.warn(AR_DEPRECATION_WARN, FutureWarning)\n"
],
[
"for i in range(20):\n results = model.fit(maxlag=i+1)\n model = ar_model.AR(y_diff)\n print('lag = ', i+1, 'aic : ', results.aic)",
"lag = 1 aic : 10.623349835083612\nlag = 2 aic : 10.605625887136187\nlag = 3 aic : 10.631794365499909\nlag = 4 aic : 10.653968819566964\nlag = 5 aic : 10.639020494849978\nlag = 6 aic : 10.497805079154896\nlag = 7 aic : 10.50164556083358\nlag = 8 aic : 10.347418412668333\nlag = 9 aic : 10.145773136713263\nlag = 10 aic : 9.547393191591683\nlag = 11 aic : 8.688494352586085\nlag = 12 aic : 8.726168706454176\nlag = 13 aic : 8.749080458269447\nlag = 14 aic : 8.787463716774608\nlag = 15 aic : 8.822181088075927\nlag = 16 aic : 8.861619646480914\nlag = 17 aic : 8.900710667979508\nlag = 18 aic : 8.712739176754758\nlag = 19 aic : 8.74636247304398\nlag = 20 aic : 8.766450545272324\n"
],
[
"model = ar_model.AR(y_diff)\nresults11 = model.fit(maxlag=12, ic='aic')",
"_____no_output_____"
],
[
"results11.k_ar",
"_____no_output_____"
],
[
"res11 = results11.resid",
"_____no_output_____"
],
[
"plt.bar(range(len(res11)), res11)",
"_____no_output_____"
],
[
"from statsmodels.graphics import tsaplots\ntsaplots.plot_pacf(res11, lags=40)",
"_____no_output_____"
],
[
"plt.plot(y.diff().dropna().values, label='observation')\nplt.plot(np.hstack([y_diff[:11], results11.fittedvalues, results11.predict(98-11, 107, dynamic=True)]), '--', label='forecast')",
"_____no_output_____"
],
[
"from statsmodels.tsa import stattools\ninfo_criteria = stattools.arma_order_select_ic(y_diff, ic=['aic', 'bic'])\ninfo_criteria.aic_min_order, info_criteria.bic_min_order",
"/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/statsmodels/base/model.py:548: HessianInversionWarning: Inverting hessian failed, no bse or cov_params available\n 'available', HessianInversionWarning)\n/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/statsmodels/base/model.py:568: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals\n ConvergenceWarning)\n"
],
[
"from statsmodels.tsa.arima_model import ARMA\nmodel = ARMA(y_diff, (2,2))\nresults = model.fit()",
"_____no_output_____"
],
[
"res = results.resid",
"_____no_output_____"
],
[
"plt.bar(range(len(res)), res)",
"_____no_output_____"
],
[
"from statsmodels.graphics import tsaplots\ntsaplots.plot_pacf(res, lags=40)",
"/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/statsmodels/regression/linear_model.py:1434: RuntimeWarning: invalid value encountered in sqrt\n return rho, np.sqrt(sigmasq)\n"
],
[
"plt.plot(y.diff().dropna().values, label='observation')\nplt.plot(np.hstack([y_diff[:2],results.fittedvalues,results.predict(99-2,115,dynamic=True)]),'--',label='forecast')",
"_____no_output_____"
],
[
"y = pd.Series(np.random.randn(1000), index=pd.date_range('2000-1-1', periods=1000))\ny = y.cumsum()\ny.plot()",
"_____no_output_____"
],
[
"from statsmodels.tsa import stattools\nctt = stattools.adfuller(y, regression='ctt')\nct = stattools.adfuller(y, regression='ct')\nc = stattools.adfuller(y, regression='c')\nnc = stattools.adfuller(y, regression='nc')\nprint(ctt)\nprint(ct)\nprint(c)\nprint(nc)",
"(-2.9796921382542516, 0.3049526406271427, 3, 996, {'1%': -4.382801184324198, '5%': -3.838332127908256, '10%': -3.5569396971160314}, 2744.5449002346004)\n(-2.0038867629415007, 0.5993148646604294, 3, 996, {'1%': -3.9678882504050086, '5%': -3.41490718677544, '10%': -3.1296499631758756}, 2746.4632309815697)\n(-1.989845370106567, 0.2910432231814395, 3, 996, {'1%': -3.4369325637409154, '5%': -2.8644462162311934, '10%': -2.568317409920808}, 2746.8970343234623)\n(-1.0810020428122085, 0.25280443294403265, 3, 996, {'1%': -2.567988435307495, '5%': -1.9412730391965518, '10%': -1.6165560435054842}, 2748.1644074971828)\n"
],
[
"y_diff = y.diff().dropna()\ny_diff.plot()",
"_____no_output_____"
],
[
"ctt = stattools.adfuller(y_diff, regression='ctt')\nct = stattools.adfuller(y_diff, regression='ct')\nc = stattools.adfuller(y_diff, regression='c')\nnc = stattools.adfuller(y_diff, regression='nc')\nprint(ctt)\nprint(ct)\nprint(c)\nprint(nc)",
"(-15.846675798487983, 1.6990309240651863e-24, 2, 996, {'1%': -4.382801184324198, '5%': -3.838332127908256, '10%': -3.5569396971160314}, 2748.915985654864)\n(-15.852824270407258, 1.1706845422689458e-22, 2, 996, {'1%': -3.9678882504050086, '5%': -3.41490718677544, '10%': -3.1296499631758756}, 2747.16601070386)\n(-15.79737140246917, 1.0842100731256007e-28, 2, 996, {'1%': -3.4369325637409154, '5%': -2.8644462162311934, '10%': -2.568317409920808}, 2747.28791879635)\n(-15.805094107221601, 1.5164616464961816e-27, 2, 996, {'1%': -2.567988435307495, '5%': -1.9412730391965518, '10%': -1.6165560435054842}, 2745.3115463798886)\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a01ee09510e62388a247233222f3efaf138804e
| 4,792 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/example-checkpoint.ipynb
|
seekasra/wizer
|
44b1787ac693f73e683c3700f19cad3b884f1130
|
[
"Apache-2.0"
] | 4 |
2020-12-18T17:26:44.000Z
|
2020-12-19T20:29:08.000Z
|
.ipynb_checkpoints/example-checkpoint.ipynb
|
seekasra/wizer
|
44b1787ac693f73e683c3700f19cad3b884f1130
|
[
"Apache-2.0"
] | null | null | null |
.ipynb_checkpoints/example-checkpoint.ipynb
|
seekasra/wizer
|
44b1787ac693f73e683c3700f19cad3b884f1130
|
[
"Apache-2.0"
] | 1 |
2020-12-21T11:36:06.000Z
|
2020-12-21T11:36:06.000Z
| 23.722772 | 146 | 0.532972 |
[
[
[
"\n# wizzer\n\n[](https://github.com/seekasra/wizzer/commits/master)\n[](https://github.com/seekasra/wizzer/blob/master/LICENSE)\n\n### What's wizzer?\nwizzer is a Python module to help programmers initialise their domain specific\nvariable(s)/configuration(s) using a wizard-like question answer chat scenario.\nThe need for this module began to develope when there was such need for\nIntent-Based Networking (IBN). Where the user would express their intention and\nexpect the system to translate and trigger setup automatically.\n### How to use?\nYou can make the file usable as a script as well as an importable module. See example1.py\n### Screenshots\n---\n### credits\nicon in wizzer logo : [Anatoly Dudko](https://thenounproject.com/tolyachudes/)\n",
"_____no_output_____"
],
[
"### step by step guide\n\n1 - import _wizzer_ package.",
"_____no_output_____"
]
],
[
[
"import wizzer",
"_____no_output_____"
]
],
[
[
"2 - have your questions (configuration parameters) ready. accepted formats are arrays, dictionaries or a single string.\n<br/> 2.1 - Here we have an array forexample:",
"_____no_output_____"
]
],
[
[
"q1 = [\n 'driver',\n 'hostname',\n 'username',\n 'password',\n 'port',\n]",
"_____no_output_____"
]
],
[
[
"2.1.1 - Now you can ask above attributes from the user. This will return a new dictinary with all answers filled-in as corresponding values.",
"_____no_output_____"
]
],
[
[
"q = wizzer.ask(q1)",
"What's the driver ? iosxr\nWhat's the hostname ? ios-xe-mgmt.cisco.com\nWhat's the username ? developer\nWhat's the password ? C1sco12345\nWhat's the port ? 8181\n"
]
],
[
[
"2.1.2 - You can review the configurations by running:",
"_____no_output_____"
]
],
[
[
"wizzer.review(q)",
"driver : iosxr\nhostname : ios-xe-mgmt.cisco.com\nusername : developer\npassword : C1sco12345\nport : 8181\n"
]
],
[
[
"2.2 - Here we have a dictionary forexample:",
"_____no_output_____"
]
],
[
[
"q2 = {\n 'driver': '',\n 'hostname': '',\n 'username': '',\n 'password': '',\n 'port': '',\n}",
"_____no_output_____"
]
],
[
[
"2.2.1 - Now you can ask above attributes from the user. This will return a new dictinary with all answers filled-in as corresponding values.",
"_____no_output_____"
]
],
[
[
"q = wizzer.ask(q2)",
"What's the driver ? iosxr\nWhat's the hostname ? ios-xe-mgmt.cisco.com\nWhat's the username ? developer\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a01f84c30303b61024d987e51b364f203aacd77
| 10,085 |
ipynb
|
Jupyter Notebook
|
T&T Lab 10.ipynb
|
MrBlu1204/Python
|
caba75ac21a3b955f7c6f1a28677900f0358156f
|
[
"Apache-2.0"
] | null | null | null |
T&T Lab 10.ipynb
|
MrBlu1204/Python
|
caba75ac21a3b955f7c6f1a28677900f0358156f
|
[
"Apache-2.0"
] | null | null | null |
T&T Lab 10.ipynb
|
MrBlu1204/Python
|
caba75ac21a3b955f7c6f1a28677900f0358156f
|
[
"Apache-2.0"
] | null | null | null | 19.658869 | 133 | 0.472186 |
[
[
[
"# T&T Lab 10 - 17th Feb\n## Manish Ranjan Behera (1828249)",
"_____no_output_____"
]
],
[
[
"my_set = {1, 2, 3,5,9,77}\nprint(my_set)",
"{1, 2, 3, 5, 9, 77}\n"
],
[
"my_set = set()\ntype(my_set)",
"_____no_output_____"
],
[
"my_set = {1, 2, 3, 4, 3, 2}\nprint(my_set)",
"{1, 2, 3, 4}\n"
],
[
"my_set.update([4, 5], {1, 6, 8})",
"_____no_output_____"
],
[
"my_set.add('x')\nprint(my_set)",
"{1, 2, 3, 4, 5, 6, 8, 'x'}\n"
],
[
"my_set.discard(4)",
"_____no_output_____"
],
[
"my_set.remove(6)",
"_____no_output_____"
],
[
"len(my_set)",
"_____no_output_____"
],
[
"A = {1, 2, 3, 4, 5}\nB = {4, 5, 6, 7, 8}\nprint(A | B)",
"{1, 2, 3, 4, 5, 6, 7, 8}\n"
],
[
"print(A & B)\nprint(A - B)\nprint(A ^ B)",
"{4, 5}\n{1, 2, 3}\n{1, 2, 3, 6, 7, 8}\n"
]
],
[
[
"### Write a Python Program to remove an item from a set if it is present in the set",
"_____no_output_____"
]
],
[
[
"from numpy import random\nnumSet={random.randint(1,100) for x in range(1,15)}\nprint(numSet)\ni=int(input(\"Enter item that has to be removed:\"))\nif i in numSet:\n numSet.remove(i)\n print(i,\"has been removed from the set\")\nelse:\n print(i,\"is not present in the set\")",
"{32, 39, 11, 76, 77, 43, 51, 84, 87, 89, 93, 62}\nEnter item that has to be removed:67\n67 is not present in the set\n"
]
],
[
[
"### Write a Python program to create an intersection of sets.",
"_____no_output_____"
]
],
[
[
"from numpy import random\nsetA={random.randint(1,100) for x in range(1,15)}\nsetB={random.randint(1,100) for x in range(1,15)}\nprint(\"Set A:\",setA)\nprint(\"Set B:\",setB)\nprint(\"Intersection of Set A & Set B:\", (setA & setB))",
"Set A: {36, 37, 7, 10, 76, 14, 15, 17, 18, 19, 23, 90, 27, 60}\nSet B: {96, 2, 35, 72, 9, 10, 77, 82, 20, 24, 89, 26, 88, 30}\nIntersection of Set A & Set B: {10}\n"
]
],
[
[
"### Write a Python program to create set difference.",
"_____no_output_____"
]
],
[
[
"print(\"Difference of Set A & Set B:\", (setA - setB))",
"Difference of Set A & Set B: {1, 97, 67, 3, 35, 71, 73, 42, 45, 78, 18, 50, 94}\n"
]
],
[
[
"### Write a Python program to find maximum and the minimum value in a set",
"_____no_output_____"
]
],
[
[
"A=list(setA)\nA.sort()\nprint(\"MAX:\",A[-1],\"MIN:\",A[0])\nA.",
"MAX: 97 MIN: 1\n"
]
],
[
[
"### Write a Python program to check if a set is a subset of another set.",
"_____no_output_____"
]
],
[
[
"if setB in setA:\n print(\"Set B is a subset of Set A\")\n\nelif setA in setB:\n print(\"Set A is a subset of Set B\")\n\nelse:\n print(\"There is no Subset\")\n\n",
"There is no Subset\n"
]
],
[
[
"### Write a Python program to find the length of a set",
"_____no_output_____"
]
],
[
[
"print(\"Length of the set:\",len(setB))",
"Length of the set: 14\n"
]
],
[
[
"### Write a Python program to check if two given sets have no elements in common",
"_____no_output_____"
]
],
[
[
"if len(setA & setB) == 0:\n print(\"Set A and Set B have NO elemnts in common\")\nelse:\n print(\"Set A and Set B have elemnts in common\")",
"Set A and Set B have elemnts in common\n"
]
],
[
[
"### Write a Python program to clear a set.",
"_____no_output_____"
]
],
[
[
"setA.clear()\nsetA",
"_____no_output_____"
]
],
[
[
"### Write a Python program to find the elements in a given set that are not in another set. ",
"_____no_output_____"
]
],
[
[
"print(\"Symmetric Difference:\",(setA ^ setB))",
"Symmetric Difference: {2, 7, 9, 14, 15, 17, 18, 19, 20, 23, 24, 26, 27, 30, 35, 36, 37, 60, 72, 76, 77, 82, 88, 89, 90, 96}\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a02011a1e49db50ba3227c67f2a54bbdba9b1d2
| 129,390 |
ipynb
|
Jupyter Notebook
|
demos/unfinished/Basic Demo.ipynb
|
pehses/bartpy
|
83ba894707f8aae2edc156bd9c31ac478a4bd966
|
[
"BSD-3-Clause"
] | 4 |
2021-08-15T12:57:49.000Z
|
2022-02-17T03:38:49.000Z
|
demos/unfinished/Basic Demo.ipynb
|
pehses/bartpy
|
83ba894707f8aae2edc156bd9c31ac478a4bd966
|
[
"BSD-3-Clause"
] | 2 |
2021-12-15T16:15:53.000Z
|
2022-03-20T17:18:04.000Z
|
demos/unfinished/Basic Demo.ipynb
|
pehses/bartpy
|
83ba894707f8aae2edc156bd9c31ac478a4bd966
|
[
"BSD-3-Clause"
] | 5 |
2021-07-12T11:15:10.000Z
|
2022-03-20T16:36:43.000Z
| 337.832898 | 61,164 | 0.93399 |
[
[
[
"# Python Bindings Demo\n\nThis is a very simple demo / playground / testing site for the Python Bindings for BART.\n\nThis is mainly used to show off Numpy interoperability and give a basic sense for how more complex tools will look in Python.",
"_____no_output_____"
],
[
"## Overview\n\nCurrently, Python users can interact with BART via a command-line wrapper. For example, the following line of Python code generates a simple Shepp-Logan phantom in K-Space and reconstructs the original image via inverse FFT.\n\n```\nshepp_ksp = bart(1, 'phantom -k -x 128')\nshepp_recon = bart(1, 'fft -i 3' shepp_recon)\n```\n\n#### The Python bindings, `bartpy`, build on this wrapper in the following ways:\n - 'Pythonic' interface with explicit functions and objects\n - (Mostly) automated generation to minimize the maintenance burden\n - Access to lower-level operators (e.g., `linops` submodule) to allow users to use BART functions seamlessly alongside Python libraries like Numpy, Sigpy, SciPy, Tensorflow or pyTorch\n - RAM-based memory management\n - Current wrapper writes data to disk, invokes the BART tools from the command line, and then reads data from disk\n - Memory-based approach is ostensibly faster",
"_____no_output_____"
],
[
"## Getting Started\n\nTo begin, we import `numpy` and `matplotlib` for array manipulation and data visualization. We will then import the Python bindings",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom matplotlib import pyplot as plt\nfrom mpl_toolkits import mplot3d\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### BART-related Imports\n\nWe will now import `bartpy` tools for generating phantoms and performing the Fast Fourier Transform (FFT), as well as utilities for interacting with `.cfl` files.",
"_____no_output_____"
]
],
[
[
"from bartpy.simu.phantom import phantom\nfrom bartpy.num.fft import fft, ifft\nfrom bartpy.utils.cfl import readcfl, writecfl",
"_____no_output_____"
]
],
[
[
"## A closer look",
"_____no_output_____"
],
[
"<span style=\"font-size: 1.3em;\">`phantom(dims, ksp, d3, ptype)`</span>\n - `dims`: iterable specifying dimensions of the phantom. Cannot exceed 16, and follows BART dimension conventions\n - `ksp`: boolean value indicating whether or not to generate the phantom in k-space\n - `d3`: boolean value indicating whether or not to generate a 3D phantom\n - `ptype`: Specifies type of phantom. ",
"_____no_output_____"
]
],
[
[
"phantom",
"_____no_output_____"
],
[
"shepp = phantom([128, 128], ksp=False, d3=False)",
"_____no_output_____"
],
[
"plt.imshow(shepp))",
"_____no_output_____"
]
],
[
[
"## Reconstruction via FFT",
"_____no_output_____"
],
[
"### Command Line\n\nHere is a simple recon task completed with BART on the command line.",
"_____no_output_____"
]
],
[
[
"!bart phantom -x 128 -k -B logo",
"_____no_output_____"
],
[
"!bart fft -i 3 logo logo_recon",
"_____no_output_____"
],
[
"gnd = readcfl('logo_recon')\nplt.imshow(abs(gnd.T))",
"_____no_output_____"
]
],
[
[
"### Pure Python\n\nNow here is our task completed entirely in Python, using `bartpy`",
"_____no_output_____"
],
[
"<span style=\"color: red\">FIXME: The order of dimensions\n is wrong</span>",
"_____no_output_____"
]
],
[
[
"logo_ksp = phantom([128, 128], ksp=True, ptype='bart')",
"_____no_output_____"
],
[
"plt.imshow(np.log(abs(logo_ksp)))",
"_____no_output_____"
],
[
"logo_recon = ifft(logo_ksp, flags=3)",
"_____no_output_____"
],
[
"plt.imshow(abs(logo_recon))",
"_____no_output_____"
]
],
[
[
"This is a brief example of the more 'Pythonic' approach offered by the Python bindings.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a0205f6e1a8b1b88b66277f5d074cae64c94970
| 607,381 |
ipynb
|
Jupyter Notebook
|
notebooks/pm1-convolutional-neural-networks.ipynb
|
morganjwilliams/09-deep-learning
|
3b4117436fad20b7691f86adcaccc2df2492c7c3
|
[
"MIT"
] | null | null | null |
notebooks/pm1-convolutional-neural-networks.ipynb
|
morganjwilliams/09-deep-learning
|
3b4117436fad20b7691f86adcaccc2df2492c7c3
|
[
"MIT"
] | null | null | null |
notebooks/pm1-convolutional-neural-networks.ipynb
|
morganjwilliams/09-deep-learning
|
3b4117436fad20b7691f86adcaccc2df2492c7c3
|
[
"MIT"
] | null | null | null | 349.06954 | 64,924 | 0.911146 |
[
[
[
"# Convolutional Neural Networks\n\n\nIn this notebook we are going to explore the [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) dataset (you don't need to download this dataset, we are going to use keras to download this dataset). This is a great dataset to train models for visual recognition and to start to build some models in Convolutional Neural Networks (CNN). This dataset consists of 60,000 32x32 colour images in 10 classes, with 6,000 images per class. There are 50,000 training images and 10,000 test images\n\nAs CNN's requires high-computational effort, we are going to use a reduced version of this training dataset. Given our time and computational resources restrictions, we are going to select 3 categories (airplane, horse and truck).\n \nIn this notebook, we are going to build two different models in order to classify the objects. First, we are going to build Shallow Neural Network based just in a few Fully-Connected Layers (aka Multi-layer Perceptron) and we are going to understand why is not feasible to classify images with such networks. Then, we are going to build a CNN network to perform the same task and evaluate its performance.\n\nAgain, in order to have a clean notebook, some functions are implemented in the file *utils.py* (e.g., plot_loss_and_accuracy). \n\nSummary:\n - [Downloading CIFAR-10 Dataset](#cifar)\n - [Data Pre-processing](#reduce)\n - [Reducing the Dataset](#red)\n - [Normalising the Dataset](#normalise)\n - [One-hot Encoding](#onehot)\n - [Building the Shallow Neural Network](#shallow)\n - [Training the Model](#train_shallow)\n - [Prediction and Performance Analysis](#performance_sh)\n - [Building the Convolutional Neural Network](#cnn)\n - [Training the Model](#train_cnn)\n - [Prediction and Performance Analysis](#performance_cnn)\n",
"_____no_output_____"
]
],
[
[
"# Standard libraries\nimport numpy as np # written in C, is faster and robust library for numerical and matrix operations\nimport pandas as pd # data manipulation library, it is widely used for data analysis and relies on numpy library.\nimport matplotlib.pyplot as plt # for plotting\nimport seaborn as sns # Plot nicely =) . Importing seaborn modifies the default matplotlib color schemes and plot \n # styles to improve readability and aesthetics.\n\n# Auxiliar functions\nfrom utils import *\n\n# the following to lines will tell to the python kernel to always update the kernel for every utils.py\n# modification, without the need of restarting the kernel.\n%load_ext autoreload\n%autoreload 2\n\n# using the 'inline' backend, your matplotlib graphs will be included in your notebook, next to the code\n%matplotlib inline\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"Using TensorFlow backend.\n"
]
],
[
[
"## Downloading CIFAR-10 Dataset\n<a id='cifar'></a>\n\nKeras provides several [datasets](https://keras.io/datasets/) for experimentation, this makes it easy to try new network architectures. In order to download the CIFAR-10 dataset, we need to import the library \"[cifar10](https://keras.io/datasets/#cifar100-small-image-classification)\" and call the method *load_data()\".",
"_____no_output_____"
]
],
[
[
"from keras.datasets import cifar10 # Implements the methods to dowload CIFAR-10 dataset\n\n(x_train, y_train), (x_test, y_test) = cifar10.load_data() #this will download the dataset\n# by defaul, the dataset was split in 50,000 images for training and 10,000 images for testing\n# we are going to use this configuration\n\ny_train = y_train.ravel() # Return a contiguous flattened y_train\ny_test = y_test.ravel() #Return a contiguous flattened y_test",
"_____no_output_____"
]
],
[
[
"Let's visualise how the images looks like. To plot the images we are going to use the function **plot_images** (see *utils.py*)",
"_____no_output_____"
]
],
[
[
"# from https://www.cs.toronto.edu/~kriz/cifar.html we can grab the class names\n# 0 1 2 3 4 5 6 7 8 9\nclass_name = np.array(\n ['airplane', 'automobile','bird','cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'])\n\n# \nplot_samples(x_train, y_train, class_name)",
"____________________________________________________________________________________________\n\nairplane - number of samples: 5000\n"
]
],
[
[
"## Data Pre-processing\n<a id='reduce'></a>\n\nAs CNN's requires high-computational effort, we are going to use a reduced training dataset. Given our time and computational resources restrictions, we are going to select 3 categories (airplane, horse and truck) and for each category and select in total 1500 images.\n\nOnce obtained the reduced version, we are going to normalise the images and generate the one-hot enconding representation of the labels.",
"_____no_output_____"
],
[
"### Reducing the Dataset\n<a id='red'></a>",
"_____no_output_____"
]
],
[
[
"# Lets select just 3 classes to make this tutorial feasible\nselected_idx = np.array([0, 7, 9])\nn_images = 1500\n\ny_train_idx = np.isin(y_train, selected_idx)\ny_test_idx = np.isin(y_test, selected_idx)\n\ny_train_red = y_train[y_train_idx][:n_images]\nx_train_red = x_train[y_train_idx][:n_images]\n\ny_test_red = y_test[y_test_idx][:n_images]\nx_test_red = x_test[y_test_idx][:n_images]\n\n# replacing the labels 0, 7 and 9 to 0, 1, 2 repectively.\ny_train_red[y_train_red == selected_idx[0]] = 0\ny_train_red[y_train_red == selected_idx[1]] = 1\ny_train_red[y_train_red == selected_idx[2]] = 2\n\ny_test_red[y_test_red == selected_idx[0]] = 0\ny_test_red[y_test_red == selected_idx[1]] = 1\ny_test_red[y_test_red == selected_idx[2]] = 2",
"_____no_output_____"
],
[
"y_test_red[:4]",
"_____no_output_____"
],
[
"# visulising the images in the reduced dataset\nplot_samples(x_train_red, y_train_red, class_name[selected_idx])",
"____________________________________________________________________________________________\n\nairplane - number of samples: 508\n"
]
],
[
[
"**Question 1**: Is the reduced dataset imbalanced?",
"_____no_output_____"
],
[
"**Question 2**: As you can see, the images have low resolution (32x32x3), how this can affect the model?",
"_____no_output_____"
],
[
"### Normalising the Dataset\n<a id='normalise'></a>\n\nHere we are going to normalise the dataset. In this task, we are going to divide each image by 255.0, as the images are represented as 'uint8' and we know that the range is from 0 to 255. By doing so, the range of the images will be between 0 and 1.",
"_____no_output_____"
]
],
[
[
"# Normalising the \nx_train_red = x_train_red.astype('float32')\nx_test_red = x_test_red.astype('float32')\nx_train_red /= 255.0\nx_test_red /= 255.0",
"_____no_output_____"
]
],
[
[
"### One-hot Encoding\n<a id='onehot'></a>\n\nThe labels are encoded as integers (0, 1 and 2), as we are going to use a *softmax layer* as output for our models we need to convert the labels as binary matrix. For example, the label 0 (considering that we have just 3 classes) can be represented as [1 0 0], which is the class 0.\n\nOne-hot enconding together with the sofmax function will give us an interesting interpretation of the output as a probability distribution over the classes. \n\nFor this task, are going to use the function *[to_categorical](https://keras.io/utils/)*, which converts a class vector (integers) to binary class matrix.",
"_____no_output_____"
]
],
[
[
"y_train_oh = keras.utils.to_categorical(y_train_red)\ny_test_oh = keras.utils.to_categorical(y_test_red)\n\nprint('Label: ',y_train_red[0], ' one-hot: ', y_train_oh[0])\nprint('Label: ',y_train_red[810], ' one-hot: ', y_train_oh[810])\nprint('Label: ',y_test_red[20], ' one-hot: ', y_test_oh[20])",
"Label: 2 one-hot: [0. 0. 1.]\nLabel: 0 one-hot: [1. 0. 0.]\nLabel: 1 one-hot: [0. 1. 0.]\n"
]
],
[
[
"## Building the Shallow Neural Network\n<a id='shallow'></a>\n\nHere we are going to build a Shallow Neural Network with 2 Fully Connected layers and one output layer. Basically, we are implemting a Multi-Layer Perceptron classifier.\n\nTo build the model, we are going use the following components from Keras:\n\n - [Sequencial](https://keras.io/models/sequential/): allows us to create models layer-by-layer. \n - [Dense](https://keras.io/layers/core/): provides a regular fully-connected layer\n - [Dropout](https://keras.io/layers/core/#dropout): provides dropout regularisation\n\nBasically, we are going to define the sequence of our model by using _Sequential()_, which include the layers:\n\n```python\n model = Sequential()\n model.add(Dense(...))\n ...\n```\nonce created the model we can configure the model for training by using the method [compile](https://keras.io/models/model/). Here we need to define the [loss](https://keras.io/losses/) function (mean squared error, categorical cross entropy, among others.), the [optimizer](https://keras.io/optimizers/) (Stochastic gradient descent, RMSprop, adam, among others) and the [metric](https://keras.io/metrics/) to define the evaluation metric to be used to evaluate the performance of the model in the training step, as follows:\n\n```python\n model.compile(loss = \"...\", \n optimizer = \"...\")\n```\n\nAlso, we have the option to see a summary representation of the model by using thebfunction [summary](https://keras.io/models/about-keras-models/#about-keras-models). This function summarise the model and tell us the number of parameters that we need to tune.",
"_____no_output_____"
]
],
[
[
"from keras.models import Sequential # implements sequential function\nfrom keras.layers import Dense # implements the fully connected layer\nfrom keras.layers import Dropout # implements Dropout regularisation\nfrom keras.layers import Flatten # implements Flatten function",
"_____no_output_____"
],
[
"mlp = Sequential()\n\n# Flatten will reshape the input an 1D array with dimension equal to 32 x 32 x 3 (3072)\n# each pixel is an input for this model.\nmlp.add(Flatten(input_shape=x_train_red.shape[1:])) #x_train.shape[1:] returns the shape \n\n# First layer with 1024 neurons and relu as activation function\nmlp.add(Dense(1024, activation='relu'))\nmlp.add(Dropout(0.7)) # regularization with 70% of keep probability\n\n# Second layer with 1024 neurons and relu as activation function\nmlp.add(Dense(1024, activation='relu'))\nmlp.add(Dropout(0.7))# regularization with 70% of keep probability\n\n# Output layer with 3 neurons and sofmax as activation function\nmlp.add(Dense(y_test_oh.shape[1], activation='softmax'))",
"_____no_output_____"
]
],
[
[
"Summarising the model",
"_____no_output_____"
]
],
[
[
"mlp.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nflatten_1 (Flatten) (None, 3072) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 1024) 3146752 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 1024) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 1024) 1049600 \n_________________________________________________________________\ndropout_2 (Dropout) (None, 1024) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 3) 3075 \n=================================================================\nTotal params: 4,199,427\nTrainable params: 4,199,427\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"# Compile:\n# Optimiser: rmsprop\n# Loss: categorical_crossentropy, as our problem is multi-label classification\n# Metric: accuracy\n\nmlp.compile(optimizer='rmsprop', \n loss='categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"### Training the Model\n<a id=train_shallow></a>\n\nOnce defined the model, we need to train it by using the function [fit](https://keras.io/models/model/). This function performs the optmisation step. Hence, we can define the following parameters such as:\n\n - batch size: defines the number of samples that will be propagated through the network\n - epochs: defines the number of times in which all the training set (x_train_scaled) are used once to update the weights\n - validation split: defines the percentage of training data to be used for validation\n - among others (click [here](https://keras.io/models/model/) for more information)\n \nThis function return the _history_ of the training, that can be used for further performance analysis.",
"_____no_output_____"
]
],
[
[
"# training the model (this will take a few minutes)\nhistory = mlp.fit(x_train_red, \n y_train_oh, \n batch_size = 256,\n epochs = 100,\n validation_split = 0.2,\n verbose = 1)",
"Train on 1200 samples, validate on 300 samples\nEpoch 1/100\n1200/1200 [==============================] - 1s 642us/step - loss: 8.8611 - accuracy: 0.3233 - val_loss: 10.2032 - val_accuracy: 0.3667\nEpoch 2/100\n1200/1200 [==============================] - 1s 464us/step - loss: 9.4976 - accuracy: 0.3575 - val_loss: 11.3331 - val_accuracy: 0.2933\nEpoch 3/100\n1200/1200 [==============================] - 1s 465us/step - loss: 9.0407 - accuracy: 0.3375 - val_loss: 7.2939 - val_accuracy: 0.3500\nEpoch 4/100\n1200/1200 [==============================] - 1s 449us/step - loss: 7.9200 - accuracy: 0.3608 - val_loss: 2.0422 - val_accuracy: 0.4267\nEpoch 5/100\n1200/1200 [==============================] - 1s 490us/step - loss: 4.9482 - accuracy: 0.4242 - val_loss: 1.7892 - val_accuracy: 0.4733\nEpoch 6/100\n1200/1200 [==============================] - 1s 491us/step - loss: 3.3828 - accuracy: 0.4033 - val_loss: 1.2247 - val_accuracy: 0.4800\nEpoch 7/100\n1200/1200 [==============================] - 0s 412us/step - loss: 1.2274 - accuracy: 0.4492 - val_loss: 0.9495 - val_accuracy: 0.6067\nEpoch 8/100\n1200/1200 [==============================] - 0s 412us/step - loss: 1.0180 - accuracy: 0.5142 - val_loss: 0.9297 - val_accuracy: 0.5267\nEpoch 9/100\n1200/1200 [==============================] - 0s 400us/step - loss: 1.1024 - accuracy: 0.4858 - val_loss: 1.0191 - val_accuracy: 0.4867\nEpoch 10/100\n1200/1200 [==============================] - 0s 407us/step - loss: 1.0276 - accuracy: 0.4950 - val_loss: 1.0041 - val_accuracy: 0.4733\nEpoch 11/100\n1200/1200 [==============================] - 0s 410us/step - loss: 1.0323 - accuracy: 0.5050 - val_loss: 0.9347 - val_accuracy: 0.5867\nEpoch 12/100\n1200/1200 [==============================] - 0s 407us/step - loss: 1.1216 - accuracy: 0.4817 - val_loss: 1.0009 - val_accuracy: 0.4800\nEpoch 13/100\n1200/1200 [==============================] - 1s 420us/step - loss: 1.0543 - accuracy: 0.4867 - val_loss: 0.9797 - val_accuracy: 0.5667\nEpoch 14/100\n1200/1200 [==============================] - 1s 441us/step - loss: 1.1684 - accuracy: 0.4692 - val_loss: 0.9307 - val_accuracy: 0.5400\nEpoch 15/100\n1200/1200 [==============================] - 1s 456us/step - loss: 1.0219 - accuracy: 0.5008 - val_loss: 1.0683 - val_accuracy: 0.4700\nEpoch 16/100\n1200/1200 [==============================] - 1s 420us/step - loss: 1.0666 - accuracy: 0.5167 - val_loss: 0.9105 - val_accuracy: 0.6467\nEpoch 17/100\n1200/1200 [==============================] - 1s 423us/step - loss: 0.9646 - accuracy: 0.5508 - val_loss: 0.9149 - val_accuracy: 0.6167\nEpoch 18/100\n1200/1200 [==============================] - 1s 424us/step - loss: 1.0344 - accuracy: 0.5233 - val_loss: 0.9316 - val_accuracy: 0.5767\nEpoch 19/100\n1200/1200 [==============================] - 1s 421us/step - loss: 0.9882 - accuracy: 0.5142 - val_loss: 1.2443 - val_accuracy: 0.4200\nEpoch 20/100\n1200/1200 [==============================] - 1s 427us/step - loss: 1.1222 - accuracy: 0.5092 - val_loss: 1.0822 - val_accuracy: 0.4633\nEpoch 21/100\n1200/1200 [==============================] - 1s 418us/step - loss: 1.0162 - accuracy: 0.5258 - val_loss: 0.8829 - val_accuracy: 0.6433\nEpoch 22/100\n1200/1200 [==============================] - 1s 421us/step - loss: 0.8933 - accuracy: 0.5842 - val_loss: 0.8503 - val_accuracy: 0.6067\nEpoch 23/100\n1200/1200 [==============================] - 0s 415us/step - loss: 0.9624 - accuracy: 0.5500 - val_loss: 0.9840 - val_accuracy: 0.5033\nEpoch 24/100\n1200/1200 [==============================] - 1s 430us/step - loss: 0.9627 - accuracy: 0.5650 - val_loss: 0.8708 - val_accuracy: 0.6633\nEpoch 25/100\n1200/1200 [==============================] - 1s 417us/step - loss: 0.8940 - accuracy: 0.5808 - val_loss: 0.8484 - val_accuracy: 0.6467\nEpoch 26/100\n1200/1200 [==============================] - 1s 420us/step - loss: 1.0177 - accuracy: 0.5500 - val_loss: 0.9934 - val_accuracy: 0.5000\nEpoch 27/100\n1200/1200 [==============================] - 1s 424us/step - loss: 0.9612 - accuracy: 0.5658 - val_loss: 0.8533 - val_accuracy: 0.6533\nEpoch 28/100\n1200/1200 [==============================] - 1s 423us/step - loss: 0.9167 - accuracy: 0.5783 - val_loss: 0.8423 - val_accuracy: 0.6200\nEpoch 29/100\n1200/1200 [==============================] - 1s 462us/step - loss: 1.0693 - accuracy: 0.5425 - val_loss: 0.9069 - val_accuracy: 0.5433\nEpoch 30/100\n1200/1200 [==============================] - 1s 523us/step - loss: 0.9874 - accuracy: 0.5558 - val_loss: 0.8876 - val_accuracy: 0.6233\nEpoch 31/100\n1200/1200 [==============================] - 1s 482us/step - loss: 0.9150 - accuracy: 0.6133 - val_loss: 0.8471 - val_accuracy: 0.6533\nEpoch 32/100\n1200/1200 [==============================] - 1s 535us/step - loss: 0.8966 - accuracy: 0.5875 - val_loss: 0.8394 - val_accuracy: 0.6567\nEpoch 33/100\n1200/1200 [==============================] - 1s 733us/step - loss: 1.0009 - accuracy: 0.5683 - val_loss: 0.8313 - val_accuracy: 0.6833\nEpoch 34/100\n1200/1200 [==============================] - 1s 675us/step - loss: 0.9055 - accuracy: 0.6000 - val_loss: 0.9092 - val_accuracy: 0.5767\nEpoch 35/100\n1200/1200 [==============================] - 1s 721us/step - loss: 0.8905 - accuracy: 0.6167 - val_loss: 0.8472 - val_accuracy: 0.6400\nEpoch 36/100\n1200/1200 [==============================] - 1s 704us/step - loss: 0.8491 - accuracy: 0.6200 - val_loss: 0.9329 - val_accuracy: 0.5733\nEpoch 37/100\n1200/1200 [==============================] - 1s 506us/step - loss: 0.8499 - accuracy: 0.6175 - val_loss: 0.8047 - val_accuracy: 0.6433\nEpoch 38/100\n1200/1200 [==============================] - 1s 564us/step - loss: 0.9421 - accuracy: 0.5925 - val_loss: 0.8730 - val_accuracy: 0.6300\nEpoch 39/100\n1200/1200 [==============================] - 1s 504us/step - loss: 0.8232 - accuracy: 0.6458 - val_loss: 1.0589 - val_accuracy: 0.5300\nEpoch 40/100\n1200/1200 [==============================] - 1s 510us/step - loss: 0.9408 - accuracy: 0.5975 - val_loss: 0.8725 - val_accuracy: 0.6133\nEpoch 41/100\n1200/1200 [==============================] - 1s 461us/step - loss: 0.8675 - accuracy: 0.6333 - val_loss: 0.9335 - val_accuracy: 0.5733\nEpoch 42/100\n1200/1200 [==============================] - 1s 435us/step - loss: 0.8780 - accuracy: 0.6067 - val_loss: 0.8065 - val_accuracy: 0.6633\nEpoch 43/100\n1200/1200 [==============================] - 1s 454us/step - loss: 0.8152 - accuracy: 0.6400 - val_loss: 0.8127 - val_accuracy: 0.6533\nEpoch 44/100\n1200/1200 [==============================] - 1s 438us/step - loss: 0.9007 - accuracy: 0.6108 - val_loss: 0.8572 - val_accuracy: 0.6400\nEpoch 45/100\n1200/1200 [==============================] - 1s 431us/step - loss: 0.8781 - accuracy: 0.6350 - val_loss: 0.8984 - val_accuracy: 0.5400\nEpoch 46/100\n1200/1200 [==============================] - 1s 518us/step - loss: 0.9065 - accuracy: 0.6067 - val_loss: 0.8419 - val_accuracy: 0.7167\nEpoch 47/100\n1200/1200 [==============================] - 1s 593us/step - loss: 0.8384 - accuracy: 0.6533 - val_loss: 0.8070 - val_accuracy: 0.7033\nEpoch 48/100\n1200/1200 [==============================] - 1s 661us/step - loss: 0.8336 - accuracy: 0.6400 - val_loss: 0.8790 - val_accuracy: 0.6067\nEpoch 49/100\n1200/1200 [==============================] - 1s 438us/step - loss: 0.8986 - accuracy: 0.6142 - val_loss: 0.7960 - val_accuracy: 0.6800\nEpoch 50/100\n1200/1200 [==============================] - 1s 474us/step - loss: 0.8036 - accuracy: 0.6475 - val_loss: 1.0725 - val_accuracy: 0.5400\nEpoch 51/100\n1200/1200 [==============================] - 1s 497us/step - loss: 0.8630 - accuracy: 0.6300 - val_loss: 0.8012 - val_accuracy: 0.7000\nEpoch 52/100\n1200/1200 [==============================] - 1s 509us/step - loss: 0.7654 - accuracy: 0.6725 - val_loss: 0.7761 - val_accuracy: 0.7067\nEpoch 53/100\n1200/1200 [==============================] - 1s 550us/step - loss: 0.8597 - accuracy: 0.6433 - val_loss: 1.1820 - val_accuracy: 0.5367\nEpoch 54/100\n1200/1200 [==============================] - 1s 509us/step - loss: 0.9133 - accuracy: 0.6308 - val_loss: 0.7860 - val_accuracy: 0.6667\nEpoch 55/100\n1200/1200 [==============================] - 1s 471us/step - loss: 0.7864 - accuracy: 0.6717 - val_loss: 0.9369 - val_accuracy: 0.5167\nEpoch 56/100\n"
]
],
[
[
"### Prediction and Performance Analysis\n<a id='performance_sh'></a>\n\nHere we plot the 'loss' and the 'Accuracy' from the training step.",
"_____no_output_____"
]
],
[
[
"plot_loss_and_accuracy_am2(history=history)",
"_____no_output_____"
]
],
[
[
"Let's evaluate the performance of this model under unseen data (x_test)",
"_____no_output_____"
]
],
[
[
"loss_value_mlp, acc_value_mlp = mlp.evaluate(x_test_red, y_test_oh, verbose=0)\nprint('Loss value: ', loss_value_mlp)\nprint('Acurracy value: ', acc_value_mlp)",
"Loss value: 0.7617508924802144\nAcurracy value: 0.6766666769981384\n"
]
],
[
[
"## Building the Convolutional Neural Network\n<a id='cnn'></a>\n\nHere we are going to build a Convolutional Neural Network (CNN) for image classification. Given the time and computational resources limitations, we are going to build a very simple CNN, however, more complex and deep CNN's architectures such as VGG, Inception and ResNet are the state of the art in computer vision and they superpass the human performance in image classification tasks. \n\nTo build the model, we are going use the following components from Keras:\n\n - [Sequencial](https://keras.io/models/sequential/): allows us to create models layer-by-layer. \n - [Dense](https://keras.io/layers/core/): provides a regular fully-connected layer\n - [Dropout](https://keras.io/layers/core/#dropout): provides dropout regularisation\n - [Conv2D](https://keras.io/layers/convolutional/): implement 2D convolution function\n - [BatchNormalization](https://keras.io/layers/normalization/): normalize the activations of the previous layer at each batch\n - [MaxPooling2D](https://keras.io/layers/pooling/): provides pooling operation for spatial data\n \nBasically, we are going to define the sequence of our model by using _Sequential()_, which include the layers:\n\n```python\n model = Sequential()\n model.add(Conv2D(...))\n ...\n```\nonce created the model the training configuration is the same as [before](#shallow):\n\n```python\n model.compile(loss = \"...\", \n optimizer = \"...\")\n```",
"_____no_output_____"
]
],
[
[
"from keras.models import Sequential\nfrom keras.layers import Dense, Flatten, Activation\nfrom keras.layers import Dropout, Conv2D, MaxPooling2D, BatchNormalization",
"_____no_output_____"
],
[
"model_cnn = Sequential()\n\n# First layer:\n# 2D convolution:\n# Depth: 32\n# Kernel shape: 3 x 3\n# Stride: 1 (default)\n# Activation layer: relu\n# Padding: valid\n# Input shape: 32 x 32 x 3 (3D representation, not Flatten as MLP)\n# as you can see now the input is an image and not an flattened array\nmodel_cnn.add(Conv2D(32, (3, 3), padding='valid', activation = 'relu', \n input_shape=x_train_red.shape[1:]))\nmodel_cnn.add(BatchNormalization())\nmodel_cnn.add(MaxPooling2D(pool_size=(5,5))) # max pooling with kernel size 5x5\nmodel_cnn.add(Dropout(0.7)) # 70% of keep probability\n\n\n# Second layer:\n# 2D convolution:\n# Depth: 64\n# Kernel shape: 3 x 3\n# Stride: 1 (default)\n# Activation layer: relu\n# Padding: valid\nmodel_cnn.add(Conv2D(64, (3, 3), padding='valid', activation = 'relu'))\nmodel_cnn.add(BatchNormalization())\nmodel_cnn.add(MaxPooling2D(pool_size=(2,2)))\nmodel_cnn.add(Dropout(0.7))\n\n# Flatten the output from the second layer to become the input of the Fully-connected\n# layer (flattened representation as MLP)\nmodel_cnn.add(Flatten())\n\n# First fully-connected layer with 128 neurons and relu as activation function\nmodel_cnn.add(Dense(128, activation = 'relu'))\n\n# Output layer with 3 neurons and sofmax as activation function\nmodel_cnn.add(Dense(y_test_oh.shape[1], activation='softmax'))",
"_____no_output_____"
]
],
[
[
"Summarising the model",
"_____no_output_____"
]
],
[
[
"model_cnn.summary()",
"Model: \"sequential_2\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_1 (Conv2D) (None, 30, 30, 32) 896 \n_________________________________________________________________\nbatch_normalization_1 (Batch (None, 30, 30, 32) 128 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 6, 6, 32) 0 \n_________________________________________________________________\ndropout_3 (Dropout) (None, 6, 6, 32) 0 \n_________________________________________________________________\nconv2d_2 (Conv2D) (None, 4, 4, 64) 18496 \n_________________________________________________________________\nbatch_normalization_2 (Batch (None, 4, 4, 64) 256 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 2, 2, 64) 0 \n_________________________________________________________________\ndropout_4 (Dropout) (None, 2, 2, 64) 0 \n_________________________________________________________________\nflatten_2 (Flatten) (None, 256) 0 \n_________________________________________________________________\ndense_4 (Dense) (None, 128) 32896 \n_________________________________________________________________\ndense_5 (Dense) (None, 3) 387 \n=================================================================\nTotal params: 53,059\nTrainable params: 52,867\nNon-trainable params: 192\n_________________________________________________________________\n"
]
],
[
[
"As you can see, the CNN model (53,059 parameters) has less parameters than the MLP model (4,199,427 parameters). So this model is less prone to overfit.",
"_____no_output_____"
]
],
[
[
"# Compile:\n# Optimiser: adam\n# Loss: categorical_crossentropy, as our problem is multi-label classification\n# Metric: accuracy\n\nmodel_cnn.compile(optimizer='adam', \n loss='categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"### Training the Model\n<a id=train_cnn></a>",
"_____no_output_____"
]
],
[
[
"# this will take a few minutes\nhistory_cnn = model_cnn.fit(x_train_red, \n y_train_oh, \n batch_size = 256,\n epochs = 100,\n validation_split = 0.2,\n verbose = 1)",
"Train on 1200 samples, validate on 300 samples\nEpoch 1/100\n1200/1200 [==============================] - 3s 3ms/step - loss: 2.3089 - accuracy: 0.3608 - val_loss: 1.0892 - val_accuracy: 0.3633\nEpoch 2/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.7711 - accuracy: 0.4450 - val_loss: 1.0868 - val_accuracy: 0.3633\nEpoch 3/100\n1200/1200 [==============================] - 3s 2ms/step - loss: 1.5541 - accuracy: 0.4683 - val_loss: 1.0803 - val_accuracy: 0.3667\nEpoch 4/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.5462 - accuracy: 0.4733 - val_loss: 1.0744 - val_accuracy: 0.3667\nEpoch 5/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.1866 - accuracy: 0.5558 - val_loss: 1.0684 - val_accuracy: 0.3667\nEpoch 6/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.2240 - accuracy: 0.5525 - val_loss: 1.0635 - val_accuracy: 0.3700\nEpoch 7/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.1125 - accuracy: 0.5642 - val_loss: 1.0601 - val_accuracy: 0.3700\nEpoch 8/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.1193 - accuracy: 0.5825 - val_loss: 1.0551 - val_accuracy: 0.3667\nEpoch 9/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.0705 - accuracy: 0.5775 - val_loss: 1.0555 - val_accuracy: 0.3667\nEpoch 10/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 1.0497 - accuracy: 0.6000 - val_loss: 1.0566 - val_accuracy: 0.3667\nEpoch 11/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.9817 - accuracy: 0.6175 - val_loss: 1.0580 - val_accuracy: 0.3800\nEpoch 12/100\n1200/1200 [==============================] - 3s 2ms/step - loss: 0.9526 - accuracy: 0.6317 - val_loss: 1.0661 - val_accuracy: 0.3867\nEpoch 13/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.9398 - accuracy: 0.6333 - val_loss: 1.0654 - val_accuracy: 0.3867\nEpoch 14/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.8973 - accuracy: 0.6458 - val_loss: 1.0649 - val_accuracy: 0.4033\nEpoch 15/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.9304 - accuracy: 0.6300 - val_loss: 1.0730 - val_accuracy: 0.4267\nEpoch 16/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.8855 - accuracy: 0.6458 - val_loss: 1.0739 - val_accuracy: 0.4300\nEpoch 17/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.8915 - accuracy: 0.6417 - val_loss: 1.0776 - val_accuracy: 0.4467\nEpoch 18/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.8279 - accuracy: 0.6608 - val_loss: 1.0840 - val_accuracy: 0.4733\nEpoch 19/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.8656 - accuracy: 0.6500 - val_loss: 1.0989 - val_accuracy: 0.4533\nEpoch 20/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.8818 - accuracy: 0.6367 - val_loss: 1.1045 - val_accuracy: 0.4667\nEpoch 21/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.8104 - accuracy: 0.6742 - val_loss: 1.1098 - val_accuracy: 0.4733\nEpoch 22/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.7910 - accuracy: 0.6925 - val_loss: 1.1121 - val_accuracy: 0.4833\nEpoch 23/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.7908 - accuracy: 0.6925 - val_loss: 1.1216 - val_accuracy: 0.4800\nEpoch 24/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.8101 - accuracy: 0.6850 - val_loss: 1.1290 - val_accuracy: 0.4833\nEpoch 25/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7883 - accuracy: 0.6875 - val_loss: 1.1312 - val_accuracy: 0.4867\nEpoch 26/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7303 - accuracy: 0.7025 - val_loss: 1.1257 - val_accuracy: 0.5133\nEpoch 27/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7893 - accuracy: 0.7000 - val_loss: 1.1171 - val_accuracy: 0.5167\nEpoch 28/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7394 - accuracy: 0.7083 - val_loss: 1.1259 - val_accuracy: 0.4833\nEpoch 29/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6972 - accuracy: 0.7233 - val_loss: 1.1543 - val_accuracy: 0.4433\nEpoch 30/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7426 - accuracy: 0.6975 - val_loss: 1.1984 - val_accuracy: 0.4167\nEpoch 31/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7136 - accuracy: 0.7117 - val_loss: 1.1843 - val_accuracy: 0.4300\nEpoch 32/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6738 - accuracy: 0.7342 - val_loss: 1.1927 - val_accuracy: 0.4300\nEpoch 33/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.6807 - accuracy: 0.7425 - val_loss: 1.2161 - val_accuracy: 0.4300\nEpoch 34/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7153 - accuracy: 0.7133 - val_loss: 1.2191 - val_accuracy: 0.4333\nEpoch 35/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7045 - accuracy: 0.7317 - val_loss: 1.2142 - val_accuracy: 0.4600\nEpoch 36/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.7076 - accuracy: 0.7200 - val_loss: 1.2037 - val_accuracy: 0.4867\nEpoch 37/100\n1200/1200 [==============================] - 3s 2ms/step - loss: 0.6762 - accuracy: 0.7225 - val_loss: 1.2040 - val_accuracy: 0.5033\nEpoch 38/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6857 - accuracy: 0.7317 - val_loss: 1.2056 - val_accuracy: 0.4900\nEpoch 39/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6457 - accuracy: 0.7533 - val_loss: 1.1939 - val_accuracy: 0.4900\nEpoch 40/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6450 - accuracy: 0.7333 - val_loss: 1.1864 - val_accuracy: 0.4900\nEpoch 41/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6742 - accuracy: 0.7258 - val_loss: 1.1593 - val_accuracy: 0.5133\nEpoch 42/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6601 - accuracy: 0.7458 - val_loss: 1.1718 - val_accuracy: 0.5067\nEpoch 43/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6794 - accuracy: 0.7258 - val_loss: 1.1902 - val_accuracy: 0.4900\nEpoch 44/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6619 - accuracy: 0.7383 - val_loss: 1.2074 - val_accuracy: 0.4867\nEpoch 45/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6483 - accuracy: 0.7592 - val_loss: 1.1901 - val_accuracy: 0.5033\nEpoch 46/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6418 - accuracy: 0.7442 - val_loss: 1.1700 - val_accuracy: 0.5133\nEpoch 47/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6831 - accuracy: 0.7250 - val_loss: 1.1497 - val_accuracy: 0.5100\nEpoch 48/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6438 - accuracy: 0.7525 - val_loss: 1.1210 - val_accuracy: 0.5333\nEpoch 49/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6450 - accuracy: 0.7550 - val_loss: 1.1223 - val_accuracy: 0.5300\nEpoch 50/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6449 - accuracy: 0.7425 - val_loss: 1.1180 - val_accuracy: 0.5333\nEpoch 51/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6143 - accuracy: 0.7467 - val_loss: 1.1060 - val_accuracy: 0.5333\nEpoch 52/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6293 - accuracy: 0.7525 - val_loss: 1.0919 - val_accuracy: 0.5367\nEpoch 53/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.6177 - accuracy: 0.7433 - val_loss: 1.1206 - val_accuracy: 0.5233\nEpoch 54/100\n1200/1200 [==============================] - 2s 1ms/step - loss: 0.6355 - accuracy: 0.7550 - val_loss: 1.1293 - val_accuracy: 0.5233\nEpoch 55/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6169 - accuracy: 0.7508 - val_loss: 1.1067 - val_accuracy: 0.5200\nEpoch 56/100\n1200/1200 [==============================] - 2s 2ms/step - loss: 0.6253 - accuracy: 0.7475 - val_loss: 1.0887 - val_accuracy: 0.5133\n"
]
],
[
[
"### Prediction and Performance Analysis\n<a id='performance_cnn'></a>",
"_____no_output_____"
]
],
[
[
"plot_loss_and_accuracy_am2(history=history_cnn)",
"_____no_output_____"
]
],
[
[
"Let's evaluate the performance of this model under unseen data (x_test)",
"_____no_output_____"
]
],
[
[
"model_cnn.evaluate(x_test_red,y_test_oh)\n\nloss_value_cnn, acc_value_cnn = model_cnn.evaluate(x_test_red, y_test_oh, verbose=0)\nprint('Loss value: ', loss_value_cnn)\nprint('Acurracy value: ', acc_value_cnn)",
"1500/1500 [==============================] - 0s 327us/step\nLoss value: 0.787270582040151\nAcurracy value: 0.6733333468437195\n"
]
],
[
[
"**Task**: Discuss CNN and MLP results.",
"_____no_output_____"
],
[
"**Your Turn**: Now we changed our mind, we found that detecting airplanes, horses and trucks is a bit boring :(. We would like to detect whether an image has a bird, a dog or a ship =)\n\nImplement a CNN to classify the images of the new reduced dataset.",
"_____no_output_____"
],
[
"**Creating the dataset**",
"_____no_output_____"
]
],
[
[
"# Lets select just 3 classes to make this tutorial feasible\nselected_idx = np.array([2, 5, 8])\nn_images = 1500\n\ny_train_idx = np.isin(y_train, selected_idx)\ny_test_idx = np.isin(y_test, selected_idx)\n\ny_train_new = y_train[y_train_idx][:n_images]\nx_train_new = x_train[y_train_idx][:n_images]\n\ny_test_new = y_test[y_test_idx][:n_images]\nx_test_new = x_test[y_test_idx][:n_images]\n\n# replacing the labels 0, 7 and 9 to 0, 1, 2 repectively.\ny_train_new[y_train_new == selected_idx[0]] = 0\ny_train_new[y_train_new == selected_idx[1]] = 1\ny_train_new[y_train_new == selected_idx[2]] = 2\n\ny_test_new[y_test_new == selected_idx[0]] = 0\ny_test_new[y_test_new == selected_idx[1]] = 1\ny_test_new[y_test_new == selected_idx[2]] = 2\n\n# visulising the images in the reduced dataset\nplot_samples(x_train_new, y_train_new, class_name[selected_idx])",
"____________________________________________________________________________________________\n\nbird - number of samples: 513\n"
]
],
[
[
"**Pre-processing the new dataset**",
"_____no_output_____"
]
],
[
[
"# normalising the data\nx_train_new = x_train_new.astype('float32')\nx_test_new = x_test_new.astype('float32')\nx_train_new /= 255.0\nx_test_new /= 255.0\n\n# creating the one-hot representation\ny_train_oh_n = keras.utils.to_categorical(y_train_new)\ny_test_oh_n = keras.utils.to_categorical(y_test_new)\n\nprint('Label: ',y_train_new[0], ' one-hot: ', y_train_oh_n[0])\nprint('Label: ',y_train_new[810], ' one-hot: ', y_train_oh_n[810])\nprint('Label: ',y_test_new[20], ' one-hot: ', y_test_oh_n[20])",
"Label: 0 one-hot: [1. 0. 0.]\nLabel: 1 one-hot: [0. 1. 0.]\nLabel: 2 one-hot: [0. 0. 1.]\n"
]
],
[
[
"**Step 1**: Create the CNN Model.\n\nFor example, you can try (Danger, Will Robinson! This model can overfits):\n\n```python\nmodel_cnn_new = Sequential()\n\nmodel_cnn_new.add(Conv2D(32, (3, 3), padding='valid', activation = 'relu', \n input_shape=x_train_new.shape[1:]))\nmodel_cnn_new.add(BatchNormalization())\nmodel_cnn_new.add(MaxPooling2D(pool_size=(2,2))) \nmodel_cnn_new.add(Dropout(0.7))\n\n# You can stack several convolution layers before apply BatchNormalization, MaxPooling2D\n# and Dropout\nmodel_cnn_new.add(Conv2D(32, (3, 3), padding='valid', activation = 'relu', \n input_shape=x_train_new.shape[1:]))\nmodel_cnn_new.add(Conv2D(16, (3, 3), padding='valid', activation = 'relu'))\nmodel_cnn_new.add(Conv2D(64, (3, 3), padding='valid', activation = 'relu'))\nmodel_cnn_new.add(BatchNormalization())\n# You can also don't use max pooling... it is up to you\n#model_cnn_new.add(MaxPooling2D(pool_size=(2,2))) # this line can lead to negative dimension problem\nmodel_cnn_new.add(Dropout(0.7))\n\nmodel_cnn_new.add(Conv2D(32, (5, 5), padding='valid', activation = 'relu'))\nmodel_cnn_new.add(BatchNormalization())\nmodel_cnn_new.add(MaxPooling2D(pool_size=(2,2)))\nmodel_cnn_new.add(Dropout(0.7))\n\nmodel_cnn_new.add(Flatten())\nmodel_cnn_new.add(Dense(128, activation = 'relu'))\n\nmodel_cnn_new.add(Dense(y_test_oh_n.shape[1], activation='softmax'))\n```",
"_____no_output_____"
],
[
"**Step 2**: Summarise the model.\n\nFor example, you can try:\n\n```python\nmodel_cnn_new.summary()\n```",
"_____no_output_____"
],
[
"**Step 3**: Define optimiser (try 'rmsprop', 'sgd', 'adagrad' or 'adadelta' if you wich), loss and metric\n \nFor example:\n``` python\nmodel_cnn_new.compile(optimizer='adam', \n loss='categorical_crossentropy',\n metrics=['accuracy'])\n```",
"_____no_output_____"
],
[
"**Step 4**: Train the model, here you can define the number of epochs and batch_size that best fit for you model\n\nFor example: \n```python \n# this can take SEVERAL minutes or even hours.. days... if your model is quite deep\nhistory_cnn_new = model_cnn_new.fit(x_train_new, \n y_train_oh_n, \n batch_size = 256,\n epochs = 100,\n validation_split = 0.2,\n verbose = 1)\n```",
"_____no_output_____"
],
[
"**Step 4**: Evaluate the model performance by using the metric that you think is the best.\n\nFor example: \n```python \nmodel_cnn_new.evaluate(x_test_new,y_test_oh_n)\n\nloss_value_cnn_n, acc_value_cnn_n = model_cnn_new.evaluate(x_test_new, y_test_oh_n, verbose=0)\nprint('Loss value: ', loss_value_cnn_n)\nprint('Acurracy value: ', acc_value_cnn_n)\n```\n\nPlot the loss and accuracy if you which.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a0208e43435d046e1e905838e01aa32dffc89cd
| 37,161 |
ipynb
|
Jupyter Notebook
|
notebooks/exercises/day 4/Day4_better.ipynb
|
anafink/advanced_python_2021-22_HD
|
d52c47a554757f67b836c2e5388ea5c0d74a30b5
|
[
"CC0-1.0"
] | null | null | null |
notebooks/exercises/day 4/Day4_better.ipynb
|
anafink/advanced_python_2021-22_HD
|
d52c47a554757f67b836c2e5388ea5c0d74a30b5
|
[
"CC0-1.0"
] | null | null | null |
notebooks/exercises/day 4/Day4_better.ipynb
|
anafink/advanced_python_2021-22_HD
|
d52c47a554757f67b836c2e5388ea5c0d74a30b5
|
[
"CC0-1.0"
] | null | null | null | 21.530127 | 170 | 0.32152 |
[
[
[
"import numpy as np\nimport plotly\nimport plotly.graph_objs as go\nfrom collections import deque\nimport pandas as pd\nimport plotly.express as px\n\naa_df = pd.read_csv(\"/Users/anafink/OneDrive - bwedu/Bachelor MoBi/5. Fachsemester/Python Praktikum/advanced_python_2021-22_HD/data/amino_acid_properties.csv\")\n\nmetrics = {}\nhydropathy_aa = {}\npI_aa = {}\nhp_type_aa = {}\nhydropathy_aa = aa_df.groupby('1-letter code')['hydropathy index (Kyte-Doolittle method)'].apply(float).to_dict()\npI_aa = aa_df.groupby('1-letter code')['pI'].apply(float).to_dict()\nmetrics = {\n \"hydropathy\" : hydropathy_aa,\n \"pI\" : pI_aa,\n}\n\n\n\nclass Protein:\n\n def __init__(self, name, id, sequence):\n self.name = name\n self.id = id\n self.sequence = sequence\n \n\n def define_metrics(self, metric_aa = \"hydropathy\"):\n metric_values = []\n for pos, aa in enumerate(self.sequence):\n metric_values.append(metrics[metric_aa][aa])\n return metric_values\n\n def get_aa_pos(self):\n aa_pos = []\n aa_pos = list(range(1,len(self.sequence)+1))\n return aa_pos\n\n def get_y_values(self, metric_aa = \"hydropathy\", window_size = 5 ):\n\n metric_values = self.define_metrics(metric_aa)\n window = deque([], maxlen = window_size)\n\n mean_values = []\n\n for value in metric_values:\n window.append(value)\n mean_values.append(np.mean(window))\n\n return mean_values\n \n def plot(self, metric=\"hydropathy\", window_size = 5):\n \n x_values = self.get_aa_pos()\n y_values = self.get_y_values(metric, window_size) \n \n data = [\n go.Bar(\n x = x_values, \n y = y_values, \n )\n ]\n \n fig = go.Figure(data=data)\n fig.update_layout(template=\"plotly_white\", title=\"Protein: \" + self.name)\n return fig\n",
"_____no_output_____"
],
[
"path = \"/Users/anafink/OneDrive - bwedu/Bachelor MoBi/5. Fachsemester/Python Praktikum/uniref-P32249-filtered-identity_1.0.fasta\"\nGPCR183_fasta = []\nwith open(path) as f:\n for line in f:\n GPCR183_fasta.append(line)\n\nGPCR183_seq = GPCR183_fasta\n\nfor pos, seq in enumerate(GPCR183_seq):\n if seq[0] == \">\":\n GPCR183_seq.pop(pos)\n \nGPCR183_seq = [x[:-1] for x in GPCR183_seq]\n\nGPCR183_seq = ''.join(GPCR183_seq)\n\ndef split(string):\n return [char for char in string]\n\nGPCR183_seq = split(GPCR183_seq)\n\nGPCR183 = Protein(\"G-protein coupled receptor 183 (P32249)\", \"9606\", GPCR183_seq)\n",
"_____no_output_____"
],
[
"figure = GPCR183.plot(window_size = 10)\nfigure.show()",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a0209a5ce673a2532b809579f9d3b1ba6d46e0f
| 19,814 |
ipynb
|
Jupyter Notebook
|
algorithms_and_data_structures_for_programming_contest/chap12-4/answer.ipynb
|
toku345/practice
|
e766d5b28456bbf6b3c07976375a8937be1225fc
|
[
"MIT"
] | 2 |
2019-11-07T07:08:46.000Z
|
2022-03-31T07:50:20.000Z
|
algorithms_and_data_structures_for_programming_contest/chap12-4/answer.ipynb
|
toku345/practice
|
e766d5b28456bbf6b3c07976375a8937be1225fc
|
[
"MIT"
] | null | null | null |
algorithms_and_data_structures_for_programming_contest/chap12-4/answer.ipynb
|
toku345/practice
|
e766d5b28456bbf6b3c07976375a8937be1225fc
|
[
"MIT"
] | null | null | null | 44.326622 | 218 | 0.481276 |
[
[
[
"from notebook_helpers import prep_n_and_M_from_file, make_graph",
"_____no_output_____"
],
[
"n, M = prep_n_and_M_from_file('./input/1.txt')\n\ndot = make_graph(M)\nprint(*M, sep='\\n')\ndot",
"[0, 1, 0, 1]\n[0, 0, 0, 1]\n[0, 0, 0, 0]\n[0, 0, 1, 0]\n"
],
[
"from answer import BFS\nBFS(M, n).bfs(0)",
"1 0\n2 1\n3 2\n4 1\n"
],
[
"BFS(M, n, True).bfs(0)",
"d: [0, 9223372036854775807, 9223372036854775807, 9223372036854775807]\nq: deque([0])\n-------------------------\nd: [0, 1, 9223372036854775807, 9223372036854775807]\nq: deque([1])\n-------------------------\nd: [0, 1, 9223372036854775807, 1]\nq: deque([1, 3])\n-------------------------\nd: [0, 1, 2, 1]\nq: deque([2])\n-------------------------\n1 0\n2 1\n3 2\n4 1\n"
],
[
"n, M = prep_n_and_M_from_file('./input/2.txt')\n\ndot = make_graph(M)\nprint(*M, sep='\\n')\ndot",
"[0, 1, 1, 1, 0, 0, 0, 0, 0, 0]\n[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\n[0, 0, 0, 0, 1, 0, 0, 0, 0, 0]\n[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]\n[0, 0, 0, 0, 0, 1, 1, 1, 1, 1]\n[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]\n[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\n[0, 0, 0, 0, 0, 0, 1, 0, 0, 0]\n[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]\n[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]\n"
],
[
"BFS(M, n, True).bfs(0)",
"d: [0, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807]\nq: deque([0])\n-------------------------\nd: [0, 1, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807]\nq: deque([1])\n-------------------------\nd: [0, 1, 1, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807]\nq: deque([1, 2])\n-------------------------\nd: [0, 1, 1, 1, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807]\nq: deque([1, 2, 3])\n-------------------------\nd: [0, 1, 1, 1, 2, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807]\nq: deque([3, 4])\n-------------------------\nd: [0, 1, 1, 1, 2, 9223372036854775807, 9223372036854775807, 9223372036854775807, 9223372036854775807, 2]\nq: deque([4, 9])\n-------------------------\nd: [0, 1, 1, 1, 2, 3, 9223372036854775807, 9223372036854775807, 9223372036854775807, 2]\nq: deque([9, 5])\n-------------------------\nd: [0, 1, 1, 1, 2, 3, 3, 9223372036854775807, 9223372036854775807, 2]\nq: deque([9, 5, 6])\n-------------------------\nd: [0, 1, 1, 1, 2, 3, 3, 3, 9223372036854775807, 2]\nq: deque([9, 5, 6, 7])\n-------------------------\nd: [0, 1, 1, 1, 2, 3, 3, 3, 3, 2]\nq: deque([9, 5, 6, 7, 8])\n-------------------------\n1 0\n2 1\n3 1\n4 1\n5 2\n6 3\n7 3\n8 3\n9 3\n10 2\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a020e0b57afb7eaaf167ad53ee656de2ae82e9a
| 370,982 |
ipynb
|
Jupyter Notebook
|
nbs_probabilistic/07- Categorical Forecast Implementation.ipynb
|
sagar-garg/WeatherBench
|
fdf208d9af6a896ccb012146dfef268722380a0d
|
[
"MIT"
] | null | null | null |
nbs_probabilistic/07- Categorical Forecast Implementation.ipynb
|
sagar-garg/WeatherBench
|
fdf208d9af6a896ccb012146dfef268722380a0d
|
[
"MIT"
] | 8 |
2020-04-28T08:21:21.000Z
|
2020-12-08T06:07:52.000Z
|
nbs_probabilistic/07- Categorical Forecast Implementation.ipynb
|
sagar-garg/WeatherBench
|
fdf208d9af6a896ccb012146dfef268722380a0d
|
[
"MIT"
] | null | null | null | 72.077327 | 15,612 | 0.62826 |
[
[
[
"Notes:\n- Using pandas.cut for binning. bin_min=-inf, bin_max=inf. Binning on normalized data only.* (Other option to explore: sklearn KBinsDiscretizer. Issue is that bins cant be predefined. We need same bins for each batch of y. advantage: inverse is easily available)\n\n- Changing y to categorical only for training. not for valid, test. so shape of y will be different. shape[batch_size, lat, lon, variable, member] Is shape ok?\n\n- Please check custom loss function in networks.py, train()- written but not verified, build_resnet_categorical(), create_predictions(), DataGenerator(), load_data() \n- \n\nToDo\n- currently works only for 2 output variables.\n- implement weighted loss. train() function.\n- sampling from output to create an ensemble.- done.\n- use diff. in temp instead of absolute values.\n- make spread-skill grid. see if spread-skill ratio close to 1 is for all places or how is it distributed.\n",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import xarray as xr\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom src.data_generator import *\nfrom src.train import *\nfrom src.utils import *\nfrom src.networks import *",
"_____no_output_____"
],
[
"tf.__version__ #gotta check. some issue. not able to use gpu.",
"_____no_output_____"
],
[
"import tensorflow as tf\nprint(\"Num GPUs Available: \", len(tf.config.experimental.list_physical_devices('GPU')))",
"Num GPUs Available: 1\n"
],
[
"os.environ[\"CUDA_VISIBLE_DEVICES\"]=str(0)\nlimit_mem()",
"_____no_output_____"
],
[
"args = load_args('../nn_configs/B/81.1-resnet_d3_dr_0.1.yml')",
"_____no_output_____"
],
[
"args['train_years']=['2017']\n#args['valid_years']=['2018']\nargs['valid_years']=['2018-01-01','2018-03-31']\nargs['test_years']=['2018-04-01','2018-12-31']\nargs['model_save_dir'] ='/home/garg/data/WeatherBench/predictions/saved_models'\nargs['datadir']='/home/garg/data/WeatherBench/5.625deg'",
"_____no_output_____"
],
[
"args['is_categorical']=True\nargs['num_bins'], args['bin_min'], args['bin_max']\n#num_bins=args['num_bins']",
"_____no_output_____"
],
[
"args['filters'] = [128, 128, 128, 128, 128, 128, 128, 128, \n 128, 128, 128, 128, 128, 128, 128, 128, \n 128, 128, 128, 128, 2*args['num_bins']]\nargs['loss'] = 'lat_categorical_loss'\n#could change it directly in build_resnet_categorical fn. Should we?",
"_____no_output_____"
],
[
"dg_train, dg_valid, dg_test = load_data(**args)",
"_____no_output_____"
],
[
"x,y=dg_train[0]; print(x.shape, y.shape)\nx,y=dg_valid[0]; print(x.shape, y.shape) \nx,y=dg_test[0]; print(x.shape, y.shape)\n#only changing train shape.",
"(32, 32, 64, 114) (32, 32, 64, 2, 50)\n(32, 32, 64, 114) (32, 32, 64, 2)\n(32, 32, 64, 114) (32, 32, 64, 2)\n"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"model = build_resnet_categorical(\n **args, input_shape=dg_train.shape,\n)\nmodel.summary()",
"Model: \"model\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) [(None, 32, 64, 114) 0 \n__________________________________________________________________________________________________\nperiodic_conv2d (PeriodicConv2D (None, 32, 64, 128) 715136 input_1[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d[0][0] \n__________________________________________________________________________________________________\nbatch_normalization (BatchNorma (None, 32, 64, 128) 512 leaky_re_lu[0][0] \n__________________________________________________________________________________________________\ndropout (Dropout) (None, 32, 64, 128) 0 batch_normalization[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_1 (PeriodicConv (None, 32, 64, 128) 147584 dropout[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_1 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_1 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_1[0][0] \n__________________________________________________________________________________________________\ndropout_1 (Dropout) (None, 32, 64, 128) 0 batch_normalization_1[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_2 (PeriodicConv (None, 32, 64, 128) 147584 dropout_1[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_2 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_2 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_2[0][0] \n__________________________________________________________________________________________________\ndropout_2 (Dropout) (None, 32, 64, 128) 0 batch_normalization_2[0][0] \n__________________________________________________________________________________________________\nadd (Add) (None, 32, 64, 128) 0 dropout[0][0] \n dropout_2[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_3 (PeriodicConv (None, 32, 64, 128) 147584 add[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_3 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_3 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_3[0][0] \n__________________________________________________________________________________________________\ndropout_3 (Dropout) (None, 32, 64, 128) 0 batch_normalization_3[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_4 (PeriodicConv (None, 32, 64, 128) 147584 dropout_3[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_4 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_4[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_4 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_4[0][0] \n__________________________________________________________________________________________________\ndropout_4 (Dropout) (None, 32, 64, 128) 0 batch_normalization_4[0][0] \n__________________________________________________________________________________________________\nadd_1 (Add) (None, 32, 64, 128) 0 add[0][0] \n dropout_4[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_5 (PeriodicConv (None, 32, 64, 128) 147584 add_1[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_5 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_5[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_5 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_5[0][0] \n__________________________________________________________________________________________________\ndropout_5 (Dropout) (None, 32, 64, 128) 0 batch_normalization_5[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_6 (PeriodicConv (None, 32, 64, 128) 147584 dropout_5[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_6 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_6 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_6[0][0] \n__________________________________________________________________________________________________\ndropout_6 (Dropout) (None, 32, 64, 128) 0 batch_normalization_6[0][0] \n__________________________________________________________________________________________________\nadd_2 (Add) (None, 32, 64, 128) 0 add_1[0][0] \n dropout_6[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_7 (PeriodicConv (None, 32, 64, 128) 147584 add_2[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_7 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_7[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_7 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_7[0][0] \n__________________________________________________________________________________________________\ndropout_7 (Dropout) (None, 32, 64, 128) 0 batch_normalization_7[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_8 (PeriodicConv (None, 32, 64, 128) 147584 dropout_7[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_8 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_8[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_8 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_8[0][0] \n__________________________________________________________________________________________________\ndropout_8 (Dropout) (None, 32, 64, 128) 0 batch_normalization_8[0][0] \n__________________________________________________________________________________________________\nadd_3 (Add) (None, 32, 64, 128) 0 add_2[0][0] \n dropout_8[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_9 (PeriodicConv (None, 32, 64, 128) 147584 add_3[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_9 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_9[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_9 (BatchNor (None, 32, 64, 128) 512 leaky_re_lu_9[0][0] \n__________________________________________________________________________________________________\ndropout_9 (Dropout) (None, 32, 64, 128) 0 batch_normalization_9[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_10 (PeriodicCon (None, 32, 64, 128) 147584 dropout_9[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_10 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_10[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_10 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_10[0][0] \n__________________________________________________________________________________________________\ndropout_10 (Dropout) (None, 32, 64, 128) 0 batch_normalization_10[0][0] \n__________________________________________________________________________________________________\nadd_4 (Add) (None, 32, 64, 128) 0 add_3[0][0] \n dropout_10[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_11 (PeriodicCon (None, 32, 64, 128) 147584 add_4[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_11 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_11[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_11 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_11[0][0] \n__________________________________________________________________________________________________\ndropout_11 (Dropout) (None, 32, 64, 128) 0 batch_normalization_11[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_12 (PeriodicCon (None, 32, 64, 128) 147584 dropout_11[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_12 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_12[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_12 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_12[0][0] \n__________________________________________________________________________________________________\ndropout_12 (Dropout) (None, 32, 64, 128) 0 batch_normalization_12[0][0] \n__________________________________________________________________________________________________\nadd_5 (Add) (None, 32, 64, 128) 0 add_4[0][0] \n dropout_12[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_13 (PeriodicCon (None, 32, 64, 128) 147584 add_5[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_13 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_13[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_13 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_13[0][0] \n__________________________________________________________________________________________________\ndropout_13 (Dropout) (None, 32, 64, 128) 0 batch_normalization_13[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_14 (PeriodicCon (None, 32, 64, 128) 147584 dropout_13[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_14 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_14[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_14 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_14[0][0] \n__________________________________________________________________________________________________\ndropout_14 (Dropout) (None, 32, 64, 128) 0 batch_normalization_14[0][0] \n__________________________________________________________________________________________________\nadd_6 (Add) (None, 32, 64, 128) 0 add_5[0][0] \n dropout_14[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_15 (PeriodicCon (None, 32, 64, 128) 147584 add_6[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_15 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_15[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_15 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_15[0][0] \n__________________________________________________________________________________________________\ndropout_15 (Dropout) (None, 32, 64, 128) 0 batch_normalization_15[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_16 (PeriodicCon (None, 32, 64, 128) 147584 dropout_15[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_16 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_16[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_16 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_16[0][0] \n__________________________________________________________________________________________________\ndropout_16 (Dropout) (None, 32, 64, 128) 0 batch_normalization_16[0][0] \n__________________________________________________________________________________________________\nadd_7 (Add) (None, 32, 64, 128) 0 add_6[0][0] \n dropout_16[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_17 (PeriodicCon (None, 32, 64, 128) 147584 add_7[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_17 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_17[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_17 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_17[0][0] \n__________________________________________________________________________________________________\ndropout_17 (Dropout) (None, 32, 64, 128) 0 batch_normalization_17[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_18 (PeriodicCon (None, 32, 64, 128) 147584 dropout_17[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_18 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_18[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_18 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_18[0][0] \n__________________________________________________________________________________________________\ndropout_18 (Dropout) (None, 32, 64, 128) 0 batch_normalization_18[0][0] \n__________________________________________________________________________________________________\nadd_8 (Add) (None, 32, 64, 128) 0 add_7[0][0] \n dropout_18[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_19 (PeriodicCon (None, 32, 64, 128) 147584 add_8[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_19 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_19[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_19 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_19[0][0] \n__________________________________________________________________________________________________\ndropout_19 (Dropout) (None, 32, 64, 128) 0 batch_normalization_19[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_20 (PeriodicCon (None, 32, 64, 128) 147584 dropout_19[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_20 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_20[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_20 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_20[0][0] \n__________________________________________________________________________________________________\ndropout_20 (Dropout) (None, 32, 64, 128) 0 batch_normalization_20[0][0] \n__________________________________________________________________________________________________\nadd_9 (Add) (None, 32, 64, 128) 0 add_8[0][0] \n dropout_20[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_21 (PeriodicCon (None, 32, 64, 128) 147584 add_9[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_21 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_21[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_21 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_21[0][0] \n__________________________________________________________________________________________________\ndropout_21 (Dropout) (None, 32, 64, 128) 0 batch_normalization_21[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_22 (PeriodicCon (None, 32, 64, 128) 147584 dropout_21[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_22 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_22[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_22 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_22[0][0] \n__________________________________________________________________________________________________\ndropout_22 (Dropout) (None, 32, 64, 128) 0 batch_normalization_22[0][0] \n__________________________________________________________________________________________________\nadd_10 (Add) (None, 32, 64, 128) 0 add_9[0][0] \n dropout_22[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_23 (PeriodicCon (None, 32, 64, 128) 147584 add_10[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_23 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_23[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_23 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_23[0][0] \n__________________________________________________________________________________________________\ndropout_23 (Dropout) (None, 32, 64, 128) 0 batch_normalization_23[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_24 (PeriodicCon (None, 32, 64, 128) 147584 dropout_23[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_24 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_24[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_24 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_24[0][0] \n__________________________________________________________________________________________________\ndropout_24 (Dropout) (None, 32, 64, 128) 0 batch_normalization_24[0][0] \n__________________________________________________________________________________________________\nadd_11 (Add) (None, 32, 64, 128) 0 add_10[0][0] \n dropout_24[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_25 (PeriodicCon (None, 32, 64, 128) 147584 add_11[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_25 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_25[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_25 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_25[0][0] \n__________________________________________________________________________________________________\ndropout_25 (Dropout) (None, 32, 64, 128) 0 batch_normalization_25[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_26 (PeriodicCon (None, 32, 64, 128) 147584 dropout_25[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_26 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_26[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_26 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_26[0][0] \n__________________________________________________________________________________________________\ndropout_26 (Dropout) (None, 32, 64, 128) 0 batch_normalization_26[0][0] \n__________________________________________________________________________________________________\nadd_12 (Add) (None, 32, 64, 128) 0 add_11[0][0] \n dropout_26[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_27 (PeriodicCon (None, 32, 64, 128) 147584 add_12[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_27 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_27[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_27 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_27[0][0] \n__________________________________________________________________________________________________\ndropout_27 (Dropout) (None, 32, 64, 128) 0 batch_normalization_27[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_28 (PeriodicCon (None, 32, 64, 128) 147584 dropout_27[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_28 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_28[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_28 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_28[0][0] \n__________________________________________________________________________________________________\ndropout_28 (Dropout) (None, 32, 64, 128) 0 batch_normalization_28[0][0] \n__________________________________________________________________________________________________\nadd_13 (Add) (None, 32, 64, 128) 0 add_12[0][0] \n dropout_28[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_29 (PeriodicCon (None, 32, 64, 128) 147584 add_13[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_29 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_29[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_29 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_29[0][0] \n__________________________________________________________________________________________________\ndropout_29 (Dropout) (None, 32, 64, 128) 0 batch_normalization_29[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_30 (PeriodicCon (None, 32, 64, 128) 147584 dropout_29[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_30 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_30[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_30 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_30[0][0] \n__________________________________________________________________________________________________\ndropout_30 (Dropout) (None, 32, 64, 128) 0 batch_normalization_30[0][0] \n__________________________________________________________________________________________________\nadd_14 (Add) (None, 32, 64, 128) 0 add_13[0][0] \n dropout_30[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_31 (PeriodicCon (None, 32, 64, 128) 147584 add_14[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_31 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_31[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_31 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_31[0][0] \n__________________________________________________________________________________________________\ndropout_31 (Dropout) (None, 32, 64, 128) 0 batch_normalization_31[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_32 (PeriodicCon (None, 32, 64, 128) 147584 dropout_31[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_32 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_32[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_32 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_32[0][0] \n__________________________________________________________________________________________________\ndropout_32 (Dropout) (None, 32, 64, 128) 0 batch_normalization_32[0][0] \n__________________________________________________________________________________________________\nadd_15 (Add) (None, 32, 64, 128) 0 add_14[0][0] \n dropout_32[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_33 (PeriodicCon (None, 32, 64, 128) 147584 add_15[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_33 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_33[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_33 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_33[0][0] \n__________________________________________________________________________________________________\ndropout_33 (Dropout) (None, 32, 64, 128) 0 batch_normalization_33[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_34 (PeriodicCon (None, 32, 64, 128) 147584 dropout_33[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_34 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_34[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_34 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_34[0][0] \n__________________________________________________________________________________________________\ndropout_34 (Dropout) (None, 32, 64, 128) 0 batch_normalization_34[0][0] \n__________________________________________________________________________________________________\nadd_16 (Add) (None, 32, 64, 128) 0 add_15[0][0] \n dropout_34[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_35 (PeriodicCon (None, 32, 64, 128) 147584 add_16[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_35 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_35[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_35 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_35[0][0] \n__________________________________________________________________________________________________\ndropout_35 (Dropout) (None, 32, 64, 128) 0 batch_normalization_35[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_36 (PeriodicCon (None, 32, 64, 128) 147584 dropout_35[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_36 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_36[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_36 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_36[0][0] \n__________________________________________________________________________________________________\ndropout_36 (Dropout) (None, 32, 64, 128) 0 batch_normalization_36[0][0] \n__________________________________________________________________________________________________\nadd_17 (Add) (None, 32, 64, 128) 0 add_16[0][0] \n dropout_36[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_37 (PeriodicCon (None, 32, 64, 128) 147584 add_17[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_37 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_37[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_37 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_37[0][0] \n__________________________________________________________________________________________________\ndropout_37 (Dropout) (None, 32, 64, 128) 0 batch_normalization_37[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_38 (PeriodicCon (None, 32, 64, 128) 147584 dropout_37[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_38 (LeakyReLU) (None, 32, 64, 128) 0 periodic_conv2d_38[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_38 (BatchNo (None, 32, 64, 128) 512 leaky_re_lu_38[0][0] \n__________________________________________________________________________________________________\ndropout_38 (Dropout) (None, 32, 64, 128) 0 batch_normalization_38[0][0] \n__________________________________________________________________________________________________\nadd_18 (Add) (None, 32, 64, 128) 0 add_17[0][0] \n dropout_38[0][0] \n__________________________________________________________________________________________________\nperiodic_conv2d_39 (PeriodicCon (None, 32, 64, 100) 115300 add_18[0][0] \n__________________________________________________________________________________________________\ntf_op_layer_strided_slice (Tens [(None, 32, 64, 50)] 0 periodic_conv2d_39[0][0] \n__________________________________________________________________________________________________\ntf_op_layer_strided_slice_1 (Te [(None, 32, 64, 50)] 0 periodic_conv2d_39[0][0] \n__________________________________________________________________________________________________\nactivation (Activation) (None, 32, 64, 50) 0 tf_op_layer_strided_slice[0][0] \n__________________________________________________________________________________________________\nactivation_1 (Activation) (None, 32, 64, 50) 0 tf_op_layer_strided_slice_1[0][0]\n__________________________________________________________________________________________________\ntf_op_layer_stack (TensorFlowOp [(None, 32, 64, 2, 5 0 activation[0][0] \n activation_1[0][0] \n==================================================================================================\nTotal params: 6,458,596\nTrainable params: 6,448,612\nNon-trainable params: 9,984\n__________________________________________________________________________________________________\n"
],
[
"args['loss']",
"_____no_output_____"
],
[
"model.compile(keras.optimizers.Adam(1e-3), loss=args['loss'])",
"_____no_output_____"
],
[
"model.compile(keras.optimizers.Adam(1e-3), loss=lat_categorical_loss)",
"_____no_output_____"
],
[
"def categorical_loss(y_true, y_pred): \n cce=tf.keras.losses.CategoricalCrossentropy()\n loss=0 #is this ok?\n for i in range(2):\n loss +=cce(y_true[:,:,:,i,:], y_pred[:,:,:,i,:])\n return loss",
"_____no_output_____"
],
[
"model.compile(keras.optimizers.Adam(1e-3), loss=categorical_loss)",
"_____no_output_____"
],
[
"model.fit(dg_train, epochs=10, shuffle=False)",
"Train for 136 steps\nEpoch 1/10\n136/136 [==============================] - 72s 531ms/step - loss: 5.4563\nEpoch 2/10\n136/136 [==============================] - 64s 473ms/step - loss: 3.5050\nEpoch 3/10\n136/136 [==============================] - 65s 477ms/step - loss: 3.2283\nEpoch 4/10\n136/136 [==============================] - 65s 476ms/step - loss: 3.1190\nEpoch 5/10\n136/136 [==============================] - 65s 477ms/step - loss: 2.9960\nEpoch 6/10\n136/136 [==============================] - 65s 477ms/step - loss: 2.9808\nEpoch 7/10\n136/136 [==============================] - 65s 476ms/step - loss: 2.9744\nEpoch 8/10\n136/136 [==============================] - 65s 477ms/step - loss: 2.8167\nEpoch 9/10\n136/136 [==============================] - 65s 476ms/step - loss: 2.7275\nEpoch 10/10\n136/136 [==============================] - 65s 477ms/step - loss: 2.6301\n"
],
[
"#exp_id=args['exp_id']\nexp_id='categorical_v3'\nmodel_save_dir=args['model_save_dir']\n\nmodel.save(f'{model_save_dir}/{exp_id}.h5')\nmodel.save_weights(f'{model_save_dir}/{exp_id}_weights.h5')\n#to_pickle(history.history, f'{model_save_dir}/{exp_id}_history.pkl')",
"_____no_output_____"
]
],
[
[
"## Predictions",
"_____no_output_____"
]
],
[
[
"exp_id='categorical_v3'\nmodel = keras.models.load_model(f\"{args['model_save_dir']}/{exp_id}.h5\", \n custom_objects={'PeriodicConv2D': PeriodicConv2D, 'categorical_loss': tf.keras.losses.mse})\n#check how to call loss correctly.",
"_____no_output_____"
],
[
"bin_min=args['bin_min']; bin_max=args['bin_max']\nnum_bins=args['num_bins']\nmember=100\n\npreds = create_predictions(model, dg_valid, is_categorical=True, \n num_bins=num_bins, bin_min=bin_min, \n bin_max=bin_max, member=member)\n#Check in datagenerator and train()",
"_____no_output_____"
],
[
"preds.to_netcdf('/home/garg/data/WeatherBench/predictions/categorical_v3.nc')",
"_____no_output_____"
],
[
"pred=np.asarray(preds.to_array(), dtype=np.float32).squeeze();\npred.shape\n#should we change shape to (2,100,1042, 32, 64)? that's what was in test-time dropout",
"_____no_output_____"
],
[
"preds",
"_____no_output_____"
]
],
[
[
"## Evaluation",
"_____no_output_____"
]
],
[
[
"datadir=args['datadir']\nz500_valid = load_test_data(f'{datadir}/geopotential_500', 'z').drop('level')\nt850_valid = load_test_data(f'{datadir}/temperature_850', 't').drop('level')\nvalid = xr.merge([z500_valid, t850_valid]).sel(time=preds.time)",
"_____no_output_____"
],
[
"ensemblemean=preds.mean('member') #ensemble\nmean_rmse_p=compute_weighted_rmse(valid,ensemblemean).load(); print(mean_rmse_p)",
"<xarray.Dataset>\nDimensions: ()\nData variables:\n z_rmse float64 800.2\n t_rmse float64 3.798\n"
],
[
"crps=compute_weighted_crps(preds,valid).load(); print(crps)",
"<xarray.Dataset>\nDimensions: ()\nData variables:\n z float64 398.8\n t float64 2.048\n"
],
[
"spread=compute_weighted_meanspread(preds).load()\nspread_skill_z=spread.z_mean_spread/mean_rmse_p.z_rmse\nspread_skill_t=spread.t_mean_spread/mean_rmse_p.t_rmse\nprint(spread_skill_z, spread_skill_t) ",
"<xarray.DataArray ()>\narray(0.92847472) <xarray.DataArray ()>\narray(0.89689769)\n"
],
[
"obs.shape, pred.shape",
"_____no_output_____"
],
[
"#!pip install rank-histogram\nfrom ranky import rankz\nobs = np.asarray(valid.to_array(), dtype=np.float32).squeeze();\nobs_z500=obs[0,...].squeeze()\nobs_t850=obs[1,...].squeeze()\n\nmask=np.ones(obs_z500.shape) #useless. #masked where 0/false.",
"_____no_output_____"
],
[
"pred=np.asarray(preds.to_array(), dtype=np.float32).squeeze();\n\nshape=pred.shape #maybe we could change shape of pred in create_predcitions() directly\npred2=pred.reshape(shape[0], shape[4],shape[1], shape[2], shape[3])\n\npred_z500=pred2[0,...].squeeze() \npred_t850=pred2[1,...].squeeze() \n# feed into rankz function\nresult = rankz(obs_z500, pred_z500, mask)\n# plot histogram\nplt.bar(range(1,pred_z500.shape[0]+2), result[0])\n# view histogram\nplt.show()",
"_____no_output_____"
],
[
"#random point.\nplt.hist(pred[1,20,30,40,:], label='preds')\nplt.hist(obs[1,20,30,40], label='truth')\nplt.legend(loc='upper right')\nplt.show()",
"_____no_output_____"
],
[
"#random point.\nplt.hist(pred[1,20,25,30,:], label='preds')\nplt.hist(obs[1,20,25,30], label='truth')\nplt.legend(loc='upper right')\nplt.show()",
"_____no_output_____"
],
[
"import seaborn\nseaborn.distplot(pred[1,20,30,40,:])",
"_____no_output_____"
],
[
"seaborn.distplot(pred[1,20,25,30,:])",
"_____no_output_____"
],
[
"#spread-skill is good. rank histogram weird. \n#density plot doesnt look like a gaussian. ",
"_____no_output_____"
]
],
[
[
"## Testing code below. Ignore.",
"_____no_output_____"
]
],
[
[
"dg=dg_valid\nlevel_names = dg.data.isel(level=dg.output_idxs).level_names\nlevel = dg.data.isel(level=dg.output_idxs).level ",
"_____no_output_____"
],
[
"x,y=dg_valid[0]\npreds=preds=model.predict(dg_valid[0])\nprint(preds.shape, y.shape)",
"(32, 32, 64, 2, 50) (32, 32, 64, 2)\n"
],
[
"bin_min=args['bin_min']; bin_max=args['bin_max']\nbins=np.linspace(bin_min, bin_max, num_bins+1)\nbins, bins.shape",
"_____no_output_____"
],
[
"interval=(bin_max-bin_min)/num_bins\nprint(interval)\nbin_mids=np.linspace(bin_min+0.5*interval, bin_max-0.5*interval, num_bins)\nbin_mids, bin_mids.shape",
"0.2\n"
],
[
"plt.plot(bin_mids, preds[0,30,0,0,:]) #some random point",
"_____no_output_____"
],
[
"plt.plot(bin_mids, preds[10,30,20,0,:]) #some random point",
"_____no_output_____"
],
[
"sample=np.random.choice(bin_mids, size=50, p=preds[0,30,0,0,:], replace=True)\nsample",
"_____no_output_____"
],
[
"plt.hist(sample, range=(bin_min,bin_max))",
"_____no_output_____"
],
[
"member=100\npreds_shape=preds.shape\npreds=preds.reshape(-1,num_bins)\npreds_new=[]\nfor i, p in enumerate(preds):\n sample=np.random.choice(bin_mids, size=member, p=preds[i,:],replace=True)\n preds_new.append(sample)",
"_____no_output_____"
],
[
"preds_new=np.array(preds_new)\nprint(preds_new.shape)\npreds_new3=preds_new.reshape(preds_shape[0],preds_shape[1],\n preds_shape[2],member, preds_shape[3],)\n\nprint(preds_new3.shape)\n",
"(131072, 100)\n(32, 32, 64, 100, 2)\n"
],
[
"preds_new=np.array(preds_new)\nprint(preds_new.shape)\npreds_new2=preds_new.reshape(preds_shape[0],preds_shape[1],preds_shape[2],preds_shape[3],member)\nprint(preds_new2.shape)",
"(131072, 100)\n(32, 32, 64, 2, 100)\n"
],
[
"preds_new_shape=preds_new2.shape\npreds_new2=preds_new2.reshape(preds_new_shape[0],preds_new_shape[1],\n preds_new_shape[2],\n preds_new_shape[4],preds_new_shape[3])\nprint(preds_new2.shape)",
"(32, 32, 64, 100, 2)\n"
],
[
" dg=dg_valid\n preds_new2 = xr.DataArray(\n preds_new2,\n dims=['time', 'lat', 'lon', 'member', 'level'],\n coords={'time': dg.valid_time[0:32], 'lat': dg.data.lat, \n 'lon': dg.data.lon,\n 'member': np.arange(member),\n 'level': level,\n 'level_names': level_names,\n },\n ) ",
"_____no_output_____"
],
[
"mean = dg.mean.isel(level=dg.output_idxs).values\nstd = dg.std.isel(level=dg.output_idxs).values\npreds_new2 = preds_new2 * std + mean",
"_____no_output_____"
],
[
"unique_vars = list(set([l.split('_')[0] for l in preds_new2.level_names.values]))",
"_____no_output_____"
],
[
" das = []\n for v in unique_vars:\n idxs = [i for i, vv in enumerate(preds_new2.level_names.values) if vv.split('_')[0] in v]\n da = preds_new2.isel(level=idxs).squeeze().drop('level_names')\n if not 'level' in da.dims: da = da.drop('level')\n das.append({v: da})\n preds_final=xr.merge(das)",
"_____no_output_____"
],
[
"preds_final",
"_____no_output_____"
],
[
"preds_final.to_netcdf('/home/garg/data/WeatherBench/predictions/categorical_v3.nc')",
"_____no_output_____"
],
[
"sample1=np.random.choice(5, 20, p=[0.05, 0.2, 0.5, 0.2, 0.05])\nsample1",
"_____no_output_____"
],
[
"args['datadir']",
"_____no_output_____"
],
[
"datadir=args['datadir']\nz500_valid = load_test_data(f'{datadir}/geopotential_500', 'z').drop('level')\nt850_valid = load_test_data(f'{datadir}/temperature_850', 't').drop('level')\nvalid = xr.merge([z500_valid, t850_valid]).sel(time=preds_final.time)",
"_____no_output_____"
],
[
"valid",
"_____no_output_____"
],
[
"ensemblemean=preds_final.mean('member') #ensemble\nmean_rmse_p=compute_weighted_rmse(valid,ensemblemean).load(); print(mean_rmse_p)",
"<xarray.Dataset>\nDimensions: ()\nData variables:\n z_rmse float64 3.406e+03\n t_rmse float64 16.23\n"
],
[
"crps=compute_weighted_crps(preds_final,valid).load(); print(crps)",
"<xarray.Dataset>\nDimensions: ()\nData variables:\n z float64 1.796e+03\n t float64 8.488\n"
],
[
"else:\n preds = xr.DataArray(\n model.predict(dg)[0] if multi_dt else model.predict(dg),\n dims=['time', 'lat', 'lon', 'level'],\n coords={'time': dg.valid_time, 'lat': dg.data.lat, 'lon': dg.data.lon,\n 'level': level,\n 'level_names': level_names\n },\n ) \n\n",
"_____no_output_____"
],
[
" if is_categorical==True:\n #Have to do this weird reshapings else cant sample, unnormalize. Not sure if its correct. Please check.\n preds=model.predict(dg)[0] if multi_dt else model.predict(dg)\n\n interval=(bin_max-bin_min)/num_bins\n bin_mids=np.linspace(bin_min+0.5*interval, bin_max-0.5*interval, num_bins)\n\n preds_shape=preds.shape\n preds=preds.reshape(-1,num_bins)\n preds_new=[]\n for i, p in enumerate(preds):\n sample=np.random.choice(bin_mids, size=member,p=preds[i,:],replace=True)\n preds_new.append(sample)\n\n preds_new=np.array(preds_new)\n preds_new=preds_new.reshape(preds_shape[0],preds_shape[1],preds_shape[2],\n preds_shape[3],member)\n \n preds_new_shape=preds_new.shape\n preds_new=preds_new.reshape(preds_new_shape[0],preds_new_shape[1],\n preds_new_shape[2],preds_new_shape[4],\n preds_new_shape[3],\n \n preds = xr.DataArray(\n preds_new,\n dims=['time', 'lat', 'lon', 'member', 'level'],\n coords={'time': dg.valid_time, 'lat': dg.data.lat, 'lon': dg.data.lon,\n 'member': np.arange(member),\n 'level': level,\n 'level_names': level_names,\n },)\n\n",
"_____no_output_____"
],
[
"if is_categorical==True:\n \n #Have to do this weird reshapings else cant sample, unnormalize. \n #Not sure if its correct. Please check.\n preds=model.predict(dg)[0] if multi_dt else model.predict(dg)\n\n interval=(bin_max-bin_min)/num_bins\n bin_mids=np.linspace(bin_min+0.5*interval, bin_max-0.5*interval, num_bins)\n\n preds_shape=preds.shape\n preds=preds.reshape(-1,num_bins)\n preds_new=[]\n for i, p in enumerate(preds):\n sample=np.random.choice(bin_mids, size=member,p=preds[i,:],replace=True)\n preds_new.append(sample)\n\n preds_new=np.array(preds_new)\n preds_new=preds_new.reshape(preds_shape[0],preds_shape[1],preds_shape[2],\n preds_shape[3],member)\n \n preds_new_shape=preds_new.shape\n preds_new=preds_new.reshape(preds_new_shape[0],preds_new_shape[1],\n preds_new_shape[2],preds_new_shape[4],\n preds_new_shape[3],\n \n preds = xr.DataArray(\n preds_new,\n dims=['time', 'lat', 'lon', 'member', 'level'],\n coords={'time': dg.valid_time, 'lat': dg.data.lat, 'lon': dg.data.lon,\n 'member': np.arange(member),\n 'level': level,\n 'level_names': level_names,\n },)\n ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a020f2f665d76170daa65d6f8c3b3e21d94faab
| 80,564 |
ipynb
|
Jupyter Notebook
|
climate_starter.ipynb
|
Harmonylm/sqlalchemy-challenge
|
411fd8f9abaf2a21cee36e3a8253ac01ccb34b1c
|
[
"ADSL"
] | null | null | null |
climate_starter.ipynb
|
Harmonylm/sqlalchemy-challenge
|
411fd8f9abaf2a21cee36e3a8253ac01ccb34b1c
|
[
"ADSL"
] | null | null | null |
climate_starter.ipynb
|
Harmonylm/sqlalchemy-challenge
|
411fd8f9abaf2a21cee36e3a8253ac01ccb34b1c
|
[
"ADSL"
] | null | null | null | 92.17849 | 23,356 | 0.817822 |
[
[
[
"%matplotlib inline\nfrom matplotlib import style\nstyle.use('fivethirtyeight')\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"import datetime as dt",
"_____no_output_____"
]
],
[
[
"# Reflect Tables into SQLAlchemy ORM",
"_____no_output_____"
]
],
[
[
"# Python SQL toolkit and Object Relational Mapper\nimport sqlalchemy\nfrom sqlalchemy.ext.automap import automap_base\nfrom sqlalchemy.orm import Session\nfrom sqlalchemy import create_engine, func",
"_____no_output_____"
],
[
"engine = create_engine(\"sqlite:///Resources/hawaii.sqlite\")",
"_____no_output_____"
],
[
"# reflect an existing database into a new model\nBase = automap_base()\n# reflect the tables\nBase.prepare(engine, reflect=True)",
"_____no_output_____"
],
[
"# We can view all of the classes that automap found\nBase.classes.keys()",
"_____no_output_____"
],
[
"# Save references to each table\nMeasurement = Base.classes.measurement\nStation = Base.classes.station",
"_____no_output_____"
],
[
"# Create our session (link) from Python to the DB\nsession = Session(engine)",
"_____no_output_____"
]
],
[
[
"# Exploratory Climate Analysis",
"_____no_output_____"
]
],
[
[
"# Calculate the date 1 year ago from the last data point in the database\none_yr_ago = dt.date(2017, 8, 23) - dt.timedelta(days=365)\n\n# Design a query to retrieve the last 12 months of precipitation data and plot the results\nmeasurement_12 = session.query(Measurement.date,Measurement.prcp).filter(Measurement.date >= one_yr_ago).order_by(Measurement.date.desc()).all()\n# for measure in measurement_12:\n# print(measure.date, measure.prcp)\n\n# Perform a query to retrieve the data and precipitation scores\ndf = pd.DataFrame(measurement_12[:2230], columns=['Date', 'Precipitation'])\ndf.set_index('Date', inplace=True )\n\n\n# Save the query results as a Pandas DataFrame and set the index to the date column\n\n# Sort the dataframe by date\nresult = df.sort_values(by='Date', ascending=False)\nresult.head(10)\n# Use Pandas Plotting with Matplotlib to plot the data\n",
"_____no_output_____"
],
[
"\n# ax = df.iloc[:20:-1].plot(kind='bar', title ='Precipitation', figsize=(15, 10), legend=True, fontsize=12)\n# ax.set_xlabel(\"Date\", fontsize=12)\n# ax.set_ylabel(\"Precipitation\", fontsize=12)\n# plt.show()\n\nresult.plot(rot=90)",
"_____no_output_____"
],
[
"# Use Pandas to calcualte the summary statistics for the precipitation data\ndf.describe()",
"_____no_output_____"
],
[
"# Design a query to show how many stations are available in this dataset?\nstation_no = session.query(Measurement,Station).filter(Measurement.station == Station.station).all()\n# station_count =station.count(station.station) \nstation_count = []\nfor stn in station_no:\n (mt,st) = stn\n station_count.append(st.station)\n\n \nlen(set(station_count))\n",
"_____no_output_____"
],
[
"# What are the most active stations? (i.e. what stations have the most rows)?\n# List the stations and the counts in descending order.\nCounter(station_count)",
"_____no_output_____"
],
[
"# Using the station id from the previous query, calculate the lowest temperature recorded, \n# highest temperature recorded, and average temperature of the most active station?\nstation_q = session.query(func.min(Measurement.tobs), func.max(Measurement.tobs), func.avg(Measurement.tobs)).\\\n filter(Measurement.station == 'USC00519281').all()\n\nstation_q",
"_____no_output_____"
],
[
"# Choose the station with the highest number of temperature observations.\n# Query the last 12 months of temperature observation data for this station and plot the results as a histogram\nimport datetime as dt\nfrom pandas.plotting import table\nprev_year = dt.date(2017, 8, 23) - dt.timedelta(days=365)\n\nresults = session.query(Measurement.tobs).\\\n filter(Measurement.station == 'USC00519281').\\\n filter(Measurement.date >= prev_year).all()\ndf = pd.DataFrame(results, columns=['tobs'])\ndf.plot.hist(bins=12)\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"## Optional Challenge Assignment",
"_____no_output_____"
]
],
[
[
"# This function called `calc_temps` will accept start date and end date in the format '%Y-%m-%d' \n# and return the minimum, average, and maximum temperatures for that range of dates\ndef calc_temps(start_date, end_date):\n \"\"\"TMIN, TAVG, and TMAX for a list of dates.\n \n Args:\n start_date (string): A date string in the format %Y-%m-%d\n end_date (string): A date string in the format %Y-%m-%d\n \n Returns:\n TMIN, TAVE, and TMAX\n \"\"\"\n \n return session.query(func.min(Measurement.tobs), func.avg(Measurement.tobs), func.max(Measurement.tobs)).\\\n filter(Measurement.date >= start_date).filter(Measurement.date <= end_date).all()\n\n# function usage example\nprint(calc_temps('2012-02-28', '2012-03-05'))",
"[(62.0, 69.57142857142857, 74.0)]\n"
],
[
"# Use your previous function `calc_temps` to calculate the tmin, tavg, and tmax \n# for your trip using the previous year's data for those same dates.\nimport datetime as dt\n\nprev_year_start = dt.date(2018, 1, 1) - dt.timedelta(days=365)\nprev_year_end = dt.date(2018, 1, 7) - dt.timedelta(days=365)\n\ntmin, tavg, tmax = calc_temps(prev_year_start.strftime(\"%Y-%m-%d\"), prev_year_end.strftime(\"%Y-%m-%d\"))[0]\nprint(tmin, tavg, tmax)",
"62.0 68.36585365853658 74.0\n"
],
[
"# Plot the results from your previous query as a bar chart. \n# Use \"Trip Avg Temp\" as your Title\n# Use the average temperature for the y value\n# Use the peak-to-peak (tmax-tmin) value as the y error bar (yerr)\nfig, ax = plt.subplots(figsize=plt.figaspect(2.))\nxpos = 1\nyerr = tmax-tmin\n\nbar = ax.bar(xpos, tmax, yerr=yerr, alpha=0.5, color='coral', align=\"center\")\nax.set(xticks=range(xpos), xticklabels=\"a\", title=\"Trip Avg Temp\", ylabel=\"Temp (F)\")\nax.margins(.2, .2)\n# fig.autofmt_xdate()\nfig.tight_layout()\nfig.show()",
"C:\\Users\\hmosb\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:14: UserWarning: Matplotlib is currently using module://ipykernel.pylab.backend_inline, which is a non-GUI backend, so cannot show the figure.\n \n"
],
[
"# Calculate the total amount of rainfall per weather station for your trip dates using the previous year's matching dates.\n# Sort this in descending order by precipitation amount and list the station, name, latitude, longitude, and elevation\nstart_date = '2012-01-01'\nend_date = '2012-01-07'\n\nsel = [Station.station, Station.name, Station.latitude, \n Station.longitude, Station.elevation, func.sum(Measurement.prcp)]\n\nresults = session.query(*sel).\\\n filter(Measurement.station == Station.station).\\\n filter(Measurement.date >= start_date).\\\n filter(Measurement.date <= end_date).\\\n group_by(Station.name).order_by(func.sum(Measurement.prcp).desc()).all()\nprint(results)",
"[('USC00516128', 'MANOA LYON ARBO 785.2, HI US', 21.3331, -157.8025, 152.4, 0.31), ('USC00519281', 'WAIHEE 837.5, HI US', 21.45167, -157.84888999999998, 32.9, 0.25), ('USC00518838', 'UPPER WAHIAWA 874.3, HI US', 21.4992, -158.0111, 306.6, 0.1), ('USC00513117', 'KANEOHE 838.1, HI US', 21.4234, -157.8015, 14.6, 0.060000000000000005), ('USC00519523', 'WAIMANALO EXPERIMENTAL FARM, HI US', 21.33556, -157.71139, 19.5, 0.0), ('USC00519397', 'WAIKIKI 717.2, HI US', 21.2716, -157.8168, 3.0, 0.0), ('USC00517948', 'PEARL CITY, HI US', 21.3934, -157.9751, 11.9, 0.0), ('USC00514830', 'KUALOA RANCH HEADQUARTERS 886.9, HI US', 21.5213, -157.8374, 7.0, 0.0), ('USC00511918', 'HONOLULU OBSERVATORY 702.2, HI US', 21.3152, -157.9992, 0.9, 0.0)]\n"
],
[
"# Create a query that will calculate the daily normals \n# (i.e. the averages for tmin, tmax, and tavg for all historic data matching a specific month and day)\n\ndef daily_normals(date):\n \"\"\"Daily Normals.\n \n Args:\n date (str): A date string in the format '%m-%d'\n \n Returns:\n A list of tuples containing the daily normals, tmin, tavg, and tmax\n \n \"\"\"\n \n sel = [func.min(Measurement.tobs), func.avg(Measurement.tobs), func.max(Measurement.tobs)]\n return session.query(*sel).filter(func.strftime(\"%m-%d\", Measurement.date) == date).all()\n \ndaily_normals(\"01-01\")",
"_____no_output_____"
],
[
"# calculate the daily normals for your trip\n# push each tuple of calculations into a list called `normals`\ntrip_start = '2018-01-01'\ntrip_end = '2018-01-07'\n# Set the start and end date of the trip\ntrip_dates = pd.date_range(trip_start, trip_end, freq='D')\n# Use the start and end date to create a range of dates\ntrip_month_day = trip_dates.strftime('%m-%d')\n# Stip off the year and save a list of %m-%d strings\n\n# Loop through the list of %m-%d strings and calculate the normals for each date\nnormals = []\nfor date in trip_month_day:\n normals.append(*daily_normals(date))\n \nnormals",
"_____no_output_____"
],
[
"# Load the previous query results into a Pandas DataFrame and add the `trip_dates` range as the `date` index\ndf = pd.DataFrame(normals, columns=['tmin', 'tavg', 'tmax'])\ndf['date'] = trip_dates\ndf.set_index(['date'],inplace=True)\ndf.head()\n",
"_____no_output_____"
],
[
"# Plot the daily normals as an area plot with `stacked=False`\ndf.plot(kind='area', stacked=False, x_compat=True, alpha=.2)\nplt.tight_layout()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a02105c459c4df133ebfc9977ce2b33517743f3
| 10,271 |
ipynb
|
Jupyter Notebook
|
votecounter/development/scrapeMiniNormals.ipynb
|
skitter30/modbot
|
6526f5bd1b8e73143ff45d71081d64c6e4aa8ea5
|
[
"MIT"
] | 2 |
2019-12-29T13:15:13.000Z
|
2020-04-27T07:32:21.000Z
|
votecounter/development/scrapeMiniNormals.ipynb
|
skitter30/modbot
|
6526f5bd1b8e73143ff45d71081d64c6e4aa8ea5
|
[
"MIT"
] | 9 |
2018-05-02T14:39:48.000Z
|
2018-05-27T22:08:53.000Z
|
votecounter/development/scrapeMiniNormals.ipynb
|
skitter30/modbot
|
6526f5bd1b8e73143ff45d71081d64c6e4aa8ea5
|
[
"MIT"
] | 6 |
2018-05-08T19:48:35.000Z
|
2018-06-03T02:58:55.000Z
| 32.503165 | 164 | 0.491773 |
[
[
[
"## Scrape Archived Mini Normals from Mafiascum.net",
"_____no_output_____"
],
[
"#### Scrapy Structure/Lingo:\n**Spiders** extract data **items**, which Scrapy send one by one to a configured **item pipeline** (if there is possible) to do post-processing on the items.)",
"_____no_output_____"
],
[
"## Import relevant packages...",
"_____no_output_____"
]
],
[
[
"import scrapy\nimport math\nimport logging\nimport json\nfrom scrapy.crawler import CrawlerProcess\nfrom scrapy.spiders import CrawlSpider, Rule\nfrom scrapy.item import Item, Field\nfrom scrapy.selector import Selector",
"_____no_output_____"
]
],
[
[
"## Initial variables...",
"_____no_output_____"
]
],
[
[
"perpage = 25\n\nclass PostItem(scrapy.Item):\n pagelink = scrapy.Field()\n forum = scrapy.Field()\n thread = scrapy.Field()\n number = scrapy.Field()\n timestamp = scrapy.Field()\n user = scrapy.Field()\n content = scrapy.Field()",
"_____no_output_____"
]
],
[
[
"## Define what happens to scrape output...",
"_____no_output_____"
]
],
[
[
"# The following pipeline stores all scraped items (from all spiders) \n# into a single items.jl file, containing one item per line serialized \n# in JSON format:\nclass JsonWriterPipeline(object):\n\n # operations performed when spider starts\n def open_spider(self, spider):\n self.file = open('posts.jl', 'w')\n\n # when the spider finishes\n def close_spider(self, spider):\n self.file.close()\n\n # when the spider yields an item\n def process_item(self, item, spider):\n line = json.dumps(dict(item)) + \"\\n\"\n self.file.write(line)\n return item",
"_____no_output_____"
]
],
[
[
"## Define spider...",
"_____no_output_____"
]
],
[
[
"class MafiaScumSpider(scrapy.Spider):\n name = 'mafiascum'\n \n # define set of threads we're going to scrape from (ie all of them)\n start_urls = [each[:each.find('\\n')] for each in open('archive.txt').read().split('\\n\\n\\n')]\n \n # settings\n custom_settings = {'LOG_LEVEL': logging.WARNING,\n 'ITEM_PIPELINES': {'__main__.JsonWriterPipeline': 1}}\n\n # get page counts and then do the REAL parse on every single page\n def parse(self, response):\n # find page count \n try:\n postcount = Selector(response).xpath(\n '//div[@class=\"pagination\"]/text()').extract()\n postcount = int(postcount[0][4:postcount[0].find(' ')])\n\n # yield parse for every page of thread\n for i in range(math.ceil(postcount/perpage)):\n yield scrapy.Request(response.url+'&start='+str(i*perpage),\n callback=self.parse_page)\n except IndexError: # if can't, the thread probably doesn't exist\n return\n \n \n def parse_page(self, response):\n # scan through posts on page and yield Post items for each\n sel = Selector(response)\n location = sel.xpath('//div[@id=\"page-body\"]/h2/a/@href').extract()[0]\n forum = location[location.find('f=')+2:location.find('&t=')]\n if location.count('&') == 1:\n thread = location[location.find('&t=')+3:]\n elif location.count('&') == 2:\n thread = location[\n location.find('&t=')+3:location.rfind('&')]\n \n posts = (sel.xpath('//div[@class=\"post bg1\"]') +\n sel.xpath('//div[@class=\"post bg2\"]'))\n \n for p in posts:\n post = PostItem()\n post['forum'] = forum\n post['thread'] = thread\n post['pagelink'] = response.url\n try:\n post['number'] = p.xpath(\n 'div/div[@class=\"postbody\"]/p/a[2]/strong/text()').extract()[0][1:]\n except IndexError:\n post['number'] = p.xpath(\n 'div[@class=\"postbody\"]/p/a[2]/strong/text()').extract()[0][1:]\n \n try:\n post['timestamp'] = p.xpath(\n 'div/div/p/text()[4]').extract()[0][23:-4]\n except IndexError:\n post['timestamp'] = p.xpath(\n 'div[@class=\"postbody\"]/p/text()[4]').extract()[0][23:-4]\n \n try:\n post['user'] = p.xpath('div/div/dl/dt/a/text()').extract()[0]\n except IndexError:\n post['user'] = '<<DELETED_USER>>'\n \n try:\n post['content'] = p.xpath(\n 'div/div/div[@class=\"content\"]').extract()[0][21:-6]\n except IndexError:\n post['content'] = p.xpath(\n 'div[@class=\"postbody\"]/div[@class=\"content\"]').extract()[0][21:-6]\n \n yield post",
"_____no_output_____"
]
],
[
[
"## Start scraping...",
"_____no_output_____"
]
],
[
[
"process = CrawlerProcess({\n 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'\n})\n\nprocess.crawl(MafiaScumSpider)\nprocess.start()",
"2017-09-25 10:26:08 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapybot)\n2017-09-25 10:26:08 [scrapy.utils.log] INFO: Overridden settings: {'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'}\n"
]
],
[
[
"...and output should be a json file in same directory as this notebook! ",
"_____no_output_____"
],
[
"## Leftover Code...",
"_____no_output_____"
]
],
[
[
"# open mini normal archive\n\n# ??? i don't remember what this does; probably helped me collect archive links some time ago\nrunthis = False\n\nif runthis:\n # relevant packages\n from selenium import webdriver\n from scrapy.selector import Selector\n import re\n\n # configure browser\n options = webdriver.ChromeOptions()\n options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'\n options.add_argument('window-size=800x841')\n driver = webdriver.Chrome(chrome_options=options)\n\n # get the thread titles and links\n links = []\n titles = []\n for i in range(0, 400, 100):\n driver.get('https://forum.mafiascum.net/viewforum.php?f=53&start=' + str(i))\n sel = Selector(text=driver.page_source)\n links += sel.xpath('//div[@class=\"forumbg\"]/div/ul[@class=\"topiclist topics\"]/li/dl/dt/a[1]/@href').extract()\n titles += sel.xpath('//div[@class=\"forumbg\"]/div/ul[@class=\"topiclist topics\"]/li/dl/dt/a[1]/text()').extract()\n\n # formatting, excluding needless threads...\n titles = titles[1:]\n links = links[1:]\n del links[titles.index('Mini Normal Archives')]\n del titles[titles.index('Mini Normal Archives')]\n titles = [re.search(r'\\d+', each).group(0) for each in titles]\n\n # match txt archive game numbers with forum archive game numbers to find links\n f = open('archive.txt', 'r')\n txtarchives = f.read().split('\\n\\n\\n')\n numbers = [re.search(r'\\d+', each[:each.find('\\n')]).group(0) for each in txtarchives]\n f.close()\n\n # store the result...\n for i, n in enumerate(numbers):\n txtarchives[i] = 'http://forum.mafiascum.net' + links[titles.index(n)][1:] + '\\n' + txtarchives[i]\n f = open('archive2.txt', 'w')\n f.write('\\n\\n\\n'.join(txtarchives))\n f.close()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a0211513e202d88dd3f7c57ea072aca012d9c95
| 25,567 |
ipynb
|
Jupyter Notebook
|
data_preparation_text_processing.ipynb
|
RohitBelwadkar/Advanced-NLP-Project
|
7ec599ff78176da918ab81904247c57341a4ae4d
|
[
"MIT"
] | 100 |
2019-04-10T11:53:30.000Z
|
2022-03-23T19:58:44.000Z
|
data_preparation_text_processing.ipynb
|
RohitBelwadkar/Advanced-NLP-Project
|
7ec599ff78176da918ab81904247c57341a4ae4d
|
[
"MIT"
] | 2 |
2019-05-03T10:08:59.000Z
|
2019-10-23T06:16:16.000Z
|
data_preparation_text_processing.ipynb
|
RohitBelwadkar/Advanced-NLP-Project
|
7ec599ff78176da918ab81904247c57341a4ae4d
|
[
"MIT"
] | 81 |
2018-12-19T14:45:14.000Z
|
2022-02-09T12:45:51.000Z
| 30.078824 | 204 | 0.413854 |
[
[
[
"While going through our script we will gradually understand the use of this packages",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf #no need to describe ;)\nimport numpy as np #allows array operation\nimport pandas as pd #we will use it to read and manipulate files and columns content\n\nfrom nltk.corpus import stopwords #provides list of english stopwords\nstop = stopwords.words('english')",
"_____no_output_____"
],
[
"#PRINT VERSION!!\ntf.__version__",
"_____no_output_____"
]
],
[
[
"To do this notebook we will use New York Times user comments (from Kaggle Datasets).\nWhen we will create the language classifier we will use other data but now let's rely on an english natural language source, so now we read the data.\n",
"_____no_output_____"
]
],
[
[
"#PLEASE DOWNLOAD THE FILE HERE: https://www.kaggle.com/aashita/nyt-comments\ntrain = pd.read_csv('CommentsApril2017.csv')\n",
"C:\\Users\\Admin\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3049: DtypeWarning: Columns (25,26) have mixed types. Specify dtype option on import or set low_memory=False.\n interactivity=interactivity, compiler=compiler, result=result)\n"
]
],
[
[
"Let's have a quick look at the data trying to find what is the column that we need.\nLooks like commentBody is the right candidate.",
"_____no_output_____"
]
],
[
[
"train.head() ",
"_____no_output_____"
]
],
[
[
"now we first put everything to lowercase and then replace undesired characters",
"_____no_output_____"
]
],
[
[
"train['commentBody_lower'] = train[\"commentBody\"].str.lower()\ntrain['commentBody_no_punctiation'] = train['commentBody_lower'].str.replace('[^\\w\\s]','')",
"_____no_output_____"
]
],
[
[
"let's check how the text looks like now!\nWell everything is lowercase and no \"ugly characters\"",
"_____no_output_____"
]
],
[
[
"train['commentBody_no_punctiation'].head() ",
"_____no_output_____"
]
],
[
[
"Now we remove stopwords and then fill empy cells with \"fillna\" word.",
"_____no_output_____"
]
],
[
[
"train['commentBody_no_stopwords'] = train['commentBody_no_punctiation'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))",
"_____no_output_____"
],
[
"train[\"commentBody_no_stopwords\"] = train[\"commentBody_no_stopwords\"].fillna(\"fillna\")",
"_____no_output_____"
]
],
[
[
"This is how our cleaned text looks like we can see that everything is lowercase and the stopwords are missing, for example \"this\". Now let's go back to slides.\n",
"_____no_output_____"
]
],
[
[
"train['commentBody_no_stopwords'].head()",
"_____no_output_____"
],
[
"tf_train = train\n",
"_____no_output_____"
]
],
[
[
"We first assign our current data frame to another to keep track of our work then we read the first sentence and count words that result to be 21",
"_____no_output_____"
]
],
[
[
"tf_train['commentBody_no_stopwords'][1]",
"_____no_output_____"
],
[
"tf_train['commentBody_no_stopwords'][1].count(' ')",
"_____no_output_____"
],
[
"max_features=5000 #we set maximum number of words to 5000\nmaxlen=100 #and maximum sequence length to 100\n",
"_____no_output_____"
],
[
"tok = tf.keras.preprocessing.text.Tokenizer(num_words=max_features) #tokenizer step",
"_____no_output_____"
],
[
"tok.fit_on_texts(list(tf_train['commentBody_no_stopwords'])) #fit to cleaned text",
"_____no_output_____"
],
[
"tf_train=tok.texts_to_sequences(list(tf_train['commentBody_no_stopwords'])) #this is how we create sequences",
"_____no_output_____"
],
[
"print(type(tf_train)) #we see that the type is now list\nprint(len(tf_train[1])) #we see that the number of words of the sentence is decreased to 16\ntf_train[1] #and this is how our sentece looks like now, exactly a sequence of integers",
"<class 'list'>\n16\n"
],
[
"tf_train=tf.keras.preprocessing.sequence.pad_sequences(tf_train, maxlen=maxlen) #let's execute pad step ",
"_____no_output_____"
],
[
"print(len(tf_train[1]))\ntf_train[1] #this is how our sentece looks like after the pad step we don't have anymore 16 words but 100 (equivalent to maxlen)",
"100\n"
],
[
"train['commentBody_no_stopwords'][1] #let's look at the input text",
"_____no_output_____"
],
[
"tf_train = pd.DataFrame(tf_train)\n\n",
"_____no_output_____"
],
[
"tf_train.head() #let's look at the final matrix that will use as an input for our deep learning algorithms, do you remember \n#how original text looked like?",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a021ba2328d1cc19b2ce8d9242e7558377947f9
| 2,097 |
ipynb
|
Jupyter Notebook
|
printer.ipynb
|
frankieattea/CMPINF0010-lab-5
|
5577fa0fcaa1d9ba658d135aa89747248c35694f
|
[
"Apache-2.0"
] | null | null | null |
printer.ipynb
|
frankieattea/CMPINF0010-lab-5
|
5577fa0fcaa1d9ba658d135aa89747248c35694f
|
[
"Apache-2.0"
] | null | null | null |
printer.ipynb
|
frankieattea/CMPINF0010-lab-5
|
5577fa0fcaa1d9ba658d135aa89747248c35694f
|
[
"Apache-2.0"
] | null | null | null | 20.558824 | 58 | 0.447783 |
[
[
[
"error_str = \"Please enter a valid age.\"\n\n# name prompt\nname = input(prompt= \"What is your name?\")\n\n# --- age check loop --- #\n# keeps asking until valid integer age is entered\n\nwhile(True):\n age = input(\"What is your age?\")\n \n # check if age is integer\n try:\n age = int(age)\n \n # check if age is inside human range\n if age <= 0 or age >= 123:\n print(error_str)\n else:\n break \n except:\n print(error_str)\n\n# --- print loop --- #\nfor i in range(age):\n print(name)",
"What is your name? FRANKie\nWhat is your age? 18\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4a0246b53fb56e8ce352bfdec6eee1cf3bc2aeed
| 247,472 |
ipynb
|
Jupyter Notebook
|
Convolutional Neural Networks/Autonomous driving application Car detection v1.ipynb
|
ayushsaklani/deep_learning_ai_coursera
|
78d940aee313b9564bb373e4537250c26ed01de1
|
[
"MIT"
] | 1 |
2017-12-26T15:35:15.000Z
|
2017-12-26T15:35:15.000Z
|
Convolutional Neural Networks/Autonomous driving application Car detection v1.ipynb
|
ayushsaklani/deep_learning_ai_coursera
|
78d940aee313b9564bb373e4537250c26ed01de1
|
[
"MIT"
] | null | null | null |
Convolutional Neural Networks/Autonomous driving application Car detection v1.ipynb
|
ayushsaklani/deep_learning_ai_coursera
|
78d940aee313b9564bb373e4537250c26ed01de1
|
[
"MIT"
] | null | null | null | 176.765714 | 179,682 | 0.854949 |
[
[
[
"# Autonomous driving - Car detection\n\nWelcome to your week 3 programming assignment. You will learn about object detection using the very powerful YOLO model. Many of the ideas in this notebook are described in the two YOLO papers: Redmon et al., 2016 (https://arxiv.org/abs/1506.02640) and Redmon and Farhadi, 2016 (https://arxiv.org/abs/1612.08242). \n\n**You will learn to**:\n- Use object detection on a car detection dataset\n- Deal with bounding boxes\n\nRun the following cell to load the packages and dependencies that are going to be useful for your journey!",
"_____no_output_____"
]
],
[
[
"import argparse\nimport os\nimport matplotlib.pyplot as plt\nfrom matplotlib.pyplot import imshow\nimport scipy.io\nimport scipy.misc\nimport numpy as np\nimport pandas as pd\nimport PIL\nimport tensorflow as tf\nfrom keras import backend as K\nfrom keras.layers import Input, Lambda, Conv2D\nfrom keras.models import load_model, Model\nfrom yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes\nfrom yad2k.models.keras_yolo import yolo_head, yolo_boxes_to_corners, preprocess_true_boxes, yolo_loss, yolo_body\n\n%matplotlib inline",
"Using TensorFlow backend.\n"
]
],
[
[
"**Important Note**: As you can see, we import Keras's backend as K. This means that to use a Keras function in this notebook, you will need to write: `K.function(...)`.",
"_____no_output_____"
],
[
"## 1 - Problem Statement\n\nYou are working on a self-driving car. As a critical component of this project, you'd like to first build a car detection system. To collect data, you've mounted a camera to the hood (meaning the front) of the car, which takes pictures of the road ahead every few seconds while you drive around. \n\n<center>\n<video width=\"400\" height=\"200\" src=\"nb_images/road_video_compressed2.mp4\" type=\"video/mp4\" controls>\n</video>\n</center>\n\n<caption><center> Pictures taken from a car-mounted camera while driving around Silicon Valley. <br> We would like to especially thank [drive.ai](https://www.drive.ai/) for providing this dataset! Drive.ai is a company building the brains of self-driving vehicles.\n</center></caption>\n\n<img src=\"nb_images/driveai.png\" style=\"width:100px;height:100;\">\n\nYou've gathered all these images into a folder and have labelled them by drawing bounding boxes around every car you found. Here's an example of what your bounding boxes look like.\n\n<img src=\"nb_images/box_label.png\" style=\"width:500px;height:250;\">\n<caption><center> <u> **Figure 1** </u>: **Definition of a box**<br> </center></caption>\n\nIf you have 80 classes that you want YOLO to recognize, you can represent the class label $c$ either as an integer from 1 to 80, or as an 80-dimensional vector (with 80 numbers) one component of which is 1 and the rest of which are 0. The video lectures had used the latter representation; in this notebook, we will use both representations, depending on which is more convenient for a particular step. \n\nIn this exercise, you will learn how YOLO works, then apply it to car detection. Because the YOLO model is very computationally expensive to train, we will load pre-trained weights for you to use. ",
"_____no_output_____"
],
[
"## 2 - YOLO",
"_____no_output_____"
],
[
"YOLO (\"you only look once\") is a popular algoritm because it achieves high accuracy while also being able to run in real-time. This algorithm \"only looks once\" at the image in the sense that it requires only one forward propagation pass through the network to make predictions. After non-max suppression, it then outputs recognized objects together with the bounding boxes.\n\n### 2.1 - Model details\n\nFirst things to know:\n- The **input** is a batch of images of shape (m, 608, 608, 3)\n- The **output** is a list of bounding boxes along with the recognized classes. Each bounding box is represented by 6 numbers $(p_c, b_x, b_y, b_h, b_w, c)$ as explained above. If you expand $c$ into an 80-dimensional vector, each bounding box is then represented by 85 numbers. \n\nWe will use 5 anchor boxes. So you can think of the YOLO architecture as the following: IMAGE (m, 608, 608, 3) -> DEEP CNN -> ENCODING (m, 19, 19, 5, 85).\n\nLets look in greater detail at what this encoding represents. \n\n<img src=\"nb_images/architecture.png\" style=\"width:700px;height:400;\">\n<caption><center> <u> **Figure 2** </u>: **Encoding architecture for YOLO**<br> </center></caption>\n\nIf the center/midpoint of an object falls into a grid cell, that grid cell is responsible for detecting that object.",
"_____no_output_____"
],
[
"Since we are using 5 anchor boxes, each of the 19 x19 cells thus encodes information about 5 boxes. Anchor boxes are defined only by their width and height.\n\nFor simplicity, we will flatten the last two last dimensions of the shape (19, 19, 5, 85) encoding. So the output of the Deep CNN is (19, 19, 425).\n\n<img src=\"nb_images/flatten.png\" style=\"width:700px;height:400;\">\n<caption><center> <u> **Figure 3** </u>: **Flattening the last two last dimensions**<br> </center></caption>",
"_____no_output_____"
],
[
"Now, for each box (of each cell) we will compute the following elementwise product and extract a probability that the box contains a certain class.\n\n<img src=\"nb_images/probability_extraction.png\" style=\"width:700px;height:400;\">\n<caption><center> <u> **Figure 4** </u>: **Find the class detected by each box**<br> </center></caption>\n\nHere's one way to visualize what YOLO is predicting on an image:\n- For each of the 19x19 grid cells, find the maximum of the probability scores (taking a max across both the 5 anchor boxes and across different classes). \n- Color that grid cell according to what object that grid cell considers the most likely.\n\nDoing this results in this picture: \n\n<img src=\"nb_images/proba_map.png\" style=\"width:300px;height:300;\">\n<caption><center> <u> **Figure 5** </u>: Each of the 19x19 grid cells colored according to which class has the largest predicted probability in that cell.<br> </center></caption>\n\nNote that this visualization isn't a core part of the YOLO algorithm itself for making predictions; it's just a nice way of visualizing an intermediate result of the algorithm. \n",
"_____no_output_____"
],
[
"Another way to visualize YOLO's output is to plot the bounding boxes that it outputs. Doing that results in a visualization like this: \n\n<img src=\"nb_images/anchor_map.png\" style=\"width:200px;height:200;\">\n<caption><center> <u> **Figure 6** </u>: Each cell gives you 5 boxes. In total, the model predicts: 19x19x5 = 1805 boxes just by looking once at the image (one forward pass through the network)! Different colors denote different classes. <br> </center></caption>\n\nIn the figure above, we plotted only boxes that the model had assigned a high probability to, but this is still too many boxes. You'd like to filter the algorithm's output down to a much smaller number of detected objects. To do so, you'll use non-max suppression. Specifically, you'll carry out these steps: \n- Get rid of boxes with a low score (meaning, the box is not very confident about detecting a class)\n- Select only one box when several boxes overlap with each other and detect the same object.\n\n",
"_____no_output_____"
],
[
"### 2.2 - Filtering with a threshold on class scores\n\nYou are going to apply a first filter by thresholding. You would like to get rid of any box for which the class \"score\" is less than a chosen threshold. \n\nThe model gives you a total of 19x19x5x85 numbers, with each box described by 85 numbers. It'll be convenient to rearrange the (19,19,5,85) (or (19,19,425)) dimensional tensor into the following variables: \n- `box_confidence`: tensor of shape $(19 \\times 19, 5, 1)$ containing $p_c$ (confidence probability that there's some object) for each of the 5 boxes predicted in each of the 19x19 cells.\n- `boxes`: tensor of shape $(19 \\times 19, 5, 4)$ containing $(b_x, b_y, b_h, b_w)$ for each of the 5 boxes per cell.\n- `box_class_probs`: tensor of shape $(19 \\times 19, 5, 80)$ containing the detection probabilities $(c_1, c_2, ... c_{80})$ for each of the 80 classes for each of the 5 boxes per cell.\n\n**Exercise**: Implement `yolo_filter_boxes()`.\n1. Compute box scores by doing the elementwise product as described in Figure 4. The following code may help you choose the right operator: \n```python\na = np.random.randn(19*19, 5, 1)\nb = np.random.randn(19*19, 5, 80)\nc = a * b # shape of c will be (19*19, 5, 80)\n```\n2. For each box, find:\n - the index of the class with the maximum box score ([Hint](https://keras.io/backend/#argmax)) (Be careful with what axis you choose; consider using axis=-1)\n - the corresponding box score ([Hint](https://keras.io/backend/#max)) (Be careful with what axis you choose; consider using axis=-1)\n3. Create a mask by using a threshold. As a reminder: `([0.9, 0.3, 0.4, 0.5, 0.1] < 0.4)` returns: `[False, True, False, False, True]`. The mask should be True for the boxes you want to keep. \n4. Use TensorFlow to apply the mask to box_class_scores, boxes and box_classes to filter out the boxes we don't want. You should be left with just the subset of boxes you want to keep. ([Hint](https://www.tensorflow.org/api_docs/python/tf/boolean_mask))\n\nReminder: to call a Keras function, you should use `K.function(...)`.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: yolo_filter_boxes\n\ndef yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = .6):\n \"\"\"Filters YOLO boxes by thresholding on object and class confidence.\n \n Arguments:\n box_confidence -- tensor of shape (19, 19, 5, 1)\n boxes -- tensor of shape (19, 19, 5, 4)\n box_class_probs -- tensor of shape (19, 19, 5, 80)\n threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box\n \n Returns:\n scores -- tensor of shape (None,), containing the class probability score for selected boxes\n boxes -- tensor of shape (None, 4), containing (b_x, b_y, b_h, b_w) coordinates of selected boxes\n classes -- tensor of shape (None,), containing the index of the class detected by the selected boxes\n \n Note: \"None\" is here because you don't know the exact number of selected boxes, as it depends on the threshold. \n For example, the actual output size of scores would be (10,) if there are 10 boxes.\n \"\"\"\n \n # Step 1: Compute box scores\n ### START CODE HERE ### (≈ 1 line)\n box_scores = box_confidence * box_class_probs\n ### END CODE HERE ###\n \n # Step 2: Find the box_classes thanks to the max box_scores, keep track of the corresponding score\n ### START CODE HERE ### (≈ 2 lines)\n box_classes = K.argmax(box_scores, axis=-1)\n box_class_scores = K.max(box_scores,axis=-1)\n ### END CODE HERE ###\n \n # Step 3: Create a filtering mask based on \"box_class_scores\" by using \"threshold\". The mask should have the\n # same dimension as box_class_scores, and be True for the boxes you want to keep (with probability >= threshold)\n ### START CODE HERE ### (≈ 1 line)\n filtering_mask = box_class_scores >= threshold\n ### END CODE HERE ###\n \n # Step 4: Apply the mask to scores, boxes and classes\n ### START CODE HERE ### (≈ 3 lines)\n scores = tf.boolean_mask(box_class_scores, filtering_mask)\n boxes = tf.boolean_mask(boxes, filtering_mask)\n classes = tf.boolean_mask(box_classes, filtering_mask)\n ### END CODE HERE ###\n \n return scores, boxes, classes",
"_____no_output_____"
],
[
"with tf.Session() as test_a:\n box_confidence = tf.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed = 1)\n boxes = tf.random_normal([19, 19, 5, 4], mean=1, stddev=4, seed = 1)\n box_class_probs = tf.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed = 1)\n scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = 0.5)\n print(\"scores[2] = \" + str(scores[2].eval()))\n print(\"boxes[2] = \" + str(boxes[2].eval()))\n print(\"classes[2] = \" + str(classes[2].eval()))\n print(\"scores.shape = \" + str(scores.shape))\n print(\"boxes.shape = \" + str(boxes.shape))\n print(\"classes.shape = \" + str(classes.shape))",
"scores[2] = 10.7506\nboxes[2] = [ 8.42653275 3.27136683 -0.5313437 -4.94137383]\nclasses[2] = 7\nscores.shape = (?,)\nboxes.shape = (?, 4)\nclasses.shape = (?,)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **scores[2]**\n </td>\n <td>\n 10.7506\n </td>\n </tr>\n <tr>\n <td>\n **boxes[2]**\n </td>\n <td>\n [ 8.42653275 3.27136683 -0.5313437 -4.94137383]\n </td>\n </tr>\n\n <tr>\n <td>\n **classes[2]**\n </td>\n <td>\n 7\n </td>\n </tr>\n <tr>\n <td>\n **scores.shape**\n </td>\n <td>\n (?,)\n </td>\n </tr>\n <tr>\n <td>\n **boxes.shape**\n </td>\n <td>\n (?, 4)\n </td>\n </tr>\n\n <tr>\n <td>\n **classes.shape**\n </td>\n <td>\n (?,)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.3 - Non-max suppression ###\n\nEven after filtering by thresholding over the classes scores, you still end up a lot of overlapping boxes. A second filter for selecting the right boxes is called non-maximum suppression (NMS). ",
"_____no_output_____"
],
[
"<img src=\"nb_images/non-max-suppression.png\" style=\"width:500px;height:400;\">\n<caption><center> <u> **Figure 7** </u>: In this example, the model has predicted 3 cars, but it's actually 3 predictions of the same car. Running non-max suppression (NMS) will select only the most accurate (highest probabiliy) one of the 3 boxes. <br> </center></caption>\n",
"_____no_output_____"
],
[
"Non-max suppression uses the very important function called **\"Intersection over Union\"**, or IoU.\n<img src=\"nb_images/iou.png\" style=\"width:500px;height:400;\">\n<caption><center> <u> **Figure 8** </u>: Definition of \"Intersection over Union\". <br> </center></caption>\n\n**Exercise**: Implement iou(). Some hints:\n- In this exercise only, we define a box using its two corners (upper left and lower right): (x1, y1, x2, y2) rather than the midpoint and height/width.\n- To calculate the area of a rectangle you need to multiply its height (y2 - y1) by its width (x2 - x1)\n- You'll also need to find the coordinates (xi1, yi1, xi2, yi2) of the intersection of two boxes. Remember that:\n - xi1 = maximum of the x1 coordinates of the two boxes\n - yi1 = maximum of the y1 coordinates of the two boxes\n - xi2 = minimum of the x2 coordinates of the two boxes\n - yi2 = minimum of the y2 coordinates of the two boxes\n \nIn this code, we use the convention that (0,0) is the top-left corner of an image, (1,0) is the upper-right corner, and (1,1) the lower-right corner. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: iou\n\ndef iou(box1, box2):\n \"\"\"Implement the intersection over union (IoU) between box1 and box2\n \n Arguments:\n box1 -- first box, list object with coordinates (x1, y1, x2, y2)\n box2 -- second box, list object with coordinates (x1, y1, x2, y2)\n \"\"\"\n\n # Calculate the (y1, x1, y2, x2) coordinates of the intersection of box1 and box2. Calculate its Area.\n ### START CODE HERE ### (≈ 5 lines)\n xi1 = np.maximum(box1[0],box2[0])\n yi1 = np.maximum(box1[1],box2[1])\n xi2 = np.minimum(box1[2],box2[2])\n yi2 = np.minimum(box1[3],box2[3])\n inter_area = (yi2-yi1) * (xi2-xi1)\n ### END CODE HERE ### \n\n # Calculate the Union area by using Formula: Union(A,B) = A + B - Inter(A,B)\n ### START CODE HERE ### (≈ 3 lines)\n box1_area = (box1[3]-box1[1]) * (box1[2]-box1[0])\n box2_area = (box2[3]-box2[1]) * (box2[2]-box2[0])\n union_area = box1_area + box2_area - inter_area\n ### END CODE HERE ###\n \n # compute the IoU\n ### START CODE HERE ### (≈ 1 line)\n iou = inter_area / union_area\n ### END CODE HERE ###\n\n return iou",
"_____no_output_____"
],
[
"box1 = (2, 1, 4, 3)\nbox2 = (1, 2, 3, 4) \nprint(\"iou = \" + str(iou(box1, box2)))",
"iou = 0.142857142857\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **iou = **\n </td>\n <td>\n 0.14285714285714285\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"You are now ready to implement non-max suppression. The key steps are: \n1. Select the box that has the highest score.\n2. Compute its overlap with all other boxes, and remove boxes that overlap it more than `iou_threshold`.\n3. Go back to step 1 and iterate until there's no more boxes with a lower score than the current selected box.\n\nThis will remove all boxes that have a large overlap with the selected boxes. Only the \"best\" boxes remain.\n\n**Exercise**: Implement yolo_non_max_suppression() using TensorFlow. TensorFlow has two built-in functions that are used to implement non-max suppression (so you don't actually need to use your `iou()` implementation):\n- [tf.image.non_max_suppression()](https://www.tensorflow.org/api_docs/python/tf/image/non_max_suppression)\n- [K.gather()](https://www.tensorflow.org/api_docs/python/tf/gather)",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: yolo_non_max_suppression\n\ndef yolo_non_max_suppression(scores, boxes, classes, max_boxes = 10, iou_threshold = 0.5):\n \"\"\"\n Applies Non-max suppression (NMS) to set of boxes\n \n Arguments:\n scores -- tensor of shape (None,), output of yolo_filter_boxes()\n boxes -- tensor of shape (None, 4), output of yolo_filter_boxes() that have been scaled to the image size (see later)\n classes -- tensor of shape (None,), output of yolo_filter_boxes()\n max_boxes -- integer, maximum number of predicted boxes you'd like\n iou_threshold -- real value, \"intersection over union\" threshold used for NMS filtering\n \n Returns:\n scores -- tensor of shape (, None), predicted score for each box\n boxes -- tensor of shape (4, None), predicted box coordinates\n classes -- tensor of shape (, None), predicted class for each box\n \n Note: The \"None\" dimension of the output tensors has obviously to be less than max_boxes. Note also that this\n function will transpose the shapes of scores, boxes, classes. This is made for convenience.\n \"\"\"\n \n max_boxes_tensor = K.variable(max_boxes, dtype='int32') # tensor to be used in tf.image.non_max_suppression()\n K.get_session().run(tf.variables_initializer([max_boxes_tensor])) # initialize variable max_boxes_tensor\n \n # Use tf.image.non_max_suppression() to get the list of indices corresponding to boxes you keep\n ### START CODE HERE ### (≈ 1 line)\n nms_indices = tf.image.non_max_suppression(boxes,scores,max_boxes,iou_threshold)\n ### END CODE HERE ###\n \n # Use K.gather() to select only nms_indices from scores, boxes and classes\n ### START CODE HERE ### (≈ 3 lines)\n scores = K.gather(scores,nms_indices)\n boxes = K.gather(boxes,nms_indices)\n classes = K.gather(classes,nms_indices)\n ### END CODE HERE ###\n \n return scores, boxes, classes",
"_____no_output_____"
],
[
"with tf.Session() as test_b:\n scores = tf.random_normal([54,], mean=1, stddev=4, seed = 1)\n boxes = tf.random_normal([54, 4], mean=1, stddev=4, seed = 1)\n classes = tf.random_normal([54,], mean=1, stddev=4, seed = 1)\n scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes)\n print(\"scores[2] = \" + str(scores[2].eval()))\n print(\"boxes[2] = \" + str(boxes[2].eval()))\n print(\"classes[2] = \" + str(classes[2].eval()))\n print(\"scores.shape = \" + str(scores.eval().shape))\n print(\"boxes.shape = \" + str(boxes.eval().shape))\n print(\"classes.shape = \" + str(classes.eval().shape))",
"scores[2] = 6.9384\nboxes[2] = [-5.299932 3.13798141 4.45036697 0.95942086]\nclasses[2] = -2.24527\nscores.shape = (10,)\nboxes.shape = (10, 4)\nclasses.shape = (10,)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **scores[2]**\n </td>\n <td>\n 6.9384\n </td>\n </tr>\n <tr>\n <td>\n **boxes[2]**\n </td>\n <td>\n [-5.299932 3.13798141 4.45036697 0.95942086]\n </td>\n </tr>\n\n <tr>\n <td>\n **classes[2]**\n </td>\n <td>\n -2.24527\n </td>\n </tr>\n <tr>\n <td>\n **scores.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n <tr>\n <td>\n **boxes.shape**\n </td>\n <td>\n (10, 4)\n </td>\n </tr>\n\n <tr>\n <td>\n **classes.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.4 Wrapping up the filtering\n\nIt's time to implement a function taking the output of the deep CNN (the 19x19x5x85 dimensional encoding) and filtering through all the boxes using the functions you've just implemented. \n\n**Exercise**: Implement `yolo_eval()` which takes the output of the YOLO encoding and filters the boxes using score threshold and NMS. There's just one last implementational detail you have to know. There're a few ways of representing boxes, such as via their corners or via their midpoint and height/width. YOLO converts between a few such formats at different times, using the following functions (which we have provided): \n\n```python\nboxes = yolo_boxes_to_corners(box_xy, box_wh) \n```\nwhich converts the yolo box coordinates (x,y,w,h) to box corners' coordinates (x1, y1, x2, y2) to fit the input of `yolo_filter_boxes`\n```python\nboxes = scale_boxes(boxes, image_shape)\n```\nYOLO's network was trained to run on 608x608 images. If you are testing this data on a different size image--for example, the car detection dataset had 720x1280 images--this step rescales the boxes so that they can be plotted on top of the original 720x1280 image. \n\nDon't worry about these two functions; we'll show you where they need to be called. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: yolo_eval\n\ndef yolo_eval(yolo_outputs, image_shape = (720., 1280.), max_boxes=10, score_threshold=.6, iou_threshold=.5):\n \"\"\"\n Converts the output of YOLO encoding (a lot of boxes) to your predicted boxes along with their scores, box coordinates and classes.\n \n Arguments:\n yolo_outputs -- output of the encoding model (for image_shape of (608, 608, 3)), contains 4 tensors:\n box_confidence: tensor of shape (None, 19, 19, 5, 1)\n box_xy: tensor of shape (None, 19, 19, 5, 2)\n box_wh: tensor of shape (None, 19, 19, 5, 2)\n box_class_probs: tensor of shape (None, 19, 19, 5, 80)\n image_shape -- tensor of shape (2,) containing the input shape, in this notebook we use (608., 608.) (has to be float32 dtype)\n max_boxes -- integer, maximum number of predicted boxes you'd like\n score_threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box\n iou_threshold -- real value, \"intersection over union\" threshold used for NMS filtering\n \n Returns:\n scores -- tensor of shape (None, ), predicted score for each box\n boxes -- tensor of shape (None, 4), predicted box coordinates\n classes -- tensor of shape (None,), predicted class for each box\n \"\"\"\n \n ### START CODE HERE ### \n \n # Retrieve outputs of the YOLO model (≈1 line)\n box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs\n\n # Convert boxes to be ready for filtering functions \n boxes = yolo_boxes_to_corners(box_xy, box_wh)\n\n # Use one of the functions you've implemented to perform Score-filtering with a threshold of score_threshold (≈1 line)\n scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, score_threshold)\n \n # Scale boxes back to original image shape.\n boxes = scale_boxes(boxes, image_shape)\n\n # Use one of the functions you've implemented to perform Non-max suppression with a threshold of iou_threshold (≈1 line)\n scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes, max_boxes, iou_threshold)\n \n ### END CODE HERE ###\n \n return scores, boxes, classes",
"_____no_output_____"
],
[
"with tf.Session() as test_b:\n yolo_outputs = (tf.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed = 1),\n tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),\n tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),\n tf.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed = 1))\n scores, boxes, classes = yolo_eval(yolo_outputs)\n print(\"scores[2] = \" + str(scores[2].eval()))\n print(\"boxes[2] = \" + str(boxes[2].eval()))\n print(\"classes[2] = \" + str(classes[2].eval()))\n print(\"scores.shape = \" + str(scores.eval().shape))\n print(\"boxes.shape = \" + str(boxes.eval().shape))\n print(\"classes.shape = \" + str(classes.eval().shape))",
"scores[2] = 138.791\nboxes[2] = [ 1292.32971191 -278.52166748 3876.98925781 -835.56494141]\nclasses[2] = 54\nscores.shape = (10,)\nboxes.shape = (10, 4)\nclasses.shape = (10,)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **scores[2]**\n </td>\n <td>\n 138.791\n </td>\n </tr>\n <tr>\n <td>\n **boxes[2]**\n </td>\n <td>\n [ 1292.32971191 -278.52166748 3876.98925781 -835.56494141]\n </td>\n </tr>\n\n <tr>\n <td>\n **classes[2]**\n </td>\n <td>\n 54\n </td>\n </tr>\n <tr>\n <td>\n **scores.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n <tr>\n <td>\n **boxes.shape**\n </td>\n <td>\n (10, 4)\n </td>\n </tr>\n\n <tr>\n <td>\n **classes.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"<font color='blue'>\n**Summary for YOLO**:\n- Input image (608, 608, 3)\n- The input image goes through a CNN, resulting in a (19,19,5,85) dimensional output. \n- After flattening the last two dimensions, the output is a volume of shape (19, 19, 425):\n - Each cell in a 19x19 grid over the input image gives 425 numbers. \n - 425 = 5 x 85 because each cell contains predictions for 5 boxes, corresponding to 5 anchor boxes, as seen in lecture. \n - 85 = 5 + 80 where 5 is because $(p_c, b_x, b_y, b_h, b_w)$ has 5 numbers, and and 80 is the number of classes we'd like to detect\n- You then select only few boxes based on:\n - Score-thresholding: throw away boxes that have detected a class with a score less than the threshold\n - Non-max suppression: Compute the Intersection over Union and avoid selecting overlapping boxes\n- This gives you YOLO's final output. ",
"_____no_output_____"
],
[
"## 3 - Test YOLO pretrained model on images",
"_____no_output_____"
],
[
"In this part, you are going to use a pretrained model and test it on the car detection dataset. As usual, you start by **creating a session to start your graph**. Run the following cell.",
"_____no_output_____"
]
],
[
[
"sess = K.get_session()",
"_____no_output_____"
]
],
[
[
"### 3.1 - Defining classes, anchors and image shape.",
"_____no_output_____"
],
[
"Recall that we are trying to detect 80 classes, and are using 5 anchor boxes. We have gathered the information about the 80 classes and 5 boxes in two files \"coco_classes.txt\" and \"yolo_anchors.txt\". Let's load these quantities into the model by running the next cell. \n\nThe car detection dataset has 720x1280 images, which we've pre-processed into 608x608 images. ",
"_____no_output_____"
]
],
[
[
"class_names = read_classes(\"model_data/coco_classes.txt\")\nanchors = read_anchors(\"model_data/yolo_anchors.txt\")\nimage_shape = (720., 1280.) ",
"_____no_output_____"
]
],
[
[
"### 3.2 - Loading a pretrained model\n\nTraining a YOLO model takes a very long time and requires a fairly large dataset of labelled bounding boxes for a large range of target classes. You are going to load an existing pretrained Keras YOLO model stored in \"yolo.h5\". (These weights come from the official YOLO website, and were converted using a function written by Allan Zelener. References are at the end of this notebook. Technically, these are the parameters from the \"YOLOv2\" model, but we will more simply refer to it as \"YOLO\" in this notebook.) Run the cell below to load the model from this file.",
"_____no_output_____"
]
],
[
[
"yolo_model = load_model(\"model_data/yolo.h5\")",
"/opt/conda/lib/python3.6/site-packages/keras/models.py:251: UserWarning: No training configuration found in save file: the model was *not* compiled. Compile it manually.\n warnings.warn('No training configuration found in save file: '\n"
]
],
[
[
"This loads the weights of a trained YOLO model. Here's a summary of the layers your model contains.",
"_____no_output_____"
]
],
[
[
"yolo_model.summary()",
"____________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n====================================================================================================\ninput_1 (InputLayer) (None, 608, 608, 3) 0 \n____________________________________________________________________________________________________\nconv2d_1 (Conv2D) (None, 608, 608, 32) 864 input_1[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_1 (BatchNorm (None, 608, 608, 32) 128 conv2d_1[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_1 (LeakyReLU) (None, 608, 608, 32) 0 batch_normalization_1[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_1 (MaxPooling2D) (None, 304, 304, 32) 0 leaky_re_lu_1[0][0] \n____________________________________________________________________________________________________\nconv2d_2 (Conv2D) (None, 304, 304, 64) 18432 max_pooling2d_1[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_2 (BatchNorm (None, 304, 304, 64) 256 conv2d_2[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_2 (LeakyReLU) (None, 304, 304, 64) 0 batch_normalization_2[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_2 (MaxPooling2D) (None, 152, 152, 64) 0 leaky_re_lu_2[0][0] \n____________________________________________________________________________________________________\nconv2d_3 (Conv2D) (None, 152, 152, 128) 73728 max_pooling2d_2[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_3 (BatchNorm (None, 152, 152, 128) 512 conv2d_3[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_3 (LeakyReLU) (None, 152, 152, 128) 0 batch_normalization_3[0][0] \n____________________________________________________________________________________________________\nconv2d_4 (Conv2D) (None, 152, 152, 64) 8192 leaky_re_lu_3[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_4 (BatchNorm (None, 152, 152, 64) 256 conv2d_4[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_4 (LeakyReLU) (None, 152, 152, 64) 0 batch_normalization_4[0][0] \n____________________________________________________________________________________________________\nconv2d_5 (Conv2D) (None, 152, 152, 128) 73728 leaky_re_lu_4[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_5 (BatchNorm (None, 152, 152, 128) 512 conv2d_5[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_5 (LeakyReLU) (None, 152, 152, 128) 0 batch_normalization_5[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_3 (MaxPooling2D) (None, 76, 76, 128) 0 leaky_re_lu_5[0][0] \n____________________________________________________________________________________________________\nconv2d_6 (Conv2D) (None, 76, 76, 256) 294912 max_pooling2d_3[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_6 (BatchNorm (None, 76, 76, 256) 1024 conv2d_6[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_6 (LeakyReLU) (None, 76, 76, 256) 0 batch_normalization_6[0][0] \n____________________________________________________________________________________________________\nconv2d_7 (Conv2D) (None, 76, 76, 128) 32768 leaky_re_lu_6[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_7 (BatchNorm (None, 76, 76, 128) 512 conv2d_7[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_7 (LeakyReLU) (None, 76, 76, 128) 0 batch_normalization_7[0][0] \n____________________________________________________________________________________________________\nconv2d_8 (Conv2D) (None, 76, 76, 256) 294912 leaky_re_lu_7[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_8 (BatchNorm (None, 76, 76, 256) 1024 conv2d_8[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_8 (LeakyReLU) (None, 76, 76, 256) 0 batch_normalization_8[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_4 (MaxPooling2D) (None, 38, 38, 256) 0 leaky_re_lu_8[0][0] \n____________________________________________________________________________________________________\nconv2d_9 (Conv2D) (None, 38, 38, 512) 1179648 max_pooling2d_4[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_9 (BatchNorm (None, 38, 38, 512) 2048 conv2d_9[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_9 (LeakyReLU) (None, 38, 38, 512) 0 batch_normalization_9[0][0] \n____________________________________________________________________________________________________\nconv2d_10 (Conv2D) (None, 38, 38, 256) 131072 leaky_re_lu_9[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_10 (BatchNor (None, 38, 38, 256) 1024 conv2d_10[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_10 (LeakyReLU) (None, 38, 38, 256) 0 batch_normalization_10[0][0] \n____________________________________________________________________________________________________\nconv2d_11 (Conv2D) (None, 38, 38, 512) 1179648 leaky_re_lu_10[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_11 (BatchNor (None, 38, 38, 512) 2048 conv2d_11[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_11 (LeakyReLU) (None, 38, 38, 512) 0 batch_normalization_11[0][0] \n____________________________________________________________________________________________________\nconv2d_12 (Conv2D) (None, 38, 38, 256) 131072 leaky_re_lu_11[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_12 (BatchNor (None, 38, 38, 256) 1024 conv2d_12[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_12 (LeakyReLU) (None, 38, 38, 256) 0 batch_normalization_12[0][0] \n____________________________________________________________________________________________________\nconv2d_13 (Conv2D) (None, 38, 38, 512) 1179648 leaky_re_lu_12[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_13 (BatchNor (None, 38, 38, 512) 2048 conv2d_13[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_13 (LeakyReLU) (None, 38, 38, 512) 0 batch_normalization_13[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_5 (MaxPooling2D) (None, 19, 19, 512) 0 leaky_re_lu_13[0][0] \n____________________________________________________________________________________________________\nconv2d_14 (Conv2D) (None, 19, 19, 1024) 4718592 max_pooling2d_5[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_14 (BatchNor (None, 19, 19, 1024) 4096 conv2d_14[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_14 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_14[0][0] \n____________________________________________________________________________________________________\nconv2d_15 (Conv2D) (None, 19, 19, 512) 524288 leaky_re_lu_14[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_15 (BatchNor (None, 19, 19, 512) 2048 conv2d_15[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_15 (LeakyReLU) (None, 19, 19, 512) 0 batch_normalization_15[0][0] \n____________________________________________________________________________________________________\nconv2d_16 (Conv2D) (None, 19, 19, 1024) 4718592 leaky_re_lu_15[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_16 (BatchNor (None, 19, 19, 1024) 4096 conv2d_16[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_16 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_16[0][0] \n____________________________________________________________________________________________________\nconv2d_17 (Conv2D) (None, 19, 19, 512) 524288 leaky_re_lu_16[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_17 (BatchNor (None, 19, 19, 512) 2048 conv2d_17[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_17 (LeakyReLU) (None, 19, 19, 512) 0 batch_normalization_17[0][0] \n____________________________________________________________________________________________________\nconv2d_18 (Conv2D) (None, 19, 19, 1024) 4718592 leaky_re_lu_17[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_18 (BatchNor (None, 19, 19, 1024) 4096 conv2d_18[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_18 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_18[0][0] \n____________________________________________________________________________________________________\nconv2d_19 (Conv2D) (None, 19, 19, 1024) 9437184 leaky_re_lu_18[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_19 (BatchNor (None, 19, 19, 1024) 4096 conv2d_19[0][0] \n____________________________________________________________________________________________________\nconv2d_21 (Conv2D) (None, 38, 38, 64) 32768 leaky_re_lu_13[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_19 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_19[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_21 (BatchNor (None, 38, 38, 64) 256 conv2d_21[0][0] \n____________________________________________________________________________________________________\nconv2d_20 (Conv2D) (None, 19, 19, 1024) 9437184 leaky_re_lu_19[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_21 (LeakyReLU) (None, 38, 38, 64) 0 batch_normalization_21[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_20 (BatchNor (None, 19, 19, 1024) 4096 conv2d_20[0][0] \n____________________________________________________________________________________________________\nspace_to_depth_x2 (Lambda) (None, 19, 19, 256) 0 leaky_re_lu_21[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_20 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_20[0][0] \n____________________________________________________________________________________________________\nconcatenate_1 (Concatenate) (None, 19, 19, 1280) 0 space_to_depth_x2[0][0] \n leaky_re_lu_20[0][0] \n____________________________________________________________________________________________________\nconv2d_22 (Conv2D) (None, 19, 19, 1024) 11796480 concatenate_1[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_22 (BatchNor (None, 19, 19, 1024) 4096 conv2d_22[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_22 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_22[0][0] \n____________________________________________________________________________________________________\nconv2d_23 (Conv2D) (None, 19, 19, 425) 435625 leaky_re_lu_22[0][0] \n====================================================================================================\nTotal params: 50,983,561\nTrainable params: 50,962,889\nNon-trainable params: 20,672\n____________________________________________________________________________________________________\n"
]
],
[
[
"**Note**: On some computers, you may see a warning message from Keras. Don't worry about it if you do--it is fine.\n\n**Reminder**: this model converts a preprocessed batch of input images (shape: (m, 608, 608, 3)) into a tensor of shape (m, 19, 19, 5, 85) as explained in Figure (2).",
"_____no_output_____"
],
[
"### 3.3 - Convert output of the model to usable bounding box tensors\n\nThe output of `yolo_model` is a (m, 19, 19, 5, 85) tensor that needs to pass through non-trivial processing and conversion. The following cell does that for you.",
"_____no_output_____"
]
],
[
[
"yolo_outputs = yolo_head(yolo_model.output, anchors, len(class_names))",
"_____no_output_____"
]
],
[
[
"You added `yolo_outputs` to your graph. This set of 4 tensors is ready to be used as input by your `yolo_eval` function.",
"_____no_output_____"
],
[
"### 3.4 - Filtering boxes\n\n`yolo_outputs` gave you all the predicted boxes of `yolo_model` in the correct format. You're now ready to perform filtering and select only the best boxes. Lets now call `yolo_eval`, which you had previously implemented, to do this. ",
"_____no_output_____"
]
],
[
[
"scores, boxes, classes = yolo_eval(yolo_outputs, image_shape)",
"_____no_output_____"
]
],
[
[
"### 3.5 - Run the graph on an image\n\nLet the fun begin. You have created a (`sess`) graph that can be summarized as follows:\n\n1. <font color='purple'> yolo_model.input </font> is given to `yolo_model`. The model is used to compute the output <font color='purple'> yolo_model.output </font>\n2. <font color='purple'> yolo_model.output </font> is processed by `yolo_head`. It gives you <font color='purple'> yolo_outputs </font>\n3. <font color='purple'> yolo_outputs </font> goes through a filtering function, `yolo_eval`. It outputs your predictions: <font color='purple'> scores, boxes, classes </font>\n\n**Exercise**: Implement predict() which runs the graph to test YOLO on an image.\nYou will need to run a TensorFlow session, to have it compute `scores, boxes, classes`.\n\nThe code below also uses the following function:\n```python\nimage, image_data = preprocess_image(\"images/\" + image_file, model_image_size = (608, 608))\n```\nwhich outputs:\n- image: a python (PIL) representation of your image used for drawing boxes. You won't need to use it.\n- image_data: a numpy-array representing the image. This will be the input to the CNN.\n\n**Important note**: when a model uses BatchNorm (as is the case in YOLO), you will need to pass an additional placeholder in the feed_dict {K.learning_phase(): 0}.",
"_____no_output_____"
]
],
[
[
"def predict(sess, image_file):\n \"\"\"\n Runs the graph stored in \"sess\" to predict boxes for \"image_file\". Prints and plots the preditions.\n \n Arguments:\n sess -- your tensorflow/Keras session containing the YOLO graph\n image_file -- name of an image stored in the \"images\" folder.\n \n Returns:\n out_scores -- tensor of shape (None, ), scores of the predicted boxes\n out_boxes -- tensor of shape (None, 4), coordinates of the predicted boxes\n out_classes -- tensor of shape (None, ), class index of the predicted boxes\n \n Note: \"None\" actually represents the number of predicted boxes, it varies between 0 and max_boxes. \n \"\"\"\n\n # Preprocess your image\n image, image_data = preprocess_image(\"images/\" + image_file, model_image_size = (608, 608))\n\n # Run the session with the correct tensors and choose the correct placeholders in the feed_dict.\n # You'll need to use feed_dict={yolo_model.input: ... , K.learning_phase(): 0})\n ### START CODE HERE ### (≈ 1 line)\n out_scores, out_boxes, out_classes = sess.run(\n [scores, boxes, classes],\n feed_dict={\n yolo_model.input: image_data,\n K.learning_phase(): 0\n })\n ### END CODE HERE ###\n\n # Print predictions info\n print('Found {} boxes for {}'.format(len(out_boxes), image_file))\n # Generate colors for drawing bounding boxes.\n colors = generate_colors(class_names)\n # Draw bounding boxes on the image file\n draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors)\n # Save the predicted bounding box on the image\n image.save(os.path.join(\"out\", image_file), quality=90)\n # Display the results in the notebook\n output_image = scipy.misc.imread(os.path.join(\"out\", image_file))\n imshow(output_image)\n \n return out_scores, out_boxes, out_classes",
"_____no_output_____"
]
],
[
[
"Run the following cell on the \"test.jpg\" image to verify that your function is correct.",
"_____no_output_____"
]
],
[
[
"out_scores, out_boxes, out_classes = predict(sess, \"test.jpg\")",
"Found 7 boxes for test.jpg\ncar 0.60 (925, 285) (1045, 374)\ncar 0.66 (706, 279) (786, 350)\nbus 0.67 (5, 266) (220, 407)\ncar 0.70 (947, 324) (1280, 705)\ncar 0.74 (159, 303) (346, 440)\ncar 0.80 (761, 282) (942, 412)\ncar 0.89 (367, 300) (745, 648)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **Found 7 boxes for test.jpg**\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.60 (925, 285) (1045, 374)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.66 (706, 279) (786, 350)\n </td>\n </tr>\n <tr>\n <td>\n **bus**\n </td>\n <td>\n 0.67 (5, 266) (220, 407)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.70 (947, 324) (1280, 705)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.74 (159, 303) (346, 440)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.80 (761, 282) (942, 412)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.89 (367, 300) (745, 648)\n </td>\n </tr>\n</table>",
"_____no_output_____"
],
[
"The model you've just run is actually able to detect 80 different classes listed in \"coco_classes.txt\". To test the model on your own images:\n 1. Click on \"File\" in the upper bar of this notebook, then click \"Open\" to go on your Coursera Hub.\n 2. Add your image to this Jupyter Notebook's directory, in the \"images\" folder\n 3. Write your image's name in the cell above code\n 4. Run the code and see the output of the algorithm!\n\nIf you were to run your session in a for loop over all your images. Here's what you would get:\n\n<center>\n<video width=\"400\" height=\"200\" src=\"nb_images/pred_video_compressed2.mp4\" type=\"video/mp4\" controls>\n</video>\n</center>\n\n<caption><center> Predictions of the YOLO model on pictures taken from a camera while driving around the Silicon Valley <br> Thanks [drive.ai](https://www.drive.ai/) for providing this dataset! </center></caption>",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- YOLO is a state-of-the-art object detection model that is fast and accurate\n- It runs an input image through a CNN which outputs a 19x19x5x85 dimensional volume. \n- The encoding can be seen as a grid where each of the 19x19 cells contains information about 5 boxes.\n- You filter through all the boxes using non-max suppression. Specifically: \n - Score thresholding on the probability of detecting a class to keep only accurate (high probability) boxes\n - Intersection over Union (IoU) thresholding to eliminate overlapping boxes\n- Because training a YOLO model from randomly initialized weights is non-trivial and requires a large dataset as well as lot of computation, we used previously trained model parameters in this exercise. If you wish, you can also try fine-tuning the YOLO model with your own dataset, though this would be a fairly non-trivial exercise. ",
"_____no_output_____"
],
[
"**References**: The ideas presented in this notebook came primarily from the two YOLO papers. The implementation here also took significant inspiration and used many components from Allan Zelener's github repository. The pretrained weights used in this exercise came from the official YOLO website. \n- Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi - [You Only Look Once: Unified, Real-Time Object Detection](https://arxiv.org/abs/1506.02640) (2015)\n- Joseph Redmon, Ali Farhadi - [YOLO9000: Better, Faster, Stronger](https://arxiv.org/abs/1612.08242) (2016)\n- Allan Zelener - [YAD2K: Yet Another Darknet 2 Keras](https://github.com/allanzelener/YAD2K)\n- The official YOLO website (https://pjreddie.com/darknet/yolo/) ",
"_____no_output_____"
],
[
"**Car detection dataset**:\n<a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/\"><img alt=\"Creative Commons License\" style=\"border-width:0\" src=\"https://i.creativecommons.org/l/by/4.0/88x31.png\" /></a><br /><span xmlns:dct=\"http://purl.org/dc/terms/\" property=\"dct:title\">The Drive.ai Sample Dataset</span> (provided by drive.ai) is licensed under a <a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/\">Creative Commons Attribution 4.0 International License</a>. We are especially grateful to Brody Huval, Chih Hu and Rahul Patel for collecting and providing this dataset. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a024d275e66cf857b1a9b30611c0c0cf35f6ec7
| 8,918 |
ipynb
|
Jupyter Notebook
|
IRIS decision tree.ipynb
|
aarroyoc/AprendizajeAutomatico
|
a3d86b11f6f8a8ab57f5c673bb6942cc164b175b
|
[
"Unlicense"
] | null | null | null |
IRIS decision tree.ipynb
|
aarroyoc/AprendizajeAutomatico
|
a3d86b11f6f8a8ab57f5c673bb6942cc164b175b
|
[
"Unlicense"
] | null | null | null |
IRIS decision tree.ipynb
|
aarroyoc/AprendizajeAutomatico
|
a3d86b11f6f8a8ab57f5c673bb6942cc164b175b
|
[
"Unlicense"
] | null | null | null | 27.781931 | 186 | 0.505719 |
[
[
[
"import numpy as np\nfrom sklearn import datasets",
"_____no_output_____"
],
[
"iris = datasets.load_iris()",
"_____no_output_____"
],
[
"print(iris.DESCR)",
".. _iris_dataset:\n\nIris plants dataset\n--------------------\n\n**Data Set Characteristics:**\n\n :Number of Instances: 150 (50 in each of three classes)\n :Number of Attributes: 4 numeric, predictive attributes and the class\n :Attribute Information:\n - sepal length in cm\n - sepal width in cm\n - petal length in cm\n - petal width in cm\n - class:\n - Iris-Setosa\n - Iris-Versicolour\n - Iris-Virginica\n \n :Summary Statistics:\n\n ============== ==== ==== ======= ===== ====================\n Min Max Mean SD Class Correlation\n ============== ==== ==== ======= ===== ====================\n sepal length: 4.3 7.9 5.84 0.83 0.7826\n sepal width: 2.0 4.4 3.05 0.43 -0.4194\n petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)\n petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)\n ============== ==== ==== ======= ===== ====================\n\n :Missing Attribute Values: None\n :Class Distribution: 33.3% for each of 3 classes.\n :Creator: R.A. Fisher\n :Donor: Michael Marshall (MARSHALL%[email protected])\n :Date: July, 1988\n\nThe famous Iris database, first used by Sir R.A. Fisher. The dataset is taken\nfrom Fisher's paper. Note that it's the same as in R, but not as in the UCI\nMachine Learning Repository, which has two wrong data points.\n\nThis is perhaps the best known database to be found in the\npattern recognition literature. Fisher's paper is a classic in the field and\nis referenced frequently to this day. (See Duda & Hart, for example.) The\ndata set contains 3 classes of 50 instances each, where each class refers to a\ntype of iris plant. One class is linearly separable from the other 2; the\nlatter are NOT linearly separable from each other.\n\n.. topic:: References\n\n - Fisher, R.A. \"The use of multiple measurements in taxonomic problems\"\n Annual Eugenics, 7, Part II, 179-188 (1936); also in \"Contributions to\n Mathematical Statistics\" (John Wiley, NY, 1950).\n - Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.\n (Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.\n - Dasarathy, B.V. (1980) \"Nosing Around the Neighborhood: A New System\n Structure and Classification Rule for Recognition in Partially Exposed\n Environments\". IEEE Transactions on Pattern Analysis and Machine\n Intelligence, Vol. PAMI-2, No. 1, 67-71.\n - Gates, G.W. (1972) \"The Reduced Nearest Neighbor Rule\". IEEE Transactions\n on Information Theory, May 1972, 431-433.\n - See also: 1988 MLC Proceedings, 54-64. Cheeseman et al\"s AUTOCLASS II\n conceptual clustering system finds 3 classes in the data.\n - Many, many more ...\n"
],
[
"x = iris.data\ny = iris.target",
"_____no_output_____"
],
[
"x.shape, y.shape",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nx_train, x_test, y_train, y_test = train_test_split(x,y,train_size=2/3,stratify=y)",
"/usr/lib/python3/dist-packages/sklearn/model_selection/_split.py:2179: FutureWarning: From version 0.21, test_size will always complement train_size unless both are specified.\n FutureWarning)\n"
],
[
"x_train.shape, x_test.shape, y_train.shape, y_test.shape",
"_____no_output_____"
],
[
"from sklearn.tree import DecisionTreeClassifier, export_graphviz\narbol = DecisionTreeClassifier(criterion='entropy')",
"_____no_output_____"
],
[
"arbol.fit(x_train,y_train)",
"_____no_output_____"
],
[
"y_test_predict = arbol.predict(x_test)",
"_____no_output_____"
],
[
"y_test_predict == y_test",
"_____no_output_____"
],
[
"np.sum(y_test_predict == y_test)/y_test.shape[0]",
"_____no_output_____"
],
[
"from sklearn.metrics import confusion_matrix\ncnf_matrix = confusion_matrix(y_test,y_test_predict)\nprint(cnf_matrix)",
"[[17 0 0]\n [ 0 16 0]\n [ 0 1 16]]\n"
],
[
"dot_data = export_graphviz(arbol, feature_names=iris.feature_names, out_file=\"arbol.dot\")",
"_____no_output_____"
],
[
"export_graphviz?",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a024fc2794a816bd0012e33249cd361ccda3363
| 247,933 |
ipynb
|
Jupyter Notebook
|
TensorflowStuff/overfitting_nn.ipynb
|
stanton119/data-analysis
|
b6fda815c6cc1798ba13a5d2680369b7e5dfcdf9
|
[
"Apache-2.0"
] | null | null | null |
TensorflowStuff/overfitting_nn.ipynb
|
stanton119/data-analysis
|
b6fda815c6cc1798ba13a5d2680369b7e5dfcdf9
|
[
"Apache-2.0"
] | 1 |
2021-02-11T23:44:52.000Z
|
2021-02-11T23:44:52.000Z
|
TensorflowStuff/overfitting_nn.ipynb
|
stanton119/data-analysis
|
b6fda815c6cc1798ba13a5d2680369b7e5dfcdf9
|
[
"Apache-2.0"
] | 1 |
2021-12-16T01:02:23.000Z
|
2021-12-16T01:02:23.000Z
| 247,933 | 247,933 | 0.7523 |
[
[
[
"# Do Neural Networks overfit?\n\nThis brief post is exploring overfitting neural networks. It comes from reading the paper:\n\nTowards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes\nhttps://arxiv.org/pdf/1706.10239.pdf\n\nWe show that fitting a hugely overparameterised model to some linear regression data works absolutely fine... The results are quite cool so I thought I would double check.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport tensorflow as tf\nimport matplotlib.pyplot as plt\nplt.style.use(\"seaborn-whitegrid\")\nrng = np.random.RandomState(0)\ntf.random.set_seed(0)",
"_____no_output_____"
]
],
[
[
"Lets generate some linear regression data. We only generate **100 data points**. This is simply a straight line with Gaussian noise - a problem linear regression is optimal for.",
"_____no_output_____"
]
],
[
[
"x = np.random.uniform(0, 20, size=(100))\ntrue_data = lambda x: 3 + 0.7*x\ny = true_data(x) + np.random.normal(scale=2.0, size=(100))\n\nfig, ax = plt.subplots(figsize=(10,6))\nax.plot(x, y, '.')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Lets try fit this with a neural network. The network is deliberating over complex with over **40,000 parameters** to tune and the relu activation function for non-linearity.",
"_____no_output_____"
]
],
[
[
"model = tf.keras.Sequential(\n [\n tf.keras.layers.Dense(\n 100, input_shape=(1,), activation=tf.keras.activations.relu\n ),\n tf.keras.layers.Dense(\n 100, activation=tf.keras.activations.relu\n ),\n tf.keras.layers.Dense(\n 100, activation=tf.keras.activations.relu\n ),\n tf.keras.layers.Dense(\n 100, activation=tf.keras.activations.relu\n ),\n tf.keras.layers.Dense(\n 100, activation=tf.keras.activations.relu\n ),\n tf.keras.layers.Dense(1),\n ]\n)\nmodel.compile(\n optimizer=tf.optimizers.Adam(learning_rate=0.01), loss=tf.keras.losses.mse\n)\nmodel.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 100) 200 \n_________________________________________________________________\ndense_1 (Dense) (None, 100) 10100 \n_________________________________________________________________\ndense_2 (Dense) (None, 100) 10100 \n_________________________________________________________________\ndense_3 (Dense) (None, 100) 10100 \n_________________________________________________________________\ndense_4 (Dense) (None, 100) 10100 \n_________________________________________________________________\ndense_5 (Dense) (None, 1) 101 \n=================================================================\nTotal params: 40,701\nTrainable params: 40,701\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"history = model.fit(x, y, epochs=200, verbose=False)\nplt.plot(history.history[\"loss\"])\nplt.xlabel('epoch')\nplt.ylabel('loss')\nplt.show()",
"_____no_output_____"
]
],
[
[
"If we make predictions from the overly complex neural network we would expect some drastically overfit results...",
"_____no_output_____"
]
],
[
[
"x_eval = np.linspace(0, 20, 1000)\ny_eval = model.predict(x_eval)\n\nfig, ax = plt.subplots(figsize=(10,6))\nax.plot(x, y, '.', label='data')\nax.plot(x_eval, y_eval, label='NN')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"The results are pretty reasonable! There isnt a crazy line that passing through all our points.\n\nWe can compare this to the results from linear regression. For laziness, we do this in tensorflow using a single layer linear network:",
"_____no_output_____"
]
],
[
[
"model_linear = tf.keras.Sequential(\n [\n tf.keras.layers.Dense(1, input_shape=(1,)),\n ]\n)\n\nmodel_linear.compile(\n optimizer=tf.optimizers.Adam(learning_rate=0.05), loss=tf.keras.losses.mse\n)\nmodel_linear.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_6 (Dense) (None, 1) 2 \n=================================================================\nTotal params: 2\nTrainable params: 2\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"history_linear = model_linear.fit(x, y, epochs=200, verbose=False)\nplt.plot(history_linear.history[\"loss\"])\ny_linear_eval = model_linear.predict(x_eval)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(10,6))\nax.plot(x, y, '.', label='data')\nax.plot(x_eval, y_eval, label='NN')\nax.plot(x_eval, y_linear_eval, label='linear regression')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"The two models look pretty similar. For more details on why this is the case - please refer to the paper in the introduction.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a028428f2d48bda6f095ee7aabea583ea5276ee
| 11,579 |
ipynb
|
Jupyter Notebook
|
chapter4.ipynb
|
falconlee236/handson-ml2
|
fc5001c0d23269020915430b867da1a6abb442d7
|
[
"Apache-2.0"
] | null | null | null |
chapter4.ipynb
|
falconlee236/handson-ml2
|
fc5001c0d23269020915430b867da1a6abb442d7
|
[
"Apache-2.0"
] | null | null | null |
chapter4.ipynb
|
falconlee236/handson-ml2
|
fc5001c0d23269020915430b867da1a6abb442d7
|
[
"Apache-2.0"
] | null | null | null | 25.448352 | 231 | 0.460489 |
[
[
[
"<a href=\"https://colab.research.google.com/github/falconlee236/handson-ml2/blob/master/chapter4.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\nX = 2 * np.random.rand(100, 1);\ny = 4 + 3 * X + np.random.randn(100, 1)\n\nplt.scatter(X, y)\nplt.ylabel('y')\nplt.xlabel('x')",
"_____no_output_____"
],
[
"X_b = np.c_[np.ones((100, 1)), X]\ntheta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)\ntheta_best",
"_____no_output_____"
],
[
"X_new = np.array([[0], [2]])\nX_new_b = np.c_[np.ones((2, 1)), X_new]\ny_predict = X_new_b.dot(theta_best)\ny_predict",
"_____no_output_____"
],
[
"plt.plot(X_new, y_predict, 'r-')\nplt.plot(X, y, 'b.')\nplt.axis([0, 2, 0, 15])\nplt.show()",
"_____no_output_____"
],
[
"from sklearn.linear_model import LinearRegression\nlin_reg = LinearRegression()\nlin_reg.fit(X, y)",
"_____no_output_____"
],
[
"lin_reg.intercept_, lin_reg.coef_",
"_____no_output_____"
],
[
"lin_reg.predict(X_new)",
"_____no_output_____"
],
[
"theta_best_svd, residuals, rank, s = np.linalg.lstsq(X_b, y, rcond=1e-6)\ntheta_best_svd",
"_____no_output_____"
],
[
"np.linalg.pinv(X_b).dot(y)",
"_____no_output_____"
],
[
"eta = 0.1\nn_iterations = 1000\nm = 100\n\ntheta = np.random.randn(2, 1)\n\nfor iteration in range(n_iterations):\n gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)\n theta -= eta * gradients\n\ntheta",
"_____no_output_____"
],
[
"from sklearn.linear_model import SGDRegressor\nsgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1)\nsgd_reg.fit(X, y.ravel())\nsgd_reg.intercept_, sgd_reg.coef_",
"_____no_output_____"
],
[
"m = 100\nX = 6 * np.random.rand(m, 1) - 3\ny = 0.5 * X**2 + X+ 2 + np.random.randn(m, 1)\nplt.plot(X, y, 'b.')",
"_____no_output_____"
],
[
"from sklearn.preprocessing import PolynomialFeatures\n\npoly_features = PolynomialFeatures(degree=2, include_bias=False)\nX_poly = poly_features.fit_transform(X)\nX[0], X_poly[0]",
"_____no_output_____"
],
[
"lin_reg = LinearRegression()\nlin_reg.fit(X_poly, y)\nlin_reg.intercept_, lin_reg.coef_",
"_____no_output_____"
],
[
"X_new = np.linspace(-3, 3, 100).reshape(100, 1)\nX_new_poly = poly_features.fit_transform(X_new)\ny_new = lin_reg.predict(X_new_poly)\n\nplt.plot(X, y, 'b.')\nplt.plot(X_new, y_new, 'r-')",
"_____no_output_____"
],
[
"from sklearn.metrics import mean_squared_error\nfrom sklearn.model_selection import train_test_split\n\ndef plot_learning_curves(model, X, y):\n X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)\n train_errors, val_errors = [], []\n for m in range(1, len(X_train)):\n model.fit(X_train[:m], y_train[:m])\n y_train_predict = model.predict(X_train[:m])\n y_val_predict = model.predict(X_val)\n train_errors.append(mean_squared_error(y_train[:m], y_train_predict))\n val_errors.append(mean_squared_error(y_val, y_val_predict))\n plt.plot(np.sqrt(train_errors), 'r-+', linewidth=2, label='train set')\n plt.plot(np.sqrt(val_errors), 'b-', linewidth=3, label='validation set')\n plt.ylim(top = 3, bottom = 0)\n plt.legend()\n",
"_____no_output_____"
],
[
"lin_reg = LinearRegression()\nplot_learning_curves(lin_reg, X, y)",
"_____no_output_____"
],
[
"from sklearn.pipeline import Pipeline\n\npolynomial_regression = Pipeline([\n ('poly_features', PolynomialFeatures(degree=10, include_bias=False)),\n ('lin_reg', LinearRegression())\n])\n\nplot_learning_curves(polynomial_regression, X, y)",
"_____no_output_____"
],
[
"from sklearn.linear_model import Ridge\nridge_reg = Ridge(alpha=1, solver='cholesky')\nridge_reg.fit(X, y)\nridge_reg.predict([[1.5]])",
"_____no_output_____"
],
[
"sgd_reg = SGDRegressor(penalty='l2')\nsgd_reg.fit(X, y.ravel())\nsgd_reg.predict([[1.5]])",
"_____no_output_____"
],
[
"from sklearn.linear_model import Lasso\nlasso_reg = Lasso(alpha=0.1)\nlasso_reg.fit(X, y)\nlasso_reg.predict([[1.5]])",
"_____no_output_____"
],
[
"from sklearn.linear_model import ElasticNet\nelastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)\nelastic_net.fit(X, y)\nelastic_net.predict([[1.5]])",
"_____no_output_____"
],
[
"from sklearn import datasets\niris = datasets.load_iris()\nlist(iris.keys())",
"_____no_output_____"
],
[
"X = iris[\"data\"][:, 3:]\ny = (iris['target'] == 2).astype(np.int)",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression\n\nlog_reg = LogisticRegression()\nlog_reg.fit(X, y)",
"_____no_output_____"
],
[
"X_new = np.linspace(0, 3, 1000).reshape(-1, 1)\ny_proba = log_reg.predict_proba(X_new)\nplt.plot(X_new, y_proba[:, 1], 'g-', label='Iris virginica')\nplt.plot(X_new, y_proba[:, 0], 'b-', label='Not Iris virginica')",
"_____no_output_____"
],
[
"X = iris['data'][:, (2, 3)]\ny = iris['target']\n\nsoftmax_reg = LogisticRegression(multi_class=\"multinomial\", solver='lbfgs', C=18)\nsoftmax_reg.fit(X, y)",
"_____no_output_____"
],
[
"softmax_reg.predict([[5, 2]])",
"_____no_output_____"
],
[
"softmax_reg.predict_proba([[5, 2]])",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a029fc9372f00817a31c1b4a114236193e2491d
| 19,073 |
ipynb
|
Jupyter Notebook
|
fennel_centrality_activated_experiments.ipynb
|
sbarakat/algorithmshop-graph-partitioning
|
db575ce585e2de0df4b0d944c24777cabc2146a3
|
[
"MIT"
] | 13 |
2017-03-26T13:47:51.000Z
|
2021-01-29T14:01:30.000Z
|
fennel_centrality_activated_experiments.ipynb
|
younes94/graph-partitioning
|
4114325de22cb446a967bcbf373531d5d86bbac5
|
[
"MIT"
] | null | null | null |
fennel_centrality_activated_experiments.ipynb
|
younes94/graph-partitioning
|
4114325de22cb446a967bcbf373531d5d86bbac5
|
[
"MIT"
] | 7 |
2017-03-21T14:01:26.000Z
|
2021-07-28T10:26:42.000Z
| 44.048499 | 242 | 0.520264 |
[
[
[
"import os\nimport csv\nimport platform\nimport pandas as pd\nimport networkx as nx\nfrom graph_partitioning import GraphPartitioning, utils\n\nrun_metrics = True\n\ncols = [\"WASTE\", \"CUT RATIO\", \"EDGES CUT\", \"TOTAL COMM VOLUME\", \"Qds\", \"CONDUCTANCE\", \"MAXPERM\", \"NMI\", \"FSCORE\", \"FSCORE RELABEL IMPROVEMENT\", \"LONELINESS\"]\n#cols = [\"WASTE\", \"CUT RATIO\", \"EDGES CUT\", \"TOTAL COMM VOLUME\", \"Q\", \"Qds\", \"CONDUCTANCE\", \"LONELINESS\", \"NETWORK PERMANENCE\", \"NORM. MUTUAL INFO\", \"EDGE CUT WEIGHT\", \"FSCORE\", \"FSCORE RELABEL IMPROVEMENT\"]\n#cols = [\"WASTE\", \"CUT RATIO\", \"EDGES CUT\", \"TOTAL COMM VOLUME\", \"MODULARITY\", \"LONELINESS\", \"NETWORK PERMANENCE\", \"NORM. MUTUAL INFO\", \"EDGE CUT WEIGHT\", \"FSCORE\", \"FSCORE RELABEL IMPROVEMENT\"]\n\npwd = %pwd\n\nconfig = {\n\n \"DATA_FILENAME\": os.path.join(pwd, \"data\", \"predition_model_tests\", \"network\", \"network_$$.txt\"),\n \"OUTPUT_DIRECTORY\": os.path.join(pwd, \"output\"),\n\n # Set which algorithm is run for the PREDICTION MODEL.\n # Either: 'FENNEL' or 'SCOTCH'\n \"PREDICTION_MODEL_ALGORITHM\": \"FENNEL\",\n\n # Alternativly, read input file for prediction model.\n # Set to empty to generate prediction model using algorithm value above.\n \"PREDICTION_MODEL\": \"\",\n\n \n \"PARTITIONER_ALGORITHM\": \"FENNEL\",\n\n # File containing simulated arrivals. This is used in simulating nodes\n # arriving at the shelter. Nodes represented by line number; value of\n # 1 represents a node as arrived; value of 0 represents the node as not\n # arrived or needing a shelter.\n \"SIMULATED_ARRIVAL_FILE\": os.path.join(pwd,\n \"data\",\n \"predition_model_tests\",\n \"dataset_1_shift_rotate\",\n \"simulated_arrival_list\",\n \"percentage_of_prediction_correct_100\",\n \"arrival_100_$$.txt\"\n ),\n\n # File containing the prediction of a node arriving. This is different to the\n # simulated arrivals, the values in this file are known before the disaster.\n \"PREDICTION_LIST_FILE\": os.path.join(pwd,\n \"data\",\n \"predition_model_tests\",\n \"dataset_1_shift_rotate\",\n \"prediction_list\",\n \"prediction_$$.txt\"\n ),\n\n # File containing the geographic location of each node, in \"x,y\" format.\n \"POPULATION_LOCATION_FILE\": os.path.join(pwd,\n \"data\",\n \"predition_model_tests\",\n \"coordinates\",\n \"coordinates_$$.txt\"\n ),\n\n # Number of shelters\n \"num_partitions\": 4,\n\n # The number of iterations when making prediction model\n \"num_iterations\": 1,\n\n # Percentage of prediction model to use before discarding\n # When set to 0, prediction model is discarded, useful for one-shot\n \"prediction_model_cut_off\": .0,\n\n # Alpha value used in one-shot (when restream_batches set to 1)\n \"one_shot_alpha\": 0.5,\n \n \"use_one_shot_alpha\": False,\n \n # Number of arrivals to batch before recalculating alpha and restreaming.\n \"restream_batches\": 50,\n\n # When the batch size is reached: if set to True, each node is assigned\n # individually as first in first out. If set to False, the entire batch\n # is processed and empty before working on the next batch.\n \"sliding_window\": False,\n\n # Create virtual nodes based on prediction model\n \"use_virtual_nodes\": False,\n\n # Virtual nodes: edge weight\n \"virtual_edge_weight\": 1.0,\n \n # Loneliness score parameter. Used when scoring a partition by how many\n # lonely nodes exist.\n \"loneliness_score_param\": 1.2,\n\n\n ####\n # GRAPH MODIFICATION FUNCTIONS\n\n # Also enables the edge calculation function.\n \"graph_modification_functions\": True,\n\n # If set, the node weight is set to 100 if the node arrives at the shelter,\n # otherwise the node is removed from the graph.\n \"alter_arrived_node_weight_to_100\": False,\n\n # Uses generalized additive models from R to generate prediction of nodes not\n # arrived. This sets the node weight on unarrived nodes the the prediction\n # given by a GAM.\n # Needs POPULATION_LOCATION_FILE to be set.\n \"alter_node_weight_to_gam_prediction\": False,\n \n # Enables edge expansion when graph_modification_functions is set to true\n \"edge_expansion_enabled\": True,\n\n # The value of 'k' used in the GAM will be the number of nodes arrived until\n # it reaches this max value.\n \"gam_k_value\": 100,\n\n # Alter the edge weight for nodes that haven't arrived. This is a way to\n # de-emphasise the prediction model for the unknown nodes.\n \"prediction_model_emphasis\": 1.0,\n \n # This applies the prediction_list_file node weights onto the nodes in the graph\n # when the prediction model is being computed and then removes the weights\n # for the cutoff and batch arrival modes\n \"apply_prediction_model_weights\": True,\n \n \"compute_metrics_enabled\": True,\n\n \"SCOTCH_LIB_PATH\": os.path.join(pwd, \"libs/scotch/macOS/libscotch.dylib\")\n if 'Darwin' in platform.system()\n else \"/usr/local/lib/libscotch.so\",\n \n # Path to the PaToH shared library\n \"PATOH_LIB_PATH\": os.path.join(pwd, \"libs/patoh/lib/macOS/libpatoh.dylib\")\n if 'Darwin' in platform.system()\n else os.path.join(pwd, \"libs/patoh/lib/linux/libpatoh.so\"),\n \n \"PATOH_ITERATIONS\": 5,\n \n # Expansion modes: 'avg_node_weight', 'total_node_weight', 'smallest_node_weight'\n # 'largest_node_weight'\n # add '_squared' or '_sqrt' at the end of any of the above for ^2 or sqrt(weight)\n # i.e. 'avg_node_weight_squared\n \"PATOH_HYPEREDGE_EXPANSION_MODE\": 'no_expansion',\n \n # Edge Expansion: average, total, minimum, maximum, product, product_squared, sqrt_product\n \"EDGE_EXPANSION_MODE\" : 'total',\n \n # Whether nodes should be reordered using a centrality metric for optimal node assignments in batch mode\n # This is specific to FENNEL and at the moment Leverage Centrality is used to compute new noder orders\n \"FENNEL_NODE_REORDERING_ENABLED\": False,\n\n # The node ordering scheme: PII_LH (political index), LEVERAGE_HL, DEGREE_HL, BOTTLENECK_HL\n \"FENNEL_NODE_REODERING_SCHEME\": 'BOTTLENECK_HL',\n \n # Whether the Friend of a Friend scoring system is active during FENNEL partitioning.\n # FOAF employs information about a node's friends to determine the best partition when\n # this node arrives at a shelter and no shelter has friends already arrived\n \"FENNEL_FRIEND_OF_A_FRIEND_ENABLED\": False,\n \n # Alters how much information to print. Keep it at 1 for this notebook.\n # 0 - will print nothing, useful for batch operations.\n # 1 - prints basic information on assignments and operations.\n # 2 - prints more information as it batches arrivals.\n \"verbose\": 1\n}\n\n#gp = GraphPartitioning(config)\n\n# Optional: shuffle the order of nodes arriving\n# Arrival order should not be shuffled if using GAM to alter node weights\n#random.shuffle(gp.arrival_order)\n\n%pylab inline",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"import scipy\nfrom copy import deepcopy\n\niterations = 1000 # the number of individual networks to run\n\n# BOTTLENECK 1 Restream, no FOAF, Lonely after\n\n# change these variables:\nordering_enabled_mode = [True]#[False, True]\n\n\nfor mode in ordering_enabled_mode:\n#for mode in range(1, 51):\n\n metricsDataPrediction = []\n metricsDataAssign = []\n \n config['FENNEL_NODE_REORDERING_ENABLED'] = mode\n config['FENNEL_NODE_REORDERING_SCHEME'] = 'BOTTLENECK_HL'\n config['FENNEL_FRIEND_OF_A_FRIEND_ENABLED'] = False\n \n print('Mode', mode)\n for i in range(0, iterations):\n if (i % 50) == 0:\n print('Mode', mode, 'Iteration', str(i))\n \n conf = deepcopy(config)\n\n #if mode == 'no_expansion':\n # config['edge_expansion_enabled'] = False\n \n #conf[\"DATA_FILENAME\"] = os.path.join(pwd, \"data\", \"predition_model_tests\", \"network\", \"network_\" + str(i + 1) + \".txt\")\n conf[\"DATA_FILENAME\"] = conf[\"DATA_FILENAME\"].replace('$$', str(i + 1))\n conf[\"SIMULATED_ARRIVAL_FILE\"] = conf[\"SIMULATED_ARRIVAL_FILE\"].replace('$$', str(i + 1))\n conf[\"PREDICTION_LIST_FILE\"] = conf[\"PREDICTION_LIST_FILE\"].replace('$$', str(i + 1))\n conf[\"POPULATION_LOCATION_FILE\"] = conf[\"POPULATION_LOCATION_FILE\"].replace('$$', str(i + 1))\n conf[\"compute_metrics_enabled\"] = False\n conf['PREDICTION_MODEL'] = conf['PREDICTION_MODEL'].replace('$$', str(i + 1))\n\n\n\n #print(i, conf)\n #print('config', config)\n \n with GraphPartitioning(conf) as gp:\n #gp = GraphPartitioning(config)\n gp.verbose = 0\n gp.load_network()\n gp.init_partitioner()\n\n m = gp.prediction_model()\n m = gp.assign_cut_off()\n m = gp.batch_arrival()\n\n Gsub = gp.G.subgraph(gp.nodes_arrived)\n gp.compute_metrics_enabled = True\n m = [gp._print_score(Gsub)]\n gp.compute_metrics_enabled = False \n\n\n totalM = len(m)\n metricsDataPrediction.append(m[totalM - 1])\n\n\n waste = ''\n cutratio = ''\n ec = ''\n tcv = ''\n qds = ''\n conductance = ''\n maxperm = ''\n nmi = ''\n lonliness = ''\n fscore = ''\n fscoreimprove = ''\n \n qdsOv = ''\n condOv = ''\n\n dataWaste = []\n dataCutRatio = []\n dataEC = []\n dataTCV = [] \n dataQDS = []\n dataCOND = []\n dataMAXPERM = []\n dataNMI = []\n dataLonliness = []\n dataFscore = []\n dataFscoreImprove = []\n\n \n for i in range(0, iterations):\n dataWaste.append(metricsDataPrediction[i][0]) \n dataCutRatio.append(metricsDataPrediction[i][1])\n dataEC.append(metricsDataPrediction[i][2])\n dataTCV.append(metricsDataPrediction[i][3])\n dataQDS.append(metricsDataPrediction[i][4])\n dataCOND.append(metricsDataPrediction[i][5])\n dataMAXPERM.append(metricsDataPrediction[i][6])\n dataNMI.append(metricsDataPrediction[i][7]) \n dataFscore.append(metricsDataPrediction[i][8]) \n dataFscoreImprove.append(metricsDataPrediction[i][9]) \n dataLonliness.append(metricsDataPrediction[i][10])\n\n\n if(len(waste)):\n waste = waste + ','\n waste = waste + str(metricsDataPrediction[i][0])\n\n if(len(cutratio)):\n cutratio = cutratio + ','\n cutratio = cutratio + str(metricsDataPrediction[i][1])\n\n if(len(ec)):\n ec = ec + ','\n ec = ec + str(metricsDataPrediction[i][2])\n \n if(len(tcv)):\n tcv = tcv + ','\n tcv = tcv + str(metricsDataPrediction[i][3])\n\n if(len(qds)):\n qds = qds + ','\n qds = qds + str(metricsDataPrediction[i][4])\n\n if(len(conductance)):\n conductance = conductance + ','\n conductance = conductance + str(metricsDataPrediction[i][5])\n\n if(len(maxperm)):\n maxperm = maxperm + ','\n maxperm = maxperm + str(metricsDataPrediction[i][6])\n\n if(len(nmi)):\n nmi = nmi + ','\n nmi = nmi + str(metricsDataPrediction[i][7])\n\n if(len(fscore)):\n fscore = fscore + ','\n fscore = fscore + str(metricsDataPrediction[i][8])\n\n if(len(fscoreimprove)):\n fscoreimprove = fscoreimprove + ','\n fscoreimprove = fscoreimprove + str(metricsDataPrediction[i][8])\n \n if(len(lonliness)):\n lonliness = lonliness + ','\n lonliness = lonliness + str(dataLonliness[i])\n \n\n waste = 'WASTE,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataWaste)) + ',' + str(scipy.std(dataWaste)) + ',' + waste\n\n cutratio = 'CUT_RATIO,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataCutRatio)) + ',' + str(scipy.std(dataCutRatio)) + ',' + cutratio\n ec = 'EC,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataEC)) + ',' + str(scipy.std(dataEC)) + ',' + ec\n tcv = 'TCV,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataTCV)) + ',' + str(scipy.std(dataTCV)) + ',' + tcv\n\n lonliness = \"LONELINESS,\" + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataLonliness)) + ',' + str(scipy.std(dataLonliness)) + ',' + lonliness\n \n qds = 'QDS,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataQDS)) + ',' + str(scipy.std(dataQDS)) + ',' + qds\n conductance = 'CONDUCTANCE,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataCOND)) + ',' + str(scipy.std(dataCOND)) + ',' + conductance\n maxperm = 'MAXPERM,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataMAXPERM)) + ',' + str(scipy.std(dataMAXPERM)) + ',' + maxperm\n nmi = 'NMI,' + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataNMI)) + ',' + str(scipy.std(dataNMI)) + ',' + nmi\n\n fscore = \"FSCORE,\" + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataFscore)) + ',' + str(scipy.std(dataFscore)) + ',' + fscore\n fscoreimprove = \"FSCORE_IMPROVE,\" + 'centrality_enabled_mode_' + str(config['FENNEL_NODE_REORDERING_ENABLED']) + ',' + str(scipy.mean(dataFscoreImprove)) + ',' + str(scipy.std(dataFscoreImprove)) + ',' + fscoreimprove\n\n print(waste)\n print(cutratio)\n print(ec)\n print(tcv)\n print(lonliness)\n print(qds)\n print(conductance)\n print(maxperm)\n print(fscore)\n print(fscoreimprove)",
"Mode True\nMode True Iteration 0\nMode True Iteration 50\nMode True Iteration 100\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a02a6ae2ef950469949ea5481f5540f3e99379b
| 46,848 |
ipynb
|
Jupyter Notebook
|
DSND_Term1-master/projects/p1_charityml/finding_donors.ipynb
|
claudiocmp/udacity-dsnd
|
2ec21703e97e382e7f5421edeb392c1f31314632
|
[
"MIT"
] | null | null | null |
DSND_Term1-master/projects/p1_charityml/finding_donors.ipynb
|
claudiocmp/udacity-dsnd
|
2ec21703e97e382e7f5421edeb392c1f31314632
|
[
"MIT"
] | null | null | null |
DSND_Term1-master/projects/p1_charityml/finding_donors.ipynb
|
claudiocmp/udacity-dsnd
|
2ec21703e97e382e7f5421edeb392c1f31314632
|
[
"MIT"
] | null | null | null | 50.266094 | 897 | 0.642888 |
[
[
[
"# Data Scientist Nanodegree\n## Supervised Learning\n## Project: Finding Donors for *CharityML*",
"_____no_output_____"
],
[
"Welcome to the first project of the Data Scientist Nanodegree! In this notebook, some template code has already been provided for you, and it will be your job to implement the additional functionality necessary to successfully complete this project. Sections that begin with **'Implementation'** in the header indicate that the following block of code will require additional functionality which you must provide. Instructions will be provided for each section and the specifics of the implementation are marked in the code block with a `'TODO'` statement. Please be sure to read the instructions carefully!\n\nIn addition to implementing code, there will be questions that you must answer which relate to the project and your implementation. Each section where you will answer a question is preceded by a **'Question X'** header. Carefully read each question and provide thorough answers in the following text boxes that begin with **'Answer:'**. Your project submission will be evaluated based on your answers to each of the questions and the implementation you provide. \n\n>**Note:** Please specify WHICH VERSION OF PYTHON you are using when submitting this notebook. Code and Markdown cells can be executed using the **Shift + Enter** keyboard shortcut. In addition, Markdown cells can be edited by typically double-clicking the cell to enter edit mode.",
"_____no_output_____"
],
[
"## Getting Started\n\nIn this project, you will employ several supervised algorithms of your choice to accurately model individuals' income using data collected from the 1994 U.S. Census. You will then choose the best candidate algorithm from preliminary results and further optimize this algorithm to best model the data. Your goal with this implementation is to construct a model that accurately predicts whether an individual makes more than $50,000. This sort of task can arise in a non-profit setting, where organizations survive on donations. Understanding an individual's income can help a non-profit better understand how large of a donation to request, or whether or not they should reach out to begin with. While it can be difficult to determine an individual's general income bracket directly from public sources, we can (as we will see) infer this value from other publically available features. \n\nThe dataset for this project originates from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/datasets/Census+Income). The datset was donated by Ron Kohavi and Barry Becker, after being published in the article _\"Scaling Up the Accuracy of Naive-Bayes Classifiers: A Decision-Tree Hybrid\"_. You can find the article by Ron Kohavi [online](https://www.aaai.org/Papers/KDD/1996/KDD96-033.pdf). The data we investigate here consists of small changes to the original dataset, such as removing the `'fnlwgt'` feature and records with missing or ill-formatted entries.",
"_____no_output_____"
],
[
"----\n## Exploring the Data\nRun the code cell below to load necessary Python libraries and load the census data. Note that the last column from this dataset, `'income'`, will be our target label (whether an individual makes more than, or at most, $50,000 annually). All other columns are features about each individual in the census database.",
"_____no_output_____"
]
],
[
[
"# Import libraries necessary for this project\nimport numpy as np\nimport pandas as pd\nfrom time import time\nfrom IPython.display import display # Allows the use of display() for DataFrames\n\n# Import supplementary visualization code visuals.py\nimport visuals as vs\n\n# Pretty display for notebooks\n%matplotlib inline\n\n# Load the Census dataset\ndata = pd.read_csv(\"census.csv\")\n\n# Success - Display the first record\ndisplay(data.head(n=1))",
"_____no_output_____"
]
],
[
[
"### Implementation: Data Exploration\nA cursory investigation of the dataset will determine how many individuals fit into either group, and will tell us about the percentage of these individuals making more than \\$50,000. In the code cell below, you will need to compute the following:\n- The total number of records, `'n_records'`\n- The number of individuals making more than \\$50,000 annually, `'n_greater_50k'`.\n- The number of individuals making at most \\$50,000 annually, `'n_at_most_50k'`.\n- The percentage of individuals making more than \\$50,000 annually, `'greater_percent'`.\n\n** HINT: ** You may need to look at the table above to understand how the `'income'` entries are formatted. ",
"_____no_output_____"
]
],
[
[
"# TODO: Total number of records\nn_records = None\n\n# TODO: Number of records where individual's income is more than $50,000\nn_greater_50k = None\n\n# TODO: Number of records where individual's income is at most $50,000\nn_at_most_50k = None\n\n# TODO: Percentage of individuals whose income is more than $50,000\ngreater_percent = None\n\n# Print the results\nprint(\"Total number of records: {}\".format(n_records))\nprint(\"Individuals making more than $50,000: {}\".format(n_greater_50k))\nprint(\"Individuals making at most $50,000: {}\".format(n_at_most_50k))\nprint(\"Percentage of individuals making more than $50,000: {}%\".format(greater_percent))",
"_____no_output_____"
]
],
[
[
"** Featureset Exploration **\n\n* **age**: continuous. \n* **workclass**: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked. \n* **education**: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool. \n* **education-num**: continuous. \n* **marital-status**: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse. \n* **occupation**: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces. \n* **relationship**: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried. \n* **race**: Black, White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other. \n* **sex**: Female, Male. \n* **capital-gain**: continuous. \n* **capital-loss**: continuous. \n* **hours-per-week**: continuous. \n* **native-country**: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.",
"_____no_output_____"
],
[
"----\n## Preparing the Data\nBefore data can be used as input for machine learning algorithms, it often must be cleaned, formatted, and restructured — this is typically known as **preprocessing**. Fortunately, for this dataset, there are no invalid or missing entries we must deal with, however, there are some qualities about certain features that must be adjusted. This preprocessing can help tremendously with the outcome and predictive power of nearly all learning algorithms.",
"_____no_output_____"
],
[
"### Transforming Skewed Continuous Features\nA dataset may sometimes contain at least one feature whose values tend to lie near a single number, but will also have a non-trivial number of vastly larger or smaller values than that single number. Algorithms can be sensitive to such distributions of values and can underperform if the range is not properly normalized. With the census dataset two features fit this description: '`capital-gain'` and `'capital-loss'`. \n\nRun the code cell below to plot a histogram of these two features. Note the range of the values present and how they are distributed.",
"_____no_output_____"
]
],
[
[
"# Split the data into features and target label\nincome_raw = data['income']\nfeatures_raw = data.drop('income', axis = 1)\n\n# Visualize skewed continuous features of original data\nvs.distribution(data)",
"_____no_output_____"
]
],
[
[
"For highly-skewed feature distributions such as `'capital-gain'` and `'capital-loss'`, it is common practice to apply a <a href=\"https://en.wikipedia.org/wiki/Data_transformation_(statistics)\">logarithmic transformation</a> on the data so that the very large and very small values do not negatively affect the performance of a learning algorithm. Using a logarithmic transformation significantly reduces the range of values caused by outliers. Care must be taken when applying this transformation however: The logarithm of `0` is undefined, so we must translate the values by a small amount above `0` to apply the the logarithm successfully.\n\nRun the code cell below to perform a transformation on the data and visualize the results. Again, note the range of values and how they are distributed. ",
"_____no_output_____"
]
],
[
[
"# Log-transform the skewed features\nskewed = ['capital-gain', 'capital-loss']\nfeatures_log_transformed = pd.DataFrame(data = features_raw)\nfeatures_log_transformed[skewed] = features_raw[skewed].apply(lambda x: np.log(x + 1))\n\n# Visualize the new log distributions\nvs.distribution(features_log_transformed, transformed = True)",
"_____no_output_____"
]
],
[
[
"### Normalizing Numerical Features\nIn addition to performing transformations on features that are highly skewed, it is often good practice to perform some type of scaling on numerical features. Applying a scaling to the data does not change the shape of each feature's distribution (such as `'capital-gain'` or `'capital-loss'` above); however, normalization ensures that each feature is treated equally when applying supervised learners. Note that once scaling is applied, observing the data in its raw form will no longer have the same original meaning, as exampled below.\n\nRun the code cell below to normalize each numerical feature. We will use [`sklearn.preprocessing.MinMaxScaler`](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html) for this.",
"_____no_output_____"
]
],
[
[
"# Import sklearn.preprocessing.StandardScaler\nfrom sklearn.preprocessing import MinMaxScaler\n\n# Initialize a scaler, then apply it to the features\nscaler = MinMaxScaler() # default=(0, 1)\nnumerical = ['age', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week']\n\nfeatures_log_minmax_transform = pd.DataFrame(data = features_log_transformed)\nfeatures_log_minmax_transform[numerical] = scaler.fit_transform(features_log_transformed[numerical])\n\n# Show an example of a record with scaling applied\ndisplay(features_log_minmax_transform.head(n = 5))",
"_____no_output_____"
]
],
[
[
"### Implementation: Data Preprocessing\n\nFrom the table in **Exploring the Data** above, we can see there are several features for each record that are non-numeric. Typically, learning algorithms expect input to be numeric, which requires that non-numeric features (called *categorical variables*) be converted. One popular way to convert categorical variables is by using the **one-hot encoding** scheme. One-hot encoding creates a _\"dummy\"_ variable for each possible category of each non-numeric feature. For example, assume `someFeature` has three possible entries: `A`, `B`, or `C`. We then encode this feature into `someFeature_A`, `someFeature_B` and `someFeature_C`.\n\n| | someFeature | | someFeature_A | someFeature_B | someFeature_C |\n| :-: | :-: | | :-: | :-: | :-: |\n| 0 | B | | 0 | 1 | 0 |\n| 1 | C | ----> one-hot encode ----> | 0 | 0 | 1 |\n| 2 | A | | 1 | 0 | 0 |\n\nAdditionally, as with the non-numeric features, we need to convert the non-numeric target label, `'income'` to numerical values for the learning algorithm to work. Since there are only two possible categories for this label (\"<=50K\" and \">50K\"), we can avoid using one-hot encoding and simply encode these two categories as `0` and `1`, respectively. In code cell below, you will need to implement the following:\n - Use [`pandas.get_dummies()`](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.get_dummies.html?highlight=get_dummies#pandas.get_dummies) to perform one-hot encoding on the `'features_log_minmax_transform'` data.\n - Convert the target label `'income_raw'` to numerical entries.\n - Set records with \"<=50K\" to `0` and records with \">50K\" to `1`.",
"_____no_output_____"
]
],
[
[
"# TODO: One-hot encode the 'features_log_minmax_transform' data using pandas.get_dummies()\nfeatures_final = None\n\n# TODO: Encode the 'income_raw' data to numerical values\nincome = None\n\n# Print the number of features after one-hot encoding\nencoded = list(features_final.columns)\nprint(\"{} total features after one-hot encoding.\".format(len(encoded)))\n\n# Uncomment the following line to see the encoded feature names\n# print encoded",
"_____no_output_____"
]
],
[
[
"### Shuffle and Split Data\nNow all _categorical variables_ have been converted into numerical features, and all numerical features have been normalized. As always, we will now split the data (both features and their labels) into training and test sets. 80% of the data will be used for training and 20% for testing.\n\nRun the code cell below to perform this split.",
"_____no_output_____"
]
],
[
[
"# Import train_test_split\nfrom sklearn.cross_validation import train_test_split\n\n# Split the 'features' and 'income' data into training and testing sets\nX_train, X_test, y_train, y_test = train_test_split(features_final, \n income, \n test_size = 0.2, \n random_state = 0)\n\n# Show the results of the split\nprint(\"Training set has {} samples.\".format(X_train.shape[0]))\nprint(\"Testing set has {} samples.\".format(X_test.shape[0]))",
"_____no_output_____"
]
],
[
[
"----\n## Evaluating Model Performance\nIn this section, we will investigate four different algorithms, and determine which is best at modeling the data. Three of these algorithms will be supervised learners of your choice, and the fourth algorithm is known as a *naive predictor*.",
"_____no_output_____"
],
[
"### Metrics and the Naive Predictor\n*CharityML*, equipped with their research, knows individuals that make more than \\$50,000 are most likely to donate to their charity. Because of this, *CharityML* is particularly interested in predicting who makes more than \\$50,000 accurately. It would seem that using **accuracy** as a metric for evaluating a particular model's performace would be appropriate. Additionally, identifying someone that *does not* make more than \\$50,000 as someone who does would be detrimental to *CharityML*, since they are looking to find individuals willing to donate. Therefore, a model's ability to precisely predict those that make more than \\$50,000 is *more important* than the model's ability to **recall** those individuals. We can use **F-beta score** as a metric that considers both precision and recall:\n\n$$ F_{\\beta} = (1 + \\beta^2) \\cdot \\frac{precision \\cdot recall}{\\left( \\beta^2 \\cdot precision \\right) + recall} $$\n\nIn particular, when $\\beta = 0.5$, more emphasis is placed on precision. This is called the **F$_{0.5}$ score** (or F-score for simplicity).\n\nLooking at the distribution of classes (those who make at most \\$50,000, and those who make more), it's clear most individuals do not make more than \\$50,000. This can greatly affect **accuracy**, since we could simply say *\"this person does not make more than \\$50,000\"* and generally be right, without ever looking at the data! Making such a statement would be called **naive**, since we have not considered any information to substantiate the claim. It is always important to consider the *naive prediction* for your data, to help establish a benchmark for whether a model is performing well. That been said, using that prediction would be pointless: If we predicted all people made less than \\$50,000, *CharityML* would identify no one as donors. \n\n\n#### Note: Recap of accuracy, precision, recall\n\n** Accuracy ** measures how often the classifier makes the correct prediction. It’s the ratio of the number of correct predictions to the total number of predictions (the number of test data points).\n\n** Precision ** tells us what proportion of messages we classified as spam, actually were spam.\nIt is a ratio of true positives(words classified as spam, and which are actually spam) to all positives(all words classified as spam, irrespective of whether that was the correct classificatio), in other words it is the ratio of\n\n`[True Positives/(True Positives + False Positives)]`\n\n** Recall(sensitivity)** tells us what proportion of messages that actually were spam were classified by us as spam.\nIt is a ratio of true positives(words classified as spam, and which are actually spam) to all the words that were actually spam, in other words it is the ratio of\n\n`[True Positives/(True Positives + False Negatives)]`\n\nFor classification problems that are skewed in their classification distributions like in our case, for example if we had a 100 text messages and only 2 were spam and the rest 98 weren't, accuracy by itself is not a very good metric. We could classify 90 messages as not spam(including the 2 that were spam but we classify them as not spam, hence they would be false negatives) and 10 as spam(all 10 false positives) and still get a reasonably good accuracy score. For such cases, precision and recall come in very handy. These two metrics can be combined to get the F1 score, which is weighted average(harmonic mean) of the precision and recall scores. This score can range from 0 to 1, with 1 being the best possible F1 score(we take the harmonic mean as we are dealing with ratios).",
"_____no_output_____"
],
[
"### Question 1 - Naive Predictor Performace\n* If we chose a model that always predicted an individual made more than $50,000, what would that model's accuracy and F-score be on this dataset? You must use the code cell below and assign your results to `'accuracy'` and `'fscore'` to be used later.\n\n** Please note ** that the the purpose of generating a naive predictor is simply to show what a base model without any intelligence would look like. In the real world, ideally your base model would be either the results of a previous model or could be based on a research paper upon which you are looking to improve. When there is no benchmark model set, getting a result better than random choice is a place you could start from.\n\n** HINT: ** \n\n* When we have a model that always predicts '1' (i.e. the individual makes more than 50k) then our model will have no True Negatives(TN) or False Negatives(FN) as we are not making any negative('0' value) predictions. Therefore our Accuracy in this case becomes the same as our Precision(True Positives/(True Positives + False Positives)) as every prediction that we have made with value '1' that should have '0' becomes a False Positive; therefore our denominator in this case is the total number of records we have in total. \n* Our Recall score(True Positives/(True Positives + False Negatives)) in this setting becomes 1 as we have no False Negatives.",
"_____no_output_____"
]
],
[
[
"'''\nTP = np.sum(income) # Counting the ones as this is the naive case. Note that 'income' is the 'income_raw' data \nencoded to numerical values done in the data preprocessing step.\nFP = income.count() - TP # Specific to the naive case\n\nTN = 0 # No predicted negatives in the naive case\nFN = 0 # No predicted negatives in the naive case\n'''\n# TODO: Calculate accuracy, precision and recall\naccuracy = None\nrecall = None\nprecision = None\n\n# TODO: Calculate F-score using the formula above for beta = 0.5 and correct values for precision and recall.\nfscore = None\n\n# Print the results \nprint(\"Naive Predictor: [Accuracy score: {:.4f}, F-score: {:.4f}]\".format(accuracy, fscore))",
"_____no_output_____"
]
],
[
[
"### Supervised Learning Models\n**The following are some of the supervised learning models that are currently available in** [`scikit-learn`](http://scikit-learn.org/stable/supervised_learning.html) **that you may choose from:**\n- Gaussian Naive Bayes (GaussianNB)\n- Decision Trees\n- Ensemble Methods (Bagging, AdaBoost, Random Forest, Gradient Boosting)\n- K-Nearest Neighbors (KNeighbors)\n- Stochastic Gradient Descent Classifier (SGDC)\n- Support Vector Machines (SVM)\n- Logistic Regression",
"_____no_output_____"
],
[
"### Question 2 - Model Application\nList three of the supervised learning models above that are appropriate for this problem that you will test on the census data. For each model chosen\n\n- Describe one real-world application in industry where the model can be applied. \n- What are the strengths of the model; when does it perform well?\n- What are the weaknesses of the model; when does it perform poorly?\n- What makes this model a good candidate for the problem, given what you know about the data?\n\n** HINT: **\n\nStructure your answer in the same format as above^, with 4 parts for each of the three models you pick. Please include references with your answer.",
"_____no_output_____"
],
[
"**Answer: **",
"_____no_output_____"
],
[
"### Implementation - Creating a Training and Predicting Pipeline\nTo properly evaluate the performance of each model you've chosen, it's important that you create a training and predicting pipeline that allows you to quickly and effectively train models using various sizes of training data and perform predictions on the testing data. Your implementation here will be used in the following section.\nIn the code block below, you will need to implement the following:\n - Import `fbeta_score` and `accuracy_score` from [`sklearn.metrics`](http://scikit-learn.org/stable/modules/classes.html#sklearn-metrics-metrics).\n - Fit the learner to the sampled training data and record the training time.\n - Perform predictions on the test data `X_test`, and also on the first 300 training points `X_train[:300]`.\n - Record the total prediction time.\n - Calculate the accuracy score for both the training subset and testing set.\n - Calculate the F-score for both the training subset and testing set.\n - Make sure that you set the `beta` parameter!",
"_____no_output_____"
]
],
[
[
"# TODO: Import two metrics from sklearn - fbeta_score and accuracy_score\n\ndef train_predict(learner, sample_size, X_train, y_train, X_test, y_test): \n '''\n inputs:\n - learner: the learning algorithm to be trained and predicted on\n - sample_size: the size of samples (number) to be drawn from training set\n - X_train: features training set\n - y_train: income training set\n - X_test: features testing set\n - y_test: income testing set\n '''\n \n results = {}\n \n # TODO: Fit the learner to the training data using slicing with 'sample_size' using .fit(training_features[:], training_labels[:])\n start = time() # Get start time\n learner = None\n end = time() # Get end time\n \n # TODO: Calculate the training time\n results['train_time'] = None\n \n # TODO: Get the predictions on the test set(X_test),\n # then get predictions on the first 300 training samples(X_train) using .predict()\n start = time() # Get start time\n predictions_test = None\n predictions_train = None\n end = time() # Get end time\n \n # TODO: Calculate the total prediction time\n results['pred_time'] = None\n \n # TODO: Compute accuracy on the first 300 training samples which is y_train[:300]\n results['acc_train'] = None\n \n # TODO: Compute accuracy on test set using accuracy_score()\n results['acc_test'] = None\n \n # TODO: Compute F-score on the the first 300 training samples using fbeta_score()\n results['f_train'] = None\n \n # TODO: Compute F-score on the test set which is y_test\n results['f_test'] = None\n \n # Success\n print(\"{} trained on {} samples.\".format(learner.__class__.__name__, sample_size))\n \n # Return the results\n return results",
"_____no_output_____"
]
],
[
[
"### Implementation: Initial Model Evaluation\nIn the code cell, you will need to implement the following:\n- Import the three supervised learning models you've discussed in the previous section.\n- Initialize the three models and store them in `'clf_A'`, `'clf_B'`, and `'clf_C'`.\n - Use a `'random_state'` for each model you use, if provided.\n - **Note:** Use the default settings for each model — you will tune one specific model in a later section.\n- Calculate the number of records equal to 1%, 10%, and 100% of the training data.\n - Store those values in `'samples_1'`, `'samples_10'`, and `'samples_100'` respectively.\n\n**Note:** Depending on which algorithms you chose, the following implementation may take some time to run!",
"_____no_output_____"
]
],
[
[
"# TODO: Import the three supervised learning models from sklearn\n\n# TODO: Initialize the three models\nclf_A = None\nclf_B = None\nclf_C = None\n\n# TODO: Calculate the number of samples for 1%, 10%, and 100% of the training data\n# HINT: samples_100 is the entire training set i.e. len(y_train)\n# HINT: samples_10 is 10% of samples_100 (ensure to set the count of the values to be `int` and not `float`)\n# HINT: samples_1 is 1% of samples_100 (ensure to set the count of the values to be `int` and not `float`)\nsamples_100 = None\nsamples_10 = None\nsamples_1 = None\n\n# Collect results on the learners\nresults = {}\nfor clf in [clf_A, clf_B, clf_C]:\n clf_name = clf.__class__.__name__\n results[clf_name] = {}\n for i, samples in enumerate([samples_1, samples_10, samples_100]):\n results[clf_name][i] = \\\n train_predict(clf, samples, X_train, y_train, X_test, y_test)\n\n# Run metrics visualization for the three supervised learning models chosen\nvs.evaluate(results, accuracy, fscore)",
"_____no_output_____"
]
],
[
[
"----\n## Improving Results\nIn this final section, you will choose from the three supervised learning models the *best* model to use on the student data. You will then perform a grid search optimization for the model over the entire training set (`X_train` and `y_train`) by tuning at least one parameter to improve upon the untuned model's F-score. ",
"_____no_output_____"
],
[
"### Question 3 - Choosing the Best Model\n\n* Based on the evaluation you performed earlier, in one to two paragraphs, explain to *CharityML* which of the three models you believe to be most appropriate for the task of identifying individuals that make more than \\$50,000. \n\n** HINT: ** \nLook at the graph at the bottom left from the cell above(the visualization created by `vs.evaluate(results, accuracy, fscore)`) and check the F score for the testing set when 100% of the training set is used. Which model has the highest score? Your answer should include discussion of the:\n* metrics - F score on the testing when 100% of the training data is used, \n* prediction/training time\n* the algorithm's suitability for the data.",
"_____no_output_____"
],
[
"**Answer: **",
"_____no_output_____"
],
[
"### Question 4 - Describing the Model in Layman's Terms\n\n* In one to two paragraphs, explain to *CharityML*, in layman's terms, how the final model chosen is supposed to work. Be sure that you are describing the major qualities of the model, such as how the model is trained and how the model makes a prediction. Avoid using advanced mathematical jargon, such as describing equations.\n\n** HINT: **\n\nWhen explaining your model, if using external resources please include all citations.",
"_____no_output_____"
],
[
"**Answer: ** ",
"_____no_output_____"
],
[
"### Implementation: Model Tuning\nFine tune the chosen model. Use grid search (`GridSearchCV`) with at least one important parameter tuned with at least 3 different values. You will need to use the entire training set for this. In the code cell below, you will need to implement the following:\n- Import [`sklearn.grid_search.GridSearchCV`](http://scikit-learn.org/0.17/modules/generated/sklearn.grid_search.GridSearchCV.html) and [`sklearn.metrics.make_scorer`](http://scikit-learn.org/stable/modules/generated/sklearn.metrics.make_scorer.html).\n- Initialize the classifier you've chosen and store it in `clf`.\n - Set a `random_state` if one is available to the same state you set before.\n- Create a dictionary of parameters you wish to tune for the chosen model.\n - Example: `parameters = {'parameter' : [list of values]}`.\n - **Note:** Avoid tuning the `max_features` parameter of your learner if that parameter is available!\n- Use `make_scorer` to create an `fbeta_score` scoring object (with $\\beta = 0.5$).\n- Perform grid search on the classifier `clf` using the `'scorer'`, and store it in `grid_obj`.\n- Fit the grid search object to the training data (`X_train`, `y_train`), and store it in `grid_fit`.\n\n**Note:** Depending on the algorithm chosen and the parameter list, the following implementation may take some time to run!",
"_____no_output_____"
]
],
[
[
"# TODO: Import 'GridSearchCV', 'make_scorer', and any other necessary libraries\n\n# TODO: Initialize the classifier\nclf = None\n\n# TODO: Create the parameters list you wish to tune, using a dictionary if needed.\n# HINT: parameters = {'parameter_1': [value1, value2], 'parameter_2': [value1, value2]}\nparameters = None\n\n# TODO: Make an fbeta_score scoring object using make_scorer()\nscorer = None\n\n# TODO: Perform grid search on the classifier using 'scorer' as the scoring method using GridSearchCV()\ngrid_obj = None\n\n# TODO: Fit the grid search object to the training data and find the optimal parameters using fit()\ngrid_fit = None\n\n# Get the estimator\nbest_clf = grid_fit.best_estimator_\n\n# Make predictions using the unoptimized and model\npredictions = (clf.fit(X_train, y_train)).predict(X_test)\nbest_predictions = best_clf.predict(X_test)\n\n# Report the before-and-afterscores\nprint(\"Unoptimized model\\n------\")\nprint(\"Accuracy score on testing data: {:.4f}\".format(accuracy_score(y_test, predictions)))\nprint(\"F-score on testing data: {:.4f}\".format(fbeta_score(y_test, predictions, beta = 0.5)))\nprint(\"\\nOptimized Model\\n------\")\nprint(\"Final accuracy score on the testing data: {:.4f}\".format(accuracy_score(y_test, best_predictions)))\nprint(\"Final F-score on the testing data: {:.4f}\".format(fbeta_score(y_test, best_predictions, beta = 0.5)))",
"_____no_output_____"
]
],
[
[
"### Question 5 - Final Model Evaluation\n\n* What is your optimized model's accuracy and F-score on the testing data? \n* Are these scores better or worse than the unoptimized model? \n* How do the results from your optimized model compare to the naive predictor benchmarks you found earlier in **Question 1**?_ \n\n**Note:** Fill in the table below with your results, and then provide discussion in the **Answer** box.",
"_____no_output_____"
],
[
"#### Results:\n\n| Metric | Unoptimized Model | Optimized Model |\n| :------------: | :---------------: | :-------------: | \n| Accuracy Score | | |\n| F-score | | EXAMPLE |\n",
"_____no_output_____"
],
[
"**Answer: **",
"_____no_output_____"
],
[
"----\n## Feature Importance\n\nAn important task when performing supervised learning on a dataset like the census data we study here is determining which features provide the most predictive power. By focusing on the relationship between only a few crucial features and the target label we simplify our understanding of the phenomenon, which is most always a useful thing to do. In the case of this project, that means we wish to identify a small number of features that most strongly predict whether an individual makes at most or more than \\$50,000.\n\nChoose a scikit-learn classifier (e.g., adaboost, random forests) that has a `feature_importance_` attribute, which is a function that ranks the importance of features according to the chosen classifier. In the next python cell fit this classifier to training set and use this attribute to determine the top 5 most important features for the census dataset.",
"_____no_output_____"
],
[
"### Question 6 - Feature Relevance Observation\nWhen **Exploring the Data**, it was shown there are thirteen available features for each individual on record in the census data. Of these thirteen records, which five features do you believe to be most important for prediction, and in what order would you rank them and why?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
],
[
"### Implementation - Extracting Feature Importance\nChoose a `scikit-learn` supervised learning algorithm that has a `feature_importance_` attribute availble for it. This attribute is a function that ranks the importance of each feature when making predictions based on the chosen algorithm.\n\nIn the code cell below, you will need to implement the following:\n - Import a supervised learning model from sklearn if it is different from the three used earlier.\n - Train the supervised model on the entire training set.\n - Extract the feature importances using `'.feature_importances_'`.",
"_____no_output_____"
]
],
[
[
"# TODO: Import a supervised learning model that has 'feature_importances_'\n\n\n# TODO: Train the supervised model on the training set using .fit(X_train, y_train)\nmodel = None\n\n# TODO: Extract the feature importances using .feature_importances_ \nimportances = None\n\n# Plot\nvs.feature_plot(importances, X_train, y_train)",
"_____no_output_____"
]
],
[
[
"### Question 7 - Extracting Feature Importance\n\nObserve the visualization created above which displays the five most relevant features for predicting if an individual makes at most or above \\$50,000. \n* How do these five features compare to the five features you discussed in **Question 6**?\n* If you were close to the same answer, how does this visualization confirm your thoughts? \n* If you were not close, why do you think these features are more relevant?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
],
[
"### Feature Selection\nHow does a model perform if we only use a subset of all the available features in the data? With less features required to train, the expectation is that training and prediction time is much lower — at the cost of performance metrics. From the visualization above, we see that the top five most important features contribute more than half of the importance of **all** features present in the data. This hints that we can attempt to *reduce the feature space* and simplify the information required for the model to learn. The code cell below will use the same optimized model you found earlier, and train it on the same training set *with only the top five important features*. ",
"_____no_output_____"
]
],
[
[
"# Import functionality for cloning a model\nfrom sklearn.base import clone\n\n# Reduce the feature space\nX_train_reduced = X_train[X_train.columns.values[(np.argsort(importances)[::-1])[:5]]]\nX_test_reduced = X_test[X_test.columns.values[(np.argsort(importances)[::-1])[:5]]]\n\n# Train on the \"best\" model found from grid search earlier\nclf = (clone(best_clf)).fit(X_train_reduced, y_train)\n\n# Make new predictions\nreduced_predictions = clf.predict(X_test_reduced)\n\n# Report scores from the final model using both versions of data\nprint(\"Final Model trained on full data\\n------\")\nprint(\"Accuracy on testing data: {:.4f}\".format(accuracy_score(y_test, best_predictions)))\nprint(\"F-score on testing data: {:.4f}\".format(fbeta_score(y_test, best_predictions, beta = 0.5)))\nprint(\"\\nFinal Model trained on reduced data\\n------\")\nprint(\"Accuracy on testing data: {:.4f}\".format(accuracy_score(y_test, reduced_predictions)))\nprint(\"F-score on testing data: {:.4f}\".format(fbeta_score(y_test, reduced_predictions, beta = 0.5)))",
"_____no_output_____"
]
],
[
[
"### Question 8 - Effects of Feature Selection\n\n* How does the final model's F-score and accuracy score on the reduced data using only five features compare to those same scores when all features are used?\n* If training time was a factor, would you consider using the reduced data as your training set?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
],
[
"> **Note**: Once you have completed all of the code implementations and successfully answered each question above, you may finalize your work by exporting the iPython Notebook as an HTML document. You can do this by using the menu above and navigating to \n**File -> Download as -> HTML (.html)**. Include the finished document along with this notebook as your submission.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a02cce45173f26fa77755adc1fbef36b6137175
| 68,549 |
ipynb
|
Jupyter Notebook
|
pocovidnet/notebooks/analysis/eval_cams.ipynb
|
ar-ambuj23/covid19_pocus_ultrasound
|
b926c4265c33674e6979172e2791b22fbf86d0da
|
[
"MIT"
] | 1 |
2022-03-08T07:48:32.000Z
|
2022-03-08T07:48:32.000Z
|
pocovidnet/notebooks/analysis/eval_cams.ipynb
|
ar-ambuj23/covid19_pocus_ultrasound
|
b926c4265c33674e6979172e2791b22fbf86d0da
|
[
"MIT"
] | null | null | null |
pocovidnet/notebooks/analysis/eval_cams.ipynb
|
ar-ambuj23/covid19_pocus_ultrasound
|
b926c4265c33674e6979172e2791b22fbf86d0da
|
[
"MIT"
] | null | null | null | 33.276214 | 198 | 0.530496 |
[
[
[
"# Class activation map evaluation",
"_____no_output_____"
]
],
[
[
"import cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport json\nimport os\nimport pandas as pd\nfrom pocovidnet.evaluate_covid19 import Evaluator\nfrom pocovidnet.grad_cam import GradCAM\nfrom pocovidnet.cam import get_class_activation_map\nfrom pocovidnet.model import get_model",
"_____no_output_____"
]
],
[
[
"## Code to crop ICLUS videos automatically",
"_____no_output_____"
]
],
[
[
"with open(os.path.join(\"../../../../data_pocovid/results_oct_wrong_crossval/iclus/\", 'ICLUS_cropping.json'), \"r\") as infile:\n frame_cut = json.load(infile)\n ",
"_____no_output_____"
],
[
"bottom = 70 # 90\ntop = 570 # 542\nleft = 470 # 480\nright = 970 # 932\n# [70:570, 470:970]\ncrop = [bottom, top, left, right]",
"_____no_output_____"
],
[
"data_dir = \"../../../data/ICLUS\"\nfor subfolder in os.listdir(data_dir):\n if \"linear\" in subfolder.lower() or subfolder.startswith(\".\") or not os.path.isdir(os.path.join(data_dir,subfolder)):\n continue\n for vid in os.listdir(os.path.join(data_dir, subfolder)):\n vid_id = vid.split(\".\")[0]\n if vid.startswith(\".\"):\n continue\n print(\"process next file \", vid)\n if vid_id not in [\"40\", \"42\"]: # frame_cut.keys():\n continue\n video_path = os.path.join(data_dir, subfolder, vid)\n crop = frame_cut[vid_id]\n while True:\n bottom, top, left, right = crop\n cap = cv2.VideoCapture(video_path)\n # count = 0\n # while cap.isOpened() and count< 1:\n for _ in range(3):\n ret, frame = cap.read()\n plt.imshow(frame[bottom:top, left:right])\n plt.show()\n crop_in = input(\"okay?\")\n if crop_in == 1 or crop_in ==\"1\":\n frame_cut[vid_id] = crop\n break\n crop_in = input(\"input list \" + str(crop))\n crop = eval(crop_in)\n print(crop)",
"_____no_output_____"
],
[
"# out_iclus_data = \"../results_oct/iclus\"\nwith open(os.path.join(data_dir, 'ICLUS_cropping.json'), \"w\") as outfile:\n json.dump(frame_cut, outfile)",
"_____no_output_____"
]
],
[
[
"### ICLUS Auswertung:",
"_____no_output_____"
]
],
[
[
"severity = pd.read_csv(\"../../../data/iclus_severity.csv\", delimiter=\";\")",
"_____no_output_____"
],
[
"convex_table = severity[severity[\"filename\"].str.contains(\"convex\")]\nconvex_vids = convex_table[\"Video\"]",
"_____no_output_____"
],
[
"# Make list of IDs that we analyze\ndata_dir = \"../../../data/ICLUS\"\nprocess_vid_numbers = []\nfor subfolder in os.listdir(data_dir):\n if \"linear\" in subfolder.lower() or subfolder.startswith(\".\") or os.path.isfile(os.path.join(data_dir,subfolder)):\n continue\n for vid in os.listdir(os.path.join(data_dir, subfolder)):\n vid_id = vid.split(\".\")[0]\n if vid.startswith(\".\"):\n continue\n video_path = os.path.join(data_dir, subfolder, vid)\n \n # print(int(vid.split(\".\")[0]) in convex_vids)\n process_vid_numbers.append(int(vid.split(\".\")[0]) )",
"_____no_output_____"
],
[
"# Check whether we cover all videos\nfor vid in convex_vids.values:\n if vid not in process_vid_numbers:\n print(\"In ICLUS tabelle but not in our folder:\", vid)\n if str(vid) not in frame_cut.keys():\n print(\"not in crop dict:\", vid)\nfor vid in process_vid_numbers:\n if vid not in convex_vids.values:\n print(\"In our folder but not in ICLUS:\", vid)",
"_____no_output_____"
],
[
"# Make label dict:\niclus_labels = dict(zip(convex_table[\"Video\"], convex_table[\"Score\"]))",
"_____no_output_____"
],
[
"in_path = os.path.join(res_dir, f\"cam_{vid_id}.npy\")\nos.path.exists(in_path)",
"_____no_output_____"
]
],
[
[
"### Analyze results",
"_____no_output_____"
]
],
[
[
"# 6 normal (Gabriel, but here 1), 25 normal (Gabriel), but here 3\niclus_labels",
"_____no_output_____"
],
[
"# directory with numpy files\nlen(iclus_labels.keys())",
"_____no_output_____"
],
[
"res_dir = \"../../../../data_pocovid/results_oct_wrong_crossval/iclus/base\"\ngt, preds, pred_probs = list(), list(), list()\nprint(\"gt pred\")\nfor vid_id in iclus_labels.keys():\n in_path = os.path.join(res_dir, f\"cam_{vid_id}.npy\")\n if not os.path.exists(in_path):\n print(\"Warning: logits do not exist\", in_path)\n continue\n logits = np.load(in_path)\n prob = np.mean(logits[:, 0])\n avg_covid_prob = np.argmax(np.mean(logits, axis=0)) # \n # print(avg_covid_prob)\n gt.append(iclus_labels[vid_id])\n pred_probs.append(prob)\n preds.append(avg_covid_prob)\n if iclus_labels[vid_id]>2 and avg_covid_prob==2 or iclus_labels[vid_id]==0 and avg_covid_prob==0:\n print(\"wrong, severity is \", iclus_labels[vid_id], \"pred is\", avg_covid_prob,\"video:\", vid_id)\n # print(gt[-1], preds[-1])",
"_____no_output_____"
],
[
"plt.scatter(gt, pred_probs)\nplt.plot([0,3], [0,1])\nplt.show()",
"_____no_output_____"
],
[
"check = \"../../models/cross_validation_neurips/\"\nfile_list = list()\nfor folder in os.listdir(check):\n if folder[0] == \".\":\n continue\n for classe in os.listdir(os.path.join(check, folder)):\n if classe[0] == \".\" or classe[0] == \"u\":\n continue\n uni = []\n is_image = 0\n for file in os.listdir(os.path.join(check, folder, classe)):\n if file[0] == \".\":\n continue\n if len(file.split(\".\")) == 2:\n is_image += 1\n uni.append(file.split(\".\")[0])\n file_list.extend(np.unique(uni).tolist())\n",
"_____no_output_____"
],
[
"with open(\"../../models/in_neurips.json\", \"w\") as outfile:\n json.dump(file_list, outfile)",
"_____no_output_____"
]
],
[
[
"### Old video evaluator",
"_____no_output_____"
]
],
[
[
"from skvideo import io",
"_____no_output_____"
],
[
"class VideoEvaluator(Evaluator):\n def __init__(self, weights_dir=\"../trained_models_cam\", ensemble=True, split=None, model_id=None, num_classes=3):\n Evaluator.__init__(\n self, ensemble=ensemble, split=split, model_id=model_id, num_classes=num_classes\n )\n \n def __call__(self, video_path):\n \"\"\"Performs a forward pass through the restored model\n\n Arguments:\n video_path: str -- file path to a video to process. Possibly types are mp4, gif, mpeg\n return_cams: int -- number of frames to return with activation maps overlayed. If zero, \n\t\t\t\t\t\tonly the predictions will be returned. Always selects the frames with \n highest probability for the predicted class\n\n Returns:\n \tcams: if return_cams>0, images with overlay are returned as a np.array of shape\n \t\t{number models} x {return_cams} x 224 x 224 x 3\n mean_preds: np array of shape {video length} x {number classes}. Contains\n \t\t\tclass probabilities per frame\n \"\"\"\n\n self.image_arr = self.read_video(video_path)\n self.predictions = np.stack([model.predict(self.image_arr) for model in self.models])\n \n mean_preds = np.mean(self.predictions, axis=0, keepdims=False)\n class_idx = np.argmax(np.mean(np.array(mean_preds), axis=0))\n \n return mean_preds\n \n def cam_important_frames(self, class_idx, threshold=0.5, nr_cams=None, zeroing=0.65, save_video_path=None): # \"out_video.mp4\"):\n mean_preds = np.mean(self.predictions, axis=0, keepdims=False)\n # compute general video class\n # class_idx = np.argmax(np.mean(np.array(mean_preds), axis=0))\n prediction = np.argmax(np.mean(np.array(mean_preds), axis=0))\n print(\"predicted\", prediction, \"gt\", class_idx)\n print(\"pred probs covid\", [round(m, 2) for m in mean_preds[:,0]])\n # get most important frames (the ones above threshold)\n if nr_cams is not None:\n best_frames = np.argsort(mean_preds[:, class_idx])[-nr_cams:]\n else:\n best_frames = np.where(mean_preds[:, class_idx]>threshold)[0]\n # best_frames = np.arange(len(mean_preds))\n print(\"frames above threshold\", best_frames)\n return_cams = len(best_frames)\n\n if len(best_frames)==0:\n print(\"no frame above threshold\")\n return 0\n \n # copy image arr - need values between 0 and 255\n copied_arr = (self.image_arr.copy() * 255).astype(int)\n\n cams = np.zeros((return_cams, 224, 224, 3))\n for j, b_frame in enumerate(best_frames):\n # get highest prob model for these frames\n model_idx = np.argmax(self.predictions[:, b_frame, class_idx], axis=0)\n take_model = self.models[model_idx]\n if \"cam\" in self.model_id:\n in_img = np.expand_dims(self.image_arr[b_frame], 0)\n # print(in_img.shape)\n cams[j] = get_class_activation_map(take_model, in_img, class_idx, image_weight=1, zeroing=zeroing).astype(int)\n else:\n # run grad cam for other models\n gradcam = GradCAM()\n cams[j] = gradcam.explain(self.image_arr[b_frame], take_model, class_idx, return_map=False,image_weight=1, layer_name=\"block5_conv3\", zeroing=zeroing, heatmap_weight=0.25)\n \n if save_video_path is None:\n return cams\n else:\n for j in range(return_cams):\n copied_arr[best_frames[j]] = cams[j]\n copied_arr = np.repeat(copied_arr, 3, axis=0)\n io.vwrite(save_video_path+\".mpeg\", copied_arr, outputdict={\"-vcodec\":\"mpeg2video\"})\n \n def read_video(self, video_path):\n assert os.path.exists(video_path), \"video file not found\"\n \n cap = cv2.VideoCapture(video_path)\n images = []\n counter = 0\n while cap.isOpened():\n ret, frame = cap.read()\n if (ret != True):\n break\n if counter<1:\n plt.imshow(frame[30:360, 100:430]) # ICLUS: [70:570, 470:970]) # [25:350, 100:425]) # LOTTE:[30:400, 80:450]\n plt.show()\n counter += 1\n continue\n counter += 1\n img_processed = self.preprocess(frame)[0]\n images.append(img_processed)\n cap.release()\n return np.array(images)\n \n def preprocess(self, image, cut=True):\n \"\"\"Apply image preprocessing pipeline\n\n Arguments:\n image {np.array} -- Arbitrary shape, quadratic preferred\n\n Returns:\n np.array -- Shape 224,224. Normalized to [0, 1].\n \"\"\"\n if cut:\n image = image[30:360, 100:430]\n image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n image = cv2.resize(image, (224, 224))\n image = np.expand_dims(np.array(image), 0) / 255.0\n return image\n \n def important_frames(self, preds, predicted_class, n_return=5):\n preds_arr = np.array(preds)\n frame_scores = preds_arr[:, predicted_class]\n best_frames = np.argsort(frame_scores)[-n_return:]\n return best_frames",
"_____no_output_____"
],
[
"evaluator = VideoEvaluator(ensemble=True, model_id=\"vgg_cam\", num_classes=4)",
"_____no_output_____"
]
],
[
[
"### Run ICLUS data",
"_____no_output_____"
]
],
[
[
"def pred_plot(preds, save_path):\n plt.figure(figsize=(15,8))\n plt.plot(preds[:,0], label=\"covid\")\n plt.plot(preds[:,1], label=\"pneu\")\n plt.plot(preds[:,2], label=\"healthy\")\n plt.legend()\n plt.savefig(save_path+\".png\")\n plt.show()\n# plt.plot(preds[:,1], label=\"pneu\")",
"_____no_output_____"
],
[
"# iclus_dir = \"Videos_31_to_40\"\niclus_dir = \"test_data_regular/pat2\"\n# iclus_dir = \"data/pocus_videos/convex/\"\n# out_iclus_data = \"vids_preds_regular_test\"\n# out_iclus_data = \"vids_preds_iclus\"\nout_iclus_data = \"reg_test/pat2\"\nGT_CLASS = 2",
"_____no_output_____"
],
[
"for vid in os.listdir(iclus_dir):\n vid_id = vid.split(\".\")[0]\n if vid.startswith(\".\") or os.path.exists(os.path.join(out_iclus_data,\"cam_\"+vid_id+\".npy\")):\n print(\"already done\", vid)\n continue\n print(\"process next file \", vid)\n preds = evaluator(os.path.join(iclus_dir, vid))\n np.save(os.path.join(out_iclus_data,\"cam_\"+vid_id+\".npy\"), preds)\n plt.imshow(evaluator.image_arr[0])\n plt.savefig(os.path.join(out_iclus_data,\"cam_\"+vid_id+\"expl_img.png\"))\n print(\"saved predictions\")\n pred_plot(preds, os.path.join(out_iclus_data,\"cam_\"+vid_id))\n print(\"saved plot\")\n evaluator.cam_important_frames(GT_CLASS, save_video_path=os.path.join(out_iclus_data, \"cam_\"+vid_id))",
"_____no_output_____"
]
],
[
[
"#### ICLUS notes:\n\n47 falsch predicted aber passt\nschaut weird aus: 48, 49, 50 (linear or what is this? alle als healthy predicted)\nMust do again: 36\n\n13, 11, 31, 32: linear probes that are deleted, 22, 24, 26 (they are all kept), 28\n\n12, 15, 16, 17, 18, 19, 20 were fine already with bad cropping\n1, 3, 9, 10 is fine already\n\nNEW PROCESSED: 14, 8, 7, 6, 4, 5, 2\n\nCODE TO PROCESS SOME AGAIN:\nif os.path.exists(\"vids_preds_iclus/cam_vid\"+vid_id+\".npy\"):\n preds_prev = np.load(\"vids_preds_iclus/cam_vid\"+vid_id+\".npy\")\n predicted_class = np.argmax(np.mean(np.array(preds_prev), axis=0))\n print(predicted_class, np.mean(np.array(preds_prev), axis=0))\n if predicted_class==0:\n print(\"file is already predicted covid\", vid)\n continue",
"_____no_output_____"
],
[
"### Evaluate on train data",
"_____no_output_____"
]
],
[
[
"vid_in_path = \"../../data/pocus_videos/Convex/\"",
"_____no_output_____"
],
[
"gt_dict = {\"Cov\":0, \"Reg\":2, \"Pne\":1, \"pne\":1}\nout_path=\"vid_outputs_cam\"\nfor vid in os.listdir(vid_in_path):\n if vid[:3] not in [\"Pne\", \"pne\", \"Cov\", \"Reg\"]:\n print(vid)\n continue\n if os.path.exists(os.path.join(out_path, vid.split(\".\")[0]+\".mpeg\")):\n print(\"already done\", vid)\n continue\n vid_in = os.path.join(vid_in_path, vid)\n print(vid_in)\n preds = evaluator(vid_in)\n gt = gt_dict[vid[:3]]\n evaluator.cam_important_frames(gt, save_video_path=os.path.join(out_path, vid.split(\".\")[0]))",
"_____no_output_____"
]
],
[
[
"### Evaluate on test data",
"_____no_output_____"
]
],
[
[
"out_path_overall=\"vid_outputs_cam_test/\"\npath_crossval = \"../../data/cross_validation\"\nper_split = [[] for _ in range(5)]\nfor fold in range(5):\n out_path = os.path.join(out_path_overall, \"fold\"+str(fold))\n # load weights of the respective fold model\n print(\"NEW FOLD\", fold)\n # make sure the variable is cleared\n evaluator = None\n # load weights\n evaluator = VideoEvaluator(ensemble=False, split=fold, model_id=\"vgg_cam\", num_classes=4)\n # get all names belonging to this fold\n vidnames = []\n for mod in [\"covid\", \"pneumonia\", \"regular\"]:\n for f in os.listdir(os.path.join(path_crossval, \"split\"+str(fold), mod)):\n if f[0]!=\".\":\n fparts = f.split(\".\")\n vidnames.append(fparts[0]+\".\"+fparts[1][:3])\n # iterate over the relevant files\n names = np.unique(vidnames)\n for name in names:\n if name[-3:] in [\"mp4\", \"mov\", \"gif\"]:\n print(name)\n vid_in = os.path.join(vid_in_path, name)\n if not os.path.exists(vid_in):\n print(\"does not exist! - butterfly?\", vid_in)\n continue\n if os.path.exists(os.path.join(out_path, name.split(\".\")[0]+\".mpeg\")):\n print(\"already done\", name)\n continue\n print(vid_in)\n preds = evaluator(vid_in)\n gt = gt_dict[name[:3]]\n evaluator.cam_important_frames(gt, save_video_path=os.path.join(out_path, name.split(\".\")[0]))",
"_____no_output_____"
]
],
[
[
"## Make point plot for CAMs",
"_____no_output_____"
]
],
[
[
"def max_kernel(heatmap, kernel_size=9):\n k2 = kernel_size//2\n # pad array\n arr = np.pad(heatmap, ((k2,k2),(k2,k2)), 'constant', constant_values=0)\n # get coordinates of maximum\n x_coords, y_coords = divmod(np.argmax(arr.flatten()), len(arr[0])) \n patch = arr[x_coords-k2:x_coords+k2+1, y_coords-k2:y_coords+k2+1]\n # print(x_coords, y_coords)\n # plt.imshow(arr)\n # plt.show()\n res_out = np.zeros((kernel_size-2,kernel_size-2))\n for i in range(kernel_size-2):\n for j in range(kernel_size-2):\n res_out[i,j] = np.mean(patch[i:i+3, j:j+3])\n max_x, max_y = divmod(np.argmax(res_out.flatten()), kernel_size-2)\n # print(max_x, max_y)\n # print(x_coords+max_x-k2+1, y_coords+max_y-k2+1)\n # plt.imshow(res_out)\n # plt.show()\n return x_coords+max_x-2*k2+1, y_coords+max_y-2*k2+1\n# max_kernel((np.random.rand(10,10)*20).astype(int))\n\ndef convolve_faster(img, kernel):\n \"\"\"\n Convolve a 2d img with a kernel, storing the output in the cell\n corresponding the the left or right upper corner\n :param img: 2d numpy array\n :param kernel: kernel (must have equal size and width)\n :param neg: if neg=0, store in upper left corner, if neg=1,\n store in upper right corner\n :return convolved image of same size\n \"\"\"\n k_size = len(kernel)\n # a = np.pad(img, ((0, k_size-1), (0, k_size-1)))\n padded = np.pad(img, ((k_size//2, k_size//2), (k_size//2, k_size//2)))\n\n s = kernel.shape + tuple(np.subtract(padded.shape, kernel.shape) + 1)\n strd = np.lib.stride_tricks.as_strided\n subM = strd(padded, shape=s, strides=padded.strides * 2)\n return np.einsum('ij,ijkl->kl', kernel, subM)\n\n# in_img = np.random.rand(20,20)\n# plt.imshow(in_img)\n# plt.show()\n# out = convolve_faster(in_img, np.ones((7,7)))\n# plt.imshow(out)\n# plt.show()\n# print(in_img.shape, out.shape)",
"_____no_output_____"
]
],
[
[
"### Process all test data",
"_____no_output_____"
]
],
[
[
"path_crossval = \"../../data/cross_validation\"\ngt_dict = {\"Reg\":2, \"Pne\":1, \"pne\":1, \"Cov\":0}\n\ngradcam = GradCAM()\n\nall_predictions = []\nheatmap_points, predicted, gt_class, overlays, fnames = [], [], [], [], []\n\nfor fold in range(5):\n # load weights of the respective fold model\n print(\"NEW FOLD\", fold)\n # make sure the variable is cleared\n evaluator = None\n # load weights\n evaluator = Evaluator(ensemble=False, split=fold, model_id=\"vgg_base\", num_classes=4)\n # get all names belonging to this fold\n all_images_arr = []\n gt, name = [], []\n for mod in [\"covid\", \"pneumonia\", \"regular\"]:\n for f in os.listdir(os.path.join(path_crossval, \"split\"+str(fold), mod)):\n if f[0]!=\".\":\n # fparts = f.split(\".\")\n # vidnames.append(fparts[0]+\".\"+fparts[1][:3])\n img_loaded = cv2.imread(os.path.join(path_crossval, \"split\"+str(fold), mod, f))\n img_preprocc = evaluator.preprocess(img_loaded)[0]\n gt.append(gt_dict[f[:3]])\n all_images_arr.append(img_preprocc)\n name.append(f)\n all_images_arr = np.array(all_images_arr)\n # get predictions\n print(\"process all images in fold\", fold, \"with shape\", all_images_arr.shape)\n fold_preds = evaluator.models[0].predict(all_images_arr)\n class_idx_per_img = np.argmax(fold_preds, axis=1)\n all_predictions.append(fold_preds)\n \n # get heatmap \n for i, img in enumerate(all_images_arr):\n # plt.imshow(img)\n # plt.show()\n # overlay, heatmap = get_class_activation_map(evaluator.models[0], img, gt[i], image_weight=1, return_map=True, zeroing=0.65)\n overlay, heatmap = gradcam.explain(img, evaluator.models[0], gt[i], return_map=True, image_weight=1, layer_name=\"block5_conv3\", zeroing=0.65, heatmap_weight=0.25) \n # plt.figure(figsize=(10,10))\n # plt.imshow(overlay.astype(int))\n # plt.show()\n overlays.append(overlay.astype(int))\n # convolve with big kernel\n convolved_overlay = convolve_faster(heatmap, np.ones((19,19)))\n # print(\"previously:\", divmod(np.argmax(heatmap.flatten()), len(heatmap[0])))\n x_coord, y_coord = divmod(np.argmax(convolved_overlay.flatten()), len(convolved_overlay[0]))\n ## previous version: 9x9 umkreis and 3x3 kernel\n # x_coord, y_coord = max_kernel(heatmap) # np.where(heatmap==np.max(heatmap))\n # print(x_coord, y_coord)\n heatmap_points.append([x_coord, y_coord])\n predicted.append(class_idx_per_img[i])\n gt_class.append(gt[i])\n fnames.append(name[i])\n # print([x_coord, y_coord], class_idx_per_img[i], gt[i])",
"_____no_output_____"
],
[
"len(predicted), len(gt_class), len(heatmap_points), np.asarray(overlays).shape",
"_____no_output_____"
],
[
"np.where(np.asarray(predicted)==3)",
"_____no_output_____"
],
[
"hm_p = np.array(heatmap_points)\nprint(hm_p.shape)\n# plt.figure(figsize=(20,20))\nplt.imshow(overlays[1])\nplt.scatter(hm_p[:,1], hm_p[:,0], c=predicted)\nplt.show()",
"_____no_output_____"
],
[
"hm_p = np.array(heatmap_points)\nprint(hm_p.shape)\n# plt.figure(figsize=(20,20))\nplt.imshow(overlays[1])\nplt.scatter(hm_p[:,1], hm_p[:,0], c=predicted)\nplt.show()",
"_____no_output_____"
],
[
"df = pd.DataFrame()\ndf[\"file\"] = fnames\ndf[\"predicted\"] = predicted\ndf[\"gt\"] = gt_class\ndf[\"max_x\"] = np.asarray(heatmap_points)[:,0].tolist()\ndf[\"max_y\"] = np.asarray(heatmap_points)[:,1].tolist()",
"_____no_output_____"
],
[
"df.to_csv(\"heatmap_points_grad.csv\")",
"_____no_output_____"
],
[
"np.save(\"overlayed_hm.npy\", overlays)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
]
],
[
[
"## ICLUS evaluation",
"_____no_output_____"
]
],
[
[
"# out_iclus_data = \"vids_preds_regular_test\"\nout_iclus_data = \"vids_preds_iclus\"",
"_____no_output_____"
],
[
"all_class_preds = []\ncorrect_frames = 0\nwrong_frames = 0\navg_corr_frames = []\nall_frames = 0\n# plt.figure(figsize=(20,10))\nfor f in os.listdir(out_iclus_data):\n if f[-3:]==\"npy\":\n preds = np.load(os.path.join(out_iclus_data, f))\n # plt.plot(preds[:,0])\n # print(preds.shape)\n # frame based\n frame_pred = np.argmax(preds, axis=1)\n all_frames += len(frame_pred)\n correct_frames += np.sum(frame_pred==0)\n wrong_frames += np.sum(frame_pred!=0)\n avg_corr_frames.append(np.sum(frame_pred==0)/len(frame_pred))\n # video classification - majority vote\n uni, counts = np.unique(frame_pred, return_counts=True)\n # all_class_preds.append(uni[np.argmax(counts)])\n # version with probabilities and not majority vote:\n vid_class_pred = np.argmax(np.mean(preds, axis=0))\n all_class_preds.append(vid_class_pred)\n if all_class_preds[-1]!=0:\n print(\"wrongly classified\", f)\n \n# print(wrong_frames+ correct_frames, all_frames)\nprint(\"Included in total ICLUS videos (without linear probes):\", len(all_class_preds))\nassert all_frames==wrong_frames+correct_frames\nprint(\"Frame accuracy:\", correct_frames/float(all_frames))\nprint(\"video class accuracy (max avg probability): \", np.sum(np.array(all_class_preds)==0)/len(all_class_preds))\nprint(\"Mean and std of ratio of correctly classified frames per video:\", np.mean(avg_corr_frames), np.std(avg_corr_frames))\n# plt.show()",
"_____no_output_____"
],
[
"iclus_preds = all_class_preds",
"_____no_output_____"
]
],
[
[
"## Evaluation Lotte's test data",
"_____no_output_____"
]
],
[
[
"reg_test_data = \"vid_outputs_REGULAR\"\nall_class_preds = []\ncorrect_frames = 0\nwrong_frames = 0\navg_corr_frames = []\nall_frames = 0\n# plt.figure(figsize=(20,10))\nfor subdir in os.listdir(reg_test_data):\n if subdir[0]==\".\":\n continue\n print(subdir)\n for f in os.listdir(os.path.join(reg_test_data, subdir)):\n if f[-3:]==\"npy\":\n preds = np.load(os.path.join(reg_test_data, subdir, f))\n print(os.path.join(reg_test_data, subdir, f))\n # print(preds.shape)\n # frame based\n frame_pred = np.argmax(preds, axis=1)\n all_frames += len(frame_pred)\n correct_frames += np.sum(frame_pred==2)\n wrong_frames += np.sum(frame_pred!=2)\n avg_corr_frames.append(np.sum(frame_pred==2)/len(frame_pred))\n # video classification - majority vote\n \n vid_class_pred = np.argmax(np.mean(preds, axis=0))\n all_class_preds.append(vid_class_pred)\n # print(frame_pred)\n if all_class_preds[-1]!=2:\n print(\"wrongly classified\", f)\n # version with probabilities and not majority vote:\n # vid_class_pred = np.argmax(np.mean(preds, axis=0))\n # all_class_preds.append(vid_class_pred)\n# print(wrong_frames+ correct_frames, all_frames)\nprint(\"Included in total ICLUS videos (without linear probes):\", len(all_class_preds))\nassert all_frames==wrong_frames+correct_frames\nprint(\"Frame accuracy:\", correct_frames/float(all_frames))\nprint(\"video class accuracy (max avg probability): \", np.sum(np.array(all_class_preds)==2)/len(all_class_preds))\nprint(\"Mean and std of ratio of correctly classified frames per video:\", np.mean(avg_corr_frames), np.std(avg_corr_frames))\n# plt.show()",
"_____no_output_____"
],
[
"reg_preds = all_class_preds",
"_____no_output_____"
],
[
"# sensitivity of both together\nall_gt = np.asarray([1 for _ in range(len(iclus_preds))] + [0 for _ in range(len(reg_preds))])\nall_preds = np.asarray(iclus_preds + reg_preds)\nall_preds = np.absolute(all_preds/2 - 1).astype(int)\nprint(all_preds)\nprint(len(all_preds), len(all_gt))\nprint(recall_score(all_gt, all_preds))\nprint(precision_score(all_gt, all_preds))",
"_____no_output_____"
],
[
"from sklearn.metrics import recall_score, precision_score, accuracy_score",
"_____no_output_____"
],
[
"accuracy_score(all_gt, all_preds)",
"_____no_output_____"
]
],
[
[
"## MD comments evaluation",
"_____no_output_____"
],
[
"### Read in and merge",
"_____no_output_____"
]
],
[
[
"mapping = pd.read_csv(\"mapping.csv\").drop(columns=[\"Unnamed: 0\"])",
"_____no_output_____"
],
[
"gb_comments = pd.read_csv(\"CAM_scores_GB.csv\")\ngb_comments = gb_comments.drop([0,1])\nlotte_comments = pd.read_csv(\"CAM_scores_lotte.csv\")",
"_____no_output_____"
],
[
"lotte_comments = lotte_comments.rename(columns={'Score - how helpful is the heatmap (0=only distracting, 5=very helpful)': 'lotte_score', \n 'Better one (put 1 if this one is the better one)': \"lotte_better\",\n 'Class (Your guess)': 'lotte_class',\n 'Patterns that can be seen':'lotte_patterns',\n 'Patterns the heatmap highlights':'lotte_heatmap_patterns'}).drop(columns=[\"Unnamed: 6\"])\ngb_comments = gb_comments.rename(columns={'Score - how helpful is the heatmap (0=only distracting, 5=very helpful)': 'gb_score', \n 'Better one (put 1 if this one is the better one)': \"gb_better\",\n 'Class (Your guess)': 'gb_class',\n 'Patterns that can be seen':'gb_patterns',\n 'Patterns the heatmap highlights':'gb_heatmap_patterns'})",
"_____no_output_____"
],
[
"lotte_comments['lotte_score'] = lotte_comments['lotte_score'].apply(lambda x: x-3 + int(x>=3))",
"_____no_output_____"
],
[
"merge_map_gb = pd.merge(mapping, gb_comments, how=\"inner\", left_on=\"new_filename\", right_on=\"Filename\")\nmerge_map_lotte = pd.merge(merge_map_gb, lotte_comments, how=\"inner\", left_on=\"new_filename\", right_on=\"Filename\")",
"_____no_output_____"
],
[
"merge_map_lotte.to_csv(\"CAM_scores_MDs.csv\")",
"_____no_output_____"
]
],
[
[
"### Clean",
"_____no_output_____"
]
],
[
[
"final_table.columns",
"_____no_output_____"
],
[
"# after manual cleaning:\nfinal_table = pd.read_csv(\"CAM_scores_MDs.csv\")",
"_____no_output_____"
],
[
"train_score_gb = 0\ntest_score_gb = 0\ntrain_score_lo = 0\ntest_score_lo = 0\ntrain_better_gb = []\ntrain_better_lo = []\nfor group_name, group_df in final_table.groupby(\"previous_filename\"):\n print(\"--------\")\n print(group_df[[\"gb_better\", \"lotte_better\", \"is_train\"]])\n if np.all(pd.isnull(group_df[\"gb_better\"])) or len(np.where(group_df[\"gb_better\"].values==\"1\")[0])==0:\n train_score_gb += 0.5\n test_score_gb += 0.5\n print(\"gb: equally good\")\n train_better_gb.append(0.5)\n else:\n # if len(np.where(group_df[\"gb_better\"].values==\"1\")[0])==0:\n # raise RuntimeError(\"no valid value found\")\n if np.where(group_df[\"gb_better\"].values==\"1\")==np.where(group_df[\"is_train\"].values==1):\n print(\"gb: train better\")\n train_score_gb += 1\n train_better_gb.append(1)\n else:\n test_score_gb += 1\n train_better_gb.append(0)\n print(\"gb: test better\")\n # get lotte score\n if np.all(pd.isnull(group_df[\"lotte_better\"])):\n train_score_gb += 0.5\n test_score_gb += 0.5\n train_better_lo.append(0.5)\n print(\"lotte: equally good\")\n else:\n if len(np.where(group_df[\"lotte_better\"].values==1)[0])==0:\n raise RuntimeError(\"no valid value found\")\n if np.where(group_df[\"lotte_better\"].values==1)==np.where(group_df[\"is_train\"].values==1):\n print(\"lotte: train better\")\n train_score_lo += 1\n train_better_lo.append(1)\n else:\n test_score_lo += 1\n train_better_lo.append(0)\n print(\"lotte: test better\")\n \n for i, row in group_df.iterrows():\n if int(row[\"is_train\"])==1:\n print(row[\"gb_better\"], row[\"lotte_better\"], row[\"is_train\"])\n # gb_scores = group_df[\"gb_better\"]\n # lotte_scores = group_df[\"lotte_better\"]\n # train_test = group_df[\"is_train\"]\n ",
"_____no_output_____"
],
[
"len(train_better_lo), len(train_better_gb)",
"_____no_output_____"
],
[
"better_arr = np.swapaxes(np.stack([train_better_lo, train_better_gb]), 1, 0)",
"_____no_output_____"
],
[
"agree = np.sum(better_arr[:,0]==better_arr[:,1])\nprint(\"agreement (both exactly same)\", agree/len(better_arr))\nprint(\"disagreement (one 1 one 0)\", len(np.where(np.absolute(better_arr[:,0]-better_arr[:,1])==1)[0])/len(better_arr))",
"_____no_output_____"
],
[
"print(\"average score for train better:\", np.mean(train_better_lo), np.mean(train_better_gb))",
"_____no_output_____"
],
[
"print(\"numbers unique\",np.unique(train_better_lo, return_counts=True), np.unique(train_better_gb, return_counts=True))",
"_____no_output_____"
]
],
[
[
"#### Evaluate scores - Add label",
"_____no_output_____"
]
],
[
[
"label = [val[:3].lower() for val in final_table[\"previous_filename\"].values]",
"_____no_output_____"
],
[
"np.unique(label, return_counts=True)",
"_____no_output_____"
],
[
"np.mean(final_table[final_table[\"is_train\"]==0][\"gb_score\"])",
"_____no_output_____"
],
[
"final_table[\"label\"] = label",
"_____no_output_____"
]
],
[
[
"#### Get average score of Lotte and Gabriel together",
"_____no_output_____"
]
],
[
[
"only_test = final_table[final_table[\"is_train\"]==0]\nall_scores = only_test[\"gb_score\"].values.tolist() + only_test[\"lotte_score\"].values.tolist()\nprint(\"Mean score lotte and gabriel together (test):\", np.mean(all_scores))\n# other method: average per video scores first:\nmean_scores = 0.5* (only_test[\"gb_score\"].values + only_test[\"lotte_score\"].values)\nprint(\"Mean score lotte and gabriel together (test) - other method:\", np.mean(mean_scores))\nprint(np.vstack([only_test[\"gb_score\"].values, only_test[\"lotte_score\"].values]))",
"_____no_output_____"
],
[
"only_test[\"mean_scores\"] = mean_scores.tolist()",
"_____no_output_____"
],
[
"only_test.groupby(\"label\").agg({\"mean_scores\":\"mean\"})",
"_____no_output_____"
]
],
[
[
"#### Test whether test better train significant",
"_____no_output_____"
]
],
[
[
"from scipy.stats import ttest_ind, ttest_rel, wilcoxon, mannwhitneyu",
"_____no_output_____"
],
[
"only_train = final_table[final_table[\"is_train\"]==1]\nall_train_scores = only_train[\"gb_score\"].values.tolist() + only_train[\"lotte_score\"].values.tolist()\nonly_test = final_table[final_table[\"is_train\"]==0]\nall_test_scores = only_test[\"gb_score\"].values.tolist() + only_test[\"lotte_score\"].values.tolist()\nprint(\"means\", np.mean(all_train_scores), np.mean(all_test_scores))\n\nprint(\"Ttest ind:\", ttest_ind(all_train_scores,all_test_scores, equal_var=False))\nprint(\"ttest related:\", ttest_rel(all_train_scores,all_test_scores))\nprint(\"Wilcoxon:\", wilcoxon(all_train_scores,all_test_scores))\nprint(\"mannwhitneyu\", mannwhitneyu(all_train_scores,all_test_scores))\n# Ttest related\n# Examples for use are scores of the same set of student in different exams, \n# or repeated sampling from the same units. The test measures whether the average score\n# differs significantly across samples (e.g. exams). If we observe a large p-value, for\n# example greater than 0.05 or 0.1 then we cannot reject the null hypothesis of identical average scores",
"_____no_output_____"
],
[
"print(len(all_train_scores), len(all_test_scores))\nplt.scatter(range(len(all_test_scores)), all_test_scores)\nplt.scatter(range(len(all_train_scores)), all_train_scores)",
"_____no_output_____"
]
],
[
[
"#### Grouped for separate scores",
"_____no_output_____"
]
],
[
[
"\nonly_test = final_table[final_table[\"is_train\"]==0]\ngrouped = only_test.groupby(\"label\").agg({\"lotte_score\":\"mean\", \"gb_score\":\"mean\"})\ngrouped",
"_____no_output_____"
],
[
"only_test = only_test.fillna(\"none\")",
"_____no_output_____"
],
[
"gb_all_with_consolidations = only_test[only_test[\"gb_patterns\"].str.contains(\"onsolida\")]\nprint(\"number of videos with consolidations\", len(gb_all_with_consolidations))\nprint(\"GB heatmap highlights consolidation\", len(gb_all_with_consolidations[gb_all_with_consolidations[\"gb_heatmap_patterns\"].str.contains(\"onsolida\")]))\nprint(\"Lotte heatmap highlights consolidation\", len(gb_all_with_consolidations[gb_all_with_consolidations[\"lotte_heatmap_patterns\"].str.contains(\"onsolida\")]))\n",
"_____no_output_____"
],
[
"gb_all_with_alines = only_test[only_test[\"gb_patterns\"].str.contains(\"A\")]\nprint(\"number of videos with A lines\", len(gb_all_with_alines))\nprint(\"GB heatmap highlights A lines\", len(gb_all_with_alines[gb_all_with_alines[\"gb_heatmap_patterns\"].str.contains(\"A\")]))\nprint(\"Lotte heatmap highlights A lines\", len(gb_all_with_alines[gb_all_with_alines[\"lotte_heatmap_patterns\"].str.contains(\"A\")]))\n",
"_____no_output_____"
],
[
"gb_all_with_blines = only_test[only_test[\"gb_patterns\"].str.contains(\"B\")]\nprint(\"number of videos with B lines\", len(gb_all_with_blines))\nprint(\"GB heatmap highlights B lines\", len(gb_all_with_blines[gb_all_with_blines[\"gb_heatmap_patterns\"].str.contains(\"B\")]))\nprint(\"Lotte heatmap highlights B lines\", len(gb_all_with_blines[gb_all_with_blines[\"lotte_heatmap_patterns\"].str.contains(\"B\")]))\nprint(\"Note: Lotte usually writes that it catches ONE bline in the video, or beginning of bline\")",
"_____no_output_____"
],
[
"class_wise = []\nfor pattern in [\"onsol\", \"B\", \"A\"]:\n print(\"--------\", pattern)\n gb_all_with_pattern = only_test[only_test[\"gb_patterns\"].str.contains(pattern)]\n for classe in [\"cov\", \"pne\", \"reg\"]:\n class_filtered = gb_all_with_pattern[gb_all_with_pattern[\"label\"]==classe]\n print(classe, pattern, len(class_filtered))\n # gb_all_with_pattern = class_filtered[class_filtered[\"gb_patterns\"].str.contains(pattern)]\n number_found = 0.5*(len(class_filtered[class_filtered[\"gb_heatmap_patterns\"].str.contains(pattern)])\n + len(class_filtered[class_filtered[\"lotte_heatmap_patterns\"].str.contains(pattern)]))\n if len(class_filtered)>0:\n print(classe, number_found/len(class_filtered))\n \n# print(gb_all_with_pattern[\"label\"])",
"_____no_output_____"
],
[
"from matplotlib import rc\nrc('text', usetex=False)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nrects = ax.barh([\"Consolidations \\n (pneumonia)\", \"A-lines \\n (healthy)\", \"Pleural line \\n (healthy if regular)\", \"B-lines \\n (COVID-19)\"], [17/18, 8/13, 9/20, 3/12], width\n , color = [\"palegreen\",\"greenyellow\",\"sandybrown\", \"indianred\"])\nax.set_xlim(0,1)\n\n# Add some text for labels, title and custom x-axis tick labels, etc.\n# ax.set_ylabel('Scores')\n# ax.set_title('Scores by group and gender')\n# ax.set_yticks([\"Consolidations \\n (pneumonia)\", \"A-lines \\n (healthy)\", \"Pleural line \\n (healthy if regular)\", \"B-lines \\n (COVID-19)\"], fontsize=13)\nax.set_xlabel(\"Ratio of samples highlighted by CAM\", fontsize=13)\nax.legend()\n\n\ndef autolabel(rects):\n \"\"\"Attach a text label above each bar in *rects*, displaying its height.\"\"\"\n for rect in rects:\n height = rect.get_height()\n ax.annotate('{}'.format(height),\n xy=(rect.get_x() + rect.get_width() / 2, height),\n xytext=(0, 3), # 3 points vertical offset\n textcoords=\"offset points\",\n ha='center', va='bottom')\nautolabel(rects)\nfig.tight_layout()",
"_____no_output_____"
],
[
"plt.figure(figsize=(6,3))\nwidth=0.5\nplt.barh([\"Consolidations \\n (pneumonia)\", \"A-lines \\n (healthy)\", \"Pleural line\", \"B-lines \\n (COVID-19)\"], [17/18, 8/13, 9/20, 3/12], width\n , color = [\"palegreen\",\"greenyellow\",\"sandybrown\", \"indianred\"])\nplt.xlim(0,1)\nplt.yticks(fontsize=13)\nplt.xlabel(\"Ratio of samples highlighted by CAM\", fontsize=13)\nplt.tight_layout()\nplt.savefig(\"barplot_cam.pdf\")",
"_____no_output_____"
],
[
"print(\"FROM GABRIELS PATTERNS:\")\nfor pattern in [\"onsolida\", \"A\", \"B\", \"ronchogram\", \"ffusion\"]:\n print(\"-------------------\")\n gb_all_with_pattern = only_test[only_test[\"gb_patterns\"].str.contains(pattern)]\n print(\"number of videos with \", pattern, len(gb_all_with_pattern))\n print(\"GB heatmap highlights \", pattern, len(gb_all_with_pattern[gb_all_with_pattern[\"gb_heatmap_patterns\"].str.contains(pattern)]))\n print(\"Lotte heatmap highlights \", pattern, len(gb_all_with_pattern[gb_all_with_pattern[\"lotte_heatmap_patterns\"].str.contains(pattern)]))\nprint(\"---------------\")\nprint(\"Note: observed that both MDs agreed where consolidations are found\")\nprint(\"Note: Lotte usually writes that it catches ONE bline in the video, or beginning of bline\")",
"_____no_output_____"
],
[
"print(\"FROM LOTTES PATTERNS:\")\nfor pattern in [\"onsolida\", \"A\", \"B\", \"ffusion\", \"leura\"]:\n print(\"-------------------\")\n gb_all_with_pattern = only_test[only_test[\"lotte_patterns\"].str.contains(pattern)]\n print(\"number of videos with \", pattern, len(gb_all_with_pattern))\n print(\"GB heatmap highlights \", pattern, len(gb_all_with_pattern[gb_all_with_pattern[\"gb_heatmap_patterns\"].str.contains(pattern)]))\n print(\"Lotte heatmap highlights \", pattern, len(gb_all_with_pattern[gb_all_with_pattern[\"lotte_heatmap_patterns\"].str.contains(pattern)]))\nprint(\"---------------\")\nprint(\"Note: observed that both MDs agreed where consolidations are found\")\nprint(\"Note: Lotte usually writes that it catches ONE bline in the video, or beginning of bline\")",
"_____no_output_____"
],
[
"print(\"overall number of videos\", len(only_test))\nfor name in [\"gb\", \"lotte\"]:\n print(\"---------- \"+name+\" --------------\")\n for pattern in [\"uscle\", \"fat\", \"skin\"]:\n print(pattern, np.sum(only_test[name+\"_heatmap_patterns\"].str.contains(pattern)))",
"_____no_output_____"
]
],
[
[
"#### Notes:\n\nGB: 1 time \"Avoids the liver, I'm impressed, but several times \"tricked by the liver\"",
"_____no_output_____"
],
[
"## Backups",
"_____no_output_____"
],
[
"## Test gradcam",
"_____no_output_____"
]
],
[
[
"normal_eval = Evaluator(ensemble=False, split=0) # , model_id=\"\")",
"_____no_output_____"
],
[
"vid_in = vid_in_path + \"Pneu_liftl_pneu_case3_clip5.mp4\"",
"_____no_output_____"
],
[
"img = cv2.imread(\"../../data/my_found_data/Cov_efsumb1_2.png\")\nimg = cv2.imread(\"../../data/pocus_images/convex/Cov_blines_covidmanifestation_paper2.png\")\n",
"_____no_output_____"
],
[
"img = evaluator.preprocess(img)",
"_____no_output_____"
],
[
"grad = GradCAM()\nout_map = grad.explain(img[0], evaluator.models[0], 0, return_map=False, layer_name=\"block5_conv3\", zeroing=0.6)",
"_____no_output_____"
],
[
"plt.imshow(out_map.astype(int))",
"_____no_output_____"
],
[
"out_cam = get_class_activation_map(evaluator.models[0], img, 1, heatmap_weight=0.1, zeroing=0.8)",
"_____no_output_____"
]
],
[
[
"### Check cross val",
"_____no_output_____"
]
],
[
[
"check = \"../../data/cross_validation\"\nfile_list = []\nfor folder in os.listdir(check):\n if folder[0]==\".\":\n continue\n for classe in os.listdir(os.path.join(check, folder)):\n if classe[0]==\".\": # or classe[0]==\"u\":\n continue\n uni = []\n is_image = 0\n for file in os.listdir(os.path.join(check, folder, classe)):\n if file[0]==\".\":\n continue\n if len(file.split(\".\"))==2:\n is_image+=1\n file_list.append(file)\n uni.append(file.split(\".\")[0])\n # assert file[:3].lower()==classe[:3], \"wrong label\"+file[:3]+classe[:3]\n print(folder, classe, len(np.unique(uni)), len(uni), is_image)\nassert len(file_list)==len(np.unique(file_list))\nprint(len(file_list))",
"_____no_output_____"
]
],
[
[
"## Copy from train and test folders, give new ideas, and construct mapping",
"_____no_output_____"
]
],
[
[
"testcam = \"vid_outputs_cam_test\"\nfiles_to_process = []\nfor subdir in os.listdir(testcam):\n if subdir[0]==\".\" or subdir==\"not taken\" :\n continue\n for f in os.listdir(os.path.join(testcam, subdir)):\n if f[0]==\".\":\n continue\n \n if not os.path.exists(os.path.join(\"vid_outputs_cam\", f)):\n print(\"does not exist in train\", subdir, f)\n # if not \"RUQ\" in f:\n # todo.append(f.split(\".\")[0])\n else:\n files_to_process.append(os.path.join(subdir, f))\n# print(todo)",
"_____no_output_____"
],
[
"# code to copy files to randomized thing\nimport shutil",
"_____no_output_____"
],
[
"drop_cams_dir = \"vids_to_check\"\ntest_cam_dir = \"vid_outputs_cam_test\"\ntrain_cam_dir = \"vid_outputs_cam\"\n# create directory\nif not os.path.exists(drop_cams_dir):\n os.makedirs(drop_cams_dir)\n# give random ids\nids = np.random.permutation(len(files_to_process))\n\n# define dataframe columns\nnew_fname = []\nold_fname = []\nis_train = []\nfold = []\nfor i, f_name_path in enumerate(files_to_process):\n split_name, f_name = tuple(f_name_path.split(os.sep))\n split = int(split_name[-1])\n # randomly add to model2\n out_f_name = \"video_\"+str(ids[i])+\"_model_\"\n old_fname.append(f_name)\n old_fname.append(f_name)\n rand_folder_train = np.random.rand()<0.5\n print(\"train gets 1?\", rand_folder_train)\n \n # copy train data\n train_outfname = out_f_name + str(int(rand_folder_train)) + \".mpeg\"\n train_to_path = os.path.join(drop_cams_dir, train_outfname)\n cp_from_path = os.path.join(train_cam_dir, f_name)\n # append for df\n is_train.append(1)\n fold.append(split)\n new_fname.append(train_outfname)\n print(\"TRAIN:\", cp_from_path, train_to_path)\n shutil.copy(cp_from_path, train_to_path)\n \n # copy test \n test_outfname = out_f_name + str(int(not rand_folder_train)) + \".mpeg\"\n test_to_path = os.path.join(drop_cams_dir, test_outfname)\n cp_from_path = os.path.join(test_cam_dir, split_name, f_name)\n # append for df\n fold.append(split)\n is_train.append(0)\n new_fname.append(test_outfname)\n print(\"TEST:\", cp_from_path, test_to_path)\n shutil.copy(cp_from_path, test_to_path)",
"_____no_output_____"
],
[
"df = pd.DataFrame()\ndf[\"previous_filename\"] = old_fname\ndf[\"new_filename\"] = new_fname\ndf[\"is_train\"] = is_train\ndf[\"fold\"] = fold\ndf.head(30)",
"_____no_output_____"
],
[
"df.to_csv(drop_cams_dir+\"/mapping.csv\")",
"_____no_output_____"
],
[
"iclus_dir = \"test_data_regular/pat1\"\n# out_path = \"iclus_videos_processed\"",
"_____no_output_____"
],
[
"FRAMERATE = 3\nMAX_FRAMES = 30\n\nfor fn in os.listdir(iclus_dir):\n if fn[0]==\".\":\n continue\n cap = cv2.VideoCapture(os.path.join(iclus_dir, fn))\n n_frames = cap.get(7)\n frameRate = cap.get(5)\n nr_selected = 0\n every_x_image = int(frameRate / FRAMERATE)\n while cap.isOpened() and nr_selected < MAX_FRAMES:\n ret, frame = cap.read()\n if (ret != True):\n break\n print(cap.get(1), cap.get(2), cap.get(3), cap.get(4), cap.get(5), cap.get(6), cap.get(7))\n h, w, _ = frame.shape\n # print(h,w)\n plt.imshow(frame[30:400, 80:450])\n plt.show()\n # SAVE\n # if ((frameId+1) % every_x_image == 0):\n # # storing the frames in a new folder named test_1\n # filename = out_path + fn + \"_frame%d.jpg\" % frameId\n # cv2.imwrite(filename, frame)\n # nr_selected += 1\n # print(frameId, nr_selected)\n cap.release()",
"_____no_output_____"
],
[
"import shutil\ncheck = \"../../data/cross_validation_segmented\"\nout = \"../../data/cross_validation_segmented_new\"\nfor folder in os.listdir(check):\n if folder[0]==\".\":\n continue\n os.makedirs(os.path.join(out, folder))\n for classe in os.listdir(os.path.join(check, folder)):\n os.makedirs(os.path.join(out, folder, classe))\n if classe[0]==\".\": # or classe[0]==\"u\":\n continue\n for f in os.listdir(os.path.join(check, folder, classe)):\n if f[-3:]==\"gif\":\n shutil.copy(os.path.join(check, folder, classe, f), os.path.join(out, folder, classe, f[:-4]))\n elif f[-3:] ==\"npz\":\n shutil.copy(os.path.join(check, folder, classe, f), os.path.join(out, folder, classe, f))",
"_____no_output_____"
]
],
[
[
"### Cut Lotte's videos",
"_____no_output_____"
]
],
[
[
"file_list = [\"pat1Image_132943.mpeg\",\n\"pat1Image_133043.mpeg\",\n\"pat1Image_133138.mpeg\",\n\"pat1Image_133232.mpeg\",\n\"pat1Image_133327.mpeg\",\n\"pat1Image_133410.mpeg\",\n\"pat2Image_133824.mpeg\",\n\"pat2Image_133952.mpeg\",\n\"pat2Image_134138.mpeg\",\n\"pat2Image_134240.mpeg\",\n\"pat2Image_134348.mpeg\",\n\"pat2Image_134441.mpeg\",\n\"pat3Image_134711.mpeg\",\n\"pat3Image_134811.mpeg\",\n\"pat3Image_134904.mpeg\",\n\"pat3Image_135026.mpeg\",\n\"pat3Image_135128.mpeg\",\n\"pat3Image_135215.mpeg\",\n\"pat4Image_135904.mpeg\",\n\"pat4Image_140024.mpeg\",\n\"pat4Image_140238.mpeg\",\n\"pat4Image_140434.mpeg\",\n\"pat4Image_140606.mpeg\",\n\"pat4Image_140705.mpeg\"]\ncopy_path = \"../../data/pocus_videos/convex/\"\nfor f in file_list:\n video_path = \"reg_propro/\"+f\n # cap = cv2.VideoCapture(video_path)\n # print(cap.get(7))\n # cap.release()\n print(\"Reg_\"+f)\n shutil.copy(video_path, copy_path+\"Reg_\"+f)",
"_____no_output_____"
],
[
"out_dir = \"reg_propro/pat4\"\nin_dir = \"test_data_regular/pat4\"\nfor vid in os.listdir(in_dir):\n if vid[0]==\".\":\n continue\n video_path = os.path.join(in_dir, vid)\n cap = cv2.VideoCapture(video_path)\n images = []\n counter = 0\n while cap.isOpened():\n ret, frame = cap.read()\n if (ret != True):\n break\n if counter<1:\n plt.imshow(frame[30:400, 80:450]) # ICLUS: [70:570, 470:970]) # [25:350, 100:425]) # LOTTE:[30:400, 80:450]\n plt.show()\n counter += 1\n continue\n counter += 1\n img_processed = frame[30:400, 80:450]\n images.append(img_processed)\n cap.release()\n \n images = np.asarray(images)\n print(images.shape)\n io.vwrite(out_dir+ vid.split(\".\")[0]+\".mpeg\", images, outputdict={\"-vcodec\":\"mpeg2video\"})",
"_____no_output_____"
]
],
[
[
"### Display logo on frames",
"_____no_output_____"
]
],
[
[
"test_vid = \"../../data/pocus_videos/convex/Pneu-Atlas-pneumonia2.gif\"\n",
"_____no_output_____"
],
[
"cap = cv2.VideoCapture(test_vid)\nret, frame = cap.read()\ncap.release()",
"_____no_output_____"
],
[
"plt.imshow(frame)\nplt.show()",
"_____no_output_____"
],
[
"logo = plt.imread(\"Logo.png\")",
"_____no_output_____"
],
[
"logo = cv2.resize(logo, (50,50), )",
"_____no_output_____"
],
[
"plt.imshow(logo)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a02d77975ec8f4fad91327b76e2338f9c04fe09
| 18,153 |
ipynb
|
Jupyter Notebook
|
Une introduction au Machine Learning.ipynb
|
SdgJlbl/french-tutorials
|
ba037524ae90ab81021c5b0932f86c9cb740581d
|
[
"Apache-2.0"
] | null | null | null |
Une introduction au Machine Learning.ipynb
|
SdgJlbl/french-tutorials
|
ba037524ae90ab81021c5b0932f86c9cb740581d
|
[
"Apache-2.0"
] | null | null | null |
Une introduction au Machine Learning.ipynb
|
SdgJlbl/french-tutorials
|
ba037524ae90ab81021c5b0932f86c9cb740581d
|
[
"Apache-2.0"
] | 1 |
2018-02-28T22:42:59.000Z
|
2018-02-28T22:42:59.000Z
| 35.180233 | 756 | 0.625296 |
[
[
[
"# Le Machine Learning, c'est pour tout le monde",
"_____no_output_____"
],
[
"## Le Machine Learning, kézako ?",
"_____no_output_____"
],
[
"Le Machine Learning, ou apprentissage automatique en français, est une façon de programmer les ordinateurs de façon à ce qu'ils exécutent une tâche souhaité sans avoir programmé explicitement les instructions pour cette tâche.\n\nEn programmation classique, on a des données en entrée (input), une suite d'instruction qui vont s'appliquer sur ces données, et un résultat en sortie (output). \n\nEn Machine Learning, on a des données en entrée, qui vont être fournies à un programme qui va \"apprendre\" un modèle de façon à ce que le résultat en sortie corresponde à ce que l'on souhaite. \nDans un second temps, on peut donner de nouvelles données au modèle qui va donc produire des résultats nouveaux. Si ces résultats correspondent à ce que l'on attendait, alors on est content et on dit que le modèle a appris.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"L'apprentissage, ça n'est pas une étape magique, c'est juste la solution d'un problème mathématique d'optimisation. En gros, on cherche à minimiser l'erreur dans un espace abstrait qui contient plein de modèles de Machine Learning. \n\nCa peut paraître un peu compliqué, mais il y a plein de mathématiciens qui ont réfléchi à la question depuis longtemps, et on a des algorithmes efficaces pour ça. ",
"_____no_output_____"
],
[
"\n\n*Une illustration de la technique d'optimisation de descente de gradient, qui consiste à suivre la plus forte pente pour trouver le minimum (un peu comme une bille lâchée du haut d'une montagne qui va aller s'arrêter au fond de la vallée).*",
"_____no_output_____"
],
[
"**Pourquoi appelle-t-on ça un modèle de Machine Learning, et non pas un programme comme tout le monde ?**\nD'abord, parce qu'on est un peu snob, et ensuite, parce que les modèles programmés peuvent aussi souvent s'exprimer en termes mathématiques, et on peut faire des preuves dessus, ect. \n\nUn modèle de Machine Learning, c'est une sous-espèce de programme informatique, qui est codé de façon un peu différente, c'est tout.",
"_____no_output_____"
],
[
"## Si les machines peuvent apprendre, pourquoi s'embêter à programmer ?",
"_____no_output_____"
],
[
"Donc pour faire du Machine Learning, il faut un problème, une tâche à résoudre, et des exemples de comment on veut que la tâche soit réalisée. \n\nCe besoin de données (les exemples) explique pourquoi on ne se sert pas du Machine Learning partout. Il y a des tas de tâches pour lesquelles il est plus simple d'expliquer à l'ordinateur comment faire étape par étape, de lui donner les instructions, plutôt que de trouver tout un tas d'exemples du comportement qu'on veut apprendre. Le Machine Learning ne remplace donc absoulement pas la programmation ! \n\nPar contre, il y a des tâches pour lesquelles c'est plus compliqué d'expliquer comment on veut que ça soit fait. Par exemple, décider de si une chanson est triste ou au contraire joyeuse. On peut bien trouver des idées de pourquoi telle chanson est mélancolique ou telle autre nous met en pleine forme, les chansons triste sont peut-être plus lentes, les chansons joyeuses ont souvent de la batterie, mais c'est compliqué d'expliquer à un ordinateur comment faire la différence. Par contre, on peut facilement classer les chansons dans deux catégories, triste et joyeuse, et donner cette classification ainsi que le spectre audio des chansons à un ordinateur, et lui demander d'apprendre de lui-même à reconnaître les chansons tristes ou joyeuses !\n",
"_____no_output_____"
],
[
"### Quelques instructions pour la suite\n\n\n*Les cellules de codes s'exécutent en cliquant sur la touche play dans la barre en haut, ou bien avec majuscule + Entrée ou Ctrl + Entrée au clavier. La cellule actuellement sélectionnée a une barre bleue à droite.*\n\n*Pour tous les morceaux de code à trou, il est possible de charger la solution en retirant le # de la ligne `# %load solutions/[nom_de_lexercice].py` et en exécutant la cellule.*",
"_____no_output_____"
],
[
"## Mon premier modèle de Machine Learning\n\nPour notre premier modèle, on ne va pas apprendre à distinguer les chansons tristes des autres, on va classer quelque chose de plus simple. \n\nOn a un ensemble de données (un dataset en anglais) qui, pour chaque configuration d'une petite expérience de physique, nous dit si la balance penche vers la droite ou vers la gauche. \n\n\n\nOn a quatre variables pour chaque expérience: la longueur du bras gauche (`dist_gauche`), la longueur du bras droit (`dist_droit`), la masse sur le plateau gauche (`masse_gauche`) et la masse sur le plateau droit (`masse_droit`). On veut que l'ordinateur apprenne le résultat de l'expérience (la balance penche à gauche ou à droite) à partir de ces quatre variables. \n\nEvidemment, dans ce cas très simple, un peu de physique pourrait nous permettre de trouver la solution et de programmer explicitement les instructions. Mais supposant qu'on a oublié nos cours de physique. Que peut-on faire ?",
"_____no_output_____"
],
[
"On commence par charger les données, les exemples d'expérience pour lesquels on a la réponse. Ces données sont dans un fichier csv, un fichier texte où les valeurs sont séparées par des virgules (*comma-separated values* en anglais). \n\nOn utilise le module csv de la librairie standart pour stocker nos données dans une grande liste, où chaque élément représentera une expérience. \n\nLe code pour charger les données est donné à titre indicatif, pas la peine de s'en inquiéter pour l'instant !",
"_____no_output_____"
]
],
[
[
"import csv\n\ntrain_dataset = []\nwith open('data/apprentissage.csv') as csvfile:\n csvreader = csv.reader(csvfile)\n for row in csvreader:\n train_dataset.append({'label': row[0], 'variables': list(map(int, row[1:]))}) ",
"_____no_output_____"
]
],
[
[
"Une expérience (un point de donnée) est caractérisée par les valeurs des quatre variable dont on a parlé ci-dessus (`masse_gauche`, `dist_gauche`, `masse_droite`, `dist_droite`), et par son **label** (le résultat de l'expérience, est-ce que la balance penche à droite (**R**) ou à gauche (**L**). \n\nOn peut par exemple regarder le premier point de données du dataset.",
"_____no_output_____"
]
],
[
[
"train_dataset[0]",
"_____no_output_____"
]
],
[
[
"On voit que les variables `masse_gauche`, `dist_gauche`, `masse_droite`, `dist_droite` ont pour valeur respectivement 5, 4, 5 et 5, et que le résultat de l'expérience est que la balance penche à droite (label **R**). \n\nToutes les valeurs des variables ont été normalisées entre 1 et 5, c'est une pratique courante en Machine Learning pour simplifier l'apprentissage. ",
"_____no_output_____"
],
[
"Maintenant que l'on a des données, comment va-t-on faire pour que l'ordinateur apprenne ? \n\nOn va utiliser l'algorithme des plus proches voisins.\n\nCet algorithme fonctionne sur le principe suivant: on va regarder quels sont les points qui sont proches du point qu'on veut évaluer en utilisant les variables qu'on a collectées. Concrètement, on cherche dans notre dataset d'apprentissage les expériences qui sont les plus similaires à l'expérience qu'on veut évaluer. Et on se dit que les choses vont se passer à peu près pareil pour notre expérience inconnue, et donc on va renvoyer le même label (on prédit la même classe). \n\n\n\nSur le schéma ci-dessus, le point vert est entouré de points rouges, on va donc lui assigner le label rouge. \n\nPour le point violet, c'est un peu plus compliqué: si on prend le point le plus proche, il serait bleu; mais si on fait la moyenne sur les 3 points les plus proches, il serait rouge. \n\nEn pratique, on fait souvent la moyenne sur quelques points (3 ou 5), afin de lisser les cas limites (comme celui du point violet). ",
"_____no_output_____"
],
[
"Notre modèle de Machine Learning va être ici composé de 3 choses : \n* le dataset d'apprentissage qu'on va utiliser pour trouver les voisins\n* la valeur *k* du nombre de voisins qu'on va considérer pour faire nos évaluations\n* la fonction qu'on va utiliser pour calculer la distance",
"_____no_output_____"
],
[
"Commençons par définir cette fonction de distance. \n\nOn va utiliser une distance dite *de Manhattan*: \n$$ d(a, b) = |a_1 - b_1| + |a_2 - b_2| + ...$$\nqui calcule la différence sur chaque variable, puis somme les valeurs absolues de ces différences. ",
"_____no_output_____"
],
[
"On va donc parcourir toutes les variables des points de données (les expériences) *a* et *b* et ajouter la valeur absolue de la différence. \n\nLa fonction `zip(a, b)` va renvoyer *a_1, b_1*, puis *a_2, b_2*, ect...\n\nC'est à vous de jouer, complétez le code ci-dessous ! \n\n(Un dernier indice, la fonction `math.fabs` vous donnera la valeur absolue.)",
"_____no_output_____"
]
],
[
[
"import math\ndef distance(a, b):\n d = 0\n for i, j in zip(a, b):\n d += ... # à compléter \n return d",
"_____no_output_____"
],
[
"# %load solutions/distance.py\n",
"_____no_output_____"
]
],
[
[
"Pour tester si notre fonction fonctionne correctement, on va calculer la distance entre les deux premiers points du dataset. Vous devrier obtenir 11.",
"_____no_output_____"
]
],
[
[
"distance(train_dataset[0]['variables'], train_dataset[1]['variables'])",
"_____no_output_____"
]
],
[
[
"Pour le nombre de voisins que l'on va considérer, on va prendre *k = 3*. ",
"_____no_output_____"
]
],
[
[
"k = 3",
"_____no_output_____"
]
],
[
[
"C'est parti, on peut à présent se lancer dans le coeur de l'algorithme. \n\nQuand on reçoit un point à évaluer, on veut connaître les labels des *k* plus proches voisins. Pour cela, on va calculer la distance du nouveau point à tous les points du dataset d'apprentissage, et stocker à chaque fois la valeur et le label.\n\n(Indice: on a déjà écrit une fonction pour calculer la distance; on veut prendre uniquement la partie 'variables' du `train_point` pour calculer la distance.)",
"_____no_output_____"
]
],
[
[
"def calculer_distances(dataset, eval_point):\n distances = []\n for train_point in dataset:\n distances.append({'label': train_point['label'], \n 'distance': ... # à compléter\n })\n return distances",
"_____no_output_____"
],
[
"# %load solutions/calculer_distances.py\n",
"_____no_output_____"
]
],
[
[
"Maintenant qu'on a toutes les distances, on peut trouver les *k* points les plus proches, en triant par distance. Python nous permet de faire ça facilement, mais les détails sont un peu techniques.",
"_____no_output_____"
]
],
[
[
"def trier_distances(distances):\n return sorted(distances, key=lambda point: point['distance'])",
"_____no_output_____"
]
],
[
[
"On peut prendre les trois premiers éléments de la liste avec `maListe[:3]`, et compter le nombre de **R** et de **L** dans les labels.",
"_____no_output_____"
]
],
[
[
"def choisir_label(distances_triees, k):\n plus_proches_voisins = distances_triees[:k]\n count_R = 0\n count_L = 0\n for voisin in plus_proches_voisins:\n if voisin['label'] == 'R':\n count_R += 1\n if voisin['label'] == 'L': \n ... # à compléter\n if count_R > count_L:\n return 'R'\n else:\n return 'L'\n ",
"_____no_output_____"
],
[
"# %load solutions/choisir_label.py\n",
"_____no_output_____"
]
],
[
[
"A présent on combine toutes nos fonctions pour avoir l'algorithme final.",
"_____no_output_____"
]
],
[
[
"def algorithme_des_plus_proches_voisins(dataset, eval_point, k):\n distances = calculer_distances(dataset, eval_point)\n distances_triees = trier_distances(distances)\n label = choisir_label(distances_triees, k)\n return label",
"_____no_output_____"
]
],
[
[
"Maintenant, on va charger de nouvelles données pour pouvoir évaluer notre algorithme. ",
"_____no_output_____"
]
],
[
[
"import csv\n\neval_dataset = []\nwith open('data/evaluation.csv') as csvfile:\n csvreader = csv.reader(csvfile)\n for row in csvreader:\n eval_dataset.append({'true_label': row[0], 'variables': list(map(int, row[1:]))}) ",
"_____no_output_____"
]
],
[
[
"On peut regarder ce que ça donne pour notre premier point d'évaluation.",
"_____no_output_____"
]
],
[
[
"algorithme_des_plus_proches_voisins(train_dataset, eval_dataset[0]['variables'], k)",
"_____no_output_____"
]
],
[
[
"On prédit que la balance va pencher à gauche ! \n\nQu'en est-il en réalité ?",
"_____no_output_____"
]
],
[
[
"eval_dataset[0]['true_label']",
"_____no_output_____"
]
],
[
[
"C'est bien ce qui a été observé ! Notre algorithme a appris, sans avoir besoin de lui expliquer les règles de la physique ! \n\nVoyons combien d'erreurs notre algorithme fait sur la totalité des points d'évaluation.",
"_____no_output_____"
]
],
[
[
"erreurs = 0\nfor point in eval_dataset:\n if algorithme_des_plus_proches_voisins(train_dataset, point['variables'], k) != point['true_label']:\n erreurs += 1\nprint(\"Nombre d'erreurs %d sur %d exemples\" % (erreurs, len(eval_dataset)))",
"_____no_output_____"
]
],
[
[
"Notre algorithme a fait quelques erreurs, mais il a correctement prédit la majorité des situations. \n\nFélicitations, vous avez programmé votre premier modèle de Machine Learning ! ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a02e010ef8c58ffcc9cac4f694b4f3c9f0f6a1d
| 934,800 |
ipynb
|
Jupyter Notebook
|
MMA831/DOS1/dos1_python.ipynb
|
uncrtv/MMA2020
|
ee5835e37c8597e77978f2bbc3a10dd24ec2bedc
|
[
"MIT"
] | null | null | null |
MMA831/DOS1/dos1_python.ipynb
|
uncrtv/MMA2020
|
ee5835e37c8597e77978f2bbc3a10dd24ec2bedc
|
[
"MIT"
] | null | null | null |
MMA831/DOS1/dos1_python.ipynb
|
uncrtv/MMA2020
|
ee5835e37c8597e77978f2bbc3a10dd24ec2bedc
|
[
"MIT"
] | null | null | null | 1,256.451613 | 395,740 | 0.957379 |
[
[
[
"# MMA 831 DOS1\nThis assignment requires R but is good Python practice.",
"_____no_output_____"
],
[
"## Some more visualizations using Python + Seaborn",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nimport pandas as pd\n\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nplt.set_cmap('Set2')\n\nimport seaborn as sns\ncolours = sns.color_palette('Set2')",
"_____no_output_____"
],
[
"plt.rcParams[\"figure.figsize\"] = (15,15)",
"_____no_output_____"
]
],
[
[
"## Load Data",
"_____no_output_____"
]
],
[
[
"dat = pd.read_csv('adv_sales.csv')",
"_____no_output_____"
]
],
[
[
"## Summary statistics etc.",
"_____no_output_____"
]
],
[
[
"dat.shape",
"_____no_output_____"
],
[
"dat.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1000 entries, 0 to 999\nData columns (total 8 columns):\nUnnamed: 0 1000 non-null int64\nstore 1000 non-null int64\nbillboard 1000 non-null int64\nprintout 1000 non-null int64\nsat 1000 non-null int64\ncomp 1000 non-null int64\nprice 1000 non-null int64\nsales 1000 non-null float64\ndtypes: float64(1), int64(7)\nmemory usage: 62.6 KB\n"
]
],
[
[
"Looks like there's an Store ID column, let's delete that, not important.",
"_____no_output_____"
]
],
[
[
"dat_noids = dat.drop('Unnamed: 0', axis = 1)",
"_____no_output_____"
],
[
"dat_noids.describe()",
"_____no_output_____"
]
],
[
[
"Looks like no outliers from here.",
"_____no_output_____"
]
],
[
[
"dat_noids.head()",
"_____no_output_____"
]
],
[
[
"## Check for missing values",
"_____no_output_____"
]
],
[
[
"dat_noids.isnull().sum()",
"_____no_output_____"
]
],
[
[
"No missing values.",
"_____no_output_____"
],
[
"## Visualizations",
"_____no_output_____"
],
[
"Here comes the fancy stuff!",
"_____no_output_____"
],
[
"### Histograms",
"_____no_output_____"
]
],
[
[
"dat_noids.hist(bins = 20, figsize = (20,20))\nplt.show()",
"_____no_output_____"
]
],
[
[
"Looks to be mostly normal, except for price and satisfaction.",
"_____no_output_____"
],
[
"### Pair plots\n\nUse `diag_kind = 'kde'` to show kernel density estimates in the diagonals.\n`kind = reg` shows regression lines for each scatterplot. This increases run time by A LOT. Can also use a correlation matrix (next plot) to visualize pairwise linear relationships.",
"_____no_output_____"
]
],
[
[
"sns.pairplot(dat_noids, palette = colours, kind = 'reg', diag_kind = 'kde')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Correlation matrix\n\nIf wanted can draw a white mask to only show half of the plot (because each half is the same), ~~but I'm too lazy~~ I did it anyway but prefer the old one more :grin:\n\nFirst we define a diverging colour palette:",
"_____no_output_____"
]
],
[
[
"diverging_palette = sns.diverging_palette(220, 10, as_cmap = True)",
"_____no_output_____"
]
],
[
[
"Plot it:\n\nMake sure to include `vmin` and `vmax` or you will get a bunch of blue cells that tell you nothing...",
"_____no_output_____"
]
],
[
[
"# sns.heatmap(dat_noids.corr(), cmap = diverging_palette, square = True, annot = True)\n# mask = np.zeros_like(dat_noids.corr(), dtype=np.bool)\n# mask[np.triu_indices_from(mask)] = True\nsns.heatmap(dat_noids.corr(), cmap = diverging_palette, square = True, annot = True,\n vmin = -1, vmax = 1)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Aside from `store` and `billboard`, no strong correlation. `price` and `sat` have weak correlation, which is understandable.",
"_____no_output_____"
],
[
"### Plot scatterplots for advertising channels",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(1, 3, figsize = (15,5), sharey = True)\nsns.scatterplot(x = 'store', y = 'sales', data = dat_noids, ax = ax[0])\nsns.scatterplot(x = 'billboard', y = 'sales', data = dat_noids, ax = ax[1])\nsns.scatterplot(x = 'printout', y = 'sales', data = dat_noids, ax = ax[2])\nfig.show()",
"_____no_output_____"
]
],
[
[
"Alternatively put it all on the same graph.\n(This took me an hour to figure out. Thanks Google and StackOverflow!)",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize = (10,10))\nax.grid(True, alpha = 0.5)\nax.scatter(x = 'store', y = 'sales', data = dat_noids, color = '#66c2a5')\nax.scatter(x = 'printout', y = 'sales', data = dat_noids, color = '#fc8d62')\nax.scatter(x = 'billboard', y = 'sales', data = dat_noids, color = '#8da0cb')\nax.set_title('Advertising vs. Sales')\nax.set_ylabel('Sales')\nax.set_xlabel('Advertising')\nax.legend(['Store', 'Printout', 'Billboard'], loc = 4, fontsize = 'large')\nfig.show()",
"_____no_output_____"
]
],
[
[
"Alternatively, do a pairplot with only the three interesting features:",
"_____no_output_____"
]
],
[
[
"sns.pairplot(dat_noids[['sales', 'store', 'billboard', 'printout']], palette = colours)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Split Train and Test",
"_____no_output_____"
]
],
[
[
"# TODO",
"_____no_output_____"
]
],
[
[
"## Linear Regression",
"_____no_output_____"
]
],
[
[
"# TODO",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a02ea157681d837fa35336386ad19353f4c03aa
| 9,658 |
ipynb
|
Jupyter Notebook
|
nobel_physics_prizes/notebooks/1.2-collect-physicists-raw-data.ipynb
|
covuworie/nobel-physics-prizes
|
f89a32cd6eb9bbc9119a231bffee89b177ae847a
|
[
"MIT"
] | 3 |
2019-08-21T05:35:42.000Z
|
2020-10-08T21:28:51.000Z
|
nobel_physics_prizes/notebooks/1.2-collect-physicists-raw-data.ipynb
|
covuworie/nobel-physics-prizes
|
f89a32cd6eb9bbc9119a231bffee89b177ae847a
|
[
"MIT"
] | 139 |
2018-09-01T23:15:59.000Z
|
2021-02-02T22:01:39.000Z
|
nobel_physics_prizes/notebooks/1.2-collect-physicists-raw-data.ipynb
|
covuworie/nobel-physics-prizes
|
f89a32cd6eb9bbc9119a231bffee89b177ae847a
|
[
"MIT"
] | null | null | null | 36.037313 | 751 | 0.626113 |
[
[
[
"# Collect Physicists Raw Data\n\nThe goal of this notebook is to collect demographic data on the list of [physicists notable for their achievements](../data/raw/physicists.txt). Wikipedia contains this semi-structured data in an *Infobox* on the top right side of the article for each physicist. However, similar data is available in a more machine readable, [JSON](https://www.json.org/) format from [DBpedia](https://wiki.dbpedia.org/about). We will need to send HTTP requests to DBpedia to get the JSON data. For an example, compare *Albert Einstein's* [Wikipedia infobox](https://en.wikipedia.org/wiki/Albert_Einstein) to his [DBPedia JSON](http://dbpedia.org/data/Albert_Einstein.json). It is important to realize, that although the data is similar, it is not identical.\n\nThe shortcomings of Wikipedia infoboxes and the advantages of DBpedia datasets are explained in section 4.3 of [DBpedia datasets](https://wiki.dbpedia.org/services-resources/datasets/dbpedia-datasets#h434-10). But basically the summary is that DBpedia data is much cleaner and better structured than Wikipedia Infoboxes as it is based on hand-generated mappings of Wikipedia infoboxes / templates to a [DBpedia ontology](https://wiki.dbpedia.org/services-resources/ontology). Consequently, we will be using DBpedia as the data source for this project.\n\nHowever, DBpedia does have the disadvantage that its content is roughly 6-18 months behind updates applied to Wikipedia content. This is due to its data being generated from a [static dump of Wikipedia content](https://wiki.dbpedia.org/online-access/DBpediaLive) in a process that takes approximately 6 months. The fact that the data is not in sync with the latest Wikipedia content is not of great significance for this project as the data is edited infrequently. Also when edits are made, they tend to be only minor.",
"_____no_output_____"
],
[
"## Setting the Environment\n\nA few initialization steps are needed to setup the environment:\n\n- The locale needs to be set for all categories to the user’s default setting (typically specified in the LANG environment variable) to enable correct sorting of physicists names with accents.\n- A bool constant `FETCH_JSON_DATA` needs to be set to decide whether to fetch the json data. Set to False so that the previously fetched data is used. In this case the results of the study are guaranteed be reproducible. Set to True so that the latest data is fetched. In this case it is possible that the results of the study will change.",
"_____no_output_____"
]
],
[
[
"import locale\n \nlocale.setlocale(locale.LC_ALL, '')",
"_____no_output_____"
],
[
"FETCH_JSON_DATA = False",
"_____no_output_____"
]
],
[
[
"## Constructing the URLs\n\nTo make the HTTP requests, we will need a list of URLs representing the resources (i.e the physicists). It's fairly easy to construct these URLs from the list of notable physicists. However, it's important to \"quote\" any physicist name in unicode since unicode characters are not allowed in URLs. OK let's create the list now.",
"_____no_output_____"
]
],
[
[
"import gzip\nimport os\nimport shutil\nfrom collections import OrderedDict\n\nimport jsonlines\nimport pandas as pd\n\nfrom src.data.jsonl_utils import read_jsonl\nfrom src.data.url_utils import DBPEDIA_DATA_URL\nfrom src.data.url_utils import fetch_json_data\nfrom src.data.url_utils import urls_progress_bar",
"_____no_output_____"
],
[
"def construct_urls(file='../data/raw/physicists.txt'):\n \"\"\"Construct DBpedia data URLs from list in file.\n\n Args:\n file (str): File containing a list of url filepaths\n with spaces replacing underscores.\n Returns:\n list(str): List of URLs.\n\n \"\"\"\n\n with open(file, encoding='utf-8') as file:\n names = [line.rstrip('\\n') for line in file]\n\n urls = [DBPEDIA_DATA_URL + name.replace(' ', '_') + '.json'\n for name in names]\n return urls",
"_____no_output_____"
],
[
"urls_to_fetch = construct_urls()\nassert(len(urls_to_fetch) == 1069)",
"_____no_output_____"
]
],
[
[
"## Fetching the Data\n\nNow we have the list of URLs, it's time to make the HTTP requests to acquire the data. The code is asynchronous, which dramatically helps with performance. It is important to set the `max_workers` parameter sensibly in order to crawl responsibly and not hammer the site's server. Although the site seems to be rate limited, it's still good etiquette.",
"_____no_output_____"
]
],
[
[
"jsonl_file = '../data/raw/physicists.jsonl'\nif FETCH_JSON_DATA:\n json_data = fetch_json_data(urls_to_fetch, max_workers=20, timeout=30,\n progress_bar=urls_progress_bar(len(urls_to_fetch)))\nelse:\n json_data = read_jsonl('../data/raw/physicists.jsonl' + '.gz')",
"_____no_output_____"
]
],
[
[
"Let's sort the data alphabetically by URL, confirm that all the data was fetched and take a look at the first JSON response.",
"_____no_output_____"
]
],
[
[
"if FETCH_JSON_DATA:\n json_data = OrderedDict(sorted(json_data.items(), key=lambda x: locale.strxfrm(x[0])))\n assert(len(json_data) == 1069)\n print(list(json_data.keys())[0])\n print(list(json_data.values())[0])\nelse:\n assert(len(json_data) == 1058)\n print(json_data[0])",
"_____no_output_____"
]
],
[
[
"It is clear that every request successfully received a response. However, we see that some responses came back empty from the server. Basically, although there are Wikipedia pages for these physicists, they do not have a corresponding page in DBpedia (or the page in DBpedia has a different name). Not to worry, there are only 11 and they are not so famous, so we will just exclude these \"Z-listers\" from the analysis.",
"_____no_output_____"
]
],
[
[
"if FETCH_JSON_DATA:\n urls_to_drop = [url for (url, data) in json_data.items() if not data]\n assert(len(urls_to_drop) == 11)\n display(urls_to_drop)",
"_____no_output_____"
],
[
"if FETCH_JSON_DATA:\n json_data = [data for data in json_data.values() if data]\n assert(len(json_data) == 1058)",
"_____no_output_____"
]
],
[
[
"## Persisting the Data\n\nNow that we have the list of JSON responses, we would like to persist them for later analysis. We will use [Json Lines](http://jsonlines.org/) as it seems like a convenient format for storing structured data that may be processed one record at a time.",
"_____no_output_____"
]
],
[
[
"if FETCH_JSON_DATA:\n with jsonlines.open(jsonl_file, 'w') as writer:\n writer.write_all(json_data)",
"_____no_output_____"
]
],
[
[
"Let's do a quick sanity check to make sure the file contains the expected number of records.",
"_____no_output_____"
]
],
[
[
"if FETCH_JSON_DATA:\n json_lines = read_jsonl(jsonl_file)\n assert(len(json_lines) == 1058)",
"_____no_output_____"
]
],
[
[
"Finally, let's compress the file to reduce its footprint.",
"_____no_output_____"
]
],
[
[
"if FETCH_JSON_DATA:\n with open(jsonl_file, 'rb') as src, gzip.open(jsonl_file + '.gz', 'wb') as dest:\n shutil.copyfileobj(src, dest)\n os.remove(jsonl_file)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a02fedbcfd2320b7c7de619b92d35fbfcbcd847
| 50,809 |
ipynb
|
Jupyter Notebook
|
1-1.ipynb
|
HirokiNakahara/ML_Tutorial
|
731a622dcdf47abc106821d442532e3a6f435b73
|
[
"MIT"
] | 1 |
2020-09-02T03:42:32.000Z
|
2020-09-02T03:42:32.000Z
|
1-1.ipynb
|
HirokiNakahara/ML_Tutorial
|
731a622dcdf47abc106821d442532e3a6f435b73
|
[
"MIT"
] | null | null | null |
1-1.ipynb
|
HirokiNakahara/ML_Tutorial
|
731a622dcdf47abc106821d442532e3a6f435b73
|
[
"MIT"
] | 1 |
2021-12-09T06:29:46.000Z
|
2021-12-09T06:29:46.000Z
| 158.283489 | 17,524 | 0.908343 |
[
[
[
"# 1-1. AIとは何か?簡単なAIを設計してみよう\n\nAIブームに伴って、様々なメディアでAIや機械学習、深層学習といった言葉が使われています。本章ではAIと機械学習(ML)、深層学習の違いを理解しましょう。",
"_____no_output_____"
],
[
"## 人工知能(AI)とは?\n\nそもそも人工知能(AI)とは何でしょうか?",
"_____no_output_____"
],
[
"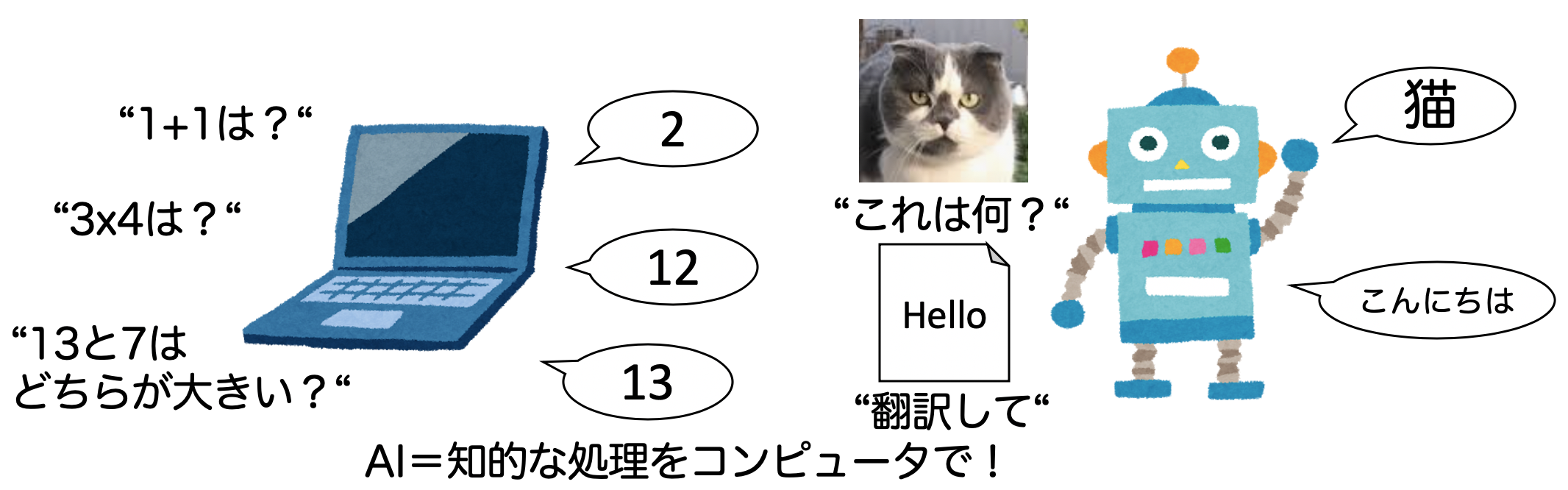\nWikipedia[1]によると、人工知能について以下のように書かれています。\n人工知能(じんこうちのう、英: artificial intelligence、AI〈エーアイ〉)とは「言語の理解や推論、問題解決などの知的行動を人間に代わってコンピュータに行わせる技術」。\n\n要は知的行動をコンピュータが行う技術のことですね。。もう少し歴史を遡ってみると、過去のコンピュータは日本語で計算機、その言葉通り「計算」をするための機械でした。今で言うと「電卓」そのものですね。つまり、電卓で行う計算\n(左の図)ではできない絵の認識や翻訳(右の図)などを知的な処理とし、その処理をコンピュータ、すなわち電卓などの計算機で行うんですね。\nつまり、こんな感じでしょうか。↓",
"_____no_output_____"
],
[
"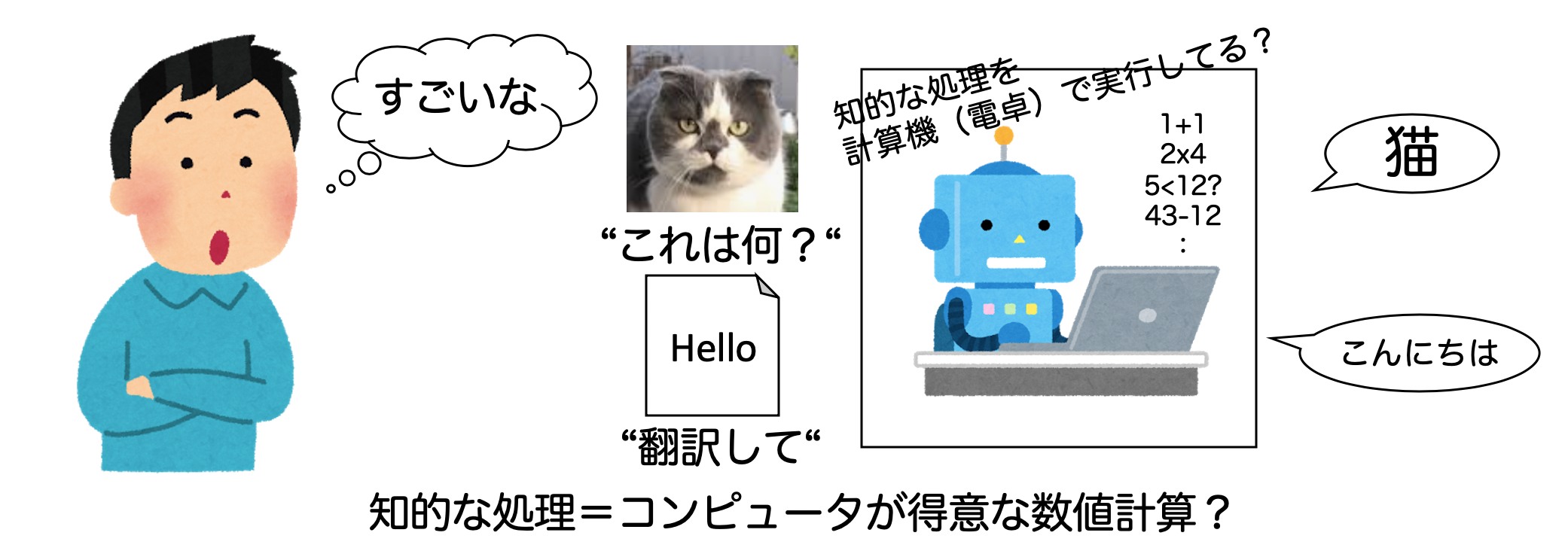\nあれ?と思われるかもしれませんが、現実は皆さんの身の回りのコンピュータが認識や翻訳をやってますよね。コンピュータに脳は入っていません。つまり、脳が行っている「知的な処理」というのをコンピュータが得意な電卓で行う計算に置き換えて処理しているのです。",
"_____no_output_____"
],
[
"## 今のコンピュータでできること\n\n\nそもそもコンピュータが得意な処理とは何でしょうか?それは電卓の例でもわかるように、数値の計算です。あと、数値の大小比較も得意です。つまり、数値にしてしまえばコンピュータで色々できそうですね。実際、写真の加工や音声の合成などはそれぞれデータを数値化することでコンピュータが処理できるようにしています。AIも数値を扱う問題に変換してしまえばよさそうですね。\n",
"_____no_output_____"
],
[
"# 簡単なAIを作ってみよう\n## ミニトマトを出荷用に収穫するかどうか判定するAI\n\n\n早速AIを作ってみてどんなものか体験してみましょう。ここではミニトマト農家になったつもりで、収穫するかどうかを自動で見分けてくれるAIを作ることにしましょう。",
"_____no_output_____"
],
[
"## コンピュータが処理できる数値の計算・比較処理に直す\n\nコンピュータは数値の計算と比較が得意なので、数値に直しましょう。例えばトマトの赤みを数値化することは画像処理(後半の章でOpenCVというライブラリを説明します)で比較的簡単にできます。市場価格はスーパーとかでトマトのパックを買って1個当たりの値段を算出すればわりと正確な値段が出ると思います。ここではあくまで私が適当に付けた値段ですが。。\n最後に、市場価格から収穫する/しないかどうかを決めます。これは予想した市場価格に対してあらかじめ決めておいた値との比較でできますね。\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nx = np.array([1,2,3,4,5])\ny = np.array([4,12,28,52,80])\n\nplt.plot(x,y, label=\"tomato\", marker=\"o\")",
"_____no_output_____"
]
],
[
[
"この関係をグラフに書いてみましょう。そうです、この関係を正しく推定できるとミニトマトの収穫を判断するAIができあがるのです!\nさて、どうやって推定しましょうか。。",
"_____no_output_____"
],
[
"## 直線で近似してみる\n\n学生時代(私は中学生)に習った直線の方程式で推定してみましょう。2次元グラフは任意の2点(x1,y1)-(x2,y2)間を直線で表現できます。\n直線による表現→y=ax+b でしたから、先ほどのグラフの数値(x1,y1)=(1,4), (x2,y2)=(5,80)より\n\n傾き: a=(y2-y1)/(x2-x1)=(80-4)/(5-1)=76/4=19\n切片: b=y-ax=4-19×1=-15\n\n従って y=19x-15 という直線式を得ました。これに間の値を代入してどの程度正しく予測できたかみてみましょう。",
"_____no_output_____"
]
],
[
[
"a = 19\nb = -15\ny_est1 = a * x + b\n\nplt.plot(x,y, label=\"tomato\", marker=\"o\")\nplt.plot(x,y_est1, label=\"estimation\", marker=\"o\")",
"_____no_output_____"
]
],
[
[
"うーん、ダメですね。。両端は上手く予想出来ていますが、その間の誤差が大きそうです。。",
"_____no_output_____"
],
[
"## 誤差を最小に抑える\n\nトライアンドエラーで誤差が最も小さくなる直線、すなわち傾きと切片を求めるのは大変そうです。そこで、全ての点の二乗誤差の合計を最小にするようにしましょう。二乗を使うのは正負に影響を受けないようにするためです。まず、傾きaの計算式は\n\na= Sum of (x-xの平均)*(y-yの平均) / Sum of (x-xの平均)^2 \n\nです。計算してみましょう。\n\nx_mean = (1+2+3+4+5)/5=3\n\na = 192/10=19.2 と計算できましたね。Jupyter NotebookはPythonプログラミングもできるので、試行錯誤しながらプログラミングするのにとても向いています。\n\n切片bは\n\nb=yの平均 - a×xの平均\n\nです。計算するとb=-22.4です。\n",
"_____no_output_____"
]
],
[
[
"a = 19.2\nb = -22.4\ny_est2 = a * x + b\n\nplt.plot(x,y, label=\"tomato\", marker=\"o\")\nplt.plot(x,y_est2, label=\"estimation (mean of squared error(MSE))\", marker=\"o\")",
"_____no_output_____"
]
],
[
[
"おお、今度はデータの間をちょうど通る直線が引けましたね!なんとなく実際の市場価格を推定できてそうです。",
"_____no_output_____"
],
[
"## 他の近似式では?\n\nするどい!何も直線式で近似する必要はないです。その通りです。2次式・多項式・さらに複雑な式、、色々ありすぎて困りますね。AIの設計は近似式をどうやって決めるかがポイントですがトライアンドエラーをするしかないのが現状です。それに、近似式のいろいろな値(今回は傾きと切片)を決めるのも大変そうですね。。\n最近ではクラウド上の計算機を大量に使って力技で探しています。ただ、それでも探す範囲が広すぎるので全自動化はまだ難しいのが現状です。",
"_____no_output_____"
],
[
"## これまでのステップは機械学習そのものだった\n\n実はこれまでの一連の作業は機械学習というAIの1分野の手法を使ったのでした。具体的には\n色や市場価格を準備する→データを収集する\n近似式を決める→モデルを設計する\n切片や傾きを求める→学習を行う(ハイパーパラメータを決める)\n推定がどれくらい正確かを確認する→モデルの検定を行う\nをやっていたのです。最近、機械学習・AIが紛れていましたが、なんとなく両者の関係がわかってきましたでしょうか?AIを設計する=機械学習で設計する、といっても過言でないくらい今日では機械学習が主流となっています。次回は機械学習をより詳しく説明します。",
"_____no_output_____"
],
[
"## 課題\n\nAIを使ったアプリケーション・製品について一つ調査し、レポートを提出してください。\n\nフォーマット:PDF形式(図、文章、参考にした文献(URL))\n提出先:T2Scholar\n締め切り: (講義中にアナウンスします)",
"_____no_output_____"
],
[
"## 参考文献\n[1] https://ja.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%9F%A5%E8%83%BD",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a03076fd681ce7614b681ac03ccae433474b71c
| 3,779 |
ipynb
|
Jupyter Notebook
|
test.ipynb
|
numediart/Crowd-Counting-with-MCNNs
|
321a98061fd9466c4750631516134d1475672b31
|
[
"MIT"
] | 7 |
2019-12-09T09:30:45.000Z
|
2020-10-20T19:47:54.000Z
|
test.ipynb
|
numediart/Crowd-Counting-with-MCNNs
|
321a98061fd9466c4750631516134d1475672b31
|
[
"MIT"
] | null | null | null |
test.ipynb
|
numediart/Crowd-Counting-with-MCNNs
|
321a98061fd9466c4750631516134d1475672b31
|
[
"MIT"
] | null | null | null | 28.201493 | 288 | 0.576872 |
[
[
[
"# Crowd-Counting using Multi-Column Convolutional Neural Networks.\nPublication: Zhang, Y., Zhou, D., Chen, S., Gao, S., & Ma, Y. (2016). Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 589-597).",
"_____no_output_____"
]
],
[
[
"from network import MCNN\nimport cv2\nfrom matplotlib import pyplot as plt",
"_____no_output_____"
],
[
"dataset='A' # A or B \nmcnn = MCNN(dataset)",
"WARNING:tensorflow:From C:\\Users\\sohai\\AppData\\Local\\conda\\conda\\envs\\deep\\lib\\site-packages\\tensorflow\\python\\framework\\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\n"
]
],
[
[
"## Test on single image",
"_____no_output_____"
]
],
[
[
"# image path\nimg_path = '.\\\\data\\\\original\\\\shanghaitech\\\\part_'+ dataset +'_final\\\\test_data\\\\images\\\\IMG_11.jpg'\nimg_path = '7.jpg'\n\n# For predicting the count of people in one Image.\nnumoppl, den_sum = mcnn.predict(img_path)\nprint('Predicted: ', int(numoppl))\nprint('Ground Truth: ', den_sum)\n\n\nimg = cv2.imread(img_path)\ncv2.putText(img, 'Prediction : ' + str(int(numoppl)), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)\ncv2.putText(img, 'Ground Tth : ' + str(den_sum), (10, 70), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 0), 2)\nimg = img[:,:,::-1]\nplt.imshow(img)\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"## Evaluation on a dataset",
"_____no_output_____"
]
],
[
[
"mcnn.test()",
"WARNING:tensorflow:From C:\\Users\\sohai\\AppData\\Local\\conda\\conda\\envs\\deep\\lib\\site-packages\\tensorflow\\python\\training\\saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse standard file APIs to check for files with this prefix.\nINFO:tensorflow:Restoring parameters from modelA/model.ckpt\nloading test data from dataset A ...\n50 / 182\n100 / 182\n150 / 182\nloading test data from dataset A finished\nEvaluating...\nAccuracy: 75.3654509084816\nmae: 149.86965705536224\nmse: 233.41499676148027\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a0307ff24c846f2b40f32dadb95483223585f81
| 28,742 |
ipynb
|
Jupyter Notebook
|
demo/spark_58_transform.ipynb
|
trancept/docker-hadoop-spark-graphframes-jupyterlab
|
a71d1509f30ffcb5010a12df7dd0d34299d131b6
|
[
"Apache-2.0"
] | null | null | null |
demo/spark_58_transform.ipynb
|
trancept/docker-hadoop-spark-graphframes-jupyterlab
|
a71d1509f30ffcb5010a12df7dd0d34299d131b6
|
[
"Apache-2.0"
] | null | null | null |
demo/spark_58_transform.ipynb
|
trancept/docker-hadoop-spark-graphframes-jupyterlab
|
a71d1509f30ffcb5010a12df7dd0d34299d131b6
|
[
"Apache-2.0"
] | null | null | null | 33.814118 | 1,686 | 0.41709 |
[
[
[
"# Pre-traitement",
"_____no_output_____"
]
],
[
[
"import pyspark\nfrom pyspark.sql import SparkSession\nspark = SparkSession \\\n .builder \\\n .appName('Transform') \\\n .getOrCreate()\nsc = spark.sparkContext",
"_____no_output_____"
]
],
[
[
"# CountVectorizer\n\n",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import CountVectorizer\n\n# Input data: Each row is a bag of words with a ID.\ndf = spark.createDataFrame([\n (0, \"secret prize a b c\".split(\" \")),\n (1, \"a b prize c prize\".split(\" \"))\n], [\"id\", \"words\"])\n\n# fit a CountVectorizerModel from the corpus.\ncv = CountVectorizer(inputCol=\"words\", outputCol=\"features\", vocabSize=5, minDF=2.0)\n\nmodel = cv.fit(df)\n\nresult = model.transform(df)\nresult.show(truncate=False)",
"+---+------------------------+-------------------------------+\n|id |words |features |\n+---+------------------------+-------------------------------+\n|0 |[secret, prize, a, b, c]|(4,[0,1,2,3],[1.0,1.0,1.0,1.0])|\n|1 |[a, b, prize, c, prize] |(4,[0,1,2,3],[2.0,1.0,1.0,1.0])|\n+---+------------------------+-------------------------------+\n\n"
]
],
[
[
"# FeatureHasher",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import FeatureHasher\n\ndataset = spark.createDataFrame([\n (2.2, True, \"1\", \"foo\"),\n (3.3, False, \"2\", \"bar\"),\n (4.4, False, \"3\", \"baz\"),\n (5.5, False, \"4\", \"foo\")\n], [\"real\", \"bool\", \"stringNum\", \"string\"])\n\nhasher = FeatureHasher(inputCols=[\"real\", \"bool\", \"stringNum\", \"string\"],\n outputCol=\"features\")\n\nfeaturized = hasher.transform(dataset)\nfeaturized.show(truncate=False)",
"+----+-----+---------+------+--------------------------------------------------------+\n|real|bool |stringNum|string|features |\n+----+-----+---------+------+--------------------------------------------------------+\n|2.2 |true |1 |foo |(262144,[174475,247670,257907,262126],[2.2,1.0,1.0,1.0])|\n|3.3 |false|2 |bar |(262144,[70644,89673,173866,174475],[1.0,1.0,1.0,3.3]) |\n|4.4 |false|3 |baz |(262144,[22406,70644,174475,187923],[1.0,1.0,4.4,1.0]) |\n|5.5 |false|4 |foo |(262144,[70644,101499,174475,257907],[1.0,1.0,5.5,1.0]) |\n+----+-----+---------+------+--------------------------------------------------------+\n\n"
]
],
[
[
"# Tokenizer",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import Tokenizer, RegexTokenizer\nfrom pyspark.sql.functions import col, udf\nfrom pyspark.sql.types import IntegerType\n\nsentenceDataFrame = spark.createDataFrame([\n (0, \"Hi I heard about Spark\"),\n (1, \"I wish Java could use case classes\"),\n (2, \"Logistic,regression,models,are,neat\")\n], [\"id\", \"sentence\"])\n\ntokenizer = Tokenizer(inputCol=\"sentence\", outputCol=\"words\")\n\nregexTokenizer = RegexTokenizer(inputCol=\"sentence\", outputCol=\"words\", pattern=\"\\\\W\")\n# alternatively, pattern=\"\\\\w+\", gaps(False)\n\ncountTokens = udf(lambda words: len(words), IntegerType())\n\ntokenized = tokenizer.transform(sentenceDataFrame)\ntokenized.select(\"sentence\", \"words\")\\\n .withColumn(\"tokens\", countTokens(col(\"words\"))).show(truncate=False)",
"+-----------------------------------+------------------------------------------+------+\n|sentence |words |tokens|\n+-----------------------------------+------------------------------------------+------+\n|Hi I heard about Spark |[hi, i, heard, about, spark] |5 |\n|I wish Java could use case classes |[i, wish, java, could, use, case, classes]|7 |\n|Logistic,regression,models,are,neat|[logistic,regression,models,are,neat] |1 |\n+-----------------------------------+------------------------------------------+------+\n\n"
]
],
[
[
"# StopWordsRemover",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import StopWordsRemover\n\nsentenceData = spark.createDataFrame([\n (0, [\"I\", \"saw\", \"the\", \"red\", \"balloon\"]),\n (1, [\"Mary\", \"had\", \"a\", \"little\", \"lamb\"])\n], [\"id\", \"raw\"])\n\nremover = StopWordsRemover(inputCol=\"raw\", outputCol=\"filtered\")\nremover.transform(sentenceData).show(truncate=False)",
"+---+----------------------------+--------------------+\n|id |raw |filtered |\n+---+----------------------------+--------------------+\n|0 |[I, saw, the, red, balloon] |[saw, red, balloon] |\n|1 |[Mary, had, a, little, lamb]|[Mary, little, lamb]|\n+---+----------------------------+--------------------+\n\n"
]
],
[
[
"# NGram",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import NGram\n\nwordDataFrame = spark.createDataFrame([\n (0, [\"Hi\", \"I\", \"heard\", \"about\", \"Spark\"]),\n (1, [\"I\", \"wish\", \"Java\", \"could\", \"use\", \"case\", \"classes\"]),\n (2, [\"Logistic\", \"regression\", \"models\", \"are\", \"neat\"])\n], [\"id\", \"words\"])\n\nngram = NGram(n=3, inputCol=\"words\", outputCol=\"ngrams\")\n\nngramDataFrame = ngram.transform(wordDataFrame)\nngramDataFrame.select(\"ngrams\").show(truncate=False)",
"+--------------------------------------------------------------------------------+\n|ngrams |\n+--------------------------------------------------------------------------------+\n|[Hi I heard, I heard about, heard about Spark] |\n|[I wish Java, wish Java could, Java could use, could use case, use case classes]|\n|[Logistic regression models, regression models are, models are neat] |\n+--------------------------------------------------------------------------------+\n\n"
]
],
[
[
"# Binarizer",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import Binarizer\n\ncontinuousDataFrame = spark.createDataFrame([\n (0, 0.1),\n (1, 0.8),\n (2, 0.2)\n], [\"id\", \"feature\"])\n\nbinarizer = Binarizer(threshold=0.5, inputCol=\"feature\", outputCol=\"binarized_feature\")\n\nbinarizedDataFrame = binarizer.transform(continuousDataFrame)\n\nprint(\"Binarizer output with Threshold = %f\" % binarizer.getThreshold())\nbinarizedDataFrame.show()",
"Binarizer output with Threshold = 0.500000\n+---+-------+-----------------+\n| id|feature|binarized_feature|\n+---+-------+-----------------+\n| 0| 0.1| 0.0|\n| 1| 0.8| 1.0|\n| 2| 0.2| 0.0|\n+---+-------+-----------------+\n\n"
]
],
[
[
"# Analyse Par Composante Principale : PCA",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import PCA\nfrom pyspark.ml.linalg import Vectors\n\ndata = [(Vectors.sparse(5, [(1, 1.0), (3, 7.0)]),),\n (Vectors.dense([2.0, 0.0, 3.0, 4.0, 5.0]),),\n (Vectors.dense([4.0, 0.0, 0.0, 6.0, 7.0]),)]\ndf = spark.createDataFrame(data, [\"features\"])\n\npca = PCA(k=3, inputCol=\"features\", outputCol=\"pcaFeatures\")\nmodel = pca.fit(df)\n\nresult = model.transform(df).select(\"pcaFeatures\")\nresult.show(truncate=False)",
"+-----------------------------------------------------------+\n|pcaFeatures |\n+-----------------------------------------------------------+\n|[1.6485728230883807,-4.013282700516296,-5.524543751369388] |\n|[-4.645104331781534,-1.1167972663619026,-5.524543751369387]|\n|[-6.428880535676489,-5.337951427775355,-5.524543751369389] |\n+-----------------------------------------------------------+\n\n"
]
],
[
[
"# PolynomialExpansion",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import PolynomialExpansion\nfrom pyspark.ml.linalg import Vectors\n\ndf = spark.createDataFrame([\n (Vectors.dense([2.0, 1.0]),),\n (Vectors.dense([0.0, 0.0]),),\n (Vectors.dense([3.0, -1.0]),)\n], [\"features\"])\n\npolyExpansion = PolynomialExpansion(degree=3, inputCol=\"features\", outputCol=\"polyFeatures\")\npolyDF = polyExpansion.transform(df)\n\npolyDF.show(truncate=False)",
"+----------+------------------------------------------+\n|features |polyFeatures |\n+----------+------------------------------------------+\n|[2.0,1.0] |[2.0,4.0,8.0,1.0,2.0,4.0,1.0,2.0,1.0] |\n|[0.0,0.0] |[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0] |\n|[3.0,-1.0]|[3.0,9.0,27.0,-1.0,-3.0,-9.0,1.0,3.0,-1.0]|\n+----------+------------------------------------------+\n\n"
]
],
[
[
"# StringIndexer",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import StringIndexer\n\ndf = spark.createDataFrame(\n [(0, \"a\"), (1, \"b\"), (2, \"c\"), (3, \"a\"), (4, \"a\"), (5, \"c\")],\n [\"id\", \"category\"])\n\nindexer = StringIndexer(inputCol=\"category\", outputCol=\"categoryIndex\")\nindexed = indexer.fit(df).transform(df)\nindexed.show()",
"+---+--------+-------------+\n| id|category|categoryIndex|\n+---+--------+-------------+\n| 0| a| 0.0|\n| 1| b| 2.0|\n| 2| c| 1.0|\n| 3| a| 0.0|\n| 4| a| 0.0|\n| 5| c| 1.0|\n+---+--------+-------------+\n\n"
]
],
[
[
"# IndexToString",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import IndexToString, StringIndexer\n\ndf = spark.createDataFrame(\n [(0, \"a\"), (1, \"b\"), (2, \"c\"), (3, \"a\"), (4, \"a\"), (5, \"c\")],\n [\"id\", \"category\"])\n\nindexer = StringIndexer(inputCol=\"category\", outputCol=\"categoryIndex\")\nmodel = indexer.fit(df)\nindexed = model.transform(df)\n\nprint(\"Transformed string column '%s' to indexed column '%s'\"\n % (indexer.getInputCol(), indexer.getOutputCol()))\nindexed.show()\n\nprint(\"StringIndexer will store labels in output column metadata\\n\")\n\nconverter = IndexToString(inputCol=\"categoryIndex\", outputCol=\"originalCategory\")\nconverted = converter.transform(indexed)\n\nprint(\"Transformed indexed column '%s' back to original string column '%s' using \"\n \"labels in metadata\" % (converter.getInputCol(), converter.getOutputCol()))\nconverted.select(\"id\", \"categoryIndex\", \"originalCategory\").show()",
"Transformed string column 'category' to indexed column 'categoryIndex'\n+---+--------+-------------+\n| id|category|categoryIndex|\n+---+--------+-------------+\n| 0| a| 0.0|\n| 1| b| 2.0|\n| 2| c| 1.0|\n| 3| a| 0.0|\n| 4| a| 0.0|\n| 5| c| 1.0|\n+---+--------+-------------+\n\nStringIndexer will store labels in output column metadata\n\nTransformed indexed column 'categoryIndex' back to original string column 'originalCategory' using labels in metadata\n+---+-------------+----------------+\n| id|categoryIndex|originalCategory|\n+---+-------------+----------------+\n| 0| 0.0| a|\n| 1| 2.0| b|\n| 2| 1.0| c|\n| 3| 0.0| a|\n| 4| 0.0| a|\n| 5| 1.0| c|\n+---+-------------+----------------+\n\n"
]
],
[
[
"# OneHotEncoder",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import OneHotEncoder\n\ndf = spark.createDataFrame([\n (0.0, 1.0),\n (1.0, 0.0),\n (2.0, 1.0),\n (0.0, 2.0),\n (0.0, 1.0),\n (2.0, 0.0)\n], [\"categoryIndex1\", \"categoryIndex2\"])\n\nencoder = OneHotEncoder(inputCols=[\"categoryIndex1\", \"categoryIndex2\"],\n outputCols=[\"categoryVec1\", \"categoryVec2\"])\nmodel = encoder.fit(df)\nencoded = model.transform(df)\nencoded.show()",
"+--------------+--------------+-------------+-------------+\n|categoryIndex1|categoryIndex2| categoryVec1| categoryVec2|\n+--------------+--------------+-------------+-------------+\n| 0.0| 1.0|(2,[0],[1.0])|(2,[1],[1.0])|\n| 1.0| 0.0|(2,[1],[1.0])|(2,[0],[1.0])|\n| 2.0| 1.0| (2,[],[])|(2,[1],[1.0])|\n| 0.0| 2.0|(2,[0],[1.0])| (2,[],[])|\n| 0.0| 1.0|(2,[0],[1.0])|(2,[1],[1.0])|\n| 2.0| 0.0| (2,[],[])|(2,[0],[1.0])|\n+--------------+--------------+-------------+-------------+\n\n"
],
[
"from pyspark.ml.feature import IndexToString, StringIndexer\n\ndf = spark.createDataFrame(\n [(0, \"a\"), (1, \"b\"), (2, \"c\"), (3, \"a\"), (4, \"a\"), (5, \"c\")],\n [\"id\", \"category\"])\n\nindexer = StringIndexer(inputCol=\"category\", outputCol=\"categoryIndex\")\nmodel = indexer.fit(df)\nindexed = model.transform(df)\n\nprint(\"Transformed string column '%s' to indexed column '%s'\"\n % (indexer.getInputCol(), indexer.getOutputCol()))\nindexed.show()\n",
"Transformed string column 'category' to indexed column 'categoryIndex'\n+---+--------+-------------+\n| id|category|categoryIndex|\n+---+--------+-------------+\n| 0| a| 0.0|\n| 1| b| 2.0|\n| 2| c| 1.0|\n| 3| a| 0.0|\n| 4| a| 0.0|\n| 5| c| 1.0|\n+---+--------+-------------+\n\n"
],
[
"indexed.collect()",
"_____no_output_____"
],
[
"df = indexed\nencoder = OneHotEncoder(inputCols=[\"categoryIndex\"],\n outputCols=[\"OneHot\"])\nmodel = encoder.fit(df)\nencoded = model.transform(df)\nencoded.show()",
"+---+--------+-------------+-------------+\n| id|category|categoryIndex| OneHot|\n+---+--------+-------------+-------------+\n| 0| a| 0.0|(2,[0],[1.0])|\n| 1| b| 2.0| (2,[],[])|\n| 2| c| 1.0|(2,[1],[1.0])|\n| 3| a| 0.0|(2,[0],[1.0])|\n| 4| a| 0.0|(2,[0],[1.0])|\n| 5| c| 1.0|(2,[1],[1.0])|\n+---+--------+-------------+-------------+\n\n"
],
[
"encoded.take(3)",
"_____no_output_____"
]
],
[
[
"# VectorIndexer",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import VectorIndexer\n\ndata = spark.read.format(\"libsvm\").load(\"/demo/spark/mllib/sample_libsvm_data.txt\")\n\nindexer = VectorIndexer(inputCol=\"features\", outputCol=\"indexed\", maxCategories=10)\nindexerModel = indexer.fit(data)\n\ncategoricalFeatures = indexerModel.categoryMaps\nprint(\"Chose %d categorical features: %s\" %\n (len(categoricalFeatures), \", \".join(str(k) for k in categoricalFeatures.keys())))\n\n# Create new column \"indexed\" with categorical values transformed to indices\nindexedData = indexerModel.transform(data)\nindexedData.show()",
"Chose 351 categorical features: 645, 69, 365, 138, 101, 479, 333, 249, 0, 555, 666, 88, 170, 115, 276, 308, 5, 449, 120, 247, 614, 677, 202, 10, 56, 533, 142, 500, 340, 670, 174, 42, 417, 24, 37, 25, 257, 389, 52, 14, 504, 110, 587, 619, 196, 559, 638, 20, 421, 46, 93, 284, 228, 448, 57, 78, 29, 475, 164, 591, 646, 253, 106, 121, 84, 480, 147, 280, 61, 221, 396, 89, 133, 116, 1, 507, 312, 74, 307, 452, 6, 248, 60, 117, 678, 529, 85, 201, 220, 366, 534, 102, 334, 28, 38, 561, 392, 70, 424, 192, 21, 137, 165, 33, 92, 229, 252, 197, 361, 65, 97, 665, 583, 285, 224, 650, 615, 9, 53, 169, 593, 141, 610, 420, 109, 256, 225, 339, 77, 193, 669, 476, 642, 637, 590, 679, 96, 393, 647, 173, 13, 41, 503, 134, 73, 105, 2, 508, 311, 558, 674, 530, 586, 618, 166, 32, 34, 148, 45, 161, 279, 64, 689, 17, 149, 584, 562, 176, 423, 191, 22, 44, 59, 118, 281, 27, 641, 71, 391, 12, 445, 54, 313, 611, 144, 49, 335, 86, 672, 172, 113, 681, 219, 419, 81, 230, 362, 451, 76, 7, 39, 649, 98, 616, 477, 367, 535, 103, 140, 621, 91, 66, 251, 668, 198, 108, 278, 223, 394, 306, 135, 563, 226, 3, 505, 80, 167, 35, 473, 675, 589, 162, 531, 680, 255, 648, 112, 617, 194, 145, 48, 557, 690, 63, 640, 18, 282, 95, 310, 50, 67, 199, 673, 16, 585, 502, 338, 643, 31, 336, 613, 11, 72, 175, 446, 612, 143, 43, 250, 231, 450, 99, 363, 556, 87, 203, 671, 688, 104, 368, 588, 40, 304, 26, 258, 390, 55, 114, 171, 139, 418, 23, 8, 75, 119, 58, 667, 478, 536, 82, 620, 447, 36, 168, 146, 30, 51, 190, 19, 422, 564, 305, 107, 4, 136, 506, 79, 195, 474, 664, 532, 94, 283, 395, 332, 528, 644, 47, 15, 163, 200, 68, 62, 277, 691, 501, 90, 111, 254, 227, 337, 122, 83, 309, 560, 639, 676, 222, 592, 364, 100\n+-----+--------------------+--------------------+\n|label| features| indexed|\n+-----+--------------------+--------------------+\n| 0.0|(692,[127,128,129...|(692,[127,128,129...|\n| 1.0|(692,[158,159,160...|(692,[158,159,160...|\n| 1.0|(692,[124,125,126...|(692,[124,125,126...|\n| 1.0|(692,[152,153,154...|(692,[152,153,154...|\n| 1.0|(692,[151,152,153...|(692,[151,152,153...|\n| 0.0|(692,[129,130,131...|(692,[129,130,131...|\n| 1.0|(692,[158,159,160...|(692,[158,159,160...|\n| 1.0|(692,[99,100,101,...|(692,[99,100,101,...|\n| 0.0|(692,[154,155,156...|(692,[154,155,156...|\n| 0.0|(692,[127,128,129...|(692,[127,128,129...|\n| 1.0|(692,[154,155,156...|(692,[154,155,156...|\n| 0.0|(692,[153,154,155...|(692,[153,154,155...|\n| 0.0|(692,[151,152,153...|(692,[151,152,153...|\n| 1.0|(692,[129,130,131...|(692,[129,130,131...|\n| 0.0|(692,[154,155,156...|(692,[154,155,156...|\n| 1.0|(692,[150,151,152...|(692,[150,151,152...|\n| 0.0|(692,[124,125,126...|(692,[124,125,126...|\n| 0.0|(692,[152,153,154...|(692,[152,153,154...|\n| 1.0|(692,[97,98,99,12...|(692,[97,98,99,12...|\n| 1.0|(692,[124,125,126...|(692,[124,125,126...|\n+-----+--------------------+--------------------+\nonly showing top 20 rows\n\n"
]
],
[
[
"# Normalizer",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import Normalizer\nfrom pyspark.ml.linalg import Vectors\n\ndataFrame = spark.createDataFrame([\n (0, Vectors.dense([1.0, 0.5, -1.0]),),\n (1, Vectors.dense([2.0, 1.0, 1.0]),),\n (2, Vectors.dense([4.0, 10.0, 2.0]),)\n], [\"id\", \"features\"])\n\n# Normalize each Vector using $L^1$ norm.\nnormalizer = Normalizer(inputCol=\"features\", outputCol=\"normFeatures\", p=1.0)\nl1NormData = normalizer.transform(dataFrame)\nprint(\"Normalized using L^1 norm\")\nl1NormData.show()\n\n# Normalize each Vector using $L^\\infty$ norm.\nlInfNormData = normalizer.transform(dataFrame, {normalizer.p: float(\"inf\")})\nprint(\"Normalized using L^inf norm\")\nlInfNormData.show()",
"Normalized using L^1 norm\n+---+--------------+------------------+\n| id| features| normFeatures|\n+---+--------------+------------------+\n| 0|[1.0,0.5,-1.0]| [0.4,0.2,-0.4]|\n| 1| [2.0,1.0,1.0]| [0.5,0.25,0.25]|\n| 2|[4.0,10.0,2.0]|[0.25,0.625,0.125]|\n+---+--------------+------------------+\n\nNormalized using L^inf norm\n+---+--------------+--------------+\n| id| features| normFeatures|\n+---+--------------+--------------+\n| 0|[1.0,0.5,-1.0]|[1.0,0.5,-1.0]|\n| 1| [2.0,1.0,1.0]| [1.0,0.5,0.5]|\n| 2|[4.0,10.0,2.0]| [0.4,1.0,0.2]|\n+---+--------------+--------------+\n\n"
]
],
[
[
"# Imputer\n\nhttps://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.feature.Imputer",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import Imputer\n\ndf = spark.createDataFrame([\n (1.0, float(\"nan\")),\n (2.0, float(\"nan\")),\n (float(\"nan\"), 3.0),\n (4.0, 4.0),\n (5.0, 5.0)\n], [\"a\", \"b\"])\n\nimputer = Imputer(inputCols=[\"a\", \"b\"], outputCols=[\"out_a\", \"out_b\"])\nmodel = imputer.fit(df)\n\nmodel.transform(df).show()",
"+---+---+-----+-----+\n| a| b|out_a|out_b|\n+---+---+-----+-----+\n|1.0|NaN| 1.0| 4.0|\n|2.0|NaN| 2.0| 4.0|\n|NaN|3.0| 3.0| 3.0|\n|4.0|4.0| 4.0| 4.0|\n|5.0|5.0| 5.0| 5.0|\n+---+---+-----+-----+\n\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a0309fc24d59392ec164d2cc69b8cc45ee830bf
| 5,124 |
ipynb
|
Jupyter Notebook
|
notebooks/summary.ipynb
|
Joshua-Robison/MLWorkflow
|
b70fd61a6a982e1c28fe6ffb02ee1a5383e1a420
|
[
"MIT"
] | null | null | null |
notebooks/summary.ipynb
|
Joshua-Robison/MLWorkflow
|
b70fd61a6a982e1c28fe6ffb02ee1a5383e1a420
|
[
"MIT"
] | null | null | null |
notebooks/summary.ipynb
|
Joshua-Robison/MLWorkflow
|
b70fd61a6a982e1c28fe6ffb02ee1a5383e1a420
|
[
"MIT"
] | null | null | null | 27.847826 | 121 | 0.510929 |
[
[
[
"# Summary: Compare model results and final model selection\n\nUsing the Titanic dataset from [this](https://www.kaggle.com/c/titanic/overview) Kaggle competition.\n\nIn this section, we will do the following:\n1. Evaluate all of our saved models on the validation set\n2. Select the best model based on performance on the validation set\n3. Evaluate that model on the holdout test set",
"_____no_output_____"
],
[
"### Read in Data",
"_____no_output_____"
]
],
[
[
"import joblib\nimport pandas as pd\nfrom sklearn.metrics import accuracy_score, precision_score, recall_score\nfrom time import time\n\nval_features = pd.read_csv('../data/val_features.csv')\nval_labels = pd.read_csv('../data/val_labels.csv')\n\nte_features = pd.read_csv('../data/test_features.csv')\nte_labels = pd.read_csv('../data/test_labels.csv')",
"_____no_output_____"
]
],
[
[
"### Read in Models",
"_____no_output_____"
]
],
[
[
"models = {}\nfor mdl in ['LR', 'SVM', 'MLP', 'RF', 'GB']:\n models[mdl] = joblib.load('../models/{}_model.pkl'.format(mdl))",
"_____no_output_____"
],
[
"models",
"_____no_output_____"
]
],
[
[
"### Evaluate models on the validation set\n\n",
"_____no_output_____"
]
],
[
[
"def evaluate_model(name, model, features, labels):\n start = time()\n pred = model.predict(features)\n end = time()\n accuracy = round(accuracy_score(labels, pred), 3)\n precision = round(precision_score(labels, pred), 3)\n recall = round(recall_score(labels, pred), 3)\n print('{} -- Accuracy: {} / Precision: {} / Recall: {} / Latency: {}ms'.format(name,\n accuracy,\n precision,\n recall,\n round((end - start) * 1000, 1)))",
"_____no_output_____"
],
[
"for name, mdl in models.items():\n evaluate_model(name, mdl, val_features, val_labels)",
"LR -- Accuracy: 0.775 / Precision: 0.712 / Recall: 0.646 / Latency: 0.0ms\nSVM -- Accuracy: 0.747 / Precision: 0.672 / Recall: 0.6 / Latency: 0.0ms\nMLP -- Accuracy: 0.781 / Precision: 0.724 / Recall: 0.646 / Latency: 0.0ms\nRF -- Accuracy: 0.803 / Precision: 0.812 / Recall: 0.6 / Latency: 15.4ms\nGB -- Accuracy: 0.815 / Precision: 0.808 / Recall: 0.646 / Latency: 0.0ms\n"
]
],
[
[
"### Evaluate best model on test set\n\n",
"_____no_output_____"
]
],
[
[
"evaluate_model('Gradient Boosted Model', models['GB'], te_features, te_labels)",
"Gradient Boosted Model -- Accuracy: 0.816 / Precision: 0.852 / Recall: 0.684 / Latency: 0.0ms\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a031c4d3ac806bb118e79fd3989d93b9bca0519
| 51,035 |
ipynb
|
Jupyter Notebook
|
Modulo4/Ejercicios/1.DataFrames y Series-ejercicio.ipynb
|
AngieAnahi/TareaPython
|
1d5ab5105fe9dddc210a1bfa5ff9bc68bf78b2c5
|
[
"Apache-2.0"
] | null | null | null |
Modulo4/Ejercicios/1.DataFrames y Series-ejercicio.ipynb
|
AngieAnahi/TareaPython
|
1d5ab5105fe9dddc210a1bfa5ff9bc68bf78b2c5
|
[
"Apache-2.0"
] | null | null | null |
Modulo4/Ejercicios/1.DataFrames y Series-ejercicio.ipynb
|
AngieAnahi/TareaPython
|
1d5ab5105fe9dddc210a1bfa5ff9bc68bf78b2c5
|
[
"Apache-2.0"
] | null | null | null | 35.465601 | 125 | 0.366494 |
[
[
[
"# Importar Pandas",
"_____no_output_____"
]
],
[
[
"#importa pandas\nimport pandas",
"_____no_output_____"
]
],
[
[
"# Crear una Serie",
"_____no_output_____"
]
],
[
[
"# Crea una Serie de los numeros 10, 20 and 10.\n\nnumeros=[\"10\",\"20\",\"10\"]",
"_____no_output_____"
],
[
"# Crea una Serie con tres objetos: 'rojo', 'verde', 'azul'\ncolores=[\"rojo\",\"verde\",\"azul\"]\n",
"_____no_output_____"
]
],
[
[
"# Crear un Dataframe",
"_____no_output_____"
]
],
[
[
"# Crea un dataframe vacío llamado 'df'\nimport pandas as pd\ndf = pd.DataFrame()\n",
"_____no_output_____"
],
[
"# Crea una nueva columna en el dataframe, y asignale la primera serie que has creado\ndf['numeros'] = numeros\ndf",
"_____no_output_____"
],
[
"# Crea otra columna en el dataframe y asignale la segunda Serie que has creado\ndf['colores'] = colores\ndf",
"_____no_output_____"
]
],
[
[
"# Leer un dataframe",
"_____no_output_____"
]
],
[
[
"# Lee el archivo llamado 'avengers.csv\" localizado en la carpeta \"data\" y crea un DataFrame, llamado 'avengers'. \n# El archivo está localizado en \"data/avengers.csv\"\navengers = pd.read_csv(\"data/pandas/avengers.csv\")\n",
"_____no_output_____"
]
],
[
[
"# Inspeccionar un dataframe",
"_____no_output_____"
]
],
[
[
"# Muestra las primeras 5 filas del DataFrame.\navengers.head(5)\n",
"_____no_output_____"
],
[
"# Muestra las primeras 10 filas del DataFrame. \navengers.head(10)",
"_____no_output_____"
],
[
"# Muestra las últimas 5 filas del DataFrame.\navengers.tail(10)\n",
"_____no_output_____"
]
],
[
[
"# Tamaño del DataFrame",
"_____no_output_____"
]
],
[
[
"# Muestra el tamaño del DataFrame\navengers.shape",
"_____no_output_____"
]
],
[
[
"# Data types en un DataFrame",
"_____no_output_____"
]
],
[
[
"# Muestra los data types del dataframe\navengers.dtypes",
"_____no_output_____"
]
],
[
[
"# Editar el indice (index)",
"_____no_output_____"
]
],
[
[
"# Cambia el indice a la columna \"fecha_inicio\".\ndf2 = avengers.set_index(\"fecha_inicio\")\ndf2",
"_____no_output_____"
]
],
[
[
"# Ordenar el indice",
"_____no_output_____"
]
],
[
[
"# Ordena el índice de forma descendiente\nby_year = df2.sort_values('fecha_inicio',ascending=False)\nby_year",
"_____no_output_____"
]
],
[
[
"# Resetear el indice",
"_____no_output_____"
]
],
[
[
"# Resetea el índice\ndf2 = df2.reset_index(drop=True)\ndf2",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a03430ebf8100b94403cebb0c88416212348071
| 11,762 |
ipynb
|
Jupyter Notebook
|
APIs/APIs_downloading_images.ipynb
|
sedv8808/APIs_UBC_ML
|
617374bdd82f7b47a83665e008c70ad1a47c6fbe
|
[
"MIT"
] | 2 |
2022-03-14T22:08:53.000Z
|
2022-03-21T04:17:08.000Z
|
APIs/APIs_downloading_images.ipynb
|
sedv8808/APIs_UBC_ML
|
617374bdd82f7b47a83665e008c70ad1a47c6fbe
|
[
"MIT"
] | null | null | null |
APIs/APIs_downloading_images.ipynb
|
sedv8808/APIs_UBC_ML
|
617374bdd82f7b47a83665e008c70ad1a47c6fbe
|
[
"MIT"
] | 1 |
2022-02-19T20:13:11.000Z
|
2022-02-19T20:13:11.000Z
| 49.838983 | 259 | 0.681177 |
[
[
[
"## UBC Intro to Machine Learning\n\n### APIs\nInstructor: Socorro Dominguez \nFebruary 05, 2022\n\n## Exercise to try in your local machine",
"_____no_output_____"
],
[
"## Motivation\n\nFor our ML class, we want to do a Classifier that differentiates images from dogs and cats.\n\n## Problem\nWe need a dataset to do this. Our friends don't have enough cats and dogs. \nLet's take free, open and legal data from the [Unsplash Image API](https://unsplash.com/developers).\n\n## Caveats\nSometimes, raw data is unsuitable for machine learning algorithms. For instance, we may want:\n- Only images that are landscape (i.e. width > height)\n- All our images to be of the same resolution",
"_____no_output_____"
],
[
"---\n## Step 1: Get cat and dog image URLs from the API\nWe will use the [`search/photos` GET method](https://unsplash.com/documentation#search-photos).",
"_____no_output_____"
]
],
[
[
"import requests\nimport config as cfg\n\n# API variables\nroot_endpoint = 'https://api.unsplash.com/'\nclient_id = cfg.splash['key']\n\n# Wrapper function for making API calls and grabbing results\ndef search_photos(search_term):\n api_method = 'search/photos'\n endpoint = root_endpoint + api_method\n response = requests.get(endpoint, \n params={'query': search_term, 'per_page': 30, 'client_id': client_id})\n status_code, result = response.status_code, response.json()\n \n if status_code != 200:\n print(f'Bad status code: {status_code}')\n \n image_urls = [img['urls']['small'] for img in result['results']]\n \n return image_urls",
"_____no_output_____"
],
[
"dog_urls = search_photos('dog')\ncat_urls = search_photos('cat')",
"_____no_output_____"
],
[
"cat_urls",
"_____no_output_____"
]
],
[
[
"---\n## Step 2: Download the images from the URLs\n(Step 2a: Google [how to download an image from a URL in Python](https://stackoverflow.com/a/40944159))\n\nWe'll just define the function to download an image for now. Later on, we'll use it on images one at a time (but after doing some processing).",
"_____no_output_____"
]
],
[
[
"from PIL import Image\n\ndef download_image(url):\n image = Image.open(requests.get(url, stream=True).raw)\n return image",
"_____no_output_____"
],
[
"test_img = download_image(cat_urls[0])\ntest_img.show()",
"_____no_output_____"
]
],
[
[
"---\n## Step 3: Download and save images that meet our requirements\nWe'll need to know how to work with the [PIL Image data type](https://pillow.readthedocs.io/en/stable/reference/Image.html), which is what our `download_image(url)` function returns. Namely, we need to be able to a) get it's resolution and b) resize it.",
"_____no_output_____"
]
],
[
[
"import os\n\ndef is_landscape(image):\n return image.width > image.height\n\n\ndef save_category_images(urls, category_name, resolution=(256, 256)):\n save_folder = f'saved_images/{category_name}'\n if not os.path.exists(save_folder):\n os.mkdir(save_folder)\n \n for i, url in enumerate(urls):\n image = download_image(url)\n if is_landscape(image):\n image = image.resize(resolution)\n filename = f'{i:05d}.jpg'\n image.save(os.path.join(save_folder, filename))",
"_____no_output_____"
],
[
"save_category_images(dog_urls, 'dogs')\nsave_category_images(cat_urls, 'cats')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a0356905189204964e17ba96ad488f7fe8c9edc
| 83,475 |
ipynb
|
Jupyter Notebook
|
sqlalchemy_tutorial/sqlalchemy_tutorial.ipynb
|
somma/ipython
|
c539e52c513a9671bd3c453197582c0f6b392d53
|
[
"MIT"
] | null | null | null |
sqlalchemy_tutorial/sqlalchemy_tutorial.ipynb
|
somma/ipython
|
c539e52c513a9671bd3c453197582c0f6b392d53
|
[
"MIT"
] | null | null | null |
sqlalchemy_tutorial/sqlalchemy_tutorial.ipynb
|
somma/ipython
|
c539e52c513a9671bd3c453197582c0f6b392d53
|
[
"MIT"
] | null | null | null | 29.727564 | 1,532 | 0.553759 |
[
[
[
"# contents from [sqlalchemy ORM tutorial](http://docs.sqlalchemy.org/en/latest/orm/tutorial.html)\n---\n\n# Version check",
"_____no_output_____"
]
],
[
[
"import sqlalchemy\nsqlalchemy.__version__",
"_____no_output_____"
]
],
[
[
"# Connecting\n+ create_engien() 함수 파라미터, database url 형식은 [여기](http://docs.sqlalchemy.org/en/latest/core/engines.html#database-urls)에서 확인",
"_____no_output_____"
]
],
[
[
"from sqlalchemy import create_engine\nengine = create_engine('sqlite:///:memory:', echo=True)",
"_____no_output_____"
]
],
[
[
"# Declare mapping\n+ `__tablename__`, `primary_key` 는 필수",
"_____no_output_____"
]
],
[
[
"from sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy import Column, Integer, String\n\nBase = declarative_base()\nprint Base",
"<class 'sqlalchemy.ext.declarative.api.Base'>\n"
],
[
"class UserA(Base):\n __tablename__ = 'users_a'\n \n id = Column(Integer, primary_key=True)\n name = Column(String)\n fullname = Column(String)\n password = Column(String)\n \n def __repr__(self):\n return \"<UserA(name='{0}', fullname='{1}', password='{3}')>\".format(self.name, self.fullname, self.password)",
"_____no_output_____"
]
],
[
[
"# Create a schema",
"_____no_output_____"
]
],
[
[
"UserA.__table__",
"_____no_output_____"
]
],
[
[
"+ Table 객체는 많은 MetaData 객체로 이루어지는데, 신경 쓸 필요없다.\n\n Table(\n 'users', MetaData(bind=None), \n Column('id', Integer(), table=<users>, primary_key=True, nullable=False), \n Column('name', String(), table=<users>), \n Column('fullname', String(), table=<users>), \n Column('password', String(), table=<users>), \n schema=None)\n\n\n+ `Base.metadata.create_all( engine )` 을 호출해서 실제로 `users` 테이블을 생성한다.",
"_____no_output_____"
],
[
"+ VARCHAR 필드에 length 가 없는데, SQLite, Postgresql 에서는 유효하지만 다른 DB 에선 그렇지 않을 수 있으며 `String(250)` 형태로 써주면 VARCHAR 에 length 를 지정할 수 있음",
"_____no_output_____"
]
],
[
[
"class User(Base):\n __tablename__ = 'users'\n __table_args__ = {'extend_existing':True} # 이미 users 테이블이 존재하는 경우 덮어씀\n \n id = Column(Integer, primary_key=True)\n name = Column(String(50))\n fullname = Column(String(255))\n password = Column(String(255))\n \n def __repr__(self):\n return \"<User(id={3}, name='{0}', fullname='{1}', password='{2}')>\".format(self.name, self.fullname, self.password, self.id)\n \n# `users` table 을 실제로 생성한다. \nBase.metadata.create_all(engine)\n\n# `users`, `user_a` 테이블을 보려면\nUser.__table__",
"2015-02-24 23:56:16,496 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1\n"
]
],
[
[
"# Create an instance of the Mapped Class",
"_____no_output_____"
]
],
[
[
"ed_user = User(name=\"ed\", fullname=\"Ed jones\", password=\"EdsPasswordz\")\nprint ed_user\nprint ed_user.id # sqlalchemy sets default value",
"<User(id=None, name='ed', fullname='Ed jones', password='EdsPasswordz')>\nNone\n"
]
],
[
[
"# Creating a session\n`create_engine()` 을 통해서 `engine` 인스턴스가 아직 만들어지지 않은 경우\n\n Session = sessionmaker()\n ...\n # engine instance 를 만든 후\n ...\n ...\n # 나중에 engine 과 연결시켜 session 인스턴스를 생성할 수 도 있다.\n session = Session.configure(bind=engine)\n ...\n ",
"_____no_output_____"
]
],
[
[
"from sqlalchemy.orm import sessionmaker\nSession = sessionmaker(bind=engine)\nsession = Session() # session 인스턴스 생성",
"_____no_output_____"
]
],
[
[
"# Adding new objects\n+ session.add() 를 호출하는 시점에 `insert` 가 이루어지지 않고, 필요한 시점을 sqlalchemy 가 캐치해서 `insert` 한다. (select 를 한다든가...)",
"_____no_output_____"
]
],
[
[
"ed_user = User(name='ed', fullname='ed jones', password='edspasswordz')\nsession.add(ed_user)\nour_user = session.query(User).filter_by(name='ed').first()\nprint our_user, our_user.id",
"2015-02-24 23:56:36,782 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)\n"
]
],
[
[
"+ 여러 `User` 객체를 insert",
"_____no_output_____"
]
],
[
[
"session.add_all([\n User(name='somma', fullname='yonghwan, noh', password='passwordzzzzzz'), \n User(name='somma1', fullname='yonghwan, noh1', password='passwordzzzzzz1'), \n User(name='somma2', fullname='yonghwan, noh2', password='passwordzzzzzz2'), \n User(name='somma3', fullname='yonghwan, noh3', password='passwordzzzzzz3'), \n User(name='somma4', fullname='yonghwan, noh4', password='passwordzzzzzz4'), \n User(name='somma5', fullname='yonghwan, noh5', password='passwordzzzzzz5'), \n User(name='somma6', fullname='yonghwan, noh6', password='passwordzzzzzz6'), \n])",
"_____no_output_____"
]
],
[
[
"+ ed_user 객체의 값을 변경하면 알아서 감지해서 처리해준다. ",
"_____no_output_____"
]
],
[
[
"print ed_user\ned_user.password = 'changed passwordzz'\nprint ed_user\n\nsession.dirty # identity map 을 통해 변경이 일어난 객체를 보여주고\n\nsession.new # 추가된 객체들...\n\nsession.commit() # db 에 쓴다.\n\ned_user.id\n",
"<User(id=1, name='ed', fullname='ed jones', password='edspasswordz')>\n<User(id=1, name='ed', fullname='ed jones', password='changed passwordzz')>\n2015-02-24 23:43:03,690 INFO sqlalchemy.engine.base.Engine UPDATE users SET password=? WHERE users.id = ?\n"
]
],
[
[
"# Rolling Back\nsession 은 transaction 안에서 동작하기 때문에 rollback 할 수 있다. ",
"_____no_output_____"
]
],
[
[
"# modify ed_user's name\nprint ed_user.name\ned_user.name = 'not ed jones'\n\n# add erroneous user, `fake_user`\nfake_user = User(name=\"fakeuser\", fullname=\"invalid\", password=\"abcde\")\nsession.add(fake_user)\n\n# query\nsession.query(User).filter(User.name.in_(['not ed jones', 'fakeuser'])).all()",
"ed\n2015-02-24 10:15:38,661 INFO sqlalchemy.engine.base.Engine UPDATE users SET name=? WHERE users.id = ?\n"
],
[
"# rollback\nsession.rollback()\nprint session.query(User).filter(User.name.in_(['not ed jones', 'fakeuser'])).all()\nprint ed_user.name\n",
"2015-02-24 10:15:43,224 INFO sqlalchemy.engine.base.Engine ROLLBACK\n"
]
],
[
[
"# Querying",
"_____no_output_____"
],
[
"## basic query, order_by, label",
"_____no_output_____"
]
],
[
[
"for instance in session.query(User).order_by(User.id):\n print instance.name, instance.fullname\n \n\nfor name, fullname in session.query(User.name, User.fullname):\n print name, fullname\n \nfor row in session.query(User, User.name).all():\n print row.User, row.name\n \nfor row in session.query(User.name.label('name_label')).all():\n print row.name_label",
"2015-02-24 23:43:26,782 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users ORDER BY users.id\n"
]
],
[
[
"## alias, limit, offset",
"_____no_output_____"
]
],
[
[
"# alias\nfrom sqlalchemy.orm import aliased\nuser_alias = aliased(User, name='user_alias')\n\nfor row in session.query(user_alias, user_alias.name).all():\n print row.user_alias\n\n# limit \nfor u in session.query(User).order_by(User.id)[1:3]:\n print u\n ",
"2015-02-24 12:40:31,642 INFO sqlalchemy.engine.base.Engine SELECT user_alias.id AS user_alias_id, user_alias.name AS user_alias_name, user_alias.fullname AS user_alias_fullname, user_alias.password AS user_alias_password \nFROM users AS user_alias\n"
]
],
[
[
"## filtering results\n`session.query()` 의 결과는 `KeyedTuple` 객체, `for name, in ...` 이렇게 쓰면 name 에는 tuple[0] 이 할당되고, `for name in ...` 이렇게 쓰면 name 은 KeyedTuple 객체이므로 출력하려면 `name[0], name[1]` 이런식으로 사용하면 됨",
"_____no_output_____"
]
],
[
[
"for name in session.query(User.name).filter_by(fullname='ed jones'):\n print name[0], type(name)\n \nfor name, in session.query(User.name).filter_by(fullname='ed jones'):\n print name\n \nfor name, in session.query(User.name).filter(User.fullname=='ed jones'):\n print name\n \nfor name, in session.query(User.name).filter(User.name == 'ed').\\\n filter(User.fullname == 'ed jones'):\n print name",
"2015-02-24 23:43:39,792 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name \nFROM users \nWHERE users.fullname = ?\n"
]
],
[
[
"## common filter operators",
"_____no_output_____"
]
],
[
[
"# is null / is not null\nprint session.query(User).filter(User.name != None).first()\nprint session.query(User).filter(User.name.is_(None)).first() \nprint session.query(User).filter(User.name.isnot(None)).first()\n\n# not in\nprint session.query(User).filter(~User.name.in_(['ed', 'somma'])).first()\n\n# in\nprint session.query(User).filter(User.name.in_(['ed', 'somma'])).first()\n \n# like\nprint session.query(User).filter(User.name.like('%somma%')).first()\n\n# not equals\nprint session.query(User).filter(User.name != 'ed').first()\n \n# equals\nprint session.query(User).filter(User.name == 'ed').first()",
"2015-02-24 23:43:51,395 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name IS NOT NULL\n LIMIT ? OFFSET ?\n"
],
[
"# and \nfrom sqlalchemy import and_\nprint session.query(User).filter(and_(User.name == 'ed', User.fullname == 'ed jones')).first()\n\n# send multiple expression to .filter()\nprint session.query(User).filter(User.name == 'ed', User.fullname == 'ed jones').first()\n\n# or chain multiple filter()/filter_by() calls\nprint session.query(User).filter(User.name == 'ed').filter(User.fullname == 'ed jones').first()",
"2015-02-24 16:34:57,168 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name = ? AND users.fullname = ?\n LIMIT ? OFFSET ?\n"
],
[
"# or\nfrom sqlalchemy import or_\nprint session.query(User).filter(or_(User.name == 'ed', User.fullname == 'ed jones' )).first()",
"2015-02-24 16:36:11,789 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name = ? OR users.fullname = ?\n LIMIT ? OFFSET ?\n"
]
],
[
[
"# Returning Lists and Scalars",
"_____no_output_____"
]
],
[
[
"# all()\nquery = session.query(User).filter(User.name.like('somm%')).order_by(User.id)\nfor row in query.all():\n print row\n \n# first() \nprint query.first()",
"2015-02-24 20:16:35,249 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name LIKE ? ORDER BY users.id\n"
],
[
"# one() \nfrom sqlalchemy.orm.exc import NoResultFound, MultipleResultsFound\n\n# if no result\ntry:\n query = session.query(User).filter(User.name == 'no_name').order_by(User.id)\n users = query.one()\nexcept NoResultFound as e:\n print 'exception = {0}'.format(e.message)\n \n# if multiple results \ntry:\n query = session.query(User).filter(User.name.like('somma%')).order_by(User.id)\n users = query.one()\n print users\nexcept MultipleResultsFound as e:\n print 'exception = {0}'.format(e.message)\n \n\n# scalar()\n# return first element of first result or None if no result present. \n# if multiple result returned, `MultipleResultsFound` exception raised.\n\ntry:\n query = session.query(User).filter(User.name.like('somma%')).order_by(User.id)\n users = query.scalar()\nexcept MultipleResultsFound as e:\n print 'exception = {0}'.format(e.message)\n\n ",
"2015-02-24 20:51:26,339 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name = ? ORDER BY users.id\n"
]
],
[
[
"# Using Literal SQL",
"_____no_output_____"
]
],
[
[
"from sqlalchemy import text\nfor user in session.query(User).filter(text('id < 3')).order_by(text('id')).all():\n print user.name\n\nfor user in session.query(User).filter(text('id < :id and name = :name')).params(id = 3, name = 'somma').all():\n print user.name\n \nfor users in session.query(User).from_statement(text('select * from users where name=:name')).params(name='ed').all():\n print users\n \nfor id, name, third_ret in session.query('id', 'name', 'the_number_12')\\\n .from_statement(text('select id, name, 12 as the_number_12 from users where name like :name'))\\\n .params(name='somma%').all():\n print '{0}, {1}, {2}'.format(id, name, third_ret)\n \n ",
"2015-02-24 23:44:12,296 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE id < 3 ORDER BY id\n"
]
],
[
[
"# Counting",
"_____no_output_____"
]
],
[
[
"print session.query(User).count()\nprint session.query(User).filter(User.name.like('somma%')).count()",
"2015-02-24 21:37:24,838 INFO sqlalchemy.engine.base.Engine SELECT count(*) AS count_1 \nFROM (SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users) AS anon_1\n"
]
],
[
[
"## count() more nicer way!",
"_____no_output_____"
]
],
[
[
"from sqlalchemy import func\nsession.query(func.count(User.name), User.name).group_by(User.name).all()\n\n# select count(*) from users\nsession.query(func.count('*')).select_from(User).scalar()\n\n# `select_from()` can be removed if express the count of User's primary key.\nsession.query(func.count(User.id)).scalar()",
"2015-02-24 21:47:12,503 INFO sqlalchemy.engine.base.Engine SELECT count(users.name) AS count_1, users.name AS users_name \nFROM users GROUP BY users.name\n"
]
],
[
[
"---\n# Building a Relationship",
"_____no_output_____"
]
],
[
[
"from sqlalchemy import ForeignKey\nfrom sqlalchemy.orm import relationship, backref\n\nclass Address(Base):\n __tablename__ = 'addresses'\n #__table_args__ = {'extend_existing':True} # 이미 users 테이블이 존재하는 경우 덮어씀\n \n id = Column(Integer, primary_key = True)\n email_address = Column(String, nullable = False)\n user_id = Column(Integer, ForeignKey('users.id'))\n\n user = relationship('User', backref = backref('addresses', order_by = id))\n \n def __repr__(self):\n return '<Address (email_address = {0})>'.format(self.email_address)\n \n# create table \nBase.metadata.create_all(engine)\n\n",
"_____no_output_____"
]
],
[
[
"---\n# Working with Related Objects",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a036565ade4e29892d778b2419aa5e9f37eca91
| 739,754 |
ipynb
|
Jupyter Notebook
|
docs/notebooks/single_stock_example.ipynb
|
quantopian-enterprise/pyfolio
|
e4af4db77e38393914b30bc06ab5a83f9675ff57
|
[
"Apache-2.0"
] | 4,542 |
2015-07-14T02:34:19.000Z
|
2022-03-31T02:12:06.000Z
|
docs/notebooks/single_stock_example.ipynb
|
quantopian-enterprise/pyfolio
|
e4af4db77e38393914b30bc06ab5a83f9675ff57
|
[
"Apache-2.0"
] | 558 |
2015-07-14T18:16:43.000Z
|
2022-03-15T02:22:23.000Z
|
docs/notebooks/single_stock_example.ipynb
|
quantopian-enterprise/pyfolio
|
e4af4db77e38393914b30bc06ab5a83f9675ff57
|
[
"Apache-2.0"
] | 1,572 |
2015-07-15T23:06:09.000Z
|
2022-03-31T17:54:33.000Z
| 2,077.960674 | 729,626 | 0.945341 |
[
[
[
"# Single stock analysis example in pyfolio\n\nHere's a simple example where we produce a set of plots, called a tear sheet, for a single stock.",
"_____no_output_____"
],
[
"## Import pyfolio and matplotlib",
"_____no_output_____"
]
],
[
[
"import pyfolio as pf\n%matplotlib inline\n\n# silence warnings\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
]
],
[
[
"## Fetch the daily returns for a stock",
"_____no_output_____"
]
],
[
[
"stock_rets = pf.utils.get_symbol_rets('FB')",
"_____no_output_____"
]
],
[
[
"## Create a returns tear sheet for the single stock\nThis will show charts and analysis about returns of the single stock.",
"_____no_output_____"
]
],
[
[
"pf.create_returns_tear_sheet(stock_rets, live_start_date='2015-12-1')",
"Entire data start date: 2012-05-21\nEntire data end date: 2017-08-22\nIn-sample months: 42\nOut-of-sample months: 20\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a0365681f738dec31027e051a4b8fd43bc38b4f
| 45,636 |
ipynb
|
Jupyter Notebook
|
analysis/optimus5/mse_benchmark_synth_seqs_two_starts_one_stop_lowSeq_l2x_and_invase_full_data.ipynb
|
willshi88/scrambler
|
fd77c05824fc99e6965d204c4f5baa1e3b0c4fb3
|
[
"MIT"
] | 19 |
2021-04-30T04:12:58.000Z
|
2022-03-07T19:09:32.000Z
|
analysis/optimus5/mse_benchmark_synth_seqs_two_starts_one_stop_lowSeq_l2x_and_invase_full_data.ipynb
|
willshi88/scrambler
|
fd77c05824fc99e6965d204c4f5baa1e3b0c4fb3
|
[
"MIT"
] | 4 |
2021-07-02T15:07:27.000Z
|
2021-08-01T12:41:28.000Z
|
analysis/optimus5/mse_benchmark_synth_seqs_two_starts_one_stop_lowSeq_l2x_and_invase_full_data.ipynb
|
willshi88/scrambler
|
fd77c05824fc99e6965d204c4f5baa1e3b0c4fb3
|
[
"MIT"
] | 4 |
2021-06-28T09:41:01.000Z
|
2022-02-28T09:13:29.000Z
| 52.394948 | 12,880 | 0.685446 |
[
[
[
"#12/29/20\n#runnign synthetic benchmark graphs for synthetic OR datasets generated\n",
"_____no_output_____"
],
[
"#making benchmark images \nimport keras\nfrom keras.models import Sequential, Model, load_model\n\nfrom keras.layers import Dense, Dropout, Activation, Flatten, Input, Lambda\nfrom keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, Conv1D, MaxPooling1D, LSTM, ConvLSTM2D, GRU, CuDNNLSTM, CuDNNGRU, BatchNormalization, LocallyConnected2D, Permute, TimeDistributed, Bidirectional\nfrom keras.layers import Concatenate, Reshape, Softmax, Conv2DTranspose, Embedding, Multiply\nfrom keras.callbacks import ModelCheckpoint, EarlyStopping, Callback\nfrom keras import regularizers\nfrom keras import backend as K\nfrom keras.utils.generic_utils import Progbar\nfrom keras.layers.merge import _Merge\nimport keras.losses\nfrom keras.datasets import mnist\n\nfrom functools import partial\n\nfrom collections import defaultdict\n\nimport tensorflow as tf\nfrom tensorflow.python.framework import ops\n\nimport isolearn.keras as iso\n\nimport numpy as np\n\nimport tensorflow as tf\nimport logging\nlogging.getLogger('tensorflow').setLevel(logging.ERROR)\n\nimport os\nimport pickle\nimport numpy as np\n\nimport isolearn.io as isoio\nimport isolearn.keras as isol\n\nimport pandas as pd\n\nimport scipy.sparse as sp\nimport scipy.io as spio\n\nimport matplotlib.pyplot as plt\n\nfrom sequence_logo_helper import dna_letter_at, plot_dna_logo\n\nfrom keras.backend.tensorflow_backend import set_session\n\ndef contain_tf_gpu_mem_usage() :\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n sess = tf.Session(config=config)\n set_session(sess)\n\ncontain_tf_gpu_mem_usage()\n\nclass EpochVariableCallback(Callback) :\n \n def __init__(self, my_variable, my_func) :\n self.my_variable = my_variable \n self.my_func = my_func\n \n def on_epoch_begin(self, epoch, logs={}) :\n K.set_value(self.my_variable, self.my_func(K.get_value(self.my_variable), epoch))\n",
"Using TensorFlow backend.\n"
],
[
"#ONLY RUN THIS CELL ONCE \nfrom tensorflow.python.framework import ops\n\n#Stochastic Binarized Neuron helper functions (Tensorflow)\n#ST Estimator code adopted from https://r2rt.com/beyond-binary-ternary-and-one-hot-neurons.html\n#See Github https://github.com/spitis/\n\ndef st_sampled_softmax(logits):\n with ops.name_scope(\"STSampledSoftmax\") as namescope :\n nt_probs = tf.nn.softmax(logits)\n onehot_dim = logits.get_shape().as_list()[1]\n sampled_onehot = tf.one_hot(tf.squeeze(tf.multinomial(logits, 1), 1), onehot_dim, 1.0, 0.0)\n with tf.get_default_graph().gradient_override_map({'Ceil': 'Identity', 'Mul': 'STMul'}):\n return tf.ceil(sampled_onehot * nt_probs)\n\ndef st_hardmax_softmax(logits):\n with ops.name_scope(\"STHardmaxSoftmax\") as namescope :\n nt_probs = tf.nn.softmax(logits)\n onehot_dim = logits.get_shape().as_list()[1]\n sampled_onehot = tf.one_hot(tf.argmax(nt_probs, 1), onehot_dim, 1.0, 0.0)\n with tf.get_default_graph().gradient_override_map({'Ceil': 'Identity', 'Mul': 'STMul'}):\n return tf.ceil(sampled_onehot * nt_probs)\n\[email protected](\"STMul\")\ndef st_mul(op, grad):\n return [grad, grad]\n\n#Gumbel Distribution Sampler\ndef gumbel_softmax(logits, temperature=0.5) :\n gumbel_dist = tf.contrib.distributions.RelaxedOneHotCategorical(temperature, logits=logits)\n batch_dim = logits.get_shape().as_list()[0]\n onehot_dim = logits.get_shape().as_list()[1]\n return gumbel_dist.sample()\n",
"_____no_output_____"
],
[
"#PWM Masking and Sampling helper functions\n\ndef mask_pwm(inputs) :\n pwm, onehot_template, onehot_mask = inputs\n\n return pwm * onehot_mask + onehot_template\n\ndef sample_pwm_st(pwm_logits) :\n n_sequences = K.shape(pwm_logits)[0]\n seq_length = K.shape(pwm_logits)[2]\n\n flat_pwm = K.reshape(pwm_logits, (n_sequences * seq_length, 4))\n sampled_pwm = st_sampled_softmax(flat_pwm)\n\n return K.reshape(sampled_pwm, (n_sequences, 1, seq_length, 4))\n\ndef sample_pwm_gumbel(pwm_logits) :\n n_sequences = K.shape(pwm_logits)[0]\n seq_length = K.shape(pwm_logits)[2]\n\n flat_pwm = K.reshape(pwm_logits, (n_sequences * seq_length, 4))\n sampled_pwm = gumbel_softmax(flat_pwm, temperature=0.5)\n\n return K.reshape(sampled_pwm, (n_sequences, 1, seq_length, 4))\n\n#Generator helper functions\ndef initialize_sequence_templates(generator, sequence_templates, background_matrices) :\n\n embedding_templates = []\n embedding_masks = []\n embedding_backgrounds = []\n\n for k in range(len(sequence_templates)) :\n sequence_template = sequence_templates[k]\n onehot_template = iso.OneHotEncoder(seq_length=len(sequence_template))(sequence_template).reshape((1, len(sequence_template), 4))\n\n for j in range(len(sequence_template)) :\n if sequence_template[j] not in ['N', 'X'] :\n nt_ix = np.argmax(onehot_template[0, j, :])\n onehot_template[:, j, :] = -4.0\n onehot_template[:, j, nt_ix] = 10.0\n elif sequence_template[j] == 'X' :\n onehot_template[:, j, :] = -1.0\n\n onehot_mask = np.zeros((1, len(sequence_template), 4))\n for j in range(len(sequence_template)) :\n if sequence_template[j] == 'N' :\n onehot_mask[:, j, :] = 1.0\n\n embedding_templates.append(onehot_template.reshape(1, -1))\n embedding_masks.append(onehot_mask.reshape(1, -1))\n embedding_backgrounds.append(background_matrices[k].reshape(1, -1))\n\n embedding_templates = np.concatenate(embedding_templates, axis=0)\n embedding_masks = np.concatenate(embedding_masks, axis=0)\n embedding_backgrounds = np.concatenate(embedding_backgrounds, axis=0)\n\n generator.get_layer('template_dense').set_weights([embedding_templates])\n generator.get_layer('template_dense').trainable = False\n\n generator.get_layer('mask_dense').set_weights([embedding_masks])\n generator.get_layer('mask_dense').trainable = False\n \n generator.get_layer('background_dense').set_weights([embedding_backgrounds])\n generator.get_layer('background_dense').trainable = False\n\n#Generator construction function\ndef build_sampler(batch_size, seq_length, n_classes=1, n_samples=1, sample_mode='st') :\n\n #Initialize Reshape layer\n reshape_layer = Reshape((1, seq_length, 4))\n \n #Initialize background matrix\n onehot_background_dense = Embedding(n_classes, seq_length * 4, embeddings_initializer='zeros', name='background_dense')\n\n #Initialize template and mask matrices\n onehot_template_dense = Embedding(n_classes, seq_length * 4, embeddings_initializer='zeros', name='template_dense')\n onehot_mask_dense = Embedding(n_classes, seq_length * 4, embeddings_initializer='ones', name='mask_dense')\n\n #Initialize Templating and Masking Lambda layer\n masking_layer = Lambda(mask_pwm, output_shape = (1, seq_length, 4), name='masking_layer')\n background_layer = Lambda(lambda x: x[0] + x[1], name='background_layer')\n \n #Initialize PWM normalization layer\n pwm_layer = Softmax(axis=-1, name='pwm')\n \n #Initialize sampling layers\n sample_func = None\n if sample_mode == 'st' :\n sample_func = sample_pwm_st\n elif sample_mode == 'gumbel' :\n sample_func = sample_pwm_gumbel\n \n upsampling_layer = Lambda(lambda x: K.tile(x, [n_samples, 1, 1, 1]), name='upsampling_layer')\n sampling_layer = Lambda(sample_func, name='pwm_sampler')\n permute_layer = Lambda(lambda x: K.permute_dimensions(K.reshape(x, (n_samples, batch_size, 1, seq_length, 4)), (1, 0, 2, 3, 4)), name='permute_layer')\n \n def _sampler_func(class_input, raw_logits) :\n \n #Get Template and Mask\n onehot_background = reshape_layer(onehot_background_dense(class_input))\n onehot_template = reshape_layer(onehot_template_dense(class_input))\n onehot_mask = reshape_layer(onehot_mask_dense(class_input))\n \n #Add Template and Multiply Mask\n pwm_logits = masking_layer([background_layer([raw_logits, onehot_background]), onehot_template, onehot_mask])\n \n #Compute PWM (Nucleotide-wise Softmax)\n pwm = pwm_layer(pwm_logits)\n \n #Tile each PWM to sample from and create sample axis\n pwm_logits_upsampled = upsampling_layer(pwm_logits)\n sampled_pwm = sampling_layer(pwm_logits_upsampled)\n sampled_pwm = permute_layer(sampled_pwm)\n\n sampled_mask = permute_layer(upsampling_layer(onehot_mask))\n \n return pwm_logits, pwm, sampled_pwm, onehot_mask, sampled_mask\n \n return _sampler_func\n\n#for formulation 2 graphing \ndef returnXMeanLogits(e_train):\n #returns x mean logits for displayign the pwm difference for the version 2 networks \n #Visualize background sequence distribution\n seq_e_train = one_hot_encode(e_train,seq_len=50)\n x_train = seq_e_train\n x_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1], x_train.shape[2]))\n\n pseudo_count = 1.0\n\n x_mean = (np.sum(x_train, axis=(0, 1)) + pseudo_count) / (x_train.shape[0] + 4. * pseudo_count)\n x_mean_logits = np.log(x_mean / (1. - x_mean))\n return x_mean_logits, x_mean\n",
"_____no_output_____"
],
[
"#loading testing dataset \n\nfrom optimusFunctions import *\nimport pandas as pd\n\ncsv_to_open = \"optimus5_synthetic_random_insert_if_uorf_2_start_1_stop_variable_loc_512.csv\"\n\n\ndataset_name = csv_to_open.replace(\".csv\", \"\")\nprint (dataset_name)\ndata_df = pd.read_csv(\"./\" + csv_to_open) #open from scores folder \n#loaded test set which is sorted by number of start/stop signals \n\nseq_e_test = one_hot_encode(data_df, seq_len=50)\nbenchmarkSet_seqs = seq_e_test\nx_test = np.reshape(benchmarkSet_seqs, (benchmarkSet_seqs.shape[0], 1, benchmarkSet_seqs.shape[1], benchmarkSet_seqs.shape[2]))\nprint (x_test.shape)\n\n",
"optimus5_synthetic_random_insert_if_uorf_2_start_1_stop_variable_loc_512\n(512, 1, 50, 4)\n"
],
[
"\n\ne_train = pd.read_csv(\"bottom5KIFuAUGTop5KIFuAUG.csv\")\n\nprint (\"training: \", e_train.shape[0], \" testing: \", x_test.shape[0])\nseq_e_train = one_hot_encode(e_train,seq_len=50)\nx_mean_logits, x_mean = returnXMeanLogits(e_train)\nseq_e_train = one_hot_encode(e_train,seq_len=50)\nx_train = seq_e_train\nx_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1], x_train.shape[2]))\n",
"training: 15008 testing: 512\n"
],
[
"#background \n\n#for formulation 2 graphing \ndef returnXMeanLogits(e_train):\n #returns x mean logits for displayign the pwm difference for the version 2 networks \n #Visualize background sequence distribution\n seq_e_train = one_hot_encode(e_train,seq_len=50)\n x_train = seq_e_train\n x_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1], x_train.shape[2]))\n\n pseudo_count = 1.0\n\n x_mean = (np.sum(x_train, axis=(0, 1)) + pseudo_count) / (x_train.shape[0] + 4. * pseudo_count)\n x_mean_logits = np.log(x_mean / (1. - x_mean))\n return x_mean_logits, x_mean\n\ne_train = pd.read_csv(\"bottom5KIFuAUGTop5KIFuAUG.csv\")\nprint (\"training: \", e_train.shape[0], \" testing: \", x_test.shape[0])\n#one hot encode with optimus encoders \nseq_e_train = one_hot_encode(e_train,seq_len=50)\nx_mean_logits, x_mean = returnXMeanLogits(e_train)\nx_train = seq_e_train\nx_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1], x_train.shape[2]))\n",
"training: 15008 testing: 512\n"
],
[
"#Define sequence template for optimus\n\nsequence_template = 'N'*50\nsequence_mask = np.array([1 if sequence_template[j] == 'N' else 0 for j in range(len(sequence_template))])\n\n#Visualize background sequence distribution\n\nsave_figs = True\nplot_dna_logo(np.copy(x_mean), sequence_template=sequence_template, figsize=(14, 0.65), logo_height=1.0, plot_start=0, plot_end=50)\n\n#Calculate mean training set conservation\n\nentropy = np.sum(x_mean * -np.log(x_mean), axis=-1) / np.log(2.0)\nconservation = 2.0 - entropy\nx_mean_conservation = np.sum(conservation) / np.sum(sequence_mask)\nprint(\"Mean conservation (bits) = \" + str(x_mean_conservation))\n\n#Calculate mean training set kl-divergence against background\nx_train_clipped = np.clip(np.copy(x_train[:, 0, :, :]), 1e-8, 1. - 1e-8)\nkl_divs = np.sum(x_train_clipped * np.log(x_train_clipped / np.tile(np.expand_dims(x_mean, axis=0), (x_train_clipped.shape[0], 1, 1))), axis=-1) / np.log(2.0)\nx_mean_kl_divs = np.sum(kl_divs * sequence_mask, axis=-1) / np.sum(sequence_mask)\nx_mean_kl_div = np.mean(x_mean_kl_divs)\nprint(\"Mean KL Div against background (bits) = \" + str(x_mean_kl_div))\n\n",
"_____no_output_____"
],
[
"#Initialize Encoder and Decoder networks\nbatch_size = 32\nseq_length = 50\nn_samples = 128\nsample_mode = 'st'\n#sample_mode = 'gumbel'\n\n#Load sampler\nsampler = build_sampler(batch_size, seq_length, n_classes=1, n_samples=n_samples, sample_mode=sample_mode)\n\n#Load Predictor\npredictor_path = 'optimusRetrainedMain.hdf5'\npredictor = load_model(predictor_path)\npredictor.trainable = False\npredictor.compile(optimizer=keras.optimizers.SGD(lr=0.1), loss='mean_squared_error')\n",
"_____no_output_____"
],
[
"#Build scrambler model\ndummy_class = Input(shape=(1,), name='dummy_class')\ninput_logits = Input(shape=(1, seq_length, 4), name='input_logits')\n\npwm_logits, pwm, sampled_pwm, pwm_mask, sampled_mask = sampler(dummy_class, input_logits)\n\nscrambler_model = Model([input_logits, dummy_class], [pwm_logits, pwm, sampled_pwm, pwm_mask, sampled_mask])\n\n#Initialize Sequence Templates and Masks\ninitialize_sequence_templates(scrambler_model, [sequence_template], [x_mean_logits])\n\nscrambler_model.trainable = False\nscrambler_model.compile(\n optimizer=keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999),\n loss='mean_squared_error'\n)\n",
"_____no_output_____"
],
[
"#open all score and reshape as needed \n\nfile_names = [\n \"l2x_\" + dataset_name + \"_importance_scores_test.npy\",\n \"invase_\" + dataset_name + \"_conv_importance_scores_test.npy\",\n \"l2x_\" + dataset_name + \"_full_data_importance_scores_test.npy\",\n \"invase_\" + dataset_name + \"_conv_full_data_importance_scores_test.npy\",\n]\n#deepexplain_optimus_utr_OR_logic_synth_1_start_2_stops_method_integrated_gradients_importance_scores_test.npy\n\nmodel_names =[\n \"l2x\",\n \"invase\",\n \"l2x_full_data\",\n \"invase_full_data\",\n]\n\nmodel_importance_scores_test = [np.load(\"./\" + file_name) for file_name in file_names]\n\nfor scores in model_importance_scores_test:\n print (scores.shape)\n\nfor model_i in range(len(model_names)) :\n if model_importance_scores_test[model_i].shape[-1] > 1 :\n model_importance_scores_test[model_i] = np.sum(model_importance_scores_test[model_i], axis=-1, keepdims=True)\n\nfor scores in model_importance_scores_test:\n print (scores.shape)\n \n#reshape for mse script -> if not (3008, 1, 50, 1) make it that shape \nidealShape = model_importance_scores_test[0].shape\nprint (idealShape)\n\nfor model_i in range(len(model_names)) :\n if model_importance_scores_test[model_i].shape != idealShape:\n model_importance_scores_test[model_i] = np.expand_dims(model_importance_scores_test[model_i], 1)\n \nfor scores in model_importance_scores_test:\n print (scores.shape)\n",
"(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n(512, 1, 50, 1)\n"
],
[
"\non_state_logit_val = 50.\nprint (x_test.shape)\n\ndummy_test = np.zeros((x_test.shape[0], 1))\nx_test_logits = 2. * x_test - 1.\n\nprint (x_test_logits.shape)\nprint (dummy_test.shape)\n\n\nx_test_squeezed = np.squeeze(x_test)\ny_pred_ref = predictor.predict([x_test_squeezed], batch_size=32, verbose=True)[0]\n\n_, _, _, pwm_mask, sampled_mask = scrambler_model.predict([x_test_logits, dummy_test], batch_size=batch_size)\n\n",
"(512, 1, 50, 4)\n(512, 1, 50, 4)\n(512, 1)\n512/512 [==============================] - 1s 3ms/step\n"
],
[
"feature_quantiles = [0.76, 0.82, 0.88]\n\nfor name in model_names:\n for quantile in feature_quantiles:\n totalName = name + \"_\" + str(quantile).replace(\".\",\"_\") + \"_quantile_MSE\"\n data_df[totalName] = None\n \nprint (data_df.columns)",
"Index(['Unnamed: 0', 'utr', 'gt', 'orig', 'l2x_0_76_quantile_MSE',\n 'l2x_0_82_quantile_MSE', 'l2x_0_88_quantile_MSE',\n 'invase_0_76_quantile_MSE', 'invase_0_82_quantile_MSE',\n 'invase_0_88_quantile_MSE', 'l2x_full_data_0_76_quantile_MSE',\n 'l2x_full_data_0_82_quantile_MSE', 'l2x_full_data_0_88_quantile_MSE',\n 'invase_full_data_0_76_quantile_MSE',\n 'invase_full_data_0_82_quantile_MSE',\n 'invase_full_data_0_88_quantile_MSE'],\n dtype='object')\n"
],
[
"\nfeature_quantiles = [0.76, 0.82, 0.88]\n\n#batch_size = 128 \nfrom sklearn import metrics\nmodel_mses = []\nfor model_i in range(len(model_names)) :\n \n print(\"Benchmarking model '\" + str(model_names[model_i]) + \"'...\")\n \n feature_quantile_mses = []\n \n for feature_quantile_i, feature_quantile in enumerate(feature_quantiles) :\n \n print(\"Feature quantile = \" + str(feature_quantile))\n \n if len(model_importance_scores_test[model_i].shape) >= 5 :\n importance_scores_test = np.abs(model_importance_scores_test[model_i][feature_quantile_i, ...])\n else :\n importance_scores_test = np.abs(model_importance_scores_test[model_i])\n \n n_to_test = importance_scores_test.shape[0] // batch_size * batch_size\n importance_scores_test = importance_scores_test[:n_to_test]\n \n importance_scores_test *= np.expand_dims(np.max(pwm_mask[:n_to_test], axis=-1), axis=-1)\n\n quantile_vals = np.quantile(importance_scores_test, axis=(1, 2, 3), q=feature_quantile, keepdims=True)\n quantile_vals = np.tile(quantile_vals, (1, importance_scores_test.shape[1], importance_scores_test.shape[2], importance_scores_test.shape[3]))\n\n top_logits_test = np.zeros(importance_scores_test.shape)\n top_logits_test[importance_scores_test > quantile_vals] = on_state_logit_val\n \n top_logits_test = np.tile(top_logits_test, (1, 1, 1, 4)) * x_test_logits[:n_to_test]\n\n _, _, samples_test, _, _ = scrambler_model.predict([top_logits_test, dummy_test[:n_to_test]], batch_size=batch_size)\n print (samples_test.shape)\n msesPerPoint = []\n for data_ix in range(samples_test.shape[0]) :\n #for each sample, look at kl divergence for the 128 size batch generated \n #for MSE, just track the pred vs original pred \n if data_ix % 1000 == 0 :\n print(\"Processing example \" + str(data_ix) + \"...\")\n \n #from optimus R^2, MSE, Pearson R script \n justPred = np.expand_dims(np.expand_dims(x_test[data_ix, 0, :, :], axis=0), axis=-1)\n justPredReshape = np.reshape(justPred, (1,50,4))\n \n expanded = np.expand_dims(samples_test[data_ix, :, 0, :, :], axis=-1) #batch size is 128 \n expandedReshape = np.reshape(expanded, (n_samples, 50,4))\n \n y_test_hat_ref = predictor.predict(x=justPredReshape, batch_size=1)[0][0]\n \n y_test_hat = predictor.predict(x=[expandedReshape], batch_size=32)\n \n pwmGenerated = y_test_hat.tolist()\n tempOriginals = [y_test_hat_ref]*y_test_hat.shape[0]\n \n asArrayOrig = np.array(tempOriginals)\n asArrayGen = np.array(pwmGenerated)\n squeezed = np.squeeze(asArrayGen)\n mse = metrics.mean_squared_error(asArrayOrig, squeezed)\n #msesPerPoint.append(mse)\n totalName = model_names[model_i] + \"_\" + str(feature_quantile).replace(\".\",\"_\") + \"_quantile_MSE\"\n data_df.at[data_ix, totalName] = mse\n msesPerPoint.append(mse)\n msesPerPoint = np.array(msesPerPoint)\n feature_quantile_mses.append(msesPerPoint)\n model_mses.append(feature_quantile_mses)",
"Benchmarking model 'l2x'...\nFeature quantile = 0.76\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.82\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.88\n(512, 128, 1, 50, 4)\nProcessing example 0...\nBenchmarking model 'invase'...\nFeature quantile = 0.76\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.82\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.88\n(512, 128, 1, 50, 4)\nProcessing example 0...\nBenchmarking model 'l2x_full_data'...\nFeature quantile = 0.76\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.82\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.88\n(512, 128, 1, 50, 4)\nProcessing example 0...\nBenchmarking model 'invase_full_data'...\nFeature quantile = 0.76\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.82\n(512, 128, 1, 50, 4)\nProcessing example 0...\nFeature quantile = 0.88\n(512, 128, 1, 50, 4)\nProcessing example 0...\n"
],
[
"#Store benchmark results as tables\n\nsave_figs = False\n\nmse_table = np.zeros((len(model_mses), len(model_mses[0])))\n\nfor i, model_name in enumerate(model_names) :\n \n for j, feature_quantile in enumerate(feature_quantiles) :\n \n mse_table[i, j] = np.mean(model_mses[i][j])\n\n#Plot and store mse table\nf = plt.figure(figsize = (4, 6))\n\ncells = np.round(mse_table, 3).tolist()\n\nprint(\"--- MSEs ---\")\nmax_len = np.max([len(model_name.upper().replace(\"\\n\", \" \")) for model_name in model_names])\nprint((\"-\" * max_len) + \" \" + \" \".join([(str(feature_quantile) + \"0\")[:4] for feature_quantile in feature_quantiles]))\nfor i in range(len(cells)) :\n \n curr_len = len([model_name.upper().replace(\"\\n\", \" \") for model_name in model_names][i])\n row_str = [model_name.upper().replace(\"\\n\", \" \") for model_name in model_names][i] + (\" \" * (max_len - curr_len))\n \n for j in range(len(cells[i])) :\n cells[i][j] = (str(cells[i][j]) + \"00000\")[:4]\n \n row_str += \" \" + cells[i][j]\n \n print(row_str)\n\nprint(\"\")\n\ntable = plt.table(cellText=cells, rowLabels=[model_name.upper().replace(\"\\n\", \" \") for model_name in model_names], colLabels=feature_quantiles, loc='center')\n\nax = plt.gca()\n#f.patch.set_visible(False)\nax.axis('off')\nax.axis('tight')\n\nplt.tight_layout()\n\nif save_figs :\n plt.savefig(dataset_name + \"_l2x_and_invase_full_data\" + \"_mse_table.png\", dpi=300, transparent=True)\n plt.savefig(dataset_name + \"_l2x_and_invase_full_data\" + \"_mse_table.eps\")\n\nplt.show()\n",
"--- MSEs ---\n---------------- 0.76 0.82 0.88\nL2X 2.49 2.51 2.61\nINVASE 2.08 2.24 2.47\nL2X_FULL_DATA 2.28 2.40 2.56\nINVASE_FULL_DATA 2.77 2.80 2.85\n\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a0371c7b19b8fe5996e055b4447f5ed38d59f10
| 218,649 |
ipynb
|
Jupyter Notebook
|
analysis_for_LHCO/SignalTrainer_BB2_REFINED_prior.ipynb
|
violatingcp/QUASAR
|
60d1c00d0c461bc706631d4210e31a80d1a3c482
|
[
"MIT"
] | 1 |
2020-05-27T20:18:15.000Z
|
2020-05-27T20:18:15.000Z
|
analysis_for_LHCO/SignalTrainer_BB2_REFINED_prior.ipynb
|
violatingcp/QUASAR
|
60d1c00d0c461bc706631d4210e31a80d1a3c482
|
[
"MIT"
] | 3 |
2021-03-19T13:53:32.000Z
|
2022-03-12T00:38:06.000Z
|
analysis_for_LHCO/SignalTrainer_BB2_REFINED_prior.ipynb
|
violatingcp/QUASAR
|
60d1c00d0c461bc706631d4210e31a80d1a3c482
|
[
"MIT"
] | 3 |
2020-05-11T08:30:01.000Z
|
2020-10-06T17:35:25.000Z
| 78.679021 | 36,584 | 0.761906 |
[
[
[
"# Signal Autoencoder",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport scipy as sp\nimport scipy.stats\nimport itertools\nimport logging\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport torch.utils.data as utils\nimport math\nimport time\nimport tqdm\n\nimport torch\nimport torch.optim as optim\nimport torch.nn.functional as F\nfrom argparse import ArgumentParser\nfrom torch.distributions import MultivariateNormal\n\nimport torch.nn as nn\nimport torch.nn.init as init\nimport sys\nsys.path.append(\"../new_flows\")\nfrom flows import RealNVP, Planar, MAF\nfrom models import NormalizingFlowModel",
"_____no_output_____"
],
[
"####MAF \nclass VAE_NF(nn.Module):\n def __init__(self, K, D):\n super().__init__()\n self.dim = D\n self.K = K\n self.encoder = nn.Sequential(\n nn.Linear(16, 50),\n nn.LeakyReLU(True),\n nn.Linear(50, 48),\n nn.LeakyReLU(True), \n nn.Linear(48, D * 2)\n )\n\n self.decoder = nn.Sequential(\n nn.Linear(D, 48),\n nn.LeakyReLU(True),\n nn.Linear(48, 50),\n nn.LeakyReLU(True),\n nn.Linear(50, 16)\n )\n \n flow_init = MAF(dim=D)\n flows_init = [flow_init for _ in range(K)]\n prior = MultivariateNormal(torch.zeros(D).cuda(), torch.eye(D).cuda())\n self.flows = NormalizingFlowModel(prior, flows_init)\n\n def forward(self, x):\n # Run Encoder and get NF params\n enc = self.encoder(x)\n mu = enc[:, :self.dim]\n log_var = enc[:, self.dim: self.dim * 2]\n\n # Re-parametrize\n sigma = (log_var * .5).exp()\n z = mu + sigma * torch.randn_like(sigma)\n kl_div = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())\n # Construct more expressive posterior with NF\n \n z_k, _, sum_ladj = self.flows(z)\n \n kl_div = kl_div / x.size(0) - sum_ladj.mean() # mean over batch\n\n # Run Decoder\n x_prime = self.decoder(z_k)\n return x_prime, kl_div",
"_____no_output_____"
],
[
"prong_2 = pd.read_hdf(\"/data/t3home000/spark/QUASAR/preprocessing/delphes_output_5000_850_450.h5\")\n#prong_3 = pd.read_hdf(\"/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_3prong_rnd.h5\")",
"_____no_output_____"
],
[
"columns = prong_2.columns",
"_____no_output_____"
],
[
"columns",
"_____no_output_____"
],
[
"dt = prong_2.values\ncorrect = (dt[:,3]>0) &(dt[:,19]>0) & (dt[:,1]>0) & (dt[:,2]>0) &(dt[:,2]>0) & (dt[:,16]>0) & (dt[:,32]>0)\ndt = dt[correct]\nfor i in range(13,19):\n dt[:,i] = dt[:,i]/dt[:,3]\n\nfor i in range(29,35):\n dt[:,i] = dt[:,i]/(dt[:,19])\n\n\ncorrect = (dt[:,16]>0) & (dt[:,29]>=0) &(dt[:,29]<=1)&(dt[:,30]>=0) &(dt[:,30]<=1)&(dt[:,31]>=0) &(dt[:,31]<=1)&(dt[:,32]>=0) &(dt[:,32]<=1)&(dt[:,33]>=0) &(dt[:,33]<=1)&(dt[:,34]>=-0.01) &(dt[:,34]<=1)\ndt = dt[correct]\n\n\n#Y = dt[:,[3,4,5,6,11,12,19,20,21,22,27,28]]\n#Y = dt[:,[4,5,6,7,8,11,12,13,14,15,16,17,18,20,21,22,23,24,27,28,29,30,31,32,33,34]] # When no jet 1,2 raw mass included\n#Y = dt[:,[3,4,5,6,11,12,13,14,15,16,17,18,19,20,21,22,27,28,29,30,31,32,33,34]]\n#idx = dt[:,-1]\n#bkg_idx = np.where(idx==0)[0]\n#signal_idx = np.where((idx==1) & (dt[:,3]>300))[0]\n#signal_idx = np.where((idx==1)) [0]\n#dt = dt[signal_idx]\n \nbsmlike = np.where(dt[:,16]>0.9)[0]\ndt = dt[bsmlike]\n",
"_____no_output_____"
],
[
"dt.shape",
"_____no_output_____"
],
[
"j1sdb = dt[:,3]*dt[:,16]\nj2sdb = dt[:,19]*dt[:,32]\n\npt = dt[:,1]\nm = j1sdb[:]\nm2 = j2sdb[:]\ntau21 = dt[:,4]\ntau32 = dt[:,5]\ntau43 = dt[:,6]\ntau54 = dt[:,7]\ntau65 = dt[:,8]\nmassratio = dt[:,16]\n\nrho = np.log((m*m)/(pt*pt))\nrhoprime = np.log((m*m)/(pt*1))\n\ntau21prime = tau21 + rhoprime * 0.088\ntau32prime = tau32 + rhoprime * 0.025\ntau43prime = tau43 + rhoprime * 0.01\ntau54prime = tau54 + rhoprime * 0.001\nj2pt = dt[:,2]\n#m = j1sdb[mrange]\nj2m = j2sdb[:]\nj2tau21 = dt[:,20]\nj2tau32 = dt[:,21]\nj2tau43 = dt[:,22]\nj2tau54 = dt[:,23]\nj2tau65 = dt[:,24]\nj2massratio = dt[:,32]\n\n\nj2rho = np.log((j2m*j2m)/(j2pt*j2pt))\nj2rhoprime = np.log((j2m*j2m)/(j2pt*1))\n\nj2tau21prime = j2tau21 + j2rhoprime * 0.086\nj2tau32prime = j2tau32 + j2rhoprime * 0.025\nj2tau43prime = j2tau43 + j2rhoprime * 0.01\nj2tau54prime = j2tau54 + j2rhoprime * 0.001",
"_____no_output_____"
],
[
"dt[:,4] = tau21prime\ndt[:,5] = tau32prime\ndt[:,6] = tau43prime\ndt[:,7] = tau54prime\n\ndt[:,20] = j2tau21prime \ndt[:,21] = j2tau32prime\ndt[:,22] = j2tau43prime\ndt[:,23] = j2tau54prime",
"_____no_output_____"
],
[
"columns[19]",
"_____no_output_____"
],
[
"m1minusm2 = dt[:,3] - dt[:,19] \n\ndt[:,19] = m1minusm2",
"_____no_output_____"
],
[
"Y = dt[:,[3,4,5,6,7,8,11,12,19,20,21,22,23,24,27,28]]",
"_____no_output_____"
],
[
"Y.shape",
"_____no_output_____"
],
[
"#if nprong == 3:\n# dt = prong_3.values\n# correct = (dt[:,3]>20) &(dt[:,19]>20)\n# dt = dt[correct]\n# for i in range(13,19):\n# dt[:,i] = dt[:,i]/dt[:,3]\n \n# for i in range(29,35):\n# dt[:,i] = dt[:,i]/(dt[:,19])\n \n# correct = (dt[:,29]>=0) &(dt[:,29]<=1)&(dt[:,30]>=0) &(dt[:,30]<=1)&(dt[:,31]>=0) &(dt[:,31]<=1)&(dt[:,32]>=0) &(dt[:,32]<=1)&(dt[:,33]>=0) &(dt[:,33]<=1)&(dt[:,34]>=-0.01) &(dt[:,34]<=1)\n# dt = dt[correct] \n \n# Y = dt[:,[4,5,6,7,8,11,12,13,14,15,16,17,18,20,21,22,23,24,27,28,29,30,31,32,33,34]]\n# #Y = dt[:,[3,4,5,6,11,12,19,20,21,22,27,28]]\n# idx = dt[:,-1]\n# bkg_idx = np.where(idx==0)[0]\n# signal_idx = np.where((idx==1) & (dt[:,3]>400))[0]\n# #signal_idx = np.where((idx==1)) [0]\n# Y = Y[signal_idx]",
"_____no_output_____"
],
[
"bins = np.linspace(0,1,100)\nbins.shape\ncolumn = 5\n#print(f_rnd.columns[column])\nplt.hist(dt[:,16],bins,alpha=0.5,color='b');\n#plt.hist(sigout[:,column],bins,alpha=0.5,color='r');\n#plt.hist(out2[:,column],bins,alpha=0.5,color='g');\n#plt.axvline(np.mean(Y[:,column]))",
"_____no_output_____"
],
[
"Y.shape",
"_____no_output_____"
],
[
"sig_mean = []\nsig_std = []\nfor i in range(16):\n mean = np.mean(Y[:,i])\n std = np.std(Y[:,i])\n sig_mean.append(mean)\n sig_std.append(std)\n Y[:,i] = (Y[:,i]-mean)/std",
"_____no_output_____"
],
[
"sig_mean",
"_____no_output_____"
],
[
"sig_std",
"_____no_output_____"
],
[
"total_sig = torch.tensor(Y)",
"_____no_output_____"
],
[
"total_sig.shape",
"_____no_output_____"
],
[
"bins = np.linspace(-3,3,100)\nbins.shape\ncolumn = 5\n#print(f_rnd.columns[column])\nplt.hist(Y[:,1],bins,alpha=0.5,color='b');\n#plt.hist(sigout[:,column],bins,alpha=0.5,color='r');\n#plt.hist(out2[:,column],bins,alpha=0.5,color='g');\n#plt.axvline(np.mean(Y[:,column]))",
"_____no_output_____"
],
[
"N_EPOCHS = 30\nPRINT_INTERVAL = 2000\nNUM_WORKERS = 4\nLR = 1e-6\n\n#N_FLOWS = 6 \n#Z_DIM = 8\n\nN_FLOWS = 10\nZ_DIM = 6\n\nn_steps = 0",
"_____no_output_____"
],
[
"sigmodel = VAE_NF(N_FLOWS, Z_DIM).cuda()",
"_____no_output_____"
],
[
"print(sigmodel)",
"VAE_NF(\n (encoder): Sequential(\n (0): Linear(in_features=16, out_features=50, bias=True)\n (1): LeakyReLU(negative_slope=True)\n (2): Linear(in_features=50, out_features=48, bias=True)\n (3): LeakyReLU(negative_slope=True)\n (4): Linear(in_features=48, out_features=12, bias=True)\n )\n (decoder): Sequential(\n (0): Linear(in_features=6, out_features=48, bias=True)\n (1): LeakyReLU(negative_slope=True)\n (2): Linear(in_features=48, out_features=50, bias=True)\n (3): LeakyReLU(negative_slope=True)\n (4): Linear(in_features=50, out_features=16, bias=True)\n )\n (flows): NormalizingFlowModel(\n (flows): ModuleList(\n (0): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (1): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (2): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (3): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (4): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (5): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (6): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (7): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (8): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (9): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n )\n )\n)\n"
],
[
"bs = 800\nsig_train_iterator = utils.DataLoader(total_sig, batch_size=bs, shuffle=True) \nsig_test_iterator = utils.DataLoader(total_sig, batch_size=bs)",
"_____no_output_____"
],
[
"sigoptimizer = optim.Adam(sigmodel.parameters(), lr=1e-6)",
"_____no_output_____"
],
[
"beta = 1",
"_____no_output_____"
],
[
"def sigtrain():\n global n_steps\n train_loss = []\n sigmodel.train()\n\n for batch_idx, x in enumerate(sig_train_iterator):\n start_time = time.time()\n \n x = x.float().cuda()\n\n x_tilde, kl_div = sigmodel(x)\n mseloss = nn.MSELoss(size_average=False)\n huberloss = nn.SmoothL1Loss(size_average=False)\n #loss_recons = F.binary_cross_entropy(x_tilde, x, size_average=False) / x.size(0)\n loss_recons = mseloss(x_tilde,x ) / x.size(0)\n #loss_recons = huberloss(x_tilde,x ) / x.size(0)\n loss = loss_recons + beta* kl_div\n\n sigoptimizer.zero_grad()\n loss.backward()\n sigoptimizer.step()\n\n train_loss.append([loss_recons.item(), kl_div.item()])\n\n if (batch_idx + 1) % PRINT_INTERVAL == 0:\n print('\\tIter [{}/{} ({:.0f}%)]\\tLoss: {} Time: {:5.3f} ms/batch'.format(\n batch_idx * len(x), 50000,\n PRINT_INTERVAL * batch_idx / 50000,\n np.asarray(train_loss)[-PRINT_INTERVAL:].mean(0),\n 1000 * (time.time() - start_time)\n ))\n\n n_steps += 1",
"_____no_output_____"
],
[
"def sigevaluate(split='valid'):\n global n_steps\n start_time = time.time()\n val_loss = []\n sigmodel.eval()\n\n with torch.no_grad():\n for batch_idx, x in enumerate(sig_test_iterator):\n \n x = x.float().cuda()\n\n x_tilde, kl_div = sigmodel(x)\n mseloss = nn.MSELoss(size_average=False)\n huberloss = nn.SmoothL1Loss(size_average=False)\n #loss_recons = F.binary_cross_entropy(x_tilde, x, size_average=False) / x.size(0)\n loss_recons = mseloss(x_tilde,x ) / x.size(0)\n #loss_recons = huberloss(x_tilde,x ) / x.size(0)\n loss = loss_recons + beta * kl_div\n\n val_loss.append(loss.item())\n #writer.add_scalar('loss/{}/ELBO'.format(split), loss.item(), n_steps)\n #writer.add_scalar('loss/{}/reconstruction'.format(split), loss_recons.item(), n_steps)\n #writer.add_scalar('loss/{}/KL'.format(split), kl_div.item(), n_steps)\n\n print('\\nEvaluation Completed ({})!\\tLoss: {:5.4f} Time: {:5.3f} s'.format(\n split,\n np.asarray(val_loss).mean(0),\n time.time() - start_time\n ))\n return np.asarray(val_loss).mean(0)",
"_____no_output_____"
],
[
"ae_def = {\n \"type\":\"sig\",\n \"trainon\":\"BB2refined\",\n \"features\":\"tauDDTwithm1andm1minusm2\",\n \"architecture\":\"MAF\",\n \"selection\":\"turnoncutandj1sdbcut0p9\",\n \"trainloss\":\"MSELoss\",\n \"beta\":\"beta1\",\n \"zdimnflow\":\"z6f10\",\n}",
"_____no_output_____"
],
[
"ae_def",
"_____no_output_____"
],
[
"N_EPOCHS = 10\nBEST_LOSS = 99\nLAST_SAVED = -1\nPATIENCE_COUNT = 0\nPATIENCE_LIMIT = 5\nfor epoch in range(1, 1000):\n print(\"Epoch {}:\".format(epoch))\n sigtrain()\n cur_loss = sigevaluate()\n\n if cur_loss <= BEST_LOSS:\n PATIENCE_COUNT = 0\n BEST_LOSS = cur_loss\n LAST_SAVED = epoch\n print(\"Saving model!\")\n torch.save(sigmodel.state_dict(),f\"/data/t3home000/spark/QUASAR/weights/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['architecture']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}.h5\")\n \n else:\n PATIENCE_COUNT += 1\n print(\"Not saving model! Last saved: {}\".format(LAST_SAVED))\n if PATIENCE_COUNT > 10:\n print(\"Patience Limit Reached\")\n break ",
"Epoch 1:\n\nEvaluation Completed (valid)!\tLoss: -47.8154 Time: 1.032 s\nSaving model!\nEpoch 2:\n\nEvaluation Completed (valid)!\tLoss: -47.4503 Time: 1.031 s\nNot saving model! Last saved: 1\nEpoch 3:\n\nEvaluation Completed (valid)!\tLoss: -47.8960 Time: 1.031 s\nSaving model!\nEpoch 4:\n\nEvaluation Completed (valid)!\tLoss: -47.8303 Time: 1.030 s\nNot saving model! Last saved: 3\nEpoch 5:\n\nEvaluation Completed (valid)!\tLoss: -47.9257 Time: 1.049 s\nSaving model!\nEpoch 6:\n\nEvaluation Completed (valid)!\tLoss: -48.0082 Time: 1.032 s\nSaving model!\nEpoch 7:\n\nEvaluation Completed (valid)!\tLoss: -48.0262 Time: 1.072 s\nSaving model!\nEpoch 8:\n\nEvaluation Completed (valid)!\tLoss: -48.1401 Time: 1.041 s\nSaving model!\nEpoch 9:\n\nEvaluation Completed (valid)!\tLoss: -48.1069 Time: 1.042 s\nNot saving model! Last saved: 8\nEpoch 10:\n\nEvaluation Completed (valid)!\tLoss: -48.2144 Time: 1.041 s\nSaving model!\nEpoch 11:\n\nEvaluation Completed (valid)!\tLoss: -48.2063 Time: 1.068 s\nNot saving model! Last saved: 10\nEpoch 12:\n\nEvaluation Completed (valid)!\tLoss: -48.4003 Time: 1.048 s\nSaving model!\nEpoch 13:\n\nEvaluation Completed (valid)!\tLoss: -48.2114 Time: 1.041 s\nNot saving model! Last saved: 12\nEpoch 14:\n\nEvaluation Completed (valid)!\tLoss: -48.5187 Time: 1.041 s\nSaving model!\nEpoch 15:\n\nEvaluation Completed (valid)!\tLoss: -47.9232 Time: 1.045 s\nNot saving model! Last saved: 14\nEpoch 16:\n\nEvaluation Completed (valid)!\tLoss: -48.5745 Time: 1.043 s\nSaving model!\nEpoch 17:\n\nEvaluation Completed (valid)!\tLoss: -48.4923 Time: 1.042 s\nNot saving model! Last saved: 16\nEpoch 18:\n\nEvaluation Completed (valid)!\tLoss: -48.5370 Time: 1.069 s\nNot saving model! Last saved: 16\nEpoch 19:\n\nEvaluation Completed (valid)!\tLoss: -48.5957 Time: 1.042 s\nSaving model!\nEpoch 20:\n\nEvaluation Completed (valid)!\tLoss: -48.5972 Time: 1.041 s\nSaving model!\nEpoch 21:\n\nEvaluation Completed (valid)!\tLoss: -48.7011 Time: 1.040 s\nSaving model!\nEpoch 22:\n\nEvaluation Completed (valid)!\tLoss: -48.6470 Time: 1.044 s\nNot saving model! Last saved: 21\nEpoch 23:\n\nEvaluation Completed (valid)!\tLoss: -48.6748 Time: 1.042 s\nNot saving model! Last saved: 21\nEpoch 24:\n"
],
[
"sigmodel.load_state_dict(torch.load(f\"/data/t3home000/spark/QUASAR/weights/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['architecture']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}.h5\"))",
"_____no_output_____"
],
[
"sigout = sigmodel(torch.tensor(Y).float().cuda())[0]\nsigout = sigout.data.cpu().numpy()",
"_____no_output_____"
],
[
"bins = np.linspace(-3,3,100)\nbins.shape\ncolumn = 3\n#print(f_rnd.columns[column]\nplt.hist(Y[:,column],bins,alpha=0.5,color='b');\nplt.hist(sigout[:,column],bins,alpha=0.5,color='r');\n#plt.hist(out2[:,column],bins,alpha=0.5,color='g');\nplt.axvline(np.mean(Y[:,column]))",
"_____no_output_____"
],
[
"inputlist = [\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB1_rnd.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB2.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB3.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_background.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_rnd.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_rnd.h5', \n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_3prong_rnd.h5' \n]",
"_____no_output_____"
],
[
"ae_def",
"_____no_output_____"
],
[
"outputlist_waic = [\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb1.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb2.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb3.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_purebkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_rndbkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_2prong.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_3prong.npy\",\n]\n\noutputlist_justloss = [\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_bb1.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_bb2.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_bb3.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_purebkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_rndbkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_2prong.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_3prong.npy\",\n]",
"_____no_output_____"
],
[
"exist_signalflag = [\n False,\n False,\n False,\n False,\n True,\n True,\n True,\n]\nis_signal = [\n False,\n False,\n False,\n False,\n False,\n True,\n True\n]\n\nnprong = [\n None,\n None,\n None,\n None,\n None,\n '2prong',\n '3prong'\n]",
"_____no_output_____"
],
[
"for in_file, out_file_waic, out_file_justloss, sigbit_flag, is_sig, n_prong in zip(inputlist,outputlist_waic,outputlist_justloss,exist_signalflag,is_signal, nprong): \n \n f_bb = pd.read_hdf(in_file)\n dt = f_bb.values\n correct = (dt[:,3]>0) &(dt[:,19]>0) & (dt[:,1]>0) & (dt[:,2]>0) &(dt[:,2]>0) & (dt[:,16]>0) & (dt[:,32]>0)\n dt = dt[correct]\n for i in range(13,19):\n dt[:,i] = dt[:,i]/dt[:,3]\n\n for i in range(29,35):\n dt[:,i] = dt[:,i]/(dt[:,19])\n\n\n correct = (dt[:,16]>0) & (dt[:,29]>=0) &(dt[:,29]<=1)&(dt[:,30]>=0) &(dt[:,30]<=1)&(dt[:,31]>=0) &(dt[:,31]<=1)&(dt[:,32]>=0) &(dt[:,32]<=1)&(dt[:,33]>=0) &(dt[:,33]<=1)&(dt[:,34]>=-0.01) &(dt[:,34]<=1)\n dt = dt[correct]\n correct = (dt[:,3]>100)\n dt = dt[correct]\n\n correct = (dt[:,19]>20)\n dt = dt[correct]\n\n correct = (dt[:,0]>=2800)\n dt = dt[correct]\n\n bsmlike = np.where(dt[:,16]>0.9)[0]\n dt = dt[bsmlike]\n \n j1sdb = dt[:,3]*dt[:,16]\n j2sdb = dt[:,19]*dt[:,32]\n\n pt = dt[:,1]\n m = j1sdb[:]\n m2 = j2sdb[:]\n tau21 = dt[:,4]\n tau32 = dt[:,5]\n tau43 = dt[:,6]\n tau54 = dt[:,7]\n tau65 = dt[:,8]\n massratio = dt[:,16]\n\n rho = np.log((m*m)/(pt*pt))\n rhoprime = np.log((m*m)/(pt*1))\n\n tau21prime = tau21 + rhoprime * 0.088\n tau32prime = tau32 + rhoprime * 0.025\n tau43prime = tau43 + rhoprime * 0.01\n tau54prime = tau54 + rhoprime * 0.001\n\n j2pt = dt[:,2]\n #m = j1sdb[mrange]\n j2m = j2sdb[:]\n j2tau21 = dt[:,20]\n j2tau32 = dt[:,21]\n j2tau43 = dt[:,22]\n j2tau54 = dt[:,23]\n j2tau65 = dt[:,24]\n j2massratio = dt[:,32]\n\n\n j2rho = np.log((j2m*j2m)/(j2pt*j2pt))\n j2rhoprime = np.log((j2m*j2m)/(j2pt*1))\n\n j2tau21prime = j2tau21 + j2rhoprime * 0.086\n j2tau32prime = j2tau32 + j2rhoprime * 0.025\n j2tau43prime = j2tau43 + j2rhoprime * 0.01\n j2tau54prime = j2tau54 + j2rhoprime * 0.001\n \n dt[:,4] = tau21prime\n dt[:,5] = tau32prime\n dt[:,6] = tau43prime\n dt[:,7] = tau54prime\n\n dt[:,20] = j2tau21prime \n dt[:,21] = j2tau32prime\n dt[:,22] = j2tau43prime\n dt[:,23] = j2tau54prime\n \n if sigbit_flag:\n idx = dt[:,-1]\n sigidx = (idx == 1)\n bkgidx = (idx == 0)\n if is_sig:\n dt = dt[sigidx]\n else:\n dt = dt[bkgidx]\n \n if n_prong == '2prong':\n correct = dt[:,3] > 300\n dt = dt[correct]\n \n if n_prong == '3prong':\n correct = dt[:,3] > 400\n dt = dt[correct] \n \n m1minusm2 = dt[:,3] - dt[:,19] \n\n dt[:,19] = m1minusm2\n Y = dt[:,[3,4,5,6,7,8,11,12,19,20,21,22,23,24,27,28]]\n #Y = dt[:,[3,4,5,6,11,12,13,14,15,16,17,18,19,20,21,22,27,28,29,30,31,32,33,34]]\n #Y = dt[:,[3,4,5,6,11,12,13,14,15,16,17,18,19,20,21,22,27,28,29,30,31,32,33,34]]\n #Y = dt[:,[3,4,5,6,11,12,19,20,21,22,27,28]]\n \n\n \n \n \n print(Y.shape)\n for i in range(16):\n Y[:,i] = (Y[:,i]-sig_mean[i])/sig_std[i]\n \n total_bb_test = torch.tensor(Y)\n #huberloss = nn.SmoothL1Loss(reduction='none')\n sigae_bbloss = torch.mean((sigmodel(total_bb_test.float().cuda())[0]- total_bb_test.float().cuda())**2,dim=1).data.cpu().numpy()\n bbvar = torch.var((sigmodel(total_bb_test.float().cuda())[0]- total_bb_test.float().cuda())**2,dim=1).data.cpu().numpy()\n waic = sigae_bbloss + bbvar\n #sigae_bbloss = torch.mean(huberloss(model(total_bb_test.float().cuda())[0],total_bb_test.float().cuda()),dim=1).data.cpu().numpy()\n print(waic[0:10])\n plt.hist(waic,bins=np.linspace(0,10,1001),density=True);\n plt.xlim([0,2])\n np.save(out_file_waic,waic)\n np.save(out_file_justloss,sigae_bbloss)",
"(239348, 16)\n[0.5621231 0.7257408 1.5456731 4.4727592 1.7192183 0.63712144\n 0.87706244 1.4546484 1.1553826 0.7346349 ]\n(242090, 16)\n[2.198793 1.2428405 0.40043712 0.8065294 1.3725975 0.74437785\n 1.089239 3.7420623 0.6250814 5.131377 ]\n(231654, 16)\n[1.4239047 1.2951014 1.4519202 1.830255 0.85408366 2.79452\n 0.6290309 3.7436433 0.7428176 0.77418315]\n(232418, 16)\n[1.6825635 0.68195534 1.64975 0.54647213 0.86837137 1.2845922\n 0.64988124 6.31655 0.72260743 3.52882 ]\n(263134, 16)\n[2.3111129 1.1483724 1.552469 1.1572509 0.7856333 1.0748676 2.098085\n 1.0541561 8.431256 0.9474761]\n(55539, 16)\n[1.2590189 0.34811112 1.9349219 2.5537033 0.9885986 0.46951413\n 1.0730138 0.8460488 1.9784346 1.7014263 ]\n(56525, 16)\n[ 0.5981696 19.111599 0.5106672 1.0296744 1.4274571 1.2144661\n 0.87782335 0.80631435 2.2813685 0.97662854]\n"
],
[
"loss_prong3 = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_3prong.npy\")\nloss_prong2 = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_2prong.npy\")\nloss_purebkg = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_purebkg.npy\")\nloss_rndbkg = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_rndbkg.npy\")\n\n\n\n\n",
"_____no_output_____"
],
[
"plt.hist(loss_purebkg,bins=np.linspace(0,4,100),density=False,alpha=0.3,label='Pure Bkg');\n#plt.hist(loss_rndbkg,bins=np.linspace(0,2,100),density=False,alpha=0.3,label='(rnd) bkg');\n\nplt.hist(loss_prong2,bins=np.linspace(0,4,100),density=False,alpha=0.3,label='2prong (rnd)sig');\nplt.hist(loss_prong3,bins=np.linspace(0,4,100),density=False,alpha=0.3,label='3prong (rnd)sig');\n#plt.yscale('log')\nplt.xlabel('Loss (SigAE trained on 2prong sig)')\nplt.legend(loc='upper right')\n#plt.savefig('sigae_trained_on_2prongsig.png')",
"_____no_output_____"
],
[
"ae_def",
"_____no_output_____"
],
[
"len(loss_prong2)",
"_____no_output_____"
],
[
"outputlist_waic",
"_____no_output_____"
],
[
"outputlist_justloss",
"_____no_output_____"
],
[
"sigae_bbloss",
"_____no_output_____"
],
[
"ae_def",
"_____no_output_____"
],
[
"sigae_bbloss",
"_____no_output_____"
],
[
"plt.hist(sigae_bbloss,bins=np.linspace(0,10,1001));",
"_____no_output_____"
],
[
"np.save('../data_strings/sigae_2prong_loss_bb3.npy',sigae_bbloss)",
"_____no_output_____"
],
[
"X_bkg = dt[:,[3,4,5,6,11,12,19,20,21,22,27,28]]\nX_bkg = X_bkg[bkg_idx]",
"_____no_output_____"
],
[
"for i in range(12):\n X_bkg[:,i] = (X_bkg[:,i]-sig_mean[i])/sig_std[i]",
"_____no_output_____"
],
[
"total_bkg_test = torch.tensor(X_bkg)",
"_____no_output_____"
],
[
"sigae_bkgloss = torch.mean((sigmodel(total_bkg_test.float().cuda())[0]- total_bkg_test.float().cuda())**2,dim=1).data.cpu().numpy()",
"_____no_output_____"
],
[
"sigae_sigloss = torch.mean((sigmodel(total_sig.float().cuda())[0]- total_sig.float().cuda())**2,dim=1).data.cpu().numpy()",
"_____no_output_____"
],
[
"f_3prong = pd.read_hdf(\"/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_3prong_rnd.h5\")",
"_____no_output_____"
],
[
"f_bb1 = pd.read_hdf('/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB1_rnd.h5')",
"_____no_output_____"
],
[
"dt_bb1 = f_bb1.values",
"_____no_output_____"
],
[
"X_bb1 = dt_bb1[:,[3,4,5,6,11,12,19,20,21,22,27,28]]",
"_____no_output_____"
],
[
"X_bb1.shape",
"_____no_output_____"
],
[
"sig_mean",
"_____no_output_____"
],
[
"sig_std",
"_____no_output_____"
],
[
"for i in range(12):\n X_bb1[:,i] = (X_bb1[:,i]-sig_mean[i])/sig_std[i]",
"_____no_output_____"
],
[
"plt.hist(X_bb1[:,0],bins = np.linspace(-2,2,10))",
"_____no_output_____"
],
[
"(torch.tensor(dt[i * chunk_size:(i + 1) * chunk_size]) for i in range ) ",
"_____no_output_____"
],
[
"def get_loss(dt):\n \n chunk_size=5000 \n total_size=1000000\n i = 0\n i_max = total_size // chunk_size\n\n print(i_max)\n \n \n \n gen = (torch.tensor(dt[i*chunk_size: (i + 1) * chunk_size]) for i in range(i_max)) \n\n \n with torch.no_grad():\n \n loss = [\n n\n for total_in_selection in gen\n for n in torch.mean((sigmodel(total_in_selection.float().cuda())[0]- total_in_selection.float().cuda())**2,dim=1).data.cpu().numpy()\n ]\n \n return loss",
"_____no_output_____"
],
[
"def get_loss(dt):\n \n def generator(dt, chunk_size=5000, total_size=1000000):\n\n i = 0\n i_max = total_size // chunk_size\n print(i_max)\n \n for i in range(i_max):\n start=i * chunk_size\n stop=(i + 1) * chunk_size\n yield torch.tensor(dt[start:stop])\n \n loss = []\n\n \n with torch.no_grad():\n \n for total_in_selection in generator(dt,chunk_size=5000, total_size=1000000):\n loss.extend(torch.mean((sigmodel(total_in_selection.float().cuda())[0]- total_in_selection.float().cuda())**2,dim=1).data.cpu().numpy())\n \n return loss",
"_____no_output_____"
],
[
"bb1_loss_sig = get_loss(X_bb1)",
"200\n"
],
[
"bb1_loss_sig = np.array(bb1_loss_sig,dtype=np.float)",
"_____no_output_____"
],
[
"print(bb1_loss_sig)",
"[1.90564466 0.96934295 1.35960376 ... 0.59359992 2.21692467 2.44283652]\n"
],
[
"plt.hist(bb1_loss_sig,bins=np.linspace(0,100,1001));",
"_____no_output_____"
],
[
"np.save('../data_strings/sigaeloss_bb1.npy',bb1_loss_sig)",
"_____no_output_____"
],
[
"dt_3prong = f_3prong.values",
"_____no_output_____"
],
[
"Z = dt_3prong[:,[3,4,5,6,11,12,19,20,21,22,27,28]]",
"_____no_output_____"
],
[
"Z.shape",
"_____no_output_____"
],
[
"for i in range(12):\n Z[:,i] = (Z[:,i]-sig_mean[i])/sig_std[i]",
"_____no_output_____"
],
[
"total_3prong = torch.tensor(Z)",
"_____no_output_____"
],
[
"bkgae_bkgloss = torch.mean((model(total_bkg_test.float().cuda())[0]- total_bkg_test.float().cuda())**2,dim=1).data.cpu().numpy()",
"_____no_output_____"
],
[
"bkgae_3prongloss = torch.mean((model(total_3prong.float().cuda())[0]- total_3prong.float().cuda())**2,dim=1).data.cpu().numpy()",
"_____no_output_____"
],
[
"sigae_3prongloss = torch.mean((sigmodel(total_3prong.float().cuda())[0]- total_3prong.float().cuda())**2,dim=1).data.cpu().numpy()",
"_____no_output_____"
],
[
"sigae_3prongloss.shape",
"_____no_output_____"
],
[
"bins = np.linspace(0,10,1001)\nplt.hist(sigae_sigloss,bins,weights = np.ones(len(signal_idx))*10,alpha=0.4,color='r',label='2 prong signal');\nplt.hist(sigae_3prongloss,bins,weights = np.ones(100000)*10,alpha=0.5,color='g',label='3 prong signal');\nplt.hist(sigae_bkgloss,bins,alpha=0.4,color='b',label='background');\n#plt.legend(bbox_to_anchor=(1.05, 1.0), loc='upper left')\nplt.legend(loc='upper right')\nplt.xlabel('Signal AE Loss',fontsize=15)\n\n",
"_____no_output_____"
],
[
"def get_tpr_fpr(sigloss,bkgloss,aetype='sig'):\n bins = np.linspace(0,50,1001)\n tpr = []\n fpr = []\n for cut in bins:\n if aetype == 'sig':\n tpr.append(np.where(sigloss<cut)[0].shape[0]/len(sigloss))\n fpr.append(np.where(bkgloss<cut)[0].shape[0]/len(bkgloss))\n if aetype == 'bkg':\n tpr.append(np.where(sigloss>cut)[0].shape[0]/len(sigloss))\n fpr.append(np.where(bkgloss>cut)[0].shape[0]/len(bkgloss))\n return tpr,fpr ",
"_____no_output_____"
],
[
"def get_precision_recall(sigloss,bkgloss,aetype='bkg'):\n bins = np.linspace(0,100,1001)\n tpr = []\n fpr = []\n precision = []\n for cut in bins:\n if aetype == 'sig':\n tpr.append(np.where(sigloss<cut)[0].shape[0]/len(sigloss))\n precision.append((np.where(sigloss<cut)[0].shape[0])/(np.where(bkgloss<cut)[0].shape[0]+np.where(sigloss<cut)[0].shape[0]))\n \n if aetype == 'bkg':\n tpr.append(np.where(sigloss>cut)[0].shape[0]/len(sigloss))\n precision.append((np.where(sigloss>cut)[0].shape[0])/(np.where(bkgloss>cut)[0].shape[0]+np.where(sigloss>cut)[0].shape[0]))\n return precision,tpr ",
"_____no_output_____"
],
[
"tpr_2prong, fpr_2prong = get_tpr_fpr(sigae_sigloss,sigae_bkgloss,'sig')\ntpr_3prong, fpr_3prong = get_tpr_fpr(sigae_3prongloss,sigae_bkgloss,'sig')",
"_____no_output_____"
],
[
"plt.plot(fpr_2prong,tpr_2prong,label='signal AE')\n#plt.plot(VAE_bkg_fpr,VAE_bkg_tpr,label='Bkg VAE-Vanilla')\nplt.plot(bkg_fpr4,bkg_tpr4,label='Bkg NFlowVAE-Planar')\n\nplt.xlabel(r'$1-\\epsilon_{bkg}$',fontsize=15)\nplt.ylabel(r'$\\epsilon_{sig}$',fontsize=15)\n#plt.semilogy()\n#plt.legend(bbox_to_anchor=(1.05, 1.0), loc='upper left')\nplt.legend(loc='lower right')\nplt.xlim([0.0,1.0])\nplt.ylim([0.0,1.0])\nplt.savefig('ROC_Curve_sigae.png')",
"_____no_output_____"
],
[
"precision,recall = get_precision_recall(loss_sig,loss_bkg,aetype='bkg')",
"_____no_output_____"
],
[
"np.save('NFLOWVAE_PlanarNEW_22var_sigloss.npy',loss_sig)\nnp.save('NFLOWVAE_PlanarNEW_22var_bkgloss.npy',loss_bkg)",
"_____no_output_____"
],
[
"np.save('NFLOWVAE_PlanarNEW_precision.npy',precision)\nnp.save('NFLOWVAE_PlanarNEW_recall.npy',recall)\nnp.save('NFLOWVAE_PlanarNEW_bkgAE_fpr.npy',bkg_fpr)\nnp.save('NFLOWVAE_PlanarNEW_bkgAE_tpr.npy',bkg_tpr)\nnp.save('NFLOWVAE_PlanarNEW_sigloss.npy',loss_sig)\nnp.save('NFLOWVAE_PlanarNEW_bkgloss.npy',loss_bkg)",
"_____no_output_____"
],
[
"plt.plot(recall,precision)",
"_____no_output_____"
],
[
"flows = [1,2,3,4,5,6]\nzdim = [1,2,3,4,5]\n\nfor N_flows in flows:\n for Z_DIM in zdim:\n model = VAE_NF(N_FLOWS, Z_DIM).cuda()\n optimizer = optim.Adam(model.parameters(), lr=LR)\n BEST_LOSS = 99999\n LAST_SAVED = -1\n PATIENCE_COUNT = 0\n PATIENCE_LIMIT = 5\n for epoch in range(1, N_EPOCHS):\n print(\"Epoch {}:\".format(epoch))\n train()\n cur_loss = evaluate()\n\n if cur_loss <= BEST_LOSS:\n PATIENCE_COUNT = 0\n BEST_LOSS = cur_loss\n LAST_SAVED = epoch\n print(\"Saving model!\")\n if mode == 'ROC':\n torch.save(model.state_dict(),f\"/data/t3home000/spark/QUASAR/weights/bkg_vae_NF_planar_RND_22var_z{Z_DIM}_f{N_FLOWS}.h5\")\n else:\n torch.save(model.state_dict(), f\"/data/t3home000/spark/QUASAR/weights/bkg_vae_NF_planar_PureBkg_22var_z{Z_DIM}_f{N_FLOWS}.h5\")\n else:\n PATIENCE_COUNT += 1\n print(\"Not saving model! Last saved: {}\".format(LAST_SAVED))\n if PATIENCE_COUNT > 3:\n print(\"Patience Limit Reached\")\n break \n \n loss_bkg = get_loss(dt_PureBkg[bkg_idx])\n loss_sig = get_loss(dt_PureBkg[signal_idx])\n np.save(f'NFLOWVAE_PlanarNEW_22var_z{Z_DIM}_f{N_flows}_sigloss.npy',loss_sig)\n np.save(f'NFLOWVAE_PlanarNEW_22var_z{Z_DIM}_f{N_flows}_bkgloss.npy',loss_bkg)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a0390829f562582a081b563f3a955602671f1dc
| 7,865 |
ipynb
|
Jupyter Notebook
|
MachineLearning/Classification/Diabetes_Training.ipynb
|
santho3110/Data-Science
|
1b75bad0df4f7202224de8e44c7cc4afb0661d5b
|
[
"MIT"
] | null | null | null |
MachineLearning/Classification/Diabetes_Training.ipynb
|
santho3110/Data-Science
|
1b75bad0df4f7202224de8e44c7cc4afb0661d5b
|
[
"MIT"
] | null | null | null |
MachineLearning/Classification/Diabetes_Training.ipynb
|
santho3110/Data-Science
|
1b75bad0df4f7202224de8e44c7cc4afb0661d5b
|
[
"MIT"
] | 2 |
2020-08-19T06:37:06.000Z
|
2022-03-04T10:08:52.000Z
| 27.12069 | 114 | 0.404577 |
[
[
[
"# Suppressing Warnings\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"import joblib\nimport numpy as np\nimport pandas as pd\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.pipeline import Pipeline",
"_____no_output_____"
]
],
[
[
"### Import the dataset",
"_____no_output_____"
]
],
[
[
"pima = pd.read_csv(\"pima_indian_diabetes.csv\")\npima.head()",
"_____no_output_____"
]
],
[
[
"### Train Test Split",
"_____no_output_____"
]
],
[
[
"X_train, X_test, y_train, y_test = train_test_split(pima.iloc[:, :-1], \n pima.Diabetes,\n train_size=0.7,\n test_size=0.3,\n random_state=100)",
"_____no_output_____"
]
],
[
[
"### Model Training",
"_____no_output_____"
]
],
[
[
"THRESHOLD = 0.65\n\npima_pipe = Pipeline([('feature_scaler', StandardScaler()), \n ('logistic_regression',LogisticRegression(penalty='l1', C=1, solver='liblinear'))])\npima_pipe.fit(X_train, y_train)\n\nsummary = pd.Series(pima_pipe.named_steps['logistic_regression'].coef_[0]).round(6)\nsummary.index = X_train.columns\n\n# predict with train data\ntrain_pred_prob = pima_pipe.predict_proba(X_train)\ntrain_pred = np.where(train_pred_prob[:,1] > THRESHOLD, 1, 0)\nsummary[\"Train accuracy\"] = str(round(accuracy_score(y_train,train_pred) *100,2))+\"%\"\n\n# predict with test data\ntest_pred_prob = pima_pipe.predict_proba(X_test)\ntest_pred = np.where(test_pred_prob[:,1] > THRESHOLD, 1, 0)\nsummary[\"Test accuracy\"] = str(round(accuracy_score(y_test,test_pred) *100,2))+\"%\"\n\nsummary",
"_____no_output_____"
]
],
[
[
"### Model Persist",
"_____no_output_____"
]
],
[
[
"joblib.dump(pima_pipe, \"diabetes_pipeline.joblib\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a039e2f273f3fe37a28e9e87a7fc45400298556
| 10,961 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Cleaning data-checkpoint.ipynb
|
nhx737/project-bla
|
eb8029cd41638d33945899546b228b1caa40c082
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Cleaning data-checkpoint.ipynb
|
nhx737/project-bla
|
eb8029cd41638d33945899546b228b1caa40c082
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Cleaning data-checkpoint.ipynb
|
nhx737/project-bla
|
eb8029cd41638d33945899546b228b1caa40c082
|
[
"MIT"
] | null | null | null | 34.796825 | 107 | 0.394033 |
[
[
[
"#Importing packages and data\nimport numpy as np\nimport pandas as pd\nfilnavn = 'anlaegprodtilnettet.xls'\ndata = pd.read_excel(filnavn,skiprows=17, usecols=range(58), skipfooter=3)\ndata.head()",
"_____no_output_____"
],
[
"#Renaming the 'Unnamed X:' columns to pYEAR to indicate eletricity production for the wind turbine\n#Removing the observations from 1977 to 2007.\nnew_cols = {}\nfor i in range(1977,2019):\n new_cols[str(i)]=f'p{i}'\ncolumn_indices = range(16,58)\nold_cols = data.columns[column_indices]\ndata.rename(columns=dict(zip(old_cols, new_cols)), inplace=True)\ndata.rename(columns=new_cols, inplace=True)\ndata.head()\n#Removing the observations from 1977 to 2007.\ndata.drop(data.iloc[:,15:47], inplace=True, axis=1)\nprint(data.columns)\n",
"Index(['Møllenummer (GSRN)', 'Dato for oprindelig nettilslutning',\n 'Kapacitet (kW)', 'Rotor-diameter (m)', 'Navhøjde (m)', 'Fabrikat',\n 'Model', 'Kommune-nr.', 'Kommune', 'Type af placering', 'Ejerlav',\n 'Matrikel-nummer', 'X (øst) koordinat \\nUTM 32 Euref89',\n 'Y (nord) koordinat \\nUTM 32 Euref89', 'Koordinatoprindelse', 'p2008',\n 'p2009', 'p2010', 'p2011', 'p2012', 'p2013', 'p2014', 'p2015', 'p2016',\n 'p2017', 'p2018'],\n dtype='object')\n"
],
[
"#Storing the data to enable usage in another notebook\n%store data",
"Stored 'data' (DataFrame)\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a03adfff9f924dd99ace84f784652fa14f2bdd6
| 36,448 |
ipynb
|
Jupyter Notebook
|
WorkingWithGenomes-VCF.ipynb
|
CompBiochBiophLab/IntroBioinfo
|
ddbfb45f6cbcede2e10b589e3d6dab840cccb484
|
[
"MIT"
] | null | null | null |
WorkingWithGenomes-VCF.ipynb
|
CompBiochBiophLab/IntroBioinfo
|
ddbfb45f6cbcede2e10b589e3d6dab840cccb484
|
[
"MIT"
] | null | null | null |
WorkingWithGenomes-VCF.ipynb
|
CompBiochBiophLab/IntroBioinfo
|
ddbfb45f6cbcede2e10b589e3d6dab840cccb484
|
[
"MIT"
] | 4 |
2020-04-03T14:04:32.000Z
|
2021-01-26T14:16:43.000Z
| 113.545171 | 27,716 | 0.862215 |
[
[
[
"Adapted from [https://github.com/PacktPublishing/Bioinformatics-with-Python-Cookbook-Second-Edition](https://github.com/PacktPublishing/Bioinformatics-with-Python-Cookbook-Second-Edition), Chapter 2.\n\n```\nconda config --add channels bioconda\nconda install tabix pyvcf\n```\nYou can also check the functions available in `scikit-allel` [here](http://alimanfoo.github.io/2017/06/14/read-vcf.html)\n\nExample of VCF file. Nice explanation by Colleen Saunders can be found [here](https://training.h3abionet.org/IBT_2017/wp-content/uploads/2017/06/Module5_Session4_part3.mp4):\n\n\n```\n##fileformat=VCFv4.3\n##reference=file:///seq/references/1000GenomesPilot-NCBI36.fasta\n##contig=<ID=20,length=62435964,assembly=B36,md5=f126cdf8a6e0c7f379d618ff66beb2da,species=\"Homo sapiens\",taxonomy=x>\n##INFO=<ID=DP,Number=1,Type=Integer,Description=\"Total Depth\">\n##INFO=<ID=AF,Number=A,Type=Float,Description=\"Allele Frequency\">\n##INFO=<ID=DB,Number=0,Type=Flag,Description=\"dbSNP membership, build 129\">\n##FILTER=<ID=q10,Description=\"Quality below 10\">\n##FILTER=<ID=s50,Description=\"Less than 50% of samples have data\">\n##FORMAT=<ID=GT,Number=1,Type=String,Description=\"Genotype\">\n##FORMAT=<ID=DP,Number=1,Type=Integer,Description=\"Read Depth\">\n#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\tNA00001\tNA00002\tNA00003\n20\t14370\trs6054257\tG\tA\t29\tPASS\tDP=14;AF=0.5;DB\tGT:DP\t0/0:1\t0/1:8\t1/1:5\n20\t17330\t.\tT\tA\t3\tq10\tDP=11;AF=0.017\tGT:DP\t0/0:3\t0/1:5\t0/0:41\n20\t1110696\trs6040355\tA\tG,T\t67\tPASS\tDP=10;AF=0.333,0.667;DB\tGT:DP\t0/2:6\t1/2:0\t2/2:4\n20\t1230237\t.\tT\t.\t47\tPASS\tDP=13\tGT:DP\t0/0:7\t0/0:4\t./.:.\n\n```\n\n# Getting the necessary data",
"_____no_output_____"
],
[
"You just need to do this only once",
"_____no_output_____"
]
],
[
[
"!rm -f data/genotypes.vcf.gz 2>/dev/null\n!tabix -fh ftp://ftp-trace.ncbi.nih.gov/1000genomes/ftp/release/20130502/supporting/vcf_with_sample_level_annotation/ALL.chr22.phase3_shapeit2_mvncall_integrated_v5_extra_anno.20130502.genotypes.vcf.gz 22:1-17000000|bgzip -c > data/genotypes.vcf.gz\n!tabix -p vcf data/genotypes.vcf.gz",
"_____no_output_____"
],
[
"from collections import defaultdict\n\n%matplotlib inline\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\nimport vcf",
"_____no_output_____"
]
],
[
[
"Variant record level\n\n* AC: total number of alternative allelels in called genotypes\n* AF: estimated allele frequency\n* NS: number of samples with data\n* AN: total number of alleles in called genotypes\n* DP: total read depth\n* (...)\n\nSample level:\n\n* GT: genotype\n* DP: per sample read depth",
"_____no_output_____"
]
],
[
[
"v = vcf.Reader(filename='data/genotypes.vcf.gz')\n\nprint('Variant Level information')\ninfos = v.infos\nfor info in infos:\n print(info)\n\nprint('Sample Level information')\nfmts = v.formats\nfor fmt in fmts:\n print(fmt)",
"Variant Level information\nCIEND\nCIPOS\nCS\nEND\nIMPRECISE\nMC\nMEINFO\nMEND\nMLEN\nMSTART\nSVLEN\nSVTYPE\nTSD\nAC\nAF\nNS\nAN\nASN_AF\nEUR_AF\nAFR_AF\nAMR_AF\nSAN_AF\nDP\nSample Level information\nGT\nDP\n"
]
],
[
[
"Let us inspect a single VCF record",
"_____no_output_____"
]
],
[
[
"v = vcf.Reader(filename='data/genotypes.vcf.gz')\nrec = next(v)\nprint('=====\\nCHROM, POS, ID, REF, ALT, QUAL, FILTER' )\nprint(rec.CHROM, rec.POS, rec.ID, rec.REF, rec.ALT, rec.QUAL, rec.FILTER)\nprint('=====\\nVariant-level info')\nprint(rec.INFO)\nprint(rec.FORMAT)\nprint('=====\\nSAMPLE ID\\'s')\nsamples = rec.samples\nprint(len(samples))\nsample = samples[0]\nprint(sample.called, sample.gt_alleles, sample.is_het, sample.is_variant, sample.phased)\nprint(int(sample['DP']))",
"=====\nCHROM, POS, ID, REF, ALT, QUAL, FILTER\n22 16050075 None A [G] 100 []\n=====\nVariant-level info\n{'AC': [1], 'AF': [0.000199681], 'AN': 5008, 'NS': 2504, 'DP': [8012], 'ASN_AF': [0.0], 'AMR_AF': [0.0], 'SAS_AF': ['0.0010'], 'EUR_AF': [0.0], 'EAS_AF': [''], 'AFR_AF': [0.0], 'SAN_AF': [0.0]}\nGT:DP\n=====\nSAMPLE ID's\n2504\nTrue ['0', '0'] False False True\n1\n"
]
],
[
[
"let us check the type of variant and the number onbiallelic SNPs",
"_____no_output_____"
]
],
[
[
"f = vcf.Reader(filename='data/genotypes.vcf.gz')\n\nmy_type = defaultdict(int)\nnum_alts = defaultdict(int)\n\nfor rec in f:\n my_type[rec.var_type, rec.var_subtype] += 1\n if rec.is_snp:\n num_alts[len(rec.ALT)] += 1\nprint(my_type)\nprint(num_alts)",
"defaultdict(<class 'int'>, {('snp', 'ts'): 10054, ('snp', 'tv'): 5917, ('sv', 'CNV'): 2, ('indel', 'del'): 273, ('snp', 'unknown'): 79, ('indel', 'ins'): 127, ('indel', 'unknown'): 13, ('sv', 'DEL'): 6, ('sv', 'SVA'): 1})\ndefaultdict(<class 'int'>, {1: 15971, 2: 79})\n"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"f = vcf.Reader(filename='data/genotypes.vcf.gz')\n\nsample_dp = defaultdict(int)\nfor rec in f:\n if not rec.is_snp or len(rec.ALT) != 1:\n continue\n for sample in rec.samples:\n dp = sample['DP']\n if dp is None:\n dp = 0\n dp = int(dp)\n sample_dp[dp] += 1",
"_____no_output_____"
],
[
"dps = list(sample_dp.keys())\ndps.sort()\ndp_dist = [sample_dp[x] for x in dps]\nfig, ax = plt.subplots(figsize=(16, 9))\nax.plot(dp_dist[:50], 'r')\nax.axvline(dp_dist.index(max(dp_dist)))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a03b4ee8489bfa461f680a72575e7a606361b2b
| 69,266 |
ipynb
|
Jupyter Notebook
|
iris_knn/iris_knn.ipynb
|
shazi4399/machine-learning-example
|
0e332bc53ff85a11887012f7d5b09be9597bb4ef
|
[
"Apache-2.0"
] | 16 |
2021-07-09T08:40:50.000Z
|
2022-03-29T03:21:18.000Z
|
iris_knn/iris_knn.ipynb
|
shazi4399/machine-learning-example
|
0e332bc53ff85a11887012f7d5b09be9597bb4ef
|
[
"Apache-2.0"
] | null | null | null |
iris_knn/iris_knn.ipynb
|
shazi4399/machine-learning-example
|
0e332bc53ff85a11887012f7d5b09be9597bb4ef
|
[
"Apache-2.0"
] | 15 |
2021-06-07T11:20:38.000Z
|
2022-03-08T15:48:50.000Z
| 69.684105 | 29,232 | 0.647143 |
[
[
[
"## 数据集介绍\n<img src=\"./img/iris数据集介绍.png\"/>",
"_____no_output_____"
]
],
[
[
"# 导入相关模块\nimport sklearn.datasets as skdata\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport pandas as pd\nimport sklearn.model_selection as skmodel\nimport sklearn.neighbors as skneighbors\nimport sklearn.preprocessing as skprep",
"_____no_output_____"
]
],
[
[
"## 加载iris数据集",
"_____no_output_____"
]
],
[
[
"iris_data = skdata.load_iris()\niris_data",
"_____no_output_____"
],
[
"type(iris_data), dir(iris_data)",
"_____no_output_____"
],
[
"iris_data.feature_names",
"_____no_output_____"
]
],
[
[
"## 可视化iris数据",
"_____no_output_____"
],
[
"Seaborn 是基于 Matplotlib 核心库进行了更高级的 API 封装,可以让你轻松地画出更漂亮的图形。而 Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。",
"_____no_output_____"
],
[
"### 将数据集转化为pandas.DataFrame类型",
"_____no_output_____"
]
],
[
[
"iris_df = pd.DataFrame(iris_data['data'], columns=\n ['sepal length (cm)',\n 'sepal width (cm)',\n 'petal length (cm)',\n 'petal width (cm)'])\niris_df['Species'] = iris_data.target\niris_df",
"_____no_output_____"
]
],
[
[
"### 绘制散点图,初步探索数据间关系",
"_____no_output_____"
]
],
[
[
"\nsns.relplot(x='sepal width (cm)', y='petal length (cm)', data=iris_df, hue='Species')\n",
"_____no_output_____"
]
],
[
[
"## 数据集的划分",
"_____no_output_____"
]
],
[
[
"x_train, x_test, y_train, y_test = skmodel.train_test_split(iris_data.data, iris_data.target, test_size=0.2)\nx_train, x_test, y_train, y_test",
"_____no_output_____"
]
],
[
[
"## 使用KNN算法做预测",
"_____no_output_____"
],
[
"sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')\n* n_neighbors:\nint,可选(默认= 5),k_neighbors查询默认使用的邻居数\n* algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}\n * 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,\n * brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。\n * kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。\n * ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。",
"_____no_output_____"
]
],
[
[
"knn_model = skneighbors.KNeighborsClassifier(n_neighbors=7)\nknn_model.fit(x_train, y_train)",
"_____no_output_____"
],
[
"y_predict = knn_model.predict(x_test)\ny_predict == y_test",
"_____no_output_____"
],
[
"# 计算准确率\nscore = knn_model.score(x_test, x_train)\nscore",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a03cd17e47b7a80726ecfcce91850dc4a59b30b
| 119,542 |
ipynb
|
Jupyter Notebook
|
Arquivos_Modulos_Pacotes/trabalhando_com_arquivos.ipynb
|
LivioAlvarenga/Built_in_Functions
|
ad28ad970cecda8e2916e49a8885b7b9e2a064d9
|
[
"MIT"
] | 1 |
2021-12-23T11:43:30.000Z
|
2021-12-23T11:43:30.000Z
|
Arquivos_Modulos_Pacotes/trabalhando_com_arquivos.ipynb
|
LivioAlvarenga/Python_3
|
ad28ad970cecda8e2916e49a8885b7b9e2a064d9
|
[
"MIT"
] | null | null | null |
Arquivos_Modulos_Pacotes/trabalhando_com_arquivos.ipynb
|
LivioAlvarenga/Python_3
|
ad28ad970cecda8e2916e49a8885b7b9e2a064d9
|
[
"MIT"
] | null | null | null | 48.105433 | 1,402 | 0.570887 |
[
[
[
"# Trabalhando com Arquivos\nTabela Modos de arquivo\n\n",
"_____no_output_____"
],
[
"# Métodos de uma lista usando biblioteca rich import inspect",
"_____no_output_____"
]
],
[
[
"from rich import inspect\na = open('arquivo1.txt', 'wt+')\ninspect(a, methods=True)",
"_____no_output_____"
]
],
[
[
"# Criando Arquivo w(write) e x\n# .close()",
"_____no_output_____"
]
],
[
[
"# cria arquivo ou abre apagando os dados de qualquer arquivo existente\na = open('arquivo1.txt', 'wt+') # w(write text) + (se não existir o arquivo crie) (t decodifica os caracteres Unicode-é default não precisa colocar)\na.close()",
"_____no_output_____"
],
[
"# cria arquivo, mas falha se o mesmo ja existir\na = open('arquivo1.txt', 'x')\na.close()",
"_____no_output_____"
]
],
[
[
"# .writefile()\nCriar arquivo pelo Jupyter Notebook",
"_____no_output_____"
]
],
[
[
"%%writefile teste.txt\nOlá este arquivo foi gerado pelo próprio Jupyter Notebook.\nPodemos gerar quantas linhas quisermos e o Jupyter gera o arquivo final.\nla...\nla....",
"Writing teste.txt\n"
]
],
[
[
"# Abrindo/Lendo arquivos r(read)",
"_____no_output_____"
]
],
[
[
"#Abre arquivo como leitura\na = open('arquivo1.txt', 'r' ,encoding=\"utf-8\") # rt(read text) (,encoding=\"utf-8\")\na.close()",
"_____no_output_____"
],
[
"#Abre arquivo como escrita e não apaga o anterior\na = open('arquivo1.txt', 'a') # at(append text)\na.close()",
"_____no_output_____"
]
],
[
[
"# .read() e encoding=\"utf-8\"\nO método read() somente funciona se abrir o arquivo como leitura ('r')\n\nAo abrir o arquivo com uma codificação diferente da que ele foi escrito, alguns caracteres podem apresentar erros, ou, em alguns sistemas operacionais, como no Mac OS, pode ser lançada uma exceção\n\nTipos de encoding:\nhttps://docs.python.org/3/library/codecs.html#standard-encodings",
"_____no_output_____"
]
],
[
[
"arq4 = open(\"teste.txt\", 'r',encoding=\"utf-8\")\nprint(arq4.read())\n",
"Olá este arquivo foi gerado pelo próprio Jupyter Notebook.\nPodemos gerar quantas linhas quisermos e o Jupyter gera o arquivo final.\nla...\nla....\n\n"
],
[
"a = open('arquivo1.txt', 'rt',encoding=\"utf-8\") # (,encoding=\"utf-8\") mostra as acentuações\nprint(a.read())\na = open('arquivo1.txt', 'rt')\nprint(a.read())\na.close()",
"Python é uma linguagem poderosa!Editando arquivo\nPython é uma linguagem poderosa!Editando arquivo\n"
],
[
"a = open('arquivo1.txt', 'rt',encoding=\"utf-8\")\nprint(a.read(3)) # Lendo os três primeiros caracteres\na.close()",
"Pyt\n"
]
],
[
[
"# .read() e encoding=\"latin_1\"\nO método read() somente funciona se abrir o arquivo como leitura ('r')\n\nAo abrir o arquivo com uma codificação diferente da que ele foi escrito, alguns caracteres podem apresentar erros, ou, em alguns sistemas operacionais, como no Mac OS, pode ser lançada uma exceção\n\nTipos de encoding:\nhttps://docs.python.org/3/library/codecs.html#standard-encodings",
"_____no_output_____"
]
],
[
[
"a = open('contatos.csv', encoding='latin_1')\nprint(a.read())\na.close()",
"1,Guilherme,[email protected]\n2,Elias,[email protected]\n3,Gabriel,[email protected]\n4,Anderson,[email protected]\n5,Alex,[email protected]\n6,Vini,[email protected]\n7,Letícia,[email protected]\n8,Giulia,[email protected]\n9,Felipe,[email protected]\n10,Luísa,luisa@luisa\n\n"
]
],
[
[
"# .readlines()\nreadlines ler linha por linha e coloca em uma lista",
"_____no_output_____"
]
],
[
[
"a = open(\"teste.txt\", 'r',encoding=\"utf-8\")\nprint(a.read())\na.seek(0)\nprint(a.readlines())\na.close()",
"Olá este arquivo foi gerado pelo próprio Jupyter Notebook.\nPodemos gerar quantas linhas quisermos e o Jupyter gera o arquivo final.\nla...\nla....\n\n['Olá este arquivo foi gerado pelo próprio Jupyter Notebook.\\n', 'Podemos gerar quantas linhas quisermos e o Jupyter gera o arquivo final.\\n', 'la...\\n', 'la....\\n']\n"
]
],
[
[
"# readline() Vs readlines()\n\nreadline() - ler somente uma linha\n\nreadlines() - coloca todas as linhas em um lista",
"_____no_output_____"
]
],
[
[
"# Testando readline()\nfrom sys import getsizeof\n\nwith open('contatos.csv', 'r', encoding='latin_1') as a:\n conteudo = a.readline()\nprint(conteudo)\nprint(f'conteudo = {getsizeof(conteudo)} bytes')",
"1,Guilherme,[email protected]\n\nconteudo = 88 bytes\n"
],
[
"# Testando readlines()\nfrom sys import getsizeof\n\nwith open('contatos.csv', 'r', encoding='latin_1') as a:\n conteudo = a.readlines()\nprint(conteudo)\nprint(f'conteudo = {getsizeof(conteudo)} bytes')",
"['1,Guilherme,[email protected]\\n', '2,Elias,[email protected]\\n', '3,Gabriel,[email protected]\\n', '4,Anderson,[email protected]\\n', '5,Alex,[email protected]\\n', '6,Vini,[email protected]\\n', '7,Letícia,[email protected]\\n', '8,Giulia,[email protected]\\n', '9,Felipe,[email protected]\\n', '10,Luísa,luisa@luisa\\n']\nconteudo = 184 bytes\n"
]
],
[
[
"# .seek()",
"_____no_output_____"
]
],
[
[
"arq4 = open(\"teste.txt\", 'r',encoding=\"utf-8\")\nprint(f'Lendo o arquivo a primeira vez:\\n\\n{arq4.read()}')\nprint(f'Tentando ler novamente e não conseguimos\\n\\n{arq4.read()}') # como ja lemos o arquivo ate o final temos que retornar com seek()\narq4.seek(0)\nprint(f'Após o uso do seek conseguimos ler novamente!\\n\\n{arq4.read()}')",
"Lendo o arquivo a primeira vez:\n\nOlá este arquivo foi gerado pelo próprio Jupyter Notebook.\nPodemos gerar quantas linhas quisermos e o Jupyter gera o arquivo final.\nla...\nla....\n\nTentando ler novamente e não conseguimos\n\n\nApós o uso do seek conseguimos ler novamente!\n\nOlá este arquivo foi gerado pelo próprio Jupyter Notebook.\nPodemos gerar quantas linhas quisermos e o Jupyter gera o arquivo final.\nla...\nla....\n\n"
]
],
[
[
"# .split()\nseparar os caracteres",
"_____no_output_____"
]
],
[
[
"# separando caracteres por linhas\nf = open('salarios.csv', 'r')\ndata = f.read()\nrows = data.split('\\n') # '\\n' é um espaço separamos por espaço\nprint(rows) # cada '' é uma linha\nf.close()",
"['Name,Position Title,Department,Employee Annual Salary', '\"AARON, ELVIA J\",WATER RATE TAKER,WATER MGMNT,$88967.00', '\"ABDELMAJEID, AZIZ\",POLICE OFFICER,POLICE,$80778.00', '\"ABDOLLAHZADEH, ALI\",FIREFIGHTER/PARAMEDIC,FIRE,$87720.00', '\"ABDUL-KARIM, MUHAMMAD A\",ENGINEERING TECHNICIAN VI,WATER MGMNT,$106104.00', '\"ABDULLAH, DANIEL N\",FIREFIGHTER-EMT,FIRE,$91764.00', '\"ABDULLAH, KEVIN\",LIEUTENANT,FIRE,$110370.00', '\"ABDULLAH, LAKENYA N\",CROSSING GUARD,POLICE,$16692.00', '\"ABDULLAH, RASHAD J\",ELECTRICAL MECHANIC-AUTO-POLICE MTR MNT,GENERAL SERVICES,$91520.00', '\"ABDUL-SHAKUR, TAHIR\",GENERAL LABORER - DSS,STREETS & SAN,$40560.00']\n"
],
[
"# separando caracteres por colunas\nf = open('salarios.csv', 'r')\ndata = f.read()\nrows = data.split('\\n') # '\\n' é um espaço separamos por espaço\ndados = []\nfor row in rows:\n split_row = row.split(',') # agora dentro de '' vamos separar por \",\" pois o arquivo é um csv\n dados.append(split_row)\n\nprint(dados)\nf.close()",
"[['Name', 'Position Title', 'Department', 'Employee Annual Salary'], ['\"AARON', ' ELVIA J\"', 'WATER RATE TAKER', 'WATER MGMNT', '$88967.00'], ['\"ABDELMAJEID', ' AZIZ\"', 'POLICE OFFICER', 'POLICE', '$80778.00'], ['\"ABDOLLAHZADEH', ' ALI\"', 'FIREFIGHTER/PARAMEDIC', 'FIRE', '$87720.00'], ['\"ABDUL-KARIM', ' MUHAMMAD A\"', 'ENGINEERING TECHNICIAN VI', 'WATER MGMNT', '$106104.00'], ['\"ABDULLAH', ' DANIEL N\"', 'FIREFIGHTER-EMT', 'FIRE', '$91764.00'], ['\"ABDULLAH', ' KEVIN\"', 'LIEUTENANT', 'FIRE', '$110370.00'], ['\"ABDULLAH', ' LAKENYA N\"', 'CROSSING GUARD', 'POLICE', '$16692.00'], ['\"ABDULLAH', ' RASHAD J\"', 'ELECTRICAL MECHANIC-AUTO-POLICE MTR MNT', 'GENERAL SERVICES', '$91520.00'], ['\"ABDUL-SHAKUR', ' TAHIR\"', 'GENERAL LABORER - DSS', 'STREETS & SAN', '$40560.00']]\n"
]
],
[
[
"# .tell()\nContar o número de caracteres",
"_____no_output_____"
]
],
[
[
"a = open('arquivo1.txt', 'r', encoding=\"utf-8\") \na.read() # Se não ler o mesmo o .tell() não funciona\nprint(a.tell())\na.close()",
"49\n"
]
],
[
[
"# .flush()\nUma característica de quando a gente está trabalhando com escrita de arquivo no Python. A gente precisa fechar o arquivo para indicar que a gente não está mais trabalhando com ele. Somente após fechar é que as edições serão salvas, mas e se não podermos fechar o arquivo?\n\nCom método **flush**, os dados vão ser escritos, porém o arquivo vai continuar aberto.",
"_____no_output_____"
]
],
[
[
"arquivos_contatos = open('contatos.csv', mode='a', encoding='latin_1')\n\nnovo_contato = '11,Livio,[email protected]\\n'\n\narquivos_contatos.write(novo_contato)\n\narquivos_contatos.flush()\n\narquivos_contatos.close()\n",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**with open**</font>",
"_____no_output_____"
]
],
[
[
"with open('arquivo1.txt', mode='r', encoding=\"utf-8\") as a:\n conteudo = a.read()\nprint(conteudo)",
"Python é uma linguagem poderosa!Editando arquivo\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\n\n"
]
],
[
[
"# <font color=#FF0000>**with open - newline=''**</font>\n\nAo final de cada linha em um arquivo temos uma instrução de quebra de linha '\\n' que significa que o texto irá para proxima linha. Este caractere é oculto, mas conseguimos ve-lo colocando **readlines()**.\n\nQuando não usamos o newline='' o caractere é igual á '\\n' (padrão Linux/unix/python) ao utilizar o newline='' o caractere muda para '\\r\\n' (padrão Microsoft)",
"_____no_output_____"
],
[
"# <font color=#FF0000>**diferença entre \\n e \\r\\n e newline=''**</font>\n\nO **\\n** significa \"new line\" ou \"line-feed\", ou seja, **\"nova linha\"**. \nO **\\r** significa \"carriage return\", ou seja **\"retorno de linha\"**. \nQuando a tabela ASCII foi padronizada, o \\n recebeu o código 10 e \\r recebeu o código 13.\n\n_A ideia originalmente, quando as tabelas de codificação de caracteres como sequências de bits foram concebidas, é que o \\n fosse interpretado como o comando para fazer o cursor se mover para baixo, e o \\r o comando para ele se mover de volta até o começo da linha._ \n\n> Essa distinção era importante para as máquinas de escrever digitais que precederam os computadores, para telégrafos digitais, para teletipos e para a programação das primeiras impressoras que surgiram. De fato, isso é surpreendentemente mais antigo do que se pensa, já aparecendo no ano de 1901 junto com algumas das primeiras dessas tabelas de codificação de caracteres.\n\nAssim sendo, em **um texto para que uma quebra-de-linha fosse inserida, fazia-se necessário utilizar-se \\r\\n**. Primeiro o cursor deveria se mover até o começo da linha e depois para baixo. **E foi esse o padrão de quebra-de-linha adotado muito mais tarde pela Microsoft.**\n\nJá o Multics (e posteriormente o Unix) seguiram um caminho diferente, e decidiram implementar o **\\n** como quebra-de-linha, o que já incluía um retorno ao começo da linha. Afinal de contas, não tem lá muito sentido ter uma coisa sem ter a outra junto, e **ao utilizá-los como sendo uma coisa só, garante-se que nunca serão separados**. Isso também tem a vantagem de economizar espaço ao usar um só byte para codificar a quebra-de-linha ao invés de dois, e naqueles anos aonde a memória era pequena e o processamento de baixo poder, cada byte economizado contava bastante.\n\nOutras empresas, como a Apple e a Commodore, também seguiram um caminho semelhante ao do Unix, mas ao invés de adotarem o \\n para quebras-de-linha, adotaram o \\r.\n\nOutras empresas menores adotaram outros códigos para a quebra-de-linha. Por exemplo, o QNX adotou o caractere 30 da tabela ASCII. A Atari adotou o 155. A Acorn e o RISC OS adotaram o \\n\\r ao invés de \\r\\n. A Sinclair adotou o 118.\n\n**_Em resumo: Linux utiliza \\n que representa \\r(retorno ao primeiro caractere da linha) e \\n(nova linha). A Apple utiliza \\r que representa \\r(retorno ao primeiro caractere da linha) e \\n(nova linha). Já a Microsoft utiliza o padrão como \\r\\n. Ao usar o redline='' representamos a quebra de linha como \\r\\n se ocultarmos o mesmo a quebra de linha será \\n._** \n",
"_____no_output_____"
]
],
[
[
"# Sem newline='' - caractere de fim de linha = '\\n' padrão UNIX/Python\nwith open('arquivo1.txt', mode='r', encoding=\"utf-8\") as a:\n \n print(a.readlines())\n# veja que ao final de cada linha temos o '\\n'. É usado para indicar o fim de uma linha de texto.",
"['Python é uma linguagem poderosa!Editando arquivo\\n', 'Editando arquivo!!!\\n', 'Editando arquivo!!!\\n', 'Editando arquivo!!!\\n', 'Editando arquivo!!!\\n', 'Editando arquivo!!!\\n', 'Editando arquivo!!!\\n']\n"
],
[
"# Com newline='' - caractere de fim de linha = '\\r\\n' padrão Microsoft\nwith open('arquivo1.txt', mode='r', encoding=\"utf-8\", newline='') as a:\n \n print(a.readlines())\n# veja que ao final de cada linha temos o '\\n'. É usado para indicar o fim de uma linha de texto..",
"['Python é uma linguagem poderosa!Editando arquivo\\r\\n', 'Editando arquivo!!!\\r\\n', 'Editando arquivo!!!\\r\\n', 'Editando arquivo!!!\\r\\n', 'Editando arquivo!!!\\r\\n', 'Editando arquivo!!!\\r\\n', 'Editando arquivo!!!\\r\\n']\n"
]
],
[
[
"# Escrevendo no arquivos a(append)",
"_____no_output_____"
]
],
[
[
"with open('arquivo1.txt', 'a', encoding=\"utf-8\") as a:\n a.write('\\nEditando arquivo!!!') #\\n é um enter, se iniciarmos com ele daremos um enter e apos isso escreveremos.\n# a.read() se usar este comando ira dar erro, lembre-se que .read() somente se abrir o arquivo como leitura ('r')\nwith open('arquivo1.txt', 'r', encoding=\"utf-8\") as a:\n print(a.read())",
"Python é uma linguagem poderosa!Editando arquivo\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\nEditando arquivo!!!\n"
]
],
[
[
"# Trabalhando em modo b(binário) (imagens)",
"_____no_output_____"
]
],
[
[
"# criando uma copia da imagem python-logo.png\nwith open(\"python-logo.png\", \"rb\") as imagem:\n data = imagem.read()\n\nwith open(\"python-logo2.png\", \"wb\") as imagem2:\n imagem2.write(data)\n",
"_____no_output_____"
]
],
[
[
"# Lendo arquivos linha a linha e protegendo uso de memoria",
"_____no_output_____"
]
],
[
[
"from sys import getsizeof\n\nwith open('contatos.csv', 'r', encoding='latin_1') as a:\n for numero, linha in enumerate(a):\n print(f'Imprimindo linha {numero} | {getsizeof(linha)}-bytes\\n {linha}', end='')",
"Imprimindo linha 0 | 88-bytes\n 1,Guilherme,[email protected]\nImprimindo linha 1 | 76-bytes\n 2,Elias,[email protected]\nImprimindo linha 2 | 82-bytes\n 3,Gabriel,[email protected]\nImprimindo linha 3 | 85-bytes\n 4,Anderson,[email protected]\nImprimindo linha 4 | 73-bytes\n 5,Alex,[email protected]\nImprimindo linha 5 | 73-bytes\n 6,Vini,[email protected]\nImprimindo linha 6 | 108-bytes\n 7,Let�cia,[email protected]\nImprimindo linha 7 | 79-bytes\n 8,Giulia,[email protected]\nImprimindo linha 8 | 79-bytes\n 9,Felipe,[email protected]\nImprimindo linha 9 | 96-bytes\n 10,Lu�sa,luisa@luisa\nImprimindo linha 10 | 77-bytes\n 11,Livio,[email protected]\n"
]
],
[
[
"# Erros comuns ao tentar abrir um arquivo.\n\n1. **FileNotFoundError** - Não encontrar o arquivo no local especificado.\n\n1. **PermissionError** - Não tem permissão de escrita/criação no diretorio.",
"_____no_output_____"
],
[
"## try + finally",
"_____no_output_____"
]
],
[
[
"# Tratando erros com try:\ntry:\n arquivo = open('contatos.csv', mode='a+', encoding='latin_1')\n # Em mode='a' o arquivo abre na ultima linha, colocamos seek(0) para retornar a 1ª linha\n # assim o readlines funcionar.\n arquivo.seek(0)\n conteudo = arquivo.readlines()\n print(conteudo)\n\n# finally será executando sempre, é comum colocarmos este tratamento para fechar o arquivo, \n# apos o uso. Assim liberando o mesmo para outras pessoas.\nfinally:\n arquivo.close()\n",
"['1,Guilherme,[email protected]\\n', '2,Elias,[email protected]\\n', '3,Gabriel,[email protected]\\n', '4,Anderson,[email protected]\\n', '5,Alex,[email protected]\\n', '6,Vini,[email protected]\\n', '7,Let�cia,[email protected]\\n', '8,Giulia,[email protected]\\n', '9,Felipe,[email protected]\\n', '10,Lu�sa,luisa@luisa\\n', '11,Livio,[email protected]\\n']\n"
]
],
[
[
"## simulando FileNotFoundError\n\n* Modificando o nome do arquivo para um arquivo que não existe.\n* Abrindo em mode='r', pois em w e a se não existir o arquivo o Python cria",
"_____no_output_____"
]
],
[
[
"try:\n arquivo = open('arquivo_nao_existe.csv', mode='r', encoding='latin_1')\n arquivo.seek(0)\n conteudo = arquivo.readlines()\n print(conteudo)\n\nfinally:\n arquivo.close()",
"_____no_output_____"
]
],
[
[
"### Solução com except FileNotFoundError:\n\n**Agora nosso script não quebra caso não encontre o arquivo**",
"_____no_output_____"
]
],
[
[
"try:\n arquivo = open('arquivo_nao_existe.csv', mode='r', encoding='latin_1')\n arquivo.seek(0)\n conteudo = arquivo.readlines()\n print(conteudo)\n\nexcept FileNotFoundError:\n print('Arquivo não encontrado')\n \nexcept PermissionError:\n print('Sem permissão de escrita')\n\nfinally:\n arquivo.close()",
"Arquivo não encontrado\n"
]
],
[
[
"### Substituindo finally por with\n\n* with fecha automaticamente um arquivo\n* usando Lists Comprehensions simples para imprimir linha a linha\n\n> Utilizamos o comando with para gerenciar o contexto de utilização do arquivo. Além de arquivos, podemos utilizar o with para gerenciar processos que precisam de uma pré e pós condição de execução; por exemplo: abrir e fechar o arquivo, realizar conexão com o banco de dados, sockets, entre outros.\n\n> O objeto que está sendo manipulado pelo with precisa implementar dois métodos mágicos: \\_\\_enter__() e \\_\\_exit__().\n\n> O método \\_\\_enter__() é executado logo no início da chamada da função e retorna uma representação do objeto que está sendo executada no contexto (ou context guard). Ao final, o método \\_\\_exit__() é invocado, e o contexto da execução, finalizado.",
"_____no_output_____"
]
],
[
[
"try:\n with open('contatos.csv', mode='r', encoding='latin_1') as arquivo:\n [print(linha, end='') for linha in arquivo]\n\nexcept FileNotFoundError:\n print('Arquivo não encontrado')\n \nexcept PermissionError:\n print('Sem permissão de escrita')\n",
"1,Guilherme,[email protected]\n2,Elias,[email protected]\n3,Gabriel,[email protected]\n4,Anderson,[email protected]\n5,Alex,[email protected]\n6,Vini,[email protected]\n7,Let�cia,[email protected]\n8,Giulia,[email protected]\n9,Felipe,[email protected]\n10,Lu�sa,luisa@luisa\n11,Livio,[email protected]\n"
]
],
[
[
"# De csv p/ Python\n\n* converter um arquivo csv para um objeto list no python\n* usando modulo csv\n* criando uma função",
"_____no_output_____"
],
[
"## Criando uma class contatos",
"_____no_output_____"
]
],
[
[
"class Contato():\n def __init__(self, id: int, nome: str, email: str):\n self.id = id\n self.nome = nome\n self.email = email\n",
"_____no_output_____"
]
],
[
[
"## Criando uma função csv para list python",
"_____no_output_____"
]
],
[
[
"import csv\n\ndef csv_para_contatos(caminho: str, encoding: str = 'Latin_1'):\n contatos: list = []\n try:\n with open(caminho, encoding=encoding) as a:\n leitor = csv.reader(a)\n for linha in leitor:\n id, nome, email = linha # desencapsulando\n \n contato = Contato(int(id), nome, email)\n contatos.append(contato)\n\n return contatos\n \n except FileNotFoundError:\n print('Arquivo não encontrado')\n \n except PermissionError:\n print('Sem permissão de escrita')",
"_____no_output_____"
]
],
[
[
"## Testando com arquivo contatos.csv",
"_____no_output_____"
]
],
[
[
"contatos = csv_para_contatos('contatos.csv')\n\nlista = [print(f'{contato.id} - {contato.nome} - {contato.email}') for contato in contatos]",
"1 - Guilherme - [email protected]\n2 - Elias - [email protected]\n3 - Gabriel - [email protected]\n4 - Anderson - [email protected]\n5 - Alex - [email protected]\n6 - Vini - [email protected]\n7 - Let�cia - [email protected]\n8 - Giulia - [email protected]\n9 - Felipe - [email protected]\n10 - Lu�sa - luisa@luisa\n11 - Livio - [email protected]\n"
]
],
[
[
"# De objeto Python para json\n\n* converter um objeto python para um arquivo json\n* usando modulo json\n* criando uma função",
"_____no_output_____"
],
[
"## Criando uma função objeto python para json",
"_____no_output_____"
]
],
[
[
"import json\n\n# escrita\ndef contatos_para_json(contatos, caminho: str):\n try:\n with open(caminho, mode='w') as a:\n json.dump(contatos, a, default=__contato_para_json)\n \n except FileNotFoundError:\n print('Arquivo não encontrado')\n \n except PermissionError:\n print('Sem permissão de escrita')\n \ndef __contato_para_json(contato):\n return contato.__dict__\n\n# leitura\ndef json_para_contatos(caminho: str):\n contatos = []\n \n try:\n with open(caminho, mode='r') as a:\n contatos_json = json.load(a)\n # Contato(contato['id'], contato['nome'], contato['email']) = Contato(**contato)\n # assim estariamos desempacotando\n [contatos.append(Contato(contato['id'], contato['nome'], contato['email']))\n for contato in contatos_json]\n \n return contatos\n \n except FileNotFoundError:\n print('Arquivo não encontrado')\n \n except PermissionError:\n print('Sem permissão de escrita')\n ",
"_____no_output_____"
]
],
[
[
"## Testando de objeto python para json",
"_____no_output_____"
]
],
[
[
"# transformando csv em objeto python\ncontatos = csv_para_contatos('contatos.csv')\n\n# transformando objeto python em json\ncontatos_para_json(contatos, 'contatos.json')\n\n# transformando json em objeto python\ncontatos = json_para_contatos('contatos.json')\n\nlista = [print(f'{contato.id} - {contato.nome} - {contato.email}') for contato in contatos]",
"1 - Guilherme - [email protected]\n2 - Elias - [email protected]\n3 - Gabriel - [email protected]\n4 - Anderson - [email protected]\n5 - Alex - [email protected]\n6 - Vini - [email protected]\n7 - Let�cia - [email protected]\n8 - Giulia - [email protected]\n9 - Felipe - [email protected]\n10 - Lu�sa - luisa@luisa\n11 - Livio - [email protected]\n"
],
[
"import json\n# json.dump = usado para gravar dados de objeto python em arquivo json\n# json.dumps = usado para transformar objetos python em objetos str json\n# json.load = usado para ler um arquivo json e transforma-lo em objto python\n\n# Codificando hierarquias básicas de objetos Python:\nlista = ['foo', {'bar': ('baz', None, 1.0, 2)}]\njson_dump = json.dumps(lista)\nprint(f'{json_dump = }')\n\ndicionario = {\"c\": 0, \"b\": 0, \"a\": 0}\njson_dump = json.dumps(dicionario, sort_keys=True)\nprint(f'{json_dump = }')\n\n# Codificação compacta:\nlista = [1, 2, 3, {'4': 5, '6': 7}]\nprint(json.dumps(lista, separators=(',', ':')))\nprint(json.dumps(lista))\n\n# Impressão bonita:\ndicionario = {'4': 5, '6': 7}\nprint(json.dumps(dicionario, sort_keys=True, indent=4))\n\n# Decodificando JSON:\ntexto = '[\"foo\", {\"bar\":[\"baz\", null, 1.0, 2]}]'\nprint(json.loads(texto))",
"json_dump = '[\"foo\", {\"bar\": [\"baz\", null, 1.0, 2]}]'\njson_dump = '{\"a\": 0, \"b\": 0, \"c\": 0}'\n[1,2,3,{\"4\":5,\"6\":7}]\n[1, 2, 3, {\"4\": 5, \"6\": 7}]\n{\n \"4\": 5,\n \"6\": 7\n}\n['foo', {'bar': ['baz', None, 1.0, 2]}]\n"
],
[
"import json\n\ndeveloper_Dict = {\n \"name\": \"Jane Doe\",\n \"salary\": 9000,\n \"skills\": [\"Python\", \"Machine Learning\", \"Web Development\"],\n \"email\": \"[email protected]\"\n}\n\nprint(type(developer_Dict))\n\ndeveloper_str = json.dumps(developer_Dict)\n\nprint(developer_Dict)\nprint(type(developer_str))",
"<class 'dict'>\n{'name': 'Jane Doe', 'salary': 9000, 'skills': ['Python', 'Machine Learning', 'Web Development'], 'email': '[email protected]'}\n<class 'str'>\n"
],
[
"import json\n\nsampleDict = {\n \"colorList\": [\"Red\", \"Green\", \"Blue\"],\n \"carTuple\": (\"BMW\", \"Audi\", \"range rover\"),\n \"sampleString\": \"pynative.com\",\n \"sampleInteger\": 457,\n \"sampleFloat\": 225.48,\n \"booleantrue\": True,\n \"booleanfalse\": False,\n \"nonevalue\": None\n}\nprint(\"Converting Python primitive types into JSON\")\nresultJSON = json.dumps(sampleDict)\nprint(\"Done converting Python primitive types into JSON\")\nprint(resultJSON)",
"Converting Python primitive types into JSON\nDone converting Python primitive types into JSON\n{\"colorList\": [\"Red\", \"Green\", \"Blue\"], \"carTuple\": [\"BMW\", \"Audi\", \"range rover\"], \"sampleString\": \"pynative.com\", \"sampleInteger\": 457, \"sampleFloat\": 225.48, \"booleantrue\": true, \"booleanfalse\": false, \"nonevalue\": null}\n"
]
],
[
[
"# <font color=#FF0000>**json**</font>\nGeralmente, anexar dados a um arquivo JSON não é uma ideia muito boa porque, para cada pequena atualização, você deve ler e analisar todo o objeto de arquivo. Se o seu arquivo JSON tiver n entradas, a complexidade do tempo de execução de apenas atualizá-lo é O (n) .\n\n**_Uma abordagem melhor seria armazenar os dados como um arquivo CSV que pode ser lido linha por linha que simplifica a análise e atualização significativamente, apenas acrescentando uma única linha ao arquivo que tem complexidade de tempo de execução constante._**",
"_____no_output_____"
],
[
"# Sintaxe de <font color=#FF0000>**json.dump()**</font> e <font color=#FF0000>**json.dumps()**</font>\n\n>json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)\n\n**É usado para gravar um objeto Python em um arquivo como dados formatados em JSON.**\n\n>json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)\n\n**É usado para escrever um objeto Python em uma String JSON.**\n\n* **obj** nada mais é que um objeto serializável Python que você deseja converter em um formato JSON.\n* A **fp** é um ponteiro de arquivo usado para gravar dados formatados em JSON em um arquivo. O módulo json Python sempre produz objetos de string, não objetos de bytes, portanto, fp.write()deve suportar a entrada de string.\n* Se **skipkeysfor** verdadeiro (padrão: False), então as chaves de dict que não são de um tipo básico, (str, int, float, bool, None) serão ignoradas em vez de aumentar a TypeError. Por exemplo, se uma de suas chaves de dicionário for um objeto Python personalizado, essa chave será omitida durante a conversão do dicionário em JSON.\n* Se **ensure_ascii** for verdadeiro (o padrão), a saída terá a garantia de ter todos os caracteres não ASCII de entrada com escape. Se ensure_asciifor falso, esses caracteres serão reproduzidos no estado em que se encontram.\n* **allow_nan** é True por padrão, então seus equivalentes JavaScript (NaN, Infinity, -Infinity) serão usados. Se for False, será um ValueError para serializar valores flutuantes fora do intervalo (nan, inf, -inf).\n* Um **indent** argumento é usado para imprimir JSON para torná-lo mais legível. O padrão é (', ', ': '). Para obter a representação JSON mais compacta, você deve usar (',', ':') para eliminar os espaços em branco.\n*Se **sort_keys** for verdadeiro (padrão: Falso), a saída dos dicionários será classificada por chave",
"_____no_output_____"
],
[
"# <font color=#FF0000>**json.load()**</font> - Lendo um arquivo json formatado e transformando em dict\n\n```json\n{\n \"permissões\": {\n \"1\": {\"nome\": \"Desenvolvedor\", \"descrição\": \"Tem acesso full ao sistema\"},\n \"2\": {\"nome\": \"Administrador Master\", \"descrição\": \"Tem acesso full as funcionalidades do sistema e não pode ser apagado\"},\n \"3\": {\"nome\": \"Administrador\", \"descrição\": \"Tem acesso full as funcionalidades do sistema e pode ser apagado\"},\n \"4\": {\"nome\": \"Escrita\", \"descrição\": \"Tem acesso para inserção de dados no sistema e pode se bloquear telas do mesmo\"},\n \"5\": {\"nome\": \"Leitura\", \"descrição\": \"Tem acesso para leitura de dados no sistema e pode se bloquear telas do mesmo\"}\n },\n \"bloqueio_tela\": {\n \"2\": {\"tela_bloqueadas\": []},\n \"3\": {\"tela_bloqueadas\": []},\n \"4\": {\"tela_bloqueadas\": []},\n \"5\": {\"tela_bloqueadas\": []}\n },\n \"telas\": {},\n \"menu_config\": {\n \"0\": [{\"icon_left\": \"account\", \"texto\": \"_users\", \"icon_right\": \"chevron-right\", \"status_icon_right\": \"True\", \"func_icon_right\": \"config_user\", \"cor\": \"False\"},\n {\"icon_left\": \"tools\", \"texto\": \"_project\", \"icon_right\": \"chevron-right\", \"status_icon_right\": \"True\", \"func_icon_right\": \"config_project\", \"cor\": \"False\"}]\n }\n}\n```\n\nAbrindo arquivo json de varios niveis e transformando o mesmo em objeto dict em python. Por fim manipulando o dict.",
"_____no_output_____"
]
],
[
[
"import json\n\nwith open('config_app.json', mode='r', encoding='utf-8') as a:\n json_obj = json.load(a)\n\nprint(f'Type = {type(json_obj)}')\n\nfor key, data in json_obj.items():\n print(f'\\n{key} - {data}')\n \nprint('-'*100)\n \nprint(f'\\n Imprimindo nivel 2:\\n{json_obj[\"permissões\"][\"5\"]}')\n\nprint(f'\\n Imprimindo nivel 3:\\n{json_obj[\"permissões\"][\"5\"][\"nome\"]}')\n",
"Type = <class 'dict'>\n\npermissões - {'1': {'nome': 'Desenvolvedor', 'descrição': 'Tem acesso full ao sistema'}, '2': {'nome': 'Administrador Master', 'descrição': 'Tem acesso full as funcionalidades do sistema e não pode ser apagado'}, '3': {'nome': 'Administrador', 'descrição': 'Tem acesso full as funcionalidades do sistema e pode ser apagado'}, '4': {'nome': 'Escrita', 'descrição': 'Tem acesso para inserção de dados no sistema e pode se bloquear telas do mesmo'}, '5': {'nome': 'Leitura', 'descrição': 'Tem acesso para leitura de dados no sistema e pode se bloquear telas do mesmo'}}\n\nbloqueio_tela - {'2': {'tela_bloqueadas': []}, '3': {'tela_bloqueadas': []}, '4': {'tela_bloqueadas': []}, '5': {'tela_bloqueadas': []}}\n\ntelas - {}\n\nmenu_config - {'0': [{'icon_left': 'account', 'texto': '_users', 'icon_right': 'chevron-right', 'status_icon_right': 'True', 'func_icon_right': 'config_user', 'cor': 'False'}, {'icon_left': 'tools', 'texto': '_project', 'icon_right': 'chevron-right', 'status_icon_right': 'True', 'func_icon_right': 'config_project', 'cor': 'False'}]}\n----------------------------------------------------------------------------------------------------\n\n Imprimindo nivel 2:\n{'nome': 'Leitura', 'descrição': 'Tem acesso para leitura de dados no sistema e pode se bloquear telas do mesmo'}\n\n Imprimindo nivel 3:\nLeitura\n"
]
],
[
[
"# <font color=#FF0000>**json.load()**</font> - Trabalhando com json.load()\n\ntransformando obj json em dict **_(json.loads)_** python e obj json **_(json.dumps)_**",
"_____no_output_____"
]
],
[
[
"import json\n\njson_string = '{\"first_name\": \"Guido\", \"last_name\":\"Rossum\"}'\nprint(f'{json_string = }')\nprint(f'{type(json_string) = }')\n\n# A mesma pode ser analisado assim:\nparsed_json = json.loads(json_string)\nprint(f'\\n{parsed_json = }')\nprint(f'{type(parsed_json) = }')\n# e agora pode ser usado como um dicionário normal:\nprint(f'\\n{parsed_json[\"first_name\"] = }')\n\n# convertendo novamente para json\njson_obj = json.dumps(parsed_json)\nprint(f'\\n{json_obj = }')\nprint(f'{type(json_obj) = }')\n",
"json_string = '{\"first_name\": \"Guido\", \"last_name\":\"Rossum\"}'\ntype(json_string) = <class 'str'>\n\nparsed_json = {'first_name': 'Guido', 'last_name': 'Rossum'}\ntype(parsed_json) = <class 'dict'>\n\nparsed_json[\"first_name\"] = 'Guido'\n\njson_obj = '{\"first_name\": \"Guido\", \"last_name\": \"Rossum\"}'\ntype(json_obj) = <class 'str'>\n"
]
],
[
[
"# <font color=#FF0000>**json.dumps()**</font> para converter tipos primitivos Python em equivalentes JSON\n\nExistem vários cenários em que você precisa usar dados JSON serializados em seu programa. Se você precisar desses dados JSON serializados em seu aplicativo de processamento adicional, poderá convertê-los em um **str objeto Python** nativo em vez de gravá-los em um arquivo.\n\nPor exemplo, você recebe uma solicitação HTTP para enviar detalhes do desenvolvedor. você buscou dados de desenvolvedor da tabela de banco de dados e os armazenou em um dicionário Python ou qualquer objeto Python, agora você precisa enviar esses dados de volta para o aplicativo solicitado, então você precisa converter o objeto de dicionário Python em uma string formatada em JSON para enviar como um resposta na string JSON. Para fazer isso, você precisa usar json.dumps().\n\nO json.dumps() retorna a representação de string JSON do Python dict.\n\n## converter o dicionário Python em uma string formatada em JSON",
"_____no_output_____"
]
],
[
[
"import json\n\ndef SendJsonResponse(resultDict):\n print(\"Convert Python dictionary into JSON formatted String\")\n developer_str = json.dumps(resultDict)\n print(developer_str)\n\n# sample developer dict\ndicionario = {\n \"name\": \"Jane Doe\",\n \"salary\": 9000,\n \"skills\": [\"Python\", \"Machine Learning\", \"Web Development\"],\n \"email\": \"[email protected]\"\n}\n\nprint(f'Type dicionario = {type(dicionario)}')\nprint(f'{dicionario = }')\n\nstring_json = json.dumps(dicionario)\n\nprint(f'\\nType string_json= {type(string_json)}')\nprint(f'{string_json = }')\n",
"Type dicionario = <class 'dict'>\ndicionario = {'name': 'Jane Doe', 'salary': 9000, 'skills': ['Python', 'Machine Learning', 'Web Development'], 'email': '[email protected]'}\n\nType string_json= <class 'str'>\nstring_json = '{\"name\": \"Jane Doe\", \"salary\": 9000, \"skills\": [\"Python\", \"Machine Learning\", \"Web Development\"], \"email\": \"[email protected]\"}'\n"
]
],
[
[
"# <font color=#FF0000>**json.dumps()**</font> - Mapeamento entre entidades JSON e Python durante a codificação\n\nPara codificar objetos Python no módulo JSON equivalente a JSON, usa-se a seguinte tabela de conversão. A json.dump() e json.dumps() executa o método as traduções quando codificam.\n\nAgora vamos ver como converter todos os tipos primitivos Python, tais como dict, list, set, tuple, str, números em JSON dados formatados. Consulte a tabela a seguir para saber o mapeamento entre os tipos de dados JSON e Python.\n\nPython | Json\n:---: | :---:\ndict | object\nlist, tuple | array\nstr | string\nint, float, int & float-derived Enums | number\nTrue | true\nFalse | false\nNone | null",
"_____no_output_____"
]
],
[
[
"import json\n\ndicionario = {\n \"colorList\": [\"Red\", \"Green\", \"Blue\"],\n \"carTuple\": (\"BMW\", \"Audi\", \"range rover\"),\n \"sampleString\": \"pynative.com\",\n \"sampleInteger\": 457,\n \"sampleFloat\": 225.48,\n \"booleantrue\": True,\n \"booleanfalse\": False,\n \"nonevalue\": None\n}\nprint(f'Type dicionario = {type(dicionario)}')\nprint(f'{dicionario = }')\n\nstring_json = json.dumps(dicionario)\n\nprint(f'\\nType string_json= {type(string_json)}')\nprint(f'{string_json = }')",
"Type dicionario = <class 'dict'>\ndicionario = {'colorList': ['Red', 'Green', 'Blue'], 'carTuple': ('BMW', 'Audi', 'range rover'), 'sampleString': 'pynative.com', 'sampleInteger': 457, 'sampleFloat': 225.48, 'booleantrue': True, 'booleanfalse': False, 'nonevalue': None}\n\nType string_json= <class 'str'>\nstring_json = '{\"colorList\": [\"Red\", \"Green\", \"Blue\"], \"carTuple\": [\"BMW\", \"Audi\", \"range rover\"], \"sampleString\": \"pynative.com\", \"sampleInteger\": 457, \"sampleFloat\": 225.48, \"booleantrue\": true, \"booleanfalse\": false, \"nonevalue\": null}'\n"
],
[
"from json import dumps\n\n#! dict para obj json\n\ncarros_dict = {'marca': 'Toyota', 'modelo': 'Corolla', 'cor': 'chumbo'}\nprint(carros_dict)\nprint(type(carros_dict))\n\n# transformando em objeto json\ncarros_json = dumps(carros_dict)\nprint(f'\\n{carros_json}')\nprint(type(carros_json))",
"{'marca': 'Toyota', 'modelo': 'Corolla', 'cor': 'chumbo'}\n<class 'dict'>\n\n{\"marca\": \"Toyota\", \"modelo\": \"Corolla\", \"cor\": \"chumbo\"}\n<class 'str'>\n"
],
[
"from json import dumps\n\n#! tuple() to array json []\n\ncarros_tuple = ('Toyota', 'VW', 'Honda', 'BMW')\nprint(carros_tuple)\nprint(type(carros_tuple))\n\n# transformando em objeto json\ncarros_json = dumps(carros_tuple)\nprint(f'\\n{carros_json}')\nprint(type(carros_json))\n",
"('Toyota', 'VW', 'Honda', 'BMW')\n<class 'tuple'>\n\n[\"Toyota\", \"VW\", \"Honda\", \"BMW\"]\n<class 'str'>\n"
],
[
"from json import dumps\n\n#! list[] to array json[]\n\ncarros_list = ['Toyota', 'VW', 'Honda', 'BMW']\nprint(carros_list)\nprint(type(carros_list))\n\n# transformando em objeto json\ncarros_json = dumps(carros_list)\nprint(f'\\n{carros_json}')\nprint(type(carros_json))",
"['Toyota', 'VW', 'Honda', 'BMW']\n<class 'list'>\n\n[\"Toyota\", \"VW\", \"Honda\", \"BMW\"]\n<class 'str'>\n"
]
],
[
[
"# <font color=#FF0000>**json.dump()**</font> - Para codificar e gravar dados JSON em um arquivo\n\nPara gravar a resposta JSON em um arquivo: Na maioria das vezes, ao executar uma solicitação GET, você recebe uma resposta no formato JSON e pode armazenar a resposta JSON em um arquivo para uso futuro ou para uso de um sistema subjacente.\n\nPor exemplo, você tem dados em uma lista ou dicionário ou qualquer objeto Python e deseja codificá-los e armazená-los em um arquivo na forma de JSON.\n\nVamos converter o dicionário Python em um formato JSON e gravá-lo em um arquivo, sendo:\n\n1. **SEM FORMATAÇÃO NO ARQUIVO JSON**. (file_json_sem_formatar.json)\n\n```json\n{\"bloqueio_tela\": {\"5\": {\"tela_bloqueadas\": []}, \"3\": {\"tela_bloqueadas\": []}, \"1\": {\"tela_bloqueadas\": []}, \"2\": {\"tela_bloqueadas\": []}}}\n```\n\n2. **RECUADOS E FORMATADOS**. (file_json_formatado.json)\n * indent=4 --> _4 espaços de indentação_\n * separators=(', ', ': ') --> _formato com espaço apos \",\" e apos \":\"_\n * sort_keys=True --> _as chavas são gravadas em ordem crescente_\n\n```json\n{\n \"bloqueio_tela\": {\n \"1\": {\n \"tela_bloqueadas\": []\n }, \n \"2\": {\n \"tela_bloqueadas\": []\n }, \n \"3\": {\n \"tela_bloqueadas\": []\n }, \n \"5\": {\n \"tela_bloqueadas\": []\n }\n }\n}\n```\n\n3. **CODIFICAÇÃO COMPACTA PARA ECONOMIZAR ESPAÇO**. (file_json_compacto.json)\n * separators=(',', ':') --> _eliminando os espaços e formatação_\n\n```json\n{\"bloqueio_tela\":{\"1\":{\"tela_bloqueadas\":[]},\"2\":{\"tela_bloqueadas\":[]},\"3\":{\"tela_bloqueadas\":[]},\"5\":{\"tela_bloqueadas\":[]}}}\n``` ",
"_____no_output_____"
]
],
[
[
"import json\n\ndicionario = {\"bloqueio_tela\": {\"5\": {\"tela_bloqueadas\": []}, \"3\": {\"tela_bloqueadas\": []}, \"1\": {\"tela_bloqueadas\": []}, \"2\": {\"tela_bloqueadas\": []}}}\n\n# criando um arquivo sem formatar:\nwith open('file_json_sem_formatar.json', mode='w', encoding='utf-8') as write_file:\n json.dump(dicionario, write_file)\n \n# criando um arquivo json formatado, com recuo, espaços apos \",\" e \":\" e em orden crescente de chaves:\nwith open('file_json_formatado.json', mode='w', encoding='utf-8') as write_file:\n json.dump(dicionario, write_file, indent=4, separators=(', ', ': '), sort_keys=True)\n \n# criando um arquivo json sem formatação e sem espaço para economizar tamanho com \",\" e \":\":\nwith open('file_json_compacto.json', mode='w', encoding='utf-8') as write_file:\n json.dump(dicionario, write_file, separators=(',', ':'), sort_keys=True)\n \n# podemos tambem trocar o sinal que divide key e chave com separators\nprint(json.dumps(dicionario, separators=(',', '='), sort_keys=True))\n",
"{\"bloqueio_tela\"={\"1\"={\"tela_bloqueadas\"=[]},\"2\"={\"tela_bloqueadas\"=[]},\"3\"={\"tela_bloqueadas\"=[]},\"5\"={\"tela_bloqueadas\"=[]}}}\n"
]
],
[
[
"# <font color=#FF0000>**json.dump()**</font> - Pule os tipos não básicos ao gravar JSON em um arquivo usando o parâmetro skipkeys\n\nO módulo json integrado do Python só pode lidar com tipos primitivos Python que tenham um equivalente JSON direto (por exemplo, dicionário, listas, strings, ints, Nenhum, etc.).\n\nSe o dicionário Python contiver um objeto Python personalizado como uma das chaves e se tentarmos convertê-lo em um formato JSON, você obterá um TypeError, isto é <font color=#FF0000>**_Object of type \"Your Class\" is not JSON serializable_**</font>,.\n\nSe este objeto personalizado não for necessário em dados JSON, você pode ignorá-lo usando um **_skipkeys=true_** argumento do json.dump() método.\nSe **_skipkeys=true_** for True, então as dict chaves que não são de um tipo básico (str, int, float, bool, None) serão ignoradas em vez de gerar um TypeError.\n\n```json\n{\"salario\": 9000, \"skills\": [\"Python\", \"Machine Learning\", \"Web Development\"], \"email\": \"[email protected]\"}\n```\nObs.: Sem o DadosPessoais: usuario\n\nArtigo para transformar tipos não basicos em json:\n<https://pynative.com/make-python-class-json-serializable/>",
"_____no_output_____"
]
],
[
[
"import json\n\nclass DadosPessoais():\n def __init__(self, name: str, age: int):\n self.name = name\n self.age = age\n\n def showInfo(self):\n print(\"Nome é \" + self.name, \"Idade é \", self.age)\n\n# instanciando um objeto\nusuario = DadosPessoais(\"João\", 36)\n\ndicionario = {\n DadosPessoais: usuario,\n \"salario\": 9000,\n \"skills\": [\"Python\", \"Machine Learning\", \"Web Development\"],\n \"email\": \"[email protected]\"\n}\n\n# criando arquivo json sem tipos não basicos (obj DadosPessoais)\nwith open(\"file_json_sem_tipos_nao_basicos.json\", mode='w', encoding='utf-8') as write_file:\n json.dump(dicionario, write_file, skipkeys=True)\n",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**json.dumps()**</font> - Lidar com caracteres não ASCII de dados JSON ao gravá-los em um arquivo\n\nO json.dump() método possui ensure_ascii parâmetro. O ensure_ascii é verdadeiro por padrão. A saída tem a garantia de ter todos os caracteres não ASCII de entrada com escape. Se ensure_ascii for falso, esses caracteres serão reproduzidos no estado em que se encontram. Se você deseja armazenar caracteres não ASCII, no estado em que se encontra, use o código a seguir.\n\nObs.: Se usar o **ensure_ascii=False** como parametro do json.dump o mesmo irá salvar palavras com acentuação no arquivo json. Uma boa pratica ao abrir estes arquivos é usar o encoding utf-8\n\n~~~\n\n# boa pratica se salvar um json com ensure_ascii=False é abrir o mesmo com encoding utf-8\nwith open(caminho, mode='r', encoding='utf-8') as read_file:\n~~~",
"_____no_output_____"
]
],
[
[
"import json\n# encoding in UTF-8\nunicode_data= {\n \"string1\": \"明彦\",\n \"string2\": u\"\\u00f8\"}\n\nprint(f'{unicode_data = }')\n\n# dumps com ensure_ascii=False\nencoded_unicode = json.dumps(unicode_data, ensure_ascii=False)\nprint(f'{encoded_unicode = }')\nencoded_unicode = json.dumps(unicode_data, ensure_ascii=True)\nprint(f'{encoded_unicode = }')\n\n# dumps com ensure_ascii=True (default)\nprint(json.loads(encoded_unicode))",
"unicode_data = {'string1': '明彦', 'string2': 'ø'}\nencoded_unicode = '{\"string1\": \"明彦\", \"string2\": \"ø\"}'\nencoded_unicode = '{\"string1\": \"\\\\u660e\\\\u5f66\", \"string2\": \"\\\\u00f8\"}'\n{'string1': '明彦', 'string2': 'ø'}\n"
]
],
[
[
"# <font color=#FF0000>**CSV (Comma Separated Values)**</font> - Trabalhando com arquivo CSV",
"_____no_output_____"
],
[
"# <font color=#FF0000>**csv.reader**</font> - Leia CSV com delimitador de vírgula\n\ncsv.reader função no modo padrão para arquivos CSV com delimitador de vírgula.\n\ncsv.reader(file) ou csv.reader(file, delimiter=',') é a mesma coisa, uma vez que o delimiter default é = ','",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open('contatos.csv', mode='r', encoding='utf8', newline='') as file:\n # csv.reader(file) ou csv.reader(file, delimiter=',') é a mesma coisa, uma vez que o delimiter default é = ','\n csv_reader = csv.reader(file)\n for row in csv_reader:\n print(row)",
"['Cod', 'Nome', 'Email']\n['1', 'Guilherme', '[email protected]']\n['2', 'Elias', '[email protected]']\n['3', 'Gabriel', '[email protected]']\n['4', 'Anderson', '[email protected]']\n['5', 'Alex', '[email protected]']\n['6', 'Vini', '[email protected]']\n['7', 'Letícia', '[email protected]']\n['8', 'Giulia', '[email protected]']\n['9', 'Felipe', '[email protected]']\n['10', 'Luísa', 'luisa@luisa']\n['11', 'Livio', '[email protected]']\n"
]
],
[
[
"# <font color=#FF0000>**csv.reader - delimiter='\\t'**</font> - Leia CSV com delimitador diferente\n\nPor padrão, uma vírgula é usada como delimitador em um arquivo CSV. No entanto, alguns arquivos CSV podem usar outros delimitadores além de vírgulas. Os populares | e \\t(tab).",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open('contatos_com_delimitador_tab.csv', mode='r', encoding='utf8', newline='') as file:\n # csv.reader(file) ou csv.reader(file, delimiter=',') é a mesma coisa, uma vez que o delimiter default é = ','\n csv_reader = csv.reader(file)\n for row in csv_reader:\n print(row)\n \n print('-' * 70)\n # utilizando seek(0) para retornar ao inicio do arquivo para ler novamente\n file.seek(0)\n \n # agora usando o delimeter '\\t'(\\t = tab)\n csv_reader = csv.reader(file, delimiter='\\t')\n for row in csv_reader:\n print(row)",
"['cod\\tnome\\temail']\n['1\\tJoao\\[email protected]']\n['2\\tAmanda\\[email protected]']\n['3\\tArthur\\[email protected]']\n['4\\tMatheus\\[email protected]']\n['5\\tGustavo\\[email protected]']\n['6\\tRenato\\[email protected]']\n----------------------------------------------------------------------\n['cod', 'nome', 'email']\n['1', 'Joao', '[email protected]']\n['2', 'Amanda', '[email protected]']\n['3', 'Arthur', '[email protected]']\n['4', 'Matheus', '[email protected]']\n['5', 'Gustavo', '[email protected]']\n['6', 'Renato', '[email protected]']\n"
]
],
[
[
"# <font color=#FF0000>**csv.reader - skipinitialspace=True**</font> - Leia arquivos CSV com espaços iniciais\n\nIsso permite que o reader objeto saiba que as entradas possuem um espaço em branco inicial. Como resultado, os espaços iniciais que estavam presentes após um delimitador são removidos.",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open('contatos_com_espaços.csv', mode='r', encoding='utf8', newline='') as file:\n csv_reader = csv.reader(file)\n for row in csv_reader:\n print(row)\n \n print('-' * 70)\n # utilizando seek(0) para retornar ao inicio do arquivo para ler novamente\n file.seek(0)\n \n # agora usando o skipinitialspace=True para eliminar os espaços \n csv_reader = csv.reader(file, skipinitialspace=True)\n for row in csv_reader:\n print(row)",
"[' Cod', ' Nome', ' Email']\n[' 1', ' Guilherme', ' [email protected]']\n[' 2', ' Elias', ' [email protected]']\n[' 3', ' Gabriel', ' [email protected]']\n[' 4', ' Anderson', ' [email protected]']\n[' 5', ' Alex', ' [email protected]']\n[' 6', ' Vini', ' [email protected]']\n[' 7', ' Letícia', ' [email protected]']\n[' 8', ' Giulia', ' [email protected]']\n[' 9', ' Felipe', ' [email protected]']\n[' 10', ' Luísa', ' luisa@luisa']\n[' 11', ' Livio', ' [email protected]']\n----------------------------------------------------------------------\n['Cod', 'Nome', 'Email']\n['1', 'Guilherme', '[email protected]']\n['2', 'Elias', '[email protected]']\n['3', 'Gabriel', '[email protected]']\n['4', 'Anderson', '[email protected]']\n['5', 'Alex', '[email protected]']\n['6', 'Vini', '[email protected]']\n['7', 'Letícia', '[email protected]']\n['8', 'Giulia', '[email protected]']\n['9', 'Felipe', '[email protected]']\n['10', 'Luísa', 'luisa@luisa']\n['11', 'Livio', '[email protected]']\n"
]
],
[
[
"# <font color=#FF0000>**csv.reader - quoting=csv.QUOTE_ALL, skipinitialspace=True**</font> - Ler arquivos CSV com aspas\n\nComo você pode ver, passamos csv.QUOTE_ALL para o quoting parâmetro. É uma constante definida pelo csv módulo.\n\ncsv.QUOTE_ALL especifica o objeto leitor que todos os valores no arquivo CSV estão presentes entre aspas.\n\nExistem 3 outras constantes predefinidas que você pode passar para o quoting parâmetro:\n\n* csv.QUOTE_MINIMAL- Especifica o reader objeto que o arquivo CSV tem aspas em torno das entradas que contêm caracteres especiais, como delimitador , quotechar ou qualquer um dos caracteres no determinador de linha .\n* csv.QUOTE_NONNUMERIC- Especifica o reader objeto que o arquivo CSV tem aspas em torno das entradas não numéricas.\n* csv.QUOTE_NONE - Especifica o objeto leitor que nenhuma das entradas tem aspas ao redor.",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open('arquivo_csv_com_aspas.csv', mode='r', encoding='utf8', newline='') as file:\n csv_reader = csv.reader(file)\n for row in csv_reader:\n print(row)\n \n print('-' * 70)\n # utilizando seek(0) para retornar ao inicio do arquivo para ler novamente\n file.seek(0)\n \n # agora usando o quoting=csv.QUOTE_ALL, skipinitialspace=True para eliminar as aspas e espaços\n csv_reader = csv.reader(file, quoting=csv.QUOTE_ALL, skipinitialspace=True)\n for row in csv_reader:\n print(row)",
"['SN', ' \"Nome\"', ' \"Citações\"']\n['1', ' Buda', ' \"O que pensamos que nos tornamos\"']\n['2', ' Mark Twain', ' \"Nunca se arrependa de nada que o tenha feito sorrir\"']\n['3', ' Oscar Wilde', ' \"Seja você mesmo', ' todo mundo já está tomado\"']\n----------------------------------------------------------------------\n['SN', 'Nome', 'Citações']\n['1', 'Buda', 'O que pensamos que nos tornamos']\n['2', 'Mark Twain', 'Nunca se arrependa de nada que o tenha feito sorrir']\n['3', 'Oscar Wilde', 'Seja você mesmo, todo mundo já está tomado']\n"
]
],
[
[
"# <font color=#FF0000>**csv.reader - dialect='myDialect'**</font> - Ler arquivos CSV usando dialeto\n\nPassamos vários parâmetros ( delimiter, quotinge, skipinitialspace) para a csv.reader()função.\n\nEssa prática é aceitável ao lidar com um ou dois arquivos. Mas isso tornará o código mais redundante e feio quando começarmos a trabalhar com vários arquivos CSV com formatos semelhantes. Como solução para isso, o csv módulo oferece dialect como parâmetro opcional.\n\nDialeto ajuda a agrupar muitos padrões de formatação específicas, como delimiter, skipinitialspace, quoting, escapecharem um único nome dialeto.\n\nEle pode então ser passado como um parâmetro para várias writer ou reader instâncias.",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open('arquivo_csv_uso_dialetos.csv', mode='r', encoding='utf8', newline='') as file:\n csv_reader = csv.reader(file)\n for row in csv_reader:\n print(row)\n \n print('-' * 70)\n # utilizando seek(0) para retornar ao inicio do arquivo para ler novamente\n file.seek(0)\n # registrando um dialeto\n csv.register_dialect('myDialect', delimiter='|', skipinitialspace=True, quoting=csv.QUOTE_ALL)\n # agora usando o dialect='myDialect'\n csv_reader = csv.reader(file, dialect='myDialect')\n for row in csv_reader:\n print(row)\n \n \"\"\"A vantagem de usar dialect é que torna o programa mais modular. Observe que podemos reutilizar\n 'myDialect' para abrir outros arquivos sem ter que especificar novamente o formato CSV.\"\"\"",
"['ID | \"Nome\" | \"O email\"']\n['A878 | \"Alfonso K. Hamby\" | \"[email protected]\"']\n['F854 | \"Susanne Briard\" | \"[email protected]\"']\n['E833 | \"Katja Mauer\" | \"[email protected]\"']\n----------------------------------------------------------------------\n['ID ', 'Nome ', 'O email']\n['A878 ', 'Alfonso K. Hamby ', '[email protected]']\n['F854 ', 'Susanne Briard ', '[email protected]']\n['E833 ', 'Katja Mauer ', '[email protected]']\n"
]
],
[
[
"# <font color=#FF0000>**csv.DictReader**</font>\n\nEntradas da primeira linha são as chaves do dicionário. E as entradas nas outras linhas são os valores do dicionário.",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open('contatos.csv', mode='r', encoding='utf8', newline='') as file:\n csv_file = csv.DictReader(file)\n for row in csv_file:\n print(row) # python >= 3.8 print(dict(row)) python < 3.8\n\n# Entradas da primeira linha são as chaves do dicionário. E as entradas nas outras linhas são os valores do dicionário.",
"{'Cod': '1', 'Nome': 'Guilherme', 'Email': '[email protected]'}\n{'Cod': '2', 'Nome': 'Elias', 'Email': '[email protected]'}\n{'Cod': '3', 'Nome': 'Gabriel', 'Email': '[email protected]'}\n{'Cod': '4', 'Nome': 'Anderson', 'Email': '[email protected]'}\n{'Cod': '5', 'Nome': 'Alex', 'Email': '[email protected]'}\n{'Cod': '6', 'Nome': 'Vini', 'Email': '[email protected]'}\n{'Cod': '7', 'Nome': 'Letícia', 'Email': '[email protected]'}\n{'Cod': '8', 'Nome': 'Giulia', 'Email': '[email protected]'}\n{'Cod': '9', 'Nome': 'Felipe', 'Email': '[email protected]'}\n{'Cod': '10', 'Nome': 'Luísa', 'Email': 'luisa@luisa'}\n{'Cod': '11', 'Nome': 'Livio', 'Email': '[email protected]'}\n"
]
],
[
[
"# <font color=#FF0000>**csv.writer writerow**</font> - Gravando linha por linha com writerow\n\nA csv.writer()função retorna um writer objeto que converte os dados do usuário em uma string delimitada. Esta string pode ser usada posteriormente para gravar em arquivos CSV usando a writerow()função. Vamos dar um exemplo.",
"_____no_output_____"
]
],
[
[
"import csv\n\n# Gravando linha por linha com writerow\nwith open('arquivo_csv_writer.csv', mode='w', encoding='utf8', newline='') as file:\n writer = csv.writer(file)\n writer.writerow([\"SN\", \"Movie\", \"Protagonist\"])\n writer.writerow([1, \"Lord of the Rings\", \"Frodo Baggins\"])\n writer.writerow([2, \"Harry Potter\", \"Harry Potter\"])",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**csv.writer writerows**</font> - Gravando várias linhas com writerows",
"_____no_output_____"
]
],
[
[
"import csv\n# Gravando varias linhas com writerows\nlista = [[\"SN\", \"Movie\", \"Protagonist\"], [1, \"Lord of the Rings\", \"Frodo Baggins\"], [2, \"Harry Potter\", \"Harry Potter\"]]\nwith open('arquivo_csv_writer_rows.csv', mode='w', encoding='utf8', newline='') as file:\n writer = csv.writer(file)\n writer.writerows(lista)",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**csv.writer - delimiter**</font> - Gravando em um arquivo CSV com delimitador\n\n```\ncod\tnome\temail\n1\tJoao\[email protected]\n2\tAmanda\[email protected]\n3\tArthur\[email protected]\n4\tMatheus\[email protected]\n5\tGustavo\[email protected]\n6\tRenato\[email protected]\n```",
"_____no_output_____"
]
],
[
[
"import csv\n\nlista = [['cod', 'nome', 'email'], ['1', 'Joao', '[email protected]'], ['2', 'Amanda', '[email protected]'],\n ['3', 'Arthur', '[email protected]'], ['4', 'Matheus', '[email protected]'], ['5', 'Gustavo', '[email protected]'], \n ['6', 'Renato', '[email protected]']]\n\nwith open('contatos_com_delimitador_tab.csv', mode='w', encoding='utf8', newline='') as file:\n writer = csv.writer(file, delimiter='\\t')\n writer.writerows(lista)",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**csv.writer - quoting=csv.QUOTE_NONNUMERIC**</font> - Gravando em um arquivo CSV com aspas\n\n* _csv.QUOTE_NONNUMERIC_ Especifica o writer objeto que as aspas devem ser adicionadas às entradas **não numéricas**.\n* _csv.QUOTE_ALL_ Especifica o writer objeto para gravar o arquivo CSV com aspas em torno de **todas as entradas**.\n* _csv.QUOTE_MINIMAL_ Especifica o writer objeto para citar apenas os campos que contêm caracteres especiais (delimitador , quotechar ou quaisquer caracteres no determinador de linha)\n* _csv.QUOTE_NONE_ Especifica o writer objeto que nenhuma das entradas deve ser citada. **É o valor padrão**.\n```\n\"cod\",\"nome\",\"email\"\n1,\"Joao\",\"[email protected]\"\n2,\"Amanda\",\"[email protected]\"\n3,\"Arthur\",\"[email protected]\"\n4,\"Matheus\",\"[email protected]\"\n5,\"Gustavo\",\"[email protected]\"\n6,\"Renato\",\"[email protected]\"\n```",
"_____no_output_____"
]
],
[
[
"import csv\n\nlista = [[\"cod\", \"nome\", \"email\"], [1, 'Joao', '[email protected]'], [2, 'Amanda', \"[email protected]\"],\n [3, 'Arthur', '[email protected]'], [4, \"Matheus\", '[email protected]'], [5, 'Gustavo', '[email protected]'], \n [6, \"Renato\", '[email protected]']]\n\nwith open('arquivo_csv_com_aspas.csv', mode='w', encoding='utf8', newline='') as file:\n writer = csv.writer(file, quoting=csv.QUOTE_NONNUMERIC)\n writer.writerows(lista)",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**csv.writer - quoting=csv.QUOTE_NONNUMERIC e quotechar='*'**</font> - Gravando arquivos CSV com caractere de citação personalizado\n\n```\n*cod*,*nome*,*email*\n*1*,*Joao*,*[email protected]*\n*2*,*Amanda*,*[email protected]*\n*3*,*Arthur*,*[email protected]*\n*4*,*Matheus*,*[email protected]*\n*5*,*Gustavo*,*[email protected]*\n*6*,*Renato*,*[email protected]*\n```",
"_____no_output_____"
]
],
[
[
"import csv\n\nlista = [['cod', 'nome', 'email'], ['1', 'Joao', '[email protected]'], ['2', 'Amanda', '[email protected]'],\n ['3', 'Arthur', '[email protected]'], ['4', 'Matheus', '[email protected]'], ['5', 'Gustavo', '[email protected]'], \n ['6', 'Renato', '[email protected]']]\n\nwith open('arquivo_csv_com_quotechar.csv', mode='w', encoding='utf8', newline='') as file:\n writer = csv.writer(file, quoting=csv.QUOTE_NONNUMERIC, quotechar='*')\n writer.writerows(lista)",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**csv.writer - dialect='myDialect'**</font> - Gravando arquivos CSV usando dialeto\n\nA vantagem de usar dialect é que torna o programa mais modular. Observe que podemos reutilizar myDialect para gravar outros arquivos CSV sem ter que especificar novamente o formato CSV.\n\n```\n*cod*|*nome*|*email*\n*1*|*Joao*|*[email protected]*\n*2*|*Amanda*|*[email protected]*\n*3*|*Arthur*|*[email protected]*\n*4*|*Matheus*|*[email protected]*\n*5*|*Gustavo*|*[email protected]*\n*6*|*Renato*|*[email protected]*\n```",
"_____no_output_____"
]
],
[
[
"import csv\n\nlista = [['cod', 'nome', 'email'], ['1', 'Joao', '[email protected]'], ['2', 'Amanda', '[email protected]'],\n ['3', 'Arthur', '[email protected]'], ['4', 'Matheus', '[email protected]'], ['5', 'Gustavo', '[email protected]'], \n ['6', 'Renato', '[email protected]']]\n\ncsv.register_dialect('myDialect', delimiter='|', quoting=csv.QUOTE_NONNUMERIC, quotechar='*')\n\nwith open('arquivo_csv_uso_dialetos.csv', mode='w', encoding='utf8', newline='') as file:\n writer = csv.writer(file, dialect='myDialect')\n writer.writerows(lista)",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**csv.DictWriter**</font> - Gravando arquivos CSV atraves de uma lista de dicionarios\n\n```\ncod,nome,email\n1,Joao,[email protected]\n2,Amanda,[email protected]\n3,Arthur,[email protected]\n4,Matheus,[email protected]\n5,Gustavo,[email protected]\n6,Renato,[email protected]\n```",
"_____no_output_____"
]
],
[
[
"import csv\n\nlista = [{'cod': 1, 'nome': 'Joao', 'email': '[email protected]'}, {'cod': 2, 'nome': 'Amanda', 'email': '[email protected]'},\n {'cod': 3, 'nome': 'Arthur', 'email': '[email protected]'}, {'cod': 4, 'nome': 'Matheus', 'email': '[email protected]'},\n {'cod': 5, 'nome': 'Gustavo', 'email': '[email protected]'}, {'cod': 6, 'nome': 'Renato', 'email': '[email protected]'}]\n\nwith open('arquivo_csv_dictWriter.csv', mode='w', encoding='utf8', newline='') as file:\n fieldnames = ['cod', 'nome', 'email']\n writer = csv.DictWriter(file, fieldnames=fieldnames)\n\n writer.writeheader()\n writer.writerows(lista)",
"_____no_output_____"
]
],
[
[
"# <font color=#FF0000>**csv to Excel com openpyxl**</font> - Transformando arquivos CSV em Excel\n",
"_____no_output_____"
]
],
[
[
"import csv\nfrom openpyxl import Workbook\nimport os\n\nwb = Workbook()\nws = wb.active\n\nwith open('salarios.csv') as f:\n reader = csv.reader(f, delimiter=',')\n for row in reader:\n ws.append(row)\n\nwb.save('salarios.xlsx')\n\nos.startfile('salarios.xlsx')\n# os.system(\"start EXCEL.EXE salarios.xlsx\")\n# os.system(\"open -a 'path/Microsoft Excel.app' 'path/file.xlsx'\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a03ce8a648c11d8c256218c0dbe03bccc118f57
| 981,896 |
ipynb
|
Jupyter Notebook
|
notebooks/SLDS_RingAttractor.ipynb
|
Kevin-Sean-Chen/ssm
|
ae997b16ab4b1dccf3cc4ef246fb85521de830f6
|
[
"MIT"
] | 1 |
2019-05-15T17:33:15.000Z
|
2019-05-15T17:33:15.000Z
|
notebooks/SLDS_RingAttractor.ipynb
|
Kevin-Sean-Chen/ssm
|
ae997b16ab4b1dccf3cc4ef246fb85521de830f6
|
[
"MIT"
] | null | null | null |
notebooks/SLDS_RingAttractor.ipynb
|
Kevin-Sean-Chen/ssm
|
ae997b16ab4b1dccf3cc4ef246fb85521de830f6
|
[
"MIT"
] | null | null | null | 997.861789 | 202,312 | 0.956531 |
[
[
[
"import autograd.numpy as np\nimport autograd.numpy.random as npr\nnpr.seed(0)\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nimport seaborn as sns\nsns.set_style(\"white\")\nsns.set_context(\"talk\")\n\ncolor_names = [\"windows blue\",\n \"red\",\n \"amber\",\n \"faded green\",\n \"dusty purple\",\n \"orange\",\n \"clay\",\n \"pink\",\n \"greyish\",\n \"mint\",\n \"light cyan\",\n \"steel blue\",\n \"forest green\",\n \"pastel purple\",\n \"salmon\",\n \"dark brown\"]\n\ncolors = sns.xkcd_palette(color_names)\n\nimport ssm\nfrom ssm.variational import SLDSMeanFieldVariationalPosterior, SLDSTriDiagVariationalPosterior\nfrom ssm.util import random_rotation, find_permutation",
"_____no_output_____"
]
],
[
[
"## Ring attractor\n\nhttps://www.sciencedirect.com/science/article/pii/S0896627318303258",
"_____no_output_____"
]
],
[
[
"###Ring attractor (multi-attractor) model\nNeu = 100 #number of cells\ntaum = 0.01 #membrain time constant\nk = 0.1 #gain\ngm = 100 #conductance\nWa = -40/gm #average weight\nWd = 33/gm #tuning-dependent\n",
"_____no_output_____"
],
[
"###synaptic weights\nWij = np.zeros((Neu,Neu)) #connectivity matrix\ndeg2rad = np.pi/180\nths = np.linspace(-90,90,Neu)*deg2rad #preferred tuning direction\nfor ii in range(Neu):\n for jj in range(Neu):\n Wij[ii,jj] = Wa + Wd/Neu*np.cos(ths[ii]-ths[jj])\n #np.exp( (np.cos(ths[ii]-ths[jj])-1)/lsyn**2 )\nWij = (Wij-np.mean(Wij))*1 ##??",
"_____no_output_____"
],
[
"plt.plot(ths,Wij);\nplt.xlabel('angle (rad)')\nplt.ylabel('weight')\nplt.figure()\nplt.imshow(Wij)\nplt.xlabel('i')\nplt.ylabel('j')",
"_____no_output_____"
],
[
"###stimulus\nT = 100 #sec\ndt = 0.01 #10ms\ntime = np.arange(0,T,dt) #time series\n\nb = 2\nc = 0.5\nAm = 0.1\ndef the2h(ti,tstim):\n return b + c*(1-Am+Am*np.cos(ti-tstim))\n#b + c*Am*np.exp( (np.cos(ti-tstim)-1)/lstim**2 )\n\ntaun = 10 #noise correlation\nnoise = 10\nh = np.zeros(len(time))\nfor tt in range(0,len(time)-1):\n h[tt+1] = h[tt] + (ths[int(len(ths)/2)]-h[tt])*dt/taun + np.sqrt(taun*dt)*np.random.randn()*noise\n# if h[tt+1]>180:\n# h[tt+1] = h[tt+1]-180\n# if h[tt+1]<0:\n# h[tt+1] = 180+h[tt+1]\n#h = h*deg2rad\n \n# smoothed = 200\n# temp = np.convolve(np.random.randn(len(time))*180,np.exp(-np.arange(1,smoothed,1)/smoothed),'same')\nh = np.mod(h,180)*deg2rad - np.pi/2",
"_____no_output_____"
],
[
"plt.plot(time,h,'o')\nplt.xlabel('time (s)')\nplt.ylabel('head angle (rad)')",
"_____no_output_____"
],
[
"###neural dynamics\nVr = 0\nV = np.zeros((Neu,len(time))) #neurons by time\nV[:,0] = Vr + np.random.randn(Neu) #initialization\nr = np.zeros((Neu,len(time)))\nr[:,0] = gm*np.tanh(k*V[:,0]) #k*(np.max((V[:,0]-V0)))**nn\n\nfor tt in range(0,len(time)-1):\n ht = np.array([the2h(hh,h[tt]) for hh in ths]) #input bump\n V[:,tt+1] = V[:,tt] + dt*(-V[:,tt] + ht + np.dot(Wij,r[:,tt]))/taum + np.sqrt(dt*taum)*np.random.randn(Neu)*1\n temp = V[:,tt+1].copy()\n temp[temp<0] = 0\n r[:,tt+1] = gm*np.tanh(k*temp) #k*(np.max((V[:,tt+1]-V0)))**nn",
"_____no_output_____"
],
[
"extent = [0,T,ths[0],ths[-1]]\nplt.imshow(r, aspect=\"auto\",extent=extent)\n#plt.plot(V.T);",
"_____no_output_____"
],
[
"plt.plot(r[:,2:].T);",
"_____no_output_____"
],
[
"###PCA test\nX = r[:,2:].copy()\nC = np.cov(X)\nu,s,v = np.linalg.svd(C)\nPCs = np.dot(u[:,:3].T,X)",
"_____no_output_____"
],
[
"from mpl_toolkits.mplot3d import Axes3D\nax = plt.axes(projection='3d')\nax.plot3D(PCs[1,:], PCs[2,:], PCs[0,:])",
"_____no_output_____"
]
],
[
[
"## SLDS fitting",
"_____no_output_____"
]
],
[
[
"XX = np.array(X[np.random.choice(np.arange(0,Neu,1),10),:])\nXX = XX[:,np.arange(0,len(time),10)]\n#XX = X.copy()",
"_____no_output_____"
],
[
"plt.imshow(XX, aspect=\"auto\")\nXX.shape",
"_____no_output_____"
],
[
"# Set the parameters of the HMM\nT = XX.shape[1] # number of time bins\nK = 3 # number of discrete states\nD = 2 # number of latent dimensions\nN = XX.shape[0] # number of observed dimensions",
"_____no_output_____"
],
[
"# Make an SLDS with the true parameters\ntrue_slds = ssm.SLDS(N, K, D, transitions=\"recurrent_only\", emissions=\"gaussian_orthog\")\nfor k in range(K):\n true_slds.dynamics.As[k] = .95 * random_rotation(D, theta=(k+1) * np.pi/20)\nz, x, y = true_slds.sample(T)\n\n# Mask off some data\ny = XX.T.copy()\nmask = npr.rand(T, N) < 0.9\ny_masked = y * mask",
"_____no_output_____"
],
[
"print(\"Fitting SLDS with SVI\")\n\n# Create the model and initialize its parameters\nslds = ssm.SLDS(N, K, D, emissions=\"gaussian_orthog\")\nslds.initialize(y_masked, masks=mask)\n\n# Create a variational posterior\nq_mf = SLDSMeanFieldVariationalPosterior(slds, y_masked, masks=mask)\nq_mf_elbos = slds.fit(q_mf, y_masked, masks=mask, num_iters=1000, initialize=False)\n\n# Get the posterior mean of the continuous states\nq_mf_x = q_mf.mean[0]\n\n# Find the permutation that matches the true and inferred states\nslds.permute(find_permutation(z, slds.most_likely_states(q_mf_x, y)))\nq_mf_z = slds.most_likely_states(q_mf_x, y)\n\n# Smooth the data under the variational posterior\nq_mf_y = slds.smooth(q_mf_x, y)",
"Fitting SLDS with SVI\nInitializing with an ARHMM using 25 steps of EM.\n"
],
[
"print(\"Fitting SLDS with SVI using structured variational posterior\")\nslds = ssm.SLDS(N, K, D, emissions=\"gaussian_orthog\")\nslds.initialize(y_masked, masks=mask)\n\nq_struct = SLDSTriDiagVariationalPosterior(slds, y_masked, masks=mask)\nq_struct_elbos = slds.fit(q_struct, y_masked, masks=mask, num_iters=1000, initialize=False)\n\n# Get the posterior mean of the continuous states\nq_struct_x = q_struct.mean[0]\n\n# Find the permutation that matches the true and inferred states\nslds.permute(find_permutation(z, slds.most_likely_states(q_struct_x, y)))\nq_struct_z = slds.most_likely_states(q_struct_x, y)\n\n# Smooth the data under the variational posterior\nq_struct_y = slds.smooth(q_struct_x, y)",
"Fitting SLDS with SVI using structured variational posterior\nInitializing with an ARHMM using 25 steps of EM.\n"
],
[
"###try with switching!\nrslds = ssm.SLDS(N, K, D, \n transitions=\"recurrent_only\",\n dynamics=\"diagonal_gaussian\",\n emissions=\"gaussian_orthog\",\n single_subspace=True)\nrslds.initialize(y)\n\nq = SLDSTriDiagVariationalPosterior(rslds, y)\nelbos = rslds.fit(q, y, num_iters=1000, initialize=False)",
"Initializing with an ARHMM using 25 steps of EM.\n"
],
[
"xhat = q.mean[0]\n\n# Find the permutation that matches the true and inferred states\nrslds.permute(find_permutation(z, rslds.most_likely_states(xhat, y)))\nzhat = rslds.most_likely_states(xhat, y)\n\nplt.figure()\nplt.plot(elbos)\nplt.xlabel(\"Iteration\")\nplt.ylabel(\"ELBO\")",
"_____no_output_____"
],
[
"plt.plot(xhat[:,0],xhat[:,1])",
"_____no_output_____"
],
[
"# Plot the ELBOs\nplt.plot(q_mf_elbos, label=\"MF\")\nplt.plot(q_struct_elbos, label=\"LDS\")\nplt.xlabel(\"Iteration\")\nplt.ylabel(\"ELBO\")\nplt.legend()",
"_____no_output_____"
],
[
"###discrete state vs. head direction\nplt.subplot(211)\nplt.imshow(np.row_stack((q_struct_z, q_mf_z)), aspect=\"auto\")\nplt.yticks([0, 1], [\"$z_{\\\\mathrm{struct}}$\", \"$z_{\\\\mathrm{mf}}$\"])\nplt.subplot(212)\nplt.plot(h)\nplt.xlim(0,len(h))\nplt.xlabel('time')\nplt.ylabel('angle (rad)')",
"_____no_output_____"
],
[
"for kk in range(K):\n pos = np.where(q_struct_z==kk)[0]\n plt.plot(q_struct_x[pos,0],q_struct_x[pos,1])",
"_____no_output_____"
],
[
"plt.plot(q_mf_x[:,0],q_mf_x[:,1])",
"_____no_output_____"
],
[
"# Plot the true and inferred states\n# xlim = (0, 500)\n\n# plt.figure(figsize=(8,4))\n# plt.imshow(np.row_stack((z, q_struct_z, q_mf_z)), aspect=\"auto\")\n# plt.plot(xlim, [0.5, 0.5], '-k', lw=2)\n# plt.yticks([0, 1, 2], [\"$z_{\\\\mathrm{true}}$\", \"$z_{\\\\mathrm{struct}}$\", \"$z_{\\\\mathrm{mf}}$\"])\n# plt.xlim(xlim)",
"_____no_output_____"
],
[
"plt.figure(figsize=(8,4))\nplt.plot(x + 4 * np.arange(D), '-k')\nfor d in range(D):\n plt.plot(q_mf_x[:,d] + 4 * d, '-', color=colors[0], label=\"MF\" if d==0 else None)\n plt.plot(q_struct_x[:,d] + 4 * d, '-', color=colors[1], label=\"Struct\" if d==0 else None)\nplt.ylabel(\"$x$\")\n#plt.xlim(xlim)\nplt.legend()",
"_____no_output_____"
],
[
"# Plot the smoothed observations\nplt.figure(figsize=(8,4))\nfor n in range(N):\n plt.plot(y[:, n] + 4 * n, '-k', label=\"True\" if n == 0 else None)\n plt.plot(q_mf_y[:, n] + 4 * n, '--', color=colors[0], label=\"MF\" if n == 0 else None)\n plt.plot(q_struct_y[:, n] + 4 * n, ':', color=colors[1], label=\"Struct\" if n == 0 else None)\nplt.legend()\nplt.xlabel(\"time\")\n#plt.xlim(xlim)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a03d44331fa095d4b7647dff11df46b616c3486
| 96,007 |
ipynb
|
Jupyter Notebook
|
qatm_pytorch.ipynb
|
gyhdtc/QATM_pytorch
|
1af21d107dea03dbe65fd87ff15ad5af37f1c514
|
[
"MIT"
] | null | null | null |
qatm_pytorch.ipynb
|
gyhdtc/QATM_pytorch
|
1af21d107dea03dbe65fd87ff15ad5af37f1c514
|
[
"MIT"
] | null | null | null |
qatm_pytorch.ipynb
|
gyhdtc/QATM_pytorch
|
1af21d107dea03dbe65fd87ff15ad5af37f1c514
|
[
"MIT"
] | null | null | null | 174.241379 | 49,208 | 0.875478 |
[
[
[
"import numpy as np\nimport cv2\nimport matplotlib.pyplot as plt\nfrom pathlib import Path\nfrom seaborn import color_palette\nimport pandas as pd\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torchvision\nfrom torchvision import models, transforms, utils\nimport copy\nfrom utils import *\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# CONVERT IMAGE TO TENSOR",
"_____no_output_____"
]
],
[
[
"class ImageDataset(torch.utils.data.Dataset):\n def __init__(self, template_dir_path, image_name, thresh_csv=None, transform=None):\n self.transform = transform\n if not self.transform:\n self.transform = transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize(\n mean=[0.485, 0.456, 0.406],\n std=[0.229, 0.224, 0.225],\n )\n ])\n self.template_path = list(template_dir_path.iterdir())\n self.image_name = image_name\n \n self.image_raw = cv2.imread(self.image_name)\n \n self.thresh_df = None\n if thresh_csv:\n self.thresh_df = pd.read_csv(thresh_csv)\n \n if self.transform:\n self.image = self.transform(self.image_raw).unsqueeze(0)\n \n def __len__(self):\n return len(self.template_names)\n \n def __getitem__(self, idx):\n template_path = str(self.template_path[idx])\n template = cv2.imread(template_path)\n if self.transform:\n template = self.transform(template)\n thresh = 0.7\n if self.thresh_df is not None:\n if self.thresh_df.path.isin([template_path]).sum() > 0:\n thresh = float(self.thresh_df[self.thresh_df.path==template_path].thresh)\n return {'image': self.image, \n 'image_raw': self.image_raw, \n 'image_name': self.image_name,\n 'template': template.unsqueeze(0), \n 'template_name': template_path, \n 'template_h': template.size()[-2],\n 'template_w': template.size()[-1],\n 'thresh': thresh}",
"_____no_output_____"
],
[
"template_dir = 'template/'\nimage_path = 'sample/sample1.jpg'\ndataset = ImageDataset(Path(template_dir), image_path, thresh_csv='thresh_template.csv')",
"_____no_output_____"
]
],
[
[
"### EXTRACT FEATURE",
"_____no_output_____"
]
],
[
[
"class Featex():\n def __init__(self, model, use_cuda):\n self.use_cuda = use_cuda\n self.feature1 = None\n self.feature2 = None\n self.model= copy.deepcopy(model.eval())\n self.model = self.model[:17]\n for param in self.model.parameters():\n param.requires_grad = False\n if self.use_cuda:\n self.model = self.model.cuda()\n self.model[2].register_forward_hook(self.save_feature1)\n self.model[16].register_forward_hook(self.save_feature2)\n \n def save_feature1(self, module, input, output):\n self.feature1 = output.detach()\n \n def save_feature2(self, module, input, output):\n self.feature2 = output.detach()\n \n def __call__(self, input, mode='big'):\n if self.use_cuda:\n input = input.cuda()\n _ = self.model(input)\n if mode=='big':\n # resize feature1 to the same size of feature2\n self.feature1 = F.interpolate(self.feature1, size=(self.feature2.size()[2], self.feature2.size()[3]), mode='bilinear', align_corners=True)\n else: \n # resize feature2 to the same size of feature1\n self.feature2 = F.interpolate(self.feature2, size=(self.feature1.size()[2], self.feature1.size()[3]), mode='bilinear', align_corners=True)\n return torch.cat((self.feature1, self.feature2), dim=1)",
"_____no_output_____"
],
[
"class MyNormLayer():\n def __call__(self, x1, x2):\n bs, _ , H, W = x1.size()\n _, _, h, w = x2.size()\n x1 = x1.view(bs, -1, H*W)\n x2 = x2.view(bs, -1, h*w)\n concat = torch.cat((x1, x2), dim=2)\n x_mean = torch.mean(concat, dim=2, keepdim=True)\n x_std = torch.std(concat, dim=2, keepdim=True)\n x1 = (x1 - x_mean) / x_std\n x2 = (x2 - x_mean) / x_std\n x1 = x1.view(bs, -1, H, W)\n x2 = x2.view(bs, -1, h, w)\n return [x1, x2]",
"_____no_output_____"
],
[
"class CreateModel():\n def __init__(self, alpha, model, use_cuda):\n self.alpha = alpha\n self.featex = Featex(model, use_cuda)\n self.I_feat = None\n self.I_feat_name = None\n def __call__(self, template, image, image_name):\n T_feat = self.featex(template)\n if self.I_feat_name is not image_name:\n self.I_feat = self.featex(image)\n self.I_feat_name = image_name\n conf_maps = None\n batchsize_T = T_feat.size()[0]\n for i in range(batchsize_T):\n T_feat_i = T_feat[i].unsqueeze(0)\n I_feat_norm, T_feat_i = MyNormLayer()(self.I_feat, T_feat_i)\n dist = torch.einsum(\"xcab,xcde->xabde\", I_feat_norm / torch.norm(I_feat_norm, dim=1, keepdim=True), T_feat_i / torch.norm(T_feat_i, dim=1, keepdim=True))\n conf_map = QATM(self.alpha)(dist)\n if conf_maps is None:\n conf_maps = conf_map\n else:\n conf_maps = torch.cat([conf_maps, conf_map], dim=0)\n return conf_maps",
"_____no_output_____"
],
[
"class QATM():\n def __init__(self, alpha):\n self.alpha = alpha\n \n def __call__(self, x):\n batch_size, ref_row, ref_col, qry_row, qry_col = x.size()\n x = x.view(batch_size, ref_row*ref_col, qry_row*qry_col)\n xm_ref = x - torch.max(x, dim=1, keepdim=True)[0]\n xm_qry = x - torch.max(x, dim=2, keepdim=True)[0]\n confidence = torch.sqrt(F.softmax(self.alpha*xm_ref, dim=1) * F.softmax(self.alpha * xm_qry, dim=2))\n conf_values, ind3 = torch.topk(confidence, 1)\n ind1, ind2 = torch.meshgrid(torch.arange(batch_size), torch.arange(ref_row*ref_col))\n ind1 = ind1.flatten()\n ind2 = ind2.flatten()\n ind3 = ind3.flatten()\n if x.is_cuda:\n ind1 = ind1.cuda()\n ind2 = ind2.cuda()\n \n values = confidence[ind1, ind2, ind3]\n values = torch.reshape(values, [batch_size, ref_row, ref_col, 1])\n return values\n def compute_output_shape( self, input_shape ):\n bs, H, W, _, _ = input_shape\n return (bs, H, W, 1)",
"_____no_output_____"
]
],
[
[
"# NMS AND PLOT",
"_____no_output_____"
],
[
"## SINGLE",
"_____no_output_____"
]
],
[
[
"def nms(score, w_ini, h_ini, thresh=0.7):\n dots = np.array(np.where(score > thresh*score.max()))\n \n x1 = dots[1] - w_ini//2\n x2 = x1 + w_ini\n y1 = dots[0] - h_ini//2\n y2 = y1 + h_ini\n\n areas = (x2 - x1 + 1) * (y2 - y1 + 1)\n scores = score[dots[0], dots[1]]\n order = scores.argsort()[::-1]\n\n keep = []\n while order.size > 0:\n i = order[0]\n keep.append(i)\n xx1 = np.maximum(x1[i], x1[order[1:]])\n yy1 = np.maximum(y1[i], y1[order[1:]])\n xx2 = np.minimum(x2[i], x2[order[1:]])\n yy2 = np.minimum(y2[i], y2[order[1:]])\n\n w = np.maximum(0.0, xx2 - xx1 + 1)\n h = np.maximum(0.0, yy2 - yy1 + 1)\n inter = w * h\n ovr = inter / (areas[i] + areas[order[1:]] - inter)\n\n inds = np.where(ovr <= 0.5)[0]\n order = order[inds + 1]\n boxes = np.array([[x1[keep], y1[keep]], [x2[keep], y2[keep]]]).transpose(2, 0, 1)\n return boxes",
"_____no_output_____"
],
[
"def plot_result(image_raw, boxes, show=False, save_name=None, color=(255, 0, 0)):\n # plot result\n d_img = image_raw.copy()\n for box in boxes:\n d_img = cv2.rectangle(d_img, tuple(box[0]), tuple(box[1]), color, 3)\n if show:\n plt.imshow(d_img)\n if save_name:\n cv2.imwrite(save_name, d_img[:,:,::-1])\n return d_img",
"_____no_output_____"
]
],
[
[
"## MULTI",
"_____no_output_____"
]
],
[
[
"def nms_multi(scores, w_array, h_array, thresh_list):\n indices = np.arange(scores.shape[0])\n maxes = np.max(scores.reshape(scores.shape[0], -1), axis=1)\n # omit not-matching templates\n scores_omit = scores[maxes > 0.1 * maxes.max()]\n indices_omit = indices[maxes > 0.1 * maxes.max()]\n # extract candidate pixels from scores\n dots = None\n dos_indices = None\n for index, score in zip(indices_omit, scores_omit):\n dot = np.array(np.where(score > thresh_list[index]*score.max()))\n if dots is None:\n dots = dot\n dots_indices = np.ones(dot.shape[-1]) * index\n else:\n dots = np.concatenate([dots, dot], axis=1)\n dots_indices = np.concatenate([dots_indices, np.ones(dot.shape[-1]) * index], axis=0)\n dots_indices = dots_indices.astype(np.int)\n x1 = dots[1] - w_array[dots_indices]//2\n x2 = x1 + w_array[dots_indices]\n y1 = dots[0] - h_array[dots_indices]//2\n y2 = y1 + h_array[dots_indices]\n\n areas = (x2 - x1 + 1) * (y2 - y1 + 1)\n scores = scores[dots_indices, dots[0], dots[1]]\n order = scores.argsort()[::-1]\n dots_indices = dots_indices[order]\n \n keep = []\n keep_index = []\n while order.size > 0:\n i = order[0]\n index = dots_indices[0]\n keep.append(i)\n keep_index.append(index)\n xx1 = np.maximum(x1[i], x1[order[1:]])\n yy1 = np.maximum(y1[i], y1[order[1:]])\n xx2 = np.minimum(x2[i], x2[order[1:]])\n yy2 = np.minimum(y2[i], y2[order[1:]])\n\n w = np.maximum(0.0, xx2 - xx1 + 1)\n h = np.maximum(0.0, yy2 - yy1 + 1)\n inter = w * h\n ovr = inter / (areas[i] + areas[order[1:]] - inter)\n\n inds = np.where(ovr <= 0.05)[0]\n order = order[inds + 1]\n dots_indices = dots_indices[inds + 1]\n \n boxes = np.array([[x1[keep], y1[keep]], [x2[keep], y2[keep]]]).transpose(2,0,1)\n return boxes, np.array(keep_index)",
"_____no_output_____"
],
[
"def plot_result_multi(image_raw, boxes, indices, show=False, save_name=None, color_list=None):\n d_img = image_raw.copy()\n if color_list is None:\n color_list = color_palette(\"hls\", indices.max()+1)\n color_list = list(map(lambda x: (int(x[0]*255), int(x[1]*255), int(x[2]*255)), color_list))\n for i in range(len(indices)):\n d_img = plot_result(d_img, boxes[i][None, :,:].copy(), color=color_list[indices[i]])\n if show:\n plt.imshow(d_img)\n if save_name:\n cv2.imwrite(save_name, d_img[:,:,::-1])\n return d_img",
"_____no_output_____"
],
[
"# RUNNING",
"_____no_output_____"
],
[
"def run_one_sample(model, template, image, image_name):\n val = model(template, image, image_name)\n if val.is_cuda:\n val = val.cpu()\n val = val.numpy()\n val = np.log(val)\n \n batch_size = val.shape[0]\n scores = []\n for i in range(batch_size):\n # compute geometry average on score map\n gray = val[i,:,:,0]\n gray = cv2.resize( gray, (image.size()[-1], image.size()[-2]) )\n h = template.size()[-2]\n w = template.size()[-1]\n score = compute_score( gray, w, h) \n score[score>-1e-7] = score.min()\n score = np.exp(score / (h*w)) # reverse number range back after computing geometry average\n scores.append(score)\n return np.array(scores)",
"_____no_output_____"
],
[
"def run_multi_sample(model, dataset):\n scores = None\n w_array = []\n h_array = []\n thresh_list = []\n for data in dataset:\n score = run_one_sample(model, data['template'], data['image'], data['image_name'])\n if scores is None:\n scores = score\n else:\n scores = np.concatenate([scores, score], axis=0)\n w_array.append(data['template_w'])\n h_array.append(data['template_h'])\n thresh_list.append(data['thresh'])\n return np.array(scores), np.array(w_array), np.array(h_array), thresh_list",
"_____no_output_____"
],
[
"model = CreateModel(model=models.vgg19(pretrained=True).features, alpha=25, use_cuda=True)",
"_____no_output_____"
],
[
"scores, w_array, h_array, thresh_list = run_multi_sample(model, dataset)",
"_____no_output_____"
],
[
"boxes, indices = nms_multi(scores, w_array, h_array, thresh_list)",
"_____no_output_____"
],
[
"d_img = plot_result_multi(dataset.image_raw, boxes, indices, show=True, save_name='result_sample.png')",
"_____no_output_____"
],
[
"plt.imshow(scores[2])",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a03dcf6294a1a85965d9c6dc62dd79f2930d4f3
| 95,673 |
ipynb
|
Jupyter Notebook
|
Assignment2- Selection Sort.ipynb
|
bblank70/MSDS432
|
f4cc8f42d1dfef8e5c42e92b9e356b43c2584052
|
[
"MIT"
] | 1 |
2021-04-28T04:35:21.000Z
|
2021-04-28T04:35:21.000Z
|
Assignment2- Selection Sort.ipynb
|
bblank70/MSDS432
|
f4cc8f42d1dfef8e5c42e92b9e356b43c2584052
|
[
"MIT"
] | null | null | null |
Assignment2- Selection Sort.ipynb
|
bblank70/MSDS432
|
f4cc8f42d1dfef8e5c42e92b9e356b43c2584052
|
[
"MIT"
] | null | null | null | 286.446108 | 31,539 | 0.687122 |
[
[
[
"# Assignment 2: Implementation of Selection Sort\n",
"_____no_output_____"
],
[
"## Deliverables:\n\nWe will again generate random data for this assignment. \n\n 1) Please set up five data arrays of length 5,000, 10,000, 15,000, 20,000, and 25,000 of uniformly distributed random numbers (you may use either integers or floating point). \n Ensure that a common random number seed is used to generate each of the arrays. \n 2) Execute the base algorithm (Selection Sort) for each of the random number arrays, noting the execution time with each execution. \n Use one of the timing methods we learned in class.\n 3) Just as in the last assignment, please organize the results of the study into a table showing the size of data array and the time taken to sort the array.\n Discuss the differences in timing and how they relate to data type and length of array. \n 4) Use Python matpl otlib or Seaborn to generate a measure of the size of the data set on the horizontal axis and with execution time in milliseconds on the vertical axis.\n The plot should show execution time against problem size for each form of the algorithm being tested.\n\n### Prepare an exec summary of your results, referring to the table and figures you have generated. Explain how your results relate to big O notation. Describe your results in language that management can understand. This summary should be included as text paragraphs in the Jupyter notebook. Explain how the algorithm works and why it is a useful to data engineers.",
"_____no_output_____"
],
[
"# Discussion\n\n### The selection sort algorithm as implemented below uses a nested for loop. The inner loop indentifies the smallest componenent of an array and it's index while the outer loop manipulates the arrays (adds the smallest element to the new array and removes the element from the parent array). Since we have these two for loops the algorithm grows at a rate of approximately n*n. There are two operations first we identify the smallest element, then we place it in the new array. In big O notation, this is denoted O(n^2). Figure 1 below shows the sort times as a function of the length of the array. It is apparent that the lowest point demonstrates the non-linear scaling of this algorithm which is confirmed by taking the square root of the time. Figure 2 shows the square root of time as a function of the length of the array and is approximately linear.\n\n### In some data retrieval systems items are required to be indexed sequentially, so we need methodologies to sort them, selection sort provides this methodology in an easy to implement fashion, however it is not very efficient due to the nested operations. Below are the two functions, required for the sort:\n\n 1) FindSmallest will start at the first index of an array and set it to an object 'smallest' which will be used in a repetative logical evaluation. \n As we progress through the length of the array, each time the next value is smaller than smallest, smallest is replaced and it's index also is captured in smallest index. \n This continues until the entire array is processed.\n\n 2) SelectionSort will find use FindSmallest to search through a given array using FindSmallest in a nested fashion to find the smallest value ('small') in the given array and append it to a new array.\n The found value is removed from the original array (via it's returned index in FindSmallest; 'smallest_index') and the algorightm continues until the are no elements in the original array. The new array is returned along with the elapsed time to complete the sort in milliseconds.\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nfrom datetime import datetime\nimport seaborn as sns\nimport time",
"_____no_output_____"
],
[
"#FindSmallest will start at the first index of an array and set it to an object 'smallest' which will be used in a repetative logical evaluation. As we progress through the length of the array, each time the next value is smaller than smallest, smallest is replaced and it's index also is captured in smallest index. This continues until the entire array is processed.\ndef FindSmallest(arr):\n smallest = arr[0]\n smallest_index=0\n for i in range(1, len(arr)):\n if arr[i] < smallest:\n smallest = arr[i]\n smallest_index = i\n return smallest_index, smallest\n\n# SelectionSort will find use FindSmallest to search through a given array using FindSmallest in a nested fashion to find the smallest value ('small') in the given array and append it to a new array. The found value is removed from the original array (via it's returned index in FindSmallest; 'smallest_index') and the algorightm continues until the are no elements in the original array. The new array is returned along with the elapsed time to complete the sort in milliseconds.\ndef SelectionSort(arr):\n newArr = []\n start = time.perf_counter()\n for i in range(len(arr)):\n smallest =FindSmallest(arr)[1]\n smallest_index = FindSmallest(arr)[0]\n newArr.append(smallest) #adds smallest element to new array.\n arr = np.delete(arr, smallest_index) # removes smallest element from parent array by index.\n end = time.perf_counter()\n return newArr , (end-start)*1E3",
"_____no_output_____"
]
],
[
[
"# A. Generate arrays with a common random seed",
"_____no_output_____"
]
],
[
[
"#Sets the Random Seed\nRANDOM_SEED = 123",
"_____no_output_____"
],
[
"np.random.seed(RANDOM_SEED) \narr5E4 = np.random.randint(low=1, high= 1000001, size=5000)#5,000 elements, 1-1E6 (inclusive)\n\nnp.random.seed(RANDOM_SEED) \narr10E4 = np.random.randint(low=1, high= 1000001, size=10000)#10,000 elements, 1-1E6 (inclusive)\n\nnp.random.seed(RANDOM_SEED) \narr15E4 = np.random.randint(low=1, high= 1000001, size=15000)#15,000 elements, 1-1E6 (inclusive)\n\nnp.random.seed(RANDOM_SEED) \narr20E4 = np.random.randint(low=1, high= 1000001, size=20000)#20,000 elements, 1-1E6 (inclusive)\n\nnp.random.seed(RANDOM_SEED) \narr25E4 = np.random.randint(low=1, high= 1000001, size=25000)#25,000 elements, 1-1E6 (inclusive)",
"_____no_output_____"
]
],
[
[
"# B. Sort using SelectionSort function",
"_____no_output_____"
]
],
[
[
"sorted_5E4 = SelectionSort(arr5E4)\nsorted_10E4 = SelectionSort(arr10E4)\nsorted_15E4 = SelectionSort(arr15E4)\nsorted_20E4 = SelectionSort(arr20E4)\nsorted_25E4 = SelectionSort(arr25E4)",
"_____no_output_____"
],
[
"Summary = {\n 'NumberOfElements': [ len(sorted_5E4[0]), len(sorted_10E4[0]), len(sorted_15E4[0]),len(sorted_20E4[0]), len(sorted_25E4[0])], \n 'Time(ms)': [ sorted_5E4[1], sorted_10E4[1], sorted_15E4[1], sorted_20E4[1], sorted_25E4[1]]}\n\ndf = pd.DataFrame.from_dict(Summary)\n",
"_____no_output_____"
],
[
"df['rt(Time)'] = np.sqrt(df['Time(ms)'])\n\ndisplay(df)",
"_____no_output_____"
]
],
[
[
"## Fig 1. Sort times in milliseconds as a function of the number of elements.",
"_____no_output_____"
]
],
[
[
"sns.scatterplot(x=df['NumberOfElements'], y=df['Time(ms)'])",
"_____no_output_____"
]
],
[
[
"## Fig 2. Square root of sort times in milliseconds as a function of the number of elements.",
"_____no_output_____"
]
],
[
[
"sns.scatterplot(x=df['NumberOfElements'], y=df['rt(Time)'])",
"_____no_output_____"
]
],
[
[
"# ------------------------ END ------------------------\n\n code graveyard ",
"_____no_output_____"
]
],
[
[
"\n\n### This code is for testing\n\n#np.random.seed(123)\n#arr7_39 = np.random.randint(low=7, high= 39, size=12)\n#print(\"the array is\",arr7_39)\n\n#small = FindSmallest(arr7_39)\n#print('the smallest index is at', small[0], 'and has value of', small[1])\n\n\n\n#testing = SelectionSort(arr7_39)\n#print('the array sorted is:', testing[0])\n#print('execution time was: ', testing[1], 'ms')",
"the array is [37 20 37 9 35 9 13 24 26 17 34 32]\nthe smallest index is at 3 and has value of 9\nthe array sorted is: [9, 9, 13, 17, 20, 24, 26, 32, 34, 35, 37, 37]\nexecution time was: 0.4926999999952386 ms\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a03df707226f3185f44f0927dd26a0a14603bb4
| 3,660 |
ipynb
|
Jupyter Notebook
|
pythonnotebook/Nucattraction.ipynb
|
pelagia/votca-scripts
|
5c10cabe6458b4682cd9c214bc665d389f34a939
|
[
"Apache-2.0"
] | 2 |
2017-10-17T16:46:28.000Z
|
2020-01-09T15:06:14.000Z
|
pythonnotebook/Nucattraction.ipynb
|
pelagia/votca-scripts
|
5c10cabe6458b4682cd9c214bc665d389f34a939
|
[
"Apache-2.0"
] | null | null | null |
pythonnotebook/Nucattraction.ipynb
|
pelagia/votca-scripts
|
5c10cabe6458b4682cd9c214bc665d389f34a939
|
[
"Apache-2.0"
] | 2 |
2018-05-25T09:15:47.000Z
|
2020-06-25T07:18:31.000Z
| 20.914286 | 91 | 0.44235 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a03e0851179332aeeec22384a3894c0abe950f9
| 6,586 |
ipynb
|
Jupyter Notebook
|
content/lessons/11/Now-You-Code/NYC4-Reddit-News-Sentiment.ipynb
|
pascumac-su/Python-Examples
|
b816d44d648ca37ec338314a395d43e3468dce04
|
[
"MIT"
] | null | null | null |
content/lessons/11/Now-You-Code/NYC4-Reddit-News-Sentiment.ipynb
|
pascumac-su/Python-Examples
|
b816d44d648ca37ec338314a395d43e3468dce04
|
[
"MIT"
] | null | null | null |
content/lessons/11/Now-You-Code/NYC4-Reddit-News-Sentiment.ipynb
|
pascumac-su/Python-Examples
|
b816d44d648ca37ec338314a395d43e3468dce04
|
[
"MIT"
] | null | null | null | 33.095477 | 326 | 0.612511 |
[
[
[
"# Now You Code 4: Reddit News Sentiment Analysis\n\nIn this assignment you're tasked with performing a sentiment analysis on top Reddit news articles. (`https://www.reddit.com/r/news/top.json`)\n\nYou should perform the analysis on the titles only. \n\nStart by getting the Reddit API to work, and extracting a list of titles only. You'll have to research the Reddit API, and can do so here: https://www.reddit.com/dev/api/ The Reddit API requires a custom 'User-Agent' You must specify this in your headers, as explained here: https://github.com/reddit/reddit/wiki/API \n\n\nAfter you get Reddit working move on to sentiment analysis. Once again, we will use (`http://text-processing.com/api/sentiment/`) like we did in the in-class coding lab. \n\nWe will start by writing the `GetRedditStories` and `GetSentiment` functions, then putting it all together.",
"_____no_output_____"
],
[
"## Step 1: Problem Analysis for `GetRedditStories`\n\nFirst let's write a function `GetRedditStories` to get the top news articles from the http://www.reddit.com site. \n\n\nInputs: None\n\nOutputs: the top `stories` as a Python object converted from JSON\n\nAlgorithm (Steps in Program):\n\n```\ntodo write algorithm here\n```\n",
"_____no_output_____"
]
],
[
[
"# Step 2: write code \n\nimport requests\n\ndef GetRedditStories():\n # todo write code return a list of dict of stories\n \n\n# testing \nGetRedditStories() # you should see some stories\n",
"_____no_output_____"
]
],
[
[
"## Step 3: Problem Analysis for `GetSentiment`\n\nNow let's write a function, that when given `text` will return the sentiment score for the text. We will use http://text-processing.com 's API for this. \n\nInputs: `text` string\n\nOutputs: a Python dictionary of sentiment information based on `text`\n\nAlgorithm (Steps in Program):\n\n```\ntodo write algorithm here\n```\n",
"_____no_output_____"
]
],
[
[
"# Step 4: write code \n\ndef GetSentiment(text):\n # todo write code to return dict of sentiment for text\n \n\n# testing\nGetSentiment(\"You are a bad, bad man!\")",
"_____no_output_____"
]
],
[
[
"## Step 5: Problem Analysis for entire program\n\nNow let's write entire program. This program should take the titles of the Reddit stories and for each one run sentiment analysis on it. It should output the sentiment label and story title, like this:\n\nExample Run (Your output will vary as news stories change...)\n\n```\nneutral : FBI Chief Comey 'Rejects' Phone Tap Allegation\npos : New Peeps-flavored Oreos reportedly turning people's poop pink\nneutral : President Trump Signs Revised Travel Ban Executive Order\nneutral : Police: Overdose survivors to be charged with misdemeanor\nneutral : Struggling students forced to wait 3-4 weeks as Utah's public colleges don't have enough mental health therapists\nneutral : Army Veteran Faces Possible Deportation to Mexico\nneutral : Rep. Scott Taylor called out at town hall for ‘blocking’ constituents on social media\nneutral : GM to suspend third shift at Delta Township plant, layoff 1,100 workers\nneutral : American citizen Khizr Khan reportedly cancels trip to Canada after being warned his 'travel privileges are being reviewed'\nneg : Mars far more likely to have had life than we thought, researchers find after new water discovery\nneutral : Bird Flu Found at U.S. Farm That Supplies Chickens to Tyson\nneutral : Investigation Reveals Huge Volume of Shark Fins Evading International Shipping Bans\nneg : Sikh man's shooting in Washington investigated as hate crime\n```\n\n### Problem Analysis\n\nInputs: (Reads current stories from Reddit)\n\nOutputs: Sentiment Label and story title for each story.\n\nAlgorithm (Steps in Program):\n\n```\ntodo write algorithm here\n```\n",
"_____no_output_____"
]
],
[
[
"## Step 6 Write final program here using the functions \n## you wrote in the previous steps! \n\n",
"_____no_output_____"
]
],
[
[
"## Step 7: Questions\n\n1. What happens to this program when you do not have connectivity to the Internet? How can this code be modified to correct the issue?\n2. Most of the news stories come back with a neutral sentiment score. Does this surprise you? Explain your answer.\n3. In what ways can this program be made better / more useful?\n",
"_____no_output_____"
],
[
"## Reminder of Evaluation Criteria\n\n1. What the problem attempted (analysis, code, and answered questions) ?\n2. What the problem analysis thought out? (does the program match the plan?)\n3. Does the code execute without syntax error?\n4. Does the code solve the intended problem?\n5. Is the code well written? (easy to understand, modular, and self-documenting, handles errors)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a03e396b035c7698a5b06df41d637d0be7b48d5
| 66,824 |
ipynb
|
Jupyter Notebook
|
site/en-snapshot/federated/tutorials/custom_federated_algorithms_1.ipynb
|
NarimaneHennouni/docs-l10n
|
39a48e0d5aa34950e29efd5c1f111c120185e9d9
|
[
"Apache-2.0"
] | null | null | null |
site/en-snapshot/federated/tutorials/custom_federated_algorithms_1.ipynb
|
NarimaneHennouni/docs-l10n
|
39a48e0d5aa34950e29efd5c1f111c120185e9d9
|
[
"Apache-2.0"
] | null | null | null |
site/en-snapshot/federated/tutorials/custom_federated_algorithms_1.ipynb
|
NarimaneHennouni/docs-l10n
|
39a48e0d5aa34950e29efd5c1f111c120185e9d9
|
[
"Apache-2.0"
] | null | null | null | 40.110444 | 264 | 0.580181 |
[
[
[
"##### Copyright 2019 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Custom Federated Algorithms, Part 1: Introduction to the Federated Core",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/federated/tutorials/custom_federated_algorithms_1\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/federated/blob/master/docs/tutorials/custom_federated_algorithms_1.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/federated/blob/master/docs/tutorials/custom_federated_algorithms_1.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"This tutorial is the first part of a two-part series that demonstrates how to\nimplement custom types of federated algorithms in TensorFlow Federated (TFF)\nusing the [Federated Core (FC)](../federated_core.md) - a set of lower-level\ninterfaces that serve as a foundation upon which we have implemented the\n[Federated Learning (FL)](../federated_learning.md) layer.\n\nThis first part is more conceptual; we introduce some of the key concepts and\nprogramming abstractions used in TFF, and we demonstrate their use on a very\nsimple example with a distributed array of temperature sensors. In\n[the second part of this series](custom_federated_algorithms_2.ipynb), we use\nthe mechanisms we introduce here to implement a simple version of federated\ntraining and evaluation algorithms. As a follow-up, we encourage you to study\n[the implementation](https://github.com/tensorflow/federated/blob/master/tensorflow_federated/python/learning/federated_averaging.py)\nof federated averaging in `tff.learning`.\n\nBy the end of this series, you should be able to recognize that the applications\nof Federated Core are not necessarily limited to learning. The programming\nabstractions we offer are quite generic, and could be used, e.g., to implement\nanalytics and other custom types of computations over distributed data.\n\nAlthough this tutorial is designed to be self-contained, we encourage you to\nfirst read tutorials on\n[image classification](federated_learning_for_image_classification.ipynb) and\n[text generation](federated_learning_for_text_generation.ipynb) for a\nhigher-level and more gentle introduction to the TensorFlow Federated framework\nand the [Federated Learning](../federated_learning.md) APIs (`tff.learning`), as\nit will help you put the concepts we describe here in context.",
"_____no_output_____"
],
[
"## Intended Uses\n\nIn a nutshell, Federated Core (FC) is a development environment that makes it\npossible to compactly express program logic that combines TensorFlow code with\ndistributed communication operators, such as those that are used in\n[Federated Averaging](https://arxiv.org/abs/1602.05629) - computing\ndistributed sums, averages, and other types of distributed aggregations over a\nset of client devices in the system, broadcasting models and parameters to those\ndevices, etc.\n\nYou may be aware of\n[`tf.contrib.distribute`](https://www.tensorflow.org/api_docs/python/tf/contrib/distribute),\nand a natural question to ask at this point may be: in what ways does this\nframework differ? Both frameworks attempt at making TensorFlow computations\ndistributed, after all.\n\nOne way to think about it is that, whereas the stated goal of\n`tf.contrib.distribute` is *to allow users to use existing models and training\ncode with minimal changes to enable distributed training*, and much focus is on\nhow to take advantage of distributed infrastructure to make existing training\ncode more efficient, the goal of TFF's Federated Core is to give researchers and\npractitioners explicit control over the specific patterns of distributed\ncommunication they will use in their systems. The focus in FC is on providing a\nflexible and extensible language for expressing distributed data flow\nalgorithms, rather than a concrete set of implemented distributed training\ncapabilities.\n\nOne of the primary target audiences for TFF's FC API is researchers and\npractitioners who might want to experiment with new federated learning\nalgorithms and evaluate the consequences of subtle design choices that affect\nthe manner in which the flow of data in the distributed system is orchestrated,\nyet without getting bogged down by system implementation details. The level of\nabstraction that FC API is aiming for roughly corresponds to pseudocode one\ncould use to describe the mechanics of a federated learning algorithm in a\nresearch publication - what data exists in the system and how it is transformed,\nbut without dropping to the level of individual point-to-point network message\nexchanges.\n\nTFF as a whole is targeting scenarios in which data is distributed, and must\nremain such, e.g., for privacy reasons, and where collecting all data at a\ncentralized location may not be a viable option. This has implication on the\nimplementation of machine learning algorithms that require an increased degree\nof explicit control, as compared to scenarios in which all data can be\naccumulated in a centralized location at a data center.",
"_____no_output_____"
],
[
"## Before we start\n\nBefore we dive into the code, please try to run the following \"Hello World\"\nexample to make sure your environment is correctly setup. If it doesn't work,\nplease refer to the [Installation](../install.md) guide for instructions.",
"_____no_output_____"
]
],
[
[
"#@test {\"skip\": true}\n!pip install --quiet --upgrade tensorflow_federated_nightly\n!pip install --quiet --upgrade nest_asyncio\n\nimport nest_asyncio\nnest_asyncio.apply()",
"_____no_output_____"
],
[
"import collections\n\nimport numpy as np\nimport tensorflow as tf\nimport tensorflow_federated as tff",
"_____no_output_____"
],
[
"@tff.federated_computation\ndef hello_world():\n return 'Hello, World!'\n\nhello_world()",
"_____no_output_____"
]
],
[
[
"## Federated data\n\nOne of the distinguishing features of TFF is that it allows you to compactly\nexpress TensorFlow-based computations on *federated data*. We will be using the\nterm *federated data* in this tutorial to refer to a collection of data items\nhosted across a group of devices in a distributed system. For example,\napplications running on mobile devices may collect data and store it locally,\nwithout uploading to a centralized location. Or, an array of distributed sensors\nmay collect and store temperature readings at their locations.\n\nFederated data like those in the above examples are treated in TFF as\n[first-class citizens](https://en.wikipedia.org/wiki/First-class_citizen), i.e.,\nthey may appear as parameters and results of functions, and they have types. To\nreinforce this notion, we will refer to federated data sets as *federated\nvalues*, or as *values of federated types*.\n\nThe important point to understand is that we are modeling the entire collection\nof data items across all devices (e.g., the entire collection temperature\nreadings from all sensors in a distributed array) as a single federated value.\n\nFor example, here's how one would define in TFF the type of a *federated float*\nhosted by a group of client devices. A collection of temperature readings that\nmaterialize across an array of distributed sensors could be modeled as a value\nof this federated type.",
"_____no_output_____"
]
],
[
[
"federated_float_on_clients = tff.type_at_clients(tf.float32)",
"_____no_output_____"
]
],
[
[
"More generally, a federated type in TFF is defined by specifying the type `T` of\nits *member constituents* - the items of data that reside on individual devices,\nand the group `G` of devices on which federated values of this type are hosted\n(plus a third, optional bit of information we'll mention shortly). We refer to\nthe group `G` of devices hosting a federated value as the value's *placement*.\nThus, `tff.CLIENTS` is an example of a placement.",
"_____no_output_____"
]
],
[
[
"str(federated_float_on_clients.member)",
"_____no_output_____"
],
[
"str(federated_float_on_clients.placement)",
"_____no_output_____"
]
],
[
[
"A federated type with member constituents `T` and placement `G` can be\nrepresented compactly as `{T}@G`, as shown below.",
"_____no_output_____"
]
],
[
[
"str(federated_float_on_clients)",
"_____no_output_____"
]
],
[
[
"The curly braces `{}` in this concise notation serve as a reminder that the\nmember constituents (items of data on different devices) may differ, as you\nwould expect e.g., of temperature sensor readings, so the clients as a group are\njointly hosting a [multi-set](https://en.wikipedia.org/wiki/Multiset) of\n`T`-typed items that together constitute the federated value.\n\nIt is important to note that the member constituents of a federated value are\ngenerally opaque to the programmer, i.e., a federated value should not be\nthought of as a simple `dict` keyed by an identifier of a device in the system -\nthese values are intended to be collectively transformed only by *federated\noperators* that abstractly represent various kinds of distributed communication\nprotocols (such as aggregation). If this sounds too abstract, don't worry - we\nwill return to this shortly, and we will illustrate it with concrete examples.\n\nFederated types in TFF come in two flavors: those where the member constituents\nof a federated value may differ (as just seen above), and those where they are\nknown to be all equal. This is controlled by the third, optional `all_equal`\nparameter in the `tff.FederatedType` constructor (defaulting to `False`).",
"_____no_output_____"
]
],
[
[
"federated_float_on_clients.all_equal",
"_____no_output_____"
]
],
[
[
"A federated type with a placement `G` in which all of the `T`-typed member\nconstituents are known to be equal can be compactly represented as `T@G` (as\nopposed to `{T}@G`, that is, with the curly braces dropped to reflect the fact\nthat the multi-set of member constituents consists of a single item).",
"_____no_output_____"
]
],
[
[
"str(tff.type_at_clients(tf.float32, all_equal=True))",
"_____no_output_____"
]
],
[
[
"One example of a federated value of such type that might arise in practical\nscenarios is a hyperparameter (such as a learning rate, a clipping norm, etc.)\nthat has been broadcasted by a server to a group of devices that participate in\nfederated training.\n\nAnother example is a set of parameters for a machine learning model pre-trained\nat the server, that were then broadcasted to a group of client devices, where\nthey can be personalized for each user.\n\nFor example, suppose we have a pair of `float32` parameters `a` and `b` for a\nsimple one-dimensional linear regression model. We can construct the\n(non-federated) type of such models for use in TFF as follows. The angle braces\n`<>` in the printed type string are a compact TFF notation for named or unnamed\ntuples.",
"_____no_output_____"
]
],
[
[
"simple_regression_model_type = (\n tff.StructType([('a', tf.float32), ('b', tf.float32)]))\n\nstr(simple_regression_model_type)",
"_____no_output_____"
]
],
[
[
"Note that we are only specifying `dtype`s above. Non-scalar types are also\nsupported. In the above code, `tf.float32` is a shortcut notation for the more\ngeneral `tff.TensorType(dtype=tf.float32, shape=[])`.\n\nWhen this model is broadcasted to clients, the type of the resulting federated\nvalue can be represented as shown below.",
"_____no_output_____"
]
],
[
[
"str(tff.type_at_clients(\n simple_regression_model_type, all_equal=True))",
"_____no_output_____"
]
],
[
[
"Per symmetry with *federated float* above, we will refer to such a type as a\n*federated tuple*. More generally, we'll often use the term *federated XYZ* to\nrefer to a federated value in which member constituents are *XYZ*-like. Thus, we\nwill talk about things like *federated tuples*, *federated sequences*,\n*federated models*, and so on.\n\nNow, coming back to `float32@CLIENTS` - while it appears replicated across\nmultiple devices, it is actually a single `float32`, since all member are the\nsame. In general, you may think of any *all-equal* federated type, i.e., one of\nthe form `T@G`, as isomorphic to a non-federated type `T`, since in both cases,\nthere's actually only a single (albeit potentially replicated) item of type `T`.\n\nGiven the isomorphism between `T` and `T@G`, you may wonder what purpose, if\nany, the latter types might serve. Read on.",
"_____no_output_____"
],
[
"## Placements\n\n### Design Overview\n\nIn the preceding section, we've introduced the concept of *placements* - groups\nof system participants that might be jointly hosting a federated value, and\nwe've demonstrated the use of `tff.CLIENTS` as an example specification of a\nplacement.\n\nTo explain why the notion of a *placement* is so fundamental that we needed to\nincorporate it into the TFF type system, recall what we mentioned at the\nbeginning of this tutorial about some of the intended uses of TFF.\n\nAlthough in this tutorial, you will only see TFF code being executed locally in\na simulated environment, our goal is for TFF to enable writing code that you\ncould deploy for execution on groups of physical devices in a distributed\nsystem, potentially including mobile or embedded devices running Android. Each\nof of those devices would receive a separate set of instructions to execute\nlocally, depending on the role it plays in the system (an end-user device, a\ncentralized coordinator, an intermediate layer in a multi-tier architecture,\netc.). It is important to be able to reason about which subsets of devices\nexecute what code, and where different portions of the data might physically\nmaterialize.\n\nThis is especially important when dealing with, e.g., application data on mobile\ndevices. Since the data is private and can be sensitive, we need the ability to\nstatically verify that this data will never leave the device (and prove facts\nabout how the data is being processed). The placement specifications are one of\nthe mechanisms designed to support this.\n\nTFF has been designed as a data-centric programming environment, and as such,\nunlike some of the existing frameworks that focus on *operations* and where\nthose operations might *run*, TFF focuses on *data*, where that data\n*materializes*, and how it's being *transformed*. Consequently, placement is\nmodeled as a property of data in TFF, rather than as a property of operations on\ndata. Indeed, as you're about to see in the next section, some of the TFF\noperations span across locations, and run \"in the network\", so to speak, rather\nthan being executed by a single machine or a group of machines.\n\nRepresenting the type of a certain value as `T@G` or `{T}@G` (as opposed to just\n`T`) makes data placement decisions explicit, and together with a static\nanalysis of programs written in TFF, it can serve as a foundation for providing\nformal privacy guarantees for sensitive on-device data.\n\nAn important thing to note at this point, however, is that while we encourage\nTFF users to be explicit about *groups* of participating devices that host the\ndata (the placements), the programmer will never deal with the raw data or\nidentities of the *individual* participants.\n\n(Note: While it goes far outside the scope of this tutorial, we should mention\nthat there is one notable exception to the above, a `tff.federated_collect`\noperator that is intended as a low-level primitive, only for specialized\nsituations. Its explicit use in situations where it can be avoided is not\nrecommended, as it may limit the possible future applications. For example, if\nduring the course of static analysis, we determine that a computation uses such\nlow-level mechanisms, we may disallow its access to certain types of data.)\n\nWithin the body of TFF code, by design, there's no way to enumerate the devices\nthat constitute the group represented by `tff.CLIENTS`, or to probe for the\nexistence of a specific device in the group. There's no concept of a device or\nclient identity anywhere in the Federated Core API, the underlying set of\narchitectural abstractions, or the core runtime infrastructure we provide to\nsupport simulations. All the computation logic you write will be expressed as\noperations on the entire client group.\n\nRecall here what we mentioned earlier about values of federated types being\nunlike Python `dict`, in that one cannot simply enumerate their member\nconstituents. Think of values that your TFF program logic manipulates as being\nassociated with placements (groups), rather than with individual participants.\n\nPlacements *are* designed to be a first-class citizen in TFF as well, and can\nappear as parameters and results of a `placement` type (to be represented by\n`tff.PlacementType` in the API). In the future, we plan to provide a variety of\noperators to transform or combine placements, but this is outside the scope of\nthis tutorial. For now, it suffices to think of `placement` as an opaque\nprimitive built-in type in TFF, similar to how `int` and `bool` are opaque\nbuilt-in types in Python, with `tff.CLIENTS` being a constant literal of this\ntype, not unlike `1` being a constant literal of type `int`.\n\n### Specifying Placements\n\nTFF provides two basic placement literals, `tff.CLIENTS` and `tff.SERVER`, to\nmake it easy to express the rich variety of practical scenarios that are\nnaturally modeled as client-server architectures, with multiple *client* devices\n(mobile phones, embedded devices, distributed databases, sensors, etc.)\norchestrated by a single centralized *server* coordinator. TFF is designed to\nalso support custom placements, multiple client groups, multi-tiered and other,\nmore general distributed architectures, but discussing them is outside the scope\nof this tutorial.\n\nTFF doesn't prescribe what either the `tff.CLIENTS` or the `tff.SERVER` actually\nrepresent.\n\nIn particular, `tff.SERVER` may be a single physical device (a member of a\nsingleton group), but it might just as well be a group of replicas in a\nfault-tolerant cluster running state machine replication - we do not make any\nspecial architectural assumptions. Rather, we use the `all_equal` bit mentioned\nin the preceding section to express the fact that we're generally dealing with\nonly a single item of data at the server.\n\nLikewise, `tff.CLIENTS` in some applications might represent all clients in the\nsystem - what in the context of federated learning we sometimes refer to as the\n*population*, but e.g., in\n[production implementations of Federated Averaging](https://arxiv.org/abs/1602.05629),\nit may represent a *cohort* - a subset of the clients selected for paticipation\nin a particular round of training. The abstractly defined placements are given\nconcrete meaning when a computation in which they appear is deployed for\nexecution (or simply invoked like a Python function in a simulated environment,\nas is demonstrated in this tutorial). In our local simulations, the group of\nclients is determined by the federated data supplied as input.",
"_____no_output_____"
],
[
"## Federated computations\n\n### Declaring federated computations\n\nTFF is designed as a strongly-typed functional programming environment that\nsupports modular development.\n\nThe basic unit of composition in TFF is a *federated computation* - a section of\nlogic that may accept federated values as input and return federated values as\noutput. Here's how you can define a computation that calculates the average of\nthe temperatures reported by the sensor array from our previous example.",
"_____no_output_____"
]
],
[
[
"@tff.federated_computation(tff.type_at_clients(tf.float32))\ndef get_average_temperature(sensor_readings):\n return tff.federated_mean(sensor_readings)",
"_____no_output_____"
]
],
[
[
"Looking at the above code, at this point you might be asking - aren't there\nalready decorator constructs to define composable units such as\n[`tf.function`](https://www.tensorflow.org/api_docs/python/tf/function)\nin TensorFlow, and if so, why introduce yet another one, and how is it\ndifferent?\n\nThe short answer is that the code generated by the `tff.federated_computation`\nwrapper is *neither* TensorFlow, *nor is it* Python - it's a specification of a\ndistributed system in an internal platform-independent *glue* language. At this\npoint, this will undoubtedly sound cryptic, but please bear this intuitive\ninterpretation of a federated computation as an abstract specification of a\ndistributed system in mind. We'll explain it in a minute.\n\nFirst, let's play with the definition a bit. TFF computations are generally\nmodeled as functions - with or without parameters, but with well-defined type\nsignatures. You can print the type signature of a computation by querying its\n`type_signature` property, as shown below.",
"_____no_output_____"
]
],
[
[
"str(get_average_temperature.type_signature)",
"_____no_output_____"
]
],
[
[
"The type signature tells us that the computation accepts a collection of\ndifferent sensor readings on client devices, and returns a single average on the\nserver.\n\nBefore we go any further, let's reflect on this for a minute - the input and\noutput of this computation are *in different places* (on `CLIENTS` vs. at the\n`SERVER`). Recall what we said in the preceding section on placements about how\n*TFF operations may span across locations, and run in the network*, and what we\njust said about federated computations as representing abstract specifications\nof distributed systems. We have just a defined one such computation - a simple\ndistributed system in which data is consumed at client devices, and the\naggregate results emerge at the server.\n\nIn many practical scenarios, the computations that represent top-level tasks\nwill tend to accept their inputs and report their outputs at the server - this\nreflects the idea that computations might be triggered by *queries* that\noriginate and terminate on the server.\n\nHowever, FC API does not impose this assumption, and many of the building blocks\nwe use internally (including numerous `tff.federated_...` operators you may find\nin the API) have inputs and outputs with distinct placements, so in general, you\nshould not think about a federated computation as something that *runs on the\nserver* or is *executed by a server*. The server is just one type of participant\nin a federated computation. In thinking about the mechanics of such\ncomputations, it's best to always default to the global network-wide\nperspective, rather than the perspective of a single centralized coordinator.\n\nIn general, functional type signatures are compactly represented as `(T -> U)`\nfor types `T` and `U` of inputs and outputs, respectively. The type of the\nformal parameter (such `sensor_readings` in this case) is specified as the\nargument to the decorator. You don't need to specify the type of the result -\nit's determined automatically.\n\nAlthough TFF does offer limited forms of polymorphism, programmers are strongly\nencouraged to be explicit about the types of data they work with, as that makes\nunderstanding, debugging, and formally verifying properties of your code easier.\nIn some cases, explicitly specifying types is a requirement (e.g., polymorphic\ncomputations are currently not directly executable).\n\n### Executing federated computations\n\nIn order to support development and debugging, TFF allows you to directly invoke\ncomputations defined this way as Python functions, as shown below. Where the\ncomputation expects a value of a federated type with the `all_equal` bit set to\n`False`, you can feed it as a plain `list` in Python, and for federated types\nwith the `all_equal` bit set to `True`, you can just directly feed the (single)\nmember constituent. This is also how the results are reported back to you.",
"_____no_output_____"
]
],
[
[
"get_average_temperature([68.5, 70.3, 69.8])",
"_____no_output_____"
]
],
[
[
"When running computations like this in simulation mode, you act as an external\nobserver with a system-wide view, who has the ability to supply inputs and\nconsume outputs at any locations in the network, as indeed is the case here -\nyou supplied client values at input, and consumed the server result.\n\nNow, let's return to a note we made earlier about the\n`tff.federated_computation` decorator emitting code in a *glue* language.\nAlthough the logic of TFF computations can be expressed as ordinary functions in\nPython (you just need to decorate them with `tff.federated_computation` as we've\ndone above), and you can directly invoke them with Python arguments just\nlike any other Python functions in this notebook, behind the scenes, as we noted\nearlier, TFF computations are actually *not* Python.\n\nWhat we mean by this is that when the Python interpreter encounters a function\ndecorated with `tff.federated_computation`, it traces the statements in this\nfunction's body once (at definition time), and then constructs a\n[serialized representation](https://github.com/tensorflow/federated/blob/master/tensorflow_federated/proto/v0/computation.proto)\nof the computation's logic for future use - whether for execution, or to be\nincorporated as a sub-component into another computation.\n\nYou can verify this by adding a print statement, as follows:",
"_____no_output_____"
]
],
[
[
"@tff.federated_computation(tff.type_at_clients(tf.float32))\ndef get_average_temperature(sensor_readings):\n\n print ('Getting traced, the argument is \"{}\".'.format(\n type(sensor_readings).__name__))\n\n return tff.federated_mean(sensor_readings)",
"Getting traced, the argument is \"ValueImpl\".\n"
]
],
[
[
"You can think of Python code that defines a federated computation similarly to\nhow you would think of Python code that builds a TensorFlow graph in a non-eager\ncontext (if you're not familiar with the non-eager uses of TensorFlow, think of\nyour Python code defining a graph of operations to be executed later, but not\nactually running them on the fly). The non-eager graph-building code in\nTensorFlow is Python, but the TensorFlow graph constructed by this code is\nplatform-independent and serializable.\n\nLikewise, TFF computations are defined in Python, but the Python statements in\ntheir bodies, such as `tff.federated_mean` in the example weve just shown,\nare compiled into a portable and platform-independent serializable\nrepresentation under the hood.\n\nAs a developer, you don't need to concern yourself with the details of this\nrepresentation, as you will never need to directly work with it, but you should\nbe aware of its existence, the fact that TFF computations are fundamentally\nnon-eager, and cannot capture arbitrary Python state. Python code contained in a\nTFF computation's body is executed at definition time, when the body of the\nPython function decorated with `tff.federated_computation` is traced before\ngetting serialized. It's not retraced again at invocation time (except when the\nfunction is polymorphic; please refer to the documentation pages for details).\n\nYou may wonder why we've chosen to introduce a dedicated internal non-Python\nrepresentation. One reason is that ultimately, TFF computations are intended to\nbe deployable to real physical environments, and hosted on mobile or embedded\ndevices, where Python may not be available.\n\nAnother reason is that TFF computations express the global behavior of\ndistributed systems, as opposed to Python programs which express the local\nbehavior of individual participants. You can see that in the simple example\nabove, with the special operator `tff.federated_mean` that accepts data on\nclient devices, but deposits the results on the server.\n\nThe operator `tff.federated_mean` cannot be easily modeled as an ordinary\noperator in Python, since it doesn't execute locally - as noted earlier, it\nrepresents a distributed system that coordinates the behavior of multiple system\nparticipants. We will refer to such operators as *federated operators*, to\ndistinguish them from ordinary (local) operators in Python.\n\nThe TFF type system, and the fundamental set of operations supported in the TFF's\nlanguage, thus deviates significantly from those in Python, necessitating the\nuse of a dedicated representation.\n\n### Composing federated computations\n\nAs noted above, federated computations and their constituents are best\nunderstood as models of distributed systems, and you can think of composing\nfederated computations as composing more complex distributed systems from\nsimpler ones. You can think of the `tff.federated_mean` operator as a kind of\nbuilt-in template federated computation with a type signature `({T}@CLIENTS ->\nT@SERVER)` (indeed, just like computations you write, this operator also has a\ncomplex structure - under the hood we break it down into simpler operators).\n\nThe same is true of composing federated computations. The computation\n`get_average_temperature` may be invoked in a body of another Python function\ndecorated with `tff.federated_computation` - doing so will cause it to be\nembedded in the body of the parent, much in the same way `tff.federated_mean`\nwas embedded in its own body earlier.\n\nAn important restriction to be aware of is that bodies of Python functions\ndecorated with `tff.federated_computation` must consist *only* of federated\noperators, i.e., they cannot directly contain TensorFlow operations. For\nexample, you cannot directly use `tf.nest` interfaces to add a pair of\nfederated values. TensorFlow code must be confined to blocks of code decorated\nwith a `tff.tf_computation` discussed in the following section. Only when\nwrapped in this manner can the wrapped TensorFlow code be invoked in the body of\na `tff.federated_computation`.\n\nThe reasons for this separation are technical (it's hard to trick operators such\nas `tf.add` to work with non-tensors) as well as architectural. The language of\nfederated computations (i.e., the logic constructed from serialized bodies of\nPython functions decorated with `tff.federated_computation`) is designed to\nserve as a platform-independent *glue* language. This glue language is currently\nused to build distributed systems from embedded sections of TensorFlow code\n(confined to `tff.tf_computation` blocks). In the fullness of time, we\nanticipate the need to embed sections of other, non-TensorFlow logic, such as\nrelational database queries that might represent input pipelines, all connected\ntogether using the same glue language (the `tff.federated_computation` blocks).",
"_____no_output_____"
],
[
"## TensorFlow logic\n\n### Declaring TensorFlow computations\n\nTFF is designed for use with TensorFlow. As such, the bulk of the code you will\nwrite in TFF is likely to be ordinary (i.e., locally-executing) TensorFlow code.\nIn order to use such code with TFF, as noted above, it just needs to be\ndecorated with `tff.tf_computation`.\n\nFor example, here's how we could implement a function that takes a number and\nadds `0.5` to it.",
"_____no_output_____"
]
],
[
[
"@tff.tf_computation(tf.float32)\ndef add_half(x):\n return tf.add(x, 0.5)",
"_____no_output_____"
]
],
[
[
"Once again, looking at this, you may be wondering why we should define another\ndecorator `tff.tf_computation` instead of simply using an existing mechanism\nsuch as `tf.function`. Unlike in the preceding section, here we are\ndealing with an ordinary block of TensorFlow code.\n\nThere are a few reasons for this, the full treatment of which goes beyond the\nscope of this tutorial, but it's worth naming the main one:\n\n* In order to embed reusable building blocks implemented using TensorFlow code\n in the bodies of federated computations, they need to satisfy certain\n properties - such as getting traced and serialized at definition time,\n having type signatures, etc. This generally requires some form of a\n decorator.\n\nIn general, we recommend using TensorFlow's native mechanisms for composition,\nsuch as `tf.function`, wherever possible, as the exact manner in\nwhich TFF's decorator interacts with eager functions can be expected to evolve.\n\nNow, coming back to the example code snippet above, the computation `add_half`\nwe just defined can be treated by TFF just like any other TFF computation. In\nparticular, it has a TFF type signature.",
"_____no_output_____"
]
],
[
[
"str(add_half.type_signature)",
"_____no_output_____"
]
],
[
[
"Note this type signature does not have placements. TensorFlow computations\ncannot consume or return federated types.\n\nYou can now also use `add_half` as a building block in other computations . For\nexample, here's how you can use the `tff.federated_map` operator to apply\n`add_half` pointwise to all member constituents of a federated float on client\ndevices.",
"_____no_output_____"
]
],
[
[
"@tff.federated_computation(tff.type_at_clients(tf.float32))\ndef add_half_on_clients(x):\n return tff.federated_map(add_half, x)",
"_____no_output_____"
],
[
"str(add_half_on_clients.type_signature)",
"_____no_output_____"
]
],
[
[
"### Executing TensorFlow computations\n\nExecution of computations defined with `tff.tf_computation` follows the same\nrules as those we described for `tff.federated_computation`. They can be invoked\nas ordinary callables in Python, as follows.",
"_____no_output_____"
]
],
[
[
"add_half_on_clients([1.0, 3.0, 2.0])",
"_____no_output_____"
]
],
[
[
"Once again, it is worth noting that invoking the computation\n`add_half_on_clients` in this manner simulates a distributed process. Data is\nconsumed on clients, and returned on clients. Indeed, this computation has each\nclient perform a local action. There is no `tff.SERVER` explicitly mentioned in\nthis system (even if in practice, orchestrating such processing might involve\none). Think of a computation defined this way as conceptually analogous to the\n`Map` stage in `MapReduce`.\n\nAlso, keep in mind that what we said in the preceding section about TFF\ncomputations getting serialized at the definition time remains true for\n`tff.tf_computation` code as well - the Python body of `add_half_on_clients`\ngets traced once at definition time. On subsequent invocations, TFF uses its\nserialized representation.\n\nThe only difference between Python methods decorated with\n`tff.federated_computation` and those decorated with `tff.tf_computation` is\nthat the latter are serialized as TensorFlow graphs (whereas the former are not\nallowed to contain TensorFlow code directly embedded in them).\n\nUnder the hood, each method decorated with `tff.tf_computation` temporarily\ndisables eager execution in order to allow the computation's structure to be\ncaptured. While eager execution is locally disabled, you are welcome to use\neager TensorFlow, AutoGraph, TensorFlow 2.0 constructs, etc., so long as you\nwrite the logic of your computation in a manner such that it can get correctly\nserialized.\n\nFor example, the following code will fail:",
"_____no_output_____"
]
],
[
[
"try:\n\n # Eager mode\n constant_10 = tf.constant(10.)\n\n @tff.tf_computation(tf.float32)\n def add_ten(x):\n return x + constant_10\n\nexcept Exception as err:\n print (err)",
"Attempting to capture an EagerTensor without building a function.\n"
]
],
[
[
"The above fails because `constant_10` has already been constructed outside of\nthe graph that `tff.tf_computation` constructs internally in the body of\n`add_ten` during the serialization process.\n\nOn the other hand, invoking python functions that modify the current graph when\ncalled inside a `tff.tf_computation` is fine:",
"_____no_output_____"
]
],
[
[
"def get_constant_10():\n return tf.constant(10.)\n\[email protected]_computation(tf.float32)\ndef add_ten(x):\n return x + get_constant_10()\n\nadd_ten(5.0)",
"_____no_output_____"
]
],
[
[
"Note that the serialization mechanisms in TensorFlow are evolving, and we expect\nthe details of how TFF serializes computations to evolve as well.\n\n### Working with `tf.data.Dataset`s\n\nAs noted earlier, a unique feature of `tff.tf_computation`s is that they allows\nyou to work with `tf.data.Dataset`s defined abstractly as formal parameters by\nyour code. Parameters to be represented in TensorFlow as data sets need to be\ndeclared using the `tff.SequenceType` constructor.\n\nFor example, the type specification `tff.SequenceType(tf.float32)` defines an\nabstract sequence of float elements in TFF. Sequences can contain either\ntensors, or complex nested structures (we'll see examples of those later). The\nconcise representation of a sequence of `T`-typed items is `T*`.",
"_____no_output_____"
]
],
[
[
"float32_sequence = tff.SequenceType(tf.float32)\n\nstr(float32_sequence)",
"_____no_output_____"
]
],
[
[
"Suppose that in our temperature sensor example, each sensor holds not just one\ntemperature reading, but multiple. Here's how you can define a TFF computation\nin TensorFlow that calculates the average of temperatures in a single local data\nset using the `tf.data.Dataset.reduce` operator.",
"_____no_output_____"
]
],
[
[
"@tff.tf_computation(tff.SequenceType(tf.float32))\ndef get_local_temperature_average(local_temperatures):\n sum_and_count = (\n local_temperatures.reduce((0.0, 0), lambda x, y: (x[0] + y, x[1] + 1)))\n return sum_and_count[0] / tf.cast(sum_and_count[1], tf.float32)",
"_____no_output_____"
],
[
"str(get_local_temperature_average.type_signature)",
"_____no_output_____"
]
],
[
[
"In the body of a method decorated with `tff.tf_computation`, formal parameters\nof a TFF sequence type are represented simply as objects that behave like\n`tf.data.Dataset`, i.e., support the same properties and methods (they are\ncurrently not implemented as subclasses of that type - this may change as the\nsupport for data sets in TensorFlow evolves).\n\nYou can easily verify this as follows.",
"_____no_output_____"
]
],
[
[
"@tff.tf_computation(tff.SequenceType(tf.int32))\ndef foo(x):\n return x.reduce(np.int32(0), lambda x, y: x + y)\n\nfoo([1, 2, 3])",
"_____no_output_____"
]
],
[
[
"Keep in mind that unlike ordinary `tf.data.Dataset`s, these dataset-like objects\nare placeholders. They don't contain any elements, since they represent abstract\nsequence-typed parameters, to be bound to concrete data when used in a concrete\ncontext. Support for abstractly-defined placeholder data sets is still somewhat\nlimited at this point, and in the early days of TFF, you may encounter certain\nrestrictions, but we won't need to worry about them in this tutorial (please\nrefer to the documentation pages for details).\n\nWhen locally executing a computation that accepts a sequence in a simulation\nmode, such as in this tutorial, you can feed the sequence as Python list, as\nbelow (as well as in other ways, e.g., as a `tf.data.Dataset` in eager mode, but\nfor now, we'll keep it simple).",
"_____no_output_____"
]
],
[
[
"get_local_temperature_average([68.5, 70.3, 69.8])",
"_____no_output_____"
]
],
[
[
"Like all other TFF types, sequences like those defined above can use the\n`tff.StructType` constructor to define nested structures. For example,\nhere's how one could declare a computation that accepts a sequence of pairs `A`,\n`B`, and returns the sum of their products. We include the tracing statements in\nthe body of the computation so that you can see how the TFF type signature\ntranslates into the dataset's `output_types` and `output_shapes`.",
"_____no_output_____"
]
],
[
[
"@tff.tf_computation(tff.SequenceType(collections.OrderedDict([('A', tf.int32), ('B', tf.int32)])))\ndef foo(ds):\n print('element_structure = {}'.format(ds.element_spec))\n return ds.reduce(np.int32(0), lambda total, x: total + x['A'] * x['B'])",
"element_structure = OrderedDict([('A', TensorSpec(shape=(), dtype=tf.int32, name=None)), ('B', TensorSpec(shape=(), dtype=tf.int32, name=None))])\n"
],
[
"str(foo.type_signature)",
"_____no_output_____"
],
[
"foo([{'A': 2, 'B': 3}, {'A': 4, 'B': 5}])",
"_____no_output_____"
]
],
[
[
"The support for using `tf.data.Datasets` as formal parameters is still somewhat\nlimited and evolving, although functional in simple scenarios such as those used\nin this tutorial.\n\n## Putting it all together\n\nNow, let's try again to use our TensorFlow computation in a federated setting.\nSuppose we have a group of sensors that each have a local sequence of\ntemperature readings. We can compute the global temperature average by averaging\nthe sensors' local averages as follows.",
"_____no_output_____"
]
],
[
[
"@tff.federated_computation(\n tff.type_at_clients(tff.SequenceType(tf.float32)))\ndef get_global_temperature_average(sensor_readings):\n return tff.federated_mean(\n tff.federated_map(get_local_temperature_average, sensor_readings))",
"_____no_output_____"
]
],
[
[
"Note that this isn't a simple average across all local temperature readings from\nall clients, as that would require weighing contributions from different clients\nby the number of readings they locally maintain. We leave it as an exercise for\nthe reader to update the above code; the `tff.federated_mean` operator\naccepts the weight as an optional second argument (expected to be a federated\nfloat).\n\nAlso note that the input to `get_global_temperature_average` now becomes a\n*federated float sequence*. Federated sequences is how we will typically represent\non-device data in federated learning, with sequence elements typically\nrepresenting data batches (you will see examples of this shortly).",
"_____no_output_____"
]
],
[
[
"str(get_global_temperature_average.type_signature)",
"_____no_output_____"
]
],
[
[
"Here's how we can locally execute the computation on a sample of data in Python.\nNotice that the way we supply the input is now as a `list` of `list`s. The outer\nlist iterates over the devices in the group represented by `tff.CLIENTS`, and\nthe inner ones iterate over elements in each device's local sequence.",
"_____no_output_____"
]
],
[
[
"get_global_temperature_average([[68.0, 70.0], [71.0], [68.0, 72.0, 70.0]])",
"_____no_output_____"
]
],
[
[
"This concludes the first part of the tutorial... we encourage you to continue on\nto the [second part](custom_federated_algorithms_2.ipynb).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a03e658ed77ab90b02884347a6778d63072eefb
| 120,813 |
ipynb
|
Jupyter Notebook
|
LogisticRegression/example3.ipynb
|
Nikeshbajaj/MachineLearningFromScratch
|
f025d3547bb7a605d62ed238536e6ae526ad55da
|
[
"MIT"
] | 15 |
2018-10-30T14:20:35.000Z
|
2021-11-23T07:05:19.000Z
|
LogisticRegression/example3.ipynb
|
Nikeshbajaj/MachineLearningFromScratch
|
f025d3547bb7a605d62ed238536e6ae526ad55da
|
[
"MIT"
] | null | null | null |
LogisticRegression/example3.ipynb
|
Nikeshbajaj/MachineLearningFromScratch
|
f025d3547bb7a605d62ed238536e6ae526ad55da
|
[
"MIT"
] | 9 |
2019-07-26T23:51:25.000Z
|
2021-11-23T07:05:24.000Z
| 130.608649 | 82,944 | 0.811121 |
[
[
[
"'''\n## Machine Learning from scrach\n### Example 3: Logistic Regression\n\n@Author _ Nikesh Bajaj\nPhD Student at Queen Mary University of London &\nUniversity of Genova\nConact _ http://nikeshbajaj.in \nn[dot][email protected]\nbajaj[dot][email protected]\n'''",
"_____no_output_____"
]
],
[
[
"import time\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.gridspec import GridSpec\nimport DataSet as ds\nfrom LogisticRegression import LR",
"_____no_output_____"
],
[
"%matplotlib notebook",
"_____no_output_____"
],
[
"plt.close('all')\n\ndtype = ['MOONS','GAUSSIANS','LINEAR','SINUSOIDAL','SPIRAL']\n\n#X, y,_ = ds.create_dataset(200, dtype[2],0.05,varargin = 'PRESET')\n\nX, y,_ = ds.create_dataset(500, dtype[0],0.05,varargin = 'PRESET')\n\nprint(X.shape, y.shape)\n\nmeans = np.mean(X,1).reshape(X.shape[0],-1)\nstds = np.std(X,1).reshape(X.shape[0],-1)\n\nX = (X-means)/stds\n\n\nClf = LR(X,y,alpha=0.001,lambd=3,polyfit=True,degree=5)\n\nfig=plt.figure(figsize=(10,4))\ndelay=0.01\ngs=GridSpec(1,2)\nax1=fig.add_subplot(gs[0,0])\nax2=fig.add_subplot(gs[0,1])\n\nfor i in range(50):\n Clf.fit(X,y,itr=10,verbose=False)\n ax1.clear()\n Clf.Bplot(ax1,hardbound=True)\n ax2.clear()\n Clf.LCurvePlot(ax2)\n fig.canvas.draw()\n time.sleep(delay)\n \nyprob,yp = Clf.predict(X)\nprint('Accuracy::: Training :',100*np.sum(yp==y)/yp.shape[1])",
"(2, 500) (1, 500)\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a03eeadf77b80ebee430b4a0a518392e0d476c1
| 21,381 |
ipynb
|
Jupyter Notebook
|
devel/validator.ipynb
|
mjirik/animalwatch
|
c77138debdec3915f1f9539278dee248348c2c61
|
[
"MIT"
] | null | null | null |
devel/validator.ipynb
|
mjirik/animalwatch
|
c77138debdec3915f1f9539278dee248348c2c61
|
[
"MIT"
] | null | null | null |
devel/validator.ipynb
|
mjirik/animalwatch
|
c77138debdec3915f1f9539278dee248348c2c61
|
[
"MIT"
] | null | null | null | 29.861732 | 135 | 0.497124 |
[
[
[
"# Animalwatch validator",
"_____no_output_____"
]
],
[
[
"import glob\nimport os.path as op\n\nimport numpy as np\nfrom io import open\nfrom ruamel.yaml import YAML\nyaml = YAML(typ=\"unsafe\")",
"_____no_output_____"
],
[
"true_annotations_path = \"E:\\\\data\\\\lynx_lynx\\\\zdo\\\\anotace\"\nannotations_path = \"E:\\\\data\\\\lynx_lynx\\\\zdo\\\\anotace_test\"\n",
"_____no_output_____"
],
[
"def evaluate_dir(true_annotations_path, annotations_path):\n \"\"\"\n :param true_annotations_path: path to directory with subdirectories with annotations\n :param annotations_path: path to students annotations with no subdirs\n \"\"\"\n \n true_annotation_files = glob.glob(op.join(true_annotations_path, \"**\", \"*.y*ml\"))\n score = []\n score_failed = []\n nok = 0\n nerr = 0\n print(\"Score - video file\")\n print(\"-------\")\n for true_annotation_fn in true_annotation_files:\n annotation_fn, video_fn = find_annotation(annotations_path, true_annotation_fn)\n if annotation_fn is None:\n print(\"0.0 - \" + str(video_fn) + \" - Annotation not found\")\n# print(\"annotations_path: \", annotations_path)\n# print(\"true_annotation_fn: \", true_annotation_fn)\n score_failed.append(0.0)\n else:\n sc = compare_yaml_objs(\n get_yaml_obj(annotation_fn),\n get_yaml_obj(true_annotation_fn)\n )\n score.append(sc)\n print(str(sc) + \" - \" + str(video_fn))\n \n print(\"=======\")\n score_ok = np.average(score)\n print(\"Score without failed (\" + str(len(score)) +\"/\" + str(len(score) + len(score_failed)) + \"): \" + str(score_ok))\n score.extend(score_failed)\n score = np.average(score)\n print(\"Score: \" + str(score))\n return score\n \n\n\ndef get_iou(bb1, bb2):\n \"\"\"\n Calculate the Intersection over Union (IoU) of two bounding boxes.\n \n by Martin Thoma\n\n Parameters\n ----------\n bb1 : dict\n Keys: {'x1', 'x2', 'y1', 'y2'}\n The (x1, y1) position is at the top left corner,\n the (x2, y2) position is at the bottom right corner\n bb2 : dict\n Keys: {'x1', 'x2', 'y1', 'y2'}\n The (x, y) position is at the top left corner,\n the (x2, y2) position is at the bottom right corner\n\n Returns\n -------\n float\n in [0, 1]\n \"\"\"\n assert bb1['x1'] < bb1['x2']\n assert bb1['y1'] < bb1['y2']\n assert bb2['x1'] < bb2['x2']\n assert bb2['y1'] < bb2['y2']\n\n # determine the coordinates of the intersection rectangle\n x_left = max(bb1['x1'], bb2['x1'])\n y_top = max(bb1['y1'], bb2['y1'])\n x_right = min(bb1['x2'], bb2['x2'])\n y_bottom = min(bb1['y2'], bb2['y2'])\n\n if x_right < x_left or y_bottom < y_top:\n return 0.0\n\n # The intersection of two axis-aligned bounding boxes is always an\n # axis-aligned bounding box\n intersection_area = (x_right - x_left) * (y_bottom - y_top)\n\n # compute the area of both AABBs\n bb1_area = (bb1['x2'] - bb1['x1']) * (bb1['y2'] - bb1['y1'])\n bb2_area = (bb2['x2'] - bb2['x1']) * (bb2['y2'] - bb2['y1'])\n\n # compute the intersection over union by taking the intersection\n # area and dividing it by the sum of prediction + ground-truth\n # areas - the interesection area\n iou = intersection_area / float(bb1_area + bb2_area - intersection_area)\n assert iou >= 0.0\n assert iou <= 1.0\n return iou\n\ndef get_iou_safe(bb1, bb2):\n if len(bb1) == 0 and len(bb2) == 0:\n score = 1.0\n else:\n try:\n score = get_iou(bb1, bb2)\n except Exception as e:\n score = 0.0\n \n \n return score\n\ndef find_annotation(annotations_path, true_annotation_file):\n annotation_files = glob.glob(op.join(annotations_path, \"*.y*ml\"))\n true_video_fn = get_video_file_name(true_annotation_file)\n found_annotation_fn = []\n for filename in annotation_files:\n video_fn = get_video_file_name(filename)\n found_annotation_fn.append(video_fn)\n# print(\"video_fn: \", video_fn)\n if video_fn.upper() == true_video_fn.upper():\n return filename, video_fn\n \n \n print(\"true_video_fn: \", true_video_fn)\n print(\"found_annotation_fn\", found_annotation_fn)\n# print(\"annotation_files: \", annotation_files)\n return None, true_video_fn\n\n\ndef compare_bboxes(bboxes1, bboxes2):\n scores = []\n lbb1 = len(bboxes1)\n lbb2 = len(bboxes2)\n \n if lbb1 == 0 and lbb2 == 0:\n return 1.0\n elif lbb1 == 0:\n return 0.0\n elif lbb2 == 0:\n return 0.0\n\n for bbox1 in bboxes1:\n scores_for_one = []\n for bbox2 in bboxes2:\n scores_for_one.append(get_iou_safe(bbox1, bbox2))\n# print(bbox1, bbox2)\n \n scores.append(np.max(scores_for_one))\n# print(\"compare_bboxes \", len(bboxes1), len(bboxes2), scores)\n return np.average(scores)\n\ndef compare_bboxes_symmetric(bboxes1, bboxes2):\n return np.average([\n compare_bboxes(bboxes1, bboxes2),\n compare_bboxes(bboxes2, bboxes1),\n ])\n \ndef compare_frames(true_yaml_obj, yaml_obj, frame_number):\n bb1 = get_bboxes_from_frame(true_yaml_obj, frame_number)\n bb2 = get_bboxes_from_frame(yaml_obj, frame_number)\n return compare_bboxes_symmetric(bb1, bb2)\n \ndef get_frame_number(yaml_obj):\n return np.max(list(yaml_obj[\"frames\"]))\n\n\ndef compare_yaml_objs(true_yaml_obj, yaml_obj):\n frame_number = int(np.max([get_frame_number(yaml_obj), get_frame_number(true_yaml_obj)]))\n scores = []\n for i in range(0, frame_number):\n scores.append(compare_frames(true_yaml_obj, yaml_obj, frame_number=i))\n \n# print(scores)\n return np.average(scores)\n \ndef get_yaml_obj(yaml_fn):\n with open(yaml_fn, encoding=\"utf-8\") as f:\n obj = yaml.load(f)\n return obj\n\ndef get_video_file_name(yaml_fn):\n obj = get_yaml_obj(yaml_fn)\n _, video_fn = op.split(obj[\"path\"])\n return video_fn\n \ndef get_bboxes_from_frame(yaml_obj, frame_number):\n# print(frame_number)\n if frame_number in yaml_obj[\"frames\"]:\n bboxes = yaml_obj[\"frames\"][frame_number]\n else:\n bboxes = [\n# {\n# \"x1\": 0,\n# \"x2\": 0,\n# \"y1\": 0,\n# \"y2\": 0,\n# }\n ]\n# print(\"zero\")\n return bboxes\n\n# def compare_bboxes(bboxes1, bboxes2):\n# scores = []\n# lbb1 = len(bboxes1)\n# lbb2 = len(bboxes2)\n \n# if lbb1 == 0 and lbb2 == 0:\n# return 1.0\n# elif lbb1 == 0:\n# return 0.0\n# elif lbb2 == 0:\n# return 0.0\n\n# for bbox1 in bboxes1:\n# scores_for_one = []\n# for bbox2 in bboxes2:\n# scores_for_one.append(get_iou_safe(bbox1, bbox2))\n# # print(bbox1, bbox2)\n \n# scores.append(np.max(scores_for_one))\n# # print(\"compare_bboxes \", len(bboxes1), len(bboxes2), scores)\n# return np.average(scores)\n\n# def compare_bboxes_symmetric(bboxes1, bboxes2):\n# return np.average([\n# compare_bboxes(bboxes1, bboxes2),\n# compare_bboxes(bboxes2, bboxes1),\n# ])\n \n# def compare_frames(true_yaml_obj, yaml_obj, frame_number):\n# bb1 = get_bboxes_from_frame(true_yaml_obj, frame_number)\n# bb2 = get_bboxes_from_frame(yaml_obj, frame_number)\n# return compare_bboxes_symmetric(bb1, bb2)\n \n# def get_frame_number(yaml_obj):\n# return np.max(list(yaml_obj[\"frames\"]))\n\n\n# def compare_yaml_objs(true_yaml_obj, yaml_obj):\n# frame_number = int(np.max([get_frame_number(yaml_obj), get_frame_number(true_yaml_obj)]))\n# scores = []\n# for i in range(0, frame_number):\n# scores.append(compare_frames(true_yaml_obj, yaml_obj, frame_number=i))\n \n# # print(scores)\n# return np.average(scores)\n \n# def get_yaml_obj(yaml_fn):\n# with open(yaml_fn, encoding=\"utf-8\") as f:\n# obj = yaml.load(f)\n# return obj\n\n# def get_video_file_name(yaml_fn):\n# obj = get_yaml_obj(yaml_fn)\n# video_fn = obj[\"path\"]\n# return video_fn\n \n# def get_bboxes_from_frame(yaml_obj, frame_number):\n# # print(frame_number)\n# if frame_number in yaml_obj[\"frames\"]:\n# bboxes = yaml_obj[\"frames\"][frame_number]\n# else:\n# bboxes = [\n# # {\n# # \"x1\": 0,\n# # \"x2\": 0,\n# # \"y1\": 0,\n# # \"y2\": 0,\n# # }\n# ]\n# # print(\"zero\")\n# return bboxes",
"_____no_output_____"
]
],
[
[
"# Example",
"_____no_output_____"
]
],
[
[
"evaluate_dir(true_annotations_path, annotations_path)",
"Score - video file\n-------\n0.0 - IMAG0017.AVI - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\01\\IMAG0017.yaml\n0.0 - IMAG0021.AVI - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\01\\IMAG0021.yaml\n0.0 - IMAG0023.AVI - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\01\\IMAG0023.yaml\n0.0 - IMAG0056.AVI - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\01\\IMAG0056.yaml\n0.48312611012433393 - IMAG0035.AVI\n1.0 - IMAG0039.AVI\n0.0 - IMAG0041.AVI - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\03\\IMAG0041.yml\n0.0 - v__00019.avi - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\03\\v__00019.yml\n0.0 - 05/IMAG0063.AVI - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\05\\imag0063.yaml\n0.0 - 05/IMAG0065.AVI - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\05\\imag0065.yaml\n0.0 - 05/V__00017.M4V - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\05\\V__00017.yaml\n0.0 - IMAG0028.avi - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\06\\anotation_IMAG0028.yaml\n1.0 - IMAG0030.avi\n0.0 - IMAG0032.avi - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\06\\anotation_IMAG0032.yaml\n0.0 - v__00015.avi - Annotation not found\nannotations_path: E:\\data\\lynx_lynx\\zdo\\anotace_test\ntrue_annotation_fn: E:\\data\\lynx_lynx\\zdo\\anotace\\06\\anotation_v__00015.yaml\n=======\nScore: 0.1655417406749556\n"
]
],
[
[
"# Debug tests",
"_____no_output_____"
]
],
[
[
"# filename = \"anotace.yaml\"\n\n# yaml = YAML(typ=\"unsafe\")\n# with open(filename, encoding=\"utf-8\") as f:\n# obj = yaml.load(f)",
"_____no_output_____"
],
[
"files = glob.glob(op.join(annotations_path, \"*.y*ml\"))\nfiles[0]",
"_____no_output_____"
],
[
"yaml_fn = files[1]\n\nvideo_fn = get_video_file_name(yaml_fn)\n# print(video_fn, yaml_fn)",
"_____no_output_____"
],
[
"true_yaml_obj = get_yaml_obj(yaml_fn)\n\nbb1 = true_yaml_obj[\"frames\"][1][0]\nbb2 = true_yaml_obj[\"frames\"][5][0]\n\nget_iou(bb1, bb2)",
"_____no_output_____"
],
[
" \n \n ",
"_____no_output_____"
],
[
"compare_bboxes(get_bboxes_from_frame(true_yaml_obj, 5), get_bboxes_from_frame(true_yaml_obj, 1))",
"_____no_output_____"
],
[
"assert(compare_bboxes(\n [{'x1': 341, 'x2': 459, 'y1': 417, 'y2': 491}, {'x1': 541, 'x2': 559, 'y1': 517, 'y2': 591}], \n [{'x1': 341, 'x2': 459, 'y1': 417, 'y2': 491}, {'x1': 541, 'x2': 559, 'y1': 517, 'y2': 591}]) == 1.0)",
"_____no_output_____"
],
[
"compare_bboxes_symmetric(\n [{'x1': 341, 'x2': 459, 'y1': 417, 'y2': 491}, {'x1': 541, 'x2': 559, 'y1': 517, 'y2': 591}],\n [{'x1': 341, 'x2': 459, 'y1': 417, 'y2': 491}], \n)",
"_____no_output_____"
],
[
"assert(\n compare_bboxes_symmetric(\n [{'x1': 341, 'x2': 459, 'y1': 417, 'y2': 491}, {'x1': 541, 'x2': 559, 'y1': 517, 'y2': 591}],\n [{'x1': 0, 'x2': 1, 'y1': 0, 'y2': 0}], \n ) == 0.0\n)",
"_____no_output_____"
],
[
"# true_yaml_obj",
"_____no_output_____"
],
[
"assert(\n compare_frames(true_yaml_obj, true_yaml_obj, frame_number=5) == 1\n)",
"_____no_output_____"
],
[
"assert(\n compare_yaml_objs(get_yaml_obj(files[0]), get_yaml_obj(files[0])) == 1\n)",
"_____no_output_____"
],
[
"assert('E:\\\\data\\\\lynx_lynx\\\\zdo\\\\anotace_test\\\\IMAG0021.yaml' in files)",
"_____no_output_____"
],
[
"fn1, fn2 = find_annotation(true_annotations_path, files[1])\nassert(fn1 is None)",
"true_video_fn: IMAG0035.AVI\nannotation_files: []\n"
],
[
"# \"asd\" == \"asd\"",
"_____no_output_____"
],
[
"# files",
"_____no_output_____"
]
],
[
[
"## Debug 4 files found",
"_____no_output_____"
]
],
[
[
"find_annotation(\n r\"C:\\Users\\miros\\projects\\zdo_lynx_lynx\\ZDO_SP_Sosnova_Cincera\\Anotace\",\n r\"E:\\data\\lynx_lynx\\zdo\\anotace\\01\\IMAG0017.yaml\"\n)",
"_____no_output_____"
],
[
"# \"sdfa\".upper()",
"_____no_output_____"
],
[
"import os.path as op\n_, uu = op.split(\"uur/safs/asdfsda.avi\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a03f573fea1bf13d4801d1888cdcdca9f0e2c5e
| 177,068 |
ipynb
|
Jupyter Notebook
|
demos/Lecture17-Demos.ipynb
|
annabellegrimes/CPEN-400Q
|
044d521f8109567ec004a9c882898f9e2eb5a19e
|
[
"MIT"
] | 6 |
2022-01-12T22:57:13.000Z
|
2022-03-15T21:20:59.000Z
|
demos/Lecture17-Demos.ipynb
|
annabellegrimes/CPEN-400Q
|
044d521f8109567ec004a9c882898f9e2eb5a19e
|
[
"MIT"
] | null | null | null |
demos/Lecture17-Demos.ipynb
|
annabellegrimes/CPEN-400Q
|
044d521f8109567ec004a9c882898f9e2eb5a19e
|
[
"MIT"
] | 3 |
2022-02-04T07:48:01.000Z
|
2022-03-22T21:40:06.000Z
| 214.627879 | 67,440 | 0.92007 |
[
[
[
"# Demos: Lecture 17",
"_____no_output_____"
],
[
"## Demo 1: bit flip errors",
"_____no_output_____"
]
],
[
[
"import pennylane as qml\nfrom pennylane import numpy as np\nimport matplotlib.pyplot as plt\n\nfrom lecture17_helpers import *\nfrom scipy.stats import unitary_group",
"/opt/conda/envs/pennylane/lib/python3.8/site-packages/_distutils_hack/__init__.py:30: UserWarning: Setuptools is replacing distutils.\n warnings.warn(\"Setuptools is replacing distutils.\")\n"
],
[
"dev = qml.device(\"default.mixed\", wires=1)\n\[email protected](dev)\ndef prepare_state(U, p):\n qml.QubitUnitary(U, wires=0)\n qml.BitFlip(p, wires=0)\n #qml.DepolarizingChannel(p, wires=0)\n return qml.state()",
"_____no_output_____"
],
[
"n_samples = 500\n\noriginal_states = []\nflipped_states = []\n\nfor _ in range(n_samples):\n U = unitary_group.rvs(2)\n original_state = prepare_state(U, 0)\n flipped_state = prepare_state(U, 0.3)\n \n original_states.append(convert_to_bloch_vector(original_state))\n flipped_states.append(convert_to_bloch_vector(flipped_state))",
"_____no_output_____"
],
[
"plot_bloch_sphere(original_states)",
"_____no_output_____"
],
[
"plot_bloch_sphere(flipped_states)",
"_____no_output_____"
]
],
[
[
"## Demo 2: depolarizing noise",
"_____no_output_____"
],
[
"## Demo 3: fidelity and trace distance",
"_____no_output_____"
],
[
"$$\nF(\\rho, \\sigma) = \\left( \\hbox{Tr} \\sqrt{\\sqrt{\\rho}\\sigma\\sqrt{\\rho}} \\right)^2\n$$",
"_____no_output_____"
]
],
[
[
"from scipy.linalg import sqrtm",
"_____no_output_____"
],
[
"def fidelity(rho, sigma):\n sqrt_rho = sqrtm(rho)\n inner_thing = np.linalg.multi_dot([sqrt_rho, sigma, sqrt_rho])\n return np.trace(sqrtm(inner_thing)) ** 2",
"_____no_output_____"
],
[
"proj_0 = np.array([[1, 0], [0, 0]])\nproj_1 = np.array([[0, 0], [0, 1]])",
"_____no_output_____"
],
[
"fidelity(proj_0, proj_0)",
"_____no_output_____"
],
[
"fidelity(proj_0, proj_1)",
"_____no_output_____"
]
],
[
[
"$$\nT(\\rho, \\sigma) = \\frac{1}{2} \\hbox{Tr} \\left( \\sqrt{(\\rho - \\sigma)^\\dagger (\\rho - \\sigma)} \\right)\n$$",
"_____no_output_____"
]
],
[
[
"def trace_distance(rho, sigma):\n rms = rho - sigma\n inner_thing = np.dot(rms.conj().T, rms)\n return 0.5 * np.trace(sqrtm(inner_thing))",
"_____no_output_____"
],
[
"U = unitary_group.rvs(2)\n\np_vals = np.linspace(0, 1, 10)",
"_____no_output_____"
],
[
"fids = []\ntr_ds = []\n\nfor p in p_vals:\n original_state = prepare_state(U, 0)\n error_state = prepare_state(U, p)\n \n fids.append(fidelity(original_state, error_state))\n tr_ds.append(trace_distance(original_state, error_state))",
"_____no_output_____"
],
[
"plt.scatter(p_vals, fids)",
"/opt/conda/envs/pennylane/lib/python3.8/site-packages/numpy/core/_asarray.py:136: ComplexWarning: Casting complex values to real discards the imaginary part\n return array(a, dtype, copy=False, order=order, subok=True)\n"
],
[
"plt.scatter(p_vals, tr_ds)",
"_____no_output_____"
]
],
[
[
"## Demo 4: VQE for $H_2$ molecule",
"_____no_output_____"
]
],
[
[
"bond_length = 1.3228\nsymbols = [\"H\", \"H\"]\ncoordinates = np.array([0.0, 0.0, -bond_length/2, 0.0, 0.0, bond_length/2])",
"_____no_output_____"
],
[
"H, n_qubits = qml.qchem.molecular_hamiltonian(symbols, coordinates)",
"_____no_output_____"
],
[
"print(H)",
" (-0.2427450172749822) [Z2]\n+ (-0.2427450172749822) [Z3]\n+ (-0.04207254303152995) [I0]\n+ (0.17771358191549907) [Z0]\n+ (0.17771358191549919) [Z1]\n+ (0.12293330460167415) [Z0 Z2]\n+ (0.12293330460167415) [Z1 Z3]\n+ (0.16768338881432715) [Z0 Z3]\n+ (0.16768338881432715) [Z1 Z2]\n+ (0.17059759240560826) [Z0 Z1]\n+ (0.17627661476093917) [Z2 Z3]\n+ (-0.04475008421265302) [Y0 Y1 X2 X3]\n+ (-0.04475008421265302) [X0 X1 Y2 Y3]\n+ (0.04475008421265302) [Y0 X1 X2 Y3]\n+ (0.04475008421265302) [X0 Y1 Y2 X3]\n"
]
],
[
[
"Ground state of $H_2$ looks like:\n\n$$\n|\\psi_g(\\theta)\\rangle = \\cos(\\theta/2) |1100\\rangle - \\sin(\\theta/2) |0011\\rangle\n$$",
"_____no_output_____"
]
],
[
[
"dev = qml.device(\"default.qubit\", wires=4)\n\ndef prepare_ground_state(theta):\n qml.PauliX(wires=0)\n qml.PauliX(wires=1)\n qml.DoubleExcitation(theta, wires=range(4))\n return qml.expval(H)",
"_____no_output_____"
],
[
"opt = qml.GradientDescentOptimizer(stepsize=0.5)\n\nideal_qnode = qml.QNode(prepare_ground_state, dev)\n\ntheta = np.array(0.0, requires_grad=True)\nenergies = []\n\nfor _ in range(30):\n theta, _energy = opt.step_and_cost(ideal_qnode, theta)\n energies.append(_energy)",
"_____no_output_____"
],
[
"plt.plot(energies)",
"_____no_output_____"
],
[
"energies[-1]",
"_____no_output_____"
],
[
"theta",
"_____no_output_____"
]
],
[
[
"## Demo 5: VQE on a noisy device",
"_____no_output_____"
]
],
[
[
"from qiskit.test.mock import FakeSantiago\nfrom qiskit.providers.aer import QasmSimulator\nfrom qiskit.providers.aer.noise import NoiseModel",
"_____no_output_____"
],
[
"device = QasmSimulator.from_backend(FakeSantiago())\n\nnoise_model = NoiseModel.from_backend(device, readout_error=False)\n\nnoisy_dev = qml.device(\n \"qiskit.aer\", backend='qasm_simulator', wires=4, shots=10000, noise_model=noise_model\n)",
"_____no_output_____"
],
[
"noisy_qnode = qml.QNode(prepare_ground_state, noisy_dev)",
"_____no_output_____"
],
[
"noisy_qnode(theta)",
"_____no_output_____"
],
[
"opt = qml.GradientDescentOptimizer(stepsize=0.5)\n\ntheta = np.array(0.0, requires_grad=True)\n\nnoisy_energies = []\n\nfor it in range(30):\n if it % 5 == 0:\n print(f\"it = {it}\")\n theta, _energy = opt.step_and_cost(noisy_qnode, theta)\n noisy_energies.append(_energy)",
"it = 0\nit = 5\nit = 10\nit = 15\nit = 20\nit = 25\n"
],
[
"plt.scatter(range(30), energies)\nplt.scatter(range(30), noisy_energies)",
"_____no_output_____"
]
],
[
[
"## Demo 6: zero-noise extrapolation",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a03fe55fab6b904a933c68dd6f77eae4155a869
| 70,404 |
ipynb
|
Jupyter Notebook
|
VGG16_CIFAR10.ipynb
|
1337Eddy/BirdRecognitionPruning
|
2e3e0ebfb2fbdd817a1a4b40f908d034b2311901
|
[
"MIT"
] | null | null | null |
VGG16_CIFAR10.ipynb
|
1337Eddy/BirdRecognitionPruning
|
2e3e0ebfb2fbdd817a1a4b40f908d034b2311901
|
[
"MIT"
] | null | null | null |
VGG16_CIFAR10.ipynb
|
1337Eddy/BirdRecognitionPruning
|
2e3e0ebfb2fbdd817a1a4b40f908d034b2311901
|
[
"MIT"
] | null | null | null | 65.431227 | 33,932 | 0.717147 |
[
[
[
"Imports",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torchvision\nimport torch.optim as optim\nimport torchvision.transforms as transforms\nfrom torchvision import models, datasets\nfrom torch.autograd import Variable\nimport shutil\nfrom torchsummary import summary\n\nimport os\nimport numpy as np\nimport pandas as pd \n\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
]
],
[
[
"Hyperparameters",
"_____no_output_____"
]
],
[
[
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nprint(device)\n\ntorch.cuda.manual_seed(1337)\n\nbatch_size = 100\ntest_batch_size = 1000\ngamma = 0.001\nlr = 0.01\nprune_rate=0.9\n\nkwargs = {'num_workers': 16, 'pin_memory': True}",
"cuda\n"
]
],
[
[
"DataLoaders",
"_____no_output_____"
]
],
[
[
"train_loader = torch.utils.data.DataLoader(\n datasets.CIFAR10('./data', train=True, download=True,\n transform=transforms.Compose([\n transforms.Pad(4),\n transforms.RandomCrop(32),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n ])),\n batch_size=batch_size, shuffle=True, **kwargs)\ntest_loader = torch.utils.data.DataLoader(\n datasets.CIFAR10('./data', train=False, transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n ])),\n batch_size=test_batch_size, shuffle=True, **kwargs)\n",
"Files already downloaded and verified\n"
]
],
[
[
"Network Model",
"_____no_output_____"
]
],
[
[
"class sequential_model(nn.Module):\n def __init__(self, layers=None):\n super(sequential_model, self).__init__()\n if layers == None:\n layers = [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512]\n num_classes = 10\n self.feature = self.make_layers(layers)\n self.classifier = nn.Linear(layers[-1], num_classes)\n \n def make_layers(self, structure):\n layers = []\n in_channels = 3\n for v in structure:\n if v == 'M':\n layers += [nn.MaxPool2d(kernel_size=2, stride=2)]\n else:\n conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1, bias=False)\n layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]\n in_channels = v\n return nn.Sequential(*layers)\n \n def forward(self, x):\n x = self.feature(x)\n x = nn.AvgPool2d(2)(x)\n x = x.view(x.size(0), -1)\n y = self.classifier(x)\n return y",
"_____no_output_____"
]
],
[
[
"Train Epoch method",
"_____no_output_____"
]
],
[
[
"def sum_scaling_factors(model):\n sum_channel_scaling_factors = 0\n \n #sum absolute value from all channel scaling factors for sparsity\n for m in model.modules():\n if isinstance(m, nn.BatchNorm2d):\n sum_channel_scaling_factors += torch.sum(m.weight.data.abs())\n return sum_channel_scaling_factors",
"_____no_output_____"
],
[
"def train(model, epoch, optimizer, data_loader=train_loader, sparsity=True):\n model.train()\n #print(data_loader)\n for idx, (data, target) in enumerate(data_loader):\n data, target = data.cuda(), target.cuda()\n data, target = Variable(data), Variable(target)\n optimizer.zero_grad()\n output = model(data)\n \n if sparsity:\n sum_channel_scaling_factors = sum_scaling_factors(model)\n loss = F.cross_entropy(output, target) + gamma * sum_channel_scaling_factors\n else:\n loss = F.cross_entropy(output, target)\n loss.backward()\n optimizer.step()\n \n \"\"\"if idx % 100 == 0:\n print('Train Epoch: {} [{}/{} ({:.1f}%)]\\tLoss: {:.6f}'.format(\n epoch, idx * len(data), len(data_loader.dataset),\n 100. * idx / len(data_loader), loss.data.item()))\"\"\"",
"_____no_output_____"
]
],
[
[
"Validation Method",
"_____no_output_____"
]
],
[
[
"#returns precision and loss of model\ndef test(model, data_loader=test_loader):\n model.eval()\n test_loss = 0\n correct = 0\n for data, target in data_loader:\n data, target = data.cuda(), target.cuda()\n data, target = Variable(data), Variable(target) \n output = model(data)\n test_loss += F.cross_entropy(output, target, size_average=False).data.item()\n pred = output.data.max(1, keepdim=True)[1]\n correct += pred.eq(target.data.view_as(pred)).cpu().sum()\n test_loss /= len(data_loader.dataset)\n print('\\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\\n'.format(\n test_loss, correct, len(data_loader.dataset),\n 100. * correct / len(data_loader.dataset)))\n return (correct / float(len(data_loader.dataset)), test_loss)",
"_____no_output_____"
]
],
[
[
"Save Model Method",
"_____no_output_____"
]
],
[
[
"def save_checkpoint(state, is_best, filename='model_best'):\n torch.save(state, filename + '_checkpoint.pth.tar')\n if is_best:\n shutil.copyfile(filename + '_checkpoint.pth.tar', filename + '.pth.tar')",
"_____no_output_____"
]
],
[
[
"Train network method",
"_____no_output_____"
]
],
[
[
"def train_model(model, epochs=10, sparsity=True, filename='best_model'):\n \n model.cuda()\n optimizer = optim.Adam(model.parameters(), lr=lr)\n best_prec = 0.\n for i in range(0, epochs):\n train(model, i, optimizer, sparsity=sparsity)\n prec, loss = test(model)\n is_best = prec > best_prec\n best_prec1 = max(prec, best_prec)\n save_checkpoint({\n 'epoch': i + 1,\n 'state_dict': model.state_dict(),\n 'best_prec1': best_prec,\n 'optimizer': optimizer.state_dict(),\n }, is_best, filename)\n return model",
"_____no_output_____"
]
],
[
[
"Load existing Model method",
"_____no_output_____"
]
],
[
[
"def load_model(checkpoint_path=\"checkpoint_sr.pth.tar\", model_path=\"model_best_sr.pth.tar\"):\n model = sequential_model()\n model.cuda()\n if os.path.isfile(model_path):\n print(\"=> loading checkpoint '{}'\".format(model_path))\n checkpoint_path = torch.load(model_path)\n best_prec1 = checkpoint_path['best_prec1']\n model.load_state_dict(checkpoint_path['state_dict'])\n print(\"=> loaded checkpoint '{}' (epoch {}) Prec1: {:f}\"\n .format(model, checkpoint_path['epoch'], best_prec1))\n else:\n print(\"=> no checkpoint found at\")\n return model",
"_____no_output_____"
]
],
[
[
"Select weak channels",
"_____no_output_____"
]
],
[
[
"def selectChannels(model, percent=0.2):\n total = 0\n for m in model.modules():\n if isinstance(m, nn.BatchNorm2d):\n total += m.weight.data.shape[0]\n\n bn = torch.zeros(total)\n index = 0\n #print(\"Typ:\")\n #print(type(model.modules()))\n for m in model.modules():\n if isinstance(m, nn.BatchNorm2d):\n size = m.weight.data.shape[0]\n bn[index:(index+size)] = m.weight.data.abs().clone()\n index += size\n\n y, i = torch.sort(bn)\n thre_index = int(total * percent)\n thre = y[thre_index]\n\n pruned = 0\n cfg = []\n cfg_mask = []\n for k, m in enumerate(model.modules()):\n if isinstance(m, nn.BatchNorm2d):\n weight_copy = m.weight.data.clone()\n #print(type(weight_copy.abs().gt(thre).float()))\n #mask is a matrix in which 1 marks the channels which are kept and 0 marks the pruned channels\n mask = weight_copy.abs().gt(thre).float().cuda() \n #pruned is the number of all pruned channels \n pruned = pruned + mask.shape[0] - torch.sum(mask)\n m.weight.data.mul_(mask)\n m.bias.data.mul_(mask)\n cfg.append(int(torch.sum(mask)))\n cfg_mask.append(mask.clone())\n #print('layer index: {:d} \\t total channel: {:d} \\t remaining channel: {:d}'.\n # format(k, mask.shape[0], int(torch.sum(mask))))\n elif isinstance(m, nn.MaxPool2d):\n cfg.append('M')\n return cfg, cfg_mask",
"_____no_output_____"
],
[
"\"\"\"\nTakes a smaller network structure in which the model is transfered.\ncfg_mask marks all parameters over model which are transfered or dropped\n\"\"\"\ndef transfer_params(cfg, cfg_mask, model):\n filtered_cfg = []\n #remove all layers with zero or one channel\n for elem in cfg:\n if type(elem) is int and elem > 1:\n filtered_cfg.append(elem)\n elif type(elem) is str:\n filtered_cfg.append(elem)\n cfg = filtered_cfg\n \n \n newmodel = sequential_model(layers=cfg)\n newmodel.cuda() \n\n layer_id_in_cfg = 0\n start_mask = torch.ones(3)\n end_mask = cfg_mask[layer_id_in_cfg]\n skip_linear = False\n \n parameters = newmodel.modules()\n layer = next(parameters)\n layer = next(parameters)\n layer = next(parameters)\n skip_next = 0\n for m0 in model.modules(): \n if isinstance(layer, nn.MaxPool2d):\n layer = next(parameters)\n if skip_next > 0:\n skip_next -= 1\n continue\n if isinstance(m0, nn.BatchNorm2d):\n idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))\n layer.weight.data = m0.weight.data[idx1].clone()\n layer.bias.data = m0.bias.data[idx1].clone()\n layer.running_mean = m0.running_mean[idx1].clone()\n layer.running_var = m0.running_var[idx1].clone()\n layer_id_in_cfg += 1\n start_mask = end_mask.clone()\n if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC\n end_mask = cfg_mask[layer_id_in_cfg]\n layer = next(parameters)\n elif isinstance(m0, nn.Conv2d):\n idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))\n idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))\n if np.size(idx1) <= 1: \n skip_next = 2\n layer_id_in_cfg += 1\n if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC\n end_mask = cfg_mask[layer_id_in_cfg]\n continue\n #print('In shape: {:d} Out shape:{:d}'.format(idx0.shape[0], idx1.shape[0]))\n w = m0.weight.data[:, idx0, :, :].clone()\n w = w[idx1, :, :, :].clone()\n layer.weight.data = w.clone()\n layer = next(parameters)\n # m1.bias.data = m0.bias.data[idx1].clone()\n elif isinstance(m0, nn.Linear):\n idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))\n layer.weight.data = m0.weight.data[:, idx0].clone() \n #layer = next(parameters)\n elif isinstance(m0, nn.ReLU):\n layer = next(parameters)\n \n return newmodel",
"_____no_output_____"
],
[
"def prune_model(model, percent=0.3):\n cfg, cfg_mask = selectChannels(model, percent)\n #print(cfg)\n prune_model = transfer_params(cfg, cfg_mask, model)\n torch.save({'cfg': cfg, 'state_dict': prune_model.state_dict()}, f='pruned_model.pt')\n return prune_model",
"_____no_output_____"
],
[
"model_sparsity = train_model(sequential_model(), epochs=10, sparsity=True, filename='epochs10_sparsity')\n#model = train_model(sequential_model(), epochs=10, sparsity=False, filename='epochs10_no_sparsity')\n#model = load_model(checkpoint_path=\"epochs10_sparsity.pth.tar\", model_path=\"epochs10_sparsity_checkpoint.pth.tar\")",
"/home/eddy/Programme/anaconda3/lib/python3.8/site-packages/torch/nn/_reduction.py:42: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.\n warnings.warn(warning.format(ret))\n"
],
[
"model_list = []\nfine_tune_epochs = 3\nsteps = 20\nfor i in range(1, steps):\n print(\"Pruning ratio: \" + str(i/steps))\n raw_pruned = prune_model(model_sparsity, i/steps)\n test_error = float(test(raw_pruned)[0])\n fine_tuned = train_model(raw_pruned, epochs=fine_tune_epochs)\n test_error_fine_tuned = float(test(fine_tuned)[0])\n model_list.append({'model': fine_tuned, 'test_error': test_error, \n 'fine_tuned_error': test_error_fine_tuned, 'prune_ratio': i/steps, \n 'fine_tune_epochs': fine_tune_epochs})\n",
"Pruning ratio: 0.05\n\nTest set: Average loss: 0.0488, Accuracy: 8283/10000 (82.8%)\n\n\nTest set: Average loss: 0.0495, Accuracy: 8445/10000 (84.4%)\n\n\nTest set: Average loss: 0.0398, Accuracy: 8498/10000 (85.0%)\n\n\nTest set: Average loss: 0.0359, Accuracy: 8686/10000 (86.9%)\n\n\nTest set: Average loss: 0.0371, Accuracy: 8686/10000 (86.9%)\n\nPruning ratio: 0.1\n\nTest set: Average loss: 0.0520, Accuracy: 8171/10000 (81.7%)\n\n\nTest set: Average loss: 0.0398, Accuracy: 8640/10000 (86.4%)\n\n\nTest set: Average loss: 0.0436, Accuracy: 8576/10000 (85.8%)\n\n\nTest set: Average loss: 0.0395, Accuracy: 8712/10000 (87.1%)\n\n\nTest set: Average loss: 0.0452, Accuracy: 8712/10000 (87.1%)\n\nPruning ratio: 0.15\n\nTest set: Average loss: 0.0671, Accuracy: 7887/10000 (78.9%)\n\n\nTest set: Average loss: 0.0443, Accuracy: 8599/10000 (86.0%)\n\n\nTest set: Average loss: 0.0392, Accuracy: 8689/10000 (86.9%)\n\n\nTest set: Average loss: 0.0385, Accuracy: 8729/10000 (87.3%)\n\n\nTest set: Average loss: 0.0413, Accuracy: 8729/10000 (87.3%)\n\nPruning ratio: 0.2\n\nTest set: Average loss: 0.0875, Accuracy: 7265/10000 (72.7%)\n\n\nTest set: Average loss: 0.0486, Accuracy: 8591/10000 (85.9%)\n\n\nTest set: Average loss: 0.0424, Accuracy: 8747/10000 (87.5%)\n\n\nTest set: Average loss: 0.0415, Accuracy: 8599/10000 (86.0%)\n\n\nTest set: Average loss: 0.0457, Accuracy: 8599/10000 (86.0%)\n\nPruning ratio: 0.25\n\nTest set: Average loss: 0.1209, Accuracy: 6717/10000 (67.2%)\n\n\nTest set: Average loss: 0.0450, Accuracy: 8581/10000 (85.8%)\n\n\nTest set: Average loss: 0.0420, Accuracy: 8567/10000 (85.7%)\n\n\nTest set: Average loss: 0.0455, Accuracy: 8574/10000 (85.7%)\n\n\nTest set: Average loss: 0.0427, Accuracy: 8574/10000 (85.7%)\n\nPruning ratio: 0.3\n\nTest set: Average loss: 0.1431, Accuracy: 6396/10000 (64.0%)\n\n\nTest set: Average loss: 0.0398, Accuracy: 8602/10000 (86.0%)\n\n\nTest set: Average loss: 0.0415, Accuracy: 8618/10000 (86.2%)\n\n\nTest set: Average loss: 0.0371, Accuracy: 8669/10000 (86.7%)\n\n\nTest set: Average loss: 0.0409, Accuracy: 8669/10000 (86.7%)\n\nPruning ratio: 0.35\n\nTest set: Average loss: 0.1914, Accuracy: 5684/10000 (56.8%)\n\n\nTest set: Average loss: 0.0454, Accuracy: 8505/10000 (85.1%)\n\n\nTest set: Average loss: 0.0376, Accuracy: 8685/10000 (86.8%)\n\n\nTest set: Average loss: 0.0366, Accuracy: 8702/10000 (87.0%)\n\n\nTest set: Average loss: 0.0325, Accuracy: 8702/10000 (87.0%)\n\nPruning ratio: 0.4\n\nTest set: Average loss: 0.2091, Accuracy: 5095/10000 (51.0%)\n\n\nTest set: Average loss: 0.0362, Accuracy: 8628/10000 (86.3%)\n\n\nTest set: Average loss: 0.0411, Accuracy: 8688/10000 (86.9%)\n\n\nTest set: Average loss: 0.0422, Accuracy: 8689/10000 (86.9%)\n\n\nTest set: Average loss: 0.0413, Accuracy: 8689/10000 (86.9%)\n\nPruning ratio: 0.45\n\nTest set: Average loss: 0.2195, Accuracy: 4385/10000 (43.8%)\n\n\nTest set: Average loss: 0.0535, Accuracy: 8248/10000 (82.5%)\n\n\nTest set: Average loss: 0.0478, Accuracy: 8573/10000 (85.7%)\n\n\nTest set: Average loss: 0.0453, Accuracy: 8572/10000 (85.7%)\n\n\nTest set: Average loss: 0.0426, Accuracy: 8572/10000 (85.7%)\n\nPruning ratio: 0.5\n\nTest set: Average loss: 0.2367, Accuracy: 2393/10000 (23.9%)\n\n\nTest set: Average loss: 0.0411, Accuracy: 8494/10000 (84.9%)\n\n\nTest set: Average loss: 0.0431, Accuracy: 8623/10000 (86.2%)\n\n\nTest set: Average loss: 0.0419, Accuracy: 8678/10000 (86.8%)\n\n\nTest set: Average loss: 0.0423, Accuracy: 8678/10000 (86.8%)\n\nPruning ratio: 0.55\n\nTest set: Average loss: 0.2299, Accuracy: 2223/10000 (22.2%)\n\n\nTest set: Average loss: 0.0493, Accuracy: 8387/10000 (83.9%)\n\n\nTest set: Average loss: 0.0476, Accuracy: 8547/10000 (85.5%)\n\n\nTest set: Average loss: 0.0457, Accuracy: 8565/10000 (85.7%)\n\n\nTest set: Average loss: 0.0431, Accuracy: 8565/10000 (85.7%)\n\nPruning ratio: 0.6\n\nTest set: Average loss: 0.4122, Accuracy: 872/10000 (8.7%)\n\n\nTest set: Average loss: 0.0389, Accuracy: 8536/10000 (85.4%)\n\n\nTest set: Average loss: 0.0501, Accuracy: 8236/10000 (82.4%)\n\n\nTest set: Average loss: 0.0442, Accuracy: 8490/10000 (84.9%)\n\n\nTest set: Average loss: 0.0537, Accuracy: 8490/10000 (84.9%)\n\nPruning ratio: 0.65\n\nTest set: Average loss: 0.3648, Accuracy: 693/10000 (6.9%)\n\n\nTest set: Average loss: 0.0534, Accuracy: 8297/10000 (83.0%)\n\n\nTest set: Average loss: 0.0473, Accuracy: 8451/10000 (84.5%)\n\n\nTest set: Average loss: 0.0493, Accuracy: 8485/10000 (84.8%)\n\n\nTest set: Average loss: 0.0447, Accuracy: 8485/10000 (84.8%)\n\nPruning ratio: 0.7\n\nTest set: Average loss: 0.3740, Accuracy: 1010/10000 (10.1%)\n\n\nTest set: Average loss: 0.0497, Accuracy: 8243/10000 (82.4%)\n\n\nTest set: Average loss: 0.0455, Accuracy: 8530/10000 (85.3%)\n\n\nTest set: Average loss: 0.0460, Accuracy: 8402/10000 (84.0%)\n\n\nTest set: Average loss: 0.0517, Accuracy: 8402/10000 (84.0%)\n\nPruning ratio: 0.75\n\nTest set: Average loss: 0.3910, Accuracy: 1000/10000 (10.0%)\n\n\nTest set: Average loss: 0.0558, Accuracy: 8205/10000 (82.1%)\n\n\nTest set: Average loss: 0.0514, Accuracy: 8278/10000 (82.8%)\n\n\nTest set: Average loss: 0.0484, Accuracy: 8337/10000 (83.4%)\n\n\nTest set: Average loss: 0.0516, Accuracy: 8337/10000 (83.4%)\n\nPruning ratio: 0.8\n\nTest set: Average loss: 0.3558, Accuracy: 1000/10000 (10.0%)\n\n\nTest set: Average loss: 0.0712, Accuracy: 7798/10000 (78.0%)\n\n\nTest set: Average loss: 0.0510, Accuracy: 8231/10000 (82.3%)\n\n\nTest set: Average loss: 0.0601, Accuracy: 7964/10000 (79.6%)\n\n\nTest set: Average loss: 0.0624, Accuracy: 7964/10000 (79.6%)\n\nPruning ratio: 0.85\n\nTest set: Average loss: 0.3404, Accuracy: 1000/10000 (10.0%)\n\n\nTest set: Average loss: 0.0738, Accuracy: 7584/10000 (75.8%)\n\n\nTest set: Average loss: 0.0706, Accuracy: 7666/10000 (76.7%)\n\n\nTest set: Average loss: 0.0610, Accuracy: 7741/10000 (77.4%)\n\n\nTest set: Average loss: 0.0609, Accuracy: 7741/10000 (77.4%)\n\nPruning ratio: 0.9\n\nTest set: Average loss: 0.3736, Accuracy: 1000/10000 (10.0%)\n\n\nTest set: Average loss: 0.0999, Accuracy: 6513/10000 (65.1%)\n\n\nTest set: Average loss: 0.0881, Accuracy: 6581/10000 (65.8%)\n\n\nTest set: Average loss: 0.0806, Accuracy: 7068/10000 (70.7%)\n\n\nTest set: Average loss: 0.0877, Accuracy: 7068/10000 (70.7%)\n\nPruning ratio: 0.95\n\nTest set: Average loss: 0.4028, Accuracy: 1000/10000 (10.0%)\n\n\nTest set: Average loss: 0.1582, Accuracy: 4507/10000 (45.1%)\n\n\nTest set: Average loss: 0.1368, Accuracy: 5046/10000 (50.5%)\n\n\nTest set: Average loss: 0.1269, Accuracy: 5444/10000 (54.4%)\n\n\nTest set: Average loss: 0.1279, Accuracy: 5444/10000 (54.4%)\n\n"
],
[
"test_error = []\nfine_tuned_error = []\nprune_ratio = []\nnum_parameters = []\nfor prune_set in model_list:\n test_error.append(prune_set['test_error'])\n fine_tuned_error.append(prune_set['fine_tuned_error'])\n prune_ratio.append(prune_set['prune_ratio'])\n num_parameters.append(sum(p.numel() for p in prune_set['model'].parameters()))\n\n\nfig, ax1 = plt.subplots() \n\ncolor = 'tab:red'\nax1.plot(prune_ratio, fine_tuned_error, color='tab:red', label='fine tuned acc')\nax1.plot(prune_ratio, test_error, color='tab:green', label='raw acc')\nax1.set_xlabel('prune ratio')\nax1.set_ylabel('fine tuned accuracy')\nax1.tick_params(axis='y', labelcolor=color)\n\nplt.legend()\nax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis\n\ncolor = 'tab:blue'\nax2.set_ylabel('num param', color=color) # we already handled the x-label with ax1\nax2.plot(prune_ratio, num_parameters, color=color, label='amount parameters')\nax2.tick_params(axis='y', labelcolor=color)\nax2.set_yscale('linear')\nplt.legend()\n\nfig.tight_layout() # otherwise the right y-label is slightly clipped\nplt.grid(axis='both', color='black', linestyle=':', linewidth=1)\nplt.show()\n",
"_____no_output_____"
],
[
"result = zip(prune_ratio, num_parameters, fine_tuned_error)\nfor ratio, num, err in result:\n print('ratio: {:f}, error: {:f}, param:{:d}'.format(ratio, err, num))",
"ratio: 0.050000, error: 0.868600, param:8673056\nratio: 0.100000, error: 0.871200, param:7944759\nratio: 0.150000, error: 0.872900, param:7200206\nratio: 0.200000, error: 0.859900, param:6420955\nratio: 0.250000, error: 0.857400, param:5621432\nratio: 0.300000, error: 0.866900, param:4895456\nratio: 0.350000, error: 0.870200, param:4237786\nratio: 0.400000, error: 0.868900, param:3620774\nratio: 0.450000, error: 0.857200, param:3029760\nratio: 0.500000, error: 0.867800, param:2497572\nratio: 0.550000, error: 0.856500, param:2021254\nratio: 0.600000, error: 0.849000, param:1601400\nratio: 0.650000, error: 0.848500, param:1224700\nratio: 0.700000, error: 0.840200, param:902460\nratio: 0.750000, error: 0.833700, param:630313\nratio: 0.800000, error: 0.796400, param:402879\nratio: 0.850000, error: 0.774100, param:231933\nratio: 0.900000, error: 0.706800, param:105632\nratio: 0.950000, error: 0.544400, param:29856\n"
],
[
"\"\"\"safed = torch.load('pruned_model.pt')\nstructure = safed['cfg']\nweights = safed['state_dict']\npruned_model = sequential_model(structure)\npruned_model.load_state_dict(weights)\npruned_model.cuda()\nprec, loss = test(pruned_model)\"\"\"",
"_____no_output_____"
],
[
"summary(model_list[18]['model'], (3, 32, 32))",
"----------------------------------------------------------------\n Layer (type) Output Shape Param #\n================================================================\n Conv2d-1 [-1, 7, 32, 32] 189\n BatchNorm2d-2 [-1, 7, 32, 32] 14\n ReLU-3 [-1, 7, 32, 32] 0\n Conv2d-4 [-1, 3, 32, 32] 189\n BatchNorm2d-5 [-1, 3, 32, 32] 6\n ReLU-6 [-1, 3, 32, 32] 0\n MaxPool2d-7 [-1, 3, 16, 16] 0\n Conv2d-8 [-1, 4, 16, 16] 108\n BatchNorm2d-9 [-1, 4, 16, 16] 8\n ReLU-10 [-1, 4, 16, 16] 0\n Conv2d-11 [-1, 3, 16, 16] 108\n BatchNorm2d-12 [-1, 3, 16, 16] 6\n ReLU-13 [-1, 3, 16, 16] 0\n MaxPool2d-14 [-1, 3, 8, 8] 0\n Conv2d-15 [-1, 14, 8, 8] 378\n BatchNorm2d-16 [-1, 14, 8, 8] 28\n ReLU-17 [-1, 14, 8, 8] 0\n Conv2d-18 [-1, 5, 8, 8] 630\n BatchNorm2d-19 [-1, 5, 8, 8] 10\n ReLU-20 [-1, 5, 8, 8] 0\n MaxPool2d-21 [-1, 5, 4, 4] 0\n Conv2d-22 [-1, 48, 4, 4] 2,160\n BatchNorm2d-23 [-1, 48, 4, 4] 96\n ReLU-24 [-1, 48, 4, 4] 0\n Conv2d-25 [-1, 40, 4, 4] 17,280\n BatchNorm2d-26 [-1, 40, 4, 4] 80\n ReLU-27 [-1, 40, 4, 4] 0\n MaxPool2d-28 [-1, 40, 2, 2] 0\n Conv2d-29 [-1, 23, 2, 2] 8,280\n BatchNorm2d-30 [-1, 23, 2, 2] 46\n ReLU-31 [-1, 23, 2, 2] 0\n Linear-32 [-1, 10] 240\n================================================================\nTotal params: 29,856\nTrainable params: 29,856\nNon-trainable params: 0\n----------------------------------------------------------------\nInput size (MB): 0.01\nForward/backward pass size (MB): 0.35\nParams size (MB): 0.11\nEstimated Total Size (MB): 0.47\n----------------------------------------------------------------\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a04221bad5e9ad8adf93819d75bcb6eeb8a3e9b
| 26,084 |
ipynb
|
Jupyter Notebook
|
Starter_Code/credit_risk_resampling.ipynb
|
poppinfresch/11-Machine-Learning
|
e5c158c7bf30f05ee7e1ffd39d3b536879dd72c8
|
[
"ADSL"
] | null | null | null |
Starter_Code/credit_risk_resampling.ipynb
|
poppinfresch/11-Machine-Learning
|
e5c158c7bf30f05ee7e1ffd39d3b536879dd72c8
|
[
"ADSL"
] | null | null | null |
Starter_Code/credit_risk_resampling.ipynb
|
poppinfresch/11-Machine-Learning
|
e5c158c7bf30f05ee7e1ffd39d3b536879dd72c8
|
[
"ADSL"
] | null | null | null | 27.572939 | 294 | 0.511386 |
[
[
[
"# Credit Risk Resampling Techniques",
"_____no_output_____"
]
],
[
[
"import warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nfrom pathlib import Path\nfrom collections import Counter\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import LabelEncoder\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import balanced_accuracy_score\nfrom sklearn.metrics import confusion_matrix\nfrom imblearn.metrics import classification_report_imbalanced\nfrom imblearn.over_sampling import RandomOverSampler, SMOTE\nfrom imblearn.under_sampling import ClusterCentroids\nfrom imblearn.combine import SMOTEENN\n\n\n",
"_____no_output_____"
]
],
[
[
"# Read the CSV into DataFrame",
"_____no_output_____"
]
],
[
[
"# Load the data\nfile_path = Path('Resources/lending_data.csv')\ndf = pd.read_csv(file_path)\ndf.tail()",
"_____no_output_____"
]
],
[
[
"# Split the Data into Training and Testing",
"_____no_output_____"
]
],
[
[
"# Create our features\nX = df.drop(columns='loan_status')\n\n# Create our target\ny = df.loan_status.to_frame('loan_status')\n",
"_____no_output_____"
],
[
"# Check the balance of our target values\ny['loan_status'].value_counts()",
"_____no_output_____"
],
[
"# Create X_train, X_test, y_train, y_test\n\n\nX_train, X_test, y_train, y_test = train_test_split(X, \n y, \n random_state=1, \n stratify=y)\nX_train.shape",
"_____no_output_____"
]
],
[
[
"## Data Pre-Processing\n\nScale the training and testing data using the `StandardScaler` from `sklearn`. Remember that when scaling the data, you only scale the features data (`X_train` and `X_testing`).",
"_____no_output_____"
]
],
[
[
"\n#need to transform homeowner column from string to integer first\nencoder = LabelEncoder()",
"_____no_output_____"
],
[
"#transform x test and train with encoder\nX_train['homeowner'] = encoder.fit_transform(X_train['homeowner'])\nX_test['homeowner'] = encoder.transform(X_test['homeowner'])",
"_____no_output_____"
],
[
"# Create the StandardScaler instance\n\nscaler = StandardScaler()",
"_____no_output_____"
],
[
"# Fit the Standard Scaler with the training data\n# When fitting scaling functions, only train on the training dataset\nX_scaler = scaler.fit(X_train)",
"_____no_output_____"
],
[
"# Scale the training and testing data\nX_train_scaled = X_scaler.transform(X_train)\nX_test_scaled = X_scaler.transform(X_test)\n",
"_____no_output_____"
]
],
[
[
"# Simple Logistic Regression",
"_____no_output_____"
]
],
[
[
"#simple logistic regression\nmodel = LogisticRegression(solver='lbfgs', random_state=1)\nmodel.fit(X_train, y_train)\ny_pred = model.predict(X_test)",
"_____no_output_____"
],
[
"# Calculated the balanced accuracy score\n\nbalanced_accuracy_score(y_test, y_pred)",
"_____no_output_____"
],
[
"# Display the confusion matrix\nconfusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"# Print the imbalanced classification report\nprint(classification_report_imbalanced(y_test, y_pred))",
" pre rec spe f1 geo iba sup\n\n high_risk 0.86 0.91 1.00 0.89 0.95 0.90 625\n low_risk 1.00 1.00 0.91 1.00 0.95 0.92 18759\n\navg / total 0.99 0.99 0.92 0.99 0.95 0.92 19384\n\n"
]
],
[
[
"# Oversampling\n\nIn this section, you will compare two oversampling algorithms to determine which algorithm results in the best performance. You will oversample the data using the naive random oversampling algorithm and the SMOTE algorithm. For each algorithm, be sure to complete the folliowing steps:\n\n1. View the count of the target classes using `Counter` from the collections library. \n3. Use the resampled data to train a logistic regression model.\n3. Calculate the balanced accuracy score from sklearn.metrics.\n4. Print the confusion matrix from sklearn.metrics.\n5. Generate a classication report using the `imbalanced_classification_report` from imbalanced-learn.\n\nNote: Use a random state of 1 for each sampling algorithm to ensure consistency between tests",
"_____no_output_____"
],
[
"### Naive Random Oversampling",
"_____no_output_____"
]
],
[
[
"# Resample the training data with the RandomOversampler\nX_train_resampled, y_train_resampled = RandomOverSampler(random_state=1).fit_resample(X_train_scaled, y_train)\n\n\n# View the count of target classes with Counter\nCounter(y_train_resampled.loan_status)",
"_____no_output_____"
],
[
"# Train the Logistic Regression model using the resampled data\n\nmodel = LogisticRegression(solver='lbfgs', random_state=1)\nmodel.fit(X_train_resampled, y_train_resampled)\n\n# Make predictions using the test data (scaled)\ny_pred = model.predict(X_test_scaled)",
"_____no_output_____"
],
[
"# Calculated the balanced accuracy score\nbalanced_accuracy_score(y_test, y_pred)\nprint(f\"Balanced accuracy score using Naive Random Oversampling: {balanced_accuracy_score(y_test, y_pred)}\")",
"Balanced accuracy score using Naive Random Oversampling: 0.9946414201183431\n"
],
[
"# Display the confusion matrix\nconfusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"# Print the imbalanced classification report\nprint(f\"Imbalanced classification report: {classification_report_imbalanced(y_test, y_pred)}\")",
"Imbalanced classification report: pre rec spe f1 geo iba sup\n\n high_risk 0.85 1.00 0.99 0.92 0.99 0.99 625\n low_risk 1.00 0.99 1.00 1.00 0.99 0.99 18759\n\navg / total 0.99 0.99 1.00 0.99 0.99 0.99 19384\n\n"
]
],
[
[
"### SMOTE Oversampling",
"_____no_output_____"
]
],
[
[
"# Resample the training data with SMOTE\nX_train_resampled, y_train_resampled = SMOTE(random_state=1).fit_resample(X_train_scaled, y_train)\n\n\n# View the count of target classes with Counter\nCounter(y_train_resampled.loan_status)\n",
"_____no_output_____"
],
[
"# Train the Logistic Regression model using the resampled data\nmodel = LogisticRegression(solver='lbfgs', random_state=1)\nmodel.fit(X_train_resampled, y_train_resampled)\n\n# predict \ny_pred = model.predict(X_test_scaled)",
"_____no_output_____"
],
[
"# Calculate the balanced accuracy score\nbalanced_accuracy_score(y_test, y_pred)\nprint(f\"Balanced accuracy score using SMOTE: {balanced_accuracy_score(y_test, y_pred)}\")",
"Balanced accuracy score using SMOTE: 0.9946414201183431\n"
],
[
"# Display the confusion matrix\nconfusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"# Print the imbalanced classification report\nprint(f\"Imbalanced classification report: {classification_report_imbalanced(y_test, y_pred)}\")",
"Imbalanced classification report: pre rec spe f1 geo iba sup\n\n high_risk 0.85 1.00 0.99 0.92 0.99 0.99 625\n low_risk 1.00 0.99 1.00 1.00 0.99 0.99 18759\n\navg / total 0.99 0.99 1.00 0.99 0.99 0.99 19384\n\n"
]
],
[
[
"# Undersampling\n\nIn this section, you will test an undersampling algorithm to determine which algorithm results in the best performance compared to the oversampling algorithms above. You will undersample the data using the Cluster Centroids algorithm and complete the folliowing steps:\n\n1. View the count of the target classes using `Counter` from the collections library. \n3. Use the resampled data to train a logistic regression model.\n3. Calculate the balanced accuracy score from sklearn.metrics.\n4. Display the confusion matrix from sklearn.metrics.\n5. Generate a classication report using the `imbalanced_classification_report` from imbalanced-learn.\n\nNote: Use a random state of 1 for each sampling algorithm to ensure consistency between tests",
"_____no_output_____"
]
],
[
[
"# Resample the data using the ClusterCentroids resampler\nX_train_resampled, y_train_resampled = ClusterCentroids(random_state=1).fit_resample(X_train_scaled, y_train)\n\n\n# View the count of target classes with Counter\nCounter(y_train_resampled.loan_status)",
"_____no_output_____"
],
[
"# Train the Logistic Regression model using the resampled data\nmodel = LogisticRegression(solver='lbfgs', random_state=1)\nmodel.fit(X_train_resampled, y_train_resampled)\n\n#predict\ny_pred = model.predict(X_test_scaled)",
"_____no_output_____"
],
[
"# Calculate the balanced accuracy score\nprint(f\"Balanced accuracy score using ClusterCentroids: {balanced_accuracy_score(y_test, y_pred)}\")\n",
"Balanced accuracy score using ClusterCentroids: 0.9932813049736127\n"
],
[
"# Display the confusion matrix\nconfusion_matrix(y_test, y_pred)\n",
"_____no_output_____"
],
[
"# Print the imbalanced classification report\nprint(f'Imbalanced Classification Report: {classification_report_imbalanced(y_test, y_pred)}')\n",
"Imbalanced Classification Report: pre rec spe f1 geo iba sup\n\n high_risk 0.86 0.99 0.99 0.92 0.99 0.99 625\n low_risk 1.00 0.99 0.99 1.00 0.99 0.99 18759\n\navg / total 1.00 0.99 0.99 0.99 0.99 0.99 19384\n\n"
]
],
[
[
"# Combination (Over and Under) Sampling\n\nIn this section, you will test a combination over- and under-sampling algorithm to determine if the algorithm results in the best performance compared to the other sampling algorithms above. You will resample the data using the SMOTEENN algorithm and complete the folliowing steps:\n\n1. View the count of the target classes using `Counter` from the collections library. \n3. Use the resampled data to train a logistic regression model.\n3. Calculate the balanced accuracy score from sklearn.metrics.\n4. Display the confusion matrix from sklearn.metrics.\n5. Generate a classication report using the `imbalanced_classification_report` from imbalanced-learn.\n\nNote: Use a random state of 1 for each sampling algorithm to ensure consistency between tests",
"_____no_output_____"
]
],
[
[
"# Resample the training data with SMOTEENN\nX_train_resampled, y_train_resampled = SMOTEENN(random_state=1).fit_resample(X_train_scaled, y_train)\n\n# View the count of target classes with Counter\nCounter(y_train_resampled.loan_status)\n",
"_____no_output_____"
],
[
"# Train the Logistic Regression model using the resampled data\nmodel = LogisticRegression(solver='lbfgs', random_state=1)\nmodel.fit(X_train_resampled, y_train_resampled)\n\ny_pred = model.predict(X_test_scaled)",
"_____no_output_____"
],
[
"# Calculate the balanced accuracy score\nprint(f\"Balanced accuracy score using SMOTEENN: {balanced_accuracy_score(y_test, y_pred)}\")\n",
"Balanced accuracy score using SMOTEENN: 0.9946414201183431\n"
],
[
"# Display the confusion matrix\nconfusion_matrix(y_test, y_pred)\n",
"_____no_output_____"
],
[
"# Print the imbalanced classification report\nprint(classification_report_imbalanced(y_test, y_pred))\n",
" pre rec spe f1 geo iba sup\n\n high_risk 0.85 1.00 0.99 0.92 0.99 0.99 625\n low_risk 1.00 0.99 1.00 1.00 0.99 0.99 18759\n\navg / total 0.99 0.99 1.00 0.99 0.99 0.99 19384\n\n"
]
],
[
[
"# Final Questions\n\n1. Which model had the best balanced accuracy score?\n\n >The 3 models with highest scores were;\n >SMOTEENN: 0.9946414201183431\n >SMOTE: 0.9946414201183431\n >Naive Random Oversampling: 0.994641420118343\n\n2. Which model had the best recall score?\n \n >SMOTEENN - HIGH:1.00,LOW:0.99\n >SMOTE - HIGH:1.00,LOW:0.99\n >NAIVE - HIGH:1.00 ,LOW:0.99\n \n\n3. Which model had the best geometric mean score?\n \n >The model with the highest mean geo score used ClusterCentroids with an avg / total = 1.00",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a0424ad5c435893e6f746e1b5369abb6aa8b826
| 202,194 |
ipynb
|
Jupyter Notebook
|
notebooks/10_Overfitting_Regularizacion.ipynb
|
aherrera3/IntroDeepLearning_202102
|
b085d5eb5c6f07bc0f4edf8ef860d95eb5fe2544
|
[
"MIT"
] | 1 |
2022-02-16T03:12:31.000Z
|
2022-02-16T03:12:31.000Z
|
notebooks/10_Overfitting_Regularizacion.ipynb
|
aherrera3/IntroDeepLearning_202102
|
b085d5eb5c6f07bc0f4edf8ef860d95eb5fe2544
|
[
"MIT"
] | null | null | null |
notebooks/10_Overfitting_Regularizacion.ipynb
|
aherrera3/IntroDeepLearning_202102
|
b085d5eb5c6f07bc0f4edf8ef860d95eb5fe2544
|
[
"MIT"
] | 7 |
2021-08-10T20:26:42.000Z
|
2022-02-16T03:11:39.000Z
| 206.742331 | 46,886 | 0.874185 |
[
[
[
"# Overfitting y Regularización\n\nEl **overfitting** o sobreajuste es otro problema común al entrenar un modelo de aprendizaje automático. Consiste en entrenar modelos que aprenden a la perfección los datos de entrenamiento, perdiendo de esta forma generalidad. De modo, que si al modelo se le pasan datos nuevos que jamás ha visto, no será capaz de realizar una buena predicción.\n\nExiste un problema opuesto al overfitting conocido como **underfitting** o subajuste, en el que el modelo no logra realizar una predicción ni siquiera cercana a los datos de entrenamiento y esta lejos de hacer una generalización.\n\n\n\nPara evitar el underfitting y el overfitting se pueden utilizar curvas de **loss**, **f1_score** o **accuracy** utilizando los datos de entrenamiento y validación. Haciendo un análisis sobre estas curvas se logra identificar estos problemas.",
"_____no_output_____"
],
[
"# Ejercicio\n\nUtilizar el dataset [MNIST](http://yann.lecun.com/exdb/mnist/) para identificar los problemas de **underfitting** y **overfitting**, utilizando una ANN de capas lineales.",
"_____no_output_____"
]
],
[
[
"#-- Descomprimimos el dataset\n# !rm -r mnist\n# !unzip mnist.zip",
"_____no_output_____"
],
[
"#--- Buscamos las direcciones de cada archivo de imagen\nfrom glob import glob\n\ntrain_files = glob('./mnist/train/*/*.png')\nvalid_files = glob('./mnist/valid/*/*.png')\ntest_files = glob('./mnist/test/*/*.png')\n\ntrain_files[0]",
"_____no_output_____"
],
[
"#--- Ordenamos los datos de forma aleatoria para evitar sesgos\nimport numpy as np\n\nnp.random.shuffle(train_files)\nnp.random.shuffle(valid_files)\nnp.random.shuffle(test_files)\n\nlen(train_files), len(valid_files), len(test_files)",
"_____no_output_____"
],
[
"#--- Cargamos los datos de entrenamiento en listas\nfrom PIL import Image\n\nN_train = len(train_files)\nX_train = []\nY_train = []\n\nfor i, train_file in enumerate(train_files):\n Y_train.append( int(train_file.split('/')[3]) )\n X_train.append(np.array(Image.open(train_file)))",
"_____no_output_____"
],
[
"#--- Cargamos los datos de validación en listas\nN_valid = len(valid_files)\nX_valid = []\nY_valid = []\n\nfor i, valid_file in enumerate(valid_files):\n Y_valid.append( int(valid_file.split('/')[3]) )\n X_valid.append( np.array(Image.open(valid_file)) )",
"_____no_output_____"
],
[
"#--- Cargamos los datos de testeo en listas\nN_test = len(test_files)\nX_test = []\nY_test = []\n\nfor i, test_file in enumerate(test_files):\n Y_test.append( int(test_file.split('/')[3]) )\n X_test.append( np.array(Image.open(test_file)) )",
"_____no_output_____"
],
[
"#--- Visualizamos el tamaño de cada subset\nlen(X_train), len(X_valid), len(X_test)",
"_____no_output_____"
],
[
"#--- Visualizamos la distribución de clases en cada subset\nfrom PIL import Image\nimport matplotlib.pyplot as plt\n\nfig = plt.figure(figsize=(15,5))\nplt.subplot(1,3,1)\nplt.hist(np.sort(Y_train))\nplt.xlabel('class')\nplt.ylabel('counts')\nplt.title('Train set')\n\nplt.subplot(1,3,2)\nplt.hist(np.sort(Y_valid))\nplt.xlabel('class')\nplt.ylabel('counts')\nplt.title('Valid set')\n\nplt.subplot(1,3,3)\nplt.hist(np.sort(Y_test))\nplt.xlabel('class')\nplt.ylabel('counts')\nplt.title('Test set')\n\nplt.show()",
"_____no_output_____"
],
[
"#-- Visualizamos los datos\nfig = plt.figure(figsize=(8,8))\nfor i in range(4):\n plt.subplot(2,2,i+1)\n plt.imshow(X_test[i*15])\n plt.title(Y_test[i*15])\n plt.axis(False)\nplt.show()",
"_____no_output_____"
],
[
"#--- Convetimos las listas con los datos a tensores de torch\nimport torch\nfrom torch.autograd import Variable\n\n\nX_train = Variable(torch.from_numpy(np.array(X_train))).float()\nY_train = Variable(torch.from_numpy(np.array(Y_train))).long()\n\nX_valid = Variable(torch.from_numpy(np.array(X_valid))).float()\nY_valid = Variable(torch.from_numpy(np.array(Y_valid))).long()\n\nX_test = Variable(torch.from_numpy(np.array(X_test))).float()\nY_test = Variable(torch.from_numpy(np.array(Y_test))).long()\n\nX_train.data.size()",
"_____no_output_____"
],
[
"#--- Definimos una función que nos permita entrenar diferentes modelos de ANN\n\nfrom sklearn.metrics import f1_score\n\ndef train_valid(model, n_epoch, optimizer, criterion):\n loss_train = []\n f1_train = []\n acc_train = []\n\n loss_valid = []\n f1_valid = []\n acc_valid = []\n\n for epoch in range(n_epoch):\n model.train()\n\n Xtr = X_train.view(X_train.size(0), -1)\n Y_pred = model(Xtr)\n\n loss = criterion(Y_pred,Y_train)\n loss_train.append(loss.item())\n\n Y_pred = torch.argmax(Y_pred, 1)\n f1_train.append( f1_score(Y_train,Y_pred, average='macro') )\n \n acc = sum(Y_train == Y_pred)/len(Y_pred)\n acc_train.append(acc)\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n print( 'Epoch [{}/{}], loss: {}. f1:{} acc: {} '.format(epoch+1,n_epoch,loss_train[-1], f1_train[-1], acc_train[-1]) )\n\n model.eval()\n Xvl = X_valid.view(X_valid.size(0), -1)\n Y_pred = model(Xvl) \n loss = criterion(Y_pred,Y_valid)\n loss_valid.append(loss.item())\n\n Y_pred = torch.argmax(Y_pred, 1)\n f1_valid.append( f1_score(Y_valid, Y_pred, average='macro') )\n\n acc = sum(Y_valid == Y_pred)/len(Y_pred)\n acc_valid.append(acc) \n\n fig = plt.figure(figsize=(15,5))\n plt.subplot(1,3,1)\n plt.plot(range(n_epoch), loss_train, label='train')\n plt.plot(range(n_epoch), loss_valid, label='valid')\n plt.xlabel('n_epoch')\n plt.ylabel('loss')\n plt.legend()\n plt.grid()\n plt.subplot(1,3,2)\n plt.plot(range(n_epoch), f1_train, label='train')\n plt.plot(range(n_epoch), f1_valid, label='valid')\n plt.xlabel('n_epoch')\n plt.ylabel('f1_score')\n plt.legend()\n plt.grid()\n plt.subplot(1,3,3)\n plt.plot(range(n_epoch), acc_train, label='train')\n plt.plot(range(n_epoch), acc_valid, label='valid')\n plt.xlabel('n_epoch')\n plt.ylabel('accuracy')\n plt.legend()\n plt.grid()",
"_____no_output_____"
]
],
[
[
"## Underfitting\n\nEl **underfitting** o sub ajuste se puede presentar en las siguientes situaciones:\n\n* **Finalización temprana**: Cuando el modelo se entrena hasta una época temprana a pesar de que la tendencia indica una posible obtención de mejores resultados.\n\n* **Modelo Simple**: Cuando el modelo es tan básico que no es capaz de extraer ningún tipo de patrón efectivo que le permita hacer una generalización de los datos.",
"_____no_output_____"
]
],
[
[
"#--- Definimos una ANN simple para identificar un error de underfitting\n\ninput_dim = 28*28\nout_dim = 10 \n\nmodel = torch.nn.Sequential(\n torch.nn.Linear(input_dim, out_dim)\n)\n\noptimizer = torch.optim.Adam(model.parameters())\ncriterion = torch.nn.CrossEntropyLoss()\n\ntrain_valid(model,30,optimizer,criterion)",
"Epoch [1/30], loss: 82.7890396118164. f1:0.05964657044852658 acc: 0.07566666603088379 \nEpoch [2/30], loss: 61.263427734375. f1:0.08784221256913727 acc: 0.09183333069086075 \nEpoch [3/30], loss: 48.82123947143555. f1:0.1282069288494235 acc: 0.1354999989271164 \nEpoch [4/30], loss: 40.34152603149414. f1:0.17930513697635247 acc: 0.18299999833106995 \nEpoch [5/30], loss: 33.02478790283203. f1:0.24577804287304678 acc: 0.2433333396911621 \nEpoch [6/30], loss: 25.911191940307617. f1:0.3352531185501092 acc: 0.33000001311302185 \nEpoch [7/30], loss: 20.18494415283203. f1:0.42613360918517024 acc: 0.4216666519641876 \nEpoch [8/30], loss: 16.217782974243164. f1:0.5030440949485462 acc: 0.49966666102409363 \nEpoch [9/30], loss: 13.666893005371094. f1:0.571786958062668 acc: 0.5718333125114441 \nEpoch [10/30], loss: 11.927987098693848. f1:0.6163640745735542 acc: 0.6200000047683716 \nEpoch [11/30], loss: 10.71108341217041. f1:0.6544728235655375 acc: 0.6598333120346069 \nEpoch [12/30], loss: 9.800261497497559. f1:0.6813431344181283 acc: 0.6861666440963745 \nEpoch [13/30], loss: 9.032669067382812. f1:0.7057095199208426 acc: 0.7083333134651184 \nEpoch [14/30], loss: 8.39493179321289. f1:0.7271447324591033 acc: 0.7281666398048401 \nEpoch [15/30], loss: 7.852660179138184. f1:0.7448913625817641 acc: 0.7446666955947876 \nEpoch [16/30], loss: 7.3753437995910645. f1:0.763139911294585 acc: 0.7620000243186951 \nEpoch [17/30], loss: 6.956728935241699. f1:0.7772739392249731 acc: 0.7754999995231628 \nEpoch [18/30], loss: 6.605902194976807. f1:0.7908273292364787 acc: 0.7889999747276306 \nEpoch [19/30], loss: 6.321659564971924. f1:0.803390824597618 acc: 0.8018333315849304 \nEpoch [20/30], loss: 6.085799694061279. f1:0.8106212574467696 acc: 0.809333324432373 \nEpoch [21/30], loss: 5.874400615692139. f1:0.8160756486083592 acc: 0.8151666522026062 \nEpoch [22/30], loss: 5.670376300811768. f1:0.8223399844073389 acc: 0.8218333125114441 \nEpoch [23/30], loss: 5.468562602996826. f1:0.8282757662545406 acc: 0.828166663646698 \nEpoch [24/30], loss: 5.272115707397461. f1:0.8323135062664075 acc: 0.8323333263397217 \nEpoch [25/30], loss: 5.088315010070801. f1:0.8368308167204846 acc: 0.8370000123977661 \nEpoch [26/30], loss: 4.9221272468566895. f1:0.8409080795712158 acc: 0.8410000205039978 \nEpoch [27/30], loss: 4.776956081390381. f1:0.8446689557945645 acc: 0.8446666598320007 \nEpoch [28/30], loss: 4.644568920135498. f1:0.8472976747077021 acc: 0.8471666574478149 \nEpoch [29/30], loss: 4.517181873321533. f1:0.850120632399087 acc: 0.8498333096504211 \nEpoch [30/30], loss: 4.387719631195068. f1:0.8546374913081296 acc: 0.8543333411216736 \n"
],
[
"#-- Evaluamos el modelo entrenado con el set de testeo\nmodel.eval()\n\nXts = X_test.view(X_test.size(0), -1)\nY_pred = model(Xts) \nloss = criterion(Y_pred,Y_test)\n\nY_pred = torch.argmax(Y_pred, 1)\nf1 = f1_score(Y_test, Y_pred, average='macro')\n\nacc = sum(Y_test == Y_pred)/len(Y_pred)\n\nprint('loss: {}, f1: {}, acc: {}'.format(loss.item(), f1, acc))",
"loss: 4.583886623382568, f1: 0.8373949440543589, acc: 0.8377016186714172\n"
]
],
[
[
"## Overfitting\n\nEl **overfitting** o sobreajuste es el caso opuesto al subajuste y se puede presentar en la siguiente situación:\nuna obtención de mejores resultados.\n\n* **Modelo Complejo**: El modelo es tan complejo que aprendió perfectamente los datos de entrenamiento, perdiendo generalidad. Cuando el modelo vea datos nuevos, diferentes a los del entrenamiento, su predicción será errónea.\n",
"_____no_output_____"
]
],
[
[
"input_dim = 28*28\nout_dim = 10\nhidden = 60\n\nmodel = torch.nn.Sequential(\n torch.nn.Linear(input_dim, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden), \n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden), \n torch.nn.ReLU(), \n torch.nn.Linear(hidden, out_dim)\n)\n\noptimizer = torch.optim.Adam(model.parameters())\ncriterion = torch.nn.CrossEntropyLoss()\n\ntrain_valid(model,100,optimizer,criterion)",
"Epoch [1/100], loss: 2.316589117050171. f1:0.03918674835607137 acc: 0.09399999678134918 \nEpoch [2/100], loss: 2.261753797531128. f1:0.0940322445990392 acc: 0.17033334076404572 \nEpoch [3/100], loss: 2.201493501663208. f1:0.17864940727608286 acc: 0.2529999911785126 \nEpoch [4/100], loss: 2.12504506111145. f1:0.27915200951355446 acc: 0.3269999921321869 \nEpoch [5/100], loss: 2.013563632965088. f1:0.3935769180542603 acc: 0.4416666626930237 \nEpoch [6/100], loss: 1.8649260997772217. f1:0.4764292557818345 acc: 0.527999997138977 \nEpoch [7/100], loss: 1.68788480758667. f1:0.5182841942268122 acc: 0.5743333101272583 \nEpoch [8/100], loss: 1.4952908754348755. f1:0.5302769705326333 acc: 0.5879999995231628 \nEpoch [9/100], loss: 1.2995336055755615. f1:0.5534800845741452 acc: 0.606333315372467 \nEpoch [10/100], loss: 1.1177304983139038. f1:0.6291660933381926 acc: 0.653333306312561 \nEpoch [11/100], loss: 0.9599166512489319. f1:0.7224765335635756 acc: 0.7246666550636292 \nEpoch [12/100], loss: 0.8359869718551636. f1:0.7631358083866557 acc: 0.762666642665863 \nEpoch [13/100], loss: 0.7317228317260742. f1:0.7911741515271828 acc: 0.7908333539962769 \nEpoch [14/100], loss: 0.6522405743598938. f1:0.8204970475186061 acc: 0.8213333487510681 \nEpoch [15/100], loss: 0.5991525650024414. f1:0.8282759905078668 acc: 0.8295000195503235 \nEpoch [16/100], loss: 0.5606774687767029. f1:0.8315033176178017 acc: 0.8331666588783264 \nEpoch [17/100], loss: 0.5623752474784851. f1:0.828175213567268 acc: 0.827833354473114 \nEpoch [18/100], loss: 0.5091431736946106. f1:0.845640700881893 acc: 0.846833348274231 \nEpoch [19/100], loss: 0.45917773246765137. f1:0.8659036651999372 acc: 0.8659999966621399 \nEpoch [20/100], loss: 0.4502609074115753. f1:0.8666929320517553 acc: 0.8661666512489319 \nEpoch [21/100], loss: 0.39942556619644165. f1:0.8796047220055977 acc: 0.8796666860580444 \nEpoch [22/100], loss: 0.3950484097003937. f1:0.87628703849687 acc: 0.8769999742507935 \nEpoch [23/100], loss: 0.36767318844795227. f1:0.8853599619658425 acc: 0.8853333592414856 \nEpoch [24/100], loss: 0.3444490134716034. f1:0.8923205473643613 acc: 0.8923333287239075 \nEpoch [25/100], loss: 0.3342856466770172. f1:0.895608408604535 acc: 0.8958333134651184 \nEpoch [26/100], loss: 0.3103731572628021. f1:0.9034638219901792 acc: 0.903333306312561 \nEpoch [27/100], loss: 0.3070124387741089. f1:0.902566118744603 acc: 0.9023333191871643 \nEpoch [28/100], loss: 0.27871668338775635. f1:0.9108170449079228 acc: 0.9106666445732117 \nEpoch [29/100], loss: 0.28074970841407776. f1:0.9094616974833117 acc: 0.909333348274231 \nEpoch [30/100], loss: 0.2558073401451111. f1:0.9178978201794307 acc: 0.9178333282470703 \nEpoch [31/100], loss: 0.2534101605415344. f1:0.9191617915887036 acc: 0.9191666841506958 \nEpoch [32/100], loss: 0.23959816992282867. f1:0.9222505187183805 acc: 0.9223333597183228 \nEpoch [33/100], loss: 0.22890877723693848. f1:0.9299297906719186 acc: 0.9300000071525574 \nEpoch [34/100], loss: 0.22161731123924255. f1:0.9323300449570431 acc: 0.9323333501815796 \nEpoch [35/100], loss: 0.21185758709907532. f1:0.9349199984189085 acc: 0.9348333477973938 \nEpoch [36/100], loss: 0.20242862403392792. f1:0.9385753258751963 acc: 0.9384999871253967 \nEpoch [37/100], loss: 0.1940024048089981. f1:0.9397111543948069 acc: 0.9398333430290222 \nEpoch [38/100], loss: 0.18622878193855286. f1:0.9438222046447583 acc: 0.9440000057220459 \nEpoch [39/100], loss: 0.1776333451271057. f1:0.9461049109997536 acc: 0.9461666941642761 \nEpoch [40/100], loss: 0.17152811586856842. f1:0.9491950445970382 acc: 0.9491666555404663 \nEpoch [41/100], loss: 0.16304410994052887. f1:0.9526665831336425 acc: 0.9526666402816772 \nEpoch [42/100], loss: 0.15769225358963013. f1:0.9547963980269797 acc: 0.9548333287239075 \nEpoch [43/100], loss: 0.15000279247760773. f1:0.9574936461556767 acc: 0.9574999809265137 \nEpoch [44/100], loss: 0.14489111304283142. f1:0.9588291925318128 acc: 0.9588333368301392 \nEpoch [45/100], loss: 0.13842549920082092. f1:0.9600027997871244 acc: 0.9599999785423279 \nEpoch [46/100], loss: 0.1324884295463562. f1:0.9630103617982673 acc: 0.9629999995231628 \nEpoch [47/100], loss: 0.128557488322258. f1:0.9646421462357958 acc: 0.9646666646003723 \nEpoch [48/100], loss: 0.12193244695663452. f1:0.9655039101397864 acc: 0.965499997138977 \nEpoch [49/100], loss: 0.11800869554281235. f1:0.9661634469528273 acc: 0.9661666750907898 \nEpoch [50/100], loss: 0.11283347755670547. f1:0.9677951995140057 acc: 0.9678333401679993 \nEpoch [51/100], loss: 0.10821647197008133. f1:0.9699525195851513 acc: 0.9700000286102295 \nEpoch [52/100], loss: 0.10404346883296967. f1:0.9708163374975282 acc: 0.9708333611488342 \nEpoch [53/100], loss: 0.0993889793753624. f1:0.9711323050658212 acc: 0.9711666703224182 \nEpoch [54/100], loss: 0.09543919563293457. f1:0.9731223583647155 acc: 0.9731666445732117 \nEpoch [55/100], loss: 0.09119988232851028. f1:0.9742968899985852 acc: 0.9743333458900452 \nEpoch [56/100], loss: 0.08738210052251816. f1:0.9756211575677195 acc: 0.9756666421890259 \nEpoch [57/100], loss: 0.08352939039468765. f1:0.9774562566521787 acc: 0.9775000214576721 \nEpoch [58/100], loss: 0.08006688207387924. f1:0.9783038028898812 acc: 0.9783333539962769 \nEpoch [59/100], loss: 0.07644286751747131. f1:0.9794684700967308 acc: 0.9794999957084656 \nEpoch [60/100], loss: 0.07345790416002274. f1:0.9816365960309446 acc: 0.9816666841506958 \nEpoch [61/100], loss: 0.06999197602272034. f1:0.982141487167007 acc: 0.9821666479110718 \nEpoch [62/100], loss: 0.06709354370832443. f1:0.9838081673803657 acc: 0.9838333129882812 \nEpoch [63/100], loss: 0.06419038027524948. f1:0.9851544412652039 acc: 0.9851666688919067 \nEpoch [64/100], loss: 0.061119772493839264. f1:0.9863249510118035 acc: 0.9863333106040955 \nEpoch [65/100], loss: 0.05864338576793671. f1:0.9879934900091779 acc: 0.9879999756813049 \nEpoch [66/100], loss: 0.055860716849565506. f1:0.9884953831824014 acc: 0.9884999990463257 \nEpoch [67/100], loss: 0.053390853106975555. f1:0.9889974842756823 acc: 0.9890000224113464 \nEpoch [68/100], loss: 0.05094008520245552. f1:0.9899963478633582 acc: 0.9900000095367432 \nEpoch [69/100], loss: 0.04859289526939392. f1:0.9901648732518546 acc: 0.9901666641235352 \nEpoch [70/100], loss: 0.04639527201652527. f1:0.9913261709519212 acc: 0.9913333058357239 \nEpoch [71/100], loss: 0.044235456734895706. f1:0.991829705759511 acc: 0.9918333292007446 \nEpoch [72/100], loss: 0.04218537360429764. f1:0.9923287131455135 acc: 0.9923333525657654 \nEpoch [73/100], loss: 0.04026540741324425. f1:0.9931632211966569 acc: 0.9931666851043701 \nEpoch [74/100], loss: 0.03837503492832184. f1:0.9929980662136861 acc: 0.9929999709129333 \nEpoch [75/100], loss: 0.0365879088640213. f1:0.9934979911008984 acc: 0.9934999942779541 \nEpoch [76/100], loss: 0.03486942499876022. f1:0.9939979924955878 acc: 0.9940000176429749 \nEpoch [77/100], loss: 0.033158399164676666. f1:0.9939990809031836 acc: 0.9940000176429749 \nEpoch [78/100], loss: 0.03158021345734596. f1:0.9943333501117186 acc: 0.9943333268165588 \nEpoch [79/100], loss: 0.03003140166401863. f1:0.9949988047768483 acc: 0.9950000047683716 \nEpoch [80/100], loss: 0.028600100427865982. f1:0.9953317073517128 acc: 0.9953333139419556 \nEpoch [81/100], loss: 0.027224253863096237. f1:0.9958316965872565 acc: 0.9958333373069763 \nEpoch [82/100], loss: 0.025862935930490494. f1:0.9959984925309628 acc: 0.9959999918937683 \nEpoch [83/100], loss: 0.024598781019449234. f1:0.9963330968943216 acc: 0.9963333606719971 \nEpoch [84/100], loss: 0.023390987887978554. f1:0.9964997913664012 acc: 0.9965000152587891 \nEpoch [85/100], loss: 0.02223576419055462. f1:0.9969989622851834 acc: 0.996999979019165 \nEpoch [86/100], loss: 0.021128695458173752. f1:0.9973331371018759 acc: 0.9973333477973938 \nEpoch [87/100], loss: 0.020073851570487022. f1:0.9973331371018759 acc: 0.9973333477973938 \nEpoch [88/100], loss: 0.01904200203716755. f1:0.9976649586408575 acc: 0.9976666569709778 \nEpoch [89/100], loss: 0.018075216561555862. f1:0.9979991361525016 acc: 0.9980000257492065 \nEpoch [90/100], loss: 0.017159298062324524. f1:0.99849928641407 acc: 0.9984999895095825 \nEpoch [91/100], loss: 0.016263071447610855. f1:0.99849928641407 acc: 0.9984999895095825 \nEpoch [92/100], loss: 0.015432629734277725. f1:0.99849928641407 acc: 0.9984999895095825 \nEpoch [93/100], loss: 0.014626535587012768. f1:0.99849928641407 acc: 0.9984999895095825 \nEpoch [94/100], loss: 0.013853060081601143. f1:0.9986661002078027 acc: 0.9986666440963745 \nEpoch [95/100], loss: 0.013118993490934372. f1:0.9986661002078027 acc: 0.9986666440963745 \nEpoch [96/100], loss: 0.012395723722875118. f1:0.9986661002078027 acc: 0.9986666440963745 \nEpoch [97/100], loss: 0.011732673272490501. f1:0.9986661002078027 acc: 0.9986666440963745 \nEpoch [98/100], loss: 0.01109602116048336. f1:0.9988329062269976 acc: 0.9988333582878113 \nEpoch [99/100], loss: 0.010490059852600098. f1:0.9988329062269976 acc: 0.9988333582878113 \nEpoch [100/100], loss: 0.009917269460856915. f1:0.9989995718577598 acc: 0.9990000128746033 \n"
],
[
"#-- Evaluamos el modelo entrenado con el set de testeo\nmodel.eval()\n\nXts = X_test.view(X_test.size(0), -1)\nY_pred = model(Xts) \nloss = criterion(Y_pred,Y_test)\n\nY_pred = torch.argmax(Y_pred, 1)\nf1 = f1_score(Y_test, Y_pred, average='macro')\n\nacc = sum(Y_test == Y_pred)/len(Y_pred)\n\nprint('loss: {}, f1: {}, acc: {}'.format(loss.item(), f1, acc))",
"loss: 0.3413091003894806, f1: 0.9271945618798025, acc: 0.9274193644523621\n"
]
],
[
[
"## Regularización\n\nUn mecanismo que permite evitar el sobreajuste es conocido como **regularización**. La cantidad de regularización afectará el rendimiento de validación del modelo. Muy poca regularización no resolverá el problema de sobreajuste. Demasiada regularización hará que el modelo sea mucho menos efectivo. La regularización actúa como una restricción sobre el conjunto de posibles funciones aprendibles.\n\n<br>\n\nSegún [Ian Goodfellow](https://en.wikipedia.org/wiki/Ian_Goodfellow), \"*La regularización es cualquier modificación que hacemos a un algoritmo de aprendizaje que tiene como objetivo reducir su error de generalización pero no su error de entrenamiento.*\" \n\n<br>\n\n**Regularización de caída de peso**\n\nLa pérdida de peso es la técnica de regularización más común (implementada en Pytorch). En PyTorch, la caída de peso se proporciona como un parámetro para el optimizador *decay_weight*. En [este](https://pytorch.org/docs/stable/optim.html) enlace se muestran otros parámetros que pueden ser usados en los optimizadores.\n\nA la caída de peso también se le llama:\n * L2\n * Ridge\n\nPara la disminución de peso, agregamos un término de penalización en la actualización de los pesos:\n\n$w(x) = w(x) − \\eta \\nabla x - \\alpha \\eta x$\n\nEste nuevo término en la actualización lleva los parámetros $w$ ligeramente hacia cero, agregando algo de **decaimiento** en los pesos con cada actualización.",
"_____no_output_____"
]
],
[
[
"input_dim = 28*28\nout_dim = 10\nhidden = 60\n\nmodel = torch.nn.Sequential(\n torch.nn.Linear(input_dim, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden),\n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden), \n torch.nn.ReLU(), \n torch.nn.Linear(hidden, hidden), \n torch.nn.ReLU(), \n torch.nn.Linear(hidden, out_dim)\n)\n\noptimizer = torch.optim.Adam(model.parameters(), weight_decay=0.01)\ncriterion = torch.nn.CrossEntropyLoss()\n\ntrain_valid(model,100,optimizer,criterion)",
"Epoch [1/100], loss: 2.305008888244629. f1:0.04176087157554081 acc: 0.09650000184774399 \nEpoch [2/100], loss: 2.2410032749176025. f1:0.1621865101844616 acc: 0.23516666889190674 \nEpoch [3/100], loss: 2.15309739112854. f1:0.2666372117920173 acc: 0.34183332324028015 \nEpoch [4/100], loss: 2.0372307300567627. f1:0.34171612998552675 acc: 0.39133334159851074 \nEpoch [5/100], loss: 1.8981510400772095. f1:0.3830362940452876 acc: 0.4235000014305115 \nEpoch [6/100], loss: 1.746296763420105. f1:0.44688707758276874 acc: 0.4830000102519989 \nEpoch [7/100], loss: 1.5816463232040405. f1:0.5528082225847062 acc: 0.5680000185966492 \nEpoch [8/100], loss: 1.4088046550750732. f1:0.634135866247361 acc: 0.6439999938011169 \nEpoch [9/100], loss: 1.2340461015701294. f1:0.6907446064188896 acc: 0.6959999799728394 \nEpoch [10/100], loss: 1.0711919069290161. f1:0.7151961328414929 acc: 0.7213333249092102 \nEpoch [11/100], loss: 0.9353795647621155. f1:0.7245347943200551 acc: 0.7329999804496765 \nEpoch [12/100], loss: 0.828378438949585. f1:0.7529119116487526 acc: 0.7576666474342346 \nEpoch [13/100], loss: 0.7464476823806763. f1:0.7733384165814801 acc: 0.7756666541099548 \nEpoch [14/100], loss: 0.7139326930046082. f1:0.7809105376866845 acc: 0.7823333144187927 \nEpoch [15/100], loss: 0.6741050481796265. f1:0.7849707460540831 acc: 0.7888333201408386 \nEpoch [16/100], loss: 0.6132544279098511. f1:0.807073857324124 acc: 0.8080000281333923 \nEpoch [17/100], loss: 0.5862399339675903. f1:0.8001175259281668 acc: 0.8036666512489319 \nEpoch [18/100], loss: 0.538285493850708. f1:0.8317252070740103 acc: 0.8330000042915344 \nEpoch [19/100], loss: 0.5223451852798462. f1:0.8334342847279101 acc: 0.8333333134651184 \nEpoch [20/100], loss: 0.4933871328830719. f1:0.8504635181735025 acc: 0.8498333096504211 \nEpoch [21/100], loss: 0.4608187973499298. f1:0.8604648647329395 acc: 0.8610000014305115 \nEpoch [22/100], loss: 0.449299693107605. f1:0.8627745369326745 acc: 0.8631666898727417 \nEpoch [23/100], loss: 0.416542649269104. f1:0.8781337317373363 acc: 0.878333330154419 \nEpoch [24/100], loss: 0.40872278809547424. f1:0.8792891868135442 acc: 0.8798333406448364 \nEpoch [25/100], loss: 0.38066092133522034. f1:0.8865553587364301 acc: 0.8866666555404663 \nEpoch [26/100], loss: 0.37125900387763977. f1:0.8867937575132283 acc: 0.8868333101272583 \nEpoch [27/100], loss: 0.3485146760940552. f1:0.894883316525271 acc: 0.8948333263397217 \nEpoch [28/100], loss: 0.3402261734008789. f1:0.8968254812679269 acc: 0.8968333601951599 \nEpoch [29/100], loss: 0.3211730420589447. f1:0.9052696045386677 acc: 0.9051666855812073 \nEpoch [30/100], loss: 0.3120555877685547. f1:0.9041481898558945 acc: 0.9043333530426025 \nEpoch [31/100], loss: 0.2979850172996521. f1:0.9085180096532351 acc: 0.9088333249092102 \nEpoch [32/100], loss: 0.28597167134284973. f1:0.9160714463989054 acc: 0.9161666631698608 \nEpoch [33/100], loss: 0.27715617418289185. f1:0.9167937466160438 acc: 0.9168333411216736 \nEpoch [34/100], loss: 0.2650849521160126. f1:0.9204513240915828 acc: 0.9204999804496765 \nEpoch [35/100], loss: 0.257636159658432. f1:0.9227327982754041 acc: 0.9228333234786987 \nEpoch [36/100], loss: 0.2471163123846054. f1:0.9240046834944096 acc: 0.9240000247955322 \nEpoch [37/100], loss: 0.23948799073696136. f1:0.9253412174812257 acc: 0.9253333210945129 \nEpoch [38/100], loss: 0.23156648874282837. f1:0.9295317356564297 acc: 0.9296666383743286 \nEpoch [39/100], loss: 0.22401773929595947. f1:0.9323608468395314 acc: 0.9325000047683716 \nEpoch [40/100], loss: 0.21643628180027008. f1:0.9342700489013696 acc: 0.934333324432373 \nEpoch [41/100], loss: 0.21020416915416718. f1:0.9362170272278669 acc: 0.9361666440963745 \nEpoch [42/100], loss: 0.20318518579006195. f1:0.9399729083972315 acc: 0.9399999976158142 \nEpoch [43/100], loss: 0.19734124839305878. f1:0.9402239990647496 acc: 0.9403333067893982 \nEpoch [44/100], loss: 0.19089862704277039. f1:0.9417284701927648 acc: 0.9418333172798157 \nEpoch [45/100], loss: 0.185815691947937. f1:0.943131650796435 acc: 0.9431666731834412 \nEpoch [46/100], loss: 0.17983193695545197. f1:0.945630709110928 acc: 0.9456666707992554 \nEpoch [47/100], loss: 0.17474859952926636. f1:0.9474674838012206 acc: 0.9474999904632568 \nEpoch [48/100], loss: 0.16985201835632324. f1:0.9500073615839458 acc: 0.949999988079071 \nEpoch [49/100], loss: 0.16461722552776337. f1:0.9530172687905909 acc: 0.953000009059906 \nEpoch [50/100], loss: 0.15997767448425293. f1:0.9544792850714756 acc: 0.9545000195503235 \nEpoch [51/100], loss: 0.15541388094425201. f1:0.9549248939232179 acc: 0.9549999833106995 \nEpoch [52/100], loss: 0.15075217187404633. f1:0.9556005889243842 acc: 0.9556666612625122 \nEpoch [53/100], loss: 0.14629241824150085. f1:0.9583545117967809 acc: 0.9583333134651184 \nEpoch [54/100], loss: 0.14193402230739594. f1:0.958363806899486 acc: 0.9583333134651184 \nEpoch [55/100], loss: 0.13769181072711945. f1:0.9586484039999901 acc: 0.9586666822433472 \nEpoch [56/100], loss: 0.1335466057062149. f1:0.9606241353424441 acc: 0.9606666564941406 \nEpoch [57/100], loss: 0.1293257176876068. f1:0.9623065941197817 acc: 0.9623333215713501 \nEpoch [58/100], loss: 0.1255214661359787. f1:0.9636655749313118 acc: 0.9636666774749756 \nEpoch [59/100], loss: 0.12147213518619537. f1:0.9651636264363146 acc: 0.9651666879653931 \nEpoch [60/100], loss: 0.11781095713376999. f1:0.9659744442069911 acc: 0.9660000205039978 \nEpoch [61/100], loss: 0.11415067315101624. f1:0.9666471973316257 acc: 0.9666666388511658 \nEpoch [62/100], loss: 0.11048128455877304. f1:0.9688316872277648 acc: 0.968833327293396 \nEpoch [63/100], loss: 0.1071179211139679. f1:0.9701636311464691 acc: 0.9701666831970215 \nEpoch [64/100], loss: 0.1036774292588234. f1:0.9706530046986928 acc: 0.9706666469573975 \nEpoch [65/100], loss: 0.1004844531416893. f1:0.9723183599971927 acc: 0.9723333120346069 \nEpoch [66/100], loss: 0.0972432866692543. f1:0.9733326285691838 acc: 0.9733333587646484 \nEpoch [67/100], loss: 0.09423089772462845. f1:0.9739974439923778 acc: 0.9739999771118164 \nEpoch [68/100], loss: 0.09119371324777603. f1:0.9746639057559522 acc: 0.9746666550636292 \nEpoch [69/100], loss: 0.088245689868927. f1:0.976488708218558 acc: 0.9764999747276306 \nEpoch [70/100], loss: 0.08545317500829697. f1:0.9774946527710828 acc: 0.9775000214576721 \nEpoch [71/100], loss: 0.0827057808637619. f1:0.9794903953738666 acc: 0.9794999957084656 \nEpoch [72/100], loss: 0.08017154783010483. f1:0.9806693528098936 acc: 0.9806666374206543 \nEpoch [73/100], loss: 0.07773801684379578. f1:0.9818204664967043 acc: 0.9818333387374878 \nEpoch [74/100], loss: 0.07567824423313141. f1:0.9825024077824767 acc: 0.9825000166893005 \nEpoch [75/100], loss: 0.07439486682415009. f1:0.9836554714964253 acc: 0.9836666584014893 \nEpoch [76/100], loss: 0.07506183534860611. f1:0.9813770332438703 acc: 0.981333315372467 \nEpoch [77/100], loss: 0.07925634831190109. f1:0.9802982051503507 acc: 0.9803333282470703 \nEpoch [78/100], loss: 0.08778347074985504. f1:0.9729657028877771 acc: 0.9728333353996277 \nEpoch [79/100], loss: 0.08613325655460358. f1:0.9750800908562123 acc: 0.9751666784286499 \nEpoch [80/100], loss: 0.06879524886608124. f1:0.9841775369113044 acc: 0.98416668176651 \nEpoch [81/100], loss: 0.06531374156475067. f1:0.9850121220645894 acc: 0.9850000143051147 \nEpoch [82/100], loss: 0.07234133034944534. f1:0.9828054713516149 acc: 0.9828333258628845 \nEpoch [83/100], loss: 0.05958870053291321. f1:0.9876626067094667 acc: 0.987666666507721 \nEpoch [84/100], loss: 0.06350981444120407. f1:0.985833595994648 acc: 0.9858333468437195 \nEpoch [85/100], loss: 0.060807932168245316. f1:0.9859832072382275 acc: 0.9860000014305115 \nEpoch [86/100], loss: 0.05573893338441849. f1:0.9884831411120277 acc: 0.9884999990463257 \nEpoch [87/100], loss: 0.05873904749751091. f1:0.9870110895379011 acc: 0.9869999885559082 \nEpoch [88/100], loss: 0.05160649120807648. f1:0.9901586158994492 acc: 0.9901666641235352 \nEpoch [89/100], loss: 0.05475456640124321. f1:0.988814175678702 acc: 0.9888333082199097 \nEpoch [90/100], loss: 0.04932434484362602. f1:0.9911533512803622 acc: 0.9911666512489319 \nEpoch [91/100], loss: 0.050947073847055435. f1:0.9906657836231003 acc: 0.9906666874885559 \nEpoch [92/100], loss: 0.047708120197057724. f1:0.9916610721729547 acc: 0.9916666746139526 \nEpoch [93/100], loss: 0.04727686569094658. f1:0.9913187869424294 acc: 0.9913333058357239 \nEpoch [94/100], loss: 0.04578389972448349. f1:0.992492891993874 acc: 0.9925000071525574 \nEpoch [95/100], loss: 0.04410844296216965. f1:0.9931648081132991 acc: 0.9931666851043701 \nEpoch [96/100], loss: 0.04371044039726257. f1:0.993324933290811 acc: 0.9933333396911621 \nEpoch [97/100], loss: 0.04142672196030617. f1:0.9934920741505922 acc: 0.9934999942779541 \nEpoch [98/100], loss: 0.04163958877325058. f1:0.9939963096678991 acc: 0.9940000176429749 \nEpoch [99/100], loss: 0.039133671671152115. f1:0.9949987300707257 acc: 0.9950000047683716 \nEpoch [100/100], loss: 0.03959168493747711. f1:0.9941629745881627 acc: 0.9941666722297668 \n"
],
[
" #-- Evaluamos el modelo entrenado con el set de testeo\nmodel.eval()\n\nXts = X_test.view(X_test.size(0), -1)\nY_pred = model(Xts) \nloss = criterion(Y_pred,Y_test)\n\nY_pred = torch.argmax(Y_pred, 1)\nf1 = f1_score(Y_test, Y_pred, average='macro')\n\nacc = sum(Y_test == Y_pred)/len(Y_pred)\n\nprint('loss: {}, f1: {}, acc: {}'.format(loss.item(), f1, acc))",
"loss: 0.22102497518062592, f1: 0.9402813616784537, acc: 0.9405242204666138\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a042ef369e38f0aa8c5c34441563fa698985bf9
| 14,161 |
ipynb
|
Jupyter Notebook
|
第18章 概率潜在语义分析/PLSA.ipynb
|
hktxt/Learn-Statistical-Learning-Method
|
14a3b65db3ff35c42743a1062a2a95cecbfad094
|
[
"MIT"
] | 434 |
2019-08-29T14:42:11.000Z
|
2022-03-30T06:31:02.000Z
|
第18章 概率潜在语义分析/PLSA.ipynb
|
hktxt/Learn-Statistical-Learning-Method
|
14a3b65db3ff35c42743a1062a2a95cecbfad094
|
[
"MIT"
] | 2 |
2020-06-03T16:06:10.000Z
|
2020-06-30T14:04:11.000Z
|
第18章 概率潜在语义分析/PLSA.ipynb
|
hktxt/Learn-Statistical-Learning-Method
|
14a3b65db3ff35c42743a1062a2a95cecbfad094
|
[
"MIT"
] | 178 |
2019-10-21T12:00:44.000Z
|
2022-03-29T01:40:51.000Z
| 31.751121 | 367 | 0.365652 |
[
[
[
"# 概率潜在语义分析",
"_____no_output_____"
],
[
"概率潜在语义分析(probabilistic latent semantic analysis, PLSA),也称概率潜在语义索引(probabilistic latent semantic indexing, PLSI),是一种利用概率生成模型对文本集合进行话题分析的无监督学习方法。\n\n模型最大特点是用隐变量表示话题,整个模型表示文本生成话题,话题生成单词,从而得到单词-文本共现数据的过程;假设每个文本由一个话题分布决定,每个话题由一个单词分布决定。",
"_____no_output_____"
],
[
"### **18.1.2 生成模型**\n\n假设有单词集合 $W = $ {$w_{1}, w_{2}, ..., w_{M}$}, 其中M是单词个数;文本(指标)集合$D = $ {$d_{1}, d_{2}, ..., d_{N}$}, 其中N是文本个数;话题集合$Z = $ {$z_{1}, z_{2}, ..., z_{K}$},其中$K$是预先设定的话题个数。随机变量 $w$ 取值于单词集合;随机变量 $d$ 取值于文本集合,随机变量 $z$ 取值于话题集合。概率分布 $P(d)$、条件概率分布 $P(z|d)$、条件概率分布 $P(w|z)$ 皆属于多项分布,其中 $P(d)$ 表示生成文本 $d$ 的概率,$P(z|d)$ 表示文本 $d$ 生成话题 $z$ 的概率,$P(w|z)$ 表示话题 $z$ 生成单词 $w$ 的概率。\n\n 每个文本 $d$ 拥有自己的话题概率分布 $P(z|d)$,每个话题 $z$ 拥有自己的单词概率分布 $P(w|z)$;也就是说**一个文本的内容由其相关话题决定,一个话题的内容由其相关单词决定**。\n \n 生成模型通过以下步骤生成文本·单词共现数据: \n (1)依据概率分布 $P(d)$,从文本(指标)集合中随机选取一个文本 $d$ , 共生成 $N$ 个文本;针对每个文本,执行以下操作; \n (2)在文本$d$ 给定条件下,依据条件概率分布 $P(z|d)$, 从话题集合随机选取一个话题 $z$, 共生成 $L$ 个话题,这里 $L$ 是文本长度; \n (3)在话题 $z$ 给定条件下,依据条件概率分布 $P(w|z)$ , 从单词集合中随机选取一个单词 $w$. \n \n 注意这里为叙述方便,假设文本都是等长的,现实中不需要这个假设。",
"_____no_output_____"
],
[
"生成模型中, 单词变量 $w$ 与文本变量 $d$ 是观测变量, 话题变量 $z$ 是隐变量, 也就是说模型生成的是单词-话题-文本三元组合 ($w, z ,d$)的集合, 但观测到的单词-文本二元组 ($w, d$)的集合, 观测数据表示为单词-文本矩阵 $T$的形式,矩阵 $T$ 的行表示单词,列表示文本, 元素表示单词-文本对($w, d$)的出现次数。 \n\n从数据的生成过程可以推出,文本-单词共现数据$T$的生成概率为所有单词-文本对($w,d$)的生成概率的乘积: \n\n$P(T) = \\prod_{w,d}P(w,d)^{n(w,d)}$ \n\n这里 $n(w,d)$ 表示 ($w,d$)的出现次数,单词-文本对出现的总次数是 $N*L$。 每个单词-文本对($w,d$)的生成概率由一下公式决定: \n\n$P(w,d) = P(d)P(w|d)$ \n\n$= P(d)\\sum_{z}P(w,z|d)$ \n\n$=P(d)\\sum_{z}P(z|d)P(w|z)$",
"_____no_output_____"
],
[
"### **18.1.3 共现模型**\n\n$P(w,d) = \\sum_{z\\in Z}P(z)P(w|z)P(d|z)$",
"_____no_output_____"
],
[
"虽然生成模型与共现模型在概率公式意义上是等价的,但是拥有不同的性质。生成模型刻画文本-单词共现数据生成的过程,共现模型描述文本-单词共现数据拥有的模式。 \n\n如果直接定义单词与文本的共现概率 $P(w,d)$, 模型参数的个数是 $O(M*N)$, 其中 $M$ 是单词数, $N$ 是文本数。 概率潜在语义分析的生成模型和共现模型的参数个数是 $O(M*K + N*K)$, 其中 $K$ 是话题数。 现实中 $K<<M$, 所以**概率潜在语义分析通过话题对数据进行了更简洁的表示,减少了学习过程中过拟合的可能性**。",
"_____no_output_____"
],
[
"### 算法 18.1 (概率潜在语义模型参数估计的EM算法)",
"_____no_output_____"
],
[
"输入: 设单词集合为 $W = ${$w_{1}, w_{2},..., w_{M}$}, 文本集合为 $D=${$d_{1}, d_{2},..., d_{N}$}, 话题集合为 $Z=${$z_{1}, z_{2},..., z_{K}$}, 共现数据 $\\left \\{ n(w_{i}, d_{j}) \\right \\}, i = 1,2,..., M, j = 1,2,...,N;$ \n\n输出: $P(w_{i}|z_{k})$ 和 $P(z_{k}|d_{j})$.\n\n1. 设置参数 $P(w_{i}|z_{k})$ 和 $P(z_{k}|d_{j})$ 的初始值。\n\n2. 迭代执行以下E步,M步,直到收敛为止。 \n\n E步: \n $P(z_{k}|w_{i},d_{j})=\\frac{P(w_{i}|z_{k})P(z_{k}|d_{j})}{\\sum_{k=1}^{K}P(w_{i}|z_{k})P(z_{k}|d_{j})}$ \n \n M步: \n $P(w_{i}|z_{k})=\\frac{\\sum_{j=1}^{N}n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}{\\sum_{m=1}^{M}\\sum_{j=1}^{N}n(w_{m},d_{j})P(z_{k}|w_{m},d_{j})}$ \n \n $P(z_{k}|d_{j}) = \\frac{\\sum_{i=1}^{M}n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}{n(d_{j})}$",
"_____no_output_____"
],
[
"#### 习题 18.3",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"X = [[0,0,1,1,0,0,0,0,0], \n [0,0,0,0,0,1,0,0,1], \n [0,1,0,0,0,0,0,1,0], \n [0,0,0,0,0,0,1,0,1], \n [1,0,0,0,0,1,0,0,0], \n [1,1,1,1,1,1,1,1,1], \n [1,0,1,0,0,0,0,0,0], \n [0,0,0,0,0,0,1,0,1], \n [0,0,0,0,0,2,0,0,1], \n [1,0,1,0,0,0,0,1,0], \n [0,0,0,1,1,0,0,0,0]]\nX = np.asarray(X);X",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"X = X.T;X",
"_____no_output_____"
],
[
"class PLSA:\n def __init__(self, K, max_iter):\n self.K = K\n self.max_iter = max_iter\n \n def fit(self, X):\n n_d, n_w = X.shape\n \n # P(z|w,d)\n p_z_dw = np.zeros((n_d, n_w, self.K))\n \n # P(z|d)\n p_z_d = np.random.rand(n_d, self.K) \n \n # P(w|z)\n p_w_z = np.random.rand(self.K, n_w) \n \n \n for i_iter in range(self.max_iter):\n # E step\n for di in range(n_d):\n for wi in range(n_w):\n sum_zk = np.zeros((self.K))\n for zi in range(self.K):\n sum_zk[zi] = p_z_d[di, zi] * p_w_z[zi, wi]\n sum1 = np.sum(sum_zk)\n if sum1 == 0:\n sum1 = 1\n for zi in range(self.K):\n p_z_dw[di, wi, zi] = sum_zk[zi] / sum1\n\n\n # M step\n\n # update P(z|d)\n for di in range(n_d):\n for zi in range(self.K):\n sum1 = 0.\n sum2 = 0.\n\n for wi in range(n_w):\n sum1 = sum1 + X[di, wi] * p_z_dw[di, wi, zi]\n sum2 = sum2 + X[di, wi]\n\n if sum2 == 0:\n sum2 = 1\n p_z_d[di, zi] = sum1 / sum2\n\n # update P(w|z)\n for zi in range(self.K):\n sum2 = np.zeros((n_w))\n for wi in range(n_w):\n for di in range(n_d):\n sum2[wi] = sum2[wi] + X[di, wi] * p_z_dw[di, wi, zi]\n sum1 = np.sum(sum2)\n if sum1 == 0:\n sum1 = 1\n for wi in range(n_w):\n p_w_z[zi, wi] = sum2[wi] / sum1\n \n \n return p_w_z, p_z_d\n \n# https://github.com/lipiji/PG_PLSA/blob/master/plsa.py",
"_____no_output_____"
],
[
"model = PLSA(2, 100)\np_w_z, p_z_d = model.fit(X)",
"_____no_output_____"
],
[
"p_w_z",
"_____no_output_____"
],
[
"p_z_d",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a043d8448c8e14e64477a1836fbb284764809fc
| 45,947 |
ipynb
|
Jupyter Notebook
|
tutorials/building_lstm_name_classifier.ipynb
|
EXAPPAI/opacus
|
11e188a2f03a8a08be51fdf2367cc1387879312a
|
[
"Apache-2.0"
] | 958 |
2020-08-28T15:34:15.000Z
|
2022-03-29T20:58:14.000Z
|
tutorials/building_lstm_name_classifier.ipynb
|
EXAPPAI/opacus
|
11e188a2f03a8a08be51fdf2367cc1387879312a
|
[
"Apache-2.0"
] | 330 |
2020-08-28T07:11:02.000Z
|
2022-03-31T19:16:10.000Z
|
tutorials/building_lstm_name_classifier.ipynb
|
EXAPPAI/opacus
|
11e188a2f03a8a08be51fdf2367cc1387879312a
|
[
"Apache-2.0"
] | 161 |
2020-08-28T06:12:10.000Z
|
2022-03-31T07:47:04.000Z
| 27.595796 | 841 | 0.476963 |
[
[
[
"## Training a differentially private LSTM model for name classification",
"_____no_output_____"
],
[
"In this tutorial we will build a differentially-private LSTM model to classify names to their source languages, which is the same task as in the tutorial **NLP From Scratch** (https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html). Since the objective of this tutorial is to demonstrate the effective use of an LSTM with privacy guarantees, we will be utilizing it in place of the bare-bones RNN model defined in the original tutorial. Specifically, we use the `DPLSTM` module from `opacus.layers.dp_lstm` to facilitate calculation of the per-example gradients, which are utilized in the addition of noise during application of differential privacy. `DPLSTM` has the same API and functionality as the `nn.LSTM`, with some restrictions (ex. we currently support single layers, the full list is given below). ",
"_____no_output_____"
],
[
"## Dataset",
"_____no_output_____"
],
[
"First, let us download the dataset of names and their associated language labels as given in https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html. We train our differentially-private LSTM on the same dataset as in that tutorial.",
"_____no_output_____"
]
],
[
[
"import os\nimport requests\n\nNAMES_DATASET_URL = \"https://download.pytorch.org/tutorial/data.zip\"\nDATA_DIR = \"names\"\n\nimport zipfile\nimport urllib\n\ndef download_and_extract(dataset_url, data_dir):\n print(\"Downloading and extracting ...\")\n filename = \"data.zip\"\n\n urllib.request.urlretrieve(dataset_url, filename)\n with zipfile.ZipFile(filename) as zip_ref:\n zip_ref.extractall(data_dir)\n os.remove(filename)\n print(\"Completed!\")\n\ndownload_and_extract(NAMES_DATASET_URL, DATA_DIR)",
"Downloading and extracting ...\nCompleted!\n"
],
[
"names_folder = os.path.join(DATA_DIR, 'data', 'names')\nall_filenames = []\n\nfor language_file in os.listdir(names_folder):\n all_filenames.append(os.path.join(names_folder, language_file))\n \nprint(os.listdir(names_folder))",
"['Arabic.txt', 'Chinese.txt', 'Czech.txt', 'Dutch.txt', 'English.txt', 'French.txt', 'German.txt', 'Greek.txt', 'Irish.txt', 'Italian.txt', 'Japanese.txt', 'Korean.txt', 'Polish.txt', 'Portuguese.txt', 'Russian.txt', 'Scottish.txt', 'Spanish.txt', 'Vietnamese.txt']\n"
],
[
"import torch\nimport torch.nn as nn\n\nclass CharByteEncoder(nn.Module):\n \"\"\"\n This encoder takes a UTF-8 string and encodes its bytes into a Tensor. It can also\n perform the opposite operation to check a result.\n Examples:\n >>> encoder = CharByteEncoder()\n >>> t = encoder('Ślusàrski') # returns tensor([256, 197, 154, 108, 117, 115, 195, 160, 114, 115, 107, 105, 257])\n >>> encoder.decode(t) # returns \"<s>Ślusàrski</s>\"\n \"\"\"\n\n def __init__(self):\n super().__init__()\n self.start_token = \"<s>\"\n self.end_token = \"</s>\"\n self.pad_token = \"<pad>\"\n\n self.start_idx = 256\n self.end_idx = 257\n self.pad_idx = 258\n\n def forward(self, s: str, pad_to=0) -> torch.LongTensor:\n \"\"\"\n Encodes a string. It will append a start token <s> (id=self.start_idx) and an end token </s>\n (id=self.end_idx).\n Args:\n s: The string to encode.\n pad_to: If not zero, pad by appending self.pad_idx until string is of length `pad_to`.\n Defaults to 0.\n Returns:\n The encoded LongTensor of indices.\n \"\"\"\n encoded = s.encode()\n n_pad = pad_to - len(encoded) if pad_to > len(encoded) else 0\n return torch.LongTensor(\n [self.start_idx]\n + [c for c in encoded] # noqa\n + [self.end_idx]\n + [self.pad_idx for _ in range(n_pad)]\n )\n\n def decode(self, char_ids_tensor: torch.LongTensor) -> str:\n \"\"\"\n The inverse of `forward`. Keeps the start, end and pad indices.\n \"\"\"\n char_ids = char_ids_tensor.cpu().detach().tolist()\n\n out = []\n buf = []\n for c in char_ids:\n if c < 256:\n buf.append(c)\n else:\n if buf:\n out.append(bytes(buf).decode())\n buf = []\n if c == self.start_idx:\n out.append(self.start_token)\n elif c == self.end_idx:\n out.append(self.end_token)\n elif c == self.pad_idx:\n out.append(self.pad_token)\n\n if buf: # in case some are left\n out.append(bytes(buf).decode())\n return \"\".join(out)\n\n def __len__(self):\n \"\"\"\n The length of our encoder space. This is fixed to 256 (one byte) + 3 special chars\n (start, end, pad).\n Returns:\n 259\n \"\"\"\n return 259",
"_____no_output_____"
]
],
[
[
"## Training / Validation Set Preparation",
"_____no_output_____"
]
],
[
[
"from torch.nn.utils.rnn import pad_sequence\n\ndef padded_collate(batch, padding_idx=0):\n x = pad_sequence(\n [elem[0] for elem in batch], batch_first=True, padding_value=padding_idx\n )\n y = torch.stack([elem[1] for elem in batch]).long()\n\n return x, y",
"_____no_output_____"
],
[
"from torch.utils.data import Dataset\nfrom pathlib import Path\n\n\nclass NamesDataset(Dataset):\n def __init__(self, root):\n self.root = Path(root)\n\n self.labels = list({langfile.stem for langfile in self.root.iterdir()})\n self.labels_dict = {label: i for i, label in enumerate(self.labels)}\n self.encoder = CharByteEncoder()\n self.samples = self.construct_samples()\n\n def __getitem__(self, i):\n return self.samples[i]\n\n def __len__(self):\n return len(self.samples)\n\n def construct_samples(self):\n samples = []\n for langfile in self.root.iterdir():\n label_name = langfile.stem\n label_id = self.labels_dict[label_name]\n with open(langfile, \"r\") as fin:\n for row in fin:\n samples.append(\n (self.encoder(row.strip()), torch.tensor(label_id).long())\n )\n return samples\n\n def label_count(self):\n cnt = Counter()\n for _x, y in self.samples:\n label = self.labels[int(y)]\n cnt[label] += 1\n return cnt\n\n\nVOCAB_SIZE = 256 + 3 # 256 alternatives in one byte, plus 3 special characters.\n",
"_____no_output_____"
]
],
[
[
"We split the dataset into a 80-20 split for training and validation. ",
"_____no_output_____"
]
],
[
[
"secure_rng = False\ntrain_split = 0.8\ntest_every = 5\nbatch_size = 800\n\nds = NamesDataset(names_folder)\ntrain_len = int(train_split * len(ds))\ntest_len = len(ds) - train_len\n\nprint(f\"{train_len} samples for training, {test_len} for testing\")\n\nif secure_rng:\n try:\n import torchcsprng as prng\n except ImportError as e:\n msg = (\n \"To use secure RNG, you must install the torchcsprng package! \"\n \"Check out the instructions here: https://github.com/pytorch/csprng#installation\"\n )\n raise ImportError(msg) from e\n\n generator = prng.create_random_device_generator(\"/dev/urandom\")\n\nelse:\n generator = None\n\ntrain_ds, test_ds = torch.utils.data.random_split(\n ds, [train_len, test_len], generator=generator\n)",
"16059 samples for training, 4015 for testing\n"
],
[
"from torch.utils.data import DataLoader\nfrom opacus.utils.uniform_sampler import UniformWithReplacementSampler\n\nsample_rate = batch_size / len(train_ds)\n\ntrain_loader = DataLoader(\n train_ds,\n num_workers=8,\n pin_memory=True,\n generator=generator,\n batch_sampler=UniformWithReplacementSampler(\n num_samples=len(train_ds),\n sample_rate=sample_rate,\n generator=generator,\n ),\n collate_fn=padded_collate,\n)\n\ntest_loader = DataLoader(\n test_ds,\n batch_size=2 * batch_size,\n shuffle=False,\n num_workers=8,\n pin_memory=True,\n collate_fn=padded_collate,\n)",
"_____no_output_____"
]
],
[
[
"After splitting the dataset into a training and a validation set, we now have to convert the data into a numeric form suitable for training the LSTM model. For each name, we set a maximum sequence length of 15, and if a name is longer than the threshold, we truncate it (this rarely happens this dataset !). If a name is smaller than the threshold, we add a dummy `#` character to pad it to the desired length. We also batch the names in the dataset and set a batch size of 256 for all the experiments in this tutorial. The function `line_to_tensor()` returns a tensor of shape [15, 256] where each element is the index (in `all_letters`) of the corresponding character.",
"_____no_output_____"
],
[
"## Training/Evaluation Cycle ",
"_____no_output_____"
],
[
"The training and the evaluation functions `train()` and `test()` are defined below. During the training loop, the per-example gradients are computed and the parameters are updated subsequent to gradient clipping (to bound their sensitivity) and addition of noise. ",
"_____no_output_____"
]
],
[
[
"from statistics import mean\n\ndef train(model, criterion, optimizer, train_loader, epoch, device=\"cuda:0\"):\n accs = []\n losses = []\n for x, y in tqdm(train_loader):\n x = x.to(device)\n y = y.to(device)\n\n logits = model(x)\n loss = criterion(logits, y)\n loss.backward()\n\n optimizer.step()\n optimizer.zero_grad()\n\n preds = logits.argmax(-1)\n n_correct = float(preds.eq(y).sum())\n batch_accuracy = n_correct / len(y)\n\n accs.append(batch_accuracy)\n losses.append(float(loss))\n\n printstr = (\n f\"\\t Epoch {epoch}. Accuracy: {mean(accs):.6f} | Loss: {mean(losses):.6f}\"\n )\n try:\n privacy_engine = optimizer.privacy_engine\n epsilon, best_alpha = privacy_engine.get_privacy_spent()\n printstr += f\" | (ε = {epsilon:.2f}, δ = {privacy_engine.target_delta}) for α = {best_alpha}\"\n except AttributeError:\n pass\n print(printstr)\n return\n\n\ndef test(model, test_loader, privacy_engine, device=\"cuda:0\"):\n accs = []\n with torch.no_grad():\n for x, y in tqdm(test_loader):\n x = x.to(device)\n y = y.to(device)\n\n preds = model(x).argmax(-1)\n n_correct = float(preds.eq(y).sum())\n batch_accuracy = n_correct / len(y)\n\n accs.append(batch_accuracy)\n printstr = \"\\n----------------------------\\n\" f\"Test Accuracy: {mean(accs):.6f}\"\n if privacy_engine:\n epsilon, best_alpha = privacy_engine.get_privacy_spent()\n printstr += f\" (ε = {epsilon:.2f}, δ = {privacy_engine.target_delta}) for α = {best_alpha}\"\n print(printstr + \"\\n----------------------------\\n\")\n return\n",
"_____no_output_____"
]
],
[
[
"## Hyper-parameters",
"_____no_output_____"
],
[
"There are two sets of hyper-parameters associated with this model. The first are hyper-parameters which we would expect in any machine learning training, such as the learning rate and batch size. The second set are related to the privacy engine, where for example we define the amount of noise added to the gradients (`noise_multiplier`), and the maximum L2 norm to which the per-sample gradients are clipped (`max_grad_norm`). ",
"_____no_output_____"
]
],
[
[
"# Training hyper-parameters\nepochs = 50\nlearning_rate = 2.0\n\n# Privacy engine hyper-parameters\nmax_per_sample_grad_norm = 1.5\ndelta = 8e-5\nepsilon = 12.0",
"_____no_output_____"
]
],
[
[
"## Model",
"_____no_output_____"
],
[
"We define the name classification model in the cell below. Note that it is a simple char-LSTM classifier, where the input characters are passed through an `nn.Embedding` layer, and are subsequently input to the DPLSTM. ",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torch import nn\nfrom opacus.layers import DPLSTM\n\nclass CharNNClassifier(nn.Module):\n def __init__(\n self,\n embedding_size,\n hidden_size,\n output_size,\n num_lstm_layers=1,\n bidirectional=False,\n vocab_size=VOCAB_SIZE,\n ):\n super().__init__()\n\n self.embedding_size = embedding_size\n self.hidden_size = hidden_size\n self.output_size = output_size\n self.vocab_size = vocab_size\n\n self.embedding = nn.Embedding(vocab_size, embedding_size)\n self.lstm = DPLSTM(\n embedding_size,\n hidden_size,\n num_layers=num_lstm_layers,\n bidirectional=bidirectional,\n batch_first=True,\n )\n self.out_layer = nn.Linear(hidden_size, output_size)\n\n def forward(self, x, hidden=None):\n x = self.embedding(x) # -> [B, T, D]\n x, _ = self.lstm(x, hidden) # -> [B, T, H]\n x = x[:, -1, :] # -> [B, H]\n x = self.out_layer(x) # -> [B, C]\n return x",
"_____no_output_____"
]
],
[
[
"We now proceed to instantiate the objects (privacy engine, model and optimizer) for our differentially-private LSTM training. However, the `nn.LSTM` is replaced with a `DPLSTM` module which enables us to calculate per-example gradients. ",
"_____no_output_____"
]
],
[
[
"# Set the device to run on a GPU\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n\n# Define classifier parameters\nembedding_size = 64\nhidden_size = 128 # Number of neurons in hidden layer after LSTM\nn_lstm_layers = 1\nbidirectional_lstm = False\n\nmodel = CharNNClassifier(\n embedding_size,\n hidden_size,\n len(ds.labels),\n n_lstm_layers,\n bidirectional_lstm,\n).to(device)",
"_____no_output_____"
]
],
[
[
"## Defining the privacy engine, optimizer and loss criterion for the problem",
"_____no_output_____"
]
],
[
[
"criterion = nn.CrossEntropyLoss()\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)",
"_____no_output_____"
],
[
"from opacus import PrivacyEngine\n\nprivacy_engine = PrivacyEngine(\n model,\n sample_rate=sample_rate,\n max_grad_norm=max_per_sample_grad_norm,\n target_delta=delta,\n target_epsilon=epsilon,\n epochs=epochs,\n secure_rng=secure_rng,\n)\nprivacy_engine.attach(optimizer)",
"/private/home/asablayrolles/code/projects/opacus/opacus/privacy_engine.py:120: UserWarning: Secure RNG turned off. This is perfectly fine for experimentation as it allows for much faster training performance, but remember to turn it on and retrain one last time before production with ``secure_rng`` turned on.\n \"Secure RNG turned off. This is perfectly fine for experimentation as it allows \"\n"
]
],
[
[
"## Training the name classifier with privacy",
"_____no_output_____"
],
[
"Finally we can start training ! We will be training for 50 epochs iterations (where each epoch corresponds to a pass over the whole dataset). We will be reporting the privacy epsilon every `test_every` epochs. We will also benchmark this differentially-private model against a model without privacy and obtain almost identical performance. Further, the private model trained with Opacus incurs only minimal overhead in training time, with the differentially-private classifier only slightly slower (by a couple of minutes) than the non-private model.",
"_____no_output_____"
]
],
[
[
"from tqdm import tqdm\n\nprint(\"Train stats: \\n\")\nfor epoch in tqdm(range(epochs)):\n train(model, criterion, optimizer, train_loader, epoch, device=device)\n if test_every:\n if epoch % test_every == 0:\n test(model, test_loader, privacy_engine, device=device)\n\ntest(model, test_loader, privacy_engine, device=device)",
"Train stats: \n\n"
]
],
[
[
"The differentially-private name classification model obtains a test accuracy of 0.73 with an epsilon of just under 12. This shows that we can achieve a good accuracy on this task, with minimal loss of privacy.",
"_____no_output_____"
],
[
"## Training the name classifier without privacy",
"_____no_output_____"
],
[
" We also run a comparison with a non-private model to see if the performance obtained with privacy is comparable to it. To do this, we keep the parameters such as learning rate and batch size the same, and only define a different instance of the model along with a separate optimizer.",
"_____no_output_____"
]
],
[
[
"model_nodp = CharNNClassifier(\n embedding_size,\n hidden_size,\n len(ds.labels),\n n_lstm_layers,\n bidirectional_lstm,\n).to(device)\n\n\noptimizer_nodp = torch.optim.SGD(model_nodp.parameters(), lr=0.5)",
"_____no_output_____"
],
[
"for epoch in tqdm(range(epochs)):\n train(model_nodp, criterion, optimizer_nodp, train_loader, epoch, device=device)\n if test_every:\n if epoch % test_every == 0:\n test(model_nodp, test_loader, None, device=device)\n\ntest(model_nodp, test_loader, None, device=device)",
"\t Epoch 0. Accuracy: 0.446188 | Loss: 1.975067\n"
]
],
[
[
"We run the training loop again, this time without privacy and for the same number of iterations. ",
"_____no_output_____"
],
[
"The non-private classifier obtains a test accuracy of around 0.75 with the same parameters and number of epochs. We are effectively trading off performance on the name classification task for a lower loss of privacy.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a045c02cf8c1d1dca0d321f3453e07d9179bb8b
| 63,591 |
ipynb
|
Jupyter Notebook
|
tensorflow_probability/examples/jupyter_notebooks/Probabilistic_Layers_VAE.ipynb
|
travelbureau/probability
|
bccfc15deded713ef00230cb4da5befca637ec3c
|
[
"Apache-2.0"
] | 1 |
2020-07-12T22:40:42.000Z
|
2020-07-12T22:40:42.000Z
|
tensorflow_probability/examples/jupyter_notebooks/Probabilistic_Layers_VAE.ipynb
|
travelbureau/probability
|
bccfc15deded713ef00230cb4da5befca637ec3c
|
[
"Apache-2.0"
] | 2 |
2019-08-01T18:31:41.000Z
|
2019-08-01T19:42:15.000Z
|
tensorflow_probability/examples/jupyter_notebooks/Probabilistic_Layers_VAE.ipynb
|
travelbureau/probability
|
bccfc15deded713ef00230cb4da5befca637ec3c
|
[
"Apache-2.0"
] | 1 |
2021-03-25T00:23:09.000Z
|
2021-03-25T00:23:09.000Z
| 81.214559 | 11,876 | 0.72916 |
[
[
[
"##### Copyright 2019 The TensorFlow Authors.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\"); { display-mode: \"form\" }\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# TFP Probabilistic Layers: Variational Auto Encoder\n\n<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Probabilistic_Layers_VAE.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Probabilistic_Layers_VAE.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"In this example we show how to fit a Variational Autoencoder using TFP's \"probabilistic layers.\"",
"_____no_output_____"
],
[
"### Dependencies & Prerequisites\n",
"_____no_output_____"
]
],
[
[
"#@title Install { display-mode: \"form\" }\nTF_Installation = 'TF2 Nightly (GPU)' #@param ['TF2 Nightly (GPU)', 'TF2 Stable (GPU)', 'TF1 Nightly (GPU)', 'TF1 Stable (GPU)','System']\n\nif TF_Installation == 'TF2 Nightly (GPU)':\n !pip install -q --upgrade tf-nightly-gpu-2.0-preview\n print('Installation of `tf-nightly-gpu-2.0-preview` complete.')\nelif TF_Installation == 'TF2 Stable (GPU)':\n !pip install -q --upgrade tensorflow-gpu==2.0.0-alpha0\n print('Installation of `tensorflow-gpu==2.0.0-alpha0` complete.')\nelif TF_Installation == 'TF1 Nightly (GPU)':\n !pip install -q --upgrade tf-nightly-gpu\n print('Installation of `tf-nightly-gpu` complete.')\nelif TF_Installation == 'TF1 Stable (GPU)':\n !pip install -q --upgrade tensorflow-gpu\n print('Installation of `tensorflow-gpu` complete.')\nelif TF_Installation == 'System':\n pass\nelse:\n raise ValueError('Selection Error: Please select a valid '\n 'installation option.')",
"_____no_output_____"
],
[
"#@title Install { display-mode: \"form\" }\nTFP_Installation = \"Nightly\" #@param [\"Nightly\", \"Stable\", \"System\"]\n\nif TFP_Installation == \"Nightly\":\n !pip install -q tfp-nightly\n print(\"Installation of `tfp-nightly` complete.\")\nelif TFP_Installation == \"Stable\":\n !pip install -q --upgrade tensorflow-probability\n print(\"Installation of `tensorflow-probability` complete.\")\nelif TFP_Installation == \"System\":\n pass\nelse:\n raise ValueError(\"Selection Error: Please select a valid \"\n \"installation option.\")",
"_____no_output_____"
],
[
"#@title Import { display-mode: \"form\" }\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport numpy as np\n\nimport tensorflow as tf\nfrom tensorflow.python import tf2\nif not tf2.enabled():\n import tensorflow.compat.v2 as tf\n tf.enable_v2_behavior()\n assert tf2.enabled()\n\nimport tensorflow_datasets as tfds\nimport tensorflow_probability as tfp\n\n\ntfk = tf.keras\ntfkl = tf.keras.layers\ntfpl = tfp.layers\ntfd = tfp.distributions",
"_____no_output_____"
]
],
[
[
"### Make things Fast!",
"_____no_output_____"
],
[
"Before we dive in, let's make sure we're using a GPU for this demo. \n\nTo do this, select \"Runtime\" -> \"Change runtime type\" -> \"Hardware accelerator\" -> \"GPU\".\n\nThe following snippet will verify that we have access to a GPU.",
"_____no_output_____"
]
],
[
[
"if tf.test.gpu_device_name() != '/device:GPU:0':\n print('WARNING: GPU device not found.')\nelse:\n print('SUCCESS: Found GPU: {}'.format(tf.test.gpu_device_name()))",
"_____no_output_____"
]
],
[
[
"Note: if for some reason you cannot access a GPU, this colab will still work. (Training will just take longer.)",
"_____no_output_____"
],
[
"### Load Dataset",
"_____no_output_____"
]
],
[
[
"datasets, datasets_info = tfds.load(name='mnist',\n with_info=True,\n as_supervised=False)\n\ndef _preprocess(sample):\n image = tf.cast(sample['image'], tf.float32) / 255. # Scale to unit interval.\n image = image < tf.random.uniform(tf.shape(image)) # Randomly binarize.\n return image, image\n\ntrain_dataset = (datasets['train']\n .map(_preprocess)\n .batch(256)\n .prefetch(tf.data.experimental.AUTOTUNE)\n .shuffle(int(10e3)))\neval_dataset = (datasets['test']\n .map(_preprocess)\n .batch(256)\n .prefetch(tf.data.experimental.AUTOTUNE))",
"_____no_output_____"
]
],
[
[
"### VAE Code Golf",
"_____no_output_____"
],
[
"#### Specify model.",
"_____no_output_____"
]
],
[
[
"input_shape = datasets_info.features['image'].shape\nencoded_size = 16\nbase_depth = 32",
"_____no_output_____"
],
[
"prior = tfd.Independent(tfd.Normal(loc=tf.zeros(encoded_size), scale=1),\n reinterpreted_batch_ndims=1)",
"_____no_output_____"
],
[
"encoder = tfk.Sequential([\n tfkl.InputLayer(input_shape=input_shape),\n tfkl.Lambda(lambda x: tf.cast(x, tf.float32) - 0.5),\n tfkl.Conv2D(base_depth, 5, strides=1,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2D(base_depth, 5, strides=2,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2D(2 * base_depth, 5, strides=1,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2D(2 * base_depth, 5, strides=2,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2D(4 * encoded_size, 7, strides=1,\n padding='valid', activation=tf.nn.leaky_relu),\n tfkl.Flatten(),\n tfkl.Dense(tfpl.MultivariateNormalTriL.params_size(encoded_size),\n activation=None),\n tfpl.MultivariateNormalTriL(\n encoded_size,\n activity_regularizer=tfpl.KLDivergenceRegularizer(prior)),\n])",
"_____no_output_____"
],
[
"decoder = tfk.Sequential([\n tfkl.InputLayer(input_shape=[encoded_size]),\n tfkl.Reshape([1, 1, encoded_size]),\n tfkl.Conv2DTranspose(2 * base_depth, 7, strides=1,\n padding='valid', activation=tf.nn.leaky_relu),\n tfkl.Conv2DTranspose(2 * base_depth, 5, strides=1,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2DTranspose(2 * base_depth, 5, strides=2,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2DTranspose(base_depth, 5, strides=1,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2DTranspose(base_depth, 5, strides=2,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2DTranspose(base_depth, 5, strides=1,\n padding='same', activation=tf.nn.leaky_relu),\n tfkl.Conv2D(filters=1, kernel_size=5, strides=1,\n padding='same', activation=None),\n tfkl.Flatten(),\n tfpl.IndependentBernoulli(input_shape, tfd.Bernoulli.logits),\n])",
"_____no_output_____"
],
[
"vae = tfk.Model(inputs=encoder.inputs,\n outputs=decoder(encoder.outputs[0]))",
"_____no_output_____"
]
],
[
[
"#### Do inference.",
"_____no_output_____"
]
],
[
[
"negloglik = lambda x, rv_x: -rv_x.log_prob(x)\n\nvae.compile(optimizer=tf.optimizers.Adam(learning_rate=1e-3),\n loss=negloglik)\n\nvae.fit(train_dataset,\n epochs=15,\n validation_data=eval_dataset)",
"Epoch 1/15\n235/235 [==============================] - 22s 94ms/step - loss: 236.9404 - val_loss: 0.0000e+00\nEpoch 2/15\n235/40 [================================================================================================================================================================================] - 18s 76ms/step - loss: 151.2015 - val_loss: 145.6309\nEpoch 3/15\n235/40 [================================================================================================================================================================================] - 17s 74ms/step - loss: 142.7853 - val_loss: 139.8294\nEpoch 4/15\n235/40 [================================================================================================================================================================================] - 18s 75ms/step - loss: 135.4361 - val_loss: 133.8475\nEpoch 5/15\n235/40 [================================================================================================================================================================================] - 17s 74ms/step - loss: 132.1213 - val_loss: 128.8696\nEpoch 6/15\n235/40 [================================================================================================================================================================================] - 18s 75ms/step - loss: 127.6682 - val_loss: 125.9351\nEpoch 7/15\n235/40 [================================================================================================================================================================================] - 18s 75ms/step - loss: 125.0283 - val_loss: 124.2726\nEpoch 8/15\n235/40 [================================================================================================================================================================================] - 18s 75ms/step - loss: 125.5399 - val_loss: 122.4221\nEpoch 9/15\n235/40 [================================================================================================================================================================================] - 18s 77ms/step - loss: 122.6315 - val_loss: 122.0207\nEpoch 10/15\n235/40 [================================================================================================================================================================================] - 18s 75ms/step - loss: 121.1640 - val_loss: 121.2397\nEpoch 11/15\n235/40 [================================================================================================================================================================================] - 17s 74ms/step - loss: 121.1660 - val_loss: 120.0015\nEpoch 12/15\n235/40 [================================================================================================================================================================================] - 18s 75ms/step - loss: 118.0253 - val_loss: 119.6703\nEpoch 13/15\n235/40 [================================================================================================================================================================================] - 18s 76ms/step - loss: 121.2379 - val_loss: 119.0393\nEpoch 14/15\n235/40 [================================================================================================================================================================================] - 17s 74ms/step - loss: 118.8705 - val_loss: 118.2071\nEpoch 15/15\n235/40 [================================================================================================================================================================================] - 18s 75ms/step - loss: 118.2430 - val_loss: 118.1639\n"
]
],
[
[
"### Look Ma, No ~~Hands~~Tensors!",
"_____no_output_____"
]
],
[
[
"# We'll just examine ten random digits.\nx = next(iter(eval_dataset))[0][:10]\nxhat = vae(x)\nassert isinstance(xhat, tfd.Distribution)",
"_____no_output_____"
],
[
"#@title Image Plot Util\nimport matplotlib.pyplot as plt\n\ndef display_imgs(x, y=None):\n if not isinstance(x, (np.ndarray, np.generic)):\n x = np.array(x)\n plt.ioff()\n n = x.shape[0]\n fig, axs = plt.subplots(1, n, figsize=(n, 1))\n if y is not None:\n fig.suptitle(np.argmax(y, axis=1))\n for i in xrange(n):\n axs.flat[i].imshow(x[i].squeeze(), interpolation='none', cmap='gray')\n axs.flat[i].axis('off')\n plt.show()\n plt.close()\n plt.ion()",
"_____no_output_____"
],
[
"print('Originals:')\ndisplay_imgs(x)\n\nprint('Decoded Random Samples:')\ndisplay_imgs(xhat.sample())\n\nprint('Decoded Modes:')\ndisplay_imgs(xhat.mode())\n\nprint('Decoded Means:')\ndisplay_imgs(xhat.mean())",
"Originals:\n"
],
[
"# Now, let's generate ten never-before-seen digits.\nz = prior.sample(10)\nxtilde = decoder(z)\nassert isinstance(xtilde, tfd.Distribution)",
"_____no_output_____"
],
[
"print('Randomly Generated Samples:')\ndisplay_imgs(xtilde.sample())\n\nprint('Randomly Generated Modes:')\ndisplay_imgs(xtilde.mode())\n\nprint('Randomly Generated Means:')\ndisplay_imgs(xtilde.mean())",
"Randomly Generated Samples:\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a045d71805dd27a05ea92f340a5e47bb9ba18bf
| 178,045 |
ipynb
|
Jupyter Notebook
|
Housing_Prices_Submission_1/Code_sub_1_vers1.ipynb
|
gndrak/kaggle_housing_prices_competition
|
07fd2683f42177b504acc44bd7a9ccca9687fb73
|
[
"Apache-2.0"
] | null | null | null |
Housing_Prices_Submission_1/Code_sub_1_vers1.ipynb
|
gndrak/kaggle_housing_prices_competition
|
07fd2683f42177b504acc44bd7a9ccca9687fb73
|
[
"Apache-2.0"
] | null | null | null |
Housing_Prices_Submission_1/Code_sub_1_vers1.ipynb
|
gndrak/kaggle_housing_prices_competition
|
07fd2683f42177b504acc44bd7a9ccca9687fb73
|
[
"Apache-2.0"
] | null | null | null | 80.308976 | 43,404 | 0.787391 |
[
[
[
"# This Python 3 environment comes with many helpful analytics libraries installed\n# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python\n# For example, here's several helpful packages to load\n\nimport numpy as np # linear algebra\nimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\n\n# Input data files are available in the read-only \"../input/\" directory\n# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory\n\nimport os\nfor dirname, _, filenames in os.walk('/kaggle/input'):\n for filename in filenames:\n print(os.path.join(dirname, filename))\n\n# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using \"Save & Run All\" \n# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session",
"/kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csv\n/kaggle/input/house-prices-advanced-regression-techniques/data_description.txt\n/kaggle/input/house-prices-advanced-regression-techniques/train.csv\n/kaggle/input/house-prices-advanced-regression-techniques/test.csv\n"
],
[
"import matplotlib.pyplot as plt\nfrom scipy import stats\nimport seaborn as sns\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.metrics import mean_absolute_error",
"_____no_output_____"
],
[
"train = pd.read_csv('../input/house-prices-advanced-regression-techniques/train.csv')\ntest = pd.read_csv('../input/house-prices-advanced-regression-techniques/test.csv')",
"_____no_output_____"
],
[
"print (\"Train data shape:\", train.shape)\nprint (\"Test data shape:\", test.shape)",
"Train data shape: (1460, 81)\nTest data shape: (1459, 80)\n"
],
[
"train.head()",
"_____no_output_____"
],
[
"plt.style.use(style='ggplot')\nplt.rcParams['figure.figsize'] = (10, 6)",
"_____no_output_____"
],
[
"train.SalePrice.describe()",
"_____no_output_____"
],
[
"print (\"Skew is:\", train.SalePrice.skew())\nplt.hist(train.SalePrice, color='blue')\nplt.show() ",
"Skew is: 1.8828757597682129\n"
],
[
"target = np.log(train.SalePrice)\ntarget.skew()",
"_____no_output_____"
],
[
"target = np.log(train.SalePrice)\nprint (\"Skew is:\", target.skew())\nplt.hist(target, color='blue')\nplt.show()",
"Skew is: 0.12133506220520406\n"
],
[
"numeric_features = train.select_dtypes(include=[np.number])\nnumeric_features.dtypes",
"_____no_output_____"
],
[
"corr = numeric_features.corr()\nprint (corr['SalePrice'].sort_values(ascending=False)[:5], '\\n')\nprint (corr['SalePrice'].sort_values(ascending=False)[-5:])",
"SalePrice 1.000000\nOverallQual 0.790982\nGrLivArea 0.708624\nGarageCars 0.640409\nGarageArea 0.623431\nName: SalePrice, dtype: float64 \n\nYrSold -0.028923\nOverallCond -0.077856\nMSSubClass -0.084284\nEnclosedPorch -0.128578\nKitchenAbvGr -0.135907\nName: SalePrice, dtype: float64\n"
],
[
"train.OverallQual.unique()",
"_____no_output_____"
],
[
"quality_pivot = train.pivot_table(index='OverallQual',\n values='SalePrice', aggfunc=np.median)\nquality_pivot",
"_____no_output_____"
],
[
"quality_pivot.plot(kind='bar', color='blue')\nplt.xlabel('Overall Quality')\nplt.ylabel('Median Sale Price')\nplt.xticks(rotation=0)\nplt.show()",
"_____no_output_____"
],
[
"train = train[train['GarageArea'] < 1200]",
"_____no_output_____"
],
[
"nulls = pd.DataFrame(train.isnull().sum().sort_values(ascending=False)[:25])\nnulls.columns = ['Null Count']\nnulls.index.name = 'Feature'\nnulls",
"_____no_output_____"
],
[
"print (\"Unique values are:\", train.MiscFeature.unique())",
"Unique values are: [nan 'Shed' 'Gar2' 'Othr' 'TenC']\n"
],
[
"categoricals = train.select_dtypes(exclude=[np.number])\ncategoricals.describe()",
"_____no_output_____"
],
[
"print (\"Original: \\n\")\nprint (train.Street.value_counts(), \"\\n\")",
"Original: \n\nPave 1450\nGrvl 5\nName: Street, dtype: int64 \n\n"
],
[
"train['enc_street'] = pd.get_dummies(train.Street, drop_first=True)\ntest['enc_street'] = pd.get_dummies(train.Street, drop_first=True)",
"_____no_output_____"
],
[
"print ('Encoded: \\n')\nprint (train.enc_street.value_counts())",
"Encoded: \n\n1 1450\n0 5\nName: enc_street, dtype: int64\n"
],
[
"condition_pivot = train.pivot_table(index='SaleCondition', values='SalePrice', aggfunc=np.median)\ncondition_pivot.plot(kind='bar', color='blue')\nplt.xlabel('Sale Condition')\nplt.ylabel('Median Sale Price')\nplt.xticks(rotation=0)\nplt.show()",
"_____no_output_____"
],
[
"def encode(x):\n return 1 if x == 'Partial' else 0\ntrain['enc_condition'] = train.SaleCondition.apply(encode)\ntest['enc_condition'] = test.SaleCondition.apply(encode)",
"_____no_output_____"
],
[
"condition_pivot = train.pivot_table(index='enc_condition', values='SalePrice', aggfunc=np.median)\ncondition_pivot.plot(kind='bar', color='blue')\nplt.xlabel('Encoded Sale Condition')\nplt.ylabel('Median Sale Price')\nplt.xticks(rotation=0)\nplt.show()",
"_____no_output_____"
],
[
"data = train.select_dtypes(include=[np.number]).interpolate().dropna()",
"_____no_output_____"
],
[
"sum(data.isnull().sum() != 0)",
"_____no_output_____"
],
[
"y = np.log(train.SalePrice)\nX = data.drop(['SalePrice', 'Id'], axis=1)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(\n X, y, random_state=42, test_size=.33)",
"_____no_output_____"
],
[
"from sklearn import linear_model\nlr = linear_model.LinearRegression()",
"_____no_output_____"
],
[
"model = lr.fit(X_train, y_train)",
"_____no_output_____"
],
[
"print (\"R^2 is: \\n\", model.score(X_test, y_test))",
"R^2 is: \n 0.8882477709262545\n"
],
[
"predictions = model.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import mean_squared_error\nprint ('RMSE is: \\n', mean_squared_error(y_test, predictions))",
"RMSE is: \n 0.017841794519567696\n"
],
[
"actual_values = y_test\nplt.scatter(predictions, actual_values, alpha=.7,\n color='b') #alpha helps to show overlapping data\nplt.xlabel('Predicted Price')\nplt.ylabel('Actual Price')\nplt.title('Linear Regression Model')\nplt.show()",
"_____no_output_____"
],
[
"try1 = pd.DataFrame()\ntry1['Id'] = test.Id",
"_____no_output_____"
],
[
"feats = test.select_dtypes(\n include=[np.number]).drop(['Id'], axis=1).interpolate()",
"_____no_output_____"
],
[
"predictions = model.predict(feats)",
"_____no_output_____"
],
[
"final_predictions = np.exp(predictions)",
"_____no_output_____"
],
[
"print (\"Original predictions are: \\n\", predictions[:5], \"\\n\")\nprint (\"Final predictions are: \\n\", final_predictions[:5])",
"Original predictions are: \n [11.76725362 11.71929504 12.07656074 12.20632678 12.11217655] \n\nFinal predictions are: \n [128959.49172586 122920.74024359 175704.82598102 200050.83263756\n 182075.46986405]\n"
],
[
"try1['SalePrice'] = final_predictions\ntry1.head()",
"_____no_output_____"
],
[
"try1.to_csv('submission1.csv', index=False)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a0463c61f7f15c273749fedb3bb74cdbe1e9579
| 94,132 |
ipynb
|
Jupyter Notebook
|
Project/SageMaker Project.ipynb
|
arief25ramadhan/sagemaker-deployment
|
98e06b27fc2d21dc1b344c11248da4c065701821
|
[
"MIT"
] | null | null | null |
Project/SageMaker Project.ipynb
|
arief25ramadhan/sagemaker-deployment
|
98e06b27fc2d21dc1b344c11248da4c065701821
|
[
"MIT"
] | null | null | null |
Project/SageMaker Project.ipynb
|
arief25ramadhan/sagemaker-deployment
|
98e06b27fc2d21dc1b344c11248da4c065701821
|
[
"MIT"
] | null | null | null | 49.027083 | 1,155 | 0.603854 |
[
[
[
"# Creating a Sentiment Analysis Web App\n## Using PyTorch and SageMaker\n\n_Deep Learning Nanodegree Program | Deployment_\n\n---\n\nNow that we have a basic understanding of how SageMaker works we will try to use it to construct a complete project from end to end. Our goal will be to have a simple web page which a user can use to enter a movie review. The web page will then send the review off to our deployed model which will predict the sentiment of the entered review.\n\n## Instructions\n\nSome template code has already been provided for you, and you will need to implement additional functionality to successfully complete this notebook. You will not need to modify the included code beyond what is requested. Sections that begin with '**TODO**' in the header indicate that you need to complete or implement some portion within them. Instructions will be provided for each section and the specifics of the implementation are marked in the code block with a `# TODO: ...` comment. Please be sure to read the instructions carefully!\n\nIn addition to implementing code, there will be questions for you to answer which relate to the task and your implementation. Each section where you will answer a question is preceded by a '**Question:**' header. Carefully read each question and provide your answer below the '**Answer:**' header by editing the Markdown cell.\n\n> **Note**: Code and Markdown cells can be executed using the **Shift+Enter** keyboard shortcut. In addition, a cell can be edited by typically clicking it (double-click for Markdown cells) or by pressing **Enter** while it is highlighted.\n\n## General Outline\n\nRecall the general outline for SageMaker projects using a notebook instance.\n\n1. Download or otherwise retrieve the data.\n2. Process / Prepare the data.\n3. Upload the processed data to S3.\n4. Train a chosen model.\n5. Test the trained model (typically using a batch transform job).\n6. Deploy the trained model.\n7. Use the deployed model.\n\nFor this project, you will be following the steps in the general outline with some modifications. \n\nFirst, you will not be testing the model in its own step. You will still be testing the model, however, you will do it by deploying your model and then using the deployed model by sending the test data to it. One of the reasons for doing this is so that you can make sure that your deployed model is working correctly before moving forward.\n\nIn addition, you will deploy and use your trained model a second time. In the second iteration you will customize the way that your trained model is deployed by including some of your own code. In addition, your newly deployed model will be used in the sentiment analysis web app.",
"_____no_output_____"
],
[
"## Step 1: Downloading the data\n\nAs in the XGBoost in SageMaker notebook, we will be using the [IMDb dataset](http://ai.stanford.edu/~amaas/data/sentiment/)\n\n> Maas, Andrew L., et al. [Learning Word Vectors for Sentiment Analysis](http://ai.stanford.edu/~amaas/data/sentiment/). In _Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies_. Association for Computational Linguistics, 2011.",
"_____no_output_____"
]
],
[
[
"%mkdir ../data\n!wget -O ../data/aclImdb_v1.tar.gz http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\n!tar -zxf ../data/aclImdb_v1.tar.gz -C ../data",
"mkdir: cannot create directory ‘../data’: File exists\n--2019-12-22 22:09:56-- http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\nResolving ai.stanford.edu (ai.stanford.edu)... 171.64.68.10\nConnecting to ai.stanford.edu (ai.stanford.edu)|171.64.68.10|:80... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 84125825 (80M) [application/x-gzip]\nSaving to: ‘../data/aclImdb_v1.tar.gz’\n\n../data/aclImdb_v1. 100%[===================>] 80.23M 23.9MB/s in 4.2s \n\n2019-12-22 22:10:01 (19.2 MB/s) - ‘../data/aclImdb_v1.tar.gz’ saved [84125825/84125825]\n\n"
]
],
[
[
"## Step 2: Preparing and Processing the data\n\nAlso, as in the XGBoost notebook, we will be doing some initial data processing. The first few steps are the same as in the XGBoost example. To begin with, we will read in each of the reviews and combine them into a single input structure. Then, we will split the dataset into a training set and a testing set.",
"_____no_output_____"
]
],
[
[
"import os\nimport glob\n\ndef read_imdb_data(data_dir='../data/aclImdb'):\n data = {}\n labels = {}\n \n for data_type in ['train', 'test']:\n data[data_type] = {}\n labels[data_type] = {}\n \n for sentiment in ['pos', 'neg']:\n data[data_type][sentiment] = []\n labels[data_type][sentiment] = []\n \n path = os.path.join(data_dir, data_type, sentiment, '*.txt')\n files = glob.glob(path)\n \n for f in files:\n with open(f) as review:\n data[data_type][sentiment].append(review.read())\n # Here we represent a positive review by '1' and a negative review by '0'\n labels[data_type][sentiment].append(1 if sentiment == 'pos' else 0)\n \n assert len(data[data_type][sentiment]) == len(labels[data_type][sentiment]), \\\n \"{}/{} data size does not match labels size\".format(data_type, sentiment)\n \n return data, labels",
"_____no_output_____"
],
[
"data, labels = read_imdb_data()\nprint(\"IMDB reviews: train = {} pos / {} neg, test = {} pos / {} neg\".format(\n len(data['train']['pos']), len(data['train']['neg']),\n len(data['test']['pos']), len(data['test']['neg'])))",
"IMDB reviews: train = 12500 pos / 12500 neg, test = 12500 pos / 12500 neg\n"
]
],
[
[
"Now that we've read the raw training and testing data from the downloaded dataset, we will combine the positive and negative reviews and shuffle the resulting records.",
"_____no_output_____"
]
],
[
[
"from sklearn.utils import shuffle\n\ndef prepare_imdb_data(data, labels):\n \"\"\"Prepare training and test sets from IMDb movie reviews.\"\"\"\n \n #Combine positive and negative reviews and labels\n data_train = data['train']['pos'] + data['train']['neg']\n data_test = data['test']['pos'] + data['test']['neg']\n labels_train = labels['train']['pos'] + labels['train']['neg']\n labels_test = labels['test']['pos'] + labels['test']['neg']\n \n #Shuffle reviews and corresponding labels within training and test sets\n data_train, labels_train = shuffle(data_train, labels_train)\n data_test, labels_test = shuffle(data_test, labels_test)\n \n # Return a unified training data, test data, training labels, test labets\n return data_train, data_test, labels_train, labels_test",
"_____no_output_____"
],
[
"train_X, test_X, train_y, test_y = prepare_imdb_data(data, labels)\nprint(\"IMDb reviews (combined): train = {}, test = {}\".format(len(train_X), len(test_X)))",
"IMDb reviews (combined): train = 25000, test = 25000\n"
]
],
[
[
"Now that we have our training and testing sets unified and prepared, we should do a quick check and see an example of the data our model will be trained on. This is generally a good idea as it allows you to see how each of the further processing steps affects the reviews and it also ensures that the data has been loaded correctly.",
"_____no_output_____"
]
],
[
[
"print(train_X[100])\nprint(train_y[100])",
"This movie was released by Roger Corman, so you know that the filmmakers didn't have much money to work with.<br /><br />Although, some viewers may miss the subtleties in this movie because of the very typical \"obsessed killer\" type marketing approach, there are unique differences about this movie.<br /><br />AMANDA, as played by the obviously talented Justine Priestley, is a complex character. Some people like these movies precisely because the violence can seem random, but here the ramifications of past abuse (dealt with in a realistic but tasteful manner) are what shape the psychosis of AMANDA. Surprisingly, Amanda redeems herself at the end with an act of love, where most of these movies turn into the typical, all out fight to the death and the evil character dies just as evil in the end as to begin with.<br /><br />Some rough edges in this picture, but I have to give it 7 out of 10 stars based on its thoughtfulness and yes, originality as compared to the usual -- especially on a budget.\n1\n"
]
],
[
[
"The first step in processing the reviews is to make sure that any html tags that appear should be removed. In addition we wish to tokenize our input, that way words such as *entertained* and *entertaining* are considered the same with regard to sentiment analysis.",
"_____no_output_____"
]
],
[
[
"import nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem.porter import *\n\nimport re\nfrom bs4 import BeautifulSoup\n\ndef review_to_words(review):\n nltk.download(\"stopwords\", quiet=True)\n stemmer = PorterStemmer()\n \n text = BeautifulSoup(review, \"html.parser\").get_text() # Remove HTML tags\n text = re.sub(r\"[^a-zA-Z0-9]\", \" \", text.lower()) # Convert to lower case\n words = text.split() # Split string into words\n words = [w for w in words if w not in stopwords.words(\"english\")] # Remove stopwords\n words = [PorterStemmer().stem(w) for w in words] # stem\n \n return words",
"_____no_output_____"
]
],
[
[
"The `review_to_words` method defined above uses `BeautifulSoup` to remove any html tags that appear and uses the `nltk` package to tokenize the reviews. As a check to ensure we know how everything is working, try applying `review_to_words` to one of the reviews in the training set.",
"_____no_output_____"
]
],
[
[
"# TODO: Apply review_to_words to a review (train_X[100] or any other review)\n\nreview_to_words(train_X[100])",
"_____no_output_____"
]
],
[
[
"**Question:** Above we mentioned that `review_to_words` method removes html formatting and allows us to tokenize the words found in a review, for example, converting *entertained* and *entertaining* into *entertain* so that they are treated as though they are the same word. What else, if anything, does this method do to the input?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
],
[
"The method below applies the `review_to_words` method to each of the reviews in the training and testing datasets. In addition it caches the results. This is because performing this processing step can take a long time. This way if you are unable to complete the notebook in the current session, you can come back without needing to process the data a second time.",
"_____no_output_____"
]
],
[
[
"import pickle\n\ncache_dir = os.path.join(\"../cache\", \"sentiment_analysis\") # where to store cache files\nos.makedirs(cache_dir, exist_ok=True) # ensure cache directory exists\n\ndef preprocess_data(data_train, data_test, labels_train, labels_test,\n cache_dir=cache_dir, cache_file=\"preprocessed_data.pkl\"):\n \"\"\"Convert each review to words; read from cache if available.\"\"\"\n\n # If cache_file is not None, try to read from it first\n cache_data = None\n if cache_file is not None:\n try:\n with open(os.path.join(cache_dir, cache_file), \"rb\") as f:\n cache_data = pickle.load(f)\n print(\"Read preprocessed data from cache file:\", cache_file)\n except:\n pass # unable to read from cache, but that's okay\n \n # If cache is missing, then do the heavy lifting\n if cache_data is None:\n # Preprocess training and test data to obtain words for each review\n #words_train = list(map(review_to_words, data_train))\n #words_test = list(map(review_to_words, data_test))\n words_train = [review_to_words(review) for review in data_train]\n words_test = [review_to_words(review) for review in data_test]\n \n # Write to cache file for future runs\n if cache_file is not None:\n cache_data = dict(words_train=words_train, words_test=words_test,\n labels_train=labels_train, labels_test=labels_test)\n with open(os.path.join(cache_dir, cache_file), \"wb\") as f:\n pickle.dump(cache_data, f)\n print(\"Wrote preprocessed data to cache file:\", cache_file)\n else:\n # Unpack data loaded from cache file\n words_train, words_test, labels_train, labels_test = (cache_data['words_train'],\n cache_data['words_test'], cache_data['labels_train'], cache_data['labels_test'])\n \n return words_train, words_test, labels_train, labels_test",
"_____no_output_____"
],
[
"# Preprocess data\ntrain_X, test_X, train_y, test_y = preprocess_data(train_X, test_X, train_y, test_y)",
"Read preprocessed data from cache file: preprocessed_data.pkl\n"
]
],
[
[
"## Transform the data\n\nIn the XGBoost notebook we transformed the data from its word representation to a bag-of-words feature representation. For the model we are going to construct in this notebook we will construct a feature representation which is very similar. To start, we will represent each word as an integer. Of course, some of the words that appear in the reviews occur very infrequently and so likely don't contain much information for the purposes of sentiment analysis. The way we will deal with this problem is that we will fix the size of our working vocabulary and we will only include the words that appear most frequently. We will then combine all of the infrequent words into a single category and, in our case, we will label it as `1`.\n\nSince we will be using a recurrent neural network, it will be convenient if the length of each review is the same. To do this, we will fix a size for our reviews and then pad short reviews with the category 'no word' (which we will label `0`) and truncate long reviews.",
"_____no_output_____"
],
[
"### (TODO) Create a word dictionary\n\nTo begin with, we need to construct a way to map words that appear in the reviews to integers. Here we fix the size of our vocabulary (including the 'no word' and 'infrequent' categories) to be `5000` but you may wish to change this to see how it affects the model.\n\n> **TODO:** Complete the implementation for the `build_dict()` method below. Note that even though the vocab_size is set to `5000`, we only want to construct a mapping for the most frequently appearing `4998` words. This is because we want to reserve the special labels `0` for 'no word' and `1` for 'infrequent word'.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef build_dict(data, vocab_size = 5000):\n \"\"\"Construct and return a dictionary mapping each of the most frequently appearing words to a unique integer.\"\"\"\n \n # TODO: Determine how often each word appears in `data`. Note that `data` is a list of sentences and that a\n # sentence is a list of words.\n \n word_count = {} # A dict storing the words that appear in the reviews along with how often they occur\n \n for sentence in data:\n for word in sentence:\n if word in word_count:\n word_count[word]+=1\n else:\n word_count[word]=1\n \n \n # TODO: Sort the words found in `data` so that sorted_words[0] is the most frequently appearing word and\n # sorted_words[-1] is the least frequently appearing word.\n \n sorted_words = sorted(word_count, key=word_count.get,reverse=True)\n \n word_dict = {} # This is what we are building, a dictionary that translates words into integers\n for idx, word in enumerate(sorted_words[:vocab_size - 2]): # The -2 is so that we save room for the 'no word'\n word_dict[word] = idx + 2 # 'infrequent' labels\n \n return word_dict",
"_____no_output_____"
],
[
"word_dict = build_dict(train_X)",
"_____no_output_____"
]
],
[
[
"**Question:** What are the five most frequently appearing (tokenized) words in the training set? Does it makes sense that these words appear frequently in the training set?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
]
],
[
[
"# TODO: Use this space to determine the five most frequently appearing words in the training set.\n\ncount = 0\n\nfor word, idx in word_dict.items():\n print(word)\n count+=1\n \n if count==5:\n break;",
"movi\nfilm\none\nlike\ntime\n"
]
],
[
[
"### Save `word_dict`\n\nLater on when we construct an endpoint which processes a submitted review we will need to make use of the `word_dict` which we have created. As such, we will save it to a file now for future use.",
"_____no_output_____"
]
],
[
[
"data_dir = '../data/pytorch' # The folder we will use for storing data\nif not os.path.exists(data_dir): # Make sure that the folder exists\n os.makedirs(data_dir)",
"_____no_output_____"
],
[
"with open(os.path.join(data_dir, 'word_dict.pkl'), \"wb\") as f:\n pickle.dump(word_dict, f)",
"_____no_output_____"
]
],
[
[
"### Transform the reviews\n\nNow that we have our word dictionary which allows us to transform the words appearing in the reviews into integers, it is time to make use of it and convert our reviews to their integer sequence representation, making sure to pad or truncate to a fixed length, which in our case is `500`.",
"_____no_output_____"
]
],
[
[
"def convert_and_pad(word_dict, sentence, pad=500):\n NOWORD = 0 # We will use 0 to represent the 'no word' category\n INFREQ = 1 # and we use 1 to represent the infrequent words, i.e., words not appearing in word_dict\n \n working_sentence = [NOWORD] * pad\n \n for word_index, word in enumerate(sentence[:pad]):\n if word in word_dict:\n working_sentence[word_index] = word_dict[word]\n else:\n working_sentence[word_index] = INFREQ\n \n return working_sentence, min(len(sentence), pad)\n\ndef convert_and_pad_data(word_dict, data, pad=500):\n result = []\n lengths = []\n \n for sentence in data:\n converted, leng = convert_and_pad(word_dict, sentence, pad)\n result.append(converted)\n lengths.append(leng)\n \n return np.array(result), np.array(lengths)",
"_____no_output_____"
],
[
"train_X, train_X_len = convert_and_pad_data(word_dict, train_X)\ntest_X, test_X_len = convert_and_pad_data(word_dict, test_X)",
"_____no_output_____"
]
],
[
[
"As a quick check to make sure that things are working as intended, check to see what one of the reviews in the training set looks like after having been processeed. Does this look reasonable? What is the length of a review in the training set?",
"_____no_output_____"
]
],
[
[
"# Use this cell to examine one of the processed reviews to make sure everything is working as intended.\ntrain_X[0]",
"_____no_output_____"
]
],
[
[
"**Question:** In the cells above we use the `preprocess_data` and `convert_and_pad_data` methods to process both the training and testing set. Why or why not might this be a problem?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
],
[
"## Step 3: Upload the data to S3\n\nAs in the XGBoost notebook, we will need to upload the training dataset to S3 in order for our training code to access it. For now we will save it locally and we will upload to S3 later on.\n\n### Save the processed training dataset locally\n\nIt is important to note the format of the data that we are saving as we will need to know it when we write the training code. In our case, each row of the dataset has the form `label`, `length`, `review[500]` where `review[500]` is a sequence of `500` integers representing the words in the review.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n \npd.concat([pd.DataFrame(train_y), pd.DataFrame(train_X_len), pd.DataFrame(train_X)], axis=1) \\\n .to_csv(os.path.join(data_dir, 'train.csv'), header=False, index=False)",
"_____no_output_____"
]
],
[
[
"### Uploading the training data\n\n\nNext, we need to upload the training data to the SageMaker default S3 bucket so that we can provide access to it while training our model.",
"_____no_output_____"
]
],
[
[
"import sagemaker\n\nsagemaker_session = sagemaker.Session()\n\nbucket = sagemaker_session.default_bucket()\nprefix = 'sagemaker/sentiment_rnn'\n\nrole = sagemaker.get_execution_role()",
"_____no_output_____"
],
[
"input_data = sagemaker_session.upload_data(path=data_dir, bucket=bucket, key_prefix=prefix)",
"_____no_output_____"
]
],
[
[
"**NOTE:** The cell above uploads the entire contents of our data directory. This includes the `word_dict.pkl` file. This is fortunate as we will need this later on when we create an endpoint that accepts an arbitrary review. For now, we will just take note of the fact that it resides in the data directory (and so also in the S3 training bucket) and that we will need to make sure it gets saved in the model directory.",
"_____no_output_____"
],
[
"## Step 4: Build and Train the PyTorch Model\n\nIn the XGBoost notebook we discussed what a model is in the SageMaker framework. In particular, a model comprises three objects\n\n - Model Artifacts,\n - Training Code, and\n - Inference Code,\n \neach of which interact with one another. In the XGBoost example we used training and inference code that was provided by Amazon. Here we will still be using containers provided by Amazon with the added benefit of being able to include our own custom code.\n\nWe will start by implementing our own neural network in PyTorch along with a training script. For the purposes of this project we have provided the necessary model object in the `model.py` file, inside of the `train` folder. You can see the provided implementation by running the cell below.",
"_____no_output_____"
]
],
[
[
"!pygmentize train/model.py",
"\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.nn\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mnn\u001b[39;49;00m\r\n\r\n\u001b[34mclass\u001b[39;49;00m \u001b[04m\u001b[32mLSTMClassifier\u001b[39;49;00m(nn.Module):\r\n \u001b[33m\"\"\"\u001b[39;49;00m\r\n\u001b[33m This is the simple RNN model we will be using to perform Sentiment Analysis.\u001b[39;49;00m\r\n\u001b[33m \"\"\"\u001b[39;49;00m\r\n\r\n \u001b[34mdef\u001b[39;49;00m \u001b[32m__init__\u001b[39;49;00m(\u001b[36mself\u001b[39;49;00m, embedding_dim, hidden_dim, vocab_size):\r\n \u001b[33m\"\"\"\u001b[39;49;00m\r\n\u001b[33m Initialize the model by settingg up the various layers.\u001b[39;49;00m\r\n\u001b[33m \"\"\"\u001b[39;49;00m\r\n \u001b[36msuper\u001b[39;49;00m(LSTMClassifier, \u001b[36mself\u001b[39;49;00m).\u001b[32m__init__\u001b[39;49;00m()\r\n\r\n \u001b[36mself\u001b[39;49;00m.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=\u001b[34m0\u001b[39;49;00m)\r\n \u001b[36mself\u001b[39;49;00m.lstm = nn.LSTM(embedding_dim, hidden_dim)\r\n \u001b[36mself\u001b[39;49;00m.dense = nn.Linear(in_features=hidden_dim, out_features=\u001b[34m1\u001b[39;49;00m)\r\n \u001b[36mself\u001b[39;49;00m.sig = nn.Sigmoid()\r\n \r\n \u001b[36mself\u001b[39;49;00m.word_dict = \u001b[36mNone\u001b[39;49;00m\r\n\r\n \u001b[34mdef\u001b[39;49;00m \u001b[32mforward\u001b[39;49;00m(\u001b[36mself\u001b[39;49;00m, x):\r\n \u001b[33m\"\"\"\u001b[39;49;00m\r\n\u001b[33m Perform a forward pass of our model on some input.\u001b[39;49;00m\r\n\u001b[33m \"\"\"\u001b[39;49;00m\r\n x = x.t()\r\n lengths = x[\u001b[34m0\u001b[39;49;00m,:]\r\n reviews = x[\u001b[34m1\u001b[39;49;00m:,:]\r\n embeds = \u001b[36mself\u001b[39;49;00m.embedding(reviews)\r\n lstm_out, _ = \u001b[36mself\u001b[39;49;00m.lstm(embeds)\r\n out = \u001b[36mself\u001b[39;49;00m.dense(lstm_out)\r\n out = out[lengths - \u001b[34m1\u001b[39;49;00m, \u001b[36mrange\u001b[39;49;00m(\u001b[36mlen\u001b[39;49;00m(lengths))]\r\n \u001b[34mreturn\u001b[39;49;00m \u001b[36mself\u001b[39;49;00m.sig(out.squeeze())\r\n"
]
],
[
[
"The important takeaway from the implementation provided is that there are three parameters that we may wish to tweak to improve the performance of our model. These are the embedding dimension, the hidden dimension and the size of the vocabulary. We will likely want to make these parameters configurable in the training script so that if we wish to modify them we do not need to modify the script itself. We will see how to do this later on. To start we will write some of the training code in the notebook so that we can more easily diagnose any issues that arise.\n\nFirst we will load a small portion of the training data set to use as a sample. It would be very time consuming to try and train the model completely in the notebook as we do not have access to a gpu and the compute instance that we are using is not particularly powerful. However, we can work on a small bit of the data to get a feel for how our training script is behaving.",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.utils.data\n\n# Read in only the first 250 rows\ntrain_sample = pd.read_csv(os.path.join(data_dir, 'train.csv'), header=None, names=None, nrows=250)\n\n# Turn the input pandas dataframe into tensors\ntrain_sample_y = torch.from_numpy(train_sample[[0]].values).float().squeeze()\ntrain_sample_X = torch.from_numpy(train_sample.drop([0], axis=1).values).long()\n\n# Build the dataset\ntrain_sample_ds = torch.utils.data.TensorDataset(train_sample_X, train_sample_y)\n# Build the dataloader\ntrain_sample_dl = torch.utils.data.DataLoader(train_sample_ds, batch_size=50)",
"_____no_output_____"
]
],
[
[
"### (TODO) Writing the training method\n\nNext we need to write the training code itself. This should be very similar to training methods that you have written before to train PyTorch models. We will leave any difficult aspects such as model saving / loading and parameter loading until a little later.",
"_____no_output_____"
]
],
[
[
"def train(model, train_loader, epochs, optimizer, loss_fn, device):\n for epoch in range(1, epochs + 1):\n model.train()\n total_loss = 0\n for batch in train_loader: \n batch_X, batch_y = batch\n \n batch_X = batch_X.to(device)\n batch_y = batch_y.to(device)\n \n # TODO: Complete this train method to train the model provided.\n model.zero_grad()\n output = model.forward(batch_X)\n loss = loss_fn(output, batch_y)\n loss.backward() #using pytorch library\n optimizer.step() #using pytorch library\n \n total_loss += loss.data.item()\n print(\"Epoch: {}, BCELoss: {}\".format(epoch, total_loss / len(train_loader)))",
"_____no_output_____"
]
],
[
[
"Supposing we have the training method above, we will test that it is working by writing a bit of code in the notebook that executes our training method on the small sample training set that we loaded earlier. The reason for doing this in the notebook is so that we have an opportunity to fix any errors that arise early when they are easier to diagnose.",
"_____no_output_____"
]
],
[
[
"import torch.optim as optim\nfrom train.model import LSTMClassifier\n\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nmodel = LSTMClassifier(32, 100, 5000).to(device)\noptimizer = optim.Adam(model.parameters())\nloss_fn = torch.nn.BCELoss()\n\ntrain(model, train_sample_dl, 5, optimizer, loss_fn, device)",
"Epoch: 1, BCELoss: 0.6949066996574402\nEpoch: 2, BCELoss: 0.6848694443702698\nEpoch: 3, BCELoss: 0.6761283159255982\nEpoch: 4, BCELoss: 0.6663175463676453\nEpoch: 5, BCELoss: 0.6540582776069641\n"
]
],
[
[
"In order to construct a PyTorch model using SageMaker we must provide SageMaker with a training script. We may optionally include a directory which will be copied to the container and from which our training code will be run. When the training container is executed it will check the uploaded directory (if there is one) for a `requirements.txt` file and install any required Python libraries, after which the training script will be run.",
"_____no_output_____"
],
[
"### (TODO) Training the model\n\nWhen a PyTorch model is constructed in SageMaker, an entry point must be specified. This is the Python file which will be executed when the model is trained. Inside of the `train` directory is a file called `train.py` which has been provided and which contains most of the necessary code to train our model. The only thing that is missing is the implementation of the `train()` method which you wrote earlier in this notebook.\n\n**TODO**: Copy the `train()` method written above and paste it into the `train/train.py` file where required.\n\nThe way that SageMaker passes hyperparameters to the training script is by way of arguments. These arguments can then be parsed and used in the training script. To see how this is done take a look at the provided `train/train.py` file.",
"_____no_output_____"
]
],
[
[
"from sagemaker.pytorch import PyTorch\n\nestimator = PyTorch(entry_point=\"train.py\",\n source_dir=\"train\",\n role=role,\n framework_version='0.4.0',\n train_instance_count=1,\n train_instance_type='ml.p2.xlarge',\n hyperparameters={\n 'epochs': 10,\n 'hidden_dim': 200,\n })",
"_____no_output_____"
],
[
"estimator.fit({'training': input_data})",
"2019-12-22 22:13:56 Starting - Starting the training job...\n2019-12-22 22:13:58 Starting - Launching requested ML instances...\n2019-12-22 22:14:55 Starting - Preparing the instances for training.........\n2019-12-22 22:16:15 Downloading - Downloading input data...\n2019-12-22 22:16:51 Training - Downloading the training image..\u001b[34mbash: cannot set terminal process group (-1): Inappropriate ioctl for device\u001b[0m\n\u001b[34mbash: no job control in this shell\u001b[0m\n\u001b[34m2019-12-22 22:17:05,493 sagemaker-containers INFO Imported framework sagemaker_pytorch_container.training\u001b[0m\n\u001b[34m2019-12-22 22:17:05,517 sagemaker_pytorch_container.training INFO Block until all host DNS lookups succeed.\u001b[0m\n\u001b[34m2019-12-22 22:17:05,520 sagemaker_pytorch_container.training INFO Invoking user training script.\u001b[0m\n\u001b[34m2019-12-22 22:17:05,757 sagemaker-containers INFO Module train does not provide a setup.py. \u001b[0m\n\u001b[34mGenerating setup.py\u001b[0m\n\u001b[34m2019-12-22 22:17:05,757 sagemaker-containers INFO Generating setup.cfg\u001b[0m\n\u001b[34m2019-12-22 22:17:05,757 sagemaker-containers INFO Generating MANIFEST.in\u001b[0m\n\u001b[34m2019-12-22 22:17:05,758 sagemaker-containers INFO Installing module with the following command:\u001b[0m\n\u001b[34m/usr/bin/python -m pip install -U . -r requirements.txt\u001b[0m\n\u001b[34mProcessing /opt/ml/code\u001b[0m\n\u001b[34mCollecting pandas (from -r requirements.txt (line 1))\n Downloading https://files.pythonhosted.org/packages/74/24/0cdbf8907e1e3bc5a8da03345c23cbed7044330bb8f73bb12e711a640a00/pandas-0.24.2-cp35-cp35m-manylinux1_x86_64.whl (10.0MB)\u001b[0m\n\u001b[34mCollecting numpy (from -r requirements.txt (line 2))\n Downloading https://files.pythonhosted.org/packages/eb/ec/d4b7855249ce87ece79783562dd6101b1f0abf461c25101c2e959d691e68/numpy-1.18.0-cp35-cp35m-manylinux1_x86_64.whl (19.9MB)\u001b[0m\n\u001b[34mCollecting nltk (from -r requirements.txt (line 3))\n Downloading https://files.pythonhosted.org/packages/f6/1d/d925cfb4f324ede997f6d47bea4d9babba51b49e87a767c170b77005889d/nltk-3.4.5.zip (1.5MB)\u001b[0m\n\u001b[34mCollecting beautifulsoup4 (from -r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/3b/c8/a55eb6ea11cd7e5ac4bacdf92bac4693b90d3ba79268be16527555e186f0/beautifulsoup4-4.8.1-py3-none-any.whl (101kB)\u001b[0m\n\u001b[34mCollecting html5lib (from -r requirements.txt (line 5))\n Downloading https://files.pythonhosted.org/packages/a5/62/bbd2be0e7943ec8504b517e62bab011b4946e1258842bc159e5dfde15b96/html5lib-1.0.1-py2.py3-none-any.whl (117kB)\u001b[0m\n\u001b[34mRequirement already satisfied, skipping upgrade: python-dateutil>=2.5.0 in /usr/local/lib/python3.5/dist-packages (from pandas->-r requirements.txt (line 1)) (2.7.5)\u001b[0m\n\u001b[34mCollecting pytz>=2011k (from pandas->-r requirements.txt (line 1))\n Downloading https://files.pythonhosted.org/packages/e7/f9/f0b53f88060247251bf481fa6ea62cd0d25bf1b11a87888e53ce5b7c8ad2/pytz-2019.3-py2.py3-none-any.whl (509kB)\u001b[0m\n\u001b[34mRequirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.5/dist-packages (from nltk->-r requirements.txt (line 3)) (1.11.0)\u001b[0m\n\u001b[34mCollecting soupsieve>=1.2 (from beautifulsoup4->-r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/81/94/03c0f04471fc245d08d0a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl\u001b[0m\n\u001b[34mCollecting webencodings (from html5lib->-r requirements.txt (line 5))\n Downloading https://files.pythonhosted.org/packages/f4/24/2a3e3df732393fed8b3ebf2ec078f05546de641fe1b667ee316ec1dcf3b7/webencodings-0.5.1-py2.py3-none-any.whl\u001b[0m\n\u001b[34mBuilding wheels for collected packages: nltk, train\n Running setup.py bdist_wheel for nltk: started\u001b[0m\n\u001b[34m Running setup.py bdist_wheel for nltk: finished with status 'done'\n Stored in directory: /root/.cache/pip/wheels/96/86/f6/68ab24c23f207c0077381a5e3904b2815136b879538a24b483\n Running setup.py bdist_wheel for train: started\u001b[0m\n\u001b[34m Running setup.py bdist_wheel for train: finished with status 'done'\n Stored in directory: /tmp/pip-ephem-wheel-cache-ki7jpuhk/wheels/35/24/16/37574d11bf9bde50616c67372a334f94fa8356bc7164af8ca3\u001b[0m\n\u001b[34mSuccessfully built nltk train\u001b[0m\n\u001b[34mInstalling collected packages: pytz, numpy, pandas, nltk, soupsieve, beautifulsoup4, webencodings, html5lib, train\n Found existing installation: numpy 1.15.4\n Uninstalling numpy-1.15.4:\u001b[0m\n\n2019-12-22 22:17:04 Training - Training image download completed. Training in progress.\u001b[34m Successfully uninstalled numpy-1.15.4\u001b[0m\n\u001b[34mSuccessfully installed beautifulsoup4-4.8.1 html5lib-1.0.1 nltk-3.4.5 numpy-1.18.0 pandas-0.24.2 pytz-2019.3 soupsieve-1.9.5 train-1.0.0 webencodings-0.5.1\u001b[0m\n\u001b[34mYou are using pip version 18.1, however version 19.3.1 is available.\u001b[0m\n\u001b[34mYou should consider upgrading via the 'pip install --upgrade pip' command.\u001b[0m\n\u001b[34m2019-12-22 22:17:17,861 sagemaker-containers INFO Invoking user script\n\u001b[0m\n\u001b[34mTraining Env:\n\u001b[0m\n\u001b[34m{\n \"input_dir\": \"/opt/ml/input\",\n \"output_data_dir\": \"/opt/ml/output/data\",\n \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n \"hosts\": [\n \"algo-1\"\n ],\n \"channel_input_dirs\": {\n \"training\": \"/opt/ml/input/data/training\"\n },\n \"log_level\": 20,\n \"module_dir\": \"s3://sagemaker-us-east-2-112618881792/sagemaker-pytorch-2019-12-22-22-13-55-989/source/sourcedir.tar.gz\",\n \"additional_framework_parameters\": {},\n \"user_entry_point\": \"train.py\",\n \"module_name\": \"train\",\n \"input_config_dir\": \"/opt/ml/input/config\",\n \"resource_config\": {\n \"network_interface_name\": \"eth0\",\n \"hosts\": [\n \"algo-1\"\n ],\n \"current_host\": \"algo-1\"\n },\n \"model_dir\": \"/opt/ml/model\",\n \"num_cpus\": 4,\n \"output_dir\": \"/opt/ml/output\",\n \"hyperparameters\": {\n \"hidden_dim\": 200,\n \"epochs\": 10\n },\n \"input_data_config\": {\n \"training\": {\n \"RecordWrapperType\": \"None\",\n \"S3DistributionType\": \"FullyReplicated\",\n \"TrainingInputMode\": \"File\"\n }\n },\n \"job_name\": \"sagemaker-pytorch-2019-12-22-22-13-55-989\",\n \"current_host\": \"algo-1\",\n \"network_interface_name\": \"eth0\",\n \"num_gpus\": 1,\n \"framework_module\": \"sagemaker_pytorch_container.training:main\"\u001b[0m\n\u001b[34m}\n\u001b[0m\n\u001b[34mEnvironment variables:\n\u001b[0m\n\u001b[34mPYTHONPATH=/usr/local/bin:/usr/lib/python35.zip:/usr/lib/python3.5:/usr/lib/python3.5/plat-x86_64-linux-gnu:/usr/lib/python3.5/lib-dynload:/usr/local/lib/python3.5/dist-packages:/usr/lib/python3/dist-packages\u001b[0m\n\u001b[34mSM_INPUT_DIR=/opt/ml/input\u001b[0m\n\u001b[34mSM_CHANNEL_TRAINING=/opt/ml/input/data/training\u001b[0m\n\u001b[34mSM_FRAMEWORK_MODULE=sagemaker_pytorch_container.training:main\u001b[0m\n\u001b[34mSM_USER_ENTRY_POINT=train.py\u001b[0m\n\u001b[34mSM_OUTPUT_DATA_DIR=/opt/ml/output/data\u001b[0m\n\u001b[34mSM_NUM_GPUS=1\u001b[0m\n\u001b[34mSM_FRAMEWORK_PARAMS={}\u001b[0m\n\u001b[34mSM_NUM_CPUS=4\u001b[0m\n\u001b[34mSM_NETWORK_INTERFACE_NAME=eth0\u001b[0m\n\u001b[34mSM_CHANNELS=[\"training\"]\u001b[0m\n\u001b[34mSM_LOG_LEVEL=20\u001b[0m\n\u001b[34mSM_CURRENT_HOST=algo-1\u001b[0m\n\u001b[34mSM_MODULE_DIR=s3://sagemaker-us-east-2-112618881792/sagemaker-pytorch-2019-12-22-22-13-55-989/source/sourcedir.tar.gz\u001b[0m\n\u001b[34mSM_HP_HIDDEN_DIM=200\u001b[0m\n\u001b[34mSM_HP_EPOCHS=10\u001b[0m\n\u001b[34mSM_USER_ARGS=[\"--epochs\",\"10\",\"--hidden_dim\",\"200\"]\u001b[0m\n\u001b[34mSM_TRAINING_ENV={\"additional_framework_parameters\":{},\"channel_input_dirs\":{\"training\":\"/opt/ml/input/data/training\"},\"current_host\":\"algo-1\",\"framework_module\":\"sagemaker_pytorch_container.training:main\",\"hosts\":[\"algo-1\"],\"hyperparameters\":{\"epochs\":10,\"hidden_dim\":200},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{\"training\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}},\"input_dir\":\"/opt/ml/input\",\"job_name\":\"sagemaker-pytorch-2019-12-22-22-13-55-989\",\"log_level\":20,\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"s3://sagemaker-us-east-2-112618881792/sagemaker-pytorch-2019-12-22-22-13-55-989/source/sourcedir.tar.gz\",\"module_name\":\"train\",\"network_interface_name\":\"eth0\",\"num_cpus\":4,\"num_gpus\":1,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"},\"user_entry_point\":\"train.py\"}\u001b[0m\n\u001b[34mSM_OUTPUT_DIR=/opt/ml/output\u001b[0m\n\u001b[34mSM_RESOURCE_CONFIG={\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"}\u001b[0m\n\u001b[34mSM_HPS={\"epochs\":10,\"hidden_dim\":200}\u001b[0m\n\u001b[34mSM_MODEL_DIR=/opt/ml/model\u001b[0m\n\u001b[34mSM_HOSTS=[\"algo-1\"]\u001b[0m\n\u001b[34mSM_MODULE_NAME=train\u001b[0m\n\u001b[34mSM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\u001b[0m\n\u001b[34mSM_INPUT_CONFIG_DIR=/opt/ml/input/config\u001b[0m\n\u001b[34mSM_INPUT_DATA_CONFIG={\"training\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}}\n\u001b[0m\n\u001b[34mInvoking script with the following command:\n\u001b[0m\n\u001b[34m/usr/bin/python -m train --epochs 10 --hidden_dim 200\n\n\u001b[0m\n\u001b[34mUsing device cuda.\u001b[0m\n\u001b[34mGet train data loader.\u001b[0m\n"
]
],
[
[
"## Step 5: Testing the model\n\nAs mentioned at the top of this notebook, we will be testing this model by first deploying it and then sending the testing data to the deployed endpoint. We will do this so that we can make sure that the deployed model is working correctly.\n\n## Step 6: Deploy the model for testing\n\nNow that we have trained our model, we would like to test it to see how it performs. Currently our model takes input of the form `review_length, review[500]` where `review[500]` is a sequence of `500` integers which describe the words present in the review, encoded using `word_dict`. Fortunately for us, SageMaker provides built-in inference code for models with simple inputs such as this.\n\nThere is one thing that we need to provide, however, and that is a function which loads the saved model. This function must be called `model_fn()` and takes as its only parameter a path to the directory where the model artifacts are stored. This function must also be present in the python file which we specified as the entry point. In our case the model loading function has been provided and so no changes need to be made.\n\n**NOTE**: When the built-in inference code is run it must import the `model_fn()` method from the `train.py` file. This is why the training code is wrapped in a main guard ( ie, `if __name__ == '__main__':` )\n\nSince we don't need to change anything in the code that was uploaded during training, we can simply deploy the current model as-is.\n\n**NOTE:** When deploying a model you are asking SageMaker to launch an compute instance that will wait for data to be sent to it. As a result, this compute instance will continue to run until *you* shut it down. This is important to know since the cost of a deployed endpoint depends on how long it has been running for.\n\nIn other words **If you are no longer using a deployed endpoint, shut it down!**\n\n**TODO:** Deploy the trained model.",
"_____no_output_____"
]
],
[
[
"# TODO: Deploy the trained model\n\npredictor = estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')",
"--------------------------------------------------------------------------------------!"
]
],
[
[
"## Step 7 - Use the model for testing\n\nOnce deployed, we can read in the test data and send it off to our deployed model to get some results. Once we collect all of the results we can determine how accurate our model is.",
"_____no_output_____"
]
],
[
[
"test_X = pd.concat([pd.DataFrame(test_X_len), pd.DataFrame(test_X)], axis=1)",
"_____no_output_____"
],
[
"# We split the data into chunks and send each chunk seperately, accumulating the results.\n\ndef predict(data, rows=512):\n split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))\n predictions = np.array([])\n for array in split_array:\n predictions = np.append(predictions, predictor.predict(array))\n \n return predictions",
"_____no_output_____"
],
[
"predictions = predict(test_X.values)\npredictions = [round(num) for num in predictions]",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score\naccuracy_score(test_y, predictions)",
"_____no_output_____"
]
],
[
[
"**Question:** How does this model compare to the XGBoost model you created earlier? Why might these two models perform differently on this dataset? Which do *you* think is better for sentiment analysis?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
],
[
"### (TODO) More testing\n\nWe now have a trained model which has been deployed and which we can send processed reviews to and which returns the predicted sentiment. However, ultimately we would like to be able to send our model an unprocessed review. That is, we would like to send the review itself as a string. For example, suppose we wish to send the following review to our model.",
"_____no_output_____"
]
],
[
[
"test_review = 'The simplest pleasures in life are the best, and this film is one of them. Combining a rather basic storyline of love and adventure this movie transcends the usual weekend fair with wit and unmitigated charm.'",
"_____no_output_____"
]
],
[
[
"The question we now need to answer is, how do we send this review to our model?\n\nRecall in the first section of this notebook we did a bunch of data processing to the IMDb dataset. In particular, we did two specific things to the provided reviews.\n - Removed any html tags and stemmed the input\n - Encoded the review as a sequence of integers using `word_dict`\n \nIn order process the review we will need to repeat these two steps.\n\n**TODO**: Using the `review_to_words` and `convert_and_pad` methods from section one, convert `test_review` into a numpy array `test_data` suitable to send to our model. Remember that our model expects input of the form `review_length, review[500]`.",
"_____no_output_____"
]
],
[
[
"# TODO: Convert test_review into a form usable by the model and save the results in test_data\ntest_data = None\ntest_data_review_to_words = review_to_words(test_review)\ntest_data = [np.array(convert_and_pad(word_dict, test_data_review_to_words)[0])]",
"_____no_output_____"
]
],
[
[
"Now that we have processed the review, we can send the resulting array to our model to predict the sentiment of the review.",
"_____no_output_____"
]
],
[
[
"predictor.predict(test_data)",
"_____no_output_____"
]
],
[
[
"Since the return value of our model is close to `1`, we can be certain that the review we submitted is positive.",
"_____no_output_____"
],
[
"### Delete the endpoint\n\nOf course, just like in the XGBoost notebook, once we've deployed an endpoint it continues to run until we tell it to shut down. Since we are done using our endpoint for now, we can delete it.",
"_____no_output_____"
]
],
[
[
"estimator.delete_endpoint()",
"_____no_output_____"
]
],
[
[
"## Step 6 (again) - Deploy the model for the web app\n\nNow that we know that our model is working, it's time to create some custom inference code so that we can send the model a review which has not been processed and have it determine the sentiment of the review.\n\nAs we saw above, by default the estimator which we created, when deployed, will use the entry script and directory which we provided when creating the model. However, since we now wish to accept a string as input and our model expects a processed review, we need to write some custom inference code.\n\nWe will store the code that we write in the `serve` directory. Provided in this directory is the `model.py` file that we used to construct our model, a `utils.py` file which contains the `review_to_words` and `convert_and_pad` pre-processing functions which we used during the initial data processing, and `predict.py`, the file which will contain our custom inference code. Note also that `requirements.txt` is present which will tell SageMaker what Python libraries are required by our custom inference code.\n\nWhen deploying a PyTorch model in SageMaker, you are expected to provide four functions which the SageMaker inference container will use.\n - `model_fn`: This function is the same function that we used in the training script and it tells SageMaker how to load our model.\n - `input_fn`: This function receives the raw serialized input that has been sent to the model's endpoint and its job is to de-serialize and make the input available for the inference code.\n - `output_fn`: This function takes the output of the inference code and its job is to serialize this output and return it to the caller of the model's endpoint.\n - `predict_fn`: The heart of the inference script, this is where the actual prediction is done and is the function which you will need to complete.\n\nFor the simple website that we are constructing during this project, the `input_fn` and `output_fn` methods are relatively straightforward. We only require being able to accept a string as input and we expect to return a single value as output. You might imagine though that in a more complex application the input or output may be image data or some other binary data which would require some effort to serialize.\n\n### (TODO) Writing inference code\n\nBefore writing our custom inference code, we will begin by taking a look at the code which has been provided.",
"_____no_output_____"
]
],
[
[
"!pygmentize serve/predict.py",
"\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36margparse\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mjson\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mos\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mpickle\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36msys\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36msagemaker_containers\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mpandas\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mpd\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mnumpy\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mnp\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.nn\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mnn\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.optim\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36moptim\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.utils.data\u001b[39;49;00m\r\n\r\n\u001b[34mfrom\u001b[39;49;00m \u001b[04m\u001b[36mmodel\u001b[39;49;00m \u001b[34mimport\u001b[39;49;00m LSTMClassifier\r\n\r\n\u001b[34mfrom\u001b[39;49;00m \u001b[04m\u001b[36mutils\u001b[39;49;00m \u001b[34mimport\u001b[39;49;00m review_to_words, convert_and_pad\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32mmodel_fn\u001b[39;49;00m(model_dir):\r\n \u001b[33m\"\"\"Load the PyTorch model from the `model_dir` directory.\"\"\"\u001b[39;49;00m\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m\"\u001b[39;49;00m\u001b[33mLoading model.\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n\r\n \u001b[37m# First, load the parameters used to create the model.\u001b[39;49;00m\r\n model_info = {}\r\n model_info_path = os.path.join(model_dir, \u001b[33m'\u001b[39;49;00m\u001b[33mmodel_info.pth\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mwith\u001b[39;49;00m \u001b[36mopen\u001b[39;49;00m(model_info_path, \u001b[33m'\u001b[39;49;00m\u001b[33mrb\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m) \u001b[34mas\u001b[39;49;00m f:\r\n model_info = torch.load(f)\r\n\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m\"\u001b[39;49;00m\u001b[33mmodel_info: {}\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m.format(model_info))\r\n\r\n \u001b[37m# Determine the device and construct the model.\u001b[39;49;00m\r\n device = torch.device(\u001b[33m\"\u001b[39;49;00m\u001b[33mcuda\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m \u001b[34mif\u001b[39;49;00m torch.cuda.is_available() \u001b[34melse\u001b[39;49;00m \u001b[33m\"\u001b[39;49;00m\u001b[33mcpu\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n model = LSTMClassifier(model_info[\u001b[33m'\u001b[39;49;00m\u001b[33membedding_dim\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m], model_info[\u001b[33m'\u001b[39;49;00m\u001b[33mhidden_dim\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m], model_info[\u001b[33m'\u001b[39;49;00m\u001b[33mvocab_size\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m])\r\n\r\n \u001b[37m# Load the store model parameters.\u001b[39;49;00m\r\n model_path = os.path.join(model_dir, \u001b[33m'\u001b[39;49;00m\u001b[33mmodel.pth\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mwith\u001b[39;49;00m \u001b[36mopen\u001b[39;49;00m(model_path, \u001b[33m'\u001b[39;49;00m\u001b[33mrb\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m) \u001b[34mas\u001b[39;49;00m f:\r\n model.load_state_dict(torch.load(f))\r\n\r\n \u001b[37m# Load the saved word_dict.\u001b[39;49;00m\r\n word_dict_path = os.path.join(model_dir, \u001b[33m'\u001b[39;49;00m\u001b[33mword_dict.pkl\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mwith\u001b[39;49;00m \u001b[36mopen\u001b[39;49;00m(word_dict_path, \u001b[33m'\u001b[39;49;00m\u001b[33mrb\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m) \u001b[34mas\u001b[39;49;00m f:\r\n model.word_dict = pickle.load(f)\r\n\r\n model.to(device).eval()\r\n\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m\"\u001b[39;49;00m\u001b[33mDone loading model.\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n \u001b[34mreturn\u001b[39;49;00m model\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32minput_fn\u001b[39;49;00m(serialized_input_data, content_type):\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mDeserializing the input data.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mif\u001b[39;49;00m content_type == \u001b[33m'\u001b[39;49;00m\u001b[33mtext/plain\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m:\r\n data = serialized_input_data.decode(\u001b[33m'\u001b[39;49;00m\u001b[33mutf-8\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mreturn\u001b[39;49;00m data\r\n \u001b[34mraise\u001b[39;49;00m \u001b[36mException\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mRequested unsupported ContentType in content_type: \u001b[39;49;00m\u001b[33m'\u001b[39;49;00m + content_type)\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32moutput_fn\u001b[39;49;00m(prediction_output, accept):\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mSerializing the generated output.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mreturn\u001b[39;49;00m \u001b[36mstr\u001b[39;49;00m(prediction_output)\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32mpredict_fn\u001b[39;49;00m(input_data, model):\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mInferring sentiment of input data.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n\r\n device = torch.device(\u001b[33m\"\u001b[39;49;00m\u001b[33mcuda\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m \u001b[34mif\u001b[39;49;00m torch.cuda.is_available() \u001b[34melse\u001b[39;49;00m \u001b[33m\"\u001b[39;49;00m\u001b[33mcpu\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n \r\n \u001b[34mif\u001b[39;49;00m model.word_dict \u001b[35mis\u001b[39;49;00m \u001b[36mNone\u001b[39;49;00m:\r\n \u001b[34mraise\u001b[39;49;00m \u001b[36mException\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mModel has not been loaded properly, no word_dict.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \r\n \u001b[37m# TODO: Process input_data so that it is ready to be sent to our model.\u001b[39;49;00m\r\n \u001b[37m# You should produce two variables:\u001b[39;49;00m\r\n \u001b[37m# data_X - A sequence of length 500 which represents the converted review\u001b[39;49;00m\r\n \u001b[37m# data_len - The length of the review\u001b[39;49;00m\r\n \r\n \u001b[37m#This is our TODO soulution\u001b[39;49;00m\r\n words = review_to_words(input_data)\r\n data_X, data_len = convert_and_pad(model.word_dict, words)\r\n\r\n \u001b[37m# Using data_X and data_len we construct an appropriate input tensor. Remember\u001b[39;49;00m\r\n \u001b[37m# that our model expects input data of the form 'len, review[500]'.\u001b[39;49;00m\r\n data_pack = np.hstack((data_len, data_X))\r\n data_pack = data_pack.reshape(\u001b[34m1\u001b[39;49;00m, -\u001b[34m1\u001b[39;49;00m)\r\n \r\n data = torch.from_numpy(data_pack)\r\n data = data.to(device)\r\n\r\n \u001b[37m# Make sure to put the model into evaluation mode\u001b[39;49;00m\r\n model.eval()\r\n\r\n \u001b[37m# TODO: Compute the result of applying the model to the input data. The variable `result` should\u001b[39;49;00m\r\n \u001b[37m# be a numpy array which contains a single integer which is either 1 or 0\u001b[39;49;00m\r\n \r\n \u001b[37m#This is our TODO solution\u001b[39;49;00m\r\n \u001b[34mwith\u001b[39;49;00m torch.no_grad():\r\n output = model.forward(data)\r\n\r\n result = np.round(output.numpy())\r\n\r\n \u001b[34mreturn\u001b[39;49;00m result\r\n"
]
],
[
[
"As mentioned earlier, the `model_fn` method is the same as the one provided in the training code and the `input_fn` and `output_fn` methods are very simple and your task will be to complete the `predict_fn` method. Make sure that you save the completed file as `predict.py` in the `serve` directory.\n\n**TODO**: Complete the `predict_fn()` method in the `serve/predict.py` file.",
"_____no_output_____"
],
[
"### Deploying the model\n\nNow that the custom inference code has been written, we will create and deploy our model. To begin with, we need to construct a new PyTorchModel object which points to the model artifacts created during training and also points to the inference code that we wish to use. Then we can call the deploy method to launch the deployment container.\n\n**NOTE**: The default behaviour for a deployed PyTorch model is to assume that any input passed to the predictor is a `numpy` array. In our case we want to send a string so we need to construct a simple wrapper around the `RealTimePredictor` class to accomodate simple strings. In a more complicated situation you may want to provide a serialization object, for example if you wanted to sent image data.",
"_____no_output_____"
]
],
[
[
"from sagemaker.predictor import RealTimePredictor\nfrom sagemaker.pytorch import PyTorchModel\n\nclass StringPredictor(RealTimePredictor):\n def __init__(self, endpoint_name, sagemaker_session):\n super(StringPredictor, self).__init__(endpoint_name, sagemaker_session, content_type='text/plain')\n\nmodel = PyTorchModel(model_data=estimator.model_data,\n role = role,\n framework_version='0.4.0',\n entry_point='predict.py',\n source_dir='serve',\n predictor_cls=StringPredictor)\npredictor = model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')",
"-------------------------------------------------------------------------------------!"
]
],
[
[
"### Testing the model\n\nNow that we have deployed our model with the custom inference code, we should test to see if everything is working. Here we test our model by loading the first `250` positive and negative reviews and send them to the endpoint, then collect the results. The reason for only sending some of the data is that the amount of time it takes for our model to process the input and then perform inference is quite long and so testing the entire data set would be prohibitive.",
"_____no_output_____"
]
],
[
[
"import glob\n\ndef test_reviews(data_dir='../data/aclImdb', stop=250):\n \n results = []\n ground = []\n \n # We make sure to test both positive and negative reviews \n for sentiment in ['pos', 'neg']:\n \n path = os.path.join(data_dir, 'test', sentiment, '*.txt')\n files = glob.glob(path)\n \n files_read = 0\n \n print('Starting ', sentiment, ' files')\n \n # Iterate through the files and send them to the predictor\n for f in files:\n with open(f) as review:\n # First, we store the ground truth (was the review positive or negative)\n if sentiment == 'pos':\n ground.append(1)\n else:\n ground.append(0)\n # Read in the review and convert to 'utf-8' for transmission via HTTP\n review_input = review.read().encode('utf-8')\n # Send the review to the predictor and store the results\n results.append(float(predictor.predict(review_input)))\n \n # Sending reviews to our endpoint one at a time takes a while so we\n # only send a small number of reviews\n files_read += 1\n if files_read == stop:\n break\n \n return ground, results",
"_____no_output_____"
],
[
"ground, results = test_reviews()",
"Starting pos files\nStarting neg files\n"
],
[
"from sklearn.metrics import accuracy_score\naccuracy_score(ground, results)",
"_____no_output_____"
]
],
[
[
"As an additional test, we can try sending the `test_review` that we looked at earlier.",
"_____no_output_____"
]
],
[
[
"predictor.predict(test_review)",
"_____no_output_____"
]
],
[
[
"Now that we know our endpoint is working as expected, we can set up the web page that will interact with it. If you don't have time to finish the project now, make sure to skip down to the end of this notebook and shut down your endpoint. You can deploy it again when you come back.",
"_____no_output_____"
],
[
"## Step 7 (again): Use the model for the web app\n\n> **TODO:** This entire section and the next contain tasks for you to complete, mostly using the AWS console.\n\nSo far we have been accessing our model endpoint by constructing a predictor object which uses the endpoint and then just using the predictor object to perform inference. What if we wanted to create a web app which accessed our model? The way things are set up currently makes that not possible since in order to access a SageMaker endpoint the app would first have to authenticate with AWS using an IAM role which included access to SageMaker endpoints. However, there is an easier way! We just need to use some additional AWS services.\n\n<img src=\"Web App Diagram.svg\">\n\nThe diagram above gives an overview of how the various services will work together. On the far right is the model which we trained above and which is deployed using SageMaker. On the far left is our web app that collects a user's movie review, sends it off and expects a positive or negative sentiment in return.\n\nIn the middle is where some of the magic happens. We will construct a Lambda function, which you can think of as a straightforward Python function that can be executed whenever a specified event occurs. We will give this function permission to send and recieve data from a SageMaker endpoint.\n\nLastly, the method we will use to execute the Lambda function is a new endpoint that we will create using API Gateway. This endpoint will be a url that listens for data to be sent to it. Once it gets some data it will pass that data on to the Lambda function and then return whatever the Lambda function returns. Essentially it will act as an interface that lets our web app communicate with the Lambda function.\n\n### Setting up a Lambda function\n\nThe first thing we are going to do is set up a Lambda function. This Lambda function will be executed whenever our public API has data sent to it. When it is executed it will receive the data, perform any sort of processing that is required, send the data (the review) to the SageMaker endpoint we've created and then return the result.\n\n#### Part A: Create an IAM Role for the Lambda function\n\nSince we want the Lambda function to call a SageMaker endpoint, we need to make sure that it has permission to do so. To do this, we will construct a role that we can later give the Lambda function.\n\nUsing the AWS Console, navigate to the **IAM** page and click on **Roles**. Then, click on **Create role**. Make sure that the **AWS service** is the type of trusted entity selected and choose **Lambda** as the service that will use this role, then click **Next: Permissions**.\n\nIn the search box type `sagemaker` and select the check box next to the **AmazonSageMakerFullAccess** policy. Then, click on **Next: Review**.\n\nLastly, give this role a name. Make sure you use a name that you will remember later on, for example `LambdaSageMakerRole`. Then, click on **Create role**.\n\n#### Part B: Create a Lambda function\n\nNow it is time to actually create the Lambda function.\n\nUsing the AWS Console, navigate to the AWS Lambda page and click on **Create a function**. When you get to the next page, make sure that **Author from scratch** is selected. Now, name your Lambda function, using a name that you will remember later on, for example `sentiment_analysis_func`. Make sure that the **Python 3.6** runtime is selected and then choose the role that you created in the previous part. Then, click on **Create Function**.\n\nOn the next page you will see some information about the Lambda function you've just created. If you scroll down you should see an editor in which you can write the code that will be executed when your Lambda function is triggered. In our example, we will use the code below. \n\n```python\n# We need to use the low-level library to interact with SageMaker since the SageMaker API\n# is not available natively through Lambda.\nimport boto3\n\ndef lambda_handler(event, context):\n\n # The SageMaker runtime is what allows us to invoke the endpoint that we've created.\n runtime = boto3.Session().client('sagemaker-runtime')\n\n # Now we use the SageMaker runtime to invoke our endpoint, sending the review we were given\n response = runtime.invoke_endpoint(EndpointName = '**ENDPOINT NAME HERE**', # The name of the endpoint we created\n ContentType = 'text/plain', # The data format that is expected\n Body = event['body']) # The actual review\n\n # The response is an HTTP response whose body contains the result of our inference\n result = response['Body'].read().decode('utf-8')\n\n return {\n 'statusCode' : 200,\n 'headers' : { 'Content-Type' : 'text/plain', 'Access-Control-Allow-Origin' : '*' },\n 'body' : result\n }\n```\n\nOnce you have copy and pasted the code above into the Lambda code editor, replace the `**ENDPOINT NAME HERE**` portion with the name of the endpoint that we deployed earlier. You can determine the name of the endpoint using the code cell below.",
"_____no_output_____"
]
],
[
[
"# We have done part A step, part B change the:\n#(1) endpoint name and (2) vocab in lambda_function.py\n#After that, try testEvent\n\npredictor.endpoint",
"_____no_output_____"
]
],
[
[
"Once you have added the endpoint name to the Lambda function, click on **Save**. Your Lambda function is now up and running. Next we need to create a way for our web app to execute the Lambda function.\n\n### Setting up API Gateway\n\nNow that our Lambda function is set up, it is time to create a new API using API Gateway that will trigger the Lambda function we have just created.\n\nUsing AWS Console, navigate to **Amazon API Gateway** and then click on **Get started**.\n\nOn the next page, make sure that **New API** is selected and give the new api a name, for example, `sentiment_analysis_api`. Then, click on **Create API**.\n\nNow we have created an API, however it doesn't currently do anything. What we want it to do is to trigger the Lambda function that we created earlier.\n\nSelect the **Actions** dropdown menu and click **Create Method**. A new blank method will be created, select its dropdown menu and select **POST**, then click on the check mark beside it.\n\nFor the integration point, make sure that **Lambda Function** is selected and click on the **Use Lambda Proxy integration**. This option makes sure that the data that is sent to the API is then sent directly to the Lambda function with no processing. It also means that the return value must be a proper response object as it will also not be processed by API Gateway.\n\nType the name of the Lambda function you created earlier into the **Lambda Function** text entry box and then click on **Save**. Click on **OK** in the pop-up box that then appears, giving permission to API Gateway to invoke the Lambda function you created.\n\nThe last step in creating the API Gateway is to select the **Actions** dropdown and click on **Deploy API**. You will need to create a new Deployment stage and name it anything you like, for example `prod`.\n\nYou have now successfully set up a public API to access your SageMaker model. Make sure to copy or write down the URL provided to invoke your newly created public API as this will be needed in the next step. This URL can be found at the top of the page, highlighted in blue next to the text **Invoke URL**.",
"_____no_output_____"
],
[
"## Step 4: Deploying our web app\n\nNow that we have a publicly available API, we can start using it in a web app. For our purposes, we have provided a simple static html file which can make use of the public api you created earlier.\n\nIn the `website` folder there should be a file called `index.html`. Download the file to your computer and open that file up in a text editor of your choice. There should be a line which contains **\\*\\*REPLACE WITH PUBLIC API URL\\*\\***. Replace this string with the url that you wrote down in the last step and then save the file.\n\nNow, if you open `index.html` on your local computer, your browser will behave as a local web server and you can use the provided site to interact with your SageMaker model.\n\nIf you'd like to go further, you can host this html file anywhere you'd like, for example using github or hosting a static site on Amazon's S3. Once you have done this you can share the link with anyone you'd like and have them play with it too!\n\n> **Important Note** In order for the web app to communicate with the SageMaker endpoint, the endpoint has to actually be deployed and running. This means that you are paying for it. Make sure that the endpoint is running when you want to use the web app but that you shut it down when you don't need it, otherwise you will end up with a surprisingly large AWS bill.\n\n**TODO:** Make sure that you include the edited `index.html` file in your project submission.",
"_____no_output_____"
],
[
"Now that your web app is working, trying playing around with it and see how well it works.\n\n**Question**: Give an example of a review that you entered into your web app. What was the predicted sentiment of your example review?",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
],
[
"### Delete the endpoint\n\nRemember to always shut down your endpoint if you are no longer using it. You are charged for the length of time that the endpoint is running so if you forget and leave it on you could end up with an unexpectedly large bill.",
"_____no_output_____"
]
],
[
[
"predictor.delete_endpoint()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4a046bcb3e17be8a02cb3e8df5804f7bc6ffea6b
| 10,789 |
ipynb
|
Jupyter Notebook
|
sagemaker-python-sdk/tensorflow_distributed_mnist/tensorflow_batch_transform_mnist.ipynb
|
Intellagent/amazon-sagemaker-examples
|
80cb4e7e43dc560f3e8febe3dab778a32b1ed0cb
|
[
"Apache-2.0"
] | 3 |
2019-03-26T14:50:17.000Z
|
2019-12-07T13:51:38.000Z
|
sagemaker-python-sdk/tensorflow_distributed_mnist/tensorflow_batch_transform_mnist.ipynb
|
Intellagent/amazon-sagemaker-examples
|
80cb4e7e43dc560f3e8febe3dab778a32b1ed0cb
|
[
"Apache-2.0"
] | null | null | null |
sagemaker-python-sdk/tensorflow_distributed_mnist/tensorflow_batch_transform_mnist.ipynb
|
Intellagent/amazon-sagemaker-examples
|
80cb4e7e43dc560f3e8febe3dab778a32b1ed0cb
|
[
"Apache-2.0"
] | 2 |
2020-02-10T17:33:38.000Z
|
2022-02-24T07:30:18.000Z
| 31.363372 | 557 | 0.602929 |
[
[
[
"# MNIST distributed training and batch transform\n\nThe SageMaker Python SDK helps you deploy your models for training and hosting in optimized, production-ready containers in SageMaker. The SageMaker Python SDK is easy to use, modular, extensible and compatible with TensorFlow and MXNet. This tutorial focuses on how to create a convolutional neural network model to train the [MNIST dataset](http://yann.lecun.com/exdb/mnist/) using TensorFlow distributed training.",
"_____no_output_____"
],
[
"## Set up the environment\n\nFirst, we'll just set up a few things needed for this example",
"_____no_output_____"
]
],
[
[
"import sagemaker\nfrom sagemaker import get_execution_role\nfrom sagemaker.session import Session\n\nsagemaker_session = sagemaker.Session()\nregion = sagemaker_session.boto_session.region_name\n\nrole = get_execution_role()",
"_____no_output_____"
]
],
[
[
"### Download the MNIST dataset\n\nWe'll now need to download the MNIST dataset, and upload it to a location in S3 after preparing for training.",
"_____no_output_____"
]
],
[
[
"import utils\nfrom tensorflow.contrib.learn.python.learn.datasets import mnist\nimport tensorflow as tf\n\ndata_sets = mnist.read_data_sets('data', dtype=tf.uint8, reshape=False, validation_size=5000)\n\nutils.convert_to(data_sets.train, 'train', 'data')\nutils.convert_to(data_sets.validation, 'validation', 'data')\nutils.convert_to(data_sets.test, 'test', 'data')",
"_____no_output_____"
]
],
[
[
"### Upload the data\nWe use the ```sagemaker.Session.upload_data``` function to upload our datasets to an S3 location. The return value inputs identifies the location -- we will use this later when we start the training job.",
"_____no_output_____"
]
],
[
[
"inputs = sagemaker_session.upload_data(path='data', key_prefix='data/DEMO-mnist')",
"_____no_output_____"
]
],
[
[
"# Construct a script for distributed training \nHere is the full code for the network model:",
"_____no_output_____"
]
],
[
[
"!cat 'mnist.py'",
"_____no_output_____"
]
],
[
[
"## Create a training job",
"_____no_output_____"
]
],
[
[
"from sagemaker.tensorflow import TensorFlow\n\nmnist_estimator = TensorFlow(entry_point='mnist.py',\n role=role,\n framework_version='1.11.0',\n training_steps=1000, \n evaluation_steps=100,\n train_instance_count=2,\n train_instance_type='ml.c4.xlarge')\n\nmnist_estimator.fit(inputs)",
"_____no_output_____"
]
],
[
[
"The `fit()` method will create a training job in two ml.c4.xlarge instances. The logs above will show the instances doing training, evaluation, and incrementing the number of training steps. \n\nIn the end of the training, the training job will generate a saved model for TF serving.",
"_____no_output_____"
],
[
"## SageMaker's transformer class\n\nAfter training, we use our TensorFlow estimator object to create a `Transformer` by invoking the `transformer()` method. This method takes arguments for configuring our options with the batch transform job; these do not need to be the same values as the one we used for the training job. The method also creates a SageMaker Model to be used for the batch transform jobs.\n\nThe `Transformer` class is responsible for running batch transform jobs, which will deploy the trained model to an endpoint and send requests for performing inference.",
"_____no_output_____"
]
],
[
[
"transformer = mnist_estimator.transformer(instance_count=1, instance_type='ml.m4.xlarge')",
"_____no_output_____"
]
],
[
[
"# Perform inference\n\nNow that we've trained a model, we're going to use it to perform inference with a SageMaker batch transform job. The request handling behavior of the Endpoint deployed during the transform job is determined by the `mnist.py` script we looked at earlier.",
"_____no_output_____"
],
[
"## Run a batch transform job\n\nFor our batch transform job, we're going to use input data that contains 1000 MNIST images, located in the public SageMaker sample data S3 bucket. To create the batch transform job, we simply call `transform()` on our transformer with information about the input data.",
"_____no_output_____"
]
],
[
[
"input_bucket_name = 'sagemaker-sample-data-{}'.format(region)\ninput_file_path = 'batch-transform/mnist-1000-samples'\n\ntransformer.transform('s3://{}/{}'.format(input_bucket_name, input_file_path), content_type='text/csv')",
"_____no_output_____"
]
],
[
[
"Now we wait for the batch transform job to complete. We have a convenience method, `wait()`, that will block until the batch transform job has completed. We can call that here to see if the batch transform job is still running; the cell will finish running when the batch transform job has completed.",
"_____no_output_____"
]
],
[
[
"transformer.wait()",
"_____no_output_____"
]
],
[
[
"## Download the results\n\nThe batch transform job uploads its predictions to S3. Since we did not specify `output_path` when creating the Transformer, one was generated based on the batch transform job name:",
"_____no_output_____"
]
],
[
[
"print(transformer.output_path)",
"_____no_output_____"
]
],
[
[
"Now let's download the first ten results from S3:",
"_____no_output_____"
]
],
[
[
"import json\nfrom six.moves.urllib import parse\n\nimport boto3\n\nparsed_url = parse.urlparse(transformer.output_path)\nbucket_name = parsed_url.netloc\nprefix = parsed_url.path[1:]\n\ns3 = boto3.resource('s3')\n\npredictions = []\nfor i in range(10):\n file_key = '{}/data-{}.csv.out'.format(prefix, i)\n\n output_obj = s3.Object(bucket_name, file_key)\n output = output_obj.get()[\"Body\"].read().decode('utf-8')\n\n predictions.extend(json.loads(output)['outputs']['classes']['int64Val'])",
"_____no_output_____"
]
],
[
[
"For demonstration purposes, we're also going to download the corresponding original input data so that we can see how the model did with its predictions.",
"_____no_output_____"
]
],
[
[
"import os\n\nimport matplotlib.pyplot as plt\nfrom numpy import genfromtxt\n\nplt.rcParams['figure.figsize'] = (2,10)\n\ndef show_digit(img, caption='', subplot=None):\n if subplot == None:\n _,(subplot) = plt.subplots(1,1)\n imgr = img.reshape((28,28))\n subplot.axis('off')\n subplot.imshow(imgr, cmap='gray')\n plt.title(caption)\n\ntmp_dir = '/tmp/data'\nif not os.path.exists(tmp_dir):\n os.makedirs(tmp_dir)\n\nfor i in range(10):\n input_file_name = 'data-{}.csv'.format(i)\n input_file_key = '{}/{}'.format(input_file_path, input_file_name)\n \n s3.Bucket(input_bucket_name).download_file(input_file_key, os.path.join(tmp_dir, input_file_name))\n input_data = genfromtxt(os.path.join(tmp_dir, input_file_name), delimiter=',')\n\n show_digit(input_data)",
"_____no_output_____"
]
],
[
[
"Here, we can see the original labels are:\n\n```\n7, 2, 1, 0, 4, 1, 4, 9, 5, 9\n```\n\nNow let's print out the predictions to compare:",
"_____no_output_____"
]
],
[
[
"print(', '.join(predictions))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a0477e3bbe76289d39123e265a63018cd6f0c71
| 14,281 |
ipynb
|
Jupyter Notebook
|
site/en/tutorials/customization/basics.ipynb
|
DorianKodelja/docs
|
186899c6252048b5a4f5cf89cc33e4dcc8426e5f
|
[
"Apache-2.0"
] | 3 |
2020-09-23T14:09:41.000Z
|
2020-09-23T19:26:32.000Z
|
site/en/tutorials/customization/basics.ipynb
|
DorianKodelja/docs
|
186899c6252048b5a4f5cf89cc33e4dcc8426e5f
|
[
"Apache-2.0"
] | 1 |
2021-02-23T20:17:39.000Z
|
2021-02-23T20:17:39.000Z
|
site/en/tutorials/customization/basics.ipynb
|
DorianKodelja/docs
|
186899c6252048b5a4f5cf89cc33e4dcc8426e5f
|
[
"Apache-2.0"
] | null | null | null | 35.34901 | 627 | 0.549471 |
[
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Customization basics: tensors and operations",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/customization/basics\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/customization/basics.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/customization/basics.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/customization/basics.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"This is an introductory TensorFlow tutorial that shows how to:\n\n* Import the required package\n* Create and use tensors\n* Use GPU acceleration\n* Demonstrate `tf.data.Dataset`",
"_____no_output_____"
],
[
"## Import TensorFlow\n\nTo get started, import the `tensorflow` module. As of TensorFlow 2, eager execution is turned on by default. This enables a more interactive frontend to TensorFlow, the details of which we will discuss much later.",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf",
"_____no_output_____"
]
],
[
[
"## Tensors\n\nA Tensor is a multi-dimensional array. Similar to NumPy `ndarray` objects, `tf.Tensor` objects have a data type and a shape. Additionally, `tf.Tensor`s can reside in accelerator memory (like a GPU). TensorFlow offers a rich library of operations ([tf.add](https://www.tensorflow.org/api_docs/python/tf/add), [tf.matmul](https://www.tensorflow.org/api_docs/python/tf/matmul), [tf.linalg.inv](https://www.tensorflow.org/api_docs/python/tf/linalg/inv) etc.) that consume and produce `tf.Tensor`s. These operations automatically convert native Python types, for example:\n",
"_____no_output_____"
]
],
[
[
"print(tf.add(1, 2))\nprint(tf.add([1, 2], [3, 4]))\nprint(tf.square(5))\nprint(tf.reduce_sum([1, 2, 3]))\n\n# Operator overloading is also supported\nprint(tf.square(2) + tf.square(3))",
"_____no_output_____"
]
],
[
[
"Each `tf.Tensor` has a shape and a datatype:",
"_____no_output_____"
]
],
[
[
"x = tf.matmul([[1]], [[2, 3]])\nprint(x)\nprint(x.shape)\nprint(x.dtype)",
"_____no_output_____"
]
],
[
[
"The most obvious differences between NumPy arrays and `tf.Tensor`s are:\n\n1. Tensors can be backed by accelerator memory (like GPU, TPU).\n2. Tensors are immutable.",
"_____no_output_____"
],
[
"### NumPy Compatibility\n\nConverting between a TensorFlow `tf.Tensor`s and a NumPy `ndarray` is easy:\n\n* TensorFlow operations automatically convert NumPy ndarrays to Tensors.\n* NumPy operations automatically convert Tensors to NumPy ndarrays.\n\nTensors are explicitly converted to NumPy ndarrays using their `.numpy()` method. These conversions are typically cheap since the array and `tf.Tensor` share the underlying memory representation, if possible. However, sharing the underlying representation isn't always possible since the `tf.Tensor` may be hosted in GPU memory while NumPy arrays are always backed by host memory, and the conversion involves a copy from GPU to host memory.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nndarray = np.ones([3, 3])\n\nprint(\"TensorFlow operations convert numpy arrays to Tensors automatically\")\ntensor = tf.multiply(ndarray, 42)\nprint(tensor)\n\n\nprint(\"And NumPy operations convert Tensors to numpy arrays automatically\")\nprint(np.add(tensor, 1))\n\nprint(\"The .numpy() method explicitly converts a Tensor to a numpy array\")\nprint(tensor.numpy())",
"_____no_output_____"
]
],
[
[
"## GPU acceleration\n\nMany TensorFlow operations are accelerated using the GPU for computation. Without any annotations, TensorFlow automatically decides whether to use the GPU or CPU for an operation—copying the tensor between CPU and GPU memory, if necessary. Tensors produced by an operation are typically backed by the memory of the device on which the operation executed, for example:",
"_____no_output_____"
]
],
[
[
"x = tf.random.uniform([3, 3])\n\nprint(\"Is there a GPU available: \"),\nprint(tf.config.experimental.list_physical_devices(\"GPU\"))\n\nprint(\"Is the Tensor on GPU #0: \"),\nprint(x.device.endswith('GPU:0'))",
"_____no_output_____"
]
],
[
[
"### Device Names\n\nThe `Tensor.device` property provides a fully qualified string name of the device hosting the contents of the tensor. This name encodes many details, such as an identifier of the network address of the host on which this program is executing and the device within that host. This is required for distributed execution of a TensorFlow program. The string ends with `GPU:<N>` if the tensor is placed on the `N`-th GPU on the host.",
"_____no_output_____"
],
[
"### Explicit Device Placement\n\nIn TensorFlow, *placement* refers to how individual operations are assigned (placed on) a device for execution. As mentioned, when there is no explicit guidance provided, TensorFlow automatically decides which device to execute an operation and copies tensors to that device, if needed. However, TensorFlow operations can be explicitly placed on specific devices using the `tf.device` context manager, for example:",
"_____no_output_____"
]
],
[
[
"import time\n\ndef time_matmul(x):\n start = time.time()\n for loop in range(10):\n tf.matmul(x, x)\n\n result = time.time()-start\n\n print(\"10 loops: {:0.2f}ms\".format(1000*result))\n\n# Force execution on CPU\nprint(\"On CPU:\")\nwith tf.device(\"CPU:0\"):\n x = tf.random.uniform([1000, 1000])\n assert x.device.endswith(\"CPU:0\")\n time_matmul(x)\n\n# Force execution on GPU #0 if available\nif tf.config.experimental.list_physical_devices(\"GPU\"):\n print(\"On GPU:\")\n with tf.device(\"GPU:0\"): # Or GPU:1 for the 2nd GPU, GPU:2 for the 3rd etc.\n x = tf.random.uniform([1000, 1000])\n assert x.device.endswith(\"GPU:0\")\n time_matmul(x)",
"_____no_output_____"
]
],
[
[
"## Datasets\n\nThis section uses the [`tf.data.Dataset` API](https://www.tensorflow.org/guide/datasets) to build a pipeline for feeding data to your model. The `tf.data.Dataset` API is used to build performant, complex input pipelines from simple, re-usable pieces that will feed your model's training or evaluation loops.",
"_____no_output_____"
],
[
"### Create a source `Dataset`\n\nCreate a *source* dataset using one of the factory functions like [`Dataset.from_tensors`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#from_tensors), [`Dataset.from_tensor_slices`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#from_tensor_slices), or using objects that read from files like [`TextLineDataset`](https://www.tensorflow.org/api_docs/python/tf/data/TextLineDataset) or [`TFRecordDataset`](https://www.tensorflow.org/api_docs/python/tf/data/TFRecordDataset). See the [TensorFlow Dataset guide](https://www.tensorflow.org/guide/datasets#reading_input_data) for more information.",
"_____no_output_____"
]
],
[
[
"ds_tensors = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5, 6])\n\n# Create a CSV file\nimport tempfile\n_, filename = tempfile.mkstemp()\n\nwith open(filename, 'w') as f:\n f.write(\"\"\"Line 1\nLine 2\nLine 3\n \"\"\")\n\nds_file = tf.data.TextLineDataset(filename)",
"_____no_output_____"
]
],
[
[
"### Apply transformations\n\nUse the transformations functions like [`map`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#map), [`batch`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#batch), and [`shuffle`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#shuffle) to apply transformations to dataset records.",
"_____no_output_____"
]
],
[
[
"ds_tensors = ds_tensors.map(tf.square).shuffle(2).batch(2)\n\nds_file = ds_file.batch(2)",
"_____no_output_____"
]
],
[
[
"### Iterate\n\n`tf.data.Dataset` objects support iteration to loop over records:",
"_____no_output_____"
]
],
[
[
"print('Elements of ds_tensors:')\nfor x in ds_tensors:\n print(x)\n\nprint('\\nElements in ds_file:')\nfor x in ds_file:\n print(x)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a048e909cf7c9ca4847197017eb30a2dbbdc99d
| 260,920 |
ipynb
|
Jupyter Notebook
|
hw05/lesson_05/.ipynb_checkpoints/SkillFactory_20180216-checkpoint.ipynb
|
rojaster/sfml
|
a82b7c7330faa52569f17bddebc4e51204bb4f01
|
[
"Naumen",
"Condor-1.1",
"MS-PL"
] | null | null | null |
hw05/lesson_05/.ipynb_checkpoints/SkillFactory_20180216-checkpoint.ipynb
|
rojaster/sfml
|
a82b7c7330faa52569f17bddebc4e51204bb4f01
|
[
"Naumen",
"Condor-1.1",
"MS-PL"
] | null | null | null |
hw05/lesson_05/.ipynb_checkpoints/SkillFactory_20180216-checkpoint.ipynb
|
rojaster/sfml
|
a82b7c7330faa52569f17bddebc4e51204bb4f01
|
[
"Naumen",
"Condor-1.1",
"MS-PL"
] | null | null | null | 204.162754 | 73,248 | 0.766162 |
[
[
[
"Давайте решим следующую задачу.<br>\nНеобходимо написать робота, который будет скачивать новости с сайта Лента.Ру и фильтровать их в зависимости от интересов пользователя. От пользователя требуется отмечать интересующие его новости, по которым система будет выделять области его интересов.<br>\nДля начала давайте разберемся с обработкой собственно текстов. Самостоятельно это можно сделать прочитав одну из двух книг: <a href='https://miem.hse.ru/clschool/the_book'>поновее</a> и <a href='http://clschool.miem.edu.ru/uploads/swfupload/files/011a69a6f0c3a9c6291d6d375f12aa27e349cb67.pdf'>постарше</a> (в старой хорошо разобраны классификация и кластеризация, в новой - тематическое моделирование и рядом лежит видео лекций).<br>\nДля обработки текста проводится два этапа анализа: <b>графематический</b> (выделение предложений и слов) и <b>морфологический</b> (определение начальной формы слова, его части речи и грамматических параметров). Этап синтаксического анализа мы разбирать не будем, так как его информация требуется не всегда.<br>\nЗадачей графематического анализа является разделение текста на составные части - врезки, абзацы, предложения, слова. В таких задачах как машинный перевод, точность данного этапа может существенно влиять на точность получаемых результатов. Например, точка, используемая для сокращений, может быть воспринята как конец предложения, что полность разорвет его семантику.<br>\nНо в некоторых задачах (например нашей) используется подход <b>\"мешок слов\"</b> - текст воспринимается как неупорядоченное множество слов, для которых можно просто посчитать их частотность в тексте. Данный подход проще реализовать, для него не нужно делать выделение составных частей текста, а необходимо только выделить слова. Именно этот подход мы и будем использовать.<br>\nВ путь!",
"_____no_output_____"
]
],
[
[
"import re # Регулярные выражения.\nimport requests # Загрузка новостей с сайта.\nfrom bs4 import BeautifulSoup # Превращалка html в текст.\nimport pymorphy2 # Морфологический анализатор.\nimport datetime # Новости будем перебирать по дате.\nfrom collections import Counter # Не считать же частоты самим.\nimport math # Корень квадратный.",
"_____no_output_____"
]
],
[
[
"Задачей морфологического анализа является определение начальной формы слова, его части речи и грамматических параметров. В некоторых случаях от слова требуется только начальная форма, в других - только начальная форма и часть речи.<br>\nСуществует два больших подхода к морфологическому анализу: <b>стемминг</b> и <b>поиск по словарю</b>. Для проведения стемминга оставляется справочник всех окончаний для данного языка. Для пришедшего слова проверяется его окончание и по нему делается прогноз начальной формы и части речи.<br>\nНапример, мы создаем справочник, в котором записываем все окончания прилагательных: <i>-ому, -ему, -ой, -ая, -ий, -ый, ...</i> Теперь все слова, которые имеют такое окончание будут считаться прилагаельными: <i>синий, циклический, красного, больному</i>. Заодно прилагательными будут считаться причастия (<i>делающий, строившему</i>) и местоимения (<i>мой, твой, твоему</i>). Также не понятно что делать со словами, имеющими пустое окончание. Отдельную проблему составляют такие слова, как <i>стекло, больной, вина</i>, которые могут разбираться несколькими вариантами (это явление называется <b>омонимией</b>). Помимо этого, стеммер может просто откусывать окончания, оставляя лишь псевдооснову.<br>\nБольшинство проблем здесь решается, но точность работы бессловарных стеммеров находится на уровне 80%. Чтобы повысить точность испольуют морфологический анализ со словарем. Разработчики составляют словарь слов, встретившихся в текстах (<a href=\"http://opencorpora.org/dict.php\">здесь</a> можно найти пример такого словаря). Теперь каждое слово будет искаться в словаре и не предсказываться, а выдаваться точно. Для слов, отсутствующих в словаре, может применяться предсказание, пообное работе стеммера.<br>\nПосмотрим как работает словарная морфология на примере системы pymorphy2.",
"_____no_output_____"
]
],
[
[
"morph=pymorphy2.MorphAnalyzer() # Создает объект морфоанализатора и загружет словарь.\nwordform=morph.parse('стекло') # Проведем анализ слова \"стекло\"...\nprint(wordform) # ... и посмотрим на результат.",
"[Parse(word='стекло', tag=OpencorporaTag('NOUN,inan,neut sing,nomn'), normal_form='стекло', score=0.75, methods_stack=((<DictionaryAnalyzer>, 'стекло', 545, 0),)), Parse(word='стекло', tag=OpencorporaTag('NOUN,inan,neut sing,accs'), normal_form='стекло', score=0.1875, methods_stack=((<DictionaryAnalyzer>, 'стекло', 545, 3),)), Parse(word='стекло', tag=OpencorporaTag('VERB,perf,intr neut,sing,past,indc'), normal_form='стечь', score=0.0625, methods_stack=((<DictionaryAnalyzer>, 'стекло', 968, 3),))]\n"
]
],
[
[
"Как видно из вывода, слово \"стекло\" может быть неодушевленным существительным среднего рода, единственного числа, именительного падежа <i>tag=OpencorporaTag('NOUN,inan,neut sing,nomn')</i>, аналогично, но в винительном падеже (<i>'NOUN,inan,neut sing,accs'</i>), и глаголом <i>'VERB,perf,intr neut,sing,past,indc'</i>. При этом в первой форме оно встречается в 75% случаев (<i>score=0.75</i>), во второй в 18,75% случаев (<i>score=0.1875</i>), а как глагол - лишь в 6,25% (<i>score=0.0625</i>). Самым простым видом борьбы с омонимией является выбор нулевого элемента из списка, возвращенного морфологическим анализом. Такой подход дает около 90% точности при выборе начальной формы и до 80% если мы обращаем внимание на грамматические параметры.<br><br>\nТеперь перейдем к загрузке новостей. Для этого нам потребуется метод requests.get(url). Библиотека requests предоставляет серьезные возможности для загрузки информации из Интернет. Метод get получает URL стараницы и возвращает ее содержимое. В нашем случае результат будет получаться в формате html. ",
"_____no_output_____"
]
],
[
[
"requests.get(\"http://lenta.ru/\")",
"_____no_output_____"
]
],
[
[
"Однако количество служебной информации в странице явно превышает объем текста новости. Мы проделаем два шага. На первом мы вырежем только саму новость с ее оформлением используя для этого регулярные выражения (библиотека re). На втором шаге мы используем библиотеку BeautifulSoup для \"выкусыввания\" тегов html.",
"_____no_output_____"
]
],
[
[
"# Компилируем регулярные выражения - так работает быстрее при большом количестве повторов.\nfindheaders = re.compile(\"<h1.+?>(.+)</h1>\", re.S)\nboa = re.compile('<div class=\"b-text clearfix js-topic__text\" itemprop=\"articleBody\">', re.S)\neoa = re.compile('<div class=\"b-box\">\\s*?<i>', re.S)\ndelscript = re.compile(\"<script.*?>.+?</script>\", re.S)\n\ndef getLentaArticle(url):\n # Получает текст страницы.\n art=requests.get(url)\n # Находим заголовок.\n title = findheaders.findall(art.text)[0]\n # Выделяем текст новости.\n text = eoa.split(boa.split(art.text)[1])\n # Иногда новость оканчивается другим набором тегов.\n if len(text)==1:\n text = re.split('<div itemprop=\"author\" itemscope=\"\"', text[0])\n # Выкусываем скрипты - BeautifulSoup не справляетсяя с ними.\n text = \"\".join(delscript.split(text[0]))\n # Выкусываем остальные теги.\n return BeautifulSoup(title+\"\\n-----\\n\"+text, \"lxml\").get_text()\n\nart_text = getLentaArticle(\"https://lenta.ru/news/2018/02/15/greben/\")\nprint(art_text)",
"Гребенщиков обматерил «лживый» фильм Серебренникова о Цое\n-----\nЛидер группы «Аквариум» Борис Гребенщиков нецензурно раскритиковал еще не вышедший фильм Кирилла Серебренникова «Лето». Его слова приводит портал MR7.ru в четверг, 15 февраля.«Сценарий — ложь от начала до конца. Мы жили по-другому. В его сценарии московские хипстеры, которые кроме как [совокупляться] за чужой счет, больше ничего не умеют. Сценарий писал человек с другой планеты. Мне кажется, в те времена сценарист бы работал в КГБ», — подчеркнул Гребенщиков.Музыкант также выразил надежду, что Серебренникова, находящегося под домашним арестом по делу о хищении бюджетных средств, освободят.Материалы по теме18:26 — 23 августа 2017«Клетка — всегда плохо»Дело Кирилла Серебренникова: реакция общественности и соцсетейРанее в феврале продюсеры «Лета» огласили актерский состав фильма. Одну из главных ролей — фронтмена рок-коллектива «Зоопарк» Майка Науменко — исполнил Рома Зверь из группы «Звери». Картина рассказывает малоизвестную историю отношений Науменко, его жены Натальи и Виктора Цоя. Сюжет разворачивается летом 1981 года в Ленинграде. Дата выхода фильма пока не раскрывается.Серебренникова поместили под домашний арест 23 августа 2017 года.\n"
]
],
[
[
"Для новостной заметки можно составить ее словарь, а также посчитать частоты всех слов. В итоге мы получим представление текста в виде вектора. В этом векторе координаты будут называться по соответствующим словам, а смещение по данной координате будет показывать частота. <br>\nПри составлении словаря будем учитывать только значимые слова - существительные, прилагательные и глаголы. Помимо этого предусмотрим возможность учитывать часть речи слова, прибавляя ее у начальной форме.<br>\nДля разделения текста на слова используем простейший алгоритм: слово - это последовательность букв русского алфавита среди которых может попадаться дефис. ",
"_____no_output_____"
]
],
[
[
"posConv={'ADJF':'_ADJ','NOUN':'_NOUN','VERB':'_VERB'}\n\ndef getArticleDictionary(text, needPos=None):\n words=[a[0] for a in re.findall(\"([А-ЯЁа-яё]+(-[А-ЯЁа-яё]+)*)\", text)]\n reswords=[]\n\n for w in words:\n wordform=morph.parse(w)[0]\n if wordform.tag.POS in ['ADJF', 'NOUN', 'VERB']:\n if needPos!=None:\n reswords.append(wordform.normal_form+posConv[wordform.tag.POS])\n else:\n reswords.append(wordform.normal_form)\n \n return Counter(reswords)\n\nstat1=getArticleDictionary(art_text, True)\nprint(stat1)\n \n",
"Counter({'серебренников_NOUN': 5, 'фильм_NOUN': 4, 'сценарий_NOUN': 3, 'гребенщик_NOUN': 3, 'зверь_NOUN': 2, 'группа_NOUN': 2, 'цой_NOUN': 2, 'август_NOUN': 2, 'дело_NOUN': 2, 'февраль_NOUN': 2, 'лето_NOUN': 2, 'домашний_ADJ': 2, 'год_NOUN': 2, 'науменко_NOUN': 2, 'арест_NOUN': 2, 'кирилл_NOUN': 2, 'счёт_NOUN': 1, 'борис_NOUN': 1, 'роль_NOUN': 1, 'освободить_VERB': 1, 'время_NOUN': 1, 'хищение_NOUN': 1, 'отношение_NOUN': 1, 'портал_NOUN': 1, 'надежда_NOUN': 1, 'картина_NOUN': 1, 'рок-коллектив_NOUN': 1, 'малоизвестный_ADJ': 1, 'наталья_NOUN': 1, 'писать_VERB': 1, 'который_ADJ': 1, 'человек_NOUN': 1, 'работать_VERB': 1, 'другой_ADJ': 1, 'общественность_NOUN': 1, 'рассказывать_VERB': 1, 'клетка_NOUN': 1, 'тема_NOUN': 1, 'бюджетный_ADJ': 1, 'средство_NOUN': 1, 'один_ADJ': 1, 'дата_NOUN': 1, 'главный_ADJ': 1, 'чужой_ADJ': 1, 'тот_ADJ': 1, 'конец_NOUN': 1, 'виктор_NOUN': 1, 'рома_NOUN': 1, 'актёрский_ADJ': 1, 'раскрываться_VERB': 1, 'лживый_ADJ': 1, 'огласить_VERB': 1, 'московский_ADJ': 1, 'жить_VERB': 1, 'зоопарк_NOUN': 1, 'уметь_VERB': 1, 'лидер_NOUN': 1, 'майк_NOUN': 1, 'материал_NOUN': 1, 'слово_NOUN': 1, 'раскритиковать_VERB': 1, 'жена_NOUN': 1, 'состав_NOUN': 1, 'приводить_VERB': 1, 'подчеркнуть_VERB': 1, 'фронтмена_NOUN': 1, 'четверг_NOUN': 1, 'разворачиваться_VERB': 1, 'сценарист_NOUN': 1, 'кгб_NOUN': 1, 'продюсер_NOUN': 1, 'обматерить_VERB': 1, 'история_NOUN': 1, 'музыкант_NOUN': 1, 'хипстер_NOUN': 1, 'начало_NOUN': 1, 'выход_NOUN': 1, 'поместить_VERB': 1, 'ложь_NOUN': 1, 'исполнить_VERB': 1, 'сюжет_NOUN': 1, 'ленинград_NOUN': 1, 'выразить_VERB': 1, 'планета_NOUN': 1, 'аквариум_NOUN': 1, 'реакция_NOUN': 1})\n"
]
],
[
[
"Для определения меры сходства двух статей теперь может использоваться косинусная мера сходства, рассчитываемая по следующей формуле: $cos(a,b)=\\frac{\\sum{a_i * b_i}}{\\sqrt {\\sum{a_i^2}*\\sum{b_i^2}}}$.<br>\nВообще-то, использовать стандартную функцию рассчета косинусной меры сходства из <a href=\"http://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.cosine_similarity.html\">sklearn</a> было бы быстрее. Но в данной задаче нам бы пришлось сводить все словари в один, чтобы на одних и тех же местах в векторе были частоты одних и тех же слов. Чтобы избежать подобной работы, напишем собственную функцию рассчета косинусного расстояния, работающую с разреженными векторами в виде питоновских словарей.",
"_____no_output_____"
]
],
[
[
"def cosineSimilarity(a, b):\n if len(a.keys())==0 or len(b.keys())==0:\n return 0\n sumab=sum([a[na]*b[na] for na in a.keys() if na in b.keys()])\n suma2=sum([a[na]*a[na] for na in a.keys()])\n sumb2=sum([b[nb]*b[nb] for nb in b.keys()])\n return sumab/math.sqrt(suma2*sumb2)\n",
"_____no_output_____"
]
],
[
[
"Посчитаем значение косинусной меры для разных статей.",
"_____no_output_____"
]
],
[
[
"stat2=getArticleDictionary(getLentaArticle(\"https://lenta.ru/news/2018/02/15/pengilly_domoi/\"), True)\nstat3=getArticleDictionary(getLentaArticle(\"https://lenta.ru/news/2018/02/15/tar_mor/\"), True)\nstat4=getArticleDictionary(getLentaArticle(\"https://lenta.ru/news/2018/02/15/olympmovies/\"), True)\n\nprint(cosineSimilarity(stat1, stat2))\nprint(cosineSimilarity(stat1, stat3))\nprint(cosineSimilarity(stat2, stat3))\nprint(cosineSimilarity(stat2, stat4))\nprint(cosineSimilarity(stat3, stat4))",
"0.06429108115745111\n0.0\n0.12321187388436787\n0.10845193904480363\n0.08038418992031009\n"
]
],
[
[
"Получилось, на самом деле, так себе - статьи очень слабо походят друг на друга. Но может быть потом выйдет лучше.<br>\nПока оформим наш код в виде класса, который помимо загрузки новостей будет уметь сохранять их на диск и читать оттуда.",
"_____no_output_____"
]
],
[
[
"class getNewsPaper:\n articles=[] # Загруженные статьи.\n dictionaries=[] # Посчитанные словари (векторное представление статей).\n \n # Конструктор - компилирует регулярные выражения и загружает морфологию.\n def __init__(self):\n self.delscript = re.compile(\"<script.*?>.+?</script>\", re.S)\n self.findheaders = re.compile(\"<h1.+?>(.+)</h1>\", re.S)\n self.boa = re.compile('<div class=\"b-text clearfix js-topic__text\" itemprop=\"articleBody\">', re.S)\n self.eoa = re.compile('<div class=\"b-box\">\\s*?<i>', re.S)\n self.findURLs = re.compile('<h3>(.+?)</h3>', re.S)\n self.rboa = re.compile('<p class=\"MegaArticleBody_first-p_2htdt\">', re.S)\n self.reoa = re.compile('<div class=\"Attribution_container_28wm1\">', re.S)\n self.rfindURLs = re.compile('''<div class=\"headlineMed\"><a href='(.+?)'>''', re.S)\n # Создаем и загружаем морфологический словарь.\n self.morph=pymorphy2.MorphAnalyzer()\n\n # Загрузка статьи по URL.\n def getLentaArticle(self, url):\n \"\"\" getLentaArticle gets the body of an article from Lenta.ru\"\"\"\n art = requests.get(url)\n title = self.findheaders.findall(art.text)[0]\n text = self.eoa.split(self.boa.split(art.text)[1])\n if len(text)==1:\n text = re.split('<div itemprop=\"author\" itemscope=\"\"', text[0])\n text = \"\".join(self.delscript.split(text[0]))\n self.articles.append(BeautifulSoup(title+\"\\n-----\\n\"+text, \"lxml\").get_text())\n\n # Загрузка всех статей за один день.\n def getLentaDay(self, url):\n \"\"\" Gets all URLs for a given day and gets all texts. \"\"\"\n try:\n day = requests.get(url) # Грузим страницу со списком всех статей.\n cand = self.findURLs.findall(day.text) # Выделяем адреса статей.\n links = ['https://lenta.ru'+re.findall('\"(.+?)\"', x)[0] for x in cand]\n for l in links: # Загружаем статьи.\n self.getLentaArticle(l)\n except:\n pass\n\n # Загрузка всех статей за несколько дней.\n def getLentaPeriod(self, start, finish):\n curdate=start\n while curdate<=finish:\n print(curdate.strftime('%Y/%m/%d')) # Just in case.\n # Список статей грузится с вот такого адреса.\n res=self.getLentaDay('https://lenta.ru/news/'+curdate.strftime('%Y/%m/%d'))\n curdate+=datetime.timedelta(days=1)\n \n # Just in case.\n def getReutersArticle(self, url):\n \"\"\" Gets the body of an article from reuters.com's archive. \"\"\"\n try:\n art = requests.get(url)\n title = self.findheaders.findall(art.text)[0]\n text = self.reoa.split(self.rboa.split(art.text)[1])[0]\n text = \"\".join(self.delscript.split(text))\n self.articles.append(BeautifulSoup(title+\"\\n-----\\n\"+text, \"lxml\").get_text())\n except:\n pass\n \n def getReutersDay(self, url):\n \"\"\" Gets all URLs for a given day and gets all texts. \"\"\"\n day = requests.get(url)\n links = self.rfindURLs.findall(day.text)\n for l in links:\n self.getReutersArticle(l)\n \n # Потроение вектора для статьи.\n posConv={'ADJF':'_ADJ','NOUN':'_NOUN','VERB':'_VERB'}\n def getArticleDictionary(self, text, needPos=None):\n words=[a[0] for a in re.findall(\"([А-ЯЁа-яё]+(-[А-ЯЁа-яё]+)*)\", text)]\n reswords=[]\n \n for w in words:\n wordform=self.morph.parse(w)[0]\n try:\n if wordform.tag.POS in ['ADJF', 'NOUN', 'VERB']:\n if needPos!=None:\n reswords.append(wordform.normal_form+self.posConv[wordform.tag.POS])\n else:\n reswords.append(wordform.normal_form)\n except:\n pass\n \n stat=Counter(reswords)\n# stat={a: stat[a] for a in stat.keys() if stat[a]>1}\n return stat\n\n # Посчитаем вектора для всех статей.\n def calcArticleDictionaries(self, needPos=None):\n self.dictionaries=[]\n for a in self.articles:\n self.dictionaries.append(self.getArticleDictionary(a, needPos))\n\n # Сохраняем стстьи в файл.\n def saveArticles(self, filename):\n \"\"\" Saves all articles to a file with a filename. \"\"\"\n newsfile=open(filename, \"w\")\n for art in self.articles:\n newsfile.write('\\n=====\\n'+art)\n newsfile.close()\n\n # Читаем статьи из файла.\n def loadArticles(self, filename):\n \"\"\" Loads and replaces all articles from a file with a filename. \"\"\"\n newsfile=open(filename)\n text=newsfile.read()\n self.articles=text.split('\\n=====\\n')[1:]\n# self.articles=[a.replace('\\xa0', ' ') for a in text.split('\\n=====\\n')[1:]]\n newsfile.close()\n\n # Для удобства - поиск статьи по ее заголовку.\n def findNewsByTitle(self, title):\n for i, a in enumerate(self.articles):\n if title==a.split('\\n-----\\n')[0]:\n return i\n return -1\n\ndef cosineSimilarity(a, b):\n if len(a.keys())==0 or len(b.keys())==0:\n return 0\n sumab=sum([a[na]*b[na] for na in a.keys() if na in b.keys()])\n suma2=sum([a[na]*a[na] for na in a.keys()])\n sumb2=sum([b[nb]*b[nb] for nb in b.keys()])\n return sumab/math.sqrt(suma2*sumb2)\n\n",
"_____no_output_____"
]
],
[
[
"Загрузим статьи.<br>\n<b>!!! Настоятельно рекомендую использовать ячейку с загрузкой статей из файла !!!</b>",
"_____no_output_____"
]
],
[
[
"# Загрузка статей за заданный период.\n# !!! Это рабоатет довольно долго, пользуйтесь сохраненными данными!!!\nlenta=getNewsPaper()\nlenta.getLentaPeriod(datetime.date(2018, 2, 1), datetime.date(2018, 2, 14))\nlenta.saveArticles(\"lenta2018.txt\")\n#lenta.loadArticles(\"lenta2018.txt\")\nlenta.calcArticleDictionaries()",
"2018/02/01\n2018/02/02\n2018/02/03\n2018/02/04\n2018/02/05\n2018/02/06\n2018/02/07\n2018/02/08\n2018/02/09\n2018/02/10\n2018/02/11\n2018/02/12\n2018/02/13\n2018/02/14\n"
],
[
"lenta=getNewsPaper()\nlenta.loadArticles(\"lenta2018.txt\")\nlenta.calcArticleDictionaries()",
"_____no_output_____"
]
],
[
[
"Из чистого любопытства попробуем найти статью, наиболее похожую на данную.",
"_____no_output_____"
]
],
[
[
"# Конечно же, правильнее делать это через np.argmax().\ni1 = 0\nmaxCos, maxpos = -1, -1\nfor i in range(len(lenta.articles)):\n if i != i1:\n c = cosineSimilarity(lenta.dictionaries[i1], lenta.dictionaries[i])\n if c>maxCos:\n maxCos, maxpos = c, i\nprint(lenta.articles[i1].split('\\n-----\\n')[0])\nprint(lenta.articles[maxpos].split('\\n-----\\n')[0])\nprint(maxCos, maxpos)",
"Раскрыто происхождение новейшей украинской крылатой ракеты\nРоссия поставила Украине оружие «сдерживания агрессора»\n0.6522716186492549 516\n"
]
],
[
[
"Сходство между статьями достаточно велико. Есть большие шансы за то, что они об одном и том же.<br><br>\nТеперь попробуем решить основную задачу.<br>\nПользователь выбирает несколько статей на интересующую его тематику. Пусть это будут олимпиада и выборы.",
"_____no_output_____"
]
],
[
[
"likesport=['Власти США обвинили МОК и ФИФА в коррупции', 'Пробирки WADA для допинг-проб оказались бракованными', 'Пожизненно отстраненных российских спортсменов оправдали', 'В Кремле порадовались за оправданных российских спортсменов', 'Россия вернется на первое место Олимпиады-2014', 'МОК разочаровало оправдание российских олимпийцев', 'Мутко загрустил после оправдания российских спортсменов', 'Оправданный призер Сочи-2014 призвал «добить ситуацию» с МОК', 'Путин предостерег от эйфории после оправдания российских олимпийцев', 'Родченков не смог вразумительно ответить на вопросы суда', 'Оправданный россиянин позлорадствовал над делившими медали Игр-2014 иностранцами', 'В CAS отказались считать оправданных россиян невиновными', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'Американская скелетонистка сочла россиян ушедшими от законного наказания']\nlikeelect=['Социологи подсчитали планирующих проголосовать на выборах-2018', 'Собчак пообещала дать Трампу пару советов', 'На выборы президента России пойдут почти 80 процентов избирателей', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Собчак съездила на завтрак с Трампом и разочаровалась', 'Грудинин уступил в популярности КПРФ', 'Собчак потребовала признать незаконной регистрацию Путина на выборах', 'У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Грудинин раскрыл историю происхождения дома в Испании', 'Путина зарегистрировали кандидатом в президенты', 'В Кремле отреагировали на слухи о голосовании Путина в Севастополе', 'Коммунистов вновь обвинили в незаконной агитации за Грудинина', 'ЦИК выявила обман со стороны Грудинина', 'Грудинин ответил на претензии ЦИК', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко']",
"_____no_output_____"
]
],
[
[
"Теперь объединим все выбранные тексты в один и посчитаем ветор для него. Сделаем это два раза для выбранных тематик.",
"_____no_output_____"
]
],
[
[
"sporttext=' '.join([lenta.articles[lenta.findNewsByTitle(likesport[i])] for i in range(len(likesport))])\nsportdict=lenta.getArticleDictionary(sporttext)\nelecttext=' '.join([lenta.articles[lenta.findNewsByTitle(likeelect[i])] for i in range(len(likeelect))])\nelectdict=lenta.getArticleDictionary(electtext)\n#print(sportdict)\n#print(electdict)",
"_____no_output_____"
]
],
[
[
"А теперь отберем все статьи, косинусная мера которых превышает некоторый порог.",
"_____no_output_____"
]
],
[
[
"thrs=0.4\nthre=0.5\ncosess=[lenta.articles[i].split('\\n-----\\n')[0] for i in range(len(lenta.dictionaries)) if cosineSimilarity(sportdict, lenta.dictionaries[i])>thrs]\nprint(cosess)\ncosese=[lenta.articles[i].split('\\n-----\\n')[0] for i in range(len(lenta.dictionaries)) if cosineSimilarity(electdict, lenta.dictionaries[i])>thre]\nprint(cosese)",
"['Пожизненно отстраненных российских спортсменов оправдали', 'В Кремле порадовались за оправданных российских спортсменов', 'Россия вернется на первое место Олимпиады-2014', 'МОК разочаровало оправдание российских олимпийцев', 'Мутко загрустил после оправдания российских спортсменов', 'Олимпиада в Пхенчхане побила рекорд по презервативам', 'Оправданный призер Сочи-2014 призвал «добить ситуацию» с МОК', 'Путин предостерег от эйфории после оправдания российских олимпийцев', 'Родченков не смог вразумительно ответить на вопросы суда', 'Оправданный россиянин позлорадствовал над делившими медали Игр-2014 иностранцами', 'В CAS отказались считать оправданных россиян невиновными', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'Американская скелетонистка сочла россиян ушедшими от законного наказания', 'Глава USADA почуял вонь российской атаки на чистый спорт', 'После оправдания российских спортсменов Макларена назвали идиотом', 'МОК посчитал оправдание российских спортсменов «торжеством обманщиков и воров»', 'Федерацию бобслея России обвинили в нежелании пускать спортсменов на Олимпиаду', 'Названы условия продолжения борьбы МОК против россиян', 'Четырехкратный олимпийский чемпион встал на сторону россиян и пристыдил МОК', 'МОК подумает над приглашением на Олимпиаду оправданных россиян', 'Оправданным россиянам запретили участвовать в Олимпиаде', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'В секретной базе найдены сотни аномальных допинг-проб', 'Назван знаменосец россиян на открытии Олимпиады', 'Комиссия МОК отказалась пустить на Олимпиаду оправданных CAS россиян', 'WADA сорвало тренировку сборной России по хоккею в Пхенчхане', 'Глава МОК рассказал о процедуре допуска оправданных россиян на Олимпиаду', 'Песков прокомментировал отказ МОК пустить на Олимпиаду оправданных россиян', 'Шесть российских сборных отказались от участия в церемонии открытия Олимпиады', 'МОК сделает из россиян пример нетерпимости к допингу', 'Лыжники присоединились к отказавшимся от церемонии открытия Олимпиады россиянам', 'Медведев пристыдил МОК', 'Президент МОК объяснил нежелание приглашать на Игры оправданных россиян', 'Немцы порадовались решению не пускать оправданных россиян на Олимпиаду', 'МОК уличил очередных российских спортсменов в употреблении допинга', 'Российские спортсмены продолжили борьбу с МОК', 'Раскрыты условия снятия запрета на российский флаг на Олимпиаде', 'Россиянам спрогнозировали девять медалей на Олимпиаде-2018', 'В Европе нашлась новая допинг-система', 'Серебряный призер Сочи пригрозила сунуть медаль между булок желающим ее забрать', 'Российские спортсмены пропустят Олимпиаду из-за затянувшегося суда', 'Американскую спортсменку разозлило оправдание российских олимпийцев', 'Названы условия появления российского флага на закрытии Игр', 'Немецкий биатлонист сравнил оправдание российских олимпийцев с плевком в лицо', 'Хакеры раскрыли канадский заговор против российского спорта', 'Российские керлингисты уступили сборной США в дебютной игре Олимпиады-2018', 'Российские олимпийцы пожаловались на слежку со стороны иностранной прессы', 'Российские олимпийцы подверглись дискриминации со стороны канадцев', 'CAS отказался рассматривать апелляции отстраненных от Олимпиады россиян', 'Российские болельщики осадили штаб-квартиру WADA', 'Потерявший шансы попасть на Олимпиаду Кулижников прокомментировал решение CAS', 'Бренды и чиновники отказались от индивидуальности ради российских спортсменов', 'Трехкратная чемпионка мира выступила против наказания невиновных россиян', 'Российские олимпийцы смогут носить шапку с триколором', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду', 'WADA возрадовалось решению CAS о недопуске россиян к Олимпиаде', 'МОК поддержал решение не допустить российских спортсменов на Олимпиаду', 'Адвокат Родченкова поблагодарил бога за недопуск россиян на Олимпиаду', 'Мутко назвал причины недопуска россиян на Олимпиаду', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'В Госдуме пообещали разобраться с главой МОК после Олимпиады', 'Бах обещал распустить CAS в случае оправдания российских атлетов', 'CAS объяснил решение о недопуске россиян на Олимпиаду', 'Елистратов посвятил медаль «подло и мерзко отстраненным» россиянам', 'Спортсменка из США обрадовалась отсутствию лидеров сборной России на Олимпиаде', 'Российских спортсменов посчитали самыми стильными на Олимпиаде', 'Попавшегося на допинге француза спугнули вопросом о Викторе Ане', 'Олимпийский чемпион окрестил российских биатлонисток «кем попало»', 'МОК предупредил российских атлетов о неожиданных допинг-тестах на Олимпиаде', 'Выигравший золото биатлонист выступил против недопуска Шипулина к Олимпиаде', 'Российский олимпиец рассказал о нежелании американцев жать ему руку', 'Родченков поведал о природе греха', 'Песков отверг обвинения Родченкова и указал на его психический недуг', 'Фуркад выиграл Олимпиаду и раскритиковал решение не допускать до нее россиян', 'МОК захотел наказать россиянина за посвящение медали отстраненным олимпийцам', 'Сдан первый положительный допинг-тест на Олимпиаде', 'Керлингисты принесли России третью медаль Олимпиады', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Два российских спортсмена пропустили Олимпиаду из-за ошибки МОК', 'МОК объяснил отсутствие двух россиян в списке приглашенных на Олимпиаду', 'Ошибочно не допущенный к Олимпиаде россиянин обиделся на МОК', 'Овечкин поблагодарил НХЛ за просмотр олимпийского хоккея по телевизору', 'Президент МОК предстал пред ликом российских олимпийцев']\n['Социологи подсчитали планирующих проголосовать на выборах-2018', 'У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Грудинин раскрыл историю происхождения дома в Испании', 'Путина зарегистрировали кандидатом в президенты', 'В Кремле отреагировали на слухи о голосовании Путина в Севастополе', 'На выборы президента России пойдут почти 80 процентов избирателей', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Собчак съездила на завтрак с Трампом и разочаровалась', 'Коммунистов вновь обвинили в незаконной агитации за Грудинина', 'Грудинин ответил на претензии ЦИК', 'Грудинин уступил в популярности КПРФ', 'Собчак потребовала признать незаконной регистрацию Путина на выборах']\n"
]
],
[
[
"Для проверки загрузим новости за какой-то другой день.",
"_____no_output_____"
]
],
[
[
"lenta_new=getNewsPaper()\n#lenta_new.getLentaPeriod(datetime.date(2018, 2, 15), datetime.date(2018, 2, 15))\n#lenta_new.saveArticles(\"lenta20180215.txt\")\nlenta_new.loadArticles(\"lenta20180215.txt\")\nlenta_new.calcArticleDictionaries()",
"_____no_output_____"
]
],
[
[
"А теперь проверим какие новости будут находиться.",
"_____no_output_____"
]
],
[
[
"thrs_new = 0.3\nthre_new = 0.3\ncosess_new = [lenta_new.articles[i].split('\\n-----\\n')[0] for i in range(len(lenta_new.dictionaries)) if cosineSimilarity(sportdict, lenta_new.dictionaries[i])>thrs_new]\nprint(cosess_new)\ncosese_new = [lenta_new.articles[i].split('\\n-----\\n')[0] for i in range(len(lenta_new.dictionaries)) if cosineSimilarity(electdict, lenta_new.dictionaries[i])>thre_new]\nprint(cosese_new)",
"['Российский сноубордист сломал ногу на Олимпиаде', 'Российскую лыжницу затравили на Олимпиаде']\n['Кремль опроверг информацию о засекречивании данных по россиянам в Сирии', 'Порошенко раскрыл детали разговора с Путиным', 'Грудинин оговорился о финансовых махинациях', 'Прогнозируемую явку на выборах президента сочли высокой']\n"
]
],
[
[
"Как видно, метод нуждается в более точном подборе и корректировке параметров.",
"_____no_output_____"
],
[
"Теперь попробуем применить для решения той же задачи модель Word2Vec, основная идея которой состоит в следующем. До сих пор мы работали в пространстве, размерность которого составляет несколько десятков, а может быть и сотен, тысяч измерений - по количеству используемых слов. Однако рядом будут находиться измерения для слов \"бегемот\" и \"гиппопотам\", являющихся синонимами. Следовательно, удалив одинаковые слова, мы можем снизить размерность пространства и уменьшить количество вычислений.<br>\nБолее того, каждое слово может быть выражено при помощи некоторых базовых понятий. Давайте попробуем отобразить теперь каждое слово в новое пространство, измерениями которого будут эти базовые понятия. Например, \"король\" будет раскладываться по измерениям \"люди\" (со значениями <b>\"мужчина\"</b> и \"женщина\"), \"возраст\" (\"молодой\", <b>\"зрелый\"</b>, \"старый\"), \"власть\" (<b>\"верховная\"</b>, \"среднее звено\", \"местная\", \"локальная\") и другим. При этом координаты не обязаны принимать заданные дискретные значения.<br>\nКоординаты слова в новом семантическом пространстве будут задаваться соседними словами. \"Кушать\" будет попадаться чаще с живыми существами, едой или посудой; \"бегать\" можно по некоторым местам и т.д. Правда, глаза могут и бегать, и есть. Это не будет добавлять модели детерминизма.<br>\nЧтобы не мучиться в выбором новой системы координат натренируем некоторую модель, которая сама будет проводить уменьшение размерности пространства, а нам будет оставаться только выбрать число измерений. Эта же модель будет заниматься преобразованием точек старого пространства в новое. В этом новом семантическом пространстве становятся возможны векторные операции - сложение и вычитание. Разработчики модели Word2Vec утверждают, что они смогли получить \"King\"+\"Man\"-\"Woman\"=\"Queen\". Посмотрим, получится ли у нас.",
"_____no_output_____"
]
],
[
[
"# Импортируем библиотеки Word2Vec\nfrom gensim.models.word2vec import Word2Vec # Собственно модель.\nfrom gensim.models.word2vec import LineSentence # Выравнивание текста по предложениям.\nfrom gensim.models import KeyedVectors # Семантические вектора.\n# На самом деле, нам потребуется только последняя.\nimport numpy as np # Вектора.",
"_____no_output_____"
]
],
[
[
"Теперь загрузим модель, обученную разработчиками проекта RusVectores для русского языка на новостях. В зависимости от того, откуда вы берете модели, они могут загружаться по-разному. Более того, модель можно обучить самому - для этого нужно просто взять много размеченных текстов.",
"_____no_output_____"
]
],
[
[
"model = KeyedVectors.load_word2vec_format('/home/edward/papers/kourses/Advanced Python/skillfactory/news_upos_cbow_600_2_2018.vec')",
"_____no_output_____"
]
],
[
[
"Теперь можно получить представление слов в новом пространстве. Имейте в виду, что в данной модели они идут с частями речи!",
"_____no_output_____"
]
],
[
[
"model['огонь_NOUN']",
"_____no_output_____"
]
],
[
[
"Среди прочего, библиотека позволяет найти наиболее близкие слова к данному. Или даже к сочетанию слов.",
"_____no_output_____"
]
],
[
[
"#model.most_similar(positive=[u'пожар_NOUN'])\n#model.most_similar(positive=[u'пожар_NOUN', u'пламя_NOUN' ])\n#model.most_similar(positive=[u'пожар_NOUN', u'пламя_NOUN' ], negative=[u'топливо_NOUN'])\n#model.most_similar(positive=[u'женщина_NOUN', u'король_NOUN' ], negative=[u'мужчина_NOUN'])\nmodel.most_similar(positive=[u'женщина_NOUN', u'король_NOUN' ])",
"_____no_output_____"
]
],
[
[
"У нас есть смысл отдельных слов. Построим на его основе смысл текста как среднее арифметическое всех векторов для слов, составляющих данный текст.",
"_____no_output_____"
]
],
[
[
"def text_to_vec(dct, model, size):\n text_vec = np.zeros((size,), dtype=\"float32\")\n n_words = 0\n\n index2word_set = set(model.index2word)\n for word in dct.keys():\n if word in index2word_set:\n n_words = n_words + 1\n text_vec = np.add(text_vec, model[word]) \n \n if n_words != 0:\n text_vec /= n_words\n return text_vec\n",
"_____no_output_____"
]
],
[
[
"Переразметим наши тексты так, чтобы они содержали в себе и часть речи.",
"_____no_output_____"
]
],
[
[
"lentaPos=getNewsPaper()\nlentaPos.loadArticles(\"lenta2018.txt\")\nlentaPos.calcArticleDictionaries(True)",
"_____no_output_____"
]
],
[
[
"Теперь посмотрим какова размерность векторов, хранимых в модели, и сколько в ней слов.",
"_____no_output_____"
]
],
[
[
"print(len(model['огонь_NOUN']))\nprint(len(model.index2word))",
"600\n289191\n"
]
],
[
[
"Размерность векторов 600 - с запасом. Почти 300 000 слов - тоже очень хорошо.<br>\nТеперь попробем найти косинусное расстояние между полученными векторами.",
"_____no_output_____"
]
],
[
[
"t2v1=text_to_vec(lentaPos.dictionaries[0], model, 600)\nt2v2=text_to_vec(lentaPos.dictionaries[1], model, 600)\nt2v516=text_to_vec(lentaPos.dictionaries[516], model, 600)\nprint(lentaPos.articles[0].split('\\n-----\\n')[0], lentaPos.articles[1].split('\\n-----\\n')[0])\nprint(cosineSimilarity(lentaPos.dictionaries[0], lentaPos.dictionaries[1]))\nprint(np.dot(t2v1, t2v2)/ np.linalg.norm(t2v1) / np.linalg.norm(t2v2))\nprint(lentaPos.articles[0].split('\\n-----\\n')[0], lentaPos.articles[516].split('\\n-----\\n')[0])\nprint(cosineSimilarity(lentaPos.dictionaries[0], lentaPos.dictionaries[516]))\nprint(np.dot(t2v1, t2v516)/ np.linalg.norm(t2v1) / np.linalg.norm(t2v516))",
"Раскрыто происхождение новейшей украинской крылатой ракеты Русских гопников назвали настоящими древними славянами\n0.056637725889743556\n0.328594\nРаскрыто происхождение новейшей украинской крылатой ракеты Россия поставила Украине оружие «сдерживания агрессора»\n0.6522716186492549\n0.872223\n"
]
],
[
[
"Как видно, значения косинусной меры несколько выросли. Но может быть вектора можно просто вычитать и складывать?",
"_____no_output_____"
]
],
[
[
"print(lentaPos.articles[0].split('\\n-----\\n')[0], lentaPos.articles[1].split('\\n-----\\n')[0])\nprint(np.linalg.norm(t2v1-t2v2))\nprint(lentaPos.articles[0].split('\\n-----\\n')[0], lentaPos.articles[516].split('\\n-----\\n')[0])\nprint(np.linalg.norm(t2v1-t2v516))",
"Раскрыто происхождение новейшей украинской крылатой ракеты Русских гопников назвали настоящими древними славянами\n0.260394\nРаскрыто происхождение новейшей украинской крылатой ракеты Россия поставила Украине оружие «сдерживания агрессора»\n0.10519\n"
]
],
[
[
"Всё логично - расстояние между последней парой статей должно быть меньше. Попробуем теперь решить нашу задачу - отбор новостей - новым методом. Для начала попробуем при помощи косинусной меры.",
"_____no_output_____"
]
],
[
[
"sportdictpos=lenta.getArticleDictionary(sporttext, True)\nelectdictpos=lenta.getArticleDictionary(electtext, True)\n\nt2vs=text_to_vec(sportdictpos, model, 600)\nt2ve=text_to_vec(electdictpos, model, 600)",
"_____no_output_____"
],
[
"\nthrs=0.85\nthre=0.85\n\ncosess=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.dot(t2vs, text_to_vec(lentaPos.dictionaries[i], model, 600))/ \\\n np.linalg.norm(t2vs) / np.linalg.norm(text_to_vec(lentaPos.dictionaries[i], model, 600)) >thrs]\ncosese=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.dot(t2ve, text_to_vec(lentaPos.dictionaries[i], model, 600))/ \\\n np.linalg.norm(t2ve) / np.linalg.norm(text_to_vec(lentaPos.dictionaries[i], model, 600)) >thre]\nprint(thrs, thre)\nprint(cosess)\nprint(cosese)\n\nthrs=0.8\nthre=0.8\n\ncosess=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.dot(t2vs, text_to_vec(lentaPos.dictionaries[i], model, 600))/ \\\n np.linalg.norm(t2vs) / np.linalg.norm(text_to_vec(lentaPos.dictionaries[i], model, 600)) >thrs]\ncosese=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.dot(t2ve, text_to_vec(lentaPos.dictionaries[i], model, 600))/ \\\n np.linalg.norm(t2ve) / np.linalg.norm(text_to_vec(lentaPos.dictionaries[i], model, 600)) >thre]\nprint(thrs, thre)\nprint(cosess)\nprint(cosese)\n\nthrs=0.9\nthre=0.9\n\ncosess=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.dot(t2vs, text_to_vec(lentaPos.dictionaries[i], model, 600))/ \\\n np.linalg.norm(t2vs) / np.linalg.norm(text_to_vec(lentaPos.dictionaries[i], model, 600)) >thrs]\ncosese=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.dot(t2ve, text_to_vec(lentaPos.dictionaries[i], model, 600))/ \\\n np.linalg.norm(t2ve) / np.linalg.norm(text_to_vec(lentaPos.dictionaries[i], model, 600)) >thre]\nprint(thrs, thre)\nprint(cosess)\nprint(cosese)",
"0.85 0.85\n['Пожизненно отстраненных российских спортсменов оправдали', 'МОК разочаровало оправдание российских олимпийцев', 'Мутко загрустил после оправдания российских спортсменов', 'Оправданный призер Сочи-2014 призвал «добить ситуацию» с МОК', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'После оправдания российских спортсменов Макларена назвали идиотом', 'Родченкова сочли борцом за правое дело и помогли деньгами', 'Федерацию бобслея России обвинили в нежелании пускать спортсменов на Олимпиаду', 'Четырехкратный олимпийский чемпион встал на сторону россиян и пристыдил МОК', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'В секретной базе найдены сотни аномальных допинг-проб', 'Немецкий биатлонист сравнил оправдание российских олимпийцев с плевком в лицо', 'Хакеры раскрыли канадский заговор против российского спорта', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Потерявший шансы попасть на Олимпиаду Кулижников прокомментировал решение CAS', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'Родченков поведал о природе греха', 'Фуркад выиграл Олимпиаду и раскритиковал решение не допускать до нее россиян', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Олимпийский чемпион признался в желании «дать леща» фигуристу Коляде', 'Ошибочно не допущенный к Олимпиаде россиянин обиделся на МОК']\n['Социологи подсчитали планирующих проголосовать на выборах-2018', 'Шефы российских спецслужб приехали в США и удивили американцев', 'Рассказавшего о скупающих черную икру украинцах политолога назвали порохоботом', 'Немецкий ультраправый политик сбежал к мусульманам из-за геев', 'ЦИК сделал Пескову замечание из-за агитации', 'Песков извинился перед ЦИК за агитацию', 'У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Песков ответил на вопрос о гарантиях желающим вернуться в Россию бизнесменам', 'Съездившие в Крым немецкие депутаты остались без наказания', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко', 'Грудинин раскрыл историю происхождения дома в Испании', 'Украинский политик констатировал превращение страны в «сельский туалет»', 'В Кремле отреагировали на слухи о голосовании Путина в Севастополе', 'Найден документ с именами виновных в «сдаче Крыма» России', 'Украинский дипломат «вправил мозги» немецким политикам из-за поездки в Крым', 'Уличенный в «сдаче Крыма» украинский министр списал обвинения на испуг', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Избежавший санкций Кудрин рассказал о последствиях «кремлевского доклада»', 'Посетившие Крым немецкие депутаты пообещали вернуться на полуостров', 'На Украине назвали причину отказа Киева воевать за Крым', 'Грудинин ответил на претензии ЦИК', 'Украинский политик устроил скандал в прямом эфире из-за Саакашвили', 'Грудинин уступил в популярности КПРФ', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма', 'Собчак потребовала признать незаконной регистрацию Путина на выборах']\n0.8 0.8\n['Власти США обвинили МОК и ФИФА в коррупции', 'Пожизненно отстраненных российских спортсменов оправдали', 'В Кремле порадовались за оправданных российских спортсменов', 'МОК разочаровало оправдание российских олимпийцев', 'Мутко загрустил после оправдания российских спортсменов', 'Оправданный призер Сочи-2014 призвал «добить ситуацию» с МОК', 'Путин предостерег от эйфории после оправдания российских олимпийцев', 'Родченков не смог вразумительно ответить на вопросы суда', 'Опубликовано ранее неизвестное интервью Бориса Ельцина 1990 года', 'В CAS отказались считать оправданных россиян невиновными', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'Американская скелетонистка сочла россиян ушедшими от законного наказания', 'Немецкий ультраправый политик сбежал к мусульманам из-за геев', 'Глава USADA почуял вонь российской атаки на чистый спорт', 'После оправдания российских спортсменов Макларена назвали идиотом', 'В США рассказали о дружбе с Россией', 'Родченкова сочли борцом за правое дело и помогли деньгами', 'МОК посчитал оправдание российских спортсменов «торжеством обманщиков и воров»', 'Федерацию бобслея России обвинили в нежелании пускать спортсменов на Олимпиаду', 'Названы условия продолжения борьбы МОК против россиян', 'Четырехкратный олимпийский чемпион встал на сторону россиян и пристыдил МОК', 'МОК подумает над приглашением на Олимпиаду оправданных россиян', 'Оправданным россиянам запретили участвовать в Олимпиаде', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'В секретной базе найдены сотни аномальных допинг-проб', 'Песков прокомментировал отказ МОК пустить на Олимпиаду оправданных россиян', 'Песков ответил на вопрос о гарантиях желающим вернуться в Россию бизнесменам', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко', 'Медведев пристыдил МОК', 'Президент МОК объяснил нежелание приглашать на Игры оправданных россиян', 'Байдену пригрозили судом в США за слова о «сукином сыне» с Украины', 'Немцы порадовались решению не пускать оправданных россиян на Олимпиаду', 'МОК уличил очередных российских спортсменов в употреблении допинга', 'Немка поработала с беженцами и предрекла Германии крах', 'В Европе нашлась новая допинг-система', 'Украинский политик констатировал превращение страны в «сельский туалет»', 'Серебряный призер Сочи пригрозила сунуть медаль между булок желающим ее забрать', 'Белорусская сборная доверила Бьорндалену откатку лыж', 'Полуголая активистка вышла на протест в замороженном Пхенчхане', 'Российские спортсмены пропустят Олимпиаду из-за затянувшегося суда', 'Американскую спортсменку разозлило оправдание российских олимпийцев', 'Найдены доказательства отсутствия расизма у Трампа', 'Названы условия появления российского флага на закрытии Игр', 'Украинский дипломат «вправил мозги» немецким политикам из-за поездки в Крым', 'Немецкий биатлонист сравнил оправдание российских олимпийцев с плевком в лицо', 'Украинская газета поведала о «захвативших власть в стране жидах»', 'Хакеры раскрыли канадский заговор против российского спорта', 'Российские олимпийцы пожаловались на слежку со стороны иностранной прессы', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Российские олимпийцы подверглись дискриминации со стороны канадцев', 'CAS отказался рассматривать апелляции отстраненных от Олимпиады россиян', 'Названа самая недобросовестная страна ЕС', 'Потерявший шансы попасть на Олимпиаду Кулижников прокомментировал решение CAS', 'Трехкратная чемпионка мира выступила против наказания невиновных россиян', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду', 'Адвокат Родченкова поблагодарил бога за недопуск россиян на Олимпиаду', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'Избежавший санкций Кудрин рассказал о последствиях «кремлевского доклада»', 'Ягудин пристыдил российского фигуриста Коляду за провал на Олимпиаде', 'Посетившие Крым немецкие депутаты пообещали вернуться на полуостров', 'Елистратов посвятил медаль «подло и мерзко отстраненным» россиянам', 'На Украине назвали причину отказа Киева воевать за Крым', 'Попавшегося на допинге француза спугнули вопросом о Викторе Ане', 'Олимпийский чемпион окрестил российских биатлонисток «кем попало»', 'ЦРУ рассказало о разводившем ведомство на деньги информаторе из России', 'МОК предупредил российских атлетов о неожиданных допинг-тестах на Олимпиаде', 'Фетисов усмотрел заговор среди возмутившихся им рабочих и ничего не понял', 'Тренеры поругались из-за саней и помешали российскому олимпийцу победить', 'Родченков объяснил изменение внешности во время интервью CBS', 'Тренеру российских биатлонистов предложили вырвать зубы из-за плохих результатов', 'Российский олимпиец рассказал о нежелании американцев жать ему руку', 'Родченков поведал о природе греха', 'Песков отверг обвинения Родченкова и указал на его психический недуг', 'Студент написал диплом об экстремизме и сел за экстремизм', 'Американец назвал Олимпиаду гейской и пожалел об этом', 'Фуркад выиграл Олимпиаду и раскритиковал решение не допускать до нее россиян', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Олимпийский чемпион признался в желании «дать леща» фигуристу Коляде', 'Украинский политик устроил скандал в прямом эфире из-за Саакашвили', 'Саакашвили из Польши пригрозил «молдавскому барыге» Порошенко', 'Два российских спортсмена пропустили Олимпиаду из-за ошибки МОК', 'Спортсмены Денщиков и Потылицына решили скрасить информационный фон и поженились', 'МОК объяснил отсутствие двух россиян в списке приглашенных на Олимпиаду', 'Ошибочно не допущенный к Олимпиаде россиянин обиделся на МОК', '«Гость из будущего» прошел проверку на детекторе лжи', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма', 'Чеченский муфтий поспорил о халяльности майнинга']\n['Социологи подсчитали планирующих проголосовать на выборах-2018', 'Китайская детская задачка поставила в тупик взрослых по всему миру', 'Шефы российских спецслужб приехали в США и удивили американцев', 'Президента Чехии уличили в связях с украинскими сепаратистами', 'США оправдались за «копипасту» списка Forbes в «кремлевском докладе»', 'Враг США начал поставлять в Соединенные Штаты черную икру', 'Рассказавшего о скупающих черную икру украинцах политолога назвали порохоботом', 'Стрелявший под кокаином у Кремля Джабраилов постреляет еще', 'Опубликовано ранее неизвестное интервью Бориса Ельцина 1990 года', 'США объяснили утаивание части «кремлевского списка»', 'Директор ЦРУ объяснил встречу с шефами российских спецслужб', 'МИД России предупредил граждан об «охоте» за ними спецслужб США', 'Пентагон обвинил Россию в попытке подорвать НАТО', 'В Крыму рассказали о рекордной популярности полуострова в мире', 'Немецкий ультраправый политик сбежал к мусульманам из-за геев', 'США сравнили Россию и Китай с колониальными державами', 'США обвинили Россию в замораживании войны в Донбассе', 'В США рассказали о дружбе с Россией', 'ЦИК сделал Пескову замечание из-за агитации', 'Песков извинился перед ЦИК за агитацию', 'Родченкова сочли борцом за правое дело и помогли деньгами', 'У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Президент Молдавии предрек войну в случае объединения страны с Румынией', 'Вместо министерства счастья в России создадут министерство одиночества', 'Педагог Макаренко попросил у Медведева денег и был уволен', 'Украина пригрозила Volkswagen и Adidas санкциями за работу в Крыму', 'Подравшиеся Сванидзе и Шевченко отказались жать друг другу руки', 'Трамп рассекретил доклад о злоупотреблениях ФБР в «деле о России»', 'Трамп пожаловался на непрекращающиеся разговоры «только о России»', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'Россия уступила Белоруссии и Украине в рейтинге верховенства права', 'В секретной базе найдены сотни аномальных допинг-проб', 'Следы сбившего российский Су-25 ПЗРК отыскали на Украине', 'Брюссель решил ускорить вступление Сербии в Евросоюз', 'Стали известны подробности работы масонских лож в элите Великобритании', 'Путину передан список желающих вернуться беглых бизнесменов', 'Экономику Украины сравнили с МММ', 'Бежавшим из России олигархам собрались простить уголовные дела', 'Песков ответил на вопрос о гарантиях желающим вернуться в Россию бизнесменам', 'Съездившие в Крым немецкие депутаты остались без наказания', 'Вкладчики разорившихся банков пожалуются Путину на АСВ', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко', 'Аресты чиновников в Дагестане сравнили с «обнесением Чечни проволокой»', 'Суд отказался вернуть детей писавшей про трансгендеров россиянке', 'Медведев пристыдил МОК', 'Зоозащитники ужаснулись мучениям раков и начали бороться за их права', 'Украина в рейтинге уровня жизни оказалась между Бангладеш и Буркина-Фасо', 'Байдену пригрозили судом в США за слова о «сукином сыне» с Украины', 'Украина в отличие от Германии захотела наказания для немецких депутатов в Крыму', 'Грудинин раскрыл историю происхождения дома в Испании', 'Путина зарегистрировали кандидатом в президенты', 'Глава российской разведки объяснил поездку в США', 'В Кремле отказались считать аресты в Дагестане политическим кризисом', 'Немка поработала с беженцами и предрекла Германии крах', 'Украинский политик констатировал превращение страны в «сельский туалет»', 'Российские олигархи столкнулись с проблемами из-за «кремлевского доклада»', 'Российскую власть проверили на умение найти общий язык с элитой', 'Назван победитель баттла Гуфа и Птахи', 'В Кремле отреагировали на слухи о голосовании Путина в Севастополе', 'Найден документ с именами виновных в «сдаче Крыма» России', 'Найдены доказательства отсутствия расизма у Трампа', 'Раскрыто имя нового министра иностранных дел Германии', 'Украинцы записались в коммунисты и геи ради убежища в Европе', 'Украинский дипломат «вправил мозги» немецким политикам из-за поездки в Крым', 'Власти Красноярска не освоили деньги и удивили Путина', 'Кудрин назвал неизбежным повышение пенсионного возраста', 'Немецкие депутаты обиделись на посла Украины и отказались ехать в Киев', 'Уличенный в «сдаче Крыма» украинский министр списал обвинения на испуг', 'Украинская газета поведала о «захвативших власть в стране жидах»', 'Собчак пообещала дать Трампу пару советов', 'Раскрыт план готовящейся атаки на Россию во время Олимпиады', 'Немецкие депутаты признали Крым безопаснее Германии', 'Миллиардер Сорос хотел остановить Brexit за символическую сумму', 'На выборы президента России пойдут почти 80 процентов избирателей', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Россия обвинила США в сокрытии совместных успехов', 'Названа самая недобросовестная страна ЕС', 'Путин признался в отсутствии смартфона', 'Сенатор от Севастополя захотел навести порядок в прокуратуре', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду', 'Ученые раскрыли технологию для вечной жизни Путина', 'Собчак съездила на завтрак с Трампом и разочаровалась', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'Президент Азербайджана назвал стратегической целью возвращение столицы Армении', 'Избежавший санкций Кудрин рассказал о последствиях «кремлевского доклада»', 'Коммунистов вновь обвинили в незаконной агитации за Грудинина', 'Россия посетовала на вынужденное противостояние с США', 'На Украине нашли объяснение невозможности вступить в НАТО', 'Украинские депутаты плюнули на заседание Рады и уехали грозить Польше танками', 'Спецназ пришел за Саакашвили и спасовал перед охранниками отеля', 'Президент Армении ответил на притязания азербайджанского коллеги на Ереван', 'Президент Франции посетит ПМЭФ по приглашению Путина', 'Порошенко пожалуется генсеку НАТО на Венгрию', 'Посетившие Крым немецкие депутаты пообещали вернуться на полуостров', 'Виктор Бут захотел судиться с журналистами из-за новости о казино в его квартире', 'Украинцев призвали отказаться от поездки на чемпионат мира в Россию', 'Уничтожение российского Су-25 раскололо боевиков', 'Россиянин обманул американскую разведку на 100 тысяч долларов и скрылся', 'Изгнанный с эфира за реплику о летчике Филипове гость объяснился', 'На Украине назвали причину отказа Киева воевать за Крым', 'Саакашвили взял на себя ответственность за всех грузин и собрался в Польшу', 'ЦРУ рассказало о разводившем ведомство на деньги информаторе из России', 'Родченков поведал о природе греха', 'Турция придумала сговор с «террористом» Асадом', 'Песков отверг обвинения Родченкова и указал на его психический недуг', 'Армения назвала условие разрешения конфликта с Азербайджаном', 'В ЦИК рассказали о желании россиян проголосовать по месту пребывания', 'Порошенко обвинил Путина в неисполнении минских соглашений', 'Студент написал диплом об экстремизме и сел за экстремизм', 'Названо число необходимых Донбассу миротворцев', 'Глава МИД Нидерландов солгал о встрече с Путиным', 'Глава украинской оборонки заявил о победе и подал в отставку', 'ЦИК выявила обман со стороны Грудинина', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Путин простудился', 'Кремль призвал помнить о находящихся не только в Сирии россиянах', 'В сети показали фото летевших в силовиков на Майдане пуль', 'Грудинин ответил на претензии ЦИК', 'Саакашвили выдворили с Украины перед допросом о расстрелах на Майдане', 'Путин отказался от бесплатного эфира на федеральном телевидении', 'Украинский политик устроил скандал в прямом эфире из-за Саакашвили', 'Саакашвили из Польши пригрозил «молдавскому барыге» Порошенко', 'Иностранные компании запаниковали из-за «кремлевского доклада»', 'Венгрия пообещала продолжить давление на Украину', 'Госдеп США согласился с «Североамериканским тупиком»', 'ЦИК предложил Первому каналу отложить показ фильма о Путине', 'Кремль прокомментировал возможный запрет на въезд россиян в Сирию', 'Песков заподозрил американцев в одержимости', 'Грудинин уступил в популярности КПРФ', 'ФСБ передумали давать еще больше полномочий', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма', 'Названы самые популярные страны для вывода денег из России', 'Первый канал отменил показ финала фильма про Путина', 'Собчак потребовала признать незаконной регистрацию Путина на выборах', 'Чеченский муфтий поспорил о халяльности майнинга', 'Саакашвили получил голландский паспорт']\n0.9 0.9\n['МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду']\n['У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма']\n"
]
],
[
[
"Как видно, результат очень сильно зависит от порогового значения. А теперь решим ее просто вычитая вектора.",
"_____no_output_____"
]
],
[
[
"\nthrs=0.15\nthre=0.15\n\ncosess=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.linalg.norm(t2vs-text_to_vec(lentaPos.dictionaries[i], model, 600))<thrs]\ncosese=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.linalg.norm(t2ve-text_to_vec(lentaPos.dictionaries[i], model, 600))<thre]\nprint(thrs, thre)\nprint(cosess)\nprint(cosese)\n\nthrs=0.2\nthre=0.2\n\ncosess=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.linalg.norm(t2vs-text_to_vec(lentaPos.dictionaries[i], model, 600))<thrs]\ncosese=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.linalg.norm(t2ve-text_to_vec(lentaPos.dictionaries[i], model, 600))<thre]\nprint(thrs, thre)\nprint(cosess)\nprint(cosese)\n\nthrs=0.1\nthre=0.1\n\ncosess=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.linalg.norm(t2vs-text_to_vec(lentaPos.dictionaries[i], model, 600))<thrs]\ncosese=[lentaPos.articles[i].split('\\n-----\\n')[0] for i in range(len(lentaPos.dictionaries)) \\\n if np.linalg.norm(t2ve-text_to_vec(lentaPos.dictionaries[i], model, 600))<thre]\nprint(thrs, thre)\nprint(cosess)\nprint(cosese)",
"0.15 0.15\n['Социологи подсчитали планирующих проголосовать на выборах-2018', 'Власти США обвинили МОК и ФИФА в коррупции', 'Китайская детская задачка поставила в тупик взрослых по всему миру', 'Пожизненно отстраненных российских спортсменов оправдали', 'В Кремле порадовались за оправданных российских спортсменов', 'МОК разочаровало оправдание российских олимпийцев', 'Мутко загрустил после оправдания российских спортсменов', 'Шефы российских спецслужб приехали в США и удивили американцев', 'Президента Чехии уличили в связях с украинскими сепаратистами', 'Оправданный призер Сочи-2014 призвал «добить ситуацию» с МОК', 'Австралиец предложил два ноутбука за собственное убийство', 'Рассказавшего о скупающих черную икру украинцах политолога назвали порохоботом', 'Стрелявший под кокаином у Кремля Джабраилов постреляет еще', 'Путин предостерег от эйфории после оправдания российских олимпийцев', 'Родченков не смог вразумительно ответить на вопросы суда', 'Опубликовано ранее неизвестное интервью Бориса Ельцина 1990 года', 'Лавров пожаловался на нацистский вирус', 'Оправданный россиянин позлорадствовал над делившими медали Игр-2014 иностранцами', 'В CAS отказались считать оправданных россиян невиновными', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'МИД России предупредил граждан об «охоте» за ними спецслужб США', 'Американская скелетонистка сочла россиян ушедшими от законного наказания', 'В Крыму рассказали о рекордной популярности полуострова в мире', 'Работники ФБР повеселились с преступниками за 25 тысяч бюджетных долларов', 'Глава USADA почуял вонь российской атаки на чистый спорт', 'США сравнили Россию и Китай с колониальными державами', 'После оправдания российских спортсменов Макларена назвали идиотом', 'В США рассказали о дружбе с Россией', 'Родченкова сочли борцом за правое дело и помогли деньгами', 'Станцевавших в БДСМ-костюмах ульяновских курсантов оставили в авиации', 'МОК посчитал оправдание российских спортсменов «торжеством обманщиков и воров»', 'Вместо министерства счастья в России создадут министерство одиночества', 'Федерацию бобслея России обвинили в нежелании пускать спортсменов на Олимпиаду', 'Названы условия продолжения борьбы МОК против россиян', 'Педофил показал звезде «Зачарованных» порно, изнасиловал и выставил на улицу', 'Четырехкратный олимпийский чемпион встал на сторону россиян и пристыдил МОК', 'Украина пригрозила Volkswagen и Adidas санкциями за работу в Крыму', 'Трамп рассекретил доклад о злоупотреблениях ФБР в «деле о России»', 'МОК подумает над приглашением на Олимпиаду оправданных россиян', 'Оправданным россиянам запретили участвовать в Олимпиаде', 'Российских олигархов заставят объяснить роскошную жизнь в Лондоне', 'Трамп пожаловался на непрекращающиеся разговоры «только о России»', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'Спасший Шамиля Басаева врач рассказал об «эпидемии красоты» в Чечне', 'МОК задумался об исключении бокса из программы Олимпиады', 'В секретной базе найдены сотни аномальных допинг-проб', 'Следы сбившего российский Су-25 ПЗРК отыскали на Украине', 'Стали известны подробности работы масонских лож в элите Великобритании', 'Путину передан список желающих вернуться беглых бизнесменов', 'Экономику Украины сравнили с МММ', 'WADA сорвало тренировку сборной России по хоккею в Пхенчхане', 'Самую дорогую рекламу в мире заменили черным экраном', 'Глава МОК рассказал о процедуре допуска оправданных россиян на Олимпиаду', 'Песков прокомментировал отказ МОК пустить на Олимпиаду оправданных россиян', 'Бежавшим из России олигархам собрались простить уголовные дела', 'Кремль объяснил действия военных в Сирии после атаки на Су-25', 'Песков ответил на вопрос о гарантиях желающим вернуться в Россию бизнесменам', 'МОК сделает из россиян пример нетерпимости к допингу', 'Вкладчики разорившихся банков пожалуются Путину на АСВ', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко', 'Суд отказался вернуть детей писавшей про трансгендеров россиянке', 'Медведев пристыдил МОК', 'Президент МОК объяснил нежелание приглашать на Игры оправданных россиян', 'Зоозащитники ужаснулись мучениям раков и начали бороться за их права', 'Байдену пригрозили судом в США за слова о «сукином сыне» с Украины', 'Немцы порадовались решению не пускать оправданных россиян на Олимпиаду', 'Допинг-офицеры запросили список российских футболистов на ЧМ-2018', 'Минобороны пристыдило «Фонтанку» за публикацию данных убитого в Сирии пилота', 'Грудинин раскрыл историю происхождения дома в Испании', 'Немецкие полицейские нашли пользу в марихуане', 'МОК уличил очередных российских спортсменов в употреблении допинга', 'Тарантино раскрыл правду об удушении и домогательствах к Уме Турман', 'Российские спортсмены продолжили борьбу с МОК', 'Раскрыты условия снятия запрета на российский флаг на Олимпиаде', 'Венгрия потребовала ввести миссию ОБСЕ на запад Украины', 'Немка поработала с беженцами и предрекла Германии крах', 'Шакро Молодой отказался от дачи показаний в суде', 'Трамп заподозрил не хлопавших ему демократов в госизмене', 'В Киеве допустили выдвижение Польшей территориальных претензий к Украине', 'В Европе нашлась новая допинг-система', 'Украинский политик констатировал превращение страны в «сельский туалет»', 'Серебряный призер Сочи пригрозила сунуть медаль между булок желающим ее забрать', 'Российские олигархи столкнулись с проблемами из-за «кремлевского доклада»', 'Полуголая активистка вышла на протест в замороженном Пхенчхане', 'В МИД России назвали истерики Вашингтона детскими капризами', 'Российскую власть проверили на умение найти общий язык с элитой', 'Российские спортсмены пропустят Олимпиаду из-за затянувшегося суда', 'Американскую спортсменку разозлило оправдание российских олимпийцев', 'Найден документ с именами виновных в «сдаче Крыма» России', 'Норвежцы привезли на Олимпиаду частично запрещенные препараты', 'Будущим миллионерам пожелали создать Tesla', 'Названы условия появления российского флага на закрытии Игр', 'Украинцы записались в коммунисты и геи ради убежища в Европе', 'Украинский дипломат «вправил мозги» немецким политикам из-за поездки в Крым', 'Власти Красноярска не освоили деньги и удивили Путина', 'Футболист из Крыма впервые получил вызов в сборную России', 'В интервью Тарантино нашли оправдание изнасилования 13-летней девочки', 'США пригрозили не дать Северной Корее «захватить» Олимпиаду', 'Немецкие депутаты обиделись на посла Украины и отказались ехать в Киев', 'Немецкий биатлонист сравнил оправдание российских олимпийцев с плевком в лицо', 'Уличенный в «сдаче Крыма» украинский министр списал обвинения на испуг', '«Роскосмос» посчитал запуск Falcon Heavy рекламой Tesla', 'Глава РФПЛ выступил за пиво на стадионах и против алкоголизма', 'Греф поностальгировал о своей работе дворником', 'Хакеры раскрыли канадский заговор против российского спорта', 'Раскрыт план готовящейся атаки на Россию во время Олимпиады', 'Врач оправдала норвежских олимпийцев-астматиков', 'Российские олимпийцы пожаловались на слежку со стороны иностранной прессы', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Россия обвинила США в сокрытии совместных успехов', 'Российские олимпийцы подверглись дискриминации со стороны канадцев', 'CAS отказался рассматривать апелляции отстраненных от Олимпиады россиян', 'Названа самая недобросовестная страна ЕС', 'Хакер из Северной Кореи рассказал о нищете и голоде в армии', 'Потерявший шансы попасть на Олимпиаду Кулижников прокомментировал решение CAS', 'В США убийца стал секс-рабом в тюрьме и нажился на этом', 'Студентов поймали на тайном соревновании по сексу с тучными женщинами', 'В сети поразились издевательству телеведущих над женщиной-политиком 50 лет назад', 'Насильник Шурыгиной назвал сумму выплаченных ей денег', 'Трехкратная чемпионка мира выступила против наказания невиновных россиян', 'Российские олимпийцы смогут носить шапку с триколором', 'Корейцы предложат гостям Олимпиады собачатину', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду', 'WADA возрадовалось решению CAS о недопуске россиян к Олимпиаде', 'Собчак съездила на завтрак с Трампом и разочаровалась', 'Адвокат Родченкова поблагодарил бога за недопуск россиян на Олимпиаду', 'Насильник Шурыгиной ответил на новое обвинение в домогательствах', 'Мутко назвал причины недопуска россиян на Олимпиаду', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'Польского туриста на Украине заставили поднять флаг УПА', 'Родченков сменил личину', 'Президент Азербайджана назвал стратегической целью возвращение столицы Армении', 'Раскрыт план США сорвать сотрудничество России и Афганистана', 'Избежавший санкций Кудрин рассказал о последствиях «кремлевского доклада»', 'Россиянин заплатил налог с комиссией в 2500 процентов', 'На Украине нашли объяснение невозможности вступить в НАТО', 'Украинские депутаты плюнули на заседание Рады и уехали грозить Польше танками', 'Президент Армении ответил на притязания азербайджанского коллеги на Ереван', 'В Госдуме пообещали разобраться с главой МОК после Олимпиады', 'Американская спортсменка приехала на Олимпиаду в статусе бомжа', 'Порошенко пожалуется генсеку НАТО на Венгрию', 'Ягудин пристыдил российского фигуриста Коляду за провал на Олимпиаде', 'Посетившие Крым немецкие депутаты пообещали вернуться на полуостров', 'Пластический хирург оценил новый облик Родченкова', 'Минобороны дало отповедь усомнившемуся в героизме Филипова «манкурту»', 'Бах обещал распустить CAS в случае оправдания российских атлетов', 'Виктор Бут захотел судиться с журналистами из-за новости о казино в его квартире', 'Украинцев призвали отказаться от поездки на чемпионат мира в Россию', 'CAS объяснил решение о недопуске россиян на Олимпиаду', 'Спортсменка из США обрадовалась отсутствию лидеров сборной России на Олимпиаде', 'Российских спортсменов посчитали самыми стильными на Олимпиаде', 'Фетисов причислил рабочих к людям второго сорта и подвергся обструкции', 'На Украине назвали причину отказа Киева воевать за Крым', 'Попавшегося на допинге француза спугнули вопросом о Викторе Ане', 'Саакашвили взял на себя ответственность за всех грузин и собрался в Польшу', 'МОК предупредил российских атлетов о неожиданных допинг-тестах на Олимпиаде', 'Фетисов усмотрел заговор среди возмутившихся им рабочих и ничего не понял', 'Тренеры поругались из-за саней и помешали российскому олимпийцу победить', 'Выигравший золото биатлонист выступил против недопуска Шипулина к Олимпиаде', 'Родченков объяснил изменение внешности во время интервью CBS', 'Тренеру российских биатлонистов предложили вырвать зубы из-за плохих результатов', 'Российский олимпиец рассказал о нежелании американцев жать ему руку', 'Супермаркет посмел нарисовать женщин на тележках и поплатился', 'Родченков поведал о природе греха', 'Турция придумала сговор с «террористом» Асадом', 'Американскую фигуристку затравили из-за критики 15-летней россиянки', 'Песков отверг обвинения Родченкова и указал на его психический недуг', 'Часовщики отказались от полуобнаженных моделей следом за «Формулой-1»', 'Власти Крыма посоветовали украинским коллегам «работать внутри своей страны»', 'Иранка притворилась мужчиной ради футбольного матча', 'Авербух усомнился в способностях раскритиковавшей Загитову американки', 'Армения назвала условие разрешения конфликта с Азербайджаном', 'Порошенко обвинил Путина в неисполнении минских соглашений', 'Многодетную мать с Урала посчитали мужчиной и обвинили в подрыве устоев', 'Главная телекомпания Украины отказалась показывать ЧМ-2018', 'Студент написал диплом об экстремизме и сел за экстремизм', 'Американец назвал Олимпиаду гейской и пожалел об этом', 'Фуркад выиграл Олимпиаду и раскритиковал решение не допускать до нее россиян', 'Охотница на олигархов собралась решить судьбу YouTube в России', 'Названо число необходимых Донбассу миротворцев', 'Глава МИД Нидерландов солгал о встрече с Путиным', 'МОК захотел наказать россиянина за посвящение медали отстраненным олимпийцам', 'Олимпийская чемпионка спасла собаку от корейских гурманов', 'Занявший 40-е место российский биатлонист перелез через забор и сбежал от прессы', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Змея «духовно» проглотила многомиллионную выручку нигерийских чиновников', 'Причиной отставки сенатора Клинцевича стала вредная болтливость', 'Кремль призвал помнить о находящихся не только в Сирии россиянах', 'Украинский политик устроил скандал в прямом эфире из-за Саакашвили', 'Саакашвили из Польши пригрозил «молдавскому барыге» Порошенко', 'Иностранные компании запаниковали из-за «кремлевского доклада»', 'России предсказали наплыв секс-рабынь во время чемпионата мира-2018', 'Два российских спортсмена пропустили Олимпиаду из-за ошибки МОК', 'Спортсмены Денщиков и Потылицына решили скрасить информационный фон и поженились', 'МОК объяснил отсутствие двух россиян в списке приглашенных на Олимпиаду', 'Ошибочно не допущенный к Олимпиаде россиянин обиделся на МОК', '«Гость из будущего» прошел проверку на детекторе лжи', 'Скромный вклад Украины в борьбу с ИГ объяснили происками России', 'Иран раскрыл сеть вражеских ящериц-шпионов', 'Кремль прокомментировал возможный запрет на въезд россиян в Сирию', 'Песков заподозрил американцев в одержимости', 'Променявший США на Россию сноубордист научился давать взятки', 'За секс с детьми в России начнут сажать пожизненно', 'Фаворитов «Оскара» обвинили в расизме, плагиате и педофилии', 'Трехкратная олимпийская чемпионка сочла российских биатлонистов недостойными Игр', 'Помощник президента поведал о закате мужского мира', 'Северная Корея поболеет на Олимпиаде за чужой счет', 'Минкульт отказался от претензий к кинотеатру из-за «Смерти Сталина»', 'Президент МОК предстал пред ликом российских олимпийцев', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма', 'Чеченский муфтий поспорил о халяльности майнинга', 'Члены «банды GTA» убивали россиян ради переворота в Узбекистане', 'Российского саночника выслали с Олимпиады без объяснения причин']\n['Социологи подсчитали планирующих проголосовать на выборах-2018', 'Китайская детская задачка поставила в тупик взрослых по всему миру', 'Россиян заставили вернуть деньги на вклады обанкротившихся банков', 'США возмутил взгляд Польши на холокост', 'В Кремле порадовались за оправданных российских спортсменов', 'Москву заинтересовал запрет Польши на «бандеровскую идеологию»', 'Гимн Канады стал гендерно-нейтральным', 'Порошенко возмутился запретом «бандеровской идеологии» в Польше', 'Мутко загрустил после оправдания российских спортсменов', 'Шефы российских спецслужб приехали в США и удивили американцев', 'Президента Чехии уличили в связях с украинскими сепаратистами', 'США оправдались за «копипасту» списка Forbes в «кремлевском докладе»', 'Австралиец предложил два ноутбука за собственное убийство', 'Враг США начал поставлять в Соединенные Штаты черную икру', 'Саниспекция запретит турку из мема элегантно солить мясо', 'Рассказавшего о скупающих черную икру украинцах политолога назвали порохоботом', 'Стрелявший под кокаином у Кремля Джабраилов постреляет еще', 'Путин предостерег от эйфории после оправдания российских олимпийцев', 'Родченков не смог вразумительно ответить на вопросы суда', 'Опубликовано ранее неизвестное интервью Бориса Ельцина 1990 года', 'Украинские силовики приготовились разогнать оппозиционных журналистов', 'Лавров пожаловался на нацистский вирус', 'США объяснили утаивание части «кремлевского списка»', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'Директор ЦРУ объяснил встречу с шефами российских спецслужб', 'МИД России предупредил граждан об «охоте» за ними спецслужб США', 'Госдеп США пригрозил новыми антироссийскими санкциями', 'Пентагон обвинил Россию в попытке подорвать НАТО', 'В Крыму рассказали о рекордной популярности полуострова в мире', 'Немецкий ультраправый политик сбежал к мусульманам из-за геев', 'Работники ФБР повеселились с преступниками за 25 тысяч бюджетных долларов', 'Российских террористов решили собрать в одном месте', 'Глава USADA почуял вонь российской атаки на чистый спорт', 'США сравнили Россию и Китай с колониальными державами', 'После оправдания российских спортсменов Макларена назвали идиотом', 'США обвинили Россию в замораживании войны в Донбассе', 'В США рассказали о дружбе с Россией', 'Международная комиссия по выбросам рутения-106 оправдала «Маяк»', 'ЦИК сделал Пескову замечание из-за агитации', 'Песков извинился перед ЦИК за агитацию', 'Родченкова сочли борцом за правое дело и помогли деньгами', 'Имущество осужденного в России водочного короля нашли на острове Мэн', 'У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Украина задумалась о создании кибервойск', 'Станцевавших в БДСМ-костюмах ульяновских курсантов оставили в авиации', 'Минфин собрался сослать торговцев криптовалютами на острова', 'Вместо министерства счастья в России создадут министерство одиночества', 'Федерацию бобслея России обвинили в нежелании пускать спортсменов на Олимпиаду', 'Педагог Макаренко попросил у Медведева денег и был уволен', 'Украина поднимет флаг УПА в ответ на запрет «бандеровской идеологии» в Польше', 'Медведев и еще четыре премьера обсудили постановление номер 666 и содрогнулись', 'Названы условия продолжения борьбы МОК против россиян', 'Педофил показал звезде «Зачарованных» порно, изнасиловал и выставил на улицу', 'Четырехкратный олимпийский чемпион встал на сторону россиян и пристыдил МОК', 'Украина пригрозила Volkswagen и Adidas санкциями за работу в Крыму', 'Россиянин создал майнинг-ферму в трамвайном депо и попался', 'Подравшиеся Сванидзе и Шевченко отказались жать друг другу руки', 'В США приготовились раскрыть предвзятость ФБР к Трампу', 'Трамп рассекретил доклад о злоупотреблениях ФБР в «деле о России»', 'Российских олигархов заставят объяснить роскошную жизнь в Лондоне', 'Детская задачка о собаках поставила родителей в тупик', 'Трамп пожаловался на непрекращающиеся разговоры «только о России»', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'Спасший Шамиля Басаева врач рассказал об «эпидемии красоты» в Чечне', 'Россия уступила Белоруссии и Украине в рейтинге верховенства права', 'Саакашвили рассказал о «железных памперсах» перепуганного Порошенко', 'Следы сбившего российский Су-25 ПЗРК отыскали на Украине', 'Брюссель решил ускорить вступление Сербии в Евросоюз', 'Стали известны подробности работы масонских лож в элите Великобритании', 'Путину передан список желающих вернуться беглых бизнесменов', 'Экономику Украины сравнили с МММ', 'В Москве раскрыли причину отсутствия реакции на «кремлевский доклад» США', 'Самую дорогую рекламу в мире заменили черным экраном', 'Глава МОК рассказал о процедуре допуска оправданных россиян на Олимпиаду', 'Песков прокомментировал отказ МОК пустить на Олимпиаду оправданных россиян', 'Бежавшим из России олигархам собрались простить уголовные дела', 'Кремль объяснил действия военных в Сирии после атаки на Су-25', 'В украинской армии заметили эпидемию самоубийств', 'Песков ответил на вопрос о гарантиях желающим вернуться в Россию бизнесменам', 'Британский гольф-клуб шокировал гостей жестоким отношением к гусям', 'Лагерь паломников у места расстрела царской семьи помешал выставке инноваций', 'Россиян предложили обложить «лунным оброком»', 'Съездившие в Крым немецкие депутаты остались без наказания', 'МОК сделает из россиян пример нетерпимости к допингу', 'Вкладчики разорившихся банков пожалуются Путину на АСВ', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко', 'Аресты чиновников в Дагестане сравнили с «обнесением Чечни проволокой»', 'Суд отказался вернуть детей писавшей про трансгендеров россиянке', 'Иностранный бизнес поверил в Россию', 'Медведев пристыдил МОК', 'Президент МОК объяснил нежелание приглашать на Игры оправданных россиян', 'Зоозащитники ужаснулись мучениям раков и начали бороться за их права', 'Байдену пригрозили судом в США за слова о «сукином сыне» с Украины', 'Литва заявила о развертывании Россией «Искандеров» под Калининградом', 'Украина в отличие от Германии захотела наказания для немецких депутатов в Крыму', 'Минобороны пристыдило «Фонтанку» за публикацию данных убитого в Сирии пилота', 'Грудинин раскрыл историю происхождения дома в Испании', 'Немецкие полицейские нашли пользу в марихуане', 'МОК уличил очередных российских спортсменов в употреблении допинга', 'Тарантино раскрыл правду об удушении и домогательствах к Уме Турман', 'Главврач лишился работы из-за использования медкарт вместо туалетной бумаги', 'Глава российской разведки объяснил поездку в США', 'В Кремле отказались считать аресты в Дагестане политическим кризисом', 'Венгрия потребовала ввести миссию ОБСЕ на запад Украины', 'Немка поработала с беженцами и предрекла Германии крах', 'Европа нацелилась на деньги россиян', 'Шакро Молодой отказался от дачи показаний в суде', 'Названо место концентрации российских маньяков', 'Трамп заподозрил не хлопавших ему демократов в госизмене', 'В Киеве допустили выдвижение Польшей территориальных претензий к Украине', 'В Европе нашлась новая допинг-система', 'Украинский политик констатировал превращение страны в «сельский туалет»', 'Российские олигархи столкнулись с проблемами из-за «кремлевского доклада»', 'В сети возненавидели «бурятского Дудя»', 'Минфин США заявил о нежелании вводить санкции против госдолга России', 'Россия начала высылать северокорейских рабочих', 'Полуголая активистка вышла на протест в замороженном Пхенчхане', 'В МИД России назвали истерики Вашингтона детскими капризами', 'Работники Азов-Сити попросили президента сохранить игорную зону', 'Джим Керри удалился из Facebook из-за России', 'Российскую власть проверили на умение найти общий язык с элитой', '«Лидерам России» дали год на образование', 'В Кремле отреагировали на слухи о голосовании Путина в Севастополе', 'США обвинили Россию в новом вмешательстве в выборы', 'Найден документ с именами виновных в «сдаче Крыма» России', 'Корейцы попытались скрыть страсть к собачатине и потерпели фиаско', 'Будущим миллионерам пожелали создать Tesla', 'Названы условия появления российского флага на закрытии Игр', 'Украинцы записались в коммунисты и геи ради убежища в Европе', 'Украинский дипломат «вправил мозги» немецким политикам из-за поездки в Крым', 'Власти Красноярска не освоили деньги и удивили Путина', 'Футболист из Крыма впервые получил вызов в сборную России', 'Кудрин назвал неизбежным повышение пенсионного возраста', 'Производитель «Арматы» оставил рабочих без отдыха и денег', 'США пригрозили не дать Северной Корее «захватить» Олимпиаду', 'Немецкие депутаты обиделись на посла Украины и отказались ехать в Киев', 'В возмущении Хорватией неисправными самолетами с Украины увидели руку Москвы', 'Уличенный в «сдаче Крыма» украинский министр списал обвинения на испуг', '«Роскосмос» посчитал запуск Falcon Heavy рекламой Tesla', 'Заподозренная в мошенничестве чиновница покончила с собой', 'Глава РФПЛ выступил за пиво на стадионах и против алкоголизма', 'Чувства атеистов Казахстана приравняют к чувствам верующих', 'Путин обещал подумать о появлении метро в Красноярске', 'В США забывчивый сотрудник спецслужб потерял секретный доклад', 'Греф поностальгировал о своей работе дворником', 'Хакеры раскрыли канадский заговор против российского спорта', 'Европе предрекли «непреднамеренную» войну с Россией', 'Собчак пообещала дать Трампу пару советов', 'В «Исламском государстве» закончились мужчины', 'Раскрыт план готовящейся атаки на Россию во время Олимпиады', 'Стали известны перспективы оснащения танка «Армата»', 'Немецкие депутаты признали Крым безопаснее Германии', 'Полицейские научились вычислять преступников в толпе', 'Миллиардер Сорос хотел остановить Brexit за символическую сумму', 'На выборы президента России пойдут почти 80 процентов избирателей', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Елена Летучая рассказала о причинах ухода из «Ревизорро»', 'Россия обвинила США в сокрытии совместных успехов', 'Кремль рассказал о географии антикоррупционных чисток', 'В квартире «оружейного барона» Виктора Бута нашли подпольное казино', 'Названа самая недобросовестная страна ЕС', 'Овсянников повысил Берковича с помощника до директора департамента', 'Хакер из Северной Кореи рассказал о нищете и голоде в армии', 'В США убийца стал секс-рабом в тюрьме и нажился на этом', 'Путин признался в отсутствии смартфона', 'Студентов поймали на тайном соревновании по сексу с тучными женщинами', 'В сети поразились издевательству телеведущих над женщиной-политиком 50 лет назад', 'Сенатор от Севастополя захотел навести порядок в прокуратуре', 'Финалистов «Лидеров России» оценили члены правительства и губернаторы', 'Насильник Шурыгиной назвал сумму выплаченных ей денег', 'Стали известны подробности задержания «пожизненника»-расчленителя', 'Христиане оценили секс с роботами', 'Корейцы предложат гостям Олимпиады собачатину', 'Раскрыт крупнейший сексуальный скандал в британской власти', 'США решили заново построить отношения с Россией', 'Ученые раскрыли технологию для вечной жизни Путина', 'Собчак съездила на завтрак с Трампом и разочаровалась', 'Обыски силовиков дошли до Ингушетии', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'Польского туриста на Украине заставили поднять флаг УПА', 'Дерипаска объявил войну Рыбке и другим лжецам', 'Родченков сменил личину', 'Президент Азербайджана назвал стратегической целью возвращение столицы Армении', 'Раскрыт план США сорвать сотрудничество России и Афганистана', 'Избежавший санкций Кудрин рассказал о последствиях «кремлевского доклада»', 'Россиянин заплатил налог с комиссией в 2500 процентов', 'Коммунистов вновь обвинили в незаконной агитации за Грудинина', 'Путину рассказали анекдот про изнасилование тракториста', 'Россия посетовала на вынужденное противостояние с США', 'На Украине нашли объяснение невозможности вступить в НАТО', 'Раскрыты преимущества рубля над криптовалютами', 'Украинские депутаты плюнули на заседание Рады и уехали грозить Польше танками', 'Спецназ пришел за Саакашвили и спасовал перед охранниками отеля', 'Поглумившегося над трупом самоубийцы блогера-богача лишили денег', 'Президент Армении ответил на притязания азербайджанского коллеги на Ереван', 'Президент Франции посетит ПМЭФ по приглашению Путина', 'Порошенко пожалуется генсеку НАТО на Венгрию', 'Посетившие Крым немецкие депутаты пообещали вернуться на полуостров', 'ВВС США и НАСА отказались от Falcon Heavy', 'Пластический хирург оценил новый облик Родченкова', 'Минобороны дало отповедь усомнившемуся в героизме Филипова «манкурту»', 'Соловьев выгнал гостя своей передачи за реплику против Героя России Филипова', 'Виктор Бут захотел судиться с журналистами из-за новости о казино в его квартире', 'Украинцев призвали отказаться от поездки на чемпионат мира в Россию', 'Россиянин обманул американскую разведку на 100 тысяч долларов и скрылся', 'Изгнанный с эфира за реплику о летчике Филипове гость объяснился', 'Венгры устроили «паспортные облавы» на украинцев', 'Британцев устрашили российскими секретными «военными игрушками»', 'Кадыров купил «долю в биткоине»', 'Фетисов причислил рабочих к людям второго сорта и подвергся обструкции', 'На Украине назвали причину отказа Киева воевать за Крым', 'Путин предостерег Нетаньяху от разрастания конфликта в Сирии', 'Саакашвили взял на себя ответственность за всех грузин и собрался в Польшу', 'Жители Латвии захотели в СССР', 'ЦРУ рассказало о разводившем ведомство на деньги информаторе из России', 'Названы условия продажи С-400 в США', 'Секс до брака политики решили наказывать пятью годами тюрьмы', 'МОК предупредил российских атлетов о неожиданных допинг-тестах на Олимпиаде', 'Фетисов усмотрел заговор среди возмутившихся им рабочих и ничего не понял', 'Северную Корею заподозрили в трансляции шпионских шифров перед Олимпиадой', 'Родченков объяснил изменение внешности во время интервью CBS', 'В МВФ заявили о неизбежности глобального регулирования криптовалют', 'Супермаркет посмел нарисовать женщин на тележках и поплатился', 'Америка подарит МКС бизнесменам', 'Родченков поведал о природе греха', 'Раскрыт источник крупнейшей утечки в истории iPhone', 'Турция придумала сговор с «террористом» Асадом', 'Песков отверг обвинения Родченкова и указал на его психический недуг', 'Во Франции закончилась рабочая сила', 'Кремль посетовал на невозможность прекратить вылазки террористов в Сирии', 'Де Ниро диагностировал у США безумие', 'Скандал с охотницей на олигархов привел к угрозе блокировки YouTube в России', 'Власти Крыма посоветовали украинским коллегам «работать внутри своей страны»', 'Иранка притворилась мужчиной ради футбольного матча', 'Армения назвала условие разрешения конфликта с Азербайджаном', 'США обвинили в сокрытии ядерного оружия', 'Порошенко обвинил Путина в неисполнении минских соглашений', 'Многодетную мать с Урала посчитали мужчиной и обвинили в подрыве устоев', 'Компания Порошенко объявила монополию на «Киевский торт»', 'Студент написал диплом об экстремизме и сел за экстремизм', 'ИГ придумало способ сорвать президентские выборы в Египте', 'Саакашвили выслали с Украины', 'Американец назвал Олимпиаду гейской и пожалел об этом', 'Охотница на олигархов собралась решить судьбу YouTube в России', 'Названо число необходимых Донбассу миротворцев', 'Кашпировский потребовал у Первого канала полмиллиона рублей за коллаж с котом', 'Глава МИД Нидерландов солгал о встрече с Путиным', 'YouTube придумал наказание для «вредных» блогеров', 'Глава украинской оборонки заявил о победе и подал в отставку', 'США выразили готовность оказать помощь в расследовании крушения Ан-148', 'Британцы вместо помощи пострадавшим гаитянам развлекались с проститутками', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Змея «духовно» проглотила многомиллионную выручку нигерийских чиновников', 'Причиной отставки сенатора Клинцевича стала вредная болтливость', 'Хакеры украли у россиян более миллиарда рублей', 'Турчинов похвастал успехами украинских военных в Донбассе', 'Путин простудился', 'Кремль призвал помнить о находящихся не только в Сирии россиянах', 'В сети показали фото летевших в силовиков на Майдане пуль', 'Грудинин ответил на претензии ЦИК', 'Мусульман научили вычислять геев', 'В России заблокировали инструкции по сборке атомной бомбы и купанию кота', 'Кремль отреагировал на желание Трампа помочь Путину', 'Эрдоган пригрозил американцам «османским шлепком»', 'Японским родителям попытались навязать школьную форму от Armani', 'Путин отказался залить мир нефтью', 'Лавров посетовал на агрессивное меньшинство на Западе', 'Жителей Донбасса оставили без украинских пенсий', 'Украинский политик устроил скандал в прямом эфире из-за Саакашвили', 'Одиноким человечкам со светофоров нашли возлюбленных', 'Подсчитана доля американцев в госдолге России', 'Саакашвили из Польши пригрозил «молдавскому барыге» Порошенко', 'Иностранные компании запаниковали из-за «кремлевского доклада»', 'Венгрия пообещала продолжить давление на Украину', 'Разведка США заявила о неспособности сирийской оппозиции свергнуть Асада', 'В США обнаружили новую угрозу национальной безопасности', 'Пентагон прокомментировал сообщения о гибели россиян в Сирии', 'Госдеп США согласился с «Североамериканским тупиком»', 'Названы самые лучшие для жизни регионы России', 'Снайперы из Грузии признались в расстреле Евромайдана в 2014 году', 'В США рассказали о попытках Китая подорвать Америку изнутри', 'Сутенеры нашли необычный способ принуждения к занятию проституцией', 'МОК объяснил отсутствие двух россиян в списке приглашенных на Олимпиаду', 'Раскрыта цель разбомбленных в Сирии российских наемников', '«Гость из будущего» прошел проверку на детекторе лжи', 'Скромный вклад Украины в борьбу с ИГ объяснили происками России', 'Иран раскрыл сеть вражеских ящериц-шпионов', 'ЦИК предложил Первому каналу отложить показ фильма о Путине', 'Песков рассказал о соболезнованиях Порошенко', 'Кремль прокомментировал возможный запрет на въезд россиян в Сирию', 'Песков заподозрил американцев в одержимости', 'За секс с детьми в России начнут сажать пожизненно', 'Американские спецслужбы запретили пользоваться китайскими смартфонами', 'Помощник президента поведал о закате мужского мира', 'Грудинин уступил в популярности КПРФ', 'Минкульт отказался от претензий к кинотеатру из-за «Смерти Сталина»', 'ФСБ передумали давать еще больше полномочий', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма', 'Названы самые популярные страны для вывода денег из России', 'Всех голландцев отправят на органы', 'Собчак потребовала признать незаконной регистрацию Путина на выборах', 'Чеченский муфтий поспорил о халяльности майнинга', 'ТНТ разрешили не извиняться за извинение перед ингушами', 'Члены «банды GTA» убивали россиян ради переворота в Узбекистане', '«Евреи за Иисуса» призвали украинцев покаяться за неоплаченные услуги ЖКХ']\n0.2 0.2\n['Раскрыто происхождение новейшей украинской крылатой ракеты', 'Русских гопников назвали настоящими древними славянами', 'Открыт первый европейский бордель с секс-куклами вместо проституток', 'Социологи подсчитали планирующих проголосовать на выборах-2018', 'Звезду сериала «Детективы» задержали за работу детектива', 'Учитель угодил под суд за оральный секс со спящим школьником', 'Украинский депутат призвал к убийствам «непатриотов»', 'Прятавший трупы в цветочных горшках серийный убийца попался в Канаде', 'США провалили испытания противоракеты', 'Неймар заставит «Барселону» расплатиться', 'Любителей порно признали самыми удобными жертвами', 'Пентагон опубликовал новое видео перехвата разведчика США российским Су-27\\u200d', 'Власти США обвинили МОК и ФИФА в коррупции', 'Составлен портрет типичного столичного преступника', 'Китайская детская задачка поставила в тупик взрослых по всему миру', 'Британский лорд опоздал на заседание и уволился со стыда', 'Звезда «Бандитского Петербурга» поспорил с Пчелой из «Бригады» о насилии', 'Пробирки WADA для допинг-проб оказались бракованными', 'Убит готовивший теракт в день выборов президента России боевик ИГ', 'Россиян заставили вернуть деньги на вклады обанкротившихся банков', 'БМП-мутант заметили на сирийско-иракской границе', 'Пожизненно отстраненных российских спортсменов оправдали', 'Хабаровские селяне отреклись от земляка-мародера', 'США возмутил взгляд Польши на холокост', 'Режиссер «Фантастических тварей» взволновал геев фразой об ориентации Дамблдора', 'Женщину отказались пустить в самолет без указания пола в документах', 'У России появился новый постпред при ООН', 'В Кремле порадовались за оправданных российских спортсменов', 'Россия вернется на первое место Олимпиады-2014', 'Джима Керри загадочно оправдали по делу о суициде подруги', 'Cтали известны имена новых ведущих «Орла и решки»', 'Москву заинтересовал запрет Польши на «бандеровскую идеологию»', 'Бывшего губернатора Белых признали виновным во взяточничестве', 'Гимн Канады стал гендерно-нейтральным', 'Хвалившийся Ferrari подросток-миллионер «по воле Аллаха» займется пошивом одежды', 'Игрокам футбольного клуба «Севастополь» выплатили долги по зарплате', 'МОК разочаровало оправдание российских олимпийцев', 'Порошенко возмутился запретом «бандеровской идеологии» в Польше', 'Дуров объяснил глобальную пропажу Telegram из AppStore', 'Белоруссия решила подзаработать на российской нефти', 'Китайского геймера парализовало после 20-часового марафона', 'Россия разместит военные самолеты на оспариваемой Японией территории', 'Мутко загрустил после оправдания российских спортсменов', 'Фанатка Тупака обвинила рэпера в групповом изнасиловании', 'Раздевшуюся при собаках Беллу Хадид обвинили в масонстве и участии в оргиях', 'Шефы российских спецслужб приехали в США и удивили американцев', 'Малолетним валлийцам запретили протыкать груди и гениталии', 'Олимпиада в Пхенчхане побила рекорд по презервативам', 'Россия оправдалась за перехват американского самолета-разведчика', 'Президента Чехии уличили в связях с украинскими сепаратистами', 'Pornhub захотел одарить полицейских сотнями литров интимной смазки', 'Украинцы утратили шансы на лучшую жизнь', 'Получившая награду детская сказка разгневала омбудсмена', 'Звезда фильма «Брат» призвал отправить Пчелу из «Бригады» в монастырь', 'Самарский подросток объяснил желание напасть на школу', 'Найдено решение главной космологической загадки десятилетия', 'Канадец ввез в страну десятки пистолетов через библиотеку', 'Цены на бензин в Туркмении за 10 лет подскочили в 20 раз', 'Оправданный призер Сочи-2014 призвал «добить ситуацию» с МОК', 'Вблизи Финляндии появится первый остров для феминисток', 'Обвиняемый предложил судье полюбоваться на его пенис', 'Американская супермодель обвинила соучредителя Guess в домогательствах', 'США оправдались за «копипасту» списка Forbes в «кремлевском докладе»', 'Боевики ИГ показали превращение детей в террористов', 'Австралиец предложил два ноутбука за собственное убийство', 'Боевым священникам-десантникам доверят рулить бронетехникой', 'Учительница ввязалась в торговлю наркотиками во имя любви', '«Аэрофлот» станет самым крупным заказчиком самолетов МС-21', '«Руки-базуки» нашел возлюбленную', 'Власти США обвинили мясника из мема в антисанитарии', 'Враг США начал поставлять в Соединенные Штаты черную икру', 'Саниспекция запретит турку из мема элегантно солить мясо', 'Рассказавшего о скупающих черную икру украинцах политолога назвали порохоботом', 'Стрелявший под кокаином у Кремля Джабраилов постреляет еще', 'Пациенты осужденного врача-гематолога Елены Мисюриной устроили флешмоб', 'Путин предостерег от эйфории после оправдания российских олимпийцев', 'Родченков не смог вразумительно ответить на вопросы суда', 'Ким Чен Ын покатался на троллейбусе', 'Из России перестали уводить деньги', 'Опубликовано ранее неизвестное интервью Бориса Ельцина 1990 года', 'Украинские силовики приготовились разогнать оппозиционных журналистов', 'Бывшего замдиректора ФСИН Коршунова уличили в махинациях со служебной обувью', 'Расшифрован разговор немцев об успешном бое с четырьмя Т-34', 'Лавров пожаловался на нацистский вирус', 'Путин оказался недоволен российской промышленностью', 'Оправданный россиянин позлорадствовал над делившими медали Игр-2014 иностранцами', 'Путин пошутил про работу комбайнером в случае неудачи на выборах', 'Художник вломился к пожилому соседу, увидел нечто и вышел из творческого кризиса', 'Американский адмирал сознался в получении взяток проститутками', 'Пожилой китаец решил позировать голым из-за маленькой пенсии', 'США объяснили утаивание части «кремлевского списка»', 'Вице-президент «Лукойла» потребовал наказать избившую его сына школьницу', 'В CAS отказались считать оправданных россиян невиновными', 'В сети оценили оригинальный способ прогулять уроки', 'Никиту Белых отправили в колонию на восемь лет', 'В Сан-Франциско объявили марихуановую амнистию', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'Директор ЦРУ объяснил встречу с шефами российских спецслужб', 'МИД России предупредил граждан об «охоте» за ними спецслужб США', 'Зеленое сердце наполнили духами', 'Путин назвал условия для развития промышленности', 'Порно с голливудскими актрисами начали уничтожать', 'Ученые предупредили о грядущей катастрофе', 'Российские олигархи за январь разбогатели на 17 миллиардов долларов', 'Американская скелетонистка сочла россиян ушедшими от законного наказания', 'Суд арестовал вызволившего из ИГ сына мужчину', 'Госдеп США пригрозил новыми антироссийскими санкциями', 'Пентагон обвинил Россию в попытке подорвать НАТО', 'Президента Бразилии госорганы посчитали мертвым', 'В Крыму рассказали о рекордной популярности полуострова в мире', 'Немецкий ультраправый политик сбежал к мусульманам из-за геев', 'Назван простой способ сбросить вес', 'Хакеры украли криптовалюту на полмиллиарда долларов', 'Сын Фиделя Кастро покончил с собой', 'Японцев предупредили о возможной войне в Корее во время Олимпиады', 'Работники ФБР повеселились с преступниками за 25 тысяч бюджетных долларов', 'Голый грабитель банка разбросал деньги по улице и ушел от наказания', 'Российских террористов решили собрать в одном месте', 'Глава USADA почуял вонь российской атаки на чистый спорт', 'США сравнили Россию и Китай с колониальными державами', 'После оправдания российских спортсменов Макларена назвали идиотом', 'США обвинили Россию в замораживании войны в Донбассе', 'В США рассказали о дружбе с Россией', 'В сеть утекли спойлеры финала «Игры престолов»', 'Бузову назвали любовницей «самого красивого преступника»', 'Американцы пришли за выигрышем в тысячу долларов и получили миллион', 'Леопард Валера привел фотографироваться тигров и оленей', 'Бывший завод Порошенко стал российской собственностью', 'Звезда «Пятидесяти оттенков» раскрыл несексуальную правду о постельных сценах', 'Украина создала для Великобритании ракету', 'Овсянников оценил качество капремонта детского лагеря «Ласпи»', 'Запасной нападающий «Зенита» пожаловался на заработанные ни за что деньги', 'Хозяину двух загрызших ребенка псов в Сибири просто усложнили жизнь', 'Создатель Людей Икс и Человека-паука экстренно госпитализирован', 'Звезда «Игры престолов» и Морган Фриман устроили огненно-ледяной баттл', 'Британка уверовала в склад паучьих яиц в своем животе', 'Макгрегор обозначил круг соперников', 'Международная комиссия по выбросам рутения-106 оправдала «Маяк»', 'ЦИК сделал Пескову замечание из-за агитации', 'Из пыточных камер гестапо сделают элитное жилье', 'Звезда «Зачарованных» вступилась за свою вагину и обматерила трансгендера', 'Умерла самая одинокая в мире птица', 'Бинбанк и «Открытие» решили объединить', 'Песков извинился перед ЦИК за агитацию', 'Украинский политик в прямом эфире набросился на журналиста', 'Родченкова сочли борцом за правое дело и помогли деньгами', 'Польского чиновника не пустили в Израиль из-за закона о холокосте', 'Российский школьник послушал трек Gucci Gang 101 раз подряд', 'Российские IT-компании и госорганы обсудили тренды информационной безопасности', 'Имущество осужденного в России водочного короля нашли на острове Мэн', 'У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Украина задумалась о создании кибервойск', 'Станцевавших в БДСМ-костюмах ульяновских курсантов оставили в авиации', 'Школьница ради Слендермена попыталась зарезать девочку и получила 40 лет лечения', 'Документы пациентов использовали вместо туалетной бумаги', 'МОК посчитал оправдание российских спортсменов «торжеством обманщиков и воров»', 'Американец обнаружил билет 19-летней давности и смог им воспользоваться', 'Детского омбудсмена уличили в тяге к маргинальным смыслам и мнению недоучек', 'Российские интернет-пользователи изобрели новый язык', 'Китаянок научили правильно получать по лицу от мужей', 'Минфин собрался сослать торговцев криптовалютами на острова', 'Президент Молдавии предрек войну в случае объединения страны с Румынией', 'Испанцы передали США подозреваемого в кибератаках россиянина', 'Виктория Бекхэм согласилась на воссоединение Spice Girls', 'Поветкин подерется на разогреве у обидчика Кличко', 'Губернатор Севастополя рассказал о судьбе детского лагеря «Горный»', 'Вместо министерства счастья в России создадут министерство одиночества', 'Богатейший человек мира заработал 6,5 миллиарда долларов за вечер', 'Аварию на российской ГЭС объяснили бракованными деталями с Украины', 'Федерацию бобслея России обвинили в нежелании пускать спортсменов на Олимпиаду', 'В секс-игрушках нашли новую опасность', 'Учительница отрезала школьнице волосы во время урока', 'Пленившие россиян боевики показали последствия своей атаки', 'Педагог Макаренко попросил у Медведева денег и был уволен', 'Маленького щенка скормили питону на глазах у публики', 'Украина поднимет флаг УПА в ответ на запрет «бандеровской идеологии» в Польше', 'Медведев и еще четыре премьера обсудили постановление номер 666 и содрогнулись', 'Создателя Counter-Strike задержали за педофилию', 'Названы условия продолжения борьбы МОК против россиян', 'Педофил показал звезде «Зачарованных» порно, изнасиловал и выставил на улицу', 'Родителей осудили за искусанного крысами младенца', '«Роснефть» в сотрудничестве с «Согаз» открыла уникальный медцентр в Геленджике', 'Молчание ботаников на спортивной викторине довело ведущего', 'Москва попала в десятку городов мира по популярности марихуаны', 'Главный архитектор Махачкалы задержан за строительство фундамента', 'Тщеславный китаец построил танк и лишился его', 'Калужский школьник изрезал лицо одноклассника и выпрыгнул в окно', 'Иранцы посоветовали женщинам целовать ноги мужей-насильников и одумались', 'Четырехкратный олимпийский чемпион встал на сторону россиян и пристыдил МОК', 'США испугались мирового кризиса из-за санкций против России', 'Украина пригрозила Volkswagen и Adidas санкциями за работу в Крыму', 'Гостям отеля предложили заказывать в номер гадалок и экстрасенсов', 'Чернокожие напомнили об истинном изобретателе русского языка', 'Учитель выложил картину с вагиной, был забанен и добился суда над Facebook', 'Путешественников из Нового Уренгоя подвез атомный ледокол', 'Россиянин создал майнинг-ферму в трамвайном депо и попался', 'Подравшиеся Сванидзе и Шевченко отказались жать друг другу руки', 'В США приготовились раскрыть предвзятость ФБР к Трампу', 'Утонувшая в США русская актриса оказалась жертвой убийства', 'Украина решила продать российские активы в Крыму', 'Российских масонов вычислили в соцсетях', 'Бывший крымский чиновник поехал на Украину за паспортом и попался', 'Одноклубник Малкина влез в криокамеру и стал мемом', 'Трамп рассекретил доклад о злоупотреблениях ФБР в «деле о России»', 'Отец подвергшихся насилию гимнасток напал на врача-педофила в зале суда', 'Учительница наступила на чернокожую ученицу на уроке о рабстве', 'США оценили возможность России первой использовать ядерное оружие', 'Умер отец посла США в России миллиардер Джон Хантсман-старший', 'Выданный США россиянин отказался признать вину в киберпреступлениях', 'Илон Маск переименовал огнеметы в «неогнеметы» из-за проблем с таможней', 'Российская армия получит новейшее гиперзвуковое оружие', '«Терминатор» появится на Красной площади', 'Олимпийский комитет США обвинили в халатности', 'Российская туристка попыталась отбелить кораллы и попала в тюрьму', 'Главные герои Doom и Wolfenstein оказались родственниками', 'МОК подумает над приглашением на Олимпиаду оправданных россиян', 'По всей России вспомнили Сталинградскую битву и олимпийцев', 'Борис Корчевников побил подчиненного на православном канале «Спас»', 'Трамп отвадил британцев от соляриев', 'Оправданным россиянам запретили участвовать в Олимпиаде', 'В Севастополе прошел митинг в поддержку внешнеполитического курса президента', 'В Китае мусульман согнали в концлагеря', 'Российских олигархов заставят объяснить роскошную жизнь в Лондоне', 'Детская задачка о собаках поставила родителей в тупик', 'Итальянец обстрелял чернокожих мигрантов и начал зиговать', 'Мутко рассказал о перспективах Дзюбы', 'Леди Гага прервала мировое турне из-за сильных болей', 'Футболист выдумал себе карьеру и подписал контракт с профессиональным клубом', 'После крушения Су-25 по позициям боевиков нанесли удар высокоточным оружием', 'Роналду вошел в положение «Реала» и заслужил повышение зарплаты', 'Российский боксер Алоян защитил титул чемпиона мира', 'Боевики запутались в выборе ответственных за сбитый Су-25', 'США открестились от поставок ПЗРК в Сирию', 'Ученые определили возраст для лучшего секса', 'Ума Турман обвинила Вайнштейна в домогательствах и разочаровала его', 'Православный монастырь в Киеве попросил ООН и Трампа о защите', 'Ким Чен Ына заметили в троллейбусе', 'Трамп пожаловался на непрекращающиеся разговоры «только о России»', 'Казахстанец притворился девушкой и прошел в финал конкурса красоты', 'В США признали превосходство российского оружия', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'Apple решила бесплатно чинить iPhone 7', 'Спасший Шамиля Басаева врач рассказал об «эпидемии красоты» в Чечне', 'МОК задумался об исключении бокса из программы Олимпиады', 'Россия уступила Белоруссии и Украине в рейтинге верховенства права', 'В США разглядели главную опасность даркнета после наркотиков', 'В секретной базе найдены сотни аномальных допинг-проб', 'Саакашвили рассказал о «железных памперсах» перепуганного Порошенко', 'Следы сбившего российский Су-25 ПЗРК отыскали на Украине', 'В логотипе Лондонского марафона углядели отсылку к ДНР и ЛНР', 'Япония улучшит Владивосток ради Курильских островов', 'Названа наиболее разочаровавшая инвесторов криптовалюта', 'Назван знаменосец россиян на открытии Олимпиады', 'В Москве оценили последствия рекордного снегопада', 'Казаки проследят за порядком на ЧМ-2018', 'Брюссель решил ускорить вступление Сербии в Евросоюз', 'Стали известны подробности работы масонских лож в элите Великобритании', 'Опубликованы документы пилота сбитого Су-25', 'Эквадорец из «Зенита» испугался российских морозов и снега', 'Путину передан список желающих вернуться беглых бизнесменов', 'Экономику Украины сравнили с МММ', 'Британские спецслужбы отказались от мысли победить хакеров', 'Китай разработал план достижения господства на море', 'Раскрыта сеть нажившихся на лысых людях мошенников', 'Названы наиболее вероятные жертвы нападения собак', 'Мужчина за два года принес в банки фальшивые платежки почти на миллиард рублей', 'Комиссия МОК отказалась пустить на Олимпиаду оправданных CAS россиян', 'Американские вуду-экзорцистки подожгли пятилетнюю девочку', 'Танцовщица изобразила надменное лицо и стала мемом', 'Футболист удерживал тренера под дулом пистолета ради места в составе', 'Американцам запретили распространять детское порно из жалости', 'Чемпион UFC собирался отрезать ногу для участия в поединке', 'Назван предмет гордости россиян в науке', 'На Западе нашли слабое место России при войне с НАТО', 'В Москве раскрыли причину отсутствия реакции на «кремлевский доклад» США', 'Ума Турман описала свое изнасилование актером в 16 лет', 'Государство снимет с себя расходы на медицину', 'Показана обычная жизнь любителей БДСМ', 'WADA сорвало тренировку сборной России по хоккею в Пхенчхане', 'Топ-менеджер Сбербанка займется доставкой еды', 'Появились данные о месте службы погибшего в Сирии пилота Су-25', 'Временно исполняющего обязанности премьера Дагестана доставили на допрос в ФСБ', 'Самую дорогую рекламу в мире заменили черным экраном', 'Толпа сибиряков осадила администрацию после гибели детей из-за коммунальщиков', 'Появились подробности ареста россиянок за хранение кораллов в Таиланде', 'Супермодель пришла в уггах на Супербоул', 'Раскрыта миссия убитого в Сирии российского пилота', 'С облысением решили бороться жареной картошкой', 'Турцию заподозрили в причастности к гибели российского Су-25', 'Уральцы на двух десятках элитных машин побили рекорд по автоподставам', 'Московская стройка превратилась в водоем', 'Фанат Путина попытался похитить Лану Дель Рей', 'Пилот сбитого в Сирии Су-25 получит награду', 'Глава МОК рассказал о процедуре допуска оправданных россиян на Олимпиаду', 'Песков прокомментировал отказ МОК пустить на Олимпиаду оправданных россиян', 'Бежавшим из России олигархам собрались простить уголовные дела', 'Появилось видео с разбившейся на съемках Умой Турман', 'Кремль объяснил действия военных в Сирии после атаки на Су-25', 'Ребенок уставился в телефон во время выступления Тимберлейка и разошелся на мемы', 'Найдена новая цель США после разгрома ИГ в Ираке', 'В украинской армии заметили эпидемию самоубийств', 'Глянцевый журнал поместил на обложку татуированных ампутантов', 'Глава поселка уволился после гибели детей по вине коммунальщиков', 'Песков ответил на вопрос о гарантиях желающим вернуться в Россию бизнесменам', 'Пилоту сбитого Су-25 решили дать Героя России', 'Модель лишилась носа из-за неудачной операции', 'Натали Портман помахала огромным синим дилдо и зачитала рэп', 'Британский гольф-клуб шокировал гостей жестоким отношением к гусям', 'Шесть российских сборных отказались от участия в церемонии открытия Олимпиады', 'Лагерь паломников у места расстрела царской семьи помешал выставке инноваций', 'Самую дорогую в мире рекламу собрали в одном месте', 'Полицейские в Орле скрыли более 400 преступлений', 'Самый богатый китаец признал бесполезность денег', 'Amazon разозлил китайцев расизмом и оставил их без извинений', 'В российскую армию вернут политруков', 'Минтруд дал совет опаздывающим на работу россиянам', 'Россиян предложили обложить «лунным оброком»', 'Крым оставят без «шузов»', 'Съездившие в Крым немецкие депутаты остались без наказания', 'МОК сделает из россиян пример нетерпимости к допингу', 'Pink выругалась в ответ на обвинение в посасывании во время гимна США', 'Суд освободил осужденную за смерть пациента врача-гематолога Елену Мисюрину', 'Задержание главы правительства Дагестана с двумя заместителями попало на видео', 'Вкладчики разорившихся банков пожалуются Путину на АСВ', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко', 'Женщины с нестандартными бедрами получат джинсы по размеру', 'Боевики подорвали российские пункты помощи в Дамаске', 'Аресты чиновников в Дагестане сравнили с «обнесением Чечни проволокой»', 'Лыжники присоединились к отказавшимся от церемонии открытия Олимпиады россиянам', 'Суд отказался вернуть детей писавшей про трансгендеров россиянке', 'США потеряли потраченные на армию 800 миллионов долларов', 'Популярного русскоязычного блогера нашли мертвым', 'Ругавшие своих военных турки оказались за решеткой', 'Жертва насильника придумала шорты для защиты от насильников', 'Британцы спасли лысых ежиков', 'Иностранный бизнес поверил в Россию', 'Медведев пристыдил МОК', 'Президент МОК объяснил нежелание приглашать на Игры оправданных россиян', 'Полиция задержала актера Алексея Панина', 'Зоозащитники ужаснулись мучениям раков и начали бороться за их права', 'Адвокат Мисюриной оказался внуком первого арестованного по «делу врачей»', 'Китайцы на спор сожгли свои деньги и поплатились', 'Украина в рейтинге уровня жизни оказалась между Бангладеш и Буркина-Фасо', 'Смертники под наркотиками разочаровались в терроризме и сдались', 'Байдену пригрозили судом в США за слова о «сукином сыне» с Украины', 'Россия поставила Украине оружие «сдерживания агрессора»', 'МВД заплатит за гибель бойца после экзамена в ОМОН', 'Литва заявила о развертывании Россией «Искандеров» под Калининградом', 'Украина в отличие от Германии захотела наказания для немецких депутатов в Крыму', 'Московского прокурора Шурыгина наказали за хамскую езду на мамином Hummer', 'Жители Уфы три года продержали мужчину в строительном рабстве', 'Немцы порадовались решению не пускать оправданных россиян на Олимпиаду', 'Блогер Илья Варламов назвал Якутию «волшебным краем» и отругал зоозащитников', 'Лауреатом премии «НОС» стал Владимир Сорокин', 'Глумившийся над трупом самоубийцы блогер попросил денег', 'Актер Панин лишился машины за долги', 'Допинг-офицеры запросили список российских футболистов на ЧМ-2018', 'Белоруссия дала добро на «Смерть Сталина»', 'На фото певиц из Spice Girls обнаружили таинственный белый порошок', 'В Индии родился четырехлапый цыпленок', 'Родители придумали ребенку рак мозга и заработали на этом', 'Выданному США российскому программисту запретили мыться и читать', 'Россиян обяжут следить за гостями-иностранцами', 'Искавшее малайзийский Boeing судно пропало с радаров', 'Китай назвал российские Су-25 старьем', 'Минобороны пристыдило «Фонтанку» за публикацию данных убитого в Сирии пилота', 'В Турции мусульманам ограничат левую руку', 'Фен из интернет-магазина оказался огнеметом', 'Бэнкси попал на видео', 'Владельцу тайского кафе пригрозили тюрьмой за полуголую официантку в рекламе', 'Минобороны купит сотню боевых вертолетов Ка-52 новой модификации', 'Россиянам предложат новый способ снятия наличных', 'Грудинин раскрыл историю происхождения дома в Испании', 'В Уссурийске выявили серию нападений хищников на детей', 'Немецкие полицейские нашли пользу в марихуане', 'МОК уличил очередных российских спортсменов в употреблении допинга', 'Рыбак поборол акулу после кражи его добычи', 'Тарантино раскрыл правду об удушении и домогательствах к Уме Турман', 'Российский посол рассказал об умирающих из-за санкций женщинах в Северной Корее', 'Российские гранаты научат наблюдать', 'Бельгиец-ловелас нашел способ путешествовать бесплатно', 'Главврач лишился работы из-за использования медкарт вместо туалетной бумаги', 'Богатейшие люди мира обеднели за день на 100 миллиардов долларов', 'В США учительница совратила ученика с задержкой развития', 'Российские спортсмены продолжили борьбу с МОК', 'Уборочную технику в Москве обстреляли из травматов и забросали яйцами', 'Главу правительства Дагестана обвинили в мошенничестве', 'Американский школьник вызвал стриптизершу на урок за счет родителей и поплатился', 'Биохакер прилюдно снял штаны и сделал себе самодельную инъекцию', 'Глава российской разведки объяснил поездку в США', 'Американцев оставят без одежды', 'Раскрыты условия снятия запрета на российский флаг на Олимпиаде', 'Забытый всеми актер требовал у работников аэропорта вспомнить его', 'В Кремле отказались считать аресты в Дагестане политическим кризисом', 'Музыкант появился на публике в килте, показал пенис и попал под суд', 'Российскую книгу о самогоноварении признали угрозой Украине', 'Россия попросила Турцию помочь забрать у боевиков обломки Су-25', 'Стюардесса забылась и сделала селфи на украденный телефон пассажирки', 'Россиян признали самыми уязвимыми в сети', 'Венгрия потребовала ввести миссию ОБСЕ на запад Украины', 'Россияне назвали главные проблемы россиян', 'Немка поработала с беженцами и предрекла Германии крах', 'Польша начнет массовый снос советских памятников', 'Отец полковника Захарченко вернул миллионы', 'Пышнобедрая модель рассказала об изнасилованиях', 'Европа нацелилась на деньги россиян', 'В Telegram нашли детскую порнографию', 'Шакро Молодой отказался от дачи показаний в суде', 'Украинец научился добывать электричество из патриотических бочек', 'Отец назвал Бейонсе недостаточно черной', 'Голый австралиец пригрозил избить полицейских пенисом', 'Названо место концентрации российских маньяков', 'Тело погибшего пилота Су-25 доставили в Россию', 'Россиянам спрогнозировали девять медалей на Олимпиаде-2018', 'Минкульт провел перепись культурных памятников России', 'Полиция потребовала для расследования фотографии пениса рэпера', '«Самое неловкое видео» из жизни Трампа и его жены насмешило соцсети', 'Путин присвоил погибшему в Сирии летчику Филипову звание Героя России', 'Загадочных российских военных увидели в Идлибе после атаки на Су-25', 'Харьковские охранники выставили на мороз малолетних противников «русского мира»', 'Таинственный мостовой танк уничтожили в Сирии', 'Маск раскрыл будущее Falcon Heavy', 'Страдавший от запора британский школьник выпил слабительное и умер', 'Трамп заподозрил не хлопавших ему демократов в госизмене', 'Кондитера засмеяли за «каменный» торт в форме вагины', 'Суд арестовал бывшего главу правительства Дагестана с золотым пистолетом', 'Бондиану решили скрестить с симфоническим концертом', 'В Киеве допустили выдвижение Польшей территориальных претензий к Украине', 'В Европе нашлась новая допинг-система', 'Турист вернул в тайский храм украденные кирпичи из-за беспокойной жизни', 'Жестокого охотника за женскими трусами поймали в Москве', 'Германия и Китай лишили Россию ракетных кораблей', 'Бывший министр обороны США пожалел о бомбардировках Югославии', 'Tele2 в пять раз снизит стоимость входящих звонков в Крыму', 'Количество жалоб на запах в районе полигона «Кучино» снизилось в разы', 'Украинский политик констатировал превращение страны в «сельский туалет»', 'В сети высмеяли баттл Гуфа и Птахи', 'Американцы захотели больше контактов с русскими', 'Серебряный призер Сочи пригрозила сунуть медаль между булок желающим ее забрать', 'Россия оставила Европу без качественной нефти в угоду Китаю', 'Противостояние трезвого шотландца и тигра закончилось позором', 'Номинант на «Оскар» заставил поклонников люкса предаться размышлениям', 'Российские олигархи столкнулись с проблемами из-за «кремлевского доклада»', 'Мохаммед Али попался на допинге', 'Баскетболиста «Зенита» назвали самым ценным игроком месяца в Единой лиге ВТБ', 'Террористы поссорились из-за тела российского летчика', 'В сети возненавидели «бурятского Дудя»', 'Минфин США заявил о нежелании вводить санкции против госдолга России', 'SpaceX впервые запустила сверхтяжелую ракету Falcon Heavy', 'Порно с голливудскими актрисами начали делать на заказ', 'Онищенко призвал не мочить манту', 'Президент Филиппин в борьбе с коррупцией раздавил десятки люксовых автомобилей', 'Военным предложили славить Украину при каждом приветствии и прощании', 'Ведомый летчика Филипова рассказал о попытках прикрыть сбитого командира', 'Apple предложила вернуть деньги за замену аккумуляторов медленных iPhone', 'Американка выиграла 560 миллионов долларов и отказалась от приза', 'Белорусская сборная доверила Бьорндалену откатку лыж', 'Создатели «Игры престолов» займутся «Звездными войнами»', 'Иллюзия с непараллельными параллельными улицами запутала пользователей сети', 'Россия начала высылать северокорейских рабочих', 'Полуголая активистка вышла на протест в замороженном Пхенчхане', 'Депрессивных людей вычислили по словам', 'Центральный ускоритель Falcon Heavy разбился при посадке', 'В МИД России назвали истерики Вашингтона детскими капризами', '«Газпром» похвастался рекордной долей на европейском рынке', 'Работники Азов-Сити попросили президента сохранить игорную зону', 'Чернокожий американец отправил в ИГ образцовое резюме и получил работу', 'Джим Керри удалился из Facebook из-за России', 'Теневая экономика в России достигла уровня африканских стран', 'Британские спортсмены пропустят открытие Олимпиады из-за морозов', 'Влюбленный алиментщик трижды пытался сбежать с Украины к новой крымской жене', 'Американка рассказала о способе сохранить идеальную талию', 'Назван самый вкусный российский шоколад', 'Трамп захотел увидеть солдат и танки около Белого дома', 'Биткоин взмыл вверх после обвала', 'Российскую власть проверили на умение найти общий язык с элитой', 'В сети рассказали о горькой судьбе водителя Tesla в космосе', 'Российская компания заставила понервничать британскую разведку', 'Омские заключенные слепили из снега «Тополь-М» в натуральную величину', 'Российские спортсмены пропустят Олимпиаду из-за затянувшегося суда', 'В Саудовской Аравии открылись бойцовские клубы для женщин', 'Назван победитель баттла Гуфа и Птахи', 'Дом и золотые пистолеты арестованного дагестанского премьера показали на видео', '«Лидерам России» дали год на образование', 'Южнокорейских полицейских заставили смотреть порно на работе', 'Банк России проверит сотрудников на детекторе лжи', 'Американскую спортсменку разозлило оправдание российских олимпийцев', 'В Кремле отреагировали на слухи о голосовании Путина в Севастополе', 'США обвинили Россию в новом вмешательстве в выборы', 'Найден документ с именами виновных в «сдаче Крыма» России', 'На воевавшую в Абхазии и Донбассе грузинскую националистку напали в Тбилиси', '«Гигантского бронемонстра» заметили в Сирии', 'Лубутену отказали в эксклюзивном праве на красные подошвы', 'Ответственность за экономический рост переложили на доходы россиян', 'Молчаливая кухарка из Китая обрела мировую славу', 'На офисных работников наденут шоры', 'В Германии поделили власть', 'Норвежцы привезли на Олимпиаду частично запрещенные препараты', 'Российским Sukhoi Superjet 100 сделают обрезание', 'Корейцы попытались скрыть страсть к собачатине и потерпели фиаско', 'Найдены доказательства отсутствия расизма у Трампа', 'Все госструктуры Дагестана начали обыскивать', 'Ким Чен Ын отправит сестру-пропагандистку на Олимпиаду', 'Раскрыто имя нового министра иностранных дел Германии', 'Греф поймал сотрудников Сбербанка на майнинге', 'Будущим миллионерам пожелали создать Tesla', 'Названы условия появления российского флага на закрытии Игр', 'Украинцы записались в коммунисты и геи ради убежища в Европе', 'Украинский дипломат «вправил мозги» немецким политикам из-за поездки в Крым', 'Дагестанским чиновникам запретили покидать Россию', 'Музыканты из России смогут выиграть 100 тысяч евро и обучение на Ибице', 'Корпорация МСП встретилась с предпринимателями Ярославской области', 'Туристам в Узбекистане разрешили кое-что снимать', 'Власти Красноярска не освоили деньги и удивили Путина', 'Назначен глава правительства Дагестана', 'Ради президента Таджикистана и его сына изменят выборы', 'Футболист из Крыма впервые получил вызов в сборную России', 'Кудрин назвал неизбежным повышение пенсионного возраста', 'В интервью Тарантино нашли оправдание изнасилования 13-летней девочки', 'Щуплость и конкуренция с Гатаговым избавили Неймара от карьеры в России', 'Показан обстрелявший российский Су-25 террорист', 'Украина объявила сроки возобновления покупки российского газа', 'Производитель «Арматы» оставил рабочих без отдыха и денег', 'США пригрозили не дать Северной Корее «захватить» Олимпиаду', 'У ФСБ нашли спецсамолет для «посадок» чиновников', 'Немецкие депутаты обиделись на посла Украины и отказались ехать в Киев', 'Немецкий биатлонист сравнил оправдание российских олимпийцев с плевком в лицо', 'В возмущении Хорватией неисправными самолетами с Украины увидели руку Москвы', 'Американских воспитательниц поймали на удалении моноброви у детей', 'Минтруд удивился бедности россиян', 'Уличенный в «сдаче Крыма» украинский министр списал обвинения на испуг', 'Курильщик прожег лик архангела Михаила, похвастался и скрылся', '«Роскосмос» посчитал запуск Falcon Heavy рекламой Tesla', 'Пожизненно осужденный маньяк-расчленитель из «Полярной Совы» переехал в Москву', 'Заподозренная в мошенничестве чиновница покончила с собой', '«Оружие Победы» всплыло на иракском черном рынке', 'Украинская газета поведала о «захвативших власть в стране жидах»', 'Раков-мутантов признали иконами феминизма', 'Глава РФПЛ выступил за пиво на стадионах и против алкоголизма', 'Чувства атеистов Казахстана приравняют к чувствам верующих', 'Раскрыты детали проекта первого гиперзвукового пассажирского лайнера', 'Немцев предупредили о смертоносной мастурбации', 'Путин обещал подумать о появлении метро в Красноярске', 'В США забывчивый сотрудник спецслужб потерял секретный доклад', 'Греф поностальгировал о своей работе дворником', 'Хакеры раскрыли канадский заговор против российского спорта', 'В США оценили вероятность ядерного удара со стороны России', 'Армянские врачи приняли чай за мочу', 'Европе предрекли «непреднамеренную» войну с Россией', 'Собчак пообещала дать Трампу пару советов', 'Мексиканская YouTube-знаменитость стала жертвой наркокартеля', 'В «Исламском государстве» закончились мужчины', 'Раскрыт план готовящейся атаки на Россию во время Олимпиады', 'Коалиция США нанесла удар по войскам Асада', 'Порно с голливудскими звездами лишилось последнего пристанища', 'В США шериф пожалел свои машины и приказал застрелить нарушителя', 'Стали известны перспективы оснащения танка «Армата»', 'Spice Girls отправятся в гастрольный тур со старыми песнями', 'Немецкие депутаты признали Крым безопаснее Германии', 'Космический аппарат-убийца догнал европейский спутник', 'Полицейские научились вычислять преступников в толпе', 'Российские керлингисты уступили сборной США в дебютной игре Олимпиады-2018', 'Индиец тайно продал почку жены из-за маленького приданого', 'Американская учительница решила доказать свое право совращать учащихся', 'Умер основатель современного интернета', 'Кексы на теле полуголой девушки оказались незаконными', 'Раскрыты подробности контракта на поставку в войска истребителей Су-57', 'США вознамерились достичь небывалой ядерной мощи для любой войны', 'Власти Приморья опровергли слухи о принудительной высылке граждан Северной Кореи', 'Врач оправдала норвежских олимпийцев-астматиков', 'Миллиардер Сорос хотел остановить Brexit за символическую сумму', 'Бойцы ВСУ отказались здороваться словами «Слава Украине»', 'На выборы президента России пойдут почти 80 процентов избирателей', 'Главный спортивный матч в США заставил женщин ринуться за порно', 'Европе пригрозили штрафом за срыв «Северного потока-2»', 'Нелегальные мигранты устроили массовые беспорядки в Сибири', 'Математики предрекли биткоину вечную нестабильность', 'Раскрыт сговор Турции и ИГ', 'Российские олимпийцы пожаловались на слежку со стороны иностранной прессы', '«Звездные войны» раскритиковали за обилие белых мужчин в съемочной группе', 'Венесуэльцы начали расплачиваться яйцами', 'Полицейским запретили убирать с дорог пьяных судей', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Елена Летучая рассказала о причинах ухода из «Ревизорро»', 'Кэти Перри посчитала хит I Kissed a Girl недостаточно лесбиянским', 'Россия обвинила США в сокрытии совместных успехов', 'Основателя сети российских пиццерий привлекли к делу о контрабанде наркотиков', 'Роналдо одобрил покупку Неймара', 'Банки научились узнавать кредитных мошенников в лицо', 'Умер вырастивший 68 лебедят гусь-бисексуал', 'Кремль рассказал о географии антикоррупционных чисток', 'Российские олимпийцы подверглись дискриминации со стороны канадцев', 'Выпущенные с моря по террористам российские ракеты подсчитали', 'В квартире «оружейного барона» Виктора Бута нашли подпольное казино', 'Раскрыта гомосексуально-наркотическая связь Марлона Брандо и Ричарда Прайора', 'Татуировщика-убийцу поймали на живца', 'Генпрокуратура назвала ущерб от махинаций с землей в Дагестане', 'Главу крупнейшей промышленной компании Украины арестовали в Москве', 'Появилось видео прощания с погибшим пилотом Су-25', 'Наркоторговец отказался от походов в туалет ради свободы', 'CAS отказался рассматривать апелляции отстраненных от Олимпиады россиян', '«Самый стильный блогер» оказался жуликом', 'Губернатор Подмосковья даст наставления «Лидерам России»', 'Российские болельщики осадили штаб-квартиру WADA', 'Названа самая недобросовестная страна ЕС', 'Украинские силовики захватили редакцию оппозиционных СМИ', 'Овсянников повысил Берковича с помощника до директора департамента', 'ФСИН объяснила освобождение пожизненно осужденного расчленителя', 'Хакер из Северной Кореи рассказал о нищете и голоде в армии', 'Власти Севастополя рассказали о переходе на новую систему обращения с отходами', 'Потерявший шансы попасть на Олимпиаду Кулижников прокомментировал решение CAS', 'Модели отвоевали право не демонстрировать наготу', 'В США убийца стал секс-рабом в тюрьме и нажился на этом', 'Путин признался в отсутствии смартфона', 'Петербуржцев напугали резким ростом мусорного тарифа', 'На Украине раскрыли детали убийства комбата ДНР Гиви', 'США по ошибке поддержали ИГ огнем', 'YouTube попытался научить детей точить ножи', 'Мексиканец отправил по почте коробку с живым тигром', 'Rambler Group объявила об изменениях в руководящем составе', 'Россиянка проведет дебютный бой в UFC с чемпионкой', 'Подставной Илон Маск обобрал доверчивых пользователей на тысячи долларов за ночь', 'Студентов поймали на тайном соревновании по сексу с тучными женщинами', 'В Москве пройдет секретная вечеринка Boiler Room', 'В МВД рассказали о найденных в пиццерии пакетах с наркотиками', 'В сети поразились издевательству телеведущих над женщиной-политиком 50 лет назад', 'Сенатор от Севастополя захотел навести порядок в прокуратуре', 'Финалистов «Лидеров России» оценили члены правительства и губернаторы', 'Распознавание лиц от NtechLab будут использовать в «умных городах» Татарстана', 'На похороны погибшего пилота Су-25 пришли 30 тысяч человек', 'Толстый таджикский генерал не захотел терять работу и похудел на 15 килограммов', 'Бренды и чиновники отказались от индивидуальности ради российских спортсменов', 'Россия испытала плазменные двигатели', 'Насильник Шурыгиной назвал сумму выплаченных ей денег', 'Стали известны подробности задержания «пожизненника»-расчленителя', 'Обмазавшегося маслом голого преступника под ЛСД остановил электрошокер', 'Трехкратная чемпионка мира выступила против наказания невиновных россиян', 'Вор пожаловался на кражу украденного', 'Затушившего сигарету об икону студента задержали', 'Христиане оценили секс с роботами', 'Российские олимпийцы смогут носить шапку с триколором', 'Легенды российского хоккея провели благотворительный матч в Норильске', 'Запущенный в космос автомобиль Tesla отнесли к спутникам', 'Пенсионеров завалили загадочными посланиями', 'Корейцы предложат гостям Олимпиады собачатину', 'Коалицию США заподозрили в намеренном уничтожении российского моста в Сирии', 'Раскрыт крупнейший сексуальный скандал в британской власти', 'Активистка Femen оголилась перед Порошенко на Венском балу', 'Хорошавина приговорили к 13 годам в колонии строгого режима', 'БДСМ-госпожу уволили из полиции в США', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду', 'Американка исследовала сушилку для рук в общественном туалете и ужаснулась', 'Наивная записка в российском подъезде растрогала пользователей сети', 'WADA возрадовалось решению CAS о недопуске россиян к Олимпиаде', 'Американские биржи рухнули второй раз за неделю', 'США решили заново построить отношения с Россией', 'Таец выиграл в лотерею миллионы, потерял билет и умер', 'Еще один банк лишился лицензии', 'Бывший глава Сахалина поразил следователей любовью к роскошным часам', 'Борца против домогательств обвинили в домогательствах', 'Вайнштейн угрожал Сальме Хайек сломанными коленями и смертью', 'МОК поддержал решение не допустить российских спортсменов на Олимпиаду', '«Отрицающие все» киргизы получили сроки за призывы к молитве', 'Индия оштрафовала Google за злоупотребления', 'Илон Маск объяснил космический провал СССР', 'Ученые раскрыли технологию для вечной жизни Путина', 'Собчак съездила на завтрак с Трампом и разочаровалась', 'Россия обвинила ИГ в заработке на онлайн-казино', 'Адвокат Родченкова поблагодарил бога за недопуск россиян на Олимпиаду', 'Насильник Шурыгиной ответил на новое обвинение в домогательствах', 'Американские компании пострадали от кумовства', 'Сельскую учительницу накажут за мат в стихах Маяковского', 'Объявивший себя русским Рой Джонс завершил карьеру', 'Секс-скандал вокруг звезды «Зачарованных» довел ее менеджера до суицида', 'Курды поймали последних джихадистов-«битлов»', 'Мост в Крым строит многотысячная команда', 'Apple подтвердила крупнейшую утечку в истории iPhone', 'Охотница на олигархов пригрозила Дерипаске походом на «Пусть говорят»', 'Мутко назвал причины недопуска россиян на Олимпиаду', 'Обыски силовиков дошли до Ингушетии', 'Охотница на олигархов назвала претензии к Дерипаске «троллингом тупых баб»', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'Рома Зверь сыграл одну из главных ролей в ленте Серебренникова о Цое', 'Оборонные предприятия России атаковали', 'Атаман пришел за наградой в футболке с надписью «У меня есть член»', 'Пенсиям россиян предрекли обвал', 'Польского туриста на Украине заставили поднять флаг УПА', 'Дерипаска объявил войну Рыбке и другим лжецам', 'Африканцы научат Европу правильно одеваться', 'Родченков сменил личину', 'Американский поклонник ИГ попытался вступить в Армию США ради джихада', 'Президент Азербайджана назвал стратегической целью возвращение столицы Армении', 'Китай решил потеснить господство доллара', 'Потушившему сигарету об икону студенту дали девять суток ареста', 'Раскрыт план США сорвать сотрудничество России и Афганистана', 'Убийцы Гиви и Моторолы оказались одними и теми же людьми', 'Избежавший санкций Кудрин рассказал о последствиях «кремлевского доклада»', 'Голодавшая из-за злого деда японка показала себя при весе в 16 килограммов', 'Россиянин заплатил налог с комиссией в 2500 процентов', 'Коммунистов вновь обвинили в незаконной агитации за Грудинина', 'Путину рассказали анекдот про изнасилование тракториста', '«Газпром» намекнул Европе на грядущий дефицит газа', 'Россия посетовала на вынужденное противостояние с США', 'Олимпиада в Пхенчхане официально стартовала', 'Американские самолеты разбомбили ракету Маска', '«Аэрофлот» ужесточит контроль за габаритами и весом ручной клади', 'На Украине нашли объяснение невозможности вступить в НАТО', 'Профессиональными наставниками захотели стать сотни россиян', 'Раскрыты преимущества рубля над криптовалютами', 'Финалистов «Лидеров России» оценят школьники', 'Россиянин с братом убивал пенсионеров и получил пожизненное', 'Украинские депутаты плюнули на заседание Рады и уехали грозить Польше танками', 'Россия захотела избавиться от господства доллара', 'Спецназ пришел за Саакашвили и спасовал перед охранниками отеля', 'Египет решил убить всех террористов перед приездом российских туристов', 'Трампа с Ким Чен Ыном заметили на открытии Олимпиады', 'Поглумившегося над трупом самоубийцы блогера-богача лишили денег', 'Кинокритики высмеяли БДСМ-мелодраму «Пятьдесят оттенков свободы»', 'Президент Армении ответил на притязания азербайджанского коллеги на Ереван', 'Украина отказалась захватывать Россию', 'Путин пообещал убрать все ради движения вперед', 'Блогер поджарил себя на плите ради славы', 'Узбеки-трансвеститы с сексуальными желаниями оказались вне закона', 'В Госдуме пообещали разобраться с главой МОК после Олимпиады', 'Курдов обвинили в массовых казнях боевиков ИГ', 'AirPods загорелись в ухе американца', 'Президент Франции посетит ПМЭФ по приглашению Путина', 'Любителям криптовалют посоветовали обратиться к психиатрам', 'Американская спортсменка приехала на Олимпиаду в статусе бомжа', '«ФосАгро» стала дважды победителем всероссийского конкурса РСПП', 'Нефтяную зависимость России предложили заменить молочной', 'Порошенко пожалуется генсеку НАТО на Венгрию', 'Ягудин пристыдил российского фигуриста Коляду за провал на Олимпиаде', 'Теневая экономика Украины обогнала российскую', 'Посетившие Крым немецкие депутаты пообещали вернуться на полуостров', 'Набитый евро чемодан оказался эффективнее молитв', 'ВВС США и НАСА отказались от Falcon Heavy', 'Пентагон открестился от намеренного разрушения российского моста', 'Парень из мема про ботаников поучаствовал в запуске Falcon Heavy', 'Пластический хирург оценил новый облик Родченкова', 'Плющенко отправил в Международный паралимпийский комитет «письмо-боль»', 'Французский суд продлил арест Павленскому', 'Минобороны дало отповедь усомнившемуся в героизме Филипова «манкурту»', 'Бах обещал распустить CAS в случае оправдания российских атлетов', 'Американский посол пожаловался на нехватку гор в Москве', 'Соловьев выгнал гостя своей передачи за реплику против Героя России Филипова', 'Трамп заблокировал публикацию записки демократов о «российском расследовании»', 'Пентагон отказался от претензий к появлению «Искандеров» под Калининградом', 'Виктор Бут захотел судиться с журналистами из-за новости о казино в его квартире', 'МЧС спрогнозировало наиболее вероятные сценарии войны с Россией', 'В Амстердаме туристам запретили смотреть на проституток', 'Американцы попытались сравнить истребители Су-35 и F-35 и не смогли', 'Умер актер из «Карточного домика»', 'Мэйуэзер согласился на новый поединок с Макгрегором', 'Ким Чен Ын позвал президента Южной Кореи в гости', 'Украинцев призвали отказаться от поездки на чемпионат мира в Россию', 'Уничтожение российского Су-25 раскололо боевиков', 'Россиянин обманул американскую разведку на 100 тысяч долларов и скрылся', 'Задержанные за хранение кораллов россиянки рассказали о тайской тюрьме', 'Изгнанный с эфира за реплику о летчике Филипове гость объяснился', 'CAS объяснил решение о недопуске россиян на Олимпиаду', 'Венгры устроили «паспортные облавы» на украинцев', 'Курды сбили турецкий вертолет и показали это на видео', 'Британцев устрашили российскими секретными «военными игрушками»', 'Кадыров купил «долю в биткоине»', 'Школьники оценили финалистов «Лидеров России»', 'Елистратов посвятил медаль «подло и мерзко отстраненным» россиянам', 'Спортсменка из США обрадовалась отсутствию лидеров сборной России на Олимпиаде', 'Российских спортсменов посчитали самыми стильными на Олимпиаде', 'Фетисов причислил рабочих к людям второго сорта и подвергся обструкции', 'В московском лицее объяснили запрет на походы в туалет без справки', 'На Украине назвали причину отказа Киева воевать за Крым', 'Дерипаска подал в суд на Рыбку и ее наставника', 'Попавшегося на допинге француза спугнули вопросом о Викторе Ане', 'Путин предостерег Нетаньяху от разрастания конфликта в Сирии', 'Олимпийский чемпион окрестил российских биатлонисток «кем попало»', 'Саакашвили взял на себя ответственность за всех грузин и собрался в Польшу', 'Жители Латвии захотели в СССР', '«Роскосмос» анонсировал уникальный запуск космического корабля', 'ЦРУ рассказало о разводившем ведомство на деньги информаторе из России', 'Русским предсказано взять власть в Латвии', 'Названы условия продажи С-400 в США', 'Украинец услышал «призыв» Путина принять конституцию и решил покончить с собой', 'Польша решила побороться с другими странами ЕС за дешевый труд украинцев', 'Секс до брака политики решили наказывать пятью годами тюрьмы', 'МОК предупредил российских атлетов о неожиданных допинг-тестах на Олимпиаде', 'Фигуристка Медведева с мировым рекордом выиграла короткую программу', 'Следователи завели дело на мешавшего фермерам министра в Забайкалье', 'Ученые выявили существенные преимущества людей без пары', 'В США разгадали план Китая по уничтожению Америки', 'Роналду встретил Нурмагомедова и заговорил по-арабски', 'Советские перехватчики потягались с израильскими истребителями в Сирии', 'Обмен шпионами между Россией и Эстонией попал на видео', 'Фетисов усмотрел заговор среди возмутившихся им рабочих и ничего не понял', 'Северную Корею заподозрили в трансляции шпионских шифров перед Олимпиадой', 'Украина модернизировала 50-летний ракетный комплекс', 'Путин поручил расследовать крушение Ан-148', 'Канадские хоккеистки разгромили россиянок в первом матче Олимпиады', 'Пассажиры рассказали об «убитых» самолетах «Саратовских авиалиний»', 'Путин отменил поездку в Сочи после крушения Ан-148', 'Министр Соколов назвал биоматериалом тела погибших в катастрофе Ан-148', 'Очевидцы сообщили о хлопке перед крушением Ан-148', 'Занявший 57-е место российский биатлонист высоко оценил собственную скорость', 'Появилась запись переговоров потерявших Ан-148 авиадиспетчеров', 'Владельцу «Саратовских авиалиний» припомнили «коробку из-под ксерокса»', 'Тренеры поругались из-за саней и помешали российскому олимпийцу победить', 'Сокамерницы избили арестованную в США россиянку до слепоты', 'Проверявшие Ан-148 техники разбились вместе с ним', 'Привезенный к дому Порошенко «столб позора» украли', 'Выигравший золото биатлонист выступил против недопуска Шипулина к Олимпиаде', 'Новые Су-25 сделали неуязвимыми для зенитных ракет', 'Спасательная операция на месте крушения Ан-148 завершена', 'Родченков объяснил изменение внешности во время интервью CBS', 'Распыление спрея от комаров в лицо ради лечения от ВИЧ сочли насилием', 'Фигуристка Загитова выиграла произвольную программу командного турнира Олимпиады', 'Тренеру российских биатлонистов предложили вырвать зубы из-за плохих результатов', 'Жительница Мекки втайне от семьи выкладывала в соцсети порновидео и поплатилась', 'Медведева прокомментировала серебро россиян в фигурном катании', 'В МВФ заявили о неизбежности глобального регулирования криптовалют', 'Бывший депутат-единоросс сломал челюсть диджею Smash', 'Российский олимпиец рассказал о нежелании американцев жать ему руку', 'Немецких трубочистов научили зиговать и нахваливать Гитлера', 'Супермаркет посмел нарисовать женщин на тележках и поплатился', 'Оренбургские чиновники отдадут семьям пассажиров Ан-148 дневной заработок', 'Правительство определилось с минимальной ценой на водку', 'Америка подарит МКС бизнесменам', '«Дикие» северокорейские болельщицы на Олимпиаде взбесили соцсети', 'Родченков поведал о природе греха', 'Бывший полицейский из команды генерала Сугробова сел за махинации с делами', 'Сценаристы назвали самые интересные фильмы 2017 года', 'Раскрыт источник крупнейшей утечки в истории iPhone', 'Овсянников поздравил севастопольцев с Масленицей', 'Турция придумала сговор с «террористом» Асадом', 'Американскую фигуристку затравили из-за критики 15-летней россиянки', 'Умирающий криминальный авторитет перед смертью рассказал свою историю', 'В Крыму поймали собиравшего информацию о Росгвардии и ФСБ украинца', 'Сбитый в Израиле иранский беспилотник оказался копией американского', 'Пятизвездочная тюрьма «раскулаченных» принцев попала на видео', 'В Нью-Йорке мужчин выставили свиньями', 'Украинцы пришли в ярость от соболезнующего родным жертв Ан-148 Климкина', 'Песков отверг обвинения Родченкова и указал на его психический недуг', 'В Кремле прокомментировали расследование крушения Ан-148', 'Во Франции закончилась рабочая сила', 'Американским школьницам запретили отказывать мальчикам в танце', '«Руки-базуки» отказался драться с Камой Пулей и предложил ему альтернативу', 'Часовщики отказались от полуобнаженных моделей следом за «Формулой-1»', 'Кремль посетовал на невозможность прекратить вылазки террористов в Сирии', 'Де Ниро диагностировал у США безумие', 'Туристы пойдут под суд за организацию порнотанцев в Камбодже', 'Ягудин осадил американскую фигуристку за критику 15-летней Загитовой', 'Звезды «Секса в большом городе» устроили скандал вокруг мертвого родственника', 'Богатейший россиянин сможет содержать Россию две недели', 'Киркорова в шикарном пуховике назвали «кудрявой бабушкой»', 'Скандал с охотницей на олигархов привел к угрозе блокировки YouTube в России', 'Похитителям 500 живых тараканов пригрозили тюрьмой', 'Власти Крыма посоветовали украинским коллегам «работать внутри своей страны»', 'Гигантская голова помешала олимпийскому тигру вписаться в дверной проем', 'США обвинили в нежелании бороться с ИГ', 'Иранка притворилась мужчиной ради футбольного матча', 'Саакашвили задержали на Украине', 'Авербух усомнился в способностях раскритиковавшей Загитову американки', 'Тимати обозвал избившего диджея Smash депутата «гнилым пидарастом»', 'Армения назвала условие разрешения конфликта с Азербайджаном', 'В ЦИК рассказали о желании россиян проголосовать по месту пребывания', 'Украина начала экспортировать пчел в Канаду', 'Лидера «Оплота» Жилина убил украинский киллер', 'Саакашвили рассказал о спасшей Сталина прабабушке', 'Богатые россияне испугались санкций и спрятали деньги в России', 'На директора реабилитационного центра завели дело после смерти актера Марьянова', 'США обвинили в сокрытии ядерного оружия', 'Водянова попыталась приучить подписчиков к прокладкам и просчиталась', 'Раскрыта роль Киева в расследовании крушения Ан-148', 'Порошенко обвинил Путина в неисполнении минских соглашений', 'Многодетную мать с Урала посчитали мужчиной и обвинили в подрыве устоев', 'Компания Порошенко объявила монополию на «Киевский торт»', 'Президент Филиппин приказал простреливать вагины протестующим', 'Главная телекомпания Украины отказалась показывать ЧМ-2018', 'Полуголые футболистки из Владивостока разъярили соцсети своими формами', 'Студент написал диплом об экстремизме и сел за экстремизм', 'Шесть сотрудников «Газпром нефти» вошли в число победителей «Лидеров России»', 'Киеву предрекли возвращение гетто', 'Известный итальянский бренд откроет магазин собственных подделок', 'ИГ придумало способ сорвать президентские выборы в Египте', 'Саакашвили выслали с Украины', 'Американец назвал Олимпиаду гейской и пожалел об этом', 'Фуркад выиграл Олимпиаду и раскритиковал решение не допускать до нее россиян', 'Охотница на олигархов собралась решить судьбу YouTube в России', 'Названо число необходимых Донбассу миротворцев', 'Сторонники Саакашвили отправились к администрации Порошенко', 'Кашпировский потребовал у Первого канала полмиллиона рублей за коллаж с котом', 'От удара американских войск в Сирии погиб россиянин', 'Обвал американских рынков объяснили эмоциями', 'Саакашвили назвал Порошенко «подлым барыгой»', 'Глава МИД Нидерландов солгал о встрече с Путиным', 'МОК захотел наказать россиянина за посвящение медали отстраненным олимпийцам', 'YouTube придумал наказание для «вредных» блогеров', 'Ямальский колледж вошел в сто лучших учебных заведений России', 'Судья пригрозила проблемами пострадавшему от ее сына мальчику', 'Изящный жест очками превратил олимпийского фигуриста в кумира интернета', 'Трамп пособолезновал Путину в связи с авиакатастрофой в Подмосковье', 'Невестка Трампа открыла конверт с белым порошком и попала в больницу', 'Олимпийская чемпионка спасла собаку от корейских гурманов', 'Глава украинской оборонки заявил о победе и подал в отставку', 'Саакашвили сравнил украинских силовиков с фашистами и пообещал вернуться', 'ЦИК выявила обман со стороны Грудинина', 'Российская художница показала лицо стран и обрела всемирную славу', 'Сдан первый положительный допинг-тест на Олимпиаде', 'Робота-собаку научили открывать двери', 'США выразили готовность оказать помощь в расследовании крушения Ан-148', 'Британцы вместо помощи пострадавшим гаитянам развлекались с проститутками', 'Более 10 оперативников таскали Саакашвили за волосы', 'Полиция озаботилась новым челленджем и призвала не ночевать в магазинах', 'Керлингисты принесли России третью медаль Олимпиады', 'Трех российских легкоатлетов не допустили до международных соревнований', 'Грузинский снайпер обвинил украинских депутатов в расстреле Майдана', 'Занявший 40-е место российский биатлонист перелез через забор и сбежал от прессы', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Змея «духовно» проглотила многомиллионную выручку нигерийских чиновников', 'Человека-рыбу из «Формы воды» расстроил посвященный ему дилдо', 'Россияне стали ярыми противниками супружеских измен', 'Причиной отставки сенатора Клинцевича стала вредная болтливость', 'Раскрыта стоимость космодрома «Морской старт»', 'Британка сбросила полцентнера из-за «ужасного секса»', 'Олимпийский чемпион признался в желании «дать леща» фигуристу Коляде', 'Поляки нашли украинского Гитлера', 'Похудевшая ради свадебного платья блогер заработала бесплодие', 'Россиян предупредили об угрозе ядерного заражения', 'Хакеры украли у россиян более миллиарда рублей', 'Советскую школу наставничества задумали возродить', 'Британских геев порадовали модной клеткой с радужными деталями', 'Запрещавший детям выходить в туалет без справки учитель лишился работы', 'Раскрыты планы США по сдерживанию России', 'Украинская биатлонистка сочла выход на олимпийскую трассу бессмысленным', 'Америка определилась со сроками покорения Луны', 'Турчинов похвастал успехами украинских военных в Донбассе', 'Путин простудился', 'Интернет-торговлю в России захотели радикально изменить', 'Влезшая в политику корейская гадалка угодила за решетку', 'По факту избиения диджея Smash возбуждено уголовное дело', 'Кремль призвал помнить о находящихся не только в Сирии россиянах', 'Кибератаку во время Олимпиады приписали россиянам', 'В сети показали фото летевших в силовиков на Майдане пуль', 'Россияне обросли долгами и отказались из них вылезать', 'Российский футболист высморкался в пятитысячную купюру и нарвался на оскорбления', 'Грудинин ответил на претензии ЦИК', 'Мусульман научили вычислять геев', 'В России заблокировали инструкции по сборке атомной бомбы и купанию кота', 'Кремль отреагировал на желание Трампа помочь Путину', 'На Урале начались поиски жертв серийного маньяка-эмчеэсовца', 'Геологи отсоветовали трогать челябинский метеорит из-за непредсказуемых бактерий', 'В России без объяснений отложили премьеру новых «Мстителей»', 'Короткая память и гей довели таджикских милиционеров до уголовного дела', 'Эрдоган пригрозил американцам «османским шлепком»', 'Саакашвили выдворили с Украины перед допросом о расстрелах на Майдане', 'Избитого Цукерберга поместили на обложку журнала', 'Украинцы обезвредили енота-агрессора из России', 'Мединский обвинил БДСМ-мелодраму в удушении российского кино', 'Японским родителям попытались навязать школьную форму от Armani', 'Иностранцы провозгласили россиянку самой сексуальной керлингисткой в истории', 'Художники получили миллионы долларов за закрашенное граффити', 'В мэрию Еревана вызвали психиатров и скорую из-за банок с фекалиями', 'Приказ простреливать вагины филиппинкам неуклюже объяснили', 'Выдвинута официальная версия катастрофы Ан-148', 'Путин отказался залить мир нефтью', 'В Томской области полиция и священник объявили войну домовому', 'В Москве обсудили новые механизмы перехода к низкоуглеродной экономике', 'США вслед за Россией возобновят создание сверхзвукового самолета', 'Лавров посетовал на агрессивное меньшинство на Западе', 'Рэпер Face посоветовал всем сваливать из России', 'На Украине осудили российских военных за госизмену', 'Охотница на олигархов Настя Рыбка обрела популярность на PornHub', 'Путина поразили двумя камнями', 'Создано идеальное лекарство от гриппа', 'Молния пробила дыру размером с человека в американском бомбардировщике', 'Генерал ФСБ ушел на службу в немецкую фирму', '«Маньяка-лизуна» посадили на пять лет за секс со спящей москвичкой', 'Жителей Донбасса оставили без украинских пенсий', 'Фотограф ужаснулась рекламе с женщинами-трупами', 'Рассекречено название первого внедорожника Rolls-Royce', 'Раскрыты новые подробности нападения на российскую базу в Сирии', 'Ковальчука покоробил женский хоккей в исполнении сборной России на Олимпиаде', 'Названы любимые любовные фильмы россиян', 'Окровавленное лицо рэпера Face заблокировали', 'Россия отстояла «Раковую шейку» у Украины', 'Украинский политик устроил скандал в прямом эфире из-за Саакашвили', 'Обнаружено «руководство по сексу» XVIII века', 'Одиноким человечкам со светофоров нашли возлюбленных', 'США уничтожили советский Т-72 в Сирии', 'Подсчитана доля американцев в госдолге России', 'Одежду российских олимпийцев украсили неожиданной символикой', 'Саакашвили из Польши пригрозил «молдавскому барыге» Порошенко', 'Совравший о встрече с Путиным голландский министр уволился', 'Google уличили в манипулировании беременными женщинами', 'Иностранные компании запаниковали из-за «кремлевского доклада»', 'Венгрия пообещала продолжить давление на Украину', 'Незнакомец с топором в московском метро заставил вспомнить классику', 'Следователи не увидели ничего плохого в избиении подростков силовиками в Чечне', 'Украина объявит крымское имущество в международный розыск', 'Российские школьники открыли новый остров в Арктике', 'Звезда «Пятидесяти оттенков» раскрыла детали постельных сцен', 'Евросоюз выделит деньги на восстановление Донбасса и децентрализацию Украины', 'Депутат предложил нюхать людей в поисках геев', 'Неполадки разбившегося Ан-148 обнаружили у Sukhoi Superjet 100', 'Появившаяся на Олимпиаде сестра Ким Чен Ына внушила ужас соцсетям', 'Разведка США заявила о неспособности сирийской оппозиции свергнуть Асада', 'В США обнаружили новую угрозу национальной безопасности', 'Ученые выявили типажи склонных к супружеским изменам людей', 'России предсказали наплыв секс-рабынь во время чемпионата мира-2018', 'Франция заявила о готовности нанести удары по Сирии', 'Пентагон прокомментировал сообщения о гибели россиян в Сирии', 'Госдеп США согласился с «Североамериканским тупиком»', 'Социологи узнали число верящих в инопланетян', 'Pornhub назвал условия получения бесплатного премиум-аккаунта', 'Названы самые лучшие для жизни регионы России', 'В Киеве рассказали подробности разговора Путина с Порошенко', 'Samsung скопирует самую бесполезную функцию iPhone X', 'Снайперы из Грузии признались в расстреле Евромайдана в 2014 году', 'В США рассказали о попытках Китая подорвать Америку изнутри', 'Два российских спортсмена пропустили Олимпиаду из-за ошибки МОК', 'В Папуа — Новой Гвинее христиане призвали прекратить сожжение ведьм', 'Крупнейший интернет-магазин доставил отцу семейства обслюнявленную зубную щетку', 'Послания инопланетян назвали смертельно опасными', 'Сутенеры нашли необычный способ принуждения к занятию проституцией', 'Спортсмены Денщиков и Потылицына решили скрасить информационный фон и поженились', 'Голландец выиграл Олимпиаду и порадовался отсутствию на ней соперника из России', 'Найден простой способ оставаться стройным', 'МОК объяснил отсутствие двух россиян в списке приглашенных на Олимпиаду', 'Российские работяги определили место женщины в стране', 'Американку приговорили к пожизненному за убийство дочери распятием', 'Оскал пса надоумил пользователей превратить его в Чужого и трехглавое чудовище', 'Исинбаева родила сына', 'Украину предостерегли от переделывания истребителя МиГ-29 в штурмовик', 'Показавший «Смерть Сталина» кинотеатр оштрафовали за фильм «Диван Сталина»', 'Раскрыта цель разбомбленных в Сирии российских наемников', 'Ургант обсмеял Кашпировского после жалобы в суд на коллаж с котом', 'Исчезновение машины Илона Маска в далеком космосе покажут в прямом эфире', 'Дерипаска решил подзаработать на майнинге', 'Ошибочно не допущенный к Олимпиаде россиянин обиделся на МОК', 'Памятник трактору завелся после освящения на глазах у заплакавших пенсионеров', '«Гость из будущего» прошел проверку на детекторе лжи', 'Скромный вклад Украины в борьбу с ИГ объяснили происками России', 'Россияне закупились секс-игрушками перед Днем святого Валентина', 'Иран раскрыл сеть вражеских ящериц-шпионов', 'ЦИК предложил Первому каналу отложить показ фильма о Путине', 'Песков рассказал о соболезнованиях Порошенко', 'Кремль прокомментировал возможный запрет на въезд россиян в Сирию', 'ФСБ пришла в банк «Финам» за документами крупного клиента', 'Овечкин поблагодарил НХЛ за просмотр олимпийского хоккея по телевизору', 'Престарелый американец подарил жене один и тот же подарок 39 раз подряд', 'Ким Чен Ын встретился с ездившей на Олимпиаду делегацией и призвал к миру', 'Песков заподозрил американцев в одержимости', 'Мэра Одессы задержали в киевском аэропорту', 'Школьники России обсудят будущее городов и профессий', 'В небе над Лондоном появился гигантский внутренний орган', '«Крупнейшая хакерская атака» не принесла организаторам ни копейки', 'Автора книги «13 причин почему» про домогательства обвинили в домогательствах', 'Российский «Кызыл» по пути из Сирии помешал британскому военному кораблю', 'Российских военных заставили есть крахмал вместо тушенки', 'Променявший США на Россию сноубордист научился давать взятки', 'За секс с детьми в России начнут сажать пожизненно', 'Поляк отказался вызывать врачей украинке с инсультом и сдал ее полиции', 'ФСБ дадут еще больше полномочий', 'Олень в США сбил вертолет', 'Пережившая развал СССР белая медведица умерла в голоде и одиночестве', 'Американские спецслужбы запретили пользоваться китайскими смартфонами', 'Фаворитов «Оскара» обвинили в расизме, плагиате и педофилии', 'Трехкратная олимпийская чемпионка сочла российских биатлонистов недостойными Игр', 'Турчинов задумался о вооруженном «освобождении» ДНР и ЛНР', 'Помощник президента поведал о закате мужского мира', 'Украинские солдаты станут лучше видеть', 'Отец сестер-супермоделей попался на сексуальных домогательствах', 'Нетаньяху назвал «дырявым сыром» обвинения во взяточничестве', 'Госдолг взвалили на семьи украинцев', 'Россиянин проиграл выборы и заказал соперника киллеру', 'Сервис Price.ru за год увеличил выручку на 65 процентов', 'Северная Корея поболеет на Олимпиаде за чужой счет', 'Ленивого заключенного обязали вернуть деньги за его содержание в колонии', 'Гостей модного показа вынудили ходить по попкорну', 'Грудинин уступил в популярности КПРФ', '«Аэрофлот» улучшил правила перевозки музыкальных инструментов как ручной клади', 'Минкульт отказался от претензий к кинотеатру из-за «Смерти Сталина»', 'Белоруссии срочно понадобились российские истребители', 'Лучших наставников России сравнили с алмазами', 'Депутат озолотилась за счет попавшей в больницу девочки', 'Американку выгнали из самолета за скандал с матерью младенца', 'Президент МОК предстал пред ликом российских олимпийцев', 'В сети поиздевались над обжорством олимпийской чемпионки', 'Устроившие резню в пермской школе не смогли объяснить свои мотивы', 'AliExpress зафиксировал рост спроса на секс-игрушки', 'ФСБ передумали давать еще больше полномочий', 'Про самого жестокого маньяка России снимут сериал', 'Самая одинокая лягушка на свете воспользовалась сайтом знакомств', 'Пенсионерка подарила мужу почку на День влюбленных', 'Тим Кук пожелал деньгам смерти', 'Российские хоккеисты проиграли словакам в первом матче на Олимпиаде', 'Россиян оставили без дневного сна', 'Рядом с Россией нашли загадочный источник радиоактивного заражения', 'Полуголая супермодель свалилась со скалы', 'США атаковали российских наемников стратегическими бомбардировщиками', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма', 'В посольства трех стран в Москве прислали конверты с белым порошком', 'Ковальчук не увидел ничего страшного в поражении от словаков на Олимпиаде', 'Фанаты «Игры престолов» раскрыли вероятную концовку сериала', '«Женщина-кошка» отвергла слухи о пластических операциях', 'Названы самые популярные страны для вывода денег из России', 'Всех голландцев отправят на органы', 'Первый канал отменил показ финала фильма про Путина', 'Собчак потребовала признать незаконной регистрацию Путина на выборах', 'Путин предложил помочь школьникам с выбором профессии', 'Художница напекла пирогов и попросила измазать себя ими', 'Чеченский муфтий поспорил о халяльности майнинга', 'Взорвавшим аэропорт террористам выплатят 50 тысяч евро', 'Созданный США самый дорогой в мире авианосец оказался непригодным', 'Восточные женщины научились обходиться без мужчин и скупили бриллианты', 'Саакашвили получил голландский паспорт', '«Газпром» решил поссориться с Германией', 'Олимпийскую чемпионку-фигуристку нарекли тайной сестрой Ким Кардашьян', 'ТНТ разрешили не извиняться за извинение перед ингушами', 'Среди талибов нашли европейцев', 'Порнозвезда раскрыла секрет создания успешного домашнего порно', 'Россия разрешила США занять первое место по добыче нефти', 'Члены «банды GTA» убивали россиян ради переворота в Узбекистане', 'Американцы в День святого Валентина предпочли животных коллегам', 'Раненые российские наемники вернулись из Сирии', '«Евреи за Иисуса» призвали украинцев покаяться за неоплаченные услуги ЖКХ', 'Британскую королеву заподозрили в порче воздуха в карете с султаном Бахрейна', 'Рынок краудинвестинга в 2018 году достигнет 10 миллиардов рублей', 'Раскрыта причина аварии во время пуска Falcon Heavy', 'Военные опровергли опасный маневр российского корабля в Босфоре', 'Российского саночника выслали с Олимпиады без объяснения причин', 'На консульстве Польши в Киеве вывесили список преступлений против Украины']\n['Раскрыто происхождение новейшей украинской крылатой ракеты', 'Русских гопников назвали настоящими древними славянами', 'Открыт первый европейский бордель с секс-куклами вместо проституток', 'Социологи подсчитали планирующих проголосовать на выборах-2018', 'Звезду сериала «Детективы» задержали за работу детектива', 'Ближний Восток становится центром роскоши', 'Учитель угодил под суд за оральный секс со спящим школьником', 'Украинский депутат призвал к убийствам «непатриотов»', 'Прятавший трупы в цветочных горшках серийный убийца попался в Канаде', 'США провалили испытания противоракеты', 'Ушастый лисенок из России стал мировой знаменитостью', 'Неймар заставит «Барселону» расплатиться', 'Любителей порно признали самыми удобными жертвами', 'Пентагон опубликовал новое видео перехвата разведчика США российским Су-27\\u200d', 'Власти США обвинили МОК и ФИФА в коррупции', 'Составлен портрет типичного столичного преступника', 'Китайская детская задачка поставила в тупик взрослых по всему миру', 'Британский лорд опоздал на заседание и уволился со стыда', 'Звезда «Бандитского Петербурга» поспорил с Пчелой из «Бригады» о насилии', 'У Илона Маска кончились огнеметы', 'Пробирки WADA для допинг-проб оказались бракованными', 'Убит готовивший теракт в день выборов президента России боевик ИГ', 'Россиян заставили вернуть деньги на вклады обанкротившихся банков', 'БМП-мутант заметили на сирийско-иракской границе', 'Пожизненно отстраненных российских спортсменов оправдали', 'Хабаровские селяне отреклись от земляка-мародера', 'США рассекретили российское космическое оружие', 'США возмутил взгляд Польши на холокост', 'Режиссер «Фантастических тварей» взволновал геев фразой об ориентации Дамблдора', 'Женщину отказались пустить в самолет без указания пола в документах', 'У России появился новый постпред при ООН', 'В Кремле порадовались за оправданных российских спортсменов', 'Джима Керри загадочно оправдали по делу о суициде подруги', 'Cтали известны имена новых ведущих «Орла и решки»', 'Москву заинтересовал запрет Польши на «бандеровскую идеологию»', 'Бывшего губернатора Белых признали виновным во взяточничестве', 'Гимн Канады стал гендерно-нейтральным', 'На Украину попытались ввезти тонну майнинг-ферм', 'Хвалившийся Ferrari подросток-миллионер «по воле Аллаха» займется пошивом одежды', 'Игрокам футбольного клуба «Севастополь» выплатили долги по зарплате', 'МОК разочаровало оправдание российских олимпийцев', 'В Поморье ученые раскрыли секрет красного снега', 'Порошенко возмутился запретом «бандеровской идеологии» в Польше', 'Дуров объяснил глобальную пропажу Telegram из AppStore', 'Белоруссия решила подзаработать на российской нефти', 'Китайского геймера парализовало после 20-часового марафона', 'Россия разместит военные самолеты на оспариваемой Японией территории', 'Российская школьница поставила смартфон на зарядку и умерла', 'Merrill Lynch назвал акции «Роснефти» фаворитом среди нефтяных компаний EEMEA', 'Закопавшийся в песок американец умер от остановки сердца', 'Мутко загрустил после оправдания российских спортсменов', 'Фанатка Тупака обвинила рэпера в групповом изнасиловании', 'Раздевшуюся при собаках Беллу Хадид обвинили в масонстве и участии в оргиях', 'Шефы российских спецслужб приехали в США и удивили американцев', 'Малолетним валлийцам запретили протыкать груди и гениталии', 'Олимпиада в Пхенчхане побила рекорд по презервативам', 'Россия оправдалась за перехват американского самолета-разведчика', 'Президента Чехии уличили в связях с украинскими сепаратистами', 'Pornhub захотел одарить полицейских сотнями литров интимной смазки', 'Украинцы утратили шансы на лучшую жизнь', 'Получившая награду детская сказка разгневала омбудсмена', 'Звезда фильма «Брат» призвал отправить Пчелу из «Бригады» в монастырь', 'Самарский подросток объяснил желание напасть на школу', 'Найдено решение главной космологической загадки десятилетия', 'Канадец ввез в страну десятки пистолетов через библиотеку', 'Цены на бензин в Туркмении за 10 лет подскочили в 20 раз', 'Оправданный призер Сочи-2014 призвал «добить ситуацию» с МОК', 'Вблизи Финляндии появится первый остров для феминисток', 'Обвиняемый предложил судье полюбоваться на его пенис', 'Американская супермодель обвинила соучредителя Guess в домогательствах', 'США оправдались за «копипасту» списка Forbes в «кремлевском докладе»', 'Названы самые погрязшие в сугробах районы столицы', 'Боевики ИГ показали превращение детей в террористов', 'Австралиец предложил два ноутбука за собственное убийство', 'Боевым священникам-десантникам доверят рулить бронетехникой', 'Учительница ввязалась в торговлю наркотиками во имя любви', '«Аэрофлот» станет самым крупным заказчиком самолетов МС-21', 'В сети появились новые фото Крымского моста', '«Руки-базуки» нашел возлюбленную', 'Власти США обвинили мясника из мема в антисанитарии', 'Враг США начал поставлять в Соединенные Штаты черную икру', 'Саниспекция запретит турку из мема элегантно солить мясо', 'Рассказавшего о скупающих черную икру украинцах политолога назвали порохоботом', 'Стрелявший под кокаином у Кремля Джабраилов постреляет еще', 'Пациенты осужденного врача-гематолога Елены Мисюриной устроили флешмоб', 'Путин предостерег от эйфории после оправдания российских олимпийцев', 'Родченков не смог вразумительно ответить на вопросы суда', 'Енотиха заставила спасателей два часа вызволять ее из вентиляции', 'Ким Чен Ын покатался на троллейбусе', 'Из России перестали уводить деньги', 'Опубликовано ранее неизвестное интервью Бориса Ельцина 1990 года', 'Украинские силовики приготовились разогнать оппозиционных журналистов', 'Бывшего замдиректора ФСИН Коршунова уличили в махинациях со служебной обувью', 'Расшифрован разговор немцев об успешном бое с четырьмя Т-34', 'Лавров пожаловался на нацистский вирус', 'Путин оказался недоволен российской промышленностью', 'Оправданный россиянин позлорадствовал над делившими медали Игр-2014 иностранцами', 'Путин пошутил про работу комбайнером в случае неудачи на выборах', 'Художник вломился к пожилому соседу, увидел нечто и вышел из творческого кризиса', 'Американский адмирал сознался в получении взяток проститутками', 'Пожилой китаец решил позировать голым из-за маленькой пенсии', 'США объяснили утаивание части «кремлевского списка»', 'Вице-президент «Лукойла» потребовал наказать избившую его сына школьницу', 'В CAS отказались считать оправданных россиян невиновными', 'В сети оценили оригинальный способ прогулять уроки', 'Украинцы майнили криптовалюту для ДНР и ЛНР', 'Никиту Белых отправили в колонию на восемь лет', 'В Сан-Франциско объявили марихуановую амнистию', 'Адвокат Родченкова заговорил о смерти чистого спорта после оправдания россиян', 'Директор ЦРУ объяснил встречу с шефами российских спецслужб', 'МИД России предупредил граждан об «охоте» за ними спецслужб США', 'Зеленое сердце наполнили духами', 'Путин назвал условия для развития промышленности', 'Порно с голливудскими актрисами начали уничтожать', 'Ученые предупредили о грядущей катастрофе', 'Российские олигархи за январь разбогатели на 17 миллиардов долларов', 'Американская скелетонистка сочла россиян ушедшими от законного наказания', 'Суд арестовал вызволившего из ИГ сына мужчину', 'Госдеп США пригрозил новыми антироссийскими санкциями', 'Пентагон обвинил Россию в попытке подорвать НАТО', 'Президента Бразилии госорганы посчитали мертвым', 'В Крыму рассказали о рекордной популярности полуострова в мире', 'Немецкий ультраправый политик сбежал к мусульманам из-за геев', 'Назван простой способ сбросить вес', 'Хакеры украли криптовалюту на полмиллиарда долларов', 'Сын Фиделя Кастро покончил с собой', 'Японцев предупредили о возможной войне в Корее во время Олимпиады', 'Работники ФБР повеселились с преступниками за 25 тысяч бюджетных долларов', 'Голый грабитель банка разбросал деньги по улице и ушел от наказания', 'Российских террористов решили собрать в одном месте', 'Глава USADA почуял вонь российской атаки на чистый спорт', 'США сравнили Россию и Китай с колониальными державами', 'Названа работа с самым большим конкурсом претендентов', 'После оправдания российских спортсменов Макларена назвали идиотом', 'США обвинили Россию в замораживании войны в Донбассе', 'В США рассказали о дружбе с Россией', 'В сеть утекли спойлеры финала «Игры престолов»', 'ЦБ отозвал лицензии у двух банков', 'Бузову назвали любовницей «самого красивого преступника»', 'На пляже в Ницце образовалась огромная круглая воронка', 'Американцы пришли за выигрышем в тысячу долларов и получили миллион', 'Бывший завод Порошенко стал российской собственностью', 'Звезда «Пятидесяти оттенков» раскрыл несексуальную правду о постельных сценах', 'Уклонившийся от огня террористов российский Су-25 попал на видео', 'Украина создала для Великобритании ракету', 'Овсянников оценил качество капремонта детского лагеря «Ласпи»', 'Хозяину двух загрызших ребенка псов в Сибири просто усложнили жизнь', 'Создатель Людей Икс и Человека-паука экстренно госпитализирован', 'На Урале сгорел дом Ельцина', 'Звезда «Игры престолов» и Морган Фриман устроили огненно-ледяной баттл', 'Макгрегор обозначил круг соперников', 'Международная комиссия по выбросам рутения-106 оправдала «Маяк»', 'ЦИК сделал Пескову замечание из-за агитации', 'Из пыточных камер гестапо сделают элитное жилье', 'Звезда «Зачарованных» вступилась за свою вагину и обматерила трансгендера', 'Бинбанк и «Открытие» решили объединить', 'Песков извинился перед ЦИК за агитацию', 'Украинский политик в прямом эфире набросился на журналиста', 'Найдены десятки ранее неизвестных городов майя', 'Родченкова сочли борцом за правое дело и помогли деньгами', 'Польского чиновника не пустили в Израиль из-за закона о холокосте', 'Российский школьник послушал трек Gucci Gang 101 раз подряд', 'Российские IT-компании и госорганы обсудили тренды информационной безопасности', 'Имущество осужденного в России водочного короля нашли на острове Мэн', 'У Грудинина обнаружили два не до конца закрытых счета в Швейцарии и Австрии', 'Подпольные майнеры окопались в Минфине Казахстана', 'Т-90С для Ирака «засветились» в порту', 'Украина задумалась о создании кибервойск', 'Станцевавших в БДСМ-костюмах ульяновских курсантов оставили в авиации', 'Документы пациентов использовали вместо туалетной бумаги', 'МОК посчитал оправдание российских спортсменов «торжеством обманщиков и воров»', 'Американец обнаружил билет 19-летней давности и смог им воспользоваться', 'Детского омбудсмена уличили в тяге к маргинальным смыслам и мнению недоучек', 'Российские интернет-пользователи изобрели новый язык', 'Китаянок научили правильно получать по лицу от мужей', 'Украина обогнала Россию по росту экономики', 'Минфин собрался сослать торговцев криптовалютами на острова', 'Президент Молдавии предрек войну в случае объединения страны с Румынией', 'Испанцы передали США подозреваемого в кибератаках россиянина', 'Продажи Maserati в России подскочили в восемь раз', 'Виктория Бекхэм согласилась на воссоединение Spice Girls', 'Губернатор Севастополя рассказал о судьбе детского лагеря «Горный»', 'Вместо министерства счастья в России создадут министерство одиночества', 'Богатейший человек мира заработал 6,5 миллиарда долларов за вечер', 'Аварию на российской ГЭС объяснили бракованными деталями с Украины', 'Федерацию бобслея России обвинили в нежелании пускать спортсменов на Олимпиаду', 'В секс-игрушках нашли новую опасность', 'Учительница отрезала школьнице волосы во время урока', 'Пленившие россиян боевики показали последствия своей атаки', 'Педагог Макаренко попросил у Медведева денег и был уволен', 'Маленького щенка скормили питону на глазах у публики', 'Украина поднимет флаг УПА в ответ на запрет «бандеровской идеологии» в Польше', 'Медведев и еще четыре премьера обсудили постановление номер 666 и содрогнулись', 'Создателя Counter-Strike задержали за педофилию', 'Названы условия продолжения борьбы МОК против россиян', 'Педофил показал звезде «Зачарованных» порно, изнасиловал и выставил на улицу', '«Роснефть» в сотрудничестве с «Согаз» открыла уникальный медцентр в Геленджике', 'Молчание ботаников на спортивной викторине довело ведущего', 'Москва попала в десятку городов мира по популярности марихуаны', 'Электромагнитная пушка на китайском корабле впервые попала на фото', 'Обвал биткоина установил рекорд', 'Главный архитектор Махачкалы задержан за строительство фундамента', 'Тщеславный китаец построил танк и лишился его', 'Калужский школьник изрезал лицо одноклассника и выпрыгнул в окно', 'Иранцы посоветовали женщинам целовать ноги мужей-насильников и одумались', 'Четырехкратный олимпийский чемпион встал на сторону россиян и пристыдил МОК', 'США испугались мирового кризиса из-за санкций против России', 'Украина пригрозила Volkswagen и Adidas санкциями за работу в Крыму', 'Гостям отеля предложили заказывать в номер гадалок и экстрасенсов', 'Чернокожие напомнили об истинном изобретателе русского языка', 'Учитель выложил картину с вагиной, был забанен и добился суда над Facebook', 'Путешественников из Нового Уренгоя подвез атомный ледокол', 'Раскрыты доходы «продавщиц» голых ног', 'Россиянин создал майнинг-ферму в трамвайном депо и попался', 'Подравшиеся Сванидзе и Шевченко отказались жать друг другу руки', 'В США приготовились раскрыть предвзятость ФБР к Трампу', 'Утонувшая в США русская актриса оказалась жертвой убийства', 'Украина решила продать российские активы в Крыму', 'Российских масонов вычислили в соцсетях', 'Бывший крымский чиновник поехал на Украину за паспортом и попался', 'Трамп рассекретил доклад о злоупотреблениях ФБР в «деле о России»', 'Отец подвергшихся насилию гимнасток напал на врача-педофила в зале суда', 'Учительница наступила на чернокожую ученицу на уроке о рабстве', 'США оценили возможность России первой использовать ядерное оружие', 'Умер отец посла США в России миллиардер Джон Хантсман-старший', 'Российские космонавты случайно побили рекорд', 'Выданный США россиянин отказался признать вину в киберпреступлениях', 'Илон Маск переименовал огнеметы в «неогнеметы» из-за проблем с таможней', 'Российская армия получит новейшее гиперзвуковое оружие', '«Терминатор» появится на Красной площади', 'Олимпийский комитет США обвинили в халатности', 'Российская туристка попыталась отбелить кораллы и попала в тюрьму', 'Главные герои Doom и Wolfenstein оказались родственниками', 'МОК подумает над приглашением на Олимпиаду оправданных россиян', 'По всей России вспомнили Сталинградскую битву и олимпийцев', 'Борис Корчевников побил подчиненного на православном канале «Спас»', 'Трамп отвадил британцев от соляриев', 'Оправданным россиянам запретили участвовать в Олимпиаде', 'В Севастополе прошел митинг в поддержку внешнеполитического курса президента', 'В Китае мусульман согнали в концлагеря', 'Российских олигархов заставят объяснить роскошную жизнь в Лондоне', 'Детская задачка о собаках поставила родителей в тупик', 'Итальянец обстрелял чернокожих мигрантов и начал зиговать', 'Мутко рассказал о перспективах Дзюбы', 'Леди Гага прервала мировое турне из-за сильных болей', 'После крушения Су-25 по позициям боевиков нанесли удар высокоточным оружием', 'Роналду вошел в положение «Реала» и заслужил повышение зарплаты', 'Пилот сбитого Су-25 принял бой', 'Боевики запутались в выборе ответственных за сбитый Су-25', 'США открестились от поставок ПЗРК в Сирию', 'Ученые определили возраст для лучшего секса', 'Ума Турман обвинила Вайнштейна в домогательствах и разочаровала его', 'Православный монастырь в Киеве попросил ООН и Трампа о защите', 'Ким Чен Ына заметили в троллейбусе', 'Трамп пожаловался на непрекращающиеся разговоры «только о России»', 'Казахстанец притворился девушкой и прошел в финал конкурса красоты', 'В США признали превосходство российского оружия', 'МОК обозначил сроки по решению о допуске оправданных россиян на Олимпиаду', 'Apple решила бесплатно чинить iPhone 7', 'Спасший Шамиля Басаева врач рассказал об «эпидемии красоты» в Чечне', 'МОК задумался об исключении бокса из программы Олимпиады', 'Россия уступила Белоруссии и Украине в рейтинге верховенства права', 'В США разглядели главную опасность даркнета после наркотиков', 'В секретной базе найдены сотни аномальных допинг-проб', 'Саакашвили рассказал о «железных памперсах» перепуганного Порошенко', 'Следы сбившего российский Су-25 ПЗРК отыскали на Украине', 'В логотипе Лондонского марафона углядели отсылку к ДНР и ЛНР', 'Япония улучшит Владивосток ради Курильских островов', 'Названа наиболее разочаровавшая инвесторов криптовалюта', 'Назван знаменосец россиян на открытии Олимпиады', 'В Москве оценили последствия рекордного снегопада', 'Житель Кубани помыл котом машину', 'Казаки проследят за порядком на ЧМ-2018', 'Брюссель решил ускорить вступление Сербии в Евросоюз', 'Стали известны подробности работы масонских лож в элите Великобритании', 'Опубликованы документы пилота сбитого Су-25', 'Эквадорец из «Зенита» испугался российских морозов и снега', 'Путину передан список желающих вернуться беглых бизнесменов', 'Пользователям заплатят за просмотр порно', 'Экономику Украины сравнили с МММ', 'Британские спецслужбы отказались от мысли победить хакеров', 'Китай разработал план достижения господства на море', 'Раскрыта сеть нажившихся на лысых людях мошенников', 'Названы наиболее вероятные жертвы нападения собак', 'Мужчина за два года принес в банки фальшивые платежки почти на миллиард рублей', 'Комиссия МОК отказалась пустить на Олимпиаду оправданных CAS россиян', 'Американские вуду-экзорцистки подожгли пятилетнюю девочку', 'Танцовщица изобразила надменное лицо и стала мемом', 'Футболист удерживал тренера под дулом пистолета ради места в составе', 'Американцам запретили распространять детское порно из жалости', 'Назван предмет гордости россиян в науке', 'На Западе нашли слабое место России при войне с НАТО', 'Омич за месяц предсказал обрушение дома с жертвами из-за халатности властей', 'В Москве раскрыли причину отсутствия реакции на «кремлевский доклад» США', 'Государство снимет с себя расходы на медицину', 'Показана обычная жизнь любителей БДСМ', 'WADA сорвало тренировку сборной России по хоккею в Пхенчхане', 'Топ-менеджер Сбербанка займется доставкой еды', 'Появились данные о месте службы погибшего в Сирии пилота Су-25', 'Раскрыты подробности нового проекта AliExpress в России', 'Временно исполняющего обязанности премьера Дагестана доставили на допрос в ФСБ', 'Самую дорогую рекламу в мире заменили черным экраном', 'Толпа сибиряков осадила администрацию после гибели детей из-за коммунальщиков', 'Появились подробности ареста россиянок за хранение кораллов в Таиланде', 'Супермодель пришла в уггах на Супербоул', 'Раскрыта миссия убитого в Сирии российского пилота', 'С облысением решили бороться жареной картошкой', 'Турцию заподозрили в причастности к гибели российского Су-25', 'Уральцы на двух десятках элитных машин побили рекорд по автоподставам', 'Московская стройка превратилась в водоем', 'Фанат Путина попытался похитить Лану Дель Рей', 'Пилот сбитого в Сирии Су-25 получит награду', 'Глава МОК рассказал о процедуре допуска оправданных россиян на Олимпиаду', 'Песков прокомментировал отказ МОК пустить на Олимпиаду оправданных россиян', 'Бежавшим из России олигархам собрались простить уголовные дела', 'Появилось видео с разбившейся на съемках Умой Турман', 'Кремль объяснил действия военных в Сирии после атаки на Су-25', 'Ребенок уставился в телефон во время выступления Тимберлейка и разошелся на мемы', 'Найдена новая цель США после разгрома ИГ в Ираке', 'В украинской армии заметили эпидемию самоубийств', 'Глава поселка уволился после гибели детей по вине коммунальщиков', 'Золотой ТТ и два автомата нашли у задержанного дагестанского премьера', 'Песков ответил на вопрос о гарантиях желающим вернуться в Россию бизнесменам', 'Пилоту сбитого Су-25 решили дать Героя России', 'Модель лишилась носа из-за неудачной операции', 'Британский гольф-клуб шокировал гостей жестоким отношением к гусям', 'Шесть российских сборных отказались от участия в церемонии открытия Олимпиады', 'Лагерь паломников у места расстрела царской семьи помешал выставке инноваций', 'Самую дорогую в мире рекламу собрали в одном месте', 'Буряты дали свой ответ на вопрос «А как поднять бабла?»', 'Вертолет упал на жилой дом в Японии', 'Сибиряки два года рыли подкоп к нефтепроводу и попались за три метра до цели', 'Полицейские в Орле скрыли более 400 преступлений', 'Самый богатый китаец признал бесполезность денег', 'Amazon разозлил китайцев расизмом и оставил их без извинений', 'В российскую армию вернут политруков', 'Минтруд дал совет опаздывающим на работу россиянам', 'Россиян предложили обложить «лунным оброком»', 'Крым оставят без «шузов»', 'Съездившие в Крым немецкие депутаты остались без наказания', 'МОК сделает из россиян пример нетерпимости к допингу', 'Pink выругалась в ответ на обвинение в посасывании во время гимна США', 'Суд освободил осужденную за смерть пациента врача-гематолога Елену Мисюрину', 'Задержание главы правительства Дагестана с двумя заместителями попало на видео', 'Вкладчики разорившихся банков пожалуются Путину на АСВ', 'Жириновский захотел сбросить ядерную бомбу на резиденцию Порошенко', 'Госкомпании захватили экономику России', 'Женщины с нестандартными бедрами получат джинсы по размеру', 'Авиабилеты подорожают в 2018 году', 'Боевики подорвали российские пункты помощи в Дамаске', 'Битва двух голов одной змеи попала на видео', 'Аресты чиновников в Дагестане сравнили с «обнесением Чечни проволокой»', 'Суд отказался вернуть детей писавшей про трансгендеров россиянке', 'США потеряли потраченные на армию 800 миллионов долларов', 'Популярного русскоязычного блогера нашли мертвым', 'Ругавшие своих военных турки оказались за решеткой', 'Жертва насильника придумала шорты для защиты от насильников', 'Британцы спасли лысых ежиков', 'Иностранный бизнес поверил в Россию', 'Медведев пристыдил МОК', 'Президент МОК объяснил нежелание приглашать на Игры оправданных россиян', 'Полиция задержала актера Алексея Панина', 'Зоозащитники ужаснулись мучениям раков и начали бороться за их права', 'Адвокат Мисюриной оказался внуком первого арестованного по «делу врачей»', 'Китайцы на спор сожгли свои деньги и поплатились', 'Украина в рейтинге уровня жизни оказалась между Бангладеш и Буркина-Фасо', 'Смертники под наркотиками разочаровались в терроризме и сдались', 'Байдену пригрозили судом в США за слова о «сукином сыне» с Украины', 'Путин простил долги Киргизии', 'Россия поставила Украине оружие «сдерживания агрессора»', 'МВД заплатит за гибель бойца после экзамена в ОМОН', 'Литва заявила о развертывании Россией «Искандеров» под Калининградом', 'Украина в отличие от Германии захотела наказания для немецких депутатов в Крыму', 'Московского прокурора Шурыгина наказали за хамскую езду на мамином Hummer', 'Жители Уфы три года продержали мужчину в строительном рабстве', 'Немцы порадовались решению не пускать оправданных россиян на Олимпиаду', 'Мурманский автостопщик и его кот добрались до Владивостока за 57 дней', 'Блогер Илья Варламов назвал Якутию «волшебным краем» и отругал зоозащитников', 'Лауреатом премии «НОС» стал Владимир Сорокин', 'Правительство Дагестана отправили в отставку', 'Глумившийся над трупом самоубийцы блогер попросил денег', 'Актер Панин лишился машины за долги', 'Допинг-офицеры запросили список российских футболистов на ЧМ-2018', 'Белоруссия дала добро на «Смерть Сталина»', 'На фото певиц из Spice Girls обнаружили таинственный белый порошок', 'В Индии родился четырехлапый цыпленок', 'Эстония отмежевалась от России', 'Родители придумали ребенку рак мозга и заработали на этом', 'Выданному США российскому программисту запретили мыться и читать', 'Россиян обяжут следить за гостями-иностранцами', 'Искавшее малайзийский Boeing судно пропало с радаров', 'Китай назвал российские Су-25 старьем', 'Минобороны пристыдило «Фонтанку» за публикацию данных убитого в Сирии пилота', 'В Турции мусульманам ограничат левую руку', 'Индекс Dow Jones продемонстрировал рекордное падение в истории', 'Фен из интернет-магазина оказался огнеметом', 'Обнаружена новая угроза для Android', 'Владельцу тайского кафе пригрозили тюрьмой за полуголую официантку в рекламе', 'ЦБ отозвал лицензию у Сибирского банка реконструкции и развития', 'Минобороны купит сотню боевых вертолетов Ка-52 новой модификации', 'Россиянам предложат новый способ снятия наличных', 'Грудинин раскрыл историю происхождения дома в Испании', 'В Уссурийске выявили серию нападений хищников на детей', 'Немецкие полицейские нашли пользу в марихуане', 'МОК уличил очередных российских спортсменов в употреблении допинга', 'Рыбак поборол акулу после кражи его добычи', 'Тарантино раскрыл правду об удушении и домогательствах к Уме Турман', 'Российский посол рассказал об умирающих из-за санкций женщинах в Северной Корее', 'Российские гранаты научат наблюдать', 'Бельгиец-ловелас нашел способ путешествовать бесплатно', 'Главврач лишился работы из-за использования медкарт вместо туалетной бумаги', 'Богатейшие люди мира обеднели за день на 100 миллиардов долларов', 'В США учительница совратила ученика с задержкой развития', 'Российские спортсмены продолжили борьбу с МОК', 'Уборочную технику в Москве обстреляли из травматов и забросали яйцами', 'Путина зарегистрировали кандидатом в президенты', 'Главу правительства Дагестана обвинили в мошенничестве', 'Защитников отечества защитят от некачественной выпивки', 'Американский школьник вызвал стриптизершу на урок за счет родителей и поплатился', 'Биохакер прилюдно снял штаны и сделал себе самодельную инъекцию', 'Глава российской разведки объяснил поездку в США', 'Американцев оставят без одежды', 'Раскрыты условия снятия запрета на российский флаг на Олимпиаде', 'Забытый всеми актер требовал у работников аэропорта вспомнить его', 'Необъяснимое нашествие птиц в США попало на видео', 'Построенный российскими военными мост через Евфрат ушел под воду', 'В Кремле отказались считать аресты в Дагестане политическим кризисом', 'Замену обвиненному в мошенничестве премьеру Дагестана нашли в Татарстане', 'Музыкант появился на публике в килте, показал пенис и попал под суд', 'Российскую книгу о самогоноварении признали угрозой Украине', 'Россия попросила Турцию помочь забрать у боевиков обломки Су-25', 'Стюардесса забылась и сделала селфи на украденный телефон пассажирки', 'Россиян признали самыми уязвимыми в сети', 'Венгрия потребовала ввести миссию ОБСЕ на запад Украины', 'Россияне назвали главные проблемы россиян', 'Немка поработала с беженцами и предрекла Германии крах', 'Польша начнет массовый снос советских памятников', 'Отец полковника Захарченко вернул миллионы', 'Пышнобедрая модель рассказала об изнасилованиях', 'В сети поверили в выдуманные обещания Трампа «зарядить собой пушку»', 'Европа нацелилась на деньги россиян', 'В Telegram нашли детскую порнографию', 'Шакро Молодой отказался от дачи показаний в суде', 'Украинец научился добывать электричество из патриотических бочек', 'Отец назвал Бейонсе недостаточно черной', 'Голый австралиец пригрозил избить полицейских пенисом', 'Названо место концентрации российских маньяков', 'Убивающие турецких солдат курды получили подкрепление', 'Японки переоделись в невидимые бикини и получили приглашение на Украину', 'Тело погибшего пилота Су-25 доставили в Россию', '«Росатом» построит АЭС «Аккую» с новыми партнерами', 'Минкульт провел перепись культурных памятников России', 'Полиция потребовала для расследования фотографии пениса рэпера', '«Самое неловкое видео» из жизни Трампа и его жены насмешило соцсети', 'Путин присвоил погибшему в Сирии летчику Филипову звание Героя России', 'Загадочных российских военных увидели в Идлибе после атаки на Су-25', 'Харьковские охранники выставили на мороз малолетних противников «русского мира»', 'Таинственный мостовой танк уничтожили в Сирии', 'Маск раскрыл будущее Falcon Heavy', 'Раскрыты подробности операции по возвращению тела летчика Су-25 в Россию', 'Трамп заподозрил не хлопавших ему демократов в госизмене', 'Участковый на Ямале заморозил до смерти задержанного и спрятал тело в сугробе', 'Кондитера засмеяли за «каменный» торт в форме вагины', 'Продавший акции «Газпрома» глава «Газпрома» решил снова купить акции «Газпрома»', 'Суд арестовал бывшего главу правительства Дагестана с золотым пистолетом', 'Бондиану решили скрестить с симфоническим концертом', 'В Киеве допустили выдвижение Польшей территориальных претензий к Украине', 'В Европе нашлась новая допинг-система', 'Турист вернул в тайский храм украденные кирпичи из-за беспокойной жизни', 'Жестокого охотника за женскими трусами поймали в Москве', 'Германия и Китай лишили Россию ракетных кораблей', 'Бывший министр обороны США пожалел о бомбардировках Югославии', 'Tele2 в пять раз снизит стоимость входящих звонков в Крыму', 'Авиационную бомбу весом в полтонны сдали в металлолом в Кировской области', 'Количество жалоб на запах в районе полигона «Кучино» снизилось в разы', 'Украинский политик констатировал превращение страны в «сельский туалет»', 'В сети высмеяли баттл Гуфа и Птахи', 'Американцы захотели больше контактов с русскими', 'Серебряный призер Сочи пригрозила сунуть медаль между булок желающим ее забрать', 'Россия оставила Европу без качественной нефти в угоду Китаю', 'Противостояние трезвого шотландца и тигра закончилось позором', 'Номинант на «Оскар» заставил поклонников люкса предаться размышлениям', 'Российское торгпредство в Дамаске обстреляли из минометов', 'Российские олигархи столкнулись с проблемами из-за «кремлевского доклада»', 'Мохаммед Али попался на допинге', 'Американцев напугали грядущей катастрофой', 'Жители Заполярья увидели фата-моргану', 'Террористы поссорились из-за тела российского летчика', 'В сети возненавидели «бурятского Дудя»', 'Минфин США заявил о нежелании вводить санкции против госдолга России', 'SpaceX впервые запустила сверхтяжелую ракету Falcon Heavy', 'Порно с голливудскими актрисами начали делать на заказ', 'Онищенко призвал не мочить манту', 'Президент Филиппин в борьбе с коррупцией раздавил десятки люксовых автомобилей', 'Военным предложили славить Украину при каждом приветствии и прощании', 'Ведомый летчика Филипова рассказал о попытках прикрыть сбитого командира', 'Apple предложила вернуть деньги за замену аккумуляторов медленных iPhone', 'Американка выиграла 560 миллионов долларов и отказалась от приза', 'Белорусская сборная доверила Бьорндалену откатку лыж', 'Иллюзия с непараллельными параллельными улицами запутала пользователей сети', 'Россия начала высылать северокорейских рабочих', 'Полуголая активистка вышла на протест в замороженном Пхенчхане', 'Депрессивных людей вычислили по словам', 'Найден способ превратить почту врага в кладбище спама', 'Центральный ускоритель Falcon Heavy разбился при посадке', 'В МИД России назвали истерики Вашингтона детскими капризами', '«Газпром» похвастался рекордной долей на европейском рынке', 'Работники Азов-Сити попросили президента сохранить игорную зону', 'Чернокожий американец отправил в ИГ образцовое резюме и получил работу', 'Джим Керри удалился из Facebook из-за России', 'Теневая экономика в России достигла уровня африканских стран', 'Британские спортсмены пропустят открытие Олимпиады из-за морозов', 'Влюбленный алиментщик трижды пытался сбежать с Украины к новой крымской жене', 'Американка рассказала о способе сохранить идеальную талию', 'Назван самый вкусный российский шоколад', 'Трамп захотел увидеть солдат и танки около Белого дома', 'Биткоин взмыл вверх после обвала', 'Российскую власть проверили на умение найти общий язык с элитой', 'Племянник главы Ингушетии найден мертвым в своем доме', 'Российская компания заставила понервничать британскую разведку', 'Омские заключенные слепили из снега «Тополь-М» в натуральную величину', 'Российские спортсмены пропустят Олимпиаду из-за затянувшегося суда', 'В Саудовской Аравии открылись бойцовские клубы для женщин', 'Назван победитель баттла Гуфа и Птахи', 'Дом и золотые пистолеты арестованного дагестанского премьера показали на видео', '«Лидерам России» дали год на образование', 'Южнокорейских полицейских заставили смотреть порно на работе', 'Банк России проверит сотрудников на детекторе лжи', 'Американскую спортсменку разозлило оправдание российских олимпийцев', 'В Кремле отреагировали на слухи о голосовании Путина в Севастополе', 'США обвинили Россию в новом вмешательстве в выборы', 'Найден документ с именами виновных в «сдаче Крыма» России', 'На воевавшую в Абхазии и Донбассе грузинскую националистку напали в Тбилиси', 'Москвич одним ударом убил работника автомойки за отказ мыть его BMW', '«Гигантского бронемонстра» заметили в Сирии', 'Лубутену отказали в эксклюзивном праве на красные подошвы', 'Ответственность за экономический рост переложили на доходы россиян', 'Молчаливая кухарка из Китая обрела мировую славу', 'На офисных работников наденут шоры', 'В Германии поделили власть', 'Норвежцы привезли на Олимпиаду частично запрещенные препараты', 'Российским Sukhoi Superjet 100 сделают обрезание', 'Корейцы попытались скрыть страсть к собачатине и потерпели фиаско', 'Найдены доказательства отсутствия расизма у Трампа', 'Все госструктуры Дагестана начали обыскивать', 'Сибиряк набрал долгов и прикинулся картофелиной', 'В центре Москвы трое на внедорожнике избили телеведущего', 'Ким Чен Ын отправит сестру-пропагандистку на Олимпиаду', 'Раскрыто имя нового министра иностранных дел Германии', 'Греф поймал сотрудников Сбербанка на майнинге', 'Будущим миллионерам пожелали создать Tesla', 'Названы условия появления российского флага на закрытии Игр', 'Forbes представил первый рейтинг биткоин-миллионеров', 'Украинцы записались в коммунисты и геи ради убежища в Европе', 'Украинский дипломат «вправил мозги» немецким политикам из-за поездки в Крым', 'Дагестанским чиновникам запретили покидать Россию', 'Массовый сбой билетных автоматов произошел в столичном метро', 'Музыканты из России смогут выиграть 100 тысяч евро и обучение на Ибице', 'Корпорация МСП встретилась с предпринимателями Ярославской области', 'Туристам в Узбекистане разрешили кое-что снимать', 'Овсянников примет участие в инвестиционном форуме в Сочи', 'Власти Красноярска не освоили деньги и удивили Путина', 'Назначен глава правительства Дагестана', 'Ради президента Таджикистана и его сына изменят выборы', 'Футболист из Крыма впервые получил вызов в сборную России', 'Кудрин назвал неизбежным повышение пенсионного возраста', 'В интервью Тарантино нашли оправдание изнасилования 13-летней девочки', 'Учитель схватил школьника за шею и ударил о стену', '«Почта России» затормозила посылку с автоматом Калашникова', 'Щуплость и конкуренция с Гатаговым избавили Неймара от карьеры в России', 'Показан обстрелявший российский Су-25 террорист', 'Украина объявила сроки возобновления покупки российского газа', 'Производитель «Арматы» оставил рабочих без отдыха и денег', 'США пригрозили не дать Северной Корее «захватить» Олимпиаду', 'У ФСБ нашли спецсамолет для «посадок» чиновников', 'Немецкие депутаты обиделись на посла Украины и отказались ехать в Киев', 'Немецкий биатлонист сравнил оправдание российских олимпийцев с плевком в лицо', 'В возмущении Хорватией неисправными самолетами с Украины увидели руку Москвы', 'Американских воспитательниц поймали на удалении моноброви у детей', 'Минтруд удивился бедности россиян', 'Уличенный в «сдаче Крыма» украинский министр списал обвинения на испуг', 'Курильщик прожег лик архангела Михаила, похвастался и скрылся', '«Норникель» и «Русская платина» создадут лидера на рынке металлов', '«Роскосмос» посчитал запуск Falcon Heavy рекламой Tesla', 'Пожизненно осужденный маньяк-расчленитель из «Полярной Совы» переехал в Москву', 'Заподозренная в мошенничестве чиновница покончила с собой', '«Оружие Победы» всплыло на иракском черном рынке', 'Украинская газета поведала о «захвативших власть в стране жидах»', 'Раков-мутантов признали иконами феминизма', 'Глава РФПЛ выступил за пиво на стадионах и против алкоголизма', 'Чувства атеистов Казахстана приравняют к чувствам верующих', 'Раскрыты детали проекта первого гиперзвукового пассажирского лайнера', 'Немцев предупредили о смертоносной мастурбации', 'Путин обещал подумать о появлении метро в Красноярске', 'В США забывчивый сотрудник спецслужб потерял секретный доклад', 'Греф поностальгировал о своей работе дворником', 'Хакеры раскрыли канадский заговор против российского спорта', 'В США оценили вероятность ядерного удара со стороны России', 'Армянские врачи приняли чай за мочу', 'Европе предрекли «непреднамеренную» войну с Россией', 'Собчак пообещала дать Трампу пару советов', 'Мексиканская YouTube-знаменитость стала жертвой наркокартеля', 'В «Исламском государстве» закончились мужчины', 'Раскрыт план готовящейся атаки на Россию во время Олимпиады', 'Коалиция США нанесла удар по войскам Асада', 'Порно с голливудскими звездами лишилось последнего пристанища', 'В США шериф пожалел свои машины и приказал застрелить нарушителя', 'Стали известны перспективы оснащения танка «Армата»', 'Spice Girls отправятся в гастрольный тур со старыми песнями', 'Немецкие депутаты признали Крым безопаснее Германии', 'Космический аппарат-убийца догнал европейский спутник', 'Полицейские научились вычислять преступников в толпе', 'Индиец тайно продал почку жены из-за маленького приданого', 'Американская учительница решила доказать свое право совращать учащихся', 'Умер основатель современного интернета', 'Кексы на теле полуголой девушки оказались незаконными', 'Раскрыты подробности контракта на поставку в войска истребителей Су-57', 'США вознамерились достичь небывалой ядерной мощи для любой войны', 'Власти Приморья опровергли слухи о принудительной высылке граждан Северной Кореи', 'Врач оправдала норвежских олимпийцев-астматиков', 'Миллиардер Сорос хотел остановить Brexit за символическую сумму', 'Бойцы ВСУ отказались здороваться словами «Слава Украине»', 'На выборы президента России пойдут почти 80 процентов избирателей', 'Главный спортивный матч в США заставил женщин ринуться за порно', 'Европе пригрозили штрафом за срыв «Северного потока-2»', 'Нелегальные мигранты устроили массовые беспорядки в Сибири', 'Математики предрекли биткоину вечную нестабильность', 'Раскрыт сговор Турции и ИГ', 'Российские олимпийцы пожаловались на слежку со стороны иностранной прессы', '«Звездные войны» раскритиковали за обилие белых мужчин в съемочной группе', 'Венесуэльцы начали расплачиваться яйцами', 'Полицейским запретили убирать с дорог пьяных судей', 'Песков вспомнил предупреждение и отказался комментировать поездку Собчак в США', 'Елена Летучая рассказала о причинах ухода из «Ревизорро»', 'Кэти Перри посчитала хит I Kissed a Girl недостаточно лесбиянским', 'Россия обвинила США в сокрытии совместных успехов', 'Основателя сети российских пиццерий привлекли к делу о контрабанде наркотиков', 'Банки научились узнавать кредитных мошенников в лицо', 'Умер вырастивший 68 лебедят гусь-бисексуал', 'Кремль рассказал о географии антикоррупционных чисток', 'Российские олимпийцы подверглись дискриминации со стороны канадцев', 'Выпущенные с моря по террористам российские ракеты подсчитали', 'В квартире «оружейного барона» Виктора Бута нашли подпольное казино', 'Раскрыта гомосексуально-наркотическая связь Марлона Брандо и Ричарда Прайора', 'Генпрокуратура назвала ущерб от махинаций с землей в Дагестане', 'Главу крупнейшей промышленной компании Украины арестовали в Москве', 'Появилось видео прощания с погибшим пилотом Су-25', 'Наркоторговец отказался от походов в туалет ради свободы', 'CAS отказался рассматривать апелляции отстраненных от Олимпиады россиян', 'Новейшие украинские ПТРК затерялись по пути на передовую', 'Илон Маск оказался «в неожиданно глубоком аду»', '«Самый стильный блогер» оказался жуликом', 'Губернатор Подмосковья даст наставления «Лидерам России»', 'Российские болельщики осадили штаб-квартиру WADA', 'Названа самая недобросовестная страна ЕС', 'Украинские силовики захватили редакцию оппозиционных СМИ', 'Овсянников повысил Берковича с помощника до директора департамента', 'ФСИН объяснила освобождение пожизненно осужденного расчленителя', 'Хакер из Северной Кореи рассказал о нищете и голоде в армии', 'Власти Севастополя рассказали о переходе на новую систему обращения с отходами', 'Потерявший шансы попасть на Олимпиаду Кулижников прокомментировал решение CAS', 'Модели отвоевали право не демонстрировать наготу', 'В США убийца стал секс-рабом в тюрьме и нажился на этом', 'Путин признался в отсутствии смартфона', 'Петербуржцев напугали резким ростом мусорного тарифа', 'На Украине раскрыли детали убийства комбата ДНР Гиви', 'В ДНР похвастались самой крупнокалиберной винтовкой в мире', 'США по ошибке поддержали ИГ огнем', 'YouTube попытался научить детей точить ножи', 'Мексиканец отправил по почте коробку с живым тигром', 'Финансовую безграмотность россиян объяснили «ментальным барьером»', 'Rambler Group объявила об изменениях в руководящем составе', 'Подставной Илон Маск обобрал доверчивых пользователей на тысячи долларов за ночь', 'Студентов поймали на тайном соревновании по сексу с тучными женщинами', '«Турецкий поток» внезапно подорожал', 'В Москве пройдет секретная вечеринка Boiler Room', 'На помощь джихадистам в Сирии пришли китайские товарищи', 'В МВД рассказали о найденных в пиццерии пакетах с наркотиками', 'В сети поразились издевательству телеведущих над женщиной-политиком 50 лет назад', 'Сенатор от Севастополя захотел навести порядок в прокуратуре', 'Финалистов «Лидеров России» оценили члены правительства и губернаторы', 'Распознавание лиц от NtechLab будут использовать в «умных городах» Татарстана', 'На похороны погибшего пилота Су-25 пришли 30 тысяч человек', 'Толстый таджикский генерал не захотел терять работу и похудел на 15 килограммов', 'Работник сварил и съел пенис начальника из-за невыплаты зарплаты', 'Пакистан защитится от терроризма стеной', 'Бренды и чиновники отказались от индивидуальности ради российских спортсменов', 'Россия испытала плазменные двигатели', 'Насильник Шурыгиной назвал сумму выплаченных ей денег', 'Стали известны подробности задержания «пожизненника»-расчленителя', 'Обмазавшегося маслом голого преступника под ЛСД остановил электрошокер', 'Трехкратная чемпионка мира выступила против наказания невиновных россиян', 'У зятя президента Туркмении нашли часы на миллион долларов', 'Российские ученые нашли в Антарктиде древнейший на планете лед', 'Вор пожаловался на кражу украденного', 'Христиане оценили секс с роботами', 'Российские олимпийцы смогут носить шапку с триколором', 'Легенды российского хоккея провели благотворительный матч в Норильске', 'Запущенный в космос автомобиль Tesla отнесли к спутникам', 'Пенсионеров завалили загадочными посланиями', 'Корейцы предложат гостям Олимпиады собачатину', 'Коалицию США заподозрили в намеренном уничтожении российского моста в Сирии', 'Раскрыт крупнейший сексуальный скандал в британской власти', 'Активистка Femen оголилась перед Порошенко на Венском балу', 'Хорошавина приговорили к 13 годам в колонии строгого режима', 'БДСМ-госпожу уволили из полиции в США', 'Отстраненные россияне лишились последнего шанса поехать на Олимпиаду', 'Американка вышла из церкви и вырвала себе глаза', 'Американка исследовала сушилку для рук в общественном туалете и ужаснулась', 'Наивная записка в российском подъезде растрогала пользователей сети', 'WADA возрадовалось решению CAS о недопуске россиян к Олимпиаде', 'Украинских военных уличили в продаже снайперских винтовок ополченцам ДНР', 'Американские биржи рухнули второй раз за неделю', 'США решили заново построить отношения с Россией', 'Таец выиграл в лотерею миллионы, потерял билет и умер', 'Еще один банк лишился лицензии', 'Бывший глава Сахалина поразил следователей любовью к роскошным часам', 'Борца против домогательств обвинили в домогательствах', 'МОК поддержал решение не допустить российских спортсменов на Олимпиаду', '«Отрицающие все» киргизы получили сроки за призывы к молитве', 'Индия оштрафовала Google за злоупотребления', 'Илон Маск объяснил космический провал СССР', 'Ученые раскрыли технологию для вечной жизни Путина', 'Собчак съездила на завтрак с Трампом и разочаровалась', 'Россия обвинила ИГ в заработке на онлайн-казино', 'Адвокат Родченкова поблагодарил бога за недопуск россиян на Олимпиаду', 'Насильник Шурыгиной ответил на новое обвинение в домогательствах', 'Американские компании пострадали от кумовства', 'Сельскую учительницу накажут за мат в стихах Маяковского', 'Объявивший себя русским Рой Джонс завершил карьеру', 'Секс-скандал вокруг звезды «Зачарованных» довел ее менеджера до суицида', 'Курды поймали последних джихадистов-«битлов»', 'Мост в Крым строит многотысячная команда', 'Apple подтвердила крупнейшую утечку в истории iPhone', 'Охотница на олигархов пригрозила Дерипаске походом на «Пусть говорят»', 'Мутко назвал причины недопуска россиян на Олимпиаду', 'Обыски силовиков дошли до Ингушетии', 'Охотница на олигархов назвала претензии к Дерипаске «троллингом тупых баб»', 'Кремль прокомментировал решение CAS о недопуске россиян к Олимпиаде', 'Рома Зверь сыграл одну из главных ролей в ленте Серебренникова о Цое', 'Украине придется покупать газ у России по максимуму', 'Оборонные предприятия России атаковали', 'Атаман пришел за наградой в футболке с надписью «У меня есть член»', 'Пенсиям россиян предрекли обвал', 'Польского туриста на Украине заставили поднять флаг УПА', 'Дерипаска объявил войну Рыбке и другим лжецам', 'Африканцы научат Европу правильно одеваться', 'Родченков сменил личину', 'Россия получит беспилотную «Армату»', 'Американский поклонник ИГ попытался вступить в Армию США ради джихада', 'Президент Азербайджана назвал стратегической целью возвращение столицы Армении', 'Китай решил потеснить господство доллара', 'Потушившему сигарету об икону студенту дали девять суток ареста', 'Раскрыт план США сорвать сотрудничество России и Афганистана', 'Убийцы Гиви и Моторолы оказались одними и теми же людьми', 'Избежавший санкций Кудрин рассказал о последствиях «кремлевского доклада»', 'Голодавшая из-за злого деда японка показала себя при весе в 16 килограммов', 'Россиянин заплатил налог с комиссией в 2500 процентов', 'Коммунистов вновь обвинили в незаконной агитации за Грудинина', 'Путину рассказали анекдот про изнасилование тракториста', '«Газпром» намекнул Европе на грядущий дефицит газа', 'Россия посетовала на вынужденное противостояние с США', 'Американские самолеты разбомбили ракету Маска', '«Аэрофлот» ужесточит контроль за габаритами и весом ручной клади', 'На Украине нашли объяснение невозможности вступить в НАТО', 'Профессиональными наставниками захотели стать сотни россиян', 'Раскрыты преимущества рубля над криптовалютами', 'Финалистов «Лидеров России» оценят школьники', 'Россиянин с братом убивал пенсионеров и получил пожизненное', 'Украинские депутаты плюнули на заседание Рады и уехали грозить Польше танками', 'Россия захотела избавиться от господства доллара', 'Спецназ пришел за Саакашвили и спасовал перед охранниками отеля', 'Египет решил убить всех террористов перед приездом российских туристов', 'Трампа с Ким Чен Ыном заметили на открытии Олимпиады', 'Поглумившегося над трупом самоубийцы блогера-богача лишили денег', 'В Российском ядерном центре рассказали о майнинге на суперкомпьютере', 'Президент Армении ответил на притязания азербайджанского коллеги на Ереван', 'Украина отказалась захватывать Россию', 'Путин пообещал убрать все ради движения вперед', 'Блогер поджарил себя на плите ради славы', 'Узбеки-трансвеститы с сексуальными желаниями оказались вне закона', 'В Госдуме пообещали разобраться с главой МОК после Олимпиады', 'Курдов обвинили в массовых казнях боевиков ИГ', 'AirPods загорелись в ухе американца', 'Президент Франции посетит ПМЭФ по приглашению Путина', 'Российских наемников увидели в зоне американского удара в Сирии', 'Любителям криптовалют посоветовали обратиться к психиатрам', 'Американская спортсменка приехала на Олимпиаду в статусе бомжа', 'Французы задумали казнить крыс на гильотинах', '«ФосАгро» стала дважды победителем всероссийского конкурса РСПП', 'Нефтяную зависимость России предложили заменить молочной', 'Порошенко пожалуется генсеку НАТО на Венгрию', 'Ягудин пристыдил российского фигуриста Коляду за провал на Олимпиаде', 'Теневая экономика Украины обогнала российскую', 'Посетившие Крым немецкие депутаты пообещали вернуться на полуостров', 'Набитый евро чемодан оказался эффективнее молитв', 'ВВС США и НАСА отказались от Falcon Heavy', 'Гендиректор «ФосАгро» получил Почетную грамоту президента России', 'Пентагон открестился от намеренного разрушения российского моста', 'Парень из мема про ботаников поучаствовал в запуске Falcon Heavy', 'Пластический хирург оценил новый облик Родченкова', 'Французский суд продлил арест Павленскому', 'Минобороны дало отповедь усомнившемуся в героизме Филипова «манкурту»', 'Бах обещал распустить CAS в случае оправдания российских атлетов', 'Американский посол пожаловался на нехватку гор в Москве', 'Соловьев выгнал гостя своей передачи за реплику против Героя России Филипова', 'Трамп заблокировал публикацию записки демократов о «российском расследовании»', 'Пентагон отказался от претензий к появлению «Искандеров» под Калининградом', 'Виктор Бут захотел судиться с журналистами из-за новости о казино в его квартире', 'МЧС спрогнозировало наиболее вероятные сценарии войны с Россией', 'В Амстердаме туристам запретили смотреть на проституток', 'Американцы попытались сравнить истребители Су-35 и F-35 и не смогли', 'Умер актер из «Карточного домика»', 'Израильские истребители ударили по Сирии и получили отпор', 'Ким Чен Ын позвал президента Южной Кореи в гости', 'Украинцев призвали отказаться от поездки на чемпионат мира в Россию', 'Уничтожение российского Су-25 раскололо боевиков', 'Россиянин обманул американскую разведку на 100 тысяч долларов и скрылся', 'В МЧС объяснили появление вероятных сценариев войны с Россией', 'Задержанные за хранение кораллов россиянки рассказали о тайской тюрьме', 'Определено сбившее израильский истребитель оружие', 'Изгнанный с эфира за реплику о летчике Филипове гость объяснился', 'CAS объяснил решение о недопуске россиян на Олимпиаду', 'Венгры устроили «паспортные облавы» на украинцев', 'Курды сбили турецкий вертолет и показали это на видео', 'Британцев устрашили российскими секретными «военными игрушками»', 'Кадыров купил «долю в биткоине»', 'Школьники оценили финалистов «Лидеров России»', 'Сайт Навального внесли в черный список', 'Спортсменка из США обрадовалась отсутствию лидеров сборной России на Олимпиаде', 'Российских спортсменов посчитали самыми стильными на Олимпиаде', 'Фетисов причислил рабочих к людям второго сорта и подвергся обструкции', 'В московском лицее объяснили запрет на походы в туалет без справки', 'На Украине назвали причину отказа Киева воевать за Крым', 'Дерипаска подал в суд на Рыбку и ее наставника', 'Попавшегося на допинге француза спугнули вопросом о Викторе Ане', 'Путин предостерег Нетаньяху от разрастания конфликта в Сирии', 'Саакашвили взял на себя ответственность за всех грузин и собрался в Польшу', 'Жители Латвии захотели в СССР', '«Роскосмос» анонсировал уникальный запуск космического корабля', 'ЦРУ рассказало о разводившем ведомство на деньги информаторе из России', 'Русским предсказано взять власть в Латвии', 'Названы условия продажи С-400 в США', 'Украинец услышал «призыв» Путина принять конституцию и решил покончить с собой', 'Польша решила побороться с другими странами ЕС за дешевый труд украинцев', 'Секс до брака политики решили наказывать пятью годами тюрьмы', 'МОК предупредил российских атлетов о неожиданных допинг-тестах на Олимпиаде', 'Следователи завели дело на мешавшего фермерам министра в Забайкалье', 'Ученые выявили существенные преимущества людей без пары', 'В США разгадали план Китая по уничтожению Америки', 'Советские перехватчики потягались с израильскими истребителями в Сирии', 'Уникальный запуск «Прогресса» перенесли', 'Обмен шпионами между Россией и Эстонией попал на видео', 'Фетисов усмотрел заговор среди возмутившихся им рабочих и ничего не понял', 'Северную Корею заподозрили в трансляции шпионских шифров перед Олимпиадой', 'Украина модернизировала 50-летний ракетный комплекс', 'Путин поручил расследовать крушение Ан-148', '«Почта России» отреагировала на новости о столкновении своего вертолета с Ан-148', 'Пассажиры рассказали об «убитых» самолетах «Саратовских авиалиний»', 'Путин отменил поездку в Сочи после крушения Ан-148', 'Министр Соколов назвал биоматериалом тела погибших в катастрофе Ан-148', 'Очевидцы сообщили о хлопке перед крушением Ан-148', 'Объявлены победители конкурса «Лидеры России»', 'Появилась запись переговоров потерявших Ан-148 авиадиспетчеров', 'Владельцу «Саратовских авиалиний» припомнили «коробку из-под ксерокса»', 'На обломках разбившегося Ан-148 не нашли следов взрывчатки', 'Названы основные версии крушения Ан-148', 'Тренеры поругались из-за саней и помешали российскому олимпийцу победить', 'Сокамерницы избили арестованную в США россиянку до слепоты', 'Проверявшие Ан-148 техники разбились вместе с ним', 'Привезенный к дому Порошенко «столб позора» украли', 'Выигравший золото биатлонист выступил против недопуска Шипулина к Олимпиаде', 'Российские военные успешно испытали новую ракету системы ПРО', 'Новые Су-25 сделали неуязвимыми для зенитных ракет', 'Спасательная операция на месте крушения Ан-148 завершена', 'Родченков объяснил изменение внешности во время интервью CBS', 'Распыление спрея от комаров в лицо ради лечения от ВИЧ сочли насилием', 'Тренеру российских биатлонистов предложили вырвать зубы из-за плохих результатов', 'Жительница Мекки втайне от семьи выкладывала в соцсети порновидео и поплатилась', '«Газпром» заведет собственный резервный фонд', 'В МВФ заявили о неизбежности глобального регулирования криптовалют', 'Бывший депутат-единоросс сломал челюсть диджею Smash', 'Российский олимпиец рассказал о нежелании американцев жать ему руку', 'Немецких трубочистов научили зиговать и нахваливать Гитлера', 'Супермаркет посмел нарисовать женщин на тележках и поплатился', 'Оренбургские чиновники отдадут семьям пассажиров Ан-148 дневной заработок', 'Правительство определилось с минимальной ценой на водку', 'На месте падения Ан-148 найден речевой самописец', 'Америка подарит МКС бизнесменам', 'Родченков поведал о природе греха', 'Россияне разлюбили банки и увлеклись микрокредитованием', 'Массовое прочесывание зоны крушения Ан-148 сняли с коптера', 'Бывший полицейский из команды генерала Сугробова сел за махинации с делами', 'Раскрыт источник крупнейшей утечки в истории iPhone', 'Овсянников поздравил севастопольцев с Масленицей', 'Турция придумала сговор с «террористом» Асадом', 'Американскую фигуристку затравили из-за критики 15-летней россиянки', 'Умирающий криминальный авторитет перед смертью рассказал свою историю', 'Сбербанк запустил собственный мессенджер', 'В Крыму поймали собиравшего информацию о Росгвардии и ФСБ украинца', 'Воронежцы залатали дорожные ямы матрасами', 'Сбитый в Израиле иранский беспилотник оказался копией американского', 'Пятизвездочная тюрьма «раскулаченных» принцев попала на видео', 'В Нью-Йорке мужчин выставили свиньями', 'Украинцы пришли в ярость от соболезнующего родным жертв Ан-148 Климкина', 'Песков отверг обвинения Родченкова и указал на его психический недуг', 'В Кремле прокомментировали расследование крушения Ан-148', 'Во Франции закончилась рабочая сила', 'Американским школьницам запретили отказывать мальчикам в танце', '«Руки-базуки» отказался драться с Камой Пулей и предложил ему альтернативу', 'Часовщики отказались от полуобнаженных моделей следом за «Формулой-1»', 'Кремль посетовал на невозможность прекратить вылазки террористов в Сирии', 'Де Ниро диагностировал у США безумие', 'Следователи исключили взрыв Ан-148 в воздухе', 'Туристы пойдут под суд за организацию порнотанцев в Камбодже', 'Ягудин осадил американскую фигуристку за критику 15-летней Загитовой', 'Звезды «Секса в большом городе» устроили скандал вокруг мертвого родственника', 'Богатейший россиянин сможет содержать Россию две недели', 'Киркорова в шикарном пуховике назвали «кудрявой бабушкой»', 'Скандал с охотницей на олигархов привел к угрозе блокировки YouTube в России', 'Похитителям 500 живых тараканов пригрозили тюрьмой', 'Украина примет участие в расследовании крушения Ан-148 в Подмосковье', 'Власти Крыма посоветовали украинским коллегам «работать внутри своей страны»', 'США обвинили в нежелании бороться с ИГ', 'Иранка притворилась мужчиной ради футбольного матча', 'Саакашвили задержали на Украине', 'Авербух усомнился в способностях раскритиковавшей Загитову американки', 'Тимати обозвал избившего диджея Smash депутата «гнилым пидарастом»', 'Армения назвала условие разрешения конфликта с Азербайджаном', 'Наркотики вернулись на YouTube', 'В ЦИК рассказали о желании россиян проголосовать по месту пребывания', 'Украина начала экспортировать пчел в Канаду', 'Губернатор Севастополя поручил навести порядок в жилом фонде', 'Лидера «Оплота» Жилина убил украинский киллер', 'Саакашвили рассказал о спасшей Сталина прабабушке', 'Богатые россияне испугались санкций и спрятали деньги в России', 'На директора реабилитационного центра завели дело после смерти актера Марьянова', 'США обвинили в сокрытии ядерного оружия', 'Водянова попыталась приучить подписчиков к прокладкам и просчиталась', 'Раскрыта роль Киева в расследовании крушения Ан-148', 'Порошенко обвинил Путина в неисполнении минских соглашений', 'Многодетную мать с Урала посчитали мужчиной и обвинили в подрыве устоев', 'Компания Порошенко объявила монополию на «Киевский торт»', 'Президент Филиппин приказал простреливать вагины протестующим', 'Главная телекомпания Украины отказалась показывать ЧМ-2018', 'Полуголые футболистки из Владивостока разъярили соцсети своими формами', 'Google скопирует «монобровь» iPhone X', 'Студент написал диплом об экстремизме и сел за экстремизм', 'Шесть сотрудников «Газпром нефти» вошли в число победителей «Лидеров России»', 'Киеву предрекли возвращение гетто', 'Известный итальянский бренд откроет магазин собственных подделок', 'ИГ придумало способ сорвать президентские выборы в Египте', 'Саакашвили выслали с Украины', 'Американец назвал Олимпиаду гейской и пожалел об этом', 'Фуркад выиграл Олимпиаду и раскритиковал решение не допускать до нее россиян', 'Сотни тысяч британцев проснулись миллионерами', 'Охотница на олигархов собралась решить судьбу YouTube в России', 'Названо число необходимых Донбассу миротворцев', 'Сторонники Саакашвили отправились к администрации Порошенко', 'Кашпировский потребовал у Первого канала полмиллиона рублей за коллаж с котом', 'От удара американских войск в Сирии погиб россиянин', 'Обвал американских рынков объяснили эмоциями', 'Саакашвили назвал Порошенко «подлым барыгой»', 'Глава МИД Нидерландов солгал о встрече с Путиным', 'МОК захотел наказать россиянина за посвящение медали отстраненным олимпийцам', 'YouTube придумал наказание для «вредных» блогеров', 'Ямальский колледж вошел в сто лучших учебных заведений России', 'Россияне стали меньше болеть', 'Судья пригрозила проблемами пострадавшему от ее сына мальчику', 'В Якутии создадут новую региональную авиакомпанию', 'Изящный жест очками превратил олимпийского фигуриста в кумира интернета', 'Трамп пособолезновал Путину в связи с авиакатастрофой в Подмосковье', 'Невестка Трампа открыла конверт с белым порошком и попала в больницу', 'Олимпийская чемпионка спасла собаку от корейских гурманов', 'В Сирии погибли балтийский казак и нацбол', 'Глава украинской оборонки заявил о победе и подал в отставку', 'Саакашвили сравнил украинских силовиков с фашистами и пообещал вернуться', 'ЦИК выявила обман со стороны Грудинина', 'Российская художница показала лицо стран и обрела всемирную славу', 'Сдан первый положительный допинг-тест на Олимпиаде', 'Робота-собаку научили открывать двери', 'США выразили готовность оказать помощь в расследовании крушения Ан-148', 'Британцы вместо помощи пострадавшим гаитянам развлекались с проститутками', 'Более 10 оперативников таскали Саакашвили за волосы', 'Полиция озаботилась новым челленджем и призвала не ночевать в магазинах', 'Трех российских легкоатлетов не допустили до международных соревнований', 'Грузинский снайпер обвинил украинских депутатов в расстреле Майдана', 'Занявший 40-е место российский биатлонист перелез через забор и сбежал от прессы', 'Елена Вяльбе предположила вербовку Родченкова в Канаде', 'Змея «духовно» проглотила многомиллионную выручку нигерийских чиновников', 'Американский самолет-разведчик в 15-й раз с начала года засекли у границ России', 'Человека-рыбу из «Формы воды» расстроил посвященный ему дилдо', 'Россияне стали ярыми противниками супружеских измен', 'Причиной отставки сенатора Клинцевича стала вредная болтливость', 'Живущим в аварийном доме россиянам запретили трогать стены', 'Раскрыта стоимость космодрома «Морской старт»', 'Британка сбросила полцентнера из-за «ужасного секса»', 'Олимпийский чемпион признался в желании «дать леща» фигуристу Коляде', 'Поляки нашли украинского Гитлера', 'Похудевшая ради свадебного платья блогер заработала бесплодие', 'Россиян предупредили об угрозе ядерного заражения', 'Хакеры украли у россиян более миллиарда рублей', 'Советскую школу наставничества задумали возродить', 'Британских геев порадовали модной клеткой с радужными деталями', 'Запрещавший детям выходить в туалет без справки учитель лишился работы', 'Раскрыты планы США по сдерживанию России', 'Америка определилась со сроками покорения Луны', 'Турчинов похвастал успехами украинских военных в Донбассе', 'Путин простудился', 'Интернет-торговлю в России захотели радикально изменить', 'Влезшая в политику корейская гадалка угодила за решетку', 'По факту избиения диджея Smash возбуждено уголовное дело', 'Кремль призвал помнить о находящихся не только в Сирии россиянах', 'Кибератаку во время Олимпиады приписали россиянам', 'В сети показали фото летевших в силовиков на Майдане пуль', 'Россияне обросли долгами и отказались из них вылезать', 'Российский футболист высморкался в пятитысячную купюру и нарвался на оскорбления', 'Грудинин ответил на претензии ЦИК', 'Мусульман научили вычислять геев', 'В России заблокировали инструкции по сборке атомной бомбы и купанию кота', 'Кремль отреагировал на желание Трампа помочь Путину', 'На Урале начались поиски жертв серийного маньяка-эмчеэсовца', 'Геологи отсоветовали трогать челябинский метеорит из-за непредсказуемых бактерий', 'В России без объяснений отложили премьеру новых «Мстителей»', 'Названа основная причина гибели Ан-148', 'Короткая память и гей довели таджикских милиционеров до уголовного дела', 'Эрдоган пригрозил американцам «османским шлепком»', 'Саакашвили выдворили с Украины перед допросом о расстрелах на Майдане', 'Избитого Цукерберга поместили на обложку журнала', 'Украинцы обезвредили енота-агрессора из России', 'Майнинг биткоинов оставит Исландию без света', 'Мединский обвинил БДСМ-мелодраму в удушении российского кино', 'Чистая прибыль Россельхозбанка по итогам 2017 года увеличилась в 3,5 раза', 'Японским родителям попытались навязать школьную форму от Armani', 'Одинокие россияне потратились на поиски любви', 'Художники получили миллионы долларов за закрашенное граффити', 'В мэрию Еревана вызвали психиатров и скорую из-за банок с фекалиями', 'Приказ простреливать вагины филиппинкам неуклюже объяснили', 'Выдвинута официальная версия катастрофы Ан-148', 'Путин отказался от бесплатного эфира на федеральном телевидении', 'Путин отказался залить мир нефтью', 'В Томской области полиция и священник объявили войну домовому', 'В Москве обсудили новые механизмы перехода к низкоуглеродной экономике', 'США вслед за Россией возобновят создание сверхзвукового самолета', 'Лавров посетовал на агрессивное меньшинство на Западе', 'Рэпер Face посоветовал всем сваливать из России', 'На Украине осудили российских военных за госизмену', 'Охотница на олигархов Настя Рыбка обрела популярность на PornHub', 'Путина поразили двумя камнями', 'Создано идеальное лекарство от гриппа', 'Все школы Саратова закрыли из-за эпидемии', 'Молния пробила дыру размером с человека в американском бомбардировщике', 'Генерал ФСБ ушел на службу в немецкую фирму', '«Маньяка-лизуна» посадили на пять лет за секс со спящей москвичкой', 'Жителей Донбасса оставили без украинских пенсий', 'Фотограф ужаснулась рекламе с женщинами-трупами', 'Рассекречено название первого внедорожника Rolls-Royce', 'Раскрыты новые подробности нападения на российскую базу в Сирии', 'Названы любимые любовные фильмы россиян', 'Окровавленное лицо рэпера Face заблокировали', 'Россия отстояла «Раковую шейку» у Украины', 'Раскрыт секрет элегантной прически Кейт Миддлтон', 'Украинский политик устроил скандал в прямом эфире из-за Саакашвили', 'У столичного уголовного розыска появился новый начальник', 'Обнаружено «руководство по сексу» XVIII века', 'Одиноким человечкам со светофоров нашли возлюбленных', 'США уничтожили советский Т-72 в Сирии', 'Подсчитана доля американцев в госдолге России', 'Саакашвили из Польши пригрозил «молдавскому барыге» Порошенко', 'Совравший о встрече с Путиным голландский министр уволился', 'Google уличили в манипулировании беременными женщинами', 'Иностранные компании запаниковали из-за «кремлевского доклада»', 'Ямальцы победили собственную инертность', 'Венгрия пообещала продолжить давление на Украину', 'Незнакомец с топором в московском метро заставил вспомнить классику', 'Опубликовано видео удара США по российским наемникам', 'Следователи не увидели ничего плохого в избиении подростков силовиками в Чечне', 'Украина объявит крымское имущество в международный розыск', 'Российские школьники открыли новый остров в Арктике', 'Звезда «Пятидесяти оттенков» раскрыла детали постельных сцен', 'Евросоюз выделит деньги на восстановление Донбасса и децентрализацию Украины', 'Депутат предложил нюхать людей в поисках геев', 'Неполадки разбившегося Ан-148 обнаружили у Sukhoi Superjet 100', 'Появившаяся на Олимпиаде сестра Ким Чен Ына внушила ужас соцсетям', 'Разведка США заявила о неспособности сирийской оппозиции свергнуть Асада', 'В США обнаружили новую угрозу национальной безопасности', 'Ученые выявили типажи склонных к супружеским изменам людей', 'России предсказали наплыв секс-рабынь во время чемпионата мира-2018', 'Франция заявила о готовности нанести удары по Сирии', 'Пентагон прокомментировал сообщения о гибели россиян в Сирии', 'Госдеп США согласился с «Североамериканским тупиком»', 'Социологи узнали число верящих в инопланетян', 'Pornhub назвал условия получения бесплатного премиум-аккаунта', 'Названы самые лучшие для жизни регионы России', 'В Киеве рассказали подробности разговора Путина с Порошенко', 'Samsung скопирует самую бесполезную функцию iPhone X', 'Снайперы из Грузии признались в расстреле Евромайдана в 2014 году', 'В США рассказали о попытках Китая подорвать Америку изнутри', 'Два российских спортсмена пропустили Олимпиаду из-за ошибки МОК', 'В Папуа — Новой Гвинее христиане призвали прекратить сожжение ведьм', 'Крупнейший интернет-магазин доставил отцу семейства обслюнявленную зубную щетку', 'Послания инопланетян назвали смертельно опасными', 'Сутенеры нашли необычный способ принуждения к занятию проституцией', 'Спортсмены Денщиков и Потылицына решили скрасить информационный фон и поженились', 'Найден простой способ оставаться стройным', 'МОК объяснил отсутствие двух россиян в списке приглашенных на Олимпиаду', 'Российские работяги определили место женщины в стране', 'Американку приговорили к пожизненному за убийство дочери распятием', 'Банк России ударит по кредитам «до зарплаты»', 'Исинбаева родила сына', 'Украину предостерегли от переделывания истребителя МиГ-29 в штурмовик', 'Показавший «Смерть Сталина» кинотеатр оштрафовали за фильм «Диван Сталина»', 'Раскрыта цель разбомбленных в Сирии российских наемников', 'Ургант обсмеял Кашпировского после жалобы в суд на коллаж с котом', 'Исчезновение машины Илона Маска в далеком космосе покажут в прямом эфире', 'Дерипаска решил подзаработать на майнинге', 'Ошибочно не допущенный к Олимпиаде россиянин обиделся на МОК', 'Памятник трактору завелся после освящения на глазах у заплакавших пенсионеров', '«Гость из будущего» прошел проверку на детекторе лжи', 'Скромный вклад Украины в борьбу с ИГ объяснили происками России', 'Россияне закупились секс-игрушками перед Днем святого Валентина', 'Иран раскрыл сеть вражеских ящериц-шпионов', 'ЦИК предложил Первому каналу отложить показ фильма о Путине', 'Песков рассказал о соболезнованиях Порошенко', 'Кремль прокомментировал возможный запрет на въезд россиян в Сирию', 'Турция отчиталась о 1,5 тысячи убитых курдов', 'ФСБ пришла в банк «Финам» за документами крупного клиента', 'Овечкин поблагодарил НХЛ за просмотр олимпийского хоккея по телевизору', 'Ким Чен Ын встретился с ездившей на Олимпиаду делегацией и призвал к миру', 'Песков заподозрил американцев в одержимости', 'Мэра Одессы задержали в киевском аэропорту', 'Школьники России обсудят будущее городов и профессий', 'В небе над Лондоном появился гигантский внутренний орган', '«Крупнейшая хакерская атака» не принесла организаторам ни копейки', 'Автора книги «13 причин почему» про домогательства обвинили в домогательствах', 'Российский «Кызыл» по пути из Сирии помешал британскому военному кораблю', 'Российских военных заставили есть крахмал вместо тушенки', 'Променявший США на Россию сноубордист научился давать взятки', 'За секс с детьми в России начнут сажать пожизненно', 'Поляк отказался вызывать врачей украинке с инсультом и сдал ее полиции', 'ФСБ дадут еще больше полномочий', 'Пережившая развал СССР белая медведица умерла в голоде и одиночестве', 'Американские спецслужбы запретили пользоваться китайскими смартфонами', 'Фаворитов «Оскара» обвинили в расизме, плагиате и педофилии', 'Трехкратная олимпийская чемпионка сочла российских биатлонистов недостойными Игр', 'Турчинов задумался о вооруженном «освобождении» ДНР и ЛНР', 'Помощник президента поведал о закате мужского мира', 'Украинские солдаты станут лучше видеть', 'Отец сестер-супермоделей попался на сексуальных домогательствах', 'Нетаньяху назвал «дырявым сыром» обвинения во взяточничестве', 'Госдолг взвалили на семьи украинцев', 'Живая улитка поселилась в гноящемся локте мальчика', 'Россиянин проиграл выборы и заказал соперника киллеру', 'Сервис Price.ru за год увеличил выручку на 65 процентов', 'Северная Корея поболеет на Олимпиаде за чужой счет', 'Ленивого заключенного обязали вернуть деньги за его содержание в колонии', 'Гостей модного показа вынудили ходить по попкорну', 'Грудинин уступил в популярности КПРФ', '«Аэрофлот» улучшил правила перевозки музыкальных инструментов как ручной клади', 'Минкульт отказался от претензий к кинотеатру из-за «Смерти Сталина»', 'Белоруссии срочно понадобились российские истребители', 'Лучших наставников России сравнили с алмазами', 'Депутат озолотилась за счет попавшей в больницу девочки', 'Американку выгнали из самолета за скандал с матерью младенца', 'Президент МОК предстал пред ликом российских олимпийцев', 'Устроившие резню в пермской школе не смогли объяснить свои мотивы', 'AliExpress зафиксировал рост спроса на секс-игрушки', 'ФСБ передумали давать еще больше полномочий', 'Про самого жестокого маньяка России снимут сериал', 'Самая одинокая лягушка на свете воспользовалась сайтом знакомств', 'Пенсионерка подарила мужу почку на День влюбленных', 'Тим Кук пожелал деньгам смерти', 'Россиян оставили без дневного сна', 'Рядом с Россией нашли загадочный источник радиоактивного заражения', 'Полуголая супермодель свалилась со скалы', 'США атаковали российских наемников стратегическими бомбардировщиками', 'Песков назвал чушью слова Пономарева о предпосылках присоединения Крыма', 'В посольства трех стран в Москве прислали конверты с белым порошком', 'Отчаявшиеся одиночки и ненавистники 14 февраля объединились против влюбленных', 'Фанаты «Игры престолов» раскрыли вероятную концовку сериала', '«Женщина-кошка» отвергла слухи о пластических операциях', 'Названы самые популярные страны для вывода денег из России', 'Всех голландцев отправят на органы', 'Первый канал отменил показ финала фильма про Путина', 'Собчак потребовала признать незаконной регистрацию Путина на выборах', 'Путин предложил помочь школьникам с выбором профессии', 'Сделка с Visa помогла популярной криптовалюте взлететь', 'Художница напекла пирогов и попросила измазать себя ими', 'Чеченский муфтий поспорил о халяльности майнинга', 'Взорвавшим аэропорт террористам выплатят 50 тысяч евро', 'Созданный США самый дорогой в мире авианосец оказался непригодным', 'Восточные женщины научились обходиться без мужчин и скупили бриллианты', 'Саакашвили получил голландский паспорт', '«Газпром» решил поссориться с Германией', 'ТНТ разрешили не извиняться за извинение перед ингушами', 'Среди талибов нашли европейцев', 'Порнозвезда раскрыла секрет создания успешного домашнего порно', 'Россия разрешила США занять первое место по добыче нефти', 'Члены «банды GTA» убивали россиян ради переворота в Узбекистане', 'Американцы в День святого Валентина предпочли животных коллегам', 'Раненые российские наемники вернулись из Сирии', '«Евреи за Иисуса» призвали украинцев покаяться за неоплаченные услуги ЖКХ', 'Раскрыты доходы руководства Сбербанка', 'Британскую королеву заподозрили в порче воздуха в карете с султаном Бахрейна', 'Рынок краудинвестинга в 2018 году достигнет 10 миллиардов рублей', 'Раскрыта причина аварии во время пуска Falcon Heavy', 'Военные опровергли опасный маневр российского корабля в Босфоре', 'Российского саночника выслали с Олимпиады без объяснения причин', 'На консульстве Польши в Киеве вывесили список преступлений против Украины']\n0.1 0.1\n['После оправдания российских спортсменов Макларена назвали идиотом', 'Родченкова сочли борцом за правое дело и помогли деньгами']\n[]\n"
]
],
[
[
"И снова мы видим сильную зависимость от выбранного порога.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a04921ff6f33a48a643a2a30f869d140870529d
| 47,362 |
ipynb
|
Jupyter Notebook
|
week3/Implementing binary decision trees.ipynb
|
chen1649chenli/Machine-Learning-Classification
|
5f8103f237a45d17268e60cfec33f81d4edf336a
|
[
"MIT"
] | 2 |
2018-09-29T16:17:58.000Z
|
2018-09-29T16:18:00.000Z
|
week3/Implementing binary decision trees.ipynb
|
chen1649chenli/Coursera-UW-Machine-Learning-Classification
|
5f8103f237a45d17268e60cfec33f81d4edf336a
|
[
"MIT"
] | null | null | null |
week3/Implementing binary decision trees.ipynb
|
chen1649chenli/Coursera-UW-Machine-Learning-Classification
|
5f8103f237a45d17268e60cfec33f81d4edf336a
|
[
"MIT"
] | null | null | null | 35.962035 | 507 | 0.471559 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport json\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### 1. Load the dataset into a data frame named loans",
"_____no_output_____"
]
],
[
[
"loans = pd.read_csv('../data/lending-club-data.csv')\nloans.head(2)",
"/Users/llchen5/anaconda3/lib/python3.5/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (19,47) have mixed types. Specify dtype option on import or set low_memory=False.\n interactivity=interactivity, compiler=compiler, result=result)\n"
],
[
"# safe_loans = 1 => safe\n# safe_loans = -1 => risky\nloans['safe_loans'] = loans['bad_loans'].apply(lambda x : +1 if x==0 else -1)\n\n#loans = loans.remove_column('bad_loans')\nloans = loans.drop('bad_loans', axis=1)",
"_____no_output_____"
],
[
"features = ['grade', # grade of the loan\n 'term', # the term of the loan\n 'home_ownership', # home_ownership status: own, mortgage or rent\n 'emp_length', # number of years of employment\n ]\ntarget = 'safe_loans'",
"_____no_output_____"
],
[
"loans = loans[features + [target]]",
"_____no_output_____"
],
[
"loans.iloc[122602]",
"_____no_output_____"
]
],
[
[
"## One-hot encoding",
"_____no_output_____"
]
],
[
[
"categorical_variables = []\nfor feat_name, feat_type in zip(loans.columns, loans.dtypes):\n if feat_type == object:\n categorical_variables.append(feat_name)\n \nfor feature in categorical_variables:\n \n loans_one_hot_encoded = pd.get_dummies(loans[feature],prefix=feature)\n #print loans_one_hot_encoded\n \n loans = loans.drop(feature, axis=1)\n for col in loans_one_hot_encoded.columns:\n loans[col] = loans_one_hot_encoded[col]\n \nprint (loans.head(2) ) \nprint (loans.columns)",
" safe_loans grade_A grade_B grade_C grade_D grade_E grade_F grade_G \\\n0 1 0 1 0 0 0 0 0 \n1 -1 0 0 1 0 0 0 0 \n\n term_ 36 months term_ 60 months ... \\\n0 1 0 ... \n1 0 1 ... \n\n emp_length_10+ years emp_length_2 years emp_length_3 years \\\n0 1 0 0 \n1 0 0 0 \n\n emp_length_4 years emp_length_5 years emp_length_6 years \\\n0 0 0 0 \n1 0 0 0 \n\n emp_length_7 years emp_length_8 years emp_length_9 years \\\n0 0 0 0 \n1 0 0 0 \n\n emp_length_< 1 year \n0 0 \n1 1 \n\n[2 rows x 25 columns]\nIndex(['safe_loans', 'grade_A', 'grade_B', 'grade_C', 'grade_D', 'grade_E',\n 'grade_F', 'grade_G', 'term_ 36 months', 'term_ 60 months',\n 'home_ownership_MORTGAGE', 'home_ownership_OTHER', 'home_ownership_OWN',\n 'home_ownership_RENT', 'emp_length_1 year', 'emp_length_10+ years',\n 'emp_length_2 years', 'emp_length_3 years', 'emp_length_4 years',\n 'emp_length_5 years', 'emp_length_6 years', 'emp_length_7 years',\n 'emp_length_8 years', 'emp_length_9 years', 'emp_length_< 1 year'],\n dtype='object')\n"
],
[
"with open('../data/module-5-assignment-2-train-idx.json') as train_data_file: \n train_idx = json.load(train_data_file)\nwith open('../data/module-5-assignment-2-test-idx.json') as test_data_file: \n test_idx = json.load(test_data_file)\n\nprint (train_idx[:3])\nprint (test_idx[:3])",
"[1, 6, 7]\n[24, 41, 60]\n"
],
[
"print len(train_idx)\nprint len(test_idx)",
"37224\n9284\n"
],
[
"train_data = loans.iloc[train_idx]\ntest_data = loans.iloc[test_idx]\n\nprint (train_data.shape)\nprint (test_data.shape)",
"(37224, 25)\n(9284, 25)\n"
]
],
[
[
"## Decision tree implementation",
"_____no_output_____"
],
[
"## Function to count number of mistakes while predicting majority class\nRecall from the lecture that prediction at an intermediate node works by predicting the majority class for all data points that belong to this node. Now, we will write a function that calculates the number of misclassified examples when predicting the majority class. This will be used to help determine which feature is the best to split on at a given node of the tree.\n\nNote: Keep in mind that in order to compute the number of mistakes for a majority classifier, we only need the label (y values) of the data points in the node.\n\nSteps to follow:\n\n- Step 1: Calculate the number of safe loans and risky loans.\n- Step 2: Since we are assuming majority class prediction, all the data points that are not in the majority class are considered mistakes.\n- Step 3: Return the number of mistakes.",
"_____no_output_____"
],
[
" 7. Now, let us write the function intermediate_node_num_mistakes which computes the number of misclassified examples of an intermediate node given the set of labels (y values) of the data points contained in the node. Your code should be analogous to ",
"_____no_output_____"
]
],
[
[
"def intermediate_node_num_mistakes(labels_in_node):\n # Corner case: If labels_in_node is empty, return 0\n if len(labels_in_node) == 0:\n return 0 \n \n safe_loan = (labels_in_node==1).sum() \n risky_loan = (labels_in_node==-1).sum()\n \n return min(safe_loan, risky_loan)",
"_____no_output_____"
]
],
[
[
"8. Because there are several steps in this assignment, we have introduced some stopping points where you can check your code and make sure it is correct before proceeding. To test your intermediate_node_num_mistakes function, run the following code until you get a Test passed!, then you should proceed. Otherwise, you should spend some time figuring out where things went wrong. Again, remember that this code is specific to SFrame, but using your software of choice, you can construct similar tests.",
"_____no_output_____"
]
],
[
[
"# Test case 1\nexample_labels = np.array([-1, -1, 1, 1, 1])\nif intermediate_node_num_mistakes(example_labels) == 2:\n print ('Test 1 passed!')\nelse:\n print ('Test 1 failed... try again!')\n\n# Test case 2\nexample_labels = np.array([-1, -1, 1, 1, 1, 1, 1])\nif intermediate_node_num_mistakes(example_labels) == 2:\n print ('Test 2 passed!')\nelse:\n print ('Test 2 failed... try again!')\n \n# Test case 3\nexample_labels = np.array([-1, -1, -1, -1, -1, 1, 1])\nif intermediate_node_num_mistakes(example_labels) == 2:\n print ('Test 3 passed!')\nelse:\n print ('Test 3 failed... try again!')",
"Test 1 passed!\nTest 2 passed!\nTest 3 passed!\n"
]
],
[
[
"## Function to pick best feature to split on\n\nThe function best_splitting_feature takes 3 arguments:\n\n- The data\n- The features to consider for splits (a list of strings of column names to consider for splits)\n- The name of the target/label column (string)\n\nThe function will loop through the list of possible features, and consider splitting on each of them. It will calculate the classification error of each split and return the feature that had the smallest classification error when split on.\n\nRecall that the classification error is defined as follows:",
"_____no_output_____"
],
[
"### 9. Follow these steps to implement best_splitting_feature:\n\n- Step 1: Loop over each feature in the feature list\n- Step 2: Within the loop, split the data into two groups: one group where all of the data has feature value 0 or False (we will call this the left split), and one group where all of the data has feature value 1 or True (we will call this the right split). Make sure the left split corresponds with 0 and the right split corresponds with 1 to ensure your implementation fits with our implementation of the tree building process.\n- Step 3: Calculate the number of misclassified examples in both groups of data and use the above formula to compute theclassification error.\n- Step 4: If the computed error is smaller than the best error found so far, store this feature and its error.\n\nNote: Remember that since we are only dealing with binary features, we do not have to consider thresholds for real-valued features. This makes the implementation of this function much easier.\n\nYour code should be analogous to",
"_____no_output_____"
]
],
[
[
"def best_splitting_feature(data, features, target):\n \n target_values = data[target]\n best_feature = None # Keep track of the best feature \n best_error = 2 # Keep track of the best error so far \n # Note: Since error is always <= 1, we should intialize it with something larger than 1.\n\n # Convert to float to make sure error gets computed correctly.\n num_data_points = float(len(data)) \n \n # Loop through each feature to consider splitting on that feature\n for feature in features:\n \n # The left split will have all data points where the feature value is 0\n left_split = data[data[feature] == 0]\n \n # The right split will have all data points where the feature value is 1\n right_split = data[data[feature] == 1]\n \n # Calculate the number of misclassified examples in the left split.\n # Remember that we implemented a function for this! (It was called intermediate_node_num_mistakes)\n left_mistakes = intermediate_node_num_mistakes(left_split[target]) \n\n # Calculate the number of misclassified examples in the right split.\n right_mistakes = intermediate_node_num_mistakes(right_split[target]) \n \n # Compute the classification error of this split.\n # Error = (# of mistakes (left) + # of mistakes (right)) / (# of data points)\n error = (left_mistakes + right_mistakes) / num_data_points\n\n # If this is the best error we have found so far, store the feature as best_feature and the error as best_error\n if error < best_error:\n best_feature = feature\n best_error = error\n \n return best_feature # Return the best feature we found",
"_____no_output_____"
]
],
[
[
"## Building the tree\n\nWith the above functions implemented correctly, we are now ready to build our decision tree. Each node in the decision tree is represented as a dictionary which contains the following keys and possible values:",
"_____no_output_____"
],
[
"### 10. First, we will write a function that creates a leaf node given a set of target values. \nYour code should be analogous to",
"_____no_output_____"
]
],
[
[
"def create_leaf(target_values): \n # Create a leaf node\n leaf = {'splitting_feature' : None,\n 'left' : None,\n 'right' : None,\n 'is_leaf': True } ## YOUR CODE HERE \n \n # Count the number of data points that are +1 and -1 in this node.\n num_ones = len(target_values[target_values == +1])\n num_minus_ones = len(target_values[target_values == -1]) \n\n # For the leaf node, set the prediction to be the majority class.\n # Store the predicted class (1 or -1) in leaf['prediction']\n if num_ones > num_minus_ones:\n leaf['prediction'] = 1 ## YOUR CODE HERE\n else:\n leaf['prediction'] = -1 ## YOUR CODE HERE \n\n # Return the leaf node\n return leaf ",
"_____no_output_____"
]
],
[
[
"11. Now, we will provide a Python skeleton of the learning algorithm. Note that this code is not complete; it needs to be completed by you if you are using Python. Otherwise, your code should be analogous to\n1. Stopping condition 1: All data points in a node are from the same class.\n1. Stopping condition 2: No more features to split on.\n1. Additional stopping condition: In addition to the above two stopping conditions covered in lecture, in this assignment we will also consider a stopping condition based on the max_depth of the tree. By not letting the tree grow too deep, we will save computational effort in the learning process.\n\n\n",
"_____no_output_____"
]
],
[
[
"def decision_tree_create(data, features, target, current_depth = 0, max_depth = 10):\n remaining_features = features[:] # Make a copy of the features.\n \n target_values = data[target]\n print (\"--------------------------------------------------------------------\")\n print (\"Subtree, depth = %s (%s data points).\" % (current_depth, len(target_values)))\n \n\n # Stopping condition 1\n # (Check if there are mistakes at current node.\n # Recall you wrote a function intermediate_node_num_mistakes to compute this.)\n if intermediate_node_num_mistakes(target_values) == 0: ## YOUR CODE HERE\n print (\"No classification error in the node. Stopping for now.\" ) \n # If not mistakes at current node, make current node a leaf node\n return create_leaf(target_values)\n \n # Stopping condition 2 (check if there are remaining features to consider splitting on)\n if remaining_features == []: ## YOUR CODE HERE\n print (\"No remaining features. Stopping for now.\") \n # If there are no remaining features to consider, make current node a leaf node\n return create_leaf(target_values) \n \n # Additional stopping condition (limit tree depth)\n if current_depth >= max_depth: ## YOUR CODE HERE\n print (\"Reached maximum depth. Stopping for now.\")\n # If the max tree depth has been reached, make current node a leaf node\n return create_leaf(target_values)\n\n # Find the best splitting feature (recall the function best_splitting_feature implemented above)\n ## YOUR CODE HERE\n splitting_feature = best_splitting_feature(data, remaining_features, target)\n \n # Split on the best feature that we found. \n left_split = data[data[splitting_feature] == 0]\n right_split = data[data[splitting_feature] == 1] ## YOUR CODE HERE\n remaining_features.remove(splitting_feature)\n print (\"Split on feature %s. (%s, %s)\" % (\\\n splitting_feature, len(left_split), len(right_split)))\n \n # Create a leaf node if the split is \"perfect\"\n if len(left_split) == len(data):\n print (\"Creating leaf node.\")\n return create_leaf(left_split[target])\n if len(right_split) == len(data):\n print (\"Creating leaf node.\")\n ## YOUR CODE HERE\n return create_leaf(right_split[target])\n \n # Repeat (recurse) on left and right subtrees\n left_tree = decision_tree_create(left_split, remaining_features, target, current_depth + 1, max_depth) \n ## YOUR CODE HERE\n right_tree = decision_tree_create(right_split, remaining_features, target, current_depth + 1, max_depth)\n\n return {'is_leaf' : False, \n 'prediction' : None,\n 'splitting_feature': splitting_feature,\n 'left' : left_tree, \n 'right' : right_tree}",
"_____no_output_____"
]
],
[
[
"12. Train a tree model on the train_data. Limit the depth to 6 (max_depth = 6) to make sure the algorithm doesn't run for too long. Call this tree my_decision_tree. Warning: The tree may take 1-2 minutes to learn.",
"_____no_output_____"
]
],
[
[
"input_features = train_data.columns\nprint (list(input_features))",
"['safe_loans', 'grade_A', 'grade_B', 'grade_C', 'grade_D', 'grade_E', 'grade_F', 'grade_G', 'term_ 36 months', 'term_ 60 months', 'home_ownership_MORTGAGE', 'home_ownership_OTHER', 'home_ownership_OWN', 'home_ownership_RENT', 'emp_length_1 year', 'emp_length_10+ years', 'emp_length_2 years', 'emp_length_3 years', 'emp_length_4 years', 'emp_length_5 years', 'emp_length_6 years', 'emp_length_7 years', 'emp_length_8 years', 'emp_length_9 years', 'emp_length_< 1 year']\n"
],
[
"feature_list = list(train_data.columns)\nfeature_list.remove('safe_loans')\n",
"_____no_output_____"
],
[
"my_decision_tree = decision_tree_create(train_data, feature_list, 'safe_loans', current_depth = 0, max_depth = 6)",
"--------------------------------------------------------------------\nSubtree, depth = 0 (37224 data points).\nSplit on feature term_ 36 months. (9223, 28001)\n--------------------------------------------------------------------\nSubtree, depth = 1 (9223 data points).\nSplit on feature grade_A. (9122, 101)\n--------------------------------------------------------------------\nSubtree, depth = 2 (9122 data points).\nSplit on feature grade_B. (8074, 1048)\n--------------------------------------------------------------------\nSubtree, depth = 3 (8074 data points).\nSplit on feature grade_C. (5884, 2190)\n--------------------------------------------------------------------\nSubtree, depth = 4 (5884 data points).\nSplit on feature grade_D. (3826, 2058)\n--------------------------------------------------------------------\nSubtree, depth = 5 (3826 data points).\nSplit on feature grade_E. (1693, 2133)\n--------------------------------------------------------------------\nSubtree, depth = 6 (1693 data points).\nReached maximum depth. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 6 (2133 data points).\nReached maximum depth. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 5 (2058 data points).\nSplit on feature grade_E. (2058, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 4 (2190 data points).\nSplit on feature grade_D. (2190, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 3 (1048 data points).\nSplit on feature emp_length_5 years. (969, 79)\n--------------------------------------------------------------------\nSubtree, depth = 4 (969 data points).\nSplit on feature grade_C. (969, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 4 (79 data points).\nSplit on feature home_ownership_MORTGAGE. (34, 45)\n--------------------------------------------------------------------\nSubtree, depth = 5 (34 data points).\nSplit on feature grade_C. (34, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 5 (45 data points).\nSplit on feature grade_C. (45, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 2 (101 data points).\nSplit on feature emp_length_< 1 year. (90, 11)\n--------------------------------------------------------------------\nSubtree, depth = 3 (90 data points).\nSplit on feature grade_B. (90, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 3 (11 data points).\nSplit on feature grade_B. (11, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 1 (28001 data points).\nSplit on feature grade_D. (23300, 4701)\n--------------------------------------------------------------------\nSubtree, depth = 2 (23300 data points).\nSplit on feature grade_E. (22024, 1276)\n--------------------------------------------------------------------\nSubtree, depth = 3 (22024 data points).\nSplit on feature grade_F. (21666, 358)\n--------------------------------------------------------------------\nSubtree, depth = 4 (21666 data points).\nSplit on feature grade_C. (14444, 7222)\n--------------------------------------------------------------------\nSubtree, depth = 5 (14444 data points).\nSplit on feature grade_G. (14347, 97)\n--------------------------------------------------------------------\nSubtree, depth = 6 (14347 data points).\nReached maximum depth. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 6 (97 data points).\nReached maximum depth. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 5 (7222 data points).\nSplit on feature home_ownership_MORTGAGE. (4303, 2919)\n--------------------------------------------------------------------\nSubtree, depth = 6 (4303 data points).\nReached maximum depth. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 6 (2919 data points).\nReached maximum depth. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 4 (358 data points).\nSplit on feature emp_length_8 years. (347, 11)\n--------------------------------------------------------------------\nSubtree, depth = 5 (347 data points).\nSplit on feature grade_A. (347, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 5 (11 data points).\nSplit on feature home_ownership_OWN. (9, 2)\n--------------------------------------------------------------------\nSubtree, depth = 6 (9 data points).\nReached maximum depth. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 6 (2 data points).\nNo classification error in the node. Stopping for now.\n--------------------------------------------------------------------\nSubtree, depth = 3 (1276 data points).\nSplit on feature grade_A. (1276, 0)\nCreating leaf node.\n--------------------------------------------------------------------\nSubtree, depth = 2 (4701 data points).\nSplit on feature grade_A. (4701, 0)\nCreating leaf node.\n"
]
],
[
[
"#### Making predictions with a decision tree",
"_____no_output_____"
],
[
"13. As discussed in the lecture, we can make predictions from the decision tree with a simple recursive function. Write a function called classify, which takes in a learned tree and a test point x to classify. Include an option annotate that describes the prediction path when set to True. Your code should be analogous to",
"_____no_output_____"
]
],
[
[
"def classify(tree, x, annotate = False):\n # if the node is a leaf node.\n if tree['is_leaf']:\n if annotate:\n print (\"At leaf, predicting %s\" % tree['prediction'])\n return tree['prediction']\n else:\n # split on feature.\n split_feature_value = x[tree['splitting_feature']]\n if annotate:\n print (\"Split on %s = %s\" % (tree['splitting_feature'], split_feature_value))\n if split_feature_value == 0:\n return classify(tree['left'], x, annotate)\n else:\n return classify(tree['right'], x, annotate)",
"_____no_output_____"
]
],
[
[
"### 14. Now, let's consider the first example of the test set and see what my_decision_tree model predicts for this data point.",
"_____no_output_____"
]
],
[
[
"print (test_data.iloc[0])\nprint ('Predicted class: %s ' % classify(my_decision_tree, test_data.iloc[0]))",
"safe_loans -1\ngrade_A 0\ngrade_B 0\ngrade_C 0\ngrade_D 1\ngrade_E 0\ngrade_F 0\ngrade_G 0\nterm_ 36 months 0\nterm_ 60 months 1\nhome_ownership_MORTGAGE 0\nhome_ownership_OTHER 0\nhome_ownership_OWN 0\nhome_ownership_RENT 1\nemp_length_1 year 0\nemp_length_10+ years 0\nemp_length_2 years 1\nemp_length_3 years 0\nemp_length_4 years 0\nemp_length_5 years 0\nemp_length_6 years 0\nemp_length_7 years 0\nemp_length_8 years 0\nemp_length_9 years 0\nemp_length_< 1 year 0\nName: 24, dtype: int64\nPredicted class: -1 \n"
]
],
[
[
"### 15. Let's add some annotations to our prediction to see what the prediction path was that lead to this predicted class:",
"_____no_output_____"
]
],
[
[
"classify(my_decision_tree, test_data.iloc[0], annotate=True)",
"Split on term_ 36 months = 0\nSplit on grade_A = 0\nSplit on grade_B = 0\nSplit on grade_C = 0\nSplit on grade_D = 1\nAt leaf, predicting -1\n"
]
],
[
[
"## Quiz question: \nWhat was the feature that my_decision_tree first split on while making the prediction for test_data[0]?\n\n## Quiz question: \nWhat was the first feature that lead to a right split of test_data[0]?\n\n## Quiz question:\nWhat was the last feature split on before reaching a leaf node for test_data[0]?",
"_____no_output_____"
],
[
"## Answer: \nterm_36 months\n## Answer: \ngrade_D\n## Answer: \ngrade_D",
"_____no_output_____"
],
[
"## Evaluating your decision tree",
"_____no_output_____"
],
[
"### 16. Now, we will write a function to evaluate a decision tree by computing the classification error of the tree on the given dataset. Write a function called evaluate_classification_error that takes in as input:\n\n- tree (as described above)\n- data (a data frame of data points)\n\nThis function should return a prediction (class label) for each row in data using the decision tree. Your code should be analogous to",
"_____no_output_____"
]
],
[
[
"def evaluate_classification_error(tree, data):\n # Apply the classify(tree, x) to each row in your data\n prediction = data.apply(lambda x: classify(tree, x), axis=1)\n \n # Once you've made the predictions, calculate the classification error and return it\n ## YOUR CODE HERE\n \n return (data['safe_loans'] != np.array(prediction)).values.sum() *1. / len(data)",
"_____no_output_____"
]
],
[
[
"### 17. Now, use this function to evaluate the classification error on the test set.",
"_____no_output_____"
]
],
[
[
"evaluate_classification_error(my_decision_tree, test_data)",
"_____no_output_____"
]
],
[
[
"## Quiz Question: \nRounded to 2nd decimal point, what is the classification error of my_decision_tree on the test_data?",
"_____no_output_____"
],
[
"## Answer:\n0.38",
"_____no_output_____"
],
[
"## Printing out a decision stump",
"_____no_output_____"
],
[
"### 18. As discussed in the lecture, we can print out a single decision stump (printing out the entire tree is left as an exercise to the curious reader). Here we provide Python code to visualize a decision stump. If you are using different software, make sure your code is analogous to:\n\n",
"_____no_output_____"
]
],
[
[
"def print_stump(tree, name = 'root'):\n split_name = tree['splitting_feature'] # split_name is something like 'term. 36 months'\n if split_name is None:\n print (\"(leaf, label: %s)\" % tree['prediction'])\n return None\n split_feature, split_value = split_name.split('_',1)\n print (' %s' % name)\n print( ' |---------------|----------------|')\n print (' | |')\n print (' | |')\n print (' | |')\n print (' [{0} == 0] [{0} == 1] '.format(split_name))\n print (' | |')\n print (' | |')\n print (' | |')\n print (' (%s) (%s)' \\\n % (('leaf, label: ' + str(tree['left']['prediction']) if tree['left']['is_leaf'] else 'subtree'),\n ('leaf, label: ' + str(tree['right']['prediction']) if tree['right']['is_leaf'] else 'subtree')))",
"_____no_output_____"
]
],
[
[
"### 19. Using this function, we can print out the root of our decision tree:",
"_____no_output_____"
]
],
[
[
"print_stump(my_decision_tree)",
" root\n |---------------|----------------|\n | |\n | |\n | |\n [term_ 36 months == 0] [term_ 36 months == 1] \n | |\n | |\n | |\n (subtree) (subtree)\n"
]
],
[
[
"## Quiz Question: \nWhat is the feature that is used for the split at the root node?",
"_____no_output_____"
],
[
"## Answer:\nterm_ 36 months",
"_____no_output_____"
],
[
"## Exploring the intermediate left subtree\nThe tree is a recursive dictionary, so we do have access to all the nodes! We can use\n\n- my_decision_tree['left'] to go left\n- my_decision_tree['right'] to go right",
"_____no_output_____"
],
[
"### 20. We can print out the left subtree by running the code",
"_____no_output_____"
]
],
[
[
"print_stump(my_decision_tree['left'], my_decision_tree['splitting_feature'])",
" term_ 36 months\n |---------------|----------------|\n | |\n | |\n | |\n [grade_A == 0] [grade_A == 1] \n | |\n | |\n | |\n (subtree) (subtree)\n"
],
[
"print_stump(my_decision_tree['left']['left'], my_decision_tree['left']['splitting_feature'])",
" grade_A\n |---------------|----------------|\n | |\n | |\n | |\n [grade_B == 0] [grade_B == 1] \n | |\n | |\n | |\n (subtree) (subtree)\n"
],
[
"print_stump(my_decision_tree['right'], my_decision_tree['splitting_feature'])",
" term_ 36 months\n |---------------|----------------|\n | |\n | |\n | |\n [grade_D == 0] [grade_D == 1] \n | |\n | |\n | |\n (subtree) (leaf, label: -1)\n"
],
[
"print_stump(my_decision_tree['right']['right'], my_decision_tree['right']['splitting_feature'])",
"(leaf, label: -1)\n"
]
],
[
[
"## Quiz question: \nWhat is the path of the first 3 feature splits considered along the left-most branch of my_decision_tree?\n\n## Quiz question: \nWhat is the path of the first 3 feature splits considered along the right-most branch of my_decision_tree?",
"_____no_output_____"
],
[
"## Answer\n- term_ 36 months\n- grade_A\n- grade_B\n\n## Answer\n- term_ 36 months\n- grade_D\n- leaf",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a04a6620fd5c1ae5ff124b9253ca2c49de5e664
| 5,910 |
ipynb
|
Jupyter Notebook
|
notebooks/Exercise 6.ipynb
|
livinNector/artificial-intelligence-lab
|
90eed0b76111af1a07724e1d43b6855e5d436de3
|
[
"MIT"
] | null | null | null |
notebooks/Exercise 6.ipynb
|
livinNector/artificial-intelligence-lab
|
90eed0b76111af1a07724e1d43b6855e5d436de3
|
[
"MIT"
] | null | null | null |
notebooks/Exercise 6.ipynb
|
livinNector/artificial-intelligence-lab
|
90eed0b76111af1a07724e1d43b6855e5d436de3
|
[
"MIT"
] | null | null | null | 29.402985 | 90 | 0.492724 |
[
[
[
"# Exercise 6 - Statistical Reasoning - ‘k’ Nearest Neighbour",
"_____no_output_____"
],
[
"### AIM:\nTo write a python program to implement the 'k' Nearest Neighbour algorithm.\n\n### ALGORITHM :\n```\nAlgorithm euclidian_dist(p1,p2)\n Input : p1,p2 - points as Tuple()s\n Output : euclidian distance between the two points\n \n return sqrt(\n sum(\n List([(p1[i]-p2[i])^2 for i <- 0 to p1.length])\n )\n )\nend Algorithm\n\nAlgorithm KNN_classify(dataset,k,p)\n Input : dataset – Dict() with class labels as keys\n and data_points for the class as values.\n p - test point p(x,y),\n k - number of nearest neighbour.\n Output : predicted class of the test point \n \n dist=List([\n Tuple(euclidian_dist(test_point,data_point),class)\n for class in dataset\n for data_point in class\n ])\n dist = first k elements of sorted(dist,ascending)\n freqs = Dict(class:(freqency of class in dist) for class in data_set)\n return (class with max value in freqs)\nend Algorithm\n```",
"_____no_output_____"
],
[
"### SOURCE CODE :",
"_____no_output_____"
]
],
[
[
"from math import sqrt\ndef euclidian_dist(p1,p2):\n return sqrt(\n sum([(x1-x2)**2 for (x1,x2) in zip(p1,p2)])\n )\n\nclass KNNClassifier:\n def __init__(self,data_set,k=3,dist=euclidian_dist):\n self.data_set = data_set\n self.k = k\n self.dist = dist\n \n def classify(self,test_point):\n distances = sorted([ \n (self.dist(data_point,test_point),data_class)\n for data_class in self.data_set\n for data_point in self.data_set[data_class]\n ])[:self.k]\n freqs={data_class:0 for data_class in self.data_set}\n for (_,data_class) in distances:\n freqs[data_class]+=1\n return max(freqs,key = freqs.get)\n\nif __name__ == \"__main__\":\n data_set = {\n \"Class 1\":{(1,12),(2,5),(3,6),(3,10),(3.5,8),(2,11),(2,9),(1,7)},\n \"Class 2\":{(5,3),(3,2),(1.5,9),(7,2),(6,1),(3.8,1),(5.6,4),(4,2),(2,5)}\n }\n test_points= [(2.5,7),(7,2.5)]\n classifier = KNNClassifier(data_set,3)\n for test_point in test_points:\n print(\n f\"The given test point {test_point} is classified to:\",\n classifier.classify(test_point)\n )",
"The given test point (2.5, 7) is classified to: Class 1\nThe given test point (7, 2.5) is classified to: Class 2\n"
]
],
[
[
"### Alternative method using numpy:",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef euclidian_dist_np(p1,p2):\n return np.sqrt(np.sum((p1-p2)**2,axis=-1))\n\nclass KNNClassifier:\n def __init__(self,train_x,train_y,k=3,dist=euclidian_dist_np):\n self.train_x = train_x\n assert train_y.dtype == np.int, \"Class labels should be integers\"\n self.train_y = train_y\n self.k = k\n self.dist = dist\n \n def classify(self,test_point):\n k_nearest_classes = self.train_y[\n # indexes of k nearest neignbours\n np.argsort(self.dist(self.train_x,test_point))[:self.k] \n ]\n # maximum occuring class \n return np.bincount(k_nearest_classes).argmax() ",
"_____no_output_____"
],
[
"if __name__ == \"__main__\":\n dataset = np.loadtxt(\"knn_dataset.csv\",dtype=np.float,delimiter=\",\")\n train_x,train_y = dataset[:,:-1], dataset[:,-1].astype(np.int)\n test_x= np.array([[2.5,7],[7,2.5]])\n k = 3\n classifier = KNNClassifier(train_x,train_y,k=k)\n for test_vector in test_x:\n print(\n f\"The given test point {test_vector} is classified to Class :\",\n classifier.classify(test_vector)\n )",
"The given test point [2.5 7. ] is classified to Class : 1\nThe given test point [7. 2.5] is classified to Class : 2\n"
]
],
[
[
"---",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a04b4f1b59054774d67383f6906d2c64081454a
| 1,203 |
ipynb
|
Jupyter Notebook
|
Alzheimers Diseases/Untitled.ipynb
|
taareek/machine_learning
|
e9e7cf3636a3adf8572e69346c08e65cfcdb1100
|
[
"MIT"
] | null | null | null |
Alzheimers Diseases/Untitled.ipynb
|
taareek/machine_learning
|
e9e7cf3636a3adf8572e69346c08e65cfcdb1100
|
[
"MIT"
] | null | null | null |
Alzheimers Diseases/Untitled.ipynb
|
taareek/machine_learning
|
e9e7cf3636a3adf8572e69346c08e65cfcdb1100
|
[
"MIT"
] | null | null | null | 18.227273 | 53 | 0.492103 |
[
[
[
"import numpy as np\nimport h5py",
"_____no_output_____"
],
[
"with h5py.File('best_fit.hdf5', 'r') as hdf:\n ls = list((hdf.keys()))\n print(\"List of datasets: \\n\", ls)",
"List of datasets: \n ['model_weights', 'optimizer_weights']\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a04cb168f08a27eac004b16f0f2c896af65f9c2
| 39,322 |
ipynb
|
Jupyter Notebook
|
notebooks/01_Exploratory/output/1.3-rp-hcad-data-view-extra_features_20200721.ipynb
|
RafaelPinto/hcad_pred
|
ea795f7b4233484e1fa88225ff60dbfe2b98235b
|
[
"BSD-3-Clause"
] | 1 |
2021-01-08T18:57:47.000Z
|
2021-01-08T18:57:47.000Z
|
notebooks/01_Exploratory/output/1.3-rp-hcad-data-view-extra_features_20200721.ipynb
|
RafaelPinto/hcad_pred
|
ea795f7b4233484e1fa88225ff60dbfe2b98235b
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/01_Exploratory/output/1.3-rp-hcad-data-view-extra_features_20200721.ipynb
|
RafaelPinto/hcad_pred
|
ea795f7b4233484e1fa88225ff60dbfe2b98235b
|
[
"BSD-3-Clause"
] | null | null | null | 30.624611 | 250 | 0.438126 |
[
[
[
"# Find the comparables: extra_features.txt\n\nThe file `extra_features.txt` contains important property information like number and quality of pools, detached garages, outbuildings, canopies, and more. Let's load this file and grab a subset with the important columns to continue our study.",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"from pathlib import Path\nimport pickle\n\nimport pandas as pd\n\nfrom src.definitions import ROOT_DIR\nfrom src.data.utils import Table, save_pickle",
"_____no_output_____"
],
[
"extra_features_fn = ROOT_DIR / 'data/external/2016/Real_building_land/extra_features.txt'\nassert extra_features_fn.exists()",
"_____no_output_____"
],
[
"extra_features = Table(extra_features_fn, '2016')",
"_____no_output_____"
],
[
"extra_features.get_header()",
"_____no_output_____"
]
],
[
[
"# Load accounts of interest\nLet's remove the account numbers that don't meet free-standing single-family home criteria that we found while processing the `building_res.txt` file.",
"_____no_output_____"
]
],
[
[
"skiprows = extra_features.get_skiprows()",
"_____no_output_____"
],
[
"extra_features_df = extra_features.get_df(skiprows=skiprows)",
"_____no_output_____"
],
[
"extra_features_df.head()",
"_____no_output_____"
],
[
"extra_features_df.dscr.value_counts()",
"_____no_output_____"
]
],
[
[
"# Grab slice of the extra features of interest\nWith the value counts on the extra feature description performed above we can see that the majority of the features land in the top 6 categories. Let's filter out the rests of the columns.",
"_____no_output_____"
]
],
[
[
"cols = extra_features_df.dscr.value_counts().head(6).index",
"_____no_output_____"
],
[
"cond0 = extra_features_df['dscr'].isin(cols)\nextra_features_df = extra_features_df.loc[cond0, :]",
"_____no_output_____"
]
],
[
[
"# Build pivot tables for count and grade\nThere appear to be two important values related to each extra feature:count and grade. Let's build individual pivot tables for each and merge them before saving them out.",
"_____no_output_____"
]
],
[
[
"extra_features_pivot_count = extra_features_df.pivot_table(index='acct',\n columns='dscr',\n values='count',\n fill_value=0)",
"_____no_output_____"
],
[
"extra_features_pivot_count.head()",
"_____no_output_____"
],
[
"extra_features_pivot_grade = extra_features_df.pivot_table(index='acct',\n columns='dscr',\n values='grade')",
"_____no_output_____"
],
[
"extra_features_pivot_grade.head()",
"_____no_output_____"
],
[
"extra_features_count_grade = extra_features_pivot_count.merge(extra_features_pivot_grade,\n how='left',\n left_index=True,\n right_index=True,\n suffixes=('_count', '_grade'),\n validate='one_to_one')",
"_____no_output_____"
],
[
"extra_features_count_grade.head()",
"_____no_output_____"
],
[
"assert extra_features_count_grade.index.is_unique",
"_____no_output_____"
]
],
[
[
"add `acct` column to make easier the merging process ahead",
"_____no_output_____"
]
],
[
[
"extra_features_count_grade.reset_index(inplace=True)",
"_____no_output_____"
]
],
[
[
"# Export real_acct",
"_____no_output_____"
]
],
[
[
"save_fn = ROOT_DIR / 'data/raw/2016/extra_features_count_grade_comps.pickle'\nsave_pickle(extra_features_count_grade, save_fn)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a04cf36251de95e191adfecb8e30b63d8de4c4d
| 39,427 |
ipynb
|
Jupyter Notebook
|
tools/python_good_practices.ipynb
|
bpesquet/machine-learning-handbook
|
1a590073cf100a0473ec30c48b35054494a31fd9
|
[
"MIT"
] | 16 |
2018-12-08T17:48:47.000Z
|
2020-06-30T12:58:07.000Z
|
tools/python_good_practices.ipynb
|
bpesquet/machine-learning-handbook
|
1a590073cf100a0473ec30c48b35054494a31fd9
|
[
"MIT"
] | null | null | null |
tools/python_good_practices.ipynb
|
bpesquet/machine-learning-handbook
|
1a590073cf100a0473ec30c48b35054494a31fd9
|
[
"MIT"
] | 3 |
2019-04-20T23:48:07.000Z
|
2020-01-22T05:55:46.000Z
| 45.898719 | 17,201 | 0.731808 |
[
[
[
"# Python good practices",
"_____no_output_____"
],
[
"## Environment setup",
"_____no_output_____"
]
],
[
[
"!pip install papermill",
"_____no_output_____"
],
[
"import platform\n\nprint(f\"Python version: {platform.python_version()}\")\nassert platform.python_version_tuple() >= (\"3\", \"6\")\n\nimport os\nimport papermill as pm\n\nfrom IPython.display import YouTubeVideo",
"Python version: 3.7.5\n"
]
],
[
[
"## Writing pythonic code",
"_____no_output_____"
]
],
[
[
"import this",
"The Zen of Python, by Tim Peters\n\nBeautiful is better than ugly.\nExplicit is better than implicit.\nSimple is better than complex.\nComplex is better than complicated.\nFlat is better than nested.\nSparse is better than dense.\nReadability counts.\nSpecial cases aren't special enough to break the rules.\nAlthough practicality beats purity.\nErrors should never pass silently.\nUnless explicitly silenced.\nIn the face of ambiguity, refuse the temptation to guess.\nThere should be one-- and preferably only one --obvious way to do it.\nAlthough that way may not be obvious at first unless you're Dutch.\nNow is better than never.\nAlthough never is often better than *right* now.\nIf the implementation is hard to explain, it's a bad idea.\nIf the implementation is easy to explain, it may be a good idea.\nNamespaces are one honking great idea -- let's do more of those!\n"
]
],
[
[
"### What does \"Pythonic\" mean?\n\n- Python code is considered _pythonic_ if it:\n - conforms to the Python philosophy;\n - takes advantage of the language's specific features.\n- Pythonic code is nothing more than **idiomatic Python code** that strives to be clean, concise and readable.",
"_____no_output_____"
],
[
"### Example: swapping two variables",
"_____no_output_____"
]
],
[
[
"a = 3\nb = 2\n\n# Non-pythonic\ntmp = a\na = b\nb = tmp\n\n# Pythonic\na, b = b, a",
"_____no_output_____"
]
],
[
[
"### Example: iterating on a list",
"_____no_output_____"
]
],
[
[
"my_list = [\"a\", \"b\", \"c\"]\n\n\ndef do_something(item):\n # print(item)\n pass\n\n\n# Non-pythonic\ni = 0\nwhile i < len(my_list):\n do_something(my_list[i])\n i += 1\n\n# Still non-pythonic\nfor i in range(len(my_list)):\n do_something(my_list[i])\n\n# Pythonic\nfor item in my_list:\n do_something(item)",
"_____no_output_____"
]
],
[
[
"### Example: indexed traversal",
"_____no_output_____"
]
],
[
[
"my_list = [\"a\", \"b\", \"c\"]\n\n# Non-pythonic\nfor i in range(len(my_list)):\n print(i, \"->\", my_list[i])\n\n# Pythonic\nfor i, item in enumerate(my_list):\n print(i, \"->\", item)",
"0 -> a\n1 -> b\n2 -> c\n0 -> a\n1 -> b\n2 -> c\n"
]
],
[
[
"### Example: searching in a list",
"_____no_output_____"
]
],
[
[
"fruits = [\"apples\", \"oranges\", \"bananas\", \"grapes\"]\nfruit = \"cherries\"\n\n# Non-pythonic\nfound = False\nsize = len(fruits)\nfor i in range(0, size):\n if fruits[i] == fruit:\n found = True\n\n# Pythonic\nfound = fruit in fruits",
"_____no_output_____"
]
],
[
[
"### Example: generating a list\n\nThis feature is called [list comprehension](https://docs.python.org/3/tutorial/datastructures.html#list-comprehensions).",
"_____no_output_____"
]
],
[
[
"numbers = [1, 2, 3, 4, 5, 6]\n\n# Non-pythonic\ndoubles = []\nfor i in range(len(numbers)):\n if numbers[i] % 2 == 0:\n doubles.append(numbers[i] * 2)\n else:\n doubles.append(numbers[i])\n\n# Pythonic\ndoubles = [x * 2 if x % 2 == 0 else x for x in numbers]",
"_____no_output_____"
]
],
[
[
"### Code style\n\n- [PEP8](https://www.python.org/dev/peps/pep-0008/) is the official style guide for Python:\n - use 4 spaces for indentation;\n - define a maximum value for line length (around 80 characters);\n - organize imports at beginning of file;\n - surround binary operators with a single space on each side;\n - ...\n- Code style should be enforced upon creation by a tool like [black](https://github.com/psf/black).",
"_____no_output_____"
],
[
"### Beyond PEP8\n\nFocusing on style and PEP8-compliance might make you miss more fundamental code imperfections.",
"_____no_output_____"
]
],
[
[
"YouTubeVideo(\"wf-BqAjZb8M\")",
"_____no_output_____"
]
],
[
[
"### Docstrings\n\nA [docstring](https://www.python.org/dev/peps/pep-0257/) is a string literal that occurs as the first statement in a module, function, class, or method definition to document it.\n\nAll modules, classes, public methods and exported functions should include a docstring.",
"_____no_output_____"
]
],
[
[
"def complex(real=0.0, imag=0.0):\n \"\"\"Form a complex number.\n\n Keyword arguments:\n real -- the real part (default 0.0)\n imag -- the imaginary part (default 0.0)\n \"\"\"\n if imag == 0.0 and real == 0.0:\n return complex_zero",
"_____no_output_____"
]
],
[
[
"### Code linting\n\n- _Linting_ is the process of checking code for syntactical and stylistic problems before execution.\n- It is useful to catch errors and improve code quality in dynamically typed, interpreted languages, where there is no compiler.\n- Several linters exist in the Python ecosystem. The most commonly used is [pylint](https://pylint.org/).",
"_____no_output_____"
],
[
"### Type annotations\n\n- Added in Python 3.5, [type annotations](https://www.python.org/dev/peps/pep-0484/) allow to add type hints to code entities like variables or functions, bringing a statically typed flavour to the language.\n- [mypy](http://mypy-lang.org/) can automatically check the code for annotation correctness.",
"_____no_output_____"
]
],
[
[
"def greeting(name: str) -> str:\n return \"Hello \" + name\n\n\n# greeting('Alice') # OK\n# greeting(3) # mypy error: incompatible type \"int\"; expected \"str\"",
"_____no_output_____"
]
],
[
[
"### Unit tests\n\nUnit tests automate the testing of individual code elements like functions or methods, thus decreasing the risk of bugs and regressions.\n\nThey can be implemented in Python using tools like [unittest](https://docs.python.org/3/library/unittest.html) or [pytest](https://docs.pytest.org).",
"_____no_output_____"
]
],
[
[
"def inc(x):\n return x + 1\n\n\ndef test_answer():\n assert inc(3) == 5 # AssertionError: assert 4 == 5",
"_____no_output_____"
]
],
[
[
"## Packaging and dependency management",
"_____no_output_____"
],
[
"### Managing dependencies in Python\n\n- Most Python apps depend on third-party libraries and frameworks (NumPy, Flask, Requests...).\n- These tools may also have external dependencies, and so on.\n- **Dependency management** is necessary to prevent version conflicts and incompatibilities. it involves two things:\n - a way for the app to declare its dependencies;\n - a tool to resolve these dependencies and install compatible versions.",
"_____no_output_____"
],
[
"### Semantic versioning\n\n- Software versioning convention used in many ecosystems.\n- A version number comes as a suite of three digits `X.Y.Z`.\n - X = major version (potentially including breaking changes).\n - Y = minor version (only non-breaking changes).\n - Z = patch.\n- Digits are incremented as new versions are shipped.",
"_____no_output_____"
],
[
"### pip and requirements.txt\n\nA `requirements.txt` file is the most basic way of declaring dependencies in Python.\n\n```text\ncertifi>=2020.11.0\nchardet==4.0.0\nclick>=6.5.0, <7.1\ndownload==0.3.5\nFlask>=1.1.0\n```\n\nThe [pip](https://pypi.org/project/pip/) package installer can read this file and act accordingly, downloading dependencies from [PyPI](https://pypi.org/).\n\n```bash\npip install -r requirements.txt\n```",
"_____no_output_____"
],
[
"### Virtual environments\n\n- A **virtual environment** is an isolated Python environment where a project's dependencies are installed.\n- Using them prevents the risk of mixing dependencies required by different projects on the same machine.\n- Several tools exist to manage virtual environments in Python, for example [virtualenv](https://virtualenv.pypa.io) and [conda](https://docs.conda.io).",
"_____no_output_____"
],
[
"### conda and environment.yml\n\nInstalled as part of the [Anaconda](https://www.anaconda.com/) distribution, the [conda](https://docs.conda.io) package manager reads an `environment.yml` file to install the dependencies associated to a specific virtual environment.\n\n```yaml\nname: example-env\n\nchannels:\n - conda-forge\n - defaults\n\ndependencies:\n - python=3.7\n - matplotlib\n - numpy\n```",
"_____no_output_____"
],
[
"### Poetry\n\n[Poetry](https://python-poetry.org) is a recent packaging and dependency management tool for Python. It downloads packages from [PyPI](https://pypi.org/) by default.\n\n```bash\n# Create a new poetry-compliant project\npoetry new <project name>\n\n# Initialize an already existing project for Poetry\npoetry init\n\n# Install defined dependencies\npoetry install\n\n# Add a package to project dependencies and install it\npoetry add <package name>\n\n# Update dependencies to sync them with configuration file\npoetry update\n```",
"_____no_output_____"
],
[
"### Poetry and virtual environments\n\nBy default, Poetry creates a virtual environment for the configured project in a user-specific folder. A standard practice is to store it in the project's folder.\n\n```bash\n# Tell Poetry to store the environment in the local project folder\npoetry config virtualenvs.in-project true\n\n# Activate the environment\npoetry shell\n```",
"_____no_output_____"
],
[
"### The pyproject.toml file\n\nPoetry configuration file, soon-to-be standard for Python projects.\n\n```toml\n[tool.poetry]\nname = \"poetry example\"\nversion = \"0.1.0\"\ndescription = \"\"\n\n[tool.poetry.dependencies]\npython = \">=3.7.1,<3.10\"\njupyter = \"^1.0.0\"\nmatplotlib = \"^3.3.2\"\nsklearn = \"^0.0\"\npandas = \"^1.1.3\"\nipython = \"^7.0.0\"\n\n[tool.poetry.dev-dependencies]\npytest = \"^6.1.1\"\n```",
"_____no_output_____"
],
[
"### Caret requirements\n\nOffers a way to precisely define dependency versions.\n\n| Requirement | Versions allowed |\n| :---------: | :--------------: |\n| ^1.2.3 | >=1.2.3 <2.0.0 |\n| ^1.2 | >=1.2.0 <2.0.0 |\n| ~1.2.3 | >=1.2.3 <1.3.0 |\n| ~1.2 | >=1.2.0 <1.3.0 |\n| 1.2.3 | 1.2.3 only |",
"_____no_output_____"
],
[
"### The poetry.lock file\n\n- The first time Poetry install dependencies, it creates a `poetry.lock` file that contains the exact versions of all installed packages.\n- Subsequent installs will use these exact versions to ensure consistency.\n- Removing this file and running another Poetry install will fetch the latest matching versions.",
"_____no_output_____"
],
[
"## Working with notebooks",
"_____no_output_____"
],
[
"### Advantages of Jupyter notebooks\n\n- Standard format for mixing text, images and (executable) code.\n- Open source and platform-independant.\n- Useful for experimenting and prototyping.\n- Growing ecosystem of [extensions](https://tljh.jupyter.org/en/latest/howto/admin/enable-extensions.html) for various purposes and cloud hosting solutions ([Colaboratory](https://colab.research.google.com/), [AI notebooks](https://www.ovhcloud.com/en/public-cloud/ai-notebook/)...).\n- Integration with tools like [Visual Studio Code](https://code.visualstudio.com/docs/datascience/jupyter-notebooks).",
"_____no_output_____"
],
[
"### Drawbacks of Jupyter notebooks\n\n- Arbitrary execution order of cells can cause confusing errors.\n- Notebooks don't encourage good programming habits like modularization, linting and tests.\n- Being JSON-based, their versioning is more difficult than for plain text files.\n- Dependency management is also difficult, thus hindering reproducibility.",
"_____no_output_____"
],
[
"### Collaborating with notebooks\n\nA common solution for sharing notebooks between a team is to use [Jupytext](https://jupytext.readthedocs.io). This tool can associate an `.ipynb` file with a Python file to facilitate collaboration and version control.\n\n[](https://jupytext.readthedocs.io/en/latest/examples.html)",
"_____no_output_____"
],
[
"### Code organization\n\nMonolithic notebooks can grow over time and become hard to understand and maintain.\n\nJust like in a traditional software project, it is possible to split them into separate parts, thus following the [separation of concerns](https://en.wikipedia.org/wiki/Separation_of_concerns) design principle.\n\nCode can be splitted into several sub-notebooks and/or external Python files. The latter facilitates unit testing and version control.",
"_____no_output_____"
],
[
"### Notebook workflow\n\nTools like [papermill](https://papermill.readthedocs.io) can orchestrate the execution of several notebooks in a row. External parameters can be passed to notebooks, and the runtime flow can depend on the execution results of each notebook.",
"_____no_output_____"
]
],
[
[
"# Doesn't work on Google Colaboratory. Workaround here: \n# https://colab.research.google.com/github/rjdoubleu/Colab-Papermill-Patch/blob/master/Colab-Papermill-Driver.ipynb\nnotebook_dir = \"./papermill\"\nresult = pm.execute_notebook(\n os.path.join(notebook_dir, \"simple_input.ipynb\"),\n os.path.join(notebook_dir, \"simple_output.ipynb\"),\n parameters={\"msg\": \"Hello\"},\n)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4a04d3a770fbb713b17bf8c0718ea06a338a125a
| 767,729 |
ipynb
|
Jupyter Notebook
|
Santander Customer Transaction Prediction/code/Kaggle-Santander-master/eda/01 EDA - Outlier Handling.ipynb
|
choco9966/kaggle
|
253c089625c67f34dc8868d97842ecf9a479d617
|
[
"MIT"
] | 36 |
2019-12-26T13:07:44.000Z
|
2022-03-27T09:59:19.000Z
|
Santander Customer Transaction Prediction/code/Kaggle-Santander-master/eda/01 EDA - Outlier Handling.ipynb
|
min0355/Kaggle
|
f4a3b931e72c65cf398afb66997f9e155a52028e
|
[
"MIT"
] | null | null | null |
Santander Customer Transaction Prediction/code/Kaggle-Santander-master/eda/01 EDA - Outlier Handling.ipynb
|
min0355/Kaggle
|
f4a3b931e72c65cf398afb66997f9e155a52028e
|
[
"MIT"
] | 8 |
2020-04-15T10:26:11.000Z
|
2021-04-05T11:27:54.000Z
| 149.80078 | 564,756 | 0.806755 |
[
[
[
"# Module",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport warnings\nimport gc\nfrom tqdm import tqdm_notebook as tqdm\nimport lightgbm as lgb\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.preprocessing import LabelEncoder, OneHotEncoder\nfrom sklearn.model_selection import StratifiedKFold\nfrom sklearn.model_selection import train_test_split\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom datetime import datetime\nfrom sklearn.metrics import roc_auc_score\nwarnings.filterwarnings(\"ignore\")\ngc.enable()",
"_____no_output_____"
],
[
"pd.set_option('max_rows', 500)\npd.set_option('max_colwidth', 500)\npd.set_option('max_columns', 500)",
"_____no_output_____"
]
],
[
[
"# Load Data",
"_____no_output_____"
]
],
[
[
"train_raw = pd.read_csv('./data/train.csv')\ntest_raw = pd.read_csv('./data/test.csv')\ntrain_raw.shape, test_raw.shape",
"_____no_output_____"
],
[
"del train, test, clf, data\ngc.collect()",
"_____no_output_____"
],
[
"train = train_raw.copy()\ntest = test_raw.copy()",
"_____no_output_____"
],
[
"col_list = train.columns[2:]",
"_____no_output_____"
],
[
"train_0 = train[train.target == 0]\ntrain_1 = train[train.target == 1]",
"_____no_output_____"
],
[
"pb_idx = np.load('./data_temp/public_LB.npy')\npv_idx = np.load('./data_temp/private_LB.npy')",
"_____no_output_____"
],
[
"test_pb = test.iloc[pb_idx].sort_index().copy()\ntest_pv = test.iloc[pv_idx].sort_index().copy()\n\ntest_real = test_pb.append(test_pv)",
"_____no_output_____"
],
[
"data = train.append(test_real)[['ID_code', 'target'] + col_list.tolist()]",
"_____no_output_____"
]
],
[
[
"# Extract Unique Value in All Data",
"_____no_output_____"
],
[
"## filter",
"_____no_output_____"
]
],
[
[
"# unique_df = data[['ID_code']]\ncon_df = data[['ID_code']]\ncon1_df = data[['ID_code']]\ncon2_df = data[['ID_code']]\ncon3_df = data[['ID_code']]\ncon4_df = data[['ID_code']]\ncon5_df = data[['ID_code']]\ncon6_df = data[['ID_code']]\ncon7_df = data[['ID_code']]\ncon8_df = data[['ID_code']]",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n# unique_df[col] = data[col].map(((data[col].value_counts() == 1) * 1).to_dict())\n con_df[col] = data[col].map((~(data[col].value_counts() == 1) * 1).to_dict())\n con1_df[col] = data[col].map(((data[col].value_counts() == 1) * 1).to_dict())\n con2_df[col] = data[col].map(((data[col].value_counts() == 2) * 1).to_dict())\n con3_df[col] = data[col].map(((data[col].value_counts() == 3) * 1).to_dict())\n con4_df[col] = data[col].map(((data[col].value_counts() == 4) * 1).to_dict())\n con5_df[col] = data[col].map(((data[col].value_counts() == 5) * 1).to_dict())\n con6_df[col] = data[col].map(((data[col].value_counts() == 6) * 1).to_dict())\n con7_df[col] = data[col].map(((data[col].value_counts() == 7) * 1).to_dict())\n con8_df[col] = data[col].map(((data[col].value_counts() == 8) * 1).to_dict())",
"_____no_output_____"
],
[
"order_df = data[['ID_code']]\nfor col in tqdm(col_list):\n temp = data[col].value_counts().sort_index().to_frame()\n order = [0]\n \n for v in temp.iterrows():\n order.append(order[-1] + v[1].values[0])\n \n temp[col] = order[:-1]\n temp = temp.to_dict()[col]\n\n order_df[col] = data[col].map(temp)",
"_____no_output_____"
]
],
[
[
"## make data",
"_____no_output_____"
]
],
[
[
"for col in tqdm(col_list):\n# data[col + '_unique'] = data[col] * unique_df[col]\n data[col + '_con'] = data[col] * con_df[col]\n data[col + '_con1'] = data[col] * con1_df[col]\n data[col + '_con2'] = data[col] * con2_df[col]\n data[col + '_con3'] = data[col] * con3_df[col]\n data[col + '_con4'] = data[col] * con4_df[col]\n data[col + '_con5'] = data[col] * con5_df[col]\n data[col + '_con6'] = data[col] * con6_df[col]\n data[col + '_con7'] = data[col] * con7_df[col]\n data[col + '_con8'] = data[col] * con8_df[col]",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n# data.loc[data[col + '_unique']==0, col + '_unique'] = np.nan\n data.loc[data[col + '_con']==0, col + '_con'] = np.nan\n data.loc[data[col + '_con1']==0, col + '_con1'] = np.nan\n data.loc[data[col + '_con2']==0, col + '_con2'] = np.nan\n data.loc[data[col + '_con3']==0, col + '_con3'] = np.nan\n data.loc[data[col + '_con4']==0, col + '_con4'] = np.nan\n data.loc[data[col + '_con5']==0, col + '_con5'] = np.nan\n data.loc[data[col + '_con6']==0, col + '_con6'] = np.nan\n data.loc[data[col + '_con7']==0, col + '_con7'] = np.nan\n data.loc[data[col + '_con8']==0, col + '_con8'] = np.nan",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n data[col + '_con_multi_counts'] = data[col + '_con'] * data[col].map(data[col].value_counts().to_dict())",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n data[col + '_con_order'] = con_df[col] * order_df[col]",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n data.loc[data[col + '_con_order']==0, col + '_con_order'] = np.nan",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n data[col + '_unique_order'] = unique_df[col] * order_df[col]",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n data.loc[data[col + '_unique_order']==0, col + '_unique_order'] = np.nan",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
]
],
[
[
"# Model",
"_____no_output_____"
]
],
[
[
"train = data[~data.target.isna()]\ntest = data[data.target.isna()]",
"_____no_output_____"
],
[
"target = train['target']",
"_____no_output_____"
],
[
"param = {\n 'bagging_freq': 5,\n 'bagging_fraction': 0.335,\n 'boost_from_average': False,\n 'boost': 'gbdt',\n 'feature_fraction_seed': 47,\n 'feature_fraction': 0.041,\n 'learning_rate': 0.01,\n 'max_depth': -1,\n 'metric':'auc',\n 'min_data_in_leaf': 80,\n 'min_sum_hessian_in_leaf': 10.0,\n 'num_leaves': 2,\n 'num_threads': 8,\n 'tree_learner': 'serial',\n 'objective': 'binary', \n 'verbosity': -1,\n 'num_threads': 8\n}",
"_____no_output_____"
]
],
[
[
"* 0.92288\n* 0.92308",
"_____no_output_____"
]
],
[
[
"folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)\n\noof_lgb = np.zeros(len(train))\npredictions_lgb = np.zeros(len(test))\nfeature_importance = pd.DataFrame()\n\ntrain_columns = [c for c in train.columns if c not in ['ID_code', 'target']]\n\nfor fold_, (trn_idx, val_idx) in enumerate(folds.split(train, target.values)): \n print(\"fold n°{}\".format(fold_))\n trn_data = lgb.Dataset(train.iloc[trn_idx][train_columns], label=target.iloc[trn_idx])\n val_data = lgb.Dataset(train.iloc[val_idx][train_columns], label=target.iloc[val_idx])\n\n num_round = 500000\n clf = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=5000, early_stopping_rounds = 3500)\n oof_lgb[val_idx] = clf.predict(train.iloc[val_idx][train_columns], num_iteration=clf.best_iteration)\n predictions_lgb += clf.predict(test[train_columns], num_iteration=clf.best_iteration) / folds.n_splits\n\n fold_importance = pd.DataFrame()\n fold_importance[\"Feature\"] = train_columns\n fold_importance[\"importance\"] = clf.feature_importance()\n fold_importance[\"fold\"] = fold_ + 1\n feature_importance = pd.concat([feature_importance, fold_importance], axis=0)\n \n print(\"CV score: {:<8.5f}\".format(roc_auc_score(target.values[val_idx], oof_lgb[val_idx])))\n \nprint(\"CV score: {:<8.5f}\".format(roc_auc_score(target.values, oof_lgb)))",
"fold n°0\nTraining until validation scores don't improve for 3500 rounds.\n[5000]\ttraining's auc: 0.891468\tvalid_1's auc: 0.883466\n[10000]\ttraining's auc: 0.913674\tvalid_1's auc: 0.904584\n[15000]\ttraining's auc: 0.923286\tvalid_1's auc: 0.912807\n[20000]\ttraining's auc: 0.928619\tvalid_1's auc: 0.916937\n[25000]\ttraining's auc: 0.932244\tvalid_1's auc: 0.919205\n[30000]\ttraining's auc: 0.934968\tvalid_1's auc: 0.920512\n[35000]\ttraining's auc: 0.937194\tvalid_1's auc: 0.921131\n[40000]\ttraining's auc: 0.939109\tvalid_1's auc: 0.921455\n[45000]\ttraining's auc: 0.940843\tvalid_1's auc: 0.921573\nEarly stopping, best iteration is:\n[43944]\ttraining's auc: 0.940483\tvalid_1's auc: 0.921616\nCV score: 0.92162 \nfold n°1\nTraining until validation scores don't improve for 3500 rounds.\n[5000]\ttraining's auc: 0.891659\tvalid_1's auc: 0.886056\n[10000]\ttraining's auc: 0.913253\tvalid_1's auc: 0.906328\n[15000]\ttraining's auc: 0.923024\tvalid_1's auc: 0.914419\n[20000]\ttraining's auc: 0.928439\tvalid_1's auc: 0.918269\n[25000]\ttraining's auc: 0.932116\tvalid_1's auc: 0.919993\n[30000]\ttraining's auc: 0.934824\tvalid_1's auc: 0.92092\n[35000]\ttraining's auc: 0.937148\tvalid_1's auc: 0.92127\n[40000]\ttraining's auc: 0.939116\tvalid_1's auc: 0.921483\nEarly stopping, best iteration is:\n[41024]\ttraining's auc: 0.939495\tvalid_1's auc: 0.921533\nCV score: 0.92153 \nfold n°2\nTraining until validation scores don't improve for 3500 rounds.\n[5000]\ttraining's auc: 0.889786\tvalid_1's auc: 0.888447\n[10000]\ttraining's auc: 0.912355\tvalid_1's auc: 0.910653\n[15000]\ttraining's auc: 0.921764\tvalid_1's auc: 0.919131\n[20000]\ttraining's auc: 0.926962\tvalid_1's auc: 0.923309\n[25000]\ttraining's auc: 0.930543\tvalid_1's auc: 0.925682\n[30000]\ttraining's auc: 0.93326\tvalid_1's auc: 0.92697\n[35000]\ttraining's auc: 0.935591\tvalid_1's auc: 0.927529\n[40000]\ttraining's auc: 0.937607\tvalid_1's auc: 0.927816\n[45000]\ttraining's auc: 0.939406\tvalid_1's auc: 0.927934\nEarly stopping, best iteration is:\n[44869]\ttraining's auc: 0.939367\tvalid_1's auc: 0.927952\nCV score: 0.92795 \nfold n°3\nTraining until validation scores don't improve for 3500 rounds.\n[5000]\ttraining's auc: 0.890822\tvalid_1's auc: 0.880974\n[10000]\ttraining's auc: 0.913606\tvalid_1's auc: 0.903442\n[15000]\ttraining's auc: 0.923032\tvalid_1's auc: 0.912273\n[20000]\ttraining's auc: 0.928358\tvalid_1's auc: 0.91666\n[25000]\ttraining's auc: 0.931955\tvalid_1's auc: 0.919231\n[30000]\ttraining's auc: 0.93467\tvalid_1's auc: 0.920659\n[35000]\ttraining's auc: 0.936923\tvalid_1's auc: 0.921509\n[40000]\ttraining's auc: 0.938861\tvalid_1's auc: 0.921954\n[45000]\ttraining's auc: 0.940593\tvalid_1's auc: 0.922133\n[50000]\ttraining's auc: 0.942127\tvalid_1's auc: 0.922127\nEarly stopping, best iteration is:\n[47823]\ttraining's auc: 0.941464\tvalid_1's auc: 0.92219\nCV score: 0.92219 \nfold n°4\nTraining until validation scores don't improve for 3500 rounds.\n[5000]\ttraining's auc: 0.892877\tvalid_1's auc: 0.881121\n[10000]\ttraining's auc: 0.914511\tvalid_1's auc: 0.901597\n[15000]\ttraining's auc: 0.92374\tvalid_1's auc: 0.91033\n[20000]\ttraining's auc: 0.929\tvalid_1's auc: 0.91483\n[25000]\ttraining's auc: 0.932466\tvalid_1's auc: 0.917515\n[30000]\ttraining's auc: 0.935136\tvalid_1's auc: 0.919065\n[35000]\ttraining's auc: 0.93738\tvalid_1's auc: 0.919934\n[40000]\ttraining's auc: 0.939337\tvalid_1's auc: 0.920425\n[45000]\ttraining's auc: 0.941065\tvalid_1's auc: 0.920642\n[50000]\ttraining's auc: 0.942573\tvalid_1's auc: 0.920655\nEarly stopping, best iteration is:\n[47887]\ttraining's auc: 0.941958\tvalid_1's auc: 0.920714\nCV score: 0.92071 \nCV score: 0.92276 \n"
],
[
"best_features = (feature_importance[[\"Feature\", \"importance\"]]\n .groupby(\"Feature\")\n .mean()\n .sort_values(by=\"importance\", ascending=False)[400:])\n\nplt.figure(figsize=(14,112))\nsns.barplot(x=\"importance\", y=\"Feature\", data=best_features.reset_index())\nplt.title('Features importance (averaged/folds)')\nplt.tight_layout()",
"_____no_output_____"
],
[
"test['target'] = predictions_lgb\nsub = pd.read_csv('./data/sample_submission.csv')\nunchange = sub[~sub.ID_code.isin(test.ID_code)]\nsub = test[['ID_code', 'target']].append(unchange).sort_index()",
"_____no_output_____"
],
[
"sample = pd.read_csv('./data/sub_lgb_5fold5aug_concategory_cv_0.9242224159538349.csv')",
"_____no_output_____"
],
[
"sample['new_target'] = sub.target",
"_____no_output_____"
],
[
"sample[sample.new_target != 0].corr()",
"_____no_output_____"
],
[
"sub.to_csv('./data/sub_lgb_noAug_cv_0.923.csv', index=False)",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n data[col + '_con_category'] = np.around(data[col + '_con'], 0)\n# data[col + '_unique_category'] = np.around(data[col + '_unique'], 0)",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n le = LabelEncoder()\n le.fit(data[col + '_con_category'].fillna(0))\n data[col + '_con_category'] = le.transform(data[col + '_con_category'].fillna(0))",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n le = LabelEncoder()\n le.fit(data[col + '_unique_category'].fillna(0))\n data[col + '_unique_category'] = le.transform(data[col + '_unique_category'].fillna(0))",
"_____no_output_____"
],
[
"for col in tqdm(col_list):\n data[col + '_unique_category'] = data[col + '_unique_category'].astype('category')",
"_____no_output_____"
],
[
"data = pd.get_dummies(data, columns=[col + '_con_category' for col in col_list])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a04e17550543907a296c8ffd80018aa7303f152
| 33,589 |
ipynb
|
Jupyter Notebook
|
zero-margins-plot.ipynb
|
trsvchn/stackoverflow-notebooks
|
09b8e280c62a267ded6bebc00899c713fd74f205
|
[
"CC0-1.0"
] | 2 |
2020-11-13T19:39:29.000Z
|
2021-10-22T02:03:53.000Z
|
zero-margins-plot.ipynb
|
trsvchn/stackoverflow-notebooks
|
09b8e280c62a267ded6bebc00899c713fd74f205
|
[
"CC0-1.0"
] | null | null | null |
zero-margins-plot.ipynb
|
trsvchn/stackoverflow-notebooks
|
09b8e280c62a267ded6bebc00899c713fd74f205
|
[
"CC0-1.0"
] | null | null | null | 425.177215 | 31,526 | 0.936378 |
[
[
[
"<!--<badge>--><a href=\"https://colab.research.google.com/github/trsvchn/stackoverflow-notebooks/blob/master/zero-margins-plot.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a><!--</badge>-->",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom matplotlib import pyplot as plt",
"_____no_output_____"
],
[
"x = np.linspace(0, 10)\ny = np.cos(x) * 7\n\nplt.figure(figsize=(15, 5))\nplt.ylabel(\"RMS value\")\nplt.xlabel(\"Interval nr.\")\nplt.plot(x, y, marker=\"o\", markersize=4)\nplt.title(\"RMS PLOT\")\nplt.margins(0)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
]
] |
4a04e7b5de004b19e2a75ab9a87888407207a69f
| 15,507 |
ipynb
|
Jupyter Notebook
|
ML/Regression/Kaggle - 5 day challenge/Regression/day2.ipynb
|
AravindVasudev/Machine-Learning-Playground
|
9d3952c854ba059f43f2f495ce3fabad3ebc4234
|
[
"MIT"
] | null | null | null |
ML/Regression/Kaggle - 5 day challenge/Regression/day2.ipynb
|
AravindVasudev/Machine-Learning-Playground
|
9d3952c854ba059f43f2f495ce3fabad3ebc4234
|
[
"MIT"
] | null | null | null |
ML/Regression/Kaggle - 5 day challenge/Regression/day2.ipynb
|
AravindVasudev/Machine-Learning-Playground
|
9d3952c854ba059f43f2f495ce3fabad3ebc4234
|
[
"MIT"
] | null | null | null | 75.643902 | 2,086 | 0.689173 |
[
[
[
"This is the second day of the 5-Day Regression Challenge. You can find the first day's challenge [here](https://www.kaggle.com/rtatman/regression-challenge-day-1). Today, we’re going to learn how to fit a model to data and how to make sure we haven’t violated any of the underlying assumptions. First, though, you need a tiny bit of background:\n____\n\n**Regression formulas in R**\n\nIn R, regression is expressed using a specific type of object called a formula. This means that the syntax for expressing a regression relationship is the same across packages that use formula objects. The general syntax for a formula looks like this:\n\n Output ~ input\n\nIf you think that more than one input might be affecting your output (for example that both the amount of time spent exercising and the number of calories consumed might affect changes in someone’s weight) you can represent that with this notation:\n\n\tOutput ~ input1 + input2\n \nWe'll talk about how to know which inputs you should include later on: for now, let's just stick to picking inputs based on questions that are interesting to you. (Figuring out how to turn a quesiton into a \n\n**What are these “residuals” everyone keeps talking about?**\n\nA residual is just how far off a model is for a single point. So if our model predicts that a 20 pound cantaloupe should sell for eight dollars and it actually sells for ten dollars, the residual for that data point would be two dollars. Most models will be off by at least a little bit for pretty much all points, but you want to make sure that there’s not a strong pattern in your residuals because that suggests that your model is failing to capture some underlying trend in your dataset.\n____\n\nToday, we're going to practice fitting a regression model to our data and examining the residuals to see if our model is a good representation of our data.\n\n___\n\n<center>\n[**You can check out a video that goes with this notebook by clicking here.**](https://www.youtube.com/embed/3C8SxyD8C7I)\n",
"_____no_output_____"
],
[
"## Example: Kaggle data science survey\n___\n\nFor our example today, we're going to use the Kaggle we’re going to use the 2017 Kaggle ML and Data Science Survey. I’m interested in seeing if we can predict the salary of data scientists based on their age. My intuition is that older data scientists, who are probably more experienced, will have higher salaries.\n\nBecause salary is a count value (you're usually paid in integer increments of a unit of currency, and hopefully you shouldn't be being paid a negative amount), we're going to model this with a Poisson regression. \n\nBefore we train a model, however, we need to set up our environment. I'm going to read in two datasets: the Kaggle Data Science Survey for the example and the Stack Overflow Developer Survey for you to work with. ",
"_____no_output_____"
]
],
[
[
"# libraries\nlibrary(tidyverse)\nlibrary(boot) #for diagnostic plots\n\n# read in data\nkaggle <- read_csv(\"../input/kaggle-survey-2017/multipleChoiceResponses.csv\")\nstackOverflow <- read_csv(\"../input/so-survey-2017/survey_results_public.csv\")",
"_____no_output_____"
]
],
[
[
"Now that we've got our environment set up, I'm going to do a tiny bit of data cleaning. First, I only want to look at rows where we have people who have reported having compensation of more than 0 units of currency. (There are many different currencies in the dataset, but for simplicity I'm going to ignore them.)",
"_____no_output_____"
]
],
[
[
"# do some data cleaning\nhas_compensation <- kaggle %>%\n filter(CompensationAmount > 0) %>% # only get salaries of > 0\n mutate(CleanedCompensationAmount = str_replace_all(CompensationAmount,\"[[:punct:]]\", \"\")) %>%\n mutate(CleanedCompensationAmount = as.numeric(CleanedCompensationAmount)) \n\n# the last two lines remove puncutation (some of the salaries has commas in them)\n# and make sure that salary is numeric",
"_____no_output_____"
]
],
[
[
"Alright, now we're ready to fit our model! To do this, we need to pass the function glm() a formula with the columns we're interested in, the name of the dataframe (so it knows where the columns are from) and the family for our model. Remember from earlier that our formula should look like this:\n\n Output ~ input\n \nWe're also predicting a count value, as discussed above, so we want to make sure the family is Poisson.",
"_____no_output_____"
]
],
[
[
"# poisson model to predict salary by age\nmodel <- glm(CleanedCompensationAmount ~ Age, data = has_compensation, family = poisson)",
"_____no_output_____"
]
],
[
[
"We'll talk about how to examine and interpret a model tomorrow. For now, we want to make sure that it's a good fit for our data and problem. To do this, let's use some diagnostic plots. ",
"_____no_output_____"
]
],
[
[
"# diagnostic plots\nglm.diag.plots(model)",
"_____no_output_____"
]
],
[
[
"All of these diagnostic plots are plotting residuals, or how much our model is off for a specific prediction. Spoiler alert: all of these plots are showing us big warning signs for this model! Here's what they should look like:\n\n* **Residuals vs Linear predictor**: You want this to look like a shapeless cloud. If there are outliers it means you've gotten some things very wrong, and if there's a clear pattern it usually means you've picked the wrong type of model. (For logistic regression, you can just ignore this plot. It's checking if the residuals are normally distributed, and logistic regression doesn't assume that they will be.)\n* **Quantiles of standard normal vs. ordered deviance residuals**: For this plot you want to see the residuals lined up along the a diagonal line that goes from the bottom left to top right. If they're strongly off that line, especially in one corner, it means you have a strong skew in your data. (For logistic regression you can ignore this plot too.)\n* **Cook's distance vs. h/(1-h)**: Here, you want your data points to be clustered near zero. If you have a data point that is far from zero (on either axis) it means that it's very influential and that one point is dramatically changing your analysis.\n* **Cook's distance vs. case**: In this plot, you want your data to be mostly around zero on the y axis. The x axis just tells you what row in your dataframe the observation is taken from. Points that are outliers on the y axis are changing your model a lot and should probably be removed (unless you have a good reason to include them).\n\nBased on these diagnostic plots, we should definitely not trust this model. There are a small handful of very influential points that are drastically changing our model. Remember, we didn't convert all the currencies to the same currency, so we're probably seeing some weirdnesses due to including a currency like the Yen, which is worth roughly one one-hundredth of a dollar. \n\nWith that in mind, let's see how the plots change when we remove any salaries above 200,000. ",
"_____no_output_____"
]
],
[
[
"# remove compensation values above 150,000\nhas_compensation <- has_compensation %>%\n filter(CleanedCompensationAmount < 150000)\n\n# linear model to predict salary by age\nmodel <- glm(CleanedCompensationAmount ~ Age, data = has_compensation, family = poisson)\n\n# diagnostic plots\nglm.diag.plots(model)",
"_____no_output_____"
]
],
[
[
"Now our plots looks much better! Our residuals are more-or-less randomly distributed (which is what the first two plots tell us) and while we still have one outstanding influential point, we can tell by comparing the Cook statistics from the first and second set of plots that it's waaaaaaaayyy less influential than the outliers we got rid of. \n\nOur first model would probably not have been very informative for a new set of observations. Our second model is more likely to be helpful. \n\nAs a final step, we can fit & plot a model to our data, like we did yesterday to see if our hunch about age and salary was correct.",
"_____no_output_____"
]
],
[
[
"# plot & add a regression line\nggplot(has_compensation, aes(x = Age, y = CleanedCompensationAmount)) + # draw a \n geom_point() + # add points\n geom_smooth(method = \"glm\", # plot a regression...\n method.args = list(family = \"poisson\")) # ...from the binomial family",
"_____no_output_____"
]
],
[
[
"It looks like we were right about older data scientists making more. It does look like there are some outliers in terms of age, which we could remove with further data cleaning (which you're free to do if you like). First, however, why don't you try your hand at fitting a model and using diagnostic plots to check it out?",
"_____no_output_____"
],
[
"## Your turn!\n___\n\nNow it's your turn to come up with a model and check it out using diagnostic plots!\n\n1. Pick a question to answer to using the Stack Overflow dataset. (You may want to check out the \"survey_results_schema.csv\" file to learn more about the data.) Pick a variable to predict and one varaible to use to predict it.\n2. Fit a GLM model of the appropriate family. (Check out [yesterday's challenge](https://www.kaggle.com/rtatman/regression-challenge-day-1) if you need a refresher.\n3. Plot diagnostic plots for your model. Does it seem like your model is a good fit for your data? Are the residuals normally distributed (no patterns in the first plot and the points in the second plot are all in a line)? Are there any influential outliers?\n4. Plot your two variables & use \"geom_smooth\" and the appropriate family to fit and plot a model\n5. Optional: If you want to share your analysis with friends or to ask for help, you’ll need to make it public so that other people can see it.\n * Publish your kernel by hitting the big blue “publish” button. (This may take a second.)\n * Change the visibility to “public” by clicking on the blue “Make Public” text (right above the “Fork Notebook” button).\n * Tag your notebook with 5daychallenge",
"_____no_output_____"
]
],
[
[
"# summary of the dataset\nsummary(stackOverflow)",
"_____no_output_____"
],
[
"# convert YearsProgram to int and filter NAs and Non US Dollar entries\nstackOverflow <- stackOverflow %>%\n mutate(YearsProgram = as.integer(str_match(YearsProgram, \"[0-9]+\"))) %>%\n filter(!is.na(Salary) & !is.na(YearsProgram) & Currency == \"U.S. dollars ($)\")\n\ntable(stackOverflow$YearsProgram)\nstackOverflow %>%\n ggplot(aes(Salary)) +\n geom_histogram()",
"_____no_output_____"
],
[
"# train the model\nmodel <- glm(Salary ~ YearsProgram, data = stackOverflow, family = \"gaussian\")\n\n# diagnostic plots\nglm.diag.plots(model)",
"_____no_output_____"
],
[
"# plot the model\nstackOverflow %>%\n ggplot(aes(YearsProgram, Salary)) +\n geom_point() +\n geom_smooth(method=\"glm\", method.args=list(family = \"gaussian\")) +\n ggtitle(\"Salary Vs YearsProgram\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a04feb6f64767f50e2ac500845dfd6129d23153
| 1,707 |
ipynb
|
Jupyter Notebook
|
pennylane-xanadu/QHack2021/Simple_Circuits_30.ipynb
|
SaashaJoshi/quantum-computing
|
53ce0f9a3ca1ecdf3184c97f356a8ee3925498aa
|
[
"Apache-2.0"
] | 5 |
2020-08-13T10:44:58.000Z
|
2022-03-22T07:57:09.000Z
|
pennylane-xanadu/QHack2021/Simple_Circuits_30.ipynb
|
SaashaJoshi/quantum-computing
|
53ce0f9a3ca1ecdf3184c97f356a8ee3925498aa
|
[
"Apache-2.0"
] | 4 |
2020-07-21T20:13:07.000Z
|
2021-02-03T09:05:48.000Z
|
pennylane-xanadu/QHack2021/Simple_Circuits_30.ipynb
|
SaashaJoshi/quantum-computing
|
53ce0f9a3ca1ecdf3184c97f356a8ee3925498aa
|
[
"Apache-2.0"
] | 4 |
2020-07-27T04:39:27.000Z
|
2022-02-26T19:05:07.000Z
| 18.966667 | 71 | 0.50205 |
[
[
[
"import pennylane as qml\nfrom pennylane import numpy as np",
"_____no_output_____"
],
[
"dev = qml.device(name = 'default.qubit', wires = 1, shots = 1000)",
"_____no_output_____"
],
[
"@qml.qnode(dev)\ndef circuit(param):\n qml.RY(param, wires = 0)\n return qml.expval(qml.PauliX(wires = 0))",
"_____no_output_____"
],
[
"param = 1.23456\nprint(circuit(param))\nprint(circuit.draw())",
"0.9440031218347898\n 0: ──RY(1.23)──┤ ⟨X⟩ \n\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a050aed4d30de222993f8bec1892b273ecfc37d
| 17,527 |
ipynb
|
Jupyter Notebook
|
Pytorch/pytorch_basic/Conv_prac.ipynb
|
IzPerfect/My-dictionary
|
6ca1e019bc063495f46ffab8cadea38bc9a250b8
|
[
"MIT"
] | null | null | null |
Pytorch/pytorch_basic/Conv_prac.ipynb
|
IzPerfect/My-dictionary
|
6ca1e019bc063495f46ffab8cadea38bc9a250b8
|
[
"MIT"
] | null | null | null |
Pytorch/pytorch_basic/Conv_prac.ipynb
|
IzPerfect/My-dictionary
|
6ca1e019bc063495f46ffab8cadea38bc9a250b8
|
[
"MIT"
] | null | null | null | 20.451575 | 166 | 0.415701 |
[
[
[
"import torch\nimport torch.nn as nn\nimport torch.nn.functional as F",
"_____no_output_____"
],
[
"x = torch.ones((4,4))\nx",
"_____no_output_____"
]
],
[
[
"Pytorch 입력의 형태\n* input type: torch.Tensor\n* input shape : `(batch_size, channel, height, width)`",
"_____no_output_____"
]
],
[
[
"x = x.view(-1, 1, 4, 4)\nx",
"_____no_output_____"
],
[
"x.shape",
"_____no_output_____"
]
],
[
[
"## Conv2d",
"_____no_output_____"
]
],
[
[
"out = nn.Conv2d(1, 1, kernel_size = 3, stride = 1, padding = 1, bias = False)",
"_____no_output_____"
],
[
"nn.init.constant_(out.weight.data, 1) # initialize weights",
"_____no_output_____"
]
],
[
[
"### Convolution output size",
"_____no_output_____"
],
[
"$$ Output\\;Size = floor(\\frac{Input\\;Size - Kernel\\;Size + (2*padding)}{Stride})+1 $$",
"_____no_output_____"
],
[
"input size= 4, filter size= 3, padding= 1, Stride= 1",
"_____no_output_____"
]
],
[
[
"out(x)",
"_____no_output_____"
],
[
"out(x).shape",
"_____no_output_____"
]
],
[
[
"input size= 4, filter size= 3, padding= 2, Stride= 1",
"_____no_output_____"
]
],
[
[
"out.kernel_size = 3\nout.padding = 2",
"_____no_output_____"
],
[
"out(x)",
"_____no_output_____"
],
[
"out(x).shape",
"_____no_output_____"
]
],
[
[
"## ConvTranspose2d\n- Refer to https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html",
"_____no_output_____"
],
[
"`padding` controls the amount of implicit zero-paddings on both sides for `dilation * (kernel_size - 1) - padding` number of points. See note below for details.",
"_____no_output_____"
],
[
"위에서의 `padding`은 Transpose Conv를 위해 input에 추가로 들어가는 padding 수를 의미. <br>\n따라서 아래 nn.ConvTranspose2d와 같이 padding = 0로 정할 경우, <br>\npadding = 1*(3-1)-0 = 2. Input Size(4X4->6X6)",
"_____no_output_____"
],
[
"결국 ConvTrnspose2d 또한 <br>\npadding을 붙이는 방식만 위와 같이 한 Conv2d 계산을 함(dilation=1일 때) ",
"_____no_output_____"
],
[
"## Padding Check",
"_____no_output_____"
]
],
[
[
"transpose = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=2, stride=1, padding=0, output_padding=0, bias=False)\nnn.init.constant_(transpose.weight.data,1)",
"_____no_output_____"
],
[
"nn.ZeroPad2d((1, 1, 1, 1))(x)",
"_____no_output_____"
],
[
"transpose(x)",
"_____no_output_____"
],
[
"transpose(x).shape",
"_____no_output_____"
],
[
"transpose = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=2, stride=1, padding=1, output_padding=0, bias=False)\nnn.init.constant_(transpose.weight.data,1)",
"_____no_output_____"
],
[
"nn.ZeroPad2d((0, 0, 0, 0))(x)",
"_____no_output_____"
],
[
"transpose(x)",
"_____no_output_____"
],
[
"transpose(x).shape",
"_____no_output_____"
]
],
[
[
"refer to https://medium.com/apache-mxnet/transposed-convolutions-explained-with-ms-excel-52d13030c7e8\n - <Figure 9>참고",
"_____no_output_____"
]
],
[
[
"transpose = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=0, output_padding=0, bias=False)\nnn.init.constant_(transpose.weight.data,1)",
"_____no_output_____"
],
[
"nn.ZeroPad2d((2, 2, 2, 2))(x)",
"_____no_output_____"
]
],
[
[
"input size= 4, filter size= 3, padding= 0, Stride= 1, output_padding = 0",
"_____no_output_____"
]
],
[
[
"transpose(x)",
"_____no_output_____"
],
[
"transpose(x).shape",
"_____no_output_____"
]
],
[
[
"input size= 4, filter size= 3, padding= 2(padding is zero), Stride= 1, output_padding = 0",
"_____no_output_____"
]
],
[
[
"nn.ZeroPad2d((0, 0, 0, 0))(x)",
"_____no_output_____"
],
[
"transpose.output_padding = 0\ntranspose.padding = 2\ntranspose.stride = 1\ntranspose(x)",
"_____no_output_____"
],
[
"transpose(x).shape",
"_____no_output_____"
]
],
[
[
"input size= 4, filter size= 3, padding= 0, Stride= 2, output_padding = 0",
"_____no_output_____"
]
],
[
[
"nn.ZeroPad2d((1, 1, 1, 1))(x)",
"_____no_output_____"
],
[
"transpose.output_padding = 0\ntranspose.padding = 2\ntranspose.stride = 2\ntranspose(x)",
"_____no_output_____"
],
[
"transpose(x).shape",
"_____no_output_____"
]
],
[
[
"## Transpose Prac",
"_____no_output_____"
]
],
[
[
"tx = torch.ones((1,2,1,1))\ntx",
"_____no_output_____"
],
[
"tx.shape",
"_____no_output_____"
],
[
"deconv1 = F.interpolate(F.leaky_relu(tx), scale_factor=2)\ndeconv1.shape",
"_____no_output_____"
],
[
"deconv1 = nn.ConvTranspose2d(2, 4, 7, bias=False, padding=0)(deconv1)\ndeconv1.shape",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a0527fda663ecbcffd24eb2fa1dd38837b5abf3
| 190,520 |
ipynb
|
Jupyter Notebook
|
binder/Index.ipynb
|
ibro191/ADRI-opt
|
3d152aee60d1786a4e80fecbce545b75674d550b
|
[
"BSD-3-Clause"
] | null | null | null |
binder/Index.ipynb
|
ibro191/ADRI-opt
|
3d152aee60d1786a4e80fecbce545b75674d550b
|
[
"BSD-3-Clause"
] | null | null | null |
binder/Index.ipynb
|
ibro191/ADRI-opt
|
3d152aee60d1786a4e80fecbce545b75674d550b
|
[
"BSD-3-Clause"
] | null | null | null | 148.1493 | 140,672 | 0.842143 |
[
[
[
"from IPython.display import display, Javascript\ndisplay(Javascript('IPython.notebook.execute_cells_below()'))",
"_____no_output_____"
]
],
[
[
"# Al Dhafra optimzation study",
"_____no_output_____"
],
[
"# inputs\n-----",
"_____no_output_____"
]
],
[
[
"%%html\n<script>\n // AUTORUN ALL CELLS ON NOTEBOOK-LOAD!\n require(\n ['base/js/namespace', 'jquery'], \n function(jupyter, $) {\n $(jupyter.events).on(\"kernel_ready.Kernel\", function () {\n console.log(\"Auto-running all cells-below...\");\n jupyter.actions.call('jupyter-notebook:run-all-cells-below');\n jupyter.actions.call('jupyter-notebook:save-notebook');\n });\n }\n );\n</script>",
"_____no_output_____"
],
[
"from IPython.display import HTML\nHTML('''<script>\ncode_show=true; \nfunction code_toggle() {\n if (code_show){\n $('div.input').hide();\n } else {\n $('div.input').show();\n }\n code_show = !code_show\n} \n$( document ).ready(code_toggle);\n</script>\nThe raw code for this IPython notebook is by default hidden for easier reading.\nTo toggle on/off the raw code, click <a href=\"javascript:code_toggle()\">here</a>.''')",
"_____no_output_____"
],
[
"%%html\n<style>.button1 {font-size:18px;}</style>",
"_____no_output_____"
]
],
[
[
"#### Battery legend choices",
"_____no_output_____"
]
],
[
[
"from ipywidgets import widgets, Layout, ButtonStyle\nimport json\n\ndesired_battery_range = []\nbattery_range = range(300, 2100 + 1, 300)\nbattery_options = {}\nhbox_list = []\ndef checkbox_event_handler(**kwargs):\n desired_battery_range = []\n for i in battery_options:\n name = str(battery_options[i].description).split(\" \")[0]\n value = battery_options[i].value\n if value is True:\n desired_battery_range.append(name)\n json.dump(desired_battery_range, open(\"desired_battery_range.json\",\"w\"))\n \n\n\n\nfor batt in battery_range:\n option = '{} kWh'.format(batt)\n battery_options[option] = widgets.Checkbox(\n value=False,\n description=option,\n disabled=False,\n indent=False\n )\n display(battery_options[option])\nwidgets.interactive_output(checkbox_event_handler,battery_options)\n",
"_____no_output_____"
],
[
"button = widgets.Button(description=\"Generate payback chart\",\n layout=Layout(width='300px', height='40px'),\n button_style='warning',)\nbutton.add_class('button1')\nbox_layout = widgets.Layout(display='flex',\n flex_flow='column',\n align_items='center',\n width='100%')\nbox = widgets.HBox(children=[button],layout=box_layout)\ndisplay(box)\n\ndef on_button_clicked(b):\n display(Javascript('IPython.notebook.execute_cells_below()'))\n\nbutton.on_click(on_button_clicked)",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nimport json\nfrom itertools import combinations\nimport math\nimport calendar\nimport os\nimport matplotlib.pyplot as plt\n%matplotlib notebook\nmarginal_payback = True\nwith open('desired_battery_range.json') as file:\n desired_battery_range = json.loads(file.read())\n# key inverter, cost reduction on DG\nDG_cost_reduction_per_month = {\n '600': 15000 / 3.672,\n '900': 15000 / 3.672,\n '300': 2850,\n}\n\nfig = plt.figure(figsize=(10, 8))\nwith open('opt_results5.json') as file:\n opt_cases = json.loads(file.read())\n\ntemp_opt_cases = {}\nfor item in opt_cases:\n if opt_cases[item]['solar'] > 0 and opt_cases[item]['battery'] == 0:\n temp_opt_cases[item] = opt_cases[item]\n\ncase_range = []\noptimization_result = []\nbattery_legend = {}\nsolar_only_legend = []\nbattery_case_name = []\nfor key in opt_cases:\n solar = opt_cases[key]['solar']\n payback = opt_cases[key]['payback']\n case_range.append(solar)\n optimization_result.append(payback)\n battery = opt_cases[key]['battery']\n c_r = opt_cases[key]['c_r']\n inv = opt_cases[key]['inverter']\n investment = opt_cases[key]['investment']\n if (str(inv) in DG_cost_reduction_per_month) and payback > 0:\n margin = round(investment / payback, 0)\n adjusted_margin = margin + (DG_cost_reduction_per_month[str(inv)] * 12)\n payback = round(investment / adjusted_margin, 1)\n if marginal_payback is True:\n for item in temp_opt_cases:\n if temp_opt_cases[item]['solar'] == solar and temp_opt_cases[item]['battery'] == 0 and battery > 0:\n marginal_payback_value = (investment - temp_opt_cases[item]['investment']) / ((investment / payback) - (temp_opt_cases[item]['investment'] / temp_opt_cases[item]['payback']))\n payback = marginal_payback_value\n else:\n continue\n case_name = '{} kWh / {} C / {} kVA'.format(battery, c_r, inv)\n if battery > 0 and str(battery) in desired_battery_range:\n if case_name in battery_legend:\n pass\n else:\n battery_legend[str(case_name)] = []\n battery_legend[case_name].append([solar, payback, key])\n elif battery == 0 and solar > 0:\n solar_only_legend.append([solar, payback, key])\n elif solar == 0 and battery == 0:\n label = \"{:.2f}\".format(payback)\n plt.annotate(label,\n (solar, payback),\n textcoords=\"offset points\",\n xytext=(0,10),\n ha='center')\n plt.plot(solar, payback, 'o-', label='DG only')\n else:\n pass\n\nfor group in battery_legend:\n x = []\n y = []\n for case in battery_legend[group]:\n x.append(case[0])\n y.append(case[1])\n label = \"{:.2f}\".format(case[1])\n plt.annotate(label,\n (case[0],case[1]),\n textcoords=\"offset points\",\n xytext=(0,10),\n ha='center')\n plt.plot(x, y, 'o-', label=group)\n\nsolar_only_x_range = []\nsolar_only_y_range = []\nfor case in solar_only_legend:\n solar_only_x_range.append(case[0])\n solar_only_y_range.append(case[1])\n label = \"{:.2f}\".format(case[1])\n plt.annotate(label,\n (case[0],case[1]),\n textcoords=\"offset points\",\n xytext=(0,10),\n ha='center')\n\nplt.plot(solar_only_x_range, solar_only_y_range,'o-', label='Solar only')\nplt.xticks(np.arange(min(case_range), max(case_range)+1, 115))\nplt.yticks(np.arange(0, 10+1, 1))\nplt.xlabel(\"Solar capacity (kWp)\", fontdict=None, labelpad=5)\nplt.ylabel(\"Payback (year)\", fontdict=None, labelpad=5, rotation=0)\naxPres = fig.add_subplot(111)\naxPres.yaxis.set_label_coords(0,1.03)\nfig.suptitle('Solar / Battery installed vs payback (Battery cases = marginal payback against solar only)', fontsize=16)\nplt.grid()\nplt.legend(loc='best')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a053454280f2d9dbe044d2a3b552f86525595a7
| 819,247 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/BruteForceStatistics-checkpoint.ipynb
|
Mariuki/AutomatedBruteForceAttack_to_FingerprintFuzzyVault
|
99c6ab5138d5b548c5ea7e4ab639fa8b2963c75b
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/BruteForceStatistics-checkpoint.ipynb
|
Mariuki/AutomatedBruteForceAttack_to_FingerprintFuzzyVault
|
99c6ab5138d5b548c5ea7e4ab639fa8b2963c75b
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/BruteForceStatistics-checkpoint.ipynb
|
Mariuki/AutomatedBruteForceAttack_to_FingerprintFuzzyVault
|
99c6ab5138d5b548c5ea7e4ab639fa8b2963c75b
|
[
"MIT"
] | null | null | null | 416.919593 | 25,092 | 0.929237 |
[
[
[
"## Brute Force Attack Analysis - Standarized Vaults",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.path import Path\nimport matplotlib.patches as patches\nfrom pylab import *\nimport itertools\nfrom sklearn.metrics import confusion_matrix\nfrom PlotUtils import *\nimport pathlib\nimport scipy.io\n\n# Para cambiar el mapa de color por defecto\nplt.rcParams[\"image.cmap\"] = \"Set2\"\n# Para cambiar el ciclo de color por defecto en Matplotlib\n# plt.rcParams['axes.prop_cycle'] = plt.cycler(color=plt.cm.Set2.colors)\n# plt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#8C6D31', '#ffdd6b', '#e9e2c9', '#dcae52', '#af7132', '#8C9363', '#637939', '#AD494A', '#E7969C', '#C4CBB9'])\n# plt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#081d58', '#253494', '#225ea8', '#1d91c0', '#41b6c4', '#7fcdbb', '#c7e9b4', '#edf8b1', '#ffffd9'])\n# plt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#084081', '#0868ac', '#2b8cbe', '#4eb3d3', '#7bccc4', '#a8ddb5', '#ccebc5', '#e0f3db', '#f7fcf0'])\n# plt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#67001f', '#b2182b', '#d6604d', '#f4a582', '#fddbc7', '#d1e5f0', '#92c5de', '#4393c3', '#2166ac','#053061'])\n# plt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#67001f', '#053061', '#b2182b', '#2166ac', '#d6604d', '#4393c3', '#f4a582', '#92c5de', '#fddbc7','#d1e5f0'])\nplt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#67001f', '#053061', '#b2182b', '#2166ac', '#d6604d', '#4393c3', '#f4a582', '#92c5de', '#fddbc7','#d1e5f0'][::-1])\n# plt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#8dd3c7', '#ffffb3', '#bebada', '#fb8072', '#80b1d3', '#fdb462', '#b3de69', '#fccde5', '#d9d9d9','#bc80bd','#ccebc5','#ffed6f'])\n# plt.rcParams[\"axes.prop_cycle\"] = plt.cycler('color', ['#8dd3c7', '#ffffb3', '#bebada', '#fb8072', '#80b1d3', '#fdb462', '#b3de69', '#fccde5', '#d9d9d9','#bc80bd','#ccebc5','#ffed6f'][::-1])",
"_____no_output_____"
],
[
"bf = pd.read_excel('ExpOctubre/StatisticsBruteForce/ResultsComplete_17-10-21.xlsx', engine='openpyxl')\nbf[48:]",
"_____no_output_____"
],
[
"help(groupedBarPlot)",
"Help on function groupedBarPlot in module PlotUtils:\n\ngroupedBarPlot(data, xticks, title, legend=True, axislabels=False, width=0.35, figsize=(25, 10), png=False, pdf=False, colors=None, lg=False, fsizes=False, adBL=False, xtick_rot=False, axisLim=False)\n Width recomendado para 2 barras agrupadas es 0.35, para 3 y 4 es 0.2\n\n"
],
[
"g1 = bf[:8]\ngroupedBarPlot({'IpV':g1['Iteraciones']}, g1['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g1['Tiempo (s)']/60}, g1['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g2 = bf[8:16]\ngroupedBarPlot({'IpV':g2['Iteraciones']}, g2['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g2['Tiempo (s)']/60}, g2['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g3 = bf[16:24]\ngroupedBarPlot({'IpV':g3['Iteraciones']}, g3['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g3['Tiempo (s)']/60}, g3['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), adBL = 2, width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g4 = bf[24:32]\ngroupedBarPlot({'IpV':g4['Iteraciones']}, g4['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g4['Tiempo (s)']/60}, g4['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g5 = bf[32:40]\ngroupedBarPlot({'IpV':g5['Iteraciones']}, g5['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g5['Tiempo (s)']/60}, g5['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g6 = bf[40:48]\ngroupedBarPlot({'IpV':g6['Iteraciones']}, g6['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g6['Tiempo (s)']/60}, g6['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g7 = bf[48:56]\ngroupedBarPlot({'IpV':g7['Iteraciones']}, g7['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g7['Tiempo (s)']/60}, g7['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2,fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g8 = bf[56:64]\ngroupedBarPlot({'IpV':g8['Iteraciones']}, g8['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g8['Tiempo (s)']/60}, g8['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g9 = bf[64:72]\ngroupedBarPlot({'IpV':g9['Iteraciones']}, g9['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g9['Tiempo (s)']/60}, g9['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 3, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g10 = bf[72:80]\ngroupedBarPlot({'IpV':g10['Iteraciones']}, g10['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g10['Tiempo (s)']/60}, g10['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"NCV = pd.read_csv('ExpOctubre/CiphVaultsBFStats/VaultsCiphResultsComplete_26-10-21.csv')\nNCV2 = NCV[NCV['Count'] != 0]\nNCV",
"_____no_output_____"
],
[
"groupedBarPlot({'IpV':NCV['Count']}, NCV['Vaults'],'Genuine points produced from encrypted vault', axislabels = ['Vaults','# of Genuine Points'], figsize = (15,6), width= 0.6, legend = False, xtick_rot = 90, fsizes={'axes':15,'xtick':10, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"groupedBarPlot({'IpV':NCV2['Count']}, NCV2['Vaults'],'Genuine points produced from encrypted vault', axislabels = ['Vaults','# of Genuine Points'], figsize = (12,6.5), width= 0.6, legend = False, xtick_rot = 0, fsizes={'axes':15,'xtick':10, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"groupedBarPlot({'IpV':NCV2['Total Combinations']}, NCV2['Vaults'],'Total posible combinations to breach encrypted vaults with genuine points found', axislabels = ['Vaults','# of Combinations'], figsize = (12,6.5), width= 0.6, legend = False, xtick_rot = 0, fsizes={'axes':15,'xtick':10, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"groupedBarPlot({'IpV':NCV2['Mean Combinations']}, NCV2['Vaults'],'Mean expected combinations to breach encrypted vaults with genuine points found', axislabels = ['Vaults','# of Combinations'], figsize = (12,6.5), width= 0.6, legend = False, xtick_rot = 0, fsizes={'axes':15,'xtick':10, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"brokenvaults = [0 for i in NCV['Count'] if i < (8+1)*2]\ngroupedBarPlot({'IpV':brokenvaults}, NCV['Vaults'],'Encrypted vaults to be breached', axislabels = ['Vaults','Breached/Not Breached'], figsize = (12,5), width= 0.6, legend = False, xtick_rot = 90, axisLim = {'ylim':[0,1]}, fsizes={'axes':15,'xtick':8, 'ytick':11, 'font':11})",
"_____no_output_____"
]
],
[
[
"## Brute Force Attack Analysis - Non-Standarized Vaults",
"_____no_output_____"
]
],
[
[
"bf = pd.read_excel('Pruebas/ResultsComplete_17-10-21.xlsx', engine='openpyxl')\nbf",
"_____no_output_____"
],
[
"bfNC = bf[bf['Iteraciones'] != 0]\nbfNC2 = bfNC[bfNC['Tiempo (s)'] != 0].reset_index().drop('index', 1)\nbfNC2",
"C:\\Users\\mario\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:2: FutureWarning: In a future version of pandas all arguments of DataFrame.drop except for the argument 'labels' will be keyword-only\n \n"
],
[
"g1 = bfNC2[:3]\ngroupedBarPlot({'IpV':g1['Iteraciones']}, g1['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g1['Tiempo (s)']/60}, g1['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g2 = bfNC2[3:6]\ngroupedBarPlot({'IpV':g2['Iteraciones']}, g2['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g2['Tiempo (s)']/60}, g2['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g3 = bfNC2[6:10]\ngroupedBarPlot({'IpV':g3['Iteraciones']}, g3['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g3['Tiempo (s)']/60}, g3['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g4 = bfNC2[10:17]\ngroupedBarPlot({'IpV':g4['Iteraciones']}, g4['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g4['Tiempo (s)']/60}, g4['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g5 = bfNC2[17:22]\ngroupedBarPlot({'IpV':g5['Iteraciones']}, g5['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g5['Tiempo (s)']/60}, g5['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g6 = bfNC2[22:30]\ngroupedBarPlot({'IpV':g6['Iteraciones']}, g6['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g6['Tiempo (s)']/60}, g6['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g7 = bfNC2[30:36]\ngroupedBarPlot({'IpV':g7['Iteraciones']}, g7['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g7['Tiempo (s)']/60}, g7['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g8 = bfNC2[36:44]\ngroupedBarPlot({'IpV':g8['Iteraciones']}, g8['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g8['Tiempo (s)']/60}, g8['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g9 = bfNC2[44:47]\ngroupedBarPlot({'IpV':g9['Iteraciones']}, g9['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g9['Tiempo (s)']/60}, g9['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"g10 = bfNC2[47:]\ngroupedBarPlot({'IpV':g10['Iteraciones']}, g10['Vault'],'Iterations to breach the vault', axislabels = ['Vaults','Iterations'], figsize = (10,6), width= 0.6, legend = False, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})\ngroupedBarPlot({'TpV':g10['Tiempo (s)']/60}, g10['Vault'],'Time tooked to breach the vault', axislabels = ['Vaults', 'Minutes'], figsize = (10,6), width= 0.6, legend = False, adBL = 2, fsizes={'axes':15,'xtick':11, 'ytick':11, 'font':11})",
"_____no_output_____"
],
[
"bfNGP = list(bf[bf['Iteraciones'] == 0]['Vault'])\nprint('Vaults without enough points to calculate Lagrange interpolation:\\n',bfNGP)\nprint('\\n\\n')\n\nbfI = bf[bf['Tiempo (s)'] == 0]\nbfI = list(bfI[bfI['Iteraciones'] != 0]['Vault'])\nprint('Vaults that take more than 1 million of iterations to be broken:\\n',bfI)",
"Vaults without enough points to calculate Lagrange interpolation:\n ['Vault101_4', 'Vault101_5', 'Vault102_5', 'Vault102_8', 'Vault107_8', 'Vault109_6']\n\n\n\nVaults that take more than 1 million of iterations to be broken:\n ['Vault101_2', 'Vault101_3', 'Vault101_8', 'Vault102_3', 'Vault102_4', 'Vault102_7', 'Vault103_2', 'Vault103_3', 'Vault103_4', 'Vault103_8', 'Vault104_5', 'Vault105_4', 'Vault105_6', 'Vault105_8', 'Vault107_3', 'Vault109_1', 'Vault109_3', 'Vault109_4', 'Vault109_8', 'Vault110_1', 'Vault110_2', 'Vault110_4']\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a05556d37d775ec2a2dadec3d1a830cbea50f11
| 5,432 |
ipynb
|
Jupyter Notebook
|
shb-mcnn/exp/11-27_18-48_SHHB_MCNN_0.0001_[crop4]/code/vis-mcnn.ipynb
|
mar-edw-kon/CCAugmentation-Experiments-Env
|
ea86a775a3088b851feb42e0fdd8bd6c4f07d4c7
|
[
"MIT"
] | 1 |
2020-11-25T01:23:00.000Z
|
2020-11-25T01:23:00.000Z
|
shb-mcnn/exp/11-27_18-48_SHHB_MCNN_0.0001_[crop4]/code/vis-mcnn.ipynb
|
mar-edw-kon/CCAugmentation-Experiments-Env
|
ea86a775a3088b851feb42e0fdd8bd6c4f07d4c7
|
[
"MIT"
] | null | null | null |
shb-mcnn/exp/11-27_18-48_SHHB_MCNN_0.0001_[crop4]/code/vis-mcnn.ipynb
|
mar-edw-kon/CCAugmentation-Experiments-Env
|
ea86a775a3088b851feb42e0fdd8bd6c4f07d4c7
|
[
"MIT"
] | null | null | null | 32.526946 | 129 | 0.566274 |
[
[
[
"import os\nimport random\nimport torch\nimport torchvision.transforms as standard_transforms\nimport scipy.io as sio\nimport matplotlib\nimport pandas as pd\nimport misc.transforms as own_transforms\nimport warnings\n\n\nfrom torch.autograd import Variable\nfrom torch.utils.data import DataLoader\nfrom PIL import Image, ImageOps\nfrom matplotlib import pyplot as plt\nfrom tqdm import trange, tqdm\nfrom misc.utils import *\nfrom models.CC import CrowdCounter\nfrom config import cfg\nimport CCAugmentation as cca\nfrom datasets.SHHB.setting import cfg_data\nfrom load_data import CustomDataset\n\ntorch.cuda.set_device(0)\ntorch.backends.cudnn.benchmark = True\nwarnings.filterwarnings('ignore')\n\nmean_std = ([0.452016860247, 0.447249650955, 0.431981861591],[0.23242045939, 0.224925786257, 0.221840232611])\n\nimg_transform = standard_transforms.Compose([\n standard_transforms.ToTensor(),\n standard_transforms.Normalize(*mean_std)\n ])\nrestore = standard_transforms.Compose([\n own_transforms.DeNormalize(*mean_std),\n standard_transforms.ToPILImage()\n ])\npil_to_tensor = standard_transforms.ToTensor()",
"_____no_output_____"
],
[
"model_path = './exp/11-26_06-00_SHHB_MCNN_0.0001_[noAug]/all_ep_146_mae_23.91_mse_35.70.pth'\nmodel_path = './exp/11-26_06-57_SHHB_MCNN_0.0001_[noAug]/all_ep_175_mae_17.92_mse_26.94.pth'\nmodel_path = './exp/11-26_07-42_SHHB_MCNN_0.0001_[noAug]/all_ep_171_mae_18.16_mse_29.66.pth'\nmodel_path = './exp/11-27_09-59_SHHB_MCNN_0.0001_[flipLR]/all_ep_180_mae_18.34_mse_30.49.pth'\nmodel_path = './exp/11-27_10-44_SHHB_MCNN_0.0001_[flipLR]/all_ep_181_mae_19.11_mse_33.26.pth'\n# model_path = './exp/11-27_11-30_SHHB_MCNN_0.0001_[flipLR]/all_ep_180_mae_18.16_mse_30.61.pth'\n\nnet = CrowdCounter(cfg.GPU_ID,cfg.NET)\nnet.load_state_dict(torch.load(model_path))\nnet.cuda()\nnet.eval() \n\n\nval_pipeline = cca.Pipeline(\n cca.examples.loading.SHHLoader(\"/dataset/ShanghaiTech\", \"test\", \"B\"), []\n ).execute_generate()\nval_loader = DataLoader(CustomDataset(val_pipeline), batch_size=cfg_data.VAL_BATCH_SIZE, num_workers=1, drop_last=False)\n\nval_img = list(val_loader)",
"_____no_output_____"
],
[
"start = 0\nN = 3\n\nfor vi, data in enumerate(val_img[start:start+N], 0):\n img, gt_map = data\n\n with torch.no_grad():\n img = Variable(img).cuda()\n pred_map = net.test_forward(img)\n pred_map = pred_map.data.cpu().numpy()\n \n new_img = img.data.cpu().numpy()\n new_img = np.moveaxis(new_img, 1, 2)\n new_img = np.moveaxis(new_img, 2, 3)\n new_img = np.squeeze(new_img)[:,:,::-1]\n \n pred_cnt = np.sum(pred_map[0])/100.0\n gt_count = np.sum(gt_map.data.cpu().numpy())/100.0\n \n fg, (ax0, ax1, ax2) = plt.subplots(1, 3, figsize=(16, 5))\n plt.suptitle(' '.join([\n 'count_label:', str(round(gt_count, 3)),\n 'count_prediction:', str(round(pred_cnt, 3))\n ]))\n ax0.imshow(np.uint8(new_img))\n ax1.imshow(np.squeeze(gt_map), cmap='jet')\n ax2.imshow(np.squeeze(pred_map), cmap='jet')\n plt.show()",
"_____no_output_____"
],
[
"mae = np.empty(len(val_img))\nmse = np.empty(len(val_img))\nfor vi, data in enumerate(tqdm(val_img), 0):\n img, gt_map = data\n\n with torch.no_grad():\n img = Variable(img).cuda()\n pred_map = net.test_forward(img)\n pred_map = pred_map.data.cpu().numpy()\n \n pred_cnt = np.sum(pred_map[0])/100.0\n gt_count = np.sum(gt_map.data.cpu().numpy())/100.0\n mae[vi] = np.abs(gt_count-pred_cnt)\n mse[vi] = (gt_count-pred_cnt)**2\n \nprint('MAE:', round(mae.mean(),2))\nprint('MSE:', round(np.sqrt(mse.mean()),2))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a055b0d0fae0d008e55540f16f4357803059724
| 121,114 |
ipynb
|
Jupyter Notebook
|
StackOverFlow Data.ipynb
|
anuraglahon16/Udacity-Project-Write-a-Data-Scientist-Blog-Post
|
bb9d38890b28b66b37b47738ff2278fc34238182
|
[
"MIT"
] | null | null | null |
StackOverFlow Data.ipynb
|
anuraglahon16/Udacity-Project-Write-a-Data-Scientist-Blog-Post
|
bb9d38890b28b66b37b47738ff2278fc34238182
|
[
"MIT"
] | null | null | null |
StackOverFlow Data.ipynb
|
anuraglahon16/Udacity-Project-Write-a-Data-Scientist-Blog-Post
|
bb9d38890b28b66b37b47738ff2278fc34238182
|
[
"MIT"
] | null | null | null | 71.243529 | 35,744 | 0.6813 |
[
[
[
"### At least three questions related to business or real-world applications of how the data could be used.",
"_____no_output_____"
],
[
"## Preparing Data ",
"_____no_output_____"
]
],
[
[
"#import necessary libraries\n#import pandas package as pd\nimport pandas as pd\n#import the numpy package as np\nimport numpy as np",
"_____no_output_____"
],
[
"#reading the csv file\nstackoverflow=pd.read_csv('C:/Users/anura/Downloads/survey_results_public.csv/survey_results_public.csv')",
"_____no_output_____"
],
[
"#Inspecting first 5 rows\nstackoverflow.head()",
"_____no_output_____"
]
],
[
[
"## Handing Missing Values",
"_____no_output_____"
]
],
[
[
"#Missing value sum of particular columns\nstackoverflow.isna().sum()",
"_____no_output_____"
],
[
"#Filling the missing value with foreward and backward fill because there are categorical value also .\n#We are not droping it as there is large percentage of missing values in our data set\n#Foreward and Backward fill filled the missing values with upper and lower rows.\n#We are not taking the mean as their is categorical values which we can't take the mean\nstackoverflow.fillna(method='ffill')\nstackoverflow.fillna(method='bfill')",
"_____no_output_____"
]
],
[
[
"## Data Understanding",
"_____no_output_____"
]
],
[
[
"#All the Columns in the dataframe\nfor colname in stackoverflow:\n print(colname)",
"Respondent\nProfessional\nProgramHobby\nCountry\nUniversity\nEmploymentStatus\nFormalEducation\nMajorUndergrad\nHomeRemote\nCompanySize\nCompanyType\nYearsProgram\nYearsCodedJob\nYearsCodedJobPast\nDeveloperType\nWebDeveloperType\nMobileDeveloperType\nNonDeveloperType\nCareerSatisfaction\nJobSatisfaction\nExCoderReturn\nExCoderNotForMe\nExCoderBalance\nExCoder10Years\nExCoderBelonged\nExCoderSkills\nExCoderWillNotCode\nExCoderActive\nPronounceGIF\nProblemSolving\nBuildingThings\nLearningNewTech\nBoringDetails\nJobSecurity\nDiversityImportant\nAnnoyingUI\nFriendsDevelopers\nRightWrongWay\nUnderstandComputers\nSeriousWork\nInvestTimeTools\nWorkPayCare\nKinshipDevelopers\nChallengeMyself\nCompetePeers\nChangeWorld\nJobSeekingStatus\nHoursPerWeek\nLastNewJob\nAssessJobIndustry\nAssessJobRole\nAssessJobExp\nAssessJobDept\nAssessJobTech\nAssessJobProjects\nAssessJobCompensation\nAssessJobOffice\nAssessJobCommute\nAssessJobRemote\nAssessJobLeaders\nAssessJobProfDevel\nAssessJobDiversity\nAssessJobProduct\nAssessJobFinances\nImportantBenefits\nClickyKeys\nJobProfile\nResumePrompted\nLearnedHiring\nImportantHiringAlgorithms\nImportantHiringTechExp\nImportantHiringCommunication\nImportantHiringOpenSource\nImportantHiringPMExp\nImportantHiringCompanies\nImportantHiringTitles\nImportantHiringEducation\nImportantHiringRep\nImportantHiringGettingThingsDone\nCurrency\nOverpaid\nTabsSpaces\nEducationImportant\nEducationTypes\nSelfTaughtTypes\nTimeAfterBootcamp\nCousinEducation\nWorkStart\nHaveWorkedLanguage\nWantWorkLanguage\nHaveWorkedFramework\nWantWorkFramework\nHaveWorkedDatabase\nWantWorkDatabase\nHaveWorkedPlatform\nWantWorkPlatform\nIDE\nAuditoryEnvironment\nMethodology\nVersionControl\nCheckInCode\nShipIt\nOtherPeoplesCode\nProjectManagement\nEnjoyDebugging\nInTheZone\nDifficultCommunication\nCollaborateRemote\nMetricAssess\nEquipmentSatisfiedMonitors\nEquipmentSatisfiedCPU\nEquipmentSatisfiedRAM\nEquipmentSatisfiedStorage\nEquipmentSatisfiedRW\nInfluenceInternet\nInfluenceWorkstation\nInfluenceHardware\nInfluenceServers\nInfluenceTechStack\nInfluenceDeptTech\nInfluenceVizTools\nInfluenceDatabase\nInfluenceCloud\nInfluenceConsultants\nInfluenceRecruitment\nInfluenceCommunication\nStackOverflowDescribes\nStackOverflowSatisfaction\nStackOverflowDevices\nStackOverflowFoundAnswer\nStackOverflowCopiedCode\nStackOverflowJobListing\nStackOverflowCompanyPage\nStackOverflowJobSearch\nStackOverflowNewQuestion\nStackOverflowAnswer\nStackOverflowMetaChat\nStackOverflowAdsRelevant\nStackOverflowAdsDistracting\nStackOverflowModeration\nStackOverflowCommunity\nStackOverflowHelpful\nStackOverflowBetter\nStackOverflowWhatDo\nStackOverflowMakeMoney\nGender\nHighestEducationParents\nRace\nSurveyLong\nQuestionsInteresting\nQuestionsConfusing\nInterestedAnswers\nSalary\nExpectedSalary\n"
],
[
"#dimensiom of the dataframe which is 51392 rows and 154 columns\nstackoverflow.shape",
"_____no_output_____"
],
[
"#reading the csv file where it explains each columns in details\nschema=pd.read_csv('C:/Users/anura/Downloads/survey_results_schema.csv')\nschema.head()",
"_____no_output_____"
]
],
[
[
"## Evaluating Results and Business Understanding",
"_____no_output_____"
],
[
"### Question 1\n### What is the average salary of particular UnderGrad Major and what is the average salary of particular Formal Education?\n",
"_____no_output_____"
],
[
"#### Average salary of UnderGrad Major and Average salary according to Formal Education",
"_____no_output_____"
]
],
[
[
"#Number of values of a particular major\nstackoverflow.MajorUndergrad.value_counts()",
"_____no_output_____"
],
[
"#Undergrad major avg salary\nMajorAvgSalary=stackoverflow.groupby('MajorUndergrad')['Salary'].mean().sort_values(ascending=False)\nMajorAvgSalary",
"_____no_output_____"
],
[
"#Plotting the graph horizontally\nMajorAvgSalary.plot(kind='barh')",
"_____no_output_____"
],
[
"#Number of value of particular Formal Education\nstackoverflow['FormalEducation'].value_counts()",
"_____no_output_____"
],
[
"#Particular Formal Education average salary\nFormalAvgSalary=stackoverflow.groupby('FormalEducation')['Salary'].mean().sort_values(ascending=False)\nFormalAvgSalary",
"_____no_output_____"
],
[
"#Plotting the graph horizontally \nFormalAvgSalary.plot(kind='barh')",
"_____no_output_____"
]
],
[
[
"##### Result :\nPsychology have the highest average salary among Majors in undergrad.\n\nDoctoral degree is the highest average salary among Formal Education.",
"_____no_output_____"
],
[
"## Question 2\n### Which company size and company type have highest salary?",
"_____no_output_____"
]
],
[
[
"#Number of company of particular company size\nstackoverflow['CompanySize'].value_counts()",
"_____no_output_____"
],
[
"#Number of companyType\nstackoverflow['CompanyType'].value_counts()",
"_____no_output_____"
],
[
"#Avg salary of company size and company type\nstackoverflow.groupby(['CompanySize','CompanyType'])['Salary'].mean().sort_values(ascending=False)",
"_____no_output_____"
],
[
"#Grouping Company Type and Company size and finding average salary in descending order\nstackoverflow.groupby(['CompanyType','CompanySize'])['Salary'].mean().sort_values(ascending=False) ",
"_____no_output_____"
]
],
[
[
"#### Result :\nPre-series A startup have the highest average salary among company type.\n\nIn Venture-funded startup , 5,000 to 9,999 employees have the highest average salary among company size.",
"_____no_output_____"
],
[
"### Question 3\n\n###### How many years of programming and formal education is highest average salary?",
"_____no_output_____"
]
],
[
[
"#NUmber of YearsProgram counts\nstackoverflow['YearsProgram'].value_counts()",
"_____no_output_____"
],
[
"#Avg salary with years Program and formal education\nAvgYearEdu=stackoverflow.groupby(['YearsProgram','FormalEducation'])['Salary'].mean().sort_values(ascending=False)\nAvgYearEdu",
"_____no_output_____"
]
],
[
[
"#### Result:\n17-18 years with Professional degree have highest average salary.",
"_____no_output_____"
],
[
"## Question 4\n\n#### Which country have the highest average salary for WorkPayCare?",
"_____no_output_____"
]
],
[
[
"#Number of particular WorkPayCare\nstackoverflow['WorkPayCare'].value_counts()",
"_____no_output_____"
],
[
"#Avg salary of WorkPayCare\nstackoverflow.groupby('WorkPayCare')['Salary'].mean().sort_values(ascending=False)",
"_____no_output_____"
],
[
"#Average salary with country and workpaycare\nstackoverflow.groupby(['Country','WorkPayCare'])['Salary'].mean().sort_values(ascending=False)",
"_____no_output_____"
]
],
[
[
"### Result:\nIn Puerto Rico have the highest avergae salary and they agree that they were give Work Pay care.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a055cb4af5e12e885acae875742ac8686284d5e
| 3,503 |
ipynb
|
Jupyter Notebook
|
sage/survey cases.ipynb
|
mo271/small_polytopes
|
a1978a4d199e2fc3b0c9fea9c43b0446c307a908
|
[
"Apache-2.0"
] | null | null | null |
sage/survey cases.ipynb
|
mo271/small_polytopes
|
a1978a4d199e2fc3b0c9fea9c43b0446c307a908
|
[
"Apache-2.0"
] | null | null | null |
sage/survey cases.ipynb
|
mo271/small_polytopes
|
a1978a4d199e2fc3b0c9fea9c43b0446c307a908
|
[
"Apache-2.0"
] | null | null | null | 25.021429 | 113 | 0.540394 |
[
[
[
"Copyright 2021 Google LLC\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n https://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.",
"_____no_output_____"
]
],
[
[
"import os",
"_____no_output_____"
],
[
"solved_path = '../small_fat_4_polys/'\nverified_solutions = {sage_eval(poly.split(\"_\")[0]) for poly in os.listdir(solved_path)}\nprint(len(verified_solutions))",
"210\n"
],
[
"nn = 23\ndef get_lower(i):\n exact_lower = ceil(i/2)\n if not (i+ exact_lower)%2:\n return exact_lower\n else:\n return exact_lower + 1\nhighest_solved = {i: get_lower(i) - 1 for i in range(nn)}\ndef get_next(solved):\n for i in range(nn):\n highest_solved[i] = max([j for (ii,j) in solved if i == ii], default=get_lower(i)-1)\n cands = [(i, j) for i in range(nn) for j in range(get_lower(i), highest_solved[i]+7) if not (i+j)%2]\n unsovled_cands = [cand for cand in cands if cand not in solved]\n return unsovled_cands",
"_____no_output_____"
],
[
"rest = get_next(verified_solutions)",
"_____no_output_____"
],
[
"with open('rest_commands', 'w') as f:\n f.write('\\n'.join(f'~/sage/sage sage/find_target.sage {a} {b}' for a, b in set(rest)))",
"_____no_output_____"
],
[
"latex_punkte = ', '.join([f'{i}/{j}/{{}}' for i,j in verified_solutions])\nwith open('../tex/all_points.tex', 'w') as f:\n f.write(latex_punkte)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a056cd9865169baab05180060ede901f25680c6
| 41,503 |
ipynb
|
Jupyter Notebook
|
Pandas and Scikit-Learn.ipynb
|
mohsincl/ML-Projects
|
5ef14257f2fdd3ae438557b8ddcdbf316bd1dc2e
|
[
"MIT"
] | null | null | null |
Pandas and Scikit-Learn.ipynb
|
mohsincl/ML-Projects
|
5ef14257f2fdd3ae438557b8ddcdbf316bd1dc2e
|
[
"MIT"
] | null | null | null |
Pandas and Scikit-Learn.ipynb
|
mohsincl/ML-Projects
|
5ef14257f2fdd3ae438557b8ddcdbf316bd1dc2e
|
[
"MIT"
] | null | null | null | 29.62384 | 383 | 0.396694 |
[
[
[
"# Pandas and Scikit-learn",
"_____no_output_____"
],
[
"Pandas is a Python library that contains high-level data structures and manipulation tools designed for data analysis. Think of Pandas as a Python version of Excel. Scikit-learn, on the other hand, is an open-source machine learning library for Python.",
"_____no_output_____"
],
[
"While Scikit-learn does a lot of the heavy lifting, what's equally important is ensuring that raw data is processed in such a way that we are able to 'feed' it to Scikit-learn. Hence, the ability to manipulate raw data with Pandas makes it an indispensible part of our toolkit.",
"_____no_output_____"
],
[
"# Kaggle",
"_____no_output_____"
],
[
"Kaggle is the leading platform for data science competitions. Participants compete for cash prizes by submitting the best predictive model to problems posted on the competition website.\n\nhttps://www.kaggle.com/competitions",
"_____no_output_____"
],
[
"Learning machine learning via Kaggle problems allows us to take a highly-directed approach because:\n1. The problems are well-defined and the data is provided, allowing us to immediately focus on manipulating the data, and\n2. The leaderboard allows us to keep track of how well we're doing.",
"_____no_output_____"
],
[
"In the following set of exercises, we will be reviewing the data from the Kaggle Titanic competition. Our aim is to make predictions on whether or not specific passengers on the Titanic survived, based on characteristics such as age, sex and class.",
"_____no_output_____"
],
[
"# Section 1-0 - First Cut",
"_____no_output_____"
],
[
"We will start by processing the training data, after which we will be able to use to 'train' (or 'fit') our model. With the trained model, we apply it to the test data to make the predictions. Finally, we output our predictions into a .csv file to make a submission to Kaggle and see how well they perform.",
"_____no_output_____"
],
[
"It is very common to encounter missing values in a data set. In this section, we will take the simplest (or perhaps, simplistic) approach of ignoring the whole row if any part of it contains an NA value. We will build on this approach in later sections.",
"_____no_output_____"
],
[
"## Pandas - Extracting data",
"_____no_output_____"
],
[
"First, we load the training data from a .csv file. This is the similar to the data found on the Kaggle website: \n\nhttps://www.kaggle.com/c/titanic-gettingStarted/data",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\ndf = pd.read_csv('../data/train.csv')",
"_____no_output_____"
]
],
[
[
"## Pandas - Cleaning data",
"_____no_output_____"
],
[
"We then review a selection of the data. ",
"_____no_output_____"
]
],
[
[
"df.head(10)",
"_____no_output_____"
]
],
[
[
"We notice that the columns describe features of the Titanic passengers, such as age, sex, and class. Of particular interest is the column Survived, which describes whether or not the passenger survived. When training our model, what we are essentially doing is assessing how each feature impacts whether or not the passenger survived (or if the feature makes an impact at all).",
"_____no_output_____"
],
[
"**Exercise**:\n- Write the code to review the tail-end section of the data. ",
"_____no_output_____"
],
[
"We observe that the columns Name and Cabin are, for our current purposes, irrelevant. We proceed to remove them from our data set.",
"_____no_output_____"
]
],
[
[
"df = df.drop(['Name', 'Ticket', 'Cabin'], axis=1)",
"_____no_output_____"
]
],
[
[
"Next, we review the type of data in the columns, and their respective counts.",
"_____no_output_____"
]
],
[
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 891 entries, 0 to 890\nData columns (total 9 columns):\nPassengerId 891 non-null int64\nSurvived 891 non-null int64\nPclass 891 non-null int64\nSex 891 non-null object\nAge 714 non-null float64\nSibSp 891 non-null int64\nParch 891 non-null int64\nFare 891 non-null float64\nEmbarked 889 non-null object\ndtypes: float64(2), int64(5), object(2)"
]
],
[
[
"We notice that the columns Age and Embarked have NAs or missing values. As previously discussed, we take the approach of simply removing the rows with missing values.",
"_____no_output_____"
]
],
[
[
"df = df.dropna()",
"_____no_output_____"
]
],
[
[
"**Question**\n\n- If you were to fill in the missing values, with what values would you fill them with? Why?",
"_____no_output_____"
],
[
"Scikit-learn only takes numerical arrays as inputs. As such, we would need to convert the categorical columns Sex and Embarked into numerical ones. We first review the range of values for the column Sex, and create a new column that represents the data as numbers.",
"_____no_output_____"
]
],
[
[
"df['Sex'].unique()",
"_____no_output_____"
],
[
"df['Gender'] = df['Sex'].map({'female': 0, 'male':1}).astype(int)",
"_____no_output_____"
]
],
[
[
"Similarly for Embarked, we review the range of values and create a new column called Port that represents, as a numerical value, where each passenger embarks from.",
"_____no_output_____"
]
],
[
[
"df['Embarked'].unique()",
"_____no_output_____"
],
[
"df['Port'] = df['Embarked'].map({'C':1, 'S':2, 'Q':3}).astype(int)",
"_____no_output_____"
]
],
[
[
"**Question**\n- What problems might we encounter by mapping C, S, and Q in the column Embarked to the values 1, 2, and 3? In other words, what does the ordering imply? Does the same problem exist for the column Sex?",
"_____no_output_____"
],
[
"Now that we have numerical columns that encapsulate the information provided by the columns Sex and Embarked, we can proceed to drop them from our data set.",
"_____no_output_____"
]
],
[
[
"df = df.drop(['Sex', 'Embarked'], axis=1)",
"_____no_output_____"
]
],
[
[
"We review the columns our final, processed data set.",
"_____no_output_____"
]
],
[
[
"cols = df.columns.tolist()\nprint(cols)",
"['PassengerId', 'Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'Gender', 'Port']\n"
]
],
[
[
"For convenience, we move the column Survived to the left-most column. We note that the left-most column is indexed as 0.",
"_____no_output_____"
]
],
[
[
"cols = [cols[1]] + cols[0:1] + cols[2:]\ndf = df[cols]",
"_____no_output_____"
]
],
[
[
"In our final review of our training data, we check that (1) the column Survived is the left-most column (2) there are no NA values, and (3) all the values are in numerical form.",
"_____no_output_____"
]
],
[
[
"df.head(10)",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 712 entries, 0 to 890\nData columns (total 9 columns):\nSurvived 712 non-null int64\nPassengerId 712 non-null int64\nPclass 712 non-null int64\nAge 712 non-null float64\nSibSp 712 non-null int64\nParch 712 non-null int64\nFare 712 non-null float64\nGender 712 non-null int64\nPort 712 non-null int64\ndtypes: float64(2), int64(7)"
]
],
[
[
"Finally, we convert the processed training data from a Pandas dataframe into a numerical (Numpy) array.",
"_____no_output_____"
]
],
[
[
"train_data = df.values",
"_____no_output_____"
]
],
[
[
"## Scikit-learn - Training the model",
"_____no_output_____"
],
[
"In this section, we'll simply use the model as a black box. We'll review more sophisticated techniques in later sections.",
"_____no_output_____"
],
[
"Here we'll be using the Random Forest model. The intuition is as follows: each feature is reviewed to see how much impact it makes to the outcome. The most prominent feature is segmented into a 'branch'. A collection of branches is a 'tree'. The Random Forest model, broadly speaking, creates a 'forest' of trees and aggregates the results.\n\nhttp://en.wikipedia.org/wiki/Random_forest",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestClassifier\n\nmodel = RandomForestClassifier(n_estimators = 100)",
"_____no_output_____"
]
],
[
[
"We use the processed training data to 'train' (or 'fit') our model. The column Survived will be our first input, and the set of other features (with the column PassengerId omitted) as the second.",
"_____no_output_____"
]
],
[
[
"model = model.fit(train_data[0:,2:],train_data[0:,0])",
"_____no_output_____"
]
],
[
[
"## Scikit-learn - Making predictions",
"_____no_output_____"
],
[
"We first load the test data.",
"_____no_output_____"
]
],
[
[
"df_test = pd.read_csv('../data/test.csv')",
"_____no_output_____"
]
],
[
[
"We then review a selection of the data.",
"_____no_output_____"
]
],
[
[
"df_test.head(10)",
"_____no_output_____"
]
],
[
[
"We notice that test data has columns similar to our training data, but not the column Survived. We'll use our trained model to predict values for the column Survived.",
"_____no_output_____"
],
[
"As before, we process the test data in a similar fashion to what we did to the training data.",
"_____no_output_____"
]
],
[
[
"df_test = df_test.drop(['Name', 'Ticket', 'Cabin'], axis=1)\n\ndf_test = df_test.dropna()\n\ndf_test['Gender'] = df_test['Sex'].map({'female': 0, 'male':1})\ndf_test['Port'] = df_test['Embarked'].map({'C':1, 'S':2, 'Q':3})\n\ndf_test = df_test.drop(['Sex', 'Embarked'], axis=1)\n\ntest_data = df_test.values",
"_____no_output_____"
]
],
[
[
"We now apply the trained model to the test data (omitting the column PassengerId) to produce an output of predictions.",
"_____no_output_____"
]
],
[
[
"output = model.predict(test_data[:,1:])",
"_____no_output_____"
]
],
[
[
"## Pandas - Preparing submission",
"_____no_output_____"
],
[
"We simply create a Pandas dataframe by combining the index from the test data with the output of predictions.",
"_____no_output_____"
]
],
[
[
"result = np.c_[test_data[:,0].astype(int), output.astype(int)]\ndf_result = pd.DataFrame(result[:,0:2], columns=['PassengerId', 'Survived'])",
"_____no_output_____"
]
],
[
[
"We briefly review our predictions.",
"_____no_output_____"
]
],
[
[
"df_result.head(10)",
"_____no_output_____"
]
],
[
[
"Finally, we output our results to a .csv file.",
"_____no_output_____"
]
],
[
[
"df_result.to_csv('../results/titanic_1-0.csv', index=False)",
"_____no_output_____"
]
],
[
[
"However, it appears that we have a problem. The Kaggle submission website expects \"the solution file to have 418 predictions.\"\n\nhttps://www.kaggle.com/c/titanic-gettingStarted/submissions/attach",
"_____no_output_____"
],
[
"We compare this to our result.",
"_____no_output_____"
]
],
[
[
"df_result.shape",
"_____no_output_____"
]
],
[
[
"Since we eliminated the rows containing NAs, we end up with a set of predictions with a smaller number of rows compared to the test data. As Kaggle requires all 418 predictions, we are unable to make a submission.",
"_____no_output_____"
],
[
"In this section, we took the simplest approach of ignoring missing values, but fail to produce a complete set of predictions. We look to build on this approach in Section 1-1.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.